Spaces:
Running
on
Zero

Running
on
Zero
- .gitattributes +2 -0
- .gitignore +166 -0
- LICENSE +21 -0
- README.md +13 -0
- app.py +5 -0
- images/webui_dl_model.png +0 -0
- images/webui_generate.png +0 -0
- images/webui_upload_model.png +0 -0
- mdxnet_models/model_data.json +354 -0
- packages.txt +3 -0
- requirements.txt +21 -0
- rvc_models/MODELS.txt +2 -0
- rvc_models/public_models.json +626 -0
- song_output/OUTPUT.txt +1 -0
- src/configs/32k.json +46 -0
- src/configs/32k_v2.json +46 -0
- src/configs/40k.json +46 -0
- src/configs/48k.json +46 -0
- src/configs/48k_v2.json +46 -0
- src/download_models.py +31 -0
- src/infer_pack/attentions.py +417 -0
- src/infer_pack/commons.py +166 -0
- src/infer_pack/models.py +1124 -0
- src/infer_pack/models_onnx.py +818 -0
- src/infer_pack/models_onnx_moess.py +849 -0
- src/infer_pack/modules.py +522 -0
- src/infer_pack/transforms.py +209 -0
- src/main.py +421 -0
- src/mdx.py +307 -0
- src/my_utils.py +21 -0
- src/rmvpe.py +422 -0
- src/rvc.py +165 -0
- src/trainset_preprocess_pipeline_print.py +146 -0
- src/vc_infer_pipeline.py +657 -0
- src/webui.py +334 -0
.gitattributes
ADDED
|
@@ -0,0 +1,2 @@
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Auto detect text files and perform LF normalization
|
| 2 |
+
* text=auto
|
.gitignore
ADDED
|
@@ -0,0 +1,166 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# MDX Models
|
| 2 |
+
mdxnet_models/*.onnx
|
| 3 |
+
|
| 4 |
+
# RVC Models
|
| 5 |
+
rvc_models/*/*.pth
|
| 6 |
+
rvc_models/*/*.index
|
| 7 |
+
rvc_models/*/*.npy
|
| 8 |
+
rvc_models/hubert_base.pt
|
| 9 |
+
rvc_models/rmvpe.pt
|
| 10 |
+
|
| 11 |
+
# Output
|
| 12 |
+
song_output/*/*.wav
|
| 13 |
+
song_output/*/*.mp3
|
| 14 |
+
|
| 15 |
+
# Byte-compiled / optimized / DLL files
|
| 16 |
+
__pycache__/
|
| 17 |
+
*.py[cod]
|
| 18 |
+
*$py.class
|
| 19 |
+
|
| 20 |
+
# C extensions
|
| 21 |
+
*.so
|
| 22 |
+
|
| 23 |
+
# Distribution / packaging
|
| 24 |
+
.Python
|
| 25 |
+
build/
|
| 26 |
+
develop-eggs/
|
| 27 |
+
dist/
|
| 28 |
+
downloads/
|
| 29 |
+
eggs/
|
| 30 |
+
.eggs/
|
| 31 |
+
lib/
|
| 32 |
+
lib64/
|
| 33 |
+
parts/
|
| 34 |
+
sdist/
|
| 35 |
+
var/
|
| 36 |
+
wheels/
|
| 37 |
+
share/python-wheels/
|
| 38 |
+
*.egg-info/
|
| 39 |
+
.installed.cfg
|
| 40 |
+
*.egg
|
| 41 |
+
MANIFEST
|
| 42 |
+
|
| 43 |
+
# PyInstaller
|
| 44 |
+
# Usually these files are written by a python script from a template
|
| 45 |
+
# before PyInstaller builds the exe, so as to inject date/other infos into it.
|
| 46 |
+
*.manifest
|
| 47 |
+
*.spec
|
| 48 |
+
|
| 49 |
+
# Installer logs
|
| 50 |
+
pip-log.txt
|
| 51 |
+
pip-delete-this-directory.txt
|
| 52 |
+
|
| 53 |
+
# Unit test / coverage reports
|
| 54 |
+
htmlcov/
|
| 55 |
+
.tox/
|
| 56 |
+
.nox/
|
| 57 |
+
.coverage
|
| 58 |
+
.coverage.*
|
| 59 |
+
.cache
|
| 60 |
+
nosetests.xml
|
| 61 |
+
coverage.xml
|
| 62 |
+
*.cover
|
| 63 |
+
*.py,cover
|
| 64 |
+
.hypothesis/
|
| 65 |
+
.pytest_cache/
|
| 66 |
+
cover/
|
| 67 |
+
|
| 68 |
+
# Translations
|
| 69 |
+
*.mo
|
| 70 |
+
*.pot
|
| 71 |
+
|
| 72 |
+
# Django stuff:
|
| 73 |
+
*.log
|
| 74 |
+
local_settings.py
|
| 75 |
+
db.sqlite3
|
| 76 |
+
db.sqlite3-journal
|
| 77 |
+
|
| 78 |
+
# Flask stuff:
|
| 79 |
+
instance/
|
| 80 |
+
.webassets-cache
|
| 81 |
+
|
| 82 |
+
# Scrapy stuff:
|
| 83 |
+
.scrapy
|
| 84 |
+
|
| 85 |
+
# Sphinx documentation
|
| 86 |
+
docs/_build/
|
| 87 |
+
|
| 88 |
+
# PyBuilder
|
| 89 |
+
.pybuilder/
|
| 90 |
+
target/
|
| 91 |
+
|
| 92 |
+
# Jupyter Notebook
|
| 93 |
+
.ipynb_checkpoints
|
| 94 |
+
|
| 95 |
+
# IPython
|
| 96 |
+
profile_default/
|
| 97 |
+
ipython_config.py
|
| 98 |
+
|
| 99 |
+
# pyenv
|
| 100 |
+
# For a library or package, you might want to ignore these files since the code is
|
| 101 |
+
# intended to run in multiple environments; otherwise, check them in:
|
| 102 |
+
# .python-version
|
| 103 |
+
|
| 104 |
+
# pipenv
|
| 105 |
+
# According to pypa/pipenv#598, it is recommended to include Pipfile.lock in version control.
|
| 106 |
+
# However, in case of collaboration, if having platform-specific dependencies or dependencies
|
| 107 |
+
# having no cross-platform support, pipenv may install dependencies that don't work, or not
|
| 108 |
+
# install all needed dependencies.
|
| 109 |
+
#Pipfile.lock
|
| 110 |
+
|
| 111 |
+
# poetry
|
| 112 |
+
# Similar to Pipfile.lock, it is generally recommended to include poetry.lock in version control.
|
| 113 |
+
# This is especially recommended for binary packages to ensure reproducibility, and is more
|
| 114 |
+
# commonly ignored for libraries.
|
| 115 |
+
# https://python-poetry.org/docs/basic-usage/#commit-your-poetrylock-file-to-version-control
|
| 116 |
+
#poetry.lock
|
| 117 |
+
|
| 118 |
+
# PEP 582; used by e.g. github.com/David-OConnor/pyflow
|
| 119 |
+
__pypackages__/
|
| 120 |
+
|
| 121 |
+
# Celery stuff
|
| 122 |
+
celerybeat-schedule
|
| 123 |
+
celerybeat.pid
|
| 124 |
+
|
| 125 |
+
# SageMath parsed files
|
| 126 |
+
*.sage.py
|
| 127 |
+
|
| 128 |
+
# Environments
|
| 129 |
+
.env
|
| 130 |
+
.venv
|
| 131 |
+
env/
|
| 132 |
+
venv/
|
| 133 |
+
ENV/
|
| 134 |
+
env.bak/
|
| 135 |
+
venv.bak/
|
| 136 |
+
|
| 137 |
+
# Spyder project settings
|
| 138 |
+
.spyderproject
|
| 139 |
+
.spyproject
|
| 140 |
+
|
| 141 |
+
# Rope project settings
|
| 142 |
+
.ropeproject
|
| 143 |
+
|
| 144 |
+
# mkdocs documentation
|
| 145 |
+
/site
|
| 146 |
+
|
| 147 |
+
# mypy
|
| 148 |
+
.mypy_cache/
|
| 149 |
+
.dmypy.json
|
| 150 |
+
dmypy.json
|
| 151 |
+
|
| 152 |
+
# Pyre type checker
|
| 153 |
+
.pyre/
|
| 154 |
+
|
| 155 |
+
# pytype static type analyzer
|
| 156 |
+
.pytype/
|
| 157 |
+
|
| 158 |
+
# Cython debug symbols
|
| 159 |
+
cython_debug/
|
| 160 |
+
|
| 161 |
+
# PyCharm
|
| 162 |
+
# JetBrains specific template is maintainted in a separate JetBrains.gitignore that can
|
| 163 |
+
# be found at https://github.com/github/gitignore/blob/main/Global/JetBrains.gitignore
|
| 164 |
+
# and can be added to the global gitignore or merged into this file. For a more nuclear
|
| 165 |
+
# option (not recommended) you can uncomment the following to ignore the entire idea folder.
|
| 166 |
+
.idea/
|
LICENSE
ADDED
|
@@ -0,0 +1,21 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
MIT License
|
| 2 |
+
|
| 3 |
+
Copyright (c) 2023 SociallyIneptWeeb
|
| 4 |
+
|
| 5 |
+
Permission is hereby granted, free of charge, to any person obtaining a copy
|
| 6 |
+
of this software and associated documentation files (the "Software"), to deal
|
| 7 |
+
in the Software without restriction, including without limitation the rights
|
| 8 |
+
to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
|
| 9 |
+
copies of the Software, and to permit persons to whom the Software is
|
| 10 |
+
furnished to do so, subject to the following conditions:
|
| 11 |
+
|
| 12 |
+
The above copyright notice and this permission notice shall be included in all
|
| 13 |
+
copies or substantial portions of the Software.
|
| 14 |
+
|
| 15 |
+
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
|
| 16 |
+
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
|
| 17 |
+
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
|
| 18 |
+
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
|
| 19 |
+
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
|
| 20 |
+
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
|
| 21 |
+
SOFTWARE.
|
README.md
ADDED
|
@@ -0,0 +1,13 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
title: AICoverGen
|
| 3 |
+
emoji: 🚀
|
| 4 |
+
colorFrom: red
|
| 5 |
+
colorTo: pink
|
| 6 |
+
sdk: gradio
|
| 7 |
+
sdk_version: 4.36.1
|
| 8 |
+
app_file: app.py
|
| 9 |
+
pinned: false
|
| 10 |
+
license: mit
|
| 11 |
+
---
|
| 12 |
+
|
| 13 |
+
Check out the configuration reference at https://huggingface.co/docs/hub/spaces-config-reference
|
app.py
ADDED
|
@@ -0,0 +1,5 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import os
|
| 2 |
+
|
| 3 |
+
os.system("pip install ort-nightly-gpu --index-url=https://aiinfra.pkgs.visualstudio.com/PublicPackages/_packaging/ort-cuda-12-nightly/pypi/simple/")
|
| 4 |
+
os.system("python src/download_models.py")
|
| 5 |
+
os.system("python src/webui.py")
|
images/webui_dl_model.png
ADDED
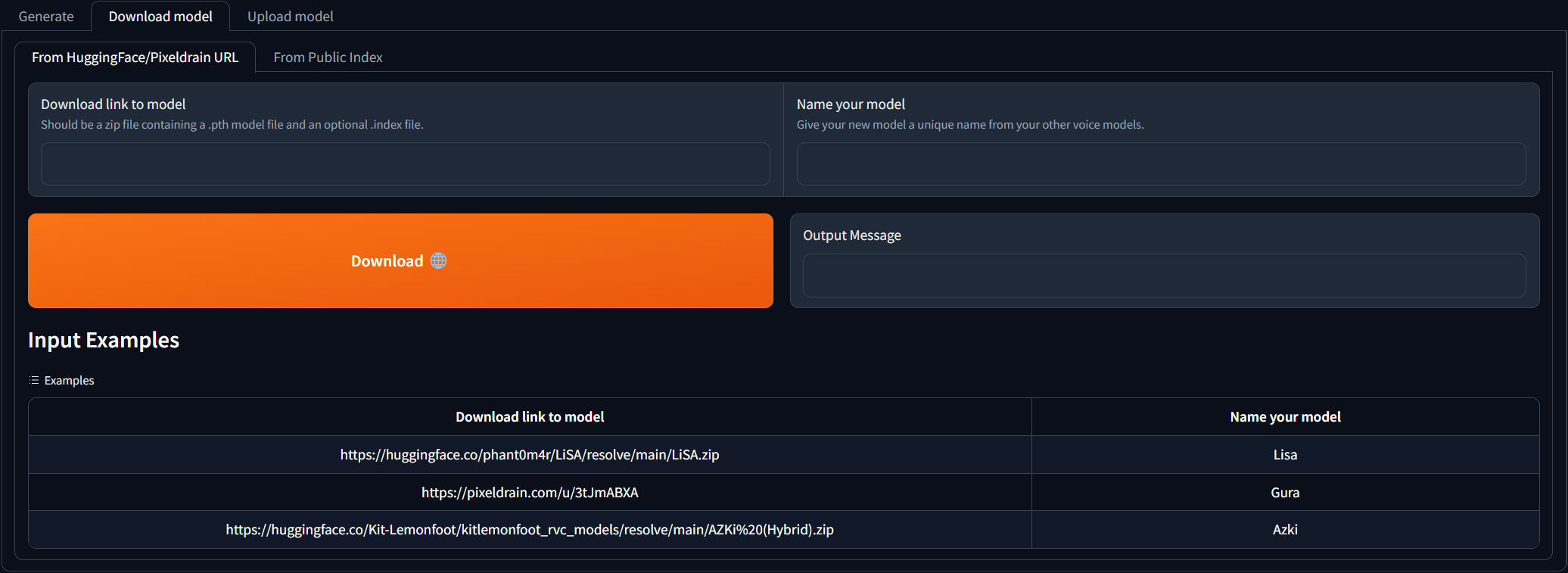
|
images/webui_generate.png
ADDED
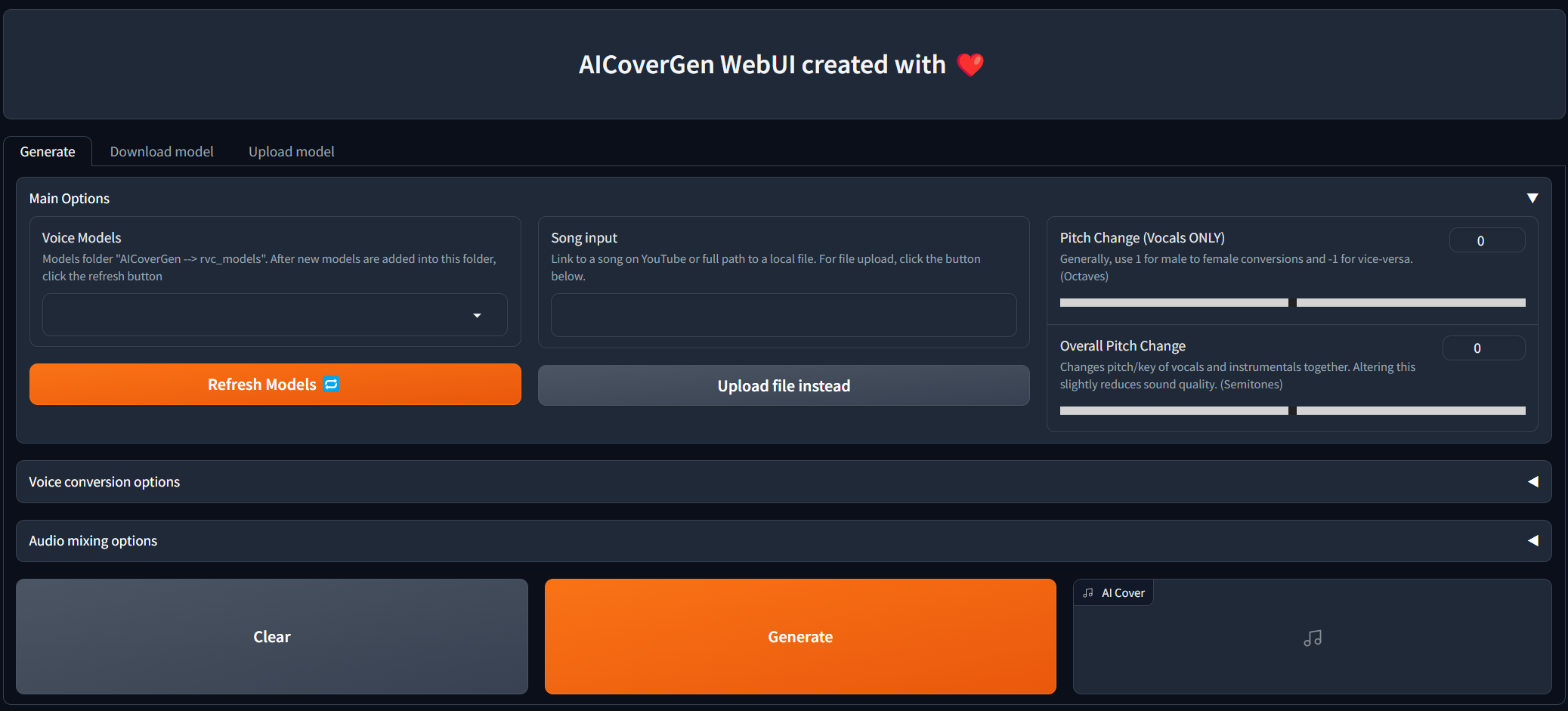
|
images/webui_upload_model.png
ADDED
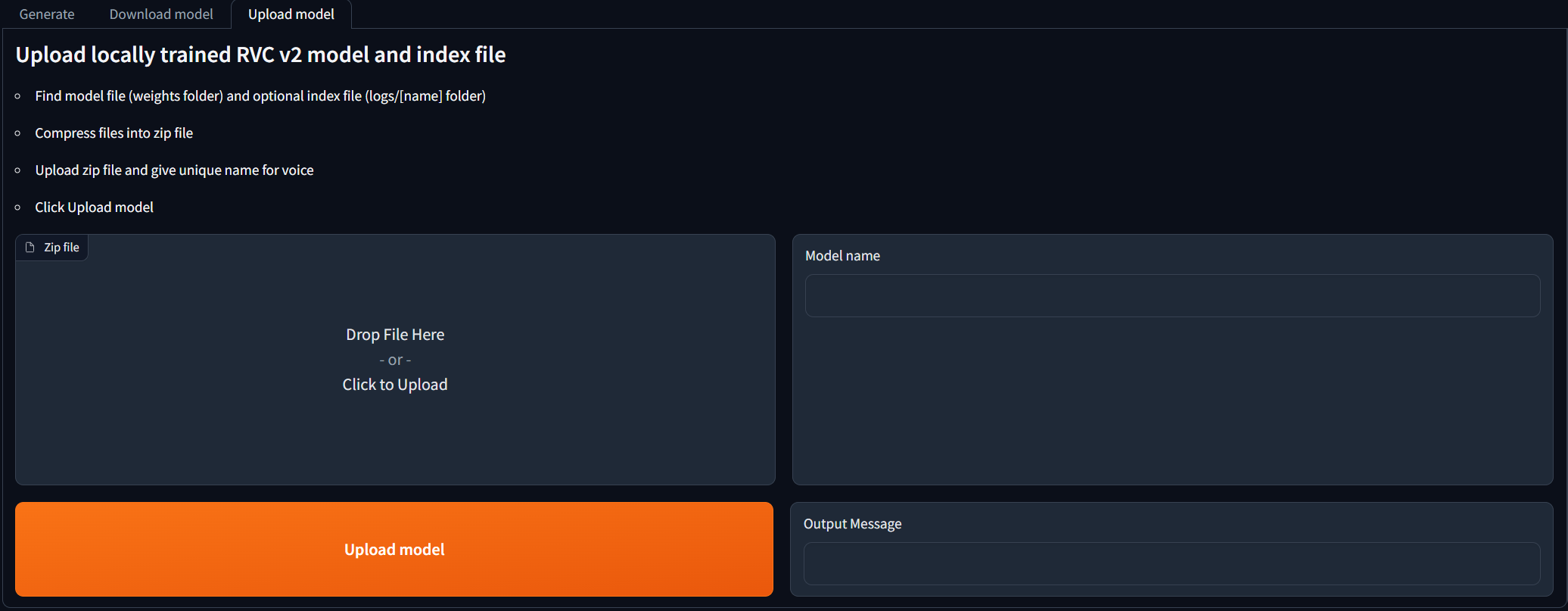
|
mdxnet_models/model_data.json
ADDED
|
@@ -0,0 +1,354 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"0ddfc0eb5792638ad5dc27850236c246": {
|
| 3 |
+
"compensate": 1.035,
|
| 4 |
+
"mdx_dim_f_set": 2048,
|
| 5 |
+
"mdx_dim_t_set": 8,
|
| 6 |
+
"mdx_n_fft_scale_set": 6144,
|
| 7 |
+
"primary_stem": "Vocals"
|
| 8 |
+
},
|
| 9 |
+
"26d308f91f3423a67dc69a6d12a8793d": {
|
| 10 |
+
"compensate": 1.035,
|
| 11 |
+
"mdx_dim_f_set": 2048,
|
| 12 |
+
"mdx_dim_t_set": 9,
|
| 13 |
+
"mdx_n_fft_scale_set": 8192,
|
| 14 |
+
"primary_stem": "Other"
|
| 15 |
+
},
|
| 16 |
+
"2cdd429caac38f0194b133884160f2c6": {
|
| 17 |
+
"compensate": 1.045,
|
| 18 |
+
"mdx_dim_f_set": 3072,
|
| 19 |
+
"mdx_dim_t_set": 8,
|
| 20 |
+
"mdx_n_fft_scale_set": 7680,
|
| 21 |
+
"primary_stem": "Instrumental"
|
| 22 |
+
},
|
| 23 |
+
"2f5501189a2f6db6349916fabe8c90de": {
|
| 24 |
+
"compensate": 1.035,
|
| 25 |
+
"mdx_dim_f_set": 2048,
|
| 26 |
+
"mdx_dim_t_set": 8,
|
| 27 |
+
"mdx_n_fft_scale_set": 6144,
|
| 28 |
+
"primary_stem": "Vocals"
|
| 29 |
+
},
|
| 30 |
+
"398580b6d5d973af3120df54cee6759d": {
|
| 31 |
+
"compensate": 1.75,
|
| 32 |
+
"mdx_dim_f_set": 3072,
|
| 33 |
+
"mdx_dim_t_set": 8,
|
| 34 |
+
"mdx_n_fft_scale_set": 7680,
|
| 35 |
+
"primary_stem": "Vocals"
|
| 36 |
+
},
|
| 37 |
+
"488b3e6f8bd3717d9d7c428476be2d75": {
|
| 38 |
+
"compensate": 1.035,
|
| 39 |
+
"mdx_dim_f_set": 3072,
|
| 40 |
+
"mdx_dim_t_set": 8,
|
| 41 |
+
"mdx_n_fft_scale_set": 7680,
|
| 42 |
+
"primary_stem": "Instrumental"
|
| 43 |
+
},
|
| 44 |
+
"4910e7827f335048bdac11fa967772f9": {
|
| 45 |
+
"compensate": 1.035,
|
| 46 |
+
"mdx_dim_f_set": 2048,
|
| 47 |
+
"mdx_dim_t_set": 7,
|
| 48 |
+
"mdx_n_fft_scale_set": 4096,
|
| 49 |
+
"primary_stem": "Drums"
|
| 50 |
+
},
|
| 51 |
+
"53c4baf4d12c3e6c3831bb8f5b532b93": {
|
| 52 |
+
"compensate": 1.043,
|
| 53 |
+
"mdx_dim_f_set": 3072,
|
| 54 |
+
"mdx_dim_t_set": 8,
|
| 55 |
+
"mdx_n_fft_scale_set": 7680,
|
| 56 |
+
"primary_stem": "Vocals"
|
| 57 |
+
},
|
| 58 |
+
"5d343409ef0df48c7d78cce9f0106781": {
|
| 59 |
+
"compensate": 1.075,
|
| 60 |
+
"mdx_dim_f_set": 3072,
|
| 61 |
+
"mdx_dim_t_set": 8,
|
| 62 |
+
"mdx_n_fft_scale_set": 7680,
|
| 63 |
+
"primary_stem": "Vocals"
|
| 64 |
+
},
|
| 65 |
+
"5f6483271e1efb9bfb59e4a3e6d4d098": {
|
| 66 |
+
"compensate": 1.035,
|
| 67 |
+
"mdx_dim_f_set": 2048,
|
| 68 |
+
"mdx_dim_t_set": 9,
|
| 69 |
+
"mdx_n_fft_scale_set": 6144,
|
| 70 |
+
"primary_stem": "Vocals"
|
| 71 |
+
},
|
| 72 |
+
"65ab5919372a128e4167f5e01a8fda85": {
|
| 73 |
+
"compensate": 1.035,
|
| 74 |
+
"mdx_dim_f_set": 2048,
|
| 75 |
+
"mdx_dim_t_set": 8,
|
| 76 |
+
"mdx_n_fft_scale_set": 8192,
|
| 77 |
+
"primary_stem": "Other"
|
| 78 |
+
},
|
| 79 |
+
"6703e39f36f18aa7855ee1047765621d": {
|
| 80 |
+
"compensate": 1.035,
|
| 81 |
+
"mdx_dim_f_set": 2048,
|
| 82 |
+
"mdx_dim_t_set": 9,
|
| 83 |
+
"mdx_n_fft_scale_set": 16384,
|
| 84 |
+
"primary_stem": "Bass"
|
| 85 |
+
},
|
| 86 |
+
"6b31de20e84392859a3d09d43f089515": {
|
| 87 |
+
"compensate": 1.035,
|
| 88 |
+
"mdx_dim_f_set": 2048,
|
| 89 |
+
"mdx_dim_t_set": 8,
|
| 90 |
+
"mdx_n_fft_scale_set": 6144,
|
| 91 |
+
"primary_stem": "Vocals"
|
| 92 |
+
},
|
| 93 |
+
"867595e9de46f6ab699008295df62798": {
|
| 94 |
+
"compensate": 1.03,
|
| 95 |
+
"mdx_dim_f_set": 3072,
|
| 96 |
+
"mdx_dim_t_set": 8,
|
| 97 |
+
"mdx_n_fft_scale_set": 7680,
|
| 98 |
+
"primary_stem": "Vocals"
|
| 99 |
+
},
|
| 100 |
+
"a3cd63058945e777505c01d2507daf37": {
|
| 101 |
+
"compensate": 1.03,
|
| 102 |
+
"mdx_dim_f_set": 2048,
|
| 103 |
+
"mdx_dim_t_set": 8,
|
| 104 |
+
"mdx_n_fft_scale_set": 6144,
|
| 105 |
+
"primary_stem": "Vocals"
|
| 106 |
+
},
|
| 107 |
+
"b33d9b3950b6cbf5fe90a32608924700": {
|
| 108 |
+
"compensate": 1.03,
|
| 109 |
+
"mdx_dim_f_set": 3072,
|
| 110 |
+
"mdx_dim_t_set": 8,
|
| 111 |
+
"mdx_n_fft_scale_set": 7680,
|
| 112 |
+
"primary_stem": "Vocals"
|
| 113 |
+
},
|
| 114 |
+
"c3b29bdce8c4fa17ec609e16220330ab": {
|
| 115 |
+
"compensate": 1.035,
|
| 116 |
+
"mdx_dim_f_set": 2048,
|
| 117 |
+
"mdx_dim_t_set": 8,
|
| 118 |
+
"mdx_n_fft_scale_set": 16384,
|
| 119 |
+
"primary_stem": "Bass"
|
| 120 |
+
},
|
| 121 |
+
"ceed671467c1f64ebdfac8a2490d0d52": {
|
| 122 |
+
"compensate": 1.035,
|
| 123 |
+
"mdx_dim_f_set": 3072,
|
| 124 |
+
"mdx_dim_t_set": 8,
|
| 125 |
+
"mdx_n_fft_scale_set": 7680,
|
| 126 |
+
"primary_stem": "Instrumental"
|
| 127 |
+
},
|
| 128 |
+
"d2a1376f310e4f7fa37fb9b5774eb701": {
|
| 129 |
+
"compensate": 1.035,
|
| 130 |
+
"mdx_dim_f_set": 3072,
|
| 131 |
+
"mdx_dim_t_set": 8,
|
| 132 |
+
"mdx_n_fft_scale_set": 7680,
|
| 133 |
+
"primary_stem": "Instrumental"
|
| 134 |
+
},
|
| 135 |
+
"d7bff498db9324db933d913388cba6be": {
|
| 136 |
+
"compensate": 1.035,
|
| 137 |
+
"mdx_dim_f_set": 2048,
|
| 138 |
+
"mdx_dim_t_set": 8,
|
| 139 |
+
"mdx_n_fft_scale_set": 6144,
|
| 140 |
+
"primary_stem": "Vocals"
|
| 141 |
+
},
|
| 142 |
+
"d94058f8c7f1fae4164868ae8ae66b20": {
|
| 143 |
+
"compensate": 1.035,
|
| 144 |
+
"mdx_dim_f_set": 2048,
|
| 145 |
+
"mdx_dim_t_set": 8,
|
| 146 |
+
"mdx_n_fft_scale_set": 6144,
|
| 147 |
+
"primary_stem": "Vocals"
|
| 148 |
+
},
|
| 149 |
+
"dc41ede5961d50f277eb846db17f5319": {
|
| 150 |
+
"compensate": 1.035,
|
| 151 |
+
"mdx_dim_f_set": 2048,
|
| 152 |
+
"mdx_dim_t_set": 9,
|
| 153 |
+
"mdx_n_fft_scale_set": 4096,
|
| 154 |
+
"primary_stem": "Drums"
|
| 155 |
+
},
|
| 156 |
+
"e5572e58abf111f80d8241d2e44e7fa4": {
|
| 157 |
+
"compensate": 1.028,
|
| 158 |
+
"mdx_dim_f_set": 3072,
|
| 159 |
+
"mdx_dim_t_set": 8,
|
| 160 |
+
"mdx_n_fft_scale_set": 7680,
|
| 161 |
+
"primary_stem": "Instrumental"
|
| 162 |
+
},
|
| 163 |
+
"e7324c873b1f615c35c1967f912db92a": {
|
| 164 |
+
"compensate": 1.03,
|
| 165 |
+
"mdx_dim_f_set": 3072,
|
| 166 |
+
"mdx_dim_t_set": 8,
|
| 167 |
+
"mdx_n_fft_scale_set": 7680,
|
| 168 |
+
"primary_stem": "Vocals"
|
| 169 |
+
},
|
| 170 |
+
"1c56ec0224f1d559c42fd6fd2a67b154": {
|
| 171 |
+
"compensate": 1.025,
|
| 172 |
+
"mdx_dim_f_set": 2048,
|
| 173 |
+
"mdx_dim_t_set": 8,
|
| 174 |
+
"mdx_n_fft_scale_set": 5120,
|
| 175 |
+
"primary_stem": "Instrumental"
|
| 176 |
+
},
|
| 177 |
+
"f2df6d6863d8f435436d8b561594ff49": {
|
| 178 |
+
"compensate": 1.035,
|
| 179 |
+
"mdx_dim_f_set": 3072,
|
| 180 |
+
"mdx_dim_t_set": 8,
|
| 181 |
+
"mdx_n_fft_scale_set": 7680,
|
| 182 |
+
"primary_stem": "Instrumental"
|
| 183 |
+
},
|
| 184 |
+
"b06327a00d5e5fbc7d96e1781bbdb596": {
|
| 185 |
+
"compensate": 1.035,
|
| 186 |
+
"mdx_dim_f_set": 3072,
|
| 187 |
+
"mdx_dim_t_set": 8,
|
| 188 |
+
"mdx_n_fft_scale_set": 6144,
|
| 189 |
+
"primary_stem": "Instrumental"
|
| 190 |
+
},
|
| 191 |
+
"94ff780b977d3ca07c7a343dab2e25dd": {
|
| 192 |
+
"compensate": 1.039,
|
| 193 |
+
"mdx_dim_f_set": 3072,
|
| 194 |
+
"mdx_dim_t_set": 8,
|
| 195 |
+
"mdx_n_fft_scale_set": 6144,
|
| 196 |
+
"primary_stem": "Instrumental"
|
| 197 |
+
},
|
| 198 |
+
"73492b58195c3b52d34590d5474452f6": {
|
| 199 |
+
"compensate": 1.043,
|
| 200 |
+
"mdx_dim_f_set": 3072,
|
| 201 |
+
"mdx_dim_t_set": 8,
|
| 202 |
+
"mdx_n_fft_scale_set": 7680,
|
| 203 |
+
"primary_stem": "Vocals"
|
| 204 |
+
},
|
| 205 |
+
"970b3f9492014d18fefeedfe4773cb42": {
|
| 206 |
+
"compensate": 1.009,
|
| 207 |
+
"mdx_dim_f_set": 3072,
|
| 208 |
+
"mdx_dim_t_set": 8,
|
| 209 |
+
"mdx_n_fft_scale_set": 7680,
|
| 210 |
+
"primary_stem": "Vocals"
|
| 211 |
+
},
|
| 212 |
+
"1d64a6d2c30f709b8c9b4ce1366d96ee": {
|
| 213 |
+
"compensate": 1.035,
|
| 214 |
+
"mdx_dim_f_set": 2048,
|
| 215 |
+
"mdx_dim_t_set": 8,
|
| 216 |
+
"mdx_n_fft_scale_set": 5120,
|
| 217 |
+
"primary_stem": "Instrumental"
|
| 218 |
+
},
|
| 219 |
+
"203f2a3955221b64df85a41af87cf8f0": {
|
| 220 |
+
"compensate": 1.035,
|
| 221 |
+
"mdx_dim_f_set": 3072,
|
| 222 |
+
"mdx_dim_t_set": 8,
|
| 223 |
+
"mdx_n_fft_scale_set": 6144,
|
| 224 |
+
"primary_stem": "Instrumental"
|
| 225 |
+
},
|
| 226 |
+
"291c2049608edb52648b96e27eb80e95": {
|
| 227 |
+
"compensate": 1.035,
|
| 228 |
+
"mdx_dim_f_set": 3072,
|
| 229 |
+
"mdx_dim_t_set": 8,
|
| 230 |
+
"mdx_n_fft_scale_set": 6144,
|
| 231 |
+
"primary_stem": "Instrumental"
|
| 232 |
+
},
|
| 233 |
+
"ead8d05dab12ec571d67549b3aab03fc": {
|
| 234 |
+
"compensate": 1.035,
|
| 235 |
+
"mdx_dim_f_set": 3072,
|
| 236 |
+
"mdx_dim_t_set": 8,
|
| 237 |
+
"mdx_n_fft_scale_set": 6144,
|
| 238 |
+
"primary_stem": "Instrumental"
|
| 239 |
+
},
|
| 240 |
+
"cc63408db3d80b4d85b0287d1d7c9632": {
|
| 241 |
+
"compensate": 1.033,
|
| 242 |
+
"mdx_dim_f_set": 3072,
|
| 243 |
+
"mdx_dim_t_set": 8,
|
| 244 |
+
"mdx_n_fft_scale_set": 6144,
|
| 245 |
+
"primary_stem": "Instrumental"
|
| 246 |
+
},
|
| 247 |
+
"cd5b2989ad863f116c855db1dfe24e39": {
|
| 248 |
+
"compensate": 1.035,
|
| 249 |
+
"mdx_dim_f_set": 3072,
|
| 250 |
+
"mdx_dim_t_set": 9,
|
| 251 |
+
"mdx_n_fft_scale_set": 6144,
|
| 252 |
+
"primary_stem": "Other"
|
| 253 |
+
},
|
| 254 |
+
"55657dd70583b0fedfba5f67df11d711": {
|
| 255 |
+
"compensate": 1.022,
|
| 256 |
+
"mdx_dim_f_set": 3072,
|
| 257 |
+
"mdx_dim_t_set": 8,
|
| 258 |
+
"mdx_n_fft_scale_set": 6144,
|
| 259 |
+
"primary_stem": "Instrumental"
|
| 260 |
+
},
|
| 261 |
+
"b6bccda408a436db8500083ef3491e8b": {
|
| 262 |
+
"compensate": 1.02,
|
| 263 |
+
"mdx_dim_f_set": 3072,
|
| 264 |
+
"mdx_dim_t_set": 8,
|
| 265 |
+
"mdx_n_fft_scale_set": 7680,
|
| 266 |
+
"primary_stem": "Instrumental"
|
| 267 |
+
},
|
| 268 |
+
"8a88db95c7fb5dbe6a095ff2ffb428b1": {
|
| 269 |
+
"compensate": 1.026,
|
| 270 |
+
"mdx_dim_f_set": 2048,
|
| 271 |
+
"mdx_dim_t_set": 8,
|
| 272 |
+
"mdx_n_fft_scale_set": 5120,
|
| 273 |
+
"primary_stem": "Instrumental"
|
| 274 |
+
},
|
| 275 |
+
"b78da4afc6512f98e4756f5977f5c6b9": {
|
| 276 |
+
"compensate": 1.021,
|
| 277 |
+
"mdx_dim_f_set": 3072,
|
| 278 |
+
"mdx_dim_t_set": 8,
|
| 279 |
+
"mdx_n_fft_scale_set": 7680,
|
| 280 |
+
"primary_stem": "Instrumental"
|
| 281 |
+
},
|
| 282 |
+
"77d07b2667ddf05b9e3175941b4454a0": {
|
| 283 |
+
"compensate": 1.021,
|
| 284 |
+
"mdx_dim_f_set": 3072,
|
| 285 |
+
"mdx_dim_t_set": 8,
|
| 286 |
+
"mdx_n_fft_scale_set": 7680,
|
| 287 |
+
"primary_stem": "Vocals"
|
| 288 |
+
},
|
| 289 |
+
"0f2a6bc5b49d87d64728ee40e23bceb1": {
|
| 290 |
+
"compensate": 1.019,
|
| 291 |
+
"mdx_dim_f_set": 2560,
|
| 292 |
+
"mdx_dim_t_set": 8,
|
| 293 |
+
"mdx_n_fft_scale_set": 5120,
|
| 294 |
+
"primary_stem": "Instrumental"
|
| 295 |
+
},
|
| 296 |
+
"b02be2d198d4968a121030cf8950b492": {
|
| 297 |
+
"compensate": 1.020,
|
| 298 |
+
"mdx_dim_f_set": 2560,
|
| 299 |
+
"mdx_dim_t_set": 8,
|
| 300 |
+
"mdx_n_fft_scale_set": 5120,
|
| 301 |
+
"primary_stem": "No Crowd"
|
| 302 |
+
},
|
| 303 |
+
"2154254ee89b2945b97a7efed6e88820": {
|
| 304 |
+
"config_yaml": "model_2_stem_061321.yaml"
|
| 305 |
+
},
|
| 306 |
+
"063aadd735d58150722926dcbf5852a9": {
|
| 307 |
+
"config_yaml": "model_2_stem_061321.yaml"
|
| 308 |
+
},
|
| 309 |
+
"fe96801369f6a148df2720f5ced88c19": {
|
| 310 |
+
"config_yaml": "model3.yaml"
|
| 311 |
+
},
|
| 312 |
+
"02e8b226f85fb566e5db894b9931c640": {
|
| 313 |
+
"config_yaml": "model2.yaml"
|
| 314 |
+
},
|
| 315 |
+
"e3de6d861635ab9c1d766149edd680d6": {
|
| 316 |
+
"config_yaml": "model1.yaml"
|
| 317 |
+
},
|
| 318 |
+
"3f2936c554ab73ce2e396d54636bd373": {
|
| 319 |
+
"config_yaml": "modelB.yaml"
|
| 320 |
+
},
|
| 321 |
+
"890d0f6f82d7574bca741a9e8bcb8168": {
|
| 322 |
+
"config_yaml": "modelB.yaml"
|
| 323 |
+
},
|
| 324 |
+
"63a3cb8c37c474681049be4ad1ba8815": {
|
| 325 |
+
"config_yaml": "modelB.yaml"
|
| 326 |
+
},
|
| 327 |
+
"a7fc5d719743c7fd6b61bd2b4d48b9f0": {
|
| 328 |
+
"config_yaml": "modelA.yaml"
|
| 329 |
+
},
|
| 330 |
+
"3567f3dee6e77bf366fcb1c7b8bc3745": {
|
| 331 |
+
"config_yaml": "modelA.yaml"
|
| 332 |
+
},
|
| 333 |
+
"a28f4d717bd0d34cd2ff7a3b0a3d065e": {
|
| 334 |
+
"config_yaml": "modelA.yaml"
|
| 335 |
+
},
|
| 336 |
+
"c9971a18da20911822593dc81caa8be9": {
|
| 337 |
+
"config_yaml": "sndfx.yaml"
|
| 338 |
+
},
|
| 339 |
+
"57d94d5ed705460d21c75a5ac829a605": {
|
| 340 |
+
"config_yaml": "sndfx.yaml"
|
| 341 |
+
},
|
| 342 |
+
"e7a25f8764f25a52c1b96c4946e66ba2": {
|
| 343 |
+
"config_yaml": "sndfx.yaml"
|
| 344 |
+
},
|
| 345 |
+
"104081d24e37217086ce5fde09147ee1": {
|
| 346 |
+
"config_yaml": "model_2_stem_061321.yaml"
|
| 347 |
+
},
|
| 348 |
+
"1e6165b601539f38d0a9330f3facffeb": {
|
| 349 |
+
"config_yaml": "model_2_stem_061321.yaml"
|
| 350 |
+
},
|
| 351 |
+
"fe0108464ce0d8271be5ab810891bd7c": {
|
| 352 |
+
"config_yaml": "model_2_stem_full_band.yaml"
|
| 353 |
+
}
|
| 354 |
+
}
|
packages.txt
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
aria2
|
| 2 |
+
ffmpeg
|
| 3 |
+
sox
|
requirements.txt
ADDED
|
@@ -0,0 +1,21 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
deemix
|
| 2 |
+
fairseq==0.12.2
|
| 3 |
+
faiss-cpu==1.7.3
|
| 4 |
+
ffmpeg-python>=0.2.0
|
| 5 |
+
gradio==3.39.0
|
| 6 |
+
lib==4.0.0
|
| 7 |
+
librosa==0.9.1
|
| 8 |
+
numpy==1.23.5
|
| 9 |
+
# onnxruntime #onnxruntime_gpu
|
| 10 |
+
praat-parselmouth>=0.4.2
|
| 11 |
+
pedalboard==0.7.7
|
| 12 |
+
pydub==0.25.1
|
| 13 |
+
pyworld==0.3.4
|
| 14 |
+
Requests==2.31.0
|
| 15 |
+
scipy==1.11.1
|
| 16 |
+
soundfile==0.12.1
|
| 17 |
+
torch==2.2.0
|
| 18 |
+
torchcrepe==0.0.20
|
| 19 |
+
tqdm==4.65.0
|
| 20 |
+
yt_dlp==2023.7.6
|
| 21 |
+
sox==1.4.1
|
rvc_models/MODELS.txt
ADDED
|
@@ -0,0 +1,2 @@
|
|
|
|
|
|
|
|
|
|
| 1 |
+
RVC Models can be added as a folder here. Each folder should contain the model file (.pth extension), and an index file (.index extension).
|
| 2 |
+
For example, a folder called Maya, containing 2 files, Maya.pth and added_IVF1905_Flat_nprobe_Maya_v2.index.
