Spaces:
Runtime error

Runtime error
Arash
commited on
Commit
·
c334626
1
Parent(s):
0e6bdc0
initial code release
Browse files- .gitignore +46 -0
- EMA.py +90 -0
- LICENSE +63 -0
- README.md +0 -16
- assets/teaser.png +0 -0
- datasets_prep/LICENSE_PyTorch +70 -0
- datasets_prep/LICENSE_torchvision +29 -0
- datasets_prep/lmdb_datasets.py +58 -0
- datasets_prep/lsun.py +170 -0
- datasets_prep/stackmnist_data.py +65 -0
- pytorch_fid/LICENSE_MIT +21 -0
- pytorch_fid/LICENSE_inception +201 -0
- pytorch_fid/LICENSE_pytorch_fid +201 -0
- pytorch_fid/fid_score.py +305 -0
- pytorch_fid/inception.py +337 -0
- pytorch_fid/inception_score.py +103 -0
- readme.md +113 -0
- requirements.txt +10 -0
- score_sde/LICENSE_Apache +201 -0
- score_sde/__init__.py +0 -0
- score_sde/models/LICENSE_MIT +21 -0
- score_sde/models/__init__.py +15 -0
- score_sde/models/dense_layer.py +83 -0
- score_sde/models/discriminator.py +239 -0
- score_sde/models/layers.py +619 -0
- score_sde/models/layerspp.py +380 -0
- score_sde/models/ncsnpp_generator_adagn.py +431 -0
- score_sde/models/up_or_down_sampling.py +262 -0
- score_sde/models/utils.py +148 -0
- score_sde/op/LICENSE_MIT +21 -0
- score_sde/op/__init__.py +2 -0
- score_sde/op/fused_act.py +105 -0
- score_sde/op/fused_bias_act.cpp +28 -0
- score_sde/op/fused_bias_act_kernel.cu +101 -0
- score_sde/op/upfirdn2d.cpp +31 -0
- score_sde/op/upfirdn2d.py +225 -0
- score_sde/op/upfirdn2d_kernel.cu +371 -0
- test_ddgan.py +275 -0
- train_ddgan.py +602 -0
.gitignore
ADDED
|
@@ -0,0 +1,46 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Node artifact files
|
| 2 |
+
node_modules/
|
| 3 |
+
dist/
|
| 4 |
+
ngc_scripts/
|
| 5 |
+
|
| 6 |
+
# Compiled Java class files
|
| 7 |
+
*.class
|
| 8 |
+
|
| 9 |
+
# Compiled Python bytecode
|
| 10 |
+
*.py[cod]
|
| 11 |
+
|
| 12 |
+
# Log files
|
| 13 |
+
*.log
|
| 14 |
+
|
| 15 |
+
# Package files
|
| 16 |
+
*.jar
|
| 17 |
+
|
| 18 |
+
# Maven
|
| 19 |
+
target/
|
| 20 |
+
dist/
|
| 21 |
+
|
| 22 |
+
# JetBrains IDE
|
| 23 |
+
.idea/
|
| 24 |
+
|
| 25 |
+
# Unit test reports
|
| 26 |
+
TEST*.xml
|
| 27 |
+
|
| 28 |
+
# Generated by MacOS
|
| 29 |
+
.DS_Store
|
| 30 |
+
|
| 31 |
+
# Generated by Windows
|
| 32 |
+
Thumbs.db
|
| 33 |
+
|
| 34 |
+
# Applications
|
| 35 |
+
*.app
|
| 36 |
+
*.exe
|
| 37 |
+
*.war
|
| 38 |
+
|
| 39 |
+
# Large media files
|
| 40 |
+
*.mp4
|
| 41 |
+
*.tiff
|
| 42 |
+
*.avi
|
| 43 |
+
*.flv
|
| 44 |
+
*.mov
|
| 45 |
+
*.wmv
|
| 46 |
+
|
EMA.py
ADDED
|
@@ -0,0 +1,90 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# ---------------------------------------------------------------
|
| 2 |
+
# Copyright (c) 2022, NVIDIA CORPORATION. All rights reserved.
|
| 3 |
+
#
|
| 4 |
+
# This work is licensed under the NVIDIA Source Code License
|
| 5 |
+
# for Denoising Diffusion GAN. To view a copy of this license, see the LICENSE file.
|
| 6 |
+
# ---------------------------------------------------------------
|
| 7 |
+
|
| 8 |
+
'''
|
| 9 |
+
Codes adapted from https://github.com/NVlabs/LSGM/blob/main/util/ema.py
|
| 10 |
+
'''
|
| 11 |
+
import warnings
|
| 12 |
+
|
| 13 |
+
import torch
|
| 14 |
+
from torch.optim import Optimizer
|
| 15 |
+
|
| 16 |
+
|
| 17 |
+
class EMA(Optimizer):
|
| 18 |
+
def __init__(self, opt, ema_decay):
|
| 19 |
+
self.ema_decay = ema_decay
|
| 20 |
+
self.apply_ema = self.ema_decay > 0.
|
| 21 |
+
self.optimizer = opt
|
| 22 |
+
self.state = opt.state
|
| 23 |
+
self.param_groups = opt.param_groups
|
| 24 |
+
|
| 25 |
+
def step(self, *args, **kwargs):
|
| 26 |
+
retval = self.optimizer.step(*args, **kwargs)
|
| 27 |
+
|
| 28 |
+
# stop here if we are not applying EMA
|
| 29 |
+
if not self.apply_ema:
|
| 30 |
+
return retval
|
| 31 |
+
|
| 32 |
+
ema, params = {}, {}
|
| 33 |
+
for group in self.optimizer.param_groups:
|
| 34 |
+
for i, p in enumerate(group['params']):
|
| 35 |
+
if p.grad is None:
|
| 36 |
+
continue
|
| 37 |
+
state = self.optimizer.state[p]
|
| 38 |
+
|
| 39 |
+
# State initialization
|
| 40 |
+
if 'ema' not in state:
|
| 41 |
+
state['ema'] = p.data.clone()
|
| 42 |
+
|
| 43 |
+
if p.shape not in params:
|
| 44 |
+
params[p.shape] = {'idx': 0, 'data': []}
|
| 45 |
+
ema[p.shape] = []
|
| 46 |
+
|
| 47 |
+
params[p.shape]['data'].append(p.data)
|
| 48 |
+
ema[p.shape].append(state['ema'])
|
| 49 |
+
|
| 50 |
+
for i in params:
|
| 51 |
+
params[i]['data'] = torch.stack(params[i]['data'], dim=0)
|
| 52 |
+
ema[i] = torch.stack(ema[i], dim=0)
|
| 53 |
+
ema[i].mul_(self.ema_decay).add_(params[i]['data'], alpha=1. - self.ema_decay)
|
| 54 |
+
|
| 55 |
+
for p in group['params']:
|
| 56 |
+
if p.grad is None:
|
| 57 |
+
continue
|
| 58 |
+
idx = params[p.shape]['idx']
|
| 59 |
+
self.optimizer.state[p]['ema'] = ema[p.shape][idx, :]
|
| 60 |
+
params[p.shape]['idx'] += 1
|
| 61 |
+
|
| 62 |
+
return retval
|
| 63 |
+
|
| 64 |
+
def load_state_dict(self, state_dict):
|
| 65 |
+
super(EMA, self).load_state_dict(state_dict)
|
| 66 |
+
# load_state_dict loads the data to self.state and self.param_groups. We need to pass this data to
|
| 67 |
+
# the underlying optimizer too.
|
| 68 |
+
self.optimizer.state = self.state
|
| 69 |
+
self.optimizer.param_groups = self.param_groups
|
| 70 |
+
|
| 71 |
+
def swap_parameters_with_ema(self, store_params_in_ema):
|
| 72 |
+
""" This function swaps parameters with their ema values. It records original parameters in the ema
|
| 73 |
+
parameters, if store_params_in_ema is true."""
|
| 74 |
+
|
| 75 |
+
# stop here if we are not applying EMA
|
| 76 |
+
if not self.apply_ema:
|
| 77 |
+
warnings.warn('swap_parameters_with_ema was called when there is no EMA weights.')
|
| 78 |
+
return
|
| 79 |
+
|
| 80 |
+
for group in self.optimizer.param_groups:
|
| 81 |
+
for i, p in enumerate(group['params']):
|
| 82 |
+
if not p.requires_grad:
|
| 83 |
+
continue
|
| 84 |
+
ema = self.optimizer.state[p]['ema']
|
| 85 |
+
if store_params_in_ema:
|
| 86 |
+
tmp = p.data.detach()
|
| 87 |
+
p.data = ema.detach()
|
| 88 |
+
self.optimizer.state[p]['ema'] = tmp
|
| 89 |
+
else:
|
| 90 |
+
p.data = ema.detach()
|
LICENSE
ADDED
|
@@ -0,0 +1,63 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
NVIDIA License
|
| 2 |
+
|
| 3 |
+
1. Definitions
|
| 4 |
+
|
| 5 |
+
“Licensor” means any person or entity that distributes its Work.
|
| 6 |
+
|
| 7 |
+
“Work” means (a) the original work of authorship made available under this license, which may include software,
|
| 8 |
+
documentation, or other files, and (b) any additions to or derivative works thereof that are made available under this license.
|
| 9 |
+
|
| 10 |
+
The terms “reproduce,” “reproduction,” “derivative works,” and “distribution” have the meaning as provided under U.S.
|
| 11 |
+
copyright law; provided, however, that for the purposes of this license, derivative works shall not include works that
|
| 12 |
+
remain separable from, or merely link (or bind by name) to the interfaces of, the Work.
|
| 13 |
+
|
| 14 |
+
Works are “made available” under this license by including in or with the Work either (a) a copyright notice
|
| 15 |
+
referencing the applicability of this license to the Work, or (b) a copy of this license.
|
| 16 |
+
|
| 17 |
+
2. License Grant
|
| 18 |
+
|
| 19 |
+
2.1 Copyright Grant. Subject to the terms and conditions of this license, each Licensor grants to you a perpetual,
|
| 20 |
+
worldwide, non-exclusive, royalty-free, copyright license to use, reproduce, prepare derivative works of, publicly
|
| 21 |
+
display, publicly perform, sublicense and distribute its Work and any resulting derivative works in any form.
|
| 22 |
+
|
| 23 |
+
3. Limitations
|
| 24 |
+
|
| 25 |
+
3.1 Redistribution. You may reproduce or distribute the Work only if (a) you do so under this license, (b) you
|
| 26 |
+
include a complete copy of this license with your distribution, and (c) you retain without modification any
|
| 27 |
+
copyright, patent, trademark, or attribution notices that are present in the Work.
|
| 28 |
+
|
| 29 |
+
3.2 Derivative Works. You may specify that additional or different terms apply to the use, reproduction, and
|
| 30 |
+
distribution of your derivative works of the Work (“Your Terms”) only if (a) Your Terms provide that the use
|
| 31 |
+
limitation in Section 3.3 applies to your derivative works, and (b) you identify the specific derivative works
|
| 32 |
+
that are subject to Your Terms. Notwithstanding Your Terms, this license (including the redistribution
|
| 33 |
+
requirements in Section 3.1) will continue to apply to the Work itself.
|
| 34 |
+
|
| 35 |
+
3.3 Use Limitation. The Work and any derivative works thereof only may be used or intended for use non-commercially.
|
| 36 |
+
Notwithstanding the foregoing, NVIDIA Corporation and its affiliates may use the Work and any derivative
|
| 37 |
+
works commercially. As used herein, “non-commercially” means for research or evaluation purposes only.
|
| 38 |
+
|
| 39 |
+
3.4 Patent Claims. If you bring or threaten to bring a patent claim against any Licensor (including any claim,
|
| 40 |
+
cross-claim or counterclaim in a lawsuit) to enforce any patents that you allege are infringed by any Work, then
|
| 41 |
+
your rights under this license from such Licensor (including the grant in Section 2.1) will terminate immediately.
|
| 42 |
+
|
| 43 |
+
3.5 Trademarks. This license does not grant any rights to use any Licensor’s or its affiliates’ names, logos,
|
| 44 |
+
or trademarks, except as necessary to reproduce the notices described in this license.
|
| 45 |
+
|
| 46 |
+
3.6 Termination. If you violate any term of this license, then your rights under this license (including the
|
| 47 |
+
grant in Section 2.1) will terminate immediately.
|
| 48 |
+
|
| 49 |
+
4. Disclaimer of Warranty.
|
| 50 |
+
|
| 51 |
+
THE WORK IS PROVIDED “AS IS” WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, EITHER EXPRESS OR IMPLIED, INCLUDING
|
| 52 |
+
WARRANTIES OR CONDITIONS OF MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE, TITLE OR NON-INFRINGEMENT. YOU
|
| 53 |
+
BEAR THE RISK OF UNDERTAKING ANY ACTIVITIES UNDER THIS LICENSE.
|
| 54 |
+
|
| 55 |
+
5. Limitation of Liability.
|
| 56 |
+
|
| 57 |
+
EXCEPT AS PROHIBITED BY APPLICABLE LAW, IN NO EVENT AND UNDER NO LEGAL THEORY, WHETHER IN TORT (INCLUDING
|
| 58 |
+
NEGLIGENCE), CONTRACT, OR OTHERWISE SHALL ANY LICENSOR BE LIABLE TO YOU FOR DAMAGES, INCLUDING ANY DIRECT,
|
| 59 |
+
INDIRECT, SPECIAL, INCIDENTAL, OR CONSEQUENTIAL DAMAGES ARISING OUT OF OR RELATED TO THIS LICENSE, THE USE OR
|
| 60 |
+
INABILITY TO USE THE WORK (INCLUDING BUT NOT LIMITED TO LOSS OF GOODWILL, BUSINESS INTERRUPTION, LOST PROFITS OR
|
| 61 |
+
DATA, COMPUTER FAILURE OR MALFUNCTION, OR ANY OTHER DAMAGES OR LOSSES), EVEN IF THE LICENSOR HAS BEEN
|
| 62 |
+
ADVISED OF THE POSSIBILITY OF SUCH DAMAGES.
|
| 63 |
+
|
README.md
DELETED
|
@@ -1,16 +0,0 @@
|
|
| 1 |
-
## <p align="center">Tackling the Generative Learning Trilemma with Denoising Diffusion GANs</p>
|
| 2 |
-
|
| 3 |
-
<div align="center">
|
| 4 |
-
<a href="https://xavierxiao.github.io/" target="_blank">Zhisheng Xiao</a>   <b>·</b>  
|
| 5 |
-
<a href="https://karstenkreis.github.io/" target="_blank">Karsten Kreis</a>   <b>·</b>  
|
| 6 |
-
<a href="http://latentspace.cc/" target="_blank">Arash Vahdat</a>
|
| 7 |
-
<br> <br>
|
| 8 |
-
<a href="https://nvlabs.github.io/denoising-diffusion-gan" target="_blank">Project Page</a>
|
| 9 |
-
</div>
|
| 10 |
-
<br><br>
|
| 11 |
-
<p align="center">:construction: :pick: :hammer_and_wrench: :construction_worker:</p>
|
| 12 |
-
<p align="center">Code coming soon (the current expected release is in March 2022). Stay tuned!</p>
|
| 13 |
-
<br><br>
|
| 14 |
-
<p align="center">
|
| 15 |
-
<img width="800" alt="teaser" src="assets/teaser.png"/>
|
| 16 |
-
</p>
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
assets/teaser.png
CHANGED
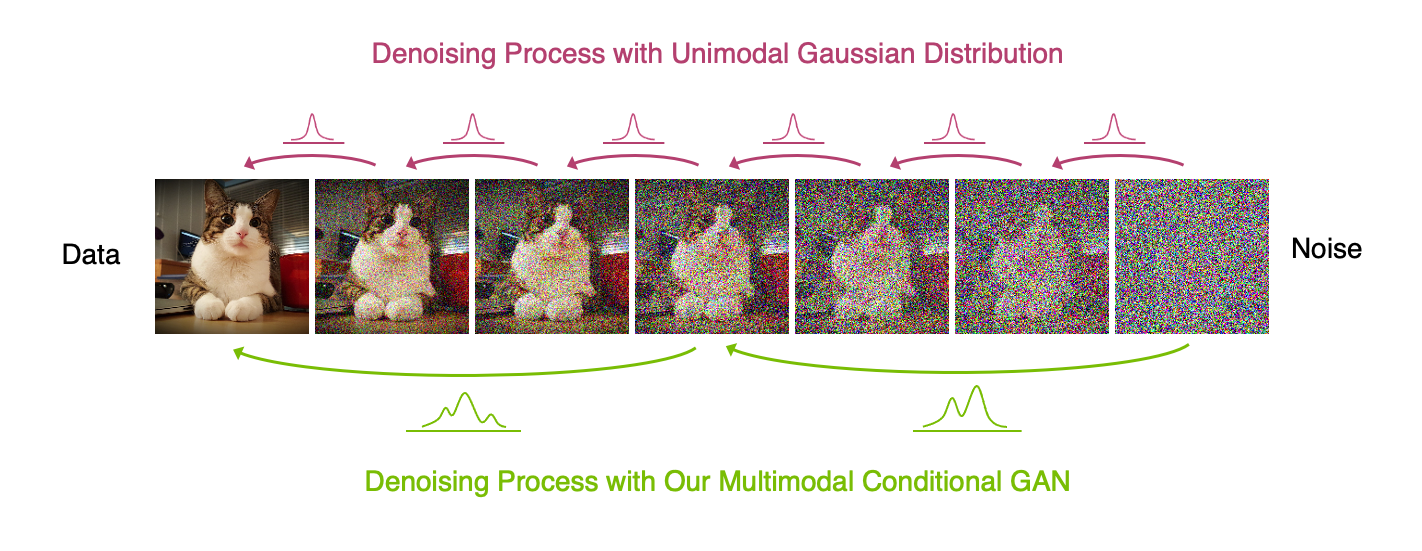
|
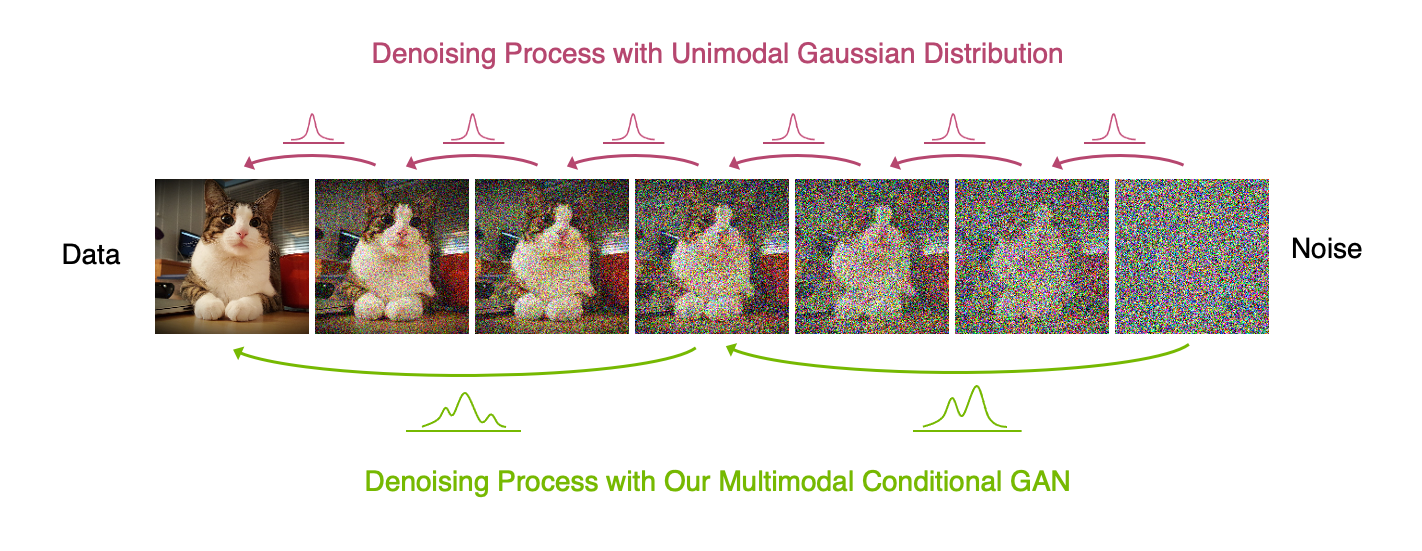
|
datasets_prep/LICENSE_PyTorch
ADDED
|
@@ -0,0 +1,70 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
From PyTorch:
|
| 2 |
+
|
| 3 |
+
Copyright (c) 2016- Facebook, Inc (Adam Paszke)
|
| 4 |
+
Copyright (c) 2014- Facebook, Inc (Soumith Chintala)
|
| 5 |
+
Copyright (c) 2011-2014 Idiap Research Institute (Ronan Collobert)
|
| 6 |
+
Copyright (c) 2012-2014 Deepmind Technologies (Koray Kavukcuoglu)
|
| 7 |
+
Copyright (c) 2011-2012 NEC Laboratories America (Koray Kavukcuoglu)
|
| 8 |
+
Copyright (c) 2011-2013 NYU (Clement Farabet)
|
| 9 |
+
Copyright (c) 2006-2010 NEC Laboratories America (Ronan Collobert, Leon Bottou, Iain Melvin, Jason Weston)
|
| 10 |
+
Copyright (c) 2006 Idiap Research Institute (Samy Bengio)
|
| 11 |
+
Copyright (c) 2001-2004 Idiap Research Institute (Ronan Collobert, Samy Bengio, Johnny Mariethoz)
|
| 12 |
+
|
| 13 |
+
From Caffe2:
|
| 14 |
+
|
| 15 |
+
Copyright (c) 2016-present, Facebook Inc. All rights reserved.
|
| 16 |
+
|
| 17 |
+
All contributions by Facebook:
|
| 18 |
+
Copyright (c) 2016 Facebook Inc.
|
| 19 |
+
|
| 20 |
+
All contributions by Google:
|
| 21 |
+
Copyright (c) 2015 Google Inc.
|
| 22 |
+
All rights reserved.
|
| 23 |
+
|
| 24 |
+
All contributions by Yangqing Jia:
|
| 25 |
+
Copyright (c) 2015 Yangqing Jia
|
| 26 |
+
All rights reserved.
|
| 27 |
+
|
| 28 |
+
All contributions from Caffe:
|
| 29 |
+
Copyright(c) 2013, 2014, 2015, the respective contributors
|
| 30 |
+
All rights reserved.
|
| 31 |
+
|
| 32 |
+
All other contributions:
|
| 33 |
+
Copyright(c) 2015, 2016 the respective contributors
|
| 34 |
+
All rights reserved.
|
| 35 |
+
|
| 36 |
+
Caffe2 uses a copyright model similar to Caffe: each contributor holds
|
| 37 |
+
copyright over their contributions to Caffe2. The project versioning records
|
| 38 |
+
all such contribution and copyright details. If a contributor wants to further
|
| 39 |
+
mark their specific copyright on a particular contribution, they should
|
| 40 |
+
indicate their copyright solely in the commit message of the change when it is
|
| 41 |
+
committed.
|
| 42 |
+
|
| 43 |
+
All rights reserved.
|
| 44 |
+
|
| 45 |
+
Redistribution and use in source and binary forms, with or without
|
| 46 |
+
modification, are permitted provided that the following conditions are met:
|
| 47 |
+
|
| 48 |
+
1. Redistributions of source code must retain the above copyright
|
| 49 |
+
notice, this list of conditions and the following disclaimer.
|
| 50 |
+
|
| 51 |
+
2. Redistributions in binary form must reproduce the above copyright
|
| 52 |
+
notice, this list of conditions and the following disclaimer in the
|
| 53 |
+
documentation and/or other materials provided with the distribution.
|
| 54 |
+
|
| 55 |
+
3. Neither the names of Facebook, Deepmind Technologies, NYU, NEC Laboratories America
|
| 56 |
+
and IDIAP Research Institute nor the names of its contributors may be
|
| 57 |
+
used to endorse or promote products derived from this software without
|
| 58 |
+
specific prior written permission.
|
| 59 |
+
|
| 60 |
+
THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS "AS IS"
|
| 61 |
+
AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE
|
| 62 |
+
IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE
|
| 63 |
+
ARE DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT OWNER OR CONTRIBUTORS BE
|
| 64 |
+
LIABLE FOR ANY DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR
|
| 65 |
+
CONSEQUENTIAL DAMAGES (INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF
|
| 66 |
+
SUBSTITUTE GOODS OR SERVICES; LOSS OF USE, DATA, OR PROFITS; OR BUSINESS
|
| 67 |
+
INTERRUPTION) HOWEVER CAUSED AND ON ANY THEORY OF LIABILITY, WHETHER IN
|
| 68 |
+
CONTRACT, STRICT LIABILITY, OR TORT (INCLUDING NEGLIGENCE OR OTHERWISE)
|
| 69 |
+
ARISING IN ANY WAY OUT OF THE USE OF THIS SOFTWARE, EVEN IF ADVISED OF THE
|
| 70 |
+
POSSIBILITY OF SUCH DAMAGE.
|
datasets_prep/LICENSE_torchvision
ADDED
|
@@ -0,0 +1,29 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
BSD 3-Clause License
|
| 2 |
+
|
| 3 |
+
Copyright (c) Soumith Chintala 2016,
|
| 4 |
+
All rights reserved.
|
| 5 |
+
|
| 6 |
+
Redistribution and use in source and binary forms, with or without
|
| 7 |
+
modification, are permitted provided that the following conditions are met:
|
| 8 |
+
|
| 9 |
+
* Redistributions of source code must retain the above copyright notice, this
|
| 10 |
+
list of conditions and the following disclaimer.
|
| 11 |
+
|
| 12 |
+
* Redistributions in binary form must reproduce the above copyright notice,
|
| 13 |
+
this list of conditions and the following disclaimer in the documentation
|
| 14 |
+
and/or other materials provided with the distribution.
|
| 15 |
+
|
| 16 |
+
* Neither the name of the copyright holder nor the names of its
|
| 17 |
+
contributors may be used to endorse or promote products derived from
|
| 18 |
+
this software without specific prior written permission.
|
| 19 |
+
|
| 20 |
+
THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS "AS IS"
|
| 21 |
+
AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE
|
| 22 |
+
IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE ARE
|
| 23 |
+
DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT HOLDER OR CONTRIBUTORS BE LIABLE
|
| 24 |
+
FOR ANY DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL
|
| 25 |
+
DAMAGES (INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR
|
| 26 |
+
SERVICES; LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER
|
| 27 |
+
CAUSED AND ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY,
|
| 28 |
+
OR TORT (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE
|
| 29 |
+
OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE.
|
datasets_prep/lmdb_datasets.py
ADDED
|
@@ -0,0 +1,58 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# ---------------------------------------------------------------
|
| 2 |
+
# Copyright (c) 2022, NVIDIA CORPORATION. All rights reserved.
|
| 3 |
+
#
|
| 4 |
+
# This work is licensed under the NVIDIA Source Code License
|
| 5 |
+
# for Denoising Diffusion GAN. To view a copy of this license, see the LICENSE file.
|
| 6 |
+
# ---------------------------------------------------------------
|
| 7 |
+
|
| 8 |
+
import torch.utils.data as data
|
| 9 |
+
import numpy as np
|
| 10 |
+
import lmdb
|
| 11 |
+
import os
|
| 12 |
+
import io
|
| 13 |
+
from PIL import Image
|
| 14 |
+
|
| 15 |
+
|
| 16 |
+
def num_samples(dataset, train):
|
| 17 |
+
if dataset == 'celeba':
|
| 18 |
+
return 27000 if train else 3000
|
| 19 |
+
|
| 20 |
+
else:
|
| 21 |
+
raise NotImplementedError('dataset %s is unknown' % dataset)
|
| 22 |
+
|
| 23 |
+
|
| 24 |
+
class LMDBDataset(data.Dataset):
|
| 25 |
+
def __init__(self, root, name='', train=True, transform=None, is_encoded=False):
|
| 26 |
+
self.train = train
|
| 27 |
+
self.name = name
|
| 28 |
+
self.transform = transform
|
| 29 |
+
if self.train:
|
| 30 |
+
lmdb_path = os.path.join(root, 'train.lmdb')
|
| 31 |
+
else:
|
| 32 |
+
lmdb_path = os.path.join(root, 'validation.lmdb')
|
| 33 |
+
self.data_lmdb = lmdb.open(lmdb_path, readonly=True, max_readers=1,
|
| 34 |
+
lock=False, readahead=False, meminit=False)
|
| 35 |
+
self.is_encoded = is_encoded
|
| 36 |
+
|
| 37 |
+
def __getitem__(self, index):
|
| 38 |
+
target = [0]
|
| 39 |
+
with self.data_lmdb.begin(write=False, buffers=True) as txn:
|
| 40 |
+
data = txn.get(str(index).encode())
|
| 41 |
+
if self.is_encoded:
|
| 42 |
+
img = Image.open(io.BytesIO(data))
|
| 43 |
+
img = img.convert('RGB')
|
| 44 |
+
else:
|
| 45 |
+
img = np.asarray(data, dtype=np.uint8)
|
| 46 |
+
# assume data is RGB
|
| 47 |
+
size = int(np.sqrt(len(img) / 3))
|
| 48 |
+
img = np.reshape(img, (size, size, 3))
|
| 49 |
+
img = Image.fromarray(img, mode='RGB')
|
| 50 |
+
|
| 51 |
+
if self.transform is not None:
|
| 52 |
+
img = self.transform(img)
|
| 53 |
+
|
| 54 |
+
return img, target
|
| 55 |
+
|
| 56 |
+
def __len__(self):
|
| 57 |
+
return num_samples(self.name, self.train)
|
| 58 |
+
|
datasets_prep/lsun.py
ADDED
|
@@ -0,0 +1,170 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# ---------------------------------------------------------------
|
| 2 |
+
# Copyright (c) 2022, NVIDIA CORPORATION. All rights reserved.
|
| 3 |
+
#
|
| 4 |
+
# This file has been modified from a file in the torchvision library
|
| 5 |
+
# which was released under the BSD 3-Clause License.
|
| 6 |
+
#
|
| 7 |
+
# Source:
|
| 8 |
+
# https://github.com/pytorch/vision/blob/ea6b879e90459006e71a164dc76b7e2cc3bff9d9/torchvision/datasets/lsun.py
|
| 9 |
+
#
|
| 10 |
+
# The license for the original version of this file can be
|
| 11 |
+
# found in this directory (LICENSE_torchvision). The modifications
|
| 12 |
+
# to this file are subject to the same BSD 3-Clause License.
|
| 13 |
+
# ---------------------------------------------------------------
|
| 14 |
+
|
| 15 |
+
from torchvision.datasets.vision import VisionDataset
|
| 16 |
+
from PIL import Image
|
| 17 |
+
import os
|
| 18 |
+
import os.path
|
| 19 |
+
import io
|
| 20 |
+
import string
|
| 21 |
+
from collections.abc import Iterable
|
| 22 |
+
import pickle
|
| 23 |
+
from torchvision.datasets.utils import verify_str_arg, iterable_to_str
|
| 24 |
+
|
| 25 |
+
|
| 26 |
+
class LSUNClass(VisionDataset):
|
| 27 |
+
def __init__(self, root, transform=None, target_transform=None):
|
| 28 |
+
import lmdb
|
| 29 |
+
super(LSUNClass, self).__init__(root, transform=transform,
|
| 30 |
+
target_transform=target_transform)
|
| 31 |
+
|
| 32 |
+
self.env = lmdb.open(root, max_readers=1, readonly=True, lock=False,
|
| 33 |
+
readahead=False, meminit=False)
|
| 34 |
+
with self.env.begin(write=False) as txn:
|
| 35 |
+
self.length = txn.stat()['entries']
|
| 36 |
+
# cache_file = '_cache_' + ''.join(c for c in root if c in string.ascii_letters)
|
| 37 |
+
# av begin
|
| 38 |
+
# We only modified the location of cache_file.
|
| 39 |
+
cache_file = os.path.join(self.root, '_cache_')
|
| 40 |
+
# av end
|
| 41 |
+
if os.path.isfile(cache_file):
|
| 42 |
+
self.keys = pickle.load(open(cache_file, "rb"))
|
| 43 |
+
else:
|
| 44 |
+
with self.env.begin(write=False) as txn:
|
| 45 |
+
self.keys = [key for key, _ in txn.cursor()]
|
| 46 |
+
pickle.dump(self.keys, open(cache_file, "wb"))
|
| 47 |
+
|
| 48 |
+
def __getitem__(self, index):
|
| 49 |
+
img, target = None, -1
|
| 50 |
+
env = self.env
|
| 51 |
+
with env.begin(write=False) as txn:
|
| 52 |
+
imgbuf = txn.get(self.keys[index])
|
| 53 |
+
|
| 54 |
+
buf = io.BytesIO()
|
| 55 |
+
buf.write(imgbuf)
|
| 56 |
+
buf.seek(0)
|
| 57 |
+
img = Image.open(buf).convert('RGB')
|
| 58 |
+
|
| 59 |
+
if self.transform is not None:
|
| 60 |
+
img = self.transform(img)
|
| 61 |
+
|
| 62 |
+
if self.target_transform is not None:
|
| 63 |
+
target = self.target_transform(target)
|
| 64 |
+
|
| 65 |
+
return img, target
|
| 66 |
+
|
| 67 |
+
def __len__(self):
|
| 68 |
+
return self.length
|
| 69 |
+
|
| 70 |
+
|
| 71 |
+
class LSUN(VisionDataset):
|
| 72 |
+
"""
|
| 73 |
+
`LSUN <https://www.yf.io/p/lsun>`_ dataset.
|
| 74 |
+
|
| 75 |
+
Args:
|
| 76 |
+
root (string): Root directory for the database files.
|
| 77 |
+
classes (string or list): One of {'train', 'val', 'test'} or a list of
|
| 78 |
+
categories to load. e,g. ['bedroom_train', 'church_outdoor_train'].
|
| 79 |
+
transform (callable, optional): A function/transform that takes in an PIL image
|
| 80 |
+
and returns a transformed version. E.g, ``transforms.RandomCrop``
|
| 81 |
+
target_transform (callable, optional): A function/transform that takes in the
|
| 82 |
+
target and transforms it.
|
| 83 |
+
"""
|
| 84 |
+
|
| 85 |
+
def __init__(self, root, classes='train', transform=None, target_transform=None):
|
| 86 |
+
super(LSUN, self).__init__(root, transform=transform,
|
| 87 |
+
target_transform=target_transform)
|
| 88 |
+
self.classes = self._verify_classes(classes)
|
| 89 |
+
|
| 90 |
+
# for each class, create an LSUNClassDataset
|
| 91 |
+
self.dbs = []
|
| 92 |
+
for c in self.classes:
|
| 93 |
+
self.dbs.append(LSUNClass(
|
| 94 |
+
root=root + '/' + c + '_lmdb',
|
| 95 |
+
transform=transform))
|
| 96 |
+
|
| 97 |
+
self.indices = []
|
| 98 |
+
count = 0
|
| 99 |
+
for db in self.dbs:
|
| 100 |
+
count += len(db)
|
| 101 |
+
self.indices.append(count)
|
| 102 |
+
|
| 103 |
+
self.length = count
|
| 104 |
+
|
| 105 |
+
def _verify_classes(self, classes):
|
| 106 |
+
categories = ['bedroom', 'bridge', 'church_outdoor', 'classroom',
|
| 107 |
+
'conference_room', 'dining_room', 'kitchen',
|
| 108 |
+
'living_room', 'restaurant', 'tower', 'cat']
|
| 109 |
+
dset_opts = ['train', 'val', 'test']
|
| 110 |
+
|
| 111 |
+
try:
|
| 112 |
+
verify_str_arg(classes, "classes", dset_opts)
|
| 113 |
+
if classes == 'test':
|
| 114 |
+
classes = [classes]
|
| 115 |
+
else:
|
| 116 |
+
classes = [c + '_' + classes for c in categories]
|
| 117 |
+
except ValueError:
|
| 118 |
+
if not isinstance(classes, Iterable):
|
| 119 |
+
msg = ("Expected type str or Iterable for argument classes, "
|
| 120 |
+
"but got type {}.")
|
| 121 |
+
raise ValueError(msg.format(type(classes)))
|
| 122 |
+
|
| 123 |
+
classes = list(classes)
|
| 124 |
+
msg_fmtstr = ("Expected type str for elements in argument classes, "
|
| 125 |
+
"but got type {}.")
|
| 126 |
+
for c in classes:
|
| 127 |
+
verify_str_arg(c, custom_msg=msg_fmtstr.format(type(c)))
|
| 128 |
+
c_short = c.split('_')
|
| 129 |
+
category, dset_opt = '_'.join(c_short[:-1]), c_short[-1]
|
| 130 |
+
|
| 131 |
+
msg_fmtstr = "Unknown value '{}' for {}. Valid values are {{{}}}."
|
| 132 |
+
msg = msg_fmtstr.format(category, "LSUN class",
|
| 133 |
+
iterable_to_str(categories))
|
| 134 |
+
verify_str_arg(category, valid_values=categories, custom_msg=msg)
|
| 135 |
+
|
| 136 |
+
msg = msg_fmtstr.format(dset_opt, "postfix", iterable_to_str(dset_opts))
|
| 137 |
+
verify_str_arg(dset_opt, valid_values=dset_opts, custom_msg=msg)
|
| 138 |
+
|
| 139 |
+
return classes
|
| 140 |
+
|
| 141 |
+
def __getitem__(self, index):
|
| 142 |
+
"""
|
| 143 |
+
Args:
|
| 144 |
+
index (int): Index
|
| 145 |
+
|
| 146 |
+
Returns:
|
| 147 |
+
tuple: Tuple (image, target) where target is the index of the target category.
|
| 148 |
+
"""
|
| 149 |
+
target = 0
|
| 150 |
+
sub = 0
|
| 151 |
+
for ind in self.indices:
|
| 152 |
+
if index < ind:
|
| 153 |
+
break
|
| 154 |
+
target += 1
|
| 155 |
+
sub = ind
|
| 156 |
+
|
| 157 |
+
db = self.dbs[target]
|
| 158 |
+
index = index - sub
|
| 159 |
+
|
| 160 |
+
if self.target_transform is not None:
|
| 161 |
+
target = self.target_transform(target)
|
| 162 |
+
|
| 163 |
+
img, _ = db[index]
|
| 164 |
+
return img, target
|
| 165 |
+
|
| 166 |
+
def __len__(self):
|
| 167 |
+
return self.length
|
| 168 |
+
|
| 169 |
+
def extra_repr(self):
|
| 170 |
+
return "Classes: {classes}".format(**self.__dict__)
|
datasets_prep/stackmnist_data.py
ADDED
|
@@ -0,0 +1,65 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# ---------------------------------------------------------------
|
| 2 |
+
# Copyright (c) 2022, NVIDIA CORPORATION. All rights reserved.
|
| 3 |
+
#
|
| 4 |
+
# This work is licensed under the NVIDIA Source Code License
|
| 5 |
+
# for Denoising Diffusion GAN. To view a copy of this license, see the LICENSE file.
|
| 6 |
+
# ---------------------------------------------------------------
|
| 7 |
+
|
| 8 |
+
|
| 9 |
+
import numpy as np
|
| 10 |
+
from PIL import Image
|
| 11 |
+
import torchvision.datasets as dset
|
| 12 |
+
import torchvision.transforms as transforms
|
| 13 |
+
|
| 14 |
+
|
| 15 |
+
class StackedMNIST(dset.MNIST):
|
| 16 |
+
def __init__(self, root, train=True, transform=None, target_transform=None,
|
| 17 |
+
download=False):
|
| 18 |
+
super(StackedMNIST, self).__init__(root=root, train=train, transform=transform,
|
| 19 |
+
target_transform=target_transform, download=download)
|
| 20 |
+
|
| 21 |
+
index1 = np.hstack([np.random.permutation(len(self.data)), np.random.permutation(len(self.data))])
|
| 22 |
+
index2 = np.hstack([np.random.permutation(len(self.data)), np.random.permutation(len(self.data))])
|
| 23 |
+
index3 = np.hstack([np.random.permutation(len(self.data)), np.random.permutation(len(self.data))])
|
| 24 |
+
self.num_images = 2 * len(self.data)
|
| 25 |
+
|
| 26 |
+
self.index = []
|
| 27 |
+
for i in range(self.num_images):
|
| 28 |
+
self.index.append((index1[i], index2[i], index3[i]))
|
| 29 |
+
|
| 30 |
+
def __len__(self):
|
| 31 |
+
return self.num_images
|
| 32 |
+
|
| 33 |
+
def __getitem__(self, index):
|
| 34 |
+
img = np.zeros((28, 28, 3), dtype=np.uint8)
|
| 35 |
+
target = 0
|
| 36 |
+
for i in range(3):
|
| 37 |
+
img_, target_ = self.data[self.index[index][i]], int(self.targets[self.index[index][i]])
|
| 38 |
+
img[:, :, i] = img_
|
| 39 |
+
target += target_ * 10 ** (2 - i)
|
| 40 |
+
|
| 41 |
+
img = Image.fromarray(img, mode="RGB")
|
| 42 |
+
|
| 43 |
+
if self.transform is not None:
|
| 44 |
+
img = self.transform(img)
|
| 45 |
+
|
| 46 |
+
if self.target_transform is not None:
|
| 47 |
+
target = self.target_transform(target)
|
| 48 |
+
|
| 49 |
+
return img, target
|
| 50 |
+
|
| 51 |
+
def _data_transforms_stacked_mnist():
|
| 52 |
+
"""Get data transforms for cifar10."""
|
| 53 |
+
train_transform = transforms.Compose([
|
| 54 |
+
transforms.Pad(padding=2),
|
| 55 |
+
transforms.ToTensor(),
|
| 56 |
+
transforms.Normalize((0.5,0.5,0.5), (0.5,0.5,0.5))
|
| 57 |
+
])
|
| 58 |
+
|
| 59 |
+
valid_transform = transforms.Compose([
|
| 60 |
+
transforms.Pad(padding=2),
|
| 61 |
+
transforms.ToTensor(),
|
| 62 |
+
transforms.Normalize((0.5,0.5,0.5), (0.5,0.5,0.5))
|
| 63 |
+
])
|
| 64 |
+
|
| 65 |
+
return train_transform, valid_transform
|
pytorch_fid/LICENSE_MIT
ADDED
|
@@ -0,0 +1,21 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
MIT License
|
| 2 |
+
|
| 3 |
+
Copyright (c) 2021 Zhifeng Kong
|
| 4 |
+
|
| 5 |
+
Permission is hereby granted, free of charge, to any person obtaining a copy
|
| 6 |
+
of this software and associated documentation files (the "Software"), to deal
|
| 7 |
+
in the Software without restriction, including without limitation the rights
|
| 8 |
+
to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
|
| 9 |
+
copies of the Software, and to permit persons to whom the Software is
|
| 10 |
+
furnished to do so, subject to the following conditions:
|
| 11 |
+
|
| 12 |
+
The above copyright notice and this permission notice shall be included in all
|
| 13 |
+
copies or substantial portions of the Software.
|
| 14 |
+
|
| 15 |
+
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
|
| 16 |
+
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
|
| 17 |
+
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
|
| 18 |
+
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
|
| 19 |
+
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
|
| 20 |
+
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
|
| 21 |
+
SOFTWARE.
|
pytorch_fid/LICENSE_inception
ADDED
|
@@ -0,0 +1,201 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
Apache License
|
| 2 |
+
Version 2.0, January 2004
|
| 3 |
+
http://www.apache.org/licenses/
|
| 4 |
+
|
| 5 |
+
TERMS AND CONDITIONS FOR USE, REPRODUCTION, AND DISTRIBUTION
|
| 6 |
+
|
| 7 |
+
1. Definitions.
|
| 8 |
+
|
| 9 |
+
"License" shall mean the terms and conditions for use, reproduction,
|
| 10 |
+
and distribution as defined by Sections 1 through 9 of this document.
|
| 11 |
+
|
| 12 |
+
"Licensor" shall mean the copyright owner or entity authorized by
|
| 13 |
+
the copyright owner that is granting the License.
|
| 14 |
+
|
| 15 |
+
"Legal Entity" shall mean the union of the acting entity and all
|
| 16 |
+
other entities that control, are controlled by, or are under common
|
| 17 |
+
control with that entity. For the purposes of this definition,
|
| 18 |
+
"control" means (i) the power, direct or indirect, to cause the
|
| 19 |
+
direction or management of such entity, whether by contract or
|
| 20 |
+
otherwise, or (ii) ownership of fifty percent (50%) or more of the
|
| 21 |
+
outstanding shares, or (iii) beneficial ownership of such entity.
|
| 22 |
+
|
| 23 |
+
"You" (or "Your") shall mean an individual or Legal Entity
|
| 24 |
+
exercising permissions granted by this License.
|
| 25 |
+
|
| 26 |
+
"Source" form shall mean the preferred form for making modifications,
|
| 27 |
+
including but not limited to software source code, documentation
|
| 28 |
+
source, and configuration files.
|
| 29 |
+
|
| 30 |
+
"Object" form shall mean any form resulting from mechanical
|
| 31 |
+
transformation or translation of a Source form, including but
|
| 32 |
+
not limited to compiled object code, generated documentation,
|
| 33 |
+
and conversions to other media types.
|
| 34 |
+
|
| 35 |
+
"Work" shall mean the work of authorship, whether in Source or
|
| 36 |
+
Object form, made available under the License, as indicated by a
|
| 37 |
+
copyright notice that is included in or attached to the work
|
| 38 |
+
(an example is provided in the Appendix below).
