
feat: fire model
Browse files- assets/chart.png +0 -0
- assets/clver_1.jpg +0 -0
- assets/fire_logo.png +0 -0
- src/__pycache__/conversation.cpython-310.pyc +0 -0
- src/conversation.py +2 -2
- src/model/model_llava.py +33 -4
- src/serve/__pycache__/gradio_block_arena_vision_named.cpython-310.pyc +0 -0
- src/serve/__pycache__/gradio_web_server.cpython-310.pyc +0 -0
- src/serve/gradio_block_arena_vision_named.py +7 -4
- src/serve/gradio_web_server.py +7 -5
assets/chart.png
ADDED
|
assets/clver_1.jpg
ADDED

|
assets/fire_logo.png
ADDED
|
|
src/__pycache__/conversation.cpython-310.pyc
CHANGED
|
Binary files a/src/__pycache__/conversation.cpython-310.pyc and b/src/__pycache__/conversation.cpython-310.pyc differ
|
|
|
src/conversation.py
CHANGED
|
@@ -2091,8 +2091,8 @@ register_conv_template(
|
|
| 2091 |
conv_llava_llama_3 = Conversation(
|
| 2092 |
name="llava-original",
|
| 2093 |
system_message="You are a helpful language and vision assistant. You are able to understand the visual content that the user provides, and assist the user with a variety of tasks using natural language.",
|
| 2094 |
-
roles=("user
|
| 2095 |
-
"assistant
|
| 2096 |
# version="llama3",
|
| 2097 |
messages=[],
|
| 2098 |
offset=0,
|
|
|
|
| 2091 |
conv_llava_llama_3 = Conversation(
|
| 2092 |
name="llava-original",
|
| 2093 |
system_message="You are a helpful language and vision assistant. You are able to understand the visual content that the user provides, and assist the user with a variety of tasks using natural language.",
|
| 2094 |
+
roles=("user",
|
| 2095 |
+
"assistant"),
|
| 2096 |
# version="llama3",
|
| 2097 |
messages=[],
|
| 2098 |
offset=0,
|
src/model/model_llava.py
CHANGED
|
@@ -26,14 +26,16 @@ def load_llava_model(lora_checkpoint=None):
|
|
| 26 |
model_path, None, model_name, device_map=device_map) # Add any other thing you want to pass in llava_model_args
|
| 27 |
else:
|
| 28 |
tokenizer, model, image_processor, max_length = load_pretrained_model(
|
| 29 |
-
lora_checkpoint, model_path,
|
| 30 |
|
| 31 |
model.eval()
|
| 32 |
model.tie_weights()
|
|
|
|
| 33 |
return tokenizer, model, image_processor, conv_template
|
| 34 |
|
| 35 |
-
tokenizer_llava, model_llava, image_processor_llava, conv_template_llava = load_llava_model(
|
| 36 |
-
|
|
|
|
| 37 |
@spaces.GPU
|
| 38 |
def inference():
|
| 39 |
image = Image.open("assets/example.jpg").convert("RGB")
|
|
@@ -77,7 +79,7 @@ def inference_by_prompt_and_images(prompt, images):
|
|
| 77 |
image_tensor = image_tensor.to(dtype=torch.float16, device=device)
|
| 78 |
input_ids = tokenizer_image_token(prompt, tokenizer_llava, IMAGE_TOKEN_INDEX, return_tensors="pt").unsqueeze(0).to(device)
|
| 79 |
image_sizes = [image.size for image in images]
|
| 80 |
-
logger.info("Shape: {};{}",input_ids.shape, image_tensor.shape)
