Spaces:
Runtime error

Runtime error
XiaoHei Studio
commited on
Commit
•
524ad56
1
Parent(s):
1f93207
Upload 40 files
Browse files- .gitattributes +1 -35
- .gitignore +167 -0
- .ruff.toml +4 -0
- LICENSE +661 -0
- README.md +569 -12
- README_zh_CN.md +570 -0
- app.py +1421 -0
- app_old.py +1428 -0
- auto_slicer.py +107 -0
- compress_model.py +72 -0
- data_utils.py +185 -0
- export_index_for_onnx.py +20 -0
- flask_api.py +60 -0
- flask_api_full_song.py +55 -0
- inference_main.py +155 -0
- models.py +487 -0
- onnx_export.py +150 -0
- onnx_export_old.py +56 -0
- onnx_export_speaker_mix.py +138 -0
- preprocess_flist_config.py +109 -0
- preprocess_hubert_f0.py +172 -0
- requirements.txt +31 -0
- requirements_onnx_encoder.txt +29 -0
- requirements_win.txt +33 -0
- resample.py +98 -0
- settings.yaml +21 -0
- setup.py +68 -0
- shadowdiffusion.png +0 -0
- sovits4_for_colab.ipynb +711 -0
- spkmix.py +11 -0
- temp.wav +0 -0
- train.py +329 -0
- train_diff.py +77 -0
- train_index.py +30 -0
- tts.py +38 -0
- tts.wav +0 -0
- tts_voices.py +306 -0
- utils.py +572 -0
- wav_upload.py +25 -0
- webUI.py +430 -0
.gitattributes
CHANGED
|
@@ -1,35 +1 @@
|
|
| 1 |
-
|
| 2 |
-
*.arrow filter=lfs diff=lfs merge=lfs -text
|
| 3 |
-
*.bin filter=lfs diff=lfs merge=lfs -text
|
| 4 |
-
*.bz2 filter=lfs diff=lfs merge=lfs -text
|
| 5 |
-
*.ckpt filter=lfs diff=lfs merge=lfs -text
|
| 6 |
-
*.ftz filter=lfs diff=lfs merge=lfs -text
|
| 7 |
-
*.gz filter=lfs diff=lfs merge=lfs -text
|
| 8 |
-
*.h5 filter=lfs diff=lfs merge=lfs -text
|
| 9 |
-
*.joblib filter=lfs diff=lfs merge=lfs -text
|
| 10 |
-
*.lfs.* filter=lfs diff=lfs merge=lfs -text
|
| 11 |
-
*.mlmodel filter=lfs diff=lfs merge=lfs -text
|
| 12 |
-
*.model filter=lfs diff=lfs merge=lfs -text
|
| 13 |
-
*.msgpack filter=lfs diff=lfs merge=lfs -text
|
| 14 |
-
*.npy filter=lfs diff=lfs merge=lfs -text
|
| 15 |
-
*.npz filter=lfs diff=lfs merge=lfs -text
|
| 16 |
-
*.onnx filter=lfs diff=lfs merge=lfs -text
|
| 17 |
-
*.ot filter=lfs diff=lfs merge=lfs -text
|
| 18 |
-
*.parquet filter=lfs diff=lfs merge=lfs -text
|
| 19 |
-
*.pb filter=lfs diff=lfs merge=lfs -text
|
| 20 |
-
*.pickle filter=lfs diff=lfs merge=lfs -text
|
| 21 |
-
*.pkl filter=lfs diff=lfs merge=lfs -text
|
| 22 |
-
*.pt filter=lfs diff=lfs merge=lfs -text
|
| 23 |
-
*.pth filter=lfs diff=lfs merge=lfs -text
|
| 24 |
-
*.rar filter=lfs diff=lfs merge=lfs -text
|
| 25 |
-
*.safetensors filter=lfs diff=lfs merge=lfs -text
|
| 26 |
-
saved_model/**/* filter=lfs diff=lfs merge=lfs -text
|
| 27 |
-
*.tar.* filter=lfs diff=lfs merge=lfs -text
|
| 28 |
-
*.tar filter=lfs diff=lfs merge=lfs -text
|
| 29 |
-
*.tflite filter=lfs diff=lfs merge=lfs -text
|
| 30 |
-
*.tgz filter=lfs diff=lfs merge=lfs -text
|
| 31 |
-
*.wasm filter=lfs diff=lfs merge=lfs -text
|
| 32 |
-
*.xz filter=lfs diff=lfs merge=lfs -text
|
| 33 |
-
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
-
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
-
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
|
|
|
| 1 |
+
* text=auto eol=lf
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
.gitignore
ADDED
|
@@ -0,0 +1,167 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
|
| 2 |
+
# Created by https://www.toptal.com/developers/gitignore/api/python
|
| 3 |
+
# Edit at https://www.toptal.com/developers/gitignore?templates=python
|
| 4 |
+
|
| 5 |
+
### Python ###
|
| 6 |
+
# Byte-compiled / optimized / DLL files
|
| 7 |
+
__pycache__/
|
| 8 |
+
*.py[cod]
|
| 9 |
+
*$py.class
|
| 10 |
+
|
| 11 |
+
# C extensions
|
| 12 |
+
*.so
|
| 13 |
+
checkpoints/
|
| 14 |
+
# Distribution / packaging
|
| 15 |
+
.Python
|
| 16 |
+
build/
|
| 17 |
+
develop-eggs/
|
| 18 |
+
dist/
|
| 19 |
+
downloads/
|
| 20 |
+
eggs/
|
| 21 |
+
.eggs/
|
| 22 |
+
lib/
|
| 23 |
+
lib64/
|
| 24 |
+
parts/
|
| 25 |
+
sdist/
|
| 26 |
+
var/
|
| 27 |
+
wheels/
|
| 28 |
+
pip-wheel-metadata/
|
| 29 |
+
share/python-wheels/
|
| 30 |
+
*.egg-info/
|
| 31 |
+
.installed.cfg
|
| 32 |
+
*.egg
|
| 33 |
+
MANIFEST
|
| 34 |
+
|
| 35 |
+
# PyInstaller
|
| 36 |
+
# Usually these files are written by a python script from a template
|
| 37 |
+
# before PyInstaller builds the exe, so as to inject date/other infos into it.
|
| 38 |
+
*.manifest
|
| 39 |
+
*.spec
|
| 40 |
+
|
| 41 |
+
# Installer logs
|
| 42 |
+
pip-log.txt
|
| 43 |
+
pip-delete-this-directory.txt
|
| 44 |
+
|
| 45 |
+
# Unit test / coverage reports
|
| 46 |
+
htmlcov/
|
| 47 |
+
.tox/
|
| 48 |
+
.nox/
|
| 49 |
+
.coverage
|
| 50 |
+
.coverage.*
|
| 51 |
+
.cache
|
| 52 |
+
nosetests.xml
|
| 53 |
+
coverage.xml
|
| 54 |
+
*.cover
|
| 55 |
+
*.py,cover
|
| 56 |
+
.hypothesis/
|
| 57 |
+
.pytest_cache/
|
| 58 |
+
pytestdebug.log
|
| 59 |
+
|
| 60 |
+
# Translations
|
| 61 |
+
*.mo
|
| 62 |
+
*.pot
|
| 63 |
+
|
| 64 |
+
# Django stuff:
|
| 65 |
+
*.log
|
| 66 |
+
local_settings.py
|
| 67 |
+
db.sqlite3
|
| 68 |
+
db.sqlite3-journal
|
| 69 |
+
|
| 70 |
+
# Flask stuff:
|
| 71 |
+
instance/
|
| 72 |
+
.webassets-cache
|
| 73 |
+
|
| 74 |
+
# Scrapy stuff:
|
| 75 |
+
.scrapy
|
| 76 |
+
|
| 77 |
+
# Sphinx documentation
|
| 78 |
+
docs/_build/
|
| 79 |
+
doc/_build/
|
| 80 |
+
|
| 81 |
+
# PyBuilder
|
| 82 |
+
target/
|
| 83 |
+
|
| 84 |
+
# Jupyter Notebook
|
| 85 |
+
.ipynb_checkpoints
|
| 86 |
+
|
| 87 |
+
# IPython
|
| 88 |
+
profile_default/
|
| 89 |
+
ipython_config.py
|
| 90 |
+
|
| 91 |
+
# pyenv
|
| 92 |
+
.python-version
|
| 93 |
+
|
| 94 |
+
# pipenv
|
| 95 |
+
# According to pypa/pipenv#598, it is recommended to include Pipfile.lock in version control.
|
| 96 |
+
# However, in case of collaboration, if having platform-specific dependencies or dependencies
|
| 97 |
+
# having no cross-platform support, pipenv may install dependencies that don't work, or not
|
| 98 |
+
# install all needed dependencies.
|
| 99 |
+
#Pipfile.lock
|
| 100 |
+
|
| 101 |
+
# PEP 582; used by e.g. github.com/David-OConnor/pyflow
|
| 102 |
+
__pypackages__/
|
| 103 |
+
|
| 104 |
+
# Celery stuff
|
| 105 |
+
celerybeat-schedule
|
| 106 |
+
celerybeat.pid
|
| 107 |
+
|
| 108 |
+
# SageMath parsed files
|
| 109 |
+
*.sage.py
|
| 110 |
+
|
| 111 |
+
# Environments
|
| 112 |
+
.env
|
| 113 |
+
.venv
|
| 114 |
+
env/
|
| 115 |
+
venv/
|
| 116 |
+
ENV/
|
| 117 |
+
env.bak/
|
| 118 |
+
venv.bak/
|
| 119 |
+
|
| 120 |
+
# Spyder project settings
|
| 121 |
+
.spyderproject
|
| 122 |
+
.spyproject
|
| 123 |
+
|
| 124 |
+
# Rope project settings
|
| 125 |
+
.ropeproject
|
| 126 |
+
|
| 127 |
+
# mkdocs documentation
|
| 128 |
+
/site
|
| 129 |
+
|
| 130 |
+
# mypy
|
| 131 |
+
.mypy_cache/
|
| 132 |
+
.dmypy.json
|
| 133 |
+
dmypy.json
|
| 134 |
+
|
| 135 |
+
# Pyre type checker
|
| 136 |
+
.pyre/
|
| 137 |
+
|
| 138 |
+
# pytype static type analyzer
|
| 139 |
+
.pytype/
|
| 140 |
+
|
| 141 |
+
# End of https://www.toptal.com/developers/gitignore/api/python
|
| 142 |
+
|
| 143 |
+
/shelf/
|
| 144 |
+
/workspace.xml
|
| 145 |
+
|
| 146 |
+
dataset
|
| 147 |
+
dataset_raw
|
| 148 |
+
raw
|
| 149 |
+
results
|
| 150 |
+
inference/chunks_temp.json
|
| 151 |
+
logs
|
| 152 |
+
hubert/checkpoint_best_legacy_500.pt
|
| 153 |
+
configs/config.json
|
| 154 |
+
filelists/test.txt
|
| 155 |
+
filelists/train.txt
|
| 156 |
+
filelists/val.txt
|
| 157 |
+
.idea/
|
| 158 |
+
.vscode/
|
| 159 |
+
.idea/modules.xml
|
| 160 |
+
.idea/so-vits-svc.iml
|
| 161 |
+
.idea/vcs.xml
|
| 162 |
+
.idea/inspectionProfiles/profiles_settings.xml
|
| 163 |
+
.idea/inspectionProfiles/Project_Default.xml
|
| 164 |
+
pretrain/
|
| 165 |
+
.vscode/launch.json
|
| 166 |
+
|
| 167 |
+
trained/**/
|
.ruff.toml
ADDED
|
@@ -0,0 +1,4 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
select = ["E", "F", "I"]
|
| 2 |
+
|
| 3 |
+
# Never enforce `E501` (line length violations).
|
| 4 |
+
ignore = ["E501", "E741"]
|
LICENSE
ADDED
|
@@ -0,0 +1,661 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
GNU AFFERO GENERAL PUBLIC LICENSE
|
| 2 |
+
Version 3, 19 November 2007
|
| 3 |
+
|
| 4 |
+
Copyright (C) 2007 Free Software Foundation, Inc. <https://fsf.org/>
|
| 5 |
+
Everyone is permitted to copy and distribute verbatim copies
|
| 6 |
+
of this license document, but changing it is not allowed.
|
| 7 |
+
|
| 8 |
+
Preamble
|
| 9 |
+
|
| 10 |
+
The GNU Affero General Public License is a free, copyleft license for
|
| 11 |
+
software and other kinds of works, specifically designed to ensure
|
| 12 |
+
cooperation with the community in the case of network server software.
|
| 13 |
+
|
| 14 |
+
The licenses for most software and other practical works are designed
|
| 15 |
+
to take away your freedom to share and change the works. By contrast,
|
| 16 |
+
our General Public Licenses are intended to guarantee your freedom to
|
| 17 |
+
share and change all versions of a program--to make sure it remains free
|
| 18 |
+
software for all its users.
|
| 19 |
+
|
| 20 |
+
When we speak of free software, we are referring to freedom, not
|
| 21 |
+
price. Our General Public Licenses are designed to make sure that you
|
| 22 |
+
have the freedom to distribute copies of free software (and charge for
|
| 23 |
+
them if you wish), that you receive source code or can get it if you
|
| 24 |
+
want it, that you can change the software or use pieces of it in new
|
| 25 |
+
free programs, and that you know you can do these things.
|
| 26 |
+
|
| 27 |
+
Developers that use our General Public Licenses protect your rights
|
| 28 |
+
with two steps: (1) assert copyright on the software, and (2) offer
|
| 29 |
+
you this License which gives you legal permission to copy, distribute
|
| 30 |
+
and/or modify the software.
|
| 31 |
+
|
| 32 |
+
A secondary benefit of defending all users' freedom is that
|
| 33 |
+
improvements made in alternate versions of the program, if they
|
| 34 |
+
receive widespread use, become available for other developers to
|
| 35 |
+
incorporate. Many developers of free software are heartened and
|
| 36 |
+
encouraged by the resulting cooperation. However, in the case of
|
| 37 |
+
software used on network servers, this result may fail to come about.
|
| 38 |
+
The GNU General Public License permits making a modified version and
|
| 39 |
+
letting the public access it on a server without ever releasing its
|
| 40 |
+
source code to the public.
|
| 41 |
+
|
| 42 |
+
The GNU Affero General Public License is designed specifically to
|
| 43 |
+
ensure that, in such cases, the modified source code becomes available
|
| 44 |
+
to the community. It requires the operator of a network server to
|
| 45 |
+
provide the source code of the modified version running there to the
|
| 46 |
+
users of that server. Therefore, public use of a modified version, on
|
| 47 |
+
a publicly accessible server, gives the public access to the source
|
| 48 |
+
code of the modified version.
|
| 49 |
+
|
| 50 |
+
An older license, called the Affero General Public License and
|
| 51 |
+
published by Affero, was designed to accomplish similar goals. This is
|
| 52 |
+
a different license, not a version of the Affero GPL, but Affero has
|
| 53 |
+
released a new version of the Affero GPL which permits relicensing under
|
| 54 |
+
this license.
|
| 55 |
+
|
| 56 |
+
The precise terms and conditions for copying, distribution and
|
| 57 |
+
modification follow.
|
| 58 |
+
|
| 59 |
+
TERMS AND CONDITIONS
|
| 60 |
+
|
| 61 |
+
0. Definitions.
|
| 62 |
+
|
| 63 |
+
"This License" refers to version 3 of the GNU Affero General Public License.
|
| 64 |
+
|
| 65 |
+
"Copyright" also means copyright-like laws that apply to other kinds of
|
| 66 |
+
works, such as semiconductor masks.
|
| 67 |
+
|
| 68 |
+
"The Program" refers to any copyrightable work licensed under this
|
| 69 |
+
License. Each licensee is addressed as "you". "Licensees" and
|
| 70 |
+
"recipients" may be individuals or organizations.
|
| 71 |
+
|
| 72 |
+
To "modify" a work means to copy from or adapt all or part of the work
|
| 73 |
+
in a fashion requiring copyright permission, other than the making of an
|
| 74 |
+
exact copy. The resulting work is called a "modified version" of the
|
| 75 |
+
earlier work or a work "based on" the earlier work.
|
| 76 |
+
|
| 77 |
+
A "covered work" means either the unmodified Program or a work based
|
| 78 |
+
on the Program.
|
| 79 |
+
|
| 80 |
+
To "propagate" a work means to do anything with it that, without
|
| 81 |
+
permission, would make you directly or secondarily liable for
|
| 82 |
+
infringement under applicable copyright law, except executing it on a
|
| 83 |
+
computer or modifying a private copy. Propagation includes copying,
|
| 84 |
+
distribution (with or without modification), making available to the
|
| 85 |
+
public, and in some countries other activities as well.
|
| 86 |
+
|
| 87 |
+
To "convey" a work means any kind of propagation that enables other
|
| 88 |
+
parties to make or receive copies. Mere interaction with a user through
|
| 89 |
+
a computer network, with no transfer of a copy, is not conveying.
|
| 90 |
+
|
| 91 |
+
An interactive user interface displays "Appropriate Legal Notices"
|
| 92 |
+
to the extent that it includes a convenient and prominently visible
|
| 93 |
+
feature that (1) displays an appropriate copyright notice, and (2)
|
| 94 |
+
tells the user that there is no warranty for the work (except to the
|
| 95 |
+
extent that warranties are provided), that licensees may convey the
|
| 96 |
+
work under this License, and how to view a copy of this License. If
|
| 97 |
+
the interface presents a list of user commands or options, such as a
|
| 98 |
+
menu, a prominent item in the list meets this criterion.
|
| 99 |
+
|
| 100 |
+
1. Source Code.
|
| 101 |
+
|
| 102 |
+
The "source code" for a work means the preferred form of the work
|
| 103 |
+
for making modifications to it. "Object code" means any non-source
|
| 104 |
+
form of a work.
|
| 105 |
+
|
| 106 |
+
A "Standard Interface" means an interface that either is an official
|
| 107 |
+
standard defined by a recognized standards body, or, in the case of
|
| 108 |
+
interfaces specified for a particular programming language, one that
|
| 109 |
+
is widely used among developers working in that language.
|
| 110 |
+
|
| 111 |
+
The "System Libraries" of an executable work include anything, other
|
| 112 |
+
than the work as a whole, that (a) is included in the normal form of
|
| 113 |
+
packaging a Major Component, but which is not part of that Major
|
| 114 |
+
Component, and (b) serves only to enable use of the work with that
|
| 115 |
+
Major Component, or to implement a Standard Interface for which an
|
| 116 |
+
implementation is available to the public in source code form. A
|
| 117 |
+
"Major Component", in this context, means a major essential component
|
| 118 |
+
(kernel, window system, and so on) of the specific operating system
|
| 119 |
+
(if any) on which the executable work runs, or a compiler used to
|
| 120 |
+
produce the work, or an object code interpreter used to run it.
|
| 121 |
+
|
| 122 |
+
The "Corresponding Source" for a work in object code form means all
|
| 123 |
+
the source code needed to generate, install, and (for an executable
|
| 124 |
+
work) run the object code and to modify the work, including scripts to
|
| 125 |
+
control those activities. However, it does not include the work's
|
| 126 |
+
System Libraries, or general-purpose tools or generally available free
|
| 127 |
+
programs which are used unmodified in performing those activities but
|
| 128 |
+
which are not part of the work. For example, Corresponding Source
|
| 129 |
+
includes interface definition files associated with source files for
|
| 130 |
+
the work, and the source code for shared libraries and dynamically
|
| 131 |
+
linked subprograms that the work is specifically designed to require,
|
| 132 |
+
such as by intimate data communication or control flow between those
|
| 133 |
+
subprograms and other parts of the work.
|
| 134 |
+
|
| 135 |
+
The Corresponding Source need not include anything that users
|
| 136 |
+
can regenerate automatically from other parts of the Corresponding
|
| 137 |
+
Source.
|
| 138 |
+
|
| 139 |
+
The Corresponding Source for a work in source code form is that
|
| 140 |
+
same work.
|
| 141 |
+
|
| 142 |
+
2. Basic Permissions.
|
| 143 |
+
|
| 144 |
+
All rights granted under this License are granted for the term of
|
| 145 |
+
copyright on the Program, and are irrevocable provided the stated
|
| 146 |
+
conditions are met. This License explicitly affirms your unlimited
|
| 147 |
+
permission to run the unmodified Program. The output from running a
|
| 148 |
+
covered work is covered by this License only if the output, given its
|
| 149 |
+
content, constitutes a covered work. This License acknowledges your
|
| 150 |
+
rights of fair use or other equivalent, as provided by copyright law.
|
| 151 |
+
|
| 152 |
+
You may make, run and propagate covered works that you do not
|
| 153 |
+
convey, without conditions so long as your license otherwise remains
|
| 154 |
+
in force. You may convey covered works to others for the sole purpose
|
| 155 |
+
of having them make modifications exclusively for you, or provide you
|
| 156 |
+
with facilities for running those works, provided that you comply with
|
| 157 |
+
the terms of this License in conveying all material for which you do
|
| 158 |
+
not control copyright. Those thus making or running the covered works
|
| 159 |
+
for you must do so exclusively on your behalf, under your direction
|
| 160 |
+
and control, on terms that prohibit them from making any copies of
|
| 161 |
+
your copyrighted material outside their relationship with you.
|
| 162 |
+
|
| 163 |
+
Conveying under any other circumstances is permitted solely under
|
| 164 |
+
the conditions stated below. Sublicensing is not allowed; section 10
|
| 165 |
+
makes it unnecessary.
|
| 166 |
+
|
| 167 |
+
3. Protecting Users' Legal Rights From Anti-Circumvention Law.
|
| 168 |
+
|
| 169 |
+
No covered work shall be deemed part of an effective technological
|
| 170 |
+
measure under any applicable law fulfilling obligations under article
|
| 171 |
+
11 of the WIPO copyright treaty adopted on 20 December 1996, or
|
| 172 |
+
similar laws prohibiting or restricting circumvention of such
|
| 173 |
+
measures.
|
| 174 |
+
|
| 175 |
+
When you convey a covered work, you waive any legal power to forbid
|
| 176 |
+
circumvention of technological measures to the extent such circumvention
|
| 177 |
+
is effected by exercising rights under this License with respect to
|
| 178 |
+
the covered work, and you disclaim any intention to limit operation or
|
| 179 |
+
modification of the work as a means of enforcing, against the work's
|
| 180 |
+
users, your or third parties' legal rights to forbid circumvention of
|
| 181 |
+
technological measures.
|
| 182 |
+
|
| 183 |
+
4. Conveying Verbatim Copies.
|
| 184 |
+
|
| 185 |
+
You may convey verbatim copies of the Program's source code as you
|
| 186 |
+
receive it, in any medium, provided that you conspicuously and
|
| 187 |
+
appropriately publish on each copy an appropriate copyright notice;
|
| 188 |
+
keep intact all notices stating that this License and any
|
| 189 |
+
non-permissive terms added in accord with section 7 apply to the code;
|
| 190 |
+
keep intact all notices of the absence of any warranty; and give all
|
| 191 |
+
recipients a copy of this License along with the Program.
|
| 192 |
+
|
| 193 |
+
You may charge any price or no price for each copy that you convey,
|
| 194 |
+
and you may offer support or warranty protection for a fee.
|
| 195 |
+
|
| 196 |
+
5. Conveying Modified Source Versions.
|
| 197 |
+
|
| 198 |
+
You may convey a work based on the Program, or the modifications to
|
| 199 |
+
produce it from the Program, in the form of source code under the
|
| 200 |
+
terms of section 4, provided that you also meet all of these conditions:
|
| 201 |
+
|
| 202 |
+
a) The work must carry prominent notices stating that you modified
|
| 203 |
+
it, and giving a relevant date.
|
| 204 |
+
|
| 205 |
+
b) The work must carry prominent notices stating that it is
|
| 206 |
+
released under this License and any conditions added under section
|
| 207 |
+
7. This requirement modifies the requirement in section 4 to
|
| 208 |
+
"keep intact all notices".
|
| 209 |
+
|
| 210 |
+
c) You must license the entire work, as a whole, under this
|
| 211 |
+
License to anyone who comes into possession of a copy. This
|
| 212 |
+
License will therefore apply, along with any applicable section 7
|
| 213 |
+
additional terms, to the whole of the work, and all its parts,
|
| 214 |
+
regardless of how they are packaged. This License gives no
|
| 215 |
+
permission to license the work in any other way, but it does not
|
| 216 |
+
invalidate such permission if you have separately received it.
|
| 217 |
+
|
| 218 |
+
d) If the work has interactive user interfaces, each must display
|
| 219 |
+
Appropriate Legal Notices; however, if the Program has interactive
|
| 220 |
+
interfaces that do not display Appropriate Legal Notices, your
|
| 221 |
+
work need not make them do so.
|
| 222 |
+
|
| 223 |
+
A compilation of a covered work with other separate and independent
|
| 224 |
+
works, which are not by their nature extensions of the covered work,
|
| 225 |
+
and which are not combined with it such as to form a larger program,
|
| 226 |
+
in or on a volume of a storage or distribution medium, is called an
|
| 227 |
+
"aggregate" if the compilation and its resulting copyright are not
|
| 228 |
+
used to limit the access or legal rights of the compilation's users
|
| 229 |
+
beyond what the individual works permit. Inclusion of a covered work
|
| 230 |
+
in an aggregate does not cause this License to apply to the other
|
| 231 |
+
parts of the aggregate.
|
| 232 |
+
|
| 233 |
+
6. Conveying Non-Source Forms.
|
| 234 |
+
|
| 235 |
+
You may convey a covered work in object code form under the terms
|
| 236 |
+
of sections 4 and 5, provided that you also convey the
|
| 237 |
+
machine-readable Corresponding Source under the terms of this License,
|
| 238 |
+
in one of these ways:
|
| 239 |
+
|
| 240 |
+
a) Convey the object code in, or embodied in, a physical product
|
| 241 |
+
(including a physical distribution medium), accompanied by the
|
| 242 |
+
Corresponding Source fixed on a durable physical medium
|
| 243 |
+
customarily used for software interchange.
|
| 244 |
+
|
| 245 |
+
b) Convey the object code in, or embodied in, a physical product
|
| 246 |
+
(including a physical distribution medium), accompanied by a
|
| 247 |
+
written offer, valid for at least three years and valid for as
|
| 248 |
+
long as you offer spare parts or customer support for that product
|
| 249 |
+
model, to give anyone who possesses the object code either (1) a
|
| 250 |
+
copy of the Corresponding Source for all the software in the
|
| 251 |
+
product that is covered by this License, on a durable physical
|
| 252 |
+
medium customarily used for software interchange, for a price no
|
| 253 |
+
more than your reasonable cost of physically performing this
|
| 254 |
+
conveying of source, or (2) access to copy the
|
| 255 |
+
Corresponding Source from a network server at no charge.
|
| 256 |
+
|
| 257 |
+
c) Convey individual copies of the object code with a copy of the
|
| 258 |
+
written offer to provide the Corresponding Source. This
|
| 259 |
+
alternative is allowed only occasionally and noncommercially, and
|
| 260 |
+
only if you received the object code with such an offer, in accord
|
| 261 |
+
with subsection 6b.
|
| 262 |
+
|
| 263 |
+
d) Convey the object code by offering access from a designated
|
| 264 |
+
place (gratis or for a charge), and offer equivalent access to the
|
| 265 |
+
Corresponding Source in the same way through the same place at no
|
| 266 |
+
further charge. You need not require recipients to copy the
|
| 267 |
+
Corresponding Source along with the object code. If the place to
|
| 268 |
+
copy the object code is a network server, the Corresponding Source
|
| 269 |
+
may be on a different server (operated by you or a third party)
|
| 270 |
+
that supports equivalent copying facilities, provided you maintain
|
| 271 |
+
clear directions next to the object code saying where to find the
|
| 272 |
+
Corresponding Source. Regardless of what server hosts the
|
| 273 |
+
Corresponding Source, you remain obligated to ensure that it is
|
| 274 |
+
available for as long as needed to satisfy these requirements.
|
| 275 |
+
|
| 276 |
+
e) Convey the object code using peer-to-peer transmission, provided
|
| 277 |
+
you inform other peers where the object code and Corresponding
|
| 278 |
+
Source of the work are being offered to the general public at no
|
| 279 |
+
charge under subsection 6d.
|
| 280 |
+
|
| 281 |
+
A separable portion of the object code, whose source code is excluded
|
| 282 |
+
from the Corresponding Source as a System Library, need not be
|
| 283 |
+
included in conveying the object code work.
|
| 284 |
+
|
| 285 |
+
A "User Product" is either (1) a "consumer product", which means any
|
| 286 |
+
tangible personal property which is normally used for personal, family,
|
| 287 |
+
or household purposes, or (2) anything designed or sold for incorporation
|
| 288 |
+
into a dwelling. In determining whether a product is a consumer product,
|
| 289 |
+
doubtful cases shall be resolved in favor of coverage. For a particular
|
| 290 |
+
product received by a particular user, "normally used" refers to a
|
| 291 |
+
typical or common use of that class of product, regardless of the status
|
| 292 |
+
of the particular user or of the way in which the particular user
|
| 293 |
+
actually uses, or expects or is expected to use, the product. A product
|
| 294 |
+
is a consumer product regardless of whether the product has substantial
|
| 295 |
+
commercial, industrial or non-consumer uses, unless such uses represent
|
| 296 |
+
the only significant mode of use of the product.
|
| 297 |
+
|
| 298 |
+
"Installation Information" for a User Product means any methods,
|
| 299 |
+
procedures, authorization keys, or other information required to install
|
| 300 |
+
and execute modified versions of a covered work in that User Product from
|
| 301 |
+
a modified version of its Corresponding Source. The information must
|
| 302 |
+
suffice to ensure that the continued functioning of the modified object
|
| 303 |
+
code is in no case prevented or interfered with solely because
|
| 304 |
+
modification has been made.
|
| 305 |
+
|
| 306 |
+
If you convey an object code work under this section in, or with, or
|
| 307 |
+
specifically for use in, a User Product, and the conveying occurs as
|
| 308 |
+
part of a transaction in which the right of possession and use of the
|
| 309 |
+
User Product is transferred to the recipient in perpetuity or for a
|
| 310 |
+
fixed term (regardless of how the transaction is characterized), the
|
| 311 |
+
Corresponding Source conveyed under this section must be accompanied
|
| 312 |
+
by the Installation Information. But this requirement does not apply
|
| 313 |
+
if neither you nor any third party retains the ability to install
|
| 314 |
+
modified object code on the User Product (for example, the work has
|
| 315 |
+
been installed in ROM).
|
| 316 |
+
|
| 317 |
+
The requirement to provide Installation Information does not include a
|
| 318 |
+
requirement to continue to provide support service, warranty, or updates
|
| 319 |
+
for a work that has been modified or installed by the recipient, or for
|
| 320 |
+
the User Product in which it has been modified or installed. Access to a
|
| 321 |
+
network may be denied when the modification itself materially and
|
| 322 |
+
adversely affects the operation of the network or violates the rules and
|
| 323 |
+
protocols for communication across the network.
|
| 324 |
+
|
| 325 |
+
Corresponding Source conveyed, and Installation Information provided,
|
| 326 |
+
in accord with this section must be in a format that is publicly
|
| 327 |
+
documented (and with an implementation available to the public in
|
| 328 |
+
source code form), and must require no special password or key for
|
| 329 |
+
unpacking, reading or copying.
|
| 330 |
+
|
| 331 |
+
7. Additional Terms.
|
| 332 |
+
|
| 333 |
+
"Additional permissions" are terms that supplement the terms of this
|
| 334 |
+
License by making exceptions from one or more of its conditions.
|
| 335 |
+
Additional permissions that are applicable to the entire Program shall
|
| 336 |
+
be treated as though they were included in this License, to the extent
|
| 337 |
+
that they are valid under applicable law. If additional permissions
|
| 338 |
+
apply only to part of the Program, that part may be used separately
|
| 339 |
+
under those permissions, but the entire Program remains governed by
|
| 340 |
+
this License without regard to the additional permissions.
|
| 341 |
+
|
| 342 |
+
When you convey a copy of a covered work, you may at your option
|
| 343 |
+
remove any additional permissions from that copy, or from any part of
|
| 344 |
+
it. (Additional permissions may be written to require their own
|
| 345 |
+
removal in certain cases when you modify the work.) You may place
|
| 346 |
+
additional permissions on material, added by you to a covered work,
|
| 347 |
+
for which you have or can give appropriate copyright permission.
|
| 348 |
+
|
| 349 |
+
Notwithstanding any other provision of this License, for material you
|
| 350 |
+
add to a covered work, you may (if authorized by the copyright holders of
|
| 351 |
+
that material) supplement the terms of this License with terms:
|
| 352 |
+
|
| 353 |
+
a) Disclaiming warranty or limiting liability differently from the
|
| 354 |
+
terms of sections 15 and 16 of this License; or
|
| 355 |
+
|
| 356 |
+
b) Requiring preservation of specified reasonable legal notices or
|
| 357 |
+
author attributions in that material or in the Appropriate Legal
|
| 358 |
+
Notices displayed by works containing it; or
|
| 359 |
+
|
| 360 |
+
c) Prohibiting misrepresentation of the origin of that material, or
|
| 361 |
+
requiring that modified versions of such material be marked in
|
| 362 |
+
reasonable ways as different from the original version; or
|
| 363 |
+
|
| 364 |
+
d) Limiting the use for publicity purposes of names of licensors or
|
| 365 |
+
authors of the material; or
|
| 366 |
+
|
| 367 |
+
e) Declining to grant rights under trademark law for use of some
|
| 368 |
+
trade names, trademarks, or service marks; or
|
| 369 |
+
|
| 370 |
+
f) Requiring indemnification of licensors and authors of that
|
| 371 |
+
material by anyone who conveys the material (or modified versions of
|
| 372 |
+
it) with contractual assumptions of liability to the recipient, for
|
| 373 |
+
any liability that these contractual assumptions directly impose on
|
| 374 |
+
those licensors and authors.
|
| 375 |
+
|
| 376 |
+
All other non-permissive additional terms are considered "further
|
| 377 |
+
restrictions" within the meaning of section 10. If the Program as you
|
| 378 |
+
received it, or any part of it, contains a notice stating that it is
|
| 379 |
+
governed by this License along with a term that is a further
|
| 380 |
+
restriction, you may remove that term. If a license document contains
|
| 381 |
+
a further restriction but permits relicensing or conveying under this
|
| 382 |
+
License, you may add to a covered work material governed by the terms
|
| 383 |
+
of that license document, provided that the further restriction does
|
| 384 |
+
not survive such relicensing or conveying.
|
| 385 |
+
|
| 386 |
+
If you add terms to a covered work in accord with this section, you
|
| 387 |
+
must place, in the relevant source files, a statement of the
|
| 388 |
+
additional terms that apply to those files, or a notice indicating
|
| 389 |
+
where to find the applicable terms.
|
| 390 |
+
|
| 391 |
+
Additional terms, permissive or non-permissive, may be stated in the
|
| 392 |
+
form of a separately written license, or stated as exceptions;
|
| 393 |
+
the above requirements apply either way.
|
| 394 |
+
|
| 395 |
+
8. Termination.
|
| 396 |
+
|
| 397 |
+
You may not propagate or modify a covered work except as expressly
|
| 398 |
+
provided under this License. Any attempt otherwise to propagate or
|
| 399 |
+
modify it is void, and will automatically terminate your rights under
|
| 400 |
+
this License (including any patent licenses granted under the third
|
| 401 |
+
paragraph of section 11).
|
| 402 |
+
|
| 403 |
+
However, if you cease all violation of this License, then your
|
| 404 |
+
license from a particular copyright holder is reinstated (a)
|
| 405 |
+
provisionally, unless and until the copyright holder explicitly and
|
| 406 |
+
finally terminates your license, and (b) permanently, if the copyright
|
| 407 |
+
holder fails to notify you of the violation by some reasonable means
|
| 408 |
+
prior to 60 days after the cessation.
|
| 409 |
+
|
| 410 |
+
Moreover, your license from a particular copyright holder is
|
| 411 |
+
reinstated permanently if the copyright holder notifies you of the
|
| 412 |
+
violation by some reasonable means, this is the first time you have
|
| 413 |
+
received notice of violation of this License (for any work) from that
|
| 414 |
+
copyright holder, and you cure the violation prior to 30 days after
|
| 415 |
+
your receipt of the notice.
|
| 416 |
+
|
| 417 |
+
Termination of your rights under this section does not terminate the
|
| 418 |
+
licenses of parties who have received copies or rights from you under
|
| 419 |
+
this License. If your rights have been terminated and not permanently
|
| 420 |
+
reinstated, you do not qualify to receive new licenses for the same
|
| 421 |
+
material under section 10.
|
| 422 |
+
|
| 423 |
+
9. Acceptance Not Required for Having Copies.
|
| 424 |
+
|
| 425 |
+
You are not required to accept this License in order to receive or
|
| 426 |
+
run a copy of the Program. Ancillary propagation of a covered work
|
| 427 |
+
occurring solely as a consequence of using peer-to-peer transmission
|
| 428 |
+
to receive a copy likewise does not require acceptance. However,
|
| 429 |
+
nothing other than this License grants you permission to propagate or
|
| 430 |
+
modify any covered work. These actions infringe copyright if you do
|
| 431 |
+
not accept this License. Therefore, by modifying or propagating a
|
| 432 |
+
covered work, you indicate your acceptance of this License to do so.
|
| 433 |
+
|
| 434 |
+
10. Automatic Licensing of Downstream Recipients.
|
| 435 |
+
|
| 436 |
+
Each time you convey a covered work, the recipient automatically
|
| 437 |
+
receives a license from the original licensors, to run, modify and
|
| 438 |
+
propagate that work, subject to this License. You are not responsible
|
| 439 |
+
for enforcing compliance by third parties with this License.
|
| 440 |
+
|
| 441 |
+
An "entity transaction" is a transaction transferring control of an
|
| 442 |
+
organization, or substantially all assets of one, or subdividing an
|
| 443 |
+
organization, or merging organizations. If propagation of a covered
|
| 444 |
+
work results from an entity transaction, each party to that
|
| 445 |
+
transaction who receives a copy of the work also receives whatever
|
| 446 |
+
licenses to the work the party's predecessor in interest had or could
|
| 447 |
+
give under the previous paragraph, plus a right to possession of the
|
| 448 |
+
Corresponding Source of the work from the predecessor in interest, if
|
| 449 |
+
the predecessor has it or can get it with reasonable efforts.
|
| 450 |
+
|
| 451 |
+
You may not impose any further restrictions on the exercise of the
|
| 452 |
+
rights granted or affirmed under this License. For example, you may
|
| 453 |
+
not impose a license fee, royalty, or other charge for exercise of
|
| 454 |
+
rights granted under this License, and you may not initiate litigation
|
| 455 |
+
(including a cross-claim or counterclaim in a lawsuit) alleging that
|
| 456 |
+
any patent claim is infringed by making, using, selling, offering for
|
| 457 |
+
sale, or importing the Program or any portion of it.
|
| 458 |
+
|
| 459 |
+
11. Patents.
|
| 460 |
+
|
| 461 |
+
A "contributor" is a copyright holder who authorizes use under this
|
| 462 |
+
License of the Program or a work on which the Program is based. The
|
| 463 |
+
work thus licensed is called the contributor's "contributor version".
|
| 464 |
+
|
| 465 |
+
A contributor's "essential patent claims" are all patent claims
|
| 466 |
+
owned or controlled by the contributor, whether already acquired or
|
| 467 |
+
hereafter acquired, that would be infringed by some manner, permitted
|
| 468 |
+
by this License, of making, using, or selling its contributor version,
|
| 469 |
+
but do not include claims that would be infringed only as a
|
| 470 |
+
consequence of further modification of the contributor version. For
|
| 471 |
+
purposes of this definition, "control" includes the right to grant
|
| 472 |
+
patent sublicenses in a manner consistent with the requirements of
|
| 473 |
+
this License.
|
| 474 |
+
|
| 475 |
+
Each contributor grants you a non-exclusive, worldwide, royalty-free
|
| 476 |
+
patent license under the contributor's essential patent claims, to
|
| 477 |
+
make, use, sell, offer for sale, import and otherwise run, modify and
|
| 478 |
+
propagate the contents of its contributor version.
|
| 479 |
+
|
| 480 |
+
In the following three paragraphs, a "patent license" is any express
|
| 481 |
+
agreement or commitment, however denominated, not to enforce a patent
|
| 482 |
+
(such as an express permission to practice a patent or covenant not to
|
| 483 |
+
sue for patent infringement). To "grant" such a patent license to a
|
| 484 |
+
party means to make such an agreement or commitment not to enforce a
|
| 485 |
+
patent against the party.
|
| 486 |
+
|
| 487 |
+
If you convey a covered work, knowingly relying on a patent license,
|
| 488 |
+
and the Corresponding Source of the work is not available for anyone
|
| 489 |
+
to copy, free of charge and under the terms of this License, through a
|
| 490 |
+
publicly available network server or other readily accessible means,
|
| 491 |
+
then you must either (1) cause the Corresponding Source to be so
|
| 492 |
+
available, or (2) arrange to deprive yourself of the benefit of the
|
| 493 |
+
patent license for this particular work, or (3) arrange, in a manner
|
| 494 |
+
consistent with the requirements of this License, to extend the patent
|
| 495 |
+
license to downstream recipients. "Knowingly relying" means you have
|
| 496 |
+
actual knowledge that, but for the patent license, your conveying the
|
| 497 |
+
covered work in a country, or your recipient's use of the covered work
|
| 498 |
+
in a country, would infringe one or more identifiable patents in that
|
| 499 |
+
country that you have reason to believe are valid.
|
| 500 |
+
|
| 501 |
+
If, pursuant to or in connection with a single transaction or
|
| 502 |
+
arrangement, you convey, or propagate by procuring conveyance of, a
|
| 503 |
+
covered work, and grant a patent license to some of the parties
|
| 504 |
+
receiving the covered work authorizing them to use, propagate, modify
|
| 505 |
+
or convey a specific copy of the covered work, then the patent license
|
| 506 |
+
you grant is automatically extended to all recipients of the covered
|
| 507 |
+
work and works based on it.
|
| 508 |
+
|
| 509 |
+
A patent license is "discriminatory" if it does not include within
|
| 510 |
+
the scope of its coverage, prohibits the exercise of, or is
|
| 511 |
+
conditioned on the non-exercise of one or more of the rights that are
|
| 512 |
+
specifically granted under this License. You may not convey a covered
|
| 513 |
+
work if you are a party to an arrangement with a third party that is
|
| 514 |
+
in the business of distributing software, under which you make payment
|
| 515 |
+
to the third party based on the extent of your activity of conveying
|
| 516 |
+
the work, and under which the third party grants, to any of the
|
| 517 |
+
parties who would receive the covered work from you, a discriminatory
|
| 518 |
+
patent license (a) in connection with copies of the covered work
|
| 519 |
+
conveyed by you (or copies made from those copies), or (b) primarily
|
| 520 |
+
for and in connection with specific products or compilations that
|
| 521 |
+
contain the covered work, unless you entered into that arrangement,
|
| 522 |
+
or that patent license was granted, prior to 28 March 2007.
|
| 523 |
+
|
| 524 |
+
Nothing in this License shall be construed as excluding or limiting
|
| 525 |
+
any implied license or other defenses to infringement that may
|
| 526 |
+
otherwise be available to you under applicable patent law.
|
| 527 |
+
|
| 528 |
+
12. No Surrender of Others' Freedom.
|
| 529 |
+
|
| 530 |
+
If conditions are imposed on you (whether by court order, agreement or
|
| 531 |
+
otherwise) that contradict the conditions of this License, they do not
|
| 532 |
+
excuse you from the conditions of this License. If you cannot convey a
|
| 533 |
+
covered work so as to satisfy simultaneously your obligations under this
|
| 534 |
+
License and any other pertinent obligations, then as a consequence you may
|
| 535 |
+
not convey it at all. For example, if you agree to terms that obligate you
|
| 536 |
+
to collect a royalty for further conveying from those to whom you convey
|
| 537 |
+
the Program, the only way you could satisfy both those terms and this
|
| 538 |
+
License would be to refrain entirely from conveying the Program.
|
| 539 |
+
|
| 540 |
+
13. Remote Network Interaction; Use with the GNU General Public License.
|
| 541 |
+
|
| 542 |
+
Notwithstanding any other provision of this License, if you modify the
|
| 543 |
+
Program, your modified version must prominently offer all users
|
| 544 |
+
interacting with it remotely through a computer network (if your version
|
| 545 |
+
supports such interaction) an opportunity to receive the Corresponding
|
| 546 |
+
Source of your version by providing access to the Corresponding Source
|
| 547 |
+
from a network server at no charge, through some standard or customary
|
| 548 |
+
means of facilitating copying of software. This Corresponding Source
|
| 549 |
+
shall include the Corresponding Source for any work covered by version 3
|
| 550 |
+
of the GNU General Public License that is incorporated pursuant to the
|
| 551 |
+
following paragraph.
|
| 552 |
+
|
| 553 |
+
Notwithstanding any other provision of this License, you have
|
| 554 |
+
permission to link or combine any covered work with a work licensed
|
| 555 |
+
under version 3 of the GNU General Public License into a single
|
| 556 |
+
combined work, and to convey the resulting work. The terms of this
|
| 557 |
+
License will continue to apply to the part which is the covered work,
|
| 558 |
+
but the work with which it is combined will remain governed by version
|
| 559 |
+
3 of the GNU General Public License.
|
| 560 |
+
|
| 561 |
+
14. Revised Versions of this License.
|
| 562 |
+
|
| 563 |
+
The Free Software Foundation may publish revised and/or new versions of
|
| 564 |
+
the GNU Affero General Public License from time to time. Such new versions
|
| 565 |
+
will be similar in spirit to the present version, but may differ in detail to
|
| 566 |
+
address new problems or concerns.
|
| 567 |
+
|
| 568 |
+
Each version is given a distinguishing version number. If the
|
| 569 |
+
Program specifies that a certain numbered version of the GNU Affero General
|
| 570 |
+
Public License "or any later version" applies to it, you have the
|
| 571 |
+
option of following the terms and conditions either of that numbered
|
| 572 |
+
version or of any later version published by the Free Software
|
| 573 |
+
Foundation. If the Program does not specify a version number of the
|
| 574 |
+
GNU Affero General Public License, you may choose any version ever published
|
| 575 |
+
by the Free Software Foundation.
|
| 576 |
+
|
| 577 |
+
If the Program specifies that a proxy can decide which future
|
| 578 |
+
versions of the GNU Affero General Public License can be used, that proxy's
|
| 579 |
+
public statement of acceptance of a version permanently authorizes you
|
| 580 |
+
to choose that version for the Program.
|
| 581 |
+
|
| 582 |
+
Later license versions may give you additional or different
|
| 583 |
+
permissions. However, no additional obligations are imposed on any
|
| 584 |
+
author or copyright holder as a result of your choosing to follow a
|
| 585 |
+
later version.
|
| 586 |
+
|
| 587 |
+
15. Disclaimer of Warranty.
|
| 588 |
+
|
| 589 |
+
THERE IS NO WARRANTY FOR THE PROGRAM, TO THE EXTENT PERMITTED BY
|
| 590 |
+
APPLICABLE LAW. EXCEPT WHEN OTHERWISE STATED IN WRITING THE COPYRIGHT
|
| 591 |
+
HOLDERS AND/OR OTHER PARTIES PROVIDE THE PROGRAM "AS IS" WITHOUT WARRANTY
|
| 592 |
+
OF ANY KIND, EITHER EXPRESSED OR IMPLIED, INCLUDING, BUT NOT LIMITED TO,
|
| 593 |
+
THE IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR
|
| 594 |
+
PURPOSE. THE ENTIRE RISK AS TO THE QUALITY AND PERFORMANCE OF THE PROGRAM
|
| 595 |
+
IS WITH YOU. SHOULD THE PROGRAM PROVE DEFECTIVE, YOU ASSUME THE COST OF
|
| 596 |
+
ALL NECESSARY SERVICING, REPAIR OR CORRECTION.
|
| 597 |
+
|
| 598 |
+
16. Limitation of Liability.
|
| 599 |
+
|
| 600 |
+
IN NO EVENT UNLESS REQUIRED BY APPLICABLE LAW OR AGREED TO IN WRITING
|
| 601 |
+
WILL ANY COPYRIGHT HOLDER, OR ANY OTHER PARTY WHO MODIFIES AND/OR CONVEYS
|
| 602 |
+
THE PROGRAM AS PERMITTED ABOVE, BE LIABLE TO YOU FOR DAMAGES, INCLUDING ANY
|
| 603 |
+
GENERAL, SPECIAL, INCIDENTAL OR CONSEQUENTIAL DAMAGES ARISING OUT OF THE
|
| 604 |
+
USE OR INABILITY TO USE THE PROGRAM (INCLUDING BUT NOT LIMITED TO LOSS OF
|
| 605 |
+
DATA OR DATA BEING RENDERED INACCURATE OR LOSSES SUSTAINED BY YOU OR THIRD
|
| 606 |
+
PARTIES OR A FAILURE OF THE PROGRAM TO OPERATE WITH ANY OTHER PROGRAMS),
|
| 607 |
+
EVEN IF SUCH HOLDER OR OTHER PARTY HAS BEEN ADVISED OF THE POSSIBILITY OF
|
| 608 |
+
SUCH DAMAGES.
|
| 609 |
+
|
| 610 |
+
17. Interpretation of Sections 15 and 16.
|
| 611 |
+
|
| 612 |
+
If the disclaimer of warranty and limitation of liability provided
|
| 613 |
+
above cannot be given local legal effect according to their terms,
|
| 614 |
+
reviewing courts shall apply local law that most closely approximates
|
| 615 |
+
an absolute waiver of all civil liability in connection with the
|
| 616 |
+
Program, unless a warranty or assumption of liability accompanies a
|
| 617 |
+
copy of the Program in return for a fee.
|
| 618 |
+
|
| 619 |
+
END OF TERMS AND CONDITIONS
|
| 620 |
+
|
| 621 |
+
How to Apply These Terms to Your New Programs
|
| 622 |
+
|
| 623 |
+
If you develop a new program, and you want it to be of the greatest
|
| 624 |
+
possible use to the public, the best way to achieve this is to make it
|
| 625 |
+
free software which everyone can redistribute and change under these terms.
|
| 626 |
+
|
| 627 |
+
To do so, attach the following notices to the program. It is safest
|
| 628 |
+
to attach them to the start of each source file to most effectively
|
| 629 |
+
state the exclusion of warranty; and each file should have at least
|
| 630 |
+
the "copyright" line and a pointer to where the full notice is found.
|
| 631 |
+
|
| 632 |
+
<one line to give the program's name and a brief idea of what it does.>
|
| 633 |
+
Copyright (C) <year> <name of author>
|
| 634 |
+
|
| 635 |
+
This program is free software: you can redistribute it and/or modify
|
| 636 |
+
it under the terms of the GNU Affero General Public License as published
|
| 637 |
+
by the Free Software Foundation, either version 3 of the License, or
|
| 638 |
+
(at your option) any later version.
|
| 639 |
+
|
| 640 |
+
This program is distributed in the hope that it will be useful,
|
| 641 |
+
but WITHOUT ANY WARRANTY; without even the implied warranty of
|
| 642 |
+
MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
|
| 643 |
+
GNU Affero General Public License for more details.
|
| 644 |
+
|
| 645 |
+
You should have received a copy of the GNU Affero General Public License
|
| 646 |
+
along with this program. If not, see <https://www.gnu.org/licenses/>.
|
| 647 |
+
|
| 648 |
+
Also add information on how to contact you by electronic and paper mail.
|
| 649 |
+
|
| 650 |
+
If your software can interact with users remotely through a computer
|
| 651 |
+
network, you should also make sure that it provides a way for users to
|
| 652 |
+
get its source. For example, if your program is a web application, its
|
| 653 |
+
interface could display a "Source" link that leads users to an archive
|
| 654 |
+
of the code. There are many ways you could offer source, and different
|
| 655 |
+
solutions will be better for different programs; see section 13 for the
|
| 656 |
+
specific requirements.
|
| 657 |
+
|
| 658 |
+
You should also get your employer (if you work as a programmer) or school,
|
| 659 |
+
if any, to sign a "copyright disclaimer" for the program, if necessary.
|
| 660 |
+
For more information on this, and how to apply and follow the GNU AGPL, see
|
| 661 |
+
<https://www.gnu.org/licenses/>.
|
README.md
CHANGED
|
@@ -1,12 +1,569 @@
|
|
| 1 |
-
|
| 2 |
-
|
| 3 |
-
|
| 4 |
-
|
| 5 |
-
|
| 6 |
-
|
| 7 |
-
|
| 8 |
-
|
| 9 |
-
|
| 10 |
-
|
| 11 |
-
|
| 12 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
<div align="center">
|
| 2 |
+
<img alt="LOGO" src="https://avatars.githubusercontent.com/u/127122328?s=400&u=5395a98a4f945a3a50cb0cc96c2747505d190dbc&v=4" width="300" height="300" />
|
| 3 |
+
|
| 4 |
+
# SoftVC VITS Singing Voice Conversion
|
| 5 |
+
|
| 6 |
+
[**English**](./README.md) | [**中文简体**](./README_zh_CN.md)
|
| 7 |
+
|
| 8 |
+
[](https://colab.research.google.com/github/svc-develop-team/so-vits-svc/blob/4.1-Stable/sovits4_for_colab.ipynb)
|
| 9 |
+
[](https://github.com/svc-develop-team/so-vits-svc/blob/4.1-Stable/LICENSE)
|
| 10 |
+
|
| 11 |
+
</div>
|
| 12 |
+
|
| 13 |
+
> ✨ A studio that contains visible f0 editor, speaker mix timeline editor and other features (Where the Onnx models are used) : [MoeVoiceStudio](https://github.com/NaruseMioShirakana/MoeVoiceStudio)
|
| 14 |
+
|
| 15 |
+
> ✨ A fork with a greatly improved user interface: [34j/so-vits-svc-fork](https://github.com/34j/so-vits-svc-fork)
|
| 16 |
+
|
| 17 |
+
> ✨ A client supports real-time conversion: [w-okada/voice-changer](https://github.com/w-okada/voice-changer)
|
| 18 |
+
|
| 19 |
+
**This project differs fundamentally from VITS, as it focuses on Singing Voice Conversion (SVC) rather than Text-to-Speech (TTS). In this project, TTS functionality is not supported, and VITS is incapable of performing SVC tasks. It's important to note that the models used in these two projects are not interchangeable or universally applicable.**
|
| 20 |
+
|
| 21 |
+
## Announcement
|
| 22 |
+
|
| 23 |
+
The purpose of this project was to enable developers to have their beloved anime characters perform singing tasks. The developers' intention was to focus solely on fictional characters and avoid any involvement of real individuals, anything related to real individuals deviates from the developer's original intention.
|
| 24 |
+
|
| 25 |
+
## Disclaimer
|
| 26 |
+
|
| 27 |
+
This project is an open-source, offline endeavor, and all members of SvcDevelopTeam, as well as other developers and maintainers involved (hereinafter referred to as contributors), have no control over the project. The contributors have never provided any form of assistance to any organization or individual, including but not limited to dataset extraction, dataset processing, computing support, training support, inference, and so on. The contributors do not and cannot be aware of the purposes for which users utilize the project. Therefore, any AI models and synthesized audio produced through the training of this project are unrelated to the contributors. Any issues or consequences arising from their use are the sole responsibility of the user.
|
| 28 |
+
|
| 29 |
+
This project is run completely offline and does not collect any user information or gather user input data. Therefore, contributors to this project are not aware of all user input and models and therefore are not responsible for any user input.
|
| 30 |
+
|
| 31 |
+
This project serves as a framework only and does not possess speech synthesis functionality by itself. All functionalities require users to train the models independently. Furthermore, this project does not come bundled with any models, and any secondary distributed projects are independent of the contributors of this project.
|
| 32 |
+
|
| 33 |
+
## 📏 Terms of Use
|
| 34 |
+
|
| 35 |
+
# Warning: Please ensure that you address any authorization issues related to the dataset on your own. You bear full responsibility for any problems arising from the usage of non-authorized datasets for training, as well as any resulting consequences. The repository and its maintainer, svc develop team, disclaim any association with or liability for the consequences.
|
| 36 |
+
|
| 37 |
+
1. This project is exclusively established for academic purposes, aiming to facilitate communication and learning. It is not intended for deployment in production environments.
|
| 38 |
+
2. Any sovits-based video posted to a video platform must clearly specify in the introduction the input source vocals and audio used for the voice changer conversion, e.g., if you use someone else's video/audio and convert it by separating the vocals as the input source, you must give a clear link to the original video or music; if you use your own vocals or a voice synthesized by another voice synthesis engine as the input source, you must also state this in your introduction.
|
| 39 |
+
3. You are solely responsible for any infringement issues caused by the input source and all consequences. When using other commercial vocal synthesis software as an input source, please ensure that you comply with the regulations of that software, noting that the regulations of many vocal synthesis engines explicitly state that they cannot be used to convert input sources!
|
| 40 |
+
4. Engaging in illegal activities, as well as religious and political activities, is strictly prohibited when using this project. The project developers vehemently oppose the aforementioned activities. If you disagree with this provision, the usage of the project is prohibited.
|
| 41 |
+
5. If you continue to use the program, you will be deemed to have agreed to the terms and conditions set forth in README and README has discouraged you and is not responsible for any subsequent problems.
|
| 42 |
+
6. If you intend to employ this project for any other purposes, kindly contact and inform the maintainers of this repository in advance.
|
| 43 |
+
|
| 44 |
+
## 📝 Model Introduction
|
| 45 |
+
|
| 46 |
+
The singing voice conversion model uses SoftVC content encoder to extract speech features from the source audio. These feature vectors are directly fed into VITS without the need for conversion to a text-based intermediate representation. As a result, the pitch and intonations of the original audio are preserved. Meanwhile, the vocoder was replaced with [NSF HiFiGAN](https://github.com/openvpi/DiffSinger/tree/refactor/modules/nsf_hifigan) to solve the problem of sound interruption.
|
| 47 |
+
|
| 48 |
+
### 🆕 4.1-Stable Version Update Content
|
| 49 |
+
|
| 50 |
+
- Feature input is changed to the 12th Layer of [Content Vec](https://github.com/auspicious3000/contentvec) Transformer output, And compatible with 4.0 branches.
|
| 51 |
+
- Update the shallow diffusion, you can use the shallow diffusion model to improve the sound quality.
|
| 52 |
+
- Added Whisper-PPG encoder support
|
| 53 |
+
- Added static/dynamic sound fusion
|
| 54 |
+
- Added loudness embedding
|
| 55 |
+
- Added Functionality of feature retrieval from [RVC](https://github.com/RVC-Project/Retrieval-based-Voice-Conversion-WebUI)
|
| 56 |
+
|
| 57 |
+
### 🆕 Questions about compatibility with the 4.0 model
|
| 58 |
+
|
| 59 |
+
- To support the 4.0 model and incorporate the speech encoder, you can make modifications to the `config.json` file. Add the `speech_encoder` field to the "model" section as shown below:
|
| 60 |
+
|
| 61 |
+
```
|
| 62 |
+
"model": {
|
| 63 |
+
.........
|
| 64 |
+
"ssl_dim": 256,
|
| 65 |
+
"n_speakers": 200,
|
| 66 |
+
"speech_encoder":"vec256l9"
|
| 67 |
+
}
|
| 68 |
+
```
|
| 69 |
+
|
| 70 |
+
### 🆕 Shallow diffusion
|
| 71 |
+

|
| 72 |
+
|
| 73 |
+
## 💬 Python Version
|
| 74 |
+
|
| 75 |
+
Based on our testing, we have determined that the project runs stable on `Python 3.8.9`.
|
| 76 |
+
|
| 77 |
+
## 📥 Pre-trained Model Files
|
| 78 |
+
|
| 79 |
+
#### **Required**
|
| 80 |
+
|
| 81 |
+
**You need to select one encoder from the list below**
|
| 82 |
+
|
| 83 |
+
##### **1. If using contentvec as speech encoder(recommended)**
|
| 84 |
+
|
| 85 |
+
`vec768l12` and `vec256l9` require the encoder
|
| 86 |
+
|
| 87 |
+
- ContentVec: [checkpoint_best_legacy_500.pt](https://ibm.box.com/s/z1wgl1stco8ffooyatzdwsqn2psd9lrr)
|
| 88 |
+
- Place it under the `pretrain` directory
|
| 89 |
+
|
| 90 |
+
Or download the following ContentVec, which is only 199MB in size but has the same effect:
|
| 91 |
+
- ContentVec: [hubert_base.pt](https://huggingface.co/lj1995/VoiceConversionWebUI/resolve/main/hubert_base.pt)
|
| 92 |
+
- Change the file name to `checkpoint_best_legacy_500.pt` and place it in the `pretrain` directory
|
| 93 |
+
|
| 94 |
+
```shell
|
| 95 |
+
# contentvec
|
| 96 |
+
wget -P pretrain/ https://huggingface.co/lj1995/VoiceConversionWebUI/resolve/main/hubert_base.pt -O checkpoint_best_legacy_500.pt
|
| 97 |
+
# Alternatively, you can manually download and place it in the hubert directory
|
| 98 |
+
```
|
| 99 |
+
|
| 100 |
+
##### **2. If hubertsoft is used as the speech encoder**
|
| 101 |
+
- soft vc hubert: [hubert-soft-0d54a1f4.pt](https://github.com/bshall/hubert/releases/download/v0.1/hubert-soft-0d54a1f4.pt)
|
| 102 |
+
- Place it under the `pretrain` directory
|
| 103 |
+
|
| 104 |
+
##### **3. If whisper-ppg as the encoder**
|
| 105 |
+
- download model at [medium.pt](https://openaipublic.azureedge.net/main/whisper/models/345ae4da62f9b3d59415adc60127b97c714f32e89e936602e85993674d08dcb1/medium.pt), the model fits `whisper-ppg`
|
| 106 |
+
- or download model at [large-v2.pt](https://openaipublic.azureedge.net/main/whisper/models/81f7c96c852ee8fc832187b0132e569d6c3065a3252ed18e56effd0b6a73e524/large-v2.pt), the model fits `whisper-ppg-large`
|
| 107 |
+
- Place it under the `pretrain` directory
|
| 108 |
+
|
| 109 |
+
##### **4. If cnhubertlarge as the encoder**
|
| 110 |
+
- download model at [chinese-hubert-large-fairseq-ckpt.pt](https://huggingface.co/TencentGameMate/chinese-hubert-large/resolve/main/chinese-hubert-large-fairseq-ckpt.pt)
|
| 111 |
+
- Place it under the `pretrain` directory
|
| 112 |
+
|
| 113 |
+
##### **5. If dphubert as the encoder**
|
| 114 |
+
- download model at [DPHuBERT-sp0.75.pth](https://huggingface.co/pyf98/DPHuBERT/resolve/main/DPHuBERT-sp0.75.pth)
|
| 115 |
+
- Place it under the `pretrain` directory
|
| 116 |
+
|
| 117 |
+
##### **6. If WavLM is used as the encoder**
|
| 118 |
+
- download model at [WavLM-Base+.pt](https://valle.blob.core.windows.net/share/wavlm/WavLM-Base+.pt?sv=2020-08-04&st=2023-03-01T07%3A51%3A05Z&se=2033-03-02T07%3A51%3A00Z&sr=c&sp=rl&sig=QJXmSJG9DbMKf48UDIU1MfzIro8HQOf3sqlNXiflY1I%3D), the model fits `wavlmbase+`
|
| 119 |
+
- Place it under the `pretrain` directory
|
| 120 |
+
|
| 121 |
+
##### **7. If OnnxHubert/ContentVec as the encoder**
|
| 122 |
+
- download model at [MoeSS-SUBModel](https://huggingface.co/NaruseMioShirakana/MoeSS-SUBModel/tree/main)
|
| 123 |
+
- Place it under the `pretrain` directory
|
| 124 |
+
|
| 125 |
+
#### **List of Encoders**
|
| 126 |
+
- "vec768l12"
|
| 127 |
+
- "vec256l9"
|
| 128 |
+
- "vec256l9-onnx"
|
| 129 |
+
- "vec256l12-onnx"
|
| 130 |
+
- "vec768l9-onnx"
|
| 131 |
+
- "vec768l12-onnx"
|
| 132 |
+
- "hubertsoft-onnx"
|
| 133 |
+
- "hubertsoft"
|
| 134 |
+
- "whisper-ppg"
|
| 135 |
+
- "cnhubertlarge"
|
| 136 |
+
- "dphubert"
|
| 137 |
+
- "whisper-ppg-large"
|
| 138 |
+
- "wavlmbase+"
|
| 139 |
+
|
| 140 |
+
#### **Optional(Strongly recommend)**
|
| 141 |
+
|
| 142 |
+
- Pre-trained model files: `G_0.pth` `D_0.pth`
|
| 143 |
+
- Place them under the `logs/44k` directory
|
| 144 |
+
|
| 145 |
+
- Diffusion model pretraining base model file: `model_0.pt`
|
| 146 |
+
- Put it in the `logs/44k/diffusion` directory
|
| 147 |
+
|
| 148 |
+
Get Sovits Pre-trained model from svc-develop-team(TBD) or anywhere else.
|
| 149 |
+
|
| 150 |
+
Diffusion model references [Diffusion-SVC](https://github.com/CNChTu/Diffusion-SVC) diffusion model. The pre-trained diffusion model is universal with the DDSP-SVC's. You can go to [Diffusion-SVC](https://github.com/CNChTu/Diffusion-SVC)'s repo to get the pre-trained diffusion model.
|
| 151 |
+
|
| 152 |
+
While the pretrained model typically does not pose copyright concerns, it is essential to remain vigilant. It is advisable to consult with the author beforehand or carefully review the description to ascertain the permissible usage of the model. This helps ensure compliance with any specified guidelines or restrictions regarding its utilization.
|
| 153 |
+
|
| 154 |
+
#### **Optional(Select as Required)**
|
| 155 |
+
|
| 156 |
+
##### NSF-HIFIGAN
|
| 157 |
+
|
| 158 |
+
If you are using the `NSF-HIFIGAN enhancer` or `shallow diffusion`, you will need to download the pre-trained NSF-HIFIGAN model.
|
| 159 |
+
|
| 160 |
+
- Pre-trained NSF-HIFIGAN Vocoder: [nsf_hifigan_20221211.zip](https://github.com/openvpi/vocoders/releases/download/nsf-hifigan-v1/nsf_hifigan_20221211.zip)
|
| 161 |
+
- Unzip and place the four files under the `pretrain/nsf_hifigan` directory
|
| 162 |
+
|
| 163 |
+
```shell
|
| 164 |
+
# nsf_hifigan
|
| 165 |
+
wget -P pretrain/ https://github.com/openvpi/vocoders/releases/download/nsf-hifigan-v1/nsf_hifigan_20221211.zip
|
| 166 |
+
unzip -od pretrain/nsf_hifigan pretrain/nsf_hifigan_20221211.zip
|
| 167 |
+
# Alternatively, you can manually download and place it in the pretrain/nsf_hifigan directory
|
| 168 |
+
# URL: https://github.com/openvpi/vocoders/releases/tag/nsf-hifigan-v1
|
| 169 |
+
```
|
| 170 |
+
|
| 171 |
+
##### RMVPE
|
| 172 |
+
|
| 173 |
+
If you are using the `rmvpe` F0 Predictor, you will need to download the pre-trained RMVPE model.
|
| 174 |
+
|
| 175 |
+
- download model at [rmvpe.pt](https://huggingface.co/datasets/ylzz1997/rmvpe_pretrain_model/resolve/main/rmvpe.pt)
|
| 176 |
+
- Place it under the `pretrain` directory
|
| 177 |
+
|
| 178 |
+
##### FCPE(Preview version)
|
| 179 |
+
|
| 180 |
+
[FCPE(Fast Context-base Pitch Estimator)](https://github.com/CNChTu/MelPE) is a dedicated F0 predictor designed for real-time voice conversion and will become the preferred F0 predictor for sovits real-time voice conversion in the future.(The paper is being written)
|
| 181 |
+
|
| 182 |
+
If you are using the `fcpe` F0 Predictor, you will need to download the pre-trained FCPE model.
|
| 183 |
+
|
| 184 |
+
- download model at [fcpe.pt](https://huggingface.co/datasets/ylzz1997/rmvpe_pretrain_model/resolve/main/fcpe.pt)
|
| 185 |
+
- Place it under the `pretrain` directory
|
| 186 |
+
|
| 187 |
+
## 📊 Dataset Preparation
|
| 188 |
+
|
| 189 |
+
Simply place the dataset in the `dataset_raw` directory with the following file structure:
|
| 190 |
+
|
| 191 |
+
```
|
| 192 |
+
dataset_raw
|
| 193 |
+
├───speaker0
|
| 194 |
+
│ ├───xxx1-xxx1.wav
|
| 195 |
+
│ ├───...
|
| 196 |
+
│ └───Lxx-0xx8.wav
|
| 197 |
+
└───speaker1
|
| 198 |
+
├───xx2-0xxx2.wav
|
| 199 |
+
├───...
|
| 200 |
+
└───xxx7-xxx007.wav
|
| 201 |
+
```
|
| 202 |
+
There are no specific restrictions on the format of the name for each audio file (naming conventions such as `000001.wav` to `999999.wav` are also valid), but the file type must be `WAV``.
|
| 203 |
+
|
| 204 |
+
You can customize the speaker's name as showed below:
|
| 205 |
+
|
| 206 |
+
```
|
| 207 |
+
dataset_raw
|
| 208 |
+
└───suijiSUI
|
| 209 |
+
├───1.wav
|
| 210 |
+
├───...
|
| 211 |
+
└───25788785-20221210-200143-856_01_(Vocals)_0_0.wav
|
| 212 |
+
```
|
| 213 |
+
|
| 214 |
+
## 🛠️ Preprocessing
|
| 215 |
+
|
| 216 |
+
### 0. Slice audio
|
| 217 |
+
|
| 218 |
+
To avoid video memory overflow during training or pre-processing, it is recommended to limit the length of audio clips. Cutting the audio to a length of "5s - 15s" is more recommended. Slightly longer times are acceptable, however, excessively long clips may cause problems such as `torch.cuda.OutOfMemoryError`.
|
| 219 |
+
|
| 220 |
+
To facilitate the slicing process, you can use [audio-slicer-GUI](https://github.com/flutydeer/audio-slicer) or [audio-slicer-CLI](https://github.com/openvpi/audio-slicer)
|
| 221 |
+
|
| 222 |
+
In general, only the `Minimum Interval` needs to be adjusted. For spoken audio, the default value usually suffices, while for singing audio, it can be adjusted to around `100` or even `50`, depending on the specific requirements.
|
| 223 |
+
|
| 224 |
+
After slicing, it is recommended to remove any audio clips that are excessively long or too short.
|
| 225 |
+
|
| 226 |
+
**If you are using whisper-ppg encoder for training, the audio clips must shorter than 30s.**
|
| 227 |
+
|
| 228 |
+
### 1. Resample to 44100Hz and mono
|
| 229 |
+
|
| 230 |
+
```shell
|
| 231 |
+
python resample.py
|
| 232 |
+
```
|
| 233 |
+
|
| 234 |
+
#### Cautions
|
| 235 |
+
|
| 236 |
+
Although this project has resample.py scripts for resampling, mono and loudness matching, the default loudness matching is to match to 0db. This can cause damage to the sound quality. While python's loudness matching package pyloudnorm does not limit the level, this can lead to sonic boom. Therefore, it is recommended to consider using professional sound processing software, such as `adobe audition` for loudness matching. If you are already using other software for loudness matching, add the parameter `-skip_loudnorm` to the run command:
|
| 237 |
+
|
| 238 |
+
```shell
|
| 239 |
+
python resample.py --skip_loudnorm
|
| 240 |
+
```
|
| 241 |
+
|
| 242 |
+
### 2. Automatically split the dataset into training and validation sets, and generate configuration files.
|
| 243 |
+
|
| 244 |
+
```shell
|
| 245 |
+
python preprocess_flist_config.py --speech_encoder vec768l12
|
| 246 |
+
```
|
| 247 |
+
|
| 248 |
+
speech_encoder has the following options
|
| 249 |
+
|
| 250 |
+
```
|
| 251 |
+
vec768l12
|
| 252 |
+
vec256l9
|
| 253 |
+
hubertsoft
|
| 254 |
+
whisper-ppg
|
| 255 |
+
cnhubertlarge
|
| 256 |
+
dphubert
|
| 257 |
+
whisper-ppg-large
|
| 258 |
+
wavlmbase+
|
| 259 |
+
```
|
| 260 |
+
|
| 261 |
+
If the speech_encoder argument is omitted, the default value is `vec768l12`
|
| 262 |
+
|
| 263 |
+
**Use loudness embedding**
|
| 264 |
+
|
| 265 |
+
Add `--vol_aug` if you want to enable loudness embedding:
|
| 266 |
+
|
| 267 |
+
```shell
|
| 268 |
+
python preprocess_flist_config.py --speech_encoder vec768l12 --vol_aug
|
| 269 |
+
```
|
| 270 |
+
|
| 271 |
+
After enabling loudness embedding, the trained model will match the loudness of the input source; otherwise, it will match the loudness of the training set.
|
| 272 |
+
|
| 273 |
+
#### You can modify some parameters in the generated config.json and diffusion.yaml
|
| 274 |
+
|
| 275 |
+
* `keep_ckpts`: Keep the the the number of previous models during training. Set to `0` to keep them all. Default is `3`.
|
| 276 |
+
|
| 277 |
+
* `all_in_mem`: Load all dataset to RAM. It can be enabled when the disk IO of some platforms is too low and the system memory is **much larger** than your dataset.
|
| 278 |
+
|
| 279 |
+
* `batch_size`: The amount of data loaded to the GPU for a single training session can be adjusted to a size lower than the GPU memory capacity.
|
| 280 |
+
|
| 281 |
+
* `vocoder_name`: Select a vocoder. The default is `nsf-hifigan`.
|
| 282 |
+
|
| 283 |
+
##### diffusion.yaml
|
| 284 |
+
|
| 285 |
+
* `cache_all_data`: Load all dataset to RAM. It can be enabled when the disk IO of some platforms is too low and the system memory is **much larger** than your dataset.
|
| 286 |
+
|
| 287 |
+
* `duration`: The duration of the audio slicing during training, can be adjusted according to the size of the video memory, **Note: this value must be less than the minimum time of the audio in the training set!**
|
| 288 |
+
|
| 289 |
+
* `batch_size`: The amount of data loaded to the GPU for a single training session can be adjusted to a size lower than the video memory capacity.
|
| 290 |
+
|
| 291 |
+
* `timesteps`: The total number of steps in the diffusion model, which defaults to 1000.
|
| 292 |
+
|
| 293 |
+
* `k_step_max`: Training can only train `k_step_max` step diffusion to save training time, note that the value must be less than `timesteps`, 0 is to train the entire diffusion model, **Note: if you do not train the entire diffusion model will not be able to use only_diffusion!**
|
| 294 |
+
|
| 295 |
+
##### **List of Vocoders**
|
| 296 |
+
|
| 297 |
+
```
|
| 298 |
+
nsf-hifigan
|
| 299 |
+
nsf-snake-hifigan
|
| 300 |
+
```
|
| 301 |
+
|
| 302 |
+
### 3. Generate hubert and f0
|
| 303 |
+
|
| 304 |
+
```shell
|
| 305 |
+
python preprocess_hubert_f0.py --f0_predictor dio
|
| 306 |
+
```
|
| 307 |
+
|
| 308 |
+
f0_predictor has the following options
|
| 309 |
+
|
| 310 |
+
```
|
| 311 |
+
crepe
|
| 312 |
+
dio
|
| 313 |
+
pm
|
| 314 |
+
harvest
|
| 315 |
+
rmvpe
|
| 316 |
+
fcpe
|
| 317 |
+
```
|
| 318 |
+
|
| 319 |
+
If the training set is too noisy,it is recommended to use `crepe` to handle f0
|
| 320 |
+
|
| 321 |
+
If the f0_predictor parameter is omitted, the default value is `dio`
|
| 322 |
+
|
| 323 |
+
If you want shallow diffusion (optional), you need to add the `--use_diff` parameter, for example:
|
| 324 |
+
|
| 325 |
+
```shell
|
| 326 |
+
python preprocess_hubert_f0.py --f0_predictor dio --use_diff
|
| 327 |
+
```
|
| 328 |
+
|
| 329 |
+
**Speed Up preprocess**
|
| 330 |
+
|
| 331 |
+
If your dataset is pretty large,you can increase the param `--num_processes` like that:
|
| 332 |
+
|
| 333 |
+
```shell
|
| 334 |
+
python preprocess_hubert_f0.py --speech_encoder vec768l12 --vol_aug --num_processes 8
|
| 335 |
+
```
|
| 336 |
+
All the worker will be assigned to different GPU if you have more than one GPUs.
|
| 337 |
+
|
| 338 |
+
After completing the above steps, the dataset directory will contain the preprocessed data, and the dataset_raw folder can be deleted.
|
| 339 |
+
|
| 340 |
+
## 🏋️ Training
|
| 341 |
+
|
| 342 |
+
### Sovits Model
|
| 343 |
+
|
| 344 |
+
```shell
|
| 345 |
+
python train.py -c configs/config.json -m 44k
|
| 346 |
+
```
|
| 347 |
+
|
| 348 |
+
### Diffusion Model (optional)
|
| 349 |
+
|
| 350 |
+
If the shallow diffusion function is needed, the diffusion model needs to be trained. The diffusion model training method is as follows:
|
| 351 |
+
|
| 352 |
+
```shell
|
| 353 |
+
python train_diff.py -c configs/diffusion.yaml
|
| 354 |
+
```
|
| 355 |
+
|
| 356 |
+
During training, the model files will be saved to `logs/44k`, and the diffusion model will be saved to `logs/44k/diffusion`
|
| 357 |
+
|
| 358 |
+
## 🤖 Inference
|
| 359 |
+
|
| 360 |
+
Use [inference_main.py](https://github.com/svc-develop-team/so-vits-svc/blob/4.0/inference_main.py)
|
| 361 |
+
|
| 362 |
+
```shell
|
| 363 |
+
# Example
|
| 364 |
+
python inference_main.py -m "logs/44k/G_30400.pth" -c "configs/config.json" -n "君の知らない物語-src.wav" -t 0 -s "nen"
|
| 365 |
+
```
|
| 366 |
+
|
| 367 |
+
Required parameters:
|
| 368 |
+
- `-m` | `--model_path`: path to the model.
|
| 369 |
+
- `-c` | `--config_path`: path to the configuration file.
|
| 370 |
+
- `-n` | `--clean_names`: a list of wav file names located in the `raw` folder.
|
| 371 |
+
- `-t` | `--trans`: pitch shift, supports positive and negative (semitone) values.
|
| 372 |
+
- `-s` | `--spk_list`: Select the speaker ID to use for conversion.
|
| 373 |
+
- `-cl` | `--clip`: Forced audio clipping, set to 0 to disable(default), setting it to a non-zero value (duration in seconds) to enable.
|
| 374 |
+
|
| 375 |
+
Optional parameters: see the next section
|
| 376 |
+
- `-lg` | `--linear_gradient`: The cross fade length of two audio slices in seconds. If there is a discontinuous voice after forced slicing, you can adjust this value. Otherwise, it is recommended to use the default value of 0.
|
| 377 |
+
- `-f0p` | `--f0_predictor`: Select a F0 predictor, options are `crepe`, `pm`, `dio`, `harvest`, `rmvpe`,`fcpe`, default value is `pm`(note: f0 mean pooling will be enable when using `crepe`)
|
| 378 |
+
- `-a` | `--auto_predict_f0`: automatic pitch prediction, do not enable this when converting singing voices as it can cause serious pitch issues.
|
| 379 |
+
- `-cm` | `--cluster_model_path`: Cluster model or feature retrieval index path, if left blank, it will be automatically set as the default path of these models. If there is no training cluster or feature retrieval, fill in at will.
|
| 380 |
+
- `-cr` | `--cluster_infer_ratio`: The proportion of clustering scheme or feature retrieval ranges from 0 to 1. If there is no training clustering model or feature retrieval, the default is 0.
|
| 381 |
+
- `-eh` | `--enhance`: Whether to use NSF_HIFIGAN enhancer, this option has certain effect on sound quality enhancement for some models with few training sets, but has negative effect on well-trained models, so it is disabled by default.
|
| 382 |
+
- `-shd` | `--shallow_diffusion`: Whether to use shallow diffusion, which can solve some electrical sound problems after use. This option is disabled by default. When this option is enabled, NSF_HIFIGAN enhancer will be disabled
|
| 383 |
+
- `-usm` | `--use_spk_mix`: whether to use dynamic voice fusion
|
| 384 |
+
- `-lea` | `--loudness_envelope_adjustment`:The adjustment of the input source's loudness envelope in relation to the fusion ratio of the output loudness envelope. The closer to 1, the more the output loudness envelope is used
|
| 385 |
+
- `-fr` | `--feature_retrieval`:Whether to use feature retrieval If clustering model is used, it will be disabled, and `cm` and `cr` parameters will become the index path and mixing ratio of feature retrieval
|
| 386 |
+
|
| 387 |
+
Shallow diffusion settings:
|
| 388 |
+
- `-dm` | `--diffusion_model_path`: Diffusion model path
|
| 389 |
+
- `-dc` | `--diffusion_config_path`: Diffusion config file path
|
| 390 |
+
- `-ks` | `--k_step`: The larger the number of k_steps, the closer it is to the result of the diffusion model. The default is 100
|
| 391 |
+
- `-od` | `--only_diffusion`: Whether to use Only diffusion mode, which does not load the sovits model to only use diffusion model inference
|
| 392 |
+
- `-se` | `--second_encoding`:which involves applying an additional encoding to the original audio before shallow diffusion. This option can yield varying results - sometimes positive and sometimes negative.
|
| 393 |
+
|
| 394 |
+
### Cautions
|
| 395 |
+
|
| 396 |
+
If inferencing using `whisper-ppg` speech encoder, you need to set `--clip` to 25 and `-lg` to 1. Otherwise it will fail to infer properly.
|
| 397 |
+
|
| 398 |
+
## 🤔 Optional Settings
|
| 399 |
+
|
| 400 |
+
If you are satisfied with the previous results, or if you do not feel you understand what follows, you can skip it and it will have no effect on the use of the model. The impact of these optional settings mentioned is relatively small, and while they may have some impact on specific datasets, in most cases the difference may not be significant.
|
| 401 |
+
|
| 402 |
+
### Automatic f0 prediction
|
| 403 |
+
|
| 404 |
+
During the training of the 4.0 model, an f0 predictor is also trained, which enables automatic pitch prediction during voice conversion. However, if the results are not satisfactory, manual pitch prediction can be used instead. Please note that when converting singing voices, it is advised not to enable this feature as it may cause significant pitch shifting.
|
| 405 |
+
|
| 406 |
+
- Set `auto_predict_f0` to `true` in `inference_main.py`.
|
| 407 |
+
|
| 408 |
+
### Cluster-based timbre leakage control
|
| 409 |
+
|
| 410 |
+
Introduction: The clustering scheme implemented in this model aims to reduce timbre leakage and enhance the similarity of the trained model to the target's timbre, although the effect may not be very pronounced. However, relying solely on clustering can reduce the model's clarity and make it sound less distinct. Therefore, a fusion method is adopted in this model to control the balance between the clustering and non-clustering approaches. This allows manual adjustment of the trade-off between "sounding like the target's timbre" and "have clear enunciation" to find an optimal balance.
