Spaces:
Running
on
CPU Upgrade

Running
on
CPU Upgrade

Commit
·
b2ecf7d
1
Parent(s):
cac61e8
🍱 Copy folders from huggingface.js
Browse filesThis view is limited to 50 files because it contains too many changes.
See raw diff
- .gitignore +2 -0
- .npmrc +2 -0
- Dockerfile +13 -0
- README.md +2 -1
- package.json +30 -0
- packages/tasks/.prettierignore +4 -0
- packages/tasks/README.md +20 -0
- packages/tasks/package.json +46 -0
- packages/tasks/pnpm-lock.yaml +14 -0
- packages/tasks/src/Types.ts +64 -0
- packages/tasks/src/audio-classification/about.md +85 -0
- packages/tasks/src/audio-classification/data.ts +77 -0
- packages/tasks/src/audio-to-audio/about.md +56 -0
- packages/tasks/src/audio-to-audio/data.ts +66 -0
- packages/tasks/src/automatic-speech-recognition/about.md +87 -0
- packages/tasks/src/automatic-speech-recognition/data.ts +78 -0
- packages/tasks/src/const.ts +59 -0
- packages/tasks/src/conversational/about.md +50 -0
- packages/tasks/src/conversational/data.ts +66 -0
- packages/tasks/src/depth-estimation/about.md +36 -0
- packages/tasks/src/depth-estimation/data.ts +52 -0
- packages/tasks/src/document-question-answering/about.md +53 -0
- packages/tasks/src/document-question-answering/data.ts +70 -0
- packages/tasks/src/feature-extraction/about.md +34 -0
- packages/tasks/src/feature-extraction/data.ts +54 -0
- packages/tasks/src/fill-mask/about.md +51 -0
- packages/tasks/src/fill-mask/data.ts +79 -0
- packages/tasks/src/image-classification/about.md +50 -0
- packages/tasks/src/image-classification/data.ts +88 -0
- packages/tasks/src/image-segmentation/about.md +63 -0
- packages/tasks/src/image-segmentation/data.ts +99 -0
- packages/tasks/src/image-to-image/about.md +79 -0
- packages/tasks/src/image-to-image/data.ts +101 -0
- packages/tasks/src/image-to-text/about.md +65 -0
- packages/tasks/src/image-to-text/data.ts +86 -0
- packages/tasks/src/index.ts +13 -0
- packages/tasks/src/modelLibraries.ts +43 -0
- packages/tasks/src/object-detection/about.md +37 -0
- packages/tasks/src/object-detection/data.ts +76 -0
- packages/tasks/src/pipelines.ts +619 -0
- packages/tasks/src/placeholder/about.md +15 -0
- packages/tasks/src/placeholder/data.ts +18 -0
- packages/tasks/src/question-answering/about.md +56 -0
- packages/tasks/src/question-answering/data.ts +71 -0
- packages/tasks/src/reinforcement-learning/about.md +167 -0
- packages/tasks/src/reinforcement-learning/data.ts +75 -0
- packages/tasks/src/sentence-similarity/about.md +97 -0
- packages/tasks/src/sentence-similarity/data.ts +101 -0
- packages/tasks/src/summarization/about.md +58 -0
- packages/tasks/src/summarization/data.ts +75 -0
.gitignore
ADDED
|
@@ -0,0 +1,2 @@
|
|
|
|
|
|
|
|
|
|
| 1 |
+
node_modules
|
| 2 |
+
dist
|
.npmrc
ADDED
|
@@ -0,0 +1,2 @@
|
|
|
|
|
|
|
|
|
|
| 1 |
+
shared-workspace-lockfile = false
|
| 2 |
+
include-workspace-root = true
|
Dockerfile
ADDED
|
@@ -0,0 +1,13 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# syntax=docker/dockerfile:1
|
| 2 |
+
# read the doc: https://huggingface.co/docs/hub/spaces-sdks-docker
|
| 3 |
+
# you will also find guides on how best to write your Dockerfile
|
| 4 |
+
FROM node:20
|
| 5 |
+
|
| 6 |
+
WORKDIR /app
|
| 7 |
+
|
| 8 |
+
RUN corepack enable
|
| 9 |
+
|
| 10 |
+
COPY --link --chown=1000 . .
|
| 11 |
+
|
| 12 |
+
RUN pnpm install
|
| 13 |
+
RUN pnpm --filter widgets dev
|
README.md
CHANGED
|
@@ -5,6 +5,7 @@ colorFrom: pink
|
|
| 5 |
colorTo: red
|
| 6 |
sdk: docker
|
| 7 |
pinned: false
|
|
|
|
| 8 |
---
|
| 9 |
|
| 10 |
-
|
|
|
|
| 5 |
colorTo: red
|
| 6 |
sdk: docker
|
| 7 |
pinned: false
|
| 8 |
+
app_port: 5173
|
| 9 |
---
|
| 10 |
|
| 11 |
+
Demo app for [Inference Widgets](https://github.com/huggingface/huggingface.js/tree/main/packages/widgets).
|
package.json
ADDED
|
@@ -0,0 +1,30 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"license": "MIT",
|
| 3 |
+
"packageManager": "pnpm@8.10.5",
|
| 4 |
+
"dependencies": {
|
| 5 |
+
"@typescript-eslint/eslint-plugin": "^5.51.0",
|
| 6 |
+
"@typescript-eslint/parser": "^5.51.0",
|
| 7 |
+
"eslint": "^8.35.0",
|
| 8 |
+
"eslint-config-prettier": "^9.0.0",
|
| 9 |
+
"eslint-plugin-prettier": "^4.2.1",
|
| 10 |
+
"eslint-plugin-svelte": "^2.30.0",
|
| 11 |
+
"prettier": "^3.0.0",
|
| 12 |
+
"prettier-plugin-svelte": "^3.0.0",
|
| 13 |
+
"typescript": "^5.0.0",
|
| 14 |
+
"vite": "4.1.4"
|
| 15 |
+
},
|
| 16 |
+
"scripts": {
|
| 17 |
+
"lint": "eslint --quiet --fix --ext .cjs,.ts .eslintrc.cjs",
|
| 18 |
+
"lint:check": "eslint --ext .cjs,.ts .eslintrc.cjs",
|
| 19 |
+
"format": "prettier --write package.json .prettierrc .vscode .eslintrc.cjs e2e .github *.md",
|
| 20 |
+
"format:check": "prettier --check package.json .prettierrc .vscode .eslintrc.cjs .github *.md"
|
| 21 |
+
},
|
| 22 |
+
"devDependencies": {
|
| 23 |
+
"@vitest/browser": "^0.29.7",
|
| 24 |
+
"semver": "^7.5.0",
|
| 25 |
+
"ts-node": "^10.9.1",
|
| 26 |
+
"tsup": "^6.7.0",
|
| 27 |
+
"vitest": "^0.29.4",
|
| 28 |
+
"webdriverio": "^8.6.7"
|
| 29 |
+
}
|
| 30 |
+
}
|
packages/tasks/.prettierignore
ADDED
|
@@ -0,0 +1,4 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
pnpm-lock.yaml
|
| 2 |
+
# In order to avoid code samples to have tabs, they don't display well on npm
|
| 3 |
+
README.md
|
| 4 |
+
dist
|
packages/tasks/README.md
ADDED
|
@@ -0,0 +1,20 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Tasks
|
| 2 |
+
|
| 3 |
+
This package contains data used for https://huggingface.co/tasks.
