Spaces:
Runtime error

Runtime error
Upload folder using huggingface_hub
Browse files- .gitattributes +1 -0
- .github/workflows/update_space.yml +28 -0
- .gitignore +164 -0
- BigModel/.gitattributes +34 -0
- BigModel/README.md +13 -0
- LICENSE.txt +201 -0
- MODEL_LICENSE.txt +33 -0
- README.md +325 -8
- README_en.md +246 -0
- __pycache__/finetune_visualglm.cpython-310.pyc +0 -0
- __pycache__/lora_mixin.cpython-310.pyc +0 -0
- api.py +51 -0
- api_hf.py +49 -0
- cli_demo.py +103 -0
- cli_demo_hf.py +69 -0
- examples/1.jpeg +3 -0
- examples/2.jpeg +0 -0
- examples/3.jpeg +0 -0
- examples/chat_example1.png +0 -0
- examples/chat_example2.png +0 -0
- examples/chat_example3.png +0 -0
- examples/example_inputs.jsonl +3 -0
- examples/thu.png +0 -0
- examples/web_demo.png +0 -0
- fewshot-data.zip +3 -0
- finetune/finetune_visualglm.sh +58 -0
- finetune/finetune_visualglm_qlora.sh +59 -0
- finetune_visualglm.py +195 -0
- lora_mixin.py +260 -0
- model/__init__.py +3 -0
- model/__pycache__/__init__.cpython-310.pyc +0 -0
- model/__pycache__/blip2.cpython-310.pyc +0 -0
- model/__pycache__/chat.cpython-310.pyc +0 -0
- model/__pycache__/infer_util.cpython-310.pyc +0 -0
- model/__pycache__/visualglm.cpython-310.pyc +0 -0
- model/blip2.py +93 -0
- model/chat.py +175 -0
- model/infer_util.py +53 -0
- model/visualglm.py +40 -0
- requirements.txt +6 -0
- requirements_wo_ds.txt +10 -0
- web_demo.py +129 -0
- web_demo_hf.py +143 -0
- your_logfile.log +2 -0
.gitattributes
CHANGED
|
@@ -32,3 +32,4 @@ saved_model/**/* filter=lfs diff=lfs merge=lfs -text
|
|
| 32 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 33 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
|
|
|
|
|
| 32 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 33 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
| 35 |
+
examples/1.jpeg filter=lfs diff=lfs merge=lfs -text
|
.github/workflows/update_space.yml
ADDED
|
@@ -0,0 +1,28 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
name: Run Python script
|
| 2 |
+
|
| 3 |
+
on:
|
| 4 |
+
push:
|
| 5 |
+
branches:
|
| 6 |
+
- main
|
| 7 |
+
|
| 8 |
+
jobs:
|
| 9 |
+
build:
|
| 10 |
+
runs-on: ubuntu-latest
|
| 11 |
+
|
| 12 |
+
steps:
|
| 13 |
+
- name: Checkout
|
| 14 |
+
uses: actions/checkout@v2
|
| 15 |
+
|
| 16 |
+
- name: Set up Python
|
| 17 |
+
uses: actions/setup-python@v2
|
| 18 |
+
with:
|
| 19 |
+
python-version: '3.9'
|
| 20 |
+
|
| 21 |
+
- name: Install Gradio
|
| 22 |
+
run: python -m pip install gradio
|
| 23 |
+
|
| 24 |
+
- name: Log in to Hugging Face
|
| 25 |
+
run: python -c 'import huggingface_hub; huggingface_hub.login(token="${{ secrets.hf_token }}")'
|
| 26 |
+
|
| 27 |
+
- name: Deploy to Spaces
|
| 28 |
+
run: gradio deploy
|
.gitignore
ADDED
|
@@ -0,0 +1,164 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
checkpoints/
|
| 2 |
+
runs/
|
| 3 |
+
model/__pycache__/
|
| 4 |
+
|
| 5 |
+
# Byte-compiled / optimized / DLL files
|
| 6 |
+
__pycache__/
|
| 7 |
+
*.py[cod]
|
| 8 |
+
*$py.class
|
| 9 |
+
|
| 10 |
+
# C extensions
|
| 11 |
+
*.so
|
| 12 |
+
|
| 13 |
+
# Distribution / packaging
|
| 14 |
+
.Python
|
| 15 |
+
build/
|
| 16 |
+
develop-eggs/
|
| 17 |
+
dist/
|
| 18 |
+
downloads/
|
| 19 |
+
eggs/
|
| 20 |
+
.eggs/
|
| 21 |
+
lib/
|
| 22 |
+
lib64/
|
| 23 |
+
parts/
|
| 24 |
+
sdist/
|
| 25 |
+
var/
|
| 26 |
+
wheels/
|
| 27 |
+
share/python-wheels/
|
| 28 |
+
*.egg-info/
|
| 29 |
+
.installed.cfg
|
| 30 |
+
*.egg
|
| 31 |
+
MANIFEST
|
| 32 |
+
|
| 33 |
+
# PyInstaller
|
| 34 |
+
# Usually these files are written by a python script from a template
|
| 35 |
+
# before PyInstaller builds the exe, so as to inject date/other infos into it.
|
| 36 |
+
*.manifest
|
| 37 |
+
*.spec
|
| 38 |
+
|
| 39 |
+
# Installer logs
|
| 40 |
+
pip-log.txt
|
| 41 |
+
pip-delete-this-directory.txt
|
| 42 |
+
|
| 43 |
+
# Unit test / coverage reports
|
| 44 |
+
htmlcov/
|
| 45 |
+
.tox/
|
| 46 |
+
.nox/
|
| 47 |
+
.coverage
|
| 48 |
+
.coverage.*
|
| 49 |
+
.cache
|
| 50 |
+
nosetests.xml
|
| 51 |
+
coverage.xml
|
| 52 |
+
*.cover
|
| 53 |
+
*.py,cover
|
| 54 |
+
.hypothesis/
|
| 55 |
+
.pytest_cache/
|
| 56 |
+
cover/
|
| 57 |
+
|
| 58 |
+
# Translations
|
| 59 |
+
*.mo
|
| 60 |
+
*.pot
|
| 61 |
+
|
| 62 |
+
# Django stuff:
|
| 63 |
+
*.log
|
| 64 |
+
local_settings.py
|
| 65 |
+
db.sqlite3
|
| 66 |
+
db.sqlite3-journal
|
| 67 |
+
|
| 68 |
+
# Flask stuff:
|
| 69 |
+
instance/
|
| 70 |
+
.webassets-cache
|
| 71 |
+
|
| 72 |
+
# Scrapy stuff:
|
| 73 |
+
.scrapy
|
| 74 |
+
|
| 75 |
+
# Sphinx documentation
|
| 76 |
+
docs/_build/
|
| 77 |
+
|
| 78 |
+
# PyBuilder
|
| 79 |
+
.pybuilder/
|
| 80 |
+
target/
|
| 81 |
+
|
| 82 |
+
# Jupyter Notebook
|
| 83 |
+
.ipynb_checkpoints
|
| 84 |
+
|
| 85 |
+
# IPython
|
| 86 |
+
profile_default/
|
| 87 |
+
ipython_config.py
|
| 88 |
+
|
| 89 |
+
# pyenv
|
| 90 |
+
# For a library or package, you might want to ignore these files since the code is
|
| 91 |
+
# intended to run in multiple environments; otherwise, check them in:
|
| 92 |
+
# .python-version
|
| 93 |
+
|
| 94 |
+
# pipenv
|
| 95 |
+
# According to pypa/pipenv#598, it is recommended to include Pipfile.lock in version control.
|
| 96 |
+
# However, in case of collaboration, if having platform-specific dependencies or dependencies
|
| 97 |
+
# having no cross-platform support, pipenv may install dependencies that don't work, or not
|
| 98 |
+
# install all needed dependencies.
|
| 99 |
+
#Pipfile.lock
|
| 100 |
+
|
| 101 |
+
# poetry
|
| 102 |
+
# Similar to Pipfile.lock, it is generally recommended to include poetry.lock in version control.
|
| 103 |
+
# This is especially recommended for binary packages to ensure reproducibility, and is more
|
| 104 |
+
# commonly ignored for libraries.
|
| 105 |
+
# https://python-poetry.org/docs/basic-usage/#commit-your-poetrylock-file-to-version-control
|
| 106 |
+
#poetry.lock
|
| 107 |
+
|
| 108 |
+
# pdm
|
| 109 |
+
# Similar to Pipfile.lock, it is generally recommended to include pdm.lock in version control.
|
| 110 |
+
#pdm.lock
|
| 111 |
+
# pdm stores project-wide configurations in .pdm.toml, but it is recommended to not include it
|
| 112 |
+
# in version control.
|
| 113 |
+
# https://pdm.fming.dev/#use-with-ide
|
| 114 |
+
.pdm.toml
|
| 115 |
+
|
| 116 |
+
# PEP 582; used by e.g. github.com/David-OConnor/pyflow and github.com/pdm-project/pdm
|
| 117 |
+
__pypackages__/
|
| 118 |
+
|
| 119 |
+
# Celery stuff
|
| 120 |
+
celerybeat-schedule
|
| 121 |
+
celerybeat.pid
|
| 122 |
+
|
| 123 |
+
# SageMath parsed files
|
| 124 |
+
*.sage.py
|
| 125 |
+
|
| 126 |
+
# Environments
|
| 127 |
+
.env
|
| 128 |
+
.venv
|
| 129 |
+
env/
|
| 130 |
+
venv/
|
| 131 |
+
ENV/
|
| 132 |
+
env.bak/
|
| 133 |
+
venv.bak/
|
| 134 |
+
|
| 135 |
+
# Spyder project settings
|
| 136 |
+
.spyderproject
|
| 137 |
+
.spyproject
|
| 138 |
+
|
| 139 |
+
# Rope project settings
|
| 140 |
+
.ropeproject
|
| 141 |
+
|
| 142 |
+
# mkdocs documentation
|
| 143 |
+
/site
|
| 144 |
+
|
| 145 |
+
# mypy
|
| 146 |
+
.mypy_cache/
|
| 147 |
+
.dmypy.json
|
| 148 |
+
dmypy.json
|
| 149 |
+
|
| 150 |
+
# Pyre type checker
|
| 151 |
+
.pyre/
|
| 152 |
+
|
| 153 |
+
# pytype static type analyzer
|
| 154 |
+
.pytype/
|
| 155 |
+
|
| 156 |
+
# Cython debug symbols
|
| 157 |
+
cython_debug/
|
| 158 |
+
|
| 159 |
+
# PyCharm
|
| 160 |
+
# JetBrains specific template is maintained in a separate JetBrains.gitignore that can
|
| 161 |
+
# be found at https://github.com/github/gitignore/blob/main/Global/JetBrains.gitignore
|
| 162 |
+
# and can be added to the global gitignore or merged into this file. For a more nuclear
|
| 163 |
+
# option (not recommended) you can uncomment the following to ignore the entire idea folder.
|
| 164 |
+
#.idea/
|
BigModel/.gitattributes
ADDED
|
@@ -0,0 +1,34 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
*.7z filter=lfs diff=lfs merge=lfs -text
|
| 2 |
+
*.arrow filter=lfs diff=lfs merge=lfs -text
|
| 3 |
+
*.bin filter=lfs diff=lfs merge=lfs -text
|
| 4 |
+
*.bz2 filter=lfs diff=lfs merge=lfs -text
|
| 5 |
+
*.ckpt filter=lfs diff=lfs merge=lfs -text
|
| 6 |
+
*.ftz filter=lfs diff=lfs merge=lfs -text
|
| 7 |
+
*.gz filter=lfs diff=lfs merge=lfs -text
|
| 8 |
+
*.h5 filter=lfs diff=lfs merge=lfs -text
|
| 9 |
+
*.joblib filter=lfs diff=lfs merge=lfs -text
|
| 10 |
+
*.lfs.* filter=lfs diff=lfs merge=lfs -text
|
| 11 |
+
*.mlmodel filter=lfs diff=lfs merge=lfs -text
|
| 12 |
+
*.model filter=lfs diff=lfs merge=lfs -text
|
| 13 |
+
*.msgpack filter=lfs diff=lfs merge=lfs -text
|
| 14 |
+
*.npy filter=lfs diff=lfs merge=lfs -text
|
| 15 |
+
*.npz filter=lfs diff=lfs merge=lfs -text
|
| 16 |
+
*.onnx filter=lfs diff=lfs merge=lfs -text
|
| 17 |
+
*.ot filter=lfs diff=lfs merge=lfs -text
|
| 18 |
+
*.parquet filter=lfs diff=lfs merge=lfs -text
|
| 19 |
+
*.pb filter=lfs diff=lfs merge=lfs -text
|
| 20 |
+
*.pickle filter=lfs diff=lfs merge=lfs -text
|
| 21 |
+
*.pkl filter=lfs diff=lfs merge=lfs -text
|
| 22 |
+
*.pt filter=lfs diff=lfs merge=lfs -text
|
| 23 |
+
*.pth filter=lfs diff=lfs merge=lfs -text
|
| 24 |
+
*.rar filter=lfs diff=lfs merge=lfs -text
|
| 25 |
+
*.safetensors filter=lfs diff=lfs merge=lfs -text
|
| 26 |
+
saved_model/**/* filter=lfs diff=lfs merge=lfs -text
|
| 27 |
+
*.tar.* filter=lfs diff=lfs merge=lfs -text
|
| 28 |
+
*.tflite filter=lfs diff=lfs merge=lfs -text
|
| 29 |
+
*.tgz filter=lfs diff=lfs merge=lfs -text
|
| 30 |
+
*.wasm filter=lfs diff=lfs merge=lfs -text
|
| 31 |
+
*.xz filter=lfs diff=lfs merge=lfs -text
|
| 32 |
+
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 33 |
+
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 34 |
+
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
BigModel/README.md
ADDED
|
@@ -0,0 +1,13 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
title: BigModel
|
| 3 |
+
emoji: 🌍
|
| 4 |
+
colorFrom: yellow
|
| 5 |
+
colorTo: red
|
| 6 |
+
sdk: gradio
|
| 7 |
+
sdk_version: 3.33.1
|
| 8 |
+
app_file: app.py
|
| 9 |
+
pinned: false
|
| 10 |
+
license: openrail
|
| 11 |
+
---
|
| 12 |
+
|
| 13 |
+
Check out the configuration reference at https://huggingface.co/docs/hub/spaces-config-reference
|
LICENSE.txt
ADDED
|
@@ -0,0 +1,201 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
Apache License
|
| 2 |
+
Version 2.0, January 2004
|
| 3 |
+
http://www.apache.org/licenses/
|
| 4 |
+
|
| 5 |
+
TERMS AND CONDITIONS FOR USE, REPRODUCTION, AND DISTRIBUTION
|
| 6 |
+
|
| 7 |
+
1. Definitions.
|
| 8 |
+
|
| 9 |
+
"License" shall mean the terms and conditions for use, reproduction,
|
| 10 |
+
and distribution as defined by Sections 1 through 9 of this document.
|
| 11 |
+
|
| 12 |
+
"Licensor" shall mean the copyright owner or entity authorized by
|
| 13 |
+
the copyright owner that is granting the License.
|
| 14 |
+
|
| 15 |
+
"Legal Entity" shall mean the union of the acting entity and all
|
| 16 |
+
other entities that control, are controlled by, or are under common
|
| 17 |
+
control with that entity. For the purposes of this definition,
|
| 18 |
+
"control" means (i) the power, direct or indirect, to cause the
|
| 19 |
+
direction or management of such entity, whether by contract or
|
| 20 |
+
otherwise, or (ii) ownership of fifty percent (50%) or more of the
|
| 21 |
+
outstanding shares, or (iii) beneficial ownership of such entity.
|
| 22 |
+
|
| 23 |
+
"You" (or "Your") shall mean an individual or Legal Entity
|
| 24 |
+
exercising permissions granted by this License.
|
| 25 |
+
|
| 26 |
+
"Source" form shall mean the preferred form for making modifications,
|
| 27 |
+
including but not limited to software source code, documentation
|
| 28 |
+
source, and configuration files.
|
| 29 |
+
|
| 30 |
+
"Object" form shall mean any form resulting from mechanical
|
| 31 |
+
transformation or translation of a Source form, including but
|
| 32 |
+
not limited to compiled object code, generated documentation,
|
| 33 |
+
and conversions to other media types.
|
| 34 |
+
|
| 35 |
+
"Work" shall mean the work of authorship, whether in Source or
|
| 36 |
+
Object form, made available under the License, as indicated by a
|
| 37 |
+
copyright notice that is included in or attached to the work
|
| 38 |
+
(an example is provided in the Appendix below).
|
| 39 |
+
|
| 40 |
+
"Derivative Works" shall mean any work, whether in Source or Object
|
| 41 |
+
form, that is based on (or derived from) the Work and for which the
|
| 42 |
+
editorial revisions, annotations, elaborations, or other modifications
|
| 43 |
+
represent, as a whole, an original work of authorship. For the purposes
|
| 44 |
+
of this License, Derivative Works shall not include works that remain
|
| 45 |
+
separable from, or merely link (or bind by name) to the interfaces of,
|
| 46 |
+
the Work and Derivative Works thereof.
|
| 47 |
+
|
| 48 |
+
"Contribution" shall mean any work of authorship, including
|
| 49 |
+
the original version of the Work and any modifications or additions
|
| 50 |
+
to that Work or Derivative Works thereof, that is intentionally
|
| 51 |
+
submitted to Licensor for inclusion in the Work by the copyright owner
|
| 52 |
+
or by an individual or Legal Entity authorized to submit on behalf of
|
| 53 |
+
the copyright owner. For the purposes of this definition, "submitted"
|
| 54 |
+
means any form of electronic, verbal, or written communication sent
|
| 55 |
+
to the Licensor or its representatives, including but not limited to
|
| 56 |
+
communication on electronic mailing lists, source code control systems,
|
| 57 |
+
and issue tracking systems that are managed by, or on behalf of, the
|
| 58 |
+
Licensor for the purpose of discussing and improving the Work, but
|
| 59 |
+
excluding communication that is conspicuously marked or otherwise
|
| 60 |
+
designated in writing by the copyright owner as "Not a Contribution."
|
| 61 |
+
|
| 62 |
+
"Contributor" shall mean Licensor and any individual or Legal Entity
|
| 63 |
+
on behalf of whom a Contribution has been received by Licensor and
|
| 64 |
+
subsequently incorporated within the Work.
|
| 65 |
+
|
| 66 |
+
2. Grant of Copyright License. Subject to the terms and conditions of
|
| 67 |
+
this License, each Contributor hereby grants to You a perpetual,
|
| 68 |
+
worldwide, non-exclusive, no-charge, royalty-free, irrevocable
|
| 69 |
+
copyright license to reproduce, prepare Derivative Works of,
|
| 70 |
+
publicly display, publicly perform, sublicense, and distribute the
|
| 71 |
+
Work and such Derivative Works in Source or Object form.
|
| 72 |
+
|
| 73 |
+
3. Grant of Patent License. Subject to the terms and conditions of
|
| 74 |
+
this License, each Contributor hereby grants to You a perpetual,
|
| 75 |
+
worldwide, non-exclusive, no-charge, royalty-free, irrevocable
|
| 76 |
+
(except as stated in this section) patent license to make, have made,
|
| 77 |
+
use, offer to sell, sell, import, and otherwise transfer the Work,
|
| 78 |
+
where such license applies only to those patent claims licensable
|
| 79 |
+
by such Contributor that are necessarily infringed by their
|
| 80 |
+
Contribution(s) alone or by combination of their Contribution(s)
|
| 81 |
+
with the Work to which such Contribution(s) was submitted. If You
|
| 82 |
+
institute patent litigation against any entity (including a
|
| 83 |
+
cross-claim or counterclaim in a lawsuit) alleging that the Work
|
| 84 |
+
or a Contribution incorporated within the Work constitutes direct
|
| 85 |
+
or contributory patent infringement, then any patent licenses
|
| 86 |
+
granted to You under this License for that Work shall terminate
|
| 87 |
+
as of the date such litigation is filed.
|
| 88 |
+
|
| 89 |
+
4. Redistribution. You may reproduce and distribute copies of the
|
| 90 |
+
Work or Derivative Works thereof in any medium, with or without
|
| 91 |
+
modifications, and in Source or Object form, provided that You
|
| 92 |
+
meet the following conditions:
|
| 93 |
+
|
| 94 |
+
(a) You must give any other recipients of the Work or
|
| 95 |
+
Derivative Works a copy of this License; and
|
| 96 |
+
|
| 97 |
+
(b) You must cause any modified files to carry prominent notices
|
| 98 |
+
stating that You changed the files; and
|
| 99 |
+
|
| 100 |
+
(c) You must retain, in the Source form of any Derivative Works
|
| 101 |
+
that You distribute, all copyright, patent, trademark, and
|
| 102 |
+
attribution notices from the Source form of the Work,
|
| 103 |
+
excluding those notices that do not pertain to any part of
|
| 104 |
+
the Derivative Works; and
|
| 105 |
+
|
| 106 |
+
(d) If the Work includes a "NOTICE" text file as part of its
|
| 107 |
+
distribution, then any Derivative Works that You distribute must
|
| 108 |
+
include a readable copy of the attribution notices contained
|
| 109 |
+
within such NOTICE file, excluding those notices that do not
|
| 110 |
+
pertain to any part of the Derivative Works, in at least one
|
| 111 |
+
of the following places: within a NOTICE text file distributed
|
| 112 |
+
as part of the Derivative Works; within the Source form or
|
| 113 |
+
documentation, if provided along with the Derivative Works; or,
|
| 114 |
+
within a display generated by the Derivative Works, if and
|
| 115 |
+
wherever such third-party notices normally appear. The contents
|
| 116 |
+
of the NOTICE file are for informational purposes only and
|
| 117 |
+
do not modify the License. You may add Your own attribution
|
| 118 |
+
notices within Derivative Works that You distribute, alongside
|
| 119 |
+
or as an addendum to the NOTICE text from the Work, provided
|
| 120 |
+
that such additional attribution notices cannot be construed
|
| 121 |
+
as modifying the License.
|
| 122 |
+
|
| 123 |
+
You may add Your own copyright statement to Your modifications and
|
| 124 |
+
may provide additional or different license terms and conditions
|
| 125 |
+
for use, reproduction, or distribution of Your modifications, or
|
| 126 |
+
for any such Derivative Works as a whole, provided Your use,
|
| 127 |
+
reproduction, and distribution of the Work otherwise complies with
|
| 128 |
+
the conditions stated in this License.
|
| 129 |
+
|
| 130 |
+
5. Submission of Contributions. Unless You explicitly state otherwise,
|
| 131 |
+
any Contribution intentionally submitted for inclusion in the Work
|
| 132 |
+
by You to the Licensor shall be under the terms and conditions of
|
| 133 |
+
this License, without any additional terms or conditions.
|
| 134 |
+
Notwithstanding the above, nothing herein shall supersede or modify
|
| 135 |
+
the terms of any separate license agreement you may have executed
|
| 136 |
+
with Licensor regarding such Contributions.
|
| 137 |
+
|
| 138 |
+
6. Trademarks. This License does not grant permission to use the trade
|
| 139 |
+
names, trademarks, service marks, or product names of the Licensor,
|
| 140 |
+
except as required for reasonable and customary use in describing the
|
| 141 |
+
origin of the Work and reproducing the content of the NOTICE file.
|
| 142 |
+
|
| 143 |
+
7. Disclaimer of Warranty. Unless required by applicable law or
|
| 144 |
+
agreed to in writing, Licensor provides the Work (and each
|
| 145 |
+
Contributor provides its Contributions) on an "AS IS" BASIS,
|
| 146 |
+
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or
|
| 147 |
+
implied, including, without limitation, any warranties or conditions
|
| 148 |
+
of TITLE, NON-INFRINGEMENT, MERCHANTABILITY, or FITNESS FOR A
|
| 149 |
+
PARTICULAR PURPOSE. You are solely responsible for determining the
|
| 150 |
+
appropriateness of using or redistributing the Work and assume any
|
| 151 |
+
risks associated with Your exercise of permissions under this License.
|
| 152 |
+
|
| 153 |
+
8. Limitation of Liability. In no event and under no legal theory,
|
| 154 |
+
whether in tort (including negligence), contract, or otherwise,
|
| 155 |
+
unless required by applicable law (such as deliberate and grossly
|
| 156 |
+
negligent acts) or agreed to in writing, shall any Contributor be
|
| 157 |
+
liable to You for damages, including any direct, indirect, special,
|
| 158 |
+
incidental, or consequential damages of any character arising as a
|
| 159 |
+
result of this License or out of the use or inability to use the
|
| 160 |
+
Work (including but not limited to damages for loss of goodwill,
|
| 161 |
+
work stoppage, computer failure or malfunction, or any and all
|
| 162 |
+
other commercial damages or losses), even if such Contributor
|
| 163 |
+
has been advised of the possibility of such damages.
|
| 164 |
+
|
| 165 |
+
9. Accepting Warranty or Additional Liability. While redistributing
|
| 166 |
+
the Work or Derivative Works thereof, You may choose to offer,
|
| 167 |
+
and charge a fee for, acceptance of support, warranty, indemnity,
|
| 168 |
+
or other liability obligations and/or rights consistent with this
|
| 169 |
+
License. However, in accepting such obligations, You may act only
|
| 170 |
+
on Your own behalf and on Your sole responsibility, not on behalf
|
| 171 |
+
of any other Contributor, and only if You agree to indemnify,
|
| 172 |
+
defend, and hold each Contributor harmless for any liability
|
| 173 |
+
incurred by, or claims asserted against, such Contributor by reason
|
| 174 |
+
of your accepting any such warranty or additional liability.
|
| 175 |
+
|
| 176 |
+
END OF TERMS AND CONDITIONS
|
| 177 |
+
|
| 178 |
+
APPENDIX: How to apply the Apache License to your work.
|
| 179 |
+
|
| 180 |
+
To apply the Apache License to your work, attach the following
|
| 181 |
+
boilerplate notice, with the fields enclosed by brackets "[]"
|
| 182 |
+
replaced with your own identifying information. (Don't include
|
| 183 |
+
the brackets!) The text should be enclosed in the appropriate
|
| 184 |
+
comment syntax for the file format. We also recommend that a
|
| 185 |
+
file or class name and description of purpose be included on the
|
| 186 |
+
same "printed page" as the copyright notice for easier
|
| 187 |
+
identification within third-party archives.
|
| 188 |
+
|
| 189 |
+
Copyright Zhengxiao Du
|
| 190 |
+
|
| 191 |
+
Licensed under the Apache License, Version 2.0 (the "License");
|
| 192 |
+
you may not use this file except in compliance with the License.
|
| 193 |
+
You may obtain a copy of the License at
|
| 194 |
+
|
| 195 |
+
http://www.apache.org/licenses/LICENSE-2.0
|
| 196 |
+
|
| 197 |
+
Unless required by applicable law or agreed to in writing, software
|
| 198 |
+
distributed under the License is distributed on an "AS IS" BASIS,
|
| 199 |
+
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
| 200 |
+
See the License for the specific language governing permissions and
|
| 201 |
+
limitations under the License.
|
MODEL_LICENSE.txt
ADDED
|
@@ -0,0 +1,33 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
The VisualGLM-6B License
|
| 2 |
+
|
| 3 |
+
1. Definitions
|
| 4 |
+
|
| 5 |
+
“Licensor” means the VisualGLM-6B Model Team that distributes its Software.
|
| 6 |
+
|
| 7 |
+
“Software” means the VisualGLM-6B model parameters made available under this license.
|
| 8 |
+
|
| 9 |
+
2. License Grant
|
| 10 |
+
|
| 11 |
+
Subject to the terms and conditions of this License, the Licensor hereby grants to you a non-exclusive, worldwide, non-transferable, non-sublicensable, revocable, royalty-free copyright license to use the Software solely for your non-commercial research purposes.
|
| 12 |
+
|
| 13 |
+
The above copyright notice and this permission notice shall be included in all copies or substantial portions of the Software.
|
| 14 |
+
|
| 15 |
+
3. Restriction
|
| 16 |
+
|
| 17 |
+
You will not use, copy, modify, merge, publish, distribute, reproduce, or create derivative works of the Software, in whole or in part, for any commercial, military, or illegal purposes.
|
| 18 |
+
|
| 19 |
+
You will not use the Software for any act that may undermine China's national security and national unity, harm the public interest of society, or infringe upon the rights and interests of human beings.
|
| 20 |
+
|
| 21 |
+
4. Disclaimer
|
| 22 |
+
|
| 23 |
+
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.
|
| 24 |
+
|
| 25 |
+
5. Limitation of Liability
|
| 26 |
+
|
| 27 |
+
EXCEPT TO THE EXTENT PROHIBITED BY APPLICABLE LAW, IN NO EVENT AND UNDER NO LEGAL THEORY, WHETHER BASED IN TORT, NEGLIGENCE, CONTRACT, LIABILITY, OR OTHERWISE WILL ANY LICENSOR BE LIABLE TO YOU FOR ANY DIRECT, INDIRECT, SPECIAL, INCIDENTAL, EXEMPLARY, OR CONSEQUENTIAL DAMAGES, OR ANY OTHER COMMERCIAL LOSSES, EVEN IF THE LICENSOR HAS BEEN ADVISED OF THE POSSIBILITY OF SUCH DAMAGES.
|
| 28 |
+
|
| 29 |
+
6. Dispute Resolution
|
| 30 |
+
|
| 31 |
+
This license shall be governed and construed in accordance with the laws of People’s Republic of China. Any dispute arising from or in connection with this License shall be submitted to Haidian District People's Court in Beijing.
|
| 32 |
+
|
| 33 |
+
Note that the license is subject to update to a more comprehensive version. For any questions related to the license and copyright, please contact us.
|
README.md
CHANGED
|
@@ -1,12 +1,329 @@
|
|
| 1 |
---
|
| 2 |
-
title: VisualGLM
|
| 3 |
-
|
| 4 |
-
colorFrom: green
|
| 5 |
-
colorTo: pink
|
| 6 |
sdk: gradio
|
| 7 |
-
sdk_version: 3.33.
|
| 8 |
-
app_file: app.py
|
| 9 |
-
pinned: false
|
| 10 |
---
|
|
|
|
| 11 |
|
| 12 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
---
|
| 2 |
+
title: VisualGLM-6B
|
| 3 |
+
app_file: web_demo_hf.py
|
|
|
|
|
|
|
| 4 |
sdk: gradio
|
| 5 |
+
sdk_version: 3.33.0
|
|
|
|
|
|
|
| 6 |
---
|
| 7 |
+
# VisualGLM-6B
|
| 8 |
|
| 9 |
+
<p align="center">
|
| 10 |
+
🤗 <a href="https://huggingface.co/THUDM/visualglm-6b" target="_blank">HF Repo</a> • ⚒️ <a href="https://github.com/THUDM/SwissArmyTransformer" target="_blank">SwissArmyTransformer (sat)</a> • 🐦 <a href="https://twitter.com/thukeg" target="_blank">Twitter</a>
|
| 11 |
+
</p>
|
| 12 |
+
<p align="center">
|
| 13 |
+
• 📃 <a href="https://arxiv.org/abs/2105.13290" target="_blank">[CogView@NeurIPS 21]</a> <a href="https://github.com/THUDM/CogView" target="_blank">[GitHub]</a> • 📃 <a href="https://arxiv.org/abs/2103.10360" target="_blank">[GLM@ACL 22]</a> <a href="https://github.com/THUDM/GLM" target="_blank">[GitHub]</a> <br>
|
| 14 |
+
</p>
|
| 15 |
+
<p align="center">
|
| 16 |
+
👋 加入我们的 <a href="https://join.slack.com/t/chatglm/shared_invite/zt-1th2q5u69-7tURzFuOPanmuHy9hsZnKA" target="_blank">Slack</a> 和 <a href="resources/WECHAT.md" target="_blank">WeChat</a>
|
| 17 |
+
</p>
|
| 18 |
+
<!-- <p align="center">
|
| 19 |
+
🤖<a href="https://huggingface.co/spaces/THUDM/visualglm-6b" target="_blank">VisualGLM-6B在线演示网站</a>
|
| 20 |
+
</p> -->
|
| 21 |
+
|
| 22 |
+
## 介绍
|
| 23 |
+
|
| 24 |
+
VisualGLM-6B is an open-source, multi-modal dialog language model that supports **images, Chinese, and English**. The language model is based on [ChatGLM-6B](https://github.com/THUDM/ChatGLM-6B) with 6.2 billion parameters; the image part builds a bridge between the visual model and the language model through the training of [BLIP2-Qformer](https://arxiv.org/abs/2301.12597), with the total model comprising 7.8 billion parameters. **[Click here for English version.](README_en.md)**
|
| 25 |
+
|
| 26 |
+
VisualGLM-6B 是一个开源的,支持**图像、中文和英文**的多模态对话语言模型,语言模型基于 [ChatGLM-6B](https://github.com/THUDM/ChatGLM-6B),具有 62 亿参数;图像部分通过训练 [BLIP2-Qformer](https://arxiv.org/abs/2301.12597) 构建起视觉模型与语言模型的桥梁,整体模型共78亿参数。
|
| 27 |
+
|
| 28 |
+
VisualGLM-6B 依靠来自于 [CogView](https://arxiv.org/abs/2105.13290) 数据集的30M高质量中文图文对,与300M经过筛选的英文图文对进行预训练,中英文权重相同。该训练方式较好地将视觉信息对齐到ChatGLM的语义空间;之后的微调阶段,模型在长视觉问答数据上训练,以生成符合人类偏好的答案。
|
| 29 |
+
|
| 30 |
+
VisualGLM-6B 由 [SwissArmyTransformer](https://github.com/THUDM/SwissArmyTransformer)(简称`sat`) 库训练,这是一个支持Transformer灵活修改、训练的工具库,支持Lora、P-tuning等参数高效微调方法。本项目提供了符合用户习惯的huggingface接口,也提供了基于sat的接口。
|
| 31 |
+
|
| 32 |
+
结合模型量化技术,用户可以在消费级的显卡上进行本地部署(INT4量化级别下最低只需8.7G显存)。
|
| 33 |
+
|
| 34 |
+
-----
|
| 35 |
+
|
| 36 |
+
VisualGLM-6B 开源模型旨在与开源社区一起推动大模型技术发展,恳请开发者和大家遵守开源协议,勿将该开源模型和代码及基于该开源项目产生的衍生物用于任何可能给国家和社会带来危害的用途以及用于任何未经过安全评估和备案的服务。目前,本项目官方未基于 VisualGLM-6B 开发任何应用,包括网站、安卓App、苹果 iOS应用及 Windows App 等。
|
| 37 |
+
|
| 38 |
+
由于 VisualGLM-6B 仍处于v1版本,目前已知其具有相当多的[**局限性**](README.md#局限性),如图像描述事实性/模型幻觉问题,图像细节信息捕捉不足,以及一些来自语言模型的局限性。尽管模型在训练的各个阶段都尽力确保数据的合规性和准确性,但由于 VisualGLM-6B 模型规模较小,且模型受概率随机性因素影响,无法保证输出内容的准确性,且模型易被误导(详见局限性部分)。在VisualGLM之后的版本中,将会着力对此类问题进行优化。本项目不承担开源模型和代码导致的数据安全、舆情风险或发生任何模型被误导、滥用、传播、不当利用而产生的风险和责任。
|
| 39 |
+
|
| 40 |
+
## 样例
|
| 41 |
+
VisualGLM-6B 可以进行图像的描述的相关知识的问答。
|
| 42 |
+