|
| 411 |
+
|
| 412 |
+
No changes are required in the existing steps. Simply train an additional clustering model, which incurs relatively low training costs.
|
| 413 |
+
|
| 414 |
+
- Training process:
|
| 415 |
+
- Train on a machine with good CPU performance. According to extant experience, it takes about 4 minutes to train each speaker on a Tencent Cloud machine with 6-core CPU.
|
| 416 |
+
- Execute `python cluster/train_cluster.py`. The output model will be saved in `logs/44k/kmeans_10000.pt`.
|
| 417 |
+
- The clustering model can currently be trained using the gpu by executing `python cluster/train_cluster.py --gpu`
|
| 418 |
+
- Inference process:
|
| 419 |
+
- Specify `cluster_model_path` in `inference_main.py`. If not specified, the default is `logs/44k/kmeans_10000.pt`.
|
| 420 |
+
- Specify `cluster_infer_ratio` in `inference_main.py`, where `0` means not using clustering at all, `1` means only using clustering, and usually `0.5` is sufficient.
|
| 421 |
+
|
| 422 |
+
### Feature retrieval
|
| 423 |
+
|
| 424 |
+
Introduction: As with the clustering scheme, the timbre leakage can be reduced, the enunciation is slightly better than clustering, but it will reduce the inference speed. By employing the fusion method, it becomes possible to linearly control the balance between feature retrieval and non-feature retrieval, allowing for fine-tuning of the desired proportion.
|
| 425 |
+
|
| 426 |
+
- Training process:
|
| 427 |
+
First, it needs to be executed after generating hubert and f0:
|
| 428 |
+
|
| 429 |
+
```shell
|
| 430 |
+
python train_index.py -c configs/config.json
|
| 431 |
+
```
|
| 432 |
+
|
| 433 |
+
The output of the model will be in `logs/44k/feature_and_index.pkl`
|
| 434 |
+
|
| 435 |
+
- Inference process:
|
| 436 |
+
- The `--feature_retrieval` needs to be formulated first, and the clustering mode automatically switches to the feature retrieval mode.
|
| 437 |
+
- Specify `cluster_model_path` in `inference_main.py`. If not specified, the default is `logs/44k/feature_and_index.pkl`.
|
| 438 |
+
- Specify `cluster_infer_ratio` in `inference_main.py`, where `0` means not using feature retrieval at all, `1` means only using feature retrieval, and usually `0.5` is sufficient.
|
| 439 |
+
|
| 440 |
+
## 🗜️ Model compression
|
| 441 |
+
|
| 442 |
+
The generated model contains data that is needed for further training. If you confirm that the model is final and not be used in further training, it is safe to remove these data to get smaller file size (about 1/3).
|
| 443 |
+
|
| 444 |
+
```shell
|
| 445 |
+
# Example
|
| 446 |
+
python compress_model.py -c="configs/config.json" -i="logs/44k/G_30400.pth" -o="logs/44k/release.pth"
|
| 447 |
+
```
|
| 448 |
+
|
| 449 |
+
## 👨🔧 Timbre mixing
|
| 450 |
+
|
| 451 |
+
### Static Tone Mixing
|
| 452 |
+
|
| 453 |
+
**Refer to `webUI.py` file for stable Timbre mixing of the gadget/lab feature.**
|
| 454 |
+
|
| 455 |
+
Introduction: This function can combine multiple models into one model (convex combination or linear combination of multiple model parameters) to create mixed voice that do not exist in reality
|
| 456 |
+
|
| 457 |
+
**Note:**
|
| 458 |
+
1. This feature is only supported for single-speaker models
|
| 459 |
+
2. If you force a multi-speaker model, it is critical to make sure there are the same number of speakers in each model. This will ensure that sounds with the same SpeakerID can be mixed correctly.
|
| 460 |
+
3. Ensure that the `model` fields in config.json of all models to be mixed are the same
|
| 461 |
+
4. The mixed model can use any config.json file from the models being synthesized. However, the clustering model will not be functional after mixed.
|
| 462 |
+
5. When batch uploading models, it is best to put the models into a folder and upload them together after selecting them
|
| 463 |
+
6. It is suggested to adjust the mixing ratio between 0 and 100, or to other numbers, but unknown effects will occur in the linear combination mode
|
| 464 |
+
7. After mixing, the file named output.pth will be saved in the root directory of the project
|
| 465 |
+
8. Convex combination mode will perform Softmax to add the mix ratio to 1, while linear combination mode will not
|
| 466 |
+
|
| 467 |
+
### Dynamic timbre mixing
|
| 468 |
+
|
| 469 |
+
**Refer to the `spkmix.py` file for an introduction to dynamic timbre mixing**
|
| 470 |
+
|
| 471 |
+
Character mix track writing rules:
|
| 472 |
+
|
| 473 |
+
Role ID: \[\[Start time 1, end time 1, start value 1, start value 1], [Start time 2, end time 2, start value 2]]
|
| 474 |
+
|
| 475 |
+
The start time must be the same as the end time of the previous one. The first start time must be 0, and the last end time must be 1 (time ranges from 0 to 1).
|
| 476 |
+
|
| 477 |
+
All roles must be filled in. For unused roles, fill \[\[0., 1., 0., 0.]]
|
| 478 |
+
|
| 479 |
+
The fusion value can be filled in arbitrarily, and the linear change from the start value to the end value within the specified period of time. The
|
| 480 |
+
|
| 481 |
+
internal linear combination will be automatically guaranteed to be 1 (convex combination condition), so it can be used safely
|
| 482 |
+
|
| 483 |
+
Use the `--use_spk_mix` parameter when reasoning to enable dynamic timbre mixing
|
| 484 |
+
|
| 485 |
+
## 📤 Exporting to Onnx
|
| 486 |
+
|
| 487 |
+
Use [onnx_export.py](https://github.com/svc-develop-team/so-vits-svc/blob/4.0/onnx_export.py)
|
| 488 |
+
|
| 489 |
+
- Create a folder named `checkpoints` and open it
|
| 490 |
+
- Create a folder in the `checkpoints` folder as your project folder, naming it after your project, for example `aziplayer`
|
| 491 |
+
- Rename your model as `model.pth`, the configuration file as `config.json`, and place them in the `aziplayer` folder you just created
|
| 492 |
+
- Modify `"NyaruTaffy"` in `path = "NyaruTaffy"` in [onnx_export.py](https://github.com/svc-develop-team/so-vits-svc/blob/4.0/onnx_export.py) to your project name, `path = "aziplayer"`(onnx_export_speaker_mix makes you can mix speaker's voice)
|
| 493 |
+
- Run [onnx_export.py](https://github.com/svc-develop-team/so-vits-svc/blob/4.0/onnx_export.py)
|
| 494 |
+
- Wait for it to finish running. A `model.onnx` will be generated in your project folder, which is the exported model.
|
| 495 |
+
|
| 496 |
+
Note: For Hubert Onnx models, please use the models provided by MoeSS. Currently, they cannot be exported on their own (Hubert in fairseq has many unsupported operators and things involving constants that can cause errors or result in problems with the input/output shape and results when exported.)
|
| 497 |
+
|
| 498 |
+
|
| 499 |
+
## 📎 Reference
|
| 500 |
+
|
| 501 |
+
| URL | Designation | Title | Implementation Source |
|
| 502 |
+
| --- | ----------- | ----- | --------------------- |
|
| 503 |
+
|[2106.06103](https://arxiv.org/abs/2106.06103) | VITS (Synthesizer)| Conditional Variational Autoencoder with Adversarial Learning for End-to-End Text-to-Speech | [jaywalnut310/vits](https://github.com/jaywalnut310/vits) |
|
| 504 |
+
|[2111.02392](https://arxiv.org/abs/2111.02392) | SoftVC (Speech Encoder)| A Comparison of Discrete and Soft Speech Units for Improved Voice Conversion | [bshall/hubert](https://github.com/bshall/hubert) |
|
| 505 |
+
|[2204.09224](https://arxiv.org/abs/2204.09224) | ContentVec (Speech Encoder)| ContentVec: An Improved Self-Supervised Speech Representation by Disentangling Speakers | [auspicious3000/contentvec](https://github.com/auspicious3000/contentvec) |
|
| 506 |
+
|[2212.04356](https://arxiv.org/abs/2212.04356) | Whisper (Speech Encoder) | Robust Speech Recognition via Large-Scale Weak Supervision | [openai/whisper](https://github.com/openai/whisper) |
|
| 507 |
+
|[2110.13900](https://arxiv.org/abs/2110.13900) | WavLM (Speech Encoder) | WavLM: Large-Scale Self-Supervised Pre-Training for Full Stack Speech Processing | [microsoft/unilm/wavlm](https://github.com/microsoft/unilm/tree/master/wavlm) |
|
| 508 |
+
|[2305.17651](https://arxiv.org/abs/2305.17651) | DPHubert (Speech Encoder) | DPHuBERT: Joint Distillation and Pruning of Self-Supervised Speech Models | [pyf98/DPHuBERT](https://github.com/pyf98/DPHuBERT) |
|
| 509 |
+
|[DOI:10.21437/Interspeech.2017-68](http://dx.doi.org/10.21437/Interspeech.2017-68) | Harvest (F0 Predictor) | Harvest: A high-performance fundamental frequency estimator from speech signals | [mmorise/World/harvest](https://github.com/mmorise/World/blob/master/src/harvest.cpp) |
|
| 510 |
+
|[aes35-000039](https://www.aes.org/e-lib/online/browse.cfm?elib=15165) | Dio (F0 Predictor) | Fast and reliable F0 estimation method based on the period extraction of vocal fold vibration of singing voice and speech | [mmorise/World/dio](https://github.com/mmorise/World/blob/master/src/dio.cpp) |
|
| 511 |
+
|[8461329](https://ieeexplore.ieee.org/document/8461329) | Crepe (F0 Predictor) | Crepe: A Convolutional Representation for Pitch Estimation | [maxrmorrison/torchcrepe](https://github.com/maxrmorrison/torchcrepe) |
|
| 512 |
+
|[DOI:10.1016/j.wocn.2018.07.001](https://doi.org/10.1016/j.wocn.2018.07.001) | Parselmouth (F0 Predictor) | Introducing Parselmouth: A Python interface to Praat | [YannickJadoul/Parselmouth](https://github.com/YannickJadoul/Parselmouth) |
|
| 513 |
+
|[2306.15412v2](https://arxiv.org/abs/2306.15412v2) | RMVPE (F0 Predictor) | RMVPE: A Robust Model for Vocal Pitch Estimation in Polyphonic Music | [Dream-High/RMVPE](https://github.com/Dream-High/RMVPE) |
|
| 514 |
+
|[2010.05646](https://arxiv.org/abs/2010.05646) | HIFIGAN (Vocoder) | HiFi-GAN: Generative Adversarial Networks for Efficient and High Fidelity Speech Synthesis | [jik876/hifi-gan](https://github.com/jik876/hifi-gan) |
|
| 515 |
+
|[1810.11946](https://arxiv.org/abs/1810.11946.pdf) | NSF (Vocoder) | Neural source-filter-based waveform model for statistical parametric speech synthesis | [openvpi/DiffSinger/modules/nsf_hifigan](https://github.com/openvpi/DiffSinger/tree/refactor/modules/nsf_hifigan)
|
| 516 |
+
|[2006.08195](https://arxiv.org/abs/2006.08195) | Snake (Vocoder) | Neural Networks Fail to Learn Periodic Functions and How to Fix It | [EdwardDixon/snake](https://github.com/EdwardDixon/snake)
|
| 517 |
+
|[2105.02446v3](https://arxiv.org/abs/2105.02446v3) | Shallow Diffusion (PostProcessing)| DiffSinger: Singing Voice Synthesis via Shallow Diffusion Mechanism | [CNChTu/Diffusion-SVC](https://github.com/CNChTu/Diffusion-SVC) |
|
| 518 |
+
|[K-means](https://citeseerx.ist.psu.edu/viewdoc/download;jsessionid=01D65490BADCC216F350D06F84D721AD?doi=10.1.1.308.8619&rep=rep1&type=pdf) | Feature K-means Clustering (PreProcessing)| Some methods for classification and analysis of multivariate observations | This repo |
|
| 519 |
+
| | Feature TopK Retrieval (PreProcessing)| Retrieval based Voice Conversion | [RVC-Project/Retrieval-based-Voice-Conversion-WebUI](https://github.com/RVC-Project/Retrieval-based-Voice-Conversion-WebUI) |
|
| 520 |
+
|
| 521 |
+
|
| 522 |
+
## ☀️ Previous contributors
|
| 523 |
+
|
| 524 |
+
For some reason the author deleted the original repository. Because of the negligence of the organization members, the contributor list was cleared because all files were directly reuploaded to this repository at the beginning of the reconstruction of this repository. Now add a previous contributor list to README.md.
|
| 525 |
+
|
| 526 |
+
*Some members have not listed according to their personal wishes.*
|
| 527 |
+
|
| 528 |
+
<table>
|
| 529 |
+
<tr>
|
| 530 |
+
<td align="center"><a href="https://github.com/MistEO"><img src="https://avatars.githubusercontent.com/u/18511905?v=4" width="100px;" alt=""/><br /><sub><b>MistEO</b></sub></a><br /></td>
|
| 531 |
+
<td align="center"><a href="https://github.com/XiaoMiku01"><img src="https://avatars.githubusercontent.com/u/54094119?v=4" width="100px;" alt=""/><br /><sub><b>XiaoMiku01</b></sub></a><br /></td>
|
| 532 |
+
<td align="center"><a href="https://github.com/ForsakenRei"><img src="https://avatars.githubusercontent.com/u/23041178?v=4" width="100px;" alt=""/><br /><sub><b>しぐれ</b></sub></a><br /></td>
|
| 533 |
+
<td align="center"><a href="https://github.com/TomoGaSukunai"><img src="https://avatars.githubusercontent.com/u/25863522?v=4" width="100px;" alt=""/><br /><sub><b>TomoGaSukunai</b></sub></a><br /></td>
|
| 534 |
+
<td align="center"><a href="https://github.com/Plachtaa"><img src="https://avatars.githubusercontent.com/u/112609742?v=4" width="100px;" alt=""/><br /><sub><b>Plachtaa</b></sub></a><br /></td>
|
| 535 |
+
<td align="center"><a href="https://github.com/zdxiaoda"><img src="https://avatars.githubusercontent.com/u/45501959?v=4" width="100px;" alt=""/><br /><sub><b>zd小达</b></sub></a><br /></td>
|
| 536 |
+
<td align="center"><a href="https://github.com/Archivoice"><img src="https://avatars.githubusercontent.com/u/107520869?v=4" width="100px;" alt=""/><br /><sub><b>凍聲響世</b></sub></a><br /></td>
|
| 537 |
+
</tr>
|
| 538 |
+
</table>
|
| 539 |
+
|
| 540 |
+
## 📚 Some legal provisions for reference
|
| 541 |
+
|
| 542 |
+
#### Any country, region, organization, or individual using this project must comply with the following laws.
|
| 543 |
+
|
| 544 |
+
#### 《民法典》
|
| 545 |
+
|
| 546 |
+
##### 第一千零一十九条
|
| 547 |
+
|
| 548 |
+
任何组织或者个人不得以丑化、污损,或者利用信息技术手段伪造等方式侵害他人的肖像权。未经肖像权人同意,不得制作、使用、公开肖像权人的肖像,但是法律另有规定的除外。未经肖像权人同意,肖像作品权利人不得以发表、复制、发行、出租、展览等方式使用或者公开肖像权人的肖像。对自然人声音的保护,参照适用肖像权保护的有关规定。
|
| 549 |
+
|
| 550 |
+
##### 第一千零二十四条
|
| 551 |
+
|
| 552 |
+
【名誉权】民事主体享有名誉权。任何组织或者个人不得以侮辱、诽谤等方式侵害他人的名誉权。
|
| 553 |
+
|
| 554 |
+
##### 第一千零二十七条
|
| 555 |
+
|
| 556 |
+
【作品侵害名誉权】行为人发表的文学、艺术作品以真人真事或者特定人为描述对象,含有侮辱、诽谤内容,侵害他人名誉权的,受害人有权依法请求该行为人承担民事责任。行为人发表的文学、艺术作品不以特定人为描述对象,仅其中的情节与该特定人的情况相似的,不承担民事责任。
|
| 557 |
+
|
| 558 |
+
#### 《[中华人民共和国宪法](http://www.gov.cn/guoqing/2018-03/22/content_5276318.htm)》
|
| 559 |
+
|
| 560 |
+
#### 《[中华人民共和国刑法](http://gongbao.court.gov.cn/Details/f8e30d0689b23f57bfc782d21035c3.html?sw=%E4%B8%AD%E5%8D%8E%E4%BA%BA%E6%B0%91%E5%85%B1%E5%92%8C%E5%9B%BD%E5%88%91%E6%B3%95)》
|
| 561 |
+
|
| 562 |
+
#### 《[中华人民共和国民法典](http://gongbao.court.gov.cn/Details/51eb6750b8361f79be8f90d09bc202.html)》
|
| 563 |
+
|
| 564 |
+
#### 《[中华人民共和国合同法](http://www.npc.gov.cn/zgrdw/npc/lfzt/rlyw/2016-07/01/content_1992739.htm)》
|
| 565 |
+
|
| 566 |
+
## 💪 Thanks to all contributors for their efforts
|
| 567 |
+
<a href="https://github.com/svc-develop-team/so-vits-svc/graphs/contributors" target="_blank">
|
| 568 |
+
<img src="https://contrib.rocks/image?repo=svc-develop-team/so-vits-svc" />
|
| 569 |
+
</a>
|
README_zh_CN.md
ADDED
|
@@ -0,0 +1,570 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
<div align="center">
|
| 2 |
+
<img alt="LOGO" src="https://avatars.githubusercontent.com/u/127122328?s=400&u=5395a98a4f945a3a50cb0cc96c2747505d190dbc&v=4" width="300" height="300" />
|
| 3 |
+
|
| 4 |
+
# SoftVC VITS Singing Voice Conversion
|
| 5 |
+
|
| 6 |
+
[**English**](./README.md) | [**中文简体**](./README_zh_CN.md)
|
| 7 |
+
|
| 8 |
+
[](https://colab.research.google.com/github/svc-develop-team/so-vits-svc/blob/4.1-Stable/sovits4_for_colab.ipynb)
|
| 9 |
+
[](https://github.com/svc-develop-team/so-vits-svc/blob/4.1-Stable/LICENSE)
|
| 10 |
+
|
| 11 |
+
</div>
|
| 12 |
+
|
| 13 |
+
|
| 14 |
+
#### ✨ 带有 F0 曲线编辑器,角色混合时间轴编辑器的推理端 (Onnx 模型的用途): [MoeVoiceStudio](https://github.com/NaruseMioShirakana/MoeVoiceStudio)
|
| 15 |
+
|
| 16 |
+
#### ✨ 改善了交互的一个分支推荐: [34j/so-vits-svc-fork](https://github.com/34j/so-vits-svc-fork)
|
| 17 |
+
|
| 18 |
+
#### ✨ 支持实时转换的一个客户端: [w-okada/voice-changer](https://github.com/w-okada/voice-changer)
|
| 19 |
+
|
| 20 |
+
**本项目与 Vits 有着根本上的不同。Vits 是 TTS,本项目是 SVC。本项目无法实现 TTS,Vits 也无法实现 SVC,这两个项目的模型是完全不通用的。**
|
| 21 |
+
|
| 22 |
+
## 重要通知
|
| 23 |
+
|
| 24 |
+
这个项目是为了让开发者最喜欢的动画角色唱歌而开发的,任何涉及真人的东西都与开发者的意图背道而驰。
|
| 25 |
+
|
| 26 |
+
## 声明
|
| 27 |
+
|
| 28 |
+
本项目为开源、离线的项目,SvcDevelopTeam 的所有成员与本项目的所有开发者以及维护者(以下简称贡献者)对本项目没有控制力。本项目的贡献者从未向任何组织或个人提供包括但不限于数据集提取、数据集加工、算力支持、训练支持、推理等一切形式的帮助;本项目的贡献者不知晓也无法知晓使用者使用该项目的用途。故一切基于本项目训练的 AI 模型和合成的音频都与本项目贡献者无关。一切由此造成的问题由使用者自行承担。
|
| 29 |
+
|
| 30 |
+
此项目完全离线运行,不能收集任何用户信息或获取用户输入数据。因此,这个项目的贡献者不知道所有的用户输入和模型,因此不负责任何用户输入。
|
| 31 |
+
|
| 32 |
+
本项目只是一个框架项目,本身并没有语音合成的功能,所有的功能都需要用户自己训练模型。同时,这个项目没有任何模型,任何二次分发的项目都与这个项目的贡献者无关。
|
| 33 |
+
|
| 34 |
+
## 📏 使用规约
|
| 35 |
+
|
| 36 |
+
# Warning:请自行解决数据集授权问题,禁止使用非授权数据集进行训练!任何由于使用非授权数据集进行训练造成的问题,需自行承担全部责任和后果!与仓库、仓库维护者、svc develop team 无关!
|
| 37 |
+
|
| 38 |
+
1. 本项目是基于学术交流目的建立,仅供交流与学习使用,并非为生产环境准备。
|
| 39 |
+
2. 任何发布到视频平台的基于 sovits 制作的视频,都必须要在简介明确指明用于变声器转换的输入源歌声、音频,例如:使用他人发布的视频 / 音频,通过分离的人声作为输入源进行转换的,必须要给出明确的原视频、音乐链接;若使用是自己的人声,或是使用其他歌声合成引擎合成的声音作为输入源进行转换的,也必须在简介加以说明。
|
| 40 |
+
3. 由输入源造成的侵权问题需自行承担全部责任和一切后果。使用其他商用歌声合成软件作为输入源时,请确保遵守该软件的使用条例,注意,许多歌声合成引擎使用条例中明确指明不可用于输入源进行转换!
|
| 41 |
+
4. 禁止使用该项目从事违法行为与宗教、政治等活动,该项目维护者坚决抵制上述行为,不同意此条则禁止使用该项目。
|
| 42 |
+
5. 继续使用视为已同意本仓库 README 所述相关条例,本仓库 README 已进行劝导义务,不对后续可能存在问题负责。
|
| 43 |
+
6. 如果将此项目用于任何其他企划,请提前联系并告知本仓库作者,十分感谢。
|
| 44 |
+
|
| 45 |
+
## 📝 模型简介
|
| 46 |
+
|
| 47 |
+
歌声音色转换模型,通过 SoftVC 内容编码器提取源音频语音特征,与 F0 同时输入 VITS 替换原本的文本输入达到歌声转换的效果。同时,更换声码器为 [NSF HiFiGAN](https://github.com/openvpi/DiffSinger/tree/refactor/modules/nsf_hifigan) 解决断音问题。
|
| 48 |
+
|
| 49 |
+
### 🆕 4.1-Stable 版本更新内容
|
| 50 |
+
|
| 51 |
+
+ 特征输入更换为 [Content Vec](https://github.com/auspicious3000/contentvec) 的第 12 层 Transformer 输出,并兼容 4.0 分支
|
| 52 |
+
+ 更新浅层扩散,可以使用浅层扩散模型提升音质
|
| 53 |
+
+ 增加 whisper 语音编码器的支持
|
| 54 |
+
+ 增加静态/动态声线融合
|
| 55 |
+
+ 增加响度嵌入
|
| 56 |
+
+ 增加特征检索,来自于 [RVC](https://github.com/RVC-Project/Retrieval-based-Voice-Conversion-WebUI)
|
| 57 |
+
|
| 58 |
+
### 🆕 关于兼容 4.0 模型的问题
|
| 59 |
+
|
| 60 |
+
+ 可通过修改 4.0 模型的 config.json 对 4.0 的模型进行支持,需要在 config.json 的 model 字段中添加 speech_encoder 字段,具体见下
|
| 61 |
+
|
| 62 |
+
```
|
| 63 |
+
"model": {
|
| 64 |
+
.........
|
| 65 |
+
"ssl_dim": 256,
|
| 66 |
+
"n_speakers": 200,
|
| 67 |
+
"speech_encoder":"vec256l9"
|
| 68 |
+
}
|
| 69 |
+
```
|
| 70 |
+
|
| 71 |
+
### 🆕 关于浅扩散
|
| 72 |
+

|
| 73 |
+
|
| 74 |
+
## 💬 关于 Python 版本问题
|
| 75 |
+
|
| 76 |
+
在进行测试后,我们认为`Python 3.8.9`能够稳定地运行该项目
|
| 77 |
+
|
| 78 |
+
## 📥 预先下载的模型文件
|
| 79 |
+
|
| 80 |
+
#### **必须项**
|
| 81 |
+
|
| 82 |
+
**以下编码器需要选择一个使用**
|
| 83 |
+
|
| 84 |
+
##### **1. 若使用 contentvec 作为声音编码器(推荐)**
|
| 85 |
+
|
| 86 |
+
`vec768l12`与`vec256l9` 需要该编码器
|
| 87 |
+
|
| 88 |
+
+ contentvec :[checkpoint_best_legacy_500.pt](https://ibm.box.com/s/z1wgl1stco8ffooyatzdwsqn2psd9lrr)
|
| 89 |
+
+ 放在`pretrain`目录下
|
| 90 |
+
|
| 91 |
+
或者下载下面的 ContentVec,大小只有 199MB,但效果相同:
|
| 92 |
+
+ contentvec :[hubert_base.pt](https://huggingface.co/lj1995/VoiceConversionWebUI/resolve/main/hubert_base.pt)
|
| 93 |
+
+ 将文件名改为`checkpoint_best_legacy_500.pt`后,放在`pretrain`目录下
|
| 94 |
+
|
| 95 |
+
```shell
|
| 96 |
+
# contentvec
|
| 97 |
+
wget -P pretrain/ https://huggingface.co/lj1995/VoiceConversionWebUI/resolve/main/hubert_base.pt -O checkpoint_best_legacy_500.pt
|
| 98 |
+
# 也可手动下载放在 pretrain 目录
|
| 99 |
+
```
|
| 100 |
+
|
| 101 |
+
##### **2. 若使用 hubertsoft 作为声音编码器**
|
| 102 |
+
+ soft vc hubert:[hubert-soft-0d54a1f4.pt](https://github.com/bshall/hubert/releases/download/v0.1/hubert-soft-0d54a1f4.pt)
|
| 103 |
+
+ 放在`pretrain`目录下
|
| 104 |
+
|
| 105 |
+
##### **3. 若使用 Whisper-ppg 作为声音编码器**
|
| 106 |
+
+ 下载模型 [medium.pt](https://openaipublic.azureedge.net/main/whisper/models/345ae4da62f9b3d59415adc60127b97c714f32e89e936602e85993674d08dcb1/medium.pt), 该模型适配`whisper-ppg`
|
| 107 |
+
+ 下载模型 [large-v2.pt](https://openaipublic.azureedge.net/main/whisper/models/81f7c96c852ee8fc832187b0132e569d6c3065a3252ed18e56effd0b6a73e524/large-v2.pt), 该模型适配`whisper-ppg-large`
|
| 108 |
+
+ 放在`pretrain`目录下
|
| 109 |
+
|
| 110 |
+
##### **4. 若使用 cnhubertlarge 作为声音编码器**
|
| 111 |
+
+ 下载模型 [chinese-hubert-large-fairseq-ckpt.pt](https://huggingface.co/TencentGameMate/chinese-hubert-large/resolve/main/chinese-hubert-large-fairseq-ckpt.pt)
|
| 112 |
+
+ 放在`pretrain`目录下
|
| 113 |
+
|
| 114 |
+
##### **5. 若使用 dphubert 作为声音编码器**
|
| 115 |
+
+ 下载模型 [DPHuBERT-sp0.75.pth](https://huggingface.co/pyf98/DPHuBERT/resolve/main/DPHuBERT-sp0.75.pth)
|
| 116 |
+
+ 放在`pretrain`目录下
|
| 117 |
+
|
| 118 |
+
##### **6. 若使用 WavLM 作为声音编码器**
|
| 119 |
+
+ 下载模型 [WavLM-Base+.pt](https://valle.blob.core.windows.net/share/wavlm/WavLM-Base+.pt?sv=2020-08-04&st=2023-03-01T07%3A51%3A05Z&se=2033-03-02T07%3A51%3A00Z&sr=c&sp=rl&sig=QJXmSJG9DbMKf48UDIU1MfzIro8HQOf3sqlNXiflY1I%3D), 该模型适配`wavlmbase+`
|
| 120 |
+
+ 放在`pretrain`目录下
|
| 121 |
+
|
| 122 |
+
##### **7. 若使用 OnnxHubert/ContentVec 作为声音编码器**
|
| 123 |
+
+ 下载模型 [MoeSS-SUBModel](https://huggingface.co/NaruseMioShirakana/MoeSS-SUBModel/tree/main)
|
| 124 |
+
+ 放在`pretrain`目录下
|
| 125 |
+
|
| 126 |
+
#### **编码器列表**
|
| 127 |
+
- "vec768l12"
|
| 128 |
+
- "vec256l9"
|
| 129 |
+
- "vec256l9-onnx"
|
| 130 |
+
- "vec256l12-onnx"
|
| 131 |
+
- "vec768l9-onnx"
|
| 132 |
+
- "vec768l12-onnx"
|
| 133 |
+
- "hubertsoft-onnx"
|
| 134 |
+
- "hubertsoft"
|
| 135 |
+
- "whisper-ppg"
|
| 136 |
+
- "cnhubertlarge"
|
| 137 |
+
- "dphubert"
|
| 138 |
+
- "whisper-ppg-large"
|
| 139 |
+
- "wavlmbase+"
|
| 140 |
+
|
| 141 |
+
#### **可选项(强烈建议使用)**
|
| 142 |
+
|
| 143 |
+
+ 预训练底模文件: `G_0.pth` `D_0.pth`
|
| 144 |
+
+ 放在`logs/44k`目录下
|
| 145 |
+
|
| 146 |
+
+ 扩散模型预训练底模文件: `model_0.pt`
|
| 147 |
+
+ 放在`logs/44k/diffusion`目录下
|
| 148 |
+
|
| 149 |
+
从 svc-develop-team(待定)或任何其他地方获取 Sovits 底模
|
| 150 |
+
|
| 151 |
+
扩散模型引用了 [Diffusion-SVC](https://github.com/CNChTu/Diffusion-SVC) 的 Diffusion Model,底模与 [Diffusion-SVC](https://github.com/CNChTu/Diffusion-SVC) 的扩散模型底模通用,可以去 [Diffusion-SVC](https://github.com/CNChTu/Diffusion-SVC) 获取扩散模型的底模
|
| 152 |
+
|
| 153 |
+
虽然底模一般不会引起什么版权问题,但还是请注意一下,比如事先询问作者,又或者作者在模型描述中明确写明了可行的用途
|
| 154 |
+
|
| 155 |
+
#### **可选项(根据情况选择)**
|
| 156 |
+
|
| 157 |
+
##### NSF-HIFIGAN
|
| 158 |
+
|
| 159 |
+
如果使用`NSF-HIFIGAN 增强器`或`浅层扩散`的话,需要下载预训练的 NSF-HIFIGAN 模型,如果不需要可以不下载
|
| 160 |
+
|
| 161 |
+
+ 预训练的 NSF-HIFIGAN 声码器 :[nsf_hifigan_20221211.zip](https://github.com/openvpi/vocoders/releases/download/nsf-hifigan-v1/nsf_hifigan_20221211.zip)
|
| 162 |
+
+ 解压后,将四个文件放在`pretrain/nsf_hifigan`目录下
|
| 163 |
+
|
| 164 |
+
```shell
|
| 165 |
+
# nsf_hifigan
|
| 166 |
+
wget -P pretrain/ https://github.com/openvpi/vocoders/releases/download/nsf-hifigan-v1/nsf_hifigan_20221211.zip
|
| 167 |
+
unzip -od pretrain/nsf_hifigan pretrain/nsf_hifigan_20221211.zip
|
| 168 |
+
# 也可手动下载放在 pretrain/nsf_hifigan 目录
|
| 169 |
+
# 地址:https://github.com/openvpi/vocoders/releases/tag/nsf-hifigan-v1
|
| 170 |
+
```
|
| 171 |
+
|
| 172 |
+
##### RMVPE
|
| 173 |
+
|
| 174 |
+
如果使用`rmvpe`F0预测器的话,需要下载预训练的 RMVPE 模型
|
| 175 |
+
|
| 176 |
+
+ 下载模型 [rmvpe.pt](https://huggingface.co/datasets/ylzz1997/rmvpe_pretrain_model/resolve/main/rmvpe.pt)
|
| 177 |
+
+ 放在`pretrain`目录下
|
| 178 |
+
|
| 179 |
+
##### FCPE(预览版)
|
| 180 |
+
|
| 181 |
+
> 你说的对,但是[FCPE](https://github.com/CNChTu/MelPE)是由svc-develop-team自主研发的一款全新的F0预测器,后面忘了
|
| 182 |
+
|
| 183 |
+
[FCPE(Fast Context-base Pitch Estimator)](https://github.com/CNChTu/MelPE)是一个为实时语音转换所设计的专用F0预测器,他将在未来成为Sovits实时语音转换的首选F0预测器.(论文未来会有的)
|
| 184 |
+
|
| 185 |
+
如果使用 `fcpe` F0预测器的话,需要下载预训练的 FCPE 模型
|
| 186 |
+
|
| 187 |
+
+ 下载模型 [fcpe.pt](https://huggingface.co/datasets/ylzz1997/rmvpe_pretrain_model/resolve/main/fcpe.pt)
|
| 188 |
+
+ 放在`pretrain`目录下
|
| 189 |
+
|
| 190 |
+
|
| 191 |
+
## 📊 数据集准备
|
| 192 |
+
|
| 193 |
+
仅需要以以下文件结构将数据集放入 dataset_raw 目录即可。
|
| 194 |
+
|
| 195 |
+
```
|
| 196 |
+
dataset_raw
|
| 197 |
+
├───speaker0
|
| 198 |
+
│ ├───xxx1-xxx1.wav
|
| 199 |
+
│ ├───...
|
| 200 |
+
│ └───Lxx-0xx8.wav
|
| 201 |
+
└───speaker1
|
| 202 |
+
├───xx2-0xxx2.wav
|
| 203 |
+
├───...
|
| 204 |
+
└───xxx7-xxx007.wav
|
| 205 |
+
```
|
| 206 |
+
对于每一个音频文件的名称并没有格式的限制(`000001.wav`~`999999.wav`之类的命名方式也是合法的),不过文件类型必须是`wav`。
|
| 207 |
+
|
| 208 |
+
可以自定义说话人名称
|
| 209 |
+
|
| 210 |
+
```
|
| 211 |
+
dataset_raw
|
| 212 |
+
└───suijiSUI
|
| 213 |
+
├───1.wav
|
| 214 |
+
├───...
|
| 215 |
+
└───25788785-20221210-200143-856_01_(Vocals)_0_0.wav
|
| 216 |
+
```
|
| 217 |
+
|
| 218 |
+
## 🛠️ 数据预处理
|
| 219 |
+
|
| 220 |
+
### 0. 音频切片
|
| 221 |
+
|
| 222 |
+
将音频切片至`5s - 15s`, 稍微长点也无伤大雅,实在太长可能会导致训练中途甚至预处理就爆显存
|
| 223 |
+
|
| 224 |
+
可以使用 [audio-slicer-GUI](https://github.com/flutydeer/audio-slicer)、[audio-slicer-CLI](https://github.com/openvpi/audio-slicer)
|
| 225 |
+
|
| 226 |
+
一般情况下只需调整其中的`Minimum Interval`,普通陈述素材通常保持默认即可,歌唱素材可以调整至`100`甚至`50`
|
| 227 |
+
|
| 228 |
+
切完之后手动删除过长过短的音频
|
| 229 |
+
|
| 230 |
+
**如果你使用 Whisper-ppg 声音编码器进行训练,所有的切片长度必须小于 30s**
|
| 231 |
+
|
| 232 |
+
### 1. 重采样至 44100Hz 单声道
|
| 233 |
+
|
| 234 |
+
```shell
|
| 235 |
+
python resample.py
|
| 236 |
+
```
|
| 237 |
+
|
| 238 |
+
#### 注意
|
| 239 |
+
|
| 240 |
+
虽然本项目拥有重采样、转换单声道与响度匹配的脚本 resample.py,但是默认的响度匹配是匹配到 0db。这可能会造成音质的受损。而 python 的响度匹配包 pyloudnorm 无法对电平进行压限,这会导致爆音。所以建议可以考虑使用专业声音处理软件如`adobe audition`等软件做响度匹配处理。若已经使用其他软件做响度匹配,可以在运行上述命令时添加`--skip_loudnorm`跳过响度匹配步骤。如:
|
| 241 |
+
|
| 242 |
+
```shell
|
| 243 |
+
python resample.py --skip_loudnorm
|
| 244 |
+
```
|
| 245 |
+
|
| 246 |
+
### 2. 自动划分训练集、验证集,以及自动生成配置文件
|
| 247 |
+
|
| 248 |
+
```shell
|
| 249 |
+
python preprocess_flist_config.py --speech_encoder vec768l12
|
| 250 |
+
```
|
| 251 |
+
|
| 252 |
+
speech_encoder 拥有以下选择
|
| 253 |
+
|
| 254 |
+
```
|
| 255 |
+
vec768l12
|
| 256 |
+
vec256l9
|
| 257 |
+
hubertsoft
|
| 258 |
+
whisper-ppg
|
| 259 |
+
whisper-ppg-large
|
| 260 |
+
cnhubertlarge
|
| 261 |
+
dphubert
|
| 262 |
+
wavlmbase+
|
| 263 |
+
```
|
| 264 |
+
|
| 265 |
+
如果省略 speech_encoder 参数,默认值为 vec768l12
|
| 266 |
+
|
| 267 |
+
**使用响度嵌入**
|
| 268 |
+
|
| 269 |
+
若使用响度嵌入,需要增加`--vol_aug`参数,比如:
|
| 270 |
+
|
| 271 |
+
```shell
|
| 272 |
+
python preprocess_flist_config.py --speech_encoder vec768l12 --vol_aug
|
| 273 |
+
```
|
| 274 |
+
使用后训练出的模型将匹配到输入源响度,否则为训练集响度。
|
| 275 |
+
|
| 276 |
+
#### 此时可以在生成的 config.json 与 diffusion.yaml 修改部分参数
|
| 277 |
+
|
| 278 |
+
##### config.json
|
| 279 |
+
|
| 280 |
+
* `keep_ckpts`:训练时保留最后几个模型,`0`为保留所有,默认只保留最后`3`个
|
| 281 |
+
|
| 282 |
+
* `all_in_mem`:加载所有数据集到内存中,某些平台的硬盘 IO 过于低下、同时内存容量 **远大于** 数据集体积时可以启用
|
| 283 |
+
|
| 284 |
+
* `batch_size`:单次训练加载到 GPU 的数据量,调整到低于显存容量的大小即可
|
| 285 |
+
|
| 286 |
+
* `vocoder_name` : 选择一种声码器,默认为`nsf-hifigan`.
|
| 287 |
+
|
| 288 |
+
##### diffusion.yaml
|
| 289 |
+
|
| 290 |
+
* `cache_all_data`:加载所有数据集到内存中,某些平台的硬盘 IO 过于低下、同时内存容量 **远大于** 数据集体积时可以启用
|
| 291 |
+
|
| 292 |
+
* `duration`:训练时音频切片时长,可根据显存大小调整,**注意,该值必须小于训练集内音频的最短时间!**
|
| 293 |
+
|
| 294 |
+
* `batch_size`:单次训练加载到 GPU 的数据量,调整到低于显存容量的大小即可
|
| 295 |
+
|
| 296 |
+
* `timesteps` : 扩散模型总步数,默认为 1000.
|
| 297 |
+
|
| 298 |
+
* `k_step_max` : 训练时可仅训练`k_step_max`步扩散以节约训练时间,注意,该值必须小于`timesteps`,0 为训练整个扩散模型,**注意,如果不训练整个扩散模型将无法使用仅扩散模型推理!**
|
| 299 |
+
|
| 300 |
+
##### **声码器列表**
|
| 301 |
+
|
| 302 |
+
```
|
| 303 |
+
nsf-hifigan
|
| 304 |
+
nsf-snake-hifigan
|
| 305 |
+
```
|
| 306 |
+
|
| 307 |
+
### 3. 生成 hubert 与 f0
|
| 308 |
+
|
| 309 |
+
```shell
|
| 310 |
+
python preprocess_hubert_f0.py --f0_predictor dio
|
| 311 |
+
```
|
| 312 |
+
|
| 313 |
+
f0_predictor 拥有以下选择
|
| 314 |
+
|
| 315 |
+
```
|
| 316 |
+
crepe
|
| 317 |
+
dio
|
| 318 |
+
pm
|
| 319 |
+
harvest
|
| 320 |
+
rmvpe
|
| 321 |
+
fcpe
|
| 322 |
+
```
|
| 323 |
+
|
| 324 |
+
如果训练集过于嘈杂,请使用 crepe 处理 f0
|
| 325 |
+
|
| 326 |
+
如果省略 f0_predictor 参数,默认值为 dio
|
| 327 |
+
|
| 328 |
+
尚若需要浅扩散功能(可选),需要增加--use_diff 参数,比如
|
| 329 |
+
|
| 330 |
+
```shell
|
| 331 |
+
python preprocess_hubert_f0.py --f0_predictor dio --use_diff
|
| 332 |
+
```
|
| 333 |
+
|
| 334 |
+
**加速预处理**
|
| 335 |
+
如若您的数据集比较大,可以尝试添加`--num_processes`参数:
|
| 336 |
+
```shell
|
| 337 |
+
python preprocess_hubert_f0.py --f0_predictor dio --use_diff --num_processes 8
|
| 338 |
+
```
|
| 339 |
+
所有的Workers会被自动分配到多个线程上
|
| 340 |
+
|
| 341 |
+
执行完以上步骤后 dataset 目录便是预处理完成的数据,可���删除 dataset_raw 文件夹了
|
| 342 |
+
|
| 343 |
+
## 🏋️ 训练
|
| 344 |
+
|
| 345 |
+
### 主模型训练
|
| 346 |
+
|
| 347 |
+
```shell
|
| 348 |
+
python train.py -c configs/config.json -m 44k
|
| 349 |
+
```
|
| 350 |
+
|
| 351 |
+
### 扩散模型(可选)
|
| 352 |
+
|
| 353 |
+
尚若需要浅扩散功能,需要训练扩散模型,扩散模型训练方法为:
|
| 354 |
+
|
| 355 |
+
```shell
|
| 356 |
+
python train_diff.py -c configs/diffusion.yaml
|
| 357 |
+
```
|
| 358 |
+
|
| 359 |
+
模型训练结束后,模型文件保存在`logs/44k`目录下,扩散模型在`logs/44k/diffusion`下
|
| 360 |
+
|
| 361 |
+
## 🤖 推理
|
| 362 |
+
|
| 363 |
+
使用 [inference_main.py](inference_main.py)
|
| 364 |
+
|
| 365 |
+
```shell
|
| 366 |
+
# 例
|
| 367 |
+
python inference_main.py -m "logs/44k/G_30400.pth" -c "configs/config.json" -n "君の知らない物語-src.wav" -t 0 -s "nen"
|
| 368 |
+
```
|
| 369 |
+
|
| 370 |
+
必填项部分:
|
| 371 |
+
+ `-m` | `--model_path`:模型路径
|
| 372 |
+
+ `-c` | `--config_path`:配置文件路径
|
| 373 |
+
+ `-n` | `--clean_names`:wav 文件名列表,放在 raw 文件夹下
|
| 374 |
+
+ `-t` | `--trans`:音高调整,支持正负(半音)
|
| 375 |
+
+ `-s` | `--spk_list`:合成目标说话人名称
|
| 376 |
+
+ `-cl` | `--clip`:音频强制切片,默认 0 为自动切片,单位为秒/s
|
| 377 |
+
|
| 378 |
+
可选项部分:部分具体见下一节
|
| 379 |
+
+ `-lg` | `--linear_gradient`:两段音频切片的交叉淡入长度,如果强制切片后出现人声不连贯可调整该数值,如果连贯建议采用默认值 0,单位为秒
|
| 380 |
+
+ `-f0p` | `--f0_predictor`:选择 F0 预测器,可选择 crepe,pm,dio,harvest,rmvpe,fcpe, 默认为 pm(注意:crepe 为原 F0 使用均值滤波器)
|
| 381 |
+
+ `-a` | `--auto_predict_f0`:语音转换自动预测音高,转换歌声时不要打开这个会严重跑调
|
| 382 |
+
+ `-cm` | `--cluster_model_path`:聚类模型或特征检索索引路径,留空则自动设为各方案模型的默认路径,如果没有训练聚类或特征检索则随便填
|
| 383 |
+
+ `-cr` | `--cluster_infer_ratio`:聚类方案或特征检索占比,范围 0-1,若没有训练聚类模型或特征检索则默认 0 即可
|
| 384 |
+
+ `-eh` | `--enhance`:是否使用 NSF_HIFIGAN 增强器,该选项对部分训练集少的模型有一定的音质增强效果,但是对训练好的模型有反面效果,默认关闭
|
| 385 |
+
+ `-shd` | `--shallow_diffusion`:是否使用浅层扩散,使用后可解决一部分电音问题,默认关闭,该选项打开时,NSF_HIFIGAN 增强器将会被禁止
|
| 386 |
+
+ `-usm` | `--use_spk_mix`:是否使用角色融合/动态声线融合
|
| 387 |
+
+ `-lea` | `--loudness_envelope_adjustment`:输入源响度包络替换输出响度包络融合比例,越靠近 1 越使用输出响度包络
|
| 388 |
+
+ `-fr` | `--feature_retrieval`:是否使用特征检索,如果使用聚类模型将被禁用,且 cm 与 cr 参数将会变成特征检索的索引路径与混合比例
|
| 389 |
+
|
| 390 |
+
浅扩散设置:
|
| 391 |
+
+ `-dm` | `--diffusion_model_path`:扩散模型路径
|
| 392 |
+
+ `-dc` | `--diffusion_config_path`:扩散模型配置文件路径
|
| 393 |
+
+ `-ks` | `--k_step`:扩散步数,越大越接近扩散模型的结果,默认 100
|
| 394 |
+
+ `-od` | `--only_diffusion`:纯扩散模式,该模式不会加载 sovits 模型,以扩散模型推理
|
| 395 |
+
+ `-se` | `--second_encoding`:二次编码,浅扩散前会对原始音频进行二次编码,玄学选项,有时候效果好,有时候效果差
|
| 396 |
+
|
| 397 |
+
### 注意!
|
| 398 |
+
|
| 399 |
+
如果使用`whisper-ppg` 声音编码器进行推理,需要将`--clip`设置为 25,`-lg`设置为 1。否则将无法正常推理。
|
| 400 |
+
|
| 401 |
+
## 🤔 可选项
|
| 402 |
+
|
| 403 |
+
如果前面的效果已经满意,或者没看明白下面在讲啥,那后面的内容都可以忽略,不影响模型使用(这些可选项影响比较小,可能在某些特定数据上有点效果,但大部分情况似乎都感知不太明显)
|
| 404 |
+
|
| 405 |
+
### 自动 f0 预测
|
| 406 |
+
|
| 407 |
+
4.0 模型训练过程会训练一个 f0 预测器,对于语音转换可以开启自动音高预测,如果效果不好也可以使用手动的,但转换歌声时请不要启用此功能!!!会严重跑调!!
|
| 408 |
+
+ 在 inference_main 中设置 auto_predict_f0 为 true 即可
|
| 409 |
+
|
| 410 |
+
### 聚类音色泄漏控制
|
| 411 |
+
|
| 412 |
+
介绍:聚类方案可以减小音色泄漏,使得模型训练出来更像目标的音色(但其实不是特别明显),但是单纯的聚类方案会降低模型的咬字(会口齿不清)(这个很明显),本模型采用了融合的方式,可以线性控制聚类方案与非聚类方案的占比,也就是可以手动在"像目标音色" 和 "咬字清晰" 之间调整比例,找到合适的折中点
|
| 413 |
+
|
| 414 |
+
使用聚类前面的已有步骤不用进行任何的变动,只需要额外训练一个聚类模型,虽然效果比较有限,但训练成本也比较低
|
| 415 |
+
|
| 416 |
+
+ 训练过程:
|
| 417 |
+
+ 使用 cpu 性能较好的机器训练,据我的经验在腾讯云 6 核 cpu 训练每个 speaker 需要约 4 分钟即可完成训练
|
| 418 |
+
+ 执行`python cluster/train_cluster.py`,模型的输出会在`logs/44k/kmeans_10000.pt`
|
| 419 |
+
+ 聚类模型目前可以使用 gpu 进行训练,执行`python cluster/train_cluster.py --gpu`
|
| 420 |
+
+ 推理过程:
|
| 421 |
+
+ `inference_main.py`中指定`cluster_model_path` 为模型输出文件,留空则默认为`logs/44k/kmeans_10000.pt`
|
| 422 |
+
+ `inference_main.py`中指定`cluster_infer_ratio`,`0`为完全不使用聚类,`1`为只使用聚类,通常设置`0.5`即可
|
| 423 |
+
|
| 424 |
+
### 特征检索
|
| 425 |
+
|
| 426 |
+
介绍:跟聚类方案一样可以减小音色泄漏,咬字比聚类稍好,但会降低推理速度,采用了融合的方式,可以线性控制特征检索与非特征检索的占比,
|
| 427 |
+
|
| 428 |
+
+ 训练过程:
|
| 429 |
+
首先需要在生成 hubert 与 f0 后执行:
|
| 430 |
+
|
| 431 |
+
```shell
|
| 432 |
+
python train_index.py -c configs/config.json
|
| 433 |
+
```
|
| 434 |
+
|
| 435 |
+
模型的输出会在`logs/44k/feature_and_index.pkl`
|
| 436 |
+
|
| 437 |
+
+ 推理过程:
|
| 438 |
+
+ 需要首先指定`--feature_retrieval`,此时聚类方案会自动切换到特征检索方案
|
| 439 |
+
+ `inference_main.py`中指定`cluster_model_path` 为模型输出文件,留空则默认为`logs/44k/feature_and_index.pkl`
|
| 440 |
+
+ `inference_main.py`中指定`cluster_infer_ratio`,`0`为完全不使用特征检索,`1`为只使用特征检索,通常设置`0.5`即可
|
| 441 |
+
|
| 442 |
+
|
| 443 |
+
## 🗜️ 模型压缩
|
| 444 |
+
|
| 445 |
+
生成的模型含有继续训练所需的信息。如果确认不再训练,可以移除模型中此部分信息,得到约 1/3 大小的最终模型。
|
| 446 |
+
|
| 447 |
+
使用 [compress_model.py](compress_model.py)
|
| 448 |
+
|
| 449 |
+
```shell
|
| 450 |
+
# 例
|
| 451 |
+
python compress_model.py -c="configs/config.json" -i="logs/44k/G_30400.pth" -o="logs/44k/release.pth"
|
| 452 |
+
```
|
| 453 |
+
|
| 454 |
+
## 👨🔧 声线混合
|
| 455 |
+
|
| 456 |
+
### 静态声线混合
|
| 457 |
+
|
| 458 |
+
**参考`webUI.py`文件中,小工具/实验室特性的静态声线融合。**
|
| 459 |
+
|
| 460 |
+
介绍:该功能可以将多个声音模型合成为一个声音模型(多个模型参数的凸组合或线性组合),从而制造出现实中不存在的声线
|
| 461 |
+
**注意:**
|
| 462 |
+
|
| 463 |
+
1. 该功能仅支持单说话人的模型
|
| 464 |
+
2. 如果强行使用多说话人模型,需要保证多个模型的说话人数量相同,这样可以混合同一个 SpaekerID 下的声音
|
| 465 |
+
3. 保证所有待混合模型的 config.json 中的 model 字段是相同的
|
| 466 |
+
4. 输出的混合模型可以使用待合成模型的任意一个 config.json,但聚类模型将不能使用
|
| 467 |
+
5. 批量上传模型的时候最好把模型放到一个文件夹选中后一起上传
|
| 468 |
+
6. 混合比例调整建议大小在 0-100 之间,也可以调为其他数字,但在线性组合模式下会出现未知的效果
|
| 469 |
+
7. 混合完毕后,文件将会保存在项目根目录中,文件名为 output.pth
|
| 470 |
+
8. 凸组合模式会将混合比例执行 Softmax 使混合比例相加为 1,而线性组合模式不会
|
| 471 |
+
|
| 472 |
+
### 动态声线混合
|
| 473 |
+
|
| 474 |
+
**参考`spkmix.py`文件中关于动态声线混合的介绍**
|
| 475 |
+
|
| 476 |
+
角色混合轨道 编写规则:
|
| 477 |
+
|
| 478 |
+
角色 ID : \[\[起始时间 1, 终止时间 1, 起始数值 1, 起始数值 1], [起始时间 2, 终止时间 2, 起始数值 2, 起始数值 2]]
|
| 479 |
+
|
| 480 |
+
起始时间和前一个的终止时间必须相同,第一个起始时间必须为 0,最后一个终止时间必须为 1 (时间的范围为 0-1)
|
| 481 |
+
|
| 482 |
+
全部角色必须填写,不使用的角色填、[\[0., 1., 0., 0.]] 即可
|
| 483 |
+
|
| 484 |
+
融合数值可以随便填,在指定的时间段内从起始数值线性变化为终止数值,内部会自动确保线性组合为 1(凸组合条件),可以放心使用
|
| 485 |
+
|
| 486 |
+
推理的时候使用`--use_spk_mix`参数即可启用动态声线混合
|
| 487 |
+
|
| 488 |
+
## 📤 Onnx 导出
|
| 489 |
+
|
| 490 |
+
使用 [onnx_export.py](onnx_export.py)
|
| 491 |
+
|
| 492 |
+
+ 新建文件夹:`checkpoints` 并打开
|
| 493 |
+
+ 在`checkpoints`文件夹中新建一个文件夹作为项目文件夹,文件夹名为你的项目名称,比如`aziplayer`
|
| 494 |
+
+ 将你的模型更名为`model.pth`,配置文件更名为`config.json`,并放置到刚才创建的`aziplayer`文件夹下
|
| 495 |
+
+ 将 [onnx_export.py](onnx_export.py) 中`path = "NyaruTaffy"` 的 `"NyaruTaffy"` 修改为你的项目名称,`path = "aziplayer" (onnx_export_speaker_mix,为支持角色混合的 onnx 导出)`
|
| 496 |
+
+ 运行 [onnx_export.py](onnx_export.py)
|
| 497 |
+
+ 等待执行完毕,在你的项目文件夹下会生成一个`model.onnx`,即为导出的模型
|
| 498 |
+
|
| 499 |
+
注意:Hubert Onnx 模型请使用 MoeSS 提供的模型,目前无法自行导出(fairseq 中 Hubert 有不少 onnx 不支持的算子和涉及到常量的东西,在导出时会报错或者导出的模型输入输出 shape 和结果都有问题)
|
| 500 |
+
|
| 501 |
+
## 📎 引用及论文
|
| 502 |
+
|
| 503 |
+
| URL | 名称 | 标题 | 源码 |
|
| 504 |
+
| --- | ----------- | ----- | --------------------- |
|
| 505 |
+
|[2106.06103](https://arxiv.org/abs/2106.06103) | VITS (Synthesizer)| Conditional Variational Autoencoder with Adversarial Learning for End-to-End Text-to-Speech | [jaywalnut310/vits](https://github.com/jaywalnut310/vits) |
|
| 506 |
+
|[2111.02392](https://arxiv.org/abs/2111.02392) | SoftVC (Speech Encoder)| A Comparison of Discrete and Soft Speech Units for Improved Voice Conversion | [bshall/hubert](https://github.com/bshall/hubert) |
|
| 507 |
+
|[2204.09224](https://arxiv.org/abs/2204.09224) | ContentVec (Speech Encoder)| ContentVec: An Improved Self-Supervised Speech Representation by Disentangling Speakers | [auspicious3000/contentvec](https://github.com/auspicious3000/contentvec) |
|
| 508 |
+
|[2212.04356](https://arxiv.org/abs/2212.04356) | Whisper (Speech Encoder) | Robust Speech Recognition via Large-Scale Weak Supervision | [openai/whisper](https://github.com/openai/whisper) |
|
| 509 |
+
|[2110.13900](https://arxiv.org/abs/2110.13900) | WavLM (Speech Encoder) | WavLM: Large-Scale Self-Supervised Pre-Training for Full Stack Speech Processing | [microsoft/unilm/wavlm](https://github.com/microsoft/unilm/tree/master/wavlm) |
|
| 510 |
+
|[2305.17651](https://arxiv.org/abs/2305.17651) | DPHubert (Speech Encoder) | DPHuBERT: Joint Distillation and Pruning of Self-Supervised Speech Models | [pyf98/DPHuBERT](https://github.com/pyf98/DPHuBERT) |
|
| 511 |
+
|[DOI:10.21437/Interspeech.2017-68](http://dx.doi.org/10.21437/Interspeech.2017-68) | Harvest (F0 Predictor) | Harvest: A high-performance fundamental frequency estimator from speech signals | [mmorise/World/harvest](https://github.com/mmorise/World/blob/master/src/harvest.cpp) |
|
| 512 |
+
|[aes35-000039](https://www.aes.org/e-lib/online/browse.cfm?elib=15165) | Dio (F0 Predictor) | Fast and reliable F0 estimation method based on the period extraction of vocal fold vibration of singing voice and speech | [mmorise/World/dio](https://github.com/mmorise/World/blob/master/src/dio.cpp) |
|
| 513 |
+
|[8461329](https://ieeexplore.ieee.org/document/8461329) | Crepe (F0 Predictor) | Crepe: A Convolutional Representation for Pitch Estimation | [maxrmorrison/torchcrepe](https://github.com/maxrmorrison/torchcrepe) |
|
| 514 |
+
|[DOI:10.1016/j.wocn.2018.07.001](https://doi.org/10.1016/j.wocn.2018.07.001) | Parselmouth (F0 Predictor) | Introducing Parselmouth: A Python interface to Praat | [YannickJadoul/Parselmouth](https://github.com/YannickJadoul/Parselmouth) |
|
| 515 |
+
|[2306.15412v2](https://arxiv.org/abs/2306.15412v2) | RMVPE (F0 Predictor) | RMVPE: A Robust Model for Vocal Pitch Estimation in Polyphonic Music | [Dream-High/RMVPE](https://github.com/Dream-High/RMVPE) |
|
| 516 |
+
|[2010.05646](https://arxiv.org/abs/2010.05646) | HIFIGAN (Vocoder) | HiFi-GAN: Generative Adversarial Networks for Efficient and High Fidelity Speech Synthesis | [jik876/hifi-gan](https://github.com/jik876/hifi-gan) |
|
| 517 |
+
|[1810.11946](https://arxiv.org/abs/1810.11946.pdf) | NSF (Vocoder) | Neural source-filter-based waveform model for statistical parametric speech synthesis | [openvpi/DiffSinger/modules/nsf_hifigan](https://github.com/openvpi/DiffSinger/tree/refactor/modules/nsf_hifigan)
|
| 518 |
+
|[2006.08195](https://arxiv.org/abs/2006.08195) | Snake (Vocoder) | Neural Networks Fail to Learn Periodic Functions and How to Fix It | [EdwardDixon/snake](https://github.com/EdwardDixon/snake)
|
| 519 |
+
|[2105.02446v3](https://arxiv.org/abs/2105.02446v3) | Shallow Diffusion (PostProcessing)| DiffSinger: Singing Voice Synthesis via Shallow Diffusion Mechanism | [CNChTu/Diffusion-SVC](https://github.com/CNChTu/Diffusion-SVC) |
|
| 520 |
+
|[K-means](https://citeseerx.ist.psu.edu/viewdoc/download;jsessionid=01D65490BADCC216F350D06F84D721AD?doi=10.1.1.308.8619&rep=rep1&type=pdf) | Feature K-means Clustering (PreProcessing)| Some methods for classification and analysis of multivariate observations | 本代码库 |
|
| 521 |
+
| | Feature TopK Retrieval (PreProcessing)| Retrieval based Voice Conversion | [RVC-Project/Retrieval-based-Voice-Conversion-WebUI](https://github.com/RVC-Project/Retrieval-based-Voice-Conversion-WebUI) |
|
| 522 |
+
|
| 523 |
+
## ☀️ 旧贡献者
|
| 524 |
+
|
| 525 |
+
因为某些原因原作者进行了删库处理,本仓库重建之初由于组织成员疏忽直接重新上传了所有文件导致以前的 contributors 全部木大,现在在 README 里重新添加一个旧贡献者列表
|
| 526 |
+
|
| 527 |
+
*某些成员已根据其个人意愿不将其列出*
|
| 528 |
+
|
| 529 |
+
<table>
|
| 530 |
+
<tr>
|
| 531 |
+
<td align="center"><a href="https://github.com/MistEO"><img src="https://avatars.githubusercontent.com/u/18511905?v=4" width="100px;" alt=""/><br /><sub><b>MistEO</b></sub></a><br /></td>
|
| 532 |
+
<td align="center"><a href="https://github.com/XiaoMiku01"><img src="https://avatars.githubusercontent.com/u/54094119?v=4" width="100px;" alt=""/><br /><sub><b>XiaoMiku01</b></sub></a><br /></td>
|
| 533 |
+
<td align="center"><a href="https://github.com/ForsakenRei"><img src="https://avatars.githubusercontent.com/u/23041178?v=4" width="100px;" alt=""/><br /><sub><b>しぐれ</b></sub></a><br /></td>
|
| 534 |
+
<td align="center"><a href="https://github.com/TomoGaSukunai"><img src="https://avatars.githubusercontent.com/u/25863522?v=4" width="100px;" alt=""/><br /><sub><b>TomoGaSukunai</b></sub></a><br /></td>
|
| 535 |
+
<td align="center"><a href="https://github.com/Plachtaa"><img src="https://avatars.githubusercontent.com/u/112609742?v=4" width="100px;" alt=""/><br /><sub><b>Plachtaa</b></sub></a><br /></td>
|
| 536 |
+
<td align="center"><a href="https://github.com/zdxiaoda"><img src="https://avatars.githubusercontent.com/u/45501959?v=4" width="100px;" alt=""/><br /><sub><b>zd 小达</b></sub></a><br /></td>
|
| 537 |
+
<td align="center"><a href="https://github.com/Archivoice"><img src="https://avatars.githubusercontent.com/u/107520869?v=4" width="100px;" alt=""/><br /><sub><b>凍聲響世</b></sub></a><br /></td>
|
| 538 |
+
</tr>
|
| 539 |
+
</table>
|
| 540 |
+
|
| 541 |
+
## 📚 一些法律条例参考
|
| 542 |
+
|
| 543 |
+
#### 任何国家,地区,组织和个人使用此项目必须遵守以下法律
|
| 544 |
+
|
| 545 |
+
#### 《民法典》
|
| 546 |
+
|
| 547 |
+
##### 第一千零一十九条
|
| 548 |
+
|
| 549 |
+
任何组织或者个人不得以丑化、污损,或者利用信息技术手段伪造等方式��害他人的肖像权。未经肖像权人同意,不得制作、使用、公开肖像权人的肖像,但是法律另有规定的除外。未经肖像权人同意,肖像作品权利人不得以发表、复制、发行、出租、展览等方式使用或者公开肖像权人的肖像。对自然人声音的保护,参照适用肖像权保护的有关规定。
|
| 550 |
+
|
| 551 |
+
##### 第一千零二十四条
|
| 552 |
+
|
| 553 |
+
【名誉权】民事主体享有名誉权。任何组织或者个人不得以侮辱、诽谤等方式侵害他人的名誉权。
|
| 554 |
+
|
| 555 |
+
##### 第一千零二十七条
|
| 556 |
+
|
| 557 |
+
【作品侵害名誉权】行为人发表的文学、艺术作品以真人真事或者特定人为描述对象,含有侮辱、诽谤内容,侵害他人名誉权的,受害人有权依法请求该行为人承担民事责任。行为人发表的文学、艺术作品不以特定人为描述对象,仅其中的情节与该特定人的情况相似的,不承担民事责任。
|
| 558 |
+
|
| 559 |
+
#### 《[中华人民共和国宪法](http://www.gov.cn/guoqing/2018-03/22/content_5276318.htm)》
|
| 560 |
+
|
| 561 |
+
#### 《[中华人民共和国刑法](http://gongbao.court.gov.cn/Details/f8e30d0689b23f57bfc782d21035c3.html?sw=中华人民共和国刑法)》
|
| 562 |
+
|
| 563 |
+
#### 《[中华人民共和国民法典](http://gongbao.court.gov.cn/Details/51eb6750b8361f79be8f90d09bc202.html)》
|
| 564 |
+
|
| 565 |
+
#### 《[中华人民共和国合同法](http://www.npc.gov.cn/zgrdw/npc/lfzt/rlyw/2016-07/01/content_1992739.htm)》
|
| 566 |
+
|
| 567 |
+
## 💪 感谢所有的贡献者
|
| 568 |
+
<a href="https://github.com/svc-develop-team/so-vits-svc/graphs/contributors" target="_blank">
|
| 569 |
+
<img src="https://contrib.rocks/image?repo=svc-develop-team/so-vits-svc" />
|
| 570 |
+
</a>
|
app.py
ADDED
|
@@ -0,0 +1,1421 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import ast
|
| 2 |
+
import datetime
|
| 3 |
+
import glob
|
| 4 |
+
import json
|
| 5 |
+
import logging
|
| 6 |
+
import multiprocessing
|
| 7 |
+
import os
|
| 8 |
+
import re
|
| 9 |
+
import shutil
|
| 10 |
+
import subprocess
|
| 11 |
+
import traceback
|
| 12 |
+
import zipfile
|
| 13 |
+
from itertools import chain
|
| 14 |
+
from pathlib import Path
|
| 15 |
+
|
| 16 |
+
import gradio as gr
|
| 17 |
+
import librosa
|
| 18 |
+
import numpy as np
|
| 19 |
+
import soundfile as sf
|
| 20 |
+
import torch
|
| 21 |
+
import yaml
|
| 22 |
+
|
| 23 |
+
from auto_slicer import AutoSlicer
|
| 24 |
+
from compress_model import removeOptimizer
|
| 25 |
+
from inference.infer_tool_webui import Svc
|
| 26 |
+
from onnx_export import main as onnx_export
|
| 27 |
+
from tts_voices import SUPPORTED_LANGUAGES
|
| 28 |
+
from utils import mix_model
|
| 29 |
+
|
| 30 |
+
os.environ["PATH"] += os.pathsep + os.path.join(os.getcwd(), "ffmpeg", "bin")
|
| 31 |
+
|
| 32 |
+
logging.getLogger('numba').setLevel(logging.WARNING)
|
| 33 |
+
logging.getLogger('markdown_it').setLevel(logging.WARNING)
|
| 34 |
+
logging.getLogger('urllib3').setLevel(logging.WARNING)
|
| 35 |
+
logging.getLogger('matplotlib').setLevel(logging.WARNING)
|
| 36 |
+
|
| 37 |
+
# Some directories
|
| 38 |
+
workdir = "logs/44k"
|
| 39 |
+
second_dir = "models"
|
| 40 |
+
diff_second_dir = "models/diffusion"
|
| 41 |
+
diff_workdir = "logs/44k/diffusion"
|
| 42 |
+
config_dir = "configs/"
|
| 43 |
+
dataset_dir = "dataset/44k"
|
| 44 |
+
raw_path = "dataset_raw"
|
| 45 |
+
raw_wavs_path = "raw"
|
| 46 |
+
models_backup_path = 'models_backup'
|
| 47 |
+
root_dir = "checkpoints"
|
| 48 |
+
default_settings_file = "settings.yaml"
|
| 49 |
+
current_mode = ""
|
| 50 |
+
# Some global variables
|
| 51 |
+
debug = False
|
| 52 |
+
precheck_ok = False
|
| 53 |
+
model = None
|
| 54 |
+
sovits_params = {}
|
| 55 |
+
diff_params = {}
|
| 56 |
+
# Some dicts for mapping
|
| 57 |
+
MODEL_TYPE = {
|
| 58 |
+
"vec768l12": 768,
|
| 59 |
+
"vec256l9": 256,
|
| 60 |
+
"hubertsoft": 256,
|
| 61 |
+
"whisper-ppg": 1024,
|
| 62 |
+
"cnhubertlarge": 1024,
|
| 63 |
+
"dphubert": 768,
|
| 64 |
+
"wavlmbase+": 768,
|
| 65 |
+
"whisper-ppg-large": 1280
|
| 66 |
+
}
|
| 67 |
+
ENCODER_PRETRAIN = {
|
| 68 |
+
"vec256l9": "pretrain/checkpoint_best_legacy_500.pt",
|
| 69 |
+
"vec768l12": "pretrain/checkpoint_best_legacy_500.pt",
|
| 70 |
+
"hubertsoft": "pretrain/hubert-soft-0d54a1f4.pt",
|
| 71 |
+
"whisper-ppg": "pretrain/medium.pt",
|
| 72 |
+
"cnhubertlarge": "pretrain/chinese-hubert-large-fairseq-ckpt.pt",
|
| 73 |
+
"dphubert": "pretrain/DPHuBERT-sp0.75.pth",
|
| 74 |
+
"wavlmbase+": "pretrain/WavLM-Base+.pt",
|
| 75 |
+
"whisper-ppg-large": "pretrain/large-v2.pt"
|
| 76 |
+
}
|
| 77 |
+
|
| 78 |
+
|
| 79 |
+
class Config:
|
| 80 |
+
def __init__(self, path, type):
|
| 81 |
+
self.path = path
|
| 82 |
+
self.type = type
|
| 83 |
+
|
| 84 |
+
def read(self):
|
| 85 |
+
if self.type == "json":
|
| 86 |
+
with open(self.path, 'r') as f:
|
| 87 |
+
return json.load(f)
|
| 88 |
+
if self.type == "yaml":
|
| 89 |
+
with open(self.path, 'r') as f:
|
| 90 |
+
return yaml.safe_load(f)
|
| 91 |
+
|
| 92 |
+
def save(self, content):
|
| 93 |
+
if self.type == "json":
|
| 94 |
+
with open(self.path, 'w') as f:
|
| 95 |
+
json.dump(content, f, indent=4)
|
| 96 |
+
if self.type == "yaml":
|
| 97 |
+
with open(self.path, 'w') as f:
|
| 98 |
+
yaml.safe_dump(content, f, default_flow_style=False, sort_keys=False)
|
| 99 |
+
|
| 100 |
+
|
| 101 |
+
class ReleasePacker:
|
| 102 |
+
def __init__(self, speaker, model):
|
| 103 |
+
self.speaker = speaker
|
| 104 |
+
self.model = model
|
| 105 |
+
self.output_path = os.path.join("release_packs", f"{speaker}_release.zip")
|
| 106 |
+
self.file_list = []
|
| 107 |
+
|
| 108 |
+
def remove_temp(self, path):
|
| 109 |
+
for filename in os.listdir(path):
|
| 110 |
+
file_path = os.path.join(path, filename)
|
| 111 |
+
if os.path.isfile(file_path) and not filename.endswith(".zip"):
|
| 112 |
+
os.remove(file_path)
|
| 113 |
+
elif os.path.isdir(file_path):
|
| 114 |
+
shutil.rmtree(file_path, ignore_errors=True)
|
| 115 |
+
|
| 116 |
+
def add_file(self, file_paths):
|
| 117 |
+
self.file_list.extend(file_paths)
|
| 118 |
+
|
| 119 |
+
def spk_to_dict(self):
|
| 120 |
+
spk_string = self.speaker.replace(',', ',')
|
| 121 |
+
spk_string = spk_string.replace(' ', '')
|
| 122 |
+
_spk = spk_string.split(',')
|
| 123 |
+
return {_spk: index for index, _spk in enumerate(_spk)}
|
| 124 |
+
|
| 125 |
+
def generate_config(self, diff_model, config_origin):
|
| 126 |
+
_config_origin = Config(os.path.join(config_read_dir, config_origin), "json")
|
| 127 |
+
_template = Config("release_packs/config_template.json", "json")
|
| 128 |
+
_d_template = Config("release_packs/diffusion_template.yaml", "yaml")
|
| 129 |
+
orig_config = _config_origin.read()
|
| 130 |
+
config_template = _template.read()
|
| 131 |
+
diff_config_template = _d_template.read()
|
| 132 |
+
spk_dict = self.spk_to_dict()
|
| 133 |
+
_net = torch.load(os.path.join(ckpt_read_dir, self.model), map_location='cpu')
|
| 134 |
+
emb_dim, model_dim = _net['model'].get('emb_g.weight', torch.empty(0, 0)).size()
|
| 135 |
+
vol_emb = _net['model'].get('emb_vol.weight')
|
| 136 |
+
if vol_emb is not None:
|
| 137 |
+
config_template["train"]["vol_aug"] = config_template["model"]["vol_embedding"] = True
|
| 138 |
+
#Keep the spk_dict length same as emb_dim
|
| 139 |
+
if emb_dim > len(spk_dict):
|
| 140 |
+
for i in range(emb_dim - len(spk_dict)):
|
| 141 |
+
spk_dict[f"spk{i}"] = len(spk_dict)
|
| 142 |
+
if emb_dim < len(spk_dict):
|
| 143 |
+
for i in range(len(spk_dict) - emb_dim):
|
| 144 |
+
spk_dict.popitem()
|
| 145 |
+
self.speaker = ','.join(spk_dict.keys())
|
| 146 |
+
config_template['model']['ssl_dim'] = config_template["model"]["filter_channels"] = config_template["model"]["gin_channels"] = model_dim
|
| 147 |
+
config_template['model']['n_speakers'] = diff_config_template['model']['n_spk'] = emb_dim
|
| 148 |
+
config_template['spk'] = diff_config_template['spk'] = spk_dict
|
| 149 |
+
encoder = [k for k, v in MODEL_TYPE.items() if v == model_dim]
|
| 150 |
+
if orig_config['model']['speech_encoder'] in encoder:
|
| 151 |
+
config_template['model']['speech_encoder'] = orig_config['model']['speech_encoder']
|
| 152 |
+
else:
|
| 153 |
+
raise Exception("Config is not compatible with the model")
|
| 154 |
+
|
| 155 |
+
if diff_model != "no_diff":
|
| 156 |
+
_diff = torch.load(os.path.join(diff_read_dir, diff_model), map_location='cpu')
|
| 157 |
+
_, diff_dim = _diff["model"].get("unit_embed.weight", torch.empty(0, 0)).size()
|
| 158 |
+
if diff_dim == 256:
|
| 159 |
+
diff_config_template['data']['encoder'] = 'hubertsoft'
|
| 160 |
+
diff_config_template['data']['encoder_out_channels'] = 256
|
| 161 |
+
elif diff_dim == 768:
|
| 162 |
+
diff_config_template['data']['encoder'] = 'vec768l12'
|
| 163 |
+
diff_config_template['data']['encoder_out_channels'] = 768
|
| 164 |
+
elif diff_dim == 1024:
|
| 165 |
+
diff_config_template['data']['encoder'] = 'whisper-ppg'
|
| 166 |
+
diff_config_template['data']['encoder_out_channels'] = 1024
|
| 167 |
+
|
| 168 |
+
with open("release_packs/install.txt", 'w') as f:
|
| 169 |
+
f.write(str(self.file_list) + '#' + str(self.speaker))
|
| 170 |
+
|
| 171 |
+
_template.save(config_template)
|
| 172 |
+
_d_template.save(diff_config_template)
|
| 173 |
+
|
| 174 |
+
def unpack(self, zip_file):
|
| 175 |
+
with zipfile.ZipFile(zip_file, 'r') as zipf:
|
| 176 |
+
zipf.extractall("release_packs")
|
| 177 |
+
|
| 178 |
+
def formatted_install(self, install_txt):
|
| 179 |
+
with open(install_txt, 'r') as f:
|
| 180 |
+
content = f.read()
|
| 181 |
+
file_list, speaker = content.split('#')
|
| 182 |
+
self.speaker = speaker
|
| 183 |
+
file_list = ast.literal_eval(file_list)
|
| 184 |
+
self.file_list = file_list
|
| 185 |
+
for _, target_path in self.file_list:
|
| 186 |
+
if target_path != "install.txt" and target_path != "":
|
| 187 |
+
shutil.move(os.path.join("release_packs", target_path), target_path)
|
| 188 |
+
self.remove_temp("release_packs")
|
| 189 |
+
return self.speaker
|
| 190 |
+
|
| 191 |
+
def pack(self):
|
| 192 |
+
with zipfile.ZipFile(self.output_path, 'w', zipfile.ZIP_DEFLATED) as zipf:
|
| 193 |
+
for file_path, target_path in self.file_list:
|
| 194 |
+
if os.path.isfile(file_path):
|
| 195 |
+
zipf.write(file_path, arcname=target_path)
|
| 196 |
+
|
| 197 |
+
|
| 198 |
+
def debug_change():
|
| 199 |
+
global debug
|
| 200 |
+
debug = debug_button.value
|
| 201 |
+
|
| 202 |
+
def get_default_settings():
|
| 203 |
+
global sovits_params, diff_params, second_dir_enable
|
| 204 |
+
config_file = Config(default_settings_file, "yaml")
|
| 205 |
+
default_settings = config_file.read()
|
| 206 |
+
sovits_params = default_settings['sovits_params']
|
| 207 |
+
diff_params = default_settings['diff_params']
|
| 208 |
+
webui_settings = default_settings['webui_settings']
|
| 209 |
+
second_dir_enable = webui_settings['second_dir']
|
| 210 |
+
return sovits_params, diff_params, second_dir_enable
|
| 211 |
+
|
| 212 |
+
def webui_change(read_second_dir):
|
| 213 |
+
global second_dir_enable
|
| 214 |
+
config_file = Config(default_settings_file, "yaml")
|
| 215 |
+
default_settings = config_file.read()
|
| 216 |
+
second_dir_enable = default_settings['webui_settings']['second_dir'] = read_second_dir
|
| 217 |
+
config_file.save(default_settings)
|
| 218 |
+
|
| 219 |
+
def get_current_mode():
|
| 220 |
+
global current_mode
|
| 221 |
+
current_mode = "当前模式:独立目录模式,将从'./models/'读取模型文件" if second_dir_enable else "当前模式:工作目录模式,将从'./logs/44k'读取模型文件"
|
| 222 |
+
return current_mode
|
| 223 |
+
|
| 224 |
+
def save_default_settings(log_interval,eval_interval,keep_ckpts,batch_size,learning_rate,amp_dtype,all_in_mem,num_workers,cache_all_data,cache_device,diff_amp_dtype,diff_batch_size,diff_lr,diff_interval_log,diff_interval_val,diff_force_save,diff_k_step_max):
|
| 225 |
+
config_file = Config(default_settings_file, "yaml")
|
| 226 |
+
default_settings = config_file.read()
|
| 227 |
+
default_settings['sovits_params']['log_interval'] = int(log_interval)
|
| 228 |
+
default_settings['sovits_params']['eval_interval'] = int(eval_interval)
|
| 229 |
+
default_settings['sovits_params']['keep_ckpts'] = int(keep_ckpts)
|
| 230 |
+
default_settings['sovits_params']['batch_size'] = int(batch_size)
|
| 231 |
+
default_settings['sovits_params']['learning_rate'] = float(learning_rate)
|
| 232 |
+
default_settings['sovits_params']['amp_dtype'] = str(amp_dtype)
|
| 233 |
+
default_settings['sovits_params']['all_in_mem'] = all_in_mem
|
| 234 |
+
default_settings['diff_params']['num_workers'] = int(num_workers)
|
| 235 |
+
default_settings['diff_params']['cache_all_data'] = cache_all_data
|
| 236 |
+
default_settings['diff_params']['cache_device'] = str(cache_device)
|
| 237 |
+
default_settings['diff_params']['amp_dtype'] = str(diff_amp_dtype)
|
| 238 |
+
default_settings['diff_params']['diff_batch_size'] = int(diff_batch_size)
|
| 239 |
+
default_settings['diff_params']['diff_lr'] = float(diff_lr)
|
| 240 |
+
default_settings['diff_params']['diff_interval_log'] = int(diff_interval_log)
|
| 241 |
+
default_settings['diff_params']['diff_interval_val'] = int(diff_interval_val)
|
| 242 |
+
default_settings['diff_params']['diff_force_save'] = int(diff_force_save)
|
| 243 |
+
default_settings['diff_params']['diff_k_step_max'] = diff_k_step_max
|
| 244 |
+
config_file.save(default_settings)
|
| 245 |
+
return "成功保存默认配置"
|
| 246 |
+
|
| 247 |
+
def get_model_info(choice_ckpt):
|
| 248 |
+
pthfile = os.path.join(ckpt_read_dir, choice_ckpt)
|
| 249 |
+
net = torch.load(pthfile, map_location=torch.device('cpu')) #cpu load to avoid using gpu memory
|
| 250 |
+
spk_emb = net["model"].get("emb_g.weight")
|
| 251 |
+
if spk_emb is None:
|
| 252 |
+
return "所选模型缺少emb_g.weight,你可能选择了一个底模"
|
| 253 |
+
_layer = spk_emb.size(1)
|
| 254 |
+
encoder = [k for k, v in MODEL_TYPE.items() if v == _layer] #通过维度对应编码器
|
| 255 |
+
encoder.sort()
|
| 256 |
+
if encoder == ["hubertsoft", "vec256l9"]:
|
| 257 |
+
encoder = ["vec256l9 / hubertsoft"]
|
| 258 |
+
if encoder == ["cnhubertlarge", "whisper-ppg"]:
|
| 259 |
+
encoder = ["whisper-ppg / cnhubertlarge"]
|
| 260 |
+
if encoder == ["dphubert", "vec768l12", "wavlmbase+"]:
|
| 261 |
+
encoder = ["vec768l12 / dphubert / wavlmbase+"]
|
| 262 |
+
return encoder[0]
|
| 263 |
+
|
| 264 |
+
def load_json_encoder(config_choice, choice_ckpt):
|
| 265 |
+
if config_choice == "no_config":
|
| 266 |
+
return "未启用自动加载,请手动选择配置文件"
|
| 267 |
+
if choice_ckpt == "no_model":
|
| 268 |
+
return "请先选择模型"
|
| 269 |
+
config_file = Config(os.path.join(config_read_dir, config_choice), "json")
|
| 270 |
+
config = config_file.read()
|
| 271 |
+
try:
|
| 272 |
+
#比对配置文件中的模型维度与该encoder的实际维度是否对应,防止古神语
|
| 273 |
+
config_encoder = config["model"].get("speech_encoder", "no_encoder")
|
| 274 |
+
config_dim = config["model"]["ssl_dim"]
|
| 275 |
+
#旧版配置文件自动匹配
|
| 276 |
+
if config_encoder == "no_encoder":
|
| 277 |
+
config_encoder = config["model"]["speech_encoder"] = "vec256l9" if config_dim == 256 else "vec768l12"
|
| 278 |
+
config_file.save(config)
|
| 279 |
+
correct_dim = MODEL_TYPE.get(config_encoder, "unknown")
|
| 280 |
+
if config_dim != correct_dim:
|
| 281 |
+
return "配置文件中的编码器与模型维度不匹配"
|
| 282 |
+
return config_encoder
|
| 283 |
+
except Exception as e:
|
| 284 |
+
return f"出错了: {e}"
|
| 285 |
+
|
| 286 |
+
def auto_load(choice_ckpt):
|
| 287 |
+
global second_dir_enable
|
| 288 |
+
model_output_msg = get_model_info(choice_ckpt)
|
| 289 |
+
json_output_msg = config_choice = ""
|
| 290 |
+
choice_ckpt_name, _ = os.path.splitext(choice_ckpt)
|
| 291 |
+
if second_dir_enable:
|
| 292 |
+
all_config = [json for json in os.listdir(second_dir) if json.endswith(".json")]
|
| 293 |
+
for config in all_config:
|
| 294 |
+
config_fname, _ = os.path.splitext(config)
|
| 295 |
+
if config_fname == choice_ckpt_name:
|
| 296 |
+
config_choice = config
|
| 297 |
+
json_output_msg = load_json_encoder(config, choice_ckpt)
|
| 298 |
+
if json_output_msg != "":
|
| 299 |
+
return model_output_msg, config_choice, json_output_msg
|
| 300 |
+
else:
|
| 301 |
+
return model_output_msg, "no_config", ""
|
| 302 |
+
else:
|
| 303 |
+
return model_output_msg, "no_config", ""
|
| 304 |
+
|
| 305 |
+
def auto_load_diff(diff_model):
|
| 306 |
+
global second_dir_enable
|
| 307 |
+
if second_dir_enable is False:
|
| 308 |
+
return "no_diff_config"
|
| 309 |
+
all_diff_config = [yaml for yaml in os.listdir(second_dir) if yaml.endswith(".yaml")]
|
| 310 |
+
for config in all_diff_config:
|
| 311 |
+
config_fname, _ = os.path.splitext(config)
|
| 312 |
+
diff_fname, _ = os.path.splitext(diff_model)
|
| 313 |
+
if config_fname == diff_fname:
|
| 314 |
+
return config
|
| 315 |
+
return "no_diff_config"
|
| 316 |
+
|
| 317 |
+
def load_model_func(ckpt_name,cluster_name,config_name,enhance,diff_model_name,diff_config_name,only_diffusion,use_spk_mix,using_device,method,speedup,cl_num):
|
| 318 |
+
global model
|
| 319 |
+
config_path = os.path.join(config_read_dir, config_name) if not only_diffusion else "configs/config.json"
|
| 320 |
+
diff_config_path = os.path.join(config_read_dir, diff_config_name) if diff_config_name != "no_diff_config" else "configs/diffusion.yaml"
|
| 321 |
+
ckpt_path = os.path.join(ckpt_read_dir, ckpt_name)
|
| 322 |
+
cluster_path = os.path.join(ckpt_read_dir, cluster_name)
|
| 323 |
+
diff_model_path = os.path.join(diff_read_dir, diff_model_name)
|
| 324 |
+
k_step_max = 1000
|
| 325 |
+
if not only_diffusion:
|
| 326 |
+
config = Config(config_path, "json").read()
|
| 327 |
+
if diff_model_name != "no_diff":
|
| 328 |
+
_diff = Config(diff_config_path, "yaml")
|
| 329 |
+
_content = _diff.read()
|
| 330 |
+
diff_spk = _content.get('spk', {})
|
| 331 |
+
diff_spk_choice = spk_choice = next(iter(diff_spk), "未检测到音色")
|
| 332 |
+
if not only_diffusion:
|
| 333 |
+
if _content['data'].get('encoder_out_channels') != config["model"].get('ssl_dim'):
|
| 334 |
+
return "扩散模型维度与主模型不匹配,请确保两个模型使用的是同一个编码器", gr.Dropdown.update(choices=[], value=""), 0, None
|
| 335 |
+
_content["infer"]["speedup"] = int(speedup)
|
| 336 |
+
_content["infer"]["method"] = str(method)
|
| 337 |
+
k_step_max = _content["model"].get('k_step_max', 0) if _content["model"].get('k_step_max', 0) != 0 else 1000
|
| 338 |
+
_diff.save(_content)
|
| 339 |
+
if not only_diffusion:
|
| 340 |
+
net = torch.load(ckpt_path, map_location=torch.device('cpu'))
|
| 341 |
+
#读取模型各维度并比对,还有小可爱无视提示硬要加载底模的就返回个未初始张量
|
| 342 |
+
emb_dim, model_dim = net["model"].get("emb_g.weight", torch.empty(0, 0)).size()
|
| 343 |
+
if emb_dim > config["model"]["n_speakers"]:
|
| 344 |
+
return "模型说话人数量与emb维度不匹配", gr.Dropdown.update(choices=[], value=""), 0, None
|
| 345 |
+
if model_dim != config["model"]["ssl_dim"]:
|
| 346 |
+
return "配置文件与模型不匹配", gr.Dropdown.update(choices=[], value=""), 0, None
|
| 347 |
+
encoder = config["model"]["speech_encoder"]
|
| 348 |
+
spk_dict = config.get('spk', {})
|
| 349 |
+
spk_choice = next(iter(spk_dict), "未检测到音色")
|
| 350 |
+
else:
|
| 351 |
+
spk_dict = diff_spk
|
| 352 |
+
spk_choice = diff_spk_choice
|
| 353 |
+
fr = cluster_name.endswith(".pkl") #如果是pkl后缀就启用特征检索
|
| 354 |
+
shallow_diffusion = diff_model_name != "no_diff" #加载了扩散模型就启用浅扩散
|
| 355 |
+
device = cuda[using_device] if "CUDA" in using_device else using_device
|
| 356 |
+
model = Svc(ckpt_path,
|
| 357 |
+
config_path,
|
| 358 |
+
device=device if device != "Auto" else None,
|
| 359 |
+
cluster_model_path=cluster_path,
|
| 360 |
+
nsf_hifigan_enhance=enhance,
|
| 361 |
+
diffusion_model_path=diff_model_path,
|
| 362 |
+
diffusion_config_path=diff_config_path,
|
| 363 |
+
shallow_diffusion=shallow_diffusion,
|
| 364 |
+
only_diffusion=only_diffusion,
|
| 365 |
+
spk_mix_enable=use_spk_mix,
|
| 366 |
+
feature_retrieval=fr)
|
| 367 |
+
spk_list = list(spk_dict.keys())
|
| 368 |
+
if not only_diffusion:
|
| 369 |
+
clip = 25 if encoder == "whisper-ppg" or encoder == "whisper-ppg-large" else cl_num #Whisper必须强制切片25秒
|
| 370 |
+
device_name = torch.cuda.get_device_properties(model.dev).name if "cuda" in str(model.dev) else str(model.dev)
|
| 371 |
+
sovits_msg = f"模型被成功加载到了{device_name}上\n"
|
| 372 |
+
else:
|
| 373 |
+
clip = cl_num
|
| 374 |
+
sovits_msg = "启用全扩散推理,未加载So-VITS模型\n"
|
| 375 |
+
index_or_kmeans = "特征索引" if fr else "聚类模型"
|
| 376 |
+
clu_load = "未加载" if cluster_name == "no_clu" else cluster_name
|
| 377 |
+
diff_load = "未加载" if diff_model_name == "no_diff" else f"{diff_model_name} | 采样器: {method} | 加速倍数:{int(speedup)} | 最大浅扩散步数:{k_step_max}"
|
| 378 |
+
output_msg = f"{sovits_msg}{index_or_kmeans}:{clu_load}\n扩散模型:{diff_load}"
|
| 379 |
+
return (
|
| 380 |
+
output_msg,
|
| 381 |
+
gr.Dropdown.update(choices=spk_list, value=spk_choice),
|
| 382 |
+
clip,
|
| 383 |
+
gr.Slider.update(value=100 if k_step_max>100 else k_step_max, minimum=speedup, maximum=k_step_max)
|
| 384 |
+
)
|
| 385 |
+
|
| 386 |
+
def model_empty_cache():
|
| 387 |
+
global model
|
| 388 |
+
if model is None:
|
| 389 |
+
return sid.update(choices = [],value=""),"没有模型需要卸载!"