|
| 81 |
with torch.inference_mode():
|
| 82 |
cont = model_llava.generate(
|
| 83 |
input_ids,
|
|
@@ -92,5 +94,32 @@ def inference_by_prompt_and_images(prompt, images):
|
|
| 92 |
logger.info("response={}", text_outputs)
|
| 93 |
return text_outputs
|
| 94 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 95 |
if __name__ == "__main__":
|
| 96 |
inference()
|
|
|
|
| 26 |
model_path, None, model_name, device_map=device_map) # Add any other thing you want to pass in llava_model_args
|
| 27 |
else:
|
| 28 |
tokenizer, model, image_processor, max_length = load_pretrained_model(
|
| 29 |
+
lora_checkpoint, model_path, "llava_lora", device_map=device_map)
|
| 30 |
|
| 31 |
model.eval()
|
| 32 |
model.tie_weights()
|
| 33 |
+
logger.info("model device {}", model.device)
|
| 34 |
return tokenizer, model, image_processor, conv_template
|
| 35 |
|
| 36 |
+
tokenizer_llava, model_llava, image_processor_llava, conv_template_llava = load_llava_model(None)
|
| 37 |
+
tokenizer_llava_fire, model_llava_fire, image_processor_llava_fire, conv_template_llava = load_llava_model("checkpoints/")
|
| 38 |
+
model_llava_fire.to("cuda")
|
| 39 |
@spaces.GPU
|
| 40 |
def inference():
|
| 41 |
image = Image.open("assets/example.jpg").convert("RGB")
|
|
|
|
| 79 |
image_tensor = image_tensor.to(dtype=torch.float16, device=device)
|
| 80 |
input_ids = tokenizer_image_token(prompt, tokenizer_llava, IMAGE_TOKEN_INDEX, return_tensors="pt").unsqueeze(0).to(device)
|
| 81 |
image_sizes = [image.size for image in images]
|
| 82 |
+
logger.info("Shape: {};{}; Devices: {};{}",input_ids.shape, image_tensor.shape, input_ids.device, image_tensor.device)
|
| 83 |
with torch.inference_mode():
|
| 84 |
cont = model_llava.generate(
|
| 85 |
input_ids,
|
|
|
|
| 94 |
logger.info("response={}", text_outputs)
|
| 95 |
return text_outputs
|
| 96 |
|
| 97 |
+
@spaces.GPU
|
| 98 |
+
def inference_by_prompt_and_images_fire(prompt, images):
|
| 99 |
+
device = "cuda"
|
| 100 |
+
if len(images) > 0 and type(images[0]) is str:
|
| 101 |
+
image_data = []
|
| 102 |
+
for image in images:
|
| 103 |
+
image_data.append(Image.open(BytesIO(base64.b64decode(image))))
|
| 104 |
+
images = image_data
|
| 105 |
+
image_tensor = process_images(images, image_processor_llava, model_llava.config)
|
| 106 |
+
image_tensor = image_tensor.to(dtype=torch.float16, device=device)
|
| 107 |
+
input_ids = tokenizer_image_token(prompt, tokenizer_llava, IMAGE_TOKEN_INDEX, return_tensors="pt").unsqueeze(0).to(device)
|
| 108 |
+
image_sizes = [image.size for image in images]
|
| 109 |
+
logger.info("Shape: {};{}; Devices: {};{}",input_ids.shape, image_tensor.shape, input_ids.device, image_tensor.device)
|
| 110 |
+
with torch.inference_mode():
|
| 111 |
+
cont = model_llava_fire.generate(
