
fix images
Browse files- README.md +0 -1
- assets/article-count-log.png +0 -0
- assets/article-count-raw-and-opinion.png +0 -0
- assets/average-4wk-scores-over-time-top-6-with-debates.png +0 -0
- assets/average-4wk-scores-over-time-top-6.png +0 -0
- assets/coleridge-shakeup.png +0 -0
- assets/dolphin_cheese.jpeg +0 -0
- assets/news-barplot-average-scores.png +0 -0
- blog.py +135 -3
- blogs/2020/sentimentr.md +49 -11
- blogs/2021/kaggle_coleridge.md +2 -13
- blogs/2022/exotic_cheese.md +10 -3
- blogs/2022/kaggle_commonlit_readability.md +2 -11
- blogs/2023/creamatorium.md +0 -0
- blogs/2023/find_those_puppies.md +17 -0
README.md
CHANGED
|
@@ -6,7 +6,6 @@ colorTo: yellow
|
|
| 6 |
sdk: docker
|
| 7 |
pinned: true
|
| 8 |
license: apache-2.0
|
| 9 |
-
header: mini
|
| 10 |
---
|
| 11 |
|
| 12 |
Check out the configuration reference at https://huggingface.co/docs/hub/spaces-config-reference
|
|
|
|
| 6 |
sdk: docker
|
| 7 |
pinned: true
|
| 8 |
license: apache-2.0
|
|
|
|
| 9 |
---
|
| 10 |
|
| 11 |
Check out the configuration reference at https://huggingface.co/docs/hub/spaces-config-reference
|
assets/article-count-log.png
ADDED
|
assets/article-count-raw-and-opinion.png
ADDED

|
assets/average-4wk-scores-over-time-top-6-with-debates.png
ADDED
|
assets/average-4wk-scores-over-time-top-6.png
ADDED

|
assets/coleridge-shakeup.png
ADDED

|
assets/dolphin_cheese.jpeg
ADDED

|
assets/news-barplot-average-scores.png
ADDED
|
blog.py
CHANGED
|
@@ -3,7 +3,7 @@ import yaml
|
|
| 3 |
import functools
|
| 4 |
|
| 5 |
from pathlib import Path
|
| 6 |
-
|
| 7 |
|
| 8 |
file_path = Path(__file__).parent
|
| 9 |
|
|
@@ -25,6 +25,12 @@ def blog_preview(blog_id):
|
|
| 25 |
)
|
| 26 |
|
| 27 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 28 |
|
| 29 |
@functools.lru_cache()
|
| 30 |
def get_blogs():
|
|
@@ -53,12 +59,138 @@ def get_blogs():
|
|
| 53 |
all_blogs, sorted_blogs = get_blogs()
|
| 54 |
|
| 55 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 56 |
|
| 57 |
def single_blog(blog_id):
|
| 58 |
"""
|
| 59 |
Return a single blog post.
|
| 60 |
|
| 61 |
"""
|
| 62 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 63 |
|
| 64 |
-
return BstPage(0,
|
|
|
|
| 3 |
import functools
|
| 4 |
|
| 5 |
from pathlib import Path
|
| 6 |
+
import re
|
| 7 |
|
| 8 |
file_path = Path(__file__).parent
|
| 9 |
|
|
|
|
| 25 |
)
|
| 26 |
|
| 27 |
|
| 28 |
+
# full width image
|
| 29 |
+
# <img src="assets/htmx-meme.png" alt="HTMX meme" class="img-fluid mx-auto d-block">
|
| 30 |
+
|
| 31 |
+
|
| 32 |
+
|
| 33 |
+
|
| 34 |
|
| 35 |
@functools.lru_cache()
|
| 36 |
def get_blogs():
|
|
|
|
| 59 |
all_blogs, sorted_blogs = get_blogs()
|
| 60 |
|
| 61 |
|
| 62 |
+
def parse_markdown_sections(markdown_text):
|
| 63 |
+
"""
|
| 64 |
+
Extracts main headers (h1) and their associated content from markdown text.
|
| 65 |
+
Preserves all subsection headers (##, ###, etc.) in the content.
|
| 66 |
+
|
| 67 |
+
Args:
|
| 68 |
+
markdown_text (str): The markdown text to parse
|
| 69 |
+
|
| 70 |
+
Returns:
|
| 71 |
+
tuple: (headers, contents) where headers is a list of h1 headers
|
| 72 |
+
and contents is a list of the text content under each header
|
| 73 |
+
"""
|
| 74 |
+
# Split the text into lines
|
| 75 |
+
lines = markdown_text.strip().split('\n\n')
|
| 76 |
+
|
| 77 |
+
headers = []
|
| 78 |
+
contents = []
|
| 79 |
+
current_content = []
|
| 80 |
+
|
| 81 |
+
for line in lines:
|
| 82 |
+
# Check if line is a main header (h1) - exactly one #
|
| 83 |
+
h1_match = re.match(r'^#\s+(.+)$', line.strip())
|
| 84 |
+
|
| 85 |
+
if h1_match:
|
| 86 |
+
# If we have accumulated content, save it for the previous header
|
| 87 |
+
if current_content and headers:
|
| 88 |
+
contents.append('\n\n'.join(current_content).strip())
|
| 89 |
+
current_content = []
|
| 90 |
+
|
| 91 |
+
# Add the new header
|
| 92 |
+
headers.append(h1_match.group(1))
|
| 93 |
+
|
| 94 |
+
else:
|
| 95 |
+
# Add all other lines (including subsection headers) to content
|
| 96 |
+
if line.strip():
|
| 97 |
+
current_content.append(line)
|
| 98 |
+
|
| 99 |
+
# Add the last section's content
|
| 100 |
+
if current_content and headers:
|
| 101 |
+
contents.append('\n\n'.join(current_content).strip())
|
| 102 |
+
|
| 103 |
+
return headers, contents
|
| 104 |
+
|
| 105 |
+
def FullWidthImage(src, alt=None, sz:SizeT=SizeT.Sm, caption=None, capcls='', pad=2, left=True, cls='', retina=True, **kw):
|
| 106 |
+
place = 'start' if left else 'end'
|
| 107 |
+
if retina: kw['srcset'] = f'{src} 2x'
|
| 108 |
+
return Figure(
|
| 109 |
+
Img(src=src, alt=alt,
|
| 110 |
+
cls=f'figure-img img-fluid {cls}', **kw),
|
| 111 |
+
Figcaption(caption, cls=f'caption-{sz} {capcls} text-center'),
|
| 112 |
+
cls=f'd-sm-table mx-{sz}-{pad+1} my-{sz}-{pad}')
|
| 113 |
+
|
| 114 |
+
def split_blog(text, figs=None):
