Spaces:
Sleeping

Sleeping
Upload 97 files
Browse filesThis view is limited to 50 files because it contains too many changes.
See raw diff
- LICENSE +203 -0
- Pose_Anything_Teaser.png +0 -0
- README.md +145 -13
- app.py +320 -0
- configs/1shot-swin/base_split1_config.py +190 -0
- configs/1shot-swin/base_split2_config.py +190 -0
- configs/1shot-swin/base_split3_config.py +190 -0
- configs/1shot-swin/base_split4_config.py +190 -0
- configs/1shot-swin/base_split5_config.py +190 -0
- configs/1shot-swin/graph_split1_config.py +191 -0
- configs/1shot-swin/graph_split2_config.py +191 -0
- configs/1shot-swin/graph_split3_config.py +191 -0
- configs/1shot-swin/graph_split4_config.py +191 -0
- configs/1shot-swin/graph_split5_config.py +191 -0
- configs/1shots/base_split1_config.py +190 -0
- configs/1shots/base_split2_config.py +190 -0
- configs/1shots/base_split3_config.py +190 -0
- configs/1shots/base_split4_config.py +190 -0
- configs/1shots/base_split5_config.py +190 -0
- configs/1shots/graph_split1_config.py +191 -0
- configs/1shots/graph_split2_config.py +191 -0
- configs/1shots/graph_split3_config.py +191 -0
- configs/1shots/graph_split4_config.py +191 -0
- configs/1shots/graph_split5_config.py +191 -0
- configs/5shot-swin/base_split1_config.py +190 -0
- configs/5shot-swin/base_split2_config.py +190 -0
- configs/5shot-swin/base_split3_config.py +190 -0
- configs/5shot-swin/base_split4_config.py +190 -0
- configs/5shot-swin/base_split5_config.py +190 -0
- configs/5shot-swin/graph_split1_config.py +191 -0
- configs/5shot-swin/graph_split2_config.py +191 -0
- configs/5shot-swin/graph_split3_config.py +191 -0
- configs/5shot-swin/graph_split4_config.py +191 -0
- configs/5shot-swin/graph_split5_config.py +191 -0
- configs/5shots/base_split1_config.py +190 -0
- configs/5shots/base_split2_config.py +190 -0
- configs/5shots/base_split3_config.py +190 -0
- configs/5shots/base_split4_config.py +190 -0
- configs/5shots/base_split5_config.py +190 -0
- configs/5shots/graph_split1_config.py +191 -0
- configs/5shots/graph_split2_config.py +191 -0
- configs/5shots/graph_split3_config.py +191 -0
- configs/5shots/graph_split4_config.py +191 -0
- configs/5shots/graph_split5_config.py +191 -0
- configs/demo.py +194 -0
- configs/demo_b.py +191 -0
- demo.py +289 -0
- docker/Dockerfile +50 -0
- gradio_teaser.png +0 -0
- models/VERSION +1 -0
LICENSE
ADDED
|
@@ -0,0 +1,203 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
Copyright (c) 2022 SenseTime. All Rights Reserved.
|
| 2 |
+
|
| 3 |
+
Apache License
|
| 4 |
+
Version 2.0, January 2004
|
| 5 |
+
http://www.apache.org/licenses/
|
| 6 |
+
|
| 7 |
+
TERMS AND CONDITIONS FOR USE, REPRODUCTION, AND DISTRIBUTION
|
| 8 |
+
|
| 9 |
+
1. Definitions.
|
| 10 |
+
|
| 11 |
+
"License" shall mean the terms and conditions for use, reproduction,
|
| 12 |
+
and distribution as defined by Sections 1 through 9 of this document.
|
| 13 |
+
|
| 14 |
+
"Licensor" shall mean the copyright owner or entity authorized by
|
| 15 |
+
the copyright owner that is granting the License.
|
| 16 |
+
|
| 17 |
+
"Legal Entity" shall mean the union of the acting entity and all
|
| 18 |
+
other entities that control, are controlled by, or are under common
|
| 19 |
+
control with that entity. For the purposes of this definition,
|
| 20 |
+
"control" means (i) the power, direct or indirect, to cause the
|
| 21 |
+
direction or management of such entity, whether by contract or
|
| 22 |
+
otherwise, or (ii) ownership of fifty percent (50%) or more of the
|
| 23 |
+
outstanding shares, or (iii) beneficial ownership of such entity.
|
| 24 |
+
|
| 25 |
+
"You" (or "Your") shall mean an individual or Legal Entity
|
| 26 |
+
exercising permissions granted by this License.
|
| 27 |
+
|
| 28 |
+
"Source" form shall mean the preferred form for making modifications,
|
| 29 |
+
including but not limited to software source code, documentation
|
| 30 |
+
source, and configuration files.
|
| 31 |
+
|
| 32 |
+
"Object" form shall mean any form resulting from mechanical
|
| 33 |
+
transformation or translation of a Source form, including but
|
| 34 |
+
not limited to compiled object code, generated documentation,
|
| 35 |
+
and conversions to other media types.
|
| 36 |
+
|
| 37 |
+
"Work" shall mean the work of authorship, whether in Source or
|
| 38 |
+
Object form, made available under the License, as indicated by a
|
| 39 |
+
copyright notice that is included in or attached to the work
|
| 40 |
+
(an example is provided in the Appendix below).
|
| 41 |
+
|
| 42 |
+
"Derivative Works" shall mean any work, whether in Source or Object
|
| 43 |
+
form, that is based on (or derived from) the Work and for which the
|
| 44 |
+
editorial revisions, annotations, elaborations, or other modifications
|
| 45 |
+
represent, as a whole, an original work of authorship. For the purposes
|
| 46 |
+
of this License, Derivative Works shall not include works that remain
|
| 47 |
+
separable from, or merely link (or bind by name) to the interfaces of,
|
| 48 |
+
the Work and Derivative Works thereof.
|
| 49 |
+
|
| 50 |
+
"Contribution" shall mean any work of authorship, including
|
| 51 |
+
the original version of the Work and any modifications or additions
|
| 52 |
+
to that Work or Derivative Works thereof, that is intentionally
|
| 53 |
+
submitted to Licensor for inclusion in the Work by the copyright owner
|
| 54 |
+
or by an individual or Legal Entity authorized to submit on behalf of
|
| 55 |
+
the copyright owner. For the purposes of this definition, "submitted"
|
| 56 |
+
means any form of electronic, verbal, or written communication sent
|
| 57 |
+
to the Licensor or its representatives, including but not limited to
|
| 58 |
+
communication on electronic mailing lists, source code control systems,
|
| 59 |
+
and issue tracking systems that are managed by, or on behalf of, the
|
| 60 |
+
Licensor for the purpose of discussing and improving the Work, but
|
| 61 |
+
excluding communication that is conspicuously marked or otherwise
|
| 62 |
+
designated in writing by the copyright owner as "Not a Contribution."
|
| 63 |
+
|
| 64 |
+
"Contributor" shall mean Licensor and any individual or Legal Entity
|
| 65 |
+
on behalf of whom a Contribution has been received by Licensor and
|
| 66 |
+
subsequently incorporated within the Work.
|
| 67 |
+
|
| 68 |
+
2. Grant of Copyright License. Subject to the terms and conditions of
|
| 69 |
+
this License, each Contributor hereby grants to You a perpetual,
|
| 70 |
+
worldwide, non-exclusive, no-charge, royalty-free, irrevocable
|
| 71 |
+
copyright license to reproduce, prepare Derivative Works of,
|
| 72 |
+
publicly display, publicly perform, sublicense, and distribute the
|
| 73 |
+
Work and such Derivative Works in Source or Object form.
|
| 74 |
+
|
| 75 |
+
3. Grant of Patent License. Subject to the terms and conditions of
|
| 76 |
+
this License, each Contributor hereby grants to You a perpetual,
|
| 77 |
+
worldwide, non-exclusive, no-charge, royalty-free, irrevocable
|
| 78 |
+
(except as stated in this section) patent license to make, have made,
|
| 79 |
+
use, offer to sell, sell, import, and otherwise transfer the Work,
|
| 80 |
+
where such license applies only to those patent claims licensable
|
| 81 |
+
by such Contributor that are necessarily infringed by their
|
| 82 |
+
Contribution(s) alone or by combination of their Contribution(s)
|
| 83 |
+
with the Work to which such Contribution(s) was submitted. If You
|
| 84 |
+
institute patent litigation against any entity (including a
|
| 85 |
+
cross-claim or counterclaim in a lawsuit) alleging that the Work
|
| 86 |
+
or a Contribution incorporated within the Work constitutes direct
|
| 87 |
+
or contributory patent infringement, then any patent licenses
|
| 88 |
+
granted to You under this License for that Work shall terminate
|
| 89 |
+
as of the date such litigation is filed.
|
| 90 |
+
|
| 91 |
+
4. Redistribution. You may reproduce and distribute copies of the
|
| 92 |
+
Work or Derivative Works thereof in any medium, with or without
|
| 93 |
+
modifications, and in Source or Object form, provided that You
|
| 94 |
+
meet the following conditions:
|
| 95 |
+
|
| 96 |
+
(a) You must give any other recipients of the Work or
|
| 97 |
+
Derivative Works a copy of this License; and
|
| 98 |
+
|
| 99 |
+
(b) You must cause any modified files to carry prominent notices
|
| 100 |
+
stating that You changed the files; and
|
| 101 |
+
|
| 102 |
+
(c) You must retain, in the Source form of any Derivative Works
|
| 103 |
+
that You distribute, all copyright, patent, trademark, and
|
| 104 |
+
attribution notices from the Source form of the Work,
|
| 105 |
+
excluding those notices that do not pertain to any part of
|
| 106 |
+
the Derivative Works; and
|
| 107 |
+
|
| 108 |
+
(d) If the Work includes a "NOTICE" text file as part of its
|
| 109 |
+
distribution, then any Derivative Works that You distribute must
|
| 110 |
+
include a readable copy of the attribution notices contained
|
| 111 |
+
within such NOTICE file, excluding those notices that do not
|
| 112 |
+
pertain to any part of the Derivative Works, in at least one
|
| 113 |
+
of the following places: within a NOTICE text file distributed
|
| 114 |
+
as part of the Derivative Works; within the Source form or
|
| 115 |
+
documentation, if provided along with the Derivative Works; or,
|
| 116 |
+
within a display generated by the Derivative Works, if and
|
| 117 |
+
wherever such third-party notices normally appear. The contents
|
| 118 |
+
of the NOTICE file are for informational purposes only and
|
| 119 |
+
do not modify the License. You may add Your own attribution
|
| 120 |
+
notices within Derivative Works that You distribute, alongside
|
| 121 |
+
or as an addendum to the NOTICE text from the Work, provided
|
| 122 |
+
that such additional attribution notices cannot be construed
|
| 123 |
+
as modifying the License.
|
| 124 |
+
|
| 125 |
+
You may add Your own copyright statement to Your modifications and
|
| 126 |
+
may provide additional or different license terms and conditions
|
| 127 |
+
for use, reproduction, or distribution of Your modifications, or
|
| 128 |
+
for any such Derivative Works as a whole, provided Your use,
|
| 129 |
+
reproduction, and distribution of the Work otherwise complies with
|
| 130 |
+
the conditions stated in this License.
|
| 131 |
+
|
| 132 |
+
5. Submission of Contributions. Unless You explicitly state otherwise,
|
| 133 |
+
any Contribution intentionally submitted for inclusion in the Work
|
| 134 |
+
by You to the Licensor shall be under the terms and conditions of
|
| 135 |
+
this License, without any additional terms or conditions.
|
| 136 |
+
Notwithstanding the above, nothing herein shall supersede or modify
|
| 137 |
+
the terms of any separate license agreement you may have executed
|
| 138 |
+
with Licensor regarding such Contributions.
|
| 139 |
+
|
| 140 |
+
6. Trademarks. This License does not grant permission to use the trade
|
| 141 |
+
names, trademarks, service marks, or product names of the Licensor,
|
| 142 |
+
except as required for reasonable and customary use in describing the
|
| 143 |
+
origin of the Work and reproducing the content of the NOTICE file.
|
| 144 |
+
|
| 145 |
+
7. Disclaimer of Warranty. Unless required by applicable law or
|
| 146 |
+
agreed to in writing, Licensor provides the Work (and each
|
| 147 |
+
Contributor provides its Contributions) on an "AS IS" BASIS,
|
| 148 |
+
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or
|
| 149 |
+
implied, including, without limitation, any warranties or conditions
|
| 150 |
+
of TITLE, NON-INFRINGEMENT, MERCHANTABILITY, or FITNESS FOR A
|
| 151 |
+
PARTICULAR PURPOSE. You are solely responsible for determining the
|
| 152 |
+
appropriateness of using or redistributing the Work and assume any
|
| 153 |
+
risks associated with Your exercise of permissions under this License.
|
| 154 |
+
|
| 155 |
+
8. Limitation of Liability. In no event and under no legal theory,
|
| 156 |
+
whether in tort (including negligence), contract, or otherwise,
|
| 157 |
+
unless required by applicable law (such as deliberate and grossly
|
| 158 |
+
negligent acts) or agreed to in writing, shall any Contributor be
|
| 159 |
+
liable to You for damages, including any direct, indirect, special,
|
| 160 |
+
incidental, or consequential damages of any character arising as a
|
| 161 |
+
result of this License or out of the use or inability to use the
|
| 162 |
+
Work (including but not limited to damages for loss of goodwill,
|
| 163 |
+
work stoppage, computer failure or malfunction, or any and all
|
| 164 |
+
other commercial damages or losses), even if such Contributor
|
| 165 |
+
has been advised of the possibility of such damages.
|
| 166 |
+
|
| 167 |
+
9. Accepting Warranty or Additional Liability. While redistributing
|
| 168 |
+
the Work or Derivative Works thereof, You may choose to offer,
|
| 169 |
+
and charge a fee for, acceptance of support, warranty, indemnity,
|
| 170 |
+
or other liability obligations and/or rights consistent with this
|
| 171 |
+
License. However, in accepting such obligations, You may act only
|
| 172 |
+
on Your own behalf and on Your sole responsibility, not on behalf
|
| 173 |
+
of any other Contributor, and only if You agree to indemnify,
|
| 174 |
+
defend, and hold each Contributor harmless for any liability
|
| 175 |
+
incurred by, or claims asserted against, such Contributor by reason
|
| 176 |
+
of your accepting any such warranty or additional liability.
|
| 177 |
+
|
| 178 |
+
END OF TERMS AND CONDITIONS
|
| 179 |
+
|
| 180 |
+
APPENDIX: How to apply the Apache License to your work.
|
| 181 |
+
|
| 182 |
+
To apply the Apache License to your work, attach the following
|
| 183 |
+
boilerplate notice, with the fields enclosed by brackets "[]"
|
| 184 |
+
replaced with your own identifying information. (Don't include
|
| 185 |
+
the brackets!) The text should be enclosed in the appropriate
|
| 186 |
+
comment syntax for the file format. We also recommend that a
|
| 187 |
+
file or class name and description of purpose be included on the
|
| 188 |
+
same "printed page" as the copyright notice for easier
|
| 189 |
+
identification within third-party archives.
|
| 190 |
+
|
| 191 |
+
Copyright 2020 MMClassification Authors.
|
| 192 |
+
|
| 193 |
+
Licensed under the Apache License, Version 2.0 (the "License");
|
| 194 |
+
you may not use this file except in compliance with the License.
|
| 195 |
+
You may obtain a copy of the License at
|
| 196 |
+
|
| 197 |
+
http://www.apache.org/licenses/LICENSE-2.0
|
| 198 |
+
|
| 199 |
+
Unless required by applicable law or agreed to in writing, software
|
| 200 |
+
distributed under the License is distributed on an "AS IS" BASIS,
|
| 201 |
+
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
| 202 |
+
See the License for the specific language governing permissions and
|
| 203 |
+
limitations under the License.
|
Pose_Anything_Teaser.png
ADDED
|
README.md
CHANGED
|
@@ -1,13 +1,145 @@
|
|
| 1 |
-
|
| 2 |
-
|
| 3 |
-
|
| 4 |
-
|
| 5 |
-
|
| 6 |
-
|
| 7 |
-
|
| 8 |
-
|
| 9 |
-
|
| 10 |
-
|
| 11 |
-
|
| 12 |
-
|
| 13 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Pose Anything: A Graph-Based Approach for Category-Agnostic Pose Estimation
|
| 2 |
+
<a href="https://orhir.github.io/pose-anything/"><img src="https://img.shields.io/static/v1?label=Project&message=Website&color=blue"></a>
|
| 3 |
+
<a href="https://arxiv.org/abs/2311.17891"><img src="https://img.shields.io/badge/arXiv-2311.17891-b31b1b.svg"></a>
|
| 4 |
+
<a href="https://www.apache.org/licenses/LICENSE-2.0.txt"><img src="https://img.shields.io/badge/License-Apache-yellow"></a>
|
| 5 |
+
[](https://paperswithcode.com/sota/2d-pose-estimation-on-mp-100?p=pose-anything-a-graph-based-approach-for)
|
| 6 |
+
|
| 7 |
+
By [Or Hirschorn](https://scholar.google.co.il/citations?user=GgFuT_QAAAAJ&hl=iw&oi=ao) and [Shai Avidan](https://scholar.google.co.il/citations?hl=iw&user=hpItE1QAAAAJ)
|
| 8 |
+
|
| 9 |
+
This repo is the official implementation of "[Pose Anything: A Graph-Based Approach for Category-Agnostic Pose Estimation](https://arxiv.org/pdf/2311.17891.pdf)".
|
| 10 |
+
<p align="center">
|
| 11 |
+
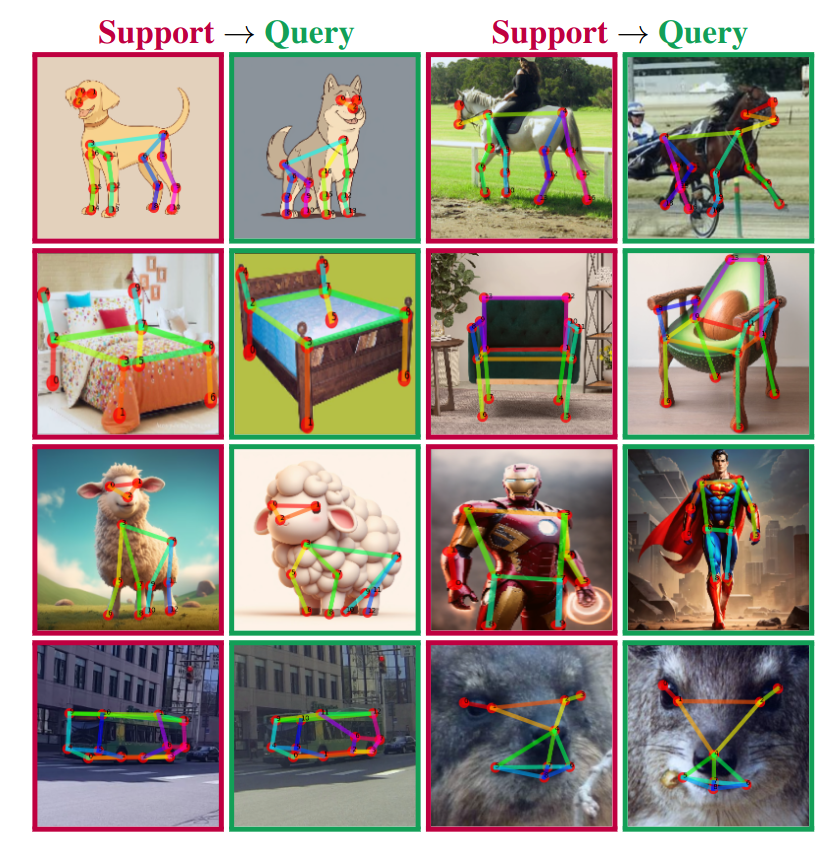
<img src="Pose_Anything_Teaser.png" width="384">
|
| 12 |
+
</p>
|
| 13 |
+
|
| 14 |
+
## Introduction
|
| 15 |
+
|
| 16 |
+
We present a novel approach to CAPE that leverages the inherent geometrical relations between keypoints through a newly designed Graph Transformer Decoder. By capturing and incorporating this crucial structural information, our method enhances the accuracy of keypoint localization, marking a significant departure from conventional CAPE techniques that treat keypoints as isolated entities.
|
| 17 |
+
|
| 18 |
+
## Citation
|
| 19 |
+
If you find this useful, please cite this work as follows:
|
| 20 |
+
```bibtex
|
| 21 |
+
@misc{hirschorn2023pose,
|
| 22 |
+
title={Pose Anything: A Graph-Based Approach for Category-Agnostic Pose Estimation},
|
| 23 |
+
author={Or Hirschorn and Shai Avidan},
|
| 24 |
+
year={2023},
|
| 25 |
+
eprint={2311.17891},
|
| 26 |
+
archivePrefix={arXiv},
|
| 27 |
+
primaryClass={cs.CV}
|
| 28 |
+
}
|
| 29 |
+
```
|
| 30 |
+
|
| 31 |
+
## Getting Started
|
| 32 |
+
|
| 33 |
+
### Docker [Recommended]
|
| 34 |
+
We provide a docker image for easy use.
|
| 35 |
+
You can simply pull the docker image from docker hub, containing all the required libraries and packages:
|
| 36 |
+
|
| 37 |
+
```
|
| 38 |
+
docker pull orhir/pose_anything
|
| 39 |
+
docker run --name pose_anything -v {DATA_DIR}:/workspace/PoseAnything/PoseAnything/data/mp100 -it orhir/pose_anything /bin/bash
|
| 40 |
+
```
|
| 41 |
+
### Conda Environment
|
| 42 |
+
We train and evaluate our model on Python 3.8 and Pytorch 2.0.1 with CUDA 12.1.
|
| 43 |
+
|
| 44 |
+
Please first install pytorch and torchvision following official documentation Pytorch.
|
| 45 |
+
Then, follow [MMPose](https://mmpose.readthedocs.io/en/latest/installation.html) to install the following packages:
|
| 46 |
+
```
|
| 47 |
+
mmcv-full=1.6.2
|
| 48 |
+
mmpose=0.29.0
|
| 49 |
+
```
|
| 50 |
+
Having installed these packages, run:
|
| 51 |
+
```
|
| 52 |
+
python setup.py develop
|
| 53 |
+
```
|
| 54 |
+
|
| 55 |
+
## Demo on Custom Images
|
| 56 |
+
We provide a demo code to test our code on custom images.
|
| 57 |
+
|
| 58 |
+
***A bigger and more accurate version of the model - COMING SOON!***
|
| 59 |
+
|
| 60 |
+
### Gradio Demo
|
| 61 |
+
We first require to install gradio:
|
| 62 |
+
```
|
| 63 |
+
pip install gradio==3.44.0
|
| 64 |
+
```
|
| 65 |
+
Then, Download the [pretrained model](https://drive.google.com/file/d/1RT1Q8AMEa1kj6k9ZqrtWIKyuR4Jn4Pqc/view?usp=drive_link) and run:
|
| 66 |
+
```
|
| 67 |
+
python app.py --checkpoint [path_to_pretrained_ckpt]
|
| 68 |
+
```
|
| 69 |
+
### Terminal Demo
|
| 70 |
+
Download
|
| 71 |
+
the [pretrained model](https://drive.google.com/file/d/1RT1Q8AMEa1kj6k9ZqrtWIKyuR4Jn4Pqc/view?usp=drive_link)
|
| 72 |
+
and run:
|
| 73 |
+
|
| 74 |
+
```
|
| 75 |
+
python demo.py --support [path_to_support_image] --query [path_to_query_image] --config configs/demo_b.py --checkpoint [path_to_pretrained_ckpt]
|
| 76 |
+
```
|
| 77 |
+
***Note:*** The demo code supports any config with suitable checkpoint file. More pre-trained models can be found in the evaluation section.
|
| 78 |
+
|
| 79 |
+
|
| 80 |
+
## MP-100 Dataset
|
| 81 |
+
Please follow the [official guide](https://github.com/luminxu/Pose-for-Everything/blob/main/mp100/README.md) to prepare the MP-100 dataset for training and evaluation, and organize the data structure properly.
|
| 82 |
+
|
| 83 |
+
We provide an updated annotation file, which includes skeleton definitions, in the following [link](https://drive.google.com/drive/folders/1uRyGB-P5Tc_6TmAZ6RnOi0SWjGq9b28T?usp=sharing).
|
| 84 |
+
|
| 85 |
+
**Please note:**
|
| 86 |
+
|
| 87 |
+
Current version of the MP-100 dataset includes some discrepancies and filenames errors:
|
| 88 |
+
1. Note that the mentioned DeepFasion dataset is actually DeepFashion2 dataset. The link in the official repo is wrong. Use this [repo](https://github.com/switchablenorms/DeepFashion2/tree/master) instead.
|
| 89 |
+
2. We provide a script to fix CarFusion filename errors, which can be run by:
|
| 90 |
+
```
|
| 91 |
+
python tools/fix_carfusion.py [path_to_CarFusion_dataset] [path_to_mp100_annotation]
|
| 92 |
+
```
|
| 93 |
+
|
| 94 |
+
## Training
|
| 95 |
+
|
| 96 |
+
### Backbone Options
|
| 97 |
+
To use pre-trained Swin-Transformer as used in our paper, we provide the weights, taken from this [repo](https://github.com/microsoft/Swin-Transformer/blob/main/MODELHUB.md), in the following [link](https://drive.google.com/drive/folders/1-q4mSxlNAUwDlevc3Hm5Ij0l_2OGkrcg?usp=sharing).
|
| 98 |
+
These should be placed in the `./pretrained` folder.
|
| 99 |
+
|
| 100 |
+
We also support DINO and ResNet backbones. To use them, you can easily change the config file to use the desired backbone.
|
| 101 |
+
This can be done by changing the `pretrained` field in the config file to `dinov2`, `dino` or `resnet` respectively (this will automatically load the pretrained weights from the official repo).
|
| 102 |
+
|
| 103 |
+
### Training
|
| 104 |
+
To train the model, run:
|
| 105 |
+
```
|
| 106 |
+
python train.py --config [path_to_config_file] --work-dir [path_to_work_dir]
|
| 107 |
+
```
|
| 108 |
+
|
| 109 |
+
## Evaluation and Pretrained Models
|
| 110 |
+
You can download the pretrained checkpoints from following [link](https://drive.google.com/drive/folders/1RmrqzE3g0qYRD5xn54-aXEzrIkdYXpEW?usp=sharing).
|
| 111 |
+
|
| 112 |
+
Here we provide the evaluation results of our pretrained models on MP-100 dataset along with the config files and checkpoints:
|
| 113 |
+
|
| 114 |
+
### 1-Shot Models
|
| 115 |
+
| Setting | split 1 | split 2 | split 3 | split 4 | split 5 |
|
| 116 |
+
|:-------:|:---------------------------------------------------------------------------------------------------------------------------------------------------:|:---------------------------------------------------------------------------------------------------------------------------------------------------:|:---------------------------------------------------------------------------------------------------------------------------------------------------:|:---------------------------------------------------------------------------------------------------------------------------------------------------:|:---------------------------------------------------------------------------------------------------------------------------------------------------:|
|
| 117 |
+
| Tiny | 91.06 | 88024 | 86.09 | 86.17 | 85.78 |
|
| 118 |
+
| | [link](https://drive.google.com/file/d/1GubmkVkqybs-eD4hiRkgBzkUVGE_rIFX/view?usp=drive_link) / [config](configs/1shots/graph_split1_config.py) | [link](https://drive.google.com/file/d/1EEekDF3xV_wJOVk7sCQWUA8ygUKzEm2l/view?usp=drive_link) / [config](configs/1shots/graph_split2_config.py) | [link](https://drive.google.com/file/d/1FuwpNBdPI3mfSovta2fDGKoqJynEXPZQ/view?usp=drive_link) / [config](configs/1shots/graph_split3_config.py) | [link](https://drive.google.com/file/d/1_SSqSANuZlbC0utzIfzvZihAW9clefcR/view?usp=drive_link) / [config](configs/1shots/graph_split4_config.py) | [link](https://drive.google.com/file/d/1nUHr07W5F55u-FKQEPFq_CECgWZOKKLF/view?usp=drive_link) / [config](configs/1shots/graph_split5_config.py) |
|
| 119 |
+
| Small | 93.66 | 90.42 | 89.79 | 88.68 | 89.61 |
|
| 120 |
+
| | [link](https://drive.google.com/file/d/1RT1Q8AMEa1kj6k9ZqrtWIKyuR4Jn4Pqc/view?usp=drive_link) / [config](configs/1shot-swin/graph_split1_config.py) | [link](https://drive.google.com/file/d/1BT5b8MlnkflcdhTFiBROIQR3HccLsPQd/view?usp=drive_link) / [config](configs/1shot-swin/graph_split2_config.py) | [link](https://drive.google.com/file/d/1Z64cw_1CSDGObabSAWKnMK0BA_bqDHxn/view?usp=drive_link) / [config](configs/1shot-swin/graph_split3_config.py) | [link](https://drive.google.com/file/d/1vf82S8LAjIzpuBcbEoDCa26cR8DqNriy/view?usp=drive_link) / [config](configs/1shot-swin/graph_split4_config.py) | [link](https://drive.google.com/file/d/14FNx0JNbkS2CvXQMiuMU_kMZKFGO2rDV/view?usp=drive_link) / [config](configs/1shot-swin/graph_split5_config.py) |
|
| 121 |
+
|
| 122 |
+
### 5-Shot Models
|
| 123 |
+
| Setting | split 1 | split 2 | split 3 | split 4 | split 5 |
|
| 124 |
+
|:-------:|:---------------------------------------------------------------------------------------------------------------------------------------------------:|:---------------------------------------------------------------------------------------------------------------------------------------------------:|:---------------------------------------------------------------------------------------------------------------------------------------------------:|:---------------------------------------------------------------------------------------------------------------------------------------------------:|:---------------------------------------------------------------------------------------------------------------------------------------------------:|
|
| 125 |
+
| Tiny | 94.18 | 91.46 | 90.50 | 90.18 | 89.47 |
|
| 126 |
+
| | [link](https://drive.google.com/file/d/1PeMuwv5YwiF3UCE5oN01Qchu5K3BaQ9L/view?usp=drive_link) / [config](configs/5shots/graph_split1_config.py) | [link](https://drive.google.com/file/d/1enIapPU1D8lZOET7q_qEjnhC1HFy3jWK/view?usp=drive_link) / [config](configs/5shots/graph_split2_config.py) | [link](https://drive.google.com/file/d/1MTeZ9Ba-ucLuqX0KBoLbBD5PaEct7VUp/view?usp=drive_link) / [config](configs/5shots/graph_split3_config.py) | [link](https://drive.google.com/file/d/1U2N7DI2F0v7NTnPCEEAgx-WKeBZNAFoa/view?usp=drive_link) / [config](configs/5shots/graph_split4_config.py) | [link](https://drive.google.com/file/d/1wapJDgtBWtmz61JNY7ktsFyvckRKiR2C/view?usp=drive_link) / [config](configs/5shots/graph_split5_config.py) |
|
| 127 |
+
| Small | 96.51 | 92.15 | 91.99 | 92.01 | 92.36 |
|
| 128 |
+
| | [link](https://drive.google.com/file/d/1p5rnA0MhmndSKEbyXMk49QXvNE03QV2p/view?usp=drive_link) / [config](configs/5shot-swin/graph_split1_config.py) | [link](https://drive.google.com/file/d/1Q3KNyUW_Gp3JytYxUPhkvXFiDYF6Hv8w/view?usp=drive_link) / [config](configs/5shot-swin/graph_split2_config.py) | [link](https://drive.google.com/file/d/1gWgTk720fSdAf_ze1FkfXTW0t7k-69dV/view?usp=drive_link) / [config](configs/5shot-swin/graph_split3_config.py) | [link](https://drive.google.com/file/d/1LuaRQ8a6AUPrkr7l5j2W6Fe_QbgASkwY/view?usp=drive_link) / [config](configs/5shot-swin/graph_split4_config.py) | [link](https://drive.google.com/file/d/1z--MAOPCwMG_GQXru9h2EStbnIvtHv1L/view?usp=drive_link) / [config](configs/5shot-swin/graph_split5_config.py) |
|
| 129 |
+
|
| 130 |
+
### Evaluation
|
| 131 |
+
The evaluation on a single GPU will take approximately 30 min.
|
| 132 |
+
|
| 133 |
+
To evaluate the pretrained model, run:
|
| 134 |
+
```
|
| 135 |
+
python test.py [path_to_config_file] [path_to_pretrained_ckpt]
|
| 136 |
+
```
|
| 137 |
+
## Acknowledgement
|
| 138 |
+
|
| 139 |
+
Our code is based on code from:
|
| 140 |
+
- [MMPose](https://github.com/open-mmlab/mmpose)
|
| 141 |
+
- [CapeFormer](https://github.com/flyinglynx/CapeFormer)
|
| 142 |
+
|
| 143 |
+
|
| 144 |
+
## License
|
| 145 |
+
This project is released under the Apache 2.0 license.
|
app.py
ADDED
|
@@ -0,0 +1,320 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import argparse
|
| 2 |
+
# Copyright (c) OpenMMLab. All rights reserved.
|
| 3 |
+
import os
|
| 4 |
+
import random
|
| 5 |
+
|
| 6 |
+
# os.system('python -m pip install timm')
|
| 7 |
+
# os.system('python -m pip install -U openxlab')
|
| 8 |
+
# os.system('python -m pip install -U pillow')
|
| 9 |
+
# os.system('python -m pip install Openmim')
|
| 10 |
+
# os.system('python -m mim install mmengine')
|
| 11 |
+
os.system('python -m mim install "mmcv-full==1.6.2"')
|
| 12 |
+
os.system('python -m mim install "mmpose==0.29.0"')
|
| 13 |
+
os.system('python -m mim install "gradio==3.44.0"')
|
| 14 |
+
os.system('python setup.py develop')
|
| 15 |
+
|
| 16 |
+
import gradio as gr
|
| 17 |
+
import numpy as np
|
| 18 |
+
import torch
|
| 19 |
+
from PIL import ImageDraw, Image
|
| 20 |
+
from matplotlib import pyplot as plt
|
| 21 |
+
from mmcv import Config
|
| 22 |
+
from mmcv.runner import load_checkpoint
|
| 23 |
+
from mmpose.core import wrap_fp16_model
|
| 24 |
+
from mmpose.models import build_posenet
|
| 25 |
+
from torchvision import transforms
|
| 26 |
+
from demo import Resize_Pad
|
| 27 |
+
from models import *
|
| 28 |
+
import matplotlib
|
| 29 |
+
|
| 30 |
+
matplotlib.use('agg')
|
| 31 |
+
|
| 32 |
+
|
| 33 |
+
def plot_results(support_img, query_img, support_kp, support_w, query_kp,
|
| 34 |
+
query_w, skeleton,
|
| 35 |
+
initial_proposals, prediction, radius=6):
|
| 36 |
+
h, w, c = support_img.shape
|
| 37 |
+
prediction = prediction[-1].cpu().numpy() * h
|
| 38 |
+
query_img = (query_img - np.min(query_img)) / (
|
| 39 |
+
np.max(query_img) - np.min(query_img))
|
| 40 |
+
for id, (img, w, keypoint) in enumerate(zip([query_img],
|
| 41 |
+
[query_w],
|
| 42 |
+
[prediction])):
|
| 43 |
+
f, axes = plt.subplots()
|
| 44 |
+
plt.imshow(img)
|
| 45 |
+
for k in range(keypoint.shape[0]):
|
| 46 |
+
if w[k] > 0:
|
| 47 |
+
kp = keypoint[k, :2]
|
| 48 |
+
c = (1, 0, 0, 0.75) if w[k] == 1 else (0, 0, 1, 0.6)
|
| 49 |
+
patch = plt.Circle(kp, radius, color=c)
|
| 50 |
+
axes.add_patch(patch)
|
| 51 |
+
axes.text(kp[0], kp[1], k)
|
| 52 |
+
plt.draw()
|
| 53 |
+
for l, limb in enumerate(skeleton):
|
| 54 |
+
kp = keypoint[:, :2]
|
| 55 |
+
if l > len(COLORS) - 1:
|
| 56 |
+
c = [x / 255 for x in random.sample(range(0, 255), 3)]
|
| 57 |
+
else:
|
| 58 |
+
c = [x / 255 for x in COLORS[l]]
|
| 59 |
+
if w[limb[0]] > 0 and w[limb[1]] > 0:
|
| 60 |
+
patch = plt.Line2D([kp[limb[0], 0], kp[limb[1], 0]],
|
| 61 |
+
[kp[limb[0], 1], kp[limb[1], 1]],
|
| 62 |
+
linewidth=6, color=c, alpha=0.6)
|
| 63 |
+
axes.add_artist(patch)
|
| 64 |
+
plt.axis('off') # command for hiding the axis.
|
| 65 |
+
plt.subplots_adjust(0, 0, 1, 1, 0, 0)
|
| 66 |
+
return plt
|
| 67 |
+
|
| 68 |
+
|
| 69 |
+
COLORS = [
|
| 70 |
+
[255, 85, 0], [255, 170, 0], [255, 255, 0], [170, 255, 0],
|
| 71 |
+
[85, 255, 0], [0, 255, 0], [0, 255, 85], [0, 255, 170], [0, 255, 255],
|
| 72 |
+
[0, 170, 255], [0, 85, 255], [0, 0, 255], [85, 0, 255], [170, 0, 255],
|
| 73 |
+
[255, 0, 255], [255, 0, 170], [255, 0, 85], [255, 0, 0]
|
| 74 |
+
]
|
| 75 |
+
|
| 76 |
+
kp_src = []
|
| 77 |
+
skeleton = []
|
| 78 |
+
count = 0
|
| 79 |
+
color_idx = 0
|
| 80 |
+
prev_pt = None
|
| 81 |
+
prev_pt_idx = None
|
| 82 |
+
prev_clicked = None
|
| 83 |
+
original_support_image = None
|
| 84 |
+
checkpoint_path = ''
|
| 85 |
+
|
| 86 |
+
def process(query_img,
|
| 87 |
+
cfg_path='configs/demo_b.py'):
|
| 88 |
+
global skeleton
|
| 89 |
+
cfg = Config.fromfile(cfg_path)
|
| 90 |
+
kp_src_np = np.array(kp_src).copy().astype(np.float32)
|
| 91 |
+
kp_src_np[:, 0] = kp_src_np[:, 0] / 128. * cfg.model.encoder_config.img_size
|
| 92 |
+
kp_src_np[:, 1] = kp_src_np[:, 1] / 128. * cfg.model.encoder_config.img_size
|
| 93 |
+
kp_src_np = np.flip(kp_src_np, 1).copy()
|
| 94 |
+
kp_src_tensor = torch.tensor(kp_src_np).float()
|
| 95 |
+
preprocess = transforms.Compose([
|
| 96 |
+
transforms.ToTensor(),
|
| 97 |
+
transforms.Normalize((0.485, 0.456, 0.406), (0.229, 0.224, 0.225)),
|
| 98 |
+
Resize_Pad(cfg.model.encoder_config.img_size,
|
| 99 |
+
cfg.model.encoder_config.img_size)])
|
| 100 |
+
|
| 101 |
+
if len(skeleton) == 0:
|
| 102 |
+
skeleton = [(0, 0)]
|
| 103 |
+
|
| 104 |
+
support_img = preprocess(original_support_image).flip(0)[None]
|
| 105 |
+
np_query = np.array(query_img)[:, :, ::-1].copy()
|
| 106 |
+
q_img = preprocess(np_query).flip(0)[None]
|
| 107 |
+
# Create heatmap from keypoints
|
| 108 |
+
genHeatMap = TopDownGenerateTargetFewShot()
|
| 109 |
+
data_cfg = cfg.data_cfg
|
| 110 |
+
data_cfg['image_size'] = np.array([cfg.model.encoder_config.img_size,
|
| 111 |
+
cfg.model.encoder_config.img_size])
|
| 112 |
+
data_cfg['joint_weights'] = None
|
| 113 |
+
data_cfg['use_different_joint_weights'] = False
|
| 114 |
+
kp_src_3d = torch.concatenate(
|
| 115 |
+
(kp_src_tensor, torch.zeros(kp_src_tensor.shape[0], 1)), dim=-1)
|
| 116 |
+
kp_src_3d_weight = torch.concatenate(
|
| 117 |
+
(torch.ones_like(kp_src_tensor),
|
| 118 |
+
torch.zeros(kp_src_tensor.shape[0], 1)), dim=-1)
|
| 119 |
+
target_s, target_weight_s = genHeatMap._msra_generate_target(data_cfg,
|
| 120 |
+
kp_src_3d,
|
| 121 |
+
kp_src_3d_weight,
|
| 122 |
+
sigma=1)
|
| 123 |
+
target_s = torch.tensor(target_s).float()[None]
|
| 124 |
+
target_weight_s = torch.ones_like(
|
| 125 |
+
torch.tensor(target_weight_s).float()[None])
|
| 126 |
+
|
| 127 |
+
data = {
|
| 128 |
+
'img_s': [support_img],
|
| 129 |
+
'img_q': q_img,
|
| 130 |
+
'target_s': [target_s],
|
| 131 |
+
'target_weight_s': [target_weight_s],
|
| 132 |
+
'target_q': None,
|
| 133 |
+
'target_weight_q': None,
|
| 134 |
+
'return_loss': False,
|
| 135 |
+
'img_metas': [{'sample_skeleton': [skeleton],
|
| 136 |
+
'query_skeleton': skeleton,
|
| 137 |
+
'sample_joints_3d': [kp_src_3d],
|
| 138 |
+
'query_joints_3d': kp_src_3d,
|
| 139 |
+
'sample_center': [kp_src_tensor.mean(dim=0)],
|
| 140 |
+
'query_center': kp_src_tensor.mean(dim=0),
|
| 141 |
+
'sample_scale': [
|
| 142 |
+
kp_src_tensor.max(dim=0)[0] -
|
| 143 |
+
kp_src_tensor.min(dim=0)[0]],
|
| 144 |
+
'query_scale': kp_src_tensor.max(dim=0)[0] -
|
| 145 |
+
kp_src_tensor.min(dim=0)[0],
|
| 146 |
+
'sample_rotation': [0],
|
| 147 |
+
'query_rotation': 0,
|
| 148 |
+
'sample_bbox_score': [1],
|
| 149 |
+
'query_bbox_score': 1,
|
| 150 |
+
'query_image_file': '',
|
| 151 |
+
'sample_image_file': [''],
|
| 152 |
+
}]
|
| 153 |
+
}
|
| 154 |
+
# Load model
|
| 155 |
+
model = build_posenet(cfg.model)
|
| 156 |
+
fp16_cfg = cfg.get('fp16', None)
|
| 157 |
+
if fp16_cfg is not None:
|
| 158 |
+
wrap_fp16_model(model)
|
| 159 |
+
load_checkpoint(model, checkpoint_path, map_location='cpu')
|
| 160 |
+
model.eval()
|
| 161 |
+
with torch.no_grad():
|
| 162 |
+
outputs = model(**data)
|
| 163 |
+
# visualize results
|
| 164 |
+
vis_s_weight = target_weight_s[0]
|
| 165 |
+
vis_q_weight = target_weight_s[0]
|
| 166 |
+
vis_s_image = support_img[0].detach().cpu().numpy().transpose(1, 2, 0)
|
| 167 |
+
vis_q_image = q_img[0].detach().cpu().numpy().transpose(1, 2, 0)
|
| 168 |
+
support_kp = kp_src_3d
|
| 169 |
+
out = plot_results(vis_s_image,
|
| 170 |
+
vis_q_image,
|
| 171 |
+
support_kp,
|
| 172 |
+
vis_s_weight,
|
| 173 |
+
None,
|
| 174 |
+
vis_q_weight,
|
| 175 |
+
skeleton,
|
| 176 |
+
None,
|
| 177 |
+
torch.tensor(outputs['points']).squeeze(0),
|
| 178 |
+
)
|
| 179 |
+
return out
|
| 180 |
+
|
| 181 |
+
|
| 182 |
+
with gr.Blocks() as demo:
|
| 183 |
+
gr.Markdown('''
|
| 184 |
+
# Pose Anything Demo
|
| 185 |
+
We present a novel approach to category agnostic pose estimation that leverages the inherent geometrical relations between keypoints through a newly designed Graph Transformer Decoder. By capturing and incorporating this crucial structural information, our method enhances the accuracy of keypoint localization, marking a significant departure from conventional CAPE techniques that treat keypoints as isolated entities.
|
| 186 |
+
### [Paper](https://arxiv.org/abs/2311.17891) | [Official Repo](https://github.com/orhir/PoseAnything)
|
| 187 |
+

