Spaces:
Runtime error

Runtime error

Commit
•
bbe9860
1
Parent(s):
8c6cfa8
Upload 14 files
Browse filesstreamlit updated
- DPR_pipeline.png +0 -0
- README.md +17 -10
- Retrieve-rerank-DPR.png +0 -0
- Retrieve-rerank-trained-cross-encoder.png +0 -0
- custom-dpr-context-embeddings.pkl +3 -0
- demo_dpr.py +315 -0
- environment.yml +31 -0
- requirements.txt +7 -1
- retrieve-rerank.png +0 -0
DPR_pipeline.png
ADDED
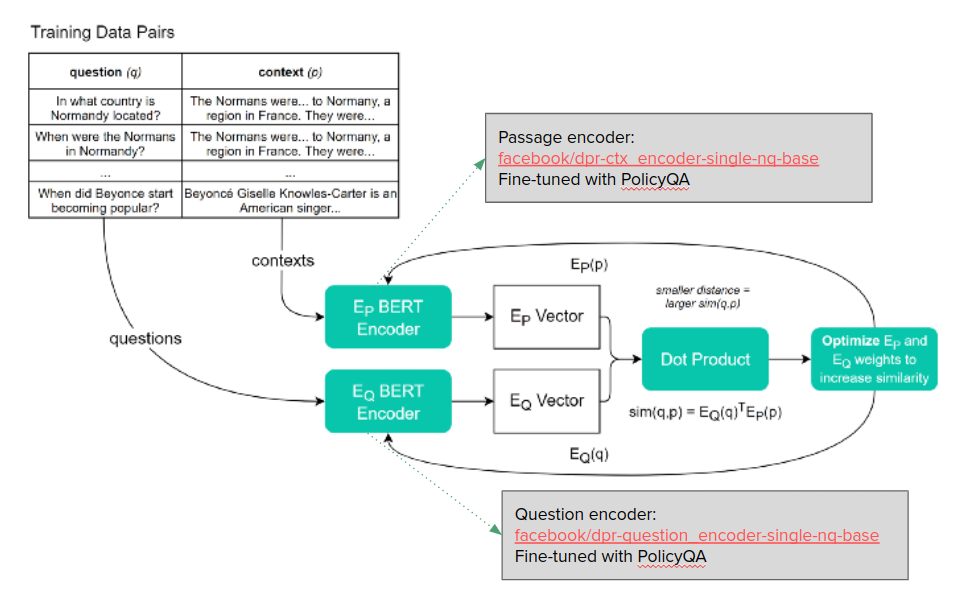
|
README.md
CHANGED
|
@@ -1,10 +1,17 @@
|
|
| 1 |
-
|
| 2 |
-
|
| 3 |
-
|
| 4 |
-
|
| 5 |
-
|
| 6 |
-
|
| 7 |
-
|
| 8 |
-
|
| 9 |
-
|
| 10 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# QuestionAnsweringDemo
|
| 2 |
+
|
| 3 |
+
## Create the environment
|
| 4 |
+
|
| 5 |
+
conda env create --file environment.yml
|
| 6 |
+
|
| 7 |
+
conda activate QADemo
|
| 8 |
+
|
| 9 |
+
After installing requirements, please make sure that you add huggingface authorization token to your ./.streamlit/secret.toml file.
