Spaces:
Running

Running
Update Blog.md
Browse files
Blog.md
CHANGED
|
@@ -1,84 +1,109 @@
|
|
| 1 |
-
# GRPO Training for SQL Query Optimization
|
| 2 |
|
| 3 |
-
|
| 4 |
-
Fine-tuned `Qwen/Qwen2.5-0.5B-Instruct` using GRPO (Group Relative Policy Optimization)
|
| 5 |
-
reinforcement learning to optimize SQL queries using a DuckDB execution environment.
|
| 6 |
|
| 7 |
-
|
| 8 |
-
|
| 9 |
-
|
| 10 |
|
| 11 |
-
|
| 12 |
|
| 13 |
-
##
|
| 14 |
-
- Used [SQL Query Optimization Environment](https://github.com/OfficialAbhinavSingh/SQL-Query-Optimization-Environment-)
|
| 15 |
-
- DuckDB-based execution environment with 5 tasks of increasing difficulty
|
| 16 |
-
- Tasks: basic antipatterns, correlated subqueries, wildcard scans, implicit joins, window functions
|
| 17 |
|
| 18 |
-
|
| 19 |
-
- **Algorithm:** GRPO (Group Relative Policy Optimization)
|
| 20 |
-
- **Base Model:** Qwen/Qwen2.5-0.5B-Instruct
|
| 21 |
-
- **Episodes:** 100
|
| 22 |
-
- **Group Size:** 4 completions per prompt
|
| 23 |
-
- **Hardware:** Kaggle GPU T4 x2
|
| 24 |
|
| 25 |
-
|
| 26 |
-
The reward function combines multiple signals:
|
| 27 |
-
- `execution_speedup`: How much faster the optimized query runs
|
| 28 |
-
- `result_correctness`: Whether the optimized query returns identical results
|
| 29 |
-
- `issue_detection`: Whether SQL anti-patterns were correctly identified
|
| 30 |
-
- `approval_correctness`: Whether the approval flag is set correctly
|
| 31 |
-
- `summary_quality`: Quality of the explanation
|
| 32 |
-
- `severity_labels`: Correctness of severity ratings
|
| 33 |
|
| 34 |
-
|
| 35 |
-
providing a useful gradient signal for partial progress.
|
| 36 |
|
| 37 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 38 |
|
| 39 |
-
### Training Progress
|
| 40 |
| Metric | Value |
|
| 41 |
|--------|-------|
|
| 42 |
-
| Start avg (
|
| 43 |
-
| End avg (
|
| 44 |
-
| Improvement | +93% |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 45 |
|
| 46 |
-
### Final Evaluation
|
| 47 |
| Task | Difficulty | Score |
|
| 48 |
|------|-----------|-------|
|
| 49 |
-
| task_1_basic_antipatterns | easy | 0.7500 ✅ |
|
| 50 |
-
| task_2_correlated_subqueries | medium | 0.8313 ✅ |
|
| 51 |
-
| task_3_wildcard_scan | medium-hard | 0.
|
| 52 |
-
| task_4_implicit_join | hard | 0.
|
| 53 |
-
| task_5_window_functions | expert | 0.
|
| 54 |
-
|
|
|
|
|
|
|
|
|
|
| 55 |
|
| 56 |
-
|
| 57 |
-
**
|
|
|
|
| 58 |
|
| 59 |
-
|
| 60 |
-

|
| 61 |
|
| 62 |
-
|
|
|
|
| 63 |
|
| 64 |
-
|
| 65 |
-
generated invalid SQL. Fixing the prompt to include schema information created reward
|
| 66 |
-
variance needed for GRPO to learn.
|
| 67 |
|
| 68 |
-
|
| 69 |
-
columns from the schema was the single most impactful fix.
|
| 70 |
|
| 71 |
-
|
| 72 |
-
signal even when SQL execution failed.
|
| 73 |
|
| 74 |
-
|
| 75 |
-
|
|
|
|
|
|
|
| 76 |
|
| 77 |
-
#
|
| 78 |
-
|
| 79 |
|
| 80 |
-
#
|
| 81 |
-
|
| 82 |
-
- [TRL Library](https://huggingface.co/docs/trl)
|
| 83 |
-
- [SQL Optimization Environment](https://github.com/OfficialAbhinavSingh/SQL-Query-Optimization-Environment-)
|
| 84 |
-
- [Qwen2.5 Model](https://huggingface.co/Qwen/Qwen2.5-0.5B-Instruct)
|
|
|
|
| 1 |
+
# GRPO Training for SQL Query Optimization (DuckDB-Verifiable Rewards)
|
| 2 |
|
| 3 |
+
Fine-tuned `Qwen/Qwen2.5-0.5B-Instruct` using **GRPO (Group Relative Policy Optimization)** to optimize SQL queries with **verifiable rewards**: we **execute** the original + rewritten SQL against a real DuckDB database and score based on measured speedup and correctness.