|
| 115 |
+
# For each blog, create a list of sections.
|
| 116 |
+
# Each fig needs to be added.
|
| 117 |
+
|
| 118 |
+
|
| 119 |
+
# fig = Image('/assets/webdev.jpg', alt='Web dev', caption=caption, left=False)
|
| 120 |
+
# h2s = 'Getting started', 'Background', 'Current Status'
|
| 121 |
+
# txts = [Markdown(s1), Div(fig, Markdown(s2)), Markdown(s3)]
|
| 122 |
+
|
| 123 |
+
headers, contents = parse_markdown_sections(text)
|
| 124 |
+
|
| 125 |
+
if figs is None:
|
| 126 |
+
return headers, [Markdown(c) for c in contents]
|
| 127 |
+
|
| 128 |
+
# match fig names such as <|img|>
|
| 129 |
+
pattern = r"<\|([a-z_]+)\|>"
|
| 130 |
+
|
| 131 |
+
sections = []
|
| 132 |
+
idx = 0
|
| 133 |
+
while idx < len(contents):
|
| 134 |
+
matches = [x for x in re.finditer(pattern, contents[idx])]
|
| 135 |
+
if len(matches):
|
| 136 |
+
temp_divs = []
|
| 137 |
+
|
| 138 |
+
prev = None
|
| 139 |
+
for match in matches:
|
| 140 |
+
fig_name = match.group(1)
|
| 141 |
+
|
| 142 |
+
|
| 143 |
+
cls_bonus = "" if figs[fig_name].get("full_width", False) else "mx-auto d-block"
|
| 144 |
+
|
| 145 |
+
|
| 146 |
+
if figs[fig_name].get("full_width", False):
|
| 147 |
+
|
| 148 |
+
image_class = FullWidthImage
|
| 149 |
+
else:
|
| 150 |
+
image_class = Image
|
| 151 |
+
|
| 152 |
+
fig = image_class(
|
| 153 |
+
src=figs[fig_name]["src"],
|
| 154 |
+
alt=figs[fig_name].get("alt", ""),
|
| 155 |
+
caption=figs[fig_name].get("caption", ""),
|
| 156 |
+
left=figs[fig_name].get("left", False),
|
| 157 |
+
sz=figs[fig_name].get("sz", "sm"),
|
| 158 |
+
cls=figs[fig_name].get("cls", "") + " " + cls_bonus,
|
| 159 |
+
pad=4,
|
| 160 |
+
)
|
| 161 |
+
|
| 162 |
+
if prev is None:
|
| 163 |
+
before = contents[idx][:match.start()]
|
| 164 |
+
else:
|
| 165 |
+
before = contents[idx][prev.end():match.start()]
|
| 166 |
+
|
| 167 |
+
temp_divs.append(Markdown(before))
|
| 168 |
+
temp_divs.append(fig)
|
| 169 |
+
prev = match
|
| 170 |
+
|
| 171 |
+
sections.append(Div(*temp_divs, Markdown(contents[idx][prev.end():])))
|
| 172 |
+
else:
|
| 173 |
+
sections.append(Markdown(contents[idx]))
|
| 174 |
+
|
| 175 |
+
idx += 1
|
| 176 |
+
|
| 177 |
+
|
| 178 |
+
return headers, sections
|
| 179 |
+
|
| 180 |
+
|
| 181 |
+
|
| 182 |
|
| 183 |
def single_blog(blog_id):
|
| 184 |
"""
|
| 185 |
Return a single blog post.
|
| 186 |
|
| 187 |
"""
|
| 188 |
+
metadata, md_text = all_blogs[blog_id]
|
| 189 |
+
|
| 190 |
+
headers, sections = split_blog(f"# {metadata['title']}\n{md_text}", metadata.get("figs", None))
|
| 191 |
+
|
| 192 |
+
secs = Sections(headers, sections)
|
| 193 |
+
|
| 194 |
+
# import pdb; pdb.set_trace()
|
| 195 |
|
| 196 |
+
return BstPage(0, "", *secs)
|
blogs/2020/sentimentr.md
CHANGED
|
@@ -4,14 +4,47 @@ desc: A tool to visualize bias in news headlines about presidential candidates
|
|
| 4 |
published: true
|
| 5 |
date_published: 2020-01-12
|
| 6 |
tags: nlp
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 7 |
---
|
| 8 |
|
| 9 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
| 10 |
|
| 11 |
With presidential primaries just around the corner, I thought it would be interesting to see if I could tell if there is a consistent bias toward one candidate or another. Could I quantitatively show that Fox News has more favorable headlines about Trump and CNN showing the opposite?
|
| 12 |
|
| 13 |
-
<!-- This year also broke the previous record with 20 candidates vying for the nomination. I thought it would be interesting to see if the general success or failure of a candidate could be seen in news headlines. To make the task easier, I limited the candidate pool to the top 5 candidates: Biden, Sanders, Warren, Harris, and Buttigieg. At the time I started Harris had not dropped out, and since there was a reasonable amount of data about Harris, I decided to keep her in the final results.
|
| 14 |
-
-->
|
| 15 |
The ideal news source is unbiased and not focusing all of their attention on one candidate; however we live in a time where "fake news" has entered everyone's daily vernacular. Unfortunately, there is scorn going both ways between liberals and conservatives with both claiming that their side knows the truth and lambasting the other side for being deceived and following villainous leaders.