|
| 10 |
+
|
| 11 |
+
It should be something like:
|
| 12 |
+
|
| 13 |
+
AUTH_TOKEN='your_auth_token_here'
|
| 14 |
+
|
| 15 |
+
## Runing the app:
|
| 16 |
+
|
| 17 |
+
streamlit run demov2.py
|
Retrieve-rerank-DPR.png
ADDED

|
Retrieve-rerank-trained-cross-encoder.png
ADDED
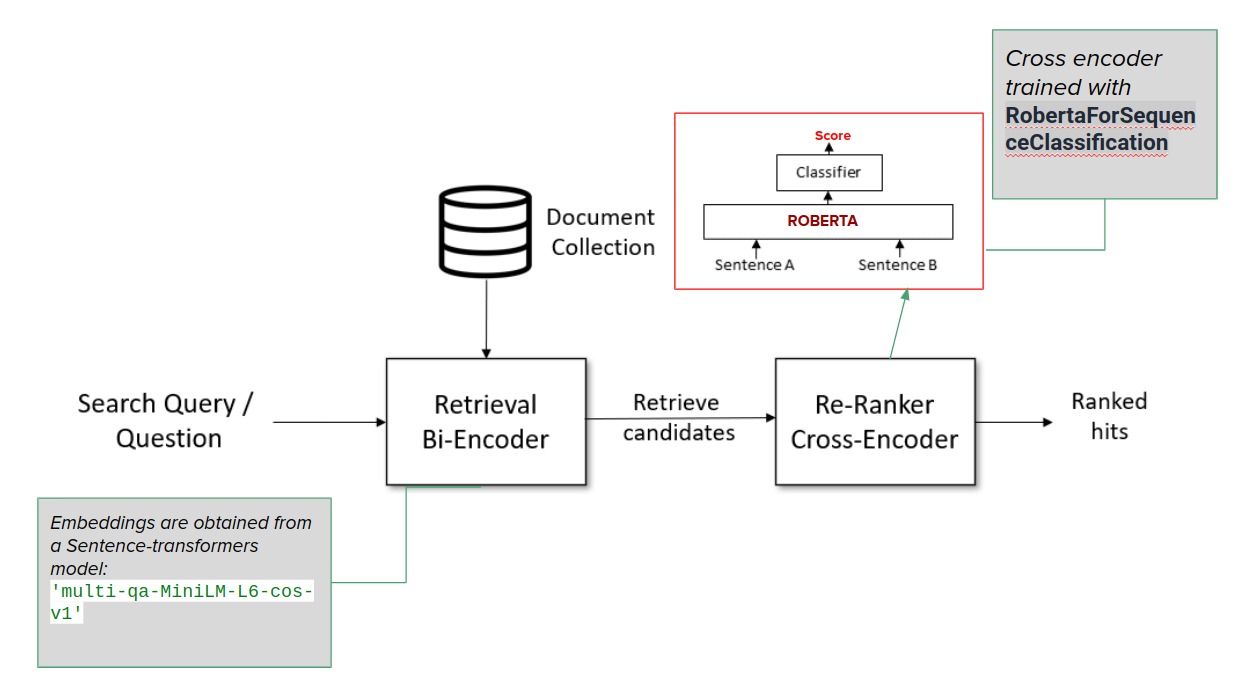
|
custom-dpr-context-embeddings.pkl
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:4370d7be3e126cfcab0d1cbffc11a44a0d7417a95a1201e35812974be5435955
|
| 3 |
+
size 931607446
|
demo_dpr.py
ADDED
|
@@ -0,0 +1,315 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import copy
|
| 2 |
+
|
| 3 |
+
import streamlit as st
|
| 4 |
+
import pandas as pd
|
| 5 |
+
from sentence_transformers import SentenceTransformer, util
|
| 6 |
+
from sentence_transformers.cross_encoder import CrossEncoder
|
| 7 |
+
from st_aggrid import GridOptionsBuilder, AgGrid
|
| 8 |
+
import pickle
|
| 9 |
+
import torch
|
| 10 |
+
from transformers import DPRQuestionEncoderTokenizer, AutoModel
|
| 11 |
+
from pathlib import Path
|
| 12 |
+
import base64
|
| 13 |
+
import regex
|
| 14 |
+
import tokenizers
|
| 15 |
+
|
| 16 |
+
st.set_page_config(layout="wide")
|
| 17 |
+
|
| 18 |
+
DATAFRAME_FILE_ORIGINAL = 'policyQA_original.csv'
|
| 19 |
+
DATAFRAME_FILE_BSBS = 'policyQA_bsbs_sentence.csv'
|
| 20 |
+
|
| 21 |
+
selectbox_selections = {
|
| 22 |
+
'Retrieve - Rerank (with fine-tuned cross-encoder)': 1,
|
| 23 |
+
'Dense Passage Retrieval':2,
|
| 24 |
+
'Retrieve - Reranking with DPR':3,
|
| 25 |
+
'Retrieve - Rerank':4
|
| 26 |
+
}
|
| 27 |
+
imagebox_selections = {
|
| 28 |
+
'Retrieve - Rerank (with fine-tuned cross-encoder)': 'Retrieve-rerank-trained-cross-encoder.png',
|
| 29 |
+
'Dense Passage Retrieval': 'DPR_pipeline.png',
|
| 30 |
+
'Retrieve - Reranking with DPR': 'Retrieve-rerank-DPR.png',
|
| 31 |
+
'Retrieve - Rerank': 'retrieve-rerank.png'
|
| 32 |
+
}
|
| 33 |
+
|
| 34 |
+
def retrieve_rerank(question):
|
| 35 |
+
# Semantic Search (Retrieve)
|
| 36 |
+
question_embedding = bi_encoder.encode(question, convert_to_tensor=True)
|
| 37 |
+
hits = util.semantic_search(question_embedding, context_embeddings, top_k=100)
|
| 38 |
+
if len(hits) == 0:
|
| 39 |
+
return []
|
| 40 |
+
hits = hits[0]
|
| 41 |
+
# Rerank - score all retrieved passages with cross-encoder
|
| 42 |
+
cross_inp = [[question, contexes[hit['corpus_id']]] for hit in hits]
|
| 43 |
+
cross_scores = cross_encoder.predict(cross_inp)
|
| 44 |
+
|
| 45 |
+
# Sort results by the cross-encoder scores
|
| 46 |
+
for idx in range(len(cross_scores)):
|
| 47 |
+
hits[idx]['cross-score'] = cross_scores[idx]
|
| 48 |
+
|
| 49 |
+
# Output of top-5 hits from re-ranker
|
| 50 |
+