|
| 390 |
+
else:
|
| 391 |
+
model.unload_model()
|
| 392 |
+
model = None
|
| 393 |
+
torch.cuda.empty_cache()
|
| 394 |
+
return sid.update(choices = [],value=""),"模型卸载完毕!"
|
| 395 |
+
|
| 396 |
+
def get_file_options(directory, extension):
|
| 397 |
+
return [file for file in os.listdir(directory) if file.endswith(extension)]
|
| 398 |
+
|
| 399 |
+
def load_options():
|
| 400 |
+
ckpt_list = [file for file in get_file_options(ckpt_read_dir, ".pth") if not file.startswith("D_") or file == "G_0.pth"]
|
| 401 |
+
config_list = get_file_options(config_read_dir, ".json")
|
| 402 |
+
cluster_list = ["no_clu"] + get_file_options(ckpt_read_dir, ".pt") + get_file_options(ckpt_read_dir, ".pkl") # 聚类和特征检索模型
|
| 403 |
+
diff_list = ["no_diff"] + get_file_options(diff_read_dir, ".pt")
|
| 404 |
+
diff_config_list = ["no_diff_config"] + get_file_options(config_read_dir, ".yaml")
|
| 405 |
+
return ckpt_list, config_list, cluster_list, diff_list, diff_config_list
|
| 406 |
+
|
| 407 |
+
def refresh_options():
|
| 408 |
+
global ckpt_read_dir, config_read_dir, diff_read_dir, current_mode
|
| 409 |
+
ckpt_read_dir = second_dir if second_dir_enable else workdir
|
| 410 |
+
config_read_dir = second_dir if second_dir_enable else config_dir
|
| 411 |
+
diff_read_dir = diff_second_dir if second_dir_enable else diff_workdir
|
| 412 |
+
ckpt_list, config_list, cluster_list, diff_list, diff_config_list = load_options()
|
| 413 |
+
current_mode = get_current_mode()
|
| 414 |
+
return (
|
| 415 |
+
choice_ckpt.update(choices=ckpt_list),
|
| 416 |
+
config_choice.update(choices=config_list),
|
| 417 |
+
cluster_choice.update(choices=cluster_list),
|
| 418 |
+
diff_choice.update(choices=diff_list),
|
| 419 |
+
diff_config_choice.update(choices=diff_config_list),
|
| 420 |
+
mode_caption.update(value=f"""{current_mode},可在页面底端切换模式""")
|
| 421 |
+
)
|
| 422 |
+
|
| 423 |
+
def source_change(use_microphone):
|
| 424 |
+
if use_microphone:
|
| 425 |
+
return vc_input3.update(source="microphone")
|
| 426 |
+
else:
|
| 427 |
+
return vc_input3.update(source="upload")
|
| 428 |
+
|
| 429 |
+
def vc_infer(output_format, sid, input_audio, sr, input_audio_path, vc_transform, auto_f0, cluster_ratio, slice_db, noise_scale, pad_seconds, cl_num, lg_num, lgr_num, f0_predictor, enhancer_adaptive_key, cr_threshold, k_step, use_spk_mix, second_encoding, loudness_envelope_adjustment):
|
| 430 |
+
if np.issubdtype(input_audio.dtype, np.integer):
|
| 431 |
+
input_audio = (input_audio / np.iinfo(input_audio.dtype).max).astype(np.float32)
|
| 432 |
+
if len(input_audio.shape) > 1:
|
| 433 |
+
input_audio = librosa.to_mono(input_audio.transpose(1, 0))
|
| 434 |
+
if sr != 44100:
|
| 435 |
+
input_audio = librosa.resample(input_audio, orig_sr=sr, target_sr=44100)
|
| 436 |
+
sf.write("temp.wav", input_audio, 44100, format="wav")
|
| 437 |
+
_audio = model.slice_inference(
|
| 438 |
+
"temp.wav",
|
| 439 |
+
sid,
|
| 440 |
+
vc_transform,
|
| 441 |
+
slice_db,
|
| 442 |
+
cluster_ratio,
|
| 443 |
+
auto_f0,
|
| 444 |
+
noise_scale,
|
| 445 |
+
pad_seconds,
|
| 446 |
+
cl_num,
|
| 447 |
+
lg_num,
|
| 448 |
+
lgr_num,
|
| 449 |
+
f0_predictor,
|
| 450 |
+
enhancer_adaptive_key,
|
| 451 |
+
cr_threshold,
|
| 452 |
+
k_step,
|
| 453 |
+
use_spk_mix,
|
| 454 |
+
second_encoding,
|
| 455 |
+
loudness_envelope_adjustment
|
| 456 |
+
)
|
| 457 |
+
model.clear_empty()
|
| 458 |
+
if not os.path.exists("results"):
|
| 459 |
+
os.makedirs("results")
|
| 460 |
+
key = "auto" if auto_f0 else f"{int(vc_transform)}key"
|
| 461 |
+
cluster = "_" if cluster_ratio == 0 else f"_{cluster_ratio}_"
|
| 462 |
+
isdiffusion = "sovits_"
|
| 463 |
+
if model.shallow_diffusion:
|
| 464 |
+
isdiffusion = "sovdiff_"
|
| 465 |
+
if model.only_diffusion:
|
| 466 |
+
isdiffusion = "diff_"
|
| 467 |
+
#Gradio上传的filepath因为未知原因会有一个无意义的固定后缀,这里去掉
|
| 468 |
+
truncated_basename = Path(input_audio_path).stem[:-6] if Path(input_audio_path).stem[-6:] == "-0-100" else Path(input_audio_path).stem
|
| 469 |
+
output_file_name = f'{truncated_basename}_{sid}_{key}{cluster}{isdiffusion}{f0_predictor}.{output_format}'
|
| 470 |
+
output_file_path = os.path.join("results", output_file_name)
|
| 471 |
+
if os.path.exists(output_file_path):
|
| 472 |
+
count = 1
|
| 473 |
+
while os.path.exists(output_file_path):
|
| 474 |
+
output_file_name = f'{truncated_basename}_{sid}_{key}{cluster}{isdiffusion}{f0_predictor}_{str(count)}.{output_format}'
|
| 475 |
+
output_file_path = os.path.join("results", output_file_name)
|
| 476 |
+
count += 1
|
| 477 |
+
sf.write(output_file_path, _audio, model.target_sample, format=output_format)
|
| 478 |
+
return output_file_path
|
| 479 |
+
|
| 480 |
+
def vc_fn(output_format, sid, input_audio, vc_transform, auto_f0, cluster_ratio, slice_db, noise_scale, pad_seconds, cl_num, lg_num, lgr_num, f0_predictor, enhancer_adaptive_key, cr_threshold, k_step, use_spk_mix, second_encoding, loudness_envelope_adjustment, progress=gr.Progress(track_tqdm=True)):
|
| 481 |
+
global model
|
| 482 |
+
try:
|
| 483 |
+
if input_audio is None:
|
| 484 |
+
return "你还没有上传音频", None
|
| 485 |
+
if model is None:
|
| 486 |
+
return "你还没有加载模型", None
|
| 487 |
+
if getattr(model, 'cluster_model', None) is None and model.feature_retrieval is False:
|
| 488 |
+
if cluster_ratio != 0:
|
| 489 |
+
return "你还未加载聚类或特征检索模型,无法启用聚类/特征检索混合比例", None
|
| 490 |
+
audio, sr = sf.read(input_audio)
|
| 491 |
+
output_file_path = vc_infer(output_format, sid, audio, sr, input_audio, vc_transform, auto_f0, cluster_ratio, slice_db, noise_scale, pad_seconds, cl_num, lg_num, lgr_num, f0_predictor, enhancer_adaptive_key, cr_threshold, k_step, use_spk_mix, second_encoding, loudness_envelope_adjustment)
|
| 492 |
+
os.remove("temp.wav")
|
| 493 |
+
return "Success", output_file_path
|
| 494 |
+
except Exception as e:
|
| 495 |
+
if debug:
|
| 496 |
+
traceback.print_exc()
|
| 497 |
+
raise gr.Error(e)
|
| 498 |
+
|
| 499 |
+
def vc_batch_fn(output_format, sid, input_audio_files, vc_transform, auto_f0, cluster_ratio, slice_db, noise_scale, pad_seconds, cl_num, lg_num, lgr_num, f0_predictor, enhancer_adaptive_key, cr_threshold, k_step, use_spk_mix, second_encoding, loudness_envelope_adjustment, progress=gr.Progress()):
|
| 500 |
+
global model
|
| 501 |
+
try:
|
| 502 |
+
if input_audio_files is None or len(input_audio_files) == 0:
|
| 503 |
+
return "你还没有上传音频"
|
| 504 |
+
if model is None:
|
| 505 |
+
return "你还没有加载模型"
|
| 506 |
+
if getattr(model, 'cluster_model', None) is None and model.feature_retrieval is False:
|
| 507 |
+
if cluster_ratio != 0:
|
| 508 |
+
return "你还未加载聚类或特征检索模型,无法启用聚类/特征检索混合比例", None
|
| 509 |
+
_output = []
|
| 510 |
+
for file_obj in progress.tqdm(input_audio_files, desc="Inferencing"):
|
| 511 |
+
print(f"Start processing: {file_obj.name}")
|
| 512 |
+
input_audio_path = file_obj.name
|
| 513 |
+
audio, sr = sf.read(input_audio_path)
|
| 514 |
+
output_file_path = vc_infer(output_format, sid, audio, sr, input_audio_path, vc_transform, auto_f0, cluster_ratio, slice_db, noise_scale, pad_seconds, cl_num, lg_num, lgr_num, f0_predictor, enhancer_adaptive_key, cr_threshold, k_step, use_spk_mix, second_encoding, loudness_envelope_adjustment)
|
| 515 |
+
_output.append(output_file_path)
|
| 516 |
+
return "批量推理完成,音频已经被保存到results文件夹"
|
| 517 |
+
except Exception as e:
|
| 518 |
+
if debug:
|
| 519 |
+
traceback.print_exc()
|
| 520 |
+
raise gr.Error(e)
|
| 521 |
+
|
| 522 |
+
def tts_fn(_text, _gender, _lang, _rate, _volume, output_format, sid, vc_transform, auto_f0,cluster_ratio, slice_db, noise_scale,pad_seconds,cl_num,lg_num,lgr_num,f0_predictor,enhancer_adaptive_key,cr_threshold, k_step,use_spk_mix,second_encoding,loudness_envelope_adjustment,progress=gr.Progress(track_tqdm=True)):
|
| 523 |
+
global model
|
| 524 |
+
try:
|
| 525 |
+
if model is None:
|
| 526 |
+
return "��还没有加载模型", None
|
| 527 |
+
if getattr(model, 'cluster_model', None) is None and model.feature_retrieval is False:
|
| 528 |
+
if cluster_ratio != 0:
|
| 529 |
+
return "你还未加载聚类或特征检索模型,无法启用聚类/特征检索混合比例", None
|
| 530 |
+
_rate = f"+{int(_rate*100)}%" if _rate >= 0 else f"{int(_rate*100)}%"
|
| 531 |
+
_volume = f"+{int(_volume*100)}%" if _volume >= 0 else f"{int(_volume*100)}%"
|
| 532 |
+
if _lang == "Auto":
|
| 533 |
+
_gender = "Male" if _gender == "男" else "Female"
|
| 534 |
+
subprocess.run([r".\workenv\python.exe", "tts.py", _text, _lang, _rate, _volume, _gender])
|
| 535 |
+
else:
|
| 536 |
+
subprocess.run([r".\workenv\python.exe", "tts.py", _text, _lang, _rate, _volume])
|
| 537 |
+
target_sr = 44100
|
| 538 |
+
y, sr = librosa.load("tts.wav")
|
| 539 |
+
resampled_y = librosa.resample(y, orig_sr=sr, target_sr=target_sr)
|
| 540 |
+
sf.write("tts.wav", resampled_y, target_sr, subtype = "PCM_16")
|
| 541 |
+
input_audio = "tts.wav"
|
| 542 |
+
audio, sr = sf.read(input_audio)
|
| 543 |
+
output_file_path = vc_infer(output_format, sid, audio, sr, input_audio, vc_transform, auto_f0, cluster_ratio, slice_db, noise_scale, pad_seconds, cl_num, lg_num, lgr_num, f0_predictor, enhancer_adaptive_key, cr_threshold, k_step, use_spk_mix, second_encoding, loudness_envelope_adjustment)
|
| 544 |
+
#os.remove("tts.wav")
|
| 545 |
+
return "Success", output_file_path
|
| 546 |
+
except Exception as e:
|
| 547 |
+
if debug:
|
| 548 |
+
traceback.print_exc()
|
| 549 |
+
raise gr.Error(e)
|
| 550 |
+
|
| 551 |
+
def load_raw_dirs():
|
| 552 |
+
global precheck_ok
|
| 553 |
+
precheck_ok = False
|
| 554 |
+
allowed_pattern = re.compile(r'^[a-zA-Z0-9_@#$%^&()_+\-=\s\.]*$')
|
| 555 |
+
illegal_files = illegal_dataset = []
|
| 556 |
+
for root, dirs, files in os.walk(raw_path):
|
| 557 |
+
for dir in dirs:
|
| 558 |
+
if not allowed_pattern.match(dir):
|
| 559 |
+
illegal_dataset.append(dir)
|
| 560 |
+
if illegal_dataset:
|
| 561 |
+
return f"数据集文件夹名只能包含数字、字母、下划线,以下文件夹不符合要求,请改名后再试:\n{illegal_dataset}"
|
| 562 |
+
if root != raw_path: # 只处理子文件夹内的文件
|
| 563 |
+
for file in files:
|
| 564 |
+
if not allowed_pattern.match(file) and file not in illegal_files:
|
| 565 |
+
illegal_files.append(file)
|
| 566 |
+
if not file.lower().endswith('.wav') and file not in illegal_files:
|
| 567 |
+
illegal_files.append(file)
|
| 568 |
+
if illegal_files:
|
| 569 |
+
return f"数据集文件名只能包含数字、字母、下划线,且必须是.wav格式,以下文件不符合要求,请改名后再试:\n{illegal_files}"
|
| 570 |
+
spk_dirs = [entry.name for entry in os.scandir(raw_path) if entry.is_dir()]
|
| 571 |
+
if spk_dirs:
|
| 572 |
+
precheck_ok = True
|
| 573 |
+
return spk_dirs
|
| 574 |
+
else:
|
| 575 |
+
return "未找到数据集,请检查dataset_raw文件夹"
|
| 576 |
+
|
| 577 |
+
def dataset_preprocess(encoder, f0_predictor, use_diff, vol_aug, skip_loudnorm, num_processes, tiny_enable):
|
| 578 |
+
if precheck_ok:
|
| 579 |
+
diff_arg = "--use_diff" if use_diff else ""
|
| 580 |
+
vol_aug_arg = "--vol_aug" if vol_aug else ""
|
| 581 |
+
skip_loudnorm_arg = "--skip_loudnorm" if skip_loudnorm else ""
|
| 582 |
+
tiny_arg = "--tiny" if tiny_enable else ""
|
| 583 |
+
preprocess_commands = [
|
| 584 |
+
r".\workenv\python.exe resample.py %s" % (skip_loudnorm_arg),
|
| 585 |
+
r".\workenv\python.exe preprocess_flist_config.py --speech_encoder %s %s %s" % (encoder, vol_aug_arg, tiny_arg),
|
| 586 |
+
r".\workenv\python.exe preprocess_hubert_f0.py --num_processes %s --f0_predictor %s %s" % (num_processes ,f0_predictor, diff_arg)
|
| 587 |
+
]
|
| 588 |
+
accumulated_output = ""
|
| 589 |
+
#清空dataset
|
| 590 |
+
dataset = os.listdir(dataset_dir)
|
| 591 |
+
if len(dataset) != 0:
|
| 592 |
+
for dir in dataset:
|
| 593 |
+
dataset_spk_dir = os.path.join(dataset_dir, str(dir))
|
| 594 |
+
if os.path.isdir(dataset_spk_dir):
|
| 595 |
+
shutil.rmtree(dataset_spk_dir)
|
| 596 |
+
accumulated_output += f"Deleting previous dataset: {dir}\n"
|
| 597 |
+
for command in preprocess_commands:
|
| 598 |
+
try:
|
| 599 |
+
result = subprocess.Popen(command, stdout=subprocess.PIPE, stderr=subprocess.STDOUT, shell=True, text=True)
|
| 600 |
+
accumulated_output += f"Command: {command}, Using Encoder: {encoder}, Using f0 Predictor: {f0_predictor}\n"
|
| 601 |
+
yield accumulated_output, None
|
| 602 |
+
progress_line = None
|
| 603 |
+
for line in result.stdout:
|
| 604 |
+
if r"it/s" in line or r"s/it" in line: #防止进度条刷屏
|
| 605 |
+
progress_line = line
|
| 606 |
+
else:
|
| 607 |
+
accumulated_output += line
|
| 608 |
+
if progress_line is None:
|
| 609 |
+
yield accumulated_output, None
|
| 610 |
+
else:
|
| 611 |
+
yield accumulated_output + progress_line, None
|
| 612 |
+
result.communicate()
|
| 613 |
+
except subprocess.CalledProcessError as e:
|
| 614 |
+
result = e.output
|
| 615 |
+
accumulated_output += f"Error: {result}\n"
|
| 616 |
+
yield accumulated_output, None
|
| 617 |
+
if progress_line is not None:
|
| 618 |
+
accumulated_output += progress_line
|
| 619 |
+
accumulated_output += '-' * 50 + '\n'
|
| 620 |
+
yield accumulated_output, None
|
| 621 |
+
config_path = "configs/config.json"
|
| 622 |
+
with open(config_path, 'r') as f:
|
| 623 |
+
config = json.load(f)
|
| 624 |
+
spk_name = config.get('spk', None)
|
| 625 |
+
yield accumulated_output, gr.Textbox.update(value=spk_name)
|
| 626 |
+
else:
|
| 627 |
+
yield "数据集识别未通过,请先识别数据集并确保没有报错信息", None
|
| 628 |
+
|
| 629 |
+
def regenerate_config(encoder, vol_aug, tiny_enable):
|
| 630 |
+
if precheck_ok is False:
|
| 631 |
+
return "数据集识别未通过,请检查识别结果的报错信息"
|
| 632 |
+
vol_aug_arg = "--vol_aug" if vol_aug else ""
|
| 633 |
+
tiny_arg = "--tiny" if tiny_enable else ""
|
| 634 |
+
cmd = r".\workenv\python.exe preprocess_flist_config.py --speech_encoder %s %s %s" % (encoder, vol_aug_arg, tiny_arg)
|
| 635 |
+
output = ""
|
| 636 |
+
try:
|
| 637 |
+
result = subprocess.Popen(cmd, stdout=subprocess.PIPE, stderr=subprocess.STDOUT, shell=True, text=True)
|
| 638 |
+
for line in result.stdout:
|
| 639 |
+
output += line
|
| 640 |
+
output += "Regenerate config file successfully."
|
| 641 |
+
except subprocess.CalledProcessError as e:
|
| 642 |
+
result = e.output
|
| 643 |
+
output += f"Error: {result}\n"
|
| 644 |
+
return output
|
| 645 |
+
|
| 646 |
+
def clear_output():
|
| 647 |
+
return gr.Textbox.update(value="Cleared!>_<")
|
| 648 |
+
|
| 649 |
+
def get_available_encoder():
|
| 650 |
+
current_pretrain = os.listdir("pretrain")
|
| 651 |
+
current_pretrain = [("pretrain/" + model) for model in current_pretrain]
|
| 652 |
+
encoder_list = []
|
| 653 |
+
for encoder, path in ENCODER_PRETRAIN.items():
|
| 654 |
+
if path in current_pretrain:
|
| 655 |
+
encoder_list.append(encoder)
|
| 656 |
+
return encoder_list
|
| 657 |
+
|
| 658 |
+
def config_fn(log_interval, eval_interval, keep_ckpts, batch_size, lr, amp_dtype, all_in_mem, diff_num_workers, diff_cache_all_data, diff_batch_size, diff_lr, diff_interval_log, diff_interval_val, diff_cache_device, diff_amp_dtype, diff_force_save, diff_k_step_max):
|
| 659 |
+
if amp_dtype == "fp16" or amp_dtype == "bf16":
|
| 660 |
+
fp16_run = True
|
| 661 |
+
else:
|
| 662 |
+
fp16_run = False
|
| 663 |
+
amp_dtype = "fp16"
|
| 664 |
+
config_origin = Config("configs/config.json", "json")
|
| 665 |
+
diff_config = Config("configs/diffusion.yaml", "yaml")
|
| 666 |
+
config_data = config_origin.read()
|
| 667 |
+
config_data['train']['log_interval'] = int(log_interval)
|
| 668 |
+
config_data['train']['eval_interval'] = int(eval_interval)
|
| 669 |
+
config_data['train']['keep_ckpts'] = int(keep_ckpts)
|
| 670 |
+
config_data['train']['batch_size'] = int(batch_size)
|
| 671 |
+
config_data['train']['learning_rate'] = float(lr)
|
| 672 |
+
config_data['train']['fp16_run'] = fp16_run
|
| 673 |
+
config_data['train']['half_type'] = str(amp_dtype)
|
| 674 |
+
config_data['train']['all_in_mem'] = all_in_mem
|
| 675 |
+
config_origin.save(config_data)
|
| 676 |
+
diff_config_data = diff_config.read()
|
| 677 |
+
diff_config_data['train']['num_workers'] = int(diff_num_workers)
|
| 678 |
+
diff_config_data['train']['cache_all_data'] = diff_cache_all_data
|
| 679 |
+
diff_config_data['train']['batch_size'] = int(diff_batch_size)
|
| 680 |
+
diff_config_data['train']['lr'] = float(diff_lr)
|
| 681 |
+
diff_config_data['train']['interval_log'] = int(diff_interval_log)
|
| 682 |
+
diff_config_data['train']['interval_val'] = int(diff_interval_val)
|
| 683 |
+
diff_config_data['train']['cache_device'] = str(diff_cache_device)
|
| 684 |
+
diff_config_data['train']['amp_dtype'] = str(diff_amp_dtype)
|
| 685 |
+
diff_config_data['train']['interval_force_save'] = int(diff_force_save)
|
| 686 |
+
diff_config_data['model']['k_step_max'] = 100 if diff_k_step_max else 0
|
| 687 |
+
diff_config.save(diff_config_data)
|
| 688 |
+
return "配置文件写入完成"
|
| 689 |
+
|
| 690 |
+
def check_dataset(dataset_path):
|
| 691 |
+
if not os.listdir(dataset_path):
|
| 692 |
+
return "数据集不存在,请检查dataset文件夹"
|
| 693 |
+
no_npy_pt_files = True
|
| 694 |
+
for root, dirs, files in os.walk(dataset_path):
|
| 695 |
+
for file in files:
|
| 696 |
+
if file.endswith('.npy') or file.endswith('.pt'):
|
| 697 |
+
no_npy_pt_files = False
|
| 698 |
+
break
|
| 699 |
+
if no_npy_pt_files:
|
| 700 |
+
return "数据集中未检测到f0和hubert文件,可能是预处理未完成"
|
| 701 |
+
return None
|
| 702 |
+
|
| 703 |
+
def training(gpu_selection, encoder, tiny_enable):
|
| 704 |
+
if tiny_enable:
|
| 705 |
+
encoder = "vec768l12_tiny"
|
| 706 |
+
config_file = Config("configs/config.json", "json")
|
| 707 |
+
config_data = config_file.read()
|
| 708 |
+
vol_emb = config_data["model"]["vol_embedding"]
|
| 709 |
+
dataset_warn = check_dataset(dataset_dir)
|
| 710 |
+
if dataset_warn is not None:
|
| 711 |
+
return dataset_warn
|
| 712 |
+
PRETRAIN = {
|
| 713 |
+
"vec256l9": ("D_0.pth", "G_0.pth", "pre_trained_model"),
|
| 714 |
+
"vec768l12": ("D_0.pth", "G_0.pth", "pre_trained_model/768l12/vol_emb" if vol_emb else "pre_trained_model/768l12"),
|
| 715 |
+
"vec768l12_tiny": ("D_0.pth", "G_0.pth", "pre_trained_model/tiny/vec768l12_vol_emb"),
|
| 716 |
+
"hubertsoft": ("D_0.pth", "G_0.pth", "pre_trained_model/hubertsoft"),
|
| 717 |
+
"whisper-ppg": ("D_0.pth", "G_0.pth", "pre_trained_model/whisper-ppg"),
|
| 718 |
+
"cnhubertlarge": ("D_0.pth", "G_0.pth", "pre_trained_model/cnhubertlarge"),
|
| 719 |
+
"dphubert": ("D_0.pth", "G_0.pth", "pre_trained_model/dphubert"),
|
| 720 |
+
"wavlmbase+": ("D_0.pth", "G_0.pth", "pre_trained_model/wavlmbase+"),
|
| 721 |
+
"whisper-ppg-large": ("D_0.pth", "G_0.pth", "pre_trained_model/whisper-ppg-large")
|
| 722 |
+
}
|
| 723 |
+
if encoder not in PRETRAIN:
|
| 724 |
+
return "未知编码器"
|
| 725 |
+
d_0_file, g_0_file, encoder_model_path = PRETRAIN[encoder]
|
| 726 |
+
d_0_path = os.path.join(encoder_model_path, d_0_file)
|
| 727 |
+
g_0_path = os.path.join(encoder_model_path, g_0_file)
|
| 728 |
+
timestamp = datetime.datetime.now().strftime('%Y_%m_%d_%H_%M')
|
| 729 |
+
new_backup_folder = os.path.join(models_backup_path, str(timestamp))
|
| 730 |
+
output_msg = ""
|
| 731 |
+
if os.listdir(workdir) != ['diffusion']:
|
| 732 |
+
os.makedirs(new_backup_folder, exist_ok=True)
|
| 733 |
+
for file in os.listdir(workdir):
|
| 734 |
+
if file != "diffusion":
|
| 735 |
+
shutil.move(os.path.join(workdir, file), os.path.join(new_backup_folder, file))
|
| 736 |
+
if os.path.isfile(g_0_path) and os.path.isfile(d_0_path):
|
| 737 |
+
shutil.copy(d_0_path, os.path.join(workdir, "D_0.pth"))
|
| 738 |
+
shutil.copy(g_0_path, os.path.join(workdir, "G_0.pth"))
|
| 739 |
+
output_msg += f"成功装载预训练模型,编码器:{encoder}\n"
|
| 740 |
+
else:
|
| 741 |
+
output_msg += f"{encoder}的预训练模型不存在,未装载预训练模型\n"
|
| 742 |
+
|
| 743 |
+
cmd = r"set CUDA_VISIBLE_DEVICES=%s && .\workenv\python.exe train.py -c configs/config.json -m 44k" % (gpu_selection)
|
| 744 |
+
subprocess.Popen(["cmd", "/c", "start", "cmd", "/k", cmd])
|
| 745 |
+
output_msg += "已经在新的终端窗口开始训练,请监看终端窗口的训练日志。在终端中按Ctrl+C可暂停训练。"
|
| 746 |
+
return output_msg
|
| 747 |
+
|
| 748 |
+
def continue_training(gpu_selection, encoder):
|
| 749 |
+
dataset_warn = check_dataset(dataset_dir)
|
| 750 |
+
if dataset_warn is not None:
|
| 751 |
+
return dataset_warn
|
| 752 |
+
if encoder == "":
|
| 753 |
+
return "请先选择预处理对应的编码器"
|
| 754 |
+
all_files = os.listdir(workdir)
|
| 755 |
+
model_files = [f for f in all_files if f.startswith('G_') and f.endswith('.pth')]
|
| 756 |
+
if len(model_files) == 0:
|
| 757 |
+
return "你还没有已开始的训练"
|
| 758 |
+
cmd = r"set CUDA_VISIBLE_DEVICES=%s && .\workenv\python.exe train.py -c configs/config.json -m 44k" % (gpu_selection)
|
| 759 |
+
subprocess.Popen(["cmd", "/c", "start", "cmd", "/k", cmd])
|
| 760 |
+
return "已经在新的终端窗口开始训练,请监看终端窗口的训练日志。在终端中按Ctrl+C可暂停训练。"
|
| 761 |
+
|
| 762 |
+
def kmeans_training(kmeans_gpu):
|
| 763 |
+
if not os.listdir(dataset_dir):
|
| 764 |
+
return "数据集不存在,请检查dataset文件夹"
|
| 765 |
+
cmd = r".\workenv\python.exe cluster/train_cluster.py --gpu" if kmeans_gpu else r".\workenv\python.exe cluster/train_cluster.py"
|
| 766 |
+
subprocess.Popen(["cmd", "/c", "start", "cmd", "/k", cmd])
|
| 767 |
+
return "已经在新的终端窗口开始训练,训练聚类模型不会输出日志,CPU训练一般需要5-10分钟左右"
|
| 768 |
+
|
| 769 |
+
def index_training():
|
| 770 |
+
if not os.listdir(dataset_dir):
|
| 771 |
+
return "数据集不存在,请检查dataset文件夹"
|
| 772 |
+
cmd = r".\workenv\python.exe train_index.py -c configs/config.json"
|
| 773 |
+
subprocess.Popen(["cmd", "/c", "start", "cmd", "/k", cmd])
|
| 774 |
+
return "已经在新的终端窗口开始训练"
|
| 775 |
+
|
| 776 |
+
def diff_training(encoder, k_step_max):
|
| 777 |
+
if not os.listdir(dataset_dir):
|
| 778 |
+
return "数据集不存在,请检查dataset文件夹"
|
| 779 |
+
timestamp = datetime.datetime.now().strftime('%Y_%m_%d_%H_%M')
|
| 780 |
+
new_backup_folder = os.path.join(models_backup_path, "diffusion", str(timestamp))
|
| 781 |
+
if len(os.listdir(diff_workdir)) != 0:
|
| 782 |
+
os.makedirs(new_backup_folder, exist_ok=True)
|
| 783 |
+
for file in os.listdir(diff_workdir):
|
| 784 |
+
shutil.move(os.path.join(diff_workdir, file), os.path.join(new_backup_folder, file))
|
| 785 |
+
DIFF_PRETRAIN = {
|
| 786 |
+
"768-kstepmax100": "pre_trained_model/diffusion/768l12/max100/model_0.pt",
|
| 787 |
+
"vec768l12": "pre_trained_model/diffusion/768l12/model_0.pt",
|
| 788 |
+
"hubertsoft": "pre_trained_model/diffusion/hubertsoft/model_0.pt",
|
| 789 |
+
"whisper-ppg": "pre_trained_model/diffusion/whisper-ppg/model_0.pt"
|
| 790 |
+
}
|
| 791 |
+
if encoder not in DIFF_PRETRAIN:
|
| 792 |
+
return "你所选的编码器暂时不支持训练扩散模型"
|
| 793 |
+
if k_step_max:
|
| 794 |
+
encoder = "768-kstepmax100"
|
| 795 |
+
diff_pretrained_model = DIFF_PRETRAIN[encoder]
|
| 796 |
+
shutil.copy(diff_pretrained_model, os.path.join(diff_workdir, "model_0.pt"))
|
| 797 |
+
subprocess.Popen(["cmd", "/c", "start", "cmd", "/k", r".\workenv\python.exe train_diff.py -c configs/diffusion.yaml"])
|
| 798 |
+
output_message = "已经在新的终端窗口开始训练,请监看终端窗口的训练日志。在终端中按Ctrl+C可暂停训练。"
|
| 799 |
+
if encoder == "768-kstepmax100":
|
| 800 |
+
output_message += "\n正在进行100步深度的浅扩散训练,已加载底模"
|
| 801 |
+
else:
|
| 802 |
+
output_message += f"\n正在进行完整深度的扩散训练,编码器{encoder}"
|
| 803 |
+
return output_message
|
| 804 |
+
|
| 805 |
+
def diff_continue_training(encoder):
|
| 806 |
+
if not os.listdir(dataset_dir):
|
| 807 |
+
return "数据集不存在,请检查dataset文件夹"
|
| 808 |
+
if encoder == "":
|
| 809 |
+
return "请先选择预处理对应的编码器"
|
| 810 |
+
all_files = os.listdir(diff_workdir)
|
| 811 |
+
model_files = [f for f in all_files if f.endswith('.pt')]
|
| 812 |
+
if len(model_files) == 0:
|
| 813 |
+
return "你还没有已开始的训练"
|
| 814 |
+
subprocess.Popen(["cmd", "/c", "start", "cmd", "/k", r".\workenv\python.exe train_diff.py -c configs/diffusion.yaml"])
|
| 815 |
+
return "已经在新的终端窗口开始训练,请监看终端窗口的训练日志。在终端中按Ctrl+C可暂停训练。"
|
| 816 |
+
|
| 817 |
+
def upload_mix_append_file(files,sfiles):
|
| 818 |
+
try:
|
| 819 |
+
if(sfiles is None):
|
| 820 |
+
file_paths = [file.name for file in files]
|
| 821 |
+
else:
|
| 822 |
+
file_paths = [file.name for file in chain(files,sfiles)]
|
| 823 |
+
p = {file:100 for file in file_paths}
|
| 824 |
+
return file_paths,mix_model_output1.update(value=json.dumps(p,indent=2))
|
| 825 |
+
except Exception as e:
|
| 826 |
+
if debug:
|
| 827 |
+
traceback.print_exc()
|
| 828 |
+
raise gr.Error(e)
|
| 829 |
+
|
| 830 |
+
def mix_submit_click(js,mode):
|
| 831 |
+
try:
|
| 832 |
+
assert js.lstrip()!=""
|
| 833 |
+
modes = {"凸组合":0, "线性组合":1}
|
| 834 |
+
mode = modes[mode]
|
| 835 |
+
data = json.loads(js)
|
| 836 |
+
data = list(data.items())
|
| 837 |
+
model_path,mix_rate = zip(*data)
|
| 838 |
+
path = mix_model(model_path,mix_rate,mode)
|
| 839 |
+
return f"成功,文件被保存在了{path}"
|
| 840 |
+
except Exception as e:
|
| 841 |
+
if debug:
|
| 842 |
+
traceback.print_exc()
|
| 843 |
+
raise gr.Error(e)
|
| 844 |
+
|
| 845 |
+
def updata_mix_info(files):
|
| 846 |
+
try:
|
| 847 |
+
if files is None:
|
| 848 |
+
return mix_model_output1.update(value="")
|
| 849 |
+
p = {file.name:100 for file in files}
|
| 850 |
+
return mix_model_output1.update(value=json.dumps(p,indent=2))
|
| 851 |
+
except Exception as e:
|
| 852 |
+
if debug:
|
| 853 |
+
traceback.print_exc()
|
| 854 |
+
raise gr.Error(e)
|
| 855 |
+
|
| 856 |
+
def pth_identify():
|
| 857 |
+
if not os.path.exists(root_dir):
|
| 858 |
+
return f"未找到{root_dir}文件夹,请先创建一个{root_dir}文件夹并按第一步流程操作"
|
| 859 |
+
model_dirs = [d for d in os.listdir(root_dir) if os.path.isdir(os.path.join(root_dir, d))]
|
| 860 |
+
if not model_dirs:
|
| 861 |
+
return f"未在{root_dir}文件夹中找到模型文件夹,请确保每个模型和配置文件都被放置在单独的文件夹中"
|
| 862 |
+
valid_model_dirs = []
|
| 863 |
+
for path in model_dirs:
|
| 864 |
+
pth_files = glob.glob(f"{root_dir}/{path}/*.pth")
|
| 865 |
+
json_files = glob.glob(f"{root_dir}/{path}/*.json")
|
| 866 |
+
if len(pth_files) != 1 or len(json_files) != 1:
|
| 867 |
+
return f"错误: 在{root_dir}/{path}中找到了{len(pth_files)}个.pth文件和{len(json_files)}个.json文件。应当确保每个文件夹内有且只有一个.pth文件和.json文件"
|
| 868 |
+
valid_model_dirs.append(path)
|
| 869 |
+
|
| 870 |
+
return f"成功识别了{len(valid_model_dirs)}个模型:{valid_model_dirs}"
|
| 871 |
+
|
| 872 |
+
def onnx_export_func():
|
| 873 |
+
model_dirs = [d for d in os.listdir(root_dir) if os.path.isdir(os.path.join(root_dir, d))]
|
| 874 |
+
output_msg = ""
|
| 875 |
+
try:
|
| 876 |
+
for path in model_dirs:
|
| 877 |
+
pth_files = glob.glob(f"{root_dir}/{path}/*.pth")
|
| 878 |
+
json_files = glob.glob(f"{root_dir}/{path}/*.json")
|
| 879 |
+
model_file = Path(pth_files[0]).name
|
| 880 |
+
json_file = Path(json_files[0]).name
|
| 881 |
+
try:
|
| 882 |
+
onnx_export(path, json_file, model_file)
|
| 883 |
+
output_msg += f"成功转换{path}\n"
|
| 884 |
+
except Exception as e:
|
| 885 |
+
output_msg += f"转换{path}时出现错误: {e}\n"
|
| 886 |
+
return output_msg
|
| 887 |
+
except Exception as e:
|
| 888 |
+
if debug:
|
| 889 |
+
traceback.print_exc()
|
| 890 |
+
raise gr.Error(e)
|
| 891 |
+
|
| 892 |
+
def load_raw_audio(audio_path):
|
| 893 |
+
if not os.path.isdir(audio_path):
|
| 894 |
+
return "请输入正确的目录", None
|
| 895 |
+
files = os.listdir(audio_path)
|
| 896 |
+
wav_files = [file for file in files if file.lower().endswith('.wav')]
|
| 897 |
+
if not wav_files:
|
| 898 |
+
return "未在目录中找到.wav音频文件", None
|
| 899 |
+
return "成功加载", wav_files
|
| 900 |
+
|
| 901 |
+
def slicer_fn(input_dir, output_dir, process_method, max_sec, min_sec):
|
| 902 |
+
if output_dir == "":
|
| 903 |
+
return "请先选择输出的文件夹"
|
| 904 |
+
if output_dir == input_dir:
|
| 905 |
+
return "输出目录不能和输入目录相同"
|
| 906 |
+
slicer = AutoSlicer()
|
| 907 |
+
if os.path.exists(output_dir) is not True:
|
| 908 |
+
os.makedirs(output_dir)
|
| 909 |
+
for filename in os.listdir(input_dir):
|
| 910 |
+
if filename.lower().endswith(".wav"):
|
| 911 |
+
slicer.auto_slice(filename, input_dir, output_dir, max_sec)
|
| 912 |
+
if process_method == "丢弃":
|
| 913 |
+
for filename in os.listdir(output_dir):
|
| 914 |
+
if filename.endswith(".wav"):
|
| 915 |
+
filepath = os.path.join(output_dir, filename)
|
| 916 |
+
audio, sr = librosa.load(filepath, sr=None, mono=False)
|
| 917 |
+
if librosa.get_duration(y=audio, sr=sr) < min_sec:
|
| 918 |
+
os.remove(filepath)
|
| 919 |
+
elif process_method == "将过短音频整合为长音频":
|
| 920 |
+
slicer.merge_short(output_dir, max_sec, min_sec)
|
| 921 |
+
file_count, max_duration, min_duration, orig_duration, final_duration = slicer.slice_count(input_dir, output_dir)
|
| 922 |
+
hrs = int(final_duration / 3600)
|
| 923 |
+
mins = int((final_duration % 3600) / 60)
|
| 924 |
+
sec = format(float(final_duration % 60), '.2f')
|
| 925 |
+
rate = format(100 * (final_duration / orig_duration), '.2f') if orig_duration != 0 else 0
|
| 926 |
+
rate_msg = f"为原始音频时长的{rate}%" if rate != 0 else "因未知问题,无法计算切片时长的占比"
|
| 927 |
+
return f"成功将音频切分为{file_count}条片段,其中最长{max_duration}秒,最短{min_duration}秒,切片后的音频总时长{hrs:02d}小时{mins:02d}分{sec}秒,{rate_msg}"
|
| 928 |
+
|
| 929 |
+
def model_compression(_model, is_fp16):
|
| 930 |
+
if _model == "":
|
| 931 |
+
return "请先选择要压缩的模型"
|
| 932 |
+
else:
|
| 933 |
+
model_path = os.path.join(ckpt_read_dir, _model)
|
| 934 |
+
filename, extension = os.path.splitext(_model)
|
| 935 |
+
output_model_name = f"{filename}_compressed{extension}"
|
| 936 |
+
output_path = os.path.join(ckpt_read_dir, output_model_name)
|
| 937 |
+
removeOptimizer("configs/config.json", model_path, is_fp16, output_path)
|
| 938 |
+
return f"模型已成功被保存在了{output_path}"
|
| 939 |
+
|
| 940 |
+
def pack_autoload(model_to_pack):
|
| 941 |
+
_, config_name, _ = auto_load(model_to_pack)
|
| 942 |
+
if config_name == "no_config":
|
| 943 |
+
return "未找到对应的配置文件,请手动选择", None
|
| 944 |
+
else:
|
| 945 |
+
_config = Config(os.path.join(config_read_dir, config_name), "json")
|
| 946 |
+
_content = _config.read()
|
| 947 |
+
spk_dict = _content["spk"]
|
| 948 |
+
spk_list = ",".join(spk_dict.keys())
|
| 949 |
+
return config_name, spk_list
|
| 950 |
+
|
| 951 |
+
def release_packing(model_to_pack, model_config, speaker, diff_to_pack, cluster_to_pack):
|
| 952 |
+
model_path = diff_path = cluster_path = ""
|
| 953 |
+
basename = os.path.splitext(model_to_pack)[0]
|
| 954 |
+
diff_basename = os.path.splitext(diff_to_pack)[0]
|
| 955 |
+
if model_to_pack == "" or model_config == "" or speaker == "":
|
| 956 |
+
return "存在必选项为空,请检查后重试"
|
| 957 |
+
released_pack = ReleasePacker(speaker, model_to_pack)
|
| 958 |
+
released_pack.remove_temp("release_packs")
|
| 959 |
+
model_path = os.path.join(ckpt_read_dir, model_to_pack)
|
| 960 |
+
config_path = os.path.join(config_read_dir, model_config)
|
| 961 |
+
if os.stat(model_path).st_size > 300000000:
|
| 962 |
+
removeOptimizer(config_path, model_path, False, os.path.join("release_packs", model_to_pack))
|
| 963 |
+
model_path = os.path.join("release_packs", model_to_pack)
|
| 964 |
+
if diff_to_pack != "no_diff":
|
| 965 |
+
diff_path = os.path.join(diff_read_dir, diff_to_pack)
|
| 966 |
+
if cluster_to_pack != "no_cluster":
|
| 967 |
+
cluster_path = os.path.join(ckpt_read_dir, cluster_to_pack)
|
| 968 |
+
shutil.copyfile("configs_template/config_template.json", "release_packs/config_template.json")
|
| 969 |
+
shutil.copyfile("configs_template/diffusion_template.yaml", "release_packs/diffusion_template.yaml")
|
| 970 |
+
files_to_pack = [
|
| 971 |
+
(model_path, f"models/{model_to_pack}"),
|
| 972 |
+
(diff_path, f"models/diffusion/{diff_to_pack}") if diff_to_pack != "no_diff" else ("", ""),
|
| 973 |
+
(cluster_path, f"models/{cluster_to_pack}") if cluster_to_pack != "no_cluster" else ("", ""),
|
| 974 |
+
(f"release_packs/{basename}.json", f"models/{basename}.json"),
|
| 975 |
+
(f"release_packs/{diff_basename}.yaml", f"models/{diff_basename}.yaml") if diff_to_pack != "no_diff" else ("", ""),
|
| 976 |
+
("release_packs/install.txt", "install.txt")
|
| 977 |
+
]
|
| 978 |
+
released_pack.add_file(files_to_pack)
|
| 979 |
+
released_pack.generate_config(diff_to_pack, model_config)
|
| 980 |
+
os.rename("release_packs/config_template.json", f"release_packs/{basename}.json")
|
| 981 |
+
os.rename("release_packs/diffusion_template.yaml", f"release_packs/{diff_basename}.yaml")
|
| 982 |
+
released_pack.pack()
|
| 983 |
+
to_remove = [file for file in os.listdir("release_packs") if not file.endswith(".zip")]
|
| 984 |
+
for file in to_remove:
|
| 985 |
+
os.remove(os.path.join("release_packs", file))
|
| 986 |
+
return "打包成功, 请在release_packs目录下查看"
|
| 987 |
+
|
| 988 |
+
def release_install(model_zip_path):
|
| 989 |
+
model_zip = ReleasePacker("", "")
|
| 990 |
+
model_zip.unpack(model_zip_path)
|
| 991 |
+
for file in os.listdir("release_packs"):
|
| 992 |
+
if file.endswith(".txt"):
|
| 993 |
+
install_txt = os.path.join("release_packs", file)
|
| 994 |
+
break
|
| 995 |
+
else:
|
| 996 |
+
model_zip.remove_temp("release_packs")
|
| 997 |
+
return "非格式化安装包,无法安装"
|
| 998 |
+
_spk = model_zip.formatted_install(install_txt)
|
| 999 |
+
model_zip.remove_temp("release_packs")
|
| 1000 |
+
return f"安装成功,可用说话人{_spk},请启用独立目录模式加载模型"
|
| 1001 |
+
|
| 1002 |
+
#read default params
|
| 1003 |
+
sovits_params, diff_params, second_dir_enable = get_default_settings()
|
| 1004 |
+
ckpt_read_dir = second_dir if second_dir_enable else workdir
|
| 1005 |
+
config_read_dir = second_dir if second_dir_enable else config_dir
|
| 1006 |
+
diff_read_dir = diff_second_dir if second_dir_enable else diff_workdir
|
| 1007 |
+
current_mode = get_current_mode()
|
| 1008 |
+
|
| 1009 |
+
# create dirs if they don't exist
|
| 1010 |
+
dirs_to_check = [
|
| 1011 |
+
workdir,
|
| 1012 |
+
second_dir,
|
| 1013 |
+
diff_workdir,
|
| 1014 |
+
diff_second_dir,
|
| 1015 |
+
dataset_dir,
|
| 1016 |
+
]
|
| 1017 |
+
for dir in dirs_to_check:
|
| 1018 |
+
if not os.path.exists(dir):
|
| 1019 |
+
os.makedirs(dir)
|
| 1020 |
+
|
| 1021 |
+
# read ckpt list
|
| 1022 |
+
ckpt_list, config_list, cluster_list, diff_list, diff_config_list = load_options()
|
| 1023 |
+
|
| 1024 |
+
# read available encoder list
|
| 1025 |
+
encoder_list = get_available_encoder()
|
| 1026 |
+
|
| 1027 |
+
#read GPU info
|
| 1028 |
+
ngpu=torch.cuda.device_count()
|
| 1029 |
+
gpu_infos=[]
|
| 1030 |
+
if(torch.cuda.is_available() is False or ngpu==0):
|
| 1031 |
+
if_gpu_ok=False
|
| 1032 |
+
else:
|
| 1033 |
+
if_gpu_ok = False
|
| 1034 |
+
for i in range(ngpu):
|
| 1035 |
+
gpu_name=torch.cuda.get_device_name(i)
|
| 1036 |
+
if("MX"in gpu_name):
|
| 1037 |
+
continue
|
| 1038 |
+
if("RTX" in gpu_name.upper() or "10"in gpu_name or "16"in gpu_name or "20"in gpu_name or "30"in gpu_name or "40"in gpu_name or "A50"in gpu_name.upper() or "70"in gpu_name or "80"in gpu_name or "90"in gpu_name or "M4"in gpu_name or"P4"in gpu_name or "T4"in gpu_name or "TITAN"in gpu_name.upper()):#A10#A100#V100#A40#P40#M40#K80
|
| 1039 |
+
if_gpu_ok=True#至少有一张能用的N卡
|
| 1040 |
+
gpu_infos.append("%s\t%s"%(i,gpu_name))
|
| 1041 |
+
gpu_info="\n".join(gpu_infos)if if_gpu_ok is True and len(gpu_infos)>0 else "很遗憾您这没有能用的显卡来支持您训练"
|
| 1042 |
+
gpus="-".join([i[0]for i in gpu_infos])
|
| 1043 |
+
|
| 1044 |
+
#read cuda info for inference
|
| 1045 |
+
cuda = {}
|
| 1046 |
+
min_vram = 0
|
| 1047 |
+
if torch.cuda.is_available():
|
| 1048 |
+
for i in range(torch.cuda.device_count()):
|
| 1049 |
+
current_vram = torch.cuda.get_device_properties(i).total_memory
|
| 1050 |
+
min_vram = current_vram if current_vram > min_vram else min_vram
|
| 1051 |
+
device_name = torch.cuda.get_device_properties(i).name
|
| 1052 |
+
cuda[f"CUDA:{i} {device_name}"] = f"cuda:{i}"
|
| 1053 |
+
total_vram = round(min_vram * 9.31322575e-10) if min_vram != 0 else 0
|
| 1054 |
+
auto_batch = total_vram - 2 if total_vram <= 12 and total_vram > 0 else total_vram
|
| 1055 |
+
print(f"Current vram: {total_vram} GiB, recommended batch size: {auto_batch}")
|
| 1056 |
+
|
| 1057 |
+
#Check BF16 support
|
| 1058 |
+
amp_options = ["fp32", "fp16"]
|
| 1059 |
+
if if_gpu_ok:
|
| 1060 |
+
if torch.cuda.is_bf16_supported():
|
| 1061 |
+
amp_options = ["fp32", "fp16", "bf16"]
|
| 1062 |
+
|
| 1063 |
+
#Get F0 Options
|
| 1064 |
+
f0_options = ["crepe","pm","dio","harvest","rmvpe","fcpe"]
|
| 1065 |
+
|
| 1066 |
+
app = gr.Blocks()
|
| 1067 |
+
with app:
|
| 1068 |
+
gr.Markdown(value="""
|
| 1069 |
+
### So-VITS-SVC 4.1-Stable WebUI 推理&训练 v2.3.13
|
| 1070 |
+
|
| 1071 |
+
制作协力:bilibili@麦哲云
|
| 1072 |
+
|
| 1073 |
+
仅供个人娱乐和非商业用途,禁止用于血腥、暴力、性相关、政治相关内容
|
| 1074 |
+
|
| 1075 |
+
[使用文档和常见报错解答](https://www.yuque.com/umoubuton/ueupp5)
|
| 1076 |
+
|
| 1077 |
+
整合包作者:bilibili@羽毛布団 | 技术交流群:742817595 | 交流二群:168254971 | 交流三群:416656175 | 交流四群:903516607
|
| 1078 |
+
|
| 1079 |
+
""")
|
| 1080 |
+
with gr.Tabs():
|
| 1081 |
+
with gr.TabItem("推理") as inference_tab:
|
| 1082 |
+
mode_caption = gr.Markdown(value=f"""
|
| 1083 |
+
{current_mode},可在页面底端切换模式
|
| 1084 |
+
""")
|
| 1085 |
+
with gr.Row():
|
| 1086 |
+
choice_ckpt = gr.Dropdown(label="模型选择", choices=ckpt_list, value="no_model")
|
| 1087 |
+
model_branch = gr.Textbox(label="模型编码器", placeholder="请先选择模型", interactive=False)
|
| 1088 |
+
with gr.Row():
|
| 1089 |
+
config_choice = gr.Dropdown(label="配置文件", choices=config_list, value="no_config")
|
| 1090 |
+
config_info = gr.Textbox(label="配置文件编码器", placeholder="请选择配置文件")
|
| 1091 |
+
gr.Markdown(value="""**请检查模型和配置文件的编码器是否匹配**""")
|
| 1092 |
+
with gr.Row():
|
| 1093 |
+
diff_choice = gr.Dropdown(label="(可选)选择扩散模型", choices=diff_list, value="no_diff", interactive=True)
|
| 1094 |
+
diff_config_choice = gr.Dropdown(label="扩散模型配置文件", choices=diff_config_list, value="no_diff_config", interactive=True)
|
| 1095 |
+
cluster_choice = gr.Dropdown(label="(可选)选择聚类模型/特征检索模型", choices=cluster_list, value="no_clu")
|
| 1096 |
+
refresh = gr.Button("刷新选项")
|
| 1097 |
+
with gr.Row():
|
| 1098 |
+
enhance = gr.Checkbox(label="是否使用NSF_HIFIGAN增强,该选项对部分训练集少的模型有一定的音质增强效果,但是对训练好的模型有反面效果,默认关闭", value=False)
|
| 1099 |
+
only_diffusion = gr.Checkbox(label="是否使用全扩散推理,开启后将不使用So-VITS模型,仅使用扩散模型进行完整扩散推理,不建议使用", value=False)
|
| 1100 |
+
with gr.Row():
|
| 1101 |
+
diffusion_method = gr.Dropdown(label="扩散模型采样器", choices=["dpm-solver++","dpm-solver","pndm","ddim","unipc"], value="dpm-solver++")
|
| 1102 |
+
diffusion_speedup = gr.Number(label="扩散加速倍数,默认为10倍", value=10)
|
| 1103 |
+
using_device = gr.Dropdown(label="推理设备,默认为自动选择", choices=["Auto",*cuda.keys(),"cpu"], value="Auto")
|
| 1104 |
+
with gr.Row():
|
| 1105 |
+
loadckpt = gr.Button("加载模型", variant="primary")
|
| 1106 |
+
unload = gr.Button("卸载模型", variant="primary")
|
| 1107 |
+
with gr.Row():
|
| 1108 |
+
model_message = gr.Textbox(label="Output Message")
|
| 1109 |
+
sid = gr.Dropdown(label="So-VITS说话人", value="speaker0")
|
| 1110 |
+
|
| 1111 |
+
inference_tab.select(refresh_options,[],[choice_ckpt,config_choice,cluster_choice,diff_choice,diff_config_choice])
|
| 1112 |
+
choice_ckpt.change(auto_load, [choice_ckpt], [model_branch, config_choice, config_info])
|
| 1113 |
+
config_choice.change(load_json_encoder, [config_choice, choice_ckpt], [config_info])
|
| 1114 |
+
diff_choice.change(auto_load_diff, [diff_choice], [diff_config_choice])
|
| 1115 |
+
refresh.click(refresh_options,[],[choice_ckpt,config_choice,cluster_choice,diff_choice,diff_config_choice,mode_caption])
|
| 1116 |
+
|
| 1117 |
+
gr.Markdown(value="""
|
| 1118 |
+
请稍等片刻,模型加载大约需要10秒。后续操作不需要重新加载模型
|
| 1119 |
+
""")
|
| 1120 |
+
with gr.Tabs():
|
| 1121 |
+
with gr.TabItem("单个音频上传"):
|
| 1122 |
+
vc_input3 = gr.Audio(label="单个音频上传", type="filepath", source="upload")
|
| 1123 |
+
use_microphone = gr.Checkbox(label="使用麦克风输入")
|
| 1124 |
+
with gr.TabItem("批量音频上传"):
|
| 1125 |
+
vc_batch_files = gr.Files(label="批量音频上传", file_types=["audio"], file_count="multiple")
|
| 1126 |
+
with gr.TabItem("文字转语音"):
|
| 1127 |
+
gr.Markdown("""
|
| 1128 |
+
文字转语音(TTS)说明:使用edge_tts服务生成音频,并转换为So-VITS模型音色。
|
| 1129 |
+
""")
|
| 1130 |
+
text_input = gr.Textbox(label = "在此输入需要转译的文字(建议打开自动f0预测)",)
|
| 1131 |
+
with gr.Row():
|
| 1132 |
+
tts_gender = gr.Radio(label = "说话人性别", choices = ["男","女"], value = "男")
|
| 1133 |
+
tts_lang = gr.Dropdown(label = "选择语言,Auto为根据输入文字自动识别", choices=SUPPORTED_LANGUAGES, value = "Auto")
|
| 1134 |
+
with gr.Row():
|
| 1135 |
+
tts_rate = gr.Slider(label = "TTS语音变速(倍速相对值)", minimum = -1, maximum = 3, value = 0, step = 0.1)
|
| 1136 |
+
tts_volume = gr.Slider(label = "TTS语音音量(相对值)", minimum = -1, maximum = 1.5, value = 0, step = 0.1)
|
| 1137 |
+
|
| 1138 |
+
with gr.Row():
|
| 1139 |
+
auto_f0 = gr.Checkbox(label="自动f0预测,配合聚类模型f0预测效果更好,会导致变调功能失效(仅限转换语音,歌声不要勾选此项会跑调)", value=False)
|
| 1140 |
+
f0_predictor = gr.Radio(label="f0预测器选择(如遇哑音可以更换f0预测器解决,crepe为原F0使用均值滤波器)", choices=f0_options, value="pm")
|
| 1141 |
+
cr_threshold = gr.Number(label="F0过滤阈值,只有使用crepe时有效. 数值范围从0-1. 降低该值可减少跑调概率,但会增加哑音", value=0.05)
|
| 1142 |
+
with gr.Row():
|
| 1143 |
+
vc_transform = gr.Number(label="变调(整数,可以正负,半音数量,升高八度就是12)", value=0)
|
| 1144 |
+
cluster_ratio = gr.Number(label="聚类模型/特征检索混合比例,0-1之间,默认为0不启用聚类或特征检索,能提升音色相似度,但会导致咬字下降", value=0)
|
| 1145 |
+
k_step = gr.Slider(label="浅扩散步数,只有使用了扩散模型才有效,步数越大越接近扩散模型的结果", value=100, minimum = 1, maximum = 1000)
|
| 1146 |
+
with gr.Row():
|
| 1147 |
+
output_format = gr.Radio(label="音频输出格式", choices=["wav", "flac", "mp3"], value = "wav")
|
| 1148 |
+
enhancer_adaptive_key = gr.Number(label="使NSF-HIFIGAN增强器适应更高的音域(单位为半音数)|默认为0", value=0)
|
| 1149 |
+
slice_db = gr.Number(label="切片阈值", value=-50)
|
| 1150 |
+
cl_num = gr.Number(label="音频自动切片,0为按默认方式切片,单位为秒/s,爆显存可以设置此处强制切片", value=0)
|
| 1151 |
+
with gr.Accordion("高级设置(一般不需要动)", open=False):
|
| 1152 |
+
noise_scale = gr.Number(label="noise_scale 建议不要动,会影响音质,玄学参数", value=0.4)
|
| 1153 |
+
pad_seconds = gr.Number(label="推理音频pad秒数,由于未知原因开头结尾会有异响,pad一小段静音段后就不会出现", value=0.5)
|
| 1154 |
+
lg_num = gr.Number(label="两端音频切片的交叉淡入长度,如果自动切片后出现人声不连贯可调整该数值,如果连贯建议采用默认值0,注意,该设置会影响推理速度,单位为秒/s", value=1)
|
| 1155 |
+
lgr_num = gr.Number(label="自动音频切片后,需要舍弃每段切片的头尾。该参数设置交叉长度保留的比例,范围0-1,左开右闭", value=0.75)
|
| 1156 |
+
second_encoding = gr.Checkbox(label = "二次编码,浅扩散前会对原始音频进行二次编码,玄学选项,效果时好时差,默认关闭", value=False)
|
| 1157 |
+
loudness_envelope_adjustment = gr.Number(label="输入源响度包络替换输出响度包络融合比例,越靠近1越使用输出响度包络", value = 0)
|
| 1158 |
+
use_spk_mix = gr.Checkbox(label="动态声线融合,需要手动编辑角色混合轨道,没做完暂时不要开启", value=False, interactive=False)
|
| 1159 |
+
with gr.Row():
|
| 1160 |
+
vc_submit = gr.Button("音频转换", variant="primary")
|
| 1161 |
+
vc_batch_submit = gr.Button("批量转换", variant="primary")
|
| 1162 |
+
vc_tts_submit = gr.Button("文本转语音", variant="primary")
|
| 1163 |
+
#interrupt_button = gr.Button("中止转换", variant="danger")
|
| 1164 |
+
vc_output1 = gr.Textbox(label="Output Message")
|
| 1165 |
+
vc_output2 = gr.Audio(label="Output Audio")
|
| 1166 |
+
|
| 1167 |
+
loadckpt.click(load_model_func,[choice_ckpt,cluster_choice,config_choice,enhance,diff_choice,diff_config_choice,only_diffusion,use_spk_mix,using_device,diffusion_method,diffusion_speedup,cl_num],[model_message, sid, cl_num, k_step])
|
| 1168 |
+
unload.click(model_empty_cache, [], [sid, model_message])
|
| 1169 |
+
use_microphone.change(source_change, [use_microphone], [vc_input3])
|
| 1170 |
+
vc_submit.click(vc_fn, [output_format, sid, vc_input3, vc_transform,auto_f0,cluster_ratio, slice_db, noise_scale,pad_seconds,cl_num,lg_num,lgr_num,f0_predictor,enhancer_adaptive_key,cr_threshold,k_step,use_spk_mix,second_encoding,loudness_envelope_adjustment], [vc_output1, vc_output2])
|
| 1171 |
+
vc_batch_submit.click(vc_batch_fn, [output_format, sid, vc_batch_files, vc_transform,auto_f0,cluster_ratio, slice_db, noise_scale,pad_seconds,cl_num,lg_num,lgr_num,f0_predictor,enhancer_adaptive_key,cr_threshold,k_step,use_spk_mix,second_encoding,loudness_envelope_adjustment], [vc_output1])
|
| 1172 |
+
vc_tts_submit.click(tts_fn, [text_input, tts_gender, tts_lang, tts_rate, tts_volume, output_format, sid, vc_transform,auto_f0,cluster_ratio, slice_db, noise_scale,pad_seconds,cl_num,lg_num,lgr_num,f0_predictor,enhancer_adaptive_key,cr_threshold,k_step,use_spk_mix,second_encoding,loudness_envelope_adjustment], [vc_output1, vc_output2])
|
| 1173 |
+
#interrupt_button.click(fn=None, inputs=None, outputs=None, cancels=[vc_event])
|
| 1174 |
+
|
| 1175 |
+
with gr.TabItem("训练"):
|
| 1176 |
+
gr.Markdown(value="""请将数据集文件夹放置在dataset_raw文件夹下,确认放置正确后点击下方获取数据集名称""")
|
| 1177 |
+
raw_dirs_list=gr.Textbox(label="Raw dataset directory(s):")
|
| 1178 |
+
get_raw_dirs=gr.Button("识别数据集", variant="primary")
|
| 1179 |
+
gr.Markdown(value="""确认数据集正确识别后请选择训练使用的特征编码器和f0预测器,**如果要训练扩散模型,请选择Vec768l12或hubertsoft或whisper-ppg,并确保So-VITS和扩散模型使用同一个编码器**""")
|
| 1180 |
+
with gr.Row():
|
| 1181 |
+
gr.Markdown(value="""**vec256l9**: ContentVec(256Layer9),旧版本叫v1,So-VITS-SVC 4.0的基础版本,**不推荐使用**
|
| 1182 |
+
**vec768l12**: 特征输入更换为ContentVec的第12层Transformer输出,模型理论上会更加还原训练集音色
|
| 1183 |
+
**hubertsoft**: So-VITS-SVC 3.0使用的编码器,咬字更为准确,但可能存在多说话人音色泄露问题
|
| 1184 |
+
**whisper-ppg**: 来自OpenAI,咬字最为准确,但和Hubertsoft一样存在多说话人音色泄露,且显存占用和训练时间有明显增加。
|
| 1185 |
+
解锁更多编码器选项,请见[这里](https://www.yuque.com/umoubuton/ueupp5/kmui02dszo5zrqkz)
|
| 1186 |
+
""")
|
| 1187 |
+
gr.Markdown(value="""**crepe**: 抗噪能力最强,但预处理速度慢(不过如果你的显卡很强的话速度会很快)
|
| 1188 |
+
**pm**: 预处理速度快,但抗噪能力较弱
|
| 1189 |
+
**dio**: 先前版本预处理默认使用的f0预测器,比较拉胯不推荐使用
|
| 1190 |
+
**harvest**: 有一定抗噪能力,预处理显存占用友好,速度比较慢
|
| 1191 |
+
**rmvpe**: 最精准的预测器,crepe的完全上位替代
|
| 1192 |
+
**fcpe**: SVC开发组自研F0预测器,有最快的速度和不输crepe的精度
|
| 1193 |
+
""")
|
| 1194 |
+
with gr.Row():
|
| 1195 |
+
branch_selection = gr.Dropdown(label="选择训练使用的编码器", choices=encoder_list, value="vec768l12", interactive=True)
|
| 1196 |
+
f0_predictor_selection = gr.Dropdown(label="选择训练使用的f0预测器", choices=f0_options, value="rmvpe", interactive=True)
|
| 1197 |
+
with gr.Row():
|
| 1198 |
+
use_diff = gr.Checkbox(label="是否使用浅扩散模型,如要训练浅扩散请勾选此项,将会在预处理时生成浅扩散必备的特征文件(确定不训练可以不勾,能节省一点空间)", value=True)
|
| 1199 |
+
vol_aug=gr.Checkbox(label="是否启用响度嵌入和音量增强,启用后可以根据输入源控制输出响度,但对数据集质量的要求更高。**仅支持vec768l12编码器**", value=False)
|
| 1200 |
+
tiny_enable = gr.Checkbox(label="是否启用TINY训练,TINY为实时专用模型,显存占用更低,推理速度更快,但质量有所削减。仅支持vec768,且必须打开响度嵌入", value=False)
|
| 1201 |
+
with gr.Row():
|
| 1202 |
+
skip_loudnorm = gr.Checkbox(label="是否跳过响度匹配,如果你已经用音频处理软件做过响度匹配,请勾选此处")
|
| 1203 |
+
num_processes = gr.Slider(label="预处理使用的CPU线程数,可以��幅加快预处理速度,但线程数过大容易爆显存,建议12G显存设置为2", minimum=1, maximum=multiprocessing.cpu_count(), value=1, step=1)
|
| 1204 |
+
with gr.Row():
|
| 1205 |
+
raw_preprocess=gr.Button("数据预处理", variant="primary")
|
| 1206 |
+
regenerate_config_btn=gr.Button("重新生成配置文件", variant="primary")
|
| 1207 |
+
preprocess_output=gr.Textbox(label="预处理输出信息,完成后请检查一下是否有报错信息,如无则可以进行下一步", max_lines=999)
|
| 1208 |
+
clear_preprocess_output=gr.Button("清空输出信息")
|
| 1209 |
+
with gr.Group():
|
| 1210 |
+
gr.Markdown(value="""填写训练设置和超参数""")
|
| 1211 |
+
with gr.Row():
|
| 1212 |
+
gr.Textbox(label="当前使用显卡信息", value=gpu_info)
|
| 1213 |
+
gpu_selection=gr.Textbox(label="多卡用户请指定希望训练使用的显卡ID(0,1,2...)", value=gpus, interactive=True)
|
| 1214 |
+
with gr.Row():
|
| 1215 |
+
log_interval=gr.Textbox(label="每隔多少步(steps)生成一次评估日志", value=sovits_params['log_interval'])
|
| 1216 |
+
eval_interval=gr.Textbox(label="每隔多少步(steps)验证并保存一次模型", value=sovits_params['eval_interval'])
|
| 1217 |
+
keep_ckpts=gr.Textbox(label="仅保留最新的X个模型,超出该数字的旧模型会被删除。设置为0则永不删除", value=sovits_params['keep_ckpts'])
|
| 1218 |
+
with gr.Row():
|
| 1219 |
+
batch_size=gr.Textbox(label="批量大小,每步取多少条数据进行训练,大batch有助于训练但显著增加显存占用。6G显存建议设定为4", value=auto_batch)
|
| 1220 |
+
lr=gr.Textbox(label="学习率,一般不用动,批量大小较大时可以适当增大学习率,但强烈不建议超过0.0002,有炸炉风险", value=sovits_params['learning_rate'])
|
| 1221 |
+
amp_dtype = gr.Radio(label="训练数据类型,fp16可能会有更快的训练速度和更低的显存占用,但容易炸炉", choices=amp_options, value=sovits_params['amp_dtype'])
|
| 1222 |
+
all_in_mem=gr.Checkbox(label="是否加载所有数据集到内存中,硬盘IO过于低下、同时内存容量远大于数据集体积时可以启用,能显著加快训练速度", value=sovits_params['all_in_mem'])
|
| 1223 |
+
with gr.Row():
|
| 1224 |
+
gr.Markdown("请检查右侧的说话人列表是否和你要训练的目标说话人一致,确认无误后点击写入配置文件,然后就可以开始训练了")
|
| 1225 |
+
speakers=gr.Textbox(label="说话人列表")
|
| 1226 |
+
with gr.Accordion(label = "扩散模型配置(训练扩散模型需要写入此处)", open=True):
|
| 1227 |
+
with gr.Row():
|
| 1228 |
+
diff_num_workers = gr.Number(label="num_workers, 如果你的电脑配置较高,可以将这里设置为0加快训练速度", value=diff_params['num_workers'])
|
| 1229 |
+
diff_k_step_max = gr.Checkbox(label="只训练100步深度的浅扩散模型。能加快训练速度并提高模型质量,代价是无法执行超过100步的浅扩散推理", value=diff_params['diff_k_step_max'])
|
| 1230 |
+
diff_cache_all_data = gr.Checkbox(label="是否缓存数据,启用后可以加快训练速度,关闭后可以节省显存或内存,但会减慢训练速度", value=diff_params['cache_all_data'])
|
| 1231 |
+
diff_cache_device = gr.Radio(label="若启用缓存数据,使用显存(cuda)还是内存(cpu)缓存,如果显卡显存充足,选择cuda以加快训练速度", choices=["cuda","cpu"], value=diff_params['cache_device'])
|
| 1232 |
+
diff_amp_dtype = gr.Radio(label="训练数据类型,fp16可能会有更快的训练速度,前提是你的显卡支持", choices=["fp32","fp16"], value=diff_params['amp_dtype'])
|
| 1233 |
+
with gr.Row():
|
| 1234 |
+
diff_batch_size = gr.Number(label="批量大小(batch_size),根据显卡显存设置,小显存适当降低该项,6G显存可以设定为48,但该数值不要超过数据集总数量的1/4", value=diff_params['diff_batch_size'])
|
| 1235 |
+
diff_lr = gr.Number(label="学习率(一般不需要动)", value=diff_params['diff_lr'])
|
| 1236 |
+
diff_interval_log = gr.Number(label="每隔多少步(steps)生成一次评估日志", value = diff_params['diff_interval_log'])
|
| 1237 |
+
diff_interval_val = gr.Number(label="每隔多少步(steps)验证并保存一次模型,如果你的批量大小较大,可以适当减少这里的数字,但不建议设置为1000以下", value=diff_params['diff_interval_val'])
|
| 1238 |
+
diff_force_save = gr.Number(label="每隔多少步强制保留模型,只有该步数的倍数保存的模型会被保留,其余会被删除。设置为与验证步数相同的值则每个模型都会被保留", value=diff_params['diff_force_save'])
|
| 1239 |
+
with gr.Row():
|
| 1240 |
+
save_params=gr.Button("将当前设置保存为默认设置", variant="primary")
|
| 1241 |
+
write_config=gr.Button("写入配置文件", variant="primary")
|
| 1242 |
+
write_config_output=gr.Textbox(label="输出信息")
|
| 1243 |
+
|
| 1244 |
+
gr.Markdown(value="""**点击从头开始训练**将会自动将已有的训练进度保存到models_backup文件夹,并自动装载预训练模型。
|
| 1245 |
+
**继续上一次的训练进度**将从上一个保存模型的进度继续训练。继续训练进度无需重新预处理和写入配置文件。
|
| 1246 |
+
关于扩散、聚类和特征检索的详细说明请看[此处](https://www.yuque.com/umoubuton/ueupp5/kmui02dszo5zrqkz)。
|
| 1247 |
+
""")
|
| 1248 |
+
with gr.Row():
|
| 1249 |
+
with gr.Column():
|
| 1250 |
+
start_training=gr.Button("从头开始训练", variant="primary")
|
| 1251 |
+
training_output=gr.Textbox(label="训练输出信息")
|
| 1252 |
+
with gr.Column():
|
| 1253 |
+
continue_training_btn=gr.Button("继续上一次的训练进度", variant="primary")
|
| 1254 |
+
continue_training_output=gr.Textbox(label="训练输出信息")
|
| 1255 |
+
with gr.Row():
|
| 1256 |
+
with gr.Column():
|
| 1257 |
+
diff_training_btn=gr.Button("从头训练扩散模型", variant="primary")
|
| 1258 |
+
diff_training_output=gr.Textbox(label="训练输出信息")
|
| 1259 |
+
with gr.Column():
|
| 1260 |
+
diff_continue_training_btn=gr.Button("继续训练扩散模型", variant="primary")
|
| 1261 |
+
diff_continue_training_output=gr.Textbox(label="训练输出信息")
|
| 1262 |
+
with gr.Accordion(label = "聚类、特征检索训练", open=False):
|
| 1263 |
+
with gr.Row():
|
| 1264 |
+
with gr.Column():
|
| 1265 |
+
kmeans_button=gr.Button("训练聚类模型", variant="primary")
|
| 1266 |
+
kmeans_gpu = gr.Checkbox(label="使用GPU训练", value=True)
|
| 1267 |
+
kmeans_output=gr.Textbox(label="训练输出信息")
|
| 1268 |
+
with gr.Column():
|
| 1269 |
+
index_button=gr.Button("训练特征检索模型", variant="primary")
|
| 1270 |
+
index_output=gr.Textbox(label="训练输出信息")
|
| 1271 |
+
|
| 1272 |
+
with gr.TabItem("小工具/实验室特性"):
|
| 1273 |
+
gr.Markdown(value="""
|
| 1274 |
+
### So-vits-svc 4.1 小工具/实验室特性
|
| 1275 |
+
提供了一些有趣或实用的小工具,可以自行探索
|
| 1276 |
+
""")
|
| 1277 |
+
with gr.Tabs():
|
| 1278 |
+
with gr.TabItem("静态声线融合"):
|
| 1279 |
+
gr.Markdown(value="""
|
| 1280 |
+
<font size=2> 介绍:该功能可以将多个声音模型合成为一个声音模型(多个模型参数的凸组合或线性组合),从而制造出现实中不存在的声线
|
| 1281 |
+
注意:
|
| 1282 |
+
1.该功能仅支持单说话人的模型
|
| 1283 |
+
2.如果强行使用多说话人模型,需要保证多个模型的说话人数量相同,这样可以混合同一个SpaekerID下的声音
|
| 1284 |
+
3.保证所有待混合模型的config.json中的model字段是相同的
|
| 1285 |
+
4.输出的混合模型可以使用待合成模型的任意一个config.json,但聚类模型将不能使用
|
| 1286 |
+
5.批量上传模型的时候最好把模型放到一个文件夹选中后一起上传
|
| 1287 |
+
6.混合比例调整建议大小在0-100之间,也可以调为其他数字,但在线性组合模式下会出现未知的效果
|
| 1288 |
+
7.混合完毕后,文件将会保存在项目根目录中,文件名为output.pth
|
| 1289 |
+
8.凸组合模式会将混合比例执行Softmax使混合比例相加为1,而线性组合模式不会
|
| 1290 |
+
</font>
|
| 1291 |
+
""")
|
| 1292 |
+
mix_model_path = gr.Files(label="选择需要混合模型文件")
|
| 1293 |
+
mix_model_upload_button = gr.UploadButton("选择/追加需要混合模型文件", file_count="multiple")
|
| 1294 |
+
mix_model_output1 = gr.Textbox(
|
| 1295 |
+
label="混合比例调整,单位/%",
|
| 1296 |
+
interactive = True
|
| 1297 |
+
)
|
| 1298 |
+
mix_mode = gr.Radio(choices=["凸组合", "线性组合"], label="融合模式",value="凸组合",interactive = True)
|
| 1299 |
+
mix_submit = gr.Button("声线融合启动", variant="primary")
|
| 1300 |
+
mix_model_output2 = gr.Textbox(
|
| 1301 |
+
label="Output Message"
|
| 1302 |
+
)
|
| 1303 |
+
with gr.TabItem("onnx转换"):
|
| 1304 |
+
gr.Markdown(value="""
|
| 1305 |
+
提供了将.pth模型(批量)转换为.onnx模型的功能
|
| 1306 |
+
源项目本身自带转换的功能,但不支���批量,操作也不够简单,这个工具可以支持在WebUI中以可视化的操作方式批量转换.onnx模型
|
| 1307 |
+
有人可能会问,转.onnx模型有什么作用呢?相信我,如果你问出了这个问题,说明这个工具你应该用不上
|
| 1308 |
+
|
| 1309 |
+
### Step 1:
|
| 1310 |
+
在整合包根目录下新建一个"checkpoints"文件夹,将pth模型和对应的json配置文件按目录分别放置到checkpoints文件夹下
|
| 1311 |
+
看起来应该像这样:
|
| 1312 |
+
checkpoints
|
| 1313 |
+
├───xxxx
|
| 1314 |
+
│ ├───xxxx.pth
|
| 1315 |
+
│ └───xxxx.json
|
| 1316 |
+
├───xxxx
|
| 1317 |
+
│ ├───xxxx.pth
|
| 1318 |
+
│ └───xxxx.json
|
| 1319 |
+
└───……
|
| 1320 |
+
""")
|
| 1321 |
+
pth_dir_msg = gr.Textbox(label="识别待转换模型", placeholder="请将模型和配置文件按上述说明放置在正确位置")
|
| 1322 |
+
pth_dir_identify_btn = gr.Button("识别", variant="primary")
|
| 1323 |
+
gr.Markdown(value="""
|
| 1324 |
+
### Step 2:
|
| 1325 |
+
识别正确后点击下方开始转换,转换一个模型可能需要一分钟甚至更久
|
| 1326 |
+
""")
|
| 1327 |
+
pth2onnx_btn = gr.Button("开始转换", variant="primary")
|
| 1328 |
+
pth2onnx_msg = gr.Textbox(label="输出信息")
|
| 1329 |
+
|
| 1330 |
+
with gr.TabItem("智能音频切片"):
|
| 1331 |
+
gr.Markdown(value="""
|
| 1332 |
+
该工具可以实现对音频的切片,无需调整参数即可完成符合要求的数据集制作。
|
| 1333 |
+
数据集要求的音频切片约在2-15秒内,用传统的Slicer-GUI切片工具需要精准调参和二次切片才能符合要求,该工具省去了上述繁琐的操作,只要上传原始音频即可一键制作数据集。
|
| 1334 |
+
""")
|
| 1335 |
+
with gr.Row():
|
| 1336 |
+
raw_audio_path = gr.Textbox(label="原始音频文件夹", placeholder="包含所有待切片音频的文件夹,示例: D:\干声\speakers")
|
| 1337 |
+
load_raw_audio_btn = gr.Button("加载原始音频", variant = "primary")
|
| 1338 |
+
load_raw_audio_output = gr.Textbox(label = "输出信息")
|
| 1339 |
+
raw_audio_dataset = gr.Textbox(label = "音频列表", value = "")
|
| 1340 |
+
slicer_output_dir = gr.Textbox(label = "输出目录", placeholder = "选择输出目录(不要和输入音频是同一个文件夹)")
|
| 1341 |
+
with gr.Row():
|
| 1342 |
+
process_method = gr.Radio(label = "对过短音频的处理方式", choices = ["丢弃","将过短音频整合为长音频"], value = "丢弃")
|
| 1343 |
+
max_sec = gr.Number(label = "切片的最长秒数", value = 15)
|
| 1344 |
+
min_sec = gr.Number(label = "切片的最短秒数", value = 2)
|
| 1345 |
+
slicer_btn = gr.Button("开始切片", variant = "primary")
|
| 1346 |
+
slicer_output_msg = gr.Textbox(label = "输出信息")
|
| 1347 |
+
|
| 1348 |
+
mix_model_path.change(updata_mix_info,[mix_model_path],[mix_model_output1])
|
| 1349 |
+
mix_model_upload_button.upload(upload_mix_append_file, [mix_model_upload_button,mix_model_path], [mix_model_path,mix_model_output1])
|
| 1350 |
+
mix_submit.click(mix_submit_click, [mix_model_output1,mix_mode], [mix_model_output2])
|
| 1351 |
+
pth_dir_identify_btn.click(pth_identify, [], [pth_dir_msg])
|
| 1352 |
+
pth2onnx_btn.click(onnx_export_func, [], [pth2onnx_msg])
|
| 1353 |
+
load_raw_audio_btn.click(load_raw_audio, [raw_audio_path], [load_raw_audio_output, raw_audio_dataset])
|
| 1354 |
+
slicer_btn.click(slicer_fn, [raw_audio_path, slicer_output_dir, process_method, max_sec, min_sec], [slicer_output_msg])
|
| 1355 |
+
|
| 1356 |
+
with gr.TabItem("模型压缩工具"):
|
| 1357 |
+
gr.Markdown(value="""
|
| 1358 |
+
该工具可以实现对模型的体积压缩,在**不影响模型推理功能**的情况下,将原本约600M的So-VITS模型压缩至约200M, 大大减少了硬盘的压力。
|
| 1359 |
+
**注意:压缩后的模型将无法继续训练,请在确认封炉后再压缩。**
|
| 1360 |
+
将模型文件放置在logs/44k下,然后选择需要压缩的模型
|
| 1361 |
+
""")
|
| 1362 |
+
model_to_compress = gr.Dropdown(label="模型选择", choices=ckpt_list, value="no_model")
|
| 1363 |
+
fp16_compress = gr.Checkbox(label="使用 fp16 压缩", value=False)
|
| 1364 |
+
compress_model_btn = gr.Button("压缩模型", variant="primary")
|
| 1365 |
+
compress_model_output = gr.Textbox(label="输出信息", value="")
|
| 1366 |
+
|
| 1367 |
+
compress_model_btn.click(model_compression, [model_to_compress, fp16_compress], [compress_model_output])