|
| 39 |
+
|
| 40 |
+
"Derivative Works" shall mean any work, whether in Source or Object
|
| 41 |
+
form, that is based on (or derived from) the Work and for which the
|
| 42 |
+
editorial revisions, annotations, elaborations, or other modifications
|
| 43 |
+
represent, as a whole, an original work of authorship. For the purposes
|
| 44 |
+
of this License, Derivative Works shall not include works that remain
|
| 45 |
+
separable from, or merely link (or bind by name) to the interfaces of,
|
| 46 |
+
the Work and Derivative Works thereof.
|
| 47 |
+
|
| 48 |
+
"Contribution" shall mean any work of authorship, including
|
| 49 |
+
the original version of the Work and any modifications or additions
|
| 50 |
+
to that Work or Derivative Works thereof, that is intentionally
|
| 51 |
+
submitted to Licensor for inclusion in the Work by the copyright owner
|
| 52 |
+
or by an individual or Legal Entity authorized to submit on behalf of
|
| 53 |
+
the copyright owner. For the purposes of this definition, "submitted"
|
| 54 |
+
means any form of electronic, verbal, or written communication sent
|
| 55 |
+
to the Licensor or its representatives, including but not limited to
|
| 56 |
+
communication on electronic mailing lists, source code control systems,
|
| 57 |
+
and issue tracking systems that are managed by, or on behalf of, the
|
| 58 |
+
Licensor for the purpose of discussing and improving the Work, but
|
| 59 |
+
excluding communication that is conspicuously marked or otherwise
|
| 60 |
+
designated in writing by the copyright owner as "Not a Contribution."
|
| 61 |
+
|
| 62 |
+
"Contributor" shall mean Licensor and any individual or Legal Entity
|
| 63 |
+
on behalf of whom a Contribution has been received by Licensor and
|
| 64 |
+
subsequently incorporated within the Work.
|
| 65 |
+
|
| 66 |
+
2. Grant of Copyright License. Subject to the terms and conditions of
|
| 67 |
+
this License, each Contributor hereby grants to You a perpetual,
|
| 68 |
+
worldwide, non-exclusive, no-charge, royalty-free, irrevocable
|
| 69 |
+
copyright license to reproduce, prepare Derivative Works of,
|
| 70 |
+
publicly display, publicly perform, sublicense, and distribute the
|
| 71 |
+
Work and such Derivative Works in Source or Object form.
|
| 72 |
+
|
| 73 |
+
3. Grant of Patent License. Subject to the terms and conditions of
|
| 74 |
+
this License, each Contributor hereby grants to You a perpetual,
|
| 75 |
+
worldwide, non-exclusive, no-charge, royalty-free, irrevocable
|
| 76 |
+
(except as stated in this section) patent license to make, have made,
|
| 77 |
+
use, offer to sell, sell, import, and otherwise transfer the Work,
|
| 78 |
+
where such license applies only to those patent claims licensable
|
| 79 |
+
by such Contributor that are necessarily infringed by their
|
| 80 |
+
Contribution(s) alone or by combination of their Contribution(s)
|
| 81 |
+
with the Work to which such Contribution(s) was submitted. If You
|
| 82 |
+
institute patent litigation against any entity (including a
|
| 83 |
+
cross-claim or counterclaim in a lawsuit) alleging that the Work
|
| 84 |
+
or a Contribution incorporated within the Work constitutes direct
|
| 85 |
+
or contributory patent infringement, then any patent licenses
|
| 86 |
+
granted to You under this License for that Work shall terminate
|
| 87 |
+
as of the date such litigation is filed.
|
| 88 |
+
|
| 89 |
+
4. Redistribution. You may reproduce and distribute copies of the
|
| 90 |
+
Work or Derivative Works thereof in any medium, with or without
|
| 91 |
+
modifications, and in Source or Object form, provided that You
|
| 92 |
+
meet the following conditions:
|
| 93 |
+
|
| 94 |
+
(a) You must give any other recipients of the Work or
|
| 95 |
+
Derivative Works a copy of this License; and
|
| 96 |
+
|
| 97 |
+
(b) You must cause any modified files to carry prominent notices
|
| 98 |
+
stating that You changed the files; and
|
| 99 |
+
|
| 100 |
+
(c) You must retain, in the Source form of any Derivative Works
|
| 101 |
+
that You distribute, all copyright, patent, trademark, and
|
| 102 |
+
attribution notices from the Source form of the Work,
|
| 103 |
+
excluding those notices that do not pertain to any part of
|
| 104 |
+
the Derivative Works; and
|
| 105 |
+
|
| 106 |
+
(d) If the Work includes a "NOTICE" text file as part of its
|
| 107 |
+
distribution, then any Derivative Works that You distribute must
|
| 108 |
+
include a readable copy of the attribution notices contained
|
| 109 |
+
within such NOTICE file, excluding those notices that do not
|
| 110 |
+
pertain to any part of the Derivative Works, in at least one
|
| 111 |
+
of the following places: within a NOTICE text file distributed
|
| 112 |
+
as part of the Derivative Works; within the Source form or
|
| 113 |
+
documentation, if provided along with the Derivative Works; or,
|
| 114 |
+
within a display generated by the Derivative Works, if and
|
| 115 |
+
wherever such third-party notices normally appear. The contents
|
| 116 |
+
of the NOTICE file are for informational purposes only and
|
| 117 |
+
do not modify the License. You may add Your own attribution
|
| 118 |
+
notices within Derivative Works that You distribute, alongside
|
| 119 |
+
or as an addendum to the NOTICE text from the Work, provided
|
| 120 |
+
that such additional attribution notices cannot be construed
|
| 121 |
+
as modifying the License.
|
| 122 |
+
|
| 123 |
+
You may add Your own copyright statement to Your modifications and
|
| 124 |
+
may provide additional or different license terms and conditions
|
| 125 |
+
for use, reproduction, or distribution of Your modifications, or
|
| 126 |
+
for any such Derivative Works as a whole, provided Your use,
|
| 127 |
+
reproduction, and distribution of the Work otherwise complies with
|
| 128 |
+
the conditions stated in this License.
|
| 129 |
+
|
| 130 |
+
5. Submission of Contributions. Unless You explicitly state otherwise,
|
| 131 |
+
any Contribution intentionally submitted for inclusion in the Work
|
| 132 |
+
by You to the Licensor shall be under the terms and conditions of
|
| 133 |
+
this License, without any additional terms or conditions.
|
| 134 |
+
Notwithstanding the above, nothing herein shall supersede or modify
|
| 135 |
+
the terms of any separate license agreement you may have executed
|
| 136 |
+
with Licensor regarding such Contributions.
|
| 137 |
+
|
| 138 |
+
6. Trademarks. This License does not grant permission to use the trade
|
| 139 |
+
names, trademarks, service marks, or product names of the Licensor,
|
| 140 |
+
except as required for reasonable and customary use in describing the
|
| 141 |
+
origin of the Work and reproducing the content of the NOTICE file.
|
| 142 |
+
|
| 143 |
+
7. Disclaimer of Warranty. Unless required by applicable law or
|
| 144 |
+
agreed to in writing, Licensor provides the Work (and each
|
| 145 |
+
Contributor provides its Contributions) on an "AS IS" BASIS,
|
| 146 |
+
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or
|
| 147 |
+
implied, including, without limitation, any warranties or conditions
|
| 148 |
+
of TITLE, NON-INFRINGEMENT, MERCHANTABILITY, or FITNESS FOR A
|
| 149 |
+
PARTICULAR PURPOSE. You are solely responsible for determining the
|
| 150 |
+
appropriateness of using or redistributing the Work and assume any
|
| 151 |
+
risks associated with Your exercise of permissions under this License.
|
| 152 |
+
|
| 153 |
+
8. Limitation of Liability. In no event and under no legal theory,
|
| 154 |
+
whether in tort (including negligence), contract, or otherwise,
|
| 155 |
+
unless required by applicable law (such as deliberate and grossly
|
| 156 |
+
negligent acts) or agreed to in writing, shall any Contributor be
|
| 157 |
+
liable to You for damages, including any direct, indirect, special,
|
| 158 |
+
incidental, or consequential damages of any character arising as a
|
| 159 |
+
result of this License or out of the use or inability to use the
|
| 160 |
+
Work (including but not limited to damages for loss of goodwill,
|
| 161 |
+
work stoppage, computer failure or malfunction, or any and all
|
| 162 |
+
other commercial damages or losses), even if such Contributor
|
| 163 |
+
has been advised of the possibility of such damages.
|
| 164 |
+
|
| 165 |
+
9. Accepting Warranty or Additional Liability. While redistributing
|
| 166 |
+
the Work or Derivative Works thereof, You may choose to offer,
|
| 167 |
+
and charge a fee for, acceptance of support, warranty, indemnity,
|
| 168 |
+
or other liability obligations and/or rights consistent with this
|
| 169 |
+
License. However, in accepting such obligations, You may act only
|
| 170 |
+
on Your own behalf and on Your sole responsibility, not on behalf
|
| 171 |
+
of any other Contributor, and only if You agree to indemnify,
|
| 172 |
+
defend, and hold each Contributor harmless for any liability
|
| 173 |
+
incurred by, or claims asserted against, such Contributor by reason
|
| 174 |
+
of your accepting any such warranty or additional liability.
|
| 175 |
+
|
| 176 |
+
END OF TERMS AND CONDITIONS
|
| 177 |
+
|
| 178 |
+
APPENDIX: How to apply the Apache License to your work.
|
| 179 |
+
|
| 180 |
+
To apply the Apache License to your work, attach the following
|
| 181 |
+
boilerplate notice, with the fields enclosed by brackets "[]"
|
| 182 |
+
replaced with your own identifying information. (Don't include
|
| 183 |
+
the brackets!) The text should be enclosed in the appropriate
|
| 184 |
+
comment syntax for the file format. We also recommend that a
|
| 185 |
+
file or class name and description of purpose be included on the
|
| 186 |
+
same "printed page" as the copyright notice for easier
|
| 187 |
+
identification within third-party archives.
|
| 188 |
+
|
| 189 |
+
Copyright [yyyy] [name of copyright owner]
|
| 190 |
+
|
| 191 |
+
Licensed under the Apache License, Version 2.0 (the "License");
|
| 192 |
+
you may not use this file except in compliance with the License.
|
| 193 |
+
You may obtain a copy of the License at
|
| 194 |
+
|
| 195 |
+
http://www.apache.org/licenses/LICENSE-2.0
|
| 196 |
+
|
| 197 |
+
Unless required by applicable law or agreed to in writing, software
|
| 198 |
+
distributed under the License is distributed on an "AS IS" BASIS,
|
| 199 |
+
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
| 200 |
+
See the License for the specific language governing permissions and
|
| 201 |
+
limitations under the License.
|
pytorch_fid/LICENSE_pytorch_fid
ADDED
|
@@ -0,0 +1,201 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
Apache License
|
| 2 |
+
Version 2.0, January 2004
|
| 3 |
+
http://www.apache.org/licenses/
|
| 4 |
+
|
| 5 |
+
TERMS AND CONDITIONS FOR USE, REPRODUCTION, AND DISTRIBUTION
|
| 6 |
+
|
| 7 |
+
1. Definitions.
|
| 8 |
+
|
| 9 |
+
"License" shall mean the terms and conditions for use, reproduction,
|
| 10 |
+
and distribution as defined by Sections 1 through 9 of this document.
|
| 11 |
+
|
| 12 |
+
"Licensor" shall mean the copyright owner or entity authorized by
|
| 13 |
+
the copyright owner that is granting the License.
|
| 14 |
+
|
| 15 |
+
"Legal Entity" shall mean the union of the acting entity and all
|
| 16 |
+
other entities that control, are controlled by, or are under common
|
| 17 |
+
control with that entity. For the purposes of this definition,
|
| 18 |
+
"control" means (i) the power, direct or indirect, to cause the
|
| 19 |
+
direction or management of such entity, whether by contract or
|
| 20 |
+
otherwise, or (ii) ownership of fifty percent (50%) or more of the
|
| 21 |
+
outstanding shares, or (iii) beneficial ownership of such entity.
|
| 22 |
+
|
| 23 |
+
"You" (or "Your") shall mean an individual or Legal Entity
|
| 24 |
+
exercising permissions granted by this License.
|
| 25 |
+
|
| 26 |
+
"Source" form shall mean the preferred form for making modifications,
|
| 27 |
+
including but not limited to software source code, documentation
|
| 28 |
+
source, and configuration files.
|
| 29 |
+
|
| 30 |
+
"Object" form shall mean any form resulting from mechanical
|
| 31 |
+
transformation or translation of a Source form, including but
|
| 32 |
+
not limited to compiled object code, generated documentation,
|
| 33 |
+
and conversions to other media types.
|
| 34 |
+
|
| 35 |
+
"Work" shall mean the work of authorship, whether in Source or
|
| 36 |
+
Object form, made available under the License, as indicated by a
|
| 37 |
+
copyright notice that is included in or attached to the work
|
| 38 |
+
(an example is provided in the Appendix below).
|
| 39 |
+
|
| 40 |
+
"Derivative Works" shall mean any work, whether in Source or Object
|
| 41 |
+
form, that is based on (or derived from) the Work and for which the
|
| 42 |
+
editorial revisions, annotations, elaborations, or other modifications
|
| 43 |
+
represent, as a whole, an original work of authorship. For the purposes
|
| 44 |
+
of this License, Derivative Works shall not include works that remain
|
| 45 |
+
separable from, or merely link (or bind by name) to the interfaces of,
|
| 46 |
+
the Work and Derivative Works thereof.
|
| 47 |
+
|
| 48 |
+
"Contribution" shall mean any work of authorship, including
|
| 49 |
+
the original version of the Work and any modifications or additions
|
| 50 |
+
to that Work or Derivative Works thereof, that is intentionally
|
| 51 |
+
submitted to Licensor for inclusion in the Work by the copyright owner
|
| 52 |
+
or by an individual or Legal Entity authorized to submit on behalf of
|
| 53 |
+
the copyright owner. For the purposes of this definition, "submitted"
|
| 54 |
+
means any form of electronic, verbal, or written communication sent
|
| 55 |
+
to the Licensor or its representatives, including but not limited to
|
| 56 |
+
communication on electronic mailing lists, source code control systems,
|
| 57 |
+
and issue tracking systems that are managed by, or on behalf of, the
|
| 58 |
+
Licensor for the purpose of discussing and improving the Work, but
|
| 59 |
+
excluding communication that is conspicuously marked or otherwise
|
| 60 |
+
designated in writing by the copyright owner as "Not a Contribution."
|
| 61 |
+
|
| 62 |
+
"Contributor" shall mean Licensor and any individual or Legal Entity
|
| 63 |
+
on behalf of whom a Contribution has been received by Licensor and
|
| 64 |
+
subsequently incorporated within the Work.
|
| 65 |
+
|
| 66 |
+
2. Grant of Copyright License. Subject to the terms and conditions of
|
| 67 |
+
this License, each Contributor hereby grants to You a perpetual,
|
| 68 |
+
worldwide, non-exclusive, no-charge, royalty-free, irrevocable
|
| 69 |
+
copyright license to reproduce, prepare Derivative Works of,
|
| 70 |
+
publicly display, publicly perform, sublicense, and distribute the
|
| 71 |
+
Work and such Derivative Works in Source or Object form.
|
| 72 |
+
|
| 73 |
+
3. Grant of Patent License. Subject to the terms and conditions of
|
| 74 |
+
this License, each Contributor hereby grants to You a perpetual,
|
| 75 |
+
worldwide, non-exclusive, no-charge, royalty-free, irrevocable
|
| 76 |
+
(except as stated in this section) patent license to make, have made,
|
| 77 |
+
use, offer to sell, sell, import, and otherwise transfer the Work,
|
| 78 |
+
where such license applies only to those patent claims licensable
|
| 79 |
+
by such Contributor that are necessarily infringed by their
|
| 80 |
+
Contribution(s) alone or by combination of their Contribution(s)
|
| 81 |
+
with the Work to which such Contribution(s) was submitted. If You
|
| 82 |
+
institute patent litigation against any entity (including a
|
| 83 |
+
cross-claim or counterclaim in a lawsuit) alleging that the Work
|
| 84 |
+
or a Contribution incorporated within the Work constitutes direct
|
| 85 |
+
or contributory patent infringement, then any patent licenses
|
| 86 |
+
granted to You under this License for that Work shall terminate
|
| 87 |
+
as of the date such litigation is filed.
|
| 88 |
+
|
| 89 |
+
4. Redistribution. You may reproduce and distribute copies of the
|
| 90 |
+
Work or Derivative Works thereof in any medium, with or without
|
| 91 |
+
modifications, and in Source or Object form, provided that You
|
| 92 |
+
meet the following conditions:
|
| 93 |
+
|
| 94 |
+
(a) You must give any other recipients of the Work or
|
| 95 |
+
Derivative Works a copy of this License; and
|
| 96 |
+
|
| 97 |
+
(b) You must cause any modified files to carry prominent notices
|
| 98 |
+
stating that You changed the files; and
|
| 99 |
+
|
| 100 |
+
(c) You must retain, in the Source form of any Derivative Works
|
| 101 |
+
that You distribute, all copyright, patent, trademark, and
|
| 102 |
+
attribution notices from the Source form of the Work,
|
| 103 |
+
excluding those notices that do not pertain to any part of
|
| 104 |
+
the Derivative Works; and
|
| 105 |
+
|
| 106 |
+
(d) If the Work includes a "NOTICE" text file as part of its
|
| 107 |
+
distribution, then any Derivative Works that You distribute must
|
| 108 |
+
include a readable copy of the attribution notices contained
|
| 109 |
+
within such NOTICE file, excluding those notices that do not
|
| 110 |
+
pertain to any part of the Derivative Works, in at least one
|
| 111 |
+
of the following places: within a NOTICE text file distributed
|
| 112 |
+
as part of the Derivative Works; within the Source form or
|
| 113 |
+
documentation, if provided along with the Derivative Works; or,
|
| 114 |
+
within a display generated by the Derivative Works, if and
|
| 115 |
+
wherever such third-party notices normally appear. The contents
|
| 116 |
+
of the NOTICE file are for informational purposes only and
|
| 117 |
+
do not modify the License. You may add Your own attribution
|
| 118 |
+
notices within Derivative Works that You distribute, alongside
|
| 119 |
+
or as an addendum to the NOTICE text from the Work, provided
|
| 120 |
+
that such additional attribution notices cannot be construed
|
| 121 |
+
as modifying the License.
|
| 122 |
+
|
| 123 |
+
You may add Your own copyright statement to Your modifications and
|
| 124 |
+
may provide additional or different license terms and conditions
|
| 125 |
+
for use, reproduction, or distribution of Your modifications, or
|
| 126 |
+
for any such Derivative Works as a whole, provided Your use,
|
| 127 |
+
reproduction, and distribution of the Work otherwise complies with
|
| 128 |
+
the conditions stated in this License.
|
| 129 |
+
|
| 130 |
+
5. Submission of Contributions. Unless You explicitly state otherwise,
|
| 131 |
+
any Contribution intentionally submitted for inclusion in the Work
|
| 132 |
+
by You to the Licensor shall be under the terms and conditions of
|
| 133 |
+
this License, without any additional terms or conditions.
|
| 134 |
+
Notwithstanding the above, nothing herein shall supersede or modify
|
| 135 |
+
the terms of any separate license agreement you may have executed
|
| 136 |
+
with Licensor regarding such Contributions.
|
| 137 |
+
|
| 138 |
+
6. Trademarks. This License does not grant permission to use the trade
|
| 139 |
+
names, trademarks, service marks, or product names of the Licensor,
|
| 140 |
+
except as required for reasonable and customary use in describing the
|
| 141 |
+
origin of the Work and reproducing the content of the NOTICE file.
|
| 142 |
+
|
| 143 |
+
7. Disclaimer of Warranty. Unless required by applicable law or
|
| 144 |
+
agreed to in writing, Licensor provides the Work (and each
|
| 145 |
+
Contributor provides its Contributions) on an "AS IS" BASIS,
|
| 146 |
+
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or
|
| 147 |
+
implied, including, without limitation, any warranties or conditions
|
| 148 |
+
of TITLE, NON-INFRINGEMENT, MERCHANTABILITY, or FITNESS FOR A
|
| 149 |
+
PARTICULAR PURPOSE. You are solely responsible for determining the
|
| 150 |
+
appropriateness of using or redistributing the Work and assume any
|
| 151 |
+
risks associated with Your exercise of permissions under this License.
|
| 152 |
+
|
| 153 |
+
8. Limitation of Liability. In no event and under no legal theory,
|
| 154 |
+
whether in tort (including negligence), contract, or otherwise,
|
| 155 |
+
unless required by applicable law (such as deliberate and grossly
|
| 156 |
+
negligent acts) or agreed to in writing, shall any Contributor be
|
| 157 |
+
liable to You for damages, including any direct, indirect, special,
|
| 158 |
+
incidental, or consequential damages of any character arising as a
|
| 159 |
+
result of this License or out of the use or inability to use the
|
| 160 |
+
Work (including but not limited to damages for loss of goodwill,
|
| 161 |
+
work stoppage, computer failure or malfunction, or any and all
|
| 162 |
+
other commercial damages or losses), even if such Contributor
|
| 163 |
+
has been advised of the possibility of such damages.
|
| 164 |
+
|
| 165 |
+
9. Accepting Warranty or Additional Liability. While redistributing
|
| 166 |
+
the Work or Derivative Works thereof, You may choose to offer,
|
| 167 |
+
and charge a fee for, acceptance of support, warranty, indemnity,
|
| 168 |
+
or other liability obligations and/or rights consistent with this
|
| 169 |
+
License. However, in accepting such obligations, You may act only
|
| 170 |
+
on Your own behalf and on Your sole responsibility, not on behalf
|
| 171 |
+
of any other Contributor, and only if You agree to indemnify,
|
| 172 |
+
defend, and hold each Contributor harmless for any liability
|
| 173 |
+
incurred by, or claims asserted against, such Contributor by reason
|
| 174 |
+
of your accepting any such warranty or additional liability.
|
| 175 |
+
|
| 176 |
+
END OF TERMS AND CONDITIONS
|
| 177 |
+
|
| 178 |
+
APPENDIX: How to apply the Apache License to your work.
|
| 179 |
+
|
| 180 |
+
To apply the Apache License to your work, attach the following
|
| 181 |
+
boilerplate notice, with the fields enclosed by brackets "[]"
|
| 182 |
+
replaced with your own identifying information. (Don't include
|
| 183 |
+
the brackets!) The text should be enclosed in the appropriate
|
| 184 |
+
comment syntax for the file format. We also recommend that a
|
| 185 |
+
file or class name and description of purpose be included on the
|
| 186 |
+
same "printed page" as the copyright notice for easier
|
| 187 |
+
identification within third-party archives.
|
| 188 |
+
|
| 189 |
+
Copyright [yyyy] [name of copyright owner]
|
| 190 |
+
|
| 191 |
+
Licensed under the Apache License, Version 2.0 (the "License");
|
| 192 |
+
you may not use this file except in compliance with the License.
|
| 193 |
+
You may obtain a copy of the License at
|
| 194 |
+
|
| 195 |
+
http://www.apache.org/licenses/LICENSE-2.0
|
| 196 |
+
|
| 197 |
+
Unless required by applicable law or agreed to in writing, software
|
| 198 |
+
distributed under the License is distributed on an "AS IS" BASIS,
|
| 199 |
+
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
| 200 |
+
See the License for the specific language governing permissions and
|
| 201 |
+
limitations under the License.
|
pytorch_fid/fid_score.py
ADDED
|
@@ -0,0 +1,305 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# ---------------------------------------------------------------
|
| 2 |
+
# Copyright (c) 2022, NVIDIA CORPORATION. All rights reserved.
|
| 3 |
+
#
|
| 4 |
+
# This file has been modified from FAST_DPM.
|
| 5 |
+
#
|
| 6 |
+
# Source:
|
| 7 |
+
# https://github.com/FengNiMa/FastDPM_pytorch/blob/6540c1cdac3799aff8a5f7b9de430269bbd0b7c3/pytorch_fid/fid_score.py
|
| 8 |
+
#
|
| 9 |
+
# The license for the original version of this file can be
|
| 10 |
+
# found in this directory (LICENSE_MIT).
|
| 11 |
+
# The modifications to this file are subject to the same license.
|
| 12 |
+
# ---------------------------------------------------------------
|
| 13 |
+
|
| 14 |
+
"""Calculates the Frechet Inception Distance (FID) to evalulate GANs
|
| 15 |
+
|
| 16 |
+
The FID metric calculates the distance between two distributions of images.
|
| 17 |
+
Typically, we have summary statistics (mean & covariance matrix) of one
|
| 18 |
+
of these distributions, while the 2nd distribution is given by a GAN.
|
| 19 |
+
|
| 20 |
+
When run as a stand-alone program, it compares the distribution of
|
| 21 |
+
images that are stored as PNG/JPEG at a specified location with a
|
| 22 |
+
distribution given by summary statistics (in pickle format).
|
| 23 |
+
|
| 24 |
+
The FID is calculated by assuming that X_1 and X_2 are the activations of
|
| 25 |
+
the pool_3 layer of the inception net for generated samples and real world
|
| 26 |
+
samples respectively.
|
| 27 |
+
|
| 28 |
+
See --help to see further details.
|
| 29 |
+
|
| 30 |
+
Code apapted from https://github.com/bioinf-jku/TTUR to use PyTorch instead
|
| 31 |
+
of Tensorflow
|
| 32 |
+
|
| 33 |
+
Copyright 2018 Institute of Bioinformatics, JKU Linz
|
| 34 |
+
|
| 35 |
+
Licensed under the Apache License, Version 2.0 (the "License");
|
| 36 |
+
you may not use this file except in compliance with the License.
|
| 37 |
+
You may obtain a copy of the License at
|
| 38 |
+
|
| 39 |
+
http://www.apache.org/licenses/LICENSE-2.0
|
| 40 |
+
|
| 41 |
+
Unless required by applicable law or agreed to in writing, software
|
| 42 |
+
distributed under the License is distributed on an "AS IS" BASIS,
|
| 43 |
+
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
| 44 |
+
See the License for the specific language governing permissions and
|
| 45 |
+
limitations under the License.
|
| 46 |
+
"""
|
| 47 |
+
import os
|
| 48 |
+
import pathlib
|
| 49 |
+
from argparse import ArgumentDefaultsHelpFormatter, ArgumentParser
|
| 50 |
+
from multiprocessing import cpu_count
|
| 51 |
+
|
| 52 |
+
import numpy as np
|
| 53 |
+
import torch
|
| 54 |
+
import torch.nn.functional as F
|
| 55 |
+
import torchvision.transforms as TF
|
| 56 |
+
from PIL import Image
|
| 57 |
+
from scipy import linalg
|
| 58 |
+
from torch.nn.functional import adaptive_avg_pool2d
|
| 59 |
+
|
| 60 |
+
try:
|
| 61 |
+
from tqdm import tqdm
|
| 62 |
+
except ImportError:
|
| 63 |
+
# If tqdm is not available, provide a mock version of it
|
| 64 |
+
def tqdm(x):
|
| 65 |
+
return x
|
| 66 |
+
|
| 67 |
+
try:
|
| 68 |
+
from inception import InceptionV3
|
| 69 |
+
except ImportError:
|
| 70 |
+
from .inception import InceptionV3
|
| 71 |
+
|
| 72 |
+
parser = ArgumentParser(formatter_class=ArgumentDefaultsHelpFormatter)
|
| 73 |
+
parser.add_argument('--batch-size', type=int, default=50,
|
| 74 |
+
help='Batch size to use')
|
| 75 |
+
parser.add_argument('--device', type=str, default=None,
|
| 76 |
+
help='Device to use. Like cuda, cuda:0 or cpu')
|
| 77 |
+
parser.add_argument('--dims', type=int, default=2048,
|
| 78 |
+
choices=list(InceptionV3.BLOCK_INDEX_BY_DIM),
|
| 79 |
+
help=('Dimensionality of Inception features to use. '
|
| 80 |
+
'By default, uses pool3 features'))
|
| 81 |
+
parser.add_argument('path', type=str, nargs=2,
|
| 82 |
+
help=('Paths to the generated images or '
|
| 83 |
+
'to .npz statistic files'))
|
| 84 |
+
|
| 85 |
+
IMAGE_EXTENSIONS = {'bmp', 'jpg', 'jpeg', 'pgm', 'png', 'ppm',
|
| 86 |
+
'tif', 'tiff', 'webp'}
|
| 87 |
+
|
| 88 |
+
|
| 89 |
+
|
| 90 |
+
|
| 91 |
+
class ImagePathDataset(torch.utils.data.Dataset):
|
| 92 |
+
def __init__(self, files, transforms=None):
|
| 93 |
+
self.files = files
|
| 94 |
+
self.transforms = transforms
|
| 95 |
+
|
| 96 |
+
def __len__(self):
|
| 97 |
+
return len(self.files)
|
| 98 |
+
|
| 99 |
+
def __getitem__(self, i):
|
| 100 |
+
path = self.files[i]
|
| 101 |
+
img = Image.open(path).convert('RGB')
|
| 102 |
+
if self.transforms is not None:
|
| 103 |
+
img = self.transforms(img)
|
| 104 |
+
return img
|
| 105 |
+
|
| 106 |
+
|
| 107 |
+
def get_activations(files, model, batch_size=50, dims=2048, device='cpu', resize=0):
|
| 108 |
+
"""Calculates the activations of the pool_3 layer for all images.
|
| 109 |
+
|
| 110 |
+
Params:
|
| 111 |
+
-- files : List of image files paths
|
| 112 |
+
-- model : Instance of inception model
|
| 113 |
+
-- batch_size : Batch size of images for the model to process at once.
|
| 114 |
+
Make sure that the number of samples is a multiple of
|
| 115 |
+
the batch size, otherwise some samples are ignored. This
|
| 116 |
+
behavior is retained to match the original FID score
|
| 117 |
+
implementation.
|
| 118 |
+
-- dims : Dimensionality of features returned by Inception
|
| 119 |
+
-- device : Device to run calculations
|
| 120 |
+
|
| 121 |
+
Returns:
|
| 122 |
+
-- A numpy array of dimension (num images, dims) that contains the
|
| 123 |
+
activations of the given tensor when feeding inception with the
|
| 124 |
+
query tensor.
|
| 125 |
+
"""
|
| 126 |
+
model.eval()
|
| 127 |
+
|
| 128 |
+
if batch_size > len(files):
|
| 129 |
+
print(('Warning: batch size is bigger than the data size. '
|
| 130 |
+
'Setting batch size to data size'))
|
| 131 |
+
batch_size = len(files)
|
| 132 |
+
|
| 133 |
+
if resize > 0:
|
| 134 |
+
print('Resized to ({}, {})'.format(resize, resize))
|
| 135 |
+
dataset = ImagePathDataset(files, transforms=TF.Compose([TF.Resize(size=(resize, resize)),
|
| 136 |
+
TF.ToTensor()]))
|
| 137 |
+
else:
|
| 138 |
+
dataset = ImagePathDataset(files, transforms=TF.ToTensor())
|
| 139 |
+
dataloader = torch.utils.data.DataLoader(dataset,
|
| 140 |
+
batch_size=batch_size,
|
| 141 |
+
shuffle=False,
|
| 142 |
+
drop_last=False,
|
| 143 |
+
num_workers=cpu_count())
|
| 144 |
+
|
| 145 |
+
pred_arr = np.empty((len(files), dims))
|
| 146 |
+
|
| 147 |
+
start_idx = 0
|
| 148 |
+
|
| 149 |
+
for batch in tqdm(dataloader):
|
| 150 |
+
batch = batch.to(device)
|
| 151 |
+
|
| 152 |
+
with torch.no_grad():
|
| 153 |
+
pred = model(batch)[0]
|
| 154 |
+
|
| 155 |
+
# If model output is not scalar, apply global spatial average pooling.
|
| 156 |
+
# This happens if you choose a dimensionality not equal 2048.
|
| 157 |
+
if pred.size(2) != 1 or pred.size(3) != 1:
|
| 158 |
+
pred = adaptive_avg_pool2d(pred, output_size=(1, 1))
|
| 159 |
+
|
| 160 |
+
pred = pred.squeeze(3).squeeze(2).cpu().numpy()
|
| 161 |
+
|
| 162 |
+
pred_arr[start_idx:start_idx + pred.shape[0]] = pred
|
| 163 |
+
|
| 164 |
+
start_idx = start_idx + pred.shape[0]
|
| 165 |
+
|
| 166 |
+
return pred_arr
|
| 167 |
+
|
| 168 |
+
|
| 169 |
+
def calculate_frechet_distance(mu1, sigma1, mu2, sigma2, eps=1e-6):
|
| 170 |
+
"""Numpy implementation of the Frechet Distance.
|
| 171 |
+
The Frechet distance between two multivariate Gaussians X_1 ~ N(mu_1, C_1)
|
| 172 |
+
and X_2 ~ N(mu_2, C_2) is
|
| 173 |
+
d^2 = ||mu_1 - mu_2||^2 + Tr(C_1 + C_2 - 2*sqrt(C_1*C_2)).
|
| 174 |
+
|
| 175 |
+
Stable version by Dougal J. Sutherland.
|
| 176 |
+
|
| 177 |
+
Params:
|
| 178 |
+
-- mu1 : Numpy array containing the activations of a layer of the
|
| 179 |
+
inception net (like returned by the function 'get_predictions')
|
| 180 |
+
for generated samples.
|
| 181 |
+
-- mu2 : The sample mean over activations, precalculated on an
|
| 182 |
+
representative data set.
|
| 183 |
+
-- sigma1: The covariance matrix over activations for generated samples.
|
| 184 |
+
-- sigma2: The covariance matrix over activations, precalculated on an
|
| 185 |
+
representative data set.
|
| 186 |
+
|
| 187 |
+
Returns:
|
| 188 |
+
-- : The Frechet Distance.
|
| 189 |
+
"""
|
| 190 |
+
|
| 191 |
+
mu1 = np.atleast_1d(mu1)
|
| 192 |
+
mu2 = np.atleast_1d(mu2)
|
| 193 |
+
|
| 194 |
+
sigma1 = np.atleast_2d(sigma1)
|
| 195 |
+
sigma2 = np.atleast_2d(sigma2)
|
| 196 |
+
|
| 197 |
+
assert mu1.shape == mu2.shape, \
|
| 198 |
+
'Training and test mean vectors have different lengths'
|
| 199 |
+
assert sigma1.shape == sigma2.shape, \
|
| 200 |
+
'Training and test covariances have different dimensions'
|
| 201 |
+
|
| 202 |
+
diff = mu1 - mu2
|
| 203 |
+
|
| 204 |
+
# Product might be almost singular
|
| 205 |
+
covmean = linalg.sqrtm(sigma1.dot(sigma2))
|
| 206 |
+
if not np.isfinite(covmean).all():
|
| 207 |
+
msg = ('fid calculation produces singular product; '
|
| 208 |
+
'adding %s to diagonal of cov estimates') % eps
|
| 209 |
+
print(msg)
|
| 210 |
+
offset = np.eye(sigma1.shape[0]) * eps
|
| 211 |
+
covmean = linalg.sqrtm((sigma1 + offset).dot(sigma2 + offset))
|
| 212 |
+
|
| 213 |
+
# Numerical error might give slight imaginary component
|
| 214 |
+
if np.iscomplexobj(covmean):
|
| 215 |
+
if not np.allclose(np.diagonal(covmean).imag, 0, atol=1e-3):
|
| 216 |
+
m = np.max(np.abs(covmean.imag))
|
| 217 |
+
raise ValueError('Imaginary component {}'.format(m))
|
| 218 |
+
covmean = covmean.real
|
| 219 |
+
|
| 220 |
+
tr_covmean = np.trace(covmean)
|
| 221 |
+
|
| 222 |
+
return (diff.dot(diff) + np.trace(sigma1)
|
| 223 |
+
+ np.trace(sigma2) - 2 * tr_covmean)
|
| 224 |
+
|
| 225 |
+
|
| 226 |
+
def calculate_activation_statistics(files, model, batch_size=50, dims=2048,
|
| 227 |
+
device='cpu', resize=0):
|
| 228 |
+
"""Calculation of the statistics used by the FID.
|
| 229 |
+
Params:
|
| 230 |
+
-- files : List of image files paths
|
| 231 |
+
-- model : Instance of inception model
|
| 232 |
+
-- batch_size : The images numpy array is split into batches with
|
| 233 |
+
batch size batch_size. A reasonable batch size
|
| 234 |
+
depends on the hardware.
|
| 235 |
+
-- dims : Dimensionality of features returned by Inception
|
| 236 |
+
-- device : Device to run calculations
|
| 237 |
+
-- resize : resize image to this shape
|
| 238 |
+
|
| 239 |
+
Returns:
|
| 240 |
+
-- mu : The mean over samples of the activations of the pool_3 layer of
|
| 241 |
+
the inception model.
|
| 242 |
+
-- sigma : The covariance matrix of the activations of the pool_3 layer of
|
| 243 |
+
the inception model.
|
| 244 |
+
"""
|
| 245 |
+
act = get_activations(files, model, batch_size, dims, device, resize)
|
| 246 |
+
mu = np.mean(act, axis=0)
|
| 247 |
+
sigma = np.cov(act, rowvar=False)
|
| 248 |
+
return mu, sigma
|
| 249 |
+
|
| 250 |
+
|
| 251 |
+
def compute_statistics_of_path(path, model, batch_size, dims, device, resize=0):
|
| 252 |
+
if path.endswith('.npz') or path.endswith('.npy'):
|
| 253 |
+
f = np.load(path, allow_pickle=True)
|
| 254 |
+
try:
|
| 255 |
+
m, s = f['mu'][:], f['sigma'][:]
|
| 256 |
+
except:
|
| 257 |
+
m, s = f.item()['mu'][:], f.item()['sigma'][:]
|
| 258 |
+
else:
|
| 259 |
+
path_str = path[:]
|
| 260 |
+
path = pathlib.Path(path)
|
| 261 |
+
files = sorted([file for ext in IMAGE_EXTENSIONS
|
| 262 |
+
for file in path.glob('*.{}'.format(ext))])
|
| 263 |
+
m, s = calculate_activation_statistics(files, model, batch_size,
|
| 264 |
+
dims, device, resize)
|
| 265 |
+
return m, s
|
| 266 |
+
|
| 267 |
+
|
| 268 |
+
def calculate_fid_given_paths(paths, batch_size, device, dims, resize=0):
|
| 269 |
+
"""Calculates the FID of two paths"""
|
| 270 |
+
for p in paths:
|
| 271 |
+
if not os.path.exists(p):
|
| 272 |
+
raise RuntimeError('Invalid path: %s' % p)
|
| 273 |
+
|
| 274 |
+
block_idx = InceptionV3.BLOCK_INDEX_BY_DIM[dims]
|
| 275 |
+
|
| 276 |
+
model = InceptionV3([block_idx]).to(device)
|
| 277 |
+
|
| 278 |
+
m1, s1 = compute_statistics_of_path(paths[0], model, batch_size,
|
| 279 |
+
dims, device, resize)
|
| 280 |
+
m2, s2 = compute_statistics_of_path(paths[1], model, batch_size,
|
| 281 |
+
dims, device, resize)
|
| 282 |
+
|
| 283 |
+
del model
|
| 284 |
+
fid_value = calculate_frechet_distance(m1, s1, m2, s2)
|
| 285 |
+
return fid_value
|
| 286 |
+
|
| 287 |
+
|
| 288 |
+
|
| 289 |
+
def main():
|
| 290 |
+
args = parser.parse_args()
|
| 291 |
+
|
| 292 |
+
if args.device is None:
|
| 293 |
+
device = torch.device('cuda' if (torch.cuda.is_available()) else 'cpu')
|
| 294 |
+
else:
|
| 295 |
+
device = torch.device(args.device)
|
| 296 |
+
|
| 297 |
+
fid_value = calculate_fid_given_paths(args.path,
|
| 298 |
+
args.batch_size,
|
| 299 |
+
device,
|
| 300 |
+
args.dims)
|
| 301 |
+
print('FID: ', fid_value)
|
| 302 |
+
|
| 303 |
+
|
| 304 |
+
if __name__ == '__main__':
|
| 305 |
+
main()
|
pytorch_fid/inception.py
ADDED
|
@@ -0,0 +1,337 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# ---------------------------------------------------------------
|
| 2 |
+
# Taken from the following link as is from:
|
| 3 |
+
# https://github.com/mseitzer/pytorch-fid/blob/3d604a25516746c3a4a5548c8610e99010b2c819/src/pytorch_fid/inception.py
|
| 4 |
+
#
|
| 5 |
+
# The license for the original version of this file can be
|
| 6 |
+
# found in this directory (LICENSE_pytorch_fid).
|
| 7 |
+
# ---------------------------------------------------------------
|
| 8 |
+
|
| 9 |
+
|
| 10 |
+
import torch
|
| 11 |
+
import torch.nn as nn
|
| 12 |
+
import torch.nn.functional as F
|
| 13 |
+
import torchvision
|
| 14 |
+
|
| 15 |
+
try:
|
| 16 |
+
from torchvision.models.utils import load_state_dict_from_url
|
| 17 |
+
except ImportError:
|
| 18 |
+
from torch.utils.model_zoo import load_url as load_state_dict_from_url
|
| 19 |
+
|
| 20 |
+
# Inception weights ported to Pytorch from
|
| 21 |
+
# http://download.tensorflow.org/models/image/imagenet/inception-2015-12-05.tgz
|
| 22 |
+
FID_WEIGHTS_URL = 'https://github.com/mseitzer/pytorch-fid/releases/download/fid_weights/pt_inception-2015-12-05-6726825d.pth' # noqa: E501
|
| 23 |
+
|
| 24 |
+
|
| 25 |
+
class InceptionV3(nn.Module):
|
| 26 |
+
"""Pretrained InceptionV3 network returning feature maps"""
|
| 27 |
+
|
| 28 |
+
# Index of default block of inception to return,
|
| 29 |
+
# corresponds to output of final average pooling
|
| 30 |
+
DEFAULT_BLOCK_INDEX = 3
|
| 31 |
+
|
| 32 |
+
# Maps feature dimensionality to their output blocks indices
|
| 33 |
+
BLOCK_INDEX_BY_DIM = {
|
| 34 |
+
64: 0, # First max pooling features
|
| 35 |
+
192: 1, # Second max pooling featurs
|
| 36 |
+
768: 2, # Pre-aux classifier features
|
| 37 |
+
2048: 3 # Final average pooling features
|
| 38 |
+
}
|
| 39 |
+
|
| 40 |
+
def __init__(self,
|
| 41 |
+
output_blocks=(DEFAULT_BLOCK_INDEX,),
|
| 42 |
+
resize_input=True,
|
| 43 |
+
normalize_input=True,
|
| 44 |
+
requires_grad=False,
|
| 45 |
+
use_fid_inception=True):
|
| 46 |
+
"""Build pretrained InceptionV3
|
| 47 |
+
|
| 48 |
+
Parameters
|
| 49 |
+
----------
|
| 50 |
+
output_blocks : list of int
|
| 51 |
+
Indices of blocks to return features of. Possible values are:
|
| 52 |
+
- 0: corresponds to output of first max pooling
|
| 53 |
+
- 1: corresponds to output of second max pooling
|
| 54 |
+
- 2: corresponds to output which is fed to aux classifier
|
| 55 |
+
- 3: corresponds to output of final average pooling
|
| 56 |
+
resize_input : bool
|
| 57 |
+
If true, bilinearly resizes input to width and height 299 before
|
| 58 |
+
feeding input to model. As the network without fully connected
|
| 59 |
+
layers is fully convolutional, it should be able to handle inputs
|
| 60 |
+
of arbitrary size, so resizing might not be strictly needed
|
| 61 |
+
normalize_input : bool
|
| 62 |
+
If true, scales the input from range (0, 1) to the range the
|
| 63 |
+
pretrained Inception network expects, namely (-1, 1)
|
| 64 |
+
requires_grad : bool
|
| 65 |
+
If true, parameters of the model require gradients. Possibly useful
|
| 66 |
+
for finetuning the network
|
| 67 |
+
use_fid_inception : bool
|
| 68 |
+
If true, uses the pretrained Inception model used in Tensorflow's
|
| 69 |
+
FID implementation. If false, uses the pretrained Inception model
|
| 70 |
+
available in torchvision. The FID Inception model has different
|
| 71 |
+
weights and a slightly different structure from torchvision's
|
| 72 |
+
Inception model. If you want to compute FID scores, you are
|
| 73 |
+
strongly advised to set this parameter to true to get comparable
|
| 74 |
+
results.
