Spaces:
Build error

Streamlit app development (#5)
Browse files* Fixed gitignore file
* Project architecture update
* Source code & tests initial work
* Repo clean up, file naming
* Streamlit app creation, testing
* Silero debugging, torch load issues
* Change silero usage to pip install, fixed zip archiving
* Updated README
* Fixed streamlit messages and updated requirements.txt
* Simplified app.py, added instructions.md and config.py
* Moved global variables to config, added voice selection step
* Updated Readme from huggingface spaces
* Fixed config imports, moved config to /src
* Separated epub_gen() from predict()
* Testing work, logging debugging
* Update .gitignore, cleaned up lib imports
* Removed pycache files
* Split write_audio from predict, fixed logging to app.log
* Implemented txt import, more pytest attempts
* HTML and PDF parsing functions implemented
* Added parsers to streamlit app, testing
* Added pdf and htm test files
* Fixed st.upload issues, tested file types
* Fixed gitignore file
* Project architecture update
* Source code & tests initial work
* Repo clean up, file naming
* Streamlit app creation, testing
* Silero debugging, torch load issues
* Change silero usage to pip install, fixed zip archiving
* Updated README
* Fixed streamlit messages and updated requirements.txt
* Simplified app.py, added instructions.md and config.py
* Moved global variables to config, added voice selection step
* Updated Readme from huggingface spaces
* Fixed config imports, moved config to /src
* Separated epub_gen() from predict()
* Testing work, logging debugging
* Update .gitignore, cleaned up lib imports
* Removed pycache files
* Split write_audio from predict, fixed logging to app.log
* Implemented txt import, more pytest attempts
* HTML and PDF parsing functions implemented
* Added parsers to streamlit app, testing
* Added pdf and htm test files
* Fixed st.upload issues, tested file types
* Improved function and file naming, removed unneeded comments, improved app instructions.
* Improved file title handling, audio output clean up
* Unexpected character handling tests
* Voice selection preview created
* Test for preprocess, updating test files
* Epub testing updates
* Update Readme to remove HuggingFace Spaces config
* PDF reading function testing, updating
* PDF reading function completed, tested
* Fixed testing file directory
* Cleaned up notebooks and example test files
* Testing predict function, added test audio tensor
* Cleaned up init.py files
* Updated package versions in GitHub Actions workflow
* Updated package versions in GitHub Actions workflow, correctly
* Testing on read_pdf function
* Updated Readme and Instructions
* Updated Readme with demo screenshot, removed non-functional test
* Fixed Readme typos, linked screenshot
* Linting and misc repo updates
* Added function docstrings
* Module headers added.
* HTML reading WIP
* Testing assemble_zip updated, improved path handling
* Assemble zip, further test updating; tests succeed locally
* Assemble zip, further test updating; tests succeed locally, fixed typos
* Pytest files corrections, np warnings handled
* Further testing work, conditionals tested, tesing running GitHub Actions locally.
* Fixed issues with path handling in output functions
* Solved not a dir error: create dir automatically if does not exist.
* Test for write_audio function completed.
* Testing for generate_audio function complete
* Test for predict function implemented, manually set seed for tests
* Formatting, removed whitespace
* Fixing test_predict, changing tolerance for difference
* Switched to torch.testing.assert_close function for test_predict
* Updates from PR comments; import style, assert style, README instructions, use pathlib instead of os
* Fixed hardcoding of paths, using pathlib paths defined in configs instead
* Testing file equality instead of multiple statements, formatting fixes, fixed load_model test
Former-commit-id: 727b3975d12143bb8d05ad51c7c299a773784b6a
- .coveragerc +1 -1
- .github/workflows/python-app.yml +3 -3
- .gitignore +3 -1
- README.md +24 -1
- app.py +66 -0
- models/latest_silero_models.yml +563 -0
- notebooks/1232-h.htm +0 -0
- notebooks/audiobook_gen_silero.ipynb +28 -387
- notebooks/parser_function_html.ipynb +389 -0
- notebooks/{pg174.epub → test.epub} +0 -0
- notebooks/test.htm +118 -0
- data/testfile.txt → outputs/.gitkeep +0 -0
- pytest.ini +2 -2
- requirements.txt +7 -0
- resources/audiobook_gen.png +0 -0
- resources/instructions.md +13 -0
- resources/speaker_en_0.wav +0 -0
- resources/speaker_en_110.wav +0 -0
- resources/speaker_en_29.wav +0 -0
- resources/speaker_en_41.wav +0 -0
- src/__inti__.py +0 -0
- src/config.py +23 -0
- src/file_readers.py +120 -0
- src/output.py +74 -0
- src/predict.py +110 -0
- tests/__pycache__/test_dummy.cpython-39-pytest-7.1.2.pyc +0 -0
- tests/data/test.epub +0 -0
- tests/data/test.htm +118 -0
- tests/data/test.pdf +0 -0
- tests/data/test.txt +19 -0
- tests/data/test_audio.pt +0 -0
- tests/data/test_predict.pt.REMOVED.git-id +1 -0
- tests/data/test_processed.txt +26 -0
- tests/test_config.py +9 -0
- tests/test_dummy.py +0 -2
- tests/test_file_readers.py +46 -0
- tests/test_output.py +50 -0
- tests/test_predict.py +63 -0
|
@@ -1,5 +1,5 @@
|
|
| 1 |
|
| 2 |
-
# .
|
| 3 |
|
| 4 |
[run]
|
| 5 |
# data_file = put a coverage file name here!!!
|
|
|
|
| 1 |
|
| 2 |
+
# .coveragerc for audiobook_gen
|
| 3 |
|
| 4 |
[run]
|
| 5 |
# data_file = put a coverage file name here!!!
|
|
@@ -19,14 +19,14 @@ jobs:
|
|
| 19 |
|
| 20 |
steps:
|
| 21 |
- uses: actions/checkout@v3
|
| 22 |
-
- name: Set up Python 3.
|
| 23 |
uses: actions/setup-python@v3
|
| 24 |
with:
|
| 25 |
-
python-version: "3.
|
| 26 |
- name: Install dependencies
|
| 27 |
run: |
|
| 28 |
python -m pip install --upgrade pip
|
| 29 |
-
pip install flake8 pytest pytest-cov
|
| 30 |
if [ -f requirements.txt ]; then pip install -r requirements.txt; fi
|
| 31 |
- name: Lint with flake8
|
| 32 |
run: |
|
|
|
|
| 19 |
|
| 20 |
steps:
|
| 21 |
- uses: actions/checkout@v3
|
| 22 |
+
- name: Set up Python 3.9.12
|
| 23 |
uses: actions/setup-python@v3
|
| 24 |
with:
|
| 25 |
+
python-version: "3.9.12"
|
| 26 |
- name: Install dependencies
|
| 27 |
run: |
|
| 28 |
python -m pip install --upgrade pip
|
| 29 |
+
pip install flake8 pytest==7.1.3 pytest-cov==3.0.0
|
| 30 |
if [ -f requirements.txt ]; then pip install -r requirements.txt; fi
|
| 31 |
- name: Lint with flake8
|
| 32 |
run: |
|
|
@@ -8,7 +8,9 @@ token
|
|
| 8 |
docs/
|
| 9 |
conda/
|
| 10 |
tmp/
|
| 11 |
-
|
|
|
|
|
|
|
| 12 |
|
| 13 |
tags
|
| 14 |
*~
|
|
|
|
| 8 |
docs/
|
| 9 |
conda/
|
| 10 |
tmp/
|
| 11 |
+
notebooks/outputs/
|
| 12 |
+
tests/__pycache__/
|
| 13 |
+
tests/.pytest_cache
|
| 14 |
|
| 15 |
tags
|
| 16 |
*~
|
|
@@ -1,4 +1,27 @@
|
|
| 1 |
Audiobook Gen
|
| 2 |
=============
|
| 3 |
|
| 4 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
Audiobook Gen
|
| 2 |
=============
|
| 3 |
|
| 4 |
+
## Description
|
| 5 |
+
Audiobook Gen is a tool that allows the users to generate an audio file of text (e.g. audiobook), read in the voice of the user's choice. This tool is based on the Silero text-to-speech toolkit and uses Streamlit to deliver the application.
|
| 6 |
+
|
| 7 |
+
## Demo
|
| 8 |
+
A demonstration of this tool is hosted at HuggingFace Spaces - see [Audiobook_Gen](https://huggingface.co/spaces/mkutarna/audiobook_gen).
|
| 9 |
+
|
| 10 |
+

|
| 11 |
+
|
| 12 |
+
#### Instructions
|
| 13 |
+
1. Upload the book file to be converted.
|
| 14 |
+
2. Select the desired voice for the audiobook.
|
| 15 |
+
3. Click to run!
|
| 16 |
+
|
| 17 |
+
## Dependencies
|
| 18 |
+
- silero
|
| 19 |
+
- streamlit
|
| 20 |
+
- ebooklib
|
| 21 |
+
- PyPDF2
|
| 22 |
+
- bs4
|
| 23 |
+
- nltk
|
| 24 |
+
- stqdm
|
| 25 |
+
|
| 26 |
+
## License
|
| 27 |
+
See [LICENSE](https://github.com/mkutarna/audiobook_gen/blob/master/LICENSE)
|
|
@@ -0,0 +1,66 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import logging
|
| 2 |
+
|
| 3 |
+
import streamlit as st
|
| 4 |
+
|
| 5 |
+
from src import file_readers, predict, output, config
|
| 6 |
+
|
| 7 |
+
logging.basicConfig(filename='app.log',
|
| 8 |
+
filemode='w',
|
| 9 |
+
format='%(name)s - %(levelname)s - %(message)s',
|
| 10 |
+
level=logging.INFO,
|
| 11 |
+
force=True)
|
| 12 |
+
|
| 13 |
+
st.title('Audiobook Generation Tool')
|
| 14 |
+
|
| 15 |
+
text_file = open(config.INSTRUCTIONS, "r")
|
| 16 |
+
readme_text = text_file.read()
|
| 17 |
+
text_file.close()
|
| 18 |
+
st.markdown(readme_text)
|
| 19 |
+
|
| 20 |
+
st.header('1. Upload your document')
|
| 21 |
+
uploaded_file = st.file_uploader(
|
| 22 |
+
label="File types accepted: epub, txt, pdf)",
|
| 23 |
+
type=['epub', 'txt', 'pdf'])
|
| 24 |
+
|
| 25 |
+
model = predict.load_model()
|
| 26 |
+
|
| 27 |
+
st.header('2. Please select voice')
|
| 28 |
+
speaker = st.radio('Available voices:', config.SPEAKER_LIST.keys(), horizontal=True)
|
| 29 |
+
|
| 30 |
+
audio_path = config.resource_path / f'speaker_{config.SPEAKER_LIST.get(speaker)}.wav'
|
| 31 |
+
audio_file = open(audio_path, 'rb')
|
| 32 |
+
audio_bytes = audio_file.read()
|
| 33 |
+
|
| 34 |
+
st.audio(audio_bytes, format='audio/ogg')
|
| 35 |
+
|
| 36 |
+
st.header('3. Run the app to generate audio')
|
| 37 |
+
if st.button('Click to run!'):
|
| 38 |
+
file_ext = uploaded_file.type
|
| 39 |
+
file_title = uploaded_file.name
|
| 40 |
+
if file_ext == 'application/epub+zip':
|
| 41 |
+
text, file_title = file_readers.read_epub(uploaded_file)
|
| 42 |
+
elif file_ext == 'text/plain':
|
| 43 |
+
file = uploaded_file.read()
|
| 44 |
+
text = file_readers.preprocess_text(file)
|
| 45 |
+
elif file_ext == 'application/pdf':
|
| 46 |
+
text = file_readers.read_pdf(uploaded_file)
|
| 47 |
+
else:
|
| 48 |
+
st.warning('Invalid file type', icon="⚠️")
|
| 49 |
+
st.success('Reading file complete!')
|
| 50 |
+
|
| 51 |
+
with st.spinner('Generating audio...'):
|
| 52 |
+
output.generate_audio(text, file_title, model, config.SPEAKER_LIST.get(speaker))
|
| 53 |
+
st.success('Audio generation complete!')
|
| 54 |
+
|
| 55 |
+
with st.spinner('Building zip file...'):
|
| 56 |
+
zip_file = output.assemble_zip(file_title)
|
| 57 |
+
title_name = f'{file_title}.zip'
|
| 58 |
+
st.success('Zip file prepared!')
|
| 59 |
+
|
| 60 |
+
with open(zip_file, "rb") as fp:
|
| 61 |
+
btn = st.download_button(
|
| 62 |
+
label="Download Audiobook",
|
| 63 |
+
data=fp,
|
| 64 |
+
file_name=title_name,
|
| 65 |
+
mime="application/zip"
|
| 66 |
+
)
|
|
@@ -0,0 +1,563 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# pre-trained STT models
|
| 2 |
+
stt_models:
|
| 3 |
+
en:
|
| 4 |
+
latest:
|
| 5 |
+
meta:
|
| 6 |
+
name: "en_v6"
|
| 7 |
+
sample: "https://models.silero.ai/examples/en_sample.wav"
|
| 8 |
+
labels: "https://models.silero.ai/models/en/en_v1_labels.json"
|
| 9 |
+
jit: "https://models.silero.ai/models/en/en_v6.jit"
|
| 10 |
+
onnx: "https://models.silero.ai/models/en/en_v5.onnx"
|
| 11 |
+
jit_q: "https://models.silero.ai/models/en/en_v6_q.jit"
|
| 12 |
+
jit_xlarge: "https://models.silero.ai/models/en/en_v6_xlarge.jit"
|
| 13 |
+
onnx_xlarge: "https://models.silero.ai/models/en/en_v6_xlarge.onnx"
|
| 14 |
+
v6:
|
| 15 |
+
meta:
|
| 16 |
+
name: "en_v6"
|
| 17 |
+
sample: "https://models.silero.ai/examples/en_sample.wav"
|
| 18 |
+
labels: "https://models.silero.ai/models/en/en_v1_labels.json"
|
| 19 |
+
jit: "https://models.silero.ai/models/en/en_v6.jit"
|
| 20 |
+
onnx: "https://models.silero.ai/models/en/en_v5.onnx"
|
| 21 |
+
jit_q: "https://models.silero.ai/models/en/en_v6_q.jit"
|
| 22 |
+
jit_xlarge: "https://models.silero.ai/models/en/en_v6_xlarge.jit"
|
| 23 |
+
onnx_xlarge: "https://models.silero.ai/models/en/en_v6_xlarge.onnx"
|
| 24 |
+
v5:
|
| 25 |
+
meta:
|
| 26 |
+
name: "en_v5"
|
| 27 |
+
sample: "https://models.silero.ai/examples/en_sample.wav"
|
| 28 |
+
labels: "https://models.silero.ai/models/en/en_v1_labels.json"
|
| 29 |
+
jit: "https://models.silero.ai/models/en/en_v5.jit"
|
| 30 |
+
onnx: "https://models.silero.ai/models/en/en_v5.onnx"
|
| 31 |
+
onnx_q: "https://models.silero.ai/models/en/en_v5_q.onnx"
|
| 32 |
+
jit_q: "https://models.silero.ai/models/en/en_v5_q.jit"
|
| 33 |
+
jit_xlarge: "https://models.silero.ai/models/en/en_v5_xlarge.jit"
|
| 34 |
+
onnx_xlarge: "https://models.silero.ai/models/en/en_v5_xlarge.onnx"
|
| 35 |
+
v4_0:
|
| 36 |
+
meta:
|
| 37 |
+
name: "en_v4_0"
|
| 38 |
+
sample: "https://models.silero.ai/examples/en_sample.wav"
|
| 39 |
+
labels: "https://models.silero.ai/models/en/en_v1_labels.json"
|
| 40 |
+
jit_large: "https://models.silero.ai/models/en/en_v4_0_jit_large.model"
|
| 41 |
+
onnx_large: "https://models.silero.ai/models/en/en_v4_0_large.onnx"
|
| 42 |
+
v3:
|
| 43 |
+
meta:
|
| 44 |
+
name: "en_v3"
|
| 45 |
+
sample: "https://models.silero.ai/examples/en_sample.wav"
|
| 46 |
+
labels: "https://models.silero.ai/models/en/en_v1_labels.json"
|
| 47 |
+
jit: "https://models.silero.ai/models/en/en_v3_jit.model"
|
| 48 |
+
onnx: "https://models.silero.ai/models/en/en_v3.onnx"
|
| 49 |
+
jit_q: "https://models.silero.ai/models/en/en_v3_jit_q.model"
|
| 50 |
+
jit_skip: "https://models.silero.ai/models/en/en_v3_jit_skips.model"
|
| 51 |
+
jit_large: "https://models.silero.ai/models/en/en_v3_jit_large.model"
|
| 52 |
+
onnx_large: "https://models.silero.ai/models/en/en_v3_large.onnx"
|
| 53 |
+
jit_xsmall: "https://models.silero.ai/models/en/en_v3_jit_xsmall.model"
|
| 54 |
+
jit_q_xsmall: "https://models.silero.ai/models/en/en_v3_jit_q_xsmall.model"
|
| 55 |
+
onnx_xsmall: "https://models.silero.ai/models/en/en_v3_xsmall.onnx"
|
| 56 |
+
v2:
|
| 57 |
+
meta:
|
| 58 |
+
name: "en_v2"
|
| 59 |
+
sample: "https://models.silero.ai/examples/en_sample.wav"
|
| 60 |
+
labels: "https://models.silero.ai/models/en/en_v1_labels.json"
|
| 61 |
+
jit: "https://models.silero.ai/models/en/en_v2_jit.model"
|
| 62 |
+
onnx: "https://models.silero.ai/models/en/en_v2.onnx"
|
| 63 |
+
tf: "https://models.silero.ai/models/en/en_v2_tf.tar.gz"
|
| 64 |
+
v1:
|
| 65 |
+
meta:
|
| 66 |
+
name: "en_v1"
|
| 67 |
+
sample: "https://models.silero.ai/examples/en_sample.wav"
|
| 68 |
+
labels: "https://models.silero.ai/models/en/en_v1_labels.json"
|
| 69 |
+
jit: "https://models.silero.ai/models/en/en_v1_jit.model"
|
| 70 |
+
onnx: "https://models.silero.ai/models/en/en_v1.onnx"
|
| 71 |
+
tf: "https://models.silero.ai/models/en/en_v1_tf.tar.gz"
|
| 72 |
+
de:
|
| 73 |
+
latest:
|
| 74 |
+
meta:
|
| 75 |
+
name: "de_v1"
|
| 76 |
+
sample: "https://models.silero.ai/examples/de_sample.wav"
|
| 77 |
+
labels: "https://models.silero.ai/models/de/de_v1_labels.json"
|
| 78 |
+
jit: "https://models.silero.ai/models/de/de_v1_jit.model"
|
| 79 |
+
onnx: "https://models.silero.ai/models/de/de_v1.onnx"
|
| 80 |
+
tf: "https://models.silero.ai/models/de/de_v1_tf.tar.gz"
|
| 81 |
+
v1:
|
| 82 |
+
meta:
|
| 83 |
+
name: "de_v1"
|
| 84 |
+
sample: "https://models.silero.ai/examples/de_sample.wav"
|
| 85 |
+
labels: "https://models.silero.ai/models/de/de_v1_labels.json"
|
| 86 |
+
jit_large: "https://models.silero.ai/models/de/de_v1_jit.model"
|
| 87 |
+
onnx: "https://models.silero.ai/models/de/de_v1.onnx"
|
| 88 |
+
tf: "https://models.silero.ai/models/de/de_v1_tf.tar.gz"
|
| 89 |
+
v3:
|
| 90 |
+
meta:
|
| 91 |
+
name: "de_v3"
|
| 92 |
+
sample: "https://models.silero.ai/examples/de_sample.wav"
|
| 93 |
+
labels: "https://models.silero.ai/models/de/de_v1_labels.json"
|
| 94 |
+
jit_large: "https://models.silero.ai/models/de/de_v3_large.jit"
|
| 95 |
+
v4:
|
| 96 |
+
meta:
|
| 97 |
+
name: "de_v4"
|
| 98 |
+
sample: "https://models.silero.ai/examples/de_sample.wav"
|
| 99 |
+
labels: "https://models.silero.ai/models/de/de_v1_labels.json"
|
| 100 |
+
jit_large: "https://models.silero.ai/models/de/de_v4_large.jit"
|
| 101 |
+
onnx_large: "https://models.silero.ai/models/de/de_v4_large.onnx"
|
| 102 |
+
es:
|
| 103 |
+
latest:
|
| 104 |
+
meta:
|
| 105 |
+
name: "es_v1"
|
| 106 |
+
sample: "https://models.silero.ai/examples/es_sample.wav"
|
| 107 |
+
labels: "https://models.silero.ai/models/es/es_v1_labels.json"
|
| 108 |
+
jit: "https://models.silero.ai/models/es/es_v1_jit.model"
|
| 109 |
+
onnx: "https://models.silero.ai/models/es/es_v1.onnx"
|
| 110 |
+
tf: "https://models.silero.ai/models/es/es_v1_tf.tar.gz"
|
| 111 |
+
ua:
|
| 112 |
+
latest:
|
| 113 |
+
meta:
|
| 114 |
+
name: "ua_v3"
|
| 115 |
+
sample: "https://models.silero.ai/examples/ua_sample.wav"
|
| 116 |
+
credits:
|
| 117 |
+
datasets:
|
| 118 |
+
speech-recognition-uk: https://github.com/egorsmkv/speech-recognition-uk
|
| 119 |
+
labels: "https://models.silero.ai/models/ua/ua_v1_labels.json"
|
| 120 |
+
jit: "https://models.silero.ai/models/ua/ua_v3_jit.model"
|
| 121 |
+
jit_q: "https://models.silero.ai/models/ua/ua_v3_jit_q.model"
|
| 122 |
+
onnx: "https://models.silero.ai/models/ua/ua_v3.onnx"
|
| 123 |
+
v3:
|
| 124 |
+
meta:
|
| 125 |
+
name: "ua_v3"
|
| 126 |
+
sample: "https://models.silero.ai/examples/ua_sample.wav"
|
| 127 |
+
credits:
|
| 128 |
+
datasets:
|
| 129 |
+
speech-recognition-uk: https://github.com/egorsmkv/speech-recognition-uk
|
| 130 |
+
labels: "https://models.silero.ai/models/ua/ua_v1_labels.json"
|
| 131 |
+
jit: "https://models.silero.ai/models/ua/ua_v3_jit.model"
|
| 132 |
+
jit_q: "https://models.silero.ai/models/ua/ua_v3_jit_q.model"
|
| 133 |
+
onnx: "https://models.silero.ai/models/ua/ua_v3.onnx"
|
| 134 |
+
v1:
|
| 135 |
+
meta:
|
| 136 |
+
name: "ua_v1"
|
| 137 |
+
sample: "https://models.silero.ai/examples/ua_sample.wav"
|
| 138 |
+
credits:
|
| 139 |
+
datasets:
|
| 140 |
+
speech-recognition-uk: https://github.com/egorsmkv/speech-recognition-uk
|
| 141 |
+
labels: "https://models.silero.ai/models/ua/ua_v1_labels.json"
|
| 142 |
+
jit: "https://models.silero.ai/models/ua/ua_v1_jit.model"
|
| 143 |
+
jit_q: "https://models.silero.ai/models/ua/ua_v1_jit_q.model"
|
| 144 |
+
tts_models:
|
| 145 |
+
ru:
|
| 146 |
+
v3_1_ru:
|
| 147 |
+
latest:
|
| 148 |
+
example: 'В н+едрах т+ундры в+ыдры в г+етрах т+ырят в в+ёдра +ядра к+едров.'