|
| 4 |
+
|
| 5 |
+
## Philosophy behind Tasks
|
| 6 |
+
|
| 7 |
+
The Task pages are made to lower the barrier of entry to understand a task that can be solved with machine learning and use or train a model to accomplish it. It's a collaborative documentation effort made to help out software developers, social scientists, or anyone with no background in machine learning that is interested in understanding how machine learning models can be used to solve a problem.
|
| 8 |
+
|
| 9 |
+
The task pages avoid jargon to let everyone understand the documentation, and if specific terminology is needed, it is explained on the most basic level possible. This is important to understand before contributing to Tasks: at the end of every task page, the user is expected to be able to find and pull a model from the Hub and use it on their data and see if it works for their use case to come up with a proof of concept.
|
| 10 |
+
|
| 11 |
+
## How to Contribute
|
| 12 |
+
You can open a pull request to contribute a new documentation about a new task. Under `src` we have a folder for every task that contains two files, `about.md` and `data.ts`. `about.md` contains the markdown part of the page, use cases, resources and minimal code block to infer a model that belongs to the task. `data.ts` contains redirections to canonical models and datasets, metrics, the schema of the task and the information the inference widget needs.
|
| 13 |
+
|
| 14 |
+
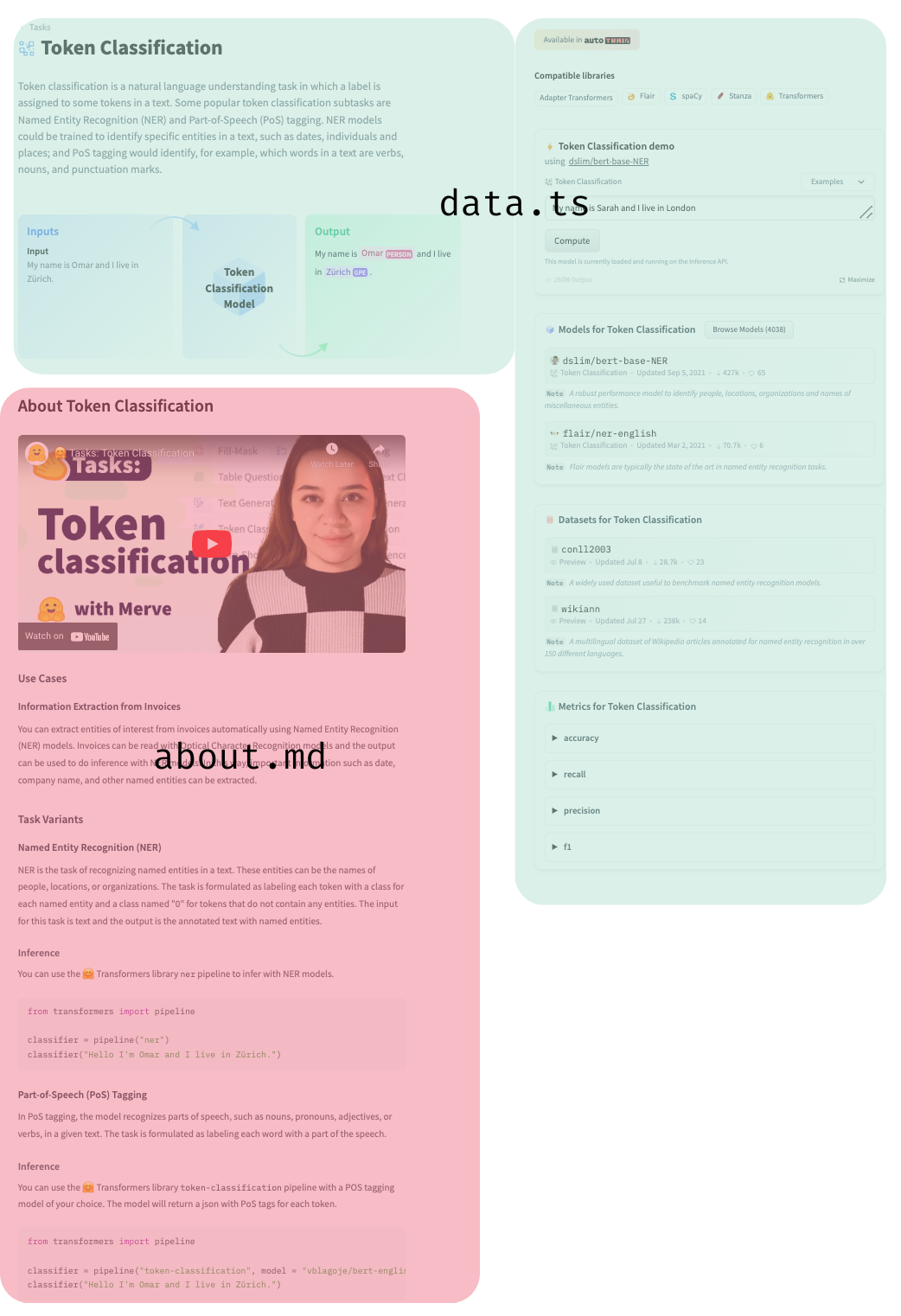
|
| 15 |
+
|
| 16 |
+
We have a [`dataset`](https://huggingface.co/datasets/huggingfacejs/tasks) that contains data used in the inference widget. The last file is `const.ts`, which has the task to library mapping (e.g. spacy to token-classification) where you can add a library. They will look in the top right corner like below.
|
| 17 |
+
|
| 18 |
+

|
| 19 |
+
|
| 20 |
+
This might seem overwhelming, but you don't necessarily need to add all of these in one pull request or on your own, you can simply contribute one section. Feel free to ask for help whenever you need.