|
|
|
|
|
|
|
| 4 |
|
| 5 |
+
- **Repo (source of truth):** https://github.com/OfficialAbhinavSingh/SQL-Query-Optimization-Environment-
|
| 6 |
+
- **Model:** https://huggingface.co/laterabhi/grpo-sql-optimizer
|
| 7 |
+
- **Space:** https://huggingface.co/spaces/laterabhi/grpo-sql-optimizer
|
| 8 |
|
| 9 |
+
---
|
| 10 |
|
| 11 |
+
## Why this matters
|
|
|
|
|
|
|
|
|
|
| 12 |
|
| 13 |
+
LLMs often generate SQL that is syntactically valid but **slow** (or subtly wrong) at scale. Classic training setups use heuristic scoring, which can be gamed. This project trains/evaluates SQL optimization with **execution-grounded feedback**.
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 14 |
|
| 15 |
+
---
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 16 |
|
| 17 |
+
## Environment (5 tasks, increasing difficulty)
|
|
|
|
| 18 |
|
| 19 |
+
We use the **SQL Query Optimization Environment** (OpenEnv compliant), backed by an in-memory DuckDB dataset:
|
| 20 |
+
|
| 21 |
+
- `users` (10k), `orders` (500k), `events` (1M), `products` (1k)
|
| 22 |
+
|
| 23 |
+
Tasks:
|
| 24 |
+
1. `task_1_basic_antipatterns` (easy)
|
| 25 |
+
2. `task_2_correlated_subqueries` (medium)
|
| 26 |
+
3. `task_3_wildcard_scan` (medium-hard)
|
| 27 |
+
4. `task_4_implicit_join` (hard)
|
| 28 |
+
5. `task_5_window_functions` (expert)
|
| 29 |
+
|
| 30 |
+
---
|
| 31 |
+
|
| 32 |
+
## Reward function (execution-grounded)
|
| 33 |
+
|
| 34 |
+
Composite reward in \[0, 1\], combining:
|
| 35 |
+
|
| 36 |
+
- **execution_speedup (35%)**: measured ratio `original_ms / optimized_ms` from DuckDB
|
| 37 |
+
- **result_correctness (20%)**: results match check (order-independent for large outputs)
|
| 38 |
+
- **issue_detection (25%)**: anti-pattern detection vs ground-truth keywords per task
|
| 39 |
+
- **approval_correctness (8%)**
|
| 40 |
+
- **summary_quality (7%)**
|
| 41 |
+
- **severity_labels (5%)**
|
| 42 |
+
|
| 43 |
+
This is designed to be **hard to game**: “fast but wrong” loses correctness; “verbose but slow” loses speedup.
|
| 44 |
+
|
| 45 |
+
---
|
| 46 |
+
|
| 47 |
+
## Training setup (GRPO)
|
| 48 |
+
|
| 49 |
+
- **Algorithm:** GRPO (group-relative policy optimization)
|
| 50 |
+
- **Base model:** `Qwen/Qwen2.5-0.5B-Instruct`
|
| 51 |
+
- **Group size:** 4 completions per prompt
|
| 52 |
+
- **Notebook:** Kaggle (linked in repo README)
|
| 53 |
+
- **Note:** `train.py` defaults to 200 episodes, but the reported curve/table below is from the 100-episode run described in the repo.
