Spaces:
Build error

Build error
Commit
·
7f7285f
1
Parent(s):
081073f
init loren for spaces
Browse filesThis view is limited to 50 files because it contains too many changes.
See raw diff
- .gitignore +225 -0
- app.py +101 -3
- cjjpy.py +249 -0
- docs/front.png +0 -0
- requirements.txt +28 -0
- src/available_models/aaai22_roberta.json +0 -0
- src/check_client/cjjpy.py +249 -0
- src/check_client/fact_checker.py +209 -0
- src/check_client/modules/cjjpy.py +249 -0
- src/check_client/modules/data_processor.py +354 -0
- src/check_client/modules/test_data_processor.py +26 -0
- src/check_client/plm_checkers/__init__.py +12 -0
- src/check_client/plm_checkers/bert_checker.py +203 -0
- src/check_client/plm_checkers/checker_utils.py +223 -0
- src/check_client/plm_checkers/roberta_checker.py +203 -0
- src/check_client/scripts/train_bert-large.sh +51 -0
- src/check_client/scripts/train_roberta.sh +51 -0
- src/check_client/train.py +647 -0
- src/check_client/utils.py +131 -0
- src/cjjpy.py +249 -0
- src/dataloaders.py +134 -0
- src/er_client/__init__.py +63 -0
- src/er_client/cjjpy.py +249 -0
- src/er_client/doc_retrieval_by_api.py +44 -0
- src/er_client/document_retrieval.py +225 -0
- src/er_client/entitylinker.py +84 -0
- src/er_client/retrieval_model/bert_model.py +775 -0
- src/er_client/retrieval_model/data_loader.py +276 -0
- src/er_client/retrieval_model/file_utils.py +249 -0
- src/er_client/retrieval_model/models.py +66 -0
- src/er_client/retrieval_model/process_data.py +41 -0
- src/er_client/retrieval_model/test.py +81 -0
- src/er_client/retrieval_model/test.sh +7 -0
- src/er_client/sentence_selection.py +54 -0
- src/eval_client/cjjpy.py +249 -0
- src/eval_client/culpa.py +61 -0
- src/eval_client/culprit/eval.human.ref.json +100 -0
- src/eval_client/fever_scorer.py +84 -0
- src/eval_client/scorer.py +153 -0
- src/loren.py +167 -0
- src/mrc_client/answer_generator.py +144 -0
- src/mrc_client/cjjpy.py +249 -0
- src/mrc_client/seq2seq/README.md +590 -0
- src/mrc_client/seq2seq/__init__.py +5 -0
- src/mrc_client/seq2seq/callbacks.py +115 -0
- src/mrc_client/seq2seq/cjjpy.py +249 -0
- src/mrc_client/seq2seq/convert_pl_checkpoint_to_hf.py +74 -0
- src/mrc_client/seq2seq/finetune.py +465 -0
- src/mrc_client/seq2seq/finetune_t5.sh +14 -0
- src/mrc_client/seq2seq/finetune_trainer.py +303 -0
.gitignore
ADDED
|
@@ -0,0 +1,225 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Created by .ignore support plugin (hsz.mobi)
|
| 2 |
+
### macOS template
|
| 3 |
+
# General
|
| 4 |
+
.DS_Store
|
| 5 |
+
.AppleDouble
|
| 6 |
+
.LSOverride
|
| 7 |
+
|
| 8 |
+
# Icon must end with two \r
|
| 9 |
+
Icon
|
| 10 |
+
|
| 11 |
+
# Thumbnails
|
| 12 |
+
._*
|
| 13 |
+
|
| 14 |
+
# Files that might appear in the root of a volume
|
| 15 |
+
.DocumentRevisions-V100
|
| 16 |
+
.fseventsd
|
| 17 |
+
.Spotlight-V100
|
| 18 |
+
.TemporaryItems
|
| 19 |
+
.Trashes
|
| 20 |
+
.VolumeIcon.icns
|
| 21 |
+
.com.apple.timemachine.donotpresent
|
| 22 |
+
|
| 23 |
+
# Directories potentially created on remote AFP share
|
| 24 |
+
.AppleDB
|
| 25 |
+
.AppleDesktop
|
| 26 |
+
Network Trash Folder
|
| 27 |
+
Temporary Items
|
| 28 |
+
.apdisk
|
| 29 |
+
### Python template
|
| 30 |
+
# Byte-compiled / optimized / DLL files
|
| 31 |
+
__pycache__/
|
| 32 |
+
*.py[cod]
|
| 33 |
+
*$py.class
|
| 34 |
+
|
| 35 |
+
# C extensions
|
| 36 |
+
*.so
|
| 37 |
+
|
| 38 |
+
# Distribution / packaging
|
| 39 |
+
.Python
|
| 40 |
+
build/
|
| 41 |
+
develop-eggs/
|
| 42 |
+
dist/
|
| 43 |
+
downloads/
|
| 44 |
+
eggs/
|
| 45 |
+
.eggs/
|
| 46 |
+
lib/
|
| 47 |
+
lib64/
|
| 48 |
+
parts/
|
| 49 |
+
sdist/
|
| 50 |
+
var/
|
| 51 |
+
wheels/
|
| 52 |
+
*.egg-info/
|
| 53 |
+
.installed.cfg
|
| 54 |
+
*.egg
|
| 55 |
+
MANIFEST
|
| 56 |
+
|
| 57 |
+
# PyInstaller
|
| 58 |
+
# Usually these files are written by a python script from a template
|
| 59 |
+
# before PyInstaller builds the exe, so as to inject date/other infos into it.
|
| 60 |
+
*.manifest
|
| 61 |
+
*.spec
|
| 62 |
+
|
| 63 |
+
# Installer logs
|
| 64 |
+
pip-log.txt
|
| 65 |
+
pip-delete-this-directory.txt
|
| 66 |
+
|
| 67 |
+
# Unit test / coverage reports
|
| 68 |
+
htmlcov/
|
| 69 |
+
.tox/
|
| 70 |
+
.coverage
|
| 71 |
+
.coverage.*
|
| 72 |
+
.cache
|
| 73 |
+
nosetests.xml
|
| 74 |
+
coverage.xml
|
| 75 |
+
*.cover
|
| 76 |
+
.hypothesis/
|
| 77 |
+
.pytest_cache/
|
| 78 |
+
|
| 79 |
+
# Translations
|
| 80 |
+
*.mo
|
| 81 |
+
*.pot
|
| 82 |
+
|
| 83 |
+
# Django stuff:
|
| 84 |
+
*.log
|
| 85 |
+
local_settings.py
|
| 86 |
+
db.sqlite3
|
| 87 |
+
|
| 88 |
+
# Flask stuff:
|
| 89 |
+
instance/
|
| 90 |
+
.webassets-cache
|
| 91 |
+
|
| 92 |
+
# Scrapy stuff:
|
| 93 |
+
.scrapy
|
| 94 |
+
|
| 95 |
+
# Sphinx documentation
|
| 96 |
+
docs/_build/
|
| 97 |
+
|
| 98 |
+
# PyBuilder
|
| 99 |
+
target/
|
| 100 |
+
|
| 101 |
+
# Jupyter Notebook
|
| 102 |
+
.ipynb_checkpoints
|
| 103 |
+
|
| 104 |
+
# pyenv
|
| 105 |
+
.python-version
|
| 106 |
+
|
| 107 |
+
# celery beat schedule file
|
| 108 |
+
celerybeat-schedule
|
| 109 |
+
|
| 110 |
+
# SageMath parsed files
|
| 111 |
+
*.sage.py
|
| 112 |
+
|
| 113 |
+
# Environments
|
| 114 |
+
.env
|
| 115 |
+
.venv
|
| 116 |
+
env/
|
| 117 |
+
venv/
|
| 118 |
+
ENV/
|
| 119 |
+
env.bak/
|
| 120 |
+
venv.bak/
|
| 121 |
+
|
| 122 |
+
# Spyder project settings
|
| 123 |
+
.spyderproject
|
| 124 |
+
.spyproject
|
| 125 |
+
|
| 126 |
+
# Rope project settings
|
| 127 |
+
.ropeproject
|
| 128 |
+
|
| 129 |
+
# mkdocs documentation
|
| 130 |
+
/site
|
| 131 |
+
|
| 132 |
+
# mypy
|
| 133 |
+
.mypy_cache/
|
| 134 |
+
### JetBrains template
|
| 135 |
+
# Covers JetBrains IDEs: IntelliJ, RubyMine, PhpStorm, AppCode, PyCharm, CLion, Android Studio and WebStorm
|
| 136 |
+
# Reference: https://intellij-support.jetbrains.com/hc/en-us/articles/206544839
|
| 137 |
+
|
| 138 |
+
# User-specific stuff
|
| 139 |
+
.idea/**/workspace.xml
|
| 140 |
+
.idea/**/tasks.xml
|
| 141 |
+
.idea/**/usage.statistics.xml
|
| 142 |
+
.idea/**/dictionaries
|
| 143 |
+
.idea/**/shelf
|
| 144 |
+
|
| 145 |
+
# Sensitive or high-churn files
|
| 146 |
+
.idea/**/dataSources/
|
| 147 |
+
.idea/**/dataSources.ids
|
| 148 |
+
.idea/**/dataSources.local.xml
|
| 149 |
+
.idea/**/sqlDataSources.xml
|
| 150 |
+
.idea/**/dynamic.xml
|
| 151 |
+
.idea/**/uiDesigner.xml
|
| 152 |
+
.idea/**/dbnavigator.xml
|
| 153 |
+
|
| 154 |
+
# Gradle
|
| 155 |
+
.idea/**/gradle.xml
|
| 156 |
+
.idea/**/libraries
|
| 157 |
+
|
| 158 |
+
# Gradle and Maven with auto-import
|
| 159 |
+
# When using Gradle or Maven with auto-import, you should exclude module files,
|
| 160 |
+
# since they will be recreated, and may cause churn. Uncomment if using
|
| 161 |
+
# auto-import.
|
| 162 |
+
# .idea/modules.xml
|
| 163 |
+
# .idea/*.iml
|
| 164 |
+
# .idea/modules
|
| 165 |
+
|
| 166 |
+
# CMake
|
| 167 |
+
cmake-build-*/
|
| 168 |
+
|
| 169 |
+
# Mongo Explorer plugin
|
| 170 |
+
.idea/**/mongoSettings.xml
|
| 171 |
+
|
| 172 |
+
# File-based project format
|
| 173 |
+
*.iws
|
| 174 |
+
|
| 175 |
+
# IntelliJ
|
| 176 |
+
out/
|
| 177 |
+
|
| 178 |
+
# mpeltonen/sbt-idea plugin
|
| 179 |
+
.idea_modules/
|
| 180 |
+
|
| 181 |
+
# JIRA plugin
|
| 182 |
+
atlassian-ide-plugin.xml
|
| 183 |
+
|
| 184 |
+
# Cursive Clojure plugin
|
| 185 |
+
.idea/replstate.xml
|
| 186 |
+
|
| 187 |
+
# Crashlytics plugin (for Android Studio and IntelliJ)
|
| 188 |
+
com_crashlytics_export_strings.xml
|
| 189 |
+
crashlytics.properties
|
| 190 |
+
crashlytics-build.properties
|
| 191 |
+
fabric.properties
|
| 192 |
+
|
| 193 |
+
# Editor-based Rest Client
|
| 194 |
+
.idea/httpRequests
|
| 195 |
+
### VirtualEnv template
|
| 196 |
+
# Virtualenv
|
| 197 |
+
# http://iamzed.com/2009/05/07/a-primer-on-virtualenv/
|
| 198 |
+
.Python
|
| 199 |
+
[Bb]in
|
| 200 |
+
[Ii]nclude
|
| 201 |
+
[Ll]ib
|
| 202 |
+
[Ll]ib64
|
| 203 |
+
[Ll]ocal
|
| 204 |
+
pyvenv.cfg
|
| 205 |
+
.venv
|
| 206 |
+
pip-selfcheck.json
|
| 207 |
+
|
| 208 |
+
.idea/
|
| 209 |
+
eden.py
|
| 210 |
+
/_tmp/
|
| 211 |
+
runs
|
| 212 |
+
*nohup*
|
| 213 |
+
*.pt
|
| 214 |
+
*.out
|
| 215 |
+
*.pkl
|
| 216 |
+
*.db
|
| 217 |
+
/cache/
|
| 218 |
+
output/
|
| 219 |
+
*.csv
|
| 220 |
+
*_resources/
|
| 221 |
+
*_proc
|
| 222 |
+
lightning_logs/
|
| 223 |
+
wandb/
|
| 224 |
+
.lock
|
| 225 |
+
*gradio*
|
app.py
CHANGED
|
@@ -1,7 +1,105 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
import gradio as gr
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 2 |
|
| 3 |
-
def greet(name):
|
| 4 |
-
return "Hello " + name + "!!"
|
| 5 |
|
| 6 |
-
iface = gr.Interface(
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 7 |
iface.launch()
|
|
|
|
| 1 |
+
# -*- coding: utf-8 -*-
|
| 2 |
+
|
| 3 |
+
"""
|
| 4 |
+
@Author : Jiangjie Chen
|
| 5 |
+
@Time : 2021/12/13 17:17
|
| 6 |
+
@Contact : jjchen19@fudan.edu.cn
|
| 7 |
+
@Description:
|
| 8 |
+
"""
|
| 9 |
+
|
| 10 |
+
import os
|
| 11 |
import gradio as gr
|
| 12 |
+
from src.loren import Loren
|
| 13 |
+
from huggingface_hub import snapshot_download
|
| 14 |
+
from prettytable import PrettyTable
|
| 15 |
+
import pandas as pd
|
| 16 |
+
|
| 17 |
+
config = {
|
| 18 |
+
"input": "demo",
|
| 19 |
+
"model_type": "roberta",
|
| 20 |
+
"model_name_or_path": "roberta-large",
|
| 21 |
+
"logic_lambda": 0.5,
|
| 22 |
+
"prior": "random",
|
| 23 |
+
"mask_rate": 0.0,
|
| 24 |
+
"cand_k": 3,
|
| 25 |
+
"max_seq2_length": 256,
|
| 26 |
+
"max_seq1_length": 128,
|
| 27 |
+
"max_num_questions": 8
|
| 28 |
+
}
|
| 29 |
+
|
| 30 |
+
model_dir = snapshot_download('Jiangjie/loren')
|
| 31 |
+
|
| 32 |
+
config['fc_dir'] = os.path.join(model_dir, 'fact_checking/roberta-large/')
|
| 33 |
+
config['mrc_dir'] = os.path.join(model_dir, 'mrc_seq2seq/bart-base/')
|
| 34 |
+
config['er_dir'] = os.path.join(model_dir, 'evidence_retrieval/')
|
| 35 |
+
|
| 36 |
+
loren = Loren(config)
|
| 37 |
+
try:
|
| 38 |
+
# js = {
|
| 39 |
+
# 'id': 0,
|
| 40 |
+
# 'evidence': ['EVIDENCE1', 'EVIDENCE2'],
|
| 41 |
+
# 'question': ['QUESTION1', 'QUESTION2'],
|
| 42 |
+
# 'claim_phrase': ['CLAIMPHRASE1', 'CLAIMPHRASE2'],
|
| 43 |
+
# 'local_premise': [['E1 ' * 100, 'E1' * 100, 'E1' * 10], ['E2', 'E2', 'E2']],
|
| 44 |
+
# 'phrase_veracity': [[0.1, 0.5, 0.4], [0.1, 0.7, 0.2]],
|
| 45 |
+
# 'claim_veracity': 'SUPPORT'
|
| 46 |
+
# }
|
| 47 |
+
js = loren.check('Donald Trump won the 2020 U.S. presidential election.')
|
| 48 |
+
except Exception as e:
|
| 49 |
+
raise ValueError(e)
|
| 50 |
+
|
| 51 |
+
|
| 52 |
+
def gradio_formatter(js, output_type):
|
| 53 |
+
if output_type == 'e':
|
| 54 |
+
data = {'Evidence': js['evidence']}
|
| 55 |
+
elif output_type == 'z':
|
| 56 |
+
data = {
|
| 57 |
+
'Claim Phrase': js['claim_phrase'],
|
| 58 |
+
'Local Premise': [x[0] for x in js['local_premise']],
|
| 59 |
+
'p_SUP': [round(x[2], 4) for x in js['phrase_veracity']],
|
| 60 |
+
'p_REF': [round(x[0], 4) for x in js['phrase_veracity']],
|
| 61 |
+
'p_NEI': [round(x[1], 4) for x in js['phrase_veracity']],
|
| 62 |
+
}
|
| 63 |
+
else:
|
| 64 |
+
raise NotImplementedError
|
| 65 |
+
data = pd.DataFrame(data)
|
| 66 |
+
pt = PrettyTable(field_names=list(data.columns))
|
| 67 |
+
for v in data.values:
|
| 68 |
+
pt.add_row(v)
|
| 69 |
+
|
| 70 |
+
html = pt.get_html_string(attributes={
|
| 71 |
+
'style': 'border-width: 1px; border-collapse: collapse',
|
| 72 |
+
}, format=True)
|
| 73 |
+
return html
|
| 74 |
+
|
| 75 |
+
|
| 76 |
+
def run(claim):
|
| 77 |
+
js = loren.check(claim)
|
| 78 |
+
ev_html = gradio_formatter(js, 'e')
|
| 79 |
+
z_html = gradio_formatter(js, 'z')
|
| 80 |
+
return ev_html, z_html, js['claim_veracity'], js
|
| 81 |
|
|
|
|
|
|
|
| 82 |
|
| 83 |
+
iface = gr.Interface(
|
| 84 |
+
fn=run,
|
| 85 |
+
inputs="text",
|
| 86 |
+
outputs=[
|
| 87 |
+
'html',
|
| 88 |
+
'html',
|
| 89 |
+
'label',
|
| 90 |
+
'json'
|
| 91 |
+
],
|
| 92 |
+
examples=['Donald Trump won the U.S. 2020 presidential election.',
|
| 93 |
+
'The first inauguration of Bill Clinton was in the United States.'],
|
| 94 |
+
title="LOREN",
|
| 95 |
+
layout='vertical',
|
| 96 |
+
description="LOREN is an interpretable Fact Verification model against Wikipedia. "
|
| 97 |
+
"This is a demo system for \"LOREN: Logic-Regularized Reasoning for Interpretable Fact Verification\". "
|
| 98 |
+
"See the paper for technical details. You can add FLAG on the bottom to record interesting or bad cases!",
|
| 99 |
+
flagging_dir='results/flagged/',
|
| 100 |
+
allow_flagging=True,
|
| 101 |
+
flagging_options=['Good Case!', 'Error: MRC', 'Error: Parsing',
|
| 102 |
+
'Error: Commonsense', 'Error: Evidence', 'Error: Other'],
|
| 103 |
+
enable_queue=True
|
| 104 |
+
)
|
| 105 |
iface.launch()
|
cjjpy.py
ADDED
|
@@ -0,0 +1,249 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# -*- coding: utf-8 -*-
|
| 2 |
+
|
| 3 |
+
'''
|
| 4 |
+
@Author : Jiangjie Chen
|
| 5 |
+
@Time : 2018/11/15 17:08
|
| 6 |
+
@Contact: jjchen19@fudan.edu.cn
|
| 7 |
+
'''
|
| 8 |
+
|
| 9 |
+
import re
|
| 10 |
+
import datetime
|
| 11 |
+
import os
|
| 12 |
+
import argparse
|
| 13 |
+
import logging
|
| 14 |
+
import traceback
|
| 15 |
+
|
| 16 |
+
try:
|
| 17 |
+
import ujson as json
|
| 18 |
+
except:
|
| 19 |
+
import json
|
| 20 |
+
|
| 21 |
+
HADOOP_BIN = 'PATH=/usr/bin/:$PATH hdfs'
|
| 22 |
+
FOR_PUBLIC = True
|
| 23 |
+
|
| 24 |
+
|
| 25 |
+
def LengthStats(filename):
|
| 26 |
+
len_list = []
|
| 27 |
+
thresholds = [0.8, 0.9, 0.95, 0.99, 0.999]
|
| 28 |
+
with open(filename) as f:
|
| 29 |
+
for line in f:
|
| 30 |
+
len_list.append(len(line.strip().split()))
|
| 31 |
+
stats = {
|
| 32 |
+
'Max': max(len_list),
|
| 33 |
+
'Min': min(len_list),
|
| 34 |
+
'Avg': round(sum(len_list) / len(len_list), 4),
|
| 35 |
+
}
|
| 36 |
+
len_list.sort()
|
| 37 |
+
for t in thresholds:
|
| 38 |
+
stats[f"Top-{t}"] = len_list[int(len(len_list) * t)]
|
| 39 |
+
|
| 40 |
+
for k in stats:
|
| 41 |
+
print(f"- {k}: {stats[k]}")
|
| 42 |
+
return stats
|
| 43 |
+
|
| 44 |
+
|
| 45 |
+
class AttrDict(dict):
|
| 46 |
+
def __init__(self, *args, **kwargs):
|
| 47 |
+
super(AttrDict, self).__init__(*args, **kwargs)
|
| 48 |
+
self.__dict__ = self
|
| 49 |
+
|
| 50 |
+
|
| 51 |
+
def TraceBack(error_msg):
|
| 52 |
+
exc = traceback.format_exc()
|
| 53 |
+
msg = f'[Error]: {error_msg}.\n[Traceback]: {exc}'
|
| 54 |
+
return msg
|
| 55 |
+
|
| 56 |
+
|
| 57 |
+
def Now():
|
| 58 |
+
return datetime.datetime.now().strftime("%Y-%m-%d %H:%M:%S")
|
| 59 |
+
|
| 60 |
+
|
| 61 |
+
def AbsParentDir(file, parent='..', postfix=None):
|
| 62 |
+
ppath = os.path.abspath(file)
|
| 63 |
+
parent_level = parent.count('.')
|
| 64 |
+
while parent_level > 0:
|
| 65 |
+
ppath = os.path.dirname(ppath)
|
| 66 |
+
parent_level -= 1
|
| 67 |
+
if postfix is not None:
|
| 68 |
+
return os.path.join(ppath, postfix)
|
| 69 |
+
else:
|
| 70 |
+
return ppath
|
| 71 |
+
|
| 72 |
+
|
| 73 |
+
def init_logger(log_file=None, log_file_level=logging.NOTSET, from_scratch=False):
|
| 74 |
+
from coloredlogs import ColoredFormatter
|
| 75 |
+
import tensorflow as tf
|
| 76 |
+
|
| 77 |
+
fmt = "[%(asctime)s %(levelname)s] %(message)s"
|
| 78 |
+
log_format = ColoredFormatter(fmt=fmt)
|
| 79 |
+
# log_format = logging.Formatter()
|
| 80 |
+
logger = logging.getLogger()
|
| 81 |
+
logger.setLevel(log_file_level)
|
| 82 |
+
|
| 83 |
+
console_handler = logging.StreamHandler()
|
| 84 |
+
console_handler.setFormatter(log_format)
|
| 85 |
+
logger.handlers = [console_handler]
|
| 86 |
+
|
| 87 |
+
if log_file and log_file != '':
|
| 88 |
+
if from_scratch and tf.io.gfile.exists(log_file):
|
| 89 |
+
logger.warning('Removing previous log file: %s' % log_file)
|
| 90 |
+
tf.io.gfile.remove(log_file)
|
| 91 |
+
path = os.path.dirname(log_file)
|
| 92 |
+
os.makedirs(path, exist_ok=True)
|
| 93 |
+
file_handler = logging.FileHandler(log_file)
|
| 94 |
+
file_handler.setLevel(log_file_level)
|
| 95 |
+
file_handler.setFormatter(log_format)
|
| 96 |
+
logger.addHandler(file_handler)
|
| 97 |
+
|
| 98 |
+
return logger
|
| 99 |
+
|
| 100 |
+
|
| 101 |
+
def OverWriteCjjPy(root='.'):
|
| 102 |
+
# import difflib
|
| 103 |
+
# diff = difflib.HtmlDiff()
|
| 104 |
+
cnt = 0
|
| 105 |
+
golden_cjjpy = os.path.join(root, 'cjjpy.py')
|
| 106 |
+
# golden_content = open(golden_cjjpy).readlines()
|
| 107 |
+
for dir, folder, file in os.walk(root):
|
| 108 |
+
for f in file:
|
| 109 |
+
if f == 'cjjpy.py':
|
| 110 |
+
cjjpy = '%s/%s' % (dir, f)
|
| 111 |
+
# content = open(cjjpy).readlines()
|
| 112 |
+
# d = diff.make_file(golden_content, content)
|
| 113 |
+
cnt += 1
|
| 114 |
+
print('[%d]: %s' % (cnt, cjjpy))
|
| 115 |
+
os.system('cp %s %s' % (golden_cjjpy, cjjpy))
|
| 116 |
+
|
| 117 |
+
|
| 118 |
+
def ChangeFileFormat(filename, new_fmt):
|
| 119 |
+
assert type(filename) is str and type(new_fmt) is str
|
| 120 |
+
spt = filename.split('.')
|
| 121 |
+
if len(spt) == 0:
|
| 122 |
+
return filename
|
| 123 |
+
else:
|
| 124 |
+
return filename.replace('.' + spt[-1], new_fmt)
|
| 125 |
+
|
| 126 |
+
|
| 127 |
+
def CountLines(fname):
|
| 128 |
+
with open(fname, 'rb') as f:
|
| 129 |
+
count = 0
|
| 130 |
+
last_data = '\n'
|
| 131 |
+
while True:
|
| 132 |
+
data = f.read(0x400000)
|
| 133 |
+
if not data:
|
| 134 |
+
break
|
| 135 |
+
count += data.count(b'\n')
|
| 136 |
+
last_data = data
|
| 137 |
+
if last_data[-1:] != b'\n':
|
| 138 |
+
count += 1 # Remove this if a wc-like count is needed
|
| 139 |
+
return count
|
| 140 |
+
|
| 141 |
+
|
| 142 |
+
def GetDate():
|
| 143 |
+
return str(datetime.datetime.now())[5:10].replace('-', '')
|
| 144 |
+
|
| 145 |
+
|
| 146 |
+
def TimeClock(seconds):
|
| 147 |
+
sec = int(seconds)
|
| 148 |
+
hour = int(sec / 3600)
|
| 149 |
+
min = int((sec - hour * 3600) / 60)
|
| 150 |
+
ssec = float(seconds) - hour * 3600 - min * 60
|
| 151 |
+
# return '%dh %dm %.2fs' % (hour, min, ssec)
|
| 152 |
+
return '{0:>2d}h{1:>3d}m{2:>6.2f}s'.format(hour, min, ssec)
|
| 153 |
+
|
| 154 |
+
|
| 155 |
+
def StripAll(text):
|
| 156 |
+
return text.strip().replace('\t', '').replace('\n', '').replace(' ', '')
|
| 157 |
+
|
| 158 |
+
|
| 159 |
+
def GetBracket(text, bracket, en_br=False):
|
| 160 |
+
# input should be aa(bb)cc, True for bracket, False for text
|
| 161 |
+
if bracket:
|
| 162 |
+
try:
|
| 163 |
+
return re.findall('\((.*?)\)', text.strip())[-1]
|
| 164 |
+
except:
|
| 165 |
+
return ''
|
| 166 |
+
else:
|
| 167 |
+
if en_br:
|
| 168 |
+
text = re.sub('\(.*?\)', '', text.strip())
|
| 169 |
+
return re.sub('(.*?)', '', text.strip())
|
| 170 |
+
|
| 171 |
+
|
| 172 |
+
def CharLang(uchar, lang):
|
| 173 |
+
assert lang.lower() in ['en', 'cn', 'zh']
|
| 174 |
+
if lang.lower() in ['cn', 'zh']:
|
| 175 |
+
if uchar >= '\u4e00' and uchar <= '\u9fa5':
|
| 176 |
+
return True
|
| 177 |
+
else:
|
| 178 |
+
return False
|
| 179 |
+
elif lang.lower() == 'en':
|
| 180 |
+
if (uchar <= 'Z' and uchar >= 'A') or (uchar <= 'z' and uchar >= 'a'):
|
| 181 |
+
return True
|
| 182 |
+
else:
|
| 183 |
+
return False
|
| 184 |
+
else:
|
| 185 |
+
raise NotImplementedError
|
| 186 |
+
|
| 187 |
+
|
| 188 |
+
def WordLang(word, lang):
|
| 189 |
+
for i in word.strip():
|
| 190 |
+
if i.isspace(): continue
|
| 191 |
+
if not CharLang(i, lang):
|
| 192 |
+
return False
|
| 193 |
+
return True
|
| 194 |
+
|
| 195 |
+
|
| 196 |
+
def SortDict(_dict, reverse=True):
|
| 197 |
+
assert type(_dict) is dict
|
| 198 |
+
return sorted(_dict.items(), key=lambda d: d[1], reverse=reverse)
|
| 199 |
+
|
| 200 |
+
|
| 201 |
+
def lark(content='test'):
|
| 202 |
+
print(content)
|
| 203 |
+
|
| 204 |
+
|
| 205 |
+
if __name__ == '__main__':
|
| 206 |
+
parser = argparse.ArgumentParser()
|
| 207 |
+
|
| 208 |
+
parser.add_argument('--diff', nargs=2,
|
| 209 |
+
help='show difference between two files, shown in downloads/diff.html')
|
| 210 |
+
parser.add_argument('--de_unicode', action='store_true', default=False,
|
| 211 |
+
help='remove unicode characters')
|
| 212 |
+
parser.add_argument('--link_entity', action='store_true', default=False,
|
| 213 |
+
help='')
|
| 214 |
+
parser.add_argument('--max_comm_len', action='store_true', default=False,
|
| 215 |
+
help='')
|
| 216 |
+
parser.add_argument('--search', nargs=2,
|
| 217 |
+
help='search key from file, 2 args: file name & key')
|
| 218 |
+
parser.add_argument('--email', nargs=2,
|
| 219 |
+
help='sending emails, 2 args: subject & content')
|
| 220 |
+
parser.add_argument('--overwrite', action='store_true', default=None,
|
| 221 |
+
help='overwrite all cjjpy under given *dir* based on *dir*/cjjpy.py')
|
| 222 |
+
parser.add_argument('--replace', nargs=3,
|
| 223 |
+
help='replace char, 3 args: file name & replaced char & replacer char')
|
| 224 |
+
parser.add_argument('--lark', nargs=1)
|
| 225 |
+
parser.add_argument('--get_hdfs', nargs=2,
|
| 226 |
+
help='easy copy from hdfs to local fs, 2 args: remote_file/dir & local_dir')
|
| 227 |
+
parser.add_argument('--put_hdfs', nargs=2,
|
| 228 |
+
help='easy put from local fs to hdfs, 2 args: local_file/dir & remote_dir')
|
| 229 |
+
parser.add_argument('--length_stats', nargs=1,
|
| 230 |
+
help='simple token lengths distribution of a line-by-line file')
|
| 231 |
+
|
| 232 |
+
args = parser.parse_args()
|
| 233 |
+
|
| 234 |
+
if args.overwrite:
|
| 235 |
+
print('* Overwriting cjjpy...')
|
| 236 |
+
OverWriteCjjPy()
|
| 237 |
+
|
| 238 |
+
if args.lark:
|
| 239 |
+
try:
|
| 240 |
+
content = args.lark[0]
|
| 241 |
+
except:
|
| 242 |
+
content = 'running complete'
|
| 243 |
+
print(f'* Larking "{content}"...')
|
| 244 |
+
lark(content)
|
| 245 |
+
|
| 246 |
+
if args.length_stats:
|
| 247 |
+
file = args.length_stats[0]
|
| 248 |
+
print(f'* Working on {file} lengths statistics...')
|
| 249 |
+
LengthStats(file)
|
docs/front.png
ADDED
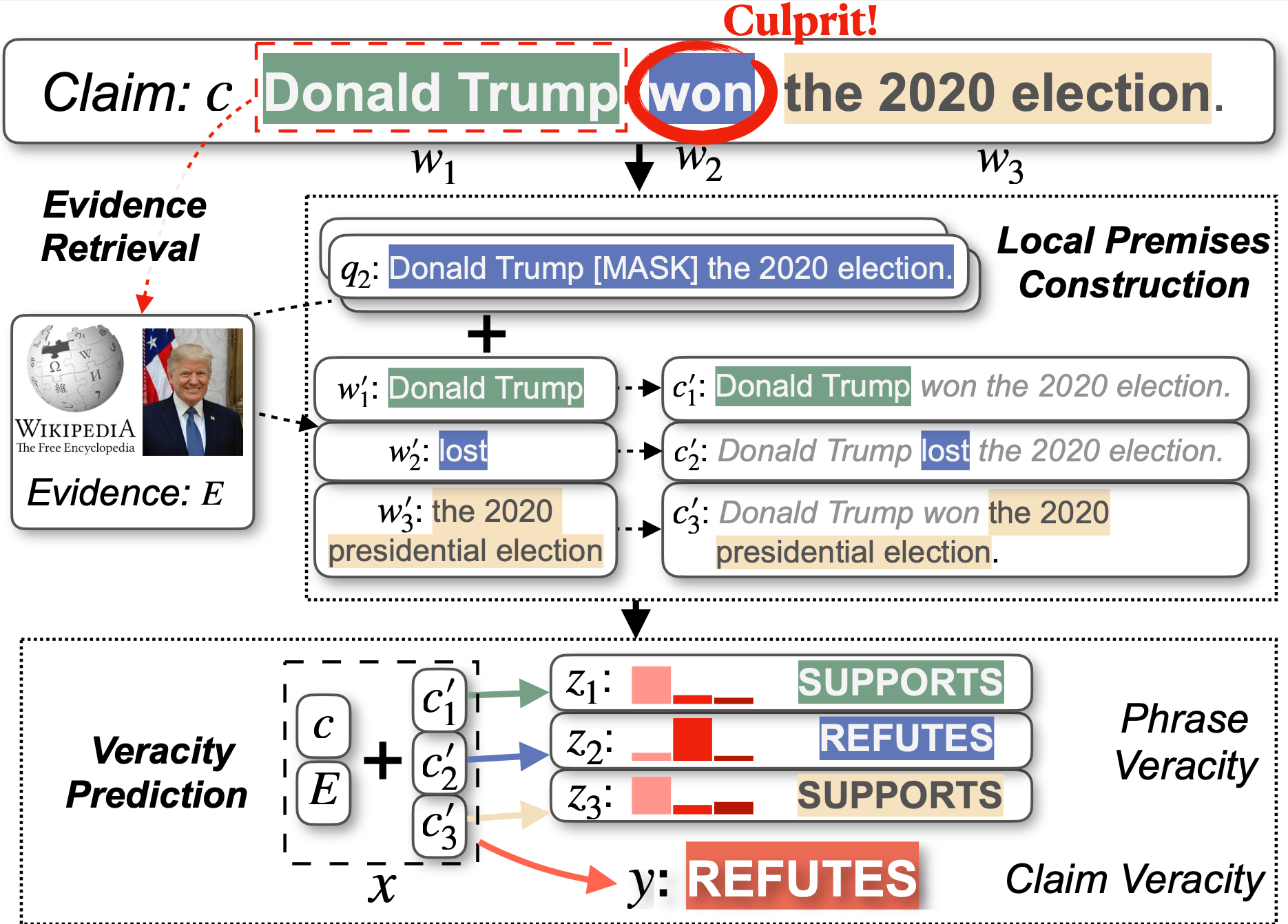
|
requirements.txt
ADDED
|
@@ -0,0 +1,28 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
nltk
|
| 2 |
+
tqdm
|
| 3 |
+
six
|
| 4 |
+
scikit-learn
|
| 5 |
+
pathlib
|
| 6 |
+
configargparse
|
| 7 |
+
bottle
|
| 8 |
+
ujson
|
| 9 |
+
GPUtil
|
| 10 |
+
coloredlogs
|
| 11 |
+
inflect
|
| 12 |
+
unidecode
|
| 13 |
+
psutil
|
| 14 |
+
wandb
|
| 15 |
+
rouge_score
|
| 16 |
+
sacrebleu
|
| 17 |
+
tagme
|
| 18 |
+
wikipedia-api
|
| 19 |
+
gradio
|
| 20 |
+
tensorflow
|
| 21 |
+
pytorch-lightning==1.0.4
|
| 22 |
+
allennlp==1.2.2
|
| 23 |
+
allennlp-models==1.2.2
|
| 24 |
+
transformers==3.5.1
|
| 25 |
+
torch==1.7.1
|
| 26 |
+
datasets
|
| 27 |
+
pandas
|
| 28 |
+
prettytable
|
src/available_models/aaai22_roberta.json
ADDED
|
File without changes
|
src/check_client/cjjpy.py
ADDED
|
@@ -0,0 +1,249 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# -*- coding: utf-8 -*-
|
| 2 |
+
|
| 3 |
+
'''
|
| 4 |
+
@Author : Jiangjie Chen
|
| 5 |
+
@Time : 2018/11/15 17:08
|
| 6 |
+
@Contact: jjchen19@fudan.edu.cn
|
| 7 |
+
'''
|
| 8 |
+
|
| 9 |
+
import re
|
| 10 |
+
import datetime
|
| 11 |
+
import os
|
| 12 |
+
import argparse
|
| 13 |
+
import logging
|
| 14 |
+
import traceback
|
| 15 |
+
|
| 16 |
+
try:
|
| 17 |
+
import ujson as json
|
| 18 |
+
except:
|
| 19 |
+
import json
|
| 20 |
+
|
| 21 |
+
HADOOP_BIN = 'PATH=/usr/bin/:$PATH hdfs'
|
| 22 |
+
FOR_PUBLIC = True
|
| 23 |
+
|
| 24 |
+
|
| 25 |
+
def LengthStats(filename):
|
| 26 |
+
len_list = []
|
| 27 |
+
thresholds = [0.8, 0.9, 0.95, 0.99, 0.999]
|
| 28 |
+
with open(filename) as f:
|
| 29 |
+
for line in f:
|
| 30 |
+
len_list.append(len(line.strip().split()))
|
| 31 |
+
stats = {
|
| 32 |
+
'Max': max(len_list),
|
| 33 |
+
'Min': min(len_list),
|
| 34 |
+
'Avg': round(sum(len_list) / len(len_list), 4),
|
| 35 |
+
}
|
| 36 |
+
len_list.sort()
|
| 37 |
+
for t in thresholds:
|
| 38 |
+
stats[f"Top-{t}"] = len_list[int(len(len_list) * t)]
|
| 39 |
+
|
| 40 |
+
for k in stats:
|
| 41 |
+
print(f"- {k}: {stats[k]}")
|
| 42 |
+
return stats
|
| 43 |
+
|
| 44 |
+
|
| 45 |
+
class AttrDict(dict):
|
| 46 |
+
def __init__(self, *args, **kwargs):
|
| 47 |
+
super(AttrDict, self).__init__(*args, **kwargs)
|
| 48 |
+
self.__dict__ = self
|
| 49 |
+
|
| 50 |
+
|
| 51 |
+
def TraceBack(error_msg):
|
| 52 |
+
exc = traceback.format_exc()
|
| 53 |
+
msg = f'[Error]: {error_msg}.\n[Traceback]: {exc}'
|
| 54 |
+
return msg
|
| 55 |
+
|
| 56 |
+
|
| 57 |
+
def Now():
|
| 58 |
+
return datetime.datetime.now().strftime("%Y-%m-%d %H:%M:%S")
|
| 59 |
+
|
| 60 |
+
|
| 61 |
+
def AbsParentDir(file, parent='..', postfix=None):
|
| 62 |
+
ppath = os.path.abspath(file)
|
| 63 |
+
parent_level = parent.count('.')
|
| 64 |
+
while parent_level > 0:
|
| 65 |
+
ppath = os.path.dirname(ppath)
|
| 66 |
+
parent_level -= 1
|
| 67 |
+
if postfix is not None:
|
| 68 |
+
return os.path.join(ppath, postfix)
|
| 69 |
+
else:
|
| 70 |
+
return ppath
|
| 71 |
+
|
| 72 |
+
|
| 73 |
+
def init_logger(log_file=None, log_file_level=logging.NOTSET, from_scratch=False):
|
| 74 |
+
from coloredlogs import ColoredFormatter
|
| 75 |
+
import tensorflow as tf
|
| 76 |
+
|
| 77 |
+
fmt = "[%(asctime)s %(levelname)s] %(message)s"
|
| 78 |
+
log_format = ColoredFormatter(fmt=fmt)
|
| 79 |
+
# log_format = logging.Formatter()
|
| 80 |
+
logger = logging.getLogger()
|
| 81 |
+
logger.setLevel(log_file_level)
|
| 82 |
+
|
| 83 |
+
console_handler = logging.StreamHandler()
|
| 84 |
+
console_handler.setFormatter(log_format)
|
| 85 |
+
logger.handlers = [console_handler]
|
| 86 |
+
|
| 87 |
+
if log_file and log_file != '':
|
| 88 |
+
if from_scratch and tf.io.gfile.exists(log_file):
|
| 89 |
+
logger.warning('Removing previous log file: %s' % log_file)
|
| 90 |
+
tf.io.gfile.remove(log_file)
|
| 91 |
+
path = os.path.dirname(log_file)
|
| 92 |
+
os.makedirs(path, exist_ok=True)
|
| 93 |
+
file_handler = logging.FileHandler(log_file)
|
| 94 |
+
file_handler.setLevel(log_file_level)
|
| 95 |
+
file_handler.setFormatter(log_format)
|
| 96 |
+
logger.addHandler(file_handler)
|
| 97 |
+
|
| 98 |
+
return logger
|
| 99 |
+
|
| 100 |
+
|
| 101 |
+
def OverWriteCjjPy(root='.'):
|
| 102 |
+
# import difflib
|
| 103 |
+
# diff = difflib.HtmlDiff()
|
| 104 |
+
cnt = 0
|
| 105 |
+
golden_cjjpy = os.path.join(root, 'cjjpy.py')
|
| 106 |
+
# golden_content = open(golden_cjjpy).readlines()
|
| 107 |
+
for dir, folder, file in os.walk(root):
|
| 108 |
+
for f in file:
|
| 109 |
+
if f == 'cjjpy.py':
|
| 110 |
+
cjjpy = '%s/%s' % (dir, f)
|
| 111 |
+
# content = open(cjjpy).readlines()
|
| 112 |
+
# d = diff.make_file(golden_content, content)
|
| 113 |
+
cnt += 1
|
| 114 |
+
print('[%d]: %s' % (cnt, cjjpy))
|
| 115 |
+
os.system('cp %s %s' % (golden_cjjpy, cjjpy))
|
| 116 |
+
|
| 117 |
+
|
| 118 |
+
def ChangeFileFormat(filename, new_fmt):
|
| 119 |
+
assert type(filename) is str and type(new_fmt) is str
|
| 120 |
+
spt = filename.split('.')
|
| 121 |
+
if len(spt) == 0:
|
| 122 |
+
return filename
|
| 123 |
+
else:
|
| 124 |
+
return filename.replace('.' + spt[-1], new_fmt)
|
| 125 |
+
|
| 126 |
+
|
| 127 |
+
def CountLines(fname):
|
| 128 |
+
with open(fname, 'rb') as f:
|
| 129 |
+
count = 0
|
| 130 |
+
last_data = '\n'
|
| 131 |
+
while True:
|
| 132 |
+
data = f.read(0x400000)
|
| 133 |
+
if not data:
|
| 134 |
+
break
|
| 135 |
+
count += data.count(b'\n')
|
| 136 |
+
last_data = data
|
| 137 |
+
if last_data[-1:] != b'\n':
|
| 138 |
+
count += 1 # Remove this if a wc-like count is needed
|
| 139 |
+
return count
|
| 140 |
+
|
| 141 |
+
|
| 142 |
+
def GetDate():
|
| 143 |
+
return str(datetime.datetime.now())[5:10].replace('-', '')
|
| 144 |
+
|
| 145 |
+
|
| 146 |
+
def TimeClock(seconds):
|
| 147 |
+
sec = int(seconds)
|
| 148 |
+
hour = int(sec / 3600)
|
| 149 |
+
min = int((sec - hour * 3600) / 60)
|
| 150 |
+
ssec = float(seconds) - hour * 3600 - min * 60
|
| 151 |
+
# return '%dh %dm %.2fs' % (hour, min, ssec)
|
| 152 |
+
return '{0:>2d}h{1:>3d}m{2:>6.2f}s'.format(hour, min, ssec)
|
| 153 |
+
|
| 154 |
+
|
| 155 |
+
def StripAll(text):
|
| 156 |
+
return text.strip().replace('\t', '').replace('\n', '').replace(' ', '')
|
| 157 |
+
|
| 158 |
+
|
| 159 |
+
def GetBracket(text, bracket, en_br=False):
|
| 160 |
+
# input should be aa(bb)cc, True for bracket, False for text
|
| 161 |
+
if bracket:
|
| 162 |
+
try:
|
| 163 |
+
return re.findall('\((.*?)\)', text.strip())[-1]
|
| 164 |
+
except:
|
| 165 |
+
return ''
|
| 166 |
+
else:
|
| 167 |
+
if en_br:
|
| 168 |
+
text = re.sub('\(.*?\)', '', text.strip())
|
| 169 |
+
return re.sub('(.*?)', '', text.strip())
|
| 170 |
+
|
| 171 |
+
|
| 172 |
+
def CharLang(uchar, lang):
|
| 173 |
+
assert lang.lower() in ['en', 'cn', 'zh']
|
| 174 |
+
if lang.lower() in ['cn', 'zh']:
|
| 175 |
+
if uchar >= '\u4e00' and uchar <= '\u9fa5':
|
| 176 |
+
return True
|
| 177 |
+
else:
|
| 178 |
+
return False
|
| 179 |
+
elif lang.lower() == 'en':
|
| 180 |
+
if (uchar <= 'Z' and uchar >= 'A') or (uchar <= 'z' and uchar >= 'a'):
|
| 181 |
+
return True
|
| 182 |
+
else:
|
| 183 |
+
return False
|
| 184 |
+
else:
|
| 185 |
+
raise NotImplementedError
|
| 186 |
+
|
| 187 |
+
|
| 188 |
+
def WordLang(word, lang):
|
| 189 |
+
for i in word.strip():
|
| 190 |
+
if i.isspace(): continue
|
| 191 |
+
if not CharLang(i, lang):
|
| 192 |
+
return False
|
| 193 |
+
return True
|
| 194 |
+
|
| 195 |
+
|
| 196 |
+
def SortDict(_dict, reverse=True):
|
| 197 |
+
assert type(_dict) is dict
|
| 198 |
+
return sorted(_dict.items(), key=lambda d: d[1], reverse=reverse)
|
| 199 |
+
|
| 200 |
+
|
| 201 |
+
def lark(content='test'):
|
| 202 |
+
print(content)
|
| 203 |
+
|
| 204 |
+
|
| 205 |
+
if __name__ == '__main__':
|
| 206 |
+
parser = argparse.ArgumentParser()
|
| 207 |
+
|
| 208 |
+
parser.add_argument('--diff', nargs=2,
|
| 209 |
+
help='show difference between two files, shown in downloads/diff.html')
|
| 210 |
+
parser.add_argument('--de_unicode', action='store_true', default=False,
|
| 211 |
+
help='remove unicode characters')
|
| 212 |
+
parser.add_argument('--link_entity', action='store_true', default=False,
|
| 213 |
+
help='')
|
| 214 |
+
parser.add_argument('--max_comm_len', action='store_true', default=False,
|
| 215 |
+
help='')
|
| 216 |
+
parser.add_argument('--search', nargs=2,
|
| 217 |
+
help='search key from file, 2 args: file name & key')
|
| 218 |
+
parser.add_argument('--email', nargs=2,
|
| 219 |
+
help='sending emails, 2 args: subject & content')
|
| 220 |
+
parser.add_argument('--overwrite', action='store_true', default=None,
|
| 221 |
+
help='overwrite all cjjpy under given *dir* based on *dir*/cjjpy.py')
|
| 222 |
+
parser.add_argument('--replace', nargs=3,
|
| 223 |
+
help='replace char, 3 args: file name & replaced char & replacer char')
|
| 224 |
+
parser.add_argument('--lark', nargs=1)
|
| 225 |
+
parser.add_argument('--get_hdfs', nargs=2,
|
| 226 |
+
help='easy copy from hdfs to local fs, 2 args: remote_file/dir & local_dir')
|
| 227 |
+
parser.add_argument('--put_hdfs', nargs=2,
|
| 228 |
+
help='easy put from local fs to hdfs, 2 args: local_file/dir & remote_dir')
|
| 229 |
+
parser.add_argument('--length_stats', nargs=1,
|
| 230 |
+
help='simple token lengths distribution of a line-by-line file')
|
| 231 |
+
|
| 232 |
+
args = parser.parse_args()
|
| 233 |
+
|
| 234 |
+
if args.overwrite:
|
| 235 |
+
print('* Overwriting cjjpy...')
|
| 236 |
+
OverWriteCjjPy()
|
| 237 |
+
|
| 238 |
+
if args.lark:
|
| 239 |
+
try:
|
| 240 |
+
content = args.lark[0]
|
| 241 |
+
except:
|
| 242 |
+
content = 'running complete'
|
| 243 |
+
print(f'* Larking "{content}"...')
|
| 244 |
+
lark(content)
|
| 245 |
+
|
| 246 |
+
if args.length_stats:
|
| 247 |
+
file = args.length_stats[0]
|
| 248 |
+
print(f'* Working on {file} lengths statistics...')
|
| 249 |
+
LengthStats(file)
|
src/check_client/fact_checker.py
ADDED
|
@@ -0,0 +1,209 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# -*- coding: utf-8 -*-
|
| 2 |
+
|
| 3 |
+
"""
|
| 4 |
+
@Author : Bao
|
| 5 |
+
@Date : 2020/8/12
|
| 6 |
+
@Desc :
|
| 7 |
+
@Last modified by : Bao
|
| 8 |
+
@Last modified date : 2020/8/20
|
| 9 |
+
"""
|
| 10 |
+
|
| 11 |
+
import os
|
| 12 |
+
import sys
|
| 13 |
+
import logging
|
| 14 |
+
import torch
|
| 15 |
+
import numpy as np
|
| 16 |
+
from tqdm import tqdm
|
| 17 |
+
import tensorflow as tf
|
| 18 |
+
import ujson as json
|
| 19 |
+
import argparse
|
| 20 |
+
import cjjpy as cjj
|
| 21 |
+
from itertools import repeat
|
| 22 |
+
from torch.utils.data import DataLoader, SequentialSampler
|
| 23 |
+
from transformers import (
|
| 24 |
+
BertConfig, BertTokenizer, AutoTokenizer,
|
| 25 |
+
RobertaConfig, RobertaTokenizer,
|
| 26 |
+
)
|
| 27 |
+
|
| 28 |
+
try:
|
| 29 |
+
from .modules.data_processor import DataProcessor
|
| 30 |
+
from .plm_checkers import BertChecker, RobertaChecker
|
| 31 |
+
from .utils import read_json_lines, compute_metrics
|
| 32 |
+
from .train import do_evaluate, set_seed
|
| 33 |
+
from ..eval_client.fever_scorer import FeverScorer
|
| 34 |
+
except:
|
| 35 |
+
sys.path.append(cjj.AbsParentDir(__file__, '.'))
|
| 36 |
+
sys.path.append(cjj.AbsParentDir(__file__, '..'))
|
| 37 |
+
from eval_client.fever_scorer import FeverScorer
|
| 38 |
+
from modules.data_processor import DataProcessor
|
| 39 |
+
from plm_checkers import BertChecker, RobertaChecker
|
| 40 |
+
from utils import read_json_lines, compute_metrics
|
| 41 |
+
from train import do_evaluate, set_seed
|
| 42 |
+
|
| 43 |
+
MODEL_MAPPING = {
|
| 44 |
+
'bert': (BertConfig, BertTokenizer, BertChecker),
|
| 45 |
+
'roberta': (RobertaConfig, RobertaTokenizer, RobertaChecker),
|
| 46 |
+
}
|
| 47 |
+
|
| 48 |
+
logger = logging.getLogger(__name__)
|
| 49 |
+
label2id = {"SUPPORTS": 2, "REFUTES": 0, 'NOT ENOUGH INFO': 1}
|
| 50 |
+
id2label = {v: k for k, v in label2id.items()}
|
| 51 |
+
|
| 52 |
+
|
| 53 |
+
class FactChecker:
|
| 54 |
+
def __init__(self, args, fc_ckpt_dir=None, mask_rate=0.):
|
| 55 |
+
self.data_processor = None
|
| 56 |
+
self.tokenizer = None
|
| 57 |
+
self.model = None
|
| 58 |
+
self.args = args
|
| 59 |
+
self.ckpt = args.fc_dir if fc_ckpt_dir is None else fc_ckpt_dir
|
| 60 |
+
self.mask_rate = mask_rate
|
| 61 |
+
|
| 62 |
+
logger.info('Initializing fact checker.')
|
| 63 |
+
self._prepare_ckpt(self.args.model_name_or_path, self.ckpt)
|
| 64 |
+
self.load_model()
|
| 65 |
+
|
| 66 |
+
def _prepare_ckpt(self, model_name_or_path, ckpt_dir):
|
| 67 |
+
tokenizer = AutoTokenizer.from_pretrained(model_name_or_path)
|
| 68 |
+
tokenizer.save_pretrained(ckpt_dir)
|
| 69 |
+
|
| 70 |
+
def load_model(self):
|
| 71 |
+
if self.model is None:
|
| 72 |
+
self.data_processor = DataProcessor(
|
| 73 |
+
self.args.model_name_or_path,
|
| 74 |
+
self.args.max_seq1_length,
|
| 75 |
+
self.args.max_seq2_length,
|
| 76 |
+
self.args.max_num_questions,
|
| 77 |
+
self.args.cand_k,
|
| 78 |
+
mask_rate=self.mask_rate
|
| 79 |
+
)
|
| 80 |
+
|
| 81 |
+
_, tokenizer_class, model_class = MODEL_MAPPING[self.args.model_type]
|
| 82 |
+
self.tokenizer = tokenizer_class.from_pretrained(
|
| 83 |
+
self.ckpt,
|
| 84 |
+
do_lower_case=self.args.do_lower_case
|
| 85 |
+
)
|
| 86 |
+
self.model = model_class.from_pretrained(
|
| 87 |
+
self.ckpt,
|
| 88 |
+
from_tf=bool(".ckpt" in self.ckpt),
|
| 89 |
+
logic_lambda=self.args.logic_lambda,
|
| 90 |
+
prior=self.args.prior,
|
| 91 |
+
)
|
| 92 |
+
self.model = torch.nn.DataParallel(self.model)
|
| 93 |
+
|
| 94 |
+
def _check(self, inputs: list, batch_size=32, verbose=True):
|
| 95 |
+
dataset = self.data_processor.convert_inputs_to_dataset(inputs, self.tokenizer, verbose=verbose)
|
| 96 |
+
sampler = SequentialSampler(dataset)
|
| 97 |
+
dataloader = DataLoader(dataset, sampler=sampler, batch_size=batch_size)
|
| 98 |
+
|
| 99 |
+
with torch.no_grad():
|
| 100 |
+
self.model.to(self.args.device)
|
| 101 |
+
self.model.eval()
|
| 102 |
+
iter = tqdm(dataloader, desc="Fact Checking") if verbose else dataloader
|
| 103 |
+
_, y_predicted, z_predicted, m_attn, mask = \
|
| 104 |
+
do_evaluate(iter, self.model, self.args, during_training=False, with_label=False)
|
| 105 |
+
|
| 106 |
+
return y_predicted, z_predicted, m_attn, mask
|
| 107 |
+
|
| 108 |
+
def check_from_file(self, in_filename, out_filename, batch_size, verbose=False):
|
| 109 |
+
if 'test' in in_filename:
|
| 110 |
+
raw_inp = f'{os.environ["PJ_HOME"]}/data/fever/shared_task_test.jsonl'
|
| 111 |
+
else:
|
| 112 |
+
raw_inp = None
|
| 113 |
+
tf.io.gfile.makedirs(os.path.dirname(out_filename))
|
| 114 |
+
inputs = list(read_json_lines(in_filename))
|
| 115 |
+
y_predicted, z_predicted, m_attn, mask = self._check(inputs, batch_size)
|
| 116 |
+
|
| 117 |
+
z_predicted = repeat(None) if z_predicted is None else z_predicted
|
| 118 |
+
m_attn = repeat(None) if m_attn is None else m_attn
|
| 119 |
+
ordered_results = {}
|
| 120 |
+
with_label = inputs[0].get('label') is not None
|
| 121 |
+
|
| 122 |
+
if with_label:
|
| 123 |
+
label_truth = [label2id[x['label']] for x in inputs]
|
| 124 |
+
_, acc_results = compute_metrics(label_truth, y_predicted, z_predicted, mask)
|
| 125 |
+
else:
|
| 126 |
+
acc_results = {}
|
| 127 |
+
|
| 128 |
+
for i, (inp, y, z, attn, _mask) in \
|
| 129 |
+
enumerate(zip(inputs, y_predicted, z_predicted, m_attn, mask)):
|
| 130 |
+
result = {'id': inp['id'],
|
| 131 |
+
'predicted_label': id2label[y],
|
| 132 |
+
'predicted_evidence': inp.get('predicted_evidence', [])}
|
| 133 |
+
if verbose:
|
| 134 |
+
if i < 5:
|
| 135 |
+
print("{}\t{}\t{}".format(inp.get("id", i), inp["claim"], y))
|
| 136 |
+
if z is not None and attn is not None:
|
| 137 |
+
result.update({
|
| 138 |
+
'z_prob': z[:torch.tensor(_mask).sum()],
|
| 139 |
+
'm_attn': attn[:torch.tensor(_mask).sum()],
|
| 140 |
+
})
|
| 141 |
+
ordered_results[inp['id']] = result
|
| 142 |
+
|
| 143 |
+
with tf.io.gfile.GFile(out_filename, 'w') as fout:
|
| 144 |
+
if raw_inp:
|
| 145 |
+
with tf.io.gfile.GFile(raw_inp) as f:
|
| 146 |
+
for line in f:
|
| 147 |
+
raw_js = json.loads(line)
|
| 148 |
+
fout.write(json.dumps(ordered_results[raw_js['id']]) + '\n')
|
| 149 |
+
else:
|
| 150 |
+
for k in ordered_results:
|
| 151 |
+
fout.write(json.dumps(ordered_results[k]) + '\n')
|
| 152 |
+
|
| 153 |
+
if ('dev' in in_filename or 'val' in in_filename) and with_label:
|
| 154 |
+
scorer = FeverScorer()
|
| 155 |
+
fever_results = scorer.get_scores(out_filename)
|
| 156 |
+
fever_results.update(acc_results)
|
| 157 |
+
|
| 158 |
+
print(fever_results)
|
| 159 |
+
return fever_results
|
| 160 |
+
|
| 161 |
+
def check_from_batch(self, inputs: list, verbose=False):
|
| 162 |
+
y_predicted, z_predicted, m_attn, mask = self._check(inputs, len(inputs), verbose)
|
| 163 |
+
return y_predicted, z_predicted, m_attn
|
| 164 |
+
|
| 165 |
+
|
| 166 |
+
if __name__ == '__main__':
|
| 167 |
+
parser = argparse.ArgumentParser()
|
| 168 |
+
parser.add_argument('--input', '-i', required=True, type=str,
|
| 169 |
+
choices=['val', 'eval', 'test', 'demo'])
|
| 170 |
+
parser.add_argument('--output', '-o', default='none', type=str)
|
| 171 |
+
parser.add_argument('--ckpt', '-c', required=True, type=str)
|
| 172 |
+
parser.add_argument('--model_type', default='roberta', type=str,
|
| 173 |
+
choices=['roberta', 'bert'])
|
| 174 |
+
parser.add_argument('--model_name_or_path', default='roberta-large', type=str)
|
| 175 |
+
parser.add_argument('--verbose', '-v', action='store_true', default=False,
|
| 176 |
+
help='whether output phrasal veracity or not')
|
| 177 |
+
parser.add_argument('--logic_lambda', '-l', required=True, type=float)
|
| 178 |
+
parser.add_argument('--prior', default='random', type=str, choices=['nli', 'uniform', 'logic', 'random'],
|
| 179 |
+
help='type of prior distribution')
|
| 180 |
+
parser.add_argument('--mask_rate', '-m', default=0., type=float)
|
| 181 |
+
|
| 182 |
+
parser.add_argument('--cand_k', '-k', default=3, type=int)
|
| 183 |
+
parser.add_argument('--max_seq1_length', default=256, type=int)
|
| 184 |
+
parser.add_argument('--max_seq2_length', default=128, type=int)
|
| 185 |
+
parser.add_argument('--max_num_questions', default=8, type=int)
|
| 186 |
+
parser.add_argument('--do_lower_case', action='store_true', default=False)
|
| 187 |
+
parser.add_argument('--batch_size', '-b', default=64, type=int)
|
| 188 |
+
parser.add_argument('--seed', default=42)
|
| 189 |
+
parser.add_argument('--n_gpu', default=4)
|
| 190 |
+
|
| 191 |
+
args = parser.parse_args()
|
| 192 |
+
|
| 193 |
+
set_seed(args)
|
| 194 |
+
|
| 195 |
+
args.device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
|
| 196 |
+
|
| 197 |
+
if args.output == 'none':
|
| 198 |
+
args.ckpt = args.ckpt[:-1] if args.ckpt.endswith('/') else args.ckpt
|
| 199 |
+
base_name = os.path.basename(args.ckpt)
|
| 200 |
+
args.output = f'{os.environ["PJ_HOME"]}/results/fact_checking/AAAI22/{args.input}.{args.model_name_or_path}_m{args.mask_rate}_l{args.logic_lambda}_{base_name}_{args.prior}.predictions.jsonl'
|
| 201 |
+
|
| 202 |
+
assert args.output.endswith('predictions.jsonl'), \
|
| 203 |
+
f"{args.output} must end with predictions.jsonl"
|
| 204 |
+
|
| 205 |
+
args.input = f'{os.environ["PJ_HOME"]}/data/fact_checking/v5/{args.input}.json'
|
| 206 |
+
|
| 207 |
+
checker = FactChecker(args, args.ckpt, args.mask_rate)
|
| 208 |
+
fever_results = checker.check_from_file(args.input, args.output, args.batch_size, args.verbose)
|
| 209 |
+
cjj.lark(f"{args.output}: {fever_results}")
|
src/check_client/modules/cjjpy.py
ADDED
|
@@ -0,0 +1,249 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# -*- coding: utf-8 -*-
|
| 2 |
+
|
| 3 |
+
'''
|
| 4 |
+
@Author : Jiangjie Chen
|
| 5 |
+
@Time : 2018/11/15 17:08
|
| 6 |
+
@Contact: jjchen19@fudan.edu.cn
|
| 7 |
+
'''
|
| 8 |
+
|
| 9 |
+
import re
|
| 10 |
+
import datetime
|
| 11 |
+
import os
|
| 12 |
+
import argparse
|
| 13 |
+
import logging
|
| 14 |
+
import traceback
|
| 15 |
+
|
| 16 |
+
try:
|
| 17 |
+
import ujson as json
|
| 18 |
+
except:
|
| 19 |
+
import json
|
| 20 |
+
|
| 21 |
+
HADOOP_BIN = 'PATH=/usr/bin/:$PATH hdfs'
|
| 22 |
+
FOR_PUBLIC = True
|
| 23 |
+
|
| 24 |
+
|
| 25 |
+
def LengthStats(filename):
|
| 26 |
+
len_list = []
|
| 27 |
+
thresholds = [0.8, 0.9, 0.95, 0.99, 0.999]
|
| 28 |
+
with open(filename) as f:
|
| 29 |
+
for line in f:
|
| 30 |
+
len_list.append(len(line.strip().split()))
|
| 31 |
+
stats = {
|
| 32 |
+
'Max': max(len_list),
|
| 33 |
+
'Min': min(len_list),
|
| 34 |
+
'Avg': round(sum(len_list) / len(len_list), 4),
|
| 35 |
+
}
|
| 36 |
+
len_list.sort()
|
| 37 |
+
for t in thresholds:
|
| 38 |
+
stats[f"Top-{t}"] = len_list[int(len(len_list) * t)]
|
| 39 |
+
|
| 40 |
+
for k in stats:
|
| 41 |
+
print(f"- {k}: {stats[k]}")
|
| 42 |
+
return stats
|
| 43 |
+
|
| 44 |
+
|
| 45 |
+
class AttrDict(dict):
|
| 46 |
+
def __init__(self, *args, **kwargs):
|
| 47 |
+
super(AttrDict, self).__init__(*args, **kwargs)
|
| 48 |
+
self.__dict__ = self
|
| 49 |
+
|
| 50 |
+
|
| 51 |
+
def TraceBack(error_msg):
|
| 52 |
+
exc = traceback.format_exc()
|
| 53 |
+
msg = f'[Error]: {error_msg}.\n[Traceback]: {exc}'
|
| 54 |
+
return msg
|
| 55 |
+
|
| 56 |
+
|
| 57 |
+
def Now():
|
| 58 |
+
return datetime.datetime.now().strftime("%Y-%m-%d %H:%M:%S")
|
| 59 |
+
|
| 60 |
+
|
| 61 |
+
def AbsParentDir(file, parent='..', postfix=None):
|
| 62 |
+
ppath = os.path.abspath(file)
|
| 63 |
+
parent_level = parent.count('.')
|
| 64 |
+
while parent_level > 0:
|
| 65 |
+
ppath = os.path.dirname(ppath)
|
| 66 |
+
parent_level -= 1
|
| 67 |
+
if postfix is not None:
|
| 68 |
+
return os.path.join(ppath, postfix)
|
| 69 |
+
else:
|
| 70 |
+
return ppath
|
| 71 |
+
|
| 72 |
+
|
| 73 |
+
def init_logger(log_file=None, log_file_level=logging.NOTSET, from_scratch=False):
|
| 74 |
+
from coloredlogs import ColoredFormatter
|
| 75 |
+
import tensorflow as tf
|
| 76 |
+
|
| 77 |
+
fmt = "[%(asctime)s %(levelname)s] %(message)s"
|
| 78 |
+
log_format = ColoredFormatter(fmt=fmt)
|
| 79 |
+
# log_format = logging.Formatter()
|
| 80 |
+
logger = logging.getLogger()
|
| 81 |
+
logger.setLevel(log_file_level)
|
| 82 |
+
|
| 83 |
+
console_handler = logging.StreamHandler()
|
| 84 |
+
console_handler.setFormatter(log_format)
|
| 85 |
+
logger.handlers = [console_handler]
|
| 86 |
+
|
| 87 |
+
if log_file and log_file != '':
|
| 88 |
+
if from_scratch and tf.io.gfile.exists(log_file):
|
| 89 |
+
logger.warning('Removing previous log file: %s' % log_file)
|
| 90 |
+
tf.io.gfile.remove(log_file)
|
| 91 |
+
path = os.path.dirname(log_file)
|
| 92 |
+
os.makedirs(path, exist_ok=True)
|
| 93 |
+
file_handler = logging.FileHandler(log_file)
|
| 94 |
+
file_handler.setLevel(log_file_level)
|
| 95 |
+
file_handler.setFormatter(log_format)
|
| 96 |
+
logger.addHandler(file_handler)
|
| 97 |
+
|
| 98 |
+
return logger
|
| 99 |
+
|
| 100 |
+
|
| 101 |
+
def OverWriteCjjPy(root='.'):
|
| 102 |
+
# import difflib
|
| 103 |
+
# diff = difflib.HtmlDiff()
|
| 104 |
+
cnt = 0
|
| 105 |
+
golden_cjjpy = os.path.join(root, 'cjjpy.py')
|
| 106 |
+
# golden_content = open(golden_cjjpy).readlines()
|
| 107 |
+
for dir, folder, file in os.walk(root):
|
| 108 |
+
for f in file:
|
| 109 |
+
if f == 'cjjpy.py':
|
| 110 |
+
cjjpy = '%s/%s' % (dir, f)
|
| 111 |
+
# content = open(cjjpy).readlines()
|
| 112 |
+
# d = diff.make_file(golden_content, content)
|
| 113 |
+
cnt += 1
|
| 114 |
+
print('[%d]: %s' % (cnt, cjjpy))
|
| 115 |
+
os.system('cp %s %s' % (golden_cjjpy, cjjpy))
|
| 116 |
+
|
| 117 |
+
|
| 118 |
+
def ChangeFileFormat(filename, new_fmt):
|
| 119 |
+
assert type(filename) is str and type(new_fmt) is str
|
| 120 |
+
spt = filename.split('.')
|
| 121 |
+
if len(spt) == 0:
|
| 122 |
+
return filename
|
| 123 |
+
else:
|
| 124 |
+
return filename.replace('.' + spt[-1], new_fmt)
|
| 125 |
+
|
| 126 |
+
|
| 127 |
+
def CountLines(fname):
|
| 128 |
+
with open(fname, 'rb') as f:
|
| 129 |
+
count = 0
|
| 130 |
+
last_data = '\n'
|
| 131 |
+
while True:
|
| 132 |
+
data = f.read(0x400000)
|
| 133 |
+
if not data:
|
| 134 |
+
break
|
| 135 |
+
count += data.count(b'\n')
|
| 136 |
+
last_data = data
|
| 137 |
+
if last_data[-1:] != b'\n':
|
| 138 |
+
count += 1 # Remove this if a wc-like count is needed
|
| 139 |
+
return count
|
| 140 |
+
|
| 141 |
+
|
| 142 |
+
def GetDate():
|
| 143 |
+
return str(datetime.datetime.now())[5:10].replace('-', '')
|
| 144 |
+
|
| 145 |
+
|
| 146 |
+
def TimeClock(seconds):
|
| 147 |
+
sec = int(seconds)
|
| 148 |
+
hour = int(sec / 3600)
|
| 149 |
+
min = int((sec - hour * 3600) / 60)
|
| 150 |
+
ssec = float(seconds) - hour * 3600 - min * 60
|
| 151 |
+
# return '%dh %dm %.2fs' % (hour, min, ssec)
|
| 152 |
+
return '{0:>2d}h{1:>3d}m{2:>6.2f}s'.format(hour, min, ssec)
|
| 153 |
+
|
| 154 |
+
|
| 155 |
+
def StripAll(text):
|
| 156 |
+
return text.strip().replace('\t', '').replace('\n', '').replace(' ', '')
|
| 157 |
+
|
| 158 |
+
|
| 159 |
+
def GetBracket(text, bracket, en_br=False):
|
| 160 |
+
# input should be aa(bb)cc, True for bracket, False for text
|
| 161 |
+
if bracket:
|
| 162 |
+
try:
|
| 163 |
+
return re.findall('\((.*?)\)', text.strip())[-1]
|
| 164 |
+
except:
|
| 165 |
+
return ''
|
| 166 |
+
else:
|
| 167 |
+
if en_br:
|
| 168 |
+
text = re.sub('\(.*?\)', '', text.strip())
|
| 169 |
+
return re.sub('(.*?)', '', text.strip())
|
| 170 |
+
|
| 171 |
+
|
| 172 |
+
def CharLang(uchar, lang):
|
| 173 |
+
assert lang.lower() in ['en', 'cn', 'zh']
|
| 174 |
+
if lang.lower() in ['cn', 'zh']:
|
| 175 |
+
if uchar >= '\u4e00' and uchar <= '\u9fa5':
|
| 176 |
+
return True
|
| 177 |
+
else:
|
| 178 |
+
return False
|
| 179 |
+
elif lang.lower() == 'en':
|
| 180 |
+
if (uchar <= 'Z' and uchar >= 'A') or (uchar <= 'z' and uchar >= 'a'):
|
| 181 |
+
return True
|
| 182 |
+
else:
|
| 183 |
+
return False
|
| 184 |
+
else:
|
| 185 |
+
raise NotImplementedError
|
| 186 |
+
|
| 187 |
+
|
| 188 |
+
def WordLang(word, lang):
|
| 189 |
+
for i in word.strip():
|
| 190 |
+
if i.isspace(): continue
|
| 191 |
+
if not CharLang(i, lang):
|
| 192 |
+
return False
|
| 193 |
+
return True
|
| 194 |
+
|
| 195 |
+
|
| 196 |
+
def SortDict(_dict, reverse=True):
|
| 197 |
+
assert type(_dict) is dict
|
| 198 |
+
return sorted(_dict.items(), key=lambda d: d[1], reverse=reverse)
|
| 199 |
+
|
| 200 |
+
|
| 201 |
+
def lark(content='test'):
|
| 202 |
+
print(content)
|
| 203 |
+
|
| 204 |
+
|
| 205 |
+
if __name__ == '__main__':
|
| 206 |
+
parser = argparse.ArgumentParser()
|
| 207 |
+
|
| 208 |
+
parser.add_argument('--diff', nargs=2,
|
| 209 |
+
help='show difference between two files, shown in downloads/diff.html')
|
| 210 |
+
parser.add_argument('--de_unicode', action='store_true', default=False,
|
| 211 |
+
help='remove unicode characters')
|
| 212 |
+
parser.add_argument('--link_entity', action='store_true', default=False,
|
| 213 |
+
help='')
|
| 214 |
+
parser.add_argument('--max_comm_len', action='store_true', default=False,
|
| 215 |
+
help='')
|
| 216 |
+
parser.add_argument('--search', nargs=2,
|
| 217 |
+
help='search key from file, 2 args: file name & key')
|
| 218 |
+
parser.add_argument('--email', nargs=2,
|
| 219 |
+
help='sending emails, 2 args: subject & content')
|
| 220 |
+
parser.add_argument('--overwrite', action='store_true', default=None,
|
| 221 |
+
help='overwrite all cjjpy under given *dir* based on *dir*/cjjpy.py')
|
| 222 |
+
parser.add_argument('--replace', nargs=3,
|
| 223 |
+
help='replace char, 3 args: file name & replaced char & replacer char')
|
| 224 |
+
parser.add_argument('--lark', nargs=1)
|
| 225 |
+
parser.add_argument('--get_hdfs', nargs=2,
|
| 226 |
+
help='easy copy from hdfs to local fs, 2 args: remote_file/dir & local_dir')
|
| 227 |
+
parser.add_argument('--put_hdfs', nargs=2,
|
| 228 |
+
help='easy put from local fs to hdfs, 2 args: local_file/dir & remote_dir')
|
| 229 |
+
parser.add_argument('--length_stats', nargs=1,
|
| 230 |
+
help='simple token lengths distribution of a line-by-line file')
|
| 231 |
+
|
| 232 |
+
args = parser.parse_args()
|
| 233 |
+
|
| 234 |
+
if args.overwrite:
|
| 235 |
+
print('* Overwriting cjjpy...')
|
| 236 |
+
OverWriteCjjPy()
|
| 237 |
+
|
| 238 |
+
if args.lark:
|
| 239 |
+
try:
|
| 240 |
+
content = args.lark[0]
|
| 241 |
+
except:
|
| 242 |
+
content = 'running complete'
|
| 243 |
+
print(f'* Larking "{content}"...')