|
| 149 |
+
package: 'https://models.silero.ai/models/tts/ru/v3_1_ru.pt'
|
| 150 |
+
sample_rate: [8000, 24000, 48000]
|
| 151 |
+
ru_v3:
|
| 152 |
+
latest:
|
| 153 |
+
example: 'В н+едрах т+ундры в+ыдры в г+етрах т+ырят в в+ёдра +ядра к+едров.'
|
| 154 |
+
package: 'https://models.silero.ai/models/tts/ru/ru_v3.pt'
|
| 155 |
+
sample_rate: [8000, 24000, 48000]
|
| 156 |
+
aidar_v2:
|
| 157 |
+
latest:
|
| 158 |
+
example: 'В н+едрах т+ундры в+ыдры в г+етрах т+ырят в в+ёдра +ядра к+едров.'
|
| 159 |
+
package: 'https://models.silero.ai/models/tts/ru/v2_aidar.pt'
|
| 160 |
+
sample_rate: [8000, 16000]
|
| 161 |
+
aidar_8khz:
|
| 162 |
+
latest:
|
| 163 |
+
tokenset: '_~абвгдеёжзийклмнопрстуфхцчшщъыьэюя +.,!?…:;–'
|
| 164 |
+
example: 'В н+едрах т+ундры в+ыдры в г+етрах т+ырят в в+ёдра +ядра к+едров.'
|
| 165 |
+
jit: 'https://models.silero.ai/models/tts/ru/v1_aidar_8000.jit'
|
| 166 |
+
sample_rate: 8000
|
| 167 |
+
v1:
|
| 168 |
+
tokenset: '_~абвгдеёжзийклмнопрстуфхцчшщъыьэюя +.,!?…:;–'
|
| 169 |
+
example: 'В н+едрах т+ундры в+ыдры в г+етрах т+ырят в в+ёдра +ядра к+едров.'
|
| 170 |
+
jit: 'https://models.silero.ai/models/tts/ru/v1_aidar_8000.jit'
|
| 171 |
+
sample_rate: 8000
|
| 172 |
+
aidar_16khz:
|
| 173 |
+
latest:
|
| 174 |
+
tokenset: '_~абвгдеёжзийклмнопрстуфхцчшщъыьэюя +.,!?…:;–'
|
| 175 |
+
example: 'В н+едрах т+ундры в+ыдры в г+етрах т+ырят в в+ёдра +ядра к+едров.'
|
| 176 |
+
jit: 'https://models.silero.ai/models/tts/ru/v1_aidar_16000.jit'
|
| 177 |
+
sample_rate: 16000
|
| 178 |
+
v1:
|
| 179 |
+
tokenset: '_~абвгдеёжзийклмнопрстуфхцчшщъыьэюя +.,!?…:;–'
|
| 180 |
+
example: 'В н+едрах т+ундры в+ыдры в г+етрах т+ырят в в+ёдра +ядра к+едров.'
|
| 181 |
+
jit: 'https://models.silero.ai/models/tts/ru/v1_aidar_16000.jit'
|
| 182 |
+
sample_rate: 16000
|
| 183 |
+
baya_v2:
|
| 184 |
+
latest:
|
| 185 |
+
example: 'В н+едрах т+ундры в+ыдры в г+етрах т+ырят в в+ёдра +ядра к+едров.'
|
| 186 |
+
package: 'https://models.silero.ai/models/tts/ru/v2_baya.pt'
|
| 187 |
+
sample_rate: [8000, 16000]
|
| 188 |
+
baya_8khz:
|
| 189 |
+
latest:
|
| 190 |
+
tokenset: '_~абвгдеёжзийклмнопрстуфхцчшщъыьэюя +.,!?…:;–'
|
| 191 |
+
example: 'В н+едрах т+ундры в+ыдры в г+етрах т+ырят в в+ёдра +ядра к+едров.'
|
| 192 |
+
jit: 'https://models.silero.ai/models/tts/ru/v1_baya_8000.jit'
|
| 193 |
+
sample_rate: 8000
|
| 194 |
+
v1:
|
| 195 |
+
tokenset: '_~абвгдеёжзийклмнопрстуфхцчшщъыьэюя +.,!?…:;–'
|
| 196 |
+
example: 'В н+едрах т+ундры в+ыдры в г+етрах т+ырят в в+ёдра +ядра к+едров.'
|
| 197 |
+
jit: 'https://models.silero.ai/models/tts/ru/v1_baya_8000.jit'
|
| 198 |
+
sample_rate: 8000
|
| 199 |
+
baya_16khz:
|
| 200 |
+
latest:
|
| 201 |
+
tokenset: '_~абвгдеёжзийклмнопрстуфхцчшщъыьэюя +.,!?…:;–'
|
| 202 |
+
example: 'В н+едрах т+ундры в+ыдры в г+етрах т+ырят в в+ёдра +ядра к+едров.'
|
| 203 |
+
jit: 'https://models.silero.ai/models/tts/ru/v1_baya_16000.jit'
|
| 204 |
+
sample_rate: 16000
|
| 205 |
+
v1:
|
| 206 |
+
tokenset: '_~абвгдеёжзийклмнопрстуфхцчшщъыьэюя +.,!?…:;–'
|
| 207 |
+
example: 'В н+едрах т+ундры в+ыдры в г+етрах т+ырят в в+ёдра +ядра к+едров.'
|
| 208 |
+
jit: 'https://models.silero.ai/models/tts/ru/v1_baya_16000.jit'
|
| 209 |
+
sample_rate: 16000
|
| 210 |
+
irina_v2:
|
| 211 |
+
latest:
|
| 212 |
+
example: 'В н+едрах т+ундры в+ыдры в г+етрах т+ырят в в+ёдра +ядра к+едров.'
|
| 213 |
+
package: 'https://models.silero.ai/models/tts/ru/v2_irina.pt'
|
| 214 |
+
sample_rate: [8000, 16000]
|
| 215 |
+
irina_8khz:
|
| 216 |
+
latest:
|
| 217 |
+
tokenset: '_~абвгдеёжзийклмнопрстуфхцчшщъыьэюя +.,!?…:;–'
|
| 218 |
+
example: 'В н+едрах т+ундры в+ыдры в г+етрах т+ырят в в+ёдра +ядра к+едров.'
|
| 219 |
+
jit: 'https://models.silero.ai/models/tts/ru/v1_irina_8000.jit'
|
| 220 |
+
sample_rate: 8000
|
| 221 |
+
v1:
|
| 222 |
+
tokenset: '_~абвгдеёжзийклмнопрстуфхцчшщъыьэюя +.,!?…:;–'
|
| 223 |
+
example: 'В н+едрах т+ундры в+ыдры в г+етрах т+ырят в в+ёдра +ядра к+едров.'
|
| 224 |
+
jit: 'https://models.silero.ai/models/tts/ru/v1_irina_8000.jit'
|
| 225 |
+
sample_rate: 8000
|
| 226 |
+
irina_16khz:
|
| 227 |
+
latest:
|
| 228 |
+
tokenset: '_~абвгдеёжзийклмнопрстуфхцчшщъыьэюя +.,!?…:;–'
|
| 229 |
+
example: 'В н+едрах т+ундры в+ыдры в г+етрах т+ырят в в+ёдра +ядра к+едров.'
|
| 230 |
+
jit: 'https://models.silero.ai/models/tts/ru/v1_irina_16000.jit'
|
| 231 |
+
sample_rate: 16000
|
| 232 |
+
v1:
|
| 233 |
+
tokenset: '_~абвгдеёжзийклмнопрстуфхцчшщъыьэюя +.,!?…:;–'
|
| 234 |
+
example: 'В н+едрах т+ундры в+ыдры в г+етрах т+ырят в в+ёдра +ядра к+едров.'
|
| 235 |
+
jit: 'https://models.silero.ai/models/tts/ru/v1_irina_16000.jit'
|
| 236 |
+
sample_rate: 16000
|
| 237 |
+
kseniya_v2:
|
| 238 |
+
latest:
|
| 239 |
+
example: 'В н+едрах т+ундры в+ыдры в г+етрах т+ырят в в+ёдра +ядра к+едров.'
|
| 240 |
+
package: 'https://models.silero.ai/models/tts/ru/v2_kseniya.pt'
|
| 241 |
+
sample_rate: [8000, 16000]
|
| 242 |
+
kseniya_8khz:
|
| 243 |
+
latest:
|
| 244 |
+
tokenset: '_~абвгдеёжзийклмнопрстуфхцчшщъыьэюя +.,!?…:;–'
|
| 245 |
+
example: 'В н+едрах т+ундры в+ыдры в г+етрах т+ырят в в+ёдра +ядра к+едров.'
|
| 246 |
+
jit: 'https://models.silero.ai/models/tts/ru/v1_kseniya_8000.jit'
|
| 247 |
+
sample_rate: 8000
|
| 248 |
+
v1:
|
| 249 |
+
tokenset: '_~абвгдеёжзийклмнопрстуфхцчшщъыьэюя +.,!?…:;–'
|
| 250 |
+
example: 'В н+едрах т+ундры в+ыдры в г+етрах т+ырят в в+ёдра +ядра к+едров.'
|
| 251 |
+
jit: 'https://models.silero.ai/models/tts/ru/v1_kseniya_8000.jit'
|
| 252 |
+
sample_rate: 8000
|
| 253 |
+
kseniya_16khz:
|
| 254 |
+
latest:
|
| 255 |
+
tokenset: '_~абвгдеёжзийклмнопрстуфхцчшщъыьэюя +.,!?…:;–'
|
| 256 |
+
example: 'В н+едрах т+ундры в+ыдры в г+етрах т+ырят в в+ёдра +ядра к+едров.'
|
| 257 |
+
jit: 'https://models.silero.ai/models/tts/ru/v1_kseniya_16000.jit'
|
| 258 |
+
sample_rate: 16000
|
| 259 |
+
v1:
|
| 260 |
+
tokenset: '_~абвгдеёжзийклмнопрстуфхцчшщъыьэюя +.,!?…:;–'
|
| 261 |
+
example: 'В н+едрах т+ундры в+ыдры в г+етрах т+ырят в в+ёдра +ядра к+едров.'
|
| 262 |
+
jit: 'https://models.silero.ai/models/tts/ru/v1_kseniya_16000.jit'
|
| 263 |
+
sample_rate: 16000
|
| 264 |
+
natasha_v2:
|
| 265 |
+
latest:
|
| 266 |
+
example: 'В н+едрах т+ундры в+ыдры в г+етрах т+ырят в в+ёдра +ядра к+едров.'
|
| 267 |
+
package: 'https://models.silero.ai/models/tts/ru/v2_natasha.pt'
|
| 268 |
+
sample_rate: [8000, 16000]
|
| 269 |
+
natasha_8khz:
|
| 270 |
+
latest:
|
| 271 |
+
tokenset: '_~абвгдеёжзийклмнопрстуфхцчшщъыьэюя +.,!?…:;–'
|
| 272 |
+
example: 'В н+едрах т+ундры в+ыдры в г+етрах т+ырят в в+ёдра +ядра к+едров.'
|
| 273 |
+
jit: 'https://models.silero.ai/models/tts/ru/v1_natasha_8000.jit'
|
| 274 |
+
sample_rate: 8000
|
| 275 |
+
v1:
|
| 276 |
+
tokenset: '_~абвгдеёжзийклмнопрстуфхцчшщъыьэюя +.,!?…:;–'
|
| 277 |
+
example: 'В н+едрах т+ундры в+ыдры в г+етрах т+ырят в в+ёдра +ядра к+едров.'
|
| 278 |
+
jit: 'https://models.silero.ai/models/tts/ru/v1_natasha_8000.jit'
|
| 279 |
+
sample_rate: 8000
|
| 280 |
+
natasha_16khz:
|
| 281 |
+
latest:
|
| 282 |
+
tokenset: '_~абвгдеёжзийклмнопрстуфхцчшщъыьэюя +.,!?…:;–'
|
| 283 |
+
example: 'В н+едрах т+ундры в+ыдры в г+етрах т+ырят в в+ёдра +ядра к+едров.'
|
| 284 |
+
jit: 'https://models.silero.ai/models/tts/ru/v1_natasha_16000.jit'
|
| 285 |
+
sample_rate: 16000
|
| 286 |
+
v1:
|
| 287 |
+
tokenset: '_~абвгдеёжзийклмнопрстуфхцчшщъыьэюя +.,!?…:;–'
|
| 288 |
+
example: 'В н+едрах т+ундры в+ыдры в г+етрах т+ырят в в+ёдра +ядра к+едров.'
|
| 289 |
+
jit: 'https://models.silero.ai/models/tts/ru/v1_natasha_16000.jit'
|
| 290 |
+
sample_rate: 16000
|
| 291 |
+
ruslan_v2:
|
| 292 |
+
latest:
|
| 293 |
+
example: 'В н+едрах т+ундры в+ыдры в г+етрах т+ырят в в+ёдра +ядра к+едров.'
|
| 294 |
+
package: 'https://models.silero.ai/models/tts/ru/v2_ruslan.pt'
|
| 295 |
+
sample_rate: [8000, 16000]
|
| 296 |
+
ruslan_8khz:
|
| 297 |
+
latest:
|
| 298 |
+
tokenset: '_~абвгдеёжзийклмнопрстуфхцчшщъыьэюя +.,!?…:;–'
|
| 299 |
+
example: 'В н+едрах т+ундры в+ыдры в г+етрах т+ырят в в+ёдра +ядра к+едров.'
|
| 300 |
+
jit: 'https://models.silero.ai/models/tts/ru/v1_ruslan_8000.jit'
|
| 301 |
+
sample_rate: 8000
|
| 302 |
+
v1:
|
| 303 |
+
tokenset: '_~абвгдеёжзийклмнопрстуфхцчшщъыьэюя +.,!?…:;–'
|
| 304 |
+
example: 'В н+едрах т+ундры в+ыдры в г+етрах т+ырят в в+ёдра +ядра к+едров.'
|
| 305 |
+
jit: 'https://models.silero.ai/models/tts/ru/v1_ruslan_8000.jit'
|
| 306 |
+
sample_rate: 8000
|
| 307 |
+
ruslan_16khz:
|
| 308 |
+
latest:
|
| 309 |
+
tokenset: '_~абвгдеёжзийклмнопрстуфхцчшщъыьэюя +.,!?…:;–'
|
| 310 |
+
example: 'В н+едрах т+ундры в+ыдры в г+етрах т+ырят в в+ёдра +ядра к+едров.'
|
| 311 |
+
jit: 'https://models.silero.ai/models/tts/ru/v1_ruslan_16000.jit'
|
| 312 |
+
sample_rate: 16000
|
| 313 |
+
v1:
|
| 314 |
+
tokenset: '_~абвгдеёжзийклмнопрстуфхцчшщъыьэюя +.,!?…:;–'
|
| 315 |
+
example: 'В н+едрах т+ундры в+ыдры в г+етрах т+ырят в в+ёдра +ядра к+едров.'
|
| 316 |
+
jit: 'https://models.silero.ai/models/tts/ru/v1_ruslan_16000.jit'
|
| 317 |
+
sample_rate: 16000
|
| 318 |
+
en:
|
| 319 |
+
v3_en:
|
| 320 |
+
latest:
|
| 321 |
+
example: 'Can you can a canned can into an un-canned can like a canner can can a canned can into an un-canned can?'
|
| 322 |
+
package: 'https://models.silero.ai/models/tts/en/v3_en.pt'
|
| 323 |
+
sample_rate: [8000, 24000, 48000]
|
| 324 |
+
v3_en_indic:
|
| 325 |
+
latest:
|
| 326 |
+
example: 'Can you can a canned can into an un-canned can like a canner can can a canned can into an un-canned can?'
|
| 327 |
+
package: 'https://models.silero.ai/models/tts/en/v3_en_indic.pt'
|
| 328 |
+
sample_rate: [8000, 24000, 48000]
|
| 329 |
+
lj_v2:
|
| 330 |
+
latest:
|
| 331 |
+
example: 'Can you can a canned can into an un-canned can like a canner can can a canned can into an un-canned can?'