|
rvc_models/public_models.json
ADDED
|
@@ -0,0 +1,626 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"tags": {
|
| 3 |
+
"English": "Character speaks English",
|
| 4 |
+
"Japanese": "Character speaks Japanese",
|
| 5 |
+
"Other Language": "The character speaks Other Language",
|
| 6 |
+
"Anime": "Character from anime",
|
| 7 |
+
"Vtuber": "Character is a vtuber",
|
| 8 |
+
"Real person": "A person who exists in the real world",
|
| 9 |
+
"Game character": "A character from the game"
|
| 10 |
+
},
|
| 11 |
+
"voice_models": [
|
| 12 |
+
{
|
| 13 |
+
"name": "Emilia",
|
| 14 |
+
"url": "https://huggingface.co/RinkaEmina/RVC_Sharing/resolve/main/Emilia%20V2%2048000.zip",
|
| 15 |
+
"description": "Emilia from Re:Zero",
|
| 16 |
+
"added": "2023-07-31",
|
| 17 |
+
"credit": "rinka4759",
|
| 18 |
+
"tags": [
|
| 19 |
+
"Anime"
|
| 20 |
+
]
|
| 21 |
+
},
|
| 22 |
+
{
|
| 23 |
+
"name": "Klee",
|
| 24 |
+
"url": "https://huggingface.co/qweshkka/Klee/resolve/main/Klee.zip",
|
| 25 |
+
"description": "Klee from Genshin Impact",
|
| 26 |
+
"added": "2023-07-31",
|
| 27 |
+
"credit": "qweshsmashjuicefruity",
|
| 28 |
+
"tags": [
|
| 29 |
+
"Game character",
|
| 30 |
+
"Japanese"
|
| 31 |
+
]
|
| 32 |
+
},
|
| 33 |
+
{
|
| 34 |
+
"name": "Yelan",
|
| 35 |
+
"url": "https://huggingface.co/iroaK/RVC2_Yelan_GenshinImpact/resolve/main/YelanJP.zip",
|
| 36 |
+
"description": "Yelan from Genshin Impact",
|
| 37 |
+
"added": "2023-07-31",
|
| 38 |
+
"credit": "iroak",
|
| 39 |
+
"tags": [
|
| 40 |
+
"Game character",
|
| 41 |
+
"Japanese"
|
| 42 |
+
]
|
| 43 |
+
},
|
| 44 |
+
{
|
| 45 |
+
"name": "Yae Miko",
|
| 46 |
+
"url": "https://huggingface.co/iroaK/RVC2_YaeMiko_GenshinImpact/resolve/main/Yae_MikoJP.zip",
|
| 47 |
+
"description": "Yae Miko from Genshin Impact",
|
| 48 |
+
"added": "2023-07-31",
|
| 49 |
+
"credit": "iroak",
|
| 50 |
+
"tags": [
|
| 51 |
+
"Game character",
|
| 52 |
+
"Japanese"
|
| 53 |
+
]
|
| 54 |
+
},
|
| 55 |
+
{
|
| 56 |
+
"name": "Lisa",
|
| 57 |
+
"url": "https://huggingface.co/qweshkka/Lisa2ver/resolve/main/Lisa.zip",
|
| 58 |
+
"description": "Lisa from Genshin Impact",
|
| 59 |
+
"added": "2023-07-31",
|
| 60 |
+
"credit": "qweshsmashjuicefruity",
|
| 61 |
+
"tags": [
|
| 62 |
+
"Game character",
|
| 63 |
+
"English"
|
| 64 |
+
]
|
| 65 |
+
},
|
| 66 |
+
{
|
| 67 |
+
"name": "Kazuha",
|
| 68 |
+
"url": "https://huggingface.co/iroaK/RVC2_Kazuha_GenshinImpact/resolve/main/Kazuha.zip",
|
| 69 |
+
"description": "Kaedehara Kazuha from Genshin Impact",
|
| 70 |
+
"added": "2023-07-31",
|
| 71 |
+
"credit": "iroak",
|
| 72 |
+
"tags": [
|
| 73 |
+
"Game character",
|
| 74 |
+
"Japanese"
|
| 75 |
+
]
|
| 76 |
+
},
|
| 77 |
+
{
|
| 78 |
+
"name": "Barbara",
|
| 79 |
+
"url": "https://huggingface.co/iroaK/RVC2_Barbara_GenshinImpact/resolve/main/BarbaraJP.zip",
|
| 80 |
+
"description": "Barbara from Genshin Impact",
|
| 81 |
+
"added": "2023-07-31",
|
| 82 |
+
"credit": "iroak",
|
| 83 |
+
"tags": [
|
| 84 |
+
"Game character",
|
| 85 |
+
"Japanese"
|
| 86 |
+
]
|
| 87 |
+
},
|
| 88 |
+
{
|
| 89 |
+
"name": "Tom Holland",
|
| 90 |
+
"url": "https://huggingface.co/TJKAI/TomHolland/resolve/main/TomHolland.zip",
|
| 91 |
+
"description": "Tom Holland (Spider-Man)",
|
| 92 |
+
"added": "2023-08-03",
|
| 93 |
+
"credit": "tjkcreative",
|
| 94 |
+
"tags": [
|
| 95 |
+
"Real person",
|
| 96 |
+
"English"
|
| 97 |
+
]
|
| 98 |
+
},
|
| 99 |
+
{
|
| 100 |
+
"name": "Kamisato Ayaka",
|
| 101 |
+
"url": "https://huggingface.co/benitheworld/ayaka-cn/resolve/main/ayaka-cn.zip",
|
| 102 |
+
"description": "Kamisato Ayaka from Genshin Impact - CN voice actor",
|
| 103 |
+
"added": "2023-08-03",
|
| 104 |
+
"credit": "kannysoap",
|
| 105 |
+
"tags": [
|
| 106 |
+
"Game character",
|
| 107 |
+
"Other Language"
|
| 108 |
+
]
|
| 109 |
+
},
|
| 110 |
+
{
|
| 111 |
+
"name": "Amai Odayaka",
|
| 112 |
+
"url": "https://huggingface.co/NoIdea4Username/NoIdeaRVCCollection/resolve/main/Amai-Odayaka.zip",
|
| 113 |
+
"description": "Amai Odayaka from Yandere Simulator",
|
| 114 |
+
"added": "2023-08-03",
|
| 115 |
+
"credit": "minecraftian47",
|
| 116 |
+
"tags": [
|
| 117 |
+
"Anime",
|
| 118 |
+
"English"
|
| 119 |
+
]
|
| 120 |
+
},
|
| 121 |
+
{
|
| 122 |
+
"name": "Compa - Hyperdimension Neptunia",
|
| 123 |
+
"url": "https://huggingface.co/zeerowiibu/WiibuRVCCollection/resolve/main/Compa%20(Choujigen%20Game%20Neptunia)%20(JPN)%20(RVC%20v2)%20(150%20Epochs).zip",
|
| 124 |
+
"description": "Compa from Choujigen Game Neptune (aka Hyperdimension Neptunia)",
|
| 125 |
+
"added": "2023-08-03",
|
| 126 |
+
"credit": "zeerowiibu",
|
| 127 |
+
"tags": [
|
| 128 |
+
"Anime",
|
| 129 |
+
"Japanese"
|
| 130 |
+
]
|
| 131 |
+
},
|
| 132 |
+
{
|
| 133 |
+
"name": "Fu Xuan",
|
| 134 |
+
"url": "https://huggingface.co/Juneuarie/FuXuan/resolve/main/FuXuan.zip",
|
| 135 |
+
"description": "Fu Xuan from Honkai Star Rail (HSR)",
|
| 136 |
+
"added": "2023-08-03",
|
| 137 |
+
"credit": "__june",
|
| 138 |
+
"tags": [
|
| 139 |
+
"Game character",
|
| 140 |
+
"English"
|
| 141 |
+
]
|
| 142 |
+
},
|
| 143 |
+
{
|
| 144 |
+
"name": "Xinyan",
|
| 145 |
+
"url": "https://huggingface.co/AnimeSessions/rvc_voice_models/resolve/main/XinyanRVC.zip",
|
| 146 |
+
"description": "Xinyan from Genshin Impact",
|
| 147 |
+
"added": "2023-08-03",
|
| 148 |
+
"credit": "shyelijah",
|
| 149 |
+
"tags": [
|
| 150 |
+
"Game character",
|
| 151 |
+
"English"
|
| 152 |
+
]
|
| 153 |
+
},
|
| 154 |
+
{
|
| 155 |
+
"name": "Enterprise",
|
| 156 |
+
"url": "https://huggingface.co/NoIdea4Username/NoIdeaRVCCollection/resolve/main/Enterprise-JP.zip",
|
| 157 |
+
"description": "Enterprise from Azur Lane",
|
| 158 |
+
"added": "2023-08-03",
|
| 159 |
+
"credit": "minecraftian47",
|
| 160 |
+
"tags": [
|
| 161 |
+
"Anime",
|
| 162 |
+
"Japanese"
|
| 163 |
+
]
|
| 164 |
+
},
|
| 165 |
+
{
|
| 166 |
+
"name": "Kurt Cobain",
|
| 167 |
+
"url": "https://huggingface.co/Florstie/Kurt_Cobain_byFlorst/resolve/main/Kurt_Florst.zip",
|
| 168 |
+
"description": "singer Kurt Cobain",
|
| 169 |
+
"added": "2023-08-03",
|
| 170 |
+
"credit": "florst",
|
| 171 |
+
"tags": [
|
| 172 |
+
"Real person",
|
| 173 |
+
"English"
|
| 174 |
+
]
|
| 175 |
+
},
|
| 176 |
+
{
|
| 177 |
+
"name": "Ironmouse",
|
| 178 |
+
"url": "https://huggingface.co/Tempo-Hawk/IronmouseV2/resolve/main/IronmouseV2.zip",
|
| 179 |
+
"description": "Ironmouse",
|
| 180 |
+
"added": "2023-08-03",
|
| 181 |
+
"credit": "ladyimpa",
|
| 182 |
+
"tags": [
|
| 183 |
+
"Vtuber",
|
| 184 |
+
"English"
|
| 185 |
+
]
|
| 186 |
+
},
|
| 187 |
+
{
|
| 188 |
+
"name": "Bratishkinoff",
|
| 189 |
+
"url": "https://huggingface.co/JHmashups/Bratishkinoff/resolve/main/bratishkin.zip",
|
| 190 |
+
"description": "Bratishkinoff (Bratishkin | Братишкин) - russian steamer ",
|
| 191 |
+
"added": "2023-08-03",
|
| 192 |
+
"credit": ".caddii",
|
| 193 |
+
"tags": [
|
| 194 |
+
"Real person",
|
| 195 |
+
"Other Language"
|
| 196 |
+
]
|
| 197 |
+
},
|
| 198 |
+
{
|
| 199 |
+
"name": "Yagami Light",
|
| 200 |
+
"url": "https://huggingface.co/geekdom-tr/Yagami-Light/resolve/main/Yagami-Light.zip",
|
| 201 |
+
"description": "Yagami Light (Miyano Mamoru) from death note",
|
| 202 |
+
"added": "2023-08-03",
|
| 203 |
+
"credit": "takka / takka#7700",
|
| 204 |
+
"tags": [
|
| 205 |
+
"Anime",
|
| 206 |
+
"Japanese"
|
| 207 |
+
]
|
| 208 |
+
},
|
| 209 |
+
{
|
| 210 |
+
"name": "Itashi",
|
| 211 |
+
"url": "https://huggingface.co/4uGGun/4uGGunRVC/resolve/main/itashi.zip",
|
| 212 |
+
"description": "Itashi (Russian fandubber AniLibria) ",
|
| 213 |
+
"added": "2023-08-03",
|
| 214 |
+
"credit": "BelochkaOff",
|
| 215 |
+
"tags": [
|
| 216 |
+
"Anime",
|
| 217 |
+
"Other Language",
|
| 218 |
+
"Real person"
|
| 219 |
+
]
|
| 220 |
+
},
|
| 221 |
+
{
|
| 222 |
+
"name": "Michiru Kagemori",
|
| 223 |
+
"url": "https://huggingface.co/WolfMK/MichiruKagemori/resolve/main/MichiruKagemori_RVC_V2.zip",
|
| 224 |
+
"description": "Michiru Kagemori from Brand New Animal (300 Epochs)",
|
| 225 |
+
"added": "2023-08-03",
|
| 226 |
+
"credit": "wolfmk",
|
| 227 |
+
"tags": [
|
| 228 |
+
"Anime",
|
| 229 |
+
"English"
|
| 230 |
+
]
|
| 231 |
+
}
|
| 232 |
+
,
|
| 233 |
+
{
|
| 234 |
+
"name": "Kaeya",
|
| 235 |
+
"url": "https://huggingface.co/nlordqting4444/nlordqtingRVC/resolve/main/Kaeya.zip",
|
| 236 |
+
"description": "Kaeya (VA: Kohsuke Toriumi) from Genshin Impact (300 Epochs)",
|
| 237 |
+
"added": "2023-08-03",
|
| 238 |
+
"credit": "nlordqting4444",
|
| 239 |
+
"tags": [
|
| 240 |
+
"Game character",
|
| 241 |
+
"Japanese"
|
| 242 |
+
]
|
| 243 |
+
},
|
| 244 |
+
{
|
| 245 |
+
"name": "Mona Megistus",
|
| 246 |
+
"url": "https://huggingface.co/AnimeSessions/rvc_voice_models/resolve/main/MonaRVC.zip",
|
| 247 |
+
"description": "Mona Megistus (VA: Felecia Angelle) from Genshin Impact (250 Epochs)",
|
| 248 |
+
"added": "2023-08-03",
|
| 249 |
+
"credit": "shyelijah",
|
| 250 |
+
"tags": [
|
| 251 |
+
"Game character",
|
| 252 |
+
"English"
|
| 253 |
+
]
|
| 254 |
+
},
|
| 255 |
+
{
|
| 256 |
+
"name": "Klee",
|
| 257 |
+
"url": "https://huggingface.co/hardbop/AI_MODEL_THINGY/resolve/main/kleeeng_rvc.zip",
|
| 258 |
+
"description": "Klee from Genshin Impact (400 Epochs)",
|
| 259 |
+
"added": "2023-08-03",
|
| 260 |
+
"credit": "hardbop",
|
| 261 |
+
"tags": [
|
| 262 |
+
"Game character",
|
| 263 |
+
"English"
|
| 264 |
+
]
|
| 265 |
+
},
|
| 266 |
+
{
|
| 267 |
+
"name": "Sakurakoji Kinako",
|
| 268 |
+
"url": "https://huggingface.co/Gorodogi/RVC2MangioCrepe/resolve/main/kinakobetatwo700.zip",
|
| 269 |
+
"description": "Sakurakoji Kinako (Suzuhara Nozomi) from Love Live! Superstar!! (700 Epoch)",
|
| 270 |
+
"added": "2023-08-03",
|
| 271 |
+
"credit": "ck1089",
|
| 272 |
+
"tags": [
|
| 273 |
+
"Anime",
|
| 274 |
+
"Japanese"
|
| 275 |
+
]
|
| 276 |
+
},
|
| 277 |
+
{
|
| 278 |
+
"name": "Minamo Kurosawa",
|
| 279 |
+
"url": "https://huggingface.co/timothy10583/RVC/resolve/main/minamo-kurosawa.zip",
|
| 280 |
+
"description": "Minamo (Nyamo) Kurosawa (Azumanga Daioh US DUB) (300 Epochs)",
|
| 281 |
+
"added": "2023-08-03",
|
| 282 |
+
"credit": "timothy10583",
|
| 283 |
+
"tags": [
|
| 284 |
+
"Anime"
|
| 285 |
+
]
|
| 286 |
+
},
|
| 287 |
+
{
|
| 288 |
+
"name": "Neco Arc",
|
| 289 |
+
"url": "https://huggingface.co/Ozzy-Helix/Neko_Arc_Neko_Aruku.RVCv2/resolve/main/Neko_Arc-V3-E600.zip",
|
| 290 |
+
"description": "Neco Arc (Neco-Aruku) (Epochs 600)",
|
| 291 |
+
"added": "2023-08-03",
|
| 292 |
+
"credit": "ozzy_helix_",
|
| 293 |
+
"tags": [
|
| 294 |
+
"Anime"
|
| 295 |
+
]
|
| 296 |
+
},
|
| 297 |
+
{
|
| 298 |
+
"name": "Makima",
|
| 299 |
+
"url": "https://huggingface.co/andolei/makimaen/resolve/main/makima-en-dub.zip",
|
| 300 |
+
"description": "Makima from Chainsaw Man (300 Epochs)",
|
| 301 |
+
"added": "2023-08-03",
|
| 302 |
+
"credit": "andpproximately",
|
| 303 |
+
"tags": [
|
| 304 |
+
"Anime",
|
| 305 |
+
"English"
|
| 306 |
+
]
|
| 307 |
+
},
|
| 308 |
+
{
|
| 309 |
+
"name": "PomPom",
|
| 310 |
+
"url": "https://huggingface.co/benitheworld/pom-pom/resolve/main/pom-pom.zip",
|
| 311 |
+
"description": "PomPom from Honkai Star Rail (HSR) (200 Epochs)",
|
| 312 |
+
"added": "2023-08-03",
|
| 313 |
+
"credit": "kannysoap",
|
| 314 |
+
"tags": [
|
| 315 |
+
"Game character",
|
| 316 |
+
"English"
|
| 317 |
+
]
|
| 318 |
+
},
|
| 319 |
+
{
|
| 320 |
+
"name": "Asuka Langley Soryu",
|
| 321 |
+
"url": "https://huggingface.co/Piegirl/asukaadv/resolve/main/asuka.zip",
|
| 322 |
+
"description": "Asuka Langley Soryu/Tiffany Grant from Neon Genesis Evangelion (400 Epochs)",
|
| 323 |
+
"added": "2023-08-03",
|
| 324 |
+
"credit": "piegirl",
|
| 325 |
+
"tags": [
|
| 326 |
+
"Anime",
|
| 327 |
+
"English"
|
| 328 |
+
]
|
| 329 |
+
},
|
| 330 |
+
{
|
| 331 |
+
"name": "Ochaco Uraraka",
|
| 332 |
+
"url": "https://huggingface.co/legitdark/JP-Uraraka-By-Dan/resolve/main/JP-Uraraka-By-Dan.zip",
|
| 333 |
+
"description": "Ochaco Uraraka from Boku no Hero Academia (320 Epochs)",
|
| 334 |
+
"added": "2023-08-03",
|
| 335 |
+
"credit": "danthevegetable",
|
| 336 |
+
"tags": [
|
| 337 |
+
"Anime",
|
| 338 |
+
"Japanese"
|
| 339 |
+
]
|
| 340 |
+
},
|
| 341 |
+
{
|
| 342 |
+
"name": "Sunaokami Shiroko",
|
| 343 |
+
"url": "https://huggingface.co/LordDavis778/BlueArchivevoicemodels/resolve/main/SunaokamiShiroko.zip",
|
| 344 |
+
"description": "Sunaokami Shiroko from Blue Archive (500 Epochs)",
|
| 345 |
+
"added": "2023-08-03",
|
| 346 |
+
"credit": "lorddavis778",
|
| 347 |
+
"tags": [
|
| 348 |
+
"Anime"
|
| 349 |
+
]
|
| 350 |
+
},
|
| 351 |
+
{
|
| 352 |
+
"name": "Dainsleif",
|
| 353 |
+
"url": "https://huggingface.co/Nasleyy/NasleyRVC/resolve/main/Voices/Dainsleif/Dainsleif.zip",
|
| 354 |
+
"description": "Dainsleif from Genshin Impact (335 Epochs)",
|
| 355 |
+
"added": "2023-08-03",
|
| 356 |
+
"credit": "nasley",
|
| 357 |
+
"tags": [
|
| 358 |
+
"Game character",
|
| 359 |
+
"English"
|
| 360 |
+
]
|
| 361 |
+
},
|
| 362 |
+
{
|
| 363 |
+
"name": "Mae Asmr",
|
| 364 |
+
"url": "https://huggingface.co/ctian/VRC/resolve/main/MaeASMR.zip",
|
| 365 |
+
"description": "Mae Asmr - harvest mommy voice (YOUTUBE) (300 Epochs)",
|
| 366 |
+
"added": "2023-08-03",
|
| 367 |
+
"credit": "ctian_04",
|
| 368 |
+
"tags": [
|
| 369 |
+
"English",
|
| 370 |
+
"Real person",
|
| 371 |
+
"Vtuber"
|
| 372 |
+
]
|
| 373 |
+
},
|
| 374 |
+
{
|
| 375 |
+
"name": "Hana Shirosaki ",
|
| 376 |
+
"url": "https://huggingface.co/Pawlik17/HanaWataten/resolve/main/HanaWATATEN.zip",
|
| 377 |
+
"description": "Hana Shirosaki / 白 咲 花 From Watashi ni Tenshi ga Maiorita! (570 Epochs)",
|
| 378 |
+
"added": "2023-08-03",
|
| 379 |
+
"credit": "tamalik",
|
| 380 |
+
"tags": [
|
| 381 |
+
"Anime",
|
| 382 |
+
"Japanese"
|
| 383 |
+
]
|
| 384 |
+
},
|
| 385 |
+
{
|
| 386 |
+
"name": "Kaguya Shinomiya ",
|
| 387 |
+
"url": "https://huggingface.co/1ski/1skiRVCModels/resolve/main/kaguyav5.zip",
|
| 388 |
+
"description": "Kaguya Shinomiya from Kaguya-Sama Love is war (200 Epochs)",
|
| 389 |
+
"added": "2023-08-03",
|
| 390 |
+
"credit": "1ski",
|
| 391 |
+
"tags": [
|
| 392 |
+
"Anime",
|
| 393 |
+
"Japanese"
|
| 394 |
+
]
|
| 395 |
+
},
|
| 396 |
+
{
|
| 397 |
+
"name": "Nai Shiro",
|
| 398 |
+
"url": "https://huggingface.co/kuushiro/Shiro-RVC-No-Game-No-Life/resolve/main/shiro-jp-360-epochs.zip",
|
| 399 |
+
"description": "Nai Shiro (Ai Kayano) from No Game No Life (360 Epochs)",
|
| 400 |
+
"added": "2023-08-03",
|
| 401 |
+
"credit": "kxouyou",
|
| 402 |
+
"tags": [
|
| 403 |
+
"Anime",
|
| 404 |
+
"Japanese"
|
| 405 |
+
]
|
| 406 |
+
},
|
| 407 |
+
{
|
| 408 |
+
"name": "Yuigahama Yui",
|
| 409 |
+
"url": "https://huggingface.co/Zerokano/Yuigahama_Yui-RVCv2/resolve/main/Yuigahama_Yui.zip",
|
| 410 |
+
"description": "Yuigahama Yui from Yahari Ore no Seishun Love Comedy wa Machigatteiru (250 Epochs)",
|
| 411 |
+
"added": "2023-08-03",
|
| 412 |
+
"credit": "zerokano",
|
| 413 |
+
"tags": [
|
| 414 |
+
"Anime",
|
| 415 |
+
"Japanese"
|
| 416 |
+
]
|
| 417 |
+
},
|
| 418 |
+
{
|
| 419 |
+
"name": "Fuwawa Abyssgard",
|
| 420 |
+
"url": "https://huggingface.co/megaaziib/my-rvc-models-collection/resolve/main/fuwawa.zip",
|
| 421 |
+
"description": "Fuwawa Abyssgard (FUWAMOCO) from Hololive gen 3 (250 Epochs)",
|
| 422 |
+
"added": "2023-08-03",
|
| 423 |
+
"credit": "megaaziib",
|
| 424 |
+
"tags": [
|
| 425 |
+
"Vtuber",
|
| 426 |
+
"English"
|
| 427 |
+
]
|
| 428 |
+
},
|
| 429 |
+
{
|
| 430 |
+
"name": "Kana Arima",
|
| 431 |
+
"url": "https://huggingface.co/ddoumakunn/arimakanna/resolve/main/arimakanna.zip",
|
| 432 |
+
"description": "Kana Arima from Oshi no Ko (250 Epochs)",
|
| 433 |
+
"added": "2023-08-03",
|
| 434 |
+
"credit": "ddoumakunn",
|
| 435 |
+
"tags": [
|
| 436 |
+
"Anime",
|
| 437 |
+
"Japanese"
|
| 438 |
+
]
|
| 439 |
+
},
|
| 440 |
+
{
|
| 441 |
+
"name": "Raiden Shogun",
|
| 442 |
+
"url": "https://huggingface.co/Nasleyy/NasleyRVC/resolve/main/Voices/RaidenShogun/RaidenShogun.zip",
|
| 443 |
+
"description": "Raiden Shogun from Genshin Impact (310 Epochs)",
|
| 444 |
+
"added": "2023-08-03",
|
| 445 |
+
"credit": "nasley",
|
| 446 |
+
"tags": [
|
| 447 |
+
"Game character",
|
| 448 |
+
"English"
|
| 449 |
+
]
|
| 450 |
+
},
|
| 451 |
+
{
|
| 452 |
+
"name": "Alhaitham",
|
| 453 |
+
"url": "https://huggingface.co/Nasleyy/NasleyRVC/resolve/main/Voices/Alhaitham/Alhaitham.zip",
|
| 454 |
+
"description": "Alhaitham from Genshin Impact (320 Epochs)",
|
| 455 |
+
"added": "2023-08-03",
|
| 456 |
+
"credit": "nasley",
|
| 457 |
+
"tags": [
|
| 458 |
+
"Game character",
|
| 459 |
+
"English"
|
| 460 |
+
]
|
| 461 |
+
},
|
| 462 |
+
{
|
| 463 |
+
"name": "Izuku Midoriya",
|
| 464 |
+
"url": "https://huggingface.co/BigGuy635/MHA/resolve/main/DekuJP.zip",
|
| 465 |
+
"description": "Izuku Midoriya from Boku no Hero Academia (100 Epochs)",
|
| 466 |
+
"added": "2023-08-03",
|
| 467 |
+
"credit": "khjjnoffical",
|
| 468 |
+
"tags": [
|
| 469 |
+
"Anime",
|
| 470 |
+
"Japanese"
|
| 471 |
+
]
|
| 472 |
+
},
|
| 473 |
+
{
|
| 474 |
+
"name": "Kurumi Shiratori",
|
| 475 |
+
"url": "https://huggingface.co/HarunaKasuga/YoshikoTsushima/resolve/main/KurumiShiratori.zip",
|
| 476 |
+
"description": "Kurumi Shiratori (VA: Ruka Fukagawa) from D4DJ (500 Epochs)",
|
| 477 |
+
"added": "2023-08-03",
|
| 478 |
+
"credit": "seakrait",
|
| 479 |
+
"tags": [
|
| 480 |
+
"Anime",
|
| 481 |
+
"Japanese"
|
| 482 |
+
]
|
| 483 |
+
},
|
| 484 |
+
{
|
| 485 |
+
"name": "Veibae",
|
| 486 |
+
"url": "https://huggingface.co/datasets/Papaquans/Veibae/resolve/main/veibae_e165_s125565.zip",
|
| 487 |
+
"description": "Veibae (165 Epochs)",
|
| 488 |
+
"added": "2023-08-03",
|
| 489 |
+
"credit": "recairo",
|
| 490 |
+
"tags": [
|
| 491 |
+
"Vtuber",
|
| 492 |
+
"English"
|
| 493 |
+
]
|
| 494 |
+
},
|
| 495 |
+
{
|
| 496 |
+
"name": "Black Panther",
|
| 497 |
+
"url": "https://huggingface.co/TJKAI/BlackPannther/resolve/main/BlackPanther.zip",
|
| 498 |
+
"description": "Black Panther (Chadwick Boseman) (300 Epochs)",
|
| 499 |
+
"added": "2023-08-03",
|
| 500 |
+
"credit": "tjkcreative",
|
| 501 |
+
"tags": [
|
| 502 |
+
"Real person",
|
| 503 |
+
"English"
|
| 504 |
+
]
|
| 505 |
+
},
|
| 506 |
+
{
|
| 507 |
+
"name": "Gawr Gura",
|
| 508 |
+
"url": "https://pixeldrain.com/u/3tJmABXA",
|
| 509 |
+
"description": "Gawr Gura from Hololive EN",
|
| 510 |
+
"added": "2023-08-05",
|
| 511 |
+
"credit": "dacoolkid44 & hijack",
|
| 512 |
+
"tags": [
|
| 513 |
+
"Vtuber"
|
| 514 |
+
]
|
| 515 |
+
},
|
| 516 |
+
{
|
| 517 |
+
"name": "Houshou Marine",
|
| 518 |
+
"url": "https://pixeldrain.com/u/L1YLfZyU",
|
| 519 |
+
"description": "Houshou Marine from Hololive JP",
|
| 520 |
+
"added": "2023-08-05",
|
| 521 |
+
"credit": "dacoolkid44 & hijack",
|
| 522 |
+
"tags": [
|
| 523 |
+
"Vtuber",
|
| 524 |
+
"Japanese"
|
| 525 |
+
]
|
| 526 |
+
},
|
| 527 |
+
{
|
| 528 |
+
"name": "Hoshimachi Suisei",
|
| 529 |
+
"url": "https://pixeldrain.com/u/YP89C21u",
|
| 530 |
+
"description": "Hoshimachi Suisei from Hololive JP",
|
| 531 |
+
"added": "2023-08-05",
|
| 532 |
+
"credit": "dacoolkid44 & hijack & Maki Ligon",
|
| 533 |
+
"tags": [
|
| 534 |
+
"Vtuber",
|
| 535 |
+
"Japanese"
|
| 536 |
+
]
|
| 537 |
+
},
|
| 538 |
+
{
|
| 539 |
+
"name": "Laplus Darkness",
|
| 540 |
+
"url": "https://pixeldrain.com/u/zmuxv5Bf",
|
| 541 |
+
"description": "Laplus Darkness from Hololive JP",
|
| 542 |
+
"added": "2023-08-05",
|
| 543 |
+
"credit": "dacoolkid44 & hijack",
|
| 544 |
+
"tags": [
|
| 545 |
+
"Vtuber",
|
| 546 |
+
"Japanese"
|
| 547 |
+
]
|
| 548 |
+
},
|
| 549 |
+
{
|
| 550 |
+
"name": "AZKi",
|
| 551 |
+
"url": "https://huggingface.co/Kit-Lemonfoot/kitlemonfoot_rvc_models/resolve/main/AZKi%20(Hybrid).zip",
|
| 552 |
+
"description": "AZKi from Hololive JP",
|
| 553 |
+
"added": "2023-08-05",
|
| 554 |
+
"credit": "Kit Lemonfoot / NSHFB",
|
| 555 |
+
"tags": [
|
| 556 |
+
"Vtuber",
|
| 557 |
+
"Japanese"
|
| 558 |
+
]
|
| 559 |
+
},
|
| 560 |
+
{
|
| 561 |
+
"name": "Ado",
|
| 562 |
+
"url": "https://huggingface.co/pjesek/AdoRVCv2/resolve/main/AdoRVCv2.zip",
|
| 563 |
+
"description": "Talented JP artist (500 epochs using every song from her first album)",
|
| 564 |
+
"added": "2023-08-05",
|
| 565 |
+
"credit": "pjesek",
|
| 566 |
+
"tags": [
|
| 567 |
+
"Real person",
|
| 568 |
+
"Japanese"
|
| 569 |
+
]
|
| 570 |
+
},
|
| 571 |
+
{
|
| 572 |
+
"name": "LiSA",
|
| 573 |
+
"url": "https://huggingface.co/phant0m4r/LiSA/resolve/main/LiSA.zip",
|
| 574 |
+
"description": "Talented JP artist (400 epochs)",
|
| 575 |
+
"added": "2023-08-05",
|
| 576 |
+
"credit": "Phant0m",
|
| 577 |
+
"tags": [
|
| 578 |
+
"Real person",
|
| 579 |
+
"Japanese"
|
| 580 |
+
]
|
| 581 |
+
},
|
| 582 |
+
{
|
| 583 |
+
"name": "Kokomi",
|
| 584 |
+
"url": "https://huggingface.co/benitheworld/kokomi-kr/resolve/main/kokomi-kr.zip",
|
| 585 |
+
"description": "Kokomi from Genshin Impact KR (300 Epochs)",
|
| 586 |
+
"added": "2023-08-09",
|
| 587 |
+
"credit": "kannysoap",
|
| 588 |
+
"tags": [
|
| 589 |
+
"Game character",
|
| 590 |
+
"Other Language"
|
| 591 |
+
]
|
| 592 |
+
},
|
| 593 |
+
{
|
| 594 |
+
"name": "Ivanzolo",
|
| 595 |
+
"url": "https://huggingface.co/fenikkusugosuto/IvanZolo2004/resolve/main/ivanZolo.zip",
|
| 596 |
+
"description": "Ivanzolo2004 russian streamer | Иван Золо 2004",
|
| 597 |
+
"added": "2023-08-09",
|
| 598 |
+
"credit": "prezervativ_naruto2009",
|
| 599 |
+
"tags": [
|
| 600 |
+
"Other Language",
|
| 601 |
+
"Real person"
|
| 602 |
+
]
|
| 603 |
+
},
|
| 604 |
+
{
|
| 605 |
+
"name": "Nilou",
|
| 606 |
+
"url": "https://huggingface.co/benitheworld/nilou-kr/resolve/main/nilou-kr.zip",
|
| 607 |
+
"description": "Nilou from Genshin Impact KR (300 Epochs)",
|
| 608 |
+
"added": "2023-08-09",
|
| 609 |
+
"credit": "kannysoap",
|
| 610 |
+
"tags": [
|
| 611 |
+
"Game character",
|
| 612 |
+
"Other Language"
|
| 613 |
+
]
|
| 614 |
+
},
|
| 615 |
+
{
|
| 616 |
+
"name": "Dr. Doofenshmirtz",
|
| 617 |
+
"url": "https://huggingface.co/Argax/doofenshmirtz-RUS/resolve/main/doofenshmirtz.zip",
|
| 618 |
+
"description": "RUS Dr. Doofenshmirtz from Phineas and Ferb (300 epochs)",
|
| 619 |
+
"added": "2023-08-09",
|
| 620 |
+
"credit": "argaxus",
|
| 621 |
+
"tags": [
|
| 622 |
+
"Other Language"
|
| 623 |
+
]
|
| 624 |
+
}
|
| 625 |
+
]
|
| 626 |
+
}
|
song_output/OUTPUT.txt
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
Output is stored in this folder, where directory names represent the YouTube IDs from the original song.
|
src/configs/32k.json
ADDED
|
@@ -0,0 +1,46 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"train": {
|
| 3 |
+
"log_interval": 200,
|
| 4 |
+
"seed": 1234,
|
| 5 |
+
"epochs": 20000,
|
| 6 |
+
"learning_rate": 1e-4,
|
| 7 |
+
"betas": [0.8, 0.99],
|
| 8 |
+
"eps": 1e-9,
|
| 9 |
+
"batch_size": 4,
|
| 10 |
+
"fp16_run": false,
|
| 11 |
+
"lr_decay": 0.999875,
|
| 12 |
+
"segment_size": 12800,
|
| 13 |
+
"init_lr_ratio": 1,
|
| 14 |
+
"warmup_epochs": 0,
|
| 15 |
+
"c_mel": 45,
|
| 16 |
+
"c_kl": 1.0
|
| 17 |
+
},
|
| 18 |
+
"data": {
|
| 19 |
+
"max_wav_value": 32768.0,
|
| 20 |
+
"sampling_rate": 32000,
|
| 21 |
+
"filter_length": 1024,
|
| 22 |
+
"hop_length": 320,
|
| 23 |
+
"win_length": 1024,
|
| 24 |
+
"n_mel_channels": 80,
|
| 25 |
+
"mel_fmin": 0.0,
|
| 26 |
+
"mel_fmax": null
|
| 27 |
+
},
|
| 28 |
+
"model": {
|
| 29 |
+
"inter_channels": 192,
|
| 30 |
+
"hidden_channels": 192,
|
| 31 |
+
"filter_channels": 768,
|
| 32 |
+
"n_heads": 2,
|
| 33 |
+
"n_layers": 6,
|
| 34 |
+
"kernel_size": 3,
|
| 35 |
+
"p_dropout": 0,
|
| 36 |
+
"resblock": "1",
|
| 37 |
+
"resblock_kernel_sizes": [3,7,11],
|
| 38 |
+
"resblock_dilation_sizes": [[1,3,5], [1,3,5], [1,3,5]],
|
| 39 |
+
"upsample_rates": [10,4,2,2,2],
|
| 40 |
+
"upsample_initial_channel": 512,
|
| 41 |
+
"upsample_kernel_sizes": [16,16,4,4,4],
|
| 42 |
+
"use_spectral_norm": false,
|
| 43 |
+
"gin_channels": 256,
|
| 44 |
+
"spk_embed_dim": 109
|
| 45 |
+
}
|
| 46 |
+
}
|
src/configs/32k_v2.json
ADDED
|
@@ -0,0 +1,46 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"train": {
|
| 3 |
+
"log_interval": 200,
|
| 4 |
+
"seed": 1234,
|
| 5 |
+
"epochs": 20000,
|
| 6 |
+
"learning_rate": 1e-4,
|
| 7 |
+
"betas": [0.8, 0.99],
|
| 8 |
+
"eps": 1e-9,
|
| 9 |
+
"batch_size": 4,
|
| 10 |
+
"fp16_run": true,
|
| 11 |
+
"lr_decay": 0.999875,
|
| 12 |
+
"segment_size": 12800,
|
| 13 |
+
"init_lr_ratio": 1,
|
| 14 |
+
"warmup_epochs": 0,
|
| 15 |
+
"c_mel": 45,
|
| 16 |
+
"c_kl": 1.0
|
| 17 |
+
},
|
| 18 |
+
"data": {
|
| 19 |
+
"max_wav_value": 32768.0,
|
| 20 |
+
"sampling_rate": 32000,
|
| 21 |
+
"filter_length": 1024,
|
| 22 |
+
"hop_length": 320,
|
| 23 |
+
"win_length": 1024,
|
| 24 |
+
"n_mel_channels": 80,
|
| 25 |
+
"mel_fmin": 0.0,
|
| 26 |
+
"mel_fmax": null
|
| 27 |
+
},
|
| 28 |
+
"model": {
|
| 29 |
+
"inter_channels": 192,
|
| 30 |
+
"hidden_channels": 192,
|
| 31 |
+
"filter_channels": 768,
|
| 32 |
+
"n_heads": 2,
|
| 33 |
+
"n_layers": 6,
|
| 34 |
+
"kernel_size": 3,
|
| 35 |
+
"p_dropout": 0,
|
| 36 |
+
"resblock": "1",
|
| 37 |
+
"resblock_kernel_sizes": [3,7,11],
|
| 38 |
+
"resblock_dilation_sizes": [[1,3,5], [1,3,5], [1,3,5]],
|
| 39 |
+
"upsample_rates": [10,8,2,2],
|
| 40 |
+
"upsample_initial_channel": 512,
|
| 41 |
+
"upsample_kernel_sizes": [20,16,4,4],
|
| 42 |
+
"use_spectral_norm": false,
|
| 43 |
+
"gin_channels": 256,
|
| 44 |
+
"spk_embed_dim": 109
|
| 45 |
+
}
|
| 46 |
+
}
|
src/configs/40k.json
ADDED
|
@@ -0,0 +1,46 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"train": {
|
| 3 |
+
"log_interval": 200,
|
| 4 |
+
"seed": 1234,
|
| 5 |
+
"epochs": 20000,
|
| 6 |
+
"learning_rate": 1e-4,
|
| 7 |
+
"betas": [0.8, 0.99],
|
| 8 |
+
"eps": 1e-9,
|
| 9 |
+
"batch_size": 4,
|
| 10 |
+
"fp16_run": false,
|
| 11 |
+
"lr_decay": 0.999875,
|
| 12 |
+
"segment_size": 12800,
|
| 13 |
+
"init_lr_ratio": 1,
|
| 14 |
+
"warmup_epochs": 0,
|
| 15 |
+
"c_mel": 45,
|
| 16 |
+
"c_kl": 1.0
|
| 17 |
+
},
|
| 18 |
+
"data": {
|
| 19 |
+
"max_wav_value": 32768.0,
|
| 20 |
+
"sampling_rate": 40000,
|
| 21 |
+
"filter_length": 2048,
|
| 22 |
+
"hop_length": 400,
|
| 23 |
+
"win_length": 2048,
|
| 24 |
+
"n_mel_channels": 125,
|
| 25 |
+
"mel_fmin": 0.0,
|
| 26 |
+
"mel_fmax": null
|
| 27 |
+
},
|
| 28 |
+
"model": {
|
| 29 |
+
"inter_channels": 192,
|
| 30 |
+
"hidden_channels": 192,
|
| 31 |
+
"filter_channels": 768,
|
| 32 |
+
"n_heads": 2,
|
| 33 |
+
"n_layers": 6,
|
| 34 |
+
"kernel_size": 3,
|
| 35 |
+
"p_dropout": 0,
|
| 36 |
+
"resblock": "1",
|
| 37 |
+
"resblock_kernel_sizes": [3,7,11],
|
| 38 |
+
"resblock_dilation_sizes": [[1,3,5], [1,3,5], [1,3,5]],
|
| 39 |
+
"upsample_rates": [10,10,2,2],
|
| 40 |
+
"upsample_initial_channel": 512,
|
| 41 |
+
"upsample_kernel_sizes": [16,16,4,4],
|
| 42 |
+
"use_spectral_norm": false,
|
| 43 |
+
"gin_channels": 256,
|
| 44 |
+
"spk_embed_dim": 109
|
| 45 |
+
}
|
| 46 |
+
}
|
src/configs/48k.json
ADDED
|
@@ -0,0 +1,46 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"train": {
|
| 3 |
+
"log_interval": 200,
|
| 4 |
+
"seed": 1234,
|
| 5 |
+
"epochs": 20000,
|
| 6 |
+
"learning_rate": 1e-4,
|
| 7 |
+
"betas": [0.8, 0.99],
|
| 8 |
+
"eps": 1e-9,
|
| 9 |
+
"batch_size": 4,
|
| 10 |
+
"fp16_run": false,
|
| 11 |
+
"lr_decay": 0.999875,
|
| 12 |
+
"segment_size": 11520,
|
| 13 |
+
"init_lr_ratio": 1,
|
| 14 |
+
"warmup_epochs": 0,
|
| 15 |
+
"c_mel": 45,
|
| 16 |
+
"c_kl": 1.0
|
| 17 |
+
},
|
| 18 |
+
"data": {
|
| 19 |
+
"max_wav_value": 32768.0,
|
| 20 |
+
"sampling_rate": 48000,
|
| 21 |
+
"filter_length": 2048,
|
| 22 |
+
"hop_length": 480,
|
| 23 |
+
"win_length": 2048,
|
| 24 |
+
"n_mel_channels": 128,
|
| 25 |
+
"mel_fmin": 0.0,
|
| 26 |
+
"mel_fmax": null
|
| 27 |
+
},
|
| 28 |
+
"model": {
|
| 29 |
+
"inter_channels": 192,
|
| 30 |
+
"hidden_channels": 192,
|
| 31 |
+
"filter_channels": 768,
|
| 32 |
+
"n_heads": 2,
|
| 33 |
+
"n_layers": 6,
|
| 34 |
+
"kernel_size": 3,
|
| 35 |
+
"p_dropout": 0,
|
| 36 |
+
"resblock": "1",
|
| 37 |
+
"resblock_kernel_sizes": [3,7,11],
|
| 38 |
+
"resblock_dilation_sizes": [[1,3,5], [1,3,5], [1,3,5]],
|
| 39 |
+
"upsample_rates": [10,6,2,2,2],
|
| 40 |
+
"upsample_initial_channel": 512,
|
| 41 |
+
"upsample_kernel_sizes": [16,16,4,4,4],
|
| 42 |
+
"use_spectral_norm": false,
|
| 43 |
+
"gin_channels": 256,
|
| 44 |
+
"spk_embed_dim": 109
|
| 45 |
+
}
|
| 46 |
+
}
|
src/configs/48k_v2.json
ADDED
|
@@ -0,0 +1,46 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"train": {
|
| 3 |
+
"log_interval": 200,
|
| 4 |
+
"seed": 1234,
|
| 5 |
+
"epochs": 20000,
|
| 6 |
+
"learning_rate": 1e-4,
|
| 7 |
+
"betas": [0.8, 0.99],
|
| 8 |
+
"eps": 1e-9,
|
| 9 |
+
"batch_size": 4,
|
| 10 |
+
"fp16_run": true,
|
| 11 |
+
"lr_decay": 0.999875,
|
| 12 |
+
"segment_size": 17280,
|
| 13 |
+
"init_lr_ratio": 1,
|
| 14 |
+
"warmup_epochs": 0,
|
| 15 |
+
"c_mel": 45,
|
| 16 |
+
"c_kl": 1.0
|
| 17 |
+
},
|
| 18 |
+
"data": {
|
| 19 |
+
"max_wav_value": 32768.0,
|
| 20 |
+
"sampling_rate": 48000,
|
| 21 |
+
"filter_length": 2048,
|
| 22 |
+
"hop_length": 480,
|
| 23 |
+
"win_length": 2048,
|
| 24 |
+
"n_mel_channels": 128,
|
| 25 |
+
"mel_fmin": 0.0,
|
| 26 |
+
"mel_fmax": null
|
| 27 |
+
},
|
| 28 |
+
"model": {
|
| 29 |
+
"inter_channels": 192,
|
| 30 |
+
"hidden_channels": 192,
|
| 31 |
+
"filter_channels": 768,
|
| 32 |
+
"n_heads": 2,
|
| 33 |
+
"n_layers": 6,
|
| 34 |
+
"kernel_size": 3,
|
| 35 |
+
"p_dropout": 0,
|
| 36 |
+
"resblock": "1",
|
| 37 |
+
"resblock_kernel_sizes": [3,7,11],
|
| 38 |
+
"resblock_dilation_sizes": [[1,3,5], [1,3,5], [1,3,5]],
|
| 39 |
+
"upsample_rates": [12,10,2,2],
|
| 40 |
+
"upsample_initial_channel": 512,
|
| 41 |
+
"upsample_kernel_sizes": [24,20,4,4],
|
| 42 |
+
"use_spectral_norm": false,
|
| 43 |
+
"gin_channels": 256,
|
| 44 |
+
"spk_embed_dim": 109
|
| 45 |
+
}
|
| 46 |
+
}
|
src/download_models.py
ADDED
|
@@ -0,0 +1,31 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from pathlib import Path
|
| 2 |
+
import requests
|
| 3 |
+
|
| 4 |
+
MDX_DOWNLOAD_LINK = 'https://github.com/TRvlvr/model_repo/releases/download/all_public_uvr_models/'
|
| 5 |
+
RVC_DOWNLOAD_LINK = 'https://huggingface.co/lj1995/VoiceConversionWebUI/resolve/main/'
|
| 6 |
+
|
| 7 |
+
BASE_DIR = Path(__file__).resolve().parent.parent
|
| 8 |
+
mdxnet_models_dir = BASE_DIR / 'mdxnet_models'
|
| 9 |
+
rvc_models_dir = BASE_DIR / 'rvc_models'
|
| 10 |
+
|
| 11 |
+
|
| 12 |
+
def dl_model(link, model_name, dir_name):
|
| 13 |
+
with requests.get(f'{link}{model_name}') as r:
|
| 14 |
+
r.raise_for_status()
|
| 15 |
+
with open(dir_name / model_name, 'wb') as f:
|
| 16 |
+
for chunk in r.iter_content(chunk_size=8192):
|
| 17 |
+
f.write(chunk)
|
| 18 |
+
|
| 19 |
+
|
| 20 |
+
if __name__ == '__main__':
|
| 21 |
+
mdx_model_names = ['UVR-MDX-NET-Inst_HQ_4.onnx', 'UVR-MDX-NET-Voc_FT.onnx', 'UVR_MDXNET_KARA_2.onnx', 'Reverb_HQ_By_FoxJoy.onnx']
|
| 22 |
+
for model in mdx_model_names:
|
| 23 |
+
print(f'Downloading {model}...')
|
| 24 |
+
dl_model(MDX_DOWNLOAD_LINK, model, mdxnet_models_dir)
|
| 25 |
+
|
| 26 |
+
rvc_model_names = ['hubert_base.pt', 'rmvpe.pt']
|
| 27 |
+
for model in rvc_model_names:
|
| 28 |
+
print(f'Downloading {model}...')
|
| 29 |
+
dl_model(RVC_DOWNLOAD_LINK, model, rvc_models_dir)
|
| 30 |
+
|
| 31 |
+
print('All models downloaded!')
|
src/infer_pack/attentions.py
ADDED
|
@@ -0,0 +1,417 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import copy
|
| 2 |
+
import math
|
| 3 |
+
import numpy as np
|
| 4 |
+
import torch
|
| 5 |
+
from torch import nn
|
| 6 |
+
from torch.nn import functional as F
|
| 7 |
+
|
| 8 |
+
from infer_pack import commons
|
| 9 |
+
from infer_pack import modules
|
| 10 |
+
from infer_pack.modules import LayerNorm
|
| 11 |
+
|
| 12 |
+
|
| 13 |
+
class Encoder(nn.Module):
|
| 14 |
+
def __init__(
|
| 15 |
+
self,
|
| 16 |
+
hidden_channels,
|
| 17 |
+
filter_channels,
|
| 18 |
+
n_heads,
|
| 19 |
+
n_layers,
|
| 20 |
+
kernel_size=1,
|
| 21 |
+
p_dropout=0.0,
|
| 22 |
+
window_size=10,
|
| 23 |
+
**kwargs
|
| 24 |
+
):
|
| 25 |
+
super().__init__()
|
| 26 |
+
self.hidden_channels = hidden_channels
|
| 27 |
+
self.filter_channels = filter_channels
|
| 28 |
+
self.n_heads = n_heads
|
| 29 |
+
self.n_layers = n_layers
|
| 30 |
+
self.kernel_size = kernel_size
|
| 31 |
+
self.p_dropout = p_dropout
|
| 32 |
+
self.window_size = window_size
|
| 33 |
+
|
| 34 |
+
self.drop = nn.Dropout(p_dropout)
|
| 35 |
+
self.attn_layers = nn.ModuleList()
|
| 36 |
+
self.norm_layers_1 = nn.ModuleList()
|
| 37 |
+
self.ffn_layers = nn.ModuleList()
|
| 38 |
+
self.norm_layers_2 = nn.ModuleList()
|
| 39 |
+
for i in range(self.n_layers):
|
| 40 |
+
self.attn_layers.append(
|
| 41 |
+
MultiHeadAttention(
|
| 42 |
+
hidden_channels,
|
| 43 |
+
hidden_channels,
|
| 44 |
+
n_heads,
|
| 45 |
+
p_dropout=p_dropout,
|
| 46 |
+
window_size=window_size,
|
| 47 |
+
)
|
| 48 |
+
)
|
| 49 |
+
self.norm_layers_1.append(LayerNorm(hidden_channels))
|
| 50 |
+
self.ffn_layers.append(
|
| 51 |
+
FFN(
|
| 52 |
+
hidden_channels,
|
| 53 |
+
hidden_channels,
|
| 54 |
+
filter_channels,
|
| 55 |
+
kernel_size,
|
| 56 |
+
p_dropout=p_dropout,
|
| 57 |
+
)
|
| 58 |
+
)
|
| 59 |
+
self.norm_layers_2.append(LayerNorm(hidden_channels))
|
| 60 |
+
|
| 61 |
+
def forward(self, x, x_mask):
|
| 62 |
+
attn_mask = x_mask.unsqueeze(2) * x_mask.unsqueeze(-1)
|
| 63 |
+
x = x * x_mask
|
| 64 |
+
for i in range(self.n_layers):
|
| 65 |
+
y = self.attn_layers[i](x, x, attn_mask)
|
| 66 |
+
y = self.drop(y)
|
| 67 |
+
x = self.norm_layers_1[i](x + y)
|
| 68 |
+
|
| 69 |
+
y = self.ffn_layers[i](x, x_mask)
|
| 70 |
+
y = self.drop(y)
|
| 71 |
+
x = self.norm_layers_2[i](x + y)
|
| 72 |
+
x = x * x_mask
|
| 73 |
+
return x
|
| 74 |
+
|
| 75 |
+
|
| 76 |
+
class Decoder(nn.Module):
|
| 77 |
+
def __init__(
|
| 78 |
+
self,
|
| 79 |
+
hidden_channels,
|
| 80 |
+
filter_channels,
|
| 81 |
+
n_heads,
|
| 82 |
+
n_layers,
|
| 83 |
+
kernel_size=1,
|
| 84 |
+
p_dropout=0.0,
|
| 85 |
+
proximal_bias=False,
|
| 86 |
+
proximal_init=True,
|
| 87 |
+
**kwargs
|
| 88 |
+
):
|
| 89 |
+
super().__init__()
|
| 90 |
+
self.hidden_channels = hidden_channels
|
| 91 |
+
self.filter_channels = filter_channels
|
| 92 |
+
self.n_heads = n_heads
|
| 93 |
+
self.n_layers = n_layers
|
| 94 |
+
self.kernel_size = kernel_size
|
| 95 |
+
self.p_dropout = p_dropout
|
| 96 |
+
self.proximal_bias = proximal_bias
|
| 97 |
+
self.proximal_init = proximal_init
|
| 98 |
+
|
| 99 |
+
self.drop = nn.Dropout(p_dropout)
|
| 100 |
+
self.self_attn_layers = nn.ModuleList()
|
| 101 |
+
self.norm_layers_0 = nn.ModuleList()
|
| 102 |
+
self.encdec_attn_layers = nn.ModuleList()
|
| 103 |
+
self.norm_layers_1 = nn.ModuleList()
|
| 104 |
+
self.ffn_layers = nn.ModuleList()
|
| 105 |
+
self.norm_layers_2 = nn.ModuleList()
|
| 106 |
+
for i in range(self.n_layers):
|
| 107 |
+
self.self_attn_layers.append(
|
| 108 |
+
MultiHeadAttention(
|
| 109 |
+
hidden_channels,
|
| 110 |
+
hidden_channels,
|
| 111 |
+
n_heads,
|
| 112 |
+
p_dropout=p_dropout,
|
| 113 |
+
proximal_bias=proximal_bias,
|
| 114 |
+
proximal_init=proximal_init,
|
| 115 |
+
)
|
| 116 |
+
)
|
| 117 |
+
self.norm_layers_0.append(LayerNorm(hidden_channels))
|
| 118 |
+
self.encdec_attn_layers.append(
|
| 119 |
+
MultiHeadAttention(
|
| 120 |
+
hidden_channels, hidden_channels, n_heads, p_dropout=p_dropout
|
| 121 |
+
)
|
| 122 |
+
)
|
| 123 |
+
self.norm_layers_1.append(LayerNorm(hidden_channels))
|
| 124 |
+
self.ffn_layers.append(
|
| 125 |
+
FFN(
|
| 126 |
+
hidden_channels,
|
| 127 |
+
hidden_channels,
|
| 128 |
+
filter_channels,
|
| 129 |
+
kernel_size,
|
| 130 |
+
p_dropout=p_dropout,
|
| 131 |
+
causal=True,
|
| 132 |
+
)
|
| 133 |
+
)
|
| 134 |
+
self.norm_layers_2.append(LayerNorm(hidden_channels))
|
| 135 |
+
|
| 136 |
+
def forward(self, x, x_mask, h, h_mask):
|
| 137 |
+
"""
|
| 138 |
+
x: decoder input
|
| 139 |
+
h: encoder output
|
| 140 |
+
"""
|
| 141 |
+
self_attn_mask = commons.subsequent_mask(x_mask.size(2)).to(
|
| 142 |
+
device=x.device, dtype=x.dtype
|
| 143 |
+
)
|
| 144 |
+
encdec_attn_mask = h_mask.unsqueeze(2) * x_mask.unsqueeze(-1)
|
| 145 |
+
x = x * x_mask
|
| 146 |
+
for i in range(self.n_layers):
|
| 147 |
+
y = self.self_attn_layers[i](x, x, self_attn_mask)
|
| 148 |
+
y = self.drop(y)
|
| 149 |
+
x = self.norm_layers_0[i](x + y)
|
| 150 |
+
|
| 151 |
+
y = self.encdec_attn_layers[i](x, h, encdec_attn_mask)
|
| 152 |
+
y = self.drop(y)
|
| 153 |
+
x = self.norm_layers_1[i](x + y)
|
| 154 |
+
|
| 155 |
+
y = self.ffn_layers[i](x, x_mask)
|
| 156 |
+
y = self.drop(y)
|
| 157 |
+
x = self.norm_layers_2[i](x + y)
|
| 158 |
+
x = x * x_mask
|
| 159 |
+
return x
|
| 160 |
+
|
| 161 |
+
|
| 162 |
+
class MultiHeadAttention(nn.Module):
|
| 163 |
+
def __init__(
|
| 164 |
+
self,
|
| 165 |
+
channels,
|
| 166 |
+
out_channels,
|
| 167 |
+
n_heads,
|
| 168 |
+
p_dropout=0.0,
|
| 169 |
+
window_size=None,
|
| 170 |
+
heads_share=True,
|
| 171 |
+
block_length=None,
|
| 172 |
+
proximal_bias=False,
|
| 173 |
+
proximal_init=False,
|
| 174 |
+
):
|
| 175 |
+
super().__init__()
|
| 176 |
+
assert channels % n_heads == 0
|
| 177 |
+
|
| 178 |
+
self.channels = channels
|
| 179 |
+
self.out_channels = out_channels
|
| 180 |
+
self.n_heads = n_heads
|
| 181 |
+
self.p_dropout = p_dropout
|
| 182 |
+
self.window_size = window_size
|
| 183 |
+
self.heads_share = heads_share
|
| 184 |
+
self.block_length = block_length
|
| 185 |
+
self.proximal_bias = proximal_bias
|
| 186 |
+
self.proximal_init = proximal_init
|
| 187 |
+
self.attn = None
|
| 188 |
+
|
| 189 |
+
self.k_channels = channels // n_heads
|
| 190 |
+
self.conv_q = nn.Conv1d(channels, channels, 1)
|
| 191 |
+
self.conv_k = nn.Conv1d(channels, channels, 1)
|
| 192 |
+
self.conv_v = nn.Conv1d(channels, channels, 1)
|
| 193 |
+
self.conv_o = nn.Conv1d(channels, out_channels, 1)
|
| 194 |
+
self.drop = nn.Dropout(p_dropout)
|
| 195 |
+
|
| 196 |
+
if window_size is not None:
|
| 197 |
+
n_heads_rel = 1 if heads_share else n_heads
|
| 198 |
+
rel_stddev = self.k_channels**-0.5
|
| 199 |
+
self.emb_rel_k = nn.Parameter(
|
| 200 |
+
torch.randn(n_heads_rel, window_size * 2 + 1, self.k_channels)
|
| 201 |
+
* rel_stddev
|
| 202 |
+
)
|
| 203 |
+
self.emb_rel_v = nn.Parameter(
|
| 204 |
+
torch.randn(n_heads_rel, window_size * 2 + 1, self.k_channels)
|
| 205 |
+
* rel_stddev
|
| 206 |
+
)
|
| 207 |
+
|
| 208 |
+
nn.init.xavier_uniform_(self.conv_q.weight)
|
| 209 |
+
nn.init.xavier_uniform_(self.conv_k.weight)
|
| 210 |
+
nn.init.xavier_uniform_(self.conv_v.weight)
|
| 211 |
+
if proximal_init:
|
| 212 |
+
with torch.no_grad():
|
| 213 |
+
self.conv_k.weight.copy_(self.conv_q.weight)
|
| 214 |
+
self.conv_k.bias.copy_(self.conv_q.bias)
|
| 215 |
+
|
| 216 |
+
def forward(self, x, c, attn_mask=None):
|
| 217 |
+
q = self.conv_q(x)
|
| 218 |
+
k = self.conv_k(c)
|
| 219 |
+
v = self.conv_v(c)
|
| 220 |
+
|
| 221 |
+
x, self.attn = self.attention(q, k, v, mask=attn_mask)
|
| 222 |
+
|
| 223 |
+
x = self.conv_o(x)
|
| 224 |
+
return x
|
| 225 |
+
|
| 226 |
+
def attention(self, query, key, value, mask=None):
|
| 227 |
+
# reshape [b, d, t] -> [b, n_h, t, d_k]
|
| 228 |
+
b, d, t_s, t_t = (*key.size(), query.size(2))
|
| 229 |
+
query = query.view(b, self.n_heads, self.k_channels, t_t).transpose(2, 3)
|
| 230 |
+
key = key.view(b, self.n_heads, self.k_channels, t_s).transpose(2, 3)
|
| 231 |
+
value = value.view(b, self.n_heads, self.k_channels, t_s).transpose(2, 3)
|
| 232 |
+
|
| 233 |
+
scores = torch.matmul(query / math.sqrt(self.k_channels), key.transpose(-2, -1))
|
| 234 |
+
if self.window_size is not None:
|
| 235 |
+
assert (
|
| 236 |
+
t_s == t_t
|
| 237 |
+
), "Relative attention is only available for self-attention."
|
| 238 |
+
key_relative_embeddings = self._get_relative_embeddings(self.emb_rel_k, t_s)
|
| 239 |
+
rel_logits = self._matmul_with_relative_keys(
|
| 240 |
+
query / math.sqrt(self.k_channels), key_relative_embeddings
|
| 241 |
+
)
|
| 242 |
+
scores_local = self._relative_position_to_absolute_position(rel_logits)
|
| 243 |
+
scores = scores + scores_local
|
| 244 |
+
if self.proximal_bias:
|
| 245 |
+
assert t_s == t_t, "Proximal bias is only available for self-attention."
|
| 246 |
+
scores = scores + self._attention_bias_proximal(t_s).to(
|
| 247 |
+
device=scores.device, dtype=scores.dtype
|
| 248 |
+
)
|
| 249 |
+
if mask is not None:
|
| 250 |
+
scores = scores.masked_fill(mask == 0, -1e4)
|
| 251 |
+
if self.block_length is not None:
|
| 252 |
+
assert (
|
| 253 |
+
t_s == t_t
|
| 254 |
+
), "Local attention is only available for self-attention."
|
| 255 |
+
block_mask = (
|
| 256 |
+
torch.ones_like(scores)
|
| 257 |
+
.triu(-self.block_length)
|
| 258 |
+
.tril(self.block_length)
|
| 259 |
+
)
|
| 260 |
+
scores = scores.masked_fill(block_mask == 0, -1e4)
|
| 261 |
+
p_attn = F.softmax(scores, dim=-1) # [b, n_h, t_t, t_s]
|
| 262 |
+
p_attn = self.drop(p_attn)
|
| 263 |
+
output = torch.matmul(p_attn, value)
|
| 264 |
+
if self.window_size is not None:
|
| 265 |
+
relative_weights = self._absolute_position_to_relative_position(p_attn)
|
| 266 |
+
value_relative_embeddings = self._get_relative_embeddings(
|
| 267 |
+
self.emb_rel_v, t_s
|
| 268 |
+
)
|
| 269 |
+
output = output + self._matmul_with_relative_values(
|
| 270 |
+
relative_weights, value_relative_embeddings
|
| 271 |
+
)
|
| 272 |
+
output = (
|
| 273 |
+
output.transpose(2, 3).contiguous().view(b, d, t_t)
|
| 274 |
+
) # [b, n_h, t_t, d_k] -> [b, d, t_t]
|
| 275 |
+
return output, p_attn
|
| 276 |
+
|
| 277 |
+
def _matmul_with_relative_values(self, x, y):
|
| 278 |
+
"""
|
| 279 |
+
x: [b, h, l, m]
|
| 280 |
+
y: [h or 1, m, d]
|
| 281 |
+
ret: [b, h, l, d]
|
| 282 |
+
"""
|
| 283 |
+
ret = torch.matmul(x, y.unsqueeze(0))
|
| 284 |
+
return ret
|
| 285 |
+
|
| 286 |
+
def _matmul_with_relative_keys(self, x, y):
|
| 287 |
+
"""
|
| 288 |
+
x: [b, h, l, d]
|
| 289 |
+
y: [h or 1, m, d]
|
| 290 |
+
ret: [b, h, l, m]
|
| 291 |
+
"""
|
| 292 |
+
ret = torch.matmul(x, y.unsqueeze(0).transpose(-2, -1))
|
| 293 |
+
return ret
|
| 294 |
+
|
| 295 |
+
def _get_relative_embeddings(self, relative_embeddings, length):
|
| 296 |
+
max_relative_position = 2 * self.window_size + 1
|
| 297 |
+
# Pad first before slice to avoid using cond ops.
|
| 298 |
+
pad_length = max(length - (self.window_size + 1), 0)
|
| 299 |
+
slice_start_position = max((self.window_size + 1) - length, 0)
|
| 300 |
+
slice_end_position = slice_start_position + 2 * length - 1
|
| 301 |
+
if pad_length > 0:
|
| 302 |
+
padded_relative_embeddings = F.pad(
|
| 303 |
+
relative_embeddings,
|
| 304 |
+
commons.convert_pad_shape([[0, 0], [pad_length, pad_length], [0, 0]]),
|
| 305 |
+
)
|
| 306 |
+
else:
|
| 307 |
+
padded_relative_embeddings = relative_embeddings
|
| 308 |
+
used_relative_embeddings = padded_relative_embeddings[
|
| 309 |
+
:, slice_start_position:slice_end_position
|
| 310 |
+
]
|
| 311 |
+
return used_relative_embeddings
|
| 312 |
+
|
| 313 |
+
def _relative_position_to_absolute_position(self, x):
|
| 314 |
+
"""
|
| 315 |
+
x: [b, h, l, 2*l-1]
|
| 316 |
+
ret: [b, h, l, l]
|
| 317 |
+
"""
|
| 318 |
+
batch, heads, length, _ = x.size()
|
| 319 |
+
# Concat columns of pad to shift from relative to absolute indexing.
|
| 320 |
+
x = F.pad(x, commons.convert_pad_shape([[0, 0], [0, 0], [0, 0], [0, 1]]))
|
| 321 |
+
|
| 322 |
+
# Concat extra elements so to add up to shape (len+1, 2*len-1).
|
| 323 |
+
x_flat = x.view([batch, heads, length * 2 * length])
|
| 324 |
+
x_flat = F.pad(
|
| 325 |
+
x_flat, commons.convert_pad_shape([[0, 0], [0, 0], [0, length - 1]])
|
| 326 |
+
)
|
| 327 |
+
|
| 328 |
+
# Reshape and slice out the padded elements.
|
| 329 |
+
x_final = x_flat.view([batch, heads, length + 1, 2 * length - 1])[
|
| 330 |
+
:, :, :length, length - 1 :
|
| 331 |
+
]
|
| 332 |
+
return x_final
|
| 333 |
+
|
| 334 |
+
def _absolute_position_to_relative_position(self, x):
|
| 335 |
+
"""
|
| 336 |
+
x: [b, h, l, l]
|
| 337 |
+
ret: [b, h, l, 2*l-1]
|
| 338 |
+
"""
|
| 339 |
+
batch, heads, length, _ = x.size()
|
| 340 |
+
# padd along column
|
| 341 |
+
x = F.pad(
|
| 342 |
+
x, commons.convert_pad_shape([[0, 0], [0, 0], [0, 0], [0, length - 1]])
|
| 343 |
+
)
|
| 344 |
+
x_flat = x.view([batch, heads, length**2 + length * (length - 1)])
|
| 345 |
+
# add 0's in the beginning that will skew the elements after reshape
|
| 346 |
+
x_flat = F.pad(x_flat, commons.convert_pad_shape([[0, 0], [0, 0], [length, 0]]))
|
| 347 |
+
x_final = x_flat.view([batch, heads, length, 2 * length])[:, :, :, 1:]
|
| 348 |
+
return x_final
|
| 349 |
+
|
| 350 |
+
def _attention_bias_proximal(self, length):
|
| 351 |
+
"""Bias for self-attention to encourage attention to close positions.
|
| 352 |
+
Args:
|
| 353 |
+
length: an integer scalar.
|
| 354 |
+
Returns:
|
| 355 |
+
a Tensor with shape [1, 1, length, length]
|
| 356 |
+
"""
|
| 357 |
+
r = torch.arange(length, dtype=torch.float32)
|
| 358 |
+
diff = torch.unsqueeze(r, 0) - torch.unsqueeze(r, 1)
|
| 359 |
+
return torch.unsqueeze(torch.unsqueeze(-torch.log1p(torch.abs(diff)), 0), 0)
|
| 360 |
+
|
| 361 |
+
|
| 362 |
+
class FFN(nn.Module):
|
| 363 |
+
def __init__(
|
| 364 |
+
self,
|
| 365 |
+
in_channels,
|
| 366 |
+
out_channels,
|
| 367 |
+
filter_channels,
|
| 368 |
+
kernel_size,
|
| 369 |
+
p_dropout=0.0,
|
| 370 |
+
activation=None,
|
| 371 |
+
causal=False,
|
| 372 |
+
):
|
| 373 |
+
super().__init__()
|
| 374 |
+
self.in_channels = in_channels
|
| 375 |
+
self.out_channels = out_channels
|
| 376 |
+
self.filter_channels = filter_channels
|
| 377 |
+
self.kernel_size = kernel_size
|
| 378 |
+
self.p_dropout = p_dropout
|
| 379 |
+
self.activation = activation
|
| 380 |
+
self.causal = causal
|
| 381 |
+
|
| 382 |
+
if causal:
|
| 383 |
+
self.padding = self._causal_padding
|
| 384 |
+
else:
|
| 385 |
+
self.padding = self._same_padding
|
| 386 |
+
|
| 387 |
+
self.conv_1 = nn.Conv1d(in_channels, filter_channels, kernel_size)
|
| 388 |
+
self.conv_2 = nn.Conv1d(filter_channels, out_channels, kernel_size)
|
| 389 |
+
self.drop = nn.Dropout(p_dropout)
|
| 390 |
+
|
| 391 |
+
def forward(self, x, x_mask):
|
| 392 |
+
x = self.conv_1(self.padding(x * x_mask))
|
| 393 |
+
if self.activation == "gelu":
|
| 394 |
+
x = x * torch.sigmoid(1.702 * x)
|
| 395 |
+
else:
|
| 396 |
+
x = torch.relu(x)
|
| 397 |
+
x = self.drop(x)
|
| 398 |
+
x = self.conv_2(self.padding(x * x_mask))
|
| 399 |
+
return x * x_mask
|
| 400 |
+
|
| 401 |
+
def _causal_padding(self, x):
|
| 402 |
+
if self.kernel_size == 1:
|
| 403 |
+
return x
|
| 404 |
+
pad_l = self.kernel_size - 1
|
| 405 |
+
pad_r = 0
|
| 406 |
+
padding = [[0, 0], [0, 0], [pad_l, pad_r]]
|
| 407 |
+
x = F.pad(x, commons.convert_pad_shape(padding))
|
| 408 |
+
return x
|
| 409 |
+
|
| 410 |
+
def _same_padding(self, x):
|
| 411 |
+
if self.kernel_size == 1:
|
| 412 |
+
return x
|
| 413 |
+
pad_l = (self.kernel_size - 1) // 2
|
| 414 |
+
pad_r = self.kernel_size // 2
|
| 415 |
+
padding = [[0, 0], [0, 0], [pad_l, pad_r]]
|
| 416 |
+
x = F.pad(x, commons.convert_pad_shape(padding))
|
| 417 |
+
return x
|
src/infer_pack/commons.py
ADDED
|
@@ -0,0 +1,166 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import math
|
| 2 |
+
import numpy as np
|
| 3 |
+
import torch
|
| 4 |
+
from torch import nn
|
| 5 |
+
from torch.nn import functional as F
|
| 6 |
+
|
| 7 |
+
|
| 8 |
+
def init_weights(m, mean=0.0, std=0.01):
|
| 9 |
+
classname = m.__class__.__name__
|
| 10 |
+
if classname.find("Conv") != -1:
|
| 11 |
+
m.weight.data.normal_(mean, std)
|
| 12 |
+
|
| 13 |
+
|
| 14 |
+
def get_padding(kernel_size, dilation=1):
|
| 15 |
+
return int((kernel_size * dilation - dilation) / 2)
|
| 16 |
+
|
| 17 |
+
|
| 18 |
+
def convert_pad_shape(pad_shape):
|
| 19 |
+
l = pad_shape[::-1]
|
| 20 |
+
pad_shape = [item for sublist in l for item in sublist]
|
| 21 |
+
return pad_shape
|
| 22 |
+
|
| 23 |
+
|
| 24 |
+
def kl_divergence(m_p, logs_p, m_q, logs_q):
|
| 25 |
+
"""KL(P||Q)"""
|
| 26 |
+
kl = (logs_q - logs_p) - 0.5
|
| 27 |
+
kl += (
|
| 28 |
+
0.5 * (torch.exp(2.0 * logs_p) + ((m_p - m_q) ** 2)) * torch.exp(-2.0 * logs_q)
|
| 29 |
+
)
|
| 30 |
+
return kl
|
| 31 |
+
|
| 32 |
+
|
| 33 |
+
def rand_gumbel(shape):
|
| 34 |
+
"""Sample from the Gumbel distribution, protect from overflows."""
