
Commit
·
e6e7a99
1
Parent(s):
17f1353
init
Browse files- .env +6 -0
- .gitattributes +2 -0
- .gitignore +2 -0
- README.md +2 -2
- app.py +228 -0
- data/bitcoin.pdf +0 -0
- data/doctest.txt +3 -0
- models/dolphin-2.1-mistral-7b.Q4_K_S.gguf +3 -0
- models/hkunlp_instructor-base/.gitattributes +34 -0
- models/hkunlp_instructor-base/1_Pooling/config.json +9 -0
- models/hkunlp_instructor-base/2_Dense/config.json +1 -0
- models/hkunlp_instructor-base/2_Dense/pytorch_model.bin +3 -0
- models/hkunlp_instructor-base/README.md +2610 -0
- models/hkunlp_instructor-base/config.json +60 -0
- models/hkunlp_instructor-base/config_sentence_transformers.json +7 -0
- models/hkunlp_instructor-base/modules.json +26 -0
- models/hkunlp_instructor-base/pytorch_model.bin +3 -0
- models/hkunlp_instructor-base/sentence_bert_config.json +4 -0
- models/hkunlp_instructor-base/special_tokens_map.json +107 -0
- models/hkunlp_instructor-base/spiece.model +3 -0
- models/hkunlp_instructor-base/tokenizer.json +0 -0
- models/hkunlp_instructor-base/tokenizer_config.json +112 -0
- requirements.txt +18 -0
- ressources/LLM_ONLY.png +0 -0
- ressources/LLM_RAG_DATABASE.png +0 -0
- ressources/Upload_File_QA.png +0 -0
.env
ADDED
|
@@ -0,0 +1,6 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
CUDA_VISIBLE_DEVICES=0
|
| 2 |
+
FORCE_CMAKE=1
|
| 3 |
+
CMAKE_ARGS="-DLLAMA_CUBLAS=on"
|
| 4 |
+
no_proxy=localhost,127.0.0.1
|
| 5 |
+
OPENAI_API_KEY=NOONEEED
|
| 6 |
+
OPENAI_API_BASE=http://localhost:1300/v1
|
.gitattributes
CHANGED
|
@@ -33,3 +33,5 @@ saved_model/**/* filter=lfs diff=lfs merge=lfs -text
|
|
| 33 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
|
|
|
|
|
|
|
|
| 33 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
| 36 |
+
models/hkunlp_instructor-base/*gguf filter=lfs diff=lfs merge=lfs -text
|
| 37 |
+
models/*gguf filter=lfs diff=lfs merge=lfs -text
|
.gitignore
ADDED
|
@@ -0,0 +1,2 @@
|
|
|
|
|
|
|
|
|
|
| 1 |
+
/draft_docs
|
| 2 |
+
short_memory.txt
|
README.md
CHANGED
|
@@ -1,7 +1,7 @@
|
|
| 1 |
---
|
| 2 |
title: Llama Index Docs Spaces
|
| 3 |
-
emoji:
|
| 4 |
-
colorFrom:
|
| 5 |
colorTo: indigo
|
| 6 |
sdk: streamlit
|
| 7 |
sdk_version: 1.28.2
|
|
|
|
| 1 |
---
|
| 2 |
title: Llama Index Docs Spaces
|
| 3 |
+
emoji: 🌍
|
| 4 |
+
colorFrom: purple
|
| 5 |
colorTo: indigo
|
| 6 |
sdk: streamlit
|
| 7 |
sdk_version: 1.28.2
|
app.py
ADDED
|
@@ -0,0 +1,228 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# --------------------------------libraries-----------------------------------
|
| 2 |
+
|
| 3 |
+
import streamlit as st
|
| 4 |
+
#import torch
|
| 5 |
+
import os
|
| 6 |
+
import logging
|
| 7 |
+
import sys
|
| 8 |
+
from llama_index.callbacks import CallbackManager, LlamaDebugHandler
|
| 9 |
+
from llama_index.llms import LlamaCPP
|
| 10 |
+
from llama_index.llms.llama_utils import messages_to_prompt, completion_to_prompt
|
| 11 |
+
from llama_index.embeddings import InstructorEmbedding
|
| 12 |
+
from llama_index import ServiceContext, VectorStoreIndex, SimpleDirectoryReader
|
| 13 |
+
from tqdm.notebook import tqdm
|
| 14 |
+
from dotenv import load_dotenv
|
| 15 |
+
|
| 16 |
+
# --------------------------------env variables-----------------------------------
|
| 17 |
+
|
| 18 |
+
# Load environment variables
|
| 19 |
+
load_dotenv(dotenv_path=".env")
|
| 20 |
+
|
| 21 |
+
no_proxy = os.getenv("no_proxy")
|
| 22 |
+
OPENAI_API_KEY = os.getenv("OPENAI_API_KEY")
|
| 23 |
+
OPENAI_API_BASE = os.getenv("OPENAI_API_BASE")
|
| 24 |
+
|
| 25 |
+
# --------------------------------cache LLM-----------------------------------
|
| 26 |
+
|
| 27 |
+
logging.basicConfig(stream=sys.stdout, level=logging.INFO)
|
| 28 |
+
logging.getLogger().addHandler(logging.StreamHandler(stream=sys.stdout))
|
| 29 |
+
llama_debug = LlamaDebugHandler(print_trace_on_end=True)
|
| 30 |
+
callback_manager = CallbackManager([llama_debug])
|
| 31 |
+
# LLM
|
| 32 |
+
@st.cache_resource
|
| 33 |
+
def load_llm_model():
|
| 34 |
+
if not os.path.exists("models"):
|
| 35 |
+
st.error("models directory does not exist. Please download and copy paste a model in folder models.")
|
| 36 |
+
os.makedirs("models")
|
| 37 |
+
return None #
|
| 38 |
+
llm = LlamaCPP(
|
| 39 |
+
#model_url="https://huggingface.co/TheBloke/Llama-2-13B-chat-GGUF/resolve/main/llama-2-13b-chat.Q5_K_M.gguf",
|
| 40 |
+
model_path="models/dolphin-2.1-mistral-7b.Q4_K_S.gguf",
|
| 41 |
+
temperature=0.0,
|
| 42 |
+
max_new_tokens=100,
|
| 43 |
+
context_window=1024,
|
| 44 |
+
generate_kwargs={},
|
| 45 |
+
model_kwargs={"n_gpu_layers": 20},
|
| 46 |
+
messages_to_prompt=messages_to_prompt,
|
| 47 |
+
completion_to_prompt=completion_to_prompt,
|
| 48 |
+
verbose=True,
|
| 49 |
+
)
|
| 50 |
+
return llm
|
| 51 |
+
|
| 52 |
+
llm = load_llm_model()
|
| 53 |
+
|
| 54 |
+
# --------------------------------cache Embedding model-----------------------------------
|
| 55 |
+
|
| 56 |
+
@st.cache_resource
|
| 57 |
+
def load_emb_model():
|
| 58 |
+
if not os.path.exists("data"):
|
| 59 |
+
st.error("Data directory does not exist. Please upload the data.")
|
| 60 |
+
os.makedirs("data")
|
| 61 |
+
return None #
|
| 62 |
+
embed_model_inst = InstructorEmbedding("models/hkunlp_instructor-base"
|
| 63 |
+
#model_name="hkunlp/instructor-base"
|
| 64 |
+
)
|
| 65 |
+
service_context = ServiceContext.from_defaults(embed_model=embed_model_inst, llm=llm)
|
| 66 |
+
documents = SimpleDirectoryReader("data").load_data()
|
| 67 |
+
print(f"Number of documents: {len(documents)}")
|
| 68 |
+
index = VectorStoreIndex.from_documents(
|
| 69 |
+
documents, service_context=service_context, show_progress=True)
|
| 70 |
+
return index.as_query_engine()
|
| 71 |
+
|
| 72 |
+
query_engine = load_emb_model()
|
| 73 |
+
|
| 74 |
+
# ------------------------------------layout----------------------------------------
|
| 75 |
+
|
| 76 |
+
with st.sidebar:
|
| 77 |
+
api_server_info = st.text_input("Local LLM API server", OPENAI_API_BASE ,key="openai_api_base")
|
| 78 |
+
st.title("🤖 Llama Index 📚")
|
| 79 |
+
if st.button('Clear Memory'):
|
| 80 |
+
st.session_state.memory = ""
|
| 81 |
+
st.write("Local LLM API server in this demo is useles, we are loading local model using llama_index integration of llama cpp")
|
| 82 |
+
st.write("🚀 This app allows you to chat with local LLM using api server or loaded in cache")
|
| 83 |
+
st.subheader("💻 System Requirements: ")
|
| 84 |
+
st.markdown("- CPU: the faster the better ")
|
| 85 |
+
st.markdown("- RAM: 16 GB or higher")
|
| 86 |
+
st.markdown("- GPU: optional but very useful for Cuda acceleration")
|
| 87 |
+
st.subheader("Developer Information:")
|
| 88 |
+
st.write("This app is developed and maintained by **@mohcineelharras**")
|
| 89 |
+
|
| 90 |
+
# Define your app's tabs
|
| 91 |
+
tab1, tab2, tab3 = st.tabs(["LLM only", "LLM RAG QA with database", "One single document Q&A"])
|
| 92 |
+
|
| 93 |
+
# -----------------------------------LLM only---------------------------------------------
|
| 94 |
+
if 'memory' not in st.session_state:
|
| 95 |
+
st.session_state.memory = ""
|
| 96 |
+
#token_count = 0
|
| 97 |
+
with tab1:
|
| 98 |
+
st.title("💬 LLM only")
|
| 99 |
+
prompt = st.text_input(
|
| 100 |
+
"Ask your question here",
|
| 101 |
+
placeholder="Who is Lionel Messi",
|
| 102 |
+
)
|
| 103 |
+
template = (
|
| 104 |
+
"system\n"
|
| 105 |
+
"You are Dolphin, a helpful AI assistant. Your responses should be based solely on the content of documents you have access to. "
|
| 106 |
+
"Do not provide information that is not contained in the documents. "
|
| 107 |
+
"If a question is asked about content not in the documents, respond with 'I do not have that information.' "
|
| 108 |
+
"Always respond in the same language as the question was asked. Be concise.\n"
|
| 109 |
+
"user\n"
|
| 110 |
+
"{prompt}\n"
|
| 111 |
+
"assistant\n"
|
| 112 |
+
)
|
| 113 |
+
if prompt:
|
| 114 |
+
contextual_prompt = st.session_state.memory + "\n" + prompt
|
| 115 |
+
formatted_prompt = template.format(prompt=contextual_prompt)
|
| 116 |
+
|
| 117 |
+
response = llm.complete(formatted_prompt,max_tokens=100, temperature=0, top_p=0.95, top_k=10)
|
| 118 |
+
#print(response)
|
| 119 |
+
text_response = response
|
| 120 |
+
#---------------------------------------------
|
| 121 |
+
# text_response = response["choices"][0]["text"]
|
| 122 |
+
# token_count += response["usage"]["total_tokens"]
|
| 123 |
+
# st.write("LLM's Response:\n", text_response)
|
| 124 |
+
# st.write("Token count:\n", token_count)
|
| 125 |
+
#---------------------------------------------
|
| 126 |
+
st.write("LLM's Response:\n",text_response)
|
| 127 |
+
st.session_state.memory = f"Prompt: {contextual_prompt}\nResponse:\n {text_response}"
|
| 128 |
+
#st.write("Memory:\n", memory)
|
| 129 |
+
with open("short_memory.txt", 'w') as file:
|
| 130 |
+
file.write(st.session_state.memory)
|
| 131 |
+
|
| 132 |
+
# -----------------------------------LLM Q&A-------------------------------------------------
|
| 133 |
+
|
| 134 |
+
with tab2:
|
| 135 |
+
st.title("💬 LLM RAG QA with database")
|
| 136 |
+
st.write("To consult files that are available in the database, go to https://huggingface.co/spaces/mohcineelharras/llama-index-docs-spaces/blob/main/data")
|
| 137 |
+
prompt = st.text_input(
|
| 138 |
+
"Ask your question here",
|
| 139 |
+
placeholder="How does the blockchain work ?",
|
| 140 |
+
)
|
| 141 |
+
if prompt:
|
| 142 |
+
response = query_engine.query(prompt)
|
| 143 |
+
st.write("Your prompt: ", prompt)
|
| 144 |
+
st.write("LLM's Response:\n"+ response.response)
|
| 145 |
+
with st.expander("Document Similarity Search"):
|
| 146 |
+
for i, node in enumerate(response.source_nodes):
|
| 147 |
+
dict_source_i = node.node.metadata
|
| 148 |
+
dict_source_i.update({"Text":node.node.text})
|
| 149 |
+
st.write("Source n°"+str(i+1), dict_source_i)
|
| 150 |
+
st.write()
|
| 151 |
+
|
| 152 |
+
# -----------------------------------Upload File Q&A-----------------------------------------
|
| 153 |
+
|
| 154 |
+
def load_emb_uploaded_document(filename):
|
| 155 |
+
# You may want to add a check to prevent execution during initialization.
|
| 156 |
+
if 'init' in st.session_state:
|
| 157 |
+
embed_model_inst = InstructorEmbedding("models/hkunlp_instructor-base")
|
| 158 |
+
service_context = ServiceContext.from_defaults(embed_model=embed_model_inst, llm=llm)
|
| 159 |
+
documents = SimpleDirectoryReader(input_files=[filename]).load_data()
|
| 160 |
+
index = VectorStoreIndex.from_documents(
|
| 161 |
+
documents, service_context=service_context, show_progress=True)
|
| 162 |
+
return index.as_query_engine()
|
| 163 |
+
return None
|
| 164 |
+
|
| 165 |
+
with tab3:
|
| 166 |
+
st.title("📝 One single document Q&A with Llama Index using local open llms")
|
| 167 |
+
uploaded_file = st.file_uploader("Upload an File", type=("txt", "csv", "md","pdf"))
|
| 168 |
+
question = st.text_input(
|
| 169 |
+
"Ask something about the files",
|
| 170 |
+
placeholder="Can you give me a short summary?",
|
| 171 |
+
disabled=not uploaded_file,
|
| 172 |
+
)
|
| 173 |
+
|
| 174 |
+
if 'init' not in st.session_state:
|
| 175 |
+
st.session_state.init = True
|
| 176 |
+
|
| 177 |
+
if uploaded_file:
|
| 178 |
+
if not os.path.exists("draft_docs"):
|
| 179 |
+
st.error("draft_docs directory does not exist. Please download and copy paste a model in folder models.")
|
| 180 |
+
os.makedirs("draft_docs")
|
| 181 |
+
|
| 182 |
+
with open("draft_docs/"+uploaded_file.name, "wb") as f:
|
| 183 |
+
text = uploaded_file.read()
|
| 184 |
+
f.write(text)
|
| 185 |
+
text = uploaded_file.read()
|
| 186 |
+
# if load_emb_uploaded_document:
|
| 187 |
+
# load_emb_uploaded_document.clear()
|
| 188 |
+
#load_emb_uploaded_document.clear()
|
| 189 |
+
query_engine = load_emb_uploaded_document("draft_docs/"+uploaded_file.name)
|
| 190 |
+
st.write("File ",uploaded_file.name, "was loaded successfully")
|
| 191 |
+
|
| 192 |
+
if uploaded_file and question and api_server_info:
|
| 193 |
+
response = prompt = f"""Based on the context presented. Respond to the question below to the best of your ability.