|
| 332 |
+
package: 'https://models.silero.ai/models/tts/en/v2_lj.pt'
|
| 333 |
+
sample_rate: [8000, 16000]
|
| 334 |
+
lj_8khz:
|
| 335 |
+
latest:
|
| 336 |
+
tokenset: '_~abcdefghijklmnopqrstuvwxyz .,!?…:;–'
|
| 337 |
+
example: 'Can you can a canned can into an un-canned can like a canner can can a canned can into an un-canned can?'
|
| 338 |
+
jit: 'https://models.silero.ai/models/tts/en/v1_lj_8000.jit'
|
| 339 |
+
sample_rate: 8000
|
| 340 |
+
v1:
|
| 341 |
+
tokenset: '_~abcdefghijklmnopqrstuvwxyz .,!?…:;–'
|
| 342 |
+
example: 'Can you can a canned can into an un-canned can like a canner can can a canned can into an un-canned can?'
|
| 343 |
+
jit: 'https://models.silero.ai/models/tts/en/v1_lj_8000.jit'
|
| 344 |
+
sample_rate: 8000
|
| 345 |
+
lj_16khz:
|
| 346 |
+
latest:
|
| 347 |
+
tokenset: '_~abcdefghijklmnopqrstuvwxyz .,!?…:;–'
|
| 348 |
+
example: 'Can you can a canned can into an un-canned can like a canner can can a canned can into an un-canned can?'
|
| 349 |
+
jit: 'https://models.silero.ai/models/tts/en/v1_lj_16000.jit'
|
| 350 |
+
sample_rate: 16000
|
| 351 |
+
v1:
|
| 352 |
+
tokenset: '_~abcdefghijklmnopqrstuvwxyz .,!?…:;–'
|
| 353 |
+
example: 'Can you can a canned can into an un-canned can like a canner can can a canned can into an un-canned can?'
|
| 354 |
+
jit: 'https://models.silero.ai/models/tts/en/v1_lj_16000.jit'
|
| 355 |
+
sample_rate: 16000
|
| 356 |
+
de:
|
| 357 |
+
v3_de:
|
| 358 |
+
latest:
|
| 359 |
+
example: 'Fischers Fritze fischt frische Fische, Frische Fische fischt Fischers Fritze.'
|
| 360 |
+
package: 'https://models.silero.ai/models/tts/de/v3_de.pt'
|
| 361 |
+
sample_rate: [8000, 24000, 48000]
|
| 362 |
+
thorsten_v2:
|
| 363 |
+
latest:
|
| 364 |
+
example: 'Fischers Fritze fischt frische Fische, Frische Fische fischt Fischers Fritze.'
|
| 365 |
+
package: 'https://models.silero.ai/models/tts/de/v2_thorsten.pt'
|
| 366 |
+
sample_rate: [8000, 16000]
|
| 367 |
+
thorsten_8khz:
|
| 368 |
+
latest:
|
| 369 |
+
tokenset: '_~abcdefghijklmnopqrstuvwxyzäöüß .,!?…:;–'
|
| 370 |
+
example: 'Fischers Fritze fischt frische Fische, Frische Fische fischt Fischers Fritze.'
|
| 371 |
+
jit: 'https://models.silero.ai/models/tts/de/v1_thorsten_8000.jit'
|
| 372 |
+
sample_rate: 8000
|
| 373 |
+
v1:
|
| 374 |
+
tokenset: '_~abcdefghijklmnopqrstuvwxyzäöüß .,!?…:;–'
|
| 375 |
+
example: 'Fischers Fritze fischt frische Fische, Frische Fische fischt Fischers Fritze.'
|
| 376 |
+
jit: 'https://models.silero.ai/models/tts/de/v1_thorsten_8000.jit'
|
| 377 |
+
sample_rate: 8000
|
| 378 |
+
thorsten_16khz:
|
| 379 |
+
latest:
|
| 380 |
+
tokenset: '_~abcdefghijklmnopqrstuvwxyzäöüß .,!?…:;–'
|
| 381 |
+
example: 'Fischers Fritze fischt frische Fische, Frische Fische fischt Fischers Fritze.'
|
| 382 |
+
jit: 'https://models.silero.ai/models/tts/de/v1_thorsten_16000.jit'
|
| 383 |
+
sample_rate: 16000
|
| 384 |
+
v1:
|
| 385 |
+
tokenset: '_~abcdefghijklmnopqrstuvwxyzäöüß .,!?…:;–'
|
| 386 |
+
example: 'Fischers Fritze fischt frische Fische, Frische Fische fischt Fischers Fritze.'
|
| 387 |
+
jit: 'https://models.silero.ai/models/tts/de/v1_thorsten_16000.jit'
|
| 388 |
+
sample_rate: 16000
|
| 389 |
+
es:
|
| 390 |
+
v3_es:
|
| 391 |
+
latest:
|
| 392 |
+
example: 'Hoy ya es ayer y ayer ya es hoy, ya llegó el día, y hoy es hoy.'
|
| 393 |
+
package: 'https://models.silero.ai/models/tts/es/v3_es.pt'
|
| 394 |
+
sample_rate: [8000, 24000, 48000]
|
| 395 |
+
tux_v2:
|
| 396 |
+
latest:
|
| 397 |
+
example: 'Hoy ya es ayer y ayer ya es hoy, ya llegó el día, y hoy es hoy.'
|
| 398 |
+
package: 'https://models.silero.ai/models/tts/es/v2_tux.pt'
|
| 399 |
+
sample_rate: [8000, 16000]
|
| 400 |
+
tux_8khz:
|
| 401 |
+
latest:
|
| 402 |
+
tokenset: '_~abcdefghijklmnopqrstuvwxyzáéíñóú .,!?…:;–¡¿'
|
| 403 |
+
example: 'Hoy ya es ayer y ayer ya es hoy, ya llegó el día, y hoy es hoy.'
|
| 404 |
+
jit: 'https://models.silero.ai/models/tts/es/v1_tux_8000.jit'
|
| 405 |
+
sample_rate: 8000
|
| 406 |
+
v1:
|
| 407 |
+
tokenset: '_~abcdefghijklmnopqrstuvwxyzáéíñóú .,!?…:;–¡¿'
|
| 408 |
+
example: 'Hoy ya es ayer y ayer ya es hoy, ya llegó el día, y hoy es hoy.'
|
| 409 |
+
jit: 'https://models.silero.ai/models/tts/es/v1_tux_8000.jit'
|
| 410 |
+
sample_rate: 8000
|
| 411 |
+
tux_16khz:
|
| 412 |
+
latest:
|
| 413 |
+
tokenset: '_~abcdefghijklmnopqrstuvwxyzáéíñóú .,!?…:;–¡¿'
|
| 414 |
+
example: 'Hoy ya es ayer y ayer ya es hoy, ya llegó el día, y hoy es hoy.'
|
| 415 |
+
jit: 'https://models.silero.ai/models/tts/es/v1_tux_16000.jit'
|
| 416 |
+
sample_rate: 16000
|
| 417 |
+
v1:
|
| 418 |
+
tokenset: '_~abcdefghijklmnopqrstuvwxyzáéíñóú .,!?…:;–¡¿'
|
| 419 |
+
example: 'Hoy ya es ayer y ayer ya es hoy, ya llegó el día, y hoy es hoy.'
|
| 420 |
+
jit: 'https://models.silero.ai/models/tts/es/v1_tux_16000.jit'
|
| 421 |
+
sample_rate: 16000
|
| 422 |
+
fr:
|
| 423 |
+
v3_fr:
|
| 424 |
+
latest:
|
| 425 |
+
example: 'Je suis ce que je suis, et si je suis ce que je suis, qu’est ce que je suis.'
|
| 426 |
+
package: 'https://models.silero.ai/models/tts/fr/v3_fr.pt'
|
| 427 |
+
sample_rate: [8000, 24000, 48000]
|
| 428 |
+
gilles_v2:
|
| 429 |
+
latest:
|
| 430 |
+
example: 'Je suis ce que je suis, et si je suis ce que je suis, qu’est ce que je suis.'
|
| 431 |
+
package: 'https://models.silero.ai/models/tts/fr/v2_gilles.pt'
|
| 432 |
+
sample_rate: [8000, 16000]
|
| 433 |
+
gilles_8khz:
|
| 434 |
+
latest:
|
| 435 |
+
tokenset: '_~abcdefghijklmnopqrstuvwxyzéàèùâêîôûç .,!?…:;–'
|
| 436 |
+
example: 'Je suis ce que je suis, et si je suis ce que je suis, qu’est ce que je suis.'
|
| 437 |
+
jit: 'https://models.silero.ai/models/tts/fr/v1_gilles_8000.jit'
|
| 438 |
+
sample_rate: 8000
|
| 439 |
+
v1:
|
| 440 |
+
tokenset: '_~abcdefghijklmnopqrstuvwxyzéàèùâêîôûç .,!?…:;–'
|
| 441 |
+
example: 'Je suis ce que je suis, et si je suis ce que je suis, qu’est ce que je suis.'
|
| 442 |
+
jit: 'https://models.silero.ai/models/tts/fr/v1_gilles_8000.jit'
|
| 443 |
+
sample_rate: 8000
|
| 444 |
+
gilles_16khz:
|
| 445 |
+
latest:
|
| 446 |
+
tokenset: '_~abcdefghijklmnopqrstuvwxyzéàèùâêîôûç .,!?…:;–'
|
| 447 |
+
example: 'Je suis ce que je suis, et si je suis ce que je suis, qu’est ce que je suis.'
|
| 448 |
+
jit: 'https://models.silero.ai/models/tts/fr/v1_gilles_16000.jit'
|
| 449 |
+
sample_rate: 16000
|
| 450 |
+
v1:
|
| 451 |
+
tokenset: '_~abcdefghijklmnopqrstuvwxyzéàèùâêîôûç .,!?…:;–'
|
| 452 |
+
example: 'Je suis ce que je suis, et si je suis ce que je suis, qu’est ce que je suis.'
|
| 453 |
+
jit: 'https://models.silero.ai/models/tts/fr/v1_gilles_16000.jit'
|
| 454 |
+
sample_rate: 16000
|
| 455 |
+
ba:
|
| 456 |
+
aigul_v2:
|
| 457 |
+
latest:
|
| 458 |
+
example: 'Салауат Юлаевтың тормошо һәм яҙмышы хаҡындағы документтарҙың һәм шиғри әҫәрҙәренең бик аҙ өлөшө генә һаҡланған.'
|
| 459 |
+
package: 'https://models.silero.ai/models/tts/ba/v2_aigul.pt'
|
| 460 |
+
sample_rate: [8000, 16000]
|
| 461 |
+
language_name: 'bashkir'
|
| 462 |
+
xal:
|
| 463 |
+
v3_xal:
|
| 464 |
+
latest:
|
| 465 |
+
example: 'Һорвн, дөрвн күн ирәд, һазань чиңгнв. Байн Цецн хаана һорвн көвүн күүндҗәнә.'
|
| 466 |
+
package: 'https://models.silero.ai/models/tts/xal/v3_xal.pt'
|
| 467 |
+
sample_rate: [8000, 24000, 48000]
|
| 468 |
+
erdni_v2:
|
| 469 |
+
latest:
|
| 470 |
+
example: 'Һорвн, дөрвн күн ирәд, һазань чиңгнв. Байн Цецн хаана һорвн көвүн күүндҗәнә.'
|
| 471 |
+
package: 'https://models.silero.ai/models/tts/xal/v2_erdni.pt'
|
| 472 |
+
sample_rate: [8000, 16000]
|
| 473 |
+
language_name: 'kalmyk'
|
| 474 |
+
tt:
|
| 475 |
+
v3_tt:
|
| 476 |
+
latest:
|
| 477 |
+
example: 'Исәнмесез, саумысез, нишләп кәҗәгезне саумыйсыз, әтәчегез күкәй салган, нишләп чыгып алмыйсыз.'
|
| 478 |
+
package: 'https://models.silero.ai/models/tts/tt/v3_tt.pt'
|
| 479 |
+
sample_rate: [8000, 24000, 48000]
|
| 480 |
+
dilyara_v2:
|
| 481 |
+
latest:
|
| 482 |
+
example: 'Ис+әнмесез, с+аумысез, нишл+әп кәҗәгезн+е с+аумыйсыз, әтәчег+ез күк+әй салг+ан, нишл+әп чыг+ып +алмыйсыз.'
|
| 483 |
+
package: 'https://models.silero.ai/models/tts/tt/v2_dilyara.pt'
|
| 484 |
+
sample_rate: [8000, 16000]
|
| 485 |
+
language_name: 'tatar'
|
| 486 |
+
uz:
|
| 487 |
+
v3_uz:
|
| 488 |
+
latest:
|
| 489 |
+
example: 'Tanishganimdan xursandman.'
|
| 490 |
+
package: 'https://models.silero.ai/models/tts/uz/v3_uz.pt'
|
| 491 |
+
sample_rate: [8000, 24000, 48000]
|
| 492 |
+
dilnavoz_v2:
|
| 493 |
+
latest:
|
| 494 |
+
example: 'Tanishganimdan xursandman.'
|
| 495 |
+
package: 'https://models.silero.ai/models/tts/uz/v2_dilnavoz.pt'
|
| 496 |
+
sample_rate: [8000, 16000]
|
| 497 |
+
language_name: 'uzbek'
|
| 498 |
+
ua:
|
| 499 |
+
v3_ua:
|
| 500 |
+
latest:
|
| 501 |
+
example: 'К+отики - пухн+асті жив+отики.'
|
| 502 |
+
package: 'https://models.silero.ai/models/tts/ua/v3_ua.pt'
|
| 503 |
+
sample_rate: [8000, 24000, 48000]
|
| 504 |
+
mykyta_v2:
|
| 505 |
+
latest:
|
| 506 |
+
example: 'К+отики - пухн+асті жив+отики.'
|
| 507 |
+
package: 'https://models.silero.ai/models/tts/ua/v22_mykyta_48k.pt'
|
| 508 |
+
sample_rate: [8000, 24000, 48000]
|
| 509 |
+
language_name: 'ukrainian'
|
| 510 |
+
indic:
|
| 511 |
+
v3_indic:
|
| 512 |
+
latest:
|
| 513 |
+
example: 'prasidda kabīra adhyētā, puruṣōttama agravāla kā yaha śōdha ālēkha, usa rāmānaṁda kī khōja karatā hai'
|
| 514 |
+
package: 'https://models.silero.ai/models/tts/indic/v3_indic.pt'
|
| 515 |
+
sample_rate: [8000, 24000, 48000]
|
| 516 |
+
multi:
|
| 517 |
+
multi_v2:
|
| 518 |
+
latest:
|
| 519 |
+
package: 'https://models.silero.ai/models/tts/multi/v2_multi.pt'
|
| 520 |
+
sample_rate: [8000, 16000]
|
| 521 |
+
speakers:
|
| 522 |
+
aidar:
|
| 523 |
+
lang: 'ru'
|
| 524 |
+
example: 'Съ+ешьте ещ+ё +этих м+ягких франц+узских б+улочек, д+а в+ыпейте ч+аю.'
|
| 525 |
+
baya:
|
| 526 |
+
lang: 'ru'
|
| 527 |
+
example: 'Съ+ешьте ещ+ё +этих м+ягких франц+узских б+улочек, д+а в+ыпейте ч+аю.'
|
| 528 |
+
kseniya:
|
| 529 |
+
lang: 'ru'
|
| 530 |
+
example: 'Съ+ешьте ещ+ё +этих м+ягких франц+узских б+улочек, д+а в+ыпейте ч+аю.'
|
| 531 |
+
irina:
|
| 532 |
+
lang: 'ru'
|
| 533 |
+
example: 'Съ+ешьте ещ+ё +этих м+ягких франц+узских б+улочек, д+а в+ыпейте ч+аю.'
|
| 534 |
+
ruslan:
|
| 535 |
+
lang: 'ru'
|
| 536 |
+
example: 'Съ+ешьте ещ+ё +этих м+ягких франц+узских б+улочек, д+а в+ыпейте ч+аю.'
|
| 537 |
+
natasha:
|
| 538 |
+
lang: 'ru'
|
| 539 |
+
example: 'Съ+ешьте ещ+ё +этих м+ягких франц+узских б+улочек, д+а в+ыпейте ч+аю.'
|
| 540 |
+
thorsten:
|
| 541 |
+
lang: 'de'
|
| 542 |
+
example: 'Fischers Fritze fischt frische Fische, Frische Fische fischt Fischers Fritze.'
|
| 543 |
+
tux:
|
| 544 |
+
lang: 'es'
|
| 545 |
+
example: 'Hoy ya es ayer y ayer ya es hoy, ya llegó el día, y hoy es hoy.'
|
| 546 |
+
gilles:
|
| 547 |
+
lang: 'fr'
|
| 548 |
+
example: 'Je suis ce que je suis, et si je suis ce que je suis, qu’est ce que je suis.'
|
| 549 |
+
lj:
|
| 550 |
+
lang: 'en'
|
| 551 |
+
example: 'Can you can a canned can into an un-canned can like a canner can can a canned can into an un-canned can?'
|
| 552 |
+
dilyara:
|
| 553 |
+
lang: 'tt'
|
| 554 |
+
example: 'Пес+и пес+и песик+әй, борыннар+ы бәләк+әй.'
|
| 555 |
+
te_models:
|
| 556 |
+
latest:
|
| 557 |
+
package: "https://models.silero.ai/te_models/v2_4lang_q.pt"
|
| 558 |
+
languages: ['en', 'de', 'ru', 'es']
|
| 559 |
+
punct: '.,-!?—'
|
| 560 |
+
v2:
|
| 561 |
+
package: "https://models.silero.ai/te_models/v2_4lang_q.pt"
|
| 562 |
+
languages: ['en', 'de', 'ru', 'es']
|
| 563 |
+
punct: '.,-!?—'
|
|
The diff for this file is too large to render.