|
| 54 |
+
|
| 55 |
+
---
|
| 56 |
+
|
| 57 |
+
## Results (from the GitHub repo)
|
| 58 |
+
|
| 59 |
+
### Training progress (100 episodes)
|
| 60 |
|
|
|
|
| 61 |
| Metric | Value |
|
| 62 |
|--------|-------|
|
| 63 |
+
| Start avg (ep 1–10) | 0.3090 |
|
| 64 |
+
| End avg (ep 91–100) | 0.5962 |
|
| 65 |
+
| Improvement | **+93%** |
|
| 66 |
+
|
| 67 |
+
**Reward curve:**
|
| 68 |
+
|
| 69 |
+
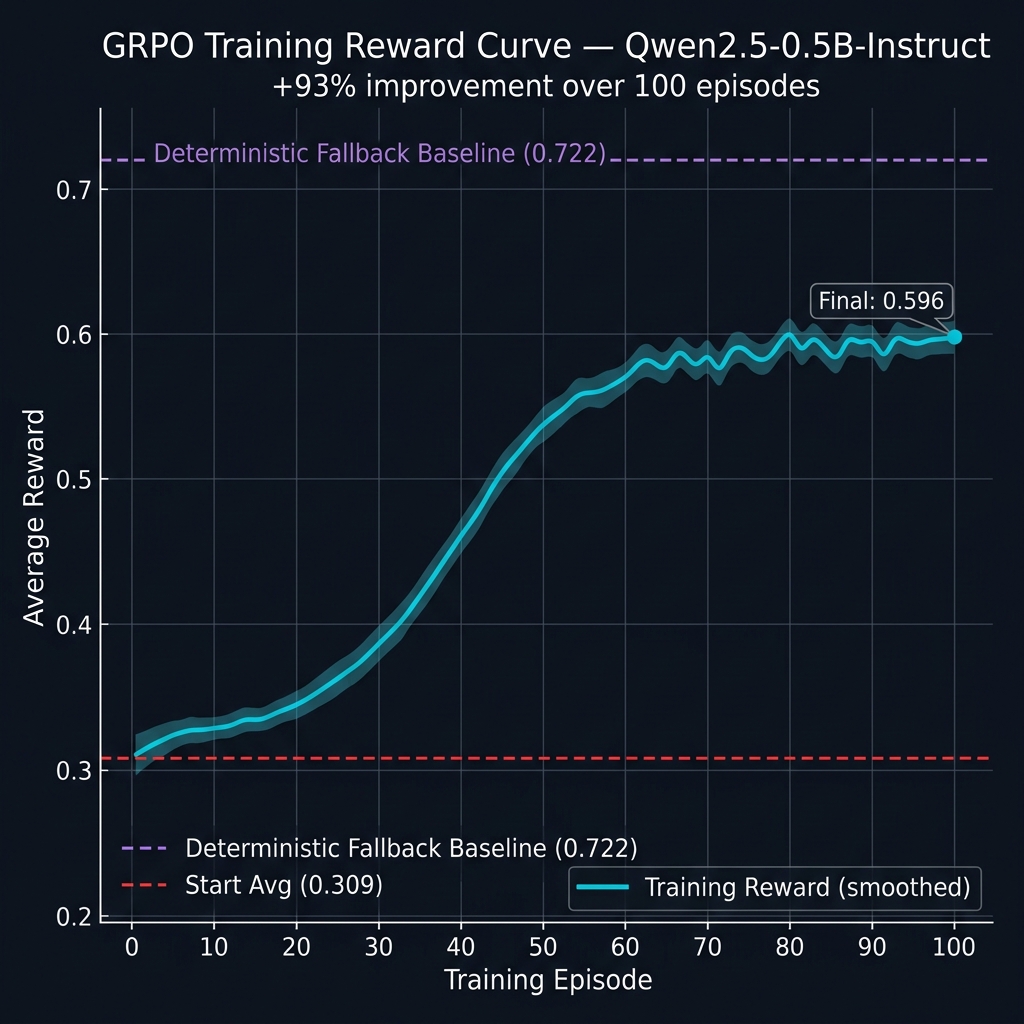
|
| 70 |
+
|
| 71 |
+
### Final evaluation (per task)
|
| 72 |
|
|
|
|
| 73 |
| Task | Difficulty | Score |
|
| 74 |
|------|-----------|-------|
|
| 75 |
+
| task_1_basic_antipatterns | easy | **0.7500** ✅ |
|
| 76 |
+
| task_2_correlated_subqueries | medium | **0.8313** ✅ |
|
| 77 |
+
| task_3_wildcard_scan | medium-hard | **0.6563** ✅ |
|
| 78 |
+
| task_4_implicit_join | hard | **0.6563** ✅ |
|
| 79 |
+
| task_5_window_functions | expert | **0.6500** ✅ |
|
| 80 |
+
|
| 81 |
+
> **Task 5 note:** `task_5_window_functions` is the **expert** scenario, so it’s expected to be the lowest. This is not an error—just the hardest distribution.