|
| 244 |
+
lark(content)
|
| 245 |
+
|
| 246 |
+
if args.length_stats:
|
| 247 |
+
file = args.length_stats[0]
|
| 248 |
+
print(f'* Working on {file} lengths statistics...')
|
| 249 |
+
LengthStats(file)
|
src/check_client/modules/data_processor.py
ADDED
|
@@ -0,0 +1,354 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# -*- coding: utf-8 -*-
|
| 2 |
+
|
| 3 |
+
"""
|
| 4 |
+
@Author : Bao
|
| 5 |
+
@Date : 2020/4/14
|
| 6 |
+
@Desc :
|
| 7 |
+
@Last modified by : Bao
|
| 8 |
+
@Last modified date : 2020/8/12
|
| 9 |
+
"""
|
| 10 |
+
|
| 11 |
+
import os
|
| 12 |
+
import copy
|
| 13 |
+
import logging
|
| 14 |
+
import ujson as json
|
| 15 |
+
import torch
|
| 16 |
+
from tqdm import tqdm
|
| 17 |
+
from torch.utils.data import TensorDataset
|
| 18 |
+
import tensorflow as tf
|
| 19 |
+
import cjjpy as cjj
|
| 20 |
+
import sys
|
| 21 |
+
|
| 22 |
+
try:
|
| 23 |
+
from ...mrc_client.answer_generator import assemble_answers_to_one
|
| 24 |
+
except:
|
| 25 |
+
sys.path.append(cjj.AbsParentDir(__file__, '...'))
|
| 26 |
+
from mrc_client.answer_generator import assemble_answers_to_one
|
| 27 |
+
|
| 28 |
+
logger = logging.getLogger(__name__)
|
| 29 |
+
|
| 30 |
+
|
| 31 |
+
class InputExample(object):
|
| 32 |
+
def __init__(self, guid, claim, evidences, questions, answers,
|
| 33 |
+
evidential, label=None, nli_labels=None):
|
| 34 |
+
self.guid = guid
|
| 35 |
+
self.claim = claim
|
| 36 |
+
self.evidences = evidences
|
| 37 |
+
self.questions = questions
|
| 38 |
+
self.answers = answers
|
| 39 |
+
self.evidential = evidential
|
| 40 |
+
self.label = label
|
| 41 |
+
self.nli_labels = nli_labels
|
| 42 |
+
|
| 43 |
+
def __repr__(self):
|
| 44 |
+
return str(self.to_json_string())
|
| 45 |
+
|
| 46 |
+
def to_dict(self):
|
| 47 |
+
"""Serializes this instance to a Python dictionary."""
|
| 48 |
+
output = copy.deepcopy(self.__dict__)
|
| 49 |
+
return output
|
| 50 |
+
|
| 51 |
+
def to_json_string(self):
|
| 52 |
+
"""Serializes this instance to a JSON string."""
|
| 53 |
+
return json.dumps(self.to_dict(), indent=2, sort_keys=True) + "\n"
|
| 54 |
+
|
| 55 |
+
|
| 56 |
+
class InputFeatures(object):
|
| 57 |
+
def __init__(
|
| 58 |
+
self,
|
| 59 |
+
guid,
|
| 60 |
+
c_input_ids,
|
| 61 |
+
c_attention_mask,
|
| 62 |
+
c_token_type_ids,
|
| 63 |
+
q_input_ids_list,
|
| 64 |
+
q_attention_mask_list,
|
| 65 |
+
q_token_type_ids_list,
|
| 66 |
+
nli_labels=None,
|
| 67 |
+
label=None,
|
| 68 |
+
):
|
| 69 |
+
self.guid = guid
|
| 70 |
+
self.c_input_ids = c_input_ids
|
| 71 |
+
self.c_attention_mask = c_attention_mask
|
| 72 |
+
self.c_token_type_ids = c_token_type_ids
|
| 73 |
+
self.q_input_ids_list = q_input_ids_list
|
| 74 |
+
self.q_attention_mask_list = q_attention_mask_list
|
| 75 |
+
self.q_token_type_ids_list = q_token_type_ids_list
|
| 76 |
+
self.nli_labels = nli_labels
|
| 77 |
+
self.label = label
|
| 78 |
+
|
| 79 |
+
def __repr__(self):
|
| 80 |
+
return str(self.to_json_string())
|
| 81 |
+
|
| 82 |
+
def to_dict(self):
|
| 83 |
+
"""Serializes this instance to a Python dictionary."""
|
| 84 |
+
output = copy.deepcopy(self.__dict__)
|
| 85 |
+
return output
|
| 86 |
+
|
| 87 |
+
def to_json_string(self):
|
| 88 |
+
"""Serializes this instance to a JSON string."""
|
| 89 |
+
return json.dumps(self.to_dict(), indent=2, sort_keys=True) + "\n"
|
| 90 |
+
|
| 91 |
+
|
| 92 |
+
def _create_input_ids_from_token_ids(token_ids_a, token_ids_b, tokenizer, max_seq_length):
|
| 93 |
+
pair = len(token_ids_b) != 0
|
| 94 |
+
|
| 95 |
+
# Truncate sequences.
|
| 96 |
+
num_special_tokens_to_add = tokenizer.num_special_tokens_to_add(pair=pair)
|
| 97 |
+
while len(token_ids_a) + len(token_ids_b) > max_seq_length - num_special_tokens_to_add:
|
| 98 |
+
if len(token_ids_b) > 0:
|
| 99 |
+
token_ids_b = token_ids_b[:-1]
|
| 100 |
+
else:
|
| 101 |
+
token_ids_a = token_ids_a[:-1]
|
| 102 |
+
|
| 103 |
+
# Add special tokens to input_ids.
|
| 104 |
+
input_ids = tokenizer.build_inputs_with_special_tokens(token_ids_a, token_ids_b if pair else None)
|
| 105 |
+
|
| 106 |
+
# The mask has 1 for real tokens and 0 for padding tokens. Only real tokens are attended to.
|
| 107 |
+
attention_mask = [1] * len(input_ids)
|
| 108 |
+
|
| 109 |
+
# Create token_type_ids.
|
| 110 |
+
token_type_ids = tokenizer.create_token_type_ids_from_sequences(token_ids_a, token_ids_b if pair else None)
|
| 111 |
+
|
| 112 |
+
# Pad up to the sequence length.
|
| 113 |
+
padding_length = max_seq_length - len(input_ids)
|
| 114 |
+
if tokenizer.padding_side == "right":
|
| 115 |
+
input_ids = input_ids + ([tokenizer.pad_token_id] * padding_length)
|
| 116 |
+
attention_mask = attention_mask + ([0] * padding_length)
|
| 117 |
+
token_type_ids = token_type_ids + ([tokenizer.pad_token_type_id] * padding_length)
|
| 118 |
+
else:
|
| 119 |
+
input_ids = ([tokenizer.pad_token_id] * padding_length) + input_ids
|
| 120 |
+
attention_mask = ([0] * padding_length) + attention_mask
|
| 121 |
+
token_type_ids = ([tokenizer.pad_token_type_id] * padding_length) + token_type_ids
|
| 122 |
+
|
| 123 |
+
assert len(input_ids) == max_seq_length
|
| 124 |
+
assert len(attention_mask) == max_seq_length
|
| 125 |
+
assert len(token_type_ids) == max_seq_length
|
| 126 |
+
|
| 127 |
+
return input_ids, attention_mask, token_type_ids
|
| 128 |
+
|
| 129 |
+
|
| 130 |
+
def convert_examples_to_features(
|
| 131 |
+
examples,
|
| 132 |
+
tokenizer,
|
| 133 |
+
max_seq1_length=256,
|
| 134 |
+
max_seq2_length=128,
|
| 135 |
+
verbose=True
|
| 136 |
+
):
|
| 137 |
+
features = []
|
| 138 |
+
iter = tqdm(examples, desc="Converting Examples") if verbose else examples
|
| 139 |
+
for (ex_index, example) in enumerate(iter):
|
| 140 |
+
encoded_outputs = {"guid": example.guid, 'label': example.label,
|
| 141 |
+
'nli_labels': example.nli_labels}
|
| 142 |
+
|
| 143 |
+
# ****** for sequence 1 ******* #
|
| 144 |
+
token_ids_a, token_ids_b = [], []
|
| 145 |
+
|
| 146 |
+
# text a in sequence 1
|
| 147 |
+
token_ids = tokenizer.encode(example.claim, add_special_tokens=False) # encode claim
|
| 148 |
+
token_ids_a.extend(token_ids)
|
| 149 |
+
|
| 150 |
+
# text b in sequence 1
|
| 151 |
+
for i, evidence in enumerate(example.evidences):
|
| 152 |
+
token_ids = tokenizer.encode(evidence, add_special_tokens=False) # encode evidence
|
| 153 |
+
token_ids_b.extend(token_ids + [tokenizer.sep_token_id])
|
| 154 |
+
# Remove last sep token in token_ids_b.
|
| 155 |
+
token_ids_b = token_ids_b[:-1]
|
| 156 |
+
token_ids_b = token_ids_b[:max_seq1_length - len(token_ids_a) - 4] # magic number for special tokens
|
| 157 |
+
|
| 158 |
+
# premise </s> </s> hypothesis
|
| 159 |
+
input_ids, attention_mask, token_type_ids = _create_input_ids_from_token_ids(
|
| 160 |
+
token_ids_b,
|
| 161 |
+
token_ids_a,
|
| 162 |
+
tokenizer,
|
| 163 |
+
max_seq1_length,
|
| 164 |
+
)
|
| 165 |
+
|
| 166 |
+
encoded_outputs["c_input_ids"] = input_ids
|
| 167 |
+
encoded_outputs["c_attention_mask"] = attention_mask
|
| 168 |
+
encoded_outputs["c_token_type_ids"] = token_type_ids
|
| 169 |
+
|
| 170 |
+
# ****** for sequence 2 ******* #
|
| 171 |
+
encoded_outputs["q_input_ids_list"] = [] # m x L
|
| 172 |
+
encoded_outputs["q_attention_mask_list"] = []
|
| 173 |
+
encoded_outputs["q_token_type_ids_list"] = []
|
| 174 |
+
|
| 175 |
+
for candidate in example.evidential:
|
| 176 |
+
# text a in sequence 2
|
| 177 |
+
token_ids_a = tokenizer.encode(example.claim, add_special_tokens=False) # encode claim
|
| 178 |
+
# text b in sequence 2
|
| 179 |
+
token_ids_b = tokenizer.encode(candidate, add_special_tokens=False) # encode candidate answer
|
| 180 |
+
# premise </s> </s> hypothesis
|
| 181 |
+
input_ids, attention_mask, token_type_ids = _create_input_ids_from_token_ids(
|
| 182 |
+
token_ids_b,
|
| 183 |
+
token_ids_a,
|
| 184 |
+
tokenizer,
|
| 185 |
+
max_seq2_length,
|
| 186 |
+
)
|
| 187 |
+
|
| 188 |
+
encoded_outputs["q_input_ids_list"].append(input_ids)
|
| 189 |
+
encoded_outputs["q_attention_mask_list"].append(attention_mask)
|
| 190 |
+
encoded_outputs["q_token_type_ids_list"].append(token_type_ids)
|
| 191 |
+
|
| 192 |
+
features.append(InputFeatures(**encoded_outputs))
|
| 193 |
+
|
| 194 |
+
if ex_index < 5 and verbose:
|
| 195 |
+
logger.info("*** Example ***")
|
| 196 |
+
logger.info("guid: {}".format(example.guid))
|
| 197 |
+
logger.info("c_input_ids: {}".format(encoded_outputs["c_input_ids"]))
|
| 198 |
+
for input_ids in encoded_outputs['q_input_ids_list']:
|
| 199 |
+
logger.info('q_input_ids: {}'.format(input_ids))
|
| 200 |
+
logger.info("label: {}".format(example.label))
|
| 201 |
+
logger.info("nli_labels: {}".format(example.nli_labels))
|
| 202 |
+
|
| 203 |
+
return features
|
| 204 |
+
|
| 205 |
+
|
| 206 |
+
class DataProcessor:
|
| 207 |
+
def __init__(
|
| 208 |
+
self,
|
| 209 |
+
model_name_or_path,
|
| 210 |
+
max_seq1_length,
|
| 211 |
+
max_seq2_length,
|
| 212 |
+
max_num_questions,
|
| 213 |
+
cand_k,
|
| 214 |
+
data_dir='',
|
| 215 |
+
cache_dir_name='cache_check',
|
| 216 |
+
overwrite_cache=False,
|
| 217 |
+
mask_rate=0.
|
| 218 |
+
):
|
| 219 |
+
self.model_name_or_path = model_name_or_path
|
| 220 |
+
self.max_seq1_length = max_seq1_length
|
| 221 |
+
self.max_seq2_length = max_seq2_length
|
| 222 |
+
self.max_num_questions = max_num_questions
|
| 223 |
+
self.k = cand_k
|
| 224 |
+
self.mask_rate = mask_rate
|
| 225 |
+
|
| 226 |
+
self.data_dir = data_dir
|
| 227 |
+
self.cached_data_dir = os.path.join(data_dir, cache_dir_name)
|
| 228 |
+
self.overwrite_cache = overwrite_cache
|
| 229 |
+
|
| 230 |
+
self.label2id = {"SUPPORTS": 2, "REFUTES": 0, 'NOT ENOUGH INFO': 1}
|
| 231 |
+
|
| 232 |
+
def _format_file(self, role):
|
| 233 |
+
return os.path.join(self.data_dir, "{}.json".format(role))
|
| 234 |
+
|
| 235 |
+
def load_and_cache_data(self, role, tokenizer, data_tag):
|
| 236 |
+
tf.io.gfile.makedirs(self.cached_data_dir)
|
| 237 |
+
cached_file = os.path.join(
|
| 238 |
+
self.cached_data_dir,
|
| 239 |
+
"cached_features_{}_{}_{}_{}_{}_{}".format(
|
| 240 |
+
role,
|
| 241 |
+
list(filter(None, self.model_name_or_path.split("/"))).pop(),
|
| 242 |
+
str(self.max_seq1_length),
|
| 243 |
+
str(self.max_seq2_length),
|
| 244 |
+
str(self.k),
|
| 245 |
+
data_tag
|
| 246 |
+
),
|
| 247 |
+
)
|
| 248 |
+
if os.path.exists(cached_file) and not self.overwrite_cache:
|
| 249 |
+
logger.info("Loading features from cached file {}".format(cached_file))
|
| 250 |
+
features = torch.load(cached_file)
|
| 251 |
+
else:
|
| 252 |
+
examples = []
|
| 253 |
+
with tf.io.gfile.GFile(self._format_file(role)) as f:
|
| 254 |
+
data = f.readlines()
|
| 255 |
+
for line in tqdm(data):
|
| 256 |
+
sample = self._load_line(line)
|
| 257 |
+
examples.append(InputExample(**sample))
|
| 258 |
+
features = convert_examples_to_features(examples, tokenizer,
|
| 259 |
+
self.max_seq1_length, self.max_seq2_length)
|
| 260 |
+
if 'train' in role or 'eval' in role:
|
| 261 |
+
logger.info("Saving features into cached file {}".format(cached_file))
|
| 262 |
+
torch.save(features, cached_file)
|
| 263 |
+
|
| 264 |
+
return self._create_tensor_dataset(features, tokenizer)
|
| 265 |
+
|
| 266 |
+
def convert_inputs_to_dataset(self, inputs, tokenizer, verbose=True):
|
| 267 |
+
examples = []
|
| 268 |
+
for line in inputs:
|
| 269 |
+
sample = self._load_line(line)
|
| 270 |
+
examples.append(InputExample(**sample))
|
| 271 |
+
features = convert_examples_to_features(examples, tokenizer,
|
| 272 |
+
self.max_seq1_length, self.max_seq2_length, verbose)
|
| 273 |
+
|
| 274 |
+
return self._create_tensor_dataset(features, tokenizer, do_predict=True)
|
| 275 |
+
|
| 276 |
+
def _create_tensor_dataset(self, features, tokenizer, do_predict=False):
|
| 277 |
+
all_c_input_ids = torch.tensor([f.c_input_ids for f in features], dtype=torch.long)
|
| 278 |
+
all_c_attention_mask = torch.tensor([f.c_attention_mask for f in features], dtype=torch.long)
|
| 279 |
+
all_c_token_type_ids = torch.tensor([f.c_token_type_ids for f in features], dtype=torch.long)
|
| 280 |
+
|
| 281 |
+
all_q_input_ids_list = []
|
| 282 |
+
all_q_attention_mask_list = []
|
| 283 |
+
all_q_token_type_ids_list = []
|
| 284 |
+
|
| 285 |
+
def _trunc_agg(self, feature, pad_token):
|
| 286 |
+
# feature: m x L
|
| 287 |
+
_input_list = [v for v in feature[:self.max_num_questions]]
|
| 288 |
+
while len(_input_list) < self.max_num_questions:
|
| 289 |
+
_input_list.append([pad_token] * self.max_seq2_length)
|
| 290 |
+
return _input_list
|
| 291 |
+
|
| 292 |
+
for f in features: # N x m x L
|
| 293 |
+
all_q_input_ids_list.append(_trunc_agg(self, f.q_input_ids_list, tokenizer.pad_token_id))
|
| 294 |
+
all_q_attention_mask_list.append(_trunc_agg(self, f.q_attention_mask_list, 0))
|
| 295 |
+
all_q_token_type_ids_list.append(_trunc_agg(self, f.q_token_type_ids_list, tokenizer.pad_token_type_id))
|
| 296 |
+
|
| 297 |
+
all_q_input_ids_list = torch.tensor(all_q_input_ids_list, dtype=torch.long)
|
| 298 |
+
all_q_attention_mask_list = torch.tensor(all_q_attention_mask_list, dtype=torch.long)
|
| 299 |
+
all_q_token_type_ids_list = torch.tensor(all_q_token_type_ids_list, dtype=torch.long)
|
| 300 |
+
|
| 301 |
+
all_nli_labels_list = []
|
| 302 |
+
for f in features:
|
| 303 |
+
all_nli_labels_list.append(f.nli_labels[:self.max_num_questions]
|
| 304 |
+
+ max(0, (self.max_num_questions - len(f.nli_labels))) * [[0., 0., 0.]])
|
| 305 |
+
all_nli_labels = torch.tensor(all_nli_labels_list, dtype=torch.float)
|
| 306 |
+
|
| 307 |
+
if not do_predict:
|
| 308 |
+
all_labels = torch.tensor([f.label for f in features], dtype=torch.long)
|
| 309 |
+
dataset = TensorDataset(
|
| 310 |
+
all_c_input_ids, all_c_attention_mask, all_c_token_type_ids,
|
| 311 |
+
all_q_input_ids_list, all_q_attention_mask_list, all_q_token_type_ids_list,
|
| 312 |
+
all_nli_labels, all_labels,
|
| 313 |
+
)
|
| 314 |
+
else:
|
| 315 |
+
dataset = TensorDataset(
|
| 316 |
+
all_c_input_ids, all_c_attention_mask, all_c_token_type_ids,
|
| 317 |
+
all_q_input_ids_list, all_q_attention_mask_list, all_q_token_type_ids_list,
|
| 318 |
+
all_nli_labels,
|
| 319 |
+
)
|
| 320 |
+
|
| 321 |
+
return dataset
|
| 322 |
+
|
| 323 |
+
def _load_line(self, line):
|
| 324 |
+
if isinstance(line, str):
|
| 325 |
+
line = json.loads(line)
|
| 326 |
+
guid = line["id"]
|
| 327 |
+
claim = line["claim"]
|
| 328 |
+
|
| 329 |
+
# TODO: hack no evidence situation
|
| 330 |
+
evidences = line["evidence"] if len(line['evidence']) > 0 else ['no idea'] * 5
|
| 331 |
+
questions = line["questions"]
|
| 332 |
+
answers = line["answers"]
|
| 333 |
+
evidential = assemble_answers_to_one(line, self.k, mask_rate=self.mask_rate)['evidential_assembled']
|
| 334 |
+
label = line.get("label", None)
|
| 335 |
+
nli_labels = line.get('nli_labels', [[0., 0., 0.]] * len(questions))
|
| 336 |
+
|
| 337 |
+
for i, e in enumerate(evidential):
|
| 338 |
+
if '<mask>' in e:
|
| 339 |
+
nli_labels[i] = [0., 0., 0.]
|
| 340 |
+
|
| 341 |
+
answers = [v[0] for v in answers] # k = 1
|
| 342 |
+
label = self.label2id.get(label)
|
| 343 |
+
|
| 344 |
+
sample = {
|
| 345 |
+
"guid": guid,
|
| 346 |
+
"claim": claim,
|
| 347 |
+
"evidences": evidences,
|
| 348 |
+
"questions": questions,
|
| 349 |
+
"answers": answers,
|
| 350 |
+
"evidential": evidential, # already assembled.
|
| 351 |
+
"label": label,
|
| 352 |
+
'nli_labels': nli_labels
|
| 353 |
+
}
|
| 354 |
+
return sample
|
src/check_client/modules/test_data_processor.py
ADDED
|
@@ -0,0 +1,26 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# -*- coding: utf-8 -*-
|
| 2 |
+
|
| 3 |
+
"""
|
| 4 |
+
@Author : Jiangjie Chen
|
| 5 |
+
@Time : 2020/12/20 18:05
|
| 6 |
+
@Contact : jjchen19@fudan.edu.cn
|
| 7 |
+
@Description:
|
| 8 |
+
"""
|
| 9 |
+
|
| 10 |
+
import os
|
| 11 |
+
from data_processor import DataProcessor
|
| 12 |
+
from transformers import RobertaTokenizer
|
| 13 |
+
|
| 14 |
+
|
| 15 |
+
root = os.environ['PJ_HOME']
|
| 16 |
+
|
| 17 |
+
tokenizer = RobertaTokenizer.from_pretrained('roberta-large')
|
| 18 |
+
dp = DataProcessor('roberta-large', 256, 128, 8, cand_k=3, data_dir=f'{root}/data/fact_checking/v5', overwrite_cache=True)
|
| 19 |
+
|
| 20 |
+
# dp.load_and_cache_data('val', tokenizer)
|
| 21 |
+
|
| 22 |
+
|
| 23 |
+
data = {"id":91198,"claim":"Colin Kaepernick became a starting quarterback during the 49ers 63rd season in the National Football League .","evidence":["Things about Colin Kaepernick: He remained the team 's starting quarterback for the rest of the season and went on to lead the 49ers to their first Super Bowl appearance since 1994 , losing to the Baltimore Ravens .","Things about Colin Kaepernick: In the following seasons , Kaepernick lost and won back his starting job , with the 49ers missing the playoffs for three years consecutively .","Things about Colin Kaepernick: During the 2013 season , his first full season as a starter , Kaepernick helped the 49ers reach the NFC Championship , losing to the Seattle Seahawks .","Things about Colin Kaepernick: Kaepernick began his professional career as a backup to Alex Smith , but became the 49ers ' starter in the middle of the 2012 season after Smith suffered a concussion .","Things about Colin Kaepernick: Colin Rand Kaepernick ( ; born November 3 , 1987 ) is an American football quarterback who is currently a free agent ."],"answers":[["Colin Kaepernick",0,16],["a starting quarterback",24,46],["49ers",58,63],["63rd season",64,75],["National Football League",83,107]],"questions":["noun","noun","noun","noun","noun"],"label":"NOT ENOUGH INFO","evidential_assembled":["Who was the starting quarterback for the 49ers in the 63rd season? or <mask> became a starting quarterback during the 49ers 63rd season in the National Football League .","What was Colin Kaepernick's first job title? or Colin Kaepernick became <mask> during the 49ers 63rd season in the National Football League .","What team was Colin Kaepernick a quarterback for? or Colin Kaepernick became a starting quarterback during the <mask> 63rd season in the National Football League .","In what season did Colin Kaepernick become a starting quarterback for the 49ers? or Colin Kaepernick became a starting quarterback during the 49ers <mask> in the National Football League .","What league was Colin Kaepernick a quarterback in? or Colin Kaepernick became a starting quarterback during the 49ers 63rd season in the <mask> ."],"evidential":[["Colin Kaepernick became a starting quarterback during the 49ers 63rd season in the National Football League .","Colin Kapit became a starting quarterback during the 49ers 63rd season in the National Football League .","Colin Kapra became a starting quarterback during the 49ers 63rd season in the National Football League .","Colin Kaepernick became a starting quarterback during the 49ers 63rd season in the National Football League .","Colin Colin Kaepernick became a starting quarterback during the 49ers 63rd season in the National Football League ."],["Colin Kaepernick became a quarterback during the 49ers 63rd season in the National Football League .","Colin Kaepernick became a starter during the 49ers 63rd season in the National Football League .","Colin Kaepernick became a starting quarterback during the 49ers 63rd season in the National Football League .","Colin Kaepernick became a backup quarterback during the 49ers 63rd season in the National Football League .","Colin Kaepernick became a starting quarterback during the 49ers 63rd season in the National Football League ,"],["Colin Kaepernick became a starting quarterback during the 49ers 63rd season in the National Football League .","Colin Kaepernick became a starting quarterback during the 49ers ' 63rd season in the National Football League .","Colin Kaepernick became a starting quarterback during the 49ers' 63rd season in the National Football League .","Colin Kaepernick became a starting quarterback during the Niners 63rd season in the National Football League .","Colin Kaepernick became a starting quarterback during the 49ers 63rd season in the National Football League ."],["Colin Kaepernick became a starting quarterback during the 49ers season in the National Football League .","Colin Kaepernick became a starting quarterback during the 49ers ' season in the National Football League .","Colin Kaepernick became a starting quarterback during the 49ers season in the National Football League .","Colin Kaepernick became a starting quarterback during the 49ers first season in the National Football League .","Colin Kaepernick became a starting quarterback during the 49ers second season in the National Football League ."],["Colin Kaepernick became a starting quarterback during the 49ers 63rd season in the Super Bowl .","Colin Kaepernick became a starting quarterback during the 49ers 63rd season in the NFC .","Colin Kaepernick became a starting quarterback during the 49ers 63rd season in the professional sports .","Colin Kaepernick became a starting quarterback during the 49ers 63rd season in the NFL .","Colin Kaepernick became a starting quarterback during the 49ers 63rd season in the league ."]]}
|
| 24 |
+
|
| 25 |
+
s = dp.convert_inputs_to_dataset([data], tokenizer, True)
|
| 26 |
+
print(s)
|
src/check_client/plm_checkers/__init__.py
ADDED
|
@@ -0,0 +1,12 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# -*- coding: utf-8 -*-
|
| 2 |
+
|
| 3 |
+
"""
|
| 4 |
+
@Author : Jiangjie Chen
|
| 5 |
+
@Time : 2020/12/27 15:41
|
| 6 |
+
@Contact : jjchen19@fudan.edu.cn
|
| 7 |
+
@Description:
|
| 8 |
+
"""
|
| 9 |
+
|
| 10 |
+
|
| 11 |
+
from .bert_checker import BertChecker
|
| 12 |
+
from .roberta_checker import RobertaChecker
|
src/check_client/plm_checkers/bert_checker.py
ADDED
|
@@ -0,0 +1,203 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# -*- coding: utf-8 -*-
|
| 2 |
+
|
| 3 |
+
'''
|
| 4 |
+
@Author : Jiangjie Chen
|
| 5 |
+
@Time : 2020/8/18 14:40
|
| 6 |
+
@Contact : jjchen19@fudan.edu.cn
|
| 7 |
+
@Description:
|
| 8 |
+
'''
|
| 9 |
+
|
| 10 |
+
import torch
|
| 11 |
+
import torch.nn as nn
|
| 12 |
+
import torch.nn.functional as F
|
| 13 |
+
|
| 14 |
+
from transformers import BertModel, BertPreTrainedModel
|
| 15 |
+
from .checker_utils import attention_mask_to_mask, ClassificationHead, soft_logic, build_pseudo_labels, \
|
| 16 |
+
get_label_embeddings, temperature_annealing
|
| 17 |
+
|
| 18 |
+
|
| 19 |
+
class BertChecker(BertPreTrainedModel):
|
| 20 |
+
def __init__(self, config, logic_lambda=0.0, prior='nli', m=8, temperature=1):
|
| 21 |
+
super().__init__(config)
|
| 22 |
+
self.num_labels = config.num_labels
|
| 23 |
+
self.hidden_size = config.hidden_size
|
| 24 |
+
self.bert = BertModel(config)
|
| 25 |
+
self.dropout = nn.Dropout(config.hidden_dropout_prob)
|
| 26 |
+
self._lambda = logic_lambda
|
| 27 |
+
self.prior = prior
|
| 28 |
+
self.temperature = temperature
|
| 29 |
+
self._step = 0
|
| 30 |
+
|
| 31 |
+
# general attention
|
| 32 |
+
self.linear_self_attn = nn.Linear(self.hidden_size, 1, bias=False)
|
| 33 |
+
self.linear_m_attn = nn.Linear(self.hidden_size * 2, 1, bias=False)
|
| 34 |
+
|
| 35 |
+
self.var_hidden_size = self.hidden_size // 4
|
| 36 |
+
|
| 37 |
+
z_hid_size = self.num_labels * m
|
| 38 |
+
self.linear_P_theta = nn.Linear(self.hidden_size * 2 + z_hid_size, self.var_hidden_size)
|
| 39 |
+
y_hid_size = self.var_hidden_size
|
| 40 |
+
self.linear_Q_phi = nn.Linear(self.hidden_size * 2 + y_hid_size, self.var_hidden_size)
|
| 41 |
+
|
| 42 |
+
self.classifier = ClassificationHead(self.var_hidden_size, self.num_labels, config.hidden_dropout_prob) # label embedding for y
|
| 43 |
+
self.z_clf = self.classifier
|
| 44 |
+
self.init_weights()
|
| 45 |
+
|
| 46 |
+
def forward(self, claim_input_ids, claim_attention_mask, claim_token_type_ids,
|
| 47 |
+
qa_input_ids_list, qa_attention_mask_list, qa_token_type_ids_list,
|
| 48 |
+
nli_labels=None, labels=None):
|
| 49 |
+
'''
|
| 50 |
+
m: num of questions; n: num of evidence; k: num of candidate answers
|
| 51 |
+
:param claim_input_ids: b x L1
|
| 52 |
+
:param claim_attention_mask: b x L1
|
| 53 |
+
:param claim_token_type_ids: b x L1
|
| 54 |
+
:param qa_input_ids_list: b x m x L2
|
| 55 |
+
:param qa_attention_mask_list: b x m x L2
|
| 56 |
+
:param qa_token_type_ids_list: b x m x L2
|
| 57 |
+
:param labels: (b,)
|
| 58 |
+
:return:
|
| 59 |
+
'''
|
| 60 |
+
self._step += 1
|
| 61 |
+
_zero = torch.tensor(0.).to(claim_input_ids.device)
|
| 62 |
+
|
| 63 |
+
global_output = self.bert(
|
| 64 |
+
claim_input_ids,
|
| 65 |
+
attention_mask=claim_attention_mask,
|
| 66 |
+
token_type_ids=claim_token_type_ids
|
| 67 |
+
)[0] # b x L1 x h
|
| 68 |
+
|
| 69 |
+
global_output = self.self_select(global_output) # b x h
|
| 70 |
+
|
| 71 |
+
_qa_input_ids_list = qa_input_ids_list.transpose(1, 0) # m x b x L2
|
| 72 |
+
_qa_attention_mask_list = qa_attention_mask_list.transpose(1, 0)
|
| 73 |
+
_qa_token_type_ids_list = qa_token_type_ids_list.transpose(1, 0)
|
| 74 |
+
|
| 75 |
+
local_output_list = []
|
| 76 |
+
for _inp, _attn, _token_ids in zip(_qa_input_ids_list, _qa_attention_mask_list, _qa_token_type_ids_list):
|
| 77 |
+
_local_output = self.bert(_inp, attention_mask=_attn,
|
| 78 |
+
token_type_ids=_token_ids)[0]
|
| 79 |
+
_local_output = self.self_select(_local_output)
|
| 80 |
+
local_output_list.append(_local_output)
|
| 81 |
+
|
| 82 |
+
local_outputs = torch.stack(local_output_list, 0) # m x b x h
|
| 83 |
+
local_outputs = local_outputs.transpose(1, 0).contiguous() # b x m x h
|
| 84 |
+
|
| 85 |
+
neg_elbo, loss, logic_loss = _zero, _zero, _zero
|
| 86 |
+
mask = attention_mask_to_mask(qa_attention_mask_list)
|
| 87 |
+
# b x h, b x m x h -> b x h
|
| 88 |
+
local_outputs_w, m_attn = self.local_attn(global_output, local_outputs, mask)
|
| 89 |
+
local_outputs = torch.cat([local_outputs, global_output.unsqueeze(1).repeat(1, local_outputs.size(1), 1)], -1)
|
| 90 |
+
|
| 91 |
+
if labels is not None:
|
| 92 |
+
# Training
|
| 93 |
+
# ======================== Q_phi ================================
|
| 94 |
+
|
| 95 |
+
labels_onehot = F.one_hot(labels, num_classes=self.num_labels).to(torch.float)
|
| 96 |
+
y_star_emb = get_label_embeddings(labels_onehot, self.classifier.out_proj.weight) # b x h
|
| 97 |
+
z = self.Q_phi(local_outputs, y_star_emb)
|
| 98 |
+
z_softmax = z.softmax(-1)
|
| 99 |
+
|
| 100 |
+
# ======================== P_theta ==============================
|
| 101 |
+
|
| 102 |
+
z_gumbel = F.gumbel_softmax(z, tau=temperature_annealing(self.temperature, self._step),
|
| 103 |
+
dim=-1, hard=True) # b x m x 3
|
| 104 |
+
y = self.P_theta(global_output, local_outputs_w, z_gumbel)
|
| 105 |
+
|
| 106 |
+
# ======================== soft logic ===========================
|
| 107 |
+
mask = mask.to(torch.int)
|
| 108 |
+
y_z = soft_logic(z_softmax, mask) # b x 3
|
| 109 |
+
logic_loss = F.kl_div(y.log_softmax(-1), y_z)
|
| 110 |
+
|
| 111 |
+
# ======================== ELBO =================================
|
| 112 |
+
elbo_neg_p_log = F.cross_entropy(y.view(-1, self.num_labels), labels.view(-1))
|
| 113 |
+
if self.prior == 'nli':
|
| 114 |
+
prior = nli_labels.softmax(dim=-1)
|
| 115 |
+
elif self.prior == 'uniform':
|
| 116 |
+
prior = torch.tensor([1 / self.num_labels] * self.num_labels).to(y)
|
| 117 |
+
prior = prior.unsqueeze(0).unsqueeze(0).repeat(mask.size(0), mask.size(1), 1)
|
| 118 |
+
elif self.prior == 'logic':
|
| 119 |
+
prior = build_pseudo_labels(labels, m_attn)
|
| 120 |
+
else:
|
| 121 |
+
raise NotImplementedError(self.prior)
|
| 122 |
+
|
| 123 |
+
elbo_kl = F.kl_div(z_softmax.log(), prior)
|
| 124 |
+
neg_elbo = elbo_kl + elbo_neg_p_log
|
| 125 |
+
|
| 126 |
+
loss = (1 - abs(self._lambda)) * neg_elbo + abs(self._lambda) * logic_loss
|
| 127 |
+
else:
|
| 128 |
+
# Inference
|
| 129 |
+
if self.prior == 'nli':
|
| 130 |
+
z = nli_labels
|
| 131 |
+
elif self.prior == 'uniform':
|
| 132 |
+
prior = torch.tensor([1 / self.num_labels] * self.num_labels).to(y)
|
| 133 |
+
z = prior.unsqueeze(0).unsqueeze(0).repeat(mask.size(0), mask.size(1), 1)
|
| 134 |
+
else:
|
| 135 |
+
z = torch.rand([local_outputs.size(0), local_outputs.size(1), self.num_labels]).to(local_outputs)
|
| 136 |
+
z_softmax = z.softmax(-1)
|
| 137 |
+
|
| 138 |
+
for i in range(3): # N = 3
|
| 139 |
+
z = z_softmax.argmax(-1)
|
| 140 |
+
z = F.one_hot(z, num_classes=3).to(torch.float)
|
| 141 |
+
y = self.P_theta(global_output, local_outputs_w, z)
|
| 142 |
+
y = y.softmax(-1)
|
| 143 |
+
y_emb = get_label_embeddings(y, self.classifier.out_proj.weight)
|
| 144 |
+
z = self.Q_phi(local_outputs, y_emb)
|
| 145 |
+
z_softmax = z.softmax(-1)
|
| 146 |
+
|
| 147 |
+
return (loss, (neg_elbo, logic_loss), y, m_attn, (z_softmax, mask)) # batch first
|
| 148 |
+
|
| 149 |
+
def Q_phi(self, X, y):
|
| 150 |
+
'''
|
| 151 |
+
X, y => z
|
| 152 |
+
:param X: b x m x h
|
| 153 |
+
:param y_emb: b x 3 / b x h'
|
| 154 |
+
:return: b x m x 3 (ref, nei, sup)
|
| 155 |
+
'''
|
| 156 |
+
y_expand = y.unsqueeze(1).repeat(1, X.size(1), 1) # b x m x 3/h'
|
| 157 |
+
z_hidden = self.linear_Q_phi(torch.cat([y_expand, X], dim=-1)) # b x m x h'
|
| 158 |
+
z_hidden = F.tanh(z_hidden)
|
| 159 |
+
z = self.z_clf(z_hidden)
|
| 160 |
+
return z
|
| 161 |
+
|
| 162 |
+
def P_theta(self, X_global, X_local, z):
|
| 163 |
+
'''
|
| 164 |
+
X, z => y*
|
| 165 |
+
:param X_global: b x h
|
| 166 |
+
:param X_local: b x m x h
|
| 167 |
+
:param z: b x m x 3
|
| 168 |
+
:param mask: b x m
|
| 169 |
+
:return: b x 3, b x m
|
| 170 |
+
'''
|
| 171 |
+
b = z.size(0)
|
| 172 |
+
# global classification
|
| 173 |
+
_logits = torch.cat([X_local, X_global, z.reshape(b, -1)], dim=-1)
|
| 174 |
+
_logits = self.dropout(_logits)
|
| 175 |
+
_logits = self.linear_P_theta(_logits)
|
| 176 |
+
_logits = torch.tanh(_logits)
|
| 177 |
+
|
| 178 |
+
y = self.classifier(_logits)
|
| 179 |
+
return y
|
| 180 |
+
|
| 181 |
+
def self_select(self, h_x):
|
| 182 |
+
'''
|
| 183 |
+
self attention on a vector
|
| 184 |
+
:param h_x: b x L x h
|
| 185 |
+
:return: b x h
|
| 186 |
+
'''
|
| 187 |
+
w = self.dropout(self.linear_self_attn(h_x).squeeze(-1)).softmax(-1)
|
| 188 |
+
return torch.einsum('blh,bl->bh', h_x, w)
|
| 189 |
+
|
| 190 |
+
def local_attn(self, global_output, local_outputs, mask):
|
| 191 |
+
'''
|
| 192 |
+
:param global_output: b x h
|
| 193 |
+
:param qa_outputs: b x m x h
|
| 194 |
+
:param mask: b x m
|
| 195 |
+
:return: b x h, b x m
|
| 196 |
+
'''
|
| 197 |
+
m = local_outputs.size(1)
|
| 198 |
+
scores = self.linear_m_attn(torch.cat([global_output.unsqueeze(1).repeat(1, m, 1),
|
| 199 |
+
local_outputs], dim=-1)).squeeze(-1) # b x m
|
| 200 |
+
mask = 1 - mask
|
| 201 |
+
scores = scores.masked_fill(mask.to(torch.bool), -1e16)
|
| 202 |
+
attn = F.softmax(scores, -1)
|
| 203 |
+
return torch.einsum('bm,bmh->bh', attn, local_outputs), attn
|
src/check_client/plm_checkers/checker_utils.py
ADDED
|
@@ -0,0 +1,223 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# -*- coding: utf-8 -*-
|
| 2 |
+
|
| 3 |
+
'''
|
| 4 |
+
@Author : Jiangjie Chen
|
| 5 |
+
@Time : 2020/10/15 16:10
|
| 6 |
+
@Contact : jjchen19@fudan.edu.cn
|
| 7 |
+
@Description:
|
| 8 |
+
'''
|
| 9 |
+
|
| 10 |
+
import torch
|
| 11 |
+
import random
|
| 12 |
+
import torch.nn.functional as F
|
| 13 |
+
import torch.nn as nn
|
| 14 |
+
|
| 15 |
+
|
| 16 |
+
class ClassificationHead(nn.Module):
|
| 17 |
+
"""Head for sentence-level classification tasks."""
|
| 18 |
+
|
| 19 |
+
def __init__(self, hidden_size, num_labels, hidden_dropout_prob=0.2):
|
| 20 |
+
super().__init__()
|
| 21 |
+
self.dropout = nn.Dropout(hidden_dropout_prob)
|
| 22 |
+
self.out_proj = nn.Linear(hidden_size, num_labels, bias=False)
|
| 23 |
+
|
| 24 |
+
def forward(self, features, **kwargs):
|
| 25 |
+
x = features
|
| 26 |
+
x = self.dropout(x)
|
| 27 |
+
x = self.out_proj(x)
|
| 28 |
+
return x
|
| 29 |
+
|
| 30 |
+
|
| 31 |
+
def temperature_annealing(tau, step):
|
| 32 |
+
if tau == 0.:
|
| 33 |
+
tau = 10. if step % 5 == 0 else 1.
|
| 34 |
+
return tau
|
| 35 |
+
|
| 36 |
+
|
| 37 |
+
def get_label_embeddings(labels, label_embedding):
|
| 38 |
+
'''
|
| 39 |
+
:param labels: b x 3
|
| 40 |
+
:param label_embedding: 3 x h'
|
| 41 |
+
:return: b x h'
|
| 42 |
+
'''
|
| 43 |
+
emb = torch.einsum('oi,bo->bi', label_embedding, labels)
|
| 44 |
+
return emb
|
| 45 |
+
|
| 46 |
+
|
| 47 |
+
def soft_logic(y_i, mask, tnorm='product'):
|
| 48 |
+
'''
|
| 49 |
+
a^b = ab
|
| 50 |
+
avb = 1 - ((1-a)(1-b))
|
| 51 |
+
:param y_i: b x m x 3
|
| 52 |
+
:param mask: b x m
|
| 53 |
+
:param tnorm: product or godel or lukasiewicz
|
| 54 |
+
:return: [b x 3]
|
| 55 |
+
'''
|
| 56 |
+
_sup = y_i[:, :, 2] # b x m
|
| 57 |
+
_ref = y_i[:, :, 0] # b x m
|
| 58 |
+
_sup = _sup * mask + (1 - mask) # pppp1111
|
| 59 |
+
_ref = _ref * mask # pppp0000
|
| 60 |
+
|
| 61 |
+
if tnorm == 'product':
|
| 62 |
+
p_sup = torch.exp(torch.log(_sup).sum(1))
|
| 63 |
+
p_ref = 1 - torch.exp(torch.log(1 - _ref).sum(1))
|
| 64 |
+
elif tnorm == 'godel':
|
| 65 |
+
p_sup = _sup.min(-1).values
|
| 66 |
+
p_ref = _ref.max(-1).values
|
| 67 |
+
elif tnorm == 'lukas':
|
| 68 |
+
raise NotImplementedError(tnorm)
|
| 69 |
+
else:
|
| 70 |
+
raise NotImplementedError(tnorm)
|
| 71 |
+
|
| 72 |
+
p_nei = 1 - p_sup - p_ref
|
| 73 |
+
p_sup = torch.max(p_sup, torch.zeros_like(p_sup))
|
| 74 |
+
p_ref = torch.max(p_ref, torch.zeros_like(p_ref))
|
| 75 |
+
p_nei = torch.max(p_nei, torch.zeros_like(p_nei))
|
| 76 |
+
logical_prob = torch.stack([p_ref, p_nei, p_sup], dim=-1)
|
| 77 |
+
assert torch.lt(logical_prob, 0).to(torch.int).sum().tolist() == 0, \
|
| 78 |
+
(logical_prob, _sup, _ref)
|
| 79 |
+
return logical_prob # b x 3
|
| 80 |
+
|
| 81 |
+
|
| 82 |
+
def build_pseudo_labels(labels, m_attn):
|
| 83 |
+
'''
|
| 84 |
+
:param labels: (b,)
|
| 85 |
+
:param m_attn: b x m
|
| 86 |
+
:return: b x m x 3
|
| 87 |
+
'''
|
| 88 |
+
mask = torch.gt(m_attn, 1e-16).to(torch.int)
|
| 89 |
+
sup_label = torch.tensor(2).to(labels)
|
| 90 |
+
nei_label = torch.tensor(1).to(labels)
|
| 91 |
+
ref_label = torch.tensor(0).to(labels)
|
| 92 |
+
pseudo_labels = []
|
| 93 |
+
for idx, label in enumerate(labels):
|
| 94 |
+
mm = mask[idx].sum(0)
|
| 95 |
+
if label == 2: # SUPPORTS
|
| 96 |
+
pseudo_label = F.one_hot(sup_label.repeat(mask.size(1)), num_classes=3).to(torch.float) # TODO: hyperparam
|
| 97 |
+
|
| 98 |
+
elif label == 0: # REFUTES
|
| 99 |
+
num_samples = magic_proportion(mm)
|
| 100 |
+
ids = torch.topk(m_attn[idx], k=num_samples).indices
|
| 101 |
+
pseudo_label = []
|
| 102 |
+
for i in range(mask.size(1)):
|
| 103 |
+
if i >= mm:
|
| 104 |
+
_label = torch.tensor([1/3, 1/3, 1/3]).to(labels)
|
| 105 |
+
elif i in ids:
|
| 106 |
+
_label = F.one_hot(ref_label, num_classes=3).to(torch.float)
|
| 107 |
+
else:
|
| 108 |
+
if random.random() > 0.5:
|
| 109 |
+
_label = torch.tensor([0., 0., 1.]).to(labels)
|
| 110 |
+
else:
|
| 111 |
+
_label = torch.tensor([0., 1., 0.]).to(labels)
|
| 112 |
+
pseudo_label.append(_label)
|
| 113 |
+
pseudo_label = torch.stack(pseudo_label)
|
| 114 |
+
|
| 115 |
+
else: # NEI
|
| 116 |
+
num_samples = magic_proportion(mm)
|
| 117 |
+
ids = torch.topk(m_attn[idx], k=num_samples).indices
|
| 118 |
+
pseudo_label = sup_label.repeat(mask.size(1))
|
| 119 |
+
pseudo_label[ids] = nei_label
|
| 120 |
+
pseudo_label = F.one_hot(pseudo_label, num_classes=3).to(torch.float) # TODO: hyperparam
|
| 121 |
+
|
| 122 |
+
pseudo_labels.append(pseudo_label)
|
| 123 |
+
return torch.stack(pseudo_labels)
|
| 124 |
+
|
| 125 |
+
|
| 126 |
+
def magic_proportion(m, magic_n=5):
|
| 127 |
+
# 1~4: 1, 5~m: 2
|
| 128 |
+
return m // magic_n + 1
|
| 129 |
+
|
| 130 |
+
|
| 131 |
+
def sequence_mask(lengths, max_len=None):
|
| 132 |
+
"""
|
| 133 |
+
Creates a boolean mask from sequence lengths.
|
| 134 |
+
"""
|
| 135 |
+
batch_size = lengths.numel()
|
| 136 |
+
max_len = max_len or lengths.max()
|
| 137 |
+
return (torch.arange(0, max_len, device=lengths.device)
|
| 138 |
+
.type_as(lengths)
|
| 139 |
+
.repeat(batch_size, 1)
|
| 140 |
+
.lt(lengths.unsqueeze(1)))
|
| 141 |
+
|
| 142 |
+
|
| 143 |
+
def collapse_w_mask(inputs, mask):
|
| 144 |
+
'''
|
| 145 |
+
:param inputs: b x L x h
|
| 146 |
+
:param mask: b x L
|
| 147 |
+
:return: b x h
|
| 148 |
+
'''
|
| 149 |
+
hidden = inputs.size(-1)
|
| 150 |
+
output = inputs * mask.unsqueeze(-1).repeat((1, 1, hidden)) # b x L x h
|
| 151 |
+
output = output.sum(-2)
|
| 152 |
+
output /= (mask.sum(-1) + 1e-6).unsqueeze(-1).repeat((1, hidden)) # b x h
|
| 153 |
+
return output
|
| 154 |
+
|
| 155 |
+
|
| 156 |
+
def parse_ce_outputs(ce_seq_output, ce_lengths):
|
| 157 |
+
'''
|
| 158 |
+
:param qa_seq_output: b x L1 x h
|
| 159 |
+
:param qa_lengths: e.g. [0,1,1,0,2,2,0,0] (b x L2)
|
| 160 |
+
:return:
|
| 161 |
+
c_output: b x h
|
| 162 |
+
e_output: b x h
|
| 163 |
+
'''
|
| 164 |
+
if ce_lengths.max() == 0:
|
| 165 |
+
b, L1, h = ce_seq_output.size()
|
| 166 |
+
return torch.zeros([b, h]).cuda(), torch.zeros([b, h]).cuda()
|
| 167 |
+
masks = []
|
| 168 |
+
for mask_id in range(1, ce_lengths.max() + 1):
|
| 169 |
+
_m = torch.ones_like(ce_lengths) * mask_id
|
| 170 |
+
mask = _m.eq(ce_lengths).to(torch.int)
|
| 171 |
+
masks.append(mask)
|
| 172 |
+
c_output = collapse_w_mask(ce_seq_output, masks[0])
|
| 173 |
+
e_output = torch.stack([collapse_w_mask(ce_seq_output, m)
|
| 174 |
+
for m in masks[1:]]).mean(0)
|
| 175 |
+
return c_output, e_output
|
| 176 |
+
|
| 177 |
+
|
| 178 |
+
def parse_qa_outputs(qa_seq_output, qa_lengths, k):
|
| 179 |
+
'''
|
| 180 |
+
:param qa_seq_output: b x L2 x h
|
| 181 |
+
:param qa_lengths: e.g. [0,1,1,0,2,2,0,3,0,4,0,5,0,0,0,0] (b x L2)
|
| 182 |
+
:return:
|
| 183 |
+
q_output: b x h
|
| 184 |
+
a_output: b x h
|
| 185 |
+
k_cand_output: k x b x h
|
| 186 |
+
'''
|
| 187 |
+
b, L2, h = qa_seq_output.size()
|
| 188 |
+
if qa_lengths.max() == 0:
|
| 189 |
+
return torch.zeros([b, h]).cuda(), torch.zeros([b, h]).cuda(), \
|
| 190 |
+
torch.zeros([k, b, h]).cuda()
|
| 191 |
+
|
| 192 |
+
masks = []
|
| 193 |
+
for mask_id in range(1, qa_lengths.max() + 1):
|
| 194 |
+
_m = torch.ones_like(qa_lengths) * mask_id
|
| 195 |
+
mask = _m.eq(qa_lengths).to(torch.int)
|
| 196 |
+
masks.append(mask)
|
| 197 |
+
|
| 198 |
+
q_output = collapse_w_mask(qa_seq_output, masks[0])
|
| 199 |
+
a_output = collapse_w_mask(qa_seq_output, masks[1])
|
| 200 |
+
k_cand_output = [collapse_w_mask(qa_seq_output, m)
|
| 201 |
+
for m in masks[2:2 + k]]
|
| 202 |
+
for i in range(k - len(k_cand_output)):
|
| 203 |
+
k_cand_output.append(torch.zeros([b, h]).cuda())
|
| 204 |
+
k_cand_output = torch.stack(k_cand_output, dim=0)
|
| 205 |
+
|
| 206 |
+
return q_output, a_output, k_cand_output
|
| 207 |
+
|
| 208 |
+
|
| 209 |
+
def attention_mask_to_mask(attention_mask):
|
| 210 |
+
'''
|
| 211 |
+
:param attention_mask: b x m x L
|
| 212 |
+
:return: b x m
|
| 213 |
+
'''
|
| 214 |
+
mask = torch.gt(attention_mask.sum(-1), 0).to(torch.int).sum(-1) # (b,)
|
| 215 |
+
mask = sequence_mask(mask, max_len=attention_mask.size(1)).to(torch.int) # (b, m)
|
| 216 |
+
return mask
|
| 217 |
+
|
| 218 |
+
|
| 219 |
+
if __name__ == "__main__":
|
| 220 |
+
y = torch.tensor([[[0.3,0.5,0.2],[0.1,0.4,0.5]]])
|
| 221 |
+
mask = torch.tensor([1,1])
|
| 222 |
+
s = soft_logic(y, mask)
|
| 223 |
+
print(s)
|
src/check_client/plm_checkers/roberta_checker.py
ADDED
|
@@ -0,0 +1,203 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# -*- coding: utf-8 -*-
|
| 2 |
+
|
| 3 |
+
'''
|
| 4 |
+
@Author : Jiangjie Chen
|
| 5 |
+
@Time : 2020/8/18 14:40
|
| 6 |
+
@Contact : jjchen19@fudan.edu.cn
|
| 7 |
+
@Description:
|
| 8 |
+
'''
|
| 9 |
+
|
| 10 |
+
import torch
|
| 11 |
+
import torch.nn as nn
|
| 12 |
+
import torch.nn.functional as F
|
| 13 |
+
|
| 14 |
+
from transformers import RobertaModel, BertPreTrainedModel, RobertaConfig
|
| 15 |
+
from .checker_utils import attention_mask_to_mask, ClassificationHead, soft_logic, build_pseudo_labels, \
|
| 16 |
+
get_label_embeddings, temperature_annealing
|
| 17 |
+
|
| 18 |
+
|
| 19 |
+
class RobertaChecker(BertPreTrainedModel):
|
| 20 |
+
config_class = RobertaConfig
|
| 21 |
+
base_model_prefix = "roberta"
|
| 22 |
+
|
| 23 |
+
def __init__(self, config, logic_lambda=0.0, prior='nli', m=8, temperature=1):
|
| 24 |
+
super().__init__(config)
|
| 25 |
+
self.num_labels = config.num_labels
|
| 26 |
+
self.hidden_size = config.hidden_size
|
| 27 |
+
self.roberta = RobertaModel(config)
|
| 28 |
+
self.dropout = nn.Dropout(config.hidden_dropout_prob)
|
| 29 |
+
self._lambda = logic_lambda
|
| 30 |
+
self.prior = prior
|
| 31 |
+
self.temperature = temperature
|
| 32 |
+
self._step = 0
|
| 33 |
+
|
| 34 |
+
# general attention
|
| 35 |
+
self.linear_self_attn = nn.Linear(self.hidden_size, 1, bias=False)
|
| 36 |
+
self.linear_m_attn = nn.Linear(self.hidden_size * 2, 1, bias=False)
|
| 37 |
+
|
| 38 |
+
self.var_hidden_size = self.hidden_size // 4
|
| 39 |
+
|
| 40 |
+
z_hid_size = self.num_labels * m
|
| 41 |
+
self.linear_P_theta = nn.Linear(self.hidden_size * 2 + z_hid_size, self.var_hidden_size)
|
| 42 |
+
y_hid_size = self.var_hidden_size
|
| 43 |
+
self.linear_Q_phi = nn.Linear(self.hidden_size * 2 + y_hid_size, self.var_hidden_size)
|
| 44 |
+
|
| 45 |
+
# TODO: y_clf => classifier. compromise for mnli
|
| 46 |
+
self.classifier = ClassificationHead(self.var_hidden_size, self.num_labels,
|
| 47 |
+
config.hidden_dropout_prob) # label embedding for y
|
| 48 |
+
self.z_clf = self.classifier
|
| 49 |
+
self.init_weights()
|
| 50 |
+
|
| 51 |
+
def forward(self, claim_input_ids, claim_attention_mask, claim_token_type_ids,
|
| 52 |
+
qa_input_ids_list, qa_attention_mask_list, qa_token_type_ids_list,
|
| 53 |
+
nli_labels=None, labels=None):
|
| 54 |
+
'''
|
| 55 |
+
m: num of questions; n: num of evidence; k: num of candidate answers
|
| 56 |
+
:param claim_input_ids: b x L1
|
| 57 |
+
:param claim_attention_mask: b x L1
|
| 58 |
+
:param claim_token_type_ids: b x L1
|
| 59 |
+
:param qa_input_ids_list: b x m x L2
|
| 60 |
+
:param qa_attention_mask_list: b x m x L2
|
| 61 |
+
:param qa_token_type_ids_list: b x m x L2
|
| 62 |
+
:param nli_labels: b x m x 3
|
| 63 |
+
:param labels: (b,)
|
| 64 |
+
:return: (loss, (neg_elbo, logic_loss), y, m_attn, (z_softmax, mask))
|
| 65 |
+
'''
|
| 66 |
+
self._step += 1
|
| 67 |
+
_zero = torch.tensor(0.).to(claim_input_ids.device)
|
| 68 |
+
|
| 69 |
+
# ====================== Representation learning =======================
|
| 70 |
+
global_output = self.roberta(claim_input_ids, attention_mask=claim_attention_mask)[0] # b x L1 x h
|
| 71 |
+
global_output = self.self_select(global_output) # b x h
|
| 72 |
+
|
| 73 |
+
_qa_input_ids_list = qa_input_ids_list.transpose(1, 0) # m x b x L2
|
| 74 |
+
_qa_attention_mask_list = qa_attention_mask_list.transpose(1, 0)
|
| 75 |
+
|
| 76 |
+
local_output_list = []
|
| 77 |
+
for _inp, _attn in zip(_qa_input_ids_list, _qa_attention_mask_list):
|
| 78 |
+
_local_output = self.roberta(_inp, attention_mask=_attn)[0]
|
| 79 |
+
_local_output = self.self_select(_local_output)
|
| 80 |
+
local_output_list.append(_local_output)
|
| 81 |
+
|
| 82 |
+
_local_outputs = torch.stack(local_output_list, 0) # m x b x h
|
| 83 |
+
local_outputs = _local_outputs.transpose(1, 0).contiguous() # b x m x h
|
| 84 |
+
|
| 85 |
+
neg_elbo, loss, logic_loss = _zero, _zero, _zero
|
| 86 |
+
mask = attention_mask_to_mask(qa_attention_mask_list)
|
| 87 |
+
# b x h, b x m x h -> b x h
|
| 88 |
+
local_outputs_w, m_attn = self.local_attn(global_output, local_outputs, mask)
|
| 89 |
+
local_outputs = torch.cat([local_outputs, global_output.unsqueeze(1).repeat(1, local_outputs.size(1), 1)], -1)
|
| 90 |
+
|
| 91 |
+
if labels is not None:
|
| 92 |
+
# Training
|
| 93 |
+
# ======================== Q_phi ================================
|
| 94 |
+
|
| 95 |
+
labels_onehot = F.one_hot(labels, num_classes=self.num_labels).to(torch.float)
|
| 96 |
+
y_star_emb = get_label_embeddings(labels_onehot, self.classifier.out_proj.weight) # b x h
|
| 97 |
+
z = self.Q_phi(local_outputs, y_star_emb)
|
| 98 |
+
z_softmax = z.softmax(-1)
|
| 99 |
+
|
| 100 |
+
# ======================== P_theta ==============================
|
| 101 |
+
|
| 102 |
+
z_gumbel = F.gumbel_softmax(z, tau=temperature_annealing(self.temperature, self._step),
|
| 103 |
+
dim=-1, hard=True) # b x m x 3
|
| 104 |
+
y = self.P_theta(global_output, local_outputs_w, z_gumbel)
|
| 105 |
+
|
| 106 |
+
# ======================== soft logic ===========================
|
| 107 |
+
mask = mask.to(torch.int)
|
| 108 |
+
y_z = soft_logic(z_softmax, mask) # b x 3
|
| 109 |
+
logic_loss = F.kl_div(y.log_softmax(-1), y_z)
|
| 110 |
+
|
| 111 |
+
# ======================== ELBO =================================
|
| 112 |
+
elbo_neg_p_log = F.cross_entropy(y.view(-1, self.num_labels), labels.view(-1))
|
| 113 |
+
if self.prior == 'nli':
|
| 114 |
+
prior = nli_labels.softmax(dim=-1)
|
| 115 |
+
elif self.prior == 'uniform':
|
| 116 |
+
prior = torch.tensor([1 / self.num_labels] * self.num_labels).to(mask.device)
|
| 117 |
+
prior = prior.unsqueeze(0).unsqueeze(0).repeat(mask.size(0), mask.size(1), 1)
|
| 118 |
+
elif self.prior == 'logic':
|
| 119 |
+
prior = build_pseudo_labels(labels, m_attn)
|
| 120 |
+
else:
|
| 121 |
+
raise NotImplementedError(self.prior)
|
| 122 |
+
|
| 123 |
+
elbo_kl = F.kl_div(z_softmax.log(), prior)
|
| 124 |
+
neg_elbo = elbo_kl + elbo_neg_p_log
|
| 125 |
+
|
| 126 |
+
loss = (1 - abs(self._lambda)) * neg_elbo + abs(self._lambda) * logic_loss
|
| 127 |
+
else:
|
| 128 |
+
# Inference
|
| 129 |
+
if self.prior == 'nli':
|
| 130 |
+
z = nli_labels
|
| 131 |
+
elif self.prior == 'uniform':
|
| 132 |
+
prior = torch.tensor([1 / self.num_labels] * self.num_labels).to(mask.device)
|
| 133 |
+
z = prior.unsqueeze(0).unsqueeze(0).repeat(mask.size(0), mask.size(1), 1)
|
| 134 |
+
else:
|
| 135 |
+
z = torch.rand([local_outputs.size(0), local_outputs.size(1), self.num_labels]).to(local_outputs)
|
| 136 |
+
z_softmax = z.softmax(-1)
|
| 137 |
+
|
| 138 |
+
for i in range(3): # N = 3
|
| 139 |
+
z = z_softmax.argmax(-1)
|
| 140 |
+
z = F.one_hot(z, num_classes=3).to(torch.float)
|
| 141 |
+
y = self.P_theta(global_output, local_outputs_w, z)
|
| 142 |
+
y = y.softmax(-1)
|
| 143 |
+
y_emb = get_label_embeddings(y, self.classifier.out_proj.weight)
|
| 144 |
+
z = self.Q_phi(local_outputs, y_emb)
|
| 145 |
+
z_softmax = z.softmax(-1)
|
| 146 |
+
|
| 147 |
+
return (loss, (neg_elbo, logic_loss), y, m_attn, (z_softmax, mask)) # batch first
|
| 148 |
+
|
| 149 |
+
def Q_phi(self, X, y):
|
| 150 |
+
'''
|
| 151 |
+
X, y => z
|
| 152 |
+
:param X: b x m x h
|
| 153 |
+
:param y_emb: b x 3 / b x h'
|
| 154 |
+
:return: b x m x 3 (ref, nei, sup)
|
| 155 |
+
'''
|
| 156 |
+
y_expand = y.unsqueeze(1).repeat(1, X.size(1), 1) # b x m x 3/h'
|
| 157 |
+
z_hidden = self.linear_Q_phi(torch.cat([y_expand, X], dim=-1)) # b x m x h'
|
| 158 |
+
z_hidden = F.tanh(z_hidden)
|
| 159 |
+
z = self.z_clf(z_hidden)
|
| 160 |
+
return z
|
| 161 |
+
|
| 162 |
+
def P_theta(self, X_global, X_local, z):
|
| 163 |
+
'''
|
| 164 |
+
X, z => y*
|
| 165 |
+
:param X_global: b x h
|
| 166 |
+
:param X_local: b x m x h
|
| 167 |
+
:param z: b x m x 3
|
| 168 |
+
:param mask: b x m
|
| 169 |
+
:return: b x 3, b x m
|
| 170 |
+
'''
|
| 171 |
+
b = z.size(0)
|
| 172 |
+
# global classification
|
| 173 |
+
_logits = torch.cat([X_local, X_global, z.reshape(b, -1)], dim=-1)
|
| 174 |
+
_logits = self.dropout(_logits)
|
| 175 |
+
_logits = self.linear_P_theta(_logits)
|
| 176 |
+
_logits = torch.tanh(_logits)
|
| 177 |
+
|
| 178 |
+
y = self.classifier(_logits)
|
| 179 |
+
return y
|
| 180 |
+
|
| 181 |
+
def self_select(self, h_x):
|
| 182 |
+
'''
|
| 183 |
+
self attention on a vector
|
| 184 |
+
:param h_x: b x L x h
|
| 185 |
+
:return: b x h
|
| 186 |
+
'''
|
| 187 |
+
w = self.dropout(self.linear_self_attn(h_x).squeeze(-1)).softmax(-1)
|
| 188 |
+
return torch.einsum('blh,bl->bh', h_x, w)
|
| 189 |
+
|
| 190 |
+
def local_attn(self, global_output, local_outputs, mask):
|
| 191 |
+
'''
|
| 192 |
+
:param global_output: b x h
|
| 193 |
+
:param qa_outputs: b x m x h
|
| 194 |
+
:param mask: b x m
|
| 195 |
+
:return: b x h, b x m
|
| 196 |
+
'''
|
| 197 |
+
m = local_outputs.size(1)
|
| 198 |
+
scores = self.linear_m_attn(torch.cat([global_output.unsqueeze(1).repeat(1, m, 1),
|
| 199 |
+
local_outputs], dim=-1)).squeeze(-1) # b x m
|
| 200 |
+
mask = 1 - mask
|
| 201 |
+
scores = scores.masked_fill(mask.to(torch.bool), -1e16)
|
| 202 |
+
attn = F.softmax(scores, -1)
|
| 203 |
+
return torch.einsum('bm,bmh->bh', attn, local_outputs), attn
|
src/check_client/scripts/train_bert-large.sh
ADDED
|
@@ -0,0 +1,51 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
#!/usr/bin/env bash
|
| 2 |
+
|
| 3 |
+
MODEL_TYPE=bert
|
| 4 |
+
MODEL_NAME_OR_PATH=bert-large-cased
|
| 5 |
+
VERSION=v5
|
| 6 |
+
MAX_NUM_QUESTIONS=8
|
| 7 |
+
|
| 8 |
+
MAX_SEQ1_LENGTH=256
|
| 9 |
+
MAX_SEQ2_LENGTH=128
|
| 10 |
+
CAND_K=3
|
| 11 |
+
LAMBDA=${1:-0.5}
|
| 12 |
+
PRIOR=${2:-nli}
|
| 13 |
+
MASK=${3:-0.0}
|
| 14 |
+
echo "lambda = $LAMBDA, prior = $PRIOR, mask = $MASK"
|
| 15 |
+
|
| 16 |
+
DATA_DIR=$PJ_HOME/data/fact_checking/${VERSION}
|
| 17 |
+
OUTPUT_DIR=$PJ_HOME/models/fact_checking/${VERSION}_${MODEL_NAME_OR_PATH}/${VERSION}_${MODEL_NAME_OR_PATH}_AAAI_K${CAND_K}_${PRIOR}_m${MASK}_l${LAMBDA}
|
| 18 |
+
NUM_TRAIN_EPOCH=7
|
| 19 |
+
GRADIENT_ACCUMULATION_STEPS=2
|
| 20 |
+
PER_GPU_TRAIN_BATCH_SIZE=8 # 4546
|
| 21 |
+
PER_GPU_EVAL_BATCH_SIZE=16
|
| 22 |
+
LOGGING_STEPS=200
|
| 23 |
+
SAVE_STEPS=200
|
| 24 |
+
|
| 25 |
+
|
| 26 |
+
python3 train.py \
|
| 27 |
+
--data_dir ${DATA_DIR} \
|
| 28 |
+
--output_dir ${OUTPUT_DIR} \
|
| 29 |
+
--model_type ${MODEL_TYPE} \
|
| 30 |
+
--model_name_or_path ${MODEL_NAME_OR_PATH} \
|
| 31 |
+
--max_seq1_length ${MAX_SEQ1_LENGTH} \
|
| 32 |
+
--max_seq2_length ${MAX_SEQ2_LENGTH} \
|
| 33 |
+
--max_num_questions ${MAX_NUM_QUESTIONS} \
|
| 34 |
+
--do_train \
|
| 35 |
+
--do_eval \
|
| 36 |
+
--evaluate_during_training \
|
| 37 |
+
--learning_rate 1e-5 \
|
| 38 |
+
--num_train_epochs ${NUM_TRAIN_EPOCH} \
|
| 39 |
+
--gradient_accumulation_steps ${GRADIENT_ACCUMULATION_STEPS} \
|
| 40 |
+
--per_gpu_train_batch_size ${PER_GPU_TRAIN_BATCH_SIZE} \
|
| 41 |
+
--per_gpu_eval_batch_size ${PER_GPU_EVAL_BATCH_SIZE} \
|
| 42 |
+
--logging_steps ${LOGGING_STEPS} \
|
| 43 |
+
--save_steps ${SAVE_STEPS} \
|
| 44 |
+
--cand_k ${CAND_K} \
|
| 45 |
+
--logic_lambda ${LAMBDA} \
|
| 46 |
+
--prior ${PRIOR} \
|
| 47 |
+
--overwrite_output_dir \
|
| 48 |
+
--temperature 1.0 \
|
| 49 |
+
--mask_rate ${MASK}
|
| 50 |
+
|
| 51 |
+
python3 cjjpy.py --lark "$OUTPUT_DIR fact checking training completed"
|
src/check_client/scripts/train_roberta.sh
ADDED
|
@@ -0,0 +1,51 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
#!/usr/bin/env bash
|
| 2 |
+
|
| 3 |
+
MODEL_TYPE=roberta
|
| 4 |
+
MODEL_NAME_OR_PATH=roberta-large
|
| 5 |
+
VERSION=v5
|
| 6 |
+
MAX_NUM_QUESTIONS=8
|
| 7 |
+
|
| 8 |
+
MAX_SEQ1_LENGTH=256
|
| 9 |
+
MAX_SEQ2_LENGTH=128
|
| 10 |
+
CAND_K=3
|
| 11 |
+
LAMBDA=${1:-0.5}
|
| 12 |
+
PRIOR=${2:-nli}
|
| 13 |
+
MASK=${3:-0.0}
|
| 14 |
+
echo "lambda = $LAMBDA, prior = $PRIOR, mask = $MASK"
|
| 15 |
+
|
| 16 |
+
DATA_DIR=$PJ_HOME/data/fact_checking/${VERSION}
|
| 17 |
+
OUTPUT_DIR=$PJ_HOME/models/fact_checking/${VERSION}_${MODEL_NAME_OR_PATH}/${VERSION}_${MODEL_NAME_OR_PATH}_AAAI_K${CAND_K}_${PRIOR}_m${MASK}_l${LAMBDA}
|
| 18 |
+
NUM_TRAIN_EPOCH=7
|
| 19 |
+
GRADIENT_ACCUMULATION_STEPS=2
|
| 20 |
+
PER_GPU_TRAIN_BATCH_SIZE=8 # 4546
|
| 21 |
+
PER_GPU_EVAL_BATCH_SIZE=16
|
| 22 |
+
LOGGING_STEPS=200
|
| 23 |
+
SAVE_STEPS=200
|
| 24 |
+
|
| 25 |
+
|
| 26 |
+
python3 train.py \
|
| 27 |
+
--data_dir ${DATA_DIR} \
|
| 28 |
+
--output_dir ${OUTPUT_DIR} \
|
| 29 |
+
--model_type ${MODEL_TYPE} \
|
| 30 |
+
--model_name_or_path ${MODEL_NAME_OR_PATH} \
|
| 31 |
+
--max_seq1_length ${MAX_SEQ1_LENGTH} \
|
| 32 |
+
--max_seq2_length ${MAX_SEQ2_LENGTH} \
|
| 33 |
+
--max_num_questions ${MAX_NUM_QUESTIONS} \
|
| 34 |
+
--do_train \
|
| 35 |
+
--do_eval \
|
| 36 |
+
--evaluate_during_training \
|
| 37 |
+
--learning_rate 1e-5 \
|
| 38 |
+
--num_train_epochs ${NUM_TRAIN_EPOCH} \
|
| 39 |
+
--gradient_accumulation_steps ${GRADIENT_ACCUMULATION_STEPS} \
|
| 40 |
+
--per_gpu_train_batch_size ${PER_GPU_TRAIN_BATCH_SIZE} \
|
| 41 |
+
--per_gpu_eval_batch_size ${PER_GPU_EVAL_BATCH_SIZE} \
|
| 42 |
+
--logging_steps ${LOGGING_STEPS} \
|
| 43 |
+
--save_steps ${SAVE_STEPS} \
|
| 44 |
+
--cand_k ${CAND_K} \
|
| 45 |
+
--logic_lambda ${LAMBDA} \
|
| 46 |
+
--prior ${PRIOR} \
|
| 47 |
+
--overwrite_output_dir \
|
| 48 |
+
--temperature 1.0 \
|
| 49 |
+
--mask_rate ${MASK}
|
| 50 |
+
|
| 51 |
+
python3 cjjpy.py --lark "$OUTPUT_DIR fact checking training completed"
|
src/check_client/train.py
ADDED
|
@@ -0,0 +1,647 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# coding=utf-8
|
| 2 |
+
# Copyright 2018 The Google AI Language Team Authors and The HuggingFace Inc. team.
|
| 3 |
+
# Copyright (c) 2018, NVIDIA CORPORATION. All rights reserved.
|
| 4 |
+
#
|
| 5 |
+
# Licensed under the Apache License, Version 2.0 (the "License");
|
| 6 |
+
# you may not use this file except in compliance with the License.
|
| 7 |
+
# You may obtain a copy of the License at
|
| 8 |
+
#
|
| 9 |
+
# http://www.apache.org/licenses/LICENSE-2.0
|
| 10 |
+
#
|
| 11 |
+
# Unless required by applicable law or agreed to in writing, software
|
| 12 |
+
# distributed under the License is distributed on an "AS IS" BASIS,
|
| 13 |
+
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
| 14 |
+
# See the License for the specific language governing permissions and
|
| 15 |
+
# limitations under the License.
|
| 16 |
+
|
| 17 |
+
import os
|
| 18 |
+
import glob
|
| 19 |
+
import argparse
|
| 20 |
+
import logging
|
| 21 |
+
import random
|
| 22 |
+
import torch
|
| 23 |
+
import numpy as np
|
| 24 |
+
from tqdm import tqdm
|
| 25 |
+
from torch.utils.data import DataLoader, RandomSampler, SequentialSampler
|
| 26 |
+
from torch.utils.data.distributed import DistributedSampler
|
| 27 |
+
from transformers import (
|
| 28 |
+
AutoConfig,
|
| 29 |
+
AutoTokenizer
|
| 30 |
+
)
|
| 31 |
+
from transformers import WEIGHTS_NAME, AdamW, get_linear_schedule_with_warmup
|
| 32 |
+
import tensorflow as tf
|
| 33 |
+
from pytorch_lightning.loggers import WandbLogger
|
| 34 |
+
|
| 35 |
+
try:
|
| 36 |
+
from .modules.data_processor import DataProcessor
|
| 37 |
+
from .plm_checkers import BertChecker, RobertaChecker, XLNetChecker, DebertaChecker
|
| 38 |
+
from .utils import init_logger, compute_metrics
|
| 39 |
+
except:
|
| 40 |
+
from modules.data_processor import DataProcessor
|
| 41 |
+
from plm_checkers import BertChecker, RobertaChecker, XLNetChecker, DebertaChecker
|
| 42 |
+
from utils import init_logger, compute_metrics
|
| 43 |
+
|
| 44 |
+
try:
|
| 45 |
+
from torch.utils.tensorboard import SummaryWriter
|
| 46 |
+
except ImportError:
|
| 47 |
+
from tensorboardX import SummaryWriter
|
| 48 |
+
|
| 49 |
+
mAutoModel = {
|
| 50 |
+
'bert': BertChecker,
|
| 51 |
+
'roberta': RobertaChecker,
|
| 52 |
+
'xlnet': XLNetChecker,
|
| 53 |
+
'deberta': DebertaChecker,
|
| 54 |
+
}
|
| 55 |
+
|
| 56 |
+
logger = logging.getLogger(__name__)
|
| 57 |
+
|
| 58 |
+
|
| 59 |
+
def set_seed(args):
|
| 60 |
+
random.seed(args.seed)
|
| 61 |
+
np.random.seed(args.seed)
|
| 62 |
+
torch.manual_seed(args.seed)
|
| 63 |
+
if args.n_gpu > 0:
|
| 64 |
+
torch.cuda.manual_seed_all(args.seed)
|
| 65 |
+
|
| 66 |
+
|
| 67 |
+
def train(args, data_processor, model, tokenizer):
|
| 68 |
+
""" Train the model """
|
| 69 |
+
global wdblogger
|
| 70 |
+
if args.local_rank in [-1, 0]:
|
| 71 |
+
tb_writer = SummaryWriter()
|
| 72 |
+
|
| 73 |
+
tf.io.gfile.makedirs(os.path.dirname(args.output_dir))
|
| 74 |
+
args.train_batch_size = args.per_gpu_train_batch_size * max(1, args.n_gpu)
|
| 75 |
+
train_dataset = data_processor.load_and_cache_data("train", tokenizer, args.data_tag)
|
| 76 |
+
train_sampler = RandomSampler(train_dataset) if args.local_rank == -1 else DistributedSampler(train_dataset)
|
| 77 |
+
train_dataloader = DataLoader(train_dataset, sampler=train_sampler,
|
| 78 |
+
drop_last=True,
|
| 79 |
+
batch_size=args.train_batch_size)
|
| 80 |
+
|
| 81 |
+
if args.max_steps > 0:
|
| 82 |
+
t_total = args.max_steps
|
| 83 |
+
args.num_train_epochs = args.max_steps // (len(train_dataloader) // args.gradient_accumulation_steps) + 1
|
| 84 |
+
else:
|
| 85 |
+
t_total = len(train_dataloader) // args.gradient_accumulation_steps * args.num_train_epochs
|
| 86 |
+
|
| 87 |
+
# Prepare optimizer and schedule (linear warmup and decay)
|
| 88 |
+
no_decay = ["bias", "LayerNorm.weight"]
|
| 89 |
+
optimizer_grouped_parameters = [
|
| 90 |
+
{
|
| 91 |
+
"params": [p for n, p in model.named_parameters() if not any(nd in n for nd in no_decay)],
|
| 92 |
+
"weight_decay": args.weight_decay,
|
| 93 |
+
},
|
| 94 |
+
{
|
| 95 |
+
"params": [p for n, p in model.named_parameters() if any(nd in n for nd in no_decay)],
|
| 96 |
+
"weight_decay": 0.0
|
| 97 |
+
},
|
| 98 |
+
]
|
| 99 |
+
optimizer = AdamW(optimizer_grouped_parameters, lr=args.learning_rate, eps=args.adam_epsilon)
|
| 100 |
+
scheduler = get_linear_schedule_with_warmup(
|
| 101 |
+
optimizer, num_warmup_steps=args.warmup_steps, num_training_steps=t_total
|
| 102 |
+
)
|
| 103 |
+
if args.fp16:
|
| 104 |
+
try:
|
| 105 |
+
from apex import amp
|
| 106 |
+
except ImportError:
|
| 107 |
+
raise ImportError("Please install apex from https://www.github.com/nvidia/apex to use fp16 training.")