|
| 75 |
+
"""
|
| 76 |
+
super(InceptionV3, self).__init__()
|
| 77 |
+
|
| 78 |
+
self.resize_input = resize_input
|
| 79 |
+
self.normalize_input = normalize_input
|
| 80 |
+
self.output_blocks = sorted(output_blocks)
|
| 81 |
+
self.last_needed_block = max(output_blocks)
|
| 82 |
+
|
| 83 |
+
assert self.last_needed_block <= 3, \
|
| 84 |
+
'Last possible output block index is 3'
|
| 85 |
+
|
| 86 |
+
self.blocks = nn.ModuleList()
|
| 87 |
+
|
| 88 |
+
if use_fid_inception:
|
| 89 |
+
inception = fid_inception_v3()
|
| 90 |
+
else:
|
| 91 |
+
inception = _inception_v3(pretrained=True)
|
| 92 |
+
|
| 93 |
+
# Block 0: input to maxpool1
|
| 94 |
+
block0 = [
|
| 95 |
+
inception.Conv2d_1a_3x3,
|
| 96 |
+
inception.Conv2d_2a_3x3,
|
| 97 |
+
inception.Conv2d_2b_3x3,
|
| 98 |
+
nn.MaxPool2d(kernel_size=3, stride=2)
|
| 99 |
+
]
|
| 100 |
+
self.blocks.append(nn.Sequential(*block0))
|
| 101 |
+
|
| 102 |
+
# Block 1: maxpool1 to maxpool2
|
| 103 |
+
if self.last_needed_block >= 1:
|
| 104 |
+
block1 = [
|
| 105 |
+
inception.Conv2d_3b_1x1,
|
| 106 |
+
inception.Conv2d_4a_3x3,
|
| 107 |
+
nn.MaxPool2d(kernel_size=3, stride=2)
|
| 108 |
+
]
|
| 109 |
+
self.blocks.append(nn.Sequential(*block1))
|
| 110 |
+
|
| 111 |
+
# Block 2: maxpool2 to aux classifier
|
| 112 |
+
if self.last_needed_block >= 2:
|
| 113 |
+
block2 = [
|
| 114 |
+
inception.Mixed_5b,
|
| 115 |
+
inception.Mixed_5c,
|
| 116 |
+
inception.Mixed_5d,
|
| 117 |
+
inception.Mixed_6a,
|
| 118 |
+
inception.Mixed_6b,
|
| 119 |
+
inception.Mixed_6c,
|
| 120 |
+
inception.Mixed_6d,
|
| 121 |
+
inception.Mixed_6e,
|
| 122 |
+
]
|
| 123 |
+
self.blocks.append(nn.Sequential(*block2))
|
| 124 |
+
|
| 125 |
+
# Block 3: aux classifier to final avgpool
|
| 126 |
+
if self.last_needed_block >= 3:
|
| 127 |
+
block3 = [
|
| 128 |
+
inception.Mixed_7a,
|
| 129 |
+
inception.Mixed_7b,
|
| 130 |
+
inception.Mixed_7c,
|
| 131 |
+
nn.AdaptiveAvgPool2d(output_size=(1, 1))
|
| 132 |
+
]
|
| 133 |
+
self.blocks.append(nn.Sequential(*block3))
|
| 134 |
+
|
| 135 |
+
for param in self.parameters():
|
| 136 |
+
param.requires_grad = requires_grad
|
| 137 |
+
|
| 138 |
+
def forward(self, inp):
|
| 139 |
+
"""Get Inception feature maps
|
| 140 |
+
|
| 141 |
+
Parameters
|
| 142 |
+
----------
|
| 143 |
+
inp : torch.autograd.Variable
|
| 144 |
+
Input tensor of shape Bx3xHxW. Values are expected to be in
|
| 145 |
+
range (0, 1)
|
| 146 |
+
|
| 147 |
+
Returns
|
| 148 |
+
-------
|
| 149 |
+
List of torch.autograd.Variable, corresponding to the selected output
|
| 150 |
+
block, sorted ascending by index
|
| 151 |
+
"""
|
| 152 |
+
outp = []
|
| 153 |
+
x = inp
|
| 154 |
+
|
| 155 |
+
if self.resize_input:
|
| 156 |
+
x = F.interpolate(x,
|
| 157 |
+
size=(299, 299),
|
| 158 |
+
mode='bilinear',
|
| 159 |
+
align_corners=False)
|
| 160 |
+
|
| 161 |
+
if self.normalize_input:
|
| 162 |
+
x = 2 * x - 1 # Scale from range (0, 1) to range (-1, 1)
|
| 163 |
+
|
| 164 |
+
for idx, block in enumerate(self.blocks):
|
| 165 |
+
x = block(x)
|
| 166 |
+
if idx in self.output_blocks:
|
| 167 |
+
outp.append(x)
|
| 168 |
+
|
| 169 |
+
if idx == self.last_needed_block:
|
| 170 |
+
break
|
| 171 |
+
|
| 172 |
+
return outp
|
| 173 |
+
|
| 174 |
+
|
| 175 |
+
def _inception_v3(*args, **kwargs):
|
| 176 |
+
"""Wraps `torchvision.models.inception_v3`
|
| 177 |
+
|
| 178 |
+
Skips default weight inititialization if supported by torchvision version.
|
| 179 |
+
See https://github.com/mseitzer/pytorch-fid/issues/28.
|
| 180 |
+
"""
|
| 181 |
+
try:
|
| 182 |
+
version = tuple(map(int, torchvision.__version__.split('.')[:2]))
|
| 183 |
+
except ValueError:
|
| 184 |
+
# Just a caution against weird version strings
|
| 185 |
+
version = (0,)
|
| 186 |
+
|
| 187 |
+
if version >= (0, 6):
|
| 188 |
+
kwargs['init_weights'] = False
|
| 189 |
+
|
| 190 |
+
return torchvision.models.inception_v3(*args, **kwargs)
|
| 191 |
+
|
| 192 |
+
|
| 193 |
+
def fid_inception_v3():
|
| 194 |
+
"""Build pretrained Inception model for FID computation
|
| 195 |
+
|
| 196 |
+
The Inception model for FID computation uses a different set of weights
|
| 197 |
+
and has a slightly different structure than torchvision's Inception.
|
| 198 |
+
|
| 199 |
+
This method first constructs torchvision's Inception and then patches the
|
| 200 |
+
necessary parts that are different in the FID Inception model.
|
| 201 |
+
"""
|
| 202 |
+
inception = _inception_v3(num_classes=1008,
|
| 203 |
+
aux_logits=False,
|
| 204 |
+
pretrained=False)
|
| 205 |
+
inception.Mixed_5b = FIDInceptionA(192, pool_features=32)
|
| 206 |
+
inception.Mixed_5c = FIDInceptionA(256, pool_features=64)
|
| 207 |
+
inception.Mixed_5d = FIDInceptionA(288, pool_features=64)
|
| 208 |
+
inception.Mixed_6b = FIDInceptionC(768, channels_7x7=128)
|
| 209 |
+
inception.Mixed_6c = FIDInceptionC(768, channels_7x7=160)
|
| 210 |
+
inception.Mixed_6d = FIDInceptionC(768, channels_7x7=160)
|
| 211 |
+
inception.Mixed_6e = FIDInceptionC(768, channels_7x7=192)
|
| 212 |
+
inception.Mixed_7b = FIDInceptionE_1(1280)
|
| 213 |
+
inception.Mixed_7c = FIDInceptionE_2(2048)
|
| 214 |
+
|
| 215 |
+
state_dict = load_state_dict_from_url(FID_WEIGHTS_URL, progress=True)
|
| 216 |
+
inception.load_state_dict(state_dict)
|
| 217 |
+
return inception
|
| 218 |
+
|
| 219 |
+
|
| 220 |
+
class FIDInceptionA(torchvision.models.inception.InceptionA):
|
| 221 |
+
"""InceptionA block patched for FID computation"""
|
| 222 |
+
def __init__(self, in_channels, pool_features):
|
| 223 |
+
super(FIDInceptionA, self).__init__(in_channels, pool_features)
|
| 224 |
+
|
| 225 |
+
def forward(self, x):
|
| 226 |
+
branch1x1 = self.branch1x1(x)
|
| 227 |
+
|
| 228 |
+
branch5x5 = self.branch5x5_1(x)
|
| 229 |
+
branch5x5 = self.branch5x5_2(branch5x5)
|
| 230 |
+
|
| 231 |
+
branch3x3dbl = self.branch3x3dbl_1(x)
|
| 232 |
+
branch3x3dbl = self.branch3x3dbl_2(branch3x3dbl)
|
| 233 |
+
branch3x3dbl = self.branch3x3dbl_3(branch3x3dbl)
|
| 234 |
+
|
| 235 |
+
# Patch: Tensorflow's average pool does not use the padded zero's in
|
| 236 |
+
# its average calculation
|
| 237 |
+
branch_pool = F.avg_pool2d(x, kernel_size=3, stride=1, padding=1,
|
| 238 |
+
count_include_pad=False)
|
| 239 |
+
branch_pool = self.branch_pool(branch_pool)
|
| 240 |
+
|
| 241 |
+
outputs = [branch1x1, branch5x5, branch3x3dbl, branch_pool]
|
| 242 |
+
return torch.cat(outputs, 1)
|
| 243 |
+
|
| 244 |
+
|
| 245 |
+
class FIDInceptionC(torchvision.models.inception.InceptionC):
|
| 246 |
+
"""InceptionC block patched for FID computation"""
|
| 247 |
+
def __init__(self, in_channels, channels_7x7):
|
| 248 |
+
super(FIDInceptionC, self).__init__(in_channels, channels_7x7)
|
| 249 |
+
|
| 250 |
+
def forward(self, x):
|
| 251 |
+
branch1x1 = self.branch1x1(x)
|
| 252 |
+
|
| 253 |
+
branch7x7 = self.branch7x7_1(x)
|
| 254 |
+
branch7x7 = self.branch7x7_2(branch7x7)
|
| 255 |
+
branch7x7 = self.branch7x7_3(branch7x7)
|
| 256 |
+
|
| 257 |
+
branch7x7dbl = self.branch7x7dbl_1(x)
|
| 258 |
+
branch7x7dbl = self.branch7x7dbl_2(branch7x7dbl)
|
| 259 |
+
branch7x7dbl = self.branch7x7dbl_3(branch7x7dbl)
|
| 260 |
+
branch7x7dbl = self.branch7x7dbl_4(branch7x7dbl)
|
| 261 |
+
branch7x7dbl = self.branch7x7dbl_5(branch7x7dbl)
|
| 262 |
+
|
| 263 |
+
# Patch: Tensorflow's average pool does not use the padded zero's in
|
| 264 |
+
# its average calculation
|
| 265 |
+
branch_pool = F.avg_pool2d(x, kernel_size=3, stride=1, padding=1,
|
| 266 |
+
count_include_pad=False)
|
| 267 |
+
branch_pool = self.branch_pool(branch_pool)
|
| 268 |
+
|
| 269 |
+
outputs = [branch1x1, branch7x7, branch7x7dbl, branch_pool]
|
| 270 |
+
return torch.cat(outputs, 1)
|
| 271 |
+
|
| 272 |
+
|
| 273 |
+
class FIDInceptionE_1(torchvision.models.inception.InceptionE):
|
| 274 |
+
"""First InceptionE block patched for FID computation"""
|
| 275 |
+
def __init__(self, in_channels):
|
| 276 |
+
super(FIDInceptionE_1, self).__init__(in_channels)
|
| 277 |
+
|
| 278 |
+
def forward(self, x):
|
| 279 |
+
branch1x1 = self.branch1x1(x)
|
| 280 |
+
|
| 281 |
+
branch3x3 = self.branch3x3_1(x)
|
| 282 |
+
branch3x3 = [
|
| 283 |
+
self.branch3x3_2a(branch3x3),
|
| 284 |
+
self.branch3x3_2b(branch3x3),
|
| 285 |
+
]
|
| 286 |
+
branch3x3 = torch.cat(branch3x3, 1)
|
| 287 |
+
|
| 288 |
+
branch3x3dbl = self.branch3x3dbl_1(x)
|
| 289 |
+
branch3x3dbl = self.branch3x3dbl_2(branch3x3dbl)
|
| 290 |
+
branch3x3dbl = [
|
| 291 |
+
self.branch3x3dbl_3a(branch3x3dbl),
|
| 292 |
+
self.branch3x3dbl_3b(branch3x3dbl),
|
| 293 |
+
]
|
| 294 |
+
branch3x3dbl = torch.cat(branch3x3dbl, 1)
|
| 295 |
+
|
| 296 |
+
# Patch: Tensorflow's average pool does not use the padded zero's in
|
| 297 |
+
# its average calculation
|
| 298 |
+
branch_pool = F.avg_pool2d(x, kernel_size=3, stride=1, padding=1,
|
| 299 |
+
count_include_pad=False)
|
| 300 |
+
branch_pool = self.branch_pool(branch_pool)
|
| 301 |
+
|
| 302 |
+
outputs = [branch1x1, branch3x3, branch3x3dbl, branch_pool]
|
| 303 |
+
return torch.cat(outputs, 1)
|
| 304 |
+
|
| 305 |
+
|
| 306 |
+
class FIDInceptionE_2(torchvision.models.inception.InceptionE):
|
| 307 |
+
"""Second InceptionE block patched for FID computation"""
|
| 308 |
+
def __init__(self, in_channels):
|
| 309 |
+
super(FIDInceptionE_2, self).__init__(in_channels)
|
| 310 |
+
|
| 311 |
+
def forward(self, x):
|
| 312 |
+
branch1x1 = self.branch1x1(x)
|
| 313 |
+
|
| 314 |
+
branch3x3 = self.branch3x3_1(x)
|
| 315 |
+
branch3x3 = [
|
| 316 |
+
self.branch3x3_2a(branch3x3),
|
| 317 |
+
self.branch3x3_2b(branch3x3),
|
| 318 |
+
]
|
| 319 |
+
branch3x3 = torch.cat(branch3x3, 1)
|
| 320 |
+
|
| 321 |
+
branch3x3dbl = self.branch3x3dbl_1(x)
|
| 322 |
+
branch3x3dbl = self.branch3x3dbl_2(branch3x3dbl)
|
| 323 |
+
branch3x3dbl = [
|
| 324 |
+
self.branch3x3dbl_3a(branch3x3dbl),
|
| 325 |
+
self.branch3x3dbl_3b(branch3x3dbl),
|
| 326 |
+
]
|
| 327 |
+
branch3x3dbl = torch.cat(branch3x3dbl, 1)
|
| 328 |
+
|
| 329 |
+
# Patch: The FID Inception model uses max pooling instead of average
|
| 330 |
+
# pooling. This is likely an error in this specific Inception
|
| 331 |
+
# implementation, as other Inception models use average pooling here
|
| 332 |
+
# (which matches the description in the paper).
|
| 333 |
+
branch_pool = F.max_pool2d(x, kernel_size=3, stride=1, padding=1)
|
| 334 |
+
branch_pool = self.branch_pool(branch_pool)
|
| 335 |
+
|
| 336 |
+
outputs = [branch1x1, branch3x3, branch3x3dbl, branch_pool]
|
| 337 |
+
return torch.cat(outputs, 1)
|
pytorch_fid/inception_score.py
ADDED
|
@@ -0,0 +1,103 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# ---------------------------------------------------------------
|
| 2 |
+
# Copyright (c) 2022, NVIDIA CORPORATION. All rights reserved.
|
| 3 |
+
#
|
| 4 |
+
# This file has been modified from inception score
|
| 5 |
+
#
|
| 6 |
+
# Source:
|
| 7 |
+
# https://github.com/tsc2017/Inception-Score/blob/04390da2ebb3c9a3860337a33297c4f270bd906d/inception_score.py
|
| 8 |
+
#
|
| 9 |
+
# The license for the original version of this file can be
|
| 10 |
+
# found in this directory (LICENSE_inception).
|
| 11 |
+
# The modifications to this file are subject to the same license.
|
| 12 |
+
# ---------------------------------------------------------------
|
| 13 |
+
|
| 14 |
+
|
| 15 |
+
'''
|
| 16 |
+
Usage:
|
| 17 |
+
Call get_inception_score(images, splits=10)
|
| 18 |
+
Args:
|
| 19 |
+
images: A numpy array with values ranging from 0 to 255 and shape in the form [N, 3, HEIGHT, WIDTH] where N, HEIGHT and WIDTH can be arbitrary. A dtype of np.uint8 is recommended to save CPU memory.
|
| 20 |
+
splits: The number of splits of the images, default is 10.
|
| 21 |
+
Returns:
|
| 22 |
+
Mean and standard deviation of the Inception Score across the splits.
|
| 23 |
+
'''
|
| 24 |
+
import argparse
|
| 25 |
+
|
| 26 |
+
import tensorflow.compat.v1 as tf
|
| 27 |
+
tf.disable_v2_behavior()
|
| 28 |
+
import tensorflow_gan as tfgan
|
| 29 |
+
import os
|
| 30 |
+
import functools
|
| 31 |
+
import numpy as np
|
| 32 |
+
import time
|
| 33 |
+
from tensorflow.python.ops import array_ops
|
| 34 |
+
# pip install tensorflow-gan
|
| 35 |
+
import tensorflow_gan as tfgan
|
| 36 |
+
session=tf.compat.v1.InteractiveSession()
|
| 37 |
+
# A smaller BATCH_SIZE reduces GPU memory usage, but at the cost of a slight slowdown
|
| 38 |
+
BATCH_SIZE = 64
|
| 39 |
+
INCEPTION_TFHUB = 'https://tfhub.dev/tensorflow/tfgan/eval/inception/1'
|
| 40 |
+
INCEPTION_OUTPUT = 'logits'
|
| 41 |
+
|
| 42 |
+
# Run images through Inception.
|
| 43 |
+
inception_images = tf.compat.v1.placeholder(tf.float32, [None, 3, None, None], name = 'inception_images')
|
| 44 |
+
def inception_logits(images = inception_images, num_splits = 1):
|
| 45 |
+
images = tf.transpose(images, [0, 2, 3, 1])
|
| 46 |
+
size = 299
|
| 47 |
+
images = tf.compat.v1.image.resize_bilinear(images, [size, size])
|
| 48 |
+
generated_images_list = array_ops.split(images, num_or_size_splits = num_splits)
|
| 49 |
+
logits = tf.map_fn(
|
| 50 |
+
fn = tfgan.eval.classifier_fn_from_tfhub(INCEPTION_TFHUB, INCEPTION_OUTPUT, True),
|
| 51 |
+
elems = array_ops.stack(generated_images_list),
|
| 52 |
+
parallel_iterations = 8,
|
| 53 |
+
back_prop = False,
|
| 54 |
+
swap_memory = True,
|
| 55 |
+
name = 'RunClassifier')
|
| 56 |
+
logits = array_ops.concat(array_ops.unstack(logits), 0)
|
| 57 |
+
return logits
|
| 58 |
+
|
| 59 |
+
logits=inception_logits()
|
| 60 |
+
|
| 61 |
+
def get_inception_probs(inps):
|
| 62 |
+
session=tf.get_default_session()
|
| 63 |
+
n_batches = int(np.ceil(float(inps.shape[0]) / BATCH_SIZE))
|
| 64 |
+
preds = np.zeros([inps.shape[0], 1000], dtype = np.float32)
|
| 65 |
+
for i in range(n_batches):
|
| 66 |
+
inp = inps[i * BATCH_SIZE:(i + 1) * BATCH_SIZE] / 255. * 2 - 1
|
| 67 |
+
preds[i * BATCH_SIZE : i * BATCH_SIZE + min(BATCH_SIZE, inp.shape[0])] = session.run(logits,{inception_images: inp})[:, :1000]
|
| 68 |
+
preds = np.exp(preds) / np.sum(np.exp(preds), 1, keepdims=True)
|
| 69 |
+
return preds
|
| 70 |
+
|
| 71 |
+
def preds2score(preds, splits=10):
|
| 72 |
+
scores = []
|
| 73 |
+
for i in range(splits):
|
| 74 |
+
part = preds[(i * preds.shape[0] // splits):((i + 1) * preds.shape[0] // splits), :]
|
| 75 |
+
kl = part * (np.log(part) - np.log(np.expand_dims(np.mean(part, 0), 0)))
|
| 76 |
+
kl = np.mean(np.sum(kl, 1))
|
| 77 |
+
scores.append(np.exp(kl))
|
| 78 |
+
return np.mean(scores), np.std(scores)
|
| 79 |
+
|
| 80 |
+
def get_inception_score(images, splits=10):
|
| 81 |
+
assert(type(images) == np.ndarray)
|
| 82 |
+
assert(len(images.shape) == 4)
|
| 83 |
+
assert(images.shape[1] == 3)
|
| 84 |
+
assert(np.min(images[0]) >= 0 and np.max(images[0]) > 10), 'Image values should be in the range [0, 255]'
|
| 85 |
+
print('Calculating Inception Score with %i images in %i splits' % (images.shape[0], splits))
|
| 86 |
+
start_time=time.time()
|
| 87 |
+
preds = get_inception_probs(images)
|
| 88 |
+
mean, std = preds2score(preds, splits)
|
| 89 |
+
print('Inception Score calculation time: %f s' % (time.time() - start_time))
|
| 90 |
+
return mean, std # Reference values: 11.38 for 50000 CIFAR-10 training set images, or mean=11.31, std=0.10 if in 10 splits.
|
| 91 |
+
|
| 92 |
+
|
| 93 |
+
if __name__ == '__main__':
|
| 94 |
+
parser = argparse.ArgumentParser()
|
| 95 |
+
parser.add_argument('--sample_dir', default='./saved_samples/', help='path to saved images')
|
| 96 |
+
opt = parser.parse_args()
|
| 97 |
+
|
| 98 |
+
data = np.load(opt.sample_dir)
|
| 99 |
+
data = np.clip(data, 0, 255)
|
| 100 |
+
m, s = get_inception_score(data, splits=1)
|
| 101 |
+
|
| 102 |
+
print('mean: ', m)
|
| 103 |
+
print('std: ', s)
|
readme.md
ADDED
|
@@ -0,0 +1,113 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Official PyTorch implementation of "Tackling the Generative Learning Trilemma with Denoising Diffusion GANs" [(ICLR 2022 Spotlight Paper)](https://arxiv.org/abs/2112.07804) #
|
| 2 |
+
|
| 3 |
+
<div align="center">
|
| 4 |
+
<a href="https://xavierxiao.github.io/" target="_blank">Zhisheng Xiao</a>   <b>·</b>  
|
| 5 |
+
<a href="https://karstenkreis.github.io/" target="_blank">Karsten Kreis</a>   <b>·</b>  
|
| 6 |
+
<a href="http://latentspace.cc/arash_vahdat/" target="_blank">Arash Vahdat</a>
|
| 7 |
+
<br> <br>
|
| 8 |
+
<a href="https://nvlabs.github.io/denoising-diffusion-gan/" target="_blank">Project Page</a>
|
| 9 |
+
</div>
|
| 10 |
+
<br>
|
| 11 |
+
<br>
|
| 12 |
+
|
| 13 |
+
<div align="center">
|
| 14 |
+
<img width="800" alt="teaser" src="assets/teaser.png"/>
|
| 15 |
+
</div>
|
| 16 |
+
|
| 17 |
+
Generative denoising diffusion models typically assume that the denoising distribution can be modeled by a Gaussian distribution. This assumption holds only for small denoising steps, which in practice translates to thousands of denoising steps in the synthesis process. In our denoising diffusion GANs, we represent the denoising model using multimodal and complex conditional GANs, enabling us to efficiently generate data in as few as two steps.
|
| 18 |
+
|
| 19 |
+
## Set up datasets ##
|
| 20 |
+
We trained on several datasets, including CIFAR10, LSUN Church Outdoor 256 and CelebA HQ 256.
|
| 21 |
+
For large datasets, we store the data in LMDB datasets for I/O efficiency. Check [here](https://github.com/NVlabs/NVAE#set-up-file-paths-and-data) for information regarding dataset preparation.
|
| 22 |
+
|
| 23 |
+
|
| 24 |
+
## Training Denoising Diffusion GANs ##
|
| 25 |
+
We use the following commands on each dataset for training denoising diffusion GANs.
|
| 26 |
+
|
| 27 |
+
#### CIFAR-10 ####
|
| 28 |
+
|
| 29 |
+
We train Denoising Diffusion GANs on CIFAR-10 using 4 32-GB V100 GPU.
|
| 30 |
+
```
|
| 31 |
+
python3 train_ddgan.py --dataset cifar10 --exp ddgan_cifar10_exp1 --num_channels 3 --num_channels_dae 128 --num_timesteps 4 \
|
| 32 |
+
--num_res_blocks 2 --batch_size 64 --num_epoch 1800 --ngf 64 --nz 100 --z_emb_dim 256 --n_mlp 4 --embedding_type positional \
|
| 33 |
+
--use_ema --ema_decay 0.9999 --r1_gamma 0.02 --lr_d 1.25e-4 --lr_g 1.6e-4 --lazy_reg 15 --num_process_per_node 4 \
|
| 34 |
+
--ch_mult 1 2 2 2 --save_content
|
| 35 |
+
```
|
| 36 |
+
|
| 37 |
+
#### LSUN Church Outdoor 256 ####
|
| 38 |
+
|
| 39 |
+
We train Denoising Diffusion GANs on LSUN Church Outdoor 256 using 8 32-GB V100 GPU.
|
| 40 |
+
```
|
| 41 |
+
python3 train_ddgan.py --dataset lsun --image_size 256 --exp ddgan_lsun_exp1 --num_channels 3 --num_channels_dae 64 --ch_mult 1 1 2 2 4 4 --num_timesteps 4 \
|
| 42 |
+
--num_res_blocks 2 --batch_size 8 --num_epoch 500 --ngf 64 --embedding_type positional --use_ema --ema_decay 0.999 --r1_gamma 1. \
|
| 43 |
+
--z_emb_dim 256 --lr_d 1e-4 --lr_g 1.6e-4 --lazy_reg 10 --num_process_per_node 8 --save_content
|
| 44 |
+
```
|
| 45 |
+
|
| 46 |
+
#### CelebA HQ 256 ####
|
| 47 |
+
|
| 48 |
+
We train Denoising Diffusion GANs on CelebA HQ 256 using 8 32-GB V100 GPUs.
|
| 49 |
+
```
|
| 50 |
+
python3 train_ddgan.py --dataset celeba_256 --image_size 256 --exp ddgan_celebahq_exp1 --num_channels 3 --num_channels_dae 64 --ch_mult 1 1 2 2 4 4 --num_timesteps 2 \
|
| 51 |
+
--num_res_blocks 2 --batch_size 4 --num_epoch 800 --ngf 64 --embedding_type positional --use_ema --r1_gamma 2. \
|
| 52 |
+
--z_emb_dim 256 --lr_d 1e-4 --lr_g 2e-4 --lazy_reg 10 --num_process_per_node 8 --save_content
|
| 53 |
+
```
|
| 54 |
+
|
| 55 |
+
## Pretrained Checkpoints ##
|
| 56 |
+
We have released pretrained checkpoints on CIFAR-10 and CelebA HQ 256 at this
|
| 57 |
+
[Google drive directory](https://drive.google.com/drive/folders/1UkzsI0SwBRstMYysRdR76C1XdSv5rQNz?usp=sharing).
|
| 58 |
+
Simply download the `saved_info` directory to the code directory. Use `--epoch_id 1200` for CIFAR-10 and `--epoch_id 550`
|
| 59 |
+
for CelebA HQ 256 in the commands below.
|
| 60 |
+
|
| 61 |
+
## Evaluation ##
|
| 62 |
+
After training, samples can be generated by calling ```test_ddgan.py```. We evaluate the models with single V100 GPU.
|
| 63 |
+
Below, we use `--epoch_id` to specify the checkpoint saved at a particular epoch.
|
| 64 |
+
Specifically, for models trained by above commands, the scripts for generating samples on CIFAR-10 is
|
| 65 |
+
```
|
| 66 |
+
python3 test_ddgan.py --dataset cifar10 --exp ddgan_cifar10_exp1 --num_channels 3 --num_channels_dae 128 --num_timesteps 4 \
|
| 67 |
+
--num_res_blocks 2 --nz 100 --z_emb_dim 256 --n_mlp 4 --ch_mult 1 2 2 2 --epoch_id $EPOCH
|
| 68 |
+
```
|
| 69 |
+
The scripts for generating samples on CelebA HQ is
|
| 70 |
+
```
|
| 71 |
+
python3 test_ddgan.py --dataset celeba_256 --image_size 256 --exp ddgan_celebahq_exp1 --num_channels 3 --num_channels_dae 64 \
|
| 72 |
+
--ch_mult 1 1 2 2 4 4 --num_timesteps 2 --num_res_blocks 2 --epoch_id $EPOCH
|
| 73 |
+
```
|
| 74 |
+
The scripts for generating samples on LSUN Church Outdoor is
|
| 75 |
+
```
|
| 76 |
+
python3 test_ddgan.py --dataset lsun --image_size 256 --exp ddgan_lsun_exp1 --num_channels 3 --num_channels_dae 64 \
|
| 77 |
+
--ch_mult 1 1 2 2 4 4 --num_timesteps 4 --num_res_blocks 2 --epoch_id $EPOCH
|
| 78 |
+
```
|
| 79 |
+
|
| 80 |
+
We use the [PyTorch](https://github.com/mseitzer/pytorch-fid) implementation to compute the FID scores, and in particular, codes for computing the FID are adapted from [FastDPM](https://github.com/FengNiMa/FastDPM_pytorch).
|
| 81 |
+
|
| 82 |
+
To compute FID, run the same scripts above for sampling, with additional arguments ```--compute_fid``` and ```--real_img_dir /path/to/real/images```.
|
| 83 |
+
|
| 84 |
+
For Inception Score, save samples in a single numpy array with pixel values in range [0, 255] and simply run
|
| 85 |
+
```
|
| 86 |
+
python ./pytorch_fid/inception_score.py --sample_dir /path/to/sampled_images
|
| 87 |
+
```
|
| 88 |
+
where the code for computing Inception Score is adapted from [here](https://github.com/tsc2017/Inception-Score).
|
| 89 |
+
|
| 90 |
+
For Improved Precision and Recall, follow the instruction [here](https://github.com/kynkaat/improved-precision-and-recall-metric).
|
| 91 |
+
|
| 92 |
+
|
| 93 |
+
## License ##
|
| 94 |
+
Please check the LICENSE file. Denoising diffusion GAN may be used non-commercially, meaning for research or
|
| 95 |
+
evaluation purposes only. For business inquiries, please contact
|
| 96 |
+
[researchinquiries@nvidia.com](mailto:researchinquiries@nvidia.com).
|
| 97 |
+
|
| 98 |
+
## Bibtex ##
|
| 99 |
+
Cite our paper using the following bibtex item:
|
| 100 |
+
|
| 101 |
+
```
|
| 102 |
+
@inproceedings{
|
| 103 |
+
xiao2022tackling,
|
| 104 |
+
title={Tackling the Generative Learning Trilemma with Denoising Diffusion GANs},
|
| 105 |
+
author={Zhisheng Xiao and Karsten Kreis and Arash Vahdat},
|
| 106 |
+
booktitle={International Conference on Learning Representations},
|
| 107 |
+
year={2022}
|
| 108 |
+
}
|
| 109 |
+
```
|
| 110 |
+
|
| 111 |
+
## Contributors ##
|
| 112 |
+
Denoising Diffusion GAN was built primarily by [Zhisheng Xiao](https://xavierxiao.github.io/) during a summer
|
| 113 |
+
internship at NVIDIA research.
|
requirements.txt
ADDED
|
@@ -0,0 +1,10 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
torch==1.8.0
|
| 2 |
+
torchvision==0.9.0
|
| 3 |
+
pillow
|
| 4 |
+
matplotlib
|
| 5 |
+
tensorboard
|
| 6 |
+
tensorboardX
|
| 7 |
+
lmdb
|
| 8 |
+
matplotlib
|
| 9 |
+
scipy
|
| 10 |
+
ninja
|
score_sde/LICENSE_Apache
ADDED
|
@@ -0,0 +1,201 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
Apache License
|
| 2 |
+
Version 2.0, January 2004
|
| 3 |
+
http://www.apache.org/licenses/
|
| 4 |
+
|
| 5 |
+
TERMS AND CONDITIONS FOR USE, REPRODUCTION, AND DISTRIBUTION
|
| 6 |
+
|
| 7 |
+
1. Definitions.
|
| 8 |
+
|
| 9 |
+
"License" shall mean the terms and conditions for use, reproduction,
|
| 10 |
+
and distribution as defined by Sections 1 through 9 of this document.
|
| 11 |
+
|
| 12 |
+
"Licensor" shall mean the copyright owner or entity authorized by
|
| 13 |
+
the copyright owner that is granting the License.
|
| 14 |
+
|
| 15 |
+
"Legal Entity" shall mean the union of the acting entity and all
|
| 16 |
+
other entities that control, are controlled by, or are under common
|
| 17 |
+
control with that entity. For the purposes of this definition,
|
| 18 |
+
"control" means (i) the power, direct or indirect, to cause the
|
| 19 |
+
direction or management of such entity, whether by contract or
|
| 20 |
+
otherwise, or (ii) ownership of fifty percent (50%) or more of the
|
| 21 |
+
outstanding shares, or (iii) beneficial ownership of such entity.
|
| 22 |
+
|
| 23 |
+
"You" (or "Your") shall mean an individual or Legal Entity
|
| 24 |
+
exercising permissions granted by this License.
|
| 25 |
+
|
| 26 |
+
"Source" form shall mean the preferred form for making modifications,
|
| 27 |
+
including but not limited to software source code, documentation
|
| 28 |
+
source, and configuration files.
|
| 29 |
+
|
| 30 |
+
"Object" form shall mean any form resulting from mechanical
|
| 31 |
+
transformation or translation of a Source form, including but
|
| 32 |
+
not limited to compiled object code, generated documentation,
|
| 33 |
+
and conversions to other media types.
|
| 34 |
+
|
| 35 |
+
"Work" shall mean the work of authorship, whether in Source or
|
| 36 |
+
Object form, made available under the License, as indicated by a
|
| 37 |
+
copyright notice that is included in or attached to the work
|
| 38 |
+
(an example is provided in the Appendix below).
|
| 39 |
+
|
| 40 |
+
"Derivative Works" shall mean any work, whether in Source or Object
|
| 41 |
+
form, that is based on (or derived from) the Work and for which the
|
| 42 |
+
editorial revisions, annotations, elaborations, or other modifications
|
| 43 |
+
represent, as a whole, an original work of authorship. For the purposes
|
| 44 |
+
of this License, Derivative Works shall not include works that remain
|
| 45 |
+
separable from, or merely link (or bind by name) to the interfaces of,
|
| 46 |
+
the Work and Derivative Works thereof.
|
| 47 |
+
|
| 48 |
+
"Contribution" shall mean any work of authorship, including
|
| 49 |
+
the original version of the Work and any modifications or additions
|
| 50 |
+
to that Work or Derivative Works thereof, that is intentionally
|
| 51 |
+
submitted to Licensor for inclusion in the Work by the copyright owner
|
| 52 |
+
or by an individual or Legal Entity authorized to submit on behalf of
|
| 53 |
+
the copyright owner. For the purposes of this definition, "submitted"
|
| 54 |
+
means any form of electronic, verbal, or written communication sent
|
| 55 |
+
to the Licensor or its representatives, including but not limited to
|
| 56 |
+
communication on electronic mailing lists, source code control systems,
|
| 57 |
+
and issue tracking systems that are managed by, or on behalf of, the
|
| 58 |
+
Licensor for the purpose of discussing and improving the Work, but
|
| 59 |
+
excluding communication that is conspicuously marked or otherwise
|
| 60 |
+
designated in writing by the copyright owner as "Not a Contribution."
|
| 61 |
+
|
| 62 |
+
"Contributor" shall mean Licensor and any individual or Legal Entity
|
| 63 |
+
on behalf of whom a Contribution has been received by Licensor and
|
| 64 |
+
subsequently incorporated within the Work.
|
| 65 |
+
|
| 66 |
+
2. Grant of Copyright License. Subject to the terms and conditions of
|
| 67 |
+
this License, each Contributor hereby grants to You a perpetual,
|
| 68 |
+
worldwide, non-exclusive, no-charge, royalty-free, irrevocable
|
| 69 |
+
copyright license to reproduce, prepare Derivative Works of,
|
| 70 |
+
publicly display, publicly perform, sublicense, and distribute the
|
| 71 |
+
Work and such Derivative Works in Source or Object form.
|
| 72 |
+
|
| 73 |
+
3. Grant of Patent License. Subject to the terms and conditions of
|
| 74 |
+
this License, each Contributor hereby grants to You a perpetual,
|
| 75 |
+
worldwide, non-exclusive, no-charge, royalty-free, irrevocable
|
| 76 |
+
(except as stated in this section) patent license to make, have made,
|
| 77 |
+
use, offer to sell, sell, import, and otherwise transfer the Work,
|
| 78 |
+
where such license applies only to those patent claims licensable
|
| 79 |
+
by such Contributor that are necessarily infringed by their
|
| 80 |
+
Contribution(s) alone or by combination of their Contribution(s)
|
| 81 |
+
with the Work to which such Contribution(s) was submitted. If You
|
| 82 |
+
institute patent litigation against any entity (including a
|
| 83 |
+
cross-claim or counterclaim in a lawsuit) alleging that the Work
|
| 84 |
+
or a Contribution incorporated within the Work constitutes direct
|
| 85 |
+
or contributory patent infringement, then any patent licenses
|
| 86 |
+
granted to You under this License for that Work shall terminate
|
| 87 |
+
as of the date such litigation is filed.
|
| 88 |
+
|
| 89 |
+
4. Redistribution. You may reproduce and distribute copies of the
|
| 90 |
+
Work or Derivative Works thereof in any medium, with or without
|
| 91 |
+
modifications, and in Source or Object form, provided that You
|
| 92 |
+
meet the following conditions:
|
| 93 |
+
|
| 94 |
+
(a) You must give any other recipients of the Work or
|
| 95 |
+
Derivative Works a copy of this License; and
|
| 96 |
+
|
| 97 |
+
(b) You must cause any modified files to carry prominent notices
|
| 98 |
+
stating that You changed the files; and
|
| 99 |
+
|
| 100 |
+
(c) You must retain, in the Source form of any Derivative Works
|
| 101 |
+
that You distribute, all copyright, patent, trademark, and
|
| 102 |
+
attribution notices from the Source form of the Work,
|
| 103 |
+
excluding those notices that do not pertain to any part of
|
| 104 |
+
the Derivative Works; and
|
| 105 |
+
|
| 106 |
+
(d) If the Work includes a "NOTICE" text file as part of its
|
| 107 |
+
distribution, then any Derivative Works that You distribute must
|
| 108 |
+
include a readable copy of the attribution notices contained
|
| 109 |
+
within such NOTICE file, excluding those notices that do not
|
| 110 |
+
pertain to any part of the Derivative Works, in at least one
|
| 111 |
+
of the following places: within a NOTICE text file distributed
|
| 112 |
+
as part of the Derivative Works; within the Source form or
|
| 113 |
+
documentation, if provided along with the Derivative Works; or,
|
| 114 |
+
within a display generated by the Derivative Works, if and
|
| 115 |
+
wherever such third-party notices normally appear. The contents
|
| 116 |
+
of the NOTICE file are for informational purposes only and
|
| 117 |
+
do not modify the License. You may add Your own attribution
|
| 118 |
+
notices within Derivative Works that You distribute, alongside
|
| 119 |
+
or as an addendum to the NOTICE text from the Work, provided
|
| 120 |
+
that such additional attribution notices cannot be construed
|
| 121 |
+
as modifying the License.
|
| 122 |
+
|
| 123 |
+
You may add Your own copyright statement to Your modifications and
|
| 124 |
+
may provide additional or different license terms and conditions
|
| 125 |
+
for use, reproduction, or distribution of Your modifications, or
|
| 126 |
+
for any such Derivative Works as a whole, provided Your use,
|
| 127 |
+
reproduction, and distribution of the Work otherwise complies with
|
| 128 |
+
the conditions stated in this License.
|
| 129 |
+
|
| 130 |
+
5. Submission of Contributions. Unless You explicitly state otherwise,
|
| 131 |
+
any Contribution intentionally submitted for inclusion in the Work
|
| 132 |
+
by You to the Licensor shall be under the terms and conditions of
|
| 133 |
+
this License, without any additional terms or conditions.
|
| 134 |
+
Notwithstanding the above, nothing herein shall supersede or modify
|
| 135 |
+
the terms of any separate license agreement you may have executed
|
| 136 |
+
with Licensor regarding such Contributions.
|
| 137 |
+
|
| 138 |
+
6. Trademarks. This License does not grant permission to use the trade
|
| 139 |
+
names, trademarks, service marks, or product names of the Licensor,
|
| 140 |
+
except as required for reasonable and customary use in describing the
|
| 141 |
+
origin of the Work and reproducing the content of the NOTICE file.
|
| 142 |
+
|
| 143 |
+
7. Disclaimer of Warranty. Unless required by applicable law or
|
| 144 |
+
agreed to in writing, Licensor provides the Work (and each
|
| 145 |
+
Contributor provides its Contributions) on an "AS IS" BASIS,
|
| 146 |
+
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or
|
| 147 |
+
implied, including, without limitation, any warranties or conditions
|
| 148 |
+
of TITLE, NON-INFRINGEMENT, MERCHANTABILITY, or FITNESS FOR A
|
| 149 |
+
PARTICULAR PURPOSE. You are solely responsible for determining the
|
| 150 |
+
appropriateness of using or redistributing the Work and assume any
|
| 151 |
+
risks associated with Your exercise of permissions under this License.
|
| 152 |
+
|
| 153 |
+
8. Limitation of Liability. In no event and under no legal theory,
|
| 154 |
+
whether in tort (including negligence), contract, or otherwise,
|
| 155 |
+
unless required by applicable law (such as deliberate and grossly
|
| 156 |
+
negligent acts) or agreed to in writing, shall any Contributor be
|
| 157 |
+
liable to You for damages, including any direct, indirect, special,
|
| 158 |
+
incidental, or consequential damages of any character arising as a
|
| 159 |
+
result of this License or out of the use or inability to use the
|
| 160 |
+
Work (including but not limited to damages for loss of goodwill,
|
| 161 |
+
work stoppage, computer failure or malfunction, or any and all
|
| 162 |
+
other commercial damages or losses), even if such Contributor
|
| 163 |
+
has been advised of the possibility of such damages.
|
| 164 |
+
|
| 165 |
+
9. Accepting Warranty or Additional Liability. While redistributing
|
| 166 |
+
the Work or Derivative Works thereof, You may choose to offer,
|
| 167 |
+
and charge a fee for, acceptance of support, warranty, indemnity,
|
| 168 |
+
or other liability obligations and/or rights consistent with this
|
| 169 |
+
License. However, in accepting such obligations, You may act only
|
| 170 |
+
on Your own behalf and on Your sole responsibility, not on behalf
|
| 171 |
+
of any other Contributor, and only if You agree to indemnify,
|
| 172 |
+
defend, and hold each Contributor harmless for any liability
|
| 173 |
+
incurred by, or claims asserted against, such Contributor by reason
|
| 174 |
+
of your accepting any such warranty or additional liability.
|
| 175 |
+
|
| 176 |
+
END OF TERMS AND CONDITIONS
|
| 177 |
+
|
| 178 |
+
APPENDIX: How to apply the Apache License to your work.
|
| 179 |
+
|
| 180 |
+
To apply the Apache License to your work, attach the following
|
| 181 |
+
boilerplate notice, with the fields enclosed by brackets "[]"
|
| 182 |
+
replaced with your own identifying information. (Don't include
|
| 183 |
+
the brackets!) The text should be enclosed in the appropriate
|
| 184 |
+
comment syntax for the file format. We also recommend that a
|
| 185 |
+
file or class name and description of purpose be included on the
|
| 186 |
+
same "printed page" as the copyright notice for easier
|
| 187 |
+
identification within third-party archives.
|
| 188 |
+
|
| 189 |
+
Copyright [yyyy] [name of copyright owner]
|
| 190 |
+
|
| 191 |
+
Licensed under the Apache License, Version 2.0 (the "License");
|
| 192 |
+
you may not use this file except in compliance with the License.
|
| 193 |
+
You may obtain a copy of the License at
|
| 194 |
+
|
| 195 |
+
http://www.apache.org/licenses/LICENSE-2.0
|
| 196 |
+
|
| 197 |
+
Unless required by applicable law or agreed to in writing, software
|
| 198 |
+
distributed under the License is distributed on an "AS IS" BASIS,
|
| 199 |
+
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
| 200 |
+
See the License for the specific language governing permissions and
|
| 201 |
+
limitations under the License.
|
score_sde/__init__.py
ADDED
|
File without changes
|
score_sde/models/LICENSE_MIT
ADDED
|
@@ -0,0 +1,21 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
MIT License
|
| 2 |
+
|
| 3 |
+
Copyright (c) 2021 Chin-Wei Huang
|
| 4 |
+
|
| 5 |
+
Permission is hereby granted, free of charge, to any person obtaining a copy
|
| 6 |
+
of this software and associated documentation files (the "Software"), to deal
|
| 7 |
+
in the Software without restriction, including without limitation the rights
|
| 8 |
+
to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
|
| 9 |
+
copies of the Software, and to permit persons to whom the Software is
|
| 10 |
+
furnished to do so, subject to the following conditions:
|
| 11 |
+
|
| 12 |
+
The above copyright notice and this permission notice shall be included in all
|
| 13 |
+
copies or substantial portions of the Software.
|
| 14 |
+
|
| 15 |
+
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
|
| 16 |
+
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
|
| 17 |
+
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
|
| 18 |
+
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
|
| 19 |
+
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
|
| 20 |
+
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
|
| 21 |
+
SOFTWARE.