|
| 35 |
+
uniform_samples = torch.rand(shape) * 0.99998 + 0.00001
|
| 36 |
+
return -torch.log(-torch.log(uniform_samples))
|
| 37 |
+
|
| 38 |
+
|
| 39 |
+
def rand_gumbel_like(x):
|
| 40 |
+
g = rand_gumbel(x.size()).to(dtype=x.dtype, device=x.device)
|
| 41 |
+
return g
|
| 42 |
+
|
| 43 |
+
|
| 44 |
+
def slice_segments(x, ids_str, segment_size=4):
|
| 45 |
+
ret = torch.zeros_like(x[:, :, :segment_size])
|
| 46 |
+
for i in range(x.size(0)):
|
| 47 |
+
idx_str = ids_str[i]
|
| 48 |
+
idx_end = idx_str + segment_size
|
| 49 |
+
ret[i] = x[i, :, idx_str:idx_end]
|
| 50 |
+
return ret
|
| 51 |
+
|
| 52 |
+
|
| 53 |
+
def slice_segments2(x, ids_str, segment_size=4):
|
| 54 |
+
ret = torch.zeros_like(x[:, :segment_size])
|
| 55 |
+
for i in range(x.size(0)):
|
| 56 |
+
idx_str = ids_str[i]
|
| 57 |
+
idx_end = idx_str + segment_size
|
| 58 |
+
ret[i] = x[i, idx_str:idx_end]
|
| 59 |
+
return ret
|
| 60 |
+
|
| 61 |
+
|
| 62 |
+
def rand_slice_segments(x, x_lengths=None, segment_size=4):
|
| 63 |
+
b, d, t = x.size()
|
| 64 |
+
if x_lengths is None:
|
| 65 |
+
x_lengths = t
|
| 66 |
+
ids_str_max = x_lengths - segment_size + 1
|
| 67 |
+
ids_str = (torch.rand([b]).to(device=x.device) * ids_str_max).to(dtype=torch.long)
|
| 68 |
+
ret = slice_segments(x, ids_str, segment_size)
|
| 69 |
+
return ret, ids_str
|
| 70 |
+
|
| 71 |
+
|
| 72 |
+
def get_timing_signal_1d(length, channels, min_timescale=1.0, max_timescale=1.0e4):
|
| 73 |
+
position = torch.arange(length, dtype=torch.float)
|
| 74 |
+
num_timescales = channels // 2
|
| 75 |
+
log_timescale_increment = math.log(float(max_timescale) / float(min_timescale)) / (
|
| 76 |
+
num_timescales - 1
|
| 77 |
+
)
|
| 78 |
+
inv_timescales = min_timescale * torch.exp(
|
| 79 |
+
torch.arange(num_timescales, dtype=torch.float) * -log_timescale_increment
|
| 80 |
+
)
|
| 81 |
+
scaled_time = position.unsqueeze(0) * inv_timescales.unsqueeze(1)
|
| 82 |
+
signal = torch.cat([torch.sin(scaled_time), torch.cos(scaled_time)], 0)
|
| 83 |
+
signal = F.pad(signal, [0, 0, 0, channels % 2])
|
| 84 |
+
signal = signal.view(1, channels, length)
|
| 85 |
+
return signal
|
| 86 |
+
|
| 87 |
+
|
| 88 |
+
def add_timing_signal_1d(x, min_timescale=1.0, max_timescale=1.0e4):
|
| 89 |
+
b, channels, length = x.size()
|
| 90 |
+
signal = get_timing_signal_1d(length, channels, min_timescale, max_timescale)
|
| 91 |
+
return x + signal.to(dtype=x.dtype, device=x.device)
|
| 92 |
+
|
| 93 |
+
|
| 94 |
+
def cat_timing_signal_1d(x, min_timescale=1.0, max_timescale=1.0e4, axis=1):
|
| 95 |
+
b, channels, length = x.size()
|
| 96 |
+
signal = get_timing_signal_1d(length, channels, min_timescale, max_timescale)
|
| 97 |
+
return torch.cat([x, signal.to(dtype=x.dtype, device=x.device)], axis)
|
| 98 |
+
|
| 99 |
+
|
| 100 |
+
def subsequent_mask(length):
|
| 101 |
+
mask = torch.tril(torch.ones(length, length)).unsqueeze(0).unsqueeze(0)
|
| 102 |
+
return mask
|
| 103 |
+
|
| 104 |
+
|
| 105 |
+
@torch.jit.script
|
| 106 |
+
def fused_add_tanh_sigmoid_multiply(input_a, input_b, n_channels):
|
| 107 |
+
n_channels_int = n_channels[0]
|
| 108 |
+
in_act = input_a + input_b
|
| 109 |
+
t_act = torch.tanh(in_act[:, :n_channels_int, :])
|
| 110 |
+
s_act = torch.sigmoid(in_act[:, n_channels_int:, :])
|
| 111 |
+
acts = t_act * s_act
|
| 112 |
+
return acts
|
| 113 |
+
|
| 114 |
+
|
| 115 |
+
def convert_pad_shape(pad_shape):
|
| 116 |
+
l = pad_shape[::-1]
|
| 117 |
+
pad_shape = [item for sublist in l for item in sublist]
|
| 118 |
+
return pad_shape
|
| 119 |
+
|
| 120 |
+
|
| 121 |
+
def shift_1d(x):
|
| 122 |
+
x = F.pad(x, convert_pad_shape([[0, 0], [0, 0], [1, 0]]))[:, :, :-1]
|
| 123 |
+
return x
|
| 124 |
+
|
| 125 |
+
|
| 126 |
+
def sequence_mask(length, max_length=None):
|
| 127 |
+
if max_length is None:
|
| 128 |
+
max_length = length.max()
|
| 129 |
+
x = torch.arange(max_length, dtype=length.dtype, device=length.device)
|
| 130 |
+
return x.unsqueeze(0) < length.unsqueeze(1)
|
| 131 |
+
|
| 132 |
+
|
| 133 |
+
def generate_path(duration, mask):
|
| 134 |
+
"""
|
| 135 |
+
duration: [b, 1, t_x]
|
| 136 |
+
mask: [b, 1, t_y, t_x]
|
| 137 |
+
"""
|
| 138 |
+
device = duration.device
|
| 139 |
+
|
| 140 |
+
b, _, t_y, t_x = mask.shape
|
| 141 |
+
cum_duration = torch.cumsum(duration, -1)
|
| 142 |
+
|
| 143 |
+
cum_duration_flat = cum_duration.view(b * t_x)
|
| 144 |
+
path = sequence_mask(cum_duration_flat, t_y).to(mask.dtype)
|
| 145 |
+
path = path.view(b, t_x, t_y)
|
| 146 |
+
path = path - F.pad(path, convert_pad_shape([[0, 0], [1, 0], [0, 0]]))[:, :-1]
|
| 147 |
+
path = path.unsqueeze(1).transpose(2, 3) * mask
|
| 148 |
+
return path
|
| 149 |
+
|
| 150 |
+
|
| 151 |
+
def clip_grad_value_(parameters, clip_value, norm_type=2):
|
| 152 |
+
if isinstance(parameters, torch.Tensor):
|
| 153 |
+
parameters = [parameters]
|
| 154 |
+
parameters = list(filter(lambda p: p.grad is not None, parameters))
|
| 155 |
+
norm_type = float(norm_type)
|
| 156 |
+
if clip_value is not None:
|
| 157 |
+
clip_value = float(clip_value)
|
| 158 |
+
|
| 159 |
+
total_norm = 0
|
| 160 |
+
for p in parameters:
|
| 161 |
+
param_norm = p.grad.data.norm(norm_type)
|
| 162 |
+
total_norm += param_norm.item() ** norm_type
|
| 163 |
+
if clip_value is not None:
|
| 164 |
+
p.grad.data.clamp_(min=-clip_value, max=clip_value)
|
| 165 |
+
total_norm = total_norm ** (1.0 / norm_type)
|
| 166 |
+
return total_norm
|
src/infer_pack/models.py
ADDED
|
@@ -0,0 +1,1124 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import math, pdb, os
|
| 2 |
+
from time import time as ttime
|
| 3 |
+
import torch
|
| 4 |
+
from torch import nn
|
| 5 |
+
from torch.nn import functional as F
|
| 6 |
+
from infer_pack import modules
|
| 7 |
+
from infer_pack import attentions
|
| 8 |
+
from infer_pack import commons
|
| 9 |
+
from infer_pack.commons import init_weights, get_padding
|
| 10 |
+
from torch.nn import Conv1d, ConvTranspose1d, AvgPool1d, Conv2d
|
| 11 |
+
from torch.nn.utils import weight_norm, remove_weight_norm, spectral_norm
|
| 12 |
+
from infer_pack.commons import init_weights
|
| 13 |
+
import numpy as np
|
| 14 |
+
from infer_pack import commons
|
| 15 |
+
|
| 16 |
+
|
| 17 |
+
class TextEncoder256(nn.Module):
|
| 18 |
+
def __init__(
|
| 19 |
+
self,
|
| 20 |
+
out_channels,
|
| 21 |
+
hidden_channels,
|
| 22 |
+
filter_channels,
|
| 23 |
+
n_heads,
|
| 24 |
+
n_layers,
|
| 25 |
+
kernel_size,
|
| 26 |
+
p_dropout,
|
| 27 |
+
f0=True,
|
| 28 |
+
):
|
| 29 |
+
super().__init__()
|
| 30 |
+
self.out_channels = out_channels
|
| 31 |
+
self.hidden_channels = hidden_channels
|
| 32 |
+
self.filter_channels = filter_channels
|
| 33 |
+
self.n_heads = n_heads
|
| 34 |
+
self.n_layers = n_layers
|
| 35 |
+
self.kernel_size = kernel_size
|
| 36 |
+
self.p_dropout = p_dropout
|
| 37 |
+
self.emb_phone = nn.Linear(256, hidden_channels)
|
| 38 |
+
self.lrelu = nn.LeakyReLU(0.1, inplace=True)
|
| 39 |
+
if f0 == True:
|
| 40 |
+
self.emb_pitch = nn.Embedding(256, hidden_channels) # pitch 256
|
| 41 |
+
self.encoder = attentions.Encoder(
|
| 42 |
+
hidden_channels, filter_channels, n_heads, n_layers, kernel_size, p_dropout
|
| 43 |
+
)
|
| 44 |
+
self.proj = nn.Conv1d(hidden_channels, out_channels * 2, 1)
|
| 45 |
+
|
| 46 |
+
def forward(self, phone, pitch, lengths):
|
| 47 |
+
if pitch == None:
|
| 48 |
+
x = self.emb_phone(phone)
|
| 49 |
+
else:
|
| 50 |
+
x = self.emb_phone(phone) + self.emb_pitch(pitch)
|
| 51 |
+
x = x * math.sqrt(self.hidden_channels) # [b, t, h]
|
| 52 |
+
x = self.lrelu(x)
|
| 53 |
+
x = torch.transpose(x, 1, -1) # [b, h, t]
|
| 54 |
+
x_mask = torch.unsqueeze(commons.sequence_mask(lengths, x.size(2)), 1).to(
|
| 55 |
+
x.dtype
|
| 56 |
+
)
|
| 57 |
+
x = self.encoder(x * x_mask, x_mask)
|
| 58 |
+
stats = self.proj(x) * x_mask
|
| 59 |
+
|
| 60 |
+
m, logs = torch.split(stats, self.out_channels, dim=1)
|
| 61 |
+
return m, logs, x_mask
|
| 62 |
+
|
| 63 |
+
|
| 64 |
+
class TextEncoder768(nn.Module):
|
| 65 |
+
def __init__(
|
| 66 |
+
self,
|
| 67 |
+
out_channels,
|
| 68 |
+
hidden_channels,
|
| 69 |
+
filter_channels,
|
| 70 |
+
n_heads,
|
| 71 |
+
n_layers,
|
| 72 |
+
kernel_size,
|
| 73 |
+
p_dropout,
|
| 74 |
+
f0=True,
|
| 75 |
+
):
|
| 76 |
+
super().__init__()
|
| 77 |
+
self.out_channels = out_channels
|
| 78 |
+
self.hidden_channels = hidden_channels
|
| 79 |
+
self.filter_channels = filter_channels
|
| 80 |
+
self.n_heads = n_heads
|
| 81 |
+
self.n_layers = n_layers
|
| 82 |
+
self.kernel_size = kernel_size
|
| 83 |
+
self.p_dropout = p_dropout
|
| 84 |
+
self.emb_phone = nn.Linear(768, hidden_channels)
|
| 85 |
+
self.lrelu = nn.LeakyReLU(0.1, inplace=True)
|
| 86 |
+
if f0 == True:
|
| 87 |
+
self.emb_pitch = nn.Embedding(256, hidden_channels) # pitch 256
|
| 88 |
+
self.encoder = attentions.Encoder(
|
| 89 |
+
hidden_channels, filter_channels, n_heads, n_layers, kernel_size, p_dropout
|
| 90 |
+
)
|
| 91 |
+
self.proj = nn.Conv1d(hidden_channels, out_channels * 2, 1)
|
| 92 |
+
|
| 93 |
+
def forward(self, phone, pitch, lengths):
|
| 94 |
+
if pitch == None:
|
| 95 |
+
x = self.emb_phone(phone)
|
| 96 |
+
else:
|
| 97 |
+
x = self.emb_phone(phone) + self.emb_pitch(pitch)
|
| 98 |
+
x = x * math.sqrt(self.hidden_channels) # [b, t, h]
|
| 99 |
+
x = self.lrelu(x)
|
| 100 |
+
x = torch.transpose(x, 1, -1) # [b, h, t]
|
| 101 |
+
x_mask = torch.unsqueeze(commons.sequence_mask(lengths, x.size(2)), 1).to(
|
| 102 |
+
x.dtype
|
| 103 |
+
)
|
| 104 |
+
x = self.encoder(x * x_mask, x_mask)
|
| 105 |
+
stats = self.proj(x) * x_mask
|
| 106 |
+
|
| 107 |
+
m, logs = torch.split(stats, self.out_channels, dim=1)
|
| 108 |
+
return m, logs, x_mask
|
| 109 |
+
|
| 110 |
+
|
| 111 |
+
class ResidualCouplingBlock(nn.Module):
|
| 112 |
+
def __init__(
|
| 113 |
+
self,
|
| 114 |
+
channels,
|
| 115 |
+
hidden_channels,
|
| 116 |
+
kernel_size,
|
| 117 |
+
dilation_rate,
|
| 118 |
+
n_layers,
|
| 119 |
+
n_flows=4,
|
| 120 |
+
gin_channels=0,
|
| 121 |
+
):
|
| 122 |
+
super().__init__()
|
| 123 |
+
self.channels = channels
|
| 124 |
+
self.hidden_channels = hidden_channels
|
| 125 |
+
self.kernel_size = kernel_size
|
| 126 |
+
self.dilation_rate = dilation_rate
|
| 127 |
+
self.n_layers = n_layers
|
| 128 |
+
self.n_flows = n_flows
|
| 129 |
+
self.gin_channels = gin_channels
|
| 130 |
+
|
| 131 |
+
self.flows = nn.ModuleList()
|
| 132 |
+
for i in range(n_flows):
|
| 133 |
+
self.flows.append(
|
| 134 |
+
modules.ResidualCouplingLayer(
|
| 135 |
+
channels,
|
| 136 |
+
hidden_channels,
|
| 137 |
+
kernel_size,
|
| 138 |
+
dilation_rate,
|
| 139 |
+
n_layers,
|
| 140 |
+
gin_channels=gin_channels,
|
| 141 |
+
mean_only=True,
|
| 142 |
+
)
|
| 143 |
+
)
|
| 144 |
+
self.flows.append(modules.Flip())
|
| 145 |
+
|
| 146 |
+
def forward(self, x, x_mask, g=None, reverse=False):
|
| 147 |
+
if not reverse:
|
| 148 |
+
for flow in self.flows:
|
| 149 |
+
x, _ = flow(x, x_mask, g=g, reverse=reverse)
|
| 150 |
+
else:
|
| 151 |
+
for flow in reversed(self.flows):
|
| 152 |
+
x = flow(x, x_mask, g=g, reverse=reverse)
|
| 153 |
+
return x
|
| 154 |
+
|
| 155 |
+
def remove_weight_norm(self):
|
| 156 |
+
for i in range(self.n_flows):
|
| 157 |
+
self.flows[i * 2].remove_weight_norm()
|
| 158 |
+
|
| 159 |
+
|
| 160 |
+
class PosteriorEncoder(nn.Module):
|
| 161 |
+
def __init__(
|
| 162 |
+
self,
|
| 163 |
+
in_channels,
|
| 164 |
+
out_channels,
|
| 165 |
+
hidden_channels,
|
| 166 |
+
kernel_size,
|
| 167 |
+
dilation_rate,
|
| 168 |
+
n_layers,
|
| 169 |
+
gin_channels=0,
|
| 170 |
+
):
|
| 171 |
+
super().__init__()
|
| 172 |
+
self.in_channels = in_channels
|
| 173 |
+
self.out_channels = out_channels
|
| 174 |
+
self.hidden_channels = hidden_channels
|
| 175 |
+
self.kernel_size = kernel_size
|
| 176 |
+
self.dilation_rate = dilation_rate
|
| 177 |
+
self.n_layers = n_layers
|
| 178 |
+
self.gin_channels = gin_channels
|
| 179 |
+
|
| 180 |
+
self.pre = nn.Conv1d(in_channels, hidden_channels, 1)
|
| 181 |
+
self.enc = modules.WN(
|
| 182 |
+
hidden_channels,
|
| 183 |
+
kernel_size,
|
| 184 |
+
dilation_rate,
|
| 185 |
+
n_layers,
|
| 186 |
+
gin_channels=gin_channels,
|
| 187 |
+
)
|
| 188 |
+
self.proj = nn.Conv1d(hidden_channels, out_channels * 2, 1)
|
| 189 |
+
|
| 190 |
+
def forward(self, x, x_lengths, g=None):
|
| 191 |
+
x_mask = torch.unsqueeze(commons.sequence_mask(x_lengths, x.size(2)), 1).to(
|
| 192 |
+
x.dtype
|
| 193 |
+
)
|
| 194 |
+
x = self.pre(x) * x_mask
|
| 195 |
+
x = self.enc(x, x_mask, g=g)
|
| 196 |
+
stats = self.proj(x) * x_mask
|
| 197 |
+
m, logs = torch.split(stats, self.out_channels, dim=1)
|
| 198 |
+
z = (m + torch.randn_like(m) * torch.exp(logs)) * x_mask
|
| 199 |
+
return z, m, logs, x_mask
|
| 200 |
+
|
| 201 |
+
def remove_weight_norm(self):
|
| 202 |
+
self.enc.remove_weight_norm()
|
| 203 |
+
|
| 204 |
+
|
| 205 |
+
class Generator(torch.nn.Module):
|
| 206 |
+
def __init__(
|
| 207 |
+
self,
|
| 208 |
+
initial_channel,
|
| 209 |
+
resblock,
|
| 210 |
+
resblock_kernel_sizes,
|
| 211 |
+
resblock_dilation_sizes,
|
| 212 |
+
upsample_rates,
|
| 213 |
+
upsample_initial_channel,
|
| 214 |
+
upsample_kernel_sizes,
|
| 215 |
+
gin_channels=0,
|
| 216 |
+
):
|
| 217 |
+
super(Generator, self).__init__()
|
| 218 |
+
self.num_kernels = len(resblock_kernel_sizes)
|
| 219 |
+
self.num_upsamples = len(upsample_rates)
|
| 220 |
+
self.conv_pre = Conv1d(
|
| 221 |
+
initial_channel, upsample_initial_channel, 7, 1, padding=3
|
| 222 |
+
)
|
| 223 |
+
resblock = modules.ResBlock1 if resblock == "1" else modules.ResBlock2
|
| 224 |
+
|
| 225 |
+
self.ups = nn.ModuleList()
|
| 226 |
+
for i, (u, k) in enumerate(zip(upsample_rates, upsample_kernel_sizes)):
|
| 227 |
+
self.ups.append(
|
| 228 |
+
weight_norm(
|
| 229 |
+
ConvTranspose1d(
|
| 230 |
+
upsample_initial_channel // (2**i),
|
| 231 |
+
upsample_initial_channel // (2 ** (i + 1)),
|
| 232 |
+
k,
|
| 233 |
+
u,
|
| 234 |
+
padding=(k - u) // 2,
|
| 235 |
+
)
|
| 236 |
+
)
|
| 237 |
+
)
|
| 238 |
+
|
| 239 |
+
self.resblocks = nn.ModuleList()
|
| 240 |
+
for i in range(len(self.ups)):
|
| 241 |
+
ch = upsample_initial_channel // (2 ** (i + 1))
|
| 242 |
+
for j, (k, d) in enumerate(
|
| 243 |
+
zip(resblock_kernel_sizes, resblock_dilation_sizes)
|
| 244 |
+
):
|
| 245 |
+
self.resblocks.append(resblock(ch, k, d))
|
| 246 |
+
|
| 247 |
+
self.conv_post = Conv1d(ch, 1, 7, 1, padding=3, bias=False)
|
| 248 |
+
self.ups.apply(init_weights)
|
| 249 |
+
|
| 250 |
+
if gin_channels != 0:
|
| 251 |
+
self.cond = nn.Conv1d(gin_channels, upsample_initial_channel, 1)
|
| 252 |
+
|
| 253 |
+
def forward(self, x, g=None):
|
| 254 |
+
x = self.conv_pre(x)
|
| 255 |
+
if g is not None:
|
| 256 |
+
x = x + self.cond(g)
|
| 257 |
+
|
| 258 |
+
for i in range(self.num_upsamples):
|
| 259 |
+
x = F.leaky_relu(x, modules.LRELU_SLOPE)
|
| 260 |
+
x = self.ups[i](x)
|
| 261 |
+
xs = None
|
| 262 |
+
for j in range(self.num_kernels):
|
| 263 |
+
if xs is None:
|
| 264 |
+
xs = self.resblocks[i * self.num_kernels + j](x)
|
| 265 |
+
else:
|
| 266 |
+
xs += self.resblocks[i * self.num_kernels + j](x)
|
| 267 |
+
x = xs / self.num_kernels
|
| 268 |
+
x = F.leaky_relu(x)
|
| 269 |
+
x = self.conv_post(x)
|
| 270 |
+
x = torch.tanh(x)
|
| 271 |
+
|
| 272 |
+
return x
|
| 273 |
+
|
| 274 |
+
def remove_weight_norm(self):
|
| 275 |
+
for l in self.ups:
|
| 276 |
+
remove_weight_norm(l)
|
| 277 |
+
for l in self.resblocks:
|
| 278 |
+
l.remove_weight_norm()
|
| 279 |
+
|
| 280 |
+
|
| 281 |
+
class SineGen(torch.nn.Module):
|
| 282 |
+
"""Definition of sine generator
|
| 283 |
+
SineGen(samp_rate, harmonic_num = 0,
|
| 284 |
+
sine_amp = 0.1, noise_std = 0.003,
|
| 285 |
+
voiced_threshold = 0,
|
| 286 |
+
flag_for_pulse=False)
|
| 287 |
+
samp_rate: sampling rate in Hz
|
| 288 |
+
harmonic_num: number of harmonic overtones (default 0)
|
| 289 |
+
sine_amp: amplitude of sine-wavefrom (default 0.1)
|
| 290 |
+
noise_std: std of Gaussian noise (default 0.003)
|
| 291 |
+
voiced_thoreshold: F0 threshold for U/V classification (default 0)
|
| 292 |
+
flag_for_pulse: this SinGen is used inside PulseGen (default False)
|
| 293 |
+
Note: when flag_for_pulse is True, the first time step of a voiced
|
| 294 |
+
segment is always sin(np.pi) or cos(0)
|
| 295 |
+
"""
|
| 296 |
+
|
| 297 |
+
def __init__(
|
| 298 |
+
self,
|
| 299 |
+
samp_rate,
|
| 300 |
+
harmonic_num=0,
|
| 301 |
+
sine_amp=0.1,
|
| 302 |
+
noise_std=0.003,
|
| 303 |
+
voiced_threshold=0,
|
| 304 |
+
flag_for_pulse=False,
|
| 305 |
+
):
|
| 306 |
+
super(SineGen, self).__init__()
|
| 307 |
+
self.sine_amp = sine_amp
|
| 308 |
+
self.noise_std = noise_std
|
| 309 |
+
self.harmonic_num = harmonic_num
|
| 310 |
+
self.dim = self.harmonic_num + 1
|
| 311 |
+
self.sampling_rate = samp_rate
|
| 312 |
+
self.voiced_threshold = voiced_threshold
|
| 313 |
+
|
| 314 |
+
def _f02uv(self, f0):
|
| 315 |
+
# generate uv signal
|
| 316 |
+
uv = torch.ones_like(f0)
|
| 317 |
+
uv = uv * (f0 > self.voiced_threshold)
|
| 318 |
+
return uv
|
| 319 |
+
|
| 320 |
+
def forward(self, f0, upp):
|
| 321 |
+
"""sine_tensor, uv = forward(f0)
|
| 322 |
+
input F0: tensor(batchsize=1, length, dim=1)
|
| 323 |
+
f0 for unvoiced steps should be 0
|
| 324 |
+
output sine_tensor: tensor(batchsize=1, length, dim)
|
| 325 |
+
output uv: tensor(batchsize=1, length, 1)
|
| 326 |
+
"""
|
| 327 |
+
with torch.no_grad():
|
| 328 |
+
f0 = f0[:, None].transpose(1, 2)
|
| 329 |
+
f0_buf = torch.zeros(f0.shape[0], f0.shape[1], self.dim, device=f0.device)
|
| 330 |
+
# fundamental component
|
| 331 |
+
f0_buf[:, :, 0] = f0[:, :, 0]
|
| 332 |
+
for idx in np.arange(self.harmonic_num):
|
| 333 |
+
f0_buf[:, :, idx + 1] = f0_buf[:, :, 0] * (
|
| 334 |
+
idx + 2
|
| 335 |
+
) # idx + 2: the (idx+1)-th overtone, (idx+2)-th harmonic
|
| 336 |
+
rad_values = (f0_buf / self.sampling_rate) % 1 ###%1意味着n_har的乘积无法后处理优化
|
| 337 |
+
rand_ini = torch.rand(
|
| 338 |
+
f0_buf.shape[0], f0_buf.shape[2], device=f0_buf.device
|
| 339 |
+
)
|
| 340 |
+
rand_ini[:, 0] = 0
|
| 341 |
+
rad_values[:, 0, :] = rad_values[:, 0, :] + rand_ini
|
| 342 |
+
tmp_over_one = torch.cumsum(rad_values, 1) # % 1 #####%1意味着后面的cumsum无法再优化
|
| 343 |
+
tmp_over_one *= upp
|
| 344 |
+
tmp_over_one = F.interpolate(
|
| 345 |
+
tmp_over_one.transpose(2, 1),
|
| 346 |
+
scale_factor=upp,
|
| 347 |
+
mode="linear",
|
| 348 |
+
align_corners=True,
|
| 349 |
+
).transpose(2, 1)
|
| 350 |
+
rad_values = F.interpolate(
|
| 351 |
+
rad_values.transpose(2, 1), scale_factor=upp, mode="nearest"
|
| 352 |
+
).transpose(
|
| 353 |
+
2, 1
|
| 354 |
+
) #######
|
| 355 |
+
tmp_over_one %= 1
|
| 356 |
+
tmp_over_one_idx = (tmp_over_one[:, 1:, :] - tmp_over_one[:, :-1, :]) < 0
|
| 357 |
+
cumsum_shift = torch.zeros_like(rad_values)
|
| 358 |
+
cumsum_shift[:, 1:, :] = tmp_over_one_idx * -1.0
|
| 359 |
+
sine_waves = torch.sin(
|
| 360 |
+
torch.cumsum(rad_values + cumsum_shift, dim=1) * 2 * np.pi
|
| 361 |
+
)
|
| 362 |
+
sine_waves = sine_waves * self.sine_amp
|
| 363 |
+
uv = self._f02uv(f0)
|
| 364 |
+
uv = F.interpolate(
|
| 365 |
+
uv.transpose(2, 1), scale_factor=upp, mode="nearest"
|
| 366 |
+
).transpose(2, 1)
|
| 367 |
+
noise_amp = uv * self.noise_std + (1 - uv) * self.sine_amp / 3
|
| 368 |
+
noise = noise_amp * torch.randn_like(sine_waves)
|
| 369 |
+
sine_waves = sine_waves * uv + noise
|
| 370 |
+
return sine_waves, uv, noise
|
| 371 |
+
|
| 372 |
+
|
| 373 |
+
class SourceModuleHnNSF(torch.nn.Module):
|
| 374 |
+
"""SourceModule for hn-nsf
|
| 375 |
+
SourceModule(sampling_rate, harmonic_num=0, sine_amp=0.1,
|
| 376 |
+
add_noise_std=0.003, voiced_threshod=0)
|
| 377 |
+
sampling_rate: sampling_rate in Hz
|
| 378 |
+
harmonic_num: number of harmonic above F0 (default: 0)
|
| 379 |
+
sine_amp: amplitude of sine source signal (default: 0.1)
|
| 380 |
+
add_noise_std: std of additive Gaussian noise (default: 0.003)
|
| 381 |
+
note that amplitude of noise in unvoiced is decided
|
| 382 |
+
by sine_amp
|
| 383 |
+
voiced_threshold: threhold to set U/V given F0 (default: 0)
|
| 384 |
+
Sine_source, noise_source = SourceModuleHnNSF(F0_sampled)
|
| 385 |
+
F0_sampled (batchsize, length, 1)
|
| 386 |
+
Sine_source (batchsize, length, 1)
|
| 387 |
+
noise_source (batchsize, length 1)
|
| 388 |
+
uv (batchsize, length, 1)
|
| 389 |
+
"""
|
| 390 |
+
|
| 391 |
+
def __init__(
|
| 392 |
+
self,
|
| 393 |
+
sampling_rate,
|
| 394 |
+
harmonic_num=0,
|
| 395 |
+
sine_amp=0.1,
|
| 396 |
+
add_noise_std=0.003,
|
| 397 |
+
voiced_threshod=0,
|
| 398 |
+
is_half=True,
|
| 399 |
+
):
|
| 400 |
+
super(SourceModuleHnNSF, self).__init__()
|
| 401 |
+
|
| 402 |
+
self.sine_amp = sine_amp
|
| 403 |
+
self.noise_std = add_noise_std
|
| 404 |
+
self.is_half = is_half
|
| 405 |
+
# to produce sine waveforms
|
| 406 |
+
self.l_sin_gen = SineGen(
|
| 407 |
+
sampling_rate, harmonic_num, sine_amp, add_noise_std, voiced_threshod
|
| 408 |
+
)
|
| 409 |
+
|
| 410 |
+
# to merge source harmonics into a single excitation
|
| 411 |
+
self.l_linear = torch.nn.Linear(harmonic_num + 1, 1)
|
| 412 |
+
self.l_tanh = torch.nn.Tanh()
|
| 413 |
+
|
| 414 |
+
def forward(self, x, upp=None):
|
| 415 |
+
sine_wavs, uv, _ = self.l_sin_gen(x, upp)
|
| 416 |
+
if self.is_half:
|
| 417 |
+
sine_wavs = sine_wavs.half()
|
| 418 |
+
sine_merge = self.l_tanh(self.l_linear(sine_wavs))
|
| 419 |
+
return sine_merge, None, None # noise, uv
|
| 420 |
+
|
| 421 |
+
|
| 422 |
+
class GeneratorNSF(torch.nn.Module):
|
| 423 |
+
def __init__(
|
| 424 |
+
self,
|
| 425 |
+
initial_channel,
|
| 426 |
+
resblock,
|
| 427 |
+
resblock_kernel_sizes,
|
| 428 |
+
resblock_dilation_sizes,
|
| 429 |
+
upsample_rates,
|
| 430 |
+
upsample_initial_channel,
|
| 431 |
+
upsample_kernel_sizes,
|
| 432 |
+
gin_channels,
|
| 433 |
+
sr,
|
| 434 |
+
is_half=False,
|
| 435 |
+
):
|
| 436 |
+
super(GeneratorNSF, self).__init__()
|
| 437 |
+
self.num_kernels = len(resblock_kernel_sizes)
|
| 438 |
+
self.num_upsamples = len(upsample_rates)
|
| 439 |
+
|
| 440 |
+
self.f0_upsamp = torch.nn.Upsample(scale_factor=np.prod(upsample_rates))
|
| 441 |
+
self.m_source = SourceModuleHnNSF(
|
| 442 |
+
sampling_rate=sr, harmonic_num=0, is_half=is_half
|
| 443 |
+
)
|
| 444 |
+
self.noise_convs = nn.ModuleList()
|
| 445 |
+
self.conv_pre = Conv1d(
|
| 446 |
+
initial_channel, upsample_initial_channel, 7, 1, padding=3
|
| 447 |
+
)
|
| 448 |
+
resblock = modules.ResBlock1 if resblock == "1" else modules.ResBlock2
|
| 449 |
+
|
| 450 |
+
self.ups = nn.ModuleList()
|
| 451 |
+
for i, (u, k) in enumerate(zip(upsample_rates, upsample_kernel_sizes)):
|
| 452 |
+
c_cur = upsample_initial_channel // (2 ** (i + 1))
|
| 453 |
+
self.ups.append(
|
| 454 |
+
weight_norm(
|
| 455 |
+
ConvTranspose1d(
|
| 456 |
+
upsample_initial_channel // (2**i),
|
| 457 |
+
upsample_initial_channel // (2 ** (i + 1)),
|
| 458 |
+
k,
|
| 459 |
+
u,
|
| 460 |
+
padding=(k - u) // 2,
|
| 461 |
+
)
|
| 462 |
+
)
|
| 463 |
+
)
|
| 464 |
+
if i + 1 < len(upsample_rates):
|
| 465 |
+
stride_f0 = np.prod(upsample_rates[i + 1 :])
|
| 466 |
+
self.noise_convs.append(
|
| 467 |
+
Conv1d(
|
| 468 |
+
1,
|
| 469 |
+
c_cur,
|
| 470 |
+
kernel_size=stride_f0 * 2,
|
| 471 |
+
stride=stride_f0,
|
| 472 |
+
padding=stride_f0 // 2,
|
| 473 |
+
)
|
| 474 |
+
)
|
| 475 |
+
else:
|
| 476 |
+
self.noise_convs.append(Conv1d(1, c_cur, kernel_size=1))
|
| 477 |
+
|
| 478 |
+
self.resblocks = nn.ModuleList()
|
| 479 |
+
for i in range(len(self.ups)):
|
| 480 |
+
ch = upsample_initial_channel // (2 ** (i + 1))
|
| 481 |
+
for j, (k, d) in enumerate(
|
| 482 |
+
zip(resblock_kernel_sizes, resblock_dilation_sizes)
|
| 483 |
+
):
|
| 484 |
+
self.resblocks.append(resblock(ch, k, d))
|
| 485 |
+
|
| 486 |
+
self.conv_post = Conv1d(ch, 1, 7, 1, padding=3, bias=False)
|
| 487 |
+
self.ups.apply(init_weights)
|
| 488 |
+
|
| 489 |
+
if gin_channels != 0:
|
| 490 |
+
self.cond = nn.Conv1d(gin_channels, upsample_initial_channel, 1)
|
| 491 |
+
|
| 492 |
+
self.upp = np.prod(upsample_rates)
|
| 493 |
+
|
| 494 |
+
def forward(self, x, f0, g=None):
|
| 495 |
+
har_source, noi_source, uv = self.m_source(f0, self.upp)
|
| 496 |
+
har_source = har_source.transpose(1, 2)
|
| 497 |
+
x = self.conv_pre(x)
|
| 498 |
+
if g is not None:
|
| 499 |
+
x = x + self.cond(g)
|
| 500 |
+
|
| 501 |
+
for i in range(self.num_upsamples):
|
| 502 |
+
x = F.leaky_relu(x, modules.LRELU_SLOPE)
|
| 503 |
+
x = self.ups[i](x)
|
| 504 |
+
x_source = self.noise_convs[i](har_source)
|
| 505 |
+
x = x + x_source
|
| 506 |
+
xs = None
|
| 507 |
+
for j in range(self.num_kernels):
|
| 508 |
+
if xs is None:
|
| 509 |
+
xs = self.resblocks[i * self.num_kernels + j](x)
|
| 510 |
+
else:
|
| 511 |
+
xs += self.resblocks[i * self.num_kernels + j](x)
|
| 512 |
+
x = xs / self.num_kernels
|
| 513 |
+
x = F.leaky_relu(x)
|
| 514 |
+
x = self.conv_post(x)
|
| 515 |
+
x = torch.tanh(x)
|
| 516 |
+
return x
|
| 517 |
+
|
| 518 |
+
def remove_weight_norm(self):
|
| 519 |
+
for l in self.ups:
|
| 520 |
+
remove_weight_norm(l)
|
| 521 |
+
for l in self.resblocks:
|
| 522 |
+
l.remove_weight_norm()
|
| 523 |
+
|
| 524 |
+
|
| 525 |
+
sr2sr = {
|
| 526 |
+
"32k": 32000,
|
| 527 |
+
"40k": 40000,
|
| 528 |
+
"48k": 48000,
|
| 529 |
+
}
|
| 530 |
+
|
| 531 |
+
|
| 532 |
+
class SynthesizerTrnMs256NSFsid(nn.Module):
|
| 533 |
+
def __init__(
|
| 534 |
+
self,
|
| 535 |
+
spec_channels,
|
| 536 |
+
segment_size,
|
| 537 |
+
inter_channels,
|
| 538 |
+
hidden_channels,
|
| 539 |
+
filter_channels,
|
| 540 |
+
n_heads,
|
| 541 |
+
n_layers,
|
| 542 |
+
kernel_size,
|
| 543 |
+
p_dropout,
|
| 544 |
+
resblock,
|
| 545 |
+
resblock_kernel_sizes,
|
| 546 |
+
resblock_dilation_sizes,
|
| 547 |
+
upsample_rates,
|
| 548 |
+
upsample_initial_channel,
|
| 549 |
+
upsample_kernel_sizes,
|
| 550 |
+
spk_embed_dim,
|
| 551 |
+
gin_channels,
|
| 552 |
+
sr,
|
| 553 |
+
**kwargs
|
| 554 |
+
):
|
| 555 |
+
super().__init__()
|
| 556 |
+
if type(sr) == type("strr"):
|
| 557 |
+
sr = sr2sr[sr]
|
| 558 |
+
self.spec_channels = spec_channels
|
| 559 |
+
self.inter_channels = inter_channels
|
| 560 |
+
self.hidden_channels = hidden_channels
|
| 561 |
+
self.filter_channels = filter_channels
|
| 562 |
+
self.n_heads = n_heads
|
| 563 |
+
self.n_layers = n_layers
|
| 564 |
+
self.kernel_size = kernel_size
|
| 565 |
+
self.p_dropout = p_dropout
|
| 566 |
+
self.resblock = resblock
|
| 567 |
+
self.resblock_kernel_sizes = resblock_kernel_sizes
|
| 568 |
+
self.resblock_dilation_sizes = resblock_dilation_sizes
|
| 569 |
+
self.upsample_rates = upsample_rates
|
| 570 |
+
self.upsample_initial_channel = upsample_initial_channel
|
| 571 |
+
self.upsample_kernel_sizes = upsample_kernel_sizes
|
| 572 |
+
self.segment_size = segment_size
|
| 573 |
+
self.gin_channels = gin_channels
|
| 574 |
+
# self.hop_length = hop_length#
|
| 575 |
+
self.spk_embed_dim = spk_embed_dim
|
| 576 |
+
self.enc_p = TextEncoder256(
|
| 577 |
+
inter_channels,
|
| 578 |
+
hidden_channels,
|
| 579 |
+
filter_channels,
|
| 580 |
+
n_heads,
|
| 581 |
+
n_layers,
|
| 582 |
+
kernel_size,
|
| 583 |
+
p_dropout,
|
| 584 |
+
)
|
| 585 |
+
self.dec = GeneratorNSF(
|
| 586 |
+
inter_channels,
|
| 587 |
+
resblock,
|
| 588 |
+
resblock_kernel_sizes,
|
| 589 |
+
resblock_dilation_sizes,
|
| 590 |
+
upsample_rates,
|
| 591 |
+
upsample_initial_channel,
|
| 592 |
+
upsample_kernel_sizes,
|
| 593 |
+
gin_channels=gin_channels,
|
| 594 |
+
sr=sr,
|
| 595 |
+
is_half=kwargs["is_half"],
|
| 596 |
+
)
|
| 597 |
+
self.enc_q = PosteriorEncoder(
|
| 598 |
+
spec_channels,
|
| 599 |
+
inter_channels,
|
| 600 |
+
hidden_channels,
|
| 601 |
+
5,
|
| 602 |
+
1,
|
| 603 |
+
16,
|
| 604 |
+
gin_channels=gin_channels,
|
| 605 |
+
)
|
| 606 |
+
self.flow = ResidualCouplingBlock(
|
| 607 |
+
inter_channels, hidden_channels, 5, 1, 3, gin_channels=gin_channels
|
| 608 |
+
)
|
| 609 |
+
self.emb_g = nn.Embedding(self.spk_embed_dim, gin_channels)
|
| 610 |
+
print("gin_channels:", gin_channels, "self.spk_embed_dim:", self.spk_embed_dim)
|
| 611 |
+
|
| 612 |
+
def remove_weight_norm(self):
|
| 613 |
+
self.dec.remove_weight_norm()
|
| 614 |
+
self.flow.remove_weight_norm()
|
| 615 |
+
self.enc_q.remove_weight_norm()
|
| 616 |
+
|
| 617 |
+
def forward(
|
| 618 |
+
self, phone, phone_lengths, pitch, pitchf, y, y_lengths, ds
|
| 619 |
+
): # 这里ds是id,[bs,1]
|
| 620 |
+
# print(1,pitch.shape)#[bs,t]
|
| 621 |
+
g = self.emb_g(ds).unsqueeze(-1) # [b, 256, 1]##1是t,广播的
|
| 622 |
+
m_p, logs_p, x_mask = self.enc_p(phone, pitch, phone_lengths)
|
| 623 |
+
z, m_q, logs_q, y_mask = self.enc_q(y, y_lengths, g=g)
|
| 624 |
+
z_p = self.flow(z, y_mask, g=g)
|
| 625 |
+
z_slice, ids_slice = commons.rand_slice_segments(
|
| 626 |
+
z, y_lengths, self.segment_size
|
| 627 |
+
)
|
| 628 |
+
# print(-1,pitchf.shape,ids_slice,self.segment_size,self.hop_length,self.segment_size//self.hop_length)
|
| 629 |
+
pitchf = commons.slice_segments2(pitchf, ids_slice, self.segment_size)
|
| 630 |
+
# print(-2,pitchf.shape,z_slice.shape)
|
| 631 |
+
o = self.dec(z_slice, pitchf, g=g)
|
| 632 |
+
return o, ids_slice, x_mask, y_mask, (z, z_p, m_p, logs_p, m_q, logs_q)
|
| 633 |
+
|
| 634 |
+
def infer(self, phone, phone_lengths, pitch, nsff0, sid, max_len=None):
|
| 635 |
+
g = self.emb_g(sid).unsqueeze(-1)
|
| 636 |
+
m_p, logs_p, x_mask = self.enc_p(phone, pitch, phone_lengths)
|
| 637 |
+
z_p = (m_p + torch.exp(logs_p) * torch.randn_like(m_p) * 0.66666) * x_mask
|
| 638 |
+
z = self.flow(z_p, x_mask, g=g, reverse=True)
|
| 639 |
+
o = self.dec((z * x_mask)[:, :, :max_len], nsff0, g=g)
|
| 640 |
+
return o, x_mask, (z, z_p, m_p, logs_p)
|
| 641 |
+
|
| 642 |
+
|
| 643 |
+
class SynthesizerTrnMs768NSFsid(nn.Module):
|
| 644 |
+
def __init__(
|
| 645 |
+
self,
|
| 646 |
+
spec_channels,
|
| 647 |
+
segment_size,
|
| 648 |
+
inter_channels,
|
| 649 |
+
hidden_channels,
|
| 650 |
+
filter_channels,
|
| 651 |
+
n_heads,
|
| 652 |
+
n_layers,
|
| 653 |
+
kernel_size,
|
| 654 |
+
p_dropout,
|
| 655 |
+
resblock,
|
| 656 |
+
resblock_kernel_sizes,
|
| 657 |
+
resblock_dilation_sizes,
|
| 658 |
+
upsample_rates,
|
| 659 |
+
upsample_initial_channel,
|
| 660 |
+
upsample_kernel_sizes,
|
| 661 |
+
spk_embed_dim,
|
| 662 |
+
gin_channels,
|
| 663 |
+
sr,
|
| 664 |
+
**kwargs
|
| 665 |
+
):
|
| 666 |
+
super().__init__()
|
| 667 |
+
if type(sr) == type("strr"):
|
| 668 |
+
sr = sr2sr[sr]
|
| 669 |
+
self.spec_channels = spec_channels
|
| 670 |
+
self.inter_channels = inter_channels
|
| 671 |
+
self.hidden_channels = hidden_channels
|
| 672 |
+
self.filter_channels = filter_channels
|
| 673 |
+
self.n_heads = n_heads
|
| 674 |
+
self.n_layers = n_layers
|
| 675 |
+
self.kernel_size = kernel_size
|
| 676 |
+
self.p_dropout = p_dropout
|
| 677 |
+
self.resblock = resblock
|
| 678 |
+
self.resblock_kernel_sizes = resblock_kernel_sizes
|
| 679 |
+
self.resblock_dilation_sizes = resblock_dilation_sizes
|
| 680 |
+
self.upsample_rates = upsample_rates
|
| 681 |
+
self.upsample_initial_channel = upsample_initial_channel
|
| 682 |
+
self.upsample_kernel_sizes = upsample_kernel_sizes
|
| 683 |
+
self.segment_size = segment_size
|
| 684 |
+
self.gin_channels = gin_channels
|
| 685 |
+
# self.hop_length = hop_length#
|
| 686 |
+
self.spk_embed_dim = spk_embed_dim
|
| 687 |
+
self.enc_p = TextEncoder768(
|
| 688 |
+
inter_channels,
|
| 689 |
+
hidden_channels,
|
| 690 |
+
filter_channels,
|
| 691 |
+
n_heads,
|
| 692 |
+
n_layers,
|
| 693 |
+
kernel_size,
|
| 694 |
+
p_dropout,
|
| 695 |
+
)
|
| 696 |
+
self.dec = GeneratorNSF(
|
| 697 |
+
inter_channels,
|
| 698 |
+
resblock,
|
| 699 |
+
resblock_kernel_sizes,
|
| 700 |
+
resblock_dilation_sizes,
|
| 701 |
+
upsample_rates,
|
| 702 |
+
upsample_initial_channel,
|
| 703 |
+
upsample_kernel_sizes,
|
| 704 |
+
gin_channels=gin_channels,
|
| 705 |
+
sr=sr,
|
| 706 |
+
is_half=kwargs["is_half"],
|
| 707 |
+
)
|
| 708 |
+
self.enc_q = PosteriorEncoder(
|
| 709 |
+
spec_channels,
|
| 710 |
+
inter_channels,
|
| 711 |
+
hidden_channels,
|
| 712 |
+
5,
|
| 713 |
+
1,
|
| 714 |
+
16,
|
| 715 |
+
gin_channels=gin_channels,
|
| 716 |
+
)
|
| 717 |
+
self.flow = ResidualCouplingBlock(
|
| 718 |
+
inter_channels, hidden_channels, 5, 1, 3, gin_channels=gin_channels
|
| 719 |
+
)
|
| 720 |
+
self.emb_g = nn.Embedding(self.spk_embed_dim, gin_channels)
|
| 721 |
+
print("gin_channels:", gin_channels, "self.spk_embed_dim:", self.spk_embed_dim)
|
| 722 |
+
|
| 723 |
+
def remove_weight_norm(self):
|
| 724 |
+
self.dec.remove_weight_norm()
|
| 725 |
+
self.flow.remove_weight_norm()
|
| 726 |
+
self.enc_q.remove_weight_norm()
|
| 727 |
+
|
| 728 |
+
def forward(
|
| 729 |
+
self, phone, phone_lengths, pitch, pitchf, y, y_lengths, ds
|
| 730 |
+
): # 这里ds是id,[bs,1]
|
| 731 |
+
# print(1,pitch.shape)#[bs,t]
|
| 732 |
+
g = self.emb_g(ds).unsqueeze(-1) # [b, 256, 1]##1是t,广播的
|
| 733 |
+
m_p, logs_p, x_mask = self.enc_p(phone, pitch, phone_lengths)
|
| 734 |
+
z, m_q, logs_q, y_mask = self.enc_q(y, y_lengths, g=g)
|
| 735 |
+
z_p = self.flow(z, y_mask, g=g)
|
| 736 |
+
z_slice, ids_slice = commons.rand_slice_segments(
|
| 737 |
+
z, y_lengths, self.segment_size
|
| 738 |
+
)
|
| 739 |
+
# print(-1,pitchf.shape,ids_slice,self.segment_size,self.hop_length,self.segment_size//self.hop_length)
|
| 740 |
+
pitchf = commons.slice_segments2(pitchf, ids_slice, self.segment_size)
|
| 741 |
+
# print(-2,pitchf.shape,z_slice.shape)
|
| 742 |
+
o = self.dec(z_slice, pitchf, g=g)
|
| 743 |
+
return o, ids_slice, x_mask, y_mask, (z, z_p, m_p, logs_p, m_q, logs_q)
|
| 744 |
+
|
| 745 |
+
def infer(self, phone, phone_lengths, pitch, nsff0, sid, max_len=None):
|
| 746 |
+
g = self.emb_g(sid).unsqueeze(-1)
|
| 747 |
+
m_p, logs_p, x_mask = self.enc_p(phone, pitch, phone_lengths)
|
| 748 |
+
z_p = (m_p + torch.exp(logs_p) * torch.randn_like(m_p) * 0.66666) * x_mask
|
| 749 |
+
z = self.flow(z_p, x_mask, g=g, reverse=True)
|
| 750 |
+
o = self.dec((z * x_mask)[:, :, :max_len], nsff0, g=g)
|
| 751 |
+
return o, x_mask, (z, z_p, m_p, logs_p)
|
| 752 |
+
|
| 753 |
+
|
| 754 |
+
class SynthesizerTrnMs256NSFsid_nono(nn.Module):
|
| 755 |
+
def __init__(
|
| 756 |
+
self,
|
| 757 |
+
spec_channels,
|
| 758 |
+
segment_size,
|
| 759 |
+
inter_channels,
|
| 760 |
+
hidden_channels,
|
| 761 |
+
filter_channels,
|
| 762 |
+
n_heads,
|
| 763 |
+
n_layers,
|
| 764 |
+
kernel_size,
|
| 765 |
+
p_dropout,
|
| 766 |
+
resblock,
|
| 767 |
+
resblock_kernel_sizes,
|
| 768 |
+
resblock_dilation_sizes,
|
| 769 |
+
upsample_rates,
|
| 770 |
+
upsample_initial_channel,
|
| 771 |
+
upsample_kernel_sizes,
|
| 772 |
+
spk_embed_dim,
|
| 773 |
+
gin_channels,
|
| 774 |
+
sr=None,
|
| 775 |
+
**kwargs
|
| 776 |
+
):
|
| 777 |
+
super().__init__()
|
| 778 |
+
self.spec_channels = spec_channels
|
| 779 |
+
self.inter_channels = inter_channels
|
| 780 |
+
self.hidden_channels = hidden_channels
|
| 781 |
+
self.filter_channels = filter_channels
|
| 782 |
+
self.n_heads = n_heads
|
| 783 |
+
self.n_layers = n_layers
|
| 784 |
+
self.kernel_size = kernel_size
|
| 785 |
+
self.p_dropout = p_dropout
|
| 786 |
+
self.resblock = resblock
|
| 787 |
+
self.resblock_kernel_sizes = resblock_kernel_sizes
|
| 788 |
+
self.resblock_dilation_sizes = resblock_dilation_sizes
|
| 789 |
+
self.upsample_rates = upsample_rates
|
| 790 |
+
self.upsample_initial_channel = upsample_initial_channel
|
| 791 |
+
self.upsample_kernel_sizes = upsample_kernel_sizes
|
| 792 |
+
self.segment_size = segment_size
|
| 793 |
+
self.gin_channels = gin_channels
|
| 794 |
+
# self.hop_length = hop_length#
|
| 795 |
+
self.spk_embed_dim = spk_embed_dim
|
| 796 |
+
self.enc_p = TextEncoder256(
|
| 797 |
+
inter_channels,
|
| 798 |
+
hidden_channels,
|
| 799 |
+
filter_channels,
|
| 800 |
+
n_heads,
|
| 801 |
+
n_layers,
|
| 802 |
+
kernel_size,
|
| 803 |
+
p_dropout,
|
| 804 |
+
f0=False,
|
| 805 |
+
)
|
| 806 |
+
self.dec = Generator(
|
| 807 |
+
inter_channels,
|
| 808 |
+
resblock,
|
| 809 |
+
resblock_kernel_sizes,
|
| 810 |
+
resblock_dilation_sizes,
|
| 811 |
+
upsample_rates,
|
| 812 |
+
upsample_initial_channel,
|
| 813 |
+
upsample_kernel_sizes,
|
| 814 |
+
gin_channels=gin_channels,
|
| 815 |
+
)
|
| 816 |
+
self.enc_q = PosteriorEncoder(
|
| 817 |
+
spec_channels,
|
| 818 |
+
inter_channels,
|
| 819 |
+
hidden_channels,
|
| 820 |
+
5,
|
| 821 |
+
1,
|
| 822 |
+
16,
|
| 823 |
+
gin_channels=gin_channels,
|
| 824 |
+
)
|
| 825 |
+
self.flow = ResidualCouplingBlock(
|
| 826 |
+
inter_channels, hidden_channels, 5, 1, 3, gin_channels=gin_channels
|
| 827 |
+
)
|
| 828 |
+
self.emb_g = nn.Embedding(self.spk_embed_dim, gin_channels)
|
| 829 |
+
print("gin_channels:", gin_channels, "self.spk_embed_dim:", self.spk_embed_dim)
|
| 830 |
+
|
| 831 |
+
def remove_weight_norm(self):
|
| 832 |
+
self.dec.remove_weight_norm()
|
| 833 |
+
self.flow.remove_weight_norm()
|
| 834 |
+