|
| 194 |
+
\n\n{question}"""
|
| 195 |
+
response = query_engine.query(prompt)
|
| 196 |
+
st.write("### Answer")
|
| 197 |
+
st.write(response.response)
|
| 198 |
+
with st.expander("Document Similarity Search"):
|
| 199 |
+
#st.write(len(response.source_nodes))
|
| 200 |
+
for i, node in enumerate(response.source_nodes):
|
| 201 |
+
dict_source_i = node.node.metadata
|
| 202 |
+
dict_source_i.update({"Text":node.node.text})
|
| 203 |
+
st.write("Source n°"+str(i+1), dict_source_i)
|
| 204 |
+
#st.write("Source n°"+str(i))
|
| 205 |
+
#st.write("Meta Data :", node.node.metadata)
|
| 206 |
+
#st.write("Text :", node.node.text)
|
| 207 |
+
#st.write()
|
| 208 |
+
#print("Is File uploaded : ",uploaded_file==True, "Is question asked : ", question==True, "Is question asked : ", api_server_info==True)
|
| 209 |
+
|
| 210 |
+
st.markdown("""
|
| 211 |
+
<div style="text-align: center; margin-top: 20px;">
|
| 212 |
+
<a href="https://github.com/mohcineelharras/llama-index-docs" target="_blank" style="margin: 10px; display: inline-block;">
|
| 213 |
+
<img src="https://img.shields.io/badge/Repository-333?logo=github&style=for-the-badge" alt="Repository" style="vertical-align: middle;">
|
| 214 |
+
</a>
|
| 215 |
+
<a href="https://www.linkedin.com/in/mohcine-el-harras" target="_blank" style="margin: 10px; display: inline-block;">
|
| 216 |
+
<img src="https://img.shields.io/badge/-LinkedIn-0077B5?style=for-the-badge&logo=linkedin" alt="LinkedIn" style="vertical-align: middle;">
|
| 217 |
+
</a>
|
| 218 |
+
<a href="https://mohcineelharras.github.io" target="_blank" style="margin: 10px; display: inline-block;">
|
| 219 |
+
<img src="https://img.shields.io/badge/Visit-Portfolio-9cf?style=for-the-badge" alt="GitHub" style="vertical-align: middle;">
|
| 220 |
+
</a>
|
| 221 |
+
</div>
|
| 222 |
+
<div style="text-align: center; margin-top: 20px; color: #666; font-size: 0.85em;">
|
| 223 |
+
© 2023 Mohcine EL HARRAS
|
| 224 |
+
</div>
|
| 225 |
+
""", unsafe_allow_html=True)
|
| 226 |
+
|
| 227 |
+
|
| 228 |
+
# -----------------------------------end-----------------------------------------
|
data/bitcoin.pdf
ADDED
|
Binary file (184 kB). View file
|
|
|
data/doctest.txt
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
Hi my name is Mohcine,
|
| 2 |
+
I am 25 years old
|
| 3 |
+
I am a freelancer
|
models/dolphin-2.1-mistral-7b.Q4_K_S.gguf
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:6fa0795eeac9ac8835a7f85ed398cf1a0881d3c9f40ee4bab51a5fd8838f68f9
|
| 3 |
+
size 4140384992
|
models/hkunlp_instructor-base/.gitattributes
ADDED
|
@@ -0,0 +1,34 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
*.7z filter=lfs diff=lfs merge=lfs -text
|
| 2 |
+
*.arrow filter=lfs diff=lfs merge=lfs -text
|
| 3 |
+
*.bin filter=lfs diff=lfs merge=lfs -text
|
| 4 |
+
*.bz2 filter=lfs diff=lfs merge=lfs -text
|
| 5 |
+
*.ckpt filter=lfs diff=lfs merge=lfs -text
|
| 6 |
+
*.ftz filter=lfs diff=lfs merge=lfs -text
|
| 7 |
+
*.gz filter=lfs diff=lfs merge=lfs -text
|
| 8 |
+
*.h5 filter=lfs diff=lfs merge=lfs -text
|
| 9 |
+
*.joblib filter=lfs diff=lfs merge=lfs -text
|
| 10 |
+
*.lfs.* filter=lfs diff=lfs merge=lfs -text
|
| 11 |
+
*.mlmodel filter=lfs diff=lfs merge=lfs -text
|
| 12 |
+
*.model filter=lfs diff=lfs merge=lfs -text
|
| 13 |
+
*.msgpack filter=lfs diff=lfs merge=lfs -text
|
| 14 |
+
*.npy filter=lfs diff=lfs merge=lfs -text
|
| 15 |
+
*.npz filter=lfs diff=lfs merge=lfs -text
|
| 16 |
+
*.onnx filter=lfs diff=lfs merge=lfs -text
|
| 17 |
+
*.ot filter=lfs diff=lfs merge=lfs -text
|
| 18 |
+
*.parquet filter=lfs diff=lfs merge=lfs -text
|
| 19 |
+
*.pb filter=lfs diff=lfs merge=lfs -text
|
| 20 |
+
*.pickle filter=lfs diff=lfs merge=lfs -text
|
| 21 |
+
*.pkl filter=lfs diff=lfs merge=lfs -text
|
| 22 |
+
*.pt filter=lfs diff=lfs merge=lfs -text
|
| 23 |
+
*.pth filter=lfs diff=lfs merge=lfs -text
|
| 24 |
+
*.rar filter=lfs diff=lfs merge=lfs -text
|
| 25 |
+
*.safetensors filter=lfs diff=lfs merge=lfs -text
|
| 26 |
+
saved_model/**/* filter=lfs diff=lfs merge=lfs -text
|
| 27 |
+
*.tar.* filter=lfs diff=lfs merge=lfs -text
|
| 28 |
+
*.tflite filter=lfs diff=lfs merge=lfs -text
|
| 29 |
+
*.tgz filter=lfs diff=lfs merge=lfs -text
|
| 30 |
+
*.wasm filter=lfs diff=lfs merge=lfs -text
|
| 31 |
+
*.xz filter=lfs diff=lfs merge=lfs -text
|
| 32 |
+
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 33 |
+
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 34 |
+
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
models/hkunlp_instructor-base/1_Pooling/config.json
ADDED
|
@@ -0,0 +1,9 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"word_embedding_dimension": 768,
|
| 3 |
+
"pooling_mode_cls_token": false,
|
| 4 |
+
"pooling_mode_mean_tokens": true,
|
| 5 |
+
"pooling_mode_max_tokens": false,
|
| 6 |
+
"pooling_mode_mean_sqrt_len_tokens": false,
|
| 7 |
+
"pooling_mode_weightedmean_tokens": false,
|
| 8 |
+
"pooling_mode_lasttoken": false
|
| 9 |
+
}
|
models/hkunlp_instructor-base/2_Dense/config.json
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
{"in_features": 768, "out_features": 768, "bias": false, "activation_function": "torch.nn.modules.linear.Identity"}
|
models/hkunlp_instructor-base/2_Dense/pytorch_model.bin
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:b4e9301dfb3d947e4e2bcc6c8c9c8da58d1c07c11db7eb5e9e1a14749883f719
|
| 3 |
+
size 2360171
|
models/hkunlp_instructor-base/README.md
ADDED
|
@@ -0,0 +1,2610 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
pipeline_tag: sentence-similarity
|
| 3 |
+
tags:
|
| 4 |
+
- text-embedding
|
| 5 |
+
- embeddings
|
| 6 |
+
- information-retrieval
|
| 7 |
+
- beir
|
| 8 |
+
- text-classification
|
| 9 |
+
- language-model
|
| 10 |
+
- text-clustering
|
| 11 |
+
- text-semantic-similarity
|
| 12 |
+
- text-evaluation
|
| 13 |
+
- prompt-retrieval
|
| 14 |
+
- text-reranking
|
| 15 |
+
- sentence-transformers
|
| 16 |
+
- feature-extraction
|
| 17 |
+
- sentence-similarity
|
| 18 |
+
- transformers
|
| 19 |
+
- t5
|
| 20 |
+
- English
|
| 21 |
+
- Sentence Similarity
|
| 22 |
+
- natural_questions
|
| 23 |
+
- ms_marco
|
| 24 |
+
- fever
|
| 25 |
+
- hotpot_qa
|
| 26 |
+
- mteb
|
| 27 |
+
language: en
|
| 28 |
+
inference: false
|
| 29 |
+
license: apache-2.0
|
| 30 |
+
model-index:
|
| 31 |
+
- name: final_base_results
|
| 32 |
+
results:
|
| 33 |
+
- task:
|
| 34 |
+
type: Classification
|
| 35 |
+
dataset:
|
| 36 |
+
type: mteb/amazon_counterfactual
|
| 37 |
+
name: MTEB AmazonCounterfactualClassification (en)
|
| 38 |
+
config: en
|
| 39 |
+
split: test
|
| 40 |
+
revision: e8379541af4e31359cca9fbcf4b00f2671dba205
|
| 41 |
+
metrics:
|
| 42 |
+
- type: accuracy
|
| 43 |
+
value: 86.2089552238806
|
| 44 |
+
- type: ap
|
| 45 |
+
value: 55.76273850794966
|
| 46 |
+
- type: f1
|
| 47 |
+
value: 81.26104211414781
|
| 48 |
+
- task:
|
| 49 |
+
type: Classification
|
| 50 |
+
dataset:
|
| 51 |
+
type: mteb/amazon_polarity
|
| 52 |
+
name: MTEB AmazonPolarityClassification
|
| 53 |
+
config: default
|
| 54 |
+
split: test
|
| 55 |
+
revision: e2d317d38cd51312af73b3d32a06d1a08b442046
|
| 56 |
+
metrics:
|
| 57 |
+
- type: accuracy
|
| 58 |
+
value: 88.35995000000001
|
| 59 |
+
- type: ap
|
| 60 |
+
value: 84.18839957309655
|
| 61 |
+
- type: f1
|
| 62 |
+
value: 88.317619250081
|
| 63 |
+
- task:
|
| 64 |
+
type: Classification
|
| 65 |
+
dataset:
|
| 66 |
+
type: mteb/amazon_reviews_multi
|
| 67 |
+
name: MTEB AmazonReviewsClassification (en)
|
| 68 |
+
config: en
|
| 69 |
+
split: test
|
| 70 |
+
revision: 1399c76144fd37290681b995c656ef9b2e06e26d
|
| 71 |
+
metrics:
|
| 72 |
+
- type: accuracy
|
| 73 |
+
value: 44.64
|
| 74 |
+
- type: f1
|
| 75 |
+
value: 42.48663956478136
|
| 76 |
+
- task:
|
| 77 |
+
type: Retrieval
|
| 78 |
+
dataset:
|
| 79 |
+
type: arguana
|
| 80 |
+
name: MTEB ArguAna
|
| 81 |
+
config: default
|
| 82 |
+
split: test
|
| 83 |
+
revision: None
|
| 84 |
+
metrics:
|
| 85 |
+
- type: map_at_1
|
| 86 |
+
value: 27.383000000000003
|
| 87 |
+
- type: map_at_10
|
| 88 |
+
value: 43.024
|
| 89 |
+
- type: map_at_100
|
| 90 |
+
value: 44.023
|
| 91 |
+
- type: map_at_1000
|
| 92 |
+
value: 44.025999999999996
|
| 93 |
+
- type: map_at_3
|
| 94 |
+
value: 37.684
|
| 95 |
+
- type: map_at_5
|
| 96 |
+
value: 40.884
|
| 97 |
+
- type: mrr_at_1
|
| 98 |
+
value: 28.094
|
| 99 |
+
- type: mrr_at_10
|
| 100 |
+
value: 43.315
|
| 101 |
+
- type: mrr_at_100
|
| 102 |
+
value: 44.313
|
| 103 |
+
- type: mrr_at_1000
|
| 104 |
+
value: 44.317
|
| 105 |
+
- type: mrr_at_3
|
| 106 |
+
value: 37.862
|
| 107 |
+
- type: mrr_at_5
|
| 108 |
+
value: 41.155
|
| 109 |
+
- type: ndcg_at_1
|
| 110 |
+
value: 27.383000000000003
|
| 111 |
+
- type: ndcg_at_10
|
| 112 |
+
value: 52.032000000000004
|
| 113 |
+
- type: ndcg_at_100
|
| 114 |
+
value: 56.19499999999999
|
| 115 |
+
- type: ndcg_at_1000
|
| 116 |
+
value: 56.272
|
| 117 |
+
- type: ndcg_at_3
|
| 118 |
+
value: 41.166000000000004
|
| 119 |
+
- type: ndcg_at_5
|
| 120 |
+
value: 46.92
|
| 121 |
+
- type: precision_at_1
|
| 122 |
+
value: 27.383000000000003
|
| 123 |
+
- type: precision_at_10
|
| 124 |
+
value: 8.087
|
| 125 |
+
- type: precision_at_100
|
| 126 |
+
value: 0.989
|
| 127 |
+
- type: precision_at_1000
|
| 128 |
+
value: 0.099
|
| 129 |
+
- type: precision_at_3
|
| 130 |
+
value: 17.093
|
| 131 |
+
- type: precision_at_5
|
| 132 |
+
value: 13.044
|
| 133 |
+
- type: recall_at_1
|
| 134 |
+
value: 27.383000000000003
|
| 135 |
+
- type: recall_at_10
|
| 136 |
+
value: 80.868
|
| 137 |
+
- type: recall_at_100
|
| 138 |
+
value: 98.86200000000001
|
| 139 |
+
- type: recall_at_1000
|
| 140 |
+
value: 99.431
|
| 141 |
+
- type: recall_at_3
|
| 142 |
+
value: 51.28
|
| 143 |
+
- type: recall_at_5
|
| 144 |
+
value: 65.22
|
| 145 |
+
- task:
|
| 146 |
+
type: Clustering
|
| 147 |
+
dataset:
|
| 148 |
+
type: mteb/arxiv-clustering-p2p
|
| 149 |
+
name: MTEB ArxivClusteringP2P
|
| 150 |
+
config: default
|
| 151 |
+
split: test
|
| 152 |
+
revision: a122ad7f3f0291bf49cc6f4d32aa80929df69d5d
|
| 153 |
+
metrics:
|
| 154 |
+
- type: v_measure
|
| 155 |
+
value: 39.68441054431849
|
| 156 |
+
- task:
|
| 157 |
+
type: Clustering
|
| 158 |
+
dataset:
|
| 159 |
+
type: mteb/arxiv-clustering-s2s
|
| 160 |
+
name: MTEB ArxivClusteringS2S
|
| 161 |
+
config: default
|
| 162 |
+
split: test
|
| 163 |
+
revision: f910caf1a6075f7329cdf8c1a6135696f37dbd53
|
| 164 |
+
metrics:
|
| 165 |
+
- type: v_measure
|
| 166 |
+
value: 29.188539728343844
|
| 167 |
+
- task:
|
| 168 |
+
type: Reranking
|
| 169 |
+
dataset:
|
| 170 |
+
type: mteb/askubuntudupquestions-reranking
|
| 171 |
+
name: MTEB AskUbuntuDupQuestions
|
| 172 |
+
config: default
|
| 173 |
+
split: test
|
| 174 |
+
revision: 2000358ca161889fa9c082cb41daa8dcfb161a54
|
| 175 |
+
metrics:
|
| 176 |
+
- type: map
|
| 177 |
+
value: 63.173362687519784
|
| 178 |
+
- type: mrr
|
| 179 |
+
value: 76.18860748362133
|
| 180 |
+
- task:
|
| 181 |
+
type: STS
|
| 182 |
+
dataset:
|
| 183 |
+
type: mteb/biosses-sts
|
| 184 |
+
name: MTEB BIOSSES
|
| 185 |
+
config: default
|
| 186 |
+
split: test
|
| 187 |
+
revision: d3fb88f8f02e40887cd149695127462bbcf29b4a
|
| 188 |
+
metrics:
|
| 189 |
+
- type: cos_sim_spearman
|
| 190 |
+
value: 82.30789953771232
|
| 191 |
+
- task:
|
| 192 |
+
type: Classification
|
| 193 |
+
dataset:
|
| 194 |
+
type: mteb/banking77
|
| 195 |
+
name: MTEB Banking77Classification
|
| 196 |
+
config: default
|
| 197 |
+
split: test
|
| 198 |
+
revision: 0fd18e25b25c072e09e0d92ab615fda904d66300
|
| 199 |
+
metrics:
|
| 200 |
+
- type: accuracy
|
| 201 |
+
value: 77.03571428571428
|
| 202 |
+
- type: f1
|
| 203 |
+
value: 75.87384305045917
|
| 204 |
+
- task:
|
| 205 |
+
type: Clustering
|
| 206 |
+
dataset:
|
| 207 |
+
type: mteb/biorxiv-clustering-p2p
|
| 208 |
+
name: MTEB BiorxivClusteringP2P
|
| 209 |
+
config: default
|
| 210 |
+
split: test
|
| 211 |
+
revision: 65b79d1d13f80053f67aca9498d9402c2d9f1f40
|
| 212 |
+
metrics:
|
| 213 |
+
- type: v_measure
|
| 214 |
+
value: 32.98041170516364
|
| 215 |
+
- task:
|
| 216 |
+
type: Clustering
|
| 217 |
+
dataset:
|
| 218 |
+
type: mteb/biorxiv-clustering-s2s
|
| 219 |
+
name: MTEB BiorxivClusteringS2S
|
| 220 |
+
config: default
|
| 221 |
+
split: test
|
| 222 |
+
revision: 258694dd0231531bc1fd9de6ceb52a0853c6d908
|
| 223 |
+
metrics:
|
| 224 |
+
- type: v_measure
|
| 225 |
+
value: 25.71652988451154
|
| 226 |
+
- task:
|
| 227 |
+
type: Retrieval
|
| 228 |
+
dataset:
|
| 229 |
+
type: BeIR/cqadupstack
|
| 230 |
+
name: MTEB CQADupstackAndroidRetrieval
|
| 231 |
+
config: default
|
| 232 |
+
split: test
|
| 233 |
+
revision: None
|
| 234 |
+
metrics:
|
| 235 |
+
- type: map_at_1
|
| 236 |
+
value: 33.739999999999995
|
| 237 |
+
- type: map_at_10
|
| 238 |
+
value: 46.197
|
| 239 |
+
- type: map_at_100
|
| 240 |
+
value: 47.814
|
| 241 |
+
- type: map_at_1000
|
| 242 |
+
value: 47.934
|
| 243 |
+
- type: map_at_3
|
| 244 |
+
value: 43.091
|
| 245 |
+
- type: map_at_5
|
| 246 |
+
value: 44.81
|
| 247 |
+
- type: mrr_at_1
|
| 248 |
+
value: 41.059
|
| 249 |
+
- type: mrr_at_10
|
| 250 |
+
value: 52.292
|
| 251 |
+
- type: mrr_at_100
|
| 252 |
+
value: 52.978
|
| 253 |
+
- type: mrr_at_1000
|
| 254 |
+
value: 53.015
|
| 255 |
+
- type: mrr_at_3
|
| 256 |
+
value: 49.976
|
| 257 |
+
- type: mrr_at_5
|
| 258 |
+
value: 51.449999999999996
|
| 259 |
+
- type: ndcg_at_1
|
| 260 |
+
value: 41.059
|
| 261 |
+
- type: ndcg_at_10
|
| 262 |
+
value: 52.608
|
| 263 |
+
- type: ndcg_at_100
|
| 264 |
+
value: 57.965
|
| 265 |
+
- type: ndcg_at_1000
|
| 266 |
+
value: 59.775999999999996
|
| 267 |
+
- type: ndcg_at_3
|
| 268 |
+
value: 48.473
|
| 269 |
+
- type: ndcg_at_5
|
| 270 |
+
value: 50.407999999999994
|
| 271 |
+
- type: precision_at_1
|
| 272 |
+
value: 41.059
|
| 273 |
+
- type: precision_at_10
|
| 274 |
+
value: 9.943
|
| 275 |
+
- type: precision_at_100
|
| 276 |
+
value: 1.6070000000000002
|
| 277 |
+
- type: precision_at_1000
|
| 278 |
+
value: 0.20500000000000002
|
| 279 |
+
- type: precision_at_3
|
| 280 |
+
value: 23.413999999999998
|
| 281 |
+
- type: precision_at_5
|
| 282 |
+
value: 16.481
|
| 283 |
+
- type: recall_at_1
|
| 284 |
+
value: 33.739999999999995
|
| 285 |
+
- type: recall_at_10
|
| 286 |
+
value: 63.888999999999996
|
| 287 |
+
- type: recall_at_100
|
| 288 |
+
value: 85.832
|
| 289 |
+
- type: recall_at_1000
|
| 290 |
+
value: 97.475
|
| 291 |
+
- type: recall_at_3
|
| 292 |
+
value: 51.953
|
| 293 |
+
- type: recall_at_5
|
| 294 |
+
value: 57.498000000000005
|
| 295 |
+
- task:
|
| 296 |
+
type: Retrieval
|
| 297 |
+
dataset:
|
| 298 |
+
type: BeIR/cqadupstack
|
| 299 |
+
name: MTEB CQADupstackEnglishRetrieval
|
| 300 |
+
config: default
|
| 301 |
+
split: test
|
| 302 |
+
revision: None
|
| 303 |
+
metrics:
|
| 304 |
+
- type: map_at_1
|
| 305 |
+
value: 31.169999999999998
|
| 306 |
+
- type: map_at_10
|
| 307 |
+
value: 41.455
|
| 308 |
+
- type: map_at_100
|
| 309 |
+
value: 42.716
|
| 310 |
+
- type: map_at_1000
|
| 311 |
+
value: 42.847
|
| 312 |
+
- type: map_at_3
|
| 313 |
+
value: 38.568999999999996
|
| 314 |
+
- type: map_at_5
|
| 315 |
+
value: 40.099000000000004
|
| 316 |