|
packages/tasks/package.json
ADDED
|
@@ -0,0 +1,46 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"name": "@huggingface/tasks",
|
| 3 |
+
"packageManager": "pnpm@8.10.5",
|
| 4 |
+
"version": "0.0.5",
|
| 5 |
+
"description": "List of ML tasks for huggingface.co/tasks",
|
| 6 |
+
"repository": "https://github.com/huggingface/huggingface.js.git",
|
| 7 |
+
"publishConfig": {
|
| 8 |
+
"access": "public"
|
| 9 |
+
},
|
| 10 |
+
"main": "./dist/index.js",
|
| 11 |
+
"module": "./dist/index.mjs",
|
| 12 |
+
"types": "./dist/index.d.ts",
|
| 13 |
+
"exports": {
|
| 14 |
+
".": {
|
| 15 |
+
"types": "./dist/index.d.ts",
|
| 16 |
+
"require": "./dist/index.js",
|
| 17 |
+
"import": "./dist/index.mjs"
|
| 18 |
+
}
|
| 19 |
+
},
|
| 20 |
+
"source": "src/index.ts",
|
| 21 |
+
"scripts": {
|
| 22 |
+
"lint": "eslint --quiet --fix --ext .cjs,.ts .",
|
| 23 |
+
"lint:check": "eslint --ext .cjs,.ts .",
|
| 24 |
+
"format": "prettier --write .",
|
| 25 |
+
"format:check": "prettier --check .",
|
| 26 |
+
"prepublishOnly": "pnpm run build",
|
| 27 |
+
"build": "tsup src/index.ts --format cjs,esm --clean --dts",
|
| 28 |
+
"prepare": "pnpm run build",
|
| 29 |
+
"check": "tsc"
|
| 30 |
+
},
|
| 31 |
+
"files": [
|
| 32 |
+
"dist",
|
| 33 |
+
"src",
|
| 34 |
+
"tsconfig.json"
|
| 35 |
+
],
|
| 36 |
+
"keywords": [
|
| 37 |
+
"huggingface",
|
| 38 |
+
"hub",
|
| 39 |
+
"languages"
|
| 40 |
+
],
|
| 41 |
+
"author": "Hugging Face",
|
| 42 |
+
"license": "MIT",
|
| 43 |
+
"devDependencies": {
|
| 44 |
+
"typescript": "^5.0.4"
|
| 45 |
+
}
|
| 46 |
+
}
|
packages/tasks/pnpm-lock.yaml
ADDED
|
@@ -0,0 +1,14 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
lockfileVersion: '6.0'
|
| 2 |
+
|
| 3 |
+
devDependencies:
|
| 4 |
+
typescript:
|
| 5 |
+
specifier: ^5.0.4
|
| 6 |
+
version: 5.0.4
|
| 7 |
+
|
| 8 |
+
packages:
|
| 9 |
+
|
| 10 |
+
/typescript@5.0.4:
|
| 11 |
+
resolution: {integrity: sha512-cW9T5W9xY37cc+jfEnaUvX91foxtHkza3Nw3wkoF4sSlKn0MONdkdEndig/qPBWXNkmplh3NzayQzCiHM4/hqw==}
|
| 12 |
+
engines: {node: '>=12.20'}
|
| 13 |
+
hasBin: true
|
| 14 |
+
dev: true
|
packages/tasks/src/Types.ts
ADDED
|
@@ -0,0 +1,64 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import type { ModelLibraryKey } from "./modelLibraries";
|
| 2 |
+
import type { PipelineType } from "./pipelines";
|
| 3 |
+
|
| 4 |
+
export interface ExampleRepo {
|
| 5 |
+
description: string;
|
| 6 |
+
id: string;
|
| 7 |
+
}
|
| 8 |
+
|
| 9 |
+
export type TaskDemoEntry =
|
| 10 |
+
| {
|
| 11 |
+
filename: string;
|
| 12 |
+
type: "audio";
|
| 13 |
+
}
|
| 14 |
+
| {
|
| 15 |
+
data: Array<{
|
| 16 |
+
label: string;
|
| 17 |
+
score: number;
|
| 18 |
+
}>;
|
| 19 |
+
type: "chart";
|
| 20 |
+
}
|
| 21 |
+
| {
|
| 22 |
+
filename: string;
|
| 23 |
+
type: "img";
|
| 24 |
+
}
|
| 25 |
+
| {
|
| 26 |
+
table: string[][];
|
| 27 |
+
type: "tabular";
|
| 28 |
+
}
|
| 29 |
+
| {
|
| 30 |
+
content: string;
|
| 31 |
+
label: string;
|
| 32 |
+
type: "text";
|
| 33 |
+
}
|
| 34 |
+
| {
|
| 35 |
+
text: string;
|
| 36 |
+
tokens: Array<{
|
| 37 |
+
end: number;
|
| 38 |
+
start: number;
|
| 39 |
+
type: string;
|
| 40 |
+
}>;
|
| 41 |
+
type: "text-with-tokens";
|
| 42 |
+
};
|
| 43 |
+
|
| 44 |
+
export interface TaskDemo {
|
| 45 |
+
inputs: TaskDemoEntry[];
|
| 46 |
+
outputs: TaskDemoEntry[];
|
| 47 |
+
}
|
| 48 |
+
|
| 49 |
+
export interface TaskData {
|
| 50 |
+
datasets: ExampleRepo[];
|
| 51 |
+
demo: TaskDemo;
|
| 52 |
+
id: PipelineType;
|
| 53 |
+
isPlaceholder?: boolean;
|
| 54 |
+
label: string;
|
| 55 |
+
libraries: ModelLibraryKey[];
|
| 56 |
+
metrics: ExampleRepo[];
|
| 57 |
+
models: ExampleRepo[];
|
| 58 |
+
spaces: ExampleRepo[];
|
| 59 |
+
summary: string;
|
| 60 |
+
widgetModels: string[];
|
| 61 |
+
youtubeId?: string;
|
| 62 |
+
}
|
| 63 |
+
|
| 64 |
+
export type TaskDataCustom = Omit<TaskData, "id" | "label" | "libraries">;
|
packages/tasks/src/audio-classification/about.md
ADDED
|
@@ -0,0 +1,85 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
## Use Cases
|
| 2 |
+
|
| 3 |
+
### Command Recognition
|
| 4 |
+
|
| 5 |
+
Command recognition or keyword spotting classifies utterances into a predefined set of commands. This is often done on-device for fast response time.
|
| 6 |
+
|
| 7 |
+
As an example, using the Google Speech Commands dataset, given an input, a model can classify which of the following commands the user is typing:
|
| 8 |
+
|
| 9 |
+
```
|
| 10 |
+
'yes', 'no', 'up', 'down', 'left', 'right', 'on', 'off', 'stop', 'go', 'unknown', 'silence'
|
| 11 |
+
```
|
| 12 |
+
|
| 13 |
+
Speechbrain models can easily perform this task with just a couple of lines of code!
|
| 14 |
+
|
| 15 |
+
```python
|
| 16 |
+
from speechbrain.pretrained import EncoderClassifier
|
| 17 |
+
model = EncoderClassifier.from_hparams(
|
| 18 |
+
"speechbrain/google_speech_command_xvector"
|
| 19 |
+
)
|
| 20 |
+
model.classify_file("file.wav")
|
| 21 |
+
```
|
| 22 |
+
|
| 23 |
+
### Language Identification
|
| 24 |
+
|
| 25 |
+
Datasets such as VoxLingua107 allow anyone to train language identification models for up to 107 languages! This can be extremely useful as a preprocessing step for other systems. Here's an example [model](https://huggingface.co/TalTechNLP/voxlingua107-epaca-tdnn)trained on VoxLingua107.
|
| 26 |
+
|
| 27 |
+
### Emotion recognition
|
| 28 |
+
|
| 29 |
+
Emotion recognition is self explanatory. In addition to trying the widgets, you can use the Inference API to perform audio classification. Here is a simple example that uses a [HuBERT](https://huggingface.co/superb/hubert-large-superb-er) model fine-tuned for this task.
|
| 30 |
+
|
| 31 |
+
```python
|
| 32 |
+
import json
|
| 33 |
+
import requests
|
| 34 |
+
|
| 35 |
+
headers = {"Authorization": f"Bearer {API_TOKEN}"}
|
| 36 |
+
API_URL = "https://api-inference.huggingface.co/models/superb/hubert-large-superb-er"
|
| 37 |
+
|
| 38 |
+
def query(filename):
|
| 39 |
+
with open(filename, "rb") as f:
|
| 40 |
+
data = f.read()
|
| 41 |
+
response = requests.request("POST", API_URL, headers=headers, data=data)
|
| 42 |
+
return json.loads(response.content.decode("utf-8"))
|
| 43 |
+
|
| 44 |
+
data = query("sample1.flac")
|
| 45 |
+
# [{'label': 'neu', 'score': 0.60},
|
| 46 |
+
# {'label': 'hap', 'score': 0.20},
|
| 47 |
+
# {'label': 'ang', 'score': 0.13},
|
| 48 |
+
# {'label': 'sad', 'score': 0.07}]
|
| 49 |
+
```
|
| 50 |
+
|
| 51 |
+
You can use [huggingface.js](https://github.com/huggingface/huggingface.js) to infer with audio classification models on Hugging Face Hub.
|
| 52 |
+
|
| 53 |
+
```javascript
|
| 54 |
+
import { HfInference } from "@huggingface/inference";
|
| 55 |
+
|
| 56 |
+
const inference = new HfInference(HF_ACCESS_TOKEN);
|
| 57 |
+
await inference.audioClassification({
|
| 58 |
+
data: await (await fetch("sample.flac")).blob(),
|
| 59 |
+
model: "facebook/mms-lid-126",
|
| 60 |
+
});
|
| 61 |
+
```
|
| 62 |
+
|
| 63 |
+
### Speaker Identification
|
| 64 |
+
|
| 65 |
+
Speaker Identification is classifying the audio of the person speaking. Speakers are usually predefined. You can try out this task with [this model](https://huggingface.co/superb/wav2vec2-base-superb-sid). A useful dataset for this task is VoxCeleb1.