|
| 188 |
+
## Instructions
|
| 189 |
+
1. Upload an image of the object you want to pose on the **left** image.
|
| 190 |
+
2. Click on the **left** image to mark keypoints.
|
| 191 |
+
3. Click on the keypoints on the **right** image to mark limbs.
|
| 192 |
+
4. Upload an image of the object you want to pose to the query image (**bottom**).
|
| 193 |
+
5. Click **Evaluate** to pose the query image.
|
| 194 |
+
''')
|
| 195 |
+
with gr.Row():
|
| 196 |
+
support_img = gr.Image(label="Support Image",
|
| 197 |
+
type="pil",
|
| 198 |
+
info='Click to mark keypoints').style(
|
| 199 |
+
height=256, width=256)
|
| 200 |
+
posed_support = gr.Image(label="Posed Support Image",
|
| 201 |
+
type="pil",
|
| 202 |
+
interactive=False).style(height=256, width=256)
|
| 203 |
+
with gr.Row():
|
| 204 |
+
query_img = gr.Image(label="Query Image",
|
| 205 |
+
type="pil").style(height=256, width=256)
|
| 206 |
+
with gr.Row():
|
| 207 |
+
eval_btn = gr.Button(value="Evaluate")
|
| 208 |
+
with gr.Row():
|
| 209 |
+
output_img = gr.Plot(label="Output Image", height=256, width=256)
|
| 210 |
+
|
| 211 |
+
|
| 212 |
+
def get_select_coords(kp_support,
|
| 213 |
+
limb_support,
|
| 214 |
+
evt: gr.SelectData,
|
| 215 |
+
r=0.015):
|
| 216 |
+
pixels_in_queue = set()
|
| 217 |
+
pixels_in_queue.add((evt.index[1], evt.index[0]))
|
| 218 |
+
while len(pixels_in_queue) > 0:
|
| 219 |
+
pixel = pixels_in_queue.pop()
|
| 220 |
+
if pixel[0] is not None and pixel[
|
| 221 |
+
1] is not None and pixel not in kp_src:
|
| 222 |
+
kp_src.append(pixel)
|
| 223 |
+
else:
|
| 224 |
+
print("Invalid pixel")
|
| 225 |
+
if limb_support is None:
|
| 226 |
+
canvas_limb = kp_support
|
| 227 |
+
else:
|
| 228 |
+
canvas_limb = limb_support
|
| 229 |
+
canvas_kp = kp_support
|
| 230 |
+
w, h = canvas_kp.size
|
| 231 |
+
draw_pose = ImageDraw.Draw(canvas_kp)
|
| 232 |
+
draw_limb = ImageDraw.Draw(canvas_limb)
|
| 233 |
+
r = int(r * w)
|
| 234 |
+
leftUpPoint = (pixel[1] - r, pixel[0] - r)
|
| 235 |
+
rightDownPoint = (pixel[1] + r, pixel[0] + r)
|
| 236 |
+
twoPointList = [leftUpPoint, rightDownPoint]
|
| 237 |
+
draw_pose.ellipse(twoPointList, fill=(255, 0, 0, 255))
|
| 238 |
+
draw_limb.ellipse(twoPointList, fill=(255, 0, 0, 255))
|
| 239 |
+
|
| 240 |
+
return canvas_kp, canvas_limb
|
| 241 |
+
|
| 242 |
+
|
| 243 |
+
def get_limbs(kp_support,
|
| 244 |
+
evt: gr.SelectData,
|
| 245 |
+
r=0.02, width=0.02):
|
| 246 |
+
global count, color_idx, prev_pt, skeleton, prev_pt_idx, prev_clicked
|
| 247 |
+
curr_pixel = (evt.index[1], evt.index[0])
|
| 248 |
+
pixels_in_queue = set()
|
| 249 |
+
pixels_in_queue.add((evt.index[1], evt.index[0]))
|
| 250 |
+
canvas_kp = kp_support
|
| 251 |
+
w, h = canvas_kp.size
|
| 252 |
+
r = int(r * w)
|
| 253 |
+
width = int(width * w)
|
| 254 |
+
while (len(pixels_in_queue) > 0 and
|
| 255 |
+
curr_pixel != prev_clicked and
|
| 256 |
+
len(kp_src) > 0):
|
| 257 |
+
pixel = pixels_in_queue.pop()
|
| 258 |
+
prev_clicked = pixel
|
| 259 |
+
closest_point = min(kp_src,
|
| 260 |
+
key=lambda p: (p[0] - pixel[0]) ** 2 +
|
| 261 |
+
(p[1] - pixel[1]) ** 2)
|
| 262 |
+
closest_point_index = kp_src.index(closest_point)
|
| 263 |
+
draw_limb = ImageDraw.Draw(canvas_kp)
|
| 264 |
+
if color_idx < len(COLORS):
|
| 265 |
+
c = COLORS[color_idx]
|
| 266 |
+
else:
|
| 267 |
+
c = random.choices(range(256), k=3)
|
| 268 |
+
leftUpPoint = (closest_point[1] - r, closest_point[0] - r)
|
| 269 |
+
rightDownPoint = (closest_point[1] + r, closest_point[0] + r)
|
| 270 |
+
twoPointList = [leftUpPoint, rightDownPoint]
|
| 271 |
+
draw_limb.ellipse(twoPointList, fill=tuple(c))
|
| 272 |
+
if count == 0:
|
| 273 |
+
prev_pt = closest_point[1], closest_point[0]
|
| 274 |
+
prev_pt_idx = closest_point_index
|
| 275 |
+
count = count + 1
|
| 276 |
+
else:
|
| 277 |
+
if prev_pt_idx != closest_point_index:
|
| 278 |
+
# Create Line and add Limb
|
| 279 |
+
draw_limb.line([prev_pt, (closest_point[1], closest_point[0])],
|
| 280 |
+
fill=tuple(c),
|
| 281 |
+
width=width)
|
| 282 |
+
skeleton.append((prev_pt_idx, closest_point_index))
|
| 283 |
+
color_idx = color_idx + 1
|
| 284 |
+
else:
|
| 285 |
+
draw_limb.ellipse(twoPointList, fill=(255, 0, 0, 255))
|
| 286 |
+
count = 0
|
| 287 |
+
return canvas_kp
|
| 288 |
+
|
| 289 |
+
|
| 290 |
+
def set_query(support_img):
|
| 291 |
+
global original_support_image
|
| 292 |
+
skeleton.clear()
|
| 293 |
+
kp_src.clear()
|
| 294 |
+
original_support_image = np.array(support_img)[:, :, ::-1].copy()
|
| 295 |
+
support_img = support_img.resize((128, 128), Image.Resampling.LANCZOS)
|
| 296 |
+
return support_img, support_img
|
| 297 |
+
|
| 298 |
+
|
| 299 |
+
support_img.select(get_select_coords,
|
| 300 |
+
[support_img, posed_support],
|
| 301 |
+
[support_img, posed_support],
|
| 302 |
+
)
|
| 303 |
+
support_img.upload(set_query,
|
| 304 |
+
inputs=support_img,
|
| 305 |
+
outputs=[support_img,posed_support])
|
| 306 |
+
posed_support.select(get_limbs,
|
| 307 |
+
posed_support,
|
| 308 |
+
posed_support)
|
| 309 |
+
eval_btn.click(fn=process,
|
| 310 |
+
inputs=[query_img],
|
| 311 |
+
outputs=output_img)
|
| 312 |
+
|
| 313 |
+
if __name__ == "__main__":
|
| 314 |
+
parser = argparse.ArgumentParser(description='Pose Anything Demo')
|
| 315 |
+
parser.add_argument('--checkpoint',
|
| 316 |
+
help='checkpoint path',
|
| 317 |
+
default='https://huggingface.co/orhir/PoseAnything/blob/main/1shot-swin_graph_split1.pth')
|
| 318 |
+
args = parser.parse_args()
|
| 319 |
+
checkpoint_path = args.checkpoint
|
| 320 |
+
demo.launch()
|
configs/1shot-swin/base_split1_config.py
ADDED
|
@@ -0,0 +1,190 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
log_level = 'INFO'
|
| 2 |
+
load_from = None
|
| 3 |
+
resume_from = None
|
| 4 |
+
dist_params = dict(backend='nccl')
|
| 5 |
+
workflow = [('train', 1)]
|
| 6 |
+
checkpoint_config = dict(interval=20)
|
| 7 |
+
evaluation = dict(
|
| 8 |
+
interval=25,
|
| 9 |
+
metric=['PCK', 'NME', 'AUC', 'EPE'],
|
| 10 |
+
key_indicator='PCK',
|
| 11 |
+
gpu_collect=True,
|
| 12 |
+
res_folder='')
|
| 13 |
+
optimizer = dict(
|
| 14 |
+
type='Adam',
|
| 15 |
+
lr=1e-5,
|
| 16 |
+
)
|
| 17 |
+
|
| 18 |
+
optimizer_config = dict(grad_clip=None)
|
| 19 |
+
# learning policy
|
| 20 |
+
lr_config = dict(
|
| 21 |
+
policy='step',
|
| 22 |
+
warmup='linear',
|
| 23 |
+
warmup_iters=1000,
|
| 24 |
+
warmup_ratio=0.001,
|
| 25 |
+
step=[160, 180])
|
| 26 |
+
total_epochs = 200
|
| 27 |
+
log_config = dict(
|
| 28 |
+
interval=50,
|
| 29 |
+
hooks=[
|
| 30 |
+
dict(type='TextLoggerHook'),
|
| 31 |
+
dict(type='TensorboardLoggerHook')
|
| 32 |
+
])
|
| 33 |
+
|
| 34 |
+
channel_cfg = dict(
|
| 35 |
+
num_output_channels=1,
|
| 36 |
+
dataset_joints=1,
|
| 37 |
+
dataset_channel=[
|
| 38 |
+
[
|
| 39 |
+
0,
|
| 40 |
+
],
|
| 41 |
+
],
|
| 42 |
+
inference_channel=[
|
| 43 |
+
0,
|
| 44 |
+
],
|
| 45 |
+
max_kpt_num=100)
|
| 46 |
+
|
| 47 |
+
# model settings
|
| 48 |
+
model = dict(
|
| 49 |
+
type='PoseAnythingModel',
|
| 50 |
+
pretrained='pretrained/swinv2_base_22k_500k.pth',
|
| 51 |
+
encoder_config=dict(
|
| 52 |
+
type='SwinTransformerV2',
|
| 53 |
+
embed_dim=128,
|
| 54 |
+
depths=[2, 2, 18, 2],
|
| 55 |
+
num_heads=[4, 8, 16, 32],
|
| 56 |
+
window_size=14,
|
| 57 |
+
pretrained_window_sizes=[12, 12, 12, 6],
|
| 58 |
+
drop_path_rate=0.1,
|
| 59 |
+
img_size=224,
|
| 60 |
+
),
|
| 61 |
+
keypoint_head=dict(
|
| 62 |
+
type='PoseHead',
|
| 63 |
+
in_channels=1024,
|
| 64 |
+
transformer=dict(
|
| 65 |
+
type='EncoderDecoder',
|
| 66 |
+
d_model=256,
|
| 67 |
+
nhead=8,
|
| 68 |
+
num_encoder_layers=3,
|
| 69 |
+
num_decoder_layers=3,
|
| 70 |
+
dim_feedforward=1024,
|
| 71 |
+
dropout=0.1,
|
| 72 |
+
similarity_proj_dim=256,
|
| 73 |
+
dynamic_proj_dim=128,
|
| 74 |
+
activation="relu",
|
| 75 |
+
normalize_before=False,
|
| 76 |
+
return_intermediate_dec=True),
|
| 77 |
+
share_kpt_branch=False,
|
| 78 |
+
num_decoder_layer=3,
|
| 79 |
+
with_heatmap_loss=True,
|
| 80 |
+
|
| 81 |
+
heatmap_loss_weight=2.0,
|
| 82 |
+
support_order_dropout=-1,
|
| 83 |
+
positional_encoding=dict(
|
| 84 |
+
type='SinePositionalEncoding', num_feats=128, normalize=True)),
|
| 85 |
+
# training and testing settings
|
| 86 |
+
train_cfg=dict(),
|
| 87 |
+
test_cfg=dict(
|
| 88 |
+
flip_test=False,
|
| 89 |
+
post_process='default',
|
| 90 |
+
shift_heatmap=True,
|
| 91 |
+
modulate_kernel=11))
|
| 92 |
+
|
| 93 |
+
data_cfg = dict(
|
| 94 |
+
image_size=[224, 224],
|
| 95 |
+
heatmap_size=[64, 64],
|
| 96 |
+
num_output_channels=channel_cfg['num_output_channels'],
|
| 97 |
+
num_joints=channel_cfg['dataset_joints'],
|
| 98 |
+
dataset_channel=channel_cfg['dataset_channel'],
|
| 99 |
+
inference_channel=channel_cfg['inference_channel'])
|
| 100 |
+
|
| 101 |
+
train_pipeline = [
|
| 102 |
+
dict(type='LoadImageFromFile'),
|
| 103 |
+
dict(
|
| 104 |
+
type='TopDownGetRandomScaleRotation', rot_factor=15,
|
| 105 |
+
scale_factor=0.15),
|
| 106 |
+
dict(type='TopDownAffineFewShot'),
|
| 107 |
+
dict(type='ToTensor'),
|
| 108 |
+
dict(
|
| 109 |
+
type='NormalizeTensor',
|
| 110 |
+
mean=[0.485, 0.456, 0.406],
|
| 111 |
+
std=[0.229, 0.224, 0.225]),
|
| 112 |
+
dict(type='TopDownGenerateTargetFewShot', sigma=1),
|
| 113 |
+
dict(
|
| 114 |
+
type='Collect',
|
| 115 |
+
keys=['img', 'target', 'target_weight'],
|
| 116 |
+
meta_keys=[
|
| 117 |
+
'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
|
| 118 |
+
'rotation', 'bbox_score', 'flip_pairs', 'category_id', 'skeleton',
|
| 119 |
+
]),
|
| 120 |
+
]
|
| 121 |
+
|
| 122 |
+
valid_pipeline = [
|
| 123 |
+
dict(type='LoadImageFromFile'),
|
| 124 |
+
dict(type='TopDownAffineFewShot'),
|
| 125 |
+
dict(type='ToTensor'),
|
| 126 |
+
dict(
|
| 127 |
+
type='NormalizeTensor',
|
| 128 |
+
mean=[0.485, 0.456, 0.406],
|
| 129 |
+
std=[0.229, 0.224, 0.225]),
|
| 130 |
+
dict(type='TopDownGenerateTargetFewShot', sigma=1),
|
| 131 |
+
dict(
|
| 132 |
+
type='Collect',
|
| 133 |
+
keys=['img', 'target', 'target_weight'],
|
| 134 |
+
meta_keys=[
|
| 135 |
+
'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale', 'rotation', 'bbox_score',
|
| 136 |
+
'flip_pairs', 'category_id',
|
| 137 |
+
'skeleton',
|
| 138 |
+
]),
|
| 139 |
+
]
|
| 140 |
+
|
| 141 |
+
test_pipeline = valid_pipeline
|
| 142 |
+
|
| 143 |
+
data_root = 'data/mp100'
|
| 144 |
+
data = dict(
|
| 145 |
+
samples_per_gpu=8,
|
| 146 |
+
workers_per_gpu=8,
|
| 147 |
+
train=dict(
|
| 148 |
+
type='TransformerPoseDataset',
|
| 149 |
+
ann_file=f'{data_root}/annotations/mp100_split1_train.json',
|
| 150 |
+
img_prefix=f'{data_root}/images/',
|
| 151 |
+
# img_prefix=f'{data_root}',
|
| 152 |
+
data_cfg=data_cfg,
|
| 153 |
+
valid_class_ids=None,
|
| 154 |
+
max_kpt_num=channel_cfg['max_kpt_num'],
|
| 155 |
+
num_shots=1,
|
| 156 |
+
pipeline=train_pipeline),
|
| 157 |
+
val=dict(
|
| 158 |
+
type='TransformerPoseDataset',
|
| 159 |
+
ann_file=f'{data_root}/annotations/mp100_split1_val.json',
|
| 160 |
+
img_prefix=f'{data_root}/images/',
|
| 161 |
+
# img_prefix=f'{data_root}',
|
| 162 |
+
data_cfg=data_cfg,
|
| 163 |
+
valid_class_ids=None,
|
| 164 |
+
max_kpt_num=channel_cfg['max_kpt_num'],
|
| 165 |
+
num_shots=1,
|
| 166 |
+
num_queries=15,
|
| 167 |
+
num_episodes=100,
|
| 168 |
+
pipeline=valid_pipeline),
|
| 169 |
+
test=dict(
|
| 170 |
+
type='TestPoseDataset',
|
| 171 |
+
ann_file=f'{data_root}/annotations/mp100_split1_test.json',
|
| 172 |
+
img_prefix=f'{data_root}/images/',
|
| 173 |
+
# img_prefix=f'{data_root}',
|
| 174 |
+
data_cfg=data_cfg,
|
| 175 |
+
valid_class_ids=None,
|
| 176 |
+
max_kpt_num=channel_cfg['max_kpt_num'],
|
| 177 |
+
num_shots=1,
|
| 178 |
+
num_queries=15,
|
| 179 |
+
num_episodes=200,
|
| 180 |
+
pck_threshold_list=[0.05, 0.10, 0.15, 0.2, 0.25],
|
| 181 |
+
pipeline=test_pipeline),
|
| 182 |
+
)
|
| 183 |
+
vis_backends = [
|
| 184 |
+
dict(type='LocalVisBackend'),
|
| 185 |
+
dict(type='TensorboardVisBackend'),
|
| 186 |
+
]
|
| 187 |
+
visualizer = dict(
|
| 188 |
+
type='PoseLocalVisualizer', vis_backends=vis_backends, name='visualizer')
|
| 189 |
+
|
| 190 |
+
shuffle_cfg = dict(interval=1)
|
configs/1shot-swin/base_split2_config.py
ADDED
|
@@ -0,0 +1,190 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
log_level = 'INFO'
|
| 2 |
+
load_from = None
|
| 3 |
+
resume_from = None
|
| 4 |
+
dist_params = dict(backend='nccl')
|
| 5 |
+
workflow = [('train', 1)]
|
| 6 |
+
checkpoint_config = dict(interval=20)
|
| 7 |
+
evaluation = dict(
|
| 8 |
+
interval=25,
|
| 9 |
+
metric=['PCK', 'NME', 'AUC', 'EPE'],
|
| 10 |
+
key_indicator='PCK',
|
| 11 |
+
gpu_collect=True,
|
| 12 |
+
res_folder='')
|
| 13 |
+
optimizer = dict(
|
| 14 |
+
type='Adam',
|
| 15 |
+
lr=1e-5,
|
| 16 |
+
)
|
| 17 |
+
|
| 18 |
+
optimizer_config = dict(grad_clip=None)
|
| 19 |
+
# learning policy
|
| 20 |
+
lr_config = dict(
|
| 21 |
+
policy='step',
|
| 22 |
+
warmup='linear',
|
| 23 |
+
warmup_iters=1000,
|
| 24 |
+
warmup_ratio=0.001,
|
| 25 |
+
step=[160, 180])
|
| 26 |
+
total_epochs = 200
|
| 27 |
+
log_config = dict(
|
| 28 |
+
interval=50,
|
| 29 |
+
hooks=[
|
| 30 |
+
dict(type='TextLoggerHook'),
|
| 31 |
+
dict(type='TensorboardLoggerHook')
|
| 32 |
+
])
|
| 33 |
+
|
| 34 |
+
channel_cfg = dict(
|
| 35 |
+
num_output_channels=1,
|
| 36 |
+
dataset_joints=1,
|
| 37 |
+
dataset_channel=[
|
| 38 |
+
[
|
| 39 |
+
0,
|
| 40 |
+
],
|
| 41 |
+
],
|
| 42 |
+
inference_channel=[
|
| 43 |
+
0,
|
| 44 |
+
],
|
| 45 |
+
max_kpt_num=100)
|
| 46 |
+
|
| 47 |
+
# model settings
|
| 48 |
+
model = dict(
|
| 49 |
+
type='PoseAnythingModel',
|
| 50 |
+
pretrained='pretrained/swinv2_base_22k_500k.pth',
|
| 51 |
+
encoder_config=dict(
|
| 52 |
+
type='SwinTransformerV2',
|
| 53 |
+
embed_dim=128,
|
| 54 |
+
depths=[2, 2, 18, 2],
|
| 55 |
+
num_heads=[4, 8, 16, 32],
|
| 56 |
+
window_size=14,
|
| 57 |
+
pretrained_window_sizes=[12, 12, 12, 6],
|
| 58 |
+
drop_path_rate=0.1,
|
| 59 |
+
img_size=224,
|
| 60 |
+
),
|
| 61 |
+
keypoint_head=dict(
|
| 62 |
+
type='PoseHead',
|
| 63 |
+
in_channels=1024,
|
| 64 |
+
transformer=dict(
|
| 65 |
+
type='EncoderDecoder',
|
| 66 |
+
d_model=256,
|
| 67 |
+
nhead=8,
|
| 68 |
+
num_encoder_layers=3,
|
| 69 |
+
num_decoder_layers=3,
|
| 70 |
+
dim_feedforward=1024,
|
| 71 |
+
dropout=0.1,
|
| 72 |
+
similarity_proj_dim=256,
|
| 73 |
+
dynamic_proj_dim=128,
|
| 74 |
+
activation="relu",
|
| 75 |
+
normalize_before=False,
|
| 76 |
+
return_intermediate_dec=True),
|
| 77 |
+
share_kpt_branch=False,
|
| 78 |
+
num_decoder_layer=3,
|
| 79 |
+
with_heatmap_loss=True,
|
| 80 |
+
|
| 81 |
+
heatmap_loss_weight=2.0,
|
| 82 |
+
support_order_dropout=-1,
|
| 83 |
+
positional_encoding=dict(
|
| 84 |
+
type='SinePositionalEncoding', num_feats=128, normalize=True)),
|
| 85 |
+
# training and testing settings
|
| 86 |
+
train_cfg=dict(),
|
| 87 |
+
test_cfg=dict(
|
| 88 |
+
flip_test=False,
|
| 89 |
+
post_process='default',
|
| 90 |
+
shift_heatmap=True,
|
| 91 |
+
modulate_kernel=11))
|
| 92 |
+
|
| 93 |
+
data_cfg = dict(
|
| 94 |
+
image_size=[224, 224],
|
| 95 |
+
heatmap_size=[64, 64],
|
| 96 |
+
num_output_channels=channel_cfg['num_output_channels'],
|
| 97 |
+
num_joints=channel_cfg['dataset_joints'],
|
| 98 |
+
dataset_channel=channel_cfg['dataset_channel'],
|
| 99 |
+
inference_channel=channel_cfg['inference_channel'])
|
| 100 |
+
|
| 101 |
+
train_pipeline = [
|
| 102 |
+
dict(type='LoadImageFromFile'),
|
| 103 |
+
dict(
|
| 104 |
+
type='TopDownGetRandomScaleRotation', rot_factor=15,
|
| 105 |
+
scale_factor=0.15),
|
| 106 |
+
dict(type='TopDownAffineFewShot'),
|
| 107 |
+
dict(type='ToTensor'),
|
| 108 |
+
dict(
|
| 109 |
+
type='NormalizeTensor',
|
| 110 |
+
mean=[0.485, 0.456, 0.406],
|
| 111 |
+
std=[0.229, 0.224, 0.225]),
|
| 112 |
+
dict(type='TopDownGenerateTargetFewShot', sigma=1),
|
| 113 |
+
dict(
|
| 114 |
+
type='Collect',
|
| 115 |
+
keys=['img', 'target', 'target_weight'],
|
| 116 |
+
meta_keys=[
|
| 117 |
+
'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
|
| 118 |
+
'rotation', 'bbox_score', 'flip_pairs', 'category_id', 'skeleton',
|
| 119 |
+
]),
|
| 120 |
+
]
|
| 121 |
+
|
| 122 |
+
valid_pipeline = [
|
| 123 |
+
dict(type='LoadImageFromFile'),
|
| 124 |
+
dict(type='TopDownAffineFewShot'),
|
| 125 |
+
dict(type='ToTensor'),
|
| 126 |
+
dict(
|
| 127 |
+
type='NormalizeTensor',
|
| 128 |
+
mean=[0.485, 0.456, 0.406],
|
| 129 |
+
std=[0.229, 0.224, 0.225]),
|
| 130 |
+
dict(type='TopDownGenerateTargetFewShot', sigma=1),
|
| 131 |
+
dict(
|
| 132 |
+
type='Collect',
|
| 133 |
+
keys=['img', 'target', 'target_weight'],
|
| 134 |
+
meta_keys=[
|
| 135 |
+
'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale', 'rotation', 'bbox_score',
|
| 136 |
+
'flip_pairs', 'category_id',
|
| 137 |
+
'skeleton',
|
| 138 |
+
]),
|
| 139 |
+
]
|
| 140 |
+
|
| 141 |
+
test_pipeline = valid_pipeline
|
| 142 |
+
|
| 143 |
+
data_root = 'data/mp100'
|
| 144 |
+
data = dict(
|
| 145 |
+
samples_per_gpu=8,
|
| 146 |
+
workers_per_gpu=8,
|
| 147 |
+
train=dict(
|
| 148 |
+
type='TransformerPoseDataset',
|
| 149 |
+
ann_file=f'{data_root}/annotations/mp100_split2_train.json',
|
| 150 |
+
img_prefix=f'{data_root}/images/',
|
| 151 |
+
# img_prefix=f'{data_root}',
|
| 152 |
+
data_cfg=data_cfg,
|
| 153 |
+
valid_class_ids=None,
|
| 154 |
+
max_kpt_num=channel_cfg['max_kpt_num'],
|
| 155 |
+
num_shots=1,
|
| 156 |
+
pipeline=train_pipeline),
|
| 157 |
+
val=dict(
|
| 158 |
+
type='TransformerPoseDataset',
|
| 159 |
+
ann_file=f'{data_root}/annotations/mp100_split2_val.json',
|
| 160 |
+
img_prefix=f'{data_root}/images/',
|
| 161 |
+
# img_prefix=f'{data_root}',
|
| 162 |
+
data_cfg=data_cfg,
|
| 163 |
+
valid_class_ids=None,
|
| 164 |
+
max_kpt_num=channel_cfg['max_kpt_num'],
|
| 165 |
+
num_shots=1,
|
| 166 |
+
num_queries=15,
|
| 167 |
+
num_episodes=100,
|
| 168 |
+
pipeline=valid_pipeline),
|
| 169 |
+
test=dict(
|
| 170 |
+
type='TestPoseDataset',
|
| 171 |
+
ann_file=f'{data_root}/annotations/mp100_split2_test.json',
|
| 172 |
+
img_prefix=f'{data_root}/images/',
|
| 173 |
+
# img_prefix=f'{data_root}',
|
| 174 |
+
data_cfg=data_cfg,
|
| 175 |
+
valid_class_ids=None,
|
| 176 |
+
max_kpt_num=channel_cfg['max_kpt_num'],
|
| 177 |
+
num_shots=1,
|
| 178 |
+
num_queries=15,
|
| 179 |
+
num_episodes=200,
|
| 180 |
+
pck_threshold_list=[0.05, 0.10, 0.15, 0.2, 0.25],
|
| 181 |
+
pipeline=test_pipeline),
|
| 182 |
+
)
|
| 183 |
+
vis_backends = [
|
| 184 |
+
dict(type='LocalVisBackend'),
|
| 185 |
+
dict(type='TensorboardVisBackend'),
|
| 186 |
+
]
|
| 187 |
+
visualizer = dict(
|
| 188 |
+
type='PoseLocalVisualizer', vis_backends=vis_backends, name='visualizer')
|
| 189 |
+
|
| 190 |
+
shuffle_cfg = dict(interval=1)
|
configs/1shot-swin/base_split3_config.py
ADDED
|
@@ -0,0 +1,190 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
log_level = 'INFO'
|
| 2 |
+
load_from = None
|
| 3 |
+
resume_from = None
|
| 4 |
+
dist_params = dict(backend='nccl')
|
| 5 |
+
workflow = [('train', 1)]
|
| 6 |
+
checkpoint_config = dict(interval=20)
|
| 7 |
+
evaluation = dict(
|
| 8 |
+
interval=25,
|
| 9 |
+
metric=['PCK', 'NME', 'AUC', 'EPE'],
|
| 10 |
+
key_indicator='PCK',
|
| 11 |
+
gpu_collect=True,
|
| 12 |
+
res_folder='')
|
| 13 |
+
optimizer = dict(
|
| 14 |
+
type='Adam',
|
| 15 |
+
lr=1e-5,
|
| 16 |
+
)
|
| 17 |
+
|
| 18 |
+
optimizer_config = dict(grad_clip=None)
|
| 19 |
+
# learning policy
|
| 20 |
+
lr_config = dict(
|
| 21 |
+
policy='step',
|
| 22 |
+
warmup='linear',
|
| 23 |
+
warmup_iters=1000,
|
| 24 |
+
warmup_ratio=0.001,
|
| 25 |
+
step=[160, 180])
|
| 26 |
+
total_epochs = 200
|
| 27 |
+
log_config = dict(
|
| 28 |
+
interval=50,
|
| 29 |
+
hooks=[
|
| 30 |
+
dict(type='TextLoggerHook'),
|
| 31 |
+
dict(type='TensorboardLoggerHook')
|
| 32 |
+
])
|
| 33 |
+
|
| 34 |
+
channel_cfg = dict(
|
| 35 |
+
num_output_channels=1,
|
| 36 |
+
dataset_joints=1,
|
| 37 |
+
dataset_channel=[
|
| 38 |
+
[
|
| 39 |
+
0,
|
| 40 |
+
],
|
| 41 |
+
],
|
| 42 |
+
inference_channel=[
|
| 43 |
+
0,
|
| 44 |
+
],
|
| 45 |
+
max_kpt_num=100)
|
| 46 |
+
|
| 47 |
+
# model settings
|
| 48 |
+
model = dict(
|
| 49 |
+
type='PoseAnythingModel',
|
| 50 |
+
pretrained='pretrained/swinv2_base_22k_500k.pth',
|
| 51 |
+
encoder_config=dict(
|
| 52 |
+
type='SwinTransformerV2',
|
| 53 |
+
embed_dim=128,
|
| 54 |
+
depths=[2, 2, 18, 2],
|
| 55 |
+
num_heads=[4, 8, 16, 32],
|
| 56 |
+
window_size=14,
|
| 57 |
+
pretrained_window_sizes=[12, 12, 12, 6],
|
| 58 |
+
drop_path_rate=0.1,
|
| 59 |
+
img_size=224,
|
| 60 |
+
),
|
| 61 |
+
keypoint_head=dict(
|
| 62 |
+
type='PoseHead',
|
| 63 |
+
in_channels=1024,
|
| 64 |
+
transformer=dict(
|
| 65 |
+
type='EncoderDecoder',
|
| 66 |
+
d_model=256,
|
| 67 |
+
nhead=8,
|
| 68 |
+
num_encoder_layers=3,
|
| 69 |
+
num_decoder_layers=3,
|
| 70 |
+
dim_feedforward=1024,
|
| 71 |
+
dropout=0.1,
|
| 72 |
+
similarity_proj_dim=256,
|
| 73 |
+
dynamic_proj_dim=128,
|
| 74 |
+
activation="relu",
|
| 75 |
+
normalize_before=False,
|
| 76 |
+
return_intermediate_dec=True),
|
| 77 |
+
share_kpt_branch=False,
|
| 78 |
+
num_decoder_layer=3,
|
| 79 |
+
with_heatmap_loss=True,
|
| 80 |
+
|
| 81 |
+
heatmap_loss_weight=2.0,
|
| 82 |
+
support_order_dropout=-1,
|
| 83 |
+
positional_encoding=dict(
|
| 84 |
+
type='SinePositionalEncoding', num_feats=128, normalize=True)),
|
| 85 |
+
# training and testing settings
|
| 86 |
+
train_cfg=dict(),
|
| 87 |
+
test_cfg=dict(
|
| 88 |
+
flip_test=False,
|
| 89 |
+
post_process='default',
|
| 90 |
+
shift_heatmap=True,
|
| 91 |
+
modulate_kernel=11))
|
| 92 |
+
|
| 93 |
+
data_cfg = dict(
|
| 94 |
+
image_size=[224, 224],
|
| 95 |
+
heatmap_size=[64, 64],
|
| 96 |
+
num_output_channels=channel_cfg['num_output_channels'],
|
| 97 |
+
num_joints=channel_cfg['dataset_joints'],
|
| 98 |
+
dataset_channel=channel_cfg['dataset_channel'],
|
| 99 |
+
inference_channel=channel_cfg['inference_channel'])
|
| 100 |
+
|
| 101 |
+
train_pipeline = [
|
| 102 |
+
dict(type='LoadImageFromFile'),
|
| 103 |
+
dict(
|
| 104 |
+
type='TopDownGetRandomScaleRotation', rot_factor=15,
|
| 105 |
+
scale_factor=0.15),
|
| 106 |
+
dict(type='TopDownAffineFewShot'),
|
| 107 |
+
dict(type='ToTensor'),
|
| 108 |
+
dict(
|
| 109 |
+
type='NormalizeTensor',
|
| 110 |
+
mean=[0.485, 0.456, 0.406],
|
| 111 |
+
std=[0.229, 0.224, 0.225]),
|
| 112 |
+
dict(type='TopDownGenerateTargetFewShot', sigma=1),
|
| 113 |
+
dict(
|
| 114 |
+
type='Collect',
|
| 115 |
+
keys=['img', 'target', 'target_weight'],
|
| 116 |
+
meta_keys=[
|
| 117 |
+
'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
|
| 118 |
+
'rotation', 'bbox_score', 'flip_pairs', 'category_id', 'skeleton',
|
| 119 |
+
]),
|
| 120 |
+
]
|
| 121 |
+
|
| 122 |
+
valid_pipeline = [
|
| 123 |
+
dict(type='LoadImageFromFile'),
|
| 124 |
+
dict(type='TopDownAffineFewShot'),
|
| 125 |
+
dict(type='ToTensor'),
|
| 126 |
+
dict(
|
| 127 |
+
type='NormalizeTensor',
|
| 128 |
+
mean=[0.485, 0.456, 0.406],
|
| 129 |
+
std=[0.229, 0.224, 0.225]),
|
| 130 |
+
dict(type='TopDownGenerateTargetFewShot', sigma=1),
|
| 131 |
+
dict(
|
| 132 |
+
type='Collect',
|
| 133 |
+
keys=['img', 'target', 'target_weight'],
|
| 134 |
+
meta_keys=[
|
| 135 |
+
'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale', 'rotation', 'bbox_score',
|
| 136 |
+
'flip_pairs', 'category_id',
|
| 137 |
+
'skeleton',
|
| 138 |
+
]),
|
| 139 |
+
]
|
| 140 |
+
|
| 141 |
+
test_pipeline = valid_pipeline
|
| 142 |
+
|
| 143 |
+
data_root = 'data/mp100'
|
| 144 |
+
data = dict(
|
| 145 |
+
samples_per_gpu=8,
|
| 146 |
+
workers_per_gpu=8,
|
| 147 |
+
train=dict(
|
| 148 |
+
type='TransformerPoseDataset',
|
| 149 |
+
ann_file=f'{data_root}/annotations/mp100_split3_train.json',
|
| 150 |
+
img_prefix=f'{data_root}/images/',
|
| 151 |
+
# img_prefix=f'{data_root}',
|
| 152 |
+
data_cfg=data_cfg,
|
| 153 |
+
valid_class_ids=None,
|
| 154 |
+
max_kpt_num=channel_cfg['max_kpt_num'],
|
| 155 |
+
num_shots=1,
|
| 156 |
+
pipeline=train_pipeline),
|
| 157 |
+
val=dict(
|
| 158 |
+
type='TransformerPoseDataset',
|
| 159 |
+
ann_file=f'{data_root}/annotations/mp100_split3_val.json',
|
| 160 |
+
img_prefix=f'{data_root}/images/',
|
| 161 |
+
# img_prefix=f'{data_root}',
|
| 162 |
+
data_cfg=data_cfg,
|
| 163 |
+
valid_class_ids=None,
|
| 164 |
+
max_kpt_num=channel_cfg['max_kpt_num'],
|
| 165 |
+
num_shots=1,
|
| 166 |
+
num_queries=15,
|
| 167 |
+
num_episodes=100,
|
| 168 |
+
pipeline=valid_pipeline),
|
| 169 |
+
test=dict(
|
| 170 |
+
type='TestPoseDataset',
|
| 171 |
+
ann_file=f'{data_root}/annotations/mp100_split3_test.json',
|
| 172 |
+
img_prefix=f'{data_root}/images/',
|
| 173 |
+
# img_prefix=f'{data_root}',
|
| 174 |
+
data_cfg=data_cfg,
|
| 175 |
+
valid_class_ids=None,
|
| 176 |
+
max_kpt_num=channel_cfg['max_kpt_num'],
|
| 177 |
+
num_shots=1,
|
| 178 |
+
num_queries=15,
|
| 179 |
+
num_episodes=200,
|
| 180 |
+
pck_threshold_list=[0.05, 0.10, 0.15, 0.2, 0.25],
|
| 181 |
+
pipeline=test_pipeline),
|
| 182 |
+
)
|
| 183 |
+
vis_backends = [
|
| 184 |
+
dict(type='LocalVisBackend'),
|
| 185 |
+
dict(type='TensorboardVisBackend'),
|
| 186 |
+
]
|
| 187 |
+
visualizer = dict(
|
| 188 |
+
type='PoseLocalVisualizer', vis_backends=vis_backends, name='visualizer')
|
| 189 |
+
|
| 190 |
+
shuffle_cfg = dict(interval=1)
|
configs/1shot-swin/base_split4_config.py
ADDED
|
@@ -0,0 +1,190 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
log_level = 'INFO'
|
| 2 |
+
load_from = None
|
| 3 |
+
resume_from = None
|
| 4 |
+
dist_params = dict(backend='nccl')
|
| 5 |
+
workflow = [('train', 1)]
|
| 6 |
+
checkpoint_config = dict(interval=20)
|
| 7 |
+
evaluation = dict(
|
| 8 |
+
interval=25,
|
| 9 |
+
metric=['PCK', 'NME', 'AUC', 'EPE'],
|
| 10 |
+
key_indicator='PCK',
|
| 11 |
+
gpu_collect=True,
|
| 12 |
+
res_folder='')
|
| 13 |
+
optimizer = dict(
|
| 14 |
+
type='Adam',
|
| 15 |
+
lr=1e-5,
|
| 16 |
+
)
|
| 17 |
+
|
| 18 |
+
optimizer_config = dict(grad_clip=None)
|
| 19 |
+
# learning policy
|
| 20 |
+
lr_config = dict(
|
| 21 |
+
policy='step',
|
| 22 |
+
warmup='linear',
|
| 23 |
+
warmup_iters=1000,
|
| 24 |
+
warmup_ratio=0.001,
|
| 25 |
+
step=[160, 180])
|
| 26 |
+
total_epochs = 200
|
| 27 |
+
log_config = dict(
|
| 28 |
+
interval=50,
|
| 29 |
+
hooks=[
|
| 30 |
+
dict(type='TextLoggerHook'),
|
| 31 |
+
dict(type='TensorboardLoggerHook')
|
| 32 |
+
])
|
| 33 |
+
|
| 34 |
+
channel_cfg = dict(
|
| 35 |
+
num_output_channels=1,
|
| 36 |
+
dataset_joints=1,
|
| 37 |
+
dataset_channel=[
|
| 38 |
+
[
|
| 39 |
+
0,
|
| 40 |
+
],
|
| 41 |
+
],
|
| 42 |
+
inference_channel=[
|
| 43 |
+
0,
|
| 44 |
+
],
|
| 45 |
+
max_kpt_num=100)
|
| 46 |
+
|
| 47 |
+
# model settings
|
| 48 |
+
model = dict(
|
| 49 |
+
type='PoseAnythingModel',
|
| 50 |
+
pretrained='pretrained/swinv2_base_22k_500k.pth',
|
| 51 |
+
encoder_config=dict(
|
| 52 |
+
type='SwinTransformerV2',
|
| 53 |
+
embed_dim=128,
|
| 54 |
+
depths=[2, 2, 18, 2],
|
| 55 |
+
num_heads=[4, 8, 16, 32],
|
| 56 |
+
window_size=14,
|
| 57 |
+
pretrained_window_sizes=[12, 12, 12, 6],
|
| 58 |
+
drop_path_rate=0.1,
|
| 59 |
+
img_size=224,
|
| 60 |
+
),
|
| 61 |
+
keypoint_head=dict(
|
| 62 |
+
type='PoseHead',
|
| 63 |
+
in_channels=1024,
|
| 64 |
+
transformer=dict(
|
| 65 |
+
type='EncoderDecoder',
|
| 66 |
+
d_model=256,
|
| 67 |
+
nhead=8,
|
| 68 |
+
num_encoder_layers=3,
|
| 69 |
+
num_decoder_layers=3,
|
| 70 |
+
dim_feedforward=1024,
|
| 71 |
+
dropout=0.1,
|
| 72 |
+
similarity_proj_dim=256,
|
| 73 |
+
dynamic_proj_dim=128,
|
| 74 |
+
activation="relu",
|
| 75 |
+
normalize_before=False,
|
| 76 |
+
return_intermediate_dec=True),
|
| 77 |
+
share_kpt_branch=False,
|
| 78 |
+
num_decoder_layer=3,
|
| 79 |
+
with_heatmap_loss=True,
|
| 80 |
+
|
| 81 |
+
heatmap_loss_weight=2.0,
|
| 82 |
+
support_order_dropout=-1,
|
| 83 |
+
positional_encoding=dict(
|
| 84 |
+
type='SinePositionalEncoding', num_feats=128, normalize=True)),
|
| 85 |
+
# training and testing settings
|
| 86 |
+
train_cfg=dict(),
|
| 87 |
+
test_cfg=dict(
|
| 88 |
+
flip_test=False,
|
| 89 |
+
post_process='default',
|
| 90 |
+
shift_heatmap=True,
|
| 91 |
+
modulate_kernel=11))
|
| 92 |
+
|
| 93 |
+
data_cfg = dict(
|
| 94 |
+
image_size=[224, 224],
|
| 95 |
+
heatmap_size=[64, 64],
|
| 96 |
+
num_output_channels=channel_cfg['num_output_channels'],
|
| 97 |
+
num_joints=channel_cfg['dataset_joints'],
|
| 98 |
+
dataset_channel=channel_cfg['dataset_channel'],
|
| 99 |
+
inference_channel=channel_cfg['inference_channel'])
|
| 100 |
+
|
| 101 |
+
train_pipeline = [
|
| 102 |
+
dict(type='LoadImageFromFile'),
|
| 103 |
+
dict(
|
| 104 |
+
type='TopDownGetRandomScaleRotation', rot_factor=15,
|
| 105 |
+
scale_factor=0.15),
|
| 106 |
+
dict(type='TopDownAffineFewShot'),
|
| 107 |
+
dict(type='ToTensor'),
|
| 108 |
+
dict(
|
| 109 |
+
type='NormalizeTensor',
|
| 110 |
+
mean=[0.485, 0.456, 0.406],
|
| 111 |
+
std=[0.229, 0.224, 0.225]),
|
| 112 |
+
dict(type='TopDownGenerateTargetFewShot', sigma=1),
|
| 113 |
+
dict(
|
| 114 |
+
type='Collect',
|
| 115 |
+
keys=['img', 'target', 'target_weight'],
|
| 116 |
+
meta_keys=[
|
| 117 |
+
'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
|
| 118 |
+
'rotation', 'bbox_score', 'flip_pairs', 'category_id', 'skeleton',
|
| 119 |
+
]),
|
| 120 |
+
]
|
| 121 |
+
|
| 122 |
+
valid_pipeline = [
|
| 123 |
+
dict(type='LoadImageFromFile'),
|
| 124 |
+
dict(type='TopDownAffineFewShot'),
|
| 125 |
+
dict(type='ToTensor'),
|
| 126 |
+
dict(
|
| 127 |
+
type='NormalizeTensor',
|
| 128 |
+
mean=[0.485, 0.456, 0.406],
|
| 129 |
+
std=[0.229, 0.224, 0.225]),
|
| 130 |
+
dict(type='TopDownGenerateTargetFewShot', sigma=1),
|
| 131 |
+
dict(
|
| 132 |
+
type='Collect',
|
| 133 |
+
keys=['img', 'target', 'target_weight'],
|
| 134 |
+
meta_keys=[
|
| 135 |
+
'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale', 'rotation', 'bbox_score',
|
| 136 |
+
'flip_pairs', 'category_id',
|
| 137 |
+
'skeleton',
|
| 138 |
+
]),
|
| 139 |
+
]
|
| 140 |
+
|
| 141 |
+
test_pipeline = valid_pipeline
|
| 142 |
+
|
| 143 |
+
data_root = 'data/mp100'
|
| 144 |
+
data = dict(
|
| 145 |
+
samples_per_gpu=8,
|
| 146 |
+
workers_per_gpu=8,
|
| 147 |
+
train=dict(
|
| 148 |
+
type='TransformerPoseDataset',
|
| 149 |
+
ann_file=f'{data_root}/annotations/mp100_split4_train.json',
|
| 150 |
+
img_prefix=f'{data_root}/images/',
|
| 151 |
+
# img_prefix=f'{data_root}',
|
| 152 |
+
data_cfg=data_cfg,
|
| 153 |
+
valid_class_ids=None,
|
| 154 |
+
max_kpt_num=channel_cfg['max_kpt_num'],
|
| 155 |
+
num_shots=1,
|
| 156 |
+
pipeline=train_pipeline),
|
| 157 |
+
val=dict(
|
| 158 |
+
type='TransformerPoseDataset',
|
| 159 |
+
ann_file=f'{data_root}/annotations/mp100_split4_val.json',
|
| 160 |
+
img_prefix=f'{data_root}/images/',
|
| 161 |
+
# img_prefix=f'{data_root}',
|
| 162 |
+
data_cfg=data_cfg,
|
| 163 |
+
valid_class_ids=None,
|
| 164 |
+
max_kpt_num=channel_cfg['max_kpt_num'],
|
| 165 |
+
num_shots=1,
|
| 166 |
+
num_queries=15,
|
| 167 |
+
num_episodes=100,
|
| 168 |
+
pipeline=valid_pipeline),
|
| 169 |
+
test=dict(
|
| 170 |
+
type='TestPoseDataset',
|
| 171 |
+
ann_file=f'{data_root}/annotations/mp100_split4_test.json',
|
| 172 |
+
img_prefix=f'{data_root}/images/',
|
| 173 |
+
# img_prefix=f'{data_root}',
|
| 174 |
+
data_cfg=data_cfg,
|
| 175 |
+
valid_class_ids=None,
|
| 176 |
+
max_kpt_num=channel_cfg['max_kpt_num'],
|
| 177 |
+
num_shots=1,
|
| 178 |
+
num_queries=15,
|
| 179 |
+
num_episodes=200,
|
| 180 |
+
pck_threshold_list=[0.05, 0.10, 0.15, 0.2, 0.25],
|
| 181 |
+
pipeline=test_pipeline),
|
| 182 |
+
)
|
| 183 |
+
vis_backends = [
|
| 184 |
+
dict(type='LocalVisBackend'),
|
| 185 |
+
dict(type='TensorboardVisBackend'),
|
| 186 |
+
]
|
| 187 |
+
visualizer = dict(
|
| 188 |
+
type='PoseLocalVisualizer', vis_backends=vis_backends, name='visualizer')
|
| 189 |
+
|
| 190 |
+
shuffle_cfg = dict(interval=1)
|
configs/1shot-swin/base_split5_config.py
ADDED
|
@@ -0,0 +1,190 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
log_level = 'INFO'
|
| 2 |
+
load_from = None
|
| 3 |
+
resume_from = None
|
| 4 |
+
dist_params = dict(backend='nccl')
|
| 5 |
+
workflow = [('train', 1)]
|
| 6 |
+
checkpoint_config = dict(interval=20)
|
| 7 |
+
evaluation = dict(
|
| 8 |
+
interval=25,
|
| 9 |
+
metric=['PCK', 'NME', 'AUC', 'EPE'],
|
| 10 |
+
key_indicator='PCK',
|
| 11 |
+
gpu_collect=True,
|
| 12 |
+
res_folder='')
|
| 13 |
+
optimizer = dict(
|
| 14 |
+
type='Adam',
|
| 15 |
+
lr=1e-5,
|
| 16 |
+
)
|
| 17 |
+
|
| 18 |
+
optimizer_config = dict(grad_clip=None)
|
| 19 |
+
# learning policy
|
| 20 |
+
lr_config = dict(
|
| 21 |
+
policy='step',
|
| 22 |
+
warmup='linear',
|
| 23 |
+
warmup_iters=1000,
|
| 24 |
+
warmup_ratio=0.001,
|
| 25 |
+
step=[160, 180])
|
| 26 |
+
total_epochs = 200
|
| 27 |
+
log_config = dict(
|
| 28 |
+
interval=50,
|
| 29 |
+
hooks=[
|
| 30 |
+
dict(type='TextLoggerHook'),
|
| 31 |
+
dict(type='TensorboardLoggerHook')
|
| 32 |
+
])
|
| 33 |
+
|
| 34 |
+
channel_cfg = dict(
|
| 35 |
+
num_output_channels=1,
|
| 36 |
+
dataset_joints=1,
|
| 37 |
+
dataset_channel=[
|
| 38 |
+
[
|
| 39 |
+
0,
|
| 40 |
+
],
|
| 41 |
+
],
|
| 42 |
+
inference_channel=[
|
| 43 |
+
0,
|
| 44 |
+
],
|
| 45 |
+
max_kpt_num=100)
|
| 46 |
+
|
| 47 |
+
# model settings
|
| 48 |
+
model = dict(
|
| 49 |
+
type='PoseAnythingModel',
|
| 50 |
+
pretrained='pretrained/swinv2_base_22k_500k.pth',
|
| 51 |
+
encoder_config=dict(
|
| 52 |
+
type='SwinTransformerV2',
|
| 53 |
+
embed_dim=128,
|
| 54 |
+
depths=[2, 2, 18, 2],
|
| 55 |
+
num_heads=[4, 8, 16, 32],
|
| 56 |
+
window_size=14,
|
| 57 |
+
pretrained_window_sizes=[12, 12, 12, 6],
|
| 58 |
+
drop_path_rate=0.1,
|
| 59 |
+
img_size=224,
|
| 60 |
+
),
|
| 61 |
+
keypoint_head=dict(
|
| 62 |
+
type='PoseHead',
|
| 63 |
+
in_channels=1024,
|
| 64 |
+
transformer=dict(
|
| 65 |
+
type='EncoderDecoder',
|
| 66 |
+
d_model=256,
|
| 67 |
+
nhead=8,
|
| 68 |
+
num_encoder_layers=3,
|
| 69 |
+
num_decoder_layers=3,
|
| 70 |
+
dim_feedforward=1024,
|
| 71 |
+
dropout=0.1,
|
| 72 |
+
similarity_proj_dim=256,
|
| 73 |
+
dynamic_proj_dim=128,
|
| 74 |
+
activation="relu",
|
| 75 |
+
normalize_before=False,
|
| 76 |
+
return_intermediate_dec=True),
|
| 77 |
+
share_kpt_branch=False,
|
| 78 |
+
num_decoder_layer=3,
|
| 79 |
+
with_heatmap_loss=True,
|
| 80 |
+
|
| 81 |
+
heatmap_loss_weight=2.0,
|
| 82 |
+
support_order_dropout=-1,
|
| 83 |
+
positional_encoding=dict(
|
| 84 |
+
type='SinePositionalEncoding', num_feats=128, normalize=True)),
|
| 85 |
+
# training and testing settings
|
| 86 |
+
train_cfg=dict(),
|
| 87 |
+
test_cfg=dict(
|
| 88 |
+
flip_test=False,
|
| 89 |
+
post_process='default',
|
| 90 |
+
shift_heatmap=True,
|
| 91 |
+
modulate_kernel=11))
|
| 92 |
+
|
| 93 |
+
data_cfg = dict(
|
| 94 |
+
image_size=[224, 224],
|
| 95 |
+
heatmap_size=[64, 64],
|
| 96 |
+
num_output_channels=channel_cfg['num_output_channels'],
|
| 97 |
+
num_joints=channel_cfg['dataset_joints'],
|
| 98 |
+
dataset_channel=channel_cfg['dataset_channel'],
|
| 99 |
+
inference_channel=channel_cfg['inference_channel'])
|
| 100 |
+
|
| 101 |
+
train_pipeline = [
|
| 102 |
+
dict(type='LoadImageFromFile'),
|
| 103 |
+
dict(
|
| 104 |
+
type='TopDownGetRandomScaleRotation', rot_factor=15,
|
| 105 |
+
scale_factor=0.15),
|
| 106 |
+
dict(type='TopDownAffineFewShot'),
|
| 107 |
+
dict(type='ToTensor'),
|
| 108 |
+
dict(
|
| 109 |
+
type='NormalizeTensor',
|
| 110 |
+
mean=[0.485, 0.456, 0.406],
|
| 111 |
+
std=[0.229, 0.224, 0.225]),
|
| 112 |
+
dict(type='TopDownGenerateTargetFewShot', sigma=1),
|
| 113 |
+
dict(
|
| 114 |
+
type='Collect',
|
| 115 |
+
keys=['img', 'target', 'target_weight'],
|
| 116 |
+
meta_keys=[
|
| 117 |
+
'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
|
| 118 |
+
'rotation', 'bbox_score', 'flip_pairs', 'category_id', 'skeleton',
|
| 119 |
+
]),
|
| 120 |
+
]
|
| 121 |
+
|
| 122 |
+
valid_pipeline = [
|
| 123 |
+
dict(type='LoadImageFromFile'),
|
| 124 |
+
dict(type='TopDownAffineFewShot'),
|
| 125 |
+
dict(type='ToTensor'),
|
| 126 |
+
dict(
|
| 127 |
+
type='NormalizeTensor',
|
| 128 |
+
mean=[0.485, 0.456, 0.406],
|
| 129 |
+
std=[0.229, 0.224, 0.225]),
|
| 130 |
+
dict(type='TopDownGenerateTargetFewShot', sigma=1),
|
| 131 |
+
dict(
|
| 132 |
+
type='Collect',
|
| 133 |
+
keys=['img', 'target', 'target_weight'],
|
| 134 |
+
meta_keys=[
|
| 135 |
+
'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale', 'rotation', 'bbox_score',
|
| 136 |
+
'flip_pairs', 'category_id',
|
| 137 |
+
'skeleton',
|
| 138 |
+
]),
|
| 139 |
+
]
|
| 140 |
+
|
| 141 |
+
test_pipeline = valid_pipeline
|
| 142 |
+
|
| 143 |
+
data_root = 'data/mp100'
|
| 144 |
+
data = dict(
|
| 145 |
+
samples_per_gpu=8,
|
| 146 |
+
workers_per_gpu=8,
|
| 147 |
+
train=dict(
|
| 148 |
+
type='TransformerPoseDataset',
|
| 149 |
+
ann_file=f'{data_root}/annotations/mp100_split5_train.json',
|
| 150 |
+
img_prefix=f'{data_root}/images/',
|
| 151 |
+
# img_prefix=f'{data_root}',
|
| 152 |
+
data_cfg=data_cfg,
|
| 153 |
+
valid_class_ids=None,
|
| 154 |
+
max_kpt_num=channel_cfg['max_kpt_num'],
|
| 155 |
+
num_shots=1,
|
| 156 |
+
pipeline=train_pipeline),
|
| 157 |
+
val=dict(
|
| 158 |
+
type='TransformerPoseDataset',
|
| 159 |
+
ann_file=f'{data_root}/annotations/mp100_split5_val.json',
|
| 160 |
+
img_prefix=f'{data_root}/images/',
|
| 161 |
+
# img_prefix=f'{data_root}',
|
| 162 |
+
data_cfg=data_cfg,
|
| 163 |
+
valid_class_ids=None,
|
| 164 |
+
max_kpt_num=channel_cfg['max_kpt_num'],
|
| 165 |
+
num_shots=1,
|
| 166 |
+
num_queries=15,
|
| 167 |
+
num_episodes=100,
|
| 168 |
+
pipeline=valid_pipeline),
|
| 169 |
+
test=dict(
|
| 170 |
+
type='TestPoseDataset',
|
| 171 |
+
ann_file=f'{data_root}/annotations/mp100_split5_test.json',
|
| 172 |
+
img_prefix=f'{data_root}/images/',
|
| 173 |
+
# img_prefix=f'{data_root}',
|
| 174 |
+
data_cfg=data_cfg,
|
| 175 |
+
valid_class_ids=None,
|
| 176 |
+
max_kpt_num=channel_cfg['max_kpt_num'],
|
| 177 |
+
num_shots=1,
|
| 178 |
+
num_queries=15,
|
| 179 |
+
num_episodes=200,
|
| 180 |
+
pck_threshold_list=[0.05, 0.10, 0.15, 0.2, 0.25],
|
| 181 |
+
pipeline=test_pipeline),
|
| 182 |
+
)
|
| 183 |
+
vis_backends = [
|
| 184 |
+
dict(type='LocalVisBackend'),
|
| 185 |
+
dict(type='TensorboardVisBackend'),
|
| 186 |
+
]
|
| 187 |
+
visualizer = dict(
|
| 188 |
+
type='PoseLocalVisualizer', vis_backends=vis_backends, name='visualizer')
|
| 189 |
+
|
| 190 |
+
shuffle_cfg = dict(interval=1)
|
configs/1shot-swin/graph_split1_config.py
ADDED
|
@@ -0,0 +1,191 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
log_level = 'INFO'
|
| 2 |
+
load_from = None
|
| 3 |
+
resume_from = None
|
| 4 |
+
dist_params = dict(backend='nccl')
|
| 5 |
+
workflow = [('train', 1)]
|
| 6 |
+
checkpoint_config = dict(interval=20)
|
| 7 |
+
evaluation = dict(
|
| 8 |
+
interval=25,
|
| 9 |
+
metric=['PCK', 'NME', 'AUC', 'EPE'],
|
| 10 |
+
key_indicator='PCK',
|
| 11 |
+
gpu_collect=True,
|
| 12 |
+
res_folder='')
|
| 13 |
+
optimizer = dict(
|
| 14 |
+
type='Adam',
|
| 15 |
+
lr=1e-5,
|
| 16 |
+
)
|
| 17 |
+
|
| 18 |
+
optimizer_config = dict(grad_clip=None)
|
| 19 |
+
# learning policy
|
| 20 |
+
lr_config = dict(
|
| 21 |
+
policy='step',
|
| 22 |
+
warmup='linear',
|
| 23 |
+
warmup_iters=1000,
|
| 24 |
+
warmup_ratio=0.001,
|
| 25 |
+
step=[160, 180])
|
| 26 |
+
total_epochs = 200
|
| 27 |
+
log_config = dict(
|
| 28 |
+
interval=50,
|
| 29 |
+
hooks=[
|
| 30 |
+
dict(type='TextLoggerHook'),
|
| 31 |
+
dict(type='TensorboardLoggerHook')
|
| 32 |
+
])
|
| 33 |
+
|
| 34 |
+
channel_cfg = dict(
|
| 35 |
+
num_output_channels=1,
|
| 36 |
+
dataset_joints=1,
|
| 37 |
+
dataset_channel=[
|
| 38 |
+
[
|
| 39 |
+
0,
|
| 40 |
+
],
|
| 41 |
+
],
|
| 42 |
+
inference_channel=[
|
| 43 |
+
0,
|
| 44 |
+
],
|
| 45 |
+
max_kpt_num=100)
|
| 46 |
+
|
| 47 |
+
# model settings
|
| 48 |
+
model = dict(
|
| 49 |
+
type='PoseAnythingModel',
|
| 50 |
+
pretrained='pretrained/swinv2_base_22k_500k.pth',
|
| 51 |
+
encoder_config=dict(
|
| 52 |
+
type='SwinTransformerV2',
|
| 53 |
+
embed_dim=128,
|
| 54 |
+
depths=[2, 2, 18, 2],
|
| 55 |
+
num_heads=[4, 8, 16, 32],
|
| 56 |
+
window_size=14,
|
| 57 |
+
pretrained_window_sizes=[12, 12, 12, 6],
|
| 58 |
+
drop_path_rate=0.1,
|
| 59 |
+
img_size=224,
|
| 60 |
+
),
|
| 61 |
+
keypoint_head=dict(
|
| 62 |
+
type='PoseHead',
|
| 63 |
+
in_channels=1024,
|
| 64 |
+
transformer=dict(
|
| 65 |
+
type='EncoderDecoder',
|
| 66 |
+
d_model=256,
|
| 67 |
+
nhead=8,
|
| 68 |
+
num_encoder_layers=3,
|
| 69 |
+
num_decoder_layers=3,
|
| 70 |
+
graph_decoder='pre',
|
| 71 |
+
dim_feedforward=1024,
|
| 72 |
+
dropout=0.1,
|
| 73 |
+
similarity_proj_dim=256,
|
| 74 |
+
dynamic_proj_dim=128,
|
| 75 |
+
activation="relu",
|
| 76 |
+
normalize_before=False,
|
| 77 |
+
return_intermediate_dec=True),
|
| 78 |
+
share_kpt_branch=False,
|
| 79 |
+
num_decoder_layer=3,
|
| 80 |
+
with_heatmap_loss=True,
|
| 81 |
+
|
| 82 |
+
heatmap_loss_weight=2.0,
|
| 83 |
+
support_order_dropout=-1,
|
| 84 |
+
positional_encoding=dict(
|
| 85 |
+
type='SinePositionalEncoding', num_feats=128, normalize=True)),
|
| 86 |
+
# training and testing settings
|
| 87 |
+
train_cfg=dict(),
|
| 88 |
+
test_cfg=dict(
|
| 89 |
+
flip_test=False,
|
| 90 |
+
post_process='default',
|
| 91 |
+
shift_heatmap=True,
|
| 92 |
+
modulate_kernel=11))
|
| 93 |
+
|
| 94 |
+
data_cfg = dict(
|
| 95 |
+
image_size=[224, 224],
|
| 96 |
+
heatmap_size=[64, 64],
|
| 97 |
+
num_output_channels=channel_cfg['num_output_channels'],
|
| 98 |
+
num_joints=channel_cfg['dataset_joints'],
|
| 99 |
+
dataset_channel=channel_cfg['dataset_channel'],
|
| 100 |
+
inference_channel=channel_cfg['inference_channel'])
|
| 101 |
+
|
| 102 |
+
train_pipeline = [
|
| 103 |
+
dict(type='LoadImageFromFile'),
|
| 104 |
+
dict(
|
| 105 |
+
type='TopDownGetRandomScaleRotation', rot_factor=15,
|
| 106 |
+
scale_factor=0.15),
|
| 107 |
+
dict(type='TopDownAffineFewShot'),
|
| 108 |
+
dict(type='ToTensor'),
|
| 109 |
+
dict(
|
| 110 |
+
type='NormalizeTensor',
|
| 111 |
+
mean=[0.485, 0.456, 0.406],
|
| 112 |
+
std=[0.229, 0.224, 0.225]),
|
| 113 |
+
dict(type='TopDownGenerateTargetFewShot', sigma=1),
|
| 114 |
+
dict(
|
| 115 |
+
type='Collect',
|
| 116 |
+
keys=['img', 'target', 'target_weight'],
|
| 117 |
+
meta_keys=[
|
| 118 |
+