+
- type: mrr_at_1
|
| 317 |
+
value: 39.427
|
| 318 |
+
- type: mrr_at_10
|
| 319 |
+
value: 47.818
|
| 320 |
+
- type: mrr_at_100
|
| 321 |
+
value: 48.519
|
| 322 |
+
- type: mrr_at_1000
|
| 323 |
+
value: 48.558
|
| 324 |
+
- type: mrr_at_3
|
| 325 |
+
value: 45.86
|
| 326 |
+
- type: mrr_at_5
|
| 327 |
+
value: 46.936
|
| 328 |
+
- type: ndcg_at_1
|
| 329 |
+
value: 39.427
|
| 330 |
+
- type: ndcg_at_10
|
| 331 |
+
value: 47.181
|
| 332 |
+
- type: ndcg_at_100
|
| 333 |
+
value: 51.737
|
| 334 |
+
- type: ndcg_at_1000
|
| 335 |
+
value: 53.74
|
| 336 |
+
- type: ndcg_at_3
|
| 337 |
+
value: 43.261
|
| 338 |
+
- type: ndcg_at_5
|
| 339 |
+
value: 44.891
|
| 340 |
+
- type: precision_at_1
|
| 341 |
+
value: 39.427
|
| 342 |
+
- type: precision_at_10
|
| 343 |
+
value: 8.847
|
| 344 |
+
- type: precision_at_100
|
| 345 |
+
value: 1.425
|
| 346 |
+
- type: precision_at_1000
|
| 347 |
+
value: 0.189
|
| 348 |
+
- type: precision_at_3
|
| 349 |
+
value: 20.785999999999998
|
| 350 |
+
- type: precision_at_5
|
| 351 |
+
value: 14.560999999999998
|
| 352 |
+
- type: recall_at_1
|
| 353 |
+
value: 31.169999999999998
|
| 354 |
+
- type: recall_at_10
|
| 355 |
+
value: 56.971000000000004
|
| 356 |
+
- type: recall_at_100
|
| 357 |
+
value: 76.31400000000001
|
| 358 |
+
- type: recall_at_1000
|
| 359 |
+
value: 88.93900000000001
|
| 360 |
+
- type: recall_at_3
|
| 361 |
+
value: 45.208
|
| 362 |
+
- type: recall_at_5
|
| 363 |
+
value: 49.923
|
| 364 |
+
- task:
|
| 365 |
+
type: Retrieval
|
| 366 |
+
dataset:
|
| 367 |
+
type: BeIR/cqadupstack
|
| 368 |
+
name: MTEB CQADupstackGamingRetrieval
|
| 369 |
+
config: default
|
| 370 |
+
split: test
|
| 371 |
+
revision: None
|
| 372 |
+
metrics:
|
| 373 |
+
- type: map_at_1
|
| 374 |
+
value: 39.682
|
| 375 |
+
- type: map_at_10
|
| 376 |
+
value: 52.766000000000005
|
| 377 |
+
- type: map_at_100
|
| 378 |
+
value: 53.84100000000001
|
| 379 |
+
- type: map_at_1000
|
| 380 |
+
value: 53.898
|
| 381 |
+
- type: map_at_3
|
| 382 |
+
value: 49.291000000000004
|
| 383 |
+
- type: map_at_5
|
| 384 |
+
value: 51.365
|
| 385 |
+
- type: mrr_at_1
|
| 386 |
+
value: 45.266
|
| 387 |
+
- type: mrr_at_10
|
| 388 |
+
value: 56.093
|
| 389 |
+
- type: mrr_at_100
|
| 390 |
+
value: 56.763
|
| 391 |
+
- type: mrr_at_1000
|
| 392 |
+
value: 56.793000000000006
|
| 393 |
+
- type: mrr_at_3
|
| 394 |
+
value: 53.668000000000006
|
| 395 |
+
- type: mrr_at_5
|
| 396 |
+
value: 55.1
|
| 397 |
+
- type: ndcg_at_1
|
| 398 |
+
value: 45.266
|
| 399 |
+
- type: ndcg_at_10
|
| 400 |
+
value: 58.836
|
| 401 |
+
- type: ndcg_at_100
|
| 402 |
+
value: 62.863
|
| 403 |
+
- type: ndcg_at_1000
|
| 404 |
+
value: 63.912
|
| 405 |
+
- type: ndcg_at_3
|
| 406 |
+
value: 53.19199999999999
|
| 407 |
+
- type: ndcg_at_5
|
| 408 |
+
value: 56.125
|
| 409 |
+
- type: precision_at_1
|
| 410 |
+
value: 45.266
|
| 411 |
+
- type: precision_at_10
|
| 412 |
+
value: 9.492
|
| 413 |
+
- type: precision_at_100
|
| 414 |
+
value: 1.236
|
| 415 |
+
- type: precision_at_1000
|
| 416 |
+
value: 0.13699999999999998
|
| 417 |
+
- type: precision_at_3
|
| 418 |
+
value: 23.762
|
| 419 |
+
- type: precision_at_5
|
| 420 |
+
value: 16.414
|
| 421 |
+
- type: recall_at_1
|
| 422 |
+
value: 39.682
|
| 423 |
+
- type: recall_at_10
|
| 424 |
+
value: 73.233
|
| 425 |
+
- type: recall_at_100
|
| 426 |
+
value: 90.335
|
| 427 |
+
- type: recall_at_1000
|
| 428 |
+
value: 97.452
|
| 429 |
+
- type: recall_at_3
|
| 430 |
+
value: 58.562000000000005
|
| 431 |
+
- type: recall_at_5
|
| 432 |
+
value: 65.569
|
| 433 |
+
- task:
|
| 434 |
+
type: Retrieval
|
| 435 |
+
dataset:
|
| 436 |
+
type: BeIR/cqadupstack
|
| 437 |
+
name: MTEB CQADupstackGisRetrieval
|
| 438 |
+
config: default
|
| 439 |
+
split: test
|
| 440 |
+
revision: None
|
| 441 |
+
metrics:
|
| 442 |
+
- type: map_at_1
|
| 443 |
+
value: 26.743
|
| 444 |
+
- type: map_at_10
|
| 445 |
+
value: 34.016000000000005
|
| 446 |
+
- type: map_at_100
|
| 447 |
+
value: 35.028999999999996
|
| 448 |
+
- type: map_at_1000
|
| 449 |
+
value: 35.113
|
| 450 |
+
- type: map_at_3
|
| 451 |
+
value: 31.763
|
| 452 |
+
- type: map_at_5
|
| 453 |
+
value: 33.013999999999996
|
| 454 |
+
- type: mrr_at_1
|
| 455 |
+
value: 28.927000000000003
|
| 456 |
+
- type: mrr_at_10
|
| 457 |
+
value: 36.32
|
| 458 |
+
- type: mrr_at_100
|
| 459 |
+
value: 37.221
|
| 460 |
+
- type: mrr_at_1000
|
| 461 |
+
value: 37.281
|
| 462 |
+
- type: mrr_at_3
|
| 463 |
+
value: 34.105000000000004
|
| 464 |
+
- type: mrr_at_5
|
| 465 |
+
value: 35.371
|
| 466 |
+
- type: ndcg_at_1
|
| 467 |
+
value: 28.927000000000003
|
| 468 |
+
- type: ndcg_at_10
|
| 469 |
+
value: 38.474000000000004
|
| 470 |
+
- type: ndcg_at_100
|
| 471 |
+
value: 43.580000000000005
|
| 472 |
+
- type: ndcg_at_1000
|
| 473 |
+
value: 45.64
|
| 474 |
+
- type: ndcg_at_3
|
| 475 |
+
value: 34.035
|
| 476 |
+
- type: ndcg_at_5
|
| 477 |
+
value: 36.186
|
| 478 |
+
- type: precision_at_1
|
| 479 |
+
value: 28.927000000000003
|
| 480 |
+
- type: precision_at_10
|
| 481 |
+
value: 5.74
|
| 482 |
+
- type: precision_at_100
|
| 483 |
+
value: 0.8710000000000001
|
| 484 |
+
- type: precision_at_1000
|
| 485 |
+
value: 0.108
|
| 486 |
+
- type: precision_at_3
|
| 487 |
+
value: 14.124
|
| 488 |
+
- type: precision_at_5
|
| 489 |
+
value: 9.74
|
| 490 |
+
- type: recall_at_1
|
| 491 |
+
value: 26.743
|
| 492 |
+
- type: recall_at_10
|
| 493 |
+
value: 49.955
|
| 494 |
+
- type: recall_at_100
|
| 495 |
+
value: 73.904
|
| 496 |
+
- type: recall_at_1000
|
| 497 |
+
value: 89.133
|
| 498 |
+
- type: recall_at_3
|
| 499 |
+
value: 38.072
|
| 500 |
+
- type: recall_at_5
|
| 501 |
+
value: 43.266
|
| 502 |
+
- task:
|
| 503 |
+
type: Retrieval
|
| 504 |
+
dataset:
|
| 505 |
+
type: BeIR/cqadupstack
|
| 506 |
+
name: MTEB CQADupstackMathematicaRetrieval
|
| 507 |
+
config: default
|
| 508 |
+
split: test
|
| 509 |
+
revision: None
|
| 510 |
+
metrics:
|
| 511 |
+
- type: map_at_1
|
| 512 |
+
value: 16.928
|
| 513 |
+
- type: map_at_10
|
| 514 |
+
value: 23.549
|
| 515 |
+
- type: map_at_100
|
| 516 |
+
value: 24.887
|
| 517 |
+
- type: map_at_1000
|
| 518 |
+
value: 25.018
|
| 519 |
+
- type: map_at_3
|
| 520 |
+
value: 21.002000000000002
|
| 521 |
+
- type: map_at_5
|
| 522 |
+
value: 22.256
|
| 523 |
+
- type: mrr_at_1
|
| 524 |
+
value: 21.02
|
| 525 |
+
- type: mrr_at_10
|
| 526 |
+
value: 27.898
|
| 527 |
+
- type: mrr_at_100
|
| 528 |
+
value: 29.018
|
| 529 |
+
- type: mrr_at_1000
|
| 530 |
+
value: 29.099999999999998
|
| 531 |
+
- type: mrr_at_3
|
| 532 |
+
value: 25.456
|
| 533 |
+
- type: mrr_at_5
|
| 534 |
+
value: 26.625
|
| 535 |
+
- type: ndcg_at_1
|
| 536 |
+
value: 21.02
|
| 537 |
+
- type: ndcg_at_10
|
| 538 |
+
value: 28.277
|
| 539 |
+
- type: ndcg_at_100
|
| 540 |
+
value: 34.54
|
| 541 |
+
- type: ndcg_at_1000
|
| 542 |
+
value: 37.719
|
| 543 |
+
- type: ndcg_at_3
|
| 544 |
+
value: 23.707
|
| 545 |
+
- type: ndcg_at_5
|
| 546 |
+
value: 25.482
|
| 547 |
+
- type: precision_at_1
|
| 548 |
+
value: 21.02
|
| 549 |
+
- type: precision_at_10
|
| 550 |
+
value: 5.361
|
| 551 |
+
- type: precision_at_100
|
| 552 |
+
value: 0.9809999999999999
|
| 553 |
+
- type: precision_at_1000
|
| 554 |
+
value: 0.13899999999999998
|
| 555 |
+
- type: precision_at_3
|
| 556 |
+
value: 11.401
|
| 557 |
+
- type: precision_at_5
|
| 558 |
+
value: 8.209
|
| 559 |
+
- type: recall_at_1
|
| 560 |
+
value: 16.928
|
| 561 |
+
- type: recall_at_10
|
| 562 |
+
value: 38.601
|
| 563 |
+
- type: recall_at_100
|
| 564 |
+
value: 65.759
|
| 565 |
+
- type: recall_at_1000
|
| 566 |
+
value: 88.543
|
| 567 |
+
- type: recall_at_3
|
| 568 |
+
value: 25.556
|
| 569 |
+
- type: recall_at_5
|
| 570 |
+
value: 30.447000000000003
|
| 571 |
+
- task:
|
| 572 |
+
type: Retrieval
|
| 573 |
+
dataset:
|
| 574 |
+
type: BeIR/cqadupstack
|
| 575 |
+
name: MTEB CQADupstackPhysicsRetrieval
|
| 576 |
+
config: default
|
| 577 |
+
split: test
|
| 578 |
+
revision: None
|
| 579 |
+
metrics:
|
| 580 |
+
- type: map_at_1
|
| 581 |
+
value: 28.549000000000003
|
| 582 |
+
- type: map_at_10
|
| 583 |
+
value: 38.426
|
| 584 |
+
- type: map_at_100
|
| 585 |
+
value: 39.845000000000006
|
| 586 |
+
- type: map_at_1000
|
| 587 |
+
value: 39.956
|
| 588 |
+
- type: map_at_3
|
| 589 |
+
value: 35.372
|
| 590 |
+
- type: map_at_5
|
| 591 |
+
value: 37.204
|
| 592 |
+
- type: mrr_at_1
|
| 593 |
+
value: 35.034
|
| 594 |
+
- type: mrr_at_10
|
| 595 |
+
value: 44.041000000000004
|
| 596 |
+
- type: mrr_at_100
|
| 597 |
+
value: 44.95
|
| 598 |
+
- type: mrr_at_1000
|
| 599 |
+
value: 44.997
|
| 600 |
+
- type: mrr_at_3
|
| 601 |
+
value: 41.498000000000005
|
| 602 |
+
- type: mrr_at_5
|
| 603 |
+
value: 43.077
|
| 604 |
+
- type: ndcg_at_1
|
| 605 |
+
value: 35.034
|
| 606 |
+
- type: ndcg_at_10
|
| 607 |
+
value: 44.218
|
| 608 |
+
- type: ndcg_at_100
|
| 609 |
+
value: 49.958000000000006
|
| 610 |
+
- type: ndcg_at_1000
|
| 611 |
+
value: 52.019000000000005
|
| 612 |
+
- type: ndcg_at_3
|
| 613 |
+
value: 39.34
|
| 614 |
+
- type: ndcg_at_5
|
| 615 |
+
value: 41.892
|
| 616 |
+
- type: precision_at_1
|
| 617 |
+
value: 35.034
|
| 618 |
+
- type: precision_at_10
|
| 619 |
+
value: 7.911
|
| 620 |
+
- type: precision_at_100
|
| 621 |
+
value: 1.26
|
| 622 |
+
- type: precision_at_1000
|
| 623 |
+
value: 0.16
|
| 624 |
+
- type: precision_at_3
|
| 625 |
+
value: 18.511
|
| 626 |
+
- type: precision_at_5
|
| 627 |
+
value: 13.205
|
| 628 |
+
- type: recall_at_1
|
| 629 |
+
value: 28.549000000000003
|
| 630 |
+
- type: recall_at_10
|
| 631 |
+
value: 56.035999999999994
|
| 632 |
+
- type: recall_at_100
|
| 633 |
+
value: 79.701
|
| 634 |
+
- type: recall_at_1000
|
| 635 |
+
value: 93.149
|
| 636 |
+
- type: recall_at_3
|
| 637 |
+
value: 42.275
|
| 638 |
+
- type: recall_at_5
|
| 639 |
+
value: 49.097
|
| 640 |
+
- task:
|
| 641 |
+
type: Retrieval
|
| 642 |
+
dataset:
|
| 643 |
+
type: BeIR/cqadupstack
|
| 644 |
+
name: MTEB CQADupstackProgrammersRetrieval
|
| 645 |
+
config: default
|
| 646 |
+
split: test
|
| 647 |
+
revision: None
|
| 648 |
+
metrics:
|
| 649 |
+
- type: map_at_1
|
| 650 |
+
value: 29.391000000000002
|
| 651 |
+
- type: map_at_10
|
| 652 |
+
value: 39.48
|
| 653 |
+
- type: map_at_100
|
| 654 |
+
value: 40.727000000000004
|
| 655 |
+
- type: map_at_1000
|
| 656 |
+
value: 40.835
|
| 657 |
+
- type: map_at_3
|
| 658 |
+
value: 36.234
|
| 659 |
+
- type: map_at_5
|
| 660 |
+
value: 37.877
|
| 661 |
+
- type: mrr_at_1
|
| 662 |
+
value: 35.959
|
| 663 |
+
- type: mrr_at_10
|
| 664 |
+
value: 44.726
|
| 665 |
+
- type: mrr_at_100
|
| 666 |
+
value: 45.531
|
| 667 |
+
- type: mrr_at_1000
|
| 668 |
+
value: 45.582
|
| 669 |
+
- type: mrr_at_3
|
| 670 |
+
value: 42.047000000000004
|
| 671 |
+
- type: mrr_at_5
|
| 672 |
+
value: 43.611
|
| 673 |
+
- type: ndcg_at_1
|
| 674 |
+
value: 35.959
|
| 675 |
+
- type: ndcg_at_10
|
| 676 |
+
value: 45.303
|
| 677 |
+
- type: ndcg_at_100
|
| 678 |
+
value: 50.683
|
| 679 |
+
- type: ndcg_at_1000
|
| 680 |
+
value: 52.818
|
| 681 |
+
- type: ndcg_at_3
|
| 682 |
+
value: 39.987
|
| 683 |
+
- type: ndcg_at_5
|
| 684 |
+
value: 42.243
|
| 685 |
+
- type: precision_at_1
|
| 686 |
+
value: 35.959
|
| 687 |
+
- type: precision_at_10
|
| 688 |
+
value: 8.241999999999999
|
| 689 |
+
- type: precision_at_100
|
| 690 |
+
value: 1.274
|
| 691 |
+
- type: precision_at_1000
|
| 692 |
+
value: 0.163
|
| 693 |
+
- type: precision_at_3
|
| 694 |
+
value: 18.836
|
| 695 |
+
- type: precision_at_5
|
| 696 |
+
value: 13.196
|
| 697 |
+
- type: recall_at_1
|
| 698 |
+
value: 29.391000000000002
|
| 699 |
+
- type: recall_at_10
|
| 700 |
+
value: 57.364000000000004
|
| 701 |
+
- type: recall_at_100
|
| 702 |
+
value: 80.683
|
| 703 |
+
- type: recall_at_1000
|
| 704 |
+
value: 94.918
|
| 705 |
+
- type: recall_at_3
|
| 706 |
+
value: 42.263
|
| 707 |
+
- type: recall_at_5
|
| 708 |
+
value: 48.634
|
| 709 |
+
- task:
|
| 710 |
+
type: Retrieval
|
| 711 |
+
dataset:
|
| 712 |
+
type: BeIR/cqadupstack
|
| 713 |
+
name: MTEB CQADupstackRetrieval
|
| 714 |
+
config: default
|
| 715 |
+
split: test
|
| 716 |
+
revision: None
|
| 717 |
+
metrics:
|
| 718 |
+
- type: map_at_1
|
| 719 |
+
value: 26.791749999999997
|
| 720 |
+
- type: map_at_10
|
| 721 |
+
value: 35.75541666666667
|
| 722 |
+
- type: map_at_100
|
| 723 |
+
value: 37.00791666666667
|
| 724 |
+
- type: map_at_1000
|
| 725 |
+
value: 37.12408333333333
|
| 726 |
+
- type: map_at_3
|
| 727 |
+
value: 33.02966666666667
|
| 728 |
+
- type: map_at_5
|
| 729 |
+
value: 34.56866666666667
|
| 730 |
+
- type: mrr_at_1
|
| 731 |
+
value: 31.744333333333337
|
| 732 |
+
- type: mrr_at_10
|
| 733 |
+
value: 39.9925
|
| 734 |
+
- type: mrr_at_100
|
| 735 |
+
value: 40.86458333333333
|
| 736 |
+
- type: mrr_at_1000
|
| 737 |
+
value: 40.92175000000001
|
| 738 |
+
- type: mrr_at_3
|
| 739 |
+
value: 37.68183333333334
|
| 740 |
+
- type: mrr_at_5
|
| 741 |
+
value: 39.028499999999994
|
| 742 |
+
- type: ndcg_at_1
|
| 743 |
+
value: 31.744333333333337
|
| 744 |
+
- type: ndcg_at_10
|
| 745 |
+
value: 40.95008333333334
|
| 746 |
+
- type: ndcg_at_100
|
| 747 |
+
value: 46.25966666666667
|
| 748 |
+
- type: ndcg_at_1000
|
| 749 |
+
value: 48.535333333333334
|
| 750 |
+
- type: ndcg_at_3
|
| 751 |
+
value: 36.43333333333333
|
| 752 |
+
- type: ndcg_at_5
|
| 753 |
+
value: 38.602333333333334
|
| 754 |
+
- type: precision_at_1
|
| 755 |
+
value: 31.744333333333337
|
| 756 |
+
- type: precision_at_10
|
| 757 |
+
value: 7.135166666666666
|
| 758 |
+
- type: precision_at_100
|
| 759 |
+
value: 1.1535833333333334
|
| 760 |
+
- type: precision_at_1000
|
| 761 |
+
value: 0.15391666666666665
|
| 762 |
+
- type: precision_at_3
|
| 763 |
+
value: 16.713
|
| 764 |
+
- type: precision_at_5
|
| 765 |
+
value: 11.828416666666666
|
| 766 |
+
- type: recall_at_1
|
| 767 |
+
value: 26.791749999999997
|
| 768 |
+
- type: recall_at_10
|
| 769 |
+
value: 51.98625
|
| 770 |
+
- type: recall_at_100
|
| 771 |
+
value: 75.30358333333334
|
| 772 |
+
- type: recall_at_1000
|
| 773 |
+
value: 91.05433333333333
|
| 774 |
+
- type: recall_at_3
|
| 775 |
+
value: 39.39583333333333
|
| 776 |
+
- type: recall_at_5
|
| 777 |
+
value: 45.05925
|
| 778 |
+
- task:
|
| 779 |
+
type: Retrieval
|
| 780 |
+
dataset:
|
| 781 |
+
type: BeIR/cqadupstack
|
| 782 |
+
name: MTEB CQADupstackStatsRetrieval
|
| 783 |
+
config: default
|
| 784 |
+
split: test
|
| 785 |
+
revision: None
|
| 786 |
+
metrics:
|
| 787 |
+
- type: map_at_1
|
| 788 |
+
value: 22.219
|
| 789 |
+
- type: map_at_10
|
| 790 |
+
value: 29.162
|
| 791 |
+
- type: map_at_100
|
| 792 |
+
value: 30.049999999999997
|
| 793 |
+
- type: map_at_1000
|
| 794 |
+
value: 30.144
|
| 795 |
+
- type: map_at_3
|
| 796 |
+
value: 27.204
|
| 797 |
+
- type: map_at_5
|
| 798 |
+
value: 28.351
|
| 799 |
+
- type: mrr_at_1
|
| 800 |
+
value: 25.153
|
| 801 |
+
- type: mrr_at_10
|
| 802 |
+
value: 31.814999999999998
|
| 803 |
+
- type: mrr_at_100
|
| 804 |
+
value: 32.573
|
| 805 |
+
- type: mrr_at_1000
|
| 806 |
+
value: 32.645
|
| 807 |
+
- type: mrr_at_3
|
| 808 |
+
value: 29.934
|
| 809 |
+
- type: mrr_at_5
|
| 810 |
+
value: 30.946
|
| 811 |
+