|
| 16 |
|
| 17 |
I gathered thousands of headlines from CNN, Fox News, and The New York Times that contain the keywords Trump, Biden, Sanders, Warren, Harris, or Buttigieg. I had to exclude many headlines that contained the names of multiple candidates because it would require making multiple models that are each tailored to one single candidate.
|
|
@@ -24,6 +57,11 @@ Here are a few instances that have contain different candidates in the same head
|
|
| 24 |
|
| 25 |
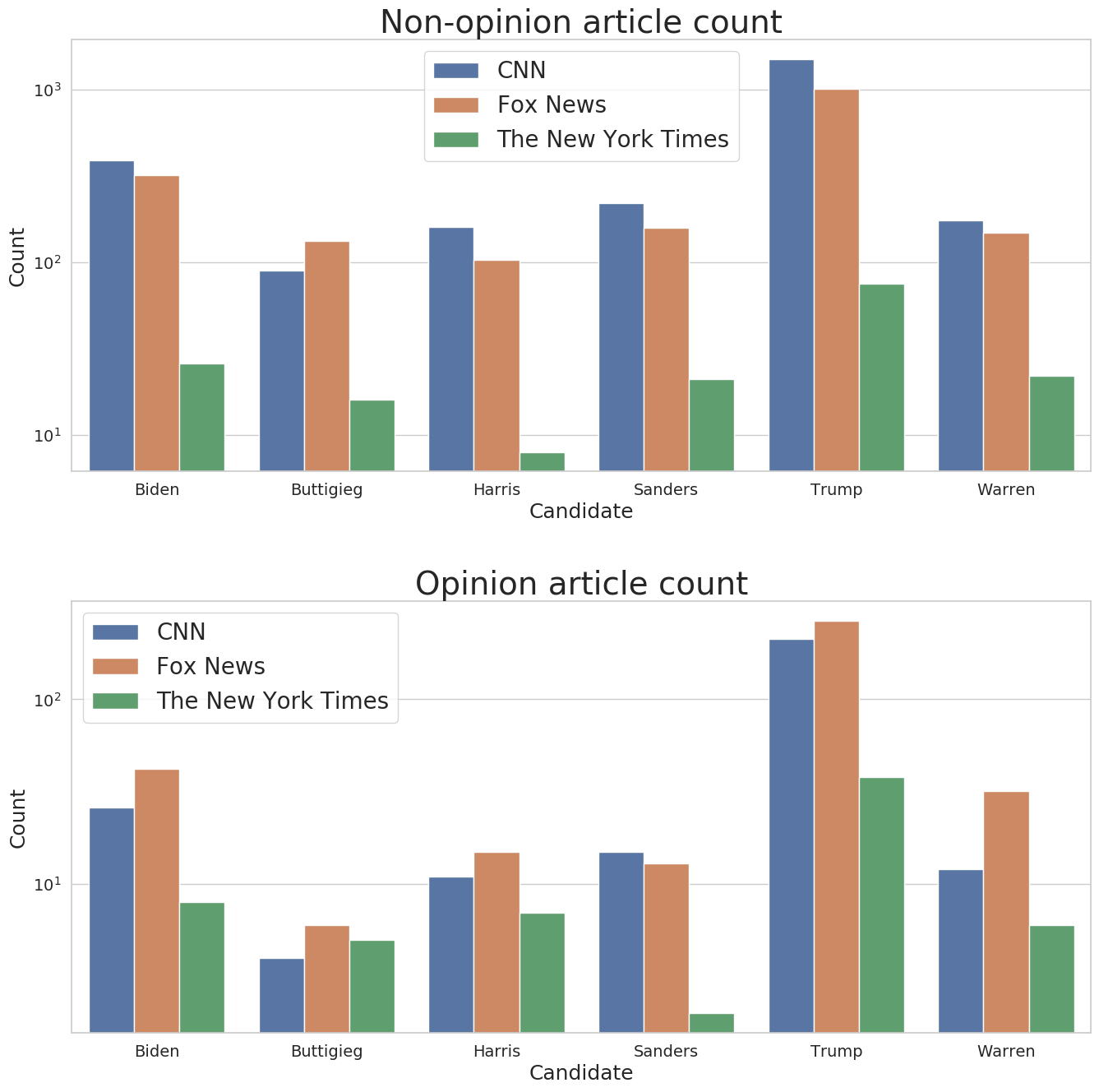
For this reason I decided to drop all headlines with the names of multiple candidates for this analysis. Thankfully, I still ended up with over 5,000 articles. Take a look at the distribution of articles for each candidate and for each news source.
|
| 26 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 27 |
<!-- {% include figure image_path="/assets/images/graphs/article-count-raw-and-opinion.png" alt="Linear Graph of Article Counts" caption="Bar plots of how many articles had a given candidate's name in it. Top is a raw count of total articles. Bottom separates it by news group."%} -->
|
| 28 |
|
| 29 |
<!--{% include figure image_path="/assets/images/graphs/article-count-log.png" alt="Logarithmic Graph of Article Counts" caption="Logarithmic barplots of how many articles had a given candidate's name in it. Blue represents CNN, orange is Fox News, and green is The New York Times."%}
|
|
@@ -33,26 +71,26 @@ Trump is by far the most talked-about candidate and for good reason: he is the s
|
|
| 33 |
I was surprised at the sheer volume of CNN articles and also The New York Times' tiny quantity.