hits = sorted(hits, key=lambda x: x['cross-score'], reverse=True)
|
| 51 |
+
top_5_contexes = []
|
| 52 |
+
top_5_scores = []
|
| 53 |
+
for hit in hits[0:20]:
|
| 54 |
+
top_5_contexes.append(contexes[hit['corpus_id']])
|
| 55 |
+
top_5_scores.append(hit['cross-score'])
|
| 56 |
+
return top_5_contexes, top_5_scores
|
| 57 |
+
|
| 58 |
+
|
| 59 |
+
|
| 60 |
+
@st.cache(show_spinner=False, allow_output_mutation=True)
|
| 61 |
+
def load_paragraphs(path):
|
| 62 |
+
with open(path, "rb") as fIn:
|
| 63 |
+
cache_data = pickle.load(fIn)
|
| 64 |
+
corpus_sentences = cache_data['contexes']
|
| 65 |
+
corpus_embeddings = cache_data['embeddings']
|
| 66 |
+
|
| 67 |
+
return corpus_embeddings, corpus_sentences
|
| 68 |
+
|
| 69 |
+
@st.cache(show_spinner=False)
|
| 70 |
+
def load_dataframes():
|
| 71 |
+
data_original = pd.read_csv(DATAFRAME_FILE_ORIGINAL, index_col=0, sep='|')
|
| 72 |
+
data_bsbs = pd.read_csv(DATAFRAME_FILE_BSBS, index_col=0, sep='|')
|
| 73 |
+
data_original = data_original.sample(frac=1).reset_index(drop=True)
|
| 74 |
+
data_bsbs = data_bsbs.sample(frac=1).reset_index(drop=True)
|
| 75 |
+
return data_original, data_bsbs
|
| 76 |
+
|
| 77 |
+
def dot_product(question_output, context_output):
|
| 78 |
+
mat1 = torch.unsqueeze(question_output, dim=1)
|
| 79 |
+
mat2 = torch.unsqueeze(context_output, dim=2)
|
| 80 |
+
result = torch.bmm(mat1, mat2)
|
| 81 |
+
result = torch.squeeze(result, dim=1)
|
| 82 |
+
result = torch.squeeze(result, dim=1)
|
| 83 |
+
return result
|
| 84 |
+
|
| 85 |
+
def retrieve_rerank_DPR(question):
|
| 86 |
+
hits = retrieve_with_dpr_embeddings(question)
|
| 87 |
+
return rerank_with_DPR(hits, question)
|
| 88 |
+
|
| 89 |
+
def DPR_reranking(question, selected_contexes, selected_embeddings):
|
| 90 |
+
scores = []
|
| 91 |
+
tokenized_question = question_tokenizer(question, padding=True, truncation=True, return_tensors="pt",
|
| 92 |
+
add_special_tokens=True)
|
| 93 |
+
question_output = dpr_trained.model.question_model(**tokenized_question)
|
| 94 |
+
question_output = question_output['pooler_output']
|
| 95 |
+
for context_embedding in selected_embeddings:
|
| 96 |
+
score = dot_product(question_output, context_embedding)
|
| 97 |
+
scores.append(score.detach().cpu())
|
| 98 |
+
|
| 99 |
+
scores_index = sorted(range(len(scores)), key=lambda x: scores[x], reverse=True)
|
| 100 |
+
contexes_list = []
|
| 101 |
+
scores_final = []
|
| 102 |
+
for i, idx in enumerate(scores_index[:5]):
|
| 103 |
+
scores_final.append(scores[idx])
|
| 104 |
+
contexes_list.append(selected_contexes[idx])
|
| 105 |
+
return scores_final, contexes_list
|
| 106 |
+
|
| 107 |
+
def search_pipeline(question, search_method):
