Spaces:
Running

Running
Clémentine
commited on
Commit
•
fe3bc07
1
Parent(s):
77043b2
fixed table of contents and figures
Browse files- assets/images/saturation.png +0 -0
- dist/assets/images/saturation.png +0 -0
- dist/distill.bundle.js +0 -0
- dist/distill.bundle.js.map +0 -0
- dist/index.html +107 -101
- src/distill.js +1 -1
- src/index.html +107 -101
assets/images/saturation.png
ADDED
|
dist/assets/images/saturation.png
ADDED
|
dist/distill.bundle.js
CHANGED
|
The diff for this file is too large to render.
See raw diff
|
|
|
dist/distill.bundle.js.map
CHANGED
|
The diff for this file is too large to render.
See raw diff
|
|
|
dist/index.html
CHANGED
|
@@ -49,7 +49,7 @@
|
|
| 49 |
</d-front-matter>
|
| 50 |
<d-title>
|
| 51 |
<h1 class="l-page" style="text-align: center;">Open-LLM performances are plateauing, let’s make it steep again </h1>
|
| 52 |
-
<div id="title-plot" class="
|
| 53 |
<figure>
|
| 54 |
<img src="assets/images/banner.png" alt="Banner">
|
| 55 |
</figure>
|
|
@@ -80,13 +80,13 @@
|
|
| 80 |
|
| 81 |
<h2>Harder, better, faster, stronger: Introducing the Leaderboard v2</h2>
|
| 82 |
|
| 83 |
-
|
| 84 |
|
| 85 |
<p>
|
| 86 |
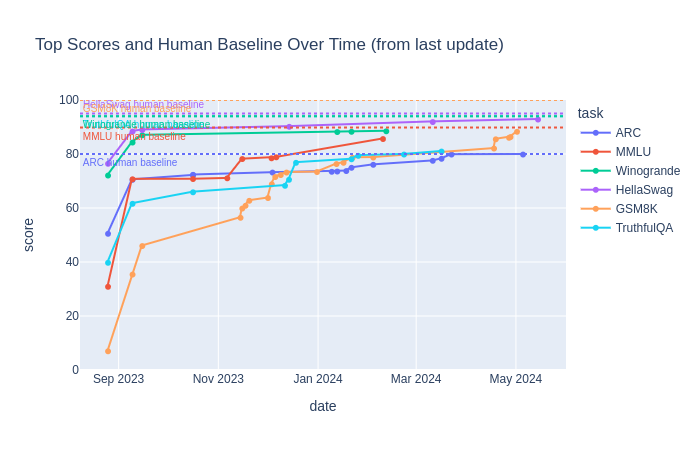
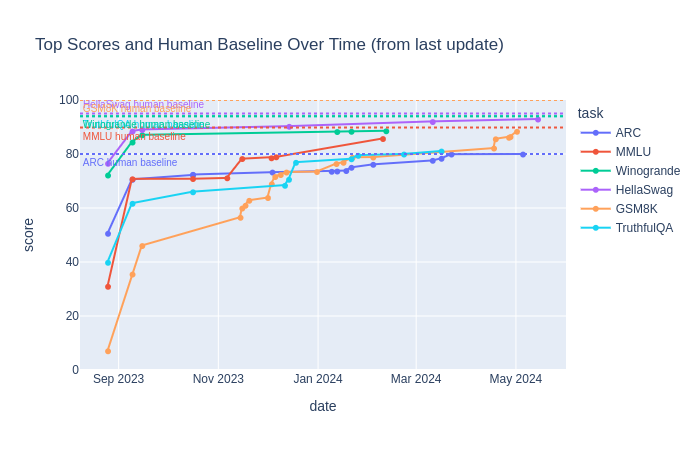
Over the past year, the benchmarks we were using got overused/saturated:
|
| 87 |
</p>
|
| 88 |
|
| 89 |
-
<div class="
|
| 90 |
<figure><img src="assets/images/saturation.png"/></figure>
|
| 91 |
<div id="saturation"></div>
|
| 92 |
</div>
|
|
@@ -146,7 +146,10 @@
|
|
| 146 |
<h3>Reporting a fairer average for ranking: using normalized scores</h3>
|
| 147 |
<p>We decided to change the final grade for the model. Instead of summing each benchmark output score, we normalized these scores between the random baseline (0 points) and the maximal possible score (100 points). We then average all normalized scores to get the final average score and compute final rankings. As a matter of example, in a benchmark containing two-choices for each questions, a random baseline will get 50 points (out of 100 points). If you use a random number generator, you will thus likely get around 50 on this evaluation. This means that scores are actually always between 50 (the lowest score you reasonably get if the benchmark is not adversarial) and 100. We therefore change the range so that a 50 on the raw score is a 0 on the normalized score. Note that for generative evaluations (like IFEval or MATH), it doesn’t change anything.</p>
|
| 148 |
|
| 149 |
-
<div class="
|
|
|
|
|
|
|
|
|
|
| 150 |
<figure><img src="assets/images/normalized_vs_raw_scores.png"/></figure>
|
| 151 |
<div id="normalisation"></div>
|
| 152 |
</div>
|
|
@@ -196,120 +199,123 @@
|
|
| 196 |
<p>We’ve also decided to remove the FAQ and About tabs from the Leaderboard, as we noticed that a number of users were not finding the tabs, and it was crowding the interface. They are now in their own dedicated documentation page, that you can find here! # Results!</p>
|
| 197 |
<p>For the version 2, we made the choice to initialize the leaderboard with the maintainer’s choice models only to start. But as always, submissions are open!</p>
|
| 198 |
|
| 199 |
-
<h2>
|
|
|
|
|
|
|
|
|
|
| 200 |
<p>When looking at the top 10 of the Open LLM Leaderboard, and comparing the v2 and v1, 5 models appear to have a relatively stable ranking: Meta’s Llama3-70B, both instruct and base version, 01-ai’s Yi-1.5-34B, chat version, Cohere’s Command R + model, and lastly Smaug-72B, from AbacusAI.</p>
|
| 201 |
-
|
| 202 |
-
|
| 203 |
-
|
| 204 |
-
|
| 205 |
-
|
| 206 |
-
|
| 207 |
-
|
| 208 |
-
|
| 209 |
-
|
| 210 |
-
|
| 211 |
-
|
| 212 |
-
|
| 213 |
-
|
| 214 |
-
|
| 215 |
-
|
| 216 |
-
|
| 217 |
-
|
| 218 |
-
|
| 219 |
-
|
| 220 |
-
|
| 221 |
-
|
| 222 |
-
|
| 223 |
-
|
| 224 |
-
|
| 225 |
-
|
| 226 |
-
|
| 227 |
-
|
| 228 |
-
|
| 229 |
-
|
| 230 |
-
|
| 231 |
-
|
| 232 |
-
|
| 233 |
-
|
| 234 |
-
|
| 235 |
-
|
| 236 |
-
|
| 237 |
-
|
| 238 |
-
|
| 239 |
-
|
| 240 |
-
|
| 241 |
-
|
| 242 |
-
|
| 243 |
-
|
| 244 |
-
|
| 245 |
-