|
| 43 |
+
|
| 44 |
+
<details>
|
| 45 |
+
<summary>也能结合常识或提出有趣的观点,点击展开/折叠更多样例</summary>
|
| 46 |
+
|
| 47 |
+

|
| 48 |
+

|
| 49 |
+
|
| 50 |
+
</details>
|
| 51 |
+
|
| 52 |
+
## 友情链接
|
| 53 |
+
|
| 54 |
+
* [XrayGLM](https://github.com/WangRongsheng/XrayGLM) 是基于visualGLM-6B在X光诊断数据集上微调的X光诊断问答的项目,能根据X光片回答医学相关询问。
|
| 55 |
+
<details>
|
| 56 |
+
<summary>点击查看样例</summary>
|
| 57 |
+
|
| 58 |
+

|
| 59 |
+
</details>
|
| 60 |
+
|
| 61 |
+
## 使用
|
| 62 |
+
|
| 63 |
+
### 模型推理
|
| 64 |
+
|
| 65 |
+
使用pip安装依赖
|
| 66 |
+
```
|
| 67 |
+
pip install -i https://pypi.org/simple -r requirements.txt
|
| 68 |
+
# 国内请使用aliyun镜像,TUNA等镜像同步最近出现问题,命令如下
|
| 69 |
+
pip install -i https://mirrors.aliyun.com/pypi/simple/ -r requirements.txt
|
| 70 |
+
```
|
| 71 |
+
此时默认会安装`deepspeed`库(支持`sat`库训练),此库对于模型推理并非必要,同时部分Windows环境安装此库时会遇到问题。
|
| 72 |
+
如果想绕过`deepspeed`安装,我们可以将命令改为
|
| 73 |
+
```
|
| 74 |
+
pip install -i https://mirrors.aliyun.com/pypi/simple/ -r requirements_wo_ds.txt
|
| 75 |
+
pip install -i https://mirrors.aliyun.com/pypi/simple/ --no-deps "SwissArmyTransformer>=0.3.6"
|
| 76 |
+
```
|
| 77 |
+
|
| 78 |
+
如果使用Huggingface transformers库调用模型(**也需要安装上述依赖包!**),可以通过如下代码(其中图像路径为本地路径):
|
| 79 |
+
```python
|
| 80 |
+
from transformers import AutoTokenizer, AutoModel
|
| 81 |
+
tokenizer = AutoTokenizer.from_pretrained("THUDM/visualglm-6b", trust_remote_code=True)
|
| 82 |
+
model = AutoModel.from_pretrained("THUDM/visualglm-6b", trust_remote_code=True).half().cuda()
|
| 83 |
+
image_path = "your image path"
|
| 84 |
+
response, history = model.chat(tokenizer, image_path, "描述这张图片。", history=[])
|
| 85 |
+
print(response)
|
| 86 |
+
response, history = model.chat(tokenizer, image_path, "这张图片可能是在什么场所拍摄的?", history=history)
|
| 87 |
+
print(response)
|
| 88 |
+
```
|
| 89 |
+
以上代码会由 `transformers` 自动下载模型实现和参数。完整的模型实现可以在 [Hugging Face Hub](https://huggingface.co/THUDM/visualglm-6b)。如果你从 Hugging Face Hub 上下载模型参数的速度较慢,可以从[这里](https://cloud.tsinghua.edu.cn/d/43ffb021ca5f4897b56a/)手动下载模型参数文件,并从本地加载模型。具体做法请参考[从本地加载模型](https://github.com/THUDM/ChatGLM-6B#%E4%BB%8E%E6%9C%AC%E5%9C%B0%E5%8A%A0%E8%BD%BD%E6%A8%A1%E5%9E%8B)。关于基于 transformers 库模型的量化、CPU推理、Mac MPS 后端加速等内容,请参考 [ChatGLM-6B 的低成本部署](https://github.com/THUDM/ChatGLM-6B#%E4%BD%8E%E6%88%90%E6%9C%AC%E9%83%A8%E7%BD%B2)。
|
| 90 |
+
|
| 91 |
+
如果使用SwissArmyTransformer库调用模型,方法类似,可以使用环境变量`SAT_HOME`决定模型下载位置。在本仓库目录下:
|
| 92 |
+
```python
|
| 93 |
+
import argparse
|
| 94 |
+
from transformers import AutoTokenizer
|
| 95 |
+
tokenizer = AutoTokenizer.from_pretrained("THUDM/chatglm-6b", trust_remote_code=True)
|
| 96 |
+
from model import chat, VisualGLMModel
|
| 97 |
+
model, model_args = VisualGLMModel.from_pretrained('visualglm-6b', args=argparse.Namespace(fp16=True, skip_init=True))
|
| 98 |
+
from sat.model.mixins import CachedAutoregressiveMixin
|
| 99 |
+
model.add_mixin('auto-regressive', CachedAutoregressiveMixin())
|
| 100 |
+
image_path = "your image path or URL"
|
| 101 |
+
response, history, cache_image = chat(image_path, model, tokenizer, "描述这张图片。", history=[])
|
| 102 |
+
print(response)
|
| 103 |
+
response, history, cache_image = chat(None, model, tokenizer, "这张图片可能是在什么场所拍摄的?", history=history, image=cache_image)
|
| 104 |
+
print(response)
|
| 105 |
+
```
|
| 106 |
+
使用`sat`库也可以轻松进行进行参数高效微调。<!-- TODO 具体代码 -->
|
| 107 |
+
|
| 108 |
+
## 模型微调
|
| 109 |
+
|
| 110 |
+
多模态任务分布广、种类多,预训练往往不能面面俱到。
|
| 111 |
+
这里我们提供了一个小样本微调的例子,使用20张标注图增强模型回答“背景”问题的能力。
|
| 112 |
+
|
| 113 |
+
解压`fewshot-data.zip`以后运行如下命令:
|
| 114 |
+
```
|
| 115 |
+
bash finetune/finetune_visualglm.sh
|
| 116 |
+
```
|
| 117 |
+
|
| 118 |
+
目前支持三种方式的微调:
|
| 119 |
+
|
| 120 |
+
* LoRA:样例中为ChatGLM模型的第0层和第14层加入了rank=10的LoRA微调,可以根据具体情景和数据量调整`--layer_range`和`--lora_rank`参数。
|
| 121 |
+
* QLoRA:如果资源有限,可以考虑使用`bash finetune/finetune_visualglm_qlora.sh`,QLoRA将ChatGLM的线性层进行了4-bit量化,只需要9.8GB显存即可微调。
|
| 122 |
+
* P-tuning:可以将`--use_lora`替换为`--use_ptuning`,不过不推荐使用,除非模型应用场景非常固定。
|
| 123 |
+
|
| 124 |
+
训练好以后可以使用如下命令推理:
|
| 125 |
+
|
| 126 |
+
```
|
| 127 |
+
python cli_demo.py --from_pretrained your_checkpoint_path --prompt_zh 这张图片的背景里有什么内容?
|
| 128 |
+
```
|
| 129 |
+
|
| 130 |
+
<details>
|
| 131 |
+
<summary>微调前后的效果对比</summary>
|
| 132 |
+
|
| 133 |
+
微调前:
|
| 134 |
+
|
| 135 |
+
```
|
| 136 |
+
欢迎使用 VisualGLM-6B 模型,输入图像URL或本地路径读图,继续输入内容对话,clear 重新开始,stop 终止程序
|
| 137 |
+
请输入图像路径或URL(回车进入纯文本对话): fewshot-data/2p.png
|
| 138 |
+
用户:这张图片的背景里有什么内容?
|
| 139 |
+
VisualGLM-6B:人们总是被生活琐事所困扰,无法摆脱束缚.
|
| 140 |
+
用户:clear
|
| 141 |
+
请输入图像路径或URL(回车进入纯文本对话): fewshot-data/meme.png
|
| 142 |
+
用户:这张图片的背景里有什么内容?
|
| 143 |
+
VisualGLM-6B:这张图片的背景是一张狗的图片,它躺在木地板上。
|
| 144 |
+
用户:clear
|
| 145 |
+
请输入图像路径或URL(回车进入纯文本对话): fewshot-data/passport.png
|
| 146 |
+
用户:这张图片的背景里有什么内容?
|
| 147 |
+
VisualGLM-6B:这张图片的背景是一台电脑键盘和两张护照。
|
| 148 |
+
用户:clear
|
| 149 |
+
请输入图像路径或URL(回车进入纯文本对话):
|
| 150 |
+
```
|
| 151 |
+
|
| 152 |
+
微调后:
|
| 153 |
+
|
| 154 |
+
```
|
| 155 |
+
欢迎使用 VisualGLM-6B 模型��输入图像URL或本地路径读图,继续输入内容对话,clear 重新开始,stop 终止程序
|
| 156 |
+
请输入图像路径或URL(回车进入纯文本对话): fewshot-data/2p.png
|
| 157 |
+
用户:这张图片的背景里有什么内容?
|
| 158 |
+
VisualGLM-6B:这张图片的背景是雨天,
|
| 159 |
+
用户:描述一下这张图片。
|
| 160 |
+
VisualGLM-6B:这张图片描绘了雨天的情景,雨水淅淅沥沥地落在地面上。人们穿着雨衣或雨伞,走在雨中,似乎在寻找着什么.
|
| 161 |
+
用户:clear
|
| 162 |
+
请输入图像路径或URL(回车进入纯文本对话): fewshot-data/meme.png
|
| 163 |
+
用户:这张图片的背景里有什么内容?
|
| 164 |
+
VisualGLM-6B:这张图片的背景是木质地板。
|
| 165 |
+
用户:什么颜色的地板
|
| 166 |
+
VisualGLM-6B:这张图片的背景是蓝色的。
|
| 167 |
+
用户:描述一下这张图片。
|
| 168 |
+
VisualGLM-6B:这张图片描绘了一只棕色的小狗躺在蓝色的木质地板上。
|
| 169 |
+
用户:clear
|
| 170 |
+
请输入图像路径或URL(回车进入纯文本对话): fewshot-data/passport.png
|
| 171 |
+
用户:这张图片的背景里有什么内容?
|
| 172 |
+
VisualGLM-6B:这张图片的背景是电脑键盘。
|
| 173 |
+
用户:描述一下这张图片。
|
| 174 |
+
VisualGLM-6B:这张图片的特点是电脑键盘和护照。
|
| 175 |
+
用户:有几张护照
|
| 176 |
+
VisualGLM-6B:两张护照。
|
| 177 |
+
用户:clear
|
| 178 |
+
请输入图像路径或URL(回车进入纯文本对话):
|
| 179 |
+
```
|
| 180 |
+
|
| 181 |
+
</details>
|
| 182 |
+
|
| 183 |
+
如果希望把LoRA部分的参数合并到原始的权重,可以调用`merge_lora()`,例如:
|
| 184 |
+
|
| 185 |
+
```python
|
| 186 |
+
from finetune_visualglm import FineTuneVisualGLMModel
|
| 187 |
+
import argparse
|
| 188 |
+
|
| 189 |
+
model, args = FineTuneVisualGLMModel.from_pretrained('checkpoints/finetune-visualglm-6b-05-19-07-36',
|
| 190 |
+
args=argparse.Namespace(
|
| 191 |
+
fp16=True,
|
| 192 |
+
skip_init=True,
|
| 193 |
+
use_gpu_initialization=True,
|
| 194 |
+
device='cuda',
|
| 195 |
+
))
|
| 196 |
+
model.get_mixin('lora').merge_lora()
|
| 197 |
+
args.layer_range = []
|
| 198 |
+
args.save = 'merge_lora'
|
| 199 |
+
args.mode = 'inference'
|
| 200 |
+
from sat.training.model_io import save_checkpoint
|
| 201 |
+
save_checkpoint(1, model, None, None, args)
|
| 202 |
+
```
|
| 203 |
+
|
| 204 |
+
微调需要安装`deepspeed`库,目前本流程仅支持linux系统,更多的样例说明和Windows系统的流程说明将在近期完成。
|
| 205 |
+
|
| 206 |
+
## 部署工具
|
| 207 |
+
|
| 208 |
+
### 命令行 Demo
|
| 209 |
+
|
| 210 |
+
```shell
|
| 211 |
+
python cli_demo.py
|
| 212 |
+
```
|
| 213 |
+
程序会自动下载sat模型,并在命令行中进行交互式的对话,输入指示并回车即可生成回复,输入 clear 可以清空对话历史,输入 stop 终止程序。
|
| 214 |
+
|
| 215 |
+