|
| 108 |
+
model, optimizer = amp.initialize(model, optimizer, opt_level=args.fp16_opt_level)
|
| 109 |
+
|
| 110 |
+
# multi-gpu training (should be after apex fp16 initialization)
|
| 111 |
+
if args.n_gpu > 1:
|
| 112 |
+
model = torch.nn.DataParallel(model)
|
| 113 |
+
|
| 114 |
+
# Distributed training (should be after apex fp16 initialization)
|
| 115 |
+
if args.local_rank != -1:
|
| 116 |
+
model = torch.nn.parallel.DistributedDataParallel(
|
| 117 |
+
model, device_ids=[args.local_rank], output_device=args.local_rank, find_unused_parameters=True
|
| 118 |
+
)
|
| 119 |
+
|
| 120 |
+
# Train!
|
| 121 |
+
logger.info("***** Running training *****")
|
| 122 |
+
logger.info("Num examples = %d", len(train_dataset))
|
| 123 |
+
logger.info("Num Epochs = %d", args.num_train_epochs)
|
| 124 |
+
logger.info("Instantaneous batch size per GPU = %d", args.per_gpu_train_batch_size)
|
| 125 |
+
logger.info(
|
| 126 |
+
"Total train batch size (w. parallel, distributed & accumulation) = %d",
|
| 127 |
+
args.train_batch_size
|
| 128 |
+
* args.gradient_accumulation_steps
|
| 129 |
+
* (torch.distributed.get_world_size() if args.local_rank != -1 else 1),
|
| 130 |
+
)
|
| 131 |
+
logger.info("Gradient Accumulation steps = %d", args.gradient_accumulation_steps)
|
| 132 |
+
logger.info("Total optimization steps = %d", t_total)
|
| 133 |
+
|
| 134 |
+
global_step = 0
|
| 135 |
+
tr_loss, logging_loss = 0.0, 0.0
|
| 136 |
+
tr_loss2, logging_loss2 = 0.0, 0.0
|
| 137 |
+
tr_loss3, logging_loss3 = 0.0, 0.0
|
| 138 |
+
set_seed(args) # Added here for reproductibility
|
| 139 |
+
model.zero_grad()
|
| 140 |
+
for _ in range(int(args.num_train_epochs)):
|
| 141 |
+
all_loss = 0.0
|
| 142 |
+
all_accuracy = 0.0
|
| 143 |
+
epoch_iterator = tqdm(train_dataloader, desc="Iteration", disable=args.local_rank not in [-1, 0])
|
| 144 |
+
for step, batch in enumerate(epoch_iterator):
|
| 145 |
+
model.train()
|
| 146 |
+
batch = tuple(t.to(args.device) for t in batch)
|
| 147 |
+
inputs = {
|
| 148 |
+
"claim_input_ids": batch[0],
|
| 149 |
+
"claim_attention_mask": batch[1],
|
| 150 |
+
"qa_input_ids_list": batch[3],
|
| 151 |
+
"qa_attention_mask_list": batch[4],
|
| 152 |
+
"nli_labels": batch[-2],
|
| 153 |
+
"labels": batch[-1],
|
| 154 |
+
}
|
| 155 |
+
if args.model_type != "distilbert":
|
| 156 |
+
# XLM, DistilBERT, RoBERTa, and XLM-RoBERTa don't use segment_ids
|
| 157 |
+
inputs["claim_token_type_ids"] = batch[2] if args.model_type in ["bert", "xlnet", "albert"] else None
|
| 158 |
+
inputs["qa_token_type_ids_list"] = batch[5] if args.model_type in ["bert", "xlnet", "albert"] else None
|
| 159 |
+
|
| 160 |
+
outputs = model(**inputs)
|
| 161 |
+
loss, _loss2, logits = outputs[0], outputs[1], outputs[2]
|
| 162 |
+
loss2, loss3 = _loss2
|
| 163 |
+
|
| 164 |
+
if args.n_gpu > 1:
|
| 165 |
+
loss = loss.mean() # mean() to average on multi-gpu parallel (not distributed) training
|
| 166 |
+
loss2 = loss2.mean()
|
| 167 |
+
loss3 = loss3.mean()
|
| 168 |
+
if args.gradient_accumulation_steps > 1:
|
| 169 |
+
loss = loss / args.gradient_accumulation_steps
|
| 170 |
+
loss2 = loss2 / args.gradient_accumulation_steps
|
| 171 |
+
loss3 = loss3 / args.gradient_accumulation_steps
|
| 172 |
+
|
| 173 |
+
if args.fp16:
|
| 174 |
+
with amp.scale_loss(loss, optimizer) as scaled_loss:
|
| 175 |
+
scaled_loss.backward()
|
| 176 |
+
else:
|
| 177 |
+
loss.backward()
|
| 178 |
+
|
| 179 |
+
tr_loss += loss.item()
|
| 180 |
+
tr_loss2 += loss2.item()
|
| 181 |
+
tr_loss3 += loss3.item()
|
| 182 |
+
|
| 183 |
+
all_loss += loss.detach().cpu().numpy() * args.gradient_accumulation_steps
|
| 184 |
+
all_accuracy += np.mean(
|
| 185 |
+
inputs["labels"].detach().cpu().numpy() == logits.detach().cpu().numpy().argmax(axis=-1)
|
| 186 |
+
)
|
| 187 |
+
description = "Global step: {:>6}, Loss: {:>.6f}, Accuracy: {:>.6f}".format(
|
| 188 |
+
global_step,
|
| 189 |
+
all_loss / (step + 1),
|
| 190 |
+
all_accuracy / (step + 1),
|
| 191 |
+
)
|
| 192 |
+
epoch_iterator.set_description(description)
|
| 193 |
+
if (step + 1) % args.gradient_accumulation_steps == 0:
|
| 194 |
+
if args.fp16:
|
| 195 |
+
torch.nn.utils.clip_grad_norm_(amp.master_params(optimizer), args.max_grad_norm)
|
| 196 |
+
else:
|
| 197 |
+
torch.nn.utils.clip_grad_norm_(model.parameters(), args.max_grad_norm)
|
| 198 |
+
|
| 199 |
+
optimizer.step()
|
| 200 |
+
scheduler.step() # Update learning rate schedule
|
| 201 |
+
model.zero_grad()
|
| 202 |
+
global_step += 1
|
| 203 |
+
|
| 204 |
+
# Log metrics
|
| 205 |
+
if args.local_rank in [-1, 0] and args.logging_steps > 0 and global_step % args.logging_steps == 0:
|
| 206 |
+
# Only evaluate when single GPU otherwise metrics may not average well
|
| 207 |
+
if args.local_rank == -1 and args.evaluate_during_training:
|
| 208 |
+
results = evaluate(args, data_processor, model, tokenizer)
|
| 209 |
+
for key, value in results.items():
|
| 210 |
+
logger.warning(f"Step: {global_step}, eval_{key}: {value}")
|
| 211 |
+
wdblogger.log_metrics({"eval_{}".format(key): value}, global_step)
|
| 212 |
+
tb_writer.add_scalar("eval_{}".format(key), value, global_step)
|
| 213 |
+
tb_writer.add_scalar("lr", scheduler.get_lr()[0], global_step)
|
| 214 |
+
wdblogger.log_metrics({"lr": scheduler.get_lr()[0]}, global_step)
|
| 215 |
+
tb_writer.add_scalar("loss", (tr_loss - logging_loss) / args.logging_steps, global_step)
|
| 216 |
+
wdblogger.log_metrics({"loss": (tr_loss - logging_loss) / args.logging_steps}, global_step)
|
| 217 |
+
wdblogger.log_metrics({"loss2": (tr_loss2 - logging_loss2) / args.logging_steps}, global_step)
|
| 218 |
+
wdblogger.log_metrics({"loss3": (tr_loss3 - logging_loss3) / args.logging_steps}, global_step)
|
| 219 |
+
|
| 220 |
+
logging_loss = tr_loss
|
| 221 |
+
logging_loss2 = tr_loss2
|
| 222 |
+
logging_loss3 = tr_loss3
|
| 223 |
+
wdblogger.save()
|
| 224 |
+
|
| 225 |
+
# Save model checkpoint
|
| 226 |
+
if args.local_rank in [-1, 0] and args.save_steps > 0 and global_step % args.save_steps == 0:
|
| 227 |
+
output_dir = os.path.join(args.output_dir, "checkpoint-{}".format(global_step))
|
| 228 |
+
if not os.path.exists(output_dir):
|
| 229 |
+
os.makedirs(output_dir)
|
| 230 |
+
# Take care of distributed/parallel training
|
| 231 |
+
model_to_save = model.module if hasattr(model, "module") else model
|
| 232 |
+
model_to_save.save_pretrained(output_dir)
|
| 233 |
+
torch.save(args, os.path.join(output_dir, "training_args.bin"))
|
| 234 |
+
logger.info("Saving model checkpoint to %s", output_dir)
|
| 235 |
+
|
| 236 |
+
if 0 < args.max_steps < global_step:
|
| 237 |
+
epoch_iterator.close()
|
| 238 |
+
break
|
| 239 |
+
if 0 < args.max_steps < global_step:
|
| 240 |
+
break
|
| 241 |
+
|
| 242 |
+
if args.local_rank in [-1, 0]:
|
| 243 |
+
tb_writer.close()
|
| 244 |
+
|
| 245 |
+
return global_step, tr_loss / global_step
|
| 246 |
+
|
| 247 |
+
|
| 248 |
+
def evaluate(args, data_processor, model, tokenizer, prefix=""):
|
| 249 |
+
if not os.path.exists(args.output_dir) and args.local_rank in [-1, 0]:
|
| 250 |
+
os.makedirs(args.output_dir)
|
| 251 |
+
|
| 252 |
+
args.eval_batch_size = args.per_gpu_eval_batch_size * max(1, args.n_gpu)
|
| 253 |
+
dataset = data_processor.load_and_cache_data("eval", tokenizer, args.data_tag)
|
| 254 |
+
eval_sampler = SequentialSampler(dataset) if args.local_rank == -1 else DistributedSampler(dataset)
|
| 255 |
+
eval_dataloader = DataLoader(dataset, sampler=eval_sampler,
|
| 256 |
+
drop_last=True,
|
| 257 |
+
batch_size=args.eval_batch_size)
|
| 258 |
+
|
| 259 |
+
# Eval!
|
| 260 |
+
logger.info("***** Running evaluation {} *****".format(prefix))
|
| 261 |
+
logger.info("Num examples = %d", len(dataset))
|
| 262 |
+
logger.info("Batch size = %d", args.eval_batch_size)
|
| 263 |
+
|
| 264 |
+
label_truth, y_predicted, z_predicted, m_attn, mask = \
|
| 265 |
+
do_evaluate(tqdm(eval_dataloader, desc="Evaluating"), model, args, during_training=True, with_label=True)
|
| 266 |
+
|
| 267 |
+
outputs, results = compute_metrics(label_truth, y_predicted, z_predicted, mask)
|
| 268 |
+
|
| 269 |
+
return results
|
| 270 |
+
|
| 271 |
+
|
| 272 |
+
def do_evaluate(dataloader, model, args, during_training=False, with_label=True):
|
| 273 |
+
label_truth = []
|
| 274 |
+
y_predicted = []
|
| 275 |
+
z_predicted = []
|
| 276 |
+
m_attn = []
|
| 277 |
+
mask = []
|
| 278 |
+
for i, batch in enumerate(dataloader):
|
| 279 |
+
model.eval()
|
| 280 |
+
batch = tuple(t.to(args.device) for t in batch)
|
| 281 |
+
with torch.no_grad():
|
| 282 |
+
inputs = {
|
| 283 |
+
"claim_input_ids": batch[0],
|
| 284 |
+
"claim_attention_mask": batch[1],
|
| 285 |
+
"qa_input_ids_list": batch[3],
|
| 286 |
+
"qa_attention_mask_list": batch[4],
|
| 287 |
+
"nli_labels": batch[6],
|
| 288 |
+
}
|
| 289 |
+
|
| 290 |
+
if args.model_type != "distilbert":
|
| 291 |
+
# XLM, DistilBERT, RoBERTa, and XLM-RoBERTa don't use segment_ids
|
| 292 |
+
inputs["claim_token_type_ids"] = batch[2] if args.model_type in ["bert", "xlnet", "albert"] else None
|
| 293 |
+
inputs["qa_token_type_ids_list"] = batch[5] if args.model_type in ["bert", "xlnet", "albert"] else None
|
| 294 |
+
|
| 295 |
+
outputs = model(**inputs)
|
| 296 |
+
|
| 297 |
+
if during_training and (i < 3 and (args.logic_lambda != 0)):
|
| 298 |
+
logger.warning(f'* m_attn:\n {outputs[-2][:5]}\n')
|
| 299 |
+
logger.warning(f'* Logic outputs:\n {outputs[-1][0][:5]}.\n Labels: {batch[-1][:5]}\n')
|
| 300 |
+
|
| 301 |
+
if with_label:
|
| 302 |
+
label_truth += batch[-1].tolist()
|
| 303 |
+
y_predicted += outputs[2].tolist()
|
| 304 |
+
mask += outputs[-1][1].tolist()
|
| 305 |
+
z_predicted += outputs[-1][0].tolist()
|
| 306 |
+
m_attn += outputs[-2].tolist()
|
| 307 |
+
|
| 308 |
+
y_predicted = np.argmax(y_predicted, axis=-1).tolist()
|
| 309 |
+
|
| 310 |
+
return label_truth, y_predicted, z_predicted, m_attn, mask
|
| 311 |
+
|
| 312 |
+
|
| 313 |
+
def main():
|
| 314 |
+
parser = argparse.ArgumentParser()
|
| 315 |
+
|
| 316 |
+
# Required parameters
|
| 317 |
+
parser.add_argument(
|
| 318 |
+
"--data_dir",
|
| 319 |
+
default=None,
|
| 320 |
+
type=str,
|
| 321 |
+
required=True,
|
| 322 |
+
help="The input data dir. Should contain the .tsv files (or other data files) for the task.",
|
| 323 |
+
)
|
| 324 |
+
parser.add_argument(
|
| 325 |
+
"--model_type",
|
| 326 |
+
default=None,
|
| 327 |
+
type=str,
|
| 328 |
+
required=True,
|
| 329 |
+
help="Model type selected in the list: " + ", ".join(mAutoModel.keys()),
|
| 330 |
+
)
|
| 331 |
+
parser.add_argument(
|
| 332 |
+
"--model_name_or_path",
|
| 333 |
+
default=None,
|
| 334 |
+
type=str,
|
| 335 |
+
required=True,
|
| 336 |
+
help="Path to pre-trained model or shortcut name",
|
| 337 |
+
)
|
| 338 |
+
parser.add_argument(
|
| 339 |
+
"--data_tag",
|
| 340 |
+
default='default',
|
| 341 |
+
type=str,
|
| 342 |
+
help='Tag to cached data'
|
| 343 |
+
)
|
| 344 |
+
parser.add_argument(
|
| 345 |
+
"--max_seq1_length",
|
| 346 |
+
default=None,
|
| 347 |
+
type=int,
|
| 348 |
+
required=True,
|
| 349 |
+
help="The maximum total input claim sequence length after tokenization. "
|
| 350 |
+
"Sequences longer than this will be truncated, sequences shorter will be padded.",
|
| 351 |
+
)
|
| 352 |
+
parser.add_argument(
|
| 353 |
+
"--max_seq2_length",
|
| 354 |
+
default=None,
|
| 355 |
+
type=int,
|
| 356 |
+
required=True,
|
| 357 |
+
help="The maximum total input claim sequence length after tokenization. "
|
| 358 |
+
"Sequences longer than this will be truncated, sequences shorter will be padded.",
|
| 359 |
+
)
|
| 360 |
+
parser.add_argument(
|
| 361 |
+
"--max_num_questions",
|
| 362 |
+
default=None,
|
| 363 |
+
type=int,
|
| 364 |
+
required=True,
|
| 365 |
+
help='The maximum number of evidences.',
|
| 366 |
+
)
|
| 367 |
+
parser.add_argument(
|
| 368 |
+
"--cand_k",
|
| 369 |
+
default=1,
|
| 370 |
+
type=int,
|
| 371 |
+
help='The number of evidential answers out of beam size'
|
| 372 |
+
)
|
| 373 |
+
parser.add_argument(
|
| 374 |
+
'--mask_rate',
|
| 375 |
+
default=0.,
|
| 376 |
+
type=float,
|
| 377 |
+
help="Mask rate of QA"
|
| 378 |
+
)
|
| 379 |
+
parser.add_argument(
|
| 380 |
+
"--output_dir",
|
| 381 |
+
default=None,
|
| 382 |
+
type=str,
|
| 383 |
+
required=True,
|
| 384 |
+
help="The output directory where the model predictions and checkpoints will be written.",
|
| 385 |
+
)
|
| 386 |
+
|
| 387 |
+
# Other parameters
|
| 388 |
+
parser.add_argument(
|
| 389 |
+
"--config_name", default="", type=str, help="Pretrained config name or path if not the same as model_name",
|
| 390 |
+
)
|
| 391 |
+
parser.add_argument(
|
| 392 |
+
"--tokenizer_name",
|
| 393 |
+
default="",
|
| 394 |
+
type=str,
|
| 395 |
+
help="Pretrained tokenizer name or path if not the same as model_name",
|
| 396 |
+
)
|
| 397 |
+
parser.add_argument(
|
| 398 |
+
"--cache_dir",
|
| 399 |
+
default="",
|
| 400 |
+
type=str,
|
| 401 |
+
help="Where do you want to store the pre-trained models downloaded from s3",
|
| 402 |
+
)
|
| 403 |
+
parser.add_argument(
|
| 404 |
+
"--max_seq_length",
|
| 405 |
+
default=128,
|
| 406 |
+
type=int,
|
| 407 |
+
help="The maximum total input sequence length after tokenization. Sequences longer "
|
| 408 |
+
"than this will be truncated, sequences shorter will be padded.",
|
| 409 |
+
)
|
| 410 |
+
parser.add_argument('--logic_lambda', required=True, type=float,
|
| 411 |
+
help='Regularization term for logic loss, also an indicator for using only logic.')
|
| 412 |
+
parser.add_argument('--prior', default='nli', type=str, choices=['nli', 'uniform', 'logic', 'random'],
|
| 413 |
+
help='type of prior distribution')
|
| 414 |
+
parser.add_argument('--temperature', required=True, type=float, help='Temperature for gumbel softmax.')
|
| 415 |
+
|
| 416 |
+
parser.add_argument("--do_train", action="store_true", help="Whether to run training.")
|
| 417 |
+
parser.add_argument("--do_eval", action="store_true", help="Whether to run eval on the dev set.")
|
| 418 |
+
parser.add_argument(
|
| 419 |
+
"--evaluate_during_training", action="store_true", help="Run evaluation during training at each logging step.",
|
| 420 |
+
)
|
| 421 |
+
parser.add_argument(
|
| 422 |
+
"--do_lower_case", action="store_true", help="Set this flag if you are using an uncased model.",
|
| 423 |
+
)
|
| 424 |
+
parser.add_argument(
|
| 425 |
+
"--per_gpu_train_batch_size", default=8, type=int, help="Batch size per GPU/CPU for training.",
|
| 426 |
+
)
|
| 427 |
+
parser.add_argument(
|
| 428 |
+
"--per_gpu_eval_batch_size", default=8, type=int, help="Batch size per GPU/CPU for evaluation.",
|
| 429 |
+
)
|
| 430 |
+
parser.add_argument(
|
| 431 |
+
"--gradient_accumulation_steps",
|
| 432 |
+
type=int,
|
| 433 |
+
default=1,
|
| 434 |
+
help="Number of updates steps to accumulate before performing a backward/update pass.",
|
| 435 |
+
)
|
| 436 |
+
parser.add_argument("--learning_rate", default=5e-5, type=float, help="The initial learning rate for Adam.")
|
| 437 |
+
parser.add_argument("--weight_decay", default=0.0, type=float, help="Weight decay if we apply some.")
|
| 438 |
+
parser.add_argument("--adam_epsilon", default=1e-8, type=float, help="Epsilon for Adam optimizer.")
|
| 439 |
+
parser.add_argument("--max_grad_norm", default=1.0, type=float, help="Max gradient norm.")
|
| 440 |
+
parser.add_argument(
|
| 441 |
+
"--num_train_epochs", default=3.0, type=float, help="Total number of training epochs to perform.",
|
| 442 |
+
)
|
| 443 |
+
parser.add_argument(
|
| 444 |
+
"--max_steps",
|
| 445 |
+
default=-1,
|
| 446 |
+
type=int,
|
| 447 |
+
help="If > 0: set total number of training steps to perform. Override num_train_epochs.",
|
| 448 |
+
)
|
| 449 |
+
parser.add_argument("--warmup_steps", default=0, type=int, help="Linear warmup over warmup_steps.")
|
| 450 |
+
parser.add_argument("--logging_steps", type=int, default=500, help="Log every X updates steps.")
|
| 451 |
+
parser.add_argument("--save_steps", type=int, default=500, help="Save checkpoint every X updates steps.")
|
| 452 |
+
parser.add_argument(
|
| 453 |
+
"--eval_all_checkpoints",
|
| 454 |
+
action="store_true",
|
| 455 |
+
help="Evaluate all checkpoints starting with the same prefix as model_name ending and ending with step number",
|
| 456 |
+
)
|
| 457 |
+
parser.add_argument("--no_cuda", action="store_true", help="Avoid using CUDA when available")
|
| 458 |
+
parser.add_argument(
|
| 459 |
+
"--overwrite_output_dir", action="store_true", help="Overwrite the content of the output directory",
|
| 460 |
+
)
|
| 461 |
+
parser.add_argument(
|
| 462 |
+
"--overwrite_cache", action="store_true", help="Overwrite the cached training and evaluation sets",
|
| 463 |
+
)
|
| 464 |
+
parser.add_argument("--seed", type=int, default=42, help="random seed for initialization")
|
| 465 |
+
parser.add_argument(
|
| 466 |
+
"--fp16",
|
| 467 |
+
action="store_true",
|
| 468 |
+
help="Whether to use 16-bit (mixed) precision (through NVIDIA apex) instead of 32-bit",
|
| 469 |
+
)
|
| 470 |
+
parser.add_argument(
|
| 471 |
+
"--fp16_opt_level",
|
| 472 |
+
type=str,
|
| 473 |
+
default="O1",
|
| 474 |
+
help="For fp16: Apex AMP optimization level selected in ['O0', 'O1', 'O2', and 'O3']."
|
| 475 |
+
"See details at https://nvidia.github.io/apex/amp.html",
|
| 476 |
+
)
|
| 477 |
+
parser.add_argument("--local_rank", type=int, default=-1, help="For distributed training: local_rank")
|
| 478 |
+
parser.add_argument("--server_ip", type=str, default="", help="For distant debugging.")
|
| 479 |
+
parser.add_argument("--server_port", type=str, default="", help="For distant debugging.")
|
| 480 |
+
args = parser.parse_args()
|
| 481 |
+
|
| 482 |
+
if (
|
| 483 |
+
os.path.exists(args.output_dir)
|
| 484 |
+
and os.listdir(args.output_dir)
|
| 485 |
+
and args.do_train
|
| 486 |
+
and not args.overwrite_output_dir
|
| 487 |
+
):
|
| 488 |
+
raise ValueError(
|
| 489 |
+
"Output directory ({}) already exists and is not empty. Use --overwrite_output_dir to overcome.".format(
|
| 490 |
+
args.output_dir
|
| 491 |
+
)
|
| 492 |
+
)
|
| 493 |
+
|
| 494 |
+
# Setup distant debugging if needed
|
| 495 |
+
if args.server_ip and args.server_port:
|
| 496 |
+
# Distant debugging - see https://code.visualstudio.com/docs/python/debugging#_attach-to-a-local-script
|
| 497 |
+
import ptvsd
|
| 498 |
+
|
| 499 |
+
print("Waiting for debugger attach")
|
| 500 |
+
ptvsd.enable_attach(address=(args.server_ip, args.server_port), redirect_output=True)
|
| 501 |
+
ptvsd.wait_for_attach()
|
| 502 |
+
|
| 503 |
+
# Setup CUDA, GPU & distributed training
|
| 504 |
+
if args.local_rank == -1 or args.no_cuda:
|
| 505 |
+
device = torch.device("cuda" if torch.cuda.is_available() and not args.no_cuda else "cpu")
|
| 506 |
+
args.n_gpu = 0 if args.no_cuda else torch.cuda.device_count()
|
| 507 |
+
else: # Initializes the distributed backend which will take care of sychronizing nodes/GPUs
|
| 508 |
+
torch.cuda.set_device(args.local_rank)
|
| 509 |
+
device = torch.device("cuda", args.local_rank)
|
| 510 |
+
torch.distributed.init_process_group(backend="nccl")
|
| 511 |
+
args.n_gpu = 1
|
| 512 |
+
args.device = device
|
| 513 |
+
|
| 514 |
+
# Setup logging
|
| 515 |
+
if args.do_train:
|
| 516 |
+
global wdblogger
|
| 517 |
+
tf.io.gfile.makedirs(args.output_dir)
|
| 518 |
+
wdblogger = WandbLogger(name=os.path.basename(args.output_dir))
|
| 519 |
+
wdblogger.log_hyperparams(args)
|
| 520 |
+
wdblogger.save()
|
| 521 |
+
log_file = os.path.join(args.output_dir, 'train.log')
|
| 522 |
+
init_logger(logging.INFO if args.local_rank in [-1, 0] else logging.WARN, log_file)
|
| 523 |
+
|
| 524 |
+
logger.warning(
|
| 525 |
+
"Process rank: %s, device: %s, n_gpu: %s, distributed training: %s, 16-bits training: %s",
|
| 526 |
+
args.local_rank,
|
| 527 |
+
device,
|
| 528 |
+
args.n_gpu,
|
| 529 |
+
bool(args.local_rank != -1),
|
| 530 |
+
args.fp16,
|
| 531 |
+
)
|
| 532 |
+
|
| 533 |
+
# Set seed
|
| 534 |
+
set_seed(args)
|
| 535 |
+
|
| 536 |
+
# Prepare task
|
| 537 |
+
data_processor = DataProcessor(
|
| 538 |
+
args.model_name_or_path,
|
| 539 |
+
args.max_seq1_length,
|
| 540 |
+
args.max_seq2_length,
|
| 541 |
+
args.max_num_questions,
|
| 542 |
+
args.cand_k,
|
| 543 |
+
data_dir=args.data_dir,
|
| 544 |
+
cache_dir_name=os.path.basename(args.output_dir),
|
| 545 |
+
overwrite_cache=args.overwrite_cache,
|
| 546 |
+
mask_rate=args.mask_rate
|
| 547 |
+
)
|
| 548 |
+
|
| 549 |
+
# Make sure only the first process in distributed training will download model & vocab
|
| 550 |
+
if args.local_rank not in [-1, 0]:
|
| 551 |
+
torch.distributed.barrier()
|
| 552 |
+
|
| 553 |
+
# Load pretrained model and tokenizer
|
| 554 |
+
args.model_type = args.model_type.lower()
|
| 555 |
+
|
| 556 |
+
config = AutoConfig.from_pretrained(
|
| 557 |
+
args.config_name if args.config_name else args.model_name_or_path,
|
| 558 |
+
num_labels=3,
|
| 559 |
+
cache_dir=args.cache_dir if args.cache_dir else None,
|
| 560 |
+
)
|
| 561 |
+
tokenizer = AutoTokenizer.from_pretrained(
|
| 562 |
+
args.tokenizer_name if args.tokenizer_name else args.model_name_or_path,
|
| 563 |
+
do_lower_case=args.do_lower_case,
|
| 564 |
+
cache_dir=args.cache_dir if args.cache_dir else None,
|
| 565 |
+
)
|
| 566 |
+
model = mAutoModel[args.model_type].from_pretrained(
|
| 567 |
+
args.model_name_or_path,
|
| 568 |
+
from_tf=bool(".ckpt" in args.model_name_or_path),
|
| 569 |
+
config=config,
|
| 570 |
+
cache_dir=args.cache_dir if args.cache_dir else None,
|
| 571 |
+
logic_lambda=args.logic_lambda,
|
| 572 |
+
m=args.max_num_questions,
|
| 573 |
+
prior=args.prior,
|
| 574 |
+
temperature=args.temperature
|
| 575 |
+
)
|
| 576 |
+
|
| 577 |
+
# Make sure only the first process in distributed training will download model & vocab
|
| 578 |
+
if args.local_rank == 0:
|
| 579 |
+
torch.distributed.barrier()
|
| 580 |
+
|
| 581 |
+
if args.do_train:
|
| 582 |
+
model.to(args.device)
|
| 583 |
+
wdblogger.watch(model)
|
| 584 |
+
|
| 585 |
+
logger.info("Training/evaluation parameters %s", args)
|
| 586 |
+
|
| 587 |
+
# Before we do anything with models, we want to ensure that we get fp16 execution of torch.einsum
|
| 588 |
+
# if args.fp16 is set. Otherwise it'll default to "promote" mode, and we'll get fp32 operations.
|
| 589 |
+
# Note that running `--fp16_opt_level="O2"` will remove the need for this code, but it is still valid.
|
| 590 |
+
if args.fp16:
|
| 591 |
+
try:
|
| 592 |
+
import apex
|
| 593 |
+
apex.amp.register_half_function(torch, "einsum")
|
| 594 |
+
except ImportError:
|
| 595 |
+
raise ImportError("Please install apex from https://www.github.com/nvidia/apex to use fp16 training.")
|
| 596 |
+
|
| 597 |
+
# Training
|
| 598 |
+
if args.do_train:
|
| 599 |
+
global_step, tr_loss = train(args, data_processor, model, tokenizer)
|
| 600 |
+
logger.info("global_step = %s, average loss = %s", global_step, tr_loss)
|
| 601 |
+
|
| 602 |
+
# Save the trained model and the tokenizer
|
| 603 |
+
if args.do_train and (args.local_rank == -1 or torch.distributed.get_rank() == 0):
|
| 604 |
+
logger.info("Saving model checkpoint to %s", args.output_dir)
|
| 605 |
+
# Save a trained model, configuration and tokenizer using `save_pretrained()`.
|
| 606 |
+
# They can then be reloaded using `from_pretrained()`
|
| 607 |
+
# Take care of distributed/parallel training
|
| 608 |
+
model_to_save = model.module if hasattr(model, "module") else model
|
| 609 |
+
model_to_save.save_pretrained(args.output_dir)
|
| 610 |
+
tokenizer.save_pretrained(args.output_dir)
|
| 611 |
+
|
| 612 |
+
# Good practice: save your training arguments together with the trained model
|
| 613 |
+
torch.save(args, os.path.join(args.output_dir, "training_args.bin"))
|
| 614 |
+
|
| 615 |
+
# Evaluation - we can ask to evaluate all the checkpoints (sub-directories) in a directory
|
| 616 |
+
results = {}
|
| 617 |
+
if args.do_eval and args.local_rank in [-1, 0]:
|
| 618 |
+
checkpoints = [args.output_dir]
|
| 619 |
+
if args.eval_all_checkpoints:
|
| 620 |
+
checkpoints = list(
|
| 621 |
+
os.path.dirname(c) for c in sorted(glob.glob(args.output_dir + "/**/" + WEIGHTS_NAME, recursive=True))
|
| 622 |
+
)
|
| 623 |
+
logging.getLogger("transformers.modeling_utils").setLevel(logging.WARN) # Reduce model loading logs
|
| 624 |
+
|
| 625 |
+
logger.info("Evaluate the following checkpoints: %s", checkpoints)
|
| 626 |
+
for checkpoint in checkpoints:
|
| 627 |
+
global_step = checkpoint.split("-")[-1] if len(checkpoints) > 1 else ""
|
| 628 |
+
model = mAutoModel[args.model_type].from_pretrained(
|
| 629 |
+
checkpoint,
|
| 630 |
+
logic_lambda=args.logic_lambda,
|
| 631 |
+
m=args.max_num_questions,
|
| 632 |
+
prior=args.prior,
|
| 633 |
+
temperature=args.temperature
|
| 634 |
+
)
|
| 635 |
+
model.to(args.device)
|
| 636 |
+
|
| 637 |
+
# Evaluate
|
| 638 |
+
result = evaluate(args, data_processor, model, tokenizer, prefix=global_step)
|
| 639 |
+
result = dict((k + ("_{}".format(global_step) if global_step else ""), v) for k, v in result.items())
|
| 640 |
+
results.update(result)
|
| 641 |
+
|
| 642 |
+
print(results)
|
| 643 |
+
return results
|
| 644 |
+
|
| 645 |
+
|
| 646 |
+
if __name__ == "__main__":
|
| 647 |
+
main()
|
src/check_client/utils.py
ADDED
|
@@ -0,0 +1,131 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# -*- coding: utf-8 -*-
|
| 2 |
+
|
| 3 |
+
"""
|
| 4 |
+
@Author : Bao
|
| 5 |
+
@Date : 2020/8/12
|
| 6 |
+
@Desc :
|
| 7 |
+
@Last modified by : Bao
|
| 8 |
+
@Last modified date : 2020/8/12
|
| 9 |
+
"""
|
| 10 |
+
|
| 11 |
+
import logging
|
| 12 |
+
from numpy.core.fromnumeric import argmax
|
| 13 |
+
import ujson as json
|
| 14 |
+
import torch
|
| 15 |
+
from plm_checkers.checker_utils import soft_logic
|
| 16 |
+
|
| 17 |
+
|
| 18 |
+
def init_logger(level, filename=None, mode='a', encoding='utf-8'):
|
| 19 |
+
logging_config = {
|
| 20 |
+
'format': '%(asctime)s - %(levelname)s - %(name)s:\t%(message)s',
|
| 21 |
+
'datefmt': '%Y-%m-%d %H:%M:%S',
|
| 22 |
+
'level': level,
|
| 23 |
+
'handlers': [logging.StreamHandler()]
|
| 24 |
+
}
|
| 25 |
+
if filename:
|
| 26 |
+
logging_config['handlers'].append(logging.FileHandler(filename, mode, encoding))
|
| 27 |
+
logging.basicConfig(**logging_config)
|
| 28 |
+
|
| 29 |
+
|
| 30 |
+
def read_json(filename, mode='r', encoding='utf-8'):
|
| 31 |
+
with open(filename, mode, encoding=encoding) as fin:
|
| 32 |
+
return json.load(fin)
|
| 33 |
+
|
| 34 |
+
|
| 35 |
+
def save_json(data, filename, mode='w', encoding='utf-8'):
|
| 36 |
+
with open(filename, mode, encoding=encoding) as fout:
|
| 37 |
+
json.dump(data, fout, ensure_ascii=False, indent=4)
|
| 38 |
+
|
| 39 |
+
|
| 40 |
+
def read_json_lines(filename, mode='r', encoding='utf-8', skip=0):
|
| 41 |
+
with open(filename, mode, encoding=encoding) as fin:
|
| 42 |
+
for line in fin:
|
| 43 |
+
if skip > 0:
|
| 44 |
+
skip -= 1
|
| 45 |
+
continue
|
| 46 |
+
yield json.loads(line)
|
| 47 |
+
|
| 48 |
+
|
| 49 |
+
def save_json_lines(data, filename, mode='w', encoding='utf-8', skip=0):
|
| 50 |
+
with open(filename, mode, encoding=encoding) as fout:
|
| 51 |
+
for line in data:
|
| 52 |
+
if skip > 0:
|
| 53 |
+
skip -= 1
|
| 54 |
+
continue
|
| 55 |
+
print(json.dumps(line, ensure_ascii=False), file=fout)
|
| 56 |
+
|
| 57 |
+
|
| 58 |
+
def read_json_dict(filename, mode='r', encoding='utf-8'):
|
| 59 |
+
with open(filename, mode, encoding=encoding) as fin:
|
| 60 |
+
key_2_id = json.load(fin)
|
| 61 |
+
id_2_key = dict(zip(key_2_id.values(), key_2_id.keys()))
|
| 62 |
+
|
| 63 |
+
return key_2_id, id_2_key
|
| 64 |
+
|
| 65 |
+
|
| 66 |
+
def save_json_dict(data, filename, mode='w', encoding='utf-8'):
|
| 67 |
+
with open(filename, mode, encoding=encoding) as fout:
|
| 68 |
+
json.dump(data, fout, ensure_ascii=False, indent=4)
|
| 69 |
+
|
| 70 |
+
|
| 71 |
+
# Calculate precision, recall and f1 value
|
| 72 |
+
# According to https://github.com/dice-group/gerbil/wiki/Precision,-Recall-and-F1-measure
|
| 73 |
+
def get_prf(res):
|
| 74 |
+
if res['TP'] == 0:
|
| 75 |
+
if res['FP'] == 0 and res['FN'] == 0:
|
| 76 |
+
precision = 1.0
|
| 77 |
+
recall = 1.0
|
| 78 |
+
f1 = 1.0
|
| 79 |
+
else:
|
| 80 |
+
precision = 0.0
|
| 81 |
+
recall = 0.0
|
| 82 |
+
f1 = 0.0
|
| 83 |
+
else:
|
| 84 |
+
precision = 1.0 * res['TP'] / (res['TP'] + res['FP'])
|
| 85 |
+
recall = 1.0 * res['TP'] / (res['TP'] + res['FN'])
|
| 86 |
+
f1 = 2 * precision * recall / (precision + recall)
|
| 87 |
+
|
| 88 |
+
return precision, recall, f1
|
| 89 |
+
|
| 90 |
+
|
| 91 |
+
def compute_metrics(truth, predicted, z_predicted, mask):
|
| 92 |
+
assert len(truth) == len(predicted)
|
| 93 |
+
|
| 94 |
+
outputs = []
|
| 95 |
+
results = {}
|
| 96 |
+
cnt = 0
|
| 97 |
+
z_cnt_h, z_cnt_s = 0, 0
|
| 98 |
+
agree_h, agree_s = 0, 0
|
| 99 |
+
for x, y, z, m in zip(truth, predicted, z_predicted, mask):
|
| 100 |
+
res = {'label': x, 'prediction': y}
|
| 101 |
+
if x == y:
|
| 102 |
+
cnt += 1
|
| 103 |
+
|
| 104 |
+
res['pred_z'] = z
|
| 105 |
+
|
| 106 |
+
y_ = soft_logic(torch.tensor([z]), torch.tensor([m]))[0]
|
| 107 |
+
if y_.argmax(-1).item() == x:
|
| 108 |
+
z_cnt_s += 1
|
| 109 |
+
if y_.argmax(-1).item() == y:
|
| 110 |
+
agree_s += 1
|
| 111 |
+
|
| 112 |
+
z_h = torch.tensor(z[:torch.tensor(m).sum()]).argmax(-1).tolist() # m' x 3
|
| 113 |
+
if 0 in z_h: # REFUTES
|
| 114 |
+
y__ = 0
|
| 115 |
+
elif 1 in z_h: # NEI
|
| 116 |
+
y__ = 1
|
| 117 |
+
else: # SUPPPORTS
|
| 118 |
+
y__ = 2
|
| 119 |
+
if y__ == x:
|
| 120 |
+
z_cnt_h += 1
|
| 121 |
+
if y__ == y:
|
| 122 |
+
agree_h += 1
|
| 123 |
+
|
| 124 |
+
outputs.append(res)
|
| 125 |
+
|
| 126 |
+
results['Accuracy'] = cnt / len(truth)
|
| 127 |
+
results['z_Acc_hard'] = z_cnt_h / len(truth)
|
| 128 |
+
results['z_Acc_soft'] = z_cnt_s / len(truth)
|
| 129 |
+
results['Agreement_hard'] = agree_h / len(truth)
|
| 130 |
+
results['Agreement_soft'] = agree_s / len(truth)
|
| 131 |
+
return outputs, results
|
src/cjjpy.py
ADDED
|
@@ -0,0 +1,249 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# -*- coding: utf-8 -*-
|
| 2 |
+
|
| 3 |
+
'''
|
| 4 |
+
@Author : Jiangjie Chen
|
| 5 |
+
@Time : 2018/11/15 17:08
|
| 6 |
+
@Contact: jjchen19@fudan.edu.cn
|
| 7 |
+
'''
|
| 8 |
+
|
| 9 |
+
import re
|
| 10 |
+
import datetime
|
| 11 |
+
import os
|
| 12 |
+
import argparse
|
| 13 |
+
import logging
|
| 14 |
+
import traceback
|
| 15 |
+
|
| 16 |
+
try:
|
| 17 |
+
import ujson as json
|
| 18 |
+
except:
|
| 19 |
+
import json
|
| 20 |
+
|
| 21 |
+
HADOOP_BIN = 'PATH=/usr/bin/:$PATH hdfs'
|
| 22 |
+
FOR_PUBLIC = True
|
| 23 |
+
|
| 24 |
+
|
| 25 |
+
def LengthStats(filename):
|
| 26 |
+
len_list = []
|
| 27 |
+
thresholds = [0.8, 0.9, 0.95, 0.99, 0.999]
|
| 28 |
+
with open(filename) as f:
|
| 29 |
+
for line in f:
|
| 30 |
+
len_list.append(len(line.strip().split()))
|
| 31 |
+
stats = {
|
| 32 |
+
'Max': max(len_list),
|
| 33 |
+
'Min': min(len_list),
|
| 34 |
+
'Avg': round(sum(len_list) / len(len_list), 4),
|
| 35 |
+
}
|
| 36 |
+
len_list.sort()
|
| 37 |
+
for t in thresholds:
|
| 38 |
+
stats[f"Top-{t}"] = len_list[int(len(len_list) * t)]
|
| 39 |
+
|
| 40 |
+
for k in stats:
|
| 41 |
+
print(f"- {k}: {stats[k]}")
|
| 42 |
+
return stats
|
| 43 |
+
|
| 44 |
+
|
| 45 |
+
class AttrDict(dict):
|
| 46 |
+
def __init__(self, *args, **kwargs):
|
| 47 |
+
super(AttrDict, self).__init__(*args, **kwargs)
|
| 48 |
+
self.__dict__ = self
|
| 49 |
+
|
| 50 |
+
|
| 51 |
+
def TraceBack(error_msg):
|
| 52 |
+
exc = traceback.format_exc()
|
| 53 |
+
msg = f'[Error]: {error_msg}.\n[Traceback]: {exc}'
|
| 54 |
+
return msg
|
| 55 |
+
|
| 56 |
+
|
| 57 |
+
def Now():
|
| 58 |
+
return datetime.datetime.now().strftime("%Y-%m-%d %H:%M:%S")
|
| 59 |
+
|
| 60 |
+
|
| 61 |
+
def AbsParentDir(file, parent='..', postfix=None):
|
| 62 |
+
ppath = os.path.abspath(file)
|
| 63 |
+
parent_level = parent.count('.')
|
| 64 |
+
while parent_level > 0:
|
| 65 |
+
ppath = os.path.dirname(ppath)
|
| 66 |
+
parent_level -= 1
|
| 67 |
+
if postfix is not None:
|
| 68 |
+
return os.path.join(ppath, postfix)
|
| 69 |
+
else:
|
| 70 |
+
return ppath
|
| 71 |
+
|
| 72 |
+
|
| 73 |
+
def init_logger(log_file=None, log_file_level=logging.NOTSET, from_scratch=False):
|
| 74 |
+
from coloredlogs import ColoredFormatter
|
| 75 |
+
import tensorflow as tf
|
| 76 |
+
|
| 77 |
+
fmt = "[%(asctime)s %(levelname)s] %(message)s"
|
| 78 |
+
log_format = ColoredFormatter(fmt=fmt)
|
| 79 |
+
# log_format = logging.Formatter()
|
| 80 |
+
logger = logging.getLogger()
|
| 81 |
+
logger.setLevel(log_file_level)
|
| 82 |
+
|
| 83 |
+
console_handler = logging.StreamHandler()
|
| 84 |
+
console_handler.setFormatter(log_format)
|
| 85 |
+
logger.handlers = [console_handler]
|
| 86 |
+
|
| 87 |
+
if log_file and log_file != '':
|
| 88 |
+
if from_scratch and tf.io.gfile.exists(log_file):
|
| 89 |
+
logger.warning('Removing previous log file: %s' % log_file)
|
| 90 |
+
tf.io.gfile.remove(log_file)
|
| 91 |
+
path = os.path.dirname(log_file)
|
| 92 |
+
os.makedirs(path, exist_ok=True)
|
| 93 |
+
file_handler = logging.FileHandler(log_file)
|
| 94 |
+
file_handler.setLevel(log_file_level)
|
| 95 |
+
file_handler.setFormatter(log_format)
|
| 96 |
+
logger.addHandler(file_handler)
|
| 97 |
+
|
| 98 |
+
return logger
|
| 99 |
+
|
| 100 |
+
|
| 101 |
+
def OverWriteCjjPy(root='.'):
|
| 102 |
+
# import difflib
|
| 103 |
+
# diff = difflib.HtmlDiff()
|
| 104 |
+
cnt = 0
|
| 105 |
+
golden_cjjpy = os.path.join(root, 'cjjpy.py')
|
| 106 |
+
# golden_content = open(golden_cjjpy).readlines()
|
| 107 |
+
for dir, folder, file in os.walk(root):
|
| 108 |
+
for f in file:
|
| 109 |
+
if f == 'cjjpy.py':
|
| 110 |
+
cjjpy = '%s/%s' % (dir, f)
|
| 111 |
+
# content = open(cjjpy).readlines()
|
| 112 |
+
# d = diff.make_file(golden_content, content)
|
| 113 |
+
cnt += 1
|
| 114 |
+
print('[%d]: %s' % (cnt, cjjpy))
|
| 115 |
+
os.system('cp %s %s' % (golden_cjjpy, cjjpy))
|
| 116 |
+
|
| 117 |
+
|
| 118 |
+
def ChangeFileFormat(filename, new_fmt):
|
| 119 |
+
assert type(filename) is str and type(new_fmt) is str
|
| 120 |
+
spt = filename.split('.')
|
| 121 |
+
if len(spt) == 0:
|
| 122 |
+
return filename
|
| 123 |
+
else:
|
| 124 |
+
return filename.replace('.' + spt[-1], new_fmt)
|
| 125 |
+
|
| 126 |
+
|
| 127 |
+
def CountLines(fname):
|
| 128 |
+
with open(fname, 'rb') as f:
|
| 129 |
+
count = 0
|
| 130 |
+
last_data = '\n'
|
| 131 |
+
while True:
|
| 132 |
+
data = f.read(0x400000)
|
| 133 |
+
if not data:
|
| 134 |
+
break
|
| 135 |
+
count += data.count(b'\n')
|
| 136 |
+
last_data = data
|
| 137 |
+
if last_data[-1:] != b'\n':
|
| 138 |
+
count += 1 # Remove this if a wc-like count is needed
|
| 139 |
+
return count
|
| 140 |
+
|
| 141 |
+
|
| 142 |
+
def GetDate():
|
| 143 |
+
return str(datetime.datetime.now())[5:10].replace('-', '')
|
| 144 |
+
|
| 145 |
+
|
| 146 |
+
def TimeClock(seconds):
|
| 147 |
+
sec = int(seconds)
|
| 148 |
+
hour = int(sec / 3600)
|
| 149 |
+
min = int((sec - hour * 3600) / 60)
|
| 150 |
+
ssec = float(seconds) - hour * 3600 - min * 60
|
| 151 |
+
# return '%dh %dm %.2fs' % (hour, min, ssec)
|
| 152 |
+
return '{0:>2d}h{1:>3d}m{2:>6.2f}s'.format(hour, min, ssec)
|
| 153 |
+
|
| 154 |
+
|
| 155 |
+
def StripAll(text):
|
| 156 |
+
return text.strip().replace('\t', '').replace('\n', '').replace(' ', '')
|
| 157 |
+
|
| 158 |
+
|
| 159 |
+
def GetBracket(text, bracket, en_br=False):
|
| 160 |
+
# input should be aa(bb)cc, True for bracket, False for text
|
| 161 |
+
if bracket:
|
| 162 |
+
try:
|
| 163 |
+
return re.findall('\((.*?)\)', text.strip())[-1]
|
| 164 |
+
except:
|
| 165 |
+
return ''
|
| 166 |
+
else:
|
| 167 |
+
if en_br:
|
| 168 |
+
text = re.sub('\(.*?\)', '', text.strip())
|
| 169 |
+
return re.sub('(.*?)', '', text.strip())
|
| 170 |
+
|
| 171 |
+
|
| 172 |
+
def CharLang(uchar, lang):
|
| 173 |
+
assert lang.lower() in ['en', 'cn', 'zh']
|
| 174 |
+
if lang.lower() in ['cn', 'zh']:
|
| 175 |
+
if uchar >= '\u4e00' and uchar <= '\u9fa5':
|
| 176 |
+
return True
|
| 177 |
+
else:
|
| 178 |
+
return False
|
| 179 |
+
elif lang.lower() == 'en':
|
| 180 |
+
if (uchar <= 'Z' and uchar >= 'A') or (uchar <= 'z' and uchar >= 'a'):
|
| 181 |
+
return True
|
| 182 |
+
else:
|
| 183 |
+
return False
|
| 184 |
+
else:
|
| 185 |
+
raise NotImplementedError
|
| 186 |
+
|
| 187 |
+
|
| 188 |
+
def WordLang(word, lang):
|
| 189 |
+
for i in word.strip():
|
| 190 |
+
if i.isspace(): continue
|
| 191 |
+
if not CharLang(i, lang):
|
| 192 |
+
return False
|
| 193 |
+
return True
|
| 194 |
+
|
| 195 |
+
|
| 196 |
+
def SortDict(_dict, reverse=True):
|
| 197 |
+
assert type(_dict) is dict
|
| 198 |
+
return sorted(_dict.items(), key=lambda d: d[1], reverse=reverse)
|
| 199 |
+
|
| 200 |
+
|
| 201 |
+
def lark(content='test'):
|
| 202 |
+
print(content)
|
| 203 |
+
|
| 204 |
+
|
| 205 |
+
if __name__ == '__main__':
|
| 206 |
+
parser = argparse.ArgumentParser()
|
| 207 |
+
|
| 208 |
+
parser.add_argument('--diff', nargs=2,
|
| 209 |
+
help='show difference between two files, shown in downloads/diff.html')
|
| 210 |
+
parser.add_argument('--de_unicode', action='store_true', default=False,
|
| 211 |
+
help='remove unicode characters')
|
| 212 |
+
parser.add_argument('--link_entity', action='store_true', default=False,
|
| 213 |
+
help='')
|
| 214 |
+
parser.add_argument('--max_comm_len', action='store_true', default=False,
|
| 215 |
+
help='')
|
| 216 |
+
parser.add_argument('--search', nargs=2,
|
| 217 |
+
help='search key from file, 2 args: file name & key')
|
| 218 |
+
parser.add_argument('--email', nargs=2,
|
| 219 |
+
help='sending emails, 2 args: subject & content')
|
| 220 |
+
parser.add_argument('--overwrite', action='store_true', default=None,
|
| 221 |
+
help='overwrite all cjjpy under given *dir* based on *dir*/cjjpy.py')
|
| 222 |
+
parser.add_argument('--replace', nargs=3,
|
| 223 |
+
help='replace char, 3 args: file name & replaced char & replacer char')
|
| 224 |
+
parser.add_argument('--lark', nargs=1)
|
| 225 |
+
parser.add_argument('--get_hdfs', nargs=2,
|
| 226 |
+
help='easy copy from hdfs to local fs, 2 args: remote_file/dir & local_dir')
|
| 227 |
+
parser.add_argument('--put_hdfs', nargs=2,
|
| 228 |
+
help='easy put from local fs to hdfs, 2 args: local_file/dir & remote_dir')
|
| 229 |
+
parser.add_argument('--length_stats', nargs=1,
|
| 230 |
+
help='simple token lengths distribution of a line-by-line file')
|
| 231 |
+
|
| 232 |
+
args = parser.parse_args()
|
| 233 |
+
|
| 234 |
+
if args.overwrite:
|
| 235 |
+
print('* Overwriting cjjpy...')
|
| 236 |
+
OverWriteCjjPy()
|
| 237 |
+
|
| 238 |
+
if args.lark:
|
| 239 |
+
try:
|
| 240 |
+
content = args.lark[0]
|
| 241 |
+
except:
|
| 242 |
+
content = 'running complete'
|
| 243 |
+
print(f'* Larking "{content}"...')
|
| 244 |
+
lark(content)
|
| 245 |
+
|
| 246 |
+
if args.length_stats:
|
| 247 |
+
file = args.length_stats[0]
|
| 248 |
+
print(f'* Working on {file} lengths statistics...')
|
| 249 |
+
LengthStats(file)
|
src/dataloaders.py
ADDED
|
@@ -0,0 +1,134 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# -*- coding: utf-8 -*-
|
| 2 |
+
|
| 3 |
+
'''
|
| 4 |
+
@Author : Jiangjie Chen
|
| 5 |
+
@Time : 2020/7/20 17:34
|
| 6 |
+
@Contact : jjchen19@fudan.edu.cn
|
| 7 |
+
@Description:
|
| 8 |
+
'''
|
| 9 |
+
|
| 10 |
+
import tensorflow as tf
|
| 11 |
+
import cjjpy as cjj
|
| 12 |
+
import os
|
| 13 |
+
import re
|
| 14 |
+
import ujson as json
|
| 15 |
+
from collections import defaultdict
|
| 16 |
+
|
| 17 |
+
pj_prefix = cjj.AbsParentDir(__file__, '..')
|
| 18 |
+
|
| 19 |
+
|
| 20 |
+
class FEVERLoader:
|
| 21 |
+
def __init__(self, role):
|
| 22 |
+
role = 'dev' if role == 'val' else role
|
| 23 |
+
assert role in ['train', 'dev', 'test', 'eval']
|
| 24 |
+
self.role = role
|
| 25 |
+
self.fever_data = defaultdict(dict)
|
| 26 |
+
self.SUPPORTS = 'SUPPORTS'
|
| 27 |
+
self.REFUTES = 'REFUTES'
|
| 28 |
+
self.NEI = 'NOT ENOUGH INFO'
|
| 29 |
+
|
| 30 |
+
def __iter__(self):
|
| 31 |
+
for k in self.fever_data:
|
| 32 |
+
yield k
|
| 33 |
+
|
| 34 |
+
def __len__(self):
|
| 35 |
+
return len(self.fever_data)
|
| 36 |
+
|
| 37 |
+
def __getitem__(self, item):
|
| 38 |
+
return self.fever_data[item]
|
| 39 |
+
|
| 40 |
+
def load_fever(self, retrieve_type='bert', clean_load=True):
|
| 41 |
+
self._load_fever_golden()
|
| 42 |
+
self._load_fever_all()
|
| 43 |
+
self._load_fever_retrieved(retrieve_type, clean_load)
|
| 44 |
+
|
| 45 |
+
def _load_json(self, fname):
|
| 46 |
+
with tf.io.gfile.GFile(fname) as f:
|
| 47 |
+
return [json.loads(x) for x in f.readlines()]
|
| 48 |
+
|
| 49 |
+
def _new_role(self):
|
| 50 |
+
role = self.role if self.role != 'eval' else 'dev'
|
| 51 |
+
return role
|
| 52 |
+
|
| 53 |
+
def _load_fever_golden(self):
|
| 54 |
+
if self.role == 'test':
|
| 55 |
+
postfix = f'data/fever/shared_task_test.jsonl'
|
| 56 |
+
for js in self._load_json(f'{pj_prefix}/{postfix}'):
|
| 57 |
+
self.fever_data[js['id']].update({
|
| 58 |
+
'id': js['id'],
|
| 59 |
+
'claim': js['claim']
|
| 60 |
+
})
|
| 61 |
+
else:
|
| 62 |
+
role = self._new_role()
|
| 63 |
+
postfix = f'data/fever/baked_data/golden_{role}.json'
|
| 64 |
+
for js in self._load_json(f'{pj_prefix}/{postfix}'):
|
| 65 |
+
self.fever_data[js['id']].update({
|
| 66 |
+
'id': js['id'],
|
| 67 |
+
'claim': js['claim'],
|
| 68 |
+
'label': js['label'],
|
| 69 |
+
'golden_evidence': self._clean_evidence(js['evidence'])
|
| 70 |
+
})
|
| 71 |
+
print('* FEVER golden loaded.')
|
| 72 |
+
|
| 73 |
+
def _load_fever_all(self):
|
| 74 |
+
role = self._new_role()
|
| 75 |
+
postfix = f'data/fever/baked_data/all_{role}.json'
|
| 76 |
+
for js in self._load_json(f'{pj_prefix}/{postfix}'):
|
| 77 |
+
self.fever_data[js['id']].update({
|
| 78 |
+
'all_evidence': self._clean_evidence(js['evidence'])
|
| 79 |
+
})
|
| 80 |
+
print('* FEVER all loaded.')
|
| 81 |
+
|
| 82 |
+
def _load_fever_retrieved(self, retrieve_type, clean_load):
|
| 83 |
+
assert retrieve_type in ['bert']
|
| 84 |
+
postfix = f'data/fever/baked_data/{retrieve_type}_{self.role}.json'
|
| 85 |
+
for js in self._load_json(f'{pj_prefix}/{postfix}'):
|
| 86 |
+
self.fever_data[js['id']].update({
|
| 87 |
+
f'{retrieve_type}_evidence': self._clean_evidence(js['evidence']) if clean_load else js['evidence']
|
| 88 |
+
})
|
| 89 |
+
print(f'* FEVER {retrieve_type} loaded.')
|
| 90 |
+
|
| 91 |
+
def clean_text(self, sentence):
|
| 92 |
+
sentence = re.sub(" \-LSB\-.*?\-RSB\-", "", sentence)
|
| 93 |
+
sentence = re.sub("\-LRB\- \-RRB\- ", "", sentence)
|
| 94 |
+
sentence = re.sub(" -LRB-", " ( ", sentence)
|
| 95 |
+
sentence = re.sub("-RRB-", " )", sentence)
|
| 96 |
+
|
| 97 |
+
sentence = re.sub(" LSB.*?RSB", "", sentence)
|
| 98 |
+
sentence = re.sub("LRB RRB ", "", sentence)
|
| 99 |
+
sentence = re.sub("LRB", " ( ", sentence)
|
| 100 |
+
sentence = re.sub("RRB", " )", sentence)
|
| 101 |
+
sentence = re.sub("--", "-", sentence)
|
| 102 |
+
sentence = re.sub("``", '"', sentence)
|
| 103 |
+
sentence = re.sub("''", '"', sentence)
|
| 104 |
+
sentence = re.sub(' ', ' ', sentence)
|
| 105 |
+
return sentence
|
| 106 |
+
|
| 107 |
+
def clean_title(self, title):
|
| 108 |
+
title = re.sub("_", " ", title)
|
| 109 |
+
title = re.sub(" -LRB-", " ( ", title)
|
| 110 |
+
title = re.sub("-RRB-", " )", title)
|
| 111 |
+
title = re.sub("-COLON-", ":", title)
|
| 112 |
+
title = re.sub(' ', ' ', title)
|
| 113 |
+
return title
|
| 114 |
+
|
| 115 |
+
def _clean_evidence(self, evidence):
|
| 116 |
+
cev = []
|
| 117 |
+
for ev in evidence:
|
| 118 |
+
if len(ev) == 4:
|
| 119 |
+
cev.append([self.clean_title(ev[0]), ev[1], self.clean_text(ev[2]), ev[3]])
|
| 120 |
+
elif len(ev) == 3:
|
| 121 |
+
cev.append([self.clean_title(ev[0]), ev[1], self.clean_text(ev[2])])
|
| 122 |
+
elif len(ev) == 0:
|
| 123 |
+
cev.append(ev)
|
| 124 |
+
else:
|
| 125 |
+
raise ValueError(ev)
|
| 126 |
+
return cev
|
| 127 |
+
|
| 128 |
+
|
| 129 |
+
if __name__ == '__main__':
|
| 130 |
+
floader = FEVERLoader('test')
|
| 131 |
+
floader.load_fever('bert', clean_load=False)
|
| 132 |
+
for k in floader:
|
| 133 |
+
print(floader[k])
|
| 134 |
+
input()
|
src/er_client/__init__.py
ADDED
|
@@ -0,0 +1,63 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# -*- coding: utf-8 -*-
|
| 2 |
+
|
| 3 |
+
'''
|
| 4 |
+
@Author : Jiangjie Chen
|
| 5 |
+
@Time : 2020/9/21 16:13
|
| 6 |
+
@Contact : jjchen19@fudan.edu.cn
|
| 7 |
+
@Description:
|
| 8 |
+
'''
|
| 9 |
+
|
| 10 |
+
import cjjpy as cjj
|
| 11 |
+
import os
|
| 12 |
+
# from .document_retrieval import DocRetrieval
|
| 13 |
+
from .doc_retrieval_by_api import DocRetrieval
|
| 14 |
+
from .sentence_selection import SentSelector
|
| 15 |
+
|
| 16 |
+
|
| 17 |
+
arg_values = {
|
| 18 |
+
'batch_size': 32,
|
| 19 |
+
'dropout': 0.6,
|
| 20 |
+
'use_cuda': True,
|
| 21 |
+
'bert_hidden_dim': 768,
|
| 22 |
+
'layer': 1,
|
| 23 |
+
'num_labels': 3,
|
| 24 |
+
'evi_num': 5,
|
| 25 |
+
'threshold': 0.0,
|
| 26 |
+
'max_len': 120,
|
| 27 |
+
}
|
| 28 |
+
|
| 29 |
+
args = cjj.AttrDict(arg_values)
|
| 30 |
+
|
| 31 |
+
class EvidenceRetrieval:
|
| 32 |
+
def __init__(self, er_model_dir=cjj.AbsParentDir(__file__, '...', 'models/evidence_retrieval/')):
|
| 33 |
+
# self.doc_retriever = DocRetrieval(cjj.AbsParentDir(__file__, '...', 'data/fever.db'),
|
| 34 |
+
# add_claim=True, k_wiki_results=7)
|
| 35 |
+
self.doc_retrieval = DocRetrieval(link_type='tagme')
|
| 36 |
+
self.sent_selector = SentSelector(os.path.join(er_model_dir, 'bert_base/'),
|
| 37 |
+
os.path.join(er_model_dir, 'retrieval_model/model.best.pt'),
|
| 38 |
+
args)
|
| 39 |
+
|
| 40 |
+
def retrieve(self, claim):
|
| 41 |
+
# noun_phrases, wiki_results, predicted_pages = self.doc_retriever.exact_match(claim)
|
| 42 |
+
# evidence = []
|
| 43 |
+
# for page in predicted_pages:
|
| 44 |
+
# evidence.extend(self.doc_retriever.db.get_doc_lines(page))
|
| 45 |
+
evidence = self.doc_retrieval.retrieve_docs(claim)
|
| 46 |
+
evidence = self.rank_sentences(claim, evidence)
|
| 47 |
+
return evidence
|
| 48 |
+
|
| 49 |
+
def rank_sentences(self, claim, sentences, id=None):
|
| 50 |
+
'''
|
| 51 |
+
:param claim: str
|
| 52 |
+
:param sentences: [(ent, num, sent) * N]
|
| 53 |
+
:param id:
|
| 54 |
+
:return: [(ent, num, sent) * k]
|
| 55 |
+
'''
|
| 56 |
+
if id is None:
|
| 57 |
+
id = len(claim)
|
| 58 |
+
|
| 59 |
+
result = self.sent_selector.rank_sentences([{'claim': claim,
|
| 60 |
+
'evidence': sentences,
|
| 61 |
+
'id': id}])
|
| 62 |
+
evidence = result.get(id, [])
|
| 63 |
+
return evidence
|
src/er_client/cjjpy.py
ADDED
|
@@ -0,0 +1,249 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# -*- coding: utf-8 -*-
|
| 2 |
+
|
| 3 |
+
'''
|
| 4 |
+
@Author : Jiangjie Chen
|
| 5 |
+
@Time : 2018/11/15 17:08
|
| 6 |
+
@Contact: jjchen19@fudan.edu.cn
|
| 7 |
+
'''
|
| 8 |
+
|
| 9 |
+
import re
|
| 10 |
+
import datetime
|
| 11 |
+
import os
|
| 12 |
+
import argparse
|
| 13 |
+
import logging
|
| 14 |
+
import traceback
|
| 15 |
+
|
| 16 |
+
try:
|
| 17 |
+
import ujson as json
|
| 18 |
+
except:
|
| 19 |
+
import json
|
| 20 |
+
|
| 21 |
+
HADOOP_BIN = 'PATH=/usr/bin/:$PATH hdfs'
|
| 22 |
+
FOR_PUBLIC = True
|
| 23 |
+
|
| 24 |
+
|
| 25 |
+
def LengthStats(filename):
|
| 26 |
+
len_list = []
|
| 27 |
+
thresholds = [0.8, 0.9, 0.95, 0.99, 0.999]
|
| 28 |
+
with open(filename) as f:
|
| 29 |
+
for line in f:
|
| 30 |
+
len_list.append(len(line.strip().split()))
|
| 31 |
+
stats = {
|
| 32 |
+
'Max': max(len_list),
|
| 33 |
+
'Min': min(len_list),
|
| 34 |
+
'Avg': round(sum(len_list) / len(len_list), 4),
|
| 35 |
+
}
|
| 36 |
+
len_list.sort()
|
| 37 |
+
for t in thresholds:
|
| 38 |
+
stats[f"Top-{t}"] = len_list[int(len(len_list) * t)]
|
| 39 |
+
|
| 40 |
+
for k in stats:
|
| 41 |
+
print(f"- {k}: {stats[k]}")
|
| 42 |
+
return stats
|
| 43 |
+
|
| 44 |
+
|
| 45 |
+
class AttrDict(dict):
|
| 46 |
+
def __init__(self, *args, **kwargs):
|
| 47 |
+
super(AttrDict, self).__init__(*args, **kwargs)
|
| 48 |
+
self.__dict__ = self
|
| 49 |
+
|
| 50 |
+
|
| 51 |
+
def TraceBack(error_msg):
|
| 52 |
+
exc = traceback.format_exc()
|
| 53 |
+
msg = f'[Error]: {error_msg}.\n[Traceback]: {exc}'
|
| 54 |
+
return msg
|
| 55 |
+
|
| 56 |
+
|
| 57 |
+
def Now():
|
| 58 |
+
return datetime.datetime.now().strftime("%Y-%m-%d %H:%M:%S")
|
| 59 |
+
|
| 60 |
+
|
| 61 |
+
def AbsParentDir(file, parent='..', postfix=None):
|
| 62 |
+
ppath = os.path.abspath(file)
|
| 63 |
+
parent_level = parent.count('.')
|
| 64 |
+
while parent_level > 0:
|
| 65 |
+
ppath = os.path.dirname(ppath)
|
| 66 |
+
parent_level -= 1
|
| 67 |
+
if postfix is not None:
|
| 68 |
+
return os.path.join(ppath, postfix)
|
| 69 |
+
else:
|
| 70 |
+
return ppath
|
| 71 |
+
|
| 72 |
+
|
| 73 |
+
def init_logger(log_file=None, log_file_level=logging.NOTSET, from_scratch=False):
|
| 74 |
+
from coloredlogs import ColoredFormatter
|
| 75 |
+
import tensorflow as tf
|
| 76 |
+
|
| 77 |
+
fmt = "[%(asctime)s %(levelname)s] %(message)s"
|
| 78 |
+
log_format = ColoredFormatter(fmt=fmt)
|
| 79 |
+
# log_format = logging.Formatter()
|
| 80 |
+
logger = logging.getLogger()
|
| 81 |
+
logger.setLevel(log_file_level)
|
| 82 |
+
|
| 83 |
+
console_handler = logging.StreamHandler()
|
| 84 |
+
console_handler.setFormatter(log_format)
|
| 85 |
+
logger.handlers = [console_handler]
|
| 86 |
+
|
| 87 |
+
if log_file and log_file != '':
|
| 88 |
+
if from_scratch and tf.io.gfile.exists(log_file):
|
| 89 |
+
logger.warning('Removing previous log file: %s' % log_file)
|
| 90 |
+
tf.io.gfile.remove(log_file)
|
| 91 |
+
path = os.path.dirname(log_file)
|
| 92 |
+
os.makedirs(path, exist_ok=True)
|
| 93 |
+
file_handler = logging.FileHandler(log_file)
|
| 94 |
+
file_handler.setLevel(log_file_level)
|
| 95 |
+
file_handler.setFormatter(log_format)
|
| 96 |
+
logger.addHandler(file_handler)
|
| 97 |
+
|
| 98 |
+
return logger
|
| 99 |
+
|
| 100 |
+
|
| 101 |
+
def OverWriteCjjPy(root='.'):
|
| 102 |
+
# import difflib
|
| 103 |
+
# diff = difflib.HtmlDiff()
|
| 104 |
+
cnt = 0
|
| 105 |
+
golden_cjjpy = os.path.join(root, 'cjjpy.py')
|
| 106 |
+
# golden_content = open(golden_cjjpy).readlines()
|
| 107 |
+
for dir, folder, file in os.walk(root):
|
| 108 |
+
for f in file:
|
| 109 |
+
if f == 'cjjpy.py':
|
| 110 |
+
cjjpy = '%s/%s' % (dir, f)
|
| 111 |
+
# content = open(cjjpy).readlines()
|
| 112 |
+
# d = diff.make_file(golden_content, content)
|
| 113 |
+
cnt += 1
|
| 114 |
+
print('[%d]: %s' % (cnt, cjjpy))
|
| 115 |
+
os.system('cp %s %s' % (golden_cjjpy, cjjpy))
|
| 116 |
+
|
| 117 |
+
|
| 118 |
+
def ChangeFileFormat(filename, new_fmt):
|
| 119 |
+
assert type(filename) is str and type(new_fmt) is str
|
| 120 |
+
spt = filename.split('.')