|
| 108 |
+
if search_method == 1: #Retrieve - rerank with fine-tuned cross encoder
|
| 109 |
+
return retrieve_rerank_with_trained_cross_encoder(question)
|
| 110 |
+
if search_method == 2:
|
| 111 |
+
return custom_dpr_pipeline(question) # DPR only
|
| 112 |
+
if search_method == 3:
|
| 113 |
+
return retrieve_rerank_DPR(question)
|
| 114 |
+
if search_method == 4:
|
| 115 |
+
return retrieve_rerank(question)
|
| 116 |
+
|
| 117 |
+
|
| 118 |
+
def custom_dpr_pipeline(question):
|
| 119 |
+
#paragraphs
|
| 120 |
+
tokenized_question = question_tokenizer(question, padding=True, truncation=True, return_tensors="pt",
|
| 121 |
+
add_special_tokens=True)
|
| 122 |
+
question_embedding = dpr_trained.model.question_model(**tokenized_question)
|
| 123 |
+
question_embedding = question_embedding['pooler_output']
|
| 124 |
+
results_list = []
|
| 125 |
+
for i,context_embedding in enumerate(dpr_context_embeddings):
|
| 126 |
+
score = dot_product(question_embedding, context_embedding)
|
| 127 |
+
results_list.append(score.detach().cpu().numpy()[0])
|
| 128 |
+
|
| 129 |
+
hits = sorted(range(len(results_list)), key=lambda i: results_list[i], reverse=True)
|
| 130 |
+
top_5_contexes = []
|
| 131 |
+
top_5_scores = []
|
| 132 |
+
for j in hits[0:5]:
|
| 133 |
+
top_5_contexes.append(dpr_contexes[j])
|
| 134 |
+
top_5_scores.append(results_list[j])
|
| 135 |
+
return top_5_contexes, top_5_scores
|
| 136 |
+
|
| 137 |
+
def retrieve(question, corpus_embeddings):
|
| 138 |
+
# Semantic Search (Retrieve)
|
| 139 |
+
question_embedding = bi_encoder.encode(question, convert_to_tensor=True)
|
| 140 |
+
hits = util.semantic_search(question_embedding, corpus_embeddings, top_k=100)
|
| 141 |
+
if len(hits) == 0:
|
| 142 |
+
return []
|
| 143 |
+
hits = hits[0]
|
| 144 |
+
return hits
|
| 145 |
+
|
| 146 |
+
def retrieve_with_dpr_embeddings(question):
|
| 147 |
+
# Semantic Search (Retrieve)
|
| 148 |
+
question_tokens = question_tokenizer(question, padding=True, truncation=True, return_tensors="pt",
|
| 149 |
+
add_special_tokens=True)
|
| 150 |
+
|
| 151 |
+
question_embedding = dpr_trained.model.question_model(**question_tokens)['pooler_output']
|
| 152 |
+
question_embedding = torch.squeeze(question_embedding, dim=0)
|
| 153 |
+
corpus_embeddings = torch.stack(dpr_context_embeddings)
|
| 154 |
+
corpus_embeddings = torch.squeeze(corpus_embeddings, dim=1)
|
| 155 |
+
hits = util.semantic_search(question_embedding, corpus_embeddings, top_k=100)
|
| 156 |
+
if len(hits) == 0:
|
| 157 |
+
return []
|
| 158 |
+
hits = hits[0]
|
| 159 |
+
return hits
|
| 160 |
+
|
| 161 |
+
def rerank_with_DPR(hits, question):
|
| 162 |
+
# Rerank - score all retrieved passages with cross-encoder
|