|
| 246 |
-
|
| 247 |
-
|
| 248 |
-
|
| 249 |
-
|
| 250 |
-
|
| 251 |
-
|
| 252 |
-
|
| 253 |
-
|
| 254 |
-
|
| 255 |
-
|
| 256 |
-
|
| 257 |
-
|
| 258 |
-
|
| 259 |
-
|
| 260 |
-
|
| 261 |
-
|
| 262 |
-
|
| 263 |
-
|
| 264 |
-
|
| 265 |
-
|
| 266 |
-
|
| 267 |
-
|
| 268 |
-
|
| 269 |
-
|
| 270 |
-
|
| 271 |
|
| 272 |
-
|
| 273 |
|
| 274 |
-
|
| 275 |
-
|
| 276 |
-
|
| 277 |
-
|
| 278 |
|
| 279 |
-
|
| 280 |
|
| 281 |
-
|
| 282 |
|
| 283 |
-
|
| 284 |
-
|
| 285 |
-
|
| 286 |
-
|
| 287 |
|
| 288 |
|
| 289 |
-
|
| 290 |
|
| 291 |
-
|
| 292 |
-
|
| 293 |
-
|
| 294 |
-
|
| 295 |
|
| 296 |
|
| 297 |
-
|
| 298 |
|
| 299 |
-
|
| 300 |
-
|
| 301 |
-
|
| 302 |
-
|
| 303 |
|
| 304 |
-
|
| 305 |
|
| 306 |
-
|
| 307 |
|
| 308 |
<h2>What’s next?</h2>
|
| 309 |
<p>Much like the v1 drove model development during the last year, especially for the community, we hope that the v2 will be a cornerstone of model evaluations.</p>
|
| 310 |
<p>You’ll still be able to find all the v1 results in the <a href="https://huggingface.co/open-llm-leaderboard-old">Open LLM Leaderboard Archive</a>, and we are preparing an in depth blog about what we learned while taking care of the leaderboard!</p>
|
| 311 |
|
| 312 |
-
<div class="
|
| 313 |
<figure><img src="assets/images/timewise_analysis_full.png"/></figure>
|
| 314 |
<div id="timewise"></div>
|
| 315 |
</div>
|
|
@@ -329,7 +335,7 @@
|
|
| 329 |
const article = document.querySelector('d-article');
|
| 330 |
const toc = document.querySelector('d-contents');
|
| 331 |
if (toc) {
|
| 332 |
-
const headings = article.querySelectorAll('
|
| 333 |
let ToC = `<nav role="navigation" class="l-text figcaption"><h3>Table of contents</h3>`;
|
| 334 |
let prevLevel = 0;
|
| 335 |
|
|
@@ -341,7 +347,7 @@
|
|
| 341 |
el.setAttribute('id', el.textContent.toLowerCase().replaceAll(" ", "_"))
|
| 342 |
const link = '<a target="_self" href="' + '#' + el.getAttribute('id') + '">' + el.textContent + '</a>';
|
| 343 |
|
| 344 |
-
const level = el.tagName === '
|
| 345 |
while (prevLevel < level) {
|
| 346 |
ToC += '<ul>'
|
| 347 |
prevLevel++;
|
|
|
|
| 49 |
</d-front-matter>
|
| 50 |
<d-title>
|
| 51 |
<h1 class="l-page" style="text-align: center;">Open-LLM performances are plateauing, let’s make it steep again </h1>
|
| 52 |
+
<div id="title-plot" class="l-body l-screen">
|
| 53 |
<figure>
|
| 54 |
<img src="assets/images/banner.png" alt="Banner">
|
| 55 |
</figure>
|
|
|
|
| 80 |
|
| 81 |
<h2>Harder, better, faster, stronger: Introducing the Leaderboard v2</h2>
|
| 82 |
|
| 83 |
+
<h3>The need for a more challenging leaderboard</h3>
|
| 84 |
|
| 85 |
<p>
|
| 86 |
Over the past year, the benchmarks we were using got overused/saturated:
|
| 87 |
</p>
|
| 88 |
|
| 89 |
+
<div class="l-body">
|
| 90 |
<figure><img src="assets/images/saturation.png"/></figure>
|
| 91 |
<div id="saturation"></div>
|
| 92 |
</div>
|
|
|
|
| 146 |
<h3>Reporting a fairer average for ranking: using normalized scores</h3>
|
| 147 |
<p>We decided to change the final grade for the model. Instead of summing each benchmark output score, we normalized these scores between the random baseline (0 points) and the maximal possible score (100 points). We then average all normalized scores to get the final average score and compute final rankings. As a matter of example, in a benchmark containing two-choices for each questions, a random baseline will get 50 points (out of 100 points). If you use a random number generator, you will thus likely get around 50 on this evaluation. This means that scores are actually always between 50 (the lowest score you reasonably get if the benchmark is not adversarial) and 100. We therefore change the range so that a 50 on the raw score is a 0 on the normalized score. Note that for generative evaluations (like IFEval or MATH), it doesn’t change anything.</p>
|
| 148 |
|
| 149 |
+
<div class="l-body">
|
| 150 |
+
<!--todo: if you use an interactive visualisation instead of a plot,
|
| 151 |
+
replace the class `l-body` by `main-plot-container` and import your interactive plot in the
