Spaces:
Running

Running
update
Browse files- README.md +8 -6
- app.py +132 -0
- examples/00000000.jpg +0 -0
- examples/00000001.jpg +0 -0
- examples/00000002.jpg +0 -0
- examples/00000003.jpg +0 -0
- examples/00000004.jpg +0 -0
- examples/00000005.jpg +0 -0
- examples/00000006.jpg +0 -0
- examples/00000007.jpg +0 -0
- examples/00000008.jpg +0 -0
- examples/00000009.jpg +0 -0
- examples/00000010.jpg +0 -0
- examples/00000011.jpg +0 -0
- examples/00000012.jpg +0 -0
- examples/00000013.jpg +0 -0
- examples/00000014.jpg +0 -0
- examples/00000015.jpg +0 -0
- examples/00000016.jpg +0 -0
- examples/00000017.jpg +0 -0
- requirements.txt +6 -0
README.md
CHANGED
|
@@ -1,12 +1,14 @@
|
|
| 1 |
---
|
| 2 |
-
title: Kurdish
|
| 3 |
-
emoji:
|
| 4 |
-
colorFrom:
|
| 5 |
-
colorTo:
|
| 6 |
sdk: gradio
|
| 7 |
-
sdk_version:
|
| 8 |
app_file: app.py
|
| 9 |
-
pinned:
|
|
|
|
|
|
|
| 10 |
---
|
| 11 |
|
| 12 |
Check out the configuration reference at https://huggingface.co/docs/hub/spaces-config-reference
|
|
|
|
| 1 |
---
|
| 2 |
+
title: Kurdish OCR
|
| 3 |
+
emoji: 🖹
|
| 4 |
+
colorFrom: indigo
|
| 5 |
+
colorTo: green
|
| 6 |
sdk: gradio
|
| 7 |
+
sdk_version: 3.23.0
|
| 8 |
app_file: app.py
|
| 9 |
+
pinned: true
|
| 10 |
+
models: ["razhan/trocr-base-ckb"]
|
| 11 |
+
license: mit
|
| 12 |
---
|
| 13 |
|
| 14 |
Check out the configuration reference at https://huggingface.co/docs/hub/spaces-config-reference
|
app.py
ADDED
|
@@ -0,0 +1,132 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import gradio as gr
|
| 2 |
+
# import cv2
|
| 3 |
+
from transformers import pipeline
|
| 4 |
+
# from PIL import Image
|
| 5 |
+
# from craft_text_detector import Craft
|
| 6 |
+
import os
|
| 7 |
+
|
| 8 |
+
model_ckpt = "razhan/trocr-base-ckb"
|
| 9 |
+
ocr = pipeline("image-to-text", model=model_ckpt)
|
| 10 |
+
|
| 11 |
+
|
| 12 |
+
# craft = Craft(
|
| 13 |
+
# output_dir=None,
|
| 14 |
+
# crop_type="poly",
|
| 15 |
+
# export_extra=False,
|
| 16 |
+
# text_threshold=0.7,
|
| 17 |
+
# link_threshold=0.4,
|
| 18 |
+
# low_text=0.4,
|
| 19 |
+
# long_size=1280,
|
| 20 |
+
# cuda=False,
|
| 21 |
+
# )
|
| 22 |
+
|
| 23 |
+
|
| 24 |
+
# def recoginition(img, prediction_result, ocr):
|
| 25 |
+
# text = []
|
| 26 |
+
# for i, j in enumerate(prediction_result["boxes"]):
|
| 27 |
+
# roi = img[
|
| 28 |
+
# int(prediction_result["boxes"][i][0][1]) : int(
|
| 29 |
+
# prediction_result["boxes"][i][2][1]
|
| 30 |
+
# ),
|
| 31 |
+
# int(prediction_result["boxes"][i][0][0]) : int(
|
| 32 |
+
# prediction_result["boxes"][i][2][0]
|
| 33 |
+
# ),
|
| 34 |
+
# ]
|
| 35 |
+
# image = Image.fromarray(roi).convert("RGB")
|
| 36 |
+
# generated_text = ocr(image)[0]["generated_text"]
|
| 37 |
+
# text.append(generated_text)
|
| 38 |
+
# return "\n".join(text)
|
| 39 |
+
|
| 40 |
+
|
| 41 |
+
# def visualize(img, prediction_result):
|
| 42 |
+
# for i, j in enumerate(prediction_result["boxes"]):
|
| 43 |
+
# y1 = int(prediction_result["boxes"][i][0][1])
|
| 44 |
+
# y2 = int(prediction_result["boxes"][i][2][1])
|
| 45 |
+
|
| 46 |
+
# x1 = int(prediction_result["boxes"][i][0][0])
|
| 47 |
+
# x2 = int(prediction_result["boxes"][i][2][0])
|
| 48 |
+
|
| 49 |
+
# cv2.rectangle(img, (x1, y1), (x2, y2), (255, 0, 0), 2)
|
| 50 |
+
|
| 51 |
+
# return Image.fromarray(img)
|
| 52 |
+
|
| 53 |
+
|
| 54 |
+
# def multi_line(img):
|
| 55 |
+
# detection = craft.detect_text(img)
|
| 56 |
+
# viz = visualize(img, detection)
|
| 57 |
+
# text = recoginition(img, detection, ocr)
|
| 58 |
+
|
| 59 |
+
# return viz, text
|
| 60 |
+
|
| 61 |
+
|
| 62 |
+