self.enc_q.remove_weight_norm()
|
| 835 |
+
|
| 836 |
+
def forward(self, phone, phone_lengths, y, y_lengths, ds): # 这里ds是id,[bs,1]
|
| 837 |
+
g = self.emb_g(ds).unsqueeze(-1) # [b, 256, 1]##1是t,广播的
|
| 838 |
+
m_p, logs_p, x_mask = self.enc_p(phone, None, phone_lengths)
|
| 839 |
+
z, m_q, logs_q, y_mask = self.enc_q(y, y_lengths, g=g)
|
| 840 |
+
z_p = self.flow(z, y_mask, g=g)
|
| 841 |
+
z_slice, ids_slice = commons.rand_slice_segments(
|
| 842 |
+
z, y_lengths, self.segment_size
|
| 843 |
+
)
|
| 844 |
+
o = self.dec(z_slice, g=g)
|
| 845 |
+
return o, ids_slice, x_mask, y_mask, (z, z_p, m_p, logs_p, m_q, logs_q)
|
| 846 |
+
|
| 847 |
+
def infer(self, phone, phone_lengths, sid, max_len=None):
|
| 848 |
+
g = self.emb_g(sid).unsqueeze(-1)
|
| 849 |
+
m_p, logs_p, x_mask = self.enc_p(phone, None, phone_lengths)
|
| 850 |
+
z_p = (m_p + torch.exp(logs_p) * torch.randn_like(m_p) * 0.66666) * x_mask
|
| 851 |
+
z = self.flow(z_p, x_mask, g=g, reverse=True)
|
| 852 |
+
o = self.dec((z * x_mask)[:, :, :max_len], g=g)
|
| 853 |
+
return o, x_mask, (z, z_p, m_p, logs_p)
|
| 854 |
+
|
| 855 |
+
|
| 856 |
+
class SynthesizerTrnMs768NSFsid_nono(nn.Module):
|
| 857 |
+
def __init__(
|
| 858 |
+
self,
|
| 859 |
+
spec_channels,
|
| 860 |
+
segment_size,
|
| 861 |
+
inter_channels,
|
| 862 |
+
hidden_channels,
|
| 863 |
+
filter_channels,
|
| 864 |
+
n_heads,
|
| 865 |
+
n_layers,
|
| 866 |
+
kernel_size,
|
| 867 |
+
p_dropout,
|
| 868 |
+
resblock,
|
| 869 |
+
resblock_kernel_sizes,
|
| 870 |
+
resblock_dilation_sizes,
|
| 871 |
+
upsample_rates,
|
| 872 |
+
upsample_initial_channel,
|
| 873 |
+
upsample_kernel_sizes,
|
| 874 |
+
spk_embed_dim,
|
| 875 |
+
gin_channels,
|
| 876 |
+
sr=None,
|
| 877 |
+
**kwargs
|
| 878 |
+
):
|
| 879 |
+
super().__init__()
|
| 880 |
+
self.spec_channels = spec_channels
|
| 881 |
+
self.inter_channels = inter_channels
|
| 882 |
+
self.hidden_channels = hidden_channels
|
| 883 |
+
self.filter_channels = filter_channels
|
| 884 |
+
self.n_heads = n_heads
|
| 885 |
+
self.n_layers = n_layers
|
| 886 |
+
self.kernel_size = kernel_size
|
| 887 |
+
self.p_dropout = p_dropout
|
| 888 |
+
self.resblock = resblock
|
| 889 |
+
self.resblock_kernel_sizes = resblock_kernel_sizes
|
| 890 |
+
self.resblock_dilation_sizes = resblock_dilation_sizes
|
| 891 |
+
self.upsample_rates = upsample_rates
|
| 892 |
+
self.upsample_initial_channel = upsample_initial_channel
|
| 893 |
+
self.upsample_kernel_sizes = upsample_kernel_sizes
|
| 894 |
+
self.segment_size = segment_size
|
| 895 |
+
self.gin_channels = gin_channels
|
| 896 |
+
# self.hop_length = hop_length#
|
| 897 |
+
self.spk_embed_dim = spk_embed_dim
|
| 898 |
+
self.enc_p = TextEncoder768(
|
| 899 |
+
inter_channels,
|
| 900 |
+
hidden_channels,
|
| 901 |
+
filter_channels,
|
| 902 |
+
n_heads,
|
| 903 |
+
n_layers,
|
| 904 |
+
kernel_size,
|
| 905 |
+
p_dropout,
|
| 906 |
+
f0=False,
|
| 907 |
+
)
|
| 908 |
+
self.dec = Generator(
|
| 909 |
+
inter_channels,
|
| 910 |
+
resblock,
|
| 911 |
+
resblock_kernel_sizes,
|
| 912 |
+
resblock_dilation_sizes,
|
| 913 |
+
upsample_rates,
|
| 914 |
+
upsample_initial_channel,
|
| 915 |
+
upsample_kernel_sizes,
|
| 916 |
+
gin_channels=gin_channels,
|
| 917 |
+
)
|
| 918 |
+
self.enc_q = PosteriorEncoder(
|
| 919 |
+
spec_channels,
|
| 920 |
+
inter_channels,
|
| 921 |
+
hidden_channels,
|
| 922 |
+
5,
|
| 923 |
+
1,
|
| 924 |
+
16,
|
| 925 |
+
gin_channels=gin_channels,
|
| 926 |
+
)
|
| 927 |
+
self.flow = ResidualCouplingBlock(
|
| 928 |
+
inter_channels, hidden_channels, 5, 1, 3, gin_channels=gin_channels
|
| 929 |
+
)
|
| 930 |
+
self.emb_g = nn.Embedding(self.spk_embed_dim, gin_channels)
|
| 931 |
+
print("gin_channels:", gin_channels, "self.spk_embed_dim:", self.spk_embed_dim)
|
| 932 |
+
|
| 933 |
+
def remove_weight_norm(self):
|
| 934 |
+
self.dec.remove_weight_norm()
|
| 935 |
+
self.flow.remove_weight_norm()
|
| 936 |
+
self.enc_q.remove_weight_norm()
|
| 937 |
+
|
| 938 |
+
def forward(self, phone, phone_lengths, y, y_lengths, ds): # 这里ds是id,[bs,1]
|
| 939 |
+
g = self.emb_g(ds).unsqueeze(-1) # [b, 256, 1]##1是t,广播的
|
| 940 |
+
m_p, logs_p, x_mask = self.enc_p(phone, None, phone_lengths)
|
| 941 |
+
z, m_q, logs_q, y_mask = self.enc_q(y, y_lengths, g=g)
|
| 942 |
+
z_p = self.flow(z, y_mask, g=g)
|
| 943 |
+
z_slice, ids_slice = commons.rand_slice_segments(
|
| 944 |
+
z, y_lengths, self.segment_size
|
| 945 |
+
)
|
| 946 |
+
o = self.dec(z_slice, g=g)
|
| 947 |
+
return o, ids_slice, x_mask, y_mask, (z, z_p, m_p, logs_p, m_q, logs_q)
|
| 948 |
+
|
| 949 |
+
def infer(self, phone, phone_lengths, sid, max_len=None):
|
| 950 |
+
g = self.emb_g(sid).unsqueeze(-1)
|
| 951 |
+
m_p, logs_p, x_mask = self.enc_p(phone, None, phone_lengths)
|
| 952 |
+
z_p = (m_p + torch.exp(logs_p) * torch.randn_like(m_p) * 0.66666) * x_mask
|
| 953 |
+
z = self.flow(z_p, x_mask, g=g, reverse=True)
|
| 954 |
+
o = self.dec((z * x_mask)[:, :, :max_len], g=g)
|
| 955 |
+
return o, x_mask, (z, z_p, m_p, logs_p)
|
| 956 |
+
|
| 957 |
+
|
| 958 |
+
class MultiPeriodDiscriminator(torch.nn.Module):
|
| 959 |
+
def __init__(self, use_spectral_norm=False):
|
| 960 |
+
super(MultiPeriodDiscriminator, self).__init__()
|
| 961 |
+
periods = [2, 3, 5, 7, 11, 17]
|
| 962 |
+
# periods = [3, 5, 7, 11, 17, 23, 37]
|
| 963 |
+
|
| 964 |
+
discs = [DiscriminatorS(use_spectral_norm=use_spectral_norm)]
|
| 965 |
+
discs = discs + [
|
| 966 |
+
DiscriminatorP(i, use_spectral_norm=use_spectral_norm) for i in periods
|
| 967 |
+
]
|
| 968 |
+
self.discriminators = nn.ModuleList(discs)
|
| 969 |
+
|
| 970 |
+
def forward(self, y, y_hat):
|
| 971 |
+
y_d_rs = [] #
|
| 972 |
+
y_d_gs = []
|
| 973 |
+
fmap_rs = []
|
| 974 |
+
fmap_gs = []
|
| 975 |
+
for i, d in enumerate(self.discriminators):
|
| 976 |
+
y_d_r, fmap_r = d(y)
|
| 977 |
+
y_d_g, fmap_g = d(y_hat)
|
| 978 |
+
# for j in range(len(fmap_r)):
|
| 979 |
+
# print(i,j,y.shape,y_hat.shape,fmap_r[j].shape,fmap_g[j].shape)
|
| 980 |
+
y_d_rs.append(y_d_r)
|
| 981 |
+
y_d_gs.append(y_d_g)
|
| 982 |
+
fmap_rs.append(fmap_r)
|
| 983 |
+
fmap_gs.append(fmap_g)
|
| 984 |
+
|
| 985 |
+
return y_d_rs, y_d_gs, fmap_rs, fmap_gs
|
| 986 |
+
|
| 987 |
+
|
| 988 |
+
class MultiPeriodDiscriminatorV2(torch.nn.Module):
|
| 989 |
+
def __init__(self, use_spectral_norm=False):
|
| 990 |
+
super(MultiPeriodDiscriminatorV2, self).__init__()
|
| 991 |
+
# periods = [2, 3, 5, 7, 11, 17]
|
| 992 |
+
periods = [2, 3, 5, 7, 11, 17, 23, 37]
|
| 993 |
+
|
| 994 |
+
discs = [DiscriminatorS(use_spectral_norm=use_spectral_norm)]
|
| 995 |
+
discs = discs + [
|
| 996 |
+
DiscriminatorP(i, use_spectral_norm=use_spectral_norm) for i in periods
|
| 997 |
+
]
|
| 998 |
+
self.discriminators = nn.ModuleList(discs)
|
| 999 |
+
|
| 1000 |
+
def forward(self, y, y_hat):
|
| 1001 |
+
y_d_rs = [] #
|
| 1002 |
+
y_d_gs = []
|
| 1003 |
+
fmap_rs = []
|
| 1004 |
+
fmap_gs = []
|
| 1005 |
+
for i, d in enumerate(self.discriminators):
|
| 1006 |
+
y_d_r, fmap_r = d(y)
|
| 1007 |
+
y_d_g, fmap_g = d(y_hat)
|
| 1008 |
+
# for j in range(len(fmap_r)):
|
| 1009 |
+
# print(i,j,y.shape,y_hat.shape,fmap_r[j].shape,fmap_g[j].shape)
|
| 1010 |
+
y_d_rs.append(y_d_r)
|
| 1011 |
+
y_d_gs.append(y_d_g)
|
| 1012 |
+
fmap_rs.append(fmap_r)
|
| 1013 |
+
fmap_gs.append(fmap_g)
|
| 1014 |
+
|
| 1015 |
+
return y_d_rs, y_d_gs, fmap_rs, fmap_gs
|
| 1016 |
+
|
| 1017 |
+
|
| 1018 |
+
class DiscriminatorS(torch.nn.Module):
|
| 1019 |
+
def __init__(self, use_spectral_norm=False):
|
| 1020 |
+
super(DiscriminatorS, self).__init__()
|
| 1021 |
+
norm_f = weight_norm if use_spectral_norm == False else spectral_norm
|
| 1022 |
+
self.convs = nn.ModuleList(
|
| 1023 |
+
[
|
| 1024 |
+
norm_f(Conv1d(1, 16, 15, 1, padding=7)),
|
| 1025 |
+
norm_f(Conv1d(16, 64, 41, 4, groups=4, padding=20)),
|
| 1026 |
+
norm_f(Conv1d(64, 256, 41, 4, groups=16, padding=20)),
|
| 1027 |
+
norm_f(Conv1d(256, 1024, 41, 4, groups=64, padding=20)),
|
| 1028 |
+
norm_f(Conv1d(1024, 1024, 41, 4, groups=256, padding=20)),
|
| 1029 |
+
norm_f(Conv1d(1024, 1024, 5, 1, padding=2)),
|
| 1030 |
+
]
|
| 1031 |
+
)
|
| 1032 |
+
self.conv_post = norm_f(Conv1d(1024, 1, 3, 1, padding=1))
|
| 1033 |
+
|
| 1034 |
+
def forward(self, x):
|
| 1035 |
+
fmap = []
|
| 1036 |
+
|
| 1037 |
+
for l in self.convs:
|
| 1038 |
+
x = l(x)
|
| 1039 |
+
x = F.leaky_relu(x, modules.LRELU_SLOPE)
|
| 1040 |
+
fmap.append(x)
|
| 1041 |
+
x = self.conv_post(x)
|
| 1042 |
+
fmap.append(x)
|
| 1043 |
+
x = torch.flatten(x, 1, -1)
|
| 1044 |
+
|
| 1045 |
+
return x, fmap
|
| 1046 |
+
|
| 1047 |
+
|
| 1048 |
+
class DiscriminatorP(torch.nn.Module):
|
| 1049 |
+
def __init__(self, period, kernel_size=5, stride=3, use_spectral_norm=False):
|
| 1050 |
+
super(DiscriminatorP, self).__init__()
|
| 1051 |
+
self.period = period
|
| 1052 |
+
self.use_spectral_norm = use_spectral_norm
|
| 1053 |
+
norm_f = weight_norm if use_spectral_norm == False else spectral_norm
|
| 1054 |
+
self.convs = nn.ModuleList(
|
| 1055 |
+
[
|
| 1056 |
+
norm_f(
|
| 1057 |
+
Conv2d(
|
| 1058 |
+
1,
|
| 1059 |
+
32,
|
| 1060 |
+
(kernel_size, 1),
|
| 1061 |
+
(stride, 1),
|
| 1062 |
+
padding=(get_padding(kernel_size, 1), 0),
|
| 1063 |
+
)
|
| 1064 |
+
),
|
| 1065 |
+
norm_f(
|
| 1066 |
+
Conv2d(
|
| 1067 |
+
32,
|
| 1068 |
+
128,
|
| 1069 |
+
(kernel_size, 1),
|
| 1070 |
+
(stride, 1),
|
| 1071 |
+
padding=(get_padding(kernel_size, 1), 0),
|
| 1072 |
+
)
|
| 1073 |
+
),
|
| 1074 |
+
norm_f(
|
| 1075 |
+
Conv2d(
|
| 1076 |
+
128,
|
| 1077 |
+
512,
|
| 1078 |
+
(kernel_size, 1),
|
| 1079 |
+
(stride, 1),
|
| 1080 |
+
padding=(get_padding(kernel_size, 1), 0),
|
| 1081 |
+
)
|
| 1082 |
+
),
|
| 1083 |
+
norm_f(
|
| 1084 |
+
Conv2d(
|
| 1085 |
+
512,
|
| 1086 |
+
1024,
|
| 1087 |
+
(kernel_size, 1),
|
| 1088 |
+
(stride, 1),
|
| 1089 |
+
padding=(get_padding(kernel_size, 1), 0),
|
| 1090 |
+
)
|
| 1091 |
+
),
|
| 1092 |
+
norm_f(
|
| 1093 |
+
Conv2d(
|
| 1094 |
+
1024,
|
| 1095 |
+
1024,
|
| 1096 |
+
(kernel_size, 1),
|
| 1097 |
+
1,
|
| 1098 |
+
padding=(get_padding(kernel_size, 1), 0),
|
| 1099 |
+
)
|
| 1100 |
+
),
|
| 1101 |
+
]
|
| 1102 |
+
)
|
| 1103 |
+
self.conv_post = norm_f(Conv2d(1024, 1, (3, 1), 1, padding=(1, 0)))
|
| 1104 |
+
|
| 1105 |
+
def forward(self, x):
|
| 1106 |
+
fmap = []
|
| 1107 |
+
|
| 1108 |
+
# 1d to 2d
|
| 1109 |
+
b, c, t = x.shape
|
| 1110 |
+
if t % self.period != 0: # pad first
|
| 1111 |
+
n_pad = self.period - (t % self.period)
|
| 1112 |
+
x = F.pad(x, (0, n_pad), "reflect")
|
| 1113 |
+
t = t + n_pad
|
| 1114 |
+
x = x.view(b, c, t // self.period, self.period)
|
| 1115 |
+
|
| 1116 |
+
for l in self.convs:
|
| 1117 |
+
x = l(x)
|
| 1118 |
+
x = F.leaky_relu(x, modules.LRELU_SLOPE)
|
| 1119 |
+
fmap.append(x)
|
| 1120 |
+
x = self.conv_post(x)
|
| 1121 |
+
fmap.append(x)
|
| 1122 |
+
x = torch.flatten(x, 1, -1)
|
| 1123 |
+
|
| 1124 |
+
return x, fmap
|
src/infer_pack/models_onnx.py
ADDED
|
@@ -0,0 +1,818 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import math, pdb, os
|
| 2 |
+
from time import time as ttime
|
| 3 |
+
import torch
|
| 4 |
+
from torch import nn
|
| 5 |
+
from torch.nn import functional as F
|
| 6 |
+
from infer_pack import modules
|
| 7 |
+
from infer_pack import attentions
|
| 8 |
+
from infer_pack import commons
|
| 9 |
+
from infer_pack.commons import init_weights, get_padding
|
| 10 |
+
from torch.nn import Conv1d, ConvTranspose1d, AvgPool1d, Conv2d
|
| 11 |
+
from torch.nn.utils import weight_norm, remove_weight_norm, spectral_norm
|
| 12 |
+
from infer_pack.commons import init_weights
|
| 13 |
+
import numpy as np
|
| 14 |
+
from infer_pack import commons
|
| 15 |
+
|
| 16 |
+
|
| 17 |
+
class TextEncoder256(nn.Module):
|
| 18 |
+
def __init__(
|
| 19 |
+
self,
|
| 20 |
+
out_channels,
|
| 21 |
+
hidden_channels,
|
| 22 |
+
filter_channels,
|
| 23 |
+
n_heads,
|
| 24 |
+
n_layers,
|
| 25 |
+
kernel_size,
|
| 26 |
+
p_dropout,
|
| 27 |
+
f0=True,
|
| 28 |
+
):
|
| 29 |
+
super().__init__()
|
| 30 |
+
self.out_channels = out_channels
|
| 31 |
+
self.hidden_channels = hidden_channels
|
| 32 |
+
self.filter_channels = filter_channels
|
| 33 |
+
self.n_heads = n_heads
|
| 34 |
+
self.n_layers = n_layers
|
| 35 |
+
self.kernel_size = kernel_size
|
| 36 |
+
self.p_dropout = p_dropout
|
| 37 |
+
self.emb_phone = nn.Linear(256, hidden_channels)
|
| 38 |
+
self.lrelu = nn.LeakyReLU(0.1, inplace=True)
|
| 39 |
+
if f0 == True:
|
| 40 |
+
self.emb_pitch = nn.Embedding(256, hidden_channels) # pitch 256
|
| 41 |
+
self.encoder = attentions.Encoder(
|
| 42 |
+
hidden_channels, filter_channels, n_heads, n_layers, kernel_size, p_dropout
|
| 43 |
+
)
|
| 44 |
+
self.proj = nn.Conv1d(hidden_channels, out_channels * 2, 1)
|
| 45 |
+
|
| 46 |
+
def forward(self, phone, pitch, lengths):
|
| 47 |
+
if pitch == None:
|
| 48 |
+
x = self.emb_phone(phone)
|
| 49 |
+
else:
|
| 50 |
+
x = self.emb_phone(phone) + self.emb_pitch(pitch)
|
| 51 |
+
x = x * math.sqrt(self.hidden_channels) # [b, t, h]
|
| 52 |
+
x = self.lrelu(x)
|
| 53 |
+
x = torch.transpose(x, 1, -1) # [b, h, t]
|
| 54 |
+
x_mask = torch.unsqueeze(commons.sequence_mask(lengths, x.size(2)), 1).to(
|
| 55 |
+
x.dtype
|
| 56 |
+
)
|
| 57 |
+
x = self.encoder(x * x_mask, x_mask)
|
| 58 |
+
stats = self.proj(x) * x_mask
|
| 59 |
+
|
| 60 |
+
m, logs = torch.split(stats, self.out_channels, dim=1)
|
| 61 |
+
return m, logs, x_mask
|
| 62 |
+
|
| 63 |
+
|
| 64 |
+
class TextEncoder768(nn.Module):
|
| 65 |
+
def __init__(
|
| 66 |
+
self,
|
| 67 |
+
out_channels,
|
| 68 |
+
hidden_channels,
|
| 69 |
+
filter_channels,
|
| 70 |
+
n_heads,
|
| 71 |
+
n_layers,
|
| 72 |
+
kernel_size,
|
| 73 |
+
p_dropout,
|
| 74 |
+
f0=True,
|
| 75 |
+
):
|
| 76 |
+
super().__init__()
|
| 77 |
+
self.out_channels = out_channels
|
| 78 |
+
self.hidden_channels = hidden_channels
|
| 79 |
+
self.filter_channels = filter_channels
|
| 80 |
+
self.n_heads = n_heads
|
| 81 |
+
self.n_layers = n_layers
|
| 82 |
+
self.kernel_size = kernel_size
|
| 83 |
+
self.p_dropout = p_dropout
|
| 84 |
+
self.emb_phone = nn.Linear(768, hidden_channels)
|
| 85 |
+
self.lrelu = nn.LeakyReLU(0.1, inplace=True)
|
| 86 |
+
if f0 == True:
|
| 87 |
+
self.emb_pitch = nn.Embedding(256, hidden_channels) # pitch 256
|
| 88 |
+
self.encoder = attentions.Encoder(
|
| 89 |
+
hidden_channels, filter_channels, n_heads, n_layers, kernel_size, p_dropout
|
| 90 |
+
)
|
| 91 |
+
self.proj = nn.Conv1d(hidden_channels, out_channels * 2, 1)
|
| 92 |
+
|
| 93 |
+
def forward(self, phone, pitch, lengths):
|
| 94 |
+
if pitch == None:
|
| 95 |
+
x = self.emb_phone(phone)
|
| 96 |
+
else:
|
| 97 |
+
x = self.emb_phone(phone) + self.emb_pitch(pitch)
|
| 98 |
+
x = x * math.sqrt(self.hidden_channels) # [b, t, h]
|
| 99 |
+
x = self.lrelu(x)
|
| 100 |
+
x = torch.transpose(x, 1, -1) # [b, h, t]
|
| 101 |
+
x_mask = torch.unsqueeze(commons.sequence_mask(lengths, x.size(2)), 1).to(
|
| 102 |
+
x.dtype
|
| 103 |
+
)
|
| 104 |
+
x = self.encoder(x * x_mask, x_mask)
|
| 105 |
+
stats = self.proj(x) * x_mask
|
| 106 |
+
|
| 107 |
+
m, logs = torch.split(stats, self.out_channels, dim=1)
|
| 108 |
+
return m, logs, x_mask
|
| 109 |
+
|
| 110 |
+
|
| 111 |
+
class ResidualCouplingBlock(nn.Module):
|
| 112 |
+
def __init__(
|
| 113 |
+
self,
|
| 114 |
+
channels,
|
| 115 |
+
hidden_channels,
|
| 116 |
+
kernel_size,
|
| 117 |
+
dilation_rate,
|
| 118 |
+
n_layers,
|
| 119 |
+
n_flows=4,
|
| 120 |
+
gin_channels=0,
|
| 121 |
+
):
|
| 122 |
+
super().__init__()
|
| 123 |
+
self.channels = channels
|
| 124 |
+
self.hidden_channels = hidden_channels
|
| 125 |
+
self.kernel_size = kernel_size
|
| 126 |
+
self.dilation_rate = dilation_rate
|
| 127 |
+
self.n_layers = n_layers
|
| 128 |
+
self.n_flows = n_flows
|
| 129 |
+
self.gin_channels = gin_channels
|
| 130 |
+
|
| 131 |
+
self.flows = nn.ModuleList()
|
| 132 |
+
for i in range(n_flows):
|
| 133 |
+
self.flows.append(
|
| 134 |
+
modules.ResidualCouplingLayer(
|
| 135 |
+
channels,
|
| 136 |
+
hidden_channels,
|
| 137 |
+
kernel_size,
|
| 138 |
+
dilation_rate,
|
| 139 |
+
n_layers,
|
| 140 |
+
gin_channels=gin_channels,
|
| 141 |
+
mean_only=True,
|
| 142 |
+
)
|
| 143 |
+
)
|
| 144 |
+
self.flows.append(modules.Flip())
|
| 145 |
+
|
| 146 |
+
def forward(self, x, x_mask, g=None, reverse=False):
|
| 147 |
+
if not reverse:
|
| 148 |
+
for flow in self.flows:
|
| 149 |
+
x, _ = flow(x, x_mask, g=g, reverse=reverse)
|
| 150 |
+
else:
|
| 151 |
+
for flow in reversed(self.flows):
|
| 152 |
+
x = flow(x, x_mask, g=g, reverse=reverse)
|
| 153 |
+
return x
|
| 154 |
+
|
| 155 |
+
def remove_weight_norm(self):
|
| 156 |
+
for i in range(self.n_flows):
|
| 157 |
+
self.flows[i * 2].remove_weight_norm()
|
| 158 |
+
|
| 159 |
+
|
| 160 |
+
class PosteriorEncoder(nn.Module):
|
| 161 |
+
def __init__(
|
| 162 |
+
self,
|
| 163 |
+
in_channels,
|
| 164 |
+
out_channels,
|
| 165 |
+
hidden_channels,
|
| 166 |
+
kernel_size,
|
| 167 |
+
dilation_rate,
|
| 168 |
+
n_layers,
|
| 169 |
+
gin_channels=0,
|
| 170 |
+
):
|
| 171 |
+
super().__init__()
|
| 172 |
+
self.in_channels = in_channels
|
| 173 |
+
self.out_channels = out_channels
|
| 174 |
+
self.hidden_channels = hidden_channels
|
| 175 |
+
self.kernel_size = kernel_size
|
| 176 |
+
self.dilation_rate = dilation_rate
|
| 177 |
+
self.n_layers = n_layers
|
| 178 |
+
self.gin_channels = gin_channels
|
| 179 |
+
|
| 180 |
+
self.pre = nn.Conv1d(in_channels, hidden_channels, 1)
|
| 181 |
+
self.enc = modules.WN(
|
| 182 |
+
hidden_channels,
|
| 183 |
+
kernel_size,
|
| 184 |
+
dilation_rate,
|
| 185 |
+
n_layers,
|
| 186 |
+
gin_channels=gin_channels,
|
| 187 |
+
)
|
| 188 |
+
self.proj = nn.Conv1d(hidden_channels, out_channels * 2, 1)
|
| 189 |
+
|
| 190 |
+
def forward(self, x, x_lengths, g=None):
|
| 191 |
+
x_mask = torch.unsqueeze(commons.sequence_mask(x_lengths, x.size(2)), 1).to(
|
| 192 |
+
x.dtype
|
| 193 |
+
)
|
| 194 |
+
x = self.pre(x) * x_mask
|
| 195 |
+
x = self.enc(x, x_mask, g=g)
|
| 196 |
+
stats = self.proj(x) * x_mask
|
| 197 |
+
m, logs = torch.split(stats, self.out_channels, dim=1)
|
| 198 |
+
z = (m + torch.randn_like(m) * torch.exp(logs)) * x_mask
|
| 199 |
+
return z, m, logs, x_mask
|
| 200 |
+
|
| 201 |
+
def remove_weight_norm(self):
|
| 202 |
+
self.enc.remove_weight_norm()
|
| 203 |
+
|
| 204 |
+
|
| 205 |
+
class Generator(torch.nn.Module):
|
| 206 |
+
def __init__(
|
| 207 |
+
self,
|
| 208 |
+
initial_channel,
|
| 209 |
+
resblock,
|
| 210 |
+
resblock_kernel_sizes,
|
| 211 |
+
resblock_dilation_sizes,
|
| 212 |
+
upsample_rates,
|
| 213 |
+
upsample_initial_channel,
|
| 214 |
+
upsample_kernel_sizes,
|
| 215 |
+
gin_channels=0,
|
| 216 |
+
):
|
| 217 |
+
super(Generator, self).__init__()
|
| 218 |
+
self.num_kernels = len(resblock_kernel_sizes)
|
| 219 |
+
self.num_upsamples = len(upsample_rates)
|
| 220 |
+
self.conv_pre = Conv1d(
|
| 221 |
+
initial_channel, upsample_initial_channel, 7, 1, padding=3
|
| 222 |
+
)
|
| 223 |
+
resblock = modules.ResBlock1 if resblock == "1" else modules.ResBlock2
|
| 224 |
+
|
| 225 |
+
self.ups = nn.ModuleList()
|
| 226 |
+
for i, (u, k) in enumerate(zip(upsample_rates, upsample_kernel_sizes)):
|
| 227 |
+
self.ups.append(
|
| 228 |
+
weight_norm(
|
| 229 |
+
ConvTranspose1d(
|
| 230 |
+
upsample_initial_channel // (2**i),
|
| 231 |
+
upsample_initial_channel // (2 ** (i + 1)),
|
| 232 |
+
k,
|
| 233 |
+
u,
|
| 234 |
+
padding=(k - u) // 2,
|
| 235 |
+
)
|
| 236 |
+
)
|
| 237 |
+
)
|
| 238 |
+
|
| 239 |
+
self.resblocks = nn.ModuleList()
|
| 240 |
+
for i in range(len(self.ups)):
|
| 241 |
+
ch = upsample_initial_channel // (2 ** (i + 1))
|
| 242 |
+
for j, (k, d) in enumerate(
|
| 243 |
+
zip(resblock_kernel_sizes, resblock_dilation_sizes)
|
| 244 |
+
):
|
| 245 |
+
self.resblocks.append(resblock(ch, k, d))
|
| 246 |
+
|
| 247 |
+
self.conv_post = Conv1d(ch, 1, 7, 1, padding=3, bias=False)
|
| 248 |
+
self.ups.apply(init_weights)
|
| 249 |
+
|
| 250 |
+
if gin_channels != 0:
|
| 251 |
+
self.cond = nn.Conv1d(gin_channels, upsample_initial_channel, 1)
|
| 252 |
+
|
| 253 |
+
def forward(self, x, g=None):
|
| 254 |
+
x = self.conv_pre(x)
|
| 255 |
+
if g is not None:
|
| 256 |
+
x = x + self.cond(g)
|
| 257 |
+
|
| 258 |
+
for i in range(self.num_upsamples):
|
| 259 |
+
x = F.leaky_relu(x, modules.LRELU_SLOPE)
|
| 260 |
+
x = self.ups[i](x)
|
| 261 |
+
xs = None
|
| 262 |
+
for j in range(self.num_kernels):
|
| 263 |
+
if xs is None:
|
| 264 |
+
xs = self.resblocks[i * self.num_kernels + j](x)
|
| 265 |
+
else:
|
| 266 |
+
xs += self.resblocks[i * self.num_kernels + j](x)
|
| 267 |
+
x = xs / self.num_kernels
|
| 268 |
+
x = F.leaky_relu(x)
|
| 269 |
+
x = self.conv_post(x)
|
| 270 |
+
x = torch.tanh(x)
|
| 271 |
+
|
| 272 |
+
return x
|
| 273 |
+
|
| 274 |
+
def remove_weight_norm(self):
|
| 275 |
+
for l in self.ups:
|
| 276 |
+
remove_weight_norm(l)
|
| 277 |
+
for l in self.resblocks:
|
| 278 |
+
l.remove_weight_norm()
|
| 279 |
+
|
| 280 |
+
|
| 281 |
+
class SineGen(torch.nn.Module):
|
| 282 |
+
"""Definition of sine generator
|
| 283 |
+
SineGen(samp_rate, harmonic_num = 0,
|
| 284 |
+
sine_amp = 0.1, noise_std = 0.003,
|
| 285 |
+
voiced_threshold = 0,
|
| 286 |
+
flag_for_pulse=False)
|
| 287 |
+
samp_rate: sampling rate in Hz
|
| 288 |
+
harmonic_num: number of harmonic overtones (default 0)
|
| 289 |
+
sine_amp: amplitude of sine-wavefrom (default 0.1)
|
| 290 |
+
noise_std: std of Gaussian noise (default 0.003)
|
| 291 |
+
voiced_thoreshold: F0 threshold for U/V classification (default 0)
|
| 292 |
+
flag_for_pulse: this SinGen is used inside PulseGen (default False)
|
| 293 |
+
Note: when flag_for_pulse is True, the first time step of a voiced
|
| 294 |
+
segment is always sin(np.pi) or cos(0)
|
| 295 |
+
"""
|
| 296 |
+
|
| 297 |
+
def __init__(
|
| 298 |
+
self,
|
| 299 |
+
samp_rate,
|
| 300 |
+
harmonic_num=0,
|
| 301 |
+
sine_amp=0.1,
|
| 302 |
+
noise_std=0.003,
|
| 303 |
+
voiced_threshold=0,
|
| 304 |
+
flag_for_pulse=False,
|
| 305 |
+
):
|
| 306 |
+
super(SineGen, self).__init__()
|
| 307 |
+
self.sine_amp = sine_amp
|
| 308 |
+
self.noise_std = noise_std
|
| 309 |
+
self.harmonic_num = harmonic_num
|
| 310 |
+
self.dim = self.harmonic_num + 1
|
| 311 |
+
self.sampling_rate = samp_rate
|
| 312 |
+
self.voiced_threshold = voiced_threshold
|
| 313 |
+
|
| 314 |
+
def _f02uv(self, f0):
|
| 315 |
+
# generate uv signal
|
| 316 |
+
uv = torch.ones_like(f0)
|
| 317 |
+
uv = uv * (f0 > self.voiced_threshold)
|
| 318 |
+
return uv
|
| 319 |
+
|
| 320 |
+
def forward(self, f0, upp):
|
| 321 |
+
"""sine_tensor, uv = forward(f0)
|
| 322 |
+
input F0: tensor(batchsize=1, length, dim=1)
|
| 323 |
+
f0 for unvoiced steps should be 0
|
| 324 |
+
output sine_tensor: tensor(batchsize=1, length, dim)
|
| 325 |
+
output uv: tensor(batchsize=1, length, 1)
|
| 326 |
+
"""
|
| 327 |
+
with torch.no_grad():
|
| 328 |
+
f0 = f0[:, None].transpose(1, 2)
|
| 329 |
+
f0_buf = torch.zeros(f0.shape[0], f0.shape[1], self.dim, device=f0.device)
|
| 330 |
+
# fundamental component
|
| 331 |
+
f0_buf[:, :, 0] = f0[:, :, 0]
|
| 332 |
+
for idx in np.arange(self.harmonic_num):
|
| 333 |
+
f0_buf[:, :, idx + 1] = f0_buf[:, :, 0] * (
|
| 334 |
+
idx + 2
|
| 335 |
+
) # idx + 2: the (idx+1)-th overtone, (idx+2)-th harmonic
|
| 336 |
+
rad_values = (f0_buf / self.sampling_rate) % 1 ###%1意味着n_har的乘积无法后处理优化
|
| 337 |
+
rand_ini = torch.rand(
|
| 338 |
+
f0_buf.shape[0], f0_buf.shape[2], device=f0_buf.device
|
| 339 |
+
)
|
| 340 |
+
rand_ini[:, 0] = 0
|
| 341 |
+
rad_values[:, 0, :] = rad_values[:, 0, :] + rand_ini
|
| 342 |
+
tmp_over_one = torch.cumsum(rad_values, 1) # % 1 #####%1意味着后面的cumsum无法再优化
|
| 343 |
+
tmp_over_one *= upp
|
| 344 |
+
tmp_over_one = F.interpolate(
|
| 345 |
+
tmp_over_one.transpose(2, 1),
|
| 346 |
+
scale_factor=upp,
|
| 347 |
+
mode="linear",
|
| 348 |
+
align_corners=True,
|
| 349 |
+
).transpose(2, 1)
|
| 350 |
+
rad_values = F.interpolate(
|
| 351 |
+
rad_values.transpose(2, 1), scale_factor=upp, mode="nearest"
|
| 352 |
+
).transpose(
|
| 353 |
+
2, 1
|
| 354 |
+
) #######
|
| 355 |
+
tmp_over_one %= 1
|
| 356 |
+
tmp_over_one_idx = (tmp_over_one[:, 1:, :] - tmp_over_one[:, :-1, :]) < 0
|
| 357 |
+
cumsum_shift = torch.zeros_like(rad_values)
|
| 358 |
+
cumsum_shift[:, 1:, :] = tmp_over_one_idx * -1.0
|
| 359 |
+
sine_waves = torch.sin(
|
| 360 |
+
torch.cumsum(rad_values + cumsum_shift, dim=1) * 2 * np.pi
|
| 361 |
+
)
|
| 362 |
+
sine_waves = sine_waves * self.sine_amp
|
| 363 |
+
uv = self._f02uv(f0)
|
| 364 |
+
uv = F.interpolate(
|
| 365 |
+
uv.transpose(2, 1), scale_factor=upp, mode="nearest"
|
| 366 |
+
).transpose(2, 1)
|
| 367 |
+
noise_amp = uv * self.noise_std + (1 - uv) * self.sine_amp / 3
|
| 368 |
+
noise = noise_amp * torch.randn_like(sine_waves)
|
| 369 |
+
sine_waves = sine_waves * uv + noise
|
| 370 |
+
return sine_waves, uv, noise
|
| 371 |
+
|
| 372 |
+
|
| 373 |
+
class SourceModuleHnNSF(torch.nn.Module):
|
| 374 |
+
"""SourceModule for hn-nsf
|
| 375 |
+
SourceModule(sampling_rate, harmonic_num=0, sine_amp=0.1,
|
| 376 |
+
add_noise_std=0.003, voiced_threshod=0)
|
| 377 |
+
sampling_rate: sampling_rate in Hz
|
| 378 |
+
harmonic_num: number of harmonic above F0 (default: 0)
|
| 379 |
+
sine_amp: amplitude of sine source signal (default: 0.1)
|
| 380 |
+
add_noise_std: std of additive Gaussian noise (default: 0.003)
|
| 381 |
+
note that amplitude of noise in unvoiced is decided
|
| 382 |
+
by sine_amp
|
| 383 |
+
voiced_threshold: threhold to set U/V given F0 (default: 0)
|
| 384 |
+
Sine_source, noise_source = SourceModuleHnNSF(F0_sampled)
|
| 385 |
+
F0_sampled (batchsize, length, 1)
|
| 386 |
+
Sine_source (batchsize, length, 1)
|
| 387 |
+
noise_source (batchsize, length 1)
|
| 388 |
+
uv (batchsize, length, 1)
|
| 389 |
+
"""
|
| 390 |
+
|
| 391 |
+
def __init__(
|
| 392 |
+
self,
|
| 393 |
+
sampling_rate,
|
| 394 |
+
harmonic_num=0,
|
| 395 |
+
sine_amp=0.1,
|
| 396 |
+
add_noise_std=0.003,
|
| 397 |
+
voiced_threshod=0,
|
| 398 |
+
is_half=True,
|
| 399 |
+
):
|
| 400 |
+
super(SourceModuleHnNSF, self).__init__()
|
| 401 |
+
|
| 402 |
+
self.sine_amp = sine_amp
|
| 403 |
+
self.noise_std = add_noise_std
|
| 404 |
+
self.is_half = is_half
|
| 405 |
+
# to produce sine waveforms
|
| 406 |
+
self.l_sin_gen = SineGen(
|
| 407 |
+
sampling_rate, harmonic_num, sine_amp, add_noise_std, voiced_threshod
|
| 408 |
+
)
|
| 409 |
+
|
| 410 |
+
# to merge source harmonics into a single excitation
|
| 411 |
+
self.l_linear = torch.nn.Linear(harmonic_num + 1, 1)
|
| 412 |
+
self.l_tanh = torch.nn.Tanh()
|
| 413 |
+
|
| 414 |
+
def forward(self, x, upp=None):
|
| 415 |
+
sine_wavs, uv, _ = self.l_sin_gen(x, upp)
|
| 416 |
+
if self.is_half:
|
| 417 |
+
sine_wavs = sine_wavs.half()
|
| 418 |
+
sine_merge = self.l_tanh(self.l_linear(sine_wavs))
|
| 419 |
+
return sine_merge, None, None # noise, uv
|
| 420 |
+
|
| 421 |
+
|
| 422 |
+
class GeneratorNSF(torch.nn.Module):
|
| 423 |
+
def __init__(
|
| 424 |
+
self,
|
| 425 |
+
initial_channel,
|
| 426 |
+
resblock,
|
| 427 |
+
resblock_kernel_sizes,
|
| 428 |
+
resblock_dilation_sizes,
|
| 429 |
+
upsample_rates,
|
| 430 |
+
upsample_initial_channel,
|
| 431 |
+
upsample_kernel_sizes,
|
| 432 |
+
gin_channels,
|
| 433 |
+
sr,
|
| 434 |
+
is_half=False,
|
| 435 |
+
):
|
| 436 |
+
super(GeneratorNSF, self).__init__()
|
| 437 |
+
self.num_kernels = len(resblock_kernel_sizes)
|
| 438 |
+
self.num_upsamples = len(upsample_rates)
|
| 439 |
+
|
| 440 |
+
self.f0_upsamp = torch.nn.Upsample(scale_factor=np.prod(upsample_rates))
|
| 441 |
+
self.m_source = SourceModuleHnNSF(
|
| 442 |
+
sampling_rate=sr, harmonic_num=0, is_half=is_half
|
| 443 |
+
)
|
| 444 |
+
self.noise_convs = nn.ModuleList()
|
| 445 |
+
self.conv_pre = Conv1d(
|
| 446 |
+
initial_channel, upsample_initial_channel, 7, 1, padding=3
|
| 447 |
+
)
|
| 448 |
+
resblock = modules.ResBlock1 if resblock == "1" else modules.ResBlock2
|
| 449 |
+
|
| 450 |
+
self.ups = nn.ModuleList()
|
| 451 |
+
for i, (u, k) in enumerate(zip(upsample_rates, upsample_kernel_sizes)):
|
| 452 |
+
c_cur = upsample_initial_channel // (2 ** (i + 1))
|
| 453 |
+
self.ups.append(
|
| 454 |
+
weight_norm(
|
| 455 |
+
ConvTranspose1d(
|
| 456 |
+
upsample_initial_channel // (2**i),
|
| 457 |
+
upsample_initial_channel // (2 ** (i + 1)),
|
| 458 |
+
k,
|
| 459 |
+
u,
|
| 460 |
+
padding=(k - u) // 2,
|
| 461 |
+
)
|
| 462 |
+
)
|
| 463 |
+
)
|
| 464 |
+
if i + 1 < len(upsample_rates):
|
| 465 |
+
stride_f0 = np.prod(upsample_rates[i + 1 :])
|
| 466 |
+
self.noise_convs.append(
|
| 467 |
+
Conv1d(
|
| 468 |
+
1,
|
| 469 |
+
c_cur,
|
| 470 |
+
kernel_size=stride_f0 * 2,
|
| 471 |
+
stride=stride_f0,
|
| 472 |
+
padding=stride_f0 // 2,
|
| 473 |
+
)
|
| 474 |
+
)
|
| 475 |
+
else:
|
| 476 |
+
self.noise_convs.append(Conv1d(1, c_cur, kernel_size=1))
|
| 477 |
+
|
| 478 |
+
self.resblocks = nn.ModuleList()
|
| 479 |
+
for i in range(len(self.ups)):
|
| 480 |
+
ch = upsample_initial_channel // (2 ** (i + 1))
|
| 481 |
+
for j, (k, d) in enumerate(
|
| 482 |
+
zip(resblock_kernel_sizes, resblock_dilation_sizes)
|
| 483 |
+
):
|
| 484 |
+
self.resblocks.append(resblock(ch, k, d))
|
| 485 |
+
|
| 486 |
+
self.conv_post = Conv1d(ch, 1, 7, 1, padding=3, bias=False)
|
| 487 |
+
self.ups.apply(init_weights)
|
| 488 |
+
|
| 489 |
+
if gin_channels != 0:
|
| 490 |
+
self.cond = nn.Conv1d(gin_channels, upsample_initial_channel, 1)
|
| 491 |
+
|
| 492 |
+
self.upp = np.prod(upsample_rates)
|
| 493 |
+
|
| 494 |
+
def forward(self, x, f0, g=None):
|
| 495 |
+
har_source, noi_source, uv = self.m_source(f0, self.upp)
|
| 496 |
+
har_source = har_source.transpose(1, 2)
|
| 497 |
+
x = self.conv_pre(x)
|
| 498 |
+
if g is not None:
|
| 499 |
+
x = x + self.cond(g)
|
| 500 |
+
|
| 501 |
+
for i in range(self.num_upsamples):
|
| 502 |
+
x = F.leaky_relu(x, modules.LRELU_SLOPE)
|
| 503 |
+
x = self.ups[i](x)
|
| 504 |
+
x_source = self.noise_convs[i](har_source)
|
| 505 |
+
x = x + x_source
|
| 506 |
+
xs = None
|
| 507 |
+
for j in range(self.num_kernels):
|
| 508 |
+
if xs is None:
|
| 509 |
+
xs = self.resblocks[i * self.num_kernels + j](x)
|
| 510 |
+
else:
|
| 511 |
+
xs += self.resblocks[i * self.num_kernels + j](x)
|
| 512 |
+
x = xs / self.num_kernels
|
| 513 |
+
x = F.leaky_relu(x)
|
| 514 |
+
x = self.conv_post(x)
|
| 515 |
+
x = torch.tanh(x)
|
| 516 |
+
return x
|
| 517 |
+
|
| 518 |
+
def remove_weight_norm(self):
|
| 519 |
+
for l in self.ups:
|
| 520 |
+
remove_weight_norm(l)
|
| 521 |
+
for l in self.resblocks:
|
| 522 |
+
l.remove_weight_norm()
|
| 523 |
+
|
| 524 |
+
|
| 525 |
+
sr2sr = {
|
| 526 |
+
"32k": 32000,
|
| 527 |
+
"40k": 40000,
|
| 528 |
+
"48k": 48000,
|
| 529 |
+
}
|
| 530 |
+
|
| 531 |
+
|
| 532 |
+
class SynthesizerTrnMsNSFsidM(nn.Module):
|
| 533 |
+
def __init__(
|
| 534 |
+
self,
|
| 535 |
+
spec_channels,
|
| 536 |
+
segment_size,
|
| 537 |
+
inter_channels,
|
| 538 |
+
hidden_channels,
|
| 539 |
+
filter_channels,
|
| 540 |
+
n_heads,
|
| 541 |
+
n_layers,
|
| 542 |
+
kernel_size,
|
| 543 |
+
p_dropout,
|
| 544 |
+
resblock,
|
| 545 |
+
resblock_kernel_sizes,
|
| 546 |
+
resblock_dilation_sizes,
|
| 547 |
+
upsample_rates,
|
| 548 |
+
upsample_initial_channel,
|
| 549 |
+
upsample_kernel_sizes,
|
| 550 |
+
spk_embed_dim,
|
| 551 |
+
gin_channels,
|
| 552 |
+
sr,
|
| 553 |
+
**kwargs
|
| 554 |
+
):
|
| 555 |
+
super().__init__()
|
| 556 |
+
if type(sr) == type("strr"):
|
| 557 |
+
sr = sr2sr[sr]
|
| 558 |
+
self.spec_channels = spec_channels
|
| 559 |
+
self.inter_channels = inter_channels
|
| 560 |
+
self.hidden_channels = hidden_channels
|
| 561 |
+
self.filter_channels = filter_channels
|
| 562 |
+
self.n_heads = n_heads
|
| 563 |
+
self.n_layers = n_layers
|
| 564 |
+
self.kernel_size = kernel_size
|
| 565 |
+
self.p_dropout = p_dropout
|
| 566 |
+
self.resblock = resblock
|
| 567 |
+
self.resblock_kernel_sizes = resblock_kernel_sizes
|
| 568 |
+
self.resblock_dilation_sizes = resblock_dilation_sizes
|
| 569 |
+
self.upsample_rates = upsample_rates
|
| 570 |
+
self.upsample_initial_channel = upsample_initial_channel
|
| 571 |
+
self.upsample_kernel_sizes = upsample_kernel_sizes
|
| 572 |
+
self.segment_size = segment_size
|
| 573 |
+
self.gin_channels = gin_channels
|
| 574 |
+
# self.hop_length = hop_length#
|
| 575 |
+
self.spk_embed_dim = spk_embed_dim
|
| 576 |
+
if self.gin_channels == 256:
|
| 577 |
+
self.enc_p = TextEncoder256(
|
| 578 |
+
inter_channels,
|
| 579 |
+
hidden_channels,
|
| 580 |
+
filter_channels,
|
| 581 |
+
n_heads,
|
| 582 |
+
n_layers,
|
| 583 |
+
kernel_size,
|
| 584 |
+
p_dropout,
|
| 585 |
+
)
|
| 586 |
+
else:
|
| 587 |
+
self.enc_p = TextEncoder768(
|
| 588 |
+
inter_channels,
|
| 589 |
+
hidden_channels,
|
| 590 |
+
filter_channels,
|
| 591 |
+
n_heads,
|
| 592 |
+
n_layers,
|
| 593 |
+
kernel_size,
|
| 594 |
+
p_dropout,
|
| 595 |
+
)
|
| 596 |
+
self.dec = GeneratorNSF(
|
| 597 |
+
inter_channels,
|
| 598 |
+
resblock,
|
| 599 |
+
resblock_kernel_sizes,
|
| 600 |
+
resblock_dilation_sizes,
|
| 601 |
+
upsample_rates,
|
| 602 |
+
upsample_initial_channel,
|
| 603 |
+
upsample_kernel_sizes,
|
| 604 |
+
gin_channels=gin_channels,
|
| 605 |
+
sr=sr,
|
| 606 |
+
is_half=kwargs["is_half"],
|
| 607 |
+
)
|
| 608 |
+
self.enc_q = PosteriorEncoder(
|
| 609 |
+
spec_channels,
|
| 610 |
+
inter_channels,
|
| 611 |
+
hidden_channels,
|
| 612 |
+
5,
|
| 613 |
+
1,
|
| 614 |
+
16,
|
| 615 |
+
gin_channels=gin_channels,
|
| 616 |
+
)
|
| 617 |
+
self.flow = ResidualCouplingBlock(
|
| 618 |
+
inter_channels, hidden_channels, 5, 1, 3, gin_channels=gin_channels
|
| 619 |
+
)
|
| 620 |
+
self.emb_g = nn.Embedding(self.spk_embed_dim, gin_channels)
|
| 621 |
+
self.speaker_map = None
|
| 622 |
+
print("gin_channels:", gin_channels, "self.spk_embed_dim:", self.spk_embed_dim)
|
| 623 |
+
|
| 624 |
+
def remove_weight_norm(self):
|
| 625 |
+
self.dec.remove_weight_norm()
|
| 626 |
+
self.flow.remove_weight_norm()
|
| 627 |
+
self.enc_q.remove_weight_norm()
|
| 628 |
+
|
| 629 |
+
def construct_spkmixmap(self, n_speaker):
|
| 630 |
+
self.speaker_map = torch.zeros((n_speaker, 1, 1, self.gin_channels))
|
| 631 |
+
for i in range(n_speaker):
|
| 632 |
+
self.speaker_map[i] = self.emb_g(torch.LongTensor([[i]]))
|
| 633 |
+
self.speaker_map = self.speaker_map.unsqueeze(0)
|
| 634 |
+
|
| 635 |
+
def forward(self, phone, phone_lengths, pitch, nsff0, g, rnd, max_len=None):
|
| 636 |
+
if self.speaker_map is not None: # [N, S] * [S, B, 1, H]
|
| 637 |
+
g = g.reshape((g.shape[0], g.shape[1], 1, 1, 1)) # [N, S, B, 1, 1]
|
| 638 |
+
g = g * self.speaker_map # [N, S, B, 1, H]
|
| 639 |
+
g = torch.sum(g, dim=1) # [N, 1, B, 1, H]
|
| 640 |
+
g = g.transpose(0, -1).transpose(0, -2).squeeze(0) # [B, H, N]
|
| 641 |
+
else:
|
| 642 |
+
g = g.unsqueeze(0)
|
| 643 |
+
g = self.emb_g(g).transpose(1, 2)
|
| 644 |
+
|
| 645 |
+
m_p, logs_p, x_mask = self.enc_p(phone, pitch, phone_lengths)
|
| 646 |
+
z_p = (m_p + torch.exp(logs_p) * rnd) * x_mask
|
| 647 |
+
z = self.flow(z_p, x_mask, g=g, reverse=True)
|
| 648 |
+
o = self.dec((z * x_mask)[:, :, :max_len], nsff0, g=g)
|
| 649 |
+
return o
|
| 650 |
+
|
| 651 |
+
|
| 652 |
+
class MultiPeriodDiscriminator(torch.nn.Module):
|
| 653 |
+
def __init__(self, use_spectral_norm=False):
|
| 654 |
+
super(MultiPeriodDiscriminator, self).__init__()
|
| 655 |
+
periods = [2, 3, 5, 7, 11, 17]
|
| 656 |
+
# periods = [3, 5, 7, 11, 17, 23, 37]
|
| 657 |
+
|
| 658 |
+
discs = [DiscriminatorS(use_spectral_norm=use_spectral_norm)]
|
| 659 |
+
discs = discs + [
|
| 660 |
+
DiscriminatorP(i, use_spectral_norm=use_spectral_norm) for i in periods
|
| 661 |
+
]
|
| 662 |
+
self.discriminators = nn.ModuleList(discs)
|
| 663 |
+
|
| 664 |
+
def forward(self, y, y_hat):
|
| 665 |
+
y_d_rs = [] #
|
| 666 |
+
y_d_gs = []
|
| 667 |
+
fmap_rs = []
|
| 668 |
+
fmap_gs = []
|
| 669 |
+
for i, d in enumerate(self.discriminators):
|
| 670 |
+
y_d_r, fmap_r = d(y)
|
| 671 |
+
y_d_g, fmap_g = d(y_hat)
|
| 672 |
+
# for j in range(len(fmap_r)):
|
| 673 |
+
# print(i,j,y.shape,y_hat.shape,fmap_r[j].shape,fmap_g[j].shape)
|
| 674 |
+
y_d_rs.append(y_d_r)
|
| 675 |
+
y_d_gs.append(y_d_g)
|
| 676 |
+
fmap_rs.append(fmap_r)
|
| 677 |
+
fmap_gs.append(fmap_g)
|
| 678 |
+
|
| 679 |
+
return y_d_rs, y_d_gs, fmap_rs, fmap_gs
|
| 680 |
+
|
| 681 |
+
|
| 682 |
+
class MultiPeriodDiscriminatorV2(torch.nn.Module):
|
| 683 |
+
def __init__(self, use_spectral_norm=False):
|
| 684 |
+
super(MultiPeriodDiscriminatorV2, self).__init__()
|
| 685 |
+
# periods = [2, 3, 5, 7, 11, 17]
|
| 686 |
+
periods = [2, 3, 5, 7, 11, 17, 23, 37]
|
| 687 |
+
|
| 688 |
+
discs = [DiscriminatorS(use_spectral_norm=use_spectral_norm)]
|
| 689 |
+
discs = discs + [
|
| 690 |
+
DiscriminatorP(i, use_spectral_norm=use_spectral_norm) for i in periods
|
| 691 |
+
]
|
| 692 |
+