See raw diff
|
|
|
|
@@ -45,7 +45,7 @@
|
|
| 45 |
},
|
| 46 |
{
|
| 47 |
"cell_type": "code",
|
| 48 |
-
"execution_count":
|
| 49 |
"metadata": {},
|
| 50 |
"outputs": [],
|
| 51 |
"source": [
|
|
@@ -79,11 +79,11 @@
|
|
| 79 |
},
|
| 80 |
{
|
| 81 |
"cell_type": "code",
|
| 82 |
-
"execution_count":
|
| 83 |
"metadata": {},
|
| 84 |
"outputs": [],
|
| 85 |
"source": [
|
| 86 |
-
"max_char_len =
|
| 87 |
"sample_rate = 24000"
|
| 88 |
]
|
| 89 |
},
|
|
@@ -122,11 +122,11 @@
|
|
| 122 |
},
|
| 123 |
{
|
| 124 |
"cell_type": "code",
|
| 125 |
-
"execution_count":
|
| 126 |
"metadata": {},
|
| 127 |
"outputs": [],
|
| 128 |
"source": [
|
| 129 |
-
"ebook_path = '
|
| 130 |
]
|
| 131 |
},
|
| 132 |
{
|
|
@@ -144,7 +144,7 @@
|
|
| 144 |
},
|
| 145 |
{
|
| 146 |
"cell_type": "code",
|
| 147 |
-
"execution_count":
|
| 148 |
"metadata": {},
|
| 149 |
"outputs": [],
|
| 150 |
"source": [
|
|
@@ -198,24 +198,9 @@
|
|
| 198 |
},
|
| 199 |
{
|
| 200 |
"cell_type": "code",
|
| 201 |
-
"execution_count":
|
| 202 |
"metadata": {},
|
| 203 |
-
"outputs": [
|
| 204 |
-
{
|
| 205 |
-
"data": {
|
| 206 |
-
"application/vnd.jupyter.widget-view+json": {
|
| 207 |
-
"model_id": "7c7a0d27b2984cac933f97c68905d393",
|
| 208 |
-
"version_major": 2,
|
| 209 |
-
"version_minor": 0
|
| 210 |
-
},
|
| 211 |
-
"text/plain": [
|
| 212 |
-
" 0%| | 0/28 [00:00<?, ?it/s]"
|
| 213 |
-
]
|
| 214 |
-
},
|
| 215 |
-
"metadata": {},
|
| 216 |
-
"output_type": "display_data"
|
| 217 |
-
}
|
| 218 |
-
],
|
| 219 |
"source": [
|
| 220 |
"ebook, title = read_ebook(ebook_path)"
|
| 221 |
]
|
|
@@ -229,24 +214,24 @@
|
|
| 229 |
},
|
| 230 |
{
|
| 231 |
"cell_type": "code",
|
| 232 |
-
"execution_count":
|
| 233 |
"metadata": {},
|
| 234 |
-
"outputs": [
|
| 235 |
-
{
|
| 236 |
-
"name": "stdout",
|
| 237 |
-
"output_type": "stream",
|
| 238 |
-
"text": [
|
| 239 |
-
"Title of ebook (path name):the_picture_of_dorian_gray\n",
|
| 240 |
-
"First paragraph (truncated for display): \n",
|
| 241 |
-
" ['CHAPTER I.', 'The studio was filled with the rich odour of roses, and when the light summer wind stirred amidst the trees of the garden, there came through the open', 'door the heavy scent of the lilac, or the more delicate perfume of the pink-flowering thorn.', 'From the corner of the divan of Persian saddle-bags on which he was lying, smoking, as was his custom, innumerable cigarettes, Lord Henry Wotton could', 'just catch the gleam of the honey-sweet and honey-coloured blossoms of a laburnum, whose tremulous branches seemed hardly able to bear the burden of a']\n"
|
| 242 |
-
]
|
| 243 |
-
}
|
| 244 |
-
],
|
| 245 |
"source": [
|
| 246 |
-
"print(f'Title of ebook (path name):{title}')\n",
|
|
|
|
| 247 |
"print(f'First paragraph (truncated for display): \\n {ebook[2][0:5]}')"
|
| 248 |
]
|
| 249 |
},
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 250 |
{
|
| 251 |
"cell_type": "markdown",
|
| 252 |
"metadata": {},
|
|
@@ -260,357 +245,13 @@
|
|
| 260 |
},
|
| 261 |
{
|
| 262 |
"cell_type": "code",
|
| 263 |
-
"execution_count":
|
| 264 |
"metadata": {},
|
| 265 |
-
"outputs": [
|
| 266 |
-
{
|
| 267 |
-
"data": {
|
| 268 |
-
"application/vnd.jupyter.widget-view+json": {
|
| 269 |
-
"model_id": "4dd296c9abb941d6817b8d5c075b0c7c",
|
| 270 |
-
"version_major": 2,
|
| 271 |
-
"version_minor": 0
|
| 272 |
-
},
|
| 273 |
-
"text/plain": [
|
| 274 |
-
" 0%| | 0/23 [00:00<?, ?it/s]"
|
| 275 |
-
]
|
| 276 |
-
},
|
| 277 |
-
"metadata": {},
|
| 278 |
-
"output_type": "display_data"
|
| 279 |
-
},
|
| 280 |
-
{
|
| 281 |
-
"data": {
|
| 282 |
-
"application/vnd.jupyter.widget-view+json": {
|
| 283 |
-
"model_id": "a7e3d37537f9495b93a092bd2125bb15",
|
| 284 |
-
"version_major": 2,
|
| 285 |
-
"version_minor": 0
|
| 286 |
-
},
|
| 287 |
-
"text/plain": [
|
| 288 |
-
" 0%| | 0/38 [00:00<?, ?it/s]"
|
| 289 |
-
]
|
| 290 |
-
},
|
| 291 |
-
"metadata": {},
|
| 292 |
-
"output_type": "display_data"
|
| 293 |
-
},
|
| 294 |
-
{
|
| 295 |
-
"data": {
|
| 296 |
-
"application/vnd.jupyter.widget-view+json": {
|
| 297 |
-
"model_id": "a16db529b19d4e86b79e056106cfa5c1",
|
| 298 |
-
"version_major": 2,
|
| 299 |
-
"version_minor": 0
|
| 300 |
-
},
|
| 301 |
-
"text/plain": [
|
| 302 |
-
" 0%| | 0/36 [00:00<?, ?it/s]"
|
| 303 |
-
]
|
| 304 |
-
},
|
| 305 |
-
"metadata": {},
|
| 306 |
-
"output_type": "display_data"
|
| 307 |
-
},
|
| 308 |
-
{
|
| 309 |
-
"data": {
|
| 310 |
-
"application/vnd.jupyter.widget-view+json": {
|
| 311 |
-
"model_id": "324fac7d6d7d44a9b38f7fc9cddb7abb",
|
| 312 |
-
"version_major": 2,
|
| 313 |
-
"version_minor": 0
|
| 314 |
-
},
|
| 315 |
-
"text/plain": [
|
| 316 |
-
" 0%| | 0/383 [00:00<?, ?it/s]"
|
| 317 |
-
]
|
| 318 |
-
},
|
| 319 |
-
"metadata": {},
|
| 320 |
-
"output_type": "display_data"
|
| 321 |
-
},
|
| 322 |
-
{
|
| 323 |
-
"data": {
|
| 324 |
-
"application/vnd.jupyter.widget-view+json": {
|
| 325 |
-
"model_id": "8b5e5cfc28da4e1d996a39d0b9254c57",
|
| 326 |
-
"version_major": 2,
|
| 327 |
-
"version_minor": 0
|
| 328 |
-
},
|
| 329 |
-
"text/plain": [
|
| 330 |
-
" 0%| | 0/517 [00:00<?, ?it/s]"
|
| 331 |
-
]
|
| 332 |
-
},
|
| 333 |
-
"metadata": {},
|
| 334 |
-
"output_type": "display_data"
|
| 335 |
-
},
|
| 336 |
-
{
|
| 337 |
-
"data": {
|
| 338 |
-
"application/vnd.jupyter.widget-view+json": {
|
| 339 |
-
"model_id": "95408c5358d64cff8cadf82d3b34d18e",
|
| 340 |
-
"version_major": 2,
|
| 341 |
-
"version_minor": 0
|
| 342 |
-
},
|
| 343 |
-
"text/plain": [
|
| 344 |
-
" 0%| | 0/385 [00:00<?, ?it/s]"
|
| 345 |
-
]
|
| 346 |
-
},
|
| 347 |
-
"metadata": {},
|
| 348 |
-
"output_type": "display_data"
|
| 349 |
-
},
|
| 350 |
-
{
|
| 351 |
-
"data": {
|
| 352 |
-
"application/vnd.jupyter.widget-view+json": {
|
| 353 |
-
"model_id": "e3322b1b54da4c949c5ad708044c84e3",
|
| 354 |
-
"version_major": 2,
|
| 355 |
-
"version_minor": 0
|
| 356 |
-
},
|
| 357 |
-
"text/plain": [
|
| 358 |
-
" 0%| | 0/491 [00:00<?, ?it/s]"
|
| 359 |
-
]
|
| 360 |
-
},
|
| 361 |
-
"metadata": {},
|
| 362 |
-
"output_type": "display_data"
|
| 363 |
-
},
|
| 364 |
-
{
|
| 365 |
-
"data": {
|
| 366 |
-
"application/vnd.jupyter.widget-view+json": {
|
| 367 |
-
"model_id": "41f7e5fda2f24e079be210224b36ff63",
|
| 368 |
-
"version_major": 2,
|
| 369 |
-
"version_minor": 0
|
| 370 |
-
},
|
| 371 |
-
"text/plain": [
|
| 372 |
-
" 0%| | 0/440 [00:00<?, ?it/s]"
|
| 373 |
-
]
|
| 374 |
-
},
|
| 375 |
-
"metadata": {},
|
| 376 |
-
"output_type": "display_data"
|
| 377 |
-
},
|
| 378 |
-
{
|
| 379 |
-
"data": {
|
| 380 |
-
"application/vnd.jupyter.widget-view+json": {
|
| 381 |
-
"model_id": "007f22618ee140058eff80b29e86501e",
|
| 382 |
-
"version_major": 2,
|
| 383 |
-
"version_minor": 0
|
| 384 |
-
},
|
| 385 |
-
"text/plain": [
|
| 386 |
-
" 0%| | 0/254 [00:00<?, ?it/s]"
|
| 387 |
-
]
|
| 388 |
-
},
|
| 389 |
-
"metadata": {},
|
| 390 |
-
"output_type": "display_data"
|
| 391 |
-
},
|
| 392 |
-
{
|
| 393 |
-
"data": {
|
| 394 |
-
"application/vnd.jupyter.widget-view+json": {
|
| 395 |
-
"model_id": "84c45b18ed994291b28ee259f2610019",
|
| 396 |
-
"version_major": 2,
|
| 397 |
-
"version_minor": 0
|
| 398 |
-
},
|
| 399 |
-
"text/plain": [
|
| 400 |
-
" 0%| | 0/419 [00:00<?, ?it/s]"
|
| 401 |
-
]
|
| 402 |
-
},
|
| 403 |
-
"metadata": {},
|
| 404 |
-
"output_type": "display_data"
|
| 405 |
-
},
|
| 406 |
-
{
|
| 407 |
-
"data": {
|
| 408 |
-
"application/vnd.jupyter.widget-view+json": {
|
| 409 |
-
"model_id": "d9f08d28db034576a6c8d3a1ef9c7e83",
|
| 410 |
-
"version_major": 2,
|
| 411 |
-
"version_minor": 0
|
| 412 |
-
},
|
| 413 |
-
"text/plain": [
|
| 414 |
-
" 0%| | 0/463 [00:00<?, ?it/s]"
|
| 415 |
-
]
|
| 416 |
-
},
|
| 417 |
-
"metadata": {},
|
| 418 |
-
"output_type": "display_data"
|
| 419 |
-
},
|
| 420 |
-
{
|
| 421 |
-
"data": {
|
| 422 |
-
"application/vnd.jupyter.widget-view+json": {
|
| 423 |
-
"model_id": "72e658ae2a2c4c76967aa6e8f8fc5cf5",
|
| 424 |
-
"version_major": 2,
|
| 425 |
-
"version_minor": 0
|
| 426 |
-
},
|
| 427 |
-
"text/plain": [
|
| 428 |
-
" 0%| | 0/361 [00:00<?, ?it/s]"
|
| 429 |
-
]
|
| 430 |
-
},
|
| 431 |
-
"metadata": {},
|
| 432 |
-
"output_type": "display_data"
|
| 433 |
-
},
|
| 434 |
-
{
|
| 435 |
-
"data": {
|
| 436 |
-
"application/vnd.jupyter.widget-view+json": {
|
| 437 |
-
"model_id": "a9c88220cfda402a9dbfd5cf3d8f0f46",
|
| 438 |
-
"version_major": 2,
|
| 439 |
-
"version_minor": 0
|
| 440 |
-
},
|
| 441 |
-
"text/plain": [
|
| 442 |
-
" 0%| | 0/253 [00:00<?, ?it/s]"
|
| 443 |
-
]
|
| 444 |
-
},
|
| 445 |
-
"metadata": {},
|
| 446 |
-
"output_type": "display_data"
|
| 447 |
-
},
|
| 448 |
-
{
|
| 449 |
-
"data": {
|
| 450 |
-
"application/vnd.jupyter.widget-view+json": {
|
| 451 |
-
"model_id": "229cd86f85d1458887b0a80c758c8dcc",
|
| 452 |
-
"version_major": 2,
|
| 453 |
-
"version_minor": 0
|
| 454 |
-
},
|
| 455 |
-
"text/plain": [
|
| 456 |
-
" 0%| | 0/401 [00:00<?, ?it/s]"
|
| 457 |
-
]
|
| 458 |
-
},
|
| 459 |
-
"metadata": {},
|
| 460 |
-
"output_type": "display_data"
|
| 461 |
-
},
|
| 462 |
-
{
|
| 463 |
-
"data": {
|
| 464 |
-
"application/vnd.jupyter.widget-view+json": {
|
| 465 |
-
"model_id": "b7d361cc2287451d886bae67da5151a9",
|
| 466 |
-
"version_major": 2,
|
| 467 |
-
"version_minor": 0
|
| 468 |
-
},
|
| 469 |
-
"text/plain": [
|
| 470 |
-
" 0%| | 0/256 [00:00<?, ?it/s]"
|
| 471 |
-
]
|
| 472 |
-
},
|
| 473 |
-
"metadata": {},
|
| 474 |
-
"output_type": "display_data"
|
| 475 |
-
},
|
| 476 |
-
{
|
| 477 |
-
"data": {
|
| 478 |
-
"application/vnd.jupyter.widget-view+json": {
|
| 479 |
-
"model_id": "c93a785804ea461398046c2cae64db00",
|
| 480 |
-
"version_major": 2,
|
| 481 |
-
"version_minor": 0
|
| 482 |
-
},
|
| 483 |
-
"text/plain": [
|
| 484 |
-
" 0%| | 0/233 [00:00<?, ?it/s]"
|
| 485 |
-
]
|
| 486 |
-
},
|
| 487 |
-
"metadata": {},
|
| 488 |
-
"output_type": "display_data"
|
| 489 |
-
},
|
| 490 |
-
{
|
| 491 |
-
"data": {
|
| 492 |
-
"application/vnd.jupyter.widget-view+json": {
|
| 493 |
-
"model_id": "269e5f35fd064d2888e62a3f6f34bdf0",
|
| 494 |
-
"version_major": 2,
|
| 495 |
-
"version_minor": 0
|
| 496 |
-
},
|
| 497 |
-
"text/plain": [
|
| 498 |
-
" 0%| | 0/405 [00:00<?, ?it/s]"
|
| 499 |
-
]
|
| 500 |
-
},
|
| 501 |
-
"metadata": {},
|
| 502 |
-
"output_type": "display_data"
|
| 503 |
-
},
|
| 504 |
-
{
|
| 505 |
-
"data": {
|
| 506 |
-
"application/vnd.jupyter.widget-view+json": {
|
| 507 |
-
"model_id": "69469c02db574342a4bb434cf80f422b",
|
| 508 |
-
"version_major": 2,
|
| 509 |
-
"version_minor": 0
|
| 510 |
-
},
|
| 511 |
-
"text/plain": [
|
| 512 |
-
" 0%| | 0/279 [00:00<?, ?it/s]"
|
| 513 |
-
]
|
| 514 |
-
},
|
| 515 |
-
"metadata": {},
|
| 516 |
-
"output_type": "display_data"
|
| 517 |
-
},
|
| 518 |
-
{
|
| 519 |
-
"data": {
|
| 520 |
-
"application/vnd.jupyter.widget-view+json": {
|
| 521 |
-
"model_id": "6979dd4c8479420198686d5a44c00887",
|
| 522 |
-
"version_major": 2,
|
| 523 |
-
"version_minor": 0
|
| 524 |
-
},
|
| 525 |
-
"text/plain": [
|
| 526 |
-
" 0%| | 0/275 [00:00<?, ?it/s]"
|
| 527 |
-
]
|
| 528 |
-
},
|
| 529 |
-
"metadata": {},
|
| 530 |
-
"output_type": "display_data"
|
| 531 |
-
},
|
| 532 |
-
{
|
| 533 |
-
"data": {
|
| 534 |
-
"application/vnd.jupyter.widget-view+json": {
|
| 535 |
-
"model_id": "356e20b91da44f93a0d7ad220fb00e79",
|
| 536 |
-
"version_major": 2,
|
| 537 |
-
"version_minor": 0
|
| 538 |
-
},
|
| 539 |
-
"text/plain": [
|
| 540 |
-
" 0%| | 0/216 [00:00<?, ?it/s]"
|
| 541 |
-
]
|
| 542 |
-
},
|
| 543 |
-
"metadata": {},
|
| 544 |
-
"output_type": "display_data"
|
| 545 |
-
},
|
| 546 |
-
{
|
| 547 |
-
"data": {
|
| 548 |
-
"application/vnd.jupyter.widget-view+json": {
|
| 549 |
-
"model_id": "1d73c481c8ef45d1add550bdbf278775",
|
| 550 |
-
"version_major": 2,
|
| 551 |
-
"version_minor": 0
|
| 552 |
-
},
|
| 553 |
-
"text/plain": [
|
| 554 |
-
" 0%| | 0/323 [00:00<?, ?it/s]"
|
| 555 |
-
]
|
| 556 |
-
},
|
| 557 |
-
"metadata": {},
|
| 558 |
-
"output_type": "display_data"
|
| 559 |
-
},
|
| 560 |
-
{
|
| 561 |
-
"data": {
|
| 562 |
-
"application/vnd.jupyter.widget-view+json": {
|
| 563 |
-
"model_id": "ae4e72fab47c4f60bb097a7dc5bca43e",
|
| 564 |
-
"version_major": 2,
|
| 565 |
-
"version_minor": 0
|
| 566 |
-
},
|
| 567 |
-
"text/plain": [
|
| 568 |
-
" 0%| | 0/352 [00:00<?, ?it/s]"
|
| 569 |
-
]
|
| 570 |
-
},
|
| 571 |
-
"metadata": {},
|
| 572 |
-
"output_type": "display_data"
|
| 573 |
-
},
|
| 574 |
-
{
|
| 575 |
-
"data": {
|
| 576 |
-
"application/vnd.jupyter.widget-view+json": {
|
| 577 |
-
"model_id": "dd1a2bed58474658977fcb6d7fa06ab1",
|
| 578 |
-
"version_major": 2,
|
| 579 |
-
"version_minor": 0
|
| 580 |
-
},
|
| 581 |
-
"text/plain": [
|
| 582 |
-
" 0%| | 0/374 [00:00<?, ?it/s]"
|
| 583 |
-
]
|
| 584 |
-
},
|
| 585 |
-
"metadata": {},
|
| 586 |
-
"output_type": "display_data"
|
| 587 |
-
},
|
| 588 |
-
{
|
| 589 |
-
"data": {
|
| 590 |
-
"application/vnd.jupyter.widget-view+json": {
|
| 591 |
-
"model_id": "c5deadfd7a9a4861868632f754c8bbc9",
|
| 592 |
-
"version_major": 2,
|
| 593 |
-
"version_minor": 0
|
| 594 |
-
},
|
| 595 |
-
"text/plain": [
|
| 596 |
-
"0it [00:00, ?it/s]"
|
| 597 |
-
]
|
| 598 |
-
},
|
| 599 |
-
"metadata": {},
|
| 600 |
-
"output_type": "display_data"
|
| 601 |
-
},
|
| 602 |
-
{
|
| 603 |
-
"name": "stdout",
|
| 604 |
-
"output_type": "stream",
|
| 605 |
-
"text": [
|
| 606 |
-
"Chapter chapter022 is empty.\n"
|
| 607 |
-
]
|
| 608 |
-
}
|
| 609 |
-
],
|
| 610 |
"source": [
|
| 611 |
-
"os.mkdir(f'outputs/{title}')\n",
|
| 612 |
"\n",
|
| 613 |
-
"for chapter in tqdm(ebook):\n",
|
| 614 |
" chapter_index = f'chapter{ebook.index(chapter):03}'\n",
|
| 615 |
" audio_list = []\n",
|
| 616 |
" for sentence in tqdm(chapter):\n",
|
|
@@ -626,7 +267,7 @@
|
|
| 626 |
"\n",
|
| 627 |
" if len(audio_list) > 0:\n",
|
| 628 |
" audio_file = torch.cat(audio_list).reshape(1, -1)\n",
|
| 629 |
-
"
|
| 630 |
" else:\n",
|
| 631 |
" print(f'Chapter {chapter_index} is empty.')"
|
| 632 |
]
|
|
@@ -672,7 +313,7 @@
|
|
| 672 |
],
|
| 673 |
"metadata": {
|
| 674 |
"kernelspec": {
|
| 675 |
-
"display_name": "Python 3
|
| 676 |
"language": "python",
|
| 677 |
"name": "python3"
|
| 678 |
},
|
|
@@ -686,7 +327,7 @@
|
|
| 686 |
"name": "python",
|
| 687 |
"nbconvert_exporter": "python",
|
| 688 |
"pygments_lexer": "ipython3",
|
| 689 |
-
"version": "3.