|
| 121 |
+
if len(spt) == 0:
|
| 122 |
+
return filename
|
| 123 |
+
else:
|
| 124 |
+
return filename.replace('.' + spt[-1], new_fmt)
|
| 125 |
+
|
| 126 |
+
|
| 127 |
+
def CountLines(fname):
|
| 128 |
+
with open(fname, 'rb') as f:
|
| 129 |
+
count = 0
|
| 130 |
+
last_data = '\n'
|
| 131 |
+
while True:
|
| 132 |
+
data = f.read(0x400000)
|
| 133 |
+
if not data:
|
| 134 |
+
break
|
| 135 |
+
count += data.count(b'\n')
|
| 136 |
+
last_data = data
|
| 137 |
+
if last_data[-1:] != b'\n':
|
| 138 |
+
count += 1 # Remove this if a wc-like count is needed
|
| 139 |
+
return count
|
| 140 |
+
|
| 141 |
+
|
| 142 |
+
def GetDate():
|
| 143 |
+
return str(datetime.datetime.now())[5:10].replace('-', '')
|
| 144 |
+
|
| 145 |
+
|
| 146 |
+
def TimeClock(seconds):
|
| 147 |
+
sec = int(seconds)
|
| 148 |
+
hour = int(sec / 3600)
|
| 149 |
+
min = int((sec - hour * 3600) / 60)
|
| 150 |
+
ssec = float(seconds) - hour * 3600 - min * 60
|
| 151 |
+
# return '%dh %dm %.2fs' % (hour, min, ssec)
|
| 152 |
+
return '{0:>2d}h{1:>3d}m{2:>6.2f}s'.format(hour, min, ssec)
|
| 153 |
+
|
| 154 |
+
|
| 155 |
+
def StripAll(text):
|
| 156 |
+
return text.strip().replace('\t', '').replace('\n', '').replace(' ', '')
|
| 157 |
+
|
| 158 |
+
|
| 159 |
+
def GetBracket(text, bracket, en_br=False):
|
| 160 |
+
# input should be aa(bb)cc, True for bracket, False for text
|
| 161 |
+
if bracket:
|
| 162 |
+
try:
|
| 163 |
+
return re.findall('\((.*?)\)', text.strip())[-1]
|
| 164 |
+
except:
|
| 165 |
+
return ''
|
| 166 |
+
else:
|
| 167 |
+
if en_br:
|
| 168 |
+
text = re.sub('\(.*?\)', '', text.strip())
|
| 169 |
+
return re.sub('(.*?)', '', text.strip())
|
| 170 |
+
|
| 171 |
+
|
| 172 |
+
def CharLang(uchar, lang):
|
| 173 |
+
assert lang.lower() in ['en', 'cn', 'zh']
|
| 174 |
+
if lang.lower() in ['cn', 'zh']:
|
| 175 |
+
if uchar >= '\u4e00' and uchar <= '\u9fa5':
|
| 176 |
+
return True
|
| 177 |
+
else:
|
| 178 |
+
return False
|
| 179 |
+
elif lang.lower() == 'en':
|
| 180 |
+
if (uchar <= 'Z' and uchar >= 'A') or (uchar <= 'z' and uchar >= 'a'):
|
| 181 |
+
return True
|
| 182 |
+
else:
|
| 183 |
+
return False
|
| 184 |
+
else:
|
| 185 |
+
raise NotImplementedError
|
| 186 |
+
|
| 187 |
+
|
| 188 |
+
def WordLang(word, lang):
|
| 189 |
+
for i in word.strip():
|
| 190 |
+
if i.isspace(): continue
|
| 191 |
+
if not CharLang(i, lang):
|
| 192 |
+
return False
|
| 193 |
+
return True
|
| 194 |
+
|
| 195 |
+
|
| 196 |
+
def SortDict(_dict, reverse=True):
|
| 197 |
+
assert type(_dict) is dict
|
| 198 |
+
return sorted(_dict.items(), key=lambda d: d[1], reverse=reverse)
|
| 199 |
+
|
| 200 |
+
|
| 201 |
+
def lark(content='test'):
|
| 202 |
+
print(content)
|
| 203 |
+
|
| 204 |
+
|
| 205 |
+
if __name__ == '__main__':
|
| 206 |
+
parser = argparse.ArgumentParser()
|
| 207 |
+
|
| 208 |
+
parser.add_argument('--diff', nargs=2,
|
| 209 |
+
help='show difference between two files, shown in downloads/diff.html')
|
| 210 |
+
parser.add_argument('--de_unicode', action='store_true', default=False,
|
| 211 |
+
help='remove unicode characters')
|
| 212 |
+
parser.add_argument('--link_entity', action='store_true', default=False,
|
| 213 |
+
help='')
|
| 214 |
+
parser.add_argument('--max_comm_len', action='store_true', default=False,
|
| 215 |
+
help='')
|
| 216 |
+
parser.add_argument('--search', nargs=2,
|
| 217 |
+
help='search key from file, 2 args: file name & key')
|
| 218 |
+
parser.add_argument('--email', nargs=2,
|
| 219 |
+
help='sending emails, 2 args: subject & content')
|
| 220 |
+
parser.add_argument('--overwrite', action='store_true', default=None,
|
| 221 |
+
help='overwrite all cjjpy under given *dir* based on *dir*/cjjpy.py')
|
| 222 |
+
parser.add_argument('--replace', nargs=3,
|
| 223 |
+
help='replace char, 3 args: file name & replaced char & replacer char')
|
| 224 |
+
parser.add_argument('--lark', nargs=1)
|
| 225 |
+
parser.add_argument('--get_hdfs', nargs=2,
|
| 226 |
+
help='easy copy from hdfs to local fs, 2 args: remote_file/dir & local_dir')
|
| 227 |
+
parser.add_argument('--put_hdfs', nargs=2,
|
| 228 |
+
help='easy put from local fs to hdfs, 2 args: local_file/dir & remote_dir')
|
| 229 |
+
parser.add_argument('--length_stats', nargs=1,
|
| 230 |
+
help='simple token lengths distribution of a line-by-line file')
|
| 231 |
+
|
| 232 |
+
args = parser.parse_args()
|
| 233 |
+
|
| 234 |
+
if args.overwrite:
|
| 235 |
+
print('* Overwriting cjjpy...')
|
| 236 |
+
OverWriteCjjPy()
|
| 237 |
+
|
| 238 |
+
if args.lark:
|
| 239 |
+
try:
|
| 240 |
+
content = args.lark[0]
|
| 241 |
+
except:
|
| 242 |
+
content = 'running complete'
|
| 243 |
+
print(f'* Larking "{content}"...')
|
| 244 |
+
lark(content)
|
| 245 |
+
|
| 246 |
+
if args.length_stats:
|
| 247 |
+
file = args.length_stats[0]
|
| 248 |
+
print(f'* Working on {file} lengths statistics...')
|
| 249 |
+
LengthStats(file)
|
src/er_client/doc_retrieval_by_api.py
ADDED
|
@@ -0,0 +1,44 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# -*- coding: utf-8 -*-
|
| 2 |
+
|
| 3 |
+
'''
|
| 4 |
+
@Author : Jiangjie Chen
|
| 5 |
+
@Time : 2020/11/12 21:19
|
| 6 |
+
@Contact : jjchen19@fudan.edu.cn
|
| 7 |
+
@Description:
|
| 8 |
+
'''
|
| 9 |
+
|
| 10 |
+
import wikipediaapi
|
| 11 |
+
import nltk
|
| 12 |
+
from nltk.tokenize import sent_tokenize
|
| 13 |
+
nltk.download('punkt')
|
| 14 |
+
try:
|
| 15 |
+
from entitylinker import ELClient
|
| 16 |
+
except:
|
| 17 |
+
from .entitylinker import ELClient
|
| 18 |
+
|
| 19 |
+
|
| 20 |
+
class DocRetrieval:
|
| 21 |
+
def __init__(self, link_type):
|
| 22 |
+
self.wiki = wikipediaapi.Wikipedia('en')
|
| 23 |
+
self.er_client = ELClient(link_type, verbose=True)
|
| 24 |
+
|
| 25 |
+
def _get_page(self, title):
|
| 26 |
+
summary = self.wiki.page(title).summary
|
| 27 |
+
sents = []
|
| 28 |
+
for i, sent in enumerate(sent_tokenize(summary)):
|
| 29 |
+
sents.append((title, i, sent, 0))
|
| 30 |
+
return sents
|
| 31 |
+
|
| 32 |
+
def retrieve_docs(self, claim):
|
| 33 |
+
el_results = self.er_client.link(claim)
|
| 34 |
+
sents = []
|
| 35 |
+
for text, label, kb_id, title in el_results:
|
| 36 |
+
if title == '': continue
|
| 37 |
+
sents += self._get_page(title)
|
| 38 |
+
return sents
|
| 39 |
+
|
| 40 |
+
|
| 41 |
+
if __name__ == '__main__':
|
| 42 |
+
doc = DocRetrieval('tagme')
|
| 43 |
+
print(doc.retrieve_docs('joe biden won the U.S. president.'))
|
| 44 |
+
print(doc.retrieve_docs('Joe Biden won the U.S. president.'))
|
src/er_client/document_retrieval.py
ADDED
|
@@ -0,0 +1,225 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# -*- coding:utf-8 -*-
|
| 2 |
+
|
| 3 |
+
"""
|
| 4 |
+
@Author : Bao
|
| 5 |
+
@Date : 2020/9/17
|
| 6 |
+
@Desc : Document selection and sentence ranking code from KGAT. Not used in LOREN.
|
| 7 |
+
@Last modified by : Bao
|
| 8 |
+
@Last modified date : 2020/9/17
|
| 9 |
+
"""
|
| 10 |
+
|
| 11 |
+
import re
|
| 12 |
+
import time
|
| 13 |
+
import json
|
| 14 |
+
import nltk
|
| 15 |
+
from tqdm import tqdm
|
| 16 |
+
from allennlp.predictors import Predictor
|
| 17 |
+
from drqa.retriever import DocDB, utils
|
| 18 |
+
from drqa.retriever.utils import normalize
|
| 19 |
+
import wikipedia
|
| 20 |
+
|
| 21 |
+
|
| 22 |
+
class FeverDocDB(DocDB):
|
| 23 |
+
def __init__(self, path=None):
|
| 24 |
+
super().__init__(path)
|
| 25 |
+
|
| 26 |
+
def get_doc_lines(self, doc_id):
|
| 27 |
+
"""Fetch the raw text of the doc for 'doc_id'."""
|
| 28 |
+
cursor = self.connection.cursor()
|
| 29 |
+
cursor.execute(
|
| 30 |
+
"SELECT lines FROM documents WHERE id = ?",
|
| 31 |
+
(utils.normalize(doc_id),)
|
| 32 |
+
)
|
| 33 |
+
result = cursor.fetchone()
|
| 34 |
+
cursor.close()
|
| 35 |
+
|
| 36 |
+
result = result[0] if result is not None else ''
|
| 37 |
+
doc_lines = []
|
| 38 |
+
for line in result.split('\n'):
|
| 39 |
+
if len(line) == 0: continue
|
| 40 |
+
line = line.split('\t')[1]
|
| 41 |
+
if len(line) == 0: continue
|
| 42 |
+
doc_lines.append((doc_id, len(doc_lines), line, 0))
|
| 43 |
+
|
| 44 |
+
return doc_lines
|
| 45 |
+
|
| 46 |
+
def get_non_empty_doc_ids(self):
|
| 47 |
+
"""Fetch all ids of docs stored in the db."""
|
| 48 |
+
cursor = self.connection.cursor()
|
| 49 |
+
cursor.execute("SELECT id FROM documents WHERE length(trim(text)) > 0")
|
| 50 |
+
results = [r[0] for r in cursor.fetchall()]
|
| 51 |
+
cursor.close()
|
| 52 |
+
return results
|
| 53 |
+
|
| 54 |
+
|
| 55 |
+
class DocRetrieval:
|
| 56 |
+
def __init__(self, database_path, add_claim=False, k_wiki_results=None):
|
| 57 |
+
self.db = FeverDocDB(database_path)
|
| 58 |
+
self.add_claim = add_claim
|
| 59 |
+
self.k_wiki_results = k_wiki_results
|
| 60 |
+
self.porter_stemmer = nltk.PorterStemmer()
|
| 61 |
+
self.tokenizer = nltk.word_tokenize
|
| 62 |
+
self.predictor = Predictor.from_path(
|
| 63 |
+
"https://storage.googleapis.com/allennlp-public-models/elmo-constituency-parser-2020.02.10.tar.gz"
|
| 64 |
+
)
|
| 65 |
+
|
| 66 |
+
def get_NP(self, tree, nps):
|
| 67 |
+
if isinstance(tree, dict):
|
| 68 |
+
if "children" not in tree:
|
| 69 |
+
if tree['nodeType'] == "NP":
|
| 70 |
+
# print(tree['word'])
|
| 71 |
+
# print(tree)
|
| 72 |
+
nps.append(tree['word'])
|
| 73 |
+
elif "children" in tree:
|
| 74 |
+
if tree['nodeType'] == "NP":
|
| 75 |
+
# print(tree['word'])
|
| 76 |
+
nps.append(tree['word'])
|
| 77 |
+
self.get_NP(tree['children'], nps)
|
| 78 |
+
else:
|
| 79 |
+
self.get_NP(tree['children'], nps)
|
| 80 |
+
elif isinstance(tree, list):
|
| 81 |
+
for sub_tree in tree:
|
| 82 |
+
self.get_NP(sub_tree, nps)
|
| 83 |
+
|
| 84 |
+
return nps
|
| 85 |
+
|
| 86 |
+
def get_subjects(self, tree):
|
| 87 |
+
subject_words = []
|
| 88 |
+
subjects = []
|
| 89 |
+
for subtree in tree['children']:
|
| 90 |
+
if subtree['nodeType'] == "VP" or subtree['nodeType'] == 'S' or subtree['nodeType'] == 'VBZ':
|
| 91 |
+
subjects.append(' '.join(subject_words))
|
| 92 |
+
subject_words.append(subtree['word'])
|
| 93 |
+
else:
|
| 94 |
+
subject_words.append(subtree['word'])
|
| 95 |
+
return subjects
|
| 96 |
+
|
| 97 |
+
def get_noun_phrases(self, claim):
|
| 98 |
+
tokens = self.predictor.predict(claim)
|
| 99 |
+
nps = []
|
| 100 |
+
tree = tokens['hierplane_tree']['root']
|
| 101 |
+
noun_phrases = self.get_NP(tree, nps)
|
| 102 |
+
subjects = self.get_subjects(tree)
|
| 103 |
+
for subject in subjects:
|
| 104 |
+
if len(subject) > 0:
|
| 105 |
+
noun_phrases.append(subject)
|
| 106 |
+
if self.add_claim:
|
| 107 |
+
noun_phrases.append(claim)
|
| 108 |
+
return list(set(noun_phrases))
|
| 109 |
+
|
| 110 |
+
def get_doc_for_claim(self, noun_phrases):
|
| 111 |
+
predicted_pages = []
|
| 112 |
+
for np in noun_phrases:
|
| 113 |
+
if len(np) > 300:
|
| 114 |
+
continue
|
| 115 |
+
i = 1
|
| 116 |
+
while i < 12:
|
| 117 |
+
try:
|
| 118 |
+
# print(np)
|
| 119 |
+
# res = server.lookup(np, keep_all=True)
|
| 120 |
+
# docs = [y for _, y in res] if res is not None else []
|
| 121 |
+
docs = wikipedia.search(np)
|
| 122 |
+
if self.k_wiki_results is not None:
|
| 123 |
+
predicted_pages.extend(docs[:self.k_wiki_results])
|
| 124 |
+
else:
|
| 125 |
+
predicted_pages.extend(docs)
|
| 126 |
+
except (ConnectionResetError, ConnectionError, ConnectionAbortedError, ConnectionRefusedError):
|
| 127 |
+
print("Connection reset error received! Trial #" + str(i))
|
| 128 |
+
time.sleep(600 * i)
|
| 129 |
+
i += 1
|
| 130 |
+
else:
|
| 131 |
+
break
|
| 132 |
+
|
| 133 |
+
# sleep_num = random.uniform(0.1,0.7)
|
| 134 |
+
# time.sleep(sleep_num)
|
| 135 |
+
predicted_pages = set(predicted_pages)
|
| 136 |
+
processed_pages = []
|
| 137 |
+
for page in predicted_pages:
|
| 138 |
+
page = page.replace(" ", "_")
|
| 139 |
+
page = page.replace("(", "-LRB-")
|
| 140 |
+
page = page.replace(")", "-RRB-")
|
| 141 |
+
page = page.replace(":", "-COLON-")
|
| 142 |
+
processed_pages.append(page)
|
| 143 |
+
|
| 144 |
+
return processed_pages
|
| 145 |
+
|
| 146 |
+
def np_conc(self, noun_phrases):
|
| 147 |
+
noun_phrases = set(noun_phrases)
|
| 148 |
+
predicted_pages = []
|
| 149 |
+
for np in noun_phrases:
|
| 150 |
+
page = np.replace('( ', '-LRB-')
|
| 151 |
+
page = page.replace(' )', '-RRB-')
|
| 152 |
+
page = page.replace(' - ', '-')
|
| 153 |
+
page = page.replace(' :', '-COLON-')
|
| 154 |
+
page = page.replace(' ,', ',')
|
| 155 |
+
page = page.replace(" 's", "'s")
|
| 156 |
+
page = page.replace(' ', '_')
|
| 157 |
+
|
| 158 |
+
if len(page) < 1:
|
| 159 |
+
continue
|
| 160 |
+
doc_lines = self.db.get_doc_lines(page)
|
| 161 |
+
if len(doc_lines) > 0:
|
| 162 |
+
predicted_pages.append(page)
|
| 163 |
+
return predicted_pages
|
| 164 |
+
|
| 165 |
+
def exact_match(self, claim):
|
| 166 |
+
noun_phrases = self.get_noun_phrases(claim)
|
| 167 |
+
wiki_results = self.get_doc_for_claim(noun_phrases)
|
| 168 |
+
wiki_results = list(set(wiki_results))
|
| 169 |
+
|
| 170 |
+
claim = claim.replace(".", "")
|
| 171 |
+
claim = claim.replace("-", " ")
|
| 172 |
+
words = [self.porter_stemmer.stem(word.lower()) for word in self.tokenizer(claim)]
|
| 173 |
+
words = set(words)
|
| 174 |
+
predicted_pages = self.np_conc(noun_phrases)
|
| 175 |
+
|
| 176 |
+
for page in wiki_results:
|
| 177 |
+
page = normalize(page)
|
| 178 |
+
processed_page = re.sub("-LRB-.*?-RRB-", "", page)
|
| 179 |
+
processed_page = re.sub("_", " ", processed_page)
|
| 180 |
+
processed_page = re.sub("-COLON-", ":", processed_page)
|
| 181 |
+
processed_page = processed_page.replace("-", " ")
|
| 182 |
+
processed_page = processed_page.replace("–", " ")
|
| 183 |
+
processed_page = processed_page.replace(".", "")
|
| 184 |
+
page_words = [self.porter_stemmer.stem(word.lower()) for word in self.tokenizer(processed_page) if
|
| 185 |
+
len(word) > 0]
|
| 186 |
+
|
| 187 |
+
if all([item in words for item in page_words]):
|
| 188 |
+
if ':' in page:
|
| 189 |
+
page = page.replace(":", "-COLON-")
|
| 190 |
+
predicted_pages.append(page)
|
| 191 |
+
predicted_pages = list(set(predicted_pages))
|
| 192 |
+
|
| 193 |
+
return noun_phrases, wiki_results, predicted_pages
|
| 194 |
+
|
| 195 |
+
|
| 196 |
+
def save_to_file(results, client, filename):
|
| 197 |
+
with open(filename, 'w', encoding='utf-8') as fout:
|
| 198 |
+
for _id, line in enumerate(results):
|
| 199 |
+
claim = line['claim']
|
| 200 |
+
evidence = []
|
| 201 |
+
for page in line['predicted_pages']:
|
| 202 |
+
evidence.extend(client.db.get_doc_lines(page))
|
| 203 |
+
print(json.dumps({'claim': claim, 'evidence': evidence}, ensure_ascii=False), file=fout)
|
| 204 |
+
|
| 205 |
+
|
| 206 |
+
if __name__ == '__main__':
|
| 207 |
+
database_path = 'data/fever.db'
|
| 208 |
+
add_claim = True
|
| 209 |
+
k_wiki_results = 7
|
| 210 |
+
client = DocRetrieval(database_path, add_claim, k_wiki_results)
|
| 211 |
+
|
| 212 |
+
results = []
|
| 213 |
+
with open('data/claims.json', 'r', encoding='utf-8') as fin:
|
| 214 |
+
for line in tqdm(fin):
|
| 215 |
+
line = json.loads(line)
|
| 216 |
+
_, _, predicted_pages = client.exact_match(line['claim'])
|
| 217 |
+
evidence = []
|
| 218 |
+
for page in predicted_pages:
|
| 219 |
+
evidence.extend(client.db.get_doc_lines(page))
|
| 220 |
+
line['evidence'] = evidence
|
| 221 |
+
results.append(line)
|
| 222 |
+
|
| 223 |
+
with open('data/pages.json', 'w', encoding='utf-8') as fout:
|
| 224 |
+
for line in results:
|
| 225 |
+
print(json.dumps(line, ensure_ascii=False), file=fout)
|
src/er_client/entitylinker.py
ADDED
|
@@ -0,0 +1,84 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# -*- coding: utf-8 -*-
|
| 2 |
+
|
| 3 |
+
'''
|
| 4 |
+
@Author : Jiangjie Chen
|
| 5 |
+
@Time : 2020/5/11 19:08
|
| 6 |
+
@Contact : jjchen19@fudan.edu.cn
|
| 7 |
+
@Description:
|
| 8 |
+
'''
|
| 9 |
+
|
| 10 |
+
import os
|
| 11 |
+
import tagme
|
| 12 |
+
|
| 13 |
+
|
| 14 |
+
def read_title_id(entity_def_path):
|
| 15 |
+
id_to_title = {}
|
| 16 |
+
with open(entity_def_path, 'r', encoding='UTF-8') as f:
|
| 17 |
+
lines = f.readlines()
|
| 18 |
+
for i, line in enumerate(lines):
|
| 19 |
+
if i > 0:
|
| 20 |
+
entity, id = line.strip().split('|')
|
| 21 |
+
id_to_title[id] = entity
|
| 22 |
+
|
| 23 |
+
return id_to_title
|
| 24 |
+
|
| 25 |
+
|
| 26 |
+
class ELClient:
|
| 27 |
+
def __init__(self, link_type, min_rho=0.1, prefix=None, verbose=False):
|
| 28 |
+
self.verbose = verbose
|
| 29 |
+
self.link_type = link_type
|
| 30 |
+
if link_type == 'tagme':
|
| 31 |
+
self.min_rho = min_rho
|
| 32 |
+
tagme.GCUBE_TOKEN = os.environ['TAGME_APIKEY']
|
| 33 |
+
elif link_type == 'spacy':
|
| 34 |
+
assert prefix is not None
|
| 35 |
+
self.init_spacy_linker(prefix)
|
| 36 |
+
else:
|
| 37 |
+
raise NotImplementedError(link_type)
|
| 38 |
+
|
| 39 |
+
def init_spacy_linker(self, prefix):
|
| 40 |
+
entity_def_path = f"{prefix}/entity_defs.csv"
|
| 41 |
+
self._print('* Loading entity linker...')
|
| 42 |
+
self.nlp = spacy.load(prefix)
|
| 43 |
+
self.id2title = read_title_id(entity_def_path)
|
| 44 |
+
self._print('* Entity linker loaded.')
|
| 45 |
+
|
| 46 |
+
def _tagme_link(self, text):
|
| 47 |
+
result = []
|
| 48 |
+
for ann in tagme.annotate(text, long_text=1).get_annotations(min_rho=self.min_rho):
|
| 49 |
+
result.append((text[ann.begin:ann.end], ann.score, ann.entity_id, ann.entity_title))
|
| 50 |
+
# result.append({'begin': ann.begin,
|
| 51 |
+
# 'end': ann.end,
|
| 52 |
+
# 'id': ann.entity_id,
|
| 53 |
+
# 'title': ann.entity_title,
|
| 54 |
+
# 'score': ann.score})
|
| 55 |
+
result.sort(key=lambda x: x[1], reverse=True)
|
| 56 |
+
return result
|
| 57 |
+
|
| 58 |
+
def link(self, text):
|
| 59 |
+
if self.link_type == 'tagme':
|
| 60 |
+
return self._tagme_link(text)
|
| 61 |
+
else:
|
| 62 |
+
return self._spacy_link(text)
|
| 63 |
+
|
| 64 |
+
def _spacy_link(self, text):
|
| 65 |
+
text = self._preprocess_text(text)
|
| 66 |
+
doc = self.nlp(text)
|
| 67 |
+
ents = [(e.text, e.label_, e.kb_id_, self.id2title.get(e.kb_id_, ''))
|
| 68 |
+
for e in doc.ents if e.kb_id_ != 'NIL']
|
| 69 |
+
return ents
|
| 70 |
+
|
| 71 |
+
def _preprocess_text(self, text):
|
| 72 |
+
if isinstance(text, list):
|
| 73 |
+
text = ' '.join(text)
|
| 74 |
+
text = text.strip().replace('-lrb-', '(').replace('-rrb-', ')')
|
| 75 |
+
return text
|
| 76 |
+
|
| 77 |
+
def _print(self, x):
|
| 78 |
+
if self.verbose: print(x)
|
| 79 |
+
|
| 80 |
+
|
| 81 |
+
if __name__ == '__main__':
|
| 82 |
+
elcl = ELClient(link_type='tagme', verbose=True)
|
| 83 |
+
res = elcl.link('Jeff Dean wants to meet Yoshua Bengio.')
|
| 84 |
+
print(res)
|
src/er_client/retrieval_model/bert_model.py
ADDED
|
@@ -0,0 +1,775 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# coding=utf-8
|
| 2 |
+
# Copyright 2018 The Google AI Language Team Authors and The HugginFace Inc. team.
|
| 3 |
+
# Copyright (c) 2018, NVIDIA CORPORATION. All rights reserved.
|
| 4 |
+
#
|
| 5 |
+
# Licensed under the Apache License, Version 2.0 (the "License");
|
| 6 |
+
# you may not use this file except in compliance with the License.
|
| 7 |
+
# You may obtain a copy of the License at
|
| 8 |
+
#
|
| 9 |
+
# http://www.apache.org/licenses/LICENSE-2.0
|
| 10 |
+
#
|
| 11 |
+
# Unless required by applicable law or agreed to in writing, software
|
| 12 |
+
# distributed under the License is distributed on an "AS IS" BASIS,
|
| 13 |
+
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
| 14 |
+
# See the License for the specific language governing permissions and
|
| 15 |
+
# limitations under the License.
|
| 16 |
+
"""PyTorch BERT model."""
|
| 17 |
+
|
| 18 |
+
from __future__ import absolute_import, division, print_function, unicode_literals
|
| 19 |
+
|
| 20 |
+
import copy
|
| 21 |
+
import json
|
| 22 |
+
import logging
|
| 23 |
+
import math
|
| 24 |
+
import os
|
| 25 |
+
import shutil
|
| 26 |
+
import tarfile
|
| 27 |
+
import tempfile
|
| 28 |
+
import sys
|
| 29 |
+
from io import open
|
| 30 |
+
|
| 31 |
+
import torch
|
| 32 |
+
from torch import nn
|
| 33 |
+
from torch.nn import CrossEntropyLoss
|
| 34 |
+
|
| 35 |
+
from .file_utils import cached_path
|
| 36 |
+
|
| 37 |
+
logger = logging.getLogger(__name__)
|
| 38 |
+
|
| 39 |
+
PRETRAINED_MODEL_ARCHIVE_MAP = {
|
| 40 |
+
'bert-base-uncased': "https://s3.amazonaws.com/models.huggingface.co/bert/bert-base-uncased.tar.gz",
|
| 41 |
+
'bert-large-uncased': "https://s3.amazonaws.com/models.huggingface.co/bert/bert-large-uncased.tar.gz",
|
| 42 |
+
'bert-base-cased': "https://s3.amazonaws.com/models.huggingface.co/bert/bert-base-cased.tar.gz",
|
| 43 |
+
'bert-large-cased': "https://s3.amazonaws.com/models.huggingface.co/bert/bert-large-cased.tar.gz",
|
| 44 |
+
'bert-base-multilingual-uncased': "https://s3.amazonaws.com/models.huggingface.co/bert/bert-base-multilingual-uncased.tar.gz",
|
| 45 |
+
'bert-base-multilingual-cased': "https://s3.amazonaws.com/models.huggingface.co/bert/bert-base-multilingual-cased.tar.gz",
|
| 46 |
+
'bert-base-chinese': "https://s3.amazonaws.com/models.huggingface.co/bert/bert-base-chinese.tar.gz",
|
| 47 |
+
}
|
| 48 |
+
CONFIG_NAME = 'bert_config.json'
|
| 49 |
+
WEIGHTS_NAME = 'pytorch_model.bin'
|
| 50 |
+
TF_WEIGHTS_NAME = 'model.ckpt'
|
| 51 |
+
|
| 52 |
+
def load_tf_weights_in_bert(model, tf_checkpoint_path):
|
| 53 |
+
""" Load tf checkpoints in a pytorch model
|
| 54 |
+
"""
|
| 55 |
+
try:
|
| 56 |
+
import re
|
| 57 |
+
import numpy as np
|
| 58 |
+
import tensorflow as tf
|
| 59 |
+
except ImportError:
|
| 60 |
+
print("Loading a TensorFlow models in PyTorch, requires TensorFlow to be installed. Please see "
|
| 61 |
+
"https://www.tensorflow.org/install/ for installation instructions.")
|
| 62 |
+
raise
|
| 63 |
+
tf_path = os.path.abspath(tf_checkpoint_path)
|
| 64 |
+
print("Converting TensorFlow checkpoint from {}".format(tf_path))
|
| 65 |
+
# Load weights from TF model
|
| 66 |
+
init_vars = tf.train.list_variables(tf_path)
|
| 67 |
+
names = []
|
| 68 |
+
arrays = []
|
| 69 |
+
for name, shape in init_vars:
|
| 70 |
+
print("Loading TF weight {} with shape {}".format(name, shape))
|
| 71 |
+
array = tf.train.load_variable(tf_path, name)
|
| 72 |
+
names.append(name)
|
| 73 |
+
arrays.append(array)
|
| 74 |
+
|
| 75 |
+
for name, array in zip(names, arrays):
|
| 76 |
+
name = name.split('/')
|
| 77 |
+
# adam_v and adam_m are variables used in AdamWeightDecayOptimizer to calculated m and v
|
| 78 |
+
# which are not required for using pretrained model
|
| 79 |
+
if any(n in ["adam_v", "adam_m"] for n in name):
|
| 80 |
+
print("Skipping {}".format("/".join(name)))
|
| 81 |
+
continue
|
| 82 |
+
pointer = model
|
| 83 |
+
for m_name in name:
|
| 84 |
+
if re.fullmatch(r'[A-Za-z]+_\d+', m_name):
|
| 85 |
+
l = re.split(r'_(\d+)', m_name)
|
| 86 |
+
else:
|
| 87 |
+
l = [m_name]
|
| 88 |
+
if l[0] == 'kernel' or l[0] == 'gamma':
|
| 89 |
+
pointer = getattr(pointer, 'weight')
|
| 90 |
+
elif l[0] == 'output_bias' or l[0] == 'beta':
|
| 91 |
+
pointer = getattr(pointer, 'bias')
|
| 92 |
+
elif l[0] == 'output_weights':
|
| 93 |
+
pointer = getattr(pointer, 'weight')
|
| 94 |
+
else:
|
| 95 |
+
pointer = getattr(pointer, l[0])
|
| 96 |
+
if len(l) >= 2:
|
| 97 |
+
num = int(l[1])
|
| 98 |
+
pointer = pointer[num]
|
| 99 |
+
if m_name[-11:] == '_embeddings':
|
| 100 |
+
pointer = getattr(pointer, 'weight')
|
| 101 |
+
elif m_name == 'kernel':
|
| 102 |
+
array = np.transpose(array)
|
| 103 |
+
try:
|
| 104 |
+
assert pointer.shape == array.shape
|
| 105 |
+
except AssertionError as e:
|
| 106 |
+
e.args += (pointer.shape, array.shape)
|
| 107 |
+
raise
|
| 108 |
+
print("Initialize PyTorch weight {}".format(name))
|
| 109 |
+
pointer.data = torch.from_numpy(array)
|
| 110 |
+
return model
|
| 111 |
+
|
| 112 |
+
|
| 113 |
+
def gelu(x):
|
| 114 |
+
"""Implementation of the gelu activation function.
|
| 115 |
+
For information: OpenAI GPT's gelu is slightly different (and gives slightly different results):
|
| 116 |
+
0.5 * x * (1 + torch.tanh(math.sqrt(2 / math.pi) * (x + 0.044715 * torch.pow(x, 3))))
|
| 117 |
+
Also see https://arxiv.org/abs/1606.08415
|
| 118 |
+
"""
|
| 119 |
+
return x * 0.5 * (1.0 + torch.erf(x / math.sqrt(2.0)))
|
| 120 |
+
|
| 121 |
+
|
| 122 |
+
def swish(x):
|
| 123 |
+
return x * torch.sigmoid(x)
|
| 124 |
+
|
| 125 |
+
|
| 126 |
+
ACT2FN = {"gelu": gelu, "relu": torch.nn.functional.relu, "swish": swish}
|
| 127 |
+
|
| 128 |
+
|
| 129 |
+
class BertConfig(object):
|
| 130 |
+
"""Configuration class to store the configuration of a `BertModel`.
|
| 131 |
+
"""
|
| 132 |
+
def __init__(self,
|
| 133 |
+
vocab_size_or_config_json_file,
|
| 134 |
+
hidden_size=768,
|
| 135 |
+
num_hidden_layers=12,
|
| 136 |
+
num_attention_heads=12,
|
| 137 |
+
intermediate_size=3072,
|
| 138 |
+
hidden_act="gelu",
|
| 139 |
+
hidden_dropout_prob=0.1,
|
| 140 |
+
attention_probs_dropout_prob=0.1,
|
| 141 |
+
max_position_embeddings=512,
|
| 142 |
+
type_vocab_size=2,
|
| 143 |
+
initializer_range=0.02):
|
| 144 |
+
"""Constructs BertConfig.
|
| 145 |
+
|
| 146 |
+
Args:
|
| 147 |
+
vocab_size_or_config_json_file: Vocabulary size of `inputs_ids` in `BertModel`.
|
| 148 |
+
hidden_size: Size of the encoder layers and the pooler layer.
|
| 149 |
+
num_hidden_layers: Number of hidden layers in the Transformer encoder.
|
| 150 |
+
num_attention_heads: Number of attention heads for each attention layer in
|
| 151 |
+
the Transformer encoder.
|
| 152 |
+
intermediate_size: The size of the "intermediate" (i.e., feed-forward)
|
| 153 |
+
layer in the Transformer encoder.
|
| 154 |
+
hidden_act: The non-linear activation function (function or string) in the
|
| 155 |
+
encoder and pooler. If string, "gelu", "relu" and "swish" are supported.
|
| 156 |
+
hidden_dropout_prob: The dropout probabilitiy for all fully connected
|
| 157 |
+
layers in the embeddings, encoder, and pooler.
|
| 158 |
+
attention_probs_dropout_prob: The dropout ratio for the attention
|
| 159 |
+
probabilities.
|
| 160 |
+
max_position_embeddings: The maximum sequence length that this model might
|
| 161 |
+
ever be used with. Typically set this to something large just in case
|
| 162 |
+
(e.g., 512 or 1024 or 2048).
|
| 163 |
+
type_vocab_size: The vocabulary size of the `token_type_ids` passed into
|
| 164 |
+
`BertModel`.
|
| 165 |
+
initializer_range: The sttdev of the truncated_normal_initializer for
|
| 166 |
+
initializing all weight matrices.
|
| 167 |
+
"""
|
| 168 |
+
if isinstance(vocab_size_or_config_json_file, str) or (sys.version_info[0] == 2
|
| 169 |
+
and isinstance(vocab_size_or_config_json_file, unicode)):
|
| 170 |
+
with open(vocab_size_or_config_json_file, "r", encoding='utf-8') as reader:
|
| 171 |
+
json_config = json.loads(reader.read())
|
| 172 |
+
for key, value in json_config.items():
|
| 173 |
+
self.__dict__[key] = value
|
| 174 |
+
elif isinstance(vocab_size_or_config_json_file, int):
|
| 175 |
+
self.vocab_size = vocab_size_or_config_json_file
|
| 176 |
+
self.hidden_size = hidden_size
|
| 177 |
+
self.num_hidden_layers = num_hidden_layers
|
| 178 |
+
self.num_attention_heads = num_attention_heads
|
| 179 |
+
self.hidden_act = hidden_act
|
| 180 |
+
self.intermediate_size = intermediate_size
|
| 181 |
+
self.hidden_dropout_prob = hidden_dropout_prob
|
| 182 |
+
self.attention_probs_dropout_prob = attention_probs_dropout_prob
|
| 183 |
+
self.max_position_embeddings = max_position_embeddings
|
| 184 |
+
self.type_vocab_size = type_vocab_size
|
| 185 |
+
self.initializer_range = initializer_range
|
| 186 |
+
else:
|
| 187 |
+
raise ValueError("First argument must be either a vocabulary size (int)"
|
| 188 |
+
"or the path to a pretrained model config file (str)")
|
| 189 |
+
|
| 190 |
+
@classmethod
|
| 191 |
+
def from_dict(cls, json_object):
|
| 192 |
+
"""Constructs a `BertConfig` from a Python dictionary of parameters."""
|
| 193 |
+
config = BertConfig(vocab_size_or_config_json_file=-1)
|
| 194 |
+
for key, value in json_object.items():
|
| 195 |
+
config.__dict__[key] = value
|
| 196 |
+
return config
|
| 197 |
+
|
| 198 |
+
@classmethod
|
| 199 |
+
def from_json_file(cls, json_file):
|
| 200 |
+
"""Constructs a `BertConfig` from a json file of parameters."""
|
| 201 |
+
with open(json_file, "r", encoding='utf-8') as reader:
|
| 202 |
+
text = reader.read()
|
| 203 |
+
return cls.from_dict(json.loads(text))
|
| 204 |
+
|
| 205 |
+
def __repr__(self):
|
| 206 |
+
return str(self.to_json_string())
|
| 207 |
+
|
| 208 |
+
def to_dict(self):
|
| 209 |
+
"""Serializes this instance to a Python dictionary."""
|
| 210 |
+
output = copy.deepcopy(self.__dict__)
|
| 211 |
+
return output
|
| 212 |
+
|
| 213 |
+
def to_json_string(self):
|
| 214 |
+
"""Serializes this instance to a JSON string."""
|
| 215 |
+
return json.dumps(self.to_dict(), indent=2, sort_keys=True) + "\n"
|
| 216 |
+
|
| 217 |
+
try:
|
| 218 |
+
from apex.normalization.fused_layer_norm import FusedLayerNorm as BertLayerNorm
|
| 219 |
+
except ImportError:
|
| 220 |
+
print("Better speed can be achieved with apex installed from https://www.github.com/nvidia/apex.")
|
| 221 |
+
class BertLayerNorm(nn.Module):
|
| 222 |
+
def __init__(self, hidden_size, eps=1e-12):
|
| 223 |
+
"""Construct a layernorm module in the TF style (epsilon inside the square root).
|
| 224 |
+
"""
|
| 225 |
+
super(BertLayerNorm, self).__init__()
|
| 226 |
+
self.weight = nn.Parameter(torch.ones(hidden_size))
|
| 227 |
+
self.bias = nn.Parameter(torch.zeros(hidden_size))
|
| 228 |
+
self.variance_epsilon = eps
|
| 229 |
+
|
| 230 |
+
def forward(self, x):
|
| 231 |
+
u = x.mean(-1, keepdim=True)
|
| 232 |
+
s = (x - u).pow(2).mean(-1, keepdim=True)
|
| 233 |
+
x = (x - u) / torch.sqrt(s + self.variance_epsilon)
|
| 234 |
+
return self.weight * x + self.bias
|
| 235 |
+
|
| 236 |
+
class BertEmbeddings(nn.Module):
|
| 237 |
+
"""Construct the embeddings from word, position and token_type embeddings.
|
| 238 |
+
"""
|
| 239 |
+
def __init__(self, config):
|
| 240 |
+
super(BertEmbeddings, self).__init__()
|
| 241 |
+
self.word_embeddings = nn.Embedding(config.vocab_size, config.hidden_size)
|
| 242 |
+
self.position_embeddings = nn.Embedding(config.max_position_embeddings, config.hidden_size)
|
| 243 |
+
self.token_type_embeddings = nn.Embedding(config.type_vocab_size, config.hidden_size)
|
| 244 |
+
|
| 245 |
+
# self.LayerNorm is not snake-cased to stick with TensorFlow model variable name and be able to load
|
| 246 |
+
# any TensorFlow checkpoint file
|
| 247 |
+
self.LayerNorm = BertLayerNorm(config.hidden_size, eps=1e-12)
|
| 248 |
+
self.dropout = nn.Dropout(config.hidden_dropout_prob)
|
| 249 |
+
|
| 250 |
+
def forward(self, input_ids, token_type_ids=None):
|
| 251 |
+
seq_length = input_ids.size(1)
|
| 252 |
+
position_ids = torch.arange(seq_length, dtype=torch.long, device=input_ids.device)
|
| 253 |
+
position_ids = position_ids.unsqueeze(0).expand_as(input_ids)
|
| 254 |
+
if token_type_ids is None:
|
| 255 |
+
token_type_ids = torch.zeros_like(input_ids)
|
| 256 |
+
|
| 257 |
+
words_embeddings = self.word_embeddings(input_ids)
|
| 258 |
+
position_embeddings = self.position_embeddings(position_ids)
|
| 259 |
+
token_type_embeddings = self.token_type_embeddings(token_type_ids)
|
| 260 |
+
|
| 261 |
+
embeddings = words_embeddings + position_embeddings + token_type_embeddings
|
| 262 |
+
embeddings = self.LayerNorm(embeddings)
|
| 263 |
+
embeddings = self.dropout(embeddings)
|
| 264 |
+
return embeddings
|
| 265 |
+
|
| 266 |
+
|
| 267 |
+
class BertSelfAttention(nn.Module):
|
| 268 |
+
def __init__(self, config):
|
| 269 |
+
super(BertSelfAttention, self).__init__()
|
| 270 |
+
if config.hidden_size % config.num_attention_heads != 0:
|
| 271 |
+
raise ValueError(
|
| 272 |
+
"The hidden size (%d) is not a multiple of the number of attention "
|
| 273 |
+
"heads (%d)" % (config.hidden_size, config.num_attention_heads))
|
| 274 |
+
self.num_attention_heads = config.num_attention_heads
|
| 275 |
+
self.attention_head_size = int(config.hidden_size / config.num_attention_heads)
|
| 276 |
+
self.all_head_size = self.num_attention_heads * self.attention_head_size
|
| 277 |
+
|
| 278 |
+
self.query = nn.Linear(config.hidden_size, self.all_head_size)
|
| 279 |
+
self.key = nn.Linear(config.hidden_size, self.all_head_size)
|
| 280 |
+
self.value = nn.Linear(config.hidden_size, self.all_head_size)
|
| 281 |
+
|
| 282 |
+
self.dropout = nn.Dropout(config.attention_probs_dropout_prob)
|
| 283 |
+
|
| 284 |
+
def transpose_for_scores(self, x):
|
| 285 |
+
new_x_shape = x.size()[:-1] + (self.num_attention_heads, self.attention_head_size)
|
| 286 |
+
x = x.view(*new_x_shape)
|
| 287 |
+
return x.permute(0, 2, 1, 3)
|
| 288 |
+
|
| 289 |
+
def forward(self, hidden_states, attention_mask):
|
| 290 |
+
mixed_query_layer = self.query(hidden_states)
|
| 291 |
+
mixed_key_layer = self.key(hidden_states)
|
| 292 |
+
mixed_value_layer = self.value(hidden_states)
|
| 293 |
+
|
| 294 |
+
query_layer = self.transpose_for_scores(mixed_query_layer)
|
| 295 |
+
key_layer = self.transpose_for_scores(mixed_key_layer)
|
| 296 |
+
value_layer = self.transpose_for_scores(mixed_value_layer)
|
| 297 |
+
|
| 298 |
+
# Take the dot product between "query" and "key" to get the raw attention scores.
|
| 299 |
+
attention_scores = torch.matmul(query_layer, key_layer.transpose(-1, -2))
|
| 300 |
+
attention_scores = attention_scores / math.sqrt(self.attention_head_size)
|
| 301 |
+
# Apply the attention mask is (precomputed for all layers in BertModel forward() function)
|
| 302 |
+
attention_scores = attention_scores + attention_mask
|
| 303 |
+
|
| 304 |
+
# Normalize the attention scores to probabilities.
|
| 305 |
+
attention_probs = nn.Softmax(dim=-1)(attention_scores)
|
| 306 |
+
|
| 307 |
+
# This is actually dropping out entire tokens to attend to, which might
|
| 308 |
+
# seem a bit unusual, but is taken from the original Transformer paper.
|
| 309 |
+
attention_probs = self.dropout(attention_probs)
|
| 310 |
+
|
| 311 |
+
context_layer = torch.matmul(attention_probs, value_layer)
|
| 312 |
+
context_layer = context_layer.permute(0, 2, 1, 3).contiguous()
|
| 313 |
+
new_context_layer_shape = context_layer.size()[:-2] + (self.all_head_size,)
|
| 314 |
+
context_layer = context_layer.view(*new_context_layer_shape)
|
| 315 |
+
return context_layer
|
| 316 |
+
|
| 317 |
+
|
| 318 |
+
class BertSelfOutput(nn.Module):
|
| 319 |
+
def __init__(self, config):
|
| 320 |
+
super(BertSelfOutput, self).__init__()
|
| 321 |
+
self.dense = nn.Linear(config.hidden_size, config.hidden_size)
|
| 322 |
+
self.LayerNorm = BertLayerNorm(config.hidden_size, eps=1e-12)
|
| 323 |
+
self.dropout = nn.Dropout(config.hidden_dropout_prob)
|
| 324 |
+
|
| 325 |
+
def forward(self, hidden_states, input_tensor):
|
| 326 |
+
hidden_states = self.dense(hidden_states)
|
| 327 |
+
hidden_states = self.dropout(hidden_states)
|
| 328 |
+
hidden_states = self.LayerNorm(hidden_states + input_tensor)
|
| 329 |
+
return hidden_states
|
| 330 |
+
|
| 331 |
+
|
| 332 |
+
class BertAttention(nn.Module):
|
| 333 |
+
def __init__(self, config):
|
| 334 |
+
super(BertAttention, self).__init__()
|
| 335 |
+
self.self = BertSelfAttention(config)
|
| 336 |
+
self.output = BertSelfOutput(config)
|
| 337 |
+
|
| 338 |
+
def forward(self, input_tensor, attention_mask):
|
| 339 |
+
self_output = self.self(input_tensor, attention_mask)
|
| 340 |
+
attention_output = self.output(self_output, input_tensor)
|
| 341 |
+
return attention_output
|
| 342 |
+
|
| 343 |
+
|
| 344 |
+
class BertIntermediate(nn.Module):
|
| 345 |
+
def __init__(self, config):
|
| 346 |
+
super(BertIntermediate, self).__init__()
|
| 347 |
+
self.dense = nn.Linear(config.hidden_size, config.intermediate_size)
|
| 348 |
+
if isinstance(config.hidden_act, str) or (sys.version_info[0] == 2 and isinstance(config.hidden_act, unicode)):
|
| 349 |
+
self.intermediate_act_fn = ACT2FN[config.hidden_act]
|
| 350 |
+
else:
|
| 351 |
+
self.intermediate_act_fn = config.hidden_act
|
| 352 |
+
|
| 353 |
+
def forward(self, hidden_states):
|
| 354 |
+
hidden_states = self.dense(hidden_states)
|
| 355 |
+
hidden_states = self.intermediate_act_fn(hidden_states)
|
| 356 |
+
return hidden_states
|
| 357 |
+
|
| 358 |
+
|
| 359 |
+
class BertOutput(nn.Module):
|
| 360 |
+
def __init__(self, config):
|
| 361 |
+
super(BertOutput, self).__init__()
|
| 362 |
+
self.dense = nn.Linear(config.intermediate_size, config.hidden_size)
|
| 363 |
+
self.LayerNorm = BertLayerNorm(config.hidden_size, eps=1e-12)
|
| 364 |
+
self.dropout = nn.Dropout(config.hidden_dropout_prob)
|
| 365 |
+
|
| 366 |
+
def forward(self, hidden_states, input_tensor):
|
| 367 |
+
hidden_states = self.dense(hidden_states)
|
| 368 |
+
hidden_states = self.dropout(hidden_states)
|
| 369 |
+
hidden_states = self.LayerNorm(hidden_states + input_tensor)
|
| 370 |
+
return hidden_states
|
| 371 |
+
|
| 372 |
+
|
| 373 |
+
class BertLayer(nn.Module):
|
| 374 |
+
def __init__(self, config):
|
| 375 |
+
super(BertLayer, self).__init__()
|
| 376 |
+
self.attention = BertAttention(config)
|
| 377 |
+
self.intermediate = BertIntermediate(config)
|
| 378 |
+
self.output = BertOutput(config)
|
| 379 |
+
|
| 380 |
+
def forward(self, hidden_states, attention_mask):
|
| 381 |
+
attention_output = self.attention(hidden_states, attention_mask)
|
| 382 |
+
intermediate_output = self.intermediate(attention_output)
|
| 383 |
+
layer_output = self.output(intermediate_output, attention_output)
|
| 384 |
+
return layer_output
|
| 385 |
+
|
| 386 |
+
|
| 387 |
+
class BertEncoder(nn.Module):
|
| 388 |
+
def __init__(self, config):
|
| 389 |
+
super(BertEncoder, self).__init__()
|
| 390 |
+
layer = BertLayer(config)
|
| 391 |
+
self.layer = nn.ModuleList([copy.deepcopy(layer) for _ in range(config.num_hidden_layers)])
|
| 392 |
+
|
| 393 |
+
def forward(self, hidden_states, attention_mask, output_all_encoded_layers=True):
|
| 394 |
+
all_encoder_layers = []
|
| 395 |
+
for layer_module in self.layer:
|
| 396 |
+
hidden_states = layer_module(hidden_states, attention_mask)
|
| 397 |
+
if output_all_encoded_layers:
|
| 398 |
+
all_encoder_layers.append(hidden_states)
|
| 399 |
+
if not output_all_encoded_layers:
|
| 400 |
+
all_encoder_layers.append(hidden_states)
|
| 401 |
+
return all_encoder_layers
|
| 402 |
+
|
| 403 |
+
|
| 404 |
+
class BertPooler(nn.Module):
|
| 405 |
+
def __init__(self, config):
|
| 406 |
+
super(BertPooler, self).__init__()
|
| 407 |
+
self.dense = nn.Linear(config.hidden_size, config.hidden_size)
|
| 408 |
+
self.activation = nn.Tanh()
|
| 409 |
+
|
| 410 |
+
def forward(self, hidden_states):
|
| 411 |
+
# We "pool" the model by simply taking the hidden state corresponding
|
| 412 |
+
# to the first token.
|
| 413 |
+
first_token_tensor = hidden_states[:, 0]
|
| 414 |
+
pooled_output = self.dense(first_token_tensor)
|
| 415 |
+
pooled_output = self.activation(pooled_output)
|
| 416 |
+
return pooled_output
|
| 417 |
+
|
| 418 |
+
|
| 419 |
+
class BertPredictionHeadTransform(nn.Module):
|
| 420 |
+
def __init__(self, config):
|
| 421 |
+
super(BertPredictionHeadTransform, self).__init__()
|
| 422 |
+
self.dense = nn.Linear(config.hidden_size, config.hidden_size)
|
| 423 |
+
if isinstance(config.hidden_act, str) or (sys.version_info[0] == 2 and isinstance(config.hidden_act, unicode)):
|
| 424 |
+
self.transform_act_fn = ACT2FN[config.hidden_act]
|
| 425 |
+
else:
|
| 426 |
+
self.transform_act_fn = config.hidden_act
|
| 427 |
+
self.LayerNorm = BertLayerNorm(config.hidden_size, eps=1e-12)
|
| 428 |
+
|
| 429 |
+
def forward(self, hidden_states):
|
| 430 |
+
hidden_states = self.dense(hidden_states)
|
| 431 |
+
hidden_states = self.transform_act_fn(hidden_states)
|
| 432 |
+
hidden_states = self.LayerNorm(hidden_states)
|
| 433 |
+
return hidden_states
|
| 434 |
+
|
| 435 |
+
|
| 436 |
+
class BertLMPredictionHead(nn.Module):
|
| 437 |
+
def __init__(self, config, bert_model_embedding_weights):
|
| 438 |
+
super(BertLMPredictionHead, self).__init__()
|
| 439 |
+
self.transform = BertPredictionHeadTransform(config)
|
| 440 |
+
|
| 441 |
+
# The output weights are the same as the input embeddings, but there is
|
| 442 |
+
# an output-only bias for each token.
|
| 443 |
+
self.decoder = nn.Linear(bert_model_embedding_weights.size(1),
|
| 444 |
+
bert_model_embedding_weights.size(0),
|
| 445 |
+
bias=False)
|
| 446 |
+
self.decoder.weight = bert_model_embedding_weights
|
| 447 |
+
self.bias = nn.Parameter(torch.zeros(bert_model_embedding_weights.size(0)))
|
| 448 |
+
|
| 449 |
+
def forward(self, hidden_states):
|
| 450 |
+
hidden_states = self.transform(hidden_states)
|
| 451 |
+
hidden_states = self.decoder(hidden_states) + self.bias
|
| 452 |
+
return hidden_states
|
| 453 |
+
|
| 454 |
+
|
| 455 |
+
class BertOnlyMLMHead(nn.Module):
|
| 456 |
+
def __init__(self, config, bert_model_embedding_weights):
|
| 457 |
+
super(BertOnlyMLMHead, self).__init__()
|
| 458 |
+
self.predictions = BertLMPredictionHead(config, bert_model_embedding_weights)
|
| 459 |
+
|
| 460 |
+
def forward(self, sequence_output):
|
| 461 |
+
prediction_scores = self.predictions(sequence_output)
|
| 462 |
+
return prediction_scores
|
| 463 |
+
|
| 464 |
+
|
| 465 |
+
class BertOnlyNSPHead(nn.Module):
|
| 466 |
+
def __init__(self, config):
|
| 467 |
+
super(BertOnlyNSPHead, self).__init__()
|
| 468 |
+
self.seq_relationship = nn.Linear(config.hidden_size, 2)
|
| 469 |
+
|
| 470 |
+
def forward(self, pooled_output):
|
| 471 |
+
seq_relationship_score = self.seq_relationship(pooled_output)
|
| 472 |
+
return seq_relationship_score
|
| 473 |
+
|
| 474 |
+
|
| 475 |
+
class BertPreTrainingHeads(nn.Module):
|
| 476 |
+
def __init__(self, config, bert_model_embedding_weights):
|
| 477 |
+
super(BertPreTrainingHeads, self).__init__()
|
| 478 |
+
self.predictions = BertLMPredictionHead(config, bert_model_embedding_weights)
|
| 479 |
+
self.seq_relationship = nn.Linear(config.hidden_size, 2)
|
| 480 |
+
|
| 481 |
+
def forward(self, sequence_output, pooled_output):
|
| 482 |
+
prediction_scores = self.predictions(sequence_output)
|
| 483 |
+
seq_relationship_score = self.seq_relationship(pooled_output)
|
| 484 |
+
return prediction_scores, seq_relationship_score
|
| 485 |
+
|
| 486 |
+
|
| 487 |
+
class BertPreTrainedModel(nn.Module):
|
| 488 |
+
""" An abstract class to handle weights initialization and
|
| 489 |
+
a simple interface for dowloading and loading pretrained models.
|
| 490 |
+
"""
|
| 491 |
+
def __init__(self, config, *inputs, **kwargs):
|
| 492 |
+
super(BertPreTrainedModel, self).__init__()
|
| 493 |
+
if not isinstance(config, BertConfig):
|
| 494 |
+
raise ValueError(
|
| 495 |
+
"Parameter config in `{}(config)` should be an instance of class `BertConfig`. "
|
| 496 |
+
"To create a model from a Google pretrained model use "
|
| 497 |
+
"`model = {}.from_pretrained(PRETRAINED_MODEL_NAME)`".format(
|
| 498 |
+
self.__class__.__name__, self.__class__.__name__
|
| 499 |
+
))
|
| 500 |
+
self.config = config
|
| 501 |
+
|
| 502 |
+
def init_bert_weights(self, module):
|
| 503 |
+
""" Initialize the weights.
|
| 504 |
+
"""
|
| 505 |
+
if isinstance(module, (nn.Linear, nn.Embedding)):
|
| 506 |
+
# Slightly different from the TF version which uses truncated_normal for initialization
|
| 507 |
+
# cf https://github.com/pytorch/pytorch/pull/5617
|
| 508 |
+
module.weight.data.normal_(mean=0.0, std=self.config.initializer_range)
|
| 509 |
+
elif isinstance(module, BertLayerNorm):
|
| 510 |
+
module.bias.data.zero_()
|
| 511 |
+
module.weight.data.fill_(1.0)
|
| 512 |
+
if isinstance(module, nn.Linear) and module.bias is not None:
|
| 513 |
+
module.bias.data.zero_()
|
| 514 |
+
|
| 515 |
+
@classmethod
|
| 516 |
+
def from_pretrained(cls, pretrained_model_name_or_path, state_dict=None, cache_dir=None,
|
| 517 |
+
from_tf=False, *inputs, **kwargs):
|
| 518 |
+
"""
|
| 519 |
+
Instantiate a BertPreTrainedModel from a pre-trained model file or a pytorch state dict.
|
| 520 |
+
Download and cache the pre-trained model file if needed.
|
| 521 |
+
|
| 522 |
+
Params:
|
| 523 |
+
pretrained_model_name_or_path: either:
|
| 524 |
+
- a str with the name of a pre-trained model to load selected in the list of:
|
| 525 |
+
. `bert-base-uncased`
|
| 526 |
+
. `bert-large-uncased`
|
| 527 |
+
. `bert-base-cased`
|
| 528 |
+
. `bert-large-cased`
|
| 529 |
+
. `bert-base-multilingual-uncased`
|
| 530 |
+
. `bert-base-multilingual-cased`
|
| 531 |
+
. `bert-base-chinese`
|
| 532 |
+
- a path or url to a pretrained model archive containing:
|
| 533 |
+
. `bert_config.json` a configuration file for the model
|
| 534 |
+
. `pytorch_model.bin` a PyTorch dump of a BertForPreTraining instance
|
| 535 |
+
- a path or url to a pretrained model archive containing:
|
| 536 |
+
. `bert_config.json` a configuration file for the model
|
| 537 |
+
. `model.chkpt` a TensorFlow checkpoint
|
| 538 |
+
from_tf: should we load the weights from a locally saved TensorFlow checkpoint
|
| 539 |
+
cache_dir: an optional path to a folder in which the pre-trained models will be cached.
|
| 540 |
+
state_dict: an optional state dictionnary (collections.OrderedDict object) to use instead of Google pre-trained models
|
| 541 |
+
*inputs, **kwargs: additional input for the specific Bert class
|
| 542 |
+
(ex: num_labels for BertForSequenceClassification)
|
| 543 |
+
"""
|
| 544 |
+
if pretrained_model_name_or_path in PRETRAINED_MODEL_ARCHIVE_MAP:
|
| 545 |
+
archive_file = PRETRAINED_MODEL_ARCHIVE_MAP[pretrained_model_name_or_path]
|
| 546 |
+
else:
|
| 547 |
+
archive_file = pretrained_model_name_or_path
|
| 548 |
+
# redirect to the cache, if necessary
|
| 549 |
+
try:
|
| 550 |
+
resolved_archive_file = cached_path(archive_file, cache_dir=cache_dir)
|
| 551 |
+
except EnvironmentError:
|
| 552 |
+
logger.error(
|
| 553 |
+
"Model name '{}' was not found in model name list ({}). "
|
| 554 |
+
"We assumed '{}' was a path or url but couldn't find any file "
|
| 555 |
+
"associated to this path or url.".format(
|
| 556 |
+
pretrained_model_name_or_path,
|
| 557 |
+
', '.join(PRETRAINED_MODEL_ARCHIVE_MAP.keys()),
|
| 558 |
+
archive_file))
|
| 559 |
+
return None
|
| 560 |
+
if resolved_archive_file == archive_file:
|
| 561 |
+
logger.info("loading archive file {}".format(archive_file))
|
| 562 |
+
else:
|
| 563 |
+
logger.info("loading archive file {} from cache at {}".format(
|
| 564 |
+
archive_file, resolved_archive_file))
|
| 565 |
+
tempdir = None
|
| 566 |
+
if os.path.isdir(resolved_archive_file) or from_tf:
|
| 567 |
+
serialization_dir = resolved_archive_file
|
| 568 |
+
else:
|
| 569 |
+
# Extract archive to temp dir
|
| 570 |
+
tempdir = tempfile.mkdtemp()
|
| 571 |
+
logger.info("extracting archive file {} to temp dir {}".format(
|
| 572 |
+
resolved_archive_file, tempdir))
|
| 573 |
+
with tarfile.open(resolved_archive_file, 'r:gz') as archive:
|
| 574 |
+
archive.extractall(tempdir)
|
| 575 |
+
serialization_dir = tempdir
|
| 576 |
+
# Load config
|
| 577 |
+
config_file = os.path.join(serialization_dir, CONFIG_NAME)
|
| 578 |
+
config = BertConfig.from_json_file(config_file)
|
| 579 |
+
logger.info("Model config {}".format(config))
|
| 580 |
+
# Instantiate model.
|
| 581 |
+
model = cls(config, *inputs, **kwargs)
|
| 582 |
+
if state_dict is None and not from_tf:
|
| 583 |
+
weights_path = os.path.join(serialization_dir, WEIGHTS_NAME)
|
| 584 |
+
state_dict = torch.load(weights_path, map_location='cpu' if not torch.cuda.is_available() else None)
|
| 585 |
+
if tempdir:
|
| 586 |
+
# Clean up temp dir
|
| 587 |
+
shutil.rmtree(tempdir)
|
| 588 |
+
if from_tf:
|
| 589 |
+
# Directly load from a TensorFlow checkpoint
|
| 590 |
+
weights_path = os.path.join(serialization_dir, TF_WEIGHTS_NAME)
|
| 591 |
+
return load_tf_weights_in_bert(model, weights_path)
|
| 592 |
+
# Load from a PyTorch state_dict
|
| 593 |
+
old_keys = []
|
| 594 |
+
new_keys = []
|
| 595 |
+
for key in state_dict.keys():
|
| 596 |
+
new_key = None
|
| 597 |
+
if 'gamma' in key:
|
| 598 |
+
new_key = key.replace('gamma', 'weight')
|
| 599 |
+
if 'beta' in key:
|
| 600 |
+
new_key = key.replace('beta', 'bias')
|
| 601 |
+
if new_key:
|
| 602 |
+
old_keys.append(key)
|
| 603 |
+
new_keys.append(new_key)
|
| 604 |
+
for old_key, new_key in zip(old_keys, new_keys):
|
| 605 |
+
state_dict[new_key] = state_dict.pop(old_key)
|
| 606 |
+
|
| 607 |
+
missing_keys = []
|
| 608 |
+
unexpected_keys = []
|
| 609 |
+
error_msgs = []
|
| 610 |
+
# copy state_dict so _load_from_state_dict can modify it
|
| 611 |
+
metadata = getattr(state_dict, '_metadata', None)
|
| 612 |
+
state_dict = state_dict.copy()
|
| 613 |
+
if metadata is not None:
|
| 614 |
+
state_dict._metadata = metadata
|
| 615 |
+
|
| 616 |
+
def load(module, prefix=''):
|
| 617 |
+
local_metadata = {} if metadata is None else metadata.get(prefix[:-1], {})
|
| 618 |
+
module._load_from_state_dict(
|
| 619 |
+
state_dict, prefix, local_metadata, True, missing_keys, unexpected_keys, error_msgs)
|
| 620 |
+
for name, child in module._modules.items():
|
| 621 |
+
if child is not None:
|
| 622 |
+
load(child, prefix + name + '.')
|
| 623 |
+
start_prefix = ''
|
| 624 |
+
if not hasattr(model, 'bert') and any(s.startswith('bert.') for s in state_dict.keys()):
|
| 625 |
+
start_prefix = 'bert.'
|
| 626 |
+
load(model, prefix=start_prefix)
|
| 627 |
+
if len(missing_keys) > 0:
|
| 628 |
+
logger.info("Weights of {} not initialized from pretrained model: {}".format(
|
| 629 |
+
model.__class__.__name__, missing_keys))
|
| 630 |
+
if len(unexpected_keys) > 0:
|
| 631 |
+
logger.info("Weights from pretrained model not used in {}: {}".format(
|
| 632 |
+
model.__class__.__name__, unexpected_keys))
|
| 633 |
+
if len(error_msgs) > 0:
|
| 634 |
+
raise RuntimeError('Error(s) in loading state_dict for {}:\n\t{}'.format(
|
| 635 |
+
model.__class__.__name__, "\n\t".join(error_msgs)))
|
| 636 |
+
return model
|
| 637 |
+
|
| 638 |
+
|
| 639 |
+
class BertModel(BertPreTrainedModel):
|
| 640 |
+
"""BERT model ("Bidirectional Embedding Representations from a Transformer").
|
| 641 |
+
|
| 642 |
+
Params:
|
| 643 |
+
config: a BertConfig class instance with the configuration to build a new model
|
| 644 |
+
|
| 645 |
+
Inputs:
|
| 646 |
+
`input_ids`: a torch.LongTensor of shape [batch_size, sequence_length]
|
| 647 |
+
with the word token indices in the vocabulary(see the tokens preprocessing logic in the scripts
|
| 648 |
+
`extract_features.py`, `run_classifier.py` and `run_squad.py`)
|
| 649 |
+
`token_type_ids`: an optional torch.LongTensor of shape [batch_size, sequence_length] with the token
|
| 650 |
+
types indices selected in [0, 1]. Type 0 corresponds to a `sentence A` and type 1 corresponds to
|
| 651 |
+
a `sentence B` token (see BERT paper for more details).
|
| 652 |
+
`attention_mask`: an optional torch.LongTensor of shape [batch_size, sequence_length] with indices
|
| 653 |
+
selected in [0, 1]. It's a mask to be used if the input sequence length is smaller than the max
|
| 654 |
+
input sequence length in the current batch. It's the mask that we typically use for attention when
|
| 655 |
+
a batch has varying length sentences.
|
| 656 |
+
`output_all_encoded_layers`: boolean which controls the content of the `encoded_layers` output as described below. Default: `True`.
|
| 657 |
+
|
| 658 |
+
Outputs: Tuple of (encoded_layers, pooled_output)
|
| 659 |
+
`encoded_layers`: controled by `output_all_encoded_layers` argument:
|
| 660 |
+
- `output_all_encoded_layers=True`: output a list of the full sequences of encoded-hidden-states at the end
|
| 661 |
+
of each attention block (i.e. 12 full sequences for BERT-base, 24 for BERT-large), each
|
| 662 |
+
encoded-hidden-state is a torch.FloatTensor of size [batch_size, sequence_length, hidden_size],
|
| 663 |
+
- `output_all_encoded_layers=False`: output only the full sequence of hidden-states corresponding
|
| 664 |
+
to the last attention block of shape [batch_size, sequence_length, hidden_size],
|
| 665 |
+
`pooled_output`: a torch.FloatTensor of size [batch_size, hidden_size] which is the output of a
|
| 666 |
+
classifier pretrained on top of the hidden state associated to the first character of the
|
| 667 |
+
input (`CLS`) to train on the Next-Sentence task (see BERT's paper).
|
| 668 |
+
|
| 669 |
+
Example usage:
|
| 670 |
+
```python
|
| 671 |
+
# Already been converted into WordPiece token ids
|
| 672 |
+
input_ids = torch.LongTensor([[31, 51, 99], [15, 5, 0]])
|
| 673 |
+
input_mask = torch.LongTensor([[1, 1, 1], [1, 1, 0]])
|
| 674 |
+
token_type_ids = torch.LongTensor([[0, 0, 1], [0, 1, 0]])
|
| 675 |
+
|
| 676 |
+
config = modeling.BertConfig(vocab_size_or_config_json_file=32000, hidden_size=768,
|
| 677 |
+
num_hidden_layers=12, num_attention_heads=12, intermediate_size=3072)
|
| 678 |
+
|
| 679 |
+
model = modeling.BertModel(config=config)
|
| 680 |
+
all_encoder_layers, pooled_output = model(input_ids, token_type_ids, input_mask)
|
| 681 |
+
```
|
| 682 |
+
"""
|
| 683 |
+
def __init__(self, config):
|
| 684 |
+
super(BertModel, self).__init__(config)
|
| 685 |
+
self.embeddings = BertEmbeddings(config)
|
| 686 |
+
self.encoder = BertEncoder(config)
|
| 687 |
+
self.pooler = BertPooler(config)
|
| 688 |
+
self.apply(self.init_bert_weights)
|
| 689 |
+
|
| 690 |
+
def forward(self, input_ids, token_type_ids=None, attention_mask=None, output_all_encoded_layers=True):
|
| 691 |
+
if attention_mask is None:
|
| 692 |
+
attention_mask = torch.ones_like(input_ids)
|
| 693 |
+
if token_type_ids is None:
|
| 694 |
+
token_type_ids = torch.zeros_like(input_ids)
|
| 695 |
+
|
| 696 |
+
# We create a 3D attention mask from a 2D tensor mask.
|
| 697 |
+
# Sizes are [batch_size, 1, 1, to_seq_length]
|
| 698 |
+
# So we can broadcast to [batch_size, num_heads, from_seq_length, to_seq_length]
|
| 699 |
+
# this attention mask is more simple than the triangular masking of causal attention
|
| 700 |
+
# used in OpenAI GPT, we just need to prepare the broadcast dimension here.
|
| 701 |
+
extended_attention_mask = attention_mask.unsqueeze(1).unsqueeze(2)
|
| 702 |
+
|
| 703 |
+
# Since attention_mask is 1.0 for positions we want to attend and 0.0 for
|
| 704 |
+
# masked positions, this operation will create a tensor which is 0.0 for
|
| 705 |
+
# positions we want to attend and -10000.0 for masked positions.
|
| 706 |
+
# Since we are adding it to the raw scores before the softmax, this is
|
| 707 |
+
# effectively the same as removing these entirely.
|
| 708 |
+
extended_attention_mask = extended_attention_mask.to(dtype=next(self.parameters()).dtype) # fp16 compatibility
|
| 709 |
+
extended_attention_mask = (1.0 - extended_attention_mask) * -10000.0
|
| 710 |
+
|
| 711 |
+
embedding_output = self.embeddings(input_ids, token_type_ids)
|
| 712 |
+
encoded_layers = self.encoder(embedding_output,
|
| 713 |
+
extended_attention_mask,
|
| 714 |
+
output_all_encoded_layers=output_all_encoded_layers)
|
| 715 |
+
sequence_output = encoded_layers[-1]
|
| 716 |
+
pooled_output = self.pooler(sequence_output)
|
| 717 |
+
if not output_all_encoded_layers:
|
| 718 |
+
encoded_layers = encoded_layers[-1]
|
| 719 |
+
return encoded_layers, pooled_output
|
| 720 |
+
|
| 721 |
+
|
| 722 |
+
|
| 723 |
+
|
| 724 |
+
|
| 725 |
+
class BertForSequenceEncoder(BertPreTrainedModel):
|
| 726 |
+
"""BERT model for classification.
|
| 727 |
+
This module is composed of the BERT model with a linear layer on top of
|
| 728 |
+
the pooled output.
|
| 729 |
+
Params:
|
| 730 |
+
`config`: a BertConfig class instance with the configuration to build a new model.
|
| 731 |
+
`num_labels`: the number of classes for the classifier. Default = 2.
|
| 732 |
+
Inputs:
|
| 733 |
+
`input_ids`: a torch.LongTensor of shape [batch_size, sequence_length]
|
| 734 |
+
with the word token indices in the vocabulary(see the tokens preprocessing logic in the scripts
|
| 735 |
+
`extract_features.py`, `run_classifier.py` and `run_squad.py`)
|
| 736 |
+
`token_type_ids`: an optional torch.LongTensor of shape [batch_size, sequence_length] with the token
|
| 737 |
+
types indices selected in [0, 1]. Type 0 corresponds to a `sentence A` and type 1 corresponds to
|
| 738 |
+
a `sentence B` token (see BERT paper for more details).
|
| 739 |
+
`attention_mask`: an optional torch.LongTensor of shape [batch_size, sequence_length] with indices
|
| 740 |
+
selected in [0, 1]. It's a mask to be used if the input sequence length is smaller than the max
|
| 741 |
+
input sequence length in the current batch. It's the mask that we typically use for attention when
|
| 742 |
+
a batch has varying length sentences.
|
| 743 |
+
`labels`: labels for the classification output: torch.LongTensor of shape [batch_size]
|
| 744 |
+
with indices selected in [0, ..., num_labels].
|
| 745 |
+
Outputs:
|
| 746 |
+
if `labels` is not `None`:
|
| 747 |
+
Outputs the CrossEntropy classification loss of the output with the labels.
|
| 748 |
+
if `labels` is `None`:
|
| 749 |
+
Outputs the classification logits of shape [batch_size, num_labels].
|
| 750 |
+
Example usage:
|
| 751 |
+
```python
|
| 752 |
+
# Already been converted into WordPiece token ids
|
| 753 |
+
input_ids = torch.LongTensor([[31, 51, 99], [15, 5, 0]])
|
| 754 |
+
input_mask = torch.LongTensor([[1, 1, 1], [1, 1, 0]])
|
| 755 |
+
token_type_ids = torch.LongTensor([[0, 0, 1], [0, 1, 0]])
|
| 756 |
+
config = BertConfig(vocab_size_or_config_json_file=32000, hidden_size=768,
|
| 757 |
+
num_hidden_layers=12, num_attention_heads=12, intermediate_size=3072)
|
| 758 |
+
num_labels = 2
|
| 759 |
+
model = BertForSequenceClassification(config, num_labels)
|
| 760 |
+
logits = model(input_ids, token_type_ids, input_mask)
|
| 761 |
+
```
|
| 762 |
+
"""
|
| 763 |
+
def __init__(self, config):
|
| 764 |
+
super(BertForSequenceEncoder, self).__init__(config)
|
| 765 |
+
self.bert = BertModel(config)
|
| 766 |
+
self.dropout = nn.Dropout(config.hidden_dropout_prob)
|
| 767 |
+
self.apply(self.init_bert_weights)
|
| 768 |
+
|
| 769 |
+
def forward(self, input_ids, attention_mask, token_type_ids):
|
| 770 |
+
output, pooled_output = self.bert(input_ids, token_type_ids, attention_mask, output_all_encoded_layers=False)
|
| 771 |
+
output = self.dropout(output)
|
| 772 |
+
pooled_output = self.dropout(pooled_output)
|
| 773 |
+
return output, pooled_output
|
| 774 |
+
|
| 775 |
+
|
src/er_client/retrieval_model/data_loader.py
ADDED
|
@@ -0,0 +1,276 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import os
|
| 2 |
+
import torch
|
| 3 |
+
import numpy as np
|
| 4 |
+
import json
|
| 5 |
+
import re
|
| 6 |
+
from torch.autograd import Variable
|
| 7 |
+
|
| 8 |
+
|
| 9 |
+
def _truncate_seq_pair(tokens_a, tokens_b, max_length):
|
| 10 |
+
"""Truncates a sequence pair in place to the maximum length."""