|
| 152 |
+
below div id, while leaving the image as such. -->
|
| 153 |
<figure><img src="assets/images/normalized_vs_raw_scores.png"/></figure>
|
| 154 |
<div id="normalisation"></div>
|
| 155 |
</div>
|
|
|
|
| 199 |
<p>We’ve also decided to remove the FAQ and About tabs from the Leaderboard, as we noticed that a number of users were not finding the tabs, and it was crowding the interface. They are now in their own dedicated documentation page, that you can find here! # Results!</p>
|
| 200 |
<p>For the version 2, we made the choice to initialize the leaderboard with the maintainer’s choice models only to start. But as always, submissions are open!</p>
|
| 201 |
|
| 202 |
+
<h2>New leaderboard, new results!</h2>
|
| 203 |
+
|
| 204 |
+
<h3>What about the rankings?</h3>
|
| 205 |
+
|
| 206 |
<p>When looking at the top 10 of the Open LLM Leaderboard, and comparing the v2 and v1, 5 models appear to have a relatively stable ranking: Meta’s Llama3-70B, both instruct and base version, 01-ai’s Yi-1.5-34B, chat version, Cohere’s Command R + model, and lastly Smaug-72B, from AbacusAI.</p>
|
| 207 |
+
<table>
|
| 208 |
+
<tr>
|
| 209 |
+
<th>Rank</th>
|
| 210 |
+
<th>Leaderboard v1</th>
|
| 211 |
+
<th>Leaderboard v2</th>
|
| 212 |
+
</tr>
|
| 213 |
+
<tr>
|
| 214 |
+
<td>⭐</td>
|
| 215 |
+
<td><b>abacusai/Smaug-72B-v0.1</b></td>
|
| 216 |
+
<td><b>meta-llama/Meta-Llama-3-70B-Instruct</b></td>
|
| 217 |
+
</tr>
|
| 218 |
+
<tr>
|
| 219 |
+
<td>2</td>
|
| 220 |
+
<td><b>meta-llama/Meta-Llama-3-70B-Instruct</b></td>
|
| 221 |
+
<td><em>microsoft/Phi-3-medium-4k-instruct</em></td>
|
| 222 |
+
</tr>
|
| 223 |
+
<tr>
|
| 224 |
+
<td>3</td>
|
| 225 |
+
<td><b>abacusai/Smaug-34B-v0.1</b></td>
|
| 226 |
+
<td>01-ai/Yi-1.5-34B-Chat</td>
|
| 227 |
+
</tr>
|
| 228 |
+
<tr>
|
| 229 |
+
<td>4</td>
|
| 230 |
+
<td>mlabonne/AlphaMonarch-7B</td>
|
| 231 |
+
<td><b>abacusai/Smaug-72B-v0.1</b></td>
|
| 232 |
+
</tr>
|
| 233 |
+
<tr>
|
| 234 |
+
<td>5</td>
|
| 235 |
+
<td>mlabonne/Beyonder-4x7B-v3</td>
|
| 236 |
+
<td><b>CohereForAI/c4ai-command-r-plus<b></td>
|
| 237 |
+
</tr>
|
| 238 |
+
<tr>
|
| 239 |
+
<td>6</td>
|
| 240 |
+
<td><b>01-ai/Yi-1.5-34B-Chat</b></td>
|
| 241 |
+
<td>Qwen/Qwen1.5-110B-Chat</td>
|
| 242 |
+
</tr>
|
| 243 |
+
<tr>
|
| 244 |
+
<td>7</td>
|
| 245 |
+
<td><b>CohereForAI/c4ai-command-r-plus</b></td>
|
| 246 |
+
<td>NousResearch/Nous-Hermes-2-Mixtral-8x7B-DPO</td>
|
| 247 |
+
</tr>
|
| 248 |
+
<tr>
|
| 249 |
+
<td>8</td>
|
| 250 |
+
<td>upstage/SOLAR-10.7B-Instruct-v1.0</td>
|
| 251 |
+
<td><b>meta-llama/Meta-Llama-3-70B</b></td>
|
| 252 |
+
</tr>
|
| 253 |
+
<tr>
|
| 254 |
+
<td>9</td>
|
| 255 |
+
<td><b>meta-llama/Meta-Llama-3-70B</b></td>
|
| 256 |
+
<td>01-ai/Yi-1.5-9B-Chat</td>
|
| 257 |
+
</tr>
|
| 258 |
+
<tr>
|
| 259 |
+
<td>10</td>
|
| 260 |
+
<td>01-ai/Yi-1.5-34B</td>
|
| 261 |
+
<td>01-ai/Yi-1.5-34B-32K</td>
|
| 262 |
+
</tr>
|
| 263 |
+
</table>
|
| 264 |
+
<p>We’ve been particularly impressed by Llama-70B-instruct, who is the best model across many evaluations (though it has 15 points less than it’s base counterpart on GPQA - does instruct tuning remove knowledge?).</p>
|
| 265 |
+
|
| 266 |
+
<p>Interestingly, a new challenger climbed the ranks to arrive in 2nd place despite its smaller size: Phi-3-medium-4K-instruct, only 13B parameters but a performance equivalent to models 2 to 4 times its size.</p>
|
| 267 |
+
|
| 268 |
+
<p>We also provide the most important top and bottom ranking changes.</p>
|
| 269 |
+
|
| 270 |
+
<div class="l-body">
|
| 271 |
+
<figure><img src="assets/images/ranking_top10_bottom10.png"/></figure>
|
| 272 |
+
<div id="ranking"></div>
|
| 273 |
+
</div>
|
| 274 |
+
|
| 275 |
+
<h3>Which evaluations should you pay most attention to?</h3>
|
| 276 |
+
<p>Depending on your use case, you should look at different aspects of the leaderboard. The overall ranking will tell you which model is better on average, but you could be interested in specific capabilities instead.</p>
|
| 277 |
|
| 278 |
+