|
| 690 |
}
|
| 691 |
},
|
| 692 |
"nbformat": 4,
|
|
|
|
| 45 |
},
|
| 46 |
{
|
| 47 |
"cell_type": "code",
|
| 48 |
+
"execution_count": null,
|
| 49 |
"metadata": {},
|
| 50 |
"outputs": [],
|
| 51 |
"source": [
|
|
|
|
| 79 |
},
|
| 80 |
{
|
| 81 |
"cell_type": "code",
|
| 82 |
+
"execution_count": null,
|
| 83 |
"metadata": {},
|
| 84 |
"outputs": [],
|
| 85 |
"source": [
|
| 86 |
+
"max_char_len = 140\n",
|
| 87 |
"sample_rate = 24000"
|
| 88 |
]
|
| 89 |
},
|
|
|
|
| 122 |
},
|
| 123 |
{
|
| 124 |
"cell_type": "code",
|
| 125 |
+
"execution_count": null,
|
| 126 |
"metadata": {},
|
| 127 |
"outputs": [],
|
| 128 |
"source": [
|
| 129 |
+
"ebook_path = 'test.epub'"
|
| 130 |
]
|
| 131 |
},
|
| 132 |
{
|
|
|
|
| 144 |
},
|
| 145 |
{
|
| 146 |
"cell_type": "code",
|
| 147 |
+
"execution_count": null,
|
| 148 |
"metadata": {},
|
| 149 |
"outputs": [],
|
| 150 |
"source": [
|
|
|
|
| 198 |
},
|
| 199 |
{
|
| 200 |
"cell_type": "code",
|
| 201 |
+
"execution_count": null,
|
| 202 |
"metadata": {},
|
| 203 |
+
"outputs": [],
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 204 |
"source": [
|
| 205 |
"ebook, title = read_ebook(ebook_path)"
|
| 206 |
]
|
|
|
|
| 214 |
},
|
| 215 |
{
|
| 216 |
"cell_type": "code",
|
| 217 |
+
"execution_count": null,
|
| 218 |
"metadata": {},
|
| 219 |
+
"outputs": [],
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 220 |
"source": [
|
| 221 |
+
"print(f'Title of ebook (path name):{title}\\n')\n",
|
| 222 |
+
"print(f'First line of the ebook:{ebook[0][0]}\\n')\n",
|
| 223 |
"print(f'First paragraph (truncated for display): \\n {ebook[2][0:5]}')"
|
| 224 |
]
|
| 225 |
},
|
| 226 |
+
{
|
| 227 |
+
"cell_type": "code",
|
| 228 |
+
"execution_count": null,
|
| 229 |
+
"metadata": {},
|
| 230 |
+
"outputs": [],
|
| 231 |
+
"source": [
|
| 232 |
+
"ebook[0][0]"
|
| 233 |
+
]
|
| 234 |
+
},
|
| 235 |
{
|
| 236 |
"cell_type": "markdown",
|
| 237 |
"metadata": {},
|
|
|
|
| 245 |
},
|
| 246 |
{
|
| 247 |
"cell_type": "code",
|
| 248 |
+
"execution_count": null,
|
| 249 |
"metadata": {},
|
| 250 |
+
"outputs": [],
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 251 |
"source": [
|
| 252 |
+
"#os.mkdir(f'outputs/{title}')\n",
|
| 253 |
"\n",
|
| 254 |
+
"for chapter in tqdm(ebook[0:3]):\n",
|
| 255 |
" chapter_index = f'chapter{ebook.index(chapter):03}'\n",
|
| 256 |
" audio_list = []\n",
|
| 257 |
" for sentence in tqdm(chapter):\n",
|
|
|
|
| 267 |
"\n",
|
| 268 |
" if len(audio_list) > 0:\n",
|
| 269 |
" audio_file = torch.cat(audio_list).reshape(1, -1)\n",
|
| 270 |
+
"# torchaudio.save(sample_path, audio_file, sample_rate)\n",
|
| 271 |
" else:\n",
|
| 272 |
" print(f'Chapter {chapter_index} is empty.')"
|
| 273 |
]
|
|
|
|
| 313 |
],
|
| 314 |
"metadata": {
|
| 315 |
"kernelspec": {
|
| 316 |
+
"display_name": "Python 3",
|
| 317 |
"language": "python",
|
| 318 |
"name": "python3"
|
| 319 |
},
|
|
|
|
| 327 |
"name": "python",
|
| 328 |
"nbconvert_exporter": "python",
|
| 329 |
"pygments_lexer": "ipython3",
|
| 330 |
+
"version": "3.8.10"
|
| 331 |
}
|
| 332 |
},
|
| 333 |
"nbformat": 4,
|
|
@@ -0,0 +1,389 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"cells": [
|
| 3 |
+
{
|
| 4 |
+
"cell_type": "code",
|
| 5 |
+
"execution_count": 1,
|
| 6 |
+
"id": "27a75ece",
|
| 7 |
+
"metadata": {},
|
| 8 |
+
"outputs": [],
|
| 9 |
+
"source": [
|
| 10 |
+
"import nltk"
|
| 11 |
+
]
|
| 12 |
+
},
|
| 13 |
+
{
|
| 14 |
+
"cell_type": "code",
|
| 15 |
+
"execution_count": null,
|
| 16 |
+
"id": "5292a160",
|
| 17 |
+
"metadata": {},
|
| 18 |
+
"outputs": [],
|
| 19 |
+
"source": [
|
| 20 |
+
"import re\n",
|
| 21 |
+
"import numpy as np\n",
|
| 22 |
+
"\n",
|
| 23 |
+
"from bs4 import BeautifulSoup\n",
|
| 24 |
+
"from nltk import tokenize, download\n",
|
| 25 |
+
"from textwrap import TextWrapper"
|
| 26 |
+
]
|
| 27 |
+
},
|
| 28 |
+
{
|
| 29 |
+
"cell_type": "code",
|
| 30 |
+
"execution_count": null,
|
| 31 |
+
"id": "68609a77",
|
| 32 |
+
"metadata": {},
|
| 33 |
+
"outputs": [],
|
| 34 |
+
"source": [
|
| 35 |
+
"# file_path = '1232-h.htm'\n",
|
| 36 |
+
"file_path = 'test.htm'"
|
| 37 |
+
]
|
| 38 |
+
},
|
| 39 |
+
{
|
| 40 |
+
"cell_type": "code",
|
| 41 |
+
"execution_count": null,
|
| 42 |
+
"id": "5c526c9b",
|
| 43 |
+
"metadata": {},
|
| 44 |
+
"outputs": [],
|
| 45 |
+
"source": [
|
| 46 |
+
"download('punkt', quiet=True)\n",
|
| 47 |
+
"wrapper = TextWrapper(140, fix_sentence_endings=True)"
|
| 48 |
+
]
|
| 49 |
+
},
|
| 50 |
+
{
|
| 51 |
+
"cell_type": "code",
|
| 52 |
+
"execution_count": null,
|
| 53 |
+
"id": "d4732304",
|
| 54 |
+
"metadata": {},
|
| 55 |
+
"outputs": [],
|
| 56 |
+
"source": [
|
| 57 |
+
"def preprocess(file):\n",
|
| 58 |
+
" input_text = BeautifulSoup(file, \"html.parser\").text\n",
|
| 59 |
+
" text_list = []\n",
|
| 60 |
+
" for paragraph in input_text.split('\\n'):\n",
|
| 61 |
+
" paragraph = paragraph.replace('—', '-')\n",
|
| 62 |
+
" paragraph = paragraph.replace(' .', '')\n",
|
| 63 |
+
" paragraph = re.sub(r'[^\\x00-\\x7f]', \"\", paragraph)\n",
|
| 64 |
+
" paragraph = re.sub(r'x0f', \" \", paragraph)\n",
|
| 65 |
+
" sentences = tokenize.sent_tokenize(paragraph)\n",
|
| 66 |
+
"\n",
|
| 67 |
+
" sentence_list = []\n",
|
| 68 |
+
" for sentence in sentences:\n",
|
| 69 |
+
" if not re.search('[a-zA-Z]', sentence):\n",
|
| 70 |
+
" sentence = ''\n",
|
| 71 |
+
" wrapped_sentences = wrapper.wrap(sentence)\n",
|
| 72 |
+
" sentence_list.append(wrapped_sentences)\n",
|
| 73 |
+
" trunc_sentences = [phrase for sublist in sentence_list for phrase in sublist]\n",
|
| 74 |
+
" text_list.append(trunc_sentences)\n",
|
| 75 |
+
" text_list = [text for sentences in text_list for text in sentences]\n",
|
| 76 |
+
" return text_list"
|
| 77 |
+
]
|
| 78 |
+
},
|
| 79 |
+
{
|
| 80 |
+
"cell_type": "code",
|
| 81 |
+
"execution_count": null,
|
| 82 |
+
"id": "3045665a",
|
| 83 |
+
"metadata": {},
|
| 84 |
+
"outputs": [],
|
| 85 |
+
"source": [
|
| 86 |
+
"def read_html(file):\n",
|
| 87 |
+
" corpus = preprocess(file)\n",
|
| 88 |
+
" return corpus"
|
| 89 |
+
]
|
| 90 |
+
},
|
| 91 |
+
{
|
| 92 |
+
"cell_type": "code",
|
| 93 |
+
"execution_count": null,
|
| 94 |
+
"id": "e18be118",
|
| 95 |
+
"metadata": {},
|
| 96 |
+
"outputs": [],
|
| 97 |
+
"source": [
|
| 98 |
+
"with open(file_path, 'r') as f:\n",
|
| 99 |
+
" ebook_upload = f.read()\n",
|
| 100 |
+
"corpus = read_html(ebook_upload)"
|
| 101 |
+
]
|
| 102 |
+
},
|
| 103 |
+
{
|
| 104 |
+
"cell_type": "code",
|
| 105 |
+
"execution_count": null,
|
| 106 |
+
"id": "ece1c7d3",
|
| 107 |
+
"metadata": {},
|
| 108 |
+
"outputs": [],
|
| 109 |
+
"source": [
|
| 110 |
+
"np.shape(corpus)"
|
| 111 |
+
]
|
| 112 |
+
},
|
| 113 |
+
{
|
| 114 |
+
"cell_type": "code",
|
| 115 |
+
"execution_count": null,
|
| 116 |
+
"id": "dc7e4010",
|
| 117 |
+
"metadata": {},
|
| 118 |
+
"outputs": [],
|
| 119 |
+
"source": [
|
| 120 |
+
"corpus[0][2]"
|
| 121 |
+
]
|
| 122 |
+
},
|
| 123 |
+
{
|
| 124 |
+
"cell_type": "code",
|
| 125 |
+
"execution_count": null,
|
| 126 |
+
"id": "6cb47a2d",
|
| 127 |
+
"metadata": {},
|
| 128 |
+
"outputs": [],
|
| 129 |
+
"source": [
|
| 130 |
+
"corpus"
|
| 131 |
+
]
|
| 132 |
+
},
|
| 133 |
+
{
|
| 134 |
+
"cell_type": "code",
|
| 135 |
+
"execution_count": null,
|
| 136 |
+
"id": "d11031c7",
|
| 137 |
+
"metadata": {},
|
| 138 |
+
"outputs": [],
|
| 139 |
+
"source": [
|
| 140 |
+
"assert title == \"1232-h\"\n",
|
| 141 |
+
"assert np.shape(corpus) == (1, 5476)\n",
|
| 142 |
+
"assert corpus[0][0] == 'The Project Gutenberg eBook of The Prince, by Nicolo Machiavelli'\n",
|
| 143 |
+
"assert corpus[0][2] == 'This eBook is for the use of anyone anywhere in the United States and'"
|
| 144 |
+
]
|
| 145 |
+
},
|
| 146 |
+
{
|
| 147 |
+
"cell_type": "code",
|
| 148 |
+
"execution_count": null,
|
| 149 |
+
"id": "0c57eec6",
|
| 150 |
+
"metadata": {},
|
| 151 |
+
"outputs": [],
|
| 152 |
+
"source": []
|
| 153 |
+
},
|
| 154 |
+
{
|
| 155 |
+
"cell_type": "code",
|
| 156 |
+
"execution_count": 2,
|
| 157 |
+
"id": "af281267",
|
| 158 |
+
"metadata": {},
|
| 159 |
+
"outputs": [],
|
| 160 |
+
"source": [
|
| 161 |
+
"import re\n",
|
| 162 |
+
"\n",
|
| 163 |
+
"from bs4 import BeautifulSoup\n",
|
| 164 |
+
"from nltk import tokenize, download\n",
|
| 165 |
+
"from textwrap import TextWrapper\n",
|
| 166 |
+
"from stqdm import stqdm"
|
| 167 |
+
]
|
| 168 |
+
},
|
| 169 |
+
{
|
| 170 |
+
"cell_type": "code",
|
| 171 |
+
"execution_count": 6,
|
| 172 |
+
"id": "676ce437",
|
| 173 |
+
"metadata": {},
|
| 174 |
+
"outputs": [],
|
| 175 |
+
"source": [
|
| 176 |
+
"download('punkt', quiet=True)\n",
|
| 177 |
+
"wrapper = TextWrapper(140, fix_sentence_endings=True)\n",
|
| 178 |
+
"file_path = 'test.txt'"
|
| 179 |
+
]
|
| 180 |
+
},
|
| 181 |
+
{
|
| 182 |
+
"cell_type": "code",
|
| 183 |
+
"execution_count": 7,
|
| 184 |
+
"id": "4d278f8e",
|
| 185 |
+
"metadata": {},
|
| 186 |
+
"outputs": [],
|
| 187 |
+
"source": [
|
| 188 |
+
"def preprocess_text(file):\n",
|
| 189 |
+
" input_text = BeautifulSoup(file, \"html.parser\").text\n",
|
| 190 |
+
" text_list = []\n",
|
| 191 |
+
" for paragraph in input_text.split('\\n'):\n",
|
| 192 |
+
" paragraph = paragraph.replace('—', '-')\n",
|
| 193 |
+
" paragraph = paragraph.replace(' .', '')\n",
|
| 194 |
+
" paragraph = re.sub(r'[^\\x00-\\x7f]', \"\", paragraph)\n",
|
| 195 |
+
" paragraph = re.sub(r'x0f', \" \", paragraph)\n",
|
| 196 |
+
" sentences = tokenize.sent_tokenize(paragraph)\n",
|
| 197 |
+
"\n",
|
| 198 |
+
" sentence_list = []\n",
|
| 199 |
+
" for sentence in sentences:\n",
|
| 200 |
+
" if not re.search('[a-zA-Z]', sentence):\n",
|
| 201 |
+
" sentence = ''\n",
|
| 202 |
+
" wrapped_sentences = wrapper.wrap(sentence)\n",
|
| 203 |
+
" sentence_list.append(wrapped_sentences)\n",
|
| 204 |
+
" trunc_sentences = [phrase for sublist in sentence_list for phrase in sublist]\n",
|
| 205 |
+
" text_list.append(trunc_sentences)\n",
|
| 206 |
+
" text_list = [text for sentences in text_list for text in sentences]\n",
|
| 207 |
+
" return text_list"
|
| 208 |
+
]
|
| 209 |
+
},
|
| 210 |
+
{
|
| 211 |
+
"cell_type": "code",
|
| 212 |
+
"execution_count": 8,
|
| 213 |
+
"id": "f67e0184",
|
| 214 |
+
"metadata": {},
|
| 215 |
+
"outputs": [],
|
| 216 |
+
"source": [
|
| 217 |
+
"with open(file_path, 'r') as uploaded_file:\n",
|
| 218 |
+
" file = uploaded_file.read()\n",
|
| 219 |
+
" text = preprocess_text(file)"
|
| 220 |
+
]
|
| 221 |
+
},
|
| 222 |
+
{
|
| 223 |
+
"cell_type": "code",
|
| 224 |
+
"execution_count": 10,
|
| 225 |
+
"id": "0bd67797",
|
| 226 |
+
"metadata": {},
|
| 227 |
+
"outputs": [
|
| 228 |
+
{
|
| 229 |
+
"data": {
|
| 230 |
+
"text/plain": [
|
| 231 |
+
"'Testing Text File \\n\\nWith generated random Lorem Ipsum and other unexpected characters!\\n\\n<a href=\"https://github.com/mkutarna/audiobook_gen/\">Link to generator repo!</a>\\n\\n此行是对非英语字符的测试\\n\\nLorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt ut labore et dolore magna aliqua. Proin fermentum leo vel orci porta non pulvinar. Pretium lectus quam id leo in vitae turpis massa sed. Donec ac odio tempor orci dapibus. Feugiat in ante metus dictum at tempor. Elementum tempus egestas sed sed risus. Adipiscing commodo elit at imperdiet dui accumsan sit. Placerat orci nulla pellentesque dignissim enim. Posuere lorem ipsum dolor sit. Id ornare arcu odio ut sem. Purus faucibus ornare suspendisse sed nisi lacus sed. Ac turpis egestas sed tempus urna et pharetra pharetra massa. Morbi quis commodo odio aenean. Malesuada proin libero nunc consequat interdum. Ut placerat orci nulla pellentesque dignissim enim sit. Elit at imperdiet dui accumsan sit amet.\\n\\nBuilt to test various characters and other possible inputs to the silero model.\\n\\nHere are some Chinese characters: 此行是对非英语字符的测试.\\n\\nThere are 24 letters in the Greek alphabet. The vowels: are α, ε, η, ι, ο, ω, υ. All the rest are consonants.\\n\\nWe can also test for mathematical symbols: ∫, ∇, ∞, δ, ε, X̄, %, √ ,a, ±, ÷, +, = ,-.\\n\\nFinally, here are some emoticons: ☺️🙂😊😀😁☹️🙁😞😟😣😖😨😧😦😱😫😩.'"
|
| 232 |
+
]
|
| 233 |
+
},
|
| 234 |
+
"execution_count": 10,
|
| 235 |
+
"metadata": {},
|
| 236 |
+
"output_type": "execute_result"
|
| 237 |
+
}
|
| 238 |
+
],
|
| 239 |
+
"source": [
|
| 240 |
+
"file"
|
| 241 |
+
]
|
| 242 |
+
},
|
| 243 |
+
{
|
| 244 |
+
"cell_type": "code",
|
| 245 |
+
"execution_count": 9,
|
| 246 |
+
"id": "064aa16b",
|
| 247 |
+
"metadata": {},
|
| 248 |
+
"outputs": [
|
| 249 |
+
{
|
| 250 |
+
"data": {
|
| 251 |
+
"text/plain": [
|
| 252 |
+
"['Testing Text File',\n",
|
| 253 |
+
" 'With generated random Lorem Ipsum and other unexpected characters!',\n",
|
| 254 |
+
" 'Link to generator repo!',\n",
|
| 255 |
+
" 'Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt ut labore et dolore magna aliqua.',\n",
|
| 256 |
+
" 'Proin fermentum leo vel orci porta non pulvinar.',\n",
|
| 257 |
+
" 'Pretium lectus quam id leo in vitae turpis massa sed.',\n",
|
| 258 |
+
" 'Donec ac odio tempor orci dapibus.',\n",
|
| 259 |
+
" 'Feugiat in ante metus dictum at tempor.',\n",
|
| 260 |
+
" 'Elementum tempus egestas sed sed risus.',\n",
|
| 261 |
+
" 'Adipiscing commodo elit at imperdiet dui accumsan sit.',\n",
|
| 262 |
+
" 'Placerat orci nulla pellentesque dignissim enim.',\n",
|
| 263 |
+
" 'Posuere lorem ipsum dolor sit.',\n",
|
| 264 |
+
" 'Id ornare arcu odio ut sem.',\n",
|
| 265 |
+
" 'Purus faucibus ornare suspendisse sed nisi lacus sed.',\n",
|
| 266 |
+
" 'Ac turpis egestas sed tempus urna et pharetra pharetra massa.',\n",
|
| 267 |
+
" 'Morbi quis commodo odio aenean.',\n",
|
| 268 |
+
" 'Malesuada proin libero nunc consequat interdum.',\n",
|
| 269 |
+
" 'Ut placerat orci nulla pellentesque dignissim enim sit.',\n",
|
| 270 |
+
" 'Elit at imperdiet dui accumsan sit amet.',\n",
|
| 271 |
+
" 'Built to test various characters and other possible inputs to the silero model.',\n",
|
| 272 |
+
" 'Here are some Chinese characters: .',\n",
|
| 273 |
+
" 'There are 24 letters in the Greek alphabet.',\n",
|
| 274 |
+
" 'The vowels: are , , , , , , .',\n",
|
| 275 |
+
" 'All the rest are consonants.',\n",
|
| 276 |
+
" 'We can also test for mathematical symbols: , , , , , X, %, ,a, , , +, = ,-.',\n",
|
| 277 |
+
" 'Finally, here are some emoticons: .']"