|
| 34 |
|
| 35 |
|
| 36 |
-
|
| 37 |
|
| 38 |
-
I used 3 different sentiment analysis models: two of which were pre-made packages. VADER and TextBlob are python packages that offer sentiment analysis trained on different subjects. VADER is a lexicon approach based off of social media tweets that contain emoticons and slang. TextBlob is a Naive Bayes approach trained on IMDB review data. My model is an LSTM with a base
|
| 39 |
|
| 40 |
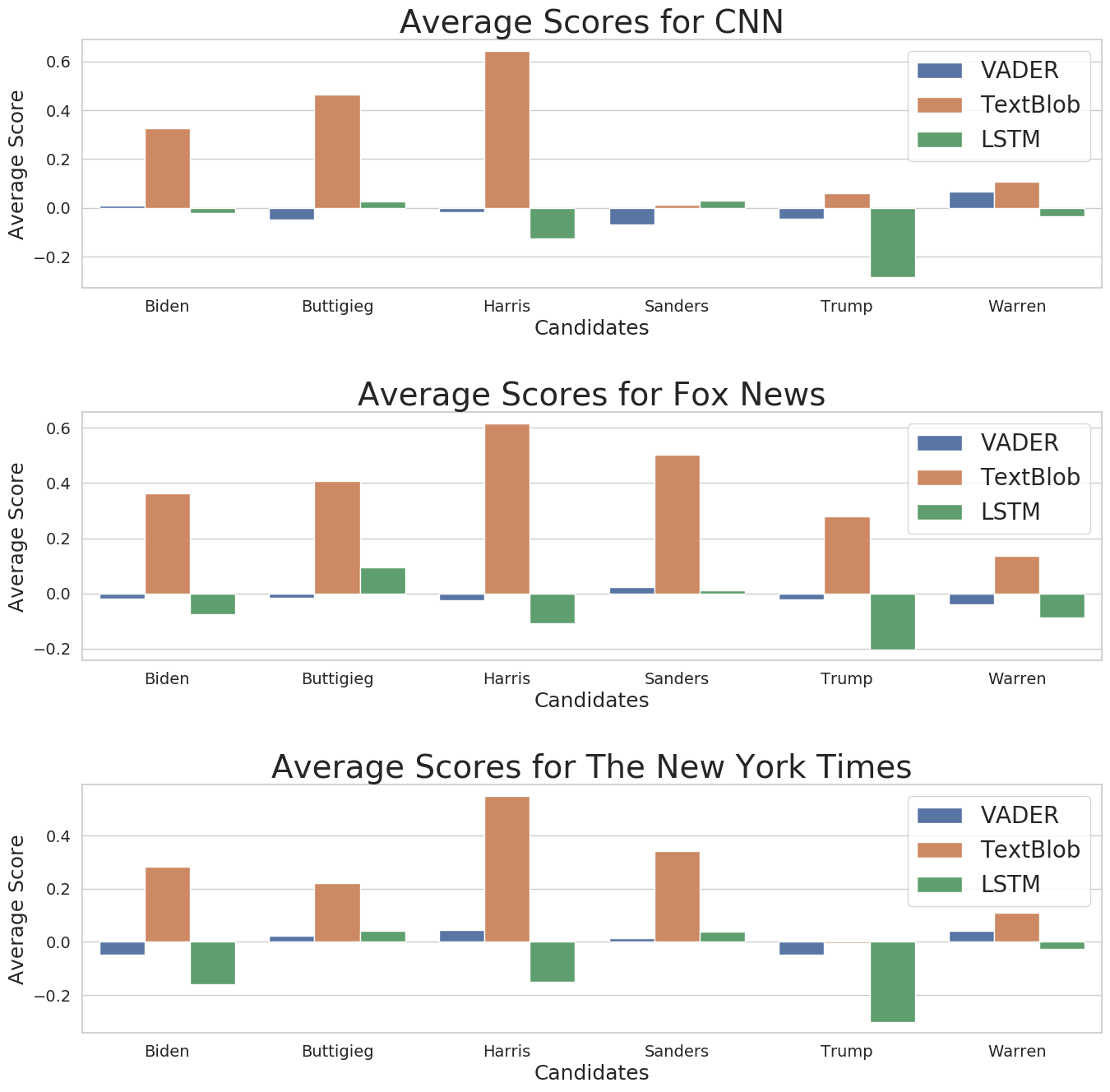
Here are the average scores for each candidate.
|
| 41 |
|
|
|
|
|
|
|
| 42 |
<!-- {% include figure image_path="/assets/images/graphs/news-barplot-average-scores.png" alt="Sentiment scores over time" caption="Bar plots of average sentiment scores separated by model and candidate."%} -->
|
| 43 |
|
| 44 |
And then looking average scores over time.