| 163 |
+
selected_contexes = [dpr_contexes[hit['corpus_id']] for hit in hits]
|
| 164 |
+
selected_embeddings = [dpr_context_embeddings[hit['corpus_id']] for hit in hits]
|
| 165 |
+
top_5_scores, top_5_contexes = DPR_reranking(question, selected_contexes, selected_embeddings)
|
| 166 |
+
return top_5_contexes, top_5_scores
|
| 167 |
+
|
| 168 |
+
def DPR_reranking(question, selected_contexes, selected_embeddings):
|
| 169 |
+
scores = []
|
| 170 |
+
tokenized_question = question_tokenizer(question, padding=True, truncation=True, return_tensors="pt",
|
| 171 |
+
add_special_tokens=True)
|
| 172 |
+
question_output = dpr_trained.model.question_model(**tokenized_question)
|
| 173 |
+
question_output = question_output['pooler_output']
|
| 174 |
+
for context_embedding in selected_embeddings:
|
| 175 |
+
score = dot_product(question_output, context_embedding)
|
| 176 |
+
scores.append(score.detach().cpu().numpy()[0])
|
| 177 |
+
|
| 178 |
+
scores_index = sorted(range(len(scores)), key=lambda x: scores[x], reverse=True)
|
| 179 |
+
contexes_list = []
|
| 180 |
+
scores_final = []
|
| 181 |
+
for i, idx in enumerate(scores_index[:5]):
|
| 182 |
+
scores_final.append(scores[idx])
|
| 183 |
+
contexes_list.append(selected_contexes[idx])
|
| 184 |
+
return scores_final, contexes_list
|
| 185 |
+
|
| 186 |
+
|
| 187 |
+
def retrieve_rerank_with_trained_cross_encoder(question):
|
| 188 |
+
hits = retrieve(question, context_embeddings)
|
| 189 |
+
cross_inp = [(question, contexes[hit['corpus_id']]) for hit in hits]
|
| 190 |
+
cross_scores = trained_cross_encoder.predict(cross_inp)
|
| 191 |
+
# Sort results by the cross-encoder scores
|
| 192 |
+
for idx in range(len(cross_scores)):
|
| 193 |
+
hits[idx]['cross-score'] = cross_scores[idx][0]
|
| 194 |
+
|
| 195 |
+
# Output of top-5 hits from re-ranker
|
| 196 |
+
hits = sorted(hits, key=lambda x: x['cross-score'], reverse=True)
|
| 197 |
+
top_5_contexes = []
|
| 198 |
+
top_5_scores = []
|
| 199 |
+
for hit in hits[0:5]:
|
| 200 |
+
top_5_contexes.append(contexes[hit['corpus_id']])
|
| 201 |
+
top_5_scores.append(hit['cross-score'])
|
| 202 |
+
return top_5_contexes, top_5_scores
|
| 203 |
+
|
| 204 |
+
|
| 205 |
+
def interactive_table(dataframe):
|
| 206 |
+
gb = GridOptionsBuilder.from_dataframe(dataframe)
|
| 207 |
+
gb.configure_pagination(paginationAutoPageSize=True)
|
| 208 |
+
gb.configure_side_bar()
|
| 209 |
+
gb.configure_selection('single', rowMultiSelectWithClick=True,
|
| 210 |
+
groupSelectsChildren="Group checkbox select children") # Enable multi-row selection
|
| 211 |
+
gridOptions = gb.build()
|
| 212 |
+
grid_response = AgGrid(
|
| 213 |
+
dataframe,