def single_line(image):
|
| 63 |
+
generated_text = ocr(image)[0]["generated_text"]
|
| 64 |
+
return generated_text
|
| 65 |
+
|
| 66 |
+
|
| 67 |
+
txt_output = gr.Textbox()
|
| 68 |
+
image_output = gr.Image(type="filepath")
|
| 69 |
+
# mode_input = gr.Radio(["single-line", "multi-line"], label="Mode", info="Wether to use the OCR model alone or with a text detection model (CRAFT)"),
|
| 70 |
+
|
| 71 |
+
|
| 72 |
+
article = "<p style='text-align: center'> Made with ❤️ by <a href='https://razhan.ai'>Razhan Hameed</a></p>"
|
| 73 |
+
# examples =[["1.jpg"], ["2.jpg"]]
|
| 74 |
+
examples = []
|
| 75 |
+
|
| 76 |
+
# get the path of all the files inside the folder data/examples put them in the format [["1.jpg"], ["2.jpg"]]
|
| 77 |
+
for file in os.listdir("examples"):
|
| 78 |
+
examples.append([os.path.join("examples", file)])
|
| 79 |
+
|
| 80 |
+
|
| 81 |
+
with gr.Blocks() as demo:
|
| 82 |
+
gr.HTML(
|
| 83 |
+
"""
|
| 84 |
+
<div style="text-align: center; max-width: 1200px; margin: 20px auto;">
|
| 85 |
+
<h1 style="font-weight: 900; font-size: 3rem; margin: 0rem"> 🚀 Kurdish OCR </h1>
|
| 86 |
+
|
| 87 |
+
<p style="font-weight: 450; font-size: 1rem; margin: 0rem"> Demo for Kurdish OCR encoder-decoder vision model on single-text line images.</p>
|
| 88 |
+
<h2 style="text-align: left; font-weight: 450; font-size: 1rem; margin-top: 0.5rem; margin-bottom: 0.5rem">
|
| 89 |
+
<ul style="list-style-type:disc;">
|
| 90 |
+
<li>The model's original training focuses on recognizing text in single lines. Once you upload the image, use the pen icon to crop the image into a single line format</li>
|
| 91 |
+
<!-- <li>For images containing multiple lines of text, you can utilize the multi-line tab. Please be aware that the CRAFT text detection used in the pipeline may encounter difficulties with Arabic letters, resulting in potential inaccuracies in detecting the boundaries and angles of the text. The OCR model will receive the identified regions, but it might not provide accurate results if certain parts of the letters are excluded in the captured regions. </li> -->
|
| 92 |
+
</ul>
|
| 93 |
+
</h2>
|
| 94 |
+
</div>
|
| 95 |
+
"""
|
| 96 |
+
)
|
| 97 |
+
|
| 98 |
+
with gr.Tab("Signle line"):
|
| 99 |
+
with gr.Row():
|
| 100 |
+
with gr.Column(scale=1):
|
| 101 |
+
image = gr.Image(type="pil", label="Image")
|
| 102 |
+
button = gr.Button("Submit")
|
| 103 |
+
|
| 104 |
+
with gr.Column(scale=1):
|
| 105 |
+
txt_output = gr.Textbox(label="Extracted text")
|
| 106 |
+
|
| 107 |
+
gr.Markdown("## Single Line Examples")
|
| 108 |
+
gr.Examples(
|
| 109 |
+
examples=examples,
|
| 110 |
+
inputs=image,
|
| 111 |
+
outputs=txt_output,
|
| 112 |
+
fn=single_line,
|
| 113 |
+
examples_per_page=20,
|
| 114 |
+
cache_examples=False,
|
| 115 |
+
run_on_click=True,
|
| 116 |
+
)
|
| 117 |
+
button.click(single_line, inputs=[image], outputs=[txt_output])
|
| 118 |
+
|
| 119 |
+
# with gr.Tab("Multi line"):
|
| 120 |
+
# with gr.Row():
|
| 121 |
+
# with gr.Column(scale=1):
|
| 122 |
+
# image = gr.Image(label="Image")
|
| 123 |
+
# button = gr.Button("Submit")
|
| 124 |
+
|
| 125 |
+
# with gr.Column(scale=1):
|
| 126 |
+
# txt_output = gr.Textbox(label="Extracted text")
|
| 127 |
+
# image_output = gr.Image(type="filepath")
|
| 128 |
+
|
| 129 |
+
# button.click(multi_line, inputs=[image], outputs=[image_output, txt_output])
|
| 130 |
+
# at the bottom write its made by Razhan
|
| 131 |
+
gr.Markdown(article)
|
| 132 |
+
demo.launch()
|
examples/00000000.jpg
ADDED
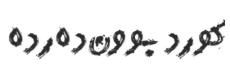
|
examples/00000001.jpg
ADDED