|
| 216 |
+
程序提供如下超参数控制生成过程与量化精度:
|
| 217 |
+
```
|
| 218 |
+
usage: cli_demo.py [-h] [--max_length MAX_LENGTH] [--top_p TOP_P] [--top_k TOP_K] [--temperature TEMPERATURE] [--english] [--quant {8,4}]
|
| 219 |
+
|
| 220 |
+
optional arguments:
|
| 221 |
+
-h, --help show this help message and exit
|
| 222 |
+
--max_length MAX_LENGTH
|
| 223 |
+
max length of the total sequence
|
| 224 |
+
--top_p TOP_P top p for nucleus sampling
|
| 225 |
+
--top_k TOP_K top k for top k sampling
|
| 226 |
+
--temperature TEMPERATURE
|
| 227 |
+
temperature for sampling
|
| 228 |
+
--english only output English
|
| 229 |
+
--quant {8,4} quantization bits
|
| 230 |
+
```
|
| 231 |
+
需要注意的是,在训练时英文问答对的提示词为`Q: A:`,而中文为`问:答:`,在网页demo中采取了中文的提示,因此英文回复会差一些且夹杂中文;如果需要英文回复,请使用`cli_demo.py`中的`--english`选项。
|
| 232 |
+
|
| 233 |
+
我们也提供了继承自`ChatGLM-6B`的打字机效果命令行工具,此工具使用Huggingface模型:
|
| 234 |
+
```shell
|
| 235 |
+
python cli_demo_hf.py
|
| 236 |
+
```
|
| 237 |
+
|
| 238 |
+
### 网页版 Demo
|
| 239 |
+

|
| 240 |
+
|
| 241 |
+
我们提供了一个基于 [Gradio](https://gradio.app) 的网页版 Demo,首先安装 Gradio:`pip install gradio`。
|
| 242 |
+
然后下载并进入本仓库运行`web_demo.py`:
|
| 243 |
+
|
| 244 |
+
```
|
| 245 |
+
git clone https://github.com/THUDM/VisualGLM-6B
|
| 246 |
+
cd VisualGLM-6B
|
| 247 |
+
python web_demo.py
|
| 248 |
+
```
|
| 249 |
+
程序会自动下载 sat 模型,并运行一个 Web Server,并输出地址。在浏览器中打开输出的地址即可使用。
|
| 250 |
+
|
| 251 |
+
|
| 252 |
+
我们也提供了继承自`ChatGLM-6B`的打字机效果网页版工具,此工具使用 Huggingface 模型,启动后将运行在`:8080`端口上:
|
| 253 |
+
```shell
|
| 254 |
+
python web_demo_hf.py
|
| 255 |
+
```
|
| 256 |
+
|
| 257 |
+
两种网页版 demo 均接受命令行参数`--share`以生成 gradio 公开链接,接受`--quant 4`和`--quant 8`以分别使用4比特量化/8比特量化减少显存占用。
|
| 258 |
+
|
| 259 |
+
### API部署
|
| 260 |
+
首先需要安装额外的依赖 `pip install fastapi uvicorn`,然后运行仓库中的 [api.py](api.py):
|
| 261 |
+
```shell
|
| 262 |
+
python api.py
|
| 263 |
+
```
|
| 264 |
+
程序会自动下载 sat 模型,默认部署在本地的 8080 端口,通过 POST 方法进行调用。下面是用`curl`请求的例子,一般而言可以也可以使用代码方法进行POST。
|
| 265 |
+
```shell
|
| 266 |
+
echo "{\"image\":\"$(base64 path/to/example.jpg)\",\"text\":\"描述这张图片\",\"history\":[]}" > temp.json
|
| 267 |
+
curl -X POST -H "Content-Type: application/json" -d @temp.json http://127.0.0.1:8080
|
| 268 |
+
```
|
| 269 |
+
得到的返回值为
|
| 270 |
+
```
|
| 271 |
+
{
|
| 272 |
+
"response":"这张图片展现了一只可爱的卡通羊驼,它站在��个透明的背景上。这只羊驼长着一张毛茸茸的耳朵和一双大大的眼睛,它的身体是白色的,带有棕色斑点。",
|
| 273 |
+
"history":[('描述这张图片', '这张图片展现了一只可爱的卡通羊驼,它站在一个透明的背景上。这只羊驼长着一张毛茸茸的耳朵和一双大大的眼睛,它的身体是白色的,带有棕色斑点。')],
|
| 274 |
+
"status":200,
|
| 275 |
+
"time":"2023-05-16 20:20:10"
|
| 276 |
+
}
|
| 277 |
+
```
|
| 278 |
+
|
| 279 |
+
我们也提供了使用Huggingface模型的 [api_hf.py](api_hf.py),用法和sat模型的api一致:
|
| 280 |
+
```shell
|
| 281 |
+
python api_hf.py
|
| 282 |
+
```
|
| 283 |
+
|
| 284 |
+
|
| 285 |
+
## 模型量化
|
| 286 |
+
在Huggingface实现中,模型默认以 FP16 精度加载,运行上述代码需要大概 15GB 显存。如果你的 GPU 显存有限,可以尝试以量化方式加载模型。
|
| 287 |
+
使用方法如下:
|
| 288 |
+
```python
|
| 289 |
+
# 按需修改,目前只支持 4/8 bit 量化。下面将只量化ChatGLM,ViT 量化时误差较大
|
| 290 |
+
model = AutoModel.from_pretrained("THUDM/visualglm-6b", trust_remote_code=True).quantize(8).half().cuda()
|
| 291 |
+
```
|
| 292 |
+
|
| 293 |
+
在sat实现中,需先传参将加载位置改为`cpu`,再进行量化。方法如下,详见`cli_demo.py`:
|
| 294 |
+
```python
|
| 295 |
+
from sat.quantization.kernels import quantize
|
| 296 |
+
model = quantize(model.transformer, args.quant).cuda()
|
| 297 |
+
# 指定 model.transformer 只量化 ChatGLM,ViT 量化时误差较大
|
| 298 |
+
```
|
| 299 |
+
|
| 300 |
+
## 局限性
|
| 301 |
+
本项目正处于V1版本视觉和语言模型的参数、计算量都较小,我们总结了如下主要存在的改进方向:
|
| 302 |
+
- 图像描述事实性/模型幻觉问题。在生成图像长描述的时候,距离图像较远时,语言模型的将占主导,有一定可能根据上下文生成并不存在于图像的内容。
|
| 303 |
+
- 属性错配问题。在多物体的场景中,部分物体的某些属性,经常被错误安插到其他物体上。
|
| 304 |
+
- 分辨率问题。本项目使用了224*224的分辨率,也是视觉模型中最为常用的尺寸;然而为了进行更细粒度的理解,更大的分辨率和计算量是必要的。
|
| 305 |
+
- 由于数据等方面原因,模型暂时不具有中文ocr的能力(英文ocr能力有一些),我们会在后续版本中增加这个能力。
|
| 306 |
+
## 协议
|
| 307 |
+
|
| 308 |
+
本仓库的代码依照 [Apache-2.0](LICENSE.txt) 协议开源,VisualGLM-6B 模型的权重的使用则需要遵循 [Model License](MODEL_LICENSE.txt)。
|
| 309 |
+
|
| 310 |
+
## 引用与致谢
|
| 311 |
+
如果你觉得我们的工作有帮助的话,请考虑引用下列论文
|
| 312 |
+
```
|
| 313 |
+
@inproceedings{du2022glm,
|
| 314 |
+
title={GLM: General Language Model Pretraining with Autoregressive Blank Infilling},
|
| 315 |
+
author={Du, Zhengxiao and Qian, Yujie and Liu, Xiao and Ding, Ming and Qiu, Jiezhong and Yang, Zhilin and Tang, Jie},
|
| 316 |
+
booktitle={Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers)},
|
| 317 |
+
pages={320--335},
|
| 318 |
+
year={2022}
|
| 319 |
+
}
|
| 320 |
+
@article{ding2021cogview,
|
| 321 |
+
title={Cogview: Mastering text-to-image generation via transformers},
|
| 322 |
+
author={Ding, Ming and Yang, Zhuoyi and Hong, Wenyi and Zheng, Wendi and Zhou, Chang and Yin, Da and Lin, Junyang and Zou, Xu and Shao, Zhou and Yang, Hongxia and others},
|
| 323 |
+
journal={Advances in Neural Information Processing Systems},
|
| 324 |
+
volume={34},
|
| 325 |
+
pages={19822--19835},
|
| 326 |
+
year={2021}
|
| 327 |
+
}
|
| 328 |
+
```
|
| 329 |
+
在VisualGLM-6B的指令微调阶段的数据集中,包含了来自[MiniGPT-4](https://github.com/Vision-CAIR/MiniGPT-4)和[LLAVA](https://github.com/haotian-liu/LLaVA)项目的一部分英文图文数据,以及许多经典的跨模态工作数据集,衷心感谢他们的贡献。
|
README_en.md
ADDED
|
@@ -0,0 +1,246 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# VisualGLM-6B
|
| 2 |
+
<p align="center">
|
| 3 |
+
🤗 <a href="https://huggingface.co/THUDM/visualglm-6b" target="_blank">HF Repo</a> • ⚒️ <a href="https://github.com/THUDM/SwissArmyTransformer" target="_blank">SwissArmyTransformer (sat)</a> • 🐦 <a href="https://twitter.com/thukeg" target="_blank">Twitter</a>
|
| 4 |
+
</p>
|
| 5 |
+
<p align="center">
|
| 6 |
+
• 📃 <a href="https://arxiv.org/abs/2105.13290" target="_blank">[CogView@NeurIPS 21]</a> <a href="https://github.com/THUDM/CogView" target="_blank">[GitHub]</a> • 📃 <a href="https://arxiv.org/abs/2103.10360" target="_blank">[GLM@ACL 22]</a> <a href="https://github.com/THUDM/GLM" target="_blank">[GitHub]</a> <br>
|
| 7 |
+
</p>
|
| 8 |
+
<p align="center">
|
| 9 |
+
👋 Join us on <a href="https://join.slack.com/t/chatglm/shared_invite/zt-1th2q5u69-7tURzFuOPanmuHy9hsZnKA" target="_blank">Slack</a> and <a href="resources/WECHAT.md" target="_blank">WeChat</a>
|
| 10 |
+
</p>
|
| 11 |
+
<!-- <p align="center">
|
| 12 |
+
🤖<a href="https://huggingface.co/spaces/THUDM/visualglm-6b" target="_blank">VisualGLM-6B Online Demo Website</a>
|
| 13 |
+
</p> -->
|
| 14 |
+
|
| 15 |
+
## Introduction
|
| 16 |
+
VisualGLM-6B is an open-source, multi-modal dialog language model that supports **images, Chinese, and English**. The language model is based on [ChatGLM-6B](https://github.com/THUDM/ChatGLM-6B) with 6.2 billion parameters; the image part builds a bridge between the visual model and the language model through the training of [BLIP2-Qformer](https://arxiv.org/abs/2301.12597), with the total model comprising 7.8 billion parameters.
|
| 17 |
+
|
| 18 |
+
VisualGLM-6B relies on 30M high-quality Chinese image-text pairs from the [CogView](https://arxiv.org/abs/2105.13290) dataset and 300M filtered English image-text pairs for pre-training, with equal weight for Chinese and English. This training method aligns visual information well to the semantic space of ChatGLM. In the subsequent fine-tuning phase, the model is trained on long visual question answering data to generate answers that align with human preferences.
|
| 19 |
+
|
| 20 |
+
VisualGLM-6B is trained using the [SwissArmyTransformer](https://github.com/THUDM/SwissArmyTransformer) (abbreviated as sat) library, a utility library for flexible modification and training of Transformer, supporting efficient fine-tuning methods like Lora and P-tuning. This project provides a user-friendly huggingface interface, as well as an interface based on sat.
|
| 21 |
+
|
| 22 |
+
However, as VisualGLM-6B is still at the v1 stage, it is known to have quite a few [**limitations**](#Limitations), such as factual inaccuracy/model hallucination in image description, lack of capturing image detail information, and some limitations from the language model. Please be aware of these issues and evaluate the potential risks before using. In future versions of VisualGLM, we will strive to optimize these issues.
|
| 23 |
+
|
| 24 |
+
With model quantization technology, users can deploy locally on consumer-grade graphics cards (requiring as little as 8.7G memory under INT4 quantization level).
|
| 25 |
+
|
| 26 |
+
## Examples
|
| 27 |
+
VisualGLM-6B can answer questions related to image description.
|
| 28 |
+

|
| 29 |
+
|
| 30 |
+
<details>
|
| 31 |
+
<summary>It can also combine common sense or propose interesting views. Click to expand/collapse more examples</summary>
|
| 32 |
+
|
| 33 |
+

|
| 34 |
+

|
| 35 |
+
|
| 36 |
+
</details>
|
| 37 |
+
|
| 38 |
+
|
| 39 |
+
## Usage
|
| 40 |
+
|
| 41 |
+
### Model Inference
|
| 42 |
+
|
| 43 |
+
Install dependencies with pip
|
| 44 |
+
```
|
| 45 |
+
pip install -i https://pypi.org/simple -r requirements.txt
|
| 46 |
+
pip install -i https://mirrors.aliyun.com/pypi/simple/ -r requirements.txt
|
| 47 |
+
```
|
| 48 |
+
This will default to installing the deepspeed library (which supports the sat library training). This library is not necessary for model inference and can cause problems when installed in some Windows environments.
|
| 49 |
+
If you want to bypass deepspeed installation, you can change the command to:
|
| 50 |
+
```
|
| 51 |
+
pip install -i https://mirrors.aliyun.com/pypi/simple/ -r requirements_wo_ds.txt
|
| 52 |
+
pip install -i https://mirrors.aliyun.com/pypi/simple/ --no-deps "SwissArmyTransformer>=0.3.6"
|
| 53 |
+
```
|
| 54 |
+
|
| 55 |
+
If you are calling the model using the Huggingface transformers library (you also need to install the above dependency packages!), you can use the following code (where the image path is the local path):
|
| 56 |
+
```python
|
| 57 |
+
from transformers import AutoTokenizer, AutoModel
|
| 58 |
+
tokenizer = AutoTokenizer.from_pretrained("THUDM/visualglm-6b", trust_remote_code=True)
|
| 59 |
+
model = AutoModel.from_pretrained("THUDM/visualglm-6b", trust_remote_code=True).half().cuda()
|
| 60 |
+
image_path = "your image path"
|
| 61 |
+
response, history = model.chat(tokenizer, image_path, "描述这张图片。", history=[])
|
| 62 |
+
print(response)
|
| 63 |
+
response, history = model.chat(tokenizer, image_path, "这张图片可能是在什么场所拍摄的?", history=history)
|
| 64 |
+
print(response)
|
| 65 |
+
```
|
| 66 |
+
|
| 67 |
+
If you use the SwissArmyTransformer library to call the model, the method is similar, and you can use the environment variable SAT_HOME to determine the model download location. In the directory of this repository:
|
| 68 |
+
```python
|
| 69 |
+
import argparse
|
| 70 |
+
from transformers import AutoTokenizer
|
| 71 |
+
tokenizer = AutoTokenizer.from_pretrained("THUDM/chatglm-6b", trust_remote_code=True)
|
| 72 |
+
from model import chat, VisualGLMModel
|
| 73 |
+
model, model_args = VisualGLMModel.from_pretrained('visualglm-6b', args=argparse.Namespace(fp16=True, skip_init=True))
|
| 74 |
+
from sat.model.mixins import CachedAutoregressiveMixin
|
| 75 |
+
model.add_mixin('auto-regressive', CachedAutoregressiveMixin())
|
| 76 |
+
image_path = "your image path or URL"
|
| 77 |
+
response, history, cache_image = chat(image_path, model, tokenizer, "Describe this picture.", history=[])
|
| 78 |
+
print(response)
|
| 79 |
+
response, history, cache_image = chat(None, model, tokenizer, "Where could this picture possibly have been taken?", history=history, image=cache_image)
|
| 80 |
+
print(response)
|
| 81 |
+
```
|
| 82 |
+
|
| 83 |
+
Using the `sat` library can also easily carry out efficient parameter fine-tuning. <!-- TODO specific code -->
|
| 84 |
+
|
| 85 |
+
Please note that the Huggingface model implementation is located in the [Huggingface repository](https://huggingface.co/THUDM/visualglm-6b), and the `sat` model implementation is included in this repository.
|
| 86 |
+
|
| 87 |
+
## Model Fine-tuning
|
| 88 |
+
|
| 89 |
+
Multimodal tasks are wide-ranging and diverse, and pre-training often cannot cover all bases.
|
| 90 |
+
Here we provide an example of small sample fine-tuning, using 20 labeled images to enhance the model's ability to answer "background" questions.
|
| 91 |
+
|
| 92 |
+
After unzipping fewshot-data.zip, run the following command:
|
| 93 |
+
```
|
| 94 |
+
bash finetune/finetune_visualglm.sh
|
| 95 |
+
```
|
| 96 |
+
|
| 97 |
+
Currently we support three types of (parameter-efficient) fine-tuning:
|
| 98 |
+
|
| 99 |
+
* LoRA: In the given example, we add rank=10 LoRA for layer 0 and layer 14 in ChatGLM. You can adjust `--layer_range` and `--lora_rank` to fit your application and data amount.
|
| 100 |
+
* QLoRA: If your resource is limited, consider using `bash finetune/finetune_visualglm_qlora.sh`, which do 4-bit quantization for ChatGLM Linear layers, reducing the required GPU memory to 9.8 GB.
|
| 101 |
+
* P-tuning: You can replace `--use_lora` to `--use_ptuning`, but not recommended, unless your application has a relatively fixed input and output template.
|
| 102 |
+
|
| 103 |
+
After training, you can use the following command for inference:
|
| 104 |
+
|
| 105 |
+
```
|
| 106 |
+
python cli_demo.py --from_pretrained your_checkpoint_path --prompt_zh 这张图片的背景里有什么内容?
|
| 107 |
+
```
|
| 108 |
+
|
| 109 |
+
Fine-tuning requires the installation of the deepspeed library, and currently this process only supports the Linux system. More examples and instructions for the Windows system will be completed in the near future.
|
| 110 |
+
|
| 111 |
+
If you want to merge LoRA weights into original weights, just call `merge_lora()`:
|
| 112 |
+
|
| 113 |
+
```python
|
| 114 |
+
from finetune_visualglm import FineTuneVisualGLMModel
|
| 115 |
+
import argparse
|
| 116 |
+
|
| 117 |
+
model, args = FineTuneVisualGLMModel.from_pretrained('checkpoints/finetune-visualglm-6b-05-19-07-36',
|
| 118 |
+
args=argparse.Namespace(
|
| 119 |
+
fp16=True,
|
| 120 |
+
skip_init=True,
|
| 121 |
+
use_gpu_initialization=True,
|
| 122 |
+
device='cuda',
|
| 123 |
+
))
|
| 124 |
+
model.get_mixin('lora').merge_lora()
|
| 125 |
+
args.layer_range = []
|
| 126 |
+
args.save = 'merge_lora'
|
| 127 |
+
args.mode = 'inference'
|
| 128 |
+
from sat.training.model_io import save_checkpoint
|
| 129 |
+
save_checkpoint(1, model, None, None, args)
|
| 130 |
+
```
|
| 131 |
+
|
| 132 |
+
## Deployment Tools
|
| 133 |
+
|
| 134 |
+
### Command Line Demo
|
| 135 |
+
|
| 136 |
+
```shell
|
| 137 |
+
python cli_demo.py
|
| 138 |
+
```
|
| 139 |
+
The program will automatically download the sat model and interact in the command line. You can generate replies by entering instructions and pressing enter. Enter 'clear' to clear the conversation history and 'stop' to stop the program.
|
| 140 |
+
|
| 141 |
+