- type: ndcg_at_1
|
| 812 |
+
value: 25.153
|
| 813 |
+
- type: ndcg_at_10
|
| 814 |
+
value: 33.099000000000004
|
| 815 |
+
- type: ndcg_at_100
|
| 816 |
+
value: 37.768
|
| 817 |
+
- type: ndcg_at_1000
|
| 818 |
+
value: 40.331
|
| 819 |
+
- type: ndcg_at_3
|
| 820 |
+
value: 29.473
|
| 821 |
+
- type: ndcg_at_5
|
| 822 |
+
value: 31.206
|
| 823 |
+
- type: precision_at_1
|
| 824 |
+
value: 25.153
|
| 825 |
+
- type: precision_at_10
|
| 826 |
+
value: 5.183999999999999
|
| 827 |
+
- type: precision_at_100
|
| 828 |
+
value: 0.8170000000000001
|
| 829 |
+
- type: precision_at_1000
|
| 830 |
+
value: 0.11100000000000002
|
| 831 |
+
- type: precision_at_3
|
| 832 |
+
value: 12.831999999999999
|
| 833 |
+
- type: precision_at_5
|
| 834 |
+
value: 8.895999999999999
|
| 835 |
+
- type: recall_at_1
|
| 836 |
+
value: 22.219
|
| 837 |
+
- type: recall_at_10
|
| 838 |
+
value: 42.637
|
| 839 |
+
- type: recall_at_100
|
| 840 |
+
value: 64.704
|
| 841 |
+
- type: recall_at_1000
|
| 842 |
+
value: 83.963
|
| 843 |
+
- type: recall_at_3
|
| 844 |
+
value: 32.444
|
| 845 |
+
- type: recall_at_5
|
| 846 |
+
value: 36.802
|
| 847 |
+
- task:
|
| 848 |
+
type: Retrieval
|
| 849 |
+
dataset:
|
| 850 |
+
type: BeIR/cqadupstack
|
| 851 |
+
name: MTEB CQADupstackTexRetrieval
|
| 852 |
+
config: default
|
| 853 |
+
split: test
|
| 854 |
+
revision: None
|
| 855 |
+
metrics:
|
| 856 |
+
- type: map_at_1
|
| 857 |
+
value: 17.427999999999997
|
| 858 |
+
- type: map_at_10
|
| 859 |
+
value: 24.029
|
| 860 |
+
- type: map_at_100
|
| 861 |
+
value: 25.119999999999997
|
| 862 |
+
- type: map_at_1000
|
| 863 |
+
value: 25.257
|
| 864 |
+
- type: map_at_3
|
| 865 |
+
value: 22.016
|
| 866 |
+
- type: map_at_5
|
| 867 |
+
value: 23.143
|
| 868 |
+
- type: mrr_at_1
|
| 869 |
+
value: 21.129
|
| 870 |
+
- type: mrr_at_10
|
| 871 |
+
value: 27.750000000000004
|
| 872 |
+
- type: mrr_at_100
|
| 873 |
+
value: 28.666999999999998
|
| 874 |
+
- type: mrr_at_1000
|
| 875 |
+
value: 28.754999999999995
|
| 876 |
+
- type: mrr_at_3
|
| 877 |
+
value: 25.849
|
| 878 |
+
- type: mrr_at_5
|
| 879 |
+
value: 26.939999999999998
|
| 880 |
+
- type: ndcg_at_1
|
| 881 |
+
value: 21.129
|
| 882 |
+
- type: ndcg_at_10
|
| 883 |
+
value: 28.203
|
| 884 |
+
- type: ndcg_at_100
|
| 885 |
+
value: 33.44
|
| 886 |
+
- type: ndcg_at_1000
|
| 887 |
+
value: 36.61
|
| 888 |
+
- type: ndcg_at_3
|
| 889 |
+
value: 24.648999999999997
|
| 890 |
+
- type: ndcg_at_5
|
| 891 |
+
value: 26.316
|
| 892 |
+
- type: precision_at_1
|
| 893 |
+
value: 21.129
|
| 894 |
+
- type: precision_at_10
|
| 895 |
+
value: 5.055
|
| 896 |
+
- type: precision_at_100
|
| 897 |
+
value: 0.909
|
| 898 |
+
- type: precision_at_1000
|
| 899 |
+
value: 0.13699999999999998
|
| 900 |
+
- type: precision_at_3
|
| 901 |
+
value: 11.666
|
| 902 |
+
- type: precision_at_5
|
| 903 |
+
value: 8.3
|
| 904 |
+
- type: recall_at_1
|
| 905 |
+
value: 17.427999999999997
|
| 906 |
+
- type: recall_at_10
|
| 907 |
+
value: 36.923
|
| 908 |
+
- type: recall_at_100
|
| 909 |
+
value: 60.606
|
| 910 |
+
- type: recall_at_1000
|
| 911 |
+
value: 83.19
|
| 912 |
+
- type: recall_at_3
|
| 913 |
+
value: 26.845000000000002
|
| 914 |
+
- type: recall_at_5
|
| 915 |
+
value: 31.247000000000003
|
| 916 |
+
- task:
|
| 917 |
+
type: Retrieval
|
| 918 |
+
dataset:
|
| 919 |
+
type: BeIR/cqadupstack
|
| 920 |
+
name: MTEB CQADupstackUnixRetrieval
|
| 921 |
+
config: default
|
| 922 |
+
split: test
|
| 923 |
+
revision: None
|
| 924 |
+
metrics:
|
| 925 |
+
- type: map_at_1
|
| 926 |
+
value: 26.457000000000004
|
| 927 |
+
- type: map_at_10
|
| 928 |
+
value: 35.228
|
| 929 |
+
- type: map_at_100
|
| 930 |
+
value: 36.475
|
| 931 |
+
- type: map_at_1000
|
| 932 |
+
value: 36.585
|
| 933 |
+
- type: map_at_3
|
| 934 |
+
value: 32.444
|
| 935 |
+
- type: map_at_5
|
| 936 |
+
value: 34.046
|
| 937 |
+
- type: mrr_at_1
|
| 938 |
+
value: 30.784
|
| 939 |
+
- type: mrr_at_10
|
| 940 |
+
value: 39.133
|
| 941 |
+
- type: mrr_at_100
|
| 942 |
+
value: 40.11
|
| 943 |
+
- type: mrr_at_1000
|
| 944 |
+
value: 40.169
|
| 945 |
+
- type: mrr_at_3
|
| 946 |
+
value: 36.692
|
| 947 |
+
- type: mrr_at_5
|
| 948 |
+
value: 38.17
|
| 949 |
+
- type: ndcg_at_1
|
| 950 |
+
value: 30.784
|
| 951 |
+
- type: ndcg_at_10
|
| 952 |
+
value: 40.358
|
| 953 |
+
- type: ndcg_at_100
|
| 954 |
+
value: 46.119
|
| 955 |
+
- type: ndcg_at_1000
|
| 956 |
+
value: 48.428
|
| 957 |
+
- type: ndcg_at_3
|
| 958 |
+
value: 35.504000000000005
|
| 959 |
+
- type: ndcg_at_5
|
| 960 |
+
value: 37.864
|
| 961 |
+
- type: precision_at_1
|
| 962 |
+
value: 30.784
|
| 963 |
+
- type: precision_at_10
|
| 964 |
+
value: 6.800000000000001
|
| 965 |
+
- type: precision_at_100
|
| 966 |
+
value: 1.083
|
| 967 |
+
- type: precision_at_1000
|
| 968 |
+
value: 0.13899999999999998
|
| 969 |
+
- type: precision_at_3
|
| 970 |
+
value: 15.920000000000002
|
| 971 |
+
- type: precision_at_5
|
| 972 |
+
value: 11.437
|
| 973 |
+
- type: recall_at_1
|
| 974 |
+
value: 26.457000000000004
|
| 975 |
+
- type: recall_at_10
|
| 976 |
+
value: 51.845
|
| 977 |
+
- type: recall_at_100
|
| 978 |
+
value: 77.046
|
| 979 |
+
- type: recall_at_1000
|
| 980 |
+
value: 92.892
|
| 981 |
+
- type: recall_at_3
|
| 982 |
+
value: 38.89
|
| 983 |
+
- type: recall_at_5
|
| 984 |
+
value: 44.688
|
| 985 |
+
- task:
|
| 986 |
+
type: Retrieval
|
| 987 |
+
dataset:
|
| 988 |
+
type: BeIR/cqadupstack
|
| 989 |
+
name: MTEB CQADupstackWebmastersRetrieval
|
| 990 |
+
config: default
|
| 991 |
+
split: test
|
| 992 |
+
revision: None
|
| 993 |
+
metrics:
|
| 994 |
+
- type: map_at_1
|
| 995 |
+
value: 29.378999999999998
|
| 996 |
+
- type: map_at_10
|
| 997 |
+
value: 37.373
|
| 998 |
+
- type: map_at_100
|
| 999 |
+
value: 39.107
|
| 1000 |
+
- type: map_at_1000
|
| 1001 |
+
value: 39.317
|
| 1002 |
+
- type: map_at_3
|
| 1003 |
+
value: 34.563
|
| 1004 |
+
- type: map_at_5
|
| 1005 |
+
value: 36.173
|
| 1006 |
+
- type: mrr_at_1
|
| 1007 |
+
value: 35.178
|
| 1008 |
+
- type: mrr_at_10
|
| 1009 |
+
value: 42.44
|
| 1010 |
+
- type: mrr_at_100
|
| 1011 |
+
value: 43.434
|
| 1012 |
+
- type: mrr_at_1000
|
| 1013 |
+
value: 43.482
|
| 1014 |
+
- type: mrr_at_3
|
| 1015 |
+
value: 39.987
|
| 1016 |
+
- type: mrr_at_5
|
| 1017 |
+
value: 41.370000000000005
|
| 1018 |
+
- type: ndcg_at_1
|
| 1019 |
+
value: 35.178
|
| 1020 |
+
- type: ndcg_at_10
|
| 1021 |
+
value: 42.82
|
| 1022 |
+
- type: ndcg_at_100
|
| 1023 |
+
value: 48.935
|
| 1024 |
+
- type: ndcg_at_1000
|
| 1025 |
+
value: 51.28
|
| 1026 |
+
- type: ndcg_at_3
|
| 1027 |
+
value: 38.562999999999995
|
| 1028 |
+
- type: ndcg_at_5
|
| 1029 |
+
value: 40.687
|
| 1030 |
+
- type: precision_at_1
|
| 1031 |
+
value: 35.178
|
| 1032 |
+
- type: precision_at_10
|
| 1033 |
+
value: 7.945
|
| 1034 |
+
- type: precision_at_100
|
| 1035 |
+
value: 1.524
|
| 1036 |
+
- type: precision_at_1000
|
| 1037 |
+
value: 0.242
|
| 1038 |
+
- type: precision_at_3
|
| 1039 |
+
value: 17.721
|
| 1040 |
+
- type: precision_at_5
|
| 1041 |
+
value: 12.925
|
| 1042 |
+
- type: recall_at_1
|
| 1043 |
+
value: 29.378999999999998
|
| 1044 |
+
- type: recall_at_10
|
| 1045 |
+
value: 52.141999999999996
|
| 1046 |
+
- type: recall_at_100
|
| 1047 |
+
value: 79.49000000000001
|
| 1048 |
+
- type: recall_at_1000
|
| 1049 |
+
value: 93.782
|
| 1050 |
+
- type: recall_at_3
|
| 1051 |
+
value: 39.579
|
| 1052 |
+
- type: recall_at_5
|
| 1053 |
+
value: 45.462
|
| 1054 |
+
- task:
|
| 1055 |
+
type: Retrieval
|
| 1056 |
+
dataset:
|
| 1057 |
+
type: BeIR/cqadupstack
|
| 1058 |
+
name: MTEB CQADupstackWordpressRetrieval
|
| 1059 |
+
config: default
|
| 1060 |
+
split: test
|
| 1061 |
+
revision: None
|
| 1062 |
+
metrics:
|
| 1063 |
+
- type: map_at_1
|
| 1064 |
+
value: 19.814999999999998
|
| 1065 |
+
- type: map_at_10
|
| 1066 |
+
value: 27.383999999999997
|
| 1067 |
+
- type: map_at_100
|
| 1068 |
+
value: 28.483999999999998
|
| 1069 |
+
- type: map_at_1000
|
| 1070 |
+
value: 28.585
|
| 1071 |
+
- type: map_at_3
|
| 1072 |
+
value: 24.807000000000002
|
| 1073 |
+
- type: map_at_5
|
| 1074 |
+
value: 26.485999999999997
|
| 1075 |
+
- type: mrr_at_1
|
| 1076 |
+
value: 21.996
|
| 1077 |
+
- type: mrr_at_10
|
| 1078 |
+
value: 29.584
|
| 1079 |
+
- type: mrr_at_100
|
| 1080 |
+
value: 30.611
|
| 1081 |
+
- type: mrr_at_1000
|
| 1082 |
+
value: 30.684
|
| 1083 |
+
- type: mrr_at_3
|
| 1084 |
+
value: 27.11
|
| 1085 |
+
- type: mrr_at_5
|
| 1086 |
+
value: 28.746
|
| 1087 |
+
- type: ndcg_at_1
|
| 1088 |
+
value: 21.996
|
| 1089 |
+
- type: ndcg_at_10
|
| 1090 |
+
value: 32.024
|
| 1091 |
+
- type: ndcg_at_100
|
| 1092 |
+
value: 37.528
|
| 1093 |
+
- type: ndcg_at_1000
|
| 1094 |
+
value: 40.150999999999996
|
| 1095 |
+
- type: ndcg_at_3
|
| 1096 |
+
value: 27.016000000000002
|
| 1097 |
+
- type: ndcg_at_5
|
| 1098 |
+
value: 29.927999999999997
|
| 1099 |
+
- type: precision_at_1
|
| 1100 |
+
value: 21.996
|
| 1101 |
+
- type: precision_at_10
|
| 1102 |
+
value: 5.102
|
| 1103 |
+
- type: precision_at_100
|
| 1104 |
+
value: 0.856
|
| 1105 |
+
- type: precision_at_1000
|
| 1106 |
+
value: 0.117
|
| 1107 |
+
- type: precision_at_3
|
| 1108 |
+
value: 11.583
|
| 1109 |
+
- type: precision_at_5
|
| 1110 |
+
value: 8.577
|
| 1111 |
+
- type: recall_at_1
|
| 1112 |
+
value: 19.814999999999998
|
| 1113 |
+
- type: recall_at_10
|
| 1114 |
+
value: 44.239
|
| 1115 |
+
- type: recall_at_100
|
| 1116 |
+
value: 69.269
|
| 1117 |
+
- type: recall_at_1000
|
| 1118 |
+
value: 89.216
|
| 1119 |
+
- type: recall_at_3
|
| 1120 |
+
value: 31.102999999999998
|
| 1121 |
+
- type: recall_at_5
|
| 1122 |
+
value: 38.078
|
| 1123 |
+
- task:
|
| 1124 |
+
type: Retrieval
|
| 1125 |
+
dataset:
|
| 1126 |
+
type: climate-fever
|
| 1127 |
+
name: MTEB ClimateFEVER
|
| 1128 |
+
config: default
|
| 1129 |
+
split: test
|
| 1130 |
+
revision: None
|
| 1131 |
+
metrics:
|
| 1132 |
+
- type: map_at_1
|
| 1133 |
+
value: 11.349
|
| 1134 |
+
- type: map_at_10
|
| 1135 |
+
value: 19.436
|
| 1136 |
+
- type: map_at_100
|
| 1137 |
+
value: 21.282999999999998
|
| 1138 |
+
- type: map_at_1000
|
| 1139 |
+
value: 21.479
|
| 1140 |
+
- type: map_at_3
|
| 1141 |
+
value: 15.841
|
| 1142 |
+
- type: map_at_5
|
| 1143 |
+
value: 17.558
|
| 1144 |
+
- type: mrr_at_1
|
| 1145 |
+
value: 25.863000000000003
|
| 1146 |
+
- type: mrr_at_10
|
| 1147 |
+
value: 37.218
|
| 1148 |
+
- type: mrr_at_100
|
| 1149 |
+
value: 38.198
|
| 1150 |
+
- type: mrr_at_1000
|
| 1151 |
+
value: 38.236
|
| 1152 |
+
- type: mrr_at_3
|
| 1153 |
+
value: 33.409
|
| 1154 |
+
- type: mrr_at_5
|
| 1155 |
+
value: 35.602000000000004
|
| 1156 |
+
- type: ndcg_at_1
|
| 1157 |
+
value: 25.863000000000003
|
| 1158 |
+
- type: ndcg_at_10
|
| 1159 |
+
value: 27.953
|
| 1160 |
+
- type: ndcg_at_100
|
| 1161 |
+
value: 35.327
|
| 1162 |
+
- type: ndcg_at_1000
|
| 1163 |
+
value: 38.708999999999996
|
| 1164 |
+
- type: ndcg_at_3
|
| 1165 |
+
value: 21.985
|
| 1166 |
+
- type: ndcg_at_5
|
| 1167 |
+
value: 23.957
|
| 1168 |
+
- type: precision_at_1
|
| 1169 |
+
value: 25.863000000000003
|
| 1170 |
+
- type: precision_at_10
|
| 1171 |
+
value: 8.99
|
| 1172 |
+
- type: precision_at_100
|
| 1173 |
+
value: 1.6889999999999998
|
| 1174 |
+
- type: precision_at_1000
|
| 1175 |
+
value: 0.232
|
| 1176 |
+
- type: precision_at_3
|
| 1177 |
+
value: 16.308
|
| 1178 |
+
- type: precision_at_5
|
| 1179 |
+
value: 12.912
|
| 1180 |
+
- type: recall_at_1
|
| 1181 |
+
value: 11.349
|
| 1182 |
+
- type: recall_at_10
|
| 1183 |
+
value: 34.581
|
| 1184 |
+
- type: recall_at_100
|
| 1185 |
+
value: 60.178
|
| 1186 |
+
- type: recall_at_1000
|
| 1187 |
+
value: 78.88199999999999
|
| 1188 |
+
- type: recall_at_3
|
| 1189 |
+
value: 20.041999999999998
|
| 1190 |
+
- type: recall_at_5
|
| 1191 |
+
value: 25.458
|
| 1192 |
+
- task:
|
| 1193 |
+
type: Retrieval
|
| 1194 |
+
dataset:
|
| 1195 |
+
type: dbpedia-entity
|
| 1196 |
+
name: MTEB DBPedia
|
| 1197 |
+
config: default
|
| 1198 |
+
split: test
|
| 1199 |
+
revision: None
|
| 1200 |
+
metrics:
|
| 1201 |
+
- type: map_at_1
|
| 1202 |
+
value: 7.893
|
| 1203 |
+
- type: map_at_10
|
| 1204 |
+
value: 15.457
|
| 1205 |
+
- type: map_at_100
|
| 1206 |
+
value: 20.905
|
| 1207 |
+
- type: map_at_1000
|
| 1208 |
+
value: 22.116
|
| 1209 |
+
- type: map_at_3
|
| 1210 |
+
value: 11.593
|
| 1211 |
+
- type: map_at_5
|
| 1212 |
+
value: 13.134
|
| 1213 |
+
- type: mrr_at_1
|
| 1214 |
+
value: 57.49999999999999
|
| 1215 |
+
- type: mrr_at_10
|
| 1216 |
+
value: 65.467
|
| 1217 |
+
- type: mrr_at_100
|
| 1218 |
+
value: 66.022
|
| 1219 |
+
- type: mrr_at_1000
|
| 1220 |
+
value: 66.039
|
| 1221 |
+
- type: mrr_at_3
|
| 1222 |
+
value: 63.458000000000006
|
| 1223 |
+
- type: mrr_at_5
|
| 1224 |
+
value: 64.546
|
| 1225 |
+
- type: ndcg_at_1
|
| 1226 |
+
value: 45.875
|
| 1227 |
+
- type: ndcg_at_10
|
| 1228 |
+
value: 33.344
|
| 1229 |
+
- type: ndcg_at_100
|
| 1230 |
+
value: 36.849
|
| 1231 |
+
- type: ndcg_at_1000
|
| 1232 |
+
value: 44.03
|
| 1233 |
+
- type: ndcg_at_3
|
| 1234 |
+
value: 37.504
|
| 1235 |
+
- type: ndcg_at_5
|
| 1236 |
+
value: 34.892
|
| 1237 |
+
- type: precision_at_1
|
| 1238 |
+
value: 57.49999999999999
|
| 1239 |
+
- type: precision_at_10
|
| 1240 |
+
value: 25.95
|
| 1241 |
+
- type: precision_at_100
|
| 1242 |
+
value: 7.89
|
| 1243 |
+
- type: precision_at_1000
|
| 1244 |
+
value: 1.669
|
| 1245 |
+
- type: precision_at_3
|
| 1246 |
+
value: 40.333000000000006
|
| 1247 |
+
- type: precision_at_5
|
| 1248 |
+
value: 33.050000000000004
|
| 1249 |
+
- type: recall_at_1
|
| 1250 |
+
value: 7.893
|
| 1251 |
+
- type: recall_at_10
|
| 1252 |
+
value: 20.724999999999998
|
| 1253 |
+
- type: recall_at_100
|
| 1254 |
+
value: 42.516
|
| 1255 |
+
- type: recall_at_1000
|
| 1256 |
+
value: 65.822
|
| 1257 |
+
- type: recall_at_3
|
| 1258 |
+
value: 12.615000000000002
|
| 1259 |
+
- type: recall_at_5
|
| 1260 |
+
value: 15.482000000000001
|
| 1261 |
+
- task:
|
| 1262 |
+
type: Classification
|
| 1263 |
+
dataset:
|
| 1264 |
+
type: mteb/emotion
|
| 1265 |
+
name: MTEB EmotionClassification
|
| 1266 |
+
config: default
|
| 1267 |
+
split: test
|
| 1268 |
+
revision: 4f58c6b202a23cf9a4da393831edf4f9183cad37
|
| 1269 |
+
metrics:
|
| 1270 |
+
- type: accuracy
|
| 1271 |
+
value: 51.760000000000005
|
| 1272 |
+
- type: f1
|
| 1273 |
+
value: 45.51690565701713
|
| 1274 |
+
- task:
|
| 1275 |
+
type: Retrieval
|
| 1276 |
+
dataset:
|
| 1277 |
+
type: fever
|
| 1278 |
+
name: MTEB FEVER
|
| 1279 |
+
config: default
|
| 1280 |
+
split: test
|
| 1281 |
+
revision: None
|
| 1282 |
+
metrics:
|
| 1283 |
+
- type: map_at_1
|
| 1284 |
+
value: 53.882
|
| 1285 |
+
- type: map_at_10
|
| 1286 |
+
value: 65.902
|
| 1287 |
+
- type: map_at_100
|
| 1288 |
+
value: 66.33
|
| 1289 |
+
- type: map_at_1000
|
| 1290 |
+
value: 66.348
|
| 1291 |
+
- type: map_at_3
|
| 1292 |
+
value: 63.75999999999999
|
| 1293 |
+
- type: map_at_5
|
| 1294 |
+
value: 65.181
|
| 1295 |
+
- type: mrr_at_1
|
| 1296 |
+
value: 58.041
|
| 1297 |
+
- type: mrr_at_10
|
| 1298 |
+
value: 70.133
|
| 1299 |
+
- type: mrr_at_100
|
| 1300 |
+
value: 70.463
|
| 1301 |
+
- type: mrr_at_1000
|