|
score_sde/models/__init__.py
ADDED
|
@@ -0,0 +1,15 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# coding=utf-8
|
| 2 |
+
# Copyright 2020 The Google Research Authors.
|
| 3 |
+
#
|
| 4 |
+
# Licensed under the Apache License, Version 2.0 (the "License");
|
| 5 |
+
# you may not use this file except in compliance with the License.
|
| 6 |
+
# You may obtain a copy of the License at
|
| 7 |
+
#
|
| 8 |
+
# http://www.apache.org/licenses/LICENSE-2.0
|
| 9 |
+
#
|
| 10 |
+
# Unless required by applicable law or agreed to in writing, software
|
| 11 |
+
# distributed under the License is distributed on an "AS IS" BASIS,
|
| 12 |
+
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
| 13 |
+
# See the License for the specific language governing permissions and
|
| 14 |
+
# limitations under the License.
|
| 15 |
+
|
score_sde/models/dense_layer.py
ADDED
|
@@ -0,0 +1,83 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# ---------------------------------------------------------------
|
| 2 |
+
# Copyright (c) 2022, NVIDIA CORPORATION. All rights reserved.
|
| 3 |
+
#
|
| 4 |
+
# This file has been modified from a file released under the MIT License.
|
| 5 |
+
#
|
| 6 |
+
# Source:
|
| 7 |
+
# https://github.com/CW-Huang/sdeflow-light/blob/524650bc5ad69522b3e0905672deef0650374512/lib/models/unet.py
|
| 8 |
+
#
|
| 9 |
+
# The license for the original version of this file can be
|
| 10 |
+
# found in this directory (LICENSE_MIT). The modifications
|
| 11 |
+
# to this file are subject to the same MIT License.
|
| 12 |
+
# ---------------------------------------------------------------
|
| 13 |
+
|
| 14 |
+
|
| 15 |
+
import math
|
| 16 |
+
import torch
|
| 17 |
+
import torch.nn as nn
|
| 18 |
+
import torch.nn.functional as F
|
| 19 |
+
from torch.nn.init import _calculate_fan_in_and_fan_out
|
| 20 |
+
import numpy as np
|
| 21 |
+
|
| 22 |
+
|
| 23 |
+
def _calculate_correct_fan(tensor, mode):
|
| 24 |
+
"""
|
| 25 |
+
copied and modified from https://github.com/pytorch/pytorch/blob/master/torch/nn/init.py#L337
|
| 26 |
+
"""
|
| 27 |
+
mode = mode.lower()
|
| 28 |
+
valid_modes = ['fan_in', 'fan_out', 'fan_avg']
|
| 29 |
+
if mode not in valid_modes:
|
| 30 |
+
raise ValueError("Mode {} not supported, please use one of {}".format(mode, valid_modes))
|
| 31 |
+
|
| 32 |
+
fan_in, fan_out = _calculate_fan_in_and_fan_out(tensor)
|
| 33 |
+
return fan_in if mode == 'fan_in' else fan_out
|
| 34 |
+
|
| 35 |
+
|
| 36 |
+
def kaiming_uniform_(tensor, gain=1., mode='fan_in'):
|
| 37 |
+
r"""Fills the input `Tensor` with values according to the method
|
| 38 |
+
described in `Delving deep into rectifiers: Surpassing human-level
|
| 39 |
+
performance on ImageNet classification` - He, K. et al. (2015), using a
|
| 40 |
+
uniform distribution. The resulting tensor will have values sampled from
|
| 41 |
+
:math:`\mathcal{U}(-\text{bound}, \text{bound})` where
|
| 42 |
+
.. math::
|
| 43 |
+
\text{bound} = \text{gain} \times \sqrt{\frac{3}{\text{fan\_mode}}}
|
| 44 |
+
Also known as He initialization.
|
| 45 |
+
Args:
|
| 46 |
+
tensor: an n-dimensional `torch.Tensor`
|
| 47 |
+
gain: multiplier to the dispersion
|
| 48 |
+
mode: either ``'fan_in'`` (default) or ``'fan_out'``. Choosing ``'fan_in'``
|
| 49 |
+
preserves the magnitude of the variance of the weights in the
|
| 50 |
+
forward pass. Choosing ``'fan_out'`` preserves the magnitudes in the
|
| 51 |
+
backwards pass.
|
| 52 |
+
Examples:
|
| 53 |
+
>>> w = torch.empty(3, 5)
|
| 54 |
+
>>> nn.init.kaiming_uniform_(w, mode='fan_in')
|
| 55 |
+
"""
|
| 56 |
+
fan = _calculate_correct_fan(tensor, mode)
|
| 57 |
+
var = gain / max(1., fan)
|
| 58 |
+
bound = math.sqrt(3.0 * var) # Calculate uniform bounds from standard deviation
|
| 59 |
+
with torch.no_grad():
|
| 60 |
+
return tensor.uniform_(-bound, bound)
|
| 61 |
+
|
| 62 |
+
|
| 63 |
+
def variance_scaling_init_(tensor, scale):
|
| 64 |
+
return kaiming_uniform_(tensor, gain=1e-10 if scale == 0 else scale, mode='fan_avg')
|
| 65 |
+
|
| 66 |
+
|
| 67 |
+
def dense(in_channels, out_channels, init_scale=1.):
|
| 68 |
+
lin = nn.Linear(in_channels, out_channels)
|
| 69 |
+
variance_scaling_init_(lin.weight, scale=init_scale)
|
| 70 |
+
nn.init.zeros_(lin.bias)
|
| 71 |
+
return lin
|
| 72 |
+
|
| 73 |
+
def conv2d(in_planes, out_planes, kernel_size=(3, 3), stride=1, dilation=1, padding=1, bias=True, padding_mode='zeros',
|
| 74 |
+
init_scale=1.):
|
| 75 |
+
conv = nn.Conv2d(in_planes, out_planes, kernel_size=kernel_size, stride=stride, padding=padding, dilation=dilation,
|
| 76 |
+
bias=bias, padding_mode=padding_mode)
|
| 77 |
+
variance_scaling_init_(conv.weight, scale=init_scale)
|
| 78 |
+
if bias:
|
| 79 |
+
nn.init.zeros_(conv.bias)
|
| 80 |
+
return conv
|
| 81 |
+
|
| 82 |
+
|
| 83 |
+
|
score_sde/models/discriminator.py
ADDED
|
@@ -0,0 +1,239 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# ---------------------------------------------------------------
|
| 2 |
+
# Copyright (c) 2022, NVIDIA CORPORATION. All rights reserved.
|
| 3 |
+
#
|
| 4 |
+
# This work is licensed under the NVIDIA Source Code License
|
| 5 |
+
# for Denoising Diffusion GAN. To view a copy of this license, see the LICENSE file.
|
| 6 |
+
# ---------------------------------------------------------------
|
| 7 |
+
import torch
|
| 8 |
+
import torch.nn as nn
|
| 9 |
+
import numpy as np
|
| 10 |
+
|
| 11 |
+
from . import up_or_down_sampling
|
| 12 |
+
from . import dense_layer
|
| 13 |
+
from . import layers
|
| 14 |
+
|
| 15 |
+
dense = dense_layer.dense
|
| 16 |
+
conv2d = dense_layer.conv2d
|
| 17 |
+
get_sinusoidal_positional_embedding = layers.get_timestep_embedding
|
| 18 |
+
|
| 19 |
+
class TimestepEmbedding(nn.Module):
|
| 20 |
+
def __init__(self, embedding_dim, hidden_dim, output_dim, act=nn.LeakyReLU(0.2)):
|
| 21 |
+
super().__init__()
|
| 22 |
+
|
| 23 |
+
self.embedding_dim = embedding_dim
|
| 24 |
+
self.output_dim = output_dim
|
| 25 |
+
self.hidden_dim = hidden_dim
|
| 26 |
+
|
| 27 |
+
self.main = nn.Sequential(
|
| 28 |
+
dense(embedding_dim, hidden_dim),
|
| 29 |
+
act,
|
| 30 |
+
dense(hidden_dim, output_dim),
|
| 31 |
+
)
|
| 32 |
+
|
| 33 |
+
def forward(self, temp):
|
| 34 |
+
temb = get_sinusoidal_positional_embedding(temp, self.embedding_dim)
|
| 35 |
+
temb = self.main(temb)
|
| 36 |
+
return temb
|
| 37 |
+
#%%
|
| 38 |
+
class DownConvBlock(nn.Module):
|
| 39 |
+
def __init__(
|
| 40 |
+
self,
|
| 41 |
+
in_channel,
|
| 42 |
+
out_channel,
|
| 43 |
+
kernel_size=3,
|
| 44 |
+
padding=1,
|
| 45 |
+
t_emb_dim = 128,
|
| 46 |
+
downsample=False,
|
| 47 |
+
act = nn.LeakyReLU(0.2),
|
| 48 |
+
fir_kernel=(1, 3, 3, 1)
|
| 49 |
+
):
|
| 50 |
+
super().__init__()
|
| 51 |
+
|
| 52 |
+
|
| 53 |
+
self.fir_kernel = fir_kernel
|
| 54 |
+
self.downsample = downsample
|
| 55 |
+
|
| 56 |
+
self.conv1 = nn.Sequential(
|
| 57 |
+
conv2d(in_channel, out_channel, kernel_size, padding=padding),
|
| 58 |
+
)
|
| 59 |
+
|
| 60 |
+
|
| 61 |
+
self.conv2 = nn.Sequential(
|
| 62 |
+
conv2d(out_channel, out_channel, kernel_size, padding=padding,init_scale=0.)
|
| 63 |
+
)
|
| 64 |
+
self.dense_t1= dense(t_emb_dim, out_channel)
|
| 65 |
+
|
| 66 |
+
|
| 67 |
+
self.act = act
|
| 68 |
+
|
| 69 |
+
|
| 70 |
+
self.skip = nn.Sequential(
|
| 71 |
+
conv2d(in_channel, out_channel, 1, padding=0, bias=False),
|
| 72 |
+
)
|
| 73 |
+
|
| 74 |
+
|
| 75 |
+
|
| 76 |
+
def forward(self, input, t_emb):
|
| 77 |
+
|
| 78 |
+
out = self.act(input)
|
| 79 |
+
out = self.conv1(out)
|
| 80 |
+
out += self.dense_t1(t_emb)[..., None, None]
|
| 81 |
+
|
| 82 |
+
out = self.act(out)
|
| 83 |
+
|
| 84 |
+
if self.downsample:
|
| 85 |
+
out = up_or_down_sampling.downsample_2d(out, self.fir_kernel, factor=2)
|
| 86 |
+
input = up_or_down_sampling.downsample_2d(input, self.fir_kernel, factor=2)
|
| 87 |
+
out = self.conv2(out)
|
| 88 |
+
|
| 89 |
+
|
| 90 |
+
skip = self.skip(input)
|
| 91 |
+
out = (out + skip) / np.sqrt(2)
|
| 92 |
+
|
| 93 |
+
|
| 94 |
+
return out
|
| 95 |
+
|
| 96 |
+
class Discriminator_small(nn.Module):
|
| 97 |
+
"""A time-dependent discriminator for small images (CIFAR10, StackMNIST)."""
|
| 98 |
+
|
| 99 |
+
def __init__(self, nc = 3, ngf = 64, t_emb_dim = 128, act=nn.LeakyReLU(0.2)):
|
| 100 |
+
super().__init__()
|
| 101 |
+
# Gaussian random feature embedding layer for time
|
| 102 |
+
self.act = act
|
| 103 |
+
|
| 104 |
+
|
| 105 |
+
self.t_embed = TimestepEmbedding(
|
| 106 |
+
embedding_dim=t_emb_dim,
|
| 107 |
+
hidden_dim=t_emb_dim,
|
| 108 |
+
output_dim=t_emb_dim,
|
| 109 |
+
act=act,
|
| 110 |
+
)
|
| 111 |
+
|
| 112 |
+
|
| 113 |
+
|
| 114 |
+
# Encoding layers where the resolution decreases
|
| 115 |
+
self.start_conv = conv2d(nc,ngf*2,1, padding=0)
|
| 116 |
+
self.conv1 = DownConvBlock(ngf*2, ngf*2, t_emb_dim = t_emb_dim,act=act)
|
| 117 |
+
|
| 118 |
+
self.conv2 = DownConvBlock(ngf*2, ngf*4, t_emb_dim = t_emb_dim, downsample=True,act=act)
|
| 119 |
+
|
| 120 |
+
|
| 121 |
+
self.conv3 = DownConvBlock(ngf*4, ngf*8, t_emb_dim = t_emb_dim, downsample=True,act=act)
|
| 122 |
+
|
| 123 |
+
|
| 124 |
+
self.conv4 = DownConvBlock(ngf*8, ngf*8, t_emb_dim = t_emb_dim, downsample=True,act=act)
|
| 125 |
+
|
| 126 |
+
|
| 127 |
+
self.final_conv = conv2d(ngf*8 + 1, ngf*8, 3,padding=1, init_scale=0.)
|
| 128 |
+
self.end_linear = dense(ngf*8, 1)
|
| 129 |
+
|
| 130 |
+
self.stddev_group = 4
|
| 131 |
+
self.stddev_feat = 1
|
| 132 |
+
|
| 133 |
+
|
| 134 |
+
def forward(self, x, t, x_t):
|
| 135 |
+
t_embed = self.act(self.t_embed(t))
|
| 136 |
+
|
| 137 |
+
|
| 138 |
+
input_x = torch.cat((x, x_t), dim = 1)
|
| 139 |
+
|
| 140 |
+
h0 = self.start_conv(input_x)
|
| 141 |
+
h1 = self.conv1(h0,t_embed)
|
| 142 |
+
|
| 143 |
+
h2 = self.conv2(h1,t_embed)
|
| 144 |
+
|
| 145 |
+
h3 = self.conv3(h2,t_embed)
|
| 146 |
+
|
| 147 |
+
|
| 148 |
+
out = self.conv4(h3,t_embed)
|
| 149 |
+
|
| 150 |
+
batch, channel, height, width = out.shape
|
| 151 |
+
group = min(batch, self.stddev_group)
|
| 152 |
+
stddev = out.view(
|
| 153 |
+
group, -1, self.stddev_feat, channel // self.stddev_feat, height, width
|
| 154 |
+
)
|
| 155 |
+
stddev = torch.sqrt(stddev.var(0, unbiased=False) + 1e-8)
|
| 156 |
+
stddev = stddev.mean([2, 3, 4], keepdims=True).squeeze(2)
|
| 157 |
+
stddev = stddev.repeat(group, 1, height, width)
|
| 158 |
+
out = torch.cat([out, stddev], 1)
|
| 159 |
+
|
| 160 |
+
out = self.final_conv(out)
|
| 161 |
+
out = self.act(out)
|
| 162 |
+
|
| 163 |
+
|
| 164 |
+
out = out.view(out.shape[0], out.shape[1], -1).sum(2)
|
| 165 |
+
out = self.end_linear(out)
|
| 166 |
+
|
| 167 |
+
return out
|
| 168 |
+
|
| 169 |
+
|
| 170 |
+
class Discriminator_large(nn.Module):
|
| 171 |
+
"""A time-dependent discriminator for large images (CelebA, LSUN)."""
|
| 172 |
+
|
| 173 |
+
def __init__(self, nc = 1, ngf = 32, t_emb_dim = 128, act=nn.LeakyReLU(0.2)):
|
| 174 |
+
super().__init__()
|
| 175 |
+
# Gaussian random feature embedding layer for time
|
| 176 |
+
self.act = act
|
| 177 |
+
|
| 178 |
+
self.t_embed = TimestepEmbedding(
|
| 179 |
+
embedding_dim=t_emb_dim,
|
| 180 |
+
hidden_dim=t_emb_dim,
|
| 181 |
+
output_dim=t_emb_dim,
|
| 182 |
+
act=act,
|
| 183 |
+
)
|
| 184 |
+
|
| 185 |
+
self.start_conv = conv2d(nc,ngf*2,1, padding=0)
|
| 186 |
+
self.conv1 = DownConvBlock(ngf*2, ngf*4, t_emb_dim = t_emb_dim, downsample = True, act=act)
|
| 187 |
+
|
| 188 |
+
self.conv2 = DownConvBlock(ngf*4, ngf*8, t_emb_dim = t_emb_dim, downsample=True,act=act)
|
| 189 |
+
|
| 190 |
+
self.conv3 = DownConvBlock(ngf*8, ngf*8, t_emb_dim = t_emb_dim, downsample=True,act=act)
|
| 191 |
+
|
| 192 |
+
|
| 193 |
+
self.conv4 = DownConvBlock(ngf*8, ngf*8, t_emb_dim = t_emb_dim, downsample=True,act=act)
|
| 194 |
+
self.conv5 = DownConvBlock(ngf*8, ngf*8, t_emb_dim = t_emb_dim, downsample=True,act=act)
|
| 195 |
+
self.conv6 = DownConvBlock(ngf*8, ngf*8, t_emb_dim = t_emb_dim, downsample=True,act=act)
|
| 196 |
+
|
| 197 |
+
|
| 198 |
+
self.final_conv = conv2d(ngf*8 + 1, ngf*8, 3,padding=1)
|
| 199 |
+
self.end_linear = dense(ngf*8, 1)
|
| 200 |
+
|
| 201 |
+
self.stddev_group = 4
|
| 202 |
+
self.stddev_feat = 1
|
| 203 |
+
|
| 204 |
+
|
| 205 |
+
def forward(self, x, t, x_t):
|
| 206 |
+
t_embed = self.act(self.t_embed(t))
|
| 207 |
+
|
| 208 |
+
input_x = torch.cat((x, x_t), dim = 1)
|
| 209 |
+
|
| 210 |
+
h = self.start_conv(input_x)
|
| 211 |
+
h = self.conv1(h,t_embed)
|
| 212 |
+
|
| 213 |
+
h = self.conv2(h,t_embed)
|
| 214 |
+
|
| 215 |
+
h = self.conv3(h,t_embed)
|
| 216 |
+
h = self.conv4(h,t_embed)
|
| 217 |
+
h = self.conv5(h,t_embed)
|
| 218 |
+
|
| 219 |
+
|
| 220 |
+
out = self.conv6(h,t_embed)
|
| 221 |
+
|
| 222 |
+
batch, channel, height, width = out.shape
|
| 223 |
+
group = min(batch, self.stddev_group)
|
| 224 |
+
stddev = out.view(
|
| 225 |
+
group, -1, self.stddev_feat, channel // self.stddev_feat, height, width
|
| 226 |
+
)
|
| 227 |
+
stddev = torch.sqrt(stddev.var(0, unbiased=False) + 1e-8)
|
| 228 |
+
stddev = stddev.mean([2, 3, 4], keepdims=True).squeeze(2)
|
| 229 |
+
stddev = stddev.repeat(group, 1, height, width)
|
| 230 |
+
out = torch.cat([out, stddev], 1)
|
| 231 |
+
|
| 232 |
+
out = self.final_conv(out)
|
| 233 |
+
out = self.act(out)
|
| 234 |
+
|
| 235 |
+
out = out.view(out.shape[0], out.shape[1], -1).sum(2)
|
| 236 |
+
out = self.end_linear(out)
|
| 237 |
+
|
| 238 |
+
return out
|
| 239 |
+
|
score_sde/models/layers.py
ADDED
|
@@ -0,0 +1,619 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# ---------------------------------------------------------------
|
| 2 |
+
# Copyright (c) 2022, NVIDIA CORPORATION. All rights reserved.
|
| 3 |
+
#
|
| 4 |
+
# This file has been modified from a file in the Score SDE library
|
| 5 |
+
# which was released under the Apache License.
|
| 6 |
+
#
|
| 7 |
+
# Source:
|
| 8 |
+
# https://github.com/yang-song/score_sde_pytorch/blob/main/models/layers.py
|
| 9 |
+
#
|
| 10 |
+
# The license for the original version of this file can be
|
| 11 |
+
# found in this directory (LICENSE_Apache). The modifications
|
| 12 |
+
# to this file are subject to the same Apache License.
|
| 13 |
+
# ---------------------------------------------------------------
|
| 14 |
+
|
| 15 |
+
# coding=utf-8
|
| 16 |
+
# Copyright 2020 The Google Research Authors.
|
| 17 |
+
#
|
| 18 |
+
# Licensed under the Apache License, Version 2.0 (the "License");
|
| 19 |
+
# you may not use this file except in compliance with the License.
|
| 20 |
+
# You may obtain a copy of the License at
|
| 21 |
+
#
|
| 22 |
+
# http://www.apache.org/licenses/LICENSE-2.0
|
| 23 |
+
#
|
| 24 |
+
# Unless required by applicable law or agreed to in writing, software
|
| 25 |
+
# distributed under the License is distributed on an "AS IS" BASIS,
|
| 26 |
+
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
| 27 |
+
# See the License for the specific language governing permissions and
|
| 28 |
+
# limitations under the License.
|
| 29 |
+
|
| 30 |
+
# pylint: skip-file
|
| 31 |
+
"""Common layers for defining score networks.
|
| 32 |
+
Adapted from https://github.com/yang-song/score_sde_pytorch/blob/main/models/layers.py
|
| 33 |
+
"""
|
| 34 |
+
import math
|
| 35 |
+
import string
|
| 36 |
+
from functools import partial
|
| 37 |
+
import torch.nn as nn
|
| 38 |
+
import torch
|
| 39 |
+
import torch.nn.functional as F
|
| 40 |
+
import numpy as np
|
| 41 |
+
|
| 42 |
+
|
| 43 |
+
def get_act(config):
|
| 44 |
+
"""Get activation functions from the config file."""
|
| 45 |
+
|
| 46 |
+
if config.model.nonlinearity.lower() == 'elu':
|
| 47 |
+
return nn.ELU()
|
| 48 |
+
elif config.model.nonlinearity.lower() == 'relu':
|
| 49 |
+
return nn.ReLU()
|
| 50 |
+
elif config.model.nonlinearity.lower() == 'lrelu':
|
| 51 |
+
return nn.LeakyReLU(negative_slope=0.2)
|
| 52 |
+
elif config.model.nonlinearity.lower() == 'swish':
|
| 53 |
+
return nn.SiLU()
|
| 54 |
+
else:
|
| 55 |
+
raise NotImplementedError('activation function does not exist!')
|
| 56 |
+
|
| 57 |
+
|
| 58 |
+
def ncsn_conv1x1(in_planes, out_planes, stride=1, bias=True, dilation=1, init_scale=1., padding=0):
|
| 59 |
+
"""1x1 convolution. Same as NCSNv1/v2."""
|
| 60 |
+
conv = nn.Conv2d(in_planes, out_planes, kernel_size=1, stride=stride, bias=bias, dilation=dilation,
|
| 61 |
+
padding=padding)
|
| 62 |
+
init_scale = 1e-10 if init_scale == 0 else init_scale
|
| 63 |
+
conv.weight.data *= init_scale
|
| 64 |
+
conv.bias.data *= init_scale
|
| 65 |
+
return conv
|
| 66 |
+
|
| 67 |
+
|
| 68 |
+
def variance_scaling(scale, mode, distribution,
|
| 69 |
+
in_axis=1, out_axis=0,
|
| 70 |
+
dtype=torch.float32,
|
| 71 |
+
device='cpu'):
|
| 72 |
+
"""Ported from JAX. """
|
| 73 |
+
|
| 74 |
+
def _compute_fans(shape, in_axis=1, out_axis=0):
|
| 75 |
+
receptive_field_size = np.prod(shape) / shape[in_axis] / shape[out_axis]
|
| 76 |
+
fan_in = shape[in_axis] * receptive_field_size
|
| 77 |
+
fan_out = shape[out_axis] * receptive_field_size
|
| 78 |
+
return fan_in, fan_out
|
| 79 |
+
|
| 80 |
+
def init(shape, dtype=dtype, device=device):
|
| 81 |
+
fan_in, fan_out = _compute_fans(shape, in_axis, out_axis)
|
| 82 |
+
if mode == "fan_in":
|
| 83 |
+
denominator = fan_in
|
| 84 |
+
elif mode == "fan_out":
|
| 85 |
+
denominator = fan_out
|
| 86 |
+
elif mode == "fan_avg":
|
| 87 |
+
denominator = (fan_in + fan_out) / 2
|
| 88 |
+
else:
|
| 89 |
+
raise ValueError(
|
| 90 |
+
"invalid mode for variance scaling initializer: {}".format(mode))
|
| 91 |
+
variance = scale / denominator
|
| 92 |
+
if distribution == "normal":
|
| 93 |
+
return torch.randn(*shape, dtype=dtype, device=device) * np.sqrt(variance)
|
| 94 |
+
elif distribution == "uniform":
|
| 95 |
+
return (torch.rand(*shape, dtype=dtype, device=device) * 2. - 1.) * np.sqrt(3 * variance)
|
| 96 |
+
else:
|
| 97 |
+
raise ValueError("invalid distribution for variance scaling initializer")
|
| 98 |
+
|
| 99 |
+
return init
|
| 100 |
+
|
| 101 |
+
|
| 102 |
+
def default_init(scale=1.):
|
| 103 |
+
"""The same initialization used in DDPM."""
|
| 104 |
+
scale = 1e-10 if scale == 0 else scale
|
| 105 |
+
return variance_scaling(scale, 'fan_avg', 'uniform')
|
| 106 |
+
|
| 107 |
+
|
| 108 |
+
class Dense(nn.Module):
|
| 109 |
+
"""Linear layer with `default_init`."""
|
| 110 |
+
def __init__(self):
|
| 111 |
+
super().__init__()
|
| 112 |
+
|
| 113 |
+
|
| 114 |
+
def ddpm_conv1x1(in_planes, out_planes, stride=1, bias=True, init_scale=1., padding=0):
|
| 115 |
+
"""1x1 convolution with DDPM initialization."""
|
| 116 |
+
conv = nn.Conv2d(in_planes, out_planes, kernel_size=1, stride=stride, padding=padding, bias=bias)
|
| 117 |
+
conv.weight.data = default_init(init_scale)(conv.weight.data.shape)
|
| 118 |
+
nn.init.zeros_(conv.bias)
|
| 119 |
+
return conv
|
| 120 |
+
|
| 121 |
+
|
| 122 |
+
def ncsn_conv3x3(in_planes, out_planes, stride=1, bias=True, dilation=1, init_scale=1., padding=1):
|
| 123 |
+
"""3x3 convolution with PyTorch initialization. Same as NCSNv1/NCSNv2."""
|
| 124 |
+
init_scale = 1e-10 if init_scale == 0 else init_scale
|
| 125 |
+
conv = nn.Conv2d(in_planes, out_planes, stride=stride, bias=bias,
|
| 126 |
+
dilation=dilation, padding=padding, kernel_size=3)
|
| 127 |
+
conv.weight.data *= init_scale
|
| 128 |
+
conv.bias.data *= init_scale
|
| 129 |
+
return conv
|
| 130 |
+
|
| 131 |
+
|
| 132 |
+
def ddpm_conv3x3(in_planes, out_planes, stride=1, bias=True, dilation=1, init_scale=1., padding=1):
|
| 133 |
+
"""3x3 convolution with DDPM initialization."""
|
| 134 |
+
conv = nn.Conv2d(in_planes, out_planes, kernel_size=3, stride=stride, padding=padding,
|
| 135 |
+
dilation=dilation, bias=bias)
|
| 136 |
+
conv.weight.data = default_init(init_scale)(conv.weight.data.shape)
|
| 137 |
+
nn.init.zeros_(conv.bias)
|
| 138 |
+
return conv
|
| 139 |
+
|
| 140 |
+
###########################################################################
|
| 141 |
+
# Functions below are ported over from the NCSNv1/NCSNv2 codebase:
|
| 142 |
+
# https://github.com/ermongroup/ncsn
|
| 143 |
+
# https://github.com/ermongroup/ncsnv2
|
| 144 |
+
###########################################################################
|
| 145 |
+
|
| 146 |
+
|
| 147 |
+
class CRPBlock(nn.Module):
|
| 148 |
+
def __init__(self, features, n_stages, act=nn.ReLU(), maxpool=True):
|
| 149 |
+
super().__init__()
|
| 150 |
+
self.convs = nn.ModuleList()
|
| 151 |
+
for i in range(n_stages):
|
| 152 |
+
self.convs.append(ncsn_conv3x3(features, features, stride=1, bias=False))
|
| 153 |
+
self.n_stages = n_stages
|
| 154 |
+
if maxpool:
|
| 155 |
+
self.pool = nn.MaxPool2d(kernel_size=5, stride=1, padding=2)
|
| 156 |
+
else:
|
| 157 |
+
self.pool = nn.AvgPool2d(kernel_size=5, stride=1, padding=2)
|
| 158 |
+
|
| 159 |
+
self.act = act
|
| 160 |
+
|
| 161 |
+
def forward(self, x):
|
| 162 |
+
x = self.act(x)
|
| 163 |
+
path = x
|
| 164 |
+
for i in range(self.n_stages):
|
| 165 |
+
path = self.pool(path)
|
| 166 |
+
path = self.convs[i](path)
|
| 167 |
+
x = path + x
|
| 168 |
+
return x
|
| 169 |
+
|
| 170 |
+
|
| 171 |
+
class CondCRPBlock(nn.Module):
|
| 172 |
+
def __init__(self, features, n_stages, num_classes, normalizer, act=nn.ReLU()):
|
| 173 |
+
super().__init__()
|
| 174 |
+
self.convs = nn.ModuleList()
|
| 175 |
+
self.norms = nn.ModuleList()
|
| 176 |
+
self.normalizer = normalizer
|
| 177 |
+
for i in range(n_stages):
|
| 178 |
+
self.norms.append(normalizer(features, num_classes, bias=True))
|
| 179 |
+
self.convs.append(ncsn_conv3x3(features, features, stride=1, bias=False))
|
| 180 |
+
|
| 181 |
+
self.n_stages = n_stages
|
| 182 |
+
self.pool = nn.AvgPool2d(kernel_size=5, stride=1, padding=2)
|
| 183 |
+
self.act = act
|
| 184 |
+
|
| 185 |
+
def forward(self, x, y):
|
| 186 |
+
x = self.act(x)
|
| 187 |
+
path = x
|
| 188 |
+
for i in range(self.n_stages):
|
| 189 |
+
path = self.norms[i](path, y)
|
| 190 |
+
path = self.pool(path)
|
| 191 |
+
path = self.convs[i](path)
|
| 192 |
+
|
| 193 |
+
x = path + x
|
| 194 |
+
return x
|
| 195 |
+
|
| 196 |
+
|
| 197 |
+
class RCUBlock(nn.Module):
|
| 198 |
+
def __init__(self, features, n_blocks, n_stages, act=nn.ReLU()):
|
| 199 |
+
super().__init__()
|
| 200 |
+
|
| 201 |
+
for i in range(n_blocks):
|
| 202 |
+
for j in range(n_stages):
|
| 203 |
+
setattr(self, '{}_{}_conv'.format(i + 1, j + 1), ncsn_conv3x3(features, features, stride=1, bias=False))
|
| 204 |
+
|
| 205 |
+
self.stride = 1
|
| 206 |
+
self.n_blocks = n_blocks
|
| 207 |
+
self.n_stages = n_stages
|
| 208 |
+
self.act = act
|
| 209 |
+
|
| 210 |
+
def forward(self, x):
|
| 211 |
+
for i in range(self.n_blocks):
|
| 212 |
+
residual = x
|
| 213 |
+
for j in range(self.n_stages):
|
| 214 |
+
x = self.act(x)
|
| 215 |
+
x = getattr(self, '{}_{}_conv'.format(i + 1, j + 1))(x)
|
| 216 |
+
|
| 217 |
+
x += residual
|
| 218 |
+
return x
|
| 219 |
+
|
| 220 |
+
|
| 221 |
+
class CondRCUBlock(nn.Module):
|
| 222 |
+
def __init__(self, features, n_blocks, n_stages, num_classes, normalizer, act=nn.ReLU()):
|
| 223 |
+
super().__init__()
|
| 224 |
+
|
| 225 |
+
for i in range(n_blocks):
|
| 226 |
+
for j in range(n_stages):
|
| 227 |
+
setattr(self, '{}_{}_norm'.format(i + 1, j + 1), normalizer(features, num_classes, bias=True))
|
| 228 |
+
setattr(self, '{}_{}_conv'.format(i + 1, j + 1), ncsn_conv3x3(features, features, stride=1, bias=False))
|
| 229 |
+
|
| 230 |
+
self.stride = 1
|
| 231 |
+
self.n_blocks = n_blocks
|
| 232 |
+
self.n_stages = n_stages
|
| 233 |
+
self.act = act
|
| 234 |
+
self.normalizer = normalizer
|
| 235 |
+
|
| 236 |
+
def forward(self, x, y):
|
| 237 |
+
for i in range(self.n_blocks):
|
| 238 |
+
residual = x
|
| 239 |
+
for j in range(self.n_stages):
|
| 240 |
+
x = getattr(self, '{}_{}_norm'.format(i + 1, j + 1))(x, y)
|
| 241 |
+
x = self.act(x)
|
| 242 |
+
x = getattr(self, '{}_{}_conv'.format(i + 1, j + 1))(x)
|
| 243 |
+
|
| 244 |
+
x += residual
|
| 245 |
+
return x
|
| 246 |
+
|
| 247 |
+
|
| 248 |
+
class MSFBlock(nn.Module):
|
| 249 |
+
def __init__(self, in_planes, features):
|
| 250 |
+
super().__init__()
|
| 251 |
+
assert isinstance(in_planes, list) or isinstance(in_planes, tuple)
|
| 252 |
+
self.convs = nn.ModuleList()
|
| 253 |
+
self.features = features
|
| 254 |
+
|
| 255 |
+
for i in range(len(in_planes)):
|
| 256 |
+
self.convs.append(ncsn_conv3x3(in_planes[i], features, stride=1, bias=True))
|
| 257 |
+
|
| 258 |
+
def forward(self, xs, shape):
|
| 259 |
+
sums = torch.zeros(xs[0].shape[0], self.features, *shape, device=xs[0].device)
|
| 260 |
+
for i in range(len(self.convs)):
|
| 261 |
+
h = self.convs[i](xs[i])
|
| 262 |
+
h = F.interpolate(h, size=shape, mode='bilinear', align_corners=True)
|
| 263 |
+
sums += h
|
| 264 |
+
return sums
|
| 265 |
+
|
| 266 |
+
|
| 267 |
+
class CondMSFBlock(nn.Module):
|
| 268 |
+
def __init__(self, in_planes, features, num_classes, normalizer):
|
| 269 |
+
super().__init__()
|
| 270 |
+
assert isinstance(in_planes, list) or isinstance(in_planes, tuple)
|
| 271 |
+
|
| 272 |
+
self.convs = nn.ModuleList()
|
| 273 |
+
self.norms = nn.ModuleList()
|
| 274 |
+
self.features = features
|
| 275 |
+
self.normalizer = normalizer
|
| 276 |
+
|
| 277 |
+
for i in range(len(in_planes)):
|
| 278 |
+
self.convs.append(ncsn_conv3x3(in_planes[i], features, stride=1, bias=True))
|
| 279 |
+
self.norms.append(normalizer(in_planes[i], num_classes, bias=True))
|
| 280 |
+
|
| 281 |
+
def forward(self, xs, y, shape):
|
| 282 |
+
sums = torch.zeros(xs[0].shape[0], self.features, *shape, device=xs[0].device)
|
| 283 |
+
for i in range(len(self.convs)):
|
| 284 |
+
h = self.norms[i](xs[i], y)
|
| 285 |
+
h = self.convs[i](h)
|
| 286 |
+
h = F.interpolate(h, size=shape, mode='bilinear', align_corners=True)
|
| 287 |
+
sums += h
|
| 288 |
+
return sums
|
| 289 |
+
|
| 290 |
+
|
| 291 |
+
class RefineBlock(nn.Module):
|
| 292 |
+
def __init__(self, in_planes, features, act=nn.ReLU(), start=False, end=False, maxpool=True):
|
| 293 |
+
super().__init__()
|
| 294 |
+
|
| 295 |
+
assert isinstance(in_planes, tuple) or isinstance(in_planes, list)
|
| 296 |
+
self.n_blocks = n_blocks = len(in_planes)
|
| 297 |
+
|
| 298 |
+
self.adapt_convs = nn.ModuleList()
|
| 299 |
+
for i in range(n_blocks):
|
| 300 |
+
self.adapt_convs.append(RCUBlock(in_planes[i], 2, 2, act))
|
| 301 |
+
|
| 302 |
+
self.output_convs = RCUBlock(features, 3 if end else 1, 2, act)
|
| 303 |
+
|
| 304 |
+
if not start:
|
| 305 |
+
self.msf = MSFBlock(in_planes, features)
|
| 306 |
+
|
| 307 |
+
self.crp = CRPBlock(features, 2, act, maxpool=maxpool)
|
| 308 |
+
|
| 309 |
+
def forward(self, xs, output_shape):
|
| 310 |
+
assert isinstance(xs, tuple) or isinstance(xs, list)
|
| 311 |
+
hs = []
|
| 312 |
+
for i in range(len(xs)):
|
| 313 |
+
h = self.adapt_convs[i](xs[i])
|
| 314 |
+
hs.append(h)
|
| 315 |
+
|
| 316 |
+
if self.n_blocks > 1:
|
| 317 |
+
h = self.msf(hs, output_shape)
|
| 318 |
+
else:
|
| 319 |
+
h = hs[0]
|
| 320 |
+
|
| 321 |
+
h = self.crp(h)
|
| 322 |
+
h = self.output_convs(h)
|
| 323 |
+
|
| 324 |
+
return h
|
| 325 |
+
|
| 326 |
+
|
| 327 |
+
class CondRefineBlock(nn.Module):
|
| 328 |
+
def __init__(self, in_planes, features, num_classes, normalizer, act=nn.ReLU(), start=False, end=False):
|
| 329 |
+
super().__init__()
|
| 330 |
+
|
| 331 |
+
assert isinstance(in_planes, tuple) or isinstance(in_planes, list)
|
| 332 |
+
self.n_blocks = n_blocks = len(in_planes)
|
| 333 |
+
|
| 334 |
+
self.adapt_convs = nn.ModuleList()
|
| 335 |
+
for i in range(n_blocks):
|
| 336 |
+
self.adapt_convs.append(
|
| 337 |
+
CondRCUBlock(in_planes[i], 2, 2, num_classes, normalizer, act)
|
| 338 |
+
)
|
| 339 |
+
|
| 340 |
+
self.output_convs = CondRCUBlock(features, 3 if end else 1, 2, num_classes, normalizer, act)
|
| 341 |
+
|
| 342 |
+
if not start:
|
| 343 |
+
self.msf = CondMSFBlock(in_planes, features, num_classes, normalizer)
|
| 344 |
+
|
| 345 |
+
self.crp = CondCRPBlock(features, 2, num_classes, normalizer, act)
|
| 346 |
+
|
| 347 |
+
def forward(self, xs, y, output_shape):
|
| 348 |
+
assert isinstance(xs, tuple) or isinstance(xs, list)
|
| 349 |
+
hs = []
|
| 350 |
+
for i in range(len(xs)):
|
| 351 |
+
h = self.adapt_convs[i](xs[i], y)
|
| 352 |
+
hs.append(h)
|
| 353 |
+
|
| 354 |
+
if self.n_blocks > 1:
|
| 355 |
+
h = self.msf(hs, y, output_shape)
|
| 356 |
+
else:
|
| 357 |
+
h = hs[0]
|
| 358 |
+
|
| 359 |
+
h = self.crp(h, y)
|
| 360 |
+
h = self.output_convs(h, y)
|
| 361 |
+
|
| 362 |
+
return h
|
| 363 |
+
|
| 364 |
+
|
| 365 |
+
class ConvMeanPool(nn.Module):
|
| 366 |
+
def __init__(self, input_dim, output_dim, kernel_size=3, biases=True, adjust_padding=False):
|
| 367 |
+
super().__init__()
|
| 368 |
+
if not adjust_padding:
|
| 369 |
+
conv = nn.Conv2d(input_dim, output_dim, kernel_size, stride=1, padding=kernel_size // 2, bias=biases)
|
| 370 |
+
self.conv = conv
|
| 371 |
+
else:
|
| 372 |
+
conv = nn.Conv2d(input_dim, output_dim, kernel_size, stride=1, padding=kernel_size // 2, bias=biases)
|
| 373 |
+
|
| 374 |
+
self.conv = nn.Sequential(
|
| 375 |
+
nn.ZeroPad2d((1, 0, 1, 0)),
|
| 376 |
+
conv
|
| 377 |
+
)
|
| 378 |
+
|
| 379 |
+
def forward(self, inputs):
|
| 380 |
+
output = self.conv(inputs)
|
| 381 |
+
output = sum([output[:, :, ::2, ::2], output[:, :, 1::2, ::2],
|
| 382 |
+
output[:, :, ::2, 1::2], output[:, :, 1::2, 1::2]]) / 4.
|
| 383 |
+
return output
|
| 384 |
+
|
| 385 |
+
|
| 386 |
+
class MeanPoolConv(nn.Module):
|
| 387 |
+
def __init__(self, input_dim, output_dim, kernel_size=3, biases=True):
|
| 388 |
+
super().__init__()
|
| 389 |
+
self.conv = nn.Conv2d(input_dim, output_dim, kernel_size, stride=1, padding=kernel_size // 2, bias=biases)
|
| 390 |
+
|
| 391 |
+
def forward(self, inputs):
|
| 392 |
+
output = inputs
|
| 393 |
+
output = sum([output[:, :, ::2, ::2], output[:, :, 1::2, ::2],
|
| 394 |
+
output[:, :, ::2, 1::2], output[:, :, 1::2, 1::2]]) / 4.
|
| 395 |
+
return self.conv(output)
|
| 396 |
+
|
| 397 |
+
|
| 398 |
+
class UpsampleConv(nn.Module):
|
| 399 |
+
def __init__(self, input_dim, output_dim, kernel_size=3, biases=True):
|
| 400 |
+
super().__init__()
|
| 401 |
+
self.conv = nn.Conv2d(input_dim, output_dim, kernel_size, stride=1, padding=kernel_size // 2, bias=biases)
|
| 402 |
+
self.pixelshuffle = nn.PixelShuffle(upscale_factor=2)
|
| 403 |
+
|
| 404 |
+
def forward(self, inputs):
|
| 405 |
+
output = inputs
|
| 406 |
+
output = torch.cat([output, output, output, output], dim=1)
|
| 407 |
+
output = self.pixelshuffle(output)
|
| 408 |
+
return self.conv(output)
|
| 409 |
+
|
| 410 |
+
|
| 411 |
+
|
| 412 |
+
|
| 413 |
+
class ResidualBlock(nn.Module):
|
| 414 |
+
def __init__(self, input_dim, output_dim, resample=None, act=nn.ELU(),
|
| 415 |
+
normalization=nn.InstanceNorm2d, adjust_padding=False, dilation=1):
|
| 416 |
+
super().__init__()
|
| 417 |
+
self.non_linearity = act
|
| 418 |
+
self.input_dim = input_dim
|
| 419 |
+
self.output_dim = output_dim
|
| 420 |
+
self.resample = resample
|
| 421 |
+
self.normalization = normalization
|
| 422 |
+
if resample == 'down':
|
| 423 |
+
if dilation > 1:
|
| 424 |
+
self.conv1 = ncsn_conv3x3(input_dim, input_dim, dilation=dilation)
|
| 425 |
+
self.normalize2 = normalization(input_dim)
|
| 426 |
+
self.conv2 = ncsn_conv3x3(input_dim, output_dim, dilation=dilation)
|
| 427 |
+
conv_shortcut = partial(ncsn_conv3x3, dilation=dilation)
|
| 428 |
+
else:
|
| 429 |
+
self.conv1 = ncsn_conv3x3(input_dim, input_dim)
|
| 430 |
+
self.normalize2 = normalization(input_dim)
|
| 431 |
+
self.conv2 = ConvMeanPool(input_dim, output_dim, 3, adjust_padding=adjust_padding)
|
| 432 |
+
conv_shortcut = partial(ConvMeanPool, kernel_size=1, adjust_padding=adjust_padding)
|
| 433 |
+
|
| 434 |
+
elif resample is None:
|
| 435 |
+
if dilation > 1:
|
| 436 |
+
conv_shortcut = partial(ncsn_conv3x3, dilation=dilation)
|
| 437 |
+
self.conv1 = ncsn_conv3x3(input_dim, output_dim, dilation=dilation)
|
| 438 |
+
self.normalize2 = normalization(output_dim)
|
| 439 |
+
self.conv2 = ncsn_conv3x3(output_dim, output_dim, dilation=dilation)
|
| 440 |
+
else:
|
| 441 |
+
# conv_shortcut = nn.Conv2d ### Something wierd here.
|
| 442 |
+
conv_shortcut = partial(ncsn_conv1x1)
|
| 443 |
+
self.conv1 = ncsn_conv3x3(input_dim, output_dim)
|
| 444 |
+
self.normalize2 = normalization(output_dim)
|
| 445 |
+
self.conv2 = ncsn_conv3x3(output_dim, output_dim)
|
| 446 |
+
else:
|
| 447 |
+
raise Exception('invalid resample value')
|
| 448 |
+
|
| 449 |
+
if output_dim != input_dim or resample is not None:
|
| 450 |
+
self.shortcut = conv_shortcut(input_dim, output_dim)
|
| 451 |
+
|
| 452 |
+
self.normalize1 = normalization(input_dim)
|
| 453 |
+
|
| 454 |
+
def forward(self, x):
|
| 455 |
+
output = self.normalize1(x)
|
| 456 |
+
output = self.non_linearity(output)
|
| 457 |
+
output = self.conv1(output)
|
| 458 |
+
output = self.normalize2(output)
|
| 459 |
+
output = self.non_linearity(output)
|
| 460 |
+
output = self.conv2(output)
|
| 461 |
+
|
| 462 |
+
if self.output_dim == self.input_dim and self.resample is None:
|
| 463 |
+
shortcut = x
|
| 464 |
+
else:
|
| 465 |
+
shortcut = self.shortcut(x)
|
| 466 |
+
|
| 467 |
+
return shortcut + output
|
| 468 |
+
|
| 469 |
+
|
| 470 |
+
###########################################################################
|
| 471 |
+
# Functions below are ported over from the DDPM codebase:
|
| 472 |
+
# https://github.com/hojonathanho/diffusion/blob/master/diffusion_tf/nn.py
|
| 473 |
+
###########################################################################
|
| 474 |
+
|
| 475 |
+
def get_timestep_embedding(timesteps, embedding_dim, max_positions=10000):
|
| 476 |
+
assert len(timesteps.shape) == 1 # and timesteps.dtype == tf.int32
|
| 477 |
+
half_dim = embedding_dim // 2
|
| 478 |
+
# magic number 10000 is from transformers
|
| 479 |
+
emb = math.log(max_positions) / (half_dim - 1)
|
| 480 |
+
emb = torch.exp(torch.arange(half_dim, dtype=torch.float32, device=timesteps.device) * -emb)
|
| 481 |
+
emb = timesteps.float()[:, None] * emb[None, :]
|
| 482 |
+
emb = torch.cat([torch.sin(emb), torch.cos(emb)], dim=1)
|
| 483 |
+
if embedding_dim % 2 == 1: # zero pad
|
| 484 |
+
emb = F.pad(emb, (0, 1), mode='constant')
|
| 485 |
+
assert emb.shape == (timesteps.shape[0], embedding_dim)
|
| 486 |
+
return emb
|
| 487 |
+
|
| 488 |
+
|
| 489 |
+
def _einsum(a, b, c, x, y):
|
| 490 |
+
einsum_str = '{},{}->{}'.format(''.join(a), ''.join(b), ''.join(c))
|
| 491 |
+
return torch.einsum(einsum_str, x, y)
|
| 492 |
+
|
| 493 |
+
|
| 494 |
+
def contract_inner(x, y):
|
| 495 |
+
"""tensordot(x, y, 1)."""