|
| 66 |
+
|
| 67 |
+
## Solving audio classification for your own data
|
| 68 |
+
|
| 69 |
+
We have some great news! You can do fine-tuning (transfer learning) to train a well-performing model without requiring as much data. Pretrained models such as Wav2Vec2 and HuBERT exist. [Facebook's Wav2Vec2 XLS-R model](https://ai.facebook.com/blog/wav2vec-20-learning-the-structure-of-speech-from-raw-audio/) is a large multilingual model trained on 128 languages and with 436K hours of speech.
|
| 70 |
+
|
| 71 |
+
## Useful Resources
|
| 72 |
+
|
| 73 |
+
Would you like to learn more about the topic? Awesome! Here you can find some curated resources that you may find helpful!
|
| 74 |
+
|
| 75 |
+
### Notebooks
|
| 76 |
+
|
| 77 |
+
- [PyTorch](https://colab.research.google.com/github/huggingface/notebooks/blob/master/examples/audio_classification.ipynb)
|
| 78 |
+
|
| 79 |
+
### Scripts for training
|
| 80 |
+
|
| 81 |
+
- [PyTorch](https://github.com/huggingface/transformers/tree/main/examples/pytorch/audio-classification)
|
| 82 |
+
|
| 83 |
+
### Documentation
|
| 84 |
+
|
| 85 |
+
- [Audio classification task guide](https://huggingface.co/docs/transformers/tasks/audio_classification)
|
packages/tasks/src/audio-classification/data.ts
ADDED
|
@@ -0,0 +1,77 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import type { TaskDataCustom } from "../Types";
|
| 2 |
+
|
| 3 |
+
const taskData: TaskDataCustom = {
|
| 4 |
+
datasets: [
|
| 5 |
+
{
|
| 6 |
+
description: "A benchmark of 10 different audio tasks.",
|
| 7 |
+
id: "superb",
|
| 8 |
+
},
|
| 9 |
+
],
|
| 10 |
+
demo: {
|
| 11 |
+
inputs: [
|
| 12 |
+
{
|
| 13 |
+
filename: "audio.wav",
|
| 14 |
+
type: "audio",
|
| 15 |
+
},
|
| 16 |
+
],
|
| 17 |
+
outputs: [
|
| 18 |
+
{
|
| 19 |
+
data: [
|
| 20 |
+
{
|
| 21 |
+
label: "Up",
|
| 22 |
+
score: 0.2,
|
| 23 |
+
},
|
| 24 |
+
{
|
| 25 |
+
label: "Down",
|
| 26 |
+
score: 0.8,
|
| 27 |
+
},
|
| 28 |
+
],
|
| 29 |
+
type: "chart",
|
| 30 |
+
},
|
| 31 |
+
],
|
| 32 |
+
},
|
| 33 |
+
metrics: [
|
| 34 |
+
{
|
| 35 |
+
description: "",
|
| 36 |
+
id: "accuracy",
|
| 37 |
+
},
|
| 38 |
+
{
|
| 39 |
+
description: "",
|
| 40 |
+
id: "recall",
|
| 41 |
+
},
|
| 42 |
+
{
|
| 43 |
+
description: "",
|
| 44 |
+
id: "precision",
|
| 45 |
+
},
|
| 46 |
+
{
|
| 47 |
+
description: "",
|
| 48 |
+
id: "f1",
|
| 49 |
+
},
|
| 50 |
+
],
|
| 51 |
+
models: [
|
| 52 |
+
{
|
| 53 |
+
description: "An easy-to-use model for Command Recognition.",
|
| 54 |
+
id: "speechbrain/google_speech_command_xvector",
|
| 55 |
+
},
|
| 56 |
+
{
|
| 57 |
+
description: "An Emotion Recognition model.",
|
| 58 |
+
id: "ehcalabres/wav2vec2-lg-xlsr-en-speech-emotion-recognition",
|
| 59 |
+
},
|
| 60 |
+
{
|
| 61 |
+
description: "A language identification model.",
|
| 62 |
+
id: "facebook/mms-lid-126",
|
| 63 |
+
},
|
| 64 |
+
],
|
| 65 |
+
spaces: [
|
| 66 |
+
{
|
| 67 |
+
description: "An application that can predict the language spoken in a given audio.",
|
| 68 |
+
id: "akhaliq/Speechbrain-audio-classification",
|
| 69 |
+
},
|
| 70 |
+
],
|
| 71 |
+
summary:
|
| 72 |
+
"Audio classification is the task of assigning a label or class to a given audio. It can be used for recognizing which command a user is giving or the emotion of a statement, as well as identifying a speaker.",
|
| 73 |
+
widgetModels: ["facebook/mms-lid-126"],
|
| 74 |
+
youtubeId: "KWwzcmG98Ds",
|
| 75 |
+
};
|
| 76 |
+
|
| 77 |
+
export default taskData;
|
packages/tasks/src/audio-to-audio/about.md
ADDED
|
@@ -0,0 +1,56 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
## Use Cases
|
| 2 |
+
|
| 3 |
+
### Speech Enhancement (Noise removal)
|
| 4 |
+
|
| 5 |
+
Speech Enhancement is a bit self explanatory. It improves (or enhances) the quality of an audio by removing noise. There are multiple libraries to solve this task, such as Speechbrain, Asteroid and ESPNet. Here is a simple example using Speechbrain
|
| 6 |
+
|
| 7 |
+
```python
|
| 8 |
+
from speechbrain.pretrained import SpectralMaskEnhancement
|
| 9 |
+
model = SpectralMaskEnhancement.from_hparams(
|
| 10 |
+
"speechbrain/mtl-mimic-voicebank"
|
| 11 |
+
)
|
| 12 |
+
model.enhance_file("file.wav")
|
| 13 |
+
```
|
| 14 |
+
|
| 15 |
+
Alternatively, you can use the [Inference API](https://huggingface.co/inference-api) to solve this task
|
| 16 |
+
|
| 17 |
+
```python
|
| 18 |
+
import json
|
| 19 |
+
import requests
|
| 20 |
+
|
| 21 |
+
headers = {"Authorization": f"Bearer {API_TOKEN}"}
|
| 22 |
+
API_URL = "https://api-inference.huggingface.co/models/speechbrain/mtl-mimic-voicebank"
|
| 23 |
+
|
| 24 |
+
def query(filename):
|
| 25 |
+
with open(filename, "rb") as f:
|
| 26 |
+
data = f.read()
|
| 27 |
+
response = requests.request("POST", API_URL, headers=headers, data=data)
|
| 28 |
+
return json.loads(response.content.decode("utf-8"))
|
| 29 |
+
|
| 30 |
+
data = query("sample1.flac")
|
| 31 |
+
```
|
| 32 |
+
|
| 33 |
+
You can use [huggingface.js](https://github.com/huggingface/huggingface.js) to infer with audio-to-audio models on Hugging Face Hub.