|
| 142 |
+
The program provides the following hyperparameters to control the generation process and quantization accuracy:
|
| 143 |
+
```
|
| 144 |
+
usage: cli_demo.py [-h] [--max_length MAX_LENGTH] [--top_p TOP_P] [--top_k TOP_K] [--temperature TEMPERATURE] [--english] [--quant {8,4}]
|
| 145 |
+
|
| 146 |
+
optional arguments:
|
| 147 |
+
-h, --help show this help message and exit
|
| 148 |
+
--max_length MAX_LENGTH
|
| 149 |
+
max length of the total sequence
|
| 150 |
+
--top_p TOP_P top p for nucleus sampling
|
| 151 |
+
--top_k TOP_K top k for top k sampling
|
| 152 |
+
--temperature TEMPERATURE
|
| 153 |
+
temperature for sampling
|
| 154 |
+
--english only output English
|
| 155 |
+
--quant {8,4} quantization bits
|
| 156 |
+
```
|
| 157 |
+
Note that during training, the prompt words for English Q&A pairs are 'Q: A:', while in Chinese they are '问:答:'. The web demo uses Chinese prompts, so the English replies will be worse and interspersed with Chinese; if you need English replies, please use the --english option in cli_demo.py.
|
| 158 |
+
|
| 159 |
+
We also provide a typewriter effect command line tool inherited from ChatGLM-6B, which uses the Huggingface model:
|
| 160 |
+
```shell
|
| 161 |
+
python cli_demo_hf.py
|
| 162 |
+
```
|
| 163 |
+
|
| 164 |
+
### Web Demo
|
| 165 |
+

|
| 166 |
+
|
| 167 |
+
We provide a web demo based on [Gradio](https://gradio.app). First, install Gradio: `pip install gradio`.
|
| 168 |
+
Then download and enter this repository and run `web_demo.py`:
|
| 169 |
+
|
| 170 |
+
```
|
| 171 |
+
git clone https://github.com/THUDM/VisualGLM-6B
|
| 172 |
+
cd VisualGLM-6B
|
| 173 |
+
python web_demo.py
|
| 174 |
+
```
|
| 175 |
+
The program will automatically download the sat model and run a Web Server, outputting the address. Open the output address in your browser to use it.
|
| 176 |
+
|
| 177 |
+
We also provide a web tool with a typewriter effect inherited from ChatGLM-6B, which uses the Huggingface model and will run on port :8080 after starting:
|
| 178 |
+
```shell
|
| 179 |
+
python web_demo_hf.py
|
| 180 |
+
```
|
| 181 |
+
|
| 182 |
+
Both web demos accept the command line parameter --share to generate a public link for gradio, and accept --quant 4 and --quant 8 to use 4-bit quantization/8-bit quantization to reduce GPU memory usage.
|
| 183 |
+
|
| 184 |
+
### API Deployment
|
| 185 |
+
First, you need to install additional dependencies pip install fastapi uvicorn, then run the api.py in the repository:
|
| 186 |
+
```shell
|
| 187 |
+
python api.py
|
| 188 |
+
```
|
| 189 |
+
The program will automatically download the sat model, and by default it will be deployed on local port 8080 and called through the POST method. Below is an example of a request with curl, but in general you can also use a code method to POST.
|
| 190 |
+
```shell
|
| 191 |
+
echo "{\"image\":\"$(base64 path/to/example.jpg)\",\"text\":\"Describe this picture\",\"history\":[]}" > temp.json
|
| 192 |
+
curl -X POST -H "Content-Type: application/json" -d @temp.json http://127.0.0.1:8080
|
| 193 |
+
```
|
| 194 |
+
|
| 195 |
+
We also provide an api_hf.py that uses the Huggingface model, which works the same way as the sat model's api:
|
| 196 |
+
```shell
|
| 197 |
+
python api_hf.py
|
| 198 |
+
```
|
| 199 |
+
|
| 200 |
+
|
| 201 |
+
## Model Quantization
|
| 202 |
+
In the Huggingface implementation, the model is loaded with FP16 precision by default, and running the above code requires about 15GB of GPU memory. If your GPU memory is limited, you can try loading the model in a quantized manner.
|
| 203 |
+
Here's how:
|
| 204 |
+
```python
|
| 205 |
+
# Modify as needed, currently only 4/8 bit quantization is supported. The following will only quantize ChatGLM, as the error is larger when quantizing ViT
|
| 206 |
+
model = AutoModel.from_pretrained("THUDM/visualglm-6b", trust_remote_code=True).quantize(8).half().cuda()
|
| 207 |
+
```
|
| 208 |
+
|
| 209 |
+
In the sat implementation, you need to change the loading location to 'cpu' first, and then perform quantization. Here's how, see cli_demo.py for details:
|
| 210 |
+
```python
|
| 211 |
+
from sat.quantization.kernels import quantize
|
| 212 |
+
model = quantize(model.transformer, args.quant).cuda()
|
| 213 |
+
# Specify model.transformer to only quantize ChatGLM, as the error is larger when quantizing ViT
|
| 214 |
+
```
|
| 215 |
+
|
| 216 |
+
## Limitations
|
| 217 |
+
This project is currently at V1 version of the visual and language model parameters, the amount of calculation is small, we have summarized the following main improvements:
|
| 218 |
+
|
| 219 |
+
- Image description factuality/model hallucination problem. When generating long descriptions of images, as the distance from the image increases, the language model will dominate, and there is a certain possibility of generating content that does not exist in the image based on the context.
|
| 220 |
+
- Attribute mismatch problem. In scenes with multiple objects, some attributes of some objects are often incorrectly inserted onto other objects.
|
| 221 |
+
- Resolution issue. This project uses a resolution of 224*224, which is the most commonly used size in visual models; however, for more fine-grained understanding, larger resolution and computation are necessary.
|
| 222 |
+
- Due to data and other reasons, the model currently does not have the ability to perform Chinese OCR (some ability for English OCR), we will add this ability in future versions.
|
| 223 |
+
## License
|
| 224 |
+
|
| 225 |
+
The code in this repository is open source under the Apache-2.0 license, while the use of the VisualGLM-6B model weights must comply with the Model License.
|
| 226 |
+
|
| 227 |
+
## Citation & Acknowledgements
|
| 228 |
+
If you find our work helpful, please consider citing the following papers
|
| 229 |
+
```
|
| 230 |
+
@inproceedings{du2022glm,
|
| 231 |
+
title={GLM: General Language Model Pretraining with Autoregressive Blank Infilling},
|
| 232 |
+
author={Du, Zhengxiao and Qian, Yujie and Liu, Xiao and Ding, Ming and Qiu, Jiezhong and Yang, Zhilin and Tang, Jie},
|
| 233 |
+
booktitle={Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers)},
|
| 234 |
+
pages={320--335},
|
| 235 |
+
year={2022}
|
| 236 |
+
}
|
| 237 |
+
@article{ding2021cogview,
|
| 238 |
+
title={Cogview: Mastering text-to-image generation via transformers},
|
| 239 |
+
author={Ding, Ming and Yang, Zhuoyi and Hong, Wenyi and Zheng, Wendi and Zhou, Chang and Yin, Da and Lin, Junyang and Zou, Xu and Shao, Zhou and Yang, Hongxia and others},
|
| 240 |
+
journal={Advances in Neural Information Processing Systems},
|
| 241 |
+
volume={34},
|
| 242 |
+
pages={19822--19835},
|
| 243 |
+
year={2021}
|
| 244 |
+
}
|
| 245 |
+
```
|
| 246 |
+
In the instruction fine-tuning phase of the VisualGLM-6B dataset, there are some English image-text data from the [MiniGPT-4](https://github.com/Vision-CAIR/MiniGPT-4) and [LLAVA](https://github.com/haotian-liu/LLaVA) projects, as well as many classic cross-modal work datasets. We sincerely thank them for their contributions.
|
__pycache__/finetune_visualglm.cpython-310.pyc
ADDED
|
Binary file (7 kB). View file
|
|
|
__pycache__/lora_mixin.cpython-310.pyc
ADDED
|
Binary file (10.6 kB). View file
|
|
|
api.py
ADDED
|
@@ -0,0 +1,51 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import os
|
| 2 |
+
import json
|
| 3 |
+
import uvicorn
|
| 4 |
+
from fastapi import FastAPI, Request
|
| 5 |
+
from model import is_chinese, get_infer_setting, generate_input, chat
|
| 6 |
+
import datetime
|
| 7 |
+
import torch
|
| 8 |
+
|
| 9 |
+
gpu_number = 0
|
| 10 |
+
model, tokenizer = get_infer_setting(gpu_device=gpu_number)
|
| 11 |
+
|
| 12 |
+
app = FastAPI()
|
| 13 |
+
@app.post('/')
|
| 14 |
+
async def visual_glm(request: Request):
|
| 15 |
+
json_post_raw = await request.json()
|
| 16 |
+
print("Start to process request")
|
| 17 |
+
|
| 18 |
+
json_post = json.dumps(json_post_raw)
|
| 19 |
+
request_data = json.loads(json_post)
|
| 20 |
+
input_text, input_image_encoded, history = request_data['text'], request_data['image'], request_data['history']
|
| 21 |
+
input_para = {
|
| 22 |
+
"max_length": 2048,
|
| 23 |
+
"min_length": 50,
|
| 24 |
+
"temperature": 0.8,
|
| 25 |
+
"top_p": 0.4,
|
| 26 |
+
"top_k": 100,
|
| 27 |
+
"repetition_penalty": 1.2
|
| 28 |
+
}
|
| 29 |
+
input_para.update(request_data)
|
| 30 |
+
|
| 31 |
+
is_zh = is_chinese(input_text)
|
| 32 |
+
input_data = generate_input(input_text, input_image_encoded, history, input_para)
|
| 33 |
+
input_image, gen_kwargs = input_data['input_image'], input_data['gen_kwargs']
|
| 34 |
+
with torch.no_grad():
|
| 35 |
+
answer, history, _ = chat(None, model, tokenizer, input_text, history=history, image=input_image, \
|
| 36 |
+
max_length=gen_kwargs['max_length'], top_p=gen_kwargs['top_p'], \
|
| 37 |
+
top_k = gen_kwargs['top_k'], temperature=gen_kwargs['temperature'], english=not is_zh)
|
| 38 |
+
|
| 39 |
+
now = datetime.datetime.now()
|
| 40 |
+
time = now.strftime("%Y-%m-%d %H:%M:%S")
|
| 41 |
+
response = {
|
| 42 |
+
"result": answer,
|
| 43 |
+
"history": history,
|
| 44 |
+
"status": 200,
|
| 45 |
+
"time": time
|
| 46 |
+
}
|
| 47 |
+
return response
|
| 48 |
+
|
| 49 |
+
|
| 50 |
+
if __name__ == '__main__':
|
| 51 |
+
uvicorn.run(app, host='0.0.0.0', port=8080, workers=1)
|
api_hf.py
ADDED
|
@@ -0,0 +1,49 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import os
|
| 2 |
+
import json
|
| 3 |
+
from transformers import AutoTokenizer, AutoModel
|
| 4 |
+
import uvicorn
|
| 5 |
+
from fastapi import FastAPI, Request
|
| 6 |
+
import datetime
|
| 7 |
+
from model import process_image
|
| 8 |
+
import torch
|
| 9 |
+
|
| 10 |
+
tokenizer = AutoTokenizer.from_pretrained("THUDM/visualglm-6b", trust_remote_code=True)
|
| 11 |
+
model = AutoModel.from_pretrained("THUDM/visualglm-6b", trust_remote_code=True).half().cuda()
|
| 12 |
+
|
| 13 |
+
|
| 14 |
+
app = FastAPI()
|
| 15 |
+
@app.post('/')
|
| 16 |
+
async def visual_glm(request: Request):
|
| 17 |
+
json_post_raw = await request.json()
|
| 18 |
+
print("Start to process request")
|
| 19 |
+
|
| 20 |
+
json_post = json.dumps(json_post_raw)
|
| 21 |
+
request_data = json.loads(json_post)
|
| 22 |
+
|
| 23 |
+
history = request_data.get("history")
|
| 24 |
+
image_encoded = request_data.get("image")
|
| 25 |
+
query = request_data.get("text")
|
| 26 |
+
image_path = process_image(image_encoded)
|
| 27 |
+
|
| 28 |
+
with torch.no_grad():
|
| 29 |
+
result = model.stream_chat(tokenizer, image_path, query, history=history)
|
| 30 |
+
last_result = None
|
| 31 |
+
for value in result:
|
| 32 |
+
last_result = value
|
| 33 |
+
answer = last_result[0]
|
| 34 |
+
|
| 35 |
+
if os.path.isfile(image_path):
|
| 36 |
+
os.remove(image_path)
|
| 37 |
+
now = datetime.datetime.now()
|
| 38 |
+
time = now.strftime("%Y-%m-%d %H:%M:%S")
|
| 39 |
+
response = {
|
| 40 |
+
"result": answer,
|
| 41 |
+
"history": history,
|
| 42 |
+
"status": 200,
|
| 43 |
+
"time": time
|
| 44 |
+
}
|
| 45 |
+
return response
|
| 46 |
+
|
| 47 |
+
|
| 48 |
+
if __name__ == "__main__":
|
| 49 |
+
uvicorn.run(app, host='0.0.0.0', port=8080, workers=1)
|
cli_demo.py
ADDED
|
@@ -0,0 +1,103 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# -*- encoding: utf-8 -*-
|
| 2 |
+
|
| 3 |
+
import os
|
| 4 |
+
import sys
|
| 5 |
+
import torch
|
| 6 |
+
import argparse
|
| 7 |
+
from transformers import AutoTokenizer
|
| 8 |
+
from sat.model.mixins import CachedAutoregressiveMixin
|
| 9 |
+
from sat.quantization.kernels import quantize
|
| 10 |
+
|
| 11 |
+
from model import VisualGLMModel, chat
|
| 12 |
+
from finetune_visualglm import FineTuneVisualGLMModel
|
| 13 |
+
from sat.model import AutoModel
|
| 14 |
+
|
| 15 |
+
|
| 16 |
+
def main():
|
| 17 |
+
parser = argparse.ArgumentParser()
|
| 18 |
+
parser.add_argument("--max_length", type=int, default=2048, help='max length of the total sequence')
|
| 19 |
+
parser.add_argument("--top_p", type=float, default=0.4, help='top p for nucleus sampling')
|
| 20 |
+
parser.add_argument("--top_k", type=int, default=100, help='top k for top k sampling')
|
| 21 |
+
parser.add_argument("--temperature", type=float, default=.8, help='temperature for sampling')
|
| 22 |
+
parser.add_argument("--english", action='store_true', help='only output English')
|
| 23 |
+
parser.add_argument("--quant", choices=[8, 4], type=int, default=None, help='quantization bits')
|
| 24 |
+
parser.add_argument("--from_pretrained", type=str, default="visualglm-6b", help='pretrained ckpt')
|
| 25 |
+
parser.add_argument("--prompt_zh", type=str, default="描述这张图片。", help='Chinese prompt for the first round')
|
| 26 |
+
parser.add_argument("--prompt_en", type=str, default="Describe the image.", help='English prompt for the first round')
|
| 27 |
+
args = parser.parse_args()
|
| 28 |
+
|
| 29 |
+
# load model
|
| 30 |
+
model, model_args = AutoModel.from_pretrained(
|
| 31 |
+
args.from_pretrained,
|
| 32 |
+
args=argparse.Namespace(
|
| 33 |
+
fp16=True,
|
| 34 |
+
skip_init=True,
|
| 35 |
+
use_gpu_initialization=True if (torch.cuda.is_available() and args.quant is None) else False,
|
| 36 |
+
device='cuda' if (torch.cuda.is_available() and args.quant is None) else 'cpu',
|
| 37 |
+
))
|
| 38 |
+
model = model.eval()
|
| 39 |
+
|
| 40 |
+
if args.quant:
|
| 41 |
+
quantize(model.transformer, args.quant)
|
| 42 |
+
if torch.cuda.is_available():
|
| 43 |
+
model = model.cuda()
|
| 44 |
+
|
| 45 |
+
model.add_mixin('auto-regressive', CachedAutoregressiveMixin())
|
| 46 |
+
|
| 47 |
+
tokenizer = AutoTokenizer.from_pretrained("THUDM/chatglm-6b", trust_remote_code=True)
|
| 48 |
+
if not args.english:
|
| 49 |
+
print('欢迎使用 VisualGLM-6B 模型,输入图像URL或本地路径读图,继续输入内容对话,clear 重新开始,stop 终止程序')
|
| 50 |
+
else:
|
| 51 |
+
print('Welcome to VisualGLM-6B model. Enter an image URL or local file path to load an image. Continue inputting text to engage in a conversation. Type "clear" to start over, or "stop" to end the program.')
|
| 52 |
+
with torch.no_grad():
|
| 53 |
+
while True:
|
| 54 |
+
history = None
|
| 55 |
+
cache_image = None
|
| 56 |
+
if not args.english:
|
| 57 |
+
image_path = input("请输入图像路径或URL(回车进入纯文本对话): ")
|
| 58 |
+
else:
|
| 59 |
+
image_path = input("Please enter the image path or URL (press Enter for plain text conversation): ")
|
| 60 |
+
|
| 61 |
+
if image_path == 'stop':
|
| 62 |
+
break
|
| 63 |
+
if len(image_path) > 0:
|
| 64 |
+
query = args.prompt_en if args.english else args.prompt_zh
|
| 65 |
+
else:
|
| 66 |
+
if not args.english:
|
| 67 |
+
query = input("用户:")
|
| 68 |
+
else:
|
| 69 |
+
query = input("User: ")
|
| 70 |
+
while True:
|
| 71 |
+
if query == "clear":
|
| 72 |
+
break
|
| 73 |
+
if query == "stop":
|
| 74 |
+
sys.exit(0)
|
| 75 |
+
try:
|
| 76 |
+
response, history, cache_image = chat(
|
| 77 |
+
image_path,
|
| 78 |
+
model,
|
| 79 |
+
tokenizer,
|
| 80 |
+
query,
|
| 81 |
+
history=history,
|
| 82 |
+
image=cache_image,
|
| 83 |
+
max_length=args.max_length,
|
| 84 |
+
top_p=args.top_p,
|
| 85 |
+
temperature=args.temperature,
|
| 86 |
+
top_k=args.top_k,
|
| 87 |
+
english=args.english,
|
| 88 |
+
invalid_slices=[slice(63823, 130000)] if args.english else []
|
| 89 |
+
)
|
| 90 |
+
except Exception as e:
|
| 91 |
+
print(e)
|
| 92 |
+
break
|
| 93 |
+
sep = 'A:' if args.english else '答:'
|
| 94 |
+
print("VisualGLM-6B:"+response.split(sep)[-1].strip())
|
| 95 |
+
image_path = None
|
| 96 |
+
if not args.english:
|
| 97 |
+
query = input("用户:")
|
| 98 |
+
else:
|
| 99 |
+
query = input("User: ")
|
| 100 |
+
|
| 101 |
+
|
| 102 |
+
if __name__ == "__main__":
|
| 103 |
+
main()
|
cli_demo_hf.py
ADDED
|
@@ -0,0 +1,69 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import os
|
| 2 |
+
import platform
|
| 3 |
+
import signal
|
| 4 |
+
from transformers import AutoTokenizer, AutoModel
|
| 5 |
+
import torch
|
| 6 |
+
|
| 7 |
+
tokenizer = AutoTokenizer.from_pretrained("THUDM/visualglm-6b", trust_remote_code=True)
|
| 8 |
+
model = AutoModel.from_pretrained("THUDM/visualglm-6b", trust_remote_code=True).half().cuda()
|
| 9 |
+
model = model.eval()
|
| 10 |
+
|
| 11 |
+
os_name = platform.system()
|
| 12 |
+
clear_command = 'cls' if os_name == 'Windows' else 'clear'
|
| 13 |
+
stop_stream = False
|
| 14 |
+
|
| 15 |
+
|
| 16 |
+
def build_prompt(history, prefix):
|
| 17 |
+
prompt = prefix
|
| 18 |
+
for query, response in history:
|
| 19 |
+
prompt += f"\n\n用户:{query}"
|
| 20 |
+
prompt += f"\n\nVisualGLM-6B:{response}"
|
| 21 |
+
return prompt
|
| 22 |
+
|
| 23 |
+
|
| 24 |
+
def signal_handler(signal, frame):
|
| 25 |
+
global stop_stream
|
| 26 |
+
stop_stream = True
|
| 27 |
+
|
| 28 |
+
|
| 29 |
+
def main():
|
| 30 |
+
global stop_stream
|
| 31 |
+
while True:
|
| 32 |
+
history = []
|
| 33 |
+
prefix = "欢迎使用 VisualGLM-6B 模型,输入图片路径和内容即可进行对话,clear 清空对话历史,stop 终止程序"
|
| 34 |
+
print(prefix)
|
| 35 |
+
image_path = input("\n请输入图片路径:")
|
| 36 |
+
if image_path == "stop":
|
| 37 |
+
break
|
| 38 |
+
prefix = prefix + "\n" + image_path
|
| 39 |
+
query = "描述这张图片。"
|
| 40 |
+
while True:
|
| 41 |
+
count = 0
|
| 42 |
+
with torch.no_grad():
|
| 43 |
+
for response, history in model.stream_chat(tokenizer, image_path, query, history=history):
|
| 44 |
+
if stop_stream:
|
| 45 |
+
stop_stream = False
|
| 46 |
+
break
|
| 47 |
+
else:
|
| 48 |
+
count += 1
|
| 49 |
+
if count % 8 == 0:
|
| 50 |
+
os.system(clear_command)
|
| 51 |
+
print(build_prompt(history, prefix), flush=True)
|
| 52 |
+
signal.signal(signal.SIGINT, signal_handler)
|
| 53 |
+
os.system(clear_command)
|
| 54 |
+
print(build_prompt(history, prefix), flush=True)
|
| 55 |
+
query = input("\n用户:")
|
| 56 |
+
if query.strip() == "clear":
|
| 57 |
+
break
|
| 58 |
+
if query.strip() == "stop":
|
| 59 |
+
stop_stream = True
|
| 60 |
+
exit(0)
|
| 61 |
+
# if query.strip() == "clear":
|
| 62 |
+
# history = []
|
| 63 |
+
# os.system(clear_command)
|
| 64 |
+
# print(prefix)
|
| 65 |
+
# continue
|
| 66 |
+
|
| 67 |
+
|
| 68 |
+
if __name__ == "__main__":
|
| 69 |
+
main()
|
examples/1.jpeg
ADDED