|
| 1368 |
+
|
| 1369 |
+
with gr.TabItem("模型发布打包/安装"):
|
| 1370 |
+
gr.Markdown(value="""
|
| 1371 |
+
如果你想将你的模型分享给他人,请使用该工具对模型进行打包。
|
| 1372 |
+
该工具可以自动生成正确的配置文件,确保你在打包过程中不出现任何遗漏和错误,接收到使用该工具打包的模型后,也可以用该工具进行自动安装。
|
| 1373 |
+
""")
|
| 1374 |
+
with gr.Tabs():
|
| 1375 |
+
with gr.TabItem("安装"):
|
| 1376 |
+
with gr.Row():
|
| 1377 |
+
model_to_install = gr.Textbox(label = "模型压缩包路径", placeholder="示例:D:\Downloads\model_packing.zip")
|
| 1378 |
+
install_model_btn = gr.Button("安装", variant="primary")
|
| 1379 |
+
install_output = gr.Textbox(label="输出信息", value="")
|
| 1380 |
+
with gr.TabItem("打包"):
|
| 1381 |
+
with gr.Row():
|
| 1382 |
+
model_to_pack = gr.Dropdown(label="选择要打包的模型", choices=ckpt_list, value="")
|
| 1383 |
+
model_config = gr.Dropdown(label="选择要打包的模型配置文件", choices=config_list, value="", interactive=True)
|
| 1384 |
+
speaker_name = gr.Textbox(label="模型说话人名称", placeholder="该模型的说话人名称,仅限数字字母下划线,如模型中有多说话人,请用逗号分割,例如:spk1,spk2,spk3", value = "")
|
| 1385 |
+
with gr.Row():
|
| 1386 |
+
diff_to_pack = gr.Dropdown(label="(可选)选择要打包的扩散模型", choices=diff_list, value="no_diff")
|
| 1387 |
+
cluster_to_pack = gr.Dropdown(label="(可选)选择要打包的聚类或特征检索模型", choices=cluster_list, value="no_cluster")
|
| 1388 |
+
packing_btn = gr.Button("开始打包", variant="primary")
|
| 1389 |
+
packing_output_msg = gr.Textbox(label = "输出信息")
|
| 1390 |
+
|
| 1391 |
+
model_to_pack.change(pack_autoload, [model_to_pack], [model_config, speaker_name])
|
| 1392 |
+
packing_btn.click(release_packing, [model_to_pack, model_config, speaker_name, diff_to_pack, cluster_to_pack], [packing_output_msg])
|
| 1393 |
+
install_model_btn.click(release_install, [model_to_install], [install_output])
|
| 1394 |
+
|
| 1395 |
+
get_raw_dirs.click(load_raw_dirs,[],[raw_dirs_list])
|
| 1396 |
+
raw_preprocess.click(dataset_preprocess,[branch_selection, f0_predictor_selection, use_diff, vol_aug, skip_loudnorm, num_processes, tiny_enable],[preprocess_output, speakers])
|
| 1397 |
+
regenerate_config_btn.click(regenerate_config,[branch_selection, vol_aug, tiny_enable],[preprocess_output])
|
| 1398 |
+
clear_preprocess_output.click(clear_output,[],[preprocess_output])
|
| 1399 |
+
save_params.click(save_default_settings, [log_interval,eval_interval,keep_ckpts,batch_size,lr,amp_dtype,all_in_mem,diff_num_workers,diff_cache_all_data,diff_cache_device,diff_amp_dtype,diff_batch_size,diff_lr,diff_interval_log,diff_interval_val,diff_force_save,diff_k_step_max], [write_config_output])
|
| 1400 |
+
write_config.click(config_fn,[log_interval, eval_interval, keep_ckpts, batch_size, lr, amp_dtype, all_in_mem, diff_num_workers, diff_cache_all_data, diff_batch_size, diff_lr, diff_interval_log, diff_interval_val, diff_cache_device, diff_amp_dtype, diff_force_save, diff_k_step_max],[write_config_output])
|
| 1401 |
+
start_training.click(training,[gpu_selection, branch_selection, tiny_enable],[training_output])
|
| 1402 |
+
diff_training_btn.click(diff_training,[branch_selection, diff_k_step_max],[diff_training_output])
|
| 1403 |
+
continue_training_btn.click(continue_training,[gpu_selection, branch_selection],[continue_training_output])
|
| 1404 |
+
diff_continue_training_btn.click(diff_continue_training,[branch_selection],[diff_continue_training_output])
|
| 1405 |
+
kmeans_button.click(kmeans_training,[kmeans_gpu],[kmeans_output])
|
| 1406 |
+
index_button.click(index_training, [], [index_output])
|
| 1407 |
+
|
| 1408 |
+
with gr.Tabs():
|
| 1409 |
+
with gr.Row(variant="panel"):
|
| 1410 |
+
with gr.Column():
|
| 1411 |
+
gr.Markdown(value="""
|
| 1412 |
+
<font size=2> WebUI设置</font>
|
| 1413 |
+
""")
|
| 1414 |
+
with gr.Row():
|
| 1415 |
+
debug_button = gr.Checkbox(label="Debug模式,反馈BUG需要打开,打开后控制台可以显示具体错误提示", value=debug)
|
| 1416 |
+
read_second_dir = gr.Checkbox(label = "独立目录模式,开启后将从独立目录(./models)读取模型和配置文件,变更后需要刷新选项才能生效", value=second_dir_enable)
|
| 1417 |
+
debug_button.change(debug_change,[],[])
|
| 1418 |
+
read_second_dir.change(webui_change,[read_second_dir],[])
|
| 1419 |
+
|
| 1420 |
+
# app.queue(concurrency_count=1022, max_size=2044).launch(server_name="127.0.0.1",inbrowser=True,quiet=True)
|
| 1421 |
+
app.queue(concurrency_count=1022, max_size=2044).launch(server_name="0.0.0.0",inbrowser=True,quiet=True)
|
app_old.py
ADDED
|
@@ -0,0 +1,1428 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import ast
|
| 2 |
+
import datetime
|
| 3 |
+
import glob
|
| 4 |
+
import json
|
| 5 |
+
import logging
|
| 6 |
+
import multiprocessing
|
| 7 |
+
import os
|
| 8 |
+
import re
|
| 9 |
+
import shutil
|
| 10 |
+
import subprocess
|
| 11 |
+
import traceback
|
| 12 |
+
import zipfile
|
| 13 |
+
from itertools import chain
|
| 14 |
+
from pathlib import Path
|
| 15 |
+
|
| 16 |
+
import gradio as gr
|
| 17 |
+
import librosa
|
| 18 |
+
import numpy as np
|
| 19 |
+
import soundfile as sf
|
| 20 |
+
import torch
|
| 21 |
+
import yaml
|
| 22 |
+
|
| 23 |
+
import utils
|
| 24 |
+
from auto_slicer import AutoSlicer
|
| 25 |
+
from compress_model import removeOptimizer
|
| 26 |
+
from inference.infer_tool import Svc
|
| 27 |
+
from onnxexport.model_onnx import SynthesizerTrn
|
| 28 |
+
from tts_voices import SUPPORTED_LANGUAGES
|
| 29 |
+
from utils import mix_model
|
| 30 |
+
|
| 31 |
+
os.environ["PATH"] += os.pathsep + os.path.join(os.getcwd(), "ffmpeg", "bin")
|
| 32 |
+
|
| 33 |
+
logging.getLogger('numba').setLevel(logging.WARNING)
|
| 34 |
+
logging.getLogger('markdown_it').setLevel(logging.WARNING)
|
| 35 |
+
logging.getLogger('urllib3').setLevel(logging.WARNING)
|
| 36 |
+
logging.getLogger('matplotlib').setLevel(logging.WARNING)
|
| 37 |
+
|
| 38 |
+
# Some directories
|
| 39 |
+
workdir = "logs/44k"
|
| 40 |
+
second_dir = "models"
|
| 41 |
+
diff_second_dir = "models/diffusion"
|
| 42 |
+
diff_workdir = "logs/44k/diffusion"
|
| 43 |
+
config_dir = "configs/"
|
| 44 |
+
dataset_dir = "dataset/44k"
|
| 45 |
+
raw_path = "dataset_raw"
|
| 46 |
+
raw_wavs_path = "raw"
|
| 47 |
+
models_backup_path = 'models_backup'
|
| 48 |
+
root_dir = "checkpoints"
|
| 49 |
+
default_settings_file = "settings.yaml"
|
| 50 |
+
current_mode = ""
|
| 51 |
+
# Some global variables
|
| 52 |
+
debug = False
|
| 53 |
+
precheck_ok = False
|
| 54 |
+
model = None
|
| 55 |
+
sovits_params = {}
|
| 56 |
+
diff_params = {}
|
| 57 |
+
# Some dicts for mapping
|
| 58 |
+
MODEL_TYPE = {
|
| 59 |
+
"vec768l12": 768,
|
| 60 |
+
"vec256l9": 256,
|
| 61 |
+
"hubertsoft": 256,
|
| 62 |
+
"whisper-ppg": 1024,
|
| 63 |
+
"cnhubertlarge": 1024,
|
| 64 |
+
"dphubert": 768,
|
| 65 |
+
"wavlmbase+": 768,
|
| 66 |
+
"whisper-ppg-large": 1280
|
| 67 |
+
}
|
| 68 |
+
ENCODER_PRETRAIN = {
|
| 69 |
+
"vec256l9": "pretrain/checkpoint_best_legacy_500.pt",
|
| 70 |
+
"vec768l12": "pretrain/checkpoint_best_legacy_500.pt",
|
| 71 |
+
"hubertsoft": "pretrain/hubert-soft-0d54a1f4.pt",
|
| 72 |
+
"whisper-ppg": "pretrain/medium.pt",
|
| 73 |
+
"cnhubertlarge": "pretrain/chinese-hubert-large-fairseq-ckpt.pt",
|
| 74 |
+
"dphubert": "pretrain/DPHuBERT-sp0.75.pth",
|
| 75 |
+
"wavlmbase+": "pretrain/WavLM-Base+.pt",
|
| 76 |
+
"whisper-ppg-large": "pretrain/large-v2.pt"
|
| 77 |
+
}
|
| 78 |
+
|
| 79 |
+
class Config:
|
| 80 |
+
def __init__(self, path, type):
|
| 81 |
+
self.path = path
|
| 82 |
+
self.type = type
|
| 83 |
+
|
| 84 |
+
def read(self):
|
| 85 |
+
if self.type == "json":
|
| 86 |
+
with open(self.path, 'r') as f:
|
| 87 |
+
return json.load(f)
|
| 88 |
+
if self.type == "yaml":
|
| 89 |
+
with open(self.path, 'r') as f:
|
| 90 |
+
return yaml.safe_load(f)
|
| 91 |
+
|
| 92 |
+
def save(self, content):
|
| 93 |
+
if self.type == "json":
|
| 94 |
+
with open(self.path, 'w') as f:
|
| 95 |
+
json.dump(content, f, indent=4)
|
| 96 |
+
if self.type == "yaml":
|
| 97 |
+
with open(self.path, 'w') as f:
|
| 98 |
+
yaml.safe_dump(content, f, default_flow_style=False, sort_keys=False)
|
| 99 |
+
|
| 100 |
+
|
| 101 |
+
class ReleasePacker:
|
| 102 |
+
def __init__(self, speaker, model):
|
| 103 |
+
self.speaker = speaker
|
| 104 |
+
self.model = model
|
| 105 |
+
self.output_path = os.path.join("release_packs", f"{speaker}_release.zip")
|
| 106 |
+
self.file_list = []
|
| 107 |
+
|
| 108 |
+
def remove_temp(self, path):
|
| 109 |
+
for filename in os.listdir(path):
|
| 110 |
+
file_path = os.path.join(path, filename)
|
| 111 |
+
if os.path.isfile(file_path) and not filename.endswith(".zip"):
|
| 112 |
+
os.remove(file_path)
|
| 113 |
+
elif os.path.isdir(file_path):
|
| 114 |
+
shutil.rmtree(file_path, ignore_errors=True)
|
| 115 |
+
|
| 116 |
+
def add_file(self, file_paths):
|
| 117 |
+
self.file_list.extend(file_paths)
|
| 118 |
+
|
| 119 |
+
def spk_to_dict(self):
|
| 120 |
+
spk_string = self.speaker.replace(',', ',')
|
| 121 |
+
spk_string = spk_string.replace(' ', '')
|
| 122 |
+
_spk = spk_string.split(',')
|
| 123 |
+
return {_spk: index for index, _spk in enumerate(_spk)}
|
| 124 |
+
|
| 125 |
+
def generate_config(self, diff_model, config_origin):
|
| 126 |
+
_config_origin = Config(os.path.join(config_read_dir, config_origin), "json")
|
| 127 |
+
_template = Config("release_packs/config_template.json", "json")
|
| 128 |
+
_d_template = Config("release_packs/diffusion_template.yaml", "yaml")
|
| 129 |
+
orig_config = _config_origin.read()
|
| 130 |
+
config_template = _template.read()
|
| 131 |
+
diff_config_template = _d_template.read()
|
| 132 |
+
spk_dict = self.spk_to_dict()
|
| 133 |
+
_net = torch.load(os.path.join(ckpt_read_dir, self.model), map_location='cpu')
|
| 134 |
+
emb_dim, model_dim = _net['model'].get('emb_g.weight', torch.empty(0, 0)).size()
|
| 135 |
+
vol_emb = _net['model'].get('emb_vol.weight')
|
| 136 |
+
if vol_emb is not None:
|
| 137 |
+
config_template["train"]["vol_aug"] = config_template["model"]["vol_embedding"] = True
|
| 138 |
+
#Keep the spk_dict length same as emb_dim
|
| 139 |
+
if emb_dim > len(spk_dict):
|
| 140 |
+
for i in range(emb_dim - len(spk_dict)):
|
| 141 |
+
spk_dict[f"spk{i}"] = len(spk_dict)
|
| 142 |
+
if emb_dim < len(spk_dict):
|
| 143 |
+
for i in range(len(spk_dict) - emb_dim):
|
| 144 |
+
spk_dict.popitem()
|
| 145 |
+
self.speaker = ','.join(spk_dict.keys())
|
| 146 |
+
config_template['model']['ssl_dim'] = config_template["model"]["filter_channels"] = config_template["model"]["gin_channels"] = model_dim
|
| 147 |
+
config_template['model']['n_speakers'] = diff_config_template['model']['n_spk'] = emb_dim
|
| 148 |
+
config_template['spk'] = diff_config_template['spk'] = spk_dict
|
| 149 |
+
encoder = [k for k, v in MODEL_TYPE.items() if v == model_dim]
|
| 150 |
+
if orig_config['model']['speech_encoder'] in encoder:
|
| 151 |
+
config_template['model']['speech_encoder'] = orig_config['model']['speech_encoder']
|
| 152 |
+
else:
|
| 153 |
+
raise Exception("Config is not compatible with the model")
|
| 154 |
+
|
| 155 |
+
if diff_model != "no_diff":
|
| 156 |
+
_diff = torch.load(os.path.join(diff_read_dir, diff_model), map_location='cpu')
|
| 157 |
+
_, diff_dim = _diff["model"].get("unit_embed.weight", torch.empty(0, 0)).size()
|
| 158 |
+
if diff_dim == 256:
|
| 159 |
+
diff_config_template['data']['encoder'] = 'hubertsoft'
|
| 160 |
+
diff_config_template['data']['encoder_out_channels'] = 256
|
| 161 |
+
elif diff_dim == 768:
|
| 162 |
+
diff_config_template['data']['encoder'] = 'vec768l12'
|
| 163 |
+
diff_config_template['data']['encoder_out_channels'] = 768
|
| 164 |
+
elif diff_dim == 1024:
|
| 165 |
+
diff_config_template['data']['encoder'] = 'whisper-ppg'
|
| 166 |
+
diff_config_template['data']['encoder_out_channels'] = 1024
|
| 167 |
+
|
| 168 |
+
with open("release_packs/install.txt", 'w') as f:
|
| 169 |
+
f.write(str(self.file_list) + '#' + str(self.speaker))
|
| 170 |
+
|
| 171 |
+
_template.save(config_template)
|
| 172 |
+
_d_template.save(diff_config_template)
|
| 173 |
+
|
| 174 |
+
def unpack(self, zip_file):
|
| 175 |
+
with zipfile.ZipFile(zip_file, 'r') as zipf:
|
| 176 |
+
zipf.extractall("release_packs")
|
| 177 |
+
|
| 178 |
+
def formatted_install(self, install_txt):
|
| 179 |
+
with open(install_txt, 'r') as f:
|
| 180 |
+
content = f.read()
|
| 181 |
+
file_list, speaker = content.split('#')
|
| 182 |
+
self.speaker = speaker
|
| 183 |
+
file_list = ast.literal_eval(file_list)
|
| 184 |
+
self.file_list = file_list
|
| 185 |
+
for _, target_path in self.file_list:
|
| 186 |
+
if target_path != "install.txt" and target_path != "":
|
| 187 |
+
shutil.move(os.path.join("release_packs", target_path), target_path)
|
| 188 |
+
self.remove_temp("release_packs")
|
| 189 |
+
return self.speaker
|
| 190 |
+
|
| 191 |
+
def pack(self):
|
| 192 |
+
with zipfile.ZipFile(self.output_path, 'w', zipfile.ZIP_DEFLATED) as zipf:
|
| 193 |
+
for file_path, target_path in self.file_list:
|
| 194 |
+
if os.path.isfile(file_path):
|
| 195 |
+
zipf.write(file_path, arcname=target_path)
|
| 196 |
+
|
| 197 |
+
|
| 198 |
+
def debug_change():
|
| 199 |
+
global debug
|
| 200 |
+
debug = debug_button.value
|
| 201 |
+
|
| 202 |
+
def get_default_settings():
|
| 203 |
+
global sovits_params, diff_params, second_dir_enable
|
| 204 |
+
config_file = Config(default_settings_file, "yaml")
|
| 205 |
+
default_settings = config_file.read()
|
| 206 |
+
sovits_params = default_settings['sovits_params']
|
| 207 |
+
diff_params = default_settings['diff_params']
|
| 208 |
+
webui_settings = default_settings['webui_settings']
|
| 209 |
+
second_dir_enable = webui_settings['second_dir']
|
| 210 |
+
return sovits_params, diff_params, second_dir_enable
|
| 211 |
+
|
| 212 |
+
def webui_change(read_second_dir):
|
| 213 |
+
global second_dir_enable
|
| 214 |
+
config_file = Config(default_settings_file, "yaml")
|
| 215 |
+
default_settings = config_file.read()
|
| 216 |
+
second_dir_enable = default_settings['webui_settings']['second_dir'] = read_second_dir
|
| 217 |
+
config_file.save(default_settings)
|
| 218 |
+
|
| 219 |
+
def get_current_mode():
|
| 220 |
+
global current_mode
|
| 221 |
+
current_mode = "当前模式:独立目录模式,将从'./models/'读取模型文件" if second_dir_enable else "当前模式:工作目录模式,将从'./logs/44k'读取模型文件"
|
| 222 |
+
return current_mode
|
| 223 |
+
|
| 224 |
+
def save_default_settings(log_interval,eval_interval,keep_ckpts,batch_size,learning_rate,amp_dtype,all_in_mem,num_workers,cache_all_data,cache_device,diff_amp_dtype,diff_batch_size,diff_lr,diff_interval_log,diff_interval_val,diff_force_save,diff_k_step_max):
|
| 225 |
+
config_file = Config(default_settings_file, "yaml")
|
| 226 |
+
default_settings = config_file.read()
|
| 227 |
+
default_settings['sovits_params']['log_interval'] = int(log_interval)
|
| 228 |
+
default_settings['sovits_params']['eval_interval'] = int(eval_interval)
|
| 229 |
+
default_settings['sovits_params']['keep_ckpts'] = int(keep_ckpts)
|
| 230 |
+
default_settings['sovits_params']['batch_size'] = int(batch_size)
|
| 231 |
+
default_settings['sovits_params']['learning_rate'] = float(learning_rate)
|
| 232 |
+
default_settings['sovits_params']['amp_dtype'] = str(amp_dtype)
|
| 233 |
+
default_settings['sovits_params']['all_in_mem'] = all_in_mem
|
| 234 |
+
default_settings['diff_params']['num_workers'] = int(num_workers)
|
| 235 |
+
default_settings['diff_params']['cache_all_data'] = cache_all_data
|
| 236 |
+
default_settings['diff_params']['cache_device'] = str(cache_device)
|
| 237 |
+
default_settings['diff_params']['amp_dtype'] = str(diff_amp_dtype)
|
| 238 |
+
default_settings['diff_params']['diff_batch_size'] = int(diff_batch_size)
|
| 239 |
+
default_settings['diff_params']['diff_lr'] = float(diff_lr)
|
| 240 |
+
default_settings['diff_params']['diff_interval_log'] = int(diff_interval_log)
|
| 241 |
+
default_settings['diff_params']['diff_interval_val'] = int(diff_interval_val)
|
| 242 |
+
default_settings['diff_params']['diff_force_save'] = int(diff_force_save)
|
| 243 |
+
default_settings['diff_params']['diff_k_step_max'] = diff_k_step_max
|
| 244 |
+
config_file.save(default_settings)
|
| 245 |
+
return "成功保存默认配置"
|
| 246 |
+
|
| 247 |
+
def get_model_info(choice_ckpt):
|
| 248 |
+
pthfile = os.path.join(ckpt_read_dir, choice_ckpt)
|
| 249 |
+
net = torch.load(pthfile, map_location=torch.device('cpu')) #cpu load to avoid using gpu memory
|
| 250 |
+
spk_emb = net["model"].get("emb_g.weight")
|
| 251 |
+
if spk_emb is None:
|
| 252 |
+
return "所选模型缺少emb_g.weight,你可能选择了一个底模"
|
| 253 |
+
_layer = spk_emb.size(1)
|
| 254 |
+
encoder = [k for k, v in MODEL_TYPE.items() if v == _layer] #通过维度对应编码器
|
| 255 |
+
encoder.sort()
|
| 256 |
+
if encoder == ["hubertsoft", "vec256l9"]:
|
| 257 |
+
encoder = ["vec256l9 / hubertsoft"]
|
| 258 |
+
if encoder == ["cnhubertlarge", "whisper-ppg"]:
|
| 259 |
+
encoder = ["whisper-ppg / cnhubertlarge"]
|
| 260 |
+
if encoder == ["dphubert", "vec768l12", "wavlmbase+"]:
|
| 261 |
+
encoder = ["vec768l12 / dphubert / wavlmbase+"]
|
| 262 |
+
return encoder[0]
|
| 263 |
+
|
| 264 |
+
def load_json_encoder(config_choice, choice_ckpt):
|
| 265 |
+
if config_choice == "no_config":
|
| 266 |
+
return "未启用自动加载,请手动选择配置文件"
|
| 267 |
+
if choice_ckpt == "no_model":
|
| 268 |
+
return "请先选择模型"
|
| 269 |
+
config_file = Config(os.path.join(config_read_dir, config_choice), "json")
|
| 270 |
+
config = config_file.read()
|
| 271 |
+
try:
|
| 272 |
+
#比对配置文件中的模型维度与该encoder的实际维度是否对应,防止古神语
|
| 273 |
+
config_encoder = config["model"].get("speech_encoder", "no_encoder")
|
| 274 |
+
config_dim = config["model"]["ssl_dim"]
|
| 275 |
+
#旧版配置文件自动匹配
|
| 276 |
+
if config_encoder == "no_encoder":
|
| 277 |
+
config_encoder = config["model"]["speech_encoder"] = "vec256l9" if config_dim == 256 else "vec768l12"
|
| 278 |
+
config_file.save(config)
|
| 279 |
+
correct_dim = MODEL_TYPE.get(config_encoder, "unknown")
|
| 280 |
+
if config_dim != correct_dim:
|
| 281 |
+
return "配置文件中的编码器与模型维度不匹配"
|
| 282 |
+
return config_encoder
|
| 283 |
+
except Exception as e:
|
| 284 |
+
return f"出错了: {e}"
|
| 285 |
+
|
| 286 |
+
def auto_load(choice_ckpt):
|
| 287 |
+
global second_dir_enable
|
| 288 |
+
model_output_msg = get_model_info(choice_ckpt)
|
| 289 |
+
json_output_msg = config_choice = ""
|
| 290 |
+
choice_ckpt_name, _ = os.path.splitext(choice_ckpt)
|
| 291 |
+
if second_dir_enable:
|
| 292 |
+
all_config = [json for json in os.listdir(second_dir) if json.endswith(".json")]
|
| 293 |
+
for config in all_config:
|
| 294 |
+
config_fname, _ = os.path.splitext(config)
|
| 295 |
+
if config_fname == choice_ckpt_name:
|
| 296 |
+
config_choice = config
|
| 297 |
+
json_output_msg = load_json_encoder(config, choice_ckpt)
|
| 298 |
+
if json_output_msg != "":
|
| 299 |
+
return model_output_msg, config_choice, json_output_msg
|
| 300 |
+
else:
|
| 301 |
+
return model_output_msg, "no_config", ""
|
| 302 |
+
else:
|
| 303 |
+
return model_output_msg, "no_config", ""
|
| 304 |
+
|
| 305 |
+
def auto_load_diff(diff_model):
|
| 306 |
+
global second_dir_enable
|
| 307 |
+
if second_dir_enable is False:
|
| 308 |
+
return "no_diff_config"
|
| 309 |
+
all_diff_config = [yaml for yaml in os.listdir(second_dir) if yaml.endswith(".yaml")]
|
| 310 |
+
for config in all_diff_config:
|
| 311 |
+
config_fname, _ = os.path.splitext(config)
|
| 312 |
+
diff_fname, _ = os.path.splitext(diff_model)
|
| 313 |
+
if config_fname == diff_fname:
|
| 314 |
+
return config
|
| 315 |
+
return "no_diff_config"
|
| 316 |
+
|
| 317 |
+
def load_model_func(ckpt_name,cluster_name,config_name,enhance,diff_model_name,diff_config_name,only_diffusion,use_spk_mix,using_device,method,speedup):
|
| 318 |
+
global model
|
| 319 |
+
config_path = os.path.join(config_read_dir, config_name) if not only_diffusion else "configs/config.json"
|
| 320 |
+
diff_config_path = os.path.join(config_read_dir, diff_config_name) if diff_config_name != "no_diff_config" else "configs/diffusion.yaml"
|
| 321 |
+
ckpt_path = os.path.join(ckpt_read_dir, ckpt_name)
|
| 322 |
+
cluster_path = os.path.join(ckpt_read_dir, cluster_name)
|
| 323 |
+
diff_model_path = os.path.join(diff_read_dir, diff_model_name)
|
| 324 |
+
k_step_max = 1000
|
| 325 |
+
if not only_diffusion:
|
| 326 |
+
config = Config(config_path, "json").read()
|
| 327 |
+
if diff_model_name != "no_diff":
|
| 328 |
+
_diff = Config(diff_config_path, "yaml")
|
| 329 |
+
_content = _diff.read()
|
| 330 |
+
diff_spk = _content.get('spk', {})
|
| 331 |
+
diff_spk_choice = spk_choice = next(iter(diff_spk), "未检测到音色")
|
| 332 |
+
if not only_diffusion:
|
| 333 |
+
if _content['data'].get('encoder_out_channels') != config["model"].get('ssl_dim'):
|
| 334 |
+
return "扩散模型维度与主模型不匹配,请确保两个模型使用的是同一个编码器", gr.Dropdown.update(choices=[], value=""), 0, None
|
| 335 |
+
_content["infer"]["speedup"] = int(speedup)
|
| 336 |
+
_content["infer"]["method"] = str(method)
|
| 337 |
+
k_step_max = _content["model"].get('k_step_max', 0) if _content["model"].get('k_step_max', 0) != 0 else 1000
|
| 338 |
+
_diff.save(_content)
|
| 339 |
+
if not only_diffusion:
|
| 340 |
+
net = torch.load(ckpt_path, map_location=torch.device('cpu'))
|
| 341 |
+
#读取模型各维度并比对,还有小可爱无视提示硬要加载底模的就返回个未初始张量
|
| 342 |
+
emb_dim, model_dim = net["model"].get("emb_g.weight", torch.empty(0, 0)).size()
|
| 343 |
+
if emb_dim > config["model"]["n_speakers"]:
|
| 344 |
+
return "模型说话人数量与emb维度不匹配", gr.Dropdown.update(choices=[], value=""), 0, None
|
| 345 |
+
if model_dim != config["model"]["ssl_dim"]:
|
| 346 |
+
return "配置文件与模型不匹配", gr.Dropdown.update(choices=[], value=""), 0, None
|
| 347 |
+
encoder = config["model"]["speech_encoder"]
|
| 348 |
+
spk_dict = config.get('spk', {})
|
| 349 |
+
spk_choice = next(iter(spk_dict), "未检测到音色")
|
| 350 |
+
else:
|
| 351 |
+
spk_dict = diff_spk
|
| 352 |
+
spk_choice = diff_spk_choice
|
| 353 |
+
fr = cluster_name.endswith(".pkl") #如果是pkl后缀就启用特征检索
|
| 354 |
+
shallow_diffusion = diff_model_name != "no_diff" #加载了扩散模型就启用浅扩散
|
| 355 |
+
device = cuda[using_device] if "CUDA" in using_device else using_device
|
| 356 |
+
model = Svc(ckpt_path,
|
| 357 |
+
config_path,
|
| 358 |
+
device=device if device != "Auto" else None,
|
| 359 |
+
cluster_model_path=cluster_path,
|
| 360 |
+
nsf_hifigan_enhance=enhance,
|
| 361 |
+
diffusion_model_path=diff_model_path,
|
| 362 |
+
diffusion_config_path=diff_config_path,
|
| 363 |
+
shallow_diffusion=shallow_diffusion,
|
| 364 |
+
only_diffusion=only_diffusion,
|
| 365 |
+
spk_mix_enable=use_spk_mix,
|
| 366 |
+
feature_retrieval=fr)
|
| 367 |
+
spk_list = list(spk_dict.keys())
|
| 368 |
+
if not only_diffusion:
|
| 369 |
+
clip = 25 if encoder == "whisper-ppg" or encoder == "whisper-ppg-large" else 0 #Whisper必须强制切片25秒
|
| 370 |
+
device_name = torch.cuda.get_device_properties(model.dev).name if "cuda" in str(model.dev) else str(model.dev)
|
| 371 |
+
sovits_msg = f"模型被成功加载到了{device_name}上\n"
|
| 372 |
+
else:
|
| 373 |
+
clip = 0
|
| 374 |
+
sovits_msg = "启用全扩散推理,未加载So-VITS模型\n"
|
| 375 |
+
index_or_kmeans = "特征索引" if fr else "聚类模型"
|
| 376 |
+
clu_load = "未加载" if cluster_name == "no_clu" else cluster_name
|
| 377 |
+
diff_load = "未加载" if diff_model_name == "no_diff" else f"{diff_model_name} | 采样器: {method} | 加速倍数:{int(speedup)} | 最大浅扩散步数:{k_step_max}"
|
| 378 |
+
output_msg = f"{sovits_msg}{index_or_kmeans}:{clu_load}\n扩散模型:{diff_load}"
|
| 379 |
+
return (
|
| 380 |
+
output_msg,
|
| 381 |
+
gr.Dropdown.update(choices=spk_list, value=spk_choice),
|
| 382 |
+
clip,
|
| 383 |
+
gr.Slider.update(value=100 if k_step_max>100 else k_step_max, minimum=speedup, maximum=k_step_max)
|
| 384 |
+
)
|
| 385 |
+
|
| 386 |
+
def model_empty_cache():
|
| 387 |
+
global model
|
| 388 |
+
if model is None:
|
| 389 |
+
return sid.update(choices = [],value=""),"没有模型需要卸载!"
|
| 390 |
+
else:
|
| 391 |
+
model.unload_model()
|
| 392 |
+
model = None
|
| 393 |
+
torch.cuda.empty_cache()
|
| 394 |
+
return sid.update(choices = [],value=""),"模型卸载完毕!"
|
| 395 |
+
|
| 396 |
+
def get_file_options(directory, extension):
|
| 397 |
+
return [file for file in os.listdir(directory) if file.endswith(extension)]
|
| 398 |
+
|
| 399 |
+
def load_options():
|
| 400 |
+
ckpt_list = [file for file in get_file_options(ckpt_read_dir, ".pth") if not file.startswith("D_") or file == "G_0.pth"]
|
| 401 |
+
config_list = get_file_options(config_read_dir, ".json")
|
| 402 |
+
cluster_list = ["no_clu"] + get_file_options(ckpt_read_dir, ".pt") + get_file_options(ckpt_read_dir, ".pkl") # 聚类和特征检索模型
|
| 403 |
+
diff_list = ["no_diff"] + get_file_options(diff_read_dir, ".pt")
|
| 404 |
+
diff_config_list = ["no_diff_config"] + get_file_options(config_read_dir, ".yaml")
|
| 405 |
+
return ckpt_list, config_list, cluster_list, diff_list, diff_config_list
|
| 406 |
+
|
| 407 |
+
def refresh_options():
|
| 408 |
+
global ckpt_read_dir, config_read_dir, diff_read_dir, current_mode
|
| 409 |
+
ckpt_read_dir = second_dir if second_dir_enable else workdir
|
| 410 |
+
config_read_dir = second_dir if second_dir_enable else config_dir
|
| 411 |
+
diff_read_dir = diff_second_dir if second_dir_enable else diff_workdir
|
| 412 |
+
ckpt_list, config_list, cluster_list, diff_list, diff_config_list = load_options()
|
| 413 |
+
current_mode = get_current_mode()
|
| 414 |
+
return (
|
| 415 |
+
choice_ckpt.update(choices=ckpt_list),
|
| 416 |
+
config_choice.update(choices=config_list),
|
| 417 |
+
cluster_choice.update(choices=cluster_list),
|
| 418 |
+
diff_choice.update(choices=diff_list),
|
| 419 |
+
diff_config_choice.update(choices=diff_config_list),
|
| 420 |
+
mode_caption.update(value=f"""{current_mode},可在页面底端切换模式""")
|
| 421 |
+
)
|
| 422 |
+
|
| 423 |
+
def vc_infer(output_format, sid, input_audio, input_audio_path, vc_transform, auto_f0, cluster_ratio, slice_db, noise_scale, pad_seconds, cl_num, lg_num, lgr_num, f0_predictor, enhancer_adaptive_key, cr_threshold, k_step, use_spk_mix, second_encoding, loudness_envelope_adjustment):
|
| 424 |
+
if np.issubdtype(input_audio.dtype, np.integer):
|
| 425 |
+
input_audio = (input_audio / np.iinfo(input_audio.dtype).max).astype(np.float32)
|
| 426 |
+
if len(input_audio.shape) > 1:
|
| 427 |
+
input_audio = librosa.to_mono(input_audio.transpose(1, 0))
|
| 428 |
+
sf.write("temp.wav", input_audio, 44100, format="wav")
|
| 429 |
+
_audio = model.slice_inference(
|
| 430 |
+
"temp.wav",
|
| 431 |
+
sid,
|
| 432 |
+
vc_transform,
|
| 433 |
+
slice_db,
|
| 434 |
+
cluster_ratio,
|
| 435 |
+
auto_f0,
|
| 436 |
+
noise_scale,
|
| 437 |
+
pad_seconds,
|
| 438 |
+
cl_num,
|
| 439 |
+
lg_num,
|
| 440 |
+
lgr_num,
|
| 441 |
+
f0_predictor,
|
| 442 |
+
enhancer_adaptive_key,
|
| 443 |
+
cr_threshold,
|
| 444 |
+
k_step,
|
| 445 |
+
use_spk_mix,
|
| 446 |
+
second_encoding,
|
| 447 |
+
loudness_envelope_adjustment
|
| 448 |
+
)
|
| 449 |
+
model.clear_empty()
|
| 450 |
+
if not os.path.exists("results"):
|
| 451 |
+
os.makedirs("results")
|
| 452 |
+
key = "auto" if auto_f0 else f"{int(vc_transform)}key"
|
| 453 |
+
cluster = "_" if cluster_ratio == 0 else f"_{cluster_ratio}_"
|
| 454 |
+
isdiffusion = "sovits"
|
| 455 |
+
if model.shallow_diffusion:
|
| 456 |
+
isdiffusion = "sovdiff"
|
| 457 |
+
if model.only_diffusion:
|
| 458 |
+
isdiffusion = "diff"
|
| 459 |
+
#Gradio上传的filepath因为未知原因会有一个无意义的固定后缀,这里去掉
|
| 460 |
+
truncated_basename = Path(input_audio_path).stem[:-6] if Path(input_audio_path).stem[-6:] == "-0-100" else Path(input_audio_path).stem
|
| 461 |
+
output_file_name = f'{truncated_basename}_{sid}_{key}{cluster}{isdiffusion}.{output_format}'
|
| 462 |
+
output_file_path = os.path.join("results", output_file_name)
|
| 463 |
+
if os.path.exists(output_file_path):
|
| 464 |
+
count = 1
|
| 465 |
+
while os.path.exists(output_file_path):
|
| 466 |
+
output_file_name = f'{truncated_basename}_{sid}_{key}{cluster}{isdiffusion}_{str(count)}.{output_format}'
|
| 467 |
+
output_file_path = os.path.join("results", output_file_name)
|
| 468 |
+
count += 1
|
| 469 |
+
sf.write(output_file_path, _audio, model.target_sample, format=output_format)
|
| 470 |
+
return output_file_path
|
| 471 |
+
|
| 472 |
+
def vc_fn(output_format, sid, input_audio, vc_transform, auto_f0, cluster_ratio, slice_db, noise_scale, pad_seconds, cl_num, lg_num, lgr_num, f0_predictor, enhancer_adaptive_key, cr_threshold, k_step, use_spk_mix, second_encoding, loudness_envelope_adjustment):
|
| 473 |
+
global model
|
| 474 |
+
try:
|
| 475 |
+
if input_audio is None:
|
| 476 |
+
return "你还没有上传音频", None
|
| 477 |
+
if model is None:
|
| 478 |
+
return "你还没有加载模型", None
|
| 479 |
+
if getattr(model, 'cluster_model', None) is None and model.feature_retrieval is False:
|
| 480 |
+
if cluster_ratio != 0:
|
| 481 |
+
return "你还未加载聚类或特征检索模型,无法启用聚类/特征检索混合比例", None
|
| 482 |
+
audio, _ = sf.read(input_audio)
|
| 483 |
+
output_file_path = vc_infer(output_format, sid, audio, input_audio, vc_transform, auto_f0, cluster_ratio, slice_db, noise_scale, pad_seconds, cl_num, lg_num, lgr_num, f0_predictor, enhancer_adaptive_key, cr_threshold, k_step, use_spk_mix, second_encoding, loudness_envelope_adjustment)
|
| 484 |
+
os.remove("temp.wav")
|
| 485 |
+
return "Success", output_file_path
|
| 486 |
+
except Exception as e:
|
| 487 |
+
if debug:
|
| 488 |
+
traceback.print_exc()
|
| 489 |
+
raise gr.Error(e)
|
| 490 |
+
|
| 491 |
+
def vc_batch_fn(output_format, sid, input_audio_files, vc_transform, auto_f0, cluster_ratio, slice_db, noise_scale, pad_seconds, cl_num, lg_num, lgr_num, f0_predictor, enhancer_adaptive_key, cr_threshold, k_step, use_spk_mix, second_encoding, loudness_envelope_adjustment):
|
| 492 |
+
global model
|
| 493 |
+
try:
|
| 494 |
+
if input_audio_files is None or len(input_audio_files) == 0:
|
| 495 |
+
return "你还没有上传音频"
|
| 496 |
+
if model is None:
|
| 497 |
+
return "你还没有加载模型"
|
| 498 |
+
if getattr(model, 'cluster_model', None) is None and model.feature_retrieval is False:
|
| 499 |
+
if cluster_ratio != 0:
|
| 500 |
+
return "你还未加载聚类或特征检索模型,无法启用聚类/特征检索混合比例", None
|
| 501 |
+
_output = []
|
| 502 |
+
for file_obj in input_audio_files:
|
| 503 |
+
print(f"Start processing: {file_obj.name}")
|
| 504 |
+
input_audio_path = file_obj.name
|
| 505 |
+
audio, _ = sf.read(input_audio_path)
|
| 506 |
+
output_file_path = vc_infer(output_format, sid, audio, input_audio_path, vc_transform, auto_f0, cluster_ratio, slice_db, noise_scale, pad_seconds, cl_num, lg_num, lgr_num, f0_predictor, enhancer_adaptive_key, cr_threshold, k_step, use_spk_mix, second_encoding, loudness_envelope_adjustment)
|
| 507 |
+
_output.append(output_file_path)
|
| 508 |
+
return "批量推理完成,音频已经被保存到results文件夹"
|
| 509 |
+
except Exception as e:
|
| 510 |
+
if debug:
|
| 511 |
+
traceback.print_exc()
|
| 512 |
+
raise gr.Error(e)
|
| 513 |
+
|
| 514 |
+
def tts_fn(_text, _gender, _lang, _rate, _volume, output_format, sid, vc_transform, auto_f0,cluster_ratio, slice_db, noise_scale,pad_seconds,cl_num,lg_num,lgr_num,f0_predictor,enhancer_adaptive_key,cr_threshold, k_step,use_spk_mix,second_encoding,loudness_envelope_adjustment):
|
| 515 |
+
global model
|
| 516 |
+
try:
|
| 517 |
+
if model is None:
|
| 518 |
+
return "你还没有加载模型", None
|
| 519 |
+
if getattr(model, 'cluster_model', None) is None and model.feature_retrieval is False:
|
| 520 |
+
if cluster_ratio != 0:
|
| 521 |
+
return "你还未加载聚类或特征检索模型,无法启用聚类/特征检索混合比例", None
|
| 522 |
+
_rate = f"+{int(_rate*100)}%" if _rate >= 0 else f"{int(_rate*100)}%"
|
| 523 |
+
_volume = f"+{int(_volume*100)}%" if _volume >= 0 else f"{int(_volume*100)}%"
|
| 524 |
+
if _lang == "Auto":
|
| 525 |
+
_gender = "Male" if _gender == "男" else "Female"
|
| 526 |
+
subprocess.run([r".\workenv\python.exe", "tts.py", _text, _lang, _rate, _volume, _gender])
|
| 527 |
+
else:
|
| 528 |
+
subprocess.run([r".\workenv\python.exe", "tts.py", _text, _lang, _rate, _volume])
|
| 529 |
+
target_sr = 44100
|
| 530 |
+
y, sr = librosa.load("tts.wav")
|
| 531 |
+
resampled_y = librosa.resample(y, orig_sr=sr, target_sr=target_sr)
|
| 532 |
+
sf.write("tts.wav", resampled_y, target_sr, subtype = "PCM_16")
|
| 533 |
+
input_audio = "tts.wav"
|
| 534 |
+
audio, _ = sf.read(input_audio)
|
| 535 |
+
output_file_path = vc_infer(output_format, sid, audio, input_audio, vc_transform, auto_f0, cluster_ratio, slice_db, noise_scale, pad_seconds, cl_num, lg_num, lgr_num, f0_predictor, enhancer_adaptive_key, cr_threshold, k_step, use_spk_mix, second_encoding, loudness_envelope_adjustment)
|
| 536 |
+
#os.remove("tts.wav")
|
| 537 |
+
return "Success", output_file_path
|
| 538 |
+
except Exception as e:
|
| 539 |
+
if debug:
|
| 540 |
+
traceback.print_exc()
|
| 541 |
+
raise gr.Error(e)
|
| 542 |
+
|
| 543 |
+
def load_raw_dirs():
|
| 544 |
+
global precheck_ok
|
| 545 |
+
precheck_ok = False
|
| 546 |
+
allowed_pattern = re.compile(r'^[a-zA-Z0-9_@#$%^&()_+\-=\s\.]*$')
|
| 547 |
+
illegal_files = illegal_dataset = []
|
| 548 |
+
for root, dirs, files in os.walk(raw_path):
|
| 549 |
+
for dir in dirs:
|
| 550 |
+
if not allowed_pattern.match(dir):
|
| 551 |
+
illegal_dataset.append(dir)
|
| 552 |
+
if illegal_dataset:
|
| 553 |
+
return f"数据集文件夹名只能包含数字、字母、下划线,以下文件夹不符合要求,请改名后再试:\n{illegal_dataset}"
|
| 554 |
+
if root != raw_path: # 只处理子文件夹内的文件
|
| 555 |
+
for file in files:
|
| 556 |
+
if not allowed_pattern.match(file) and file not in illegal_files:
|
| 557 |
+
illegal_files.append(file)
|
| 558 |
+
if not file.lower().endswith('.wav') and file not in illegal_files:
|
| 559 |
+
illegal_files.append(file)
|
| 560 |
+
if illegal_files:
|
| 561 |
+
return f"数据集文件名只能包含数字、字母、下划线,且必须是.wav格式,以下文件不符合要求,请改名后再试:\n{illegal_files}"
|
| 562 |
+
spk_dirs = [entry.name for entry in os.scandir(raw_path) if entry.is_dir()]
|
| 563 |
+
if spk_dirs:
|
| 564 |
+
precheck_ok = True
|
| 565 |
+
return spk_dirs
|
| 566 |
+
else:
|
| 567 |
+
return "未找到数据集,请检查dataset_raw文件夹"
|
| 568 |
+
|
| 569 |
+
def dataset_preprocess(encoder, f0_predictor, use_diff, vol_aug, skip_loudnorm, num_processes):
|
| 570 |
+
if precheck_ok:
|
| 571 |
+
diff_arg = "--use_diff" if use_diff else ""
|
| 572 |
+
vol_aug_arg = "--vol_aug" if vol_aug else ""
|
| 573 |
+
skip_loudnorm_arg = "--skip_loudnorm" if skip_loudnorm else ""
|
| 574 |
+
preprocess_commands = [
|
| 575 |
+
r".\workenv\python.exe resample.py %s" % (skip_loudnorm_arg),
|
| 576 |
+
r".\workenv\python.exe preprocess_flist_config.py --speech_encoder %s %s" % (encoder, vol_aug_arg),
|
| 577 |
+
r".\workenv\python.exe preprocess_hubert_f0.py --num_processes %s --f0_predictor %s %s" % (num_processes ,f0_predictor, diff_arg)
|
| 578 |
+
]
|
| 579 |
+
accumulated_output = ""
|
| 580 |
+
#清空dataset
|
| 581 |
+
dataset = os.listdir(dataset_dir)
|
| 582 |
+
if len(dataset) != 0:
|
| 583 |
+
for dir in dataset:
|
| 584 |
+
dataset_spk_dir = os.path.join(dataset_dir, str(dir))
|
| 585 |
+
if os.path.isdir(dataset_spk_dir):
|
| 586 |
+
shutil.rmtree(dataset_spk_dir)
|
| 587 |
+
accumulated_output += f"Deleting previous dataset: {dir}\n"
|
| 588 |
+
for command in preprocess_commands:
|
| 589 |
+
try:
|
| 590 |
+
result = subprocess.Popen(command, stdout=subprocess.PIPE, stderr=subprocess.STDOUT, shell=True, text=True)
|
| 591 |
+
accumulated_output += f"Command: {command}, Using Encoder: {encoder}, Using f0 Predictor: {f0_predictor}\n"
|
| 592 |
+
yield accumulated_output, None
|
| 593 |
+
progress_line = None
|
| 594 |
+
for line in result.stdout:
|
| 595 |
+
if r"it/s" in line or r"s/it" in line: #防止进度条刷屏
|
| 596 |
+
progress_line = line
|
| 597 |
+
else:
|
| 598 |
+
accumulated_output += line
|
| 599 |
+
if progress_line is None:
|
| 600 |
+
yield accumulated_output, None
|
| 601 |
+
else:
|
| 602 |
+
yield accumulated_output + progress_line, None
|
| 603 |
+
result.communicate()
|
| 604 |
+
except subprocess.CalledProcessError as e:
|
| 605 |
+
result = e.output
|
| 606 |
+
accumulated_output += f"Error: {result}\n"
|
| 607 |
+
yield accumulated_output, None
|
| 608 |
+
if progress_line is not None:
|
| 609 |
+
accumulated_output += progress_line
|
| 610 |
+
accumulated_output += '-' * 50 + '\n'
|
| 611 |
+
yield accumulated_output, None
|
| 612 |
+
config_path = "configs/config.json"
|
| 613 |
+
with open(config_path, 'r') as f:
|
| 614 |
+
config = json.load(f)
|
| 615 |
+
spk_name = config.get('spk', None)
|
| 616 |
+
yield accumulated_output, gr.Textbox.update(value=spk_name)
|
| 617 |
+
else:
|
| 618 |
+
yield "数据集识别未通过,请先识别数据集并确保没有报错信息", None
|
| 619 |
+
|
| 620 |
+
def regenerate_config(encoder, vol_aug):
|
| 621 |
+
if precheck_ok is False:
|
| 622 |
+
return "数据集识别未通过,请检查识别结果的报错信息"
|
| 623 |
+
vol_aug_arg = "--vol_aug" if vol_aug else ""
|
| 624 |
+
cmd = r".\workenv\python.exe preprocess_flist_config.py --speech_encoder %s %s" % (encoder, vol_aug_arg)
|
| 625 |
+
output = ""
|
| 626 |
+
try:
|
| 627 |
+
result = subprocess.Popen(cmd, stdout=subprocess.PIPE, stderr=subprocess.STDOUT, shell=True, text=True)
|
| 628 |
+
for line in result.stdout:
|
| 629 |
+
output += line
|
| 630 |
+
output += "Regenerate config file successfully."
|
| 631 |
+
except subprocess.CalledProcessError as e:
|
| 632 |
+
result = e.output
|
| 633 |
+
output += f"Error: {result}\n"
|
| 634 |
+
return output
|
| 635 |
+
|
| 636 |
+
def clear_output():
|
| 637 |
+
return gr.Textbox.update(value="Cleared!>_<")
|
| 638 |
+
|
| 639 |
+
def get_available_encoder():
|
| 640 |
+
current_pretrain = os.listdir("pretrain")
|
| 641 |
+
current_pretrain = [("pretrain/" + model) for model in current_pretrain]
|
| 642 |
+
encoder_list = []
|
| 643 |
+
for encoder, path in ENCODER_PRETRAIN.items():
|
| 644 |
+
if path in current_pretrain:
|
| 645 |
+
encoder_list.append(encoder)
|
| 646 |
+
return encoder_list
|
| 647 |
+
|
| 648 |
+
def config_fn(log_interval, eval_interval, keep_ckpts, batch_size, lr, amp_dtype, all_in_mem, diff_num_workers, diff_cache_all_data, diff_batch_size, diff_lr, diff_interval_log, diff_interval_val, diff_cache_device, diff_amp_dtype, diff_force_save, diff_k_step_max):
|
| 649 |
+
if amp_dtype == "fp16" or amp_dtype == "bf16":
|
| 650 |
+
fp16_run = True
|
| 651 |
+
else:
|
| 652 |
+
fp16_run = False
|
| 653 |
+
amp_dtype = "fp16"
|
| 654 |
+
config_origin = Config("configs/config.json", "json")
|
| 655 |
+
diff_config = Config("configs/diffusion.yaml", "yaml")
|
| 656 |
+
config_data = config_origin.read()
|
| 657 |
+
config_data['train']['log_interval'] = int(log_interval)
|
| 658 |
+
config_data['train']['eval_interval'] = int(eval_interval)
|
| 659 |
+
config_data['train']['keep_ckpts'] = int(keep_ckpts)
|
| 660 |
+
config_data['train']['batch_size'] = int(batch_size)
|
| 661 |
+
config_data['train']['learning_rate'] = float(lr)
|
| 662 |
+
config_data['train']['fp16_run'] = fp16_run
|
| 663 |
+
config_data['train']['half_type'] = str(amp_dtype)
|
| 664 |
+
config_data['train']['all_in_mem'] = all_in_mem
|
| 665 |
+
config_origin.save(config_data)
|
| 666 |
+
diff_config_data = diff_config.read()
|
| 667 |
+
diff_config_data['train']['num_workers'] = int(diff_num_workers)
|
| 668 |
+
diff_config_data['train']['cache_all_data'] = diff_cache_all_data
|
| 669 |
+
diff_config_data['train']['batch_size'] = int(diff_batch_size)
|
| 670 |
+
diff_config_data['train']['lr'] = float(diff_lr)
|
| 671 |
+
diff_config_data['train']['interval_log'] = int(diff_interval_log)
|
| 672 |
+
diff_config_data['train']['interval_val'] = int(diff_interval_val)
|
| 673 |
+
diff_config_data['train']['cache_device'] = str(diff_cache_device)
|
| 674 |
+
diff_config_data['train']['amp_dtype'] = str(diff_amp_dtype)
|
| 675 |
+
diff_config_data['train']['interval_force_save'] = int(diff_force_save)
|
| 676 |
+
diff_config_data['model']['k_step_max'] = 100 if diff_k_step_max else 0
|
| 677 |
+
diff_config.save(diff_config_data)
|
| 678 |
+
return "配置文件写入完成"
|
| 679 |
+
|
| 680 |
+
def check_dataset(dataset_path):
|
| 681 |
+
if not os.listdir(dataset_path):
|
| 682 |
+
return "数据集不存在,请检查dataset文件夹"
|
| 683 |
+
no_npy_pt_files = True
|
| 684 |
+
for root, dirs, files in os.walk(dataset_path):
|
| 685 |
+
for file in files:
|
| 686 |
+
if file.endswith('.npy') or file.endswith('.pt'):
|
| 687 |
+
no_npy_pt_files = False
|
| 688 |
+
break
|
| 689 |
+
if no_npy_pt_files:
|
| 690 |
+
return "数据集中未检测到f0和hubert文件,可能是预处理未完成"
|
| 691 |
+
return None
|
| 692 |
+
|
| 693 |
+
def training(gpu_selection, encoder):
|
| 694 |
+
config_file = Config("configs/config.json", "json")
|
| 695 |
+
config_data = config_file.read()
|
| 696 |
+
vol_emb = config_data["model"]["vol_embedding"]
|
| 697 |
+
dataset_warn = check_dataset(dataset_dir)
|
| 698 |
+
if dataset_warn is not None:
|
| 699 |
+
return dataset_warn
|
| 700 |
+
PRETRAIN = {
|
| 701 |
+
"vec256l9": ("D_0.pth", "G_0.pth", "pre_trained_model"),
|
| 702 |
+
"vec768l12": ("D_0.pth", "G_0.pth", "pre_trained_model/768l12/vol_emb" if vol_emb else "pre_trained_model/768l12"),
|
| 703 |
+
"hubertsoft": ("D_0.pth", "G_0.pth", "pre_trained_model/hubertsoft"),
|
| 704 |
+
"whisper-ppg": ("D_0.pth", "G_0.pth", "pre_trained_model/whisper-ppg"),
|
| 705 |
+
"cnhubertlarge": ("D_0.pth", "G_0.pth", "pre_trained_model/cnhubertlarge"),
|
| 706 |
+
"dphubert": ("D_0.pth", "G_0.pth", "pre_trained_model/dphubert"),
|
| 707 |
+
"wavlmbase+": ("D_0.pth", "G_0.pth", "pre_trained_model/wavlmbase+"),
|
| 708 |
+
"whisper-ppg-large": ("D_0.pth", "G_0.pth", "pre_trained_model/whisper-ppg-large")
|
| 709 |
+
}
|
| 710 |
+
if encoder not in PRETRAIN:
|
| 711 |
+
return "未知编码器"
|
| 712 |
+
d_0_file, g_0_file, encoder_model_path = PRETRAIN[encoder]
|
| 713 |
+
d_0_path = os.path.join(encoder_model_path, d_0_file)
|
| 714 |
+
g_0_path = os.path.join(encoder_model_path, g_0_file)
|
| 715 |
+
timestamp = datetime.datetime.now().strftime('%Y_%m_%d_%H_%M')
|
| 716 |
+
new_backup_folder = os.path.join(models_backup_path, str(timestamp))
|
| 717 |
+
output_msg = ""
|
| 718 |
+
if os.listdir(workdir) != ['diffusion']:
|
| 719 |
+
os.makedirs(new_backup_folder, exist_ok=True)
|
| 720 |
+
for file in os.listdir(workdir):
|
| 721 |
+
if file != "diffusion":
|
| 722 |
+
shutil.move(os.path.join(workdir, file), os.path.join(new_backup_folder, file))
|
| 723 |
+
if os.path.isfile(g_0_path) and os.path.isfile(d_0_path):
|
| 724 |
+
shutil.copy(d_0_path, os.path.join(workdir, "D_0.pth"))
|
| 725 |
+
shutil.copy(g_0_path, os.path.join(workdir, "G_0.pth"))
|
| 726 |
+
output_msg += f"成功装载预训练模型,编码器:{encoder}\n"
|
| 727 |
+
else:
|
| 728 |
+
output_msg += f"{encoder}的预训练模型不存在,未装载预训练模型\n"
|
| 729 |
+
cmd = r"set CUDA_VISIBLE_DEVICES=%s && .\workenv\python.exe train.py -c configs/config.json -m 44k" % (gpu_selection)
|
| 730 |
+
subprocess.Popen(["cmd", "/c", "start", "cmd", "/k", cmd])
|
| 731 |
+
output_msg += "已经在新的终端窗口开始训练,请监看终端窗口的训练日志。在终端中按Ctrl+C可暂停训练。"
|
| 732 |
+
return output_msg
|
| 733 |
+
|
| 734 |
+
def continue_training(gpu_selection, encoder):
|
| 735 |
+
dataset_warn = check_dataset(dataset_dir)
|
| 736 |
+
if dataset_warn is not None:
|
| 737 |
+
return dataset_warn
|
| 738 |
+
if encoder == "":
|
| 739 |
+
return "请先选择预处理对应的编码器"
|
| 740 |
+
all_files = os.listdir(workdir)
|
| 741 |
+
model_files = [f for f in all_files if f.startswith('G_') and f.endswith('.pth')]
|
| 742 |
+
if len(model_files) == 0:
|
| 743 |
+
return "你还没有已开始的训练"
|
| 744 |
+
cmd = r"set CUDA_VISIBLE_DEVICES=%s && .\workenv\python.exe train.py -c configs/config.json -m 44k" % (gpu_selection)
|
| 745 |
+
subprocess.Popen(["cmd", "/c", "start", "cmd", "/k", cmd])
|
| 746 |
+
return "已经在新的终端窗口开始训练,请监看终端窗口的训练日志。在终端中按Ctrl+C可暂停训练。"
|
| 747 |
+
|
| 748 |
+
def kmeans_training(kmeans_gpu):
|
| 749 |
+
if not os.listdir(dataset_dir):
|
| 750 |
+
return "数据集不存在,请检查dataset文件夹"
|
| 751 |
+
cmd = r".\workenv\python.exe cluster/train_cluster.py --gpu" if kmeans_gpu else r".\workenv\python.exe cluster/train_cluster.py"
|
| 752 |
+
subprocess.Popen(["cmd", "/c", "start", "cmd", "/k", cmd])
|
| 753 |
+
return "已经在新的终端窗口开始训练,训练聚类模型不会输出日志,CPU训练一般需要5-10分钟左右"
|
| 754 |
+
|
| 755 |
+
def index_training():
|
| 756 |
+
if not os.listdir(dataset_dir):
|
| 757 |
+
return "数据集不存在,请检查dataset文件夹"
|
| 758 |
+
cmd = r".\workenv\python.exe train_index.py -c configs/config.json"
|
| 759 |
+
subprocess.Popen(["cmd", "/c", "start", "cmd", "/k", cmd])
|
| 760 |
+
return "已经在新的终端窗口开始训练"
|
| 761 |
+
|
| 762 |
+
def diff_training(encoder, k_step_max):
|
| 763 |
+
if not os.listdir(dataset_dir):
|
| 764 |
+
return "数据集不存在,请检查dataset文件夹"
|
| 765 |
+
timestamp = datetime.datetime.now().strftime('%Y_%m_%d_%H_%M')
|
| 766 |
+
new_backup_folder = os.path.join(models_backup_path, "diffusion", str(timestamp))
|
| 767 |
+
if len(os.listdir(diff_workdir)) != 0:
|
| 768 |
+
os.makedirs(new_backup_folder, exist_ok=True)
|
| 769 |
+
for file in os.listdir(diff_workdir):
|
| 770 |
+
shutil.move(os.path.join(diff_workdir, file), os.path.join(new_backup_folder, file))
|
| 771 |
+
DIFF_PRETRAIN = {
|
| 772 |
+
"768-kstepmax100": "pre_trained_model/diffusion/768l12/max100/model_0.pt",
|
| 773 |
+
"vec768l12": "pre_trained_model/diffusion/768l12/model_0.pt",
|
| 774 |
+
"hubertsoft": "pre_trained_model/diffusion/hubertsoft/model_0.pt",
|
| 775 |
+
"whisper-ppg": "pre_trained_model/diffusion/whisper-ppg/model_0.pt"
|
| 776 |
+
}
|
| 777 |
+
if encoder not in DIFF_PRETRAIN:
|
| 778 |
+
return "你所选的编码器暂时不支持训练扩散模型"
|
| 779 |
+
if k_step_max:
|
| 780 |
+
encoder = "768-kstepmax100"
|
| 781 |
+
diff_pretrained_model = DIFF_PRETRAIN[encoder]
|
| 782 |
+
shutil.copy(diff_pretrained_model, os.path.join(diff_workdir, "model_0.pt"))
|
| 783 |
+
subprocess.Popen(["cmd", "/c", "start", "cmd", "/k", r".\workenv\python.exe train_diff.py -c configs/diffusion.yaml"])
|
| 784 |
+
output_message = "已经在新的终端窗口开始训练,请监看终端窗口的训练日志。在终端中按Ctrl+C可暂停训练。"
|
| 785 |
+
if encoder == "768-kstepmax100":
|
| 786 |
+
output_message += "\n正在进行100步深度的浅扩散训练,已加载底模"
|
| 787 |
+
else:
|
| 788 |
+
output_message += f"\n正在进行完整深度的扩散训练,编码器{encoder}"
|
| 789 |
+
return output_message
|
| 790 |
+
|
| 791 |
+
def diff_continue_training(encoder):
|
| 792 |
+
if not os.listdir(dataset_dir):
|
| 793 |
+
return "数据集不存在,请检查dataset文件夹"
|
| 794 |
+
if encoder == "":
|
| 795 |
+
return "请先选择预处理对应的编码器"
|
| 796 |
+
all_files = os.listdir(diff_workdir)
|
| 797 |
+
model_files = [f for f in all_files if f.endswith('.pt')]
|
| 798 |
+
if len(model_files) == 0:
|
| 799 |
+
return "你还没有已开始的训练"
|
| 800 |
+
subprocess.Popen(["cmd", "/c", "start", "cmd", "/k", r".\workenv\python.exe train_diff.py -c configs/diffusion.yaml"])
|
| 801 |
+
return "已经在新的终端窗口开始训练,请监看终端窗口的训练日志。在终端中按Ctrl+C可暂停训练。"
|
| 802 |
+
|
| 803 |
+
def upload_mix_append_file(files,sfiles):
|
| 804 |
+
try:
|
| 805 |
+
if(sfiles is None):
|
| 806 |
+
file_paths = [file.name for file in files]
|
| 807 |
+
else:
|
| 808 |
+
file_paths = [file.name for file in chain(files,sfiles)]
|
| 809 |
+
p = {file:100 for file in file_paths}
|
| 810 |
+
return file_paths,mix_model_output1.update(value=json.dumps(p,indent=2))
|
| 811 |
+
except Exception as e:
|
| 812 |
+
if debug:
|
| 813 |
+
traceback.print_exc()
|
| 814 |
+
raise gr.Error(e)
|
| 815 |
+
|
| 816 |
+
def mix_submit_click(js,mode):
|
| 817 |
+
try:
|
| 818 |
+
assert js.lstrip()!=""
|
| 819 |
+
modes = {"凸组合":0, "线性组合":1}
|
| 820 |
+
mode = modes[mode]
|
| 821 |
+
data = json.loads(js)
|
| 822 |
+
data = list(data.items())
|
| 823 |
+
model_path,mix_rate = zip(*data)
|
| 824 |
+
path = mix_model(model_path,mix_rate,mode)
|
| 825 |
+
return f"成功,文件被保存在了{path}"
|
| 826 |
+
except Exception as e:
|
| 827 |
+
if debug:
|
| 828 |
+
traceback.print_exc()
|
| 829 |
+
raise gr.Error(e)
|
| 830 |
+
|
| 831 |
+
def updata_mix_info(files):
|
| 832 |
+
try:
|
| 833 |
+
if files is None:
|
| 834 |
+
return mix_model_output1.update(value="")
|
| 835 |
+
p = {file.name:100 for file in files}
|
| 836 |
+
return mix_model_output1.update(value=json.dumps(p,indent=2))
|
| 837 |
+
except Exception as e:
|
| 838 |
+
if debug:
|
| 839 |
+
traceback.print_exc()
|
| 840 |
+
raise gr.Error(e)
|
| 841 |
+
|
| 842 |
+
def pth_identify():
|
| 843 |
+
if not os.path.exists(root_dir):
|
| 844 |
+
return f"未找到{root_dir}文件夹,请先创建一个{root_dir}文件夹并按第一步流程操作"
|
| 845 |
+
model_dirs = [d for d in os.listdir(root_dir) if os.path.isdir(os.path.join(root_dir, d))]
|
| 846 |
+
if not model_dirs:
|
| 847 |
+
return f"未在{root_dir}文件夹中找到模型文件夹,请确保每个模型和配置文件都被放置在单独的文件夹中"
|
| 848 |
+
valid_model_dirs = []
|
| 849 |
+
for path in model_dirs:
|
| 850 |
+
pth_files = glob.glob(f"{root_dir}/{path}/*.pth")
|
| 851 |
+
json_files = glob.glob(f"{root_dir}/{path}/*.json")
|
| 852 |
+
if len(pth_files) != 1 or len(json_files) != 1:
|
| 853 |
+
return f"错误: 在{root_dir}/{path}中找到了{len(pth_files)}个.pth文件和{len(json_files)}个.json文件。应当确保每个文件夹内有且只有一个.pth文件和.json文件"
|
| 854 |
+
valid_model_dirs.append(path)
|
| 855 |
+
|
| 856 |
+
return f"成功识别了{len(valid_model_dirs)}个模型:{valid_model_dirs}"
|
| 857 |
+
|
| 858 |
+
def onnx_export():
|
| 859 |
+
model_dirs = [d for d in os.listdir(root_dir) if os.path.isdir(os.path.join(root_dir, d))]
|
| 860 |
+
try:
|
| 861 |
+
for path in model_dirs:
|
| 862 |
+
pth_files = glob.glob(f"{root_dir}/{path}/*.pth")
|
| 863 |
+
json_files = glob.glob(f"{root_dir}/{path}/*.json")
|
| 864 |
+
model_file = pth_files[0]
|
| 865 |
+
json_file = json_files[0]
|
| 866 |
+
device = torch.device("cpu")
|
| 867 |
+
hps = utils.get_hparams_from_file(json_file)
|
| 868 |
+
SVCVITS = SynthesizerTrn(
|
| 869 |
+
hps.data.filter_length // 2 + 1,
|
| 870 |
+
hps.train.segment_size // hps.data.hop_length,
|
| 871 |
+
**hps.model)
|
| 872 |
+
_ = utils.load_checkpoint(model_file, SVCVITS, None)
|
| 873 |
+
_ = SVCVITS.eval().to(device)
|
| 874 |
+
for i in SVCVITS.parameters():
|
| 875 |
+
i.requires_grad = False
|
| 876 |
+
n_frame = 10
|
| 877 |
+
test_hidden_unit = torch.rand(1, n_frame, 256)
|
| 878 |
+
test_pitch = torch.rand(1, n_frame)
|
| 879 |
+
test_mel2ph = torch.arange(0, n_frame, dtype=torch.int64)[None] # torch.LongTensor([0, 1, 2, 3, 4, 5, 6, 7, 8, 9]).unsqueeze(0)
|
| 880 |
+
test_uv = torch.ones(1, n_frame, dtype=torch.float32)
|
| 881 |
+
test_noise = torch.randn(1, 192, n_frame)
|
| 882 |
+
test_sid = torch.LongTensor([0])
|
| 883 |
+
input_names = ["c", "f0", "mel2ph", "uv", "noise", "sid"]
|
| 884 |
+
output_names = ["audio", ]
|
| 885 |
+
onnx_file = os.path.splitext(model_file)[0] + ".onnx"
|
| 886 |
+
torch.onnx.export(SVCVITS,
|
| 887 |
+
(
|
| 888 |
+
test_hidden_unit.to(device),
|
| 889 |
+
test_pitch.to(device),
|
| 890 |
+
test_mel2ph.to(device),
|
| 891 |
+
test_uv.to(device),
|
| 892 |
+
test_noise.to(device),
|
| 893 |
+
test_sid.to(device)
|
| 894 |
+
),
|
| 895 |
+
onnx_file,
|
| 896 |
+
dynamic_axes={
|
| 897 |
+
"c": [0, 1],
|
| 898 |
+
"f0": [1],
|
| 899 |
+
"mel2ph": [1],
|
| 900 |
+
"uv": [1],
|
| 901 |
+
"noise": [2],
|
| 902 |
+
},
|
| 903 |
+
do_constant_folding=False,
|
| 904 |
+
opset_version=16,
|
| 905 |
+
verbose=False,
|
| 906 |
+
input_names=input_names,
|
| 907 |
+
output_names=output_names)
|
| 908 |
+
return "转换成功,模型被保存在了checkpoints下的对应目录"
|
| 909 |
+
except Exception as e:
|
| 910 |
+
if debug:
|
| 911 |
+
traceback.print_exc()
|
| 912 |
+
raise gr.Error(e)
|
| 913 |
+
|
| 914 |
+
def load_raw_audio(audio_path):
|
| 915 |
+
if not os.path.isdir(audio_path):
|
| 916 |
+
return "请输入正确的目录", None
|
| 917 |
+
files = os.listdir(audio_path)
|
| 918 |
+
wav_files = [file for file in files if file.lower().endswith('.wav')]
|
| 919 |
+
if not wav_files:
|
| 920 |
+
return "未在目录中找到.wav音频文件", None
|
| 921 |
+
return "成功加载", wav_files
|
| 922 |
+
|
| 923 |
+
def slicer_fn(input_dir, output_dir, process_method, max_sec, min_sec):
|
| 924 |
+
if output_dir == "":
|
| 925 |
+
return "请先选择输出的文件夹"
|
| 926 |
+
if output_dir == input_dir:
|
| 927 |
+
return "输出目录不能和输入目录相同"
|
| 928 |
+
slicer = AutoSlicer()
|
| 929 |
+
if os.path.exists(output_dir) is not True:
|
| 930 |
+
os.makedirs(output_dir)
|
| 931 |
+
for filename in os.listdir(input_dir):
|
| 932 |
+
if filename.lower().endswith(".wav"):
|
| 933 |
+
slicer.auto_slice(filename, input_dir, output_dir, max_sec)
|
| 934 |
+
if process_method == "丢弃":
|
| 935 |
+
for filename in os.listdir(output_dir):
|
| 936 |
+
if filename.endswith(".wav"):
|
| 937 |
+
filepath = os.path.join(output_dir, filename)
|
| 938 |
+
audio, sr = librosa.load(filepath, sr=None, mono=False)
|
| 939 |
+
if librosa.get_duration(y=audio, sr=sr) < min_sec:
|
| 940 |
+
os.remove(filepath)
|
| 941 |
+
elif process_method == "将过短音频整合为长音频":
|
| 942 |
+
slicer.merge_short(output_dir, max_sec, min_sec)
|
| 943 |
+
file_count, max_duration, min_duration, orig_duration, final_duration = slicer.slice_count(input_dir, output_dir)
|
| 944 |
+
hrs = int(final_duration / 3600)
|
| 945 |
+
mins = int((final_duration % 3600) / 60)
|
| 946 |
+
sec = format(float(final_duration % 60), '.2f')
|
| 947 |
+
rate = format(100 * (final_duration / orig_duration), '.2f') if orig_duration != 0 else 0
|
| 948 |
+
rate_msg = f"为原始音频时长的{rate}%" if rate != 0 else "因未知问题,无法计算切片时长的占比"
|
| 949 |
+
return f"成功将音频切分为{file_count}条片段,其中最长{max_duration}秒,最短{min_duration}秒,切片后的音频总时长{hrs:02d}小时{mins:02d}分{sec}秒,{rate_msg}"
|
| 950 |
+
|
| 951 |
+
def model_compression(_model):
|
| 952 |
+
if _model == "":
|
| 953 |
+
return "请先选择要压缩的模型"
|
| 954 |
+
else:
|
| 955 |
+
model_path = os.path.join(ckpt_read_dir, _model)
|
| 956 |
+
filename, extension = os.path.splitext(_model)
|
| 957 |
+
output_model_name = f"{filename}_compressed{extension}"
|
| 958 |
+
output_path = os.path.join(ckpt_read_dir, output_model_name)
|
| 959 |
+
removeOptimizer(model_path, output_path)
|
| 960 |
+
return f"模型已成功被保存在了{output_path}"
|
| 961 |
+
|
| 962 |
+
def pack_autoload(model_to_pack):
|
| 963 |
+
_, config_name, _ = auto_load(model_to_pack)
|
| 964 |
+
if config_name == "no_config":
|
| 965 |
+
return "未找到对应的配置文件,请手动选择", None
|
| 966 |
+
else:
|
| 967 |
+
_config = Config(os.path.join(config_read_dir, config_name), "json")
|
| 968 |
+
_content = _config.read()
|
| 969 |
+
spk_dict = _content["spk"]
|
| 970 |
+
spk_list = ",".join(spk_dict.keys())
|
| 971 |
+
return config_name, spk_list
|
| 972 |
+
|
| 973 |
+
def release_packing(model_to_pack, model_config, speaker, diff_to_pack, cluster_to_pack):
|
| 974 |
+
model_path = diff_path = cluster_path = ""
|
| 975 |
+
basename = os.path.splitext(model_to_pack)[0]
|
| 976 |
+
diff_basename = os.path.splitext(diff_to_pack)[0]
|
| 977 |
+
if model_to_pack == "" or model_config == "" or speaker == "":
|
| 978 |
+
return "存在必选项为空,请检查后重试"
|
| 979 |
+
released_pack = ReleasePacker(speaker, model_to_pack)
|
| 980 |
+
released_pack.remove_temp("release_packs")
|
| 981 |
+
model_path = os.path.join(ckpt_read_dir, model_to_pack)
|
| 982 |
+
if os.stat(model_path).st_size > 300000000:
|
| 983 |
+
removeOptimizer(model_path, os.path.join("release_packs", model_to_pack))
|
| 984 |
+
model_path = os.path.join("release_packs", model_to_pack)
|
| 985 |
+
if diff_to_pack != "no_diff":
|
| 986 |
+
diff_path = os.path.join(diff_read_dir, diff_to_pack)
|
| 987 |
+
if cluster_to_pack != "no_cluster":
|
| 988 |
+
cluster_path = os.path.join(ckpt_read_dir, cluster_to_pack)
|
| 989 |
+
shutil.copyfile("configs_template/config_template.json", "release_packs/config_template.json")
|
| 990 |
+
shutil.copyfile("configs_template/diffusion_template.yaml", "release_packs/diffusion_template.yaml")
|
| 991 |
+
files_to_pack = [
|
| 992 |
+
(model_path, f"models/{model_to_pack}"),
|
| 993 |
+
(diff_path, f"models/diffusion/{diff_to_pack}") if diff_to_pack != "no_diff" else ("", ""),
|
| 994 |
+
(cluster_path, f"models/{cluster_to_pack}") if cluster_to_pack != "no_cluster" else ("", ""),
|
| 995 |
+
(f"release_packs/{basename}.json", f"models/{basename}.json"),
|
| 996 |
+
(f"release_packs/{diff_basename}.yaml", f"models/{diff_basename}.yaml") if diff_to_pack != "no_diff" else ("", ""),
|
| 997 |
+
("release_packs/install.txt", "install.txt")
|
| 998 |
+
]
|
| 999 |
+
released_pack.add_file(files_to_pack)
|
| 1000 |
+
released_pack.generate_config(diff_to_pack, model_config)
|
| 1001 |
+
os.rename("release_packs/config_template.json", f"release_packs/{basename}.json")