self.discriminators = nn.ModuleList(discs)
|
| 693 |
+
|
| 694 |
+
def forward(self, y, y_hat):
|
| 695 |
+
y_d_rs = [] #
|
| 696 |
+
y_d_gs = []
|
| 697 |
+
fmap_rs = []
|
| 698 |
+
fmap_gs = []
|
| 699 |
+
for i, d in enumerate(self.discriminators):
|
| 700 |
+
y_d_r, fmap_r = d(y)
|
| 701 |
+
y_d_g, fmap_g = d(y_hat)
|
| 702 |
+
# for j in range(len(fmap_r)):
|
| 703 |
+
# print(i,j,y.shape,y_hat.shape,fmap_r[j].shape,fmap_g[j].shape)
|
| 704 |
+
y_d_rs.append(y_d_r)
|
| 705 |
+
y_d_gs.append(y_d_g)
|
| 706 |
+
fmap_rs.append(fmap_r)
|
| 707 |
+
fmap_gs.append(fmap_g)
|
| 708 |
+
|
| 709 |
+
return y_d_rs, y_d_gs, fmap_rs, fmap_gs
|
| 710 |
+
|
| 711 |
+
|
| 712 |
+
class DiscriminatorS(torch.nn.Module):
|
| 713 |
+
def __init__(self, use_spectral_norm=False):
|
| 714 |
+
super(DiscriminatorS, self).__init__()
|
| 715 |
+
norm_f = weight_norm if use_spectral_norm == False else spectral_norm
|
| 716 |
+
self.convs = nn.ModuleList(
|
| 717 |
+
[
|
| 718 |
+
norm_f(Conv1d(1, 16, 15, 1, padding=7)),
|
| 719 |
+
norm_f(Conv1d(16, 64, 41, 4, groups=4, padding=20)),
|
| 720 |
+
norm_f(Conv1d(64, 256, 41, 4, groups=16, padding=20)),
|
| 721 |
+
norm_f(Conv1d(256, 1024, 41, 4, groups=64, padding=20)),
|
| 722 |
+
norm_f(Conv1d(1024, 1024, 41, 4, groups=256, padding=20)),
|
| 723 |
+
norm_f(Conv1d(1024, 1024, 5, 1, padding=2)),
|
| 724 |
+
]
|
| 725 |
+
)
|
| 726 |
+
self.conv_post = norm_f(Conv1d(1024, 1, 3, 1, padding=1))
|
| 727 |
+
|
| 728 |
+
def forward(self, x):
|
| 729 |
+
fmap = []
|
| 730 |
+
|
| 731 |
+
for l in self.convs:
|
| 732 |
+
x = l(x)
|
| 733 |
+
x = F.leaky_relu(x, modules.LRELU_SLOPE)
|
| 734 |
+
fmap.append(x)
|
| 735 |
+
x = self.conv_post(x)
|
| 736 |
+
fmap.append(x)
|
| 737 |
+
x = torch.flatten(x, 1, -1)
|
| 738 |
+
|
| 739 |
+
return x, fmap
|
| 740 |
+
|
| 741 |
+
|
| 742 |
+
class DiscriminatorP(torch.nn.Module):
|
| 743 |
+
def __init__(self, period, kernel_size=5, stride=3, use_spectral_norm=False):
|
| 744 |
+
super(DiscriminatorP, self).__init__()
|
| 745 |
+
self.period = period
|
| 746 |
+
self.use_spectral_norm = use_spectral_norm
|
| 747 |
+
norm_f = weight_norm if use_spectral_norm == False else spectral_norm
|
| 748 |
+
self.convs = nn.ModuleList(
|
| 749 |
+
[
|
| 750 |
+
norm_f(
|
| 751 |
+
Conv2d(
|
| 752 |
+
1,
|
| 753 |
+
32,
|
| 754 |
+
(kernel_size, 1),
|
| 755 |
+
(stride, 1),
|
| 756 |
+
padding=(get_padding(kernel_size, 1), 0),
|
| 757 |
+
)
|
| 758 |
+
),
|
| 759 |
+
norm_f(
|
| 760 |
+
Conv2d(
|
| 761 |
+
32,
|
| 762 |
+
128,
|
| 763 |
+
(kernel_size, 1),
|
| 764 |
+
(stride, 1),
|
| 765 |
+
padding=(get_padding(kernel_size, 1), 0),
|
| 766 |
+
)
|
| 767 |
+
),
|
| 768 |
+
norm_f(
|
| 769 |
+
Conv2d(
|
| 770 |
+
128,
|
| 771 |
+
512,
|
| 772 |
+
(kernel_size, 1),
|
| 773 |
+
(stride, 1),
|
| 774 |
+
padding=(get_padding(kernel_size, 1), 0),
|
| 775 |
+
)
|
| 776 |
+
),
|
| 777 |
+
norm_f(
|
| 778 |
+
Conv2d(
|
| 779 |
+
512,
|
| 780 |
+
1024,
|
| 781 |
+
(kernel_size, 1),
|
| 782 |
+
(stride, 1),
|
| 783 |
+
padding=(get_padding(kernel_size, 1), 0),
|
| 784 |
+
)
|
| 785 |
+
),
|
| 786 |
+
norm_f(
|
| 787 |
+
Conv2d(
|
| 788 |
+
1024,
|
| 789 |
+
1024,
|
| 790 |
+
(kernel_size, 1),
|
| 791 |
+
1,
|
| 792 |
+
padding=(get_padding(kernel_size, 1), 0),
|
| 793 |
+
)
|
| 794 |
+
),
|
| 795 |
+
]
|
| 796 |
+
)
|
| 797 |
+
self.conv_post = norm_f(Conv2d(1024, 1, (3, 1), 1, padding=(1, 0)))
|
| 798 |
+
|
| 799 |
+
def forward(self, x):
|
| 800 |
+
fmap = []
|
| 801 |
+
|
| 802 |
+
# 1d to 2d
|
| 803 |
+
b, c, t = x.shape
|
| 804 |
+
if t % self.period != 0: # pad first
|
| 805 |
+
n_pad = self.period - (t % self.period)
|
| 806 |
+
x = F.pad(x, (0, n_pad), "reflect")
|
| 807 |
+
t = t + n_pad
|
| 808 |
+
x = x.view(b, c, t // self.period, self.period)
|
| 809 |
+
|
| 810 |
+
for l in self.convs:
|
| 811 |
+
x = l(x)
|
| 812 |
+
x = F.leaky_relu(x, modules.LRELU_SLOPE)
|
| 813 |
+
fmap.append(x)
|
| 814 |
+
x = self.conv_post(x)
|
| 815 |
+
fmap.append(x)
|
| 816 |
+
x = torch.flatten(x, 1, -1)
|
| 817 |
+
|
| 818 |
+
return x, fmap
|
src/infer_pack/models_onnx_moess.py
ADDED
|
@@ -0,0 +1,849 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import math, pdb, os
|
| 2 |
+
from time import time as ttime
|
| 3 |
+
import torch
|
| 4 |
+
from torch import nn
|
| 5 |
+
from torch.nn import functional as F
|
| 6 |
+
from infer_pack import modules
|
| 7 |
+
from infer_pack import attentions
|
| 8 |
+
from infer_pack import commons
|
| 9 |
+
from infer_pack.commons import init_weights, get_padding
|
| 10 |
+
from torch.nn import Conv1d, ConvTranspose1d, AvgPool1d, Conv2d
|
| 11 |
+
from torch.nn.utils import weight_norm, remove_weight_norm, spectral_norm
|
| 12 |
+
from infer_pack.commons import init_weights
|
| 13 |
+
import numpy as np
|
| 14 |
+
from infer_pack import commons
|
| 15 |
+
|
| 16 |
+
|
| 17 |
+
class TextEncoder256(nn.Module):
|
| 18 |
+
def __init__(
|
| 19 |
+
self,
|
| 20 |
+
out_channels,
|
| 21 |
+
hidden_channels,
|
| 22 |
+
filter_channels,
|
| 23 |
+
n_heads,
|
| 24 |
+
n_layers,
|
| 25 |
+
kernel_size,
|
| 26 |
+
p_dropout,
|
| 27 |
+
f0=True,
|
| 28 |
+
):
|
| 29 |
+
super().__init__()
|
| 30 |
+
self.out_channels = out_channels
|
| 31 |
+
self.hidden_channels = hidden_channels
|
| 32 |
+
self.filter_channels = filter_channels
|
| 33 |
+
self.n_heads = n_heads
|
| 34 |
+
self.n_layers = n_layers
|
| 35 |
+
self.kernel_size = kernel_size
|
| 36 |
+
self.p_dropout = p_dropout
|
| 37 |
+
self.emb_phone = nn.Linear(256, hidden_channels)
|
| 38 |
+
self.lrelu = nn.LeakyReLU(0.1, inplace=True)
|
| 39 |
+
if f0 == True:
|
| 40 |
+
self.emb_pitch = nn.Embedding(256, hidden_channels) # pitch 256
|
| 41 |
+
self.encoder = attentions.Encoder(
|
| 42 |
+
hidden_channels, filter_channels, n_heads, n_layers, kernel_size, p_dropout
|
| 43 |
+
)
|
| 44 |
+
self.proj = nn.Conv1d(hidden_channels, out_channels * 2, 1)
|
| 45 |
+
|
| 46 |
+
def forward(self, phone, pitch, lengths):
|
| 47 |
+
if pitch == None:
|
| 48 |
+
x = self.emb_phone(phone)
|
| 49 |
+
else:
|
| 50 |
+
x = self.emb_phone(phone) + self.emb_pitch(pitch)
|
| 51 |
+
x = x * math.sqrt(self.hidden_channels) # [b, t, h]
|
| 52 |
+
x = self.lrelu(x)
|
| 53 |
+
x = torch.transpose(x, 1, -1) # [b, h, t]
|
| 54 |
+
x_mask = torch.unsqueeze(commons.sequence_mask(lengths, x.size(2)), 1).to(
|
| 55 |
+
x.dtype
|
| 56 |
+
)
|
| 57 |
+
x = self.encoder(x * x_mask, x_mask)
|
| 58 |
+
stats = self.proj(x) * x_mask
|
| 59 |
+
|
| 60 |
+
m, logs = torch.split(stats, self.out_channels, dim=1)
|
| 61 |
+
return m, logs, x_mask
|
| 62 |
+
|
| 63 |
+
|
| 64 |
+
class TextEncoder256Sim(nn.Module):
|
| 65 |
+
def __init__(
|
| 66 |
+
self,
|
| 67 |
+
out_channels,
|
| 68 |
+
hidden_channels,
|
| 69 |
+
filter_channels,
|
| 70 |
+
n_heads,
|
| 71 |
+
n_layers,
|
| 72 |
+
kernel_size,
|
| 73 |
+
p_dropout,
|
| 74 |
+
f0=True,
|
| 75 |
+
):
|
| 76 |
+
super().__init__()
|
| 77 |
+
self.out_channels = out_channels
|
| 78 |
+
self.hidden_channels = hidden_channels
|
| 79 |
+
self.filter_channels = filter_channels
|
| 80 |
+
self.n_heads = n_heads
|
| 81 |
+
self.n_layers = n_layers
|
| 82 |
+
self.kernel_size = kernel_size
|
| 83 |
+
self.p_dropout = p_dropout
|
| 84 |
+
self.emb_phone = nn.Linear(256, hidden_channels)
|
| 85 |
+
self.lrelu = nn.LeakyReLU(0.1, inplace=True)
|
| 86 |
+
if f0 == True:
|
| 87 |
+
self.emb_pitch = nn.Embedding(256, hidden_channels) # pitch 256
|
| 88 |
+
self.encoder = attentions.Encoder(
|
| 89 |
+
hidden_channels, filter_channels, n_heads, n_layers, kernel_size, p_dropout
|
| 90 |
+
)
|
| 91 |
+
self.proj = nn.Conv1d(hidden_channels, out_channels, 1)
|
| 92 |
+
|
| 93 |
+
def forward(self, phone, pitch, lengths):
|
| 94 |
+
if pitch == None:
|
| 95 |
+
x = self.emb_phone(phone)
|
| 96 |
+
else:
|
| 97 |
+
x = self.emb_phone(phone) + self.emb_pitch(pitch)
|
| 98 |
+
x = x * math.sqrt(self.hidden_channels) # [b, t, h]
|
| 99 |
+
x = self.lrelu(x)
|
| 100 |
+
x = torch.transpose(x, 1, -1) # [b, h, t]
|
| 101 |
+
x_mask = torch.unsqueeze(commons.sequence_mask(lengths, x.size(2)), 1).to(
|
| 102 |
+
x.dtype
|
| 103 |
+
)
|
| 104 |
+
x = self.encoder(x * x_mask, x_mask)
|
| 105 |
+
x = self.proj(x) * x_mask
|
| 106 |
+
return x, x_mask
|
| 107 |
+
|
| 108 |
+
|
| 109 |
+
class ResidualCouplingBlock(nn.Module):
|
| 110 |
+
def __init__(
|
| 111 |
+
self,
|
| 112 |
+
channels,
|
| 113 |
+
hidden_channels,
|
| 114 |
+
kernel_size,
|
| 115 |
+
dilation_rate,
|
| 116 |
+
n_layers,
|
| 117 |
+
n_flows=4,
|
| 118 |
+
gin_channels=0,
|
| 119 |
+
):
|
| 120 |
+
super().__init__()
|
| 121 |
+
self.channels = channels
|
| 122 |
+
self.hidden_channels = hidden_channels
|
| 123 |
+
self.kernel_size = kernel_size
|
| 124 |
+
self.dilation_rate = dilation_rate
|
| 125 |
+
self.n_layers = n_layers
|
| 126 |
+
self.n_flows = n_flows
|
| 127 |
+
self.gin_channels = gin_channels
|
| 128 |
+
|
| 129 |
+
self.flows = nn.ModuleList()
|
| 130 |
+
for i in range(n_flows):
|
| 131 |
+
self.flows.append(
|
| 132 |
+
modules.ResidualCouplingLayer(
|
| 133 |
+
channels,
|
| 134 |
+
hidden_channels,
|
| 135 |
+
kernel_size,
|
| 136 |
+
dilation_rate,
|
| 137 |
+
n_layers,
|
| 138 |
+
gin_channels=gin_channels,
|
| 139 |
+
mean_only=True,
|
| 140 |
+
)
|
| 141 |
+
)
|
| 142 |
+
self.flows.append(modules.Flip())
|
| 143 |
+
|
| 144 |
+
def forward(self, x, x_mask, g=None, reverse=False):
|
| 145 |
+
if not reverse:
|
| 146 |
+
for flow in self.flows:
|
| 147 |
+
x, _ = flow(x, x_mask, g=g, reverse=reverse)
|
| 148 |
+
else:
|
| 149 |
+
for flow in reversed(self.flows):
|
| 150 |
+
x = flow(x, x_mask, g=g, reverse=reverse)
|
| 151 |
+
return x
|
| 152 |
+
|
| 153 |
+
def remove_weight_norm(self):
|
| 154 |
+
for i in range(self.n_flows):
|
| 155 |
+
self.flows[i * 2].remove_weight_norm()
|
| 156 |
+
|
| 157 |
+
|
| 158 |
+
class PosteriorEncoder(nn.Module):
|
| 159 |
+
def __init__(
|
| 160 |
+
self,
|
| 161 |
+
in_channels,
|
| 162 |
+
out_channels,
|
| 163 |
+
hidden_channels,
|
| 164 |
+
kernel_size,
|
| 165 |
+
dilation_rate,
|
| 166 |
+
n_layers,
|
| 167 |
+
gin_channels=0,
|
| 168 |
+
):
|
| 169 |
+
super().__init__()
|
| 170 |
+
self.in_channels = in_channels
|
| 171 |
+
self.out_channels = out_channels
|
| 172 |
+
self.hidden_channels = hidden_channels
|
| 173 |
+
self.kernel_size = kernel_size
|
| 174 |
+
self.dilation_rate = dilation_rate
|
| 175 |
+
self.n_layers = n_layers
|
| 176 |
+
self.gin_channels = gin_channels
|
| 177 |
+
|
| 178 |
+
self.pre = nn.Conv1d(in_channels, hidden_channels, 1)
|
| 179 |
+
self.enc = modules.WN(
|
| 180 |
+
hidden_channels,
|
| 181 |
+
kernel_size,
|
| 182 |
+
dilation_rate,
|
| 183 |
+
n_layers,
|
| 184 |
+
gin_channels=gin_channels,
|
| 185 |
+
)
|
| 186 |
+
self.proj = nn.Conv1d(hidden_channels, out_channels * 2, 1)
|
| 187 |
+
|
| 188 |
+
def forward(self, x, x_lengths, g=None):
|
| 189 |
+
x_mask = torch.unsqueeze(commons.sequence_mask(x_lengths, x.size(2)), 1).to(
|
| 190 |
+
x.dtype
|
| 191 |
+
)
|
| 192 |
+
x = self.pre(x) * x_mask
|
| 193 |
+
x = self.enc(x, x_mask, g=g)
|
| 194 |
+
stats = self.proj(x) * x_mask
|
| 195 |
+
m, logs = torch.split(stats, self.out_channels, dim=1)
|
| 196 |
+
z = (m + torch.randn_like(m) * torch.exp(logs)) * x_mask
|
| 197 |
+
return z, m, logs, x_mask
|
| 198 |
+
|
| 199 |
+
def remove_weight_norm(self):
|
| 200 |
+
self.enc.remove_weight_norm()
|
| 201 |
+
|
| 202 |
+
|
| 203 |
+
class Generator(torch.nn.Module):
|
| 204 |
+
def __init__(
|
| 205 |
+
self,
|
| 206 |
+
initial_channel,
|
| 207 |
+
resblock,
|
| 208 |
+
resblock_kernel_sizes,
|
| 209 |
+
resblock_dilation_sizes,
|
| 210 |
+
upsample_rates,
|
| 211 |
+
upsample_initial_channel,
|
| 212 |
+
upsample_kernel_sizes,
|
| 213 |
+
gin_channels=0,
|
| 214 |
+
):
|
| 215 |
+
super(Generator, self).__init__()
|
| 216 |
+
self.num_kernels = len(resblock_kernel_sizes)
|
| 217 |
+
self.num_upsamples = len(upsample_rates)
|
| 218 |
+
self.conv_pre = Conv1d(
|
| 219 |
+
initial_channel, upsample_initial_channel, 7, 1, padding=3
|
| 220 |
+
)
|
| 221 |
+
resblock = modules.ResBlock1 if resblock == "1" else modules.ResBlock2
|
| 222 |
+
|
| 223 |
+
self.ups = nn.ModuleList()
|
| 224 |
+
for i, (u, k) in enumerate(zip(upsample_rates, upsample_kernel_sizes)):
|
| 225 |
+
self.ups.append(
|
| 226 |
+
weight_norm(
|
| 227 |
+
ConvTranspose1d(
|
| 228 |
+
upsample_initial_channel // (2**i),
|
| 229 |
+
upsample_initial_channel // (2 ** (i + 1)),
|
| 230 |
+
k,
|
| 231 |
+
u,
|
| 232 |
+
padding=(k - u) // 2,
|
| 233 |
+
)
|
| 234 |
+
)
|
| 235 |
+
)
|
| 236 |
+
|
| 237 |
+
self.resblocks = nn.ModuleList()
|
| 238 |
+
for i in range(len(self.ups)):
|
| 239 |
+
ch = upsample_initial_channel // (2 ** (i + 1))
|
| 240 |
+
for j, (k, d) in enumerate(
|
| 241 |
+
zip(resblock_kernel_sizes, resblock_dilation_sizes)
|
| 242 |
+
):
|
| 243 |
+
self.resblocks.append(resblock(ch, k, d))
|
| 244 |
+
|
| 245 |
+
self.conv_post = Conv1d(ch, 1, 7, 1, padding=3, bias=False)
|
| 246 |
+
self.ups.apply(init_weights)
|
| 247 |
+
|
| 248 |
+
if gin_channels != 0:
|
| 249 |
+
self.cond = nn.Conv1d(gin_channels, upsample_initial_channel, 1)
|
| 250 |
+
|
| 251 |
+
def forward(self, x, g=None):
|
| 252 |
+
x = self.conv_pre(x)
|
| 253 |
+
if g is not None:
|
| 254 |
+
x = x + self.cond(g)
|
| 255 |
+
|
| 256 |
+
for i in range(self.num_upsamples):
|
| 257 |
+
x = F.leaky_relu(x, modules.LRELU_SLOPE)
|
| 258 |
+
x = self.ups[i](x)
|
| 259 |
+
xs = None
|
| 260 |
+
for j in range(self.num_kernels):
|
| 261 |
+
if xs is None:
|
| 262 |
+
xs = self.resblocks[i * self.num_kernels + j](x)
|
| 263 |
+
else:
|
| 264 |
+
xs += self.resblocks[i * self.num_kernels + j](x)
|
| 265 |
+
x = xs / self.num_kernels
|
| 266 |
+
x = F.leaky_relu(x)
|
| 267 |
+
x = self.conv_post(x)
|
| 268 |
+
x = torch.tanh(x)
|
| 269 |
+
|
| 270 |
+
return x
|
| 271 |
+
|
| 272 |
+
def remove_weight_norm(self):
|
| 273 |
+
for l in self.ups:
|
| 274 |
+
remove_weight_norm(l)
|
| 275 |
+
for l in self.resblocks:
|
| 276 |
+
l.remove_weight_norm()
|
| 277 |
+
|
| 278 |
+
|
| 279 |
+
class SineGen(torch.nn.Module):
|
| 280 |
+
"""Definition of sine generator
|
| 281 |
+
SineGen(samp_rate, harmonic_num = 0,
|
| 282 |
+
sine_amp = 0.1, noise_std = 0.003,
|
| 283 |
+
voiced_threshold = 0,
|
| 284 |
+
flag_for_pulse=False)
|
| 285 |
+
samp_rate: sampling rate in Hz
|
| 286 |
+
harmonic_num: number of harmonic overtones (default 0)
|
| 287 |
+
sine_amp: amplitude of sine-wavefrom (default 0.1)
|
| 288 |
+
noise_std: std of Gaussian noise (default 0.003)
|
| 289 |
+
voiced_thoreshold: F0 threshold for U/V classification (default 0)
|
| 290 |
+
flag_for_pulse: this SinGen is used inside PulseGen (default False)
|
| 291 |
+
Note: when flag_for_pulse is True, the first time step of a voiced
|
| 292 |
+
segment is always sin(np.pi) or cos(0)
|
| 293 |
+
"""
|
| 294 |
+
|
| 295 |
+
def __init__(
|
| 296 |
+
self,
|
| 297 |
+
samp_rate,
|
| 298 |
+
harmonic_num=0,
|
| 299 |
+
sine_amp=0.1,
|
| 300 |
+
noise_std=0.003,
|
| 301 |
+
voiced_threshold=0,
|
| 302 |
+
flag_for_pulse=False,
|
| 303 |
+
):
|
| 304 |
+
super(SineGen, self).__init__()
|
| 305 |
+
self.sine_amp = sine_amp
|
| 306 |
+
self.noise_std = noise_std
|
| 307 |
+
self.harmonic_num = harmonic_num
|
| 308 |
+
self.dim = self.harmonic_num + 1
|
| 309 |
+
self.sampling_rate = samp_rate
|
| 310 |
+
self.voiced_threshold = voiced_threshold
|
| 311 |
+
|
| 312 |
+
def _f02uv(self, f0):
|
| 313 |
+
# generate uv signal
|
| 314 |
+
uv = torch.ones_like(f0)
|
| 315 |
+
uv = uv * (f0 > self.voiced_threshold)
|
| 316 |
+
return uv
|
| 317 |
+
|
| 318 |
+
def forward(self, f0, upp):
|
| 319 |
+
"""sine_tensor, uv = forward(f0)
|
| 320 |
+
input F0: tensor(batchsize=1, length, dim=1)
|
| 321 |
+
f0 for unvoiced steps should be 0
|
| 322 |
+
output sine_tensor: tensor(batchsize=1, length, dim)
|
| 323 |
+
output uv: tensor(batchsize=1, length, 1)
|
| 324 |
+
"""
|
| 325 |
+
with torch.no_grad():
|
| 326 |
+
f0 = f0[:, None].transpose(1, 2)
|
| 327 |
+
f0_buf = torch.zeros(f0.shape[0], f0.shape[1], self.dim, device=f0.device)
|
| 328 |
+
# fundamental component
|
| 329 |
+
f0_buf[:, :, 0] = f0[:, :, 0]
|
| 330 |
+
for idx in np.arange(self.harmonic_num):
|
| 331 |
+
f0_buf[:, :, idx + 1] = f0_buf[:, :, 0] * (
|
| 332 |
+
idx + 2
|
| 333 |
+
) # idx + 2: the (idx+1)-th overtone, (idx+2)-th harmonic
|
| 334 |
+
rad_values = (f0_buf / self.sampling_rate) % 1 ###%1意味着n_har的乘积无法后处理优化
|
| 335 |
+
rand_ini = torch.rand(
|
| 336 |
+
f0_buf.shape[0], f0_buf.shape[2], device=f0_buf.device
|
| 337 |
+
)
|
| 338 |
+
rand_ini[:, 0] = 0
|
| 339 |
+
rad_values[:, 0, :] = rad_values[:, 0, :] + rand_ini
|
| 340 |
+
tmp_over_one = torch.cumsum(rad_values, 1) # % 1 #####%1意味着后面的cumsum无法再优化
|
| 341 |
+
tmp_over_one *= upp
|
| 342 |
+
tmp_over_one = F.interpolate(
|
| 343 |
+
tmp_over_one.transpose(2, 1),
|
| 344 |
+
scale_factor=upp,
|
| 345 |
+
mode="linear",
|
| 346 |
+
align_corners=True,
|
| 347 |
+
).transpose(2, 1)
|
| 348 |
+
rad_values = F.interpolate(
|
| 349 |
+
rad_values.transpose(2, 1), scale_factor=upp, mode="nearest"
|
| 350 |
+
).transpose(
|
| 351 |
+
2, 1
|
| 352 |
+
) #######
|
| 353 |
+
tmp_over_one %= 1
|
| 354 |
+
tmp_over_one_idx = (tmp_over_one[:, 1:, :] - tmp_over_one[:, :-1, :]) < 0
|
| 355 |
+
cumsum_shift = torch.zeros_like(rad_values)
|
| 356 |
+
cumsum_shift[:, 1:, :] = tmp_over_one_idx * -1.0
|
| 357 |
+
sine_waves = torch.sin(
|
| 358 |
+
torch.cumsum(rad_values + cumsum_shift, dim=1) * 2 * np.pi
|
| 359 |
+
)
|
| 360 |
+
sine_waves = sine_waves * self.sine_amp
|
| 361 |
+
uv = self._f02uv(f0)
|
| 362 |
+
uv = F.interpolate(
|
| 363 |
+
uv.transpose(2, 1), scale_factor=upp, mode="nearest"
|
| 364 |
+
).transpose(2, 1)
|
| 365 |
+
noise_amp = uv * self.noise_std + (1 - uv) * self.sine_amp / 3
|
| 366 |
+
noise = noise_amp * torch.randn_like(sine_waves)
|
| 367 |
+
sine_waves = sine_waves * uv + noise
|
| 368 |
+
return sine_waves, uv, noise
|
| 369 |
+
|
| 370 |
+
|
| 371 |
+
class SourceModuleHnNSF(torch.nn.Module):
|
| 372 |
+
"""SourceModule for hn-nsf
|
| 373 |
+
SourceModule(sampling_rate, harmonic_num=0, sine_amp=0.1,
|
| 374 |
+
add_noise_std=0.003, voiced_threshod=0)
|
| 375 |
+
sampling_rate: sampling_rate in Hz
|
| 376 |
+
harmonic_num: number of harmonic above F0 (default: 0)
|
| 377 |
+
sine_amp: amplitude of sine source signal (default: 0.1)
|
| 378 |
+
add_noise_std: std of additive Gaussian noise (default: 0.003)
|
| 379 |
+
note that amplitude of noise in unvoiced is decided
|
| 380 |
+
by sine_amp
|
| 381 |
+
voiced_threshold: threhold to set U/V given F0 (default: 0)
|
| 382 |
+
Sine_source, noise_source = SourceModuleHnNSF(F0_sampled)
|
| 383 |
+
F0_sampled (batchsize, length, 1)
|
| 384 |
+
Sine_source (batchsize, length, 1)
|
| 385 |
+
noise_source (batchsize, length 1)
|
| 386 |
+
uv (batchsize, length, 1)
|
| 387 |
+
"""
|
| 388 |
+
|
| 389 |
+
def __init__(
|
| 390 |
+
self,
|
| 391 |
+
sampling_rate,
|
| 392 |
+
harmonic_num=0,
|
| 393 |
+
sine_amp=0.1,
|
| 394 |
+
add_noise_std=0.003,
|
| 395 |
+
voiced_threshod=0,
|
| 396 |
+
is_half=True,
|
| 397 |
+
):
|
| 398 |
+
super(SourceModuleHnNSF, self).__init__()
|
| 399 |
+
|
| 400 |
+
self.sine_amp = sine_amp
|
| 401 |
+
self.noise_std = add_noise_std
|
| 402 |
+
self.is_half = is_half
|
| 403 |
+
# to produce sine waveforms
|
| 404 |
+
self.l_sin_gen = SineGen(
|
| 405 |
+
sampling_rate, harmonic_num, sine_amp, add_noise_std, voiced_threshod
|
| 406 |
+
)
|
| 407 |
+
|
| 408 |
+
# to merge source harmonics into a single excitation
|
| 409 |
+
self.l_linear = torch.nn.Linear(harmonic_num + 1, 1)
|
| 410 |
+
self.l_tanh = torch.nn.Tanh()
|
| 411 |
+
|
| 412 |
+
def forward(self, x, upp=None):
|
| 413 |
+
sine_wavs, uv, _ = self.l_sin_gen(x, upp)
|
| 414 |
+
if self.is_half:
|
| 415 |
+
sine_wavs = sine_wavs.half()
|
| 416 |
+
sine_merge = self.l_tanh(self.l_linear(sine_wavs))
|
| 417 |
+
return sine_merge, None, None # noise, uv
|
| 418 |
+
|
| 419 |
+
|
| 420 |
+
class GeneratorNSF(torch.nn.Module):
|
| 421 |
+
def __init__(
|
| 422 |
+
self,
|
| 423 |
+
initial_channel,
|
| 424 |
+
resblock,
|
| 425 |
+
resblock_kernel_sizes,
|
| 426 |
+
resblock_dilation_sizes,
|
| 427 |
+
upsample_rates,
|
| 428 |
+
upsample_initial_channel,
|
| 429 |
+
upsample_kernel_sizes,
|
| 430 |
+
gin_channels,
|
| 431 |
+
sr,
|
| 432 |
+
is_half=False,
|
| 433 |
+
):
|
| 434 |
+
super(GeneratorNSF, self).__init__()
|
| 435 |
+
self.num_kernels = len(resblock_kernel_sizes)
|
| 436 |
+
self.num_upsamples = len(upsample_rates)
|
| 437 |
+
|
| 438 |
+
self.f0_upsamp = torch.nn.Upsample(scale_factor=np.prod(upsample_rates))
|
| 439 |
+
self.m_source = SourceModuleHnNSF(
|
| 440 |
+
sampling_rate=sr, harmonic_num=0, is_half=is_half
|
| 441 |
+
)
|
| 442 |
+
self.noise_convs = nn.ModuleList()
|
| 443 |
+
self.conv_pre = Conv1d(
|
| 444 |
+
initial_channel, upsample_initial_channel, 7, 1, padding=3
|
| 445 |
+
)
|
| 446 |
+
resblock = modules.ResBlock1 if resblock == "1" else modules.ResBlock2
|
| 447 |
+
|
| 448 |
+
self.ups = nn.ModuleList()
|
| 449 |
+
for i, (u, k) in enumerate(zip(upsample_rates, upsample_kernel_sizes)):
|
| 450 |
+
c_cur = upsample_initial_channel // (2 ** (i + 1))
|
| 451 |
+
self.ups.append(
|
| 452 |
+
weight_norm(
|
| 453 |
+
ConvTranspose1d(
|
| 454 |
+
upsample_initial_channel // (2**i),
|
| 455 |
+
upsample_initial_channel // (2 ** (i + 1)),
|
| 456 |
+
k,
|
| 457 |
+
u,
|
| 458 |
+
padding=(k - u) // 2,
|
| 459 |
+
)
|
| 460 |
+
)
|
| 461 |
+
)
|
| 462 |
+
if i + 1 < len(upsample_rates):
|
| 463 |
+
stride_f0 = np.prod(upsample_rates[i + 1 :])
|
| 464 |
+
self.noise_convs.append(
|
| 465 |
+
Conv1d(
|
| 466 |
+
1,
|
| 467 |
+
c_cur,
|
| 468 |
+
kernel_size=stride_f0 * 2,
|
| 469 |
+
stride=stride_f0,
|
| 470 |
+
padding=stride_f0 // 2,
|
| 471 |
+
)
|
| 472 |
+
)
|
| 473 |
+
else:
|
| 474 |
+
self.noise_convs.append(Conv1d(1, c_cur, kernel_size=1))
|
| 475 |
+
|
| 476 |
+
self.resblocks = nn.ModuleList()
|
| 477 |
+
for i in range(len(self.ups)):
|
| 478 |
+
ch = upsample_initial_channel // (2 ** (i + 1))
|
| 479 |
+
for j, (k, d) in enumerate(
|
| 480 |
+
zip(resblock_kernel_sizes, resblock_dilation_sizes)
|
| 481 |
+
):
|
| 482 |
+
self.resblocks.append(resblock(ch, k, d))
|
| 483 |
+
|
| 484 |
+
self.conv_post = Conv1d(ch, 1, 7, 1, padding=3, bias=False)
|
| 485 |
+
self.ups.apply(init_weights)
|
| 486 |
+
|
| 487 |
+
if gin_channels != 0:
|
| 488 |
+
self.cond = nn.Conv1d(gin_channels, upsample_initial_channel, 1)
|
| 489 |
+
|
| 490 |
+
self.upp = np.prod(upsample_rates)
|
| 491 |
+
|
| 492 |
+
def forward(self, x, f0, g=None):
|
| 493 |
+
har_source, noi_source, uv = self.m_source(f0, self.upp)
|
| 494 |
+
har_source = har_source.transpose(1, 2)
|
| 495 |
+
x = self.conv_pre(x)
|
| 496 |
+
if g is not None:
|
| 497 |
+
x = x + self.cond(g)
|
| 498 |
+
|
| 499 |
+
for i in range(self.num_upsamples):
|
| 500 |
+
x = F.leaky_relu(x, modules.LRELU_SLOPE)
|
| 501 |
+
x = self.ups[i](x)
|
| 502 |
+
x_source = self.noise_convs[i](har_source)
|
| 503 |
+
x = x + x_source
|
| 504 |
+
xs = None
|
| 505 |
+
for j in range(self.num_kernels):
|
| 506 |
+
if xs is None:
|
| 507 |
+
xs = self.resblocks[i * self.num_kernels + j](x)
|
| 508 |
+
else:
|
| 509 |
+
xs += self.resblocks[i * self.num_kernels + j](x)
|
| 510 |
+
x = xs / self.num_kernels
|
| 511 |
+
x = F.leaky_relu(x)
|
| 512 |
+
x = self.conv_post(x)
|
| 513 |
+
x = torch.tanh(x)
|
| 514 |
+
return x
|
| 515 |
+
|
| 516 |
+
def remove_weight_norm(self):
|
| 517 |
+
for l in self.ups:
|
| 518 |
+
remove_weight_norm(l)
|
| 519 |
+
for l in self.resblocks:
|
| 520 |
+
l.remove_weight_norm()
|
| 521 |
+
|
| 522 |
+
|
| 523 |
+
sr2sr = {
|
| 524 |
+
"32k": 32000,
|
| 525 |
+
"40k": 40000,
|
| 526 |
+
"48k": 48000,
|
| 527 |
+
}
|
| 528 |
+
|
| 529 |
+
|
| 530 |
+
class SynthesizerTrnMs256NSFsidM(nn.Module):
|
| 531 |
+
def __init__(
|
| 532 |
+
self,
|
| 533 |
+
spec_channels,
|
| 534 |
+
segment_size,
|
| 535 |
+
inter_channels,
|
| 536 |
+
hidden_channels,
|
| 537 |
+
filter_channels,
|
| 538 |
+
n_heads,
|
| 539 |
+
n_layers,
|
| 540 |
+
kernel_size,
|
| 541 |
+
p_dropout,
|
| 542 |
+
resblock,
|
| 543 |
+
resblock_kernel_sizes,
|
| 544 |
+
resblock_dilation_sizes,
|
| 545 |
+
upsample_rates,
|
| 546 |
+
upsample_initial_channel,
|
| 547 |
+
upsample_kernel_sizes,
|
| 548 |
+
spk_embed_dim,
|
| 549 |
+
gin_channels,
|
| 550 |
+
sr,
|
| 551 |
+
**kwargs
|
| 552 |
+
):
|
| 553 |
+
super().__init__()
|
| 554 |
+
if type(sr) == type("strr"):
|
| 555 |
+
sr = sr2sr[sr]
|
| 556 |
+
self.spec_channels = spec_channels
|
| 557 |
+
self.inter_channels = inter_channels
|
| 558 |
+
self.hidden_channels = hidden_channels
|
| 559 |
+
self.filter_channels = filter_channels
|
| 560 |
+
self.n_heads = n_heads
|
| 561 |
+
self.n_layers = n_layers
|
| 562 |
+
self.kernel_size = kernel_size
|
| 563 |
+
self.p_dropout = p_dropout
|
| 564 |
+
self.resblock = resblock
|
| 565 |
+
self.resblock_kernel_sizes = resblock_kernel_sizes
|
| 566 |
+
self.resblock_dilation_sizes = resblock_dilation_sizes
|
| 567 |
+
self.upsample_rates = upsample_rates
|
| 568 |
+
self.upsample_initial_channel = upsample_initial_channel
|
| 569 |
+
self.upsample_kernel_sizes = upsample_kernel_sizes
|
| 570 |
+
self.segment_size = segment_size
|
| 571 |
+
self.gin_channels = gin_channels
|
| 572 |
+
# self.hop_length = hop_length#
|
| 573 |
+
self.spk_embed_dim = spk_embed_dim
|
| 574 |
+
self.enc_p = TextEncoder256(
|
| 575 |
+
inter_channels,
|
| 576 |
+
hidden_channels,
|
| 577 |
+
filter_channels,
|
| 578 |
+
n_heads,
|
| 579 |
+
n_layers,
|
| 580 |
+
kernel_size,
|
| 581 |
+
p_dropout,
|
| 582 |
+
)
|
| 583 |
+
self.dec = GeneratorNSF(
|
| 584 |
+
inter_channels,
|
| 585 |
+
resblock,
|
| 586 |
+
resblock_kernel_sizes,
|
| 587 |
+
resblock_dilation_sizes,
|
| 588 |
+
upsample_rates,
|
| 589 |
+
upsample_initial_channel,
|
| 590 |
+
upsample_kernel_sizes,
|
| 591 |
+
gin_channels=gin_channels,
|
| 592 |
+
sr=sr,
|
| 593 |
+
is_half=kwargs["is_half"],
|
| 594 |
+
)
|
| 595 |
+
self.enc_q = PosteriorEncoder(
|
| 596 |
+
spec_channels,
|
| 597 |
+
inter_channels,
|
| 598 |
+
hidden_channels,
|
| 599 |
+
5,
|
| 600 |
+
1,
|
| 601 |
+
16,
|
| 602 |
+
gin_channels=gin_channels,
|
| 603 |
+
)
|
| 604 |
+
self.flow = ResidualCouplingBlock(
|
| 605 |
+
inter_channels, hidden_channels, 5, 1, 3, gin_channels=gin_channels
|
| 606 |
+
)
|
| 607 |
+
self.emb_g = nn.Embedding(self.spk_embed_dim, gin_channels)
|
| 608 |
+
print("gin_channels:", gin_channels, "self.spk_embed_dim:", self.spk_embed_dim)
|
| 609 |
+
|
| 610 |
+
def remove_weight_norm(self):
|
| 611 |
+
self.dec.remove_weight_norm()
|
| 612 |
+
self.flow.remove_weight_norm()
|
| 613 |
+
self.enc_q.remove_weight_norm()
|
| 614 |
+
|
| 615 |
+
def forward(self, phone, phone_lengths, pitch, nsff0, sid, rnd, max_len=None):
|
| 616 |
+
g = self.emb_g(sid).unsqueeze(-1)
|
| 617 |
+
m_p, logs_p, x_mask = self.enc_p(phone, pitch, phone_lengths)
|
| 618 |
+
z_p = (m_p + torch.exp(logs_p) * rnd) * x_mask
|
| 619 |
+
z = self.flow(z_p, x_mask, g=g, reverse=True)
|
| 620 |
+
o = self.dec((z * x_mask)[:, :, :max_len], nsff0, g=g)
|
| 621 |
+
return o
|
| 622 |
+
|
| 623 |
+
|
| 624 |
+
class SynthesizerTrnMs256NSFsid_sim(nn.Module):
|
| 625 |
+
"""
|
| 626 |
+
Synthesizer for Training
|
| 627 |
+
"""
|
| 628 |
+
|
| 629 |
+
def __init__(
|
| 630 |
+
self,
|
| 631 |
+
spec_channels,
|
| 632 |
+
segment_size,
|
| 633 |
+
inter_channels,
|
| 634 |
+
hidden_channels,
|
| 635 |
+
filter_channels,
|
| 636 |
+
n_heads,
|
| 637 |
+
n_layers,
|
| 638 |
+
kernel_size,
|
| 639 |
+
p_dropout,
|
| 640 |
+
resblock,
|
| 641 |
+
resblock_kernel_sizes,
|
| 642 |
+
resblock_dilation_sizes,
|
| 643 |
+
upsample_rates,
|
| 644 |
+
upsample_initial_channel,
|
| 645 |
+
upsample_kernel_sizes,
|
| 646 |
+
spk_embed_dim,
|
| 647 |
+
# hop_length,
|
| 648 |
+
gin_channels=0,
|
| 649 |
+
use_sdp=True,
|
| 650 |
+
**kwargs
|
| 651 |
+
):
|
| 652 |
+
super().__init__()
|
| 653 |
+
self.spec_channels = spec_channels
|
| 654 |
+
self.inter_channels = inter_channels
|
| 655 |
+
self.hidden_channels = hidden_channels
|
| 656 |
+
self.filter_channels = filter_channels
|
| 657 |
+
self.n_heads = n_heads
|
| 658 |
+
self.n_layers = n_layers
|
| 659 |
+
self.kernel_size = kernel_size
|
| 660 |
+
self.p_dropout = p_dropout
|
| 661 |
+
self.resblock = resblock
|
| 662 |
+
self.resblock_kernel_sizes = resblock_kernel_sizes
|
| 663 |
+
self.resblock_dilation_sizes = resblock_dilation_sizes
|
| 664 |
+
self.upsample_rates = upsample_rates
|
| 665 |
+
self.upsample_initial_channel = upsample_initial_channel
|
| 666 |
+
self.upsample_kernel_sizes = upsample_kernel_sizes
|
| 667 |
+
self.segment_size = segment_size
|
| 668 |
+
self.gin_channels = gin_channels
|
| 669 |
+
# self.hop_length = hop_length#
|
| 670 |
+
self.spk_embed_dim = spk_embed_dim
|
| 671 |
+
self.enc_p = TextEncoder256Sim(
|
| 672 |
+
inter_channels,
|
| 673 |
+
hidden_channels,
|
| 674 |
+
filter_channels,
|
| 675 |
+
n_heads,
|
| 676 |
+
n_layers,
|
| 677 |
+
kernel_size,
|
| 678 |
+
p_dropout,
|
| 679 |
+
)
|
| 680 |
+
self.dec = GeneratorNSF(
|
| 681 |
+
inter_channels,
|
| 682 |
+
resblock,
|
| 683 |
+
resblock_kernel_sizes,
|
| 684 |
+
resblock_dilation_sizes,
|
| 685 |
+
upsample_rates,
|
| 686 |
+
upsample_initial_channel,
|
| 687 |
+
upsample_kernel_sizes,
|
| 688 |
+
gin_channels=gin_channels,
|
| 689 |
+
is_half=kwargs["is_half"],
|
| 690 |
+
)
|
| 691 |
+
|
| 692 |
+
self.flow = ResidualCouplingBlock(
|
| 693 |
+
inter_channels, hidden_channels, 5, 1, 3, gin_channels=gin_channels
|
| 694 |
+
)
|
| 695 |
+
self.emb_g = nn.Embedding(self.spk_embed_dim, gin_channels)
|
| 696 |
+
print("gin_channels:", gin_channels, "self.spk_embed_dim:", self.spk_embed_dim)
|
| 697 |
+
|
| 698 |
+
def remove_weight_norm(self):
|
| 699 |
+
self.dec.remove_weight_norm()
|
| 700 |
+
self.flow.remove_weight_norm()
|
| 701 |
+
self.enc_q.remove_weight_norm()
|
| 702 |
+
|
| 703 |
+
def forward(
|
| 704 |
+
self, phone, phone_lengths, pitch, pitchf, ds, max_len=None
|
| 705 |
+
): # y是spec不需要了现在
|
| 706 |
+
g = self.emb_g(ds.unsqueeze(0)).unsqueeze(-1) # [b, 256, 1]##1是t,广播的
|
| 707 |
+
x, x_mask = self.enc_p(phone, pitch, phone_lengths)
|
| 708 |
+
x = self.flow(x, x_mask, g=g, reverse=True)
|
| 709 |
+
o = self.dec((x * x_mask)[:, :, :max_len], pitchf, g=g)
|
| 710 |
+
return o
|
| 711 |
+
|
| 712 |
+
|
| 713 |
+
class MultiPeriodDiscriminator(torch.nn.Module):
|
| 714 |
+
def __init__(self, use_spectral_norm=False):
|
| 715 |
+
super(MultiPeriodDiscriminator, self).__init__()
|
| 716 |
+
periods = [2, 3, 5, 7, 11, 17]
|
| 717 |
+
# periods = [3, 5, 7, 11, 17, 23, 37]
|
| 718 |
+
|
| 719 |
+
discs = [DiscriminatorS(use_spectral_norm=use_spectral_norm)]
|
| 720 |
+
discs = discs + [
|
| 721 |
+
DiscriminatorP(i, use_spectral_norm=use_spectral_norm) for i in periods
|
| 722 |
+
]
|
| 723 |
+
self.discriminators = nn.ModuleList(discs)
|
| 724 |
+
|
| 725 |
+
def forward(self, y, y_hat):
|
| 726 |
+
y_d_rs = [] #
|
| 727 |
+
y_d_gs = []
|
| 728 |
+
fmap_rs = []
|
| 729 |
+
fmap_gs = []
|
| 730 |
+
for i, d in enumerate(self.discriminators):
|
| 731 |
+
y_d_r, fmap_r = d(y)
|
| 732 |
+
y_d_g, fmap_g = d(y_hat)
|
| 733 |
+
# for j in range(len(fmap_r)):
|
| 734 |
+
# print(i,j,y.shape,y_hat.shape,fmap_r[j].shape,fmap_g[j].shape)
|
| 735 |
+
y_d_rs.append(y_d_r)
|
| 736 |
+
y_d_gs.append(y_d_g)
|
| 737 |
+
fmap_rs.append(fmap_r)
|
| 738 |
+
fmap_gs.append(fmap_g)
|
| 739 |
+
|
| 740 |
+
return y_d_rs, y_d_gs, fmap_rs, fmap_gs
|
| 741 |
+
|
| 742 |
+
|
| 743 |
+
class DiscriminatorS(torch.nn.Module):
|
| 744 |
+
def __init__(self, use_spectral_norm=False):
|
| 745 |
+
super(DiscriminatorS, self).__init__()
|
| 746 |
+
norm_f = weight_norm if use_spectral_norm == False else spectral_norm
|
| 747 |
+
self.convs = nn.ModuleList(
|
| 748 |
+
[
|
| 749 |
+
norm_f(Conv1d(1, 16, 15, 1, padding=7)),
|
| 750 |
+
norm_f(Conv1d(16, 64, 41, 4, groups=4, padding=20)),
|
| 751 |
+
norm_f(Conv1d(64, 256, 41, 4, groups=16, padding=20)),
|
| 752 |
+
norm_f(Conv1d(256, 1024, 41, 4, groups=64, padding=20)),
|
| 753 |
+
norm_f(Conv1d(1024, 1024, 41, 4, groups=256, padding=20)),
|
| 754 |
+
norm_f(Conv1d(1024, 1024, 5, 1, padding=2)),
|
| 755 |
+
]
|
| 756 |
+
)
|
| 757 |
+
self.conv_post = norm_f(Conv1d(1024, 1, 3, 1, padding=1))
|
| 758 |
+
|
| 759 |
+
def forward(self, x):
|
| 760 |
+
fmap = []
|
| 761 |
+
|
| 762 |
+
for l in self.convs:
|
| 763 |
+
x = l(x)
|
| 764 |
+
x = F.leaky_relu(x, modules.LRELU_SLOPE)
|
| 765 |
+
fmap.append(x)
|
| 766 |
+
x = self.conv_post(x)
|
| 767 |
+
fmap.append(x)
|
| 768 |
+
x = torch.flatten(x, 1, -1)
|
| 769 |
+
|
| 770 |
+
return x, fmap
|
| 771 |
+
|
| 772 |
+
|
| 773 |
+
class DiscriminatorP(torch.nn.Module):
|
| 774 |
+
def __init__(self, period, kernel_size=5, stride=3, use_spectral_norm=False):
|
| 775 |
+
super(DiscriminatorP, self).__init__()
|
| 776 |
+
self.period = period
|
| 777 |
+
self.use_spectral_norm = use_spectral_norm
|
| 778 |
+
norm_f = weight_norm if use_spectral_norm == False else spectral_norm
|
| 779 |
+
self.convs = nn.ModuleList(
|
| 780 |
+
[
|
| 781 |
+
norm_f(
|
| 782 |
+
Conv2d(
|
| 783 |
+
1,
|
| 784 |
+
32,
|
| 785 |
+
(kernel_size, 1),
|
| 786 |
+
(stride, 1),
|
| 787 |
+
padding=(get_padding(kernel_size, 1), 0),
|
| 788 |
+
)
|
| 789 |
+
),
|
| 790 |
+
norm_f(
|
| 791 |
+
Conv2d(
|
| 792 |
+
32,
|
| 793 |
+
128,
|
| 794 |
+
(kernel_size, 1),
|
| 795 |
+
(stride, 1),
|
| 796 |
+
padding=(get_padding(kernel_size, 1), 0),
|
| 797 |
+
)
|
| 798 |
+
),
|
| 799 |
+
norm_f(
|
| 800 |
+
Conv2d(
|
| 801 |
+
128,
|
| 802 |
+
512,
|
| 803 |
+
(kernel_size, 1),
|
| 804 |
+
(stride, 1),
|
| 805 |
+
padding=(get_padding(kernel_size, 1), 0),
|
| 806 |
+
)
|
| 807 |
+
),
|
| 808 |
+
norm_f(
|
| 809 |
+
Conv2d(
|
| 810 |
+
512,
|
| 811 |
+
1024,
|
| 812 |
+
(kernel_size, 1),
|
| 813 |
+
(stride, 1),
|
| 814 |
+
padding=(get_padding(kernel_size, 1), 0),
|
| 815 |
+
)
|
| 816 |
+
),
|
| 817 |
+
norm_f(
|
| 818 |
+
Conv2d(
|
| 819 |
+
1024,
|
| 820 |
+
1024,
|
| 821 |
+
(kernel_size, 1),
|
| 822 |
+
1,
|
| 823 |
+
padding=(get_padding(kernel_size, 1), 0),
|
| 824 |
+
)
|
| 825 |
+
),
|
| 826 |
+
]
|
| 827 |
+
)
|
| 828 |
+
self.conv_post = norm_f(Conv2d(1024, 1, (3, 1), 1, padding=(1, 0)))
|
| 829 |
+
|
| 830 |
+
def forward(self, x):
|
| 831 |
+
fmap = []
|
| 832 |
+
|
| 833 |
+
# 1d to 2d
|
| 834 |
+
b, c, t = x.shape
|
| 835 |
+
if t % self.period != 0: # pad first
|
| 836 |
+
n_pad = self.period - (t % self.period)
|
| 837 |
+
x = F.pad(x, (0, n_pad), "reflect")
|
| 838 |
+
t = t + n_pad
|
| 839 |
+
x = x.view(b, c, t // self.period, self.period)
|
| 840 |
+
|
| 841 |
+
for l in self.convs:
|
| 842 |
+
x = l(x)
|
| 843 |
+
x = F.leaky_relu(x, modules.LRELU_SLOPE)
|
| 844 |
+
fmap.append(x)
|
| 845 |
+
x = self.conv_post(x)
|
| 846 |
+
fmap.append(x)
|
| 847 |
+
x = torch.flatten(x, 1, -1)
|
| 848 |
+
|
| 849 |
+
return x, fmap
|
src/infer_pack/modules.py
ADDED
|
@@ -0,0 +1,522 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import copy
|
| 2 |
+
import math
|
| 3 |
+
import numpy as np
|
| 4 |
+
import scipy
|
| 5 |
+
import torch
|
| 6 |
+
from torch import nn
|
| 7 |
+
from torch.nn import functional as F
|
| 8 |
+
|
| 9 |
+
from torch.nn import Conv1d, ConvTranspose1d, AvgPool1d, Conv2d
|
| 10 |
+
from torch.nn.utils import weight_norm, remove_weight_norm
|
| 11 |
+
|
| 12 |
+
from infer_pack import commons
|
| 13 |
+
from infer_pack.commons import init_weights, get_padding
|
| 14 |
+
from infer_pack.transforms import piecewise_rational_quadratic_transform
|
| 15 |
+
|
| 16 |
+
|
| 17 |
+
LRELU_SLOPE = 0.1
|
| 18 |
+
|
| 19 |
+
|
| 20 |
+
class LayerNorm(nn.Module):
|
| 21 |
+
def __init__(self, channels, eps=1e-5):
|
| 22 |
+
super().__init__()
|
| 23 |
+
self.channels = channels
|
| 24 |
+
self.eps = eps
|
| 25 |
+
|
| 26 |
+
self.gamma = nn.Parameter(torch.ones(channels))
|
| 27 |
+
self.beta = nn.Parameter(torch.zeros(channels))
|
| 28 |
+
|
| 29 |
+
def forward(self, x):
|
| 30 |
+
x = x.transpose(1, -1)
|
| 31 |
+
x = F.layer_norm(x, (self.channels,), self.gamma, self.beta, self.eps)
|
| 32 |
+
return x.transpose(1, -1)
|
| 33 |
+
|
| 34 |
+
|
| 35 |
+
class ConvReluNorm(nn.Module):
|
| 36 |
+
def __init__(
|
| 37 |
+
self,
|
| 38 |
+
in_channels,
|
| 39 |
+
hidden_channels,
|
| 40 |
+
out_channels,
|
| 41 |
+
kernel_size,
|
| 42 |
+
n_layers,
|
| 43 |
+
p_dropout,
|
| 44 |
+
):
|
| 45 |
+
super().__init__()
|
| 46 |
+
self.in_channels = in_channels
|
| 47 |
+
self.hidden_channels = hidden_channels
|
| 48 |
+
self.out_channels = out_channels
|
| 49 |
+
self.kernel_size = kernel_size
|
| 50 |
+
self.n_layers = n_layers
|
| 51 |
+
self.p_dropout = p_dropout
|
| 52 |
+
assert n_layers > 1, "Number of layers should be larger than 0."