<p>For example, our different evaluations results are not all correlated with one another, which is expected.</p>
|
| 279 |
|
| 280 |
+
<div class="l-body">
|
| 281 |
+
<figure><img src="assets/images/v2_correlation_heatmap.png"/></figure>
|
| 282 |
+
<div id="heatmap"></div>
|
| 283 |
+
</div>
|
| 284 |
|
| 285 |
+
<p>MMLU-Pro, BBH and ARC-challenge are well correlated together. It is known that these 3 are well correlated with human preference (as they tend to align with human judgment on LMSys’s chatbot arena).</p>
|
| 286 |
|
| 287 |
+
<p>IFEval is also linked to chat-related capabilities, since it investigates whether models can follow precise instructions or not. However, contrary to the others, its format discriminates against chat or instruction tuned models, with pretrained models having a harder time performing as well.</p>
|
| 288 |
|
| 289 |
+
<div class="l-body">
|
| 290 |
+
<figure><img src="assets/images/ifeval_score_per_model_type.png"/></figure>
|
| 291 |
+
<div id="ifeval"></div>
|
| 292 |
+
</div>
|
| 293 |
|
| 294 |
|
| 295 |
+
<p>If you are more interested in knowledge than alignment with human preference, the most relevant evaluations for you would be MMLU-Pro and GPQA.</p>
|
| 296 |
|
| 297 |
+
<div class="l-body">
|
| 298 |
+
<figure><img src="assets/images/v2_fn_of_mmlu.png"/></figure>
|
| 299 |
+
<div id="mmlu"></div>
|
| 300 |
+
</div>
|
| 301 |
|
| 302 |
|
| 303 |
+
<p>Both MMLU-PRO scores (in orange) and GPQA scores (in yellow) are reasonably correlated with reference MMLU scores from the Open LLM Leaderboard v1. However, since GPQA is much harder, the scores are overall much lower.</p>
|
| 304 |
|
| 305 |
+
<div class="l-body">
|
| 306 |
+
<figure><img src="assets/images/math_fn_gsm8k.png"/></figure>
|
| 307 |
+
<div id="math"></div>
|
| 308 |
+
</div>
|
| 309 |
|
| 310 |
+
<p>MATH-Lvl5 is, obviously, interesting for people concerned with math capabilities. Its results are correlated with GSM8K, except for some outliers. In the green box are models which scored 0 on GSM8K in the first leaderboard, but now have good scores on MATH-Level5 (mostly models from 01-ai) - it’s likely they were penalized by the previous format and stop tokens. In the red box are models which scored high on GSM8K but are now at 0 on MATH-Lvl5.From our current observations, these would appear to be mostly chat versions of base models (where the base models score higher on MATH!).This seems to imply that some chat tuning can impair math capabilities (from our observations, by making models exceedingly verbose).</p>
|
| 311 |
|
| 312 |
+
<p>MuSR, our last evaluation, is particularly interesting for long context models. We’ve observed that the best performers are models with 10K and plus of context size, and it seems discriminative enough to target long context reasoning specifically.</p>
|
| 313 |
|
| 314 |
<h2>What’s next?</h2>
|
| 315 |
<p>Much like the v1 drove model development during the last year, especially for the community, we hope that the v2 will be a cornerstone of model evaluations.</p>
|
| 316 |
<p>You’ll still be able to find all the v1 results in the <a href="https://huggingface.co/open-llm-leaderboard-old">Open LLM Leaderboard Archive</a>, and we are preparing an in depth blog about what we learned while taking care of the leaderboard!</p>
|
| 317 |
|
| 318 |
+
<div class="l-body">
|
| 319 |
<figure><img src="assets/images/timewise_analysis_full.png"/></figure>
|
| 320 |
<div id="timewise"></div>
|
| 321 |
</div>
|
|
|
|
| 335 |
const article = document.querySelector('d-article');
|
| 336 |
const toc = document.querySelector('d-contents');
|
| 337 |
if (toc) {
|
| 338 |
+
const headings = article.querySelectorAll('h2, h3, h4');
|
| 339 |
let ToC = `<nav role="navigation" class="l-text figcaption"><h3>Table of contents</h3>`;
|
| 340 |
let prevLevel = 0;
|
| 341 |
|
|
|
|
| 347 |
el.setAttribute('id', el.textContent.toLowerCase().replaceAll(" ", "_"))
|
| 348 |
const link = '<a target="_self" href="' + '#' + el.getAttribute('id') + '">' + el.textContent + '</a>';
|
| 349 |
