|
import gradio as gr |
|
import pytz |
|
|
|
from datetime import datetime |
|
|
|
from utilities import extract, create_time_series_features, train_model, process_personalized_collection, my_loss, \ |
|
cleanup |
|
from memory_states import get_my_memory_states |
|
from plot import make_plot |
|
|
|
|
|
def anki_optimizer(file, timezone, next_day_starts_at, revlog_start_date, requestRetention, |
|
progress=gr.Progress(track_tqdm=True)): |
|
now = datetime.now() |
|
prefix = now.strftime(f'%Y_%m_%d_%H_%M_%S') |
|
proj_dir = extract(file, prefix) |
|
type_sequence, df_out = create_time_series_features(revlog_start_date, timezone, next_day_starts_at, proj_dir) |
|
w, dataset = train_model(proj_dir) |
|
my_collection, rating_markdown = process_personalized_collection(requestRetention, w) |
|
difficulty_distribution_padding, difficulty_distribution = get_my_memory_states(proj_dir, dataset, my_collection) |
|
fig, suggested_retention_markdown = make_plot(proj_dir, type_sequence, w, difficulty_distribution_padding) |
|
loss_markdown = my_loss(dataset, w) |
|
difficulty_distribution = difficulty_distribution.to_string().replace("\n", "\n\n") |
|
markdown_out = f""" |
|
{suggested_retention_markdown} |
|
|
|
# Loss Information |
|
{loss_markdown} |
|
|
|
# Difficulty Distribution |
|
{difficulty_distribution} |
|
|
|
# Ratings |
|
{rating_markdown} |
|
""" |
|
|
|
w_markdown = f""" |
|
# These are the weights for step 5 |
|
`var w = {w};`""" |
|
files = ['prediction.tsv', 'revlog.csv', 'revlog_history.tsv', 'stability_for_analysis.tsv', |
|
'expected_repetitions.csv'] |
|
files_out = [proj_dir / file for file in files] |
|
cleanup(proj_dir, files) |
|
return w_markdown, df_out, fig, markdown_out, files_out |
|
|
|
|
|
with gr.Blocks() as demo: |
|
with gr.Tab("FSRS4Anki Optimizer"): |
|
with gr.Box(): |
|
gr.Markdown(""" |
|
Based on the [tutorial](https://medium.com/@JarrettYe/how-to-use-the-next-generation-spaced-repetition-algorithm-fsrs-on-anki-5a591ca562e2) of [Jarrett Ye](https://github.com/L-M-Sherlock) |
|
Check out the instructions on the next tab. |
|
""") |
|
with gr.Box(): |
|
with gr.Row(): |
|
file = gr.File(label='Review Logs') |
|
timezone = gr.Dropdown(label="Choose your timezone", choices=pytz.all_timezones) |
|
with gr.Row(): |
|
next_day_starts_at = gr.Number(value=4, |
|
label="Replace it with your Anki's setting in Preferences -> Scheduling.", |
|
precision=0) |
|
with gr.Accordion(label="Advanced Settings", open=False): |
|
requestRetention = gr.Number(value=.9, label="Recommended to set between 0.8 0.9") |
|
with gr.Row(): |
|
revlog_start_date = gr.Textbox(value="2006-10-05", |
|
label="Replace it if you don't want the optimizer to use the review logs before a specific date.") |
|
with gr.Row(): |
|
btn_plot = gr.Button('Optimize your Anki!') |
|
with gr.Row(): |
|
w_output = gr.Markdown() |
|
with gr.Tab("Instructions"): |
|
with gr.Box(): |
|
gr.Markdown(""" |
|
# How to get personalized Anki parameters |
|
If you have been using Anki for some time and have accumulated a lot of review logs, you can try this FSRS4Anki |
|
optimizer app to generate parameters for you. |
|
|
|
This is based on the amazing work of [Jarrett Ye](https://github.com/L-M-Sherlock) |
|
# Step 1 - Get the review logs to upload |
|
1. Click the gear icon to the right of a deck’s name |
|
2. Export |
|
3. Check “Include scheduling information” and “Support older Anki versions” |
|
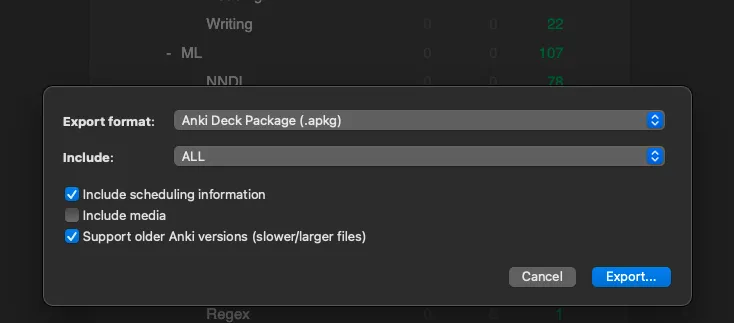 |
|
4. Export and upload that file to the app |
|
|
|
# Step 2 - Get the `next_day_starts_at` parameter |
|
1. Open preferences |
|
2. Copy the next day starts at value and paste it in the app |
|
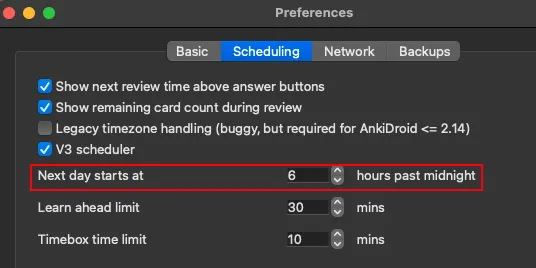 |
|
|
|
# Step 3 - Fill in the rest of the settings |
|
|
|
# Step 4 Click run |
|
|
|
# Step 5 - Replace the default parameters in FSRS4Anki with the optimized parameters |
|
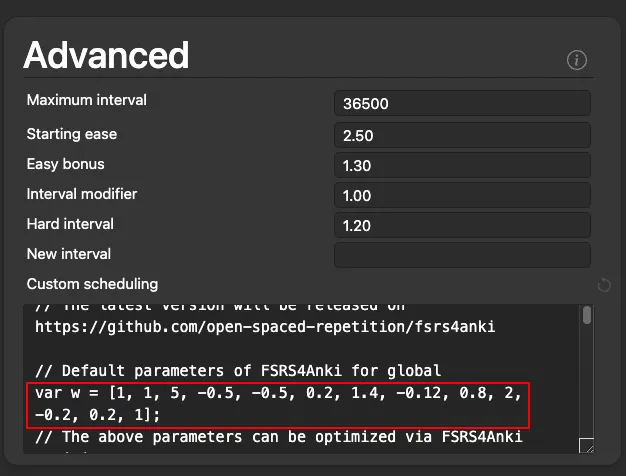 |
|
""") |
|
with gr.Tab("Analysis"): |
|
with gr.Row(): |
|
markdown_output = gr.Markdown() |
|
df_output = gr.DataFrame() |
|
with gr.Row(): |
|
plot_output = gr.Plot() |
|
with gr.Row(): |
|
files_output = gr.Files(label="Analysis Files") |
|
|
|
btn_plot.click(anki_optimizer, |
|
inputs=[file, timezone, next_day_starts_at, revlog_start_date, requestRetention], |
|
outputs=[w_output, df_output, plot_output, markdown_output, files_output]) |
|
demo.queue().launch(debug=True, show_error=True) |
|
|
|
|
|
|