|
| 53 |
+
|
| 54 |
+
self.conv_layers = nn.ModuleList()
|
| 55 |
+
self.norm_layers = nn.ModuleList()
|
| 56 |
+
self.conv_layers.append(
|
| 57 |
+
nn.Conv1d(
|
| 58 |
+
in_channels, hidden_channels, kernel_size, padding=kernel_size // 2
|
| 59 |
+
)
|
| 60 |
+
)
|
| 61 |
+
self.norm_layers.append(LayerNorm(hidden_channels))
|
| 62 |
+
self.relu_drop = nn.Sequential(nn.ReLU(), nn.Dropout(p_dropout))
|
| 63 |
+
for _ in range(n_layers - 1):
|
| 64 |
+
self.conv_layers.append(
|
| 65 |
+
nn.Conv1d(
|
| 66 |
+
hidden_channels,
|
| 67 |
+
hidden_channels,
|
| 68 |
+
kernel_size,
|
| 69 |
+
padding=kernel_size // 2,
|
| 70 |
+
)
|
| 71 |
+
)
|
| 72 |
+
self.norm_layers.append(LayerNorm(hidden_channels))
|
| 73 |
+
self.proj = nn.Conv1d(hidden_channels, out_channels, 1)
|
| 74 |
+
self.proj.weight.data.zero_()
|
| 75 |
+
self.proj.bias.data.zero_()
|
| 76 |
+
|
| 77 |
+
def forward(self, x, x_mask):
|
| 78 |
+
x_org = x
|
| 79 |
+
for i in range(self.n_layers):
|
| 80 |
+
x = self.conv_layers[i](x * x_mask)
|
| 81 |
+
x = self.norm_layers[i](x)
|
| 82 |
+
x = self.relu_drop(x)
|
| 83 |
+
x = x_org + self.proj(x)
|
| 84 |
+
return x * x_mask
|
| 85 |
+
|
| 86 |
+
|
| 87 |
+
class DDSConv(nn.Module):
|
| 88 |
+
"""
|
| 89 |
+
Dialted and Depth-Separable Convolution
|
| 90 |
+
"""
|
| 91 |
+
|
| 92 |
+
def __init__(self, channels, kernel_size, n_layers, p_dropout=0.0):
|
| 93 |
+
super().__init__()
|
| 94 |
+
self.channels = channels
|
| 95 |
+
self.kernel_size = kernel_size
|
| 96 |
+
self.n_layers = n_layers
|
| 97 |
+
self.p_dropout = p_dropout
|
| 98 |
+
|
| 99 |
+
self.drop = nn.Dropout(p_dropout)
|
| 100 |
+
self.convs_sep = nn.ModuleList()
|
| 101 |
+
self.convs_1x1 = nn.ModuleList()
|
| 102 |
+
self.norms_1 = nn.ModuleList()
|
| 103 |
+
self.norms_2 = nn.ModuleList()
|
| 104 |
+
for i in range(n_layers):
|
| 105 |
+
dilation = kernel_size**i
|
| 106 |
+
padding = (kernel_size * dilation - dilation) // 2
|
| 107 |
+
self.convs_sep.append(
|
| 108 |
+
nn.Conv1d(
|
| 109 |
+
channels,
|
| 110 |
+
channels,
|
| 111 |
+
kernel_size,
|
| 112 |
+
groups=channels,
|
| 113 |
+
dilation=dilation,
|
| 114 |
+
padding=padding,
|
| 115 |
+
)
|
| 116 |
+
)
|
| 117 |
+
self.convs_1x1.append(nn.Conv1d(channels, channels, 1))
|
| 118 |
+
self.norms_1.append(LayerNorm(channels))
|
| 119 |
+
self.norms_2.append(LayerNorm(channels))
|
| 120 |
+
|
| 121 |
+
def forward(self, x, x_mask, g=None):
|
| 122 |
+
if g is not None:
|
| 123 |
+
x = x + g
|
| 124 |
+
for i in range(self.n_layers):
|
| 125 |
+
y = self.convs_sep[i](x * x_mask)
|
| 126 |
+
y = self.norms_1[i](y)
|
| 127 |
+
y = F.gelu(y)
|
| 128 |
+
y = self.convs_1x1[i](y)
|
| 129 |
+
y = self.norms_2[i](y)
|
| 130 |
+
y = F.gelu(y)
|
| 131 |
+
y = self.drop(y)
|
| 132 |
+
x = x + y
|
| 133 |
+
return x * x_mask
|
| 134 |
+
|
| 135 |
+
|
| 136 |
+
class WN(torch.nn.Module):
|
| 137 |
+
def __init__(
|
| 138 |
+
self,
|
| 139 |
+
hidden_channels,
|
| 140 |
+
kernel_size,
|
| 141 |
+
dilation_rate,
|
| 142 |
+
n_layers,
|
| 143 |
+
gin_channels=0,
|
| 144 |
+
p_dropout=0,
|
| 145 |
+
):
|
| 146 |
+
super(WN, self).__init__()
|
| 147 |
+
assert kernel_size % 2 == 1
|
| 148 |
+
self.hidden_channels = hidden_channels
|
| 149 |
+
self.kernel_size = (kernel_size,)
|
| 150 |
+
self.dilation_rate = dilation_rate
|
| 151 |
+
self.n_layers = n_layers
|
| 152 |
+
self.gin_channels = gin_channels
|
| 153 |
+
self.p_dropout = p_dropout
|
| 154 |
+
|
| 155 |
+
self.in_layers = torch.nn.ModuleList()
|
| 156 |
+
self.res_skip_layers = torch.nn.ModuleList()
|
| 157 |
+
self.drop = nn.Dropout(p_dropout)
|
| 158 |
+
|
| 159 |
+
if gin_channels != 0:
|
| 160 |
+
cond_layer = torch.nn.Conv1d(
|
| 161 |
+
gin_channels, 2 * hidden_channels * n_layers, 1
|
| 162 |
+
)
|
| 163 |
+
self.cond_layer = torch.nn.utils.weight_norm(cond_layer, name="weight")
|
| 164 |
+
|
| 165 |
+
for i in range(n_layers):
|
| 166 |
+
dilation = dilation_rate**i
|
| 167 |
+
padding = int((kernel_size * dilation - dilation) / 2)
|
| 168 |
+
in_layer = torch.nn.Conv1d(
|
| 169 |
+
hidden_channels,
|
| 170 |
+
2 * hidden_channels,
|
| 171 |
+
kernel_size,
|
| 172 |
+
dilation=dilation,
|
| 173 |
+
padding=padding,
|
| 174 |
+
)
|
| 175 |
+
in_layer = torch.nn.utils.weight_norm(in_layer, name="weight")
|
| 176 |
+
self.in_layers.append(in_layer)
|
| 177 |
+
|
| 178 |
+
# last one is not necessary
|
| 179 |
+
if i < n_layers - 1:
|
| 180 |
+
res_skip_channels = 2 * hidden_channels
|
| 181 |
+
else:
|
| 182 |
+
res_skip_channels = hidden_channels
|
| 183 |
+
|
| 184 |
+
res_skip_layer = torch.nn.Conv1d(hidden_channels, res_skip_channels, 1)
|
| 185 |
+
res_skip_layer = torch.nn.utils.weight_norm(res_skip_layer, name="weight")
|
| 186 |
+
self.res_skip_layers.append(res_skip_layer)
|
| 187 |
+
|
| 188 |
+
def forward(self, x, x_mask, g=None, **kwargs):
|
| 189 |
+
output = torch.zeros_like(x)
|
| 190 |
+
n_channels_tensor = torch.IntTensor([self.hidden_channels])
|
| 191 |
+
|
| 192 |
+
if g is not None:
|
| 193 |
+
g = self.cond_layer(g)
|
| 194 |
+
|
| 195 |
+
for i in range(self.n_layers):
|
| 196 |
+
x_in = self.in_layers[i](x)
|
| 197 |
+
if g is not None:
|
| 198 |
+
cond_offset = i * 2 * self.hidden_channels
|
| 199 |
+
g_l = g[:, cond_offset : cond_offset + 2 * self.hidden_channels, :]
|
| 200 |
+
else:
|
| 201 |
+
g_l = torch.zeros_like(x_in)
|
| 202 |
+
|
| 203 |
+
acts = commons.fused_add_tanh_sigmoid_multiply(x_in, g_l, n_channels_tensor)
|
| 204 |
+
acts = self.drop(acts)
|
| 205 |
+
|
| 206 |
+
res_skip_acts = self.res_skip_layers[i](acts)
|
| 207 |
+
if i < self.n_layers - 1:
|
| 208 |
+
res_acts = res_skip_acts[:, : self.hidden_channels, :]
|
| 209 |
+
x = (x + res_acts) * x_mask
|
| 210 |
+
output = output + res_skip_acts[:, self.hidden_channels :, :]
|
| 211 |
+
else:
|
| 212 |
+
output = output + res_skip_acts
|
| 213 |
+
return output * x_mask
|
| 214 |
+
|
| 215 |
+
def remove_weight_norm(self):
|
| 216 |
+
if self.gin_channels != 0:
|
| 217 |
+
torch.nn.utils.remove_weight_norm(self.cond_layer)
|
| 218 |
+
for l in self.in_layers:
|
| 219 |
+
torch.nn.utils.remove_weight_norm(l)
|
| 220 |
+
for l in self.res_skip_layers:
|
| 221 |
+
torch.nn.utils.remove_weight_norm(l)
|
| 222 |
+
|
| 223 |
+
|
| 224 |
+
class ResBlock1(torch.nn.Module):
|
| 225 |
+
def __init__(self, channels, kernel_size=3, dilation=(1, 3, 5)):
|
| 226 |
+
super(ResBlock1, self).__init__()
|
| 227 |
+
self.convs1 = nn.ModuleList(
|
| 228 |
+
[
|
| 229 |
+
weight_norm(
|
| 230 |
+
Conv1d(
|
| 231 |
+
channels,
|
| 232 |
+
channels,
|
| 233 |
+
kernel_size,
|
| 234 |
+
1,
|
| 235 |
+
dilation=dilation[0],
|
| 236 |
+
padding=get_padding(kernel_size, dilation[0]),
|
| 237 |
+
)
|
| 238 |
+
),
|
| 239 |
+
weight_norm(
|
| 240 |
+
Conv1d(
|
| 241 |
+
channels,
|
| 242 |
+
channels,
|
| 243 |
+
kernel_size,
|
| 244 |
+
1,
|
| 245 |
+
dilation=dilation[1],
|
| 246 |
+
padding=get_padding(kernel_size, dilation[1]),
|
| 247 |
+
)
|
| 248 |
+
),
|
| 249 |
+
weight_norm(
|
| 250 |
+
Conv1d(
|
| 251 |
+
channels,
|
| 252 |
+
channels,
|
| 253 |
+
kernel_size,
|
| 254 |
+
1,
|
| 255 |
+
dilation=dilation[2],
|
| 256 |
+
padding=get_padding(kernel_size, dilation[2]),
|
| 257 |
+
)
|
| 258 |
+
),
|
| 259 |
+
]
|
| 260 |
+
)
|
| 261 |
+
self.convs1.apply(init_weights)
|
| 262 |
+
|
| 263 |
+
self.convs2 = nn.ModuleList(
|
| 264 |
+
[
|
| 265 |
+
weight_norm(
|
| 266 |
+
Conv1d(
|
| 267 |
+
channels,
|
| 268 |
+
channels,
|
| 269 |
+
kernel_size,
|
| 270 |
+
1,
|
| 271 |
+
dilation=1,
|
| 272 |
+
padding=get_padding(kernel_size, 1),
|
| 273 |
+
)
|
| 274 |
+
),
|
| 275 |
+
weight_norm(
|
| 276 |
+
Conv1d(
|
| 277 |
+
channels,
|
| 278 |
+
channels,
|
| 279 |
+
kernel_size,
|
| 280 |
+
1,
|
| 281 |
+
dilation=1,
|
| 282 |
+
padding=get_padding(kernel_size, 1),
|
| 283 |
+
)
|
| 284 |
+
),
|
| 285 |
+
weight_norm(
|
| 286 |
+
Conv1d(
|
| 287 |
+
channels,
|
| 288 |
+
channels,
|
| 289 |
+
kernel_size,
|
| 290 |
+
1,
|
| 291 |
+
dilation=1,
|
| 292 |
+
padding=get_padding(kernel_size, 1),
|
| 293 |
+
)
|
| 294 |
+
),
|
| 295 |
+
]
|
| 296 |
+
)
|
| 297 |
+
self.convs2.apply(init_weights)
|
| 298 |
+
|
| 299 |
+
def forward(self, x, x_mask=None):
|
| 300 |
+
for c1, c2 in zip(self.convs1, self.convs2):
|
| 301 |
+
xt = F.leaky_relu(x, LRELU_SLOPE)
|
| 302 |
+
if x_mask is not None:
|
| 303 |
+
xt = xt * x_mask
|
| 304 |
+
xt = c1(xt)
|
| 305 |
+
xt = F.leaky_relu(xt, LRELU_SLOPE)
|
| 306 |
+
if x_mask is not None:
|
| 307 |
+
xt = xt * x_mask
|
| 308 |
+
xt = c2(xt)
|
| 309 |
+
x = xt + x
|
| 310 |
+
if x_mask is not None:
|
| 311 |
+
x = x * x_mask
|
| 312 |
+
return x
|
| 313 |
+
|
| 314 |
+
def remove_weight_norm(self):
|
| 315 |
+
for l in self.convs1:
|
| 316 |
+
remove_weight_norm(l)
|
| 317 |
+
for l in self.convs2:
|
| 318 |
+
remove_weight_norm(l)
|
| 319 |
+
|
| 320 |
+
|
| 321 |
+
class ResBlock2(torch.nn.Module):
|
| 322 |
+
def __init__(self, channels, kernel_size=3, dilation=(1, 3)):
|
| 323 |
+
super(ResBlock2, self).__init__()
|
| 324 |
+
self.convs = nn.ModuleList(
|
| 325 |
+
[
|
| 326 |
+
weight_norm(
|
| 327 |
+
Conv1d(
|
| 328 |
+
channels,
|
| 329 |
+
channels,
|
| 330 |
+
kernel_size,
|
| 331 |
+
1,
|
| 332 |
+
dilation=dilation[0],
|
| 333 |
+
padding=get_padding(kernel_size, dilation[0]),
|
| 334 |
+
)
|
| 335 |
+
),
|
| 336 |
+
weight_norm(
|
| 337 |
+
Conv1d(
|
| 338 |
+
channels,
|
| 339 |
+
channels,
|
| 340 |
+
kernel_size,
|
| 341 |
+
1,
|
| 342 |
+
dilation=dilation[1],
|
| 343 |
+
padding=get_padding(kernel_size, dilation[1]),
|
| 344 |
+
)
|
| 345 |
+
),
|
| 346 |
+
]
|
| 347 |
+
)
|
| 348 |
+
self.convs.apply(init_weights)
|
| 349 |
+
|
| 350 |
+
def forward(self, x, x_mask=None):
|
| 351 |
+
for c in self.convs:
|
| 352 |
+
xt = F.leaky_relu(x, LRELU_SLOPE)
|
| 353 |
+
if x_mask is not None:
|
| 354 |
+
xt = xt * x_mask
|
| 355 |
+
xt = c(xt)
|
| 356 |
+
x = xt + x
|
| 357 |
+
if x_mask is not None:
|
| 358 |
+
x = x * x_mask
|
| 359 |
+
return x
|
| 360 |
+
|
| 361 |
+
def remove_weight_norm(self):
|
| 362 |
+
for l in self.convs:
|
| 363 |
+
remove_weight_norm(l)
|
| 364 |
+
|
| 365 |
+
|
| 366 |
+
class Log(nn.Module):
|
| 367 |
+
def forward(self, x, x_mask, reverse=False, **kwargs):
|
| 368 |
+
if not reverse:
|
| 369 |
+
y = torch.log(torch.clamp_min(x, 1e-5)) * x_mask
|
| 370 |
+
logdet = torch.sum(-y, [1, 2])
|
| 371 |
+
return y, logdet
|
| 372 |
+
else:
|
| 373 |
+
x = torch.exp(x) * x_mask
|
| 374 |
+
return x
|
| 375 |
+
|
| 376 |
+
|
| 377 |
+
class Flip(nn.Module):
|
| 378 |
+
def forward(self, x, *args, reverse=False, **kwargs):
|
| 379 |
+
x = torch.flip(x, [1])
|
| 380 |
+
if not reverse:
|
| 381 |
+
logdet = torch.zeros(x.size(0)).to(dtype=x.dtype, device=x.device)
|
| 382 |
+
return x, logdet
|
| 383 |
+
else:
|
| 384 |
+
return x
|
| 385 |
+
|
| 386 |
+
|
| 387 |
+
class ElementwiseAffine(nn.Module):
|
| 388 |
+
def __init__(self, channels):
|
| 389 |
+
super().__init__()
|
| 390 |
+
self.channels = channels
|
| 391 |
+
self.m = nn.Parameter(torch.zeros(channels, 1))
|
| 392 |
+
self.logs = nn.Parameter(torch.zeros(channels, 1))
|
| 393 |
+
|
| 394 |
+
def forward(self, x, x_mask, reverse=False, **kwargs):
|
| 395 |
+
if not reverse:
|
| 396 |
+
y = self.m + torch.exp(self.logs) * x
|
| 397 |
+
y = y * x_mask
|
| 398 |
+
logdet = torch.sum(self.logs * x_mask, [1, 2])
|
| 399 |
+
return y, logdet
|
| 400 |
+
else:
|
| 401 |
+
x = (x - self.m) * torch.exp(-self.logs) * x_mask
|
| 402 |
+
return x
|
| 403 |
+
|
| 404 |
+
|
| 405 |
+
class ResidualCouplingLayer(nn.Module):
|
| 406 |
+
def __init__(
|
| 407 |
+
self,
|
| 408 |
+
channels,
|
| 409 |
+
hidden_channels,
|
| 410 |
+
kernel_size,
|
| 411 |
+
dilation_rate,
|
| 412 |
+
n_layers,
|
| 413 |
+
p_dropout=0,
|
| 414 |
+
gin_channels=0,
|
| 415 |
+
mean_only=False,
|
| 416 |
+
):
|
| 417 |
+
assert channels % 2 == 0, "channels should be divisible by 2"
|
| 418 |
+
super().__init__()
|
| 419 |
+
self.channels = channels
|
| 420 |
+
self.hidden_channels = hidden_channels
|
| 421 |
+
self.kernel_size = kernel_size
|
| 422 |
+
self.dilation_rate = dilation_rate
|
| 423 |
+
self.n_layers = n_layers
|
| 424 |
+
self.half_channels = channels // 2
|
| 425 |
+
self.mean_only = mean_only
|
| 426 |
+
|
| 427 |
+
self.pre = nn.Conv1d(self.half_channels, hidden_channels, 1)
|
| 428 |
+
self.enc = WN(
|
| 429 |
+
hidden_channels,
|
| 430 |
+
kernel_size,
|
| 431 |
+
dilation_rate,
|
| 432 |
+
n_layers,
|
| 433 |
+
p_dropout=p_dropout,
|
| 434 |
+
gin_channels=gin_channels,
|
| 435 |
+
)
|
| 436 |
+
self.post = nn.Conv1d(hidden_channels, self.half_channels * (2 - mean_only), 1)
|
| 437 |
+
self.post.weight.data.zero_()
|
| 438 |
+
self.post.bias.data.zero_()
|
| 439 |
+
|
| 440 |
+
def forward(self, x, x_mask, g=None, reverse=False):
|
| 441 |
+
x0, x1 = torch.split(x, [self.half_channels] * 2, 1)
|
| 442 |
+
h = self.pre(x0) * x_mask
|
| 443 |
+
h = self.enc(h, x_mask, g=g)
|
| 444 |
+
stats = self.post(h) * x_mask
|
| 445 |
+
if not self.mean_only:
|
| 446 |
+
m, logs = torch.split(stats, [self.half_channels] * 2, 1)
|
| 447 |
+
else:
|
| 448 |
+
m = stats
|
| 449 |
+
logs = torch.zeros_like(m)
|
| 450 |
+
|
| 451 |
+
if not reverse:
|
| 452 |
+
x1 = m + x1 * torch.exp(logs) * x_mask
|
| 453 |
+
x = torch.cat([x0, x1], 1)
|
| 454 |
+
logdet = torch.sum(logs, [1, 2])
|
| 455 |
+
return x, logdet
|
| 456 |
+
else:
|
| 457 |
+
x1 = (x1 - m) * torch.exp(-logs) * x_mask
|
| 458 |
+
x = torch.cat([x0, x1], 1)
|
| 459 |
+
return x
|
| 460 |
+
|
| 461 |
+
def remove_weight_norm(self):
|
| 462 |
+
self.enc.remove_weight_norm()
|
| 463 |
+
|
| 464 |
+
|
| 465 |
+
class ConvFlow(nn.Module):
|
| 466 |
+
def __init__(
|
| 467 |
+
self,
|
| 468 |
+
in_channels,
|
| 469 |
+
filter_channels,
|
| 470 |
+
kernel_size,
|
| 471 |
+
n_layers,
|
| 472 |
+
num_bins=10,
|
| 473 |
+
tail_bound=5.0,
|
| 474 |
+
):
|
| 475 |
+
super().__init__()
|
| 476 |
+
self.in_channels = in_channels
|
| 477 |
+
self.filter_channels = filter_channels
|
| 478 |
+
self.kernel_size = kernel_size
|
| 479 |
+
self.n_layers = n_layers
|
| 480 |
+
self.num_bins = num_bins
|
| 481 |
+
self.tail_bound = tail_bound
|
| 482 |
+
self.half_channels = in_channels // 2
|
| 483 |
+
|
| 484 |
+
self.pre = nn.Conv1d(self.half_channels, filter_channels, 1)
|
| 485 |
+
self.convs = DDSConv(filter_channels, kernel_size, n_layers, p_dropout=0.0)
|
| 486 |
+
self.proj = nn.Conv1d(
|
| 487 |
+
filter_channels, self.half_channels * (num_bins * 3 - 1), 1
|
| 488 |
+
)
|
| 489 |
+
self.proj.weight.data.zero_()
|
| 490 |
+
self.proj.bias.data.zero_()
|
| 491 |
+
|
| 492 |
+
def forward(self, x, x_mask, g=None, reverse=False):
|
| 493 |
+
x0, x1 = torch.split(x, [self.half_channels] * 2, 1)
|
| 494 |
+
h = self.pre(x0)
|
| 495 |
+
h = self.convs(h, x_mask, g=g)
|
| 496 |
+
h = self.proj(h) * x_mask
|
| 497 |
+
|
| 498 |
+
b, c, t = x0.shape
|
| 499 |
+
h = h.reshape(b, c, -1, t).permute(0, 1, 3, 2) # [b, cx?, t] -> [b, c, t, ?]
|
| 500 |
+
|
| 501 |
+
unnormalized_widths = h[..., : self.num_bins] / math.sqrt(self.filter_channels)
|
| 502 |
+
unnormalized_heights = h[..., self.num_bins : 2 * self.num_bins] / math.sqrt(
|
| 503 |
+
self.filter_channels
|
| 504 |
+
)
|
| 505 |
+
unnormalized_derivatives = h[..., 2 * self.num_bins :]
|
| 506 |
+
|
| 507 |
+
x1, logabsdet = piecewise_rational_quadratic_transform(
|
| 508 |
+
x1,
|
| 509 |
+
unnormalized_widths,
|
| 510 |
+
unnormalized_heights,
|
| 511 |
+
unnormalized_derivatives,
|
| 512 |
+
inverse=reverse,
|
| 513 |
+
tails="linear",
|
| 514 |
+
tail_bound=self.tail_bound,
|
| 515 |
+
)
|
| 516 |
+
|
| 517 |
+
x = torch.cat([x0, x1], 1) * x_mask
|
| 518 |
+
logdet = torch.sum(logabsdet * x_mask, [1, 2])
|
| 519 |
+
if not reverse:
|
| 520 |
+
return x, logdet
|
| 521 |
+
else:
|
| 522 |
+
return x
|
src/infer_pack/transforms.py
ADDED
|
@@ -0,0 +1,209 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import torch
|
| 2 |
+
from torch.nn import functional as F
|
| 3 |
+
|
| 4 |
+
import numpy as np
|
| 5 |
+
|
| 6 |
+
|
| 7 |
+
DEFAULT_MIN_BIN_WIDTH = 1e-3
|
| 8 |
+
DEFAULT_MIN_BIN_HEIGHT = 1e-3
|
| 9 |
+
DEFAULT_MIN_DERIVATIVE = 1e-3
|
| 10 |
+
|
| 11 |
+
|
| 12 |
+
def piecewise_rational_quadratic_transform(
|
| 13 |
+
inputs,
|
| 14 |
+
unnormalized_widths,
|
| 15 |
+
unnormalized_heights,
|
| 16 |
+
unnormalized_derivatives,
|
| 17 |
+
inverse=False,
|
| 18 |
+
tails=None,
|
| 19 |
+
tail_bound=1.0,
|
| 20 |
+
min_bin_width=DEFAULT_MIN_BIN_WIDTH,
|
| 21 |
+
min_bin_height=DEFAULT_MIN_BIN_HEIGHT,
|
| 22 |
+
min_derivative=DEFAULT_MIN_DERIVATIVE,
|
| 23 |
+
):
|
| 24 |
+
if tails is None:
|
| 25 |
+
spline_fn = rational_quadratic_spline
|
| 26 |
+
spline_kwargs = {}
|
| 27 |
+
else:
|
| 28 |
+
spline_fn = unconstrained_rational_quadratic_spline
|
| 29 |
+
spline_kwargs = {"tails": tails, "tail_bound": tail_bound}
|
| 30 |
+
|
| 31 |
+
outputs, logabsdet = spline_fn(
|
| 32 |
+
inputs=inputs,
|
| 33 |
+
unnormalized_widths=unnormalized_widths,
|
| 34 |
+
unnormalized_heights=unnormalized_heights,
|
| 35 |
+
unnormalized_derivatives=unnormalized_derivatives,
|
| 36 |
+
inverse=inverse,
|
| 37 |
+
min_bin_width=min_bin_width,
|
| 38 |
+
min_bin_height=min_bin_height,
|
| 39 |
+
min_derivative=min_derivative,
|
| 40 |
+
**spline_kwargs
|
| 41 |
+
)
|
| 42 |
+
return outputs, logabsdet
|
| 43 |
+
|
| 44 |
+
|
| 45 |
+
def searchsorted(bin_locations, inputs, eps=1e-6):
|
| 46 |
+
bin_locations[..., -1] += eps
|
| 47 |
+
return torch.sum(inputs[..., None] >= bin_locations, dim=-1) - 1
|
| 48 |
+
|
| 49 |
+
|
| 50 |
+
def unconstrained_rational_quadratic_spline(
|
| 51 |
+
inputs,
|
| 52 |
+
unnormalized_widths,
|
| 53 |
+
unnormalized_heights,
|
| 54 |
+
unnormalized_derivatives,
|
| 55 |
+
inverse=False,
|
| 56 |
+
tails="linear",
|
| 57 |
+
tail_bound=1.0,
|
| 58 |
+
min_bin_width=DEFAULT_MIN_BIN_WIDTH,
|
| 59 |
+
min_bin_height=DEFAULT_MIN_BIN_HEIGHT,
|
| 60 |
+
min_derivative=DEFAULT_MIN_DERIVATIVE,
|
| 61 |
+
):
|
| 62 |
+
inside_interval_mask = (inputs >= -tail_bound) & (inputs <= tail_bound)
|
| 63 |
+
outside_interval_mask = ~inside_interval_mask
|
| 64 |
+
|
| 65 |
+
outputs = torch.zeros_like(inputs)
|
| 66 |
+
logabsdet = torch.zeros_like(inputs)
|
| 67 |
+
|
| 68 |
+
if tails == "linear":
|
| 69 |
+
unnormalized_derivatives = F.pad(unnormalized_derivatives, pad=(1, 1))
|
| 70 |
+
constant = np.log(np.exp(1 - min_derivative) - 1)
|
| 71 |
+
unnormalized_derivatives[..., 0] = constant
|
| 72 |
+
unnormalized_derivatives[..., -1] = constant
|
| 73 |
+
|
| 74 |
+
outputs[outside_interval_mask] = inputs[outside_interval_mask]
|
| 75 |
+
logabsdet[outside_interval_mask] = 0
|
| 76 |
+
else:
|
| 77 |
+
raise RuntimeError("{} tails are not implemented.".format(tails))
|
| 78 |
+
|
| 79 |
+
(
|
| 80 |
+
outputs[inside_interval_mask],
|
| 81 |
+
logabsdet[inside_interval_mask],
|
| 82 |
+
) = rational_quadratic_spline(
|
| 83 |
+
inputs=inputs[inside_interval_mask],
|
| 84 |
+
unnormalized_widths=unnormalized_widths[inside_interval_mask, :],
|
| 85 |
+
unnormalized_heights=unnormalized_heights[inside_interval_mask, :],
|
| 86 |
+
unnormalized_derivatives=unnormalized_derivatives[inside_interval_mask, :],
|
| 87 |
+
inverse=inverse,
|
| 88 |
+
left=-tail_bound,
|
| 89 |
+
right=tail_bound,
|
| 90 |
+
bottom=-tail_bound,
|
| 91 |
+
top=tail_bound,
|
| 92 |
+
min_bin_width=min_bin_width,
|
| 93 |
+
min_bin_height=min_bin_height,
|
| 94 |
+
min_derivative=min_derivative,
|
| 95 |
+
)
|
| 96 |
+
|
| 97 |
+
return outputs, logabsdet
|
| 98 |
+
|
| 99 |
+
|
| 100 |
+
def rational_quadratic_spline(
|
| 101 |
+
inputs,
|
| 102 |
+
unnormalized_widths,
|
| 103 |
+
unnormalized_heights,
|
| 104 |
+
unnormalized_derivatives,
|
| 105 |
+
inverse=False,
|
| 106 |
+
left=0.0,
|
| 107 |
+
right=1.0,
|
| 108 |
+
bottom=0.0,
|
| 109 |
+
top=1.0,
|
| 110 |
+
min_bin_width=DEFAULT_MIN_BIN_WIDTH,
|
| 111 |
+
min_bin_height=DEFAULT_MIN_BIN_HEIGHT,
|
| 112 |
+
min_derivative=DEFAULT_MIN_DERIVATIVE,
|
| 113 |
+
):
|
| 114 |
+
if torch.min(inputs) < left or torch.max(inputs) > right:
|
| 115 |
+
raise ValueError("Input to a transform is not within its domain")
|
| 116 |
+
|
| 117 |
+
num_bins = unnormalized_widths.shape[-1]
|
| 118 |
+
|
| 119 |
+
if min_bin_width * num_bins > 1.0:
|
| 120 |
+
raise ValueError("Minimal bin width too large for the number of bins")
|
| 121 |
+
if min_bin_height * num_bins > 1.0:
|
| 122 |
+
raise ValueError("Minimal bin height too large for the number of bins")
|
| 123 |
+
|
| 124 |
+
widths = F.softmax(unnormalized_widths, dim=-1)
|
| 125 |
+
widths = min_bin_width + (1 - min_bin_width * num_bins) * widths
|
| 126 |
+
cumwidths = torch.cumsum(widths, dim=-1)
|
| 127 |
+
cumwidths = F.pad(cumwidths, pad=(1, 0), mode="constant", value=0.0)
|
| 128 |
+
cumwidths = (right - left) * cumwidths + left
|
| 129 |
+
cumwidths[..., 0] = left
|
| 130 |
+
cumwidths[..., -1] = right
|
| 131 |
+
widths = cumwidths[..., 1:] - cumwidths[..., :-1]
|
| 132 |
+
|
| 133 |
+
derivatives = min_derivative + F.softplus(unnormalized_derivatives)
|
| 134 |
+
|
| 135 |
+
heights = F.softmax(unnormalized_heights, dim=-1)
|
| 136 |
+
heights = min_bin_height + (1 - min_bin_height * num_bins) * heights
|
| 137 |
+
cumheights = torch.cumsum(heights, dim=-1)
|
| 138 |
+
cumheights = F.pad(cumheights, pad=(1, 0), mode="constant", value=0.0)
|
| 139 |
+
cumheights = (top - bottom) * cumheights + bottom
|
| 140 |
+
cumheights[..., 0] = bottom
|
| 141 |
+
cumheights[..., -1] = top
|
| 142 |
+
heights = cumheights[..., 1:] - cumheights[..., :-1]
|
| 143 |
+
|
| 144 |
+
if inverse:
|
| 145 |
+
bin_idx = searchsorted(cumheights, inputs)[..., None]
|
| 146 |
+
else:
|
| 147 |
+
bin_idx = searchsorted(cumwidths, inputs)[..., None]
|
| 148 |
+
|
| 149 |
+
input_cumwidths = cumwidths.gather(-1, bin_idx)[..., 0]
|
| 150 |
+
input_bin_widths = widths.gather(-1, bin_idx)[..., 0]
|
| 151 |
+
|
| 152 |
+
input_cumheights = cumheights.gather(-1, bin_idx)[..., 0]
|
| 153 |
+
delta = heights / widths
|
| 154 |
+
input_delta = delta.gather(-1, bin_idx)[..., 0]
|
| 155 |
+
|
| 156 |
+
input_derivatives = derivatives.gather(-1, bin_idx)[..., 0]
|
| 157 |
+
input_derivatives_plus_one = derivatives[..., 1:].gather(-1, bin_idx)[..., 0]
|
| 158 |
+
|
| 159 |
+
input_heights = heights.gather(-1, bin_idx)[..., 0]
|
| 160 |
+
|
| 161 |
+
if inverse:
|
| 162 |
+
a = (inputs - input_cumheights) * (
|
| 163 |
+
input_derivatives + input_derivatives_plus_one - 2 * input_delta
|
| 164 |
+
) + input_heights * (input_delta - input_derivatives)
|
| 165 |
+
b = input_heights * input_derivatives - (inputs - input_cumheights) * (
|
| 166 |
+
input_derivatives + input_derivatives_plus_one - 2 * input_delta
|
| 167 |
+
)
|
| 168 |
+
c = -input_delta * (inputs - input_cumheights)
|
| 169 |
+
|
| 170 |
+
discriminant = b.pow(2) - 4 * a * c
|
| 171 |
+
assert (discriminant >= 0).all()
|
| 172 |
+
|
| 173 |
+
root = (2 * c) / (-b - torch.sqrt(discriminant))
|
| 174 |
+
outputs = root * input_bin_widths + input_cumwidths
|
| 175 |
+
|
| 176 |
+
theta_one_minus_theta = root * (1 - root)
|
| 177 |
+
denominator = input_delta + (
|
| 178 |
+
(input_derivatives + input_derivatives_plus_one - 2 * input_delta)
|
| 179 |
+
* theta_one_minus_theta
|
| 180 |
+
)
|
| 181 |
+
derivative_numerator = input_delta.pow(2) * (
|
| 182 |
+
input_derivatives_plus_one * root.pow(2)
|
| 183 |
+
+ 2 * input_delta * theta_one_minus_theta
|
| 184 |
+
+ input_derivatives * (1 - root).pow(2)
|
| 185 |
+
)
|
| 186 |
+
logabsdet = torch.log(derivative_numerator) - 2 * torch.log(denominator)
|
| 187 |
+
|
| 188 |
+
return outputs, -logabsdet
|
| 189 |
+
else:
|
| 190 |
+
theta = (inputs - input_cumwidths) / input_bin_widths
|
| 191 |
+
theta_one_minus_theta = theta * (1 - theta)
|
| 192 |
+
|
| 193 |
+
numerator = input_heights * (
|
| 194 |
+
input_delta * theta.pow(2) + input_derivatives * theta_one_minus_theta
|
| 195 |
+
)
|
| 196 |
+
denominator = input_delta + (
|
| 197 |
+
(input_derivatives + input_derivatives_plus_one - 2 * input_delta)
|
| 198 |
+
* theta_one_minus_theta
|
| 199 |
+
)
|
| 200 |
+
outputs = input_cumheights + numerator / denominator
|
| 201 |
+
|
| 202 |
+
derivative_numerator = input_delta.pow(2) * (
|
| 203 |
+
input_derivatives_plus_one * theta.pow(2)
|
| 204 |
+
+ 2 * input_delta * theta_one_minus_theta
|
| 205 |
+
+ input_derivatives * (1 - theta).pow(2)
|
| 206 |
+
)
|
| 207 |
+
logabsdet = torch.log(derivative_numerator) - 2 * torch.log(denominator)
|
| 208 |
+
|
| 209 |
+
return outputs, logabsdet
|
src/main.py
ADDED
|
@@ -0,0 +1,421 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import spaces
|
| 2 |
+
import torch
|
| 3 |
+
import argparse
|
| 4 |
+
import gc
|
| 5 |
+
import hashlib
|
| 6 |
+
import json
|
| 7 |
+
import os
|
| 8 |
+
import shlex
|
| 9 |
+
import subprocess
|
| 10 |
+
from contextlib import suppress
|
| 11 |
+
from urllib.parse import urlparse, parse_qs
|
| 12 |
+
|
| 13 |
+
import gradio as gr
|
| 14 |
+
import librosa
|
| 15 |
+
import numpy as np
|
| 16 |
+
import soundfile as sf
|
| 17 |
+
import sox
|
| 18 |
+
import yt_dlp
|
| 19 |
+
from pedalboard import Pedalboard, Reverb, Compressor, HighpassFilter
|
| 20 |
+
from pedalboard.io import AudioFile
|
| 21 |
+
from pydub import AudioSegment
|
| 22 |
+
|
| 23 |
+
from mdx import run_mdx
|
| 24 |
+
from rvc import Config, load_hubert, get_vc, rvc_infer
|
| 25 |
+
|
| 26 |
+
BASE_DIR = os.path.dirname(os.path.dirname(os.path.abspath(__file__)))
|
| 27 |
+
|
| 28 |
+
mdxnet_models_dir = os.path.join(BASE_DIR, 'mdxnet_models')
|
| 29 |
+
rvc_models_dir = os.path.join(BASE_DIR, 'rvc_models')
|
| 30 |
+
output_dir = os.path.join(BASE_DIR, 'song_output')
|
| 31 |
+
|
| 32 |
+
|
| 33 |
+
def get_youtube_video_id(url, ignore_playlist=True):
|
| 34 |
+
"""
|
| 35 |
+
Examples:
|
| 36 |
+
http://youtu.be/SA2iWivDJiE
|
| 37 |
+
http://www.youtube.com/watch?v=_oPAwA_Udwc&feature=feedu
|
| 38 |
+
http://www.youtube.com/embed/SA2iWivDJiE
|
| 39 |
+
http://www.youtube.com/v/SA2iWivDJiE?version=3&hl=en_US
|
| 40 |
+
"""
|
| 41 |
+
if "m.youtube.com" in url:
|
| 42 |
+
url = url.replace("m.youtube.com", "www.youtube.com")
|
| 43 |
+
query = urlparse(url)
|
| 44 |
+
if query.hostname == 'youtu.be':
|
| 45 |
+
if query.path[1:] == 'watch':
|
| 46 |
+
return query.query[2:]
|
| 47 |
+
return query.path[1:]
|
| 48 |
+
|
| 49 |
+
if query.hostname in {'www.youtube.com', 'youtube.com', 'music.youtube.com'}:
|
| 50 |
+
if not ignore_playlist:
|
| 51 |
+
# use case: get playlist id not current video in playlist
|
| 52 |
+
with suppress(KeyError):
|
| 53 |
+
return parse_qs(query.query)['list'][0]
|
| 54 |
+
if query.path == '/watch':
|
| 55 |
+
return parse_qs(query.query)['v'][0]
|
| 56 |
+
if query.path[:7] == '/watch/':
|
| 57 |
+
return query.path.split('/')[1]
|
| 58 |
+
if query.path[:7] == '/embed/':
|
| 59 |
+
return query.path.split('/')[2]
|
| 60 |
+
if query.path[:3] == '/v/':
|
| 61 |
+
return query.path.split('/')[2]
|
| 62 |
+
|
| 63 |
+
# returns None for invalid YouTube url
|
| 64 |
+
return None
|
| 65 |
+
|
| 66 |
+
|
| 67 |
+
def yt_download(link):
|
| 68 |
+
ydl_opts = {
|
| 69 |
+
'format': 'bestaudio',
|
| 70 |
+
'outtmpl': '%(title)s',
|
| 71 |
+
'nocheckcertificate': True,
|
| 72 |
+
'ignoreerrors': True,
|
| 73 |
+
'no_warnings': True,
|
| 74 |
+
'quiet': True,
|
| 75 |
+
'extractaudio': True,
|
| 76 |
+
'postprocessors': [{'key': 'FFmpegExtractAudio', 'preferredcodec': 'mp3'}],
|
| 77 |
+
}
|
| 78 |
+
with yt_dlp.YoutubeDL(ydl_opts) as ydl:
|
| 79 |
+
result = ydl.extract_info(link, download=True)
|
| 80 |
+
download_path = ydl.prepare_filename(result, outtmpl='%(title)s.mp3')
|
| 81 |
+
|
| 82 |
+
return download_path
|
| 83 |
+
|
| 84 |
+
|
| 85 |
+
def raise_exception(error_msg, is_webui):
|
| 86 |
+
if is_webui:
|
| 87 |
+
raise gr.Error(error_msg)
|
| 88 |
+
else:
|
| 89 |
+
raise Exception(error_msg)
|
| 90 |
+
|
| 91 |
+
|
| 92 |
+
def get_rvc_model(voice_model, is_webui):
|
| 93 |
+
rvc_model_filename, rvc_index_filename = None, None
|
| 94 |
+
model_dir = os.path.join(rvc_models_dir, voice_model)
|
| 95 |
+
for file in os.listdir(model_dir):
|
| 96 |
+
ext = os.path.splitext(file)[1]
|
| 97 |
+
if ext == '.pth':
|
| 98 |
+
rvc_model_filename = file
|
| 99 |
+
if ext == '.index':
|
| 100 |
+
rvc_index_filename = file
|
| 101 |
+
|
| 102 |
+
if rvc_model_filename is None:
|
| 103 |
+
error_msg = f'No model file exists in {model_dir}.'
|
| 104 |
+
raise_exception(error_msg, is_webui)
|
| 105 |
+
|
| 106 |
+
return os.path.join(model_dir, rvc_model_filename), os.path.join(model_dir, rvc_index_filename) if rvc_index_filename else ''
|
| 107 |
+
|
| 108 |
+
|
| 109 |
+
def get_audio_paths(song_dir):
|
| 110 |
+
orig_song_path = None
|
| 111 |
+
instrumentals_path = None
|
| 112 |
+
main_vocals_dereverb_path = None
|
| 113 |
+
backup_vocals_path = None
|
| 114 |
+
|
| 115 |
+
for file in os.listdir(song_dir):
|
| 116 |
+
if file.endswith('_Instrumental.wav'):
|
| 117 |
+
instrumentals_path = os.path.join(song_dir, file)
|
| 118 |
+
orig_song_path = instrumentals_path.replace('_Instrumental', '')
|
| 119 |
+
|
| 120 |
+
elif file.endswith('_Vocals_Main_DeReverb.wav'):
|
| 121 |
+
main_vocals_dereverb_path = os.path.join(song_dir, file)
|
| 122 |
+
|
| 123 |
+
elif file.endswith('_Vocals_Backup.wav'):
|
| 124 |
+
backup_vocals_path = os.path.join(song_dir, file)
|
| 125 |
+
|
| 126 |
+
return orig_song_path, instrumentals_path, main_vocals_dereverb_path, backup_vocals_path
|
| 127 |
+
|
| 128 |
+
|
| 129 |
+
def convert_to_stereo(audio_path):
|
| 130 |
+
wave, sr = librosa.load(audio_path, mono=False, sr=44100)
|
| 131 |
+
|
| 132 |
+
# check if mono
|
| 133 |
+
if type(wave[0]) != np.ndarray:
|
| 134 |
+
stereo_path = f'{os.path.splitext(audio_path)[0]}_stereo.wav'
|
| 135 |
+
command = shlex.split(f'ffmpeg -y -loglevel error -i "{audio_path}" -ac 2 -f wav "{stereo_path}"')
|
| 136 |
+
subprocess.run(command)
|
| 137 |
+
return stereo_path
|
| 138 |
+
else:
|
| 139 |
+
return audio_path
|
| 140 |
+
|
| 141 |
+
|
| 142 |
+
def pitch_shift(audio_path, pitch_change):
|
| 143 |
+
output_path = f'{os.path.splitext(audio_path)[0]}_p{pitch_change}.wav'
|
| 144 |
+
if not os.path.exists(output_path):
|
| 145 |
+
y, sr = sf.read(audio_path)
|
| 146 |
+
tfm = sox.Transformer()
|
| 147 |
+
tfm.pitch(pitch_change)
|
| 148 |
+
y_shifted = tfm.build_array(input_array=y, sample_rate_in=sr)
|
| 149 |
+
sf.write(output_path, y_shifted, sr)
|
| 150 |
+
|
| 151 |
+
return output_path
|
| 152 |
+
|
| 153 |
+
|
| 154 |
+
def get_hash(filepath):
|
| 155 |
+
with open(filepath, 'rb') as f:
|
| 156 |
+
file_hash = hashlib.blake2b()
|
| 157 |
+
while chunk := f.read(8192):
|
| 158 |
+
file_hash.update(chunk)
|
| 159 |
+
|
| 160 |
+
return file_hash.hexdigest()[:11]
|
| 161 |
+
|
| 162 |
+
|
| 163 |
+
def display_progress(message, percent, is_webui, progress=None):
|
| 164 |
+
if is_webui:
|
| 165 |
+
progress(percent, desc=message)
|
| 166 |
+
else:
|
| 167 |
+
print(message)
|
| 168 |
+
|
| 169 |
+
|
| 170 |
+
def preprocess_song(song_input, mdx_model_params, song_id, is_webui, input_type, progress, keep_orig, orig_song_path):
|
| 171 |
+
|
| 172 |
+
song_output_dir = os.path.join(output_dir, song_id)
|
| 173 |
+
|
| 174 |
+
display_progress('[~] Separating Vocals from Instrumental...', 0.1, is_webui, progress)
|
| 175 |
+
vocals_path, instrumentals_path = run_mdx(mdx_model_params, song_output_dir, os.path.join(mdxnet_models_dir, 'UVR-MDX-NET-Voc_FT.onnx'), orig_song_path, denoise=True, keep_orig=keep_orig)
|
| 176 |
+
|
| 177 |
+
display_progress('[~] Separating Main Vocals from Backup Vocals...', 0.2, is_webui, progress)
|
| 178 |
+
backup_vocals_path, main_vocals_path = run_mdx(mdx_model_params, song_output_dir, os.path.join(mdxnet_models_dir, 'UVR_MDXNET_KARA_2.onnx'), vocals_path, suffix='Backup', invert_suffix='Main', denoise=True)
|
| 179 |
+
|
| 180 |
+
display_progress('[~] Applying DeReverb to Vocals...', 0.3, is_webui, progress)
|
| 181 |
+
_, main_vocals_dereverb_path = run_mdx(mdx_model_params, song_output_dir, os.path.join(mdxnet_models_dir, 'Reverb_HQ_By_FoxJoy.onnx'), main_vocals_path, invert_suffix='DeReverb', exclude_main=True, denoise=True)
|
| 182 |
+
|
| 183 |
+
return orig_song_path, vocals_path, instrumentals_path, main_vocals_path, backup_vocals_path, main_vocals_dereverb_path
|
| 184 |
+
|
| 185 |
+
|
| 186 |
+
def get_audio_file(song_input, is_webui, input_type, progress):
|
| 187 |
+
keep_orig = False
|
| 188 |
+
if input_type == 'yt':
|
| 189 |
+
display_progress('[~] Downloading song...', 0, is_webui, progress)
|
| 190 |
+
song_link = song_input.split('&')[0]
|
| 191 |
+
orig_song_path = yt_download(song_link)
|
| 192 |
+
elif input_type == 'local':
|
| 193 |
+
orig_song_path = song_input
|
| 194 |
+
keep_orig = True
|
| 195 |
+
else:
|
| 196 |
+
orig_song_path = None
|
| 197 |
+
return keep_orig, orig_song_path
|
| 198 |
+
|
| 199 |
+
|
| 200 |
+
# @spaces.GPU(enable_queue=True)
|
| 201 |
+
def voice_change(voice_model, vocals_path, output_path, pitch_change, f0_method, index_rate, filter_radius, rms_mix_rate, protect, crepe_hop_length, is_webui):
|
| 202 |
+
rvc_model_path, rvc_index_path = get_rvc_model(voice_model, is_webui)
|
| 203 |
+
device = "cuda:0" if torch.cuda.is_available() else "cpu"
|
| 204 |
+
compute_half = True if torch.cuda.is_available() else False
|
| 205 |
+
config = Config(device, compute_half)
|
| 206 |
+
|
| 207 |
+
hubert_model = load_hubert(device, config.is_half, os.path.join(rvc_models_dir, 'hubert_base.pt'))
|
| 208 |
+
cpt, version, net_g, tgt_sr, vc = get_vc(device, config.is_half, config, rvc_model_path)
|
| 209 |
+
|
| 210 |
+
# convert main vocals
|
| 211 |
+
rvc_infer(rvc_index_path, index_rate, vocals_path, output_path, pitch_change, f0_method, cpt, version, net_g, filter_radius, tgt_sr, rms_mix_rate, protect, crepe_hop_length, vc, hubert_model)
|
| 212 |
+
del hubert_model, cpt
|
| 213 |
+
gc.collect()
|
| 214 |
+
|
| 215 |
+
|
| 216 |
+
def add_audio_effects(audio_path, reverb_rm_size, reverb_wet, reverb_dry, reverb_damping):
|
| 217 |
+
output_path = f'{os.path.splitext(audio_path)[0]}_mixed.wav'
|
| 218 |
+
|
| 219 |
+
# Initialize audio effects plugins
|
| 220 |
+
board = Pedalboard(
|
| 221 |
+
[
|
| 222 |
+
HighpassFilter(),
|
| 223 |
+
Compressor(ratio=4, threshold_db=-15),
|
| 224 |
+
Reverb(room_size=reverb_rm_size, dry_level=reverb_dry, wet_level=reverb_wet, damping=reverb_damping)
|
| 225 |
+
]
|
| 226 |
+
)
|
| 227 |
+
|
| 228 |
+
with AudioFile(audio_path) as f:
|
| 229 |
+
with AudioFile(output_path, 'w', f.samplerate, f.num_channels) as o:
|
| 230 |
+
# Read one second of audio at a time, until the file is empty:
|
| 231 |
+
while f.tell() < f.frames:
|
| 232 |
+
chunk = f.read(int(f.samplerate))
|
| 233 |
+
effected = board(chunk, f.samplerate, reset=False)
|
| 234 |
+
o.write(effected)
|
| 235 |
+
|
| 236 |
+
return output_path
|
| 237 |
+
|
| 238 |
+
|
| 239 |
+
def combine_audio(audio_paths, output_path, main_gain, backup_gain, inst_gain, output_format):
|
| 240 |
+
main_vocal_audio = AudioSegment.from_wav(audio_paths[0]) - 4 + main_gain
|
| 241 |
+
backup_vocal_audio = AudioSegment.from_wav(audio_paths[1]) - 6 + backup_gain
|
| 242 |
+
instrumental_audio = AudioSegment.from_wav(audio_paths[2]) - 7 + inst_gain
|
| 243 |
+
main_vocal_audio.overlay(backup_vocal_audio).overlay(instrumental_audio).export(output_path, format=output_format)
|
| 244 |
+
|
| 245 |
+
|
| 246 |
+
# @spaces.GPU(enable_queue=True, duration=130)
|
| 247 |
+
@spaces.GPU(duration=130)
|
| 248 |
+
def process_song(
|
| 249 |
+
song_dir, song_input, mdx_model_params, song_id, is_webui, input_type, progress,
|
| 250 |
+
keep_files, pitch_change, pitch_change_all, voice_model, index_rate, filter_radius,
|
| 251 |
+
rms_mix_rate, protect, f0_method, crepe_hop_length, output_format, keep_orig, orig_song_path
|
| 252 |
+
):
|
| 253 |
+
if not os.path.exists(song_dir):
|
| 254 |
+
os.makedirs(song_dir)
|
| 255 |
+
orig_song_path, vocals_path, instrumentals_path, main_vocals_path, backup_vocals_path, main_vocals_dereverb_path = preprocess_song(song_input, mdx_model_params, song_id, is_webui, input_type, progress, keep_orig, orig_song_path)
|
| 256 |
+
else:
|
| 257 |
+
vocals_path, main_vocals_path = None, None
|
| 258 |
+
paths = get_audio_paths(song_dir)
|
| 259 |
+
|
| 260 |
+
# if any of the audio files aren't available or keep intermediate files, rerun preprocess
|
| 261 |
+
if any(path is None for path in paths) or keep_files:
|
| 262 |
+
orig_song_path, vocals_path, instrumentals_path, main_vocals_path, backup_vocals_path, main_vocals_dereverb_path = preprocess_song(song_input, mdx_model_params, song_id, is_webui, input_type, progress, keep_orig, orig_song_path)
|
| 263 |
+
else:
|
| 264 |
+
orig_song_path, instrumentals_path, main_vocals_dereverb_path, backup_vocals_path = paths
|
| 265 |
+
|
| 266 |
+
pitch_change = pitch_change * 12 + pitch_change_all
|
| 267 |
+
ai_vocals_path = os.path.join(song_dir, f'{os.path.splitext(os.path.basename(orig_song_path))[0]}_{voice_model}_p{pitch_change}_i{index_rate}_fr{filter_radius}_rms{rms_mix_rate}_pro{protect}_{f0_method}{"" if f0_method != "mangio-crepe" else f"_{crepe_hop_length}"}.wav')
|
| 268 |
+
ai_cover_path = os.path.join(song_dir, f'{os.path.splitext(os.path.basename(orig_song_path))[0]} ({voice_model} Ver).{output_format}')
|
| 269 |
+
|
| 270 |
+
if not os.path.exists(ai_vocals_path):
|
| 271 |
+
display_progress('[~] Converting voice using RVC...', 0.5, is_webui, progress)
|
| 272 |
+
voice_change(voice_model, main_vocals_dereverb_path, ai_vocals_path, pitch_change, f0_method, index_rate, filter_radius, rms_mix_rate, protect, crepe_hop_length, is_webui)
|
| 273 |
+
|
| 274 |
+
return ai_vocals_path, ai_cover_path, instrumentals_path, backup_vocals_path, vocals_path, main_vocals_path
|
| 275 |
+
|
| 276 |
+
|
| 277 |
+
# @spaces.GPU(duration=140)
|
| 278 |
+
def song_cover_pipeline(song_input, voice_model, pitch_change, keep_files,
|
| 279 |
+
is_webui=0, main_gain=0, backup_gain=0, inst_gain=0, index_rate=0.5, filter_radius=3,
|
| 280 |
+
rms_mix_rate=0.25, f0_method='rmvpe', crepe_hop_length=128, protect=0.33, pitch_change_all=0,
|
| 281 |
+
reverb_rm_size=0.15, reverb_wet=0.2, reverb_dry=0.8, reverb_damping=0.7, output_format='mp3',
|
| 282 |
+
progress=gr.Progress()):
|
| 283 |
+
try:
|
| 284 |
+
if not song_input or not voice_model:
|
| 285 |
+
raise_exception('Ensure that the song input field and voice model field is filled.', is_webui)
|
| 286 |
+
|
| 287 |
+
display_progress('[~] Starting AI Cover Generation Pipeline...', 0, is_webui, progress)
|
| 288 |
+
|
| 289 |
+
with open(os.path.join(mdxnet_models_dir, 'model_data.json')) as infile:
|
| 290 |
+
mdx_model_params = json.load(infile)
|
| 291 |
+
|
| 292 |
+
# if youtube url
|
| 293 |
+
if urlparse(song_input).scheme == 'https':
|
| 294 |
+
input_type = 'yt'
|
| 295 |
+
song_id = get_youtube_video_id(song_input)
|
| 296 |
+
if song_id is None:
|
| 297 |
+
error_msg = 'Invalid YouTube url.'
|
| 298 |
+
raise_exception(error_msg, is_webui)
|
| 299 |
+
|
| 300 |
+
# local audio file
|
| 301 |
+
else:
|
| 302 |
+
input_type = 'local'
|
| 303 |
+
song_input = song_input.strip('\"')
|
| 304 |
+
if os.path.exists(song_input):
|
| 305 |
+
song_id = get_hash(song_input)
|
| 306 |
+
else:
|
| 307 |
+
error_msg = f'{song_input} does not exist.'
|
| 308 |
+
song_id = None
|
| 309 |
+
raise_exception(error_msg, is_webui)
|
| 310 |
+
|
| 311 |
+
song_dir = os.path.join(output_dir, song_id)
|
| 312 |
+
|
| 313 |
+
keep_orig, orig_song_path = get_audio_file(song_input, is_webui, input_type, progress)
|
| 314 |
+
orig_song_path = convert_to_stereo(orig_song_path)
|
| 315 |
+
|
| 316 |
+
(
|
| 317 |
+
ai_vocals_path,
|
| 318 |
+
ai_cover_path,
|
| 319 |
+
instrumentals_path,
|
| 320 |
+
backup_vocals_path,
|
| 321 |
+
vocals_path,
|
| 322 |
+
main_vocals_path
|
| 323 |
+
) = process_song(
|
| 324 |
+
song_dir,
|
| 325 |
+
song_input,
|
| 326 |
+
mdx_model_params,
|
| 327 |
+
song_id,
|
| 328 |
+
is_webui,
|
| 329 |
+
input_type,
|
| 330 |
+
progress,
|
| 331 |
+
keep_files,
|
| 332 |
+
pitch_change,
|
| 333 |
+
pitch_change_all,
|
| 334 |
+
voice_model,
|
| 335 |
+
index_rate,
|
| 336 |
+
filter_radius,
|
| 337 |
+
rms_mix_rate,
|
| 338 |
+
protect,
|
| 339 |
+
f0_method,
|
| 340 |
+
crepe_hop_length,
|
| 341 |
+
output_format,
|
| 342 |
+
keep_orig,
|
| 343 |
+
orig_song_path,
|
| 344 |
+
)
|
| 345 |
+
|
| 346 |
+
display_progress('[~] Applying audio effects to Vocals...', 0.8, is_webui, progress)
|
| 347 |
+
ai_vocals_mixed_path = add_audio_effects(ai_vocals_path, reverb_rm_size, reverb_wet, reverb_dry, reverb_damping)
|
| 348 |
+
|
| 349 |
+
instrumentals_path, _ = run_mdx(
|
| 350 |
+
mdx_model_params,
|
| 351 |
+
os.path.join(output_dir, song_id),
|
| 352 |
+
os.path.join(mdxnet_models_dir, "UVR-MDX-NET-Inst_HQ_4.onnx"),
|
| 353 |
+
instrumentals_path,
|
| 354 |
+
# exclude_main=False,
|
| 355 |
+
exclude_inversion=True,
|
| 356 |
+
suffix="Voiceless",
|
| 357 |
+
denoise=False,
|
| 358 |
+
keep_orig=True,
|
| 359 |
+
base_device=""
|
| 360 |
+
)
|
| 361 |
+
|
| 362 |
+
if pitch_change_all != 0:
|
| 363 |
+
display_progress('[~] Applying overall pitch change', 0.85, is_webui, progress)
|
| 364 |
+
instrumentals_path = pitch_shift(instrumentals_path, pitch_change_all)
|
| 365 |
+
backup_vocals_path = pitch_shift(backup_vocals_path, pitch_change_all)
|
| 366 |
+
|
| 367 |
+
display_progress('[~] Combining AI Vocals and Instrumentals...', 0.9, is_webui, progress)
|
| 368 |
+
combine_audio([ai_vocals_mixed_path, backup_vocals_path, instrumentals_path], ai_cover_path, main_gain, backup_gain, inst_gain, output_format)
|
| 369 |
+
|
| 370 |
+
if not keep_files:
|
| 371 |
+
display_progress('[~] Removing intermediate audio files...', 0.95, is_webui, progress)
|
| 372 |
+
intermediate_files = [vocals_path, main_vocals_path, ai_vocals_mixed_path]
|
| 373 |
+
if pitch_change_all != 0:
|
| 374 |
+
intermediate_files += [instrumentals_path, backup_vocals_path]
|
| 375 |
+
for file in intermediate_files:
|
| 376 |
+
if file and os.path.exists(file):
|
| 377 |
+
os.remove(file)
|
| 378 |
+
|
| 379 |
+
return ai_cover_path
|
| 380 |
+
|
| 381 |
+
except Exception as e:
|
| 382 |
+
raise_exception(str(e), is_webui)
|
| 383 |
+
|
| 384 |
+
|
| 385 |
+
if __name__ == '__main__':
|
| 386 |
+
parser = argparse.ArgumentParser(description='Generate a AI cover song in the song_output/id directory.', add_help=True)
|
| 387 |
+
parser.add_argument('-i', '--song-input', type=str, required=True, help='Link to a YouTube video or the filepath to a local mp3/wav file to create an AI cover of')
|
| 388 |
+
parser.add_argument('-dir', '--rvc-dirname', type=str, required=True, help='Name of the folder in the rvc_models directory containing the RVC model file and optional index file to use')
|
| 389 |
+
parser.add_argument('-p', '--pitch-change', type=int, required=True, help='Change the pitch of AI Vocals only. Generally, use 1 for male to female and -1 for vice-versa. (Octaves)')
|
| 390 |
+
parser.add_argument('-k', '--keep-files', action=argparse.BooleanOptionalAction, help='Whether to keep all intermediate audio files generated in the song_output/id directory, e.g. Isolated Vocals/Instrumentals')
|
| 391 |
+
parser.add_argument('-ir', '--index-rate', type=float, default=0.5, help='A decimal number e.g. 0.5, used to reduce/resolve the timbre leakage problem. If set to 1, more biased towards the timbre quality of the training dataset')
|
| 392 |
+
parser.add_argument('-fr', '--filter-radius', type=int, default=3, help='A number between 0 and 7. If >=3: apply median filtering to the harvested pitch results. The value represents the filter radius and can reduce breathiness.')
|
| 393 |
+
parser.add_argument('-rms', '--rms-mix-rate', type=float, default=0.25, help="A decimal number e.g. 0.25. Control how much to use the original vocal's loudness (0) or a fixed loudness (1).")
|
| 394 |
+
parser.add_argument('-palgo', '--pitch-detection-algo', type=str, default='rmvpe', help='Best option is rmvpe (clarity in vocals), then mangio-crepe (smoother vocals).')
|
| 395 |
+
parser.add_argument('-hop', '--crepe-hop-length', type=int, default=128, help='If pitch detection algo is mangio-crepe, controls how often it checks for pitch changes in milliseconds. The higher the value, the faster the conversion and less risk of voice cracks, but there is less pitch accuracy. Recommended: 128.')
|
| 396 |
+
parser.add_argument('-pro', '--protect', type=float, default=0.33, help='A decimal number e.g. 0.33. Protect voiceless consonants and breath sounds to prevent artifacts such as tearing in electronic music. Set to 0.5 to disable. Decrease the value to increase protection, but it may reduce indexing accuracy.')
|
| 397 |
+
parser.add_argument('-mv', '--main-vol', type=int, default=0, help='Volume change for AI main vocals in decibels. Use -3 to decrease by 3 decibels and 3 to increase by 3 decibels')
|
| 398 |
+
parser.add_argument('-bv', '--backup-vol', type=int, default=0, help='Volume change for backup vocals in decibels')
|
| 399 |
+
parser.add_argument('-iv', '--inst-vol', type=int, default=0, help='Volume change for instrumentals in decibels')
|
| 400 |
+
parser.add_argument('-pall', '--pitch-change-all', type=int, default=0, help='Change the pitch/key of vocals and instrumentals. Changing this slightly reduces sound quality')
|
| 401 |
+
parser.add_argument('-rsize', '--reverb-size', type=float, default=0.15, help='Reverb room size between 0 and 1')
|
| 402 |
+
parser.add_argument('-rwet', '--reverb-wetness', type=float, default=0.2, help='Reverb wet level between 0 and 1')
|
| 403 |
+
parser.add_argument('-rdry', '--reverb-dryness', type=float, default=0.8, help='Reverb dry level between 0 and 1')
|
| 404 |
+
parser.add_argument('-rdamp', '--reverb-damping', type=float, default=0.7, help='Reverb damping between 0 and 1')
|
| 405 |
+
parser.add_argument('-oformat', '--output-format', type=str, default='mp3', help='Output format of audio file. mp3 for smaller file size, wav for best quality')
|
| 406 |
+
args = parser.parse_args()
|
| 407 |
+
|
| 408 |
+
rvc_dirname = args.rvc_dirname
|
| 409 |
+
if not os.path.exists(os.path.join(rvc_models_dir, rvc_dirname)):
|
| 410 |
+
raise Exception(f'The folder {os.path.join(rvc_models_dir, rvc_dirname)} does not exist.')
|
| 411 |
+
|
| 412 |
+
cover_path = song_cover_pipeline(args.song_input, rvc_dirname, args.pitch_change, args.keep_files,
|
| 413 |
+
main_gain=args.main_vol, backup_gain=args.backup_vol, inst_gain=args.inst_vol,
|
| 414 |
+
index_rate=args.index_rate, filter_radius=args.filter_radius,
|
| 415 |
+
rms_mix_rate=args.rms_mix_rate, f0_method=args.pitch_detection_algo,
|
| 416 |
+
crepe_hop_length=args.crepe_hop_length, protect=args.protect,
|
| 417 |
+
pitch_change_all=args.pitch_change_all,
|
| 418 |
+
reverb_rm_size=args.reverb_size, reverb_wet=args.reverb_wetness,
|
| 419 |
+
reverb_dry=args.reverb_dryness, reverb_damping=args.reverb_damping,
|
| 420 |
+
output_format=args.output_format)
|
| 421 |
+
print(f'[+] Cover generated at {cover_path}')
|
src/mdx.py
ADDED
|
@@ -0,0 +1,307 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import gc
|
| 2 |
+
import hashlib
|
| 3 |
+
import os
|
| 4 |
+
import queue
|
| 5 |
+
import threading
|
| 6 |
+
import warnings
|
| 7 |
+
from multiprocessing import cpu_count
|
| 8 |
+
import librosa
|
| 9 |
+
import numpy as np
|
| 10 |
+
import onnxruntime as ort
|
| 11 |
+
import soundfile as sf
|
| 12 |
+
import torch
|
| 13 |
+
from tqdm import tqdm
|
| 14 |
+
|
| 15 |
+
warnings.filterwarnings("ignore")
|
| 16 |
+
stem_naming = {'Vocals': 'Instrumental', 'Other': 'Instruments', 'Instrumental': 'Vocals', 'Drums': 'Drumless', 'Bass': 'Bassless'}
|
| 17 |
+
|
| 18 |
+
|
| 19 |
+
class MDXModel:
|
| 20 |
+
def __init__(self, device, dim_f, dim_t, n_fft, hop=1024, stem_name=None, compensation=1.000):
|
| 21 |
+
self.dim_f = dim_f
|
| 22 |
+
self.dim_t = dim_t
|
| 23 |
+
self.dim_c = 4
|
| 24 |
+
self.n_fft = n_fft
|
| 25 |
+
self.hop = hop
|
| 26 |
+
self.stem_name = stem_name
|
| 27 |
+
self.compensation = compensation
|
| 28 |
+
|
| 29 |
+
self.n_bins = self.n_fft // 2 + 1
|
| 30 |
+
self.chunk_size = hop * (self.dim_t - 1)
|
| 31 |
+
self.window = torch.hann_window(window_length=self.n_fft, periodic=True).to(device)
|
| 32 |
+
|
| 33 |
+
out_c = self.dim_c
|
| 34 |
+
|
| 35 |
+
self.freq_pad = torch.zeros([1, out_c, self.n_bins - self.dim_f, self.dim_t]).to(device)
|
| 36 |
+
|
| 37 |
+
def stft(self, x):
|
| 38 |
+
x = x.reshape([-1, self.chunk_size])
|
| 39 |
+
x = torch.stft(x, n_fft=self.n_fft, hop_length=self.hop, window=self.window, center=True, return_complex=True)
|
| 40 |
+
x = torch.view_as_real(x)
|
| 41 |
+
x = x.permute([0, 3, 1, 2])
|
| 42 |
+
x = x.reshape([-1, 2, 2, self.n_bins, self.dim_t]).reshape([-1, 4, self.n_bins, self.dim_t])
|
| 43 |
+
return x[:, :, :self.dim_f]
|
| 44 |
+
|
| 45 |
+
def istft(self, x, freq_pad=None):
|
| 46 |
+
freq_pad = self.freq_pad.repeat([x.shape[0], 1, 1, 1]) if freq_pad is None else freq_pad
|
| 47 |
+
x = torch.cat([x, freq_pad], -2)
|
| 48 |
+
# c = 4*2 if self.target_name=='*' else 2
|
| 49 |
+
x = x.reshape([-1, 2, 2, self.n_bins, self.dim_t]).reshape([-1, 2, self.n_bins, self.dim_t])
|
| 50 |
+
x = x.permute([0, 2, 3, 1])
|
| 51 |
+
x = x.contiguous()
|
| 52 |
+
x = torch.view_as_complex(x)
|
| 53 |
+
x = torch.istft(x, n_fft=self.n_fft, hop_length=self.hop, window=self.window, center=True)
|
| 54 |
+
return x.reshape([-1, 2, self.chunk_size])
|
| 55 |
+
|
| 56 |
+
|
| 57 |
+
class MDX:
|
| 58 |
+
DEFAULT_SR = 44100
|
| 59 |
+
# Unit: seconds
|
| 60 |
+
DEFAULT_CHUNK_SIZE = 0 * DEFAULT_SR
|
| 61 |
+
DEFAULT_MARGIN_SIZE = 1 * DEFAULT_SR
|
| 62 |
+
|
| 63 |
+
def __init__(self, model_path: str, params: MDXModel, processor=0):
|
| 64 |
+
|
| 65 |
+
# Set the device and the provider (CPU or CUDA)
|
| 66 |
+
self.device = (
|
| 67 |
+
torch.device(f"cuda:{processor}")
|
| 68 |
+
if processor >= 0
|
| 69 |
+
else torch.device("cpu")
|
| 70 |
+
)
|
| 71 |
+
self.provider = (
|
| 72 |
+
["CUDAExecutionProvider"]
|
| 73 |
+
if processor >= 0
|
| 74 |
+
else ["CPUExecutionProvider"]
|
| 75 |
+
)
|
| 76 |
+
|
| 77 |
+
print(self.provider, self.device)
|
| 78 |
+
|
| 79 |
+
self.model = params
|
| 80 |
+
|
| 81 |
+
# Load the ONNX model using ONNX Runtime
|
| 82 |
+
self.ort = ort.InferenceSession(model_path, providers=self.provider)
|
| 83 |
+
# Preload the model for faster performance
|
| 84 |
+
self.ort.run(None, {'input': torch.rand(1, 4, params.dim_f, params.dim_t).numpy()})
|
| 85 |
+
self.process = lambda spec: self.ort.run(None, {'input': spec.cpu().numpy()})[0]
|
| 86 |
+
|
| 87 |
+
self.prog = None
|
| 88 |
+
|
| 89 |
+
@staticmethod
|
| 90 |
+
def get_hash(model_path):
|
| 91 |
+
try:
|
| 92 |
+
with open(model_path, 'rb') as f:
|
| 93 |
+
f.seek(- 10000 * 1024, 2)
|
| 94 |
+
model_hash = hashlib.md5(f.read()).hexdigest()
|
| 95 |
+
except:
|
| 96 |
+
model_hash = hashlib.md5(open(model_path, 'rb').read()).hexdigest()
|
| 97 |
+
|
| 98 |
+
return model_hash
|
| 99 |
+
|
| 100 |
+
@staticmethod
|
| 101 |
+
def segment(wave, combine=True, chunk_size=DEFAULT_CHUNK_SIZE, margin_size=DEFAULT_MARGIN_SIZE):
|
| 102 |
+
"""
|
| 103 |
+
Segment or join segmented wave array
|
| 104 |
+
|
| 105 |
+
Args:
|
| 106 |
+
wave: (np.array) Wave array to be segmented or joined
|
| 107 |
+
combine: (bool) If True, combines segmented wave array. If False, segments wave array.