'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
|
| 119 |
+
'rotation', 'bbox_score', 'flip_pairs', 'category_id', 'skeleton',
|
| 120 |
+
]),
|
| 121 |
+
]
|
| 122 |
+
|
| 123 |
+
valid_pipeline = [
|
| 124 |
+
dict(type='LoadImageFromFile'),
|
| 125 |
+
dict(type='TopDownAffineFewShot'),
|
| 126 |
+
dict(type='ToTensor'),
|
| 127 |
+
dict(
|
| 128 |
+
type='NormalizeTensor',
|
| 129 |
+
mean=[0.485, 0.456, 0.406],
|
| 130 |
+
std=[0.229, 0.224, 0.225]),
|
| 131 |
+
dict(type='TopDownGenerateTargetFewShot', sigma=1),
|
| 132 |
+
dict(
|
| 133 |
+
type='Collect',
|
| 134 |
+
keys=['img', 'target', 'target_weight'],
|
| 135 |
+
meta_keys=[
|
| 136 |
+
'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale', 'rotation', 'bbox_score',
|
| 137 |
+
'flip_pairs', 'category_id',
|
| 138 |
+
'skeleton',
|
| 139 |
+
]),
|
| 140 |
+
]
|
| 141 |
+
|
| 142 |
+
test_pipeline = valid_pipeline
|
| 143 |
+
|
| 144 |
+
data_root = 'data/mp100'
|
| 145 |
+
data = dict(
|
| 146 |
+
samples_per_gpu=8,
|
| 147 |
+
workers_per_gpu=8,
|
| 148 |
+
train=dict(
|
| 149 |
+
type='TransformerPoseDataset',
|
| 150 |
+
ann_file=f'{data_root}/annotations/mp100_split1_train.json',
|
| 151 |
+
img_prefix=f'{data_root}/images/',
|
| 152 |
+
# img_prefix=f'{data_root}',
|
| 153 |
+
data_cfg=data_cfg,
|
| 154 |
+
valid_class_ids=None,
|
| 155 |
+
max_kpt_num=channel_cfg['max_kpt_num'],
|
| 156 |
+
num_shots=1,
|
| 157 |
+
pipeline=train_pipeline),
|
| 158 |
+
val=dict(
|
| 159 |
+
type='TransformerPoseDataset',
|
| 160 |
+
ann_file=f'{data_root}/annotations/mp100_split1_val.json',
|
| 161 |
+
img_prefix=f'{data_root}/images/',
|
| 162 |
+
# img_prefix=f'{data_root}',
|
| 163 |
+
data_cfg=data_cfg,
|
| 164 |
+
valid_class_ids=None,
|
| 165 |
+
max_kpt_num=channel_cfg['max_kpt_num'],
|
| 166 |
+
num_shots=1,
|
| 167 |
+
num_queries=15,
|
| 168 |
+
num_episodes=100,
|
| 169 |
+
pipeline=valid_pipeline),
|
| 170 |
+
test=dict(
|
| 171 |
+
type='TestPoseDataset',
|
| 172 |
+
ann_file=f'{data_root}/annotations/mp100_split1_test.json',
|
| 173 |
+
img_prefix=f'{data_root}/images/',
|
| 174 |
+
# img_prefix=f'{data_root}',
|
| 175 |
+
data_cfg=data_cfg,
|
| 176 |
+
valid_class_ids=None,
|
| 177 |
+
max_kpt_num=channel_cfg['max_kpt_num'],
|
| 178 |
+
num_shots=1,
|
| 179 |
+
num_queries=15,
|
| 180 |
+
num_episodes=200,
|
| 181 |
+
pck_threshold_list=[0.05, 0.10, 0.15, 0.2, 0.25],
|
| 182 |
+
pipeline=test_pipeline),
|
| 183 |
+
)
|
| 184 |
+
vis_backends = [
|
| 185 |
+
dict(type='LocalVisBackend'),
|
| 186 |
+
dict(type='TensorboardVisBackend'),
|
| 187 |
+
]
|
| 188 |
+
visualizer = dict(
|
| 189 |
+
type='PoseLocalVisualizer', vis_backends=vis_backends, name='visualizer')
|
| 190 |
+
|
| 191 |
+
shuffle_cfg = dict(interval=1)
|
configs/1shot-swin/graph_split2_config.py
ADDED
|
@@ -0,0 +1,191 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
log_level = 'INFO'
|
| 2 |
+
load_from = None
|
| 3 |
+
resume_from = None
|
| 4 |
+
dist_params = dict(backend='nccl')
|
| 5 |
+
workflow = [('train', 1)]
|
| 6 |
+
checkpoint_config = dict(interval=20)
|
| 7 |
+
evaluation = dict(
|
| 8 |
+
interval=25,
|
| 9 |
+
metric=['PCK', 'NME', 'AUC', 'EPE'],
|
| 10 |
+
key_indicator='PCK',
|
| 11 |
+
gpu_collect=True,
|
| 12 |
+
res_folder='')
|
| 13 |
+
optimizer = dict(
|
| 14 |
+
type='Adam',
|
| 15 |
+
lr=1e-5,
|
| 16 |
+
)
|
| 17 |
+
|
| 18 |
+
optimizer_config = dict(grad_clip=None)
|
| 19 |
+
# learning policy
|
| 20 |
+
lr_config = dict(
|
| 21 |
+
policy='step',
|
| 22 |
+
warmup='linear',
|
| 23 |
+
warmup_iters=1000,
|
| 24 |
+
warmup_ratio=0.001,
|
| 25 |
+
step=[160, 180])
|
| 26 |
+
total_epochs = 200
|
| 27 |
+
log_config = dict(
|
| 28 |
+
interval=50,
|
| 29 |
+
hooks=[
|
| 30 |
+
dict(type='TextLoggerHook'),
|
| 31 |
+
dict(type='TensorboardLoggerHook')
|
| 32 |
+
])
|
| 33 |
+
|
| 34 |
+
channel_cfg = dict(
|
| 35 |
+
num_output_channels=1,
|
| 36 |
+
dataset_joints=1,
|
| 37 |
+
dataset_channel=[
|
| 38 |
+
[
|
| 39 |
+
0,
|
| 40 |
+
],
|
| 41 |
+
],
|
| 42 |
+
inference_channel=[
|
| 43 |
+
0,
|
| 44 |
+
],
|
| 45 |
+
max_kpt_num=100)
|
| 46 |
+
|
| 47 |
+
# model settings
|
| 48 |
+
model = dict(
|
| 49 |
+
type='PoseAnythingModel',
|
| 50 |
+
pretrained='pretrained/swinv2_base_22k_500k.pth',
|
| 51 |
+
encoder_config=dict(
|
| 52 |
+
type='SwinTransformerV2',
|
| 53 |
+
embed_dim=128,
|
| 54 |
+
depths=[2, 2, 18, 2],
|
| 55 |
+
num_heads=[4, 8, 16, 32],
|
| 56 |
+
window_size=14,
|
| 57 |
+
pretrained_window_sizes=[12, 12, 12, 6],
|
| 58 |
+
drop_path_rate=0.1,
|
| 59 |
+
img_size=224,
|
| 60 |
+
),
|
| 61 |
+
keypoint_head=dict(
|
| 62 |
+
type='PoseHead',
|
| 63 |
+
in_channels=1024,
|
| 64 |
+
transformer=dict(
|
| 65 |
+
type='EncoderDecoder',
|
| 66 |
+
d_model=256,
|
| 67 |
+
nhead=8,
|
| 68 |
+
num_encoder_layers=3,
|
| 69 |
+
num_decoder_layers=3,
|
| 70 |
+
graph_decoder='pre',
|
| 71 |
+
dim_feedforward=1024,
|
| 72 |
+
dropout=0.1,
|
| 73 |
+
similarity_proj_dim=256,
|
| 74 |
+
dynamic_proj_dim=128,
|
| 75 |
+
activation="relu",
|
| 76 |
+
normalize_before=False,
|
| 77 |
+
return_intermediate_dec=True),
|
| 78 |
+
share_kpt_branch=False,
|
| 79 |
+
num_decoder_layer=3,
|
| 80 |
+
with_heatmap_loss=True,
|
| 81 |
+
|
| 82 |
+
heatmap_loss_weight=2.0,
|
| 83 |
+
support_order_dropout=-1,
|
| 84 |
+
positional_encoding=dict(
|
| 85 |
+
type='SinePositionalEncoding', num_feats=128, normalize=True)),
|
| 86 |
+
# training and testing settings
|
| 87 |
+
train_cfg=dict(),
|
| 88 |
+
test_cfg=dict(
|
| 89 |
+
flip_test=False,
|
| 90 |
+
post_process='default',
|
| 91 |
+
shift_heatmap=True,
|
| 92 |
+
modulate_kernel=11))
|
| 93 |
+
|
| 94 |
+
data_cfg = dict(
|
| 95 |
+
image_size=[224, 224],
|
| 96 |
+
heatmap_size=[64, 64],
|
| 97 |
+
num_output_channels=channel_cfg['num_output_channels'],
|
| 98 |
+
num_joints=channel_cfg['dataset_joints'],
|
| 99 |
+
dataset_channel=channel_cfg['dataset_channel'],
|
| 100 |
+
inference_channel=channel_cfg['inference_channel'])
|
| 101 |
+
|
| 102 |
+
train_pipeline = [
|
| 103 |
+
dict(type='LoadImageFromFile'),
|
| 104 |
+
dict(
|
| 105 |
+
type='TopDownGetRandomScaleRotation', rot_factor=15,
|
| 106 |
+
scale_factor=0.15),
|
| 107 |
+
dict(type='TopDownAffineFewShot'),
|
| 108 |
+
dict(type='ToTensor'),
|
| 109 |
+
dict(
|
| 110 |
+
type='NormalizeTensor',
|
| 111 |
+
mean=[0.485, 0.456, 0.406],
|
| 112 |
+
std=[0.229, 0.224, 0.225]),
|
| 113 |
+
dict(type='TopDownGenerateTargetFewShot', sigma=1),
|
| 114 |
+
dict(
|
| 115 |
+
type='Collect',
|
| 116 |
+
keys=['img', 'target', 'target_weight'],
|
| 117 |
+
meta_keys=[
|
| 118 |
+
'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
|
| 119 |
+
'rotation', 'bbox_score', 'flip_pairs', 'category_id', 'skeleton',
|
| 120 |
+
]),
|
| 121 |
+
]
|
| 122 |
+
|
| 123 |
+
valid_pipeline = [
|
| 124 |
+
dict(type='LoadImageFromFile'),
|
| 125 |
+
dict(type='TopDownAffineFewShot'),
|
| 126 |
+
dict(type='ToTensor'),
|
| 127 |
+
dict(
|
| 128 |
+
type='NormalizeTensor',
|
| 129 |
+
mean=[0.485, 0.456, 0.406],
|
| 130 |
+
std=[0.229, 0.224, 0.225]),
|
| 131 |
+
dict(type='TopDownGenerateTargetFewShot', sigma=1),
|
| 132 |
+
dict(
|
| 133 |
+
type='Collect',
|
| 134 |
+
keys=['img', 'target', 'target_weight'],
|
| 135 |
+
meta_keys=[
|
| 136 |
+
'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale', 'rotation', 'bbox_score',
|
| 137 |
+
'flip_pairs', 'category_id',
|
| 138 |
+
'skeleton',
|
| 139 |
+
]),
|
| 140 |
+
]
|
| 141 |
+
|
| 142 |
+
test_pipeline = valid_pipeline
|
| 143 |
+
|
| 144 |
+
data_root = 'data/mp100'
|
| 145 |
+
data = dict(
|
| 146 |
+
samples_per_gpu=8,
|
| 147 |
+
workers_per_gpu=8,
|
| 148 |
+
train=dict(
|
| 149 |
+
type='TransformerPoseDataset',
|
| 150 |
+
ann_file=f'{data_root}/annotations/mp100_split2_train.json',
|
| 151 |
+
img_prefix=f'{data_root}/images/',
|
| 152 |
+
# img_prefix=f'{data_root}',
|
| 153 |
+
data_cfg=data_cfg,
|
| 154 |
+
valid_class_ids=None,
|
| 155 |
+
max_kpt_num=channel_cfg['max_kpt_num'],
|
| 156 |
+
num_shots=1,
|
| 157 |
+
pipeline=train_pipeline),
|
| 158 |
+
val=dict(
|
| 159 |
+
type='TransformerPoseDataset',
|
| 160 |
+
ann_file=f'{data_root}/annotations/mp100_split2_val.json',
|
| 161 |
+
img_prefix=f'{data_root}/images/',
|
| 162 |
+
# img_prefix=f'{data_root}',
|
| 163 |
+
data_cfg=data_cfg,
|
| 164 |
+
valid_class_ids=None,
|
| 165 |
+
max_kpt_num=channel_cfg['max_kpt_num'],
|
| 166 |
+
num_shots=1,
|
| 167 |
+
num_queries=15,
|
| 168 |
+
num_episodes=100,
|
| 169 |
+
pipeline=valid_pipeline),
|
| 170 |
+
test=dict(
|
| 171 |
+
type='TestPoseDataset',
|
| 172 |
+
ann_file=f'{data_root}/annotations/mp100_split2_test.json',
|
| 173 |
+
img_prefix=f'{data_root}/images/',
|
| 174 |
+
# img_prefix=f'{data_root}',
|
| 175 |
+
data_cfg=data_cfg,
|
| 176 |
+
valid_class_ids=None,
|
| 177 |
+
max_kpt_num=channel_cfg['max_kpt_num'],
|
| 178 |
+
num_shots=1,
|
| 179 |
+
num_queries=15,
|
| 180 |
+
num_episodes=200,
|
| 181 |
+
pck_threshold_list=[0.05, 0.10, 0.15, 0.2, 0.25],
|
| 182 |
+
pipeline=test_pipeline),
|
| 183 |
+
)
|
| 184 |
+
vis_backends = [
|
| 185 |
+
dict(type='LocalVisBackend'),
|
| 186 |
+
dict(type='TensorboardVisBackend'),
|
| 187 |
+
]
|
| 188 |
+
visualizer = dict(
|
| 189 |
+
type='PoseLocalVisualizer', vis_backends=vis_backends, name='visualizer')
|
| 190 |
+
|
| 191 |
+
shuffle_cfg = dict(interval=1)
|
configs/1shot-swin/graph_split3_config.py
ADDED
|
@@ -0,0 +1,191 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
log_level = 'INFO'
|
| 2 |
+
load_from = None
|
| 3 |
+
resume_from = None
|
| 4 |
+
dist_params = dict(backend='nccl')
|
| 5 |
+
workflow = [('train', 1)]
|
| 6 |
+
checkpoint_config = dict(interval=20)
|
| 7 |
+
evaluation = dict(
|
| 8 |
+
interval=25,
|
| 9 |
+
metric=['PCK', 'NME', 'AUC', 'EPE'],
|
| 10 |
+
key_indicator='PCK',
|
| 11 |
+
gpu_collect=True,
|
| 12 |
+
res_folder='')
|
| 13 |
+
optimizer = dict(
|
| 14 |
+
type='Adam',
|
| 15 |
+
lr=1e-5,
|
| 16 |
+
)
|
| 17 |
+
|
| 18 |
+
optimizer_config = dict(grad_clip=None)
|
| 19 |
+
# learning policy
|
| 20 |
+
lr_config = dict(
|
| 21 |
+
policy='step',
|
| 22 |
+
warmup='linear',
|
| 23 |
+
warmup_iters=1000,
|
| 24 |
+
warmup_ratio=0.001,
|
| 25 |
+
step=[160, 180])
|
| 26 |
+
total_epochs = 200
|
| 27 |
+
log_config = dict(
|
| 28 |
+
interval=50,
|
| 29 |
+
hooks=[
|
| 30 |
+
dict(type='TextLoggerHook'),
|
| 31 |
+
dict(type='TensorboardLoggerHook')
|
| 32 |
+
])
|
| 33 |
+
|
| 34 |
+
channel_cfg = dict(
|
| 35 |
+
num_output_channels=1,
|
| 36 |
+
dataset_joints=1,
|
| 37 |
+
dataset_channel=[
|
| 38 |
+
[
|
| 39 |
+
0,
|
| 40 |
+
],
|
| 41 |
+
],
|
| 42 |
+
inference_channel=[
|
| 43 |
+
0,
|
| 44 |
+
],
|
| 45 |
+
max_kpt_num=100)
|
| 46 |
+
|
| 47 |
+
# model settings
|
| 48 |
+
model = dict(
|
| 49 |
+
type='PoseAnythingModel',
|
| 50 |
+
pretrained='pretrained/swinv2_base_22k_500k.pth',
|
| 51 |
+
encoder_config=dict(
|
| 52 |
+
type='SwinTransformerV2',
|
| 53 |
+
embed_dim=128,
|
| 54 |
+
depths=[2, 2, 18, 2],
|
| 55 |
+
num_heads=[4, 8, 16, 32],
|
| 56 |
+
window_size=14,
|
| 57 |
+
pretrained_window_sizes=[12, 12, 12, 6],
|
| 58 |
+
drop_path_rate=0.1,
|
| 59 |
+
img_size=224,
|
| 60 |
+
),
|
| 61 |
+
keypoint_head=dict(
|
| 62 |
+
type='PoseHead',
|
| 63 |
+
in_channels=1024,
|
| 64 |
+
transformer=dict(
|
| 65 |
+
type='EncoderDecoder',
|
| 66 |
+
d_model=256,
|
| 67 |
+
nhead=8,
|
| 68 |
+
num_encoder_layers=3,
|
| 69 |
+
num_decoder_layers=3,
|
| 70 |
+
graph_decoder='pre',
|
| 71 |
+
dim_feedforward=1024,
|
| 72 |
+
dropout=0.1,
|
| 73 |
+
similarity_proj_dim=256,
|
| 74 |
+
dynamic_proj_dim=128,
|
| 75 |
+
activation="relu",
|
| 76 |
+
normalize_before=False,
|
| 77 |
+
return_intermediate_dec=True),
|
| 78 |
+
share_kpt_branch=False,
|
| 79 |
+
num_decoder_layer=3,
|
| 80 |
+
with_heatmap_loss=True,
|
| 81 |
+
|
| 82 |
+
heatmap_loss_weight=2.0,
|
| 83 |
+
support_order_dropout=-1,
|
| 84 |
+
positional_encoding=dict(
|
| 85 |
+
type='SinePositionalEncoding', num_feats=128, normalize=True)),
|
| 86 |
+
# training and testing settings
|
| 87 |
+
train_cfg=dict(),
|
| 88 |
+
test_cfg=dict(
|
| 89 |
+
flip_test=False,
|
| 90 |
+
post_process='default',
|
| 91 |
+
shift_heatmap=True,
|
| 92 |
+
modulate_kernel=11))
|
| 93 |
+
|
| 94 |
+
data_cfg = dict(
|
| 95 |
+
image_size=[224, 224],
|
| 96 |
+
heatmap_size=[64, 64],
|
| 97 |
+
num_output_channels=channel_cfg['num_output_channels'],
|
| 98 |
+
num_joints=channel_cfg['dataset_joints'],
|
| 99 |
+
dataset_channel=channel_cfg['dataset_channel'],
|
| 100 |
+
inference_channel=channel_cfg['inference_channel'])
|
| 101 |
+
|
| 102 |
+
train_pipeline = [
|
| 103 |
+
dict(type='LoadImageFromFile'),
|
| 104 |
+
dict(
|
| 105 |
+
type='TopDownGetRandomScaleRotation', rot_factor=15,
|
| 106 |
+
scale_factor=0.15),
|
| 107 |
+
dict(type='TopDownAffineFewShot'),
|
| 108 |
+
dict(type='ToTensor'),
|
| 109 |
+
dict(
|
| 110 |
+
type='NormalizeTensor',
|
| 111 |
+
mean=[0.485, 0.456, 0.406],
|
| 112 |
+
std=[0.229, 0.224, 0.225]),
|
| 113 |
+
dict(type='TopDownGenerateTargetFewShot', sigma=1),
|
| 114 |
+
dict(
|
| 115 |
+
type='Collect',
|
| 116 |
+
keys=['img', 'target', 'target_weight'],
|
| 117 |
+
meta_keys=[
|
| 118 |
+
'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
|
| 119 |
+
'rotation', 'bbox_score', 'flip_pairs', 'category_id', 'skeleton',
|
| 120 |
+
]),
|
| 121 |
+
]
|
| 122 |
+
|
| 123 |
+
valid_pipeline = [
|
| 124 |
+
dict(type='LoadImageFromFile'),
|
| 125 |
+
dict(type='TopDownAffineFewShot'),
|
| 126 |
+
dict(type='ToTensor'),
|
| 127 |
+
dict(
|
| 128 |
+
type='NormalizeTensor',
|
| 129 |
+
mean=[0.485, 0.456, 0.406],
|
| 130 |
+
std=[0.229, 0.224, 0.225]),
|
| 131 |
+
dict(type='TopDownGenerateTargetFewShot', sigma=1),
|
| 132 |
+
dict(
|
| 133 |
+
type='Collect',
|
| 134 |
+
keys=['img', 'target', 'target_weight'],
|
| 135 |
+
meta_keys=[
|
| 136 |
+
'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale', 'rotation', 'bbox_score',
|
| 137 |
+
'flip_pairs', 'category_id',
|
| 138 |
+
'skeleton',
|
| 139 |
+
]),
|
| 140 |
+
]
|
| 141 |
+
|
| 142 |
+
test_pipeline = valid_pipeline
|
| 143 |
+
|
| 144 |
+
data_root = 'data/mp100'
|
| 145 |
+
data = dict(
|
| 146 |
+
samples_per_gpu=8,
|
| 147 |
+
workers_per_gpu=8,
|
| 148 |
+
train=dict(
|
| 149 |
+
type='TransformerPoseDataset',
|
| 150 |
+
ann_file=f'{data_root}/annotations/mp100_split3_train.json',
|
| 151 |
+
img_prefix=f'{data_root}/images/',
|
| 152 |
+
# img_prefix=f'{data_root}',
|
| 153 |
+
data_cfg=data_cfg,
|
| 154 |
+
valid_class_ids=None,
|
| 155 |
+
max_kpt_num=channel_cfg['max_kpt_num'],
|
| 156 |
+
num_shots=1,
|
| 157 |
+
pipeline=train_pipeline),
|
| 158 |
+
val=dict(
|
| 159 |
+
type='TransformerPoseDataset',
|
| 160 |
+
ann_file=f'{data_root}/annotations/mp100_split3_val.json',
|
| 161 |
+
img_prefix=f'{data_root}/images/',
|
| 162 |
+
# img_prefix=f'{data_root}',
|
| 163 |
+
data_cfg=data_cfg,
|
| 164 |
+
valid_class_ids=None,
|
| 165 |
+
max_kpt_num=channel_cfg['max_kpt_num'],
|
| 166 |
+
num_shots=1,
|
| 167 |
+
num_queries=15,
|
| 168 |
+
num_episodes=100,
|
| 169 |
+
pipeline=valid_pipeline),
|
| 170 |
+
test=dict(
|
| 171 |
+
type='TestPoseDataset',
|
| 172 |
+
ann_file=f'{data_root}/annotations/mp100_split3_test.json',
|
| 173 |
+
img_prefix=f'{data_root}/images/',
|
| 174 |
+
# img_prefix=f'{data_root}',
|
| 175 |
+
data_cfg=data_cfg,
|
| 176 |
+
valid_class_ids=None,
|
| 177 |
+
max_kpt_num=channel_cfg['max_kpt_num'],
|
| 178 |
+
num_shots=1,
|
| 179 |
+
num_queries=15,
|
| 180 |
+
num_episodes=200,
|
| 181 |
+
pck_threshold_list=[0.05, 0.10, 0.15, 0.2, 0.25],
|
| 182 |
+
pipeline=test_pipeline),
|
| 183 |
+
)
|
| 184 |
+
vis_backends = [
|
| 185 |
+
dict(type='LocalVisBackend'),
|
| 186 |
+
dict(type='TensorboardVisBackend'),
|
| 187 |
+
]
|
| 188 |
+
visualizer = dict(
|
| 189 |
+
type='PoseLocalVisualizer', vis_backends=vis_backends, name='visualizer')
|
| 190 |
+
|
| 191 |
+
shuffle_cfg = dict(interval=1)
|
configs/1shot-swin/graph_split4_config.py
ADDED
|
@@ -0,0 +1,191 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
log_level = 'INFO'
|
| 2 |
+
load_from = None
|
| 3 |
+
resume_from = None
|
| 4 |
+
dist_params = dict(backend='nccl')
|
| 5 |
+
workflow = [('train', 1)]
|
| 6 |
+
checkpoint_config = dict(interval=20)
|
| 7 |
+
evaluation = dict(
|
| 8 |
+
interval=25,
|
| 9 |
+
metric=['PCK', 'NME', 'AUC', 'EPE'],
|
| 10 |
+
key_indicator='PCK',
|
| 11 |
+
gpu_collect=True,
|
| 12 |
+
res_folder='')
|
| 13 |
+
optimizer = dict(
|
| 14 |
+
type='Adam',
|
| 15 |
+
lr=1e-5,
|
| 16 |
+
)
|
| 17 |
+
|
| 18 |
+
optimizer_config = dict(grad_clip=None)
|
| 19 |
+
# learning policy
|
| 20 |
+
lr_config = dict(
|
| 21 |
+
policy='step',
|
| 22 |
+
warmup='linear',
|
| 23 |
+
warmup_iters=1000,
|
| 24 |
+
warmup_ratio=0.001,
|
| 25 |
+
step=[160, 180])
|
| 26 |
+
total_epochs = 200
|
| 27 |
+
log_config = dict(
|
| 28 |
+
interval=50,
|
| 29 |
+
hooks=[
|
| 30 |
+
dict(type='TextLoggerHook'),
|
| 31 |
+
dict(type='TensorboardLoggerHook')
|
| 32 |
+
])
|
| 33 |
+
|
| 34 |
+
channel_cfg = dict(
|
| 35 |
+
num_output_channels=1,
|
| 36 |
+
dataset_joints=1,
|
| 37 |
+
dataset_channel=[
|
| 38 |
+
[
|
| 39 |
+
0,
|
| 40 |
+
],
|
| 41 |
+
],
|
| 42 |
+
inference_channel=[
|
| 43 |
+
0,
|
| 44 |
+
],
|
| 45 |
+
max_kpt_num=100)
|
| 46 |
+
|
| 47 |
+
# model settings
|
| 48 |
+
model = dict(
|
| 49 |
+
type='PoseAnythingModel',
|
| 50 |
+
pretrained='pretrained/swinv2_base_22k_500k.pth',
|
| 51 |
+
encoder_config=dict(
|
| 52 |
+
type='SwinTransformerV2',
|
| 53 |
+
embed_dim=128,
|
| 54 |
+
depths=[2, 2, 18, 2],
|
| 55 |
+
num_heads=[4, 8, 16, 32],
|
| 56 |
+
window_size=14,
|
| 57 |
+
pretrained_window_sizes=[12, 12, 12, 6],
|
| 58 |
+
drop_path_rate=0.1,
|
| 59 |
+
img_size=224,
|
| 60 |
+
),
|
| 61 |
+
keypoint_head=dict(
|
| 62 |
+
type='PoseHead',
|
| 63 |
+
in_channels=1024,
|
| 64 |
+
transformer=dict(
|
| 65 |
+
type='EncoderDecoder',
|
| 66 |
+
d_model=256,
|
| 67 |
+
nhead=8,
|
| 68 |
+
num_encoder_layers=3,
|
| 69 |
+
num_decoder_layers=3,
|
| 70 |
+
graph_decoder='pre',
|
| 71 |
+
dim_feedforward=1024,
|
| 72 |
+
dropout=0.1,
|
| 73 |
+
similarity_proj_dim=256,
|
| 74 |
+
dynamic_proj_dim=128,
|
| 75 |
+
activation="relu",
|
| 76 |
+
normalize_before=False,
|
| 77 |
+
return_intermediate_dec=True),
|
| 78 |
+
share_kpt_branch=False,
|
| 79 |
+
num_decoder_layer=3,
|
| 80 |
+
with_heatmap_loss=True,
|
| 81 |
+
|
| 82 |
+
heatmap_loss_weight=2.0,
|
| 83 |
+
support_order_dropout=-1,
|
| 84 |
+
positional_encoding=dict(
|
| 85 |
+
type='SinePositionalEncoding', num_feats=128, normalize=True)),
|
| 86 |
+
# training and testing settings
|
| 87 |
+
train_cfg=dict(),
|
| 88 |
+
test_cfg=dict(
|
| 89 |
+
flip_test=False,
|
| 90 |
+
post_process='default',
|
| 91 |
+
shift_heatmap=True,
|
| 92 |
+
modulate_kernel=11))
|
| 93 |
+
|
| 94 |
+
data_cfg = dict(
|
| 95 |
+
image_size=[224, 224],
|
| 96 |
+
heatmap_size=[64, 64],
|
| 97 |
+
num_output_channels=channel_cfg['num_output_channels'],
|
| 98 |
+
num_joints=channel_cfg['dataset_joints'],
|
| 99 |
+
dataset_channel=channel_cfg['dataset_channel'],
|
| 100 |
+
inference_channel=channel_cfg['inference_channel'])
|
| 101 |
+
|
| 102 |
+
train_pipeline = [
|
| 103 |
+
dict(type='LoadImageFromFile'),
|
| 104 |
+
dict(
|
| 105 |
+
type='TopDownGetRandomScaleRotation', rot_factor=15,
|
| 106 |
+
scale_factor=0.15),
|
| 107 |
+
dict(type='TopDownAffineFewShot'),
|
| 108 |
+
dict(type='ToTensor'),
|
| 109 |
+
dict(
|
| 110 |
+
type='NormalizeTensor',
|
| 111 |
+
mean=[0.485, 0.456, 0.406],
|
| 112 |
+
std=[0.229, 0.224, 0.225]),
|
| 113 |
+
dict(type='TopDownGenerateTargetFewShot', sigma=1),
|
| 114 |
+
dict(
|
| 115 |
+
type='Collect',
|
| 116 |
+
keys=['img', 'target', 'target_weight'],
|
| 117 |
+
meta_keys=[
|
| 118 |
+
'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
|
| 119 |
+
'rotation', 'bbox_score', 'flip_pairs', 'category_id', 'skeleton',
|
| 120 |
+
]),
|
| 121 |
+
]
|
| 122 |
+
|
| 123 |
+
valid_pipeline = [
|
| 124 |
+
dict(type='LoadImageFromFile'),
|
| 125 |
+
dict(type='TopDownAffineFewShot'),
|
| 126 |
+
dict(type='ToTensor'),
|
| 127 |
+
dict(
|
| 128 |
+
type='NormalizeTensor',
|
| 129 |
+
mean=[0.485, 0.456, 0.406],
|
| 130 |
+
std=[0.229, 0.224, 0.225]),
|
| 131 |
+
dict(type='TopDownGenerateTargetFewShot', sigma=1),
|
| 132 |
+
dict(
|
| 133 |
+
type='Collect',
|
| 134 |
+
keys=['img', 'target', 'target_weight'],
|
| 135 |
+
meta_keys=[
|
| 136 |
+
'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale', 'rotation', 'bbox_score',
|
| 137 |
+
'flip_pairs', 'category_id',
|
| 138 |
+
'skeleton',
|
| 139 |
+
]),
|
| 140 |
+
]
|
| 141 |
+
|
| 142 |
+
test_pipeline = valid_pipeline
|
| 143 |
+
|
| 144 |
+
data_root = 'data/mp100'
|
| 145 |
+
data = dict(
|
| 146 |
+
samples_per_gpu=8,
|
| 147 |
+
workers_per_gpu=8,
|
| 148 |
+
train=dict(
|
| 149 |
+
type='TransformerPoseDataset',
|
| 150 |
+
ann_file=f'{data_root}/annotations/mp100_split4_train.json',
|
| 151 |
+
img_prefix=f'{data_root}/images/',
|
| 152 |
+
# img_prefix=f'{data_root}',
|
| 153 |
+
data_cfg=data_cfg,
|
| 154 |
+
valid_class_ids=None,
|
| 155 |
+
max_kpt_num=channel_cfg['max_kpt_num'],
|
| 156 |
+
num_shots=1,
|
| 157 |
+
pipeline=train_pipeline),
|
| 158 |
+
val=dict(
|
| 159 |
+
type='TransformerPoseDataset',
|
| 160 |
+
ann_file=f'{data_root}/annotations/mp100_split4_val.json',
|
| 161 |
+
img_prefix=f'{data_root}/images/',
|
| 162 |
+
# img_prefix=f'{data_root}',
|
| 163 |
+
data_cfg=data_cfg,
|
| 164 |
+
valid_class_ids=None,
|
| 165 |
+
max_kpt_num=channel_cfg['max_kpt_num'],
|
| 166 |
+
num_shots=1,
|
| 167 |
+
num_queries=15,
|
| 168 |
+
num_episodes=100,
|
| 169 |
+
pipeline=valid_pipeline),
|
| 170 |
+
test=dict(
|
| 171 |
+
type='TestPoseDataset',
|
| 172 |
+
ann_file=f'{data_root}/annotations/mp100_split4_test.json',
|
| 173 |
+
img_prefix=f'{data_root}/images/',
|
| 174 |
+
# img_prefix=f'{data_root}',
|
| 175 |
+
data_cfg=data_cfg,
|
| 176 |
+
valid_class_ids=None,
|
| 177 |
+
max_kpt_num=channel_cfg['max_kpt_num'],
|
| 178 |
+
num_shots=1,
|
| 179 |
+
num_queries=15,
|
| 180 |
+
num_episodes=200,
|
| 181 |
+
pck_threshold_list=[0.05, 0.10, 0.15, 0.2, 0.25],
|
| 182 |
+
pipeline=test_pipeline),
|
| 183 |
+
)
|
| 184 |
+
vis_backends = [
|
| 185 |
+
dict(type='LocalVisBackend'),
|
| 186 |
+
dict(type='TensorboardVisBackend'),
|
| 187 |
+
]
|
| 188 |
+
visualizer = dict(
|
| 189 |
+
type='PoseLocalVisualizer', vis_backends=vis_backends, name='visualizer')
|
| 190 |
+
|
| 191 |
+
shuffle_cfg = dict(interval=1)
|
configs/1shot-swin/graph_split5_config.py
ADDED
|
@@ -0,0 +1,191 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
log_level = 'INFO'
|
| 2 |
+
load_from = None
|
| 3 |
+
resume_from = None
|
| 4 |
+
dist_params = dict(backend='nccl')
|
| 5 |
+
workflow = [('train', 1)]
|
| 6 |
+
checkpoint_config = dict(interval=20)
|
| 7 |
+
evaluation = dict(
|
| 8 |
+
interval=25,
|
| 9 |
+
metric=['PCK', 'NME', 'AUC', 'EPE'],
|
| 10 |
+
key_indicator='PCK',
|
| 11 |
+
gpu_collect=True,
|
| 12 |
+
res_folder='')
|
| 13 |
+
optimizer = dict(
|
| 14 |
+
type='Adam',
|
| 15 |
+
lr=1e-5,
|
| 16 |
+
)
|
| 17 |
+
|
| 18 |
+
optimizer_config = dict(grad_clip=None)
|
| 19 |
+
# learning policy
|
| 20 |
+
lr_config = dict(
|
| 21 |
+
policy='step',
|
| 22 |
+
warmup='linear',
|
| 23 |
+
warmup_iters=1000,
|
| 24 |
+
warmup_ratio=0.001,
|
| 25 |
+
step=[160, 180])
|
| 26 |
+
total_epochs = 200
|
| 27 |
+
log_config = dict(
|
| 28 |
+
interval=50,
|
| 29 |
+
hooks=[
|
| 30 |
+
dict(type='TextLoggerHook'),
|
| 31 |
+
dict(type='TensorboardLoggerHook')
|
| 32 |
+
])
|
| 33 |
+
|
| 34 |
+
channel_cfg = dict(
|
| 35 |
+
num_output_channels=1,
|
| 36 |
+
dataset_joints=1,
|
| 37 |
+
dataset_channel=[
|
| 38 |
+
[
|
| 39 |
+
0,
|
| 40 |
+
],
|
| 41 |
+
],
|
| 42 |
+
inference_channel=[
|
| 43 |
+
0,
|
| 44 |
+
],
|
| 45 |
+
max_kpt_num=100)
|
| 46 |
+
|
| 47 |
+
# model settings
|
| 48 |
+
model = dict(
|
| 49 |
+
type='PoseAnythingModel',
|
| 50 |
+
pretrained='pretrained/swinv2_base_22k_500k.pth',
|
| 51 |
+
encoder_config=dict(
|
| 52 |
+
type='SwinTransformerV2',
|
| 53 |
+
embed_dim=128,
|
| 54 |
+
depths=[2, 2, 18, 2],
|
| 55 |
+
num_heads=[4, 8, 16, 32],
|
| 56 |
+
window_size=14,
|
| 57 |
+
pretrained_window_sizes=[12, 12, 12, 6],
|
| 58 |
+
drop_path_rate=0.1,
|
| 59 |
+
img_size=224,
|
| 60 |
+
),
|
| 61 |
+
keypoint_head=dict(
|
| 62 |
+
type='PoseHead',
|
| 63 |
+
in_channels=1024,
|
| 64 |
+
transformer=dict(
|
| 65 |
+
type='EncoderDecoder',
|
| 66 |
+
d_model=256,
|
| 67 |
+
nhead=8,
|
| 68 |
+
num_encoder_layers=3,
|
| 69 |
+
num_decoder_layers=3,
|
| 70 |
+
graph_decoder='pre',
|
| 71 |
+
dim_feedforward=1024,
|
| 72 |
+
dropout=0.1,
|
| 73 |
+
similarity_proj_dim=256,
|
| 74 |
+
dynamic_proj_dim=128,
|
| 75 |
+
activation="relu",
|
| 76 |
+
normalize_before=False,
|
| 77 |
+
return_intermediate_dec=True),
|
| 78 |
+
share_kpt_branch=False,
|
| 79 |
+
num_decoder_layer=3,
|
| 80 |
+
with_heatmap_loss=True,
|
| 81 |
+
|
| 82 |
+
heatmap_loss_weight=2.0,
|
| 83 |
+
support_order_dropout=-1,
|
| 84 |
+
positional_encoding=dict(
|
| 85 |
+
type='SinePositionalEncoding', num_feats=128, normalize=True)),
|
| 86 |
+
# training and testing settings
|
| 87 |
+
train_cfg=dict(),
|
| 88 |
+
test_cfg=dict(
|
| 89 |
+
flip_test=False,
|
| 90 |
+
post_process='default',
|
| 91 |
+
shift_heatmap=True,
|
| 92 |
+
modulate_kernel=11))
|
| 93 |
+
|
| 94 |
+
data_cfg = dict(
|
| 95 |
+
image_size=[224, 224],
|
| 96 |
+
heatmap_size=[64, 64],
|
| 97 |
+
num_output_channels=channel_cfg['num_output_channels'],
|
| 98 |
+
num_joints=channel_cfg['dataset_joints'],
|
| 99 |
+
dataset_channel=channel_cfg['dataset_channel'],
|
| 100 |
+
inference_channel=channel_cfg['inference_channel'])
|
| 101 |
+
|
| 102 |
+
train_pipeline = [
|
| 103 |
+
dict(type='LoadImageFromFile'),
|
| 104 |
+
dict(
|
| 105 |
+
type='TopDownGetRandomScaleRotation', rot_factor=15,
|
| 106 |
+
scale_factor=0.15),
|
| 107 |
+
dict(type='TopDownAffineFewShot'),
|
| 108 |
+
dict(type='ToTensor'),
|
| 109 |
+
dict(
|
| 110 |
+
type='NormalizeTensor',
|
| 111 |
+
mean=[0.485, 0.456, 0.406],
|
| 112 |
+
std=[0.229, 0.224, 0.225]),
|
| 113 |
+
dict(type='TopDownGenerateTargetFewShot', sigma=1),
|
| 114 |
+
dict(
|
| 115 |
+
type='Collect',
|
| 116 |
+
keys=['img', 'target', 'target_weight'],
|
| 117 |
+
meta_keys=[
|
| 118 |
+
'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
|
| 119 |
+
'rotation', 'bbox_score', 'flip_pairs', 'category_id', 'skeleton',
|
| 120 |
+
]),
|
| 121 |
+
]
|
| 122 |
+
|
| 123 |
+
valid_pipeline = [
|
| 124 |
+
dict(type='LoadImageFromFile'),
|
| 125 |
+
dict(type='TopDownAffineFewShot'),
|
| 126 |
+
dict(type='ToTensor'),
|
| 127 |
+
dict(
|
| 128 |
+
type='NormalizeTensor',
|
| 129 |
+
mean=[0.485, 0.456, 0.406],
|
| 130 |
+
std=[0.229, 0.224, 0.225]),
|
| 131 |
+
dict(type='TopDownGenerateTargetFewShot', sigma=1),
|
| 132 |
+
dict(
|
| 133 |
+
type='Collect',
|
| 134 |
+
keys=['img', 'target', 'target_weight'],
|
| 135 |
+
meta_keys=[
|
| 136 |
+
'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale', 'rotation', 'bbox_score',
|
| 137 |
+
'flip_pairs', 'category_id',
|
| 138 |
+
'skeleton',
|
| 139 |
+
]),
|
| 140 |
+
]
|
| 141 |
+
|
| 142 |
+
test_pipeline = valid_pipeline
|
| 143 |
+
|
| 144 |
+
data_root = 'data/mp100'
|
| 145 |
+
data = dict(
|
| 146 |
+
samples_per_gpu=8,
|
| 147 |
+
workers_per_gpu=8,
|
| 148 |
+
train=dict(
|
| 149 |
+
type='TransformerPoseDataset',
|
| 150 |
+
ann_file=f'{data_root}/annotations/mp100_split5_train.json',
|
| 151 |
+
img_prefix=f'{data_root}/images/',
|
| 152 |
+
# img_prefix=f'{data_root}',
|
| 153 |
+
data_cfg=data_cfg,
|
| 154 |
+
valid_class_ids=None,
|
| 155 |
+
max_kpt_num=channel_cfg['max_kpt_num'],
|
| 156 |
+
num_shots=1,
|
| 157 |
+
pipeline=train_pipeline),
|
| 158 |
+
val=dict(
|
| 159 |
+
type='TransformerPoseDataset',
|
| 160 |
+
ann_file=f'{data_root}/annotations/mp100_split5_val.json',
|
| 161 |
+
img_prefix=f'{data_root}/images/',
|
| 162 |
+
# img_prefix=f'{data_root}',
|
| 163 |
+
data_cfg=data_cfg,
|
| 164 |
+
valid_class_ids=None,
|
| 165 |
+
max_kpt_num=channel_cfg['max_kpt_num'],
|
| 166 |
+
num_shots=1,
|
| 167 |
+
num_queries=15,
|
| 168 |
+
num_episodes=100,
|
| 169 |
+
pipeline=valid_pipeline),
|
| 170 |
+
test=dict(
|
| 171 |
+
type='TestPoseDataset',
|
| 172 |
+
ann_file=f'{data_root}/annotations/mp100_split5_test.json',
|
| 173 |
+
img_prefix=f'{data_root}/images/',
|
| 174 |
+
# img_prefix=f'{data_root}',
|
| 175 |
+
data_cfg=data_cfg,
|
| 176 |
+
valid_class_ids=None,
|
| 177 |
+
max_kpt_num=channel_cfg['max_kpt_num'],
|
| 178 |
+
num_shots=1,
|
| 179 |
+
num_queries=15,
|
| 180 |
+
num_episodes=200,
|
| 181 |
+
pck_threshold_list=[0.05, 0.10, 0.15, 0.2, 0.25],
|
| 182 |
+
pipeline=test_pipeline),
|
| 183 |
+
)
|
| 184 |
+
vis_backends = [
|
| 185 |
+
dict(type='LocalVisBackend'),
|
| 186 |
+
dict(type='TensorboardVisBackend'),
|
| 187 |
+
]
|
| 188 |
+
visualizer = dict(
|
| 189 |
+
type='PoseLocalVisualizer', vis_backends=vis_backends, name='visualizer')
|
| 190 |
+
|
| 191 |
+
shuffle_cfg = dict(interval=1)
|
configs/1shots/base_split1_config.py
ADDED
|
@@ -0,0 +1,190 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
log_level = 'INFO'
|
| 2 |
+
load_from = None
|
| 3 |
+
resume_from = None
|
| 4 |
+
dist_params = dict(backend='nccl')
|
| 5 |
+
workflow = [('train', 1)]
|
| 6 |
+
checkpoint_config = dict(interval=20)
|
| 7 |
+
evaluation = dict(
|
| 8 |
+
interval=25,
|
| 9 |
+
metric=['PCK', 'NME', 'AUC', 'EPE'],
|
| 10 |
+
key_indicator='PCK',
|
| 11 |
+
gpu_collect=True,
|
| 12 |
+
res_folder='')
|
| 13 |
+
optimizer = dict(
|
| 14 |
+
type='Adam',
|
| 15 |
+
lr=1e-5,
|
| 16 |
+
)
|
| 17 |
+
|
| 18 |
+
optimizer_config = dict(grad_clip=None)
|
| 19 |
+
# learning policy
|
| 20 |
+
lr_config = dict(
|
| 21 |
+
policy='step',
|
| 22 |
+
warmup='linear',
|
| 23 |
+
warmup_iters=1000,
|
| 24 |
+
warmup_ratio=0.001,
|
| 25 |
+
step=[160, 180])
|
| 26 |
+
total_epochs = 200
|
| 27 |
+
log_config = dict(
|
| 28 |
+
interval=50,
|
| 29 |
+
hooks=[
|
| 30 |
+
dict(type='TextLoggerHook'),
|
| 31 |
+
dict(type='TensorboardLoggerHook')
|
| 32 |
+
])
|
| 33 |
+
|
| 34 |
+
channel_cfg = dict(
|
| 35 |
+
num_output_channels=1,
|
| 36 |
+
dataset_joints=1,
|
| 37 |
+
dataset_channel=[
|
| 38 |
+
[
|
| 39 |
+
0,
|
| 40 |
+
],
|
| 41 |
+
],
|
| 42 |
+
inference_channel=[
|
| 43 |
+
0,
|
| 44 |
+
],
|
| 45 |
+
max_kpt_num=100)
|
| 46 |
+
|
| 47 |
+
# model settings
|
| 48 |
+
model = dict(
|
| 49 |
+
type='PoseAnythingModel',
|
| 50 |
+
pretrained='pretrained/swinv2_tiny_patch4_window16_256.pth',
|
| 51 |
+
encoder_config=dict(
|
| 52 |
+
type='SwinTransformerV2',
|
| 53 |
+
embed_dim=96,
|
| 54 |
+
depths=[2, 2, 6, 2],
|
| 55 |
+
num_heads=[3, 6, 12, 24],
|
| 56 |
+
window_size=16,
|
| 57 |
+
drop_path_rate=0.2,
|
| 58 |
+
img_size=256,
|
| 59 |
+
upsample="bilinear"
|
| 60 |
+
),
|
| 61 |
+
keypoint_head=dict(
|
| 62 |
+
type='PoseHead',
|
| 63 |
+
in_channels=768,
|
| 64 |
+
transformer=dict(
|
| 65 |
+
type='EncoderDecoder',
|
| 66 |
+
d_model=256,
|
| 67 |
+
nhead=8,
|
| 68 |
+
num_encoder_layers=3,
|
| 69 |
+
num_decoder_layers=3,
|
| 70 |
+
dim_feedforward=768,
|
| 71 |
+
dropout=0.1,
|
| 72 |
+
similarity_proj_dim=256,
|
| 73 |
+
dynamic_proj_dim=128,
|
| 74 |
+
activation="relu",
|
| 75 |
+
normalize_before=False,
|
| 76 |
+
return_intermediate_dec=True),
|
| 77 |
+
share_kpt_branch=False,
|
| 78 |
+
num_decoder_layer=3,
|
| 79 |
+
with_heatmap_loss=True,
|
| 80 |
+
heatmap_loss_weight=2.0,
|
| 81 |
+
support_order_dropout=-1,
|
| 82 |
+
positional_encoding=dict(
|
| 83 |
+
type='SinePositionalEncoding', num_feats=128, normalize=True)),
|
| 84 |
+
|
| 85 |
+
# training and testing settings
|
| 86 |
+
train_cfg=dict(),
|
| 87 |
+
test_cfg=dict(
|
| 88 |
+
flip_test=False,
|
| 89 |
+
post_process='default',
|
| 90 |
+
shift_heatmap=True,
|
| 91 |
+
modulate_kernel=11))
|
| 92 |
+
|
| 93 |
+
data_cfg = dict(
|
| 94 |
+
image_size=[256, 256],
|
| 95 |
+
heatmap_size=[64, 64],
|
| 96 |
+
num_output_channels=channel_cfg['num_output_channels'],
|
| 97 |
+
num_joints=channel_cfg['dataset_joints'],
|
| 98 |
+
dataset_channel=channel_cfg['dataset_channel'],
|
| 99 |
+
inference_channel=channel_cfg['inference_channel'])
|
| 100 |
+
|
| 101 |
+
train_pipeline = [
|
| 102 |
+
dict(type='LoadImageFromFile'),
|
| 103 |
+
dict(
|
| 104 |
+
type='TopDownGetRandomScaleRotation', rot_factor=15,
|
| 105 |
+
scale_factor=0.15),
|
| 106 |
+
dict(type='TopDownAffineFewShot'),
|
| 107 |
+
dict(type='ToTensor'),
|
| 108 |
+
dict(
|
| 109 |
+
type='NormalizeTensor',
|
| 110 |
+
mean=[0.485, 0.456, 0.406],
|
| 111 |
+
std=[0.229, 0.224, 0.225]),
|
| 112 |
+
dict(type='TopDownGenerateTargetFewShot', sigma=1),
|
| 113 |
+
dict(
|
| 114 |
+
type='Collect',
|
| 115 |
+
keys=['img', 'target', 'target_weight'],
|
| 116 |
+
meta_keys=[
|
| 117 |
+
'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
|
| 118 |
+
'rotation', 'bbox_score', 'flip_pairs', 'category_id', 'skeleton',
|
| 119 |
+
]),
|
| 120 |
+
]
|
| 121 |
+
|
| 122 |
+
valid_pipeline = [
|
| 123 |
+
dict(type='LoadImageFromFile'),
|
| 124 |
+
dict(type='TopDownAffineFewShot'),
|
| 125 |
+
dict(type='ToTensor'),
|
| 126 |
+
dict(
|
| 127 |
+
type='NormalizeTensor',
|
| 128 |
+
mean=[0.485, 0.456, 0.406],
|
| 129 |
+
std=[0.229, 0.224, 0.225]),
|
| 130 |
+
dict(type='TopDownGenerateTargetFewShot', sigma=1),
|
| 131 |
+
dict(
|
| 132 |
+
type='Collect',
|
| 133 |
+
keys=['img', 'target', 'target_weight'],
|
| 134 |
+
meta_keys=[
|
| 135 |
+
'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale', 'rotation', 'bbox_score',
|
| 136 |
+
'flip_pairs', 'category_id',
|
| 137 |
+
'skeleton',
|
| 138 |
+
]),
|
| 139 |
+
]
|
| 140 |
+
|
| 141 |
+
test_pipeline = valid_pipeline
|
| 142 |
+
|
| 143 |
+
data_root = 'data/mp100'
|
| 144 |
+
data = dict(
|
| 145 |
+
samples_per_gpu=16,
|
| 146 |
+
workers_per_gpu=8,
|
| 147 |
+
train=dict(
|
| 148 |
+
type='TransformerPoseDataset',
|
| 149 |
+
ann_file=f'{data_root}/annotations/mp100_split1_train.json',
|
| 150 |
+
img_prefix=f'{data_root}/images/',
|
| 151 |
+
# img_prefix=f'{data_root}',
|
| 152 |
+
data_cfg=data_cfg,
|
| 153 |
+
valid_class_ids=None,
|
| 154 |
+
max_kpt_num=channel_cfg['max_kpt_num'],
|
| 155 |
+
num_shots=1,
|
| 156 |
+
pipeline=train_pipeline),
|
| 157 |
+
val=dict(
|
| 158 |
+
type='TransformerPoseDataset',
|
| 159 |
+
ann_file=f'{data_root}/annotations/mp100_split1_val.json',
|
| 160 |
+
img_prefix=f'{data_root}/images/',
|
| 161 |
+
# img_prefix=f'{data_root}',
|
| 162 |
+
data_cfg=data_cfg,
|
| 163 |
+
valid_class_ids=None,
|
| 164 |
+
max_kpt_num=channel_cfg['max_kpt_num'],
|
| 165 |
+
num_shots=1,
|
| 166 |
+
num_queries=15,
|
| 167 |
+
num_episodes=100,
|
| 168 |
+
pipeline=valid_pipeline),
|
| 169 |
+
test=dict(
|
| 170 |
+
type='TestPoseDataset',
|
| 171 |
+
ann_file=f'{data_root}/annotations/mp100_split1_test.json',
|
| 172 |
+
img_prefix=f'{data_root}/images/',
|
| 173 |
+
# img_prefix=f'{data_root}',
|
| 174 |
+
data_cfg=data_cfg,
|
| 175 |
+
valid_class_ids=None,
|
| 176 |
+
max_kpt_num=channel_cfg['max_kpt_num'],
|
| 177 |
+
num_shots=1,
|
| 178 |
+
num_queries=15,
|
| 179 |
+
num_episodes=200,
|
| 180 |
+
pck_threshold_list=[0.05, 0.10, 0.15, 0.2, 0.25],
|
| 181 |
+
pipeline=test_pipeline),
|
| 182 |
+
)
|
| 183 |
+
vis_backends = [
|
| 184 |
+
dict(type='LocalVisBackend'),
|
| 185 |
+
dict(type='TensorboardVisBackend'),
|
| 186 |
+
]
|
| 187 |
+
visualizer = dict(
|
| 188 |
+
type='PoseLocalVisualizer', vis_backends=vis_backends, name='visualizer')
|
| 189 |
+
|
| 190 |
+
shuffle_cfg = dict(interval=1)
|
configs/1shots/base_split2_config.py
ADDED
|
@@ -0,0 +1,190 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
log_level = 'INFO'
|
| 2 |
+
load_from = None
|
| 3 |
+
resume_from = None
|
| 4 |
+
dist_params = dict(backend='nccl')
|
| 5 |
+
workflow = [('train', 1)]
|
| 6 |
+
checkpoint_config = dict(interval=20)
|
| 7 |
+
evaluation = dict(
|
| 8 |
+
interval=25,
|
| 9 |
+
metric=['PCK', 'NME', 'AUC', 'EPE'],
|
| 10 |
+
key_indicator='PCK',
|
| 11 |
+
gpu_collect=True,
|
| 12 |
+
res_folder='')
|
| 13 |
+
optimizer = dict(
|
| 14 |
+
type='Adam',
|
| 15 |
+
lr=1e-5,
|
| 16 |
+
)
|
| 17 |
+
|
| 18 |
+
optimizer_config = dict(grad_clip=None)
|
| 19 |
+
# learning policy
|
| 20 |
+
lr_config = dict(
|
| 21 |
+
policy='step',
|
| 22 |
+
warmup='linear',
|
| 23 |
+
warmup_iters=1000,
|
| 24 |
+
warmup_ratio=0.001,
|
| 25 |
+
step=[160, 180])
|
| 26 |
+
total_epochs = 200
|
| 27 |
+
log_config = dict(
|
| 28 |
+
interval=50,
|
| 29 |
+
hooks=[
|
| 30 |
+
dict(type='TextLoggerHook'),
|
| 31 |
+
dict(type='TensorboardLoggerHook')
|
| 32 |
+
])
|
| 33 |
+
|
| 34 |
+
channel_cfg = dict(
|
| 35 |
+
num_output_channels=1,
|
| 36 |
+
dataset_joints=1,
|
| 37 |
+
dataset_channel=[
|
| 38 |
+
[
|
| 39 |
+
0,
|
| 40 |
+
],
|
| 41 |
+
],
|
| 42 |
+
inference_channel=[
|
| 43 |
+
0,
|
| 44 |
+
],
|
| 45 |
+
max_kpt_num=100)
|
| 46 |
+
|
| 47 |
+
# model settings
|
| 48 |
+
model = dict(
|
| 49 |
+
type='PoseAnythingModel',
|
| 50 |
+
pretrained='pretrained/swinv2_tiny_patch4_window16_256.pth',
|
| 51 |
+
encoder_config=dict(
|
| 52 |
+
type='SwinTransformerV2',
|
| 53 |
+
embed_dim=96,
|
| 54 |
+
depths=[2, 2, 6, 2],
|
| 55 |
+
num_heads=[3, 6, 12, 24],
|
| 56 |
+
window_size=16,
|
| 57 |
+
drop_path_rate=0.2,
|
| 58 |
+
img_size=256,
|
| 59 |
+
upsample="bilinear"
|
| 60 |
+
),
|
| 61 |
+
keypoint_head=dict(
|
| 62 |
+
type='PoseHead',
|
| 63 |
+
in_channels=768,
|
| 64 |
+
transformer=dict(
|
| 65 |
+
type='EncoderDecoder',
|
| 66 |
+
d_model=256,
|
| 67 |
+
nhead=8,
|
| 68 |
+
num_encoder_layers=3,
|
| 69 |
+
num_decoder_layers=3,
|
| 70 |
+
dim_feedforward=768,
|
| 71 |
+
dropout=0.1,
|
| 72 |
+
similarity_proj_dim=256,
|
| 73 |
+
dynamic_proj_dim=128,
|
| 74 |
+
activation="relu",
|
| 75 |
+
normalize_before=False,
|
| 76 |
+
return_intermediate_dec=True),
|
| 77 |
+
share_kpt_branch=False,
|
| 78 |
+
num_decoder_layer=3,
|
| 79 |
+
with_heatmap_loss=True,
|
| 80 |
+
|
| 81 |
+
heatmap_loss_weight=2.0,
|
| 82 |
+
support_order_dropout=-1,
|
| 83 |
+
positional_encoding=dict(
|
| 84 |
+
type='SinePositionalEncoding', num_feats=128, normalize=True)),
|
| 85 |
+
# training and testing settings
|
| 86 |
+
train_cfg=dict(),
|
| 87 |
+
test_cfg=dict(
|
| 88 |
+
flip_test=False,
|
| 89 |
+
post_process='default',
|
| 90 |
+
shift_heatmap=True,
|
| 91 |
+
modulate_kernel=11))
|
| 92 |
+
|
| 93 |
+
data_cfg = dict(
|
| 94 |
+
image_size=[256, 256],
|
| 95 |
+
heatmap_size=[64, 64],
|
| 96 |
+
num_output_channels=channel_cfg['num_output_channels'],
|
| 97 |
+
num_joints=channel_cfg['dataset_joints'],
|
| 98 |
+
dataset_channel=channel_cfg['dataset_channel'],
|
| 99 |
+
inference_channel=channel_cfg['inference_channel'])
|
| 100 |
+
|
| 101 |
+
train_pipeline = [
|
| 102 |
+
dict(type='LoadImageFromFile'),
|
| 103 |
+
dict(
|
| 104 |
+
type='TopDownGetRandomScaleRotation', rot_factor=15,
|
| 105 |
+
scale_factor=0.15),
|
| 106 |
+
dict(type='TopDownAffineFewShot'),
|
| 107 |
+
dict(type='ToTensor'),
|
| 108 |
+
dict(
|
| 109 |
+
type='NormalizeTensor',
|
| 110 |
+
mean=[0.485, 0.456, 0.406],
|
| 111 |
+
std=[0.229, 0.224, 0.225]),
|
| 112 |
+
dict(type='TopDownGenerateTargetFewShot', sigma=1),
|
| 113 |
+
dict(
|
| 114 |
+
type='Collect',
|
| 115 |
+
keys=['img', 'target', 'target_weight'],
|
| 116 |
+
meta_keys=[
|
| 117 |
+
'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
|
| 118 |
+
'rotation', 'bbox_score', 'flip_pairs', 'category_id', 'skeleton',
|
| 119 |
+
]),
|
| 120 |
+
]
|
| 121 |
+
|
| 122 |
+
valid_pipeline = [
|
| 123 |
+
dict(type='LoadImageFromFile'),
|
| 124 |
+
dict(type='TopDownAffineFewShot'),
|
| 125 |
+
dict(type='ToTensor'),
|
| 126 |
+
dict(
|
| 127 |
+
type='NormalizeTensor',
|
| 128 |
+
mean=[0.485, 0.456, 0.406],
|
| 129 |
+
std=[0.229, 0.224, 0.225]),
|
| 130 |
+
dict(type='TopDownGenerateTargetFewShot', sigma=1),
|
| 131 |
+
dict(
|
| 132 |
+
type='Collect',
|
| 133 |
+
keys=['img', 'target', 'target_weight'],
|
| 134 |
+
meta_keys=[
|
| 135 |
+
'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale', 'rotation', 'bbox_score',
|
| 136 |
+
'flip_pairs', 'category_id',
|
| 137 |
+
'skeleton',
|
| 138 |
+
]),
|
| 139 |
+
]
|
| 140 |
+
|
| 141 |
+
test_pipeline = valid_pipeline
|
| 142 |
+
|
| 143 |
+
data_root = 'data/mp100'
|
| 144 |
+
data = dict(
|
| 145 |
+
samples_per_gpu=16,
|
| 146 |
+
workers_per_gpu=8,
|
| 147 |
+
train=dict(
|
| 148 |
+
type='TransformerPoseDataset',
|
| 149 |
+
ann_file=f'{data_root}/annotations/mp100_split2_train.json',
|
| 150 |
+
img_prefix=f'{data_root}/images/',
|
| 151 |
+
# img_prefix=f'{data_root}',
|
| 152 |
+
data_cfg=data_cfg,
|
| 153 |
+
valid_class_ids=None,
|
| 154 |
+
max_kpt_num=channel_cfg['max_kpt_num'],
|
| 155 |
+
num_shots=1,
|
| 156 |
+
pipeline=train_pipeline),
|
| 157 |
+
val=dict(
|
| 158 |
+
type='TransformerPoseDataset',
|
| 159 |
+
ann_file=f'{data_root}/annotations/mp100_split2_val.json',
|
| 160 |
+
img_prefix=f'{data_root}/images/',
|
| 161 |
+
# img_prefix=f'{data_root}',
|
| 162 |
+
data_cfg=data_cfg,
|
| 163 |
+
valid_class_ids=None,
|
| 164 |
+
max_kpt_num=channel_cfg['max_kpt_num'],
|
| 165 |
+
num_shots=1,
|
| 166 |
+
num_queries=15,
|
| 167 |
+
num_episodes=100,
|
| 168 |
+
pipeline=valid_pipeline),
|
| 169 |
+
test=dict(
|
| 170 |
+
type='TestPoseDataset',
|
| 171 |
+
ann_file=f'{data_root}/annotations/mp100_split2_test.json',
|
| 172 |
+
img_prefix=f'{data_root}/images/',
|
| 173 |
+
# img_prefix=f'{data_root}',
|
| 174 |
+
data_cfg=data_cfg,
|
| 175 |
+
valid_class_ids=None,
|
| 176 |
+
max_kpt_num=channel_cfg['max_kpt_num'],
|
| 177 |
+
num_shots=1,
|
| 178 |
+
num_queries=15,
|
| 179 |
+
num_episodes=200,
|
| 180 |
+
pck_threshold_list=[0.05, 0.10, 0.15, 0.2, 0.25],
|
| 181 |
+
pipeline=test_pipeline),
|
| 182 |
+
)
|
| 183 |
+
vis_backends = [
|
| 184 |
+
dict(type='LocalVisBackend'),
|
| 185 |
+
dict(type='TensorboardVisBackend'),
|
| 186 |
+
]
|
| 187 |
+
visualizer = dict(
|
| 188 |
+
type='PoseLocalVisualizer', vis_backends=vis_backends, name='visualizer')
|
| 189 |
+
|
| 190 |
+
shuffle_cfg = dict(interval=1)
|
configs/1shots/base_split3_config.py