| 1302 |
+
value: 70.47
|
| 1303 |
+
- type: mrr_at_3
|
| 1304 |
+
value: 68.164
|
| 1305 |
+
- type: mrr_at_5
|
| 1306 |
+
value: 69.465
|
| 1307 |
+
- type: ndcg_at_1
|
| 1308 |
+
value: 58.041
|
| 1309 |
+
- type: ndcg_at_10
|
| 1310 |
+
value: 71.84700000000001
|
| 1311 |
+
- type: ndcg_at_100
|
| 1312 |
+
value: 73.699
|
| 1313 |
+
- type: ndcg_at_1000
|
| 1314 |
+
value: 74.06700000000001
|
| 1315 |
+
- type: ndcg_at_3
|
| 1316 |
+
value: 67.855
|
| 1317 |
+
- type: ndcg_at_5
|
| 1318 |
+
value: 70.203
|
| 1319 |
+
- type: precision_at_1
|
| 1320 |
+
value: 58.041
|
| 1321 |
+
- type: precision_at_10
|
| 1322 |
+
value: 9.427000000000001
|
| 1323 |
+
- type: precision_at_100
|
| 1324 |
+
value: 1.049
|
| 1325 |
+
- type: precision_at_1000
|
| 1326 |
+
value: 0.11
|
| 1327 |
+
- type: precision_at_3
|
| 1328 |
+
value: 27.278000000000002
|
| 1329 |
+
- type: precision_at_5
|
| 1330 |
+
value: 17.693
|
| 1331 |
+
- type: recall_at_1
|
| 1332 |
+
value: 53.882
|
| 1333 |
+
- type: recall_at_10
|
| 1334 |
+
value: 85.99
|
| 1335 |
+
- type: recall_at_100
|
| 1336 |
+
value: 94.09100000000001
|
| 1337 |
+
- type: recall_at_1000
|
| 1338 |
+
value: 96.612
|
| 1339 |
+
- type: recall_at_3
|
| 1340 |
+
value: 75.25
|
| 1341 |
+
- type: recall_at_5
|
| 1342 |
+
value: 80.997
|
| 1343 |
+
- task:
|
| 1344 |
+
type: Retrieval
|
| 1345 |
+
dataset:
|
| 1346 |
+
type: fiqa
|
| 1347 |
+
name: MTEB FiQA2018
|
| 1348 |
+
config: default
|
| 1349 |
+
split: test
|
| 1350 |
+
revision: None
|
| 1351 |
+
metrics:
|
| 1352 |
+
- type: map_at_1
|
| 1353 |
+
value: 19.165
|
| 1354 |
+
- type: map_at_10
|
| 1355 |
+
value: 31.845000000000002
|
| 1356 |
+
- type: map_at_100
|
| 1357 |
+
value: 33.678999999999995
|
| 1358 |
+
- type: map_at_1000
|
| 1359 |
+
value: 33.878
|
| 1360 |
+
- type: map_at_3
|
| 1361 |
+
value: 27.881
|
| 1362 |
+
- type: map_at_5
|
| 1363 |
+
value: 30.049999999999997
|
| 1364 |
+
- type: mrr_at_1
|
| 1365 |
+
value: 38.272
|
| 1366 |
+
- type: mrr_at_10
|
| 1367 |
+
value: 47.04
|
| 1368 |
+
- type: mrr_at_100
|
| 1369 |
+
value: 47.923
|
| 1370 |
+
- type: mrr_at_1000
|
| 1371 |
+
value: 47.973
|
| 1372 |
+
- type: mrr_at_3
|
| 1373 |
+
value: 44.985
|
| 1374 |
+
- type: mrr_at_5
|
| 1375 |
+
value: 46.150000000000006
|
| 1376 |
+
- type: ndcg_at_1
|
| 1377 |
+
value: 38.272
|
| 1378 |
+
- type: ndcg_at_10
|
| 1379 |
+
value: 39.177
|
| 1380 |
+
- type: ndcg_at_100
|
| 1381 |
+
value: 45.995000000000005
|
| 1382 |
+
- type: ndcg_at_1000
|
| 1383 |
+
value: 49.312
|
| 1384 |
+
- type: ndcg_at_3
|
| 1385 |
+
value: 36.135
|
| 1386 |
+
- type: ndcg_at_5
|
| 1387 |
+
value: 36.936
|
| 1388 |
+
- type: precision_at_1
|
| 1389 |
+
value: 38.272
|
| 1390 |
+
- type: precision_at_10
|
| 1391 |
+
value: 10.926
|
| 1392 |
+
- type: precision_at_100
|
| 1393 |
+
value: 1.809
|
| 1394 |
+
- type: precision_at_1000
|
| 1395 |
+
value: 0.23700000000000002
|
| 1396 |
+
- type: precision_at_3
|
| 1397 |
+
value: 24.331
|
| 1398 |
+
- type: precision_at_5
|
| 1399 |
+
value: 17.747
|
| 1400 |
+
- type: recall_at_1
|
| 1401 |
+
value: 19.165
|
| 1402 |
+
- type: recall_at_10
|
| 1403 |
+
value: 45.103
|
| 1404 |
+
- type: recall_at_100
|
| 1405 |
+
value: 70.295
|
| 1406 |
+
- type: recall_at_1000
|
| 1407 |
+
value: 90.592
|
| 1408 |
+
- type: recall_at_3
|
| 1409 |
+
value: 32.832
|
| 1410 |
+
- type: recall_at_5
|
| 1411 |
+
value: 37.905
|
| 1412 |
+
- task:
|
| 1413 |
+
type: Retrieval
|
| 1414 |
+
dataset:
|
| 1415 |
+
type: hotpotqa
|
| 1416 |
+
name: MTEB HotpotQA
|
| 1417 |
+
config: default
|
| 1418 |
+
split: test
|
| 1419 |
+
revision: None
|
| 1420 |
+
metrics:
|
| 1421 |
+
- type: map_at_1
|
| 1422 |
+
value: 32.397
|
| 1423 |
+
- type: map_at_10
|
| 1424 |
+
value: 44.83
|
| 1425 |
+
- type: map_at_100
|
| 1426 |
+
value: 45.716
|
| 1427 |
+
- type: map_at_1000
|
| 1428 |
+
value: 45.797
|
| 1429 |
+
- type: map_at_3
|
| 1430 |
+
value: 41.955999999999996
|
| 1431 |
+
- type: map_at_5
|
| 1432 |
+
value: 43.736999999999995
|
| 1433 |
+
- type: mrr_at_1
|
| 1434 |
+
value: 64.794
|
| 1435 |
+
- type: mrr_at_10
|
| 1436 |
+
value: 71.866
|
| 1437 |
+
- type: mrr_at_100
|
| 1438 |
+
value: 72.22
|
| 1439 |
+
- type: mrr_at_1000
|
| 1440 |
+
value: 72.238
|
| 1441 |
+
- type: mrr_at_3
|
| 1442 |
+
value: 70.416
|
| 1443 |
+
- type: mrr_at_5
|
| 1444 |
+
value: 71.304
|
| 1445 |
+
- type: ndcg_at_1
|
| 1446 |
+
value: 64.794
|
| 1447 |
+
- type: ndcg_at_10
|
| 1448 |
+
value: 54.186
|
| 1449 |
+
- type: ndcg_at_100
|
| 1450 |
+
value: 57.623000000000005
|
| 1451 |
+
- type: ndcg_at_1000
|
| 1452 |
+
value: 59.302
|
| 1453 |
+
- type: ndcg_at_3
|
| 1454 |
+
value: 49.703
|
| 1455 |
+
- type: ndcg_at_5
|
| 1456 |
+
value: 52.154999999999994
|
| 1457 |
+
- type: precision_at_1
|
| 1458 |
+
value: 64.794
|
| 1459 |
+
- type: precision_at_10
|
| 1460 |
+
value: 11.219
|
| 1461 |
+
- type: precision_at_100
|
| 1462 |
+
value: 1.394
|
| 1463 |
+
- type: precision_at_1000
|
| 1464 |
+
value: 0.16199999999999998
|
| 1465 |
+
- type: precision_at_3
|
| 1466 |
+
value: 30.767
|
| 1467 |
+
- type: precision_at_5
|
| 1468 |
+
value: 20.397000000000002
|
| 1469 |
+
- type: recall_at_1
|
| 1470 |
+
value: 32.397
|
| 1471 |
+
- type: recall_at_10
|
| 1472 |
+
value: 56.096999999999994
|
| 1473 |
+
- type: recall_at_100
|
| 1474 |
+
value: 69.696
|
| 1475 |
+
- type: recall_at_1000
|
| 1476 |
+
value: 80.88499999999999
|
| 1477 |
+
- type: recall_at_3
|
| 1478 |
+
value: 46.150999999999996
|
| 1479 |
+
- type: recall_at_5
|
| 1480 |
+
value: 50.993
|
| 1481 |
+
- task:
|
| 1482 |
+
type: Classification
|
| 1483 |
+
dataset:
|
| 1484 |
+
type: mteb/imdb
|
| 1485 |
+
name: MTEB ImdbClassification
|
| 1486 |
+
config: default
|
| 1487 |
+
split: test
|
| 1488 |
+
revision: 3d86128a09e091d6018b6d26cad27f2739fc2db7
|
| 1489 |
+
metrics:
|
| 1490 |
+
- type: accuracy
|
| 1491 |
+
value: 81.1744
|
| 1492 |
+
- type: ap
|
| 1493 |
+
value: 75.44973697032414
|
| 1494 |
+
- type: f1
|
| 1495 |
+
value: 81.09901117955782
|
| 1496 |
+
- task:
|
| 1497 |
+
type: Retrieval
|
| 1498 |
+
dataset:
|
| 1499 |
+
type: msmarco
|
| 1500 |
+
name: MTEB MSMARCO
|
| 1501 |
+
config: default
|
| 1502 |
+
split: dev
|
| 1503 |
+
revision: None
|
| 1504 |
+
metrics:
|
| 1505 |
+
- type: map_at_1
|
| 1506 |
+
value: 19.519000000000002
|
| 1507 |
+
- type: map_at_10
|
| 1508 |
+
value: 31.025000000000002
|
| 1509 |
+
- type: map_at_100
|
| 1510 |
+
value: 32.275999999999996
|
| 1511 |
+
- type: map_at_1000
|
| 1512 |
+
value: 32.329
|
| 1513 |
+
- type: map_at_3
|
| 1514 |
+
value: 27.132
|
| 1515 |
+
- type: map_at_5
|
| 1516 |
+
value: 29.415999999999997
|
| 1517 |
+
- type: mrr_at_1
|
| 1518 |
+
value: 20.115
|
| 1519 |
+
- type: mrr_at_10
|
| 1520 |
+
value: 31.569000000000003
|
| 1521 |
+
- type: mrr_at_100
|
| 1522 |
+
value: 32.768
|
| 1523 |
+
- type: mrr_at_1000
|
| 1524 |
+
value: 32.816
|
| 1525 |
+
- type: mrr_at_3
|
| 1526 |
+
value: 27.748
|
| 1527 |
+
- type: mrr_at_5
|
| 1528 |
+
value: 29.956
|
| 1529 |
+
- type: ndcg_at_1
|
| 1530 |
+
value: 20.115
|
| 1531 |
+
- type: ndcg_at_10
|
| 1532 |
+
value: 37.756
|
| 1533 |
+
- type: ndcg_at_100
|
| 1534 |
+
value: 43.858000000000004
|
| 1535 |
+
- type: ndcg_at_1000
|
| 1536 |
+
value: 45.199
|
| 1537 |
+
- type: ndcg_at_3
|
| 1538 |
+
value: 29.818
|
| 1539 |
+
- type: ndcg_at_5
|
| 1540 |
+
value: 33.875
|
| 1541 |
+
- type: precision_at_1
|
| 1542 |
+
value: 20.115
|
| 1543 |
+
- type: precision_at_10
|
| 1544 |
+
value: 6.122
|
| 1545 |
+
- type: precision_at_100
|
| 1546 |
+
value: 0.919
|
| 1547 |
+
- type: precision_at_1000
|
| 1548 |
+
value: 0.10300000000000001
|
| 1549 |
+
- type: precision_at_3
|
| 1550 |
+
value: 12.794
|
| 1551 |
+
- type: precision_at_5
|
| 1552 |
+
value: 9.731
|
| 1553 |
+
- type: recall_at_1
|
| 1554 |
+
value: 19.519000000000002
|
| 1555 |
+
- type: recall_at_10
|
| 1556 |
+
value: 58.62500000000001
|
| 1557 |
+
- type: recall_at_100
|
| 1558 |
+
value: 86.99
|
| 1559 |
+
- type: recall_at_1000
|
| 1560 |
+
value: 97.268
|
| 1561 |
+
- type: recall_at_3
|
| 1562 |
+
value: 37.002
|
| 1563 |
+
- type: recall_at_5
|
| 1564 |
+
value: 46.778
|
| 1565 |
+
- task:
|
| 1566 |
+
type: Classification
|
| 1567 |
+
dataset:
|
| 1568 |
+
type: mteb/mtop_domain
|
| 1569 |
+
name: MTEB MTOPDomainClassification (en)
|
| 1570 |
+
config: en
|
| 1571 |
+
split: test
|
| 1572 |
+
revision: d80d48c1eb48d3562165c59d59d0034df9fff0bf
|
| 1573 |
+
metrics:
|
| 1574 |
+
- type: accuracy
|
| 1575 |
+
value: 93.71865025079799
|
| 1576 |
+
- type: f1
|
| 1577 |
+
value: 93.38906173610519
|
| 1578 |
+
- task:
|
| 1579 |
+
type: Classification
|
| 1580 |
+
dataset:
|
| 1581 |
+
type: mteb/mtop_intent
|
| 1582 |
+
name: MTEB MTOPIntentClassification (en)
|
| 1583 |
+
config: en
|
| 1584 |
+
split: test
|
| 1585 |
+
revision: ae001d0e6b1228650b7bd1c2c65fb50ad11a8aba
|
| 1586 |
+
metrics:
|
| 1587 |
+
- type: accuracy
|
| 1588 |
+
value: 70.2576379388965
|
| 1589 |
+
- type: f1
|
| 1590 |
+
value: 49.20405830249464
|
| 1591 |
+
- task:
|
| 1592 |
+
type: Classification
|
| 1593 |
+
dataset:
|
| 1594 |
+
type: mteb/amazon_massive_intent
|
| 1595 |
+
name: MTEB MassiveIntentClassification (en)
|
| 1596 |
+
config: en
|
| 1597 |
+
split: test
|
| 1598 |
+
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
|
| 1599 |
+
metrics:
|
| 1600 |
+
- type: accuracy
|
| 1601 |
+
value: 67.48486886348351
|
| 1602 |
+
- type: f1
|
| 1603 |
+
value: 64.92199176095157
|
| 1604 |
+
- task:
|
| 1605 |
+
type: Classification
|
| 1606 |
+
dataset:
|
| 1607 |
+
type: mteb/amazon_massive_scenario
|
| 1608 |
+
name: MTEB MassiveScenarioClassification (en)
|
| 1609 |
+
config: en
|
| 1610 |
+
split: test
|
| 1611 |
+
revision: 7d571f92784cd94a019292a1f45445077d0ef634
|
| 1612 |
+
metrics:
|
| 1613 |
+
- type: accuracy
|
| 1614 |
+
value: 72.59246805648958
|
| 1615 |
+
- type: f1
|
| 1616 |
+
value: 72.1222026389164
|
| 1617 |
+
- task:
|
| 1618 |
+
type: Clustering
|
| 1619 |
+
dataset:
|
| 1620 |
+
type: mteb/medrxiv-clustering-p2p
|
| 1621 |
+
name: MTEB MedrxivClusteringP2P
|
| 1622 |
+
config: default
|
| 1623 |
+
split: test
|
| 1624 |
+
revision: e7a26af6f3ae46b30dde8737f02c07b1505bcc73
|
| 1625 |
+
metrics:
|
| 1626 |
+
- type: v_measure
|
| 1627 |
+
value: 30.887642595096825
|
| 1628 |
+
- task:
|
| 1629 |
+
type: Clustering
|
| 1630 |
+
dataset:
|
| 1631 |
+
type: mteb/medrxiv-clustering-s2s
|
| 1632 |
+
name: MTEB MedrxivClusteringS2S
|
| 1633 |
+
config: default
|
| 1634 |
+
split: test
|
| 1635 |
+
revision: 35191c8c0dca72d8ff3efcd72aa802307d469663
|
| 1636 |
+
metrics:
|
| 1637 |
+
- type: v_measure
|
| 1638 |
+
value: 28.3764418784054
|
| 1639 |
+
- task:
|
| 1640 |
+
type: Reranking
|
| 1641 |
+
dataset:
|
| 1642 |
+
type: mteb/mind_small
|
| 1643 |
+
name: MTEB MindSmallReranking
|
| 1644 |
+
config: default
|
| 1645 |
+
split: test
|
| 1646 |
+
revision: 3bdac13927fdc888b903db93b2ffdbd90b295a69
|
| 1647 |
+
metrics:
|
| 1648 |
+
- type: map
|
| 1649 |
+
value: 31.81544126336991
|
| 1650 |
+
- type: mrr
|
| 1651 |
+
value: 32.82666576268031
|
| 1652 |
+
- task:
|
| 1653 |
+
type: Retrieval
|
| 1654 |
+
dataset:
|
| 1655 |
+
type: nfcorpus
|
| 1656 |
+
name: MTEB NFCorpus
|
| 1657 |
+
config: default
|
| 1658 |
+
split: test
|
| 1659 |
+
revision: None
|
| 1660 |
+
metrics:
|
| 1661 |
+
- type: map_at_1
|
| 1662 |
+
value: 5.185
|
| 1663 |
+
- type: map_at_10
|
| 1664 |
+
value: 11.158
|
| 1665 |
+
- type: map_at_100
|
| 1666 |
+
value: 14.041
|
| 1667 |
+
- type: map_at_1000
|
| 1668 |
+
value: 15.360999999999999
|
| 1669 |
+
- type: map_at_3
|
| 1670 |
+
value: 8.417
|
| 1671 |
+
- type: map_at_5
|
| 1672 |
+
value: 9.378
|
| 1673 |
+
- type: mrr_at_1
|
| 1674 |
+
value: 44.582
|
| 1675 |
+
- type: mrr_at_10
|
| 1676 |
+
value: 53.083999999999996
|
| 1677 |
+
- type: mrr_at_100
|
| 1678 |
+
value: 53.787
|
| 1679 |
+
- type: mrr_at_1000
|
| 1680 |
+
value: 53.824000000000005
|
| 1681 |
+
- type: mrr_at_3
|
| 1682 |
+
value: 51.187000000000005
|
| 1683 |
+
- type: mrr_at_5
|
| 1684 |
+
value: 52.379
|
| 1685 |
+
- type: ndcg_at_1
|
| 1686 |
+
value: 42.57
|
| 1687 |
+
- type: ndcg_at_10
|
| 1688 |
+
value: 31.593
|
| 1689 |
+
- type: ndcg_at_100
|
| 1690 |
+
value: 29.093999999999998
|
| 1691 |
+
- type: ndcg_at_1000
|
| 1692 |
+
value: 37.909
|
| 1693 |
+
- type: ndcg_at_3
|
| 1694 |
+
value: 37.083
|
| 1695 |
+
- type: ndcg_at_5
|
| 1696 |
+
value: 34.397
|
| 1697 |
+
- type: precision_at_1
|
| 1698 |
+
value: 43.963
|
| 1699 |
+
- type: precision_at_10
|
| 1700 |
+
value: 23.498
|
| 1701 |
+
- type: precision_at_100
|
| 1702 |
+
value: 7.6160000000000005
|
| 1703 |
+
- type: precision_at_1000
|
| 1704 |
+
value: 2.032
|
| 1705 |
+
- type: precision_at_3
|
| 1706 |
+
value: 34.572
|
| 1707 |
+
- type: precision_at_5
|
| 1708 |
+
value: 29.412
|
| 1709 |
+
- type: recall_at_1
|
| 1710 |
+
value: 5.185
|
| 1711 |
+
- type: recall_at_10
|
| 1712 |
+
value: 15.234
|
| 1713 |
+
- type: recall_at_100
|
| 1714 |
+
value: 29.49
|
| 1715 |
+
- type: recall_at_1000
|
| 1716 |
+
value: 62.273999999999994
|
| 1717 |
+
- type: recall_at_3
|
| 1718 |
+
value: 9.55
|
| 1719 |
+
- type: recall_at_5
|
| 1720 |
+
value: 11.103
|
| 1721 |
+
- task:
|
| 1722 |
+
type: Retrieval
|
| 1723 |
+
dataset:
|
| 1724 |
+
type: nq
|
| 1725 |
+
name: MTEB NQ
|
| 1726 |
+
config: default
|
| 1727 |
+
split: test
|
| 1728 |
+
revision: None
|
| 1729 |
+
metrics:
|
| 1730 |
+
- type: map_at_1
|
| 1731 |
+
value: 23.803
|
| 1732 |
+
- type: map_at_10
|
| 1733 |
+
value: 38.183
|
| 1734 |
+
- type: map_at_100
|
| 1735 |
+
value: 39.421
|
| 1736 |
+
- type: map_at_1000
|
| 1737 |
+
value: 39.464
|
| 1738 |
+
- type: map_at_3
|
| 1739 |
+
value: 33.835
|
| 1740 |
+
- type: map_at_5
|
| 1741 |
+
value: 36.327
|
| 1742 |
+
- type: mrr_at_1
|
| 1743 |
+
value: 26.68
|
| 1744 |
+
- type: mrr_at_10
|
| 1745 |
+
value: 40.439
|
| 1746 |
+
- type: mrr_at_100
|
| 1747 |
+
value: 41.415
|
| 1748 |
+
- type: mrr_at_1000
|
| 1749 |
+
value: 41.443999999999996
|
| 1750 |
+
- type: mrr_at_3
|
| 1751 |
+
value: 36.612
|
| 1752 |
+
- type: mrr_at_5
|
| 1753 |
+
value: 38.877
|
| 1754 |
+
- type: ndcg_at_1
|
| 1755 |
+
value: 26.68
|
| 1756 |
+
- type: ndcg_at_10
|
| 1757 |
+
value: 45.882
|
| 1758 |
+
- type: ndcg_at_100
|
| 1759 |
+
value: 51.227999999999994
|
| 1760 |
+
- type: ndcg_at_1000
|
| 1761 |
+
value: 52.207
|
| 1762 |
+
- type: ndcg_at_3
|
| 1763 |
+
value: 37.511
|
| 1764 |
+
- type: ndcg_at_5
|
| 1765 |
+
value: 41.749
|
| 1766 |
+
- type: precision_at_1
|
| 1767 |
+
value: 26.68
|
| 1768 |
+
- type: precision_at_10
|
| 1769 |
+
value: 7.9750000000000005
|
| 1770 |
+
- type: precision_at_100
|
| 1771 |
+
value: 1.0959999999999999
|
| 1772 |
+
- type: precision_at_1000
|
| 1773 |
+
value: 0.11900000000000001
|
| 1774 |
+
- type: precision_at_3
|
| 1775 |
+
value: 17.449
|
| 1776 |
+
- type: precision_at_5
|
| 1777 |
+
value: 12.897
|
| 1778 |
+
- type: recall_at_1
|
| 1779 |
+
value: 23.803
|
| 1780 |
+
- type: recall_at_10
|
| 1781 |
+
value: 67.152
|
| 1782 |
+
- type: recall_at_100
|
| 1783 |
+
value: 90.522
|
| 1784 |
+
- type: recall_at_1000