|
| 11 |
+
|
| 12 |
+
# This is a simple heuristic which will always truncate the longer sequence
|
| 13 |
+
# one token at a time. This makes more sense than truncating an equal percent
|
| 14 |
+
# of tokens from each, since if one sequence is very short then each token
|
| 15 |
+
# that's truncated likely contains more information than a longer sequence.
|
| 16 |
+
while True:
|
| 17 |
+
total_length = len(tokens_a) + len(tokens_b)
|
| 18 |
+
if total_length <= max_length:
|
| 19 |
+
break
|
| 20 |
+
if len(tokens_a) > len(tokens_b):
|
| 21 |
+
tokens_a.pop()
|
| 22 |
+
else:
|
| 23 |
+
tokens_b.pop()
|
| 24 |
+
|
| 25 |
+
|
| 26 |
+
def tok2int_sent(sentence, tokenizer, max_seq_length):
|
| 27 |
+
"""Loads a data file into a list of `InputBatch`s."""
|
| 28 |
+
sent_a, sent_b = sentence
|
| 29 |
+
tokens_a = tokenizer.tokenize(sent_a)
|
| 30 |
+
|
| 31 |
+
tokens_b = None
|
| 32 |
+
if sent_b:
|
| 33 |
+
tokens_b = tokenizer.tokenize(sent_b)
|
| 34 |
+
_truncate_seq_pair(tokens_a, tokens_b, max_seq_length - 3)
|
| 35 |
+
else:
|
| 36 |
+
# Account for [CLS] and [SEP] with "- 2"
|
| 37 |
+
if len(tokens_a) > max_seq_length - 2:
|
| 38 |
+
tokens_a = tokens_a[:(max_seq_length - 2)]
|
| 39 |
+
|
| 40 |
+
tokens = ["[CLS]"] + tokens_a + ["[SEP]"]
|
| 41 |
+
segment_ids = [0] * len(tokens)
|
| 42 |
+
if tokens_b:
|
| 43 |
+
tokens = tokens + tokens_b + ["[SEP]"]
|
| 44 |
+
segment_ids += [1] * (len(tokens_b) + 1)
|
| 45 |
+
input_ids = tokenizer.convert_tokens_to_ids(tokens)
|
| 46 |
+
input_mask = [1] * len(input_ids)
|
| 47 |
+
padding = [0] * (max_seq_length - len(input_ids))
|
| 48 |
+
|
| 49 |
+
input_ids += padding
|
| 50 |
+
input_mask += padding
|
| 51 |
+
segment_ids += padding
|
| 52 |
+
|
| 53 |
+
assert len(input_ids) == max_seq_length
|
| 54 |
+
assert len(input_mask) == max_seq_length
|
| 55 |
+
assert len(segment_ids) == max_seq_length
|
| 56 |
+
|
| 57 |
+
return input_ids, input_mask, segment_ids
|
| 58 |
+
|
| 59 |
+
|
| 60 |
+
def tok2int_list(src_list, tokenizer, max_seq_length, max_seq_size=-1):
|
| 61 |
+
inp_padding = list()
|
| 62 |
+
msk_padding = list()
|
| 63 |
+
seg_padding = list()
|
| 64 |
+
for step, sent in enumerate(src_list):
|
| 65 |
+
input_ids, input_mask, input_seg = tok2int_sent(sent, tokenizer, max_seq_length)
|
| 66 |
+
inp_padding.append(input_ids)
|
| 67 |
+
msk_padding.append(input_mask)
|
| 68 |
+
seg_padding.append(input_seg)
|
| 69 |
+
# if max_seq_size != -1:
|
| 70 |
+
# inp_padding = inp_padding[:max_seq_size]
|
| 71 |
+
# msk_padding = msk_padding[:max_seq_size]
|
| 72 |
+
# seg_padding = seg_padding[:max_seq_size]
|
| 73 |
+
# inp_padding += ([[0] * max_seq_length] * (max_seq_size - len(inp_padding)))
|
| 74 |
+
# msk_padding += ([[0] * max_seq_length] * (max_seq_size - len(msk_padding)))
|
| 75 |
+
# seg_padding += ([[0] * max_seq_length] * (max_seq_size - len(seg_padding)))
|
| 76 |
+
return inp_padding, msk_padding, seg_padding
|
| 77 |
+
|
| 78 |
+
|
| 79 |
+
class DataLoader(object):
|
| 80 |
+
''' For data iteration '''
|
| 81 |
+
|
| 82 |
+
def __init__(self, data_path, tokenizer, args, test=False, cuda=True, batch_size=64):
|
| 83 |
+
self.cuda = cuda
|
| 84 |
+
|
| 85 |
+
self.batch_size = batch_size
|
| 86 |
+
self.tokenizer = tokenizer
|
| 87 |
+
self.max_len = args.max_len
|
| 88 |
+
self.evi_num = args.evi_num
|
| 89 |
+
self.threshold = args.threshold
|
| 90 |
+
self.data_path = data_path
|
| 91 |
+
self.test = test
|
| 92 |
+
examples = self.read_file(data_path)
|
| 93 |
+
self.examples = examples
|
| 94 |
+
self.total_num = len(examples)
|
| 95 |
+
if self.test:
|
| 96 |
+
self.total_num = 100000
|
| 97 |
+
self.total_step = np.ceil(self.total_num * 1.0 / batch_size)
|
| 98 |
+
self.shuffle()
|
| 99 |
+
else:
|
| 100 |
+
self.total_step = self.total_num / batch_size
|
| 101 |
+
self.shuffle()
|
| 102 |
+
self.step = 0
|
| 103 |
+
|
| 104 |
+
def process_sent(self, sentence):
|
| 105 |
+
sentence = re.sub(" \-LSB\-.*?\-RSB\-", "", sentence)
|
| 106 |
+
sentence = re.sub("\-LRB\- \-RRB\- ", "", sentence)
|
| 107 |
+
sentence = re.sub(" -LRB-", " ( ", sentence)
|
| 108 |
+
sentence = re.sub("-RRB-", " )", sentence)
|
| 109 |
+
sentence = re.sub("--", "-", sentence)
|
| 110 |
+
sentence = re.sub("``", '"', sentence)
|
| 111 |
+
sentence = re.sub("''", '"', sentence)
|
| 112 |
+
|
| 113 |
+
return sentence
|
| 114 |
+
|
| 115 |
+
def process_wiki_title(self, title):
|
| 116 |
+
title = re.sub("_", " ", title)
|
| 117 |
+
title = re.sub(" -LRB-", " ( ", title)
|
| 118 |
+
title = re.sub("-RRB-", " )", title)
|
| 119 |
+
title = re.sub("-COLON-", ":", title)
|
| 120 |
+
return title
|
| 121 |
+
|
| 122 |
+
def read_file(self, data_path):
|
| 123 |
+
examples = list()
|
| 124 |
+
with open(data_path) as fin:
|
| 125 |
+
for step, line in enumerate(fin):
|
| 126 |
+
sublines = line.strip().split("\t")
|
| 127 |
+
examples.append(
|
| 128 |
+
[self.process_sent(sublines[0]), self.process_sent(sublines[2]), self.process_sent(sublines[4])])
|
| 129 |
+
return examples
|
| 130 |
+
|
| 131 |
+
def shuffle(self):
|
| 132 |
+
np.random.shuffle(self.examples)
|
| 133 |
+
|
| 134 |
+
def __iter__(self):
|
| 135 |
+
return self
|
| 136 |
+
|
| 137 |
+
def __next__(self):
|
| 138 |
+
return self.next()
|
| 139 |
+
|
| 140 |
+
def __len__(self):
|
| 141 |
+
return self._n_batch
|
| 142 |
+
|
| 143 |
+
def next(self):
|
| 144 |
+
''' Get the next batch '''
|
| 145 |
+
if self.step < self.total_step:
|
| 146 |
+
examples = self.examples[self.step * self.batch_size: (self.step + 1) * self.batch_size]
|
| 147 |
+
pos_inputs = list()
|
| 148 |
+
neg_inputs = list()
|
| 149 |
+
for example in examples:
|
| 150 |
+
pos_inputs.append([example[0], example[1]])
|
| 151 |
+
neg_inputs.append([example[0], example[2]])
|
| 152 |
+
inp_pos, msk_pos, seg_pos = tok2int_list(pos_inputs, self.tokenizer, self.max_len)
|
| 153 |
+
inp_neg, msk_neg, seg_neg = tok2int_list(neg_inputs, self.tokenizer, self.max_len)
|
| 154 |
+
|
| 155 |
+
inp_tensor_pos = Variable(
|
| 156 |
+
torch.LongTensor(inp_pos))
|
| 157 |
+
msk_tensor_pos = Variable(
|
| 158 |
+
torch.LongTensor(msk_pos))
|
| 159 |
+
seg_tensor_pos = Variable(
|
| 160 |
+
torch.LongTensor(seg_pos))
|
| 161 |
+
inp_tensor_neg = Variable(
|
| 162 |
+
torch.LongTensor(inp_neg))
|
| 163 |
+
msk_tensor_neg = Variable(
|
| 164 |
+
torch.LongTensor(msk_neg))
|
| 165 |
+
seg_tensor_neg = Variable(
|
| 166 |
+
torch.LongTensor(seg_neg))
|
| 167 |
+
|
| 168 |
+
if self.cuda:
|
| 169 |
+
inp_tensor_pos = inp_tensor_pos.cuda()
|
| 170 |
+
msk_tensor_pos = msk_tensor_pos.cuda()
|
| 171 |
+
seg_tensor_pos = seg_tensor_pos.cuda()
|
| 172 |
+
inp_tensor_neg = inp_tensor_neg.cuda()
|
| 173 |
+
msk_tensor_neg = msk_tensor_neg.cuda()
|
| 174 |
+
seg_tensor_neg = seg_tensor_neg.cuda()
|
| 175 |
+
self.step += 1
|
| 176 |
+
return inp_tensor_pos, msk_tensor_pos, seg_tensor_pos, inp_tensor_neg, msk_tensor_neg, seg_tensor_neg
|
| 177 |
+
else:
|
| 178 |
+
self.step = 0
|
| 179 |
+
if not self.test:
|
| 180 |
+
# examples = self.read_file(self.data_path)
|
| 181 |
+
# self.examples = examples
|
| 182 |
+
self.shuffle()
|
| 183 |
+
raise StopIteration()
|
| 184 |
+
|
| 185 |
+
|
| 186 |
+
class DataLoaderTest(object):
|
| 187 |
+
''' For data iteration '''
|
| 188 |
+
|
| 189 |
+
def __init__(self, data_path, tokenizer, args, cuda=True, batch_size=64):
|
| 190 |
+
self.cuda = cuda
|
| 191 |
+
|
| 192 |
+
self.batch_size = batch_size
|
| 193 |
+
self.tokenizer = tokenizer
|
| 194 |
+
self.max_len = args.max_len
|
| 195 |
+
self.evi_num = args.evi_num
|
| 196 |
+
self.threshold = args.threshold
|
| 197 |
+
self.data_path = data_path
|
| 198 |
+
inputs, ids, evi_list = self.read_all(data_path)
|
| 199 |
+
self.inputs = inputs
|
| 200 |
+
self.ids = ids
|
| 201 |
+
self.evi_list = evi_list
|
| 202 |
+
|
| 203 |
+
self.total_num = len(inputs)
|
| 204 |
+
self.total_step = np.ceil(self.total_num * 1.0 / batch_size)
|
| 205 |
+
self.step = 0
|
| 206 |
+
|
| 207 |
+
def process_sent(self, sentence):
|
| 208 |
+
sentence = re.sub(" \-LSB\-.*?\-RSB\-", "", sentence)
|
| 209 |
+
sentence = re.sub("\-LRB\- \-RRB\- ", "", sentence)
|
| 210 |
+
sentence = re.sub(" -LRB-", " ( ", sentence)
|
| 211 |
+
sentence = re.sub("-RRB-", " )", sentence)
|
| 212 |
+
sentence = re.sub("--", "-", sentence)
|
| 213 |
+
sentence = re.sub("``", '"', sentence)
|
| 214 |
+
sentence = re.sub("''", '"', sentence)
|
| 215 |
+
|
| 216 |
+
return sentence
|
| 217 |
+
|
| 218 |
+
def process_wiki_title(self, title):
|
| 219 |
+
title = re.sub("_", " ", title)
|
| 220 |
+
title = re.sub(" -LRB-", " ( ", title)
|
| 221 |
+
title = re.sub("-RRB-", " )", title)
|
| 222 |
+
title = re.sub("-COLON-", ":", title)
|
| 223 |
+
return title
|
| 224 |
+
|
| 225 |
+
def read_all(self, data):
|
| 226 |
+
if not isinstance(data, list):
|
| 227 |
+
with open(data) as f:
|
| 228 |
+
data_ = [json.loads(line) for line in f]
|
| 229 |
+
else:
|
| 230 |
+
data_ = data
|
| 231 |
+
inputs = list()
|
| 232 |
+
ids = list()
|
| 233 |
+
evi_list = list()
|
| 234 |
+
for instance in data_:
|
| 235 |
+
claim = instance['claim']
|
| 236 |
+
id = instance['id']
|
| 237 |
+
for evidence in instance['evidence']:
|
| 238 |
+
ids.append(id)
|
| 239 |
+
inputs.append([self.process_sent(claim), self.process_sent(evidence[2])])
|
| 240 |
+
evi_list.append(evidence)
|
| 241 |
+
return inputs, ids, evi_list
|
| 242 |
+
|
| 243 |
+
def shuffle(self):
|
| 244 |
+
np.random.shuffle(self.examples)
|
| 245 |
+
|
| 246 |
+
def __iter__(self):
|
| 247 |
+
return self
|
| 248 |
+
|
| 249 |
+
def __next__(self):
|
| 250 |
+
return self.next()
|
| 251 |
+
|
| 252 |
+
def __len__(self):
|
| 253 |
+
return self._n_batch
|
| 254 |
+
|
| 255 |
+
def next(self):
|
| 256 |
+
''' Get the next batch '''
|
| 257 |
+
if self.step < self.total_step:
|
| 258 |
+
inputs = self.inputs[self.step * self.batch_size: (self.step + 1) * self.batch_size]
|
| 259 |
+
ids = self.ids[self.step * self.batch_size: (self.step + 1) * self.batch_size]
|
| 260 |
+
evi_list = self.evi_list[self.step * self.batch_size: (self.step + 1) * self.batch_size]
|
| 261 |
+
inp, msk, seg = tok2int_list(inputs, self.tokenizer, self.max_len, -1)
|
| 262 |
+
inp_tensor_input = Variable(
|
| 263 |
+
torch.LongTensor(inp))
|
| 264 |
+
msk_tensor_input = Variable(
|
| 265 |
+
torch.LongTensor(msk))
|
| 266 |
+
seg_tensor_input = Variable(
|
| 267 |
+
torch.LongTensor(seg))
|
| 268 |
+
if self.cuda:
|
| 269 |
+
inp_tensor_input = inp_tensor_input.cuda()
|
| 270 |
+
msk_tensor_input = msk_tensor_input.cuda()
|
| 271 |
+
seg_tensor_input = seg_tensor_input.cuda()
|
| 272 |
+
self.step += 1
|
| 273 |
+
return inp_tensor_input, msk_tensor_input, seg_tensor_input, ids, evi_list
|
| 274 |
+
else:
|
| 275 |
+
self.step = 0
|
| 276 |
+
raise StopIteration()
|
src/er_client/retrieval_model/file_utils.py
ADDED
|
@@ -0,0 +1,249 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""
|
| 2 |
+
Utilities for working with the local dataset cache.
|
| 3 |
+
This file is adapted from the AllenNLP library at https://github.com/allenai/allennlp
|
| 4 |
+
Copyright by the AllenNLP authors.
|
| 5 |
+
"""
|
| 6 |
+
from __future__ import (absolute_import, division, print_function, unicode_literals)
|
| 7 |
+
|
| 8 |
+
import json
|
| 9 |
+
import logging
|
| 10 |
+
import os
|
| 11 |
+
import shutil
|
| 12 |
+
import tempfile
|
| 13 |
+
from functools import wraps
|
| 14 |
+
from hashlib import sha256
|
| 15 |
+
import sys
|
| 16 |
+
from io import open
|
| 17 |
+
|
| 18 |
+
import boto3
|
| 19 |
+
import requests
|
| 20 |
+
from botocore.exceptions import ClientError
|
| 21 |
+
from tqdm import tqdm
|
| 22 |
+
|
| 23 |
+
try:
|
| 24 |
+
from urllib.parse import urlparse
|
| 25 |
+
except ImportError:
|
| 26 |
+
from urlparse import urlparse
|
| 27 |
+
|
| 28 |
+
try:
|
| 29 |
+
from pathlib import Path
|
| 30 |
+
PYTORCH_PRETRAINED_BERT_CACHE = Path(os.getenv('PYTORCH_PRETRAINED_BERT_CACHE',
|
| 31 |
+
Path.home() / '.pytorch_pretrained_bert'))
|
| 32 |
+
except AttributeError:
|
| 33 |
+
PYTORCH_PRETRAINED_BERT_CACHE = os.getenv('PYTORCH_PRETRAINED_BERT_CACHE',
|
| 34 |
+
os.path.join(os.path.expanduser("~"), '.pytorch_pretrained_bert'))
|
| 35 |
+
|
| 36 |
+
logger = logging.getLogger(__name__) # pylint: disable=invalid-name
|
| 37 |
+
|
| 38 |
+
|
| 39 |
+
def url_to_filename(url, etag=None):
|
| 40 |
+
"""
|
| 41 |
+
Convert `url` into a hashed filename in a repeatable way.
|
| 42 |
+
If `etag` is specified, append its hash to the url's, delimited
|
| 43 |
+
by a period.
|
| 44 |
+
"""
|
| 45 |
+
url_bytes = url.encode('utf-8')
|
| 46 |
+
url_hash = sha256(url_bytes)
|
| 47 |
+
filename = url_hash.hexdigest()
|
| 48 |
+
|
| 49 |
+
if etag:
|
| 50 |
+
etag_bytes = etag.encode('utf-8')
|
| 51 |
+
etag_hash = sha256(etag_bytes)
|
| 52 |
+
filename += '.' + etag_hash.hexdigest()
|
| 53 |
+
|
| 54 |
+
return filename
|
| 55 |
+
|
| 56 |
+
|
| 57 |
+
def filename_to_url(filename, cache_dir=None):
|
| 58 |
+
"""
|
| 59 |
+
Return the url and etag (which may be ``None``) stored for `filename`.
|
| 60 |
+
Raise ``EnvironmentError`` if `filename` or its stored metadata do not exist.
|
| 61 |
+
"""
|
| 62 |
+
if cache_dir is None:
|
| 63 |
+
cache_dir = PYTORCH_PRETRAINED_BERT_CACHE
|
| 64 |
+
if sys.version_info[0] == 3 and isinstance(cache_dir, Path):
|
| 65 |
+
cache_dir = str(cache_dir)
|
| 66 |
+
|
| 67 |
+
cache_path = os.path.join(cache_dir, filename)
|
| 68 |
+
if not os.path.exists(cache_path):
|
| 69 |
+
raise EnvironmentError("file {} not found".format(cache_path))
|
| 70 |
+
|
| 71 |
+
meta_path = cache_path + '.json'
|
| 72 |
+
if not os.path.exists(meta_path):
|
| 73 |
+
raise EnvironmentError("file {} not found".format(meta_path))
|
| 74 |
+
|
| 75 |
+
with open(meta_path, encoding="utf-8") as meta_file:
|
| 76 |
+
metadata = json.load(meta_file)
|
| 77 |
+
url = metadata['url']
|
| 78 |
+
etag = metadata['etag']
|
| 79 |
+
|
| 80 |
+
return url, etag
|
| 81 |
+
|
| 82 |
+
|
| 83 |
+
def cached_path(url_or_filename, cache_dir=None):
|
| 84 |
+
"""
|
| 85 |
+
Given something that might be a URL (or might be a local path),
|
| 86 |
+
determine which. If it's a URL, download the file and cache it, and
|
| 87 |
+
return the path to the cached file. If it's already a local path,
|
| 88 |
+
make sure the file exists and then return the path.
|
| 89 |
+
"""
|
| 90 |
+
if cache_dir is None:
|
| 91 |
+
cache_dir = PYTORCH_PRETRAINED_BERT_CACHE
|
| 92 |
+
if sys.version_info[0] == 3 and isinstance(url_or_filename, Path):
|
| 93 |
+
url_or_filename = str(url_or_filename)
|
| 94 |
+
if sys.version_info[0] == 3 and isinstance(cache_dir, Path):
|
| 95 |
+
cache_dir = str(cache_dir)
|
| 96 |
+
|
| 97 |
+
parsed = urlparse(url_or_filename)
|
| 98 |
+
|
| 99 |
+
if parsed.scheme in ('http', 'https', 's3'):
|
| 100 |
+
# URL, so get it from the cache (downloading if necessary)
|
| 101 |
+
return get_from_cache(url_or_filename, cache_dir)
|
| 102 |
+
elif os.path.exists(url_or_filename):
|
| 103 |
+
# File, and it exists.
|
| 104 |
+
return url_or_filename
|
| 105 |
+
elif parsed.scheme == '':
|
| 106 |
+
# File, but it doesn't exist.
|
| 107 |
+
raise EnvironmentError("file {} not found".format(url_or_filename))
|
| 108 |
+
else:
|
| 109 |
+
# Something unknown
|
| 110 |
+
raise ValueError("unable to parse {} as a URL or as a local path".format(url_or_filename))
|
| 111 |
+
|
| 112 |
+
|
| 113 |
+
def split_s3_path(url):
|
| 114 |
+
"""Split a full s3 path into the bucket name and path."""
|
| 115 |
+
parsed = urlparse(url)
|
| 116 |
+
if not parsed.netloc or not parsed.path:
|
| 117 |
+
raise ValueError("bad s3 path {}".format(url))
|
| 118 |
+
bucket_name = parsed.netloc
|
| 119 |
+
s3_path = parsed.path
|
| 120 |
+
# Remove '/' at beginning of path.
|
| 121 |
+
if s3_path.startswith("/"):
|
| 122 |
+
s3_path = s3_path[1:]
|
| 123 |
+
return bucket_name, s3_path
|
| 124 |
+
|
| 125 |
+
|
| 126 |
+
def s3_request(func):
|
| 127 |
+
"""
|
| 128 |
+
Wrapper function for s3 requests in order to create more helpful error
|
| 129 |
+
messages.
|
| 130 |
+
"""
|
| 131 |
+
|
| 132 |
+
@wraps(func)
|
| 133 |
+
def wrapper(url, *args, **kwargs):
|
| 134 |
+
try:
|
| 135 |
+
return func(url, *args, **kwargs)
|
| 136 |
+
except ClientError as exc:
|
| 137 |
+
if int(exc.response["Error"]["Code"]) == 404:
|
| 138 |
+
raise EnvironmentError("file {} not found".format(url))
|
| 139 |
+
else:
|
| 140 |
+
raise
|
| 141 |
+
|
| 142 |
+
return wrapper
|
| 143 |
+
|
| 144 |
+
|
| 145 |
+
@s3_request
|
| 146 |
+
def s3_etag(url):
|
| 147 |
+
"""Check ETag on S3 object."""
|
| 148 |
+
s3_resource = boto3.resource("s3")
|
| 149 |
+
bucket_name, s3_path = split_s3_path(url)
|
| 150 |
+
s3_object = s3_resource.Object(bucket_name, s3_path)
|
| 151 |
+
return s3_object.e_tag
|
| 152 |
+
|
| 153 |
+
|
| 154 |
+
@s3_request
|
| 155 |
+
def s3_get(url, temp_file):
|
| 156 |
+
"""Pull a file directly from S3."""
|
| 157 |
+
s3_resource = boto3.resource("s3")
|
| 158 |
+
bucket_name, s3_path = split_s3_path(url)
|
| 159 |
+
s3_resource.Bucket(bucket_name).download_fileobj(s3_path, temp_file)
|
| 160 |
+
|
| 161 |
+
|
| 162 |
+
def http_get(url, temp_file):
|
| 163 |
+
req = requests.get(url, stream=True)
|
| 164 |
+
content_length = req.headers.get('Content-Length')
|
| 165 |
+
total = int(content_length) if content_length is not None else None
|
| 166 |
+
progress = tqdm(unit="B", total=total)
|
| 167 |
+
for chunk in req.iter_content(chunk_size=1024):
|
| 168 |
+
if chunk: # filter out keep-alive new chunks
|
| 169 |
+
progress.update(len(chunk))
|
| 170 |
+
temp_file.write(chunk)
|
| 171 |
+
progress.close()
|
| 172 |
+
|
| 173 |
+
|
| 174 |
+
def get_from_cache(url, cache_dir=None):
|
| 175 |
+
"""
|
| 176 |
+
Given a URL, look for the corresponding dataset in the local cache.
|
| 177 |
+
If it's not there, download it. Then return the path to the cached file.
|
| 178 |
+
"""
|
| 179 |
+
if cache_dir is None:
|
| 180 |
+
cache_dir = PYTORCH_PRETRAINED_BERT_CACHE
|
| 181 |
+
if sys.version_info[0] == 3 and isinstance(cache_dir, Path):
|
| 182 |
+
cache_dir = str(cache_dir)
|
| 183 |
+
|
| 184 |
+
if not os.path.exists(cache_dir):
|
| 185 |
+
os.makedirs(cache_dir)
|
| 186 |
+
|
| 187 |
+
# Get eTag to add to filename, if it exists.
|
| 188 |
+
if url.startswith("s3://"):
|
| 189 |
+
etag = s3_etag(url)
|
| 190 |
+
else:
|
| 191 |
+
response = requests.head(url, allow_redirects=True)
|
| 192 |
+
if response.status_code != 200:
|
| 193 |
+
raise IOError("HEAD request failed for url {} with status code {}"
|
| 194 |
+
.format(url, response.status_code))
|
| 195 |
+
etag = response.headers.get("ETag")
|
| 196 |
+
|
| 197 |
+
filename = url_to_filename(url, etag)
|
| 198 |
+
|
| 199 |
+
# get cache path to put the file
|
| 200 |
+
cache_path = os.path.join(cache_dir, filename)
|
| 201 |
+
|
| 202 |
+
if not os.path.exists(cache_path):
|
| 203 |
+
# Download to temporary file, then copy to cache dir once finished.
|
| 204 |
+
# Otherwise you get corrupt cache entries if the download gets interrupted.
|
| 205 |
+
with tempfile.NamedTemporaryFile() as temp_file:
|
| 206 |
+
logger.info("%s not found in cache, downloading to %s", url, temp_file.name)
|
| 207 |
+
|
| 208 |
+
# GET file object
|
| 209 |
+
if url.startswith("s3://"):
|
| 210 |
+
s3_get(url, temp_file)
|
| 211 |
+
else:
|
| 212 |
+
http_get(url, temp_file)
|
| 213 |
+
|
| 214 |
+
# we are copying the file before closing it, so flush to avoid truncation
|
| 215 |
+
temp_file.flush()
|
| 216 |
+
# shutil.copyfileobj() starts at the current position, so go to the start
|
| 217 |
+
temp_file.seek(0)
|
| 218 |
+
|
| 219 |
+
logger.info("copying %s to cache at %s", temp_file.name, cache_path)
|
| 220 |
+
with open(cache_path, 'wb') as cache_file:
|
| 221 |
+
shutil.copyfileobj(temp_file, cache_file)
|
| 222 |
+
|
| 223 |
+
logger.info("creating metadata file for %s", cache_path)
|
| 224 |
+
meta = {'url': url, 'etag': etag}
|
| 225 |
+
meta_path = cache_path + '.json'
|
| 226 |
+
with open(meta_path, 'w', encoding="utf-8") as meta_file:
|
| 227 |
+
json.dump(meta, meta_file)
|
| 228 |
+
|
| 229 |
+
logger.info("removing temp file %s", temp_file.name)
|
| 230 |
+
|
| 231 |
+
return cache_path
|
| 232 |
+
|
| 233 |
+
|
| 234 |
+
def read_set_from_file(filename):
|
| 235 |
+
'''
|
| 236 |
+
Extract a de-duped collection (set) of text from a file.
|
| 237 |
+
Expected file format is one item per line.
|
| 238 |
+
'''
|
| 239 |
+
collection = set()
|
| 240 |
+
with open(filename, 'r', encoding='utf-8') as file_:
|
| 241 |
+
for line in file_:
|
| 242 |
+
collection.add(line.rstrip())
|
| 243 |
+
return collection
|
| 244 |
+
|
| 245 |
+
|
| 246 |
+
def get_file_extension(path, dot=True, lower=True):
|
| 247 |
+
ext = os.path.splitext(path)[1]
|
| 248 |
+
ext = ext if dot else ext[1:]
|
| 249 |
+
return ext.lower() if lower else ext
|
src/er_client/retrieval_model/models.py
ADDED
|
@@ -0,0 +1,66 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import math
|
| 2 |
+
import torch
|
| 3 |
+
import torch.nn as nn
|
| 4 |
+
import torch.nn.functional as F
|
| 5 |
+
from torch.nn import BatchNorm1d, Linear, ReLU
|
| 6 |
+
from .bert_model import BertForSequenceEncoder
|
| 7 |
+
|
| 8 |
+
from torch.nn import BatchNorm1d, Linear, ReLU
|
| 9 |
+
from .bert_model import BertForSequenceEncoder
|
| 10 |
+
from torch.autograd import Variable
|
| 11 |
+
import numpy as np
|
| 12 |
+
|
| 13 |
+
|
| 14 |
+
|
| 15 |
+
|
| 16 |
+
def kernal_mus(n_kernels):
|
| 17 |
+
"""
|
| 18 |
+
get the mu for each guassian kernel. Mu is the middle of each bin
|
| 19 |
+
:param n_kernels: number of kernels (including exact match). first one is exact match
|
| 20 |
+
:return: l_mu, a list of mu.
|
| 21 |
+
"""
|
| 22 |
+
l_mu = [1]
|
| 23 |
+
if n_kernels == 1:
|
| 24 |
+
return l_mu
|
| 25 |
+
|
| 26 |
+
bin_size = 2.0 / (n_kernels - 1) # score range from [-1, 1]
|
| 27 |
+
l_mu.append(1 - bin_size / 2) # mu: middle of the bin
|
| 28 |
+
for i in range(1, n_kernels - 1):
|
| 29 |
+
l_mu.append(l_mu[i] - bin_size)
|
| 30 |
+
return l_mu
|
| 31 |
+
|
| 32 |
+
|
| 33 |
+
def kernel_sigmas(n_kernels):
|
| 34 |
+
"""
|
| 35 |
+
get sigmas for each guassian kernel.
|
| 36 |
+
:param n_kernels: number of kernels (including exactmath.)
|
| 37 |
+
:param lamb:
|
| 38 |
+
:param use_exact:
|
| 39 |
+
:return: l_sigma, a list of simga
|
| 40 |
+
"""
|
| 41 |
+
bin_size = 2.0 / (n_kernels - 1)
|
| 42 |
+
l_sigma = [0.001] # for exact match. small variance -> exact match
|
| 43 |
+
if n_kernels == 1:
|
| 44 |
+
return l_sigma
|
| 45 |
+
|
| 46 |
+
l_sigma += [0.1] * (n_kernels - 1)
|
| 47 |
+
return l_sigma
|
| 48 |
+
|
| 49 |
+
class inference_model(nn.Module):
|
| 50 |
+
def __init__(self, bert_model, args):
|
| 51 |
+
super(inference_model, self).__init__()
|
| 52 |
+
self.bert_hidden_dim = args.bert_hidden_dim
|
| 53 |
+
self.dropout = nn.Dropout(args.dropout)
|
| 54 |
+
self.max_len = args.max_len
|
| 55 |
+
self.num_labels = args.num_labels
|
| 56 |
+
self.pred_model = bert_model
|
| 57 |
+
#self.proj_hidden = nn.Linear(self.bert_hidden_dim, 128)
|
| 58 |
+
self.proj_match = nn.Linear(self.bert_hidden_dim, 1)
|
| 59 |
+
|
| 60 |
+
|
| 61 |
+
def forward(self, inp_tensor, msk_tensor, seg_tensor):
|
| 62 |
+
_, inputs = self.pred_model(inp_tensor, msk_tensor, seg_tensor)
|
| 63 |
+
inputs = self.dropout(inputs)
|
| 64 |
+
score = self.proj_match(inputs).squeeze(-1)
|
| 65 |
+
score = torch.tanh(score)
|
| 66 |
+
return score
|
src/er_client/retrieval_model/process_data.py
ADDED
|
@@ -0,0 +1,41 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import json
|
| 2 |
+
import os
|
| 3 |
+
import argparse
|
| 4 |
+
|
| 5 |
+
if __name__ == "__main__":
|
| 6 |
+
parser = argparse.ArgumentParser()
|
| 7 |
+
parser.add_argument('--gold_file')
|
| 8 |
+
parser.add_argument('--retrieval_file')
|
| 9 |
+
parser.add_argument('--output')
|
| 10 |
+
parser.add_argument('--test', action='store_true', default=False)
|
| 11 |
+
args = parser.parse_args()
|
| 12 |
+
filter_dict = dict()
|
| 13 |
+
data_dict = dict()
|
| 14 |
+
golden_dict = dict()
|
| 15 |
+
with open(args.gold_file) as f:
|
| 16 |
+
for line in f:
|
| 17 |
+
data = json.loads(line)
|
| 18 |
+
data_dict[data["id"]] = {"id": data["id"], "evidence":[], "claim": data["claim"]}
|
| 19 |
+
if "label" in data:
|
| 20 |
+
data_dict[data["id"]]["label"] = data["label"]
|
| 21 |
+
if not args.test:
|
| 22 |
+
for evidence in data["evidence"]:
|
| 23 |
+
data_dict[data["id"]]["evidence"].append([evidence[0], evidence[1], evidence[2], 1.0])
|
| 24 |
+
string = str(data["id"]) + "_" + evidence[0] + "_" + str(evidence[1])
|
| 25 |
+
golden_dict[string] = 1
|
| 26 |
+
with open(args.retrieval_file) as f:
|
| 27 |
+
for line in f:
|
| 28 |
+
data = json.loads(line)
|
| 29 |
+
for step, evidence in enumerate(data["evidence"]):
|
| 30 |
+
string = str(data["id"]) + "_" + str(evidence[0]) + "_" + str(evidence[1])
|
| 31 |
+
if string not in golden_dict and string not in filter_dict:
|
| 32 |
+
data_dict[data["id"]]["evidence"].append([evidence[0], evidence[1], evidence[2], evidence[4]])
|
| 33 |
+
filter_dict[string] = 1
|
| 34 |
+
with open(args.output, "w") as out:
|
| 35 |
+
for data in data_dict.values():
|
| 36 |
+
evidence_tmp = data["evidence"]
|
| 37 |
+
evidence_tmp = sorted(evidence_tmp, key=lambda x:x[3], reverse=True)
|
| 38 |
+
data["evidence"] = evidence_tmp[:5]
|
| 39 |
+
out.write(json.dumps(data) + "\n")
|
| 40 |
+
|
| 41 |
+
|
src/er_client/retrieval_model/test.py
ADDED
|
@@ -0,0 +1,81 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import logging
|
| 2 |
+
import argparse
|
| 3 |
+
import os
|
| 4 |
+
import json
|
| 5 |
+
import torch
|
| 6 |
+
from tqdm import tqdm
|
| 7 |
+
from transformers import BertTokenizer
|
| 8 |
+
|
| 9 |
+
from .models import inference_model
|
| 10 |
+
from .data_loader import DataLoaderTest
|
| 11 |
+
from .bert_model import BertForSequenceEncoder
|
| 12 |
+
|
| 13 |
+
logger = logging.getLogger(__name__)
|
| 14 |
+
|
| 15 |
+
|
| 16 |
+
def save_to_file(all_predict, outpath, evi_num):
|
| 17 |
+
with open(outpath, "w") as out:
|
| 18 |
+
for key, values in all_predict.items():
|
| 19 |
+
sorted_values = sorted(values, key=lambda x:x[-1], reverse=True)
|
| 20 |
+
data = json.dumps({"id": key, "evidence": sorted_values[:evi_num]})
|
| 21 |
+
out.write(data + "\n")
|
| 22 |
+
|
| 23 |
+
|
| 24 |
+
def eval_model(model, validset_reader):
|
| 25 |
+
model.eval()
|
| 26 |
+
all_predict = dict()
|
| 27 |
+
for inp_tensor, msk_tensor, seg_tensor, ids, evi_list in tqdm(validset_reader):
|
| 28 |
+
probs = model(inp_tensor, msk_tensor, seg_tensor)
|
| 29 |
+
probs = probs.tolist()
|
| 30 |
+
assert len(probs) == len(evi_list)
|
| 31 |
+
for i in range(len(probs)):
|
| 32 |
+
if ids[i] not in all_predict:
|
| 33 |
+
all_predict[ids[i]] = []
|
| 34 |
+
#if probs[i][1] >= probs[i][0]:
|
| 35 |
+
all_predict[ids[i]].append(evi_list[i] + [probs[i]])
|
| 36 |
+
return all_predict
|
| 37 |
+
|
| 38 |
+
|
| 39 |
+
if __name__ == "__main__":
|
| 40 |
+
parser = argparse.ArgumentParser()
|
| 41 |
+
parser.add_argument('--test_path', help='train path')
|
| 42 |
+
parser.add_argument('--name', help='train path')
|
| 43 |
+
parser.add_argument("--batch_size", default=32, type=int, help="Total batch size for training.")
|
| 44 |
+
parser.add_argument('--outdir', required=True, help='path to output directory')
|
| 45 |
+
parser.add_argument('--bert_pretrain', required=True)
|
| 46 |
+
parser.add_argument('--checkpoint', required=True)
|
| 47 |
+
parser.add_argument('--dropout', type=float, default=0.6, help='Dropout.')
|
| 48 |
+
parser.add_argument('--no-cuda', action='store_true', default=False, help='Disables CUDA training.')
|
| 49 |
+
parser.add_argument("--bert_hidden_dim", default=768, type=int, help="Total batch size for training.")
|
| 50 |
+
parser.add_argument("--layer", type=int, default=1, help='Graph Layer.')
|
| 51 |
+
parser.add_argument("--num_labels", type=int, default=3)
|
| 52 |
+
parser.add_argument("--evi_num", type=int, default=5, help='Evidence num.')
|
| 53 |
+
parser.add_argument("--threshold", type=float, default=0.0, help='Evidence num.')
|
| 54 |
+
parser.add_argument("--max_len", default=120, type=int,
|
| 55 |
+
help="The maximum total input sequence length after WordPiece tokenization. Sequences "
|
| 56 |
+
"longer than this will be truncated, and sequences shorter than this will be padded.")
|
| 57 |
+
args = parser.parse_args()
|
| 58 |
+
|
| 59 |
+
if not os.path.exists(args.outdir):
|
| 60 |
+
os.mkdir(args.outdir)
|
| 61 |
+
args.cuda = not args.no_cuda and torch.cuda.is_available()
|
| 62 |
+
handlers = [logging.FileHandler(os.path.abspath(args.outdir) + '/train_log.txt'), logging.StreamHandler()]
|
| 63 |
+
logging.basicConfig(format='[%(asctime)s] %(levelname)s: %(message)s', level=logging.DEBUG,
|
| 64 |
+
datefmt='%d-%m-%Y %H:%M:%S', handlers=handlers)
|
| 65 |
+
logger.info(args)
|
| 66 |
+
logger.info('Start training!')
|
| 67 |
+
|
| 68 |
+
tokenizer = BertTokenizer.from_pretrained(args.bert_pretrain, do_lower_case=False)
|
| 69 |
+
logger.info("loading training set")
|
| 70 |
+
validset_reader = DataLoaderTest(args.test_path, tokenizer, args, batch_size=args.batch_size)
|
| 71 |
+
|
| 72 |
+
logger.info('initializing estimator model')
|
| 73 |
+
bert_model = BertForSequenceEncoder.from_pretrained(args.bert_pretrain)
|
| 74 |
+
bert_model = bert_model.cuda()
|
| 75 |
+
model = inference_model(bert_model, args)
|
| 76 |
+
model.load_state_dict(torch.load(args.checkpoint)['model'])
|
| 77 |
+
model = model.cuda()
|
| 78 |
+
logger.info('Start eval!')
|
| 79 |
+
save_path = args.outdir + "/" + args.name
|
| 80 |
+
predict_dict = eval_model(model, validset_reader)
|
| 81 |
+
save_to_file(predict_dict, save_path, args.evi_num)
|
src/er_client/retrieval_model/test.sh
ADDED
|
@@ -0,0 +1,7 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
python test.py \
|
| 2 |
+
--test_path ../data/pages.json \
|
| 3 |
+
--bert_pretrain ../evidence_retrieval/bert_base \
|
| 4 |
+
--checkpoint ../evidence_retrieval/retrieval_model/model.best.pt \
|
| 5 |
+
--evi_num 5 \
|
| 6 |
+
--outdir ../data \
|
| 7 |
+
--name evidence.json
|
src/er_client/sentence_selection.py
ADDED
|
@@ -0,0 +1,54 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# -*- coding: utf-8 -*-
|
| 2 |
+
|
| 3 |
+
'''
|
| 4 |
+
@Author : Jiangjie Chen
|
| 5 |
+
@Time : 2020/9/20 11:42
|
| 6 |
+
@Contact : jjchen19@fudan.edu.cn
|
| 7 |
+
@Description:
|
| 8 |
+
'''
|
| 9 |
+
|
| 10 |
+
import torch
|
| 11 |
+
from transformers import BertTokenizer
|
| 12 |
+
from .retrieval_model.bert_model import BertForSequenceEncoder
|
| 13 |
+
from .retrieval_model.models import inference_model
|
| 14 |
+
from .retrieval_model.data_loader import DataLoaderTest
|
| 15 |
+
|
| 16 |
+
|
| 17 |
+
class SentSelector:
|
| 18 |
+
def __init__(self, pretrained_bert_path, select_model_path, args):
|
| 19 |
+
self.args = args
|
| 20 |
+
self.use_cuda = self.args.use_cuda and torch.cuda.is_available()
|
| 21 |
+
|
| 22 |
+
self.tokenizer = BertTokenizer.from_pretrained('bert-base-cased')
|
| 23 |
+
self.bert_model = BertForSequenceEncoder.from_pretrained(pretrained_bert_path)
|
| 24 |
+
|
| 25 |
+
self.rank_model = inference_model(self.bert_model, self.args)
|
| 26 |
+
self.rank_model.load_state_dict(torch.load(select_model_path)['model'])
|
| 27 |
+
|
| 28 |
+
if self.use_cuda:
|
| 29 |
+
self.bert_model = self.bert_model.cuda()
|
| 30 |
+
self.rank_model.cuda()
|
| 31 |
+
|
| 32 |
+
def rank_sentences(self, js: list):
|
| 33 |
+
'''
|
| 34 |
+
:param js: [{'claim': xxx, 'id': xx, 'evidence': xxx}]
|
| 35 |
+
:return: [(ent, num, sent, prob), (ent, num, sent, prob)]
|
| 36 |
+
'''
|
| 37 |
+
data_reader = DataLoaderTest(js, self.tokenizer, self.args, self.use_cuda)
|
| 38 |
+
self.rank_model.eval()
|
| 39 |
+
all_predict = dict()
|
| 40 |
+
for inp_tensor, msk_tensor, seg_tensor, ids, evi_list in data_reader:
|
| 41 |
+
probs = self.rank_model(inp_tensor, msk_tensor, seg_tensor)
|
| 42 |
+
probs = probs.tolist()
|
| 43 |
+
assert len(probs) == len(evi_list)
|
| 44 |
+
for i in range(len(probs)):
|
| 45 |
+
if ids[i] not in all_predict:
|
| 46 |
+
all_predict[ids[i]] = []
|
| 47 |
+
# if probs[i][1] >= probs[i][0]:
|
| 48 |
+
all_predict[ids[i]].append(tuple(evi_list[i]) + (probs[i],))
|
| 49 |
+
|
| 50 |
+
results = {}
|
| 51 |
+
for k, v in all_predict.items():
|
| 52 |
+
sorted_v = sorted(v, key=lambda x: x[-1], reverse=True)
|
| 53 |
+
results[k] = sorted_v[:self.args.evi_num]
|
| 54 |
+
return results
|
src/eval_client/cjjpy.py
ADDED
|
@@ -0,0 +1,249 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# -*- coding: utf-8 -*-
|
| 2 |
+
|
| 3 |
+
'''
|
| 4 |
+
@Author : Jiangjie Chen
|
| 5 |
+
@Time : 2018/11/15 17:08
|
| 6 |
+
@Contact: jjchen19@fudan.edu.cn
|
| 7 |
+
'''
|
| 8 |
+
|
| 9 |
+
import re
|
| 10 |
+
import datetime
|
| 11 |
+
import os
|
| 12 |
+
import argparse
|
| 13 |
+
import logging
|
| 14 |
+
import traceback
|
| 15 |
+
|
| 16 |
+
try:
|
| 17 |
+
import ujson as json
|
| 18 |
+
except:
|
| 19 |
+
import json
|
| 20 |
+
|
| 21 |
+
HADOOP_BIN = 'PATH=/usr/bin/:$PATH hdfs'
|
| 22 |
+
FOR_PUBLIC = True
|
| 23 |
+
|
| 24 |
+
|
| 25 |
+
def LengthStats(filename):
|
| 26 |
+
len_list = []
|
| 27 |
+
thresholds = [0.8, 0.9, 0.95, 0.99, 0.999]
|
| 28 |
+
with open(filename) as f:
|
| 29 |
+
for line in f:
|
| 30 |
+
len_list.append(len(line.strip().split()))
|
| 31 |
+
stats = {
|
| 32 |
+
'Max': max(len_list),
|
| 33 |
+
'Min': min(len_list),
|
| 34 |
+
'Avg': round(sum(len_list) / len(len_list), 4),
|
| 35 |
+
}
|
| 36 |
+
len_list.sort()
|
| 37 |
+
for t in thresholds:
|
| 38 |
+
stats[f"Top-{t}"] = len_list[int(len(len_list) * t)]
|
| 39 |
+
|
| 40 |
+
for k in stats:
|
| 41 |
+
print(f"- {k}: {stats[k]}")
|
| 42 |
+
return stats
|
| 43 |
+
|
| 44 |
+
|
| 45 |
+
class AttrDict(dict):
|
| 46 |
+
def __init__(self, *args, **kwargs):
|
| 47 |
+
super(AttrDict, self).__init__(*args, **kwargs)
|
| 48 |
+
self.__dict__ = self
|
| 49 |
+
|
| 50 |
+
|
| 51 |
+
def TraceBack(error_msg):
|
| 52 |
+
exc = traceback.format_exc()
|
| 53 |
+
msg = f'[Error]: {error_msg}.\n[Traceback]: {exc}'
|
| 54 |
+
return msg
|
| 55 |
+
|
| 56 |
+
|
| 57 |
+
def Now():
|
| 58 |
+
return datetime.datetime.now().strftime("%Y-%m-%d %H:%M:%S")
|
| 59 |
+
|
| 60 |
+
|
| 61 |
+
def AbsParentDir(file, parent='..', postfix=None):
|
| 62 |
+
ppath = os.path.abspath(file)
|
| 63 |
+
parent_level = parent.count('.')
|
| 64 |
+
while parent_level > 0:
|
| 65 |
+
ppath = os.path.dirname(ppath)
|
| 66 |
+
parent_level -= 1
|
| 67 |
+
if postfix is not None:
|
| 68 |
+
return os.path.join(ppath, postfix)
|
| 69 |
+
else:
|
| 70 |
+
return ppath
|
| 71 |
+
|
| 72 |
+
|
| 73 |
+
def init_logger(log_file=None, log_file_level=logging.NOTSET, from_scratch=False):
|
| 74 |
+
from coloredlogs import ColoredFormatter
|
| 75 |
+
import tensorflow as tf
|
| 76 |
+
|
| 77 |
+
fmt = "[%(asctime)s %(levelname)s] %(message)s"
|
| 78 |
+
log_format = ColoredFormatter(fmt=fmt)
|
| 79 |
+
# log_format = logging.Formatter()
|
| 80 |
+
logger = logging.getLogger()
|
| 81 |
+
logger.setLevel(log_file_level)
|
| 82 |
+
|
| 83 |
+
console_handler = logging.StreamHandler()
|
| 84 |
+
console_handler.setFormatter(log_format)
|
| 85 |
+
logger.handlers = [console_handler]
|
| 86 |
+
|
| 87 |
+
if log_file and log_file != '':
|
| 88 |
+
if from_scratch and tf.io.gfile.exists(log_file):
|
| 89 |
+
logger.warning('Removing previous log file: %s' % log_file)
|
| 90 |
+
tf.io.gfile.remove(log_file)
|
| 91 |
+
path = os.path.dirname(log_file)
|
| 92 |
+
os.makedirs(path, exist_ok=True)
|
| 93 |
+
file_handler = logging.FileHandler(log_file)
|
| 94 |
+
file_handler.setLevel(log_file_level)
|
| 95 |
+
file_handler.setFormatter(log_format)
|
| 96 |
+
logger.addHandler(file_handler)
|
| 97 |
+
|
| 98 |
+
return logger
|
| 99 |
+
|
| 100 |
+
|
| 101 |
+
def OverWriteCjjPy(root='.'):
|
| 102 |
+
# import difflib
|
| 103 |
+
# diff = difflib.HtmlDiff()
|
| 104 |
+
cnt = 0
|
| 105 |
+
golden_cjjpy = os.path.join(root, 'cjjpy.py')
|
| 106 |
+
# golden_content = open(golden_cjjpy).readlines()
|
| 107 |
+
for dir, folder, file in os.walk(root):
|
| 108 |
+
for f in file:
|
| 109 |
+
if f == 'cjjpy.py':
|
| 110 |
+
cjjpy = '%s/%s' % (dir, f)
|
| 111 |
+
# content = open(cjjpy).readlines()
|
| 112 |
+
# d = diff.make_file(golden_content, content)
|
| 113 |
+
cnt += 1
|
| 114 |
+
print('[%d]: %s' % (cnt, cjjpy))
|
| 115 |
+
os.system('cp %s %s' % (golden_cjjpy, cjjpy))
|
| 116 |
+
|
| 117 |
+
|
| 118 |
+
def ChangeFileFormat(filename, new_fmt):
|
| 119 |
+
assert type(filename) is str and type(new_fmt) is str
|
| 120 |
+
spt = filename.split('.')
|
| 121 |
+
if len(spt) == 0:
|
| 122 |
+
return filename
|
| 123 |
+
else:
|
| 124 |
+
return filename.replace('.' + spt[-1], new_fmt)
|
| 125 |
+
|
| 126 |
+
|
| 127 |
+
def CountLines(fname):
|
| 128 |
+
with open(fname, 'rb') as f:
|
| 129 |
+
count = 0
|
| 130 |
+
last_data = '\n'
|
| 131 |
+
while True:
|
| 132 |
+
data = f.read(0x400000)
|
| 133 |
+
if not data:
|
| 134 |
+
break
|
| 135 |
+
count += data.count(b'\n')
|
| 136 |
+
last_data = data
|
| 137 |
+
if last_data[-1:] != b'\n':
|
| 138 |
+
count += 1 # Remove this if a wc-like count is needed
|
| 139 |
+
return count
|
| 140 |
+
|
| 141 |
+
|
| 142 |
+
def GetDate():
|
| 143 |
+
return str(datetime.datetime.now())[5:10].replace('-', '')
|
| 144 |
+
|
| 145 |
+
|
| 146 |
+
def TimeClock(seconds):
|
| 147 |
+
sec = int(seconds)
|
| 148 |
+
hour = int(sec / 3600)
|
| 149 |
+
min = int((sec - hour * 3600) / 60)
|
| 150 |
+
ssec = float(seconds) - hour * 3600 - min * 60
|
| 151 |
+
# return '%dh %dm %.2fs' % (hour, min, ssec)
|
| 152 |
+
return '{0:>2d}h{1:>3d}m{2:>6.2f}s'.format(hour, min, ssec)
|
| 153 |
+
|
| 154 |
+
|
| 155 |
+
def StripAll(text):
|
| 156 |
+
return text.strip().replace('\t', '').replace('\n', '').replace(' ', '')
|
| 157 |
+
|
| 158 |
+
|
| 159 |
+
def GetBracket(text, bracket, en_br=False):
|
| 160 |
+
# input should be aa(bb)cc, True for bracket, False for text
|
| 161 |
+
if bracket:
|
| 162 |
+
try:
|
| 163 |
+
return re.findall('\((.*?)\)', text.strip())[-1]
|
| 164 |
+
except:
|
| 165 |
+
return ''
|
| 166 |
+
else:
|
| 167 |
+
if en_br:
|
| 168 |
+
text = re.sub('\(.*?\)', '', text.strip())
|
| 169 |
+
return re.sub('(.*?)', '', text.strip())
|
| 170 |
+
|
| 171 |
+
|
| 172 |
+
def CharLang(uchar, lang):
|
| 173 |
+
assert lang.lower() in ['en', 'cn', 'zh']
|
| 174 |
+
if lang.lower() in ['cn', 'zh']:
|
| 175 |
+
if uchar >= '\u4e00' and uchar <= '\u9fa5':
|
| 176 |
+
return True
|
| 177 |
+
else:
|
| 178 |
+
return False
|
| 179 |
+
elif lang.lower() == 'en':
|
| 180 |
+
if (uchar <= 'Z' and uchar >= 'A') or (uchar <= 'z' and uchar >= 'a'):
|
| 181 |
+
return True
|
| 182 |
+
else:
|
| 183 |
+
return False
|
| 184 |
+
else:
|
| 185 |
+
raise NotImplementedError
|
| 186 |
+
|
| 187 |
+
|
| 188 |
+
def WordLang(word, lang):
|
| 189 |
+
for i in word.strip():
|
| 190 |
+
if i.isspace(): continue
|
| 191 |
+
if not CharLang(i, lang):
|
| 192 |
+
return False
|
| 193 |
+
return True
|
| 194 |
+
|
| 195 |
+
|
| 196 |
+
def SortDict(_dict, reverse=True):
|
| 197 |
+
assert type(_dict) is dict
|
| 198 |
+
return sorted(_dict.items(), key=lambda d: d[1], reverse=reverse)
|
| 199 |
+
|
| 200 |
+
|
| 201 |
+
def lark(content='test'):
|
| 202 |
+
print(content)
|
| 203 |
+
|
| 204 |
+
|
| 205 |
+
if __name__ == '__main__':
|
| 206 |
+
parser = argparse.ArgumentParser()
|
| 207 |
+
|
| 208 |
+
parser.add_argument('--diff', nargs=2,
|
| 209 |
+
help='show difference between two files, shown in downloads/diff.html')
|
| 210 |
+
parser.add_argument('--de_unicode', action='store_true', default=False,
|
| 211 |
+
help='remove unicode characters')
|
| 212 |
+
parser.add_argument('--link_entity', action='store_true', default=False,
|
| 213 |
+
help='')
|
| 214 |
+
parser.add_argument('--max_comm_len', action='store_true', default=False,
|
| 215 |
+
help='')
|
| 216 |
+
parser.add_argument('--search', nargs=2,
|
| 217 |
+
help='search key from file, 2 args: file name & key')
|
| 218 |
+
parser.add_argument('--email', nargs=2,
|
| 219 |
+
help='sending emails, 2 args: subject & content')
|
| 220 |
+
parser.add_argument('--overwrite', action='store_true', default=None,
|
| 221 |
+
help='overwrite all cjjpy under given *dir* based on *dir*/cjjpy.py')
|
| 222 |
+
parser.add_argument('--replace', nargs=3,
|
| 223 |
+
help='replace char, 3 args: file name & replaced char & replacer char')
|
| 224 |
+
parser.add_argument('--lark', nargs=1)
|
| 225 |
+
parser.add_argument('--get_hdfs', nargs=2,
|
| 226 |
+
help='easy copy from hdfs to local fs, 2 args: remote_file/dir & local_dir')
|
| 227 |
+
parser.add_argument('--put_hdfs', nargs=2,
|
| 228 |
+
help='easy put from local fs to hdfs, 2 args: local_file/dir & remote_dir')
|
| 229 |
+
parser.add_argument('--length_stats', nargs=1,
|
| 230 |
+
help='simple token lengths distribution of a line-by-line file')
|
| 231 |
+
|
| 232 |
+
args = parser.parse_args()
|
| 233 |
+
|
| 234 |
+
if args.overwrite:
|
| 235 |
+
print('* Overwriting cjjpy...')
|
| 236 |
+
OverWriteCjjPy()
|
| 237 |
+
|
| 238 |
+
if args.lark:
|
| 239 |
+
try:
|
| 240 |
+
content = args.lark[0]
|
| 241 |
+
except:
|
| 242 |
+
content = 'running complete'
|
| 243 |
+
print(f'* Larking "{content}"...')
|
| 244 |
+
lark(content)
|
| 245 |
+
|
| 246 |
+
if args.length_stats:
|
| 247 |
+
file = args.length_stats[0]
|
| 248 |
+
print(f'* Working on {file} lengths statistics...')
|
| 249 |
+
LengthStats(file)
|
src/eval_client/culpa.py
ADDED
|
@@ -0,0 +1,61 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# -*- coding:utf-8 -*-
|
| 2 |
+
|
| 3 |
+
"""
|
| 4 |
+
@Author : Bao
|
| 5 |
+
@Date : 2021/9/7
|
| 6 |
+
@Desc :
|
| 7 |
+
@Last modified by : Bao
|
| 8 |
+
@Last modified date : 2021/9/7
|
| 9 |
+
"""
|
| 10 |
+
|
| 11 |
+
import json
|
| 12 |
+
import numpy as np
|
| 13 |
+
import argparse
|
| 14 |
+
from collections import defaultdict
|
| 15 |
+
from sklearn.metrics import precision_recall_fscore_support
|
| 16 |
+
|
| 17 |
+
# ref --> label 1, nei & sup --> label 0
|
| 18 |
+
idx2label = {0: 1, 1: 0, 2: 0}
|
| 19 |
+
|
| 20 |
+
|
| 21 |
+
def read_json_lines(filename, mode='r', encoding='utf-8', skip=0):
|
| 22 |
+
with open(filename, mode, encoding=encoding) as fin:
|
| 23 |
+
for line in fin:
|
| 24 |
+
if skip > 0:
|
| 25 |
+
skip -= 1
|
| 26 |
+
continue
|
| 27 |
+
yield json.loads(line)
|
| 28 |
+
|
| 29 |
+
|
| 30 |
+
def process(filein):
|
| 31 |
+
id2info = defaultdict(dict)
|
| 32 |
+
for line in read_json_lines('eval.human.ref.merged.json'):
|
| 33 |
+
labels = [0] * len(line['questions'])
|
| 34 |
+
for cul in line['culprit']:
|
| 35 |
+
labels[cul] = 1
|
| 36 |
+
id2info[line['id']].update({'id': line['id'], 'labels': labels})
|
| 37 |
+
|
| 38 |
+
for line in read_json_lines(filein):
|
| 39 |
+
if line['id'] not in id2info: continue
|
| 40 |
+
predicted = [idx2label[_] for _ in np.argmax(line['z_prob'], axis=-1)]
|
| 41 |
+
id2info[line['id']]['predicted'] = predicted
|
| 42 |
+
|
| 43 |
+
ps, rs, fs = [], [], []
|
| 44 |
+
for info in id2info.values():
|
| 45 |
+
p, r, f, _ = precision_recall_fscore_support(info['labels'], info['predicted'], average='binary')
|
| 46 |
+
ps.append(p)
|
| 47 |
+
rs.append(r)
|
| 48 |
+
fs.append(f)
|
| 49 |
+
print(filein)
|
| 50 |
+
print('Precision: {}'.format(sum(ps) / len(ps)))
|
| 51 |
+
print('Recall: {}'.format(sum(rs) / len(rs)))
|
| 52 |
+
print('F1: {}'.format(sum(fs) / len(fs)))
|
| 53 |
+
|
| 54 |
+
return sum(ps) / len(ps), sum(rs) / len(rs), sum(fs) / len(fs)
|
| 55 |
+
|
| 56 |
+
|
| 57 |
+
if __name__ == '__main__':
|
| 58 |
+
parser = argparse.ArgumentParser()
|
| 59 |
+
parser.add_argument('-i', type=str, help='predicted jsonl file with phrasal veracity predictions.')