ADDED
|
@@ -0,0 +1,190 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
log_level = 'INFO'
|
| 2 |
+
load_from = None
|
| 3 |
+
resume_from = None
|
| 4 |
+
dist_params = dict(backend='nccl')
|
| 5 |
+
workflow = [('train', 1)]
|
| 6 |
+
checkpoint_config = dict(interval=20)
|
| 7 |
+
evaluation = dict(
|
| 8 |
+
interval=25,
|
| 9 |
+
metric=['PCK', 'NME', 'AUC', 'EPE'],
|
| 10 |
+
key_indicator='PCK',
|
| 11 |
+
gpu_collect=True,
|
| 12 |
+
res_folder='')
|
| 13 |
+
optimizer = dict(
|
| 14 |
+
type='Adam',
|
| 15 |
+
lr=1e-5,
|
| 16 |
+
)
|
| 17 |
+
|
| 18 |
+
optimizer_config = dict(grad_clip=None)
|
| 19 |
+
# learning policy
|
| 20 |
+
lr_config = dict(
|
| 21 |
+
policy='step',
|
| 22 |
+
warmup='linear',
|
| 23 |
+
warmup_iters=1000,
|
| 24 |
+
warmup_ratio=0.001,
|
| 25 |
+
step=[160, 180])
|
| 26 |
+
total_epochs = 200
|
| 27 |
+
log_config = dict(
|
| 28 |
+
interval=50,
|
| 29 |
+
hooks=[
|
| 30 |
+
dict(type='TextLoggerHook'),
|
| 31 |
+
dict(type='TensorboardLoggerHook')
|
| 32 |
+
])
|
| 33 |
+
|
| 34 |
+
channel_cfg = dict(
|
| 35 |
+
num_output_channels=1,
|
| 36 |
+
dataset_joints=1,
|
| 37 |
+
dataset_channel=[
|
| 38 |
+
[
|
| 39 |
+
0,
|
| 40 |
+
],
|
| 41 |
+
],
|
| 42 |
+
inference_channel=[
|
| 43 |
+
0,
|
| 44 |
+
],
|
| 45 |
+
max_kpt_num=100)
|
| 46 |
+
|
| 47 |
+
# model settings
|
| 48 |
+
model = dict(
|
| 49 |
+
type='PoseAnythingModel',
|
| 50 |
+
pretrained='pretrained/swinv2_tiny_patch4_window16_256.pth',
|
| 51 |
+
encoder_config=dict(
|
| 52 |
+
type='SwinTransformerV2',
|
| 53 |
+
embed_dim=96,
|
| 54 |
+
depths=[2, 2, 6, 2],
|
| 55 |
+
num_heads=[3, 6, 12, 24],
|
| 56 |
+
window_size=16,
|
| 57 |
+
drop_path_rate=0.2,
|
| 58 |
+
img_size=256,
|
| 59 |
+
upsample="bilinear"
|
| 60 |
+
),
|
| 61 |
+
keypoint_head=dict(
|
| 62 |
+
type='PoseHead',
|
| 63 |
+
in_channels=768,
|
| 64 |
+
transformer=dict(
|
| 65 |
+
type='EncoderDecoder',
|
| 66 |
+
d_model=256,
|
| 67 |
+
nhead=8,
|
| 68 |
+
num_encoder_layers=3,
|
| 69 |
+
num_decoder_layers=3,
|
| 70 |
+
dim_feedforward=768,
|
| 71 |
+
dropout=0.1,
|
| 72 |
+
similarity_proj_dim=256,
|
| 73 |
+
dynamic_proj_dim=128,
|
| 74 |
+
activation="relu",
|
| 75 |
+
normalize_before=False,
|
| 76 |
+
return_intermediate_dec=True),
|
| 77 |
+
share_kpt_branch=False,
|
| 78 |
+
num_decoder_layer=3,
|
| 79 |
+
with_heatmap_loss=True,
|
| 80 |
+
|
| 81 |
+
heatmap_loss_weight=2.0,
|
| 82 |
+
support_order_dropout=-1,
|
| 83 |
+
positional_encoding=dict(
|
| 84 |
+
type='SinePositionalEncoding', num_feats=128, normalize=True)),
|
| 85 |
+
# training and testing settings
|
| 86 |
+
train_cfg=dict(),
|
| 87 |
+
test_cfg=dict(
|
| 88 |
+
flip_test=False,
|
| 89 |
+
post_process='default',
|
| 90 |
+
shift_heatmap=True,
|
| 91 |
+
modulate_kernel=11))
|
| 92 |
+
|
| 93 |
+
data_cfg = dict(
|
| 94 |
+
image_size=[256, 256],
|
| 95 |
+
heatmap_size=[64, 64],
|
| 96 |
+
num_output_channels=channel_cfg['num_output_channels'],
|
| 97 |
+
num_joints=channel_cfg['dataset_joints'],
|
| 98 |
+
dataset_channel=channel_cfg['dataset_channel'],
|
| 99 |
+
inference_channel=channel_cfg['inference_channel'])
|
| 100 |
+
|
| 101 |
+
train_pipeline = [
|
| 102 |
+
dict(type='LoadImageFromFile'),
|
| 103 |
+
dict(
|
| 104 |
+
type='TopDownGetRandomScaleRotation', rot_factor=15,
|
| 105 |
+
scale_factor=0.15),
|
| 106 |
+
dict(type='TopDownAffineFewShot'),
|
| 107 |
+
dict(type='ToTensor'),
|
| 108 |
+
dict(
|
| 109 |
+
type='NormalizeTensor',
|
| 110 |
+
mean=[0.485, 0.456, 0.406],
|
| 111 |
+
std=[0.229, 0.224, 0.225]),
|
| 112 |
+
dict(type='TopDownGenerateTargetFewShot', sigma=1),
|
| 113 |
+
dict(
|
| 114 |
+
type='Collect',
|
| 115 |
+
keys=['img', 'target', 'target_weight'],
|
| 116 |
+
meta_keys=[
|
| 117 |
+
'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
|
| 118 |
+
'rotation', 'bbox_score', 'flip_pairs', 'category_id', 'skeleton',
|
| 119 |
+
]),
|
| 120 |
+
]
|
| 121 |
+
|
| 122 |
+
valid_pipeline = [
|
| 123 |
+
dict(type='LoadImageFromFile'),
|
| 124 |
+
dict(type='TopDownAffineFewShot'),
|
| 125 |
+
dict(type='ToTensor'),
|
| 126 |
+
dict(
|
| 127 |
+
type='NormalizeTensor',
|
| 128 |
+
mean=[0.485, 0.456, 0.406],
|
| 129 |
+
std=[0.229, 0.224, 0.225]),
|
| 130 |
+
dict(type='TopDownGenerateTargetFewShot', sigma=1),
|
| 131 |
+
dict(
|
| 132 |
+
type='Collect',
|
| 133 |
+
keys=['img', 'target', 'target_weight'],
|
| 134 |
+
meta_keys=[
|
| 135 |
+
'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale', 'rotation', 'bbox_score',
|
| 136 |
+
'flip_pairs', 'category_id',
|
| 137 |
+
'skeleton',
|
| 138 |
+
]),
|
| 139 |
+
]
|
| 140 |
+
|
| 141 |
+
test_pipeline = valid_pipeline
|
| 142 |
+
|
| 143 |
+
data_root = 'data/mp100'
|
| 144 |
+
data = dict(
|
| 145 |
+
samples_per_gpu=16,
|
| 146 |
+
workers_per_gpu=8,
|
| 147 |
+
train=dict(
|
| 148 |
+
type='TransformerPoseDataset',
|
| 149 |
+
ann_file=f'{data_root}/annotations/mp100_split3_train.json',
|
| 150 |
+
img_prefix=f'{data_root}/images/',
|
| 151 |
+
# img_prefix=f'{data_root}',
|
| 152 |
+
data_cfg=data_cfg,
|
| 153 |
+
valid_class_ids=None,
|
| 154 |
+
max_kpt_num=channel_cfg['max_kpt_num'],
|
| 155 |
+
num_shots=1,
|
| 156 |
+
pipeline=train_pipeline),
|
| 157 |
+
val=dict(
|
| 158 |
+
type='TransformerPoseDataset',
|
| 159 |
+
ann_file=f'{data_root}/annotations/mp100_split3_val.json',
|
| 160 |
+
img_prefix=f'{data_root}/images/',
|
| 161 |
+
# img_prefix=f'{data_root}',
|
| 162 |
+
data_cfg=data_cfg,
|
| 163 |
+
valid_class_ids=None,
|
| 164 |
+
max_kpt_num=channel_cfg['max_kpt_num'],
|
| 165 |
+
num_shots=1,
|
| 166 |
+
num_queries=15,
|
| 167 |
+
num_episodes=100,
|
| 168 |
+
pipeline=valid_pipeline),
|
| 169 |
+
test=dict(
|
| 170 |
+
type='TestPoseDataset',
|
| 171 |
+
ann_file=f'{data_root}/annotations/mp100_split3_test.json',
|
| 172 |
+
img_prefix=f'{data_root}/images/',
|
| 173 |
+
# img_prefix=f'{data_root}',
|
| 174 |
+
data_cfg=data_cfg,
|
| 175 |
+
valid_class_ids=None,
|
| 176 |
+
max_kpt_num=channel_cfg['max_kpt_num'],
|
| 177 |
+
num_shots=1,
|
| 178 |
+
num_queries=15,
|
| 179 |
+
num_episodes=200,
|
| 180 |
+
pck_threshold_list=[0.05, 0.10, 0.15, 0.2, 0.25],
|
| 181 |
+
pipeline=test_pipeline),
|
| 182 |
+
)
|
| 183 |
+
vis_backends = [
|
| 184 |
+
dict(type='LocalVisBackend'),
|
| 185 |
+
dict(type='TensorboardVisBackend'),
|
| 186 |
+
]
|
| 187 |
+
visualizer = dict(
|
| 188 |
+
type='PoseLocalVisualizer', vis_backends=vis_backends, name='visualizer')
|
| 189 |
+
|
| 190 |
+
shuffle_cfg = dict(interval=1)
|
configs/1shots/base_split4_config.py
ADDED
|
@@ -0,0 +1,190 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
log_level = 'INFO'
|
| 2 |
+
load_from = None
|
| 3 |
+
resume_from = None
|
| 4 |
+
dist_params = dict(backend='nccl')
|
| 5 |
+
workflow = [('train', 1)]
|
| 6 |
+
checkpoint_config = dict(interval=20)
|
| 7 |
+
evaluation = dict(
|
| 8 |
+
interval=25,
|
| 9 |
+
metric=['PCK', 'NME', 'AUC', 'EPE'],
|
| 10 |
+
key_indicator='PCK',
|
| 11 |
+
gpu_collect=True,
|
| 12 |
+
res_folder='')
|
| 13 |
+
optimizer = dict(
|
| 14 |
+
type='Adam',
|
| 15 |
+
lr=1e-5,
|
| 16 |
+
)
|
| 17 |
+
|
| 18 |
+
optimizer_config = dict(grad_clip=None)
|
| 19 |
+
# learning policy
|
| 20 |
+
lr_config = dict(
|
| 21 |
+
policy='step',
|
| 22 |
+
warmup='linear',
|
| 23 |
+
warmup_iters=1000,
|
| 24 |
+
warmup_ratio=0.001,
|
| 25 |
+
step=[160, 180])
|
| 26 |
+
total_epochs = 200
|
| 27 |
+
log_config = dict(
|
| 28 |
+
interval=50,
|
| 29 |
+
hooks=[
|
| 30 |
+
dict(type='TextLoggerHook'),
|
| 31 |
+
dict(type='TensorboardLoggerHook')
|
| 32 |
+
])
|
| 33 |
+
|
| 34 |
+
channel_cfg = dict(
|
| 35 |
+
num_output_channels=1,
|
| 36 |
+
dataset_joints=1,
|
| 37 |
+
dataset_channel=[
|
| 38 |
+
[
|
| 39 |
+
0,
|
| 40 |
+
],
|
| 41 |
+
],
|
| 42 |
+
inference_channel=[
|
| 43 |
+
0,
|
| 44 |
+
],
|
| 45 |
+
max_kpt_num=100)
|
| 46 |
+
|
| 47 |
+
# model settings
|
| 48 |
+
model = dict(
|
| 49 |
+
type='PoseAnythingModel',
|
| 50 |
+
pretrained='pretrained/swinv2_tiny_patch4_window16_256.pth',
|
| 51 |
+
encoder_config=dict(
|
| 52 |
+
type='SwinTransformerV2',
|
| 53 |
+
embed_dim=96,
|
| 54 |
+
depths=[2, 2, 6, 2],
|
| 55 |
+
num_heads=[3, 6, 12, 24],
|
| 56 |
+
window_size=16,
|
| 57 |
+
drop_path_rate=0.2,
|
| 58 |
+
img_size=256,
|
| 59 |
+
upsample="bilinear"
|
| 60 |
+
),
|
| 61 |
+
keypoint_head=dict(
|
| 62 |
+
type='PoseHead',
|
| 63 |
+
in_channels=768,
|
| 64 |
+
transformer=dict(
|
| 65 |
+
type='EncoderDecoder',
|
| 66 |
+
d_model=256,
|
| 67 |
+
nhead=8,
|
| 68 |
+
num_encoder_layers=3,
|
| 69 |
+
num_decoder_layers=3,
|
| 70 |
+
dim_feedforward=768,
|
| 71 |
+
dropout=0.1,
|
| 72 |
+
similarity_proj_dim=256,
|
| 73 |
+
dynamic_proj_dim=128,
|
| 74 |
+
activation="relu",
|
| 75 |
+
normalize_before=False,
|
| 76 |
+
return_intermediate_dec=True),
|
| 77 |
+
share_kpt_branch=False,
|
| 78 |
+
num_decoder_layer=3,
|
| 79 |
+
with_heatmap_loss=True,
|
| 80 |
+
|
| 81 |
+
heatmap_loss_weight=2.0,
|
| 82 |
+
support_order_dropout=-1,
|
| 83 |
+
positional_encoding=dict(
|
| 84 |
+
type='SinePositionalEncoding', num_feats=128, normalize=True)),
|
| 85 |
+
# training and testing settings
|
| 86 |
+
train_cfg=dict(),
|
| 87 |
+
test_cfg=dict(
|
| 88 |
+
flip_test=False,
|
| 89 |
+
post_process='default',
|
| 90 |
+
shift_heatmap=True,
|
| 91 |
+
modulate_kernel=11))
|
| 92 |
+
|
| 93 |
+
data_cfg = dict(
|
| 94 |
+
image_size=[256, 256],
|
| 95 |
+
heatmap_size=[64, 64],
|
| 96 |
+
num_output_channels=channel_cfg['num_output_channels'],
|
| 97 |
+
num_joints=channel_cfg['dataset_joints'],
|
| 98 |
+
dataset_channel=channel_cfg['dataset_channel'],
|
| 99 |
+
inference_channel=channel_cfg['inference_channel'])
|
| 100 |
+
|
| 101 |
+
train_pipeline = [
|
| 102 |
+
dict(type='LoadImageFromFile'),
|
| 103 |
+
dict(
|
| 104 |
+
type='TopDownGetRandomScaleRotation', rot_factor=15,
|
| 105 |
+
scale_factor=0.15),
|
| 106 |
+
dict(type='TopDownAffineFewShot'),
|
| 107 |
+
dict(type='ToTensor'),
|
| 108 |
+
dict(
|
| 109 |
+
type='NormalizeTensor',
|
| 110 |
+
mean=[0.485, 0.456, 0.406],
|
| 111 |
+
std=[0.229, 0.224, 0.225]),
|
| 112 |
+
dict(type='TopDownGenerateTargetFewShot', sigma=1),
|
| 113 |
+
dict(
|
| 114 |
+
type='Collect',
|
| 115 |
+
keys=['img', 'target', 'target_weight'],
|
| 116 |
+
meta_keys=[
|
| 117 |
+
'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
|
| 118 |
+
'rotation', 'bbox_score', 'flip_pairs', 'category_id', 'skeleton',
|
| 119 |
+
]),
|
| 120 |
+
]
|
| 121 |
+
|
| 122 |
+
valid_pipeline = [
|
| 123 |
+
dict(type='LoadImageFromFile'),
|
| 124 |
+
dict(type='TopDownAffineFewShot'),
|
| 125 |
+
dict(type='ToTensor'),
|
| 126 |
+
dict(
|
| 127 |
+
type='NormalizeTensor',
|
| 128 |
+
mean=[0.485, 0.456, 0.406],
|
| 129 |
+
std=[0.229, 0.224, 0.225]),
|
| 130 |
+
dict(type='TopDownGenerateTargetFewShot', sigma=1),
|
| 131 |
+
dict(
|
| 132 |
+
type='Collect',
|
| 133 |
+
keys=['img', 'target', 'target_weight'],
|
| 134 |
+
meta_keys=[
|
| 135 |
+
'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale', 'rotation', 'bbox_score',
|
| 136 |
+
'flip_pairs', 'category_id',
|
| 137 |
+
'skeleton',
|
| 138 |
+
]),
|
| 139 |
+
]
|
| 140 |
+
|
| 141 |
+
test_pipeline = valid_pipeline
|
| 142 |
+
|
| 143 |
+
data_root = 'data/mp100'
|
| 144 |
+
data = dict(
|
| 145 |
+
samples_per_gpu=16,
|
| 146 |
+
workers_per_gpu=8,
|
| 147 |
+
train=dict(
|
| 148 |
+
type='TransformerPoseDataset',
|
| 149 |
+
ann_file=f'{data_root}/annotations/mp100_split4_train.json',
|
| 150 |
+
img_prefix=f'{data_root}/images/',
|
| 151 |
+
# img_prefix=f'{data_root}',
|
| 152 |
+
data_cfg=data_cfg,
|
| 153 |
+
valid_class_ids=None,
|
| 154 |
+
max_kpt_num=channel_cfg['max_kpt_num'],
|
| 155 |
+
num_shots=1,
|
| 156 |
+
pipeline=train_pipeline),
|
| 157 |
+
val=dict(
|
| 158 |
+
type='TransformerPoseDataset',
|
| 159 |
+
ann_file=f'{data_root}/annotations/mp100_split4_val.json',
|
| 160 |
+
img_prefix=f'{data_root}/images/',
|
| 161 |
+
# img_prefix=f'{data_root}',
|
| 162 |
+
data_cfg=data_cfg,
|
| 163 |
+
valid_class_ids=None,
|
| 164 |
+
max_kpt_num=channel_cfg['max_kpt_num'],
|
| 165 |
+
num_shots=1,
|
| 166 |
+
num_queries=15,
|
| 167 |
+
num_episodes=100,
|
| 168 |
+
pipeline=valid_pipeline),
|
| 169 |
+
test=dict(
|
| 170 |
+
type='TestPoseDataset',
|
| 171 |
+
ann_file=f'{data_root}/annotations/mp100_split4_test.json',
|
| 172 |
+
img_prefix=f'{data_root}/images/',
|
| 173 |
+
# img_prefix=f'{data_root}',
|
| 174 |
+
data_cfg=data_cfg,
|
| 175 |
+
valid_class_ids=None,
|
| 176 |
+
max_kpt_num=channel_cfg['max_kpt_num'],
|
| 177 |
+
num_shots=1,
|
| 178 |
+
num_queries=15,
|
| 179 |
+
num_episodes=200,
|
| 180 |
+
pck_threshold_list=[0.05, 0.10, 0.15, 0.2, 0.25],
|
| 181 |
+
pipeline=test_pipeline),
|
| 182 |
+
)
|
| 183 |
+
vis_backends = [
|
| 184 |
+
dict(type='LocalVisBackend'),
|
| 185 |
+
dict(type='TensorboardVisBackend'),
|
| 186 |
+
]
|
| 187 |
+
visualizer = dict(
|
| 188 |
+
type='PoseLocalVisualizer', vis_backends=vis_backends, name='visualizer')
|
| 189 |
+
|
| 190 |
+
shuffle_cfg = dict(interval=1)
|
configs/1shots/base_split5_config.py
ADDED
|
@@ -0,0 +1,190 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
log_level = 'INFO'
|
| 2 |
+
load_from = None
|
| 3 |
+
resume_from = None
|
| 4 |
+
dist_params = dict(backend='nccl')
|
| 5 |
+
workflow = [('train', 1)]
|
| 6 |
+
checkpoint_config = dict(interval=20)
|
| 7 |
+
evaluation = dict(
|
| 8 |
+
interval=25,
|
| 9 |
+
metric=['PCK', 'NME', 'AUC', 'EPE'],
|
| 10 |
+
key_indicator='PCK',
|
| 11 |
+
gpu_collect=True,
|
| 12 |
+
res_folder='')
|
| 13 |
+
optimizer = dict(
|
| 14 |
+
type='Adam',
|
| 15 |
+
lr=1e-5,
|
| 16 |
+
)
|
| 17 |
+
|
| 18 |
+
optimizer_config = dict(grad_clip=None)
|
| 19 |
+
# learning policy
|
| 20 |
+
lr_config = dict(
|
| 21 |
+
policy='step',
|
| 22 |
+
warmup='linear',
|
| 23 |
+
warmup_iters=1000,
|
| 24 |
+
warmup_ratio=0.001,
|
| 25 |
+
step=[160, 180])
|
| 26 |
+
total_epochs = 200
|
| 27 |
+
log_config = dict(
|
| 28 |
+
interval=50,
|
| 29 |
+
hooks=[
|
| 30 |
+
dict(type='TextLoggerHook'),
|
| 31 |
+
dict(type='TensorboardLoggerHook')
|
| 32 |
+
])
|
| 33 |
+
|
| 34 |
+
channel_cfg = dict(
|
| 35 |
+
num_output_channels=1,
|
| 36 |
+
dataset_joints=1,
|
| 37 |
+
dataset_channel=[
|
| 38 |
+
[
|
| 39 |
+
0,
|
| 40 |
+
],
|
| 41 |
+
],
|
| 42 |
+
inference_channel=[
|
| 43 |
+
0,
|
| 44 |
+
],
|
| 45 |
+
max_kpt_num=100)
|
| 46 |
+
|
| 47 |
+
# model settings
|
| 48 |
+
model = dict(
|
| 49 |
+
type='PoseAnythingModel',
|
| 50 |
+
pretrained='pretrained/swinv2_tiny_patch4_window16_256.pth',
|
| 51 |
+
encoder_config=dict(
|
| 52 |
+
type='SwinTransformerV2',
|
| 53 |
+
embed_dim=96,
|
| 54 |
+
depths=[2, 2, 6, 2],
|
| 55 |
+
num_heads=[3, 6, 12, 24],
|
| 56 |
+
window_size=16,
|
| 57 |
+
drop_path_rate=0.2,
|
| 58 |
+
img_size=256,
|
| 59 |
+
upsample="bilinear"
|
| 60 |
+
),
|
| 61 |
+
keypoint_head=dict(
|
| 62 |
+
type='PoseHead',
|
| 63 |
+
in_channels=768,
|
| 64 |
+
transformer=dict(
|
| 65 |
+
type='EncoderDecoder',
|
| 66 |
+
d_model=256,
|
| 67 |
+
nhead=8,
|
| 68 |
+
num_encoder_layers=3,
|
| 69 |
+
num_decoder_layers=3,
|
| 70 |
+
dim_feedforward=768,
|
| 71 |
+
dropout=0.1,
|
| 72 |
+
similarity_proj_dim=256,
|
| 73 |
+
dynamic_proj_dim=128,
|
| 74 |
+
activation="relu",
|
| 75 |
+
normalize_before=False,
|
| 76 |
+
return_intermediate_dec=True),
|
| 77 |
+
share_kpt_branch=False,
|
| 78 |
+
num_decoder_layer=3,
|
| 79 |
+
with_heatmap_loss=True,
|
| 80 |
+
|
| 81 |
+
heatmap_loss_weight=2.0,
|
| 82 |
+
support_order_dropout=-1,
|
| 83 |
+
positional_encoding=dict(
|
| 84 |
+
type='SinePositionalEncoding', num_feats=128, normalize=True)),
|
| 85 |
+
# training and testing settings
|
| 86 |
+
train_cfg=dict(),
|
| 87 |
+
test_cfg=dict(
|
| 88 |
+
flip_test=False,
|
| 89 |
+
post_process='default',
|
| 90 |
+
shift_heatmap=True,
|
| 91 |
+
modulate_kernel=11))
|
| 92 |
+
|
| 93 |
+
data_cfg = dict(
|
| 94 |
+
image_size=[256, 256],
|
| 95 |
+
heatmap_size=[64, 64],
|
| 96 |
+
num_output_channels=channel_cfg['num_output_channels'],
|
| 97 |
+
num_joints=channel_cfg['dataset_joints'],
|
| 98 |
+
dataset_channel=channel_cfg['dataset_channel'],
|
| 99 |
+
inference_channel=channel_cfg['inference_channel'])
|
| 100 |
+
|
| 101 |
+
train_pipeline = [
|
| 102 |
+
dict(type='LoadImageFromFile'),
|
| 103 |
+
dict(
|
| 104 |
+
type='TopDownGetRandomScaleRotation', rot_factor=15,
|
| 105 |
+
scale_factor=0.15),
|
| 106 |
+
dict(type='TopDownAffineFewShot'),
|
| 107 |
+
dict(type='ToTensor'),
|
| 108 |
+
dict(
|
| 109 |
+
type='NormalizeTensor',
|
| 110 |
+
mean=[0.485, 0.456, 0.406],
|
| 111 |
+
std=[0.229, 0.224, 0.225]),
|
| 112 |
+
dict(type='TopDownGenerateTargetFewShot', sigma=1),
|
| 113 |
+
dict(
|
| 114 |
+
type='Collect',
|
| 115 |
+
keys=['img', 'target', 'target_weight'],
|
| 116 |
+
meta_keys=[
|
| 117 |
+
'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
|
| 118 |
+
'rotation', 'bbox_score', 'flip_pairs', 'category_id', 'skeleton',
|
| 119 |
+
]),
|
| 120 |
+
]
|
| 121 |
+
|
| 122 |
+
valid_pipeline = [
|
| 123 |
+
dict(type='LoadImageFromFile'),
|
| 124 |
+
dict(type='TopDownAffineFewShot'),
|
| 125 |
+
dict(type='ToTensor'),
|
| 126 |
+
dict(
|
| 127 |
+
type='NormalizeTensor',
|
| 128 |
+
mean=[0.485, 0.456, 0.406],
|
| 129 |
+
std=[0.229, 0.224, 0.225]),
|
| 130 |
+
dict(type='TopDownGenerateTargetFewShot', sigma=1),
|
| 131 |
+
dict(
|
| 132 |
+
type='Collect',
|
| 133 |
+
keys=['img', 'target', 'target_weight'],
|
| 134 |
+
meta_keys=[
|
| 135 |
+
'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale', 'rotation', 'bbox_score',
|
| 136 |
+
'flip_pairs', 'category_id',
|
| 137 |
+
'skeleton',
|
| 138 |
+
]),
|
| 139 |
+
]
|
| 140 |
+
|
| 141 |
+
test_pipeline = valid_pipeline
|
| 142 |
+
|
| 143 |
+
data_root = 'data/mp100'
|
| 144 |
+
data = dict(
|
| 145 |
+
samples_per_gpu=16,
|
| 146 |
+
workers_per_gpu=8,
|
| 147 |
+
train=dict(
|
| 148 |
+
type='TransformerPoseDataset',
|
| 149 |
+
ann_file=f'{data_root}/annotations/mp100_split5_train.json',
|
| 150 |
+
img_prefix=f'{data_root}/images/',
|
| 151 |
+
# img_prefix=f'{data_root}',
|
| 152 |
+
data_cfg=data_cfg,
|
| 153 |
+
valid_class_ids=None,
|
| 154 |
+
max_kpt_num=channel_cfg['max_kpt_num'],
|
| 155 |
+
num_shots=1,
|
| 156 |
+
pipeline=train_pipeline),
|
| 157 |
+
val=dict(
|
| 158 |
+
type='TransformerPoseDataset',
|
| 159 |
+
ann_file=f'{data_root}/annotations/mp100_split5_val.json',
|
| 160 |
+
img_prefix=f'{data_root}/images/',
|
| 161 |
+
# img_prefix=f'{data_root}',
|
| 162 |
+
data_cfg=data_cfg,
|
| 163 |
+
valid_class_ids=None,
|
| 164 |
+
max_kpt_num=channel_cfg['max_kpt_num'],
|
| 165 |
+
num_shots=1,
|
| 166 |
+
num_queries=15,
|
| 167 |
+
num_episodes=100,
|
| 168 |
+
pipeline=valid_pipeline),
|
| 169 |
+
test=dict(
|
| 170 |
+
type='TestPoseDataset',
|
| 171 |
+
ann_file=f'{data_root}/annotations/mp100_split5_test.json',
|
| 172 |
+
img_prefix=f'{data_root}/images/',
|
| 173 |
+
# img_prefix=f'{data_root}',
|
| 174 |
+
data_cfg=data_cfg,
|
| 175 |
+
valid_class_ids=None,
|
| 176 |
+
max_kpt_num=channel_cfg['max_kpt_num'],
|
| 177 |
+
num_shots=1,
|
| 178 |
+
num_queries=15,
|
| 179 |
+
num_episodes=200,
|
| 180 |
+
pck_threshold_list=[0.05, 0.10, 0.15, 0.2, 0.25],
|
| 181 |
+
pipeline=test_pipeline),
|
| 182 |
+
)
|
| 183 |
+
vis_backends = [
|
| 184 |
+
dict(type='LocalVisBackend'),
|
| 185 |
+
dict(type='TensorboardVisBackend'),
|
| 186 |
+
]
|
| 187 |
+
visualizer = dict(
|
| 188 |
+
type='PoseLocalVisualizer', vis_backends=vis_backends, name='visualizer')
|
| 189 |
+
|
| 190 |
+
shuffle_cfg = dict(interval=1)
|
configs/1shots/graph_split1_config.py
ADDED
|
@@ -0,0 +1,191 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
log_level = 'INFO'
|
| 2 |
+
load_from = None
|
| 3 |
+
resume_from = None
|
| 4 |
+
dist_params = dict(backend='nccl')
|
| 5 |
+
workflow = [('train', 1)]
|
| 6 |
+
checkpoint_config = dict(interval=20)
|
| 7 |
+
evaluation = dict(
|
| 8 |
+
interval=25,
|
| 9 |
+
metric=['PCK', 'NME', 'AUC', 'EPE'],
|
| 10 |
+
key_indicator='PCK',
|
| 11 |
+
gpu_collect=True,
|
| 12 |
+
res_folder='')
|
| 13 |
+
optimizer = dict(
|
| 14 |
+
type='Adam',
|
| 15 |
+
lr=1e-5,
|
| 16 |
+
)
|
| 17 |
+
|
| 18 |
+
optimizer_config = dict(grad_clip=None)
|
| 19 |
+
# learning policy
|
| 20 |
+
lr_config = dict(
|
| 21 |
+
policy='step',
|
| 22 |
+
warmup='linear',
|
| 23 |
+
warmup_iters=1000,
|
| 24 |
+
warmup_ratio=0.001,
|
| 25 |
+
step=[160, 180])
|
| 26 |
+
total_epochs = 200
|
| 27 |
+
log_config = dict(
|
| 28 |
+
interval=50,
|
| 29 |
+
hooks=[
|
| 30 |
+
dict(type='TextLoggerHook'),
|
| 31 |
+
dict(type='TensorboardLoggerHook')
|
| 32 |
+
])
|
| 33 |
+
|
| 34 |
+
channel_cfg = dict(
|
| 35 |
+
num_output_channels=1,
|
| 36 |
+
dataset_joints=1,
|
| 37 |
+
dataset_channel=[
|
| 38 |
+
[
|
| 39 |
+
0,
|
| 40 |
+
],
|
| 41 |
+
],
|
| 42 |
+
inference_channel=[
|
| 43 |
+
0,
|
| 44 |
+
],
|
| 45 |
+
max_kpt_num=100)
|
| 46 |
+
|
| 47 |
+
# model settings
|
| 48 |
+
model = dict(
|
| 49 |
+
type='PoseAnythingModel',
|
| 50 |
+
pretrained='pretrained/swinv2_tiny_patch4_window16_256.pth',
|
| 51 |
+
encoder_config=dict(
|
| 52 |
+
type='SwinTransformerV2',
|
| 53 |
+
embed_dim=96,
|
| 54 |
+
depths=[2, 2, 6, 2],
|
| 55 |
+
num_heads=[3, 6, 12, 24],
|
| 56 |
+
window_size=16,
|
| 57 |
+
drop_path_rate=0.2,
|
| 58 |
+
img_size=256,
|
| 59 |
+
upsample="bilinear"
|
| 60 |
+
),
|
| 61 |
+
keypoint_head=dict(
|
| 62 |
+
type='PoseHead',
|
| 63 |
+
in_channels=768,
|
| 64 |
+
transformer=dict(
|
| 65 |
+
type='EncoderDecoder',
|
| 66 |
+
d_model=256,
|
| 67 |
+
nhead=8,
|
| 68 |
+
num_encoder_layers=3,
|
| 69 |
+
num_decoder_layers=3,
|
| 70 |
+
graph_decoder='pre',
|
| 71 |
+
dim_feedforward=768,
|
| 72 |
+
dropout=0.1,
|
| 73 |
+
similarity_proj_dim=256,
|
| 74 |
+
dynamic_proj_dim=128,
|
| 75 |
+
activation="relu",
|
| 76 |
+
normalize_before=False,
|
| 77 |
+
return_intermediate_dec=True),
|
| 78 |
+
share_kpt_branch=False,
|
| 79 |
+
num_decoder_layer=3,
|
| 80 |
+
with_heatmap_loss=True,
|
| 81 |
+
|
| 82 |
+
heatmap_loss_weight=2.0,
|
| 83 |
+
support_order_dropout=-1,
|
| 84 |
+
positional_encoding=dict(
|
| 85 |
+
type='SinePositionalEncoding', num_feats=128, normalize=True)),
|
| 86 |
+
# training and testing settings
|
| 87 |
+
train_cfg=dict(),
|
| 88 |
+
test_cfg=dict(
|
| 89 |
+
flip_test=False,
|
| 90 |
+
post_process='default',
|
| 91 |
+
shift_heatmap=True,
|
| 92 |
+
modulate_kernel=11))
|
| 93 |
+
|
| 94 |
+
data_cfg = dict(
|
| 95 |
+
image_size=[256, 256],
|
| 96 |
+
heatmap_size=[64, 64],
|
| 97 |
+
num_output_channels=channel_cfg['num_output_channels'],
|
| 98 |
+
num_joints=channel_cfg['dataset_joints'],
|
| 99 |
+
dataset_channel=channel_cfg['dataset_channel'],
|
| 100 |
+
inference_channel=channel_cfg['inference_channel'])
|
| 101 |
+
|
| 102 |
+
train_pipeline = [
|
| 103 |
+
dict(type='LoadImageFromFile'),
|
| 104 |
+
dict(
|
| 105 |
+
type='TopDownGetRandomScaleRotation', rot_factor=15,
|
| 106 |
+
scale_factor=0.15),
|
| 107 |
+
dict(type='TopDownAffineFewShot'),
|
| 108 |
+
dict(type='ToTensor'),
|
| 109 |
+
dict(
|
| 110 |
+
type='NormalizeTensor',
|
| 111 |
+
mean=[0.485, 0.456, 0.406],
|
| 112 |
+
std=[0.229, 0.224, 0.225]),
|
| 113 |
+
dict(type='TopDownGenerateTargetFewShot', sigma=1),
|
| 114 |
+
dict(
|
| 115 |
+
type='Collect',
|
| 116 |
+
keys=['img', 'target', 'target_weight'],
|
| 117 |
+
meta_keys=[
|
| 118 |
+
'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
|
| 119 |
+
'rotation', 'bbox_score', 'flip_pairs', 'category_id', 'skeleton',
|
| 120 |
+
]),
|
| 121 |
+
]
|
| 122 |
+
|
| 123 |
+
valid_pipeline = [
|
| 124 |
+
dict(type='LoadImageFromFile'),
|
| 125 |
+
dict(type='TopDownAffineFewShot'),
|
| 126 |
+
dict(type='ToTensor'),
|
| 127 |
+
dict(
|
| 128 |
+
type='NormalizeTensor',
|
| 129 |
+
mean=[0.485, 0.456, 0.406],
|
| 130 |
+
std=[0.229, 0.224, 0.225]),
|
| 131 |
+
dict(type='TopDownGenerateTargetFewShot', sigma=1),
|
| 132 |
+
dict(
|
| 133 |
+
type='Collect',
|
| 134 |
+
keys=['img', 'target', 'target_weight'],
|
| 135 |
+
meta_keys=[
|
| 136 |
+
'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale', 'rotation', 'bbox_score',
|
| 137 |
+
'flip_pairs', 'category_id',
|
| 138 |
+
'skeleton',
|
| 139 |
+
]),
|
| 140 |
+
]
|
| 141 |
+
|
| 142 |
+
test_pipeline = valid_pipeline
|
| 143 |
+
|
| 144 |
+
data_root = 'data/mp100'
|
| 145 |
+
data = dict(
|
| 146 |
+
samples_per_gpu=16,
|
| 147 |
+
workers_per_gpu=8,
|
| 148 |
+
train=dict(
|
| 149 |
+
type='TransformerPoseDataset',
|
| 150 |
+
ann_file=f'{data_root}/annotations/mp100_split1_train.json',
|
| 151 |
+
img_prefix=f'{data_root}/images/',
|
| 152 |
+
# img_prefix=f'{data_root}',
|
| 153 |
+
data_cfg=data_cfg,
|
| 154 |
+
valid_class_ids=None,
|
| 155 |
+
max_kpt_num=channel_cfg['max_kpt_num'],
|
| 156 |
+
num_shots=1,
|
| 157 |
+
pipeline=train_pipeline),
|
| 158 |
+
val=dict(
|
| 159 |
+
type='TransformerPoseDataset',
|
| 160 |
+
ann_file=f'{data_root}/annotations/mp100_split1_val.json',
|
| 161 |
+
img_prefix=f'{data_root}/images/',
|
| 162 |
+
# img_prefix=f'{data_root}',
|
| 163 |
+
data_cfg=data_cfg,
|
| 164 |
+
valid_class_ids=None,
|
| 165 |
+
max_kpt_num=channel_cfg['max_kpt_num'],
|
| 166 |
+
num_shots=1,
|
| 167 |
+
num_queries=15,
|
| 168 |
+
num_episodes=100,
|
| 169 |
+
pipeline=valid_pipeline),
|
| 170 |
+
test=dict(
|
| 171 |
+
type='TestPoseDataset',
|
| 172 |
+
ann_file=f'{data_root}/annotations/mp100_split1_test.json',
|
| 173 |
+
img_prefix=f'{data_root}/images/',
|
| 174 |
+
# img_prefix=f'{data_root}',
|
| 175 |
+
data_cfg=data_cfg,
|
| 176 |
+
valid_class_ids=None,
|
| 177 |
+
max_kpt_num=channel_cfg['max_kpt_num'],
|
| 178 |
+
num_shots=1,
|
| 179 |
+
num_queries=15,
|
| 180 |
+
num_episodes=200,
|
| 181 |
+
pck_threshold_list=[0.05, 0.10, 0.15, 0.2, 0.25],
|
| 182 |
+
pipeline=test_pipeline),
|
| 183 |
+
)
|
| 184 |
+
vis_backends = [
|
| 185 |
+
dict(type='LocalVisBackend'),
|
| 186 |
+
dict(type='TensorboardVisBackend'),
|
| 187 |
+
]
|
| 188 |
+
visualizer = dict(
|
| 189 |
+
type='PoseLocalVisualizer', vis_backends=vis_backends, name='visualizer')
|
| 190 |
+
|
| 191 |
+
shuffle_cfg = dict(interval=1)
|
configs/1shots/graph_split2_config.py
ADDED
|
@@ -0,0 +1,191 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
log_level = 'INFO'
|
| 2 |
+
load_from = None
|
| 3 |
+
resume_from = None
|
| 4 |
+
dist_params = dict(backend='nccl')
|
| 5 |
+
workflow = [('train', 1)]
|
| 6 |
+
checkpoint_config = dict(interval=20)
|
| 7 |
+
evaluation = dict(
|
| 8 |
+
interval=25,
|
| 9 |
+
metric=['PCK', 'NME', 'AUC', 'EPE'],
|
| 10 |
+
key_indicator='PCK',
|
| 11 |
+
gpu_collect=True,
|
| 12 |
+
res_folder='')
|
| 13 |
+
optimizer = dict(
|
| 14 |
+
type='Adam',
|
| 15 |
+
lr=1e-5,
|
| 16 |
+
)
|
| 17 |
+
|
| 18 |
+
optimizer_config = dict(grad_clip=None)
|
| 19 |
+
# learning policy
|
| 20 |
+
lr_config = dict(
|
| 21 |
+
policy='step',
|
| 22 |
+
warmup='linear',
|
| 23 |
+
warmup_iters=1000,
|
| 24 |
+
warmup_ratio=0.001,
|
| 25 |
+
step=[160, 180])
|
| 26 |
+
total_epochs = 200
|
| 27 |
+
log_config = dict(
|
| 28 |
+
interval=50,
|
| 29 |
+
hooks=[
|
| 30 |
+
dict(type='TextLoggerHook'),
|
| 31 |
+
dict(type='TensorboardLoggerHook')
|
| 32 |
+
])
|
| 33 |
+
|
| 34 |
+
channel_cfg = dict(
|
| 35 |
+
num_output_channels=1,
|
| 36 |
+
dataset_joints=1,
|
| 37 |
+
dataset_channel=[
|
| 38 |
+
[
|
| 39 |
+
0,
|
| 40 |
+
],
|
| 41 |
+
],
|
| 42 |
+
inference_channel=[
|
| 43 |
+
0,
|
| 44 |
+
],
|
| 45 |
+
max_kpt_num=100)
|
| 46 |
+
|
| 47 |
+
# model settings
|
| 48 |
+
model = dict(
|
| 49 |
+
type='PoseAnythingModel',
|
| 50 |
+
pretrained='pretrained/swinv2_tiny_patch4_window16_256.pth',
|
| 51 |
+
encoder_config=dict(
|
| 52 |
+
type='SwinTransformerV2',
|
| 53 |
+
embed_dim=96,
|
| 54 |
+
depths=[2, 2, 6, 2],
|
| 55 |
+
num_heads=[3, 6, 12, 24],
|
| 56 |
+
window_size=16,
|
| 57 |
+
drop_path_rate=0.2,
|
| 58 |
+
img_size=256,
|
| 59 |
+
upsample="bilinear"
|
| 60 |
+
),
|
| 61 |
+
keypoint_head=dict(
|
| 62 |
+
type='PoseHead',
|
| 63 |
+
in_channels=768,
|
| 64 |
+
transformer=dict(
|
| 65 |
+
type='EncoderDecoder',
|
| 66 |
+
d_model=256,
|
| 67 |
+
nhead=8,
|
| 68 |
+
num_encoder_layers=3,
|
| 69 |
+
num_decoder_layers=3,
|
| 70 |
+
graph_decoder='pre',
|
| 71 |
+
dim_feedforward=768,
|
| 72 |
+
dropout=0.1,
|
| 73 |
+
similarity_proj_dim=256,
|
| 74 |
+
dynamic_proj_dim=128,
|
| 75 |
+
activation="relu",
|
| 76 |
+
normalize_before=False,
|
| 77 |
+
return_intermediate_dec=True),
|
| 78 |
+
share_kpt_branch=False,
|
| 79 |
+
num_decoder_layer=3,
|
| 80 |
+
with_heatmap_loss=True,
|
| 81 |
+
|
| 82 |
+
heatmap_loss_weight=2.0,
|
| 83 |
+
support_order_dropout=-1,
|
| 84 |
+
positional_encoding=dict(
|
| 85 |
+
type='SinePositionalEncoding', num_feats=128, normalize=True)),
|
| 86 |
+
# training and testing settings
|
| 87 |
+
train_cfg=dict(),
|
| 88 |
+
test_cfg=dict(
|
| 89 |
+
flip_test=False,
|
| 90 |
+
post_process='default',
|
| 91 |
+
shift_heatmap=True,
|
| 92 |
+
modulate_kernel=11))
|
| 93 |
+
|
| 94 |
+
data_cfg = dict(
|
| 95 |
+
image_size=[256, 256],
|
| 96 |
+
heatmap_size=[64, 64],
|
| 97 |
+
num_output_channels=channel_cfg['num_output_channels'],
|
| 98 |
+
num_joints=channel_cfg['dataset_joints'],
|
| 99 |
+
dataset_channel=channel_cfg['dataset_channel'],
|
| 100 |
+
inference_channel=channel_cfg['inference_channel'])
|
| 101 |
+
|
| 102 |
+
train_pipeline = [
|
| 103 |
+
dict(type='LoadImageFromFile'),
|
| 104 |
+
dict(
|
| 105 |
+
type='TopDownGetRandomScaleRotation', rot_factor=15,
|
| 106 |
+
scale_factor=0.15),
|
| 107 |
+
dict(type='TopDownAffineFewShot'),
|
| 108 |
+
dict(type='ToTensor'),
|
| 109 |
+
dict(
|
| 110 |
+
type='NormalizeTensor',
|
| 111 |
+
mean=[0.485, 0.456, 0.406],
|
| 112 |
+
std=[0.229, 0.224, 0.225]),
|
| 113 |
+
dict(type='TopDownGenerateTargetFewShot', sigma=1),
|
| 114 |
+
dict(
|
| 115 |
+
type='Collect',
|
| 116 |
+
keys=['img', 'target', 'target_weight'],
|
| 117 |
+
meta_keys=[
|
| 118 |
+
'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
|
| 119 |
+
'rotation', 'bbox_score', 'flip_pairs', 'category_id', 'skeleton',
|
| 120 |
+
]),
|
| 121 |
+
]
|
| 122 |
+
|
| 123 |
+
valid_pipeline = [
|
| 124 |
+
dict(type='LoadImageFromFile'),
|
| 125 |
+
dict(type='TopDownAffineFewShot'),
|
| 126 |
+
dict(type='ToTensor'),
|
| 127 |
+
dict(
|
| 128 |
+
type='NormalizeTensor',
|
| 129 |
+
mean=[0.485, 0.456, 0.406],
|
| 130 |
+
std=[0.229, 0.224, 0.225]),
|
| 131 |
+
dict(type='TopDownGenerateTargetFewShot', sigma=1),
|
| 132 |
+
dict(
|
| 133 |
+
type='Collect',
|
| 134 |
+
keys=['img', 'target', 'target_weight'],
|
| 135 |
+
meta_keys=[
|
| 136 |
+
'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale', 'rotation', 'bbox_score',
|
| 137 |
+
'flip_pairs', 'category_id',
|
| 138 |
+
'skeleton',
|
| 139 |
+
]),
|
| 140 |
+
]
|
| 141 |
+
|
| 142 |
+
test_pipeline = valid_pipeline
|
| 143 |
+
|
| 144 |
+
data_root = 'data/mp100'
|
| 145 |
+
data = dict(
|
| 146 |
+
samples_per_gpu=16,
|
| 147 |
+
workers_per_gpu=8,
|
| 148 |
+
train=dict(
|
| 149 |
+
type='TransformerPoseDataset',
|
| 150 |
+
ann_file=f'{data_root}/annotations/mp100_split2_train.json',
|
| 151 |
+
img_prefix=f'{data_root}/images/',
|
| 152 |
+
# img_prefix=f'{data_root}',
|
| 153 |
+
data_cfg=data_cfg,
|
| 154 |
+
valid_class_ids=None,
|
| 155 |
+
max_kpt_num=channel_cfg['max_kpt_num'],
|
| 156 |
+
num_shots=1,
|
| 157 |
+
pipeline=train_pipeline),
|
| 158 |
+
val=dict(
|
| 159 |
+
type='TransformerPoseDataset',
|
| 160 |
+
ann_file=f'{data_root}/annotations/mp100_split2_val.json',
|
| 161 |
+
img_prefix=f'{data_root}/images/',
|
| 162 |
+
# img_prefix=f'{data_root}',
|
| 163 |
+
data_cfg=data_cfg,
|
| 164 |
+
valid_class_ids=None,
|
| 165 |
+
max_kpt_num=channel_cfg['max_kpt_num'],
|
| 166 |
+
num_shots=1,
|
| 167 |
+
num_queries=15,
|
| 168 |
+
num_episodes=100,
|
| 169 |
+
pipeline=valid_pipeline),
|
| 170 |
+
test=dict(
|
| 171 |
+
type='TestPoseDataset',
|
| 172 |
+
ann_file=f'{data_root}/annotations/mp100_split2_test.json',
|
| 173 |
+
img_prefix=f'{data_root}/images/',
|
| 174 |
+
# img_prefix=f'{data_root}',
|
| 175 |
+
data_cfg=data_cfg,
|
| 176 |
+
valid_class_ids=None,
|
| 177 |
+
max_kpt_num=channel_cfg['max_kpt_num'],
|
| 178 |
+
num_shots=1,
|
| 179 |
+
num_queries=15,
|
| 180 |
+
num_episodes=200,
|
| 181 |
+
pck_threshold_list=[0.05, 0.10, 0.15, 0.2, 0.25],
|
| 182 |
+
pipeline=test_pipeline),
|
| 183 |
+
)
|
| 184 |
+
vis_backends = [
|
| 185 |
+
dict(type='LocalVisBackend'),
|
| 186 |
+
dict(type='TensorboardVisBackend'),
|
| 187 |
+
]
|
| 188 |
+
visualizer = dict(
|
| 189 |
+
type='PoseLocalVisualizer', vis_backends=vis_backends, name='visualizer')
|
| 190 |
+
|
| 191 |
+
shuffle_cfg = dict(interval=1)
|
configs/1shots/graph_split3_config.py
ADDED
|
@@ -0,0 +1,191 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
log_level = 'INFO'
|
| 2 |
+
load_from = None
|
| 3 |
+
resume_from = None
|
| 4 |
+
dist_params = dict(backend='nccl')
|
| 5 |
+
workflow = [('train', 1)]
|
| 6 |
+
checkpoint_config = dict(interval=20)
|
| 7 |
+
evaluation = dict(
|
| 8 |
+
interval=25,
|
| 9 |
+
metric=['PCK', 'NME', 'AUC', 'EPE'],
|
| 10 |
+
key_indicator='PCK',
|
| 11 |
+
gpu_collect=True,
|
| 12 |
+
res_folder='')
|
| 13 |
+
optimizer = dict(
|
| 14 |
+
type='Adam',
|
| 15 |
+
lr=1e-5,
|
| 16 |
+
)
|
| 17 |
+
|
| 18 |
+
optimizer_config = dict(grad_clip=None)
|
| 19 |
+
# learning policy
|
| 20 |
+
lr_config = dict(
|
| 21 |
+
policy='step',
|
| 22 |
+
warmup='linear',
|
| 23 |
+
warmup_iters=1000,
|
| 24 |
+
warmup_ratio=0.001,
|
| 25 |
+
step=[160, 180])
|
| 26 |
+
total_epochs = 200
|
| 27 |
+
log_config = dict(
|
| 28 |
+
interval=50,
|
| 29 |
+
hooks=[
|
| 30 |
+
dict(type='TextLoggerHook'),
|
| 31 |
+
dict(type='TensorboardLoggerHook')
|
| 32 |
+
])
|
| 33 |
+
|
| 34 |
+
channel_cfg = dict(
|
| 35 |
+
num_output_channels=1,
|
| 36 |
+
dataset_joints=1,
|
| 37 |
+
dataset_channel=[
|
| 38 |
+
[
|
| 39 |
+
0,
|
| 40 |
+
],
|
| 41 |
+
],
|
| 42 |
+
inference_channel=[
|
| 43 |
+
0,
|
| 44 |
+
],
|
| 45 |
+
max_kpt_num=100)
|
| 46 |
+
|
| 47 |
+
# model settings
|
| 48 |
+
model = dict(
|
| 49 |
+
type='PoseAnythingModel',
|
| 50 |
+
pretrained='pretrained/swinv2_tiny_patch4_window16_256.pth',
|
| 51 |
+
encoder_config=dict(
|
| 52 |
+
type='SwinTransformerV2',
|
| 53 |
+
embed_dim=96,
|
| 54 |
+
depths=[2, 2, 6, 2],
|
| 55 |
+
num_heads=[3, 6, 12, 24],
|
| 56 |
+
window_size=16,
|
| 57 |
+
drop_path_rate=0.2,
|
| 58 |
+
img_size=256,
|
| 59 |
+
upsample="bilinear"
|
| 60 |
+
),
|
| 61 |
+
keypoint_head=dict(
|
| 62 |
+
type='PoseHead',
|
| 63 |
+
in_channels=768,
|
| 64 |
+
transformer=dict(
|
| 65 |
+
type='EncoderDecoder',
|
| 66 |
+
d_model=256,
|
| 67 |
+
nhead=8,
|
| 68 |
+
num_encoder_layers=3,
|
| 69 |
+
num_decoder_layers=3,
|
| 70 |
+
graph_decoder='pre',
|
| 71 |
+
dim_feedforward=768,
|
| 72 |
+
dropout=0.1,
|
| 73 |
+
similarity_proj_dim=256,
|
| 74 |
+
dynamic_proj_dim=128,
|
| 75 |
+
activation="relu",
|
| 76 |
+
normalize_before=False,
|
| 77 |
+
return_intermediate_dec=True),
|
| 78 |
+
share_kpt_branch=False,
|
| 79 |
+
num_decoder_layer=3,
|
| 80 |
+
with_heatmap_loss=True,
|
| 81 |
+
|
| 82 |
+
heatmap_loss_weight=2.0,
|
| 83 |
+
support_order_dropout=-1,
|
| 84 |
+
positional_encoding=dict(
|
| 85 |
+
type='SinePositionalEncoding', num_feats=128, normalize=True)),
|
| 86 |
+
# training and testing settings
|
| 87 |
+
train_cfg=dict(),
|
| 88 |
+
test_cfg=dict(
|
| 89 |
+
flip_test=False,
|
| 90 |
+
post_process='default',
|
| 91 |
+
shift_heatmap=True,
|
| 92 |
+
modulate_kernel=11))
|
| 93 |
+
|
| 94 |
+
data_cfg = dict(
|
| 95 |
+
image_size=[256, 256],
|
| 96 |
+
heatmap_size=[64, 64],
|
| 97 |
+
num_output_channels=channel_cfg['num_output_channels'],
|
| 98 |
+
num_joints=channel_cfg['dataset_joints'],
|
| 99 |
+
dataset_channel=channel_cfg['dataset_channel'],
|
| 100 |
+
inference_channel=channel_cfg['inference_channel'])
|
| 101 |
+
|
| 102 |
+
train_pipeline = [
|
| 103 |
+
dict(type='LoadImageFromFile'),
|
| 104 |
+
dict(
|
| 105 |
+
type='TopDownGetRandomScaleRotation', rot_factor=15,
|
| 106 |
+
scale_factor=0.15),
|
| 107 |
+
dict(type='TopDownAffineFewShot'),
|
| 108 |
+
dict(type='ToTensor'),
|
| 109 |
+
dict(
|
| 110 |
+
type='NormalizeTensor',
|
| 111 |
+
mean=[0.485, 0.456, 0.406],
|
| 112 |
+
std=[0.229, 0.224, 0.225]),
|
| 113 |
+
dict(type='TopDownGenerateTargetFewShot', sigma=1),
|
| 114 |
+
dict(
|
| 115 |
+
type='Collect',
|
| 116 |
+
keys=['img', 'target', 'target_weight'],
|
| 117 |
+
meta_keys=[
|
| 118 |
+
'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
|
| 119 |
+
'rotation', 'bbox_score', 'flip_pairs', 'category_id', 'skeleton',
|
| 120 |
+
]),
|
| 121 |
+
]
|
| 122 |
+
|
| 123 |
+
valid_pipeline = [
|
| 124 |
+
dict(type='LoadImageFromFile'),
|
| 125 |
+
dict(type='TopDownAffineFewShot'),
|
| 126 |
+
dict(type='ToTensor'),
|
| 127 |
+
dict(
|
| 128 |
+
type='NormalizeTensor',
|
| 129 |
+
mean=[0.485, 0.456, 0.406],
|
| 130 |
+
std=[0.229, 0.224, 0.225]),
|
| 131 |
+
dict(type='TopDownGenerateTargetFewShot', sigma=1),
|
| 132 |
+
dict(
|
| 133 |
+
type='Collect',
|
| 134 |
+
keys=['img', 'target', 'target_weight'],
|
| 135 |
+
meta_keys=[
|
| 136 |
+
'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale', 'rotation', 'bbox_score',
|
| 137 |
+
'flip_pairs', 'category_id',
|
| 138 |
+
'skeleton',
|
| 139 |
+
]),
|
| 140 |
+
]
|
| 141 |
+
|
| 142 |
+
test_pipeline = valid_pipeline
|
| 143 |
+
|
| 144 |
+
data_root = 'data/mp100'
|
| 145 |
+
data = dict(
|
| 146 |
+
samples_per_gpu=16,
|
| 147 |
+
workers_per_gpu=8,
|
| 148 |
+
train=dict(
|
| 149 |
+
type='TransformerPoseDataset',
|
| 150 |
+
ann_file=f'{data_root}/annotations/mp100_split3_train.json',
|
| 151 |
+
img_prefix=f'{data_root}/images/',
|
| 152 |
+
# img_prefix=f'{data_root}',
|
| 153 |
+
data_cfg=data_cfg,
|
| 154 |
+
valid_class_ids=None,
|
| 155 |
+
max_kpt_num=channel_cfg['max_kpt_num'],
|
| 156 |
+
num_shots=1,
|
| 157 |
+
pipeline=train_pipeline),
|
| 158 |
+
val=dict(
|
| 159 |
+
type='TransformerPoseDataset',
|
| 160 |
+
ann_file=f'{data_root}/annotations/mp100_split3_val.json',
|
| 161 |
+
img_prefix=f'{data_root}/images/',
|
| 162 |
+
# img_prefix=f'{data_root}',
|
| 163 |
+
data_cfg=data_cfg,
|
| 164 |
+
valid_class_ids=None,
|
| 165 |
+
max_kpt_num=channel_cfg['max_kpt_num'],
|
| 166 |
+
num_shots=1,
|
| 167 |
+
num_queries=15,
|
| 168 |
+
num_episodes=100,
|
| 169 |
+
pipeline=valid_pipeline),
|
| 170 |
+
test=dict(
|
| 171 |
+
type='TestPoseDataset',
|
| 172 |
+
ann_file=f'{data_root}/annotations/mp100_split3_test.json',
|
| 173 |
+
img_prefix=f'{data_root}/images/',
|
| 174 |
+
# img_prefix=f'{data_root}',
|
| 175 |
+
data_cfg=data_cfg,
|
| 176 |
+
valid_class_ids=None,
|
| 177 |
+
max_kpt_num=channel_cfg['max_kpt_num'],
|
| 178 |
+
num_shots=1,
|
| 179 |
+
num_queries=15,
|
| 180 |
+
num_episodes=200,
|
| 181 |
+
pck_threshold_list=[0.05, 0.10, 0.15, 0.2, 0.25],
|
| 182 |
+
pipeline=test_pipeline),
|
| 183 |
+
)
|
| 184 |
+
vis_backends = [
|
| 185 |
+
dict(type='LocalVisBackend'),
|
| 186 |
+
dict(type='TensorboardVisBackend'),
|
| 187 |
+
]
|
| 188 |
+
visualizer = dict(
|
| 189 |
+
type='PoseLocalVisualizer', vis_backends=vis_backends, name='visualizer')
|
| 190 |
+
|
| 191 |
+
shuffle_cfg = dict(interval=1)
|
configs/1shots/graph_split4_config.py
ADDED
|
@@ -0,0 +1,191 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
log_level = 'INFO'
|
| 2 |
+
load_from = None
|
| 3 |
+
resume_from = None
|
| 4 |
+
dist_params = dict(backend='nccl')
|
| 5 |
+
workflow = [('train', 1)]
|
| 6 |
+
checkpoint_config = dict(interval=20)
|
| 7 |
+
evaluation = dict(
|
| 8 |
+
interval=25,
|
| 9 |
+
metric=['PCK', 'NME', 'AUC', 'EPE'],
|
| 10 |
+
key_indicator='PCK',
|
| 11 |
+
gpu_collect=True,
|
| 12 |
+
res_folder='')
|
| 13 |
+
optimizer = dict(
|
| 14 |
+
type='Adam',
|
| 15 |
+
lr=1e-5,
|
| 16 |
+
)
|
| 17 |
+
|
| 18 |
+
optimizer_config = dict(grad_clip=None)
|
| 19 |
+
# learning policy
|
| 20 |
+
lr_config = dict(
|
| 21 |
+
policy='step',
|
| 22 |
+
warmup='linear',
|
| 23 |
+
warmup_iters=1000,
|
| 24 |
+
warmup_ratio=0.001,
|
| 25 |
+
step=[160, 180])
|
| 26 |
+
total_epochs = 200
|
| 27 |
+
log_config = dict(
|
| 28 |
+
interval=50,
|
| 29 |
+
hooks=[
|
| 30 |
+
dict(type='TextLoggerHook'),
|
| 31 |
+
dict(type='TensorboardLoggerHook')
|
| 32 |
+
])
|
| 33 |
+
|
| 34 |
+
channel_cfg = dict(
|
| 35 |
+
num_output_channels=1,
|
| 36 |
+
dataset_joints=1,
|
| 37 |
+
dataset_channel=[
|
| 38 |
+
[
|
| 39 |
+
0,
|
| 40 |
+
],
|
| 41 |
+
],
|
| 42 |
+
inference_channel=[
|
| 43 |
+
0,
|
| 44 |
+
],
|
| 45 |
+
max_kpt_num=100)
|
| 46 |
+
|
| 47 |
+
# model settings
|
| 48 |
+
model = dict(
|
| 49 |
+
type='PoseAnythingModel',
|
| 50 |
+
pretrained='pretrained/swinv2_tiny_patch4_window16_256.pth',
|
| 51 |
+
encoder_config=dict(
|
| 52 |
+
type='SwinTransformerV2',
|
| 53 |
+
embed_dim=96,
|
| 54 |
+
depths=[2, 2, 6, 2],
|
| 55 |
+
num_heads=[3, 6, 12, 24],
|
| 56 |
+
window_size=16,
|
| 57 |
+
drop_path_rate=0.2,
|
| 58 |
+
img_size=256,
|
| 59 |
+
upsample="bilinear"
|
| 60 |
+
),
|
| 61 |
+
keypoint_head=dict(
|
| 62 |
+
type='PoseHead',
|
| 63 |
+
in_channels=768,
|
| 64 |
+
transformer=dict(
|
| 65 |
+
type='EncoderDecoder',
|
| 66 |
+
d_model=256,
|
| 67 |
+
nhead=8,
|
| 68 |
+
num_encoder_layers=3,
|
| 69 |
+
num_decoder_layers=3,
|
| 70 |
+
graph_decoder='pre',
|
| 71 |
+
dim_feedforward=768,
|
| 72 |
+
dropout=0.1,
|
| 73 |
+
similarity_proj_dim=256,
|
| 74 |
+
dynamic_proj_dim=128,
|
| 75 |
+
activation="relu",
|
| 76 |
+
normalize_before=False,
|
| 77 |
+
return_intermediate_dec=True),
|
| 78 |
+
share_kpt_branch=False,
|
| 79 |
+
num_decoder_layer=3,
|
| 80 |
+
with_heatmap_loss=True,
|
| 81 |
+
|
| 82 |
+
heatmap_loss_weight=2.0,
|
| 83 |
+
support_order_dropout=-1,
|
| 84 |
+
positional_encoding=dict(
|
| 85 |
+
type='SinePositionalEncoding', num_feats=128, normalize=True)),
|
| 86 |
+
# training and testing settings
|
| 87 |
+
train_cfg=dict(),
|
| 88 |
+
test_cfg=dict(
|
| 89 |
+
flip_test=False,
|
| 90 |
+
post_process='default',
|
| 91 |
+
shift_heatmap=True,
|
| 92 |
+
modulate_kernel=11))
|
| 93 |
+
|
| 94 |
+
data_cfg = dict(
|