|
| 496 |
+
x_chars = list(string.ascii_lowercase[:len(x.shape)])
|
| 497 |
+
y_chars = list(string.ascii_lowercase[len(x.shape):len(y.shape) + len(x.shape)])
|
| 498 |
+
y_chars[0] = x_chars[-1] # first axis of y and last of x get summed
|
| 499 |
+
out_chars = x_chars[:-1] + y_chars[1:]
|
| 500 |
+
return _einsum(x_chars, y_chars, out_chars, x, y)
|
| 501 |
+
|
| 502 |
+
|
| 503 |
+
class NIN(nn.Module):
|
| 504 |
+
def __init__(self, in_dim, num_units, init_scale=0.1):
|
| 505 |
+
super().__init__()
|
| 506 |
+
self.W = nn.Parameter(default_init(scale=init_scale)((in_dim, num_units)), requires_grad=True)
|
| 507 |
+
self.b = nn.Parameter(torch.zeros(num_units), requires_grad=True)
|
| 508 |
+
|
| 509 |
+
def forward(self, x):
|
| 510 |
+
x = x.permute(0, 2, 3, 1)
|
| 511 |
+
y = contract_inner(x, self.W) + self.b
|
| 512 |
+
return y.permute(0, 3, 1, 2)
|
| 513 |
+
|
| 514 |
+
|
| 515 |
+
class AttnBlock(nn.Module):
|
| 516 |
+
"""Channel-wise self-attention block."""
|
| 517 |
+
def __init__(self, channels):
|
| 518 |
+
super().__init__()
|
| 519 |
+
self.GroupNorm_0 = nn.GroupNorm(num_groups=32, num_channels=channels, eps=1e-6)
|
| 520 |
+
self.NIN_0 = NIN(channels, channels)
|
| 521 |
+
self.NIN_1 = NIN(channels, channels)
|
| 522 |
+
self.NIN_2 = NIN(channels, channels)
|
| 523 |
+
self.NIN_3 = NIN(channels, channels, init_scale=0.)
|
| 524 |
+
|
| 525 |
+
def forward(self, x):
|
| 526 |
+
B, C, H, W = x.shape
|
| 527 |
+
h = self.GroupNorm_0(x)
|
| 528 |
+
q = self.NIN_0(h)
|
| 529 |
+
k = self.NIN_1(h)
|
| 530 |
+
v = self.NIN_2(h)
|
| 531 |
+
|
| 532 |
+
w = torch.einsum('bchw,bcij->bhwij', q, k) * (int(C) ** (-0.5))
|
| 533 |
+
w = torch.reshape(w, (B, H, W, H * W))
|
| 534 |
+
w = F.softmax(w, dim=-1)
|
| 535 |
+
w = torch.reshape(w, (B, H, W, H, W))
|
| 536 |
+
h = torch.einsum('bhwij,bcij->bchw', w, v)
|
| 537 |
+
h = self.NIN_3(h)
|
| 538 |
+
return x + h
|
| 539 |
+
|
| 540 |
+
|
| 541 |
+
class Upsample(nn.Module):
|
| 542 |
+
def __init__(self, channels, with_conv=False):
|
| 543 |
+
super().__init__()
|
| 544 |
+
if with_conv:
|
| 545 |
+
self.Conv_0 = ddpm_conv3x3(channels, channels)
|
| 546 |
+
self.with_conv = with_conv
|
| 547 |
+
|
| 548 |
+
def forward(self, x):
|
| 549 |
+
B, C, H, W = x.shape
|
| 550 |
+
h = F.interpolate(x, (H * 2, W * 2), mode='nearest')
|
| 551 |
+
if self.with_conv:
|
| 552 |
+
h = self.Conv_0(h)
|
| 553 |
+
return h
|
| 554 |
+
|
| 555 |
+
|
| 556 |
+
class Downsample(nn.Module):
|
| 557 |
+
def __init__(self, channels, with_conv=False):
|
| 558 |
+
super().__init__()
|
| 559 |
+
if with_conv:
|
| 560 |
+
self.Conv_0 = ddpm_conv3x3(channels, channels, stride=2, padding=0)
|
| 561 |
+
self.with_conv = with_conv
|
| 562 |
+
|
| 563 |
+
def forward(self, x):
|
| 564 |
+
B, C, H, W = x.shape
|
| 565 |
+
# Emulate 'SAME' padding
|
| 566 |
+
if self.with_conv:
|
| 567 |
+
x = F.pad(x, (0, 1, 0, 1))
|
| 568 |
+
x = self.Conv_0(x)
|
| 569 |
+
else:
|
| 570 |
+
x = F.avg_pool2d(x, kernel_size=2, stride=2, padding=0)
|
| 571 |
+
|
| 572 |
+
assert x.shape == (B, C, H // 2, W // 2)
|
| 573 |
+
return x
|
| 574 |
+
|
| 575 |
+
|
| 576 |
+
class ResnetBlockDDPM(nn.Module):
|
| 577 |
+
"""The ResNet Blocks used in DDPM."""
|
| 578 |
+
def __init__(self, act, in_ch, out_ch=None, temb_dim=None, conv_shortcut=False, dropout=0.1):
|
| 579 |
+
super().__init__()
|
| 580 |
+
if out_ch is None:
|
| 581 |
+
out_ch = in_ch
|
| 582 |
+
self.GroupNorm_0 = nn.GroupNorm(num_groups=32, num_channels=in_ch, eps=1e-6)
|
| 583 |
+
self.act = act
|
| 584 |
+
self.Conv_0 = ddpm_conv3x3(in_ch, out_ch)
|
| 585 |
+
if temb_dim is not None:
|
| 586 |
+
self.Dense_0 = nn.Linear(temb_dim, out_ch)
|
| 587 |
+
self.Dense_0.weight.data = default_init()(self.Dense_0.weight.data.shape)
|
| 588 |
+
nn.init.zeros_(self.Dense_0.bias)
|
| 589 |
+
|
| 590 |
+
self.GroupNorm_1 = nn.GroupNorm(num_groups=32, num_channels=out_ch, eps=1e-6)
|
| 591 |
+
self.Dropout_0 = nn.Dropout(dropout)
|
| 592 |
+
self.Conv_1 = ddpm_conv3x3(out_ch, out_ch, init_scale=0.)
|
| 593 |
+
if in_ch != out_ch:
|
| 594 |
+
if conv_shortcut:
|
| 595 |
+
self.Conv_2 = ddpm_conv3x3(in_ch, out_ch)
|
| 596 |
+
else:
|
| 597 |
+
self.NIN_0 = NIN(in_ch, out_ch)
|
| 598 |
+
self.out_ch = out_ch
|
| 599 |
+
self.in_ch = in_ch
|
| 600 |
+
self.conv_shortcut = conv_shortcut
|
| 601 |
+
|
| 602 |
+
def forward(self, x, temb=None):
|
| 603 |
+
B, C, H, W = x.shape
|
| 604 |
+
assert C == self.in_ch
|
| 605 |
+
out_ch = self.out_ch if self.out_ch else self.in_ch
|
| 606 |
+
h = self.act(self.GroupNorm_0(x))
|
| 607 |
+
h = self.Conv_0(h)
|
| 608 |
+
# Add bias to each feature map conditioned on the time embedding
|
| 609 |
+
if temb is not None:
|
| 610 |
+
h += self.Dense_0(self.act(temb))[:, :, None, None]
|
| 611 |
+
h = self.act(self.GroupNorm_1(h))
|
| 612 |
+
h = self.Dropout_0(h)
|
| 613 |
+
h = self.Conv_1(h)
|
| 614 |
+
if C != out_ch:
|
| 615 |
+
if self.conv_shortcut:
|
| 616 |
+
x = self.Conv_2(x)
|
| 617 |
+
else:
|
| 618 |
+
x = self.NIN_0(x)
|
| 619 |
+
return x + h
|
score_sde/models/layerspp.py
ADDED
|
@@ -0,0 +1,380 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# ---------------------------------------------------------------
|
| 2 |
+
# Copyright (c) 2022, NVIDIA CORPORATION. All rights reserved.
|
| 3 |
+
#
|
| 4 |
+
# This file has been modified from a file in the Score SDE library
|
| 5 |
+
# which was released under the Apache License.
|
| 6 |
+
#
|
| 7 |
+
# Source:
|
| 8 |
+
# https://github.com/yang-song/score_sde_pytorch/blob/main/models/layerspp.py
|
| 9 |
+
#
|
| 10 |
+
# The license for the original version of this file can be
|
| 11 |
+
# found in this directory (LICENSE_Apache). The modifications
|
| 12 |
+
# to this file are subject to the same Apache License.
|
| 13 |
+
# ---------------------------------------------------------------
|
| 14 |
+
|
| 15 |
+
# coding=utf-8
|
| 16 |
+
# Copyright 2020 The Google Research Authors.
|
| 17 |
+
#
|
| 18 |
+
# Licensed under the Apache License, Version 2.0 (the "License");
|
| 19 |
+
# you may not use this file except in compliance with the License.
|
| 20 |
+
# You may obtain a copy of the License at
|
| 21 |
+
#
|
| 22 |
+
# http://www.apache.org/licenses/LICENSE-2.0
|
| 23 |
+
#
|
| 24 |
+
# Unless required by applicable law or agreed to in writing, software
|
| 25 |
+
# distributed under the License is distributed on an "AS IS" BASIS,
|
| 26 |
+
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
| 27 |
+
# See the License for the specific language governing permissions and
|
| 28 |
+
# limitations under the License.
|
| 29 |
+
|
| 30 |
+
# pylint: skip-file
|
| 31 |
+
|
| 32 |
+
from . import layers
|
| 33 |
+
from . import up_or_down_sampling, dense_layer
|
| 34 |
+
import torch.nn as nn
|
| 35 |
+
import torch
|
| 36 |
+
import torch.nn.functional as F
|
| 37 |
+
import numpy as np
|
| 38 |
+
|
| 39 |
+
|
| 40 |
+
conv1x1 = layers.ddpm_conv1x1
|
| 41 |
+
conv3x3 = layers.ddpm_conv3x3
|
| 42 |
+
NIN = layers.NIN
|
| 43 |
+
default_init = layers.default_init
|
| 44 |
+
dense = dense_layer.dense
|
| 45 |
+
|
| 46 |
+
class AdaptiveGroupNorm(nn.Module):
|
| 47 |
+
def __init__(self, num_groups,in_channel, style_dim):
|
| 48 |
+
super().__init__()
|
| 49 |
+
|
| 50 |
+
self.norm = nn.GroupNorm(num_groups, in_channel, affine=False, eps=1e-6)
|
| 51 |
+
self.style = dense(style_dim, in_channel * 2)
|
| 52 |
+
|
| 53 |
+
self.style.bias.data[:in_channel] = 1
|
| 54 |
+
self.style.bias.data[in_channel:] = 0
|
| 55 |
+
|
| 56 |
+
def forward(self, input, style):
|
| 57 |
+
style = self.style(style).unsqueeze(2).unsqueeze(3)
|
| 58 |
+
gamma, beta = style.chunk(2, 1)
|
| 59 |
+
|
| 60 |
+
out = self.norm(input)
|
| 61 |
+
out = gamma * out + beta
|
| 62 |
+
|
| 63 |
+
return out
|
| 64 |
+
|
| 65 |
+
class GaussianFourierProjection(nn.Module):
|
| 66 |
+
"""Gaussian Fourier embeddings for noise levels."""
|
| 67 |
+
|
| 68 |
+
def __init__(self, embedding_size=256, scale=1.0):
|
| 69 |
+
super().__init__()
|
| 70 |
+
self.W = nn.Parameter(torch.randn(embedding_size) * scale, requires_grad=False)
|
| 71 |
+
|
| 72 |
+
def forward(self, x):
|
| 73 |
+
x_proj = x[:, None] * self.W[None, :] * 2 * np.pi
|
| 74 |
+
return torch.cat([torch.sin(x_proj), torch.cos(x_proj)], dim=-1)
|
| 75 |
+
|
| 76 |
+
|
| 77 |
+
class Combine(nn.Module):
|
| 78 |
+
"""Combine information from skip connections."""
|
| 79 |
+
|
| 80 |
+
def __init__(self, dim1, dim2, method='cat'):
|
| 81 |
+
super().__init__()
|
| 82 |
+
self.Conv_0 = conv1x1(dim1, dim2)
|
| 83 |
+
self.method = method
|
| 84 |
+
|
| 85 |
+
def forward(self, x, y):
|
| 86 |
+
h = self.Conv_0(x)
|
| 87 |
+
if self.method == 'cat':
|
| 88 |
+
return torch.cat([h, y], dim=1)
|
| 89 |
+
elif self.method == 'sum':
|
| 90 |
+
return h + y
|
| 91 |
+
else:
|
| 92 |
+
raise ValueError(f'Method {self.method} not recognized.')
|
| 93 |
+
|
| 94 |
+
|
| 95 |
+
class AttnBlockpp(nn.Module):
|
| 96 |
+
"""Channel-wise self-attention block. Modified from DDPM."""
|
| 97 |
+
|
| 98 |
+
def __init__(self, channels, skip_rescale=False, init_scale=0.):
|
| 99 |
+
super().__init__()
|
| 100 |
+
self.GroupNorm_0 = nn.GroupNorm(num_groups=min(channels // 4, 32), num_channels=channels,
|
| 101 |
+
eps=1e-6)
|
| 102 |
+
self.NIN_0 = NIN(channels, channels)
|
| 103 |
+
self.NIN_1 = NIN(channels, channels)
|
| 104 |
+
self.NIN_2 = NIN(channels, channels)
|
| 105 |
+
self.NIN_3 = NIN(channels, channels, init_scale=init_scale)
|
| 106 |
+
self.skip_rescale = skip_rescale
|
| 107 |
+
|
| 108 |
+
def forward(self, x):
|
| 109 |
+
B, C, H, W = x.shape
|
| 110 |
+
h = self.GroupNorm_0(x)
|
| 111 |
+
q = self.NIN_0(h)
|
| 112 |
+
k = self.NIN_1(h)
|
| 113 |
+
v = self.NIN_2(h)
|
| 114 |
+
|
| 115 |
+
w = torch.einsum('bchw,bcij->bhwij', q, k) * (int(C) ** (-0.5))
|
| 116 |
+
w = torch.reshape(w, (B, H, W, H * W))
|
| 117 |
+
w = F.softmax(w, dim=-1)
|
| 118 |
+
w = torch.reshape(w, (B, H, W, H, W))
|
| 119 |
+
h = torch.einsum('bhwij,bcij->bchw', w, v)
|
| 120 |
+
h = self.NIN_3(h)
|
| 121 |
+
if not self.skip_rescale:
|
| 122 |
+
return x + h
|
| 123 |
+
else:
|
| 124 |
+
return (x + h) / np.sqrt(2.)
|
| 125 |
+
|
| 126 |
+
|
| 127 |
+
class Upsample(nn.Module):
|
| 128 |
+
def __init__(self, in_ch=None, out_ch=None, with_conv=False, fir=False,
|
| 129 |
+
fir_kernel=(1, 3, 3, 1)):
|
| 130 |
+
super().__init__()
|
| 131 |
+
out_ch = out_ch if out_ch else in_ch
|
| 132 |
+
if not fir:
|
| 133 |
+
if with_conv:
|
| 134 |
+
self.Conv_0 = conv3x3(in_ch, out_ch)
|
| 135 |
+
else:
|
| 136 |
+
if with_conv:
|
| 137 |
+
self.Conv2d_0 = up_or_down_sampling.Conv2d(in_ch, out_ch,
|
| 138 |
+
kernel=3, up=True,
|
| 139 |
+
resample_kernel=fir_kernel,
|
| 140 |
+
use_bias=True,
|
| 141 |
+
kernel_init=default_init())
|
| 142 |
+
self.fir = fir
|
| 143 |
+
self.with_conv = with_conv
|
| 144 |
+
self.fir_kernel = fir_kernel
|
| 145 |
+
self.out_ch = out_ch
|
| 146 |
+
|
| 147 |
+
def forward(self, x):
|
| 148 |
+
B, C, H, W = x.shape
|
| 149 |
+
if not self.fir:
|
| 150 |
+
h = F.interpolate(x, (H * 2, W * 2), 'nearest')
|
| 151 |
+
if self.with_conv:
|
| 152 |
+
h = self.Conv_0(h)
|
| 153 |
+
else:
|
| 154 |
+
if not self.with_conv:
|
| 155 |
+
h = up_or_down_sampling.upsample_2d(x, self.fir_kernel, factor=2)
|
| 156 |
+
else:
|
| 157 |
+
h = self.Conv2d_0(x)
|
| 158 |
+
|
| 159 |
+
return h
|
| 160 |
+
|
| 161 |
+
|
| 162 |
+
class Downsample(nn.Module):
|
| 163 |
+
def __init__(self, in_ch=None, out_ch=None, with_conv=False, fir=False,
|
| 164 |
+
fir_kernel=(1, 3, 3, 1)):
|
| 165 |
+
super().__init__()
|
| 166 |
+
out_ch = out_ch if out_ch else in_ch
|
| 167 |
+
if not fir:
|
| 168 |
+
if with_conv:
|
| 169 |
+
self.Conv_0 = conv3x3(in_ch, out_ch, stride=2, padding=0)
|
| 170 |
+
else:
|
| 171 |
+
if with_conv:
|
| 172 |
+
self.Conv2d_0 = up_or_down_sampling.Conv2d(in_ch, out_ch,
|
| 173 |
+
kernel=3, down=True,
|
| 174 |
+
resample_kernel=fir_kernel,
|
| 175 |
+
use_bias=True,
|
| 176 |
+
kernel_init=default_init())
|
| 177 |
+
self.fir = fir
|
| 178 |
+
self.fir_kernel = fir_kernel
|
| 179 |
+
self.with_conv = with_conv
|
| 180 |
+
self.out_ch = out_ch
|
| 181 |
+
|
| 182 |
+
def forward(self, x):
|
| 183 |
+
B, C, H, W = x.shape
|
| 184 |
+
if not self.fir:
|
| 185 |
+
if self.with_conv:
|
| 186 |
+
x = F.pad(x, (0, 1, 0, 1))
|
| 187 |
+
x = self.Conv_0(x)
|
| 188 |
+
else:
|
| 189 |
+
x = F.avg_pool2d(x, 2, stride=2)
|
| 190 |
+
else:
|
| 191 |
+
if not self.with_conv:
|
| 192 |
+
x = up_or_down_sampling.downsample_2d(x, self.fir_kernel, factor=2)
|
| 193 |
+
else:
|
| 194 |
+
x = self.Conv2d_0(x)
|
| 195 |
+
|
| 196 |
+
return x
|
| 197 |
+
|
| 198 |
+
|
| 199 |
+
class ResnetBlockDDPMpp_Adagn(nn.Module):
|
| 200 |
+
"""ResBlock adapted from DDPM."""
|
| 201 |
+
|
| 202 |
+
def __init__(self, act, in_ch, out_ch=None, temb_dim=None, zemb_dim=None, conv_shortcut=False,
|
| 203 |
+
dropout=0.1, skip_rescale=False, init_scale=0.):
|
| 204 |
+
super().__init__()
|
| 205 |
+
out_ch = out_ch if out_ch else in_ch
|
| 206 |
+
self.GroupNorm_0 = AdaptiveGroupNorm(min(in_ch // 4, 32), in_ch, zemb_dim)
|
| 207 |
+
self.Conv_0 = conv3x3(in_ch, out_ch)
|
| 208 |
+
if temb_dim is not None:
|
| 209 |
+
self.Dense_0 = nn.Linear(temb_dim, out_ch)
|
| 210 |
+
self.Dense_0.weight.data = default_init()(self.Dense_0.weight.data.shape)
|
| 211 |
+
nn.init.zeros_(self.Dense_0.bias)
|
| 212 |
+
|
| 213 |
+
|
| 214 |
+
self.GroupNorm_1 = AdaptiveGroupNorm(min(out_ch // 4, 32), out_ch, zemb_dim)
|
| 215 |
+
self.Dropout_0 = nn.Dropout(dropout)
|
| 216 |
+
self.Conv_1 = conv3x3(out_ch, out_ch, init_scale=init_scale)
|
| 217 |
+
if in_ch != out_ch:
|
| 218 |
+
if conv_shortcut:
|
| 219 |
+
self.Conv_2 = conv3x3(in_ch, out_ch)
|
| 220 |
+
else:
|
| 221 |
+
self.NIN_0 = NIN(in_ch, out_ch)
|
| 222 |
+
|
| 223 |
+
self.skip_rescale = skip_rescale
|
| 224 |
+
self.act = act
|
| 225 |
+
self.out_ch = out_ch
|
| 226 |
+
self.conv_shortcut = conv_shortcut
|
| 227 |
+
|
| 228 |
+
def forward(self, x, temb=None, zemb=None):
|
| 229 |
+
h = self.act(self.GroupNorm_0(x, zemb))
|
| 230 |
+
h = self.Conv_0(h)
|
| 231 |
+
if temb is not None:
|
| 232 |
+
h += self.Dense_0(self.act(temb))[:, :, None, None]
|
| 233 |
+
h = self.act(self.GroupNorm_1(h, zemb))
|
| 234 |
+
h = self.Dropout_0(h)
|
| 235 |
+
h = self.Conv_1(h)
|
| 236 |
+
if x.shape[1] != self.out_ch:
|
| 237 |
+
if self.conv_shortcut:
|
| 238 |
+
x = self.Conv_2(x)
|
| 239 |
+
else:
|
| 240 |
+
x = self.NIN_0(x)
|
| 241 |
+
if not self.skip_rescale:
|
| 242 |
+
return x + h
|
| 243 |
+
else:
|
| 244 |
+
return (x + h) / np.sqrt(2.)
|
| 245 |
+
|
| 246 |
+
|
| 247 |
+
class ResnetBlockBigGANpp_Adagn(nn.Module):
|
| 248 |
+
def __init__(self, act, in_ch, out_ch=None, temb_dim=None, zemb_dim=None, up=False, down=False,
|
| 249 |
+
dropout=0.1, fir=False, fir_kernel=(1, 3, 3, 1),
|
| 250 |
+
skip_rescale=True, init_scale=0.):
|
| 251 |
+
super().__init__()
|
| 252 |
+
|
| 253 |
+
out_ch = out_ch if out_ch else in_ch
|
| 254 |
+
self.GroupNorm_0 = AdaptiveGroupNorm(min(in_ch // 4, 32), in_ch, zemb_dim)
|
| 255 |
+
|
| 256 |
+
self.up = up
|
| 257 |
+
self.down = down
|
| 258 |
+
self.fir = fir
|
| 259 |
+
self.fir_kernel = fir_kernel
|
| 260 |
+
|
| 261 |
+
self.Conv_0 = conv3x3(in_ch, out_ch)
|
| 262 |
+
if temb_dim is not None:
|
| 263 |
+
self.Dense_0 = nn.Linear(temb_dim, out_ch)
|
| 264 |
+
self.Dense_0.weight.data = default_init()(self.Dense_0.weight.shape)
|
| 265 |
+
nn.init.zeros_(self.Dense_0.bias)
|
| 266 |
+
|
| 267 |
+
self.GroupNorm_1 = AdaptiveGroupNorm(min(out_ch // 4, 32), out_ch, zemb_dim)
|
| 268 |
+
self.Dropout_0 = nn.Dropout(dropout)
|
| 269 |
+
self.Conv_1 = conv3x3(out_ch, out_ch, init_scale=init_scale)
|
| 270 |
+
if in_ch != out_ch or up or down:
|
| 271 |
+
self.Conv_2 = conv1x1(in_ch, out_ch)
|
| 272 |
+
|
| 273 |
+
self.skip_rescale = skip_rescale
|
| 274 |
+
self.act = act
|
| 275 |
+
self.in_ch = in_ch
|
| 276 |
+
self.out_ch = out_ch
|
| 277 |
+
|
| 278 |
+
def forward(self, x, temb=None, zemb=None):
|
| 279 |
+
h = self.act(self.GroupNorm_0(x, zemb))
|
| 280 |
+
|
| 281 |
+
if self.up:
|
| 282 |
+
if self.fir:
|
| 283 |
+
h = up_or_down_sampling.upsample_2d(h, self.fir_kernel, factor=2)
|
| 284 |
+
x = up_or_down_sampling.upsample_2d(x, self.fir_kernel, factor=2)
|
| 285 |
+
else:
|
| 286 |
+
h = up_or_down_sampling.naive_upsample_2d(h, factor=2)
|
| 287 |
+
x = up_or_down_sampling.naive_upsample_2d(x, factor=2)
|
| 288 |
+
elif self.down:
|
| 289 |
+
if self.fir:
|
| 290 |
+
h = up_or_down_sampling.downsample_2d(h, self.fir_kernel, factor=2)
|
| 291 |
+
x = up_or_down_sampling.downsample_2d(x, self.fir_kernel, factor=2)
|
| 292 |
+
else:
|
| 293 |
+
h = up_or_down_sampling.naive_downsample_2d(h, factor=2)
|
| 294 |
+
x = up_or_down_sampling.naive_downsample_2d(x, factor=2)
|
| 295 |
+
|
| 296 |
+
h = self.Conv_0(h)
|
| 297 |
+
# Add bias to each feature map conditioned on the time embedding
|
| 298 |
+
if temb is not None:
|
| 299 |
+
h += self.Dense_0(self.act(temb))[:, :, None, None]
|
| 300 |
+
h = self.act(self.GroupNorm_1(h, zemb))
|
| 301 |
+
h = self.Dropout_0(h)
|
| 302 |
+
h = self.Conv_1(h)
|
| 303 |
+
|
| 304 |
+
if self.in_ch != self.out_ch or self.up or self.down:
|
| 305 |
+
x = self.Conv_2(x)
|
| 306 |
+
|
| 307 |
+
if not self.skip_rescale:
|
| 308 |
+
return x + h
|
| 309 |
+
else:
|
| 310 |
+
return (x + h) / np.sqrt(2.)
|
| 311 |
+
|
| 312 |
+
|
| 313 |
+
class ResnetBlockBigGANpp_Adagn_one(nn.Module):
|
| 314 |
+
def __init__(self, act, in_ch, out_ch=None, temb_dim=None, zemb_dim=None, up=False, down=False,
|
| 315 |
+
dropout=0.1, fir=False, fir_kernel=(1, 3, 3, 1),
|
| 316 |
+
skip_rescale=True, init_scale=0.):
|
| 317 |
+
super().__init__()
|
| 318 |
+
|
| 319 |
+
out_ch = out_ch if out_ch else in_ch
|
| 320 |
+
self.GroupNorm_0 = AdaptiveGroupNorm(min(in_ch // 4, 32), in_ch, zemb_dim)
|
| 321 |
+
|
| 322 |
+
self.up = up
|
| 323 |
+
self.down = down
|
| 324 |
+
self.fir = fir
|
| 325 |
+
self.fir_kernel = fir_kernel
|
| 326 |
+
|
| 327 |
+
self.Conv_0 = conv3x3(in_ch, out_ch)
|
| 328 |
+
if temb_dim is not None:
|
| 329 |
+
self.Dense_0 = nn.Linear(temb_dim, out_ch)
|
| 330 |
+
self.Dense_0.weight.data = default_init()(self.Dense_0.weight.shape)
|
| 331 |
+
nn.init.zeros_(self.Dense_0.bias)
|
| 332 |
+
|
| 333 |
+
|
| 334 |
+
self.GroupNorm_1 = nn.GroupNorm(num_groups=min(out_ch // 4, 32), num_channels=out_ch, eps=1e-6)
|
| 335 |
+
|
| 336 |
+
self.Dropout_0 = nn.Dropout(dropout)
|
| 337 |
+
self.Conv_1 = conv3x3(out_ch, out_ch, init_scale=init_scale)
|
| 338 |
+
if in_ch != out_ch or up or down:
|
| 339 |
+
self.Conv_2 = conv1x1(in_ch, out_ch)
|
| 340 |
+
|
| 341 |
+
self.skip_rescale = skip_rescale
|
| 342 |
+
self.act = act
|
| 343 |
+
self.in_ch = in_ch
|
| 344 |
+
self.out_ch = out_ch
|
| 345 |
+
|
| 346 |
+
def forward(self, x, temb=None, zemb=None):
|
| 347 |
+
h = self.act(self.GroupNorm_0(x, zemb))
|
| 348 |
+
|
| 349 |
+
if self.up:
|
| 350 |
+
if self.fir:
|
| 351 |
+
h = up_or_down_sampling.upsample_2d(h, self.fir_kernel, factor=2)
|
| 352 |
+
x = up_or_down_sampling.upsample_2d(x, self.fir_kernel, factor=2)
|
| 353 |
+
else:
|
| 354 |
+
h = up_or_down_sampling.naive_upsample_2d(h, factor=2)
|
| 355 |
+
x = up_or_down_sampling.naive_upsample_2d(x, factor=2)
|
| 356 |
+
elif self.down:
|
| 357 |
+
if self.fir:
|
| 358 |
+
h = up_or_down_sampling.downsample_2d(h, self.fir_kernel, factor=2)
|
| 359 |
+
x = up_or_down_sampling.downsample_2d(x, self.fir_kernel, factor=2)
|
| 360 |
+
else:
|
| 361 |
+
h = up_or_down_sampling.naive_downsample_2d(h, factor=2)
|
| 362 |
+
x = up_or_down_sampling.naive_downsample_2d(x, factor=2)
|
| 363 |
+
|
| 364 |
+
h = self.Conv_0(h)
|
| 365 |
+
# Add bias to each feature map conditioned on the time embedding
|
| 366 |
+
if temb is not None:
|
| 367 |
+
h += self.Dense_0(self.act(temb))[:, :, None, None]
|
| 368 |
+
h = self.act(self.GroupNorm_1(h))
|
| 369 |
+
h = self.Dropout_0(h)
|
| 370 |
+
h = self.Conv_1(h)
|
| 371 |
+
|
| 372 |
+
|
| 373 |
+
if self.in_ch != self.out_ch or self.up or self.down:
|
| 374 |
+
x = self.Conv_2(x)
|
| 375 |
+
|
| 376 |
+
if not self.skip_rescale:
|
| 377 |
+
return x + h
|
| 378 |
+
else:
|
| 379 |
+
return (x + h) / np.sqrt(2.)
|
| 380 |
+
|
score_sde/models/ncsnpp_generator_adagn.py
ADDED
|
@@ -0,0 +1,431 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# ---------------------------------------------------------------
|
| 2 |
+
# Copyright (c) 2022, NVIDIA CORPORATION. All rights reserved.
|
| 3 |
+
#
|
| 4 |
+
# This file has been modified from a file in the Score SDE library
|
| 5 |
+
# which was released under the Apache License.
|
| 6 |
+
#
|
| 7 |
+
# Source:
|
| 8 |
+
# https://github.com/yang-song/score_sde_pytorch/blob/main/models/layerspp.py
|
| 9 |
+
#
|
| 10 |
+
# The license for the original version of this file can be
|
| 11 |
+
# found in this directory (LICENSE_Apache). The modifications
|
| 12 |
+
# to this file are subject to the same Apache License.
|
| 13 |
+
# ---------------------------------------------------------------
|
| 14 |
+
|
| 15 |
+
# coding=utf-8
|
| 16 |
+
# Copyright 2020 The Google Research Authors.
|
| 17 |
+
#
|
| 18 |
+
# Licensed under the Apache License, Version 2.0 (the "License");
|
| 19 |
+
# you may not use this file except in compliance with the License.
|
| 20 |
+
# You may obtain a copy of the License at
|
| 21 |
+
#
|
| 22 |
+
# http://www.apache.org/licenses/LICENSE-2.0
|
| 23 |
+
#
|
| 24 |
+
# Unless required by applicable law or agreed to in writing, software
|
| 25 |
+
# distributed under the License is distributed on an "AS IS" BASIS,
|
| 26 |
+
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
| 27 |
+
# See the License for the specific language governing permissions and
|
| 28 |
+
# limitations under the License.
|
| 29 |
+
|
| 30 |
+
# pylint: skip-file
|
| 31 |
+
''' Codes adapted from https://github.com/yang-song/score_sde_pytorch/blob/main/models/ncsnpp.py
|
| 32 |
+
'''
|
| 33 |
+
|
| 34 |
+
from . import utils, layers, layerspp, dense_layer
|
| 35 |
+
import torch.nn as nn
|
| 36 |
+
import functools
|
| 37 |
+
import torch
|
| 38 |
+
import numpy as np
|
| 39 |
+
|
| 40 |
+
|
| 41 |
+
ResnetBlockDDPM = layerspp.ResnetBlockDDPMpp_Adagn
|
| 42 |
+
ResnetBlockBigGAN = layerspp.ResnetBlockBigGANpp_Adagn
|
| 43 |
+
ResnetBlockBigGAN_one = layerspp.ResnetBlockBigGANpp_Adagn_one
|
| 44 |
+
Combine = layerspp.Combine
|
| 45 |
+
conv3x3 = layerspp.conv3x3
|
| 46 |
+
conv1x1 = layerspp.conv1x1
|
| 47 |
+
get_act = layers.get_act
|
| 48 |
+
default_initializer = layers.default_init
|
| 49 |
+
dense = dense_layer.dense
|
| 50 |
+
|
| 51 |
+
class PixelNorm(nn.Module):
|
| 52 |
+
def __init__(self):
|
| 53 |
+
super().__init__()
|
| 54 |
+
|
| 55 |
+
def forward(self, input):
|
| 56 |
+
return input / torch.sqrt(torch.mean(input ** 2, dim=1, keepdim=True) + 1e-8)
|
| 57 |
+
|
| 58 |
+
|
| 59 |
+
@utils.register_model(name='ncsnpp')
|
| 60 |
+
class NCSNpp(nn.Module):
|
| 61 |
+
"""NCSN++ model"""
|
| 62 |
+
|
| 63 |
+
def __init__(self, config):
|
| 64 |
+
super().__init__()
|
| 65 |
+
self.config = config
|
| 66 |
+
self.not_use_tanh = config.not_use_tanh
|
| 67 |
+
self.act = act = nn.SiLU()
|
| 68 |
+
self.z_emb_dim = z_emb_dim = config.z_emb_dim
|
| 69 |
+
|
| 70 |
+
self.nf = nf = config.num_channels_dae
|
| 71 |
+
ch_mult = config.ch_mult
|
| 72 |
+
self.num_res_blocks = num_res_blocks = config.num_res_blocks
|
| 73 |
+
self.attn_resolutions = attn_resolutions = config.attn_resolutions
|
| 74 |
+
dropout = config.dropout
|
| 75 |
+
resamp_with_conv = config.resamp_with_conv
|
| 76 |
+
self.num_resolutions = num_resolutions = len(ch_mult)
|
| 77 |
+
self.all_resolutions = all_resolutions = [config.image_size // (2 ** i) for i in range(num_resolutions)]
|
| 78 |
+
|
| 79 |
+
self.conditional = conditional = config.conditional # noise-conditional
|
| 80 |
+
fir = config.fir
|
| 81 |
+
fir_kernel = config.fir_kernel
|
| 82 |
+
self.skip_rescale = skip_rescale = config.skip_rescale
|
| 83 |
+
self.resblock_type = resblock_type = config.resblock_type.lower()
|
| 84 |
+
self.progressive = progressive = config.progressive.lower()
|
| 85 |
+
self.progressive_input = progressive_input = config.progressive_input.lower()
|
| 86 |
+
self.embedding_type = embedding_type = config.embedding_type.lower()
|
| 87 |
+
init_scale = 0.
|
| 88 |
+
assert progressive in ['none', 'output_skip', 'residual']
|
| 89 |
+
assert progressive_input in ['none', 'input_skip', 'residual']
|
| 90 |
+
assert embedding_type in ['fourier', 'positional']
|
| 91 |
+
combine_method = config.progressive_combine.lower()
|
| 92 |
+
combiner = functools.partial(Combine, method=combine_method)
|
| 93 |
+
|
| 94 |
+
modules = []
|
| 95 |
+
# timestep/noise_level embedding; only for continuous training
|
| 96 |
+
if embedding_type == 'fourier':
|
| 97 |
+
# Gaussian Fourier features embeddings.
|
| 98 |
+
#assert config.training.continuous, "Fourier features are only used for continuous training."
|
| 99 |
+
|
| 100 |
+
modules.append(layerspp.GaussianFourierProjection(
|
| 101 |
+
embedding_size=nf, scale=config.fourier_scale
|
| 102 |
+
))
|
| 103 |
+
embed_dim = 2 * nf
|
| 104 |
+
|
| 105 |
+
elif embedding_type == 'positional':
|
| 106 |
+
embed_dim = nf
|
| 107 |
+
|
| 108 |
+
else:
|
| 109 |
+
raise ValueError(f'embedding type {embedding_type} unknown.')
|
| 110 |
+
|
| 111 |
+
if conditional:
|
| 112 |
+
modules.append(nn.Linear(embed_dim, nf * 4))
|
| 113 |
+
modules[-1].weight.data = default_initializer()(modules[-1].weight.shape)
|
| 114 |
+
nn.init.zeros_(modules[-1].bias)
|
| 115 |
+
modules.append(nn.Linear(nf * 4, nf * 4))
|
| 116 |
+
modules[-1].weight.data = default_initializer()(modules[-1].weight.shape)
|
| 117 |
+
nn.init.zeros_(modules[-1].bias)
|
| 118 |
+
|
| 119 |
+
AttnBlock = functools.partial(layerspp.AttnBlockpp,
|
| 120 |
+
init_scale=init_scale,
|
| 121 |
+
skip_rescale=skip_rescale)
|
| 122 |
+
|
| 123 |
+
Upsample = functools.partial(layerspp.Upsample,
|
| 124 |
+
with_conv=resamp_with_conv, fir=fir, fir_kernel=fir_kernel)
|
| 125 |
+
|
| 126 |
+
if progressive == 'output_skip':
|
| 127 |
+
self.pyramid_upsample = layerspp.Upsample(fir=fir, fir_kernel=fir_kernel, with_conv=False)
|
| 128 |
+
elif progressive == 'residual':
|
| 129 |
+
pyramid_upsample = functools.partial(layerspp.Upsample,
|
| 130 |
+
fir=fir, fir_kernel=fir_kernel, with_conv=True)
|
| 131 |
+
|
| 132 |
+
Downsample = functools.partial(layerspp.Downsample,
|
| 133 |
+
with_conv=resamp_with_conv, fir=fir, fir_kernel=fir_kernel)
|
| 134 |
+
|
| 135 |
+
if progressive_input == 'input_skip':
|
| 136 |
+
self.pyramid_downsample = layerspp.Downsample(fir=fir, fir_kernel=fir_kernel, with_conv=False)
|
| 137 |
+
elif progressive_input == 'residual':
|
| 138 |
+
pyramid_downsample = functools.partial(layerspp.Downsample,
|
| 139 |
+
fir=fir, fir_kernel=fir_kernel, with_conv=True)
|
| 140 |
+
|
| 141 |
+
if resblock_type == 'ddpm':
|
| 142 |
+
ResnetBlock = functools.partial(ResnetBlockDDPM,
|
| 143 |
+
act=act,
|
| 144 |
+
dropout=dropout,
|
| 145 |
+
init_scale=init_scale,
|
| 146 |
+
skip_rescale=skip_rescale,
|
| 147 |
+
temb_dim=nf * 4,
|
| 148 |
+
zemb_dim = z_emb_dim)
|
| 149 |
+
|
| 150 |
+
elif resblock_type == 'biggan':
|
| 151 |
+
ResnetBlock = functools.partial(ResnetBlockBigGAN,
|
| 152 |
+
act=act,
|
| 153 |
+
dropout=dropout,
|
| 154 |
+
fir=fir,
|
| 155 |
+
fir_kernel=fir_kernel,
|
| 156 |
+
init_scale=init_scale,
|
| 157 |
+
skip_rescale=skip_rescale,
|
| 158 |
+
temb_dim=nf * 4,
|
| 159 |
+
zemb_dim = z_emb_dim)
|
| 160 |
+
elif resblock_type == 'biggan_oneadagn':
|
| 161 |
+
ResnetBlock = functools.partial(ResnetBlockBigGAN_one,
|
| 162 |
+
act=act,
|
| 163 |
+
dropout=dropout,
|
| 164 |
+
fir=fir,
|
| 165 |
+
fir_kernel=fir_kernel,
|
| 166 |
+
init_scale=init_scale,
|
| 167 |
+
skip_rescale=skip_rescale,
|
| 168 |
+
temb_dim=nf * 4,
|
| 169 |
+
zemb_dim = z_emb_dim)
|
| 170 |
+
|
| 171 |
+
else:
|
| 172 |
+
raise ValueError(f'resblock type {resblock_type} unrecognized.')
|
| 173 |
+
|
| 174 |
+
# Downsampling block
|
| 175 |
+
|
| 176 |
+
channels = config.num_channels
|
| 177 |
+
if progressive_input != 'none':
|
| 178 |
+
input_pyramid_ch = channels
|
| 179 |
+
|
| 180 |
+
modules.append(conv3x3(channels, nf))
|
| 181 |
+
hs_c = [nf]
|
| 182 |
+
|
| 183 |
+
in_ch = nf
|
| 184 |
+
for i_level in range(num_resolutions):
|
| 185 |
+
# Residual blocks for this resolution
|
| 186 |
+
for i_block in range(num_res_blocks):
|
| 187 |
+
out_ch = nf * ch_mult[i_level]
|
| 188 |
+
modules.append(ResnetBlock(in_ch=in_ch, out_ch=out_ch))
|
| 189 |
+
in_ch = out_ch
|
| 190 |
+
|
| 191 |
+
if all_resolutions[i_level] in attn_resolutions:
|
| 192 |
+
modules.append(AttnBlock(channels=in_ch))
|
| 193 |
+
hs_c.append(in_ch)
|
| 194 |
+
|
| 195 |
+
if i_level != num_resolutions - 1:
|
| 196 |
+
if resblock_type == 'ddpm':
|
| 197 |
+
modules.append(Downsample(in_ch=in_ch))
|
| 198 |
+
else:
|
| 199 |
+
modules.append(ResnetBlock(down=True, in_ch=in_ch))
|
| 200 |
+
|
| 201 |
+
if progressive_input == 'input_skip':
|
| 202 |
+
modules.append(combiner(dim1=input_pyramid_ch, dim2=in_ch))
|
| 203 |
+
if combine_method == 'cat':
|
| 204 |
+
in_ch *= 2
|
| 205 |
+
|
| 206 |
+
elif progressive_input == 'residual':
|
| 207 |
+
modules.append(pyramid_downsample(in_ch=input_pyramid_ch, out_ch=in_ch))
|
| 208 |
+
input_pyramid_ch = in_ch
|
| 209 |
+
|
| 210 |
+
hs_c.append(in_ch)
|
| 211 |
+
|
| 212 |
+
in_ch = hs_c[-1]
|
| 213 |
+
modules.append(ResnetBlock(in_ch=in_ch))
|
| 214 |
+
modules.append(AttnBlock(channels=in_ch))
|
| 215 |
+
modules.append(ResnetBlock(in_ch=in_ch))
|
| 216 |
+
|
| 217 |
+
pyramid_ch = 0
|
| 218 |
+
# Upsampling block
|
| 219 |
+
for i_level in reversed(range(num_resolutions)):
|
| 220 |
+
for i_block in range(num_res_blocks + 1):
|
| 221 |
+
out_ch = nf * ch_mult[i_level]
|
| 222 |
+
modules.append(ResnetBlock(in_ch=in_ch + hs_c.pop(),
|
| 223 |
+
out_ch=out_ch))
|
| 224 |
+
in_ch = out_ch
|
| 225 |
+
|
| 226 |
+
if all_resolutions[i_level] in attn_resolutions:
|
| 227 |
+
modules.append(AttnBlock(channels=in_ch))
|
| 228 |
+
|
| 229 |
+
if progressive != 'none':
|
| 230 |
+
if i_level == num_resolutions - 1:
|
| 231 |
+
if progressive == 'output_skip':
|
| 232 |
+
modules.append(nn.GroupNorm(num_groups=min(in_ch // 4, 32),
|
| 233 |
+
num_channels=in_ch, eps=1e-6))
|
| 234 |
+
modules.append(conv3x3(in_ch, channels, init_scale=init_scale))
|
| 235 |
+
pyramid_ch = channels
|
| 236 |
+
elif progressive == 'residual':
|
| 237 |
+
modules.append(nn.GroupNorm(num_groups=min(in_ch // 4, 32),
|
| 238 |
+
num_channels=in_ch, eps=1e-6))
|
| 239 |
+
modules.append(conv3x3(in_ch, in_ch, bias=True))
|
| 240 |
+
pyramid_ch = in_ch
|
| 241 |
+
else:
|
| 242 |
+
raise ValueError(f'{progressive} is not a valid name.')