|
| 108 |
+
chunk_size: (int) Size of each segment (in samples)
|
| 109 |
+
margin_size: (int) Size of margin between segments (in samples)
|
| 110 |
+
|
| 111 |
+
Returns:
|
| 112 |
+
numpy array: Segmented or joined wave array
|
| 113 |
+
"""
|
| 114 |
+
|
| 115 |
+
if combine:
|
| 116 |
+
processed_wave = None # Initializing as None instead of [] for later numpy array concatenation
|
| 117 |
+
for segment_count, segment in enumerate(wave):
|
| 118 |
+
start = 0 if segment_count == 0 else margin_size
|
| 119 |
+
end = None if segment_count == len(wave) - 1 else -margin_size
|
| 120 |
+
if margin_size == 0:
|
| 121 |
+
end = None
|
| 122 |
+
if processed_wave is None: # Create array for first segment
|
| 123 |
+
processed_wave = segment[:, start:end]
|
| 124 |
+
else: # Concatenate to existing array for subsequent segments
|
| 125 |
+
processed_wave = np.concatenate((processed_wave, segment[:, start:end]), axis=-1)
|
| 126 |
+
|
| 127 |
+
else:
|
| 128 |
+
processed_wave = []
|
| 129 |
+
sample_count = wave.shape[-1]
|
| 130 |
+
|
| 131 |
+
if chunk_size <= 0 or chunk_size > sample_count:
|
| 132 |
+
chunk_size = sample_count
|
| 133 |
+
|
| 134 |
+
if margin_size > chunk_size:
|
| 135 |
+
margin_size = chunk_size
|
| 136 |
+
|
| 137 |
+
for segment_count, skip in enumerate(range(0, sample_count, chunk_size)):
|
| 138 |
+
|
| 139 |
+
margin = 0 if segment_count == 0 else margin_size
|
| 140 |
+
end = min(skip + chunk_size + margin_size, sample_count)
|
| 141 |
+
start = skip - margin
|
| 142 |
+
|
| 143 |
+
cut = wave[:, start:end].copy()
|
| 144 |
+
processed_wave.append(cut)
|
| 145 |
+
|
| 146 |
+
if end == sample_count:
|
| 147 |
+
break
|
| 148 |
+
|
| 149 |
+
return processed_wave
|
| 150 |
+
|
| 151 |
+
def pad_wave(self, wave):
|
| 152 |
+
"""
|
| 153 |
+
Pad the wave array to match the required chunk size
|
| 154 |
+
|
| 155 |
+
Args:
|
| 156 |
+
wave: (np.array) Wave array to be padded
|
| 157 |
+
|
| 158 |
+
Returns:
|
| 159 |
+
tuple: (padded_wave, pad, trim)
|
| 160 |
+
- padded_wave: Padded wave array
|
| 161 |
+
- pad: Number of samples that were padded
|
| 162 |
+
- trim: Number of samples that were trimmed
|
| 163 |
+
"""
|
| 164 |
+
n_sample = wave.shape[1]
|
| 165 |
+
trim = self.model.n_fft // 2
|
| 166 |
+
gen_size = self.model.chunk_size - 2 * trim
|
| 167 |
+
pad = gen_size - n_sample % gen_size
|
| 168 |
+
|
| 169 |
+
# Padded wave
|
| 170 |
+
wave_p = np.concatenate((np.zeros((2, trim)), wave, np.zeros((2, pad)), np.zeros((2, trim))), 1)
|
| 171 |
+
|
| 172 |
+
mix_waves = []
|
| 173 |
+
for i in range(0, n_sample + pad, gen_size):
|
| 174 |
+
waves = np.array(wave_p[:, i:i + self.model.chunk_size])
|
| 175 |
+
mix_waves.append(waves)
|
| 176 |
+
|
| 177 |
+
# print(self.device)
|
| 178 |
+
|
| 179 |
+
mix_waves = torch.tensor(mix_waves, dtype=torch.float32).to(self.device)
|
| 180 |
+
|
| 181 |
+
return mix_waves, pad, trim
|
| 182 |
+
|
| 183 |
+
def _process_wave(self, mix_waves, trim, pad, q: queue.Queue, _id: int):
|
| 184 |
+
"""
|
| 185 |
+
Process each wave segment in a multi-threaded environment
|
| 186 |
+
|
| 187 |
+
Args:
|
| 188 |
+
mix_waves: (torch.Tensor) Wave segments to be processed
|
| 189 |
+
trim: (int) Number of samples trimmed during padding
|
| 190 |
+
pad: (int) Number of samples padded during padding
|
| 191 |
+
q: (queue.Queue) Queue to hold the processed wave segments
|
| 192 |
+
_id: (int) Identifier of the processed wave segment
|
| 193 |
+
|
| 194 |
+
Returns:
|
| 195 |
+
numpy array: Processed wave segment
|
| 196 |
+
"""
|
| 197 |
+
mix_waves = mix_waves.split(1)
|
| 198 |
+
with torch.no_grad():
|
| 199 |
+
pw = []
|
| 200 |
+
for mix_wave in mix_waves:
|
| 201 |
+
self.prog.update()
|
| 202 |
+
spec = self.model.stft(mix_wave)
|
| 203 |
+
processed_spec = torch.tensor(self.process(spec))
|
| 204 |
+
processed_wav = self.model.istft(processed_spec.to(self.device))
|
| 205 |
+
processed_wav = processed_wav[:, :, trim:-trim].transpose(0, 1).reshape(2, -1).cpu().numpy()
|
| 206 |
+
pw.append(processed_wav)
|
| 207 |
+
processed_signal = np.concatenate(pw, axis=-1)[:, :-pad]
|
| 208 |
+
q.put({_id: processed_signal})
|
| 209 |
+
return processed_signal
|
| 210 |
+
|
| 211 |
+
def process_wave(self, wave: np.array, mt_threads=1):
|
| 212 |
+
"""
|
| 213 |
+
Process the wave array in a multi-threaded environment
|
| 214 |
+
|
| 215 |
+
Args:
|
| 216 |
+
wave: (np.array) Wave array to be processed
|
| 217 |
+
mt_threads: (int) Number of threads to be used for processing
|
| 218 |
+
|
| 219 |
+
Returns:
|
| 220 |
+
numpy array: Processed wave array
|
| 221 |
+
"""
|
| 222 |
+
self.prog = tqdm(total=0)
|
| 223 |
+
chunk = wave.shape[-1] // mt_threads
|
| 224 |
+
waves = self.segment(wave, False, chunk)
|
| 225 |
+
|
| 226 |
+
# Create a queue to hold the processed wave segments
|
| 227 |
+
q = queue.Queue()
|
| 228 |
+
threads = []
|
| 229 |
+
for c, batch in enumerate(waves):
|
| 230 |
+
mix_waves, pad, trim = self.pad_wave(batch)
|
| 231 |
+
self.prog.total = len(mix_waves) * mt_threads
|
| 232 |
+
thread = threading.Thread(target=self._process_wave, args=(mix_waves, trim, pad, q, c))
|
| 233 |
+
thread.start()
|
| 234 |
+
threads.append(thread)
|
| 235 |
+
for thread in threads:
|
| 236 |
+
thread.join()
|
| 237 |
+
self.prog.close()
|
| 238 |
+
|
| 239 |
+
processed_batches = []
|
| 240 |
+
while not q.empty():
|
| 241 |
+
processed_batches.append(q.get())
|
| 242 |
+
processed_batches = [list(wave.values())[0] for wave in
|
| 243 |
+
sorted(processed_batches, key=lambda d: list(d.keys())[0])]
|
| 244 |
+
assert len(processed_batches) == len(waves), 'Incomplete processed batches, please reduce batch size!'
|
| 245 |
+
return self.segment(processed_batches, True, chunk)
|
| 246 |
+
|
| 247 |
+
|
| 248 |
+
def run_mdx(model_params, output_dir, model_path, filename, exclude_main=False, exclude_inversion=False, suffix=None, invert_suffix=None, denoise=False, keep_orig=True, m_threads=2, base_device="cuda"):
|
| 249 |
+
|
| 250 |
+
if base_device == "cuda" and torch.cuda.is_available():
|
| 251 |
+
device = torch.device("cuda:0")
|
| 252 |
+
device_properties = torch.cuda.get_device_properties(device)
|
| 253 |
+
vram_gb = device_properties.total_memory / 1024**3
|
| 254 |
+
m_threads = 1 if vram_gb < 8 else (8 if vram_gb > 32 else 2)
|
| 255 |
+
print(f"threads: {m_threads} vram: {vram_gb}")
|
| 256 |
+
processor_num = 0
|
| 257 |
+
else:
|
| 258 |
+
device = torch.device("cpu")
|
| 259 |
+
m_threads = 2
|
| 260 |
+
if torch.cuda.is_available():
|
| 261 |
+
m_threads = 16
|
| 262 |
+
print(f"threads: {m_threads}")
|
| 263 |
+
processor_num = -1
|
| 264 |
+
|
| 265 |
+
model_hash = MDX.get_hash(model_path)
|
| 266 |
+
mp = model_params.get(model_hash)
|
| 267 |
+
model = MDXModel(
|
| 268 |
+
device,
|
| 269 |
+
dim_f=mp["mdx_dim_f_set"],
|
| 270 |
+
dim_t=2 ** mp["mdx_dim_t_set"],
|
| 271 |
+
n_fft=mp["mdx_n_fft_scale_set"],
|
| 272 |
+
stem_name=mp["primary_stem"],
|
| 273 |
+
compensation=mp["compensate"]
|
| 274 |
+
)
|
| 275 |
+
|
| 276 |
+
mdx_sess = MDX(model_path, model, processor=processor_num)
|
| 277 |
+
wave, sr = librosa.load(filename, mono=False, sr=44100)
|
| 278 |
+
# normalizing input wave gives better output
|
| 279 |
+
peak = max(np.max(wave), abs(np.min(wave)))
|
| 280 |
+
wave /= peak
|
| 281 |
+
if denoise:
|
| 282 |
+
wave_processed = -(mdx_sess.process_wave(-wave, m_threads)) + (mdx_sess.process_wave(wave, m_threads))
|
| 283 |
+
wave_processed *= 0.5
|
| 284 |
+
else:
|
| 285 |
+
wave_processed = mdx_sess.process_wave(wave, m_threads)
|
| 286 |
+
# return to previous peak
|
| 287 |
+
wave_processed *= peak
|
| 288 |
+
stem_name = model.stem_name if suffix is None else suffix
|
| 289 |
+
|
| 290 |
+
main_filepath = None
|
| 291 |
+
if not exclude_main:
|
| 292 |
+
main_filepath = os.path.join(output_dir, f"{os.path.basename(os.path.splitext(filename)[0])}_{stem_name}.wav")
|
| 293 |
+
sf.write(main_filepath, wave_processed.T, sr)
|
| 294 |
+
|
| 295 |
+
invert_filepath = None
|
| 296 |
+
if not exclude_inversion:
|
| 297 |
+
diff_stem_name = stem_naming.get(stem_name) if invert_suffix is None else invert_suffix
|
| 298 |
+
stem_name = f"{stem_name}_diff" if diff_stem_name is None else diff_stem_name
|
| 299 |
+
invert_filepath = os.path.join(output_dir, f"{os.path.basename(os.path.splitext(filename)[0])}_{stem_name}.wav")
|
| 300 |
+
sf.write(invert_filepath, (-wave_processed.T * model.compensation) + wave.T, sr)
|
| 301 |
+
|
| 302 |
+
if not keep_orig:
|
| 303 |
+
os.remove(filename)
|
| 304 |
+
|
| 305 |
+
del mdx_sess, wave_processed, wave
|
| 306 |
+
gc.collect()
|
| 307 |
+
return main_filepath, invert_filepath
|
src/my_utils.py
ADDED
|
@@ -0,0 +1,21 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import ffmpeg
|
| 2 |
+
import numpy as np
|
| 3 |
+
|
| 4 |
+
|
| 5 |
+
def load_audio(file, sr):
|
| 6 |
+
try:
|
| 7 |
+
# https://github.com/openai/whisper/blob/main/whisper/audio.py#L26
|
| 8 |
+
# This launches a subprocess to decode audio while down-mixing and resampling as necessary.
|
| 9 |
+
# Requires the ffmpeg CLI and `ffmpeg-python` package to be installed.
|
| 10 |
+
file = (
|
| 11 |
+
file.strip(" ").strip('"').strip("\n").strip('"').strip(" ")
|
| 12 |
+
) # 防止小白拷路径头尾带了空格和"和回车
|
| 13 |
+
out, _ = (
|
| 14 |
+
ffmpeg.input(file, threads=0)
|
| 15 |
+
.output("-", format="f32le", acodec="pcm_f32le", ac=1, ar=sr)
|
| 16 |
+
.run(cmd=["ffmpeg", "-nostdin"], capture_stdout=True, capture_stderr=True)
|
| 17 |
+
)
|
| 18 |
+
except Exception as e:
|
| 19 |
+
raise RuntimeError(f"Failed to load audio: {e}")
|
| 20 |
+
|
| 21 |
+
return np.frombuffer(out, np.float32).flatten()
|
src/rmvpe.py
ADDED
|
@@ -0,0 +1,422 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import torch, numpy as np
|
| 2 |
+
import torch.nn as nn
|
| 3 |
+
import torch.nn.functional as F
|
| 4 |
+
|
| 5 |
+
|
| 6 |
+
|
| 7 |
+
class BiGRU(nn.Module):
|
| 8 |
+
def __init__(self, input_features, hidden_features, num_layers):
|
| 9 |
+
super(BiGRU, self).__init__()
|
| 10 |
+
self.gru = nn.GRU(
|
| 11 |
+
input_features,
|
| 12 |
+
hidden_features,
|
| 13 |
+
num_layers=num_layers,
|
| 14 |
+
batch_first=True,
|
| 15 |
+
bidirectional=True,
|
| 16 |
+
)
|
| 17 |
+
|
| 18 |
+
def forward(self, x):
|
| 19 |
+
return self.gru(x)[0]
|
| 20 |
+
|
| 21 |
+
|
| 22 |
+
class ConvBlockRes(nn.Module):
|
| 23 |
+
def __init__(self, in_channels, out_channels, momentum=0.01):
|
| 24 |
+
super(ConvBlockRes, self).__init__()
|
| 25 |
+
self.conv = nn.Sequential(
|
| 26 |
+
nn.Conv2d(
|
| 27 |
+
in_channels=in_channels,
|
| 28 |
+
out_channels=out_channels,
|
| 29 |
+
kernel_size=(3, 3),
|
| 30 |
+
stride=(1, 1),
|
| 31 |
+
padding=(1, 1),
|
| 32 |
+
bias=False,
|
| 33 |
+
),
|
| 34 |
+
nn.BatchNorm2d(out_channels, momentum=momentum),
|
| 35 |
+
nn.ReLU(),
|
| 36 |
+
nn.Conv2d(
|
| 37 |
+
in_channels=out_channels,
|
| 38 |
+
out_channels=out_channels,
|
| 39 |
+
kernel_size=(3, 3),
|
| 40 |
+
stride=(1, 1),
|
| 41 |
+
padding=(1, 1),
|
| 42 |
+
bias=False,
|
| 43 |
+
),
|
| 44 |
+
nn.BatchNorm2d(out_channels, momentum=momentum),
|
| 45 |
+
nn.ReLU(),
|
| 46 |
+
)
|
| 47 |
+
if in_channels != out_channels:
|
| 48 |
+
self.shortcut = nn.Conv2d(in_channels, out_channels, (1, 1))
|
| 49 |
+
self.is_shortcut = True
|
| 50 |
+
else:
|
| 51 |
+
self.is_shortcut = False
|
| 52 |
+
|
| 53 |
+
def forward(self, x):
|
| 54 |
+
if self.is_shortcut:
|
| 55 |
+
return self.conv(x) + self.shortcut(x)
|
| 56 |
+
else:
|
| 57 |
+
return self.conv(x) + x
|
| 58 |
+
|
| 59 |
+
|
| 60 |
+
class Encoder(nn.Module):
|
| 61 |
+
def __init__(
|
| 62 |
+
self,
|
| 63 |
+
in_channels,
|
| 64 |
+
in_size,
|
| 65 |
+
n_encoders,
|
| 66 |
+
kernel_size,
|
| 67 |
+
n_blocks,
|
| 68 |
+
out_channels=16,
|
| 69 |
+
momentum=0.01,
|
| 70 |
+
):
|
| 71 |
+
super(Encoder, self).__init__()
|
| 72 |
+
self.n_encoders = n_encoders
|
| 73 |
+
self.bn = nn.BatchNorm2d(in_channels, momentum=momentum)
|
| 74 |
+
self.layers = nn.ModuleList()
|
| 75 |
+
self.latent_channels = []
|
| 76 |
+
for i in range(self.n_encoders):
|
| 77 |
+
self.layers.append(
|
| 78 |
+
ResEncoderBlock(
|
| 79 |
+
in_channels, out_channels, kernel_size, n_blocks, momentum=momentum
|
| 80 |
+
)
|
| 81 |
+
)
|
| 82 |
+
self.latent_channels.append([out_channels, in_size])
|
| 83 |
+
in_channels = out_channels
|
| 84 |
+
out_channels *= 2
|
| 85 |
+
in_size //= 2
|
| 86 |
+
self.out_size = in_size
|
| 87 |
+
self.out_channel = out_channels
|
| 88 |
+
|
| 89 |
+
def forward(self, x):
|
| 90 |
+
concat_tensors = []
|
| 91 |
+
x = self.bn(x)
|
| 92 |
+
for i in range(self.n_encoders):
|
| 93 |
+
_, x = self.layers[i](x)
|
| 94 |
+
concat_tensors.append(_)
|
| 95 |
+
return x, concat_tensors
|
| 96 |
+
|
| 97 |
+
|
| 98 |
+
class ResEncoderBlock(nn.Module):
|
| 99 |
+
def __init__(
|
| 100 |
+
self, in_channels, out_channels, kernel_size, n_blocks=1, momentum=0.01
|
| 101 |
+
):
|
| 102 |
+
super(ResEncoderBlock, self).__init__()
|
| 103 |
+
self.n_blocks = n_blocks
|
| 104 |
+
self.conv = nn.ModuleList()
|
| 105 |
+
self.conv.append(ConvBlockRes(in_channels, out_channels, momentum))
|
| 106 |
+
for i in range(n_blocks - 1):
|
| 107 |
+
self.conv.append(ConvBlockRes(out_channels, out_channels, momentum))
|
| 108 |
+
self.kernel_size = kernel_size
|
| 109 |
+
if self.kernel_size is not None:
|
| 110 |
+
self.pool = nn.AvgPool2d(kernel_size=kernel_size)
|
| 111 |
+
|
| 112 |
+
def forward(self, x):
|
| 113 |
+
for i in range(self.n_blocks):
|
| 114 |
+
x = self.conv[i](x)
|
| 115 |
+
if self.kernel_size is not None:
|
| 116 |
+
return x, self.pool(x)
|
| 117 |
+
else:
|
| 118 |
+
return x
|
| 119 |
+
|
| 120 |
+
|
| 121 |
+
class Intermediate(nn.Module): #
|
| 122 |
+
def __init__(self, in_channels, out_channels, n_inters, n_blocks, momentum=0.01):
|
| 123 |
+
super(Intermediate, self).__init__()
|
| 124 |
+
self.n_inters = n_inters
|
| 125 |
+
self.layers = nn.ModuleList()
|
| 126 |
+
self.layers.append(
|
| 127 |
+
ResEncoderBlock(in_channels, out_channels, None, n_blocks, momentum)
|
| 128 |
+
)
|
| 129 |
+
for i in range(self.n_inters - 1):
|
| 130 |
+
self.layers.append(
|
| 131 |
+
ResEncoderBlock(out_channels, out_channels, None, n_blocks, momentum)
|
| 132 |
+
)
|
| 133 |
+
|
| 134 |
+
def forward(self, x):
|
| 135 |
+
for i in range(self.n_inters):
|
| 136 |
+
x = self.layers[i](x)
|
| 137 |
+
return x
|
| 138 |
+
|
| 139 |
+
|
| 140 |
+
class ResDecoderBlock(nn.Module):
|
| 141 |
+
def __init__(self, in_channels, out_channels, stride, n_blocks=1, momentum=0.01):
|
| 142 |
+
super(ResDecoderBlock, self).__init__()
|
| 143 |
+
out_padding = (0, 1) if stride == (1, 2) else (1, 1)
|
| 144 |
+
self.n_blocks = n_blocks
|
| 145 |
+
self.conv1 = nn.Sequential(
|
| 146 |
+
nn.ConvTranspose2d(
|
| 147 |
+
in_channels=in_channels,
|
| 148 |
+
out_channels=out_channels,
|
| 149 |
+
kernel_size=(3, 3),
|
| 150 |
+
stride=stride,
|
| 151 |
+
padding=(1, 1),
|
| 152 |
+
output_padding=out_padding,
|
| 153 |
+
bias=False,
|
| 154 |
+
),
|
| 155 |
+
nn.BatchNorm2d(out_channels, momentum=momentum),
|
| 156 |
+
nn.ReLU(),
|
| 157 |
+
)
|
| 158 |
+
self.conv2 = nn.ModuleList()
|
| 159 |
+
self.conv2.append(ConvBlockRes(out_channels * 2, out_channels, momentum))
|
| 160 |
+
for i in range(n_blocks - 1):
|
| 161 |
+
self.conv2.append(ConvBlockRes(out_channels, out_channels, momentum))
|
| 162 |
+
|
| 163 |
+
def forward(self, x, concat_tensor):
|
| 164 |
+
x = self.conv1(x)
|
| 165 |
+
x = torch.cat((x, concat_tensor), dim=1)
|
| 166 |
+
for i in range(self.n_blocks):
|
| 167 |
+
x = self.conv2[i](x)
|
| 168 |
+
return x
|
| 169 |
+
|
| 170 |
+
|
| 171 |
+
class Decoder(nn.Module):
|
| 172 |
+
def __init__(self, in_channels, n_decoders, stride, n_blocks, momentum=0.01):
|
| 173 |
+
super(Decoder, self).__init__()
|
| 174 |
+
self.layers = nn.ModuleList()
|
| 175 |
+
self.n_decoders = n_decoders
|
| 176 |
+
for i in range(self.n_decoders):
|
| 177 |
+
out_channels = in_channels // 2
|
| 178 |
+
self.layers.append(
|
| 179 |
+
ResDecoderBlock(in_channels, out_channels, stride, n_blocks, momentum)
|
| 180 |
+
)
|
| 181 |
+
in_channels = out_channels
|
| 182 |
+
|
| 183 |
+
def forward(self, x, concat_tensors):
|
| 184 |
+
for i in range(self.n_decoders):
|
| 185 |
+
x = self.layers[i](x, concat_tensors[-1 - i])
|
| 186 |
+
return x
|
| 187 |
+
|
| 188 |
+
|
| 189 |
+
class DeepUnet(nn.Module):
|
| 190 |
+
def __init__(
|
| 191 |
+
self,
|
| 192 |
+
kernel_size,
|
| 193 |
+
n_blocks,
|
| 194 |
+
en_de_layers=5,
|
| 195 |
+
inter_layers=4,
|
| 196 |
+
in_channels=1,
|
| 197 |
+
en_out_channels=16,
|
| 198 |
+
):
|
| 199 |
+
super(DeepUnet, self).__init__()
|
| 200 |
+
self.encoder = Encoder(
|
| 201 |
+
in_channels, 128, en_de_layers, kernel_size, n_blocks, en_out_channels
|
| 202 |
+
)
|
| 203 |
+
self.intermediate = Intermediate(
|
| 204 |
+
self.encoder.out_channel // 2,
|
| 205 |
+
self.encoder.out_channel,
|
| 206 |
+
inter_layers,
|
| 207 |
+
n_blocks,
|
| 208 |
+
)
|
| 209 |
+
self.decoder = Decoder(
|
| 210 |
+
self.encoder.out_channel, en_de_layers, kernel_size, n_blocks
|
| 211 |
+
)
|
| 212 |
+
|
| 213 |
+
def forward(self, x):
|
| 214 |
+
x, concat_tensors = self.encoder(x)
|
| 215 |
+
x = self.intermediate(x)
|
| 216 |
+
x = self.decoder(x, concat_tensors)
|
| 217 |
+
return x
|
| 218 |
+
|
| 219 |
+
|
| 220 |
+
class E2E(nn.Module):
|
| 221 |
+
def __init__(
|
| 222 |
+
self,
|
| 223 |
+
n_blocks,
|
| 224 |
+
n_gru,
|
| 225 |
+
kernel_size,
|
| 226 |
+
en_de_layers=5,
|
| 227 |
+
inter_layers=4,
|
| 228 |
+
in_channels=1,
|
| 229 |
+
en_out_channels=16,
|
| 230 |
+
):
|
| 231 |
+
super(E2E, self).__init__()
|
| 232 |
+
self.unet = DeepUnet(
|
| 233 |
+
kernel_size,
|
| 234 |
+
n_blocks,
|
| 235 |
+
en_de_layers,
|
| 236 |
+
inter_layers,
|
| 237 |
+
in_channels,
|
| 238 |
+
en_out_channels,
|
| 239 |
+
)
|
| 240 |
+
self.cnn = nn.Conv2d(en_out_channels, 3, (3, 3), padding=(1, 1))
|
| 241 |
+
if n_gru:
|
| 242 |
+
self.fc = nn.Sequential(
|
| 243 |
+
BiGRU(3 * 128, 256, n_gru),
|
| 244 |
+
nn.Linear(512, 360),
|
| 245 |
+
nn.Dropout(0.25),
|
| 246 |
+
nn.Sigmoid(),
|
| 247 |
+
)
|
| 248 |
+
else:
|
| 249 |
+
self.fc = nn.Sequential(
|
| 250 |
+
nn.Linear(3 * nn.N_MELS, nn.N_CLASS), nn.Dropout(0.25), nn.Sigmoid()
|
| 251 |
+
)
|
| 252 |
+
|
| 253 |
+
def forward(self, mel):
|
| 254 |
+
mel = mel.transpose(-1, -2).unsqueeze(1)
|
| 255 |
+
x = self.cnn(self.unet(mel)).transpose(1, 2).flatten(-2)
|
| 256 |
+
x = self.fc(x)
|
| 257 |
+
return x
|
| 258 |
+
|
| 259 |
+
|
| 260 |
+
from librosa.filters import mel
|
| 261 |
+
|
| 262 |
+
|
| 263 |
+
class MelSpectrogram(torch.nn.Module):
|
| 264 |
+
def __init__(
|
| 265 |
+
self,
|
| 266 |
+
is_half,
|
| 267 |
+
n_mel_channels,
|
| 268 |
+
sampling_rate,
|
| 269 |
+
win_length,
|
| 270 |
+
hop_length,
|
| 271 |
+
n_fft=None,
|
| 272 |
+
mel_fmin=0,
|
| 273 |
+
mel_fmax=None,
|
| 274 |
+
clamp=1e-5,
|
| 275 |
+
):
|
| 276 |
+
super().__init__()
|
| 277 |
+
n_fft = win_length if n_fft is None else n_fft
|
| 278 |
+
self.hann_window = {}
|
| 279 |
+
mel_basis = mel(
|
| 280 |
+
sr=sampling_rate,
|
| 281 |
+
n_fft=n_fft,
|
| 282 |
+
n_mels=n_mel_channels,
|
| 283 |
+
fmin=mel_fmin,
|
| 284 |
+
fmax=mel_fmax,
|
| 285 |
+
htk=True,
|
| 286 |
+
)
|
| 287 |
+
mel_basis = torch.from_numpy(mel_basis).float()
|
| 288 |
+
self.register_buffer("mel_basis", mel_basis)
|
| 289 |
+
self.n_fft = win_length if n_fft is None else n_fft
|
| 290 |
+
self.hop_length = hop_length
|
| 291 |
+
self.win_length = win_length
|
| 292 |
+
self.sampling_rate = sampling_rate
|
| 293 |
+
self.n_mel_channels = n_mel_channels
|
| 294 |
+
self.clamp = clamp
|
| 295 |
+
self.is_half = is_half
|
| 296 |
+
|
| 297 |
+
def forward(self, audio, keyshift=0, speed=1, center=True):
|
| 298 |
+
factor = 2 ** (keyshift / 12)
|
| 299 |
+
n_fft_new = int(np.round(self.n_fft * factor))
|
| 300 |
+
win_length_new = int(np.round(self.win_length * factor))
|
| 301 |
+
hop_length_new = int(np.round(self.hop_length * speed))
|
| 302 |
+
keyshift_key = str(keyshift) + "_" + str(audio.device)
|
| 303 |
+
if keyshift_key not in self.hann_window:
|
| 304 |
+
self.hann_window[keyshift_key] = torch.hann_window(win_length_new).to(
|
| 305 |
+
audio.device
|
| 306 |
+
)
|
| 307 |
+
fft = torch.stft(
|
| 308 |
+
audio,
|
| 309 |
+
n_fft=n_fft_new,
|
| 310 |
+
hop_length=hop_length_new,
|
| 311 |
+
win_length=win_length_new,
|
| 312 |
+
window=self.hann_window[keyshift_key],
|
| 313 |
+
center=center,
|
| 314 |
+
return_complex=True,
|
| 315 |
+
)
|
| 316 |
+
magnitude = torch.sqrt(fft.real.pow(2) + fft.imag.pow(2))
|
| 317 |
+
if keyshift != 0:
|
| 318 |
+
size = self.n_fft // 2 + 1
|
| 319 |
+
resize = magnitude.size(1)
|
| 320 |
+
if resize < size:
|
| 321 |
+
magnitude = F.pad(magnitude, (0, 0, 0, size - resize))
|
| 322 |
+
magnitude = magnitude[:, :size, :] * self.win_length / win_length_new
|
| 323 |
+
mel_output = torch.matmul(self.mel_basis, magnitude)
|
| 324 |
+
if self.is_half == True:
|
| 325 |
+
mel_output = mel_output.half()
|
| 326 |
+
log_mel_spec = torch.log(torch.clamp(mel_output, min=self.clamp))
|
| 327 |
+
return log_mel_spec
|
| 328 |
+
|
| 329 |
+
|
| 330 |
+
class RMVPE:
|
| 331 |
+
def __init__(self, model_path, is_half, device=None):
|
| 332 |
+
self.resample_kernel = {}
|
| 333 |
+
model = E2E(4, 1, (2, 2))
|
| 334 |
+
ckpt = torch.load(model_path, map_location="cpu")
|
| 335 |
+
model.load_state_dict(ckpt)
|
| 336 |
+
model.eval()
|
| 337 |
+
if is_half == True:
|
| 338 |
+
model = model.half()
|
| 339 |
+
self.model = model
|
| 340 |
+
self.resample_kernel = {}
|
| 341 |
+
self.is_half = is_half
|
| 342 |
+
if device is None:
|
| 343 |
+
device = "cuda" if torch.cuda.is_available() else "cpu"
|
| 344 |
+
self.device = device
|
| 345 |
+
self.mel_extractor = MelSpectrogram(
|
| 346 |
+
is_half, 128, 16000, 1024, 160, None, 30, 8000
|
| 347 |
+
).to(device)
|
| 348 |
+
self.model = self.model.to(device)
|
| 349 |
+
cents_mapping = 20 * np.arange(360) + 1997.3794084376191
|
| 350 |
+
self.cents_mapping = np.pad(cents_mapping, (4, 4)) # 368
|
| 351 |
+
|
| 352 |
+
def mel2hidden(self, mel):
|
| 353 |
+
with torch.no_grad():
|
| 354 |
+
n_frames = mel.shape[-1]
|
| 355 |
+
mel = F.pad(
|
| 356 |
+
mel, (0, 32 * ((n_frames - 1) // 32 + 1) - n_frames), mode="reflect"
|
| 357 |
+
)
|
| 358 |
+
hidden = self.model(mel)
|
| 359 |
+
return hidden[:, :n_frames]
|
| 360 |
+
|
| 361 |
+
def decode(self, hidden, thred=0.03):
|
| 362 |
+
cents_pred = self.to_local_average_cents(hidden, thred=thred)
|
| 363 |
+
f0 = 10 * (2 ** (cents_pred / 1200))
|
| 364 |
+
f0[f0 == 10] = 0
|
| 365 |
+
# f0 = np.array([10 * (2 ** (cent_pred / 1200)) if cent_pred else 0 for cent_pred in cents_pred])
|
| 366 |
+
return f0
|
| 367 |
+
|
| 368 |
+
def infer_from_audio(self, audio, thred=0.03):
|
| 369 |
+
audio = torch.from_numpy(audio).float().to(self.device).unsqueeze(0)
|
| 370 |
+
# torch.cuda.synchronize()
|
| 371 |
+
# t0=ttime()
|
| 372 |
+
mel = self.mel_extractor(audio, center=True)
|
| 373 |
+
# torch.cuda.synchronize()
|
| 374 |
+
# t1=ttime()
|
| 375 |
+
hidden = self.mel2hidden(mel)
|
| 376 |
+
# torch.cuda.synchronize()
|
| 377 |
+
# t2=ttime()
|
| 378 |
+
hidden = hidden.squeeze(0).cpu().numpy()
|
| 379 |
+
if self.is_half == True:
|
| 380 |
+
hidden = hidden.astype("float32")
|
| 381 |
+
f0 = self.decode(hidden, thred=thred)
|
| 382 |
+
# torch.cuda.synchronize()
|
| 383 |
+
# t3=ttime()
|
| 384 |
+
# print("hmvpe:%s\t%s\t%s\t%s"%(t1-t0,t2-t1,t3-t2,t3-t0))
|
| 385 |
+
return f0
|
| 386 |
+
|
| 387 |
+
def pitch_based_audio_inference(self, audio, thred=0.03, f0_min=50, f0_max=1100):
|
| 388 |
+
audio = torch.from_numpy(audio).float().to(self.device).unsqueeze(0)
|
| 389 |
+
mel = self.mel_extractor(audio, center=True)
|
| 390 |
+
hidden = self.mel2hidden(mel)
|
| 391 |
+
hidden = hidden.squeeze(0).cpu().numpy()
|
| 392 |
+
if self.is_half == True:
|
| 393 |
+
hidden = hidden.astype("float32")
|
| 394 |
+
f0 = self.decode(hidden, thred=thred)
|
| 395 |
+
f0[(f0 < f0_min) | (f0 > f0_max)] = 0
|
| 396 |
+
return f0
|
| 397 |
+
|
| 398 |
+
def to_local_average_cents(self, salience, thred=0.05):
|
| 399 |
+
# t0 = ttime()
|
| 400 |
+
center = np.argmax(salience, axis=1) # frame length#index
|
| 401 |
+
salience = np.pad(salience, ((0, 0), (4, 4))) # frame length,368
|
| 402 |
+
# t1 = ttime()
|
| 403 |
+
center += 4
|
| 404 |
+
todo_salience = []
|
| 405 |
+
todo_cents_mapping = []
|
| 406 |
+
starts = center - 4
|
| 407 |
+
ends = center + 5
|
| 408 |
+
for idx in range(salience.shape[0]):
|
| 409 |
+
todo_salience.append(salience[:, starts[idx] : ends[idx]][idx])
|
| 410 |
+
todo_cents_mapping.append(self.cents_mapping[starts[idx] : ends[idx]])
|
| 411 |
+
# t2 = ttime()
|
| 412 |
+
todo_salience = np.array(todo_salience) # frame length,9
|
| 413 |
+
todo_cents_mapping = np.array(todo_cents_mapping) # frame length,9
|
| 414 |
+
product_sum = np.sum(todo_salience * todo_cents_mapping, 1)
|
| 415 |
+
weight_sum = np.sum(todo_salience, 1) # frame length
|
| 416 |
+
devided = product_sum / weight_sum # frame length
|
| 417 |
+
# t3 = ttime()
|
| 418 |
+
maxx = np.max(salience, axis=1) # frame length
|
| 419 |
+
devided[maxx <= thred] = 0
|
| 420 |
+
# t4 = ttime()
|
| 421 |
+
# print("decode:%s\t%s\t%s\t%s" % (t1 - t0, t2 - t1, t3 - t2, t4 - t3))
|
| 422 |
+
return devided
|
src/rvc.py
ADDED
|
@@ -0,0 +1,165 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from multiprocessing import cpu_count
|
| 2 |
+
from pathlib import Path
|
| 3 |
+
import torch
|
| 4 |
+
from scipy.io import wavfile
|
| 5 |
+
from infer_pack.models import (
|
| 6 |
+
SynthesizerTrnMs256NSFsid,
|
| 7 |
+
SynthesizerTrnMs256NSFsid_nono,
|
| 8 |
+
SynthesizerTrnMs768NSFsid,
|
| 9 |
+
SynthesizerTrnMs768NSFsid_nono,
|
| 10 |
+
)
|
| 11 |
+
from my_utils import load_audio
|
| 12 |
+
from vc_infer_pipeline import VC
|
| 13 |
+
|
| 14 |
+
BASE_DIR = Path(__file__).resolve().parent.parent
|
| 15 |
+
|
| 16 |
+
|
| 17 |
+
# config cpu
|
| 18 |
+
def use_fp32_config():
|
| 19 |
+
for config_file in [
|
| 20 |
+
"32k.json",
|
| 21 |
+
"40k.json",
|
| 22 |
+
"48k.json",
|
| 23 |
+
"48k_v2.json",
|
| 24 |
+
"32k_v2.json",
|
| 25 |
+
]:
|
| 26 |
+
with open(f"src/configs/{config_file}", "r") as f:
|
| 27 |
+
strr = f.read().replace("true", "false")
|
| 28 |
+
with open(f"src/configs/{config_file}", "w") as f:
|
| 29 |
+
f.write(strr)
|
| 30 |
+
|
| 31 |
+
class Config:
|
| 32 |
+
def __init__(self, device, is_half):
|
| 33 |
+
self.device = device
|
| 34 |
+
self.is_half = is_half
|
| 35 |
+
self.n_cpu = 2 # set cpu cores
|
| 36 |
+
self.gpu_name = None
|
| 37 |
+
self.gpu_mem = None
|
| 38 |
+
self.x_pad, self.x_query, self.x_center, self.x_max = self.device_config()
|
| 39 |
+
|
| 40 |
+
def device_config(self) -> tuple:
|
| 41 |
+
if torch.cuda.is_available():
|
| 42 |
+
i_device = int(self.device.split(":")[-1])
|
| 43 |
+
self.gpu_name = torch.cuda.get_device_name(i_device)
|
| 44 |
+
if (
|
| 45 |
+
("16" in self.gpu_name and "V100" not in self.gpu_name.upper())
|
| 46 |
+
or "P40" in self.gpu_name.upper()
|
| 47 |
+
or "1060" in self.gpu_name
|
| 48 |
+
or "1070" in self.gpu_name
|
| 49 |
+
or "1080" in self.gpu_name
|
| 50 |
+
):
|
| 51 |
+
print("16 series/10 series P40 forced single precision")
|
| 52 |
+
self.is_half = False
|
| 53 |
+
for config_file in ["32k.json", "40k.json", "48k.json"]:
|
| 54 |
+
with open(BASE_DIR / "src" / "configs" / config_file, "r") as f:
|
| 55 |
+
strr = f.read().replace("true", "false")
|
| 56 |
+
with open(BASE_DIR / "src" / "configs" / config_file, "w") as f:
|
| 57 |
+
f.write(strr)
|
| 58 |
+
with open(BASE_DIR / "src" / "trainset_preprocess_pipeline_print.py", "r") as f:
|
| 59 |
+
strr = f.read().replace("3.7", "3.0")
|
| 60 |
+
with open(BASE_DIR / "src" / "trainset_preprocess_pipeline_print.py", "w") as f:
|
| 61 |
+
f.write(strr)
|
| 62 |
+
else:
|
| 63 |
+
self.gpu_name = None
|
| 64 |
+
self.gpu_mem = int(
|
| 65 |
+
torch.cuda.get_device_properties(i_device).total_memory
|
| 66 |
+
/ 1024
|
| 67 |
+
/ 1024
|
| 68 |
+
/ 1024
|
| 69 |
+
+ 0.4
|
| 70 |
+
)
|
| 71 |
+
if self.gpu_mem <= 4:
|
| 72 |
+
with open(BASE_DIR / "src" / "trainset_preprocess_pipeline_print.py", "r") as f:
|
| 73 |
+
strr = f.read().replace("3.7", "3.0")
|
| 74 |
+
with open(BASE_DIR / "src" / "trainset_preprocess_pipeline_print.py", "w") as f:
|
| 75 |
+
f.write(strr)
|
| 76 |
+
elif torch.backends.mps.is_available():
|
| 77 |
+
print("No supported N-card found, use MPS for inference")
|
| 78 |
+
self.device = "mps"
|
| 79 |
+
else:
|
| 80 |
+
print("No supported N-card found, use CPU for inference")
|
| 81 |
+
self.device = "cpu"
|
| 82 |
+
self.is_half = False
|
| 83 |
+
use_fp32_config() # cpu config
|
| 84 |
+
|
| 85 |
+
if self.n_cpu == 0:
|
| 86 |
+
self.n_cpu = cpu_count()
|
| 87 |
+
|
| 88 |
+
if self.is_half:
|
| 89 |
+
# 6G memory config
|
| 90 |
+
x_pad = 3
|
| 91 |
+
x_query = 10
|
| 92 |
+
x_center = 60
|
| 93 |
+
x_max = 65
|
| 94 |
+
else:
|
| 95 |
+
# 5G memory config
|
| 96 |
+
x_pad = 1
|
| 97 |
+
x_query = 6
|
| 98 |
+
x_center = 38
|
| 99 |
+
x_max = 41
|
| 100 |
+
|
| 101 |
+
if self.gpu_mem != None and self.gpu_mem <= 4:
|
| 102 |
+
x_pad = 1
|
| 103 |
+
x_query = 5
|
| 104 |
+
x_center = 30
|
| 105 |
+
x_max = 32
|
| 106 |
+
|
| 107 |
+
return x_pad, x_query, x_center, x_max
|
| 108 |
+
|
| 109 |
+
|
| 110 |
+
def load_hubert(device, is_half, model_path):
|
| 111 |
+
from fairseq import checkpoint_utils
|
| 112 |
+
|
| 113 |
+
models, saved_cfg, task = checkpoint_utils.load_model_ensemble_and_task([model_path], suffix='', )
|
| 114 |
+
hubert = models[0]
|
| 115 |
+
hubert = hubert.to(device)
|
| 116 |
+
|
| 117 |
+
if is_half:
|
| 118 |
+
hubert = hubert.half()
|
| 119 |
+
else:
|
| 120 |
+
hubert = hubert.float()
|
| 121 |
+
|
| 122 |
+
hubert.eval()
|
| 123 |
+
return hubert
|
| 124 |
+
|
| 125 |
+
|
| 126 |
+
def get_vc(device, is_half, config, model_path):
|
| 127 |
+
cpt = torch.load(model_path, map_location='cpu')
|
| 128 |
+
if "config" not in cpt or "weight" not in cpt:
|
| 129 |
+
raise ValueError(f'Incorrect format for {model_path}. Use a voice model trained using RVC v2 instead.')
|
| 130 |
+
|
| 131 |
+
tgt_sr = cpt["config"][-1]
|
| 132 |
+
cpt["config"][-3] = cpt["weight"]["emb_g.weight"].shape[0]
|
| 133 |
+
if_f0 = cpt.get("f0", 1)
|
| 134 |
+
version = cpt.get("version", "v1")
|
| 135 |
+
|
| 136 |
+
if version == "v1":
|
| 137 |
+
if if_f0 == 1:
|
| 138 |
+
net_g = SynthesizerTrnMs256NSFsid(*cpt["config"], is_half=is_half)
|
| 139 |
+
else:
|
| 140 |
+
net_g = SynthesizerTrnMs256NSFsid_nono(*cpt["config"])
|
| 141 |
+
elif version == "v2":
|
| 142 |
+
if if_f0 == 1:
|
| 143 |
+
net_g = SynthesizerTrnMs768NSFsid(*cpt["config"], is_half=is_half)
|
| 144 |
+
else:
|
| 145 |
+
net_g = SynthesizerTrnMs768NSFsid_nono(*cpt["config"])
|
| 146 |
+
|
| 147 |
+
del net_g.enc_q
|
| 148 |
+
print(net_g.load_state_dict(cpt["weight"], strict=False))
|
| 149 |
+
net_g.eval().to(device)
|
| 150 |
+
|
| 151 |
+
if is_half:
|
| 152 |
+
net_g = net_g.half()
|
| 153 |
+
else:
|
| 154 |
+
net_g = net_g.float()
|
| 155 |
+
|
| 156 |
+
vc = VC(tgt_sr, config)
|
| 157 |
+
return cpt, version, net_g, tgt_sr, vc
|
| 158 |
+
|
| 159 |
+
|
| 160 |
+
def rvc_infer(index_path, index_rate, input_path, output_path, pitch_change, f0_method, cpt, version, net_g, filter_radius, tgt_sr, rms_mix_rate, protect, crepe_hop_length, vc, hubert_model):
|
| 161 |
+
audio = load_audio(input_path, 16000)
|
| 162 |
+
times = [0, 0, 0]
|
| 163 |
+
if_f0 = cpt.get('f0', 1)
|
| 164 |
+
audio_opt = vc.pipeline(hubert_model, net_g, 0, audio, input_path, times, pitch_change, f0_method, index_path, index_rate, if_f0, filter_radius, tgt_sr, 0, rms_mix_rate, version, protect, crepe_hop_length)
|
| 165 |
+
wavfile.write(output_path, tgt_sr, audio_opt)
|
src/trainset_preprocess_pipeline_print.py
ADDED
|
@@ -0,0 +1,146 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import sys, os, multiprocessing
|
| 2 |
+
from scipy import signal
|
| 3 |
+
|
| 4 |
+
now_dir = os.getcwd()
|
| 5 |
+
sys.path.append(now_dir)
|
| 6 |
+
|
| 7 |
+
inp_root = sys.argv[1]
|
| 8 |
+
sr = int(sys.argv[2])
|
| 9 |
+
n_p = int(sys.argv[3])
|
| 10 |
+
exp_dir = sys.argv[4]
|
| 11 |
+
noparallel = sys.argv[5] == "True"
|
| 12 |
+
import numpy as np, os, traceback
|
| 13 |
+
from slicer2 import Slicer
|
| 14 |
+
import librosa, traceback
|
| 15 |
+
from scipy.io import wavfile
|
| 16 |
+
import multiprocessing
|
| 17 |
+
from my_utils import load_audio
|
| 18 |
+
import tqdm
|
| 19 |
+
|
| 20 |
+
DoFormant = False
|
| 21 |
+
Quefrency = 1.0
|
| 22 |
+
Timbre = 1.0
|
| 23 |
+
|
| 24 |
+
mutex = multiprocessing.Lock()
|
| 25 |
+
f = open("%s/preprocess.log" % exp_dir, "a+")
|
| 26 |
+
|
| 27 |
+
|
| 28 |
+
def println(strr):
|
| 29 |
+
mutex.acquire()
|
| 30 |
+
print(strr)
|
| 31 |
+
f.write("%s\n" % strr)
|
| 32 |
+
f.flush()
|
| 33 |
+
mutex.release()
|
| 34 |
+
|
| 35 |
+
|
| 36 |
+
class PreProcess:
|
| 37 |
+
def __init__(self, sr, exp_dir):
|
| 38 |
+
self.slicer = Slicer(
|
| 39 |
+
sr=sr,
|
| 40 |
+
threshold=-42,
|
| 41 |
+
min_length=1500,
|
| 42 |
+
min_interval=400,
|
| 43 |
+
hop_size=15,
|
| 44 |
+
max_sil_kept=500,
|
| 45 |
+
)
|
| 46 |
+
self.sr = sr
|
| 47 |
+
self.bh, self.ah = signal.butter(N=5, Wn=48, btype="high", fs=self.sr)
|
| 48 |
+
self.per = 3.0
|
| 49 |
+
self.overlap = 0.3
|
| 50 |
+
self.tail = self.per + self.overlap
|
| 51 |
+
self.max = 0.9
|
| 52 |
+
self.alpha = 0.75
|
| 53 |
+
self.exp_dir = exp_dir
|
| 54 |
+
self.gt_wavs_dir = "%s/0_gt_wavs" % exp_dir
|
| 55 |
+
self.wavs16k_dir = "%s/1_16k_wavs" % exp_dir
|
| 56 |
+
os.makedirs(self.exp_dir, exist_ok=True)
|
| 57 |
+
os.makedirs(self.gt_wavs_dir, exist_ok=True)
|
| 58 |
+
os.makedirs(self.wavs16k_dir, exist_ok=True)
|
| 59 |
+
|
| 60 |
+
def norm_write(self, tmp_audio, idx0, idx1):
|
| 61 |
+
tmp_max = np.abs(tmp_audio).max()
|
| 62 |
+
if tmp_max > 2.5:
|
| 63 |
+
print("%s-%s-%s-filtered" % (idx0, idx1, tmp_max))
|
| 64 |
+
return
|
| 65 |
+
tmp_audio = (tmp_audio / tmp_max * (self.max * self.alpha)) + (
|
| 66 |
+
1 - self.alpha
|
| 67 |
+
) * tmp_audio
|
| 68 |
+
wavfile.write(
|
| 69 |
+
"%s/%s_%s.wav" % (self.gt_wavs_dir, idx0, idx1),
|
| 70 |
+
self.sr,
|
| 71 |
+
tmp_audio.astype(np.float32),
|
| 72 |
+
)
|
| 73 |
+
tmp_audio = librosa.resample(
|
| 74 |
+
tmp_audio, orig_sr=self.sr, target_sr=16000
|
| 75 |
+
) # , res_type="soxr_vhq"
|
| 76 |
+
wavfile.write(
|
| 77 |
+
"%s/%s_%s.wav" % (self.wavs16k_dir, idx0, idx1),
|
| 78 |
+
16000,
|
| 79 |
+
tmp_audio.astype(np.float32),
|
| 80 |
+
)
|
| 81 |
+
|
| 82 |
+
def pipeline(self, path, idx0):
|
| 83 |
+
try:
|
| 84 |
+
audio = load_audio(path, self.sr, DoFormant, Quefrency, Timbre)
|
| 85 |
+
# zero phased digital filter cause pre-ringing noise...
|
| 86 |
+
# audio = signal.filtfilt(self.bh, self.ah, audio)
|
| 87 |
+
audio = signal.lfilter(self.bh, self.ah, audio)
|
| 88 |
+
|
| 89 |
+
idx1 = 0
|
| 90 |
+
for audio in self.slicer.slice(audio):
|
| 91 |
+
i = 0
|
| 92 |
+
while 1:
|
| 93 |
+
start = int(self.sr * (self.per - self.overlap) * i)
|
| 94 |
+
i += 1
|
| 95 |
+
if len(audio[start:]) > self.tail * self.sr:
|
| 96 |
+
tmp_audio = audio[start : start + int(self.per * self.sr)]
|
| 97 |
+
self.norm_write(tmp_audio, idx0, idx1)
|
| 98 |
+
idx1 += 1
|
| 99 |
+
else:
|
| 100 |
+
tmp_audio = audio[start:]
|
| 101 |
+
idx1 += 1
|
| 102 |
+
break
|
| 103 |
+
self.norm_write(tmp_audio, idx0, idx1)
|
| 104 |
+
# println("%s->Suc." % path)
|
| 105 |
+
except:
|
| 106 |
+
println("%s->%s" % (path, traceback.format_exc()))
|
| 107 |
+
|
| 108 |
+
def pipeline_mp(self, infos, thread_n):
|
| 109 |
+
for path, idx0 in tqdm.tqdm(
|
| 110 |
+
infos, position=thread_n, leave=True, desc="thread:%s" % thread_n
|
| 111 |
+
):
|
| 112 |
+
self.pipeline(path, idx0)
|
| 113 |
+
|
| 114 |
+
def pipeline_mp_inp_dir(self, inp_root, n_p):
|
| 115 |
+
try:
|
| 116 |
+
infos = [
|
| 117 |
+
("%s/%s" % (inp_root, name), idx)
|
| 118 |
+
for idx, name in enumerate(sorted(list(os.listdir(inp_root))))
|
| 119 |
+
]
|
| 120 |
+
if noparallel:
|
| 121 |
+
for i in range(n_p):
|
| 122 |
+
self.pipeline_mp(infos[i::n_p])
|
| 123 |
+
else:
|
| 124 |
+
ps = []
|
| 125 |
+
for i in range(n_p):
|
| 126 |
+
p = multiprocessing.Process(
|
| 127 |
+
target=self.pipeline_mp, args=(infos[i::n_p], i)
|
| 128 |
+
)
|
| 129 |
+
ps.append(p)
|
| 130 |
+
p.start()
|
| 131 |
+
for i in range(n_p):
|
| 132 |
+
ps[i].join()
|
| 133 |
+
except:
|
| 134 |
+
println("Fail. %s" % traceback.format_exc())
|
| 135 |
+
|
| 136 |
+
|
| 137 |
+
def preprocess_trainset(inp_root, sr, n_p, exp_dir):
|
| 138 |
+
pp = PreProcess(sr, exp_dir)
|
| 139 |
+
println("start preprocess")
|
| 140 |
+
println(sys.argv)
|
| 141 |
+
pp.pipeline_mp_inp_dir(inp_root, n_p)
|
| 142 |
+
println("end preprocess")
|
| 143 |
+
|
| 144 |
+
|
| 145 |
+
if __name__ == "__main__":
|
| 146 |
+
preprocess_trainset(inp_root, sr, n_p, exp_dir)
|
src/vc_infer_pipeline.py
ADDED
|
@@ -0,0 +1,657 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from functools import lru_cache
|
| 2 |
+
from time import time as ttime
|
| 3 |
+
import faiss
|
| 4 |
+
import librosa
|
| 5 |
+
import numpy as np
|
| 6 |
+
import os
|
| 7 |
+
import parselmouth
|
| 8 |
+
import pyworld
|
| 9 |
+
import sys
|
| 10 |
+
import torch
|
| 11 |
+
import torch.nn.functional as F
|
| 12 |
+
import torchcrepe
|
| 13 |
+
import traceback
|
| 14 |
+
from scipy import signal
|
| 15 |
+
from torch import Tensor
|
| 16 |
+
|
| 17 |
+
BASE_DIR = os.path.dirname(os.path.dirname(os.path.abspath(__file__)))
|
| 18 |
+
now_dir = os.path.join(BASE_DIR, 'src')
|
| 19 |
+
sys.path.append(now_dir)
|
| 20 |
+
|
| 21 |
+
bh, ah = signal.butter(N=5, Wn=48, btype="high", fs=16000)
|
| 22 |
+
|
| 23 |
+
input_audio_path2wav = {}
|
| 24 |
+
|
| 25 |
+
|
| 26 |
+
@lru_cache
|
| 27 |
+
def cache_harvest_f0(input_audio_path, fs, f0max, f0min, frame_period):
|
| 28 |
+
audio = input_audio_path2wav[input_audio_path]
|
| 29 |
+
f0, t = pyworld.harvest(
|
| 30 |
+
audio,
|
| 31 |
+
fs=fs,
|
| 32 |
+
f0_ceil=f0max,
|
| 33 |
+
f0_floor=f0min,
|
| 34 |
+
frame_period=frame_period,
|
| 35 |
+
)
|
| 36 |
+
f0 = pyworld.stonemask(audio, f0, t, fs)
|
| 37 |
+
return f0
|
| 38 |
+
|
| 39 |
+
|
| 40 |
+
def change_rms(data1, sr1, data2, sr2, rate): # 1是输入音频,2是输出音频,rate是2的占比
|
| 41 |
+
# print(data1.max(),data2.max())
|
| 42 |
+
rms1 = librosa.feature.rms(
|
| 43 |
+
y=data1, frame_length=sr1 // 2 * 2, hop_length=sr1 // 2
|
| 44 |
+
) # 每半秒一个点
|
| 45 |
+
rms2 = librosa.feature.rms(y=data2, frame_length=sr2 // 2 * 2, hop_length=sr2 // 2)
|
| 46 |
+
rms1 = torch.from_numpy(rms1)
|
| 47 |
+
rms1 = F.interpolate(
|
| 48 |
+
rms1.unsqueeze(0), size=data2.shape[0], mode="linear"
|
| 49 |
+
).squeeze()
|
| 50 |
+
rms2 = torch.from_numpy(rms2)
|
| 51 |
+
rms2 = F.interpolate(
|
| 52 |
+
rms2.unsqueeze(0), size=data2.shape[0], mode="linear"
|
| 53 |
+
).squeeze()
|
| 54 |
+
rms2 = torch.max(rms2, torch.zeros_like(rms2) + 1e-6)
|
| 55 |
+
data2 *= (
|
| 56 |
+
torch.pow(rms1, torch.tensor(1 - rate))
|
| 57 |
+
* torch.pow(rms2, torch.tensor(rate - 1))
|
| 58 |
+
).numpy()
|
| 59 |
+
return data2
|
| 60 |
+
|
| 61 |
+
|
| 62 |
+
class VC(object):
|
| 63 |
+
def __init__(self, tgt_sr, config):
|
| 64 |
+
self.x_pad, self.x_query, self.x_center, self.x_max, self.is_half = (
|
| 65 |
+
config.x_pad,
|
| 66 |
+
config.x_query,
|
| 67 |
+
config.x_center,
|
| 68 |
+
config.x_max,
|
| 69 |
+
config.is_half,
|
| 70 |
+
)
|
| 71 |
+
self.sr = 16000 # hubert输入采样率
|
| 72 |
+
self.window = 160 # 每帧点数
|
| 73 |
+
self.t_pad = self.sr * self.x_pad # 每条前后pad时间
|
| 74 |
+
self.t_pad_tgt = tgt_sr * self.x_pad
|
| 75 |
+
self.t_pad2 = self.t_pad * 2
|
| 76 |
+
self.t_query = self.sr * self.x_query # 查询切点前后查询时间
|
| 77 |
+
self.t_center = self.sr * self.x_center # 查询切点位置
|
| 78 |
+
self.t_max = self.sr * self.x_max # 免查询时长阈值
|
| 79 |
+
self.device = config.device
|
| 80 |
+
|
| 81 |
+
# Fork Feature: Get the best torch device to use for f0 algorithms that require a torch device. Will return the type (torch.device)
|
| 82 |
+
def get_optimal_torch_device(self, index: int = 0) -> torch.device:
|
| 83 |
+
# Get cuda device
|
| 84 |
+
if torch.cuda.is_available():
|
| 85 |
+
return torch.device(
|
| 86 |
+
f"cuda:{index % torch.cuda.device_count()}"
|
| 87 |
+
) # Very fast
|
| 88 |
+
elif torch.backends.mps.is_available():
|
| 89 |
+
return torch.device("mps")
|
| 90 |
+
# Insert an else here to grab "xla" devices if available. TO DO later. Requires the torch_xla.core.xla_model library
|
| 91 |
+
# Else wise return the "cpu" as a torch device,
|
| 92 |
+
return torch.device("cpu")
|
| 93 |
+
|
| 94 |
+
# Fork Feature: Compute f0 with the crepe method
|
| 95 |
+
def get_f0_crepe_computation(
|
| 96 |
+
self,
|
| 97 |
+
x,
|
| 98 |
+
f0_min,
|
| 99 |
+
f0_max,
|
| 100 |
+
p_len,
|
| 101 |
+
hop_length=160, # 512 before. Hop length changes the speed that the voice jumps to a different dramatic pitch. Lower hop lengths means more pitch accuracy but longer inference time.