|
| 45 |
|
|
|
|
|
|
|
|
|
|
| 46 |
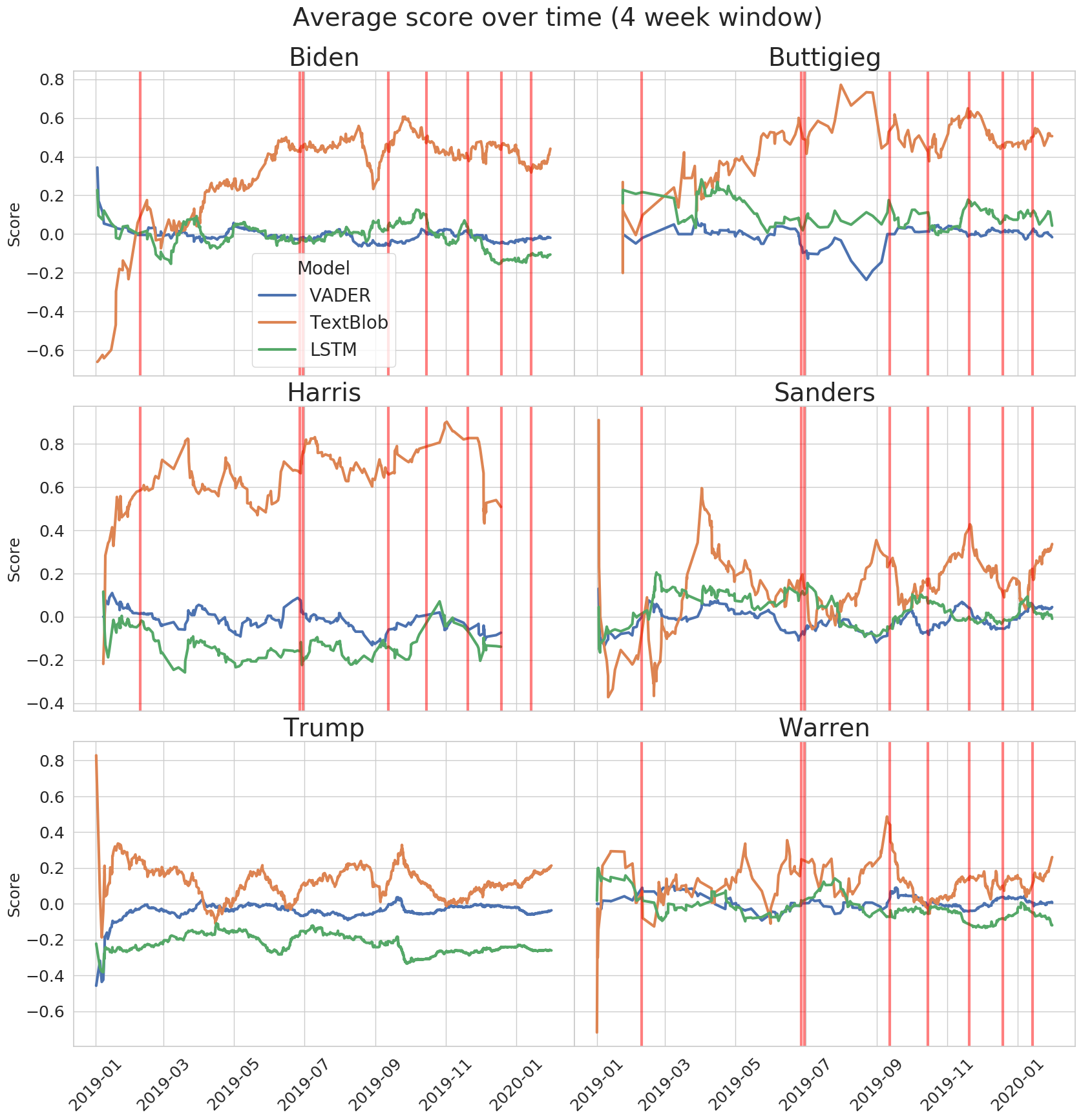
<!-- {% include figure image_path="/assets/images/graphs/average-4wk-scores-over-time-top-6.png" alt="Sentiment scores over time" caption="Line plots of sentiment scores separated by model and candidate."%} -->
|
| 47 |
|
| 48 |
I should also note that these scores have been smoothed by a sliding average with a window size of 4 weeks. Without smoothing it looks much more chaotic. Smoothing hopefully shows longterm trends. Even with smoothing it is a bit hard to tell if there are any consistent trends. The next thing I tried was to superimpose debate dates onto the democratic candidates to see if the candidate's performance could be seen after a debate. In some cases, there does seem to be a rise or drop in scores after a debate, but whether they are correlated remains unknown.
|
| 49 |
|
|
|
|
| 50 |
|
| 51 |
<!-- {% include figure image_path="/assets/images/graphs/average-4wk-scores-over-time-top-6-with-debates.png" alt="Sentiment scores over time" caption="Line plots of sentiment scores separated by model and candidate with debates superimposed over."%} -->
|
| 52 |
|
| 53 |
-
|
| 54 |
-
<!-- Out of 477,
|
| 55 |
-
vader got 261,
|
| 56 |
-
textblob got 151,
|
| 57 |
-
lstm got 233
|
| 58 |
-
-->
|
|
|
|
| 4 |
published: true
|
| 5 |
date_published: 2020-01-12
|
| 6 |
tags: nlp
|
| 7 |
+
figs:
|
| 8 |
+
linear:
|
| 9 |
+
src: /assets/article-count-raw-and-opinion.png
|
| 10 |
+
alt: Linear Graph of Article Counts
|
| 11 |
+
caption: Bar plots of how many articles had a given candidate's name in it. Top is a raw count of total articles. Bottom separates it by news group.
|
| 12 |
+
full_width: yes
|
| 13 |
+
left: no
|
| 14 |
+
log:
|
| 15 |
+
src: /assets/article-count-log.png
|
| 16 |
+
alt: Logarithmic Graph of Article Counts
|
| 17 |
+
caption: Logarithmic barplots of how many articles had a given candidate's name in it. Blue represents CNN, orange is Fox News, and green is The New York Times.
|
| 18 |
+
full_width: yes
|
| 19 |
+
left: no
|
| 20 |
+
bar:
|
| 21 |
+
src: /assets/news-barplot-average-scores.png
|
| 22 |
+
alt: Sentiment scores over time
|
| 23 |
+
caption: Bar plots of average sentiment scores separated by model and candidate.
|
| 24 |
+
left: no
|
| 25 |
+
full_width: yes
|
| 26 |
+
avg_over_time:
|
| 27 |
+
src: /assets/average-4wk-scores-over-time-top-6.png
|
| 28 |
+
alt: Sentiment scores over time
|
| 29 |
+
caption: Line plots of sentiment scores separated by model and candidate."
|
| 30 |
+
left: no
|
| 31 |
+
full_width: yes
|
| 32 |
+
avg_w_debates:
|
| 33 |
+
src: /assets/average-4wk-scores-over-time-top-6-with-debates.png
|
| 34 |
+
alt: Sentiment scores over time
|
| 35 |
+
caption: Line plots of sentiment scores separated by model and candidate with debates superimposed over.