|
| 60 |
+
args = parser.parse_args()
|
| 61 |
+
process(args.i)
|
src/eval_client/culprit/eval.human.ref.json
ADDED
|
@@ -0,0 +1,100 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{"id": 102600, "claim": "Sausage Party was released in May of 2016 .", "questions": ["What was the name of the new album released in May 2016? or <mask> was released in May of 2016 .", "When was Sausage Party released? or Sausage Party was released in <mask> of 2016 .", "When was Sausage Party released? or Sausage Party was released in May of <mask> .", "What was Sausage Party's release date? or Sausage Party was <mask> in May of 2016 ."], "answers": [["Sausage Party", 0, 13], ["May", 30, 33], ["2016", 37, 41], ["released", 18, 26]], "evidential": [["Sausage Party", "The Sausage Party", "A Sausage Party", "Sausage party"], ["August", "the summer", "March", "the fall"], ["2016", "the year 2016", "March 2016", "2015"], ["released", "announced", "premiered", "released domestically"]], "culprit": [1]}
|
| 2 |
+
{"id": 92833, "claim": "Anne Boleyn did not live in England in 1522 .", "questions": ["Who did not live in England in 1522? or <mask> did not live in England in 1522 .", "Where did Anne Boleyn live in 1522? or Anne Boleyn did not live in <mask> in 1522 .", "When did Anne Boleyn not live in England? or Anne Boleyn did not live in England in <mask> .", "What did Anne Boleyn not do in England? or Anne Boleyn did not <mask> in England in 1522 ."], "answers": [["Anne Boleyn", 0, 11], ["England", 28, 35], ["1522", 39, 43], ["live", 20, 24]], "evidential": [["Anne Boleyn", "Ann Boleyn", "Anne Bolyn", "A woman"], ["England", "Europe", "the world", "the UK"], ["1532", "1536", "1533", "1534"], ["live", "stay", "marry", "reside"]], "culprit": [1, 2]}
|
| 3 |
+
{"id": 159707, "claim": "Edgar Wright is only a producer .", "questions": ["Who is the only producer? or <mask> is only a producer .", "What is Edgar Wright's job title? or Edgar Wright is <mask> ."], "answers": [["Edgar Wright", 0, 12], ["only a producer", 16, 31]], "evidential": [["Edgar Wright", "Edgar Wright Jr.", "Edgar W. Wright", "Edgar Wayne Wright"], ["a producer", "a director", "a screenwriter", "a film producer"]], "culprit": [1]}
|
| 4 |
+
{"id": 146055, "claim": "The Giver is a bill .", "questions": ["What is a bill called? or <mask> is a bill .", "What is the Giver? or The Giver is <mask> ."], "answers": [["The Giver", 0, 9], ["a bill", 13, 19]], "evidential": [["The Giver", "A The Giver", "The giver", "The Giver Act"], ["a film", "a work", "a motion picture", "a movie"]], "culprit": [1]}
|
| 5 |
+
{"id": 8443, "claim": "A Milli is by Justin Bieber .", "questions": ["What is the name of Justin Bieber's song? or <mask> is by Justin Bieber .", "Who is A Milli by? or A Milli is by <mask> ."], "answers": [["A Milli", 0, 7], ["Justin Bieber", 14, 27]], "evidential": [["A Milli", "A Milli song", "A Milli Song", "A Milli."], ["Justin Bieber", "a Justin Bieber", "an artist", "a musician"]], "culprit": [1]}
|
| 6 |
+
{"id": 67833, "claim": "Shane McMahon did not win the Hardcore Championship once .", "questions": ["Who won the Hardcore Championship once? or <mask> did not win the Hardcore Championship once .", "What did Shane McMahon not win once? or Shane McMahon did not win <mask> once .", "What did Shane McMahon not do once? or Shane McMahon did not <mask> the Hardcore Championship once ."], "answers": [["Shane McMahon", 0, 13], ["the Hardcore Championship", 26, 51], ["win", 22, 25]], "evidential": [["Shane McMahon", "Shane McMahon", "Shane McMah", "Shane McMahon ("], ["the European Championship", "the Hardcore Championship", "a wrestling championship", "a championship"], ["win", "won", "achieve", "earn"]], "culprit": [1]}
|
| 7 |
+
{"id": 116789, "claim": "Minor League Baseball is a hierarchy of only amateur baseball leagues .", "questions": ["What is the name of the only amateur baseball league? or <mask> is a hierarchy of only amateur baseball leagues .", "What is Minor League Baseball? or Minor League Baseball is <mask> of only amateur baseball leagues .", "What is Minor League Baseball a hierarchy of? or Minor League Baseball is a hierarchy of <mask> ."], "answers": [["Minor League Baseball", 0, 21], ["a hierarchy", 25, 36], ["only amateur baseball leagues", 40, 69]], "evidential": [["Minor League Baseball", "The Minor League Baseball", "Minor league Baseball", "Major League Baseball"], ["a hierarchy", "an organization", "a system", "a structure"], ["professional baseball leagues", "minor league baseball", "professional baseball teams", "baseball leagues"]], "culprit": [2]}
|
| 8 |
+
{"id": 12454, "claim": "Tangled is a silent film .", "questions": ["What is the name of the film that is a silent film? or <mask> is a silent film .", "What type of film is Tangled? or Tangled is <mask> ."], "answers": [["Tangled", 0, 7], ["a silent film", 11, 24]], "evidential": [["Tangled", "Tangles", "Tangled (", "Tangling"], ["an animated film", "a musical fantasy film", "a fantasy film", "a film"]], "culprit": [1]}
|
| 9 |
+
{"id": 149501, "claim": "Kung Fu Panda was number three at the box office .", "questions": ["What movie was number three at the box office? or <mask> was number three at the box office .", "What was Kung Fu Panda's box office number? or Kung Fu Panda was <mask> at the box office .", "Where was Kung Fu Panda number three? or Kung Fu Panda was number three at <mask> ."], "answers": [["Kung Fu Panda", 0, 13], ["number three", 18, 30], ["the box office", 34, 48]], "evidential": [["Kung Fu Panda", "Kung fu Panda", "Kung F Panda", "Kungfu Panda"], ["the number one", "number one", "the number one movie", "the number one film"], ["the box office", "the movie box office", "the US box office", "a box office"]], "culprit": [1]}
|
| 10 |
+
{"id": 51962, "claim": "Mandy Moore is a Canadian film actress .", "questions": ["Who is the name of the Canadian film actress? or <mask> is a Canadian film actress .", "What nationality is Mandy Moore? or Mandy Moore is <mask> film actress .", "What is Mandy Moore's career? or Mandy Moore is a Canadian <mask> ."], "answers": [["Mandy Moore", 0, 11], ["a Canadian", 15, 25], ["film actress", 26, 38]], "evidential": [["Mandy Moore", "Mandy Moore ( choreographer )", "Mandy Moore ( dancer )", "Mandy Moore( choreographer )"], ["an American", "an american", "a North American", "an North American"], ["actress", "film actress", "actor", "singer"]], "culprit": [1]}
|
| 11 |
+
{"id": 217102, "claim": "Innovation is viewed as the application of better solutions that negate market needs .", "questions": ["What is viewed as the application of better solutions that negate market needs? or <mask> is viewed as the application of better solutions that negate market needs .", "Innovation is viewed as what? or Innovation is viewed as <mask> of better solutions that negate market needs .", "Innovation is viewed as the application of what? or Innovation is viewed as the application of <mask> that negate market needs .", "Innovation is viewed as the application of better solutions that negate what? or Innovation is viewed as the application of better solutions that negate <mask> .", "What is innovation <mask> as? or Innovation is <mask> as the application of better solutions that negate market needs .", "Innovation is viewed as the application of better solutions that do what to market needs? or Innovation is viewed as the application of better solutions that <mask> market needs ."], "answers": [["Innovation", 0, 10], ["the application", 24, 39], ["better solutions", 43, 59], ["market needs", 72, 84], ["viewed", 14, 20], ["negate", 65, 71]], "evidential": [["Innovation", "Technology innovation", "Insulin", "In innovation"], ["the application", "an application", "a application", "the applications"], ["solutions", "new solutions", "better solutions", "products"], ["new requirements", "existing market needs", "existing market requirements", "existing requirements"], ["viewed", "perceived", "characterized", "described"], ["meet", "meet existing", "meet current", "met"]], "culprit": [5]}
|
| 12 |
+
{"id": 202314, "claim": "The New Jersey Turnpike has zero shoulders .", "questions": ["What has zero shoulders? or <mask> has zero shoulders .", "What is the total length of the New Jersey Turnpike? or The New Jersey Turnpike has <mask> ."], "answers": [["The New Jersey Turnpike", 0, 23], ["zero shoulders", 28, 42]], "evidential": [["The New Jersey Turnpike", "New Jersey Turnpike", "A New Jersey Turnpike", "the New Jersey Turnpike"], ["12 ft lanes", "a total length", "12 feet long", "12 feet"]], "culprit": [1]}
|
| 13 |
+
{"id": 226106, "claim": "Bongwater is set outside of Oregon .", "questions": ["What is the name of the town outside of Oregon? or <mask> is set outside of Oregon .", "What state is Bongwater located outside of? or Bongwater is set outside of <mask> .", "Where is Bongwater located outside of Oregon? or Bongwater is <mask> outside of Oregon .", "Where is Bongwater located? or Bongwater is set <mask> of Oregon ."], "answers": [["Bongwater", 0, 9], ["Oregon", 28, 34], ["set", 13, 16], ["outside", 17, 24]], "evidential": [["Bongwater", "The film Bongwater", "Bongwwater", "Bongswater"], ["Oregon", "a state", "Washington State", "the Oregon"], ["set", "located", "filmed", "based"], ["the state", "outside", "the city", "the coast"]], "culprit": [3]}
|
| 14 |
+
{"id": 182051, "claim": "The Fly was first released in 1999 .", "questions": ["What was the name of the first film released in 1999? or <mask> was first released in 1999 .", "When was The Fly first released? or The Fly was first released in <mask> .", "When was The Fly first <mask>? or The Fly was first <mask> in 1999 .", "When was The Fly released? or The Fly was <mask> released in 1999 ."], "answers": [["The Fly", 0, 7], ["1999", 30, 34], ["released", 18, 26], ["first", 12, 17]], "evidential": [["The Fly", "The Fly 's", "A film The Fly", "The fly"], ["August 1986", "1986", "the 1980s", "the eighties"], ["released", "published", "distributed", "release"], ["first", "originally", "last", "only"]], "culprit": [1]}
|
| 15 |
+
{"id": 65598, "claim": "Uganda was not ruled by the British .", "questions": ["What country was not ruled by the British? or <mask> was not ruled by the British .", "Who ruled Uganda? or Uganda was not ruled by <mask> .", "What was Uganda not <mask> by the British? or Uganda was not <mask> by the British ."], "answers": [["Uganda", 0, 6], ["the British", 24, 35], ["ruled", 15, 20]], "evidential": [["Uganda", "Uganda", "Ugandan", "Uganda"], ["the British", "Britain", "a colony", "British"], ["ruled", "controlled", "governed", "owned"]], "culprit": [1]}
|
| 16 |
+
{"id": 117126, "claim": "Pocahontas was not the daughter of Powhatan .", "questions": ["Who was not the daughter of Powhatan? or <mask> was not the daughter of Powhatan .", "What was Pocahontas' mother's name? or Pocahontas was not <mask> of Powhatan .", "Who was Pocahontas' father? or Pocahontas was not the daughter of <mask> ."], "answers": [["Pocahontas", 0, 10], ["the daughter", 19, 31], ["Powhatan", 35, 43]], "evidential": [["Pocahontas", "Pocahonta", "Pocahontas n't", "Pocahontas Jr."], ["the daughter", "a daughter", "the granddaughter", "the child"], ["Powhatan", "a Native American", "a chief", "a person"]], "culprit": [1, 2]}
|
| 17 |
+
{"id": 164506, "claim": "The Nobel Prize in Chemistry was awarded to a person from anywhere except the Netherlands .", "questions": ["What award was given to a person from anywhere except the Netherlands? or <mask> was awarded to a person from anywhere except the Netherlands .", "Who was the Nobel Prize in Chemistry awarded to? or The Nobel Prize in Chemistry was awarded to <mask> from anywhere except the Netherlands .", "Where was the Nobel Prize in Chemistry awarded to? or The Nobel Prize in Chemistry was awarded to a person from <mask> except the Netherlands .", "Where was the Nobel Prize in Chemistry awarded to? or The Nobel Prize in Chemistry was awarded to a person from anywhere except <mask> .", "How is the Nobel Prize in Chemistry <mask>? or The Nobel Prize in Chemistry was <mask> to a person from anywhere except the Netherlands ."], "answers": [["The Nobel Prize in Chemistry", 0, 28], ["a person", 44, 52], ["anywhere", 58, 66], ["the Netherlands", 74, 89], ["awarded", 33, 40]], "evidential": [["The Nobel Prize in Chemistry", "A Nobel Prize in Chemistry", "Nobel Prize in Chemistry", "The Nobel prize in Chemistry"], ["scientists", "a scientist", "people", "anyone"], ["every country", "every state", "every place", "all"], ["the Netherlands", "Sweden", "Europe", "Norway"], ["awarded", "given", "presented", "distributed"]], "culprit": [2, 3]}
|
| 18 |
+
{"id": 113010, "claim": "Duane Chapman is not a former bail bondsman .", "questions": ["Who is not a former bail bondsman? or <mask> is not a former bail bondsman .", "What is Duane Chapman's profession? or Duane Chapman is not <mask> ."], "answers": [["Duane Chapman", 0, 13], ["a former bail bondsman", 21, 43]], "evidential": [["Duane Chapman", "Duane ChapmanI.", "Duane Chapman I.", "Duane Chapman II."], ["a bail bondsman", "a bounty hunter", "a former bail bondsman", "a bail bondsman"]], "culprit": [1]}
|
| 19 |
+
{"id": 109582, "claim": "US Airways Flight 1549 did not have any people on board .", "questions": ["What flight did not have any people on board? or <mask> did not have any people on board .", "What was not on board the US Airways Flight 1549? or US Airways Flight 1549 did not have any <mask> on board .", "What was the name of the aircraft that did not have any people on? or US Airways Flight 1549 did not have any people on <mask> ."], "answers": [["US Airways Flight 1549", 0, 22], ["people", 40, 46], ["board", 50, 55]], "evidential": [["US Airways Flight 1549", "The US Airways Flight 1549", "American Airways Flight 1549", "United Airways Flight 1549"], ["people", "passengers", "humans", "birds"], ["an aircraft", "an Airbus A320", "the Airbus A320", "an airliner"]], "culprit": [2]}
|
| 20 |
+
{"id": 23766, "claim": "Charles de Gaulle was a Polish Resistance leader .", "questions": ["Who was the leader of the Polish Resistance? or <mask> was a Polish Resistance leader .", "What nationality was Charles de Gaulle? or Charles de Gaulle was <mask> Resistance leader .", "What political party was Charles de Gaulle a leader of? or Charles de Gaulle was a Polish <mask> leader .", "What was Charles de Gaulle's role in the Polish Resistance? or Charles de Gaulle was a Polish Resistance <mask> ."], "answers": [["Charles de Gaulle", 0, 17], ["a Polish", 22, 30], ["Resistance", 31, 41], ["leader", 42, 48]], "evidential": [["Charles de Gaulle", "Charles De Gaulle", "Charles de Gaulle", "Louis de Gaulle"], ["a French", "an American", "the French", "an English"], ["French", "Nationalist", "Communist", "National Socialist"], ["leader", "chief leader", "person", "chief strategist"]], "culprit": [1]}
|
| 21 |
+
{"id": 94556, "claim": "Pirates of the Caribbean has yet to be opened in Disneyland Paris .", "questions": ["What is the name of the movie that has yet to be opened at Disneyland Paris? or <mask> has yet to be opened in Disneyland Paris .", "Where is Pirates of the Caribbean currently located? or Pirates of the Caribbean has yet to be opened in <mask> .", "What is the name of the first attraction to open at Disneyland Paris? or Pirates of the Caribbean has yet to be <mask> in Disneyland Paris .", "How long has it been since the Pirates of the Caribbean opened? or Pirates of the Caribbean has <mask> to be opened in Disneyland Paris ."], "answers": [["Pirates of the Caribbean", 0, 24], ["Disneyland Paris", 49, 65], ["opened", 39, 45], ["yet", 29, 32]], "evidential": [["Pirates of the Caribbean", "The Pirates of the Caribbean", "Pirates of The Caribbean", "Pirates of Caribbean"], ["Disneyland Paris", "Disney Disneyland Paris", "Disney Paris", "Disney Park"], ["an attraction", "the first attraction", "a ride", "the first ride"], ["yet", "a decade", "a year", "the time"]], "culprit": [2, 3]}
|
| 22 |
+
{"id": 225871, "claim": "Revolver has only ever topped a single chart .", "questions": ["What has only ever topped a single chart? or <mask> has only ever topped a single chart .", "How many charts has Revolver ever topped? or Revolver has only ever topped <mask> .", "How many times has Revolver ever <mask> a single chart? or Revolver has only ever <mask> a single chart .", "How many times has Revolver topped a single chart? or Revolver has <mask> ever topped a single chart ."], "answers": [["Revolver", 0, 8], ["a single chart", 30, 44], ["topped", 23, 29], ["only", 13, 17]], "evidential": [["Revolver", "Revololver", "Revolver Record", "The Revolver"], ["four charts", "two charts", "three charts", "zero charts"], ["topped", "charted", "reached", "appeared"], ["never", "n't", "only", "rarely"]], "culprit": [1, 3]}
|
| 23 |
+
{"id": 164417, "claim": "Carey Hayes was born in 1897 .", "questions": ["Who was born in 1897? or <mask> was born in 1897 .", "When was Carey Hayes born? or Carey Hayes was born in <mask> .", "What was Carey Hayes' birth year? or Carey Hayes was <mask> in 1897 ."], "answers": [["Carey Hayes", 0, 11], ["1897", 24, 28], ["born", 16, 20]], "evidential": [["Carey Hayes", "Carey Hayes (", "Carey Hayes", "Carey Hayden"], ["1961", "the 1960s", "the 1960 's", "the 20th century"], ["born", "conceived", "created", "born in"]], "culprit": [1]}
|
| 24 |
+
{"id": 70311, "claim": "IMDb is a professional Dota 2 player .", "questions": ["What is the name of the professional Dota 2 player? or <mask> is a professional Dota 2 player .", "What is IMDb's professional name? or IMDb is a professional <mask> 2 player .", "How many players does IMDb have? or IMDb is a professional Dota <mask> .", "IMDb is what type of player? or IMDb is <mask> Dota 2 player ."], "answers": [["IMDb", 0, 4], ["Dota", 23, 27], ["2 player", 28, 36], ["a professional", 8, 22]], "evidential": [["IMDb", "The Internet Movie Database", "The internet movie database", "The internet Movie Database"], ["Game", "Web", "video game", "Webmaster"], ["users", "one player", "one user", "user"], ["an online database", "a fictional", "a popular", "a professional"]], "culprit": [1, 2, 3]}
|
| 25 |
+
{"id": 123479, "claim": "The Hundred Years ' War does not include the Lancastrian War .", "questions": ["What does not include the Lancastrian War? or <mask> does not include the Lancastrian War .", "What is not included in the Hundred Years' War? or The Hundred Years ' War does not include <mask> .", "What does the Hundred Years' War not <mask>? or The Hundred Years ' War does not <mask> the Lancastrian War ."], "answers": [["The Hundred Years ' War", 0, 23], ["the Lancastrian War", 41, 60], ["include", 33, 40]], "evidential": [["The Hundred Years ' War", "The Hundred Years' War", "Hundred Years ' War", "A Hundred Years ' War"], ["a conflict", "local conflicts", "a war", "several conflicts"], ["mention", "name", "see", "include"]], "culprit": [1]}
|
| 26 |
+
{"id": 16811, "claim": "Efraim Diveroli is a Spaniard .", "questions": ["Who is a Spaniard? or <mask> is a Spaniard .", "What is Efraim Diveroli's nationality? or Efraim Diveroli is <mask> ."], "answers": [["Efraim Diveroli", 0, 15], ["a Spaniard", 19, 29]], "evidential": [["Efraim Diveroli", "Efranim Diveroli", "Efriim Diveroli", "Efrafri Diveroli"], ["an American", "American", "North American", "a North American"]], "culprit": [1]}
|
| 27 |
+
{"id": 183618, "claim": "Finding Dory was written by anyone except Andrew Stanton .", "questions": ["What was the name of the book that was written by anyone other than Andrew Stanton? or <mask> was written by anyone except Andrew Stanton .", "Who wrote Finding Dory? or Finding Dory was written by <mask> except Andrew Stanton .", "Who wrote Finding Dory? or Finding Dory was written by anyone except <mask> .", "Who else wrote Finding Dory? or Finding Dory was <mask> by anyone except Andrew Stanton ."], "answers": [["Finding Dory", 0, 12], ["anyone", 28, 34], ["Andrew Stanton", 42, 56], ["written", 17, 24]], "evidential": [["Finding Dory", "The Finding Dory", "Finding dory", "Finding Dory 2"], ["anyone", "every person", "almost anyone", "almost all"], ["Andrew Stanton", "Andrew Strouse", "Andrew Stanton", "Andy Stanton"], ["written", "penned", "directed", "authored"]], "culprit": [2]}
|
| 28 |
+
{"id": 125315, "claim": "Phoenix , Arizona is the most populous city in Massachusetts .", "questions": ["What is the most populous city in Massachusetts? or <mask> , Arizona is the most populous city in Massachusetts .", "What state is Phoenix located in? or Phoenix , <mask> is the most populous city in Massachusetts .", "What state is Phoenix located in? or Phoenix , Arizona is the most populous city in <mask> .", "What is the population of Phoenix in Massachusetts? or Phoenix , Arizona is <mask> populous city in Massachusetts .", "What is the population of Phoenix? or Phoenix , Arizona is the most <mask> city in Massachusetts ."], "answers": [["Phoenix", 0, 7], ["Arizona", 10, 17], ["Massachusetts", 47, 60], ["the most", 21, 29], ["populous", 30, 38]], "evidential": [["Phoenix", "The Phoenix", "Arizona Phoenix", "Tempe"], ["Arizona", "Arizona Republic", "Arizona State", "United States"], ["the United States", "the US", "Arizona", "a state"], ["the most", "the fifth most", "the 5th most", "the fourth most"], ["populous", "populous city", "populous US", "large"]], "culprit": [2]}
|
| 29 |
+
{"id": 216367, "claim": "All speakers of the Chagatai language lived in France .", "questions": ["Who lived in France? or All <mask> of the Chagatai language lived in France .", "What language did all French speakers speak? or All speakers of <mask> lived in France .", "Where did the Chagatai language live? or All speakers of the Chagatai language lived in <mask> .", "Where did all speakers of the Chagatai language live? or All speakers of the Chagatai language <mask> in France ."], "answers": [["speakers", 4, 12], ["the Chagatai language", 16, 37], ["France", 47, 53], ["lived", 38, 43]], "evidential": [["The authors", "An author", "People", "A person"], ["the Chagatai language", "Chagatai language", "The Chagatai language", "a Chagatai language"], ["Europe", "a place", "France", "Asia"], ["lived", "existed", "resided", "originated"]], "culprit": [2]}
|
| 30 |
+
{"id": 23428, "claim": "The Cincinnati Kid was directed by Norman Jewison in 1960 .", "questions": ["What movie was directed by Norman Jewison? or <mask> was directed by Norman Jewison in 1960 .", "Who directed The Cincinnati Kid? or The Cincinnati Kid was directed by <mask> in 1960 .", "When was The Cincinnati Kid directed? or The Cincinnati Kid was directed by Norman Jewison in <mask> .", "What was the name of the film that was produced by Norman Jewison? or The Cincinnati Kid was <mask> by Norman Jewison in 1960 ."], "answers": [["The Cincinnati Kid", 0, 18], ["Norman Jewison", 35, 49], ["1960", 53, 57], ["directed", 23, 31]], "evidential": [["The Cincinnati Kid", "the Cincinnati Kid", "The CincinnatiKid", "Cincinnati Kid"], ["Norman Jewison", "a man", "Norman JewISON", "Norman Jewisons"], ["1965", "the 1960s", "the 1960 's", "the late 1960s"], ["directed", "produced", "written", "filmed"]], "culprit": [2]}
|
| 31 |
+
{"id": 67903, "claim": "Murda Beatz 's real name is Donald Trump .", "questions": ["Who is Donald Trump's real name? or <mask> 's real name is Donald Trump .", "What is Beatz' real name? or Murda Beatz 's real name is <mask> .", "What is the <mask> name of Murda Beatz? or Murda Beatz 's <mask> name is Donald Trump ."], "answers": [["Murda Beatz", 0, 11], ["Donald Trump", 28, 40], ["real", 15, 19]], "evidential": [["Murda Beatz", "Murdas Beatz", "Murda beatz", "Murdac Beatz"], ["Donald Trump", "a Donald Trump", "Donald Donald Trump", "Donald John Trump"], ["middle", "real", "full", "legal"]], "culprit": [1]}
|
| 32 |
+
{"id": 45585, "claim": "Harris Jayaraj is from Idaho .", "questions": ["Who is from Idaho? or <mask> is from Idaho .", "Where is Harris Jayaraj from? or Harris Jayaraj is from <mask> ."], "answers": [["Harris Jayaraj", 0, 14], ["Idaho", 23, 28]], "evidential": [["Harris Jayaraj", "Harris Jayaram", "Harris Jayarbaj", "Harris Jayaraja"], ["a state", "Idaho", "a place", "America"]], "culprit": [1]}
|
| 33 |
+
{"id": 95601, "claim": "Ian Gillan is only a singer .", "questions": ["Who is the only singer? or <mask> is only a singer .", "What is Ian Gillan's job? or Ian Gillan is <mask> ."], "answers": [["Ian Gillan", 0, 10], ["only a singer", 14, 27]], "evidential": [["Ian Gillan", "Ian Gillan", "Ian Gillan", "Ian Gillans"], ["a singer", "a vocalist", "a singer and songwriter", "a performer"]], "culprit": [1]}
|
| 34 |
+
{"id": 122348, "claim": "Wolfgang Amadeus Mozart never married .", "questions": ["Who never married? or <mask> never married .", "What did Wolfgang Amadeus Mozart never do? or Wolfgang Amadeus Mozart never <mask> .", "How did Wolfgang Amadeus Mozart get married? or Wolfgang Amadeus Mozart <mask> married ."], "answers": [["Wolfgang Amadeus Mozart", 0, 23], ["married", 30, 37], ["never", 24, 29]], "evidential": [["Wolfgang Amadeus Mozart", "Amadeus Mozart", "Johannes Amadeus Mozart", "Wolfgang Amadeu Mozart"], ["married", "marry", "died", "live"], ["got", "eventually", "later", "was"]], "culprit": [2]}
|
| 35 |
+
{"id": 146157, "claim": "The New England Patriots lost five Super Bowls .", "questions": ["Who lost five Super Bowls? or <mask> lost five Super Bowls .", "What type of game did the New England Patriots lose? or The New England Patriots lost five <mask> .", "How many Super Bowls did the New England Patriots win? or The New England Patriots <mask> five Super Bowls .", "How many Super Bowls did the New England Patriots lose? or The New England Patriots lost <mask> Super Bowls ."], "answers": [["The New England Patriots", 0, 24], ["Super Bowls", 35, 46], ["lost", 25, 29], ["five", 30, 34]], "evidential": [["New England Patriots", "The Patriots", "The New Patriots", "Patriots"], ["Super Bowls", "a Super Bowl", "the Super Bowl", "a football game"], ["won", "played", "reached", "achieved"], ["five", "5", "least five", "seven"]], "culprit": [2]}
|
| 36 |
+
{"id": 107699, "claim": "Floyd Mayweather Jr. is incapable of boxing .", "questions": ["Who is incapable of boxing? or <mask> is incapable of boxing .", "Floyd Mayweather Jr. is incapable of what sport? or Floyd Mayweather Jr. is incapable of <mask> .", "Is Floyd Mayweather Jr. capable or <mask> of boxing? or Floyd Mayweather Jr. is <mask> of boxing ."], "answers": [["Floyd Mayweather Jr.", 0, 20], ["boxing", 37, 43], ["incapable", 24, 33]], "evidential": [["Floyd Mayweather Jr.", "Floyd Mayweather Jr .", "Floyd Mayweather Jr.?", "Floyd Mayweather Jr.:"], ["boxing", "professional boxing", "boxed", "a sport"], ["incapable", "capable", "a capable", "an athlete"]], "culprit": [2]}
|
| 37 |
+
{"id": 216594, "claim": "Calcaneal spurs are only detected by a dancing technique .", "questions": ["What is only detected by a dancing technique? or <mask> are only detected by a dancing technique .", "What is the only way to detect Calcaneal spurs? or Calcaneal spurs are only detected by <mask> .", "How are Calcaneal spurs <mask>? or Calcaneal spurs are only <mask> by a dancing technique .", "How are Calcaneal spurs detected by a dancing technique? or Calcaneal spurs are <mask> detected by a dancing technique ."], "answers": [["Calcaneal spurs", 0, 15], ["a dancing technique", 37, 56], ["detected", 25, 33], ["only", 20, 24]], "evidential": [["Calcaneal spurs", "Calcaneal spur", "Calcaneals spurs", "Calcane al spurs"], ["a radiographic examination", "an x ray", "radiographic examination", "a radiographic exam"], ["detected", "observed", "seen", "indicated"], ["typically", "usually", "often", "frequently"]], "culprit": [1, 3]}
|
| 38 |
+
{"id": 118068, "claim": "Liverpool is unrelated to The Beatles .", "questions": ["What city is not related to The Beatles? or <mask> is unrelated to The Beatles .", "Liverpool is not related to what band? or Liverpool is unrelated to <mask> .", "Is Liverpool related to The Beatles? or Liverpool is <mask> to The Beatles ."], "answers": [["Liverpool", 0, 9], ["The Beatles", 26, 37], ["unrelated", 13, 22]], "evidential": [["Liverpool", "The Liverpool", "Liverpool City", "Liverpool"], ["The Beatles", "the Beatles", "a rock band", "a band"], ["related", "connected", "a home", "home"]], "culprit": [2]}
|
| 39 |
+
{"id": 110504, "claim": "The Mighty Ducks was only distributed by a subsidiary of 20th Century Fox .", "questions": ["What was the name of the show that was distributed by 20th Century Fox? or <mask> was only distributed by a subsidiary of 20th Century Fox .", "Who distributed the Mighty Ducks? or The Mighty Ducks was only distributed by <mask> of 20th Century Fox .", "Who distributed the Mighty Ducks? or The Mighty Ducks was only distributed by a subsidiary of <mask> .", "How was the Mighty Ducks <mask>? or The Mighty Ducks was only <mask> by a subsidiary of 20th Century Fox .", "How many times was The Mighty Ducks distributed by 20th Century Fox? or The Mighty Ducks was <mask> distributed by a subsidiary of 20th Century Fox ."], "answers": [["The Mighty Ducks", 0, 16], ["a subsidiary", 41, 53], ["20th Century Fox", 57, 73], ["distributed", 26, 37], ["only", 21, 25]], "evidential": [["The Mighty Ducks", "The Mighty Ducks of Anaheim", "The Mighty Duck", "Mighty Ducks"], ["the parent company", "a division", "a subsidiary", "the company"], ["Walt Disney Pictures", "Disney Pictures", "a company", "Walt Disney Productions"], ["distributed", "produced", "released", "created"], ["only", "never", "twice", "previously"]], "culprit": [1, 2, 4]}
|
| 40 |
+
{"id": 161151, "claim": "No Strings Attached was released on May 21 .", "questions": ["What was released on May 21? or No <mask> was released on May 21 .", "When was No Strings Attached released? or No Strings Attached was released on <mask> .", "When was No Strings Attached <mask>? or No Strings Attached was <mask> on May 21 ."], "answers": [["Strings Attached", 3, 19], ["May 21", 36, 42], ["released", 24, 32]], "evidential": [["Strings Attached", "strings Attached", "Strings Attached album", "Strings Attached film"], ["January 21 , 2011", "January 21st", "January 21st 2011", "January 21"], ["released", "published", "issued", "distributed"]], "culprit": [1]}
|
| 41 |
+
{"id": 150099, "claim": "Sherilyn Fenn is Japanese .", "questions": ["Who is the name of the Japanese woman who is a native of Japan? or <mask> is Japanese .", "What language is Sherilyn Fenn? or Sherilyn Fenn is <mask> ."], "answers": [["Sherilyn Fenn", 0, 13], ["Japanese", 17, 25]], "evidential": [["Sherilyn Fenn", "The Sherilyn Fenn", "Sherilyn Fenna", "Cherilyn Fenn"], ["American", "English", "North American", "French"]], "culprit": [1]}
|
| 42 |
+
{"id": 157652, "claim": "Touchscreens are only used in gaming computers .", "questions": ["What type of screen is used in gaming computers? or <mask> are only used in gaming computers .", "What type of computers are touch screens used for? or Touchscreens are only used in <mask> .", "What is the only way a touch screen can be <mask> in gaming computers? or Touchscreens are only <mask> in gaming computers .", "How are touchscreens used in gaming computers? or Touchscreens are <mask> used in gaming computers ."], "answers": [["Touchscreens", 0, 12], ["gaming computers", 30, 46], ["used", 22, 26], ["only", 17, 21]], "evidential": [["Touchscreens", "Touchscreen", "Touchscreen devices", "Touch screens"], ["personal computers", "electronic voting machines", "computer systems", "mobile computers"], ["common", "used", "found", "prevalent"], ["commonly", "frequently", "increasingly", "widely"]], "culprit": [3]}
|
| 43 |
+
{"id": 209863, "claim": "In a Lonely Place had nothing to do with any novel by Dorthy B. Hughes .", "questions": ["What was the name of the book that had nothing to do with any novel by Dorthy or <mask> had nothing to do with any novel by Dorthy B. Hughes .", "What did In a Lonely Place have to do with Dorthy B. Hughes or In a Lonely Place had <mask> to do with any novel by Dorthy B. Hughes .", "What type of work did In a Lonely Place have nothing to do with? or In a Lonely Place had nothing to do with any <mask> by Dorthy B. Hughes .", "Who wrote In a Lonely Place? or In a Lonely Place had nothing to do with any novel by <mask> ."], "answers": [["In a Lonely Place", 0, 17], ["nothing", 22, 29], ["novel", 45, 50], ["Dorthy B. Hughes", 54, 70]], "evidential": [["In a Lonely Place", "in a Lonely Place", "In a Lonely place", "In a Lonely Place ."], ["a lot", "a thing", "nothing", "a script"], ["novels", "mystery work", "written work", "written works"], ["Dorothy B. Hughes", "a mystery writer", "the mystery writer", "the author"]], "culprit": [1, 2, 3]}
|
| 44 |
+
{"id": 3305, "claim": "Julianne Moore was not in the television series As the World Turns .", "questions": ["Who was not in the television series As The World Turns? or <mask> was not in the television series As the World Turns .", "What was Julianne Moore not in? or Julianne Moore was not in <mask> As the World Turns .", "What television series did Julianne Moore not appear in? or Julianne Moore was not in the television series As <mask> ."], "answers": [["Julianne Moore", 0, 14], ["the television series", 26, 47], ["the World Turns", 51, 66]], "evidential": [["Julianne Moore", "Juliene Moore", "Juliann Moore", "Julianna Moore"], ["the soap opera", "the television show", "the television series", "the show"], ["the World Turns", "The World Turns", "the World turns", "a World Turns"]], "culprit": [1, 2]}
|
| 45 |
+
{"id": 83351, "claim": "In 2015 , among Mexicans , 70 % of adults had consumed alcoholic drink in the last year .", "questions": ["In what year did 70 % of Mexican adults drink alcohol? or In <mask> , among Mexicans , 70 % of adults had consumed alcoholic drink in the last year .", "What ethnicity had the highest percentage of alcoholic beverages in 2015? or In 2015 , among <mask> , 70 % of adults had consumed alcoholic drink in the last year .", "What percentage of Mexican adults had consumed alcohol in 2015? or In 2015 , among Mexicans , <mask> of adults had consumed alcoholic drink in the last year .", "What group of Mexicans consumed alcohol in 2015? or In 2015 , among Mexicans , 70 % of <mask> had consumed alcoholic drink in the last year .", "What type of drink did 70 % of Mexican adults consume in 2015? or In 2015 , among Mexicans , 70 % of adults had consumed <mask> in the last year .", "In what year did 70 % of Mexican adults drink alcohol? or In 2015 , among Mexicans , 70 % of adults had consumed alcoholic drink in <mask> .", "What did 70 % of adults in Mexico do with alcoholic beverages? or In 2015 , among Mexicans , 70 % of adults had <mask> alcoholic drink in the last year ."], "answers": [["2015", 3, 7], ["Mexicans", 16, 24], ["70 %", 27, 31], ["adults", 35, 41], ["alcoholic drink", 55, 70], ["the last year", 74, 87], ["consumed", 46, 54]], "evidential": [["2015", "2015 's", "the 2015 year", "the last year"], ["Americans", "Mexican", "the Mexican", "Mexicans"], ["89 %", "90 %", "70 %", "87 %"], ["adults", "people", "adult", "Americans"], ["alcohol", "alcoholic drink", "alcoholic drinks", "alcoholic beverages"], ["the last year", "the past year", "the year", "2015"], ["drank", "drunk", "consumed", "drinking"]], "culprit": [1]}
|
| 46 |
+
{"id": 97937, "claim": "Watchmen is a film set in the future .", "questions": ["What is the name of the film set in the future? or <mask> is a film set in the future .", "What type of film is Watchmen? or Watchmen is <mask> set in the future .", "What is the setting of Watchmen? or Watchmen is a film set in <mask> .", "Where is Watchmen <mask>? or Watchmen is a film <mask> in the future ."], "answers": [["Watchmen", 0, 8], ["a film", 12, 18], ["the future", 26, 36], ["set", 19, 22]], "evidential": [["Watchmen", "Watchmen ( film )", "Watchmen( film )", "Watchmen(film )"], ["a superhero film", "a film", "a dystopian film", "a cinematic film"], ["an alternate history", "a dystopian history", "a dystopian future", "a past"], ["set", "located", "filmed", "based"]], "culprit": [2]}
|
| 47 |
+
{"id": 8298, "claim": "Simon Pegg is only a banker .", "questions": ["Who is a banker? or <mask> is only a banker .", "What is Simon Pegg's job title? or Simon Pegg is <mask> ."], "answers": [["Simon Pegg", 0, 10], ["only a banker", 14, 27]], "evidential": [["Simon Pegg", "Simon Pgg", "Simon pegg", "Simon Pegg"], ["a producer", "a screenwriter", "an entertainer", "an executive producer"]], "culprit": [1]}
|
| 48 |
+
{"id": 193862, "claim": "Barry Van Dyke is the first son of Dick Van Dyke .", "questions": ["Who is the first son of Dick Van Dyke? or <mask> is the first son of Dick Van Dyke .", "What is Barry Van Dyke's first name? or Barry Van Dyke is <mask> of Dick Van Dyke .", "Who is Barry Van Dyke's father? or Barry Van Dyke is the first son of <mask> ."], "answers": [["Barry Van Dyke", 0, 14], ["the first son", 18, 31], ["Dick Van Dyke", 35, 48]], "evidential": [["Barry Van Dyke", "Barry van Dyke", "Dick Van Dyke", "A man"], ["the second son", "the first son", "the second child", "the son"], ["Dick Van Dyke", "an entertainer", "an actor", "a comedian"]], "culprit": [1]}
|
| 49 |
+
{"id": 55279, "claim": "Helmand Province contains a city .", "questions": ["What province contains a city? or <mask> contains a city .", "What does Helmand Province contain? or Helmand Province contains <mask> .", "What is the name of the city in Helmand Province? or Helmand Province <mask> a city ."], "answers": [["Helmand Province", 0, 16], ["a city", 26, 32], ["contains", 17, 25]], "evidential": [["Helmand Province", "Helmand province", "Helmand Provincial", "Helmand District"], ["people", "a city", "a town", "a population"], ["contains", "includes", "possesses", "features"]], "culprit": [1]}
|
| 50 |
+
{"id": 69871, "claim": "Robert Zemeckis has rarely directed movies .", "questions": ["Who has rarely directed a movie? or <mask> has rarely directed movies .", "What type of film has Zemeckis rarely directed? or Robert Zemeckis has rarely directed <mask> .", "What type of movies has Zemeckis rarely made? or Robert Zemeckis has rarely <mask> movies .", "How often has Zemeckis directed movies? or Robert Zemeckis has <mask> directed movies ."], "answers": [["Robert Zemeckis", 0, 15], ["movies", 36, 42], ["directed", 27, 35], ["rarely", 20, 26]], "evidential": [["Robert Zemeckis", "Robert Zemeckis", "Robert Zemckis", "Robert Memeckis"], ["a film", "a drama film", "a comedy", "a comedy film"], ["directed", "direct", "produced", "directing"], ["never", "rarely", "always", "only"]], "culprit": [3]}
|
| 51 |
+
{"id": 48276, "claim": "Raees ( film ) stars an Indian film actor born in April 1965 .", "questions": ["What film stars an Indian actor? or <mask> stars an Indian film actor born in April 1965 .", "What nationality is Raees? or Raees ( film ) stars <mask> film actor born in April 1965 .", "What is Raees' career? or Raees ( film ) stars an Indian <mask> born in April 1965 .", "When was Raees born? or Raees ( film ) stars an Indian film actor born in <mask> .", "What is Raees' career? or Raees ( film ) <mask> an Indian film actor born in April 1965 .", "What is the birth year of Raees? or Raees ( film ) stars an Indian film actor <mask> in April 1965 ."], "answers": [["Raees ( film )", 0, 14], ["an Indian", 21, 30], ["film actor", 31, 41], ["April 1965", 50, 60], ["stars", 15, 20], ["born", 42, 46]], "evidential": [["Raees ( film )", "Raees", "Raees( film )", "Raes ( film )"], ["an Indian", "a Indian", "An Indian", "an India"], ["film actor", "film actor and television personality", "actor", "television personality"], ["1965", "the sixties", "the 1960s", "the year 1965"], ["stars", "features", "starred", "includes"], ["born", "birth year", "birth date", "founded"]], "culprit": [3]}
|
| 52 |
+
{"id": 101845, "claim": "Richard Kuklinski is a innocent man .", "questions": ["Who is an innocent man? or <mask> is a innocent man .", "What is Richard Kuklinski? or Richard Kuklinski is <mask> ."], "answers": [["Richard Kuklinski", 0, 17], ["a innocent man", 21, 35]], "evidential": [["Richard Kuklinski", "Richard Kuklinski", "Richard Kuklinsky", "Richard Kuplinski"], ["a person", "a killer", "a serial killer", "a criminal"]], "culprit": [1]}
|
| 53 |
+
{"id": 44240, "claim": "Amancio Ortega refuses to be a businessman .", "questions": ["Who refuses to be a businessman? or <mask> refuses to be a businessman .", "What does Amancio Ortega refuse to be? or Amancio Ortega refuses to be <mask> .", "What does Amancio Ortega do to be a businessman? or Amancio Ortega <mask> to be a businessman ."], "answers": [["Amancio Ortega", 0, 14], ["a businessman", 29, 42], ["refuses", 15, 22]], "evidential": [["Amancio Ortega", "Amancio Ortega Gaona", "Amancio Ortega Jr.", "Amancio Orlando Ortega"], ["a businessman", "a tycoon", "a person", "a businessperson"], ["wants", "used", "works", "acts"]], "culprit": [2]}
|
| 54 |
+
{"id": 142735, "claim": "Elizabeth I was the daughter of a salesman .", "questions": ["What was my mother's name? or <mask> I was the daughter of a salesman .", "What was Elizabeth I's mother's name? or Elizabeth I was <mask> of a salesman .", "What was Elizabeth I's father's occupation? or Elizabeth I was the daughter of <mask> ."], "answers": [["Elizabeth", 0, 9], ["the daughter", 16, 28], ["a salesman", 32, 42]], "evidential": [["Elizabeth", "Elizabeth I", "ElizabethI", "Elizabeth II"], ["the daughter", "the second daughter", "the first daughter", "the second wife"], ["a man", "a second wife", "Henry VIII", "a person"]], "culprit": [2]}
|
| 55 |
+
{"id": 167977, "claim": "Don Bradman was called the \" greatest living Australian \" by a President .", "questions": ["Who was called the \"greatest living Australian\" by a President? or <mask> was called the \" greatest living Australian \" by a President .", "What nationality was Don Bradman? or Don Bradman was called the \" greatest living <mask> \" by a President .", "What was Bradman called by a President? or Don Bradman was called the \" greatest living Australian <mask> by a President .", "Who called Don Bradman the \"greatest living Australian\"? or Don Bradman was called the \" greatest living Australian \" by <mask> .", "What was Don Bradman called by a President? or Don Bradman was called <mask> Australian \" by a President ."], "answers": [["Don Bradman", 0, 11], ["Australian", 45, 55], ["\"", 56, 57], ["a President", 61, 72], ["the \" greatest living", 23, 44]], "evidential": [["Don Bradman", "Donald Bradman", "Don Bradm", "An Australian"], ["Australian", "American", "an Australian", "Australia"], ["person", "\"", "honored", "icon"], ["Prime Minister John Howard", "John Howard", "a Prime Minister", "the Prime Minister"], ["the \" greatest living", "the \" great living", "the \" best living", "the \" Greatest living"]], "culprit": [3]}
|
| 56 |
+
{"id": 227084, "claim": "Roar ( song ) is a Katy Perry song from her fifth album .", "questions": ["What is the name of Katy Perry's fifth album? or <mask> is a Katy Perry song from her fifth album .", "What is the name of the song Roar? or Roar ( song ) is <mask> song from her fifth album .", "What is Roar? or Roar ( song ) is a Katy Perry <mask> from her fifth album .", "What album is Roar from? or Roar ( song ) is a Katy Perry song from her <mask> ."], "answers": [["Roar ( song )", 0, 13], ["a Katy Perry", 17, 29], ["song", 30, 34], ["fifth album", 44, 55]], "evidential": [["Roar", "Roars", "Roar .", "Rar"], ["a Katy Perry", "an Katy Perry", "an American", "an artist 's"], ["song", "title", "single", "track"], ["fourth studio album", "fourth album", "fourth record", "fourth studio record"]], "culprit": [3]}
|
| 57 |
+
{"id": 205646, "claim": "St. Anger is the second studio album by Metallica .", "questions": ["What is the name of Metallica's second album? or <mask> is the second studio album by Metallica .", "What is the name of the second album by Metallica? or St. Anger is <mask> by Metallica .", "What band released St. Anger? or St. Anger is the second studio album by <mask> ."], "answers": [["St. Anger", 0, 9], ["the second studio album", 13, 36], ["Metallica", 40, 49]], "evidential": [["St. Anger", "The St. Anger", "St . Anger", "St. Anger ."], ["the eighth studio album", "an album", "an eighth studio album", "the eighth album"], ["Metallica", "a heavy metal band", "the Metallica", "a heavy metal group"]], "culprit": [1]}
|
| 58 |
+
{"id": 209095, "claim": "Stadium Arcadium was released after 2009 .", "questions": ["What stadium was released after 2009? or <mask> was released after 2009 .", "In what year was Stadium Arcadium released? or Stadium Arcadium was released after <mask> .", "What happened to Stadium Arcadium after 2009? or Stadium Arcadium was <mask> after 2009 .", "When was Stadium Arcadium released? or Stadium Arcadium was released <mask> 2009 ."], "answers": [["Stadium Arcadium", 0, 16], ["2009", 36, 40], ["released", 21, 29], ["after", 30, 35]], "evidential": [["Stadium Arcadium", "Stadium Arcadia", "Stadium Arcadadium", "Stadium Arcadion"], ["2006", "the 2000s", "a different year", "a 2006 album"], ["released", "disbanded", "dropped", "cancelled"], ["before", "after", "around", "back"]], "culprit": [1, 3]}
|
| 59 |
+
{"id": 155657, "claim": "The Prowler was created by Stan Lee , John Buscema , and dust .", "questions": ["What was the name of the film created by Stan Lee, John Buscema and Dust or <mask> was created by Stan Lee , John Buscema , and dust .", "Who created The Prowler? or The Prowler was created by <mask> , John Buscema , and dust .", "Who created The Prowler? or The Prowler was created by Stan Lee , <mask> , and dust .", "What was the Prowler made of? or The Prowler was created by Stan Lee , John Buscema , and <mask> .", "How was The Prowler <mask>? or The Prowler was <mask> by Stan Lee , John Buscema , and dust ."], "answers": [["The Prowler", 0, 11], ["Stan Lee", 27, 35], ["John Buscema", 38, 50], ["dust", 57, 61], ["created", 16, 23]], "evidential": [["The Prowler", "The Prowler ( 1981 film )", "The Prowler( 1981 film )", "Prowler ( 1981 film )"], ["Stan Lee", "Jim Mooney", "writer editor", "writer and editor"], ["comics editor", "comics writers", "people", "comics editors"], ["a writer", "a person", "characters", "comics"], ["created", "produced", "designed", "invented"]], "culprit": [3]}
|
| 60 |
+
{"id": 172095, "claim": "Selena Gomez & the Scene 's debut album was released in any month except September .", "questions": ["What group's debut album was released in any month except September? or <mask> 's debut album was released in any month except September .", "Selena Gomez & the Scene's debut album was released in what <mask> or Selena Gomez & the Scene 's debut album was released in any <mask> except September .", "Selena Gomez & the Scene's debut album was released in what month or Selena Gomez & the Scene 's debut album was released in any month except <mask> .", "When was Selena Gomez's debut album <mask>? or Selena Gomez & the Scene 's debut album was <mask> in any month except September ."], "answers": [["Selena Gomez & the Scene", 0, 24], ["month", 60, 65], ["September", 73, 82], ["released", 44, 52]], "evidential": [["Selena Gomez & the Scene", "The Selena Gomez & the Scene", "Selena Gomez & The Scene", "Selena Gomez & the Scene"], ["September", "the month", "the US", "the summer"], ["September", "October", "July", "August"], ["released", "published", "issued", "launched"]], "culprit": [2]}
|
| 61 |
+
{"id": 191441, "claim": "Keith Urban was released by Sony Music Entertainment .", "questions": ["What artist was released by Sony Music Entertainment? or <mask> was released by Sony Music Entertainment .", "What company released Keith Urban? or Keith Urban was released by <mask> .", "When was Keith Urban <mask>? or Keith Urban was <mask> by Sony Music Entertainment ."], "answers": [["Keith Urban", 0, 11], ["Sony Music Entertainment", 28, 52], ["released", 16, 24]], "evidential": [["Keith Urban", "Keith Urban II", "Keith U.", "The Keith Urban"], ["Capitol Nashville", "Capitol Records", "a company", "Capitol"], ["released", "created", "signed", "founded"]], "culprit": [1]}
|
| 62 |
+
{"id": 188640, "claim": "Foot Locker operates in only 11 countries .", "questions": ["What company operates in only 11 countries? or <mask> operates in only 11 countries .", "How many countries does Foot Locker operate in? or Foot Locker operates in <mask> countries .", "How does Foot Locker operate in 11 countries? or Foot Locker <mask> in only 11 countries ."], "answers": [["Foot Locker", 0, 11], ["only 11", 24, 31], ["operates", 12, 20]], "evidential": [["Foot Locker", "Foot Locker , Inc.", "Foot Locker ( Inc.", "Foot Locker Inc."], ["28", "least 28", "27", "29"], ["operates", "operate", "exists", "runs"]], "culprit": [1]}
|
| 63 |
+
{"id": 164407, "claim": "Carey Hayes is only a German lawyer .", "questions": ["Who is a German lawyer? or <mask> is only a German lawyer .", "What nationality is Hayes? or Carey Hayes is only <mask> lawyer .", "What is Hayes' profession? or Carey Hayes is only a German <mask> .", "How old is Carey Hayes? or Carey Hayes is <mask> German lawyer ."], "answers": [["Carey Hayes", 0, 11], ["a German", 20, 28], ["lawyer", 29, 35], ["only a", 15, 21]], "evidential": [["Carey Hayes", "Carey Hayes Jr.", "Carey Hayes", "Carey Hayden"], ["an American", "an american", "a North American", "an Oregon"], ["writer", "screenwriter", "a writer", "author"], ["a 21st century", "a 21 year old", "a 21-year old", "a young"]], "culprit": [1, 2, 3]}
|
| 64 |
+
{"id": 83545, "claim": "Volkswagen Group declines financing , leasing , and fleet management .", "questions": ["Which company declines financing, leasing and fleet management? or <mask> declines financing , leasing , and fleet management .", "What does Volkswagen Group decline? or Volkswagen Group declines financing , leasing , and <mask> .", "What does Volkswagen Group do with financing, leasing and fleet management? or Volkswagen Group <mask> financing , leasing , and fleet management ."], "answers": [["Volkswagen Group", 0, 16], ["fleet management", 52, 68], ["declines", 17, 25]], "evidential": [["Volkswagen Group", "The Volkswagen Group", "VW Group", "Volkswagen group"], ["fleet management", "fleet management services", "fleets management", "vehicles fleet management"], ["offers", "provides", "performs", "facilitates"]], "culprit": [2]}
|
| 65 |
+
{"id": 97837, "claim": "Caroline Kennedy is against diplomacy .", "questions": ["Who is against diplomacy? or <mask> is against diplomacy .", "Caroline Kennedy is against what? or Caroline Kennedy is against <mask> ."], "answers": [["Caroline Kennedy", 0, 16], ["diplomacy", 28, 37]], "evidential": [["Caroline Kennedy", "Caroline Flemming", "Caroline Klemming", "Caroline Kennedy"], ["politics", "the Democratic Party", "a presidential election", "a presidential campaign"]], "culprit": [1]}
|
| 66 |
+
{"id": 229309, "claim": "A working animal is released by humans .", "questions": ["What is released by humans? or <mask> is released by humans .", "Who releases a working animal? or A working animal is released by <mask> .", "What happens to a working animal when it is <mask>? or A working animal is <mask> by humans ."], "answers": [["A working animal", 0, 16], ["humans", 32, 38], ["released", 20, 28]], "evidential": [["A working animal", "A Working animal", "Working animal", "An animal"], ["humans", "a human", "human beings", "people"], ["kept", "domesticated", "raised", "captured"]], "culprit": [2]}
|
| 67 |
+
{"id": 98672, "claim": "Balibo ( film ) starts in the year 1995 .", "questions": ["What film was released in 1995? or <mask> starts in the year 1995 .", "When does Balibo begin? or Balibo ( film ) starts in <mask> .", "When does Balibo begin? or Balibo ( film ) <mask> in the year 1995 ."], "answers": [["Balibo ( film )", 0, 15], ["the year 1995", 26, 39], ["starts", 16, 22]], "evidential": [["Balibo", "Balibo ( film )", "Balibo( film )", "Balibo ( films )"], ["1975", "the 1970s", "the 1980s", "the year 1975"], ["begins", "starts", "began", "begin"]], "culprit": [1]}
|
| 68 |
+
{"id": 55239, "claim": "Victor Frankenstein is only a romance film .", "questions": ["What is the name of the film that is a romance? or <mask> is only a romance film .", "What is the purpose of Victor Frankenstein? or Victor Frankenstein is <mask> ."], "answers": [["Victor Frankenstein", 0, 19], ["only a romance film", 23, 42]], "evidential": [["Victor Frankenstein ( film )", "Victor Frankenstein", "Victor Frankenstein( film )", "Victor Frankenstein ( films )"], ["a film", "a motion picture", "a recorded work", "directed"]], "culprit": [1]}
|
| 69 |
+
{"id": 7728, "claim": "Hinduism has zero textual resources .", "questions": ["What religion has zero textual resources? or <mask> has zero textual resources .", "How many textual resources does Hinduism have? or Hinduism has <mask> ."], "answers": [["Hinduism", 0, 8], ["zero textual resources", 13, 35]], "evidential": [["Hinduism", "Hindu religion", "Indianism", "Buddhism"], ["multiple textual resources", "many shared textual resources", "shared textual resources", "many textual resources"]], "culprit": [1]}
|
| 70 |
+
{"id": 202475, "claim": "Tinker Tailor Soldier Spy only stars Gary Oldman .", "questions": ["What movie stars Gary Oldman? or <mask> only stars Gary Oldman .", "Who stars in Tinker Tailor Soldier Spy? or Tinker Tailor Soldier Spy only stars <mask> .", "What is Gary Oldman's first name? or Tinker Tailor Soldier Spy only <mask> Gary Oldman .", "How many episodes does Tinker Tailor Soldier Spy have? or Tinker Tailor Soldier Spy <mask> stars Gary Oldman ."], "answers": [["Tinker Tailor Soldier Spy", 0, 25], ["Gary Oldman", 37, 48], ["stars", 31, 36], ["only", 26, 30]], "evidential": [["Tinker Tailor Soldier Spy", "The Tinker Tailor Soldier Spy", "Tinker Tailor Soldier Spy", "Tinker Tailor Soldier Spy movie"], ["Gary Oldman", "an actor", "George Smiley", "a man"], ["stars", "features", "includes", "contains"], ["only", "one episode", "2 episodes", "one series"]], "culprit": [2, 3]}
|
| 71 |
+
{"id": 159091, "claim": "Guatemala has lived without war for its entire existence .", "questions": ["What country has lived without war for its entire existence? or <mask> has lived without war for its entire existence .", "What has Guatemala lived without? or Guatemala has lived without <mask> for its entire existence .", "How long has Guatemala lived without war? or Guatemala has lived without war for its <mask> .", "How long has Guatemala been without war? or Guatemala has <mask> without war for its entire existence ."], "answers": [["Guatemala", 0, 9], ["war", 28, 31], ["entire existence", 40, 56], ["lived", 14, 19]], "evidential": [["Guatemala", "Central America Guatemala", "Guatemalan", "Central America"], ["a military", "a government", "war", "a war"], ["time", "existence", "decade", "decades"], ["existed", "gone", "lived", "been"]], "culprit": [1, 2]}
|
| 72 |
+
{"id": 24481, "claim": "David Spade was fired from being in Joe Dirt 2 : Beautiful Loser .", "questions": ["Who was fired from being in Joe Dirt 2? or <mask> was fired from being in Joe Dirt 2 : Beautiful Loser .", "What was David Spade's first role in? or David Spade was fired from being in <mask> 2 : Beautiful Loser .", "How many episodes of Joe Dirt did Spade have? or David Spade was fired from being in Joe Dirt <mask> : Beautiful Loser .", "What was the title of Joe Dirt 2? or David Spade was fired from being in Joe Dirt 2 : <mask> .", "How did David Spade react to being in Joe Dirt 2? or David Spade was <mask> from being in Joe Dirt 2 : Beautiful Loser ."], "answers": [["David Spade", 0, 11], ["Joe Dirt", 36, 44], ["2", 45, 46], ["Beautiful Loser", 49, 64], ["fired", 16, 21]], "evidential": [["David Spade", "David Spades", "David Spade", "David Spader"], ["Joe Dirt", "the comedy Joe Dirt", "the film Joe Dirt", "the movie Joe Dirt"], ["2", "two episodes", "two", "2 :"], ["Beautiful Loser", "Beautiful Ler", "BeautifulLoser", "Beautiful Losers"], ["distracted", "banned", "traumatized", "disheartened"]], "culprit": [4]}
|
| 73 |
+
{"id": 67876, "claim": "Britt Robertson was not in the television series Girlboss .", "questions": ["Who was not in the television series Girlboss? or <mask> was not in the television series Girlboss .", "What television series did Britt Robertson not appear in? or Britt Robertson was not in the television series <mask> .", "What was Britt Robertson not in? or Britt Robertson was not in <mask> Girlboss ."], "answers": [["Britt Robertson", 0, 15], ["Girlboss", 49, 57], ["the television series", 27, 48]], "evidential": [["Britt Robertson", "Brittany Robertson", "Britt Roberts", "Brit Robertson"], ["Girlboss", "The Secret Circle", "Girlsboss", "a Netflix comedy"], ["the comedy television series", "the show", "the comedy TV series", "the TV series"]], "culprit": [1, 2]}
|
| 74 |
+
{"id": 76324, "claim": "Richard Dawson is still alive .", "questions": ["Who is still alive? or <mask> is still alive .", "How old is Richard Dawson? or Richard Dawson is <mask> alive .", "What is Richard Dawson's age? or Richard Dawson is still <mask> ."], "answers": [["Richard Dawson", 0, 14], ["still", 18, 23], ["alive", 24, 29]], "evidential": [["Richard Dawson", "Richard Dwayne Dawson", "Richard Dawsons", "Richard D Dawson"], ["still", "alive", "barely", "currently"], ["dead", "deceased", "alive", "63"]], "culprit": [1, 2]}
|
| 75 |
+
{"id": 104710, "claim": "Miranda Otto is the son of Barry Otto .", "questions": ["Who is the son of Barry Otto? or <mask> is the son of Barry Otto .", "What is Miranda Otto's biological name? or Miranda Otto is <mask> of Barry Otto .", "Who is Miranda Otto's father? or Miranda Otto is the son of <mask> ."], "answers": [["Miranda Otto", 0, 12], ["the son", 16, 23], ["Barry Otto", 27, 37]], "evidential": [["Miranda Otto", "Miriam Otto", "Miranda Oster", "Miranda Oste"], ["the daughter", "the sister", "the biological daughter", "the granddaughter"], ["an actor", "Barry Otto", "an actress", "a man"]], "culprit": [1]}
|
| 76 |
+
{"id": 92988, "claim": "See You on the Other Side is a boat .", "questions": ["What side of the boat is See You on? or See You on the Other <mask> is a boat .", "What is See You on the Other Side? or See You on the Other Side is <mask> .", "What is the name of the boat that is on the other side? or <mask> You on the Other Side is a boat ."], "answers": [["Side", 21, 25], ["a boat", 29, 35], ["See", 0, 3]], "evidential": [["Side", "side", "side 2", "Side 2"], ["an album", "a recorded work", "a record", "a work"], ["See", "The album", "See '", "see"]], "culprit": [1]}
|
| 77 |
+
{"id": 150834, "claim": "Tool has not produced albums .", "questions": ["Which tool has not produced an album? or <mask> has not produced albums .", "Tool has not produced what? or Tool has not produced <mask> .", "Tool has not what type of albums? or Tool has not <mask> albums ."], "answers": [["Tool", 0, 4], ["albums", 22, 28], ["produced", 13, 21]], "evidential": [["Tool", "Tool ( band )", "Tool( band )", "Tool(band )"], ["albums", "an album", "music", "records"], ["produced", "released", "created", "published"]], "culprit": [1]}
|
| 78 |
+
{"id": 135684, "claim": "Elizabeth I was the son of Anne Boleyn .", "questions": ["Who was the son of Anne Boleyn? or <mask> I was the son of Anne Boleyn .", "What was Elizabeth I's father's name? or Elizabeth I was <mask> of Anne Boleyn .", "Who was Elizabeth I's mother? or Elizabeth I was the son of <mask> ."], "answers": [["Elizabeth", 0, 9], ["the son", 16, 23], ["Anne Boleyn", 27, 38]], "evidential": [["Elizabeth", "Elizabeth I", "Queen Elizabeth", "ElizabethI"], ["the daughter", "the child", "the son", "a daughter"], ["Anne Boleyn", "Ann Boleyn", "Anne Bolyn", "a woman"]], "culprit": [1]}
|
| 79 |
+
{"id": 124045, "claim": "Ron Weasley was denied membership to Gryffindor house .", "questions": ["Who was denied membership to Gryffindor house? or <mask> was denied membership to Gryffindor house .", "What was Ron Weasley denied? or Ron Weasley was denied <mask> to Gryffindor house .", "What house was Ron Weasley denied membership to? or Ron Weasley was denied membership to <mask> house .", "What was Ron Weasley denied membership to? or Ron Weasley was denied membership to Gryffindor <mask> .", "What was Ron Weasley's status as a member of Gryffindor or Ron Weasley was <mask> membership to Gryffindor house ."], "answers": [["Ron Weasley", 0, 11], ["membership", 23, 33], ["Gryffindor", 37, 47], ["house", 48, 53], ["denied", 16, 22]], "evidential": [["Ron Weasley", "The Ron Weasley", "A Ron Weasley", "Ronald Weasley"], ["access", "a visit", "membership", "a membership"], ["the Gryffindor", "a Gryffindor", "The Gryffindor", "the Gryfindor"], ["house", "family", "houses", "home"], ["given", "granted", "denied", "required"]], "culprit": [4]}
|
| 80 |
+
{"id": 56381, "claim": "Lorelai Gilmore 's uncle was played by Edward Herrmann .", "questions": ["Who was the uncle of Edward Herrmann? or <mask> 's uncle was played by Edward Herrmann .", "Who played Lorelai Gilmore's uncle? or Lorelai Gilmore 's uncle was played by <mask> .", "What role did Edward Herrmann play in Lorelai Gilmore's uncle? or Lorelai Gilmore 's uncle was <mask> by Edward Herrmann ."], "answers": [["Lorelai Gilmore", 0, 15], ["Edward Herrmann", 39, 54], ["played", 29, 35]], "evidential": [["Lorelai Gilmore", "Lorelai Gilmore", "Lorelai Gilpin", "Lorelai Glyn"], ["Edward Herrmann", "an actor", "Edward Herrman", "a man"], ["played", "portrayed", "performed", "voiced"]], "culprit": [1]}
|
| 81 |
+
{"id": 78742, "claim": "Tim Roth is not an English actor .", "questions": ["Who is an English actor? or <mask> is not an English actor .", "What is Tim Roth's nationality? or Tim Roth is not <mask> actor .", "What is Tim Roth's profession? or Tim Roth is not an English <mask> ."], "answers": [["Tim Roth", 0, 8], ["an English", 16, 26], ["actor", 27, 32]], "evidential": [["Tim Roth", "Timothy Roth", "Tim Roth", "Tim R Roth"], ["an English", "a European", "a British", "an European"], ["actor", "director", "film actor", "film director"]], "culprit": [1, 2]}
|
| 82 |
+
{"id": 180717, "claim": "Victoria ( Dance Exponents song ) was released in New Zealand in 1980 .", "questions": ["What song was released in New Zealand in 1980? or <mask> was released in New Zealand in 1980 .", "Where was Victoria released? or Victoria ( Dance Exponents song ) was released in <mask> in 1980 .", "When was Victoria released in New Zealand? or Victoria ( Dance Exponents song ) was released in New Zealand in <mask> .", "What was the name of Victoria's song? or Victoria ( Dance Exponents song ) was <mask> in New Zealand in 1980 ."], "answers": [["Victoria ( Dance Exponents song )", 0, 33], ["New Zealand", 50, 61], ["1980", 65, 69], ["released", 38, 46]], "evidential": [["Victoria / Dance Exponents song", "Victoria", "Victoria Song", "Victoria song"], ["New Zealand", "China", "Australia", "the world"], ["1982", "the 1980s", "the eighties", "the nineties"], ["released", "performed", "played", "recorded"]], "culprit": [2]}
|
| 83 |
+
{"id": 125491, "claim": "Hot Right Now is from the album Escape from Planet Monday .", "questions": ["What is the name of the song from the album Escape from Planet Monday? or <mask> is from the album Escape from Planet Monday .", "What is the name of the album that Hot Right Now is from? or Hot Right Now is from <mask> from Planet Monday .", "What album is Hot Right Now from? or Hot Right Now is from the album <mask> ."], "answers": [["Hot Right Now", 0, 13], ["the album Escape", 22, 38], ["Escape from Planet Monday", 32, 57]], "evidential": [["Hot Right Now", "Hot right Now", "Hit Right Now", "Hot Right now"], ["Escape", "the album Escape", "an album", "the single Escape"], ["Escape from Planet Monday", "Nextlevelism", "Escape From Planet Monday", "Next Levelism"]], "culprit": [1, 2]}
|
| 84 |
+
{"id": 100204, "claim": "Shadowhunters did not premiere in 2016 .", "questions": ["What movie did not premiere in 2016? or <mask> did not premiere in 2016 .", "When did Shadowhunters not premiere? or Shadowhunters did not premiere in <mask> .", "What did Shadowhunters not do in 2016? or Shadowhunters did not <mask> in 2016 ."], "answers": [["Shadowhunters", 0, 13], ["2016", 34, 38], ["premiere", 22, 30]], "evidential": [["Shadowhunters", "The Shadowhunters", "Shadowshunters", "Shadowhunterters"], ["2016", "2015", "January 2016", "the 2010s"], ["premiere", "air", "start", "launch"]], "culprit": [1]}
|
| 85 |
+
{"id": 73208, "claim": "Reign Over Me was written and directed by Spike Lee .", "questions": ["What movie was directed by Spike Lee? or <mask> was written and directed by Spike Lee .", "Who directed Reign Over Me? or Reign Over Me was written and directed by <mask> .", "What was the name of the film that directed it? or Reign Over Me was <mask> and directed by Spike Lee .", "What was the film <mask> by Spike Lee? or Reign Over Me was written and <mask> by Spike Lee ."], "answers": [["Reign Over Me", 0, 13], ["Spike Lee", 42, 51], ["written", 18, 25], ["directed", 30, 38]], "evidential": [["Reign Over Me", "Reign over Me", "Reign of Me", "Reign Over me"], ["a man", "an American", "a person", "an actor"], ["written", "penned", "authored", "wrote"], ["directed", "produced", "written", "created"]], "culprit": [1]}
|
| 86 |
+
{"id": 225871, "claim": "Revolver has only ever topped a single chart .", "questions": ["What has only ever topped a single chart? or <mask> has only ever topped a single chart .", "How many charts has Revolver ever topped? or Revolver has only ever topped <mask> .", "How many times has Revolver ever <mask> a single chart? or Revolver has only ever <mask> a single chart .", "How many times has Revolver topped a single chart? or Revolver has <mask> ever topped a single chart ."], "answers": [["Revolver", 0, 8], ["a single chart", 30, 44], ["topped", 23, 29], ["only", 13, 17]], "evidential": [["Revolver", "Revololver", "Revolver Record", "The Revolver"], ["four charts", "two charts", "three charts", "zero charts"], ["topped", "charted", "reached", "appeared"], ["never", "n't", "only", "rarely"]], "culprit": [1, 3]}
|
| 87 |
+
{"id": 125225, "claim": "Omar Khadr has always been free .", "questions": ["Who has always been free? or <mask> has always been free .", "How long has Omar Khadr been free? or Omar Khadr has <mask> been free .", "Omar Khadr has always been what? or Omar Khadr has always been <mask> ."], "answers": [["Omar Khadr", 0, 10], ["always", 15, 21], ["free", 27, 31]], "evidential": [["Omar Khadr", "Omar Khadri", "Omar Khadr", "Om Khadr"], ["yet", "never", "always", "since"], ["a prisoner", "a person", "a human", "a detainee"]], "culprit": [1, 2]}
|
| 88 |
+
{"id": 174514, "claim": "Red Bull Racing was eradicated in the United Kingdom .", "questions": ["What was the name of the race that was eradicated in the UK? or <mask> was eradicated in the United Kingdom .", "Where was Red Bull Racing eradicated? or Red Bull Racing was eradicated in <mask> .", "What happened to Red Bull Racing in the UK? or Red Bull Racing was <mask> in the United Kingdom ."], "answers": [["Red Bull Racing", 0, 15], ["the United Kingdom", 34, 52], ["eradicated", 20, 30]], "evidential": [["Red Bull Racing", "Red Bull R&B Racing", "Red Bull Racing", "Red Bull racing"], ["Austria", "Europe", "the UK", "England"], ["acquired", "founded", "established", "created"]], "culprit": [2]}
|
| 89 |
+
{"id": 67464, "claim": "Louie ( season 1 ) was created by David Benioff .", "questions": ["What was the name of the show created by David Benioff? or <mask> was created by David Benioff .", "Who created Louie? or Louie ( season 1 ) was created by <mask> .", "What was the name of Louie? or Louie ( season 1 ) was <mask> by David Benioff ."], "answers": [["Louie ( season 1 )", 0, 18], ["David Benioff", 34, 47], ["created", 23, 30]], "evidential": [["Louie", "Louie ( season 1 )", "Louis C.K.", "The show Louie"], ["Louis C.K", "a person", "a series creator", "a man"], ["created", "written", "penned", "produced"]], "culprit": [1, 2]}
|
| 90 |
+
{"id": 84710, "claim": "Buffy the Vampire Slayer is created by Joss Whedon in 1990 .", "questions": ["What movie was created by Joss Whedon? or <mask> is created by Joss Whedon in 1990 .", "Who created Buffy the Vampire Slayer? or Buffy the Vampire Slayer is created by <mask> in 1990 .", "When was Buffy the Vampire Slayer created? or Buffy the Vampire Slayer is created by Joss Whedon in <mask> .", "What was the name of the film that made Buffy the Vampire Slayer? or Buffy the Vampire Slayer is <mask> by Joss Whedon in 1990 ."], "answers": [["Buffy the Vampire Slayer", 0, 24], ["Joss Whedon", 39, 50], ["1990", 54, 58], ["created", 28, 35]], "evidential": [["Buffy the Vampire Slayer", "The Buffy the Vampire Slayer", "Buffy The Vampire Slayer", "Buffy of the Vampire Slayer"], ["Joss Whedon", "a person", "a man", "an American"], ["the 1990s", "the 2000s", "the nineties", "1992"], ["created", "produced", "directed", "a film"]], "culprit": [2]}
|
| 91 |
+
{"id": 198041, "claim": "The New York City Landmarks Preservation Commission includes zero architects .", "questions": ["What organization has zero architects? or <mask> includes zero architects .", "How many architects does the New York City Landmarks Preservation Commission have? or The New York City Landmarks Preservation Commission includes <mask> .", "How many architects does the New York City Landmarks Preservation Commission have? or The New York City Landmarks Preservation Commission <mask> zero architects ."], "answers": [["The New York City Landmarks Preservation Commission", 0, 51], ["zero architects", 61, 76], ["includes", 52, 60]], "evidential": [["The New York City Landmarks Preservation Commission", "New York City Landmarks Preservation Commission", "The New York City Landmarks Preservation commission", "A New York City Landmarks Preservation Commission"], ["11 architects", "three architects", "11 commissioners", "ten architects"], ["includes", "contains", "consists", "involves"]], "culprit": [1]}
|
| 92 |
+
{"id": 42390, "claim": "Jack Falahee is Mongolian .", "questions": ["Who is the Mongolian whose name is? or <mask> is Mongolian .", "What nationality is Jack Falahee? or Jack Falahee is <mask> ."], "answers": [["Jack Falahee", 0, 12], ["Mongolian", 16, 25]], "evidential": [["Jack Falahee", "Jack Falahe", "John Falahee", "Jack Falaefhee"], ["American", "an American", "North American", "European"]], "culprit": [1]}
|
| 93 |
+
{"id": 175736, "claim": "The Cry of the Owl is based on Patricia Highsmith 's eighth movie .", "questions": ["What is the name of the movie based on Patricia Highsmith's eighth film? or <mask> is based on Patricia Highsmith 's eighth movie .", "Who wrote the movie The Cry of the Owl? or The Cry of the Owl is based on <mask> 's eighth movie .", "What is the story of The Cry Of The Owl? or The Cry of the Owl is <mask> on Patricia Highsmith 's eighth movie .", "What was the first movie based on? or The Cry of the Owl is based on Patricia Highsmith 's <mask> movie ."], "answers": [["The Cry of the Owl", 0, 18], ["Patricia Highsmith", 31, 49], ["based", 22, 27], ["eighth", 53, 59]], "evidential": [["The Cry of the Owl", "The Cry of the Owl ( 2009 film )", "The Cry of the Owl( 2009 film )", "The Cry of the Owl(2009 film )"], ["Patricia Highsmith", "an author", "a writer", "a novelist"], ["based", "a story", "a novel", "loosely"], ["first", "book", "novel", "a novel"]], "culprit": [3]}
|
| 94 |
+
{"id": 152929, "claim": "Firefox is an operating system shell .", "questions": ["What is the name of the operating system shell? or <mask> is an operating system shell .", "What is Firefox? or Firefox is <mask> ."], "answers": [["Firefox", 0, 7], ["an operating system shell", 11, 36]], "evidential": [["Firefox", "Mozilla", "Mozilla Firefox", "The Firefox"], ["a web browser", "a free web browser", "open source", "a free software application"]], "culprit": [1]}
|
| 95 |
+
{"id": 183589, "claim": "Finding Dory was directed by Ingmar Bergman .", "questions": ["What movie was directed by Ingmar Bergman? or <mask> was directed by Ingmar Bergman .", "Who directed Finding Dory? or Finding Dory was directed by <mask> .", "What was the name of the film that starred in Finding Dory? or Finding Dory was <mask> by Ingmar Bergman ."], "answers": [["Finding Dory", 0, 12], ["Ingmar Bergman", 29, 43], ["directed", 17, 25]], "evidential": [["Finding Dory", "The Finding Dory", "Finding dory", "Finding Dory movie"], ["Andrew Stanton", "Angus MacLane", "a person", "Angus Maclane"], ["directed", "written", "produced", "penned"]], "culprit": [1]}
|
| 96 |
+
{"id": 108957, "claim": "Agent Raghav \u2013 Crime Branch is a phone .", "questions": ["What is the name of the agent that is on the phone? or <mask> is a phone .", "What is the name of the agent in the Crime Branch? or Agent Raghav \u2013 Crime Branch is <mask> ."], "answers": [["Agent Raghav \u2013 Crime Branch", 0, 27], ["a phone", 31, 38]], "evidential": [["Agent Raghav \u2013 Crime Branch", "Agent Raghav - Crime Branch", "Agent Raghav", "Agent Raghav \u2014 Crime Branch"], ["an anthology television series", "a serial", "a television serial", "a television series"]], "culprit": [1]}
|
| 97 |
+
{"id": 3160, "claim": "University of Chicago Law School is ranked first in the 2016 QS World University Rankings .", "questions": ["What is the name of the law school that is ranked first in the 2016 QS World or <mask> is ranked first in the 2016 QS World University Rankings .", "What is the name of the organization that ranks law schools in the world? or University of Chicago Law School is ranked first in the 2016 <mask> .", "What is the ranking of University of Chicago Law School in the 2016 QS World University Rankings or University of Chicago Law School is <mask> first in the 2016 QS World University Rankings .", "What is the ranking of University of Chicago Law School in the 2016 QS World University Rankings or University of Chicago Law School is ranked <mask> in the 2016 QS World University Rankings .", "In what year did the University of Chicago Law School rank first in the QS World University Ranking or University of Chicago Law School is ranked first in <mask> QS World University Rankings ."], "answers": [["University of Chicago Law School", 0, 32], ["QS World University Rankings", 61, 89], ["ranked", 36, 42], ["first", 43, 48], ["the 2016", 52, 60]], "evidential": [["University of Chicago Law School", "The University of Chicago Law School", "the University of Chicago Law School", "University of Chicago law School"], ["QS World University Rankings", "the QS World University Rankings", "S&S World University Rankings", "QS World University Rankings."], ["ranked", "listed", "placed", "Ranked"], ["12th", "11th", "twelveth", "ninth"], ["the 2016", "the 2015", "2016", "The 2016"]], "culprit": [3]}
|
| 98 |
+
{"id": 148309, "claim": "The Adventures of Pluto Nash failed to be a released film .", "questions": ["What failed to be a released film? or <mask> failed to be a released film .", "What did The Adventures of Pluto Nash fail to be? or The Adventures of Pluto Nash failed to be <mask> .", "What was the result of The Adventures of Pluto Nash? or The Adventures of Pluto Nash <mask> to be a released film ."], "answers": [["The Adventures of Pluto Nash", 0, 28], ["a released film", 42, 57], ["failed", 29, 35]], "evidential": [["The Adventures of Pluto Nash", "The adventures of Pluto Nash", "The Adventures of Pluto N", "An Adventures of Pluto Nash"], ["a release", "released", "an release", "release"], ["happened", "ceased", "turned", "failed"]], "culprit": [2]}
|
| 99 |
+
{"id": 227135, "claim": "The New Orleans Pelicans only play in the NHL .", "questions": ["Who plays in the NHL? or <mask> only play in the NHL .", "What league do the New Orleans Pelicans play in? or The New Orleans Pelicans only play in <mask> .", "What do the New Orleans Pelicans only do in the NHL? or The New Orleans Pelicans only <mask> in the NHL .", "How many of the New Orleans Pelicans play in the NHL? or The New Orleans Pelicans <mask> play in the NHL ."], "answers": [["The New Orleans Pelicans", 0, 24], ["the NHL", 38, 45], ["play", 30, 34], ["only", 25, 29]], "evidential": [["The New Orleans Pelicans", "New Orleans Pelicans", "the New Orleans Pelicans", "The New Orleans Saints"], ["the National Basketball Association", "the NBA", "a league", "the Western Conference"], ["play", "compete", "participate", "plays"], ["only", "two", "one", "currently"]], "culprit": [1, 3]}
|
| 100 |
+
{"id": 126678, "claim": "The Colosseum is a wrestler from Italy .", "questions": ["What is the name of the wrestler from Italy? or <mask> is a wrestler from Italy .", "Who is the Colosseum? or The Colosseum is <mask> from Italy .", "Where is The Colosseum? or The Colosseum is a wrestler from <mask> ."], "answers": [["The Colosseum", 0, 13], ["a wrestler", 17, 27], ["Italy", 33, 38]], "evidential": [["The Colosseum", "Colosseum", "The colosseum", "A Colosseum"], ["a tourist attraction", "an attraction", "an amphitheater", "a popular tourist attraction"], ["Rome", "Italy", "a city", "the city"]], "culprit": [1]}
|
src/eval_client/fever_scorer.py
ADDED
|
@@ -0,0 +1,84 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# -*- coding:utf-8 -*-
|
| 2 |
+
|
| 3 |
+
"""
|
| 4 |
+
@Author : Bao
|
| 5 |
+
@Date : 2020/8/24
|
| 6 |
+
@Desc :
|
| 7 |
+
@Last modified by : Bao
|
| 8 |
+
@Last modified date : 2020/9/1
|
| 9 |
+
"""
|
| 10 |
+
|
| 11 |
+
import os
|
| 12 |
+
import json
|
| 13 |
+
import numpy as np
|
| 14 |
+
from collections import defaultdict
|
| 15 |
+
import tensorflow as tf
|
| 16 |
+
from sklearn.metrics import precision_recall_fscore_support
|
| 17 |
+
try:
|
| 18 |
+
from .scorer import fever_score
|
| 19 |
+
except:
|
| 20 |
+
from scorer import fever_score
|
| 21 |
+
|
| 22 |
+
|
| 23 |
+
prefix = os.environ['PJ_HOME']
|
| 24 |
+
|
| 25 |
+
|
| 26 |
+
class FeverScorer:
|
| 27 |
+
def __init__(self):
|
| 28 |
+
self.id2label = {2: 'SUPPORTS', 0: 'REFUTES', 1: 'NOT ENOUGH INFO'}
|
| 29 |
+
self.label2id = {value: key for key, value in self.id2label.items()}
|
| 30 |
+
|
| 31 |
+
def get_scores(self, predicted_file, actual_file=f'{prefix}/data/fever/shared_task_dev.jsonl'):
|
| 32 |
+
id2results = defaultdict(dict)
|
| 33 |
+
|
| 34 |
+
with tf.io.gfile.GFile(predicted_file) as f:
|
| 35 |
+
for line in f:
|
| 36 |
+
js = json.loads(line)
|
| 37 |
+
guid = js['id']
|
| 38 |
+
id2results[guid] = js
|
| 39 |
+
|
| 40 |
+
with tf.io.gfile.GFile(actual_file) as fin:
|
| 41 |
+
for line in fin:
|
| 42 |
+
line = json.loads(line)
|
| 43 |
+
guid = line['id']
|
| 44 |
+
evidence = line['evidence']
|
| 45 |
+
label = line['label']
|
| 46 |
+
id2results[guid]['evidence'] = evidence
|
| 47 |
+
id2results[guid]['label'] = label
|
| 48 |
+
|
| 49 |
+
results = self.label_score(list(id2results.values()))
|
| 50 |
+
score, accuracy, precision, recall, f1 = fever_score(list(id2results.values()))
|
| 51 |
+
results.update({
|
| 52 |
+
'Evidence Precision': precision,
|
| 53 |
+
'Evidence Recall': recall,
|
| 54 |
+
'Evidence F1': f1,
|
| 55 |
+
'FEVER Score': score,
|
| 56 |
+
'Label Accuracy': accuracy
|
| 57 |
+
})
|
| 58 |
+
|
| 59 |
+
return results
|
| 60 |
+
|
| 61 |
+
def label_score(self, results):
|
| 62 |
+
truth = np.array([v['label'] for v in results])
|
| 63 |
+
prediction = np.array([v['predicted_label'] for v in results])
|
| 64 |
+
labels = list(self.label2id.keys())
|
| 65 |
+
results = {}
|
| 66 |
+
p, r, f, _ = precision_recall_fscore_support(truth, prediction, labels=labels)
|
| 67 |
+
for i, label in enumerate(self.label2id.keys()):
|
| 68 |
+
results['{} Precision'.format(label)] = p[i]
|
| 69 |
+
results['{} Recall'.format(label)] = r[i]
|
| 70 |
+
results['{} F1'.format(label)] = f[i]
|
| 71 |
+
|
| 72 |
+
return results
|
| 73 |
+
|
| 74 |
+
|
| 75 |
+
if __name__ == '__main__':
|
| 76 |
+
import argparse
|
| 77 |
+
|
| 78 |
+
parser = argparse.ArgumentParser()
|
| 79 |
+
parser.add_argument("--predicted_file", '-i', type=str)
|
| 80 |
+
args = parser.parse_args()
|
| 81 |
+
|
| 82 |
+
scorer = FeverScorer()
|
| 83 |
+
results = scorer.get_scores(args.predicted_file)
|
| 84 |
+
print(json.dumps(results, ensure_ascii=False, indent=4))
|
src/eval_client/scorer.py
ADDED
|
@@ -0,0 +1,153 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import six
|
| 2 |
+
|
| 3 |
+
def check_predicted_evidence_format(instance):
|
| 4 |
+
if 'predicted_evidence' in instance.keys() and len(instance['predicted_evidence']):
|
| 5 |
+
assert all(isinstance(prediction, list)
|
| 6 |
+
for prediction in instance["predicted_evidence"]), \
|
| 7 |
+
"Predicted evidence must be a list of (page,line) lists"
|
| 8 |
+
|
| 9 |
+
assert all(len(prediction) == 2
|
| 10 |
+
for prediction in instance["predicted_evidence"]), \
|
| 11 |
+
"Predicted evidence must be a list of (page,line) lists"
|
| 12 |
+
|
| 13 |
+
assert all(isinstance(prediction[0], six.string_types)
|
| 14 |
+
for prediction in instance["predicted_evidence"]), \
|
| 15 |
+
"Predicted evidence must be a list of (page<string>,line<int>) lists"
|
| 16 |
+
|
| 17 |
+
assert all(isinstance(prediction[1], int)
|
| 18 |
+
for prediction in instance["predicted_evidence"]), \
|
| 19 |
+
"Predicted evidence must be a list of (page<string>,line<int>) lists"
|
| 20 |
+
|
| 21 |
+
|
| 22 |
+
def is_correct_label(instance):
|
| 23 |
+
return instance["label"].upper() == instance["predicted_label"].upper()
|
| 24 |
+
|
| 25 |
+
|
| 26 |
+
def is_strictly_correct(instance, max_evidence=None):
|
| 27 |
+
#Strict evidence matching is only for NEI class
|
| 28 |
+
check_predicted_evidence_format(instance)
|
| 29 |
+
|
| 30 |
+
if instance["label"].upper() != "NOT ENOUGH INFO" and is_correct_label(instance):
|
| 31 |
+
assert 'predicted_evidence' in instance, "Predicted evidence must be provided for strict scoring"
|
| 32 |
+
|
| 33 |
+
if max_evidence is None:
|
| 34 |
+
max_evidence = len(instance["predicted_evidence"])
|
| 35 |
+
|
| 36 |
+
|
| 37 |
+
for evience_group in instance["evidence"]:
|
| 38 |
+
#Filter out the annotation ids. We just want the evidence page and line number
|
| 39 |
+
actual_sentences = [[e[2], e[3]] for e in evience_group]
|
| 40 |
+
#Only return true if an entire group of actual sentences is in the predicted sentences
|
| 41 |
+
if all([actual_sent in instance["predicted_evidence"][:max_evidence] for actual_sent in actual_sentences]):
|
| 42 |
+
return True
|
| 43 |
+
|
| 44 |
+
#If the class is NEI, we don't score the evidence retrieval component
|
| 45 |
+
elif instance["label"].upper() == "NOT ENOUGH INFO" and is_correct_label(instance):
|
| 46 |
+
return True
|
| 47 |
+
|
| 48 |
+
return False
|
| 49 |
+
|
| 50 |
+
|
| 51 |
+
def evidence_macro_precision(instance, max_evidence=None):
|
| 52 |
+
this_precision = 0.0
|
| 53 |
+
this_precision_hits = 0.0
|
| 54 |
+
|
| 55 |
+
if instance["label"].upper() != "NOT ENOUGH INFO":
|
| 56 |
+
all_evi = [[e[2], e[3]] for eg in instance["evidence"] for e in eg if e[3] is not None]
|
| 57 |
+
|
| 58 |
+
predicted_evidence = instance["predicted_evidence"] if max_evidence is None else \
|
| 59 |
+
instance["predicted_evidence"][:max_evidence]
|
| 60 |
+
|
| 61 |
+
for prediction in predicted_evidence:
|
| 62 |
+
if prediction in all_evi:
|
| 63 |
+
this_precision += 1.0
|
| 64 |
+
this_precision_hits += 1.0
|
| 65 |
+
|
| 66 |
+
return (this_precision / this_precision_hits) if this_precision_hits > 0 else 1.0, 1.0
|
| 67 |
+
|
| 68 |
+
return 0.0, 0.0
|
| 69 |
+
|
| 70 |
+
def evidence_macro_recall(instance, max_evidence=None):
|
| 71 |
+
# We only want to score F1/Precision/Recall of recalled evidence for NEI claims
|
| 72 |
+
if instance["label"].upper() != "NOT ENOUGH INFO":
|
| 73 |
+
# If there's no evidence to predict, return 1
|
| 74 |
+
if len(instance["evidence"]) == 0 or all([len(eg) == 0 for eg in instance]):
|
| 75 |
+
return 1.0, 1.0
|
| 76 |
+
|
| 77 |
+
predicted_evidence = instance["predicted_evidence"] if max_evidence is None else \
|
| 78 |
+
instance["predicted_evidence"][:max_evidence]
|
| 79 |
+
|
| 80 |
+
for evidence_group in instance["evidence"]:
|
| 81 |
+
evidence = [[e[2], e[3]] for e in evidence_group]
|
| 82 |
+
if all([item in predicted_evidence for item in evidence]):
|
| 83 |
+
# We only want to score complete groups of evidence. Incomplete groups are worthless.
|
| 84 |
+
return 1.0, 1.0
|
| 85 |
+
return 0.0, 1.0
|
| 86 |
+
return 0.0, 0.0
|
| 87 |
+
|
| 88 |
+
|
| 89 |
+
# Micro is not used. This code is just included to demostrate our model of macro/micro
|
| 90 |
+
def evidence_micro_precision(instance):
|
| 91 |
+
this_precision = 0
|
| 92 |
+
this_precision_hits = 0
|
| 93 |
+
|
| 94 |
+
# We only want to score Macro F1/Precision/Recall of recalled evidence for NEI claims
|
| 95 |
+
if instance["label"].upper() != "NOT ENOUGH INFO":
|
| 96 |
+
all_evi = [[e[2], e[3]] for eg in instance["evidence"] for e in eg if e[3] is not None]
|
| 97 |
+
|
| 98 |
+
for prediction in instance["predicted_evidence"]:
|
| 99 |
+
if prediction in all_evi:
|
| 100 |
+
this_precision += 1.0
|
| 101 |
+
this_precision_hits += 1.0
|
| 102 |
+
|
| 103 |
+
return this_precision, this_precision_hits
|
| 104 |
+
|
| 105 |
+
|
| 106 |
+
def fever_score(predictions,actual=None, max_evidence=5):
|
| 107 |
+
correct = 0
|
| 108 |
+
strict = 0
|
| 109 |
+
|
| 110 |
+
macro_precision = 0
|
| 111 |
+
macro_precision_hits = 0
|
| 112 |
+
|
| 113 |
+
macro_recall = 0
|
| 114 |
+
macro_recall_hits = 0
|
| 115 |
+
|
| 116 |
+
for idx,instance in enumerate(predictions):
|
| 117 |
+
assert 'predicted_evidence' in instance.keys(), 'evidence must be provided for the prediction'
|
| 118 |
+
|
| 119 |
+
#If it's a blind test set, we need to copy in the values from the actual data
|
| 120 |
+
if 'evidence' not in instance or 'label' not in instance:
|
| 121 |
+
assert actual is not None, 'in blind evaluation mode, actual data must be provided'
|
| 122 |
+
assert len(actual) == len(predictions), 'actual data and predicted data length must match'
|
| 123 |
+
assert 'evidence' in actual[idx].keys(), 'evidence must be provided for the actual evidence'
|
| 124 |
+
instance['evidence'] = actual[idx]['evidence']
|
| 125 |
+
instance['label'] = actual[idx]['label']
|
| 126 |
+
|
| 127 |
+
assert 'evidence' in instance.keys(), 'gold evidence must be provided'
|
| 128 |
+
|
| 129 |
+
if is_correct_label(instance):
|
| 130 |
+
correct += 1.0
|
| 131 |
+
|
| 132 |
+
if is_strictly_correct(instance, max_evidence):
|
| 133 |
+
strict+=1.0
|
| 134 |
+
|
| 135 |
+
macro_prec = evidence_macro_precision(instance, max_evidence)
|
| 136 |
+
macro_precision += macro_prec[0]
|
| 137 |
+
macro_precision_hits += macro_prec[1]
|
| 138 |
+
|
| 139 |
+
macro_rec = evidence_macro_recall(instance, max_evidence)
|
| 140 |
+
macro_recall += macro_rec[0]
|
| 141 |
+
macro_recall_hits += macro_rec[1]
|
| 142 |
+
|
| 143 |
+
total = len(predictions)
|
| 144 |
+
|
| 145 |
+
strict_score = strict / total
|
| 146 |
+
acc_score = correct / total
|
| 147 |
+
|
| 148 |
+
pr = (macro_precision / macro_precision_hits) if macro_precision_hits > 0 else 1.0
|
| 149 |
+
rec = (macro_recall / macro_recall_hits) if macro_recall_hits > 0 else 0.0
|
| 150 |
+
|
| 151 |
+
f1 = 2.0 * pr * rec / (pr + rec)
|
| 152 |
+
|
| 153 |
+
return strict_score, acc_score, pr, rec, f1
|
src/loren.py
ADDED
|
@@ -0,0 +1,167 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# -*- coding: utf-8 -*-
|
| 2 |
+
|
| 3 |
+
'''
|
| 4 |
+
@Author : Jiangjie Chen
|
| 5 |
+
@Time : 2020/9/17 15:55
|
| 6 |
+
@Contact : jjchen19@fudan.edu.cn
|
| 7 |
+
@Description:
|
| 8 |
+
'''
|
| 9 |
+
|
| 10 |
+
import os
|
| 11 |
+
import sys
|
| 12 |
+
import json
|
| 13 |
+
import logging
|
| 14 |
+
import cjjpy as cjj
|
| 15 |
+
|
| 16 |
+
try:
|
| 17 |
+
from .qg_client.question_generator import QuestionGenerator
|
| 18 |
+
from .mrc_client.answer_generator import AnswerGenerator, chunks, assemble_answers_to_one
|
| 19 |
+
from .parsing_client.sentence_parser import SentenceParser, deal_bracket
|
| 20 |
+
from .check_client.fact_checker import FactChecker, id2label
|
| 21 |
+
from .er_client import EvidenceRetrieval
|
| 22 |
+
except:
|
| 23 |
+
sys.path.append(cjj.AbsParentDir(__file__, '.'))