|
| 350 |
+
const level = el.tagName === 'H2' ? 0 : (el.tagName === 'H3' ? 1 : 2);
|
| 351 |
while (prevLevel < level) {
|
| 352 |
ToC += '<ul>'
|
| 353 |
prevLevel++;
|
src/distill.js
CHANGED
|
@@ -2102,7 +2102,7 @@ d-appendix > distill-appendix {
|
|
| 2102 |
</div>
|
| 2103 |
<div >
|
| 2104 |
<h3>Published</h3>
|
| 2105 |
-
<div>
|
| 2106 |
</div>
|
| 2107 |
</div>
|
| 2108 |
`;
|
|
|
|
| 2102 |
</div>
|
| 2103 |
<div >
|
| 2104 |
<h3>Published</h3>
|
| 2105 |
+
<div>Jun 26, 2024</div>
|
| 2106 |
</div>
|
| 2107 |
</div>
|
| 2108 |
`;
|
src/index.html
CHANGED
|
@@ -49,7 +49,7 @@
|
|
| 49 |
</d-front-matter>
|
| 50 |
<d-title>
|
| 51 |
<h1 class="l-page" style="text-align: center;">Open-LLM performances are plateauing, let’s make it steep again </h1>
|
| 52 |
-
<div id="title-plot" class="
|
| 53 |
<figure>
|
| 54 |
<img src="assets/images/banner.png" alt="Banner">
|
| 55 |
</figure>
|
|
@@ -80,13 +80,13 @@
|
|
| 80 |
|
| 81 |
<h2>Harder, better, faster, stronger: Introducing the Leaderboard v2</h2>
|
| 82 |
|
| 83 |
-
|
| 84 |
|
| 85 |
<p>
|
| 86 |
Over the past year, the benchmarks we were using got overused/saturated:
|
| 87 |
</p>
|
| 88 |
|
| 89 |
-
<div class="
|
| 90 |
<figure><img src="assets/images/saturation.png"/></figure>
|
| 91 |
<div id="saturation"></div>
|
| 92 |
</div>
|
|
@@ -146,7 +146,10 @@
|
|
| 146 |
<h3>Reporting a fairer average for ranking: using normalized scores</h3>
|
| 147 |
<p>We decided to change the final grade for the model. Instead of summing each benchmark output score, we normalized these scores between the random baseline (0 points) and the maximal possible score (100 points). We then average all normalized scores to get the final average score and compute final rankings. As a matter of example, in a benchmark containing two-choices for each questions, a random baseline will get 50 points (out of 100 points). If you use a random number generator, you will thus likely get around 50 on this evaluation. This means that scores are actually always between 50 (the lowest score you reasonably get if the benchmark is not adversarial) and 100. We therefore change the range so that a 50 on the raw score is a 0 on the normalized score. Note that for generative evaluations (like IFEval or MATH), it doesn’t change anything.</p>
|
| 148 |
|
| 149 |
-
<div class="
|
|
|
|
|
|
|
|
|
|
| 150 |
<figure><img src="assets/images/normalized_vs_raw_scores.png"/></figure>
|
| 151 |
<div id="normalisation"></div>
|
| 152 |
</div>
|
|
@@ -196,120 +199,123 @@
|
|
| 196 |
<p>We’ve also decided to remove the FAQ and About tabs from the Leaderboard, as we noticed that a number of users were not finding the tabs, and it was crowding the interface. They are now in their own dedicated documentation page, that you can find here! # Results!</p>
|
| 197 |
<p>For the version 2, we made the choice to initialize the leaderboard with the maintainer’s choice models only to start. But as always, submissions are open!</p>
|
| 198 |
|
| 199 |
-
<h2>
|
|
|
|
|
|
|
|
|
|
| 200 |
<p>When looking at the top 10 of the Open LLM Leaderboard, and comparing the v2 and v1, 5 models appear to have a relatively stable ranking: Meta’s Llama3-70B, both instruct and base version, 01-ai’s Yi-1.5-34B, chat version, Cohere’s Command R + model, and lastly Smaug-72B, from AbacusAI.</p>
|
| 201 |
-
|
| 202 |
-
|
| 203 |
-
|
| 204 |
-
|
| 205 |
-
|
| 206 |
-
|
| 207 |
-
|
| 208 |
-
|
| 209 |
-
|
| 210 |
-
|
| 211 |
-
|
| 212 |
-
|
| 213 |
-
|
| 214 |
-
|
| 215 |
-
|
| 216 |
-
|
| 217 |
-
|
| 218 |
-
|
| 219 |
-
|
| 220 |
-
|
| 221 |
-
|
| 222 |
-
|
| 223 |
-
|
| 224 |
-
|
| 225 |
-
|
| 226 |
-
|
| 227 |
-
|
| 228 |
-
|
| 229 |
-
|
| 230 |
-
|
| 231 |
-
|
| 232 |
-
|
| 233 |
-
|
| 234 |
-
|
| 235 |
-
|
| 236 |
-
|
| 237 |
-
|
| 238 |
-
|
| 239 |
-
|
| 240 |
-
|
| 241 |
-
|
| 242 |
-
|
| 243 |
-
|
| 244 |
-
|
| 245 |
-
|
| 246 |
-
|
| 247 |
-
|
| 248 |
-
|
| 249 |
-
|
| 250 |
-
|
| 251 |
-
|
| 252 |
-
|
| 253 |
-
|
| 254 |
-
|
| 255 |
-
|
| 256 |
-
|
| 257 |
-
|
| 258 |
-
|
| 259 |
-
|