|
| 278 |
+
]
|
| 279 |
+
},
|
| 280 |
+
"execution_count": 9,
|
| 281 |
+
"metadata": {},
|
| 282 |
+
"output_type": "execute_result"
|
| 283 |
+
}
|
| 284 |
+
],
|
| 285 |
+
"source": [
|
| 286 |
+
"text"
|
| 287 |
+
]
|
| 288 |
+
},
|
| 289 |
+
{
|
| 290 |
+
"cell_type": "code",
|
| 291 |
+
"execution_count": 22,
|
| 292 |
+
"id": "3e8e7965",
|
| 293 |
+
"metadata": {},
|
| 294 |
+
"outputs": [],
|
| 295 |
+
"source": [
|
| 296 |
+
"with open('test_processed.txt', 'w') as output_file:\n",
|
| 297 |
+
" for line in text:\n",
|
| 298 |
+
" output_file.write(line)\n",
|
| 299 |
+
" output_file.write('\\n')"
|
| 300 |
+
]
|
| 301 |
+
},
|
| 302 |
+
{
|
| 303 |
+
"cell_type": "code",
|
| 304 |
+
"execution_count": 26,
|
| 305 |
+
"id": "2aa4c8ff",
|
| 306 |
+
"metadata": {},
|
| 307 |
+
"outputs": [],
|
| 308 |
+
"source": [
|
| 309 |
+
"with open('test_processed.txt', 'r') as process_file:\n",
|
| 310 |
+
" out_file = [line.strip() for line in process_file.readlines()]"
|
| 311 |
+
]
|
| 312 |
+
},
|
| 313 |
+
{
|
| 314 |
+
"cell_type": "code",
|
| 315 |
+
"execution_count": 27,
|
| 316 |
+
"id": "c483fb65",
|
| 317 |
+
"metadata": {},
|
| 318 |
+
"outputs": [
|
| 319 |
+
{
|
| 320 |
+
"data": {
|
| 321 |
+
"text/plain": [
|
| 322 |
+
"['Testing Text File',\n",
|
| 323 |
+
" 'With generated random Lorem Ipsum and other unexpected characters!',\n",
|
| 324 |
+
" 'Link to generator repo!',\n",
|
| 325 |
+
" 'Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt ut labore et dolore magna aliqua.',\n",
|
| 326 |
+
" 'Proin fermentum leo vel orci porta non pulvinar.',\n",
|
| 327 |
+
" 'Pretium lectus quam id leo in vitae turpis massa sed.',\n",
|
| 328 |
+
" 'Donec ac odio tempor orci dapibus.',\n",
|
| 329 |
+
" 'Feugiat in ante metus dictum at tempor.',\n",
|
| 330 |
+
" 'Elementum tempus egestas sed sed risus.',\n",
|
| 331 |
+
" 'Adipiscing commodo elit at imperdiet dui accumsan sit.',\n",
|
| 332 |
+
" 'Placerat orci nulla pellentesque dignissim enim.',\n",
|
| 333 |
+
" 'Posuere lorem ipsum dolor sit.',\n",
|
| 334 |
+
" 'Id ornare arcu odio ut sem.',\n",
|
| 335 |
+
" 'Purus faucibus ornare suspendisse sed nisi lacus sed.',\n",
|
| 336 |
+
" 'Ac turpis egestas sed tempus urna et pharetra pharetra massa.',\n",
|
| 337 |
+
" 'Morbi quis commodo odio aenean.',\n",
|
| 338 |
+
" 'Malesuada proin libero nunc consequat interdum.',\n",
|
| 339 |
+
" 'Ut placerat orci nulla pellentesque dignissim enim sit.',\n",
|
| 340 |
+
" 'Elit at imperdiet dui accumsan sit amet.',\n",
|
| 341 |
+
" 'Built to test various characters and other possible inputs to the silero model.',\n",
|
| 342 |
+
" 'Here are some Chinese characters: .',\n",
|
| 343 |
+
" 'There are 24 letters in the Greek alphabet.',\n",
|
| 344 |
+
" 'The vowels: are , , , , , , .',\n",
|
| 345 |
+
" 'All the rest are consonants.',\n",
|
| 346 |
+
" 'We can also test for mathematical symbols: , , , , , X, %, ,a, , , +, = ,-.',\n",
|
| 347 |
+
" 'Finally, here are some emoticons: .']"
|
| 348 |
+
]
|
| 349 |
+
},
|
| 350 |
+
"execution_count": 27,
|
| 351 |
+
"metadata": {},
|
| 352 |
+
"output_type": "execute_result"
|
| 353 |
+
}
|
| 354 |
+
],
|
| 355 |
+
"source": [
|
| 356 |
+
"out_file"
|
| 357 |
+
]
|
| 358 |
+
},
|
| 359 |
+
{
|
| 360 |
+
"cell_type": "code",
|
| 361 |
+
"execution_count": null,
|
| 362 |
+
"id": "65646961",
|
| 363 |
+
"metadata": {},
|
| 364 |
+
"outputs": [],
|
| 365 |
+
"source": []
|
| 366 |
+
}
|
| 367 |
+
],
|
| 368 |
+
"metadata": {
|
| 369 |
+
"kernelspec": {
|
| 370 |
+
"display_name": "Python 3",
|
| 371 |
+
"language": "python",
|
| 372 |
+
"name": "python3"
|
| 373 |
+
},
|
| 374 |
+
"language_info": {
|
| 375 |
+
"codemirror_mode": {
|
| 376 |
+
"name": "ipython",
|
| 377 |
+
"version": 3
|
| 378 |
+
},
|
| 379 |
+
"file_extension": ".py",
|
| 380 |
+
"mimetype": "text/x-python",
|
| 381 |
+
"name": "python",
|
| 382 |
+
"nbconvert_exporter": "python",
|
| 383 |
+
"pygments_lexer": "ipython3",
|
| 384 |
+
"version": "3.8.10"
|
| 385 |
+
}
|
| 386 |
+
},
|
| 387 |
+
"nbformat": 4,
|
| 388 |
+
"nbformat_minor": 5
|
| 389 |
+
}
|
|
Binary files a/notebooks/pg174.epub and b/notebooks/test.epub differ
|
|
|
|
@@ -0,0 +1,118 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Strict//EN"
|
| 2 |
+
"http://www.w3.org/TR/xhtml1/DTD/xhtml1-strict.dtd">
|
| 3 |
+
<html xmlns="http://www.w3.org/1999/xhtml" xml:lang="en" lang="en">
|
| 4 |
+
<head>
|
| 5 |
+
<meta http-equiv="Content-Type" content="text/html;charset=utf-8" />
|
| 6 |
+
<meta http-equiv="Content-Style-Type" content="text/css" />
|
| 7 |
+
<title>Lorem Ipsum</title>
|
| 8 |
+
|
| 9 |
+
<style type="text/css">
|
| 10 |
+
|
| 11 |
+
body { margin-left: 20%;
|
| 12 |
+
margin-right: 20%;
|
| 13 |
+
text-align: justify; }
|
| 14 |
+
|
| 15 |
+
h1, h2, h3, h4, h5 {text-align: center; font-style: normal; font-weight:
|
| 16 |
+
normal; line-height: 1.5; margin-top: .5em; margin-bottom: .5em;}
|
| 17 |
+
|
| 18 |
+
h1 {font-size: 300%;
|
| 19 |
+
margin-top: 0.6em;
|
| 20 |
+
margin-bottom: 0.6em;
|
| 21 |
+
letter-spacing: 0.12em;
|
| 22 |
+
word-spacing: 0.2em;
|
| 23 |
+
text-indent: 0em;}
|
| 24 |
+
h2 {font-size: 150%; margin-top: 2em; margin-bottom: 1em;}
|
| 25 |
+
h3 {font-size: 130%; margin-top: 1em;}
|
| 26 |
+
h4 {font-size: 120%;}
|
| 27 |
+
h5 {font-size: 110%;}
|
| 28 |
+
|
| 29 |
+
.no-break {page-break-before: avoid;} /* for epubs */
|
| 30 |
+
|
| 31 |
+
div.chapter {page-break-before: always; margin-top: 4em;}
|
| 32 |
+
|
| 33 |
+
hr {width: 80%; margin-top: 2em; margin-bottom: 2em;}
|
| 34 |
+
|
| 35 |
+
p {text-indent: 1em;
|
| 36 |
+
margin-top: 0.25em;
|
| 37 |
+
margin-bottom: 0.25em; }
|
| 38 |
+
|
| 39 |
+
.p2 {margin-top: 2em;}
|
| 40 |
+
|
| 41 |
+
p.poem {text-indent: 0%;
|
| 42 |
+
margin-left: 10%;
|
| 43 |
+
font-size: 90%;
|
| 44 |
+
margin-top: 1em;
|
| 45 |
+
margin-bottom: 1em; }
|
| 46 |
+
|
| 47 |
+
p.letter {text-indent: 0%;
|
| 48 |
+
margin-left: 10%;
|
| 49 |
+
margin-right: 10%;
|
| 50 |
+
margin-top: 1em;
|
| 51 |
+
margin-bottom: 1em; }
|
| 52 |
+
|
| 53 |
+
p.noindent {text-indent: 0% }
|
| 54 |
+
|
| 55 |
+
p.center {text-align: center;
|
| 56 |
+
text-indent: 0em;
|
| 57 |
+
margin-top: 1em;
|
| 58 |
+
margin-bottom: 1em; }
|
| 59 |
+
|
| 60 |
+
p.footnote {font-size: 90%;
|
| 61 |
+
text-indent: 0%;
|
| 62 |
+
margin-left: 10%;
|
| 63 |
+
margin-right: 10%;
|
| 64 |
+
margin-top: 1em;
|
| 65 |
+
margin-bottom: 1em; }
|
| 66 |
+
|
| 67 |
+
sup { vertical-align: top; font-size: 0.6em; }
|
| 68 |
+
|
| 69 |
+
a:link {color:blue; text-decoration:none}
|
| 70 |
+
a:visited {color:blue; text-decoration:none}
|
| 71 |
+
a:hover {color:red}
|
| 72 |
+
|
| 73 |
+
</style>
|
| 74 |
+
|
| 75 |
+
</head>
|
| 76 |
+
|
| 77 |
+
<body>
|
| 78 |
+
|
| 79 |
+
<div style='display:block; margin:1em 0'>
|
| 80 |
+
This eBook is a generated Lorem Ipsum for the purposes of testing the Audiobook Gen app.
|
| 81 |
+
</div>
|
| 82 |
+
<div style='display:block; margin:1em 0'>Language: English</div>
|
| 83 |
+
<div style='display:block; margin:1em 0'>Character set encoding: UTF-8</div>
|
| 84 |
+
|
| 85 |
+
|
| 86 |
+
<p class="letter">
|
| 87 |
+
<i>
|
| 88 |
+
Diam vel quam elementum pulvinar etiam non quam. At tellus at urna condimentum mattis. Nisi scelerisque eu ultrices vitae auctor eu augue ut. Integer malesuada nunc vel risus commodo viverra maecenas accumsan. Ornare suspendisse sed nisi lacus. Sapien faucibus et molestie ac feugiat sed lectus. Quam elementum pulvinar etiam non. Elementum integer enim neque volutpat ac tincidunt. Justo laoreet sit amet cursus sit. Amet venenatis urna cursus eget nunc scelerisque viverra mauris. Cras semper auctor neque vitae tempus quam pellentesque nec nam. Fermentum iaculis eu non diam phasellus vestibulum lorem sed. Non pulvinar neque laoreet suspendisse interdum consectetur libero. Nec tincidunt praesent semper feugiat nibh sed. Sed id semper risus in hendrerit gravida rutrum. Suspendisse in est ante in nibh. Dui ut ornare lectus sit amet est placerat in.
|
| 89 |
+
</i>
|
| 90 |
+
</p>
|
| 91 |
+
|
| 92 |
+
</div><!--end chapter-->
|
| 93 |
+
|
| 94 |
+
<div class="chapter">
|
| 95 |
+
|
| 96 |
+
<h2><a name="pref01"></a>A NEW LOREM</h2>
|
| 97 |
+
|
| 98 |
+
<p>
|
| 99 |
+
Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt ut labore et dolore magna aliqua. Proin fermentum leo vel orci porta non pulvinar. Pretium lectus quam id leo in vitae turpis massa sed. Donec ac odio tempor orci dapibus. Feugiat in ante metus dictum at tempor. Elementum tempus egestas sed sed risus. Adipiscing commodo elit at imperdiet dui accumsan sit. Placerat orci nulla pellentesque dignissim enim. Posuere lorem ipsum dolor sit. Id ornare arcu odio ut sem. Purus faucibus ornare suspendisse sed nisi lacus sed. Ac turpis egestas sed tempus urna et pharetra pharetra massa. Morbi quis commodo odio aenean. Malesuada proin libero nunc consequat interdum. Ut placerat orci nulla pellentesque dignissim enim sit. Elit at imperdiet dui accumsan sit amet.
|
| 100 |
+
</p>
|
| 101 |
+
|
| 102 |
+
<p>
|
| 103 |
+
Nunc sed id semper risus in hendrerit gravida rutrum quisque. Augue interdum velit euismod in pellentesque. Elementum curabitur vitae nunc sed velit dignissim sodales ut eu. Mi in nulla posuere sollicitudin aliquam ultrices sagittis orci a. Quisque sagittis purus sit amet volutpat consequat mauris. Risus in hendrerit gravida rutrum. Quis vel eros donec ac odio. Eget nunc lobortis mattis aliquam faucibus. Lobortis scelerisque fermentum dui faucibus. Est velit egestas dui id ornare arcu odio. Sed ullamcorper morbi tincidunt ornare massa eget egestas purus. Nisi porta lorem mollis aliquam ut porttitor leo a. Ut morbi tincidunt augue interdum velit. Egestas diam in arcu cursus euismod. Tortor id aliquet lectus proin nibh nisl condimentum id venenatis. Lectus sit amet est placerat in egestas erat imperdiet sed. Amet tellus cras adipiscing enim eu turpis egestas pretium. Et leo duis ut diam quam.
|
| 104 |
+
</p>
|
| 105 |
+
|
| 106 |
+
</div><!--end chapter-->
|
| 107 |
+
|
| 108 |
+
<div class="chapter">
|
| 109 |
+
|
| 110 |
+
<h2><a name="pref02"></a>IPSUM STRIKES BACK</h2>
|
| 111 |
+
|
| 112 |
+
<p>
|
| 113 |
+
Egestas diam in arcu cursus euismod quis. Leo in vitae turpis massa sed elementum tempus egestas. Amet nulla facilisi morbi tempus iaculis urna id volutpat. Parturient montes nascetur ridiculus mus. Erat pellentesque adipiscing commodo elit at imperdiet. Egestas congue quisque egestas diam in arcu cursus. Diam ut venenatis tellus in metus. Ullamcorper eget nulla facilisi etiam. Blandit turpis cursus in hac habitasse platea dictumst quisque. Cursus euismod quis viverra nibh cras pulvinar. Neque viverra justo nec ultrices. Dui ut ornare lectus sit. Mauris ultrices eros in cursus turpis massa tincidunt. Lobortis elementum nibh tellus molestie nunc non blandit massa enim. Ullamcorper morbi tincidunt ornare massa eget egestas purus viverra.
|
| 114 |
+
</p>
|
| 115 |
+
|
| 116 |
+
<p>
|
| 117 |
+
Mauris in aliquam sem fringilla ut morbi. Nunc sed blandit libero volutpat. Amet venenatis urna cursus eget nunc scelerisque. Sagittis nisl rhoncus mattis rhoncus urna neque. Felis eget nunc lobortis mattis aliquam faucibus purus in massa. Fringilla ut morbi tincidunt augue interdum. Nibh mauris cursus mattis molestie a iaculis at erat. Lacus sed turpis tincidunt id aliquet risus feugiat in. Nulla facilisi etiam dignissim diam quis enim lobortis. Vitae congue eu consequat ac felis donec et. Scelerisque viverra mauris in aliquam sem fringilla ut morbi tincidunt. Blandit volutpat maecenas volutpat blandit aliquam. Ultrices tincidunt arcu non sodales neque sodales ut etiam. Sollicitudin aliquam ultrices sagittis orci a scelerisque. Id cursus metus aliquam eleifend mi. Magna eget est lorem ipsum dolor sit amet consectetur. Eleifend mi in nulla posuere sollicitudin aliquam ultrices. Neque sodales ut etiam sit amet. Enim neque volutpat ac tincidunt vitae semper quis lectus nulla.
|
| 118 |
+
</p>
|
|
File without changes
|
|
@@ -1,4 +1,4 @@
|
|
| 1 |
# pytest.ini
|
| 2 |
[pytest]
|
| 3 |
-
|
| 4 |
-
|
|
|
|
| 1 |
# pytest.ini
|
| 2 |
[pytest]
|
| 3 |
+
pythonpath = . src
|
| 4 |
+
testpaths = tests
|
|
@@ -0,0 +1,7 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
silero
|
| 2 |
+
streamlit
|
| 3 |
+
ebooklib
|
| 4 |
+
PyPDF2
|
| 5 |
+
bs4
|
| 6 |
+
nltk
|
| 7 |
+
stqdm
|
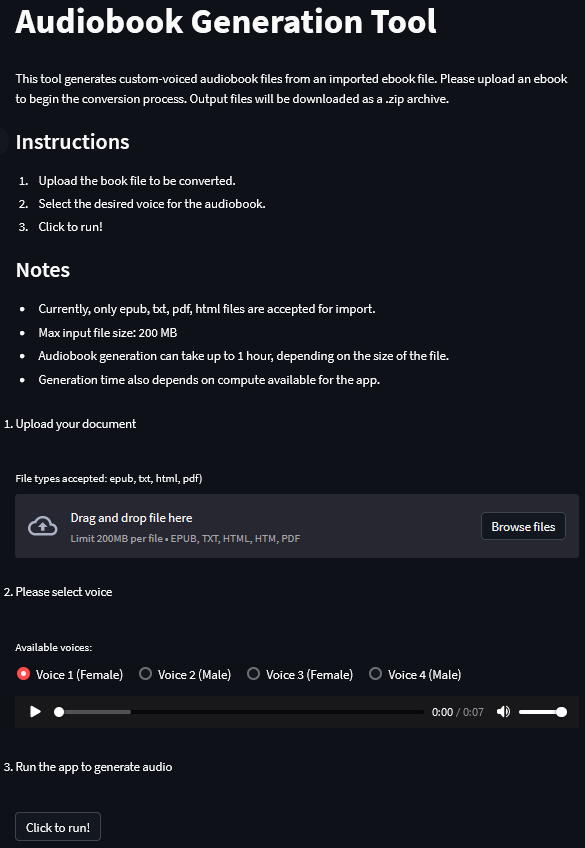
|
|
@@ -0,0 +1,13 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
This tool generates custom-voiced audiobook files from an imported ebook file. Please upload an ebook to begin the conversion process. Output files will be downloaded as a .zip archive.