|
examples/00000002.jpg
ADDED

|
examples/00000003.jpg
ADDED

|
examples/00000004.jpg
ADDED

|
examples/00000005.jpg
ADDED

|
examples/00000006.jpg
ADDED

|
examples/00000007.jpg
ADDED

|
examples/00000008.jpg
ADDED

|
examples/00000009.jpg
ADDED

|
examples/00000010.jpg
ADDED

|
examples/00000011.jpg
ADDED
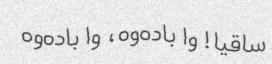
|
examples/00000012.jpg
ADDED

|
examples/00000013.jpg
ADDED

|
examples/00000014.jpg
ADDED
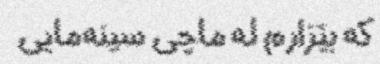
|
examples/00000015.jpg
ADDED

|
examples/00000016.jpg
ADDED

|
examples/00000017.jpg
ADDED
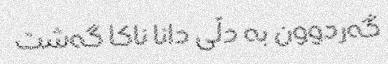
|
requirements.txt
ADDED
|
@@ -0,0 +1,6 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
gradio==4.19.1
|
| 2 |
+
#opencv-python-headless==4.5.5.62
|
| 3 |
+
--extra-index-url https://download.pytorch.org/whl/cu113
|
| 4 |
+
torch==2.1.2
|
| 5 |
+
transformers
|
| 6 |
+
# git+https://github.com/Hrazhan/craft-text-detector
|