
add all files
Browse files- .gitattributes +1 -0
- assets/apify.png +3 -0
- assets/demo.png +0 -0
- data/clothing_data_preprocessed.csv +0 -0
- data/clothing_similarity_search.csv +0 -0
- data/embeddings.npy +3 -0
- notebooks/Clothing_Similarity_Search.ipynb +0 -0
- requirements.txt +8 -0
- utils/preprocess.py +40 -0
- utils/similarity.py +27 -0
.gitattributes
CHANGED
|
@@ -32,3 +32,4 @@ saved_model/**/* filter=lfs diff=lfs merge=lfs -text
|
|
| 32 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 33 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
|
|
|
|
|
| 32 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 33 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
| 35 |
+
assets/apify.png filter=lfs diff=lfs merge=lfs -text
|
assets/apify.png
ADDED

|
Git LFS Details
|
assets/demo.png
ADDED
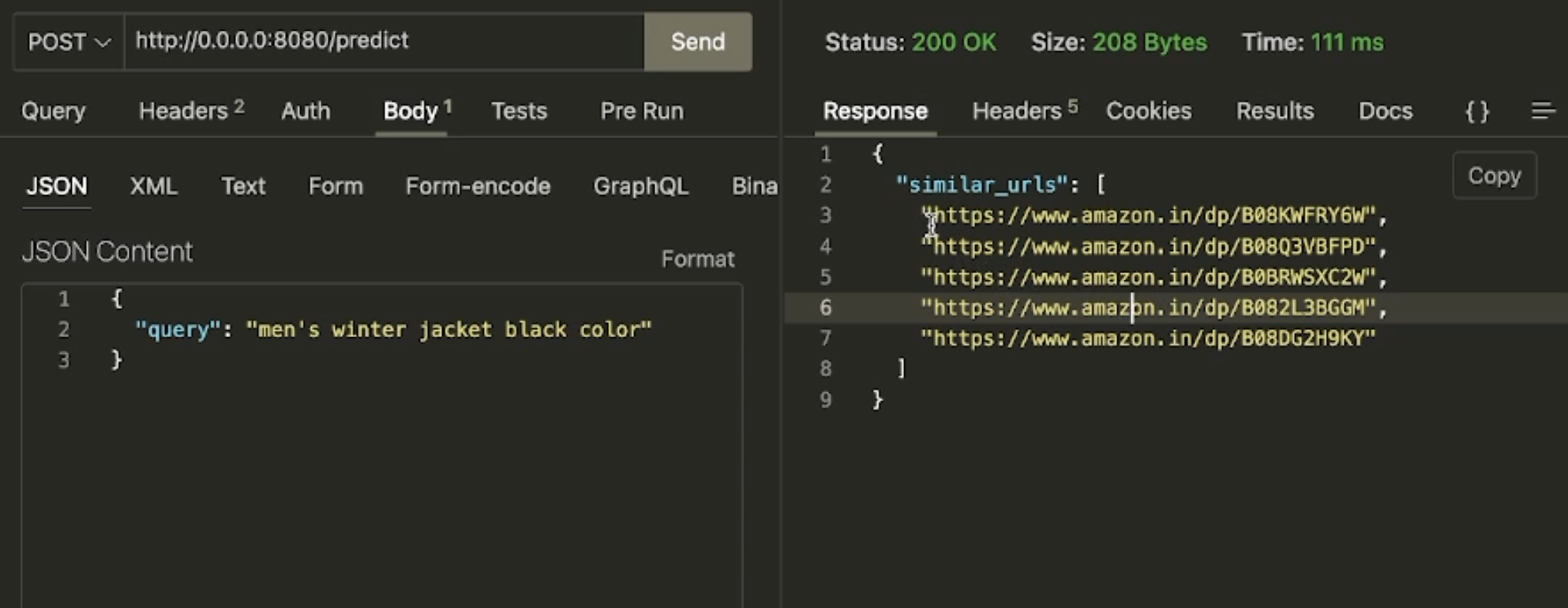
|
data/clothing_data_preprocessed.csv
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
data/clothing_similarity_search.csv
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
data/embeddings.npy
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:c69fef9a8e91493b831b17f9a05acbb171c132bfff4abf60128e29ab0b11de3e
|
| 3 |
+
size 4454528
|
notebooks/Clothing_Similarity_Search.ipynb
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
requirements.txt
ADDED
|
@@ -0,0 +1,8 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
pandas
|
| 2 |
+
nltk
|
| 3 |
+
transformers
|
| 4 |
+
sentence-transformers
|
| 5 |
+
fastapi
|
| 6 |
+
numpy
|
| 7 |
+
uvicorn
|
| 8 |
+
gunicorn==19.9.0
|
utils/preprocess.py
ADDED
|
@@ -0,0 +1,40 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import pandas as pd
|
| 2 |
+
import nltk
|
| 3 |
+
import string
|
| 4 |
+
from nltk.tokenize import word_tokenize
|
| 5 |
+
from nltk.corpus import stopwords
|
| 6 |
+
from nltk.stem import WordNetLemmatizer
|
| 7 |
+
|
| 8 |
+
|
| 9 |
+
df = pd.read_csv('data/clothing_similarity_search.csv')
|
| 10 |
+
# Using DataFrame.apply() and lambda function
|
| 11 |
+
df["product"] = df['title'].fillna('') + df['description'].fillna('')