|
| 1002 |
+
os.rename("release_packs/diffusion_template.yaml", f"release_packs/{diff_basename}.yaml")
|
| 1003 |
+
released_pack.pack()
|
| 1004 |
+
to_remove = [file for file in os.listdir("release_packs") if not file.endswith(".zip")]
|
| 1005 |
+
for file in to_remove:
|
| 1006 |
+
os.remove(os.path.join("release_packs", file))
|
| 1007 |
+
return "打包成功, 请在release_packs目录下查看"
|
| 1008 |
+
|
| 1009 |
+
def release_install(model_zip_path):
|
| 1010 |
+
model_zip = ReleasePacker("", "")
|
| 1011 |
+
model_zip.unpack(model_zip_path)
|
| 1012 |
+
for file in os.listdir("release_packs"):
|
| 1013 |
+
if file.endswith(".txt"):
|
| 1014 |
+
install_txt = os.path.join("release_packs", file)
|
| 1015 |
+
break
|
| 1016 |
+
else:
|
| 1017 |
+
model_zip.remove_temp("release_packs")
|
| 1018 |
+
return "非格式化安装包,无法安装"
|
| 1019 |
+
_spk = model_zip.formatted_install(install_txt)
|
| 1020 |
+
model_zip.remove_temp("release_packs")
|
| 1021 |
+
return f"安装成功,可用说话人{_spk},请启用独立目录模式加载模型"
|
| 1022 |
+
|
| 1023 |
+
#read default params
|
| 1024 |
+
sovits_params, diff_params, second_dir_enable = get_default_settings()
|
| 1025 |
+
ckpt_read_dir = second_dir if second_dir_enable else workdir
|
| 1026 |
+
config_read_dir = second_dir if second_dir_enable else config_dir
|
| 1027 |
+
diff_read_dir = diff_second_dir if second_dir_enable else diff_workdir
|
| 1028 |
+
current_mode = get_current_mode()
|
| 1029 |
+
|
| 1030 |
+
# create dirs if they don't exist
|
| 1031 |
+
dirs_to_check = [
|
| 1032 |
+
workdir,
|
| 1033 |
+
second_dir,
|
| 1034 |
+
diff_workdir,
|
| 1035 |
+
diff_second_dir,
|
| 1036 |
+
dataset_dir,
|
| 1037 |
+
]
|
| 1038 |
+
for dir in dirs_to_check:
|
| 1039 |
+
if not os.path.exists(dir):
|
| 1040 |
+
os.makedirs(dir)
|
| 1041 |
+
|
| 1042 |
+
# read ckpt list
|
| 1043 |
+
ckpt_list, config_list, cluster_list, diff_list, diff_config_list = load_options()
|
| 1044 |
+
|
| 1045 |
+
# read available encoder list
|
| 1046 |
+
encoder_list = get_available_encoder()
|
| 1047 |
+
|
| 1048 |
+
#read GPU info
|
| 1049 |
+
ngpu=torch.cuda.device_count()
|
| 1050 |
+
gpu_infos=[]
|
| 1051 |
+
if(torch.cuda.is_available() is False or ngpu==0):
|
| 1052 |
+
if_gpu_ok=False
|
| 1053 |
+
else:
|
| 1054 |
+
if_gpu_ok = False
|
| 1055 |
+
for i in range(ngpu):
|
| 1056 |
+
gpu_name=torch.cuda.get_device_name(i)
|
| 1057 |
+
if("MX"in gpu_name):
|
| 1058 |
+
continue
|
| 1059 |
+
if("RTX" in gpu_name.upper() or "10"in gpu_name or "16"in gpu_name or "20"in gpu_name or "30"in gpu_name or "40"in gpu_name or "A50"in gpu_name.upper() or "70"in gpu_name or "80"in gpu_name or "90"in gpu_name or "M4"in gpu_name or"P4"in gpu_name or "T4"in gpu_name or "TITAN"in gpu_name.upper()):#A10#A100#V100#A40#P40#M40#K80
|
| 1060 |
+
if_gpu_ok=True#至少有一张能用的N卡
|
| 1061 |
+
gpu_infos.append("%s\t%s"%(i,gpu_name))
|
| 1062 |
+
gpu_info="\n".join(gpu_infos)if if_gpu_ok is True and len(gpu_infos)>0 else "很遗憾您这没有能用的显卡来支持您训练"
|
| 1063 |
+
gpus="-".join([i[0]for i in gpu_infos])
|
| 1064 |
+
|
| 1065 |
+
#read cuda info for inference
|
| 1066 |
+
cuda = {}
|
| 1067 |
+
if torch.cuda.is_available():
|
| 1068 |
+
for i in range(torch.cuda.device_count()):
|
| 1069 |
+
device_name = torch.cuda.get_device_properties(i).name
|
| 1070 |
+
cuda[f"CUDA:{i} {device_name}"] = f"cuda:{i}"
|
| 1071 |
+
|
| 1072 |
+
#Check BF16 support
|
| 1073 |
+
amp_options = ["fp32", "fp16", "bf16"] if torch.cuda.is_bf16_supported() else ["fp32", "fp16"]
|
| 1074 |
+
|
| 1075 |
+
#Get F0 Options
|
| 1076 |
+
f0_options = ["crepe","pm","dio","harvest","rmvpe"] if os.path.exists("pretrain/rmvpe.pt") else ["crepe","pm","dio","harvest"]
|
| 1077 |
+
|
| 1078 |
+
app = gr.Blocks()
|
| 1079 |
+
with app:
|
| 1080 |
+
gr.Markdown(value="""
|
| 1081 |
+
### So-VITS-SVC 4.1-Stable WebUI 推理&训练 v2.3.8
|
| 1082 |
+
|
| 1083 |
+
制作协力:bilibili@麦哲云
|
| 1084 |
+
|
| 1085 |
+
仅供个人娱乐和非商业用途,禁止用于血腥、暴力、性相关、政治相关内容
|
| 1086 |
+
|
| 1087 |
+
[使用文档和常见报错解答](https://www.yuque.com/umoubuton/ueupp5)
|
| 1088 |
+
|
| 1089 |
+
整合包作者:bilibili@羽毛布団 | 技术交流群:742817595 | 交流二群:168254971 | 交流三群:416656175
|
| 1090 |
+
|
| 1091 |
+
""")
|
| 1092 |
+
with gr.Tabs():
|
| 1093 |
+
with gr.TabItem("推理") as inference_tab:
|
| 1094 |
+
mode_caption = gr.Markdown(value=f"""
|
| 1095 |
+
{current_mode},可在页面底端切换模式
|
| 1096 |
+
""")
|
| 1097 |
+
with gr.Row():
|
| 1098 |
+
choice_ckpt = gr.Dropdown(label="模型选择", choices=ckpt_list, value="no_model")
|
| 1099 |
+
model_branch = gr.Textbox(label="模型编码器", placeholder="请先选择模型", interactive=False)
|
| 1100 |
+
with gr.Row():
|
| 1101 |
+
config_choice = gr.Dropdown(label="配置文件", choices=config_list, value="no_config")
|
| 1102 |
+
config_info = gr.Textbox(label="配置文件编码器", placeholder="请选择配置文件")
|
| 1103 |
+
gr.Markdown(value="""**请检查模型和配置文件的编码器是否匹配**""")
|
| 1104 |
+
with gr.Row():
|
| 1105 |
+
diff_choice = gr.Dropdown(label="(可选)选择扩散模型", choices=diff_list, value="no_diff", interactive=True)
|
| 1106 |
+
diff_config_choice = gr.Dropdown(label="扩散模型配置文件", choices=diff_config_list, value="no_diff_config", interactive=True)
|
| 1107 |
+
cluster_choice = gr.Dropdown(label="(可选)选择聚类模型/特征检索模型", choices=cluster_list, value="no_clu")
|
| 1108 |
+
refresh = gr.Button("刷新选项")
|
| 1109 |
+
with gr.Row():
|
| 1110 |
+
enhance = gr.Checkbox(label="是否使用NSF_HIFIGAN增强,该选项对部分训练集少的模型有一定的音质增强效果,但是对训练好的模型有反面效果,默认关闭", value=False)
|
| 1111 |
+
only_diffusion = gr.Checkbox(label="是否使用全扩散推理,开启后将不使用So-VITS模型,仅使用扩散模型进行完整扩散推理,不建议使用", value=False)
|
| 1112 |
+
with gr.Row():
|
| 1113 |
+
diffusion_method = gr.Dropdown(label="扩散模型采样器", choices=["dpm-solver++","dpm-solver","pndm","ddim","unipc"], value="dpm-solver")
|
| 1114 |
+
diffusion_speedup = gr.Number(label="扩散加速倍数,默认为10倍", value=10)
|
| 1115 |
+
using_device = gr.Dropdown(label="推理设备,默认为自动选择", choices=["Auto",*cuda.keys(),"cpu"], value="Auto")
|
| 1116 |
+
with gr.Row():
|
| 1117 |
+
loadckpt = gr.Button("加载模型", variant="primary")
|
| 1118 |
+
unload = gr.Button("卸载模型", variant="primary")
|
| 1119 |
+
with gr.Row():
|
| 1120 |
+
model_message = gr.Textbox(label="Output Message")
|
| 1121 |
+
sid = gr.Dropdown(label="So-VITS说话人", value="speaker0")
|
| 1122 |
+
|
| 1123 |
+
inference_tab.select(refresh_options,[],[choice_ckpt,config_choice,cluster_choice,diff_choice,diff_config_choice])
|
| 1124 |
+
choice_ckpt.change(auto_load, [choice_ckpt], [model_branch, config_choice, config_info])
|
| 1125 |
+
config_choice.change(load_json_encoder, [config_choice, choice_ckpt], [config_info])
|
| 1126 |
+
diff_choice.change(auto_load_diff, [diff_choice], [diff_config_choice])
|
| 1127 |
+
refresh.click(refresh_options,[],[choice_ckpt,config_choice,cluster_choice,diff_choice,diff_config_choice,mode_caption])
|
| 1128 |
+
|
| 1129 |
+
gr.Markdown(value="""
|
| 1130 |
+
请稍等片刻,模型加载大约需要10秒。后续操作不需要重新加载模型
|
| 1131 |
+
""")
|
| 1132 |
+
with gr.Tabs():
|
| 1133 |
+
with gr.TabItem("单个音频上传"):
|
| 1134 |
+
vc_input3 = gr.Audio(label="单个音频上传", type="filepath")
|
| 1135 |
+
with gr.TabItem("批量音频上传"):
|
| 1136 |
+
vc_batch_files = gr.Files(label="批量音频上传", file_types=["audio"], file_count="multiple")
|
| 1137 |
+
with gr.TabItem("文字转语音"):
|
| 1138 |
+
gr.Markdown("""
|
| 1139 |
+
文字转语音(TTS)说明:使用edge_tts服务生成音频,并转换为So-VITS模型音色。
|
| 1140 |
+
""")
|
| 1141 |
+
text_input = gr.Textbox(label = "在此输入需要转译的文字(建议打开自动f0预测)",)
|
| 1142 |
+
with gr.Row():
|
| 1143 |
+
tts_gender = gr.Radio(label = "说话人性别", choices = ["男","女"], value = "男")
|
| 1144 |
+
tts_lang = gr.Dropdown(label = "选择语言,Auto为根据输入文字自动识别", choices=SUPPORTED_LANGUAGES, value = "Auto")
|
| 1145 |
+
with gr.Row():
|
| 1146 |
+
tts_rate = gr.Slider(label = "TTS语音变速(倍速相对值)", minimum = -1, maximum = 3, value = 0, step = 0.1)
|
| 1147 |
+
tts_volume = gr.Slider(label = "TTS语音音量(相对值)", minimum = -1, maximum = 1.5, value = 0, step = 0.1)
|
| 1148 |
+
|
| 1149 |
+
with gr.Row():
|
| 1150 |
+
auto_f0 = gr.Checkbox(label="自动f0预测,配合聚类模型f0预测效果更好,会导致变调功能失效(仅限转换语音,歌声不要勾选此项会跑调)", value=False)
|
| 1151 |
+
f0_predictor = gr.Radio(label="f0预测器选择(如遇哑音可以更换f0预测器解决,crepe为原F0使用均值滤波器)", choices=f0_options, value="pm")
|
| 1152 |
+
cr_threshold = gr.Number(label="F0过滤阈值,只有使用crepe时有效. 数值范围从0-1. 降低该值可减少跑调概率,但会增加哑音", value=0.05)
|
| 1153 |
+
with gr.Row():
|
| 1154 |
+
vc_transform = gr.Number(label="变调(整数,可以正负,半音数量,升高八度就是12)", value=0)
|
| 1155 |
+
cluster_ratio = gr.Number(label="聚类模型/特征检索混合比例,0-1之间,默认为0不启用聚类或特征检索,能提升音色相似度,但会导致咬字下降", value=0)
|
| 1156 |
+
k_step = gr.Slider(label="浅扩散步数,只有使用了扩散模型才有效,步数越大越接近扩散模型的结果", value=100, minimum = 1, maximum = 1000)
|
| 1157 |
+
with gr.Row():
|
| 1158 |
+
output_format = gr.Radio(label="音频输出格式", choices=["wav", "flac", "mp3"], value = "wav")
|
| 1159 |
+
enhancer_adaptive_key = gr.Number(label="使NSF-HIFIGAN增强器适应更高的音域(单位为半音数)|默认为0", value=0)
|
| 1160 |
+
slice_db = gr.Number(label="切片阈值", value=-50)
|
| 1161 |
+
cl_num = gr.Number(label="音频自动切片,0为按默认方式切片,单位为秒/s,爆显存可以设置此处强制切片", value=0)
|
| 1162 |
+
with gr.Accordion("高级设置(一般不需要动)", open=False):
|
| 1163 |
+
noise_scale = gr.Number(label="noise_scale 建议不要动,会影响音质,玄学参数", value=0.4)
|
| 1164 |
+
pad_seconds = gr.Number(label="推理音频pad秒数,由于未知原因开头结尾会有异响,pad一小段静音段后就不会出现", value=0.5)
|
| 1165 |
+
lg_num = gr.Number(label="两端音频切片的交叉淡入长度,如果自动切片后出现人声不连贯可调整该数值,如果连贯建议采用默认值0,注意,该设置会影响推理速度,单位为秒/s", value=1)
|
| 1166 |
+
lgr_num = gr.Number(label="自动音频切片后,需要舍弃每段切片的头尾。该参数设置交叉长度保留的比例,范围0-1,左开右闭", value=0.75)
|
| 1167 |
+
second_encoding = gr.Checkbox(label = "二次编码,浅扩散前会对原始音频进行二次编码,玄学选项,效果时好时差,默认关闭", value=False)
|
| 1168 |
+
loudness_envelope_adjustment = gr.Number(label="输入源响度包络替换输出响度包络融合比例,越靠近1越使用输出响度包络", value = 0)
|
| 1169 |
+
use_spk_mix = gr.Checkbox(label="动态声线融合,需要手动编辑角色混合轨道,没做完暂时不要开启", value=False, interactive=False)
|
| 1170 |
+
with gr.Row():
|
| 1171 |
+
vc_submit = gr.Button("音频转换", variant="primary")
|
| 1172 |
+
vc_batch_submit = gr.Button("批量转换", variant="primary")
|
| 1173 |
+
vc_tts_submit = gr.Button("文本转语音", variant="primary")
|
| 1174 |
+
vc_output1 = gr.Textbox(label="Output Message")
|
| 1175 |
+
vc_output2 = gr.Audio(label="Output Audio")
|
| 1176 |
+
|
| 1177 |
+
loadckpt.click(load_model_func,[choice_ckpt,cluster_choice,config_choice,enhance,diff_choice,diff_config_choice,only_diffusion,use_spk_mix,using_device,diffusion_method,diffusion_speedup],[model_message, sid, cl_num, k_step])
|
| 1178 |
+
unload.click(model_empty_cache, [], [sid, model_message])
|
| 1179 |
+
vc_submit.click(vc_fn, [output_format, sid, vc_input3, vc_transform,auto_f0,cluster_ratio, slice_db, noise_scale,pad_seconds,cl_num,lg_num,lgr_num,f0_predictor,enhancer_adaptive_key,cr_threshold,k_step,use_spk_mix,second_encoding,loudness_envelope_adjustment], [vc_output1, vc_output2])
|
| 1180 |
+
vc_batch_submit.click(vc_batch_fn, [output_format, sid, vc_batch_files, vc_transform,auto_f0,cluster_ratio, slice_db, noise_scale,pad_seconds,cl_num,lg_num,lgr_num,f0_predictor,enhancer_adaptive_key,cr_threshold,k_step,use_spk_mix,second_encoding,loudness_envelope_adjustment], [vc_output1])
|
| 1181 |
+
vc_tts_submit.click(tts_fn, [text_input, tts_gender, tts_lang, tts_rate, tts_volume, output_format, sid, vc_transform,auto_f0,cluster_ratio, slice_db, noise_scale,pad_seconds,cl_num,lg_num,lgr_num,f0_predictor,enhancer_adaptive_key,cr_threshold,k_step,use_spk_mix,second_encoding,loudness_envelope_adjustment], [vc_output1, vc_output2])
|
| 1182 |
+
|
| 1183 |
+
|
| 1184 |
+
with gr.TabItem("训练"):
|
| 1185 |
+
gr.Markdown(value="""请将数据集文件夹放置在dataset_raw文件夹下,确认放置正确后点击下方获取数据集名称""")
|
| 1186 |
+
raw_dirs_list=gr.Textbox(label="Raw dataset directory(s):")
|
| 1187 |
+
get_raw_dirs=gr.Button("识别数据集", variant="primary")
|
| 1188 |
+
gr.Markdown(value="""确认数据集正确识别后请选择训练使用的特征编码器和f0预测器,**如果要训练扩散模型,请选择Vec768l12或hubertsoft或whisper-ppg,并确保So-VITS和扩散模型使用同一个编码器**""")
|
| 1189 |
+
with gr.Row():
|
| 1190 |
+
gr.Markdown(value="""**vec256l9**: ContentVec(256Layer9),旧版本叫v1,So-VITS-SVC 4.0的基础版本,**不推荐使用**
|
| 1191 |
+
**vec768l12**: 特征输入更换为ContentVec的第12层Transformer输出,模型理论上会更加还原训练集音色
|
| 1192 |
+
**hubertsoft**: So-VITS-SVC 3.0使用的编码器,咬字更为准确,但可能存在多说话人音色泄露问题
|
| 1193 |
+
**whisper-ppg**: 来自OpenAI,咬字最为准确,但和Hubertsoft一样存在多说话人音色泄露,且显存占用和训练时间有明显增加。
|
| 1194 |
+
解锁更多编码器选项,请见[这里](https://www.yuque.com/umoubuton/ueupp5/kmui02dszo5zrqkz)
|
| 1195 |
+
""")
|
| 1196 |
+
gr.Markdown(value="""**crepe**: 抗噪能力最强,但预处理速度慢(不过如果你的显卡很强的话速度会很快)
|
| 1197 |
+
**pm**: 预处理速度快,但抗噪能力较弱
|
| 1198 |
+
**dio**: 先前版本预处理默认使用的f0预测器
|
| 1199 |
+
**harvest**: 有一定抗噪能力,预处理显存占用友好,速度比较慢
|
| 1200 |
+
""")
|
| 1201 |
+
with gr.Row():
|
| 1202 |
+
branch_selection = gr.Dropdown(label="选择训练使用的编码器", choices=encoder_list, value="vec768l12", interactive=True)
|
| 1203 |
+
f0_predictor_selection = gr.Dropdown(label="选择训练使用的f0预测器", choices=f0_options, value="crepe", interactive=True)
|
| 1204 |
+
with gr.Row():
|
| 1205 |
+
use_diff = gr.Checkbox(label="是否使用浅扩散模型,如要训练浅扩散模型请勾选此项", value=True)
|
| 1206 |
+
vol_aug=gr.Checkbox(label="是否启用响度嵌入和音量增强,启用后可以根据输入源控制输出响度,但对数据集质量的要求更高。**仅支持vec768l12编码器**", value=False)
|
| 1207 |
+
with gr.Row():
|
| 1208 |
+
skip_loudnorm = gr.Checkbox(label="是否跳过响度匹配,如果你已经用音频处理软件做过响度匹配,请勾选此处")
|
| 1209 |
+
num_processes = gr.Slider(label="预处理使用的CPU线程数,可以大幅加快预处理速度,但线程数过大容易爆显存,建议12G显存设置为2", minimum=1, maximum=multiprocessing.cpu_count(), value=1, step=1)
|
| 1210 |
+
with gr.Row():
|
| 1211 |
+
raw_preprocess=gr.Button("数据预处理", variant="primary")
|
| 1212 |
+
regenerate_config_btn=gr.Button("重新生成配置文件", variant="primary")
|
| 1213 |
+
preprocess_output=gr.Textbox(label="预处理输出信息,完成后请检查一下是否有报错信息,如无则可以进行下一步", max_lines=999)
|
| 1214 |
+
clear_preprocess_output=gr.Button("清空输出信息")
|
| 1215 |
+
with gr.Group():
|
| 1216 |
+
gr.Markdown(value="""填写训练设置和超参数""")
|
| 1217 |
+
with gr.Row():
|
| 1218 |
+
gr.Textbox(label="当前使用显卡信息", value=gpu_info)
|
| 1219 |
+
gpu_selection=gr.Textbox(label="多卡用户请指定希望训练使用的显卡ID(0,1,2...)", value=gpus, interactive=True)
|
| 1220 |
+
with gr.Row():
|
| 1221 |
+
log_interval=gr.Textbox(label="每隔多少步(steps)生成一次评估日志", value=sovits_params['log_interval'])
|
| 1222 |
+
eval_interval=gr.Textbox(label="每隔多少步(steps)验证并保存一次模型", value=sovits_params['eval_interval'])
|
| 1223 |
+
keep_ckpts=gr.Textbox(label="仅保留最新的X个模型,超出该数字的旧模型会被删除。设置为0则永不删除", value=sovits_params['keep_ckpts'])
|
| 1224 |
+
with gr.Row():
|
| 1225 |
+
batch_size=gr.Textbox(label="批量大小,每步取多少条数据进行训练,大batch有助于训练但显著增加显存占用。6G显存建议设定为4", value=sovits_params['batch_size'])
|
| 1226 |
+
lr=gr.Textbox(label="学习率,一般不用动,批量大小较大时可以适当增大学习率,但强烈不建议超过0.0002,有炸炉风险", value=sovits_params['learning_rate'])
|
| 1227 |
+
#fp16_run=gr.Checkbox(label="是否使用fp16混合精度训练,fp16训练可能降低显存占用和训练时间,但对模型质量的影响尚未查证", value=sovits_params['fp16_run'])
|
| 1228 |
+
amp_dtype = gr.Radio(label="训练数据类型,fp16可能会有更快的训练速度和更低的显存占用,但容易炸炉", choices=amp_options, value=sovits_params['amp_dtype'])
|
| 1229 |
+
all_in_mem=gr.Checkbox(label="是否加载所有数据集到内存中,硬盘IO过于低下、同时内存容量远大于数据集体积时可以启用,能显著加快训练速度", value=sovits_params['all_in_mem'])
|
| 1230 |
+
with gr.Row():
|
| 1231 |
+
#tiny_enable = gr.Checkbox(label="是否启用TINY训练,TINY模型的显存占用更低,推理速度更快,但质量有所削减。仅支持vec768的响度嵌入", value=False)
|
| 1232 |
+
gr.Markdown("请检查右侧的说话人列表是否和你要训练的目标说话人一致,确认无误后点击写入配置文件,然后就可以开始训练了")
|
| 1233 |
+
speakers=gr.Textbox(label="说话人列表")
|
| 1234 |
+
with gr.Accordion(label = "扩散模型配置(训练扩散模型需要写入此处)", open=True):
|
| 1235 |
+
with gr.Row():
|
| 1236 |
+
diff_num_workers = gr.Number(label="num_workers, 如果你的电脑配置较高,可以将这里设置为0加快训练速度", value=diff_params['num_workers'])
|
| 1237 |
+
diff_k_step_max = gr.Checkbox(label="只训练100步深度的浅扩散模型。能加快训练速度并提高模型质量,代价是无法执行超过100步的浅扩散推理", value=diff_params['diff_k_step_max'])
|
| 1238 |
+
diff_cache_all_data = gr.Checkbox(label="是否缓存数据,启用后可以加快训练速度,关闭后可以节省显存或内存,但会减慢训练速度", value=diff_params['cache_all_data'])
|
| 1239 |
+
diff_cache_device = gr.Radio(label="若启用缓存数据,使用显存(cuda)还是内存(cpu)缓存,如果显卡显存充足,选择cuda以加快训练速度", choices=["cuda","cpu"], value=diff_params['cache_device'])
|
| 1240 |
+
diff_amp_dtype = gr.Radio(label="训练数据类型,fp16可能会有更快的训练速度,前提是你的显卡支持", choices=["fp32","fp16"], value=diff_params['amp_dtype'])
|
| 1241 |
+
with gr.Row():
|
| 1242 |
+
diff_batch_size = gr.Number(label="批量大小(batch_size),根据显卡显存设置,小显存适当降低该项,6G显存可以设定为48,但该数值不要超过数据集总数量的1/4", value=diff_params['diff_batch_size'])
|
| 1243 |
+
diff_lr = gr.Number(label="学习率(一般不需要动)", value=diff_params['diff_lr'])
|
| 1244 |
+
diff_interval_log = gr.Number(label="每隔多少步(steps)生成一次评估日志", value = diff_params['diff_interval_log'])
|
| 1245 |
+
diff_interval_val = gr.Number(label="每隔多少步(steps)验证并保存一次模型,如果你的批量大小较大,可以适当减少这里的数字,但不建议设置为1000以下", value=diff_params['diff_interval_val'])
|
| 1246 |
+
diff_force_save = gr.Number(label="每隔多少步强制保留模型,只有该步数的倍数保存的模型会被保留,其余会被删除。设置为与验证步数相同的值则每个模型都会被保留", value=diff_params['diff_force_save'])
|
| 1247 |
+
with gr.Row():
|
| 1248 |
+
save_params=gr.Button("将当前设置保存为默认设置", variant="primary")
|
| 1249 |
+
write_config=gr.Button("写入配置文件", variant="primary")
|
| 1250 |
+
write_config_output=gr.Textbox(label="输出信息")
|
| 1251 |
+
|
| 1252 |
+
gr.Markdown(value="""**点击从头开始训练**将会自动将已有的训练进度保存到models_backup文件夹,并自动装载预训练模型。
|
| 1253 |
+
**继续上一次的训练进度**将从上一个保存模型的进度继续训练。继续训练进度无需重新预处理和写入配置文件。
|
| 1254 |
+
关于扩散、聚类和特征检索的详细说明请看[此处](https://www.yuque.com/umoubuton/ueupp5/kmui02dszo5zrqkz)。
|
| 1255 |
+
""")
|
| 1256 |
+
with gr.Row():
|
| 1257 |
+
with gr.Column():
|
| 1258 |
+
start_training=gr.Button("从头开始训练", variant="primary")
|
| 1259 |
+
training_output=gr.Textbox(label="训练输出信息")
|
| 1260 |
+
with gr.Column():
|
| 1261 |
+
continue_training_btn=gr.Button("继续上一次的训练进度", variant="primary")
|
| 1262 |
+
continue_training_output=gr.Textbox(label="训练输出信息")
|
| 1263 |
+
with gr.Row():
|
| 1264 |
+
with gr.Column():
|
| 1265 |
+
diff_training_btn=gr.Button("从头训练扩散模型", variant="primary")
|
| 1266 |
+
diff_training_output=gr.Textbox(label="训练输出信息")
|
| 1267 |
+
with gr.Column():
|
| 1268 |
+
diff_continue_training_btn=gr.Button("继续训练扩散模型", variant="primary")
|
| 1269 |
+
diff_continue_training_output=gr.Textbox(label="训练输出信息")
|
| 1270 |
+
with gr.Accordion(label = "聚类、特征检索训练", open=False):
|
| 1271 |
+
with gr.Row():
|
| 1272 |
+
with gr.Column():
|
| 1273 |
+
kmeans_button=gr.Button("训练聚类模型", variant="primary")
|
| 1274 |
+
kmeans_gpu = gr.Checkbox(label="使用GPU训练", value=True)
|
| 1275 |
+
kmeans_output=gr.Textbox(label="训练输出信息")
|
| 1276 |
+
with gr.Column():
|
| 1277 |
+
index_button=gr.Button("训练特征检索模型", variant="primary")
|
| 1278 |
+
index_output=gr.Textbox(label="训练输出信息")
|
| 1279 |
+
|
| 1280 |
+
with gr.TabItem("小工具/实验室特性"):
|
| 1281 |
+
gr.Markdown(value="""
|
| 1282 |
+
### So-vits-svc 4.1 小工具/实验室特性
|
| 1283 |
+
提供了一些有趣或实用的小工具,可以自行探索
|
| 1284 |
+
""")
|
| 1285 |
+
with gr.Tabs():
|
| 1286 |
+
with gr.TabItem("静态声线融合"):
|
| 1287 |
+
gr.Markdown(value="""
|
| 1288 |
+
<font size=2> 介绍:该功能可以将多个声音模型合成为一个声音模型(多个模型参数的凸组合或线性组合),从而制造出现实中不存在的声线
|
| 1289 |
+
注意:
|
| 1290 |
+
1.该功能仅支持单说话人的模型
|
| 1291 |
+
2.如果强行使用多说话人模型,需要保证多个模型的说话人数量相同,这样可以混合同一个SpaekerID下的声音
|
| 1292 |
+
3.保证所有待混合模型的config.json中的model字段是相同的
|
| 1293 |
+
4.输出的混合模型可以使用待合成模型的任意一个config.json,但聚类模型将不能使用
|
| 1294 |
+
5.批量上传模型的时候最好把模型放到一个文件夹选中后一起上传
|
| 1295 |
+
6.混合比例调整建议大小在0-100之间,也可以调为其他数字,但在线性组合模式下会出现未知的效果
|
| 1296 |
+
7.混合完毕后,文件将会保存在项目根目录中,文件名为output.pth
|
| 1297 |
+
8.凸组合模式会将混合比例执行Softmax使混合比例相加为1,而线性组合模式不会
|
| 1298 |
+
</font>
|
| 1299 |
+
""")
|
| 1300 |
+
mix_model_path = gr.Files(label="选择需要混合模型文件")
|
| 1301 |
+
mix_model_upload_button = gr.UploadButton("选择/追加需要混合模型文件", file_count="multiple")
|
| 1302 |
+
mix_model_output1 = gr.Textbox(
|
| 1303 |
+
label="混合比例调整,单位/%",
|
| 1304 |
+
interactive = True
|
| 1305 |
+
)
|
| 1306 |
+
mix_mode = gr.Radio(choices=["凸组合", "线性组合"], label="融合模式",value="凸组合",interactive = True)
|
| 1307 |
+
mix_submit = gr.Button("声线融合启动", variant="primary")
|
| 1308 |
+
mix_model_output2 = gr.Textbox(
|
| 1309 |
+
label="Output Message"
|
| 1310 |
+
)
|
| 1311 |
+
with gr.TabItem("onnx转换"):
|
| 1312 |
+
gr.Markdown(value="""
|
| 1313 |
+
提供了将.pth模型(批量)转换为.onnx模型的功能
|
| 1314 |
+
源项目本身自带转换的功能,但不支持批量,操作也不够简单,这个工具可以支持在WebUI中以可视化的操作方式批量转换.onnx模型
|
| 1315 |
+
有人可能会问,转.onnx模型有什么作用呢?相信我,如果你问出了这个问题,说明这个工具你应该用不上
|
| 1316 |
+
|
| 1317 |
+
### Step 1:
|
| 1318 |
+
在整合包根目录下新建一个"checkpoints"文件夹,将pth模型和对应的json配置文件按目录分别放置到checkpoints文件夹下
|
| 1319 |
+
看起来应该像这样:
|
| 1320 |
+
checkpoints
|
| 1321 |
+
├───xxxx
|
| 1322 |
+
│ ├───xxxx.pth
|
| 1323 |
+
│ └───xxxx.json
|
| 1324 |
+
├───xxxx
|
| 1325 |
+
│ ├───xxxx.pth
|
| 1326 |
+
│ └───xxxx.json
|
| 1327 |
+
└───……
|
| 1328 |
+
""")
|
| 1329 |
+
pth_dir_msg = gr.Textbox(label="识别待转换模型", placeholder="请将模型和配置文件按上述说明放置在正确位置")
|
| 1330 |
+
pth_dir_identify_btn = gr.Button("识别", variant="primary")
|
| 1331 |
+
gr.Markdown(value="""
|
| 1332 |
+
### Step 2:
|
| 1333 |
+
识别正确后点击下方开始转换,转换一个模型可能需要一分钟甚至更久
|
| 1334 |
+
""")
|
| 1335 |
+
pth2onnx_btn = gr.Button("开始转换", variant="primary")
|
| 1336 |
+
pth2onnx_msg = gr.Textbox(label="输出信息")
|
| 1337 |
+
|
| 1338 |
+
with gr.TabItem("智能音频切片"):
|
| 1339 |
+
gr.Markdown(value="""
|
| 1340 |
+
该工具可以实现对音频的切片,无需调整参数即可完成符合要求的数据集制作。
|
| 1341 |
+
数据集要求的音频切片约在2-15秒内,用传统的Slicer-GUI切片工具需要精准调参和二次切片才能符合要求,该工具省去了上述繁琐的操作,只要上传原始音频即可一键制作数据集。
|
| 1342 |
+
""")
|
| 1343 |
+
with gr.Row():
|
| 1344 |
+
raw_audio_path = gr.Textbox(label="原始音频文件夹", placeholder="包含所有待切片音频的文件夹,示例: D:\干声\speakers")
|
| 1345 |
+
load_raw_audio_btn = gr.Button("加载原始音频", variant = "primary")
|
| 1346 |
+
load_raw_audio_output = gr.Textbox(label = "输出信息")
|
| 1347 |
+
raw_audio_dataset = gr.Textbox(label = "音频列表", value = "")
|
| 1348 |
+
slicer_output_dir = gr.Textbox(label = "输出目录", placeholder = "选择输出目录(不要和输入音频是同一个文件夹)")
|
| 1349 |
+
with gr.Row():
|
| 1350 |
+
process_method = gr.Radio(label = "对过短音频的处理方式", choices = ["丢弃","将过短音频整合为长音频"], value = "丢弃")
|
| 1351 |
+
max_sec = gr.Number(label = "切片的最长秒数", value = 15)
|
| 1352 |
+
min_sec = gr.Number(label = "切片的最短秒数", value = 2)
|
| 1353 |
+
slicer_btn = gr.Button("开始切片", variant = "primary")
|
| 1354 |
+
slicer_output_msg = gr.Textbox(label = "输出信息")
|
| 1355 |
+
|
| 1356 |
+
mix_model_path.change(updata_mix_info,[mix_model_path],[mix_model_output1])
|
| 1357 |
+
mix_model_upload_button.upload(upload_mix_append_file, [mix_model_upload_button,mix_model_path], [mix_model_path,mix_model_output1])
|
| 1358 |
+
mix_submit.click(mix_submit_click, [mix_model_output1,mix_mode], [mix_model_output2])
|
| 1359 |
+
pth_dir_identify_btn.click(pth_identify, [], [pth_dir_msg])
|
| 1360 |
+
pth2onnx_btn.click(onnx_export, [], [pth2onnx_msg])
|
| 1361 |
+
load_raw_audio_btn.click(load_raw_audio, [raw_audio_path], [load_raw_audio_output, raw_audio_dataset])
|
| 1362 |
+
slicer_btn.click(slicer_fn, [raw_audio_path, slicer_output_dir, process_method, max_sec, min_sec], [slicer_output_msg])
|
| 1363 |
+
|
| 1364 |
+
with gr.TabItem("模型压缩工具"):
|
| 1365 |
+
gr.Markdown(value="""
|
| 1366 |
+
该工具可以实现对模型的体积压缩,在**不影响模型推理功能**的情况下,将原本约600M的So-VITS模型压缩至约200M, 大大减少了硬盘的压力。
|
| 1367 |
+
**注意:压缩后的模型将无法继续训练,请在确认封炉后再压缩。**
|
| 1368 |
+
将模型文件放置在logs/44k下,然后选择需要压缩的模型
|
| 1369 |
+
""")
|
| 1370 |
+
model_to_compress = gr.Dropdown(label="模型选择", choices=ckpt_list, value="no_model")
|
| 1371 |
+
fp16_compress = gr.Checkbox(label="使用 fp16 压缩", value=False)
|
| 1372 |
+
compress_model_btn = gr.Button("压缩模型", variant="primary")
|
| 1373 |
+
compress_model_output = gr.Textbox(label="输出信息", value="")
|
| 1374 |
+
|
| 1375 |
+
compress_model_btn.click(model_compression, [model_to_compress], [compress_model_output])
|
| 1376 |
+
|
| 1377 |
+
with gr.TabItem("模型发布打包/安装"):
|
| 1378 |
+
gr.Markdown(value="""
|
| 1379 |
+
如果你想将你的模型分享给他人,请使用该工具对模型进行打包。
|
| 1380 |
+
该工具可以自动生成正确的配置文件,确保你在打包过程中不出现任何遗漏和错误,接收到使用该工具打包的模型后,也可以用该工具进行自动安装。
|
| 1381 |
+
""")
|
| 1382 |
+
with gr.Tabs():
|
| 1383 |
+
with gr.TabItem("安装"):
|
| 1384 |
+
with gr.Row():
|
| 1385 |
+
model_to_install = gr.Textbox(label = "模型压缩包路径", placeholder="示例:D:\Downloads\model_packing.zip")
|
| 1386 |
+
install_model_btn = gr.Button("安装", variant="primary")
|
| 1387 |
+
install_output = gr.Textbox(label="输出信息", value="")
|
| 1388 |
+
with gr.TabItem("打包"):
|
| 1389 |
+
with gr.Row():
|
| 1390 |
+
model_to_pack = gr.Dropdown(label="选择要打包的模型", choices=ckpt_list, value="")
|
| 1391 |
+
model_config = gr.Dropdown(label="选择要打包的模型配置文件", choices=config_list, value="", interactive=True)
|
| 1392 |
+
speaker_name = gr.Textbox(label="模型说话人名称", placeholder="该模型的说话人名称,仅限数字字母下划线,如模型中有多说话人,请用逗号分割,例如:spk1,spk2,spk3", value = "")
|
| 1393 |
+
with gr.Row():
|
| 1394 |
+
diff_to_pack = gr.Dropdown(label="(可选)选择要打包的扩散模型", choices=diff_list, value="no_diff")
|
| 1395 |
+
cluster_to_pack = gr.Dropdown(label="(可选)选择要打包的聚类或特征检索模型", choices=cluster_list, value="no_cluster")
|
| 1396 |
+
packing_btn = gr.Button("开始打包", variant="primary")
|
| 1397 |
+
packing_output_msg = gr.Textbox(label = "输出信息")
|
| 1398 |
+
|
| 1399 |
+
model_to_pack.change(pack_autoload, [model_to_pack], [model_config, speaker_name])
|
| 1400 |
+
packing_btn.click(release_packing, [model_to_pack, model_config, speaker_name, diff_to_pack, cluster_to_pack], [packing_output_msg])
|
| 1401 |
+
install_model_btn.click(release_install, [model_to_install], [install_output])
|
| 1402 |
+
|
| 1403 |
+
get_raw_dirs.click(load_raw_dirs,[],[raw_dirs_list])
|
| 1404 |
+
raw_preprocess.click(dataset_preprocess,[branch_selection, f0_predictor_selection, use_diff, vol_aug, skip_loudnorm, num_processes],[preprocess_output, speakers])
|
| 1405 |
+
regenerate_config_btn.click(regenerate_config,[branch_selection, vol_aug],[preprocess_output])
|
| 1406 |
+
clear_preprocess_output.click(clear_output,[],[preprocess_output])
|
| 1407 |
+
save_params.click(save_default_settings, [log_interval,eval_interval,keep_ckpts,batch_size,lr,amp_dtype,all_in_mem,diff_num_workers,diff_cache_all_data,diff_cache_device,diff_amp_dtype,diff_batch_size,diff_lr,diff_interval_log,diff_interval_val,diff_force_save,diff_k_step_max], [write_config_output])
|
| 1408 |
+
write_config.click(config_fn,[log_interval, eval_interval, keep_ckpts, batch_size, lr, amp_dtype, all_in_mem, diff_num_workers, diff_cache_all_data, diff_batch_size, diff_lr, diff_interval_log, diff_interval_val, diff_cache_device, diff_amp_dtype, diff_force_save, diff_k_step_max],[write_config_output])
|
| 1409 |
+
start_training.click(training,[gpu_selection, branch_selection],[training_output])
|
| 1410 |
+
diff_training_btn.click(diff_training,[branch_selection, diff_k_step_max],[diff_training_output])
|
| 1411 |
+
continue_training_btn.click(continue_training,[gpu_selection, branch_selection],[continue_training_output])
|
| 1412 |
+
diff_continue_training_btn.click(diff_continue_training,[branch_selection],[diff_continue_training_output])
|
| 1413 |
+
kmeans_button.click(kmeans_training,[kmeans_gpu],[kmeans_output])
|
| 1414 |
+
index_button.click(index_training, [], [index_output])
|
| 1415 |
+
|
| 1416 |
+
with gr.Tabs():
|
| 1417 |
+
with gr.Row(variant="panel"):
|
| 1418 |
+
with gr.Column():
|
| 1419 |
+
gr.Markdown(value="""
|
| 1420 |
+
<font size=2> WebUI设置</font>
|
| 1421 |
+
""")
|
| 1422 |
+
with gr.Row():
|
| 1423 |
+
debug_button = gr.Checkbox(label="Debug模式,反馈BUG需要打开,打开后控制台可以显示具体错误提示", value=debug)
|
| 1424 |
+
read_second_dir = gr.Checkbox(label = "独立目录模式,开启后将从独立目录(./models)读取模型和配置文件,变更后需要刷新选项才能生效", value=second_dir_enable)
|
| 1425 |
+
debug_button.change(debug_change,[],[])
|
| 1426 |
+
read_second_dir.change(webui_change,[read_second_dir],[])
|
| 1427 |
+
|
| 1428 |
+
app.queue(concurrency_count=1022, max_size=2044).launch(server_name="127.0.0.1",inbrowser=True,quiet=True)
|
auto_slicer.py
ADDED
|
@@ -0,0 +1,107 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import os
|
| 2 |
+
from typing import final
|
| 3 |
+
import numpy as np
|
| 4 |
+
import librosa
|
| 5 |
+
import soundfile as sf
|
| 6 |
+
from modules.slicer2 import Slicer
|
| 7 |
+
|
| 8 |
+
class AutoSlicer:
|
| 9 |
+
def __init__(self):
|
| 10 |
+
self.slicer_params = {
|
| 11 |
+
"threshold": -40,
|
| 12 |
+
"min_length": 5000,
|
| 13 |
+
"min_interval": 300,
|
| 14 |
+
"hop_size": 10,
|
| 15 |
+
"max_sil_kept": 500,
|
| 16 |
+
}
|
| 17 |
+
self.original_min_interval = self.slicer_params["min_interval"]
|
| 18 |
+
|
| 19 |
+
def auto_slice(self, filename, input_dir, output_dir, max_sec):
|
| 20 |
+
audio, sr = librosa.load(os.path.join(input_dir, filename), sr=None, mono=False)
|
| 21 |
+
slicer = Slicer(sr=sr, **self.slicer_params)
|
| 22 |
+
chunks = slicer.slice(audio)
|
| 23 |
+
files_to_delete = []
|
| 24 |
+
for i, chunk in enumerate(chunks):
|
| 25 |
+
if len(chunk.shape) > 1:
|
| 26 |
+
chunk = chunk.T
|
| 27 |
+
output_filename = f"{os.path.splitext(filename)[0]}_{i}"
|
| 28 |
+
output_filename = "".join(c for c in output_filename if c.isascii() or c == "_") + ".wav"
|
| 29 |
+
output_filepath = os.path.join(output_dir, output_filename)
|
| 30 |
+
sf.write(output_filepath, chunk, sr)
|
| 31 |
+
#Check and re-slice audio that more than max_sec.
|
| 32 |
+
while True:
|
| 33 |
+
new_audio, sr = librosa.load(output_filepath, sr=None, mono=False)
|
| 34 |
+
if librosa.get_duration(y=new_audio, sr=sr) <= max_sec:
|
| 35 |
+
break
|
| 36 |
+
self.slicer_params["min_interval"] = self.slicer_params["min_interval"] // 2
|
| 37 |
+
if self.slicer_params["min_interval"] >= self.slicer_params["hop_size"]:
|
| 38 |
+
new_chunks = Slicer(sr=sr, **self.slicer_params).slice(new_audio)
|
| 39 |
+
for j, new_chunk in enumerate(new_chunks):
|
| 40 |
+
if len(new_chunk.shape) > 1:
|
| 41 |
+
new_chunk = new_chunk.T
|
| 42 |
+
new_output_filename = f"{os.path.splitext(output_filename)[0]}_{j}.wav"
|
| 43 |
+
sf.write(os.path.join(output_dir, new_output_filename), new_chunk, sr)
|
| 44 |
+
files_to_delete.append(output_filepath)
|
| 45 |
+
else:
|
| 46 |
+
break
|
| 47 |
+
self.slicer_params["min_interval"] = self.original_min_interval
|
| 48 |
+
for file_path in files_to_delete:
|
| 49 |
+
if os.path.exists(file_path):
|
| 50 |
+
os.remove(file_path)
|
| 51 |
+
|
| 52 |
+
def merge_short(self, output_dir, max_sec, min_sec):
|
| 53 |
+
short_files = []
|
| 54 |
+
for filename in os.listdir(output_dir):
|
| 55 |
+
filepath = os.path.join(output_dir, filename)
|
| 56 |
+
if filename.endswith(".wav"):
|
| 57 |
+
audio, sr = librosa.load(filepath, sr=None, mono=False)
|
| 58 |
+
duration = librosa.get_duration(y=audio, sr=sr)
|
| 59 |
+
if duration < min_sec:
|
| 60 |
+
short_files.append((filepath, audio, duration))
|
| 61 |
+
short_files.sort(key=lambda x: x[2], reverse=True)
|
| 62 |
+
merged_audio = []
|
| 63 |
+
current_duration = 0
|
| 64 |
+
for filepath, audio, duration in short_files:
|
| 65 |
+
if current_duration + duration <= max_sec:
|
| 66 |
+
merged_audio.append(audio)
|
| 67 |
+
current_duration += duration
|
| 68 |
+
os.remove(filepath)
|
| 69 |
+
else:
|
| 70 |
+
if merged_audio:
|
| 71 |
+
output_audio = np.concatenate(merged_audio, axis=-1)
|
| 72 |
+
if len(output_audio.shape) > 1:
|
| 73 |
+
output_audio = output_audio.T
|
| 74 |
+
output_filename = f"merged_{len(os.listdir(output_dir))}.wav"
|
| 75 |
+
sf.write(os.path.join(output_dir, output_filename), output_audio, sr)
|
| 76 |
+
merged_audio = [audio]
|
| 77 |
+
current_duration = duration
|
| 78 |
+
os.remove(filepath)
|
| 79 |
+
if merged_audio and current_duration >= min_sec:
|
| 80 |
+
output_audio = np.concatenate(merged_audio, axis=-1)
|
| 81 |
+
if len(output_audio.shape) > 1:
|
| 82 |
+
output_audio = output_audio.T
|
| 83 |
+
output_filename = f"merged_{len(os.listdir(output_dir))}.wav"
|
| 84 |
+
sf.write(os.path.join(output_dir, output_filename), output_audio, sr)
|
| 85 |
+
|
| 86 |
+
def slice_count(self, input_dir, output_dir):
|
| 87 |
+
orig_duration = final_duration = 0
|
| 88 |
+
for file in os.listdir(input_dir):
|
| 89 |
+
if file.endswith(".wav"):
|
| 90 |
+
_audio, _sr = librosa.load(os.path.join(input_dir, file), sr=None, mono=False)
|
| 91 |
+
orig_duration += librosa.get_duration(y=_audio, sr=_sr)
|
| 92 |
+
wav_files = [file for file in os.listdir(output_dir) if file.endswith(".wav")]
|
| 93 |
+
num_files = len(wav_files)
|
| 94 |
+
max_duration = -1
|
| 95 |
+
min_duration = float("inf")
|
| 96 |
+
for file in wav_files:
|
| 97 |
+
file_path = os.path.join(output_dir, file)
|
| 98 |
+
audio, sr = librosa.load(file_path, sr=None, mono=False)
|
| 99 |
+
duration = librosa.get_duration(y=audio, sr=sr)
|
| 100 |
+
final_duration += float(duration)
|
| 101 |
+
if duration > max_duration:
|
| 102 |
+
max_duration = float(duration)
|
| 103 |
+
if duration < min_duration:
|
| 104 |
+
min_duration = float(duration)
|
| 105 |
+
return num_files, max_duration, min_duration, orig_duration, final_duration
|
| 106 |
+
|
| 107 |
+
|
compress_model.py
ADDED
|
@@ -0,0 +1,72 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from collections import OrderedDict
|
| 2 |
+
|
| 3 |
+
import torch
|
| 4 |
+
|
| 5 |
+
import utils
|
| 6 |
+
from models import SynthesizerTrn
|
| 7 |
+
|
| 8 |
+
|
| 9 |
+
def copyStateDict(state_dict):
|
| 10 |
+
if list(state_dict.keys())[0].startswith('module'):
|
| 11 |
+
start_idx = 1
|
| 12 |
+
else:
|
| 13 |
+
start_idx = 0
|
| 14 |
+
new_state_dict = OrderedDict()
|
| 15 |
+
for k, v in state_dict.items():
|
| 16 |
+
name = ','.join(k.split('.')[start_idx:])
|
| 17 |
+
new_state_dict[name] = v
|
| 18 |
+
return new_state_dict
|
| 19 |
+
|
| 20 |
+
|
| 21 |
+
def removeOptimizer(config: str, input_model: str, ishalf: bool, output_model: str):
|
| 22 |
+
hps = utils.get_hparams_from_file(config)
|
| 23 |
+
|
| 24 |
+
net_g = SynthesizerTrn(hps.data.filter_length // 2 + 1,
|
| 25 |
+
hps.train.segment_size // hps.data.hop_length,
|
| 26 |
+
**hps.model)
|
| 27 |
+
|
| 28 |
+
optim_g = torch.optim.AdamW(net_g.parameters(),
|
| 29 |
+
hps.train.learning_rate,
|
| 30 |
+
betas=hps.train.betas,
|
| 31 |
+
eps=hps.train.eps)
|
| 32 |
+
|
| 33 |
+
state_dict_g = torch.load(input_model, map_location="cpu")
|
| 34 |
+
new_dict_g = copyStateDict(state_dict_g)
|
| 35 |
+
keys = []
|
| 36 |
+
for k, v in new_dict_g['model'].items():
|
| 37 |
+
if "enc_q" in k: continue # noqa: E701
|
| 38 |
+
keys.append(k)
|
| 39 |
+
|
| 40 |
+
new_dict_g = {k: new_dict_g['model'][k].half() for k in keys} if ishalf else {k: new_dict_g['model'][k] for k in keys}
|
| 41 |
+
|
| 42 |
+
torch.save(
|
| 43 |
+
{
|
| 44 |
+
'model': new_dict_g,
|
| 45 |
+
'iteration': 0,
|
| 46 |
+
'optimizer': optim_g.state_dict(),
|
| 47 |
+
'learning_rate': 0.0001
|
| 48 |
+
}, output_model)
|
| 49 |
+
|
| 50 |
+
|
| 51 |
+
if __name__ == "__main__":
|
| 52 |
+
import argparse
|
| 53 |
+
parser = argparse.ArgumentParser()
|
| 54 |
+
parser.add_argument("-c",
|
| 55 |
+
"--config",
|
| 56 |
+
type=str,
|
| 57 |
+
default='configs/config.json')
|
| 58 |
+
parser.add_argument("-i", "--input", type=str)
|
| 59 |
+
parser.add_argument("-o", "--output", type=str, default=None)
|
| 60 |
+
parser.add_argument('-hf', '--half', action='store_true', default=False, help='Save as FP16')
|
| 61 |
+
|
| 62 |
+
args = parser.parse_args()
|
| 63 |
+
|
| 64 |
+
output = args.output
|
| 65 |
+
|
| 66 |
+
if output is None:
|
| 67 |
+
import os.path
|
| 68 |
+
filename, ext = os.path.splitext(args.input)
|
| 69 |
+
half = "_half" if args.half else ""
|
| 70 |
+
output = filename + "_release" + half + ext
|
| 71 |
+
|
| 72 |
+
removeOptimizer(args.config, args.input, args.half, output)
|
data_utils.py
ADDED
|
@@ -0,0 +1,185 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import os
|
| 2 |
+
import random
|
| 3 |
+
|
| 4 |
+
import numpy as np
|
| 5 |
+
import torch
|
| 6 |
+
import torch.utils.data
|
| 7 |
+
|
| 8 |
+
import utils
|
| 9 |
+
from modules.mel_processing import spectrogram_torch
|
| 10 |
+
from utils import load_filepaths_and_text, load_wav_to_torch
|
| 11 |
+
|
| 12 |
+
# import h5py
|
| 13 |
+
|
| 14 |
+
|
| 15 |
+
"""Multi speaker version"""
|
| 16 |
+
|
| 17 |
+
|
| 18 |
+
class TextAudioSpeakerLoader(torch.utils.data.Dataset):
|
| 19 |
+
"""
|
| 20 |
+
1) loads audio, speaker_id, text pairs
|
| 21 |
+
2) normalizes text and converts them to sequences of integers
|
| 22 |
+
3) computes spectrograms from audio files.
|
| 23 |
+
"""
|
| 24 |
+
|
| 25 |
+
def __init__(self, audiopaths, hparams, all_in_mem: bool = False, vol_aug: bool = True):
|
| 26 |
+
self.audiopaths = load_filepaths_and_text(audiopaths)
|
| 27 |
+
self.hparams = hparams
|
| 28 |
+
self.max_wav_value = hparams.data.max_wav_value
|
| 29 |
+
self.sampling_rate = hparams.data.sampling_rate
|
| 30 |
+
self.filter_length = hparams.data.filter_length
|
| 31 |
+
self.hop_length = hparams.data.hop_length
|
| 32 |
+
self.win_length = hparams.data.win_length
|
| 33 |
+
self.unit_interpolate_mode = hparams.data.unit_interpolate_mode
|
| 34 |
+
self.sampling_rate = hparams.data.sampling_rate
|
| 35 |
+
self.use_sr = hparams.train.use_sr
|
| 36 |
+
self.spec_len = hparams.train.max_speclen
|
| 37 |
+
self.spk_map = hparams.spk
|
| 38 |
+
self.vol_emb = hparams.model.vol_embedding
|
| 39 |
+
self.vol_aug = hparams.train.vol_aug and vol_aug
|
| 40 |
+
random.seed(1234)
|
| 41 |
+
random.shuffle(self.audiopaths)
|
| 42 |
+
|
| 43 |
+
self.all_in_mem = all_in_mem
|
| 44 |
+
if self.all_in_mem:
|
| 45 |
+
self.cache = [self.get_audio(p[0]) for p in self.audiopaths]
|
| 46 |
+
|
| 47 |
+
def get_audio(self, filename):
|
| 48 |
+
filename = filename.replace("\\", "/")
|
| 49 |
+
audio, sampling_rate = load_wav_to_torch(filename)
|
| 50 |
+
if sampling_rate != self.sampling_rate:
|
| 51 |
+
raise ValueError(
|
| 52 |
+
"Sample Rate not match. Expect {} but got {} from {}".format(
|
| 53 |
+
self.sampling_rate, sampling_rate, filename))
|
| 54 |
+
audio_norm = audio / self.max_wav_value
|
| 55 |
+
audio_norm = audio_norm.unsqueeze(0)
|
| 56 |
+
spec_filename = filename.replace(".wav", ".spec.pt")
|
| 57 |
+
|
| 58 |
+
# Ideally, all data generated after Mar 25 should have .spec.pt
|
| 59 |
+
if os.path.exists(spec_filename):
|
| 60 |
+
spec = torch.load(spec_filename)
|
| 61 |
+
else:
|
| 62 |
+
spec = spectrogram_torch(audio_norm, self.filter_length,
|
| 63 |
+
self.sampling_rate, self.hop_length, self.win_length,
|
| 64 |
+
center=False)
|
| 65 |
+
spec = torch.squeeze(spec, 0)
|
| 66 |
+
torch.save(spec, spec_filename)
|
| 67 |
+
|
| 68 |
+
spk = filename.split("/")[-2]
|
| 69 |
+
spk = torch.LongTensor([self.spk_map[spk]])
|
| 70 |
+
|
| 71 |
+
f0, uv = np.load(filename + ".f0.npy",allow_pickle=True)
|
| 72 |
+
|
| 73 |
+
f0 = torch.FloatTensor(np.array(f0,dtype=float))
|
| 74 |
+
uv = torch.FloatTensor(np.array(uv,dtype=float))
|
| 75 |
+
|
| 76 |
+
c = torch.load(filename+ ".soft.pt")
|
| 77 |
+
c = utils.repeat_expand_2d(c.squeeze(0), f0.shape[0], mode=self.unit_interpolate_mode)
|
| 78 |
+
if self.vol_emb:
|
| 79 |
+
volume_path = filename + ".vol.npy"
|
| 80 |
+
volume = np.load(volume_path)
|
| 81 |
+
volume = torch.from_numpy(volume).float()
|
| 82 |
+
else:
|
| 83 |
+
volume = None
|
| 84 |
+
|
| 85 |
+
lmin = min(c.size(-1), spec.size(-1))
|
| 86 |
+
assert abs(c.size(-1) - spec.size(-1)) < 3, (c.size(-1), spec.size(-1), f0.shape, filename)
|
| 87 |
+
assert abs(audio_norm.shape[1]-lmin * self.hop_length) < 3 * self.hop_length
|
| 88 |
+
spec, c, f0, uv = spec[:, :lmin], c[:, :lmin], f0[:lmin], uv[:lmin]
|
| 89 |
+
audio_norm = audio_norm[:, :lmin * self.hop_length]
|
| 90 |
+
if volume is not None:
|
| 91 |
+
volume = volume[:lmin]
|
| 92 |
+
return c, f0, spec, audio_norm, spk, uv, volume
|
| 93 |
+
|
| 94 |
+
def random_slice(self, c, f0, spec, audio_norm, spk, uv, volume):
|
| 95 |
+
# if spec.shape[1] < 30:
|
| 96 |
+
# print("skip too short audio:", filename)
|
| 97 |
+
# return None
|
| 98 |
+
|
| 99 |
+
if random.choice([True, False]) and self.vol_aug and volume is not None:
|
| 100 |
+
max_amp = float(torch.max(torch.abs(audio_norm))) + 1e-5
|
| 101 |
+
max_shift = min(1, np.log10(1/max_amp))
|
| 102 |
+
log10_vol_shift = random.uniform(-1, max_shift)
|
| 103 |
+
audio_norm = audio_norm * (10 ** log10_vol_shift)
|
| 104 |
+
volume = volume * (10 ** log10_vol_shift)
|
| 105 |
+
spec = spectrogram_torch(audio_norm,
|
| 106 |
+
self.hparams.data.filter_length,
|
| 107 |
+
self.hparams.data.sampling_rate,
|
| 108 |
+
self.hparams.data.hop_length,
|
| 109 |
+
self.hparams.data.win_length,
|
| 110 |
+
center=False)[0]
|
| 111 |
+
|
| 112 |
+
if spec.shape[1] > 800:
|
| 113 |
+
start = random.randint(0, spec.shape[1]-800)
|
| 114 |
+
end = start + 790
|
| 115 |
+
spec, c, f0, uv = spec[:, start:end], c[:, start:end], f0[start:end], uv[start:end]
|
| 116 |
+
audio_norm = audio_norm[:, start * self.hop_length : end * self.hop_length]
|
| 117 |
+
if volume is not None:
|
| 118 |
+
volume = volume[start:end]
|
| 119 |
+
return c, f0, spec, audio_norm, spk, uv,volume
|
| 120 |
+
|
| 121 |
+
def __getitem__(self, index):
|
| 122 |
+
if self.all_in_mem:
|
| 123 |
+
return self.random_slice(*self.cache[index])
|
| 124 |
+
else:
|
| 125 |
+
return self.random_slice(*self.get_audio(self.audiopaths[index][0]))
|
| 126 |
+
|
| 127 |
+
def __len__(self):
|
| 128 |
+
return len(self.audiopaths)
|
| 129 |
+
|
| 130 |
+
|
| 131 |
+
class TextAudioCollate:
|
| 132 |
+
|
| 133 |
+
def __call__(self, batch):
|
| 134 |
+
batch = [b for b in batch if b is not None]
|
| 135 |
+
|
| 136 |
+
input_lengths, ids_sorted_decreasing = torch.sort(
|
| 137 |
+
torch.LongTensor([x[0].shape[1] for x in batch]),
|
| 138 |
+
dim=0, descending=True)
|
| 139 |
+
|
| 140 |
+
max_c_len = max([x[0].size(1) for x in batch])
|
| 141 |
+
max_wav_len = max([x[3].size(1) for x in batch])
|
| 142 |
+
|
| 143 |
+
lengths = torch.LongTensor(len(batch))
|
| 144 |
+
|
| 145 |
+
c_padded = torch.FloatTensor(len(batch), batch[0][0].shape[0], max_c_len)
|
| 146 |
+
f0_padded = torch.FloatTensor(len(batch), max_c_len)
|
| 147 |
+
spec_padded = torch.FloatTensor(len(batch), batch[0][2].shape[0], max_c_len)
|
| 148 |
+
wav_padded = torch.FloatTensor(len(batch), 1, max_wav_len)
|
| 149 |
+
spkids = torch.LongTensor(len(batch), 1)
|
| 150 |
+
uv_padded = torch.FloatTensor(len(batch), max_c_len)
|
| 151 |
+
volume_padded = torch.FloatTensor(len(batch), max_c_len)
|
| 152 |
+
|
| 153 |
+
c_padded.zero_()
|
| 154 |
+
spec_padded.zero_()
|
| 155 |
+
f0_padded.zero_()
|
| 156 |
+
wav_padded.zero_()
|
| 157 |
+
uv_padded.zero_()
|
| 158 |
+
volume_padded.zero_()
|
| 159 |
+
|
| 160 |
+
for i in range(len(ids_sorted_decreasing)):
|
| 161 |
+
row = batch[ids_sorted_decreasing[i]]
|
| 162 |
+
|
| 163 |
+
c = row[0]
|
| 164 |
+
c_padded[i, :, :c.size(1)] = c
|
| 165 |
+
lengths[i] = c.size(1)
|
| 166 |
+
|
| 167 |
+
f0 = row[1]
|
| 168 |
+
f0_padded[i, :f0.size(0)] = f0
|
| 169 |
+
|
| 170 |
+
spec = row[2]
|
| 171 |
+
spec_padded[i, :, :spec.size(1)] = spec
|
| 172 |
+
|
| 173 |
+
wav = row[3]
|
| 174 |
+
wav_padded[i, :, :wav.size(1)] = wav
|
| 175 |
+
|
| 176 |
+
spkids[i, 0] = row[4]
|
| 177 |
+
|
| 178 |
+
uv = row[5]
|
| 179 |
+
uv_padded[i, :uv.size(0)] = uv
|
| 180 |
+
volume = row[6]
|
| 181 |
+
if volume is not None:
|
| 182 |
+
volume_padded[i, :volume.size(0)] = volume
|
| 183 |
+
else :
|
| 184 |
+
volume_padded = None
|
| 185 |
+
return c_padded, f0_padded, spec_padded, wav_padded, spkids, lengths, uv_padded, volume_padded
|
export_index_for_onnx.py
ADDED
|
@@ -0,0 +1,20 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import os
|
| 2 |
+
import pickle
|
| 3 |
+
|
| 4 |
+
import faiss
|
| 5 |
+
|
| 6 |
+
path = "crs"
|
| 7 |
+
indexs_file_path = f"checkpoints/{path}/feature_and_index.pkl"
|
| 8 |
+
indexs_out_dir = f"checkpoints/{path}/"
|
| 9 |
+
|
| 10 |
+
with open("feature_and_index.pkl",mode="rb") as f:
|
| 11 |
+
indexs = pickle.load(f)
|
| 12 |
+
|
| 13 |
+
for k in indexs:
|
| 14 |
+
print(f"Save {k} index")
|
| 15 |
+
faiss.write_index(
|
| 16 |
+
indexs[k],
|
| 17 |
+
os.path.join(indexs_out_dir,f"Index-{k}.index")
|
| 18 |
+
)
|
| 19 |
+
|
| 20 |
+
print("Saved all index")
|
flask_api.py
ADDED
|
@@ -0,0 +1,60 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import io
|
| 2 |
+
import logging
|
| 3 |
+
|
| 4 |
+
import soundfile
|
| 5 |
+
import torch
|
| 6 |
+
import torchaudio
|
| 7 |
+
from flask import Flask, request, send_file
|
| 8 |
+
from flask_cors import CORS
|
| 9 |
+
|
| 10 |
+
from inference.infer_tool import RealTimeVC, Svc
|
| 11 |
+
|
| 12 |
+
app = Flask(__name__)
|
| 13 |
+
|
| 14 |
+
CORS(app)
|
| 15 |
+
|
| 16 |
+
logging.getLogger('numba').setLevel(logging.WARNING)
|
| 17 |
+
|
| 18 |
+
|
| 19 |
+
@app.route("/voiceChangeModel", methods=["POST"])
|
| 20 |
+
def voice_change_model():
|
| 21 |
+
request_form = request.form
|
| 22 |
+
wave_file = request.files.get("sample", None)
|
| 23 |
+
# 变调信息
|
| 24 |
+
f_pitch_change = float(request_form.get("fPitchChange", 0))
|
| 25 |
+
# DAW所需的采样率
|
| 26 |
+
daw_sample = int(float(request_form.get("sampleRate", 0)))
|
| 27 |
+
speaker_id = int(float(request_form.get("sSpeakId", 0)))
|
| 28 |
+
# http获得wav文件并转换
|
| 29 |
+
input_wav_path = io.BytesIO(wave_file.read())
|
| 30 |
+
|
| 31 |
+
# 模型推理
|
| 32 |
+
if raw_infer:
|
| 33 |
+
# out_audio, out_sr = svc_model.infer(speaker_id, f_pitch_change, input_wav_path)
|
| 34 |
+
out_audio, out_sr = svc_model.infer(speaker_id, f_pitch_change, input_wav_path, cluster_infer_ratio=0,
|
| 35 |
+
auto_predict_f0=False, noice_scale=0.4, f0_filter=False)
|
| 36 |
+
tar_audio = torchaudio.functional.resample(out_audio, svc_model.target_sample, daw_sample)
|
| 37 |
+
else:
|
| 38 |
+
out_audio = svc.process(svc_model, speaker_id, f_pitch_change, input_wav_path, cluster_infer_ratio=0,
|
| 39 |
+
auto_predict_f0=False, noice_scale=0.4, f0_filter=False)
|
| 40 |
+
tar_audio = torchaudio.functional.resample(torch.from_numpy(out_audio), svc_model.target_sample, daw_sample)
|
| 41 |
+
# 返回音频
|
| 42 |
+
out_wav_path = io.BytesIO()
|
| 43 |
+
soundfile.write(out_wav_path, tar_audio.cpu().numpy(), daw_sample, format="wav")
|
| 44 |
+
out_wav_path.seek(0)
|
| 45 |
+
return send_file(out_wav_path, download_name="temp.wav", as_attachment=True)
|
| 46 |
+
|
| 47 |
+
|
| 48 |
+
if __name__ == '__main__':
|
| 49 |
+
# 启用则为直接切片合成,False为交叉淡化方式
|
| 50 |
+
# vst插件调整0.3-0.5s切片时间可以降低延迟,直接切片方法会有连接处爆音、交叉淡化会有轻微重叠声音
|
| 51 |
+
# 自行选择能接受的方法,或将vst最大切片时间调整为1s,此处设为Ture,延迟大音质稳定一些
|
| 52 |
+
raw_infer = True
|
| 53 |
+
# 每个模型和config是唯一对应的
|
| 54 |
+
model_name = "logs/32k/G_174000-Copy1.pth"
|
| 55 |
+
config_name = "configs/config.json"
|
| 56 |
+
cluster_model_path = "logs/44k/kmeans_10000.pt"
|
| 57 |
+
svc_model = Svc(model_name, config_name, cluster_model_path=cluster_model_path)
|
| 58 |
+
svc = RealTimeVC()
|
| 59 |
+
# 此处与vst插件对应,不建议更改
|
| 60 |
+
app.run(port=6842, host="0.0.0.0", debug=False, threaded=False)
|
flask_api_full_song.py
ADDED
|
@@ -0,0 +1,55 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import io
|
| 2 |
+
|
| 3 |
+
import numpy as np
|
| 4 |
+
import soundfile
|
| 5 |
+
from flask import Flask, request, send_file
|
| 6 |
+
|
| 7 |
+
from inference import infer_tool, slicer
|
| 8 |
+
|
| 9 |
+
app = Flask(__name__)
|
| 10 |
+
|
| 11 |
+
|
| 12 |
+
@app.route("/wav2wav", methods=["POST"])
|
| 13 |
+
def wav2wav():
|
| 14 |
+
request_form = request.form
|
| 15 |
+
audio_path = request_form.get("audio_path", None) # wav文件地址
|
| 16 |
+
tran = int(float(request_form.get("tran", 0))) # 音调
|
| 17 |
+
spk = request_form.get("spk", 0) # 说话人(id或者name都可以,具体看你的config)
|
| 18 |
+
wav_format = request_form.get("wav_format", 'wav') # 范围文件格式
|
| 19 |
+
infer_tool.format_wav(audio_path)
|
| 20 |
+
chunks = slicer.cut(audio_path, db_thresh=-40)
|
| 21 |
+
audio_data, audio_sr = slicer.chunks2audio(audio_path, chunks)
|
| 22 |
+
|
| 23 |
+
audio = []
|
| 24 |
+
for (slice_tag, data) in audio_data:
|
| 25 |
+
print(f'#=====segment start, {round(len(data) / audio_sr, 3)}s======')
|
| 26 |
+
|
| 27 |
+
length = int(np.ceil(len(data) / audio_sr * svc_model.target_sample))
|
| 28 |
+
if slice_tag:
|
| 29 |
+
print('jump empty segment')
|
| 30 |
+
_audio = np.zeros(length)
|
| 31 |
+
else:
|
| 32 |
+
# padd
|
| 33 |
+
pad_len = int(audio_sr * 0.5)
|
| 34 |
+
data = np.concatenate([np.zeros([pad_len]), data, np.zeros([pad_len])])
|
| 35 |
+
raw_path = io.BytesIO()
|
| 36 |
+
soundfile.write(raw_path, data, audio_sr, format="wav")
|
| 37 |
+
raw_path.seek(0)
|
| 38 |
+
out_audio, out_sr = svc_model.infer(spk, tran, raw_path)
|
| 39 |
+
svc_model.clear_empty()
|
| 40 |
+
_audio = out_audio.cpu().numpy()
|
| 41 |
+
pad_len = int(svc_model.target_sample * 0.5)
|
| 42 |
+
_audio = _audio[pad_len:-pad_len]
|
| 43 |
+
|
| 44 |
+
audio.extend(list(infer_tool.pad_array(_audio, length)))
|
| 45 |
+
out_wav_path = io.BytesIO()
|
| 46 |
+
soundfile.write(out_wav_path, audio, svc_model.target_sample, format=wav_format)
|
| 47 |
+
out_wav_path.seek(0)
|
| 48 |
+
return send_file(out_wav_path, download_name=f"temp.{wav_format}", as_attachment=True)
|
| 49 |
+
|
| 50 |
+
|
| 51 |
+
if __name__ == '__main__':
|
| 52 |
+
model_name = "logs/44k/G_60000.pth" # 模型地址
|
| 53 |
+
config_name = "configs/config.json" # config地址
|
| 54 |
+
svc_model = infer_tool.Svc(model_name, config_name)
|
| 55 |
+
app.run(port=1145, host="0.0.0.0", debug=False, threaded=False)
|
inference_main.py
ADDED
|
@@ -0,0 +1,155 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import logging
|
| 2 |
+
|
| 3 |
+
import soundfile
|
| 4 |
+
|
| 5 |
+
from inference import infer_tool
|
| 6 |
+
from inference.infer_tool import Svc
|
| 7 |
+
from spkmix import spk_mix_map
|
| 8 |
+
|
| 9 |
+
logging.getLogger('numba').setLevel(logging.WARNING)
|
| 10 |
+
chunks_dict = infer_tool.read_temp("inference/chunks_temp.json")
|
| 11 |
+
|
| 12 |
+
|
| 13 |
+
|
| 14 |
+
def main():
|
| 15 |
+
import argparse
|
| 16 |
+
|
| 17 |
+
parser = argparse.ArgumentParser(description='sovits4 inference')
|
| 18 |
+
|
| 19 |
+
# 一定要设置的部分
|
| 20 |
+
parser.add_argument('-m', '--model_path', type=str, default="logs/44k/G_37600.pth", help='模型路径')
|
| 21 |
+
parser.add_argument('-c', '--config_path', type=str, default="logs/44k/config.json", help='配置文件路径')
|
| 22 |
+
parser.add_argument('-cl', '--clip', type=float, default=0, help='音频强制切片,默认0为自动切片,单位为秒/s')
|
| 23 |
+
parser.add_argument('-n', '--clean_names', type=str, nargs='+', default=["君の知らない物語-src.wav"], help='wav文件名列表,放在raw文件夹下')
|
| 24 |
+
parser.add_argument('-t', '--trans', type=int, nargs='+', default=[0], help='音高调整,支持正负(半音)')
|
| 25 |
+
parser.add_argument('-s', '--spk_list', type=str, nargs='+', default=['buyizi'], help='合成目标说话人名称')
|
| 26 |
+
|
| 27 |
+
# 可选项部分
|
| 28 |
+
parser.add_argument('-a', '--auto_predict_f0', action='store_true', default=False, help='语音转换自动预测音高,转换歌声时不要打开这个会严重跑调')
|
| 29 |
+
parser.add_argument('-cm', '--cluster_model_path', type=str, default="", help='聚类模型或特征检索索引路径,留空则自动设为各方案模型的默认路径,如果没有训练聚类或特征检索则随便填')
|
| 30 |
+
parser.add_argument('-cr', '--cluster_infer_ratio', type=float, default=0, help='聚类方案或特征检索占比,范围0-1,若没有训练聚类模型或特征检索则默认0即可')
|
| 31 |
+
parser.add_argument('-lg', '--linear_gradient', type=float, default=0, help='两段音频切片的交叉淡入长度,如果强制切片后出现人声不连贯可调整该数值,如果连贯建议采用默认值0,单位为秒')
|
| 32 |
+
parser.add_argument('-f0p', '--f0_predictor', type=str, default="pm", help='选择F0预测器,可选择crepe,pm,dio,harvest,rmvpe,fcpe默认为pm(注意:crepe为原F0使用均值滤波器)')
|
| 33 |
+
parser.add_argument('-eh', '--enhance', action='store_true', default=False, help='是否使用NSF_HIFIGAN增强器,该选项对部分训练集少的模型有一定的音质增强效果,但是对训练好的模型有反面效果,默认关闭')
|
| 34 |
+
parser.add_argument('-shd', '--shallow_diffusion', action='store_true', default=False, help='是否使用浅层扩散,使用后可解决一部分电音问题,默认关闭,该选项打开时,NSF_HIFIGAN增强器将会被禁止')
|
| 35 |
+
parser.add_argument('-usm', '--use_spk_mix', action='store_true', default=False, help='是否使用角色融合')
|
| 36 |
+
parser.add_argument('-lea', '--loudness_envelope_adjustment', type=float, default=1, help='输入源响度包络替换输出响度包络融合比例,越靠近1越使用输出响度包络')
|
| 37 |
+
parser.add_argument('-fr', '--feature_retrieval', action='store_true', default=False, help='是否使用特征检索,如果使用聚类模型将被禁用,且cm与cr参数将会变成特征检索的索引路径与混合比例')
|
| 38 |
+
|
| 39 |
+
# 浅扩散设置
|
| 40 |
+
parser.add_argument('-dm', '--diffusion_model_path', type=str, default="logs/44k/diffusion/model_0.pt", help='扩散模型路径')
|
| 41 |
+
parser.add_argument('-dc', '--diffusion_config_path', type=str, default="logs/44k/diffusion/config.yaml", help='扩散模型配置文件路径')
|
| 42 |
+
parser.add_argument('-ks', '--k_step', type=int, default=100, help='扩散步数,越大越接近扩散模型的结果,默认100')
|
| 43 |
+
parser.add_argument('-se', '--second_encoding', action='store_true', default=False, help='二次编码,浅扩散前会对原始音频进行二次编码,玄学选项,有时候效果好,有时候效果差')
|
| 44 |
+
parser.add_argument('-od', '--only_diffusion', action='store_true', default=False, help='纯扩散模式,该模式不会加载sovits模型,以扩散模型推理')
|
| 45 |
+
|
| 46 |
+
|
| 47 |
+
# 不用动的部分
|
| 48 |
+
parser.add_argument('-sd', '--slice_db', type=int, default=-40, help='默认-40,嘈杂的音频可以-30,干声保留呼吸可以-50')
|
| 49 |
+
parser.add_argument('-d', '--device', type=str, default=None, help='推理设备,None则为自动选择cpu和gpu')
|
| 50 |
+
parser.add_argument('-ns', '--noice_scale', type=float, default=0.4, help='噪音级别,会影响咬字和音质,较为玄学')
|
| 51 |
+
parser.add_argument('-p', '--pad_seconds', type=float, default=0.5, help='推理音频pad秒数,由于未知原因开头结尾会有异响,pad一小段静音段后就不会出现')
|
| 52 |
+
parser.add_argument('-wf', '--wav_format', type=str, default='flac', help='音频输出格式')
|
| 53 |
+
parser.add_argument('-lgr', '--linear_gradient_retain', type=float, default=0.75, help='自动音频切片后,需要舍弃每段切片的头尾。该参数设置交叉长度保留的比例,范围0-1,左开右闭')
|
| 54 |
+
parser.add_argument('-eak', '--enhancer_adaptive_key', type=int, default=0, help='使增强器适应更高的音域(单位为半音数)|默认为0')
|
| 55 |
+
parser.add_argument('-ft', '--f0_filter_threshold', type=float, default=0.05,help='F0过滤阈值,只有使用crepe时有效. 数值范围从0-1. 降低该值可减少跑调概率,但会增加哑音')
|
| 56 |
+
|
| 57 |
+
|
| 58 |
+
args = parser.parse_args()
|
| 59 |
+
|
| 60 |
+
clean_names = args.clean_names
|
| 61 |
+
trans = args.trans
|
| 62 |
+
spk_list = args.spk_list
|
| 63 |
+
slice_db = args.slice_db
|
| 64 |
+
wav_format = args.wav_format
|
| 65 |
+
auto_predict_f0 = args.auto_predict_f0
|
| 66 |
+
cluster_infer_ratio = args.cluster_infer_ratio
|
| 67 |
+
noice_scale = args.noice_scale
|
| 68 |
+
pad_seconds = args.pad_seconds
|
| 69 |
+
clip = args.clip
|
| 70 |
+
lg = args.linear_gradient
|
| 71 |
+
lgr = args.linear_gradient_retain
|
| 72 |
+
f0p = args.f0_predictor
|
| 73 |
+
enhance = args.enhance
|
| 74 |
+
enhancer_adaptive_key = args.enhancer_adaptive_key
|
| 75 |
+
cr_threshold = args.f0_filter_threshold
|
| 76 |
+
diffusion_model_path = args.diffusion_model_path
|
| 77 |
+
diffusion_config_path = args.diffusion_config_path
|
| 78 |
+
k_step = args.k_step
|
| 79 |
+
only_diffusion = args.only_diffusion
|
| 80 |
+
shallow_diffusion = args.shallow_diffusion
|
| 81 |
+
use_spk_mix = args.use_spk_mix
|
| 82 |
+
second_encoding = args.second_encoding
|
| 83 |
+
loudness_envelope_adjustment = args.loudness_envelope_adjustment
|
| 84 |
+
|
| 85 |
+
if cluster_infer_ratio != 0:
|
| 86 |
+
if args.cluster_model_path == "":
|
| 87 |
+
if args.feature_retrieval: # 若指定了占比但没有指定模型路径,则按是否使用特征检索分配默认的模型路径
|
| 88 |
+
args.cluster_model_path = "logs/44k/feature_and_index.pkl"
|
| 89 |
+
else:
|
| 90 |
+
args.cluster_model_path = "logs/44k/kmeans_10000.pt"
|
| 91 |
+
else: # 若未指定占比,则无论是否指定模型路径,都将其置空以避免之后的模型加载
|
| 92 |
+
args.cluster_model_path = ""
|
| 93 |
+
|
| 94 |
+
svc_model = Svc(args.model_path,
|
| 95 |
+
args.config_path,
|
| 96 |
+
args.device,
|
| 97 |
+
args.cluster_model_path,
|
| 98 |
+
enhance,
|
| 99 |
+
diffusion_model_path,
|
| 100 |
+
diffusion_config_path,
|
| 101 |
+
shallow_diffusion,
|
| 102 |
+
only_diffusion,
|
| 103 |
+
use_spk_mix,
|
| 104 |
+
args.feature_retrieval)
|
| 105 |
+
|
| 106 |
+
infer_tool.mkdir(["raw", "results"])
|
| 107 |
+
|
| 108 |
+
if len(spk_mix_map)<=1:
|
| 109 |
+
use_spk_mix = False
|
| 110 |
+
if use_spk_mix:
|
| 111 |
+
spk_list = [spk_mix_map]
|
| 112 |
+
|
| 113 |
+
infer_tool.fill_a_to_b(trans, clean_names)
|
| 114 |
+
for clean_name, tran in zip(clean_names, trans):
|
| 115 |
+
raw_audio_path = f"raw/{clean_name}"
|
| 116 |
+
if "." not in raw_audio_path:
|
| 117 |
+
raw_audio_path += ".wav"
|
| 118 |
+
infer_tool.format_wav(raw_audio_path)