|
| 34 |
+
|
| 35 |
+
```javascript
|
| 36 |
+
import { HfInference } from "@huggingface/inference";
|
| 37 |
+
|
| 38 |
+
const inference = new HfInference(HF_ACCESS_TOKEN);
|
| 39 |
+
await inference.audioToAudio({
|
| 40 |
+
data: await (await fetch("sample.flac")).blob(),
|
| 41 |
+
model: "speechbrain/sepformer-wham",
|
| 42 |
+
});
|
| 43 |
+
```
|
| 44 |
+
|
| 45 |
+
### Audio Source Separation
|
| 46 |
+
|
| 47 |
+
Audio Source Separation allows you to isolate different sounds from individual sources. For example, if you have an audio file with multiple people speaking, you can get an audio file for each of them. You can then use an Automatic Speech Recognition system to extract the text from each of these sources as an initial step for your system!
|
| 48 |
+
|
| 49 |
+
Audio-to-Audio can also be used to remove noise from audio files: you get one audio for the person speaking and another audio for the noise. This can also be useful when you have multi-person audio with some noise: yyou can get one audio for each person and then one audio for the noise.
|
| 50 |
+
|
| 51 |
+
## Training a model for your own data
|
| 52 |
+
|
| 53 |
+
If you want to learn how to train models for the Audio-to-Audio task, we recommend the following tutorials:
|
| 54 |
+
|
| 55 |
+
- [Speech Enhancement](https://speechbrain.github.io/tutorial_enhancement.html)
|
| 56 |
+
- [Source Separation](https://speechbrain.github.io/tutorial_separation.html)
|
packages/tasks/src/audio-to-audio/data.ts
ADDED
|
@@ -0,0 +1,66 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import type { TaskDataCustom } from "../Types";
|
| 2 |
+
|
| 3 |
+
const taskData: TaskDataCustom = {
|
| 4 |
+
datasets: [
|
| 5 |
+
{
|
| 6 |
+
description: "512-element X-vector embeddings of speakers from CMU ARCTIC dataset.",
|
| 7 |
+
id: "Matthijs/cmu-arctic-xvectors",
|
| 8 |
+
},
|
| 9 |
+
],
|
| 10 |
+
demo: {
|
| 11 |
+
inputs: [
|
| 12 |
+
{
|
| 13 |
+
filename: "input.wav",
|
| 14 |
+
type: "audio",
|
| 15 |
+
},
|
| 16 |
+
],
|
| 17 |
+
outputs: [
|
| 18 |
+
{
|
| 19 |
+
filename: "label-0.wav",
|
| 20 |
+
type: "audio",
|
| 21 |
+
},
|
| 22 |
+
{
|
| 23 |
+
filename: "label-1.wav",
|
| 24 |
+
type: "audio",
|
| 25 |
+
},
|
| 26 |
+
],
|
| 27 |
+
},
|
| 28 |
+
metrics: [
|
| 29 |
+
{
|
| 30 |
+
description:
|
| 31 |
+
"The Signal-to-Noise ratio is the relationship between the target signal level and the background noise level. It is calculated as the logarithm of the target signal divided by the background noise, in decibels.",
|
| 32 |
+
id: "snri",
|
| 33 |
+
},
|
| 34 |
+
{
|
| 35 |
+
description:
|
| 36 |
+
"The Signal-to-Distortion ratio is the relationship between the target signal and the sum of noise, interference, and artifact errors",
|
| 37 |
+
id: "sdri",
|
| 38 |
+
},
|
| 39 |
+
],
|
| 40 |
+
models: [
|
| 41 |
+
{
|
| 42 |
+
description: "A solid model of audio source separation.",
|
| 43 |
+
id: "speechbrain/sepformer-wham",
|
| 44 |
+
},
|
| 45 |
+
{
|
| 46 |
+
description: "A speech enhancement model.",
|
| 47 |
+
id: "speechbrain/metricgan-plus-voicebank",
|
| 48 |
+
},
|
| 49 |
+
],
|
| 50 |
+
spaces: [
|
| 51 |
+
{
|
| 52 |
+
description: "An application for speech separation.",
|
| 53 |
+
id: "younver/speechbrain-speech-separation",
|
| 54 |
+
},
|
| 55 |
+
{
|
| 56 |
+
description: "An application for audio style transfer.",
|
| 57 |
+
id: "nakas/audio-diffusion_style_transfer",
|
| 58 |
+
},
|
| 59 |
+
],
|
| 60 |
+
summary:
|
| 61 |
+
"Audio-to-Audio is a family of tasks in which the input is an audio and the output is one or multiple generated audios. Some example tasks are speech enhancement and source separation.",
|
| 62 |
+
widgetModels: ["speechbrain/sepformer-wham"],
|
| 63 |
+
youtubeId: "iohj7nCCYoM",
|
| 64 |
+
};
|
| 65 |
+
|
| 66 |
+
export default taskData;
|
packages/tasks/src/automatic-speech-recognition/about.md
ADDED
|
@@ -0,0 +1,87 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
## Use Cases
|
| 2 |
+
|
| 3 |
+
### Virtual Speech Assistants
|
| 4 |
+
|
| 5 |
+
Many edge devices have an embedded virtual assistant to interact with the end users better. These assistances rely on ASR models to recognize different voice commands to perform various tasks. For instance, you can ask your phone for dialing a phone number, ask a general question, or schedule a meeting.
|
| 6 |
+
|
| 7 |
+
### Caption Generation
|
| 8 |
+
|
| 9 |
+
A caption generation model takes audio as input from sources to generate automatic captions through transcription, for live-streamed or recorded videos. This can help with content accessibility. For example, an audience watching a video that includes a non-native language, can rely on captions to interpret the content. It can also help with information retention at online-classes environments improving knowledge assimilation while reading and taking notes faster.
|
| 10 |
+
|
| 11 |
+
## Task Variants
|
| 12 |
+
|
| 13 |
+
### Multilingual ASR
|
| 14 |
+
|
| 15 |
+
Multilingual ASR models can convert audio inputs with multiple languages into transcripts. Some multilingual ASR models include [language identification](https://huggingface.co/tasks/audio-classification) blocks to improve the performance.
|
| 16 |
+
|
| 17 |
+
The use of Multilingual ASR has become popular, the idea of maintaining just a single model for all language can simplify the production pipeline. Take a look at [Whisper](https://huggingface.co/openai/whisper-large-v2) to get an idea on how 100+ languages can be processed by a single model.
|
| 18 |
+
|
| 19 |
+
## Inference
|
| 20 |
+
|
| 21 |
+
The Hub contains over [~9,000 ASR models](https://huggingface.co/models?pipeline_tag=automatic-speech-recognition&sort=downloads) that you can use right away by trying out the widgets directly in the browser or calling the models as a service using the Inference API. Here is a simple code snippet to do exactly this:
|
| 22 |
+
|
| 23 |
+
```python
|
| 24 |
+
import json
|
| 25 |
+
import requests
|
| 26 |
+
|
| 27 |
+
headers = {"Authorization": f"Bearer {API_TOKEN}"}
|
| 28 |
+
API_URL = "https://api-inference.huggingface.co/models/openai/whisper-large-v2"
|
| 29 |
+
|
| 30 |
+
def query(filename):
|
| 31 |
+
with open(filename, "rb") as f:
|
| 32 |
+
data = f.read()
|
| 33 |
+
response = requests.request("POST", API_URL, headers=headers, data=data)
|
| 34 |
+
return json.loads(response.content.decode("utf-8"))
|
| 35 |
+
|
| 36 |
+
data = query("sample1.flac")
|
| 37 |
+
```
|
| 38 |
+
|
| 39 |
+
You can also use libraries such as [transformers](https://huggingface.co/models?library=transformers&pipeline_tag=automatic-speech-recognition&sort=downloads), [speechbrain](https://huggingface.co/models?library=speechbrain&pipeline_tag=automatic-speech-recognition&sort=downloads), [NeMo](https://huggingface.co/models?pipeline_tag=automatic-speech-recognition&library=nemo&sort=downloads) and [espnet](https://huggingface.co/models?library=espnet&pipeline_tag=automatic-speech-recognition&sort=downloads) if you want one-click managed Inference without any hassle.