|
| 243 |
+
else:
|
| 244 |
+
if progressive == 'output_skip':
|
| 245 |
+
modules.append(nn.GroupNorm(num_groups=min(in_ch // 4, 32),
|
| 246 |
+
num_channels=in_ch, eps=1e-6))
|
| 247 |
+
modules.append(conv3x3(in_ch, channels, bias=True, init_scale=init_scale))
|
| 248 |
+
pyramid_ch = channels
|
| 249 |
+
elif progressive == 'residual':
|
| 250 |
+
modules.append(pyramid_upsample(in_ch=pyramid_ch, out_ch=in_ch))
|
| 251 |
+
pyramid_ch = in_ch
|
| 252 |
+
else:
|
| 253 |
+
raise ValueError(f'{progressive} is not a valid name')
|
| 254 |
+
|
| 255 |
+
if i_level != 0:
|
| 256 |
+
if resblock_type == 'ddpm':
|
| 257 |
+
modules.append(Upsample(in_ch=in_ch))
|
| 258 |
+
else:
|
| 259 |
+
modules.append(ResnetBlock(in_ch=in_ch, up=True))
|
| 260 |
+
|
| 261 |
+
assert not hs_c
|
| 262 |
+
|
| 263 |
+
if progressive != 'output_skip':
|
| 264 |
+
modules.append(nn.GroupNorm(num_groups=min(in_ch // 4, 32),
|
| 265 |
+
num_channels=in_ch, eps=1e-6))
|
| 266 |
+
modules.append(conv3x3(in_ch, channels, init_scale=init_scale))
|
| 267 |
+
|
| 268 |
+
self.all_modules = nn.ModuleList(modules)
|
| 269 |
+
|
| 270 |
+
|
| 271 |
+
mapping_layers = [PixelNorm(),
|
| 272 |
+
dense(config.nz, z_emb_dim),
|
| 273 |
+
self.act,]
|
| 274 |
+
for _ in range(config.n_mlp):
|
| 275 |
+
mapping_layers.append(dense(z_emb_dim, z_emb_dim))
|
| 276 |
+
mapping_layers.append(self.act)
|
| 277 |
+
self.z_transform = nn.Sequential(*mapping_layers)
|
| 278 |
+
|
| 279 |
+
|
| 280 |
+
def forward(self, x, time_cond, z):
|
| 281 |
+
# timestep/noise_level embedding; only for continuous training
|
| 282 |
+
zemb = self.z_transform(z)
|
| 283 |
+
modules = self.all_modules
|
| 284 |
+
m_idx = 0
|
| 285 |
+
if self.embedding_type == 'fourier':
|
| 286 |
+
# Gaussian Fourier features embeddings.
|
| 287 |
+
used_sigmas = time_cond
|
| 288 |
+
temb = modules[m_idx](torch.log(used_sigmas))
|
| 289 |
+
m_idx += 1
|
| 290 |
+
|
| 291 |
+
elif self.embedding_type == 'positional':
|
| 292 |
+
# Sinusoidal positional embeddings.
|
| 293 |
+
timesteps = time_cond
|
| 294 |
+
|
| 295 |
+
temb = layers.get_timestep_embedding(timesteps, self.nf)
|
| 296 |
+
|
| 297 |
+
else:
|
| 298 |
+
raise ValueError(f'embedding type {self.embedding_type} unknown.')
|
| 299 |
+
|
| 300 |
+
if self.conditional:
|
| 301 |
+
temb = modules[m_idx](temb)
|
| 302 |
+
m_idx += 1
|
| 303 |
+
temb = modules[m_idx](self.act(temb))
|
| 304 |
+
m_idx += 1
|
| 305 |
+
else:
|
| 306 |
+
temb = None
|
| 307 |
+
|
| 308 |
+
if not self.config.centered:
|
| 309 |
+
# If input data is in [0, 1]
|
| 310 |
+
x = 2 * x - 1.
|
| 311 |
+
|
| 312 |
+
# Downsampling block
|
| 313 |
+
input_pyramid = None
|
| 314 |
+
if self.progressive_input != 'none':
|
| 315 |
+
input_pyramid = x
|
| 316 |
+
|
| 317 |
+
hs = [modules[m_idx](x)]
|
| 318 |
+
m_idx += 1
|
| 319 |
+
for i_level in range(self.num_resolutions):
|
| 320 |
+
# Residual blocks for this resolution
|
| 321 |
+
for i_block in range(self.num_res_blocks):
|
| 322 |
+
h = modules[m_idx](hs[-1], temb, zemb)
|
| 323 |
+
m_idx += 1
|
| 324 |
+
if h.shape[-1] in self.attn_resolutions:
|
| 325 |
+
h = modules[m_idx](h)
|
| 326 |
+
m_idx += 1
|
| 327 |
+
|
| 328 |
+
hs.append(h)
|
| 329 |
+
|
| 330 |
+
if i_level != self.num_resolutions - 1:
|
| 331 |
+
if self.resblock_type == 'ddpm':
|
| 332 |
+
h = modules[m_idx](hs[-1])
|
| 333 |
+
m_idx += 1
|
| 334 |
+
else:
|
| 335 |
+
h = modules[m_idx](hs[-1], temb, zemb)
|
| 336 |
+
m_idx += 1
|
| 337 |
+
|
| 338 |
+
if self.progressive_input == 'input_skip':
|
| 339 |
+
input_pyramid = self.pyramid_downsample(input_pyramid)
|
| 340 |
+
h = modules[m_idx](input_pyramid, h)
|
| 341 |
+
m_idx += 1
|
| 342 |
+
|
| 343 |
+
elif self.progressive_input == 'residual':
|
| 344 |
+
input_pyramid = modules[m_idx](input_pyramid)
|
| 345 |
+
m_idx += 1
|
| 346 |
+
if self.skip_rescale:
|
| 347 |
+
input_pyramid = (input_pyramid + h) / np.sqrt(2.)
|
| 348 |
+
else:
|
| 349 |
+
input_pyramid = input_pyramid + h
|
| 350 |
+
h = input_pyramid
|
| 351 |
+
|
| 352 |
+
hs.append(h)
|
| 353 |
+
|
| 354 |
+
h = hs[-1]
|
| 355 |
+
h = modules[m_idx](h, temb, zemb)
|
| 356 |
+
m_idx += 1
|
| 357 |
+
h = modules[m_idx](h)
|
| 358 |
+
m_idx += 1
|
| 359 |
+
h = modules[m_idx](h, temb, zemb)
|
| 360 |
+
m_idx += 1
|
| 361 |
+
|
| 362 |
+
pyramid = None
|
| 363 |
+
|
| 364 |
+
# Upsampling block
|
| 365 |
+
for i_level in reversed(range(self.num_resolutions)):
|
| 366 |
+
for i_block in range(self.num_res_blocks + 1):
|
| 367 |
+
h = modules[m_idx](torch.cat([h, hs.pop()], dim=1), temb, zemb)
|
| 368 |
+
m_idx += 1
|
| 369 |
+
|
| 370 |
+
if h.shape[-1] in self.attn_resolutions:
|
| 371 |
+
h = modules[m_idx](h)
|
| 372 |
+
m_idx += 1
|
| 373 |
+
|
| 374 |
+
if self.progressive != 'none':
|
| 375 |
+
if i_level == self.num_resolutions - 1:
|
| 376 |
+
if self.progressive == 'output_skip':
|
| 377 |
+
pyramid = self.act(modules[m_idx](h))
|
| 378 |
+
m_idx += 1
|
| 379 |
+
pyramid = modules[m_idx](pyramid)
|
| 380 |
+
m_idx += 1
|
| 381 |
+
elif self.progressive == 'residual':
|
| 382 |
+
pyramid = self.act(modules[m_idx](h))
|
| 383 |
+
m_idx += 1
|
| 384 |
+
pyramid = modules[m_idx](pyramid)
|
| 385 |
+
m_idx += 1
|
| 386 |
+
else:
|
| 387 |
+
raise ValueError(f'{self.progressive} is not a valid name.')
|
| 388 |
+
else:
|
| 389 |
+
if self.progressive == 'output_skip':
|
| 390 |
+
pyramid = self.pyramid_upsample(pyramid)
|
| 391 |
+
pyramid_h = self.act(modules[m_idx](h))
|
| 392 |
+
m_idx += 1
|
| 393 |
+
pyramid_h = modules[m_idx](pyramid_h)
|
| 394 |
+
m_idx += 1
|
| 395 |
+
pyramid = pyramid + pyramid_h
|
| 396 |
+
elif self.progressive == 'residual':
|
| 397 |
+
pyramid = modules[m_idx](pyramid)
|
| 398 |
+
m_idx += 1
|
| 399 |
+
if self.skip_rescale:
|
| 400 |
+
pyramid = (pyramid + h) / np.sqrt(2.)
|
| 401 |
+
else:
|
| 402 |
+
pyramid = pyramid + h
|
| 403 |
+
h = pyramid
|
| 404 |
+
else:
|
| 405 |
+
raise ValueError(f'{self.progressive} is not a valid name')
|
| 406 |
+
|
| 407 |
+
if i_level != 0:
|
| 408 |
+
if self.resblock_type == 'ddpm':
|
| 409 |
+
h = modules[m_idx](h)
|
| 410 |
+
m_idx += 1
|
| 411 |
+
else:
|
| 412 |
+
h = modules[m_idx](h, temb, zemb)
|
| 413 |
+
m_idx += 1
|
| 414 |
+
|
| 415 |
+
assert not hs
|
| 416 |
+
|
| 417 |
+
if self.progressive == 'output_skip':
|
| 418 |
+
h = pyramid
|
| 419 |
+
else:
|
| 420 |
+
h = self.act(modules[m_idx](h))
|
| 421 |
+
m_idx += 1
|
| 422 |
+
h = modules[m_idx](h)
|
| 423 |
+
m_idx += 1
|
| 424 |
+
|
| 425 |
+
assert m_idx == len(modules)
|
| 426 |
+
|
| 427 |
+
if not self.not_use_tanh:
|
| 428 |
+
|
| 429 |
+
return torch.tanh(h)
|
| 430 |
+
else:
|
| 431 |
+
return h
|
score_sde/models/up_or_down_sampling.py
ADDED
|
@@ -0,0 +1,262 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# ---------------------------------------------------------------
|
| 2 |
+
# Copyright (c) 2022, NVIDIA CORPORATION. All rights reserved.
|
| 3 |
+
# ---------------------------------------------------------------
|
| 4 |
+
|
| 5 |
+
|
| 6 |
+
"""Layers used for up-sampling or down-sampling images.
|
| 7 |
+
|
| 8 |
+
Many functions are ported from https://github.com/NVlabs/stylegan2.
|
| 9 |
+
"""
|
| 10 |
+
|
| 11 |
+
import torch.nn as nn
|
| 12 |
+
import torch
|
| 13 |
+
import torch.nn.functional as F
|
| 14 |
+
import numpy as np
|
| 15 |
+
from score_sde.op import upfirdn2d
|
| 16 |
+
|
| 17 |
+
|
| 18 |
+
# Function ported from StyleGAN2
|
| 19 |
+
def get_weight(module,
|
| 20 |
+
shape,
|
| 21 |
+
weight_var='weight',
|
| 22 |
+
kernel_init=None):
|
| 23 |
+
"""Get/create weight tensor for a convolution or fully-connected layer."""
|
| 24 |
+
|
| 25 |
+
return module.param(weight_var, kernel_init, shape)
|
| 26 |
+
|
| 27 |
+
|
| 28 |
+
class Conv2d(nn.Module):
|
| 29 |
+
"""Conv2d layer with optimal upsampling and downsampling (StyleGAN2)."""
|
| 30 |
+
|
| 31 |
+
def __init__(self, in_ch, out_ch, kernel, up=False, down=False,
|
| 32 |
+
resample_kernel=(1, 3, 3, 1),
|
| 33 |
+
use_bias=True,
|
| 34 |
+
kernel_init=None):
|
| 35 |
+
super().__init__()
|
| 36 |
+
assert not (up and down)
|
| 37 |
+
assert kernel >= 1 and kernel % 2 == 1
|
| 38 |
+
self.weight = nn.Parameter(torch.zeros(out_ch, in_ch, kernel, kernel))
|
| 39 |
+
if kernel_init is not None:
|
| 40 |
+
self.weight.data = kernel_init(self.weight.data.shape)
|
| 41 |
+
if use_bias:
|
| 42 |
+
self.bias = nn.Parameter(torch.zeros(out_ch))
|
| 43 |
+
|
| 44 |
+
self.up = up
|
| 45 |
+
self.down = down
|
| 46 |
+
self.resample_kernel = resample_kernel
|
| 47 |
+
self.kernel = kernel
|
| 48 |
+
self.use_bias = use_bias
|
| 49 |
+
|
| 50 |
+
def forward(self, x):
|
| 51 |
+
if self.up:
|
| 52 |
+
x = upsample_conv_2d(x, self.weight, k=self.resample_kernel)
|
| 53 |
+
elif self.down:
|
| 54 |
+
x = conv_downsample_2d(x, self.weight, k=self.resample_kernel)
|
| 55 |
+
else:
|
| 56 |
+
x = F.conv2d(x, self.weight, stride=1, padding=self.kernel // 2)
|
| 57 |
+
|
| 58 |
+
if self.use_bias:
|
| 59 |
+
x = x + self.bias.reshape(1, -1, 1, 1)
|
| 60 |
+
|
| 61 |
+
return x
|
| 62 |
+
|
| 63 |
+
|
| 64 |
+
def naive_upsample_2d(x, factor=2):
|
| 65 |
+
_N, C, H, W = x.shape
|
| 66 |
+
x = torch.reshape(x, (-1, C, H, 1, W, 1))
|
| 67 |
+
x = x.repeat(1, 1, 1, factor, 1, factor)
|
| 68 |
+
return torch.reshape(x, (-1, C, H * factor, W * factor))
|
| 69 |
+
|
| 70 |
+
|
| 71 |
+
def naive_downsample_2d(x, factor=2):
|
| 72 |
+
_N, C, H, W = x.shape
|
| 73 |
+
x = torch.reshape(x, (-1, C, H // factor, factor, W // factor, factor))
|
| 74 |
+
return torch.mean(x, dim=(3, 5))
|
| 75 |
+
|
| 76 |
+
|
| 77 |
+
def upsample_conv_2d(x, w, k=None, factor=2, gain=1):
|
| 78 |
+
"""Fused `upsample_2d()` followed by `tf.nn.conv2d()`.
|
| 79 |
+
|
| 80 |
+
Padding is performed only once at the beginning, not between the
|
| 81 |
+
operations.
|
| 82 |
+
The fused op is considerably more efficient than performing the same
|
| 83 |
+
calculation
|
| 84 |
+
using standard TensorFlow ops. It supports gradients of arbitrary order.
|
| 85 |
+
Args:
|
| 86 |
+
x: Input tensor of the shape `[N, C, H, W]` or `[N, H, W,
|
| 87 |
+
C]`.
|
| 88 |
+
w: Weight tensor of the shape `[filterH, filterW, inChannels,
|
| 89 |
+
outChannels]`. Grouped convolution can be performed by `inChannels =
|
| 90 |
+
x.shape[0] // numGroups`.
|
| 91 |
+
k: FIR filter of the shape `[firH, firW]` or `[firN]`
|
| 92 |
+
(separable). The default is `[1] * factor`, which corresponds to
|
| 93 |
+
nearest-neighbor upsampling.
|
| 94 |
+
factor: Integer upsampling factor (default: 2).
|
| 95 |
+
gain: Scaling factor for signal magnitude (default: 1.0).
|
| 96 |
+
|
| 97 |
+
Returns:
|
| 98 |
+
Tensor of the shape `[N, C, H * factor, W * factor]` or
|
| 99 |
+
`[N, H * factor, W * factor, C]`, and same datatype as `x`.
|
| 100 |
+
"""
|
| 101 |
+
|
| 102 |
+
assert isinstance(factor, int) and factor >= 1
|
| 103 |
+
|
| 104 |
+
# Check weight shape.
|
| 105 |
+
assert len(w.shape) == 4
|
| 106 |
+
convH = w.shape[2]
|
| 107 |
+
convW = w.shape[3]
|
| 108 |
+
inC = w.shape[1]
|
| 109 |
+
outC = w.shape[0]
|
| 110 |
+
|
| 111 |
+
assert convW == convH
|
| 112 |
+
|
| 113 |
+
# Setup filter kernel.
|
| 114 |
+
if k is None:
|
| 115 |
+
k = [1] * factor
|
| 116 |
+
k = _setup_kernel(k) * (gain * (factor ** 2))
|
| 117 |
+
p = (k.shape[0] - factor) - (convW - 1)
|
| 118 |
+
|
| 119 |
+
stride = (factor, factor)
|
| 120 |
+
|
| 121 |
+
# Determine data dimensions.
|
| 122 |
+
stride = [1, 1, factor, factor]
|
| 123 |
+
output_shape = ((_shape(x, 2) - 1) * factor + convH, (_shape(x, 3) - 1) * factor + convW)
|
| 124 |
+
output_padding = (output_shape[0] - (_shape(x, 2) - 1) * stride[0] - convH,
|
| 125 |
+
output_shape[1] - (_shape(x, 3) - 1) * stride[1] - convW)
|
| 126 |
+
assert output_padding[0] >= 0 and output_padding[1] >= 0
|
| 127 |
+
num_groups = _shape(x, 1) // inC
|
| 128 |
+
|
| 129 |
+
# Transpose weights.
|
| 130 |
+
w = torch.reshape(w, (num_groups, -1, inC, convH, convW))
|
| 131 |
+
w = w[..., ::-1, ::-1].permute(0, 2, 1, 3, 4)
|
| 132 |
+
w = torch.reshape(w, (num_groups * inC, -1, convH, convW))
|
| 133 |
+
|
| 134 |
+
x = F.conv_transpose2d(x, w, stride=stride, output_padding=output_padding, padding=0)
|
| 135 |
+
## Original TF code.
|
| 136 |
+
# x = tf.nn.conv2d_transpose(
|
| 137 |
+
# x,
|
| 138 |
+
# w,
|
| 139 |
+
# output_shape=output_shape,
|
| 140 |
+
# strides=stride,
|
| 141 |
+
# padding='VALID',
|
| 142 |
+
# data_format=data_format)
|
| 143 |
+
## JAX equivalent
|
| 144 |
+
|
| 145 |
+
return upfirdn2d(x, torch.tensor(k, device=x.device),
|
| 146 |
+
pad=((p + 1) // 2 + factor - 1, p // 2 + 1))
|
| 147 |
+
|
| 148 |
+
|
| 149 |
+
def conv_downsample_2d(x, w, k=None, factor=2, gain=1):
|
| 150 |
+
"""Fused `tf.nn.conv2d()` followed by `downsample_2d()`.
|
| 151 |
+
|
| 152 |
+
Padding is performed only once at the beginning, not between the operations.
|
| 153 |
+
The fused op is considerably more efficient than performing the same
|
| 154 |
+
calculation
|
| 155 |
+
using standard TensorFlow ops. It supports gradients of arbitrary order.
|
| 156 |
+
Args:
|
| 157 |
+
x: Input tensor of the shape `[N, C, H, W]` or `[N, H, W,
|
| 158 |
+
C]`.
|
| 159 |
+
w: Weight tensor of the shape `[filterH, filterW, inChannels,
|
| 160 |
+
outChannels]`. Grouped convolution can be performed by `inChannels =
|
| 161 |
+
x.shape[0] // numGroups`.
|
| 162 |
+
k: FIR filter of the shape `[firH, firW]` or `[firN]`
|
| 163 |
+
(separable). The default is `[1] * factor`, which corresponds to
|
| 164 |
+
average pooling.
|
| 165 |
+
factor: Integer downsampling factor (default: 2).
|
| 166 |
+
gain: Scaling factor for signal magnitude (default: 1.0).
|
| 167 |
+
|
| 168 |
+
Returns:
|
| 169 |
+
Tensor of the shape `[N, C, H // factor, W // factor]` or
|
| 170 |
+
`[N, H // factor, W // factor, C]`, and same datatype as `x`.
|
| 171 |
+
"""
|
| 172 |
+
|
| 173 |
+
assert isinstance(factor, int) and factor >= 1
|
| 174 |
+
_outC, _inC, convH, convW = w.shape
|
| 175 |
+
assert convW == convH
|
| 176 |
+
if k is None:
|
| 177 |
+
k = [1] * factor
|
| 178 |
+
k = _setup_kernel(k) * gain
|
| 179 |
+
p = (k.shape[0] - factor) + (convW - 1)
|
| 180 |
+
s = [factor, factor]
|
| 181 |
+
x = upfirdn2d(x, torch.tensor(k, device=x.device),
|
| 182 |
+
pad=((p + 1) // 2, p // 2))
|
| 183 |
+
return F.conv2d(x, w, stride=s, padding=0)
|
| 184 |
+
|
| 185 |
+
|
| 186 |
+
def _setup_kernel(k):
|
| 187 |
+
k = np.asarray(k, dtype=np.float32)
|
| 188 |
+
if k.ndim == 1:
|
| 189 |
+
k = np.outer(k, k)
|
| 190 |
+
k /= np.sum(k)
|
| 191 |
+
assert k.ndim == 2
|
| 192 |
+
assert k.shape[0] == k.shape[1]
|
| 193 |
+
return k
|
| 194 |
+
|
| 195 |
+
|
| 196 |
+
def _shape(x, dim):
|
| 197 |
+
return x.shape[dim]
|
| 198 |
+
|
| 199 |
+
|
| 200 |
+
def upsample_2d(x, k=None, factor=2, gain=1):
|
| 201 |
+
r"""Upsample a batch of 2D images with the given filter.
|
| 202 |
+
|
| 203 |
+
Accepts a batch of 2D images of the shape `[N, C, H, W]` or `[N, H, W, C]`
|
| 204 |
+
and upsamples each image with the given filter. The filter is normalized so
|
| 205 |
+
that
|
| 206 |
+
if the input pixels are constant, they will be scaled by the specified
|
| 207 |
+
`gain`.
|
| 208 |
+
Pixels outside the image are assumed to be zero, and the filter is padded
|
| 209 |
+
with
|
| 210 |
+
zeros so that its shape is a multiple of the upsampling factor.
|
| 211 |
+
Args:
|
| 212 |
+
x: Input tensor of the shape `[N, C, H, W]` or `[N, H, W,
|
| 213 |
+
C]`.
|
| 214 |
+
k: FIR filter of the shape `[firH, firW]` or `[firN]`
|
| 215 |
+
(separable). The default is `[1] * factor`, which corresponds to
|
| 216 |
+
nearest-neighbor upsampling.
|
| 217 |
+
factor: Integer upsampling factor (default: 2).
|
| 218 |
+
gain: Scaling factor for signal magnitude (default: 1.0).
|
| 219 |
+
|
| 220 |
+
Returns:
|
| 221 |
+
Tensor of the shape `[N, C, H * factor, W * factor]`
|
| 222 |
+
"""
|
| 223 |
+
assert isinstance(factor, int) and factor >= 1
|
| 224 |
+
if k is None:
|
| 225 |
+
k = [1] * factor
|
| 226 |
+
k = _setup_kernel(k) * (gain * (factor ** 2))
|
| 227 |
+
p = k.shape[0] - factor
|
| 228 |
+
return upfirdn2d(x, torch.tensor(k, device=x.device),
|
| 229 |
+
up=factor, pad=((p + 1) // 2 + factor - 1, p // 2))
|
| 230 |
+
|
| 231 |
+
|
| 232 |
+
def downsample_2d(x, k=None, factor=2, gain=1):
|
| 233 |
+
r"""Downsample a batch of 2D images with the given filter.
|
| 234 |
+
|
| 235 |
+
Accepts a batch of 2D images of the shape `[N, C, H, W]` or `[N, H, W, C]`
|
| 236 |
+
and downsamples each image with the given filter. The filter is normalized
|
| 237 |
+
so that
|
| 238 |
+
if the input pixels are constant, they will be scaled by the specified
|
| 239 |
+
`gain`.
|
| 240 |
+
Pixels outside the image are assumed to be zero, and the filter is padded
|
| 241 |
+
with
|
| 242 |
+
zeros so that its shape is a multiple of the downsampling factor.
|
| 243 |
+
Args:
|
| 244 |
+
x: Input tensor of the shape `[N, C, H, W]` or `[N, H, W,
|
| 245 |
+
C]`.
|
| 246 |
+
k: FIR filter of the shape `[firH, firW]` or `[firN]`
|
| 247 |
+
(separable). The default is `[1] * factor`, which corresponds to
|
| 248 |
+
average pooling.
|
| 249 |
+
factor: Integer downsampling factor (default: 2).
|
| 250 |
+
gain: Scaling factor for signal magnitude (default: 1.0).
|
| 251 |
+
|
| 252 |
+
Returns:
|
| 253 |
+
Tensor of the shape `[N, C, H // factor, W // factor]`
|
| 254 |
+
"""
|
| 255 |
+
|
| 256 |
+
assert isinstance(factor, int) and factor >= 1
|
| 257 |
+
if k is None:
|
| 258 |
+
k = [1] * factor
|
| 259 |
+
k = _setup_kernel(k) * gain
|
| 260 |
+
p = k.shape[0] - factor
|
| 261 |
+
return upfirdn2d(x, torch.tensor(k, device=x.device),
|
| 262 |
+
down=factor, pad=((p + 1) // 2, p // 2))
|
score_sde/models/utils.py
ADDED
|
@@ -0,0 +1,148 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# ---------------------------------------------------------------
|
| 2 |
+
# Copyright (c) 2022, NVIDIA CORPORATION. All rights reserved.
|
| 3 |
+
#
|
| 4 |
+
# This file has been modified from a file in the Score SDE library
|
| 5 |
+
# which was released under the Apache License.
|
| 6 |
+
#
|
| 7 |
+
# Source:
|
| 8 |
+
# https://github.com/yang-song/score_sde_pytorch/blob/main/models/utils.py
|
| 9 |
+
#
|
| 10 |
+
# The license for the original version of this file can be
|
| 11 |
+
# found in this directory (LICENSE_Apache). The modifications
|
| 12 |
+
# to this file are subject to the same Apache License.
|
| 13 |
+
# ---------------------------------------------------------------
|
| 14 |
+
|
| 15 |
+
# coding=utf-8
|
| 16 |
+
# Copyright 2020 The Google Research Authors.
|
| 17 |
+
#
|
| 18 |
+
# Licensed under the Apache License, Version 2.0 (the "License");
|
| 19 |
+
# you may not use this file except in compliance with the License.
|
| 20 |
+
# You may obtain a copy of the License at
|
| 21 |
+
#
|
| 22 |
+
# http://www.apache.org/licenses/LICENSE-2.0
|
| 23 |
+
#
|
| 24 |
+
# Unless required by applicable law or agreed to in writing, software
|
| 25 |
+
# distributed under the License is distributed on an "AS IS" BASIS,
|
| 26 |
+
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
| 27 |
+
# See the License for the specific language governing permissions and
|
| 28 |
+
# limitations under the License.
|
| 29 |
+
|
| 30 |
+
import torch
|
| 31 |
+
import numpy as np
|
| 32 |
+
|
| 33 |
+
|
| 34 |
+
_MODELS = {}
|
| 35 |
+
|
| 36 |
+
|
| 37 |
+
def register_model(cls=None, *, name=None):
|
| 38 |
+
"""A decorator for registering model classes."""
|
| 39 |
+
|
| 40 |
+
def _register(cls):
|
| 41 |
+
if name is None:
|
| 42 |
+
local_name = cls.__name__
|
| 43 |
+
else:
|
| 44 |
+
local_name = name
|
| 45 |
+
if local_name in _MODELS:
|
| 46 |
+
raise ValueError(f'Already registered model with name: {local_name}')
|
| 47 |
+
_MODELS[local_name] = cls
|
| 48 |
+
return cls
|
| 49 |
+
|
| 50 |
+
if cls is None:
|
| 51 |
+
return _register
|
| 52 |
+
else:
|
| 53 |
+
return _register(cls)
|
| 54 |
+
|
| 55 |
+
|
| 56 |
+
def get_model(name):
|
| 57 |
+
return _MODELS[name]
|
| 58 |
+
|
| 59 |
+
|
| 60 |
+
def get_sigmas(config):
|
| 61 |
+
"""Get sigmas --- the set of noise levels for SMLD from config files.
|
| 62 |
+
Args:
|
| 63 |
+
config: A ConfigDict object parsed from the config file
|
| 64 |
+
Returns:
|
| 65 |
+
sigmas: a jax numpy arrary of noise levels
|
| 66 |
+
"""
|
| 67 |
+
sigmas = np.exp(
|
| 68 |
+
np.linspace(np.log(config.model.sigma_max), np.log(config.model.sigma_min), config.model.num_scales))
|
| 69 |
+
|
| 70 |
+
return sigmas
|
| 71 |
+
|
| 72 |
+
|
| 73 |
+
def get_ddpm_params(config):
|
| 74 |
+
"""Get betas and alphas --- parameters used in the original DDPM paper."""
|
| 75 |
+
num_diffusion_timesteps = 1000
|
| 76 |
+
# parameters need to be adapted if number of time steps differs from 1000
|
| 77 |
+
beta_start = config.model.beta_min / config.model.num_scales
|
| 78 |
+
beta_end = config.model.beta_max / config.model.num_scales
|
| 79 |
+
betas = np.linspace(beta_start, beta_end, num_diffusion_timesteps, dtype=np.float64)
|
| 80 |
+
|
| 81 |
+
alphas = 1. - betas
|
| 82 |
+
alphas_cumprod = np.cumprod(alphas, axis=0)
|
| 83 |
+
sqrt_alphas_cumprod = np.sqrt(alphas_cumprod)
|
| 84 |
+
sqrt_1m_alphas_cumprod = np.sqrt(1. - alphas_cumprod)
|
| 85 |
+
|
| 86 |
+
return {
|
| 87 |
+
'betas': betas,
|
| 88 |
+
'alphas': alphas,
|
| 89 |
+
'alphas_cumprod': alphas_cumprod,
|
| 90 |
+
'sqrt_alphas_cumprod': sqrt_alphas_cumprod,
|
| 91 |
+
'sqrt_1m_alphas_cumprod': sqrt_1m_alphas_cumprod,
|
| 92 |
+
'beta_min': beta_start * (num_diffusion_timesteps - 1),
|
| 93 |
+
'beta_max': beta_end * (num_diffusion_timesteps - 1),
|
| 94 |
+
'num_diffusion_timesteps': num_diffusion_timesteps
|
| 95 |
+
}
|
| 96 |
+
|
| 97 |
+
|
| 98 |
+
def create_model(config):
|
| 99 |
+
"""Create the score model."""
|
| 100 |
+
model_name = config.model.name
|
| 101 |
+
score_model = get_model(model_name)(config)
|
| 102 |
+
score_model = score_model.to(config.device)
|
| 103 |
+
score_model = torch.nn.DataParallel(score_model)
|
| 104 |
+
return score_model
|
| 105 |
+
|
| 106 |
+
|
| 107 |
+
def get_model_fn(model, train=False):
|
| 108 |
+
"""Create a function to give the output of the score-based model.
|
| 109 |
+
|
| 110 |
+
Args:
|
| 111 |
+
model: The score model.
|
| 112 |
+
train: `True` for training and `False` for evaluation.
|
| 113 |
+
|
| 114 |
+
Returns:
|
| 115 |
+
A model function.
|
| 116 |
+
"""
|
| 117 |
+
|
| 118 |
+
def model_fn(x, labels):
|
| 119 |
+
"""Compute the output of the score-based model.
|
| 120 |
+
|
| 121 |
+
Args:
|
| 122 |
+
x: A mini-batch of input data.
|
| 123 |
+
labels: A mini-batch of conditioning variables for time steps. Should be interpreted differently
|
| 124 |
+
for different models.
|
| 125 |
+
|
| 126 |
+
Returns:
|
| 127 |
+
A tuple of (model output, new mutable states)
|
| 128 |
+
"""
|
| 129 |
+
if not train:
|
| 130 |
+
model.eval()
|
| 131 |
+
return model(x, labels)
|
| 132 |
+
else:
|
| 133 |
+
model.train()
|
| 134 |
+
return model(x, labels)
|
| 135 |
+
|
| 136 |
+
return model_fn
|
| 137 |
+
|
| 138 |
+
|
| 139 |
+
|
| 140 |
+
|
| 141 |
+
def to_flattened_numpy(x):
|
| 142 |
+
"""Flatten a torch tensor `x` and convert it to numpy."""
|
| 143 |
+
return x.detach().cpu().numpy().reshape((-1,))
|
| 144 |
+
|
| 145 |
+
|
| 146 |
+
def from_flattened_numpy(x, shape):
|
| 147 |
+
"""Form a torch tensor with the given `shape` from a flattened numpy array `x`."""
|
| 148 |
+
return torch.from_numpy(x.reshape(shape))
|
score_sde/op/LICENSE_MIT
ADDED
|
@@ -0,0 +1,21 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
MIT License
|
| 2 |
+
|
| 3 |
+
Copyright (c) 2019 Kim Seonghyeon
|
| 4 |
+
|
| 5 |
+
Permission is hereby granted, free of charge, to any person obtaining a copy
|
| 6 |
+
of this software and associated documentation files (the "Software"), to deal
|
| 7 |
+
in the Software without restriction, including without limitation the rights
|
| 8 |
+
to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
|
| 9 |
+
copies of the Software, and to permit persons to whom the Software is
|
| 10 |
+
furnished to do so, subject to the following conditions:
|
| 11 |
+
|
| 12 |
+
The above copyright notice and this permission notice shall be included in all
|
| 13 |
+
copies or substantial portions of the Software.
|
| 14 |
+
|
| 15 |
+
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
|
| 16 |
+
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
|
| 17 |
+
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
|
| 18 |
+
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
|
| 19 |
+
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
|
| 20 |
+
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
|
| 21 |
+
SOFTWARE.
|
score_sde/op/__init__.py
ADDED
|
@@ -0,0 +1,2 @@
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from .fused_act import FusedLeakyReLU, fused_leaky_relu
|
| 2 |
+
from .upfirdn2d import upfirdn2d
|
score_sde/op/fused_act.py
ADDED
|
@@ -0,0 +1,105 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# ---------------------------------------------------------------
|
| 2 |
+
# Copyright (c) 2022, NVIDIA CORPORATION. All rights reserved.
|
| 3 |
+
# ---------------------------------------------------------------
|
| 4 |
+
|
| 5 |
+
""" Originated from https://github.com/rosinality/stylegan2-pytorch
|
| 6 |
+
The license for the original version of this file can be found in this directory (LICENSE_MIT).
|
| 7 |
+
"""
|
| 8 |
+
|
| 9 |
+
import os
|
| 10 |
+
|
| 11 |
+
import torch
|
| 12 |
+
from torch import nn
|
| 13 |
+
from torch.nn import functional as F
|
| 14 |
+
from torch.autograd import Function
|
| 15 |
+
from torch.utils.cpp_extension import load
|
| 16 |
+
|
| 17 |
+
|
| 18 |
+
module_path = os.path.dirname(__file__)
|
| 19 |
+
fused = load(
|
| 20 |
+
"fused",
|
| 21 |
+
sources=[
|
| 22 |
+
os.path.join(module_path, "fused_bias_act.cpp"),
|
| 23 |
+
os.path.join(module_path, "fused_bias_act_kernel.cu"),
|
| 24 |
+
],
|
| 25 |
+
)
|
| 26 |
+
|
| 27 |
+
|
| 28 |
+
class FusedLeakyReLUFunctionBackward(Function):
|
| 29 |
+
@staticmethod
|
| 30 |
+
def forward(ctx, grad_output, out, negative_slope, scale):
|
| 31 |
+
ctx.save_for_backward(out)
|
| 32 |
+
ctx.negative_slope = negative_slope
|
| 33 |
+
ctx.scale = scale
|
| 34 |
+
|
| 35 |
+
empty = grad_output.new_empty(0)
|
| 36 |
+
|
| 37 |
+
grad_input = fused.fused_bias_act(
|
| 38 |
+
grad_output, empty, out, 3, 1, negative_slope, scale
|
| 39 |
+
)
|
| 40 |
+
|
| 41 |
+
dim = [0]
|
| 42 |
+
|
| 43 |
+
if grad_input.ndim > 2:
|
| 44 |
+
dim += list(range(2, grad_input.ndim))
|
| 45 |
+
|
| 46 |
+
grad_bias = grad_input.sum(dim).detach()
|
| 47 |
+
|
| 48 |
+
return grad_input, grad_bias
|
| 49 |
+
|
| 50 |
+
@staticmethod
|
| 51 |
+
def backward(ctx, gradgrad_input, gradgrad_bias):
|
| 52 |
+
out, = ctx.saved_tensors
|
| 53 |
+
gradgrad_out = fused.fused_bias_act(
|
| 54 |
+
gradgrad_input, gradgrad_bias, out, 3, 1, ctx.negative_slope, ctx.scale
|
| 55 |
+
)
|
| 56 |
+
|
| 57 |
+
return gradgrad_out, None, None, None
|
| 58 |
+
|
| 59 |
+
|
| 60 |
+
class FusedLeakyReLUFunction(Function):
|
| 61 |
+
@staticmethod
|
| 62 |
+
def forward(ctx, input, bias, negative_slope, scale):
|
| 63 |
+
empty = input.new_empty(0)
|
| 64 |
+
out = fused.fused_bias_act(input, bias, empty, 3, 0, negative_slope, scale)
|
| 65 |
+
ctx.save_for_backward(out)
|
| 66 |
+
ctx.negative_slope = negative_slope
|
| 67 |
+
ctx.scale = scale
|
| 68 |
+
|
| 69 |
+
return out
|
| 70 |
+
|
| 71 |
+
@staticmethod
|
| 72 |
+
def backward(ctx, grad_output):
|
| 73 |
+
out, = ctx.saved_tensors
|
| 74 |
+
|
| 75 |
+
grad_input, grad_bias = FusedLeakyReLUFunctionBackward.apply(
|
| 76 |
+
grad_output, out, ctx.negative_slope, ctx.scale
|
| 77 |
+
)
|
| 78 |
+
|
| 79 |
+
return grad_input, grad_bias, None, None
|
| 80 |
+
|
| 81 |
+
|
| 82 |
+
class FusedLeakyReLU(nn.Module):
|
| 83 |
+
def __init__(self, channel, negative_slope=0.2, scale=2 ** 0.5):
|
| 84 |
+
super().__init__()
|
| 85 |
+
|
| 86 |
+
self.bias = nn.Parameter(torch.zeros(channel))
|
| 87 |
+
self.negative_slope = negative_slope
|
| 88 |
+
self.scale = scale
|
| 89 |
+
|
| 90 |
+
def forward(self, input):
|
| 91 |
+
return fused_leaky_relu(input, self.bias, self.negative_slope, self.scale)
|
| 92 |
+
|
| 93 |
+
|
| 94 |
+
def fused_leaky_relu(input, bias, negative_slope=0.2, scale=2 ** 0.5):
|
| 95 |
+
if input.device.type == "cpu":
|
| 96 |
+
rest_dim = [1] * (input.ndim - bias.ndim - 1)
|
| 97 |
+
return (
|
| 98 |
+
F.leaky_relu(
|
| 99 |
+
input + bias.view(1, bias.shape[0], *rest_dim), negative_slope=0.2
|
| 100 |
+
)
|
| 101 |
+
* scale
|
| 102 |
+
)
|
| 103 |
+
|
| 104 |
+
else:
|
| 105 |
+
return FusedLeakyReLUFunction.apply(input, bias, negative_slope, scale)
|
score_sde/op/fused_bias_act.cpp
ADDED
|
@@ -0,0 +1,28 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
// ---------------------------------------------------------------
|
| 2 |
+
// Copyright (c) 2022, NVIDIA CORPORATION. All rights reserved.
|
| 3 |
+
// ---------------------------------------------------------------
|
| 4 |
+
|
| 5 |
+
// Originated from https://github.com/rosinality/stylegan2-pytorch
|
| 6 |
+
// The license for the original version of this file can be found in this directory (LICENSE_MIT).
|
| 7 |
+
|
| 8 |
+
#include <torch/extension.h>
|
| 9 |
+
|
| 10 |
+
|
| 11 |
+
torch::Tensor fused_bias_act_op(const torch::Tensor& input, const torch::Tensor& bias, const torch::Tensor& refer,
|
| 12 |
+
int act, int grad, float alpha, float scale);
|
| 13 |
+
|
| 14 |
+
#define CHECK_CUDA(x) TORCH_CHECK(x.type().is_cuda(), #x " must be a CUDA tensor")
|
| 15 |
+
#define CHECK_CONTIGUOUS(x) TORCH_CHECK(x.is_contiguous(), #x " must be contiguous")
|
| 16 |
+
#define CHECK_INPUT(x) CHECK_CUDA(x); CHECK_CONTIGUOUS(x)
|
| 17 |
+
|
| 18 |
+
torch::Tensor fused_bias_act(const torch::Tensor& input, const torch::Tensor& bias, const torch::Tensor& refer,
|
| 19 |
+
int act, int grad, float alpha, float scale) {
|
| 20 |
+
CHECK_CUDA(input);
|
| 21 |
+
CHECK_CUDA(bias);
|
| 22 |
+
|
| 23 |
+
return fused_bias_act_op(input, bias, refer, act, grad, alpha, scale);
|
| 24 |
+
}
|
| 25 |
+
|
| 26 |
+
PYBIND11_MODULE(TORCH_EXTENSION_NAME, m) {
|
| 27 |
+
m.def("fused_bias_act", &fused_bias_act, "fused bias act (CUDA)");
|
| 28 |
+
}
|
score_sde/op/fused_bias_act_kernel.cu
ADDED
|
@@ -0,0 +1,101 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
// ---------------------------------------------------------------
|
| 2 |
+
// Copyright (c) 2019-2022, NVIDIA Corporation. All rights reserved.
|
| 3 |
+
// ---------------------------------------------------------------
|
| 4 |
+
//
|
| 5 |
+
// This work is made available under the Nvidia Source Code License-NC.
|
| 6 |
+
// To view a copy of this license, visit
|
| 7 |
+
// https://nvlabs.github.io/stylegan2/license.html
|
| 8 |
+
|
| 9 |
+
#include <torch/types.h>
|
| 10 |
+
|
| 11 |
+
#include <ATen/ATen.h>
|
| 12 |
+
#include <ATen/AccumulateType.h>
|
| 13 |
+
#include <ATen/cuda/CUDAContext.h>
|
| 14 |
+
#include <ATen/cuda/CUDAApplyUtils.cuh>
|
| 15 |
+
|
| 16 |
+
#include <cuda.h>
|
| 17 |
+
#include <cuda_runtime.h>
|
| 18 |
+
|
| 19 |
+
|
| 20 |
+
template <typename scalar_t>
|
| 21 |
+
static __global__ void fused_bias_act_kernel(scalar_t* out, const scalar_t* p_x, const scalar_t* p_b, const scalar_t* p_ref,
|
| 22 |
+
int act, int grad, scalar_t alpha, scalar_t scale, int loop_x, int size_x, int step_b, int size_b, int use_bias, int use_ref) {
|
| 23 |
+
int xi = blockIdx.x * loop_x * blockDim.x + threadIdx.x;
|
| 24 |
+
|
| 25 |
+
scalar_t zero = 0.0;
|
| 26 |
+
|
| 27 |
+
for (int loop_idx = 0; loop_idx < loop_x && xi < size_x; loop_idx++, xi += blockDim.x) {
|
| 28 |
+
scalar_t x = p_x[xi];
|
| 29 |
+
|
| 30 |
+
if (use_bias) {
|
| 31 |
+
x += p_b[(xi / step_b) % size_b];
|
| 32 |
+
}
|
| 33 |
+
|
| 34 |
+
scalar_t ref = use_ref ? p_ref[xi] : zero;
|
| 35 |
+
|
| 36 |
+
scalar_t y;
|
| 37 |
+
|
| 38 |
+
switch (act * 10 + grad) {
|
| 39 |
+
default:
|
| 40 |
+
case 10: y = x; break;
|
| 41 |
+
case 11: y = x; break;
|
| 42 |
+
case 12: y = 0.0; break;
|
| 43 |
+
|
| 44 |
+
case 30: y = (x > 0.0) ? x : x * alpha; break;
|
| 45 |
+
case 31: y = (ref > 0.0) ? x : x * alpha; break;
|
| 46 |
+
case 32: y = 0.0; break;
|
| 47 |
+
}
|
| 48 |
+
|
| 49 |
+
out[xi] = y * scale;
|
| 50 |
+
}
|
| 51 |
+
}
|
| 52 |
+
|
| 53 |
+
|
| 54 |
+
torch::Tensor fused_bias_act_op(const torch::Tensor& input, const torch::Tensor& bias, const torch::Tensor& refer,
|
| 55 |
+
int act, int grad, float alpha, float scale) {
|
| 56 |
+
int curDevice = -1;
|
| 57 |
+
cudaGetDevice(&curDevice);
|
| 58 |
+
cudaStream_t stream = at::cuda::getCurrentCUDAStream(curDevice);
|
| 59 |
+
|
| 60 |
+
auto x = input.contiguous();
|
| 61 |
+
auto b = bias.contiguous();
|
| 62 |
+
auto ref = refer.contiguous();
|
| 63 |
+
|
| 64 |
+
int use_bias = b.numel() ? 1 : 0;
|
| 65 |
+
int use_ref = ref.numel() ? 1 : 0;
|
| 66 |
+
|
| 67 |
+
int size_x = x.numel();
|
| 68 |
+
int size_b = b.numel();
|
| 69 |
+
int step_b = 1;
|
| 70 |
+
|
| 71 |
+
for (int i = 1 + 1; i < x.dim(); i++) {
|
| 72 |
+
step_b *= x.size(i);
|
| 73 |
+
}
|
| 74 |
+
|
| 75 |
+
int loop_x = 4;
|
| 76 |
+
int block_size = 4 * 32;
|
| 77 |
+
int grid_size = (size_x - 1) / (loop_x * block_size) + 1;
|
| 78 |
+
|
| 79 |
+
auto y = torch::empty_like(x);
|
| 80 |
+
|
| 81 |
+
AT_DISPATCH_FLOATING_TYPES_AND_HALF(x.scalar_type(), "fused_bias_act_kernel", [&] {
|
| 82 |
+
fused_bias_act_kernel<scalar_t><<<grid_size, block_size, 0, stream>>>(
|
| 83 |
+
y.data_ptr<scalar_t>(),
|
| 84 |
+
x.data_ptr<scalar_t>(),
|
| 85 |
+
b.data_ptr<scalar_t>(),
|
| 86 |
+
ref.data_ptr<scalar_t>(),
|
| 87 |
+
act,
|
| 88 |
+
grad,
|
| 89 |
+
alpha,
|
| 90 |
+
scale,
|
| 91 |
+
loop_x,
|
| 92 |
+
size_x,
|
| 93 |
+
step_b,
|
| 94 |
+
size_b,
|
| 95 |
+
use_bias,
|
| 96 |
+
use_ref
|
| 97 |
+
);
|
| 98 |
+
});
|
| 99 |
+
|
| 100 |
+
return y;
|
| 101 |
+
}
|
score_sde/op/upfirdn2d.cpp
ADDED
|
@@ -0,0 +1,31 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
// ---------------------------------------------------------------
|
| 2 |
+
// Copyright (c) 2022, NVIDIA CORPORATION. All rights reserved.