|
| 119 |
+
for spk in spk_list:
|
| 120 |
+
kwarg = {
|
| 121 |
+
"raw_audio_path" : raw_audio_path,
|
| 122 |
+
"spk" : spk,
|
| 123 |
+
"tran" : tran,
|
| 124 |
+
"slice_db" : slice_db,
|
| 125 |
+
"cluster_infer_ratio" : cluster_infer_ratio,
|
| 126 |
+
"auto_predict_f0" : auto_predict_f0,
|
| 127 |
+
"noice_scale" : noice_scale,
|
| 128 |
+
"pad_seconds" : pad_seconds,
|
| 129 |
+
"clip_seconds" : clip,
|
| 130 |
+
"lg_num": lg,
|
| 131 |
+
"lgr_num" : lgr,
|
| 132 |
+
"f0_predictor" : f0p,
|
| 133 |
+
"enhancer_adaptive_key" : enhancer_adaptive_key,
|
| 134 |
+
"cr_threshold" : cr_threshold,
|
| 135 |
+
"k_step":k_step,
|
| 136 |
+
"use_spk_mix":use_spk_mix,
|
| 137 |
+
"second_encoding":second_encoding,
|
| 138 |
+
"loudness_envelope_adjustment":loudness_envelope_adjustment
|
| 139 |
+
}
|
| 140 |
+
audio = svc_model.slice_inference(**kwarg)
|
| 141 |
+
key = "auto" if auto_predict_f0 else f"{tran}key"
|
| 142 |
+
cluster_name = "" if cluster_infer_ratio == 0 else f"_{cluster_infer_ratio}"
|
| 143 |
+
isdiffusion = "sovits"
|
| 144 |
+
if shallow_diffusion :
|
| 145 |
+
isdiffusion = "sovdiff"
|
| 146 |
+
if only_diffusion :
|
| 147 |
+
isdiffusion = "diff"
|
| 148 |
+
if use_spk_mix:
|
| 149 |
+
spk = "spk_mix"
|
| 150 |
+
res_path = f'results/{clean_name}_{key}_{spk}{cluster_name}_{isdiffusion}_{f0p}.{wav_format}'
|
| 151 |
+
soundfile.write(res_path, audio, svc_model.target_sample, format=wav_format)
|
| 152 |
+
svc_model.clear_empty()
|
| 153 |
+
|
| 154 |
+
if __name__ == '__main__':
|
| 155 |
+
main()
|
models.py
ADDED
|
@@ -0,0 +1,487 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import torch
|
| 2 |
+
from torch import nn
|
| 3 |
+
from torch.nn import Conv1d, Conv2d
|
| 4 |
+
from torch.nn import functional as F
|
| 5 |
+
from torch.nn.utils import spectral_norm, weight_norm
|
| 6 |
+
|
| 7 |
+
import modules.attentions as attentions
|
| 8 |
+
import modules.commons as commons
|
| 9 |
+
import modules.modules as modules
|
| 10 |
+
import utils
|
| 11 |
+
from modules.commons import get_padding
|
| 12 |
+
from utils import f0_to_coarse
|
| 13 |
+
|
| 14 |
+
|
| 15 |
+
class ResidualCouplingBlock(nn.Module):
|
| 16 |
+
def __init__(self,
|
| 17 |
+
channels,
|
| 18 |
+
hidden_channels,
|
| 19 |
+
kernel_size,
|
| 20 |
+
dilation_rate,
|
| 21 |
+
n_layers,
|
| 22 |
+
n_flows=4,
|
| 23 |
+
gin_channels=0,
|
| 24 |
+
share_parameter=False
|
| 25 |
+
):
|
| 26 |
+
super().__init__()
|
| 27 |
+
self.channels = channels
|
| 28 |
+
self.hidden_channels = hidden_channels
|
| 29 |
+
self.kernel_size = kernel_size
|
| 30 |
+
self.dilation_rate = dilation_rate
|
| 31 |
+
self.n_layers = n_layers
|
| 32 |
+
self.n_flows = n_flows
|
| 33 |
+
self.gin_channels = gin_channels
|
| 34 |
+
|
| 35 |
+
self.flows = nn.ModuleList()
|
| 36 |
+
|
| 37 |
+
self.wn = modules.WN(hidden_channels, kernel_size, dilation_rate, n_layers, p_dropout=0, gin_channels=gin_channels) if share_parameter else None
|
| 38 |
+
|
| 39 |
+
for i in range(n_flows):
|
| 40 |
+
self.flows.append(
|
| 41 |
+
modules.ResidualCouplingLayer(channels, hidden_channels, kernel_size, dilation_rate, n_layers,
|
| 42 |
+
gin_channels=gin_channels, mean_only=True, wn_sharing_parameter=self.wn))
|
| 43 |
+
self.flows.append(modules.Flip())
|
| 44 |
+
|
| 45 |
+
def forward(self, x, x_mask, g=None, reverse=False):
|
| 46 |
+
if not reverse:
|
| 47 |
+
for flow in self.flows:
|
| 48 |
+
x, _ = flow(x, x_mask, g=g, reverse=reverse)
|
| 49 |
+
else:
|
| 50 |
+
for flow in reversed(self.flows):
|
| 51 |
+
x = flow(x, x_mask, g=g, reverse=reverse)
|
| 52 |
+
return x
|
| 53 |
+
|
| 54 |
+
|
| 55 |
+
class Encoder(nn.Module):
|
| 56 |
+
def __init__(self,
|
| 57 |
+
in_channels,
|
| 58 |
+
out_channels,
|
| 59 |
+
hidden_channels,
|
| 60 |
+
kernel_size,
|
| 61 |
+
dilation_rate,
|
| 62 |
+
n_layers,
|
| 63 |
+
gin_channels=0):
|
| 64 |
+
super().__init__()
|
| 65 |
+
self.in_channels = in_channels
|
| 66 |
+
self.out_channels = out_channels
|
| 67 |
+
self.hidden_channels = hidden_channels
|
| 68 |
+
self.kernel_size = kernel_size
|
| 69 |
+
self.dilation_rate = dilation_rate
|
| 70 |
+
self.n_layers = n_layers
|
| 71 |
+
self.gin_channels = gin_channels
|
| 72 |
+
|
| 73 |
+
self.pre = nn.Conv1d(in_channels, hidden_channels, 1)
|
| 74 |
+
self.enc = modules.WN(hidden_channels, kernel_size, dilation_rate, n_layers, gin_channels=gin_channels)
|
| 75 |
+
self.proj = nn.Conv1d(hidden_channels, out_channels * 2, 1)
|
| 76 |
+
|
| 77 |
+
def forward(self, x, x_lengths, g=None):
|
| 78 |
+
# print(x.shape,x_lengths.shape)
|
| 79 |
+
x_mask = torch.unsqueeze(commons.sequence_mask(x_lengths, x.size(2)), 1).to(x.dtype)
|
| 80 |
+
x = self.pre(x) * x_mask
|
| 81 |
+
x = self.enc(x, x_mask, g=g)
|
| 82 |
+
stats = self.proj(x) * x_mask
|
| 83 |
+
m, logs = torch.split(stats, self.out_channels, dim=1)
|
| 84 |
+
z = (m + torch.randn_like(m) * torch.exp(logs)) * x_mask
|
| 85 |
+
return z, m, logs, x_mask
|
| 86 |
+
|
| 87 |
+
|
| 88 |
+
class TextEncoder(nn.Module):
|
| 89 |
+
def __init__(self,
|
| 90 |
+
out_channels,
|
| 91 |
+
hidden_channels,
|
| 92 |
+
kernel_size,
|
| 93 |
+
n_layers,
|
| 94 |
+
gin_channels=0,
|
| 95 |
+
filter_channels=None,
|
| 96 |
+
n_heads=None,
|
| 97 |
+
p_dropout=None):
|
| 98 |
+
super().__init__()
|
| 99 |
+
self.out_channels = out_channels
|
| 100 |
+
self.hidden_channels = hidden_channels
|
| 101 |
+
self.kernel_size = kernel_size
|
| 102 |
+
self.n_layers = n_layers
|
| 103 |
+
self.gin_channels = gin_channels
|
| 104 |
+
self.proj = nn.Conv1d(hidden_channels, out_channels * 2, 1)
|
| 105 |
+
self.f0_emb = nn.Embedding(256, hidden_channels)
|
| 106 |
+
|
| 107 |
+
self.enc_ = attentions.Encoder(
|
| 108 |
+
hidden_channels,
|
| 109 |
+
filter_channels,
|
| 110 |
+
n_heads,
|
| 111 |
+
n_layers,
|
| 112 |
+
kernel_size,
|
| 113 |
+
p_dropout)
|
| 114 |
+
|
| 115 |
+
def forward(self, x, x_mask, f0=None, noice_scale=1):
|
| 116 |
+
x = x + self.f0_emb(f0).transpose(1, 2)
|
| 117 |
+
x = self.enc_(x * x_mask, x_mask)
|
| 118 |
+
stats = self.proj(x) * x_mask
|
| 119 |
+
m, logs = torch.split(stats, self.out_channels, dim=1)
|
| 120 |
+
z = (m + torch.randn_like(m) * torch.exp(logs) * noice_scale) * x_mask
|
| 121 |
+
|
| 122 |
+
return z, m, logs, x_mask
|
| 123 |
+
|
| 124 |
+
|
| 125 |
+
class DiscriminatorP(torch.nn.Module):
|
| 126 |
+
def __init__(self, period, kernel_size=5, stride=3, use_spectral_norm=False):
|
| 127 |
+
super(DiscriminatorP, self).__init__()
|
| 128 |
+
self.period = period
|
| 129 |
+
self.use_spectral_norm = use_spectral_norm
|
| 130 |
+
norm_f = weight_norm if use_spectral_norm is False else spectral_norm
|
| 131 |
+
self.convs = nn.ModuleList([
|
| 132 |
+
norm_f(Conv2d(1, 32, (kernel_size, 1), (stride, 1), padding=(get_padding(kernel_size, 1), 0))),
|
| 133 |
+
norm_f(Conv2d(32, 128, (kernel_size, 1), (stride, 1), padding=(get_padding(kernel_size, 1), 0))),
|
| 134 |
+
norm_f(Conv2d(128, 512, (kernel_size, 1), (stride, 1), padding=(get_padding(kernel_size, 1), 0))),
|
| 135 |
+
norm_f(Conv2d(512, 1024, (kernel_size, 1), (stride, 1), padding=(get_padding(kernel_size, 1), 0))),
|
| 136 |
+
norm_f(Conv2d(1024, 1024, (kernel_size, 1), 1, padding=(get_padding(kernel_size, 1), 0))),
|
| 137 |
+
])
|
| 138 |
+
self.conv_post = norm_f(Conv2d(1024, 1, (3, 1), 1, padding=(1, 0)))
|
| 139 |
+
|
| 140 |
+
def forward(self, x):
|
| 141 |
+
fmap = []
|
| 142 |
+
|
| 143 |
+
# 1d to 2d
|
| 144 |
+
b, c, t = x.shape
|
| 145 |
+
if t % self.period != 0: # pad first
|
| 146 |
+
n_pad = self.period - (t % self.period)
|
| 147 |
+
x = F.pad(x, (0, n_pad), "reflect")
|
| 148 |
+
t = t + n_pad
|
| 149 |
+
x = x.view(b, c, t // self.period, self.period)
|
| 150 |
+
|
| 151 |
+
for l in self.convs:
|
| 152 |
+
x = l(x)
|
| 153 |
+
x = F.leaky_relu(x, modules.LRELU_SLOPE)
|
| 154 |
+
fmap.append(x)
|
| 155 |
+
x = self.conv_post(x)
|
| 156 |
+
fmap.append(x)
|
| 157 |
+
x = torch.flatten(x, 1, -1)
|
| 158 |
+
|
| 159 |
+
return x, fmap
|
| 160 |
+
|
| 161 |
+
|
| 162 |
+
class DiscriminatorS(torch.nn.Module):
|
| 163 |
+
def __init__(self, use_spectral_norm=False):
|
| 164 |
+
super(DiscriminatorS, self).__init__()
|
| 165 |
+
norm_f = weight_norm if use_spectral_norm is False else spectral_norm
|
| 166 |
+
self.convs = nn.ModuleList([
|
| 167 |
+
norm_f(Conv1d(1, 16, 15, 1, padding=7)),
|
| 168 |
+
norm_f(Conv1d(16, 64, 41, 4, groups=4, padding=20)),
|
| 169 |
+
norm_f(Conv1d(64, 256, 41, 4, groups=16, padding=20)),
|
| 170 |
+
norm_f(Conv1d(256, 1024, 41, 4, groups=64, padding=20)),
|
| 171 |
+
norm_f(Conv1d(1024, 1024, 41, 4, groups=256, padding=20)),
|
| 172 |
+
norm_f(Conv1d(1024, 1024, 5, 1, padding=2)),
|
| 173 |
+
])
|
| 174 |
+
self.conv_post = norm_f(Conv1d(1024, 1, 3, 1, padding=1))
|
| 175 |
+
|
| 176 |
+
def forward(self, x):
|
| 177 |
+
fmap = []
|
| 178 |
+
|
| 179 |
+
for l in self.convs:
|
| 180 |
+
x = l(x)
|
| 181 |
+
x = F.leaky_relu(x, modules.LRELU_SLOPE)
|
| 182 |
+
fmap.append(x)
|
| 183 |
+
x = self.conv_post(x)
|
| 184 |
+
fmap.append(x)
|
| 185 |
+
x = torch.flatten(x, 1, -1)
|
| 186 |
+
|
| 187 |
+
return x, fmap
|
| 188 |
+
|
| 189 |
+
|
| 190 |
+
class MultiPeriodDiscriminator(torch.nn.Module):
|
| 191 |
+
def __init__(self, use_spectral_norm=False):
|
| 192 |
+
super(MultiPeriodDiscriminator, self).__init__()
|
| 193 |
+
periods = [2, 3, 5, 7, 11]
|
| 194 |
+
|
| 195 |
+
discs = [DiscriminatorS(use_spectral_norm=use_spectral_norm)]
|
| 196 |
+
discs = discs + [DiscriminatorP(i, use_spectral_norm=use_spectral_norm) for i in periods]
|
| 197 |
+
self.discriminators = nn.ModuleList(discs)
|
| 198 |
+
|
| 199 |
+
def forward(self, y, y_hat):
|
| 200 |
+
y_d_rs = []
|
| 201 |
+
y_d_gs = []
|
| 202 |
+
fmap_rs = []
|
| 203 |
+
fmap_gs = []
|
| 204 |
+
for i, d in enumerate(self.discriminators):
|
| 205 |
+
y_d_r, fmap_r = d(y)
|
| 206 |
+
y_d_g, fmap_g = d(y_hat)
|
| 207 |
+
y_d_rs.append(y_d_r)
|
| 208 |
+
y_d_gs.append(y_d_g)
|
| 209 |
+
fmap_rs.append(fmap_r)
|
| 210 |
+
fmap_gs.append(fmap_g)
|
| 211 |
+
|
| 212 |
+
return y_d_rs, y_d_gs, fmap_rs, fmap_gs
|
| 213 |
+
|
| 214 |
+
|
| 215 |
+
class SpeakerEncoder(torch.nn.Module):
|
| 216 |
+
def __init__(self, mel_n_channels=80, model_num_layers=3, model_hidden_size=256, model_embedding_size=256):
|
| 217 |
+
super(SpeakerEncoder, self).__init__()
|
| 218 |
+
self.lstm = nn.LSTM(mel_n_channels, model_hidden_size, model_num_layers, batch_first=True)
|
| 219 |
+
self.linear = nn.Linear(model_hidden_size, model_embedding_size)
|
| 220 |
+
self.relu = nn.ReLU()
|
| 221 |
+
|
| 222 |
+
def forward(self, mels):
|
| 223 |
+
self.lstm.flatten_parameters()
|
| 224 |
+
_, (hidden, _) = self.lstm(mels)
|
| 225 |
+
embeds_raw = self.relu(self.linear(hidden[-1]))
|
| 226 |
+
return embeds_raw / torch.norm(embeds_raw, dim=1, keepdim=True)
|
| 227 |
+
|
| 228 |
+
def compute_partial_slices(self, total_frames, partial_frames, partial_hop):
|
| 229 |
+
mel_slices = []
|
| 230 |
+
for i in range(0, total_frames - partial_frames, partial_hop):
|
| 231 |
+
mel_range = torch.arange(i, i + partial_frames)
|
| 232 |
+
mel_slices.append(mel_range)
|
| 233 |
+
|
| 234 |
+
return mel_slices
|
| 235 |
+
|
| 236 |
+
def embed_utterance(self, mel, partial_frames=128, partial_hop=64):
|
| 237 |
+
mel_len = mel.size(1)
|
| 238 |
+
last_mel = mel[:, -partial_frames:]
|
| 239 |
+
|
| 240 |
+
if mel_len > partial_frames:
|
| 241 |
+
mel_slices = self.compute_partial_slices(mel_len, partial_frames, partial_hop)
|
| 242 |
+
mels = list(mel[:, s] for s in mel_slices)
|
| 243 |
+
mels.append(last_mel)
|
| 244 |
+
mels = torch.stack(tuple(mels), 0).squeeze(1)
|
| 245 |
+
|
| 246 |
+
with torch.no_grad():
|
| 247 |
+
partial_embeds = self(mels)
|
| 248 |
+
embed = torch.mean(partial_embeds, axis=0).unsqueeze(0)
|
| 249 |
+
# embed = embed / torch.linalg.norm(embed, 2)
|
| 250 |
+
else:
|
| 251 |
+
with torch.no_grad():
|
| 252 |
+
embed = self(last_mel)
|
| 253 |
+
|
| 254 |
+
return embed
|
| 255 |
+
|
| 256 |
+
class F0Decoder(nn.Module):
|
| 257 |
+
def __init__(self,
|
| 258 |
+
out_channels,
|
| 259 |
+
hidden_channels,
|
| 260 |
+
filter_channels,
|
| 261 |
+
n_heads,
|
| 262 |
+
n_layers,
|
| 263 |
+
kernel_size,
|
| 264 |
+
p_dropout,
|
| 265 |
+
spk_channels=0):
|
| 266 |
+
super().__init__()
|
| 267 |
+
self.out_channels = out_channels
|
| 268 |
+
self.hidden_channels = hidden_channels
|
| 269 |
+
self.filter_channels = filter_channels
|
| 270 |
+
self.n_heads = n_heads
|
| 271 |
+
self.n_layers = n_layers
|
| 272 |
+
self.kernel_size = kernel_size
|
| 273 |
+
self.p_dropout = p_dropout
|
| 274 |
+
self.spk_channels = spk_channels
|
| 275 |
+
|
| 276 |
+
self.prenet = nn.Conv1d(hidden_channels, hidden_channels, 3, padding=1)
|
| 277 |
+
self.decoder = attentions.FFT(
|
| 278 |
+
hidden_channels,
|
| 279 |
+
filter_channels,
|
| 280 |
+
n_heads,
|
| 281 |
+
n_layers,
|
| 282 |
+
kernel_size,
|
| 283 |
+
p_dropout)
|
| 284 |
+
self.proj = nn.Conv1d(hidden_channels, out_channels, 1)
|
| 285 |
+
self.f0_prenet = nn.Conv1d(1, hidden_channels, 3, padding=1)
|
| 286 |
+
self.cond = nn.Conv1d(spk_channels, hidden_channels, 1)
|
| 287 |
+
|
| 288 |
+
def forward(self, x, norm_f0, x_mask, spk_emb=None):
|
| 289 |
+
x = torch.detach(x)
|
| 290 |
+
if (spk_emb is not None):
|
| 291 |
+
x = x + self.cond(spk_emb)
|
| 292 |
+
x += self.f0_prenet(norm_f0)
|
| 293 |
+
x = self.prenet(x) * x_mask
|
| 294 |
+
x = self.decoder(x * x_mask, x_mask)
|
| 295 |
+
x = self.proj(x) * x_mask
|
| 296 |
+
return x
|
| 297 |
+
|
| 298 |
+
|
| 299 |
+
class SynthesizerTrn(nn.Module):
|
| 300 |
+
"""
|
| 301 |
+
Synthesizer for Training
|
| 302 |
+
"""
|
| 303 |
+
|
| 304 |
+
def __init__(self,
|
| 305 |
+
spec_channels,
|
| 306 |
+
segment_size,
|
| 307 |
+
inter_channels,
|
| 308 |
+
hidden_channels,
|
| 309 |
+
filter_channels,
|
| 310 |
+
n_heads,
|
| 311 |
+
n_layers,
|
| 312 |
+
kernel_size,
|
| 313 |
+
p_dropout,
|
| 314 |
+
resblock,
|
| 315 |
+
resblock_kernel_sizes,
|
| 316 |
+
resblock_dilation_sizes,
|
| 317 |
+
upsample_rates,
|
| 318 |
+
upsample_initial_channel,
|
| 319 |
+
upsample_kernel_sizes,
|
| 320 |
+
gin_channels,
|
| 321 |
+
ssl_dim,
|
| 322 |
+
n_speakers,
|
| 323 |
+
sampling_rate=44100,
|
| 324 |
+
vol_embedding=False,
|
| 325 |
+
vocoder_name = "nsf-hifigan",
|
| 326 |
+
use_depthwise_conv = False,
|
| 327 |
+
use_automatic_f0_prediction = True,
|
| 328 |
+
flow_share_parameter = False,
|
| 329 |
+
n_flow_layer = 4,
|
| 330 |
+
**kwargs):
|
| 331 |
+
|
| 332 |
+
super().__init__()
|
| 333 |
+
self.spec_channels = spec_channels
|
| 334 |
+
self.inter_channels = inter_channels
|
| 335 |
+
self.hidden_channels = hidden_channels
|
| 336 |
+
self.filter_channels = filter_channels
|
| 337 |
+
self.n_heads = n_heads
|
| 338 |
+
self.n_layers = n_layers
|
| 339 |
+
self.kernel_size = kernel_size
|
| 340 |
+
self.p_dropout = p_dropout
|
| 341 |
+
self.resblock = resblock
|
| 342 |
+
self.resblock_kernel_sizes = resblock_kernel_sizes
|
| 343 |
+
self.resblock_dilation_sizes = resblock_dilation_sizes
|
| 344 |
+
self.upsample_rates = upsample_rates
|
| 345 |
+
self.upsample_initial_channel = upsample_initial_channel
|
| 346 |
+
self.upsample_kernel_sizes = upsample_kernel_sizes
|
| 347 |
+
self.segment_size = segment_size
|
| 348 |
+
self.gin_channels = gin_channels
|
| 349 |
+
self.ssl_dim = ssl_dim
|
| 350 |
+
self.vol_embedding = vol_embedding
|
| 351 |
+
self.emb_g = nn.Embedding(n_speakers, gin_channels)
|
| 352 |
+
self.use_depthwise_conv = use_depthwise_conv
|
| 353 |
+
self.use_automatic_f0_prediction = use_automatic_f0_prediction
|
| 354 |
+
if vol_embedding:
|
| 355 |
+
self.emb_vol = nn.Linear(1, hidden_channels)
|
| 356 |
+
|
| 357 |
+
self.pre = nn.Conv1d(ssl_dim, hidden_channels, kernel_size=5, padding=2)
|
| 358 |
+
|
| 359 |
+
self.enc_p = TextEncoder(
|
| 360 |
+
inter_channels,
|
| 361 |
+
hidden_channels,
|
| 362 |
+
filter_channels=filter_channels,
|
| 363 |
+
n_heads=n_heads,
|
| 364 |
+
n_layers=n_layers,
|
| 365 |
+
kernel_size=kernel_size,
|
| 366 |
+
p_dropout=p_dropout
|
| 367 |
+
)
|
| 368 |
+
hps = {
|
| 369 |
+
"sampling_rate": sampling_rate,
|
| 370 |
+
"inter_channels": inter_channels,
|
| 371 |
+
"resblock": resblock,
|
| 372 |
+
"resblock_kernel_sizes": resblock_kernel_sizes,
|
| 373 |
+
"resblock_dilation_sizes": resblock_dilation_sizes,
|
| 374 |
+
"upsample_rates": upsample_rates,
|
| 375 |
+
"upsample_initial_channel": upsample_initial_channel,
|
| 376 |
+
"upsample_kernel_sizes": upsample_kernel_sizes,
|
| 377 |
+
"gin_channels": gin_channels,
|
| 378 |
+
"use_depthwise_conv":use_depthwise_conv
|
| 379 |
+
}
|
| 380 |
+
|
| 381 |
+
modules.set_Conv1dModel(self.use_depthwise_conv)
|
| 382 |
+
|
| 383 |
+
if vocoder_name == "nsf-hifigan":
|
| 384 |
+
from vdecoder.hifigan.models import Generator
|
| 385 |
+
self.dec = Generator(h=hps)
|
| 386 |
+
elif vocoder_name == "nsf-snake-hifigan":
|
| 387 |
+
from vdecoder.hifiganwithsnake.models import Generator
|
| 388 |
+
self.dec = Generator(h=hps)
|
| 389 |
+
else:
|
| 390 |
+
print("[?] Unkown vocoder: use default(nsf-hifigan)")
|
| 391 |
+
from vdecoder.hifigan.models import Generator
|
| 392 |
+
self.dec = Generator(h=hps)
|
| 393 |
+
|
| 394 |
+
self.enc_q = Encoder(spec_channels, inter_channels, hidden_channels, 5, 1, 16, gin_channels=gin_channels)
|
| 395 |
+
self.flow = ResidualCouplingBlock(inter_channels, hidden_channels, 5, 1, n_flow_layer, gin_channels=gin_channels, share_parameter= flow_share_parameter)
|
| 396 |
+
if self.use_automatic_f0_prediction:
|
| 397 |
+
self.f0_decoder = F0Decoder(
|
| 398 |
+
1,
|
| 399 |
+
hidden_channels,
|
| 400 |
+
filter_channels,
|
| 401 |
+
n_heads,
|
| 402 |
+
n_layers,
|
| 403 |
+
kernel_size,
|
| 404 |
+
p_dropout,
|
| 405 |
+
spk_channels=gin_channels
|
| 406 |
+
)
|
| 407 |
+
self.emb_uv = nn.Embedding(2, hidden_channels)
|
| 408 |
+
self.character_mix = False
|
| 409 |
+
|
| 410 |
+
def EnableCharacterMix(self, n_speakers_map, device):
|
| 411 |
+
self.speaker_map = torch.zeros((n_speakers_map, 1, 1, self.gin_channels)).to(device)
|
| 412 |
+
for i in range(n_speakers_map):
|
| 413 |
+
self.speaker_map[i] = self.emb_g(torch.LongTensor([[i]]).to(device))
|
| 414 |
+
self.speaker_map = self.speaker_map.unsqueeze(0).to(device)
|
| 415 |
+
self.character_mix = True
|
| 416 |
+
|
| 417 |
+
def forward(self, c, f0, uv, spec, g=None, c_lengths=None, spec_lengths=None, vol = None):
|
| 418 |
+
g = self.emb_g(g).transpose(1,2)
|
| 419 |
+
|
| 420 |
+
# vol proj
|
| 421 |
+
vol = self.emb_vol(vol[:,:,None]).transpose(1,2) if vol is not None and self.vol_embedding else 0
|
| 422 |
+
|
| 423 |
+
# ssl prenet
|
| 424 |
+
x_mask = torch.unsqueeze(commons.sequence_mask(c_lengths, c.size(2)), 1).to(c.dtype)
|
| 425 |
+
x = self.pre(c) * x_mask + self.emb_uv(uv.long()).transpose(1,2) + vol
|
| 426 |
+
|
| 427 |
+
# f0 predict
|
| 428 |
+
if self.use_automatic_f0_prediction:
|
| 429 |
+
lf0 = 2595. * torch.log10(1. + f0.unsqueeze(1) / 700.) / 500
|
| 430 |
+
norm_lf0 = utils.normalize_f0(lf0, x_mask, uv)
|
| 431 |
+
pred_lf0 = self.f0_decoder(x, norm_lf0, x_mask, spk_emb=g)
|
| 432 |
+
else:
|
| 433 |
+
lf0 = 0
|
| 434 |
+
norm_lf0 = 0
|
| 435 |
+
pred_lf0 = 0
|
| 436 |
+
# encoder
|
| 437 |
+
z_ptemp, m_p, logs_p, _ = self.enc_p(x, x_mask, f0=f0_to_coarse(f0))
|
| 438 |
+
z, m_q, logs_q, spec_mask = self.enc_q(spec, spec_lengths, g=g)
|
| 439 |
+
|
| 440 |
+
# flow
|
| 441 |
+
z_p = self.flow(z, spec_mask, g=g)
|
| 442 |
+
z_slice, pitch_slice, ids_slice = commons.rand_slice_segments_with_pitch(z, f0, spec_lengths, self.segment_size)
|
| 443 |
+
|
| 444 |
+
# nsf decoder
|
| 445 |
+
o = self.dec(z_slice, g=g, f0=pitch_slice)
|
| 446 |
+
|
| 447 |
+
return o, ids_slice, spec_mask, (z, z_p, m_p, logs_p, m_q, logs_q), pred_lf0, norm_lf0, lf0
|
| 448 |
+
|
| 449 |
+
@torch.no_grad()
|
| 450 |
+
def infer(self, c, f0, uv, g=None, noice_scale=0.35, seed=52468, predict_f0=False, vol = None):
|
| 451 |
+
|
| 452 |
+
if c.device == torch.device("cuda"):
|
| 453 |
+
torch.cuda.manual_seed_all(seed)
|
| 454 |
+
else:
|
| 455 |
+
torch.manual_seed(seed)
|
| 456 |
+
|
| 457 |
+
c_lengths = (torch.ones(c.size(0)) * c.size(-1)).to(c.device)
|
| 458 |
+
|
| 459 |
+
if self.character_mix and len(g) > 1: # [N, S] * [S, B, 1, H]
|
| 460 |
+
g = g.reshape((g.shape[0], g.shape[1], 1, 1, 1)) # [N, S, B, 1, 1]
|
| 461 |
+
g = g * self.speaker_map # [N, S, B, 1, H]
|
| 462 |
+
g = torch.sum(g, dim=1) # [N, 1, B, 1, H]
|
| 463 |
+
g = g.transpose(0, -1).transpose(0, -2).squeeze(0) # [B, H, N]
|
| 464 |
+
else:
|
| 465 |
+
if g.dim() == 1:
|
| 466 |
+
g = g.unsqueeze(0)
|
| 467 |
+
g = self.emb_g(g).transpose(1, 2)
|
| 468 |
+
|
| 469 |
+
x_mask = torch.unsqueeze(commons.sequence_mask(c_lengths, c.size(2)), 1).to(c.dtype)
|
| 470 |
+
# vol proj
|
| 471 |
+
|
| 472 |
+
vol = self.emb_vol(vol[:,:,None]).transpose(1,2) if vol is not None and self.vol_embedding else 0
|
| 473 |
+
|
| 474 |
+
x = self.pre(c) * x_mask + self.emb_uv(uv.long()).transpose(1, 2) + vol
|
| 475 |
+
|
| 476 |
+
|
| 477 |
+
if self.use_automatic_f0_prediction and predict_f0:
|
| 478 |
+
lf0 = 2595. * torch.log10(1. + f0.unsqueeze(1) / 700.) / 500
|
| 479 |
+
norm_lf0 = utils.normalize_f0(lf0, x_mask, uv, random_scale=False)
|
| 480 |
+
pred_lf0 = self.f0_decoder(x, norm_lf0, x_mask, spk_emb=g)
|
| 481 |
+
f0 = (700 * (torch.pow(10, pred_lf0 * 500 / 2595) - 1)).squeeze(1)
|
| 482 |
+
|
| 483 |
+
z_p, m_p, logs_p, c_mask = self.enc_p(x, x_mask, f0=f0_to_coarse(f0), noice_scale=noice_scale)
|
| 484 |
+
z = self.flow(z_p, c_mask, g=g, reverse=True)
|
| 485 |
+
o = self.dec(z * c_mask, g=g, f0=f0)
|
| 486 |
+
return o,f0
|
| 487 |
+
|
onnx_export.py
ADDED
|
@@ -0,0 +1,150 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import json
|
| 2 |
+
|
| 3 |
+
import torch
|
| 4 |
+
|
| 5 |
+
import utils
|
| 6 |
+
from onnxexport.model_onnx_speaker_mix import SynthesizerTrn
|
| 7 |
+
|
| 8 |
+
|
| 9 |
+
def main(path, config, model):
|
| 10 |
+
#path = "crs"
|
| 11 |
+
|
| 12 |
+
device = torch.device("cpu")
|
| 13 |
+
hps = utils.get_hparams_from_file(f"checkpoints/{path}/{config}")
|
| 14 |
+
SVCVITS = SynthesizerTrn(
|
| 15 |
+
hps.data.filter_length // 2 + 1,
|
| 16 |
+
hps.train.segment_size // hps.data.hop_length,
|
| 17 |
+
**hps.model)
|
| 18 |
+
_ = utils.load_checkpoint(f"checkpoints/{path}/{model}", SVCVITS, None)
|
| 19 |
+
_ = SVCVITS.eval().to(device)
|
| 20 |
+
for i in SVCVITS.parameters():
|
| 21 |
+
i.requires_grad = False
|
| 22 |
+
|
| 23 |
+
num_frames = 200
|
| 24 |
+
|
| 25 |
+
test_hidden_unit = torch.rand(1, num_frames, SVCVITS.gin_channels)
|
| 26 |
+
test_pitch = torch.rand(1, num_frames)
|
| 27 |
+
test_vol = torch.rand(1, num_frames)
|
| 28 |
+
test_mel2ph = torch.LongTensor(torch.arange(0, num_frames)).unsqueeze(0)
|
| 29 |
+
test_uv = torch.ones(1, num_frames, dtype=torch.float32)
|
| 30 |
+
test_noise = torch.randn(1, 192, num_frames)
|
| 31 |
+
test_sid = torch.LongTensor([0])
|
| 32 |
+
export_mix = True
|
| 33 |
+
if len(hps.spk) < 2:
|
| 34 |
+
export_mix = False
|
| 35 |
+
|
| 36 |
+
if export_mix:
|
| 37 |
+
spk_mix = []
|
| 38 |
+
n_spk = len(hps.spk)
|
| 39 |
+
for i in range(n_spk):
|
| 40 |
+
spk_mix.append(1.0/float(n_spk))
|
| 41 |
+
test_sid = torch.tensor(spk_mix)
|
| 42 |
+
SVCVITS.export_chara_mix(hps.spk)
|
| 43 |
+
test_sid = test_sid.unsqueeze(0)
|
| 44 |
+
test_sid = test_sid.repeat(num_frames, 1)
|
| 45 |
+
|
| 46 |
+
SVCVITS.eval()
|
| 47 |
+
|
| 48 |
+
if export_mix:
|
| 49 |
+
daxes = {
|
| 50 |
+
"c": [0, 1],
|
| 51 |
+
"f0": [1],
|
| 52 |
+
"mel2ph": [1],
|
| 53 |
+
"uv": [1],
|
| 54 |
+
"noise": [2],
|
| 55 |
+
"sid":[0]
|
| 56 |
+
}
|
| 57 |
+
else:
|
| 58 |
+
daxes = {
|
| 59 |
+
"c": [0, 1],
|
| 60 |
+
"f0": [1],
|
| 61 |
+
"mel2ph": [1],
|
| 62 |
+
"uv": [1],
|
| 63 |
+
"noise": [2]
|
| 64 |
+
}
|
| 65 |
+
|
| 66 |
+
input_names = ["c", "f0", "mel2ph", "uv", "noise", "sid"]
|
| 67 |
+
output_names = ["audio", ]
|
| 68 |
+
|
| 69 |
+
if SVCVITS.vol_embedding:
|
| 70 |
+
input_names.append("vol")
|
| 71 |
+
vol_dadict = {"vol" : [1]}
|
| 72 |
+
daxes.update(vol_dadict)
|
| 73 |
+
test_inputs = (
|
| 74 |
+
test_hidden_unit.to(device),
|
| 75 |
+
test_pitch.to(device),
|
| 76 |
+
test_mel2ph.to(device),
|
| 77 |
+
test_uv.to(device),
|
| 78 |
+
test_noise.to(device),
|
| 79 |
+
test_sid.to(device),
|
| 80 |
+
test_vol.to(device)
|
| 81 |
+
)
|
| 82 |
+
else:
|
| 83 |
+
test_inputs = (
|
| 84 |
+
test_hidden_unit.to(device),
|
| 85 |
+
test_pitch.to(device),
|
| 86 |
+
test_mel2ph.to(device),
|
| 87 |
+
test_uv.to(device),
|
| 88 |
+
test_noise.to(device),
|
| 89 |
+
test_sid.to(device)
|
| 90 |
+
)
|
| 91 |
+
|
| 92 |
+
# SVCVITS = torch.jit.script(SVCVITS)
|
| 93 |
+
SVCVITS(test_hidden_unit.to(device),
|
| 94 |
+
test_pitch.to(device),
|
| 95 |
+
test_mel2ph.to(device),
|
| 96 |
+
test_uv.to(device),
|
| 97 |
+
test_noise.to(device),
|
| 98 |
+
test_sid.to(device),
|
| 99 |
+
test_vol.to(device))
|
| 100 |
+
|
| 101 |
+
SVCVITS.dec.OnnxExport()
|
| 102 |
+
|
| 103 |
+
torch.onnx.export(
|
| 104 |
+
SVCVITS,
|
| 105 |
+
test_inputs,
|
| 106 |
+
f"checkpoints/{path}/{path}_SoVits.onnx",
|
| 107 |
+
dynamic_axes=daxes,
|
| 108 |
+
do_constant_folding=False,
|
| 109 |
+
opset_version=16,
|
| 110 |
+
verbose=False,
|
| 111 |
+
input_names=input_names,
|
| 112 |
+
output_names=output_names
|
| 113 |
+
)
|
| 114 |
+
|
| 115 |
+
vec_lay = "layer-12" if SVCVITS.gin_channels == 768 else "layer-9"
|
| 116 |
+
spklist = []
|
| 117 |
+
for key in hps.spk.keys():
|
| 118 |
+
spklist.append(key)
|
| 119 |
+
|
| 120 |
+
MoeVSConf = {
|
| 121 |
+
"Folder" : f"{path}",
|
| 122 |
+
"Name" : f"{path}",
|
| 123 |
+
"Type" : "SoVits",
|
| 124 |
+
"Rate" : hps.data.sampling_rate,
|
| 125 |
+
"Hop" : hps.data.hop_length,
|
| 126 |
+
"Hubert": f"vec-{SVCVITS.gin_channels}-{vec_lay}",
|
| 127 |
+
"SoVits4": True,
|
| 128 |
+
"SoVits3": False,
|
| 129 |
+
"CharaMix": export_mix,
|
| 130 |
+
"Volume": SVCVITS.vol_embedding,
|
| 131 |
+
"HiddenSize": SVCVITS.gin_channels,
|
| 132 |
+
"Characters": spklist
|
| 133 |
+
}
|
| 134 |
+
|
| 135 |
+
with open(f"checkpoints/{path}/{model}_MoeVS.json", 'w') as MoeVsConfFile:
|
| 136 |
+
json.dump(MoeVSConf, MoeVsConfFile, indent = 4)
|
| 137 |
+
|
| 138 |
+
|
| 139 |
+
if __name__ == '__main__':
|
| 140 |
+
import argparse
|
| 141 |
+
parser = argparse.ArgumentParser()
|
| 142 |
+
parser.add_argument('-p', '--path', type=str, default="crs")
|
| 143 |
+
parser.add_argument('-c', '--config', type=str, default='config.json')
|
| 144 |
+
parser.add_argument('-m', '--model', type=str, default='model.pth')
|
| 145 |
+
args = parser.parse_args()
|
| 146 |
+
|
| 147 |
+
path = args.path
|
| 148 |
+
config = args.config
|
| 149 |
+
model = args.model
|
| 150 |
+
main(path, config, model)
|
onnx_export_old.py
ADDED
|
@@ -0,0 +1,56 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import torch
|
| 2 |
+
|
| 3 |
+
import utils
|
| 4 |
+
from onnxexport.model_onnx import SynthesizerTrn
|
| 5 |
+
|
| 6 |
+
|
| 7 |
+
def main(NetExport):
|
| 8 |
+
path = "SoVits4.0"
|
| 9 |
+
if NetExport:
|
| 10 |
+
device = torch.device("cpu")
|
| 11 |
+
hps = utils.get_hparams_from_file(f"checkpoints/{path}/config.json")
|
| 12 |
+
SVCVITS = SynthesizerTrn(
|
| 13 |
+
hps.data.filter_length // 2 + 1,
|
| 14 |
+
hps.train.segment_size // hps.data.hop_length,
|
| 15 |
+
**hps.model)
|
| 16 |
+
_ = utils.load_checkpoint(f"checkpoints/{path}/model.pth", SVCVITS, None)
|
| 17 |
+
_ = SVCVITS.eval().to(device)
|
| 18 |
+
for i in SVCVITS.parameters():
|
| 19 |
+
i.requires_grad = False
|
| 20 |
+
|
| 21 |
+
n_frame = 10
|
| 22 |
+
test_hidden_unit = torch.rand(1, n_frame, 256)
|
| 23 |
+
test_pitch = torch.rand(1, n_frame)
|
| 24 |
+
test_mel2ph = torch.arange(0, n_frame, dtype=torch.int64)[None] # torch.LongTensor([0, 1, 2, 3, 4, 5, 6, 7, 8, 9]).unsqueeze(0)
|
| 25 |
+
test_uv = torch.ones(1, n_frame, dtype=torch.float32)
|
| 26 |
+
test_noise = torch.randn(1, 192, n_frame)
|
| 27 |
+
test_sid = torch.LongTensor([0])
|
| 28 |
+
input_names = ["c", "f0", "mel2ph", "uv", "noise", "sid"]
|
| 29 |
+
output_names = ["audio", ]
|
| 30 |
+
|
| 31 |
+
torch.onnx.export(SVCVITS,
|
| 32 |
+
(
|
| 33 |
+
test_hidden_unit.to(device),
|
| 34 |
+
test_pitch.to(device),
|
| 35 |
+
test_mel2ph.to(device),
|
| 36 |
+
test_uv.to(device),
|
| 37 |
+
test_noise.to(device),
|
| 38 |
+
test_sid.to(device)
|
| 39 |
+
),
|
| 40 |
+
f"checkpoints/{path}/model.onnx",
|
| 41 |
+
dynamic_axes={
|
| 42 |
+
"c": [0, 1],
|
| 43 |
+
"f0": [1],
|
| 44 |
+
"mel2ph": [1],
|
| 45 |
+
"uv": [1],
|
| 46 |
+
"noise": [2],
|
| 47 |
+
},
|
| 48 |
+
do_constant_folding=False,
|
| 49 |
+
opset_version=16,
|
| 50 |
+
verbose=False,
|
| 51 |
+
input_names=input_names,
|
| 52 |
+
output_names=output_names)
|
| 53 |
+
|
| 54 |
+
|
| 55 |
+
if __name__ == '__main__':
|
| 56 |
+
main(True)
|
onnx_export_speaker_mix.py
ADDED
|
@@ -0,0 +1,138 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import json
|
| 2 |
+
|
| 3 |
+
import torch
|
| 4 |
+
|
| 5 |
+
import utils
|
| 6 |
+
from onnxexport.model_onnx_speaker_mix import SynthesizerTrn
|
| 7 |
+
|
| 8 |
+
|
| 9 |
+
def main():
|
| 10 |
+
path = "crs"
|
| 11 |
+
|
| 12 |
+
device = torch.device("cpu")
|
| 13 |
+
hps = utils.get_hparams_from_file(f"checkpoints/{path}/config.json")
|
| 14 |
+
SVCVITS = SynthesizerTrn(
|
| 15 |
+
hps.data.filter_length // 2 + 1,
|
| 16 |
+
hps.train.segment_size // hps.data.hop_length,
|
| 17 |
+
**hps.model)
|
| 18 |
+
_ = utils.load_checkpoint(f"checkpoints/{path}/model.pth", SVCVITS, None)
|
| 19 |
+
_ = SVCVITS.eval().to(device)
|
| 20 |
+
for i in SVCVITS.parameters():
|
| 21 |
+
i.requires_grad = False
|
| 22 |
+
|
| 23 |
+
num_frames = 200
|
| 24 |
+
|
| 25 |
+
test_hidden_unit = torch.rand(1, num_frames, SVCVITS.gin_channels)
|
| 26 |
+
test_pitch = torch.rand(1, num_frames)
|
| 27 |
+
test_vol = torch.rand(1, num_frames)
|
| 28 |
+
test_mel2ph = torch.LongTensor(torch.arange(0, num_frames)).unsqueeze(0)
|
| 29 |
+
test_uv = torch.ones(1, num_frames, dtype=torch.float32)
|
| 30 |
+
test_noise = torch.randn(1, 192, num_frames)
|
| 31 |
+
test_sid = torch.LongTensor([0])
|
| 32 |
+
export_mix = True
|
| 33 |
+
if len(hps.spk) < 2:
|
| 34 |
+
export_mix = False
|
| 35 |
+
|
| 36 |
+
if export_mix:
|
| 37 |
+
spk_mix = []
|
| 38 |
+
n_spk = len(hps.spk)
|
| 39 |
+
for i in range(n_spk):
|
| 40 |
+
spk_mix.append(1.0/float(n_spk))
|
| 41 |
+
test_sid = torch.tensor(spk_mix)
|
| 42 |
+
SVCVITS.export_chara_mix(hps.spk)
|
| 43 |
+
test_sid = test_sid.unsqueeze(0)
|
| 44 |
+
test_sid = test_sid.repeat(num_frames, 1)
|
| 45 |
+
|
| 46 |
+
SVCVITS.eval()
|
| 47 |
+
|
| 48 |
+
if export_mix:
|
| 49 |
+
daxes = {
|
| 50 |
+
"c": [0, 1],
|
| 51 |
+
"f0": [1],
|
| 52 |
+
"mel2ph": [1],
|
| 53 |
+
"uv": [1],
|
| 54 |
+
"noise": [2],
|
| 55 |
+
"sid":[0]
|
| 56 |
+
}
|
| 57 |
+
else:
|
| 58 |
+
daxes = {
|
| 59 |
+
"c": [0, 1],
|
| 60 |
+
"f0": [1],
|
| 61 |
+
"mel2ph": [1],
|
| 62 |
+
"uv": [1],
|
| 63 |
+
"noise": [2]
|
| 64 |
+
}
|
| 65 |
+
|
| 66 |
+
input_names = ["c", "f0", "mel2ph", "uv", "noise", "sid"]
|
| 67 |
+
output_names = ["audio", ]
|
| 68 |
+
|
| 69 |
+
if SVCVITS.vol_embedding:
|
| 70 |
+
input_names.append("vol")
|
| 71 |
+
vol_dadict = {"vol" : [1]}
|
| 72 |
+
daxes.update(vol_dadict)
|
| 73 |
+
test_inputs = (
|
| 74 |
+
test_hidden_unit.to(device),
|
| 75 |
+
test_pitch.to(device),
|
| 76 |
+
test_mel2ph.to(device),
|
| 77 |
+
test_uv.to(device),
|
| 78 |
+
test_noise.to(device),
|
| 79 |
+
test_sid.to(device),
|
| 80 |
+
test_vol.to(device)
|
| 81 |
+
)
|
| 82 |
+
else:
|
| 83 |
+
test_inputs = (
|
| 84 |
+
test_hidden_unit.to(device),
|
| 85 |
+
test_pitch.to(device),
|
| 86 |
+
test_mel2ph.to(device),
|
| 87 |
+
test_uv.to(device),
|
| 88 |
+
test_noise.to(device),
|
| 89 |
+
test_sid.to(device)
|
| 90 |
+
)
|
| 91 |
+
|
| 92 |
+
# SVCVITS = torch.jit.script(SVCVITS)
|
| 93 |
+
SVCVITS(test_hidden_unit.to(device),
|
| 94 |
+
test_pitch.to(device),
|
| 95 |
+
test_mel2ph.to(device),
|
| 96 |
+
test_uv.to(device),
|
| 97 |
+
test_noise.to(device),
|
| 98 |
+
test_sid.to(device),
|
| 99 |
+
test_vol.to(device))
|
| 100 |
+
|
| 101 |
+
torch.onnx.export(
|
| 102 |
+
SVCVITS,
|
| 103 |
+
test_inputs,
|
| 104 |
+
f"checkpoints/{path}/{path}_SoVits.onnx",
|
| 105 |
+
dynamic_axes=daxes,
|
| 106 |
+
do_constant_folding=False,
|
| 107 |
+
opset_version=16,
|
| 108 |
+
verbose=False,
|
| 109 |
+
input_names=input_names,
|
| 110 |
+
output_names=output_names
|
| 111 |
+
)
|
| 112 |
+
|
| 113 |
+
vec_lay = "layer-12" if SVCVITS.gin_channels == 768 else "layer-9"
|
| 114 |
+
spklist = []
|
| 115 |
+
for key in hps.spk.keys():
|
| 116 |
+
spklist.append(key)
|
| 117 |
+
|
| 118 |
+
MoeVSConf = {
|
| 119 |
+
"Folder" : f"{path}",
|
| 120 |
+
"Name" : f"{path}",
|
| 121 |
+
"Type" : "SoVits",
|
| 122 |
+
"Rate" : hps.data.sampling_rate,
|
| 123 |
+
"Hop" : hps.data.hop_length,
|
| 124 |
+
"Hubert": f"vec-{SVCVITS.gin_channels}-{vec_lay}",
|
| 125 |
+
"SoVits4": True,
|
| 126 |
+
"SoVits3": False,
|
| 127 |
+
"CharaMix": export_mix,
|
| 128 |
+
"Volume": SVCVITS.vol_embedding,
|
| 129 |
+
"HiddenSize": SVCVITS.gin_channels,
|
| 130 |
+
"Characters": spklist
|
| 131 |
+
}
|
| 132 |
+
|
| 133 |
+
with open(f"checkpoints/{path}.json", 'w') as MoeVsConfFile:
|
| 134 |
+
json.dump(MoeVSConf, MoeVsConfFile, indent = 4)
|
| 135 |
+
|
| 136 |
+
|
| 137 |
+
if __name__ == '__main__':
|
| 138 |
+
main()
|
preprocess_flist_config.py
ADDED
|
@@ -0,0 +1,109 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import argparse
|
| 2 |
+
import json
|
| 3 |
+
import os
|
| 4 |
+
import re
|
| 5 |
+
import wave
|
| 6 |
+
from random import shuffle
|
| 7 |
+
|
| 8 |
+
from loguru import logger
|
| 9 |
+
from tqdm import tqdm
|
| 10 |
+
|
| 11 |
+
import diffusion.logger.utils as du
|
| 12 |
+
|
| 13 |
+
pattern = re.compile(r'^[\.a-zA-Z0-9_\/]+$')
|
| 14 |
+
|
| 15 |
+
def get_wav_duration(file_path):
|
| 16 |
+
with wave.open(file_path, 'rb') as wav_file:
|
| 17 |
+
# 获取音频帧数
|
| 18 |
+
n_frames = wav_file.getnframes()
|
| 19 |
+
# 获取采样率
|
| 20 |
+
framerate = wav_file.getframerate()
|
| 21 |
+
# 计算时长(秒)
|
| 22 |
+
duration = n_frames / float(framerate)
|
| 23 |
+
return duration
|
| 24 |
+
|
| 25 |
+
if __name__ == "__main__":
|
| 26 |
+
parser = argparse.ArgumentParser()
|
| 27 |
+
parser.add_argument("--train_list", type=str, default="./filelists/train.txt", help="path to train list")
|
| 28 |
+
parser.add_argument("--val_list", type=str, default="./filelists/val.txt", help="path to val list")
|
| 29 |
+
parser.add_argument("--source_dir", type=str, default="./dataset/44k", help="path to source dir")
|
| 30 |
+
parser.add_argument("--speech_encoder", type=str, default="vec768l12", help="choice a speech encoder|'vec768l12','vec256l9','hubertsoft','whisper-ppg','cnhubertlarge','dphubert','whisper-ppg-large','wavlmbase+'")
|
| 31 |
+
parser.add_argument("--vol_aug", action="store_true", help="Whether to use volume embedding and volume augmentation")
|
| 32 |
+
parser.add_argument("--tiny", action="store_true", help="Whether to train sovits tiny")
|
| 33 |
+
args = parser.parse_args()
|
| 34 |
+
|
| 35 |
+
config_template = json.load(open("configs_template/config_tiny_template.json")) if args.tiny else json.load(open("configs_template/config_template.json"))
|
| 36 |
+
train = []
|
| 37 |
+
val = []
|
| 38 |
+
idx = 0
|
| 39 |
+
spk_dict = {}
|
| 40 |
+
spk_id = 0
|
| 41 |
+
|
| 42 |
+
for speaker in tqdm(os.listdir(args.source_dir)):
|
| 43 |
+
spk_dict[speaker] = spk_id
|
| 44 |
+
spk_id += 1
|
| 45 |
+
wavs = ["/".join([args.source_dir, speaker, i]) for i in os.listdir(os.path.join(args.source_dir, speaker))]
|
| 46 |
+
new_wavs = []
|
| 47 |
+
for file in wavs:
|
| 48 |
+
if not file.endswith("wav"):
|
| 49 |
+
continue
|
| 50 |
+
if not pattern.match(file):
|
| 51 |
+
logger.warning(f"文件名{file}中包含非字母数字下划线,可能会导致错误。(也可能不会)")
|
| 52 |
+
if get_wav_duration(file) < 0.3:
|
| 53 |
+
logger.info("Skip too short audio:" + file)
|
| 54 |
+
continue
|
| 55 |
+
new_wavs.append(file)
|
| 56 |
+
wavs = new_wavs
|
| 57 |
+
shuffle(wavs)
|
| 58 |
+
train += wavs[2:]
|
| 59 |
+
val += wavs[:2]
|
| 60 |
+
|
| 61 |
+
shuffle(train)
|
| 62 |
+
shuffle(val)
|
| 63 |
+
|
| 64 |
+
logger.info("Writing" + args.train_list)
|
| 65 |
+
with open(args.train_list, "w") as f:
|
| 66 |
+
for fname in tqdm(train):
|
| 67 |
+
wavpath = fname
|
| 68 |
+
f.write(wavpath + "\n")
|
| 69 |
+
|
| 70 |
+
logger.info("Writing" + args.val_list)
|
| 71 |
+
with open(args.val_list, "w") as f:
|
| 72 |
+
for fname in tqdm(val):
|
| 73 |
+
wavpath = fname
|
| 74 |
+
f.write(wavpath + "\n")
|
| 75 |
+
|
| 76 |
+
|
| 77 |
+
d_config_template = du.load_config("configs_template/diffusion_template.yaml")
|
| 78 |
+
d_config_template["model"]["n_spk"] = spk_id
|
| 79 |
+
d_config_template["data"]["encoder"] = args.speech_encoder
|
| 80 |
+
d_config_template["spk"] = spk_dict
|
| 81 |
+
|
| 82 |
+
config_template["spk"] = spk_dict
|
| 83 |
+
config_template["model"]["n_speakers"] = spk_id
|
| 84 |
+
config_template["model"]["speech_encoder"] = args.speech_encoder
|
| 85 |
+
|
| 86 |
+
if args.speech_encoder == "vec768l12" or args.speech_encoder == "dphubert" or args.speech_encoder == "wavlmbase+":
|
| 87 |
+
config_template["model"]["ssl_dim"] = config_template["model"]["filter_channels"] = config_template["model"]["gin_channels"] = 768
|
| 88 |
+
d_config_template["data"]["encoder_out_channels"] = 768
|
| 89 |
+
elif args.speech_encoder == "vec256l9" or args.speech_encoder == 'hubertsoft':
|
| 90 |
+
config_template["model"]["ssl_dim"] = config_template["model"]["gin_channels"] = 256
|
| 91 |
+
d_config_template["data"]["encoder_out_channels"] = 256
|
| 92 |
+
elif args.speech_encoder == "whisper-ppg" or args.speech_encoder == 'cnhubertlarge':
|
| 93 |
+
config_template["model"]["ssl_dim"] = config_template["model"]["filter_channels"] = config_template["model"]["gin_channels"] = 1024
|
| 94 |
+
d_config_template["data"]["encoder_out_channels"] = 1024
|
| 95 |
+
elif args.speech_encoder == "whisper-ppg-large":
|
| 96 |
+
config_template["model"]["ssl_dim"] = config_template["model"]["filter_channels"] = config_template["model"]["gin_channels"] = 1280
|
| 97 |
+
d_config_template["data"]["encoder_out_channels"] = 1280
|
| 98 |
+
|
| 99 |
+
if args.vol_aug:
|
| 100 |
+
config_template["train"]["vol_aug"] = config_template["model"]["vol_embedding"] = True
|
| 101 |
+
|
| 102 |
+
if args.tiny:
|
| 103 |
+
config_template["model"]["filter_channels"] = 512
|
| 104 |
+
|
| 105 |
+
logger.info("Writing to configs/config.json")
|
| 106 |
+
with open("configs/config.json", "w") as f:
|
| 107 |
+
json.dump(config_template, f, indent=2)
|
| 108 |
+
logger.info("Writing to configs/diffusion.yaml")
|
| 109 |
+
du.save_config("configs/diffusion.yaml",d_config_template)
|
preprocess_hubert_f0.py
ADDED
|
@@ -0,0 +1,172 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import argparse
|
| 2 |
+
import logging
|
| 3 |
+
import os
|
| 4 |
+
import random
|
| 5 |
+
from concurrent.futures import ProcessPoolExecutor
|
| 6 |
+
from glob import glob
|
| 7 |
+
from random import shuffle
|
| 8 |
+
|
| 9 |
+
import librosa
|
| 10 |
+
import numpy as np
|
| 11 |
+
import torch
|
| 12 |
+
import torch.multiprocessing as mp
|
| 13 |
+
from loguru import logger
|
| 14 |
+
from tqdm import tqdm
|
| 15 |
+
|
| 16 |
+
import diffusion.logger.utils as du
|
| 17 |
+
import utils
|
| 18 |
+
from diffusion.vocoder import Vocoder
|
| 19 |
+
from modules.mel_processing import spectrogram_torch
|
| 20 |
+
|
| 21 |
+
logging.getLogger("numba").setLevel(logging.WARNING)
|
| 22 |
+
logging.getLogger("matplotlib").setLevel(logging.WARNING)
|
| 23 |
+
|
| 24 |
+
hps = utils.get_hparams_from_file("configs/config.json")
|
| 25 |
+
dconfig = du.load_config("configs/diffusion.yaml")
|
| 26 |
+
sampling_rate = hps.data.sampling_rate
|
| 27 |
+
hop_length = hps.data.hop_length
|
| 28 |
+
speech_encoder = hps["model"]["speech_encoder"]
|
| 29 |
+
|
| 30 |
+
|
| 31 |
+
def process_one(filename, hmodel, f0p, device, diff=False, mel_extractor=None):
|
| 32 |
+
wav, sr = librosa.load(filename, sr=sampling_rate)
|
| 33 |
+
audio_norm = torch.FloatTensor(wav)
|
| 34 |
+
audio_norm = audio_norm.unsqueeze(0)
|
| 35 |
+
soft_path = filename + ".soft.pt"
|
| 36 |
+
if not os.path.exists(soft_path):
|
| 37 |
+
wav16k = librosa.resample(wav, orig_sr=sampling_rate, target_sr=16000)
|
| 38 |
+
wav16k = torch.from_numpy(wav16k).to(device)
|
| 39 |
+
c = hmodel.encoder(wav16k)
|
| 40 |
+
torch.save(c.cpu(), soft_path)
|
| 41 |
+
|
| 42 |
+
f0_path = filename + ".f0.npy"
|
| 43 |
+
if not os.path.exists(f0_path):
|
| 44 |
+
f0_predictor = utils.get_f0_predictor(f0p,sampling_rate=sampling_rate, hop_length=hop_length,device=None,threshold=0.05)
|
| 45 |
+
f0,uv = f0_predictor.compute_f0_uv(
|
| 46 |
+
wav
|
| 47 |
+
)
|
| 48 |
+
np.save(f0_path, np.asanyarray((f0,uv),dtype=object))
|
| 49 |
+
|
| 50 |
+
|
| 51 |
+
spec_path = filename.replace(".wav", ".spec.pt")
|
| 52 |
+
if not os.path.exists(spec_path):
|
| 53 |
+
# Process spectrogram
|
| 54 |
+
# The following code can't be replaced by torch.FloatTensor(wav)
|
| 55 |
+
# because load_wav_to_torch return a tensor that need to be normalized
|
| 56 |
+
|
| 57 |
+
if sr != hps.data.sampling_rate:
|
| 58 |
+
raise ValueError(
|
| 59 |
+
"{} SR doesn't match target {} SR".format(
|
| 60 |
+
sr, hps.data.sampling_rate
|
| 61 |
+
)
|
| 62 |
+
)
|
| 63 |
+
|
| 64 |
+
#audio_norm = audio / hps.data.max_wav_value
|
| 65 |
+
|
| 66 |
+
spec = spectrogram_torch(
|
| 67 |
+
audio_norm,
|
| 68 |
+
hps.data.filter_length,
|
| 69 |
+
hps.data.sampling_rate,
|
| 70 |
+
hps.data.hop_length,
|
| 71 |
+
hps.data.win_length,
|
| 72 |
+
center=False,
|
| 73 |
+
)
|
| 74 |
+
spec = torch.squeeze(spec, 0)
|
| 75 |
+
torch.save(spec, spec_path)
|
| 76 |
+
|
| 77 |
+
if diff or hps.model.vol_embedding:
|
| 78 |
+
volume_path = filename + ".vol.npy"
|
| 79 |
+
volume_extractor = utils.Volume_Extractor(hop_length)
|
| 80 |
+
if not os.path.exists(volume_path):
|
| 81 |
+
volume = volume_extractor.extract(audio_norm)
|
| 82 |
+
np.save(volume_path, volume.to('cpu').numpy())
|
| 83 |
+
|
| 84 |
+
if diff:
|
| 85 |
+
mel_path = filename + ".mel.npy"
|
| 86 |
+
if not os.path.exists(mel_path) and mel_extractor is not None:
|
| 87 |
+
mel_t = mel_extractor.extract(audio_norm.to(device), sampling_rate)
|
| 88 |
+
mel = mel_t.squeeze().to('cpu').numpy()
|
| 89 |
+
np.save(mel_path, mel)
|
| 90 |
+
aug_mel_path = filename + ".aug_mel.npy"
|
| 91 |
+
aug_vol_path = filename + ".aug_vol.npy"
|
| 92 |
+
max_amp = float(torch.max(torch.abs(audio_norm))) + 1e-5
|
| 93 |
+
max_shift = min(1, np.log10(1/max_amp))
|
| 94 |
+
log10_vol_shift = random.uniform(-1, max_shift)
|
| 95 |
+
keyshift = random.uniform(-5, 5)
|
| 96 |
+
if mel_extractor is not None:
|
| 97 |
+
aug_mel_t = mel_extractor.extract(audio_norm * (10 ** log10_vol_shift), sampling_rate, keyshift = keyshift)
|
| 98 |
+
aug_mel = aug_mel_t.squeeze().to('cpu').numpy()
|
| 99 |
+
aug_vol = volume_extractor.extract(audio_norm * (10 ** log10_vol_shift))
|
| 100 |
+
if not os.path.exists(aug_mel_path):
|
| 101 |
+
np.save(aug_mel_path,np.asanyarray((aug_mel,keyshift),dtype=object))
|
| 102 |
+
if not os.path.exists(aug_vol_path):
|
| 103 |
+
np.save(aug_vol_path,aug_vol.to('cpu').numpy())
|
| 104 |
+
|
| 105 |
+
|
| 106 |
+
def process_batch(file_chunk, f0p, diff=False, mel_extractor=None, device="cpu"):
|
| 107 |
+
logger.info("Loading speech encoder for content...")
|
| 108 |
+
rank = mp.current_process()._identity
|
| 109 |
+
rank = rank[0] if len(rank) > 0 else 0
|
| 110 |
+
if torch.cuda.is_available():
|
| 111 |
+
gpu_id = rank % torch.cuda.device_count()
|
| 112 |
+
device = torch.device(f"cuda:{gpu_id}")
|
| 113 |
+
logger.info(f"Rank {rank} uses device {device}")
|
| 114 |
+
hmodel = utils.get_speech_encoder(speech_encoder, device=device)
|
| 115 |
+
logger.info(f"Loaded speech encoder for rank {rank}")
|
| 116 |
+
for filename in tqdm(file_chunk):
|
| 117 |
+
process_one(filename, hmodel, f0p, device, diff, mel_extractor)
|
| 118 |
+
|
| 119 |
+
def parallel_process(filenames, num_processes, f0p, diff, mel_extractor, device):
|
| 120 |
+
with ProcessPoolExecutor(max_workers=num_processes) as executor:
|
| 121 |
+
tasks = []
|
| 122 |
+
for i in range(num_processes):
|
| 123 |
+
start = int(i * len(filenames) / num_processes)
|
| 124 |
+
end = int((i + 1) * len(filenames) / num_processes)
|
| 125 |
+
file_chunk = filenames[start:end]
|
| 126 |
+
tasks.append(executor.submit(process_batch, file_chunk, f0p, diff, mel_extractor, device=device))
|
| 127 |
+
for task in tqdm(tasks):
|
| 128 |
+
task.result()
|
| 129 |
+
|
| 130 |
+
if __name__ == "__main__":
|
| 131 |
+
parser = argparse.ArgumentParser()
|
| 132 |
+
parser.add_argument('-d', '--device', type=str, default=None)
|
| 133 |
+
parser.add_argument(
|
| 134 |
+
"--in_dir", type=str, default="dataset/44k", help="path to input dir"
|
| 135 |
+
)
|
| 136 |
+
parser.add_argument(
|
| 137 |
+
'--use_diff',action='store_true', help='Whether to use the diffusion model'
|
| 138 |
+
)
|
| 139 |
+
parser.add_argument(
|
| 140 |
+
'--f0_predictor', type=str, default="dio", help='Select F0 predictor, can select crepe,pm,dio,harvest,rmvpe,fcpe|default: pm(note: crepe is original F0 using mean filter)'
|
| 141 |
+
)
|
| 142 |
+
parser.add_argument(
|
| 143 |
+
'--num_processes', type=int, default=1, help='You are advised to set the number of processes to the same as the number of CPU cores'
|
| 144 |
+
)
|
| 145 |
+
args = parser.parse_args()
|
| 146 |
+
f0p = args.f0_predictor
|
| 147 |
+
device = args.device
|
| 148 |
+
if device is None:
|
| 149 |
+
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
|
| 150 |
+
|
| 151 |
+
print(speech_encoder)
|
| 152 |
+
logger.info("Using device: ", device)
|
| 153 |
+
logger.info("Using SpeechEncoder: " + speech_encoder)
|
| 154 |
+
logger.info("Using extractor: " + f0p)
|
| 155 |
+
logger.info("Using diff Mode: " + str( args.use_diff))
|
| 156 |
+
|
| 157 |
+
if args.use_diff:
|
| 158 |
+
print("use_diff")
|
| 159 |
+
print("Loading Mel Extractor...")
|
| 160 |
+
mel_extractor = Vocoder(dconfig.vocoder.type, dconfig.vocoder.ckpt, device=device)
|
| 161 |
+
print("Loaded Mel Extractor.")
|
| 162 |
+
else:
|
| 163 |
+
mel_extractor = None
|
| 164 |
+
filenames = glob(f"{args.in_dir}/*/*.wav", recursive=True) # [:10]
|
| 165 |
+
shuffle(filenames)
|
| 166 |
+
mp.set_start_method("spawn", force=True)
|
| 167 |
+
|
| 168 |
+
num_processes = args.num_processes
|
| 169 |
+
if num_processes == 0:
|
| 170 |
+
num_processes = os.cpu_count()
|
| 171 |
+
|
| 172 |
+
parallel_process(filenames, num_processes, f0p, args.use_diff, mel_extractor, device)
|
requirements.txt
ADDED
|
@@ -0,0 +1,31 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
ffmpeg-python
|
| 2 |
+
Flask
|
| 3 |
+
Flask_Cors
|
| 4 |
+
gradio>=3.7.0
|
| 5 |
+
numpy==1.23.5
|
| 6 |
+
pyworld
|
| 7 |
+
scipy==1.10.0
|
| 8 |
+
SoundFile==0.12.1
|
| 9 |
+
torch
|
| 10 |
+
torchaudio
|
| 11 |
+
torchcrepe
|
| 12 |
+
tqdm
|
| 13 |
+
rich
|
| 14 |
+
loguru
|
| 15 |
+
scikit-maad
|
| 16 |
+
praat-parselmouth
|
| 17 |
+
onnx
|
| 18 |
+
onnxsim
|
| 19 |
+
onnxoptimizer
|
| 20 |
+
fairseq==0.12.2
|
| 21 |
+
librosa==0.9.1
|
| 22 |
+
tensorboard
|
| 23 |
+
tensorboardX
|
| 24 |
+
transformers
|
| 25 |
+
edge_tts
|
| 26 |
+
langdetect
|
| 27 |
+
pyyaml
|
| 28 |
+
pynvml
|
| 29 |
+
faiss-cpu
|
| 30 |
+
einops
|
| 31 |
+
local_attention
|
requirements_onnx_encoder.txt
ADDED
|
@@ -0,0 +1,29 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
Flask
|
| 2 |
+
Flask_Cors
|
| 3 |
+
gradio>=3.7.0
|
| 4 |
+
numpy==1.23.0
|
| 5 |
+
pyworld==0.2.5
|
| 6 |
+
scipy==1.10.0
|
| 7 |
+
SoundFile==0.12.1
|
| 8 |
+
torch==1.13.1
|
| 9 |
+
torchaudio==0.13.1
|
| 10 |
+
torchcrepe
|
| 11 |
+
tqdm
|
| 12 |
+
rich.progress
|
| 13 |
+
loguru
|
| 14 |
+
scikit-maad
|
| 15 |
+
praat-parselmouth
|
| 16 |
+
onnx
|
| 17 |
+
onnxsim
|
| 18 |
+
onnxoptimizer
|
| 19 |
+
onnxruntime-gpu
|
| 20 |
+
librosa==0.9.1
|
| 21 |
+
tensorboard
|
| 22 |
+
tensorboardX
|
| 23 |
+
edge_tts
|
| 24 |
+
langdetect
|
| 25 |
+
pyyaml
|
| 26 |
+
pynvml
|
| 27 |
+
transformers
|
| 28 |
+
ffmpeg-python
|
| 29 |
+
faiss-cpu
|
requirements_win.txt
ADDED
|
@@ -0,0 +1,33 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
librosa==0.9.1
|
| 2 |
+
fairseq==0.12.2
|
| 3 |
+
ffmpeg-python
|
| 4 |
+
Flask==2.1.2
|
| 5 |
+
Flask_Cors==3.0.10
|
| 6 |
+
gradio>=3.7.0
|
| 7 |
+
numpy
|
| 8 |
+
playsound==1.3.0
|
| 9 |
+
PyAudio==0.2.12
|
| 10 |
+
pydub==0.25.1
|
| 11 |
+
pyworld==0.3.0
|
| 12 |
+
requests==2.28.1
|
| 13 |
+
scipy==1.7.3
|
| 14 |
+
sounddevice==0.4.5
|
| 15 |
+
SoundFile==0.10.3.post1
|
| 16 |
+
starlette==0.19.1
|
| 17 |
+
tqdm==4.63.0
|
| 18 |
+
rich
|
| 19 |
+
loguru
|
| 20 |
+
torchcrepe
|
| 21 |
+
scikit-maad
|
| 22 |
+
praat-parselmouth
|
| 23 |
+
onnx
|
| 24 |
+
onnxsim
|
| 25 |
+
onnxoptimizer
|
| 26 |
+
tensorboard
|
| 27 |
+
tensorboardX
|
| 28 |
+
transformers
|
| 29 |
+
edge_tts
|
| 30 |
+
langdetect
|
| 31 |
+
pyyaml
|
| 32 |
+
pynvml
|
| 33 |
+
faiss-cpu
|
resample.py
ADDED
|
@@ -0,0 +1,98 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import argparse
|
| 2 |
+
import concurrent.futures
|
| 3 |
+
import os
|
| 4 |
+
from concurrent.futures import ProcessPoolExecutor
|
| 5 |
+
from multiprocessing import cpu_count
|
| 6 |
+
|
| 7 |
+
import librosa
|
| 8 |
+
import numpy as np
|
| 9 |
+
from rich.progress import track
|
| 10 |
+
from scipy.io import wavfile
|
| 11 |
+
|
| 12 |
+
|
| 13 |
+
def load_wav(wav_path):
|
| 14 |
+
return librosa.load(wav_path, sr=None)
|
| 15 |
+
|
| 16 |
+
|
| 17 |
+
def trim_wav(wav, top_db=40):
|
| 18 |
+
return librosa.effects.trim(wav, top_db=top_db)
|
| 19 |
+
|
| 20 |
+
|
| 21 |
+
def normalize_peak(wav, threshold=1.0):
|
| 22 |
+
peak = np.abs(wav).max()
|
| 23 |
+
if peak > threshold:
|
| 24 |
+
wav = 0.98 * wav / peak
|
| 25 |
+
return wav
|
| 26 |
+
|
| 27 |
+
|
| 28 |
+
def resample_wav(wav, sr, target_sr):
|
| 29 |
+
return librosa.resample(wav, orig_sr=sr, target_sr=target_sr)
|
| 30 |
+
|
| 31 |
+
|
| 32 |
+
def save_wav_to_path(wav, save_path, sr):
|
| 33 |
+
wavfile.write(
|
| 34 |
+
save_path,
|
| 35 |
+
sr,
|
| 36 |
+
(wav * np.iinfo(np.int16).max).astype(np.int16)
|
| 37 |
+
)
|
| 38 |
+
|
| 39 |
+
|
| 40 |
+
def process(item):
|
| 41 |
+
spkdir, wav_name, args = item
|
| 42 |
+
speaker = spkdir.replace("\\", "/").split("/")[-1]
|
| 43 |
+
|
| 44 |
+
wav_path = os.path.join(args.in_dir, speaker, wav_name)
|
| 45 |
+
if os.path.exists(wav_path) and '.wav' in wav_path:
|
| 46 |
+
os.makedirs(os.path.join(args.out_dir2, speaker), exist_ok=True)
|
| 47 |
+
|
| 48 |
+
wav, sr = load_wav(wav_path)
|
| 49 |
+
wav, _ = trim_wav(wav)
|
| 50 |
+
wav = normalize_peak(wav)
|
| 51 |
+
resampled_wav = resample_wav(wav, sr, args.sr2)
|
| 52 |
+
|
| 53 |
+
if not args.skip_loudnorm:
|
| 54 |
+
resampled_wav /= np.max(np.abs(resampled_wav))
|
| 55 |
+
|
| 56 |
+
save_path2 = os.path.join(args.out_dir2, speaker, wav_name)
|
| 57 |
+
save_wav_to_path(resampled_wav, save_path2, args.sr2)
|
| 58 |
+
|
| 59 |
+
|
| 60 |
+
"""
|
| 61 |
+
def process_all_speakers():
|
| 62 |
+
process_count = 30 if os.cpu_count() > 60 else (os.cpu_count() - 2 if os.cpu_count() > 4 else 1)
|
| 63 |
+
|
| 64 |
+
with ThreadPoolExecutor(max_workers=process_count) as executor:
|
| 65 |
+
for speaker in speakers:
|
| 66 |
+
spk_dir = os.path.join(args.in_dir, speaker)
|
| 67 |
+
if os.path.isdir(spk_dir):
|
| 68 |
+
print(spk_dir)
|
| 69 |
+
futures = [executor.submit(process, (spk_dir, i, args)) for i in os.listdir(spk_dir) if i.endswith("wav")]
|
| 70 |
+
for _ in tqdm(concurrent.futures.as_completed(futures), total=len(futures)):
|
| 71 |
+
pass
|
| 72 |
+
"""
|
| 73 |
+
# multi process
|
| 74 |
+
|
| 75 |
+
|
| 76 |
+
def process_all_speakers():
|
| 77 |
+
process_count = 30 if os.cpu_count() > 60 else (os.cpu_count() - 2 if os.cpu_count() > 4 else 1)
|
| 78 |
+
with ProcessPoolExecutor(max_workers=process_count) as executor:
|
| 79 |
+
for speaker in speakers:
|
| 80 |
+
spk_dir = os.path.join(args.in_dir, speaker)
|
| 81 |
+
if os.path.isdir(spk_dir):
|
| 82 |
+
print(spk_dir)
|
| 83 |
+
futures = [executor.submit(process, (spk_dir, i, args)) for i in os.listdir(spk_dir) if i.endswith("wav")]
|
| 84 |
+
for _ in track(concurrent.futures.as_completed(futures), total=len(futures), description="resampling:"):
|
| 85 |
+
pass
|
| 86 |
+
|
| 87 |
+
|
| 88 |
+
if __name__ == "__main__":
|
| 89 |
+
parser = argparse.ArgumentParser()
|
| 90 |
+
parser.add_argument("--sr2", type=int, default=44100, help="sampling rate")
|
| 91 |
+
parser.add_argument("--in_dir", type=str, default="./dataset_raw", help="path to source dir")
|
| 92 |
+
parser.add_argument("--out_dir2", type=str, default="./dataset/44k", help="path to target dir")
|
| 93 |
+
parser.add_argument("--skip_loudnorm", action="store_true", help="Skip loudness matching if you have done it")
|
| 94 |
+
args = parser.parse_args()
|
| 95 |
+
|
| 96 |
+
print(f"CPU count: {cpu_count()}")
|
| 97 |
+
speakers = os.listdir(args.in_dir)
|
| 98 |
+
process_all_speakers()
|
settings.yaml
ADDED
|
@@ -0,0 +1,21 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
sovits_params:
|
| 2 |
+
log_interval: 200
|
| 3 |
+
eval_interval: 800
|
| 4 |
+
keep_ckpts: 10
|
| 5 |
+
batch_size: 6
|
| 6 |
+
learning_rate: 0.0001
|
| 7 |
+
amp_dtype: fp32
|
| 8 |
+
all_in_mem: false
|
| 9 |
+
diff_params:
|
| 10 |
+
num_workers: 2
|
| 11 |
+
cache_all_data: false
|
| 12 |
+
cache_device: cpu
|
| 13 |
+
amp_dtype: fp32
|
| 14 |
+
diff_batch_size: 48
|
| 15 |
+
diff_lr: 0.0002
|
| 16 |
+
diff_interval_log: 10
|
| 17 |
+
diff_interval_val: 2000
|
| 18 |
+
diff_force_save: 2000
|
| 19 |
+
diff_k_step_max: false
|
| 20 |
+
webui_settings:
|
| 21 |
+
second_dir: false
|
setup.py
ADDED
|
@@ -0,0 +1,68 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import os
|
| 2 |
+
import re
|
| 3 |
+
import socket
|
| 4 |
+
import subprocess
|
| 5 |
+
import sys
|
| 6 |
+
|
| 7 |
+
import psutil
|
| 8 |
+
|
| 9 |
+
|
| 10 |
+
def check_ffmpeg_path():
|
| 11 |
+
cwd = os.getcwd()
|
| 12 |
+
ffmpeg_path = os.path.join(cwd, "ffmpeg", "bin", "ffmpeg.exe")
|
| 13 |
+
ffprobe_path = os.path.join(cwd, "ffmpeg", "bin", "ffprobe.exe")
|
| 14 |
+
return os.path.isfile(ffmpeg_path) and os.path.isfile(ffprobe_path)
|
| 15 |
+
|
| 16 |
+
def get_default_browser():
|
| 17 |
+
browser = ""
|
| 18 |
+
try:
|
| 19 |
+
cmd = r'reg query HKEY_CURRENT_USER\Software\Microsoft\Windows\Shell\Associations\UrlAssociations\http\UserChoice /v ProgId'
|
| 20 |
+
output = subprocess.check_output(cmd, shell=True).decode()
|
| 21 |
+
browser = output.split()[-1].split('\\')[-1]
|
| 22 |
+
except Exception as e:
|
| 23 |
+
print(f"Error: {e}")
|
| 24 |
+
browser = "Unknown"
|
| 25 |
+
return browser
|
| 26 |
+
|
| 27 |
+
def get_hostname():
|
| 28 |
+
try:
|
| 29 |
+
hostname = socket.gethostname()
|
| 30 |
+
return hostname
|
| 31 |
+
except socket.error as e:
|
| 32 |
+
print("Error: ", e)
|
| 33 |
+
|
| 34 |
+
def get_pagefile_size():
|
| 35 |
+
try:
|
| 36 |
+
pagefile = psutil.swap_memory().total
|
| 37 |
+
except UnboundLocalError:
|
| 38 |
+
pagefile = 0
|
| 39 |
+
except RuntimeError:
|
| 40 |
+
pagefile = None
|
| 41 |
+
return pagefile
|
| 42 |
+
|
| 43 |
+
|
| 44 |
+
def main():
|
| 45 |
+
allowed_pattern = re.compile(r'^[a-zA-Z0-9_@#$%^&()_+\-=\s\.]*$')
|
| 46 |
+
hostname = get_hostname()
|
| 47 |
+
pagefile = get_pagefile_size()
|
| 48 |
+
default_browser = get_default_browser()
|
| 49 |
+
if check_ffmpeg_path():
|
| 50 |
+
print("FFmpeg already installed, skipping...")