| 95 |
+
image_size=[256, 256],
|
| 96 |
+
heatmap_size=[64, 64],
|
| 97 |
+
num_output_channels=channel_cfg['num_output_channels'],
|
| 98 |
+
num_joints=channel_cfg['dataset_joints'],
|
| 99 |
+
dataset_channel=channel_cfg['dataset_channel'],
|
| 100 |
+
inference_channel=channel_cfg['inference_channel'])
|
| 101 |
+
|
| 102 |
+
train_pipeline = [
|
| 103 |
+
dict(type='LoadImageFromFile'),
|
| 104 |
+
dict(
|
| 105 |
+
type='TopDownGetRandomScaleRotation', rot_factor=15,
|
| 106 |
+
scale_factor=0.15),
|
| 107 |
+
dict(type='TopDownAffineFewShot'),
|
| 108 |
+
dict(type='ToTensor'),
|
| 109 |
+
dict(
|
| 110 |
+
type='NormalizeTensor',
|
| 111 |
+
mean=[0.485, 0.456, 0.406],
|
| 112 |
+
std=[0.229, 0.224, 0.225]),
|
| 113 |
+
dict(type='TopDownGenerateTargetFewShot', sigma=1),
|
| 114 |
+
dict(
|
| 115 |
+
type='Collect',
|
| 116 |
+
keys=['img', 'target', 'target_weight'],
|
| 117 |
+
meta_keys=[
|
| 118 |
+
'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
|
| 119 |
+
'rotation', 'bbox_score', 'flip_pairs', 'category_id', 'skeleton',
|
| 120 |
+
]),
|
| 121 |
+
]
|
| 122 |
+
|
| 123 |
+
valid_pipeline = [
|
| 124 |
+
dict(type='LoadImageFromFile'),
|
| 125 |
+
dict(type='TopDownAffineFewShot'),
|
| 126 |
+
dict(type='ToTensor'),
|
| 127 |
+
dict(
|
| 128 |
+
type='NormalizeTensor',
|
| 129 |
+
mean=[0.485, 0.456, 0.406],
|
| 130 |
+
std=[0.229, 0.224, 0.225]),
|
| 131 |
+
dict(type='TopDownGenerateTargetFewShot', sigma=1),
|
| 132 |
+
dict(
|
| 133 |
+
type='Collect',
|
| 134 |
+
keys=['img', 'target', 'target_weight'],
|
| 135 |
+
meta_keys=[
|
| 136 |
+
'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale', 'rotation', 'bbox_score',
|
| 137 |
+
'flip_pairs', 'category_id',
|
| 138 |
+
'skeleton',
|
| 139 |
+
]),
|
| 140 |
+
]
|
| 141 |
+
|
| 142 |
+
test_pipeline = valid_pipeline
|
| 143 |
+
|
| 144 |
+
data_root = 'data/mp100'
|
| 145 |
+
data = dict(
|
| 146 |
+
samples_per_gpu=16,
|
| 147 |
+
workers_per_gpu=8,
|
| 148 |
+
train=dict(
|
| 149 |
+
type='TransformerPoseDataset',
|
| 150 |
+
ann_file=f'{data_root}/annotations/mp100_split4_train.json',
|
| 151 |
+
img_prefix=f'{data_root}/images/',
|
| 152 |
+
# img_prefix=f'{data_root}',
|
| 153 |
+
data_cfg=data_cfg,
|
| 154 |
+
valid_class_ids=None,
|
| 155 |
+
max_kpt_num=channel_cfg['max_kpt_num'],
|
| 156 |
+
num_shots=1,
|
| 157 |
+
pipeline=train_pipeline),
|
| 158 |
+
val=dict(
|
| 159 |
+
type='TransformerPoseDataset',
|
| 160 |
+
ann_file=f'{data_root}/annotations/mp100_split4_val.json',
|
| 161 |
+
img_prefix=f'{data_root}/images/',
|
| 162 |
+
# img_prefix=f'{data_root}',
|
| 163 |
+
data_cfg=data_cfg,
|
| 164 |
+
valid_class_ids=None,
|
| 165 |
+
max_kpt_num=channel_cfg['max_kpt_num'],
|
| 166 |
+
num_shots=1,
|
| 167 |
+
num_queries=15,
|
| 168 |
+
num_episodes=100,
|
| 169 |
+
pipeline=valid_pipeline),
|
| 170 |
+
test=dict(
|
| 171 |
+
type='TestPoseDataset',
|
| 172 |
+
ann_file=f'{data_root}/annotations/mp100_split4_test.json',
|
| 173 |
+
img_prefix=f'{data_root}/images/',
|
| 174 |
+
# img_prefix=f'{data_root}',
|
| 175 |
+
data_cfg=data_cfg,
|
| 176 |
+
valid_class_ids=None,
|
| 177 |
+
max_kpt_num=channel_cfg['max_kpt_num'],
|
| 178 |
+
num_shots=1,
|
| 179 |
+
num_queries=15,
|
| 180 |
+
num_episodes=200,
|
| 181 |
+
pck_threshold_list=[0.05, 0.10, 0.15, 0.2, 0.25],
|
| 182 |
+
pipeline=test_pipeline),
|
| 183 |
+
)
|
| 184 |
+
vis_backends = [
|
| 185 |
+
dict(type='LocalVisBackend'),
|
| 186 |
+
dict(type='TensorboardVisBackend'),
|
| 187 |
+
]
|
| 188 |
+
visualizer = dict(
|
| 189 |
+
type='PoseLocalVisualizer', vis_backends=vis_backends, name='visualizer')
|
| 190 |
+
|
| 191 |
+
shuffle_cfg = dict(interval=1)
|
configs/1shots/graph_split5_config.py
ADDED
|
@@ -0,0 +1,191 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
log_level = 'INFO'
|
| 2 |
+
load_from = None
|
| 3 |
+
resume_from = None
|
| 4 |
+
dist_params = dict(backend='nccl')
|
| 5 |
+
workflow = [('train', 1)]
|
| 6 |
+
checkpoint_config = dict(interval=20)
|
| 7 |
+
evaluation = dict(
|
| 8 |
+
interval=25,
|
| 9 |
+
metric=['PCK', 'NME', 'AUC', 'EPE'],
|
| 10 |
+
key_indicator='PCK',
|
| 11 |
+
gpu_collect=True,
|
| 12 |
+
res_folder='')
|
| 13 |
+
optimizer = dict(
|
| 14 |
+
type='Adam',
|
| 15 |
+
lr=1e-5,
|
| 16 |
+
)
|
| 17 |
+
|
| 18 |
+
optimizer_config = dict(grad_clip=None)
|
| 19 |
+
# learning policy
|
| 20 |
+
lr_config = dict(
|
| 21 |
+
policy='step',
|
| 22 |
+
warmup='linear',
|
| 23 |
+
warmup_iters=1000,
|
| 24 |
+
warmup_ratio=0.001,
|
| 25 |
+
step=[160, 180])
|
| 26 |
+
total_epochs = 200
|
| 27 |
+
log_config = dict(
|
| 28 |
+
interval=50,
|
| 29 |
+
hooks=[
|
| 30 |
+
dict(type='TextLoggerHook'),
|
| 31 |
+
dict(type='TensorboardLoggerHook')
|
| 32 |
+
])
|
| 33 |
+
|
| 34 |
+
channel_cfg = dict(
|
| 35 |
+
num_output_channels=1,
|
| 36 |
+
dataset_joints=1,
|
| 37 |
+
dataset_channel=[
|
| 38 |
+
[
|
| 39 |
+
0,
|
| 40 |
+
],
|
| 41 |
+
],
|
| 42 |
+
inference_channel=[
|
| 43 |
+
0,
|
| 44 |
+
],
|
| 45 |
+
max_kpt_num=100)
|
| 46 |
+
|
| 47 |
+
# model settings
|
| 48 |
+
model = dict(
|
| 49 |
+
type='PoseAnythingModel',
|
| 50 |
+
pretrained='pretrained/swinv2_tiny_patch4_window16_256.pth',
|
| 51 |
+
encoder_config=dict(
|
| 52 |
+
type='SwinTransformerV2',
|
| 53 |
+
embed_dim=96,
|
| 54 |
+
depths=[2, 2, 6, 2],
|
| 55 |
+
num_heads=[3, 6, 12, 24],
|
| 56 |
+
window_size=16,
|
| 57 |
+
drop_path_rate=0.2,
|
| 58 |
+
img_size=256,
|
| 59 |
+
upsample="bilinear"
|
| 60 |
+
),
|
| 61 |
+
keypoint_head=dict(
|
| 62 |
+
type='PoseHead',
|
| 63 |
+
in_channels=768,
|
| 64 |
+
transformer=dict(
|
| 65 |
+
type='EncoderDecoder',
|
| 66 |
+
d_model=256,
|
| 67 |
+
nhead=8,
|
| 68 |
+
num_encoder_layers=3,
|
| 69 |
+
num_decoder_layers=3,
|
| 70 |
+
graph_decoder='pre',
|
| 71 |
+
dim_feedforward=768,
|
| 72 |
+
dropout=0.1,
|
| 73 |
+
similarity_proj_dim=256,
|
| 74 |
+
dynamic_proj_dim=128,
|
| 75 |
+
activation="relu",
|
| 76 |
+
normalize_before=False,
|
| 77 |
+
return_intermediate_dec=True),
|
| 78 |
+
share_kpt_branch=False,
|
| 79 |
+
num_decoder_layer=3,
|
| 80 |
+
with_heatmap_loss=True,
|
| 81 |
+
|
| 82 |
+
heatmap_loss_weight=2.0,
|
| 83 |
+
support_order_dropout=-1,
|
| 84 |
+
positional_encoding=dict(
|
| 85 |
+
type='SinePositionalEncoding', num_feats=128, normalize=True)),
|
| 86 |
+
# training and testing settings
|
| 87 |
+
train_cfg=dict(),
|
| 88 |
+
test_cfg=dict(
|
| 89 |
+
flip_test=False,
|
| 90 |
+
post_process='default',
|
| 91 |
+
shift_heatmap=True,
|
| 92 |
+
modulate_kernel=11))
|
| 93 |
+
|
| 94 |
+
data_cfg = dict(
|
| 95 |
+
image_size=[256, 256],
|
| 96 |
+
heatmap_size=[64, 64],
|
| 97 |
+
num_output_channels=channel_cfg['num_output_channels'],
|
| 98 |
+
num_joints=channel_cfg['dataset_joints'],
|
| 99 |
+
dataset_channel=channel_cfg['dataset_channel'],
|
| 100 |
+
inference_channel=channel_cfg['inference_channel'])
|
| 101 |
+
|
| 102 |
+
train_pipeline = [
|
| 103 |
+
dict(type='LoadImageFromFile'),
|
| 104 |
+
dict(
|
| 105 |
+
type='TopDownGetRandomScaleRotation', rot_factor=15,
|
| 106 |
+
scale_factor=0.15),
|
| 107 |
+
dict(type='TopDownAffineFewShot'),
|
| 108 |
+
dict(type='ToTensor'),
|
| 109 |
+
dict(
|
| 110 |
+
type='NormalizeTensor',
|
| 111 |
+
mean=[0.485, 0.456, 0.406],
|
| 112 |
+
std=[0.229, 0.224, 0.225]),
|
| 113 |
+
dict(type='TopDownGenerateTargetFewShot', sigma=1),
|
| 114 |
+
dict(
|
| 115 |
+
type='Collect',
|
| 116 |
+
keys=['img', 'target', 'target_weight'],
|
| 117 |
+
meta_keys=[
|
| 118 |
+
'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
|
| 119 |
+
'rotation', 'bbox_score', 'flip_pairs', 'category_id', 'skeleton',
|
| 120 |
+
]),
|
| 121 |
+
]
|
| 122 |
+
|
| 123 |
+
valid_pipeline = [
|
| 124 |
+
dict(type='LoadImageFromFile'),
|
| 125 |
+
dict(type='TopDownAffineFewShot'),
|
| 126 |
+
dict(type='ToTensor'),
|
| 127 |
+
dict(
|
| 128 |
+
type='NormalizeTensor',
|
| 129 |
+
mean=[0.485, 0.456, 0.406],
|
| 130 |
+
std=[0.229, 0.224, 0.225]),
|
| 131 |
+
dict(type='TopDownGenerateTargetFewShot', sigma=1),
|
| 132 |
+
dict(
|
| 133 |
+
type='Collect',
|
| 134 |
+
keys=['img', 'target', 'target_weight'],
|
| 135 |
+
meta_keys=[
|
| 136 |
+
'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale', 'rotation', 'bbox_score',
|
| 137 |
+
'flip_pairs', 'category_id',
|
| 138 |
+
'skeleton',
|
| 139 |
+
]),
|
| 140 |
+
]
|
| 141 |
+
|
| 142 |
+
test_pipeline = valid_pipeline
|
| 143 |
+
|
| 144 |
+
data_root = 'data/mp100'
|
| 145 |
+
data = dict(
|
| 146 |
+
samples_per_gpu=16,
|
| 147 |
+
workers_per_gpu=8,
|
| 148 |
+
train=dict(
|
| 149 |
+
type='TransformerPoseDataset',
|
| 150 |
+
ann_file=f'{data_root}/annotations/mp100_split5_train.json',
|
| 151 |
+
img_prefix=f'{data_root}/images/',
|
| 152 |
+
# img_prefix=f'{data_root}',
|
| 153 |
+
data_cfg=data_cfg,
|
| 154 |
+
valid_class_ids=None,
|
| 155 |
+
max_kpt_num=channel_cfg['max_kpt_num'],
|
| 156 |
+
num_shots=1,
|
| 157 |
+
pipeline=train_pipeline),
|
| 158 |
+
val=dict(
|
| 159 |
+
type='TransformerPoseDataset',
|
| 160 |
+
ann_file=f'{data_root}/annotations/mp100_split5_val.json',
|
| 161 |
+
img_prefix=f'{data_root}/images/',
|
| 162 |
+
# img_prefix=f'{data_root}',
|
| 163 |
+
data_cfg=data_cfg,
|
| 164 |
+
valid_class_ids=None,
|
| 165 |
+
max_kpt_num=channel_cfg['max_kpt_num'],
|
| 166 |
+
num_shots=1,
|
| 167 |
+
num_queries=15,
|
| 168 |
+
num_episodes=100,
|
| 169 |
+
pipeline=valid_pipeline),
|
| 170 |
+
test=dict(
|
| 171 |
+
type='TestPoseDataset',
|
| 172 |
+
ann_file=f'{data_root}/annotations/mp100_split5_test.json',
|
| 173 |
+
img_prefix=f'{data_root}/images/',
|
| 174 |
+
# img_prefix=f'{data_root}',
|
| 175 |
+
data_cfg=data_cfg,
|
| 176 |
+
valid_class_ids=None,
|
| 177 |
+
max_kpt_num=channel_cfg['max_kpt_num'],
|
| 178 |
+
num_shots=1,
|
| 179 |
+
num_queries=15,
|
| 180 |
+
num_episodes=200,
|
| 181 |
+
pck_threshold_list=[0.05, 0.10, 0.15, 0.2, 0.25],
|
| 182 |
+
pipeline=test_pipeline),
|
| 183 |
+
)
|
| 184 |
+
vis_backends = [
|
| 185 |
+
dict(type='LocalVisBackend'),
|
| 186 |
+
dict(type='TensorboardVisBackend'),
|
| 187 |
+
]
|
| 188 |
+
visualizer = dict(
|
| 189 |
+
type='PoseLocalVisualizer', vis_backends=vis_backends, name='visualizer')
|
| 190 |
+
|
| 191 |
+
shuffle_cfg = dict(interval=1)
|
configs/5shot-swin/base_split1_config.py
ADDED
|
@@ -0,0 +1,190 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
log_level = 'INFO'
|
| 2 |
+
load_from = None
|
| 3 |
+
resume_from = None
|
| 4 |
+
dist_params = dict(backend='nccl')
|
| 5 |
+
workflow = [('train', 1)]
|
| 6 |
+
checkpoint_config = dict(interval=20)
|
| 7 |
+
evaluation = dict(
|
| 8 |
+
interval=25,
|
| 9 |
+
metric=['PCK', 'NME', 'AUC', 'EPE'],
|
| 10 |
+
key_indicator='PCK',
|
| 11 |
+
gpu_collect=True,
|
| 12 |
+
res_folder='')
|
| 13 |
+
optimizer = dict(
|
| 14 |
+
type='Adam',
|
| 15 |
+
lr=1e-5,
|
| 16 |
+
)
|
| 17 |
+
|
| 18 |
+
optimizer_config = dict(grad_clip=None)
|
| 19 |
+
# learning policy
|
| 20 |
+
lr_config = dict(
|
| 21 |
+
policy='step',
|
| 22 |
+
warmup='linear',
|
| 23 |
+
warmup_iters=1000,
|
| 24 |
+
warmup_ratio=0.001,
|
| 25 |
+
step=[160, 180])
|
| 26 |
+
total_epochs = 200
|
| 27 |
+
log_config = dict(
|
| 28 |
+
interval=50,
|
| 29 |
+
hooks=[
|
| 30 |
+
dict(type='TextLoggerHook'),
|
| 31 |
+
dict(type='TensorboardLoggerHook')
|
| 32 |
+
])
|
| 33 |
+
|
| 34 |
+
channel_cfg = dict(
|
| 35 |
+
num_output_channels=1,
|
| 36 |
+
dataset_joints=1,
|
| 37 |
+
dataset_channel=[
|
| 38 |
+
[
|
| 39 |
+
0,
|
| 40 |
+
],
|
| 41 |
+
],
|
| 42 |
+
inference_channel=[
|
| 43 |
+
0,
|
| 44 |
+
],
|
| 45 |
+
max_kpt_num=100)
|
| 46 |
+
|
| 47 |
+
# model settings
|
| 48 |
+
model = dict(
|
| 49 |
+
type='PoseAnythingModel',
|
| 50 |
+
pretrained='pretrained/swinv2_base_22k_500k.pth',
|
| 51 |
+
encoder_config=dict(
|
| 52 |
+
type='SwinTransformerV2',
|
| 53 |
+
embed_dim=128,
|
| 54 |
+
depths=[2, 2, 18, 2],
|
| 55 |
+
num_heads=[4, 8, 16, 32],
|
| 56 |
+
window_size=14,
|
| 57 |
+
pretrained_window_sizes=[12, 12, 12, 6],
|
| 58 |
+
drop_path_rate=0.1,
|
| 59 |
+
img_size=224,
|
| 60 |
+
),
|
| 61 |
+
keypoint_head=dict(
|
| 62 |
+
type='PoseHead',
|
| 63 |
+
in_channels=1024,
|
| 64 |
+
transformer=dict(
|
| 65 |
+
type='EncoderDecoder',
|
| 66 |
+
d_model=256,
|
| 67 |
+
nhead=8,
|
| 68 |
+
num_encoder_layers=3,
|
| 69 |
+
num_decoder_layers=3,
|
| 70 |
+
dim_feedforward=1024,
|
| 71 |
+
dropout=0.1,
|
| 72 |
+
similarity_proj_dim=256,
|
| 73 |
+
dynamic_proj_dim=128,
|
| 74 |
+
activation="relu",
|
| 75 |
+
normalize_before=False,
|
| 76 |
+
return_intermediate_dec=True),
|
| 77 |
+
share_kpt_branch=False,
|
| 78 |
+
num_decoder_layer=3,
|
| 79 |
+
with_heatmap_loss=True,
|
| 80 |
+
|
| 81 |
+
heatmap_loss_weight=2.0,
|
| 82 |
+
support_order_dropout=-1,
|
| 83 |
+
positional_encoding=dict(
|
| 84 |
+
type='SinePositionalEncoding', num_feats=128, normalize=True)),
|
| 85 |
+
# training and testing settings
|
| 86 |
+
train_cfg=dict(),
|
| 87 |
+
test_cfg=dict(
|
| 88 |
+
flip_test=False,
|
| 89 |
+
post_process='default',
|
| 90 |
+
shift_heatmap=True,
|
| 91 |
+
modulate_kernel=11))
|
| 92 |
+
|
| 93 |
+
data_cfg = dict(
|
| 94 |
+
image_size=[224, 224],
|
| 95 |
+
heatmap_size=[64, 64],
|
| 96 |
+
num_output_channels=channel_cfg['num_output_channels'],
|
| 97 |
+
num_joints=channel_cfg['dataset_joints'],
|
| 98 |
+
dataset_channel=channel_cfg['dataset_channel'],
|
| 99 |
+
inference_channel=channel_cfg['inference_channel'])
|
| 100 |
+
|
| 101 |
+
train_pipeline = [
|
| 102 |
+
dict(type='LoadImageFromFile'),
|
| 103 |
+
dict(
|
| 104 |
+
type='TopDownGetRandomScaleRotation', rot_factor=15,
|
| 105 |
+
scale_factor=0.15),
|
| 106 |
+
dict(type='TopDownAffineFewShot'),
|
| 107 |
+
dict(type='ToTensor'),
|
| 108 |
+
dict(
|
| 109 |
+
type='NormalizeTensor',
|
| 110 |
+
mean=[0.485, 0.456, 0.406],
|
| 111 |
+
std=[0.229, 0.224, 0.225]),
|
| 112 |
+
dict(type='TopDownGenerateTargetFewShot', sigma=1),
|
| 113 |
+
dict(
|
| 114 |
+
type='Collect',
|
| 115 |
+
keys=['img', 'target', 'target_weight'],
|
| 116 |
+
meta_keys=[
|
| 117 |
+
'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
|
| 118 |
+
'rotation', 'bbox_score', 'flip_pairs', 'category_id', 'skeleton',
|
| 119 |
+
]),
|
| 120 |
+
]
|
| 121 |
+
|
| 122 |
+
valid_pipeline = [
|
| 123 |
+
dict(type='LoadImageFromFile'),
|
| 124 |
+
dict(type='TopDownAffineFewShot'),
|
| 125 |
+
dict(type='ToTensor'),
|
| 126 |
+
dict(
|
| 127 |
+
type='NormalizeTensor',
|
| 128 |
+
mean=[0.485, 0.456, 0.406],
|
| 129 |
+
std=[0.229, 0.224, 0.225]),
|
| 130 |
+
dict(type='TopDownGenerateTargetFewShot', sigma=1),
|
| 131 |
+
dict(
|
| 132 |
+
type='Collect',
|
| 133 |
+
keys=['img', 'target', 'target_weight'],
|
| 134 |
+
meta_keys=[
|
| 135 |
+
'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale', 'rotation', 'bbox_score',
|
| 136 |
+
'flip_pairs', 'category_id',
|
| 137 |
+
'skeleton',
|
| 138 |
+
]),
|
| 139 |
+
]
|
| 140 |
+
|
| 141 |
+
test_pipeline = valid_pipeline
|
| 142 |
+
|
| 143 |
+
data_root = 'data/mp100'
|
| 144 |
+
data = dict(
|
| 145 |
+
samples_per_gpu=8,
|
| 146 |
+
workers_per_gpu=8,
|
| 147 |
+
train=dict(
|
| 148 |
+
type='TransformerPoseDataset',
|
| 149 |
+
ann_file=f'{data_root}/annotations/mp100_split1_train.json',
|
| 150 |
+
img_prefix=f'{data_root}/images/',
|
| 151 |
+
# img_prefix=f'{data_root}',
|
| 152 |
+
data_cfg=data_cfg,
|
| 153 |
+
valid_class_ids=None,
|
| 154 |
+
max_kpt_num=channel_cfg['max_kpt_num'],
|
| 155 |
+
num_shots=5,
|
| 156 |
+
pipeline=train_pipeline),
|
| 157 |
+
val=dict(
|
| 158 |
+
type='TransformerPoseDataset',
|
| 159 |
+
ann_file=f'{data_root}/annotations/mp100_split1_val.json',
|
| 160 |
+
img_prefix=f'{data_root}/images/',
|
| 161 |
+
# img_prefix=f'{data_root}',
|
| 162 |
+
data_cfg=data_cfg,
|
| 163 |
+
valid_class_ids=None,
|
| 164 |
+
max_kpt_num=channel_cfg['max_kpt_num'],
|
| 165 |
+
num_shots=5,
|
| 166 |
+
num_queries=15,
|
| 167 |
+
num_episodes=100,
|
| 168 |
+
pipeline=valid_pipeline),
|
| 169 |
+
test=dict(
|
| 170 |
+
type='TestPoseDataset',
|
| 171 |
+
ann_file=f'{data_root}/annotations/mp100_split1_test.json',
|
| 172 |
+
img_prefix=f'{data_root}/images/',
|
| 173 |
+
# img_prefix=f'{data_root}',
|
| 174 |
+
data_cfg=data_cfg,
|
| 175 |
+
valid_class_ids=None,
|
| 176 |
+
max_kpt_num=channel_cfg['max_kpt_num'],
|
| 177 |
+
num_shots=5,
|
| 178 |
+
num_queries=15,
|
| 179 |
+
num_episodes=200,
|
| 180 |
+
pck_threshold_list=[0.05, 0.10, 0.15, 0.2, 0.25],
|
| 181 |
+
pipeline=test_pipeline),
|
| 182 |
+
)
|
| 183 |
+
vis_backends = [
|
| 184 |
+
dict(type='LocalVisBackend'),
|
| 185 |
+
dict(type='TensorboardVisBackend'),
|
| 186 |
+
]
|
| 187 |
+
visualizer = dict(
|
| 188 |
+
type='PoseLocalVisualizer', vis_backends=vis_backends, name='visualizer')
|
| 189 |
+
|
| 190 |
+
shuffle_cfg = dict(interval=1)
|
configs/5shot-swin/base_split2_config.py
ADDED
|
@@ -0,0 +1,190 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
log_level = 'INFO'
|
| 2 |
+
load_from = None
|
| 3 |
+
resume_from = None
|
| 4 |
+
dist_params = dict(backend='nccl')
|
| 5 |
+
workflow = [('train', 1)]
|
| 6 |
+
checkpoint_config = dict(interval=20)
|
| 7 |
+
evaluation = dict(
|
| 8 |
+
interval=25,
|
| 9 |
+
metric=['PCK', 'NME', 'AUC', 'EPE'],
|
| 10 |
+
key_indicator='PCK',
|
| 11 |
+
gpu_collect=True,
|
| 12 |
+
res_folder='')
|
| 13 |
+
optimizer = dict(
|
| 14 |
+
type='Adam',
|
| 15 |
+
lr=1e-5,
|
| 16 |
+
)
|
| 17 |
+
|
| 18 |
+
optimizer_config = dict(grad_clip=None)
|
| 19 |
+
# learning policy
|
| 20 |
+
lr_config = dict(
|
| 21 |
+
policy='step',
|
| 22 |
+
warmup='linear',
|
| 23 |
+
warmup_iters=1000,
|
| 24 |
+
warmup_ratio=0.001,
|
| 25 |
+
step=[160, 180])
|
| 26 |
+
total_epochs = 200
|
| 27 |
+
log_config = dict(
|
| 28 |
+
interval=50,
|
| 29 |
+
hooks=[
|
| 30 |
+
dict(type='TextLoggerHook'),
|
| 31 |
+
dict(type='TensorboardLoggerHook')
|
| 32 |
+
])
|
| 33 |
+
|
| 34 |
+
channel_cfg = dict(
|
| 35 |
+
num_output_channels=1,
|
| 36 |
+
dataset_joints=1,
|
| 37 |
+
dataset_channel=[
|
| 38 |
+
[
|
| 39 |
+
0,
|
| 40 |
+
],
|
| 41 |
+
],
|
| 42 |
+
inference_channel=[
|
| 43 |
+
0,
|
| 44 |
+
],
|
| 45 |
+
max_kpt_num=100)
|
| 46 |
+
|
| 47 |
+
# model settings
|
| 48 |
+
model = dict(
|
| 49 |
+
type='PoseAnythingModel',
|
| 50 |
+
pretrained='pretrained/swinv2_base_22k_500k.pth',
|
| 51 |
+
encoder_config=dict(
|
| 52 |
+
type='SwinTransformerV2',
|
| 53 |
+
embed_dim=128,
|
| 54 |
+
depths=[2, 2, 18, 2],
|
| 55 |
+
num_heads=[4, 8, 16, 32],
|
| 56 |
+
window_size=14,
|
| 57 |
+
pretrained_window_sizes=[12, 12, 12, 6],
|
| 58 |
+
drop_path_rate=0.1,
|
| 59 |
+
img_size=224,
|
| 60 |
+
),
|
| 61 |
+
keypoint_head=dict(
|
| 62 |
+
type='PoseHead',
|
| 63 |
+
in_channels=1024,
|
| 64 |
+
transformer=dict(
|
| 65 |
+
type='EncoderDecoder',
|
| 66 |
+
d_model=256,
|
| 67 |
+
nhead=8,
|
| 68 |
+
num_encoder_layers=3,
|
| 69 |
+
num_decoder_layers=3,
|
| 70 |
+
dim_feedforward=1024,
|
| 71 |
+
dropout=0.1,
|
| 72 |
+
similarity_proj_dim=256,
|
| 73 |
+
dynamic_proj_dim=128,
|
| 74 |
+
activation="relu",
|
| 75 |
+
normalize_before=False,
|
| 76 |
+
return_intermediate_dec=True),
|
| 77 |
+
share_kpt_branch=False,
|
| 78 |
+
num_decoder_layer=3,
|
| 79 |
+
with_heatmap_loss=True,
|
| 80 |
+
|
| 81 |
+
heatmap_loss_weight=2.0,
|
| 82 |
+
support_order_dropout=-1,
|
| 83 |
+
positional_encoding=dict(
|
| 84 |
+
type='SinePositionalEncoding', num_feats=128, normalize=True)),
|
| 85 |
+
# training and testing settings
|
| 86 |
+
train_cfg=dict(),
|
| 87 |
+
test_cfg=dict(
|
| 88 |
+
flip_test=False,
|
| 89 |
+
post_process='default',
|
| 90 |
+
shift_heatmap=True,
|
| 91 |
+
modulate_kernel=11))
|
| 92 |
+
|
| 93 |
+
data_cfg = dict(
|
| 94 |
+
image_size=[224, 224],
|
| 95 |
+
heatmap_size=[64, 64],
|
| 96 |
+
num_output_channels=channel_cfg['num_output_channels'],
|
| 97 |
+
num_joints=channel_cfg['dataset_joints'],
|
| 98 |
+
dataset_channel=channel_cfg['dataset_channel'],
|
| 99 |
+
inference_channel=channel_cfg['inference_channel'])
|
| 100 |
+
|
| 101 |
+
train_pipeline = [
|
| 102 |
+
dict(type='LoadImageFromFile'),
|
| 103 |
+
dict(
|
| 104 |
+
type='TopDownGetRandomScaleRotation', rot_factor=15,
|
| 105 |
+
scale_factor=0.15),
|
| 106 |
+
dict(type='TopDownAffineFewShot'),
|
| 107 |
+
dict(type='ToTensor'),
|
| 108 |
+
dict(
|
| 109 |
+
type='NormalizeTensor',
|
| 110 |
+
mean=[0.485, 0.456, 0.406],
|
| 111 |
+
std=[0.229, 0.224, 0.225]),
|
| 112 |
+
dict(type='TopDownGenerateTargetFewShot', sigma=1),
|
| 113 |
+
dict(
|
| 114 |
+
type='Collect',
|
| 115 |
+
keys=['img', 'target', 'target_weight'],
|
| 116 |
+
meta_keys=[
|
| 117 |
+
'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
|
| 118 |
+
'rotation', 'bbox_score', 'flip_pairs', 'category_id', 'skeleton',
|
| 119 |
+
]),
|
| 120 |
+
]
|
| 121 |
+
|
| 122 |
+
valid_pipeline = [
|
| 123 |
+
dict(type='LoadImageFromFile'),
|
| 124 |
+
dict(type='TopDownAffineFewShot'),
|
| 125 |
+
dict(type='ToTensor'),
|
| 126 |
+
dict(
|
| 127 |
+
type='NormalizeTensor',
|
| 128 |
+
mean=[0.485, 0.456, 0.406],
|
| 129 |
+
std=[0.229, 0.224, 0.225]),
|
| 130 |
+
dict(type='TopDownGenerateTargetFewShot', sigma=1),
|
| 131 |
+
dict(
|
| 132 |
+
type='Collect',
|
| 133 |
+
keys=['img', 'target', 'target_weight'],
|
| 134 |
+
meta_keys=[
|
| 135 |
+
'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale', 'rotation', 'bbox_score',
|
| 136 |
+
'flip_pairs', 'category_id',
|
| 137 |
+
'skeleton',
|
| 138 |
+
]),
|
| 139 |
+
]
|
| 140 |
+
|
| 141 |
+
test_pipeline = valid_pipeline
|
| 142 |
+
|
| 143 |
+
data_root = 'data/mp100'
|
| 144 |
+
data = dict(
|
| 145 |
+
samples_per_gpu=8,
|
| 146 |
+
workers_per_gpu=8,
|
| 147 |
+
train=dict(
|
| 148 |
+
type='TransformerPoseDataset',
|
| 149 |
+
ann_file=f'{data_root}/annotations/mp100_split2_train.json',
|
| 150 |
+
img_prefix=f'{data_root}/images/',
|
| 151 |
+
# img_prefix=f'{data_root}',
|
| 152 |
+
data_cfg=data_cfg,
|
| 153 |
+
valid_class_ids=None,
|
| 154 |
+
max_kpt_num=channel_cfg['max_kpt_num'],
|
| 155 |
+
num_shots=5,
|
| 156 |
+
pipeline=train_pipeline),
|
| 157 |
+
val=dict(
|
| 158 |
+
type='TransformerPoseDataset',
|
| 159 |
+
ann_file=f'{data_root}/annotations/mp100_split2_val.json',
|
| 160 |
+
img_prefix=f'{data_root}/images/',
|
| 161 |
+
# img_prefix=f'{data_root}',
|
| 162 |
+
data_cfg=data_cfg,
|
| 163 |
+
valid_class_ids=None,
|
| 164 |
+
max_kpt_num=channel_cfg['max_kpt_num'],
|
| 165 |
+
num_shots=5,
|
| 166 |
+
num_queries=15,
|
| 167 |
+
num_episodes=100,
|
| 168 |
+
pipeline=valid_pipeline),
|
| 169 |
+
test=dict(
|
| 170 |
+
type='TestPoseDataset',
|
| 171 |
+
ann_file=f'{data_root}/annotations/mp100_split2_test.json',
|
| 172 |
+
img_prefix=f'{data_root}/images/',
|
| 173 |
+
# img_prefix=f'{data_root}',
|
| 174 |
+
data_cfg=data_cfg,
|
| 175 |
+
valid_class_ids=None,
|
| 176 |
+
max_kpt_num=channel_cfg['max_kpt_num'],
|
| 177 |
+
num_shots=5,
|
| 178 |
+
num_queries=15,
|
| 179 |
+
num_episodes=200,
|
| 180 |
+
pck_threshold_list=[0.05, 0.10, 0.15, 0.2, 0.25],
|
| 181 |
+
pipeline=test_pipeline),
|
| 182 |
+
)
|
| 183 |
+
vis_backends = [
|
| 184 |
+
dict(type='LocalVisBackend'),
|
| 185 |
+
dict(type='TensorboardVisBackend'),
|
| 186 |
+
]
|
| 187 |
+
visualizer = dict(
|
| 188 |
+
type='PoseLocalVisualizer', vis_backends=vis_backends, name='visualizer')
|
| 189 |
+
|
| 190 |
+
shuffle_cfg = dict(interval=1)
|
configs/5shot-swin/base_split3_config.py
ADDED
|
@@ -0,0 +1,190 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
log_level = 'INFO'
|
| 2 |
+
load_from = None
|
| 3 |
+
resume_from = None
|
| 4 |
+
dist_params = dict(backend='nccl')
|
| 5 |
+
workflow = [('train', 1)]
|
| 6 |
+
checkpoint_config = dict(interval=20)
|
| 7 |
+
evaluation = dict(
|
| 8 |
+
interval=25,
|
| 9 |
+
metric=['PCK', 'NME', 'AUC', 'EPE'],
|
| 10 |
+
key_indicator='PCK',
|
| 11 |
+
gpu_collect=True,
|
| 12 |
+
res_folder='')
|
| 13 |
+
optimizer = dict(
|
| 14 |
+
type='Adam',
|
| 15 |
+
lr=1e-5,
|
| 16 |
+
)
|
| 17 |
+
|
| 18 |
+
optimizer_config = dict(grad_clip=None)
|
| 19 |
+
# learning policy
|
| 20 |
+
lr_config = dict(
|
| 21 |
+
policy='step',
|
| 22 |
+
warmup='linear',
|
| 23 |
+
warmup_iters=1000,
|
| 24 |
+
warmup_ratio=0.001,
|
| 25 |
+
step=[160, 180])
|
| 26 |
+
total_epochs = 200
|
| 27 |
+
log_config = dict(
|
| 28 |
+
interval=50,
|
| 29 |
+
hooks=[
|
| 30 |
+
dict(type='TextLoggerHook'),
|
| 31 |
+
dict(type='TensorboardLoggerHook')
|
| 32 |
+
])
|
| 33 |
+
|
| 34 |
+
channel_cfg = dict(
|
| 35 |
+
num_output_channels=1,
|
| 36 |
+
dataset_joints=1,
|
| 37 |
+
dataset_channel=[
|
| 38 |
+
[
|
| 39 |
+
0,
|
| 40 |
+
],
|
| 41 |
+
],
|
| 42 |
+
inference_channel=[
|
| 43 |
+
0,
|
| 44 |
+
],
|
| 45 |
+
max_kpt_num=100)
|
| 46 |
+
|
| 47 |
+
# model settings
|
| 48 |
+
model = dict(
|
| 49 |
+
type='PoseAnythingModel',
|
| 50 |
+
pretrained='pretrained/swinv2_base_22k_500k.pth',
|
| 51 |
+
encoder_config=dict(
|
| 52 |
+
type='SwinTransformerV2',
|
| 53 |
+
embed_dim=128,
|
| 54 |
+
depths=[2, 2, 18, 2],
|
| 55 |
+
num_heads=[4, 8, 16, 32],
|
| 56 |
+
window_size=14,
|
| 57 |
+
pretrained_window_sizes=[12, 12, 12, 6],
|
| 58 |
+
drop_path_rate=0.1,
|
| 59 |
+
img_size=224,
|
| 60 |
+
),
|
| 61 |
+
keypoint_head=dict(
|
| 62 |
+
type='PoseHead',
|
| 63 |
+
in_channels=1024,
|
| 64 |
+
transformer=dict(
|
| 65 |
+
type='EncoderDecoder',
|
| 66 |
+
d_model=256,
|
| 67 |
+
nhead=8,
|
| 68 |
+
num_encoder_layers=3,
|
| 69 |
+
num_decoder_layers=3,
|
| 70 |
+
dim_feedforward=1024,
|
| 71 |
+
dropout=0.1,
|
| 72 |
+
similarity_proj_dim=256,
|
| 73 |
+
dynamic_proj_dim=128,
|
| 74 |
+
activation="relu",
|
| 75 |
+
normalize_before=False,
|
| 76 |
+
return_intermediate_dec=True),
|
| 77 |
+
share_kpt_branch=False,
|
| 78 |
+
num_decoder_layer=3,
|
| 79 |
+
with_heatmap_loss=True,
|
| 80 |
+
|
| 81 |
+
heatmap_loss_weight=2.0,
|
| 82 |
+
support_order_dropout=-1,
|
| 83 |
+
positional_encoding=dict(
|
| 84 |
+
type='SinePositionalEncoding', num_feats=128, normalize=True)),
|
| 85 |
+
# training and testing settings
|
| 86 |
+
train_cfg=dict(),
|
| 87 |
+
test_cfg=dict(
|
| 88 |
+
flip_test=False,
|
| 89 |
+
post_process='default',
|
| 90 |
+
shift_heatmap=True,
|
| 91 |
+
modulate_kernel=11))
|
| 92 |
+
|
| 93 |
+
data_cfg = dict(
|
| 94 |
+
image_size=[224, 224],
|
| 95 |
+
heatmap_size=[64, 64],
|
| 96 |
+
num_output_channels=channel_cfg['num_output_channels'],
|
| 97 |
+
num_joints=channel_cfg['dataset_joints'],
|
| 98 |
+
dataset_channel=channel_cfg['dataset_channel'],
|
| 99 |
+
inference_channel=channel_cfg['inference_channel'])
|
| 100 |
+
|
| 101 |
+
train_pipeline = [
|
| 102 |
+
dict(type='LoadImageFromFile'),
|
| 103 |
+
dict(
|
| 104 |
+
type='TopDownGetRandomScaleRotation', rot_factor=15,
|
| 105 |
+
scale_factor=0.15),
|
| 106 |
+
dict(type='TopDownAffineFewShot'),
|
| 107 |
+
dict(type='ToTensor'),
|
| 108 |
+
dict(
|
| 109 |
+
type='NormalizeTensor',
|
| 110 |
+
mean=[0.485, 0.456, 0.406],
|
| 111 |
+
std=[0.229, 0.224, 0.225]),
|
| 112 |
+
dict(type='TopDownGenerateTargetFewShot', sigma=1),
|
| 113 |
+
dict(
|
| 114 |
+
type='Collect',
|
| 115 |
+
keys=['img', 'target', 'target_weight'],
|
| 116 |
+
meta_keys=[
|
| 117 |
+
'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
|
| 118 |
+
'rotation', 'bbox_score', 'flip_pairs', 'category_id', 'skeleton',
|
| 119 |
+
]),
|
| 120 |
+
]
|
| 121 |
+
|
| 122 |
+
valid_pipeline = [
|
| 123 |
+
dict(type='LoadImageFromFile'),
|
| 124 |
+
dict(type='TopDownAffineFewShot'),
|
| 125 |
+
dict(type='ToTensor'),
|
| 126 |
+
dict(
|
| 127 |
+
type='NormalizeTensor',
|
| 128 |
+
mean=[0.485, 0.456, 0.406],
|
| 129 |
+
std=[0.229, 0.224, 0.225]),
|
| 130 |
+
dict(type='TopDownGenerateTargetFewShot', sigma=1),
|
| 131 |
+
dict(
|
| 132 |
+
type='Collect',
|
| 133 |
+
keys=['img', 'target', 'target_weight'],
|
| 134 |
+
meta_keys=[
|
| 135 |
+
'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale', 'rotation', 'bbox_score',
|
| 136 |
+
'flip_pairs', 'category_id',
|
| 137 |
+
'skeleton',
|
| 138 |
+
]),
|
| 139 |
+
]
|
| 140 |
+
|
| 141 |
+
test_pipeline = valid_pipeline
|
| 142 |
+
|
| 143 |
+
data_root = 'data/mp100'
|
| 144 |
+
data = dict(
|
| 145 |
+
samples_per_gpu=8,
|
| 146 |
+
workers_per_gpu=8,
|
| 147 |
+
train=dict(
|
| 148 |
+
type='TransformerPoseDataset',
|
| 149 |
+
ann_file=f'{data_root}/annotations/mp100_split3_train.json',
|
| 150 |
+
img_prefix=f'{data_root}/images/',
|
| 151 |
+
# img_prefix=f'{data_root}',
|
| 152 |
+
data_cfg=data_cfg,
|
| 153 |
+
valid_class_ids=None,
|
| 154 |
+
max_kpt_num=channel_cfg['max_kpt_num'],
|
| 155 |
+
num_shots=5,
|
| 156 |
+
pipeline=train_pipeline),
|
| 157 |
+
val=dict(
|
| 158 |
+
type='TransformerPoseDataset',
|
| 159 |
+
ann_file=f'{data_root}/annotations/mp100_split3_val.json',
|
| 160 |
+
img_prefix=f'{data_root}/images/',
|
| 161 |
+
# img_prefix=f'{data_root}',
|
| 162 |
+
data_cfg=data_cfg,
|
| 163 |
+
valid_class_ids=None,
|
| 164 |
+
max_kpt_num=channel_cfg['max_kpt_num'],
|
| 165 |
+
num_shots=5,
|
| 166 |
+
num_queries=15,
|
| 167 |
+
num_episodes=100,
|
| 168 |
+
pipeline=valid_pipeline),
|
| 169 |
+
test=dict(
|
| 170 |
+
type='TestPoseDataset',
|
| 171 |
+
ann_file=f'{data_root}/annotations/mp100_split3_test.json',
|
| 172 |
+
img_prefix=f'{data_root}/images/',
|
| 173 |
+
# img_prefix=f'{data_root}',
|
| 174 |
+
data_cfg=data_cfg,
|
| 175 |
+
valid_class_ids=None,
|
| 176 |
+
max_kpt_num=channel_cfg['max_kpt_num'],
|
| 177 |
+
num_shots=5,
|
| 178 |
+
num_queries=15,
|
| 179 |
+
num_episodes=200,
|
| 180 |
+
pck_threshold_list=[0.05, 0.10, 0.15, 0.2, 0.25],
|
| 181 |
+
pipeline=test_pipeline),
|
| 182 |
+
)
|
| 183 |
+
vis_backends = [
|
| 184 |
+
dict(type='LocalVisBackend'),
|
| 185 |
+
dict(type='TensorboardVisBackend'),
|
| 186 |
+
]
|
| 187 |
+
visualizer = dict(
|
| 188 |
+
type='PoseLocalVisualizer', vis_backends=vis_backends, name='visualizer')
|
| 189 |
+
|
| 190 |
+
shuffle_cfg = dict(interval=1)
|
configs/5shot-swin/base_split4_config.py
ADDED
|
@@ -0,0 +1,190 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
log_level = 'INFO'
|
| 2 |
+
load_from = None
|
| 3 |
+
resume_from = None
|
| 4 |
+
dist_params = dict(backend='nccl')
|
| 5 |
+
workflow = [('train', 1)]
|
| 6 |
+
checkpoint_config = dict(interval=20)
|
| 7 |
+
evaluation = dict(
|
| 8 |
+
interval=25,
|
| 9 |
+
metric=['PCK', 'NME', 'AUC', 'EPE'],
|
| 10 |
+
key_indicator='PCK',
|
| 11 |
+
gpu_collect=True,
|
| 12 |
+
res_folder='')
|
| 13 |
+
optimizer = dict(
|
| 14 |
+
type='Adam',
|
| 15 |
+
lr=1e-5,
|
| 16 |
+
)
|
| 17 |
+
|
| 18 |
+
optimizer_config = dict(grad_clip=None)
|
| 19 |
+
# learning policy
|
| 20 |
+
lr_config = dict(
|
| 21 |
+
policy='step',
|
| 22 |
+
warmup='linear',
|
| 23 |
+
warmup_iters=1000,
|
| 24 |
+
warmup_ratio=0.001,
|
| 25 |
+
step=[160, 180])
|
| 26 |
+
total_epochs = 200
|
| 27 |
+
log_config = dict(
|
| 28 |
+
interval=50,
|
| 29 |
+
hooks=[
|
| 30 |
+
dict(type='TextLoggerHook'),
|
| 31 |
+
dict(type='TensorboardLoggerHook')
|
| 32 |
+
])
|
| 33 |
+
|
| 34 |
+
channel_cfg = dict(
|
| 35 |
+
num_output_channels=1,
|
| 36 |
+
dataset_joints=1,
|
| 37 |
+
dataset_channel=[
|
| 38 |
+
[
|
| 39 |
+
0,
|
| 40 |
+
],
|
| 41 |
+
],
|
| 42 |
+
inference_channel=[
|
| 43 |
+
0,
|
| 44 |
+
],
|
| 45 |
+
max_kpt_num=100)
|
| 46 |
+
|
| 47 |
+
# model settings
|
| 48 |
+
model = dict(
|
| 49 |
+
type='PoseAnythingModel',
|
| 50 |
+
pretrained='pretrained/swinv2_base_22k_500k.pth',
|
| 51 |
+
encoder_config=dict(
|
| 52 |
+
type='SwinTransformerV2',
|
| 53 |
+
embed_dim=128,
|
| 54 |
+
depths=[2, 2, 18, 2],
|
| 55 |
+
num_heads=[4, 8, 16, 32],
|
| 56 |
+
window_size=14,
|
| 57 |
+
pretrained_window_sizes=[12, 12, 12, 6],
|
| 58 |
+
drop_path_rate=0.1,
|
| 59 |
+
img_size=224,
|
| 60 |
+
),
|
| 61 |
+
keypoint_head=dict(
|
| 62 |
+
type='PoseHead',
|
| 63 |
+
in_channels=1024,
|
| 64 |
+
transformer=dict(
|
| 65 |
+
type='EncoderDecoder',
|
| 66 |
+
d_model=256,
|
| 67 |
+
nhead=8,
|
| 68 |
+
num_encoder_layers=3,
|
| 69 |
+
num_decoder_layers=3,
|
| 70 |
+
dim_feedforward=1024,
|
| 71 |
+
dropout=0.1,
|
| 72 |
+
similarity_proj_dim=256,
|
| 73 |
+
dynamic_proj_dim=128,
|
| 74 |
+
activation="relu",
|
| 75 |
+
normalize_before=False,
|
| 76 |
+
return_intermediate_dec=True),
|
| 77 |
+
share_kpt_branch=False,
|
| 78 |
+
num_decoder_layer=3,
|
| 79 |
+
with_heatmap_loss=True,
|
| 80 |
+
|
| 81 |
+
heatmap_loss_weight=2.0,
|
| 82 |
+
support_order_dropout=-1,
|
| 83 |
+
positional_encoding=dict(
|
| 84 |
+
type='SinePositionalEncoding', num_feats=128, normalize=True)),
|
| 85 |
+
# training and testing settings
|
| 86 |
+
train_cfg=dict(),
|
| 87 |
+
test_cfg=dict(
|
| 88 |
+
flip_test=False,
|
| 89 |
+
post_process='default',
|
| 90 |
+
shift_heatmap=True,
|
| 91 |
+
modulate_kernel=11))
|
| 92 |
+
|
| 93 |
+
data_cfg = dict(
|
| 94 |
+
image_size=[224, 224],
|
| 95 |
+
heatmap_size=[64, 64],
|
| 96 |
+
num_output_channels=channel_cfg['num_output_channels'],
|
| 97 |
+
num_joints=channel_cfg['dataset_joints'],
|
| 98 |
+
dataset_channel=channel_cfg['dataset_channel'],
|
| 99 |
+
inference_channel=channel_cfg['inference_channel'])
|
| 100 |
+
|
| 101 |
+
train_pipeline = [
|
| 102 |
+
dict(type='LoadImageFromFile'),
|
| 103 |
+
dict(
|
| 104 |
+
type='TopDownGetRandomScaleRotation', rot_factor=15,
|
| 105 |
+
scale_factor=0.15),
|
| 106 |
+
dict(type='TopDownAffineFewShot'),
|
| 107 |
+
dict(type='ToTensor'),
|
| 108 |
+
dict(
|
| 109 |
+
type='NormalizeTensor',
|
| 110 |
+
mean=[0.485, 0.456, 0.406],
|
| 111 |
+
std=[0.229, 0.224, 0.225]),
|
| 112 |
+
dict(type='TopDownGenerateTargetFewShot', sigma=1),
|
| 113 |
+
dict(
|
| 114 |
+
type='Collect',
|
| 115 |
+
keys=['img', 'target', 'target_weight'],
|
| 116 |
+
meta_keys=[
|
| 117 |
+
'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
|
| 118 |
+
'rotation', 'bbox_score', 'flip_pairs', 'category_id', 'skeleton',
|
| 119 |
+
]),
|
| 120 |
+
]
|
| 121 |
+
|
| 122 |
+
valid_pipeline = [
|
| 123 |
+
dict(type='LoadImageFromFile'),
|
| 124 |
+
dict(type='TopDownAffineFewShot'),
|
| 125 |
+
dict(type='ToTensor'),
|
| 126 |
+
dict(
|
| 127 |
+
type='NormalizeTensor',
|
| 128 |
+
mean=[0.485, 0.456, 0.406],
|
| 129 |
+
std=[0.229, 0.224, 0.225]),
|
| 130 |
+
dict(type='TopDownGenerateTargetFewShot', sigma=1),
|
| 131 |
+
dict(
|
| 132 |
+
type='Collect',
|
| 133 |
+
keys=['img', 'target', 'target_weight'],
|
| 134 |
+
meta_keys=[
|
| 135 |
+
'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale', 'rotation', 'bbox_score',
|
| 136 |
+
'flip_pairs', 'category_id',
|
| 137 |
+
'skeleton',
|
| 138 |
+
]),
|
| 139 |
+
]
|
| 140 |
+
|
| 141 |
+
test_pipeline = valid_pipeline
|
| 142 |
+
|
| 143 |
+
data_root = 'data/mp100'
|
| 144 |
+
data = dict(
|
| 145 |
+
samples_per_gpu=8,
|
| 146 |
+
workers_per_gpu=8,
|
| 147 |
+
train=dict(
|
| 148 |
+
type='TransformerPoseDataset',
|
| 149 |
+
ann_file=f'{data_root}/annotations/mp100_split4_train.json',
|
| 150 |
+
img_prefix=f'{data_root}/images/',
|
| 151 |
+
# img_prefix=f'{data_root}',
|
| 152 |
+
data_cfg=data_cfg,
|
| 153 |
+
valid_class_ids=None,
|
| 154 |
+
max_kpt_num=channel_cfg['max_kpt_num'],
|
| 155 |
+
num_shots=5,
|
| 156 |
+
pipeline=train_pipeline),
|
| 157 |
+
val=dict(
|
| 158 |
+
type='TransformerPoseDataset',
|
| 159 |
+
ann_file=f'{data_root}/annotations/mp100_split4_val.json',
|
| 160 |
+
img_prefix=f'{data_root}/images/',
|
| 161 |
+
# img_prefix=f'{data_root}',
|
| 162 |
+
data_cfg=data_cfg,
|
| 163 |
+
valid_class_ids=None,
|
| 164 |
+
max_kpt_num=channel_cfg['max_kpt_num'],
|
| 165 |
+
num_shots=5,
|
| 166 |
+
num_queries=15,
|
| 167 |
+
num_episodes=100,
|
| 168 |
+
pipeline=valid_pipeline),
|
| 169 |
+
test=dict(
|
| 170 |
+
type='TestPoseDataset',
|
| 171 |
+
ann_file=f'{data_root}/annotations/mp100_split4_test.json',
|
| 172 |
+
img_prefix=f'{data_root}/images/',
|
| 173 |
+
# img_prefix=f'{data_root}',
|
| 174 |
+
data_cfg=data_cfg,
|
| 175 |
+
valid_class_ids=None,
|
| 176 |
+
max_kpt_num=channel_cfg['max_kpt_num'],
|
| 177 |
+
num_shots=5,
|
| 178 |
+
num_queries=15,
|
| 179 |
+
num_episodes=200,
|
| 180 |
+
pck_threshold_list=[0.05, 0.10, 0.15, 0.2, 0.25],
|
| 181 |
+
pipeline=test_pipeline),
|
| 182 |
+
)
|
| 183 |
+
vis_backends = [
|
| 184 |
+
dict(type='LocalVisBackend'),
|
| 185 |
+
dict(type='TensorboardVisBackend'),
|
| 186 |
+
]
|
| 187 |
+
visualizer = dict(
|
| 188 |
+
type='PoseLocalVisualizer', vis_backends=vis_backends, name='visualizer')
|
| 189 |
+
|
| 190 |
+
shuffle_cfg = dict(interval=1)
|
configs/5shot-swin/base_split5_config.py
ADDED
|
@@ -0,0 +1,190 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
log_level = 'INFO'
|
| 2 |
+
load_from = None
|
| 3 |
+
resume_from = None
|
| 4 |
+
dist_params = dict(backend='nccl')
|
| 5 |
+
workflow = [('train', 1)]
|
| 6 |
+
checkpoint_config = dict(interval=20)
|
| 7 |
+
evaluation = dict(
|
| 8 |
+
interval=25,
|
| 9 |
+
metric=['PCK', 'NME', 'AUC', 'EPE'],
|
| 10 |
+
key_indicator='PCK',
|
| 11 |
+
gpu_collect=True,
|
| 12 |
+
res_folder='')
|
| 13 |
+
optimizer = dict(
|
| 14 |
+
type='Adam',
|
| 15 |
+
lr=1e-5,
|
| 16 |
+
)
|
| 17 |
+
|
| 18 |
+
optimizer_config = dict(grad_clip=None)
|
| 19 |
+
# learning policy
|
| 20 |
+
lr_config = dict(
|
| 21 |
+
policy='step',
|
| 22 |
+
warmup='linear',
|
| 23 |
+
warmup_iters=1000,
|
| 24 |
+
warmup_ratio=0.001,
|
| 25 |
+
step=[160, 180])
|
| 26 |
+
total_epochs = 200
|
| 27 |
+
log_config = dict(
|
| 28 |
+
interval=50,
|
| 29 |
+
hooks=[
|
| 30 |
+
dict(type='TextLoggerHook'),
|
| 31 |
+
dict(type='TensorboardLoggerHook')
|
| 32 |
+
])
|
| 33 |
+
|
| 34 |
+
channel_cfg = dict(
|
| 35 |
+
num_output_channels=1,
|
| 36 |
+
dataset_joints=1,
|
| 37 |
+
dataset_channel=[
|
| 38 |
+
[
|
| 39 |
+
0,
|
| 40 |
+
],
|
| 41 |
+
],
|
| 42 |
+
inference_channel=[
|
| 43 |
+
0,
|
| 44 |
+
],
|
| 45 |
+
max_kpt_num=100)
|
| 46 |
+
|
| 47 |
+
# model settings
|
| 48 |
+
model = dict(
|
| 49 |
+
type='PoseAnythingModel',
|
| 50 |
+
pretrained='pretrained/swinv2_base_22k_500k.pth',
|
| 51 |
+
encoder_config=dict(
|
| 52 |
+
type='SwinTransformerV2',
|
| 53 |
+
embed_dim=128,
|
| 54 |
+
depths=[2, 2, 18, 2],
|
| 55 |
+
num_heads=[4, 8, 16, 32],
|
| 56 |
+
window_size=14,
|
| 57 |
+
pretrained_window_sizes=[12, 12, 12, 6],
|
| 58 |
+
drop_path_rate=0.1,
|
| 59 |
+
img_size=224,
|
| 60 |
+
),
|
| 61 |
+
keypoint_head=dict(
|
| 62 |
+
type='PoseHead',
|
| 63 |
+
in_channels=1024,
|
| 64 |
+
transformer=dict(
|
| 65 |
+
type='EncoderDecoder',
|
| 66 |
+
d_model=256,
|
| 67 |
+
nhead=8,
|
| 68 |
+
num_encoder_layers=3,
|
| 69 |
+
num_decoder_layers=3,
|
| 70 |
+
dim_feedforward=1024,
|
| 71 |
+
dropout=0.1,
|
| 72 |
+
similarity_proj_dim=256,
|
| 73 |
+
dynamic_proj_dim=128,
|
| 74 |
+
activation="relu",
|
| 75 |
+
normalize_before=False,
|
| 76 |
+
return_intermediate_dec=True),
|
| 77 |
+
share_kpt_branch=False,
|
| 78 |
+
num_decoder_layer=3,
|
| 79 |
+
with_heatmap_loss=True,
|
| 80 |
+
|
| 81 |
+
heatmap_loss_weight=2.0,
|
| 82 |
+
support_order_dropout=-1,
|
| 83 |
+
positional_encoding=dict(
|
| 84 |
+
type='SinePositionalEncoding', num_feats=128, normalize=True)),
|
| 85 |
+
# training and testing settings
|
| 86 |
+
train_cfg=dict(),
|
| 87 |
+
test_cfg=dict(
|
| 88 |
+
flip_test=False,
|
| 89 |
+
post_process='default',
|
| 90 |
+
shift_heatmap=True,
|
| 91 |
+
modulate_kernel=11))
|
| 92 |
+
|
| 93 |
+
data_cfg = dict(
|
| 94 |
+
image_size=[224, 224],
|
| 95 |
+
heatmap_size=[64, 64],
|
| 96 |
+
num_output_channels=channel_cfg['num_output_channels'],
|
| 97 |
+
num_joints=channel_cfg['dataset_joints'],
|
| 98 |
+
dataset_channel=channel_cfg['dataset_channel'],
|
| 99 |
+
inference_channel=channel_cfg['inference_channel'])
|
| 100 |
+
|
| 101 |
+
train_pipeline = [
|
| 102 |
+
dict(type='LoadImageFromFile'),
|
| 103 |
+
dict(
|
| 104 |
+
type='TopDownGetRandomScaleRotation', rot_factor=15,
|
| 105 |
+
scale_factor=0.15),
|
| 106 |
+
dict(type='TopDownAffineFewShot'),
|
| 107 |
+
dict(type='ToTensor'),
|
| 108 |
+
dict(
|
| 109 |
+
type='NormalizeTensor',
|
| 110 |
+
mean=[0.485, 0.456, 0.406],
|
| 111 |
+
std=[0.229, 0.224, 0.225]),
|
| 112 |
+
dict(type='TopDownGenerateTargetFewShot', sigma=1),
|
| 113 |
+
dict(
|
| 114 |
+
type='Collect',
|
| 115 |
+
keys=['img', 'target', 'target_weight'],
|
| 116 |
+
meta_keys=[
|
| 117 |
+
'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
|
| 118 |
+
'rotation', 'bbox_score', 'flip_pairs', 'category_id', 'skeleton',
|
| 119 |
+
]),
|
| 120 |
+
]
|
| 121 |
+
|
| 122 |
+
valid_pipeline = [
|
| 123 |
+
dict(type='LoadImageFromFile'),
|
| 124 |
+
dict(type='TopDownAffineFewShot'),
|
| 125 |
+
dict(type='ToTensor'),
|
| 126 |
+
dict(
|
| 127 |
+
type='NormalizeTensor',
|
| 128 |
+
mean=[0.485, 0.456, 0.406],
|
| 129 |
+
std=[0.229, 0.224, 0.225]),
|
| 130 |
+
dict(type='TopDownGenerateTargetFewShot', sigma=1),
|
| 131 |
+
dict(
|
| 132 |
+
type='Collect',
|
| 133 |
+
keys=['img', 'target', 'target_weight'],
|
| 134 |
+
meta_keys=[
|
| 135 |
+
'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale', 'rotation', 'bbox_score',
|
| 136 |
+
'flip_pairs', 'category_id',
|
| 137 |
+
'skeleton',
|
| 138 |
+
]),
|
| 139 |
+
]
|
| 140 |
+
|
| 141 |
+
test_pipeline = valid_pipeline
|
| 142 |
+
|
| 143 |
+
data_root = 'data/mp100'
|
| 144 |
+
data = dict(
|
| 145 |
+
samples_per_gpu=8,
|
| 146 |
+
workers_per_gpu=8,
|
| 147 |
+
train=dict(
|
| 148 |
+
type='TransformerPoseDataset',
|
| 149 |
+
ann_file=f'{data_root}/annotations/mp100_split5_train.json',
|
| 150 |
+
img_prefix=f'{data_root}/images/',
|
| 151 |
+
# img_prefix=f'{data_root}',
|
| 152 |
+
data_cfg=data_cfg,
|
| 153 |
+
valid_class_ids=None,
|
| 154 |
+
max_kpt_num=channel_cfg['max_kpt_num'],
|
| 155 |
+
num_shots=5,
|
| 156 |
+
pipeline=train_pipeline),
|
| 157 |
+
val=dict(
|
| 158 |
+
type='TransformerPoseDataset',
|
| 159 |
+
ann_file=f'{data_root}/annotations/mp100_split5_val.json',
|
| 160 |
+
img_prefix=f'{data_root}/images/',
|
| 161 |
+
# img_prefix=f'{data_root}',
|
| 162 |
+
data_cfg=data_cfg,
|
| 163 |
+
valid_class_ids=None,
|
| 164 |
+
max_kpt_num=channel_cfg['max_kpt_num'],
|
| 165 |
+
num_shots=5,
|
| 166 |
+
num_queries=15,
|
| 167 |
+
num_episodes=100,
|
| 168 |
+
pipeline=valid_pipeline),
|
| 169 |