|
| 2 |
+
|
| 3 |
+
### Instructions
|
| 4 |
+
1. Upload the book file to be converted.
|
| 5 |
+
2. Select the desired voice for the audiobook.
|
| 6 |
+
3. Click to run!
|
| 7 |
+
|
| 8 |
+
|
| 9 |
+
### Notes
|
| 10 |
+
- Currently, only epub, txt, pdf files are accepted for import.
|
| 11 |
+
- Max input file size: 200 MB
|
| 12 |
+
- Audiobook generation can take up to 1 hour, depending on the size of the file.
|
| 13 |
+
- Generation time also depends on compute available for the app.
|
|
Binary file (629 kB). View file
|
|
|
|
Binary file (580 kB). View file
|
|
|
|
Binary file (546 kB). View file
|
|
|
|
Binary file (574 kB). View file
|
|
|
|
File without changes
|
|
@@ -0,0 +1,23 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""
|
| 2 |
+
Notes
|
| 3 |
+
-----
|
| 4 |
+
This module contains the configuration entries for audiobook_gen.
|
| 5 |
+
"""
|
| 6 |
+
|
| 7 |
+
from pathlib import Path
|
| 8 |
+
|
| 9 |
+
output_path = Path("outputs")
|
| 10 |
+
resource_path = Path("resources")
|
| 11 |
+
INSTRUCTIONS = Path("resources/instructions.md")
|
| 12 |
+
|
| 13 |
+
DEVICE = 'cpu'
|
| 14 |
+
LANGUAGE = 'en'
|
| 15 |
+
MAX_CHAR_LEN = 140
|
| 16 |
+
MODEL_ID = 'v3_en'
|
| 17 |
+
SAMPLE_RATE = 24000
|
| 18 |
+
SPEAKER_LIST = {
|
| 19 |
+
'Voice 1 (Female)': 'en_0',
|
| 20 |
+
'Voice 2 (Male)': 'en_29',
|
| 21 |
+
'Voice 3 (Female)': 'en_41',
|
| 22 |
+
'Voice 4 (Male)': 'en_110'
|
| 23 |
+
}
|
|
@@ -0,0 +1,120 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""
|
| 2 |
+
Notes
|
| 3 |
+
-----
|
| 4 |
+
This module contains the functions for audiobook_gen that read in the
|
| 5 |
+
file formats that require for parsing than plain text (pdf, html, epub),
|
| 6 |
+
as well as the preprocessing function for all input files.
|
| 7 |
+
"""
|
| 8 |
+
import re
|
| 9 |
+
|
| 10 |
+
from bs4 import BeautifulSoup
|
| 11 |
+
from nltk import tokenize, download
|
| 12 |
+
from textwrap import TextWrapper
|
| 13 |
+
from stqdm import stqdm
|
| 14 |
+
|
| 15 |
+
from src import config
|
| 16 |
+
|
| 17 |
+
download('punkt', quiet=True)
|
| 18 |
+
wrapper = TextWrapper(config.MAX_CHAR_LEN, fix_sentence_endings=True)
|
| 19 |
+
|
| 20 |
+
|
| 21 |
+
def preprocess_text(file):
|
| 22 |
+
"""
|
| 23 |
+
Preprocesses and tokenizes a section of text from the corpus:
|
| 24 |
+
1. Removes residual HTML tags
|
| 25 |
+
2. Handles un-supported characters
|
| 26 |
+
3. Tokenizes text and confirms max token size
|
| 27 |
+
|
| 28 |
+
Parameters
|
| 29 |
+
----------
|
| 30 |
+
file : file_like
|
| 31 |
+
list of strings,
|
| 32 |
+
section of corpus to be pre-processed and tokenized
|
| 33 |
+
|
| 34 |
+
Returns
|
| 35 |
+
-------
|
| 36 |
+
text_list : : array_like
|
| 37 |
+
list of strings,
|
| 38 |
+
body of tokenized text from which audio is generated
|
| 39 |
+
|
| 40 |
+
"""
|
| 41 |
+
input_text = BeautifulSoup(file, "html.parser").text
|
| 42 |
+
text_list = []
|
| 43 |
+
for paragraph in input_text.split('\n'):
|
| 44 |
+
paragraph = paragraph.replace('—', '-')
|
| 45 |
+
paragraph = paragraph.replace(' .', '')
|
| 46 |
+
paragraph = re.sub(r'[^\x00-\x7f]', "", paragraph)
|
| 47 |
+
paragraph = re.sub(r'x0f', " ", paragraph)
|
| 48 |
+
sentences = tokenize.sent_tokenize(paragraph)
|
| 49 |
+
|
| 50 |
+
sentence_list = []
|
| 51 |
+
for sentence in sentences:
|
| 52 |
+
if not re.search('[a-zA-Z]', sentence):
|
| 53 |
+
sentence = ''
|
| 54 |
+
wrapped_sentences = wrapper.wrap(sentence)
|
| 55 |
+
sentence_list.append(wrapped_sentences)
|
| 56 |
+
trunc_sentences = [phrase for sublist in sentence_list for phrase in sublist]
|
| 57 |
+
text_list.append(trunc_sentences)
|
| 58 |
+
text_list = [text for sentences in text_list for text in sentences]
|
| 59 |
+
return text_list
|
| 60 |
+
|
| 61 |
+
|
| 62 |
+
def read_pdf(file):
|
| 63 |
+
"""
|
| 64 |
+
Invokes PyPDF2 PdfReader to extract main body text from PDF file_like input,
|
| 65 |
+
and preprocesses text section by section.
|
| 66 |
+
|
| 67 |
+
Parameters
|
| 68 |
+
----------
|
| 69 |
+
file : file_like
|
| 70 |
+
PDF file input to be parsed and preprocessed
|
| 71 |
+
|
| 72 |
+
Returns
|
| 73 |
+
-------
|
| 74 |
+
corpus : array_like
|
| 75 |
+
list of list of strings,
|
| 76 |
+
body of tokenized text from which audio is generated
|
| 77 |
+
|
| 78 |
+
"""
|
| 79 |
+
from PyPDF2 import PdfReader
|
| 80 |
+
|
| 81 |
+
reader = PdfReader(file)
|
| 82 |
+
corpus = []
|
| 83 |
+
for item in stqdm(list(reader.pages), desc="Pages in pdf:"):
|
| 84 |
+
text_list = preprocess_text(item.extract_text())
|
| 85 |
+
corpus.append(text_list)
|
| 86 |
+
return corpus
|
| 87 |
+
|
| 88 |
+
|
| 89 |
+
def read_epub(file):
|
| 90 |
+
"""
|
| 91 |
+
Invokes ebooklib read_epub to extract main body text from epub file_like input,
|
| 92 |
+
and preprocesses text section by section.
|
| 93 |
+
|
| 94 |
+
Parameters
|
| 95 |
+
----------
|
| 96 |
+
file : file_like
|
| 97 |
+
EPUB file input to be parsed and preprocessed
|
| 98 |
+
|
| 99 |
+
Returns
|
| 100 |
+
-------
|
| 101 |
+
corpus : array_like
|
| 102 |
+
list of list of strings,
|
| 103 |
+
body of tokenized text from which audio is generated
|
| 104 |
+
|
| 105 |
+
file_title : str
|
| 106 |
+
title of document, used to name output files
|
| 107 |
+
|
| 108 |
+
"""
|
| 109 |
+
import ebooklib
|
| 110 |
+
from ebooklib import epub
|
| 111 |
+
|
| 112 |
+
book = epub.read_epub(file)
|
| 113 |
+
file_title = book.get_metadata('DC', 'title')[0][0]
|
| 114 |
+
file_title = file_title.lower().replace(' ', '_')
|
| 115 |
+
corpus = []
|
| 116 |
+
for item in stqdm(list(book.get_items()), desc="Chapters in ebook:"):
|
| 117 |
+
if item.get_type() == ebooklib.ITEM_DOCUMENT:
|
| 118 |
+
text_list = preprocess_text(item.get_content())
|
| 119 |
+
corpus.append(text_list)
|
| 120 |
+
return corpus, file_title
|
|
@@ -0,0 +1,74 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""
|
| 2 |
+
Notes
|
| 3 |
+
-----
|
| 4 |
+
This module contains the functions for audiobook_gen that take the generated audio tensors and output to audio files,
|
| 5 |
+
as well as assembling the final zip archive for user download.
|
| 6 |
+
"""
|
| 7 |
+
import logging
|
| 8 |
+
|
| 9 |
+
from src import config
|
| 10 |
+
|
| 11 |
+
|
| 12 |
+
def write_audio(audio_list, sample_path):
|
| 13 |
+
"""
|
| 14 |
+
Invokes torchaudio to save generated audio tensors to a file.
|
| 15 |
+
|
| 16 |
+
Parameters
|
| 17 |
+
----------
|
| 18 |
+
audio_list : torch.tensor
|
| 19 |
+
pytorch tensor containing generated audio
|
| 20 |
+
|
| 21 |
+
sample_path : str
|
| 22 |
+
file name and path for outputting tensor to audio file
|
| 23 |
+
|
| 24 |
+
Returns
|
| 25 |
+
-------
|
| 26 |
+
None
|
| 27 |
+
|
| 28 |
+
"""
|
| 29 |
+
import torch
|
| 30 |
+
import torchaudio
|
| 31 |
+
from src import config as cf
|
| 32 |
+
|
| 33 |
+
if not config.output_path.exists():
|
| 34 |
+
config.output_path.mkdir()
|
| 35 |
+
|
| 36 |
+
if len(audio_list) > 0:
|
| 37 |
+
audio_file = torch.cat(audio_list).reshape(1, -1)
|
| 38 |
+
torchaudio.save(sample_path, audio_file, cf.SAMPLE_RATE)
|
| 39 |
+
logging.info(f'Audio generated at: {sample_path}')
|
| 40 |
+
else:
|
| 41 |
+
logging.info(f'Audio at: {sample_path} is empty.')
|
| 42 |
+
|
| 43 |
+
|
| 44 |
+
def assemble_zip(title):
|
| 45 |
+
"""
|
| 46 |
+
Creates a zip file and inserts all .wav files in the output directory,
|
| 47 |
+
and returns the name / path of the zip file.
|
| 48 |
+
|
| 49 |
+
Parameters
|
| 50 |
+
----------
|
| 51 |
+
title : str
|
| 52 |
+
title of document, used to name zip directory
|
| 53 |
+
|
| 54 |
+
Returns
|
| 55 |
+
-------
|
| 56 |
+
zip_name : str
|
| 57 |
+
name and path of zip directory generated
|
| 58 |
+
|
| 59 |
+
"""
|
| 60 |
+
import zipfile
|
| 61 |
+
from stqdm import stqdm
|
| 62 |
+
|
| 63 |
+
if not config.output_path.exists():
|
| 64 |
+
config.output_path.mkdir()
|
| 65 |
+
|
| 66 |
+
zip_name = config.output_path / f'{title}.zip'
|
| 67 |
+
|
| 68 |
+
with zipfile.ZipFile(zip_name, mode="w") as archive:
|
| 69 |
+
for file_path in stqdm(config.output_path.iterdir()):
|
| 70 |
+
if file_path.suffix == '.wav':
|
| 71 |
+
archive.write(file_path, arcname=file_path.name)
|
| 72 |
+
file_path.unlink()
|
| 73 |
+
|
| 74 |
+
return zip_name
|
|
@@ -0,0 +1,110 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""
|
| 2 |
+
Notes
|
| 3 |
+
-----
|
| 4 |
+
This module contains the functions for audiobook_gen that handle text-to-speech generation.
|
| 5 |
+
The functions take in the preprocessed text and invoke the Silero package to generate audio tensors.
|
| 6 |
+
"""
|
| 7 |
+
import logging
|
| 8 |
+
|
| 9 |
+
import torch
|
| 10 |
+
from stqdm import stqdm
|
| 11 |
+
|
| 12 |
+
from src import output, config
|
| 13 |
+
|
| 14 |
+
|
| 15 |
+
def load_model():
|
| 16 |
+
"""
|
| 17 |
+
Load Silero package containg the model information
|
| 18 |
+
for the language and speaker set in config.py
|
| 19 |
+
and converts it to the set device.
|
| 20 |
+
|
| 21 |
+
Parameters
|
| 22 |
+
----------
|
| 23 |
+
None
|
| 24 |
+
|
| 25 |
+
Returns
|
| 26 |
+
-------
|
| 27 |
+
model : torch.package
|
| 28 |
+
|
| 29 |
+
"""
|
| 30 |
+
from silero import silero_tts
|
| 31 |
+
|
| 32 |
+
model, _ = silero_tts(language=config.LANGUAGE, speaker=config.MODEL_ID)
|
| 33 |
+
model.to(config.DEVICE)
|
| 34 |
+
return model
|
| 35 |
+
|
| 36 |
+
|
| 37 |
+
def generate_audio(corpus, title, model, speaker):
|
| 38 |
+
"""
|
| 39 |
+
For each section within the corpus, calls predict() function to generate audio tensors
|
| 40 |
+
and then calls write_audio() to output the tensors to audio files.
|
| 41 |
+
|
| 42 |
+
Parameters
|
| 43 |
+
----------
|
| 44 |
+
corpus : array_like
|
| 45 |
+
list of list of strings,
|
| 46 |
+
body of tokenized text from which audio is generated
|
| 47 |
+
|
| 48 |
+
title : str
|
| 49 |
+
title of document, used to name output files
|
| 50 |
+
|
| 51 |
+
model : torch.package
|
| 52 |
+
torch package containing model for language and speaker specified
|
| 53 |
+
|
| 54 |
+
speaker : str
|
| 55 |
+
identifier of selected speaker for audio generation
|
| 56 |
+
|
| 57 |
+
Returns
|
| 58 |
+
-------
|
| 59 |
+
None
|
| 60 |
+
|
| 61 |
+
"""
|
| 62 |
+
for section in stqdm(corpus, desc="Sections in document:"):
|
| 63 |
+
section_index = f'part{corpus.index(section):03}'
|
| 64 |
+
audio_list, sample_path = predict(section, section_index, title, model, speaker)
|
| 65 |
+
output.write_audio(audio_list, sample_path)
|
| 66 |
+
|
| 67 |
+
|
| 68 |
+
def predict(text_section, section_index, title, model, speaker):
|
| 69 |
+
"""
|
| 70 |
+
Applies Silero TTS engine for each token within the corpus section,
|
| 71 |
+
appending it to the output tensor array, and creates file path for output.
|
| 72 |
+
|
| 73 |
+
Parameters
|
| 74 |
+
----------
|
| 75 |
+
text_section : array_like
|
| 76 |
+
list of strings,
|
| 77 |
+
body of tokenized text from which audio is generated
|
| 78 |
+
|
| 79 |
+
section_index : int
|
| 80 |
+
index of current section within corpus
|
| 81 |
+
|
| 82 |
+
title : str
|
| 83 |
+
title of document, used to name output files
|
| 84 |
+
|
| 85 |
+
model : torch.package
|
| 86 |
+
torch package containing model for language and speaker specified
|
| 87 |
+
|
| 88 |
+
speaker : str
|
| 89 |
+
identifier of selected speaker for audio generation
|
| 90 |
+
|
| 91 |
+
Returns
|
| 92 |
+
-------
|
| 93 |
+
audio_list : torch.tensor
|
| 94 |
+
pytorch tensor containing generated audio
|
| 95 |
+
|
| 96 |
+
sample_path : str
|
| 97 |
+
file name and path for outputting tensor to audio file
|
| 98 |
+
|
| 99 |
+
"""
|
| 100 |
+
audio_list = []
|
| 101 |
+
for sentence in stqdm(text_section, desc="Sentences in section:"):
|
| 102 |
+
audio = model.apply_tts(text=sentence, speaker=speaker, sample_rate=config.SAMPLE_RATE)
|
| 103 |
+
if len(audio) > 0 and isinstance(audio, torch.Tensor):
|
| 104 |
+
audio_list.append(audio)
|
| 105 |
+
logging.info(f'Tensor generated for sentence: \n {sentence}')
|
| 106 |
+
else:
|
| 107 |
+
logging.info(f'Tensor for sentence is not valid: \n {sentence}')
|
| 108 |
+
|
| 109 |
+
sample_path = config.output_path / f'{title}_{section_index}.wav'
|
| 110 |
+
return audio_list, sample_path
|
|
Binary file (661 Bytes)
|
|
|
|
Binary file (90.4 kB). View file
|
|
|
|
@@ -0,0 +1,118 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Strict//EN"
|
| 2 |
+
"http://www.w3.org/TR/xhtml1/DTD/xhtml1-strict.dtd">
|
| 3 |
+
<html xmlns="http://www.w3.org/1999/xhtml" xml:lang="en" lang="en">
|
| 4 |
+
<head>
|
| 5 |
+
<meta http-equiv="Content-Type" content="text/html;charset=utf-8" />
|
| 6 |
+
<meta http-equiv="Content-Style-Type" content="text/css" />
|
| 7 |
+
<title>Lorem Ipsum</title>
|
| 8 |
+
|
| 9 |
+
<style type="text/css">
|
| 10 |
+
|
| 11 |
+
body { margin-left: 20%;
|
| 12 |
+
margin-right: 20%;
|
| 13 |
+
text-align: justify; }
|
| 14 |
+
|
| 15 |
+
h1, h2, h3, h4, h5 {text-align: center; font-style: normal; font-weight:
|
| 16 |
+
normal; line-height: 1.5; margin-top: .5em; margin-bottom: .5em;}
|
| 17 |
+
|
| 18 |
+
h1 {font-size: 300%;
|
| 19 |
+
margin-top: 0.6em;
|
| 20 |
+
margin-bottom: 0.6em;
|
| 21 |
+
letter-spacing: 0.12em;
|
| 22 |
+
word-spacing: 0.2em;
|
| 23 |
+
text-indent: 0em;}
|
| 24 |
+
h2 {font-size: 150%; margin-top: 2em; margin-bottom: 1em;}
|
| 25 |
+
h3 {font-size: 130%; margin-top: 1em;}
|
| 26 |
+
h4 {font-size: 120%;}
|
| 27 |
+
h5 {font-size: 110%;}
|
| 28 |
+
|
| 29 |
+
.no-break {page-break-before: avoid;} /* for epubs */
|
| 30 |
+
|
| 31 |
+
div.chapter {page-break-before: always; margin-top: 4em;}
|
| 32 |
+
|
| 33 |
+
hr {width: 80%; margin-top: 2em; margin-bottom: 2em;}
|
| 34 |
+
|
| 35 |
+
p {text-indent: 1em;
|
| 36 |
+
margin-top: 0.25em;
|
| 37 |
+
margin-bottom: 0.25em; }
|
| 38 |
+
|
| 39 |
+
.p2 {margin-top: 2em;}
|
| 40 |
+
|
| 41 |
+
p.poem {text-indent: 0%;
|
| 42 |
+
margin-left: 10%;
|
| 43 |
+
font-size: 90%;
|
| 44 |
+
margin-top: 1em;
|
| 45 |
+
margin-bottom: 1em; }
|
| 46 |
+
|
| 47 |
+
p.letter {text-indent: 0%;
|
| 48 |
+
margin-left: 10%;
|
| 49 |
+
margin-right: 10%;
|
| 50 |
+
margin-top: 1em;
|
| 51 |
+
margin-bottom: 1em; }
|
| 52 |
+
|
| 53 |
+
p.noindent {text-indent: 0% }
|
| 54 |
+
|
| 55 |
+
p.center {text-align: center;
|
| 56 |
+
text-indent: 0em;
|
| 57 |
+
margin-top: 1em;
|
| 58 |
+
margin-bottom: 1em; }
|
| 59 |
+
|
| 60 |
+
p.footnote {font-size: 90%;
|
| 61 |
+
text-indent: 0%;
|
| 62 |
+
margin-left: 10%;
|
| 63 |
+
margin-right: 10%;
|
| 64 |
+
margin-top: 1em;
|
| 65 |
+
margin-bottom: 1em; }
|
| 66 |
+
|
| 67 |
+
sup { vertical-align: top; font-size: 0.6em; }
|
| 68 |
+
|
| 69 |
+
a:link {color:blue; text-decoration:none}
|
| 70 |
+
a:visited {color:blue; text-decoration:none}
|
| 71 |
+
a:hover {color:red}
|
| 72 |
+
|
| 73 |
+
</style>
|
| 74 |
+
|
| 75 |
+
</head>
|
| 76 |
+
|
| 77 |
+
<body>
|
| 78 |
+
|
| 79 |
+
<div style='display:block; margin:1em 0'>
|
| 80 |
+
This eBook is a generated Lorem Ipsum for the purposes of testing the Audiobook Gen app.