|
| 112 |
+
input_ids,
|
| 113 |
+
images=image_tensor,
|
| 114 |
+
image_sizes=image_sizes,
|
| 115 |
+
do_sample=False,
|
| 116 |
+
temperature=0,
|
| 117 |
+
max_new_tokens=256,
|
| 118 |
+
use_cache=True
|
| 119 |
+
)
|
| 120 |
+
text_outputs = tokenizer_llava.batch_decode(cont, skip_special_tokens=True)
|
| 121 |
+
logger.info("response={}", text_outputs)
|
| 122 |
+
return text_outputs
|
| 123 |
+
|
| 124 |
if __name__ == "__main__":
|
| 125 |
inference()
|
src/serve/__pycache__/gradio_block_arena_vision_named.cpython-310.pyc
CHANGED
|
Binary files a/src/serve/__pycache__/gradio_block_arena_vision_named.cpython-310.pyc and b/src/serve/__pycache__/gradio_block_arena_vision_named.cpython-310.pyc differ
|
|
|
src/serve/__pycache__/gradio_web_server.cpython-310.pyc
CHANGED
|
Binary files a/src/serve/__pycache__/gradio_web_server.cpython-310.pyc and b/src/serve/__pycache__/gradio_web_server.cpython-310.pyc differ
|
|
|
src/serve/gradio_block_arena_vision_named.py
CHANGED
|
@@ -243,8 +243,7 @@ def add_text(
|
|
| 243 |
|
| 244 |
def build_side_by_side_vision_ui_named(models, random_questions=None):
|
| 245 |
notice_markdown = """
|
| 246 |
-
# ⚔️ Vision Arena ⚔️ : Benchmarking
|
| 247 |
-
| [Blog](https://lmsys.org/blog/2023-05-03-arena/) | [GitHub](https://github.com/lm-sys/FastChat) | [Paper](https://arxiv.org/abs/2306.05685) | [Dataset](https://github.com/lm-sys/FastChat/blob/main/docs/dataset_release.md) | [Twitter](https://twitter.com/lmsysorg) | [Discord](https://discord.gg/HSWAKCrnFx) |
|
| 248 |
|
| 249 |
## 📜 Rules
|
| 250 |
- Chat with any two models side-by-side and vote!
|
|
@@ -334,7 +333,11 @@ def build_side_by_side_vision_ui_named(models, random_questions=None):
|
|
| 334 |
clear_btn = gr.Button(value="🗑️ Clear history", interactive=False)
|
| 335 |
regenerate_btn = gr.Button(value="🔄 Regenerate", interactive=False)
|
| 336 |
share_btn = gr.Button(value="📷 Share")
|
| 337 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
| 338 |
with gr.Accordion("Parameters", open=False) as parameter_row:
|
| 339 |
temperature = gr.Slider(
|
| 340 |
minimum=0.0,
|
|
@@ -402,7 +405,7 @@ def build_side_by_side_vision_ui_named(models, random_questions=None):
|
|
| 402 |
flash_buttons, [], btn_list
|
| 403 |
)
|
| 404 |
clear_btn.click(clear_history, None, states + chatbots + [textbox] + btn_list)
|
| 405 |
-
|
| 406 |
share_js = """
|
| 407 |
function (a, b, c, d) {
|
| 408 |
const captureElement = document.querySelector('#share-region-named');
|
|
|
|
| 243 |
|
| 244 |
def build_side_by_side_vision_ui_named(models, random_questions=None):
|
| 245 |
notice_markdown = """
|
| 246 |
+
# ⚔️ Vision Arena ⚔️ : Benchmarking LLAVA-FIRE VS. LLAVA
|
|
|
|
| 247 |
|
| 248 |
## 📜 Rules
|
| 249 |
- Chat with any two models side-by-side and vote!