+
test=dict(
|
| 170 |
+
type='TestPoseDataset',
|
| 171 |
+
ann_file=f'{data_root}/annotations/mp100_split5_test.json',
|
| 172 |
+
img_prefix=f'{data_root}/images/',
|
| 173 |
+
# img_prefix=f'{data_root}',
|
| 174 |
+
data_cfg=data_cfg,
|
| 175 |
+
valid_class_ids=None,
|
| 176 |
+
max_kpt_num=channel_cfg['max_kpt_num'],
|
| 177 |
+
num_shots=5,
|
| 178 |
+
num_queries=15,
|
| 179 |
+
num_episodes=200,
|
| 180 |
+
pck_threshold_list=[0.05, 0.10, 0.15, 0.2, 0.25],
|
| 181 |
+
pipeline=test_pipeline),
|
| 182 |
+
)
|
| 183 |
+
vis_backends = [
|
| 184 |
+
dict(type='LocalVisBackend'),
|
| 185 |
+
dict(type='TensorboardVisBackend'),
|
| 186 |
+
]
|
| 187 |
+
visualizer = dict(
|
| 188 |
+
type='PoseLocalVisualizer', vis_backends=vis_backends, name='visualizer')
|
| 189 |
+
|
| 190 |
+
shuffle_cfg = dict(interval=1)
|
configs/5shot-swin/graph_split1_config.py
ADDED
|
@@ -0,0 +1,191 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
log_level = 'INFO'
|
| 2 |
+
load_from = None
|
| 3 |
+
resume_from = None
|
| 4 |
+
dist_params = dict(backend='nccl')
|
| 5 |
+
workflow = [('train', 1)]
|
| 6 |
+
checkpoint_config = dict(interval=20)
|
| 7 |
+
evaluation = dict(
|
| 8 |
+
interval=25,
|
| 9 |
+
metric=['PCK', 'NME', 'AUC', 'EPE'],
|
| 10 |
+
key_indicator='PCK',
|
| 11 |
+
gpu_collect=True,
|
| 12 |
+
res_folder='')
|
| 13 |
+
optimizer = dict(
|
| 14 |
+
type='Adam',
|
| 15 |
+
lr=1e-5,
|
| 16 |
+
)
|
| 17 |
+
|
| 18 |
+
optimizer_config = dict(grad_clip=None)
|
| 19 |
+
# learning policy
|
| 20 |
+
lr_config = dict(
|
| 21 |
+
policy='step',
|
| 22 |
+
warmup='linear',
|
| 23 |
+
warmup_iters=1000,
|
| 24 |
+
warmup_ratio=0.001,
|
| 25 |
+
step=[160, 180])
|
| 26 |
+
total_epochs = 200
|
| 27 |
+
log_config = dict(
|
| 28 |
+
interval=50,
|
| 29 |
+
hooks=[
|
| 30 |
+
dict(type='TextLoggerHook'),
|
| 31 |
+
dict(type='TensorboardLoggerHook')
|
| 32 |
+
])
|
| 33 |
+
|
| 34 |
+
channel_cfg = dict(
|
| 35 |
+
num_output_channels=1,
|
| 36 |
+
dataset_joints=1,
|
| 37 |
+
dataset_channel=[
|
| 38 |
+
[
|
| 39 |
+
0,
|
| 40 |
+
],
|
| 41 |
+
],
|
| 42 |
+
inference_channel=[
|
| 43 |
+
0,
|
| 44 |
+
],
|
| 45 |
+
max_kpt_num=100)
|
| 46 |
+
|
| 47 |
+
# model settings
|
| 48 |
+
model = dict(
|
| 49 |
+
type='PoseAnythingModel',
|
| 50 |
+
pretrained='pretrained/swinv2_base_22k_500k.pth',
|
| 51 |
+
encoder_config=dict(
|
| 52 |
+
type='SwinTransformerV2',
|
| 53 |
+
embed_dim=128,
|
| 54 |
+
depths=[2, 2, 18, 2],
|
| 55 |
+
num_heads=[4, 8, 16, 32],
|
| 56 |
+
window_size=14,
|
| 57 |
+
pretrained_window_sizes=[12, 12, 12, 6],
|
| 58 |
+
drop_path_rate=0.1,
|
| 59 |
+
img_size=224,
|
| 60 |
+
),
|
| 61 |
+
keypoint_head=dict(
|
| 62 |
+
type='PoseHead',
|
| 63 |
+
in_channels=1024,
|
| 64 |
+
transformer=dict(
|
| 65 |
+
type='EncoderDecoder',
|
| 66 |
+
d_model=256,
|
| 67 |
+
nhead=8,
|
| 68 |
+
num_encoder_layers=3,
|
| 69 |
+
num_decoder_layers=3,
|
| 70 |
+
graph_decoder='pre',
|
| 71 |
+
dim_feedforward=1024,
|
| 72 |
+
dropout=0.1,
|
| 73 |
+
similarity_proj_dim=256,
|
| 74 |
+
dynamic_proj_dim=128,
|
| 75 |
+
activation="relu",
|
| 76 |
+
normalize_before=False,
|
| 77 |
+
return_intermediate_dec=True),
|
| 78 |
+
share_kpt_branch=False,
|
| 79 |
+
num_decoder_layer=3,
|
| 80 |
+
with_heatmap_loss=True,
|
| 81 |
+
|
| 82 |
+
heatmap_loss_weight=2.0,
|
| 83 |
+
support_order_dropout=-1,
|
| 84 |
+
positional_encoding=dict(
|
| 85 |
+
type='SinePositionalEncoding', num_feats=128, normalize=True)),
|
| 86 |
+
# training and testing settings
|
| 87 |
+
train_cfg=dict(),
|
| 88 |
+
test_cfg=dict(
|
| 89 |
+
flip_test=False,
|
| 90 |
+
post_process='default',
|
| 91 |
+
shift_heatmap=True,
|
| 92 |
+
modulate_kernel=11))
|
| 93 |
+
|
| 94 |
+
data_cfg = dict(
|
| 95 |
+
image_size=[224, 224],
|
| 96 |
+
heatmap_size=[64, 64],
|
| 97 |
+
num_output_channels=channel_cfg['num_output_channels'],
|
| 98 |
+
num_joints=channel_cfg['dataset_joints'],
|
| 99 |
+
dataset_channel=channel_cfg['dataset_channel'],
|
| 100 |
+
inference_channel=channel_cfg['inference_channel'])
|
| 101 |
+
|
| 102 |
+
train_pipeline = [
|
| 103 |
+
dict(type='LoadImageFromFile'),
|
| 104 |
+
dict(
|
| 105 |
+
type='TopDownGetRandomScaleRotation', rot_factor=15,
|
| 106 |
+
scale_factor=0.15),
|
| 107 |
+
dict(type='TopDownAffineFewShot'),
|
| 108 |
+
dict(type='ToTensor'),
|
| 109 |
+
dict(
|
| 110 |
+
type='NormalizeTensor',
|
| 111 |
+
mean=[0.485, 0.456, 0.406],
|
| 112 |
+
std=[0.229, 0.224, 0.225]),
|
| 113 |
+
dict(type='TopDownGenerateTargetFewShot', sigma=1),
|
| 114 |
+
dict(
|
| 115 |
+
type='Collect',
|
| 116 |
+
keys=['img', 'target', 'target_weight'],
|
| 117 |
+
meta_keys=[
|
| 118 |
+
'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
|
| 119 |
+
'rotation', 'bbox_score', 'flip_pairs', 'category_id', 'skeleton',
|
| 120 |
+
]),
|
| 121 |
+
]
|
| 122 |
+
|
| 123 |
+
valid_pipeline = [
|
| 124 |
+
dict(type='LoadImageFromFile'),
|
| 125 |
+
dict(type='TopDownAffineFewShot'),
|
| 126 |
+
dict(type='ToTensor'),
|
| 127 |
+
dict(
|
| 128 |
+
type='NormalizeTensor',
|
| 129 |
+
mean=[0.485, 0.456, 0.406],
|
| 130 |
+
std=[0.229, 0.224, 0.225]),
|
| 131 |
+
dict(type='TopDownGenerateTargetFewShot', sigma=1),
|
| 132 |
+
dict(
|
| 133 |
+
type='Collect',
|
| 134 |
+
keys=['img', 'target', 'target_weight'],
|
| 135 |
+
meta_keys=[
|
| 136 |
+
'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale', 'rotation', 'bbox_score',
|
| 137 |
+
'flip_pairs', 'category_id',
|
| 138 |
+
'skeleton',
|
| 139 |
+
]),
|
| 140 |
+
]
|
| 141 |
+
|
| 142 |
+
test_pipeline = valid_pipeline
|
| 143 |
+
|
| 144 |
+
data_root = 'data/mp100'
|
| 145 |
+
data = dict(
|
| 146 |
+
samples_per_gpu=8,
|
| 147 |
+
workers_per_gpu=8,
|
| 148 |
+
train=dict(
|
| 149 |
+
type='TransformerPoseDataset',
|
| 150 |
+
ann_file=f'{data_root}/annotations/mp100_split1_train.json',
|
| 151 |
+
img_prefix=f'{data_root}/images/',
|
| 152 |
+
# img_prefix=f'{data_root}',
|
| 153 |
+
data_cfg=data_cfg,
|
| 154 |
+
valid_class_ids=None,
|
| 155 |
+
max_kpt_num=channel_cfg['max_kpt_num'],
|
| 156 |
+
num_shots=5,
|
| 157 |
+
pipeline=train_pipeline),
|
| 158 |
+
val=dict(
|
| 159 |
+
type='TransformerPoseDataset',
|
| 160 |
+
ann_file=f'{data_root}/annotations/mp100_split1_val.json',
|
| 161 |
+
img_prefix=f'{data_root}/images/',
|
| 162 |
+
# img_prefix=f'{data_root}',
|
| 163 |
+
data_cfg=data_cfg,
|
| 164 |
+
valid_class_ids=None,
|
| 165 |
+
max_kpt_num=channel_cfg['max_kpt_num'],
|
| 166 |
+
num_shots=5,
|
| 167 |
+
num_queries=15,
|
| 168 |
+
num_episodes=100,
|
| 169 |
+
pipeline=valid_pipeline),
|
| 170 |
+
test=dict(
|
| 171 |
+
type='TestPoseDataset',
|
| 172 |
+
ann_file=f'{data_root}/annotations/mp100_split1_test.json',
|
| 173 |
+
img_prefix=f'{data_root}/images/',
|
| 174 |
+
# img_prefix=f'{data_root}',
|
| 175 |
+
data_cfg=data_cfg,
|
| 176 |
+
valid_class_ids=None,
|
| 177 |
+
max_kpt_num=channel_cfg['max_kpt_num'],
|
| 178 |
+
num_shots=5,
|
| 179 |
+
num_queries=15,
|
| 180 |
+
num_episodes=200,
|
| 181 |
+
pck_threshold_list=[0.05, 0.10, 0.15, 0.2, 0.25],
|
| 182 |
+
pipeline=test_pipeline),
|
| 183 |
+
)
|
| 184 |
+
vis_backends = [
|
| 185 |
+
dict(type='LocalVisBackend'),
|
| 186 |
+
dict(type='TensorboardVisBackend'),
|
| 187 |
+
]
|
| 188 |
+
visualizer = dict(
|
| 189 |
+
type='PoseLocalVisualizer', vis_backends=vis_backends, name='visualizer')
|
| 190 |
+
|
| 191 |
+
shuffle_cfg = dict(interval=1)
|
configs/5shot-swin/graph_split2_config.py
ADDED
|
@@ -0,0 +1,191 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
log_level = 'INFO'
|
| 2 |
+
load_from = None
|
| 3 |
+
resume_from = None
|
| 4 |
+
dist_params = dict(backend='nccl')
|
| 5 |
+
workflow = [('train', 1)]
|
| 6 |
+
checkpoint_config = dict(interval=20)
|
| 7 |
+
evaluation = dict(
|
| 8 |
+
interval=25,
|
| 9 |
+
metric=['PCK', 'NME', 'AUC', 'EPE'],
|
| 10 |
+
key_indicator='PCK',
|
| 11 |
+
gpu_collect=True,
|
| 12 |
+
res_folder='')
|
| 13 |
+
optimizer = dict(
|
| 14 |
+
type='Adam',
|
| 15 |
+
lr=1e-5,
|
| 16 |
+
)
|
| 17 |
+
|
| 18 |
+
optimizer_config = dict(grad_clip=None)
|
| 19 |
+
# learning policy
|
| 20 |
+
lr_config = dict(
|
| 21 |
+
policy='step',
|
| 22 |
+
warmup='linear',
|
| 23 |
+
warmup_iters=1000,
|
| 24 |
+
warmup_ratio=0.001,
|
| 25 |
+
step=[160, 180])
|
| 26 |
+
total_epochs = 200
|
| 27 |
+
log_config = dict(
|
| 28 |
+
interval=50,
|
| 29 |
+
hooks=[
|
| 30 |
+
dict(type='TextLoggerHook'),
|
| 31 |
+
dict(type='TensorboardLoggerHook')
|
| 32 |
+
])
|
| 33 |
+
|
| 34 |
+
channel_cfg = dict(
|
| 35 |
+
num_output_channels=1,
|
| 36 |
+
dataset_joints=1,
|
| 37 |
+
dataset_channel=[
|
| 38 |
+
[
|
| 39 |
+
0,
|
| 40 |
+
],
|
| 41 |
+
],
|
| 42 |
+
inference_channel=[
|
| 43 |
+
0,
|
| 44 |
+
],
|
| 45 |
+
max_kpt_num=100)
|
| 46 |
+
|
| 47 |
+
# model settings
|
| 48 |
+
model = dict(
|
| 49 |
+
type='PoseAnythingModel',
|
| 50 |
+
pretrained='pretrained/swinv2_base_22k_500k.pth',
|
| 51 |
+
encoder_config=dict(
|
| 52 |
+
type='SwinTransformerV2',
|
| 53 |
+
embed_dim=128,
|
| 54 |
+
depths=[2, 2, 18, 2],
|
| 55 |
+
num_heads=[4, 8, 16, 32],
|
| 56 |
+
window_size=14,
|
| 57 |
+
pretrained_window_sizes=[12, 12, 12, 6],
|
| 58 |
+
drop_path_rate=0.1,
|
| 59 |
+
img_size=224,
|
| 60 |
+
),
|
| 61 |
+
keypoint_head=dict(
|
| 62 |
+
type='PoseHead',
|
| 63 |
+
in_channels=1024,
|
| 64 |
+
transformer=dict(
|
| 65 |
+
type='EncoderDecoder',
|
| 66 |
+
d_model=256,
|
| 67 |
+
nhead=8,
|
| 68 |
+
num_encoder_layers=3,
|
| 69 |
+
num_decoder_layers=3,
|
| 70 |
+
graph_decoder='pre',
|
| 71 |
+
dim_feedforward=1024,
|
| 72 |
+
dropout=0.1,
|
| 73 |
+
similarity_proj_dim=256,
|
| 74 |
+
dynamic_proj_dim=128,
|
| 75 |
+
activation="relu",
|
| 76 |
+
normalize_before=False,
|
| 77 |
+
return_intermediate_dec=True),
|
| 78 |
+
share_kpt_branch=False,
|
| 79 |
+
num_decoder_layer=3,
|
| 80 |
+
with_heatmap_loss=True,
|
| 81 |
+
|
| 82 |
+
heatmap_loss_weight=2.0,
|
| 83 |
+
support_order_dropout=-1,
|
| 84 |
+
positional_encoding=dict(
|
| 85 |
+
type='SinePositionalEncoding', num_feats=128, normalize=True)),
|
| 86 |
+
# training and testing settings
|
| 87 |
+
train_cfg=dict(),
|
| 88 |
+
test_cfg=dict(
|
| 89 |
+
flip_test=False,
|
| 90 |
+
post_process='default',
|
| 91 |
+
shift_heatmap=True,
|
| 92 |
+
modulate_kernel=11))
|
| 93 |
+
|
| 94 |
+
data_cfg = dict(
|
| 95 |
+
image_size=[224, 224],
|
| 96 |
+
heatmap_size=[64, 64],
|
| 97 |
+
num_output_channels=channel_cfg['num_output_channels'],
|
| 98 |
+
num_joints=channel_cfg['dataset_joints'],
|
| 99 |
+
dataset_channel=channel_cfg['dataset_channel'],
|
| 100 |
+
inference_channel=channel_cfg['inference_channel'])
|
| 101 |
+
|
| 102 |
+
train_pipeline = [
|
| 103 |
+
dict(type='LoadImageFromFile'),
|
| 104 |
+
dict(
|
| 105 |
+
type='TopDownGetRandomScaleRotation', rot_factor=15,
|
| 106 |
+
scale_factor=0.15),
|
| 107 |
+
dict(type='TopDownAffineFewShot'),
|
| 108 |
+
dict(type='ToTensor'),
|
| 109 |
+
dict(
|
| 110 |
+
type='NormalizeTensor',
|
| 111 |
+
mean=[0.485, 0.456, 0.406],
|
| 112 |
+
std=[0.229, 0.224, 0.225]),
|
| 113 |
+
dict(type='TopDownGenerateTargetFewShot', sigma=1),
|
| 114 |
+
dict(
|
| 115 |
+
type='Collect',
|
| 116 |
+
keys=['img', 'target', 'target_weight'],
|
| 117 |
+
meta_keys=[
|
| 118 |
+
'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
|
| 119 |
+
'rotation', 'bbox_score', 'flip_pairs', 'category_id', 'skeleton',
|
| 120 |
+
]),
|
| 121 |
+
]
|
| 122 |
+
|
| 123 |
+
valid_pipeline = [
|
| 124 |
+
dict(type='LoadImageFromFile'),
|
| 125 |
+
dict(type='TopDownAffineFewShot'),
|
| 126 |
+
dict(type='ToTensor'),
|
| 127 |
+
dict(
|
| 128 |
+
type='NormalizeTensor',
|
| 129 |
+
mean=[0.485, 0.456, 0.406],
|
| 130 |
+
std=[0.229, 0.224, 0.225]),
|
| 131 |
+
dict(type='TopDownGenerateTargetFewShot', sigma=1),
|
| 132 |
+
dict(
|
| 133 |
+
type='Collect',
|
| 134 |
+
keys=['img', 'target', 'target_weight'],
|
| 135 |
+
meta_keys=[
|
| 136 |
+
'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale', 'rotation', 'bbox_score',
|
| 137 |
+
'flip_pairs', 'category_id',
|
| 138 |
+
'skeleton',
|
| 139 |
+
]),
|
| 140 |
+
]
|
| 141 |
+
|
| 142 |
+
test_pipeline = valid_pipeline
|
| 143 |
+
|
| 144 |
+
data_root = 'data/mp100'
|
| 145 |
+
data = dict(
|
| 146 |
+
samples_per_gpu=8,
|
| 147 |
+
workers_per_gpu=8,
|
| 148 |
+
train=dict(
|
| 149 |
+
type='TransformerPoseDataset',
|
| 150 |
+
ann_file=f'{data_root}/annotations/mp100_split2_train.json',
|
| 151 |
+
img_prefix=f'{data_root}/images/',
|
| 152 |
+
# img_prefix=f'{data_root}',
|
| 153 |
+
data_cfg=data_cfg,
|
| 154 |
+
valid_class_ids=None,
|
| 155 |
+
max_kpt_num=channel_cfg['max_kpt_num'],
|
| 156 |
+
num_shots=5,
|
| 157 |
+
pipeline=train_pipeline),
|
| 158 |
+
val=dict(
|
| 159 |
+
type='TransformerPoseDataset',
|
| 160 |
+
ann_file=f'{data_root}/annotations/mp100_split2_val.json',
|
| 161 |
+
img_prefix=f'{data_root}/images/',
|
| 162 |
+
# img_prefix=f'{data_root}',
|
| 163 |
+
data_cfg=data_cfg,
|
| 164 |
+
valid_class_ids=None,
|
| 165 |
+
max_kpt_num=channel_cfg['max_kpt_num'],
|
| 166 |
+
num_shots=5,
|
| 167 |
+
num_queries=15,
|
| 168 |
+
num_episodes=100,
|
| 169 |
+
pipeline=valid_pipeline),
|
| 170 |
+
test=dict(
|
| 171 |
+
type='TestPoseDataset',
|
| 172 |
+
ann_file=f'{data_root}/annotations/mp100_split2_test.json',
|
| 173 |
+
img_prefix=f'{data_root}/images/',
|
| 174 |
+
# img_prefix=f'{data_root}',
|
| 175 |
+
data_cfg=data_cfg,
|
| 176 |
+
valid_class_ids=None,
|
| 177 |
+
max_kpt_num=channel_cfg['max_kpt_num'],
|
| 178 |
+
num_shots=5,
|
| 179 |
+
num_queries=15,
|
| 180 |
+
num_episodes=200,
|
| 181 |
+
pck_threshold_list=[0.05, 0.10, 0.15, 0.2, 0.25],
|
| 182 |
+
pipeline=test_pipeline),
|
| 183 |
+
)
|
| 184 |
+
vis_backends = [
|
| 185 |
+
dict(type='LocalVisBackend'),
|
| 186 |
+
dict(type='TensorboardVisBackend'),
|
| 187 |
+
]
|
| 188 |
+
visualizer = dict(
|
| 189 |
+
type='PoseLocalVisualizer', vis_backends=vis_backends, name='visualizer')
|
| 190 |
+
|
| 191 |
+
shuffle_cfg = dict(interval=1)
|
configs/5shot-swin/graph_split3_config.py
ADDED
|
@@ -0,0 +1,191 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
log_level = 'INFO'
|
| 2 |
+
load_from = None
|
| 3 |
+
resume_from = None
|
| 4 |
+
dist_params = dict(backend='nccl')
|
| 5 |
+
workflow = [('train', 1)]
|
| 6 |
+
checkpoint_config = dict(interval=20)
|
| 7 |
+
evaluation = dict(
|
| 8 |
+
interval=25,
|
| 9 |
+
metric=['PCK', 'NME', 'AUC', 'EPE'],
|
| 10 |
+
key_indicator='PCK',
|
| 11 |
+
gpu_collect=True,
|
| 12 |
+
res_folder='')
|
| 13 |
+
optimizer = dict(
|
| 14 |
+
type='Adam',
|
| 15 |
+
lr=1e-5,
|
| 16 |
+
)
|
| 17 |
+
|
| 18 |
+
optimizer_config = dict(grad_clip=None)
|
| 19 |
+
# learning policy
|
| 20 |
+
lr_config = dict(
|
| 21 |
+
policy='step',
|
| 22 |
+
warmup='linear',
|
| 23 |
+
warmup_iters=1000,
|
| 24 |
+
warmup_ratio=0.001,
|
| 25 |
+
step=[160, 180])
|
| 26 |
+
total_epochs = 200
|
| 27 |
+
log_config = dict(
|
| 28 |
+
interval=50,
|
| 29 |
+
hooks=[
|
| 30 |
+
dict(type='TextLoggerHook'),
|
| 31 |
+
dict(type='TensorboardLoggerHook')
|
| 32 |
+
])
|
| 33 |
+
|
| 34 |
+
channel_cfg = dict(
|
| 35 |
+
num_output_channels=1,
|
| 36 |
+
dataset_joints=1,
|
| 37 |
+
dataset_channel=[
|
| 38 |
+
[
|
| 39 |
+
0,
|
| 40 |
+
],
|
| 41 |
+
],
|
| 42 |
+
inference_channel=[
|
| 43 |
+
0,
|
| 44 |
+
],
|
| 45 |
+
max_kpt_num=100)
|
| 46 |
+
|
| 47 |
+
# model settings
|
| 48 |
+
model = dict(
|
| 49 |
+
type='PoseAnythingModel',
|
| 50 |
+
pretrained='pretrained/swinv2_base_22k_500k.pth',
|
| 51 |
+
encoder_config=dict(
|
| 52 |
+
type='SwinTransformerV2',
|
| 53 |
+
embed_dim=128,
|
| 54 |
+
depths=[2, 2, 18, 2],
|
| 55 |
+
num_heads=[4, 8, 16, 32],
|
| 56 |
+
window_size=14,
|
| 57 |
+
pretrained_window_sizes=[12, 12, 12, 6],
|
| 58 |
+
drop_path_rate=0.1,
|
| 59 |
+
img_size=224,
|
| 60 |
+
),
|
| 61 |
+
keypoint_head=dict(
|
| 62 |
+
type='PoseHead',
|
| 63 |
+
in_channels=1024,
|
| 64 |
+
transformer=dict(
|
| 65 |
+
type='EncoderDecoder',
|
| 66 |
+
d_model=256,
|
| 67 |
+
nhead=8,
|
| 68 |
+
num_encoder_layers=3,
|
| 69 |
+
num_decoder_layers=3,
|
| 70 |
+
graph_decoder='pre',
|
| 71 |
+
dim_feedforward=1024,
|
| 72 |
+
dropout=0.1,
|
| 73 |
+
similarity_proj_dim=256,
|
| 74 |
+
dynamic_proj_dim=128,
|
| 75 |
+
activation="relu",
|
| 76 |
+
normalize_before=False,
|
| 77 |
+
return_intermediate_dec=True),
|
| 78 |
+
share_kpt_branch=False,
|
| 79 |
+
num_decoder_layer=3,
|
| 80 |
+
with_heatmap_loss=True,
|
| 81 |
+
|
| 82 |
+
heatmap_loss_weight=2.0,
|
| 83 |
+
support_order_dropout=-1,
|
| 84 |
+
positional_encoding=dict(
|
| 85 |
+
type='SinePositionalEncoding', num_feats=128, normalize=True)),
|
| 86 |
+
# training and testing settings
|
| 87 |
+
train_cfg=dict(),
|
| 88 |
+
test_cfg=dict(
|
| 89 |
+
flip_test=False,
|
| 90 |
+
post_process='default',
|
| 91 |
+
shift_heatmap=True,
|
| 92 |
+
modulate_kernel=11))
|
| 93 |
+
|
| 94 |
+
data_cfg = dict(
|
| 95 |
+
image_size=[224, 224],
|
| 96 |
+
heatmap_size=[64, 64],
|
| 97 |
+
num_output_channels=channel_cfg['num_output_channels'],
|
| 98 |
+
num_joints=channel_cfg['dataset_joints'],
|
| 99 |
+
dataset_channel=channel_cfg['dataset_channel'],
|
| 100 |
+
inference_channel=channel_cfg['inference_channel'])
|
| 101 |
+
|
| 102 |
+
train_pipeline = [
|
| 103 |
+
dict(type='LoadImageFromFile'),
|
| 104 |
+
dict(
|
| 105 |
+
type='TopDownGetRandomScaleRotation', rot_factor=15,
|
| 106 |
+
scale_factor=0.15),
|
| 107 |
+
dict(type='TopDownAffineFewShot'),
|
| 108 |
+
dict(type='ToTensor'),
|
| 109 |
+
dict(
|
| 110 |
+
type='NormalizeTensor',
|
| 111 |
+
mean=[0.485, 0.456, 0.406],
|
| 112 |
+
std=[0.229, 0.224, 0.225]),
|
| 113 |
+
dict(type='TopDownGenerateTargetFewShot', sigma=1),
|
| 114 |
+
dict(
|
| 115 |
+
type='Collect',
|
| 116 |
+
keys=['img', 'target', 'target_weight'],
|
| 117 |
+
meta_keys=[
|
| 118 |
+
'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
|
| 119 |
+
'rotation', 'bbox_score', 'flip_pairs', 'category_id', 'skeleton',
|
| 120 |
+
]),
|
| 121 |
+
]
|
| 122 |
+
|
| 123 |
+
valid_pipeline = [
|
| 124 |
+
dict(type='LoadImageFromFile'),
|
| 125 |
+
dict(type='TopDownAffineFewShot'),
|
| 126 |
+
dict(type='ToTensor'),
|
| 127 |
+
dict(
|
| 128 |
+
type='NormalizeTensor',
|
| 129 |
+
mean=[0.485, 0.456, 0.406],
|
| 130 |
+
std=[0.229, 0.224, 0.225]),
|
| 131 |
+
dict(type='TopDownGenerateTargetFewShot', sigma=1),
|
| 132 |
+
dict(
|
| 133 |
+
type='Collect',
|
| 134 |
+
keys=['img', 'target', 'target_weight'],
|
| 135 |
+
meta_keys=[
|
| 136 |
+
'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale', 'rotation', 'bbox_score',
|
| 137 |
+
'flip_pairs', 'category_id',
|
| 138 |
+
'skeleton',
|
| 139 |
+
]),
|
| 140 |
+
]
|
| 141 |
+
|
| 142 |
+
test_pipeline = valid_pipeline
|
| 143 |
+
|
| 144 |
+
data_root = 'data/mp100'
|
| 145 |
+
data = dict(
|
| 146 |
+
samples_per_gpu=8,
|
| 147 |
+
workers_per_gpu=8,
|
| 148 |
+
train=dict(
|
| 149 |
+
type='TransformerPoseDataset',
|
| 150 |
+
ann_file=f'{data_root}/annotations/mp100_split3_train.json',
|
| 151 |
+
img_prefix=f'{data_root}/images/',
|
| 152 |
+
# img_prefix=f'{data_root}',
|
| 153 |
+
data_cfg=data_cfg,
|
| 154 |
+
valid_class_ids=None,
|
| 155 |
+
max_kpt_num=channel_cfg['max_kpt_num'],
|
| 156 |
+
num_shots=5,
|
| 157 |
+
pipeline=train_pipeline),
|
| 158 |
+
val=dict(
|
| 159 |
+
type='TransformerPoseDataset',
|
| 160 |
+
ann_file=f'{data_root}/annotations/mp100_split3_val.json',
|
| 161 |
+
img_prefix=f'{data_root}/images/',
|
| 162 |
+
# img_prefix=f'{data_root}',
|
| 163 |
+
data_cfg=data_cfg,
|
| 164 |
+
valid_class_ids=None,
|
| 165 |
+
max_kpt_num=channel_cfg['max_kpt_num'],
|
| 166 |
+
num_shots=5,
|
| 167 |
+
num_queries=15,
|
| 168 |
+
num_episodes=100,
|
| 169 |
+
pipeline=valid_pipeline),
|
| 170 |
+
test=dict(
|
| 171 |
+
type='TestPoseDataset',
|
| 172 |
+
ann_file=f'{data_root}/annotations/mp100_split3_test.json',
|
| 173 |
+
img_prefix=f'{data_root}/images/',
|
| 174 |
+
# img_prefix=f'{data_root}',
|
| 175 |
+
data_cfg=data_cfg,
|
| 176 |
+
valid_class_ids=None,
|
| 177 |
+
max_kpt_num=channel_cfg['max_kpt_num'],
|
| 178 |
+
num_shots=5,
|
| 179 |
+
num_queries=15,
|
| 180 |
+
num_episodes=200,
|
| 181 |
+
pck_threshold_list=[0.05, 0.10, 0.15, 0.2, 0.25],
|
| 182 |
+
pipeline=test_pipeline),
|
| 183 |
+
)
|
| 184 |
+
vis_backends = [
|
| 185 |
+
dict(type='LocalVisBackend'),
|
| 186 |
+
dict(type='TensorboardVisBackend'),
|
| 187 |
+
]
|
| 188 |
+
visualizer = dict(
|
| 189 |
+
type='PoseLocalVisualizer', vis_backends=vis_backends, name='visualizer')
|
| 190 |
+
|
| 191 |
+
shuffle_cfg = dict(interval=1)
|
configs/5shot-swin/graph_split4_config.py
ADDED
|
@@ -0,0 +1,191 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
log_level = 'INFO'
|
| 2 |
+
load_from = None
|
| 3 |
+
resume_from = None
|
| 4 |
+
dist_params = dict(backend='nccl')
|
| 5 |
+
workflow = [('train', 1)]
|
| 6 |
+
checkpoint_config = dict(interval=20)
|
| 7 |
+
evaluation = dict(
|
| 8 |
+
interval=25,
|
| 9 |
+
metric=['PCK', 'NME', 'AUC', 'EPE'],
|
| 10 |
+
key_indicator='PCK',
|
| 11 |
+
gpu_collect=True,
|
| 12 |
+
res_folder='')
|
| 13 |
+
optimizer = dict(
|
| 14 |
+
type='Adam',
|
| 15 |
+
lr=1e-5,
|
| 16 |
+
)
|
| 17 |
+
|
| 18 |
+
optimizer_config = dict(grad_clip=None)
|
| 19 |
+
# learning policy
|
| 20 |
+
lr_config = dict(
|
| 21 |
+
policy='step',
|
| 22 |
+
warmup='linear',
|
| 23 |
+
warmup_iters=1000,
|
| 24 |
+
warmup_ratio=0.001,
|
| 25 |
+
step=[160, 180])
|
| 26 |
+
total_epochs = 200
|
| 27 |
+
log_config = dict(
|
| 28 |
+
interval=50,
|
| 29 |
+
hooks=[
|
| 30 |
+
dict(type='TextLoggerHook'),
|
| 31 |
+
dict(type='TensorboardLoggerHook')
|
| 32 |
+
])
|
| 33 |
+
|
| 34 |
+
channel_cfg = dict(
|
| 35 |
+
num_output_channels=1,
|
| 36 |
+
dataset_joints=1,
|
| 37 |
+
dataset_channel=[
|
| 38 |
+
[
|
| 39 |
+
0,
|
| 40 |
+
],
|
| 41 |
+
],
|
| 42 |
+
inference_channel=[
|
| 43 |
+
0,
|
| 44 |
+
],
|
| 45 |
+
max_kpt_num=100)
|
| 46 |
+
|
| 47 |
+
# model settings
|
| 48 |
+
model = dict(
|
| 49 |
+
type='PoseAnythingModel',
|
| 50 |
+
pretrained='pretrained/swinv2_base_22k_500k.pth',
|
| 51 |
+
encoder_config=dict(
|
| 52 |
+
type='SwinTransformerV2',
|
| 53 |
+
embed_dim=128,
|
| 54 |
+
depths=[2, 2, 18, 2],
|
| 55 |
+
num_heads=[4, 8, 16, 32],
|
| 56 |
+
window_size=14,
|
| 57 |
+
pretrained_window_sizes=[12, 12, 12, 6],
|
| 58 |
+
drop_path_rate=0.1,
|
| 59 |
+
img_size=224,
|
| 60 |
+
),
|
| 61 |
+
keypoint_head=dict(
|
| 62 |
+
type='PoseHead',
|
| 63 |
+
in_channels=1024,
|
| 64 |
+
transformer=dict(
|
| 65 |
+
type='EncoderDecoder',
|
| 66 |
+
d_model=256,
|
| 67 |
+
nhead=8,
|
| 68 |
+
num_encoder_layers=3,
|
| 69 |
+
num_decoder_layers=3,
|
| 70 |
+
graph_decoder='pre',
|
| 71 |
+
dim_feedforward=1024,
|
| 72 |
+
dropout=0.1,
|
| 73 |
+
similarity_proj_dim=256,
|
| 74 |
+
dynamic_proj_dim=128,
|
| 75 |
+
activation="relu",
|
| 76 |
+
normalize_before=False,
|
| 77 |
+
return_intermediate_dec=True),
|
| 78 |
+
share_kpt_branch=False,
|
| 79 |
+
num_decoder_layer=3,
|
| 80 |
+
with_heatmap_loss=True,
|
| 81 |
+
|
| 82 |
+
heatmap_loss_weight=2.0,
|
| 83 |
+
support_order_dropout=-1,
|
| 84 |
+
positional_encoding=dict(
|
| 85 |
+
type='SinePositionalEncoding', num_feats=128, normalize=True)),
|
| 86 |
+
# training and testing settings
|
| 87 |
+
train_cfg=dict(),
|
| 88 |
+
test_cfg=dict(
|
| 89 |
+
flip_test=False,
|
| 90 |
+
post_process='default',
|
| 91 |
+
shift_heatmap=True,
|
| 92 |
+
modulate_kernel=11))
|
| 93 |
+
|
| 94 |
+
data_cfg = dict(
|
| 95 |
+
image_size=[224, 224],
|
| 96 |
+
heatmap_size=[64, 64],
|
| 97 |
+
num_output_channels=channel_cfg['num_output_channels'],
|
| 98 |
+
num_joints=channel_cfg['dataset_joints'],
|
| 99 |
+
dataset_channel=channel_cfg['dataset_channel'],
|
| 100 |
+
inference_channel=channel_cfg['inference_channel'])
|
| 101 |
+
|
| 102 |
+
train_pipeline = [
|
| 103 |
+
dict(type='LoadImageFromFile'),
|
| 104 |
+
dict(
|
| 105 |
+
type='TopDownGetRandomScaleRotation', rot_factor=15,
|
| 106 |
+
scale_factor=0.15),
|
| 107 |
+
dict(type='TopDownAffineFewShot'),
|
| 108 |
+
dict(type='ToTensor'),
|
| 109 |
+
dict(
|
| 110 |
+
type='NormalizeTensor',
|
| 111 |
+
mean=[0.485, 0.456, 0.406],
|
| 112 |
+
std=[0.229, 0.224, 0.225]),
|
| 113 |
+
dict(type='TopDownGenerateTargetFewShot', sigma=1),
|
| 114 |
+
dict(
|
| 115 |
+
type='Collect',
|
| 116 |
+
keys=['img', 'target', 'target_weight'],
|
| 117 |
+
meta_keys=[
|
| 118 |
+
'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
|
| 119 |
+
'rotation', 'bbox_score', 'flip_pairs', 'category_id', 'skeleton',
|
| 120 |
+
]),
|
| 121 |
+
]
|
| 122 |
+
|
| 123 |
+
valid_pipeline = [
|
| 124 |
+
dict(type='LoadImageFromFile'),
|
| 125 |
+
dict(type='TopDownAffineFewShot'),
|
| 126 |
+
dict(type='ToTensor'),
|
| 127 |
+
dict(
|
| 128 |
+
type='NormalizeTensor',
|
| 129 |
+
mean=[0.485, 0.456, 0.406],
|
| 130 |
+
std=[0.229, 0.224, 0.225]),
|
| 131 |
+
dict(type='TopDownGenerateTargetFewShot', sigma=1),
|
| 132 |
+
dict(
|
| 133 |
+
type='Collect',
|
| 134 |
+
keys=['img', 'target', 'target_weight'],
|
| 135 |
+
meta_keys=[
|
| 136 |
+
'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale', 'rotation', 'bbox_score',
|
| 137 |
+
'flip_pairs', 'category_id',
|
| 138 |
+
'skeleton',
|
| 139 |
+
]),
|
| 140 |
+
]
|
| 141 |
+
|
| 142 |
+
test_pipeline = valid_pipeline
|
| 143 |
+
|
| 144 |
+
data_root = 'data/mp100'
|
| 145 |
+
data = dict(
|
| 146 |
+
samples_per_gpu=8,
|
| 147 |
+
workers_per_gpu=8,
|
| 148 |
+
train=dict(
|
| 149 |
+
type='TransformerPoseDataset',
|
| 150 |
+
ann_file=f'{data_root}/annotations/mp100_split4_train.json',
|
| 151 |
+
img_prefix=f'{data_root}/images/',
|
| 152 |
+
# img_prefix=f'{data_root}',
|
| 153 |
+
data_cfg=data_cfg,
|
| 154 |
+
valid_class_ids=None,
|
| 155 |
+
max_kpt_num=channel_cfg['max_kpt_num'],
|
| 156 |
+
num_shots=5,
|
| 157 |
+
pipeline=train_pipeline),
|
| 158 |
+
val=dict(
|
| 159 |
+
type='TransformerPoseDataset',
|
| 160 |
+
ann_file=f'{data_root}/annotations/mp100_split4_val.json',
|
| 161 |
+
img_prefix=f'{data_root}/images/',
|
| 162 |
+
# img_prefix=f'{data_root}',
|
| 163 |
+
data_cfg=data_cfg,
|
| 164 |
+
valid_class_ids=None,
|
| 165 |
+
max_kpt_num=channel_cfg['max_kpt_num'],
|
| 166 |
+
num_shots=5,
|
| 167 |
+
num_queries=15,
|
| 168 |
+
num_episodes=100,
|
| 169 |
+
pipeline=valid_pipeline),
|
| 170 |
+
test=dict(
|
| 171 |
+
type='TestPoseDataset',
|
| 172 |
+
ann_file=f'{data_root}/annotations/mp100_split4_test.json',
|
| 173 |
+
img_prefix=f'{data_root}/images/',
|
| 174 |
+
# img_prefix=f'{data_root}',
|
| 175 |
+
data_cfg=data_cfg,
|
| 176 |
+
valid_class_ids=None,
|
| 177 |
+
max_kpt_num=channel_cfg['max_kpt_num'],
|
| 178 |
+
num_shots=5,
|
| 179 |
+
num_queries=15,
|
| 180 |
+
num_episodes=200,
|
| 181 |
+
pck_threshold_list=[0.05, 0.10, 0.15, 0.2, 0.25],
|
| 182 |
+
pipeline=test_pipeline),
|
| 183 |
+
)
|
| 184 |
+
vis_backends = [
|
| 185 |
+
dict(type='LocalVisBackend'),
|
| 186 |
+
dict(type='TensorboardVisBackend'),
|
| 187 |
+
]
|
| 188 |
+
visualizer = dict(
|
| 189 |
+
type='PoseLocalVisualizer', vis_backends=vis_backends, name='visualizer')
|
| 190 |
+
|
| 191 |
+
shuffle_cfg = dict(interval=1)
|
configs/5shot-swin/graph_split5_config.py
ADDED
|
@@ -0,0 +1,191 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
log_level = 'INFO'
|
| 2 |
+
load_from = None
|
| 3 |
+
resume_from = None
|
| 4 |
+
dist_params = dict(backend='nccl')
|
| 5 |
+
workflow = [('train', 1)]
|
| 6 |
+
checkpoint_config = dict(interval=20)
|
| 7 |
+
evaluation = dict(
|
| 8 |
+
interval=25,
|
| 9 |
+
metric=['PCK', 'NME', 'AUC', 'EPE'],
|
| 10 |
+
key_indicator='PCK',
|
| 11 |
+
gpu_collect=True,
|
| 12 |
+
res_folder='')
|
| 13 |
+
optimizer = dict(
|
| 14 |
+
type='Adam',
|
| 15 |
+
lr=1e-5,
|
| 16 |
+
)
|
| 17 |
+
|
| 18 |
+
optimizer_config = dict(grad_clip=None)
|
| 19 |
+
# learning policy
|
| 20 |
+
lr_config = dict(
|
| 21 |
+
policy='step',
|
| 22 |
+
warmup='linear',
|
| 23 |
+
warmup_iters=1000,
|
| 24 |
+
warmup_ratio=0.001,
|
| 25 |
+
step=[160, 180])
|
| 26 |
+
total_epochs = 200
|
| 27 |
+
log_config = dict(
|
| 28 |
+
interval=50,
|
| 29 |
+
hooks=[
|
| 30 |
+
dict(type='TextLoggerHook'),
|
| 31 |
+
dict(type='TensorboardLoggerHook')
|
| 32 |
+
])
|
| 33 |
+
|
| 34 |
+
channel_cfg = dict(
|
| 35 |
+
num_output_channels=1,
|
| 36 |
+
dataset_joints=1,
|
| 37 |
+
dataset_channel=[
|
| 38 |
+
[
|
| 39 |
+
0,
|
| 40 |
+
],
|
| 41 |
+
],
|
| 42 |
+
inference_channel=[
|
| 43 |
+
0,
|
| 44 |
+
],
|
| 45 |
+
max_kpt_num=100)
|
| 46 |
+
|
| 47 |
+
# model settings
|
| 48 |
+
model = dict(
|
| 49 |
+
type='PoseAnythingModel',
|
| 50 |
+
pretrained='pretrained/swinv2_base_22k_500k.pth',
|
| 51 |
+
encoder_config=dict(
|
| 52 |
+
type='SwinTransformerV2',
|
| 53 |
+
embed_dim=128,
|
| 54 |
+
depths=[2, 2, 18, 2],
|
| 55 |
+
num_heads=[4, 8, 16, 32],
|
| 56 |
+
window_size=14,
|
| 57 |
+
pretrained_window_sizes=[12, 12, 12, 6],
|
| 58 |
+
drop_path_rate=0.1,
|
| 59 |
+
img_size=224,
|
| 60 |
+
),
|
| 61 |
+
keypoint_head=dict(
|
| 62 |
+
type='PoseHead',
|
| 63 |
+
in_channels=1024,
|
| 64 |
+
transformer=dict(
|
| 65 |
+
type='EncoderDecoder',
|
| 66 |
+
d_model=256,
|
| 67 |
+
nhead=8,
|
| 68 |
+
num_encoder_layers=3,
|
| 69 |
+
num_decoder_layers=3,
|
| 70 |
+
graph_decoder='pre',
|
| 71 |
+
dim_feedforward=1024,
|
| 72 |
+
dropout=0.1,
|
| 73 |
+
similarity_proj_dim=256,
|
| 74 |
+
dynamic_proj_dim=128,
|
| 75 |
+
activation="relu",
|
| 76 |
+
normalize_before=False,
|
| 77 |
+
return_intermediate_dec=True),
|
| 78 |
+
share_kpt_branch=False,
|
| 79 |
+
num_decoder_layer=3,
|
| 80 |
+
with_heatmap_loss=True,
|
| 81 |
+
|
| 82 |
+
heatmap_loss_weight=2.0,
|
| 83 |
+
support_order_dropout=-1,
|
| 84 |
+
positional_encoding=dict(
|
| 85 |
+
type='SinePositionalEncoding', num_feats=128, normalize=True)),
|
| 86 |
+
# training and testing settings
|
| 87 |
+
train_cfg=dict(),
|
| 88 |
+
test_cfg=dict(
|
| 89 |
+
flip_test=False,
|
| 90 |
+
post_process='default',
|
| 91 |
+
shift_heatmap=True,
|
| 92 |
+
modulate_kernel=11))
|
| 93 |
+
|
| 94 |
+
data_cfg = dict(
|
| 95 |
+
image_size=[224, 224],
|
| 96 |
+
heatmap_size=[64, 64],
|
| 97 |
+
num_output_channels=channel_cfg['num_output_channels'],
|
| 98 |
+
num_joints=channel_cfg['dataset_joints'],
|
| 99 |
+
dataset_channel=channel_cfg['dataset_channel'],
|
| 100 |
+
inference_channel=channel_cfg['inference_channel'])
|
| 101 |
+
|
| 102 |
+
train_pipeline = [
|
| 103 |
+
dict(type='LoadImageFromFile'),
|
| 104 |
+
dict(
|
| 105 |
+
type='TopDownGetRandomScaleRotation', rot_factor=15,
|
| 106 |
+
scale_factor=0.15),
|
| 107 |
+
dict(type='TopDownAffineFewShot'),
|
| 108 |
+
dict(type='ToTensor'),
|
| 109 |
+
dict(
|
| 110 |
+
type='NormalizeTensor',
|
| 111 |
+
mean=[0.485, 0.456, 0.406],
|
| 112 |
+
std=[0.229, 0.224, 0.225]),
|
| 113 |
+
dict(type='TopDownGenerateTargetFewShot', sigma=1),
|
| 114 |
+
dict(
|
| 115 |
+
type='Collect',
|
| 116 |
+
keys=['img', 'target', 'target_weight'],
|
| 117 |
+
meta_keys=[
|
| 118 |
+
'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
|
| 119 |
+
'rotation', 'bbox_score', 'flip_pairs', 'category_id', 'skeleton',
|
| 120 |
+
]),
|
| 121 |
+
]
|
| 122 |
+
|
| 123 |
+
valid_pipeline = [
|
| 124 |
+
dict(type='LoadImageFromFile'),
|
| 125 |
+
dict(type='TopDownAffineFewShot'),
|
| 126 |
+
dict(type='ToTensor'),
|
| 127 |
+
dict(
|
| 128 |
+
type='NormalizeTensor',
|
| 129 |
+
mean=[0.485, 0.456, 0.406],
|
| 130 |
+
std=[0.229, 0.224, 0.225]),
|
| 131 |
+
dict(type='TopDownGenerateTargetFewShot', sigma=1),
|
| 132 |
+
dict(
|
| 133 |
+
type='Collect',
|
| 134 |
+
keys=['img', 'target', 'target_weight'],
|
| 135 |
+
meta_keys=[
|
| 136 |
+
'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale', 'rotation', 'bbox_score',
|
| 137 |
+
'flip_pairs', 'category_id',
|
| 138 |
+
'skeleton',
|
| 139 |
+
]),
|
| 140 |
+
]
|
| 141 |
+
|
| 142 |
+
test_pipeline = valid_pipeline
|
| 143 |
+
|
| 144 |
+
data_root = 'data/mp100'
|
| 145 |
+
data = dict(
|
| 146 |
+
samples_per_gpu=8,
|
| 147 |
+
workers_per_gpu=8,
|
| 148 |
+
train=dict(
|
| 149 |
+
type='TransformerPoseDataset',
|
| 150 |
+
ann_file=f'{data_root}/annotations/mp100_split5_train.json',
|
| 151 |
+
img_prefix=f'{data_root}/images/',
|
| 152 |
+
# img_prefix=f'{data_root}',
|
| 153 |
+
data_cfg=data_cfg,
|
| 154 |
+
valid_class_ids=None,
|
| 155 |
+
max_kpt_num=channel_cfg['max_kpt_num'],
|
| 156 |
+
num_shots=5,
|
| 157 |
+
pipeline=train_pipeline),
|
| 158 |
+
val=dict(
|
| 159 |
+
type='TransformerPoseDataset',
|
| 160 |
+
ann_file=f'{data_root}/annotations/mp100_split5_val.json',
|
| 161 |
+
img_prefix=f'{data_root}/images/',
|
| 162 |
+
# img_prefix=f'{data_root}',
|
| 163 |
+
data_cfg=data_cfg,
|
| 164 |
+
valid_class_ids=None,
|
| 165 |
+
max_kpt_num=channel_cfg['max_kpt_num'],
|
| 166 |
+
num_shots=5,
|
| 167 |
+
num_queries=15,
|
| 168 |
+
num_episodes=100,
|
| 169 |
+
pipeline=valid_pipeline),
|
| 170 |
+
test=dict(
|
| 171 |
+
type='TestPoseDataset',
|
| 172 |
+
ann_file=f'{data_root}/annotations/mp100_split5_test.json',
|
| 173 |
+
img_prefix=f'{data_root}/images/',
|
| 174 |
+
# img_prefix=f'{data_root}',
|
| 175 |
+
data_cfg=data_cfg,
|
| 176 |
+
valid_class_ids=None,
|
| 177 |
+
max_kpt_num=channel_cfg['max_kpt_num'],
|
| 178 |
+
num_shots=5,
|
| 179 |
+
num_queries=15,
|
| 180 |
+
num_episodes=200,
|
| 181 |
+
pck_threshold_list=[0.05, 0.10, 0.15, 0.2, 0.25],
|
| 182 |
+
pipeline=test_pipeline),
|
| 183 |
+
)
|
| 184 |
+
vis_backends = [
|
| 185 |
+
dict(type='LocalVisBackend'),
|
| 186 |
+
dict(type='TensorboardVisBackend'),
|
| 187 |
+
]
|
| 188 |
+
visualizer = dict(
|
| 189 |
+
type='PoseLocalVisualizer', vis_backends=vis_backends, name='visualizer')
|
| 190 |
+
|
| 191 |
+
shuffle_cfg = dict(interval=1)
|
configs/5shots/base_split1_config.py
ADDED
|
@@ -0,0 +1,190 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
log_level = 'INFO'
|
| 2 |
+
load_from = None
|
| 3 |
+
resume_from = None
|
| 4 |
+
dist_params = dict(backend='nccl')
|
| 5 |
+
workflow = [('train', 1)]
|
| 6 |
+
checkpoint_config = dict(interval=20)
|
| 7 |
+
evaluation = dict(
|
| 8 |
+
interval=25,
|
| 9 |
+
metric=['PCK', 'NME', 'AUC', 'EPE'],
|
| 10 |
+
key_indicator='PCK',
|
| 11 |
+
gpu_collect=True,
|
| 12 |
+
res_folder='')
|
| 13 |
+
optimizer = dict(
|
| 14 |
+
type='Adam',
|
| 15 |
+
lr=1e-5,
|
| 16 |
+
)
|
| 17 |
+
|
| 18 |
+
optimizer_config = dict(grad_clip=None)
|
| 19 |
+
# learning policy
|
| 20 |
+
lr_config = dict(
|
| 21 |
+
policy='step',
|
| 22 |
+
warmup='linear',
|
| 23 |
+
warmup_iters=1000,
|
| 24 |
+
warmup_ratio=0.001,
|
| 25 |
+
step=[160, 180])
|
| 26 |
+
total_epochs = 200
|
| 27 |
+
log_config = dict(
|
| 28 |
+
interval=50,
|
| 29 |
+
hooks=[
|
| 30 |
+
dict(type='TextLoggerHook'),
|
| 31 |
+
dict(type='TensorboardLoggerHook')
|
| 32 |
+
])
|
| 33 |
+
|
| 34 |
+
channel_cfg = dict(
|
| 35 |
+
num_output_channels=1,
|
| 36 |
+
dataset_joints=1,
|
| 37 |
+
dataset_channel=[
|
| 38 |
+
[
|
| 39 |
+
0,
|
| 40 |
+
],
|
| 41 |
+
],
|
| 42 |
+
inference_channel=[
|
| 43 |
+
0,
|
| 44 |
+
],
|
| 45 |
+
max_kpt_num=100)
|
| 46 |
+
|
| 47 |
+
# model settings
|
| 48 |
+
model = dict(
|
| 49 |
+
type='PoseAnythingModel',
|
| 50 |
+
pretrained='pretrained/swinv2_tiny_patch4_window16_256.pth',
|
| 51 |
+
encoder_config=dict(
|
| 52 |
+
type='SwinTransformerV2',
|
| 53 |
+
embed_dim=96,
|
| 54 |
+
depths=[2, 2, 6, 2],
|
| 55 |
+
num_heads=[3, 6, 12, 24],
|
| 56 |
+
window_size=16,
|
| 57 |
+
drop_path_rate=0.2,
|
| 58 |
+
img_size=256,
|
| 59 |
+
upsample="bilinear"
|
| 60 |
+
),
|
| 61 |
+
keypoint_head=dict(
|
| 62 |
+
type='PoseHead',
|
| 63 |
+
in_channels=768,
|
| 64 |
+
transformer=dict(
|
| 65 |
+
type='EncoderDecoder',
|
| 66 |
+
d_model=256,
|
| 67 |
+
nhead=8,
|
| 68 |
+
num_encoder_layers=3,
|
| 69 |
+
num_decoder_layers=3,
|
| 70 |
+
dim_feedforward=768,
|
| 71 |
+
dropout=0.1,
|
| 72 |
+
similarity_proj_dim=256,
|
| 73 |
+
dynamic_proj_dim=128,
|
| 74 |
+
activation="relu",
|
| 75 |
+
normalize_before=False,
|
| 76 |
+
return_intermediate_dec=True),
|
| 77 |
+
share_kpt_branch=False,
|
| 78 |
+
num_decoder_layer=3,
|
| 79 |
+
with_heatmap_loss=True,
|
| 80 |
+
|
| 81 |
+
heatmap_loss_weight=2.0,
|
| 82 |
+
support_order_dropout=-1,
|
| 83 |
+
positional_encoding=dict(
|
| 84 |
+
type='SinePositionalEncoding', num_feats=128, normalize=True)),
|
| 85 |
+
# training and testing settings
|
| 86 |
+
train_cfg=dict(),
|
| 87 |
+
test_cfg=dict(
|
| 88 |
+
flip_test=False,
|
| 89 |
+
post_process='default',
|
| 90 |
+
shift_heatmap=True,
|
| 91 |
+
modulate_kernel=11))
|
| 92 |
+
|
| 93 |
+
data_cfg = dict(
|
| 94 |
+
image_size=[256, 256],
|
| 95 |
+
heatmap_size=[64, 64],
|
| 96 |
+
num_output_channels=channel_cfg['num_output_channels'],
|
| 97 |
+
num_joints=channel_cfg['dataset_joints'],
|
| 98 |
+
dataset_channel=channel_cfg['dataset_channel'],
|
| 99 |
+
inference_channel=channel_cfg['inference_channel'])
|
| 100 |
+
|
| 101 |
+
train_pipeline = [
|
| 102 |
+
dict(type='LoadImageFromFile'),
|
| 103 |
+
dict(
|
| 104 |
+
type='TopDownGetRandomScaleRotation', rot_factor=15,
|
| 105 |
+
scale_factor=0.15),
|
| 106 |
+
dict(type='TopDownAffineFewShot'),
|
| 107 |
+
dict(type='ToTensor'),
|
| 108 |
+
dict(
|
| 109 |
+
type='NormalizeTensor',
|
| 110 |
+
mean=[0.485, 0.456, 0.406],
|
| 111 |
+
std=[0.229, 0.224, 0.225]),
|
| 112 |
+
dict(type='TopDownGenerateTargetFewShot', sigma=1),
|
| 113 |
+
dict(
|
| 114 |
+
type='Collect',
|
| 115 |
+
keys=['img', 'target', 'target_weight'],
|
| 116 |
+
meta_keys=[
|
| 117 |
+
'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
|
| 118 |
+
'rotation', 'bbox_score', 'flip_pairs', 'category_id', 'skeleton',
|
| 119 |
+
]),
|
| 120 |
+
]
|
| 121 |
+
|
| 122 |
+
valid_pipeline = [
|
| 123 |
+
dict(type='LoadImageFromFile'),
|
| 124 |
+
dict(type='TopDownAffineFewShot'),
|
| 125 |
+
dict(type='ToTensor'),
|
| 126 |
+
dict(
|
| 127 |
+
type='NormalizeTensor',
|
| 128 |
+
mean=[0.485, 0.456, 0.406],
|
| 129 |
+
std=[0.229, 0.224, 0.225]),
|
| 130 |
+
dict(type='TopDownGenerateTargetFewShot', sigma=1),
|
| 131 |
+
dict(
|
| 132 |
+
type='Collect',
|
| 133 |
+
keys=['img', 'target', 'target_weight'],
|
| 134 |
+
meta_keys=[
|
| 135 |
+
'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale', 'rotation', 'bbox_score',
|
| 136 |
+
'flip_pairs', 'category_id',
|
| 137 |
+
'skeleton',
|
| 138 |
+
]),
|
| 139 |
+
]
|
| 140 |
+
|
| 141 |
+
test_pipeline = valid_pipeline
|
| 142 |
+
|
| 143 |
+
data_root = 'data/mp100'
|
| 144 |
+
data = dict(
|
| 145 |
+
samples_per_gpu=8,
|
| 146 |
+
workers_per_gpu=8,
|
| 147 |
+
train=dict(
|
| 148 |
+
type='TransformerPoseDataset',
|
| 149 |
+
ann_file=f'{data_root}/annotations/mp100_split1_train.json',
|
| 150 |
+
img_prefix=f'{data_root}/images/',
|
| 151 |
+
# img_prefix=f'{data_root}',
|
| 152 |
+
data_cfg=data_cfg,
|
| 153 |
+
valid_class_ids=None,
|
| 154 |
+
max_kpt_num=channel_cfg['max_kpt_num'],
|
| 155 |
+
num_shots=5,
|
| 156 |
+
pipeline=train_pipeline),
|
| 157 |
+
val=dict(
|
| 158 |
+
type='TransformerPoseDataset',
|
| 159 |
+
ann_file=f'{data_root}/annotations/mp100_split1_val.json',
|
| 160 |
+
img_prefix=f'{data_root}/images/',
|
| 161 |
+
# img_prefix=f'{data_root}',
|
| 162 |
+
data_cfg=data_cfg,
|
| 163 |
+
valid_class_ids=None,
|
| 164 |
+
max_kpt_num=channel_cfg['max_kpt_num'],
|
| 165 |
+
num_shots=5,
|
| 166 |
+
num_queries=15,
|
| 167 |
+
num_episodes=100,
|
| 168 |
+
pipeline=valid_pipeline),
|
| 169 |
+
test=dict(
|
| 170 |
+
type='TestPoseDataset',
|
| 171 |
+
ann_file=f'{data_root}/annotations/mp100_split1_test.json',
|
| 172 |
+
img_prefix=f'{data_root}/images/',
|
| 173 |
+
# img_prefix=f'{data_root}',
|
| 174 |
+
data_cfg=data_cfg,
|
| 175 |
+
valid_class_ids=None,
|
| 176 |
+
max_kpt_num=channel_cfg['max_kpt_num'],
|
| 177 |
+
num_shots=5,
|
| 178 |
+
num_queries=15,
|
| 179 |
+
num_episodes=200,
|
| 180 |
+
pck_threshold_list=[0.05, 0.10, 0.15, 0.2, 0.25],
|
| 181 |
+
pipeline=test_pipeline),
|
| 182 |
+
)
|
| 183 |
+
vis_backends = [
|
| 184 |
+
dict(type='LocalVisBackend'),
|
| 185 |
+
dict(type='TensorboardVisBackend'),
|
| 186 |
+
]
|
| 187 |
+
visualizer = dict(
|
| 188 |
+
type='PoseLocalVisualizer', vis_backends=vis_backends, name='visualizer')
|
| 189 |
+
|
| 190 |
+
shuffle_cfg = dict(interval=1)
|
configs/5shots/base_split2_config.py
ADDED
|
@@ -0,0 +1,190 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
log_level = 'INFO'
|
| 2 |
+
load_from = None
|
| 3 |
+
resume_from = None
|
| 4 |
+
dist_params = dict(backend='nccl')
|
| 5 |
+
workflow = [('train', 1)]
|
| 6 |
+
checkpoint_config = dict(interval=20)
|
| 7 |
+
evaluation = dict(
|
| 8 |
+
interval=25,
|
| 9 |
+
metric=['PCK', 'NME', 'AUC', 'EPE'],
|
| 10 |
+
key_indicator='PCK',
|
| 11 |
+
gpu_collect=True,
|
| 12 |
+
res_folder='')
|
| 13 |
+
optimizer = dict(
|
| 14 |
+
type='Adam',
|
| 15 |
+
lr=1e-5,
|
| 16 |
+
)
|
| 17 |
+
|
| 18 |
+
optimizer_config = dict(grad_clip=None)
|
| 19 |
+
# learning policy
|
| 20 |
+
lr_config = dict(
|
| 21 |
+
policy='step',
|
| 22 |
+
warmup='linear',
|
| 23 |
+
warmup_iters=1000,
|
| 24 |
+
warmup_ratio=0.001,
|
| 25 |
+
step=[160, 180])
|
| 26 |
+
total_epochs = 200
|
| 27 |
+
log_config = dict(
|
| 28 |
+
interval=50,
|
| 29 |
+
hooks=[
|
| 30 |
+
dict(type='TextLoggerHook'),
|
| 31 |
+
dict(type='TensorboardLoggerHook')
|
| 32 |
+
])
|
| 33 |
+
|
| 34 |
+
channel_cfg = dict(
|
| 35 |
+
num_output_channels=1,
|
| 36 |
+
dataset_joints=1,
|
| 37 |
+
dataset_channel=[
|
| 38 |
+
[
|
| 39 |
+
0,
|
| 40 |
+
],
|
| 41 |
+
],
|
| 42 |
+
inference_channel=[
|
| 43 |
+
0,
|
| 44 |
+
],
|
| 45 |
+
max_kpt_num=100)
|
| 46 |
+
|
| 47 |
+
# model settings
|
| 48 |
+
model = dict(
|
| 49 |
+
type='PoseAnythingModel',
|
| 50 |
+
pretrained='pretrained/swinv2_tiny_patch4_window16_256.pth',
|
| 51 |
+
encoder_config=dict(
|
| 52 |
+
type='SwinTransformerV2',
|
| 53 |
+
embed_dim=96,
|
| 54 |
+
depths=[2, 2, 6, 2],
|
| 55 |
+
num_heads=[3, 6, 12, 24],
|
| 56 |
+
window_size=16,
|
| 57 |
+
drop_path_rate=0.2,
|
| 58 |
+
img_size=256,
|
| 59 |
+
upsample="bilinear"
|
| 60 |
+
),
|
| 61 |
+
keypoint_head=dict(
|
| 62 |
+
type='PoseHead',
|
| 63 |
+