|
| 1785 |
+
value: 97.743
|
| 1786 |
+
- type: recall_at_3
|
| 1787 |
+
value: 45.338
|
| 1788 |
+
- type: recall_at_5
|
| 1789 |
+
value: 55.106
|
| 1790 |
+
- task:
|
| 1791 |
+
type: Retrieval
|
| 1792 |
+
dataset:
|
| 1793 |
+
type: quora
|
| 1794 |
+
name: MTEB QuoraRetrieval
|
| 1795 |
+
config: default
|
| 1796 |
+
split: test
|
| 1797 |
+
revision: None
|
| 1798 |
+
metrics:
|
| 1799 |
+
- type: map_at_1
|
| 1800 |
+
value: 70.473
|
| 1801 |
+
- type: map_at_10
|
| 1802 |
+
value: 84.452
|
| 1803 |
+
- type: map_at_100
|
| 1804 |
+
value: 85.101
|
| 1805 |
+
- type: map_at_1000
|
| 1806 |
+
value: 85.115
|
| 1807 |
+
- type: map_at_3
|
| 1808 |
+
value: 81.435
|
| 1809 |
+
- type: map_at_5
|
| 1810 |
+
value: 83.338
|
| 1811 |
+
- type: mrr_at_1
|
| 1812 |
+
value: 81.19
|
| 1813 |
+
- type: mrr_at_10
|
| 1814 |
+
value: 87.324
|
| 1815 |
+
- type: mrr_at_100
|
| 1816 |
+
value: 87.434
|
| 1817 |
+
- type: mrr_at_1000
|
| 1818 |
+
value: 87.435
|
| 1819 |
+
- type: mrr_at_3
|
| 1820 |
+
value: 86.31
|
| 1821 |
+
- type: mrr_at_5
|
| 1822 |
+
value: 87.002
|
| 1823 |
+
- type: ndcg_at_1
|
| 1824 |
+
value: 81.21000000000001
|
| 1825 |
+
- type: ndcg_at_10
|
| 1826 |
+
value: 88.19
|
| 1827 |
+
- type: ndcg_at_100
|
| 1828 |
+
value: 89.44
|
| 1829 |
+
- type: ndcg_at_1000
|
| 1830 |
+
value: 89.526
|
| 1831 |
+
- type: ndcg_at_3
|
| 1832 |
+
value: 85.237
|
| 1833 |
+
- type: ndcg_at_5
|
| 1834 |
+
value: 86.892
|
| 1835 |
+
- type: precision_at_1
|
| 1836 |
+
value: 81.21000000000001
|
| 1837 |
+
- type: precision_at_10
|
| 1838 |
+
value: 13.417000000000002
|
| 1839 |
+
- type: precision_at_100
|
| 1840 |
+
value: 1.537
|
| 1841 |
+
- type: precision_at_1000
|
| 1842 |
+
value: 0.157
|
| 1843 |
+
- type: precision_at_3
|
| 1844 |
+
value: 37.31
|
| 1845 |
+
- type: precision_at_5
|
| 1846 |
+
value: 24.59
|
| 1847 |
+
- type: recall_at_1
|
| 1848 |
+
value: 70.473
|
| 1849 |
+
- type: recall_at_10
|
| 1850 |
+
value: 95.367
|
| 1851 |
+
- type: recall_at_100
|
| 1852 |
+
value: 99.616
|
| 1853 |
+
- type: recall_at_1000
|
| 1854 |
+
value: 99.996
|
| 1855 |
+
- type: recall_at_3
|
| 1856 |
+
value: 86.936
|
| 1857 |
+
- type: recall_at_5
|
| 1858 |
+
value: 91.557
|
| 1859 |
+
- task:
|
| 1860 |
+
type: Clustering
|
| 1861 |
+
dataset:
|
| 1862 |
+
type: mteb/reddit-clustering
|
| 1863 |
+
name: MTEB RedditClustering
|
| 1864 |
+
config: default
|
| 1865 |
+
split: test
|
| 1866 |
+
revision: 24640382cdbf8abc73003fb0fa6d111a705499eb
|
| 1867 |
+
metrics:
|
| 1868 |
+
- type: v_measure
|
| 1869 |
+
value: 59.25776525253911
|
| 1870 |
+
- task:
|
| 1871 |
+
type: Clustering
|
| 1872 |
+
dataset:
|
| 1873 |
+
type: mteb/reddit-clustering-p2p
|
| 1874 |
+
name: MTEB RedditClusteringP2P
|
| 1875 |
+
config: default
|
| 1876 |
+
split: test
|
| 1877 |
+
revision: 282350215ef01743dc01b456c7f5241fa8937f16
|
| 1878 |
+
metrics:
|
| 1879 |
+
- type: v_measure
|
| 1880 |
+
value: 63.22135271663078
|
| 1881 |
+
- task:
|
| 1882 |
+
type: Retrieval
|
| 1883 |
+
dataset:
|
| 1884 |
+
type: scidocs
|
| 1885 |
+
name: MTEB SCIDOCS
|
| 1886 |
+
config: default
|
| 1887 |
+
split: test
|
| 1888 |
+
revision: None
|
| 1889 |
+
metrics:
|
| 1890 |
+
- type: map_at_1
|
| 1891 |
+
value: 4.003
|
| 1892 |
+
- type: map_at_10
|
| 1893 |
+
value: 10.062999999999999
|
| 1894 |
+
- type: map_at_100
|
| 1895 |
+
value: 11.854000000000001
|
| 1896 |
+
- type: map_at_1000
|
| 1897 |
+
value: 12.145999999999999
|
| 1898 |
+
- type: map_at_3
|
| 1899 |
+
value: 7.242
|
| 1900 |
+
- type: map_at_5
|
| 1901 |
+
value: 8.652999999999999
|
| 1902 |
+
- type: mrr_at_1
|
| 1903 |
+
value: 19.7
|
| 1904 |
+
- type: mrr_at_10
|
| 1905 |
+
value: 29.721999999999998
|
| 1906 |
+
- type: mrr_at_100
|
| 1907 |
+
value: 30.867
|
| 1908 |
+
- type: mrr_at_1000
|
| 1909 |
+
value: 30.944
|
| 1910 |
+
- type: mrr_at_3
|
| 1911 |
+
value: 26.683
|
| 1912 |
+
- type: mrr_at_5
|
| 1913 |
+
value: 28.498
|
| 1914 |
+
- type: ndcg_at_1
|
| 1915 |
+
value: 19.7
|
| 1916 |
+
- type: ndcg_at_10
|
| 1917 |
+
value: 17.095
|
| 1918 |
+
- type: ndcg_at_100
|
| 1919 |
+
value: 24.375
|
| 1920 |
+
- type: ndcg_at_1000
|
| 1921 |
+
value: 29.831000000000003
|
| 1922 |
+
- type: ndcg_at_3
|
| 1923 |
+
value: 16.305
|
| 1924 |
+
- type: ndcg_at_5
|
| 1925 |
+
value: 14.291
|
| 1926 |
+
- type: precision_at_1
|
| 1927 |
+
value: 19.7
|
| 1928 |
+
- type: precision_at_10
|
| 1929 |
+
value: 8.799999999999999
|
| 1930 |
+
- type: precision_at_100
|
| 1931 |
+
value: 1.9349999999999998
|
| 1932 |
+
- type: precision_at_1000
|
| 1933 |
+
value: 0.32399999999999995
|
| 1934 |
+
- type: precision_at_3
|
| 1935 |
+
value: 15.2
|
| 1936 |
+
- type: precision_at_5
|
| 1937 |
+
value: 12.540000000000001
|
| 1938 |
+
- type: recall_at_1
|
| 1939 |
+
value: 4.003
|
| 1940 |
+
- type: recall_at_10
|
| 1941 |
+
value: 17.877000000000002
|
| 1942 |
+
- type: recall_at_100
|
| 1943 |
+
value: 39.217
|
| 1944 |
+
- type: recall_at_1000
|
| 1945 |
+
value: 65.862
|
| 1946 |
+
- type: recall_at_3
|
| 1947 |
+
value: 9.242
|
| 1948 |
+
- type: recall_at_5
|
| 1949 |
+
value: 12.715000000000002
|
| 1950 |
+
- task:
|
| 1951 |
+
type: STS
|
| 1952 |
+
dataset:
|
| 1953 |
+
type: mteb/sickr-sts
|
| 1954 |
+
name: MTEB SICK-R
|
| 1955 |
+
config: default
|
| 1956 |
+
split: test
|
| 1957 |
+
revision: a6ea5a8cab320b040a23452cc28066d9beae2cee
|
| 1958 |
+
metrics:
|
| 1959 |
+
- type: cos_sim_spearman
|
| 1960 |
+
value: 80.25888668589654
|
| 1961 |
+
- task:
|
| 1962 |
+
type: STS
|
| 1963 |
+
dataset:
|
| 1964 |
+
type: mteb/sts12-sts
|
| 1965 |
+
name: MTEB STS12
|
| 1966 |
+
config: default
|
| 1967 |
+
split: test
|
| 1968 |
+
revision: a0d554a64d88156834ff5ae9920b964011b16384
|
| 1969 |
+
metrics:
|
| 1970 |
+
- type: cos_sim_spearman
|
| 1971 |
+
value: 77.02037527837669
|
| 1972 |
+
- task:
|
| 1973 |
+
type: STS
|
| 1974 |
+
dataset:
|
| 1975 |
+
type: mteb/sts13-sts
|
| 1976 |
+
name: MTEB STS13
|
| 1977 |
+
config: default
|
| 1978 |
+
split: test
|
| 1979 |
+
revision: 7e90230a92c190f1bf69ae9002b8cea547a64cca
|
| 1980 |
+
metrics:
|
| 1981 |
+
- type: cos_sim_spearman
|
| 1982 |
+
value: 86.58432681008449
|
| 1983 |
+
- task:
|
| 1984 |
+
type: STS
|
| 1985 |
+
dataset:
|
| 1986 |
+
type: mteb/sts14-sts
|
| 1987 |
+
name: MTEB STS14
|
| 1988 |
+
config: default
|
| 1989 |
+
split: test
|
| 1990 |
+
revision: 6031580fec1f6af667f0bd2da0a551cf4f0b2375
|
| 1991 |
+
metrics:
|
| 1992 |
+
- type: cos_sim_spearman
|
| 1993 |
+
value: 81.31697756099051
|
| 1994 |
+
- task:
|
| 1995 |
+
type: STS
|
| 1996 |
+
dataset:
|
| 1997 |
+
type: mteb/sts15-sts
|
| 1998 |
+
name: MTEB STS15
|
| 1999 |
+
config: default
|
| 2000 |
+
split: test
|
| 2001 |
+
revision: ae752c7c21bf194d8b67fd573edf7ae58183cbe3
|
| 2002 |
+
metrics:
|
| 2003 |
+
- type: cos_sim_spearman
|
| 2004 |
+
value: 88.18867599667057
|
| 2005 |
+
- task:
|
| 2006 |
+
type: STS
|
| 2007 |
+
dataset:
|
| 2008 |
+
type: mteb/sts16-sts
|
| 2009 |
+
name: MTEB STS16
|
| 2010 |
+
config: default
|
| 2011 |
+
split: test
|
| 2012 |
+
revision: 4d8694f8f0e0100860b497b999b3dbed754a0513
|
| 2013 |
+
metrics:
|
| 2014 |
+
- type: cos_sim_spearman
|
| 2015 |
+
value: 84.87853941747623
|
| 2016 |
+
- task:
|
| 2017 |
+
type: STS
|
| 2018 |
+
dataset:
|
| 2019 |
+
type: mteb/sts17-crosslingual-sts
|
| 2020 |
+
name: MTEB STS17 (en-en)
|
| 2021 |
+
config: en-en
|
| 2022 |
+
split: test
|
| 2023 |
+
revision: af5e6fb845001ecf41f4c1e033ce921939a2a68d
|
| 2024 |
+
metrics:
|
| 2025 |
+
- type: cos_sim_spearman
|
| 2026 |
+
value: 89.46479925383916
|
| 2027 |
+
- task:
|
| 2028 |
+
type: STS
|
| 2029 |
+
dataset:
|
| 2030 |
+
type: mteb/sts22-crosslingual-sts
|
| 2031 |
+
name: MTEB STS22 (en)
|
| 2032 |
+
config: en
|
| 2033 |
+
split: test
|
| 2034 |
+
revision: 6d1ba47164174a496b7fa5d3569dae26a6813b80
|
| 2035 |
+
metrics:
|
| 2036 |
+
- type: cos_sim_spearman
|
| 2037 |
+
value: 66.45272113649146
|
| 2038 |
+
- task:
|
| 2039 |
+
type: STS
|
| 2040 |
+
dataset:
|
| 2041 |
+
type: mteb/stsbenchmark-sts
|
| 2042 |
+
name: MTEB STSBenchmark
|
| 2043 |
+
config: default
|
| 2044 |
+
split: test
|
| 2045 |
+
revision: b0fddb56ed78048fa8b90373c8a3cfc37b684831
|
| 2046 |
+
metrics:
|
| 2047 |
+
- type: cos_sim_spearman
|
| 2048 |
+
value: 86.43357313527851
|
| 2049 |
+
- task:
|
| 2050 |
+
type: Reranking
|
| 2051 |
+
dataset:
|
| 2052 |
+
type: mteb/scidocs-reranking
|
| 2053 |
+
name: MTEB SciDocsRR
|
| 2054 |
+
config: default
|
| 2055 |
+
split: test
|
| 2056 |
+
revision: d3c5e1fc0b855ab6097bf1cda04dd73947d7caab
|
| 2057 |
+
metrics:
|
| 2058 |
+
- type: map
|
| 2059 |
+
value: 78.82761687254882
|
| 2060 |
+
- type: mrr
|
| 2061 |
+
value: 93.46223674655047
|
| 2062 |
+
- task:
|
| 2063 |
+
type: Retrieval
|
| 2064 |
+
dataset:
|
| 2065 |
+
type: scifact
|
| 2066 |
+
name: MTEB SciFact
|
| 2067 |
+
config: default
|
| 2068 |
+
split: test
|
| 2069 |
+
revision: None
|
| 2070 |
+
metrics:
|
| 2071 |
+
- type: map_at_1
|
| 2072 |
+
value: 44.583
|
| 2073 |
+
- type: map_at_10
|
| 2074 |
+
value: 52.978
|
| 2075 |
+
- type: map_at_100
|
| 2076 |
+
value: 53.803
|
| 2077 |
+
- type: map_at_1000
|
| 2078 |
+
value: 53.839999999999996
|
| 2079 |
+
- type: map_at_3
|
| 2080 |
+
value: 50.03300000000001
|
| 2081 |
+
- type: map_at_5
|
| 2082 |
+
value: 51.939
|
| 2083 |
+
- type: mrr_at_1
|
| 2084 |
+
value: 47.0
|
| 2085 |
+
- type: mrr_at_10
|
| 2086 |
+
value: 54.730000000000004
|
| 2087 |
+
- type: mrr_at_100
|
| 2088 |
+
value: 55.31399999999999
|
| 2089 |
+
- type: mrr_at_1000
|
| 2090 |
+
value: 55.346
|
| 2091 |
+
- type: mrr_at_3
|
| 2092 |
+
value: 52.0
|
| 2093 |
+
- type: mrr_at_5
|
| 2094 |
+
value: 53.783
|
| 2095 |
+
- type: ndcg_at_1
|
| 2096 |
+
value: 47.0
|
| 2097 |
+
- type: ndcg_at_10
|
| 2098 |
+
value: 57.82899999999999
|
| 2099 |
+
- type: ndcg_at_100
|
| 2100 |
+
value: 61.49400000000001
|
| 2101 |
+
- type: ndcg_at_1000
|
| 2102 |
+
value: 62.676
|
| 2103 |
+
- type: ndcg_at_3
|
| 2104 |
+
value: 52.373000000000005
|
| 2105 |
+
- type: ndcg_at_5
|
| 2106 |
+
value: 55.481
|
| 2107 |
+
- type: precision_at_1
|
| 2108 |
+
value: 47.0
|
| 2109 |
+
- type: precision_at_10
|
| 2110 |
+
value: 7.867
|
| 2111 |
+
- type: precision_at_100
|
| 2112 |
+
value: 0.997
|
| 2113 |
+
- type: precision_at_1000
|
| 2114 |
+
value: 0.11
|
| 2115 |
+
- type: precision_at_3
|
| 2116 |
+
value: 20.556
|
| 2117 |
+
- type: precision_at_5
|
| 2118 |
+
value: 14.066999999999998
|
| 2119 |
+
- type: recall_at_1
|
| 2120 |
+
value: 44.583
|
| 2121 |
+
- type: recall_at_10
|
| 2122 |
+
value: 71.172
|
| 2123 |
+
- type: recall_at_100
|
| 2124 |
+
value: 87.7
|
| 2125 |
+
- type: recall_at_1000
|
| 2126 |
+
value: 97.333
|
| 2127 |
+
- type: recall_at_3
|
| 2128 |
+
value: 56.511
|
| 2129 |
+
- type: recall_at_5
|
| 2130 |
+
value: 64.206
|
| 2131 |
+
- task:
|
| 2132 |
+
type: PairClassification
|
| 2133 |
+
dataset:
|
| 2134 |
+
type: mteb/sprintduplicatequestions-pairclassification
|
| 2135 |
+
name: MTEB SprintDuplicateQuestions
|
| 2136 |
+
config: default
|
| 2137 |
+
split: test
|
| 2138 |
+
revision: d66bd1f72af766a5cc4b0ca5e00c162f89e8cc46
|
| 2139 |
+
metrics:
|
| 2140 |
+
- type: cos_sim_accuracy
|
| 2141 |
+
value: 99.66237623762376
|
| 2142 |
+
- type: cos_sim_ap
|
| 2143 |
+
value: 90.35465126226322
|
| 2144 |
+
- type: cos_sim_f1
|
| 2145 |
+
value: 82.44575936883628
|
| 2146 |
+
- type: cos_sim_precision
|
| 2147 |
+
value: 81.32295719844358
|
| 2148 |
+
- type: cos_sim_recall
|
| 2149 |
+
value: 83.6
|
| 2150 |
+
- type: dot_accuracy
|
| 2151 |
+
value: 99.66237623762376
|
| 2152 |
+
- type: dot_ap
|
| 2153 |
+
value: 90.35464287920453
|
| 2154 |
+
- type: dot_f1
|
| 2155 |
+
value: 82.44575936883628
|
| 2156 |
+
- type: dot_precision
|
| 2157 |
+
value: 81.32295719844358
|
| 2158 |
+
- type: dot_recall
|
| 2159 |
+
value: 83.6
|
| 2160 |
+
- type: euclidean_accuracy
|
| 2161 |
+
value: 99.66237623762376
|
| 2162 |
+
- type: euclidean_ap
|
| 2163 |
+
value: 90.3546512622632
|
| 2164 |
+
- type: euclidean_f1
|
| 2165 |
+
value: 82.44575936883628
|
| 2166 |
+
- type: euclidean_precision
|
| 2167 |
+
value: 81.32295719844358
|
| 2168 |
+
- type: euclidean_recall
|
| 2169 |
+
value: 83.6
|
| 2170 |
+
- type: manhattan_accuracy
|
| 2171 |
+
value: 99.65940594059406
|
| 2172 |
+
- type: manhattan_ap
|
| 2173 |
+
value: 90.29220174849843
|
| 2174 |
+
- type: manhattan_f1
|
| 2175 |
+
value: 82.4987605354487
|
| 2176 |
+
- type: manhattan_precision
|
| 2177 |
+
value: 81.80924287118977
|
| 2178 |
+
- type: manhattan_recall
|
| 2179 |
+
value: 83.2
|
| 2180 |
+
- type: max_accuracy
|
| 2181 |
+
value: 99.66237623762376
|
| 2182 |
+
- type: max_ap
|
| 2183 |
+
value: 90.35465126226322
|
| 2184 |
+
- type: max_f1
|
| 2185 |
+
value: 82.4987605354487
|
| 2186 |
+
- task:
|
| 2187 |
+
type: Clustering
|
| 2188 |
+
dataset:
|
| 2189 |
+
type: mteb/stackexchange-clustering
|
| 2190 |
+
name: MTEB StackExchangeClustering
|
| 2191 |
+
config: default
|
| 2192 |
+
split: test
|
| 2193 |
+
revision: 6cbc1f7b2bc0622f2e39d2c77fa502909748c259
|
| 2194 |
+
metrics:
|
| 2195 |
+
- type: v_measure
|
| 2196 |
+
value: 65.0394225901397
|
| 2197 |
+
- task:
|
| 2198 |
+
type: Clustering
|
| 2199 |
+
dataset:
|
| 2200 |
+
type: mteb/stackexchange-clustering-p2p
|
| 2201 |
+
name: MTEB StackExchangeClusteringP2P
|
| 2202 |
+
config: default
|
| 2203 |
+
split: test
|
| 2204 |
+
revision: 815ca46b2622cec33ccafc3735d572c266efdb44
|
| 2205 |
+
metrics:
|
| 2206 |
+
- type: v_measure
|
| 2207 |
+
value: 35.27954189859326
|
| 2208 |
+
- task:
|
| 2209 |
+
type: Reranking
|
| 2210 |
+
dataset:
|
| 2211 |
+
type: mteb/stackoverflowdupquestions-reranking
|
| 2212 |
+
name: MTEB StackOverflowDupQuestions
|
| 2213 |
+
config: default
|
| 2214 |
+
split: test
|
| 2215 |
+
revision: e185fbe320c72810689fc5848eb6114e1ef5ec69
|
| 2216 |
+
metrics:
|
| 2217 |
+
- type: map
|
| 2218 |
+
value: 50.99055979974896
|
| 2219 |
+
- type: mrr
|
| 2220 |
+
value: 51.82745257193787
|
| 2221 |
+
- task:
|
| 2222 |
+
type: Summarization
|
| 2223 |
+
dataset:
|
| 2224 |
+
type: mteb/summeval
|
| 2225 |
+
name: MTEB SummEval
|
| 2226 |
+
config: default
|
| 2227 |
+
split: test
|
| 2228 |
+
revision: cda12ad7615edc362dbf25a00fdd61d3b1eaf93c
|
| 2229 |
+
metrics:
|
| 2230 |
+
- type: cos_sim_pearson
|
| 2231 |
+
value: 30.21655465344237
|
| 2232 |
+
- type: cos_sim_spearman
|
| 2233 |
+
value: 29.853205339630172
|
| 2234 |
+
- type: dot_pearson
|
| 2235 |
+
value: 30.216540628083564
|
| 2236 |
+
- type: dot_spearman
|
| 2237 |
+
value: 29.868978894753027
|
| 2238 |
+
- task:
|
| 2239 |
+
type: Retrieval
|
| 2240 |
+
dataset:
|
| 2241 |
+
type: trec-covid
|
| 2242 |
+
name: MTEB TRECCOVID
|
| 2243 |
+
config: default
|
| 2244 |
+
split: test
|
| 2245 |
+
revision: None
|
| 2246 |
+
metrics:
|
| 2247 |
+
- type: map_at_1
|
| 2248 |
+
value: 0.2
|
| 2249 |
+
- type: map_at_10
|
| 2250 |
+
value: 1.398
|
| 2251 |
+
- type: map_at_100
|
| 2252 |
+
value: 7.406
|
| 2253 |
+
- type: map_at_1000
|
| 2254 |
+
value: 18.401
|
| 2255 |
+
- type: map_at_3
|
| 2256 |
+
value: 0.479
|
| 2257 |
+
- type: map_at_5