|
| 81 |
+
</div>
|
| 82 |
+
<div style='display:block; margin:1em 0'>Language: English</div>
|
| 83 |
+
<div style='display:block; margin:1em 0'>Character set encoding: UTF-8</div>
|
| 84 |
+
|
| 85 |
+
|
| 86 |
+
<p class="letter">
|
| 87 |
+
<i>
|
| 88 |
+
Diam vel quam elementum pulvinar etiam non quam. At tellus at urna condimentum mattis. Nisi scelerisque eu ultrices vitae auctor eu augue ut. Integer malesuada nunc vel risus commodo viverra maecenas accumsan. Ornare suspendisse sed nisi lacus. Sapien faucibus et molestie ac feugiat sed lectus. Quam elementum pulvinar etiam non. Elementum integer enim neque volutpat ac tincidunt. Justo laoreet sit amet cursus sit. Amet venenatis urna cursus eget nunc scelerisque viverra mauris. Cras semper auctor neque vitae tempus quam pellentesque nec nam. Fermentum iaculis eu non diam phasellus vestibulum lorem sed. Non pulvinar neque laoreet suspendisse interdum consectetur libero. Nec tincidunt praesent semper feugiat nibh sed. Sed id semper risus in hendrerit gravida rutrum. Suspendisse in est ante in nibh. Dui ut ornare lectus sit amet est placerat in.
|
| 89 |
+
</i>
|
| 90 |
+
</p>
|
| 91 |
+
|
| 92 |
+
</div><!--end chapter-->
|
| 93 |
+
|
| 94 |
+
<div class="chapter">
|
| 95 |
+
|
| 96 |
+
<h2><a name="pref01"></a>A NEW LOREM</h2>
|
| 97 |
+
|
| 98 |
+
<p>
|
| 99 |
+
Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt ut labore et dolore magna aliqua. Proin fermentum leo vel orci porta non pulvinar. Pretium lectus quam id leo in vitae turpis massa sed. Donec ac odio tempor orci dapibus. Feugiat in ante metus dictum at tempor. Elementum tempus egestas sed sed risus. Adipiscing commodo elit at imperdiet dui accumsan sit. Placerat orci nulla pellentesque dignissim enim. Posuere lorem ipsum dolor sit. Id ornare arcu odio ut sem. Purus faucibus ornare suspendisse sed nisi lacus sed. Ac turpis egestas sed tempus urna et pharetra pharetra massa. Morbi quis commodo odio aenean. Malesuada proin libero nunc consequat interdum. Ut placerat orci nulla pellentesque dignissim enim sit. Elit at imperdiet dui accumsan sit amet.
|
| 100 |
+
</p>
|
| 101 |
+
|
| 102 |
+
<p>
|
| 103 |
+
Nunc sed id semper risus in hendrerit gravida rutrum quisque. Augue interdum velit euismod in pellentesque. Elementum curabitur vitae nunc sed velit dignissim sodales ut eu. Mi in nulla posuere sollicitudin aliquam ultrices sagittis orci a. Quisque sagittis purus sit amet volutpat consequat mauris. Risus in hendrerit gravida rutrum. Quis vel eros donec ac odio. Eget nunc lobortis mattis aliquam faucibus. Lobortis scelerisque fermentum dui faucibus. Est velit egestas dui id ornare arcu odio. Sed ullamcorper morbi tincidunt ornare massa eget egestas purus. Nisi porta lorem mollis aliquam ut porttitor leo a. Ut morbi tincidunt augue interdum velit. Egestas diam in arcu cursus euismod. Tortor id aliquet lectus proin nibh nisl condimentum id venenatis. Lectus sit amet est placerat in egestas erat imperdiet sed. Amet tellus cras adipiscing enim eu turpis egestas pretium. Et leo duis ut diam quam.
|
| 104 |
+
</p>
|
| 105 |
+
|
| 106 |
+
</div><!--end chapter-->
|
| 107 |
+
|
| 108 |
+
<div class="chapter">
|
| 109 |
+
|
| 110 |
+
<h2><a name="pref02"></a>IPSUM STRIKES BACK</h2>
|
| 111 |
+
|
| 112 |
+
<p>
|
| 113 |
+
Egestas diam in arcu cursus euismod quis. Leo in vitae turpis massa sed elementum tempus egestas. Amet nulla facilisi morbi tempus iaculis urna id volutpat. Parturient montes nascetur ridiculus mus. Erat pellentesque adipiscing commodo elit at imperdiet. Egestas congue quisque egestas diam in arcu cursus. Diam ut venenatis tellus in metus. Ullamcorper eget nulla facilisi etiam. Blandit turpis cursus in hac habitasse platea dictumst quisque. Cursus euismod quis viverra nibh cras pulvinar. Neque viverra justo nec ultrices. Dui ut ornare lectus sit. Mauris ultrices eros in cursus turpis massa tincidunt. Lobortis elementum nibh tellus molestie nunc non blandit massa enim. Ullamcorper morbi tincidunt ornare massa eget egestas purus viverra.
|
| 114 |
+
</p>
|
| 115 |
+
|
| 116 |
+
<p>
|
| 117 |
+
Mauris in aliquam sem fringilla ut morbi. Nunc sed blandit libero volutpat. Amet venenatis urna cursus eget nunc scelerisque. Sagittis nisl rhoncus mattis rhoncus urna neque. Felis eget nunc lobortis mattis aliquam faucibus purus in massa. Fringilla ut morbi tincidunt augue interdum. Nibh mauris cursus mattis molestie a iaculis at erat. Lacus sed turpis tincidunt id aliquet risus feugiat in. Nulla facilisi etiam dignissim diam quis enim lobortis. Vitae congue eu consequat ac felis donec et. Scelerisque viverra mauris in aliquam sem fringilla ut morbi tincidunt. Blandit volutpat maecenas volutpat blandit aliquam. Ultrices tincidunt arcu non sodales neque sodales ut etiam. Sollicitudin aliquam ultrices sagittis orci a scelerisque. Id cursus metus aliquam eleifend mi. Magna eget est lorem ipsum dolor sit amet consectetur. Eleifend mi in nulla posuere sollicitudin aliquam ultrices. Neque sodales ut etiam sit amet. Enim neque volutpat ac tincidunt vitae semper quis lectus nulla.
|
| 118 |
+
</p>
|
|
Binary file (99.9 kB). View file
|
|
|
|
@@ -0,0 +1,19 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
Testing Text File
|
| 2 |
+
|
| 3 |
+
With generated random Lorem Ipsum and other unexpected characters!
|
| 4 |
+
|
| 5 |
+
<a href="https://github.com/mkutarna/audiobook_gen/">Link to generator repo!</a>
|
| 6 |
+
|
| 7 |
+
此行是对非英语字符的测试
|
| 8 |
+
|
| 9 |
+
Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt ut labore et dolore magna aliqua. Proin fermentum leo vel orci porta non pulvinar. Pretium lectus quam id leo in vitae turpis massa sed. Donec ac odio tempor orci dapibus. Feugiat in ante metus dictum at tempor. Elementum tempus egestas sed sed risus. Adipiscing commodo elit at imperdiet dui accumsan sit. Placerat orci nulla pellentesque dignissim enim. Posuere lorem ipsum dolor sit. Id ornare arcu odio ut sem. Purus faucibus ornare suspendisse sed nisi lacus sed. Ac turpis egestas sed tempus urna et pharetra pharetra massa. Morbi quis commodo odio aenean. Malesuada proin libero nunc consequat interdum. Ut placerat orci nulla pellentesque dignissim enim sit. Elit at imperdiet dui accumsan sit amet.
|
| 10 |
+
|
| 11 |
+
Built to test various characters and other possible inputs to the silero model.
|
| 12 |
+
|
| 13 |
+
Here are some Chinese characters: 此行是对非英语字符的测试.
|
| 14 |
+
|
| 15 |
+
There are 24 letters in the Greek alphabet. The vowels: are α, ε, η, ι, ο, ω, υ. All the rest are consonants.
|
| 16 |
+
|
| 17 |
+
We can also test for mathematical symbols: ∫, ∇, ∞, δ, ε, X̄, %, √ ,a, ±, ÷, +, = ,-.
|
| 18 |
+
|
| 19 |
+
Finally, here are some emoticons: ☺️🙂😊😀😁☹️🙁😞😟😣😖😨😧😦😱😫😩.
|
|
Binary file (594 kB). View file
|
|
|
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
84cf0cd8d8bede5ff60d18475d71e26543d5d7ad
|
|
@@ -0,0 +1,26 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
Testing Text File
|
| 2 |
+
With generated random Lorem Ipsum and other unexpected characters!
|
| 3 |
+
Link to generator repo!
|
| 4 |
+
Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt ut labore et dolore magna aliqua.
|
| 5 |
+
Proin fermentum leo vel orci porta non pulvinar.
|
| 6 |
+
Pretium lectus quam id leo in vitae turpis massa sed.
|
| 7 |
+
Donec ac odio tempor orci dapibus.
|
| 8 |
+
Feugiat in ante metus dictum at tempor.
|
| 9 |
+
Elementum tempus egestas sed sed risus.
|
| 10 |
+
Adipiscing commodo elit at imperdiet dui accumsan sit.
|
| 11 |
+
Placerat orci nulla pellentesque dignissim enim.
|
| 12 |
+
Posuere lorem ipsum dolor sit.
|
| 13 |
+
Id ornare arcu odio ut sem.
|
| 14 |
+
Purus faucibus ornare suspendisse sed nisi lacus sed.
|
| 15 |
+
Ac turpis egestas sed tempus urna et pharetra pharetra massa.
|
| 16 |
+
Morbi quis commodo odio aenean.
|
| 17 |
+
Malesuada proin libero nunc consequat interdum.
|
| 18 |
+
Ut placerat orci nulla pellentesque dignissim enim sit.
|
| 19 |
+
Elit at imperdiet dui accumsan sit amet.
|
| 20 |
+
Built to test various characters and other possible inputs to the silero model.
|
| 21 |
+
Here are some Chinese characters: .
|
| 22 |
+
There are 24 letters in the Greek alphabet.
|
| 23 |
+
The vowels: are , , , , , , .
|
| 24 |
+
All the rest are consonants.
|
| 25 |
+
We can also test for mathematical symbols: , , , , , X, %, ,a, , , +, = ,-.
|
| 26 |
+
Finally, here are some emoticons: .
|
|
@@ -0,0 +1,9 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""
|
| 2 |
+
Notes
|
| 3 |
+
-----
|
| 4 |
+
This module contains the configuration entries for audiobook_gen tests.
|
| 5 |
+
"""
|
| 6 |
+
|
| 7 |
+
from pathlib import Path
|
| 8 |
+
|
| 9 |
+
data_path = Path("tests/data")
|
|
@@ -1,2 +0,0 @@
|
|
| 1 |
-
def test_dummy():
|
| 2 |
-
assert 1 == 1
|
|
|
|
|
|
|
|
|
|
@@ -0,0 +1,46 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import pytest
|
| 2 |
+
import numpy as np
|
| 3 |
+
|
| 4 |
+
from src import file_readers
|
| 5 |
+
import test_config
|
| 6 |
+
|
| 7 |
+
|
| 8 |
+
def test_preprocess_text():
|
| 9 |
+
"""
|
| 10 |
+
Tests preprocess function by asserting title,
|
| 11 |
+
shape of corpus, and correct line reading.
|
| 12 |
+
"""
|
| 13 |
+
test_path = test_config.data_path / "test.txt"
|
| 14 |
+
processed_path = test_config.data_path / "test_processed.txt"
|
| 15 |
+
with open(test_path, 'r') as file:
|
| 16 |
+
test_corpus = file_readers.preprocess_text(file)
|
| 17 |
+
with open(processed_path, 'r') as process_file:
|
| 18 |
+
processed_corpus = [line.strip() for line in process_file.readlines()]
|
| 19 |
+
|
| 20 |
+
assert processed_corpus == test_corpus
|
| 21 |
+
|
| 22 |
+
|
| 23 |
+
def test_read_pdf():
|
| 24 |
+
pdf_path = test_config.data_path / "test.pdf"
|
| 25 |
+
corpus = np.array(file_readers.read_pdf(pdf_path), dtype=object)
|
| 26 |
+
|
| 27 |
+
assert np.shape(corpus) == (4, )
|
| 28 |
+
assert np.shape(corpus[0]) == (3, )
|
| 29 |
+
assert corpus[0][0] == 'Lorem Ipsum'
|
| 30 |
+
assert corpus[2][0] == 'Preface'
|
| 31 |
+
|
| 32 |
+
|
| 33 |
+
def test_read_epub():
|
| 34 |
+
"""
|
| 35 |
+
Tests read_epub function by asserting title,
|
| 36 |
+
shape of corpus, and correct line reading.
|
| 37 |
+
"""
|
| 38 |
+
ebook_path = test_config.data_path / "test.epub"
|
| 39 |
+
corpus, title = file_readers.read_epub(ebook_path)
|
| 40 |
+
corpus_arr = np.array(corpus, dtype=object)
|
| 41 |
+
|
| 42 |
+
assert title == "the_picture_of_dorian_gray"
|
| 43 |
+
assert np.shape(corpus_arr) == (6,)
|
| 44 |
+
assert np.shape(corpus_arr[0]) == (39,)
|
| 45 |
+
assert corpus[0][0] == 'The Project Gutenberg eBook of The Picture of Dorian Gray, by Oscar Wilde'
|
| 46 |
+
assert corpus[2][0] == 'CHAPTER I.'
|
|
@@ -0,0 +1,50 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import pytest
|
| 2 |
+
|
| 3 |
+
from src import output, config
|
| 4 |
+
import test_config
|
| 5 |
+
|
| 6 |
+
|
| 7 |
+
def test_write_audio():
|
| 8 |
+
"""
|
| 9 |
+
Tests write_audio function, takes in an audio tensor with a file path and writes the audio to a file.
|
| 10 |
+
"""
|
| 11 |
+
import torch
|
| 12 |
+
|
| 13 |
+
test_path = test_config.data_path / 'test_audio.wav'
|
| 14 |
+
audio_path = test_config.data_path / 'test_audio.pt'
|
| 15 |
+
audio_list = torch.load(audio_path)
|
| 16 |
+
|
| 17 |
+
output.write_audio(audio_list, test_path)
|
| 18 |
+
|
| 19 |
+
assert test_path.is_file()
|
| 20 |
+
assert test_path.stat().st_size == 592858
|
| 21 |
+
|
| 22 |
+
test_path.unlink()
|
| 23 |
+
|
| 24 |
+
|
| 25 |
+
def test_assemble_zip():
|
| 26 |
+
"""
|
| 27 |
+
Tests assemble_zip function, which collects all the audio files from the output directory,
|
| 28 |
+
and zips them up into a zip directory.
|
| 29 |
+
"""
|
| 30 |
+
from shutil import copy2
|
| 31 |
+
|
| 32 |
+
if not config.output_path.exists():
|
| 33 |
+
config.output_path.mkdir()
|
| 34 |
+
|
| 35 |
+
title = "speaker_samples"
|
| 36 |
+
zip_path = config.output_path / 'speaker_samples.zip'
|
| 37 |
+
wav1_path = config.output_path / 'speaker_en_0.wav'
|
| 38 |
+
wav2_path = config.output_path / 'speaker_en_110.wav'
|
| 39 |
+
|
| 40 |
+
for file_path in config.resource_path.iterdir():
|
| 41 |
+
if file_path.suffix == '.wav':
|
| 42 |
+
copy2(file_path, config.output_path)
|
| 43 |
+
|
| 44 |
+
_ = output.assemble_zip(title)
|
| 45 |
+
|
| 46 |
+
assert zip_path.is_file()
|
| 47 |
+
assert not wav1_path.is_file()
|
| 48 |
+
assert not wav2_path.is_file()
|
| 49 |
+
|
| 50 |
+
zip_path.unlink()
|
|
@@ -0,0 +1,63 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import pytest
|
| 2 |
+
import torch
|
| 3 |
+
import numpy as np
|
| 4 |
+
|
| 5 |
+
from src import predict, file_readers, config
|
| 6 |
+
import test_config
|
| 7 |
+
|
| 8 |
+
|
| 9 |
+
def test_load_model():
|
| 10 |
+
"""
|
| 11 |
+
Tests load_model function, which loads the silero TTS model.
|
| 12 |
+
"""
|
| 13 |
+
model = predict.load_model()
|
| 14 |
+
|
| 15 |
+
assert model.speakers[0] == 'en_0'
|
| 16 |
+
assert np.shape(model.speakers) == (119,)
|
| 17 |
+
|
| 18 |
+
|
| 19 |
+
def test_generate_audio():
|
| 20 |
+
"""
|
| 21 |
+
Tests generate_audio function, which takes the TTS model and file input,
|
| 22 |
+
and uses the predict & write_audio functions to output the audio file.
|
| 23 |
+
"""
|
| 24 |
+
ebook_path = test_config.data_path / "test.epub"
|
| 25 |
+
wav1_path = config.output_path / 'the_picture_of_dorian_gray_part000.wav'
|
| 26 |
+
wav2_path = config.output_path / 'the_picture_of_dorian_gray_part001.wav'
|
| 27 |
+
wav3_path = config.output_path / 'the_picture_of_dorian_gray_part002.wav'
|
| 28 |
+
corpus, title = file_readers.read_epub(ebook_path)
|
| 29 |
+
|
| 30 |
+
model = predict.load_model()
|
| 31 |
+
speaker = 'en_110'
|
| 32 |
+
predict.generate_audio(corpus[0:2], title, model, speaker)
|
| 33 |
+
|
| 34 |
+
assert wav1_path.is_file()
|
| 35 |
+
assert wav2_path.is_file()
|
| 36 |
+
assert not wav3_path.is_file()
|
| 37 |
+
|
| 38 |
+
wav1_path.unlink()
|
| 39 |
+
wav2_path.unlink()
|
| 40 |
+
|
| 41 |
+
|
| 42 |
+
def test_predict():
|
| 43 |
+
"""
|
| 44 |
+
Tests predict function, generates audio tensors for each token in the text section,
|
| 45 |
+
and appends them together along with a generated file path for output.
|
| 46 |
+
"""
|
| 47 |
+
seed = 1337
|
| 48 |
+
torch.manual_seed(seed)
|
| 49 |
+
torch.cuda.manual_seed(seed)
|
| 50 |
+
model = predict.load_model()
|
| 51 |
+
|
| 52 |
+
tensor_path = test_config.data_path / "test_predict.pt"
|
| 53 |
+
test_tensor = torch.load(tensor_path)
|
| 54 |
+
|
| 55 |
+
ebook_path = test_config.data_path / "test.epub"
|
| 56 |
+
corpus, title = file_readers.read_epub(ebook_path)
|
| 57 |
+
section_index = 'part001'
|
| 58 |
+
speaker = 'en_110'
|
| 59 |
+
|
| 60 |
+
audio_list, _ = predict.predict(corpus[1], section_index, title, model, speaker)
|
| 61 |
+
audio_tensor = torch.cat(audio_list).reshape(1, -1)
|
| 62 |
+
|
| 63 |
+
torch.testing.assert_close(audio_tensor, test_tensor, atol=1e-3, rtol=0.2)
|