|
Git LFS Details
|
examples/2.jpeg
ADDED

|
examples/3.jpeg
ADDED

|
examples/chat_example1.png
ADDED
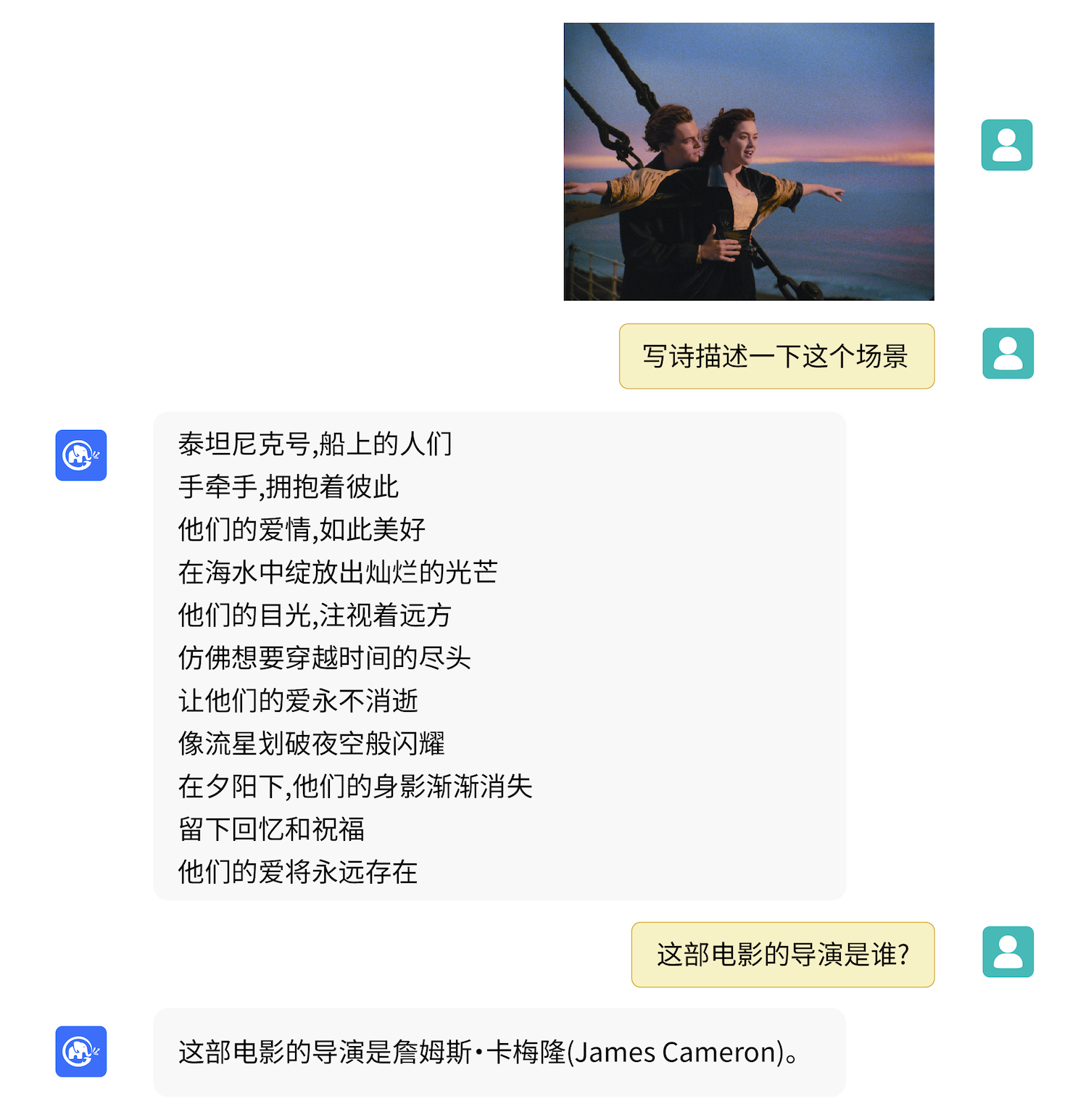
|
examples/chat_example2.png
ADDED

|
examples/chat_example3.png
ADDED

|
examples/example_inputs.jsonl
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{"id":1, "text": "描述一下这个场景", "image": "examples/1.jpeg"}
|
| 2 |
+
{"id":2, "text": "这是什么东西", "image": "examples/2.jpeg"}
|
| 3 |
+
{"id":3, "text": "这张图片描述了什么", "image": "examples/3.jpeg"}
|
examples/thu.png
ADDED