|
| 40 |
+
|
| 41 |
+
```python
|
| 42 |
+
from transformers import pipeline
|
| 43 |
+
|
| 44 |
+
with open("sample.flac", "rb") as f:
|
| 45 |
+
data = f.read()
|
| 46 |
+
|
| 47 |
+
pipe = pipeline("automatic-speech-recognition", "openai/whisper-large-v2")
|
| 48 |
+
pipe("sample.flac")
|
| 49 |
+
# {'text': "GOING ALONG SLUSHY COUNTRY ROADS AND SPEAKING TO DAMP AUDIENCES IN DRAUGHTY SCHOOL ROOMS DAY AFTER DAY FOR A FORTNIGHT HE'LL HAVE TO PUT IN AN APPEARANCE AT SOME PLACE OF WORSHIP ON SUNDAY MORNING AND HE CAN COME TO US IMMEDIATELY AFTERWARDS"}
|
| 50 |
+
```
|
| 51 |
+
|
| 52 |
+
You can use [huggingface.js](https://github.com/huggingface/huggingface.js) to transcribe text with javascript using models on Hugging Face Hub.
|
| 53 |
+
|
| 54 |
+
```javascript
|
| 55 |
+
import { HfInference } from "@huggingface/inference";
|
| 56 |
+
|
| 57 |
+
const inference = new HfInference(HF_ACCESS_TOKEN);
|
| 58 |
+
await inference.automaticSpeechRecognition({
|
| 59 |
+
data: await (await fetch("sample.flac")).blob(),
|
| 60 |
+
model: "openai/whisper-large-v2",
|
| 61 |
+
});
|
| 62 |
+
```
|
| 63 |
+
|
| 64 |
+
## Solving ASR for your own data
|
| 65 |
+
|
| 66 |
+
We have some great news! You can fine-tune (transfer learning) a foundational speech model on a specific language without tonnes of data. Pretrained models such as Whisper, Wav2Vec2-MMS and HuBERT exist. [OpenAI's Whisper model](https://huggingface.co/openai/whisper-large-v2) is a large multilingual model trained on 100+ languages and with 680K hours of speech.
|
| 67 |
+
|
| 68 |
+
The following detailed [blog post](https://huggingface.co/blog/fine-tune-whisper) shows how to fine-tune a pre-trained Whisper checkpoint on labeled data for ASR. With the right data and strategy you can fine-tune a high-performant model on a free Google Colab instance too. We suggest to read the blog post for more info!
|
| 69 |
+
|
| 70 |
+
## Hugging Face Whisper Event
|
| 71 |
+
|
| 72 |
+
On December 2022, over 450 participants collaborated, fine-tuned and shared 600+ ASR Whisper models in 100+ different languages. You can compare these models on the event's speech recognition [leaderboard](https://huggingface.co/spaces/whisper-event/leaderboard?dataset=mozilla-foundation%2Fcommon_voice_11_0&config=ar&split=test).
|
| 73 |
+
|
| 74 |
+
These events help democratize ASR for all languages, including low-resource languages. In addition to the trained models, the [event](https://github.com/huggingface/community-events/tree/main/whisper-fine-tuning-event) helps to build practical collaborative knowledge.
|
| 75 |
+
|
| 76 |
+
## Useful Resources
|
| 77 |
+
|
| 78 |
+
- [Fine-tuning MetaAI's MMS Adapter Models for Multi-Lingual ASR](https://huggingface.co/blog/mms_adapters)
|
| 79 |
+
- [Making automatic speech recognition work on large files with Wav2Vec2 in 🤗 Transformers](https://huggingface.co/blog/asr-chunking)
|
| 80 |
+
- [Boosting Wav2Vec2 with n-grams in 🤗 Transformers](https://huggingface.co/blog/wav2vec2-with-ngram)
|
| 81 |
+
- [ML for Audio Study Group - Intro to Audio and ASR Deep Dive](https://www.youtube.com/watch?v=D-MH6YjuIlE)
|
| 82 |
+
- [Massively Multilingual ASR: 50 Languages, 1 Model, 1 Billion Parameters](https://arxiv.org/pdf/2007.03001.pdf)
|
| 83 |
+
- An ASR toolkit made by [NVIDIA: NeMo](https://github.com/NVIDIA/NeMo) with code and pretrained models useful for new ASR models. Watch the [introductory video](https://www.youtube.com/embed/wBgpMf_KQVw) for an overview.
|
| 84 |
+
- [An introduction to SpeechT5, a multi-purpose speech recognition and synthesis model](https://huggingface.co/blog/speecht5)
|
| 85 |
+
- [A guide on Fine-tuning Whisper For Multilingual ASR with 🤗Transformers](https://huggingface.co/blog/fine-tune-whisper)
|
| 86 |
+
- [Automatic speech recognition task guide](https://huggingface.co/docs/transformers/tasks/asr)
|
| 87 |
+
- [Speech Synthesis, Recognition, and More With SpeechT5](https://huggingface.co/blog/speecht5)
|
packages/tasks/src/automatic-speech-recognition/data.ts
ADDED
|
@@ -0,0 +1,78 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import type { TaskDataCustom } from "../Types";
|
| 2 |
+
|
| 3 |
+
const taskData: TaskDataCustom = {
|
| 4 |
+
datasets: [
|
| 5 |
+
{
|
| 6 |
+
description: "18,000 hours of multilingual audio-text dataset in 108 languages.",
|
| 7 |
+
id: "mozilla-foundation/common_voice_13_0",
|
| 8 |
+
},
|
| 9 |
+
{
|
| 10 |
+
description: "An English dataset with 1,000 hours of data.",
|
| 11 |
+
id: "librispeech_asr",
|
| 12 |
+
},
|
| 13 |
+
{
|
| 14 |
+
description: "High quality, multi-speaker audio data and their transcriptions in various languages.",
|
| 15 |
+
id: "openslr",
|
| 16 |
+
},
|
| 17 |
+
],
|
| 18 |
+
demo: {
|
| 19 |
+
inputs: [
|
| 20 |
+
{
|
| 21 |
+
filename: "input.flac",
|
| 22 |
+
type: "audio",
|
| 23 |
+
},
|
| 24 |
+
],
|
| 25 |
+
outputs: [
|
| 26 |
+
{
|
| 27 |
+
/// GOING ALONG SLUSHY COUNTRY ROADS AND SPEAKING TO DAMP AUDIENCES I
|
| 28 |
+
label: "Transcript",
|
| 29 |
+
content: "Going along slushy country roads and speaking to damp audiences in...",
|
| 30 |
+
type: "text",
|
| 31 |
+
},
|
| 32 |
+
],
|
| 33 |
+
},
|
| 34 |
+
metrics: [
|
| 35 |
+
{
|
| 36 |
+
description: "",
|
| 37 |
+
id: "wer",
|
| 38 |
+
},
|
| 39 |
+
{
|
| 40 |
+
description: "",
|
| 41 |
+
id: "cer",
|
| 42 |
+
},
|
| 43 |
+
],
|
| 44 |
+
models: [
|
| 45 |
+
{
|
| 46 |
+
description: "A powerful ASR model by OpenAI.",
|
| 47 |
+
id: "openai/whisper-large-v2",
|
| 48 |
+
},
|
| 49 |
+
{
|
| 50 |
+
description: "A good generic ASR model by MetaAI.",
|
| 51 |
+
id: "facebook/wav2vec2-base-960h",
|
| 52 |
+
},
|
| 53 |
+
{
|
| 54 |
+
description: "An end-to-end model that performs ASR and Speech Translation by MetaAI.",
|
| 55 |
+
id: "facebook/s2t-small-mustc-en-fr-st",
|
| 56 |
+
},
|
| 57 |
+
],
|
| 58 |
+
spaces: [
|
| 59 |
+
{
|
| 60 |
+