|
| 51 |
+
else:
|
| 52 |
+
try:
|
| 53 |
+
sys.exit(0)
|
| 54 |
+
finally:
|
| 55 |
+
print("未找到FFmpeg,整合包可能不完整,请重新下载")
|
| 56 |
+
if pagefile is None:
|
| 57 |
+
print("WARNING | 系统未开启性能计数器,无法获取当前虚拟内存状态,确保虚拟内存大于30G后可忽略此警告")
|
| 58 |
+
elif pagefile < 31457280000: # 30 GiB
|
| 59 |
+
print("WARNING | 虚拟内存不足30GB,可能会导致使用问题,请将虚拟内存设置为至少30G")
|
| 60 |
+
if "chrome" not in default_browser.lower() and "edge" not in default_browser.lower() and "firefox" not in default_browser.lower():
|
| 61 |
+
print("WARNING | 默认浏览器不符合要求,可能会影响使用,请更换为Chrome或Edge浏览器")
|
| 62 |
+
if not allowed_pattern.match(hostname):
|
| 63 |
+
print("WARNING | 计算机主机名中含有非西文字符,启动Tensorboard时可能出错,请在计算机设置中修改")
|
| 64 |
+
|
| 65 |
+
os.system("workenv\python.exe app.py")
|
| 66 |
+
|
| 67 |
+
if __name__ == "__main__":
|
| 68 |
+
main()
|
shadowdiffusion.png
ADDED
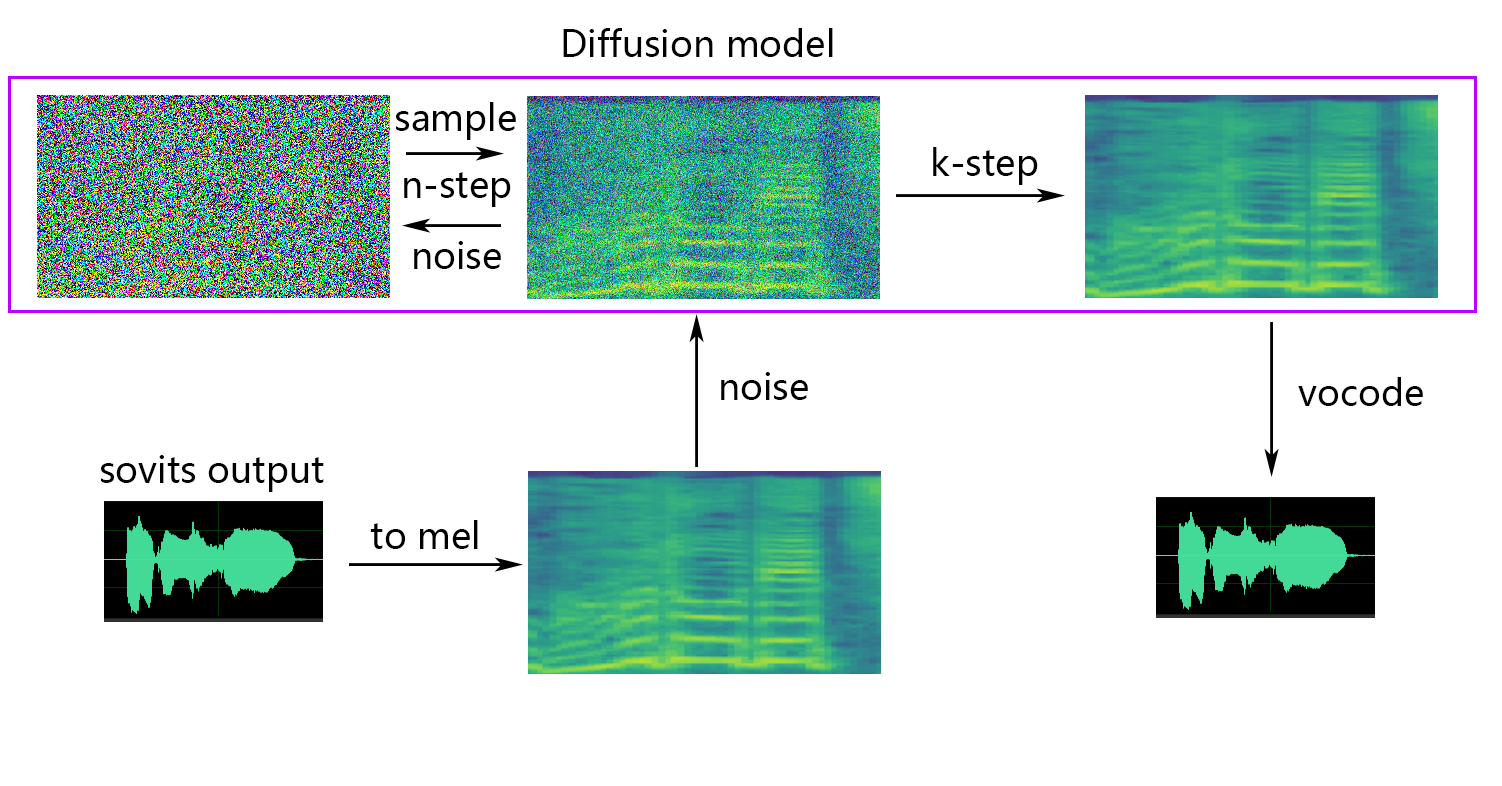
|
sovits4_for_colab.ipynb
ADDED
|
@@ -0,0 +1,711 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"cells": [
|
| 3 |
+
{
|
| 4 |
+
"attachments": {},
|
| 5 |
+
"cell_type": "markdown",
|
| 6 |
+
"metadata": {
|
| 7 |
+
"id": "2q0l56aFQhAM"
|
| 8 |
+
},
|
| 9 |
+
"source": [
|
| 10 |
+
"# Terms of Use\n",
|
| 11 |
+
"\n",
|
| 12 |
+
"### Please solve the authorization problem of the dataset on your own. You shall be solely responsible for any problems caused by the use of non-authorized datasets for training and all consequences thereof.The repository and its maintainer, svc develop team, have nothing to do with the consequences!\n",
|
| 13 |
+
"\n",
|
| 14 |
+
"1. This project is established for academic exchange purposes only and is intended for communication and learning purposes. It is not intended for production environments.\n",
|
| 15 |
+
"2. Any videos based on sovits that are published on video platforms must clearly indicate in the description that they are used for voice changing and specify the input source of the voice or audio, for example, using videos or audios published by others and separating the vocals as input source for conversion, which must provide clear original video or music links. If your own voice or other synthesized voices from other commercial vocal synthesis software are used as the input source for conversion, you must also explain it in the description.\n",
|
| 16 |
+
"3. You shall be solely responsible for any infringement problems caused by the input source. When using other commercial vocal synthesis software as input source, please ensure that you comply with the terms of use of the software. Note that many vocal synthesis engines clearly state in their terms of use that they cannot be used for input source conversion.\n",
|
| 17 |
+
"4. Continuing to use this project is deemed as agreeing to the relevant provisions stated in this repository README. This repository README has the obligation to persuade, and is not responsible for any subsequent problems that may arise.\n",
|
| 18 |
+
"5. If you distribute this repository's code or publish any results produced by this project publicly (including but not limited to video sharing platforms), please indicate the original author and code source (this repository).\n",
|
| 19 |
+
"6. If you use this project for any other plan, please contact and inform the author of this repository in advance. Thank you very much.\n"
|
| 20 |
+
]
|
| 21 |
+
},
|
| 22 |
+
{
|
| 23 |
+
"attachments": {},
|
| 24 |
+
"cell_type": "markdown",
|
| 25 |
+
"metadata": {
|
| 26 |
+
"id": "M_RcDbVPhivj"
|
| 27 |
+
},
|
| 28 |
+
"source": [
|
| 29 |
+
"## **Note:**\n",
|
| 30 |
+
"## **Make sure there is no a directory named `sovits4data` in your google drive at the first time you use this notebook.**\n",
|
| 31 |
+
"## **It will be created to store some necessary files.** \n",
|
| 32 |
+
"## **For sure you can change it to another directory by modifying `sovits_data_dir` variable.**"
|
| 33 |
+
]
|
| 34 |
+
},
|
| 35 |
+
{
|
| 36 |
+
"attachments": {},
|
| 37 |
+
"cell_type": "markdown",
|
| 38 |
+
"metadata": {
|
| 39 |
+
"id": "fHaw6hGEa_Nk"
|
| 40 |
+
},
|
| 41 |
+
"source": [
|
| 42 |
+
"# **Initialize environment**"
|
| 43 |
+
]
|
| 44 |
+
},
|
| 45 |
+
{
|
| 46 |
+
"cell_type": "code",
|
| 47 |
+
"execution_count": null,
|
| 48 |
+
"metadata": {
|
| 49 |
+
"id": "0gQcIZ8RsOkn"
|
| 50 |
+
},
|
| 51 |
+
"outputs": [],
|
| 52 |
+
"source": [
|
| 53 |
+
"#@title Connect to colab runtime and check GPU\n",
|
| 54 |
+
"\n",
|
| 55 |
+
"#@markdown # Connect to colab runtime and check GPU\n",
|
| 56 |
+
"\n",
|
| 57 |
+
"#@markdown\n",
|
| 58 |
+
"\n",
|
| 59 |
+
"!nvidia-smi"
|
| 60 |
+
]
|
| 61 |
+
},
|
| 62 |
+
{
|
| 63 |
+
"cell_type": "code",
|
| 64 |
+
"execution_count": null,
|
| 65 |
+
"metadata": {
|
| 66 |
+
"id": "0YUGpYrXhMck"
|
| 67 |
+
},
|
| 68 |
+
"outputs": [],
|
| 69 |
+
"source": [
|
| 70 |
+
"#@title Clone repository and install requirements\n",
|
| 71 |
+
"\n",
|
| 72 |
+
"#@markdown # Clone repository and install requirements\n",
|
| 73 |
+
"\n",
|
| 74 |
+
"#@markdown\n",
|
| 75 |
+
"\n",
|
| 76 |
+
"#@markdown ### After the execution is completed, the runtime will **automatically restart**\n",
|
| 77 |
+
"\n",
|
| 78 |
+
"#@markdown\n",
|
| 79 |
+
"\n",
|
| 80 |
+
"!git clone https://github.com/svc-develop-team/so-vits-svc -b 4.1-Stable\n",
|
| 81 |
+
"%cd /content/so-vits-svc\n",
|
| 82 |
+
"%pip install --upgrade pip setuptools\n",
|
| 83 |
+
"%pip install -r requirements.txt --extra-index-url https://download.pytorch.org/whl/cu118\n",
|
| 84 |
+
"exit()"
|
| 85 |
+
]
|
| 86 |
+
},
|
| 87 |
+
{
|
| 88 |
+
"cell_type": "code",
|
| 89 |
+
"execution_count": null,
|
| 90 |
+
"metadata": {
|
| 91 |
+
"id": "wmUkpUmfn_Hs"
|
| 92 |
+
},
|
| 93 |
+
"outputs": [],
|
| 94 |
+
"source": [
|
| 95 |
+
"#@title Mount google drive and select which directories to sync with google drive\n",
|
| 96 |
+
"\n",
|
| 97 |
+
"#@markdown # Mount google drive and select which directories to sync with google drive\n",
|
| 98 |
+
"\n",
|
| 99 |
+
"#@markdown\n",
|
| 100 |
+
"\n",
|
| 101 |
+
"from google.colab import drive\n",
|
| 102 |
+
"drive.mount(\"/content/drive\")\n",
|
| 103 |
+
"\n",
|
| 104 |
+
"#@markdown Directory to store **necessary files**, dont miss the slash at the end👇.\n",
|
| 105 |
+
"sovits_data_dir = \"/content/drive/MyDrive/sovits4data/\" #@param {type:\"string\"}\n",
|
| 106 |
+
"#@markdown By default it will create a `sovits4data/` folder in your google drive.\n",
|
| 107 |
+
"RAW_DIR = sovits_data_dir + \"raw/\"\n",
|
| 108 |
+
"RESULTS_DIR = sovits_data_dir + \"results/\"\n",
|
| 109 |
+
"FILELISTS_DIR = sovits_data_dir + \"filelists/\"\n",
|
| 110 |
+
"CONFIGS_DIR = sovits_data_dir + \"configs/\"\n",
|
| 111 |
+
"LOGS_DIR = sovits_data_dir + \"logs/44k/\"\n",
|
| 112 |
+
"\n",
|
| 113 |
+
"#@markdown\n",
|
| 114 |
+
"\n",
|
| 115 |
+
"#@markdown ### These folders will be synced with your google drvie\n",
|
| 116 |
+
"\n",
|
| 117 |
+
"#@markdown ### **Strongly recommend to check all.**\n",
|
| 118 |
+
"\n",
|
| 119 |
+
"#@markdown Sync **input audios** and **output audios**\n",
|
| 120 |
+
"sync_raw_and_results = True #@param {type:\"boolean\"}\n",
|
| 121 |
+
"if sync_raw_and_results:\n",
|
| 122 |
+
" !mkdir -p {RAW_DIR}\n",
|
| 123 |
+
" !mkdir -p {RESULTS_DIR}\n",
|
| 124 |
+
" !rm -rf /content/so-vits-svc/raw\n",
|
| 125 |
+
" !rm -rf /content/so-vits-svc/results\n",
|
| 126 |
+
" !ln -s {RAW_DIR} /content/so-vits-svc/raw\n",
|
| 127 |
+
" !ln -s {RESULTS_DIR} /content/so-vits-svc/results\n",
|
| 128 |
+
"\n",
|
| 129 |
+
"#@markdown Sync **config** and **models**\n",
|
| 130 |
+
"sync_configs_and_logs = True #@param {type:\"boolean\"}\n",
|
| 131 |
+
"if sync_configs_and_logs:\n",
|
| 132 |
+
" !mkdir -p {FILELISTS_DIR}\n",
|
| 133 |
+
" !mkdir -p {CONFIGS_DIR}\n",
|
| 134 |
+
" !mkdir -p {LOGS_DIR}\n",
|
| 135 |
+
" !rm -rf /content/so-vits-svc/filelists\n",
|
| 136 |
+
" !rm -rf /content/so-vits-svc/configs\n",
|
| 137 |
+
" !rm -rf /content/so-vits-svc/logs/44k\n",
|
| 138 |
+
" !ln -s {FILELISTS_DIR} /content/so-vits-svc/filelists\n",
|
| 139 |
+
" !ln -s {CONFIGS_DIR} /content/so-vits-svc/configs\n",
|
| 140 |
+
" !ln -s {LOGS_DIR} /content/so-vits-svc/logs/44k"
|
| 141 |
+
]
|
| 142 |
+
},
|
| 143 |
+
{
|
| 144 |
+
"cell_type": "code",
|
| 145 |
+
"execution_count": null,
|
| 146 |
+
"metadata": {
|
| 147 |
+
"id": "G_PMPCN6wvgZ"
|
| 148 |
+
},
|
| 149 |
+
"outputs": [],
|
| 150 |
+
"source": [
|
| 151 |
+
"#@title Get pretrained model(Optional but strongly recommend).\n",
|
| 152 |
+
"\n",
|
| 153 |
+
"#@markdown # Get pretrained model(Optional but strongly recommend).\n",
|
| 154 |
+
"\n",
|
| 155 |
+
"#@markdown\n",
|
| 156 |
+
"\n",
|
| 157 |
+
"#@markdown - Pre-trained model files: `G_0.pth` `D_0.pth`\n",
|
| 158 |
+
"#@markdown - Place them under /sovits4data/logs/44k/ in your google drive manualy\n",
|
| 159 |
+
"\n",
|
| 160 |
+
"#@markdown Get them from svc-develop-team(TBD) or anywhere else.\n",
|
| 161 |
+
"\n",
|
| 162 |
+
"#@markdown Although the pretrained model generally does not cause any copyright problems, please pay attention to it. For example, ask the author in advance, or the author has indicated the feasible use in the description clearly.\n",
|
| 163 |
+
"\n",
|
| 164 |
+
"download_pretrained_model = True #@param {type:\"boolean\"}\n",
|
| 165 |
+
"D_0_URL = \"https://huggingface.co/datasets/ms903/sovits4.0-768vec-layer12/resolve/main/sovits_768l12_pre_large_320k/clean_D_320000.pth\" #@param [\"https://huggingface.co/datasets/ms903/sovits4.0-768vec-layer12/resolve/main/sovits_768l12_pre_large_320k/clean_D_320000.pth\", \"https://huggingface.co/1asbgdh/sovits4.0-volemb-vec768/resolve/main/clean_D_320000.pth\"] {allow-input: true}\n",
|
| 166 |
+
"G_0_URL = \"https://huggingface.co/datasets/ms903/sovits4.0-768vec-layer12/resolve/main/sovits_768l12_pre_large_320k/clean_G_320000.pth\" #@param [\"https://huggingface.co/datasets/ms903/sovits4.0-768vec-layer12/resolve/main/sovits_768l12_pre_large_320k/clean_G_320000.pth\", \"https://huggingface.co/1asbgdh/sovits4.0-volemb-vec768/resolve/main/clean_G_320000.pth\"] {allow-input: true}\n",
|
| 167 |
+
"\n",
|
| 168 |
+
"download_pretrained_diffusion_model = True #@param {type:\"boolean\"}\n",
|
| 169 |
+
"diff_model_URL = \"https://huggingface.co/datasets/ms903/Diff-SVC-refactor-pre-trained-model/resolve/main/fix_pitch_add_vctk_600k/model_0.pt\" #@param {type:\"string\"}\n",
|
| 170 |
+
"\n",
|
| 171 |
+
"%cd /content/so-vits-svc\n",
|
| 172 |
+
"\n",
|
| 173 |
+
"if download_pretrained_model:\n",
|
| 174 |
+
" !curl -L {D_0_URL} -o logs/44k/D_0.pth\n",
|
| 175 |
+
" !md5sum logs/44k/D_0.pth\n",
|
| 176 |
+
" !curl -L {G_0_URL} -o logs/44k/G_0.pth\n",
|
| 177 |
+
" !md5sum logs/44k/G_0.pth\n",
|
| 178 |
+
"\n",
|
| 179 |
+
"if download_pretrained_diffusion_model:\n",
|
| 180 |
+
" !mkdir -p logs/44k/diffusion\n",
|
| 181 |
+
" !curl -L {diff_model_URL} -o logs/44k/diffusion/model_0.pt\n",
|
| 182 |
+
" !md5sum logs/44k/diffusion/model_0.pt"
|
| 183 |
+
]
|
| 184 |
+
},
|
| 185 |
+
{
|
| 186 |
+
"attachments": {},
|
| 187 |
+
"cell_type": "markdown",
|
| 188 |
+
"metadata": {
|
| 189 |
+
"id": "k1qadJBFehMo"
|
| 190 |
+
},
|
| 191 |
+
"source": [
|
| 192 |
+
"# **Dataset preprocessing**"
|
| 193 |
+
]
|
| 194 |
+
},
|
| 195 |
+
{
|
| 196 |
+
"attachments": {},
|
| 197 |
+
"cell_type": "markdown",
|
| 198 |
+
"metadata": {
|
| 199 |
+
"id": "kBlju6Q3lSM6"
|
| 200 |
+
},
|
| 201 |
+
"source": [
|
| 202 |
+
"Pack and upload your raw dataset(dataset_raw/) to your google drive.\n",
|
| 203 |
+
"\n",
|
| 204 |
+
"Makesure the file structure in your zip file looks like this:\n",
|
| 205 |
+
"\n",
|
| 206 |
+
"```\n",
|
| 207 |
+
"YourZIPforSingleSpeakers.zip\n",
|
| 208 |
+
"└───speaker\n",
|
| 209 |
+
" ├───xxx1-xxx1.wav\n",
|
| 210 |
+
" ├───...\n",
|
| 211 |
+
" └───Lxx-0xx8.wav\n",
|
| 212 |
+
"```\n",
|
| 213 |
+
"\n",
|
| 214 |
+
"```\n",
|
| 215 |
+
"YourZIPforMultipleSpeakers.zip\n",
|
| 216 |
+
"├───speaker0\n",
|
| 217 |
+
"│ ├───xxx1-xxx1.wav\n",
|
| 218 |
+
"│ ├───...\n",
|
| 219 |
+
"│ └───Lxx-0xx8.wav\n",
|
| 220 |
+
"└───speaker1\n",
|
| 221 |
+
" ├───xx2-0xxx2.wav\n",
|
| 222 |
+
" ├───...\n",
|
| 223 |
+
" └───xxx7-xxx007.wav\n",
|
| 224 |
+
"```\n",
|
| 225 |
+
"\n",
|
| 226 |
+
"**Even if there is only one speaker, a folder named `{speaker_name}` is needed.**"
|
| 227 |
+
]
|
| 228 |
+
},
|
| 229 |
+
{
|
| 230 |
+
"cell_type": "code",
|
| 231 |
+
"execution_count": null,
|
| 232 |
+
"metadata": {
|
| 233 |
+
"id": "U05CXlAipvJR"
|
| 234 |
+
},
|
| 235 |
+
"outputs": [],
|
| 236 |
+
"source": [
|
| 237 |
+
"#@title Get raw dataset from google drive\n",
|
| 238 |
+
"\n",
|
| 239 |
+
"#@markdown # Get raw dataset from google drive\n",
|
| 240 |
+
"\n",
|
| 241 |
+
"#@markdown\n",
|
| 242 |
+
"\n",
|
| 243 |
+
"#@markdown Directory where **your zip file** located in, dont miss the slash at the end👇.\n",
|
| 244 |
+
"sovits_data_dir = \"/content/drive/MyDrive/sovits4data/\" #@param {type:\"string\"}\n",
|
| 245 |
+
"#@markdown Filename of **your zip file**, do NOT be \"dataset.zip\"\n",
|
| 246 |
+
"zip_filename = \"YourZIPFilenameofRawDataset.zip\" #@param {type:\"string\"}\n",
|
| 247 |
+
"ZIP_PATH = sovits_data_dir + zip_filename\n",
|
| 248 |
+
"\n",
|
| 249 |
+
"!unzip -od /content/so-vits-svc/dataset_raw {ZIP_PATH}"
|
| 250 |
+
]
|
| 251 |
+
},
|
| 252 |
+
{
|
| 253 |
+
"cell_type": "code",
|
| 254 |
+
"execution_count": null,
|
| 255 |
+
"metadata": {
|
| 256 |
+
"id": "_ThKTzYs5CfL"
|
| 257 |
+
},
|
| 258 |
+
"outputs": [],
|
| 259 |
+
"source": [
|
| 260 |
+
"#@title Resample to 44100Hz and mono\n",
|
| 261 |
+
"\n",
|
| 262 |
+
"#@markdown # Resample to 44100Hz and mono\n",
|
| 263 |
+
"\n",
|
| 264 |
+
"#@markdown\n",
|
| 265 |
+
"\n",
|
| 266 |
+
"%cd /content/so-vits-svc\n",
|
| 267 |
+
"!python resample.py"
|
| 268 |
+
]
|
| 269 |
+
},
|
| 270 |
+
{
|
| 271 |
+
"cell_type": "code",
|
| 272 |
+
"execution_count": null,
|
| 273 |
+
"metadata": {
|
| 274 |
+
"id": "svITReeL5N8K"
|
| 275 |
+
},
|
| 276 |
+
"outputs": [],
|
| 277 |
+
"source": [
|
| 278 |
+
"#@title Divide filelists and generate config.json\n",
|
| 279 |
+
"\n",
|
| 280 |
+
"#@markdown # Divide filelists and generate config.json\n",
|
| 281 |
+
"\n",
|
| 282 |
+
"#@markdown\n",
|
| 283 |
+
"\n",
|
| 284 |
+
"%cd /content/so-vits-svc\n",
|
| 285 |
+
"\n",
|
| 286 |
+
"speech_encoder = \"vec768l12\" #@param [\"vec768l12\", \"vec256l9\", \"hubertsoft\", \"whisper-ppg\", \"whisper-ppg-large\"]\n",
|
| 287 |
+
"use_vol_aug = False #@param {type:\"boolean\"}\n",
|
| 288 |
+
"vol_aug = \"--vol_aug\" if use_vol_aug else \"\"\n",
|
| 289 |
+
"\n",
|
| 290 |
+
"from pretrain.meta import download_dict\n",
|
| 291 |
+
"download_dict = download_dict()\n",
|
| 292 |
+
"\n",
|
| 293 |
+
"url = download_dict[speech_encoder][\"url\"]\n",
|
| 294 |
+
"output = download_dict[speech_encoder][\"output\"]\n",
|
| 295 |
+
"\n",
|
| 296 |
+
"import os\n",
|
| 297 |
+
"if not os.path.exists(output):\n",
|
| 298 |
+
" !curl -L {url} -o {output}\n",
|
| 299 |
+
" !md5sum {output}\n",
|
| 300 |
+
"\n",
|
| 301 |
+
"!python preprocess_flist_config.py --speech_encoder={speech_encoder} {vol_aug}"
|
| 302 |
+
]
|
| 303 |
+
},
|
| 304 |
+
{
|
| 305 |
+
"cell_type": "code",
|
| 306 |
+
"execution_count": null,
|
| 307 |
+
"metadata": {
|
| 308 |
+
"id": "xHUXMi836DMe"
|
| 309 |
+
},
|
| 310 |
+
"outputs": [],
|
| 311 |
+
"source": [
|
| 312 |
+
"#@title Generate hubert and f0\n",
|
| 313 |
+
"\n",
|
| 314 |
+
"#@markdown # Generate hubert and f0\n",
|
| 315 |
+
"\n",
|
| 316 |
+
"#@markdown\n",
|
| 317 |
+
"%cd /content/so-vits-svc\n",
|
| 318 |
+
"\n",
|
| 319 |
+
"f0_predictor = \"crepe\" #@param [\"crepe\", \"pm\", \"dio\", \"harvest\", \"rmvpe\"]\n",
|
| 320 |
+
"use_diff = True #@param {type:\"boolean\"}\n",
|
| 321 |
+
"\n",
|
| 322 |
+
"import os\n",
|
| 323 |
+
"if f0_predictor == \"rmvpe\" and not os.path.exists(\"./pretrain/rmvpe.pt\"):\n",
|
| 324 |
+
" !curl -L https://huggingface.co/datasets/ylzz1997/rmvpe_pretrain_model/resolve/main/rmvpe.pt -o pretrain/rmvpe.pt\n",
|
| 325 |
+
"\n",
|
| 326 |
+
"diff_param = \"\"\n",
|
| 327 |
+
"if use_diff:\n",
|
| 328 |
+
" diff_param = \"--use_diff\"\n",
|
| 329 |
+
"\n",
|
| 330 |
+
" if not os.path.exists(\"./pretrain/nsf_hifigan/model\"):\n",
|
| 331 |
+
" !curl -L https://github.com/openvpi/vocoders/releases/download/nsf-hifigan-v1/nsf_hifigan_20221211.zip -o nsf_hifigan_20221211.zip\n",
|
| 332 |
+
" !md5sum nsf_hifigan_20221211.zip\n",
|
| 333 |
+
" !unzip nsf_hifigan_20221211.zip\n",
|
| 334 |
+
" !rm -rf pretrain/nsf_hifigan\n",
|
| 335 |
+
" !mv -v nsf_hifigan pretrain\n",
|
| 336 |
+
"\n",
|
| 337 |
+
"!python preprocess_hubert_f0.py --f0_predictor={f0_predictor} {diff_param}"
|
| 338 |
+
]
|
| 339 |
+
},
|
| 340 |
+
{
|
| 341 |
+
"cell_type": "code",
|
| 342 |
+
"execution_count": null,
|
| 343 |
+
"metadata": {
|
| 344 |
+
"id": "Wo4OTmTAUXgj"
|
| 345 |
+
},
|
| 346 |
+
"outputs": [],
|
| 347 |
+
"source": [
|
| 348 |
+
"#@title Save the preprocessed dataset to google drive\n",
|
| 349 |
+
"\n",
|
| 350 |
+
"#@markdown # Save the preprocessed dataset to google drive\n",
|
| 351 |
+
"\n",
|
| 352 |
+
"#@markdown\n",
|
| 353 |
+
"\n",
|
| 354 |
+
"#@markdown You can save the dataset and related files to your google drive for the next training\n",
|
| 355 |
+
"\n",
|
| 356 |
+
"#@markdown **Directory for saving**, dont miss the slash at the end👇.\n",
|
| 357 |
+
"sovits_data_dir = \"/content/drive/MyDrive/sovits4data/\" #@param {type:\"string\"}\n",
|
| 358 |
+
"\n",
|
| 359 |
+
"#@markdown There will be a `dataset.zip` contained `dataset/` in your google drive, which is preprocessed data.\n",
|
| 360 |
+
"\n",
|
| 361 |
+
"!mkdir -p {sovits_data_dir}\n",
|
| 362 |
+
"!zip -r dataset.zip /content/so-vits-svc/dataset\n",
|
| 363 |
+
"!cp -vr dataset.zip \"{sovits_data_dir}\""
|
| 364 |
+
]
|
| 365 |
+
},
|
| 366 |
+
{
|
| 367 |
+
"cell_type": "code",
|
| 368 |
+
"execution_count": null,
|
| 369 |
+
"metadata": {
|
| 370 |
+
"id": "P2G6v_6zblWK"
|
| 371 |
+
},
|
| 372 |
+
"outputs": [],
|
| 373 |
+
"source": [
|
| 374 |
+
"#@title Unzip preprocessed dataset from google drive directly if you have preprocessed already.\n",
|
| 375 |
+
"\n",
|
| 376 |
+
"#@markdown # Unzip preprocessed dataset from google drive directly if you have preprocessed already.\n",
|
| 377 |
+
"\n",
|
| 378 |
+
"#@markdown\n",
|
| 379 |
+
"\n",
|
| 380 |
+
"#@markdown Directory where **your preprocessed dataset** located in, dont miss the slash at the end👇.\n",
|
| 381 |
+
"sovits_data_dir = \"/content/drive/MyDrive/sovits4data/\" #@param {type:\"string\"}\n",
|
| 382 |
+
"CONFIG = sovits_data_dir + \"configs/\"\n",
|
| 383 |
+
"FILELISTS = sovits_data_dir + \"filelists/\"\n",
|
| 384 |
+
"DATASET = sovits_data_dir + \"dataset.zip\"\n",
|
| 385 |
+
"\n",
|
| 386 |
+
"!cp -vr {CONFIG} /content/so-vits-svc/\n",
|
| 387 |
+
"!cp -vr {FILELISTS} /content/so-vits-svc/\n",
|
| 388 |
+
"!unzip {DATASET} -d /"
|
| 389 |
+
]
|
| 390 |
+
},
|
| 391 |
+
{
|
| 392 |
+
"attachments": {},
|
| 393 |
+
"cell_type": "markdown",
|
| 394 |
+
"metadata": {
|
| 395 |
+
"id": "ENoH-pShel7w"
|
| 396 |
+
},
|
| 397 |
+
"source": [
|
| 398 |
+
"# **Trainning**"
|
| 399 |
+
]
|
| 400 |
+
},
|
| 401 |
+
{
|
| 402 |
+
"cell_type": "code",
|
| 403 |
+
"execution_count": null,
|
| 404 |
+
"metadata": {
|
| 405 |
+
"id": "-hEFFTCfZf57"
|
| 406 |
+
},
|
| 407 |
+
"outputs": [],
|
| 408 |
+
"source": [
|
| 409 |
+
"#@title Start training\n",
|
| 410 |
+
"\n",
|
| 411 |
+
"#@markdown # Start training\n",
|
| 412 |
+
"\n",
|
| 413 |
+
"#@markdown If you want to use pre-trained models, upload them to /sovits4data/logs/44k/ in your google drive manualy.\n",
|
| 414 |
+
"\n",
|
| 415 |
+
"#@markdown\n",
|
| 416 |
+
"\n",
|
| 417 |
+
"%cd /content/so-vits-svc\n",
|
| 418 |
+
"\n",
|
| 419 |
+
"#@markdown Whether to enable tensorboard\n",
|
| 420 |
+
"tensorboard_on = True #@param {type:\"boolean\"}\n",
|
| 421 |
+
"\n",
|
| 422 |
+
"if tensorboard_on:\n",
|
| 423 |
+
" %load_ext tensorboard\n",
|
| 424 |
+
" %tensorboard --logdir logs/44k\n",
|
| 425 |
+
"\n",
|
| 426 |
+
"config_path = \"configs/config.json\"\n",
|
| 427 |
+
"\n",
|
| 428 |
+
"from pretrain.meta import get_speech_encoder\n",
|
| 429 |
+
"url, output = get_speech_encoder(config_path)\n",
|
| 430 |
+
"\n",
|
| 431 |
+
"import os\n",
|
| 432 |
+
"if not os.path.exists(output):\n",
|
| 433 |
+
" !curl -L {url} -o {output}\n",
|
| 434 |
+
"\n",
|
| 435 |
+
"!python train.py -c {config_path} -m 44k"
|
| 436 |
+
]
|
| 437 |
+
},
|
| 438 |
+
{
|
| 439 |
+
"cell_type": "code",
|
| 440 |
+
"execution_count": null,
|
| 441 |
+
"metadata": {
|
| 442 |
+
"id": "ZThaMxmIJgWy"
|
| 443 |
+
},
|
| 444 |
+
"outputs": [],
|
| 445 |
+
"source": [
|
| 446 |
+
"#@title Train cluster model (Optional)\n",
|
| 447 |
+
"\n",
|
| 448 |
+
"#@markdown # Train cluster model (Optional)\n",
|
| 449 |
+
"\n",
|
| 450 |
+
"#@markdown #### Details see [README.md#cluster-based-timbre-leakage-control](https://github.com/svc-develop-team/so-vits-svc#cluster-based-timbre-leakage-control)\n",
|
| 451 |
+
"\n",
|
| 452 |
+
"#@markdown\n",
|
| 453 |
+
"\n",
|
| 454 |
+
"%cd /content/so-vits-svc\n",
|
| 455 |
+
"!python cluster/train_cluster.py --gpu"
|
| 456 |
+
]
|
| 457 |
+
},
|
| 458 |
+
{
|
| 459 |
+
"cell_type": "code",
|
| 460 |
+
"execution_count": null,
|
| 461 |
+
"metadata": {},
|
| 462 |
+
"outputs": [],
|
| 463 |
+
"source": [
|
| 464 |
+
"#@title Train index model (Optional)\n",
|
| 465 |
+
"\n",
|
| 466 |
+
"#@markdown # Train index model (Optional)\n",
|
| 467 |
+
"\n",
|
| 468 |
+
"#@markdown #### Details see [README.md#feature-retrieval](https://github.com/svc-develop-team/so-vits-svc#feature-retrieval)\n",
|
| 469 |
+
"\n",
|
| 470 |
+
"#@markdown\n",
|
| 471 |
+
"\n",
|
| 472 |
+
"%cd /content/so-vits-svc\n",
|
| 473 |
+
"!python train_index.py -c configs/config.json"
|
| 474 |
+
]
|
| 475 |
+
},
|
| 476 |
+
{
|
| 477 |
+
"cell_type": "code",
|
| 478 |
+
"execution_count": null,
|
| 479 |
+
"metadata": {},
|
| 480 |
+
"outputs": [],
|
| 481 |
+
"source": [
|
| 482 |
+
"#@title Train diffusion model (Optional)\n",
|
| 483 |
+
"\n",
|
| 484 |
+
"#@markdown # Train diffusion model (Optional)\n",
|
| 485 |
+
"\n",
|
| 486 |
+
"#@markdown #### Details see [README.md#-about-shallow-diffusion](https://github.com/svc-develop-team/so-vits-svc#-about-shallow-diffusion)\n",
|
| 487 |
+
"\n",
|
| 488 |
+
"#@markdown\n",
|
| 489 |
+
"\n",
|
| 490 |
+
"%cd /content/so-vits-svc\n",
|
| 491 |
+
"\n",
|
| 492 |
+
"import os\n",
|
| 493 |
+
"if not os.path.exists(\"./pretrain/nsf_hifigan/model\"):\n",
|
| 494 |
+
" !curl -L https://github.com/openvpi/vocoders/releases/download/nsf-hifigan-v1/nsf_hifigan_20221211.zip -o nsf_hifigan_20221211.zip\n",
|
| 495 |
+
" !unzip nsf_hifigan_20221211.zip\n",
|
| 496 |
+
" !rm -rf pretrain/nsf_hifigan\n",
|
| 497 |
+
" !mv -v nsf_hifigan pretrain\n",
|
| 498 |
+
"\n",
|
| 499 |
+
"#@markdown Whether to enable tensorboard\n",
|
| 500 |
+
"tensorboard_on = True #@param {type:\"boolean\"}\n",
|
| 501 |
+
"\n",
|
| 502 |
+
"if tensorboard_on:\n",
|
| 503 |
+
" %load_ext tensorboard\n",
|
| 504 |
+
" %tensorboard --logdir logs/44k\n",
|
| 505 |
+
"\n",
|
| 506 |
+
"!python train_diff.py -c configs/diffusion.yaml"
|
| 507 |
+
]
|
| 508 |
+
},
|
| 509 |
+
{
|
| 510 |
+
"attachments": {},
|
| 511 |
+
"cell_type": "markdown",
|
| 512 |
+
"metadata": {},
|
| 513 |
+
"source": [
|
| 514 |
+
"# keep colab alive\n",
|
| 515 |
+
"Open the devtools and copy & paste to run the scrips.\n",
|
| 516 |
+
"\n",
|
| 517 |
+
"\n",
|
| 518 |
+
"```JavaScript\n",
|
| 519 |
+
"const ping = () => {\n",
|
| 520 |
+
" const btn = document.querySelector(\"colab-connect-button\");\n",
|
| 521 |
+
" const inner_btn = btn.shadowRoot.querySelector(\"#connect\");\n",
|
| 522 |
+
" if (inner_btn) {\n",
|
| 523 |
+
" inner_btn.click();\n",
|
| 524 |
+
" console.log(\"Clicked on connect button\");\n",
|
| 525 |
+
" } else {\n",
|
| 526 |
+
" console.log(\"connect button not found\");\n",
|
| 527 |
+
" }\n",
|
| 528 |
+
"\n",
|
| 529 |
+
" const nextTime = 50000 + Math.random() * 10000;\n",
|
| 530 |
+
"\n",
|
| 531 |
+
" setTimeout(ping, nextTime);\n",
|
| 532 |
+
"};\n",
|
| 533 |
+
"\n",
|
| 534 |
+
"ping();\n",
|
| 535 |
+
"```"
|
| 536 |
+
]
|
| 537 |
+
},
|
| 538 |
+
{
|
| 539 |
+
"attachments": {},
|
| 540 |
+
"cell_type": "markdown",
|
| 541 |
+
"metadata": {
|
| 542 |
+
"id": "oCnbX-OT897k"
|
| 543 |
+
},
|
| 544 |
+
"source": [
|
| 545 |
+
"# **Inference**\n",
|
| 546 |
+
"### Upload wav files from this notebook\n",
|
| 547 |
+
"### **OR**\n",
|
| 548 |
+
"### Upload to `sovits4data/raw/` in your google drive manualy (should be faster)"
|
| 549 |
+
]
|
| 550 |
+
},
|
| 551 |
+
{
|
| 552 |
+
"cell_type": "code",
|
| 553 |
+
"execution_count": null,
|
| 554 |
+
"metadata": {},
|
| 555 |
+
"outputs": [],
|
| 556 |
+
"source": [
|
| 557 |
+
"#title Download nsf_hifigan if you need it\n",
|
| 558 |
+
"\n",
|
| 559 |
+
"%cd /content/so-vits-svc\n",
|
| 560 |
+
"!curl -L https://github.com/openvpi/vocoders/releases/download/nsf-hifigan-v1/nsf_hifigan_20221211.zip -o /content/so-vits-svc/nsf_hifigan_20221211.zip\n",
|
| 561 |
+
"!unzip nsf_hifigan_20221211.zip\n",
|
| 562 |
+
"!rm -rf pretrain/nsf_hifigan\n",
|
| 563 |
+
"!mv -v nsf_hifigan pretrain\n"
|
| 564 |
+
]
|
| 565 |
+
},
|
| 566 |
+
{
|
| 567 |
+
"cell_type": "code",
|
| 568 |
+
"execution_count": null,
|
| 569 |
+
"metadata": {
|
| 570 |
+
"colab": {
|
| 571 |
+
"base_uri": "https://localhost:8080/",
|
| 572 |
+
"height": 75
|
| 573 |
+
},
|
| 574 |
+
"executionInfo": {
|
| 575 |
+
"elapsed": 94633,
|
| 576 |
+
"status": "ok",
|
| 577 |
+
"timestamp": 1678591088790,
|
| 578 |
+
"user": {
|
| 579 |
+
"displayName": "謬紗特",
|
| 580 |
+
"userId": "09445825975794260265"
|
| 581 |
+
},
|
| 582 |
+
"user_tz": -480
|
| 583 |
+
},
|
| 584 |
+
"id": "XUsmGkgCMD_Q",
|
| 585 |
+
"outputId": "8bbfde13-030a-4ba0-bbdb-7eb6b89c02b4"
|
| 586 |
+
},
|
| 587 |
+
"outputs": [],
|
| 588 |
+
"source": [
|
| 589 |
+
"#@title Upload wav files, the filename should not contain any special symbols like `#` `$` `(` `)`\n",
|
| 590 |
+
"\n",
|
| 591 |
+
"#@markdown # Upload wav files, the filename should not contain any special symbols like `#` `$` `(` `)`\n",
|
| 592 |
+
"\n",
|
| 593 |
+
"#@markdown\n",
|
| 594 |
+
"\n",
|
| 595 |
+
"%cd /content/so-vits-svc\n",
|
| 596 |
+
"%run wav_upload.py --type audio"
|
| 597 |
+
]
|
| 598 |
+
},
|
| 599 |
+
{
|
| 600 |
+
"cell_type": "code",
|
| 601 |
+
"execution_count": null,
|
| 602 |
+
"metadata": {
|
| 603 |
+
"id": "dYnKuKTIj3z1"
|
| 604 |
+
},
|
| 605 |
+
"outputs": [],
|
| 606 |
+
"source": [
|
| 607 |
+
"#@title Start inference (and download)\n",
|
| 608 |
+
"\n",
|
| 609 |
+
"#@markdown # Start inference (and download)\n",
|
| 610 |
+
"\n",
|
| 611 |
+
"#@markdown Parameters see [README.MD#Inference](https://github.com/svc-develop-team/so-vits-svc#-inference)\n",
|
| 612 |
+
"\n",
|
| 613 |
+
"#@markdown\n",
|
| 614 |
+
"\n",
|
| 615 |
+
"wav_filename = \"YourWAVFile.wav\" #@param {type:\"string\"}\n",
|
| 616 |
+
"model_filename = \"G_210000.pth\" #@param {type:\"string\"}\n",
|
| 617 |
+
"model_path = \"/content/so-vits-svc/logs/44k/\" + model_filename\n",
|
| 618 |
+
"speaker = \"YourSpeaker\" #@param {type:\"string\"}\n",
|
| 619 |
+
"trans = \"0\" #@param {type:\"string\"}\n",
|
| 620 |
+
"cluster_infer_ratio = \"0\" #@param {type:\"string\"}\n",
|
| 621 |
+
"auto_predict_f0 = False #@param {type:\"boolean\"}\n",
|
| 622 |
+
"apf = \"\"\n",
|
| 623 |
+
"if auto_predict_f0:\n",
|
| 624 |
+
" apf = \" -a \"\n",
|
| 625 |
+
"\n",
|
| 626 |
+
"f0_predictor = \"crepe\" #@param [\"crepe\", \"pm\", \"dio\", \"harvest\", \"rmvpe\"]\n",
|
| 627 |
+
"\n",
|
| 628 |
+
"enhance = False #@param {type:\"boolean\"}\n",
|
| 629 |
+
"ehc = \"\"\n",
|
| 630 |
+
"if enhance:\n",
|
| 631 |
+
" ehc = \" -eh \"\n",
|
| 632 |
+
"#@markdown\n",
|
| 633 |
+
"\n",
|
| 634 |
+
"#@markdown Generally keep default:\n",
|
| 635 |
+
"config_filename = \"config.json\" #@param {type:\"string\"}\n",
|
| 636 |
+
"config_path = \"/content/so-vits-svc/configs/\" + config_filename\n",
|
| 637 |
+
"\n",
|
| 638 |
+
"from pretrain.meta import get_speech_encoder\n",
|
| 639 |
+
"url, output = get_speech_encoder(config_path)\n",
|
| 640 |
+
"\n",
|
| 641 |
+
"import os\n",
|
| 642 |
+
"\n",
|
| 643 |
+
"if f0_predictor == \"rmvpe\" and not os.path.exists(\"./pretrain/rmvpe.pt\"):\n",
|
| 644 |
+
" !curl -L https://huggingface.co/datasets/ylzz1997/rmvpe_pretrain_model/resolve/main/rmvpe.pt -o pretrain/rmvpe.pt\n",
|
| 645 |
+
"\n",
|
| 646 |
+
"if not os.path.exists(output):\n",
|
| 647 |
+
" !curl -L {url} -o {output}\n",
|
| 648 |
+
"\n",
|
| 649 |
+
"kmeans_filenname = \"kmeans_10000.pt\" #@param {type:\"string\"}\n",
|
| 650 |
+
"kmeans_path = \"/content/so-vits-svc/logs/44k/\" + kmeans_filenname\n",
|
| 651 |
+
"slice_db = \"-40\" #@param {type:\"string\"}\n",
|
| 652 |
+
"wav_format = \"flac\" #@param {type:\"string\"}\n",
|
| 653 |
+
"\n",
|
| 654 |
+
"key = \"auto\" if auto_predict_f0 else f\"{trans}key\"\n",
|
| 655 |
+
"cluster_name = \"\" if cluster_infer_ratio == \"0\" else f\"_{cluster_infer_ratio}\"\n",
|
| 656 |
+
"isdiffusion = \"sovits\"\n",
|
| 657 |
+
"wav_output = f\"/content/so-vits-svc/results/{wav_filename}_{key}_{speaker}{cluster_name}_{isdiffusion}_{f0_predictor}.{wav_format}\"\n",
|
| 658 |
+
"\n",
|
| 659 |
+
"%cd /content/so-vits-svc\n",
|
| 660 |
+
"!python inference_main.py -n {wav_filename} -m {model_path} -s {speaker} -t {trans} -cr {cluster_infer_ratio} -c {config_path} -cm {kmeans_path} -sd {slice_db} -wf {wav_format} {apf} --f0_predictor={f0_predictor} {ehc}\n",
|
| 661 |
+
"\n",
|
| 662 |
+
"#@markdown\n",
|
| 663 |
+
"\n",
|
| 664 |
+
"#@markdown If you dont want to download from here, uncheck this.\n",
|
| 665 |
+
"download_after_inference = True #@param {type:\"boolean\"}\n",
|
| 666 |
+
"\n",
|
| 667 |
+
"if download_after_inference:\n",
|
| 668 |
+
" from google.colab import files\n",
|
| 669 |
+
" files.download(wav_output)"
|
| 670 |
+
]
|
| 671 |
+
}
|
| 672 |
+
],
|
| 673 |
+
"metadata": {
|
| 674 |
+
"accelerator": "GPU",
|
| 675 |
+
"colab": {
|
| 676 |
+
"provenance": [
|
| 677 |
+
{
|
| 678 |
+
"file_id": "19fxpo-ZoL_ShEUeZIZi6Di-YioWrEyhR",
|
| 679 |
+
"timestamp": 1678516497580
|
| 680 |
+
},
|
| 681 |
+
{
|
| 682 |
+
"file_id": "1rCUOOVG7-XQlVZuWRAj5IpGrMM8t07pE",
|
| 683 |
+
"timestamp": 1673086970071
|
| 684 |
+
},
|
| 685 |
+
{
|
| 686 |
+
"file_id": "1Ul5SmzWiSHBj0MaKA0B682C-RZKOycwF",
|
| 687 |
+
"timestamp": 1670483515921
|
| 688 |
+
}
|
| 689 |
+
]
|
| 690 |
+
},
|
| 691 |
+
"gpuClass": "standard",
|
| 692 |
+
"kernelspec": {
|
| 693 |
+
"display_name": "Python 3",
|
| 694 |
+
"name": "python3"
|
| 695 |
+
},
|
| 696 |
+
"language_info": {
|
| 697 |
+
"codemirror_mode": {
|
| 698 |
+
"name": "ipython",
|
| 699 |
+
"version": 3
|
| 700 |
+
},
|
| 701 |
+
"file_extension": ".py",
|
| 702 |
+
"mimetype": "text/x-python",
|
| 703 |
+
"name": "python",
|
| 704 |
+
"nbconvert_exporter": "python",
|
| 705 |
+
"pygments_lexer": "ipython3",
|
| 706 |
+
"version": "3.8.16"
|
| 707 |
+
}
|
| 708 |
+
},
|
| 709 |
+
"nbformat": 4,
|
| 710 |
+
"nbformat_minor": 0
|
| 711 |
+
}
|
spkmix.py
ADDED
|
@@ -0,0 +1,11 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# 角色混合轨道 编写规则:
|
| 2 |
+
# 角色ID : [[起始时间1, 终止时间1, 起始数值1, 起始数值1], [起始时间2, 终止时间2, 起始数值2, 起始数值2]]
|
| 3 |
+
# 起始时间和前一个的终止时间必须相同,第一个起始时间必须为0,最后一个终止时间必须为1 (时间的范围为0-1)
|
| 4 |
+
# 全部角色必须填写,不使用的角色填[[0., 1., 0., 0.]]即可
|
| 5 |
+
# 融合数值可以随便填,在指定的时间段内从起始数值线性变化为终止数值,内部会自动确保线性组合为1,可以放心使用
|
| 6 |
+
|
| 7 |
+
spk_mix_map = {
|
| 8 |
+
0 : [[0., 0.5, 1, 0.5], [0.5, 1, 0.5, 1]],
|
| 9 |
+
1 : [[0., 0.35, 1, 0.5], [0.35, 0.75, 0.75, 1], [0.75, 1, 0.45, 1]],
|
| 10 |
+
2 : [[0., 0.35, 1, 0.5], [0.35, 0.75, 0.75, 1], [0.75, 1, 0.45, 1]]
|
| 11 |
+
}
|
temp.wav
ADDED
|
Binary file (286 kB). View file
|
|
|
train.py
ADDED
|
@@ -0,0 +1,329 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import logging
|
| 2 |
+
import multiprocessing
|
| 3 |
+
import os
|
| 4 |
+
import time
|
| 5 |
+
|
| 6 |
+
import torch
|
| 7 |
+
import torch.distributed as dist
|
| 8 |
+
import torch.multiprocessing as mp
|
| 9 |
+
from torch.cuda.amp import GradScaler, autocast
|
| 10 |
+
from torch.nn import functional as F
|
| 11 |
+
from torch.nn.parallel import DistributedDataParallel as DDP
|
| 12 |
+
from torch.utils.data import DataLoader
|
| 13 |
+
from torch.utils.tensorboard import SummaryWriter
|
| 14 |
+
|
| 15 |
+
import modules.commons as commons
|
| 16 |
+
import utils
|
| 17 |
+
from data_utils import TextAudioCollate, TextAudioSpeakerLoader
|
| 18 |
+
from models import (
|
| 19 |
+
MultiPeriodDiscriminator,
|
| 20 |
+
SynthesizerTrn,
|
| 21 |
+
)
|
| 22 |
+
from modules.losses import discriminator_loss, feature_loss, generator_loss, kl_loss
|
| 23 |
+
from modules.mel_processing import mel_spectrogram_torch, spec_to_mel_torch
|
| 24 |
+
|
| 25 |
+
logging.getLogger('matplotlib').setLevel(logging.WARNING)
|
| 26 |
+
logging.getLogger('numba').setLevel(logging.WARNING)
|
| 27 |
+
|
| 28 |
+
torch.backends.cudnn.benchmark = True
|
| 29 |
+
global_step = 0
|
| 30 |
+
start_time = time.time()
|
| 31 |
+
|
| 32 |
+
# os.environ['TORCH_DISTRIBUTED_DEBUG'] = 'INFO'
|
| 33 |
+
|
| 34 |
+
|
| 35 |
+
def main():
|
| 36 |
+
"""Assume Single Node Multi GPUs Training Only"""
|
| 37 |
+
assert torch.cuda.is_available(), "CPU training is not allowed."
|
| 38 |
+
hps = utils.get_hparams()
|
| 39 |
+
|
| 40 |
+
n_gpus = torch.cuda.device_count()
|
| 41 |
+
os.environ['MASTER_ADDR'] = 'localhost'
|
| 42 |
+
os.environ['MASTER_PORT'] = hps.train.port
|
| 43 |
+
|
| 44 |
+
mp.spawn(run, nprocs=n_gpus, args=(n_gpus, hps,))
|
| 45 |
+
|
| 46 |
+
|
| 47 |
+
def run(rank, n_gpus, hps):
|
| 48 |
+
global global_step
|
| 49 |
+
if rank == 0:
|
| 50 |
+
logger = utils.get_logger(hps.model_dir)
|
| 51 |
+
logger.info(hps)
|
| 52 |
+
utils.check_git_hash(hps.model_dir)
|
| 53 |
+
writer = SummaryWriter(log_dir=hps.model_dir)
|
| 54 |
+
writer_eval = SummaryWriter(log_dir=os.path.join(hps.model_dir, "eval"))
|
| 55 |
+
|
| 56 |
+
# for pytorch on win, backend use gloo
|
| 57 |
+
dist.init_process_group(backend= 'gloo' if os.name == 'nt' else 'nccl', init_method='env://', world_size=n_gpus, rank=rank)
|
| 58 |
+
torch.manual_seed(hps.train.seed)
|
| 59 |
+
torch.cuda.set_device(rank)
|
| 60 |
+
collate_fn = TextAudioCollate()
|
| 61 |
+
all_in_mem = hps.train.all_in_mem # If you have enough memory, turn on this option to avoid disk IO and speed up training.
|
| 62 |
+
train_dataset = TextAudioSpeakerLoader(hps.data.training_files, hps, all_in_mem=all_in_mem)
|
| 63 |
+
num_workers = 5 if multiprocessing.cpu_count() > 4 else multiprocessing.cpu_count()
|
| 64 |
+
if all_in_mem:
|
| 65 |
+
num_workers = 0
|
| 66 |
+
train_loader = DataLoader(train_dataset, num_workers=num_workers, shuffle=False, pin_memory=True,
|
| 67 |
+
batch_size=hps.train.batch_size, collate_fn=collate_fn)
|
| 68 |
+
if rank == 0:
|
| 69 |
+
eval_dataset = TextAudioSpeakerLoader(hps.data.validation_files, hps, all_in_mem=all_in_mem,vol_aug = False)
|
| 70 |
+
eval_loader = DataLoader(eval_dataset, num_workers=1, shuffle=False,
|
| 71 |
+
batch_size=1, pin_memory=False,
|
| 72 |
+
drop_last=False, collate_fn=collate_fn)
|
| 73 |
+
|
| 74 |
+
net_g = SynthesizerTrn(
|
| 75 |
+
hps.data.filter_length // 2 + 1,
|
| 76 |
+
hps.train.segment_size // hps.data.hop_length,
|
| 77 |
+
**hps.model).cuda(rank)
|
| 78 |
+
net_d = MultiPeriodDiscriminator(hps.model.use_spectral_norm).cuda(rank)
|
| 79 |
+
optim_g = torch.optim.AdamW(
|
| 80 |
+
net_g.parameters(),
|
| 81 |
+
hps.train.learning_rate,
|
| 82 |
+
betas=hps.train.betas,
|
| 83 |
+
eps=hps.train.eps)
|
| 84 |
+
optim_d = torch.optim.AdamW(
|
| 85 |
+
net_d.parameters(),
|
| 86 |
+
hps.train.learning_rate,
|
| 87 |
+
betas=hps.train.betas,
|
| 88 |
+
eps=hps.train.eps)
|
| 89 |
+
net_g = DDP(net_g, device_ids=[rank]) # , find_unused_parameters=True)
|
| 90 |
+
net_d = DDP(net_d, device_ids=[rank])
|
| 91 |
+
|
| 92 |
+
skip_optimizer = False
|
| 93 |
+
try:
|
| 94 |
+
_, _, _, epoch_str = utils.load_checkpoint(utils.latest_checkpoint_path(hps.model_dir, "G_*.pth"), net_g,
|
| 95 |
+
optim_g, skip_optimizer)
|
| 96 |
+
_, _, _, epoch_str = utils.load_checkpoint(utils.latest_checkpoint_path(hps.model_dir, "D_*.pth"), net_d,
|
| 97 |
+
optim_d, skip_optimizer)
|
| 98 |
+
epoch_str = max(epoch_str, 1)
|
| 99 |
+
name=utils.latest_checkpoint_path(hps.model_dir, "D_*.pth")
|
| 100 |
+
global_step=int(name[name.rfind("_")+1:name.rfind(".")])+1
|
| 101 |
+
#global_step = (epoch_str - 1) * len(train_loader)
|
| 102 |
+
except Exception:
|
| 103 |
+
print("load old checkpoint failed...")
|
| 104 |
+
epoch_str = 1
|
| 105 |
+
global_step = 0
|
| 106 |
+
if skip_optimizer:
|
| 107 |
+
epoch_str = 1
|
| 108 |
+
global_step = 0
|
| 109 |
+
|
| 110 |
+
warmup_epoch = hps.train.warmup_epochs
|
| 111 |
+
scheduler_g = torch.optim.lr_scheduler.ExponentialLR(optim_g, gamma=hps.train.lr_decay, last_epoch=epoch_str - 2)
|
| 112 |
+
scheduler_d = torch.optim.lr_scheduler.ExponentialLR(optim_d, gamma=hps.train.lr_decay, last_epoch=epoch_str - 2)
|
| 113 |
+
|
| 114 |
+
scaler = GradScaler(enabled=hps.train.fp16_run)
|
| 115 |
+
|
| 116 |
+
for epoch in range(epoch_str, hps.train.epochs + 1):
|
| 117 |
+
# set up warm-up learning rate
|
| 118 |
+
if epoch <= warmup_epoch:
|
| 119 |
+
for param_group in optim_g.param_groups:
|
| 120 |
+
param_group['lr'] = hps.train.learning_rate / warmup_epoch * epoch
|
| 121 |
+
for param_group in optim_d.param_groups:
|
| 122 |
+
param_group['lr'] = hps.train.learning_rate / warmup_epoch * epoch
|
| 123 |
+
# training
|
| 124 |
+
if rank == 0:
|
| 125 |
+
train_and_evaluate(rank, epoch, hps, [net_g, net_d], [optim_g, optim_d], [scheduler_g, scheduler_d], scaler,
|
| 126 |
+
[train_loader, eval_loader], logger, [writer, writer_eval])
|
| 127 |
+
else:
|
| 128 |
+
train_and_evaluate(rank, epoch, hps, [net_g, net_d], [optim_g, optim_d], [scheduler_g, scheduler_d], scaler,
|
| 129 |
+
[train_loader, None], None, None)
|
| 130 |
+
# update learning rate
|
| 131 |
+
scheduler_g.step()
|
| 132 |
+
scheduler_d.step()
|
| 133 |
+
|
| 134 |
+
|
| 135 |
+
def train_and_evaluate(rank, epoch, hps, nets, optims, schedulers, scaler, loaders, logger, writers):
|
| 136 |
+
net_g, net_d = nets
|
| 137 |
+
optim_g, optim_d = optims
|
| 138 |
+
scheduler_g, scheduler_d = schedulers
|
| 139 |
+
train_loader, eval_loader = loaders
|
| 140 |
+
if writers is not None:
|
| 141 |
+
writer, writer_eval = writers
|
| 142 |
+
|
| 143 |
+
half_type = torch.bfloat16 if hps.train.half_type=="bf16" else torch.float16
|
| 144 |
+
|
| 145 |
+
# train_loader.batch_sampler.set_epoch(epoch)
|
| 146 |
+
global global_step
|
| 147 |
+
|
| 148 |
+
net_g.train()
|
| 149 |
+
net_d.train()
|
| 150 |
+
for batch_idx, items in enumerate(train_loader):
|
| 151 |
+
c, f0, spec, y, spk, lengths, uv,volume = items
|
| 152 |
+
g = spk.cuda(rank, non_blocking=True)
|
| 153 |
+
spec, y = spec.cuda(rank, non_blocking=True), y.cuda(rank, non_blocking=True)
|
| 154 |
+
c = c.cuda(rank, non_blocking=True)
|
| 155 |
+
f0 = f0.cuda(rank, non_blocking=True)
|
| 156 |
+
uv = uv.cuda(rank, non_blocking=True)
|
| 157 |
+
lengths = lengths.cuda(rank, non_blocking=True)
|
| 158 |
+
mel = spec_to_mel_torch(
|
| 159 |
+
spec,
|
| 160 |
+
hps.data.filter_length,
|
| 161 |
+
hps.data.n_mel_channels,
|
| 162 |
+
hps.data.sampling_rate,
|
| 163 |
+
hps.data.mel_fmin,
|
| 164 |
+
hps.data.mel_fmax)
|
| 165 |
+
|
| 166 |
+
with autocast(enabled=hps.train.fp16_run, dtype=half_type):
|
| 167 |
+
y_hat, ids_slice, z_mask, \
|
| 168 |
+
(z, z_p, m_p, logs_p, m_q, logs_q), pred_lf0, norm_lf0, lf0 = net_g(c, f0, uv, spec, g=g, c_lengths=lengths,
|
| 169 |
+
spec_lengths=lengths,vol = volume)
|
| 170 |
+
|
| 171 |
+
y_mel = commons.slice_segments(mel, ids_slice, hps.train.segment_size // hps.data.hop_length)
|
| 172 |
+
y_hat_mel = mel_spectrogram_torch(
|
| 173 |
+
y_hat.squeeze(1),
|
| 174 |
+
hps.data.filter_length,
|
| 175 |
+
hps.data.n_mel_channels,
|
| 176 |
+
hps.data.sampling_rate,
|
| 177 |
+
hps.data.hop_length,
|
| 178 |
+
hps.data.win_length,
|
| 179 |
+
hps.data.mel_fmin,
|
| 180 |
+
hps.data.mel_fmax
|
| 181 |
+
)
|
| 182 |
+
y = commons.slice_segments(y, ids_slice * hps.data.hop_length, hps.train.segment_size) # slice
|
| 183 |
+
|
| 184 |
+
# Discriminator
|
| 185 |
+
y_d_hat_r, y_d_hat_g, _, _ = net_d(y, y_hat.detach())
|
| 186 |
+
|
| 187 |
+
with autocast(enabled=False, dtype=half_type):
|
| 188 |
+
loss_disc, losses_disc_r, losses_disc_g = discriminator_loss(y_d_hat_r, y_d_hat_g)
|
| 189 |
+
loss_disc_all = loss_disc
|
| 190 |
+
|
| 191 |
+
optim_d.zero_grad()
|
| 192 |
+
scaler.scale(loss_disc_all).backward()
|
| 193 |
+
scaler.unscale_(optim_d)
|
| 194 |
+
grad_norm_d = commons.clip_grad_value_(net_d.parameters(), None)
|
| 195 |
+
scaler.step(optim_d)
|
| 196 |
+
|
| 197 |
+
|
| 198 |
+
with autocast(enabled=hps.train.fp16_run, dtype=half_type):
|
| 199 |
+
# Generator
|
| 200 |
+
y_d_hat_r, y_d_hat_g, fmap_r, fmap_g = net_d(y, y_hat)
|
| 201 |
+
with autocast(enabled=False, dtype=half_type):
|
| 202 |
+
loss_mel = F.l1_loss(y_mel, y_hat_mel) * hps.train.c_mel
|
| 203 |
+
loss_kl = kl_loss(z_p, logs_q, m_p, logs_p, z_mask) * hps.train.c_kl
|
| 204 |
+
loss_fm = feature_loss(fmap_r, fmap_g)
|
| 205 |
+
loss_gen, losses_gen = generator_loss(y_d_hat_g)
|
| 206 |
+
loss_lf0 = F.mse_loss(pred_lf0, lf0) if net_g.module.use_automatic_f0_prediction else 0
|
| 207 |
+
loss_gen_all = loss_gen + loss_fm + loss_mel + loss_kl + loss_lf0
|
| 208 |
+
optim_g.zero_grad()
|
| 209 |
+
scaler.scale(loss_gen_all).backward()
|
| 210 |
+
scaler.unscale_(optim_g)
|
| 211 |
+
grad_norm_g = commons.clip_grad_value_(net_g.parameters(), None)
|
| 212 |
+
scaler.step(optim_g)
|
| 213 |
+
scaler.update()
|
| 214 |
+
|
| 215 |
+
if rank == 0:
|
| 216 |
+
if global_step % hps.train.log_interval == 0:
|
| 217 |
+
lr = optim_g.param_groups[0]['lr']
|
| 218 |
+
losses = [loss_disc, loss_gen, loss_fm, loss_mel, loss_kl]
|
| 219 |
+
reference_loss=0
|
| 220 |
+
for i in losses:
|
| 221 |
+
reference_loss += i
|
| 222 |
+
logger.info('Train Epoch: {} [{:.0f}%]'.format(
|
| 223 |
+
epoch,
|
| 224 |
+
100. * batch_idx / len(train_loader)))
|
| 225 |
+
logger.info(f"Losses: {[x.item() for x in losses]}, step: {global_step}, lr: {lr}, reference_loss: {reference_loss}")
|
| 226 |
+
|
| 227 |
+
scalar_dict = {"loss/g/total": loss_gen_all, "loss/d/total": loss_disc_all, "learning_rate": lr,
|
| 228 |
+
"grad_norm_d": grad_norm_d, "grad_norm_g": grad_norm_g}
|
| 229 |
+
scalar_dict.update({"loss/g/fm": loss_fm, "loss/g/mel": loss_mel, "loss/g/kl": loss_kl,
|
| 230 |
+
"loss/g/lf0": loss_lf0})
|
| 231 |
+
|
| 232 |
+
# scalar_dict.update({"loss/g/{}".format(i): v for i, v in enumerate(losses_gen)})
|
| 233 |
+
# scalar_dict.update({"loss/d_r/{}".format(i): v for i, v in enumerate(losses_disc_r)})
|
| 234 |
+
# scalar_dict.update({"loss/d_g/{}".format(i): v for i, v in enumerate(losses_disc_g)})
|
| 235 |
+
image_dict = {
|
| 236 |
+
"slice/mel_org": utils.plot_spectrogram_to_numpy(y_mel[0].data.cpu().numpy()),
|
| 237 |
+
"slice/mel_gen": utils.plot_spectrogram_to_numpy(y_hat_mel[0].data.cpu().numpy()),
|
| 238 |
+
"all/mel": utils.plot_spectrogram_to_numpy(mel[0].data.cpu().numpy())
|
| 239 |
+
}
|
| 240 |
+
|
| 241 |
+
if net_g.module.use_automatic_f0_prediction:
|
| 242 |
+
image_dict.update({
|
| 243 |
+
"all/lf0": utils.plot_data_to_numpy(lf0[0, 0, :].cpu().numpy(),
|
| 244 |
+
pred_lf0[0, 0, :].detach().cpu().numpy()),
|
| 245 |
+
"all/norm_lf0": utils.plot_data_to_numpy(lf0[0, 0, :].cpu().numpy(),
|
| 246 |
+
norm_lf0[0, 0, :].detach().cpu().numpy())
|
| 247 |
+
})
|
| 248 |
+
|
| 249 |
+
utils.summarize(
|
| 250 |
+
writer=writer,
|
| 251 |
+
global_step=global_step,
|
| 252 |
+
images=image_dict,
|
| 253 |
+
scalars=scalar_dict
|
| 254 |
+
)
|
| 255 |
+
|
| 256 |
+
if global_step % hps.train.eval_interval == 0:
|
| 257 |
+
evaluate(hps, net_g, eval_loader, writer_eval)
|
| 258 |
+
utils.save_checkpoint(net_g, optim_g, hps.train.learning_rate, epoch,
|
| 259 |
+
os.path.join(hps.model_dir, "G_{}.pth".format(global_step)))
|
| 260 |
+
utils.save_checkpoint(net_d, optim_d, hps.train.learning_rate, epoch,
|
| 261 |
+
os.path.join(hps.model_dir, "D_{}.pth".format(global_step)))
|
| 262 |
+
keep_ckpts = getattr(hps.train, 'keep_ckpts', 0)
|
| 263 |
+
if keep_ckpts > 0:
|
| 264 |
+
utils.clean_checkpoints(path_to_models=hps.model_dir, n_ckpts_to_keep=keep_ckpts, sort_by_time=True)
|
| 265 |
+
|
| 266 |
+
global_step += 1
|
| 267 |
+
|
| 268 |
+
if rank == 0:
|
| 269 |
+
global start_time
|
| 270 |
+
now = time.time()
|
| 271 |
+
durtaion = format(now - start_time, '.2f')
|
| 272 |
+
logger.info(f'====> Epoch: {epoch}, cost {durtaion} s')
|
| 273 |
+
start_time = now
|
| 274 |
+
|
| 275 |
+
|
| 276 |
+
def evaluate(hps, generator, eval_loader, writer_eval):
|
| 277 |
+
generator.eval()
|
| 278 |
+
image_dict = {}
|
| 279 |
+
audio_dict = {}
|
| 280 |
+
with torch.no_grad():
|
| 281 |
+
for batch_idx, items in enumerate(eval_loader):
|
| 282 |
+
c, f0, spec, y, spk, _, uv,volume = items
|
| 283 |
+
g = spk[:1].cuda(0)
|
| 284 |
+
spec, y = spec[:1].cuda(0), y[:1].cuda(0)
|
| 285 |
+
c = c[:1].cuda(0)
|
| 286 |
+
f0 = f0[:1].cuda(0)
|
| 287 |
+
uv= uv[:1].cuda(0)
|
| 288 |
+
if volume is not None:
|
| 289 |
+
volume = volume[:1].cuda(0)
|
| 290 |
+
mel = spec_to_mel_torch(
|
| 291 |
+
spec,
|
| 292 |
+
hps.data.filter_length,
|
| 293 |
+
hps.data.n_mel_channels,
|
| 294 |
+
hps.data.sampling_rate,
|
| 295 |
+
hps.data.mel_fmin,
|
| 296 |
+
hps.data.mel_fmax)
|
| 297 |
+
y_hat,_ = generator.module.infer(c, f0, uv, g=g,vol = volume)
|
| 298 |
+
|
| 299 |
+
y_hat_mel = mel_spectrogram_torch(
|
| 300 |
+
y_hat.squeeze(1).float(),
|
| 301 |
+
hps.data.filter_length,
|
| 302 |
+
hps.data.n_mel_channels,
|
| 303 |
+
hps.data.sampling_rate,
|
| 304 |
+
hps.data.hop_length,
|
| 305 |
+
hps.data.win_length,
|
| 306 |
+
hps.data.mel_fmin,
|
| 307 |
+
hps.data.mel_fmax
|
| 308 |
+
)
|
| 309 |
+
|
| 310 |
+
audio_dict.update({
|
| 311 |
+
f"gen/audio_{batch_idx}": y_hat[0],
|
| 312 |
+
f"gt/audio_{batch_idx}": y[0]
|
| 313 |
+
})
|
| 314 |
+
image_dict.update({
|
| 315 |
+
"gen/mel": utils.plot_spectrogram_to_numpy(y_hat_mel[0].cpu().numpy()),
|
| 316 |
+
"gt/mel": utils.plot_spectrogram_to_numpy(mel[0].cpu().numpy())
|
| 317 |
+
})
|
| 318 |
+
utils.summarize(
|
| 319 |
+
writer=writer_eval,
|
| 320 |
+
global_step=global_step,
|
| 321 |
+
images=image_dict,
|
| 322 |
+
audios=audio_dict,
|
| 323 |
+
audio_sampling_rate=hps.data.sampling_rate
|
| 324 |
+
)
|
| 325 |
+
generator.train()
|
| 326 |
+
|
| 327 |
+
|
| 328 |
+
if __name__ == "__main__":
|
| 329 |
+
main()
|
train_diff.py
ADDED
|
@@ -0,0 +1,77 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import argparse
|
| 2 |
+
|
| 3 |
+
import torch
|
| 4 |
+
from loguru import logger
|
| 5 |
+
from torch.optim import lr_scheduler
|
| 6 |
+
|
| 7 |
+
from diffusion.data_loaders import get_data_loaders
|
| 8 |
+
from diffusion.logger import utils
|
| 9 |
+
from diffusion.solver import train
|
| 10 |
+
from diffusion.unit2mel import Unit2Mel
|
| 11 |
+
from diffusion.vocoder import Vocoder
|
| 12 |
+
|
| 13 |
+
|
| 14 |
+
def parse_args(args=None, namespace=None):
|
| 15 |
+
"""Parse command-line arguments."""
|
| 16 |
+
parser = argparse.ArgumentParser()
|
| 17 |
+
parser.add_argument(
|
| 18 |
+
"-c",
|
| 19 |
+
"--config",
|
| 20 |
+
type=str,
|
| 21 |
+
required=True,
|
| 22 |
+
help="path to the config file")
|
| 23 |
+
return parser.parse_args(args=args, namespace=namespace)
|
| 24 |
+
|
| 25 |
+
|
| 26 |
+
if __name__ == '__main__':
|
| 27 |
+
# parse commands
|
| 28 |
+
cmd = parse_args()
|
| 29 |
+
|
| 30 |
+
# load config
|
| 31 |
+
args = utils.load_config(cmd.config)
|
| 32 |
+
logger.info(' > config:'+ cmd.config)
|
| 33 |
+
logger.info(' > exp:'+ args.env.expdir)
|
| 34 |
+
|
| 35 |
+
# load vocoder
|
| 36 |
+
vocoder = Vocoder(args.vocoder.type, args.vocoder.ckpt, device=args.device)
|
| 37 |
+
|
| 38 |
+
# load model
|
| 39 |
+
model = Unit2Mel(
|
| 40 |
+
args.data.encoder_out_channels,
|
| 41 |
+
args.model.n_spk,
|
| 42 |
+
args.model.use_pitch_aug,
|
| 43 |
+
vocoder.dimension,
|
| 44 |
+
args.model.n_layers,
|
| 45 |
+
args.model.n_chans,
|
| 46 |
+
args.model.n_hidden,
|
| 47 |
+
args.model.timesteps,
|
| 48 |
+
args.model.k_step_max
|
| 49 |
+
)
|
| 50 |
+
|
| 51 |
+
logger.info(f' > Now model timesteps is {model.timesteps}, and k_step_max is {model.k_step_max}')
|
| 52 |
+
|
| 53 |
+
# load parameters
|
| 54 |
+
optimizer = torch.optim.AdamW(model.parameters())
|
| 55 |
+
initial_global_step, model, optimizer = utils.load_model(args.env.expdir, model, optimizer, device=args.device)
|
| 56 |
+
for param_group in optimizer.param_groups:
|
| 57 |
+
param_group['initial_lr'] = args.train.lr
|
| 58 |
+
param_group['lr'] = args.train.lr * (args.train.gamma ** max(((initial_global_step-2)//args.train.decay_step),0) )
|
| 59 |
+
param_group['weight_decay'] = args.train.weight_decay
|
| 60 |
+
scheduler = lr_scheduler.StepLR(optimizer, step_size=args.train.decay_step, gamma=args.train.gamma,last_epoch=initial_global_step-2)
|
| 61 |
+
|
| 62 |
+
# device
|
| 63 |
+
if args.device == 'cuda':
|
| 64 |
+
torch.cuda.set_device(args.env.gpu_id)
|
| 65 |
+
model.to(args.device)
|
| 66 |
+
|
| 67 |
+
for state in optimizer.state.values():
|
| 68 |
+
for k, v in state.items():
|
| 69 |
+
if torch.is_tensor(v):
|
| 70 |
+
state[k] = v.to(args.device)
|
| 71 |
+
|
| 72 |
+
# datas
|
| 73 |
+
loader_train, loader_valid = get_data_loaders(args, whole_audio=False)
|
| 74 |
+
|
| 75 |
+
# run
|
| 76 |
+
train(args, initial_global_step, model, optimizer, scheduler, vocoder, loader_train, loader_valid)
|
| 77 |
+
|
train_index.py
ADDED
|
@@ -0,0 +1,30 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import argparse
|
| 2 |
+
import os
|
| 3 |
+
import pickle
|
| 4 |
+
|
| 5 |
+
import utils
|
| 6 |
+
|
| 7 |
+
if __name__ == "__main__":
|
| 8 |
+
parser = argparse.ArgumentParser()
|
| 9 |
+
parser.add_argument(
|
| 10 |
+
"--root_dir", type=str, default="dataset/44k", help="path to root dir"
|
| 11 |
+
)
|
| 12 |
+
parser.add_argument('-c', '--config', type=str, default="./configs/config.json",
|
| 13 |
+
help='JSON file for configuration')
|
| 14 |
+
parser.add_argument(
|
| 15 |
+
"--output_dir", type=str, default="logs/44k", help="path to output dir"
|
| 16 |
+
)
|
| 17 |
+
|
| 18 |
+
args = parser.parse_args()
|
| 19 |
+
|
| 20 |
+
hps = utils.get_hparams_from_file(args.config)
|
| 21 |
+
spk_dic = hps.spk
|
| 22 |
+
result = {}
|
| 23 |
+
|
| 24 |
+
for k,v in spk_dic.items():
|
| 25 |
+
print(f"now, index {k} feature...")
|
| 26 |
+
index = utils.train_index(k,args.root_dir)
|
| 27 |
+
result[v] = index
|
| 28 |
+
|
| 29 |
+
with open(os.path.join(args.output_dir,"feature_and_index.pkl"),"wb") as f:
|
| 30 |
+
pickle.dump(result,f)
|
tts.py
ADDED
|
@@ -0,0 +1,38 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import asyncio
|
| 2 |
+
import random
|
| 3 |
+
import edge_tts
|
| 4 |
+
from edge_tts import VoicesManager
|
| 5 |
+
import sys
|
| 6 |
+
from langdetect import detect
|
| 7 |
+
from langdetect import DetectorFactory
|
| 8 |
+
|
| 9 |
+
DetectorFactory.seed = 0
|
| 10 |
+
|
| 11 |
+
TEXT = sys.argv[1]
|
| 12 |
+
LANG = detect(TEXT) if sys.argv[2] == "Auto" else sys.argv[2]
|
| 13 |
+
if LANG == "zh-cn" or LANG == "zh-tw":
|
| 14 |
+
LOCALE = LANG[:-2] + LANG[-2:].upper()
|
| 15 |
+
RATE = sys.argv[3]
|
| 16 |
+
VOLUME = sys.argv[4]
|
| 17 |
+
GENDER = sys.argv[5] if len(sys.argv) == 6 else None
|
| 18 |
+
OUTPUT_FILE = "tts.wav"
|
| 19 |
+
|
| 20 |
+
print("Running TTS...")