|
| 102 |
+
model="full", # Either use crepe-tiny "tiny" or crepe "full". Default is full
|
| 103 |
+
):
|
| 104 |
+
x = x.astype(
|
| 105 |
+
np.float32
|
| 106 |
+
) # fixes the F.conv2D exception. We needed to convert double to float.
|
| 107 |
+
x /= np.quantile(np.abs(x), 0.999)
|
| 108 |
+
torch_device = self.get_optimal_torch_device()
|
| 109 |
+
audio = torch.from_numpy(x).to(torch_device, copy=True)
|
| 110 |
+
audio = torch.unsqueeze(audio, dim=0)
|
| 111 |
+
if audio.ndim == 2 and audio.shape[0] > 1:
|
| 112 |
+
audio = torch.mean(audio, dim=0, keepdim=True).detach()
|
| 113 |
+
audio = audio.detach()
|
| 114 |
+
print("Initiating prediction with a crepe_hop_length of: " + str(hop_length))
|
| 115 |
+
pitch: Tensor = torchcrepe.predict(
|
| 116 |
+
audio,
|
| 117 |
+
self.sr,
|
| 118 |
+
hop_length,
|
| 119 |
+
f0_min,
|
| 120 |
+
f0_max,
|
| 121 |
+
model,
|
| 122 |
+
batch_size=hop_length * 2,
|
| 123 |
+
device=torch_device,
|
| 124 |
+
pad=True,
|
| 125 |
+
)
|
| 126 |
+
p_len = p_len or x.shape[0] // hop_length
|
| 127 |
+
# Resize the pitch for final f0
|
| 128 |
+
source = np.array(pitch.squeeze(0).cpu().float().numpy())
|
| 129 |
+
source[source < 0.001] = np.nan
|
| 130 |
+
target = np.interp(
|
| 131 |
+
np.arange(0, len(source) * p_len, len(source)) / p_len,
|
| 132 |
+
np.arange(0, len(source)),
|
| 133 |
+
source,
|
| 134 |
+
)
|
| 135 |
+
f0 = np.nan_to_num(target)
|
| 136 |
+
return f0 # Resized f0
|
| 137 |
+
|
| 138 |
+
def get_f0_official_crepe_computation(
|
| 139 |
+
self,
|
| 140 |
+
x,
|
| 141 |
+
f0_min,
|
| 142 |
+
f0_max,
|
| 143 |
+
model="full",
|
| 144 |
+
):
|
| 145 |
+
# Pick a batch size that doesn't cause memory errors on your gpu
|
| 146 |
+
batch_size = 512
|
| 147 |
+
# Compute pitch using first gpu
|
| 148 |
+
audio = torch.tensor(np.copy(x))[None].float()
|
| 149 |
+
f0, pd = torchcrepe.predict(
|
| 150 |
+
audio,
|
| 151 |
+
self.sr,
|
| 152 |
+
self.window,
|
| 153 |
+
f0_min,
|
| 154 |
+
f0_max,
|
| 155 |
+
model,
|
| 156 |
+
batch_size=batch_size,
|
| 157 |
+
device=self.device,
|
| 158 |
+
return_periodicity=True,
|
| 159 |
+
)
|
| 160 |
+
pd = torchcrepe.filter.median(pd, 3)
|
| 161 |
+
f0 = torchcrepe.filter.mean(f0, 3)
|
| 162 |
+
f0[pd < 0.1] = 0
|
| 163 |
+
f0 = f0[0].cpu().numpy()
|
| 164 |
+
return f0
|
| 165 |
+
|
| 166 |
+
# Fork Feature: Compute pYIN f0 method
|
| 167 |
+
def get_f0_pyin_computation(self, x, f0_min, f0_max):
|
| 168 |
+
y, sr = librosa.load("saudio/Sidney.wav", self.sr, mono=True)
|
| 169 |
+
f0, _, _ = librosa.pyin(y, sr=self.sr, fmin=f0_min, fmax=f0_max)
|
| 170 |
+
f0 = f0[1:] # Get rid of extra first frame
|
| 171 |
+
return f0
|
| 172 |
+
|
| 173 |
+
# Fork Feature: Acquire median hybrid f0 estimation calculation
|
| 174 |
+
def get_f0_hybrid_computation(
|
| 175 |
+
self,
|
| 176 |
+
methods_str,
|
| 177 |
+
input_audio_path,
|
| 178 |
+
x,
|
| 179 |
+
f0_min,
|
| 180 |
+
f0_max,
|
| 181 |
+
p_len,
|
| 182 |
+
filter_radius,
|
| 183 |
+
crepe_hop_length,
|
| 184 |
+
time_step,
|
| 185 |
+
):
|
| 186 |
+
# Get various f0 methods from input to use in the computation stack
|
| 187 |
+
s = methods_str
|
| 188 |
+
s = s.split("hybrid")[1]
|
| 189 |
+
s = s.replace("[", "").replace("]", "")
|
| 190 |
+
methods = s.split("+")
|
| 191 |
+
f0_computation_stack = []
|
| 192 |
+
|
| 193 |
+
print("Calculating f0 pitch estimations for methods: %s" % str(methods))
|
| 194 |
+
x = x.astype(np.float32)
|
| 195 |
+
x /= np.quantile(np.abs(x), 0.999)
|
| 196 |
+
# Get f0 calculations for all methods specified
|
| 197 |
+
for method in methods:
|
| 198 |
+
f0 = None
|
| 199 |
+
if method == "pm":
|
| 200 |
+
f0 = (
|
| 201 |
+
parselmouth.Sound(x, self.sr)
|
| 202 |
+
.to_pitch_ac(
|
| 203 |
+
time_step=time_step / 1000,
|
| 204 |
+
voicing_threshold=0.6,
|
| 205 |
+
pitch_floor=f0_min,
|
| 206 |
+
pitch_ceiling=f0_max,
|
| 207 |
+
)
|
| 208 |
+
.selected_array["frequency"]
|
| 209 |
+
)
|
| 210 |
+
pad_size = (p_len - len(f0) + 1) // 2
|
| 211 |
+
if pad_size > 0 or p_len - len(f0) - pad_size > 0:
|
| 212 |
+
f0 = np.pad(
|
| 213 |
+
f0, [[pad_size, p_len - len(f0) - pad_size]], mode="constant"
|
| 214 |
+
)
|
| 215 |
+
elif method == "crepe":
|
| 216 |
+
f0 = self.get_f0_official_crepe_computation(x, f0_min, f0_max)
|
| 217 |
+
f0 = f0[1:] # Get rid of extra first frame
|
| 218 |
+
elif method == "crepe-tiny":
|
| 219 |
+
f0 = self.get_f0_official_crepe_computation(x, f0_min, f0_max, "tiny")
|
| 220 |
+
f0 = f0[1:] # Get rid of extra first frame
|
| 221 |
+
elif method == "mangio-crepe":
|
| 222 |
+
f0 = self.get_f0_crepe_computation(
|
| 223 |
+
x, f0_min, f0_max, p_len, crepe_hop_length
|
| 224 |
+
)
|
| 225 |
+
elif method == "mangio-crepe-tiny":
|
| 226 |
+
f0 = self.get_f0_crepe_computation(
|
| 227 |
+
x, f0_min, f0_max, p_len, crepe_hop_length, "tiny"
|
| 228 |
+
)
|
| 229 |
+
elif method == "harvest":
|
| 230 |
+
f0 = cache_harvest_f0(input_audio_path, self.sr, f0_max, f0_min, 10)
|
| 231 |
+
if filter_radius > 2:
|
| 232 |
+
f0 = signal.medfilt(f0, 3)
|
| 233 |
+
f0 = f0[1:] # Get rid of first frame.
|
| 234 |
+
elif method == "dio": # Potentially buggy?
|
| 235 |
+
f0, t = pyworld.dio(
|
| 236 |
+
x.astype(np.double),
|
| 237 |
+
fs=self.sr,
|
| 238 |
+
f0_ceil=f0_max,
|
| 239 |
+
f0_floor=f0_min,
|
| 240 |
+
frame_period=10,
|
| 241 |
+
)
|
| 242 |
+
f0 = pyworld.stonemask(x.astype(np.double), f0, t, self.sr)
|
| 243 |
+
f0 = signal.medfilt(f0, 3)
|
| 244 |
+
f0 = f0[1:]
|
| 245 |
+
# elif method == "pyin": Not Working just yet
|
| 246 |
+
# f0 = self.get_f0_pyin_computation(x, f0_min, f0_max)
|
| 247 |
+
# Push method to the stack
|
| 248 |
+
f0_computation_stack.append(f0)
|
| 249 |
+
|
| 250 |
+
for fc in f0_computation_stack:
|
| 251 |
+
print(len(fc))
|
| 252 |
+
|
| 253 |
+
print("Calculating hybrid median f0 from the stack of: %s" % str(methods))
|
| 254 |
+
f0_median_hybrid = None
|
| 255 |
+
if len(f0_computation_stack) == 1:
|
| 256 |
+
f0_median_hybrid = f0_computation_stack[0]
|
| 257 |
+
else:
|
| 258 |
+
f0_median_hybrid = np.nanmedian(f0_computation_stack, axis=0)
|
| 259 |
+
return f0_median_hybrid
|
| 260 |
+
|
| 261 |
+
def get_f0(
|
| 262 |
+
self,
|
| 263 |
+
input_audio_path,
|
| 264 |
+
x,
|
| 265 |
+
p_len,
|
| 266 |
+
f0_up_key,
|
| 267 |
+
f0_method,
|
| 268 |
+
filter_radius,
|
| 269 |
+
crepe_hop_length,
|
| 270 |
+
inp_f0=None,
|
| 271 |
+
):
|
| 272 |
+
global input_audio_path2wav
|
| 273 |
+
time_step = self.window / self.sr * 1000
|
| 274 |
+
f0_min = 50
|
| 275 |
+
f0_max = 1100
|
| 276 |
+
f0_mel_min = 1127 * np.log(1 + f0_min / 700)
|
| 277 |
+
f0_mel_max = 1127 * np.log(1 + f0_max / 700)
|
| 278 |
+
if f0_method == "pm":
|
| 279 |
+
f0 = (
|
| 280 |
+
parselmouth.Sound(x, self.sr)
|
| 281 |
+
.to_pitch_ac(
|
| 282 |
+
time_step=time_step / 1000,
|
| 283 |
+
voicing_threshold=0.6,
|
| 284 |
+
pitch_floor=f0_min,
|
| 285 |
+
pitch_ceiling=f0_max,
|
| 286 |
+
)
|
| 287 |
+
.selected_array["frequency"]
|
| 288 |
+
)
|
| 289 |
+
pad_size = (p_len - len(f0) + 1) // 2
|
| 290 |
+
if pad_size > 0 or p_len - len(f0) - pad_size > 0:
|
| 291 |
+
f0 = np.pad(
|
| 292 |
+
f0, [[pad_size, p_len - len(f0) - pad_size]], mode="constant"
|
| 293 |
+
)
|
| 294 |
+
elif f0_method == "harvest":
|
| 295 |
+
input_audio_path2wav[input_audio_path] = x.astype(np.double)
|
| 296 |
+
f0 = cache_harvest_f0(input_audio_path, self.sr, f0_max, f0_min, 10)
|
| 297 |
+
if filter_radius > 2:
|
| 298 |
+
f0 = signal.medfilt(f0, 3)
|
| 299 |
+
elif f0_method == "dio": # Potentially Buggy?
|
| 300 |
+
f0, t = pyworld.dio(
|
| 301 |
+
x.astype(np.double),
|
| 302 |
+
fs=self.sr,
|
| 303 |
+
f0_ceil=f0_max,
|
| 304 |
+
f0_floor=f0_min,
|
| 305 |
+
frame_period=10,
|
| 306 |
+
)
|
| 307 |
+
f0 = pyworld.stonemask(x.astype(np.double), f0, t, self.sr)
|
| 308 |
+
f0 = signal.medfilt(f0, 3)
|
| 309 |
+
elif f0_method == "crepe":
|
| 310 |
+
f0 = self.get_f0_official_crepe_computation(x, f0_min, f0_max)
|
| 311 |
+
elif f0_method == "crepe-tiny":
|
| 312 |
+
f0 = self.get_f0_official_crepe_computation(x, f0_min, f0_max, "tiny")
|
| 313 |
+
elif f0_method == "mangio-crepe":
|
| 314 |
+
f0 = self.get_f0_crepe_computation(
|
| 315 |
+
x, f0_min, f0_max, p_len, crepe_hop_length
|
| 316 |
+
)
|
| 317 |
+
elif f0_method == "mangio-crepe-tiny":
|
| 318 |
+
f0 = self.get_f0_crepe_computation(
|
| 319 |
+
x, f0_min, f0_max, p_len, crepe_hop_length, "tiny"
|
| 320 |
+
)
|
| 321 |
+
elif "rmvpe" in f0_method:
|
| 322 |
+
if hasattr(self, "model_rmvpe") == False:
|
| 323 |
+
from rmvpe import RMVPE
|
| 324 |
+
|
| 325 |
+
self.model_rmvpe = RMVPE(
|
| 326 |
+
os.path.join(BASE_DIR, 'rvc_models', 'rmvpe.pt'), is_half=self.is_half, device=self.device
|
| 327 |
+
)
|
| 328 |
+
thred = 0.03
|
| 329 |
+
if "+" in f0_method:
|
| 330 |
+
f0 = self.model_rmvpe.pitch_based_audio_inference(x, thred, f0_min, f0_max)
|
| 331 |
+
else:
|
| 332 |
+
f0 = self.model_rmvpe.infer_from_audio(x, thred)
|
| 333 |
+
elif "hybrid" in f0_method:
|
| 334 |
+
# Perform hybrid median pitch estimation
|
| 335 |
+
input_audio_path2wav[input_audio_path] = x.astype(np.double)
|
| 336 |
+
f0 = self.get_f0_hybrid_computation(
|
| 337 |
+
f0_method,
|
| 338 |
+
input_audio_path,
|
| 339 |
+
x,
|
| 340 |
+
f0_min,
|
| 341 |
+
f0_max,
|
| 342 |
+
p_len,
|
| 343 |
+
filter_radius,
|
| 344 |
+
crepe_hop_length,
|
| 345 |
+
time_step,
|
| 346 |
+
)
|
| 347 |
+
|
| 348 |
+
f0 *= pow(2, f0_up_key / 12)
|
| 349 |
+
# with open("test.txt","w")as f:f.write("\n".join([str(i)for i in f0.tolist()]))
|
| 350 |
+
tf0 = self.sr // self.window # 每秒f0点数
|
| 351 |
+
if inp_f0 is not None:
|
| 352 |
+
delta_t = np.round(
|
| 353 |
+
(inp_f0[:, 0].max() - inp_f0[:, 0].min()) * tf0 + 1
|
| 354 |
+
).astype("int16")
|
| 355 |
+
replace_f0 = np.interp(
|
| 356 |
+
list(range(delta_t)), inp_f0[:, 0] * 100, inp_f0[:, 1]
|
| 357 |
+
)
|
| 358 |
+
shape = f0[self.x_pad * tf0 : self.x_pad * tf0 + len(replace_f0)].shape[0]
|
| 359 |
+
f0[self.x_pad * tf0 : self.x_pad * tf0 + len(replace_f0)] = replace_f0[
|
| 360 |
+
:shape
|
| 361 |
+
]
|
| 362 |
+
# with open("test_opt.txt","w")as f:f.write("\n".join([str(i)for i in f0.tolist()]))
|
| 363 |
+
f0bak = f0.copy()
|
| 364 |
+
f0_mel = 1127 * np.log(1 + f0 / 700)
|
| 365 |
+
f0_mel[f0_mel > 0] = (f0_mel[f0_mel > 0] - f0_mel_min) * 254 / (
|
| 366 |
+
f0_mel_max - f0_mel_min
|
| 367 |
+
) + 1
|
| 368 |
+
f0_mel[f0_mel <= 1] = 1
|
| 369 |
+
f0_mel[f0_mel > 255] = 255
|
| 370 |
+
f0_coarse = np.rint(f0_mel).astype(np.int)
|
| 371 |
+
|
| 372 |
+
return f0_coarse, f0bak # 1-0
|
| 373 |
+
|
| 374 |
+
def vc(
|
| 375 |
+
self,
|
| 376 |
+
model,
|
| 377 |
+
net_g,
|
| 378 |
+
sid,
|
| 379 |
+
audio0,
|
| 380 |
+
pitch,
|
| 381 |
+
pitchf,
|
| 382 |
+
times,
|
| 383 |
+
index,
|
| 384 |
+
big_npy,
|
| 385 |
+
index_rate,
|
| 386 |
+
version,
|
| 387 |
+
protect,
|
| 388 |
+
): # ,file_index,file_big_npy
|
| 389 |
+
feats = torch.from_numpy(audio0)
|
| 390 |
+
if self.is_half:
|
| 391 |
+
feats = feats.half()
|
| 392 |
+
else:
|
| 393 |
+
feats = feats.float()
|
| 394 |
+
if feats.dim() == 2: # double channels
|
| 395 |
+
feats = feats.mean(-1)
|
| 396 |
+
assert feats.dim() == 1, feats.dim()
|
| 397 |
+
feats = feats.view(1, -1)
|
| 398 |
+
padding_mask = torch.BoolTensor(feats.shape).to(self.device).fill_(False)
|
| 399 |
+
|
| 400 |
+
inputs = {
|
| 401 |
+
"source": feats.to(self.device),
|
| 402 |
+
"padding_mask": padding_mask,
|
| 403 |
+
"output_layer": 9 if version == "v1" else 12,
|
| 404 |
+
}
|
| 405 |
+
t0 = ttime()
|
| 406 |
+
with torch.no_grad():
|
| 407 |
+
logits = model.extract_features(**inputs)
|
| 408 |
+
feats = model.final_proj(logits[0]) if version == "v1" else logits[0]
|
| 409 |
+
if protect < 0.5 and pitch != None and pitchf != None:
|
| 410 |
+
feats0 = feats.clone()
|
| 411 |
+
if (
|
| 412 |
+
isinstance(index, type(None)) == False
|
| 413 |
+
and isinstance(big_npy, type(None)) == False
|
| 414 |
+
and index_rate != 0
|
| 415 |
+
):
|
| 416 |
+
npy = feats[0].cpu().numpy()
|
| 417 |
+
if self.is_half:
|
| 418 |
+
npy = npy.astype("float32")
|
| 419 |
+
|
| 420 |
+
# _, I = index.search(npy, 1)
|
| 421 |
+
# npy = big_npy[I.squeeze()]
|
| 422 |
+
|
| 423 |
+
score, ix = index.search(npy, k=8)
|
| 424 |
+
weight = np.square(1 / score)
|
| 425 |
+
weight /= weight.sum(axis=1, keepdims=True)
|
| 426 |
+
npy = np.sum(big_npy[ix] * np.expand_dims(weight, axis=2), axis=1)
|
| 427 |
+
|
| 428 |
+
if self.is_half:
|
| 429 |
+
npy = npy.astype("float16")
|
| 430 |
+
feats = (
|
| 431 |
+
torch.from_numpy(npy).unsqueeze(0).to(self.device) * index_rate
|
| 432 |
+
+ (1 - index_rate) * feats
|
| 433 |
+
)
|
| 434 |
+
|
| 435 |
+
feats = F.interpolate(feats.permute(0, 2, 1), scale_factor=2).permute(0, 2, 1)
|
| 436 |
+
if protect < 0.5 and pitch != None and pitchf != None:
|
| 437 |
+
feats0 = F.interpolate(feats0.permute(0, 2, 1), scale_factor=2).permute(
|
| 438 |
+
0, 2, 1
|
| 439 |
+
)
|
| 440 |
+
t1 = ttime()
|
| 441 |
+
p_len = audio0.shape[0] // self.window
|
| 442 |
+
if feats.shape[1] < p_len:
|
| 443 |
+
p_len = feats.shape[1]
|
| 444 |
+
if pitch != None and pitchf != None:
|
| 445 |
+
pitch = pitch[:, :p_len]
|
| 446 |
+
pitchf = pitchf[:, :p_len]
|
| 447 |
+
|
| 448 |
+
if protect < 0.5 and pitch != None and pitchf != None:
|
| 449 |
+
pitchff = pitchf.clone()
|
| 450 |
+
pitchff[pitchf > 0] = 1
|
| 451 |
+
pitchff[pitchf < 1] = protect
|
| 452 |
+
pitchff = pitchff.unsqueeze(-1)
|
| 453 |
+
feats = feats * pitchff + feats0 * (1 - pitchff)
|
| 454 |
+
feats = feats.to(feats0.dtype)
|
| 455 |
+
p_len = torch.tensor([p_len], device=self.device).long()
|
| 456 |
+
with torch.no_grad():
|
| 457 |
+
if pitch != None and pitchf != None:
|
| 458 |
+
audio1 = (
|
| 459 |
+
(net_g.infer(feats, p_len, pitch, pitchf, sid)[0][0, 0])
|
| 460 |
+
.data.cpu()
|
| 461 |
+
.float()
|
| 462 |
+
.numpy()
|
| 463 |
+
)
|
| 464 |
+
else:
|
| 465 |
+
audio1 = (
|
| 466 |
+
(net_g.infer(feats, p_len, sid)[0][0, 0]).data.cpu().float().numpy()
|
| 467 |
+
)
|
| 468 |
+
del feats, p_len, padding_mask
|
| 469 |
+
if torch.cuda.is_available():
|
| 470 |
+
torch.cuda.empty_cache()
|
| 471 |
+
t2 = ttime()
|
| 472 |
+
times[0] += t1 - t0
|
| 473 |
+
times[2] += t2 - t1
|
| 474 |
+
return audio1
|
| 475 |
+
|
| 476 |
+
def pipeline(
|
| 477 |
+
self,
|
| 478 |
+
model,
|
| 479 |
+
net_g,
|
| 480 |
+
sid,
|
| 481 |
+
audio,
|
| 482 |
+
input_audio_path,
|
| 483 |
+
times,
|
| 484 |
+
f0_up_key,
|
| 485 |
+
f0_method,
|
| 486 |
+
file_index,
|
| 487 |
+
# file_big_npy,
|
| 488 |
+
index_rate,
|
| 489 |
+
if_f0,
|
| 490 |
+
filter_radius,
|
| 491 |
+
tgt_sr,
|
| 492 |
+
resample_sr,
|
| 493 |
+
rms_mix_rate,
|
| 494 |
+
version,
|
| 495 |
+
protect,
|
| 496 |
+
crepe_hop_length,
|
| 497 |
+
f0_file=None,
|
| 498 |
+
):
|
| 499 |
+
if (
|
| 500 |
+
file_index != ""
|
| 501 |
+
# and file_big_npy != ""
|
| 502 |
+
# and os.path.exists(file_big_npy) == True
|
| 503 |
+
and os.path.exists(file_index) == True
|
| 504 |
+
and index_rate != 0
|
| 505 |
+
):
|
| 506 |
+
try:
|
| 507 |
+
index = faiss.read_index(file_index)
|
| 508 |
+
# big_npy = np.load(file_big_npy)
|
| 509 |
+
big_npy = index.reconstruct_n(0, index.ntotal)
|
| 510 |
+
except:
|
| 511 |
+
traceback.print_exc()
|
| 512 |
+
index = big_npy = None
|
| 513 |
+
index_rate = 0
|
| 514 |
+
else:
|
| 515 |
+
index = big_npy = None
|
| 516 |
+
index_rate = 0
|
| 517 |
+
audio = signal.filtfilt(bh, ah, audio)
|
| 518 |
+
audio_pad = np.pad(audio, (self.window // 2, self.window // 2), mode="reflect")
|
| 519 |
+
opt_ts = []
|
| 520 |
+
if audio_pad.shape[0] > self.t_max:
|
| 521 |
+
audio_sum = np.zeros_like(audio)
|
| 522 |
+
for i in range(self.window):
|
| 523 |
+
audio_sum += audio_pad[i : i - self.window]
|
| 524 |
+
for t in range(self.t_center, audio.shape[0], self.t_center):
|
| 525 |
+
opt_ts.append(
|
| 526 |
+
t
|
| 527 |
+
- self.t_query
|
| 528 |
+
+ np.where(
|
| 529 |
+
np.abs(audio_sum[t - self.t_query : t + self.t_query])
|
| 530 |
+
== np.abs(audio_sum[t - self.t_query : t + self.t_query]).min()
|
| 531 |
+
)[0][0]
|
| 532 |
+
)
|
| 533 |
+
s = 0
|
| 534 |
+
audio_opt = []
|
| 535 |
+
t = None
|
| 536 |
+
t1 = ttime()
|
| 537 |
+
audio_pad = np.pad(audio, (self.t_pad, self.t_pad), mode="reflect")
|
| 538 |
+
p_len = audio_pad.shape[0] // self.window
|
| 539 |
+
inp_f0 = None
|
| 540 |
+
if hasattr(f0_file, "name") == True:
|
| 541 |
+
try:
|
| 542 |
+
with open(f0_file.name, "r") as f:
|
| 543 |
+
lines = f.read().strip("\n").split("\n")
|
| 544 |
+
inp_f0 = []
|
| 545 |
+
for line in lines:
|
| 546 |
+
inp_f0.append([float(i) for i in line.split(",")])
|
| 547 |
+
inp_f0 = np.array(inp_f0, dtype="float32")
|
| 548 |
+
except:
|
| 549 |
+
traceback.print_exc()
|
| 550 |
+
sid = torch.tensor(sid, device=self.device).unsqueeze(0).long()
|
| 551 |
+
pitch, pitchf = None, None
|
| 552 |
+
if if_f0 == 1:
|
| 553 |
+
pitch, pitchf = self.get_f0(
|
| 554 |
+
input_audio_path,
|
| 555 |
+
audio_pad,
|
| 556 |
+
p_len,
|
| 557 |
+
f0_up_key,
|
| 558 |
+
f0_method,
|
| 559 |
+
filter_radius,
|
| 560 |
+
crepe_hop_length,
|
| 561 |
+
inp_f0,
|
| 562 |
+
)
|
| 563 |
+
pitch = pitch[:p_len]
|
| 564 |
+
pitchf = pitchf[:p_len]
|
| 565 |
+
if self.device == "mps":
|
| 566 |
+
pitchf = pitchf.astype(np.float32)
|
| 567 |
+
pitch = torch.tensor(pitch, device=self.device).unsqueeze(0).long()
|
| 568 |
+
pitchf = torch.tensor(pitchf, device=self.device).unsqueeze(0).float()
|
| 569 |
+
t2 = ttime()
|
| 570 |
+
times[1] += t2 - t1
|
| 571 |
+
for t in opt_ts:
|
| 572 |
+
t = t // self.window * self.window
|
| 573 |
+
if if_f0 == 1:
|
| 574 |
+
audio_opt.append(
|
| 575 |
+
self.vc(
|
| 576 |
+
model,
|
| 577 |
+
net_g,
|
| 578 |
+
sid,
|
| 579 |
+
audio_pad[s : t + self.t_pad2 + self.window],
|
| 580 |
+
pitch[:, s // self.window : (t + self.t_pad2) // self.window],
|
| 581 |
+
pitchf[:, s // self.window : (t + self.t_pad2) // self.window],
|
| 582 |
+
times,
|
| 583 |
+
index,
|
| 584 |
+
big_npy,
|
| 585 |
+
index_rate,
|
| 586 |
+
version,
|
| 587 |
+
protect,
|
| 588 |
+
)[self.t_pad_tgt : -self.t_pad_tgt]
|
| 589 |
+
)
|
| 590 |
+
else:
|
| 591 |
+
audio_opt.append(
|
| 592 |
+
self.vc(
|
| 593 |
+
model,
|
| 594 |
+
net_g,
|
| 595 |
+
sid,
|
| 596 |
+
audio_pad[s : t + self.t_pad2 + self.window],
|
| 597 |
+
None,
|
| 598 |
+
None,
|
| 599 |
+
times,
|
| 600 |
+
index,
|
| 601 |
+
big_npy,
|
| 602 |
+
index_rate,
|
| 603 |
+
version,
|
| 604 |
+
protect,
|
| 605 |
+
)[self.t_pad_tgt : -self.t_pad_tgt]
|
| 606 |
+
)
|
| 607 |
+
s = t
|
| 608 |
+
if if_f0 == 1:
|
| 609 |
+
audio_opt.append(
|
| 610 |
+
self.vc(
|
| 611 |
+
model,
|
| 612 |
+
net_g,
|
| 613 |
+
sid,
|
| 614 |
+
audio_pad[t:],
|
| 615 |
+
pitch[:, t // self.window :] if t is not None else pitch,
|
| 616 |
+
pitchf[:, t // self.window :] if t is not None else pitchf,
|
| 617 |
+
times,
|
| 618 |
+
index,
|
| 619 |
+
big_npy,
|
| 620 |
+
index_rate,
|
| 621 |
+
version,
|
| 622 |
+
protect,
|
| 623 |
+
)[self.t_pad_tgt : -self.t_pad_tgt]
|
| 624 |
+
)
|
| 625 |
+
else:
|
| 626 |
+
audio_opt.append(
|
| 627 |
+
self.vc(
|
| 628 |
+
model,
|
| 629 |
+
net_g,
|
| 630 |
+
sid,
|
| 631 |
+
audio_pad[t:],
|
| 632 |
+
None,
|
| 633 |
+
None,
|
| 634 |
+
times,
|
| 635 |
+
index,
|
| 636 |
+
big_npy,
|
| 637 |
+
index_rate,
|
| 638 |
+
version,
|
| 639 |
+
protect,
|
| 640 |
+
)[self.t_pad_tgt : -self.t_pad_tgt]
|
| 641 |
+
)
|
| 642 |
+
audio_opt = np.concatenate(audio_opt)
|
| 643 |
+
if rms_mix_rate != 1:
|
| 644 |
+
audio_opt = change_rms(audio, 16000, audio_opt, tgt_sr, rms_mix_rate)
|
| 645 |
+
if resample_sr >= 16000 and tgt_sr != resample_sr:
|
| 646 |
+
audio_opt = librosa.resample(
|
| 647 |
+
audio_opt, orig_sr=tgt_sr, target_sr=resample_sr
|
| 648 |
+
)
|
| 649 |
+
audio_max = np.abs(audio_opt).max() / 0.99
|
| 650 |
+
max_int16 = 32768
|
| 651 |
+
if audio_max > 1:
|
| 652 |
+
max_int16 /= audio_max
|
| 653 |
+
audio_opt = (audio_opt * max_int16).astype(np.int16)
|
| 654 |
+
del pitch, pitchf, sid
|
| 655 |
+
if torch.cuda.is_available():
|
| 656 |
+
torch.cuda.empty_cache()
|
| 657 |
+
return audio_opt
|
src/webui.py
ADDED
|
@@ -0,0 +1,334 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import json
|
| 2 |
+
import os
|
| 3 |
+
import shutil
|
| 4 |
+
import urllib.request
|
| 5 |
+
import zipfile
|
| 6 |
+
from argparse import ArgumentParser
|
| 7 |
+
import spaces
|
| 8 |
+
import gradio as gr
|
| 9 |
+
|
| 10 |
+
from main import song_cover_pipeline
|
| 11 |
+
|
| 12 |
+
BASE_DIR = os.path.dirname(os.path.dirname(os.path.abspath(__file__)))
|
| 13 |
+
|
| 14 |
+
mdxnet_models_dir = os.path.join(BASE_DIR, 'mdxnet_models')
|
| 15 |
+
rvc_models_dir = os.path.join(BASE_DIR, 'rvc_models')
|
| 16 |
+
output_dir = os.path.join(BASE_DIR, 'song_output')
|
| 17 |
+
|
| 18 |
+
|
| 19 |
+
def get_current_models(models_dir):
|
| 20 |
+
models_list = os.listdir(models_dir)
|
| 21 |
+
items_to_remove = ['hubert_base.pt', 'MODELS.txt', 'public_models.json', 'rmvpe.pt']
|
| 22 |
+
return [item for item in models_list if item not in items_to_remove]
|
| 23 |
+
|
| 24 |
+
|
| 25 |
+
def update_models_list():
|
| 26 |
+
models_l = get_current_models(rvc_models_dir)
|
| 27 |
+
return gr.update(choices=models_l)
|
| 28 |
+
|
| 29 |
+
|
| 30 |
+
def load_public_models():
|
| 31 |
+
models_table = []
|
| 32 |
+
for model in public_models['voice_models']:
|
| 33 |
+
if not model['name'] in voice_models:
|
| 34 |
+
model = [model['name'], model['description'], model['credit'], model['url'], ', '.join(model['tags'])]
|
| 35 |
+
models_table.append(model)
|
| 36 |
+
|
| 37 |
+
tags = list(public_models['tags'].keys())
|
| 38 |
+
return gr.update(value=models_table), gr.update(choices=tags)
|
| 39 |
+
|
| 40 |
+
|
| 41 |
+
def extract_zip(extraction_folder, zip_name):
|
| 42 |
+
os.makedirs(extraction_folder)
|
| 43 |
+
with zipfile.ZipFile(zip_name, 'r') as zip_ref:
|
| 44 |
+
zip_ref.extractall(extraction_folder)
|
| 45 |
+
os.remove(zip_name)
|
| 46 |
+
|
| 47 |
+
index_filepath, model_filepath = None, None
|
| 48 |
+
for root, dirs, files in os.walk(extraction_folder):
|
| 49 |
+
for name in files:
|
| 50 |
+
if name.endswith('.index') and os.stat(os.path.join(root, name)).st_size > 1024 * 100:
|
| 51 |
+
index_filepath = os.path.join(root, name)
|
| 52 |
+
|
| 53 |
+
if name.endswith('.pth') and os.stat(os.path.join(root, name)).st_size > 1024 * 1024 * 40:
|
| 54 |
+
model_filepath = os.path.join(root, name)
|
| 55 |
+
|
| 56 |
+
if not model_filepath:
|
| 57 |
+
raise gr.Error(f'No .pth model file was found in the extracted zip. Please check {extraction_folder}.')
|
| 58 |
+
|
| 59 |
+
# move model and index file to extraction folder
|
| 60 |
+
os.rename(model_filepath, os.path.join(extraction_folder, os.path.basename(model_filepath)))
|
| 61 |
+
if index_filepath:
|
| 62 |
+
os.rename(index_filepath, os.path.join(extraction_folder, os.path.basename(index_filepath)))
|
| 63 |
+
|
| 64 |
+
# remove any unnecessary nested folders
|
| 65 |
+
for filepath in os.listdir(extraction_folder):
|
| 66 |
+
if os.path.isdir(os.path.join(extraction_folder, filepath)):
|
| 67 |
+
shutil.rmtree(os.path.join(extraction_folder, filepath))
|
| 68 |
+
|
| 69 |
+
|
| 70 |
+
def download_online_model(url, dir_name, progress=gr.Progress()):
|
| 71 |
+
try:
|
| 72 |
+
progress(0, desc=f'[~] Downloading voice model with name {dir_name}...')
|
| 73 |
+
zip_name = url.split('/')[-1]
|
| 74 |
+
extraction_folder = os.path.join(rvc_models_dir, dir_name)
|
| 75 |
+
if os.path.exists(extraction_folder):
|
| 76 |
+
raise gr.Error(f'Voice model directory {dir_name} already exists! Choose a different name for your voice model.')
|
| 77 |
+
|
| 78 |
+
if 'pixeldrain.com' in url:
|
| 79 |
+
url = f'https://pixeldrain.com/api/file/{zip_name}'
|
| 80 |
+
|
| 81 |
+
urllib.request.urlretrieve(url, zip_name)
|
| 82 |
+
|
| 83 |
+
progress(0.5, desc='[~] Extracting zip...')
|
| 84 |
+
extract_zip(extraction_folder, zip_name)
|
| 85 |
+
return f'[+] {dir_name} Model successfully downloaded!'
|
| 86 |
+
|
| 87 |
+
except Exception as e:
|
| 88 |
+
raise gr.Error(str(e))
|
| 89 |
+
|
| 90 |
+
|
| 91 |
+
def upload_local_model(zip_path, dir_name, progress=gr.Progress()):
|
| 92 |
+
try:
|
| 93 |
+
extraction_folder = os.path.join(rvc_models_dir, dir_name)
|
| 94 |
+
if os.path.exists(extraction_folder):
|
| 95 |
+
raise gr.Error(f'Voice model directory {dir_name} already exists! Choose a different name for your voice model.')
|
| 96 |
+
|
| 97 |
+
zip_name = zip_path.name
|
| 98 |
+
progress(0.5, desc='[~] Extracting zip...')
|
| 99 |
+
extract_zip(extraction_folder, zip_name)
|
| 100 |
+
return f'[+] {dir_name} Model successfully uploaded!'
|
| 101 |
+
|
| 102 |
+
except Exception as e:
|
| 103 |
+
raise gr.Error(str(e))
|
| 104 |
+
|
| 105 |
+
|
| 106 |
+
def filter_models(tags, query):
|
| 107 |
+
models_table = []
|
| 108 |
+
|
| 109 |
+
# no filter
|
| 110 |
+
if len(tags) == 0 and len(query) == 0:
|
| 111 |
+
for model in public_models['voice_models']:
|
| 112 |
+
models_table.append([model['name'], model['description'], model['credit'], model['url'], model['tags']])
|
| 113 |
+
|
| 114 |
+
# filter based on tags and query
|
| 115 |
+
elif len(tags) > 0 and len(query) > 0:
|
| 116 |
+
for model in public_models['voice_models']:
|
| 117 |
+
if all(tag in model['tags'] for tag in tags):
|
| 118 |
+
model_attributes = f"{model['name']} {model['description']} {model['credit']} {' '.join(model['tags'])}".lower()
|
| 119 |
+
if query.lower() in model_attributes:
|
| 120 |
+
models_table.append([model['name'], model['description'], model['credit'], model['url'], model['tags']])
|
| 121 |
+
|
| 122 |
+
# filter based on only tags
|
| 123 |
+
elif len(tags) > 0:
|
| 124 |
+
for model in public_models['voice_models']:
|
| 125 |
+
if all(tag in model['tags'] for tag in tags):
|
| 126 |
+
models_table.append([model['name'], model['description'], model['credit'], model['url'], model['tags']])
|
| 127 |
+
|
| 128 |
+
# filter based on only query
|
| 129 |
+
else:
|
| 130 |
+
for model in public_models['voice_models']:
|
| 131 |
+
model_attributes = f"{model['name']} {model['description']} {model['credit']} {' '.join(model['tags'])}".lower()
|
| 132 |
+
if query.lower() in model_attributes:
|
| 133 |
+
models_table.append([model['name'], model['description'], model['credit'], model['url'], model['tags']])
|
| 134 |
+
|
| 135 |
+
return gr.update(value=models_table)
|
| 136 |
+
|
| 137 |
+
|
| 138 |
+
def pub_dl_autofill(pub_models, event: gr.SelectData):
|
| 139 |
+
return gr.update(value=pub_models.loc[event.index[0], 'URL']), gr.update(value=pub_models.loc[event.index[0], 'Model Name'])
|
| 140 |
+
|
| 141 |
+
|
| 142 |
+
def swap_visibility():
|
| 143 |
+
return gr.update(visible=True), gr.update(visible=False), gr.update(value=''), gr.update(value=None)
|
| 144 |
+
|
| 145 |
+
|
| 146 |
+
def process_file_upload(file):
|
| 147 |
+
return file.name, gr.update(value=file.name)
|
| 148 |
+
|
| 149 |
+
|
| 150 |
+
def show_hop_slider(pitch_detection_algo):
|
| 151 |
+
if pitch_detection_algo == 'mangio-crepe':
|
| 152 |
+
return gr.update(visible=True)
|
| 153 |
+
else:
|
| 154 |
+
return gr.update(visible=False)
|
| 155 |
+
|
| 156 |
+
|
| 157 |
+
if __name__ == '__main__':
|
| 158 |
+
parser = ArgumentParser(description='Generate a AI cover song in the song_output/id directory.', add_help=True)
|
| 159 |
+
parser.add_argument("--share", action="store_true", dest="share_enabled", default=False, help="Enable sharing")
|
| 160 |
+
parser.add_argument("--listen", action="store_true", default=False, help="Make the WebUI reachable from your local network.")
|
| 161 |
+
parser.add_argument('--listen-host', type=str, help='The hostname that the server will use.')
|
| 162 |
+
parser.add_argument('--listen-port', type=int, help='The listening port that the server will use.')
|
| 163 |
+
args = parser.parse_args()
|
| 164 |
+
|
| 165 |
+
voice_models = get_current_models(rvc_models_dir)
|
| 166 |
+
with open(os.path.join(rvc_models_dir, 'public_models.json'), encoding='utf8') as infile:
|
| 167 |
+
public_models = json.load(infile)
|
| 168 |
+
|
| 169 |
+
with gr.Blocks(title='AICoverGenWebUI') as app:
|
| 170 |
+
|
| 171 |
+
gr.Label('AICoverGen WebUI created with ❤️', show_label=False)
|
| 172 |
+
gr.Markdown(
|
| 173 |
+
"""
|
| 174 |
+
<details>
|
| 175 |
+
<summary style="font-size: 1.5em;">⚠️ Important (click to expand)</summary>
|
| 176 |
+
<ul>
|
| 177 |
+
<li>🚀 This demo use a Zero GPU, which is available only for a limited time. It's recommended to use audio files that are no longer than 5 minutes. If you want to use it without time restrictions, you can duplicate the 'old CPU space'. ⏳</li>
|
| 178 |
+
</ul>
|
| 179 |
+
</details>
|
| 180 |
+
"""
|
| 181 |
+
)
|
| 182 |
+
gr.Markdown("Duplicate the old CPU space for use in private: [](https://huggingface.co/spaces/r3gm/AICoverGen_old_stable_cpu?duplicate=true)\n\n")
|
| 183 |
+
|
| 184 |
+
# main tab
|
| 185 |
+
with gr.Tab("Generate"):
|
| 186 |
+
|
| 187 |
+
with gr.Accordion('Main Options'):
|
| 188 |
+
with gr.Row():
|
| 189 |
+
with gr.Column():
|
| 190 |
+
rvc_model = gr.Dropdown(voice_models, label='Voice Models', info='Models folder "AICoverGen --> rvc_models". After new models are added into this folder, click the refresh button')
|
| 191 |
+
ref_btn = gr.Button('Refresh Models 🔁', variant='primary')
|
| 192 |
+
|
| 193 |
+
with gr.Column() as yt_link_col:
|
| 194 |
+
song_input = gr.Text(label='Song input', info='Link to a song on YouTube or full path to a local file. For file upload, click the button below. Example: https://www.youtube.com/watch?v=M-mtdN6R3bQ')
|
| 195 |
+
show_file_upload_button = gr.Button('Upload file instead')
|
| 196 |
+
|
| 197 |
+
with gr.Column(visible=False) as file_upload_col:
|
| 198 |
+
local_file = gr.File(label='Audio file')
|
| 199 |
+
song_input_file = gr.UploadButton('Upload 📂', file_types=['audio'], variant='primary')
|
| 200 |
+
show_yt_link_button = gr.Button('Paste YouTube link/Path to local file instead')
|
| 201 |
+
song_input_file.upload(process_file_upload, inputs=[song_input_file], outputs=[local_file, song_input])
|
| 202 |
+
|
| 203 |
+
with gr.Column():
|
| 204 |
+
pitch = gr.Slider(-3, 3, value=0, step=1, label='Pitch Change (Vocals ONLY)', info='Generally, use 1 for male to female conversions and -1 for vice-versa. (Octaves)')
|
| 205 |
+
pitch_all = gr.Slider(-12, 12, value=0, step=1, label='Overall Pitch Change', info='Changes pitch/key of vocals and instrumentals together. Altering this slightly reduces sound quality. (Semitones)')
|
| 206 |
+
show_file_upload_button.click(swap_visibility, outputs=[file_upload_col, yt_link_col, song_input, local_file])
|
| 207 |
+
show_yt_link_button.click(swap_visibility, outputs=[yt_link_col, file_upload_col, song_input, local_file])
|
| 208 |
+
|
| 209 |
+
with gr.Accordion('Voice conversion options', open=False):
|
| 210 |
+
with gr.Row():
|
| 211 |
+
index_rate = gr.Slider(0, 1, value=0.5, label='Index Rate', info="Controls how much of the AI voice's accent to keep in the vocals")
|
| 212 |
+
filter_radius = gr.Slider(0, 7, value=3, step=1, label='Filter radius', info='If >=3: apply median filtering median filtering to the harvested pitch results. Can reduce breathiness')
|
| 213 |
+
rms_mix_rate = gr.Slider(0, 1, value=0.25, label='RMS mix rate', info="Control how much to mimic the original vocal's loudness (0) or a fixed loudness (1)")
|
| 214 |
+
protect = gr.Slider(0, 0.5, value=0.33, label='Protect rate', info='Protect voiceless consonants and breath sounds. Set to 0.5 to disable.')
|
| 215 |
+
with gr.Column():
|
| 216 |
+
f0_method = gr.Dropdown(['rmvpe+', 'rmvpe', 'mangio-crepe'], value='rmvpe', label='Pitch detection algorithm', info='Best option is rmvpe (clarity in vocals), then mangio-crepe (smoother vocals), rmvpe+ use a minimum and maximum allowed pitch values.')
|
| 217 |
+
crepe_hop_length = gr.Slider(32, 320, value=128, step=1, visible=False, label='Crepe hop length', info='Lower values leads to longer conversions and higher risk of voice cracks, but better pitch accuracy.')
|
| 218 |
+
f0_method.change(show_hop_slider, inputs=f0_method, outputs=crepe_hop_length)
|
| 219 |
+
keep_files = gr.Checkbox(True, label='Keep intermediate files', info='Keep all audio files generated in the song_output/id directory, e.g. Isolated Vocals/Instrumentals. Leave unchecked to save space')
|
| 220 |
+
|
| 221 |
+
with gr.Accordion('Audio mixing options', open=False):
|
| 222 |
+
gr.Markdown('### Volume Change (decibels)')
|
| 223 |
+
with gr.Row():
|
| 224 |
+
main_gain = gr.Slider(-20, 20, value=0, step=1, label='Main Vocals')
|
| 225 |
+
backup_gain = gr.Slider(-20, 20, value=0, step=1, label='Backup Vocals')
|
| 226 |
+
inst_gain = gr.Slider(-20, 20, value=0, step=1, label='Music')
|
| 227 |
+
|
| 228 |
+
gr.Markdown('### Reverb Control on AI Vocals')
|
| 229 |
+
with gr.Row():
|
| 230 |
+
reverb_rm_size = gr.Slider(0, 1, value=0.15, label='Room size', info='The larger the room, the longer the reverb time')
|
| 231 |
+
reverb_wet = gr.Slider(0, 1, value=0.2, label='Wetness level', info='Level of AI vocals with reverb')
|
| 232 |
+
reverb_dry = gr.Slider(0, 1, value=0.8, label='Dryness level', info='Level of AI vocals without reverb')
|
| 233 |
+
reverb_damping = gr.Slider(0, 1, value=0.7, label='Damping level', info='Absorption of high frequencies in the reverb')
|
| 234 |
+
|
| 235 |
+
gr.Markdown('### Audio Output Format')
|
| 236 |
+
output_format = gr.Dropdown(['mp3', 'wav'], value='mp3', label='Output file type', info='mp3: small file size, decent quality. wav: Large file size, best quality')
|
| 237 |
+
|
| 238 |
+
with gr.Row():
|
| 239 |
+
clear_btn = gr.ClearButton(value='Clear', components=[song_input, rvc_model, keep_files, local_file])
|
| 240 |
+
generate_btn = gr.Button("Generate", variant='primary')
|
| 241 |
+
ai_cover = gr.Audio(label='AI Cover', show_share_button=False)
|
| 242 |
+
|
| 243 |
+
ref_btn.click(update_models_list, None, outputs=rvc_model)
|
| 244 |
+
is_webui = gr.Number(value=1, visible=False)
|
| 245 |
+
generate_btn.click(song_cover_pipeline,
|
| 246 |
+
inputs=[song_input, rvc_model, pitch, keep_files, is_webui, main_gain, backup_gain,
|
| 247 |
+
inst_gain, index_rate, filter_radius, rms_mix_rate, f0_method, crepe_hop_length,
|
| 248 |
+
protect, pitch_all, reverb_rm_size, reverb_wet, reverb_dry, reverb_damping,
|
| 249 |
+
output_format],
|
| 250 |
+
outputs=[ai_cover])
|
| 251 |
+
clear_btn.click(lambda: [0, 0, 0, 0, 0.5, 3, 0.25, 0.33, 'rmvpe', 128, 0, 0.15, 0.2, 0.8, 0.7, 'mp3', None],
|
| 252 |
+
outputs=[pitch, main_gain, backup_gain, inst_gain, index_rate, filter_radius, rms_mix_rate,
|
| 253 |
+
protect, f0_method, crepe_hop_length, pitch_all, reverb_rm_size, reverb_wet,
|
| 254 |
+
reverb_dry, reverb_damping, output_format, ai_cover])
|
| 255 |
+
|
| 256 |
+
# Download tab
|
| 257 |
+
with gr.Tab('Download model'):
|
| 258 |
+
|
| 259 |
+
with gr.Tab('From HuggingFace/Pixeldrain URL'):
|
| 260 |
+
with gr.Row():
|
| 261 |
+
model_zip_link = gr.Text(label='Download link to model', info='Should be a zip file containing a .pth model file and an optional .index file.')
|
| 262 |
+
model_name = gr.Text(label='Name your model', info='Give your new model a unique name from your other voice models.')
|
| 263 |
+
|
| 264 |
+
with gr.Row():
|
| 265 |
+
download_btn = gr.Button('Download 🌐', variant='primary', scale=19)
|
| 266 |
+
dl_output_message = gr.Text(label='Output Message', interactive=False, scale=20)
|
| 267 |
+
|
| 268 |
+
download_btn.click(download_online_model, inputs=[model_zip_link, model_name], outputs=dl_output_message)
|
| 269 |
+
|
| 270 |
+
gr.Markdown('## Input Examples')
|
| 271 |
+
gr.Examples(
|
| 272 |
+
[
|
| 273 |
+
['https://huggingface.co/phant0m4r/LiSA/resolve/main/LiSA.zip', 'Lisa'],
|
| 274 |
+
['https://pixeldrain.com/u/3tJmABXA', 'Gura'],
|
| 275 |
+
['https://huggingface.co/Kit-Lemonfoot/kitlemonfoot_rvc_models/resolve/main/AZKi%20(Hybrid).zip', 'Azki']
|
| 276 |
+
],
|
| 277 |
+
[model_zip_link, model_name],
|
| 278 |
+
[],
|
| 279 |
+
download_online_model,
|
| 280 |
+
cache_examples=False,
|
| 281 |
+
)
|
| 282 |
+
|
| 283 |
+
with gr.Tab('From Public Index'):
|
| 284 |
+
|
| 285 |
+
gr.Markdown('## How to use')
|
| 286 |
+
gr.Markdown('- Click Initialize public models table')
|
| 287 |
+
gr.Markdown('- Filter models using tags or search bar')
|
| 288 |
+
gr.Markdown('- Select a row to autofill the download link and model name')
|
| 289 |
+
gr.Markdown('- Click Download')
|
| 290 |
+
|
| 291 |
+
with gr.Row():
|
| 292 |
+
pub_zip_link = gr.Text(label='Download link to model')
|
| 293 |
+
pub_model_name = gr.Text(label='Model name')
|
| 294 |
+
|
| 295 |
+
with gr.Row():
|
| 296 |
+
download_pub_btn = gr.Button('Download 🌐', variant='primary', scale=19)
|
| 297 |
+
pub_dl_output_message = gr.Text(label='Output Message', interactive=False, scale=20)
|
| 298 |
+
|
| 299 |
+
filter_tags = gr.CheckboxGroup(value=[], label='Show voice models with tags', choices=[])
|
| 300 |
+
search_query = gr.Text(label='Search')
|
| 301 |
+
load_public_models_button = gr.Button(value='Initialize public models table', variant='primary')
|
| 302 |
+
|
| 303 |
+
public_models_table = gr.DataFrame(value=[], headers=['Model Name', 'Description', 'Credit', 'URL', 'Tags'], label='Available Public Models', interactive=False)
|
| 304 |
+
public_models_table.select(pub_dl_autofill, inputs=[public_models_table], outputs=[pub_zip_link, pub_model_name])
|
| 305 |
+
load_public_models_button.click(load_public_models, outputs=[public_models_table, filter_tags])
|
| 306 |
+
search_query.change(filter_models, inputs=[filter_tags, search_query], outputs=public_models_table)
|
| 307 |
+
filter_tags.change(filter_models, inputs=[filter_tags, search_query], outputs=public_models_table)
|
| 308 |
+
download_pub_btn.click(download_online_model, inputs=[pub_zip_link, pub_model_name], outputs=pub_dl_output_message)
|
| 309 |
+
|
| 310 |
+
# Upload tab
|
| 311 |
+
with gr.Tab('Upload model'):
|
| 312 |
+
gr.Markdown('## Upload locally trained RVC v2 model and index file')
|
| 313 |
+
gr.Markdown('- Find model file (weights folder) and optional index file (logs/[name] folder)')
|
| 314 |
+
gr.Markdown('- Compress files into zip file')
|
| 315 |
+
gr.Markdown('- Upload zip file and give unique name for voice')
|
| 316 |
+
gr.Markdown('- Click Upload model')
|
| 317 |
+
|
| 318 |
+
with gr.Row():
|
| 319 |
+
with gr.Column():
|
| 320 |
+
zip_file = gr.File(label='Zip file')
|
| 321 |
+
|
| 322 |
+
local_model_name = gr.Text(label='Model name')
|
| 323 |
+
|
| 324 |
+
with gr.Row():
|
| 325 |
+
model_upload_button = gr.Button('Upload model', variant='primary', scale=19)
|
| 326 |
+
local_upload_output_message = gr.Text(label='Output Message', interactive=False, scale=20)
|
| 327 |
+
model_upload_button.click(upload_local_model, inputs=[zip_file, local_model_name], outputs=local_upload_output_message)
|
| 328 |
+
|
| 329 |
+
app.launch(
|
| 330 |
+
share=args.share_enabled,
|
| 331 |
+
# enable_queue=True,
|
| 332 |
+
server_name=None if not args.listen else (args.listen_host or '0.0.0.0'),
|
| 333 |
+
server_port=args.listen_port,
|
| 334 |
+
)
|