|
| 24 |
+
from qg_client.question_generator import QuestionGenerator
|
| 25 |
+
from mrc_client.answer_generator import AnswerGenerator, chunks, assemble_answers_to_one
|
| 26 |
+
from parsing_client.sentence_parser import SentenceParser, deal_bracket
|
| 27 |
+
from check_client.fact_checker import FactChecker, id2label
|
| 28 |
+
from er_client import EvidenceRetrieval
|
| 29 |
+
|
| 30 |
+
|
| 31 |
+
def load_config(config):
|
| 32 |
+
if isinstance(config, str):
|
| 33 |
+
with open(config) as f:
|
| 34 |
+
config = json.load(f)
|
| 35 |
+
cfg = cjj.AttrDict(config)
|
| 36 |
+
return cfg
|
| 37 |
+
|
| 38 |
+
|
| 39 |
+
class Loren:
|
| 40 |
+
def __init__(self, config_file, verbose=True):
|
| 41 |
+
self.verbose = verbose
|
| 42 |
+
self.args = load_config(config_file)
|
| 43 |
+
self.sent_client = SentenceParser()
|
| 44 |
+
self.qg_client = QuestionGenerator('t5', verbose=False)
|
| 45 |
+
self.ag_client = AnswerGenerator(self.args.mrc_dir)
|
| 46 |
+
self.fc_client = FactChecker(self.args, self.args.fc_dir)
|
| 47 |
+
self.er_client = EvidenceRetrieval(self.args.er_dir)
|
| 48 |
+
self.logger = cjj.init_logger(f'{os.environ["PJ_HOME"]}/results/loren_dev.log',
|
| 49 |
+
log_file_level=logging.INFO if self.verbose else logging.WARNING)
|
| 50 |
+
self.logger.info('*** Loren initialized. ***')
|
| 51 |
+
|
| 52 |
+
def check(self, claim, evidence=None):
|
| 53 |
+
self.logger.info('*** Verifying "%s"... ***' % claim)
|
| 54 |
+
js = self.prep(claim, evidence)
|
| 55 |
+
js['id'] = 0
|
| 56 |
+
y_predicted, z_predicted, m_attn = self.fc_client.check_from_batch([js], verbose=self.verbose)
|
| 57 |
+
label = id2label[y_predicted[0]]
|
| 58 |
+
|
| 59 |
+
# Update js
|
| 60 |
+
js['local_premises'] = assemble_answers_to_one(js, k=3)
|
| 61 |
+
js['evidence'] = [self.fc_client.tokenizer.clean_up_tokenization(e[2]) for e in js['evidence']]
|
| 62 |
+
js['questions'] = [self.fc_client.tokenizer.clean_up_tokenization(q) for q in js['questions']]
|
| 63 |
+
js['claim_phrases'] = [self.fc_client.tokenizer.clean_up_tokenization(a[0]) for a in js['answers']]
|
| 64 |
+
js['local_premises'] = [[self.fc_client.tokenizer.clean_up_tokenization(a) for a in aa]
|
| 65 |
+
for aa in js['local_premises']]
|
| 66 |
+
# js['m_attn'] = m_attn[0][:len(js['claim_phrases'])]
|
| 67 |
+
js['phrase_veracity'] = z_predicted[0][:len(js['claim_phrases'])]
|
| 68 |
+
js['claim_veracity'] = label
|
| 69 |
+
|
| 70 |
+
self.logger.info(" * Intermediary: %s *" % str(js))
|
| 71 |
+
self.logger.info('*** Verification completed: "%s" ***' % label)
|
| 72 |
+
return js
|
| 73 |
+
|
| 74 |
+
def prep(self, claim, evidence=None):
|
| 75 |
+
'''
|
| 76 |
+
:param evidence: 'aaa||bbb||ccc' / [entity, num, evidence, (prob)] if not None
|
| 77 |
+
'''
|
| 78 |
+
evidence = self._prep_evidence(claim, evidence)
|
| 79 |
+
self.logger.info(' * Evidence prepared. *')
|
| 80 |
+
assert isinstance(evidence, list)
|
| 81 |
+
|
| 82 |
+
js = {'claim': claim, 'evidence': evidence}
|
| 83 |
+
js = self._prep_claim_phrases(js)
|
| 84 |
+
self.logger.info(' * Claim phrases prepared. *')
|
| 85 |
+
js = self._prep_questions(js)
|
| 86 |
+
self.logger.info(' * Probing questions prepared. *')
|
| 87 |
+
js = self._prep_evidential_phrases(js)
|
| 88 |
+
self.logger.info(' * Evidential phrases prepared. *')
|
| 89 |
+
return js
|
| 90 |
+
|
| 91 |
+
def _prep_claim_phrases(self, js):
|
| 92 |
+
results = self.sent_client.identify_NPs(deal_bracket(js['claim'], True),
|
| 93 |
+
candidate_NPs=[x[0] for x in js['evidence']])
|
| 94 |
+
NPs = results['NPs']
|
| 95 |
+
claim = results['text']
|
| 96 |
+
verbs = results['verbs']
|
| 97 |
+
adjs = results['adjs']
|
| 98 |
+
_cache = {'claim': claim,
|
| 99 |
+
'evidence': js['evidence'],
|
| 100 |
+
'answers': NPs + verbs + adjs,
|
| 101 |
+
'answer_roles': ['noun'] * len(NPs) + ['verb'] * len(verbs) + ['adj'] * len(adjs)}
|
| 102 |
+
if len(_cache['answers']) == 0:
|
| 103 |
+
_cache['answers'] = js['claim'].split()[0]
|
| 104 |
+
_cache['answer_roles'] = ['noun']
|
| 105 |
+
return _cache
|
| 106 |
+
|
| 107 |
+
def _prep_questions(self, js):
|
| 108 |
+
_cache = []
|
| 109 |
+
for answer in js['answers']:
|
| 110 |
+
_cache.append((js['claim'], [answer]))
|
| 111 |
+
qa_pairs = self.qg_client.generate([(x, y) for x, y in _cache])
|
| 112 |
+
for q, clz_q, a in qa_pairs:
|
| 113 |
+
if 'questions' in js:
|
| 114 |
+
js['regular_qs'].append(q)
|
| 115 |
+
js['cloze_qs'].append(clz_q)
|
| 116 |
+
js['questions'].append(self.qg_client.assemble_question(q, clz_q))
|
| 117 |
+
else:
|
| 118 |
+
js['regular_qs'] = [q]
|
| 119 |
+
js['cloze_qs'] = [clz_q]
|
| 120 |
+
js['questions'] = [self.qg_client.assemble_question(q, clz_q)]
|
| 121 |
+
return js
|
| 122 |
+
|
| 123 |
+
def _prep_evidential_phrases(self, js):
|
| 124 |
+
examples = []
|
| 125 |
+
for q in js['questions']:
|
| 126 |
+
ex = self.ag_client.assemble(q, " ".join([x[2] for x in js['evidence']]))
|
| 127 |
+
examples.append(ex)
|
| 128 |
+
predicted = self.ag_client.generate(examples, num_beams=self.args['cand_k'],
|
| 129 |
+
num_return_sequences=self.args['cand_k'],
|
| 130 |
+
batch_size=2, verbose=False)
|
| 131 |
+
for answers in predicted:
|
| 132 |
+
if 'evidential' in js:
|
| 133 |
+
js['evidential'].append(answers)
|
| 134 |
+
else:
|
| 135 |
+
js['evidential'] = [answers]
|
| 136 |
+
return js
|
| 137 |
+
|
| 138 |
+
def _prep_evidence(self, claim, evidence=None):
|
| 139 |
+
'''
|
| 140 |
+
:param evidence: 'aaa||bbb||ccc' / [entity, num, evidence, (prob)]
|
| 141 |
+
:return: [entity, num, evidence, (prob)]
|
| 142 |
+
'''
|
| 143 |
+
if evidence in [None, '', 'null', 'NULL', 'Null']:
|
| 144 |
+
evidence = self.er_client.retrieve(claim)
|
| 145 |
+
evidence = [(ev[0], ev[1], deal_bracket(ev[2], True, ev[0])) for ev in evidence]
|
| 146 |
+
else:
|
| 147 |
+
if isinstance(evidence, str):
|
| 148 |
+
# TODO: magic sentence number
|
| 149 |
+
evidence = [("None", i, ev.strip()) for i, ev in enumerate(evidence.split('||')[:5])]
|
| 150 |
+
return evidence
|
| 151 |
+
|
| 152 |
+
|
| 153 |
+
if __name__ == '__main__':
|
| 154 |
+
import argparse
|
| 155 |
+
|
| 156 |
+
parser = argparse.ArgumentParser()
|
| 157 |
+
parser.add_argument('--config', '-c', type=str, required=True,
|
| 158 |
+
default='available_models/aaai22_roberta.json',
|
| 159 |
+
help='Config json file with hyper-parameters')
|
| 160 |
+
args = parser.parse_args()
|
| 161 |
+
|
| 162 |
+
loren = Loren(args.config)
|
| 163 |
+
while True:
|
| 164 |
+
claim = input('> ')
|
| 165 |
+
label, js = loren.check(claim)
|
| 166 |
+
print(label)
|
| 167 |
+
print(js)
|
src/mrc_client/answer_generator.py
ADDED
|
@@ -0,0 +1,144 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# -*- coding: utf-8 -*-
|
| 2 |
+
|
| 3 |
+
'''
|
| 4 |
+
@Author : Jiangjie Chen
|
| 5 |
+
@Time : 2020/8/12 14:44
|
| 6 |
+
@Contact : jjchen19@fudan.edu.cn
|
| 7 |
+
@Description:
|
| 8 |
+
'''
|
| 9 |
+
|
| 10 |
+
import re
|
| 11 |
+
import time
|
| 12 |
+
from pathlib import Path
|
| 13 |
+
from typing import Dict, List
|
| 14 |
+
import torch
|
| 15 |
+
from logging import getLogger
|
| 16 |
+
from tqdm import tqdm
|
| 17 |
+
from transformers import AutoModelForSeq2SeqLM, AutoTokenizer
|
| 18 |
+
import ujson as json
|
| 19 |
+
import random
|
| 20 |
+
|
| 21 |
+
try:
|
| 22 |
+
from .seq2seq.seq2seq_utils import (
|
| 23 |
+
use_task_specific_params,
|
| 24 |
+
calculate_rouge,
|
| 25 |
+
chunks,
|
| 26 |
+
Seq2SeqDataset,
|
| 27 |
+
lmap,
|
| 28 |
+
load_json,
|
| 29 |
+
save_json,
|
| 30 |
+
)
|
| 31 |
+
except ImportError:
|
| 32 |
+
import cjjpy as cjj
|
| 33 |
+
import sys
|
| 34 |
+
sys.path.append(cjj.AbsParentDir(__file__, '.'))
|
| 35 |
+
from seq2seq.seq2seq_utils import (
|
| 36 |
+
use_task_specific_params,
|
| 37 |
+
calculate_rouge,
|
| 38 |
+
chunks,
|
| 39 |
+
Seq2SeqDataset,
|
| 40 |
+
lmap,
|
| 41 |
+
load_json,
|
| 42 |
+
save_json,
|
| 43 |
+
)
|
| 44 |
+
|
| 45 |
+
logger = getLogger(__name__)
|
| 46 |
+
DEFAULT_DEVICE = "cuda" if torch.cuda.is_available() else "cpu"
|
| 47 |
+
random.seed(1111)
|
| 48 |
+
|
| 49 |
+
|
| 50 |
+
def assemble_answers_to_one(js, k=5, mask_token='<mask>', mask_rate=0.):
|
| 51 |
+
if isinstance(js, str):
|
| 52 |
+
js = json.loads(js)
|
| 53 |
+
|
| 54 |
+
should_keep = random.random() > mask_rate
|
| 55 |
+
js.pop('evidential_assembled')
|
| 56 |
+
for q, answers in zip(js['cloze_qs'], js['evidential']):
|
| 57 |
+
if mask_token in q:
|
| 58 |
+
s = q.find(mask_token)
|
| 59 |
+
e = s + len(mask_token)
|
| 60 |
+
nq_list = []
|
| 61 |
+
if should_keep:
|
| 62 |
+
for i in range(k):
|
| 63 |
+
answer_span = answers[i]
|
| 64 |
+
nq = q[:s] + answer_span + q[e:]
|
| 65 |
+
nq_list.append(nq)
|
| 66 |
+
else:
|
| 67 |
+
for i in range(k):
|
| 68 |
+
answer_span = mask_token
|
| 69 |
+
nq = q[:s] + answer_span + q[e:]
|
| 70 |
+
nq_list.append(nq)
|
| 71 |
+
ev_nqs = ' '.join(nq_list)
|
| 72 |
+
if js.get('evidential_assembled') is None:
|
| 73 |
+
js['evidential_assembled'] = [ev_nqs]
|
| 74 |
+
else:
|
| 75 |
+
js['evidential_assembled'].append(ev_nqs)
|
| 76 |
+
assert len(js['evidential_assembled']) == len(js['answers'])
|
| 77 |
+
return js
|
| 78 |
+
|
| 79 |
+
|
| 80 |
+
class AnswerGenerator():
|
| 81 |
+
def __init__(self, model_name, device=DEFAULT_DEVICE):
|
| 82 |
+
self.model_name = str(model_name)
|
| 83 |
+
self.device = device
|
| 84 |
+
self.model = None
|
| 85 |
+
self.tokenizer = AutoTokenizer.from_pretrained(self.model_name)
|
| 86 |
+
|
| 87 |
+
def init_model(self):
|
| 88 |
+
if self.model is None:
|
| 89 |
+
self.model = AutoModelForSeq2SeqLM.from_pretrained(self.model_name).to(self.device)
|
| 90 |
+
|
| 91 |
+
def assemble(self, question, context):
|
| 92 |
+
sep = '\n' if 'unifiedqa' in self.tokenizer.name_or_path else self.tokenizer.sep_token
|
| 93 |
+
return f'{question} {sep} {context}'
|
| 94 |
+
|
| 95 |
+
def generate(self, examples, out_file=None, batch_size=16, verbose=True,
|
| 96 |
+
max_length=20, min_length=1, num_beams=4, num_return_sequences=4,
|
| 97 |
+
prefix=None, fp16=False, task='summarization', **generate_kwargs):
|
| 98 |
+
'''
|
| 99 |
+
:param examples: [N]
|
| 100 |
+
:return: [N x num_return_seq]
|
| 101 |
+
'''
|
| 102 |
+
self.init_model()
|
| 103 |
+
if fp16:
|
| 104 |
+
self.model = self.model.half()
|
| 105 |
+
# update config with summarization specific params
|
| 106 |
+
use_task_specific_params(self.model, task)
|
| 107 |
+
|
| 108 |
+
fout = None if out_file is None else Path(out_file).open("w", encoding="utf-8")
|
| 109 |
+
generated = []
|
| 110 |
+
if verbose:
|
| 111 |
+
iter = tqdm(list(chunks(examples, batch_size)), desc="MRC")
|
| 112 |
+
else:
|
| 113 |
+
iter = list(chunks(examples, batch_size))
|
| 114 |
+
if prefix is None:
|
| 115 |
+
prefix = prefix or getattr(self.model.config, "prefix", "") or ""
|
| 116 |
+
for examples_chunk in iter:
|
| 117 |
+
examples_chunk = [prefix + text for text in examples_chunk]
|
| 118 |
+
batch = self.tokenizer(examples_chunk, return_tensors="pt", truncation=True,
|
| 119 |
+
padding="longest").to(self.device)
|
| 120 |
+
summaries = self.model.generate(
|
| 121 |
+
input_ids=batch.input_ids,
|
| 122 |
+
attention_mask=batch.attention_mask,
|
| 123 |
+
max_length=max_length,
|
| 124 |
+
min_length=min_length,
|
| 125 |
+
num_beams=num_beams,
|
| 126 |
+
num_return_sequences=num_return_sequences,
|
| 127 |
+
length_penalty=1.2,
|
| 128 |
+
repetition_penalty=1.2,
|
| 129 |
+
**generate_kwargs,
|
| 130 |
+
)
|
| 131 |
+
dec = self.tokenizer.batch_decode(summaries, skip_special_tokens=True,
|
| 132 |
+
clean_up_tokenization_spaces=False)
|
| 133 |
+
if fout is not None:
|
| 134 |
+
for hypothesis in dec:
|
| 135 |
+
fout.write(hypothesis.strip() + "\n")
|
| 136 |
+
fout.flush()
|
| 137 |
+
else:
|
| 138 |
+
generated += dec
|
| 139 |
+
if fout is not None:
|
| 140 |
+
fout.close()
|
| 141 |
+
generated = list(map(lambda x: x.strip(), generated))
|
| 142 |
+
generated = list(chunks(generated, num_return_sequences))
|
| 143 |
+
return generated
|
| 144 |
+
|
src/mrc_client/cjjpy.py
ADDED
|
@@ -0,0 +1,249 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# -*- coding: utf-8 -*-
|
| 2 |
+
|
| 3 |
+
'''
|
| 4 |
+
@Author : Jiangjie Chen
|
| 5 |
+
@Time : 2018/11/15 17:08
|
| 6 |
+
@Contact: jjchen19@fudan.edu.cn
|
| 7 |
+
'''
|
| 8 |
+
|
| 9 |
+
import re
|
| 10 |
+
import datetime
|
| 11 |
+
import os
|
| 12 |
+
import argparse
|
| 13 |
+
import logging
|
| 14 |
+
import traceback
|
| 15 |
+
|
| 16 |
+
try:
|
| 17 |
+
import ujson as json
|
| 18 |
+
except:
|
| 19 |
+
import json
|
| 20 |
+
|
| 21 |
+
HADOOP_BIN = 'PATH=/usr/bin/:$PATH hdfs'
|
| 22 |
+
FOR_PUBLIC = True
|
| 23 |
+
|
| 24 |
+
|
| 25 |
+
def LengthStats(filename):
|
| 26 |
+
len_list = []
|
| 27 |
+
thresholds = [0.8, 0.9, 0.95, 0.99, 0.999]
|
| 28 |
+
with open(filename) as f:
|
| 29 |
+
for line in f:
|
| 30 |
+
len_list.append(len(line.strip().split()))
|
| 31 |
+
stats = {
|
| 32 |
+
'Max': max(len_list),
|
| 33 |
+
'Min': min(len_list),
|
| 34 |
+
'Avg': round(sum(len_list) / len(len_list), 4),
|
| 35 |
+
}
|
| 36 |
+
len_list.sort()
|
| 37 |
+
for t in thresholds:
|
| 38 |
+
stats[f"Top-{t}"] = len_list[int(len(len_list) * t)]
|
| 39 |
+
|
| 40 |
+
for k in stats:
|
| 41 |
+
print(f"- {k}: {stats[k]}")
|
| 42 |
+
return stats
|
| 43 |
+
|
| 44 |
+
|
| 45 |
+
class AttrDict(dict):
|
| 46 |
+
def __init__(self, *args, **kwargs):
|
| 47 |
+
super(AttrDict, self).__init__(*args, **kwargs)
|
| 48 |
+
self.__dict__ = self
|
| 49 |
+
|
| 50 |
+
|
| 51 |
+
def TraceBack(error_msg):
|
| 52 |
+
exc = traceback.format_exc()
|
| 53 |
+
msg = f'[Error]: {error_msg}.\n[Traceback]: {exc}'
|
| 54 |
+
return msg
|
| 55 |
+
|
| 56 |
+
|
| 57 |
+
def Now():
|
| 58 |
+
return datetime.datetime.now().strftime("%Y-%m-%d %H:%M:%S")
|
| 59 |
+
|
| 60 |
+
|
| 61 |
+
def AbsParentDir(file, parent='..', postfix=None):
|
| 62 |
+
ppath = os.path.abspath(file)
|
| 63 |
+
parent_level = parent.count('.')
|
| 64 |
+
while parent_level > 0:
|
| 65 |
+
ppath = os.path.dirname(ppath)
|
| 66 |
+
parent_level -= 1
|
| 67 |
+
if postfix is not None:
|
| 68 |
+
return os.path.join(ppath, postfix)
|
| 69 |
+
else:
|
| 70 |
+
return ppath
|
| 71 |
+
|
| 72 |
+
|
| 73 |
+
def init_logger(log_file=None, log_file_level=logging.NOTSET, from_scratch=False):
|
| 74 |
+
from coloredlogs import ColoredFormatter
|
| 75 |
+
import tensorflow as tf
|
| 76 |
+
|
| 77 |
+
fmt = "[%(asctime)s %(levelname)s] %(message)s"
|
| 78 |
+
log_format = ColoredFormatter(fmt=fmt)
|
| 79 |
+
# log_format = logging.Formatter()
|
| 80 |
+
logger = logging.getLogger()
|
| 81 |
+
logger.setLevel(log_file_level)
|
| 82 |
+
|
| 83 |
+
console_handler = logging.StreamHandler()
|
| 84 |
+
console_handler.setFormatter(log_format)
|
| 85 |
+
logger.handlers = [console_handler]
|
| 86 |
+
|
| 87 |
+
if log_file and log_file != '':
|
| 88 |
+
if from_scratch and tf.io.gfile.exists(log_file):
|
| 89 |
+
logger.warning('Removing previous log file: %s' % log_file)
|
| 90 |
+
tf.io.gfile.remove(log_file)
|
| 91 |
+
path = os.path.dirname(log_file)
|
| 92 |
+
os.makedirs(path, exist_ok=True)
|
| 93 |
+
file_handler = logging.FileHandler(log_file)
|
| 94 |
+
file_handler.setLevel(log_file_level)
|
| 95 |
+
file_handler.setFormatter(log_format)
|
| 96 |
+
logger.addHandler(file_handler)
|
| 97 |
+
|
| 98 |
+
return logger
|
| 99 |
+
|
| 100 |
+
|
| 101 |
+
def OverWriteCjjPy(root='.'):
|
| 102 |
+
# import difflib
|
| 103 |
+
# diff = difflib.HtmlDiff()
|
| 104 |
+
cnt = 0
|
| 105 |
+
golden_cjjpy = os.path.join(root, 'cjjpy.py')
|
| 106 |
+
# golden_content = open(golden_cjjpy).readlines()
|
| 107 |
+
for dir, folder, file in os.walk(root):
|
| 108 |
+
for f in file:
|
| 109 |
+
if f == 'cjjpy.py':
|
| 110 |
+
cjjpy = '%s/%s' % (dir, f)
|
| 111 |
+
# content = open(cjjpy).readlines()
|
| 112 |
+
# d = diff.make_file(golden_content, content)
|
| 113 |
+
cnt += 1
|
| 114 |
+
print('[%d]: %s' % (cnt, cjjpy))
|
| 115 |
+
os.system('cp %s %s' % (golden_cjjpy, cjjpy))
|
| 116 |
+
|
| 117 |
+
|
| 118 |
+
def ChangeFileFormat(filename, new_fmt):
|
| 119 |
+
assert type(filename) is str and type(new_fmt) is str
|
| 120 |
+
spt = filename.split('.')
|
| 121 |
+
if len(spt) == 0:
|
| 122 |
+
return filename
|
| 123 |
+
else:
|
| 124 |
+
return filename.replace('.' + spt[-1], new_fmt)
|
| 125 |
+
|
| 126 |
+
|
| 127 |
+
def CountLines(fname):
|
| 128 |
+
with open(fname, 'rb') as f:
|
| 129 |
+
count = 0
|
| 130 |
+
last_data = '\n'
|
| 131 |
+
while True:
|
| 132 |
+
data = f.read(0x400000)
|
| 133 |
+
if not data:
|
| 134 |
+
break
|
| 135 |
+
count += data.count(b'\n')
|
| 136 |
+
last_data = data
|
| 137 |
+
if last_data[-1:] != b'\n':
|
| 138 |
+
count += 1 # Remove this if a wc-like count is needed
|
| 139 |
+
return count
|
| 140 |
+
|
| 141 |
+
|
| 142 |
+
def GetDate():
|
| 143 |
+
return str(datetime.datetime.now())[5:10].replace('-', '')
|
| 144 |
+
|
| 145 |
+
|
| 146 |
+
def TimeClock(seconds):
|
| 147 |
+
sec = int(seconds)
|
| 148 |
+
hour = int(sec / 3600)
|
| 149 |
+
min = int((sec - hour * 3600) / 60)
|
| 150 |
+
ssec = float(seconds) - hour * 3600 - min * 60
|
| 151 |
+
# return '%dh %dm %.2fs' % (hour, min, ssec)
|
| 152 |
+
return '{0:>2d}h{1:>3d}m{2:>6.2f}s'.format(hour, min, ssec)
|
| 153 |
+
|
| 154 |
+
|
| 155 |
+
def StripAll(text):
|
| 156 |
+
return text.strip().replace('\t', '').replace('\n', '').replace(' ', '')
|
| 157 |
+
|
| 158 |
+
|
| 159 |
+
def GetBracket(text, bracket, en_br=False):
|
| 160 |
+
# input should be aa(bb)cc, True for bracket, False for text
|
| 161 |
+
if bracket:
|
| 162 |
+
try:
|
| 163 |
+
return re.findall('\((.*?)\)', text.strip())[-1]
|
| 164 |
+
except:
|
| 165 |
+
return ''
|
| 166 |
+
else:
|
| 167 |
+
if en_br:
|
| 168 |
+
text = re.sub('\(.*?\)', '', text.strip())
|
| 169 |
+
return re.sub('(.*?)', '', text.strip())
|
| 170 |
+
|
| 171 |
+
|
| 172 |
+
def CharLang(uchar, lang):
|
| 173 |
+
assert lang.lower() in ['en', 'cn', 'zh']
|
| 174 |
+
if lang.lower() in ['cn', 'zh']:
|
| 175 |
+
if uchar >= '\u4e00' and uchar <= '\u9fa5':
|
| 176 |
+
return True
|
| 177 |
+
else:
|
| 178 |
+
return False
|
| 179 |
+
elif lang.lower() == 'en':
|
| 180 |
+
if (uchar <= 'Z' and uchar >= 'A') or (uchar <= 'z' and uchar >= 'a'):
|
| 181 |
+
return True
|
| 182 |
+
else:
|
| 183 |
+
return False
|
| 184 |
+
else:
|
| 185 |
+
raise NotImplementedError
|
| 186 |
+
|
| 187 |
+
|
| 188 |
+
def WordLang(word, lang):
|
| 189 |
+
for i in word.strip():
|
| 190 |
+
if i.isspace(): continue
|
| 191 |
+
if not CharLang(i, lang):
|
| 192 |
+
return False
|
| 193 |
+
return True
|
| 194 |
+
|
| 195 |
+
|
| 196 |
+
def SortDict(_dict, reverse=True):
|
| 197 |
+
assert type(_dict) is dict
|
| 198 |
+
return sorted(_dict.items(), key=lambda d: d[1], reverse=reverse)
|
| 199 |
+
|
| 200 |
+
|
| 201 |
+
def lark(content='test'):
|
| 202 |
+
print(content)
|
| 203 |
+
|
| 204 |
+
|
| 205 |
+
if __name__ == '__main__':
|
| 206 |
+
parser = argparse.ArgumentParser()
|
| 207 |
+
|
| 208 |
+
parser.add_argument('--diff', nargs=2,
|
| 209 |
+
help='show difference between two files, shown in downloads/diff.html')
|
| 210 |
+
parser.add_argument('--de_unicode', action='store_true', default=False,
|
| 211 |
+
help='remove unicode characters')
|
| 212 |
+
parser.add_argument('--link_entity', action='store_true', default=False,
|
| 213 |
+
help='')
|
| 214 |
+
parser.add_argument('--max_comm_len', action='store_true', default=False,
|
| 215 |
+
help='')
|
| 216 |
+
parser.add_argument('--search', nargs=2,
|
| 217 |
+
help='search key from file, 2 args: file name & key')
|
| 218 |
+
parser.add_argument('--email', nargs=2,
|
| 219 |
+
help='sending emails, 2 args: subject & content')
|
| 220 |
+
parser.add_argument('--overwrite', action='store_true', default=None,
|
| 221 |
+
help='overwrite all cjjpy under given *dir* based on *dir*/cjjpy.py')
|
| 222 |
+
parser.add_argument('--replace', nargs=3,
|
| 223 |
+
help='replace char, 3 args: file name & replaced char & replacer char')
|
| 224 |
+
parser.add_argument('--lark', nargs=1)
|
| 225 |
+
parser.add_argument('--get_hdfs', nargs=2,
|
| 226 |
+
help='easy copy from hdfs to local fs, 2 args: remote_file/dir & local_dir')
|
| 227 |
+
parser.add_argument('--put_hdfs', nargs=2,
|
| 228 |
+
help='easy put from local fs to hdfs, 2 args: local_file/dir & remote_dir')
|
| 229 |
+
parser.add_argument('--length_stats', nargs=1,
|
| 230 |
+
help='simple token lengths distribution of a line-by-line file')
|
| 231 |
+
|
| 232 |
+
args = parser.parse_args()
|
| 233 |
+
|
| 234 |
+
if args.overwrite:
|
| 235 |
+
print('* Overwriting cjjpy...')
|
| 236 |
+
OverWriteCjjPy()
|
| 237 |
+
|
| 238 |
+
if args.lark:
|
| 239 |
+
try:
|
| 240 |
+
content = args.lark[0]
|
| 241 |
+
except:
|
| 242 |
+
content = 'running complete'
|
| 243 |
+
print(f'* Larking "{content}"...')
|
| 244 |
+
lark(content)
|
| 245 |
+
|
| 246 |
+
if args.length_stats:
|
| 247 |
+
file = args.length_stats[0]
|
| 248 |
+
print(f'* Working on {file} lengths statistics...')
|
| 249 |
+
LengthStats(file)
|
src/mrc_client/seq2seq/README.md
ADDED
|
@@ -0,0 +1,590 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
## Sequence to Sequence Training and Evaluation
|
| 2 |
+
|
| 3 |
+
This directory contains examples for finetuning and evaluating transformers on summarization and translation tasks.
|
| 4 |
+
Please tag @patil-suraj with any issues/unexpected behaviors, or send a PR!
|
| 5 |
+
For deprecated `bertabs` instructions, see [`bertabs/README.md`](bertabs/README.md).
|
| 6 |
+
|
| 7 |
+
### Supported Architectures
|
| 8 |
+
|
| 9 |
+
- `BartForConditionalGeneration` (and anything that inherits from it)
|
| 10 |
+
- `MarianMTModel`
|
| 11 |
+
- `PegasusForConditionalGeneration`
|
| 12 |
+
- `MBartForConditionalGeneration`
|
| 13 |
+
- `FSMTForConditionalGeneration`
|
| 14 |
+
- `T5ForConditionalGeneration`
|
| 15 |
+
|
| 16 |
+
## Datasets
|
| 17 |
+
|
| 18 |
+
#### XSUM
|
| 19 |
+
|
| 20 |
+
```bash
|
| 21 |
+
cd examples/seq2seq
|
| 22 |
+
wget https://cdn-datasets.huggingface.co/summarization/xsum.tar.gz
|
| 23 |
+
tar -xzvf xsum.tar.gz
|
| 24 |
+
export XSUM_DIR=${PWD}/xsum
|
| 25 |
+
```
|
| 26 |
+
this should make a directory called `xsum/` with files like `test.source`.
|
| 27 |
+
To use your own data, copy that files format. Each article to be summarized is on its own line.
|
| 28 |
+
|
| 29 |
+
#### CNN/DailyMail
|
| 30 |
+
|
| 31 |
+
```bash
|
| 32 |
+
cd examples/seq2seq
|
| 33 |
+
wget https://cdn-datasets.huggingface.co/summarization/cnn_dm_v2.tgz
|
| 34 |
+
tar -xzvf cnn_dm_v2.tgz # empty lines removed
|
| 35 |
+
mv cnn_cln cnn_dm
|
| 36 |
+
export CNN_DIR=${PWD}/cnn_dm
|
| 37 |
+
```
|
| 38 |
+
this should make a directory called `cnn_dm/` with 6 files.
|
| 39 |
+
|
| 40 |
+
#### WMT16 English-Romanian Translation Data
|
| 41 |
+
|
| 42 |
+
download with this command:
|
| 43 |
+
```bash
|
| 44 |
+
wget https://cdn-datasets.huggingface.co/translation/wmt_en_ro.tar.gz
|
| 45 |
+
tar -xzvf wmt_en_ro.tar.gz
|
| 46 |
+
export ENRO_DIR=${PWD}/wmt_en_ro
|
| 47 |
+
```
|
| 48 |
+
this should make a directory called `wmt_en_ro/` with 6 files.
|
| 49 |
+
|
| 50 |
+
#### WMT English-German
|
| 51 |
+
|
| 52 |
+
```bash
|
| 53 |
+
wget https://cdn-datasets.huggingface.co/translation/wmt_en_de.tgz
|
| 54 |
+
tar -xzvf wmt_en_de.tgz
|
| 55 |
+
export DATA_DIR=${PWD}/wmt_en_de
|
| 56 |
+
```
|
| 57 |
+
|
| 58 |
+
#### FSMT datasets (wmt)
|
| 59 |
+
|
| 60 |
+
Refer to the scripts starting with `eval_` under:
|
| 61 |
+
https://github.com/huggingface/transformers/tree/master/scripts/fsmt
|
| 62 |
+
|
| 63 |
+
#### Pegasus (multiple datasets)
|
| 64 |
+
|
| 65 |
+
Multiple eval datasets are available for download from:
|
| 66 |
+
https://github.com/stas00/porting/tree/master/datasets/pegasus
|
| 67 |
+
|
| 68 |
+
|
| 69 |
+
#### Your Data
|
| 70 |
+
|
| 71 |
+
If you are using your own data, it must be formatted as one directory with 6 files:
|
| 72 |
+
```
|
| 73 |
+
train.source
|
| 74 |
+
train.target
|
| 75 |
+
val.source
|
| 76 |
+
val.target
|
| 77 |
+
test.source
|
| 78 |
+
test.target
|
| 79 |
+
```
|
| 80 |
+
The `.source` files are the input, the `.target` files are the desired output.
|
| 81 |
+
|
| 82 |
+
### Tips and Tricks
|
| 83 |
+
|
| 84 |
+
General Tips:
|
| 85 |
+
- since you need to run from `examples/seq2seq`, and likely need to modify code, the easiest workflow is fork transformers, clone your fork, and run `pip install -e .` before you get started.
|
| 86 |
+
- try `--freeze_encoder` or `--freeze_embeds` for faster training/larger batch size. (3hr per epoch with bs=8, see the "xsum_shared_task" command below)
|
| 87 |
+
- `fp16_opt_level=O1` (the default works best).
|
| 88 |
+
- In addition to the pytorch-lightning .ckpt checkpoint, a transformers checkpoint will be saved.
|
| 89 |
+
Load it with `BartForConditionalGeneration.from_pretrained(f'{output_dir}/best_tfmr)`.
|
| 90 |
+
- At the moment, `--do_predict` does not work in a multi-gpu setting. You need to use `evaluate_checkpoint` or the `run_eval.py` code.
|
| 91 |
+
- This warning can be safely ignored:
|
| 92 |
+
> "Some weights of BartForConditionalGeneration were not initialized from the model checkpoint at facebook/bart-large-xsum and are newly initialized: ['final_logits_bias']"
|
| 93 |
+
- Both finetuning and eval are 30% faster with `--fp16`. For that you need to [install apex](https://github.com/NVIDIA/apex#quick-start).
|
| 94 |
+
- Read scripts before you run them!
|
| 95 |
+
|
| 96 |
+
Summarization Tips:
|
| 97 |
+
- (summ) 1 epoch at batch size 1 for bart-large takes 24 hours and requires 13GB GPU RAM with fp16 on an NVIDIA-V100.
|
| 98 |
+
- If you want to run experiments on improving the summarization finetuning process, try the XSUM Shared Task (below). It's faster to train than CNNDM because the summaries are shorter.
|
| 99 |
+
- For CNN/DailyMail, the default `val_max_target_length` and `test_max_target_length` will truncate the ground truth labels, resulting in slightly higher rouge scores. To get accurate rouge scores, you should rerun calculate_rouge on the `{output_dir}/test_generations.txt` file saved by `trainer.test()`
|
| 100 |
+
- `--max_target_length=60 --val_max_target_length=60 --test_max_target_length=100 ` is a reasonable setting for XSUM.
|
| 101 |
+
- `wandb` can be used by specifying `--logger_name wandb`. It is useful for reproducibility. Specify the environment variable `WANDB_PROJECT='hf_xsum'` to do the XSUM shared task.
|
| 102 |
+
- If you are finetuning on your own dataset, start from `distilbart-cnn-12-6` if you want long summaries and `distilbart-xsum-12-6` if you want short summaries.
|
| 103 |
+
(It rarely makes sense to start from `bart-large` unless you are a researching finetuning methods).
|
| 104 |
+
|
| 105 |
+
**Update 2018-07-18**
|
| 106 |
+
Datasets: `LegacySeq2SeqDataset` will be used for all tokenizers without a `prepare_seq2seq_batch` method. Otherwise, `Seq2SeqDataset` will be used.
|
| 107 |
+
Future work/help wanted: A new dataset to support multilingual tasks.
|
| 108 |
+
|
| 109 |
+
|
| 110 |
+
### Finetuning Scripts
|
| 111 |
+
All finetuning bash scripts call finetune.py (or distillation.py) with reasonable command line arguments. They usually require extra command line arguments to work.
|
| 112 |
+
|
| 113 |
+
To see all the possible command line options, run:
|
| 114 |
+
|
| 115 |
+
```bash
|
| 116 |
+
./finetune.py --help
|
| 117 |
+
```
|
| 118 |
+
|
| 119 |
+
### Finetuning Training Params
|
| 120 |
+
|
| 121 |
+
To override the pretrained model's training params, you can pass them to `./finetune.sh`:
|
| 122 |
+
|
| 123 |
+
```bash
|
| 124 |
+
./finetune.sh \
|
| 125 |
+
[...]
|
| 126 |
+
--encoder_layerdrop 0.1 \
|
| 127 |
+
--decoder_layerdrop 0.1 \
|
| 128 |
+
--dropout 0.1 \
|
| 129 |
+
--attention_dropout 0.1 \
|
| 130 |
+
```
|
| 131 |
+
|
| 132 |
+
### Summarization Finetuning
|
| 133 |
+
Run/modify `finetune.sh`
|
| 134 |
+
|
| 135 |
+
The following command should work on a 16GB GPU:
|
| 136 |
+
```bash
|
| 137 |
+
./finetune.sh \
|
| 138 |
+
--data_dir $XSUM_DIR \
|
| 139 |
+
--train_batch_size=1 \
|
| 140 |
+
--eval_batch_size=1 \
|
| 141 |
+
--output_dir=xsum_results \
|
| 142 |
+
--num_train_epochs 6 \
|
| 143 |
+
--model_name_or_path facebook/bart-large
|
| 144 |
+
```
|
| 145 |
+
|
| 146 |
+
There is a starter finetuning script for pegasus at `finetune_pegasus_xsum.sh`.
|
| 147 |
+
|
| 148 |
+
### Translation Finetuning
|
| 149 |
+
|
| 150 |
+
First, follow the wmt_en_ro download instructions.
|
| 151 |
+
Then you can finetune mbart_cc25 on english-romanian with the following command.
|
| 152 |
+
**Recommendation:** Read and potentially modify the fairly opinionated defaults in `train_mbart_cc25_enro.sh` script before running it.
|
| 153 |
+
|
| 154 |
+
Best performing command:
|
| 155 |
+
```bash
|
| 156 |
+
# optionally
|
| 157 |
+
export ENRO_DIR='wmt_en_ro' # Download instructions above
|
| 158 |
+
# export WANDB_PROJECT="MT" # optional
|
| 159 |
+
export MAX_LEN=128
|
| 160 |
+
export BS=4
|
| 161 |
+
./train_mbart_cc25_enro.sh --output_dir enro_finetune_baseline --label_smoothing 0.1 --fp16_opt_level=O1 --logger_name wandb --sortish_sampler
|
| 162 |
+
```
|
| 163 |
+
This should take < 6h/epoch on a 16GB v100 and achieve test BLEU above 26
|
| 164 |
+
To get results in line with fairseq, you need to do some postprocessing. (see `romanian_postprocessing.md`)
|
| 165 |
+
|
| 166 |
+
MultiGPU command
|
| 167 |
+
(using 8 GPUS as an example)
|
| 168 |
+
```bash
|
| 169 |
+
export ENRO_DIR='wmt_en_ro' # Download instructions above
|
| 170 |
+
# export WANDB_PROJECT="MT" # optional
|
| 171 |
+
export MAX_LEN=128
|
| 172 |
+
export BS=4
|
| 173 |
+
./train_mbart_cc25_enro.sh --output_dir enro_finetune_baseline --gpus 8 --logger_name wandb
|
| 174 |
+
```
|
| 175 |
+
### Finetuning Outputs
|
| 176 |
+
As you train, `output_dir` will be filled with files, that look kind of like this (comments are mine).
|
| 177 |
+
Some of them are metrics, some of them are checkpoints, some of them are metadata. Here is a quick tour:
|
| 178 |
+
|
| 179 |
+
```bash
|
| 180 |
+
output_dir
|
| 181 |
+
├── best_tfmr # this is a huggingface checkpoint generated by save_pretrained. It is the same model as the PL .ckpt file below
|
| 182 |
+
│ ├── config.json
|
| 183 |
+
│ ├── merges.txt
|
| 184 |
+
│ ├── pytorch_model.bin
|
| 185 |
+
│ ├── special_tokens_map.json
|
| 186 |
+
│ ├── tokenizer_config.json
|
| 187 |
+
│ └── vocab.json
|
| 188 |
+
├── git_log.json # repo, branch, and commit hash
|
| 189 |
+
├── val_avg_rouge2=0.1984-step_count=11.ckpt # this is a pytorch lightning checkpoint associated with the best val score. (it will be called BLEU for MT)
|
| 190 |
+
├── metrics.json # new validation metrics will continually be appended to this
|
| 191 |
+
├── student # this is a huggingface checkpoint generated by SummarizationDistiller. It is the student before it gets finetuned.
|
| 192 |
+
│ ├── config.json
|
| 193 |
+
│ └── pytorch_model.bin
|
| 194 |
+
├── test_generations.txt
|
| 195 |
+
# ^^ are the summaries or translations produced by your best checkpoint on the test data. Populated when training is done
|
| 196 |
+
├── test_results.txt # a convenience file with the test set metrics. This data is also in metrics.json['test']
|
| 197 |
+
├── hparams.pkl # the command line args passed after some light preprocessing. Should be saved fairly quickly.
|
| 198 |
+
```
|
| 199 |
+
After training, you can recover the best checkpoint by running
|
| 200 |
+
```python
|
| 201 |
+
from transformers import AutoModelForSeq2SeqLM
|
| 202 |
+
model = AutoModelForSeq2SeqLM.from_pretrained(f'{output_dir}/best_tfmr')
|
| 203 |
+
```
|
| 204 |
+
|
| 205 |
+
### Fine-tuning using Seq2SeqTrainer
|
| 206 |
+
To use `Seq2SeqTrainer` for fine-tuning you should use the `finetune_trainer.py` script. It subclasses `Trainer` to extend it for seq2seq training. Except the `Trainer` releated `TrainingArguments`, it shares the same argument names as that of `finetune.py` file. One notable difference is that, calculating generative metrics (BLEU, ROUGE) is optional and is controlled using the `--predict_with_generate` argument, set this argument to calculate BLEU and ROUGE metrics.
|
| 207 |
+
|
| 208 |
+
With PyTorch 1.6+ it'll automatically use `native AMP` when `--fp16` is set.
|
| 209 |
+
|
| 210 |
+
To see all the possible command line options, run:
|
| 211 |
+
|
| 212 |
+
```bash
|
| 213 |
+
./builtin_trainer/finetune.sh --help # This calls python finetune_trainer.py --help
|
| 214 |
+
```
|
| 215 |
+
|
| 216 |
+
**At the moment, `Seq2SeqTrainer` does not support *with teacher* distillation.**
|
| 217 |
+
|
| 218 |
+
All `Seq2SeqTrainer` based fine-tuning scripts are included in the `builtin_trainer` directory.
|
| 219 |
+
|
| 220 |
+
#### TPU Training
|
| 221 |
+
`Seq2SeqTrainer` supports TPU training with few caveats
|
| 222 |
+
1. As `generate` method does not work on TPU at the moment, `predict_with_generate` can not be used. You should use `--prediction_loss_only` to only calculate loss, and do not set `--do_predict` and `--predict_with_generate`.
|
| 223 |
+
2. All sequences should be padded to be of equal length otherwise it leads to extremely slow training. (`finetune_trainer.py` does this automatically when running on TPU.)
|
| 224 |
+
|
| 225 |
+
We provide a very simple launcher script named `xla_spawn.py` that lets you run our example scripts on multiple TPU cores without any boilerplate. Just pass a --num_cores flag to this script, then your regular training script with its arguments (this is similar to the torch.distributed.launch helper for torch.distributed).
|
| 226 |
+
|
| 227 |
+
`builtin_trainer/finetune_tpu.sh` script provides minimal arguments needed for TPU training.
|
| 228 |
+
|
| 229 |
+
Following command fine-tunes `sshleifer/student_marian_en_ro_6_3` on TPU V3-8 and should complete one epoch in ~5-6 mins.
|
| 230 |
+
|
| 231 |
+
```bash
|
| 232 |
+
./builtin_trainer/train_distil_marian_enro_tpu.sh
|
| 233 |
+
```
|
| 234 |
+
|
| 235 |
+
# DistilBART
|
| 236 |
+
<!---It should be called distilling bart and pegasus, but I don't want to break the link in the paper.-->
|
| 237 |
+
This section describes all code and artifacts from our [Paper](http://arxiv.org/abs/2010.13002)
|
| 238 |
+
|
| 239 |
+

|
| 240 |
+
|
| 241 |
+
+ For the CNN/DailyMail dataset, (relatively longer, more extractive summaries), we found a simple technique that works, which we call "Shrink and Fine-tune", or SFT.
|
| 242 |
+
you just copy alternating layers from `facebook/bart-large-cnn` and fine-tune more on the cnn/dm data. `sshleifer/distill-pegasus-cnn-16-4`, `sshleifer/distilbart-cnn-12-6` and all other checkpoints under `sshleifer` that start with `distilbart-cnn` were trained this way.
|
| 243 |
+
+ For the XSUM dataset, training on pseudo-labels worked best for Pegasus (`sshleifer/distill-pegasus-16-4`), while training with KD worked best for `distilbart-xsum-12-6`
|
| 244 |
+
+ For `sshleifer/dbart-xsum-12-3`
|
| 245 |
+
+ We ran 100s experiments, and didn't want to document 100s of commands. If you want a command to replicate a figure from the paper that is not documented below, feel free to ask on the [forums](https://discuss.huggingface.co/t/seq2seq-distillation-methodology-questions/1270) and tag `@sshleifer`.
|
| 246 |
+
+ You can see the performance tradeoffs of model sizes [here](https://docs.google.com/spreadsheets/d/1EkhDMwVO02m8jCD1cG3RoFPLicpcL1GQHTQjfvDYgIM/edit#gid=0).
|
| 247 |
+
and more granular timing results [here](https://docs.google.com/spreadsheets/d/1EkhDMwVO02m8jCD1cG3RoFPLicpcL1GQHTQjfvDYgIM/edit#gid=1753259047&range=B2:I23).
|
| 248 |
+
|
| 249 |
+
### Evaluation
|
| 250 |
+
|
| 251 |
+
use [run_distributed_eval](./run_distributed_eval.py), with the following convenient alias
|
| 252 |
+
```bash
|
| 253 |
+
deval () {
|
| 254 |
+
proc=$1
|
| 255 |
+
m=$2
|
| 256 |
+
dd=$3
|
| 257 |
+
sd=$4
|
| 258 |
+
shift
|
| 259 |
+
shift
|
| 260 |
+
shift
|
| 261 |
+
shift
|
| 262 |
+
python -m torch.distributed.launch --nproc_per_node=$proc run_distributed_eval.py \
|
| 263 |
+
--model_name $m --save_dir $sd --data_dir $dd $@
|
| 264 |
+
}
|
| 265 |
+
```
|
| 266 |
+
On a 1 GPU system, here are four commands (that assume `xsum`, `cnn_dm` are downloaded, cmd-F for those links in this file).
|
| 267 |
+
|
| 268 |
+
`distilBART`:
|
| 269 |
+
```bash
|
| 270 |
+
deval 1 sshleifer/distilbart-xsum-12-3 xsum dbart_12_3_xsum_eval --fp16 # --help for more choices.
|
| 271 |
+
deval 1 sshleifer/distilbart-cnn_dm-12-6 cnn_dm dbart_12_6_cnn_eval --fp16
|
| 272 |
+
```
|
| 273 |
+
|
| 274 |
+
`distill-pegasus`:
|
| 275 |
+
```bash
|
| 276 |
+
deval 1 sshleifer/distill-pegasus-cnn-16-4 cnn_dm dpx_cnn_eval
|
| 277 |
+
deval 1 sshleifer/distill-pegasus-xsum-16-4 xsum dpx_xsum_eval
|
| 278 |
+
```
|
| 279 |
+
|
| 280 |
+
### Distillation
|
| 281 |
+
+ For all of the following commands, you can get roughly equivalent result and faster run times by passing `--num_beams=4`. That's not what we did for the paper.
|
| 282 |
+
+ Besides the KD section, you can also run commands with the built-in transformers trainer. See, for example, [builtin_trainer/train_distilbart_cnn.sh](./builtin_trainer/train_distilbart_cnn.sh).
|
| 283 |
+
+ Large performance deviations (> 5X slower or more than 0.5 Rouge-2 worse), should be reported.
|
| 284 |
+
+ Multi-gpu (controlled with `--gpus` should work, but might require more epochs).
|
| 285 |
+
|
| 286 |
+
#### Recommended Workflow
|
| 287 |
+
+ Get your dataset in the right format. (see 6 files above).
|
| 288 |
+
+ Find a teacher model [Pegasus](https://huggingface.co/models?search=pegasus) (slower, better ROUGE) or `facebook/bart-large-xsum`/`facebook/bart-large-cnn` (faster, slightly lower.).
|
| 289 |
+
Choose the checkpoint where the corresponding dataset is most similar (or identical to) your dataset.
|
| 290 |
+
+ Follow the sections in order below. You can stop after SFT if you are satisfied, or move on to pseudo-labeling if you want more performance.
|
| 291 |
+
+ student size: If you want a close to free 50% speedup, cut the decoder in half. If you want a larger speedup, cut it in 4.
|
| 292 |
+
+ If your SFT run starts at a validation ROUGE-2 that is more than 10 pts below the teacher's validation ROUGE-2, you have a bug. Switching to a more expensive technique will not help. Try setting a breakpoint and looking at generation and truncation defaults/hyper-parameters, and share your experience on the forums!
|
| 293 |
+
|
| 294 |
+
|
| 295 |
+
#### Initialization
|
| 296 |
+
We use [make_student.py](./make_student.py) to copy alternating layers from the teacher, and save the resulting model to disk
|
| 297 |
+
```bash
|
| 298 |
+
python make_student.py facebook/bart-large-xsum --save_path dbart_xsum_12_3 -e 12 -d 3
|
| 299 |
+
```
|
| 300 |
+
or for `pegasus-xsum`
|
| 301 |
+
```bash
|
| 302 |
+
python make_student.py google/pegasus-xsum --save_path dpx_xsum_16_4 --e 16 --d 4
|
| 303 |
+
```
|
| 304 |
+
we now have an initialized student saved to `dbart_xsum_12_3`, which we will use for the following commands.
|
| 305 |
+
+ Extension: To replicate more complicated initialize experiments in section 6.1, or try your own. Use the `create_student_by_copying_alternating_layers` function.
|
| 306 |
+
|
| 307 |
+
#### Pegasus
|
| 308 |
+
+ The following commands are written for BART and will require, at minimum, the following modifications
|
| 309 |
+
+ reduce batch size, and increase gradient accumulation steps so that the product `gpus * batch size * gradient_accumulation_steps = 256`. We used `--learning-rate` = 1e-4 * gradient accumulation steps.
|
| 310 |
+
+ don't use fp16
|
| 311 |
+
+ `--tokenizer_name google/pegasus-large`
|
| 312 |
+
|
| 313 |
+
### SFT (No Teacher Distillation)
|
| 314 |
+
You don't need `distillation.py`, you can just run:
|
| 315 |
+
|
| 316 |
+
```bash
|
| 317 |
+
python finetune.py \
|
| 318 |
+
--data_dir xsum \
|
| 319 |
+
--freeze_encoder --freeze_embeds \
|
| 320 |
+
--learning_rate=3e-4 \
|
| 321 |
+
--do_train \
|
| 322 |
+
--do_predict \
|
| 323 |
+
--fp16 --fp16_opt_level=O1 \
|
| 324 |
+
--val_check_interval 0.1 --n_val 1000 --eval_beams 2 --length_penalty=0.5 \
|
| 325 |
+
--max_target_length=60 --val_max_target_length=60 --test_max_target_length=100 \
|
| 326 |
+
--model_name_or_path dbart_xsum_12_3 \
|
| 327 |
+
--train_batch_size=64 --eval_batch_size=64 \
|
| 328 |
+
--sortish_sampler \
|
| 329 |
+
--num_train_epochs=6 \
|
| 330 |
+
--warmup_steps 500 \
|
| 331 |
+
--output_dir distilbart_xsum_sft_12_3 --gpus 1
|
| 332 |
+
```
|
| 333 |
+
|
| 334 |
+
+ Note: The command that produced `sshleifer/distilbart-cnn-12-6` is at [train_distilbart_cnn.sh](./[train_distilbart_cnn.sh)
|
| 335 |
+
|
| 336 |
+
```bash
|
| 337 |
+
./train_distilbart_cnn.sh
|
| 338 |
+
```
|
| 339 |
+
<!--- runtime: 6H on NVIDIA RTX 24GB GPU -->
|
| 340 |
+
+ Tip: You can get the same simple distillation logic by using `distillation.py --no_teacher ` followed by identical arguments as the ones in `train_distilbart_cnn.sh`.
|
| 341 |
+
If you are using `wandb` and comparing the two distillation methods, using this entry point will make your logs consistent,
|
| 342 |
+
because you will have the same hyper-parameters logged in every run.
|
| 343 |
+
|
| 344 |
+
### Pseudo-Labeling
|
| 345 |
+
+ You don't need `distillation.py`.
|
| 346 |
+
+ Instructions to generate pseudo-labels and use pre-computed pseudo-labels can be found [here](./precomputed_pseudo_labels.md).
|
| 347 |
+
Simply run `finetune.py` with one of those pseudo-label datasets as `--data_dir` (`DATA`, below).
|
| 348 |
+
|
| 349 |
+
```bash
|
| 350 |
+
python finetune.py \
|
| 351 |
+
--teacher facebook/bart-large-xsum --data_dir DATA \
|
| 352 |
+
--freeze_encoder --freeze_embeds \
|
| 353 |
+
--learning_rate=3e-4 \
|
| 354 |
+
--do_train \
|
| 355 |
+
--do_predict \
|
| 356 |
+
--fp16 --fp16_opt_level=O1 \
|
| 357 |
+
--val_check_interval 0.1 --n_val 1000 --eval_beams 2 --length_penalty=0.5 \
|
| 358 |
+
--max_target_length=60 --val_max_target_length=60 --test_max_target_length=100 \
|
| 359 |
+
--model_name_or_path dbart_xsum_12_3 \
|
| 360 |
+
--train_batch_size=32 --eval_batch_size=32 \
|
| 361 |
+
--sortish_sampler \
|
| 362 |
+
--num_train_epochs=5 \
|
| 363 |
+
--warmup_steps 500 \
|
| 364 |
+
--output_dir dbart_xsum_12_3_PL --gpus 1 --logger_name wandb
|
| 365 |
+
```
|
| 366 |
+
|
| 367 |
+
|
| 368 |
+
|
| 369 |
+
To combine datasets, as in Section 6.2, try something like:
|
| 370 |
+
```bash
|
| 371 |
+
curl -S https://cdn-datasets.huggingface.co/pseudo/xsum/bart_xsum_pl.tgz | tar -xvz -C .
|
| 372 |
+
curl -S https://cdn-datasets.huggingface.co/pseudo/xsum/pegasus_xsum.tgz | tar -xvz -C .
|
| 373 |
+
curl -S https://cdn-datasets.huggingface.co/summarization/xsum.tar.gz | tar -xvz -C .
|
| 374 |
+
mkdir all_pl
|
| 375 |
+
cat bart_xsum_pl/train.source pegasus_xsum/train.source xsum/train.source > all_pl/train.source
|
| 376 |
+
cat bart_xsum_pl/train.target pegasus_xsum/train.target xsum/train.target > all_pl/train.target
|
| 377 |
+
cp xsum/val* all_pl
|
| 378 |
+
cp xsum/test* all_pl
|
| 379 |
+
```
|
| 380 |
+
then use `all_pl` as DATA in the command above.
|
| 381 |
+
|
| 382 |
+
#### Direct Knowledge Distillation (KD)
|
| 383 |
+
+ In this method, we use try to enforce that the student and teacher produce similar encoder_outputs, logits, and hidden_states using `BartSummarizationDistiller`.
|
| 384 |
+
+ This method was used for `sshleifer/distilbart-xsum-12-6`, `6-6`, and `9-6` checkpoints were produced.
|
| 385 |
+
+ You must use [`distillation.py`](./distillation.py). Note that this command initializes the student for you.
|
| 386 |
+
|
| 387 |
+
The command that produced `sshleifer/distilbart-xsum-12-6` is at [./train_distilbart_xsum.sh](train_distilbart_xsum.sh)
|
| 388 |
+
```bash
|
| 389 |
+
./train_distilbart_xsum.sh --logger_name wandb --gpus 1
|
| 390 |
+
```
|
| 391 |
+
|
| 392 |
+
+ Expected ROUGE-2 between 21.3 and 21.6, run time ~13H.
|
| 393 |
+
+ direct KD + Pegasus is VERY slow and works best with `--supervise_forward --normalize_hidden`.
|
| 394 |
+
|
| 395 |
+
<!--- runtime: 13H on V-100 16GB GPU. -->
|
| 396 |
+
|
| 397 |
+
### Citation
|
| 398 |
+
|
| 399 |
+
```bibtex
|
| 400 |
+
@misc{shleifer2020pretrained,
|
| 401 |
+
title={Pre-trained Summarization Distillation},
|
| 402 |
+
author={Sam Shleifer and Alexander M. Rush},
|
| 403 |
+
year={2020},
|
| 404 |
+
eprint={2010.13002},
|
| 405 |
+
archivePrefix={arXiv},
|
| 406 |
+
primaryClass={cs.CL}
|
| 407 |
+
}
|
| 408 |
+
@article{Wolf2019HuggingFacesTS,
|
| 409 |
+
title={HuggingFace's Transformers: State-of-the-art Natural Language Processing},
|
| 410 |
+
author={Thomas Wolf and Lysandre Debut and Victor Sanh and Julien Chaumond and Clement Delangue and Anthony Moi and Pierric Cistac and Tim Rault and Rémi Louf and Morgan Funtowicz and Joe Davison and Sam Shleifer and Patrick von Platen and Clara Ma and Yacine Jernite and Julien Plu and Canwen Xu and Teven Le Scao and Sylvain Gugger and Mariama Drame and Quentin Lhoest and Alexander M. Rush},
|
| 411 |
+
journal={ArXiv},
|
| 412 |
+
year={2019},
|
| 413 |
+
volume={abs/1910.03771}
|
| 414 |
+
}
|
| 415 |
+
```
|
| 416 |
+
|
| 417 |
+
This is the end of the distillation section, the rest of this doc pertains to general seq2seq commands.
|
| 418 |
+
|
| 419 |
+
## Evaluation Commands
|
| 420 |
+
|
| 421 |
+
To create summaries for each article in dataset, we use `run_eval.py`, here are a few commands that run eval for different tasks and models.
|
| 422 |
+
If 'translation' is in your task name, the computed metric will be BLEU. Otherwise, ROUGE will be used.
|
| 423 |
+
|
| 424 |
+
For t5, you need to specify --task translation_{src}_to_{tgt} as follows:
|
| 425 |
+
```bash
|
| 426 |
+
export DATA_DIR=wmt_en_ro
|
| 427 |
+
./run_eval.py t5-base \
|
| 428 |
+
$DATA_DIR/val.source t5_val_generations.txt \
|
| 429 |
+
--reference_path $DATA_DIR/val.target \
|
| 430 |
+
--score_path enro_bleu.json \
|
| 431 |
+
--task translation_en_to_ro \
|
| 432 |
+
--n_obs 100 \
|
| 433 |
+
--device cuda \
|
| 434 |
+
--fp16 \
|
| 435 |
+
--bs 32
|
| 436 |
+
```
|
| 437 |
+
|
| 438 |
+
This command works for MBART, although the BLEU score is suspiciously low.
|
| 439 |
+
```bash
|
| 440 |
+
export DATA_DIR=wmt_en_ro
|
| 441 |
+
./run_eval.py facebook/mbart-large-en-ro $DATA_DIR/val.source mbart_val_generations.txt \
|
| 442 |
+
--reference_path $DATA_DIR/val.target \
|
| 443 |
+
--score_path enro_bleu.json \
|
| 444 |
+
--task translation \
|
| 445 |
+
--n_obs 100 \
|
| 446 |
+
--device cuda \
|
| 447 |
+
--fp16 \
|
| 448 |
+
--bs 32
|
| 449 |
+
```
|
| 450 |
+
|
| 451 |
+
Summarization (xsum will be very similar):
|
| 452 |
+
```bash
|
| 453 |
+
export DATA_DIR=cnn_dm
|
| 454 |
+
./run_eval.py sshleifer/distilbart-cnn-12-6 $DATA_DIR/val.source dbart_val_generations.txt \
|
| 455 |
+
--reference_path $DATA_DIR/val.target \
|
| 456 |
+
--score_path cnn_rouge.json \
|
| 457 |
+
--task summarization \
|
| 458 |
+
--n_obs 100 \
|
| 459 |
+
|
| 460 |
+
th 56 \
|
| 461 |
+
--fp16 \
|
| 462 |
+
--bs 32
|
| 463 |
+
```
|
| 464 |
+
|
| 465 |
+
### Multi-GPU Evaluation
|
| 466 |
+
here is a command to run xsum evaluation on 8 GPUS. It is more than linearly faster than run_eval.py in some cases
|
| 467 |
+
because it uses SortishSampler to minimize padding. You can also use it on 1 GPU. `data_dir` must have
|
| 468 |
+
`{type_path}.source` and `{type_path}.target`. Run `./run_distributed_eval.py --help` for all clargs.
|
| 469 |
+
|
| 470 |
+
```bash
|
| 471 |
+
python -m torch.distributed.launch --nproc_per_node=8 run_distributed_eval.py \
|
| 472 |
+
--model_name sshleifer/distilbart-large-xsum-12-3 \
|
| 473 |
+
--save_dir xsum_generations \
|
| 474 |
+
--data_dir xsum \
|
| 475 |
+
--fp16 # you can pass generate kwargs like num_beams here, just like run_eval.py
|
| 476 |
+
```
|
| 477 |
+
|
| 478 |
+
Contributions that implement this command for other distributed hardware setups are welcome!
|
| 479 |
+
|
| 480 |
+
#### Single-GPU Eval: Tips and Tricks
|
| 481 |
+
|
| 482 |
+
When using `run_eval.py`, the following features can be useful:
|
| 483 |
+
|
| 484 |
+
* if you running the script multiple times and want to make it easier to track what arguments produced that output, use `--dump-args`. Along with the results it will also dump any custom params that were passed to the script. For example if you used: `--num_beams 8 --early_stopping true`, the output will be:
|
| 485 |
+
```
|
| 486 |
+
{'bleu': 26.887, 'n_obs': 10, 'runtime': 1, 'seconds_per_sample': 0.1, 'num_beams': 8, 'early_stopping': True}
|
| 487 |
+
```
|
| 488 |
+
|
| 489 |
+
`--info` is an additional argument available for the same purpose of tracking the conditions of the experiment. It's useful to pass things that weren't in the argument list, e.g. a language pair `--info "lang:en-ru"`. But also if you pass `--info` without a value it will fallback to the current date/time string, e.g. `2020-09-13 18:44:43`.
|
| 490 |
+
|
| 491 |
+
If using `--dump-args --info`, the output will be:
|
| 492 |
+
|
| 493 |
+
```
|
| 494 |
+
{'bleu': 26.887, 'n_obs': 10, 'runtime': 1, 'seconds_per_sample': 0.1, 'num_beams': 8, 'early_stopping': True, 'info': '2020-09-13 18:44:43'}
|
| 495 |
+
```
|
| 496 |
+
|
| 497 |
+
If using `--dump-args --info "pair:en-ru chkpt=best`, the output will be:
|
| 498 |
+
|
| 499 |
+
```
|
| 500 |
+
{'bleu': 26.887, 'n_obs': 10, 'runtime': 1, 'seconds_per_sample': 0.1, 'num_beams': 8, 'early_stopping': True, 'info': 'pair=en-ru chkpt=best'}
|
| 501 |
+
```
|
| 502 |
+
|
| 503 |
+
|
| 504 |
+
* if you need to perform a parametric search in order to find the best ones that lead to the highest BLEU score, let `run_eval_search.py` to do the searching for you.
|
| 505 |
+
|
| 506 |
+
The script accepts the exact same arguments as `run_eval.py`, plus an additional argument `--search`. The value of `--search` is parsed, reformatted and fed to ``run_eval.py`` as additional args.
|
| 507 |
+
|
| 508 |
+
The format for the `--search` value is a simple string with hparams and colon separated values to try, e.g.:
|
| 509 |
+
```
|
| 510 |
+
--search "num_beams=5:10 length_penalty=0.8:1.0:1.2 early_stopping=true:false"
|
| 511 |
+
```
|
| 512 |
+
which will generate `12` `(2*3*2)` searches for a product of each hparam. For example the example that was just used will invoke `run_eval.py` repeatedly with:
|
| 513 |
+
|
| 514 |
+
```
|
| 515 |
+
--num_beams 5 --length_penalty 0.8 --early_stopping true
|
| 516 |
+
--num_beams 5 --length_penalty 0.8 --early_stopping false
|
| 517 |
+
[...]
|
| 518 |
+
--num_beams 10 --length_penalty 1.2 --early_stopping false
|
| 519 |
+
```
|
| 520 |
+
|
| 521 |
+
On completion, this function prints a markdown table of the results sorted by the best BLEU score and the winning arguments.