|
| 82 |
+
|
| 83 |
+
### “Before / After” (environment-only, no API keys)
|
| 84 |
|
| 85 |
+
We also provide a **reproducible** before/after contrast:
|
| 86 |
+
- **Before:** suggestions present but `optimized_query` empty (no speedup/correctness signal)
|
| 87 |
+
- **After:** deterministic fallback policy with a real optimized query
|
| 88 |
|
| 89 |
+
Table + chart are committed in the repo:
|
|
|
|
| 90 |
|
| 91 |
+
- `results/before_after_table.md`
|
| 92 |
+
- `results/before_after_chart.png`
|
| 93 |
|
| 94 |
+
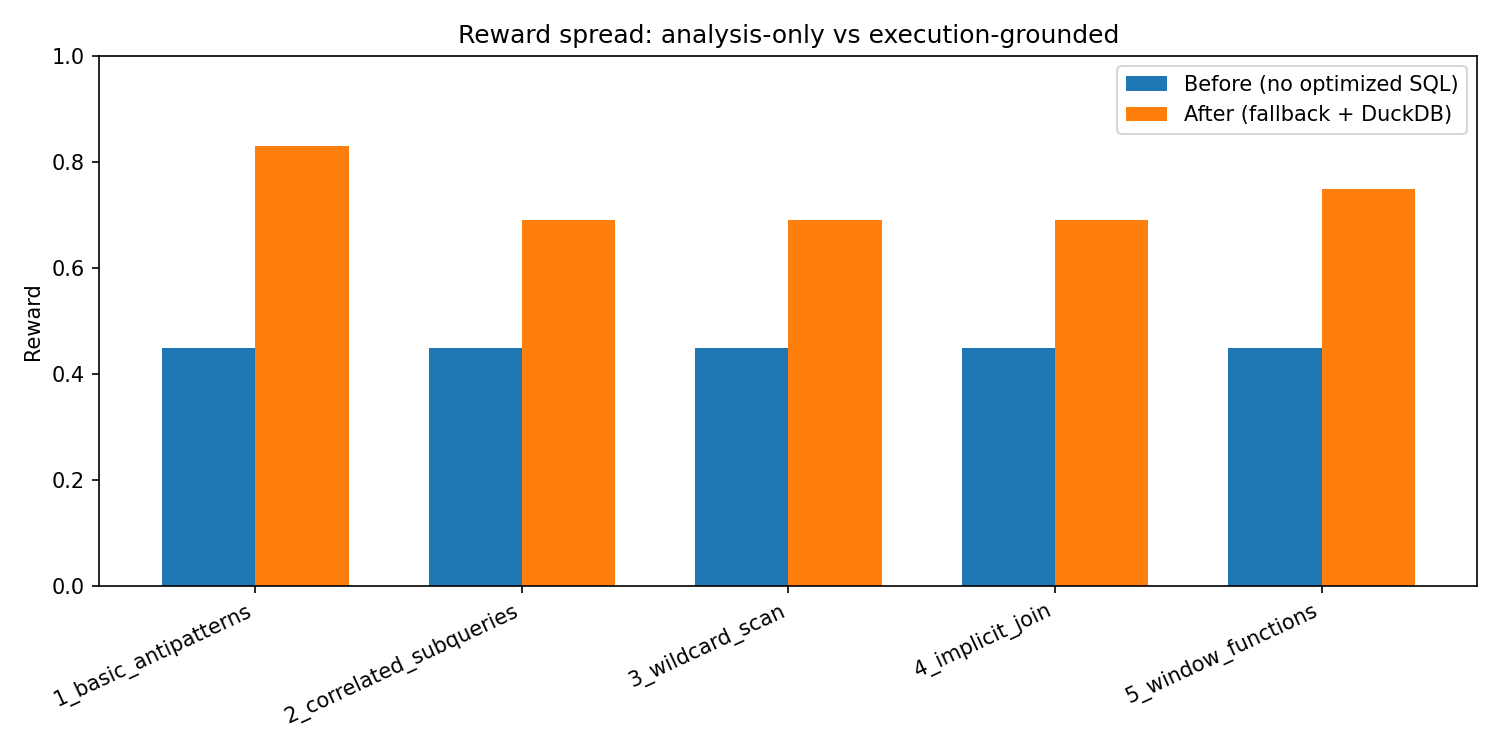
|
|
|
|
|
|
|
| 95 |
|
| 96 |
+
---
|
|
|
|
| 97 |
|
| 98 |
+
## How to reproduce (locally)
|
|
|
|
| 99 |
|
| 100 |
+
```bash
|
| 101 |
+
git clone https://github.com/OfficialAbhinavSingh/SQL-Query-Optimization-Environment-.git
|
| 102 |
+
cd SQL-Query-Optimization-Environment-
|
| 103 |
+
pip install -r requirements.txt
|
| 104 |
|
| 105 |
+
# Baselines (fallback + optional LLM if HF_TOKEN set)
|
| 106 |
+
python baseline_runner.py
|
| 107 |
|
| 108 |
+
# Environment-only before/after (no API keys)
|
| 109 |
+
python training/eval_before_after.py --save-dir results
|
|
|
|
|
|
|
|
|