|
| 36 |
+
left: no
|
| 37 |
+
full_width: yes
|
| 38 |
---
|
| 39 |
|
| 40 |
+
<div class="d-flex justify-content-center my-4">
|
| 41 |
+
|
| 42 |
+
<a data-flickr-embed="true" href="https://www.flickr.com/photos/janitors/30280548214" title="2016 U.S. presidential election party, Riga, Latvia"><img src="https://live.staticflickr.com/5523/30280548214_2810c4f91f.jpg" width="500" height="333" alt="2016 U.S. presidential election party, Riga, Latvia"/></a><script async src="//embedr.flickr.com/assets/client-code.js" charset="utf-8"></script>
|
| 43 |
+
</div>
|
| 44 |
+
|
| 45 |
|
| 46 |
With presidential primaries just around the corner, I thought it would be interesting to see if I could tell if there is a consistent bias toward one candidate or another. Could I quantitatively show that Fox News has more favorable headlines about Trump and CNN showing the opposite?
|
| 47 |
|
|
|
|
|
|
|
| 48 |
The ideal news source is unbiased and not focusing all of their attention on one candidate; however we live in a time where "fake news" has entered everyone's daily vernacular. Unfortunately, there is scorn going both ways between liberals and conservatives with both claiming that their side knows the truth and lambasting the other side for being deceived and following villainous leaders.
|
| 49 |
|
| 50 |
I gathered thousands of headlines from CNN, Fox News, and The New York Times that contain the keywords Trump, Biden, Sanders, Warren, Harris, or Buttigieg. I had to exclude many headlines that contained the names of multiple candidates because it would require making multiple models that are each tailored to one single candidate.
|
|
|
|
| 57 |
|
| 58 |
For this reason I decided to drop all headlines with the names of multiple candidates for this analysis. Thankfully, I still ended up with over 5,000 articles. Take a look at the distribution of articles for each candidate and for each news source.
|
| 59 |
|
| 60 |
+
|
| 61 |
+
<|linear|>
|
| 62 |
+
|
| 63 |
+
<|log|>
|
| 64 |
+
|
| 65 |
<!-- {% include figure image_path="/assets/images/graphs/article-count-raw-and-opinion.png" alt="Linear Graph of Article Counts" caption="Bar plots of how many articles had a given candidate's name in it. Top is a raw count of total articles. Bottom separates it by news group."%} -->
|
| 66 |
|
| 67 |
<!--{% include figure image_path="/assets/images/graphs/article-count-log.png" alt="Logarithmic Graph of Article Counts" caption="Logarithmic barplots of how many articles had a given candidate's name in it. Blue represents CNN, orange is Fox News, and green is The New York Times."%}
|
|
|
|
| 71 |
I was surprised at the sheer volume of CNN articles and also The New York Times' tiny quantity.
|
| 72 |
|
| 73 |
|
| 74 |
+
# Sentiment Analysis Models
|
| 75 |
|
| 76 |
+
I used 3 different sentiment analysis models: two of which were pre-made packages. VADER and TextBlob are python packages that offer sentiment analysis trained on different subjects. VADER is a lexicon approach based off of social media tweets that contain emoticons and slang. TextBlob is a Naive Bayes approach trained on IMDB review data. My model is an LSTM with a base language model based off of the [AWD-LSTM](https://arxiv.org/abs/1708.02182). I then trained its language model on news articles. Following that, I trained it on hand-labeled (by me 😤) article headlines.
|
| 77 |
|
| 78 |
Here are the average scores for each candidate.
|
| 79 |
|
| 80 |
+
<|bar|>
|
| 81 |
+
|
| 82 |
<!-- {% include figure image_path="/assets/images/graphs/news-barplot-average-scores.png" alt="Sentiment scores over time" caption="Bar plots of average sentiment scores separated by model and candidate."%} -->
|
| 83 |
|
| 84 |
And then looking average scores over time.
|
| 85 |
|
| 86 |
+
|
| 87 |
+
<|avg_over_time|>
|
| 88 |
+
|
| 89 |
<!-- {% include figure image_path="/assets/images/graphs/average-4wk-scores-over-time-top-6.png" alt="Sentiment scores over time" caption="Line plots of sentiment scores separated by model and candidate."%} -->
|
| 90 |
|
| 91 |
I should also note that these scores have been smoothed by a sliding average with a window size of 4 weeks. Without smoothing it looks much more chaotic. Smoothing hopefully shows longterm trends. Even with smoothing it is a bit hard to tell if there are any consistent trends. The next thing I tried was to superimpose debate dates onto the democratic candidates to see if the candidate's performance could be seen after a debate. In some cases, there does seem to be a rise or drop in scores after a debate, but whether they are correlated remains unknown.
|
| 92 |
|
| 93 |
+
<|avg_w_debates|>
|
| 94 |
|
| 95 |
<!-- {% include figure image_path="/assets/images/graphs/average-4wk-scores-over-time-top-6-with-debates.png" alt="Sentiment scores over time" caption="Line plots of sentiment scores separated by model and candidate with debates superimposed over."%} -->
|
| 96 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
blogs/2021/kaggle_coleridge.md
CHANGED
|
@@ -21,7 +21,7 @@ As this was my first Kaggle competition, I quickly realized that it was much mor
|
|
| 21 |
|
| 22 |
Moreover, the final results of the competition were very surprising because my team jumped over 1400 spots from the public to private leaderboard to end at 47th out of 1610 teams, earning us a silver medal (top 3%). If you would like to know more about why there are separate public and private leaderboards, [read this post here.](https://qr.ae/pG6Xc1) I've included a plot below of public ranking vs private ranking to show how much "shake-up" there was. My team had the 3rd highest positive delta, meaning that only 2 other teams jumped more positions from public to private. The person who probably had the worst day went from 176 (just outside the medal range) to 1438. To understand the figure, there are essentially 3 different categories. The first category would be any point on the line y=x. This means that the team had the exact same score on public and private leaderboards. The further the points get away from y=x, the bigger the difference between public and private leaderboards. The second category is for the teams who dropped from public to private -- they are in the region between the line y=x and the y-axis. The final category is for the teams that went up from public to private leaderboards: the region from the line y=x to the x-axis. My team fell into this third category and we were practically in the bottom right corner.