|
| 3 |
+
// ---------------------------------------------------------------
|
| 4 |
+
|
| 5 |
+
// Originated from https://github.com/rosinality/stylegan2-pytorch
|
| 6 |
+
// The license for the original version of this file can be found in this directory (LICENSE_MIT).
|
| 7 |
+
|
| 8 |
+
|
| 9 |
+
#include <torch/extension.h>
|
| 10 |
+
|
| 11 |
+
|
| 12 |
+
torch::Tensor upfirdn2d_op(const torch::Tensor& input, const torch::Tensor& kernel,
|
| 13 |
+
int up_x, int up_y, int down_x, int down_y,
|
| 14 |
+
int pad_x0, int pad_x1, int pad_y0, int pad_y1);
|
| 15 |
+
|
| 16 |
+
#define CHECK_CUDA(x) TORCH_CHECK(x.type().is_cuda(), #x " must be a CUDA tensor")
|
| 17 |
+
#define CHECK_CONTIGUOUS(x) TORCH_CHECK(x.is_contiguous(), #x " must be contiguous")
|
| 18 |
+
#define CHECK_INPUT(x) CHECK_CUDA(x); CHECK_CONTIGUOUS(x)
|
| 19 |
+
|
| 20 |
+
torch::Tensor upfirdn2d(const torch::Tensor& input, const torch::Tensor& kernel,
|
| 21 |
+
int up_x, int up_y, int down_x, int down_y,
|
| 22 |
+
int pad_x0, int pad_x1, int pad_y0, int pad_y1) {
|
| 23 |
+
CHECK_CUDA(input);
|
| 24 |
+
CHECK_CUDA(kernel);
|
| 25 |
+
|
| 26 |
+
return upfirdn2d_op(input, kernel, up_x, up_y, down_x, down_y, pad_x0, pad_x1, pad_y0, pad_y1);
|
| 27 |
+
}
|
| 28 |
+
|
| 29 |
+
PYBIND11_MODULE(TORCH_EXTENSION_NAME, m) {
|
| 30 |
+
m.def("upfirdn2d", &upfirdn2d, "upfirdn2d (CUDA)");
|
| 31 |
+
}
|
score_sde/op/upfirdn2d.py
ADDED
|
@@ -0,0 +1,225 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# ---------------------------------------------------------------
|
| 2 |
+
# Copyright (c) 2022, NVIDIA CORPORATION. All rights reserved.
|
| 3 |
+
# ---------------------------------------------------------------
|
| 4 |
+
|
| 5 |
+
""" Originated from https://github.com/rosinality/stylegan2-pytorch
|
| 6 |
+
The license for the original version of this file can be found in this directory (LICENSE_MIT).
|
| 7 |
+
"""
|
| 8 |
+
|
| 9 |
+
import os
|
| 10 |
+
|
| 11 |
+
import torch
|
| 12 |
+
from torch.nn import functional as F
|
| 13 |
+
from torch.autograd import Function
|
| 14 |
+
from torch.utils.cpp_extension import load
|
| 15 |
+
from collections import abc
|
| 16 |
+
|
| 17 |
+
module_path = os.path.dirname(__file__)
|
| 18 |
+
upfirdn2d_op = load(
|
| 19 |
+
"upfirdn2d",
|
| 20 |
+
sources=[
|
| 21 |
+
os.path.join(module_path, "upfirdn2d.cpp"),
|
| 22 |
+
os.path.join(module_path, "upfirdn2d_kernel.cu"),
|
| 23 |
+
],
|
| 24 |
+
)
|
| 25 |
+
|
| 26 |
+
|
| 27 |
+
class UpFirDn2dBackward(Function):
|
| 28 |
+
@staticmethod
|
| 29 |
+
def forward(
|
| 30 |
+
ctx, grad_output, kernel, grad_kernel, up, down, pad, g_pad, in_size, out_size
|
| 31 |
+
):
|
| 32 |
+
|
| 33 |
+
up_x, up_y = up
|
| 34 |
+
down_x, down_y = down
|
| 35 |
+
g_pad_x0, g_pad_x1, g_pad_y0, g_pad_y1 = g_pad
|
| 36 |
+
|
| 37 |
+
grad_output = grad_output.reshape(-1, out_size[0], out_size[1], 1)
|
| 38 |
+
|
| 39 |
+
grad_input = upfirdn2d_op.upfirdn2d(
|
| 40 |
+
grad_output,
|
| 41 |
+
grad_kernel,
|
| 42 |
+
down_x,
|
| 43 |
+
down_y,
|
| 44 |
+
up_x,
|
| 45 |
+
up_y,
|
| 46 |
+
g_pad_x0,
|
| 47 |
+
g_pad_x1,
|
| 48 |
+
g_pad_y0,
|
| 49 |
+
g_pad_y1,
|
| 50 |
+
)
|
| 51 |
+
grad_input = grad_input.view(in_size[0], in_size[1], in_size[2], in_size[3])
|
| 52 |
+
|
| 53 |
+
ctx.save_for_backward(kernel)
|
| 54 |
+
|
| 55 |
+
pad_x0, pad_x1, pad_y0, pad_y1 = pad
|
| 56 |
+
|
| 57 |
+
ctx.up_x = up_x
|
| 58 |
+
ctx.up_y = up_y
|
| 59 |
+
ctx.down_x = down_x
|
| 60 |
+
ctx.down_y = down_y
|
| 61 |
+
ctx.pad_x0 = pad_x0
|
| 62 |
+
ctx.pad_x1 = pad_x1
|
| 63 |
+
ctx.pad_y0 = pad_y0
|
| 64 |
+
ctx.pad_y1 = pad_y1
|
| 65 |
+
ctx.in_size = in_size
|
| 66 |
+
ctx.out_size = out_size
|
| 67 |
+
|
| 68 |
+
return grad_input
|
| 69 |
+
|
| 70 |
+
@staticmethod
|
| 71 |
+
def backward(ctx, gradgrad_input):
|
| 72 |
+
kernel, = ctx.saved_tensors
|
| 73 |
+
|
| 74 |
+
gradgrad_input = gradgrad_input.reshape(-1, ctx.in_size[2], ctx.in_size[3], 1)
|
| 75 |
+
|
| 76 |
+
gradgrad_out = upfirdn2d_op.upfirdn2d(
|
| 77 |
+
gradgrad_input,
|
| 78 |
+
kernel,
|
| 79 |
+
ctx.up_x,
|
| 80 |
+
ctx.up_y,
|
| 81 |
+
ctx.down_x,
|
| 82 |
+
ctx.down_y,
|
| 83 |
+
ctx.pad_x0,
|
| 84 |
+
ctx.pad_x1,
|
| 85 |
+
ctx.pad_y0,
|
| 86 |
+
ctx.pad_y1,
|
| 87 |
+
)
|
| 88 |
+
# gradgrad_out = gradgrad_out.view(ctx.in_size[0], ctx.out_size[0], ctx.out_size[1], ctx.in_size[3])
|
| 89 |
+
gradgrad_out = gradgrad_out.view(
|
| 90 |
+
ctx.in_size[0], ctx.in_size[1], ctx.out_size[0], ctx.out_size[1]
|
| 91 |
+
)
|
| 92 |
+
|
| 93 |
+
return gradgrad_out, None, None, None, None, None, None, None, None
|
| 94 |
+
|
| 95 |
+
|
| 96 |
+
class UpFirDn2d(Function):
|
| 97 |
+
@staticmethod
|
| 98 |
+
def forward(ctx, input, kernel, up, down, pad):
|
| 99 |
+
up_x, up_y = up
|
| 100 |
+
down_x, down_y = down
|
| 101 |
+
pad_x0, pad_x1, pad_y0, pad_y1 = pad
|
| 102 |
+
|
| 103 |
+
kernel_h, kernel_w = kernel.shape
|
| 104 |
+
batch, channel, in_h, in_w = input.shape
|
| 105 |
+
ctx.in_size = input.shape
|
| 106 |
+
|
| 107 |
+
input = input.reshape(-1, in_h, in_w, 1)
|
| 108 |
+
|
| 109 |
+
ctx.save_for_backward(kernel, torch.flip(kernel, [0, 1]))
|
| 110 |
+
|
| 111 |
+
out_h = (in_h * up_y + pad_y0 + pad_y1 - kernel_h) // down_y + 1
|
| 112 |
+
out_w = (in_w * up_x + pad_x0 + pad_x1 - kernel_w) // down_x + 1
|
| 113 |
+
ctx.out_size = (out_h, out_w)
|
| 114 |
+
|
| 115 |
+
ctx.up = (up_x, up_y)
|
| 116 |
+
ctx.down = (down_x, down_y)
|
| 117 |
+
ctx.pad = (pad_x0, pad_x1, pad_y0, pad_y1)
|
| 118 |
+
|
| 119 |
+
g_pad_x0 = kernel_w - pad_x0 - 1
|
| 120 |
+
g_pad_y0 = kernel_h - pad_y0 - 1
|
| 121 |
+
g_pad_x1 = in_w * up_x - out_w * down_x + pad_x0 - up_x + 1
|
| 122 |
+
g_pad_y1 = in_h * up_y - out_h * down_y + pad_y0 - up_y + 1
|
| 123 |
+
|
| 124 |
+
ctx.g_pad = (g_pad_x0, g_pad_x1, g_pad_y0, g_pad_y1)
|
| 125 |
+
|
| 126 |
+
out = upfirdn2d_op.upfirdn2d(
|
| 127 |
+
input, kernel, up_x, up_y, down_x, down_y, pad_x0, pad_x1, pad_y0, pad_y1
|
| 128 |
+
)
|
| 129 |
+
# out = out.view(major, out_h, out_w, minor)
|
| 130 |
+
out = out.view(-1, channel, out_h, out_w)
|
| 131 |
+
|
| 132 |
+
return out
|
| 133 |
+
|
| 134 |
+
@staticmethod
|
| 135 |
+
def backward(ctx, grad_output):
|
| 136 |
+
kernel, grad_kernel = ctx.saved_tensors
|
| 137 |
+
|
| 138 |
+
grad_input = UpFirDn2dBackward.apply(
|
| 139 |
+
grad_output,
|
| 140 |
+
kernel,
|
| 141 |
+
grad_kernel,
|
| 142 |
+
ctx.up,
|
| 143 |
+
ctx.down,
|
| 144 |
+
ctx.pad,
|
| 145 |
+
ctx.g_pad,
|
| 146 |
+
ctx.in_size,
|
| 147 |
+
ctx.out_size,
|
| 148 |
+
)
|
| 149 |
+
|
| 150 |
+
return grad_input, None, None, None, None
|
| 151 |
+
|
| 152 |
+
|
| 153 |
+
def upfirdn2d(input, kernel, up=1, down=1, pad=(0, 0)):
|
| 154 |
+
if input.device.type == "cpu":
|
| 155 |
+
out = upfirdn2d_native(
|
| 156 |
+
input, kernel, up, up, down, down, pad[0], pad[1], pad[0], pad[1]
|
| 157 |
+
)
|
| 158 |
+
|
| 159 |
+
else:
|
| 160 |
+
out = UpFirDn2d.apply(
|
| 161 |
+
input, kernel, (up, up), (down, down), (pad[0], pad[1], pad[0], pad[1])
|
| 162 |
+
)
|
| 163 |
+
|
| 164 |
+
return out
|
| 165 |
+
|
| 166 |
+
def upfirdn2d_ada(input, kernel, up=1, down=1, pad=(0, 0)):
|
| 167 |
+
if not isinstance(up, abc.Iterable):
|
| 168 |
+
up = (up, up)
|
| 169 |
+
|
| 170 |
+
if not isinstance(down, abc.Iterable):
|
| 171 |
+
down = (down, down)
|
| 172 |
+
|
| 173 |
+
if len(pad) == 2:
|
| 174 |
+
pad = (pad[0], pad[1], pad[0], pad[1])
|
| 175 |
+
|
| 176 |
+
if input.device.type == "cpu":
|
| 177 |
+
out = upfirdn2d_native(input, kernel, *up, *down, *pad)
|
| 178 |
+
|
| 179 |
+
else:
|
| 180 |
+
out = UpFirDn2d.apply(input, kernel, up, down, pad)
|
| 181 |
+
|
| 182 |
+
return out
|
| 183 |
+
|
| 184 |
+
def upfirdn2d_native(
|
| 185 |
+
input, kernel, up_x, up_y, down_x, down_y, pad_x0, pad_x1, pad_y0, pad_y1
|
| 186 |
+
):
|
| 187 |
+
_, channel, in_h, in_w = input.shape
|
| 188 |
+
input = input.reshape(-1, in_h, in_w, 1)
|
| 189 |
+
|
| 190 |
+
_, in_h, in_w, minor = input.shape
|
| 191 |
+
kernel_h, kernel_w = kernel.shape
|
| 192 |
+
|
| 193 |
+
out = input.view(-1, in_h, 1, in_w, 1, minor)
|
| 194 |
+
out = F.pad(out, [0, 0, 0, up_x - 1, 0, 0, 0, up_y - 1])
|
| 195 |
+
out = out.view(-1, in_h * up_y, in_w * up_x, minor)
|
| 196 |
+
|
| 197 |
+
out = F.pad(
|
| 198 |
+
out, [0, 0, max(pad_x0, 0), max(pad_x1, 0), max(pad_y0, 0), max(pad_y1, 0)]
|
| 199 |
+
)
|
| 200 |
+
out = out[
|
| 201 |
+
:,
|
| 202 |
+
max(-pad_y0, 0) : out.shape[1] - max(-pad_y1, 0),
|
| 203 |
+
max(-pad_x0, 0) : out.shape[2] - max(-pad_x1, 0),
|
| 204 |
+
:,
|
| 205 |
+
]
|
| 206 |
+
|
| 207 |
+
out = out.permute(0, 3, 1, 2)
|
| 208 |
+
out = out.reshape(
|
| 209 |
+
[-1, 1, in_h * up_y + pad_y0 + pad_y1, in_w * up_x + pad_x0 + pad_x1]
|
| 210 |
+
)
|
| 211 |
+
w = torch.flip(kernel, [0, 1]).view(1, 1, kernel_h, kernel_w)
|
| 212 |
+
out = F.conv2d(out, w)
|
| 213 |
+
out = out.reshape(
|
| 214 |
+
-1,
|
| 215 |
+
minor,
|
| 216 |
+
in_h * up_y + pad_y0 + pad_y1 - kernel_h + 1,
|
| 217 |
+
in_w * up_x + pad_x0 + pad_x1 - kernel_w + 1,
|
| 218 |
+
)
|
| 219 |
+
out = out.permute(0, 2, 3, 1)
|
| 220 |
+
out = out[:, ::down_y, ::down_x, :]
|
| 221 |
+
|
| 222 |
+
out_h = (in_h * up_y + pad_y0 + pad_y1 - kernel_h) // down_y + 1
|
| 223 |
+
out_w = (in_w * up_x + pad_x0 + pad_x1 - kernel_w) // down_x + 1
|
| 224 |
+
|
| 225 |
+
return out.view(-1, channel, out_h, out_w)
|
score_sde/op/upfirdn2d_kernel.cu
ADDED
|
@@ -0,0 +1,371 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
// ---------------------------------------------------------------
|
| 2 |
+
// Copyright (c) 2019-2022, NVIDIA Corporation. All rights reserved.
|
| 3 |
+
// ---------------------------------------------------------------
|
| 4 |
+
//
|
| 5 |
+
// This work is made available under the Nvidia Source Code License-NC.
|
| 6 |
+
// To view a copy of this license, visit
|
| 7 |
+
// https://nvlabs.github.io/stylegan2/license.html
|
| 8 |
+
|
| 9 |
+
#include <torch/types.h>
|
| 10 |
+
|
| 11 |
+
#include <ATen/ATen.h>
|
| 12 |
+
#include <ATen/AccumulateType.h>
|
| 13 |
+
#include <ATen/cuda/CUDAApplyUtils.cuh>
|
| 14 |
+
#include <ATen/cuda/CUDAContext.h>
|
| 15 |
+
|
| 16 |
+
#include <cuda.h>
|
| 17 |
+
#include <cuda_runtime.h>
|
| 18 |
+
|
| 19 |
+
static __host__ __device__ __forceinline__ int floor_div(int a, int b) {
|
| 20 |
+
int c = a / b;
|
| 21 |
+
|
| 22 |
+
if (c * b > a) {
|
| 23 |
+
c--;
|
| 24 |
+
}
|
| 25 |
+
|
| 26 |
+
return c;
|
| 27 |
+
}
|
| 28 |
+
|
| 29 |
+
struct UpFirDn2DKernelParams {
|
| 30 |
+
int up_x;
|
| 31 |
+
int up_y;
|
| 32 |
+
int down_x;
|
| 33 |
+
int down_y;
|
| 34 |
+
int pad_x0;
|
| 35 |
+
int pad_x1;
|
| 36 |
+
int pad_y0;
|
| 37 |
+
int pad_y1;
|
| 38 |
+
|
| 39 |
+
int major_dim;
|
| 40 |
+
int in_h;
|
| 41 |
+
int in_w;
|
| 42 |
+
int minor_dim;
|
| 43 |
+
int kernel_h;
|
| 44 |
+
int kernel_w;
|
| 45 |
+
int out_h;
|
| 46 |
+
int out_w;
|
| 47 |
+
int loop_major;
|
| 48 |
+
int loop_x;
|
| 49 |
+
};
|
| 50 |
+
|
| 51 |
+
template <typename scalar_t>
|
| 52 |
+
__global__ void upfirdn2d_kernel_large(scalar_t *out, const scalar_t *input,
|
| 53 |
+
const scalar_t *kernel,
|
| 54 |
+
const UpFirDn2DKernelParams p) {
|
| 55 |
+
int minor_idx = blockIdx.x * blockDim.x + threadIdx.x;
|
| 56 |
+
int out_y = minor_idx / p.minor_dim;
|
| 57 |
+
minor_idx -= out_y * p.minor_dim;
|
| 58 |
+
int out_x_base = blockIdx.y * p.loop_x * blockDim.y + threadIdx.y;
|
| 59 |
+
int major_idx_base = blockIdx.z * p.loop_major;
|
| 60 |
+
|
| 61 |
+
if (out_x_base >= p.out_w || out_y >= p.out_h ||
|
| 62 |
+
major_idx_base >= p.major_dim) {
|
| 63 |
+
return;
|
| 64 |
+
}
|
| 65 |
+
|
| 66 |
+
int mid_y = out_y * p.down_y + p.up_y - 1 - p.pad_y0;
|
| 67 |
+
int in_y = min(max(floor_div(mid_y, p.up_y), 0), p.in_h);
|
| 68 |
+
int h = min(max(floor_div(mid_y + p.kernel_h, p.up_y), 0), p.in_h) - in_y;
|
| 69 |
+
int kernel_y = mid_y + p.kernel_h - (in_y + 1) * p.up_y;
|
| 70 |
+
|
| 71 |
+
for (int loop_major = 0, major_idx = major_idx_base;
|
| 72 |
+
loop_major < p.loop_major && major_idx < p.major_dim;
|
| 73 |
+
loop_major++, major_idx++) {
|
| 74 |
+
for (int loop_x = 0, out_x = out_x_base;
|
| 75 |
+
loop_x < p.loop_x && out_x < p.out_w; loop_x++, out_x += blockDim.y) {
|
| 76 |
+
int mid_x = out_x * p.down_x + p.up_x - 1 - p.pad_x0;
|
| 77 |
+
int in_x = min(max(floor_div(mid_x, p.up_x), 0), p.in_w);
|
| 78 |
+
int w = min(max(floor_div(mid_x + p.kernel_w, p.up_x), 0), p.in_w) - in_x;
|
| 79 |
+
int kernel_x = mid_x + p.kernel_w - (in_x + 1) * p.up_x;
|
| 80 |
+
|
| 81 |
+
const scalar_t *x_p =
|
| 82 |
+
&input[((major_idx * p.in_h + in_y) * p.in_w + in_x) * p.minor_dim +
|
| 83 |
+
minor_idx];
|
| 84 |
+
const scalar_t *k_p = &kernel[kernel_y * p.kernel_w + kernel_x];
|
| 85 |
+
int x_px = p.minor_dim;
|
| 86 |
+
int k_px = -p.up_x;
|
| 87 |
+
int x_py = p.in_w * p.minor_dim;
|
| 88 |
+
int k_py = -p.up_y * p.kernel_w;
|
| 89 |
+
|
| 90 |
+
scalar_t v = 0.0f;
|
| 91 |
+
|
| 92 |
+
for (int y = 0; y < h; y++) {
|
| 93 |
+
for (int x = 0; x < w; x++) {
|
| 94 |
+
v += static_cast<scalar_t>(*x_p) * static_cast<scalar_t>(*k_p);
|
| 95 |
+
x_p += x_px;
|
| 96 |
+
k_p += k_px;
|
| 97 |
+
}
|
| 98 |
+
|
| 99 |
+
x_p += x_py - w * x_px;
|
| 100 |
+
k_p += k_py - w * k_px;
|
| 101 |
+
}
|
| 102 |
+
|
| 103 |
+
out[((major_idx * p.out_h + out_y) * p.out_w + out_x) * p.minor_dim +
|
| 104 |
+
minor_idx] = v;
|
| 105 |
+
}
|
| 106 |
+
}
|
| 107 |
+
}
|
| 108 |
+
|
| 109 |
+
template <typename scalar_t, int up_x, int up_y, int down_x, int down_y,
|
| 110 |
+
int kernel_h, int kernel_w, int tile_out_h, int tile_out_w>
|
| 111 |
+
__global__ void upfirdn2d_kernel(scalar_t *out, const scalar_t *input,
|
| 112 |
+
const scalar_t *kernel,
|
| 113 |
+
const UpFirDn2DKernelParams p) {
|
| 114 |
+
const int tile_in_h = ((tile_out_h - 1) * down_y + kernel_h - 1) / up_y + 1;
|
| 115 |
+
const int tile_in_w = ((tile_out_w - 1) * down_x + kernel_w - 1) / up_x + 1;
|
| 116 |
+
|
| 117 |
+
__shared__ volatile float sk[kernel_h][kernel_w];
|
| 118 |
+
__shared__ volatile float sx[tile_in_h][tile_in_w];
|
| 119 |
+
|
| 120 |
+
int minor_idx = blockIdx.x;
|
| 121 |
+
int tile_out_y = minor_idx / p.minor_dim;
|
| 122 |
+
minor_idx -= tile_out_y * p.minor_dim;
|
| 123 |
+
tile_out_y *= tile_out_h;
|
| 124 |
+
int tile_out_x_base = blockIdx.y * p.loop_x * tile_out_w;
|
| 125 |
+
int major_idx_base = blockIdx.z * p.loop_major;
|
| 126 |
+
|
| 127 |
+
if (tile_out_x_base >= p.out_w | tile_out_y >= p.out_h |
|
| 128 |
+
major_idx_base >= p.major_dim) {
|
| 129 |
+
return;
|
| 130 |
+
}
|
| 131 |
+
|
| 132 |
+
for (int tap_idx = threadIdx.x; tap_idx < kernel_h * kernel_w;
|
| 133 |
+
tap_idx += blockDim.x) {
|
| 134 |
+
int ky = tap_idx / kernel_w;
|
| 135 |
+
int kx = tap_idx - ky * kernel_w;
|
| 136 |
+
scalar_t v = 0.0;
|
| 137 |
+
|
| 138 |
+
if (kx < p.kernel_w & ky < p.kernel_h) {
|
| 139 |
+
v = kernel[(p.kernel_h - 1 - ky) * p.kernel_w + (p.kernel_w - 1 - kx)];
|
| 140 |
+
}
|
| 141 |
+
|
| 142 |
+
sk[ky][kx] = v;
|
| 143 |
+
}
|
| 144 |
+
|
| 145 |
+
for (int loop_major = 0, major_idx = major_idx_base;
|
| 146 |
+
loop_major < p.loop_major & major_idx < p.major_dim;
|
| 147 |
+
loop_major++, major_idx++) {
|
| 148 |
+
for (int loop_x = 0, tile_out_x = tile_out_x_base;
|
| 149 |
+
loop_x < p.loop_x & tile_out_x < p.out_w;
|
| 150 |
+
loop_x++, tile_out_x += tile_out_w) {
|
| 151 |
+
int tile_mid_x = tile_out_x * down_x + up_x - 1 - p.pad_x0;
|
| 152 |
+
int tile_mid_y = tile_out_y * down_y + up_y - 1 - p.pad_y0;
|
| 153 |
+
int tile_in_x = floor_div(tile_mid_x, up_x);
|
| 154 |
+
int tile_in_y = floor_div(tile_mid_y, up_y);
|
| 155 |
+
|
| 156 |
+
__syncthreads();
|
| 157 |
+
|
| 158 |
+
for (int in_idx = threadIdx.x; in_idx < tile_in_h * tile_in_w;
|
| 159 |
+
in_idx += blockDim.x) {
|
| 160 |
+
int rel_in_y = in_idx / tile_in_w;
|
| 161 |
+
int rel_in_x = in_idx - rel_in_y * tile_in_w;
|
| 162 |
+
int in_x = rel_in_x + tile_in_x;
|
| 163 |
+
int in_y = rel_in_y + tile_in_y;
|
| 164 |
+
|
| 165 |
+
scalar_t v = 0.0;
|
| 166 |
+
|
| 167 |
+
if (in_x >= 0 & in_y >= 0 & in_x < p.in_w & in_y < p.in_h) {
|
| 168 |
+
v = input[((major_idx * p.in_h + in_y) * p.in_w + in_x) *
|
| 169 |
+
p.minor_dim +
|
| 170 |
+
minor_idx];
|
| 171 |
+
}
|
| 172 |
+
|
| 173 |
+
sx[rel_in_y][rel_in_x] = v;
|
| 174 |
+
}
|
| 175 |
+
|
| 176 |
+
__syncthreads();
|
| 177 |
+
for (int out_idx = threadIdx.x; out_idx < tile_out_h * tile_out_w;
|
| 178 |
+
out_idx += blockDim.x) {
|
| 179 |
+
int rel_out_y = out_idx / tile_out_w;
|
| 180 |
+
int rel_out_x = out_idx - rel_out_y * tile_out_w;
|
| 181 |
+
int out_x = rel_out_x + tile_out_x;
|
| 182 |
+
int out_y = rel_out_y + tile_out_y;
|
| 183 |
+
|
| 184 |
+
int mid_x = tile_mid_x + rel_out_x * down_x;
|
| 185 |
+
int mid_y = tile_mid_y + rel_out_y * down_y;
|
| 186 |
+
int in_x = floor_div(mid_x, up_x);
|
| 187 |
+
int in_y = floor_div(mid_y, up_y);
|
| 188 |
+
int rel_in_x = in_x - tile_in_x;
|
| 189 |
+
int rel_in_y = in_y - tile_in_y;
|
| 190 |
+
int kernel_x = (in_x + 1) * up_x - mid_x - 1;
|
| 191 |
+
int kernel_y = (in_y + 1) * up_y - mid_y - 1;
|
| 192 |
+
|
| 193 |
+
scalar_t v = 0.0;
|
| 194 |
+
|
| 195 |
+
#pragma unroll
|
| 196 |
+
for (int y = 0; y < kernel_h / up_y; y++)
|
| 197 |
+
#pragma unroll
|
| 198 |
+
for (int x = 0; x < kernel_w / up_x; x++)
|
| 199 |
+
v += sx[rel_in_y + y][rel_in_x + x] *
|
| 200 |
+
sk[kernel_y + y * up_y][kernel_x + x * up_x];
|
| 201 |
+
|
| 202 |
+
if (out_x < p.out_w & out_y < p.out_h) {
|
| 203 |
+
out[((major_idx * p.out_h + out_y) * p.out_w + out_x) * p.minor_dim +
|
| 204 |
+
minor_idx] = v;
|
| 205 |
+
}
|
| 206 |
+
}
|
| 207 |
+
}
|
| 208 |
+
}
|
| 209 |
+
}
|
| 210 |
+
|
| 211 |
+
torch::Tensor upfirdn2d_op(const torch::Tensor &input,
|
| 212 |
+
const torch::Tensor &kernel, int up_x, int up_y,
|
| 213 |
+
int down_x, int down_y, int pad_x0, int pad_x1,
|
| 214 |
+
int pad_y0, int pad_y1) {
|
| 215 |
+
int curDevice = -1;
|
| 216 |
+
cudaGetDevice(&curDevice);
|
| 217 |
+
cudaStream_t stream = at::cuda::getCurrentCUDAStream(curDevice);
|
| 218 |
+
|
| 219 |
+
UpFirDn2DKernelParams p;
|
| 220 |
+
|
| 221 |
+
auto x = input.contiguous();
|
| 222 |
+
auto k = kernel.contiguous();
|
| 223 |
+
|
| 224 |
+
p.major_dim = x.size(0);
|
| 225 |
+
p.in_h = x.size(1);
|
| 226 |
+
p.in_w = x.size(2);
|
| 227 |
+
p.minor_dim = x.size(3);
|
| 228 |
+
p.kernel_h = k.size(0);
|
| 229 |
+
p.kernel_w = k.size(1);
|
| 230 |
+
p.up_x = up_x;
|
| 231 |
+
p.up_y = up_y;
|
| 232 |
+
p.down_x = down_x;
|
| 233 |
+
p.down_y = down_y;
|
| 234 |
+
p.pad_x0 = pad_x0;
|
| 235 |
+
p.pad_x1 = pad_x1;
|
| 236 |
+
p.pad_y0 = pad_y0;
|
| 237 |
+
p.pad_y1 = pad_y1;
|
| 238 |
+
|
| 239 |
+
p.out_h = (p.in_h * p.up_y + p.pad_y0 + p.pad_y1 - p.kernel_h + p.down_y) /
|
| 240 |
+
p.down_y;
|
| 241 |
+
p.out_w = (p.in_w * p.up_x + p.pad_x0 + p.pad_x1 - p.kernel_w + p.down_x) /
|
| 242 |
+
p.down_x;
|
| 243 |
+
|
| 244 |
+
auto out =
|
| 245 |
+
at::empty({p.major_dim, p.out_h, p.out_w, p.minor_dim}, x.options());
|
| 246 |
+
|
| 247 |
+
int mode = -1;
|
| 248 |
+
|
| 249 |
+
int tile_out_h = -1;
|
| 250 |
+
int tile_out_w = -1;
|
| 251 |
+
|
| 252 |
+
if (p.up_x == 1 && p.up_y == 1 && p.down_x == 1 && p.down_y == 1 &&
|
| 253 |
+
p.kernel_h <= 4 && p.kernel_w <= 4) {
|
| 254 |
+
mode = 1;
|
| 255 |
+
tile_out_h = 16;
|
| 256 |
+
tile_out_w = 64;
|
| 257 |
+
}
|
| 258 |
+
|
| 259 |
+
if (p.up_x == 1 && p.up_y == 1 && p.down_x == 1 && p.down_y == 1 &&
|
| 260 |
+
p.kernel_h <= 3 && p.kernel_w <= 3) {
|
| 261 |
+
mode = 2;
|
| 262 |
+
tile_out_h = 16;
|
| 263 |
+
tile_out_w = 64;
|
| 264 |
+
}
|
| 265 |
+
|
| 266 |
+
if (p.up_x == 2 && p.up_y == 2 && p.down_x == 1 && p.down_y == 1 &&
|
| 267 |
+
p.kernel_h <= 4 && p.kernel_w <= 4) {
|
| 268 |
+
mode = 3;
|
| 269 |
+
tile_out_h = 16;
|
| 270 |
+
tile_out_w = 64;
|
| 271 |
+
}
|
| 272 |
+
|
| 273 |
+
if (p.up_x == 2 && p.up_y == 2 && p.down_x == 1 && p.down_y == 1 &&
|
| 274 |
+
p.kernel_h <= 2 && p.kernel_w <= 2) {
|
| 275 |
+
mode = 4;
|
| 276 |
+
tile_out_h = 16;
|
| 277 |
+
tile_out_w = 64;
|
| 278 |
+
}
|
| 279 |
+
|
| 280 |
+
if (p.up_x == 1 && p.up_y == 1 && p.down_x == 2 && p.down_y == 2 &&
|
| 281 |
+
p.kernel_h <= 4 && p.kernel_w <= 4) {
|
| 282 |
+
mode = 5;
|
| 283 |
+
tile_out_h = 8;
|
| 284 |
+
tile_out_w = 32;
|
| 285 |
+
}
|
| 286 |
+
|
| 287 |
+
if (p.up_x == 1 && p.up_y == 1 && p.down_x == 2 && p.down_y == 2 &&
|
| 288 |
+
p.kernel_h <= 2 && p.kernel_w <= 2) {
|
| 289 |
+
mode = 6;
|
| 290 |
+
tile_out_h = 8;
|
| 291 |
+
tile_out_w = 32;
|
| 292 |
+
}
|
| 293 |
+
|
| 294 |
+
dim3 block_size;
|
| 295 |
+
dim3 grid_size;
|
| 296 |
+
|
| 297 |
+
if (tile_out_h > 0 && tile_out_w > 0) {
|
| 298 |
+
p.loop_major = (p.major_dim - 1) / 16384 + 1;
|
| 299 |
+
p.loop_x = 1;
|
| 300 |
+
block_size = dim3(32 * 8, 1, 1);
|
| 301 |
+
grid_size = dim3(((p.out_h - 1) / tile_out_h + 1) * p.minor_dim,
|
| 302 |
+
(p.out_w - 1) / (p.loop_x * tile_out_w) + 1,
|
| 303 |
+
(p.major_dim - 1) / p.loop_major + 1);
|
| 304 |
+
} else {
|
| 305 |
+
p.loop_major = (p.major_dim - 1) / 16384 + 1;
|
| 306 |
+
p.loop_x = 4;
|
| 307 |
+
block_size = dim3(4, 32, 1);
|
| 308 |
+
grid_size = dim3((p.out_h * p.minor_dim - 1) / block_size.x + 1,
|
| 309 |
+
(p.out_w - 1) / (p.loop_x * block_size.y) + 1,
|
| 310 |
+
(p.major_dim - 1) / p.loop_major + 1);
|
| 311 |
+
}
|
| 312 |
+
|
| 313 |
+
AT_DISPATCH_FLOATING_TYPES_AND_HALF(x.scalar_type(), "upfirdn2d_cuda", [&] {
|
| 314 |
+
switch (mode) {
|
| 315 |
+
case 1:
|
| 316 |
+
upfirdn2d_kernel<scalar_t, 1, 1, 1, 1, 4, 4, 16, 64>
|
| 317 |
+
<<<grid_size, block_size, 0, stream>>>(out.data_ptr<scalar_t>(),
|
| 318 |
+
x.data_ptr<scalar_t>(),
|
| 319 |
+
k.data_ptr<scalar_t>(), p);
|
| 320 |
+
|
| 321 |
+
break;
|
| 322 |
+
|
| 323 |
+
case 2:
|
| 324 |
+
upfirdn2d_kernel<scalar_t, 1, 1, 1, 1, 3, 3, 16, 64>
|
| 325 |
+
<<<grid_size, block_size, 0, stream>>>(out.data_ptr<scalar_t>(),
|
| 326 |
+
x.data_ptr<scalar_t>(),
|
| 327 |
+
k.data_ptr<scalar_t>(), p);
|
| 328 |
+
|
| 329 |
+
break;
|
| 330 |
+
|
| 331 |
+
case 3:
|
| 332 |
+
upfirdn2d_kernel<scalar_t, 2, 2, 1, 1, 4, 4, 16, 64>
|
| 333 |
+
<<<grid_size, block_size, 0, stream>>>(out.data_ptr<scalar_t>(),
|
| 334 |
+
x.data_ptr<scalar_t>(),
|
| 335 |
+
k.data_ptr<scalar_t>(), p);
|
| 336 |
+
|
| 337 |
+
break;
|
| 338 |
+
|
| 339 |
+
case 4:
|
| 340 |
+
upfirdn2d_kernel<scalar_t, 2, 2, 1, 1, 2, 2, 16, 64>
|
| 341 |
+
<<<grid_size, block_size, 0, stream>>>(out.data_ptr<scalar_t>(),
|
| 342 |
+
x.data_ptr<scalar_t>(),
|
| 343 |
+
k.data_ptr<scalar_t>(), p);
|
| 344 |
+
|
| 345 |
+
break;
|
| 346 |
+
|
| 347 |
+
case 5:
|
| 348 |
+
upfirdn2d_kernel<scalar_t, 1, 1, 2, 2, 4, 4, 8, 32>
|
| 349 |
+
<<<grid_size, block_size, 0, stream>>>(out.data_ptr<scalar_t>(),
|
| 350 |
+
x.data_ptr<scalar_t>(),
|
| 351 |
+
k.data_ptr<scalar_t>(), p);
|
| 352 |
+
|
| 353 |
+
break;
|
| 354 |
+
|
| 355 |
+
case 6:
|
| 356 |
+
upfirdn2d_kernel<scalar_t, 1, 1, 2, 2, 4, 4, 8, 32>
|
| 357 |
+
<<<grid_size, block_size, 0, stream>>>(out.data_ptr<scalar_t>(),
|
| 358 |
+
x.data_ptr<scalar_t>(),
|
| 359 |
+
k.data_ptr<scalar_t>(), p);
|
| 360 |
+
|
| 361 |
+
break;
|
| 362 |
+
|
| 363 |
+
default:
|
| 364 |
+
upfirdn2d_kernel_large<scalar_t><<<grid_size, block_size, 0, stream>>>(
|
| 365 |
+
out.data_ptr<scalar_t>(), x.data_ptr<scalar_t>(),
|
| 366 |
+
k.data_ptr<scalar_t>(), p);
|
| 367 |
+
}
|
| 368 |
+
});
|
| 369 |
+
|
| 370 |
+
return out;
|
| 371 |
+
}
|
test_ddgan.py
ADDED
|
@@ -0,0 +1,275 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# ---------------------------------------------------------------
|
| 2 |
+
# Copyright (c) 2022, NVIDIA CORPORATION. All rights reserved.
|
| 3 |
+
#
|
| 4 |
+
# This work is licensed under the NVIDIA Source Code License
|
| 5 |
+
# for Denoising Diffusion GAN. To view a copy of this license, see the LICENSE file.
|
| 6 |
+
# ---------------------------------------------------------------
|
| 7 |
+
import argparse
|
| 8 |
+
import torch
|
| 9 |
+
import numpy as np
|
| 10 |
+
|
| 11 |
+
import os
|
| 12 |
+
|
| 13 |
+
import torchvision
|
| 14 |
+
from score_sde.models.ncsnpp_generator_adagn import NCSNpp
|
| 15 |
+
from pytorch_fid.fid_score import calculate_fid_given_paths
|
| 16 |
+
|
| 17 |
+
#%% Diffusion coefficients
|
| 18 |
+
def var_func_vp(t, beta_min, beta_max):
|
| 19 |
+
log_mean_coeff = -0.25 * t ** 2 * (beta_max - beta_min) - 0.5 * t * beta_min
|
| 20 |
+
var = 1. - torch.exp(2. * log_mean_coeff)
|
| 21 |
+
return var
|
| 22 |
+
|
| 23 |
+
def var_func_geometric(t, beta_min, beta_max):
|
| 24 |
+
return beta_min * ((beta_max / beta_min) ** t)
|
| 25 |
+
|
| 26 |
+
def extract(input, t, shape):
|
| 27 |
+
out = torch.gather(input, 0, t)
|
| 28 |
+
reshape = [shape[0]] + [1] * (len(shape) - 1)
|
| 29 |
+
out = out.reshape(*reshape)
|
| 30 |
+
|
| 31 |
+
return out
|
| 32 |
+
|
| 33 |
+
def get_time_schedule(args, device):
|
| 34 |
+
n_timestep = args.num_timesteps
|
| 35 |
+
eps_small = 1e-3
|
| 36 |
+
t = np.arange(0, n_timestep + 1, dtype=np.float64)
|
| 37 |
+
t = t / n_timestep
|
| 38 |
+
t = torch.from_numpy(t) * (1. - eps_small) + eps_small
|
| 39 |
+
return t.to(device)
|
| 40 |
+
|
| 41 |
+
def get_sigma_schedule(args, device):
|
| 42 |
+
n_timestep = args.num_timesteps
|
| 43 |
+
beta_min = args.beta_min
|
| 44 |
+
beta_max = args.beta_max
|
| 45 |
+
eps_small = 1e-3
|
| 46 |
+
|
| 47 |
+
t = np.arange(0, n_timestep + 1, dtype=np.float64)
|
| 48 |
+
t = t / n_timestep
|
| 49 |
+
t = torch.from_numpy(t) * (1. - eps_small) + eps_small
|
| 50 |
+
|
| 51 |
+
if args.use_geometric:
|
| 52 |
+
var = var_func_geometric(t, beta_min, beta_max)
|
| 53 |
+
else:
|
| 54 |
+
var = var_func_vp(t, beta_min, beta_max)
|
| 55 |
+
alpha_bars = 1.0 - var
|
| 56 |
+
betas = 1 - alpha_bars[1:] / alpha_bars[:-1]
|
| 57 |
+
|
| 58 |
+
first = torch.tensor(1e-8)
|
| 59 |
+
betas = torch.cat((first[None], betas)).to(device)
|
| 60 |
+
betas = betas.type(torch.float32)
|
| 61 |
+
sigmas = betas**0.5
|
| 62 |
+
a_s = torch.sqrt(1-betas)
|
| 63 |
+
return sigmas, a_s, betas
|
| 64 |
+
|
| 65 |
+
#%% posterior sampling
|
| 66 |
+
class Posterior_Coefficients():
|
| 67 |
+
def __init__(self, args, device):
|
| 68 |
+
|
| 69 |
+
_, _, self.betas = get_sigma_schedule(args, device=device)
|
| 70 |
+
|
| 71 |
+
#we don't need the zeros
|
| 72 |
+
self.betas = self.betas.type(torch.float32)[1:]
|
| 73 |
+
|
| 74 |
+
self.alphas = 1 - self.betas
|
| 75 |
+
self.alphas_cumprod = torch.cumprod(self.alphas, 0)
|
| 76 |
+
self.alphas_cumprod_prev = torch.cat(
|
| 77 |
+
(torch.tensor([1.], dtype=torch.float32,device=device), self.alphas_cumprod[:-1]), 0
|
| 78 |
+
)
|
| 79 |
+
self.posterior_variance = self.betas * (1 - self.alphas_cumprod_prev) / (1 - self.alphas_cumprod)
|
| 80 |
+
|
| 81 |
+
self.sqrt_alphas_cumprod = torch.sqrt(self.alphas_cumprod)
|
| 82 |
+
self.sqrt_recip_alphas_cumprod = torch.rsqrt(self.alphas_cumprod)
|
| 83 |
+
self.sqrt_recipm1_alphas_cumprod = torch.sqrt(1 / self.alphas_cumprod - 1)
|
| 84 |
+
|
| 85 |
+
self.posterior_mean_coef1 = (self.betas * torch.sqrt(self.alphas_cumprod_prev) / (1 - self.alphas_cumprod))
|
| 86 |
+
self.posterior_mean_coef2 = ((1 - self.alphas_cumprod_prev) * torch.sqrt(self.alphas) / (1 - self.alphas_cumprod))
|
| 87 |
+
|
| 88 |
+
self.posterior_log_variance_clipped = torch.log(self.posterior_variance.clamp(min=1e-20))
|
| 89 |
+
|
| 90 |
+
def sample_posterior(coefficients, x_0,x_t, t):
|
| 91 |
+
|
| 92 |
+
def q_posterior(x_0, x_t, t):
|
| 93 |
+
mean = (
|
| 94 |
+
extract(coefficients.posterior_mean_coef1, t, x_t.shape) * x_0
|
| 95 |
+
+ extract(coefficients.posterior_mean_coef2, t, x_t.shape) * x_t
|
| 96 |
+
)
|
| 97 |
+
var = extract(coefficients.posterior_variance, t, x_t.shape)
|
| 98 |
+
log_var_clipped = extract(coefficients.posterior_log_variance_clipped, t, x_t.shape)
|
| 99 |
+
return mean, var, log_var_clipped
|
| 100 |
+
|
| 101 |
+
|
| 102 |
+
def p_sample(x_0, x_t, t):
|
| 103 |
+
mean, _, log_var = q_posterior(x_0, x_t, t)
|
| 104 |
+
|
| 105 |
+
noise = torch.randn_like(x_t)
|
| 106 |
+
|
| 107 |
+
nonzero_mask = (1 - (t == 0).type(torch.float32))
|
| 108 |
+
|
| 109 |
+
return mean + nonzero_mask[:,None,None,None] * torch.exp(0.5 * log_var) * noise
|
| 110 |
+
|
| 111 |
+
sample_x_pos = p_sample(x_0, x_t, t)
|
| 112 |
+
|
| 113 |
+
return sample_x_pos
|
| 114 |
+
|
| 115 |
+
def sample_from_model(coefficients, generator, n_time, x_init, T, opt):
|
| 116 |
+
x = x_init
|
| 117 |
+
with torch.no_grad():
|
| 118 |
+
for i in reversed(range(n_time)):
|
| 119 |
+
t = torch.full((x.size(0),), i, dtype=torch.int64).to(x.device)
|
| 120 |
+
|
| 121 |
+
t_time = t
|
| 122 |
+
latent_z = torch.randn(x.size(0), opt.nz, device=x.device)#.to(x.device)
|
| 123 |
+
x_0 = generator(x, t_time, latent_z)
|
| 124 |
+
x_new = sample_posterior(coefficients, x_0, x, t)
|
| 125 |
+
x = x_new.detach()
|
| 126 |
+
|
| 127 |
+
return x
|
| 128 |
+
|
| 129 |
+
#%%
|
| 130 |
+
def sample_and_test(args):
|
| 131 |
+
torch.manual_seed(42)
|
| 132 |
+
device = 'cuda:0'
|
| 133 |
+
|
| 134 |
+
if args.dataset == 'cifar10':
|
| 135 |
+
real_img_dir = 'pytorch_fid/cifar10_train_stat.npy'
|
| 136 |
+
elif args.dataset == 'celeba_256':
|
| 137 |
+
real_img_dir = 'pytorch_fid/celeba_256_stat.npy'
|
| 138 |
+
elif args.dataset == 'lsun':
|
| 139 |
+
real_img_dir = 'pytorch_fid/lsun_church_stat.npy'
|
| 140 |
+
else:
|
| 141 |
+
real_img_dir = args.real_img_dir
|
| 142 |
+
|
| 143 |
+
to_range_0_1 = lambda x: (x + 1.) / 2.