| 260 |
-
|
| 261 |
-
|
| 262 |
-
|
| 263 |
-
|
| 264 |
-
|
| 265 |
-
|
| 266 |
-
|
| 267 |
-
|
| 268 |
-
|
| 269 |
-
|
| 270 |
-
|
| 271 |
|
| 272 |
-
|
| 273 |
|
| 274 |
-
|
| 275 |
-
|
| 276 |
-
|
| 277 |
-
|
| 278 |
|
| 279 |
-
|
| 280 |
|
| 281 |
-
|
| 282 |
|
| 283 |
-
|
| 284 |
-
|
| 285 |
-
|
| 286 |
-
|
| 287 |
|
| 288 |
|
| 289 |
-
|
| 290 |
|
| 291 |
-
|
| 292 |
-
|
| 293 |
-
|
| 294 |
-
|
| 295 |
|
| 296 |
|
| 297 |
-
|
| 298 |
|
| 299 |
-
|
| 300 |
-
|
| 301 |
-
|
| 302 |
-
|
| 303 |
|
| 304 |
-
|
| 305 |
|
| 306 |
-
|
| 307 |
|
| 308 |
<h2>What’s next?</h2>
|
| 309 |
<p>Much like the v1 drove model development during the last year, especially for the community, we hope that the v2 will be a cornerstone of model evaluations.</p>
|
| 310 |
<p>You’ll still be able to find all the v1 results in the <a href="https://huggingface.co/open-llm-leaderboard-old">Open LLM Leaderboard Archive</a>, and we are preparing an in depth blog about what we learned while taking care of the leaderboard!</p>
|
| 311 |
|
| 312 |
-
<div class="
|
| 313 |
<figure><img src="assets/images/timewise_analysis_full.png"/></figure>
|
| 314 |
<div id="timewise"></div>
|
| 315 |
</div>
|
|
@@ -329,7 +335,7 @@
|
|
| 329 |
const article = document.querySelector('d-article');
|
| 330 |
const toc = document.querySelector('d-contents');
|
| 331 |
if (toc) {
|
| 332 |
-
const headings = article.querySelectorAll('
|
| 333 |
let ToC = `<nav role="navigation" class="l-text figcaption"><h3>Table of contents</h3>`;
|
| 334 |
let prevLevel = 0;
|
| 335 |
|
|
@@ -341,7 +347,7 @@
|
|
| 341 |
el.setAttribute('id', el.textContent.toLowerCase().replaceAll(" ", "_"))
|
| 342 |
const link = '<a target="_self" href="' + '#' + el.getAttribute('id') + '">' + el.textContent + '</a>';
|
| 343 |
|
| 344 |
-
const level = el.tagName === '
|
| 345 |
while (prevLevel < level) {
|
| 346 |
ToC += '<ul>'
|
| 347 |
prevLevel++;
|
|
|
|
| 49 |
</d-front-matter>
|
| 50 |
<d-title>
|
| 51 |
<h1 class="l-page" style="text-align: center;">Open-LLM performances are plateauing, let’s make it steep again </h1>
|
| 52 |
+
<div id="title-plot" class="l-body l-screen">
|
| 53 |
<figure>
|
| 54 |
<img src="assets/images/banner.png" alt="Banner">
|
| 55 |
</figure>
|
|
|
|
| 80 |
|
| 81 |
<h2>Harder, better, faster, stronger: Introducing the Leaderboard v2</h2>
|
| 82 |
|
| 83 |
+
<h3>The need for a more challenging leaderboard</h3>
|
| 84 |
|
| 85 |
<p>
|
| 86 |
Over the past year, the benchmarks we were using got overused/saturated:
|
| 87 |
</p>
|
| 88 |
|
| 89 |
+
<div class="l-body">
|
| 90 |
<figure><img src="assets/images/saturation.png"/></figure>
|
| 91 |
<div id="saturation"></div>
|
| 92 |
</div>
|
|
|
|
| 146 |
<h3>Reporting a fairer average for ranking: using normalized scores</h3>
|
| 147 |
<p>We decided to change the final grade for the model. Instead of summing each benchmark output score, we normalized these scores between the random baseline (0 points) and the maximal possible score (100 points). We then average all normalized scores to get the final average score and compute final rankings. As a matter of example, in a benchmark containing two-choices for each questions, a random baseline will get 50 points (out of 100 points). If you use a random number generator, you will thus likely get around 50 on this evaluation. This means that scores are actually always between 50 (the lowest score you reasonably get if the benchmark is not adversarial) and 100. We therefore change the range so that a 50 on the raw score is a 0 on the normalized score. Note that for generative evaluations (like IFEval or MATH), it doesn’t change anything.</p>
|
| 148 |
|
| 149 |
+
<div class="l-body">
|
| 150 |
+
<!--todo: if you use an interactive visualisation instead of a plot,
|
| 151 |
+
replace the class `l-body` by `main-plot-container` and import your interactive plot in the
|
| 152 |
+
below div id, while leaving the image as such. -->
|
| 153 |
<figure><img src="assets/images/normalized_vs_raw_scores.png"/></figure>
|
| 154 |