description: "A powerful general-purpose speech recognition application.",
|
| 61 |
+
id: "openai/whisper",
|
| 62 |
+
},
|
| 63 |
+
{
|
| 64 |
+
description: "Fastest speech recognition application.",
|
| 65 |
+
id: "sanchit-gandhi/whisper-jax",
|
| 66 |
+
},
|
| 67 |
+
{
|
| 68 |
+
description: "An application that transcribes speeches in YouTube videos.",
|
| 69 |
+
id: "jeffistyping/Youtube-Whisperer",
|
| 70 |
+
},
|
| 71 |
+
],
|
| 72 |
+
summary:
|
| 73 |
+
"Automatic Speech Recognition (ASR), also known as Speech to Text (STT), is the task of transcribing a given audio to text. It has many applications, such as voice user interfaces.",
|
| 74 |
+
widgetModels: ["openai/whisper-large-v2"],
|
| 75 |
+
youtubeId: "TksaY_FDgnk",
|
| 76 |
+
};
|
| 77 |
+
|
| 78 |
+
export default taskData;
|
packages/tasks/src/const.ts
ADDED
|
@@ -0,0 +1,59 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import type { ModelLibraryKey } from "./modelLibraries";
|
| 2 |
+
import type { PipelineType } from "./pipelines";
|
| 3 |
+
|
| 4 |
+
/**
|
| 5 |
+
* Model libraries compatible with each ML task
|
| 6 |
+
*/
|
| 7 |
+
export const TASKS_MODEL_LIBRARIES: Record<PipelineType, ModelLibraryKey[]> = {
|
| 8 |
+
"audio-classification": ["speechbrain", "transformers"],
|
| 9 |
+
"audio-to-audio": ["asteroid", "speechbrain"],
|
| 10 |
+
"automatic-speech-recognition": ["espnet", "nemo", "speechbrain", "transformers", "transformers.js"],
|
| 11 |
+
conversational: ["transformers"],
|
| 12 |
+
"depth-estimation": ["transformers"],
|
| 13 |
+
"document-question-answering": ["transformers"],
|
| 14 |
+
"feature-extraction": ["sentence-transformers", "transformers", "transformers.js"],
|
| 15 |
+
"fill-mask": ["transformers", "transformers.js"],
|
| 16 |
+
"graph-ml": ["transformers"],
|
| 17 |
+
"image-classification": ["keras", "timm", "transformers", "transformers.js"],
|
| 18 |
+
"image-segmentation": ["transformers", "transformers.js"],
|
| 19 |
+
"image-to-image": [],
|
| 20 |
+
"image-to-text": ["transformers.js"],
|
| 21 |
+
"video-classification": [],
|
| 22 |
+
"multiple-choice": ["transformers"],
|
| 23 |
+
"object-detection": ["transformers", "transformers.js"],
|
| 24 |
+
other: [],
|
| 25 |
+
"question-answering": ["adapter-transformers", "allennlp", "transformers", "transformers.js"],
|
| 26 |
+
robotics: [],
|
| 27 |
+
"reinforcement-learning": ["transformers", "stable-baselines3", "ml-agents", "sample-factory"],
|
| 28 |
+
"sentence-similarity": ["sentence-transformers", "spacy", "transformers.js"],
|
| 29 |
+
summarization: ["transformers", "transformers.js"],
|
| 30 |
+
"table-question-answering": ["transformers"],
|
| 31 |
+
"table-to-text": ["transformers"],
|
| 32 |
+
"tabular-classification": ["sklearn"],
|
| 33 |
+
"tabular-regression": ["sklearn"],
|
| 34 |
+
"tabular-to-text": ["transformers"],
|
| 35 |
+
"text-classification": ["adapter-transformers", "spacy", "transformers", "transformers.js"],
|
| 36 |
+
"text-generation": ["transformers", "transformers.js"],
|
| 37 |
+
"text-retrieval": [],
|
| 38 |
+
"text-to-image": [],
|
| 39 |
+
"text-to-speech": ["espnet", "tensorflowtts", "transformers"],
|
| 40 |
+
"text-to-audio": ["transformers"],
|
| 41 |
+
"text-to-video": [],
|
| 42 |
+
"text2text-generation": ["transformers", "transformers.js"],
|
| 43 |
+
"time-series-forecasting": [],
|
| 44 |
+
"token-classification": [
|
| 45 |
+
"adapter-transformers",
|
| 46 |
+
"flair",
|
| 47 |
+
"spacy",
|
| 48 |
+
"span-marker",
|
| 49 |
+
"stanza",
|
| 50 |
+
"transformers",
|
| 51 |
+
"transformers.js",
|
| 52 |
+
],
|
| 53 |
+
translation: ["transformers", "transformers.js"],
|
| 54 |
+
"unconditional-image-generation": [],
|
| 55 |
+
"visual-question-answering": [],
|
| 56 |
+
"voice-activity-detection": [],
|
| 57 |
+
"zero-shot-classification": ["transformers", "transformers.js"],
|
| 58 |
+
"zero-shot-image-classification": ["transformers.js"],
|
| 59 |
+
};
|
packages/tasks/src/conversational/about.md
ADDED
|
@@ -0,0 +1,50 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
## Use Cases
|
| 2 |
+
|
| 3 |
+
### Chatbot 💬
|
| 4 |
+
|
| 5 |
+
Chatbots are used to have conversations instead of providing direct contact with a live human. They are used to provide customer service, sales, and can even be used to play games (see [ELIZA](https://en.wikipedia.org/wiki/ELIZA) from 1966 for one of the earliest examples).
|
| 6 |
+
|
| 7 |
+
## Voice Assistants 🎙️
|
| 8 |
+
|
| 9 |
+
Conversational response models are used as part of voice assistants to provide appropriate responses to voice based queries.
|
| 10 |
+
|
| 11 |
+
## Inference
|
| 12 |
+
|
| 13 |
+
You can infer with Conversational models with the 🤗 Transformers library using the `conversational` pipeline. This pipeline takes a conversation prompt or a list of conversations and generates responses for each prompt. The models that this pipeline can use are models that have been fine-tuned on a multi-turn conversational task (see https://huggingface.co/models?filter=conversational for a list of updated Conversational models).
|
| 14 |
+
|
| 15 |
+
```python
|
| 16 |
+
from transformers import pipeline, Conversation
|
| 17 |
+
converse = pipeline("conversational")
|
| 18 |
+
|
| 19 |
+
conversation_1 = Conversation("Going to the movies tonight - any suggestions?")
|
| 20 |
+
conversation_2 = Conversation("What's the last book you have read?")
|
| 21 |
+
converse([conversation_1, conversation_2])
|
| 22 |
+
|
| 23 |
+
## Output:
|
| 24 |
+
## Conversation 1
|
| 25 |
+
## user >> Going to the movies tonight - any suggestions?
|
| 26 |
+
## bot >> The Big Lebowski ,
|
| 27 |
+
## Conversation 2
|
| 28 |
+
## user >> What's the last book you have read?
|
| 29 |
+
## bot >> The Last Question
|
| 30 |
+
```
|
| 31 |
+
|
| 32 |
+
You can use [huggingface.js](https://github.com/huggingface/huggingface.js) to infer with conversational models on Hugging Face Hub.