|
| 2258 |
+
value: 0.772
|
| 2259 |
+
- type: mrr_at_1
|
| 2260 |
+
value: 70.0
|
| 2261 |
+
- type: mrr_at_10
|
| 2262 |
+
value: 79.25999999999999
|
| 2263 |
+
- type: mrr_at_100
|
| 2264 |
+
value: 79.25999999999999
|
| 2265 |
+
- type: mrr_at_1000
|
| 2266 |
+
value: 79.25999999999999
|
| 2267 |
+
- type: mrr_at_3
|
| 2268 |
+
value: 77.333
|
| 2269 |
+
- type: mrr_at_5
|
| 2270 |
+
value: 78.133
|
| 2271 |
+
- type: ndcg_at_1
|
| 2272 |
+
value: 63.0
|
| 2273 |
+
- type: ndcg_at_10
|
| 2274 |
+
value: 58.548
|
| 2275 |
+
- type: ndcg_at_100
|
| 2276 |
+
value: 45.216
|
| 2277 |
+
- type: ndcg_at_1000
|
| 2278 |
+
value: 41.149
|
| 2279 |
+
- type: ndcg_at_3
|
| 2280 |
+
value: 60.641999999999996
|
| 2281 |
+
- type: ndcg_at_5
|
| 2282 |
+
value: 61.135
|
| 2283 |
+
- type: precision_at_1
|
| 2284 |
+
value: 70.0
|
| 2285 |
+
- type: precision_at_10
|
| 2286 |
+
value: 64.0
|
| 2287 |
+
- type: precision_at_100
|
| 2288 |
+
value: 46.92
|
| 2289 |
+
- type: precision_at_1000
|
| 2290 |
+
value: 18.642
|
| 2291 |
+
- type: precision_at_3
|
| 2292 |
+
value: 64.667
|
| 2293 |
+
- type: precision_at_5
|
| 2294 |
+
value: 66.4
|
| 2295 |
+
- type: recall_at_1
|
| 2296 |
+
value: 0.2
|
| 2297 |
+
- type: recall_at_10
|
| 2298 |
+
value: 1.6729999999999998
|
| 2299 |
+
- type: recall_at_100
|
| 2300 |
+
value: 10.856
|
| 2301 |
+
- type: recall_at_1000
|
| 2302 |
+
value: 38.964999999999996
|
| 2303 |
+
- type: recall_at_3
|
| 2304 |
+
value: 0.504
|
| 2305 |
+
- type: recall_at_5
|
| 2306 |
+
value: 0.852
|
| 2307 |
+
- task:
|
| 2308 |
+
type: Retrieval
|
| 2309 |
+
dataset:
|
| 2310 |
+
type: webis-touche2020
|
| 2311 |
+
name: MTEB Touche2020
|
| 2312 |
+
config: default
|
| 2313 |
+
split: test
|
| 2314 |
+
revision: None
|
| 2315 |
+
metrics:
|
| 2316 |
+
- type: map_at_1
|
| 2317 |
+
value: 1.6629999999999998
|
| 2318 |
+
- type: map_at_10
|
| 2319 |
+
value: 8.601
|
| 2320 |
+
- type: map_at_100
|
| 2321 |
+
value: 14.354
|
| 2322 |
+
- type: map_at_1000
|
| 2323 |
+
value: 15.927
|
| 2324 |
+
- type: map_at_3
|
| 2325 |
+
value: 4.1930000000000005
|
| 2326 |
+
- type: map_at_5
|
| 2327 |
+
value: 5.655
|
| 2328 |
+
- type: mrr_at_1
|
| 2329 |
+
value: 18.367
|
| 2330 |
+
- type: mrr_at_10
|
| 2331 |
+
value: 34.466
|
| 2332 |
+
- type: mrr_at_100
|
| 2333 |
+
value: 35.235
|
| 2334 |
+
- type: mrr_at_1000
|
| 2335 |
+
value: 35.27
|
| 2336 |
+
- type: mrr_at_3
|
| 2337 |
+
value: 28.571
|
| 2338 |
+
- type: mrr_at_5
|
| 2339 |
+
value: 31.531
|
| 2340 |
+
- type: ndcg_at_1
|
| 2341 |
+
value: 14.285999999999998
|
| 2342 |
+
- type: ndcg_at_10
|
| 2343 |
+
value: 20.374
|
| 2344 |
+
- type: ndcg_at_100
|
| 2345 |
+
value: 33.532000000000004
|
| 2346 |
+
- type: ndcg_at_1000
|
| 2347 |
+
value: 45.561
|
| 2348 |
+
- type: ndcg_at_3
|
| 2349 |
+
value: 18.442
|
| 2350 |
+
- type: ndcg_at_5
|
| 2351 |
+
value: 18.076
|
| 2352 |
+
- type: precision_at_1
|
| 2353 |
+
value: 18.367
|
| 2354 |
+
- type: precision_at_10
|
| 2355 |
+
value: 20.204
|
| 2356 |
+
- type: precision_at_100
|
| 2357 |
+
value: 7.489999999999999
|
| 2358 |
+
- type: precision_at_1000
|
| 2359 |
+
value: 1.5630000000000002
|
| 2360 |
+
- type: precision_at_3
|
| 2361 |
+
value: 21.769
|
| 2362 |
+
- type: precision_at_5
|
| 2363 |
+
value: 20.408
|
| 2364 |
+
- type: recall_at_1
|
| 2365 |
+
value: 1.6629999999999998
|
| 2366 |
+
- type: recall_at_10
|
| 2367 |
+
value: 15.549
|
| 2368 |
+
- type: recall_at_100
|
| 2369 |
+
value: 47.497
|
| 2370 |
+
- type: recall_at_1000
|
| 2371 |
+
value: 84.524
|
| 2372 |
+
- type: recall_at_3
|
| 2373 |
+
value: 5.289
|
| 2374 |
+
- type: recall_at_5
|
| 2375 |
+
value: 8.035
|
| 2376 |
+
- task:
|
| 2377 |
+
type: Classification
|
| 2378 |
+
dataset:
|
| 2379 |
+
type: mteb/toxic_conversations_50k
|
| 2380 |
+
name: MTEB ToxicConversationsClassification
|
| 2381 |
+
config: default
|
| 2382 |
+
split: test
|
| 2383 |
+
revision: d7c0de2777da35d6aae2200a62c6e0e5af397c4c
|
| 2384 |
+
metrics:
|
| 2385 |
+
- type: accuracy
|
| 2386 |
+
value: 71.8194
|
| 2387 |
+
- type: ap
|
| 2388 |
+
value: 14.447702451658554
|
| 2389 |
+
- type: f1
|
| 2390 |
+
value: 55.13659412856185
|
| 2391 |
+
- task:
|
| 2392 |
+
type: Classification
|
| 2393 |
+
dataset:
|
| 2394 |
+
type: mteb/tweet_sentiment_extraction
|
| 2395 |
+
name: MTEB TweetSentimentExtractionClassification
|
| 2396 |
+
config: default
|
| 2397 |
+
split: test
|
| 2398 |
+
revision: d604517c81ca91fe16a244d1248fc021f9ecee7a
|
| 2399 |
+
metrics:
|
| 2400 |
+
- type: accuracy
|
| 2401 |
+
value: 63.310696095076416
|
| 2402 |
+
- type: f1
|
| 2403 |
+
value: 63.360434851097814
|
| 2404 |
+
- task:
|
| 2405 |
+
type: Clustering
|
| 2406 |
+
dataset:
|
| 2407 |
+
type: mteb/twentynewsgroups-clustering
|
| 2408 |
+
name: MTEB TwentyNewsgroupsClustering
|
| 2409 |
+
config: default
|
| 2410 |
+
split: test
|
| 2411 |
+
revision: 6125ec4e24fa026cec8a478383ee943acfbd5449
|
| 2412 |
+
metrics:
|
| 2413 |
+
- type: v_measure
|
| 2414 |
+
value: 51.30677907335145
|
| 2415 |
+
- task:
|
| 2416 |
+
type: PairClassification
|
| 2417 |
+
dataset:
|
| 2418 |
+
type: mteb/twittersemeval2015-pairclassification
|
| 2419 |
+
name: MTEB TwitterSemEval2015
|
| 2420 |
+
config: default
|
| 2421 |
+
split: test
|
| 2422 |
+
revision: 70970daeab8776df92f5ea462b6173c0b46fd2d1
|
| 2423 |
+
metrics:
|
| 2424 |
+
- type: cos_sim_accuracy
|
| 2425 |
+
value: 86.12386004649221
|
| 2426 |
+
- type: cos_sim_ap
|
| 2427 |
+
value: 73.99096426215495
|
| 2428 |
+
- type: cos_sim_f1
|
| 2429 |
+
value: 68.18416968442834
|
| 2430 |
+
- type: cos_sim_precision
|
| 2431 |
+
value: 66.86960933536275
|
| 2432 |
+
- type: cos_sim_recall
|
| 2433 |
+
value: 69.55145118733509
|
| 2434 |
+
- type: dot_accuracy
|
| 2435 |
+
value: 86.12386004649221
|
| 2436 |
+
- type: dot_ap
|
| 2437 |
+
value: 73.99096813038672
|
| 2438 |
+
- type: dot_f1
|
| 2439 |
+
value: 68.18416968442834
|
| 2440 |
+
- type: dot_precision
|
| 2441 |
+
value: 66.86960933536275
|
| 2442 |
+
- type: dot_recall
|
| 2443 |
+
value: 69.55145118733509
|
| 2444 |
+
- type: euclidean_accuracy
|
| 2445 |
+
value: 86.12386004649221
|
| 2446 |
+
- type: euclidean_ap
|
| 2447 |
+
value: 73.99095984980165
|
| 2448 |
+
- type: euclidean_f1
|
| 2449 |
+
value: 68.18416968442834
|
| 2450 |
+
- type: euclidean_precision
|
| 2451 |
+
value: 66.86960933536275
|
| 2452 |
+
- type: euclidean_recall
|
| 2453 |
+
value: 69.55145118733509
|
| 2454 |
+
- type: manhattan_accuracy
|
| 2455 |
+
value: 86.09405734040651
|
| 2456 |
+
- type: manhattan_ap
|
| 2457 |
+
value: 73.96825745608601
|
| 2458 |
+
- type: manhattan_f1
|
| 2459 |
+
value: 68.13888179729383
|
| 2460 |
+
- type: manhattan_precision
|
| 2461 |
+
value: 65.99901088031652
|
| 2462 |
+
- type: manhattan_recall
|
| 2463 |
+
value: 70.42216358839049
|
| 2464 |
+
- type: max_accuracy
|
| 2465 |
+
value: 86.12386004649221
|
| 2466 |
+
- type: max_ap
|
| 2467 |
+
value: 73.99096813038672
|
| 2468 |
+
- type: max_f1
|
| 2469 |
+
value: 68.18416968442834
|
| 2470 |
+
- task:
|
| 2471 |
+
type: PairClassification
|
| 2472 |
+
dataset:
|
| 2473 |
+
type: mteb/twitterurlcorpus-pairclassification
|
| 2474 |
+
name: MTEB TwitterURLCorpus
|
| 2475 |
+
config: default
|
| 2476 |
+
split: test
|
| 2477 |
+
revision: 8b6510b0b1fa4e4c4f879467980e9be563ec1cdf
|
| 2478 |
+
metrics:
|
| 2479 |
+
- type: cos_sim_accuracy
|
| 2480 |
+
value: 88.99367407924865
|
| 2481 |
+
- type: cos_sim_ap
|
| 2482 |
+
value: 86.19720829843081
|
| 2483 |
+
- type: cos_sim_f1
|
| 2484 |
+
value: 78.39889075384951
|
| 2485 |
+
- type: cos_sim_precision
|
| 2486 |
+
value: 74.5110278818144
|
| 2487 |
+
- type: cos_sim_recall
|
| 2488 |
+
value: 82.71481367416075
|
| 2489 |
+
- type: dot_accuracy
|
| 2490 |
+
value: 88.99367407924865
|
| 2491 |
+
- type: dot_ap
|
| 2492 |
+
value: 86.19718471454047
|
| 2493 |
+
- type: dot_f1
|
| 2494 |
+
value: 78.39889075384951
|
| 2495 |
+
- type: dot_precision
|
| 2496 |
+
value: 74.5110278818144
|
| 2497 |
+
- type: dot_recall
|
| 2498 |
+
value: 82.71481367416075
|
| 2499 |
+
- type: euclidean_accuracy
|
| 2500 |
+
value: 88.99367407924865
|
| 2501 |
+
- type: euclidean_ap
|
| 2502 |
+
value: 86.1972021422436
|
| 2503 |
+
- type: euclidean_f1
|
| 2504 |
+
value: 78.39889075384951
|
| 2505 |
+
- type: euclidean_precision
|
| 2506 |
+
value: 74.5110278818144
|
| 2507 |
+
- type: euclidean_recall
|
| 2508 |
+
value: 82.71481367416075
|
| 2509 |
+
- type: manhattan_accuracy
|
| 2510 |
+
value: 88.95680521597392
|
| 2511 |
+
- type: manhattan_ap
|
| 2512 |
+
value: 86.16659921351506
|
| 2513 |
+
- type: manhattan_f1
|
| 2514 |
+
value: 78.39125971550081
|
| 2515 |
+
- type: manhattan_precision
|
| 2516 |
+
value: 74.82502799552073
|
| 2517 |
+
- type: manhattan_recall
|
| 2518 |
+
value: 82.31444410224823
|
| 2519 |
+
- type: max_accuracy
|
| 2520 |
+
value: 88.99367407924865
|
| 2521 |
+
- type: max_ap
|
| 2522 |
+
value: 86.19720829843081
|
| 2523 |
+
- type: max_f1
|
| 2524 |
+
value: 78.39889075384951
|
| 2525 |
+
---
|
| 2526 |
+
|
| 2527 |
+
# hkunlp/instructor-base
|
| 2528 |
+
We introduce **Instructor**👨🏫, an instruction-finetuned text embedding model that can generate text embeddings tailored to any task (e.g., classification, retrieval, clustering, text evaluation, etc.) and domains (e.g., science, finance, etc.) ***by simply providing the task instruction, without any finetuning***. Instructor👨 achieves sota on 70 diverse embedding tasks!
|
| 2529 |
+
The model is easy to use with **our customized** `sentence-transformer` library. For more details, check out [our paper](https://arxiv.org/abs/2212.09741) and [project page](https://instructor-embedding.github.io/)!
|
| 2530 |
+
|
| 2531 |
+
**************************** **Updates** ****************************
|
| 2532 |
+
|
| 2533 |
+
* 01/21: We released a new [checkpoint](https://huggingface.co/hkunlp/instructor-base) trained with hard negatives, which gives better performance.
|
| 2534 |
+
* 12/21: We released our [paper](https://arxiv.org/abs/2212.09741), [code](https://github.com/HKUNLP/instructor-embedding), [checkpoint](https://huggingface.co/hkunlp/instructor-base) and [project page](https://instructor-embedding.github.io/)! Check them out!
|
| 2535 |
+
|
| 2536 |
+
## Quick start
|
| 2537 |
+
<hr />
|
| 2538 |
+
|
| 2539 |
+
## Installation
|
| 2540 |
+
```bash
|
| 2541 |
+
pip install InstructorEmbedding
|
| 2542 |
+
```
|
| 2543 |
+
|
| 2544 |
+
## Compute your customized embeddings
|
| 2545 |
+
Then you can use the model like this to calculate domain-specific and task-aware embeddings:
|
| 2546 |
+
```python
|
| 2547 |
+
from InstructorEmbedding import INSTRUCTOR
|
| 2548 |
+
model = INSTRUCTOR('hkunlp/instructor-base')
|
| 2549 |
+
sentence = "3D ActionSLAM: wearable person tracking in multi-floor environments"
|
| 2550 |
+
instruction = "Represent the Science title:"
|
| 2551 |
+
embeddings = model.encode([[instruction,sentence]])
|
| 2552 |
+
print(embeddings)
|
| 2553 |
+
```
|
| 2554 |
+
|
| 2555 |
+
## Use cases
|
| 2556 |
+
<hr />
|
| 2557 |
+
|
| 2558 |
+
## Calculate embeddings for your customized texts
|
| 2559 |
+
If you want to calculate customized embeddings for specific sentences, you may follow the unified template to write instructions:
|
| 2560 |
+
|
| 2561 |
+
Represent the `domain` `text_type` for `task_objective`:
|
| 2562 |
+
* `domain` is optional, and it specifies the domain of the text, e.g., science, finance, medicine, etc.
|
| 2563 |
+
* `text_type` is required, and it specifies the encoding unit, e.g., sentence, document, paragraph, etc.
|
| 2564 |
+
* `task_objective` is optional, and it specifies the objective of embedding, e.g., retrieve a document, classify the sentence, etc.
|
| 2565 |
+
|
| 2566 |
+
## Calculate Sentence similarities
|
| 2567 |
+
You can further use the model to compute similarities between two groups of sentences, with **customized embeddings**.
|
| 2568 |
+
```python
|
| 2569 |
+
from sklearn.metrics.pairwise import cosine_similarity
|
| 2570 |
+
sentences_a = [['Represent the Science sentence: ','Parton energy loss in QCD matter'],
|
| 2571 |
+
['Represent the Financial statement: ','The Federal Reserve on Wednesday raised its benchmark interest rate.']]
|
| 2572 |
+
sentences_b = [['Represent the Science sentence: ','The Chiral Phase Transition in Dissipative Dynamics'],
|
| 2573 |
+
['Represent the Financial statement: ','The funds rose less than 0.5 per cent on Friday']]
|
| 2574 |
+
embeddings_a = model.encode(sentences_a)
|
| 2575 |
+
embeddings_b = model.encode(sentences_b)
|
| 2576 |
+
similarities = cosine_similarity(embeddings_a,embeddings_b)
|
| 2577 |
+
print(similarities)
|
| 2578 |
+
```
|
| 2579 |
+
|
| 2580 |
+
## Information Retrieval
|
| 2581 |
+
You can also use **customized embeddings** for information retrieval.
|
| 2582 |
+
```python
|
| 2583 |
+
import numpy as np
|
| 2584 |
+
from sklearn.metrics.pairwise import cosine_similarity
|
| 2585 |
+
query = [['Represent the Wikipedia question for retrieving supporting documents: ','where is the food stored in a yam plant']]
|
| 2586 |
+
corpus = [['Represent the Wikipedia document for retrieval: ','Capitalism has been dominant in the Western world since the end of feudalism, but most feel[who?] that the term "mixed economies" more precisely describes most contemporary economies, due to their containing both private-owned and state-owned enterprises. In capitalism, prices determine the demand-supply scale. For example, higher demand for certain goods and services lead to higher prices and lower demand for certain goods lead to lower prices.'],
|
| 2587 |
+
['Represent the Wikipedia document for retrieval: ',"The disparate impact theory is especially controversial under the Fair Housing Act because the Act regulates many activities relating to housing, insurance, and mortgage loans—and some scholars have argued that the theory's use under the Fair Housing Act, combined with extensions of the Community Reinvestment Act, contributed to rise of sub-prime lending and the crash of the U.S. housing market and ensuing global economic recession"],
|
| 2588 |
+
['Represent the Wikipedia document for retrieval: ','Disparate impact in United States labor law refers to practices in employment, housing, and other areas that adversely affect one group of people of a protected characteristic more than another, even though rules applied by employers or landlords are formally neutral. Although the protected classes vary by statute, most federal civil rights laws protect based on race, color, religion, national origin, and sex as protected traits, and some laws include disability status and other traits as well.']]
|
| 2589 |
+
query_embeddings = model.encode(query)
|
| 2590 |
+
corpus_embeddings = model.encode(corpus)
|
| 2591 |
+
similarities = cosine_similarity(query_embeddings,corpus_embeddings)
|
| 2592 |
+
retrieved_doc_id = np.argmax(similarities)
|
| 2593 |
+
print(retrieved_doc_id)
|
| 2594 |
+
```
|
| 2595 |
+
|
| 2596 |
+
## Clustering
|
| 2597 |
+
Use **customized embeddings** for clustering texts in groups.