<div id="normalisation"></div>
|
| 155 |
</div>
|
|
|
|
| 199 |
<p>We’ve also decided to remove the FAQ and About tabs from the Leaderboard, as we noticed that a number of users were not finding the tabs, and it was crowding the interface. They are now in their own dedicated documentation page, that you can find here! # Results!</p>
|
| 200 |
<p>For the version 2, we made the choice to initialize the leaderboard with the maintainer’s choice models only to start. But as always, submissions are open!</p>
|
| 201 |
|
| 202 |
+
<h2>New leaderboard, new results!</h2>
|
| 203 |
+
|
| 204 |
+
<h3>What about the rankings?</h3>
|
| 205 |
+
|
| 206 |
<p>When looking at the top 10 of the Open LLM Leaderboard, and comparing the v2 and v1, 5 models appear to have a relatively stable ranking: Meta’s Llama3-70B, both instruct and base version, 01-ai’s Yi-1.5-34B, chat version, Cohere’s Command R + model, and lastly Smaug-72B, from AbacusAI.</p>
|
| 207 |
+
<table>
|
| 208 |
+
<tr>
|
| 209 |
+
<th>Rank</th>
|
| 210 |
+
<th>Leaderboard v1</th>
|
| 211 |
+
<th>Leaderboard v2</th>
|
| 212 |
+
</tr>
|
| 213 |
+
<tr>
|
| 214 |
+
<td>⭐</td>
|
| 215 |
+
<td><b>abacusai/Smaug-72B-v0.1</b></td>
|
| 216 |
+
<td><b>meta-llama/Meta-Llama-3-70B-Instruct</b></td>
|
| 217 |
+
</tr>
|
| 218 |
+
<tr>
|
| 219 |
+
<td>2</td>
|
| 220 |
+
<td><b>meta-llama/Meta-Llama-3-70B-Instruct</b></td>
|
| 221 |
+
<td><em>microsoft/Phi-3-medium-4k-instruct</em></td>
|
| 222 |
+
</tr>
|
| 223 |
+
<tr>
|
| 224 |
+
<td>3</td>
|
| 225 |
+
<td><b>abacusai/Smaug-34B-v0.1</b></td>
|
| 226 |
+
<td>01-ai/Yi-1.5-34B-Chat</td>
|
| 227 |
+
</tr>
|
| 228 |
+
<tr>
|
| 229 |
+
<td>4</td>
|
| 230 |
+
<td>mlabonne/AlphaMonarch-7B</td>
|
| 231 |
+
<td><b>abacusai/Smaug-72B-v0.1</b></td>
|
| 232 |
+
</tr>
|
| 233 |
+
<tr>
|
| 234 |
+
<td>5</td>
|
| 235 |
+
<td>mlabonne/Beyonder-4x7B-v3</td>
|
| 236 |
+
<td><b>CohereForAI/c4ai-command-r-plus<b></td>
|
| 237 |
+
</tr>
|
| 238 |
+
<tr>
|
| 239 |
+
<td>6</td>
|
| 240 |
+
<td><b>01-ai/Yi-1.5-34B-Chat</b></td>
|
| 241 |
+
<td>Qwen/Qwen1.5-110B-Chat</td>
|
| 242 |
+
</tr>
|
| 243 |
+
<tr>
|
| 244 |
+
<td>7</td>
|
| 245 |
+
<td><b>CohereForAI/c4ai-command-r-plus</b></td>
|
| 246 |
+
<td>NousResearch/Nous-Hermes-2-Mixtral-8x7B-DPO</td>
|
| 247 |
+
</tr>
|
| 248 |
+
<tr>
|
| 249 |
+
<td>8</td>
|
| 250 |
+
<td>upstage/SOLAR-10.7B-Instruct-v1.0</td>
|
| 251 |
+
<td><b>meta-llama/Meta-Llama-3-70B</b></td>
|
| 252 |
+
</tr>
|
| 253 |
+
<tr>
|
| 254 |
+
<td>9</td>
|
| 255 |
+
<td><b>meta-llama/Meta-Llama-3-70B</b></td>
|
| 256 |
+
<td>01-ai/Yi-1.5-9B-Chat</td>
|
| 257 |
+
</tr>
|
| 258 |
+
<tr>
|
| 259 |
+
<td>10</td>
|
| 260 |
+
<td>01-ai/Yi-1.5-34B</td>
|
| 261 |
+
<td>01-ai/Yi-1.5-34B-32K</td>
|
| 262 |
+
</tr>
|
| 263 |
+
</table>
|
| 264 |
+
<p>We’ve been particularly impressed by Llama-70B-instruct, who is the best model across many evaluations (though it has 15 points less than it’s base counterpart on GPQA - does instruct tuning remove knowledge?).</p>
|
| 265 |
+
|
| 266 |
+
<p>Interestingly, a new challenger climbed the ranks to arrive in 2nd place despite its smaller size: Phi-3-medium-4K-instruct, only 13B parameters but a performance equivalent to models 2 to 4 times its size.</p>
|
| 267 |
+
|
| 268 |
+
<p>We also provide the most important top and bottom ranking changes.</p>
|
| 269 |
+
|
| 270 |
+
<div class="l-body">
|
| 271 |
+
<figure><img src="assets/images/ranking_top10_bottom10.png"/></figure>
|
| 272 |
+
<div id="ranking"></div>
|
| 273 |
+
</div>
|
| 274 |
+
|
| 275 |
+
<h3>Which evaluations should you pay most attention to?</h3>
|
| 276 |
+
<p>Depending on your use case, you should look at different aspects of the leaderboard. The overall ranking will tell you which model is better on average, but you could be interested in specific capabilities instead.</p>
|
| 277 |
|
| 278 |
+
<p>For example, our different evaluations results are not all correlated with one another, which is expected.</p>
|
| 279 |
|
| 280 |
+
<div class="l-body">
|
| 281 |
+