|
| 214 |
+
gridOptions=gridOptions,
|
| 215 |
+
data_return_mode='AS_INPUT',
|
| 216 |
+
update_mode='SELECTION_CHANGED',
|
| 217 |
+
enable_enterprise_modules=False,
|
| 218 |
+
fit_columns_on_grid_load=False,
|
| 219 |
+
theme='streamlit', # Add theme color to the table
|
| 220 |
+
height=350,
|
| 221 |
+
width='100%',
|
| 222 |
+
reload_data=False
|
| 223 |
+
)
|
| 224 |
+
return grid_response
|
| 225 |
+
|
| 226 |
+
def img_to_bytes(img_path):
|
| 227 |
+
img_bytes = Path(img_path).read_bytes()
|
| 228 |
+
encoded = base64.b64encode(img_bytes).decode()
|
| 229 |
+
return encoded
|
| 230 |
+
|
| 231 |
+
def qa_main_widgetsv2():
|
| 232 |
+
st.title("Question Answering Demo")
|
| 233 |
+
st.markdown("""---""")
|
| 234 |
+
option = st.selectbox("Select a search method:", list(selectbox_selections.keys()))
|
| 235 |
+
header_html = "<center> <img src='data:image/png;base64,{}' class='img-fluid' width='60%', height='40%'> </center>".format(
|
| 236 |
+
img_to_bytes(imagebox_selections[option])
|
| 237 |
+
)
|
| 238 |
+
st.markdown(
|
| 239 |
+
header_html, unsafe_allow_html=True,
|
| 240 |
+
)
|
| 241 |
+
st.markdown("""---""")
|
| 242 |
+
col1, col2, col3 = st.columns([2, 1, 1])
|
| 243 |
+
with col1:
|
| 244 |
+
form = st.form(key='first_form')
|
| 245 |
+
question = form.text_area("What is your question?:", height=200)
|
| 246 |
+
submit = form.form_submit_button('Submit')
|
| 247 |
+
if "form_submit" not in st.session_state:
|
| 248 |
+
st.session_state.form_submit = False
|
| 249 |
+
if submit:
|
| 250 |
+
st.session_state.form_submit = True
|
| 251 |
+
if st.session_state.form_submit and question != '':
|
| 252 |
+
with st.spinner(text='Related context search in progress..'):
|
| 253 |
+
top_5_contexes, top_5_scores = search_pipeline(question.strip(), selectbox_selections[option])
|
| 254 |
+
if len(top_5_contexes) == 0:
|
| 255 |
+
st.error("Related context not found!")
|
| 256 |
+
st.session_state.form_submit = False
|
| 257 |
+
else:
|
| 258 |
+
for i, context in enumerate(top_5_contexes):
|
| 259 |
+
st.markdown(f"## Related Context - {i + 1} (score: {top_5_scores[i]:.2f})")
|
| 260 |
+
st.markdown(context)
|
| 261 |
+
st.markdown("""---""")
|
| 262 |
+
with col2:
|
| 263 |
+
st.markdown("## Original Questions")
|
| 264 |
+
grid_response = interactive_table(dataframe_original)
|
| 265 |
+
data1 = grid_response['selected_rows']
|
| 266 |
+
if "grid_click_1" not in st.session_state:
|
| 267 |
+
st.session_state.grid_click_1 = False
|
| 268 |
+
if len(data1) > 0:
|
| 269 |
+
st.session_state.grid_click_1 = True
|
| 270 |
+
if st.session_state.grid_click_1:
|
| 271 |
+
selection = data1[0]
|
| 272 |
+
# st.markdown("## Context & Answer:")
|