|
| 2598 |
+
```python
|
| 2599 |
+
import sklearn.cluster
|
| 2600 |
+
sentences = [['Represent the Medicine sentence for clustering: ','Dynamical Scalar Degree of Freedom in Horava-Lifshitz Gravity'],
|
| 2601 |
+
['Represent the Medicine sentence for clustering: ','Comparison of Atmospheric Neutrino Flux Calculations at Low Energies'],
|
| 2602 |
+
['Represent the Medicine sentence for clustering: ','Fermion Bags in the Massive Gross-Neveu Model'],
|
| 2603 |
+
['Represent the Medicine sentence for clustering: ',"QCD corrections to Associated t-tbar-H production at the Tevatron"],
|
| 2604 |
+
['Represent the Medicine sentence for clustering: ','A New Analysis of the R Measurements: Resonance Parameters of the Higher, Vector States of Charmonium']]
|
| 2605 |
+
embeddings = model.encode(sentences)
|
| 2606 |
+
clustering_model = sklearn.cluster.MiniBatchKMeans(n_clusters=2)
|
| 2607 |
+
clustering_model.fit(embeddings)
|
| 2608 |
+
cluster_assignment = clustering_model.labels_
|
| 2609 |
+
print(cluster_assignment)
|
| 2610 |
+
```
|
models/hkunlp_instructor-base/config.json
ADDED
|
@@ -0,0 +1,60 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"_name_or_path": "/scratch/acd14245px/metatrain_models/enhanced_large/0103_base_fever_40000/checkpoint-200/",
|
| 3 |
+
"architectures": [
|
| 4 |
+
"T5EncoderModel"
|
| 5 |
+
],
|
| 6 |
+
"d_ff": 3072,
|
| 7 |
+
"d_kv": 64,
|
| 8 |
+
"d_model": 768,
|
| 9 |
+
"decoder_start_token_id": 0,
|
| 10 |
+
"dense_act_fn": "relu",
|
| 11 |
+
"dropout_rate": 0.1,
|
| 12 |
+
"eos_token_id": 1,
|
| 13 |
+
"feed_forward_proj": "relu",
|
| 14 |
+
"initializer_factor": 1.0,
|
| 15 |
+
"is_encoder_decoder": true,
|
| 16 |
+
"is_gated_act": false,
|
| 17 |
+
"layer_norm_epsilon": 1e-06,
|
| 18 |
+
"model_type": "t5",
|
| 19 |
+
"n_positions": 512,
|
| 20 |
+
"num_decoder_layers": 12,
|
| 21 |
+
"num_heads": 12,
|
| 22 |
+
"num_layers": 12,
|
| 23 |
+
"output_past": true,
|
| 24 |
+
"pad_token_id": 0,
|
| 25 |
+
"relative_attention_max_distance": 128,
|
| 26 |
+
"relative_attention_num_buckets": 32,
|
| 27 |
+
"task_specific_params": {
|
| 28 |
+
"summarization": {
|
| 29 |
+
"early_stopping": true,
|
| 30 |
+
"length_penalty": 2.0,
|
| 31 |
+
"max_length": 200,
|
| 32 |
+
"min_length": 30,
|
| 33 |
+
"no_repeat_ngram_size": 3,
|
| 34 |
+
"num_beams": 4,
|
| 35 |
+
"prefix": "summarize: "
|
| 36 |
+
},
|
| 37 |
+
"translation_en_to_de": {
|
| 38 |
+
"early_stopping": true,
|
| 39 |
+
"max_length": 300,
|
| 40 |
+
"num_beams": 4,
|
| 41 |
+
"prefix": "translate English to German: "
|
| 42 |
+
},
|
| 43 |
+
"translation_en_to_fr": {
|
| 44 |
+
"early_stopping": true,
|
| 45 |
+
"max_length": 300,
|
| 46 |
+
"num_beams": 4,
|
| 47 |
+
"prefix": "translate English to French: "
|
| 48 |
+
},
|
| 49 |
+
"translation_en_to_ro": {
|
| 50 |
+
"early_stopping": true,
|
| 51 |
+
"max_length": 300,
|
| 52 |
+
"num_beams": 4,
|
| 53 |
+
"prefix": "translate English to Romanian: "
|
| 54 |
+
}
|
| 55 |
+
},
|
| 56 |
+
"torch_dtype": "float32",
|
| 57 |
+
"transformers_version": "4.20.0.dev0",
|
| 58 |
+
"use_cache": true,
|
| 59 |
+
"vocab_size": 32128
|
| 60 |
+
}
|
models/hkunlp_instructor-base/config_sentence_transformers.json
ADDED
|
@@ -0,0 +1,7 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"__version__": {
|
| 3 |
+
"sentence_transformers": "2.2.0",
|
| 4 |
+
"transformers": "4.7.0",
|
| 5 |
+
"pytorch": "1.9.0+cu102"
|
| 6 |
+
}
|
| 7 |
+
}
|
models/hkunlp_instructor-base/modules.json
ADDED
|
@@ -0,0 +1,26 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
[
|
| 2 |
+
{
|
| 3 |
+
"idx": 0,
|
| 4 |
+
"name": "0",
|
| 5 |
+
"path": "",
|
| 6 |
+
"type": "sentence_transformers.models.Transformer"
|
| 7 |
+
},
|
| 8 |
+
{
|
| 9 |
+
"idx": 1,
|
| 10 |
+
"name": "1",
|
| 11 |
+
"path": "1_Pooling",
|
| 12 |
+
"type": "sentence_transformers.models.Pooling"
|
| 13 |
+
},
|
| 14 |
+
{
|
| 15 |
+
"idx": 2,
|
| 16 |
+
"name": "2",
|
| 17 |
+
"path": "2_Dense",
|
| 18 |
+
"type": "sentence_transformers.models.Dense"
|
| 19 |
+
},
|
| 20 |
+
{
|
| 21 |
+
"idx": 3,
|
| 22 |
+
"name": "3",
|
| 23 |
+
"path": "3_Normalize",
|
| 24 |
+
"type": "sentence_transformers.models.Normalize"
|
| 25 |
+
}
|
| 26 |
+
]
|
models/hkunlp_instructor-base/pytorch_model.bin
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:cbb27fdef368c06ce639fd65d301e8488e7be742eb6ac1ff6177d1de853c08a8
|
| 3 |
+
size 438546812
|
models/hkunlp_instructor-base/sentence_bert_config.json
ADDED
|
@@ -0,0 +1,4 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"max_seq_length": 512,
|
| 3 |
+
"do_lower_case": false
|
| 4 |
+
}
|
models/hkunlp_instructor-base/special_tokens_map.json
ADDED
|
@@ -0,0 +1,107 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"additional_special_tokens": [
|
| 3 |
+
"<extra_id_0>",
|
| 4 |
+
"<extra_id_1>",
|
| 5 |
+
"<extra_id_2>",
|
| 6 |
+
"<extra_id_3>",
|
| 7 |
+
"<extra_id_4>",
|
| 8 |
+
"<extra_id_5>",
|
| 9 |
+
"<extra_id_6>",
|
| 10 |
+
"<extra_id_7>",
|
| 11 |
+
"<extra_id_8>",
|
| 12 |
+
"<extra_id_9>",
|
| 13 |
+
"<extra_id_10>",
|
| 14 |
+
"<extra_id_11>",
|
| 15 |
+
"<extra_id_12>",
|
| 16 |
+
"<extra_id_13>",
|
| 17 |
+
"<extra_id_14>",
|
| 18 |
+
"<extra_id_15>",
|
| 19 |
+
"<extra_id_16>",
|
| 20 |
+
"<extra_id_17>",
|
| 21 |
+
"<extra_id_18>",
|
| 22 |
+
"<extra_id_19>",
|
| 23 |
+
"<extra_id_20>",
|
| 24 |
+
"<extra_id_21>",
|
| 25 |
+
"<extra_id_22>",
|
| 26 |
+
"<extra_id_23>",
|
| 27 |
+
"<extra_id_24>",
|
| 28 |
+
"<extra_id_25>",
|
| 29 |
+
"<extra_id_26>",
|
| 30 |
+
"<extra_id_27>",
|
| 31 |
+
"<extra_id_28>",
|
| 32 |
+
"<extra_id_29>",
|
| 33 |
+
"<extra_id_30>",
|
| 34 |
+
"<extra_id_31>",
|
| 35 |
+
"<extra_id_32>",
|
| 36 |
+
"<extra_id_33>",
|
| 37 |
+
"<extra_id_34>",
|
| 38 |
+
"<extra_id_35>",
|
| 39 |
+
"<extra_id_36>",
|
| 40 |
+
"<extra_id_37>",
|
| 41 |
+
"<extra_id_38>",
|
| 42 |
+
"<extra_id_39>",
|
| 43 |
+
"<extra_id_40>",
|
| 44 |
+
"<extra_id_41>",
|
| 45 |
+
"<extra_id_42>",
|
| 46 |
+
"<extra_id_43>",
|
| 47 |
+
"<extra_id_44>",
|
| 48 |
+
"<extra_id_45>",
|
| 49 |
+
"<extra_id_46>",
|
| 50 |
+
"<extra_id_47>",
|
| 51 |
+
"<extra_id_48>",
|
| 52 |
+
"<extra_id_49>",
|
| 53 |
+
"<extra_id_50>",
|
| 54 |
+
"<extra_id_51>",
|
| 55 |
+
"<extra_id_52>",
|
| 56 |
+
"<extra_id_53>",
|
| 57 |
+
"<extra_id_54>",
|
| 58 |
+
"<extra_id_55>",
|
| 59 |
+
"<extra_id_56>",
|
| 60 |
+
"<extra_id_57>",
|
| 61 |
+
"<extra_id_58>",
|
| 62 |
+
"<extra_id_59>",
|
| 63 |
+
"<extra_id_60>",
|
| 64 |
+
"<extra_id_61>",
|
| 65 |
+
"<extra_id_62>",
|
| 66 |
+
"<extra_id_63>",
|
| 67 |
+
"<extra_id_64>",
|
| 68 |
+
"<extra_id_65>",
|
| 69 |
+
"<extra_id_66>",
|
| 70 |
+
"<extra_id_67>",
|
| 71 |
+
"<extra_id_68>",
|
| 72 |
+
"<extra_id_69>",
|
| 73 |
+
"<extra_id_70>",
|
| 74 |
+
"<extra_id_71>",
|
| 75 |
+
"<extra_id_72>",
|
| 76 |
+
"<extra_id_73>",
|
| 77 |
+
"<extra_id_74>",
|
| 78 |
+
"<extra_id_75>",
|
| 79 |
+
"<extra_id_76>",
|
| 80 |
+
"<extra_id_77>",
|
| 81 |
+
"<extra_id_78>",
|
| 82 |
+
"<extra_id_79>",
|
| 83 |
+
"<extra_id_80>",
|
| 84 |
+
"<extra_id_81>",
|
| 85 |
+
"<extra_id_82>",
|
| 86 |
+
"<extra_id_83>",
|
| 87 |
+
"<extra_id_84>",
|
| 88 |
+
"<extra_id_85>",
|
| 89 |
+
"<extra_id_86>",
|
| 90 |
+
"<extra_id_87>",
|
| 91 |
+
"<extra_id_88>",
|
| 92 |
+
"<extra_id_89>",
|
| 93 |
+
"<extra_id_90>",
|
| 94 |
+
"<extra_id_91>",
|
| 95 |
+
"<extra_id_92>",
|
| 96 |
+
"<extra_id_93>",
|
| 97 |
+
"<extra_id_94>",
|
| 98 |
+
"<extra_id_95>",
|
| 99 |
+
"<extra_id_96>",
|
| 100 |
+
"<extra_id_97>",
|
| 101 |
+
"<extra_id_98>",
|
| 102 |
+
"<extra_id_99>"
|
| 103 |
+
],
|
| 104 |
+
"eos_token": "</s>",
|
| 105 |
+
"pad_token": "<pad>",
|
| 106 |
+
"unk_token": "<unk>"
|
| 107 |
+
}
|
models/hkunlp_instructor-base/spiece.model
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:d60acb128cf7b7f2536e8f38a5b18a05535c9e14c7a355904270e15b0945ea86
|
| 3 |
+
size 791656
|
models/hkunlp_instructor-base/tokenizer.json
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
models/hkunlp_instructor-base/tokenizer_config.json
ADDED
|
@@ -0,0 +1,112 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"additional_special_tokens": [
|
| 3 |
+
"<extra_id_0>",
|
| 4 |
+
"<extra_id_1>",
|
| 5 |
+
"<extra_id_2>",
|
| 6 |
+
"<extra_id_3>",
|
| 7 |
+
"<extra_id_4>",
|
| 8 |
+
"<extra_id_5>",
|
| 9 |
+
"<extra_id_6>",
|
| 10 |
+
"<extra_id_7>",
|
| 11 |
+
"<extra_id_8>",
|
| 12 |
+
"<extra_id_9>",
|
| 13 |
+
"<extra_id_10>",
|
| 14 |
+
"<extra_id_11>",
|
| 15 |
+
"<extra_id_12>",
|
| 16 |
+
"<extra_id_13>",
|
| 17 |
+
"<extra_id_14>",
|
| 18 |
+
"<extra_id_15>",
|
| 19 |
+
"<extra_id_16>",
|
| 20 |
+
"<extra_id_17>",
|
| 21 |
+
"<extra_id_18>",
|
| 22 |
+
"<extra_id_19>",
|
| 23 |
+
"<extra_id_20>",
|
| 24 |
+
"<extra_id_21>",
|
| 25 |
+
"<extra_id_22>",
|
| 26 |
+
"<extra_id_23>",
|
| 27 |
+
"<extra_id_24>",
|
| 28 |
+
"<extra_id_25>",
|
| 29 |
+
"<extra_id_26>",
|
| 30 |
+
"<extra_id_27>",
|
| 31 |
+
"<extra_id_28>",
|
| 32 |
+
"<extra_id_29>",
|
| 33 |
+
"<extra_id_30>",
|
| 34 |
+
"<extra_id_31>",
|
| 35 |
+
"<extra_id_32>",
|
| 36 |
+
"<extra_id_33>",
|
| 37 |
+
"<extra_id_34>",
|
| 38 |
+
"<extra_id_35>",
|
| 39 |
+
"<extra_id_36>",
|
| 40 |
+
"<extra_id_37>",
|
| 41 |
+
"<extra_id_38>",
|
| 42 |
+
"<extra_id_39>",
|
| 43 |
+
"<extra_id_40>",
|
| 44 |
+
"<extra_id_41>",
|
| 45 |
+
"<extra_id_42>",
|
| 46 |
+
"<extra_id_43>",
|
| 47 |
+
"<extra_id_44>",
|
| 48 |
+
"<extra_id_45>",
|
| 49 |
+
"<extra_id_46>",
|
| 50 |
+
"<extra_id_47>",
|
| 51 |
+
"<extra_id_48>",
|
| 52 |
+
"<extra_id_49>",
|
| 53 |
+
"<extra_id_50>",
|
| 54 |
+
"<extra_id_51>",
|
| 55 |
+
"<extra_id_52>",
|
| 56 |
+
"<extra_id_53>",
|
| 57 |
+
"<extra_id_54>",
|
| 58 |
+
"<extra_id_55>",
|
| 59 |
+
"<extra_id_56>",
|
| 60 |
+
"<extra_id_57>",
|
| 61 |
+
"<extra_id_58>",
|
| 62 |
+
"<extra_id_59>",
|
| 63 |
+
"<extra_id_60>",
|
| 64 |
+
"<extra_id_61>",
|
| 65 |
+
"<extra_id_62>",
|
| 66 |
+
"<extra_id_63>",
|
| 67 |
+
"<extra_id_64>",
|
| 68 |
+
"<extra_id_65>",
|
| 69 |
+
"<extra_id_66>",
|
| 70 |
+
"<extra_id_67>",
|
| 71 |
+
"<extra_id_68>",
|
| 72 |
+
"<extra_id_69>",
|
| 73 |
+
"<extra_id_70>",
|
| 74 |
+
"<extra_id_71>",
|
| 75 |
+
"<extra_id_72>",
|
| 76 |
+
"<extra_id_73>",
|
| 77 |
+
"<extra_id_74>",
|
| 78 |
+
"<extra_id_75>",
|
| 79 |
+
"<extra_id_76>",
|
| 80 |
+
"<extra_id_77>",
|
| 81 |
+
"<extra_id_78>",
|
| 82 |
+
"<extra_id_79>",
|
| 83 |
+
"<extra_id_80>",
|
| 84 |
+
"<extra_id_81>",
|
| 85 |
+
"<extra_id_82>",
|
| 86 |
+
"<extra_id_83>",
|
| 87 |
+
"<extra_id_84>",
|
| 88 |
+
"<extra_id_85>",
|
| 89 |
+
"<extra_id_86>",
|
| 90 |
+
"<extra_id_87>",
|
| 91 |
+
"<extra_id_88>",
|
| 92 |
+
"<extra_id_89>",
|
| 93 |
+
"<extra_id_90>",
|
| 94 |
+
"<extra_id_91>",
|
| 95 |
+
"<extra_id_92>",
|
| 96 |
+
"<extra_id_93>",
|
| 97 |
+
"<extra_id_94>",
|
| 98 |
+
"<extra_id_95>",
|
| 99 |
+
"<extra_id_96>",
|
| 100 |
+
"<extra_id_97>",
|
| 101 |
+
"<extra_id_98>",
|
| 102 |
+
"<extra_id_99>"
|
| 103 |
+
],
|
| 104 |
+
"eos_token": "</s>",
|
| 105 |
+
"extra_ids": 100,
|
| 106 |
+
"model_max_length": 512,
|
| 107 |
+
"name_or_path": "/scratch/acd14245px/metatrain_models/enhanced_large/0103_base_fever_40000/checkpoint-200",
|
| 108 |
+
"pad_token": "<pad>",
|
| 109 |
+
"special_tokens_map_file": null,
|
| 110 |
+
"tokenizer_class": "T5Tokenizer",
|
| 111 |
+
"unk_token": "<unk>"
|
| 112 |
+
}
|
requirements.txt
ADDED
|
@@ -0,0 +1,18 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
streamlit
|
| 2 |
+
numpy
|
| 3 |
+
pandas
|
| 4 |
+
seaborn
|
| 5 |
+
plotly
|
| 6 |
+
ipykernel
|
| 7 |
+
jupyterlab
|
| 8 |
+
jupyter
|
| 9 |
+
tqdm
|
| 10 |
+
llama-index
|
| 11 |
+
InstructorEmbedding
|
| 12 |
+
pypdf
|
| 13 |
+
langchain
|
| 14 |
+
transformers
|
| 15 |
+
huggingface
|
| 16 |
+
sentence-transformers
|
| 17 |
+
llama-cpp-python
|
| 18 |
+
python-dotenv
|
ressources/LLM_ONLY.png
ADDED
|
ressources/LLM_RAG_DATABASE.png
ADDED

|
ressources/Upload_File_QA.png
ADDED
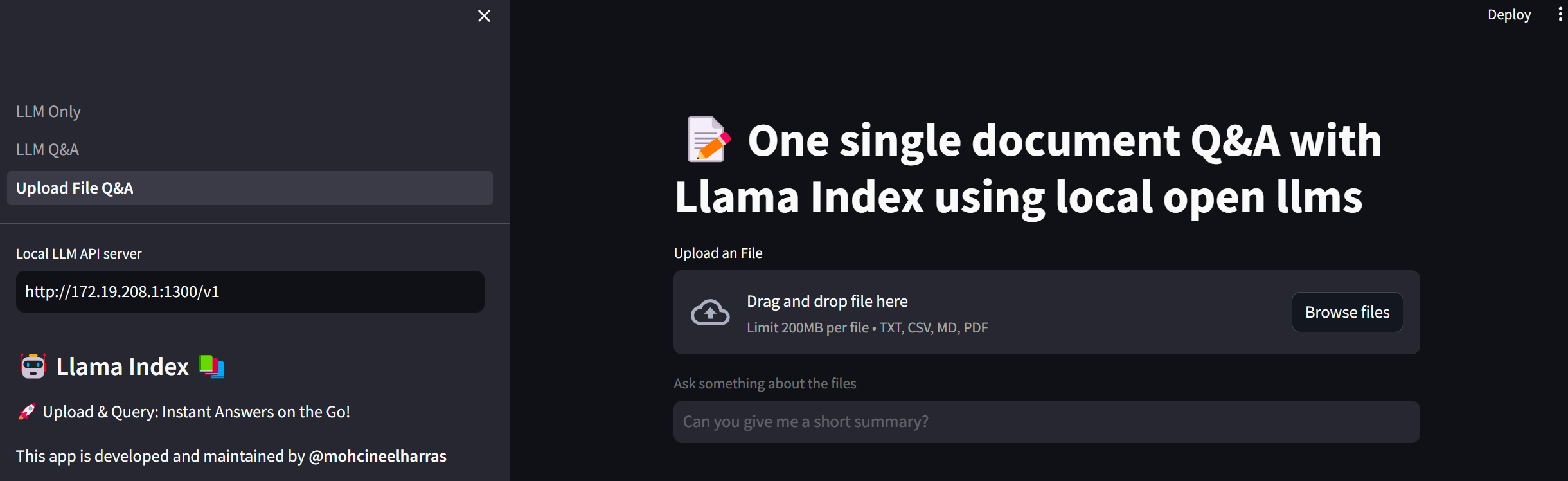
|