<figure><img src="assets/images/v2_correlation_heatmap.png"/></figure>
|
| 282 |
+
<div id="heatmap"></div>
|
| 283 |
+
</div>
|
| 284 |
|
| 285 |
+
<p>MMLU-Pro, BBH and ARC-challenge are well correlated together. It is known that these 3 are well correlated with human preference (as they tend to align with human judgment on LMSys’s chatbot arena).</p>
|
| 286 |
|
| 287 |
+
<p>IFEval is also linked to chat-related capabilities, since it investigates whether models can follow precise instructions or not. However, contrary to the others, its format discriminates against chat or instruction tuned models, with pretrained models having a harder time performing as well.</p>
|
| 288 |
|
| 289 |
+
<div class="l-body">
|
| 290 |
+
<figure><img src="assets/images/ifeval_score_per_model_type.png"/></figure>
|
| 291 |
+
<div id="ifeval"></div>
|
| 292 |
+
</div>
|
| 293 |
|
| 294 |
|
| 295 |
+
<p>If you are more interested in knowledge than alignment with human preference, the most relevant evaluations for you would be MMLU-Pro and GPQA.</p>
|
| 296 |
|
| 297 |
+
<div class="l-body">
|
| 298 |
+
<figure><img src="assets/images/v2_fn_of_mmlu.png"/></figure>
|
| 299 |
+
<div id="mmlu"></div>
|
| 300 |
+
</div>
|
| 301 |
|
| 302 |
|
| 303 |
+
<p>Both MMLU-PRO scores (in orange) and GPQA scores (in yellow) are reasonably correlated with reference MMLU scores from the Open LLM Leaderboard v1. However, since GPQA is much harder, the scores are overall much lower.</p>
|
| 304 |
|
| 305 |
+
<div class="l-body">
|
| 306 |
+
<figure><img src="assets/images/math_fn_gsm8k.png"/></figure>
|
| 307 |
+
<div id="math"></div>
|
| 308 |
+
</div>
|
| 309 |
|
| 310 |
+
<p>MATH-Lvl5 is, obviously, interesting for people concerned with math capabilities. Its results are correlated with GSM8K, except for some outliers. In the green box are models which scored 0 on GSM8K in the first leaderboard, but now have good scores on MATH-Level5 (mostly models from 01-ai) - it’s likely they were penalized by the previous format and stop tokens. In the red box are models which scored high on GSM8K but are now at 0 on MATH-Lvl5.From our current observations, these would appear to be mostly chat versions of base models (where the base models score higher on MATH!).This seems to imply that some chat tuning can impair math capabilities (from our observations, by making models exceedingly verbose).</p>
|
| 311 |
|
| 312 |
+
<p>MuSR, our last evaluation, is particularly interesting for long context models. We’ve observed that the best performers are models with 10K and plus of context size, and it seems discriminative enough to target long context reasoning specifically.</p>
|
| 313 |
|
| 314 |
<h2>What’s next?</h2>
|
| 315 |
<p>Much like the v1 drove model development during the last year, especially for the community, we hope that the v2 will be a cornerstone of model evaluations.</p>
|
| 316 |
<p>You’ll still be able to find all the v1 results in the <a href="https://huggingface.co/open-llm-leaderboard-old">Open LLM Leaderboard Archive</a>, and we are preparing an in depth blog about what we learned while taking care of the leaderboard!</p>
|
| 317 |
|
| 318 |
+
<div class="l-body">
|
| 319 |
<figure><img src="assets/images/timewise_analysis_full.png"/></figure>
|
| 320 |
<div id="timewise"></div>
|
| 321 |
</div>
|
|
|
|
| 335 |
const article = document.querySelector('d-article');
|
| 336 |
const toc = document.querySelector('d-contents');
|
| 337 |
if (toc) {
|
| 338 |
+
const headings = article.querySelectorAll('h2, h3, h4');
|
| 339 |
let ToC = `<nav role="navigation" class="l-text figcaption"><h3>Table of contents</h3>`;
|
| 340 |
let prevLevel = 0;
|
| 341 |
|
|
|
|
| 347 |
el.setAttribute('id', el.textContent.toLowerCase().replaceAll(" ", "_"))
|
| 348 |
const link = '<a target="_self" href="' + '#' + el.getAttribute('id') + '">' + el.textContent + '</a>';
|
| 349 |
|
| 350 |
+
const level = el.tagName === 'H2' ? 0 : (el.tagName === 'H3' ? 1 : 2);
|
| 351 |
while (prevLevel < level) {
|
| 352 |
ToC += '<ul>'
|
| 353 |
prevLevel++;
|