|
examples/web_demo.png
ADDED
|
fewshot-data.zip
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:e96484834c7d9bda898f8da5f658ea63268ebd3aa10ac7f0da3b3dc40a86e1b7
|
| 3 |
+
size 6695260
|
finetune/finetune_visualglm.sh
ADDED
|
@@ -0,0 +1,58 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
#! /bin/bash
|
| 2 |
+
NUM_WORKERS=1
|
| 3 |
+
NUM_GPUS_PER_WORKER=8
|
| 4 |
+
MP_SIZE=1
|
| 5 |
+
|
| 6 |
+
script_path=$(realpath $0)
|
| 7 |
+
script_dir=$(dirname $script_path)
|
| 8 |
+
main_dir=$(dirname $script_dir)
|
| 9 |
+
MODEL_TYPE="visualglm-6b"
|
| 10 |
+
MODEL_ARGS="--max_source_length 64 \
|
| 11 |
+
--max_target_length 256 \
|
| 12 |
+
--lora_rank 10 \
|
| 13 |
+
--layer_range 0 14 \
|
| 14 |
+
--pre_seq_len 4"
|
| 15 |
+
|
| 16 |
+
# OPTIONS_SAT="SAT_HOME=$1" #"SAT_HOME=/raid/dm/sat_models"
|
| 17 |
+
OPTIONS_NCCL="NCCL_DEBUG=info NCCL_IB_DISABLE=0 NCCL_NET_GDR_LEVEL=2"
|
| 18 |
+
HOST_FILE_PATH="hostfile"
|
| 19 |
+
HOST_FILE_PATH="hostfile_single"
|
| 20 |
+
|
| 21 |
+
train_data="./fewshot-data/dataset.json"
|
| 22 |
+
eval_data="./fewshot-data/dataset.json"
|
| 23 |
+
|
| 24 |
+
|
| 25 |
+
gpt_options=" \
|
| 26 |
+
--experiment-name finetune-$MODEL_TYPE \
|
| 27 |
+
--model-parallel-size ${MP_SIZE} \
|
| 28 |
+
--mode finetune \
|
| 29 |
+
--train-iters 300 \
|
| 30 |
+
--resume-dataloader \
|
| 31 |
+
$MODEL_ARGS \
|
| 32 |
+
--train-data ${train_data} \
|
| 33 |
+
--valid-data ${eval_data} \
|
| 34 |
+
--distributed-backend nccl \
|
| 35 |
+
--lr-decay-style cosine \
|
| 36 |
+
--warmup .02 \
|
| 37 |
+
--checkpoint-activations \
|
| 38 |
+
--save-interval 300 \
|
| 39 |
+
--eval-interval 10000 \
|
| 40 |
+
--save "./checkpoints" \
|
| 41 |
+
--split 1 \
|
| 42 |
+
--eval-iters 10 \
|
| 43 |
+
--eval-batch-size 8 \
|
| 44 |
+
--zero-stage 1 \
|
| 45 |
+
--lr 0.0001 \
|
| 46 |
+
--batch-size 4 \
|
| 47 |
+
--skip-init \
|
| 48 |
+
--fp16 \
|
| 49 |
+
--use_lora
|
| 50 |
+
"
|
| 51 |
+
|
| 52 |
+
|
| 53 |
+
|
| 54 |
+
run_cmd="${OPTIONS_NCCL} ${OPTIONS_SAT} deepspeed --master_port 16666 --hostfile ${HOST_FILE_PATH} finetune_visualglm.py ${gpt_options}"
|
| 55 |
+
echo ${run_cmd}
|
| 56 |
+
eval ${run_cmd}
|
| 57 |
+
|
| 58 |
+
set +x
|
finetune/finetune_visualglm_qlora.sh
ADDED
|
@@ -0,0 +1,59 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
#! /bin/bash
|
| 2 |
+
NUM_WORKERS=1
|
| 3 |
+
NUM_GPUS_PER_WORKER=8
|
| 4 |
+
MP_SIZE=1
|
| 5 |
+
|
| 6 |
+
script_path=$(realpath $0)
|
| 7 |
+
script_dir=$(dirname $script_path)
|
| 8 |
+
main_dir=$(dirname $script_dir)
|
| 9 |
+
MODEL_TYPE="visualglm-6b"
|
| 10 |
+
MODEL_ARGS="--max_source_length 64 \
|
| 11 |
+
--max_target_length 256 \
|
| 12 |
+
--lora_rank 10 \
|
| 13 |
+
--layer_range 0 14 \
|
| 14 |
+
--pre_seq_len 4"
|
| 15 |
+
|
| 16 |
+
# OPTIONS_SAT="SAT_HOME=$1" #"SAT_HOME=/raid/dm/sat_models"
|
| 17 |
+
OPTIONS_NCCL="NCCL_DEBUG=info NCCL_IB_DISABLE=0 NCCL_NET_GDR_LEVEL=2"
|
| 18 |
+
HOST_FILE_PATH="hostfile"
|
| 19 |
+
HOST_FILE_PATH="hostfile_single"
|
| 20 |
+
|
| 21 |
+
train_data="./fewshot-data/dataset.json"
|
| 22 |
+
eval_data="./fewshot-data/dataset.json"
|
| 23 |
+
|
| 24 |
+
|
| 25 |
+
gpt_options=" \
|
| 26 |
+
--experiment-name finetune-$MODEL_TYPE \
|
| 27 |
+
--model-parallel-size ${MP_SIZE} \
|
| 28 |
+
--mode finetune \
|
| 29 |
+
--train-iters 300 \
|
| 30 |
+
--resume-dataloader \
|
| 31 |
+
$MODEL_ARGS \
|
| 32 |
+
--train-data ${train_data} \
|
| 33 |
+
--valid-data ${eval_data} \
|
| 34 |
+
--distributed-backend nccl \
|
| 35 |
+
--lr-decay-style cosine \
|
| 36 |
+
--warmup .02 \
|
| 37 |
+
--checkpoint-activations \
|
| 38 |
+
--save-interval 300 \
|
| 39 |
+
--eval-interval 10000 \
|
| 40 |
+
--save "./checkpoints" \
|
| 41 |
+
--split 1 \
|
| 42 |
+
--eval-iters 10 \
|
| 43 |
+
--eval-batch-size 8 \
|
| 44 |
+
--zero-stage 1 \
|
| 45 |
+
--lr 0.0001 \
|
| 46 |
+
--batch-size 1 \
|
| 47 |
+
--gradient-accumulation-steps 4 \
|
| 48 |
+
--skip-init \
|
| 49 |
+
--fp16 \
|
| 50 |
+
--use_qlora
|
| 51 |
+
"
|
| 52 |
+
|
| 53 |
+
|
| 54 |
+
|
| 55 |
+
run_cmd="${OPTIONS_NCCL} ${OPTIONS_SAT} deepspeed --master_port 16666 --include localhost:0 --hostfile ${HOST_FILE_PATH} finetune_visualglm.py ${gpt_options}"
|
| 56 |
+
echo ${run_cmd}
|
| 57 |
+
eval ${run_cmd}
|
| 58 |
+
|
| 59 |
+
set +x
|
finetune_visualglm.py
ADDED
|
@@ -0,0 +1,195 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import os
|
| 2 |
+
import torch
|
| 3 |
+
import argparse
|
| 4 |
+
|
| 5 |
+
from sat import mpu, get_args, get_tokenizer
|
| 6 |
+
from sat.training.deepspeed_training import training_main
|
| 7 |
+
from model import VisualGLMModel
|
| 8 |
+
from sat.model.finetune import PTuningV2Mixin
|
| 9 |
+
from lora_mixin import LoraMixin
|
| 10 |
+
|
| 11 |
+
class FineTuneVisualGLMModel(VisualGLMModel):
|
| 12 |
+
def __init__(self, args, transformer=None, parallel_output=True, **kw_args):
|
| 13 |
+
super().__init__(args, transformer=transformer, parallel_output=parallel_output, **kw_args)
|
| 14 |
+
if args.use_ptuning:
|
| 15 |
+
self.add_mixin("ptuning", PTuningV2Mixin(args.num_layers, args.hidden_size // args.num_attention_heads, args.num_attention_heads, args.pre_seq_len))
|
| 16 |
+
if args.use_lora:
|
| 17 |
+
# If you use lora on other "normal" Transformer, just use it with head_first=False (by default)
|
| 18 |
+
self.add_mixin("lora", LoraMixin(args.num_layers, args.lora_rank, head_first=True, num_attention_heads=args.num_attention_heads, hidden_size_per_attention_head=args.hidden_size // args.num_attention_heads, layer_range=args.layer_range), reinit=True)
|
| 19 |
+
# self.get_mixin("eva").model.glm_proj = replace_linear_with_lora(self.get_mixin("eva").model.glm_proj, LoraLinear, args.lora_rank)
|
| 20 |
+
elif args.use_qlora:
|
| 21 |
+
self.add_mixin("lora", LoraMixin(args.num_layers, args.lora_rank, head_first=True, num_attention_heads=args.num_attention_heads, hidden_size_per_attention_head=args.hidden_size // args.num_attention_heads, layer_range=args.layer_range, qlora=True), reinit=True)
|
| 22 |
+
self.args = args
|
| 23 |
+
|
| 24 |
+
@classmethod
|
| 25 |
+
def add_model_specific_args(cls, parser):
|
| 26 |
+
group = parser.add_argument_group('VisualGLM-finetune', 'VisualGLM finetune Configurations')
|
| 27 |
+
group.add_argument('--pre_seq_len', type=int, default=8)
|
| 28 |
+
group.add_argument('--lora_rank', type=int, default=10)
|
| 29 |
+
group.add_argument('--use_ptuning', action="store_true")
|
| 30 |
+
group.add_argument('--use_lora', action="store_true")
|
| 31 |
+
group.add_argument('--use_qlora', action="store_true")
|
| 32 |
+
group.add_argument('--layer_range', nargs='+', type=int, default=None)
|
| 33 |
+
return super().add_model_specific_args(parser)
|
| 34 |
+
|
| 35 |
+
def disable_untrainable_params(self):
|
| 36 |
+
enable = []
|
| 37 |
+
if self.args.use_ptuning:
|
| 38 |
+
enable.extend(['ptuning'])
|
| 39 |
+
if self.args.use_lora or self.args.use_qlora:
|
| 40 |
+
enable.extend(['matrix_A', 'matrix_B'])
|
| 41 |
+
for n, p in self.named_parameters():
|
| 42 |
+
flag = False
|
| 43 |
+
for e in enable:
|
| 44 |
+
if e.lower() in n.lower():
|
| 45 |
+
flag = True
|
| 46 |
+
break
|
| 47 |
+
if not flag:
|
| 48 |
+
p.requires_grad_(False)
|
| 49 |
+
else:
|
| 50 |
+
print(n)
|
| 51 |
+
|
| 52 |
+
|
| 53 |
+
def get_batch(data_iterator, args, timers):
|
| 54 |
+
# Items and their type.
|
| 55 |
+
keys = ['input_ids', 'labels']
|
| 56 |
+
datatype = torch.int64
|
| 57 |
+
|
| 58 |
+
# Broadcast data.
|
| 59 |
+
timers('data loader').start()
|
| 60 |
+
if data_iterator is not None:
|
| 61 |
+
data = next(data_iterator)
|
| 62 |
+
else:
|
| 63 |
+
data = None
|
| 64 |
+
timers('data loader').stop()
|
| 65 |
+
data_b = mpu.broadcast_data(keys, data, datatype)
|
| 66 |
+
data_i = mpu.broadcast_data(['image'], data, torch.float32)
|
| 67 |
+
# Unpack.
|
| 68 |
+
tokens = data_b['input_ids'].long()
|
| 69 |
+
labels = data_b['labels'].long()
|
| 70 |
+
img = data_i['image']
|
| 71 |
+
if args.fp16:
|
| 72 |
+
img = img.half()
|
| 73 |
+
|
| 74 |
+
return tokens, labels, img, data['pre_image']
|
| 75 |
+
|
| 76 |
+
|
| 77 |
+
from torch.nn import CrossEntropyLoss
|
| 78 |
+
|
| 79 |
+
def forward_step(data_iterator, model, args, timers):
|
| 80 |
+
"""Forward step."""
|
| 81 |
+
|
| 82 |
+
# Get the batch.
|
| 83 |
+
timers('batch generator').start()
|
| 84 |
+
tokens, labels, image, pre_image = get_batch(
|
| 85 |
+
data_iterator, args, timers)
|
| 86 |
+
timers('batch generator').stop()
|
| 87 |
+
|
| 88 |
+
logits = model(input_ids=tokens, image=image, pre_image=pre_image)[0]
|
| 89 |
+
dtype = logits.dtype
|
| 90 |
+
lm_logits = logits.to(torch.float32)
|
| 91 |
+
|
| 92 |
+
# Shift so that tokens < n predict n
|
| 93 |
+
shift_logits = lm_logits[..., :-1, :].contiguous()
|
| 94 |
+
shift_labels = labels[..., 1:].contiguous()
|
| 95 |
+
# Flatten the tokens
|
| 96 |
+
loss_fct = CrossEntropyLoss(ignore_index=-100)
|
| 97 |
+
loss = loss_fct(shift_logits.view(-1, shift_logits.size(-1)), shift_labels.view(-1))
|
| 98 |
+
|
| 99 |
+
lm_logits = lm_logits.to(dtype)
|
| 100 |
+
loss = loss.to(dtype)
|
| 101 |
+
return loss, {'loss': loss}
|
| 102 |
+
|
| 103 |
+
|
| 104 |
+
from model.blip2 import BlipImageEvalProcessor
|
| 105 |
+
from torch.utils.data import Dataset
|
| 106 |
+
import json
|
| 107 |
+
from PIL import Image
|
| 108 |
+
|
| 109 |
+
class FewShotDataset(Dataset):
|
| 110 |
+
def __init__(self, path, processor, tokenizer, args):
|
| 111 |
+
max_seq_length = args.max_source_length + args.max_target_length
|
| 112 |
+
with open(path, 'r', encoding='utf-8') as f:
|
| 113 |
+
data = json.load(f)
|
| 114 |
+
self.images = []
|
| 115 |
+
self.input_ids = []
|
| 116 |
+
self.labels = []
|
| 117 |
+
for item in data:
|
| 118 |
+
image = processor(Image.open(item['img']).convert('RGB'))
|
| 119 |
+
input0 = tokenizer.encode("<img>", add_special_tokens=False)
|
| 120 |
+
input1 = [tokenizer.pad_token_id] * args.image_length
|
| 121 |
+
input2 = tokenizer.encode("</img>问:"+item['prompt']+"\n答��", add_special_tokens=False)
|
| 122 |
+
a_ids = sum([input0, input1, input2], [])
|
| 123 |
+
b_ids = tokenizer.encode(text=item['label'], add_special_tokens=False)
|
| 124 |
+
if len(a_ids) > args.max_source_length - 1:
|
| 125 |
+
a_ids = a_ids[: args.max_source_length - 1]
|
| 126 |
+
if len(b_ids) > args.max_target_length - 2:
|
| 127 |
+
b_ids = b_ids[: args.max_target_length - 2]
|
| 128 |
+
pre_image = len(input0)
|
| 129 |
+
input_ids = tokenizer.build_inputs_with_special_tokens(a_ids, b_ids)
|
| 130 |
+
|
| 131 |
+
context_length = input_ids.index(tokenizer.bos_token_id)
|
| 132 |
+
mask_position = context_length - 1
|
| 133 |
+
labels = [-100] * context_length + input_ids[mask_position+1:]
|
| 134 |
+
|
| 135 |
+
pad_len = max_seq_length - len(input_ids)
|
| 136 |
+
input_ids = input_ids + [tokenizer.pad_token_id] * pad_len
|
| 137 |
+
labels = labels + [tokenizer.pad_token_id] * pad_len
|
| 138 |
+
if args.ignore_pad_token_for_loss:
|
| 139 |
+
labels = [(l if l != tokenizer.pad_token_id else -100) for l in labels]
|
| 140 |
+
self.images.append(image)
|
| 141 |
+
self.input_ids.append(input_ids)
|
| 142 |
+
self.labels.append(labels)
|
| 143 |
+
self.pre_image = pre_image
|
| 144 |
+
|
| 145 |
+
def __len__(self):
|
| 146 |
+
return len(self.images)
|
| 147 |
+
|
| 148 |
+
def __getitem__(self, idx):
|
| 149 |
+
return {
|
| 150 |
+
"image": self.images[idx],
|
| 151 |
+
"input_ids": self.input_ids[idx],
|
| 152 |
+
"labels": self.labels[idx],
|
| 153 |
+
"pre_image": self.pre_image
|
| 154 |
+
}
|
| 155 |
+
|
| 156 |
+
|
| 157 |
+
def create_dataset_function(path, args):
|
| 158 |
+
tokenizer = get_tokenizer(args)
|
| 159 |
+
image_processor = BlipImageEvalProcessor(224)
|
| 160 |
+
|
| 161 |
+
dataset = FewShotDataset(path, image_processor, tokenizer, args)
|
| 162 |
+
return dataset
|
| 163 |
+
|
| 164 |
+
|
| 165 |
+
if __name__ == '__main__':
|
| 166 |
+
py_parser = argparse.ArgumentParser(add_help=False)
|
| 167 |
+
py_parser.add_argument('--max_source_length', type=int)
|
| 168 |
+
py_parser.add_argument('--max_target_length', type=int)
|
| 169 |
+
py_parser.add_argument('--ignore_pad_token_for_loss', type=bool, default=True)
|
| 170 |
+
# py_parser.add_argument('--old_checkpoint', action="store_true")
|
| 171 |
+
py_parser.add_argument('--source_prefix', type=str, default="")
|
| 172 |
+
py_parser = FineTuneVisualGLMModel.add_model_specific_args(py_parser)
|
| 173 |
+
known, args_list = py_parser.parse_known_args()
|
| 174 |
+
args = get_args(args_list)
|
| 175 |
+
args = argparse.Namespace(**vars(args), **vars(known))
|
| 176 |
+
args.device = 'cpu'
|
| 177 |
+
|
| 178 |
+
model_type = 'visualglm-6b'
|
| 179 |
+
model, args = FineTuneVisualGLMModel.from_pretrained(model_type, args)
|
| 180 |
+
if torch.cuda.is_available():
|
| 181 |
+
model = model.to('cuda')
|
| 182 |
+
tokenizer = get_tokenizer(args)
|
| 183 |
+
label_pad_token_id = -100 if args.ignore_pad_token_for_loss else tokenizer.pad_token_id
|
| 184 |
+
def data_collator(examples):
|
| 185 |
+
for example in examples:
|
| 186 |
+
example['input_ids'] = torch.tensor(example['input_ids'], dtype=torch.long)
|
| 187 |
+
example['labels'] = torch.tensor(example['labels'], dtype=torch.long)
|
| 188 |
+
ret = {
|
| 189 |
+
'input_ids': torch.stack([example['input_ids'] for example in examples]),
|
| 190 |
+
'labels': torch.stack([example['labels'] for example in examples]),
|
| 191 |
+
'image': torch.stack([example['image'] for example in examples]),
|
| 192 |
+
'pre_image': example['pre_image']
|
| 193 |
+
}
|
| 194 |
+
return ret
|
| 195 |
+
training_main(args, model_cls=model, forward_step_function=forward_step, create_dataset_function=create_dataset_function, collate_fn=data_collator)
|
lora_mixin.py
ADDED
|
@@ -0,0 +1,260 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""
|
| 2 |
+
In this mixin, I use a different implementation than sat/model/finetune/lora.py
|
| 3 |
+
I just use a fake linear layer to replace any model with lora mixin.
|
| 4 |
+
"""
|
| 5 |
+
|
| 6 |
+
import torch
|
| 7 |
+
import torch.nn as nn
|
| 8 |
+
from sat.model.base_model import BaseMixin
|
| 9 |
+
import math
|
| 10 |
+
from sat.helpers import print_all
|
| 11 |
+
from sat.model.transformer import RowParallelLinear, ColumnParallelLinear
|
| 12 |
+
|
| 13 |
+
class HackLinear(nn.Linear):
|
| 14 |
+
def _load_from_state_dict(self, state_dict, prefix, local_metadata, strict, missing_keys, unexpected_keys, error_msgs):
|
| 15 |
+
if prefix + 'weight' in state_dict:
|
| 16 |
+
self.weight.data.copy_(state_dict[prefix+'weight'])
|
| 17 |
+
if prefix + 'bias' in state_dict:
|
| 18 |
+
self.bias.data.copy_(state_dict[prefix+'bias'])
|
| 19 |
+
|
| 20 |
+
class HackRowParallelLinear(RowParallelLinear):
|
| 21 |
+
def _load_from_state_dict(self, state_dict, prefix, local_metadata, strict, missing_keys, unexpected_keys, error_msgs):
|
| 22 |
+
if prefix + 'weight' in state_dict:
|
| 23 |
+
self.weight.data.copy_(state_dict[prefix+'weight'])
|
| 24 |
+
if prefix + 'bias' in state_dict:
|
| 25 |
+
self.bias.data.copy_(state_dict[prefix+'bias'])
|
| 26 |
+
|
| 27 |
+
class HackColumnParallelLinear(ColumnParallelLinear):
|
| 28 |
+
def _load_from_state_dict(self, state_dict, prefix, local_metadata, strict, missing_keys, unexpected_keys, error_msgs):
|
| 29 |
+
if prefix + 'weight' in state_dict:
|
| 30 |
+
self.weight.data.copy_(state_dict[prefix+'weight'])
|
| 31 |
+
if prefix + 'bias' in state_dict:
|
| 32 |
+
self.bias.data.copy_(state_dict[prefix+'bias'])
|
| 33 |
+
|
| 34 |
+
try:
|
| 35 |
+
from bitsandbytes.nn import LinearNF4
|
| 36 |
+
def copy_nested_list(src, dst):
|
| 37 |
+
for i in range(len(dst)):
|
| 38 |
+
if type(dst[i]) is torch.Tensor:
|
| 39 |
+
dst[i].copy_(src[i])
|
| 40 |
+
elif type(dst[i]) is list:
|
| 41 |
+
copy_nested_list(src[i], dst[i])
|
| 42 |
+
else:
|
| 43 |
+
dst[i] = src[i]
|
| 44 |
+
class HackLinearNF4(LinearNF4):
|
| 45 |
+
def _load_from_state_dict(self, state_dict, prefix, local_metadata, strict, missing_keys, unexpected_keys, error_msgs):
|
| 46 |
+
if prefix + 'weight' in state_dict:
|
| 47 |
+
self.weight.data.copy_(state_dict[prefix+'weight'])
|
| 48 |
+
if self.weight.data.dtype == torch.uint8:
|
| 49 |
+
copy_nested_list(state_dict[prefix+'quant_state'], self.weight.quant_state)
|
| 50 |
+
if prefix + 'bias' in state_dict:
|
| 51 |
+
self.bias.data.copy_(state_dict[prefix+'bias'])
|
| 52 |
+
def _save_to_state_dict(self, destination, prefix, keep_vars):
|
| 53 |
+
super()._save_to_state_dict(destination, prefix, keep_vars)
|
| 54 |
+
destination[prefix+'quant_state'] = self.weight.quant_state
|
| 55 |
+
except Exception as exception:
|
| 56 |
+
print_all("Failed to load bitsandbytes:" + str(exception), level='WARNING')
|
| 57 |
+
|
| 58 |
+
|
| 59 |
+
class HackParameterList(nn.ParameterList):
|
| 60 |
+
def _load_from_state_dict(self, state_dict, prefix, local_metadata, strict, missing_keys, unexpected_keys, error_msgs):
|
| 61 |
+
for i in range(len(self)):
|
| 62 |
+
if prefix + str(i) in state_dict:
|
| 63 |
+
self[i].data.copy_(state_dict[prefix+str(i)])
|
| 64 |
+
|
| 65 |
+
map_cls = {
|
| 66 |
+
nn.Linear: (HackLinear, {}),
|
| 67 |
+
ColumnParallelLinear: (HackColumnParallelLinear, {'gather_output': False}),
|
| 68 |
+
RowParallelLinear: (HackRowParallelLinear, {'input_is_parallel': True})
|
| 69 |
+
}
|
| 70 |
+
|
| 71 |
+
class LoraLinear(nn.Module):
|
| 72 |
+
def __init__(self, original_cls, partition, in_dim, out_dim, r, lora_alpha=1., lora_dropout=0., head_first=False, num_attention_heads=None, hidden_size_per_attention_head=None, qlora=False):
|
| 73 |
+
"""
|
| 74 |
+
You can use safely with this layer, ONLY WHEN query_key_value output is query_key_value order.
|
| 75 |
+
If you use a different order like ChatGLM
|
| 76 |
+
"""
|
| 77 |
+
super().__init__()
|
| 78 |
+
if lora_dropout and lora_dropout > 0:
|
| 79 |
+
self.lora_dropout = nn.Dropout(p=lora_dropout)
|
| 80 |
+
else:
|
| 81 |
+
self.lora_dropout = lambda x: x
|
| 82 |
+
self.r = r
|
| 83 |
+
self.lora_alpha = lora_alpha
|
| 84 |
+
self.scaling = self.lora_alpha / self.r
|
| 85 |
+
if qlora:
|
| 86 |
+
try:
|
| 87 |
+
self.original = HackLinearNF4(in_dim, out_dim)
|
| 88 |
+
except:
|
| 89 |
+
raise Exception('Build 4bit layer failed. You need to install the latest bitsandbytes. Try `pip install bitsandbytes`. If you still meet error after installation, try running `from bitsandbytes.nn import LinearNF4` with python and fix the error.')
|
| 90 |
+
else:
|
| 91 |
+
base_cls, kwargs = map_cls[original_cls]
|
| 92 |
+
self.original = base_cls(in_dim, out_dim, **kwargs)
|
| 93 |
+
self.matrix_A = HackParameterList([nn.Parameter(torch.empty((r, in_dim))) for _ in range(partition)])
|
| 94 |
+
self.matrix_B = HackParameterList([nn.Parameter(torch.empty((out_dim // partition, r))) for _ in range(partition)])
|
| 95 |
+
for i in range(partition):
|
| 96 |
+
nn.init.kaiming_uniform_(self.matrix_A[i], a=math.sqrt(5))
|
| 97 |
+
nn.init.zeros_(self.matrix_B[i])
|
| 98 |
+
self.head_first = head_first
|
| 99 |
+
self.partition = partition
|
| 100 |
+
if head_first:
|
| 101 |
+
assert num_attention_heads is not None and hidden_size_per_attention_head is not None, "You should set num_attention_heads and hidden_size_per_attention_head if you use head_first=True!"
|
| 102 |
+
self.num_attention_heads = num_attention_heads
|
| 103 |
+
self.hidden_size_per_attention_head = hidden_size_per_attention_head
|
| 104 |
+
|
| 105 |
+
def _load_from_state_dict(self, state_dict, prefix, local_metadata, strict, missing_keys, unexpected_keys, error_msgs):
|
| 106 |
+
# This is not a perfect version, becuase it doesn't handle errors and unexpected keys.
|
| 107 |
+
if prefix + 'weight' in state_dict:
|
| 108 |
+
# load from normal Linear
|
| 109 |
+