|
| 23 |
|
| 24 |
-
|
| 25 |
|
| 26 |
## Why the shake-up?
|
| 27 |
|
|
@@ -53,15 +53,4 @@ As mentioned earlier, my NER models were absolutely dreadful. I figured that ide
|
|
| 53 |
|
| 54 |
|
| 55 |
|
| 56 |
-
I don't think this was a typical Kaggle competition, and it was a little surprising to see how some top teams relied much more on good rule-based approaches rather than on deep learning models. I think most Kagglers default to using the biggest, most complicated transformer-based approach because they've heard so much about BERT et al. While transformers have been able to accomplish remarkable scores on numerous benchmarks, they can't do everything! I fell into this trap too, and I think my final score was mainly due to luck. 🍀
|
| 57 |
-
|
| 58 |
-
|
| 59 |
-
|
| 60 |
-
### Current stats
|
| 61 |
-
|
| 62 |
-

|
| 63 |
-

|
| 64 |
-

|
| 65 |
-

|
| 66 |
-
|
| 67 |
-
If you want to add Kaggle badges to your GitHub profile or website, use this: <https://github.com/subinium/kaggle-badge>
|
|
|
|
| 21 |
|
| 22 |
Moreover, the final results of the competition were very surprising because my team jumped over 1400 spots from the public to private leaderboard to end at 47th out of 1610 teams, earning us a silver medal (top 3%). If you would like to know more about why there are separate public and private leaderboards, [read this post here.](https://qr.ae/pG6Xc1) I've included a plot below of public ranking vs private ranking to show how much "shake-up" there was. My team had the 3rd highest positive delta, meaning that only 2 other teams jumped more positions from public to private. The person who probably had the worst day went from 176 (just outside the medal range) to 1438. To understand the figure, there are essentially 3 different categories. The first category would be any point on the line y=x. This means that the team had the exact same score on public and private leaderboards. The further the points get away from y=x, the bigger the difference between public and private leaderboards. The second category is for the teams who dropped from public to private -- they are in the region between the line y=x and the y-axis. The final category is for the teams that went up from public to private leaderboards: the region from the line y=x to the x-axis. My team fell into this third category and we were practically in the bottom right corner.
|
| 23 |
|
| 24 |
+
<img src="/assets/coleridge-shakeup.png" alt="Public vs private leaderboard rank for Coleridge competition" class="img-fluid mx-auto d-block">
|
| 25 |
|
| 26 |
## Why the shake-up?
|
| 27 |
|
|
|
|
| 53 |
|
| 54 |
|
| 55 |
|
| 56 |
+
I don't think this was a typical Kaggle competition, and it was a little surprising to see how some top teams relied much more on good rule-based approaches rather than on deep learning models. I think most Kagglers default to using the biggest, most complicated transformer-based approach because they've heard so much about BERT et al. While transformers have been able to accomplish remarkable scores on numerous benchmarks, they can't do everything! I fell into this trap too, and I think my final score was mainly due to luck. 🍀
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
blogs/2022/exotic_cheese.md
CHANGED
|
@@ -4,17 +4,24 @@ desc: I like cheese
|
|
| 4 |
published: true
|
| 5 |
date_published: 2022-07-04
|
| 6 |
tags: fun
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 7 |
---
|
| 8 |
|
| 9 |
-
# 🧀
|
| 10 |
-
|
| 11 |
While I am nowhere close to becoming a billionaire, I do occasionally daydream about frivolous scenarios that, in all likelihood, will never happen but are entertaining nonetheless. One scenario I keep returning to is the one where I'm a billionaire. "Regular" billionaires like Bezos and Musk might take trips into outer space, but I've decided that my first eccentric billionaire hobby will be to open up an exotic cheese shop.
|
| 12 |
|
| 13 |
> You might be saying, "Exotic cheese? Aren't there better ways of spending your money?" Yes, and since this is a fictional scenario, let's just assume I've already funded the research that cured cancer, I've already ended child poverty and hunger, and I've already fixed whichever tragic cause is closest to your heart. Even after all of that heroic philanthropy, I will still have tons of cash to do dumb shit.
|
| 14 |
|
|
|
|
|
|
|
|
|
|
| 15 |
Ok, back to exotic cheese. Have you ever wondered what jaguar cheese tastes like? What about elephant cheese? Dolphin cheese? It's questions like this that keep me up at night.
|
| 16 |
|
| 17 |
-
|
| 18 |
|
| 19 |
This cheese shop will only be possible if the milk from any mammal can be turned into cheese, which may or may not be true. For the sake of this fantasy, let's assume it is possible.
|
| 20 |
|
|
|
|
| 4 |
published: true
|
| 5 |
date_published: 2022-07-04
|
| 6 |
tags: fun
|
| 7 |
+
figs:
|
| 8 |
+
cheese_meme:
|
| 9 |
+
src: /assets/dolphin_cheese.jpeg
|
| 10 |
+
alt: "Woman: He's probably thinking about other women. Man: I wonder what dolphin cheese tastes like."
|
| 11 |
+
caption: It keeps me up at night.
|
| 12 |
+
left: no
|
| 13 |
---
|
| 14 |
|
|
|
|
|
|
|
| 15 |
While I am nowhere close to becoming a billionaire, I do occasionally daydream about frivolous scenarios that, in all likelihood, will never happen but are entertaining nonetheless. One scenario I keep returning to is the one where I'm a billionaire. "Regular" billionaires like Bezos and Musk might take trips into outer space, but I've decided that my first eccentric billionaire hobby will be to open up an exotic cheese shop.
|
| 16 |
|
| 17 |
> You might be saying, "Exotic cheese? Aren't there better ways of spending your money?" Yes, and since this is a fictional scenario, let's just assume I've already funded the research that cured cancer, I've already ended child poverty and hunger, and I've already fixed whichever tragic cause is closest to your heart. Even after all of that heroic philanthropy, I will still have tons of cash to do dumb shit.