in_channels=768,
|
| 64 |
+
transformer=dict(
|
| 65 |
+
type='EncoderDecoder',
|
| 66 |
+
d_model=256,
|
| 67 |
+
nhead=8,
|
| 68 |
+
num_encoder_layers=3,
|
| 69 |
+
num_decoder_layers=3,
|
| 70 |
+
dim_feedforward=768,
|
| 71 |
+
dropout=0.1,
|
| 72 |
+
similarity_proj_dim=256,
|
| 73 |
+
dynamic_proj_dim=128,
|
| 74 |
+
activation="relu",
|
| 75 |
+
normalize_before=False,
|
| 76 |
+
return_intermediate_dec=True),
|
| 77 |
+
share_kpt_branch=False,
|
| 78 |
+
num_decoder_layer=3,
|
| 79 |
+
with_heatmap_loss=True,
|
| 80 |
+
|
| 81 |
+
heatmap_loss_weight=2.0,
|
| 82 |
+
support_order_dropout=-1,
|
| 83 |
+
positional_encoding=dict(
|
| 84 |
+
type='SinePositionalEncoding', num_feats=128, normalize=True)),
|
| 85 |
+
# training and testing settings
|
| 86 |
+
train_cfg=dict(),
|
| 87 |
+
test_cfg=dict(
|
| 88 |
+
flip_test=False,
|
| 89 |
+
post_process='default',
|
| 90 |
+
shift_heatmap=True,
|
| 91 |
+
modulate_kernel=11))
|
| 92 |
+
|
| 93 |
+
data_cfg = dict(
|
| 94 |
+
image_size=[256, 256],
|
| 95 |
+
heatmap_size=[64, 64],
|
| 96 |
+
num_output_channels=channel_cfg['num_output_channels'],
|
| 97 |
+
num_joints=channel_cfg['dataset_joints'],
|
| 98 |
+
dataset_channel=channel_cfg['dataset_channel'],
|
| 99 |
+
inference_channel=channel_cfg['inference_channel'])
|
| 100 |
+
|
| 101 |
+
train_pipeline = [
|
| 102 |
+
dict(type='LoadImageFromFile'),
|
| 103 |
+
dict(
|
| 104 |
+
type='TopDownGetRandomScaleRotation', rot_factor=15,
|
| 105 |
+
scale_factor=0.15),
|
| 106 |
+
dict(type='TopDownAffineFewShot'),
|
| 107 |
+
dict(type='ToTensor'),
|
| 108 |
+
dict(
|
| 109 |
+
type='NormalizeTensor',
|
| 110 |
+
mean=[0.485, 0.456, 0.406],
|
| 111 |
+
std=[0.229, 0.224, 0.225]),
|
| 112 |
+
dict(type='TopDownGenerateTargetFewShot', sigma=1),
|
| 113 |
+
dict(
|
| 114 |
+
type='Collect',
|
| 115 |
+
keys=['img', 'target', 'target_weight'],
|
| 116 |
+
meta_keys=[
|
| 117 |
+
'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
|
| 118 |
+
'rotation', 'bbox_score', 'flip_pairs', 'category_id', 'skeleton',
|
| 119 |
+
]),
|
| 120 |
+
]
|
| 121 |
+
|
| 122 |
+
valid_pipeline = [
|
| 123 |
+
dict(type='LoadImageFromFile'),
|
| 124 |
+
dict(type='TopDownAffineFewShot'),
|
| 125 |
+
dict(type='ToTensor'),
|
| 126 |
+
dict(
|
| 127 |
+
type='NormalizeTensor',
|
| 128 |
+
mean=[0.485, 0.456, 0.406],
|
| 129 |
+
std=[0.229, 0.224, 0.225]),
|
| 130 |
+
dict(type='TopDownGenerateTargetFewShot', sigma=1),
|
| 131 |
+
dict(
|
| 132 |
+
type='Collect',
|
| 133 |
+
keys=['img', 'target', 'target_weight'],
|
| 134 |
+
meta_keys=[
|
| 135 |
+
'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale', 'rotation', 'bbox_score',
|
| 136 |
+
'flip_pairs', 'category_id',
|
| 137 |
+
'skeleton',
|
| 138 |
+
]),
|
| 139 |
+
]
|
| 140 |
+
|
| 141 |
+
test_pipeline = valid_pipeline
|
| 142 |
+
|
| 143 |
+
data_root = 'data/mp100'
|
| 144 |
+
data = dict(
|
| 145 |
+
samples_per_gpu=8,
|
| 146 |
+
workers_per_gpu=8,
|
| 147 |
+
train=dict(
|
| 148 |
+
type='TransformerPoseDataset',
|
| 149 |
+
ann_file=f'{data_root}/annotations/mp100_split2_train.json',
|
| 150 |
+
img_prefix=f'{data_root}/images/',
|
| 151 |
+
# img_prefix=f'{data_root}',
|
| 152 |
+
data_cfg=data_cfg,
|
| 153 |
+
valid_class_ids=None,
|
| 154 |
+
max_kpt_num=channel_cfg['max_kpt_num'],
|
| 155 |
+
num_shots=5,
|
| 156 |
+
pipeline=train_pipeline),
|
| 157 |
+
val=dict(
|
| 158 |
+
type='TransformerPoseDataset',
|
| 159 |
+
ann_file=f'{data_root}/annotations/mp100_split2_val.json',
|
| 160 |
+
img_prefix=f'{data_root}/images/',
|
| 161 |
+
# img_prefix=f'{data_root}',
|
| 162 |
+
data_cfg=data_cfg,
|
| 163 |
+
valid_class_ids=None,
|
| 164 |
+
max_kpt_num=channel_cfg['max_kpt_num'],
|
| 165 |
+
num_shots=5,
|
| 166 |
+
num_queries=15,
|
| 167 |
+
num_episodes=100,
|
| 168 |
+
pipeline=valid_pipeline),
|
| 169 |
+
test=dict(
|
| 170 |
+
type='TestPoseDataset',
|
| 171 |
+
ann_file=f'{data_root}/annotations/mp100_split2_test.json',
|
| 172 |
+
img_prefix=f'{data_root}/images/',
|
| 173 |
+
# img_prefix=f'{data_root}',
|
| 174 |
+
data_cfg=data_cfg,
|
| 175 |
+
valid_class_ids=None,
|
| 176 |
+
max_kpt_num=channel_cfg['max_kpt_num'],
|
| 177 |
+
num_shots=5,
|
| 178 |
+
num_queries=15,
|
| 179 |
+
num_episodes=200,
|
| 180 |
+
pck_threshold_list=[0.05, 0.10, 0.15, 0.2, 0.25],
|
| 181 |
+
pipeline=test_pipeline),
|
| 182 |
+
)
|
| 183 |
+
vis_backends = [
|
| 184 |
+
dict(type='LocalVisBackend'),
|
| 185 |
+
dict(type='TensorboardVisBackend'),
|
| 186 |
+
]
|
| 187 |
+
visualizer = dict(
|
| 188 |
+
type='PoseLocalVisualizer', vis_backends=vis_backends, name='visualizer')
|
| 189 |
+
|
| 190 |
+
shuffle_cfg = dict(interval=1)
|
configs/5shots/base_split3_config.py
ADDED
|
@@ -0,0 +1,190 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
log_level = 'INFO'
|
| 2 |
+
load_from = None
|
| 3 |
+
resume_from = None
|
| 4 |
+
dist_params = dict(backend='nccl')
|
| 5 |
+
workflow = [('train', 1)]
|
| 6 |
+
checkpoint_config = dict(interval=20)
|
| 7 |
+
evaluation = dict(
|
| 8 |
+
interval=25,
|
| 9 |
+
metric=['PCK', 'NME', 'AUC', 'EPE'],
|
| 10 |
+
key_indicator='PCK',
|
| 11 |
+
gpu_collect=True,
|
| 12 |
+
res_folder='')
|
| 13 |
+
optimizer = dict(
|
| 14 |
+
type='Adam',
|
| 15 |
+
lr=1e-5,
|
| 16 |
+
)
|
| 17 |
+
|
| 18 |
+
optimizer_config = dict(grad_clip=None)
|
| 19 |
+
# learning policy
|
| 20 |
+
lr_config = dict(
|
| 21 |
+
policy='step',
|
| 22 |
+
warmup='linear',
|
| 23 |
+
warmup_iters=1000,
|
| 24 |
+
warmup_ratio=0.001,
|
| 25 |
+
step=[160, 180])
|
| 26 |
+
total_epochs = 200
|
| 27 |
+
log_config = dict(
|
| 28 |
+
interval=50,
|
| 29 |
+
hooks=[
|
| 30 |
+
dict(type='TextLoggerHook'),
|
| 31 |
+
dict(type='TensorboardLoggerHook')
|
| 32 |
+
])
|
| 33 |
+
|
| 34 |
+
channel_cfg = dict(
|
| 35 |
+
num_output_channels=1,
|
| 36 |
+
dataset_joints=1,
|
| 37 |
+
dataset_channel=[
|
| 38 |
+
[
|
| 39 |
+
0,
|
| 40 |
+
],
|
| 41 |
+
],
|
| 42 |
+
inference_channel=[
|
| 43 |
+
0,
|
| 44 |
+
],
|
| 45 |
+
max_kpt_num=100)
|
| 46 |
+
|
| 47 |
+
# model settings
|
| 48 |
+
model = dict(
|
| 49 |
+
type='PoseAnythingModel',
|
| 50 |
+
pretrained='pretrained/swinv2_tiny_patch4_window16_256.pth',
|
| 51 |
+
encoder_config=dict(
|
| 52 |
+
type='SwinTransformerV2',
|
| 53 |
+
embed_dim=96,
|
| 54 |
+
depths=[2, 2, 6, 2],
|
| 55 |
+
num_heads=[3, 6, 12, 24],
|
| 56 |
+
window_size=16,
|
| 57 |
+
drop_path_rate=0.2,
|
| 58 |
+
img_size=256,
|
| 59 |
+
upsample="bilinear"
|
| 60 |
+
),
|
| 61 |
+
keypoint_head=dict(
|
| 62 |
+
type='PoseHead',
|
| 63 |
+
in_channels=768,
|
| 64 |
+
transformer=dict(
|
| 65 |
+
type='EncoderDecoder',
|
| 66 |
+
d_model=256,
|
| 67 |
+
nhead=8,
|
| 68 |
+
num_encoder_layers=3,
|
| 69 |
+
num_decoder_layers=3,
|
| 70 |
+
dim_feedforward=768,
|
| 71 |
+
dropout=0.1,
|
| 72 |
+
similarity_proj_dim=256,
|
| 73 |
+
dynamic_proj_dim=128,
|
| 74 |
+
activation="relu",
|
| 75 |
+
normalize_before=False,
|
| 76 |
+
return_intermediate_dec=True),
|
| 77 |
+
share_kpt_branch=False,
|
| 78 |
+
num_decoder_layer=3,
|
| 79 |
+
with_heatmap_loss=True,
|
| 80 |
+
|
| 81 |
+
heatmap_loss_weight=2.0,
|
| 82 |
+
support_order_dropout=-1,
|
| 83 |
+
positional_encoding=dict(
|
| 84 |
+
type='SinePositionalEncoding', num_feats=128, normalize=True)),
|
| 85 |
+
# training and testing settings
|
| 86 |
+
train_cfg=dict(),
|
| 87 |
+
test_cfg=dict(
|
| 88 |
+
flip_test=False,
|
| 89 |
+
post_process='default',
|
| 90 |
+
shift_heatmap=True,
|
| 91 |
+
modulate_kernel=11))
|
| 92 |
+
|
| 93 |
+
data_cfg = dict(
|
| 94 |
+
image_size=[256, 256],
|
| 95 |
+
heatmap_size=[64, 64],
|
| 96 |
+
num_output_channels=channel_cfg['num_output_channels'],
|
| 97 |
+
num_joints=channel_cfg['dataset_joints'],
|
| 98 |
+
dataset_channel=channel_cfg['dataset_channel'],
|
| 99 |
+
inference_channel=channel_cfg['inference_channel'])
|
| 100 |
+
|
| 101 |
+
train_pipeline = [
|
| 102 |
+
dict(type='LoadImageFromFile'),
|
| 103 |
+
dict(
|
| 104 |
+
type='TopDownGetRandomScaleRotation', rot_factor=15,
|
| 105 |
+
scale_factor=0.15),
|
| 106 |
+
dict(type='TopDownAffineFewShot'),
|
| 107 |
+
dict(type='ToTensor'),
|
| 108 |
+
dict(
|
| 109 |
+
type='NormalizeTensor',
|
| 110 |
+
mean=[0.485, 0.456, 0.406],
|
| 111 |
+
std=[0.229, 0.224, 0.225]),
|
| 112 |
+
dict(type='TopDownGenerateTargetFewShot', sigma=1),
|
| 113 |
+
dict(
|
| 114 |
+
type='Collect',
|
| 115 |
+
keys=['img', 'target', 'target_weight'],
|
| 116 |
+
meta_keys=[
|
| 117 |
+
'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
|
| 118 |
+
'rotation', 'bbox_score', 'flip_pairs', 'category_id', 'skeleton',
|
| 119 |
+
]),
|
| 120 |
+
]
|
| 121 |
+
|
| 122 |
+
valid_pipeline = [
|
| 123 |
+
dict(type='LoadImageFromFile'),
|
| 124 |
+
dict(type='TopDownAffineFewShot'),
|
| 125 |
+
dict(type='ToTensor'),
|
| 126 |
+
dict(
|
| 127 |
+
type='NormalizeTensor',
|
| 128 |
+
mean=[0.485, 0.456, 0.406],
|
| 129 |
+
std=[0.229, 0.224, 0.225]),
|
| 130 |
+
dict(type='TopDownGenerateTargetFewShot', sigma=1),
|
| 131 |
+
dict(
|
| 132 |
+
type='Collect',
|
| 133 |
+
keys=['img', 'target', 'target_weight'],
|
| 134 |
+
meta_keys=[
|
| 135 |
+
'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale', 'rotation', 'bbox_score',
|
| 136 |
+
'flip_pairs', 'category_id',
|
| 137 |
+
'skeleton',
|
| 138 |
+
]),
|
| 139 |
+
]
|
| 140 |
+
|
| 141 |
+
test_pipeline = valid_pipeline
|
| 142 |
+
|
| 143 |
+
data_root = 'data/mp100'
|
| 144 |
+
data = dict(
|
| 145 |
+
samples_per_gpu=8,
|
| 146 |
+
workers_per_gpu=8,
|
| 147 |
+
train=dict(
|
| 148 |
+
type='TransformerPoseDataset',
|
| 149 |
+
ann_file=f'{data_root}/annotations/mp100_split3_train.json',
|
| 150 |
+
img_prefix=f'{data_root}/images/',
|
| 151 |
+
# img_prefix=f'{data_root}',
|
| 152 |
+
data_cfg=data_cfg,
|
| 153 |
+
valid_class_ids=None,
|
| 154 |
+
max_kpt_num=channel_cfg['max_kpt_num'],
|
| 155 |
+
num_shots=5,
|
| 156 |
+
pipeline=train_pipeline),
|
| 157 |
+
val=dict(
|
| 158 |
+
type='TransformerPoseDataset',
|
| 159 |
+
ann_file=f'{data_root}/annotations/mp100_split3_val.json',
|
| 160 |
+
img_prefix=f'{data_root}/images/',
|
| 161 |
+
# img_prefix=f'{data_root}',
|
| 162 |
+
data_cfg=data_cfg,
|
| 163 |
+
valid_class_ids=None,
|
| 164 |
+
max_kpt_num=channel_cfg['max_kpt_num'],
|
| 165 |
+
num_shots=5,
|
| 166 |
+
num_queries=15,
|
| 167 |
+
num_episodes=100,
|
| 168 |
+
pipeline=valid_pipeline),
|
| 169 |
+
test=dict(
|
| 170 |
+
type='TestPoseDataset',
|
| 171 |
+
ann_file=f'{data_root}/annotations/mp100_split3_test.json',
|
| 172 |
+
img_prefix=f'{data_root}/images/',
|
| 173 |
+
# img_prefix=f'{data_root}',
|
| 174 |
+
data_cfg=data_cfg,
|
| 175 |
+
valid_class_ids=None,
|
| 176 |
+
max_kpt_num=channel_cfg['max_kpt_num'],
|
| 177 |
+
num_shots=5,
|
| 178 |
+
num_queries=15,
|
| 179 |
+
num_episodes=200,
|
| 180 |
+
pck_threshold_list=[0.05, 0.10, 0.15, 0.2, 0.25],
|
| 181 |
+
pipeline=test_pipeline),
|
| 182 |
+
)
|
| 183 |
+
vis_backends = [
|
| 184 |
+
dict(type='LocalVisBackend'),
|
| 185 |
+
dict(type='TensorboardVisBackend'),
|
| 186 |
+
]
|
| 187 |
+
visualizer = dict(
|
| 188 |
+
type='PoseLocalVisualizer', vis_backends=vis_backends, name='visualizer')
|
| 189 |
+
|
| 190 |
+
shuffle_cfg = dict(interval=1)
|
configs/5shots/base_split4_config.py
ADDED
|
@@ -0,0 +1,190 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
log_level = 'INFO'
|
| 2 |
+
load_from = None
|
| 3 |
+
resume_from = None
|
| 4 |
+
dist_params = dict(backend='nccl')
|
| 5 |
+
workflow = [('train', 1)]
|
| 6 |
+
checkpoint_config = dict(interval=20)
|
| 7 |
+
evaluation = dict(
|
| 8 |
+
interval=25,
|
| 9 |
+
metric=['PCK', 'NME', 'AUC', 'EPE'],
|
| 10 |
+
key_indicator='PCK',
|
| 11 |
+
gpu_collect=True,
|
| 12 |
+
res_folder='')
|
| 13 |
+
optimizer = dict(
|
| 14 |
+
type='Adam',
|
| 15 |
+
lr=1e-5,
|
| 16 |
+
)
|
| 17 |
+
|
| 18 |
+
optimizer_config = dict(grad_clip=None)
|
| 19 |
+
# learning policy
|
| 20 |
+
lr_config = dict(
|
| 21 |
+
policy='step',
|
| 22 |
+
warmup='linear',
|
| 23 |
+
warmup_iters=1000,
|
| 24 |
+
warmup_ratio=0.001,
|
| 25 |
+
step=[160, 180])
|
| 26 |
+
total_epochs = 200
|
| 27 |
+
log_config = dict(
|
| 28 |
+
interval=50,
|
| 29 |
+
hooks=[
|
| 30 |
+
dict(type='TextLoggerHook'),
|
| 31 |
+
dict(type='TensorboardLoggerHook')
|
| 32 |
+
])
|
| 33 |
+
|
| 34 |
+
channel_cfg = dict(
|
| 35 |
+
num_output_channels=1,
|
| 36 |
+
dataset_joints=1,
|
| 37 |
+
dataset_channel=[
|
| 38 |
+
[
|
| 39 |
+
0,
|
| 40 |
+
],
|
| 41 |
+
],
|
| 42 |
+
inference_channel=[
|
| 43 |
+
0,
|
| 44 |
+
],
|
| 45 |
+
max_kpt_num=100)
|
| 46 |
+
|
| 47 |
+
# model settings
|
| 48 |
+
model = dict(
|
| 49 |
+
type='PoseAnythingModel',
|
| 50 |
+
pretrained='pretrained/swinv2_tiny_patch4_window16_256.pth',
|
| 51 |
+
encoder_config=dict(
|
| 52 |
+
type='SwinTransformerV2',
|
| 53 |
+
embed_dim=96,
|
| 54 |
+
depths=[2, 2, 6, 2],
|
| 55 |
+
num_heads=[3, 6, 12, 24],
|
| 56 |
+
window_size=16,
|
| 57 |
+
drop_path_rate=0.2,
|
| 58 |
+
img_size=256,
|
| 59 |
+
upsample="bilinear"
|
| 60 |
+
),
|
| 61 |
+
keypoint_head=dict(
|
| 62 |
+
type='PoseHead',
|
| 63 |
+
in_channels=768,
|
| 64 |
+
transformer=dict(
|
| 65 |
+
type='EncoderDecoder',
|
| 66 |
+
d_model=256,
|
| 67 |
+
nhead=8,
|
| 68 |
+
num_encoder_layers=3,
|
| 69 |
+
num_decoder_layers=3,
|
| 70 |
+
dim_feedforward=768,
|
| 71 |
+
dropout=0.1,
|
| 72 |
+
similarity_proj_dim=256,
|
| 73 |
+
dynamic_proj_dim=128,
|
| 74 |
+
activation="relu",
|
| 75 |
+
normalize_before=False,
|
| 76 |
+
return_intermediate_dec=True),
|
| 77 |
+
share_kpt_branch=False,
|
| 78 |
+
num_decoder_layer=3,
|
| 79 |
+
with_heatmap_loss=True,
|
| 80 |
+
|
| 81 |
+
heatmap_loss_weight=2.0,
|
| 82 |
+
support_order_dropout=-1,
|
| 83 |
+
positional_encoding=dict(
|
| 84 |
+
type='SinePositionalEncoding', num_feats=128, normalize=True)),
|
| 85 |
+
# training and testing settings
|
| 86 |
+
train_cfg=dict(),
|
| 87 |
+
test_cfg=dict(
|
| 88 |
+
flip_test=False,
|
| 89 |
+
post_process='default',
|
| 90 |
+
shift_heatmap=True,
|
| 91 |
+
modulate_kernel=11))
|
| 92 |
+
|
| 93 |
+
data_cfg = dict(
|
| 94 |
+
image_size=[256, 256],
|
| 95 |
+
heatmap_size=[64, 64],
|
| 96 |
+
num_output_channels=channel_cfg['num_output_channels'],
|
| 97 |
+
num_joints=channel_cfg['dataset_joints'],
|
| 98 |
+
dataset_channel=channel_cfg['dataset_channel'],
|
| 99 |
+
inference_channel=channel_cfg['inference_channel'])
|
| 100 |
+
|
| 101 |
+
train_pipeline = [
|
| 102 |
+
dict(type='LoadImageFromFile'),
|
| 103 |
+
dict(
|
| 104 |
+
type='TopDownGetRandomScaleRotation', rot_factor=15,
|
| 105 |
+
scale_factor=0.15),
|
| 106 |
+
dict(type='TopDownAffineFewShot'),
|
| 107 |
+
dict(type='ToTensor'),
|
| 108 |
+
dict(
|
| 109 |
+
type='NormalizeTensor',
|
| 110 |
+
mean=[0.485, 0.456, 0.406],
|
| 111 |
+
std=[0.229, 0.224, 0.225]),
|
| 112 |
+
dict(type='TopDownGenerateTargetFewShot', sigma=1),
|
| 113 |
+
dict(
|
| 114 |
+
type='Collect',
|
| 115 |
+
keys=['img', 'target', 'target_weight'],
|
| 116 |
+
meta_keys=[
|
| 117 |
+
'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
|
| 118 |
+
'rotation', 'bbox_score', 'flip_pairs', 'category_id', 'skeleton',
|
| 119 |
+
]),
|
| 120 |
+
]
|
| 121 |
+
|
| 122 |
+
valid_pipeline = [
|
| 123 |
+
dict(type='LoadImageFromFile'),
|
| 124 |
+
dict(type='TopDownAffineFewShot'),
|
| 125 |
+
dict(type='ToTensor'),
|
| 126 |
+
dict(
|
| 127 |
+
type='NormalizeTensor',
|
| 128 |
+
mean=[0.485, 0.456, 0.406],
|
| 129 |
+
std=[0.229, 0.224, 0.225]),
|
| 130 |
+
dict(type='TopDownGenerateTargetFewShot', sigma=1),
|
| 131 |
+
dict(
|
| 132 |
+
type='Collect',
|
| 133 |
+
keys=['img', 'target', 'target_weight'],
|
| 134 |
+
meta_keys=[
|
| 135 |
+
'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale', 'rotation', 'bbox_score',
|
| 136 |
+
'flip_pairs', 'category_id',
|
| 137 |
+
'skeleton',
|
| 138 |
+
]),
|
| 139 |
+
]
|
| 140 |
+
|
| 141 |
+
test_pipeline = valid_pipeline
|
| 142 |
+
|
| 143 |
+
data_root = 'data/mp100'
|
| 144 |
+
data = dict(
|
| 145 |
+
samples_per_gpu=8,
|
| 146 |
+
workers_per_gpu=8,
|
| 147 |
+
train=dict(
|
| 148 |
+
type='TransformerPoseDataset',
|
| 149 |
+
ann_file=f'{data_root}/annotations/mp100_split4_train.json',
|
| 150 |
+
img_prefix=f'{data_root}/images/',
|
| 151 |
+
# img_prefix=f'{data_root}',
|
| 152 |
+
data_cfg=data_cfg,
|
| 153 |
+
valid_class_ids=None,
|
| 154 |
+
max_kpt_num=channel_cfg['max_kpt_num'],
|
| 155 |
+
num_shots=5,
|
| 156 |
+
pipeline=train_pipeline),
|
| 157 |
+
val=dict(
|
| 158 |
+
type='TransformerPoseDataset',
|
| 159 |
+
ann_file=f'{data_root}/annotations/mp100_split4_val.json',
|
| 160 |
+
img_prefix=f'{data_root}/images/',
|
| 161 |
+
# img_prefix=f'{data_root}',
|
| 162 |
+
data_cfg=data_cfg,
|
| 163 |
+
valid_class_ids=None,
|
| 164 |
+
max_kpt_num=channel_cfg['max_kpt_num'],
|
| 165 |
+
num_shots=5,
|
| 166 |
+
num_queries=15,
|
| 167 |
+
num_episodes=100,
|
| 168 |
+
pipeline=valid_pipeline),
|
| 169 |
+
test=dict(
|
| 170 |
+
type='TestPoseDataset',
|
| 171 |
+
ann_file=f'{data_root}/annotations/mp100_split4_test.json',
|
| 172 |
+
img_prefix=f'{data_root}/images/',
|
| 173 |
+
# img_prefix=f'{data_root}',
|
| 174 |
+
data_cfg=data_cfg,
|
| 175 |
+
valid_class_ids=None,
|
| 176 |
+
max_kpt_num=channel_cfg['max_kpt_num'],
|
| 177 |
+
num_shots=5,
|
| 178 |
+
num_queries=15,
|
| 179 |
+
num_episodes=200,
|
| 180 |
+
pck_threshold_list=[0.05, 0.10, 0.15, 0.2, 0.25],
|
| 181 |
+
pipeline=test_pipeline),
|
| 182 |
+
)
|
| 183 |
+
vis_backends = [
|
| 184 |
+
dict(type='LocalVisBackend'),
|
| 185 |
+
dict(type='TensorboardVisBackend'),
|
| 186 |
+
]
|
| 187 |
+
visualizer = dict(
|
| 188 |
+
type='PoseLocalVisualizer', vis_backends=vis_backends, name='visualizer')
|
| 189 |
+
|
| 190 |
+
shuffle_cfg = dict(interval=1)
|
configs/5shots/base_split5_config.py
ADDED
|
@@ -0,0 +1,190 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
log_level = 'INFO'
|
| 2 |
+
load_from = None
|
| 3 |
+
resume_from = None
|
| 4 |
+
dist_params = dict(backend='nccl')
|
| 5 |
+
workflow = [('train', 1)]
|
| 6 |
+
checkpoint_config = dict(interval=20)
|
| 7 |
+
evaluation = dict(
|
| 8 |
+
interval=25,
|
| 9 |
+
metric=['PCK', 'NME', 'AUC', 'EPE'],
|
| 10 |
+
key_indicator='PCK',
|
| 11 |
+
gpu_collect=True,
|
| 12 |
+
res_folder='')
|
| 13 |
+
optimizer = dict(
|
| 14 |
+
type='Adam',
|
| 15 |
+
lr=1e-5,
|
| 16 |
+
)
|
| 17 |
+
|
| 18 |
+
optimizer_config = dict(grad_clip=None)
|
| 19 |
+
# learning policy
|
| 20 |
+
lr_config = dict(
|
| 21 |
+
policy='step',
|
| 22 |
+
warmup='linear',
|
| 23 |
+
warmup_iters=1000,
|
| 24 |
+
warmup_ratio=0.001,
|
| 25 |
+
step=[160, 180])
|
| 26 |
+
total_epochs = 200
|
| 27 |
+
log_config = dict(
|
| 28 |
+
interval=50,
|
| 29 |
+
hooks=[
|
| 30 |
+
dict(type='TextLoggerHook'),
|
| 31 |
+
dict(type='TensorboardLoggerHook')
|
| 32 |
+
])
|
| 33 |
+
|
| 34 |
+
channel_cfg = dict(
|
| 35 |
+
num_output_channels=1,
|
| 36 |
+
dataset_joints=1,
|
| 37 |
+
dataset_channel=[
|
| 38 |
+
[
|
| 39 |
+
0,
|
| 40 |
+
],
|
| 41 |
+
],
|
| 42 |
+
inference_channel=[
|
| 43 |
+
0,
|
| 44 |
+
],
|
| 45 |
+
max_kpt_num=100)
|
| 46 |
+
|
| 47 |
+
# model settings
|
| 48 |
+
model = dict(
|
| 49 |
+
type='PoseAnythingModel',
|
| 50 |
+
pretrained='pretrained/swinv2_tiny_patch4_window16_256.pth',
|
| 51 |
+
encoder_config=dict(
|
| 52 |
+
type='SwinTransformerV2',
|
| 53 |
+
embed_dim=96,
|
| 54 |
+
depths=[2, 2, 6, 2],
|
| 55 |
+
num_heads=[3, 6, 12, 24],
|
| 56 |
+
window_size=16,
|
| 57 |
+
drop_path_rate=0.2,
|
| 58 |
+
img_size=256,
|
| 59 |
+
upsample="bilinear"
|
| 60 |
+
),
|
| 61 |
+
keypoint_head=dict(
|
| 62 |
+
type='PoseHead',
|
| 63 |
+
in_channels=768,
|
| 64 |
+
transformer=dict(
|
| 65 |
+
type='EncoderDecoder',
|
| 66 |
+
d_model=256,
|
| 67 |
+
nhead=8,
|
| 68 |
+
num_encoder_layers=3,
|
| 69 |
+
num_decoder_layers=3,
|
| 70 |
+
dim_feedforward=768,
|
| 71 |
+
dropout=0.1,
|
| 72 |
+
similarity_proj_dim=256,
|
| 73 |
+
dynamic_proj_dim=128,
|
| 74 |
+
activation="relu",
|
| 75 |
+
normalize_before=False,
|
| 76 |
+
return_intermediate_dec=True),
|
| 77 |
+
share_kpt_branch=False,
|
| 78 |
+
num_decoder_layer=3,
|
| 79 |
+
with_heatmap_loss=True,
|
| 80 |
+
|
| 81 |
+
heatmap_loss_weight=2.0,
|
| 82 |
+
support_order_dropout=-1,
|
| 83 |
+
positional_encoding=dict(
|
| 84 |
+
type='SinePositionalEncoding', num_feats=128, normalize=True)),
|
| 85 |
+
# training and testing settings
|
| 86 |
+
train_cfg=dict(),
|
| 87 |
+
test_cfg=dict(
|
| 88 |
+
flip_test=False,
|
| 89 |
+
post_process='default',
|
| 90 |
+
shift_heatmap=True,
|
| 91 |
+
modulate_kernel=11))
|
| 92 |
+
|
| 93 |
+
data_cfg = dict(
|
| 94 |
+
image_size=[256, 256],
|
| 95 |
+
heatmap_size=[64, 64],
|
| 96 |
+
num_output_channels=channel_cfg['num_output_channels'],
|
| 97 |
+
num_joints=channel_cfg['dataset_joints'],
|
| 98 |
+
dataset_channel=channel_cfg['dataset_channel'],
|
| 99 |
+
inference_channel=channel_cfg['inference_channel'])
|
| 100 |
+
|
| 101 |
+
train_pipeline = [
|
| 102 |
+
dict(type='LoadImageFromFile'),
|
| 103 |
+
dict(
|
| 104 |
+
type='TopDownGetRandomScaleRotation', rot_factor=15,
|
| 105 |
+
scale_factor=0.15),
|
| 106 |
+
dict(type='TopDownAffineFewShot'),
|
| 107 |
+
dict(type='ToTensor'),
|
| 108 |
+
dict(
|
| 109 |
+
type='NormalizeTensor',
|
| 110 |
+
mean=[0.485, 0.456, 0.406],
|
| 111 |
+
std=[0.229, 0.224, 0.225]),
|
| 112 |
+
dict(type='TopDownGenerateTargetFewShot', sigma=1),
|
| 113 |
+
dict(
|
| 114 |
+
type='Collect',
|
| 115 |
+
keys=['img', 'target', 'target_weight'],
|
| 116 |
+
meta_keys=[
|
| 117 |
+
'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
|
| 118 |
+
'rotation', 'bbox_score', 'flip_pairs', 'category_id', 'skeleton',
|
| 119 |
+
]),
|
| 120 |
+
]
|
| 121 |
+
|
| 122 |
+
valid_pipeline = [
|
| 123 |
+
dict(type='LoadImageFromFile'),
|
| 124 |
+
dict(type='TopDownAffineFewShot'),
|
| 125 |
+
dict(type='ToTensor'),
|
| 126 |
+
dict(
|
| 127 |
+
type='NormalizeTensor',
|
| 128 |
+
mean=[0.485, 0.456, 0.406],
|
| 129 |
+
std=[0.229, 0.224, 0.225]),
|
| 130 |
+
dict(type='TopDownGenerateTargetFewShot', sigma=1),
|
| 131 |
+
dict(
|
| 132 |
+
type='Collect',
|
| 133 |
+
keys=['img', 'target', 'target_weight'],
|
| 134 |
+
meta_keys=[
|
| 135 |
+
'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale', 'rotation', 'bbox_score',
|
| 136 |
+
'flip_pairs', 'category_id',
|
| 137 |
+
'skeleton',
|
| 138 |
+
]),
|
| 139 |
+
]
|
| 140 |
+
|
| 141 |
+
test_pipeline = valid_pipeline
|
| 142 |
+
|
| 143 |
+
data_root = 'data/mp100'
|
| 144 |
+
data = dict(
|
| 145 |
+
samples_per_gpu=8,
|
| 146 |
+
workers_per_gpu=8,
|
| 147 |
+
train=dict(
|
| 148 |
+
type='TransformerPoseDataset',
|
| 149 |
+
ann_file=f'{data_root}/annotations/mp100_split5_train.json',
|
| 150 |
+
img_prefix=f'{data_root}/images/',
|
| 151 |
+
# img_prefix=f'{data_root}',
|
| 152 |
+
data_cfg=data_cfg,
|
| 153 |
+
valid_class_ids=None,
|
| 154 |
+
max_kpt_num=channel_cfg['max_kpt_num'],
|
| 155 |
+
num_shots=5,
|
| 156 |
+
pipeline=train_pipeline),
|
| 157 |
+
val=dict(
|
| 158 |
+
type='TransformerPoseDataset',
|
| 159 |
+
ann_file=f'{data_root}/annotations/mp100_split5_val.json',
|
| 160 |
+
img_prefix=f'{data_root}/images/',
|
| 161 |
+
# img_prefix=f'{data_root}',
|
| 162 |
+
data_cfg=data_cfg,
|
| 163 |
+
valid_class_ids=None,
|
| 164 |
+
max_kpt_num=channel_cfg['max_kpt_num'],
|
| 165 |
+
num_shots=5,
|
| 166 |
+
num_queries=15,
|
| 167 |
+
num_episodes=100,
|
| 168 |
+
pipeline=valid_pipeline),
|
| 169 |
+
test=dict(
|
| 170 |
+
type='TestPoseDataset',
|
| 171 |
+
ann_file=f'{data_root}/annotations/mp100_split5_test.json',
|
| 172 |
+
img_prefix=f'{data_root}/images/',
|
| 173 |
+
# img_prefix=f'{data_root}',
|
| 174 |
+
data_cfg=data_cfg,
|
| 175 |
+
valid_class_ids=None,
|
| 176 |
+
max_kpt_num=channel_cfg['max_kpt_num'],
|
| 177 |
+
num_shots=5,
|
| 178 |
+
num_queries=15,
|
| 179 |
+
num_episodes=200,
|
| 180 |
+
pck_threshold_list=[0.05, 0.10, 0.15, 0.2, 0.25],
|
| 181 |
+
pipeline=test_pipeline),
|
| 182 |
+
)
|
| 183 |
+
vis_backends = [
|
| 184 |
+
dict(type='LocalVisBackend'),
|
| 185 |
+
dict(type='TensorboardVisBackend'),
|
| 186 |
+
]
|
| 187 |
+
visualizer = dict(
|
| 188 |
+
type='PoseLocalVisualizer', vis_backends=vis_backends, name='visualizer')
|
| 189 |
+
|
| 190 |
+
shuffle_cfg = dict(interval=1)
|
configs/5shots/graph_split1_config.py
ADDED
|
@@ -0,0 +1,191 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
log_level = 'INFO'
|
| 2 |
+
load_from = None
|
| 3 |
+
resume_from = None
|
| 4 |
+
dist_params = dict(backend='nccl')
|
| 5 |
+
workflow = [('train', 1)]
|
| 6 |
+
checkpoint_config = dict(interval=20)
|
| 7 |
+
evaluation = dict(
|
| 8 |
+
interval=25,
|
| 9 |
+
metric=['PCK', 'NME', 'AUC', 'EPE'],
|
| 10 |
+
key_indicator='PCK',
|
| 11 |
+
gpu_collect=True,
|
| 12 |
+
res_folder='')
|
| 13 |
+
optimizer = dict(
|
| 14 |
+
type='Adam',
|
| 15 |
+
lr=1e-5,
|
| 16 |
+
)
|
| 17 |
+
|
| 18 |
+
optimizer_config = dict(grad_clip=None)
|
| 19 |
+
# learning policy
|
| 20 |
+
lr_config = dict(
|
| 21 |
+
policy='step',
|
| 22 |
+
warmup='linear',
|
| 23 |
+
warmup_iters=1000,
|
| 24 |
+
warmup_ratio=0.001,
|
| 25 |
+
step=[160, 180])
|
| 26 |
+
total_epochs = 200
|
| 27 |
+
log_config = dict(
|
| 28 |
+
interval=50,
|
| 29 |
+
hooks=[
|
| 30 |
+
dict(type='TextLoggerHook'),
|
| 31 |
+
dict(type='TensorboardLoggerHook')
|
| 32 |
+
])
|
| 33 |
+
|
| 34 |
+
channel_cfg = dict(
|
| 35 |
+
num_output_channels=1,
|
| 36 |
+
dataset_joints=1,
|
| 37 |
+
dataset_channel=[
|
| 38 |
+
[
|
| 39 |
+
0,
|
| 40 |
+
],
|
| 41 |
+
],
|
| 42 |
+
inference_channel=[
|
| 43 |
+
0,
|
| 44 |
+
],
|
| 45 |
+
max_kpt_num=100)
|
| 46 |
+
|
| 47 |
+
# model settings
|
| 48 |
+
model = dict(
|
| 49 |
+
type='PoseAnythingModel',
|
| 50 |
+
pretrained='pretrained/swinv2_tiny_patch4_window16_256.pth',
|
| 51 |
+
encoder_config=dict(
|
| 52 |
+
type='SwinTransformerV2',
|
| 53 |
+
embed_dim=96,
|
| 54 |
+
depths=[2, 2, 6, 2],
|
| 55 |
+
num_heads=[3, 6, 12, 24],
|
| 56 |
+
window_size=16,
|
| 57 |
+
drop_path_rate=0.2,
|
| 58 |
+
img_size=256,
|
| 59 |
+
upsample="bilinear"
|
| 60 |
+
),
|
| 61 |
+
keypoint_head=dict(
|
| 62 |
+
type='PoseHead',
|
| 63 |
+
in_channels=768,
|
| 64 |
+
transformer=dict(
|
| 65 |
+
type='EncoderDecoder',
|
| 66 |
+
d_model=256,
|
| 67 |
+
nhead=8,
|
| 68 |
+
num_encoder_layers=3,
|
| 69 |
+
num_decoder_layers=3,
|
| 70 |
+
graph_decoder='pre',
|
| 71 |
+
dim_feedforward=768,
|
| 72 |
+
dropout=0.1,
|
| 73 |
+
similarity_proj_dim=256,
|
| 74 |
+
dynamic_proj_dim=128,
|
| 75 |
+
activation="relu",
|
| 76 |
+
normalize_before=False,
|
| 77 |
+
return_intermediate_dec=True),
|
| 78 |
+
share_kpt_branch=False,
|
| 79 |
+
num_decoder_layer=3,
|
| 80 |
+
with_heatmap_loss=True,
|
| 81 |
+
|
| 82 |
+
heatmap_loss_weight=2.0,
|
| 83 |
+
support_order_dropout=-1,
|
| 84 |
+
positional_encoding=dict(
|
| 85 |
+
type='SinePositionalEncoding', num_feats=128, normalize=True)),
|
| 86 |
+
# training and testing settings
|
| 87 |
+
train_cfg=dict(),
|
| 88 |
+
test_cfg=dict(
|
| 89 |
+
flip_test=False,
|
| 90 |
+
post_process='default',
|
| 91 |
+
shift_heatmap=True,
|
| 92 |
+
modulate_kernel=11))
|
| 93 |
+
|
| 94 |
+
data_cfg = dict(
|
| 95 |
+
image_size=[256, 256],
|
| 96 |
+
heatmap_size=[64, 64],
|
| 97 |
+
num_output_channels=channel_cfg['num_output_channels'],
|
| 98 |
+
num_joints=channel_cfg['dataset_joints'],
|
| 99 |
+
dataset_channel=channel_cfg['dataset_channel'],
|
| 100 |
+
inference_channel=channel_cfg['inference_channel'])
|
| 101 |
+
|
| 102 |
+
train_pipeline = [
|
| 103 |
+
dict(type='LoadImageFromFile'),
|
| 104 |
+
dict(
|
| 105 |
+
type='TopDownGetRandomScaleRotation', rot_factor=15,
|
| 106 |
+
scale_factor=0.15),
|
| 107 |
+
dict(type='TopDownAffineFewShot'),
|
| 108 |
+
dict(type='ToTensor'),
|
| 109 |
+
dict(
|
| 110 |
+
type='NormalizeTensor',
|
| 111 |
+
mean=[0.485, 0.456, 0.406],
|
| 112 |
+
std=[0.229, 0.224, 0.225]),
|
| 113 |
+
dict(type='TopDownGenerateTargetFewShot', sigma=1),
|
| 114 |
+
dict(
|
| 115 |
+
type='Collect',
|
| 116 |
+
keys=['img', 'target', 'target_weight'],
|
| 117 |
+
meta_keys=[
|
| 118 |
+
'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
|
| 119 |
+
'rotation', 'bbox_score', 'flip_pairs', 'category_id', 'skeleton',
|
| 120 |
+
]),
|
| 121 |
+
]
|
| 122 |
+
|
| 123 |
+
valid_pipeline = [
|
| 124 |
+
dict(type='LoadImageFromFile'),
|
| 125 |
+
dict(type='TopDownAffineFewShot'),
|
| 126 |
+
dict(type='ToTensor'),
|
| 127 |
+
dict(
|
| 128 |
+
type='NormalizeTensor',
|
| 129 |
+
mean=[0.485, 0.456, 0.406],
|
| 130 |
+
std=[0.229, 0.224, 0.225]),
|
| 131 |
+
dict(type='TopDownGenerateTargetFewShot', sigma=1),
|
| 132 |
+
dict(
|
| 133 |
+
type='Collect',
|
| 134 |
+
keys=['img', 'target', 'target_weight'],
|
| 135 |
+
meta_keys=[
|
| 136 |
+
'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale', 'rotation', 'bbox_score',
|
| 137 |
+
'flip_pairs', 'category_id',
|
| 138 |
+
'skeleton',
|
| 139 |
+
]),
|
| 140 |
+
]
|
| 141 |
+
|
| 142 |
+
test_pipeline = valid_pipeline
|
| 143 |
+
|
| 144 |
+
data_root = 'data/mp100'
|
| 145 |
+
data = dict(
|
| 146 |
+
samples_per_gpu=8,
|
| 147 |
+
workers_per_gpu=8,
|
| 148 |
+
train=dict(
|
| 149 |
+
type='TransformerPoseDataset',
|
| 150 |
+
ann_file=f'{data_root}/annotations/mp100_split1_train.json',
|
| 151 |
+
img_prefix=f'{data_root}/images/',
|
| 152 |
+
# img_prefix=f'{data_root}',
|
| 153 |
+
data_cfg=data_cfg,
|
| 154 |
+
valid_class_ids=None,
|
| 155 |
+
max_kpt_num=channel_cfg['max_kpt_num'],
|
| 156 |
+
num_shots=5,
|
| 157 |
+
pipeline=train_pipeline),
|
| 158 |
+
val=dict(
|
| 159 |
+
type='TransformerPoseDataset',
|
| 160 |
+
ann_file=f'{data_root}/annotations/mp100_split1_val.json',
|
| 161 |
+
img_prefix=f'{data_root}/images/',
|
| 162 |
+
# img_prefix=f'{data_root}',
|
| 163 |
+
data_cfg=data_cfg,
|
| 164 |
+
valid_class_ids=None,
|
| 165 |
+
max_kpt_num=channel_cfg['max_kpt_num'],
|
| 166 |
+
num_shots=5,
|
| 167 |
+
num_queries=15,
|
| 168 |
+
num_episodes=100,
|
| 169 |
+
pipeline=valid_pipeline),
|
| 170 |
+
test=dict(
|
| 171 |
+
type='TestPoseDataset',
|
| 172 |
+
ann_file=f'{data_root}/annotations/mp100_split1_test.json',
|
| 173 |
+
img_prefix=f'{data_root}/images/',
|
| 174 |
+
# img_prefix=f'{data_root}',
|
| 175 |
+
data_cfg=data_cfg,
|
| 176 |
+
valid_class_ids=None,
|
| 177 |
+
max_kpt_num=channel_cfg['max_kpt_num'],
|
| 178 |
+
num_shots=5,
|
| 179 |
+
num_queries=15,
|
| 180 |
+
num_episodes=200,
|
| 181 |
+
pck_threshold_list=[0.05, 0.10, 0.15, 0.2, 0.25],
|
| 182 |
+
pipeline=test_pipeline),
|
| 183 |
+
)
|
| 184 |
+
vis_backends = [
|
| 185 |
+
dict(type='LocalVisBackend'),
|
| 186 |
+
dict(type='TensorboardVisBackend'),
|
| 187 |
+
]
|
| 188 |
+
visualizer = dict(
|
| 189 |
+
type='PoseLocalVisualizer', vis_backends=vis_backends, name='visualizer')
|
| 190 |
+
|
| 191 |
+
shuffle_cfg = dict(interval=1)
|
configs/5shots/graph_split2_config.py
ADDED
|
@@ -0,0 +1,191 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
log_level = 'INFO'
|
| 2 |
+
load_from = None
|
| 3 |
+
resume_from = None
|
| 4 |
+
dist_params = dict(backend='nccl')
|
| 5 |
+
workflow = [('train', 1)]
|
| 6 |
+
checkpoint_config = dict(interval=20)
|
| 7 |
+
evaluation = dict(
|
| 8 |
+
interval=25,
|
| 9 |
+
metric=['PCK', 'NME', 'AUC', 'EPE'],
|
| 10 |
+
key_indicator='PCK',
|
| 11 |
+
gpu_collect=True,
|
| 12 |
+
res_folder='')
|
| 13 |
+
optimizer = dict(
|
| 14 |
+
type='Adam',
|
| 15 |
+
lr=1e-5,
|
| 16 |
+
)
|
| 17 |
+
|
| 18 |
+
optimizer_config = dict(grad_clip=None)
|
| 19 |
+
# learning policy
|
| 20 |
+
lr_config = dict(
|
| 21 |
+
policy='step',
|
| 22 |
+
warmup='linear',
|
| 23 |
+
warmup_iters=1000,
|
| 24 |
+
warmup_ratio=0.001,
|
| 25 |
+
step=[160, 180])
|
| 26 |
+
total_epochs = 200
|
| 27 |
+
log_config = dict(
|
| 28 |
+
interval=50,
|
| 29 |
+
hooks=[
|
| 30 |
+
dict(type='TextLoggerHook'),
|
| 31 |
+
dict(type='TensorboardLoggerHook')
|
| 32 |
+
])
|
| 33 |
+
|
| 34 |
+
channel_cfg = dict(
|
| 35 |
+
num_output_channels=1,
|
| 36 |
+
dataset_joints=1,
|
| 37 |
+
dataset_channel=[
|
| 38 |
+
[
|
| 39 |
+
0,
|
| 40 |
+
],
|
| 41 |
+
],
|
| 42 |
+
inference_channel=[
|
| 43 |
+
0,
|
| 44 |
+
],
|
| 45 |
+
max_kpt_num=100)
|
| 46 |
+
|
| 47 |
+
# model settings
|
| 48 |
+
model = dict(
|
| 49 |
+
type='PoseAnythingModel',
|
| 50 |
+
pretrained='pretrained/swinv2_tiny_patch4_window16_256.pth',
|
| 51 |
+
encoder_config=dict(
|
| 52 |
+
type='SwinTransformerV2',
|
| 53 |
+
embed_dim=96,
|
| 54 |
+
depths=[2, 2, 6, 2],
|
| 55 |
+
num_heads=[3, 6, 12, 24],
|
| 56 |
+
window_size=16,
|
| 57 |
+
drop_path_rate=0.2,
|
| 58 |
+
img_size=256,
|
| 59 |
+
upsample="bilinear"
|
| 60 |
+
),
|
| 61 |
+
keypoint_head=dict(
|
| 62 |
+
type='PoseHead',
|
| 63 |
+
in_channels=768,
|
| 64 |
+
transformer=dict(
|
| 65 |
+
type='EncoderDecoder',
|
| 66 |
+
d_model=256,
|
| 67 |
+
nhead=8,
|
| 68 |
+
num_encoder_layers=3,
|
| 69 |
+
num_decoder_layers=3,
|
| 70 |
+
graph_decoder='pre',
|
| 71 |
+
dim_feedforward=768,
|
| 72 |
+
dropout=0.1,
|
| 73 |
+
similarity_proj_dim=256,
|
| 74 |
+
dynamic_proj_dim=128,
|
| 75 |
+
activation="relu",
|
| 76 |
+
normalize_before=False,
|
| 77 |
+
return_intermediate_dec=True),
|
| 78 |
+
share_kpt_branch=False,
|
| 79 |
+
num_decoder_layer=3,
|
| 80 |
+
with_heatmap_loss=True,
|
| 81 |
+
|
| 82 |
+
heatmap_loss_weight=2.0,
|
| 83 |
+
support_order_dropout=-1,
|
| 84 |
+
positional_encoding=dict(
|
| 85 |
+
type='SinePositionalEncoding', num_feats=128, normalize=True)),
|
| 86 |
+
# training and testing settings
|
| 87 |
+
train_cfg=dict(),
|
| 88 |
+
test_cfg=dict(
|
| 89 |
+
flip_test=False,
|
| 90 |
+
post_process='default',
|
| 91 |
+
shift_heatmap=True,
|
| 92 |
+
modulate_kernel=11))
|
| 93 |
+
|
| 94 |
+
data_cfg = dict(
|
| 95 |
+
image_size=[256, 256],
|
| 96 |
+
heatmap_size=[64, 64],
|
| 97 |
+
num_output_channels=channel_cfg['num_output_channels'],
|
| 98 |
+
num_joints=channel_cfg['dataset_joints'],
|
| 99 |
+
dataset_channel=channel_cfg['dataset_channel'],
|
| 100 |
+
inference_channel=channel_cfg['inference_channel'])
|
| 101 |
+
|
| 102 |
+
train_pipeline = [
|
| 103 |
+
dict(type='LoadImageFromFile'),
|
| 104 |
+
dict(
|
| 105 |
+
type='TopDownGetRandomScaleRotation', rot_factor=15,
|
| 106 |
+
scale_factor=0.15),
|
| 107 |
+
dict(type='TopDownAffineFewShot'),
|
| 108 |
+
dict(type='ToTensor'),
|
| 109 |
+
dict(
|
| 110 |
+
type='NormalizeTensor',
|
| 111 |
+
mean=[0.485, 0.456, 0.406],
|
| 112 |
+
std=[0.229, 0.224, 0.225]),
|
| 113 |
+
dict(type='TopDownGenerateTargetFewShot', sigma=1),
|
| 114 |
+
dict(
|
| 115 |
+
type='Collect',
|
| 116 |
+
keys=['img', 'target', 'target_weight'],
|
| 117 |
+
meta_keys=[
|
| 118 |
+
'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
|
| 119 |
+
'rotation', 'bbox_score', 'flip_pairs', 'category_id', 'skeleton',
|
| 120 |
+
]),
|
| 121 |
+
]
|
| 122 |
+
|
| 123 |
+
valid_pipeline = [
|
| 124 |
+
dict(type='LoadImageFromFile'),
|
| 125 |
+
dict(type='TopDownAffineFewShot'),
|
| 126 |
+
dict(type='ToTensor'),
|
| 127 |
+
dict(
|
| 128 |
+
type='NormalizeTensor',
|
| 129 |
+
mean=[0.485, 0.456, 0.406],
|
| 130 |
+
std=[0.229, 0.224, 0.225]),
|
| 131 |
+
dict(type='TopDownGenerateTargetFewShot', sigma=1),
|
| 132 |
+
dict(
|
| 133 |
+
type='Collect',
|
| 134 |
+
keys=['img', 'target', 'target_weight'],
|
| 135 |
+
meta_keys=[
|
| 136 |
+
'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale', 'rotation', 'bbox_score',
|
| 137 |
+
'flip_pairs', 'category_id',
|
| 138 |
+
'skeleton',
|
| 139 |
+
]),
|
| 140 |
+
]
|
| 141 |
+
|
| 142 |
+
test_pipeline = valid_pipeline
|
| 143 |
+
|
| 144 |
+
data_root = 'data/mp100'
|
| 145 |
+
data = dict(
|
| 146 |
+
samples_per_gpu=8,
|
| 147 |
+
workers_per_gpu=8,
|
| 148 |
+
train=dict(
|
| 149 |
+
type='TransformerPoseDataset',
|
| 150 |
+
ann_file=f'{data_root}/annotations/mp100_split2_train.json',
|
| 151 |
+
img_prefix=f'{data_root}/images/',
|
| 152 |
+
# img_prefix=f'{data_root}',
|
| 153 |
+
data_cfg=data_cfg,
|
| 154 |
+
valid_class_ids=None,
|
| 155 |
+
max_kpt_num=channel_cfg['max_kpt_num'],
|
| 156 |
+
num_shots=5,
|
| 157 |
+
pipeline=train_pipeline),
|
| 158 |
+
val=dict(
|
| 159 |
+
type='TransformerPoseDataset',
|
| 160 |
+
ann_file=f'{data_root}/annotations/mp100_split2_val.json',
|
| 161 |
+
img_prefix=f'{data_root}/images/',
|
| 162 |
+
# img_prefix=f'{data_root}',
|
| 163 |
+
data_cfg=data_cfg,
|
| 164 |
+
valid_class_ids=None,
|
| 165 |
+
max_kpt_num=channel_cfg['max_kpt_num'],
|
| 166 |
+
num_shots=5,
|
| 167 |
+
num_queries=15,
|
| 168 |
+
num_episodes=100,
|
| 169 |
+
pipeline=valid_pipeline),
|
| 170 |
+
test=dict(
|
| 171 |
+
type='TestPoseDataset',
|
| 172 |
+
ann_file=f'{data_root}/annotations/mp100_split2_test.json',
|
| 173 |
+
img_prefix=f'{data_root}/images/',
|
| 174 |
+
# img_prefix=f'{data_root}',
|
| 175 |
+
data_cfg=data_cfg,
|
| 176 |
+
valid_class_ids=None,
|
| 177 |
+
max_kpt_num=channel_cfg['max_kpt_num'],
|
| 178 |
+
num_shots=5,
|
| 179 |
+
num_queries=15,
|
| 180 |
+
num_episodes=200,
|
| 181 |
+
pck_threshold_list=[0.05, 0.10, 0.15, 0.2, 0.25],
|
| 182 |
+
pipeline=test_pipeline),
|
| 183 |
+
)
|
| 184 |
+
vis_backends = [
|
| 185 |
+
dict(type='LocalVisBackend'),
|
| 186 |
+
dict(type='TensorboardVisBackend'),
|
| 187 |
+
]
|
| 188 |
+
visualizer = dict(
|
| 189 |
+
type='PoseLocalVisualizer', vis_backends=vis_backends, name='visualizer')
|
| 190 |
+
|
| 191 |
+
shuffle_cfg = dict(interval=1)
|
configs/5shots/graph_split3_config.py
ADDED
|
@@ -0,0 +1,191 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
log_level = 'INFO'
|
| 2 |
+
load_from = None
|
| 3 |
+
resume_from = None
|
| 4 |
+
dist_params = dict(backend='nccl')
|
| 5 |
+
workflow = [('train', 1)]
|
| 6 |
+
checkpoint_config = dict(interval=20)
|
| 7 |
+
evaluation = dict(
|
| 8 |
+
interval=25,
|
| 9 |
+
metric=['PCK', 'NME', 'AUC', 'EPE'],
|
| 10 |
+
key_indicator='PCK',
|
| 11 |
+
gpu_collect=True,
|
| 12 |
+
res_folder='')
|
| 13 |
+
optimizer = dict(
|
| 14 |
+
type='Adam',
|
| 15 |
+
lr=1e-5,
|
| 16 |
+
)
|
| 17 |
+
|
| 18 |
+
optimizer_config = dict(grad_clip=None)
|
| 19 |
+
# learning policy
|
| 20 |
+
lr_config = dict(
|
| 21 |
+
policy='step',
|
| 22 |
+
warmup='linear',
|
| 23 |
+
warmup_iters=1000,
|
| 24 |
+
warmup_ratio=0.001,
|
| 25 |
+
step=[160, 180])
|
| 26 |
+
total_epochs = 200
|
| 27 |
+
log_config = dict(
|
| 28 |
+
interval=50,
|
| 29 |
+
hooks=[
|
| 30 |
+
dict(type='TextLoggerHook'),
|
| 31 |
+
dict(type='TensorboardLoggerHook')
|
| 32 |
+
])
|
| 33 |
+
|
| 34 |
+
channel_cfg = dict(
|
| 35 |
+
num_output_channels=1,
|
| 36 |
+
dataset_joints=1,
|
| 37 |
+
dataset_channel=[
|
| 38 |
+
[
|
| 39 |
+
0,
|
| 40 |
+
],
|
| 41 |
+
],
|
| 42 |
+
inference_channel=[
|
| 43 |
+
0,
|
| 44 |
+
],
|
| 45 |
+
max_kpt_num=100)
|
| 46 |
+
|
| 47 |
+
# model settings
|
| 48 |
+
model = dict(
|
| 49 |
+
type='PoseAnythingModel',
|
| 50 |
+
pretrained='pretrained/swinv2_tiny_patch4_window16_256.pth',
|
| 51 |
+
encoder_config=dict(
|
| 52 |
+
type='SwinTransformerV2',
|
| 53 |
+
embed_dim=96,
|
| 54 |
+
depths=[2, 2, 6, 2],
|
| 55 |
+
num_heads=[3, 6, 12, 24],
|
| 56 |
+
window_size=16,
|
| 57 |
+
drop_path_rate=0.2,
|
| 58 |
+
img_size=256,
|
| 59 |
+
upsample="bilinear"
|
| 60 |
+
),
|
| 61 |
+
keypoint_head=dict(
|
| 62 |
+
type='PoseHead',
|
| 63 |
+
in_channels=768,
|
| 64 |
+
transformer=dict(
|
| 65 |
+
type='EncoderDecoder',
|
| 66 |
+
d_model=256,
|
| 67 |
+
nhead=8,
|
| 68 |
+
num_encoder_layers=3,
|
| 69 |
+
num_decoder_layers=3,
|
| 70 |
+
graph_decoder='pre',
|
| 71 |
+
dim_feedforward=768,
|
| 72 |
+
dropout=0.1,
|
| 73 |
+
similarity_proj_dim=256,
|
| 74 |
+
dynamic_proj_dim=128,
|
| 75 |
+
activation="relu",
|
| 76 |
+
normalize_before=False,
|
| 77 |
+
return_intermediate_dec=True),
|
| 78 |
+
share_kpt_branch=False,
|
| 79 |
+
num_decoder_layer=3,
|
| 80 |
+
with_heatmap_loss=True,
|
| 81 |
+
|
| 82 |
+
heatmap_loss_weight=2.0,
|
| 83 |
+
support_order_dropout=-1,
|
| 84 |
+
positional_encoding=dict(
|
| 85 |
+
type='SinePositionalEncoding', num_feats=128, normalize=True)),
|
| 86 |
+
# training and testing settings
|
| 87 |
+
train_cfg=dict(),
|
| 88 |
+
test_cfg=dict(
|
| 89 |
+
flip_test=False,
|
| 90 |
+
post_process='default',
|
| 91 |
+
shift_heatmap=True,
|
| 92 |
+
modulate_kernel=11))
|
| 93 |
+
|
| 94 |
+
data_cfg = dict(
|
| 95 |
+
image_size=[256, 256],
|
| 96 |
+
heatmap_size=[64, 64],
|
| 97 |
+
num_output_channels=channel_cfg['num_output_channels'],
|
| 98 |
+
num_joints=channel_cfg['dataset_joints'],
|
| 99 |
+
dataset_channel=channel_cfg['dataset_channel'],
|
| 100 |
+
inference_channel=channel_cfg['inference_channel'])
|
| 101 |
+
|
| 102 |
+
train_pipeline = [
|
| 103 |
+
dict(type='LoadImageFromFile'),
|
| 104 |
+
dict(
|
| 105 |
+
type='TopDownGetRandomScaleRotation', rot_factor=15,
|
| 106 |
+
scale_factor=0.15),
|
| 107 |
+
dict(type='TopDownAffineFewShot'),
|
| 108 |
+
dict(type='ToTensor'),
|
| 109 |
+
dict(
|
| 110 |
+
type='NormalizeTensor',
|
| 111 |
+
mean=[0.485, 0.456, 0.406],
|
| 112 |
+
std=[0.229, 0.224, 0.225]),
|
| 113 |
+
dict(type='TopDownGenerateTargetFewShot', sigma=1),
|
| 114 |
+
dict(
|
| 115 |
+
type='Collect',
|
| 116 |
+
keys=['img', 'target', 'target_weight'],
|
| 117 |
+
meta_keys=[
|
| 118 |
+
'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
|
| 119 |
+
'rotation', 'bbox_score', 'flip_pairs', 'category_id', 'skeleton',
|
| 120 |
+
]),
|
| 121 |
+
]
|
| 122 |
+
|
| 123 |
+
valid_pipeline = [
|
| 124 |
+
dict(type='LoadImageFromFile'),
|
| 125 |
+
dict(type='TopDownAffineFewShot'),
|
| 126 |
+
dict(type='ToTensor'),
|
| 127 |
+
dict(
|
| 128 |
+
type='NormalizeTensor',
|
| 129 |
+
mean=[0.485, 0.456, 0.406],
|
| 130 |
+
std=[0.229, 0.224, 0.225]),
|
| 131 |
+
dict(type='TopDownGenerateTargetFewShot', sigma=1),
|
| 132 |
+
dict(
|
| 133 |
+
type='Collect',
|
| 134 |
+
keys=['img', 'target', 'target_weight'],
|
| 135 |
+
meta_keys=[
|
| 136 |
+
'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale', 'rotation', 'bbox_score',
|
| 137 |
+
'flip_pairs', 'category_id',
|
| 138 |
+
'skeleton',
|
| 139 |
+
]),
|
| 140 |
+
]
|
| 141 |
+
|
| 142 |
+
test_pipeline = valid_pipeline
|
| 143 |
+
|
| 144 |
+
data_root = 'data/mp100'
|
| 145 |