| 273 |
+
st.markdown("### Context:")
|
| 274 |
+
st.write(selection['context'])
|
| 275 |
+
st.markdown("### Question:")
|
| 276 |
+
st.write(selection['question'])
|
| 277 |
+
st.markdown("### Answer:")
|
| 278 |
+
st.write(selection['answer'])
|
| 279 |
+
st.session_state.grid_click_1 = False
|
| 280 |
+
with col3:
|
| 281 |
+
st.markdown("## Our Questions")
|
| 282 |
+
grid_response = interactive_table(dataframe_bsbs)
|
| 283 |
+
data2 = grid_response['selected_rows']
|
| 284 |
+
if "grid_click_2" not in st.session_state:
|
| 285 |
+
st.session_state.grid_click_2 = False
|
| 286 |
+
if len(data2) > 0:
|
| 287 |
+
st.session_state.grid_click_2 = True
|
| 288 |
+
if st.session_state.grid_click_2:
|
| 289 |
+
selection = data2[0]
|
| 290 |
+
# st.markdown("## Context & Answer:")
|
| 291 |
+
st.markdown("### Context:")
|
| 292 |
+
st.write(selection['context'])
|
| 293 |
+
st.markdown("### Question:")
|
| 294 |
+
st.write(selection['question'])
|
| 295 |
+
st.markdown("### Answer:")
|
| 296 |
+
st.write(selection['answer'])
|
| 297 |
+
st.session_state.grid_click_2 = False
|
| 298 |
+
|
| 299 |
+
@st.cache(show_spinner=False, allow_output_mutation = True)
|
| 300 |
+
def load_models(dpr_model_path, auth_token, cross_encoder_model_path):
|
| 301 |
+
dpr_trained = AutoModel.from_pretrained(dpr_model_path, use_auth_token=auth_token,
|
| 302 |
+
trust_remote_code=True)
|
| 303 |
+
bi_encoder = SentenceTransformer('multi-qa-MiniLM-L6-cos-v1')
|
| 304 |
+
cross_encoder = CrossEncoder('cross-encoder/ms-marco-MiniLM-L-6-v2')
|
| 305 |
+
bi_encoder.max_seq_length = 500
|
| 306 |
+
trained_cross_encoder = CrossEncoder(cross_encoder_model_path)
|
| 307 |
+
question_tokenizer = DPRQuestionEncoderTokenizer.from_pretrained('facebook/dpr-question_encoder-single-nq-base')
|
| 308 |
+
return dpr_trained, bi_encoder, cross_encoder, trained_cross_encoder, question_tokenizer
|
| 309 |
+
|
| 310 |
+
context_embeddings, contexes = load_paragraphs('context-embeddings.pkl')
|
| 311 |
+
dpr_context_embeddings, dpr_contexes = load_paragraphs('custom-dpr-context-embeddings.pkl')
|
| 312 |
+
dataframe_original, dataframe_bsbs = load_dataframes()
|
| 313 |
+
dpr_trained, bi_encoder, cross_encoder, trained_cross_encoder, question_tokenizer = copy.deepcopy(load_models(st.secrets["DPR_MODEL_PATH"], st.secrets["AUTH_TOKEN"], st.secrets["CROSS_ENCODER_MODEL_PATH"]))
|
| 314 |
+
|
| 315 |
+
qa_main_widgetsv2()
|
environment.yml
ADDED
|
@@ -0,0 +1,31 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
name: QADemo
|
| 2 |
+
channels:
|
| 3 |
+
- pytorch
|
| 4 |
+
- conda-forge
|
| 5 |
+
- defaults
|
| 6 |
+
dependencies:
|
| 7 |
+
- cudatoolkit=11.6.0
|
| 8 |
+