|
| 12 |
+
|
| 13 |
+
# Using DataFrame.copy() create new DaraFrame.
|
| 14 |
+
clothing_data = df[['url', 'product']].copy()
|
| 15 |
+
|
| 16 |
+
def preprocess_text(text):
|
| 17 |
+
# Tokenize the text into individual words
|
| 18 |
+
tokens = word_tokenize(text)
|
| 19 |
+
tokens = [token.lower() for token in tokens]
|
| 20 |
+
# Remove special characters and punctuation
|
| 21 |
+
tokens = [token.translate(str.maketrans('', '', string.punctuation)) for token in tokens]
|
| 22 |
+
# Remove stopwords
|
| 23 |
+
stop_words = set(stopwords.words('english'))
|
| 24 |
+
tokens = [token for token in tokens if token not in stop_words]
|
| 25 |
+
# Lemmatize the tokens
|
| 26 |
+
lemmatizer = WordNetLemmatizer()
|
| 27 |
+
tokens = [lemmatizer.lemmatize(token) for token in tokens]
|
| 28 |
+
# Join the tokens back into a single string
|
| 29 |
+
preprocessed_text = ' '.join(tokens)
|
| 30 |
+
return preprocessed_text
|
| 31 |
+
|
| 32 |
+
preprocessed_products = []
|
| 33 |
+
for index, row in clothing_data.iterrows():
|
| 34 |
+
preprocessed_product = preprocess_text(row['product'])
|
| 35 |
+
preprocessed_products.append(preprocessed_product)
|
| 36 |
+
|
| 37 |
+
# Add the preprocessed text to a new column in the clothing_data
|
| 38 |
+
clothing_data['preprocessed_product'] = preprocessed_products
|
| 39 |
+
|
| 40 |
+
clothing_data.to_csv('data/clothing_data_updated.csv')
|
utils/similarity.py
ADDED
|
@@ -0,0 +1,27 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from sentence_transformers import SentenceTransformer, util
|
| 2 |
+
import pandas as pd
|
| 3 |
+
import numpy as np
|
| 4 |
+
|
| 5 |
+
clothing_data = pd.read_csv('data/clothing_data_preprocessed.csv')
|
| 6 |
+
|
| 7 |
+
model = SentenceTransformer('model')
|
| 8 |
+
embeddings = np.load('data/embeddings.npy')
|
| 9 |
+
|
| 10 |
+
def get_similar_items(query, embeddings, clothing_data, top_k):
|
| 11 |
+
# Encode the query text
|
| 12 |
+
query_embedding = model.encode([query], convert_to_tensor=True)
|
| 13 |
+
# Compute similarity scores
|
| 14 |
+
similarity_scores = util.pytorch_cos_sim(query_embedding, embeddings)[0]
|
| 15 |
+
# Sort indices based on similarity scores
|
| 16 |
+
sorted_indices = similarity_scores.argsort(descending=True)
|
| 17 |
+
# Get the top-k most similar indices
|
| 18 |
+
similar_indices = sorted_indices[:top_k].cpu().numpy()
|
| 19 |
+
# Get the URLs of the top-k similar items
|
| 20 |
+
similar_urls = clothing_data.loc[similar_indices, 'url'].tolist()
|
| 21 |
+
|
| 22 |
+
return similar_urls
|
| 23 |
+
|
| 24 |
+
# Assuming you have the embeddings and clothing_data available
|
| 25 |
+
query = "Men's jeans black color"
|
| 26 |
+
similar_urls = get_similar_items(query, embeddings, clothing_data, top_k=5)
|
| 27 |
+
print(similar_urls)
|