|
| 144 |
+
|
| 145 |
+
|
| 146 |
+
netG = NCSNpp(args).to(device)
|
| 147 |
+
ckpt = torch.load('./saved_info/dd_gan/{}/{}/netG_{}.pth'.format(args.dataset, args.exp, args.epoch_id), map_location=device)
|
| 148 |
+
|
| 149 |
+
#loading weights from ddp in single gpu
|
| 150 |
+
for key in list(ckpt.keys()):
|
| 151 |
+
ckpt[key[7:]] = ckpt.pop(key)
|
| 152 |
+
netG.load_state_dict(ckpt)
|
| 153 |
+
netG.eval()
|
| 154 |
+
|
| 155 |
+
|
| 156 |
+
T = get_time_schedule(args, device)
|
| 157 |
+
|
| 158 |
+
pos_coeff = Posterior_Coefficients(args, device)
|
| 159 |
+
|
| 160 |
+
iters_needed = 50000 //args.batch_size
|
| 161 |
+
|
| 162 |
+
save_dir = "./generated_samples/{}".format(args.dataset)
|
| 163 |
+
|
| 164 |
+
if not os.path.exists(save_dir):
|
| 165 |
+
os.makedirs(save_dir)
|
| 166 |
+
|
| 167 |
+
if args.compute_fid:
|
| 168 |
+
for i in range(iters_needed):
|
| 169 |
+
with torch.no_grad():
|
| 170 |
+
x_t_1 = torch.randn(args.batch_size, args.num_channels,args.image_size, args.image_size).to(device)
|
| 171 |
+
fake_sample = sample_from_model(pos_coeff, netG, args.num_timesteps, x_t_1,T, args)
|
| 172 |
+
|
| 173 |
+
fake_sample = to_range_0_1(fake_sample)
|
| 174 |
+
for j, x in enumerate(fake_sample):
|
| 175 |
+
index = i * args.batch_size + j
|
| 176 |
+
torchvision.utils.save_image(x, './generated_samples/{}/{}.jpg'.format(args.dataset, index))
|
| 177 |
+
print('generating batch ', i)
|
| 178 |
+
|
| 179 |
+
paths = [save_dir, real_img_dir]
|
| 180 |
+
|
| 181 |
+
kwargs = {'batch_size': 100, 'device': device, 'dims': 2048}
|
| 182 |
+
fid = calculate_fid_given_paths(paths=paths, **kwargs)
|
| 183 |
+
print('FID = {}'.format(fid))
|
| 184 |
+
else:
|
| 185 |
+
x_t_1 = torch.randn(args.batch_size, args.num_channels,args.image_size, args.image_size).to(device)
|
| 186 |
+
fake_sample = sample_from_model(pos_coeff, netG, args.num_timesteps, x_t_1,T, args)
|
| 187 |
+
fake_sample = to_range_0_1(fake_sample)
|
| 188 |
+
torchvision.utils.save_image(fake_sample, './samples_{}.jpg'.format(args.dataset))
|
| 189 |
+
|
| 190 |
+
|
| 191 |
+
|
| 192 |
+
|
| 193 |
+
|
| 194 |
+
if __name__ == '__main__':
|
| 195 |
+
parser = argparse.ArgumentParser('ddgan parameters')
|
| 196 |
+
parser.add_argument('--seed', type=int, default=1024,
|
| 197 |
+
help='seed used for initialization')
|
| 198 |
+
parser.add_argument('--compute_fid', action='store_true', default=False,
|
| 199 |
+
help='whether or not compute FID')
|
| 200 |
+
parser.add_argument('--epoch_id', type=int,default=1000)
|
| 201 |
+
parser.add_argument('--num_channels', type=int, default=3,
|
| 202 |
+
help='channel of image')
|
| 203 |
+
parser.add_argument('--centered', action='store_false', default=True,
|
| 204 |
+
help='-1,1 scale')
|
| 205 |
+
parser.add_argument('--use_geometric', action='store_true',default=False)
|
| 206 |
+
parser.add_argument('--beta_min', type=float, default= 0.1,
|
| 207 |
+
help='beta_min for diffusion')
|
| 208 |
+
parser.add_argument('--beta_max', type=float, default=20.,
|
| 209 |
+
help='beta_max for diffusion')
|
| 210 |
+
|
| 211 |
+
|
| 212 |
+
parser.add_argument('--num_channels_dae', type=int, default=128,
|
| 213 |
+
help='number of initial channels in denosing model')
|
| 214 |
+
parser.add_argument('--n_mlp', type=int, default=3,
|
| 215 |
+
help='number of mlp layers for z')
|
| 216 |
+
parser.add_argument('--ch_mult', nargs='+', type=int,
|
| 217 |
+
help='channel multiplier')
|
| 218 |
+
|
| 219 |
+
parser.add_argument('--num_res_blocks', type=int, default=2,
|
| 220 |
+
help='number of resnet blocks per scale')
|
| 221 |
+
parser.add_argument('--attn_resolutions', default=(16,),
|
| 222 |
+
help='resolution of applying attention')
|
| 223 |
+
parser.add_argument('--dropout', type=float, default=0.,
|
| 224 |
+
help='drop-out rate')
|
| 225 |
+
parser.add_argument('--resamp_with_conv', action='store_false', default=True,
|
| 226 |
+
help='always up/down sampling with conv')
|
| 227 |
+
parser.add_argument('--conditional', action='store_false', default=True,
|
| 228 |
+
help='noise conditional')
|
| 229 |
+
parser.add_argument('--fir', action='store_false', default=True,
|
| 230 |
+
help='FIR')
|
| 231 |
+
parser.add_argument('--fir_kernel', default=[1, 3, 3, 1],
|
| 232 |
+
help='FIR kernel')
|
| 233 |
+
parser.add_argument('--skip_rescale', action='store_false', default=True,
|
| 234 |
+
help='skip rescale')
|
| 235 |
+
parser.add_argument('--resblock_type', default='biggan',
|
| 236 |
+
help='tyle of resnet block, choice in biggan and ddpm')
|
| 237 |
+
parser.add_argument('--progressive', type=str, default='none', choices=['none', 'output_skip', 'residual'],
|
| 238 |
+
help='progressive type for output')
|
| 239 |
+
parser.add_argument('--progressive_input', type=str, default='residual', choices=['none', 'input_skip', 'residual'],
|
| 240 |
+
help='progressive type for input')
|
| 241 |
+
parser.add_argument('--progressive_combine', type=str, default='sum', choices=['sum', 'cat'],
|
| 242 |
+
help='progressive combine method.')
|
| 243 |
+
|
| 244 |
+
parser.add_argument('--embedding_type', type=str, default='positional', choices=['positional', 'fourier'],
|
| 245 |
+
help='type of time embedding')
|
| 246 |
+
parser.add_argument('--fourier_scale', type=float, default=16.,
|
| 247 |
+
help='scale of fourier transform')
|
| 248 |
+
parser.add_argument('--not_use_tanh', action='store_true',default=False)
|
| 249 |
+
|
| 250 |
+
#geenrator and training
|
| 251 |
+
parser.add_argument('--exp', default='experiment_cifar_default', help='name of experiment')
|
| 252 |
+
parser.add_argument('--real_img_dir', default='./pytorch_fid/cifar10_train_stat.npy', help='directory to real images for FID computation')
|
| 253 |
+
|
| 254 |
+
parser.add_argument('--dataset', default='cifar10', help='name of dataset')
|
| 255 |
+
parser.add_argument('--image_size', type=int, default=32,
|
| 256 |
+
help='size of image')
|
| 257 |
+
|
| 258 |
+
parser.add_argument('--nz', type=int, default=100)
|
| 259 |
+
parser.add_argument('--num_timesteps', type=int, default=4)
|
| 260 |
+
|
| 261 |
+
|
| 262 |
+
parser.add_argument('--z_emb_dim', type=int, default=256)
|
| 263 |
+
parser.add_argument('--t_emb_dim', type=int, default=256)
|
| 264 |
+
parser.add_argument('--batch_size', type=int, default=200, help='sample generating batch size')
|
| 265 |
+
|
| 266 |
+
|
| 267 |
+
|
| 268 |
+
|
| 269 |
+
|
| 270 |
+
args = parser.parse_args()
|
| 271 |
+
|
| 272 |
+
sample_and_test(args)
|
| 273 |
+
|
| 274 |
+
|
| 275 |
+
|
train_ddgan.py
ADDED
|
@@ -0,0 +1,602 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# ---------------------------------------------------------------
|
| 2 |
+
# Copyright (c) 2022, NVIDIA CORPORATION. All rights reserved.
|
| 3 |
+
#
|
| 4 |
+
# This work is licensed under the NVIDIA Source Code License
|
| 5 |
+
# for Denoising Diffusion GAN. To view a copy of this license, see the LICENSE file.
|
| 6 |
+
# ---------------------------------------------------------------
|
| 7 |
+
|
| 8 |
+
|
| 9 |
+
import argparse
|
| 10 |
+
import torch
|
| 11 |
+
import numpy as np
|
| 12 |
+
|
| 13 |
+
import os
|
| 14 |
+
|
| 15 |
+
import torch.nn as nn
|
| 16 |
+
import torch.nn.functional as F
|
| 17 |
+
import torch.optim as optim
|
| 18 |
+
import torchvision
|
| 19 |
+
|
| 20 |
+
import torchvision.transforms as transforms
|
| 21 |
+
from torchvision.datasets import CIFAR10
|
| 22 |
+
from datasets_prep.lsun import LSUN
|
| 23 |
+
from datasets_prep.stackmnist_data import StackedMNIST, _data_transforms_stacked_mnist
|
| 24 |
+
from datasets_prep.lmdb_datasets import LMDBDataset
|
| 25 |
+
|
| 26 |
+
|
| 27 |
+
from torch.multiprocessing import Process
|
| 28 |
+
import torch.distributed as dist
|
| 29 |
+
import shutil
|
| 30 |
+
|
| 31 |
+
def copy_source(file, output_dir):
|
| 32 |
+
shutil.copyfile(file, os.path.join(output_dir, os.path.basename(file)))
|
| 33 |
+
|
| 34 |
+
def broadcast_params(params):
|
| 35 |
+
for param in params:
|
| 36 |
+
dist.broadcast(param.data, src=0)
|
| 37 |
+
|
| 38 |
+
|
| 39 |
+
#%% Diffusion coefficients
|
| 40 |
+
def var_func_vp(t, beta_min, beta_max):
|
| 41 |
+
log_mean_coeff = -0.25 * t ** 2 * (beta_max - beta_min) - 0.5 * t * beta_min
|
| 42 |
+
var = 1. - torch.exp(2. * log_mean_coeff)
|
| 43 |
+
return var
|
| 44 |
+
|
| 45 |
+
def var_func_geometric(t, beta_min, beta_max):
|
| 46 |
+
return beta_min * ((beta_max / beta_min) ** t)
|
| 47 |
+
|
| 48 |
+
def extract(input, t, shape):
|
| 49 |
+
out = torch.gather(input, 0, t)
|
| 50 |
+
reshape = [shape[0]] + [1] * (len(shape) - 1)
|
| 51 |
+
out = out.reshape(*reshape)
|
| 52 |
+
|
| 53 |
+
return out
|
| 54 |
+
|
| 55 |
+
def get_time_schedule(args, device):
|
| 56 |
+
n_timestep = args.num_timesteps
|
| 57 |
+
eps_small = 1e-3
|
| 58 |
+
t = np.arange(0, n_timestep + 1, dtype=np.float64)
|
| 59 |
+
t = t / n_timestep
|
| 60 |
+
t = torch.from_numpy(t) * (1. - eps_small) + eps_small
|
| 61 |
+
return t.to(device)
|
| 62 |
+
|
| 63 |
+
def get_sigma_schedule(args, device):
|
| 64 |
+
n_timestep = args.num_timesteps
|
| 65 |
+
beta_min = args.beta_min
|
| 66 |
+
beta_max = args.beta_max
|
| 67 |
+
eps_small = 1e-3
|
| 68 |
+
|
| 69 |
+
t = np.arange(0, n_timestep + 1, dtype=np.float64)
|
| 70 |
+
t = t / n_timestep
|
| 71 |
+
t = torch.from_numpy(t) * (1. - eps_small) + eps_small
|
| 72 |
+
|
| 73 |
+
if args.use_geometric:
|
| 74 |
+
var = var_func_geometric(t, beta_min, beta_max)
|
| 75 |
+
else:
|
| 76 |
+
var = var_func_vp(t, beta_min, beta_max)
|
| 77 |
+
alpha_bars = 1.0 - var
|
| 78 |
+
betas = 1 - alpha_bars[1:] / alpha_bars[:-1]
|
| 79 |
+
|
| 80 |
+
first = torch.tensor(1e-8)
|
| 81 |
+
betas = torch.cat((first[None], betas)).to(device)
|
| 82 |
+
betas = betas.type(torch.float32)
|
| 83 |
+
sigmas = betas**0.5
|
| 84 |
+
a_s = torch.sqrt(1-betas)
|
| 85 |
+
return sigmas, a_s, betas
|
| 86 |
+
|
| 87 |
+
class Diffusion_Coefficients():
|
| 88 |
+
def __init__(self, args, device):
|
| 89 |
+
|
| 90 |
+
self.sigmas, self.a_s, _ = get_sigma_schedule(args, device=device)
|
| 91 |
+
self.a_s_cum = np.cumprod(self.a_s.cpu())
|
| 92 |
+
self.sigmas_cum = np.sqrt(1 - self.a_s_cum ** 2)
|
| 93 |
+
self.a_s_prev = self.a_s.clone()
|
| 94 |
+
self.a_s_prev[-1] = 1
|
| 95 |
+
|
| 96 |
+
self.a_s_cum = self.a_s_cum.to(device)
|
| 97 |
+
self.sigmas_cum = self.sigmas_cum.to(device)
|
| 98 |
+
self.a_s_prev = self.a_s_prev.to(device)
|
| 99 |
+
|
| 100 |
+
def q_sample(coeff, x_start, t, *, noise=None):
|
| 101 |
+
"""
|
| 102 |
+
Diffuse the data (t == 0 means diffused for t step)
|
| 103 |
+
"""
|
| 104 |
+
if noise is None:
|
| 105 |
+
noise = torch.randn_like(x_start)
|
| 106 |
+
|
| 107 |
+
x_t = extract(coeff.a_s_cum, t, x_start.shape) * x_start + \
|
| 108 |
+
extract(coeff.sigmas_cum, t, x_start.shape) * noise
|
| 109 |
+
|
| 110 |
+
return x_t
|
| 111 |
+
|
| 112 |
+
def q_sample_pairs(coeff, x_start, t):
|
| 113 |
+
"""
|
| 114 |
+
Generate a pair of disturbed images for training
|
| 115 |
+
:param x_start: x_0
|
| 116 |
+
:param t: time step t
|
| 117 |
+
:return: x_t, x_{t+1}
|
| 118 |
+
"""
|
| 119 |
+
noise = torch.randn_like(x_start)
|
| 120 |
+
x_t = q_sample(coeff, x_start, t)
|
| 121 |
+
x_t_plus_one = extract(coeff.a_s, t+1, x_start.shape) * x_t + \
|
| 122 |
+
extract(coeff.sigmas, t+1, x_start.shape) * noise
|
| 123 |
+
|
| 124 |
+
return x_t, x_t_plus_one
|
| 125 |
+
#%% posterior sampling
|
| 126 |
+
class Posterior_Coefficients():
|
| 127 |
+
def __init__(self, args, device):
|
| 128 |
+
|
| 129 |
+
_, _, self.betas = get_sigma_schedule(args, device=device)
|
| 130 |
+
|
| 131 |
+
#we don't need the zeros
|
| 132 |
+
self.betas = self.betas.type(torch.float32)[1:]
|
| 133 |
+
|
| 134 |
+
self.alphas = 1 - self.betas
|
| 135 |
+
self.alphas_cumprod = torch.cumprod(self.alphas, 0)
|
| 136 |
+
self.alphas_cumprod_prev = torch.cat(
|
| 137 |
+
(torch.tensor([1.], dtype=torch.float32,device=device), self.alphas_cumprod[:-1]), 0
|
| 138 |
+
)
|
| 139 |
+
self.posterior_variance = self.betas * (1 - self.alphas_cumprod_prev) / (1 - self.alphas_cumprod)
|
| 140 |
+
|
| 141 |
+
self.sqrt_alphas_cumprod = torch.sqrt(self.alphas_cumprod)
|
| 142 |
+
self.sqrt_recip_alphas_cumprod = torch.rsqrt(self.alphas_cumprod)
|
| 143 |
+
self.sqrt_recipm1_alphas_cumprod = torch.sqrt(1 / self.alphas_cumprod - 1)
|
| 144 |
+
|
| 145 |
+
self.posterior_mean_coef1 = (self.betas * torch.sqrt(self.alphas_cumprod_prev) / (1 - self.alphas_cumprod))
|
| 146 |
+
self.posterior_mean_coef2 = ((1 - self.alphas_cumprod_prev) * torch.sqrt(self.alphas) / (1 - self.alphas_cumprod))
|
| 147 |
+
|
| 148 |
+
self.posterior_log_variance_clipped = torch.log(self.posterior_variance.clamp(min=1e-20))
|
| 149 |
+
|
| 150 |
+
def sample_posterior(coefficients, x_0,x_t, t):
|
| 151 |
+
|
| 152 |
+
def q_posterior(x_0, x_t, t):
|
| 153 |
+
mean = (
|
| 154 |
+
extract(coefficients.posterior_mean_coef1, t, x_t.shape) * x_0
|
| 155 |
+
+ extract(coefficients.posterior_mean_coef2, t, x_t.shape) * x_t
|
| 156 |
+
)
|
| 157 |
+
var = extract(coefficients.posterior_variance, t, x_t.shape)
|
| 158 |
+
log_var_clipped = extract(coefficients.posterior_log_variance_clipped, t, x_t.shape)
|
| 159 |
+
return mean, var, log_var_clipped
|
| 160 |
+
|
| 161 |
+
|
| 162 |
+
def p_sample(x_0, x_t, t):
|
| 163 |
+
mean, _, log_var = q_posterior(x_0, x_t, t)
|
| 164 |
+
|
| 165 |
+
noise = torch.randn_like(x_t)
|
| 166 |
+
|
| 167 |
+
nonzero_mask = (1 - (t == 0).type(torch.float32))
|
| 168 |
+
|
| 169 |
+
return mean + nonzero_mask[:,None,None,None] * torch.exp(0.5 * log_var) * noise
|
| 170 |
+
|
| 171 |
+
sample_x_pos = p_sample(x_0, x_t, t)
|
| 172 |
+
|
| 173 |
+
return sample_x_pos
|
| 174 |
+
|
| 175 |
+
def sample_from_model(coefficients, generator, n_time, x_init, T, opt):
|
| 176 |
+
x = x_init
|
| 177 |
+
with torch.no_grad():
|
| 178 |
+
for i in reversed(range(n_time)):
|
| 179 |
+
t = torch.full((x.size(0),), i, dtype=torch.int64).to(x.device)
|
| 180 |
+
|
| 181 |
+
t_time = t
|
| 182 |
+
latent_z = torch.randn(x.size(0), opt.nz, device=x.device)
|
| 183 |
+
x_0 = generator(x, t_time, latent_z)
|
| 184 |
+
x_new = sample_posterior(coefficients, x_0, x, t)
|
| 185 |
+
x = x_new.detach()
|
| 186 |
+
|
| 187 |
+
return x
|
| 188 |
+
|
| 189 |
+
#%%
|
| 190 |
+
def train(rank, gpu, args):
|
| 191 |
+
from score_sde.models.discriminator import Discriminator_small, Discriminator_large
|
| 192 |
+
from score_sde.models.ncsnpp_generator_adagn import NCSNpp
|
| 193 |
+
from EMA import EMA
|
| 194 |
+
|
| 195 |
+
torch.manual_seed(args.seed + rank)
|
| 196 |
+
torch.cuda.manual_seed(args.seed + rank)
|
| 197 |
+
torch.cuda.manual_seed_all(args.seed + rank)
|
| 198 |
+
device = torch.device('cuda:{}'.format(gpu))
|
| 199 |
+
|
| 200 |
+
batch_size = args.batch_size
|
| 201 |
+
|
| 202 |
+
nz = args.nz #latent dimension
|
| 203 |
+
|
| 204 |
+
if args.dataset == 'cifar10':
|
| 205 |
+
dataset = CIFAR10('./data', train=True, transform=transforms.Compose([
|
| 206 |
+
transforms.Resize(32),
|
| 207 |
+
transforms.RandomHorizontalFlip(),
|
| 208 |
+
transforms.ToTensor(),
|
| 209 |
+
transforms.Normalize((0.5,0.5,0.5), (0.5,0.5,0.5))]), download=True)
|
| 210 |
+
|
| 211 |
+
|
| 212 |
+
elif args.dataset == 'stackmnist':
|
| 213 |
+
train_transform, valid_transform = _data_transforms_stacked_mnist()
|
| 214 |
+
dataset = StackedMNIST(root='./data', train=True, download=False, transform=train_transform)
|
| 215 |
+
|
| 216 |
+
elif args.dataset == 'lsun':
|
| 217 |
+
|
| 218 |
+
train_transform = transforms.Compose([
|
| 219 |
+
transforms.Resize(args.image_size),
|
| 220 |
+
transforms.CenterCrop(args.image_size),
|
| 221 |
+
transforms.RandomHorizontalFlip(),
|
| 222 |
+
transforms.ToTensor(),
|
| 223 |
+
transforms.Normalize((0.5,0.5,0.5), (0.5,0.5,0.5))
|
| 224 |
+
])
|
| 225 |
+
|
| 226 |
+
train_data = LSUN(root='/datasets/LSUN/', classes=['church_outdoor_train'], transform=train_transform)
|
| 227 |
+
subset = list(range(0, 120000))
|
| 228 |
+
dataset = torch.utils.data.Subset(train_data, subset)
|
| 229 |
+
|
| 230 |
+
|
| 231 |
+
elif args.dataset == 'celeba_256':
|
| 232 |
+
train_transform = transforms.Compose([
|
| 233 |
+
transforms.Resize(args.image_size),
|
| 234 |
+
transforms.RandomHorizontalFlip(),
|
| 235 |
+
transforms.ToTensor(),
|
| 236 |
+
transforms.Normalize((0.5,0.5,0.5), (0.5,0.5,0.5))
|
| 237 |
+
])
|
| 238 |
+
dataset = LMDBDataset(root='/datasets/celeba-lmdb/', name='celeba', train=True, transform=train_transform)
|
| 239 |
+
|
| 240 |
+
|
| 241 |
+
|
| 242 |
+
train_sampler = torch.utils.data.distributed.DistributedSampler(dataset,
|
| 243 |
+
num_replicas=args.world_size,
|
| 244 |
+
rank=rank)
|
| 245 |
+
data_loader = torch.utils.data.DataLoader(dataset,
|
| 246 |
+
batch_size=batch_size,
|
| 247 |
+
shuffle=False,
|
| 248 |
+
num_workers=4,
|
| 249 |
+
pin_memory=True,
|
| 250 |
+
sampler=train_sampler,
|
| 251 |
+
drop_last = True)
|
| 252 |
+
|
| 253 |
+
netG = NCSNpp(args).to(device)
|
| 254 |
+
|
| 255 |
+
|
| 256 |
+
if args.dataset == 'cifar10' or args.dataset == 'stackmnist':
|
| 257 |
+
netD = Discriminator_small(nc = 2*args.num_channels, ngf = args.ngf,
|
| 258 |
+
t_emb_dim = args.t_emb_dim,
|
| 259 |
+
act=nn.LeakyReLU(0.2)).to(device)
|
| 260 |
+
else:
|
| 261 |
+
netD = Discriminator_large(nc = 2*args.num_channels, ngf = args.ngf,
|
| 262 |
+
t_emb_dim = args.t_emb_dim,
|
| 263 |
+
act=nn.LeakyReLU(0.2)).to(device)
|
| 264 |
+
|
| 265 |
+
broadcast_params(netG.parameters())
|
| 266 |
+
broadcast_params(netD.parameters())
|
| 267 |
+
|
| 268 |
+
optimizerD = optim.Adam(netD.parameters(), lr=args.lr_d, betas = (args.beta1, args.beta2))
|
| 269 |
+
|
| 270 |
+
optimizerG = optim.Adam(netG.parameters(), lr=args.lr_g, betas = (args.beta1, args.beta2))
|
| 271 |
+
|
| 272 |
+
if args.use_ema:
|
| 273 |
+
optimizerG = EMA(optimizerG, ema_decay=args.ema_decay)
|
| 274 |
+
|
| 275 |
+
schedulerG = torch.optim.lr_scheduler.CosineAnnealingLR(optimizerG, args.num_epoch, eta_min=1e-5)
|
| 276 |
+
schedulerD = torch.optim.lr_scheduler.CosineAnnealingLR(optimizerD, args.num_epoch, eta_min=1e-5)
|
| 277 |
+
|
| 278 |
+
|
| 279 |
+
|
| 280 |
+
#ddp
|
| 281 |
+
netG = nn.parallel.DistributedDataParallel(netG, device_ids=[gpu])
|
| 282 |
+
netD = nn.parallel.DistributedDataParallel(netD, device_ids=[gpu])
|
| 283 |
+
|
| 284 |
+
|
| 285 |
+
exp = args.exp
|
| 286 |
+
parent_dir = "./saved_info/dd_gan/{}".format(args.dataset)
|
| 287 |
+
|
| 288 |
+
exp_path = os.path.join(parent_dir,exp)
|
| 289 |
+
if rank == 0:
|
| 290 |
+
if not os.path.exists(exp_path):
|
| 291 |
+
os.makedirs(exp_path)
|
| 292 |
+
copy_source(__file__, exp_path)
|
| 293 |
+
shutil.copytree('score_sde/models', os.path.join(exp_path, 'score_sde/models'))
|
| 294 |
+
|
| 295 |
+
|
| 296 |
+
coeff = Diffusion_Coefficients(args, device)
|
| 297 |
+
pos_coeff = Posterior_Coefficients(args, device)
|
| 298 |
+
T = get_time_schedule(args, device)
|
| 299 |
+
|
| 300 |
+
if args.resume:
|
| 301 |
+
checkpoint_file = os.path.join(exp_path, 'content.pth')
|
| 302 |
+
checkpoint = torch.load(checkpoint_file, map_location=device)
|
| 303 |
+
init_epoch = checkpoint['epoch']
|
| 304 |
+
epoch = init_epoch
|
| 305 |
+
netG.load_state_dict(checkpoint['netG_dict'])
|
| 306 |
+
# load G
|
| 307 |
+
|
| 308 |
+
optimizerG.load_state_dict(checkpoint['optimizerG'])
|
| 309 |
+
schedulerG.load_state_dict(checkpoint['schedulerG'])
|
| 310 |
+
# load D
|
| 311 |
+
netD.load_state_dict(checkpoint['netD_dict'])
|
| 312 |
+
optimizerD.load_state_dict(checkpoint['optimizerD'])
|
| 313 |
+
schedulerD.load_state_dict(checkpoint['schedulerD'])
|
| 314 |
+
global_step = checkpoint['global_step']
|
| 315 |
+
print("=> loaded checkpoint (epoch {})"
|
| 316 |
+
.format(checkpoint['epoch']))
|
| 317 |
+
else:
|
| 318 |
+
global_step, epoch, init_epoch = 0, 0, 0
|
| 319 |
+
|
| 320 |
+
|
| 321 |
+
for epoch in range(init_epoch, args.num_epoch+1):
|
| 322 |
+
train_sampler.set_epoch(epoch)
|
| 323 |
+
|
| 324 |
+
for iteration, (x, y) in enumerate(data_loader):
|
| 325 |
+
for p in netD.parameters():
|
| 326 |
+
p.requires_grad = True
|
| 327 |
+
|
| 328 |
+
|
| 329 |
+
netD.zero_grad()
|
| 330 |
+
|
| 331 |
+
#sample from p(x_0)
|
| 332 |
+
real_data = x.to(device, non_blocking=True)
|
| 333 |
+
|
| 334 |
+
#sample t
|
| 335 |
+
t = torch.randint(0, args.num_timesteps, (real_data.size(0),), device=device)
|
| 336 |
+
|
| 337 |
+
x_t, x_tp1 = q_sample_pairs(coeff, real_data, t)
|
| 338 |
+
x_t.requires_grad = True
|
| 339 |
+
|
| 340 |
+
|
| 341 |
+
# train with real
|
| 342 |
+
D_real = netD(x_t, t, x_tp1.detach()).view(-1)
|
| 343 |
+
|
| 344 |
+
errD_real = F.softplus(-D_real)
|
| 345 |
+
errD_real = errD_real.mean()
|
| 346 |
+
|
| 347 |
+
errD_real.backward(retain_graph=True)
|
| 348 |
+
|
| 349 |
+
|
| 350 |
+
if args.lazy_reg is None:
|
| 351 |
+
grad_real = torch.autograd.grad(
|
| 352 |
+
outputs=D_real.sum(), inputs=x_t, create_graph=True
|
| 353 |
+
)[0]
|
| 354 |
+
grad_penalty = (
|
| 355 |
+
grad_real.view(grad_real.size(0), -1).norm(2, dim=1) ** 2
|
| 356 |
+
).mean()
|
| 357 |
+
|
| 358 |
+
|
| 359 |
+
grad_penalty = args.r1_gamma / 2 * grad_penalty
|
| 360 |
+
grad_penalty.backward()
|
| 361 |
+
else:
|
| 362 |
+
if global_step % args.lazy_reg == 0:
|
| 363 |
+
grad_real = torch.autograd.grad(
|
| 364 |
+
outputs=D_real.sum(), inputs=x_t, create_graph=True
|
| 365 |
+
)[0]
|
| 366 |
+
grad_penalty = (
|
| 367 |
+
grad_real.view(grad_real.size(0), -1).norm(2, dim=1) ** 2
|
| 368 |
+
).mean()
|
| 369 |
+
|
| 370 |
+
|
| 371 |
+
grad_penalty = args.r1_gamma / 2 * grad_penalty
|
| 372 |
+
grad_penalty.backward()
|
| 373 |
+
|
| 374 |
+
# train with fake
|
| 375 |
+
latent_z = torch.randn(batch_size, nz, device=device)
|
| 376 |
+
|
| 377 |
+
|
| 378 |
+
x_0_predict = netG(x_tp1.detach(), t, latent_z)
|
| 379 |
+
x_pos_sample = sample_posterior(pos_coeff, x_0_predict, x_tp1, t)
|
| 380 |
+
|
| 381 |
+
output = netD(x_pos_sample, t, x_tp1.detach()).view(-1)
|
| 382 |
+
|
| 383 |
+
|
| 384 |
+
errD_fake = F.softplus(output)
|
| 385 |
+
errD_fake = errD_fake.mean()
|
| 386 |
+
errD_fake.backward()
|
| 387 |
+
|
| 388 |
+
|
| 389 |
+
errD = errD_real + errD_fake
|
| 390 |
+
# Update D
|
| 391 |
+
optimizerD.step()
|
| 392 |
+
|
| 393 |
+
|
| 394 |
+
#update G
|
| 395 |
+
for p in netD.parameters():
|
| 396 |
+
p.requires_grad = False
|
| 397 |
+
netG.zero_grad()
|
| 398 |
+
|
| 399 |
+
|
| 400 |
+
t = torch.randint(0, args.num_timesteps, (real_data.size(0),), device=device)
|
| 401 |
+
|
| 402 |
+
|
| 403 |
+
x_t, x_tp1 = q_sample_pairs(coeff, real_data, t)
|
| 404 |
+
|
| 405 |
+
|
| 406 |
+
latent_z = torch.randn(batch_size, nz,device=device)
|
| 407 |
+
|
| 408 |
+
|
| 409 |
+
|
| 410 |
+
|
| 411 |
+
x_0_predict = netG(x_tp1.detach(), t, latent_z)
|
| 412 |
+
x_pos_sample = sample_posterior(pos_coeff, x_0_predict, x_tp1, t)
|
| 413 |
+
|
| 414 |
+
output = netD(x_pos_sample, t, x_tp1.detach()).view(-1)
|
| 415 |
+
|
| 416 |
+
|
| 417 |
+
errG = F.softplus(-output)
|
| 418 |
+
errG = errG.mean()
|
| 419 |
+
|
| 420 |
+
errG.backward()
|
| 421 |
+
optimizerG.step()
|
| 422 |
+
|
| 423 |
+
|
| 424 |
+
|
| 425 |
+
global_step += 1
|
| 426 |
+
if iteration % 100 == 0:
|
| 427 |
+
if rank == 0:
|
| 428 |
+
print('epoch {} iteration{}, G Loss: {}, D Loss: {}'.format(epoch,iteration, errG.item(), errD.item()))
|
| 429 |
+
|
| 430 |
+
if not args.no_lr_decay:
|
| 431 |
+
|
| 432 |
+
schedulerG.step()
|
| 433 |
+
schedulerD.step()
|
| 434 |
+
|
| 435 |
+
if rank == 0:
|
| 436 |
+
if epoch % 10 == 0:
|
| 437 |
+
torchvision.utils.save_image(x_pos_sample, os.path.join(exp_path, 'xpos_epoch_{}.png'.format(epoch)), normalize=True)
|
| 438 |
+
|
| 439 |
+
x_t_1 = torch.randn_like(real_data)
|
| 440 |
+
fake_sample = sample_from_model(pos_coeff, netG, args.num_timesteps, x_t_1, T, args)
|
| 441 |
+
torchvision.utils.save_image(fake_sample, os.path.join(exp_path, 'sample_discrete_epoch_{}.png'.format(epoch)), normalize=True)
|
| 442 |
+
|
| 443 |
+
if args.save_content:
|
| 444 |
+
if epoch % args.save_content_every == 0:
|
| 445 |
+
print('Saving content.')
|
| 446 |
+
content = {'epoch': epoch + 1, 'global_step': global_step, 'args': args,
|
| 447 |
+
'netG_dict': netG.state_dict(), 'optimizerG': optimizerG.state_dict(),
|
| 448 |
+
'schedulerG': schedulerG.state_dict(), 'netD_dict': netD.state_dict(),
|
| 449 |
+
'optimizerD': optimizerD.state_dict(), 'schedulerD': schedulerD.state_dict()}
|
| 450 |
+
|
| 451 |
+
torch.save(content, os.path.join(exp_path, 'content.pth'))
|
| 452 |
+
|
| 453 |
+
if epoch % args.save_ckpt_every == 0:
|
| 454 |
+
if args.use_ema:
|
| 455 |
+
optimizerG.swap_parameters_with_ema(store_params_in_ema=True)
|
| 456 |
+
|
| 457 |
+
torch.save(netG.state_dict(), os.path.join(exp_path, 'netG_{}.pth'.format(epoch)))
|
| 458 |
+
if args.use_ema:
|
| 459 |
+
optimizerG.swap_parameters_with_ema(store_params_in_ema=True)
|
| 460 |
+
|
| 461 |
+
|
| 462 |
+
|
| 463 |
+
def init_processes(rank, size, fn, args):
|
| 464 |
+
""" Initialize the distributed environment. """
|
| 465 |
+
os.environ['MASTER_ADDR'] = args.master_address
|
| 466 |
+
os.environ['MASTER_PORT'] = '6020'
|
| 467 |
+
torch.cuda.set_device(args.local_rank)
|
| 468 |
+
gpu = args.local_rank
|
| 469 |
+
dist.init_process_group(backend='nccl', init_method='env://', rank=rank, world_size=size)
|
| 470 |
+
fn(rank, gpu, args)
|
| 471 |
+
dist.barrier()
|
| 472 |
+
cleanup()
|
| 473 |
+
|
| 474 |
+
def cleanup():
|
| 475 |
+
dist.destroy_process_group()
|
| 476 |
+
#%%
|
| 477 |
+
if __name__ == '__main__':
|
| 478 |
+
parser = argparse.ArgumentParser('ddgan parameters')
|
| 479 |
+
parser.add_argument('--seed', type=int, default=1024,
|
| 480 |
+
help='seed used for initialization')
|
| 481 |
+
|
| 482 |
+
parser.add_argument('--resume', action='store_true',default=False)
|
| 483 |
+
|
| 484 |
+
parser.add_argument('--image_size', type=int, default=32,
|
| 485 |
+
help='size of image')
|
| 486 |
+
parser.add_argument('--num_channels', type=int, default=3,
|
| 487 |
+
help='channel of image')
|
| 488 |
+
parser.add_argument('--centered', action='store_false', default=True,
|
| 489 |
+
help='-1,1 scale')
|
| 490 |
+
parser.add_argument('--use_geometric', action='store_true',default=False)
|
| 491 |
+
parser.add_argument('--beta_min', type=float, default= 0.1,
|
| 492 |
+
help='beta_min for diffusion')
|
| 493 |
+
parser.add_argument('--beta_max', type=float, default=20.,
|
| 494 |
+
help='beta_max for diffusion')
|
| 495 |
+
|
| 496 |
+
|
| 497 |
+
parser.add_argument('--num_channels_dae', type=int, default=128,
|
| 498 |
+
help='number of initial channels in denosing model')
|
| 499 |
+
parser.add_argument('--n_mlp', type=int, default=3,
|
| 500 |
+
help='number of mlp layers for z')
|
| 501 |
+
parser.add_argument('--ch_mult', nargs='+', type=int,
|
| 502 |
+
help='channel multiplier')
|
| 503 |
+
parser.add_argument('--num_res_blocks', type=int, default=2,
|
| 504 |
+
help='number of resnet blocks per scale')
|
| 505 |
+
parser.add_argument('--attn_resolutions', default=(16,),
|
| 506 |
+
help='resolution of applying attention')
|
| 507 |
+
parser.add_argument('--dropout', type=float, default=0.,
|
| 508 |
+
help='drop-out rate')
|
| 509 |
+
parser.add_argument('--resamp_with_conv', action='store_false', default=True,
|
| 510 |
+
help='always up/down sampling with conv')
|
| 511 |
+
parser.add_argument('--conditional', action='store_false', default=True,
|
| 512 |
+
help='noise conditional')
|
| 513 |
+
parser.add_argument('--fir', action='store_false', default=True,
|
| 514 |
+
help='FIR')
|
| 515 |
+
parser.add_argument('--fir_kernel', default=[1, 3, 3, 1],
|
| 516 |
+
help='FIR kernel')
|
| 517 |
+
parser.add_argument('--skip_rescale', action='store_false', default=True,
|
| 518 |
+
help='skip rescale')
|
| 519 |
+
parser.add_argument('--resblock_type', default='biggan',
|
| 520 |
+
help='tyle of resnet block, choice in biggan and ddpm')
|
| 521 |
+
parser.add_argument('--progressive', type=str, default='none', choices=['none', 'output_skip', 'residual'],
|
| 522 |
+
help='progressive type for output')
|
| 523 |
+
parser.add_argument('--progressive_input', type=str, default='residual', choices=['none', 'input_skip', 'residual'],
|
| 524 |
+
help='progressive type for input')
|
| 525 |
+
parser.add_argument('--progressive_combine', type=str, default='sum', choices=['sum', 'cat'],
|
| 526 |
+
help='progressive combine method.')
|
| 527 |
+
|
| 528 |
+
parser.add_argument('--embedding_type', type=str, default='positional', choices=['positional', 'fourier'],
|
| 529 |
+
help='type of time embedding')
|
| 530 |
+
parser.add_argument('--fourier_scale', type=float, default=16.,
|
| 531 |
+
help='scale of fourier transform')
|
| 532 |
+
parser.add_argument('--not_use_tanh', action='store_true',default=False)
|
| 533 |
+
|
| 534 |
+
#geenrator and training
|
| 535 |
+
parser.add_argument('--exp', default='experiment_cifar_default', help='name of experiment')
|
| 536 |
+
parser.add_argument('--dataset', default='cifar10', help='name of dataset')
|
| 537 |
+
parser.add_argument('--nz', type=int, default=100)
|
| 538 |
+
parser.add_argument('--num_timesteps', type=int, default=4)
|
| 539 |
+
|
| 540 |
+
parser.add_argument('--z_emb_dim', type=int, default=256)
|
| 541 |
+
parser.add_argument('--t_emb_dim', type=int, default=256)
|
| 542 |
+
parser.add_argument('--batch_size', type=int, default=128, help='input batch size')
|
| 543 |
+
parser.add_argument('--num_epoch', type=int, default=1200)
|
| 544 |
+
parser.add_argument('--ngf', type=int, default=64)
|
| 545 |
+
|
| 546 |
+
parser.add_argument('--lr_g', type=float, default=1.5e-4, help='learning rate g')
|
| 547 |
+
parser.add_argument('--lr_d', type=float, default=1e-4, help='learning rate d')
|
| 548 |
+
parser.add_argument('--beta1', type=float, default=0.5,
|
| 549 |
+
help='beta1 for adam')
|
| 550 |
+
parser.add_argument('--beta2', type=float, default=0.9,
|
| 551 |
+
help='beta2 for adam')
|
| 552 |
+
parser.add_argument('--no_lr_decay',action='store_true', default=False)
|
| 553 |
+
|
| 554 |
+
parser.add_argument('--use_ema', action='store_true', default=False,
|
| 555 |
+
help='use EMA or not')
|
| 556 |
+
parser.add_argument('--ema_decay', type=float, default=0.9999, help='decay rate for EMA')
|
| 557 |
+
|
| 558 |
+
parser.add_argument('--r1_gamma', type=float, default=0.05, help='coef for r1 reg')
|
| 559 |
+
parser.add_argument('--lazy_reg', type=int, default=None,
|
| 560 |
+
help='lazy regulariation.')
|
| 561 |
+
|
| 562 |
+
parser.add_argument('--save_content', action='store_true',default=False)
|
| 563 |
+
parser.add_argument('--save_content_every', type=int, default=50, help='save content for resuming every x epochs')
|
| 564 |
+
parser.add_argument('--save_ckpt_every', type=int, default=25, help='save ckpt every x epochs')
|
| 565 |
+
|
| 566 |
+
###ddp
|
| 567 |
+
parser.add_argument('--num_proc_node', type=int, default=1,
|
| 568 |
+
help='The number of nodes in multi node env.')
|
| 569 |
+
parser.add_argument('--num_process_per_node', type=int, default=1,
|
| 570 |
+
help='number of gpus')
|
| 571 |
+
parser.add_argument('--node_rank', type=int, default=0,
|
| 572 |
+
help='The index of node.')
|
| 573 |
+
parser.add_argument('--local_rank', type=int, default=0,
|
| 574 |
+
help='rank of process in the node')
|
| 575 |
+
parser.add_argument('--master_address', type=str, default='127.0.0.1',
|
| 576 |
+
help='address for master')
|
| 577 |
+
|
| 578 |
+
|
| 579 |
+
args = parser.parse_args()
|
| 580 |
+
args.world_size = args.num_proc_node * args.num_process_per_node
|
| 581 |
+
size = args.num_process_per_node
|
| 582 |
+
|
| 583 |
+
if size > 1:
|
| 584 |
+
processes = []
|
| 585 |
+
for rank in range(size):
|
| 586 |
+
args.local_rank = rank
|
| 587 |
+
global_rank = rank + args.node_rank * args.num_process_per_node
|
| 588 |
+
global_size = args.num_proc_node * args.num_process_per_node
|
| 589 |
+
args.global_rank = global_rank
|
| 590 |
+
print('Node rank %d, local proc %d, global proc %d' % (args.node_rank, rank, global_rank))
|
| 591 |
+
p = Process(target=init_processes, args=(global_rank, global_size, train, args))
|
| 592 |
+
p.start()
|
| 593 |
+
processes.append(p)
|
| 594 |
+
|
| 595 |
+
for p in processes:
|
| 596 |
+
p.join()
|
| 597 |
+
else:
|
| 598 |
+
print('starting in debug mode')
|
| 599 |
+
|
| 600 |
+
init_processes(0, size, train, args)
|
| 601 |
+
|
| 602 |
+
|