|
|
|
|
| 333 |
clear_btn = gr.Button(value="🗑️ Clear history", interactive=False)
|
| 334 |
regenerate_btn = gr.Button(value="🔄 Regenerate", interactive=False)
|
| 335 |
share_btn = gr.Button(value="📷 Share")
|
| 336 |
+
with gr.Row():
|
| 337 |
+
gr.Examples(examples=[
|
| 338 |
+
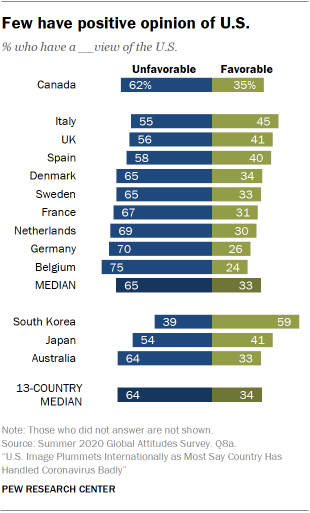
[{"files":["assets/chart.png"], "text": "What's the percentage value of Japan who have a favorable view of the US? Answer the question using a single word or phrase."}],
|
| 339 |
+
[{"files":["assets/clver_1.jpg"], "text": "Hint: Please answer the question and provide the correct option letter, e.g., A, B, C, D, at the end.\nQuestion: Is the number of metal cars that are left of the tiny matte school bus greater than the number of tiny cyan double buss?\nChoices:\n(A) Yes\n(B) No"}],
|
| 340 |
+
],inputs=[textbox])
|
| 341 |
with gr.Accordion("Parameters", open=False) as parameter_row:
|
| 342 |
temperature = gr.Slider(
|
| 343 |
minimum=0.0,
|
|
|
|
| 405 |
flash_buttons, [], btn_list
|
| 406 |
)
|
| 407 |
clear_btn.click(clear_history, None, states + chatbots + [textbox] + btn_list)
|
| 408 |
+
|
| 409 |
share_js = """
|
| 410 |
function (a, b, c, d) {
|
| 411 |
const captureElement = document.querySelector('#share-region-named');
|
src/serve/gradio_web_server.py
CHANGED
|
@@ -410,7 +410,7 @@ def bot_response(
|
|
| 410 |
top_p,
|
| 411 |
max_new_tokens,
|
| 412 |
request: gr.Request,
|
| 413 |
-
apply_rate_limit=
|
| 414 |
use_recommended_config=False,
|
| 415 |
):
|
| 416 |
ip = get_ip(request)
|
|
@@ -440,14 +440,16 @@ def bot_response(
|
|
| 440 |
api_endpoint_info[model_name] if model_name in api_endpoint_info else None
|
| 441 |
)
|
| 442 |
images = conv.get_images()
|
| 443 |
-
logger.info(f"model_name: {model_name};model_api_dict: {model_api_dict}")
|
| 444 |
if model_api_dict is None:
|
| 445 |
if model_name == "llava-original":
|
| 446 |
-
from src.model.model_llava import
|
| 447 |
-
logger.info(f"prompt: {conv.get_prompt()}; images: {images}")
|
| 448 |
output_text = inference_by_prompt_and_images(conv.get_prompt(), images)[0]
|
| 449 |
else:
|
| 450 |
-
|
|
|
|
|
|
|
| 451 |
stream_iter = [{
|
| 452 |
"error_code": 0,
|
| 453 |
"text": output_text
|
|
|
|
| 410 |
top_p,
|
| 411 |
max_new_tokens,
|
| 412 |
request: gr.Request,
|
| 413 |
+
apply_rate_limit=False,
|
| 414 |
use_recommended_config=False,
|
| 415 |
):
|
| 416 |
ip = get_ip(request)
|
|
|
|
| 440 |
api_endpoint_info[model_name] if model_name in api_endpoint_info else None
|
| 441 |
)
|
| 442 |
images = conv.get_images()
|
| 443 |
+
logger.info(f"model_name: {model_name}; model_api_dict: {model_api_dict}; msg: {conv.messages}")
|
| 444 |
if model_api_dict is None:
|
| 445 |
if model_name == "llava-original":
|
| 446 |
+
from src.model.model_llava import inference_by_prompt_and_images
|
| 447 |
+
logger.info(f"prompt for llava-original: {conv.get_prompt()}; images: {len(images)}")
|
| 448 |
output_text = inference_by_prompt_and_images(conv.get_prompt(), images)[0]
|
| 449 |
else:
|
| 450 |
+
from src.model.model_llava import inference_by_prompt_and_images_fire
|
| 451 |
+
logger.info(f"prompt for llava-fire: {conv.get_prompt()}; images: {len(images)}")
|
| 452 |
+
output_text = inference_by_prompt_and_images_fire(conv.get_prompt(), images)[0]
|
| 453 |
stream_iter = [{
|
| 454 |
"error_code": 0,
|
| 455 |
"text": output_text
|