- numpy-base=1.23.1
|
| 9 |
+
- pip=22.2.2
|
| 10 |
+
- python=3.10.6
|
| 11 |
+
- pytorch=1.12.1
|
| 12 |
+
- torchaudio=0.12.1
|
| 13 |
+
- torchvision=0.13.1
|
| 14 |
+
- pip:
|
| 15 |
+
- en-core-web-sm @ https://github.com/explosion/spacy-models/releases/download/en_core_web_sm-3.2.0/en_core_web_sm-3.2.0-py3-none-any.whl
|
| 16 |
+
- huggingface-hub==0.10.0
|
| 17 |
+
- nltk==3.7
|
| 18 |
+
- numpy==1.23.3
|
| 19 |
+
- pandas==1.5.0
|
| 20 |
+
- scikit-learn==1.1.2
|
| 21 |
+
- scipy==1.9.2
|
| 22 |
+
- sentence-transformers==2.2.2
|
| 23 |
+
- spacy==3.2.0
|
| 24 |
+
- sentencepiece==0.1.97
|
| 25 |
+
- streamlit==1.13.0
|
| 26 |
+
- streamlit-aggrid==0.3.3
|
| 27 |
+
- tokenizers==0.12.1
|
| 28 |
+
- toml==0.10.2
|
| 29 |
+
- toolz==0.12.0
|
| 30 |
+
- tqdm==4.64.1
|
| 31 |
+
- transformers==4.22.2
|
requirements.txt
CHANGED
|
@@ -1,3 +1,4 @@
|
|
|
|
|
| 1 |
argon2-cffi==21.3.0
|
| 2 |
argon2-cffi-bindings==21.2.0
|
| 3 |
asttokens==2.0.5
|
|
@@ -20,6 +21,7 @@ cymem==2.0.7
|
|
| 20 |
debugpy==1.6.0
|
| 21 |
decorator==5.1.1
|
| 22 |
defusedxml==0.7.1
|
|
|
|
| 23 |
entrypoints==0.4
|
| 24 |
executing==0.8.3
|
| 25 |
fastjsonschema==2.15.3
|
|
@@ -47,7 +49,12 @@ jupyterlab-widgets==1.1.1
|
|
| 47 |
kiwisolver==1.4.3
|
| 48 |
langcodes==3.3.0
|
| 49 |
MarkupSafe==2.1.1
|
|
|
|
|
|
|
| 50 |
mistune==0.8.4
|
|
|
|
|
|
|
|
|
|
| 51 |
mpmath==1.2.1
|
| 52 |
murmurhash==1.0.9
|
| 53 |
nbclient==0.6.4
|
|
@@ -106,7 +113,6 @@ six==1.16.0
|
|
| 106 |
smart-open==5.2.1
|
| 107 |
smmap==5.0.0
|
| 108 |
soupsieve==2.3.2.post1
|
| 109 |
-
en-core-web-sm @ https://github.com/explosion/spacy-models/releases/download/en_core_web_sm-3.2.0/en_core_web_sm-3.2.0-py3-none-any.whl
|
| 110 |
spacy==3.2.0
|
| 111 |
spacy-legacy==3.0.10
|
| 112 |
spacy-loggers==1.0.3
|
|
|
|
| 1 |
+
altair==4.2.0
|
| 2 |
argon2-cffi==21.3.0
|
| 3 |
argon2-cffi-bindings==21.2.0
|
| 4 |
asttokens==2.0.5
|
|
|
|
| 21 |
debugpy==1.6.0
|
| 22 |
decorator==5.1.1
|
| 23 |
defusedxml==0.7.1
|
| 24 |
+
en-core-web-sm==3.2.0
|
| 25 |
entrypoints==0.4
|
| 26 |
executing==0.8.3
|
| 27 |
fastjsonschema==2.15.3
|
|
|
|
| 49 |
kiwisolver==1.4.3
|
| 50 |
langcodes==3.3.0
|
| 51 |
MarkupSafe==2.1.1
|
| 52 |
+
matplotlib==3.5.2
|
| 53 |
+
matplotlib-inline==0.1.3
|
| 54 |
mistune==0.8.4
|
| 55 |
+
mkl-fft==1.3.1
|
| 56 |
+
mkl-random==1.2.2
|
| 57 |
+
mkl-service==2.4.0
|
| 58 |
mpmath==1.2.1
|
| 59 |
murmurhash==1.0.9
|
| 60 |
nbclient==0.6.4
|
|
|
|
| 113 |
smart-open==5.2.1
|
| 114 |
smmap==5.0.0
|
| 115 |
soupsieve==2.3.2.post1
|
|
|
|
| 116 |
spacy==3.2.0
|
| 117 |
spacy-legacy==3.0.10
|
| 118 |
spacy-loggers==1.0.3
|
retrieve-rerank.png
ADDED
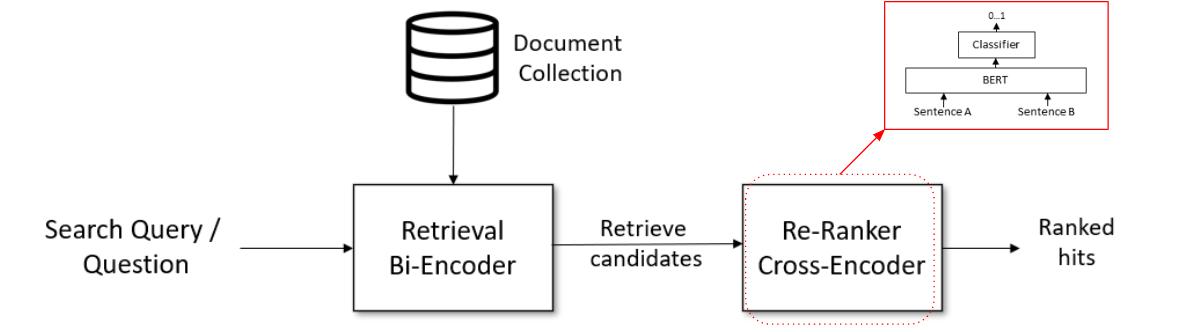
|