|
| 522 |
+
|
| 523 |
+
```
|
| 524 |
+
bleu | num_beams | length_penalty | early_stopping
|
| 525 |
+
----- | --------- | -------------- | --------------
|
| 526 |
+
26.71 | 5 | 1.1 | 1
|
| 527 |
+
26.66 | 5 | 0.9 | 1
|
| 528 |
+
26.66 | 5 | 0.9 | 0
|
| 529 |
+
26.41 | 5 | 1.1 | 0
|
| 530 |
+
21.94 | 1 | 0.9 | 1
|
| 531 |
+
21.94 | 1 | 0.9 | 0
|
| 532 |
+
21.94 | 1 | 1.1 | 1
|
| 533 |
+
21.94 | 1 | 1.1 | 0
|
| 534 |
+
|
| 535 |
+
Best score args:
|
| 536 |
+
stas/wmt19-en-ru data/en-ru/val.source data/en-ru/test_translations.txt --reference_path data/en-ru/val.target --score_path data/en-ru/test_bleu.json --bs 8 --task translation --num_beams 5 --length_penalty 1.1 --early_stopping True
|
| 537 |
+
```
|
| 538 |
+
|
| 539 |
+
If you pass `--info "some experiment-specific info"` it will get printed before the results table - this is useful for scripting and multiple runs, so one can tell the different sets of results from each other.
|
| 540 |
+
|
| 541 |
+
|
| 542 |
+
### Contributing
|
| 543 |
+
- follow the standard contributing guidelines and code of conduct.
|
| 544 |
+
- add tests to `test_seq2seq_examples.py`
|
| 545 |
+
- To run only the seq2seq tests, you must be in the root of the repository and run:
|
| 546 |
+
```bash
|
| 547 |
+
pytest examples/seq2seq/
|
| 548 |
+
```
|
| 549 |
+
|
| 550 |
+
### Converting pytorch-lightning checkpoints
|
| 551 |
+
pytorch lightning ``-do_predict`` often fails, after you are done training, the best way to evaluate your model is to convert it.
|
| 552 |
+
|
| 553 |
+
This should be done for you, with a file called `{save_dir}/best_tfmr`.
|
| 554 |
+
|
| 555 |
+
If that file doesn't exist but you have a lightning `.ckpt` file, you can run
|
| 556 |
+
```bash
|
| 557 |
+
python convert_pl_checkpoint_to_hf.py PATH_TO_CKPT randomly_initialized_hf_model_path save_dir/best_tfmr
|
| 558 |
+
```
|
| 559 |
+
Then either `run_eval` or `run_distributed_eval` with `save_dir/best_tfmr` (see previous sections)
|
| 560 |
+
|
| 561 |
+
|
| 562 |
+
# Experimental Features
|
| 563 |
+
These features are harder to use and not always useful.
|
| 564 |
+
|
| 565 |
+
### Dynamic Batch Size for MT
|
| 566 |
+
`finetune.py` has a command line arg `--max_tokens_per_batch` that allows batches to be dynamically sized.
|
| 567 |
+
This feature can only be used:
|
| 568 |
+
- with fairseq installed
|
| 569 |
+
- on 1 GPU
|
| 570 |
+
- without sortish sampler
|
| 571 |
+
- after calling `./save_len_file.py $tok $data_dir`
|
| 572 |
+
|
| 573 |
+
For example,
|
| 574 |
+
```bash
|
| 575 |
+
./save_len_file.py Helsinki-NLP/opus-mt-en-ro wmt_en_ro
|
| 576 |
+
./dynamic_bs_example.sh --max_tokens_per_batch=2000 --output_dir benchmark_dynamic_bs
|
| 577 |
+
```
|
| 578 |
+
splits `wmt_en_ro/train` into 11,197 uneven lengthed batches and can finish 1 epoch in 8 minutes on a v100.
|
| 579 |
+
|
| 580 |
+
For comparison,
|
| 581 |
+
```bash
|
| 582 |
+
./dynamic_bs_example.sh --sortish_sampler --train_batch_size 48
|
| 583 |
+
```
|
| 584 |
+
uses 12,723 batches of length 48 and takes slightly more time 9.5 minutes.
|
| 585 |
+
|
| 586 |
+
The feature is still experimental, because:
|
| 587 |
+
+ we can make it much more robust if we have memory mapped/preprocessed datasets.
|
| 588 |
+
+ The speedup over sortish sampler is not that large at the moment.
|
| 589 |
+
|
| 590 |
+
|
src/mrc_client/seq2seq/__init__.py
ADDED
|
@@ -0,0 +1,5 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import os
|
| 2 |
+
import sys
|
| 3 |
+
|
| 4 |
+
|
| 5 |
+
sys.path.insert(1, os.path.dirname(os.path.realpath(__file__)))
|
src/mrc_client/seq2seq/callbacks.py
ADDED
|
@@ -0,0 +1,115 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import logging
|
| 2 |
+
import os
|
| 3 |
+
from pathlib import Path
|
| 4 |
+
|
| 5 |
+
import numpy as np
|
| 6 |
+
import pytorch_lightning as pl
|
| 7 |
+
import torch
|
| 8 |
+
from pytorch_lightning.callbacks import EarlyStopping, ModelCheckpoint
|
| 9 |
+
from pytorch_lightning.utilities import rank_zero_only
|
| 10 |
+
|
| 11 |
+
from seq2seq_utils import save_json
|
| 12 |
+
|
| 13 |
+
|
| 14 |
+
def count_trainable_parameters(model):
|
| 15 |
+
model_parameters = filter(lambda p: p.requires_grad, model.parameters())
|
| 16 |
+
params = sum([np.prod(p.size()) for p in model_parameters])
|
| 17 |
+
return params
|
| 18 |
+
|
| 19 |
+
|
| 20 |
+
logger = logging.getLogger(__name__)
|
| 21 |
+
|
| 22 |
+
|
| 23 |
+
class Seq2SeqLoggingCallback(pl.Callback):
|
| 24 |
+
def on_batch_end(self, trainer, pl_module):
|
| 25 |
+
lrs = {f"lr_group_{i}": param["lr"] for i, param in enumerate(pl_module.trainer.optimizers[0].param_groups)}
|
| 26 |
+
pl_module.logger.log_metrics(lrs)
|
| 27 |
+
|
| 28 |
+
@rank_zero_only
|
| 29 |
+
def _write_logs(
|
| 30 |
+
self, trainer: pl.Trainer, pl_module: pl.LightningModule, type_path: str, save_generations=True
|
| 31 |
+
) -> None:
|
| 32 |
+
logger.info(f"***** {type_path} results at step {trainer.global_step:05d} *****")
|
| 33 |
+
metrics = trainer.callback_metrics
|
| 34 |
+
trainer.logger.log_metrics({k: v for k, v in metrics.items() if k not in ["log", "progress_bar", "preds"]})
|
| 35 |
+
# Log results
|
| 36 |
+
od = Path(pl_module.hparams.output_dir)
|
| 37 |
+
if type_path == "test":
|
| 38 |
+
results_file = od / "test_results.txt"
|
| 39 |
+
generations_file = od / "test_generations.txt"
|
| 40 |
+
else:
|
| 41 |
+
# this never gets hit. I prefer not to save intermediate generations, and results are in metrics.json
|
| 42 |
+
# If people want this it will be easy enough to add back.
|
| 43 |
+
results_file = od / f"{type_path}_results/{trainer.global_step:05d}.txt"
|
| 44 |
+
generations_file = od / f"{type_path}_generations/{trainer.global_step:05d}.txt"
|
| 45 |
+
results_file.parent.mkdir(exist_ok=True)
|
| 46 |
+
generations_file.parent.mkdir(exist_ok=True)
|
| 47 |
+
with open(results_file, "a+") as writer:
|
| 48 |
+
for key in sorted(metrics):
|
| 49 |
+
if key in ["log", "progress_bar", "preds"]:
|
| 50 |
+
continue
|
| 51 |
+
val = metrics[key]
|
| 52 |
+
if isinstance(val, torch.Tensor):
|
| 53 |
+
val = val.item()
|
| 54 |
+
msg = f"{key}: {val:.6f}\n"
|
| 55 |
+
writer.write(msg)
|
| 56 |
+
|
| 57 |
+
if not save_generations:
|
| 58 |
+
return
|
| 59 |
+
|
| 60 |
+
if "preds" in metrics:
|
| 61 |
+
content = "\n".join(metrics["preds"])
|
| 62 |
+
generations_file.open("w+").write(content)
|
| 63 |
+
|
| 64 |
+
@rank_zero_only
|
| 65 |
+
def on_train_start(self, trainer, pl_module):
|
| 66 |
+
try:
|
| 67 |
+
npars = pl_module.model.model.num_parameters()
|
| 68 |
+
except AttributeError:
|
| 69 |
+
npars = pl_module.model.num_parameters()
|
| 70 |
+
|
| 71 |
+
n_trainable_pars = count_trainable_parameters(pl_module)
|
| 72 |
+
# mp stands for million parameters
|
| 73 |
+
trainer.logger.log_metrics({"n_params": npars, "mp": npars / 1e6, "grad_mp": n_trainable_pars / 1e6})
|
| 74 |
+
|
| 75 |
+
@rank_zero_only
|
| 76 |
+
def on_test_end(self, trainer: pl.Trainer, pl_module: pl.LightningModule):
|
| 77 |
+
save_json(pl_module.metrics, pl_module.metrics_save_path)
|
| 78 |
+
return self._write_logs(trainer, pl_module, "test")
|
| 79 |
+
|
| 80 |
+
@rank_zero_only
|
| 81 |
+
def on_validation_end(self, trainer: pl.Trainer, pl_module):
|
| 82 |
+
save_json(pl_module.metrics, pl_module.metrics_save_path)
|
| 83 |
+
# Uncommenting this will save val generations
|
| 84 |
+
# return self._write_logs(trainer, pl_module, "valid")
|
| 85 |
+
|
| 86 |
+
|
| 87 |
+
def get_checkpoint_callback(output_dir, metric, save_top_k=1, lower_is_better=False):
|
| 88 |
+
"""Saves the best model by validation ROUGE2 score."""
|
| 89 |
+
if metric == "rouge2":
|
| 90 |
+
exp = "{val_avg_rouge2:.4f}-{step_count}"
|
| 91 |
+
elif metric == "bleu":
|
| 92 |
+
exp = "{val_avg_bleu:.4f}-{step_count}"
|
| 93 |
+
elif metric == "loss":
|
| 94 |
+
exp = "{val_avg_loss:.4f}-{step_count}"
|
| 95 |
+
else:
|
| 96 |
+
raise NotImplementedError(
|
| 97 |
+
f"seq2seq callbacks only support rouge2, bleu and loss, got {metric}, You can make your own by adding to this function."
|
| 98 |
+
)
|
| 99 |
+
|
| 100 |
+
checkpoint_callback = ModelCheckpoint(
|
| 101 |
+
filepath=os.path.join(output_dir, exp),
|
| 102 |
+
monitor=f"val_{metric}",
|
| 103 |
+
mode="min" if "loss" in metric else "max",
|
| 104 |
+
save_top_k=save_top_k,
|
| 105 |
+
)
|
| 106 |
+
return checkpoint_callback
|
| 107 |
+
|
| 108 |
+
|
| 109 |
+
def get_early_stopping_callback(metric, patience):
|
| 110 |
+
return EarlyStopping(
|
| 111 |
+
monitor=f"val_{metric}", # does this need avg?
|
| 112 |
+
mode="min" if "loss" in metric else "max",
|
| 113 |
+
patience=patience,
|
| 114 |
+
verbose=True,
|
| 115 |
+
)
|
src/mrc_client/seq2seq/cjjpy.py
ADDED
|
@@ -0,0 +1,249 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# -*- coding: utf-8 -*-
|
| 2 |
+
|
| 3 |
+
'''
|
| 4 |
+
@Author : Jiangjie Chen
|
| 5 |
+
@Time : 2018/11/15 17:08
|
| 6 |
+
@Contact: jjchen19@fudan.edu.cn
|
| 7 |
+
'''
|
| 8 |
+
|
| 9 |
+
import re
|
| 10 |
+
import datetime
|
| 11 |
+
import os
|
| 12 |
+
import argparse
|
| 13 |
+
import logging
|
| 14 |
+
import traceback
|
| 15 |
+
|
| 16 |
+
try:
|
| 17 |
+
import ujson as json
|
| 18 |
+
except:
|
| 19 |
+
import json
|
| 20 |
+
|
| 21 |
+
HADOOP_BIN = 'PATH=/usr/bin/:$PATH hdfs'
|
| 22 |
+
FOR_PUBLIC = True
|
| 23 |
+
|
| 24 |
+
|
| 25 |
+
def LengthStats(filename):
|
| 26 |
+
len_list = []
|
| 27 |
+
thresholds = [0.8, 0.9, 0.95, 0.99, 0.999]
|
| 28 |
+
with open(filename) as f:
|
| 29 |
+
for line in f:
|
| 30 |
+
len_list.append(len(line.strip().split()))
|
| 31 |
+
stats = {
|
| 32 |
+
'Max': max(len_list),
|
| 33 |
+
'Min': min(len_list),
|
| 34 |
+
'Avg': round(sum(len_list) / len(len_list), 4),
|
| 35 |
+
}
|
| 36 |
+
len_list.sort()
|
| 37 |
+
for t in thresholds:
|
| 38 |
+
stats[f"Top-{t}"] = len_list[int(len(len_list) * t)]
|
| 39 |
+
|
| 40 |
+
for k in stats:
|
| 41 |
+
print(f"- {k}: {stats[k]}")
|
| 42 |
+
return stats
|
| 43 |
+
|
| 44 |
+
|
| 45 |
+
class AttrDict(dict):
|
| 46 |
+
def __init__(self, *args, **kwargs):
|
| 47 |
+
super(AttrDict, self).__init__(*args, **kwargs)
|
| 48 |
+
self.__dict__ = self
|
| 49 |
+
|
| 50 |
+
|
| 51 |
+
def TraceBack(error_msg):
|
| 52 |
+
exc = traceback.format_exc()
|
| 53 |
+
msg = f'[Error]: {error_msg}.\n[Traceback]: {exc}'
|
| 54 |
+
return msg
|
| 55 |
+
|
| 56 |
+
|
| 57 |
+
def Now():
|
| 58 |
+
return datetime.datetime.now().strftime("%Y-%m-%d %H:%M:%S")
|
| 59 |
+
|
| 60 |
+
|
| 61 |
+
def AbsParentDir(file, parent='..', postfix=None):
|
| 62 |
+
ppath = os.path.abspath(file)
|
| 63 |
+
parent_level = parent.count('.')
|
| 64 |
+
while parent_level > 0:
|
| 65 |
+
ppath = os.path.dirname(ppath)
|
| 66 |
+
parent_level -= 1
|
| 67 |
+
if postfix is not None:
|
| 68 |
+
return os.path.join(ppath, postfix)
|
| 69 |
+
else:
|
| 70 |
+
return ppath
|
| 71 |
+
|
| 72 |
+
|
| 73 |
+
def init_logger(log_file=None, log_file_level=logging.NOTSET, from_scratch=False):
|
| 74 |
+
from coloredlogs import ColoredFormatter
|
| 75 |
+
import tensorflow as tf
|
| 76 |
+
|
| 77 |
+
fmt = "[%(asctime)s %(levelname)s] %(message)s"
|
| 78 |
+
log_format = ColoredFormatter(fmt=fmt)
|
| 79 |
+
# log_format = logging.Formatter()
|
| 80 |
+
logger = logging.getLogger()
|
| 81 |
+
logger.setLevel(log_file_level)
|
| 82 |
+
|
| 83 |
+
console_handler = logging.StreamHandler()
|
| 84 |
+
console_handler.setFormatter(log_format)
|
| 85 |
+
logger.handlers = [console_handler]
|
| 86 |
+
|
| 87 |
+
if log_file and log_file != '':
|
| 88 |
+
if from_scratch and tf.io.gfile.exists(log_file):
|
| 89 |
+
logger.warning('Removing previous log file: %s' % log_file)
|
| 90 |
+
tf.io.gfile.remove(log_file)
|
| 91 |
+
path = os.path.dirname(log_file)
|
| 92 |
+
os.makedirs(path, exist_ok=True)
|
| 93 |
+
file_handler = logging.FileHandler(log_file)
|
| 94 |
+
file_handler.setLevel(log_file_level)
|
| 95 |
+
file_handler.setFormatter(log_format)
|
| 96 |
+
logger.addHandler(file_handler)
|
| 97 |
+
|
| 98 |
+
return logger
|
| 99 |
+
|
| 100 |
+
|
| 101 |
+
def OverWriteCjjPy(root='.'):
|
| 102 |
+
# import difflib
|
| 103 |
+
# diff = difflib.HtmlDiff()
|
| 104 |
+
cnt = 0
|
| 105 |
+
golden_cjjpy = os.path.join(root, 'cjjpy.py')
|
| 106 |
+
# golden_content = open(golden_cjjpy).readlines()
|
| 107 |
+
for dir, folder, file in os.walk(root):
|
| 108 |
+
for f in file:
|
| 109 |
+
if f == 'cjjpy.py':
|
| 110 |
+
cjjpy = '%s/%s' % (dir, f)
|
| 111 |
+
# content = open(cjjpy).readlines()
|
| 112 |
+
# d = diff.make_file(golden_content, content)
|
| 113 |
+
cnt += 1
|
| 114 |
+
print('[%d]: %s' % (cnt, cjjpy))
|
| 115 |
+
os.system('cp %s %s' % (golden_cjjpy, cjjpy))
|
| 116 |
+
|
| 117 |
+
|
| 118 |
+
def ChangeFileFormat(filename, new_fmt):
|
| 119 |
+
assert type(filename) is str and type(new_fmt) is str
|
| 120 |
+
spt = filename.split('.')
|
| 121 |
+
if len(spt) == 0:
|
| 122 |
+
return filename
|
| 123 |
+
else:
|
| 124 |
+
return filename.replace('.' + spt[-1], new_fmt)
|
| 125 |
+
|
| 126 |
+
|
| 127 |
+
def CountLines(fname):
|
| 128 |
+
with open(fname, 'rb') as f:
|
| 129 |
+
count = 0
|
| 130 |
+
last_data = '\n'
|
| 131 |
+
while True:
|
| 132 |
+
data = f.read(0x400000)
|
| 133 |
+
if not data:
|
| 134 |
+
break
|
| 135 |
+
count += data.count(b'\n')
|
| 136 |
+
last_data = data
|
| 137 |
+
if last_data[-1:] != b'\n':
|
| 138 |
+
count += 1 # Remove this if a wc-like count is needed
|
| 139 |
+
return count
|
| 140 |
+
|
| 141 |
+
|
| 142 |
+
def GetDate():
|
| 143 |
+
return str(datetime.datetime.now())[5:10].replace('-', '')
|
| 144 |
+
|
| 145 |
+
|
| 146 |
+
def TimeClock(seconds):
|
| 147 |
+
sec = int(seconds)
|
| 148 |
+
hour = int(sec / 3600)
|
| 149 |
+
min = int((sec - hour * 3600) / 60)
|
| 150 |
+
ssec = float(seconds) - hour * 3600 - min * 60
|
| 151 |
+
# return '%dh %dm %.2fs' % (hour, min, ssec)
|
| 152 |
+
return '{0:>2d}h{1:>3d}m{2:>6.2f}s'.format(hour, min, ssec)
|
| 153 |
+
|
| 154 |
+
|
| 155 |
+
def StripAll(text):
|
| 156 |
+
return text.strip().replace('\t', '').replace('\n', '').replace(' ', '')
|
| 157 |
+
|
| 158 |
+
|
| 159 |
+
def GetBracket(text, bracket, en_br=False):
|
| 160 |
+
# input should be aa(bb)cc, True for bracket, False for text
|
| 161 |
+
if bracket:
|
| 162 |
+
try:
|
| 163 |
+
return re.findall('\((.*?)\)', text.strip())[-1]
|
| 164 |
+
except:
|
| 165 |
+
return ''
|
| 166 |
+
else:
|
| 167 |
+
if en_br:
|
| 168 |
+
text = re.sub('\(.*?\)', '', text.strip())
|
| 169 |
+
return re.sub('(.*?)', '', text.strip())
|
| 170 |
+
|
| 171 |
+
|
| 172 |
+
def CharLang(uchar, lang):
|
| 173 |
+
assert lang.lower() in ['en', 'cn', 'zh']
|
| 174 |
+
if lang.lower() in ['cn', 'zh']:
|
| 175 |
+
if uchar >= '\u4e00' and uchar <= '\u9fa5':
|
| 176 |
+
return True
|
| 177 |
+
else:
|
| 178 |
+
return False
|
| 179 |
+
elif lang.lower() == 'en':
|
| 180 |
+
if (uchar <= 'Z' and uchar >= 'A') or (uchar <= 'z' and uchar >= 'a'):
|
| 181 |
+
return True
|
| 182 |
+
else:
|
| 183 |
+
return False
|
| 184 |
+
else:
|
| 185 |
+
raise NotImplementedError
|
| 186 |
+
|
| 187 |
+
|
| 188 |
+
def WordLang(word, lang):
|
| 189 |
+
for i in word.strip():
|
| 190 |
+
if i.isspace(): continue
|
| 191 |
+
if not CharLang(i, lang):
|
| 192 |
+
return False
|
| 193 |
+
return True
|
| 194 |
+
|
| 195 |
+
|
| 196 |
+
def SortDict(_dict, reverse=True):
|
| 197 |
+
assert type(_dict) is dict
|
| 198 |
+
return sorted(_dict.items(), key=lambda d: d[1], reverse=reverse)
|
| 199 |
+
|
| 200 |
+
|
| 201 |
+
def lark(content='test'):
|
| 202 |
+
print(content)
|
| 203 |
+
|
| 204 |
+
|
| 205 |
+
if __name__ == '__main__':
|
| 206 |
+
parser = argparse.ArgumentParser()
|
| 207 |
+
|
| 208 |
+
parser.add_argument('--diff', nargs=2,
|
| 209 |
+
help='show difference between two files, shown in downloads/diff.html')
|
| 210 |
+
parser.add_argument('--de_unicode', action='store_true', default=False,
|
| 211 |
+
help='remove unicode characters')
|
| 212 |
+
parser.add_argument('--link_entity', action='store_true', default=False,
|
| 213 |
+
help='')
|
| 214 |
+
parser.add_argument('--max_comm_len', action='store_true', default=False,
|
| 215 |
+
help='')
|
| 216 |
+
parser.add_argument('--search', nargs=2,
|
| 217 |
+
help='search key from file, 2 args: file name & key')
|
| 218 |
+
parser.add_argument('--email', nargs=2,
|
| 219 |
+
help='sending emails, 2 args: subject & content')
|
| 220 |
+
parser.add_argument('--overwrite', action='store_true', default=None,
|
| 221 |
+
help='overwrite all cjjpy under given *dir* based on *dir*/cjjpy.py')
|
| 222 |
+
parser.add_argument('--replace', nargs=3,
|
| 223 |
+
help='replace char, 3 args: file name & replaced char & replacer char')
|
| 224 |
+
parser.add_argument('--lark', nargs=1)
|
| 225 |
+
parser.add_argument('--get_hdfs', nargs=2,
|
| 226 |
+
help='easy copy from hdfs to local fs, 2 args: remote_file/dir & local_dir')
|
| 227 |
+
parser.add_argument('--put_hdfs', nargs=2,
|
| 228 |
+
help='easy put from local fs to hdfs, 2 args: local_file/dir & remote_dir')
|
| 229 |
+
parser.add_argument('--length_stats', nargs=1,
|
| 230 |
+
help='simple token lengths distribution of a line-by-line file')
|
| 231 |
+
|
| 232 |
+
args = parser.parse_args()
|
| 233 |
+
|
| 234 |
+
if args.overwrite:
|
| 235 |
+
print('* Overwriting cjjpy...')
|
| 236 |
+
OverWriteCjjPy()
|
| 237 |
+
|
| 238 |
+
if args.lark:
|
| 239 |
+
try:
|
| 240 |
+
content = args.lark[0]
|
| 241 |
+
except:
|
| 242 |
+
content = 'running complete'
|
| 243 |
+
print(f'* Larking "{content}"...')
|
| 244 |
+
lark(content)
|
| 245 |
+
|
| 246 |
+
if args.length_stats:
|
| 247 |
+
file = args.length_stats[0]
|
| 248 |
+
print(f'* Working on {file} lengths statistics...')
|
| 249 |
+
LengthStats(file)
|
src/mrc_client/seq2seq/convert_pl_checkpoint_to_hf.py
ADDED
|
@@ -0,0 +1,74 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
#!/usr/bin/env python
|
| 2 |
+
|
| 3 |
+
import os
|
| 4 |
+
from pathlib import Path
|
| 5 |
+
from typing import Dict, List
|
| 6 |
+
|
| 7 |
+
import fire
|
| 8 |
+
import torch
|
| 9 |
+
|
| 10 |
+
from transformers import AutoModelForSeq2SeqLM, AutoTokenizer
|
| 11 |
+
from transformers.utils.logging import get_logger
|
| 12 |
+
|
| 13 |
+
|
| 14 |
+
logger = get_logger(__name__)
|
| 15 |
+
|
| 16 |
+
|
| 17 |
+
def remove_prefix(text: str, prefix: str):
|
| 18 |
+
if text.startswith(prefix):
|
| 19 |
+
return text[len(prefix) :]
|
| 20 |
+
return text # or whatever
|
| 21 |
+
|
| 22 |
+
|
| 23 |
+
def sanitize(sd):
|
| 24 |
+
return {remove_prefix(k, "model."): v for k, v in sd.items()}
|
| 25 |
+
|
| 26 |
+
|
| 27 |
+
def average_state_dicts(state_dicts: List[Dict[str, torch.Tensor]]):
|
| 28 |
+
new_sd = {}
|
| 29 |
+
for k in state_dicts[0].keys():
|
| 30 |
+
tensors = [sd[k] for sd in state_dicts]
|
| 31 |
+
new_t = sum(tensors) / len(tensors)
|
| 32 |
+
assert isinstance(new_t, torch.Tensor)
|
| 33 |
+
new_sd[k] = new_t
|
| 34 |
+
return new_sd
|
| 35 |
+
|
| 36 |
+
|
| 37 |
+
def convert_pl_to_hf(pl_ckpt_path: str, hf_src_model_dir: str, save_path: str) -> None:
|
| 38 |
+
"""Cleanup a pytorch-lightning .ckpt file or experiment dir and save a huggingface model with that state dict.
|
| 39 |
+
Silently allows extra pl keys (like teacher.) Puts all ckpt models into CPU RAM at once!
|
| 40 |
+
|
| 41 |
+
Args:
|
| 42 |
+
pl_ckpt_path (:obj:`str`): Path to a .ckpt file saved by pytorch_lightning or dir containing ckpt files.
|
| 43 |
+
If a directory is passed, all .ckpt files inside it will be averaged!
|
| 44 |
+
hf_src_model_dir (:obj:`str`): Path to a directory containing a correctly shaped checkpoint
|
| 45 |
+
save_path (:obj:`str`): Directory to save the new model
|
| 46 |
+
|
| 47 |
+
"""
|
| 48 |
+
hf_model = AutoModelForSeq2SeqLM.from_pretrained(hf_src_model_dir)
|
| 49 |
+
if os.path.isfile(pl_ckpt_path):
|
| 50 |
+
ckpt_files = [pl_ckpt_path]
|
| 51 |
+
else:
|
| 52 |
+
assert os.path.isdir(pl_ckpt_path)
|
| 53 |
+
ckpt_files = list(Path(pl_ckpt_path).glob("*.ckpt"))
|
| 54 |
+
assert ckpt_files, f"could not find any ckpt files inside the {pl_ckpt_path} directory"
|
| 55 |
+
|
| 56 |
+
if len(ckpt_files) > 1:
|
| 57 |
+
logger.info(f"averaging the weights of {ckpt_files}")
|
| 58 |
+
|
| 59 |
+
state_dicts = [sanitize(torch.load(x, map_location="cpu")["state_dict"]) for x in ckpt_files]
|
| 60 |
+
state_dict = average_state_dicts(state_dicts)
|
| 61 |
+
|
| 62 |
+
missing, unexpected = hf_model.load_state_dict(state_dict, strict=False)
|
| 63 |
+
assert not missing, f"missing keys: {missing}"
|
| 64 |
+
hf_model.save_pretrained(save_path)
|
| 65 |
+
try:
|
| 66 |
+
tok = AutoTokenizer.from_pretrained(hf_src_model_dir)
|
| 67 |
+
tok.save_pretrained(save_path)
|
| 68 |
+
except Exception:
|
| 69 |
+
pass
|
| 70 |
+
# dont copy tokenizer if cant
|
| 71 |
+
|
| 72 |
+
|
| 73 |
+
if __name__ == "__main__":
|
| 74 |
+
fire.Fire(convert_pl_to_hf)
|
src/mrc_client/seq2seq/finetune.py
ADDED
|
@@ -0,0 +1,465 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
#!/usr/bin/env python
|
| 2 |
+
|
| 3 |
+
import argparse
|
| 4 |
+
import glob
|
| 5 |
+
import logging
|
| 6 |
+
import os
|
| 7 |
+
import sys
|
| 8 |
+
import time
|
| 9 |
+
from collections import defaultdict
|
| 10 |
+
from pathlib import Path
|
| 11 |
+
from typing import Dict, List, Tuple
|
| 12 |
+
|
| 13 |
+
import numpy as np
|
| 14 |
+
import pytorch_lightning as pl
|
| 15 |
+
import torch
|
| 16 |
+
from torch.utils.data import DataLoader
|
| 17 |
+
|
| 18 |
+
from callbacks import Seq2SeqLoggingCallback, get_checkpoint_callback, get_early_stopping_callback
|
| 19 |
+
from transformers import MBartTokenizer, T5ForConditionalGeneration
|
| 20 |
+
try:
|
| 21 |
+
from transformers.modeling_bart import shift_tokens_right
|
| 22 |
+
except:
|
| 23 |
+
from transformers.models.bart.modeling_bart import shift_tokens_right
|
| 24 |
+
from seq2seq_utils import (
|
| 25 |
+
ROUGE_KEYS,
|
| 26 |
+
LegacySeq2SeqDataset,
|
| 27 |
+
Seq2SeqDataset,
|
| 28 |
+
UniQASeq2SeqDataset,
|
| 29 |
+
assert_all_frozen,
|
| 30 |
+
calculate_bleu,
|
| 31 |
+
calculate_rouge,
|
| 32 |
+
check_output_dir,
|
| 33 |
+
flatten_list,
|
| 34 |
+
freeze_embeds,
|
| 35 |
+
freeze_params,
|
| 36 |
+
get_git_info,
|
| 37 |
+
label_smoothed_nll_loss,
|
| 38 |
+
lmap,
|
| 39 |
+
pickle_save,
|
| 40 |
+
save_git_info,
|
| 41 |
+
save_json,
|
| 42 |
+
use_task_specific_params,
|
| 43 |
+
)
|
| 44 |
+
|
| 45 |
+
|
| 46 |
+
# need the parent dir module
|
| 47 |
+
sys.path.insert(2, str(Path(__file__).resolve().parents[1]))
|
| 48 |
+
from lightning_base import BaseTransformer, add_generic_args, generic_train # noqa
|
| 49 |
+
|
| 50 |
+
|
| 51 |
+
logger = logging.getLogger(__name__)
|
| 52 |
+
|
| 53 |
+
|
| 54 |
+
class SummarizationModule(BaseTransformer):
|
| 55 |
+
mode = "summarization"
|
| 56 |
+
loss_names = ["loss"]
|
| 57 |
+
metric_names = ROUGE_KEYS
|
| 58 |
+
default_val_metric = "rouge2"
|
| 59 |
+
|
| 60 |
+
def __init__(self, hparams, **kwargs):
|
| 61 |
+
if hparams.sortish_sampler and hparams.gpus > 1:
|
| 62 |
+
hparams.replace_sampler_ddp = False
|
| 63 |
+
elif hparams.max_tokens_per_batch is not None:
|
| 64 |
+
if hparams.gpus > 1:
|
| 65 |
+
raise NotImplementedError("Dynamic Batch size does not work for multi-gpu training")
|
| 66 |
+
if hparams.sortish_sampler:
|
| 67 |
+
raise ValueError("--sortish_sampler and --max_tokens_per_batch may not be used simultaneously")
|
| 68 |
+
|
| 69 |
+
super().__init__(hparams, num_labels=None, mode=self.mode, **kwargs)
|
| 70 |
+
use_task_specific_params(self.model, "summarization")
|
| 71 |
+
# TODO: hard-encoded length constraint
|
| 72 |
+
self.model.config.min_length = hparams.min_target_length
|
| 73 |
+
self.model.config.max_length = hparams.max_target_length
|
| 74 |
+
save_git_info(self.hparams.output_dir)
|
| 75 |
+
self.metrics_save_path = Path(self.output_dir) / "metrics.json"
|
| 76 |
+
self.hparams_save_path = Path(self.output_dir) / "hparams.pkl"
|
| 77 |
+
pickle_save(self.hparams, self.hparams_save_path)
|
| 78 |
+
self.step_count = 0
|
| 79 |
+
self.metrics = defaultdict(list)
|
| 80 |
+
self.model_type = self.config.model_type
|
| 81 |
+
self.vocab_size = self.config.tgt_vocab_size if self.model_type == "fsmt" else self.config.vocab_size
|
| 82 |
+
|
| 83 |
+
self.dataset_kwargs: dict = dict(
|
| 84 |
+
data_dir=self.hparams.data_dir,
|
| 85 |
+
max_source_length=self.hparams.max_source_length,
|
| 86 |
+
prefix=self.model.config.prefix or "",
|
| 87 |
+
)
|
| 88 |
+
n_observations_per_split = {
|
| 89 |
+
"train": self.hparams.n_train,
|
| 90 |
+
"val": self.hparams.n_val,
|
| 91 |
+
"test": self.hparams.n_test,
|
| 92 |
+
}
|
| 93 |
+
self.n_obs = {k: v if v >= 0 else None for k, v in n_observations_per_split.items()}
|
| 94 |
+
|
| 95 |
+
self.target_lens = {
|
| 96 |
+
"train": self.hparams.max_target_length,
|
| 97 |
+
"val": self.hparams.val_max_target_length,
|
| 98 |
+
"test": self.hparams.test_max_target_length,
|
| 99 |
+
}
|
| 100 |
+
assert self.target_lens["train"] <= self.target_lens["val"], f"target_lens: {self.target_lens}"
|
| 101 |
+
assert self.target_lens["train"] <= self.target_lens["test"], f"target_lens: {self.target_lens}"
|
| 102 |
+
if self.hparams.freeze_embeds:
|
| 103 |
+
freeze_embeds(self.model)
|
| 104 |
+
if self.hparams.freeze_encoder:
|
| 105 |
+
freeze_params(self.model.get_encoder())
|
| 106 |
+
assert_all_frozen(self.model.get_encoder())
|
| 107 |
+
|
| 108 |
+
self.hparams.git_sha = get_git_info()["repo_sha"]
|
| 109 |
+
self.num_workers = hparams.num_workers
|
| 110 |
+
self.decoder_start_token_id = None # default to config
|
| 111 |
+
if self.model.config.decoder_start_token_id is None and isinstance(self.tokenizer, MBartTokenizer):
|
| 112 |
+
self.decoder_start_token_id = self.tokenizer.lang_code_to_id[hparams.tgt_lang]
|
| 113 |
+
self.model.config.decoder_start_token_id = self.decoder_start_token_id
|
| 114 |
+
|
| 115 |
+
if 'unifiedqa' in self.hparams.model_name_or_path:
|
| 116 |
+
self.dataset_class = (UniQASeq2SeqDataset)
|
| 117 |
+
else:
|
| 118 |
+
self.dataset_class = (
|
| 119 |
+
Seq2SeqDataset if hasattr(self.tokenizer, "prepare_seq2seq_batch") else LegacySeq2SeqDataset
|
| 120 |
+
)
|
| 121 |
+
self.already_saved_batch = False
|
| 122 |
+
self.eval_beams = self.model.config.num_beams if self.hparams.eval_beams is None else self.hparams.eval_beams
|
| 123 |
+
if self.hparams.eval_max_gen_length is not None:
|
| 124 |
+
self.eval_max_length = self.hparams.eval_max_gen_length
|
| 125 |
+
else:
|
| 126 |
+
self.eval_max_length = self.model.config.max_length
|
| 127 |
+
if self.hparams.min_target_length is not None:
|
| 128 |
+
self.min_length = self.hparams.min_target_length
|
| 129 |
+
else:
|
| 130 |
+
self.min_length = self.model.config.min_length
|
| 131 |
+
|
| 132 |
+
self.val_metric = self.default_val_metric if self.hparams.val_metric is None else self.hparams.val_metric
|
| 133 |
+
|
| 134 |
+
def save_readable_batch(self, batch: Dict[str, torch.Tensor]) -> Dict[str, List[str]]:
|
| 135 |
+
"""A debugging utility"""
|
| 136 |
+
readable_batch = {
|
| 137 |
+
k: self.tokenizer.batch_decode(v.tolist()) if "mask" not in k else v.shape for k, v in batch.items()
|
| 138 |
+
}
|
| 139 |
+
save_json(readable_batch, Path(self.output_dir) / "text_batch.json")
|
| 140 |
+
save_json({k: v.tolist() for k, v in batch.items()}, Path(self.output_dir) / "tok_batch.json")
|
| 141 |
+
|
| 142 |
+
self.already_saved_batch = True
|
| 143 |
+
return readable_batch
|
| 144 |
+
|
| 145 |
+
def forward(self, input_ids, **kwargs):
|
| 146 |
+
return self.model(input_ids, **kwargs)
|
| 147 |
+
|
| 148 |
+
def ids_to_clean_text(self, generated_ids: List[int]):
|
| 149 |
+
gen_text = self.tokenizer.batch_decode(
|
| 150 |
+
generated_ids, skip_special_tokens=True, clean_up_tokenization_spaces=True
|
| 151 |
+
)
|
| 152 |
+
return lmap(str.strip, gen_text)
|
| 153 |
+
|
| 154 |
+
def _step(self, batch: dict) -> Tuple:
|
| 155 |
+
pad_token_id = self.tokenizer.pad_token_id
|
| 156 |
+
src_ids, src_mask = batch["input_ids"], batch["attention_mask"]
|
| 157 |
+
tgt_ids = batch["labels"]
|
| 158 |
+
if isinstance(self.model, T5ForConditionalGeneration):
|
| 159 |
+
decoder_input_ids = self.model._shift_right(tgt_ids)
|
| 160 |
+
else:
|
| 161 |
+
decoder_input_ids = shift_tokens_right(tgt_ids, pad_token_id)
|
| 162 |
+
if not self.already_saved_batch: # This would be slightly better if it only happened on rank zero
|
| 163 |
+
batch["decoder_input_ids"] = decoder_input_ids
|
| 164 |
+
self.save_readable_batch(batch)
|
| 165 |
+
|
| 166 |
+
outputs = self(src_ids, attention_mask=src_mask, decoder_input_ids=decoder_input_ids, use_cache=False)
|
| 167 |
+
lm_logits = outputs[0]
|
| 168 |
+
if self.hparams.label_smoothing == 0:
|
| 169 |
+
# Same behavior as modeling_bart.py, besides ignoring pad_token_id
|
| 170 |
+
ce_loss_fct = torch.nn.CrossEntropyLoss(ignore_index=pad_token_id)
|
| 171 |
+
|
| 172 |
+
assert lm_logits.shape[-1] == self.vocab_size
|
| 173 |
+
loss = ce_loss_fct(lm_logits.view(-1, lm_logits.shape[-1]), tgt_ids.view(-1))
|
| 174 |
+
else:
|
| 175 |
+
lprobs = torch.nn.functional.log_softmax(lm_logits, dim=-1)
|
| 176 |
+
loss, nll_loss = label_smoothed_nll_loss(
|
| 177 |
+
lprobs, tgt_ids, self.hparams.label_smoothing, ignore_index=pad_token_id
|
| 178 |
+
)
|
| 179 |
+
return (loss,)
|
| 180 |
+
|
| 181 |
+
@property
|
| 182 |
+
def pad(self) -> int:
|
| 183 |
+
return self.tokenizer.pad_token_id
|
| 184 |
+
|
| 185 |
+
def training_step(self, batch, batch_idx) -> Dict:
|
| 186 |
+
loss_tensors = self._step(batch)
|
| 187 |
+
|
| 188 |
+
logs = {name: loss for name, loss in zip(self.loss_names, loss_tensors)}
|
| 189 |
+
# tokens per batch
|
| 190 |
+
logs["tpb"] = batch["input_ids"].ne(self.pad).sum() + batch["labels"].ne(self.pad).sum()
|
| 191 |
+
logs["bs"] = batch["input_ids"].shape[0]
|
| 192 |
+
logs["src_pad_tok"] = batch["input_ids"].eq(self.pad).sum()
|
| 193 |
+
logs["src_pad_frac"] = batch["input_ids"].eq(self.pad).float().mean()
|
| 194 |
+
# TODO(SS): make a wandb summary metric for this
|
| 195 |
+
return {"loss": loss_tensors[0], "log": logs}
|
| 196 |
+
|
| 197 |
+
def validation_step(self, batch, batch_idx) -> Dict:
|
| 198 |
+
return self._generative_step(batch)
|
| 199 |
+
|
| 200 |
+
def validation_epoch_end(self, outputs, prefix="val") -> Dict:
|
| 201 |
+
self.step_count += 1
|
| 202 |
+
losses = {k: torch.stack([x[k] for x in outputs]).mean() for k in self.loss_names}
|
| 203 |
+
loss = losses["loss"]
|
| 204 |
+
generative_metrics = {
|
| 205 |
+
k: np.array([x[k] for x in outputs]).mean() for k in self.metric_names + ["gen_time", "gen_len"]
|
| 206 |
+
}
|
| 207 |
+
metric_val = (
|
| 208 |
+
generative_metrics[self.val_metric] if self.val_metric in generative_metrics else losses[self.val_metric]
|
| 209 |
+
)
|
| 210 |
+
metric_tensor: torch.FloatTensor = torch.tensor(metric_val).type_as(loss)
|
| 211 |
+
generative_metrics.update({k: v.item() for k, v in losses.items()})
|
| 212 |
+
losses.update(generative_metrics)
|
| 213 |
+
all_metrics = {f"{prefix}_avg_{k}": x for k, x in losses.items()}
|
| 214 |
+
all_metrics["step_count"] = self.step_count
|
| 215 |
+
self.metrics[prefix].append(all_metrics) # callback writes this to self.metrics_save_path
|
| 216 |
+
preds = flatten_list([x["preds"] for x in outputs])
|
| 217 |
+
return {
|
| 218 |
+
"log": all_metrics,
|
| 219 |
+
"preds": preds,
|
| 220 |
+
f"{prefix}_loss": loss,
|
| 221 |
+
f"{prefix}_{self.val_metric}": metric_tensor,
|
| 222 |
+
}
|
| 223 |
+
|
| 224 |
+
def calc_generative_metrics(self, preds, target) -> Dict:
|
| 225 |
+
return calculate_rouge(preds, target)
|
| 226 |
+
|
| 227 |
+
def _generative_step(self, batch: dict) -> dict:
|
| 228 |
+
t0 = time.time()
|
| 229 |
+
|
| 230 |
+
# parser.add_argument('--eval_max_gen_length', type=int, default=None, help='never generate more than n tokens')
|
| 231 |
+
generated_ids = self.model.generate(
|
| 232 |
+
batch["input_ids"],
|
| 233 |
+
attention_mask=batch["attention_mask"],
|
| 234 |
+
use_cache=True,
|
| 235 |
+
decoder_start_token_id=self.decoder_start_token_id,
|
| 236 |
+
num_beams=self.eval_beams,
|
| 237 |
+
max_length=self.eval_max_length,
|
| 238 |
+
min_length=self.min_length
|
| 239 |
+
)
|
| 240 |
+
gen_time = (time.time() - t0) / batch["input_ids"].shape[0]
|
| 241 |
+
preds: List[str] = self.ids_to_clean_text(generated_ids)
|
| 242 |
+
target: List[str] = self.ids_to_clean_text(batch["labels"])
|
| 243 |
+
loss_tensors = self._step(batch)
|
| 244 |
+
base_metrics = {name: loss for name, loss in zip(self.loss_names, loss_tensors)}
|
| 245 |
+
rouge: Dict = self.calc_generative_metrics(preds, target)
|
| 246 |
+
summ_len = np.mean(lmap(len, generated_ids))
|
| 247 |
+
base_metrics.update(gen_time=gen_time, gen_len=summ_len, preds=preds, target=target, **rouge)
|
| 248 |
+
return base_metrics
|
| 249 |
+
|
| 250 |
+
def test_step(self, batch, batch_idx):
|
| 251 |
+
return self._generative_step(batch)
|
| 252 |
+
|
| 253 |
+
def test_epoch_end(self, outputs):
|
| 254 |
+
return self.validation_epoch_end(outputs, prefix="test")
|
| 255 |
+
|
| 256 |
+
def get_dataset(self, type_path) -> Seq2SeqDataset:
|
| 257 |
+
n_obs = self.n_obs[type_path]
|
| 258 |
+
max_target_length = self.target_lens[type_path]
|
| 259 |
+
dataset = self.dataset_class(
|
| 260 |
+
self.tokenizer,
|
| 261 |
+
type_path=type_path,
|
| 262 |
+
n_obs=n_obs,
|
| 263 |
+
max_target_length=max_target_length,
|
| 264 |
+
**self.dataset_kwargs,
|
| 265 |
+
)
|
| 266 |
+
return dataset
|
| 267 |
+
|
| 268 |
+
def get_dataloader(self, type_path: str, batch_size: int, shuffle: bool = False) -> DataLoader:
|
| 269 |
+
dataset = self.get_dataset(type_path)
|
| 270 |
+
|
| 271 |
+
if self.hparams.sortish_sampler and type_path != "test" and type_path != "val":
|
| 272 |
+
sampler = dataset.make_sortish_sampler(batch_size, distributed=self.hparams.gpus > 1)
|
| 273 |
+
return DataLoader(
|
| 274 |
+
dataset,
|
| 275 |
+
batch_size=batch_size,
|
| 276 |
+
collate_fn=dataset.collate_fn,
|
| 277 |
+
shuffle=False,
|
| 278 |
+
num_workers=self.num_workers,
|
| 279 |
+
sampler=sampler,
|
| 280 |
+
)
|
| 281 |
+
|
| 282 |
+
elif self.hparams.max_tokens_per_batch is not None and type_path != "test" and type_path != "val":
|
| 283 |
+
batch_sampler = dataset.make_dynamic_sampler(
|
| 284 |
+
self.hparams.max_tokens_per_batch, distributed=self.hparams.gpus > 1
|
| 285 |
+
)
|
| 286 |
+
return DataLoader(
|
| 287 |
+
dataset,
|
| 288 |
+
batch_sampler=batch_sampler,
|
| 289 |
+
collate_fn=dataset.collate_fn,
|
| 290 |
+
# shuffle=False,
|
| 291 |
+
num_workers=self.num_workers,
|
| 292 |
+
# batch_size=None,
|
| 293 |
+
)
|
| 294 |
+
else:
|
| 295 |
+
return DataLoader(
|
| 296 |
+
dataset,
|
| 297 |
+
batch_size=batch_size,
|
| 298 |
+
collate_fn=dataset.collate_fn,
|
| 299 |
+
shuffle=shuffle,
|
| 300 |
+
num_workers=self.num_workers,
|
| 301 |
+
sampler=None,
|
| 302 |
+
)
|
| 303 |
+
|
| 304 |
+
def train_dataloader(self) -> DataLoader:
|
| 305 |
+
dataloader = self.get_dataloader("train", batch_size=self.hparams.train_batch_size, shuffle=True)
|
| 306 |
+
return dataloader
|
| 307 |
+
|
| 308 |
+
def val_dataloader(self) -> DataLoader:
|
| 309 |
+
return self.get_dataloader("val", batch_size=self.hparams.eval_batch_size)
|
| 310 |
+
|
| 311 |
+
def test_dataloader(self) -> DataLoader:
|
| 312 |
+
return self.get_dataloader("test", batch_size=self.hparams.eval_batch_size)
|
| 313 |
+
|
| 314 |
+
@staticmethod
|
| 315 |
+
def add_model_specific_args(parser, root_dir):
|
| 316 |
+
BaseTransformer.add_model_specific_args(parser, root_dir)
|
| 317 |
+
add_generic_args(parser, root_dir)
|
| 318 |
+
parser.add_argument(
|
| 319 |
+
"--min_target_length",
|
| 320 |
+
default=1,
|
| 321 |
+
type=int,
|
| 322 |
+
help="The minimum total target sequence length after tokenization.",
|
| 323 |
+
)
|
| 324 |
+
parser.add_argument(
|
| 325 |
+
"--max_source_length",
|
| 326 |
+
default=1024,
|
| 327 |
+
type=int,
|
| 328 |
+
help="The maximum total input sequence length after tokenization. Sequences longer "
|
| 329 |
+
"than this will be truncated, sequences shorter will be padded.",
|
| 330 |
+
)
|
| 331 |
+
parser.add_argument(
|
| 332 |
+
"--max_target_length",
|
| 333 |
+
default=56,
|
| 334 |
+
type=int,
|
| 335 |
+
help="The maximum total input sequence length after tokenization. Sequences longer "
|
| 336 |
+
"than this will be truncated, sequences shorter will be padded.",
|
| 337 |
+
)
|
| 338 |
+
parser.add_argument(
|
| 339 |
+
"--val_max_target_length",
|
| 340 |
+
default=142, # these defaults are optimized for CNNDM. For xsum, see README.md.
|
| 341 |
+
type=int,
|
| 342 |
+
help="The maximum total input sequence length after tokenization. Sequences longer "
|
| 343 |
+
"than this will be truncated, sequences shorter will be padded.",
|
| 344 |
+
)
|
| 345 |
+
parser.add_argument(
|
| 346 |
+
"--test_max_target_length",
|
| 347 |
+
default=142,
|
| 348 |
+
type=int,
|
| 349 |
+
help="The maximum total input sequence length after tokenization. Sequences longer "
|
| 350 |
+
"than this will be truncated, sequences shorter will be padded.",
|
| 351 |
+
)
|
| 352 |
+
parser.add_argument("--freeze_encoder", action="store_true")
|
| 353 |
+
parser.add_argument("--freeze_embeds", action="store_true")
|
| 354 |
+
parser.add_argument("--sortish_sampler", action="store_true", default=False)
|
| 355 |
+
parser.add_argument("--overwrite_output_dir", action="store_true", default=False)
|
| 356 |
+
parser.add_argument("--max_tokens_per_batch", type=int, default=None)
|
| 357 |
+
parser.add_argument("--logger_name", type=str, choices=["default", "wandb", "wandb_shared"], default="default")
|
| 358 |
+
parser.add_argument("--n_train", type=int, default=-1, required=False, help="# examples. -1 means use all.")
|
| 359 |
+
parser.add_argument("--n_val", type=int, default=500, required=False, help="# examples. -1 means use all.")
|
| 360 |
+
parser.add_argument("--n_test", type=int, default=-1, required=False, help="# examples. -1 means use all.")
|
| 361 |
+
parser.add_argument(
|
| 362 |
+
"--task", type=str, default="summarization", required=False, help="# examples. -1 means use all."
|
| 363 |
+
)
|
| 364 |
+
parser.add_argument("--label_smoothing", type=float, default=0.0, required=False)
|
| 365 |
+
parser.add_argument("--src_lang", type=str, default="", required=False)
|
| 366 |
+
parser.add_argument("--tgt_lang", type=str, default="", required=False)
|
| 367 |
+
parser.add_argument("--eval_beams", type=int, default=None, required=False)
|
| 368 |
+
parser.add_argument(
|
| 369 |
+
"--val_metric", type=str, default=None, required=False, choices=["bleu", "rouge2", "loss", None]
|
| 370 |
+
)
|
| 371 |
+
parser.add_argument("--eval_max_gen_length", type=int, default=None, help="never generate more than n tokens")
|
| 372 |
+
parser.add_argument("--save_top_k", type=int, default=1, required=False, help="How many checkpoints to save")
|
| 373 |
+
parser.add_argument(
|
| 374 |
+
"--early_stopping_patience",
|
| 375 |
+
type=int,
|
| 376 |
+
default=-1,
|
| 377 |
+
required=False,
|
| 378 |
+
help="-1 means never early stop. early_stopping_patience is measured in validation checks, not epochs. So val_check_interval will effect it.",
|
| 379 |
+
)
|
| 380 |
+
return parser
|
| 381 |
+
|
| 382 |
+
|
| 383 |
+
class TranslationModule(SummarizationModule):
|
| 384 |
+
mode = "translation"
|
| 385 |
+
loss_names = ["loss"]
|
| 386 |
+
metric_names = ["bleu"]
|
| 387 |
+
default_val_metric = "bleu"
|
| 388 |
+
|
| 389 |
+
def __init__(self, hparams, **kwargs):
|
| 390 |
+
super().__init__(hparams, **kwargs)
|
| 391 |
+
self.dataset_kwargs["src_lang"] = hparams.src_lang
|
| 392 |
+
self.dataset_kwargs["tgt_lang"] = hparams.tgt_lang
|
| 393 |
+
|
| 394 |
+
def calc_generative_metrics(self, preds, target) -> dict:
|
| 395 |
+
return calculate_bleu(preds, target)
|
| 396 |
+
|
| 397 |
+
|
| 398 |
+
def main(args, model=None) -> SummarizationModule:
|
| 399 |
+
Path(args.output_dir).mkdir(exist_ok=True)
|
| 400 |
+
check_output_dir(args, expected_items=3)
|
| 401 |
+
|
| 402 |
+
if model is None:
|
| 403 |
+
if "summarization" in args.task:
|
| 404 |
+
model: SummarizationModule = SummarizationModule(args)
|
| 405 |
+
else:
|
| 406 |
+
model: SummarizationModule = TranslationModule(args)
|
| 407 |
+
dataset = Path(args.data_dir).name
|
| 408 |
+
if (
|
| 409 |
+
args.logger_name == "default"
|
| 410 |
+
or args.fast_dev_run
|
| 411 |
+
or str(args.output_dir).startswith("/tmp")
|
| 412 |
+
or str(args.output_dir).startswith("/var")
|
| 413 |
+
):
|
| 414 |
+
logger = True # don't pollute wandb logs unnecessarily
|
| 415 |
+
elif args.logger_name == "wandb":
|
| 416 |
+
from pytorch_lightning.loggers import WandbLogger
|
| 417 |
+
|
| 418 |
+
project = os.environ.get("WANDB_PROJECT", dataset)
|
| 419 |
+
logger = WandbLogger(name=model.output_dir.name, project=project)
|
| 420 |
+
|
| 421 |
+
elif args.logger_name == "wandb_shared":
|
| 422 |
+
from pytorch_lightning.loggers import WandbLogger
|
| 423 |
+
|
| 424 |
+
logger = WandbLogger(name=model.output_dir.name, project=f"hf_{dataset}")
|
| 425 |
+
|
| 426 |
+
if args.early_stopping_patience >= 0:
|
| 427 |
+
es_callback = get_early_stopping_callback(model.val_metric, args.early_stopping_patience)
|
| 428 |
+
else:
|
| 429 |
+
es_callback = False
|
| 430 |
+
|
| 431 |
+
lower_is_better = args.val_metric == "loss"
|
| 432 |
+
trainer: pl.Trainer = generic_train(
|
| 433 |
+
model,
|
| 434 |
+
args,
|
| 435 |
+
logging_callback=Seq2SeqLoggingCallback(),
|
| 436 |
+
checkpoint_callback=get_checkpoint_callback(
|
| 437 |
+
args.output_dir, model.val_metric, args.save_top_k, lower_is_better
|
| 438 |
+
),
|
| 439 |
+
early_stopping_callback=es_callback,
|
| 440 |
+
logger=logger,
|
| 441 |
+
)
|
| 442 |
+
pickle_save(model.hparams, model.output_dir / "hparams.pkl")
|
| 443 |
+
if not args.do_predict:
|
| 444 |
+
return model
|
| 445 |
+
|
| 446 |
+
model.hparams.test_checkpoint = ""
|
| 447 |
+
checkpoints = list(sorted(glob.glob(os.path.join(args.output_dir, "*.ckpt"), recursive=True)))
|
| 448 |
+
if checkpoints:
|
| 449 |
+
model.hparams.test_checkpoint = checkpoints[-1]
|
| 450 |
+
trainer.resume_from_checkpoint = checkpoints[-1]
|
| 451 |
+
trainer.logger.log_hyperparams(model.hparams)
|
| 452 |
+
|
| 453 |
+
# test() without a model tests using the best checkpoint automatically
|
| 454 |
+
trainer.test()
|
| 455 |
+
return model
|
| 456 |
+
|
| 457 |
+
|
| 458 |
+
if __name__ == "__main__":
|
| 459 |
+
parser = argparse.ArgumentParser()
|
| 460 |
+
parser = pl.Trainer.add_argparse_args(parser)
|
| 461 |
+
parser = SummarizationModule.add_model_specific_args(parser, os.getcwd())
|
| 462 |
+
|
| 463 |
+
args = parser.parse_args()
|
| 464 |
+
|
| 465 |
+
main(args)
|
src/mrc_client/seq2seq/finetune_t5.sh
ADDED
|
@@ -0,0 +1,14 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Add parent directory to python path to access lightning_base.py
|
| 2 |
+
export PYTHONPATH="../":"${PYTHONPATH}"
|
| 3 |
+
|
| 4 |
+
python finetune.py \
|
| 5 |
+
--data_dir=$CNN_DIR \
|
| 6 |
+
--learning_rate=3e-5 \
|
| 7 |
+
--train_batch_size=$BS \
|
| 8 |
+
--eval_batch_size=$BS \
|
| 9 |
+
--output_dir=$OUTPUT_DIR \
|
| 10 |
+
--max_source_length=512 \
|
| 11 |
+
--max_target_length=56 \
|
| 12 |
+
--val_check_interval=0.1 --n_val=200 \
|
| 13 |
+
--do_train --do_predict \
|
| 14 |
+
"$@"
|
src/mrc_client/seq2seq/finetune_trainer.py
ADDED
|
@@ -0,0 +1,303 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import logging
|
| 2 |
+
import os
|
| 3 |
+
import sys
|
| 4 |
+
from dataclasses import dataclass, field
|
| 5 |
+
from typing import Optional
|
| 6 |
+
|
| 7 |
+
from seq2seq_trainer import Seq2SeqTrainer
|
| 8 |
+
from seq2seq_training_args import Seq2SeqTrainingArguments
|
| 9 |
+
from transformers import AutoConfig, AutoModelForSeq2SeqLM, AutoTokenizer, HfArgumentParser, MBartTokenizer, set_seed
|
| 10 |
+
from transformers.trainer_utils import EvaluationStrategy
|
| 11 |
+
from seq2seq_utils import (
|
| 12 |
+
Seq2SeqDataCollator,
|
| 13 |
+
Seq2SeqDataset,
|
| 14 |
+
assert_all_frozen,
|
| 15 |
+
build_compute_metrics_fn,
|
| 16 |
+
check_output_dir,
|
| 17 |
+
freeze_embeds,
|
| 18 |
+
freeze_params,
|
| 19 |
+
lmap,
|
| 20 |
+
save_json,
|
| 21 |
+
use_task_specific_params,
|
| 22 |
+
write_txt_file,
|
| 23 |
+
)
|
| 24 |
+
|
| 25 |
+
|
| 26 |
+
logger = logging.getLogger(__name__)
|
| 27 |
+
|
| 28 |
+
|
| 29 |
+
@dataclass
|
| 30 |
+
class ModelArguments:
|
| 31 |
+
"""
|
| 32 |
+
Arguments pertaining to which model/config/tokenizer we are going to fine-tune from.
|
| 33 |
+
"""
|
| 34 |
+
|
| 35 |
+
model_name_or_path: str = field(
|
| 36 |
+
metadata={"help": "Path to pretrained model or model identifier from huggingface.co/models"}
|
| 37 |
+
)
|
| 38 |
+
config_name: Optional[str] = field(
|
| 39 |
+
default=None, metadata={"help": "Pretrained config name or path if not the same as model_name"}
|
| 40 |
+
)
|
| 41 |
+
tokenizer_name: Optional[str] = field(
|
| 42 |
+
default=None, metadata={"help": "Pretrained tokenizer name or path if not the same as model_name"}
|
| 43 |
+
)
|
| 44 |
+
cache_dir: Optional[str] = field(
|
| 45 |
+
default=None, metadata={"help": "Where do you want to store the pretrained models downloaded from s3"}
|
| 46 |
+
)
|
| 47 |
+
freeze_encoder: bool = field(default=False, metadata={"help": "Whether tp freeze the encoder."})
|
| 48 |
+
freeze_embeds: bool = field(default=False, metadata={"help": "Whether to freeze the embeddings."})
|
| 49 |
+
|
| 50 |
+
|
| 51 |
+
@dataclass
|
| 52 |
+
class DataTrainingArguments:
|
| 53 |
+
"""
|
| 54 |
+
Arguments pertaining to what data we are going to input our model for training and eval.
|
| 55 |
+
"""
|
| 56 |
+
|
| 57 |
+
data_dir: str = field(
|
| 58 |
+
metadata={"help": "The input data dir. Should contain the .tsv files (or other data files) for the task."}
|
| 59 |
+
)
|
| 60 |
+
task: Optional[str] = field(
|
| 61 |
+
default="summarization",
|
| 62 |
+
metadata={"help": "Task name, summarization (or summarization_{dataset} for pegasus) or translation"},
|
| 63 |
+
)
|
| 64 |
+
max_source_length: Optional[int] = field(
|
| 65 |
+
default=1024,
|
| 66 |
+
metadata={
|
| 67 |
+
"help": "The maximum total input sequence length after tokenization. Sequences longer "
|
| 68 |
+
"than this will be truncated, sequences shorter will be padded."
|
| 69 |
+
},
|
| 70 |
+
)
|
| 71 |
+
max_target_length: Optional[int] = field(
|
| 72 |
+
default=128,
|
| 73 |
+
metadata={
|
| 74 |
+
"help": "The maximum total sequence length for target text after tokenization. Sequences longer "
|
| 75 |
+
"than this will be truncated, sequences shorter will be padded."
|
| 76 |
+
},
|
| 77 |
+
)
|
| 78 |
+
val_max_target_length: Optional[int] = field(
|
| 79 |
+
default=142,
|
| 80 |
+
metadata={
|
| 81 |
+
"help": "The maximum total sequence length for validation target text after tokenization. Sequences longer "
|
| 82 |
+
"than this will be truncated, sequences shorter will be padded."
|
| 83 |
+
},
|
| 84 |
+
)
|
| 85 |
+
test_max_target_length: Optional[int] = field(
|
| 86 |
+
default=142,
|
| 87 |
+
metadata={
|
| 88 |
+
"help": "The maximum total sequence length for test target text after tokenization. Sequences longer "
|
| 89 |
+
"than this will be truncated, sequences shorter will be padded."
|
| 90 |
+
},
|
| 91 |
+
)
|
| 92 |
+
n_train: Optional[int] = field(default=-1, metadata={"help": "# training examples. -1 means use all."})
|
| 93 |
+
n_val: Optional[int] = field(default=-1, metadata={"help": "# validation examples. -1 means use all."})
|
| 94 |
+
n_test: Optional[int] = field(default=-1, metadata={"help": "# test examples. -1 means use all."})
|
| 95 |
+
src_lang: Optional[str] = field(default=None, metadata={"help": "Source language id for translation."})
|
| 96 |
+
tgt_lang: Optional[str] = field(default=None, metadata={"help": "Target language id for translation."})
|
| 97 |
+
eval_beams: Optional[int] = field(default=None, metadata={"help": "# num_beams to use for evaluation."})
|
| 98 |
+
ignore_pad_token_for_loss: bool = field(
|
| 99 |
+
default=True,
|
| 100 |
+
metadata={"help": "If only pad tokens should be ignored. This assumes that `config.pad_token_id` is defined."},
|
| 101 |
+
)
|
| 102 |
+
|
| 103 |
+
|
| 104 |
+
def main():
|
| 105 |
+
# See all possible arguments in src/transformers/training_args.py
|
| 106 |
+
# or by passing the --help flag to this script.
|
| 107 |
+
# We now keep distinct sets of args, for a cleaner separation of concerns.
|
| 108 |
+
|
| 109 |
+
parser = HfArgumentParser((ModelArguments, DataTrainingArguments, Seq2SeqTrainingArguments))
|
| 110 |
+
|
| 111 |
+
if len(sys.argv) == 2 and sys.argv[1].endswith(".json"):
|
| 112 |
+
# If we pass only one argument to the script and it's the path to a json file,
|
| 113 |
+
# let's parse it to get our arguments.
|
| 114 |
+
model_args, data_args, training_args = parser.parse_json_file(json_file=os.path.abspath(sys.argv[1]))
|
| 115 |
+
else:
|
| 116 |
+
model_args, data_args, training_args = parser.parse_args_into_dataclasses()
|
| 117 |
+
|
| 118 |
+
check_output_dir(training_args)
|
| 119 |
+
|
| 120 |
+
# Setup logging
|
| 121 |
+
logging.basicConfig(
|
| 122 |
+
format="%(asctime)s - %(levelname)s - %(name)s - %(message)s",
|
| 123 |
+
datefmt="%m/%d/%Y %H:%M:%S",
|
| 124 |
+
level=logging.INFO if training_args.local_rank in [-1, 0] else logging.WARN,
|
| 125 |
+
)
|
| 126 |
+
logger.warning(
|
| 127 |
+
"Process rank: %s, device: %s, n_gpu: %s, distributed training: %s, 16-bits training: %s",
|
| 128 |
+
training_args.local_rank,
|
| 129 |
+
training_args.device,
|
| 130 |
+
training_args.n_gpu,
|
| 131 |
+
bool(training_args.local_rank != -1),
|
| 132 |
+
training_args.fp16,
|
| 133 |
+
)
|
| 134 |
+
logger.info("Training/evaluation parameters %s", training_args)
|
| 135 |
+
|
| 136 |
+
# Set seed
|
| 137 |
+
set_seed(training_args.seed)
|
| 138 |
+
|
| 139 |
+
# Load pretrained model and tokenizer
|
| 140 |
+
#
|
| 141 |
+
# Distributed training:
|
| 142 |
+
# The .from_pretrained methods guarantee that only one local process can concurrently
|
| 143 |
+
# download model & vocab.
|
| 144 |
+
|
| 145 |
+
config = AutoConfig.from_pretrained(
|
| 146 |
+
model_args.config_name if model_args.config_name else model_args.model_name_or_path,
|
| 147 |
+
cache_dir=model_args.cache_dir,
|
| 148 |
+
)
|
| 149 |
+
|
| 150 |
+
extra_model_params = ("encoder_layerdrop", "decoder_layerdrop", "dropout", "attention_dropout")
|
| 151 |
+
for p in extra_model_params:
|
| 152 |
+
if getattr(training_args, p, None):
|
| 153 |
+
assert hasattr(config, p), f"({config.__class__.__name__}) doesn't have a `{p}` attribute"
|
| 154 |
+
setattr(config, p, getattr(training_args, p))
|
| 155 |
+
|
| 156 |
+
tokenizer = AutoTokenizer.from_pretrained(
|
| 157 |
+
model_args.tokenizer_name if model_args.tokenizer_name else model_args.model_name_or_path,
|
| 158 |
+
cache_dir=model_args.cache_dir,
|
| 159 |
+
)
|
| 160 |
+
model = AutoModelForSeq2SeqLM.from_pretrained(
|
| 161 |
+
model_args.model_name_or_path,
|
| 162 |
+
from_tf=".ckpt" in model_args.model_name_or_path,
|
| 163 |
+
config=config,
|
| 164 |
+
cache_dir=model_args.cache_dir,
|
| 165 |
+
)
|
| 166 |
+
|
| 167 |
+
# use task specific params
|
| 168 |
+
use_task_specific_params(model, data_args.task)
|
| 169 |
+
|
| 170 |
+
# set num_beams for evaluation
|
| 171 |
+
if data_args.eval_beams is None:
|
| 172 |
+
data_args.eval_beams = model.config.num_beams
|
| 173 |
+
|
| 174 |
+
# set decoder_start_token_id for MBart
|
| 175 |
+
if model.config.decoder_start_token_id is None and isinstance(tokenizer, MBartTokenizer):
|
| 176 |
+
assert (
|
| 177 |
+
data_args.tgt_lang is not None and data_args.src_lang is not None
|
| 178 |
+
), "mBart requires --tgt_lang and --src_lang"
|
| 179 |
+
model.config.decoder_start_token_id = tokenizer.lang_code_to_id[data_args.tgt_lang]
|
| 180 |
+
|
| 181 |
+
if model_args.freeze_embeds:
|
| 182 |
+
freeze_embeds(model)
|
| 183 |
+
if model_args.freeze_encoder:
|
| 184 |
+
freeze_params(model.get_encoder())
|
| 185 |
+
assert_all_frozen(model.get_encoder())
|
| 186 |
+
|
| 187 |
+
dataset_class = Seq2SeqDataset
|
| 188 |
+
|
| 189 |
+
# Get datasets
|
| 190 |
+
train_dataset = (
|
| 191 |
+
dataset_class(
|
| 192 |
+
tokenizer,
|
| 193 |
+
type_path="train",
|
| 194 |
+
data_dir=data_args.data_dir,
|
| 195 |
+
n_obs=data_args.n_train,
|
| 196 |
+
max_target_length=data_args.max_target_length,
|
| 197 |
+
max_source_length=data_args.max_source_length,
|
| 198 |
+
prefix=model.config.prefix or "",
|
| 199 |
+
)
|
| 200 |
+
if training_args.do_train
|
| 201 |
+
else None
|
| 202 |
+
)
|
| 203 |
+
eval_dataset = (
|
| 204 |
+
dataset_class(
|
| 205 |
+
tokenizer,
|
| 206 |
+
type_path="val",
|
| 207 |
+
data_dir=data_args.data_dir,
|
| 208 |
+
n_obs=data_args.n_val,
|
| 209 |
+
max_target_length=data_args.val_max_target_length,
|
| 210 |
+
max_source_length=data_args.max_source_length,
|
| 211 |
+
prefix=model.config.prefix or "",
|
| 212 |
+
)
|
| 213 |
+
if training_args.do_eval or training_args.evaluation_strategy != EvaluationStrategy.NO
|
| 214 |
+
else None
|
| 215 |
+
)
|
| 216 |
+
test_dataset = (
|
| 217 |
+
dataset_class(
|
| 218 |
+
tokenizer,
|
| 219 |
+
type_path="test",
|
| 220 |
+
data_dir=data_args.data_dir,
|
| 221 |
+
n_obs=data_args.n_test,
|
| 222 |
+
max_target_length=data_args.test_max_target_length,
|
| 223 |
+
max_source_length=data_args.max_source_length,
|
| 224 |
+
prefix=model.config.prefix or "",
|
| 225 |
+
)
|
| 226 |
+
if training_args.do_predict
|
| 227 |
+
else None
|
| 228 |
+
)
|
| 229 |
+
|
| 230 |
+
# Initialize our Trainer
|
| 231 |
+
compute_metrics_fn = (
|
| 232 |
+
build_compute_metrics_fn(data_args.task, tokenizer) if training_args.predict_with_generate else None
|
| 233 |
+
)
|
| 234 |
+
trainer = Seq2SeqTrainer(
|
| 235 |
+
model=model,
|
| 236 |
+
config=config,
|
| 237 |
+
args=training_args,
|
| 238 |
+
train_dataset=train_dataset,
|
| 239 |
+
eval_dataset=eval_dataset,
|
| 240 |
+
data_collator=Seq2SeqDataCollator(tokenizer, data_args, training_args.tpu_num_cores),
|
| 241 |
+
compute_metrics=compute_metrics_fn,
|
| 242 |
+
data_args=data_args,
|
| 243 |
+
)
|
| 244 |
+
|
| 245 |
+
# Training
|
| 246 |
+
if training_args.do_train:
|
| 247 |
+
trainer.train(
|
| 248 |
+
model_path=model_args.model_name_or_path if os.path.isdir(model_args.model_name_or_path) else None
|
| 249 |
+
)
|
| 250 |
+
trainer.save_model()
|
| 251 |
+
# For convenience, we also re-save the tokenizer to the same directory,
|
| 252 |
+
# so that you can share your model easily on huggingface.co/models =)
|
| 253 |
+
if trainer.is_world_process_zero():
|
| 254 |
+
trainer.state.save_to_json(os.path.join(training_args.output_dir, "trainer_state.json"))
|
| 255 |
+
tokenizer.save_pretrained(training_args.output_dir)
|
| 256 |
+
|
| 257 |
+
# Evaluation
|
| 258 |
+
eval_results = {}
|
| 259 |
+
if training_args.do_eval:
|
| 260 |
+
logger.info("*** Evaluate ***")
|
| 261 |
+
|
| 262 |
+
result = trainer.evaluate()
|
| 263 |
+
|
| 264 |
+
if trainer.is_world_process_zero():
|
| 265 |
+
logger.info("***** Eval results *****")
|
| 266 |
+
for key, value in result.items():
|
| 267 |
+
logger.info(" %s = %s", key, value)
|
| 268 |
+
save_json(result, os.path.join(training_args.output_dir, "eval_results.json"))
|
| 269 |
+
eval_results.update(result)
|
| 270 |
+
|
| 271 |
+
if training_args.do_predict:
|
| 272 |
+
logging.info("*** Test ***")
|
| 273 |
+
|
| 274 |
+
test_output = trainer.predict(test_dataset=test_dataset)
|
| 275 |
+
test_metrics = {k.replace("eval", "test"): v for k, v in test_output.metrics.items()}
|
| 276 |
+
|
| 277 |
+
if trainer.is_world_process_zero():
|
| 278 |
+
logger.info("***** Test results *****")
|
| 279 |
+
for key, value in test_metrics.items():
|
| 280 |
+
logger.info(" %s = %s", key, value)
|
| 281 |
+
|
| 282 |
+
save_json(test_metrics, os.path.join(training_args.output_dir, "test_results.json"))
|
| 283 |
+
eval_results.update(test_metrics)
|
| 284 |
+
|
| 285 |
+
if training_args.predict_with_generate:
|
| 286 |
+
test_preds = tokenizer.batch_decode(
|
| 287 |
+
test_output.predictions, skip_special_tokens=True, clean_up_tokenization_spaces=True
|
| 288 |
+
)
|
| 289 |
+
test_preds = lmap(str.strip, test_preds)
|
| 290 |
+
write_txt_file(test_preds, os.path.join(training_args.output_dir, "test_generations.txt"))
|
| 291 |
+
|
| 292 |
+
if trainer.is_world_process_zero():
|
| 293 |
+
save_json(eval_results, "all_results.json")
|
| 294 |
+
return eval_results
|
| 295 |
+
|
| 296 |
+
|
| 297 |
+
def _mp_fn(index):
|
| 298 |
+
# For xla_spawn (TPUs)
|
| 299 |
+
main()
|
| 300 |
+
|
| 301 |
+
|
| 302 |
+
if __name__ == "__main__":
|
| 303 |
+
main()
|