|
| 21 |
+
print(f"Text: {TEXT}, Language: {LANG}, Gender: {GENDER}, Rate: {RATE}, Volume: {VOLUME}")
|
| 22 |
+
|
| 23 |
+
async def _main() -> None:
|
| 24 |
+
voices = await VoicesManager.create()
|
| 25 |
+
if not GENDER is None:
|
| 26 |
+
if LANG.startswith("zh"):
|
| 27 |
+
voice = voices.find(Gender=GENDER, Locale=LOCALE)
|
| 28 |
+
else:
|
| 29 |
+
voice = voices.find(Gender=GENDER, Language=LANG)
|
| 30 |
+
VOICE = random.choice(voice)["Name"]
|
| 31 |
+
else:
|
| 32 |
+
VOICE = LANG
|
| 33 |
+
communicate = edge_tts.Communicate(text = TEXT, voice = VOICE, rate = RATE, volume = VOLUME)
|
| 34 |
+
await communicate.save(OUTPUT_FILE)
|
| 35 |
+
|
| 36 |
+
if __name__ == "__main__":
|
| 37 |
+
asyncio.set_event_loop_policy(asyncio.WindowsSelectorEventLoopPolicy())
|
| 38 |
+
asyncio.run(_main())
|
tts.wav
ADDED
|
Binary file (286 kB). View file
|
|
|
tts_voices.py
ADDED
|
@@ -0,0 +1,306 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
#List of Supported Voices for edge_TTS
|
| 2 |
+
SUPPORTED_VOICES = {
|
| 3 |
+
'zh-CN-XiaoxiaoNeural': 'zh-CN',
|
| 4 |
+
'zh-CN-XiaoyiNeural': 'zh-CN',
|
| 5 |
+
'zh-CN-YunjianNeural': 'zh-CN',
|
| 6 |
+
'zh-CN-YunxiNeural': 'zh-CN',
|
| 7 |
+
'zh-CN-YunxiaNeural': 'zh-CN',
|
| 8 |
+
'zh-CN-YunyangNeural': 'zh-CN',
|
| 9 |
+
'zh-HK-HiuGaaiNeural': 'zh-HK',
|
| 10 |
+
'zh-HK-HiuMaanNeural': 'zh-HK',
|
| 11 |
+
'zh-HK-WanLungNeural': 'zh-HK',
|
| 12 |
+
'zh-TW-HsiaoChenNeural': 'zh-TW',
|
| 13 |
+
'zh-TW-YunJheNeural': 'zh-TW',
|
| 14 |
+
'zh-TW-HsiaoYuNeural': 'zh-TW',
|
| 15 |
+
'af-ZA-AdriNeural': 'af-ZA',
|
| 16 |
+
'af-ZA-WillemNeural': 'af-ZA',
|
| 17 |
+
'am-ET-AmehaNeural': 'am-ET',
|
| 18 |
+
'am-ET-MekdesNeural': 'am-ET',
|
| 19 |
+
'ar-AE-FatimaNeural': 'ar-AE',
|
| 20 |
+
'ar-AE-HamdanNeural': 'ar-AE',
|
| 21 |
+
'ar-BH-AliNeural': 'ar-BH',
|
| 22 |
+
'ar-BH-LailaNeural': 'ar-BH',
|
| 23 |
+
'ar-DZ-AminaNeural': 'ar-DZ',
|
| 24 |
+
'ar-DZ-IsmaelNeural': 'ar-DZ',
|
| 25 |
+
'ar-EG-SalmaNeural': 'ar-EG',
|
| 26 |
+
'ar-EG-ShakirNeural': 'ar-EG',
|
| 27 |
+
'ar-IQ-BasselNeural': 'ar-IQ',
|
| 28 |
+
'ar-IQ-RanaNeural': 'ar-IQ',
|
| 29 |
+
'ar-JO-SanaNeural': 'ar-JO',
|
| 30 |
+
'ar-JO-TaimNeural': 'ar-JO',
|
| 31 |
+
'ar-KW-FahedNeural': 'ar-KW',
|
| 32 |
+
'ar-KW-NouraNeural': 'ar-KW',
|
| 33 |
+
'ar-LB-LaylaNeural': 'ar-LB',
|
| 34 |
+
'ar-LB-RamiNeural': 'ar-LB',
|
| 35 |
+
'ar-LY-ImanNeural': 'ar-LY',
|
| 36 |
+
'ar-LY-OmarNeural': 'ar-LY',
|
| 37 |
+
'ar-MA-JamalNeural': 'ar-MA',
|
| 38 |
+
'ar-MA-MounaNeural': 'ar-MA',
|
| 39 |
+
'ar-OM-AbdullahNeural': 'ar-OM',
|
| 40 |
+
'ar-OM-AyshaNeural': 'ar-OM',
|
| 41 |
+
'ar-QA-AmalNeural': 'ar-QA',
|
| 42 |
+
'ar-QA-MoazNeural': 'ar-QA',
|
| 43 |
+
'ar-SA-HamedNeural': 'ar-SA',
|
| 44 |
+
'ar-SA-ZariyahNeural': 'ar-SA',
|
| 45 |
+
'ar-SY-AmanyNeural': 'ar-SY',
|
| 46 |
+
'ar-SY-LaithNeural': 'ar-SY',
|
| 47 |
+
'ar-TN-HediNeural': 'ar-TN',
|
| 48 |
+
'ar-TN-ReemNeural': 'ar-TN',
|
| 49 |
+
'ar-YE-MaryamNeural': 'ar-YE',
|
| 50 |
+
'ar-YE-SalehNeural': 'ar-YE',
|
| 51 |
+
'az-AZ-BabekNeural': 'az-AZ',
|
| 52 |
+
'az-AZ-BanuNeural': 'az-AZ',
|
| 53 |
+
'bg-BG-BorislavNeural': 'bg-BG',
|
| 54 |
+
'bg-BG-KalinaNeural': 'bg-BG',
|
| 55 |
+
'bn-BD-NabanitaNeural': 'bn-BD',
|
| 56 |
+
'bn-BD-PradeepNeural': 'bn-BD',
|
| 57 |
+
'bn-IN-BashkarNeural': 'bn-IN',
|
| 58 |
+
'bn-IN-TanishaaNeural': 'bn-IN',
|
| 59 |
+
'bs-BA-GoranNeural': 'bs-BA',
|
| 60 |
+
'bs-BA-VesnaNeural': 'bs-BA',
|
| 61 |
+
'ca-ES-EnricNeural': 'ca-ES',
|
| 62 |
+
'ca-ES-JoanaNeural': 'ca-ES',
|
| 63 |
+
'cs-CZ-AntoninNeural': 'cs-CZ',
|
| 64 |
+
'cs-CZ-VlastaNeural': 'cs-CZ',
|
| 65 |
+
'cy-GB-AledNeural': 'cy-GB',
|
| 66 |
+
'cy-GB-NiaNeural': 'cy-GB',
|
| 67 |
+
'da-DK-ChristelNeural': 'da-DK',
|
| 68 |
+
'da-DK-JeppeNeural': 'da-DK',
|
| 69 |
+
'de-AT-IngridNeural': 'de-AT',
|
| 70 |
+
'de-AT-JonasNeural': 'de-AT',
|
| 71 |
+
'de-CH-JanNeural': 'de-CH',
|
| 72 |
+
'de-CH-LeniNeural': 'de-CH',
|
| 73 |
+
'de-DE-AmalaNeural': 'de-DE',
|
| 74 |
+
'de-DE-ConradNeural': 'de-DE',
|
| 75 |
+
'de-DE-KatjaNeural': 'de-DE',
|
| 76 |
+
'de-DE-KillianNeural': 'de-DE',
|
| 77 |
+
'el-GR-AthinaNeural': 'el-GR',
|
| 78 |
+
'el-GR-NestorasNeural': 'el-GR',
|
| 79 |
+
'en-AU-NatashaNeural': 'en-AU',
|
| 80 |
+
'en-AU-WilliamNeural': 'en-AU',
|
| 81 |
+
'en-CA-ClaraNeural': 'en-CA',
|
| 82 |
+
'en-CA-LiamNeural': 'en-CA',
|
| 83 |
+
'en-GB-LibbyNeural': 'en-GB',
|
| 84 |
+
'en-GB-MaisieNeural': 'en-GB',
|
| 85 |
+
'en-GB-RyanNeural': 'en-GB',
|
| 86 |
+
'en-GB-SoniaNeural': 'en-GB',
|
| 87 |
+
'en-GB-ThomasNeural': 'en-GB',
|
| 88 |
+
'en-HK-SamNeural': 'en-HK',
|
| 89 |
+
'en-HK-YanNeural': 'en-HK',
|
| 90 |
+
'en-IE-ConnorNeural': 'en-IE',
|
| 91 |
+
'en-IE-EmilyNeural': 'en-IE',
|
| 92 |
+
'en-IN-NeerjaNeural': 'en-IN',
|
| 93 |
+
'en-IN-PrabhatNeural': 'en-IN',
|
| 94 |
+
'en-KE-AsiliaNeural': 'en-KE',
|
| 95 |
+
'en-KE-ChilembaNeural': 'en-KE',
|
| 96 |
+
'en-NG-AbeoNeural': 'en-NG',
|
| 97 |
+
'en-NG-EzinneNeural': 'en-NG',
|
| 98 |
+
'en-NZ-MitchellNeural': 'en-NZ',
|
| 99 |
+
'en-NZ-MollyNeural': 'en-NZ',
|
| 100 |
+
'en-PH-JamesNeural': 'en-PH',
|
| 101 |
+
'en-PH-RosaNeural': 'en-PH',
|
| 102 |
+
'en-SG-LunaNeural': 'en-SG',
|
| 103 |
+
'en-SG-WayneNeural': 'en-SG',
|
| 104 |
+
'en-TZ-ElimuNeural': 'en-TZ',
|
| 105 |
+
'en-TZ-ImaniNeural': 'en-TZ',
|
| 106 |
+
'en-US-AnaNeural': 'en-US',
|
| 107 |
+
'en-US-AriaNeural': 'en-US',
|
| 108 |
+
'en-US-ChristopherNeural': 'en-US',
|
| 109 |
+
'en-US-EricNeural': 'en-US',
|
| 110 |
+
'en-US-GuyNeural': 'en-US',
|
| 111 |
+
'en-US-JennyNeural': 'en-US',
|
| 112 |
+
'en-US-MichelleNeural': 'en-US',
|
| 113 |
+
'en-ZA-LeahNeural': 'en-ZA',
|
| 114 |
+
'en-ZA-LukeNeural': 'en-ZA',
|
| 115 |
+
'es-AR-ElenaNeural': 'es-AR',
|
| 116 |
+
'es-AR-TomasNeural': 'es-AR',
|
| 117 |
+
'es-BO-MarceloNeural': 'es-BO',
|
| 118 |
+
'es-BO-SofiaNeural': 'es-BO',
|
| 119 |
+
'es-CL-CatalinaNeural': 'es-CL',
|
| 120 |
+
'es-CL-LorenzoNeural': 'es-CL',
|
| 121 |
+
'es-CO-GonzaloNeural': 'es-CO',
|
| 122 |
+
'es-CO-SalomeNeural': 'es-CO',
|
| 123 |
+
'es-CR-JuanNeural': 'es-CR',
|
| 124 |
+
'es-CR-MariaNeural': 'es-CR',
|
| 125 |
+
'es-CU-BelkysNeural': 'es-CU',
|
| 126 |
+
'es-CU-ManuelNeural': 'es-CU',
|
| 127 |
+
'es-DO-EmilioNeural': 'es-DO',
|
| 128 |
+
'es-DO-RamonaNeural': 'es-DO',
|
| 129 |
+
'es-EC-AndreaNeural': 'es-EC',
|
| 130 |
+
'es-EC-LuisNeural': 'es-EC',
|
| 131 |
+
'es-ES-AlvaroNeural': 'es-ES',
|
| 132 |
+
'es-ES-ElviraNeural': 'es-ES',
|
| 133 |
+
'es-ES-ManuelEsCUNeural': 'es-ES',
|
| 134 |
+
'es-GQ-JavierNeural': 'es-GQ',
|
| 135 |
+
'es-GQ-TeresaNeural': 'es-GQ',
|
| 136 |
+
'es-GT-AndresNeural': 'es-GT',
|
| 137 |
+
'es-GT-MartaNeural': 'es-GT',
|
| 138 |
+
'es-HN-CarlosNeural': 'es-HN',
|
| 139 |
+
'es-HN-KarlaNeural': 'es-HN',
|
| 140 |
+
'es-MX-DaliaNeural': 'es-MX',
|
| 141 |
+
'es-MX-JorgeNeural': 'es-MX',
|
| 142 |
+
'es-MX-LorenzoEsCLNeural': 'es-MX',
|
| 143 |
+
'es-NI-FedericoNeural': 'es-NI',
|
| 144 |
+
'es-NI-YolandaNeural': 'es-NI',
|
| 145 |
+
'es-PA-MargaritaNeural': 'es-PA',
|
| 146 |
+
'es-PA-RobertoNeural': 'es-PA',
|
| 147 |
+
'es-PE-AlexNeural': 'es-PE',
|
| 148 |
+
'es-PE-CamilaNeural': 'es-PE',
|
| 149 |
+
'es-PR-KarinaNeural': 'es-PR',
|
| 150 |
+
'es-PR-VictorNeural': 'es-PR',
|
| 151 |
+
'es-PY-MarioNeural': 'es-PY',
|
| 152 |
+
'es-PY-TaniaNeural': 'es-PY',
|
| 153 |
+
'es-SV-LorenaNeural': 'es-SV',
|
| 154 |
+
'es-SV-RodrigoNeural': 'es-SV',
|
| 155 |
+
'es-US-AlonsoNeural': 'es-US',
|
| 156 |
+
'es-US-PalomaNeural': 'es-US',
|
| 157 |
+
'es-UY-MateoNeural': 'es-UY',
|
| 158 |
+
'es-UY-ValentinaNeural': 'es-UY',
|
| 159 |
+
'es-VE-PaolaNeural': 'es-VE',
|
| 160 |
+
'es-VE-SebastianNeural': 'es-VE',
|
| 161 |
+
'et-EE-AnuNeural': 'et-EE',
|
| 162 |
+
'et-EE-KertNeural': 'et-EE',
|
| 163 |
+
'fa-IR-DilaraNeural': 'fa-IR',
|
| 164 |
+
'fa-IR-FaridNeural': 'fa-IR',
|
| 165 |
+
'fi-FI-HarriNeural': 'fi-FI',
|
| 166 |
+
'fi-FI-NooraNeural': 'fi-FI',
|
| 167 |
+
'fil-PH-AngeloNeural': 'fil-PH',
|
| 168 |
+
'fil-PH-BlessicaNeural': 'fil-PH',
|
| 169 |
+
'fr-BE-CharlineNeural': 'fr-BE',
|
| 170 |
+
'fr-BE-GerardNeural': 'fr-BE',
|
| 171 |
+
'fr-CA-AntoineNeural': 'fr-CA',
|
| 172 |
+
'fr-CA-JeanNeural': 'fr-CA',
|
| 173 |
+
'fr-CA-SylvieNeural': 'fr-CA',
|
| 174 |
+
'fr-CH-ArianeNeural': 'fr-CH',
|
| 175 |
+
'fr-CH-FabriceNeural': 'fr-CH',
|
| 176 |
+
'fr-FR-DeniseNeural': 'fr-FR',
|
| 177 |
+
'fr-FR-EloiseNeural': 'fr-FR',
|
| 178 |
+
'fr-FR-HenriNeural': 'fr-FR',
|
| 179 |
+
'ga-IE-ColmNeural': 'ga-IE',
|
| 180 |
+
'ga-IE-OrlaNeural': 'ga-IE',
|
| 181 |
+
'gl-ES-RoiNeural': 'gl-ES',
|
| 182 |
+
'gl-ES-SabelaNeural': 'gl-ES',
|
| 183 |
+
'gu-IN-DhwaniNeural': 'gu-IN',
|
| 184 |
+
'gu-IN-NiranjanNeural': 'gu-IN',
|
| 185 |
+
'he-IL-AvriNeural': 'he-IL',
|
| 186 |
+
'he-IL-HilaNeural': 'he-IL',
|
| 187 |
+
'hi-IN-MadhurNeural': 'hi-IN',
|
| 188 |
+
'hi-IN-SwaraNeural': 'hi-IN',
|
| 189 |
+
'hr-HR-GabrijelaNeural': 'hr-HR',
|
| 190 |
+
'hr-HR-SreckoNeural': 'hr-HR',
|
| 191 |
+
'hu-HU-NoemiNeural': 'hu-HU',
|
| 192 |
+
'hu-HU-TamasNeural': 'hu-HU',
|
| 193 |
+
'id-ID-ArdiNeural': 'id-ID',
|
| 194 |
+
'id-ID-GadisNeural': 'id-ID',
|
| 195 |
+
'is-IS-GudrunNeural': 'is-IS',
|
| 196 |
+
'is-IS-GunnarNeural': 'is-IS',
|
| 197 |
+
'it-IT-DiegoNeural': 'it-IT',
|
| 198 |
+
'it-IT-ElsaNeural': 'it-IT',
|
| 199 |
+
'it-IT-IsabellaNeural': 'it-IT',
|
| 200 |
+
'ja-JP-KeitaNeural': 'ja-JP',
|
| 201 |
+
'ja-JP-NanamiNeural': 'ja-JP',
|
| 202 |
+
'jv-ID-DimasNeural': 'jv-ID',
|
| 203 |
+
'jv-ID-SitiNeural': 'jv-ID',
|
| 204 |
+
'ka-GE-EkaNeural': 'ka-GE',
|
| 205 |
+
'ka-GE-GiorgiNeural': 'ka-GE',
|
| 206 |
+
'kk-KZ-AigulNeural': 'kk-KZ',
|
| 207 |
+
'kk-KZ-DauletNeural': 'kk-KZ',
|
| 208 |
+
'km-KH-PisethNeural': 'km-KH',
|
| 209 |
+
'km-KH-SreymomNeural': 'km-KH',
|
| 210 |
+
'kn-IN-GaganNeural': 'kn-IN',
|
| 211 |
+
'kn-IN-SapnaNeural': 'kn-IN',
|
| 212 |
+
'ko-KR-InJoonNeural': 'ko-KR',
|
| 213 |
+
'ko-KR-SunHiNeural': 'ko-KR',
|
| 214 |
+
'lo-LA-ChanthavongNeural': 'lo-LA',
|
| 215 |
+
'lo-LA-KeomanyNeural': 'lo-LA',
|
| 216 |
+
'lt-LT-LeonasNeural': 'lt-LT',
|
| 217 |
+
'lt-LT-OnaNeural': 'lt-LT',
|
| 218 |
+
'lv-LV-EveritaNeural': 'lv-LV',
|
| 219 |
+
'lv-LV-NilsNeural': 'lv-LV',
|
| 220 |
+
'mk-MK-AleksandarNeural': 'mk-MK',
|
| 221 |
+
'mk-MK-MarijaNeural': 'mk-MK',
|
| 222 |
+
'ml-IN-MidhunNeural': 'ml-IN',
|
| 223 |
+
'ml-IN-SobhanaNeural': 'ml-IN',
|
| 224 |
+
'mn-MN-BataaNeural': 'mn-MN',
|
| 225 |
+
'mn-MN-YesuiNeural': 'mn-MN',
|
| 226 |
+
'mr-IN-AarohiNeural': 'mr-IN',
|
| 227 |
+
'mr-IN-ManoharNeural': 'mr-IN',
|
| 228 |
+
'ms-MY-OsmanNeural': 'ms-MY',
|
| 229 |
+
'ms-MY-YasminNeural': 'ms-MY',
|
| 230 |
+
'mt-MT-GraceNeural': 'mt-MT',
|
| 231 |
+
'mt-MT-JosephNeural': 'mt-MT',
|
| 232 |
+
'my-MM-NilarNeural': 'my-MM',
|
| 233 |
+
'my-MM-ThihaNeural': 'my-MM',
|
| 234 |
+
'nb-NO-FinnNeural': 'nb-NO',
|
| 235 |
+
'nb-NO-PernilleNeural': 'nb-NO',
|
| 236 |
+
'ne-NP-HemkalaNeural': 'ne-NP',
|
| 237 |
+
'ne-NP-SagarNeural': 'ne-NP',
|
| 238 |
+
'nl-BE-ArnaudNeural': 'nl-BE',
|
| 239 |
+
'nl-BE-DenaNeural': 'nl-BE',
|
| 240 |
+
'nl-NL-ColetteNeural': 'nl-NL',
|
| 241 |
+
'nl-NL-FennaNeural': 'nl-NL',
|
| 242 |
+
'nl-NL-MaartenNeural': 'nl-NL',
|
| 243 |
+
'pl-PL-MarekNeural': 'pl-PL',
|
| 244 |
+
'pl-PL-ZofiaNeural': 'pl-PL',
|
| 245 |
+
'ps-AF-GulNawazNeural': 'ps-AF',
|
| 246 |
+
'ps-AF-LatifaNeural': 'ps-AF',
|
| 247 |
+
'pt-BR-AntonioNeural': 'pt-BR',
|
| 248 |
+
'pt-BR-FranciscaNeural': 'pt-BR',
|
| 249 |
+
'pt-PT-DuarteNeural': 'pt-PT',
|
| 250 |
+
'pt-PT-RaquelNeural': 'pt-PT',
|
| 251 |
+
'ro-RO-AlinaNeural': 'ro-RO',
|
| 252 |
+
'ro-RO-EmilNeural': 'ro-RO',
|
| 253 |
+
'ru-RU-DmitryNeural': 'ru-RU',
|
| 254 |
+
'ru-RU-SvetlanaNeural': 'ru-RU',
|
| 255 |
+
'si-LK-SameeraNeural': 'si-LK',
|
| 256 |
+
'si-LK-ThiliniNeural': 'si-LK',
|
| 257 |
+
'sk-SK-LukasNeural': 'sk-SK',
|
| 258 |
+
'sk-SK-ViktoriaNeural': 'sk-SK',
|
| 259 |
+
'sl-SI-PetraNeural': 'sl-SI',
|
| 260 |
+
'sl-SI-RokNeural': 'sl-SI',
|
| 261 |
+
'so-SO-MuuseNeural': 'so-SO',
|
| 262 |
+
'so-SO-UbaxNeural': 'so-SO',
|
| 263 |
+
'sq-AL-AnilaNeural': 'sq-AL',
|
| 264 |
+
'sq-AL-IlirNeural': 'sq-AL',
|
| 265 |
+
'sr-RS-NicholasNeural': 'sr-RS',
|
| 266 |
+
'sr-RS-SophieNeural': 'sr-RS',
|
| 267 |
+
'su-ID-JajangNeural': 'su-ID',
|
| 268 |
+
'su-ID-TutiNeural': 'su-ID',
|
| 269 |
+
'sv-SE-MattiasNeural': 'sv-SE',
|
| 270 |
+
'sv-SE-SofieNeural': 'sv-SE',
|
| 271 |
+
'sw-KE-RafikiNeural': 'sw-KE',
|
| 272 |
+
'sw-KE-ZuriNeural': 'sw-KE',
|
| 273 |
+
'sw-TZ-DaudiNeural': 'sw-TZ',
|
| 274 |
+
'sw-TZ-RehemaNeural': 'sw-TZ',
|
| 275 |
+
'ta-IN-PallaviNeural': 'ta-IN',
|
| 276 |
+
'ta-IN-ValluvarNeural': 'ta-IN',
|
| 277 |
+
'ta-LK-KumarNeural': 'ta-LK',
|
| 278 |
+
'ta-LK-SaranyaNeural': 'ta-LK',
|
| 279 |
+
'ta-MY-KaniNeural': 'ta-MY',
|
| 280 |
+
'ta-MY-SuryaNeural': 'ta-MY',
|
| 281 |
+
'ta-SG-AnbuNeural': 'ta-SG',
|
| 282 |
+
'ta-SG-VenbaNeural': 'ta-SG',
|
| 283 |
+
'te-IN-MohanNeural': 'te-IN',
|
| 284 |
+
'te-IN-ShrutiNeural': 'te-IN',
|
| 285 |
+
'th-TH-NiwatNeural': 'th-TH',
|
| 286 |
+
'th-TH-PremwadeeNeural': 'th-TH',
|
| 287 |
+
'tr-TR-AhmetNeural': 'tr-TR',
|
| 288 |
+
'tr-TR-EmelNeural': 'tr-TR',
|
| 289 |
+
'uk-UA-OstapNeural': 'uk-UA',
|
| 290 |
+
'uk-UA-PolinaNeural': 'uk-UA',
|
| 291 |
+
'ur-IN-GulNeural': 'ur-IN',
|
| 292 |
+
'ur-IN-SalmanNeural': 'ur-IN',
|
| 293 |
+
'ur-PK-AsadNeural': 'ur-PK',
|
| 294 |
+
'ur-PK-UzmaNeural': 'ur-PK',
|
| 295 |
+
'uz-UZ-MadinaNeural': 'uz-UZ',
|
| 296 |
+
'uz-UZ-SardorNeural': 'uz-UZ',
|
| 297 |
+
'vi-VN-HoaiMyNeural': 'vi-VN',
|
| 298 |
+
'vi-VN-NamMinhNeural': 'vi-VN',
|
| 299 |
+
'zu-ZA-ThandoNeural': 'zu-ZA',
|
| 300 |
+
'zu-ZA-ThembaNeural': 'zu-ZA',
|
| 301 |
+
}
|
| 302 |
+
|
| 303 |
+
SUPPORTED_LANGUAGES = [
|
| 304 |
+
"Auto",
|
| 305 |
+
*SUPPORTED_VOICES.keys()
|
| 306 |
+
]
|
utils.py
ADDED
|
@@ -0,0 +1,572 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import argparse
|
| 2 |
+
import glob
|
| 3 |
+
import json
|
| 4 |
+
import logging
|
| 5 |
+
import os
|
| 6 |
+
import re
|
| 7 |
+
import subprocess
|
| 8 |
+
import sys
|
| 9 |
+
import traceback
|
| 10 |
+
from multiprocessing import cpu_count
|
| 11 |
+
|
| 12 |
+
import faiss
|
| 13 |
+
import librosa
|
| 14 |
+
import numpy as np
|
| 15 |
+
import torch
|
| 16 |
+
from scipy.io.wavfile import read
|
| 17 |
+
from sklearn.cluster import MiniBatchKMeans
|
| 18 |
+
from torch.nn import functional as F
|
| 19 |
+
|
| 20 |
+
MATPLOTLIB_FLAG = False
|
| 21 |
+
|
| 22 |
+
logging.basicConfig(stream=sys.stdout, level=logging.WARN)
|
| 23 |
+
logger = logging
|
| 24 |
+
|
| 25 |
+
f0_bin = 256
|
| 26 |
+
f0_max = 1100.0
|
| 27 |
+
f0_min = 50.0
|
| 28 |
+
f0_mel_min = 1127 * np.log(1 + f0_min / 700)
|
| 29 |
+
f0_mel_max = 1127 * np.log(1 + f0_max / 700)
|
| 30 |
+
|
| 31 |
+
def normalize_f0(f0, x_mask, uv, random_scale=True):
|
| 32 |
+
# calculate means based on x_mask
|
| 33 |
+
uv_sum = torch.sum(uv, dim=1, keepdim=True)
|
| 34 |
+
uv_sum[uv_sum == 0] = 9999
|
| 35 |
+
means = torch.sum(f0[:, 0, :] * uv, dim=1, keepdim=True) / uv_sum
|
| 36 |
+
|
| 37 |
+
if random_scale:
|
| 38 |
+
factor = torch.Tensor(f0.shape[0], 1).uniform_(0.8, 1.2).to(f0.device)
|
| 39 |
+
else:
|
| 40 |
+
factor = torch.ones(f0.shape[0], 1).to(f0.device)
|
| 41 |
+
# normalize f0 based on means and factor
|
| 42 |
+
f0_norm = (f0 - means.unsqueeze(-1)) * factor.unsqueeze(-1)
|
| 43 |
+
if torch.isnan(f0_norm).any():
|
| 44 |
+
exit(0)
|
| 45 |
+
return f0_norm * x_mask
|
| 46 |
+
def plot_data_to_numpy(x, y):
|
| 47 |
+
global MATPLOTLIB_FLAG
|
| 48 |
+
if not MATPLOTLIB_FLAG:
|
| 49 |
+
import matplotlib
|
| 50 |
+
matplotlib.use("Agg")
|
| 51 |
+
MATPLOTLIB_FLAG = True
|
| 52 |
+
mpl_logger = logging.getLogger('matplotlib')
|
| 53 |
+
mpl_logger.setLevel(logging.WARNING)
|
| 54 |
+
import matplotlib.pylab as plt
|
| 55 |
+
import numpy as np
|
| 56 |
+
|
| 57 |
+
fig, ax = plt.subplots(figsize=(10, 2))
|
| 58 |
+
plt.plot(x)
|
| 59 |
+
plt.plot(y)
|
| 60 |
+
plt.tight_layout()
|
| 61 |
+
|
| 62 |
+
fig.canvas.draw()
|
| 63 |
+
data = np.fromstring(fig.canvas.tostring_rgb(), dtype=np.uint8, sep='')
|
| 64 |
+
data = data.reshape(fig.canvas.get_width_height()[::-1] + (3,))
|
| 65 |
+
plt.close()
|
| 66 |
+
return data
|
| 67 |
+
|
| 68 |
+
|
| 69 |
+
def f0_to_coarse(f0):
|
| 70 |
+
f0_mel = 1127 * (1 + f0 / 700).log()
|
| 71 |
+
a = (f0_bin - 2) / (f0_mel_max - f0_mel_min)
|
| 72 |
+
b = f0_mel_min * a - 1.
|
| 73 |
+
f0_mel = torch.where(f0_mel > 0, f0_mel * a - b, f0_mel)
|
| 74 |
+
# torch.clip_(f0_mel, min=1., max=float(f0_bin - 1))
|
| 75 |
+
f0_coarse = torch.round(f0_mel).long()
|
| 76 |
+
f0_coarse = f0_coarse * (f0_coarse > 0)
|
| 77 |
+
f0_coarse = f0_coarse + ((f0_coarse < 1) * 1)
|
| 78 |
+
f0_coarse = f0_coarse * (f0_coarse < f0_bin)
|
| 79 |
+
f0_coarse = f0_coarse + ((f0_coarse >= f0_bin) * (f0_bin - 1))
|
| 80 |
+
return f0_coarse
|
| 81 |
+
|
| 82 |
+
def get_content(cmodel, y):
|
| 83 |
+
with torch.no_grad():
|
| 84 |
+
c = cmodel.extract_features(y.squeeze(1))[0]
|
| 85 |
+
c = c.transpose(1, 2)
|
| 86 |
+
return c
|
| 87 |
+
|
| 88 |
+
def get_f0_predictor(f0_predictor,hop_length,sampling_rate,**kargs):
|
| 89 |
+
if f0_predictor == "pm":
|
| 90 |
+
from modules.F0Predictor.PMF0Predictor import PMF0Predictor
|
| 91 |
+
f0_predictor_object = PMF0Predictor(hop_length=hop_length,sampling_rate=sampling_rate)
|
| 92 |
+
elif f0_predictor == "crepe":
|
| 93 |
+
from modules.F0Predictor.CrepeF0Predictor import CrepeF0Predictor
|
| 94 |
+
f0_predictor_object = CrepeF0Predictor(hop_length=hop_length,sampling_rate=sampling_rate,device=kargs["device"],threshold=kargs["threshold"])
|
| 95 |
+
elif f0_predictor == "harvest":
|
| 96 |
+
from modules.F0Predictor.HarvestF0Predictor import HarvestF0Predictor
|
| 97 |
+
f0_predictor_object = HarvestF0Predictor(hop_length=hop_length,sampling_rate=sampling_rate)
|
| 98 |
+
elif f0_predictor == "dio":
|
| 99 |
+
from modules.F0Predictor.DioF0Predictor import DioF0Predictor
|
| 100 |
+
f0_predictor_object = DioF0Predictor(hop_length=hop_length,sampling_rate=sampling_rate)
|
| 101 |
+
elif f0_predictor == "rmvpe":
|
| 102 |
+
from modules.F0Predictor.RMVPEF0Predictor import RMVPEF0Predictor
|
| 103 |
+
f0_predictor_object = RMVPEF0Predictor(hop_length=hop_length,sampling_rate=sampling_rate,dtype=torch.float32 ,device=kargs["device"],threshold=kargs["threshold"])
|
| 104 |
+
elif f0_predictor == "fcpe":
|
| 105 |
+
from modules.F0Predictor.FCPEF0Predictor import FCPEF0Predictor
|
| 106 |
+
f0_predictor_object = FCPEF0Predictor(hop_length=hop_length,sampling_rate=sampling_rate,dtype=torch.float32 ,device=kargs["device"],threshold=kargs["threshold"])
|
| 107 |
+
else:
|
| 108 |
+
raise Exception("Unknown f0 predictor")
|
| 109 |
+
return f0_predictor_object
|
| 110 |
+
|
| 111 |
+
def get_speech_encoder(speech_encoder,device=None,**kargs):
|
| 112 |
+
if speech_encoder == "vec768l12":
|
| 113 |
+
from vencoder.ContentVec768L12 import ContentVec768L12
|
| 114 |
+
speech_encoder_object = ContentVec768L12(device = device)
|
| 115 |
+
elif speech_encoder == "vec256l9":
|
| 116 |
+
from vencoder.ContentVec256L9 import ContentVec256L9
|
| 117 |
+
speech_encoder_object = ContentVec256L9(device = device)
|
| 118 |
+
elif speech_encoder == "vec256l9-onnx":
|
| 119 |
+
from vencoder.ContentVec256L9_Onnx import ContentVec256L9_Onnx
|
| 120 |
+
speech_encoder_object = ContentVec256L9_Onnx(device = device)
|
| 121 |
+
elif speech_encoder == "vec256l12-onnx":
|
| 122 |
+
from vencoder.ContentVec256L12_Onnx import ContentVec256L12_Onnx
|
| 123 |
+
speech_encoder_object = ContentVec256L12_Onnx(device = device)
|
| 124 |
+
elif speech_encoder == "vec768l9-onnx":
|
| 125 |
+
from vencoder.ContentVec768L9_Onnx import ContentVec768L9_Onnx
|
| 126 |
+
speech_encoder_object = ContentVec768L9_Onnx(device = device)
|
| 127 |
+
elif speech_encoder == "vec768l12-onnx":
|
| 128 |
+
from vencoder.ContentVec768L12_Onnx import ContentVec768L12_Onnx
|
| 129 |
+
speech_encoder_object = ContentVec768L12_Onnx(device = device)
|
| 130 |
+
elif speech_encoder == "hubertsoft-onnx":
|
| 131 |
+
from vencoder.HubertSoft_Onnx import HubertSoft_Onnx
|
| 132 |
+
speech_encoder_object = HubertSoft_Onnx(device = device)
|
| 133 |
+
elif speech_encoder == "hubertsoft":
|
| 134 |
+
from vencoder.HubertSoft import HubertSoft
|
| 135 |
+
speech_encoder_object = HubertSoft(device = device)
|
| 136 |
+
elif speech_encoder == "whisper-ppg":
|
| 137 |
+
from vencoder.WhisperPPG import WhisperPPG
|
| 138 |
+
speech_encoder_object = WhisperPPG(device = device)
|
| 139 |
+
elif speech_encoder == "cnhubertlarge":
|
| 140 |
+
from vencoder.CNHubertLarge import CNHubertLarge
|
| 141 |
+
speech_encoder_object = CNHubertLarge(device = device)
|
| 142 |
+
elif speech_encoder == "dphubert":
|
| 143 |
+
from vencoder.DPHubert import DPHubert
|
| 144 |
+
speech_encoder_object = DPHubert(device = device)
|
| 145 |
+
elif speech_encoder == "whisper-ppg-large":
|
| 146 |
+
from vencoder.WhisperPPGLarge import WhisperPPGLarge
|
| 147 |
+
speech_encoder_object = WhisperPPGLarge(device = device)
|
| 148 |
+
elif speech_encoder == "wavlmbase+":
|
| 149 |
+
from vencoder.WavLMBasePlus import WavLMBasePlus
|
| 150 |
+
speech_encoder_object = WavLMBasePlus(device = device)
|
| 151 |
+
else:
|
| 152 |
+
raise Exception("Unknown speech encoder")
|
| 153 |
+
return speech_encoder_object
|
| 154 |
+
|
| 155 |
+
def load_checkpoint(checkpoint_path, model, optimizer=None, skip_optimizer=False):
|
| 156 |
+
assert os.path.isfile(checkpoint_path)
|
| 157 |
+
checkpoint_dict = torch.load(checkpoint_path, map_location='cpu')
|
| 158 |
+
iteration = checkpoint_dict['iteration']
|
| 159 |
+
learning_rate = checkpoint_dict['learning_rate']
|
| 160 |
+
if optimizer is not None and not skip_optimizer and checkpoint_dict['optimizer'] is not None:
|
| 161 |
+
optimizer.load_state_dict(checkpoint_dict['optimizer'])
|
| 162 |
+
saved_state_dict = checkpoint_dict['model']
|
| 163 |
+
model = model.to(list(saved_state_dict.values())[0].dtype)
|
| 164 |
+
if hasattr(model, 'module'):
|
| 165 |
+
state_dict = model.module.state_dict()
|
| 166 |
+
else:
|
| 167 |
+
state_dict = model.state_dict()
|
| 168 |
+
new_state_dict = {}
|
| 169 |
+
for k, v in state_dict.items():
|
| 170 |
+
try:
|
| 171 |
+
# assert "dec" in k or "disc" in k
|
| 172 |
+
# print("load", k)
|
| 173 |
+
new_state_dict[k] = saved_state_dict[k]
|
| 174 |
+
assert saved_state_dict[k].shape == v.shape, (saved_state_dict[k].shape, v.shape)
|
| 175 |
+
except Exception:
|
| 176 |
+
if "enc_q" not in k or "emb_g" not in k:
|
| 177 |
+
print("%s is not in the checkpoint,please check your checkpoint.If you're using pretrain model,just ignore this warning." % k)
|
| 178 |
+
logger.info("%s is not in the checkpoint" % k)
|
| 179 |
+
new_state_dict[k] = v
|
| 180 |
+
if hasattr(model, 'module'):
|
| 181 |
+
model.module.load_state_dict(new_state_dict)
|
| 182 |
+
else:
|
| 183 |
+
model.load_state_dict(new_state_dict)
|
| 184 |
+
print("load ")
|
| 185 |
+
logger.info("Loaded checkpoint '{}' (iteration {})".format(
|
| 186 |
+
checkpoint_path, iteration))
|
| 187 |
+
return model, optimizer, learning_rate, iteration
|
| 188 |
+
|
| 189 |
+
|
| 190 |
+
def save_checkpoint(model, optimizer, learning_rate, iteration, checkpoint_path):
|
| 191 |
+
logger.info("Saving model and optimizer state at iteration {} to {}".format(
|
| 192 |
+
iteration, checkpoint_path))
|
| 193 |
+
if hasattr(model, 'module'):
|
| 194 |
+
state_dict = model.module.state_dict()
|
| 195 |
+
else:
|
| 196 |
+
state_dict = model.state_dict()
|
| 197 |
+
torch.save({'model': state_dict,
|
| 198 |
+
'iteration': iteration,
|
| 199 |
+
'optimizer': optimizer.state_dict(),
|
| 200 |
+
'learning_rate': learning_rate}, checkpoint_path)
|
| 201 |
+
|
| 202 |
+
def clean_checkpoints(path_to_models='logs/44k/', n_ckpts_to_keep=2, sort_by_time=True):
|
| 203 |
+
"""Freeing up space by deleting saved ckpts
|
| 204 |
+
|
| 205 |
+
Arguments:
|
| 206 |
+
path_to_models -- Path to the model directory
|
| 207 |
+
n_ckpts_to_keep -- Number of ckpts to keep, excluding G_0.pth and D_0.pth
|
| 208 |
+
sort_by_time -- True -> chronologically delete ckpts
|
| 209 |
+
False -> lexicographically delete ckpts
|
| 210 |
+
"""
|
| 211 |
+
ckpts_files = [f for f in os.listdir(path_to_models) if os.path.isfile(os.path.join(path_to_models, f))]
|
| 212 |
+
def name_key(_f):
|
| 213 |
+
return int(re.compile("._(\\d+)\\.pth").match(_f).group(1))
|
| 214 |
+
def time_key(_f):
|
| 215 |
+
return os.path.getmtime(os.path.join(path_to_models, _f))
|
| 216 |
+
sort_key = time_key if sort_by_time else name_key
|
| 217 |
+
def x_sorted(_x):
|
| 218 |
+
return sorted([f for f in ckpts_files if f.startswith(_x) and not f.endswith("_0.pth")], key=sort_key)
|
| 219 |
+
to_del = [os.path.join(path_to_models, fn) for fn in
|
| 220 |
+
(x_sorted('G')[:-n_ckpts_to_keep] + x_sorted('D')[:-n_ckpts_to_keep])]
|
| 221 |
+
def del_info(fn):
|
| 222 |
+
return logger.info(f".. Free up space by deleting ckpt {fn}")
|
| 223 |
+
def del_routine(x):
|
| 224 |
+
return [os.remove(x), del_info(x)]
|
| 225 |
+
[del_routine(fn) for fn in to_del]
|
| 226 |
+
|
| 227 |
+
def summarize(writer, global_step, scalars={}, histograms={}, images={}, audios={}, audio_sampling_rate=22050):
|
| 228 |
+
for k, v in scalars.items():
|
| 229 |
+
writer.add_scalar(k, v, global_step)
|
| 230 |
+
for k, v in histograms.items():
|
| 231 |
+
writer.add_histogram(k, v, global_step)
|
| 232 |
+
for k, v in images.items():
|
| 233 |
+
writer.add_image(k, v, global_step, dataformats='HWC')
|
| 234 |
+
for k, v in audios.items():
|
| 235 |
+
writer.add_audio(k, v, global_step, audio_sampling_rate)
|
| 236 |
+
|
| 237 |
+
|
| 238 |
+
def latest_checkpoint_path(dir_path, regex="G_*.pth"):
|
| 239 |
+
f_list = glob.glob(os.path.join(dir_path, regex))
|
| 240 |
+
f_list.sort(key=lambda f: int("".join(filter(str.isdigit, f))))
|
| 241 |
+
x = f_list[-1]
|
| 242 |
+
print(x)
|
| 243 |
+
return x
|
| 244 |
+
|
| 245 |
+
|
| 246 |
+
def plot_spectrogram_to_numpy(spectrogram):
|
| 247 |
+
global MATPLOTLIB_FLAG
|
| 248 |
+
if not MATPLOTLIB_FLAG:
|
| 249 |
+
import matplotlib
|
| 250 |
+
matplotlib.use("Agg")
|
| 251 |
+
MATPLOTLIB_FLAG = True
|
| 252 |
+
mpl_logger = logging.getLogger('matplotlib')
|
| 253 |
+
mpl_logger.setLevel(logging.WARNING)
|
| 254 |
+
import matplotlib.pylab as plt
|
| 255 |
+
import numpy as np
|
| 256 |
+
|
| 257 |
+
fig, ax = plt.subplots(figsize=(10,2))
|
| 258 |
+
im = ax.imshow(spectrogram, aspect="auto", origin="lower",
|
| 259 |
+
interpolation='none')
|
| 260 |
+
plt.colorbar(im, ax=ax)
|
| 261 |
+
plt.xlabel("Frames")
|
| 262 |
+
plt.ylabel("Channels")
|
| 263 |
+
plt.tight_layout()
|
| 264 |
+
|
| 265 |
+
fig.canvas.draw()
|
| 266 |
+
data = np.fromstring(fig.canvas.tostring_rgb(), dtype=np.uint8, sep='')
|
| 267 |
+
data = data.reshape(fig.canvas.get_width_height()[::-1] + (3,))
|
| 268 |
+
plt.close()
|
| 269 |
+
return data
|
| 270 |
+
|
| 271 |
+
|
| 272 |
+
def plot_alignment_to_numpy(alignment, info=None):
|
| 273 |
+
global MATPLOTLIB_FLAG
|
| 274 |
+
if not MATPLOTLIB_FLAG:
|
| 275 |
+
import matplotlib
|
| 276 |
+
matplotlib.use("Agg")
|
| 277 |
+
MATPLOTLIB_FLAG = True
|
| 278 |
+
mpl_logger = logging.getLogger('matplotlib')
|
| 279 |
+
mpl_logger.setLevel(logging.WARNING)
|
| 280 |
+
import matplotlib.pylab as plt
|
| 281 |
+
import numpy as np
|
| 282 |
+
|
| 283 |
+
fig, ax = plt.subplots(figsize=(6, 4))
|
| 284 |
+
im = ax.imshow(alignment.transpose(), aspect='auto', origin='lower',
|
| 285 |
+
interpolation='none')
|
| 286 |
+
fig.colorbar(im, ax=ax)
|
| 287 |
+
xlabel = 'Decoder timestep'
|
| 288 |
+
if info is not None:
|
| 289 |
+
xlabel += '\n\n' + info
|
| 290 |
+
plt.xlabel(xlabel)
|
| 291 |
+
plt.ylabel('Encoder timestep')
|
| 292 |
+
plt.tight_layout()
|
| 293 |
+
|
| 294 |
+
fig.canvas.draw()
|
| 295 |
+
data = np.fromstring(fig.canvas.tostring_rgb(), dtype=np.uint8, sep='')
|
| 296 |
+
data = data.reshape(fig.canvas.get_width_height()[::-1] + (3,))
|
| 297 |
+
plt.close()
|
| 298 |
+
return data
|
| 299 |
+
|
| 300 |
+
|
| 301 |
+
def load_wav_to_torch(full_path):
|
| 302 |
+
sampling_rate, data = read(full_path)
|
| 303 |
+
return torch.FloatTensor(data.astype(np.float32)), sampling_rate
|
| 304 |
+
|
| 305 |
+
|
| 306 |
+
def load_filepaths_and_text(filename, split="|"):
|
| 307 |
+
with open(filename, encoding='utf-8') as f:
|
| 308 |
+
filepaths_and_text = [line.strip().split(split) for line in f]
|
| 309 |
+
return filepaths_and_text
|
| 310 |
+
|
| 311 |
+
|
| 312 |
+
def get_hparams(init=True):
|
| 313 |
+
parser = argparse.ArgumentParser()
|
| 314 |
+
parser.add_argument('-c', '--config', type=str, default="./configs/config.json",
|
| 315 |
+
help='JSON file for configuration')
|
| 316 |
+
parser.add_argument('-m', '--model', type=str, required=True,
|
| 317 |
+
help='Model name')
|
| 318 |
+
|
| 319 |
+
args = parser.parse_args()
|
| 320 |
+
model_dir = os.path.join("./logs", args.model)
|
| 321 |
+
|
| 322 |
+
if not os.path.exists(model_dir):
|
| 323 |
+
os.makedirs(model_dir)
|
| 324 |
+
|
| 325 |
+
config_path = args.config
|
| 326 |
+
config_save_path = os.path.join(model_dir, "config.json")
|
| 327 |
+
if init:
|
| 328 |
+
with open(config_path, "r") as f:
|
| 329 |
+
data = f.read()
|
| 330 |
+
with open(config_save_path, "w") as f:
|
| 331 |
+
f.write(data)
|
| 332 |
+
else:
|
| 333 |
+
with open(config_save_path, "r") as f:
|
| 334 |
+
data = f.read()
|
| 335 |
+
config = json.loads(data)
|
| 336 |
+
|
| 337 |
+
hparams = HParams(**config)
|
| 338 |
+
hparams.model_dir = model_dir
|
| 339 |
+
return hparams
|
| 340 |
+
|
| 341 |
+
|
| 342 |
+
def get_hparams_from_dir(model_dir):
|
| 343 |
+
config_save_path = os.path.join(model_dir, "config.json")
|
| 344 |
+
with open(config_save_path, "r") as f:
|
| 345 |
+
data = f.read()
|
| 346 |
+
config = json.loads(data)
|
| 347 |
+
|
| 348 |
+
hparams =HParams(**config)
|
| 349 |
+
hparams.model_dir = model_dir
|
| 350 |
+
return hparams
|
| 351 |
+
|
| 352 |
+
|
| 353 |
+
def get_hparams_from_file(config_path, infer_mode = False):
|
| 354 |
+
with open(config_path, "r") as f:
|
| 355 |
+
data = f.read()
|
| 356 |
+
config = json.loads(data)
|
| 357 |
+
hparams =HParams(**config) if not infer_mode else InferHParams(**config)
|
| 358 |
+
return hparams
|
| 359 |
+
|
| 360 |
+
|
| 361 |
+
def check_git_hash(model_dir):
|
| 362 |
+
source_dir = os.path.dirname(os.path.realpath(__file__))
|
| 363 |
+
if not os.path.exists(os.path.join(source_dir, ".git")):
|
| 364 |
+
logger.warn("{} is not a git repository, therefore hash value comparison will be ignored.".format(
|
| 365 |
+
source_dir
|
| 366 |
+
))
|
| 367 |
+
return
|
| 368 |
+
|
| 369 |
+
cur_hash = subprocess.getoutput("git rev-parse HEAD")
|
| 370 |
+
|
| 371 |
+
path = os.path.join(model_dir, "githash")
|
| 372 |
+
if os.path.exists(path):
|
| 373 |
+
saved_hash = open(path).read()
|
| 374 |
+
if saved_hash != cur_hash:
|
| 375 |
+
logger.warn("git hash values are different. {}(saved) != {}(current)".format(
|
| 376 |
+
saved_hash[:8], cur_hash[:8]))
|
| 377 |
+
else:
|
| 378 |
+
open(path, "w").write(cur_hash)
|
| 379 |
+
|
| 380 |
+
|
| 381 |
+
def get_logger(model_dir, filename="train.log"):
|
| 382 |
+
global logger
|
| 383 |
+
logger = logging.getLogger(os.path.basename(model_dir))
|
| 384 |
+
logger.setLevel(logging.DEBUG)
|
| 385 |
+
|
| 386 |
+
formatter = logging.Formatter("%(asctime)s\t%(name)s\t%(levelname)s\t%(message)s")
|
| 387 |
+
if not os.path.exists(model_dir):
|
| 388 |
+
os.makedirs(model_dir)
|
| 389 |
+
h = logging.FileHandler(os.path.join(model_dir, filename))
|
| 390 |
+
h.setLevel(logging.DEBUG)
|
| 391 |
+
h.setFormatter(formatter)
|
| 392 |
+
logger.addHandler(h)
|
| 393 |
+
return logger
|
| 394 |
+
|
| 395 |
+
|
| 396 |
+
def repeat_expand_2d(content, target_len, mode = 'left'):
|
| 397 |
+
# content : [h, t]
|
| 398 |
+
return repeat_expand_2d_left(content, target_len) if mode == 'left' else repeat_expand_2d_other(content, target_len, mode)
|
| 399 |
+
|
| 400 |
+
|
| 401 |
+
|
| 402 |
+
def repeat_expand_2d_left(content, target_len):
|
| 403 |
+
# content : [h, t]
|
| 404 |
+
|
| 405 |
+
src_len = content.shape[-1]
|
| 406 |
+
target = torch.zeros([content.shape[0], target_len], dtype=torch.float).to(content.device)
|
| 407 |
+
temp = torch.arange(src_len+1) * target_len / src_len
|
| 408 |
+
current_pos = 0
|
| 409 |
+
for i in range(target_len):
|
| 410 |
+
if i < temp[current_pos+1]:
|
| 411 |
+
target[:, i] = content[:, current_pos]
|
| 412 |
+
else:
|
| 413 |
+
current_pos += 1
|
| 414 |
+
target[:, i] = content[:, current_pos]
|
| 415 |
+
|
| 416 |
+
return target
|
| 417 |
+
|
| 418 |
+
|
| 419 |
+
# mode : 'nearest'| 'linear'| 'bilinear'| 'bicubic'| 'trilinear'| 'area'
|
| 420 |
+
def repeat_expand_2d_other(content, target_len, mode = 'nearest'):
|
| 421 |
+
# content : [h, t]
|
| 422 |
+
content = content[None,:,:]
|
| 423 |
+
target = F.interpolate(content,size=target_len,mode=mode)[0]
|
| 424 |
+
return target
|
| 425 |
+
|
| 426 |
+
|
| 427 |
+
def mix_model(model_paths,mix_rate,mode):
|
| 428 |
+
mix_rate = torch.FloatTensor(mix_rate)/100
|
| 429 |
+
model_tem = torch.load(model_paths[0])
|
| 430 |
+
models = [torch.load(path)["model"] for path in model_paths]
|
| 431 |
+
if mode == 0:
|
| 432 |
+
mix_rate = F.softmax(mix_rate,dim=0)
|
| 433 |
+
for k in model_tem["model"].keys():
|
| 434 |
+
model_tem["model"][k] = torch.zeros_like(model_tem["model"][k])
|
| 435 |
+
for i,model in enumerate(models):
|
| 436 |
+
model_tem["model"][k] += model[k]*mix_rate[i]
|
| 437 |
+
torch.save(model_tem,os.path.join(os.path.curdir,"output.pth"))
|
| 438 |
+
return os.path.join(os.path.curdir,"output.pth")
|
| 439 |
+
|
| 440 |
+
def change_rms(data1, sr1, data2, sr2, rate): # 1是输入音频,2是输出音频,rate是2的占比 from RVC
|
| 441 |
+
# print(data1.max(),data2.max())
|
| 442 |
+
rms1 = librosa.feature.rms(
|
| 443 |
+
y=data1, frame_length=sr1 // 2 * 2, hop_length=sr1 // 2
|
| 444 |
+
) # 每半秒一个点
|
| 445 |
+
rms2 = librosa.feature.rms(y=data2.detach().cpu().numpy(), frame_length=sr2 // 2 * 2, hop_length=sr2 // 2)
|
| 446 |
+
rms1 = torch.from_numpy(rms1).to(data2.device)
|
| 447 |
+
rms1 = F.interpolate(
|
| 448 |
+
rms1.unsqueeze(0), size=data2.shape[0], mode="linear"
|
| 449 |
+
).squeeze()
|
| 450 |
+
rms2 = torch.from_numpy(rms2).to(data2.device)
|
| 451 |
+
rms2 = F.interpolate(
|
| 452 |
+
rms2.unsqueeze(0), size=data2.shape[0], mode="linear"
|
| 453 |
+
).squeeze()
|
| 454 |
+
rms2 = torch.max(rms2, torch.zeros_like(rms2) + 1e-6)
|
| 455 |
+
data2 *= (
|
| 456 |
+
torch.pow(rms1, torch.tensor(1 - rate))
|
| 457 |
+
* torch.pow(rms2, torch.tensor(rate - 1))
|
| 458 |
+
)
|
| 459 |
+
return data2
|
| 460 |
+
|
| 461 |
+
def train_index(spk_name,root_dir = "dataset/44k/"): #from: RVC https://github.com/RVC-Project/Retrieval-based-Voice-Conversion-WebUI
|
| 462 |
+
n_cpu = cpu_count()
|
| 463 |
+
print("The feature index is constructing.")
|
| 464 |
+
exp_dir = os.path.join(root_dir,spk_name)
|
| 465 |
+
listdir_res = []
|
| 466 |
+
for file in os.listdir(exp_dir):
|
| 467 |
+
if ".wav.soft.pt" in file:
|
| 468 |
+
listdir_res.append(os.path.join(exp_dir,file))
|
| 469 |
+
if len(listdir_res) == 0:
|
| 470 |
+
raise Exception("You need to run preprocess_hubert_f0.py!")
|
| 471 |
+
npys = []
|
| 472 |
+
for name in sorted(listdir_res):
|
| 473 |
+
phone = torch.load(name)[0].transpose(-1,-2).numpy()
|
| 474 |
+
npys.append(phone)
|
| 475 |
+
big_npy = np.concatenate(npys, 0)
|
| 476 |
+
big_npy_idx = np.arange(big_npy.shape[0])
|
| 477 |
+
np.random.shuffle(big_npy_idx)
|
| 478 |
+
big_npy = big_npy[big_npy_idx]
|
| 479 |
+
if big_npy.shape[0] > 2e5:
|
| 480 |
+
# if(1):
|
| 481 |
+
info = "Trying doing kmeans %s shape to 10k centers." % big_npy.shape[0]
|
| 482 |
+
print(info)
|
| 483 |
+
try:
|
| 484 |
+
big_npy = (
|
| 485 |
+
MiniBatchKMeans(
|
| 486 |
+
n_clusters=10000,
|
| 487 |
+
verbose=True,
|
| 488 |
+
batch_size=256 * n_cpu,
|
| 489 |
+
compute_labels=False,
|
| 490 |
+
init="random",
|
| 491 |
+
)
|
| 492 |
+
.fit(big_npy)
|
| 493 |
+
.cluster_centers_
|
| 494 |
+
)
|
| 495 |
+
except Exception:
|
| 496 |
+
info = traceback.format_exc()
|
| 497 |
+
print(info)
|
| 498 |
+
n_ivf = min(int(16 * np.sqrt(big_npy.shape[0])), big_npy.shape[0] // 39)
|
| 499 |
+
index = faiss.index_factory(big_npy.shape[1] , "IVF%s,Flat" % n_ivf)
|
| 500 |
+
index_ivf = faiss.extract_index_ivf(index) #
|
| 501 |
+
index_ivf.nprobe = 1
|
| 502 |
+
index.train(big_npy)
|
| 503 |
+
batch_size_add = 8192
|
| 504 |
+
for i in range(0, big_npy.shape[0], batch_size_add):
|
| 505 |
+
index.add(big_npy[i : i + batch_size_add])
|
| 506 |
+
# faiss.write_index(
|
| 507 |
+
# index,
|
| 508 |
+
# f"added_{spk_name}.index"
|
| 509 |
+
# )
|
| 510 |
+
print("Successfully build index")
|
| 511 |
+
return index
|
| 512 |
+
|
| 513 |
+
|
| 514 |
+
class HParams():
|
| 515 |
+
def __init__(self, **kwargs):
|
| 516 |
+
for k, v in kwargs.items():
|
| 517 |
+
if type(v) == dict:
|
| 518 |
+
v = HParams(**v)
|
| 519 |
+
self[k] = v
|
| 520 |
+
|
| 521 |
+
def keys(self):
|
| 522 |
+
return self.__dict__.keys()
|
| 523 |
+
|
| 524 |
+
def items(self):
|
| 525 |
+
return self.__dict__.items()
|
| 526 |
+
|
| 527 |
+
def values(self):
|
| 528 |
+
return self.__dict__.values()
|
| 529 |
+
|
| 530 |
+
def __len__(self):
|
| 531 |
+
return len(self.__dict__)
|
| 532 |
+
|
| 533 |
+
def __getitem__(self, key):
|
| 534 |
+
return getattr(self, key)
|
| 535 |
+
|
| 536 |
+
def __setitem__(self, key, value):
|
| 537 |
+
return setattr(self, key, value)
|
| 538 |
+
|
| 539 |
+
def __contains__(self, key):
|
| 540 |
+
return key in self.__dict__
|
| 541 |
+
|
| 542 |
+
def __repr__(self):
|
| 543 |
+
return self.__dict__.__repr__()
|
| 544 |
+
|
| 545 |
+
def get(self,index):
|
| 546 |
+
return self.__dict__.get(index)
|
| 547 |
+
|
| 548 |
+
|
| 549 |
+
class InferHParams(HParams):
|
| 550 |
+
def __init__(self, **kwargs):
|
| 551 |
+
for k, v in kwargs.items():
|
| 552 |
+
if type(v) == dict:
|
| 553 |
+
v = InferHParams(**v)
|
| 554 |
+
self[k] = v
|
| 555 |
+
|
| 556 |
+
def __getattr__(self,index):
|
| 557 |
+
return self.get(index)
|
| 558 |
+
|
| 559 |
+
|
| 560 |
+
class Volume_Extractor:
|
| 561 |
+
def __init__(self, hop_size = 512):
|
| 562 |
+
self.hop_size = hop_size
|
| 563 |
+
|
| 564 |
+
def extract(self, audio): # audio: 2d tensor array
|
| 565 |
+
if not isinstance(audio,torch.Tensor):
|
| 566 |
+
audio = torch.Tensor(audio)
|
| 567 |
+
n_frames = int(audio.size(-1) // self.hop_size)
|
| 568 |
+
audio2 = audio ** 2
|
| 569 |
+
audio2 = torch.nn.functional.pad(audio2, (int(self.hop_size // 2), int((self.hop_size + 1) // 2)), mode = 'reflect')
|
| 570 |
+
volume = torch.nn.functional.unfold(audio2[:,None,None,:],(1,self.hop_size),stride=self.hop_size)[:,:,:n_frames].mean(dim=1)[0]
|
| 571 |
+
volume = torch.sqrt(volume)
|
| 572 |
+
return volume
|
wav_upload.py
ADDED
|
@@ -0,0 +1,25 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import argparse
|
| 2 |
+
import os
|
| 3 |
+
import shutil
|
| 4 |
+
|
| 5 |
+
from google.colab import files
|
| 6 |
+
|
| 7 |
+
if __name__ == "__main__":
|
| 8 |
+
parser = argparse.ArgumentParser()
|
| 9 |
+
parser.add_argument("--type", type=str, required=True, help="type of file to upload")
|
| 10 |
+
args = parser.parse_args()
|
| 11 |
+
file_type = args.type
|
| 12 |
+
|
| 13 |
+
basepath = os.getcwd()
|
| 14 |
+
uploaded = files.upload() # 上传文件
|
| 15 |
+
assert(file_type in ['zip', 'audio'])
|
| 16 |
+
if file_type == "zip":
|
| 17 |
+
upload_path = "./upload/"
|
| 18 |
+
for filename in uploaded.keys():
|
| 19 |
+
#将上传的文件移动到指定的位置上
|
| 20 |
+
shutil.move(os.path.join(basepath, filename), os.path.join(upload_path, "userzip.zip"))
|
| 21 |
+
elif file_type == "audio":
|
| 22 |
+
upload_path = "./raw/"
|
| 23 |
+
for filename in uploaded.keys():
|
| 24 |
+
#将上传的文件移动到指定的位置上
|
| 25 |
+
shutil.move(os.path.join(basepath, filename), os.path.join(upload_path, filename))
|
webUI.py
ADDED
|
@@ -0,0 +1,430 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import glob
|
| 2 |
+
import json
|
| 3 |
+
import logging
|
| 4 |
+
import os
|
| 5 |
+
import re
|
| 6 |
+
import subprocess
|
| 7 |
+
import sys
|
| 8 |
+
import time
|
| 9 |
+
import traceback
|
| 10 |
+
from itertools import chain
|
| 11 |
+
from pathlib import Path
|
| 12 |
+
|
| 13 |
+
# os.system("wget -P cvec/ https://huggingface.co/spaces/innnky/nanami/resolve/main/checkpoint_best_legacy_500.pt")
|
| 14 |
+
import gradio as gr
|
| 15 |
+
import librosa
|
| 16 |
+
import numpy as np
|
| 17 |
+
import soundfile
|
| 18 |
+
import torch
|
| 19 |
+
|
| 20 |
+
from compress_model import removeOptimizer
|
| 21 |
+
from edgetts.tts_voices import SUPPORTED_LANGUAGES
|
| 22 |
+
from inference.infer_tool import Svc
|
| 23 |
+
from utils import mix_model
|
| 24 |
+
|
| 25 |
+
logging.getLogger('numba').setLevel(logging.WARNING)
|
| 26 |
+
logging.getLogger('markdown_it').setLevel(logging.WARNING)
|
| 27 |
+
logging.getLogger('urllib3').setLevel(logging.WARNING)
|
| 28 |
+
logging.getLogger('matplotlib').setLevel(logging.WARNING)
|
| 29 |
+
logging.getLogger('multipart').setLevel(logging.WARNING)
|
| 30 |
+
|
| 31 |
+
model = None
|
| 32 |
+
spk = None
|
| 33 |
+
debug = False
|
| 34 |
+
|
| 35 |
+
local_model_root = './trained'
|
| 36 |
+
|
| 37 |
+
cuda = {}
|
| 38 |
+
if torch.cuda.is_available():
|
| 39 |
+
for i in range(torch.cuda.device_count()):
|
| 40 |
+
device_name = torch.cuda.get_device_properties(i).name
|
| 41 |
+
cuda[f"CUDA:{i} {device_name}"] = f"cuda:{i}"
|
| 42 |
+
|
| 43 |
+
def upload_mix_append_file(files,sfiles):
|
| 44 |
+
try:
|
| 45 |
+
if(sfiles is None):
|
| 46 |
+
file_paths = [file.name for file in files]
|
| 47 |
+
else:
|
| 48 |
+
file_paths = [file.name for file in chain(files,sfiles)]
|
| 49 |
+
p = {file:100 for file in file_paths}
|
| 50 |
+
return file_paths,mix_model_output1.update(value=json.dumps(p,indent=2))
|
| 51 |
+
except Exception as e:
|
| 52 |
+
if debug:
|
| 53 |
+
traceback.print_exc()
|
| 54 |
+
raise gr.Error(e)
|
| 55 |
+
|
| 56 |
+
def mix_submit_click(js,mode):
|
| 57 |
+
try:
|
| 58 |
+
assert js.lstrip()!=""
|
| 59 |
+
modes = {"凸组合":0, "线性组合":1}
|
| 60 |
+
mode = modes[mode]
|
| 61 |
+
data = json.loads(js)
|
| 62 |
+
data = list(data.items())
|
| 63 |
+
model_path,mix_rate = zip(*data)
|
| 64 |
+
path = mix_model(model_path,mix_rate,mode)
|
| 65 |
+
return f"成功,文件被保存在了{path}"
|
| 66 |
+
except Exception as e:
|
| 67 |
+
if debug:
|
| 68 |
+
traceback.print_exc()
|
| 69 |
+
raise gr.Error(e)
|
| 70 |
+
|
| 71 |
+
def updata_mix_info(files):
|
| 72 |
+
try:
|
| 73 |
+
if files is None :
|
| 74 |
+
return mix_model_output1.update(value="")
|
| 75 |
+
p = {file.name:100 for file in files}
|
| 76 |
+
return mix_model_output1.update(value=json.dumps(p,indent=2))
|
| 77 |
+
except Exception as e:
|
| 78 |
+
if debug:
|
| 79 |
+
traceback.print_exc()
|
| 80 |
+
raise gr.Error(e)
|
| 81 |
+
|
| 82 |
+
def modelAnalysis(model_path,config_path,cluster_model_path,device,enhance,diff_model_path,diff_config_path,only_diffusion,use_spk_mix,local_model_enabled,local_model_selection):
|
| 83 |
+
global model
|
| 84 |
+
try:
|
| 85 |
+
device = cuda[device] if "CUDA" in device else device
|
| 86 |
+
cluster_filepath = os.path.split(cluster_model_path.name) if cluster_model_path is not None else "no_cluster"
|
| 87 |
+
# get model and config path
|
| 88 |
+
if (local_model_enabled):
|
| 89 |
+
# local path
|
| 90 |
+
model_path = glob.glob(os.path.join(local_model_selection, '*.pth'))[0]
|
| 91 |
+
config_path = glob.glob(os.path.join(local_model_selection, '*.json'))[0]
|
| 92 |
+
else:
|
| 93 |
+
# upload from webpage
|
| 94 |
+
model_path = model_path.name
|
| 95 |
+
config_path = config_path.name
|
| 96 |
+
fr = ".pkl" in cluster_filepath[1]
|
| 97 |
+
model = Svc(model_path,
|
| 98 |
+
config_path,
|
| 99 |
+
device=device if device != "Auto" else None,
|
| 100 |
+
cluster_model_path = cluster_model_path.name if cluster_model_path is not None else "",
|
| 101 |
+
nsf_hifigan_enhance=enhance,
|
| 102 |
+
diffusion_model_path = diff_model_path.name if diff_model_path is not None else "",
|
| 103 |
+
diffusion_config_path = diff_config_path.name if diff_config_path is not None else "",
|
| 104 |
+
shallow_diffusion = True if diff_model_path is not None else False,
|
| 105 |
+
only_diffusion = only_diffusion,
|
| 106 |
+
spk_mix_enable = use_spk_mix,
|
| 107 |
+
feature_retrieval = fr
|
| 108 |
+
)
|
| 109 |
+
spks = list(model.spk2id.keys())
|
| 110 |
+
device_name = torch.cuda.get_device_properties(model.dev).name if "cuda" in str(model.dev) else str(model.dev)
|
| 111 |
+
msg = f"成功加载模型到设备{device_name}上\n"
|
| 112 |
+
if cluster_model_path is None:
|
| 113 |
+
msg += "未加载聚类模型或特征检索模型\n"
|
| 114 |
+
elif fr:
|
| 115 |
+
msg += f"特征检索模型{cluster_filepath[1]}加载成功\n"
|
| 116 |
+
else:
|
| 117 |
+
msg += f"聚类模型{cluster_filepath[1]}加载成功\n"
|
| 118 |
+
if diff_model_path is None:
|
| 119 |
+
msg += "未加载扩散模型\n"
|
| 120 |
+
else:
|
| 121 |
+
msg += f"扩散模型{diff_model_path.name}加载成功\n"
|
| 122 |
+
msg += "当前模型的可用音色:\n"
|
| 123 |
+
for i in spks:
|
| 124 |
+
msg += i + " "
|
| 125 |
+
return sid.update(choices = spks,value=spks[0]), msg
|
| 126 |
+
except Exception as e:
|
| 127 |
+
if debug:
|
| 128 |
+
traceback.print_exc()
|
| 129 |
+
raise gr.Error(e)
|
| 130 |
+
|
| 131 |
+
|
| 132 |
+
def modelUnload():
|
| 133 |
+
global model
|
| 134 |
+
if model is None:
|
| 135 |
+
return sid.update(choices = [],value=""),"没有模型需要卸载!"
|
| 136 |
+
else:
|
| 137 |
+
model.unload_model()
|
| 138 |
+
model = None
|
| 139 |
+
torch.cuda.empty_cache()
|
| 140 |
+
return sid.update(choices = [],value=""),"模型卸载完毕!"
|
| 141 |
+
|
| 142 |
+
def vc_infer(output_format, sid, audio_path, truncated_basename, vc_transform, auto_f0, cluster_ratio, slice_db, noise_scale, pad_seconds, cl_num, lg_num, lgr_num, f0_predictor, enhancer_adaptive_key, cr_threshold, k_step, use_spk_mix, second_encoding, loudness_envelope_adjustment):
|
| 143 |
+
global model
|
| 144 |
+
_audio = model.slice_inference(
|
| 145 |
+
audio_path,
|
| 146 |
+
sid,
|
| 147 |
+
vc_transform,
|
| 148 |
+
slice_db,
|
| 149 |
+
cluster_ratio,
|
| 150 |
+
auto_f0,
|
| 151 |
+
noise_scale,
|
| 152 |
+
pad_seconds,
|
| 153 |
+
cl_num,
|
| 154 |
+
lg_num,
|
| 155 |
+
lgr_num,
|
| 156 |
+
f0_predictor,
|
| 157 |
+
enhancer_adaptive_key,
|
| 158 |
+
cr_threshold,
|
| 159 |
+
k_step,
|
| 160 |
+
use_spk_mix,
|
| 161 |
+
second_encoding,
|
| 162 |
+
loudness_envelope_adjustment
|
| 163 |
+
)
|
| 164 |
+
model.clear_empty()
|
| 165 |
+
#构建保存文件的路径,并保存到results文件夹内
|
| 166 |
+
str(int(time.time()))
|
| 167 |
+
if not os.path.exists("results"):
|
| 168 |
+
os.makedirs("results")
|
| 169 |
+
key = "auto" if auto_f0 else f"{int(vc_transform)}key"
|
| 170 |
+
cluster = "_" if cluster_ratio == 0 else f"_{cluster_ratio}_"
|
| 171 |
+
isdiffusion = "sovits"
|
| 172 |
+
if model.shallow_diffusion:
|
| 173 |
+
isdiffusion = "sovdiff"
|
| 174 |
+
|
| 175 |
+
if model.only_diffusion:
|
| 176 |
+
isdiffusion = "diff"
|
| 177 |
+
|
| 178 |
+
output_file_name = 'result_'+truncated_basename+f'_{sid}_{key}{cluster}{isdiffusion}.{output_format}'
|
| 179 |
+
output_file = os.path.join("results", output_file_name)
|
| 180 |
+
soundfile.write(output_file, _audio, model.target_sample, format=output_format)
|
| 181 |
+
return output_file
|
| 182 |
+
|
| 183 |
+
def vc_fn(sid, input_audio, output_format, vc_transform, auto_f0,cluster_ratio, slice_db, noise_scale,pad_seconds,cl_num,lg_num,lgr_num,f0_predictor,enhancer_adaptive_key,cr_threshold,k_step,use_spk_mix,second_encoding,loudness_envelope_adjustment):
|
| 184 |
+
global model
|
| 185 |
+
try:
|
| 186 |
+
if input_audio is None:
|
| 187 |
+
return "You need to upload an audio", None
|
| 188 |
+
if model is None:
|
| 189 |
+
return "You need to upload an model", None
|
| 190 |
+
if getattr(model, 'cluster_model', None) is None and model.feature_retrieval is False:
|
| 191 |
+
if cluster_ratio != 0:
|
| 192 |
+
return "You need to upload an cluster model or feature retrieval model before assigning cluster ratio!", None
|
| 193 |
+
#print(input_audio)
|
| 194 |
+
audio, sampling_rate = soundfile.read(input_audio)
|
| 195 |
+
#print(audio.shape,sampling_rate)
|
| 196 |
+
if np.issubdtype(audio.dtype, np.integer):
|
| 197 |
+
audio = (audio / np.iinfo(audio.dtype).max).astype(np.float32)
|
| 198 |
+
#print(audio.dtype)
|
| 199 |
+
if len(audio.shape) > 1:
|
| 200 |
+
audio = librosa.to_mono(audio.transpose(1, 0))
|
| 201 |
+
# 未知原因Gradio上传的filepath会有一个奇怪的固定后缀,这里去掉
|
| 202 |
+
truncated_basename = Path(input_audio).stem[:-6]
|
| 203 |
+
processed_audio = os.path.join("raw", f"{truncated_basename}.wav")
|
| 204 |
+
soundfile.write(processed_audio, audio, sampling_rate, format="wav")
|
| 205 |
+
output_file = vc_infer(output_format, sid, processed_audio, truncated_basename, vc_transform, auto_f0, cluster_ratio, slice_db, noise_scale, pad_seconds, cl_num, lg_num, lgr_num, f0_predictor, enhancer_adaptive_key, cr_threshold, k_step, use_spk_mix, second_encoding, loudness_envelope_adjustment)
|
| 206 |
+
|
| 207 |
+
return "Success", output_file
|
| 208 |
+
except Exception as e:
|
| 209 |
+
if debug:
|
| 210 |
+
traceback.print_exc()
|
| 211 |
+
raise gr.Error(e)
|
| 212 |
+
|
| 213 |
+
def text_clear(text):
|
| 214 |
+
return re.sub(r"[\n\,\(\) ]", "", text)
|
| 215 |
+
|
| 216 |
+
def vc_fn2(_text, _lang, _gender, _rate, _volume, sid, output_format, vc_transform, auto_f0,cluster_ratio, slice_db, noise_scale,pad_seconds,cl_num,lg_num,lgr_num,f0_predictor,enhancer_adaptive_key,cr_threshold, k_step,use_spk_mix,second_encoding,loudness_envelope_adjustment):
|
| 217 |
+
global model
|
| 218 |
+
try:
|
| 219 |
+
if model is None:
|
| 220 |
+
return "You need to upload an model", None
|
| 221 |
+
if getattr(model, 'cluster_model', None) is None and model.feature_retrieval is False:
|
| 222 |
+
if cluster_ratio != 0:
|
| 223 |
+
return "You need to upload an cluster model or feature retrieval model before assigning cluster ratio!", None
|
| 224 |
+
_rate = f"+{int(_rate*100)}%" if _rate >= 0 else f"{int(_rate*100)}%"
|
| 225 |
+
_volume = f"+{int(_volume*100)}%" if _volume >= 0 else f"{int(_volume*100)}%"
|
| 226 |
+
if _lang == "Auto":
|
| 227 |
+
_gender = "Male" if _gender == "男" else "Female"
|
| 228 |
+
subprocess.run([sys.executable, "edgetts/tts.py", _text, _lang, _rate, _volume, _gender])
|
| 229 |
+
else:
|
| 230 |
+
subprocess.run([sys.executable, "edgetts/tts.py", _text, _lang, _rate, _volume])
|
| 231 |
+
target_sr = 44100
|
| 232 |
+
y, sr = librosa.load("tts.wav")
|
| 233 |
+
resampled_y = librosa.resample(y, orig_sr=sr, target_sr=target_sr)
|
| 234 |
+
soundfile.write("tts.wav", resampled_y, target_sr, subtype = "PCM_16")
|
| 235 |
+
input_audio = "tts.wav"
|
| 236 |
+
#audio, _ = soundfile.read(input_audio)
|
| 237 |
+
output_file_path = vc_infer(output_format, sid, input_audio, "tts", vc_transform, auto_f0, cluster_ratio, slice_db, noise_scale, pad_seconds, cl_num, lg_num, lgr_num, f0_predictor, enhancer_adaptive_key, cr_threshold, k_step, use_spk_mix, second_encoding, loudness_envelope_adjustment)
|
| 238 |
+
os.remove("tts.wav")
|
| 239 |
+
return "Success", output_file_path
|
| 240 |
+
except Exception as e:
|
| 241 |
+
if debug: traceback.print_exc() # noqa: E701
|
| 242 |
+
raise gr.Error(e)
|
| 243 |
+
|
| 244 |
+
def model_compression(_model):
|
| 245 |
+
if _model == "":
|
| 246 |
+
return "请先选择要压缩的模型"
|
| 247 |
+
else:
|
| 248 |
+
model_path = os.path.split(_model.name)
|
| 249 |
+
filename, extension = os.path.splitext(model_path[1])
|
| 250 |
+
output_model_name = f"{filename}_compressed{extension}"
|
| 251 |
+
output_path = os.path.join(os.getcwd(), output_model_name)
|
| 252 |
+
removeOptimizer(_model.name, output_path)
|
| 253 |
+
return f"模型已成功被保存在了{output_path}"
|
| 254 |
+
|
| 255 |
+
def scan_local_models():
|
| 256 |
+
res = []
|
| 257 |
+
candidates = glob.glob(os.path.join(local_model_root, '**', '*.json'), recursive=True)
|
| 258 |
+
candidates = set([os.path.dirname(c) for c in candidates])
|
| 259 |
+
for candidate in candidates:
|
| 260 |
+
jsons = glob.glob(os.path.join(candidate, '*.json'))
|
| 261 |
+
pths = glob.glob(os.path.join(candidate, '*.pth'))
|
| 262 |
+
if (len(jsons) == 1 and len(pths) == 1):
|
| 263 |
+
# must contain exactly one json and one pth file
|
| 264 |
+
res.append(candidate)
|
| 265 |
+
return res
|
| 266 |
+
|
| 267 |
+
def local_model_refresh_fn():
|
| 268 |
+
choices = scan_local_models()
|
| 269 |
+
return gr.Dropdown.update(choices=choices)
|
| 270 |
+
|
| 271 |
+
def debug_change():
|
| 272 |
+
global debug
|
| 273 |
+
debug = debug_button.value
|
| 274 |
+
|
| 275 |
+
with gr.Blocks(
|
| 276 |
+
theme=gr.themes.Base(
|
| 277 |
+
primary_hue = gr.themes.colors.green,
|
| 278 |
+
font=["Source Sans Pro", "Arial", "sans-serif"],
|
| 279 |
+
font_mono=['JetBrains mono', "Consolas", 'Courier New']
|
| 280 |
+
),
|
| 281 |
+
) as app:
|
| 282 |
+
with gr.Tabs():
|
| 283 |
+
with gr.TabItem("推理"):
|
| 284 |
+
gr.Markdown(value="""
|
| 285 |
+
So-vits-svc 4.0 推理 webui
|
| 286 |
+
""")
|
| 287 |
+
with gr.Row(variant="panel"):
|
| 288 |
+
with gr.Column():
|
| 289 |
+
gr.Markdown(value="""
|
| 290 |
+
<font size=2> 模型设置</font>
|
| 291 |
+
""")
|
| 292 |
+
with gr.Tabs():
|
| 293 |
+
# invisible checkbox that tracks tab status
|
| 294 |
+
local_model_enabled = gr.Checkbox(value=False, visible=False)
|
| 295 |
+
with gr.TabItem('上传') as local_model_tab_upload:
|
| 296 |
+
with gr.Row():
|
| 297 |
+
model_path = gr.File(label="选择模型文件")
|
| 298 |
+
config_path = gr.File(label="选择配置文件")
|
| 299 |
+
with gr.TabItem('本地') as local_model_tab_local:
|
| 300 |
+
gr.Markdown(f'模型应当放置于{local_model_root}文件夹下')
|
| 301 |
+
local_model_refresh_btn = gr.Button('刷新本地模型列表')
|
| 302 |
+
local_model_selection = gr.Dropdown(label='选择模型文件夹', choices=[], interactive=True)
|
| 303 |
+
with gr.Row():
|
| 304 |
+
diff_model_path = gr.File(label="选择扩散模型文件")
|
| 305 |
+
diff_config_path = gr.File(label="选择扩散模型配置文件")
|
| 306 |
+
cluster_model_path = gr.File(label="选择聚类模型或特征检索文件(没有可以不选)")
|
| 307 |
+
device = gr.Dropdown(label="推理设备,默认为自动选择CPU和GPU", choices=["Auto",*cuda.keys(),"cpu"], value="Auto")
|
| 308 |
+
enhance = gr.Checkbox(label="是否使用NSF_HIFIGAN增强,该选项对部分训练集少的模型有一定的音质增强效果,但是对训练好的模型有反面效果,默认关闭", value=False)
|
| 309 |
+
only_diffusion = gr.Checkbox(label="是否使用全扩散推理,开启后将不使用So-VITS模型,仅使用扩散模型进行完整扩散推理,默认关闭", value=False)
|
| 310 |
+
with gr.Column():
|
| 311 |
+
gr.Markdown(value="""
|
| 312 |
+
<font size=3>左侧文件全部选择完毕后(全部文件模块显示download),点击“加载模型”进行解析:</font>
|
| 313 |
+
""")
|
| 314 |
+
model_load_button = gr.Button(value="加载模型", variant="primary")
|
| 315 |
+
model_unload_button = gr.Button(value="卸载模型", variant="primary")
|
| 316 |
+
sid = gr.Dropdown(label="音色(说话人)")
|
| 317 |
+
sid_output = gr.Textbox(label="Output Message")
|
| 318 |
+
|
| 319 |
+
|
| 320 |
+
with gr.Row(variant="panel"):
|
| 321 |
+
with gr.Column():
|
| 322 |
+
gr.Markdown(value="""
|
| 323 |
+
<font size=2> 推理设置</font>
|
| 324 |
+
""")
|
| 325 |
+
auto_f0 = gr.Checkbox(label="自动f0预测,配合聚类模型f0预测效果更好,会导致变调功能失效(仅限转换语音,歌声勾选此项会究极跑调)", value=False)
|
| 326 |
+
f0_predictor = gr.Dropdown(label="选择F0预测器,可选择crepe,pm,dio,harvest,rmvpe,默认为pm(注意:crepe为原F0使用均值滤波器)", choices=["pm","dio","harvest","crepe","rmvpe"], value="pm")
|
| 327 |
+
vc_transform = gr.Number(label="变调(整数,可以正负,半音数量,升高八度就是12)", value=0)
|
| 328 |
+
cluster_ratio = gr.Number(label="聚类模型/特征检索混合比例,0-1之间,0即不启用聚类/特征检索。使用聚类/特征检索能提升音色相似度,但会导致咬字下降(如果使用建议0.5左右)", value=0)
|
| 329 |
+
slice_db = gr.Number(label="切片阈值", value=-40)
|
| 330 |
+
output_format = gr.Radio(label="音频输出格式", choices=["wav", "flac", "mp3"], value = "wav")
|
| 331 |
+
noise_scale = gr.Number(label="noise_scale 建议不要动,会影响音质,玄学参数", value=0.4)
|
| 332 |
+
k_step = gr.Slider(label="浅扩散步数,只有使用了扩散模型才有效,步数越大越接近扩散模型的结果", value=100, minimum = 1, maximum = 1000)
|
| 333 |
+
with gr.Column():
|
| 334 |
+
pad_seconds = gr.Number(label="推理音频pad秒数,由于未知原因开头结尾会有异响,pad一小段静音段后就不会出现", value=0.5)
|
| 335 |
+
cl_num = gr.Number(label="音频自动切片,0为不切片,单位为秒(s)", value=0)
|
| 336 |
+
lg_num = gr.Number(label="两端音频切片的交叉淡入长度,如果自动切片后出现人声不连贯可调整该数值,如果连贯建议采用默认值0,注意,该设置会影响推理速度,单位为秒/s", value=0)
|
| 337 |
+
lgr_num = gr.Number(label="自动音频切片后,需要舍弃每段切片的头尾。该参数设置交叉长度保留的比例,范围0-1,左开右闭", value=0.75)
|
| 338 |
+
enhancer_adaptive_key = gr.Number(label="使增强器适应更高的音域(单位为半音数)|默认为0", value=0)
|
| 339 |
+
cr_threshold = gr.Number(label="F0过滤阈值,只有启动crepe时有效. 数值范围从0-1. 降低该值可减少跑调概率,但会增加哑音", value=0.05)
|
| 340 |
+
loudness_envelope_adjustment = gr.Number(label="输入源响度包络替换输出响度包络融合比例,越靠近1越使用输出响度包络", value = 0)
|
| 341 |
+
second_encoding = gr.Checkbox(label = "二次编码,浅扩散前会对原始音频进行二次编码,玄学选项,效果时好时差,默认关闭", value=False)
|
| 342 |
+
use_spk_mix = gr.Checkbox(label = "动态声线融合", value = False, interactive = False)
|
| 343 |
+
with gr.Tabs():
|
| 344 |
+
with gr.TabItem("音频转音频"):
|
| 345 |
+
vc_input3 = gr.Audio(label="选择音频", type="filepath")
|
| 346 |
+
vc_submit = gr.Button("音频转换", variant="primary")
|
| 347 |
+
with gr.TabItem("文字转音频"):
|
| 348 |
+
text2tts=gr.Textbox(label="在此输入要转译的文字。注意,使用该功能建议打开F0预测,不然会很怪")
|
| 349 |
+
with gr.Row():
|
| 350 |
+
tts_gender = gr.Radio(label = "说话人性别", choices = ["男","女"], value = "男")
|
| 351 |
+
tts_lang = gr.Dropdown(label = "选择语言,Auto为根据输入文字自动识别", choices=SUPPORTED_LANGUAGES, value = "Auto")
|
| 352 |
+
tts_rate = gr.Slider(label = "TTS语音变速(倍速相对值)", minimum = -1, maximum = 3, value = 0, step = 0.1)
|
| 353 |
+
tts_volume = gr.Slider(label = "TTS语音音量(相对值)", minimum = -1, maximum = 1.5, value = 0, step = 0.1)
|
| 354 |
+
vc_submit2 = gr.Button("文字转换", variant="primary")
|
| 355 |
+
with gr.Row():
|
| 356 |
+
with gr.Column():
|
| 357 |
+
vc_output1 = gr.Textbox(label="Output Message")
|
| 358 |
+
with gr.Column():
|
| 359 |
+
vc_output2 = gr.Audio(label="Output Audio", interactive=False)
|
| 360 |
+
|
| 361 |
+
with gr.TabItem("小工具/实验室特性"):
|
| 362 |
+
gr.Markdown(value="""
|
| 363 |
+
<font size=2> So-vits-svc 4.0 小工具/实验室特性</font>
|
| 364 |
+
""")
|
| 365 |
+
with gr.Tabs():
|
| 366 |
+
with gr.TabItem("静态声线融合"):
|
| 367 |
+
gr.Markdown(value="""
|
| 368 |
+
<font size=2> 介绍:该功能可以将多个声音模型合成为一个声音模型(多个模型参数的凸组合或线性组合),从而制造出现实中不存在的声线
|
| 369 |
+
注意:
|
| 370 |
+
1.该功能仅支持单说话人的模型
|
| 371 |
+
2.如果强行使用多说话人模型,需要保证多个模型的说话人数量相同,这样可以混合同一个SpaekerID下的声音
|
| 372 |
+
3.保证所有待混合模型的config.json中的model字段是相同的
|
| 373 |
+
4.输出的混合模型可以使用待合成模型的任意一个config.json,但聚类模型将不能使用
|
| 374 |
+
5.批量上传模型��时候最好把模型放到一个文件夹选中后一起上传
|
| 375 |
+
6.混合比例调整建议大小在0-100之间,也可以调为其他数字,但在线性组合模式下会出现未知的效果
|
| 376 |
+
7.混合完毕后,文件将会保存在项目根目录中,文件名为output.pth
|
| 377 |
+
8.凸组合模式会将混合比例执行Softmax使混合比例相加为1,而线性组合模式不会
|
| 378 |
+
</font>
|
| 379 |
+
""")
|
| 380 |
+
mix_model_path = gr.Files(label="选择需要混合模型文件")
|
| 381 |
+
mix_model_upload_button = gr.UploadButton("选择/追加需要混合模型文件", file_count="multiple")
|
| 382 |
+
mix_model_output1 = gr.Textbox(
|
| 383 |
+
label="混合比例调整,单位/%",
|
| 384 |
+
interactive = True
|
| 385 |
+
)
|
| 386 |
+
mix_mode = gr.Radio(choices=["凸组合", "线性组合"], label="融合模式",value="凸组合",interactive = True)
|
| 387 |
+
mix_submit = gr.Button("声线融合启动", variant="primary")
|
| 388 |
+
mix_model_output2 = gr.Textbox(
|
| 389 |
+
label="Output Message"
|
| 390 |
+
)
|
| 391 |
+
mix_model_path.change(updata_mix_info,[mix_model_path],[mix_model_output1])
|
| 392 |
+
mix_model_upload_button.upload(upload_mix_append_file, [mix_model_upload_button,mix_model_path], [mix_model_path,mix_model_output1])
|
| 393 |
+
mix_submit.click(mix_submit_click, [mix_model_output1,mix_mode], [mix_model_output2])
|
| 394 |
+
|
| 395 |
+
with gr.TabItem("模型压缩工具"):
|
| 396 |
+
gr.Markdown(value="""
|
| 397 |
+
该工具可以实现对模型的体积压缩,在**不影响模型推理功能**的情况下,将原本约600M的So-VITS模型压缩至约200M, 大大减少了硬盘的压力。
|
| 398 |
+
**注意:压缩后的模型将无法继续训练,请在确认封炉后再压缩。**
|
| 399 |
+
""")
|
| 400 |
+
model_to_compress = gr.File(label="模型上传")
|
| 401 |
+
compress_model_btn = gr.Button("压缩模型", variant="primary")
|
| 402 |
+
compress_model_output = gr.Textbox(label="输出信息", value="")
|
| 403 |
+
|
| 404 |
+
compress_model_btn.click(model_compression, [model_to_compress], [compress_model_output])
|
| 405 |
+
|
| 406 |
+
|
| 407 |
+
with gr.Tabs():
|
| 408 |
+
with gr.Row(variant="panel"):
|
| 409 |
+
with gr.Column():
|
| 410 |
+
gr.Markdown(value="""
|
| 411 |
+
<font size=2> WebUI设置</font>
|
| 412 |
+
""")
|
| 413 |
+
debug_button = gr.Checkbox(label="Debug模式,如果向社区反馈BUG需要打开,打开后控制台可以显示具体错误提示", value=debug)
|
| 414 |
+
# refresh local model list
|
| 415 |
+
local_model_refresh_btn.click(local_model_refresh_fn, outputs=local_model_selection)
|
| 416 |
+
# set local enabled/disabled on tab switch
|
| 417 |
+
local_model_tab_upload.select(lambda: False, outputs=local_model_enabled)
|
| 418 |
+
local_model_tab_local.select(lambda: True, outputs=local_model_enabled)
|
| 419 |
+
|
| 420 |
+
vc_submit.click(vc_fn, [sid, vc_input3, output_format, vc_transform,auto_f0,cluster_ratio, slice_db, noise_scale,pad_seconds,cl_num,lg_num,lgr_num,f0_predictor,enhancer_adaptive_key,cr_threshold,k_step,use_spk_mix,second_encoding,loudness_envelope_adjustment], [vc_output1, vc_output2])
|
| 421 |
+
vc_submit2.click(vc_fn2, [text2tts, tts_lang, tts_gender, tts_rate, tts_volume, sid, output_format, vc_transform,auto_f0,cluster_ratio, slice_db, noise_scale,pad_seconds,cl_num,lg_num,lgr_num,f0_predictor,enhancer_adaptive_key,cr_threshold,k_step,use_spk_mix,second_encoding,loudness_envelope_adjustment], [vc_output1, vc_output2])
|
| 422 |
+
|
| 423 |
+
debug_button.change(debug_change,[],[])
|
| 424 |
+
model_load_button.click(modelAnalysis,[model_path,config_path,cluster_model_path,device,enhance,diff_model_path,diff_config_path,only_diffusion,use_spk_mix,local_model_enabled,local_model_selection],[sid,sid_output])
|
| 425 |
+
model_unload_button.click(modelUnload,[],[sid,sid_output])
|
| 426 |
+
os.system("start http://127.0.0.1:7860")
|
| 427 |
+
app.launch()
|
| 428 |
+
|
| 429 |
+
|
| 430 |
+
|