+
data = dict(
|
| 146 |
+
samples_per_gpu=8,
|
| 147 |
+
workers_per_gpu=8,
|
| 148 |
+
train=dict(
|
| 149 |
+
type='TransformerPoseDataset',
|
| 150 |
+
ann_file=f'{data_root}/annotations/mp100_split3_train.json',
|
| 151 |
+
img_prefix=f'{data_root}/images/',
|
| 152 |
+
# img_prefix=f'{data_root}',
|
| 153 |
+
data_cfg=data_cfg,
|
| 154 |
+
valid_class_ids=None,
|
| 155 |
+
max_kpt_num=channel_cfg['max_kpt_num'],
|
| 156 |
+
num_shots=5,
|
| 157 |
+
pipeline=train_pipeline),
|
| 158 |
+
val=dict(
|
| 159 |
+
type='TransformerPoseDataset',
|
| 160 |
+
ann_file=f'{data_root}/annotations/mp100_split3_val.json',
|
| 161 |
+
img_prefix=f'{data_root}/images/',
|
| 162 |
+
# img_prefix=f'{data_root}',
|
| 163 |
+
data_cfg=data_cfg,
|
| 164 |
+
valid_class_ids=None,
|
| 165 |
+
max_kpt_num=channel_cfg['max_kpt_num'],
|
| 166 |
+
num_shots=5,
|
| 167 |
+
num_queries=15,
|
| 168 |
+
num_episodes=100,
|
| 169 |
+
pipeline=valid_pipeline),
|
| 170 |
+
test=dict(
|
| 171 |
+
type='TestPoseDataset',
|
| 172 |
+
ann_file=f'{data_root}/annotations/mp100_split3_test.json',
|
| 173 |
+
img_prefix=f'{data_root}/images/',
|
| 174 |
+
# img_prefix=f'{data_root}',
|
| 175 |
+
data_cfg=data_cfg,
|
| 176 |
+
valid_class_ids=None,
|
| 177 |
+
max_kpt_num=channel_cfg['max_kpt_num'],
|
| 178 |
+
num_shots=5,
|
| 179 |
+
num_queries=15,
|
| 180 |
+
num_episodes=200,
|
| 181 |
+
pck_threshold_list=[0.05, 0.10, 0.15, 0.2, 0.25],
|
| 182 |
+
pipeline=test_pipeline),
|
| 183 |
+
)
|
| 184 |
+
vis_backends = [
|
| 185 |
+
dict(type='LocalVisBackend'),
|
| 186 |
+
dict(type='TensorboardVisBackend'),
|
| 187 |
+
]
|
| 188 |
+
visualizer = dict(
|
| 189 |
+
type='PoseLocalVisualizer', vis_backends=vis_backends, name='visualizer')
|
| 190 |
+
|
| 191 |
+
shuffle_cfg = dict(interval=1)
|
configs/5shots/graph_split4_config.py
ADDED
|
@@ -0,0 +1,191 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
log_level = 'INFO'
|
| 2 |
+
load_from = None
|
| 3 |
+
resume_from = None
|
| 4 |
+
dist_params = dict(backend='nccl')
|
| 5 |
+
workflow = [('train', 1)]
|
| 6 |
+
checkpoint_config = dict(interval=20)
|
| 7 |
+
evaluation = dict(
|
| 8 |
+
interval=25,
|
| 9 |
+
metric=['PCK', 'NME', 'AUC', 'EPE'],
|
| 10 |
+
key_indicator='PCK',
|
| 11 |
+
gpu_collect=True,
|
| 12 |
+
res_folder='')
|
| 13 |
+
optimizer = dict(
|
| 14 |
+
type='Adam',
|
| 15 |
+
lr=1e-5,
|
| 16 |
+
)
|
| 17 |
+
|
| 18 |
+
optimizer_config = dict(grad_clip=None)
|
| 19 |
+
# learning policy
|
| 20 |
+
lr_config = dict(
|
| 21 |
+
policy='step',
|
| 22 |
+
warmup='linear',
|
| 23 |
+
warmup_iters=1000,
|
| 24 |
+
warmup_ratio=0.001,
|
| 25 |
+
step=[160, 180])
|
| 26 |
+
total_epochs = 200
|
| 27 |
+
log_config = dict(
|
| 28 |
+
interval=50,
|
| 29 |
+
hooks=[
|
| 30 |
+
dict(type='TextLoggerHook'),
|
| 31 |
+
dict(type='TensorboardLoggerHook')
|
| 32 |
+
])
|
| 33 |
+
|
| 34 |
+
channel_cfg = dict(
|
| 35 |
+
num_output_channels=1,
|
| 36 |
+
dataset_joints=1,
|
| 37 |
+
dataset_channel=[
|
| 38 |
+
[
|
| 39 |
+
0,
|
| 40 |
+
],
|
| 41 |
+
],
|
| 42 |
+
inference_channel=[
|
| 43 |
+
0,
|
| 44 |
+
],
|
| 45 |
+
max_kpt_num=100)
|
| 46 |
+
|
| 47 |
+
# model settings
|
| 48 |
+
model = dict(
|
| 49 |
+
type='PoseAnythingModel',
|
| 50 |
+
pretrained='pretrained/swinv2_tiny_patch4_window16_256.pth',
|
| 51 |
+
encoder_config=dict(
|
| 52 |
+
type='SwinTransformerV2',
|
| 53 |
+
embed_dim=96,
|
| 54 |
+
depths=[2, 2, 6, 2],
|
| 55 |
+
num_heads=[3, 6, 12, 24],
|
| 56 |
+
window_size=16,
|
| 57 |
+
drop_path_rate=0.2,
|
| 58 |
+
img_size=256,
|
| 59 |
+
upsample="bilinear"
|
| 60 |
+
),
|
| 61 |
+
keypoint_head=dict(
|
| 62 |
+
type='PoseHead',
|
| 63 |
+
in_channels=768,
|
| 64 |
+
transformer=dict(
|
| 65 |
+
type='EncoderDecoder',
|
| 66 |
+
d_model=256,
|
| 67 |
+
nhead=8,
|
| 68 |
+
num_encoder_layers=3,
|
| 69 |
+
num_decoder_layers=3,
|
| 70 |
+
graph_decoder='pre',
|
| 71 |
+
dim_feedforward=768,
|
| 72 |
+
dropout=0.1,
|
| 73 |
+
similarity_proj_dim=256,
|
| 74 |
+
dynamic_proj_dim=128,
|
| 75 |
+
activation="relu",
|
| 76 |
+
normalize_before=False,
|
| 77 |
+
return_intermediate_dec=True),
|
| 78 |
+
share_kpt_branch=False,
|
| 79 |
+
num_decoder_layer=3,
|
| 80 |
+
with_heatmap_loss=True,
|
| 81 |
+
|
| 82 |
+
heatmap_loss_weight=2.0,
|
| 83 |
+
support_order_dropout=-1,
|
| 84 |
+
positional_encoding=dict(
|
| 85 |
+
type='SinePositionalEncoding', num_feats=128, normalize=True)),
|
| 86 |
+
# training and testing settings
|
| 87 |
+
train_cfg=dict(),
|
| 88 |
+
test_cfg=dict(
|
| 89 |
+
flip_test=False,
|
| 90 |
+
post_process='default',
|
| 91 |
+
shift_heatmap=True,
|
| 92 |
+
modulate_kernel=11))
|
| 93 |
+
|
| 94 |
+
data_cfg = dict(
|
| 95 |
+
image_size=[256, 256],
|
| 96 |
+
heatmap_size=[64, 64],
|
| 97 |
+
num_output_channels=channel_cfg['num_output_channels'],
|
| 98 |
+
num_joints=channel_cfg['dataset_joints'],
|
| 99 |
+
dataset_channel=channel_cfg['dataset_channel'],
|
| 100 |
+
inference_channel=channel_cfg['inference_channel'])
|
| 101 |
+
|
| 102 |
+
train_pipeline = [
|
| 103 |
+
dict(type='LoadImageFromFile'),
|
| 104 |
+
dict(
|
| 105 |
+
type='TopDownGetRandomScaleRotation', rot_factor=15,
|
| 106 |
+
scale_factor=0.15),
|
| 107 |
+
dict(type='TopDownAffineFewShot'),
|
| 108 |
+
dict(type='ToTensor'),
|
| 109 |
+
dict(
|
| 110 |
+
type='NormalizeTensor',
|
| 111 |
+
mean=[0.485, 0.456, 0.406],
|
| 112 |
+
std=[0.229, 0.224, 0.225]),
|
| 113 |
+
dict(type='TopDownGenerateTargetFewShot', sigma=1),
|
| 114 |
+
dict(
|
| 115 |
+
type='Collect',
|
| 116 |
+
keys=['img', 'target', 'target_weight'],
|
| 117 |
+
meta_keys=[
|
| 118 |
+
'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
|
| 119 |
+
'rotation', 'bbox_score', 'flip_pairs', 'category_id', 'skeleton',
|
| 120 |
+
]),
|
| 121 |
+
]
|
| 122 |
+
|
| 123 |
+
valid_pipeline = [
|
| 124 |
+
dict(type='LoadImageFromFile'),
|
| 125 |
+
dict(type='TopDownAffineFewShot'),
|
| 126 |
+
dict(type='ToTensor'),
|
| 127 |
+
dict(
|
| 128 |
+
type='NormalizeTensor',
|
| 129 |
+
mean=[0.485, 0.456, 0.406],
|
| 130 |
+
std=[0.229, 0.224, 0.225]),
|
| 131 |
+
dict(type='TopDownGenerateTargetFewShot', sigma=1),
|
| 132 |
+
dict(
|
| 133 |
+
type='Collect',
|
| 134 |
+
keys=['img', 'target', 'target_weight'],
|
| 135 |
+
meta_keys=[
|
| 136 |
+
'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale', 'rotation', 'bbox_score',
|
| 137 |
+
'flip_pairs', 'category_id',
|
| 138 |
+
'skeleton',
|
| 139 |
+
]),
|
| 140 |
+
]
|
| 141 |
+
|
| 142 |
+
test_pipeline = valid_pipeline
|
| 143 |
+
|
| 144 |
+
data_root = 'data/mp100'
|
| 145 |
+
data = dict(
|
| 146 |
+
samples_per_gpu=8,
|
| 147 |
+
workers_per_gpu=8,
|
| 148 |
+
train=dict(
|
| 149 |
+
type='TransformerPoseDataset',
|
| 150 |
+
ann_file=f'{data_root}/annotations/mp100_split4_train.json',
|
| 151 |
+
img_prefix=f'{data_root}/images/',
|
| 152 |
+
# img_prefix=f'{data_root}',
|
| 153 |
+
data_cfg=data_cfg,
|
| 154 |
+
valid_class_ids=None,
|
| 155 |
+
max_kpt_num=channel_cfg['max_kpt_num'],
|
| 156 |
+
num_shots=5,
|
| 157 |
+
pipeline=train_pipeline),
|
| 158 |
+
val=dict(
|
| 159 |
+
type='TransformerPoseDataset',
|
| 160 |
+
ann_file=f'{data_root}/annotations/mp100_split4_val.json',
|
| 161 |
+
img_prefix=f'{data_root}/images/',
|
| 162 |
+
# img_prefix=f'{data_root}',
|
| 163 |
+
data_cfg=data_cfg,
|
| 164 |
+
valid_class_ids=None,
|
| 165 |
+
max_kpt_num=channel_cfg['max_kpt_num'],
|
| 166 |
+
num_shots=5,
|
| 167 |
+
num_queries=15,
|
| 168 |
+
num_episodes=100,
|
| 169 |
+
pipeline=valid_pipeline),
|
| 170 |
+
test=dict(
|
| 171 |
+
type='TestPoseDataset',
|
| 172 |
+
ann_file=f'{data_root}/annotations/mp100_split4_test.json',
|
| 173 |
+
img_prefix=f'{data_root}/images/',
|
| 174 |
+
# img_prefix=f'{data_root}',
|
| 175 |
+
data_cfg=data_cfg,
|
| 176 |
+
valid_class_ids=None,
|
| 177 |
+
max_kpt_num=channel_cfg['max_kpt_num'],
|
| 178 |
+
num_shots=5,
|
| 179 |
+
num_queries=15,
|
| 180 |
+
num_episodes=200,
|
| 181 |
+
pck_threshold_list=[0.05, 0.10, 0.15, 0.2, 0.25],
|
| 182 |
+
pipeline=test_pipeline),
|
| 183 |
+
)
|
| 184 |
+
vis_backends = [
|
| 185 |
+
dict(type='LocalVisBackend'),
|
| 186 |
+
dict(type='TensorboardVisBackend'),
|
| 187 |
+
]
|
| 188 |
+
visualizer = dict(
|
| 189 |
+
type='PoseLocalVisualizer', vis_backends=vis_backends, name='visualizer')
|
| 190 |
+
|
| 191 |
+
shuffle_cfg = dict(interval=1)
|
configs/5shots/graph_split5_config.py
ADDED
|
@@ -0,0 +1,191 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
log_level = 'INFO'
|
| 2 |
+
load_from = None
|
| 3 |
+
resume_from = None
|
| 4 |
+
dist_params = dict(backend='nccl')
|
| 5 |
+
workflow = [('train', 1)]
|
| 6 |
+
checkpoint_config = dict(interval=20)
|
| 7 |
+
evaluation = dict(
|
| 8 |
+
interval=25,
|
| 9 |
+
metric=['PCK', 'NME', 'AUC', 'EPE'],
|
| 10 |
+
key_indicator='PCK',
|
| 11 |
+
gpu_collect=True,
|
| 12 |
+
res_folder='')
|
| 13 |
+
optimizer = dict(
|
| 14 |
+
type='Adam',
|
| 15 |
+
lr=1e-5,
|
| 16 |
+
)
|
| 17 |
+
|
| 18 |
+
optimizer_config = dict(grad_clip=None)
|
| 19 |
+
# learning policy
|
| 20 |
+
lr_config = dict(
|
| 21 |
+
policy='step',
|
| 22 |
+
warmup='linear',
|
| 23 |
+
warmup_iters=1000,
|
| 24 |
+
warmup_ratio=0.001,
|
| 25 |
+
step=[160, 180])
|
| 26 |
+
total_epochs = 200
|
| 27 |
+
log_config = dict(
|
| 28 |
+
interval=50,
|
| 29 |
+
hooks=[
|
| 30 |
+
dict(type='TextLoggerHook'),
|
| 31 |
+
dict(type='TensorboardLoggerHook')
|
| 32 |
+
])
|
| 33 |
+
|
| 34 |
+
channel_cfg = dict(
|
| 35 |
+
num_output_channels=1,
|
| 36 |
+
dataset_joints=1,
|
| 37 |
+
dataset_channel=[
|
| 38 |
+
[
|
| 39 |
+
0,
|
| 40 |
+
],
|
| 41 |
+
],
|
| 42 |
+
inference_channel=[
|
| 43 |
+
0,
|
| 44 |
+
],
|
| 45 |
+
max_kpt_num=100)
|
| 46 |
+
|
| 47 |
+
# model settings
|
| 48 |
+
model = dict(
|
| 49 |
+
type='PoseAnythingModel',
|
| 50 |
+
pretrained='pretrained/swinv2_tiny_patch4_window16_256.pth',
|
| 51 |
+
encoder_config=dict(
|
| 52 |
+
type='SwinTransformerV2',
|
| 53 |
+
embed_dim=96,
|
| 54 |
+
depths=[2, 2, 6, 2],
|
| 55 |
+
num_heads=[3, 6, 12, 24],
|
| 56 |
+
window_size=16,
|
| 57 |
+
drop_path_rate=0.2,
|
| 58 |
+
img_size=256,
|
| 59 |
+
upsample="bilinear"
|
| 60 |
+
),
|
| 61 |
+
keypoint_head=dict(
|
| 62 |
+
type='PoseHead',
|
| 63 |
+
in_channels=768,
|
| 64 |
+
transformer=dict(
|
| 65 |
+
type='EncoderDecoder',
|
| 66 |
+
d_model=256,
|
| 67 |
+
nhead=8,
|
| 68 |
+
num_encoder_layers=3,
|
| 69 |
+
num_decoder_layers=3,
|
| 70 |
+
graph_decoder='pre',
|
| 71 |
+
dim_feedforward=768,
|
| 72 |
+
dropout=0.1,
|
| 73 |
+
similarity_proj_dim=256,
|
| 74 |
+
dynamic_proj_dim=128,
|
| 75 |
+
activation="relu",
|
| 76 |
+
normalize_before=False,
|
| 77 |
+
return_intermediate_dec=True),
|
| 78 |
+
share_kpt_branch=False,
|
| 79 |
+
num_decoder_layer=3,
|
| 80 |
+
with_heatmap_loss=True,
|
| 81 |
+
|
| 82 |
+
heatmap_loss_weight=2.0,
|
| 83 |
+
support_order_dropout=-1,
|
| 84 |
+
positional_encoding=dict(
|
| 85 |
+
type='SinePositionalEncoding', num_feats=128, normalize=True)),
|
| 86 |
+
# training and testing settings
|
| 87 |
+
train_cfg=dict(),
|
| 88 |
+
test_cfg=dict(
|
| 89 |
+
flip_test=False,
|
| 90 |
+
post_process='default',
|
| 91 |
+
shift_heatmap=True,
|
| 92 |
+
modulate_kernel=11))
|
| 93 |
+
|
| 94 |
+
data_cfg = dict(
|
| 95 |
+
image_size=[256, 256],
|
| 96 |
+
heatmap_size=[64, 64],
|
| 97 |
+
num_output_channels=channel_cfg['num_output_channels'],
|
| 98 |
+
num_joints=channel_cfg['dataset_joints'],
|
| 99 |
+
dataset_channel=channel_cfg['dataset_channel'],
|
| 100 |
+
inference_channel=channel_cfg['inference_channel'])
|
| 101 |
+
|
| 102 |
+
train_pipeline = [
|
| 103 |
+
dict(type='LoadImageFromFile'),
|
| 104 |
+
dict(
|
| 105 |
+
type='TopDownGetRandomScaleRotation', rot_factor=15,
|
| 106 |
+
scale_factor=0.15),
|
| 107 |
+
dict(type='TopDownAffineFewShot'),
|
| 108 |
+
dict(type='ToTensor'),
|
| 109 |
+
dict(
|
| 110 |
+
type='NormalizeTensor',
|
| 111 |
+
mean=[0.485, 0.456, 0.406],
|
| 112 |
+
std=[0.229, 0.224, 0.225]),
|
| 113 |
+
dict(type='TopDownGenerateTargetFewShot', sigma=1),
|
| 114 |
+
dict(
|
| 115 |
+
type='Collect',
|
| 116 |
+
keys=['img', 'target', 'target_weight'],
|
| 117 |
+
meta_keys=[
|
| 118 |
+
'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
|
| 119 |
+
'rotation', 'bbox_score', 'flip_pairs', 'category_id', 'skeleton',
|
| 120 |
+
]),
|
| 121 |
+
]
|
| 122 |
+
|
| 123 |
+
valid_pipeline = [
|
| 124 |
+
dict(type='LoadImageFromFile'),
|
| 125 |
+
dict(type='TopDownAffineFewShot'),
|
| 126 |
+
dict(type='ToTensor'),
|
| 127 |
+
dict(
|
| 128 |
+
type='NormalizeTensor',
|
| 129 |
+
mean=[0.485, 0.456, 0.406],
|
| 130 |
+
std=[0.229, 0.224, 0.225]),
|
| 131 |
+
dict(type='TopDownGenerateTargetFewShot', sigma=1),
|
| 132 |
+
dict(
|
| 133 |
+
type='Collect',
|
| 134 |
+
keys=['img', 'target', 'target_weight'],
|
| 135 |
+
meta_keys=[
|
| 136 |
+
'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale', 'rotation', 'bbox_score',
|
| 137 |
+
'flip_pairs', 'category_id',
|
| 138 |
+
'skeleton',
|
| 139 |
+
]),
|
| 140 |
+
]
|
| 141 |
+
|
| 142 |
+
test_pipeline = valid_pipeline
|
| 143 |
+
|
| 144 |
+
data_root = 'data/mp100'
|
| 145 |
+
data = dict(
|
| 146 |
+
samples_per_gpu=8,
|
| 147 |
+
workers_per_gpu=8,
|
| 148 |
+
train=dict(
|
| 149 |
+
type='TransformerPoseDataset',
|
| 150 |
+
ann_file=f'{data_root}/annotations/mp100_split5_train.json',
|
| 151 |
+
img_prefix=f'{data_root}/images/',
|
| 152 |
+
# img_prefix=f'{data_root}',
|
| 153 |
+
data_cfg=data_cfg,
|
| 154 |
+
valid_class_ids=None,
|
| 155 |
+
max_kpt_num=channel_cfg['max_kpt_num'],
|
| 156 |
+
num_shots=5,
|
| 157 |
+
pipeline=train_pipeline),
|
| 158 |
+
val=dict(
|
| 159 |
+
type='TransformerPoseDataset',
|
| 160 |
+
ann_file=f'{data_root}/annotations/mp100_split5_val.json',
|
| 161 |
+
img_prefix=f'{data_root}/images/',
|
| 162 |
+
# img_prefix=f'{data_root}',
|
| 163 |
+
data_cfg=data_cfg,
|
| 164 |
+
valid_class_ids=None,
|
| 165 |
+
max_kpt_num=channel_cfg['max_kpt_num'],
|
| 166 |
+
num_shots=5,
|
| 167 |
+
num_queries=15,
|
| 168 |
+
num_episodes=100,
|
| 169 |
+
pipeline=valid_pipeline),
|
| 170 |
+
test=dict(
|
| 171 |
+
type='TestPoseDataset',
|
| 172 |
+
ann_file=f'{data_root}/annotations/mp100_split5_test.json',
|
| 173 |
+
img_prefix=f'{data_root}/images/',
|
| 174 |
+
# img_prefix=f'{data_root}',
|
| 175 |
+
data_cfg=data_cfg,
|
| 176 |
+
valid_class_ids=None,
|
| 177 |
+
max_kpt_num=channel_cfg['max_kpt_num'],
|
| 178 |
+
num_shots=5,
|
| 179 |
+
num_queries=15,
|
| 180 |
+
num_episodes=200,
|
| 181 |
+
pck_threshold_list=[0.05, 0.10, 0.15, 0.2, 0.25],
|
| 182 |
+
pipeline=test_pipeline),
|
| 183 |
+
)
|
| 184 |
+
vis_backends = [
|
| 185 |
+
dict(type='LocalVisBackend'),
|
| 186 |
+
dict(type='TensorboardVisBackend'),
|
| 187 |
+
]
|
| 188 |
+
visualizer = dict(
|
| 189 |
+
type='PoseLocalVisualizer', vis_backends=vis_backends, name='visualizer')
|
| 190 |
+
|
| 191 |
+
shuffle_cfg = dict(interval=1)
|
configs/demo.py
ADDED
|
@@ -0,0 +1,194 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
log_level = 'INFO'
|
| 2 |
+
load_from = None
|
| 3 |
+
resume_from = None
|
| 4 |
+
dist_params = dict(backend='nccl')
|
| 5 |
+
workflow = [('train', 1)]
|
| 6 |
+
checkpoint_config = dict(interval=20)
|
| 7 |
+
evaluation = dict(
|
| 8 |
+
interval=25,
|
| 9 |
+
metric=['PCK', 'NME', 'AUC', 'EPE'],
|
| 10 |
+
key_indicator='PCK',
|
| 11 |
+
gpu_collect=True,
|
| 12 |
+
res_folder='')
|
| 13 |
+
optimizer = dict(
|
| 14 |
+
type='Adam',
|
| 15 |
+
lr=1e-5,
|
| 16 |
+
)
|
| 17 |
+
|
| 18 |
+
optimizer_config = dict(grad_clip=None)
|
| 19 |
+
# learning policy
|
| 20 |
+
lr_config = dict(
|
| 21 |
+
policy='step',
|
| 22 |
+
warmup='linear',
|
| 23 |
+
warmup_iters=1000,
|
| 24 |
+
warmup_ratio=0.001,
|
| 25 |
+
step=[160, 180])
|
| 26 |
+
total_epochs = 200
|
| 27 |
+
log_config = dict(
|
| 28 |
+
interval=50,
|
| 29 |
+
hooks=[
|
| 30 |
+
dict(type='TextLoggerHook'),
|
| 31 |
+
dict(type='TensorboardLoggerHook')
|
| 32 |
+
])
|
| 33 |
+
|
| 34 |
+
channel_cfg = dict(
|
| 35 |
+
num_output_channels=1,
|
| 36 |
+
dataset_joints=1,
|
| 37 |
+
dataset_channel=[
|
| 38 |
+
[
|
| 39 |
+
0,
|
| 40 |
+
],
|
| 41 |
+
],
|
| 42 |
+
inference_channel=[
|
| 43 |
+
0,
|
| 44 |
+
],
|
| 45 |
+
max_kpt_num=100)
|
| 46 |
+
|
| 47 |
+
# model settings
|
| 48 |
+
model = dict(
|
| 49 |
+
type='TransformerPoseTwoStage',
|
| 50 |
+
pretrained='swinv2_large',
|
| 51 |
+
encoder_config=dict(
|
| 52 |
+
type='SwinTransformerV2',
|
| 53 |
+
embed_dim=192,
|
| 54 |
+
depths=[2, 2, 18, 2],
|
| 55 |
+
num_heads=[6, 12, 24, 48],
|
| 56 |
+
window_size=16,
|
| 57 |
+
pretrained_window_sizes=[12, 12, 12, 6],
|
| 58 |
+
drop_path_rate=0.2,
|
| 59 |
+
img_size=256,
|
| 60 |
+
),
|
| 61 |
+
keypoint_head=dict(
|
| 62 |
+
type='TwoStageHead',
|
| 63 |
+
in_channels=1536,
|
| 64 |
+
transformer=dict(
|
| 65 |
+
type='TwoStageSupportRefineTransformer',
|
| 66 |
+
d_model=384,
|
| 67 |
+
nhead=8,
|
| 68 |
+
num_encoder_layers=3,
|
| 69 |
+
num_decoder_layers=3,
|
| 70 |
+
dim_feedforward=1536,
|
| 71 |
+
dropout=0.1,
|
| 72 |
+
similarity_proj_dim=384,
|
| 73 |
+
dynamic_proj_dim=192,
|
| 74 |
+
activation="relu",
|
| 75 |
+
normalize_before=False,
|
| 76 |
+
return_intermediate_dec=True),
|
| 77 |
+
share_kpt_branch=False,
|
| 78 |
+
num_decoder_layer=3,
|
| 79 |
+
with_heatmap_loss=True,
|
| 80 |
+
support_pos_embed=False,
|
| 81 |
+
heatmap_loss_weight=2.0,
|
| 82 |
+
skeleton_loss_weight=0.02,
|
| 83 |
+
num_samples=0,
|
| 84 |
+
support_embedding_type="fixed",
|
| 85 |
+
num_support=100,
|
| 86 |
+
support_order_dropout=-1,
|
| 87 |
+
positional_encoding=dict(
|
| 88 |
+
type='SinePositionalEncoding', num_feats=192, normalize=True)),
|
| 89 |
+
# training and testing settings
|
| 90 |
+
train_cfg=dict(),
|
| 91 |
+
test_cfg=dict(
|
| 92 |
+
flip_test=False,
|
| 93 |
+
post_process='default',
|
| 94 |
+
shift_heatmap=True,
|
| 95 |
+
modulate_kernel=11))
|
| 96 |
+
|
| 97 |
+
data_cfg = dict(
|
| 98 |
+
image_size=[256, 256],
|
| 99 |
+
heatmap_size=[64, 64],
|
| 100 |
+
num_output_channels=channel_cfg['num_output_channels'],
|
| 101 |
+
num_joints=channel_cfg['dataset_joints'],
|
| 102 |
+
dataset_channel=channel_cfg['dataset_channel'],
|
| 103 |
+
inference_channel=channel_cfg['inference_channel'])
|
| 104 |
+
|
| 105 |
+
train_pipeline = [
|
| 106 |
+
dict(type='LoadImageFromFile'),
|
| 107 |
+
dict(
|
| 108 |
+
type='TopDownGetRandomScaleRotation', rot_factor=15,
|
| 109 |
+
scale_factor=0.15),
|
| 110 |
+
dict(type='TopDownAffineFewShot'),
|
| 111 |
+
dict(type='ToTensor'),
|
| 112 |
+
dict(
|
| 113 |
+
type='NormalizeTensor',
|
| 114 |
+
mean=[0.485, 0.456, 0.406],
|
| 115 |
+
std=[0.229, 0.224, 0.225]),
|
| 116 |
+
dict(type='TopDownGenerateTargetFewShot', sigma=1),
|
| 117 |
+
dict(
|
| 118 |
+
type='Collect',
|
| 119 |
+
keys=['img', 'target', 'target_weight'],
|
| 120 |
+
meta_keys=[
|
| 121 |
+
'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
|
| 122 |
+
'rotation', 'bbox_score', 'flip_pairs', 'category_id', 'skeleton',
|
| 123 |
+
]),
|
| 124 |
+
]
|
| 125 |
+
|
| 126 |
+
valid_pipeline = [
|
| 127 |
+
dict(type='LoadImageFromFile'),
|
| 128 |
+
dict(type='TopDownAffineFewShot'),
|
| 129 |
+
dict(type='ToTensor'),
|
| 130 |
+
dict(
|
| 131 |
+
type='NormalizeTensor',
|
| 132 |
+
mean=[0.485, 0.456, 0.406],
|
| 133 |
+
std=[0.229, 0.224, 0.225]),
|
| 134 |
+
dict(type='TopDownGenerateTargetFewShot', sigma=1),
|
| 135 |
+
dict(
|
| 136 |
+
type='Collect',
|
| 137 |
+
keys=['img', 'target', 'target_weight'],
|
| 138 |
+
meta_keys=[
|
| 139 |
+
'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale', 'rotation', 'bbox_score',
|
| 140 |
+
'flip_pairs', 'category_id',
|
| 141 |
+
'skeleton',
|
| 142 |
+
]),
|
| 143 |
+
]
|
| 144 |
+
|
| 145 |
+
test_pipeline = valid_pipeline
|
| 146 |
+
|
| 147 |
+
data_root = 'data/mp100'
|
| 148 |
+
data = dict(
|
| 149 |
+
samples_per_gpu=8,
|
| 150 |
+
workers_per_gpu=8,
|
| 151 |
+
train=dict(
|
| 152 |
+
type='TransformerPoseDataset',
|
| 153 |
+
ann_file=f'{data_root}/annotations/mp100_all.json',
|
| 154 |
+
img_prefix=f'{data_root}/images/',
|
| 155 |
+
# img_prefix=f'{data_root}',
|
| 156 |
+
data_cfg=data_cfg,
|
| 157 |
+
valid_class_ids=None,
|
| 158 |
+
max_kpt_num=channel_cfg['max_kpt_num'],
|
| 159 |
+
num_shots=1,
|
| 160 |
+
pipeline=train_pipeline),
|
| 161 |
+
val=dict(
|
| 162 |
+
type='TransformerPoseDataset',
|
| 163 |
+
ann_file=f'{data_root}/annotations/mp100_split1_val.json',
|
| 164 |
+
img_prefix=f'{data_root}/images/',
|
| 165 |
+
# img_prefix=f'{data_root}',
|
| 166 |
+
data_cfg=data_cfg,
|
| 167 |
+
valid_class_ids=None,
|
| 168 |
+
max_kpt_num=channel_cfg['max_kpt_num'],
|
| 169 |
+
num_shots=1,
|
| 170 |
+
num_queries=15,
|
| 171 |
+
num_episodes=100,
|
| 172 |
+
pipeline=valid_pipeline),
|
| 173 |
+
test=dict(
|
| 174 |
+
type='TestPoseDataset',
|
| 175 |
+
ann_file=f'{data_root}/annotations/mp100_split1_test.json',
|
| 176 |
+
img_prefix=f'{data_root}/images/',
|
| 177 |
+
# img_prefix=f'{data_root}',
|
| 178 |
+
data_cfg=data_cfg,
|
| 179 |
+
valid_class_ids=None,
|
| 180 |
+
max_kpt_num=channel_cfg['max_kpt_num'],
|
| 181 |
+
num_shots=1,
|
| 182 |
+
num_queries=15,
|
| 183 |
+
num_episodes=200,
|
| 184 |
+
pck_threshold_list=[0.05, 0.10, 0.15, 0.2, 0.25],
|
| 185 |
+
pipeline=test_pipeline),
|
| 186 |
+
)
|
| 187 |
+
vis_backends = [
|
| 188 |
+
dict(type='LocalVisBackend'),
|
| 189 |
+
dict(type='TensorboardVisBackend'),
|
| 190 |
+
]
|
| 191 |
+
visualizer = dict(
|
| 192 |
+
type='PoseLocalVisualizer', vis_backends=vis_backends, name='visualizer')
|
| 193 |
+
|
| 194 |
+
shuffle_cfg = dict(interval=1)
|
configs/demo_b.py
ADDED
|
@@ -0,0 +1,191 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
log_level = 'INFO'
|
| 2 |
+
load_from = None
|
| 3 |
+
resume_from = None
|
| 4 |
+
dist_params = dict(backend='nccl')
|
| 5 |
+
workflow = [('train', 1)]
|
| 6 |
+
checkpoint_config = dict(interval=20)
|
| 7 |
+
evaluation = dict(
|
| 8 |
+
interval=25,
|
| 9 |
+
metric=['PCK', 'NME', 'AUC', 'EPE'],
|
| 10 |
+
key_indicator='PCK',
|
| 11 |
+
gpu_collect=True,
|
| 12 |
+
res_folder='')
|
| 13 |
+
optimizer = dict(
|
| 14 |
+
type='Adam',
|
| 15 |
+
lr=1e-5,
|
| 16 |
+
)
|
| 17 |
+
|
| 18 |
+
optimizer_config = dict(grad_clip=None)
|
| 19 |
+
# learning policy
|
| 20 |
+
lr_config = dict(
|
| 21 |
+
policy='step',
|
| 22 |
+
warmup='linear',
|
| 23 |
+
warmup_iters=1000,
|
| 24 |
+
warmup_ratio=0.001,
|
| 25 |
+
step=[160, 180])
|
| 26 |
+
total_epochs = 200
|
| 27 |
+
log_config = dict(
|
| 28 |
+
interval=50,
|
| 29 |
+
hooks=[
|
| 30 |
+
dict(type='TextLoggerHook'),
|
| 31 |
+
dict(type='TensorboardLoggerHook')
|
| 32 |
+
])
|
| 33 |
+
|
| 34 |
+
channel_cfg = dict(
|
| 35 |
+
num_output_channels=1,
|
| 36 |
+
dataset_joints=1,
|
| 37 |
+
dataset_channel=[
|
| 38 |
+
[
|
| 39 |
+
0,
|
| 40 |
+
],
|
| 41 |
+
],
|
| 42 |
+
inference_channel=[
|
| 43 |
+
0,
|
| 44 |
+
],
|
| 45 |
+
max_kpt_num=100)
|
| 46 |
+
|
| 47 |
+
# model settings
|
| 48 |
+
model = dict(
|
| 49 |
+
type='PoseAnythingModel',
|
| 50 |
+
pretrained='swinv2_base',
|
| 51 |
+
encoder_config=dict(
|
| 52 |
+
type='SwinTransformerV2',
|
| 53 |
+
embed_dim=128,
|
| 54 |
+
depths=[2, 2, 18, 2],
|
| 55 |
+
num_heads=[4, 8, 16, 32],
|
| 56 |
+
window_size=14,
|
| 57 |
+
pretrained_window_sizes=[12, 12, 12, 6],
|
| 58 |
+
drop_path_rate=0.1,
|
| 59 |
+
img_size=224,
|
| 60 |
+
),
|
| 61 |
+
keypoint_head=dict(
|
| 62 |
+
type='PoseHead',
|
| 63 |
+
in_channels=1024,
|
| 64 |
+
transformer=dict(
|
| 65 |
+
type='EncoderDecoder',
|
| 66 |
+
d_model=256,
|
| 67 |
+
nhead=8,
|
| 68 |
+
num_encoder_layers=3,
|
| 69 |
+
num_decoder_layers=3,
|
| 70 |
+
graph_decoder='pre',
|
| 71 |
+
dim_feedforward=1024,
|
| 72 |
+
dropout=0.1,
|
| 73 |
+
similarity_proj_dim=256,
|
| 74 |
+
dynamic_proj_dim=128,
|
| 75 |
+
activation="relu",
|
| 76 |
+
normalize_before=False,
|
| 77 |
+
return_intermediate_dec=True),
|
| 78 |
+
share_kpt_branch=False,
|
| 79 |
+
num_decoder_layer=3,
|
| 80 |
+
with_heatmap_loss=True,
|
| 81 |
+
|
| 82 |
+
heatmap_loss_weight=2.0,
|
| 83 |
+
support_order_dropout=-1,
|
| 84 |
+
positional_encoding=dict(
|
| 85 |
+
type='SinePositionalEncoding', num_feats=128, normalize=True)),
|
| 86 |
+
# training and testing settings
|
| 87 |
+
train_cfg=dict(),
|
| 88 |
+
test_cfg=dict(
|
| 89 |
+
flip_test=False,
|
| 90 |
+
post_process='default',
|
| 91 |
+
shift_heatmap=True,
|
| 92 |
+
modulate_kernel=11))
|
| 93 |
+
|
| 94 |
+
data_cfg = dict(
|
| 95 |
+
image_size=[224, 224],
|
| 96 |
+
heatmap_size=[64, 64],
|
| 97 |
+
num_output_channels=channel_cfg['num_output_channels'],
|
| 98 |
+
num_joints=channel_cfg['dataset_joints'],
|
| 99 |
+
dataset_channel=channel_cfg['dataset_channel'],
|
| 100 |
+
inference_channel=channel_cfg['inference_channel'])
|
| 101 |
+
|
| 102 |
+
train_pipeline = [
|
| 103 |
+
dict(type='LoadImageFromFile'),
|
| 104 |
+
dict(
|
| 105 |
+
type='TopDownGetRandomScaleRotation', rot_factor=15,
|
| 106 |
+
scale_factor=0.15),
|
| 107 |
+
dict(type='TopDownAffineFewShot'),
|
| 108 |
+
dict(type='ToTensor'),
|
| 109 |
+
dict(
|
| 110 |
+
type='NormalizeTensor',
|
| 111 |
+
mean=[0.485, 0.456, 0.406],
|
| 112 |
+
std=[0.229, 0.224, 0.225]),
|
| 113 |
+
dict(type='TopDownGenerateTargetFewShot', sigma=1),
|
| 114 |
+
dict(
|
| 115 |
+
type='Collect',
|
| 116 |
+
keys=['img', 'target', 'target_weight'],
|
| 117 |
+
meta_keys=[
|
| 118 |
+
'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
|
| 119 |
+
'rotation', 'bbox_score', 'flip_pairs', 'category_id', 'skeleton',
|
| 120 |
+
]),
|
| 121 |
+
]
|
| 122 |
+
|
| 123 |
+
valid_pipeline = [
|
| 124 |
+
dict(type='LoadImageFromFile'),
|
| 125 |
+
dict(type='TopDownAffineFewShot'),
|
| 126 |
+
dict(type='ToTensor'),
|
| 127 |
+
dict(
|
| 128 |
+
type='NormalizeTensor',
|
| 129 |
+
mean=[0.485, 0.456, 0.406],
|
| 130 |
+
std=[0.229, 0.224, 0.225]),
|
| 131 |
+
dict(type='TopDownGenerateTargetFewShot', sigma=1),
|
| 132 |
+
dict(
|
| 133 |
+
type='Collect',
|
| 134 |
+
keys=['img', 'target', 'target_weight'],
|
| 135 |
+
meta_keys=[
|
| 136 |
+
'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale', 'rotation', 'bbox_score',
|
| 137 |
+
'flip_pairs', 'category_id',
|
| 138 |
+
'skeleton',
|
| 139 |
+
]),
|
| 140 |
+
]
|
| 141 |
+
|
| 142 |
+
test_pipeline = valid_pipeline
|
| 143 |
+
|
| 144 |
+
data_root = 'data/mp100'
|
| 145 |
+
data = dict(
|
| 146 |
+
samples_per_gpu=8,
|
| 147 |
+
workers_per_gpu=8,
|
| 148 |
+
train=dict(
|
| 149 |
+
type='TransformerPoseDataset',
|
| 150 |
+
ann_file=f'{data_root}/annotations/mp100_split1_train.json',
|
| 151 |
+
img_prefix=f'{data_root}/images/',
|
| 152 |
+
# img_prefix=f'{data_root}',
|
| 153 |
+
data_cfg=data_cfg,
|
| 154 |
+
valid_class_ids=None,
|
| 155 |
+
max_kpt_num=channel_cfg['max_kpt_num'],
|
| 156 |
+
num_shots=1,
|
| 157 |
+
pipeline=train_pipeline),
|
| 158 |
+
val=dict(
|
| 159 |
+
type='TransformerPoseDataset',
|
| 160 |
+
ann_file=f'{data_root}/annotations/mp100_split1_val.json',
|
| 161 |
+
img_prefix=f'{data_root}/images/',
|
| 162 |
+
# img_prefix=f'{data_root}',
|
| 163 |
+
data_cfg=data_cfg,
|
| 164 |
+
valid_class_ids=None,
|
| 165 |
+
max_kpt_num=channel_cfg['max_kpt_num'],
|
| 166 |
+
num_shots=1,
|
| 167 |
+
num_queries=15,
|
| 168 |
+
num_episodes=100,
|
| 169 |
+
pipeline=valid_pipeline),
|
| 170 |
+
test=dict(
|
| 171 |
+
type='TestPoseDataset',
|
| 172 |
+
ann_file=f'{data_root}/annotations/mp100_split1_test.json',
|
| 173 |
+
img_prefix=f'{data_root}/images/',
|
| 174 |
+
# img_prefix=f'{data_root}',
|
| 175 |
+
data_cfg=data_cfg,
|
| 176 |
+
valid_class_ids=None,
|
| 177 |
+
max_kpt_num=channel_cfg['max_kpt_num'],
|
| 178 |
+
num_shots=1,
|
| 179 |
+
num_queries=15,
|
| 180 |
+
num_episodes=200,
|
| 181 |
+
pck_threshold_list=[0.05, 0.10, 0.15, 0.2, 0.25],
|
| 182 |
+
pipeline=test_pipeline),
|
| 183 |
+
)
|
| 184 |
+
vis_backends = [
|
| 185 |
+
dict(type='LocalVisBackend'),
|
| 186 |
+
dict(type='TensorboardVisBackend'),
|
| 187 |
+
]
|
| 188 |
+
visualizer = dict(
|
| 189 |
+
type='PoseLocalVisualizer', vis_backends=vis_backends, name='visualizer')
|
| 190 |
+
|
| 191 |
+
shuffle_cfg = dict(interval=1)
|
demo.py
ADDED
|
@@ -0,0 +1,289 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import argparse
|
| 2 |
+
import copy
|
| 3 |
+
import os
|
| 4 |
+
import pickle
|
| 5 |
+
import random
|
| 6 |
+
import cv2
|
| 7 |
+
import numpy as np
|
| 8 |
+
import torch
|
| 9 |
+
from mmcv import Config, DictAction
|
| 10 |
+
from mmcv.cnn import fuse_conv_bn
|
| 11 |
+
from mmcv.runner import load_checkpoint
|
| 12 |
+
from mmpose.core import wrap_fp16_model
|
| 13 |
+
from mmpose.models import build_posenet
|
| 14 |
+
from torchvision import transforms
|
| 15 |
+
from models import *
|
| 16 |
+
import torchvision.transforms.functional as F
|
| 17 |
+
|
| 18 |
+
from tools.visualization import plot_results
|
| 19 |
+
|
| 20 |
+
COLORS = [
|
| 21 |
+
[255, 0, 0], [255, 85, 0], [255, 170, 0], [255, 255, 0], [170, 255, 0],
|
| 22 |
+
[85, 255, 0], [0, 255, 0], [0, 255, 85], [0, 255, 170], [0, 255, 255],
|
| 23 |
+
[0, 170, 255], [0, 85, 255], [0, 0, 255], [85, 0, 255], [170, 0, 255],
|
| 24 |
+
[255, 0, 255], [255, 0, 170], [255, 0, 85], [255, 0, 0]]
|
| 25 |
+
|
| 26 |
+
class Resize_Pad:
|
| 27 |
+
def __init__(self, w=256, h=256):
|
| 28 |
+
self.w = w
|
| 29 |
+
self.h = h
|
| 30 |
+
|
| 31 |
+
def __call__(self, image):
|
| 32 |
+
_, w_1, h_1 = image.shape
|
| 33 |
+
ratio_1 = w_1 / h_1
|
| 34 |
+
# check if the original and final aspect ratios are the same within a margin
|
| 35 |
+
if round(ratio_1, 2) != 1:
|
| 36 |
+
# padding to preserve aspect ratio
|
| 37 |
+
if ratio_1 > 1: # Make the image higher
|
| 38 |
+
hp = int(w_1 - h_1)
|
| 39 |
+
hp = hp // 2
|
| 40 |
+
image = F.pad(image, (hp, 0, hp, 0), 0, "constant")
|
| 41 |
+
return F.resize(image, [self.h, self.w])
|
| 42 |
+
else:
|
| 43 |
+
wp = int(h_1 - w_1)
|
| 44 |
+
wp = wp // 2
|
| 45 |
+
image = F.pad(image, (0, wp, 0, wp), 0, "constant")
|
| 46 |
+
return F.resize(image, [self.h, self.w])
|
| 47 |
+
else:
|
| 48 |
+
return F.resize(image, [self.h, self.w])
|
| 49 |
+
|
| 50 |
+
|
| 51 |
+
def transform_keypoints_to_pad_and_resize(keypoints, image_size):
|
| 52 |
+
trans_keypoints = keypoints.clone()
|
| 53 |
+
h, w = image_size[:2]
|
| 54 |
+
ratio_1 = w / h
|
| 55 |
+
if ratio_1 > 1:
|
| 56 |
+
# width is bigger than height - pad height
|
| 57 |
+
hp = int(w - h)
|
| 58 |
+
hp = hp // 2
|
| 59 |
+
trans_keypoints[:, 1] = keypoints[:, 1] + hp
|
| 60 |
+
trans_keypoints *= (256. / w)
|
| 61 |
+
else:
|
| 62 |
+
# height is bigger than width - pad width
|
| 63 |
+
wp = int(image_size[1] - image_size[0])
|
| 64 |
+
wp = wp // 2
|
| 65 |
+
trans_keypoints[:, 0] = keypoints[:, 0] + wp
|
| 66 |
+
trans_keypoints *= (256. / h)
|
| 67 |
+
return trans_keypoints
|
| 68 |
+
|
| 69 |
+
|
| 70 |
+
def parse_args():
|
| 71 |
+
parser = argparse.ArgumentParser(description='Pose Anything Demo')
|
| 72 |
+
parser.add_argument('--support', help='Image file')
|
| 73 |
+
parser.add_argument('--query', help='Image file')
|
| 74 |
+
parser.add_argument('--config', default=None, help='test config file path')
|
| 75 |
+
parser.add_argument('--checkpoint', default=None, help='checkpoint file')
|
| 76 |
+
parser.add_argument('--outdir', default='output', help='checkpoint file')
|
| 77 |
+
|
| 78 |
+
parser.add_argument(
|
| 79 |
+
'--fuse-conv-bn',
|
| 80 |
+
action='store_true',
|
| 81 |
+
help='Whether to fuse conv and bn, this will slightly increase'
|
| 82 |
+
'the inference speed')
|
| 83 |
+
parser.add_argument(
|
| 84 |
+
'--cfg-options',
|
| 85 |
+
nargs='+',
|
| 86 |
+
action=DictAction,
|
| 87 |
+
default={},
|
| 88 |
+
help='override some settings in the used config, the key-value pair '
|
| 89 |
+
'in xxx=yyy format will be merged into config file. For example, '
|
| 90 |
+
"'--cfg-options model.backbone.depth=18 model.backbone.with_cp=True'")
|
| 91 |
+
args = parser.parse_args()
|
| 92 |
+
return args
|
| 93 |
+
|
| 94 |
+
|
| 95 |
+
def merge_configs(cfg1, cfg2):
|
| 96 |
+
# Merge cfg2 into cfg1
|
| 97 |
+
# Overwrite cfg1 if repeated, ignore if value is None.
|
| 98 |
+
cfg1 = {} if cfg1 is None else cfg1.copy()
|
| 99 |
+
cfg2 = {} if cfg2 is None else cfg2
|
| 100 |
+
for k, v in cfg2.items():
|
| 101 |
+
if v:
|
| 102 |
+
cfg1[k] = v
|
| 103 |
+
return cfg1
|
| 104 |
+
|
| 105 |
+
|
| 106 |
+
def main():
|
| 107 |
+
random.seed(0)
|
| 108 |
+
np.random.seed(0)
|
| 109 |
+
torch.manual_seed(0)
|
| 110 |
+
|
| 111 |
+
args = parse_args()
|
| 112 |
+
cfg = Config.fromfile(args.config)
|
| 113 |
+
|
| 114 |
+
if args.cfg_options is not None:
|
| 115 |
+
cfg.merge_from_dict(args.cfg_options)
|
| 116 |
+
# set cudnn_benchmark
|
| 117 |
+
if cfg.get('cudnn_benchmark', False):
|
| 118 |
+
torch.backends.cudnn.benchmark = True
|
| 119 |
+
cfg.data.test.test_mode = True
|
| 120 |
+
|
| 121 |
+
os.makedirs(args.outdir, exist_ok=True)
|
| 122 |
+
|
| 123 |
+
# Load data
|
| 124 |
+
support_img = cv2.imread(args.support)
|
| 125 |
+
query_img = cv2.imread(args.query)
|
| 126 |
+
if support_img is None or query_img is None:
|
| 127 |
+
raise ValueError('Fail to read images')
|
| 128 |
+
|
| 129 |
+
preprocess = transforms.Compose([
|
| 130 |
+
transforms.ToTensor(),
|
| 131 |
+
Resize_Pad(cfg.model.encoder_config.img_size, cfg.model.encoder_config.img_size)])
|
| 132 |
+
|
| 133 |
+
# frame = copy.deepcopy(support_img)
|
| 134 |
+
padded_support_img = preprocess(support_img).cpu().numpy().transpose(1, 2, 0) * 255
|
| 135 |
+
frame = copy.deepcopy(padded_support_img.astype(np.uint8).copy())
|
| 136 |
+
kp_src = []
|
| 137 |
+
skeleton = []
|
| 138 |
+
count = 0
|
| 139 |
+
prev_pt = None
|
| 140 |
+
prev_pt_idx = None
|
| 141 |
+
color_idx = 0
|
| 142 |
+
|
| 143 |
+
def selectKP(event, x, y, flags, param):
|
| 144 |
+
nonlocal kp_src, frame
|
| 145 |
+
# if we are in points selection mode, the mouse was clicked,
|
| 146 |
+
# list of points with the (x, y) location of the click
|
| 147 |
+
# and draw the circle
|
| 148 |
+
|
| 149 |
+
if event == cv2.EVENT_LBUTTONDOWN:
|
| 150 |
+
kp_src.append((x, y))
|
| 151 |
+
cv2.circle(frame, (x, y), 2, (0, 0, 255), 1)
|
| 152 |
+
cv2.imshow("Source", frame)
|
| 153 |
+
|
| 154 |
+
if event == cv2.EVENT_RBUTTONDOWN:
|
| 155 |
+
kp_src = []
|
| 156 |
+
frame = copy.deepcopy(support_img)
|
| 157 |
+
cv2.imshow("Source", frame)
|
| 158 |
+
|
| 159 |
+
def draw_line(event, x, y, flags, param):
|
| 160 |
+
nonlocal skeleton, kp_src, frame, count, prev_pt, prev_pt_idx, marked_frame, color_idx
|
| 161 |
+
if event == cv2.EVENT_LBUTTONDOWN:
|
| 162 |
+
closest_point = min(kp_src, key=lambda p: (p[0] - x) ** 2 + (p[1] - y) ** 2)
|
| 163 |
+
closest_point_index = kp_src.index(closest_point)
|
| 164 |
+
if color_idx < len(COLORS):
|
| 165 |
+
c = COLORS[color_idx]
|
| 166 |
+
else:
|
| 167 |
+
c = random.choices(range(256), k=3)
|
| 168 |
+
color = color_idx
|
| 169 |
+
cv2.circle(frame, closest_point, 2, c, 1)
|
| 170 |
+
if count == 0:
|
| 171 |
+
prev_pt = closest_point
|
| 172 |
+
prev_pt_idx = closest_point_index
|
| 173 |
+
count = count + 1
|
| 174 |
+
cv2.imshow("Source", frame)
|
| 175 |
+
else:
|
| 176 |
+
cv2.line(frame, prev_pt, closest_point, c, 2)
|
| 177 |
+
cv2.imshow("Source", frame)
|
| 178 |
+
count = 0
|
| 179 |
+
skeleton.append((prev_pt_idx, closest_point_index))
|
| 180 |
+
color_idx = color_idx + 1
|
| 181 |
+
elif event == cv2.EVENT_RBUTTONDOWN:
|
| 182 |
+
frame = copy.deepcopy(marked_frame)
|
| 183 |
+
cv2.imshow("Source", frame)
|
| 184 |
+
count = 0
|
| 185 |
+
color_idx = 0
|
| 186 |
+
skeleton = []
|
| 187 |
+
prev_pt = None
|
| 188 |
+
|
| 189 |
+
cv2.namedWindow("Source", cv2.WINDOW_NORMAL)
|
| 190 |
+
cv2.resizeWindow('Source', 800, 600)
|
| 191 |
+
cv2.setMouseCallback("Source", selectKP)
|
| 192 |
+
cv2.imshow("Source", frame)
|
| 193 |
+
|
| 194 |
+
# keep looping until points have been selected
|
| 195 |
+
print('Press any key when finished marking the points!! ')
|
| 196 |
+
while True:
|
| 197 |
+
if cv2.waitKey(1) > 0:
|
| 198 |
+
break
|
| 199 |
+
|
| 200 |
+
marked_frame = copy.deepcopy(frame)
|
| 201 |
+
cv2.setMouseCallback("Source", draw_line)
|
| 202 |
+
print('Press any key when finished creating skeleton!!')
|
| 203 |
+
while True:
|
| 204 |
+
if cv2.waitKey(1) > 0:
|
| 205 |
+
break
|
| 206 |
+
|
| 207 |
+
cv2.destroyAllWindows()
|
| 208 |
+
kp_src = torch.tensor(kp_src).float()
|
| 209 |
+
preprocess = transforms.Compose([
|
| 210 |
+
transforms.ToTensor(),
|
| 211 |
+
transforms.Normalize((0.485, 0.456, 0.406), (0.229, 0.224, 0.225)),
|
| 212 |
+
Resize_Pad(cfg.model.encoder_config.img_size, cfg.model.encoder_config.img_size)])
|
| 213 |
+
|
| 214 |
+
if len(skeleton) == 0:
|
| 215 |
+
skeleton = [(0, 0)]
|
| 216 |
+
|
| 217 |
+
support_img = preprocess(support_img).flip(0)[None]
|
| 218 |
+
query_img = preprocess(query_img).flip(0)[None]
|
| 219 |
+
# Create heatmap from keypoints
|
| 220 |
+
genHeatMap = TopDownGenerateTargetFewShot()
|
| 221 |
+
data_cfg = cfg.data_cfg
|
| 222 |
+
data_cfg['image_size'] = np.array([cfg.model.encoder_config.img_size, cfg.model.encoder_config.img_size])
|
| 223 |
+
data_cfg['joint_weights'] = None
|
| 224 |
+
data_cfg['use_different_joint_weights'] = False
|
| 225 |
+
kp_src_3d = torch.concatenate((kp_src, torch.zeros(kp_src.shape[0], 1)), dim=-1)
|
| 226 |
+
kp_src_3d_weight = torch.concatenate((torch.ones_like(kp_src), torch.zeros(kp_src.shape[0], 1)), dim=-1)
|
| 227 |
+
target_s, target_weight_s = genHeatMap._msra_generate_target(data_cfg, kp_src_3d, kp_src_3d_weight, sigma=1)
|
| 228 |
+
target_s = torch.tensor(target_s).float()[None]
|
| 229 |
+
target_weight_s = torch.tensor(target_weight_s).float()[None]
|
| 230 |
+
|
| 231 |
+
data = {
|
| 232 |
+
'img_s': [support_img],
|
| 233 |
+
'img_q': query_img,
|
| 234 |
+
'target_s': [target_s],
|
| 235 |
+
'target_weight_s': [target_weight_s],
|
| 236 |
+
'target_q': None,
|
| 237 |
+
'target_weight_q': None,
|
| 238 |
+
'return_loss': False,
|
| 239 |
+
'img_metas': [{'sample_skeleton': [skeleton],
|
| 240 |
+
'query_skeleton': skeleton,
|
| 241 |
+
'sample_joints_3d': [kp_src_3d],
|
| 242 |
+
'query_joints_3d': kp_src_3d,
|
| 243 |
+
'sample_center': [kp_src.mean(dim=0)],
|
| 244 |
+
'query_center': kp_src.mean(dim=0),
|
| 245 |
+
'sample_scale': [kp_src.max(dim=0)[0] - kp_src.min(dim=0)[0]],
|
| 246 |
+
'query_scale': kp_src.max(dim=0)[0] - kp_src.min(dim=0)[0],
|
| 247 |
+
'sample_rotation': [0],
|
| 248 |
+
'query_rotation': 0,
|
| 249 |
+
'sample_bbox_score': [1],
|
| 250 |
+
'query_bbox_score': 1,
|
| 251 |
+
'query_image_file': '',
|
| 252 |
+
'sample_image_file': [''],
|
| 253 |
+
}]
|
| 254 |
+
}
|
| 255 |
+
|
| 256 |
+
# Load model
|
| 257 |
+
model = build_posenet(cfg.model)
|
| 258 |
+
fp16_cfg = cfg.get('fp16', None)
|
| 259 |
+
if fp16_cfg is not None:
|
| 260 |
+
wrap_fp16_model(model)
|
| 261 |
+
load_checkpoint(model, args.checkpoint, map_location='cpu')
|
| 262 |
+
if args.fuse_conv_bn:
|
| 263 |
+
model = fuse_conv_bn(model)
|
| 264 |
+
model.eval()
|
| 265 |
+
|
| 266 |
+
with torch.no_grad():
|
| 267 |
+
outputs = model(**data)
|
| 268 |
+
|
| 269 |
+
# visualize results
|
| 270 |
+
vis_s_weight = target_weight_s[0]
|
| 271 |
+
vis_q_weight = target_weight_s[0]
|
| 272 |
+
vis_s_image = support_img[0].detach().cpu().numpy().transpose(1, 2, 0)
|
| 273 |
+
vis_q_image = query_img[0].detach().cpu().numpy().transpose(1, 2, 0)
|
| 274 |
+
support_kp = kp_src_3d
|
| 275 |
+
|
| 276 |
+
plot_results(vis_s_image,
|
| 277 |
+
vis_q_image,
|
| 278 |
+
support_kp,
|
| 279 |
+
vis_s_weight,
|
| 280 |
+
None,
|
| 281 |
+
vis_q_weight,
|
| 282 |
+
skeleton,
|
| 283 |
+
None,
|
| 284 |
+
torch.tensor(outputs['points']).squeeze(0),
|
| 285 |
+
out_dir=args.outdir)
|
| 286 |
+
|
| 287 |
+
|
| 288 |
+
if __name__ == '__main__':
|
| 289 |
+
main()
|
docker/Dockerfile
ADDED
|
@@ -0,0 +1,50 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
ARG PYTORCH="2.0.1"
|
| 2 |
+
ARG CUDA="11.7"
|
| 3 |
+
ARG CUDNN="8"
|
| 4 |
+
|
| 5 |
+
FROM pytorch/pytorch:${PYTORCH}-cuda${CUDA}-cudnn${CUDNN}-devel
|
| 6 |
+
|
| 7 |
+
ENV TORCH_CUDA_ARCH_LIST="6.0 6.1 7.0+PTX"
|
| 8 |
+
ENV TORCH_NVCC_FLAGS="-Xfatbin -compress-all"
|
| 9 |
+
ENV CMAKE_PREFIX_PATH="$(dirname $(which conda))/../"
|
| 10 |
+
ENV TZ=Asia/Kolkata DEBIAN_FRONTEND=noninteractive
|
| 11 |
+
# To fix GPG key error when running apt-get update
|
| 12 |
+
RUN apt-key adv --fetch-keys https://developer.download.nvidia.com/compute/cuda/repos/ubuntu1804/x86_64/3bf863cc.pub
|
| 13 |
+
RUN apt-key adv --fetch-keys https://developer.download.nvidia.com/compute/machine-learning/repos/ubuntu1804/x86_64/7fa2af80.pub
|
| 14 |
+
|
| 15 |
+
RUN apt-get update && apt-get install -y git ninja-build libglib2.0-0 libsm6 libxrender-dev libxext6 libgl1-mesa-glx\
|
| 16 |
+
&& apt-get clean \
|
| 17 |
+
&& rm -rf /var/lib/apt/lists/*
|
| 18 |
+
|
| 19 |
+
# Install xtcocotools
|
| 20 |
+
RUN pip install cython
|
| 21 |
+
RUN pip install xtcocotools
|
| 22 |
+
# Install MMEngine and MMCV
|
| 23 |
+
RUN pip install openmim
|
| 24 |
+
RUN mim install mmengine
|
| 25 |
+
RUN mim install "mmpose==0.28.1"
|
| 26 |
+
RUN mim install "mmcv-full==1.5.3"
|
| 27 |
+
RUN pip install -U torchmetrics timm
|
| 28 |
+
RUN pip install numpy scipy --upgrade
|
| 29 |
+
RUN pip install future tensorboard
|
| 30 |
+
|
| 31 |
+
WORKDIR PoseAnything
|
| 32 |
+
|
| 33 |
+
COPY models PoseAnything/models
|
| 34 |
+
COPY configs PoseAnything/configs
|
| 35 |
+
COPY pretrained PoseAnything/pretrained
|
| 36 |
+
COPY requirements.txt PoseAnything/
|
| 37 |
+
COPY tools PoseAnything/tools
|
| 38 |
+
COPY setup.cfg PoseAnything/
|
| 39 |
+
COPY setup.py PoseAnything/
|
| 40 |
+
COPY test.py PoseAnything/
|
| 41 |
+
COPY train.py PoseAnything/
|
| 42 |
+
COPY README.md PoseAnything/
|
| 43 |
+
|
| 44 |
+
RUN mkdir -p PoseAnything/data/mp100
|
| 45 |
+
WORKDIR PoseAnything
|
| 46 |
+
|
| 47 |
+
# Install MMPose
|
| 48 |
+
RUN conda clean --all
|
| 49 |
+
ENV FORCE_CUDA="1"
|
| 50 |
+
RUN python setup.py develop
|
gradio_teaser.png
ADDED

|
models/VERSION
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
0.2.0
|