self.original._load_from_state_dict(state_dict, prefix, local_metadata, strict, missing_keys, unexpected_keys, error_msgs)
|
| 110 |
+
else:
|
| 111 |
+
# load from LoraLinear
|
| 112 |
+
super()._load_from_state_dict(state_dict, prefix, local_metadata, strict, missing_keys, unexpected_keys, error_msgs)
|
| 113 |
+
|
| 114 |
+
def forward(self, x):
|
| 115 |
+
mixed_raw_layer = self.original(x)
|
| 116 |
+
lora_outputs = []
|
| 117 |
+
for i in range(self.partition):
|
| 118 |
+
lora_outputs.append((self.lora_dropout(x) @ self.matrix_A[i].T @ self.matrix_B[i].T) * self.scaling)
|
| 119 |
+
if self.head_first:
|
| 120 |
+
new_tensor_shape = lora_outputs[0].size()[:-1] + (
|
| 121 |
+
self.num_attention_heads,
|
| 122 |
+
self.hidden_size_per_attention_head,
|
| 123 |
+
)
|
| 124 |
+
for i in range(self.partition):
|
| 125 |
+
lora_outputs[i] = lora_outputs[i].view(*new_tensor_shape)
|
| 126 |
+
mixed_raw_layer = mixed_raw_layer + torch.cat(lora_outputs, -1).view(*mixed_raw_layer.size())
|
| 127 |
+
else:
|
| 128 |
+
mixed_raw_layer = mixed_raw_layer + torch.cat(lora_outputs, -1)
|
| 129 |
+
|
| 130 |
+
return mixed_raw_layer
|
| 131 |
+
|
| 132 |
+
|
| 133 |
+
def replace_linear_with_lora(lin, partition, r, *args, **kw_args):
|
| 134 |
+
# not supported for linear without bias for now
|
| 135 |
+
out_dim, in_dim = lin.weight.shape
|
| 136 |
+
original_cls = type(lin)
|
| 137 |
+
del lin
|
| 138 |
+
return LoraLinear(original_cls, partition, in_dim, out_dim, r, *args, **kw_args)
|
| 139 |
+
|
| 140 |
+
def merge_linear_lora(lin):
|
| 141 |
+
if lin.original.weight.data.dtype is not torch.uint8:
|
| 142 |
+
weight = lin.original.weight
|
| 143 |
+
out_dim, in_dim = weight.shape
|
| 144 |
+
new_lin = nn.Linear(in_dim, out_dim)
|
| 145 |
+
else:
|
| 146 |
+
import bitsandbytes.functional as F
|
| 147 |
+
weight = F.dequantize_fp4(lin.original.weight.data, lin.original.weight.quant_state).to(lin.original.bias.data.dtype)
|
| 148 |
+
out_dim, in_dim = weight.shape
|
| 149 |
+
new_lin = HackLinearNF4(in_dim, out_dim)
|
| 150 |
+
new_lin.bias.data = lin.original.bias.data
|
| 151 |
+
new_qkv = []
|
| 152 |
+
for i in range(lin.partition):
|
| 153 |
+
new_qkv.append(lin.matrix_A[i].data.T.float() @ lin.matrix_B[i].data.T.float() * lin.scaling)
|
| 154 |
+
if lin.head_first:
|
| 155 |
+
ini_shape = new_qkv[0].shape
|
| 156 |
+
new_qkv = [x.view(ini_shape[0], lin.num_attention_heads, -1) for x in new_qkv]
|
| 157 |
+
new_qkv = torch.cat(new_qkv, -1).view(ini_shape[0], lin.partition*ini_shape[1])
|
| 158 |
+
else:
|
| 159 |
+
new_qkv = torch.cat(new_qkv, -1)
|
| 160 |
+
new_lin.weight.data = weight + new_qkv.T.to(lin.original.bias.data.dtype)
|
| 161 |
+
return new_lin.cuda() if torch.cuda.is_available() else new_lin
|
| 162 |
+
|
| 163 |
+
class LoraMixin(BaseMixin):
|
| 164 |
+
def __init__(self,
|
| 165 |
+
layer_num,
|
| 166 |
+
r: int = 0,
|
| 167 |
+
lora_alpha: int = 1,
|
| 168 |
+
lora_dropout: float = 0.,
|
| 169 |
+
layer_range = None,
|
| 170 |
+
head_first = False,
|
| 171 |
+
num_attention_heads = None,
|
| 172 |
+
hidden_size_per_attention_head = None,
|
| 173 |
+
qlora = False,
|
| 174 |
+
cross_attention = True):
|
| 175 |
+
super().__init__()
|
| 176 |
+
self.r = r
|
| 177 |
+
self.lora_alpha = lora_alpha
|
| 178 |
+
self.lora_dropout = lora_dropout
|
| 179 |
+
|
| 180 |
+
if layer_range is None:
|
| 181 |
+
layer_range = [i for i in range(layer_num)]
|
| 182 |
+
self.layer_range = layer_range
|
| 183 |
+
|
| 184 |
+
self.scaling = self.lora_alpha / self.r
|
| 185 |
+
self.head_first = head_first
|
| 186 |
+
self.num_attention_heads = num_attention_heads
|
| 187 |
+
self.hidden_size_per_attention_head = hidden_size_per_attention_head
|
| 188 |
+
self.qlora = qlora
|
| 189 |
+
self.cross_attention = cross_attention
|
| 190 |
+
|
| 191 |
+
def reinit(self, parent_model):
|
| 192 |
+
for i in self.layer_range:
|
| 193 |
+
print(f'replacing layer {i} attention with lora')
|
| 194 |
+
parent_model.transformer.layers[i].attention.dense = replace_linear_with_lora(parent_model.transformer.layers[i].attention.dense, 1, self.r, self.lora_alpha, self.lora_dropout, qlora=self.qlora)
|
| 195 |
+
parent_model.transformer.layers[i].attention.query_key_value = replace_linear_with_lora(parent_model.transformer.layers[i].attention.query_key_value, 3, self.r, self.lora_alpha, self.lora_dropout, head_first=self.head_first, num_attention_heads=self.num_attention_heads, hidden_size_per_attention_head=self.hidden_size_per_attention_head, qlora=self.qlora)
|
| 196 |
+
if self.cross_attention and parent_model.transformer.layers[i].is_decoder:
|
| 197 |
+
print(f'replacing layer {i} cross attention with lora')
|
| 198 |
+
parent_model.transformer.layers[i].cross_attention.dense = replace_linear_with_lora(parent_model.transformer.layers[i].cross_attention.dense, 1, self.r, self.lora_alpha, self.lora_dropout, qlora=self.qlora)
|
| 199 |
+
parent_model.transformer.layers[i].cross_attention.query = replace_linear_with_lora(parent_model.transformer.layers[i].cross_attention.query, 1, self.r, self.lora_alpha, self.lora_dropout, qlora=self.qlora)
|
| 200 |
+
parent_model.transformer.layers[i].cross_attention.key_value = replace_linear_with_lora(parent_model.transformer.layers[i].cross_attention.key_value, 2, self.r, self.lora_alpha, self.lora_dropout, qlora=self.qlora)
|
| 201 |
+
if self.qlora:
|
| 202 |
+
print('replacing chatglm linear layer with 4bit')
|
| 203 |
+
def replace_linear_with_nf4(model, name=None, cache={}):
|
| 204 |
+
if type(model) in (nn.Linear, RowParallelLinear, ColumnParallelLinear):
|
| 205 |
+
out_dim, in_dim = model.weight.shape
|
| 206 |
+
return HackLinearNF4(in_dim, out_dim)
|
| 207 |
+
names = set()
|
| 208 |
+
for name, child in model.named_children():
|
| 209 |
+
if name not in names:
|
| 210 |
+
if child in cache:
|
| 211 |
+
new_child = cache[child]
|
| 212 |
+
else:
|
| 213 |
+
new_child = replace_linear_with_nf4(child, name=name, cache=cache)
|
| 214 |
+
cache[child] = new_child
|
| 215 |
+
setattr(model, name, new_child)
|
| 216 |
+
names.add(name)
|
| 217 |
+
flag = True
|
| 218 |
+
while flag:
|
| 219 |
+
flag = False
|
| 220 |
+
for name, child in model.named_children():
|
| 221 |
+
if name not in names:
|
| 222 |
+
setattr(model, name, cache[child])
|
| 223 |
+
names.add(name)
|
| 224 |
+
flag = True
|
| 225 |
+
return model
|
| 226 |
+
replace_linear_with_nf4(parent_model.transformer, None, {})
|
| 227 |
+
|
| 228 |
+
def merge_lora(self):
|
| 229 |
+
for i in self.layer_range:
|
| 230 |
+
print(f'merge layer {i} lora attention back to linear')
|
| 231 |
+
self.transformer.layers[i].attention.dense = merge_linear_lora(self.transformer.layers[i].attention.dense)
|
| 232 |
+
self.transformer.layers[i].attention.query_key_value = merge_linear_lora(self.transformer.layers[i].attention.query_key_value)
|
| 233 |
+
if self.transformer.layers[i].is_decoder:
|
| 234 |
+
print(f'merge layer {i} lora cross attention back to linear')
|
| 235 |
+
self.transformer.layers[i].cross_attention.dense = merge_linear_lora(self.transformer.layers[i].cross_attention.dense)
|
| 236 |
+
self.transformer.layers[i].cross_attention.query = merge_linear_lora(self.transformer.layers[i].cross_attention.query)
|
| 237 |
+
self.transformer.layers[i].cross_attention.key_value = merge_linear_lora(self.transformer.layers[i].cross_attention.key_value)
|
| 238 |
+
|
| 239 |
+
if __name__ == '__main__':
|
| 240 |
+
class Model(nn.Module):
|
| 241 |
+
def __init__(self):
|
| 242 |
+
super().__init__()
|
| 243 |
+
self.child = nn.Linear(100, 200)
|
| 244 |
+
|
| 245 |
+
def forward(self, x):
|
| 246 |
+
return self.child(x)
|
| 247 |
+
|
| 248 |
+
model = Model()
|
| 249 |
+
torch.save(model.state_dict(), "linear.pt")
|
| 250 |
+
x = torch.randn(2, 100)
|
| 251 |
+
out1 = model(x)
|
| 252 |
+
model.child = LoraLinear(100, 200, 10)
|
| 253 |
+
model.load_state_dict(torch.load("linear.pt"), strict=False)
|
| 254 |
+
out2 = model(x)
|
| 255 |
+
torch.save(model.state_dict(), "lora.pt")
|
| 256 |
+
ckpt = torch.load("lora.pt")
|
| 257 |
+
breakpoint()
|
| 258 |
+
model.load_state_dict(ckpt, strict=False)
|
| 259 |
+
out3 = model(x)
|
| 260 |
+
breakpoint()
|
model/__init__.py
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from .chat import chat
|
| 2 |
+
from .infer_util import *
|
| 3 |
+
from .blip2 import BlipImageEvalProcessor
|
model/__pycache__/__init__.cpython-310.pyc
ADDED
|
Binary file (235 Bytes). View file
|
|
|
model/__pycache__/blip2.cpython-310.pyc
ADDED
|
Binary file (4.66 kB). View file
|
|
|
model/__pycache__/chat.cpython-310.pyc
ADDED
|
Binary file (4.89 kB). View file
|
|
|
model/__pycache__/infer_util.cpython-310.pyc
ADDED
|
Binary file (1.98 kB). View file
|
|
|
model/__pycache__/visualglm.cpython-310.pyc
ADDED
|
Binary file (2.25 kB). View file
|
|
|
model/blip2.py
ADDED
|
@@ -0,0 +1,93 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import torch
|
| 2 |
+
import torch.nn as nn
|
| 3 |
+
|
| 4 |
+
from sat.model import ViTModel, BaseModel
|
| 5 |
+
from sat.model import BaseMixin
|
| 6 |
+
from sat import AutoModel
|
| 7 |
+
from copy import deepcopy
|
| 8 |
+
from torchvision import transforms
|
| 9 |
+
from torchvision.transforms.functional import InterpolationMode
|
| 10 |
+
|
| 11 |
+
class LNFinalyMixin(BaseMixin):
|
| 12 |
+
def __init__(self, hidden_size):
|
| 13 |
+
super().__init__()
|
| 14 |
+
self.ln_vision = nn.LayerNorm(hidden_size)
|
| 15 |
+
|
| 16 |
+
def final_forward(self, logits, **kw_args):
|
| 17 |
+
return self.ln_vision(logits)
|
| 18 |
+
|
| 19 |
+
class EVAViT(ViTModel):
|
| 20 |
+
def __init__(self, args, transformer=None, parallel_output=True, **kwargs):
|
| 21 |
+
super().__init__(args, transformer=transformer, parallel_output=parallel_output, **kwargs)
|
| 22 |
+
self.del_mixin("cls")
|
| 23 |
+
self.add_mixin("cls", LNFinalyMixin(args.hidden_size))
|
| 24 |
+
|
| 25 |
+
def forward(self, image):
|
| 26 |
+
batch_size = image.size(0)
|
| 27 |
+
input_ids = torch.zeros(batch_size, 1, dtype=torch.long, device=image.device)
|
| 28 |
+
attention_mask = torch.tensor([[1.]], dtype=image.dtype, device=image.device)
|
| 29 |
+
return super().forward(input_ids=input_ids, position_ids=None, attention_mask=attention_mask, image=image)
|
| 30 |
+
|
| 31 |
+
class QFormer(BaseModel):
|
| 32 |
+
def __init__(self, args, transformer=None, parallel_output=True, **kwargs):
|
| 33 |
+
super().__init__(args, transformer=transformer, parallel_output=parallel_output, activation_func=nn.functional.gelu, **kwargs)
|
| 34 |
+
self.transformer.position_embeddings = None
|
| 35 |
+
|
| 36 |
+
def final_forward(self, logits, **kw_args):
|
| 37 |
+
return logits
|
| 38 |
+
|
| 39 |
+
def position_embedding_forward(self, position_ids, **kw_args):
|
| 40 |
+
return None
|
| 41 |
+
|
| 42 |
+
def forward(self, encoder_outputs):
|
| 43 |
+
batch_size = encoder_outputs.size(0)
|
| 44 |
+
input_ids = torch.arange(32, dtype=torch.long, device=encoder_outputs.device).unsqueeze(0).expand(batch_size, -1)
|
| 45 |
+
attention_mask = torch.tensor([[1.]], dtype=encoder_outputs.dtype, device=encoder_outputs.device)
|
| 46 |
+
cross_attention_mask = torch.tensor([[1.]], dtype=encoder_outputs.dtype, device=encoder_outputs.device)
|
| 47 |
+
return super().forward(input_ids=input_ids, position_ids=None, attention_mask=attention_mask, encoder_outputs=encoder_outputs, cross_attention_mask=cross_attention_mask)
|
| 48 |
+
|
| 49 |
+
|
| 50 |
+
class BLIP2(torch.nn.Module):
|
| 51 |
+
def __init__(self, eva_args, qformer_args, vit=None, qformer=None, **kwargs):
|
| 52 |
+
super().__init__()
|
| 53 |
+
if vit is not None:
|
| 54 |
+
self.vit = vit
|
| 55 |
+
else:
|
| 56 |
+
self.vit = EVAViT(EVAViT.get_args(**eva_args))
|
| 57 |
+
if qformer is not None:
|
| 58 |
+
self.qformer = qformer
|
| 59 |
+
else:
|
| 60 |
+
self.qformer = QFormer(QFormer.get_args(**qformer_args))
|
| 61 |
+
|
| 62 |
+
self.glm_proj = nn.Linear(768, 4096).to(self.qformer.parameters().__next__().device).to(self.qformer.parameters().__next__().dtype)
|
| 63 |
+
|
| 64 |
+
def forward(self, image, **kwargs):
|
| 65 |
+
enc = self.vit(image)[0]
|
| 66 |
+
out = self.qformer(enc)[0]
|
| 67 |
+
return self.glm_proj(out)
|
| 68 |
+
|
| 69 |
+
class BlipImageBaseProcessor():
|
| 70 |
+
def __init__(self, mean=None, std=None):
|
| 71 |
+
if mean is None:
|
| 72 |
+
mean = (0.48145466, 0.4578275, 0.40821073)
|
| 73 |
+
if std is None:
|
| 74 |
+
std = (0.26862954, 0.26130258, 0.27577711)
|
| 75 |
+
|
| 76 |
+
self.normalize = transforms.Normalize(mean, std)
|
| 77 |
+
|
| 78 |
+
class BlipImageEvalProcessor(BlipImageBaseProcessor):
|
| 79 |
+
def __init__(self, image_size=384, mean=None, std=None):
|
| 80 |
+
super().__init__(mean=mean, std=std)
|
| 81 |
+
|
| 82 |
+
self.transform = transforms.Compose(
|
| 83 |
+
[
|
| 84 |
+
transforms.Resize(
|
| 85 |
+
(image_size, image_size), interpolation=InterpolationMode.BICUBIC
|
| 86 |
+
),
|
| 87 |
+
transforms.ToTensor(),
|
| 88 |
+
self.normalize,
|
| 89 |
+
]
|
| 90 |
+
)
|
| 91 |
+
|
| 92 |
+
def __call__(self, item):
|
| 93 |
+
return self.transform(item)
|
model/chat.py
ADDED
|
@@ -0,0 +1,175 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# -*- encoding: utf-8 -*-
|
| 2 |
+
'''
|
| 3 |
+
@File : chat.py
|
| 4 |
+
@Time : 2023/05/08 19:10:08
|
| 5 |
+
@Author : Ming Ding
|
| 6 |
+
@Contact : dm18@mails.tsinghua.edu.cn
|
| 7 |
+
'''
|
| 8 |
+
|
| 9 |
+
import os
|
| 10 |
+
import sys
|
| 11 |
+
import re
|
| 12 |
+
from functools import partial
|
| 13 |
+
from typing import Optional, Tuple, Union, List, Callable, Dict, Any
|
| 14 |
+
import requests
|
| 15 |
+
from PIL import Image
|
| 16 |
+
from io import BytesIO
|
| 17 |
+
|
| 18 |
+
import torch
|
| 19 |
+
from sat.generation.autoregressive_sampling import filling_sequence, BaseStrategy
|
| 20 |
+
|
| 21 |
+
from .blip2 import BlipImageEvalProcessor
|
| 22 |
+
|
| 23 |
+
def get_masks_and_position_ids_glm(seq, mask_position, context_length):
|
| 24 |
+
'''GLM model, different from GPT.
|
| 25 |
+
Args:
|
| 26 |
+
seq: torch.IntTensor, [seq_len]
|
| 27 |
+
mask_position: int, the position of the masked place.
|
| 28 |
+
context_length: int, the length of context.
|
| 29 |
+
Returns:
|
| 30 |
+
tokens: torch.IntTensor, [1, seq_len]
|
| 31 |
+
attention_mask: torch.FloatTensor, [1, seq_len, seq_len]
|
| 32 |
+
position_ids: torch.IntTensor, [2, seq_len]
|
| 33 |
+
'''
|
| 34 |
+
tokens = seq.unsqueeze(0)
|
| 35 |
+
|
| 36 |
+
attention_mask = torch.ones((1, len(seq), len(seq)), device=tokens.device)
|
| 37 |
+
attention_mask.tril_()
|
| 38 |
+
attention_mask[..., :context_length] = 1
|
| 39 |
+
attention_mask.unsqueeze_(1)
|
| 40 |
+
|
| 41 |
+
# 2D position ids
|
| 42 |
+
position_ids = torch.zeros(2, len(seq), device=tokens.device, dtype=torch.long)
|
| 43 |
+
torch.arange(0, context_length, out=position_ids[0, :context_length])
|
| 44 |
+
position_ids[0, context_length:] = mask_position
|
| 45 |
+
torch.arange(1, len(seq) - context_length + 1, out=position_ids[1, context_length:])
|
| 46 |
+
|
| 47 |
+
position_ids = position_ids.unsqueeze(0)
|
| 48 |
+
return tokens, attention_mask, position_ids
|
| 49 |
+
|
| 50 |
+
def process_response(response):
|
| 51 |
+
response = response.strip()
|
| 52 |
+
response = response.replace("[[训练时间]]", "2023年")
|
| 53 |
+
punkts = [
|
| 54 |
+
[",", ","],
|
| 55 |
+
["!", "!"],
|
| 56 |
+
[":", ":"],
|
| 57 |
+
[";", ";"],
|
| 58 |
+
["\?", "?"],
|
| 59 |
+
]
|
| 60 |
+
for item in punkts:
|
| 61 |
+
response = re.sub(r"([\u4e00-\u9fff])%s" % item[0], r"\1%s" % item[1], response)
|
| 62 |
+
response = re.sub(r"%s([\u4e00-\u9fff])" % item[0], r"%s\1" % item[1], response)
|
| 63 |
+
return response
|
| 64 |
+
|
| 65 |
+
def process_image(text, image=None):
|
| 66 |
+
'''Process image in text.
|
| 67 |
+
Args:
|
| 68 |
+
text: str, text.
|
| 69 |
+
image: Optional, image path / url / PIL image.
|
| 70 |
+
'''
|
| 71 |
+
image_position = text.rfind("<img>") + 5
|
| 72 |
+
# extract path from <img></img> using re
|
| 73 |
+
image_path = re.findall(r"<img>(.*?)</img>", text)
|
| 74 |
+
image_path = image_path[-1] if image_path[-1] else None
|
| 75 |
+
if image_path is not None:
|
| 76 |
+
assert image is None, "image and image_path cannot be both not None."
|
| 77 |
+
text = text.replace(image_path, "")
|
| 78 |
+
image_path = image_path.strip()
|
| 79 |
+
# url
|
| 80 |
+
if image_path.startswith("http"):
|
| 81 |
+
response = requests.get(image_path, timeout=10)
|
| 82 |
+
image = Image.open(BytesIO(response.content))
|
| 83 |
+
# local path
|
| 84 |
+
else:
|
| 85 |
+
image = Image.open(image_path)
|
| 86 |
+
if image is not None and isinstance(image, Image.Image):
|
| 87 |
+
processor = BlipImageEvalProcessor(224)
|
| 88 |
+
image = processor(image.convert('RGB'))
|
| 89 |
+
image = image.unsqueeze(0)
|
| 90 |
+
return text, image_position, image
|
| 91 |
+
|
| 92 |
+
|
| 93 |
+
def chat(image_path, model, tokenizer,
|
| 94 |
+
query: str, history: List[Tuple[str, str]] = None, image: Image = None,
|
| 95 |
+
max_length: int = 1024, top_p=0.7, top_k=30, temperature=0.95, repetition_penalty=1.2,
|
| 96 |
+
invalid_slices=[], english=False
|
| 97 |
+
):
|
| 98 |
+
if not history:
|
| 99 |
+
history = []
|
| 100 |
+
if image_path:
|
| 101 |
+
prompt = "<img>{}</img>".format(image_path if image_path else "")
|
| 102 |
+
else:
|
| 103 |
+
prompt = "<img></img>"
|
| 104 |
+
if english:
|
| 105 |
+
for i, (old_query, response) in enumerate(history):
|
| 106 |
+
prompt += "Q:{}\nA:{}\n".format(old_query, response)
|
| 107 |
+
prompt += "Q:{}\nA:".format(query)
|
| 108 |
+
else:
|
| 109 |
+
for i, (old_query, response) in enumerate(history):
|
| 110 |
+
prompt += "问:{}\n答:{}\n".format(old_query, response)
|
| 111 |
+
prompt += "问:{}\n答:".format(query)
|
| 112 |
+
# ---------------
|
| 113 |
+
# tokenizer, this is an example of huggingface tokenizer.
|
| 114 |
+
# input str, output['input_ids'] = tensor([[tokenized str, gmask, sop]])
|
| 115 |
+
prompt, image_position, torch_image = process_image(prompt, image=image)
|
| 116 |
+
if torch_image is not None:
|
| 117 |
+
torch_image = torch_image.to(next(model.parameters()).dtype).to(next(model.parameters()).device)
|
| 118 |
+
if image_position < 5: # no image
|
| 119 |
+
inputs = tokenizer([prompt], return_tensors="pt").to(model.parameters().__next__().device)['input_ids'][0]
|
| 120 |
+
pre_image = 0
|
| 121 |
+
else:
|
| 122 |
+
input0 = tokenizer.encode(prompt[:image_position], add_special_tokens=False)
|
| 123 |
+
input1 = [tokenizer.pad_token_id] * model.image_length
|
| 124 |
+
input2 = tokenizer.encode(prompt[image_position:], add_special_tokens=False)
|
| 125 |
+
inputs = sum([input0, input1, input2], [])
|
| 126 |
+
inputs = torch.tensor(tokenizer.build_inputs_with_special_tokens(inputs)).to(model.parameters().__next__().device)
|
| 127 |
+
pre_image = len(input0)
|
| 128 |
+
# ---------------
|
| 129 |
+
# Next, we manually set the format to keep flexibility.
|
| 130 |
+
mask_position = len(inputs) - 2
|
| 131 |
+
context_length = len(inputs) - 1 # all before sop
|
| 132 |
+
get_func = partial(get_masks_and_position_ids_glm, mask_position=mask_position, context_length=context_length)
|
| 133 |
+
seq = torch.cat(
|
| 134 |
+
[inputs, torch.tensor([-1]*(max_length-len(inputs)), device=inputs.device)], dim=0
|
| 135 |
+
)
|
| 136 |
+
# ---------------
|
| 137 |
+
# from sat.generation.sampling_strategies import BeamSearchStrategy
|
| 138 |
+
# strategy = BeamSearchStrategy(num_beams, length_penalty=1., prefer_min_length=5, end_tokens=[tokenizer.eos_token_id], consider_end=True, no_repeat_ngram_size=5, stop_n_iter_unchanged=30, temperature=temperature, top_p=top_p, top_k=60, repetition_penalty=1.1)
|
| 139 |
+