|
| 18 |
|
| 19 |
+
|
| 20 |
+
# Curiosity milked the (exotic) cat
|
| 21 |
+
|
| 22 |
Ok, back to exotic cheese. Have you ever wondered what jaguar cheese tastes like? What about elephant cheese? Dolphin cheese? It's questions like this that keep me up at night.
|
| 23 |
|
| 24 |
+
<|cheese_meme|>
|
| 25 |
|
| 26 |
This cheese shop will only be possible if the milk from any mammal can be turned into cheese, which may or may not be true. For the sake of this fantasy, let's assume it is possible.
|
| 27 |
|
blogs/2022/kaggle_commonlit_readability.md
CHANGED
|
@@ -8,7 +8,8 @@ tags: kaggle nlp
|
|
| 8 |
|
| 9 |
The [CommonLit Readability Prize](https://www.kaggle.com/c/commonlitreadabilityprize) was my second Kaggle competition, as well as my worst leaderboard finish. In retrospect, it was a great learning opportunity and I'm still only a *little* disappointed that I didn't rank higher. Here are some details about what I learned, what I was impressed by, and what I would do differently in the future.
|
| 10 |
|
| 11 |
-
|
|
|
|
| 12 |
|
| 13 |
## Competition Details 🏆
|
| 14 |
|
|
@@ -51,13 +52,3 @@ One interesting discovery during this competition was the bizarre effect of drop
|
|
| 51 |
## Lessons Learned 👨🏫
|
| 52 |
|
| 53 |
Looking back, I can identify two main reasons why I struggled: working alone and refusing to use public notebooks. Due to a combination of factors I decided to fly solo, which meant I was able to learn a lot, but it also meant I went slowly and didn't have great support when running into problems. This was useful for learning purposes but it wasted a lot of valuable time when there were good public notebooks and models available. I realized how foolish my decision was when I read how the [person who got 1st place used the public notebooks to make even better models](https://www.kaggle.com/c/commonlitreadabilityprize/discussion/257844). I'm still a little salty that I didn't do better, but I'm taking it as a learning opportunity and moving forward. 🤷♂️ Onto the next one!
|
| 54 |
-
|
| 55 |
-
|
| 56 |
-
### Current stats
|
| 57 |
-
|
| 58 |
-

|
| 59 |
-

|
| 60 |
-

|
| 61 |
-

|
| 62 |
-
|
| 63 |
-
If you want to add Kaggle badges to your GitHub profile or website, use this: <https://github.com/subinium/kaggle-badge>
|
|
|
|
| 8 |
|
| 9 |
The [CommonLit Readability Prize](https://www.kaggle.com/c/commonlitreadabilityprize) was my second Kaggle competition, as well as my worst leaderboard finish. In retrospect, it was a great learning opportunity and I'm still only a *little* disappointed that I didn't rank higher. Here are some details about what I learned, what I was impressed by, and what I would do differently in the future.
|
| 10 |
|
| 11 |
+
<img src="https://upload.wikimedia.org/wikipedia/commons/7/74/Open_books_stacked.jpg" alt="open books" title="Hh1718, CC BY-SA 4.0 https://creativecommons.org/licenses/by-sa/4.0, via Wikimedia Commons" class="img-fluid mx-auto d-block">
|
| 12 |
+
|
| 13 |
|
| 14 |
## Competition Details 🏆
|
| 15 |
|
|
|
|
| 52 |
## Lessons Learned 👨🏫
|
| 53 |
|
| 54 |
Looking back, I can identify two main reasons why I struggled: working alone and refusing to use public notebooks. Due to a combination of factors I decided to fly solo, which meant I was able to learn a lot, but it also meant I went slowly and didn't have great support when running into problems. This was useful for learning purposes but it wasted a lot of valuable time when there were good public notebooks and models available. I realized how foolish my decision was when I read how the [person who got 1st place used the public notebooks to make even better models](https://www.kaggle.com/c/commonlitreadabilityprize/discussion/257844). I'm still a little salty that I didn't do better, but I'm taking it as a learning opportunity and moving forward. 🤷♂️ Onto the next one!
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
blogs/2023/creamatorium.md
ADDED
|
File without changes
|
blogs/2023/find_those_puppies.md
ADDED
|
@@ -0,0 +1,17 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
title: "Eccentric billionaire hobby #2 - finding my dog's puppies"
|
| 3 |
+
desc: Can money find my dog's children?
|
| 4 |
+
published: true
|
| 5 |
+
date_published: 2023-03-18
|
| 6 |
+
tags: fun
|
| 7 |
+
---
|
| 8 |
+
|
| 9 |
+
I adopted my dog in the summer of 2020 in North Carolina, and it was quite apparent that she had recently birthed a litter of puppies. The rescue org had no idea about what happened to the puppies, and I have frequently wondered whether my dog thinks about her puppies at all. If I were fabulously wealthy, perhaps I'd be able to find one of them!
|
| 10 |
+
|
| 11 |
+
What would this entail? Ideally, I could have done this as soon as I adopted her, because there would have been a greater chance of the puppies still being located within the area. Alas, I am still not ludicrously wealthy, but let's imagine I was. I would purchase dog DNA kits for every dog in the area, put advertisements on tv, social media, radio, highways, and any other format that would reach as many people as possible. If the DNA kits actually got used, then the kit company would easily be able to detect if any of the dogs were my dog.
|
| 12 |
+
|
| 13 |
+
What would I put on the advertisement? I would of course add physical details, but since she is a mutt, there is a high likelihood that her puppies could look very different from her. Are personality traits inheritable? If that's the case, then I would ask people if their dog likes chasing squirrels and rabbits, has a fear of slippery surfaces, is very affectionate, and likes sleeping a lot.
|
| 14 |
+
|
| 15 |
+
If I did find one of her puppies, would she even recognize it? It has been several years since she was last around them, but maybe there would be an identifiable scent. I would have to admit, it would be very disappointing if I went through all this effort only for her to not even have a big reaction.
|
| 16 |
+
|
| 17 |
+
> To read the first "eccentric billionaire hobby", click [here](/blog/exotic_cheese)
|