strategy = BaseStrategy(temperature=temperature, top_p=top_p, top_k=top_k, end_tokens=[tokenizer.eos_token_id],
|
| 140 |
+
invalid_slices=invalid_slices, repetition_penalty=repetition_penalty)
|
| 141 |
+
output = filling_sequence(
|
| 142 |
+
model, seq,
|
| 143 |
+
batch_size=1,
|
| 144 |
+
get_masks_and_position_ids=get_func,
|
| 145 |
+
strategy=strategy,
|
| 146 |
+
pre_image=pre_image,
|
| 147 |
+
image=torch_image,
|
| 148 |
+
)[0] # drop memory
|
| 149 |
+
|
| 150 |
+
# ---------------
|
| 151 |
+
# port from inference_glm.py, more general than chat mode
|
| 152 |
+
# clip -1s and fill back generated things into seq
|
| 153 |
+
if type(output) is not list:
|
| 154 |
+
output_list = output.tolist()
|
| 155 |
+
else:
|
| 156 |
+
output_list = output
|
| 157 |
+
for i in range(len(output_list)):
|
| 158 |
+
output = output_list[i]
|
| 159 |
+
if type(output) is not list:
|
| 160 |
+
output = output.tolist()
|
| 161 |
+
try:
|
| 162 |
+
unfinished = output.index(-1)
|
| 163 |
+
except ValueError:
|
| 164 |
+
unfinished = len(output)
|
| 165 |
+
if output[unfinished - 1] == tokenizer.eos_token_id:
|
| 166 |
+
unfinished -= 1
|
| 167 |
+
bog = output.index(tokenizer.bos_token_id)
|
| 168 |
+
output_list[i] = output[:mask_position] + output[bog + 1:unfinished] + output[mask_position + 1:bog]
|
| 169 |
+
# ---------------
|
| 170 |
+
|
| 171 |
+
response = tokenizer.decode(output_list[0])
|
| 172 |
+
sep = 'A:' if english else '答:'
|
| 173 |
+
response = process_response(response).split(sep)[-1].strip()
|
| 174 |
+
history = history + [(query, response)]
|
| 175 |
+
return response, history, torch_image
|
model/infer_util.py
ADDED
|
@@ -0,0 +1,53 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import os
|
| 2 |
+
from PIL import Image
|
| 3 |
+
from io import BytesIO
|
| 4 |
+
import base64
|
| 5 |
+
import re
|
| 6 |
+
import argparse
|
| 7 |
+
import torch
|
| 8 |
+
from transformers import AutoTokenizer
|
| 9 |
+
from sat.model.mixins import CachedAutoregressiveMixin
|
| 10 |
+
from sat.quantization.kernels import quantize
|
| 11 |
+
import hashlib
|
| 12 |
+
from .visualglm import VisualGLMModel
|
| 13 |
+
|
| 14 |
+
def get_infer_setting(gpu_device=0, quant=None):
|
| 15 |
+
os.environ['CUDA_VISIBLE_DEVICES'] = str(gpu_device)
|
| 16 |
+
args = argparse.Namespace(
|
| 17 |
+
fp16=True,
|
| 18 |
+
skip_init=True,
|
| 19 |
+
device='cuda' if quant is None else 'cpu',
|
| 20 |
+
)
|
| 21 |
+
model, args = VisualGLMModel.from_pretrained('visualglm-6b', args)
|
| 22 |
+
model.add_mixin('auto-regressive', CachedAutoregressiveMixin())
|
| 23 |
+
assert quant in [None, 4, 8]
|
| 24 |
+
if quant is not None:
|
| 25 |
+
quantize(model.transformer, quant)
|
| 26 |
+
model.eval()
|
| 27 |
+
model = model.cuda()
|
| 28 |
+
tokenizer = AutoTokenizer.from_pretrained("THUDM/chatglm-6b", trust_remote_code=True)
|
| 29 |
+
return model, tokenizer
|
| 30 |
+
|
| 31 |
+
def is_chinese(text):
|
| 32 |
+
zh_pattern = re.compile(u'[\u4e00-\u9fa5]+')
|
| 33 |
+
return zh_pattern.search(text)
|
| 34 |
+
|
| 35 |
+
def generate_input(input_text, input_image_prompt, history=[], input_para=None, image_is_encoded=True):
|
| 36 |
+
if not image_is_encoded:
|
| 37 |
+
image = input_image_prompt
|
| 38 |
+
else:
|
| 39 |
+
decoded_image = base64.b64decode(input_image_prompt)
|
| 40 |
+
image = Image.open(BytesIO(decoded_image))
|
| 41 |
+
|
| 42 |
+
input_data = {'input_query': input_text, 'input_image': image, 'history': history, 'gen_kwargs': input_para}
|
| 43 |
+
return input_data
|
| 44 |
+
|
| 45 |
+
|
| 46 |
+
def process_image(image_encoded):
|
| 47 |
+
decoded_image = base64.b64decode(image_encoded)
|
| 48 |
+
image = Image.open(BytesIO(decoded_image))
|
| 49 |
+
image_hash = hashlib.sha256(image.tobytes()).hexdigest()
|
| 50 |
+
image_path = f'./examples/{image_hash}.png'
|
| 51 |
+
if not os.path.isfile(image_path):
|
| 52 |
+
image.save(image_path)
|
| 53 |
+
return os.path.abspath(image_path)
|
model/visualglm.py
ADDED
|
@@ -0,0 +1,40 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import torch
|
| 2 |
+
from sat.model.official import ChatGLMModel
|
| 3 |
+
from sat.model.base_model import BaseMixin
|
| 4 |
+
from copy import deepcopy
|
| 5 |
+
import json
|
| 6 |
+
from .blip2 import BLIP2
|
| 7 |
+
|
| 8 |
+
from sat.resources.urls import MODEL_URLS
|
| 9 |
+
MODEL_URLS['visualglm-6b'] = 'https://cloud.tsinghua.edu.cn/f/348b98dffcc940b6a09d/?dl=1'
|
| 10 |
+
|
| 11 |
+
class ImageMixin(BaseMixin):
|
| 12 |
+
def __init__(self, args):
|
| 13 |
+
super().__init__()
|
| 14 |
+
self.args = deepcopy(args)
|
| 15 |
+
self.model = BLIP2(args.eva_args, args.qformer_args)
|
| 16 |
+
|
| 17 |
+
def word_embedding_forward(self, input_ids, output_cross_layer, **kw_args):
|
| 18 |
+
if kw_args["pre_image"] > input_ids.shape[1] or kw_args.get("image", None) is None:
|
| 19 |
+
return self.transformer.word_embeddings(input_ids)
|
| 20 |
+
image_emb = self.model(**kw_args)
|
| 21 |
+
# the image is inserted after 问:<img>, override 32 pads
|
| 22 |
+
pre_id, pads, post_id = torch.tensor_split(input_ids, [kw_args["pre_image"], kw_args["pre_image"]+self.args.image_length], dim=1)
|
| 23 |
+
pre_txt_emb = self.transformer.word_embeddings(pre_id)
|
| 24 |
+
post_txt_emb = self.transformer.word_embeddings(post_id)
|
| 25 |
+
return torch.cat([pre_txt_emb, image_emb, post_txt_emb], dim=1)
|
| 26 |
+
|
| 27 |
+
class VisualGLMModel(ChatGLMModel):
|
| 28 |
+
def __init__(self, args, transformer=None, **kwargs):
|
| 29 |
+
super().__init__(args, transformer=transformer, **kwargs)
|
| 30 |
+
self.image_length = args.image_length
|
| 31 |
+
self.add_mixin("eva", ImageMixin(args))
|
| 32 |
+
|
| 33 |
+
@classmethod
|
| 34 |
+
def add_model_specific_args(cls, parser):
|
| 35 |
+
group = parser.add_argument_group('VisualGLM', 'VisualGLM Configurations')
|
| 36 |
+
group.add_argument('--image_length', type=int, default=32)
|
| 37 |
+
group.add_argument('--eva_args', type=json.loads, default={})
|
| 38 |
+
group.add_argument('--qformer_args', type=json.loads, default={})
|
| 39 |
+
return super().add_model_specific_args(parser)
|
| 40 |
+
|
requirements.txt
ADDED
|
@@ -0,0 +1,6 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
SwissArmyTransformer>=0.3.6
|
| 2 |
+
torch>1.10.0
|
| 3 |
+
torchvision
|
| 4 |
+
transformers>=4.27.1
|
| 5 |
+
mdtex2html
|
| 6 |
+
gradio
|
requirements_wo_ds.txt
ADDED
|
@@ -0,0 +1,10 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
torch>1.10.0
|
| 2 |
+
torchvision
|
| 3 |
+
transformers>=4.27.1
|
| 4 |
+
mdtex2html
|
| 5 |
+
gradio
|
| 6 |
+
sentencepiece
|
| 7 |
+
tensorboardX
|
| 8 |
+
datasets
|
| 9 |
+
cpm_kernels
|
| 10 |
+
einops
|
web_demo.py
ADDED
|
@@ -0,0 +1,129 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
#!/usr/bin/env python
|
| 2 |
+
|
| 3 |
+
import gradio as gr
|
| 4 |
+
from PIL import Image
|
| 5 |
+
import os
|
| 6 |
+
import json
|
| 7 |
+
from model import is_chinese, get_infer_setting, generate_input, chat
|
| 8 |
+
import torch
|
| 9 |
+
|
| 10 |
+
def generate_text_with_image(input_text, image, history=[], request_data=dict(), is_zh=True):
|
| 11 |
+
input_para = {
|
| 12 |
+
"max_length": 2048,
|
| 13 |
+
"min_length": 50,
|
| 14 |
+
"temperature": 0.8,
|
| 15 |
+
"top_p": 0.4,
|
| 16 |
+
"top_k": 100,
|
| 17 |
+
"repetition_penalty": 1.2
|
| 18 |
+
}
|
| 19 |
+
input_para.update(request_data)
|
| 20 |
+
|
| 21 |
+
input_data = generate_input(input_text, image, history, input_para, image_is_encoded=False)
|
| 22 |
+
input_image, gen_kwargs = input_data['input_image'], input_data['gen_kwargs']
|
| 23 |
+
with torch.no_grad():
|
| 24 |
+
answer, history, _ = chat(None, model, tokenizer, input_text, history=history, image=input_image, \
|
| 25 |
+
max_length=gen_kwargs['max_length'], top_p=gen_kwargs['top_p'], \
|
| 26 |
+
top_k = gen_kwargs['top_k'], temperature=gen_kwargs['temperature'], english=not is_zh)
|
| 27 |
+
return answer
|
| 28 |
+
|
| 29 |
+
|
| 30 |
+
def request_model(input_text, temperature, top_p, image_prompt, result_previous):
|
| 31 |
+
result_text = [(ele[0], ele[1]) for ele in result_previous]
|
| 32 |
+
for i in range(len(result_text)-1, -1, -1):
|
| 33 |
+
if result_text[i][0] == "" or result_text[i][1] == "":
|
| 34 |
+
del result_text[i]
|
| 35 |
+
print(f"history {result_text}")
|
| 36 |
+
|
| 37 |
+
is_zh = is_chinese(input_text)
|
| 38 |
+
if image_prompt is None:
|
| 39 |
+
if is_zh:
|
| 40 |
+
result_text.append((input_text, '图片为空!请上传图片并重试。'))
|
| 41 |
+
else:
|
| 42 |
+
result_text.append((input_text, 'Image empty! Please upload a image and retry.'))
|
| 43 |
+
return input_text, result_text
|
| 44 |
+
elif input_text == "":
|
| 45 |
+
result_text.append((input_text, 'Text empty! Please enter text and retry.'))
|
| 46 |
+
return "", result_text
|
| 47 |
+
|
| 48 |
+
request_para = {"temperature": temperature, "top_p": top_p}
|
| 49 |
+
image = Image.open(image_prompt)
|
| 50 |
+
try:
|
| 51 |
+
answer = generate_text_with_image(input_text, image, result_text.copy(), request_para, is_zh)
|
| 52 |
+
except Exception as e:
|
| 53 |
+
print(f"error: {e}")
|
| 54 |
+
if is_zh:
|
| 55 |
+
result_text.append((input_text, '超时!请稍等几分钟再重试。'))
|
| 56 |
+
else:
|
| 57 |
+
result_text.append((input_text, 'Timeout! Please wait a few minutes and retry.'))
|
| 58 |
+
return "", result_text
|
| 59 |
+
|
| 60 |
+
result_text.append((input_text, answer))
|
| 61 |
+
print(result_text)
|
| 62 |
+
return "", result_text
|
| 63 |
+
|
| 64 |
+
|
| 65 |
+
DESCRIPTION = '''# <a href="https://github.com/THUDM/VisualGLM-6B">VisualGLM</a>'''
|
| 66 |
+
|
| 67 |
+
MAINTENANCE_NOTICE1 = 'Hint 1: If the app report "Something went wrong, connection error out", please turn off your proxy and retry.\nHint 2: If you upload a large size of image like 10MB, it may take some time to upload and process. Please be patient and wait.'
|
| 68 |
+
MAINTENANCE_NOTICE2 = '提示1: 如果应用报了“Something went wrong, connection error out”的错误,请关闭代理并重试。\n提示2: 如果你上传了很大的图片,比如10MB大小,那将需要一些时间来上传和处理,请耐心等待。'
|
| 69 |
+
|
| 70 |
+
NOTES = 'This app is adapted from <a href="https://github.com/THUDM/VisualGLM-6B">https://github.com/THUDM/VisualGLM-6B</a>. It would be recommended to check out the repo if you want to see the detail of our model and training process.'
|
| 71 |
+
|
| 72 |
+
|
| 73 |
+
def clear_fn(value):
|
| 74 |
+
return "", [("", "Hi, What do you want to know about this image?")], None
|
| 75 |
+
|
| 76 |
+
def clear_fn2(value):
|
| 77 |
+
return [("", "Hi, What do you want to know about this image?")]
|
| 78 |
+
|
| 79 |
+
|
| 80 |
+
def main(args):
|
| 81 |
+
gr.close_all()
|
| 82 |
+
global model, tokenizer
|
| 83 |
+
model, tokenizer = get_infer_setting(gpu_device=0, quant=args.quant)
|
| 84 |
+
|
| 85 |
+
with gr.Blocks(css='style.css') as demo:
|
| 86 |
+
gr.Markdown(DESCRIPTION)
|
| 87 |
+
with gr.Row():
|
| 88 |
+
with gr.Column(scale=4.5):
|
| 89 |
+
with gr.Group():
|
| 90 |
+
input_text = gr.Textbox(label='Input Text', placeholder='Please enter text prompt below and press ENTER.')
|
| 91 |
+
with gr.Row():
|
| 92 |
+
run_button = gr.Button('Generate')
|
| 93 |
+
clear_button = gr.Button('Clear')
|
| 94 |
+
|
| 95 |
+
image_prompt = gr.Image(type="filepath", label="Image Prompt", value=None)
|
| 96 |
+
with gr.Row():
|
| 97 |
+
temperature = gr.Slider(maximum=1, value=0.8, minimum=0, label='Temperature')
|
| 98 |
+
top_p = gr.Slider(maximum=1, value=0.4, minimum=0, label='Top P')
|
| 99 |
+
with gr.Group():
|
| 100 |
+
with gr.Row():
|
| 101 |
+
maintenance_notice = gr.Markdown(MAINTENANCE_NOTICE1)
|
| 102 |
+
with gr.Column(scale=5.5):
|
| 103 |
+
result_text = gr.components.Chatbot(label='Multi-round conversation History', value=[("", "Hi, What do you want to know about this image?")]).style(height=550)
|
| 104 |
+
|
| 105 |
+
gr.Markdown(NOTES)
|
| 106 |
+
|
| 107 |
+
print(gr.__version__)
|
| 108 |
+
run_button.click(fn=request_model,inputs=[input_text, temperature, top_p, image_prompt, result_text],
|
| 109 |
+
outputs=[input_text, result_text])
|
| 110 |
+
input_text.submit(fn=request_model,inputs=[input_text, temperature, top_p, image_prompt, result_text],
|
| 111 |
+
outputs=[input_text, result_text])
|
| 112 |
+
clear_button.click(fn=clear_fn, inputs=clear_button, outputs=[input_text, result_text, image_prompt])
|
| 113 |
+
image_prompt.upload(fn=clear_fn2, inputs=clear_button, outputs=[result_text])
|
| 114 |
+
image_prompt.clear(fn=clear_fn2, inputs=clear_button, outputs=[result_text])
|
| 115 |
+
|
| 116 |
+
print(gr.__version__)
|
| 117 |
+
|
| 118 |
+
demo.queue(concurrency_count=10)
|
| 119 |
+
demo.launch(share=args.share)
|
| 120 |
+
|
| 121 |
+
|
| 122 |
+
if __name__ == '__main__':
|
| 123 |
+
import argparse
|
| 124 |
+
parser = argparse.ArgumentParser()
|
| 125 |
+
parser.add_argument("--quant", choices=[8, 4], type=int, default=None)
|
| 126 |
+
parser.add_argument("--share", action="store_true")
|
| 127 |
+
args = parser.parse_args()
|
| 128 |
+
args.share = "True"
|
| 129 |
+
main(args)
|
web_demo_hf.py
ADDED
|
@@ -0,0 +1,143 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from transformers import AutoModel, AutoTokenizer
|
| 2 |
+
import gradio as gr
|
| 3 |
+
import mdtex2html
|
| 4 |
+
import torch
|
| 5 |
+
|
| 6 |
+
"""Override Chatbot.postprocess"""
|
| 7 |
+
|
| 8 |
+
def postprocess(self, y):
|
| 9 |
+
if y is None:
|
| 10 |
+
return []
|
| 11 |
+
for i, (message, response) in enumerate(y):
|
| 12 |
+
y[i] = (
|
| 13 |
+
None if message is None else mdtex2html.convert((message)),
|
| 14 |
+
None if response is None else mdtex2html.convert(response),
|
| 15 |
+
)
|
| 16 |
+
return y
|
| 17 |
+
|
| 18 |
+
gr.Chatbot.postprocess = postprocess
|
| 19 |
+
|
| 20 |
+
|
| 21 |
+
def parse_text(text):
|
| 22 |
+
"""copy from https://github.com/GaiZhenbiao/ChuanhuChatGPT/"""
|
| 23 |
+
lines = text.split("\n")
|
| 24 |
+
lines = [line for line in lines if line != ""]
|
| 25 |
+
count = 0
|
| 26 |
+
for i, line in enumerate(lines):
|
| 27 |
+
if "```" in line:
|
| 28 |
+
count += 1
|
| 29 |
+
items = line.split('`')
|
| 30 |
+
if count % 2 == 1:
|
| 31 |
+
lines[i] = f'<pre><code class="language-{items[-1]}">'
|
| 32 |
+
else:
|
| 33 |
+
lines[i] = f'<br></code></pre>'
|
| 34 |
+
else:
|
| 35 |
+
if i > 0:
|
| 36 |
+
if count % 2 == 1:
|
| 37 |
+
line = line.replace("`", "\`")
|
| 38 |
+
line = line.replace("<", "<")
|
| 39 |
+
line = line.replace(">", ">")
|
| 40 |
+
line = line.replace(" ", " ")
|
| 41 |
+
line = line.replace("*", "*")
|
| 42 |
+
line = line.replace("_", "_")
|
| 43 |
+
line = line.replace("-", "-")
|
| 44 |
+
line = line.replace(".", ".")
|
| 45 |
+
line = line.replace("!", "!")
|
| 46 |
+
line = line.replace("(", "(")
|
| 47 |
+
line = line.replace(")", ")")
|
| 48 |
+
line = line.replace("$", "$")
|
| 49 |
+
lines[i] = "<br>"+line
|
| 50 |
+
text = "".join(lines)
|
| 51 |
+
return text
|
| 52 |
+
|
| 53 |
+
|
| 54 |
+
def predict(input, image_path, chatbot, max_length, top_p, temperature, history):
|
| 55 |
+
if image_path is None:
|
| 56 |
+
return [(input, "图片不能为空。请重新上传图片并重试。")], []
|
| 57 |
+
chatbot.append((parse_text(input), ""))
|
| 58 |
+
with torch.no_grad():
|
| 59 |
+
for response, history in model.stream_chat(tokenizer, image_path, input, history, max_length=max_length, top_p=top_p,
|
| 60 |
+
temperature=temperature):
|
| 61 |
+
chatbot[-1] = (parse_text(input), parse_text(response))
|
| 62 |
+
|
| 63 |
+
yield chatbot, history
|
| 64 |
+
|
| 65 |
+
|
| 66 |
+
def predict_new_image(image_path, chatbot, max_length, top_p, temperature):
|
| 67 |
+
input, history = "描述这张图片。", []
|
| 68 |
+
chatbot.append((parse_text(input), ""))
|
| 69 |
+
with torch.no_grad():
|
| 70 |
+
for response, history in model.stream_chat(tokenizer, image_path, input, history, max_length=max_length,
|
| 71 |
+
top_p=top_p,
|
| 72 |
+
temperature=temperature):
|
| 73 |
+
chatbot[-1] = (parse_text(input), parse_text(response))
|
| 74 |
+
|
| 75 |
+
yield chatbot, history
|
| 76 |
+
|
| 77 |
+
|
| 78 |
+
def reset_user_input():
|
| 79 |
+
return gr.update(value='')
|
| 80 |
+
|
| 81 |
+
|
| 82 |
+
def reset_state():
|
| 83 |
+
return None, [], []
|
| 84 |
+
|
| 85 |
+
|
| 86 |
+
DESCRIPTION = '''<h1 align="center"><a href="https://github.com/THUDM/VisualGLM-6B">VisualGLM</a></h1>'''
|
| 87 |
+
MAINTENANCE_NOTICE = 'Hint 1: If the app report "Something went wrong, connection error out", please turn off your proxy and retry.\nHint 2: If you upload a large size of image like 10MB, it may take some time to upload and process. Please be patient and wait.'
|
| 88 |
+
NOTES = 'This app is adapted from <a href="https://github.com/THUDM/VisualGLM-6B">https://github.com/THUDM/VisualGLM-6B</a>. It would be recommended to check out the repo if you want to see the detail of our model and training process.'
|
| 89 |
+
|
| 90 |
+
def main(args):
|
| 91 |
+
global model, tokenizer
|
| 92 |
+
tokenizer = AutoTokenizer.from_pretrained("THUDM/visualglm-6b", trust_remote_code=True)
|
| 93 |
+
if args.quant in [4, 8]:
|
| 94 |
+
model = AutoModel.from_pretrained("THUDM/visualglm-6b", trust_remote_code=True).quantize(args.quant).half().cuda()
|
| 95 |
+
else:
|
| 96 |
+
model = AutoModel.from_pretrained("THUDM/visualglm-6b", trust_remote_code=True).half().cuda()
|
| 97 |
+
model = model.eval()
|
| 98 |
+
|
| 99 |
+
with gr.Blocks(css='style.css') as demo:
|
| 100 |
+
gr.HTML(DESCRIPTION)
|
| 101 |
+
|
| 102 |
+
with gr.Row():
|
| 103 |
+
with gr.Column(scale=2):
|
| 104 |
+
image_path = gr.Image(type="filepath", label="Image Prompt", value=None).style(height=504)
|
| 105 |
+
with gr.Column(scale=4):
|
| 106 |
+
chatbot = gr.Chatbot().style(height=480)
|
| 107 |
+
with gr.Row():
|
| 108 |
+
with gr.Column(scale=2, min_width=100):
|
| 109 |
+
max_length = gr.Slider(0, 4096, value=2048, step=1.0, label="Maximum length", interactive=True)
|
| 110 |
+
top_p = gr.Slider(0, 1, value=0.4, step=0.01, label="Top P", interactive=True)
|
| 111 |
+
temperature = gr.Slider(0, 1, value=0.8, step=0.01, label="Temperature", interactive=True)
|
| 112 |
+
with gr.Column(scale=4):
|
| 113 |
+
with gr.Box():
|
| 114 |
+
with gr.Row():
|
| 115 |
+
with gr.Column(scale=2):
|
| 116 |
+
user_input = gr.Textbox(show_label=False, placeholder="Input...", lines=4).style(
|
| 117 |
+
container=False)
|
| 118 |
+
with gr.Column(scale=1, min_width=64):
|
| 119 |
+
submitBtn = gr.Button("Submit", variant="primary")
|
| 120 |
+
emptyBtn = gr.Button("Clear History")
|
| 121 |
+
gr.Markdown(MAINTENANCE_NOTICE + '\n' + NOTES)
|
| 122 |
+
history = gr.State([])
|
| 123 |
+
|
| 124 |
+
|
| 125 |
+
submitBtn.click(predict, [user_input, image_path, chatbot, max_length, top_p, temperature, history], [chatbot, history],
|
| 126 |
+
show_progress=True)
|
| 127 |
+
image_path.upload(predict_new_image, [image_path, chatbot, max_length, top_p, temperature], [chatbot, history],
|
| 128 |
+
show_progress=True)
|
| 129 |
+
image_path.clear(reset_state, outputs=[image_path, chatbot, history], show_progress=True)
|
| 130 |
+
submitBtn.click(reset_user_input, [], [user_input])
|
| 131 |
+
emptyBtn.click(reset_state, outputs=[image_path, chatbot, history], show_progress=True)
|
| 132 |
+
|
| 133 |
+
print(gr.__version__)
|
| 134 |
+
|
| 135 |
+
demo.queue().launch(share=args.share, inbrowser=True, server_name='0.0.0.0', server_port=8080)
|
| 136 |
+
|
| 137 |
+
if __name__ == '__main__':
|
| 138 |
+
import argparse
|
| 139 |
+
parser = argparse.ArgumentParser()
|
| 140 |
+
parser.add_argument("--quant", choices=[8, 4], type=int, default=None)
|
| 141 |
+
parser.add_argument("--share", action="store_true")
|
| 142 |
+
args = parser.parse_args()
|
| 143 |
+
main(args)
|
your_logfile.log
ADDED
|
@@ -0,0 +1,2 @@
|
|
|
|
|
|
|
|
|
|
| 1 |
+
nohup: 忽略输入
|
| 2 |
+
python: can't open file '/root/VisualGLM-6B/your_program.py': [Errno 2] No such file or directory
|