|
| 33 |
+
|
| 34 |
+
```javascript
|
| 35 |
+
import { HfInference } from "@huggingface/inference";
|
| 36 |
+
|
| 37 |
+
const inference = new HfInference(HF_ACCESS_TOKEN);
|
| 38 |
+
await inference.conversational({
|
| 39 |
+
model: "facebook/blenderbot-400M-distill",
|
| 40 |
+
inputs: "Going to the movies tonight - any suggestions?",
|
| 41 |
+
});
|
| 42 |
+
```
|
| 43 |
+
|
| 44 |
+
## Useful Resources
|
| 45 |
+
|
| 46 |
+
- Learn how ChatGPT and InstructGPT work in this blog: [Illustrating Reinforcement Learning from Human Feedback (RLHF)](https://huggingface.co/blog/rlhf)
|
| 47 |
+
- [Reinforcement Learning from Human Feedback From Zero to ChatGPT](https://www.youtube.com/watch?v=EAd4oQtEJOM)
|
| 48 |
+
- [A guide on Dialog Agents](https://huggingface.co/blog/dialog-agents)
|
| 49 |
+
|
| 50 |
+
This page was made possible thanks to the efforts of [Viraat Aryabumi](https://huggingface.co/viraat).
|
packages/tasks/src/conversational/data.ts
ADDED
|
@@ -0,0 +1,66 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import type { TaskDataCustom } from "../Types";
|
| 2 |
+
|
| 3 |
+
const taskData: TaskDataCustom = {
|
| 4 |
+
datasets: [
|
| 5 |
+
{
|
| 6 |
+
description:
|
| 7 |
+
"A dataset of 7k conversations explicitly designed to exhibit multiple conversation modes: displaying personality, having empathy, and demonstrating knowledge.",
|
| 8 |
+
id: "blended_skill_talk",
|
| 9 |
+
},
|
| 10 |
+
{
|
| 11 |
+
description:
|
| 12 |
+
"ConvAI is a dataset of human-to-bot conversations labeled for quality. This data can be used to train a metric for evaluating dialogue systems",
|
| 13 |
+
id: "conv_ai_2",
|
| 14 |
+
},
|
| 15 |
+
{
|
| 16 |
+
description: "EmpatheticDialogues, is a dataset of 25k conversations grounded in emotional situations",
|
| 17 |
+
id: "empathetic_dialogues",
|
| 18 |
+
},
|
| 19 |
+
],
|
| 20 |
+
demo: {
|
| 21 |
+
inputs: [
|
| 22 |
+
{
|
| 23 |
+
label: "Input",
|
| 24 |
+
content: "Hey my name is Julien! How are you?",
|
| 25 |
+
type: "text",
|
| 26 |
+
},
|
| 27 |
+
],
|
| 28 |
+
outputs: [
|
| 29 |
+
{
|
| 30 |
+
label: "Answer",
|
| 31 |
+
content: "Hi Julien! My name is Julia! I am well.",
|
| 32 |
+
type: "text",
|
| 33 |
+
},
|
| 34 |
+
],
|
| 35 |
+
},
|
| 36 |
+
metrics: [
|
| 37 |
+
{
|
| 38 |
+
description:
|
| 39 |
+
"BLEU score is calculated by counting the number of shared single or subsequent tokens between the generated sequence and the reference. Subsequent n tokens are called “n-grams”. Unigram refers to a single token while bi-gram refers to token pairs and n-grams refer to n subsequent tokens. The score ranges from 0 to 1, where 1 means the translation perfectly matched and 0 did not match at all",
|
| 40 |
+
id: "bleu",
|
| 41 |
+
},
|
| 42 |
+
],
|
| 43 |
+
models: [
|
| 44 |
+
{
|
| 45 |
+
description: "A faster and smaller model than the famous BERT model.",
|
| 46 |
+
id: "facebook/blenderbot-400M-distill",
|
| 47 |
+
},
|
| 48 |
+
{
|
| 49 |
+
description:
|
| 50 |
+
"DialoGPT is a large-scale pretrained dialogue response generation model for multiturn conversations.",
|
| 51 |
+
id: "microsoft/DialoGPT-large",
|
| 52 |
+
},
|
| 53 |
+
],
|
| 54 |
+
spaces: [
|
| 55 |
+
{
|
| 56 |
+
description: "A chatbot based on Blender model.",
|
| 57 |
+
id: "EXFINITE/BlenderBot-UI",
|
| 58 |
+
},
|
| 59 |
+
],
|
| 60 |
+
summary:
|
| 61 |
+
"Conversational response modelling is the task of generating conversational text that is relevant, coherent and knowledgable given a prompt. These models have applications in chatbots, and as a part of voice assistants",
|
| 62 |
+
widgetModels: ["facebook/blenderbot-400M-distill"],
|
| 63 |
+
youtubeId: "",
|
| 64 |
+
};
|
| 65 |
+
|
| 66 |
+
export default taskData;
|
packages/tasks/src/depth-estimation/about.md
ADDED
|
@@ -0,0 +1,36 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
## Use Cases
|
| 2 |
+
Depth estimation models can be used to estimate the depth of different objects present in an image.
|
| 3 |
+
|
| 4 |
+
### Estimation of Volumetric Information
|
| 5 |
+
Depth estimation models are widely used to study volumetric formation of objects present inside an image. This is an important use case in the domain of computer graphics.
|
| 6 |
+
|
| 7 |
+
### 3D Representation
|
| 8 |
+
|
| 9 |
+
Depth estimation models can also be used to develop a 3D representation from a 2D image.
|
| 10 |
+
|
| 11 |
+
## Inference
|
| 12 |
+
|
| 13 |
+
With the `transformers` library, you can use the `depth-estimation` pipeline to infer with image classification models. You can initialize the pipeline with a model id from the Hub. If you do not provide a model id it will initialize with [Intel/dpt-large](https://huggingface.co/Intel/dpt-large) by default. When calling the pipeline you just need to specify a path, http link or an image loaded in PIL. Additionally, you can find a comprehensive list of various depth estimation models at [this link](https://huggingface.co/models?pipeline_tag=depth-estimation).
|
| 14 |
+
|
| 15 |
+
```python
|
| 16 |
+
from transformers import pipeline
|
| 17 |
+
|
| 18 |
+
estimator = pipeline(task="depth-estimation", model="Intel/dpt-large")
|
| 19 |
+
result = estimator(images="http://images.cocodataset.org/val2017/000000039769.jpg")
|
| 20 |
+
result
|
| 21 |
+
|
| 22 |
+
# {'predicted_depth': tensor([[[ 6.3199, 6.3629, 6.4148, ..., 10.4104, 10.5109, 10.3847],
|
| 23 |
+
# [ 6.3850, 6.3615, 6.4166, ..., 10.4540, 10.4384, 10.4554],
|
| 24 |
+
# [ 6.3519, 6.3176, 6.3575, ..., 10.4247, 10.4618, 10.4257],
|
| 25 |
+
# ...,
|
| 26 |
+
# [22.3772, 22.4624, 22.4227, ..., 22.5207, 22.5593, 22.5293],
|
| 27 |
+
# [22.5073, 22.5148, 22.5114, ..., 22.6604, 22.6344, 22.5871],
|
| 28 |
+
# [22.5176, 22.5275, 22.5218, ..., 22.6282, 22.6216, 22.6108]]]),
|
| 29 |
+
# 'depth': <PIL.Image.Image image mode=L size=640x480 at 0x7F1A8BFE5D90>}
|
| 30 |
+
|
| 31 |
+
# You can visualize the result just by calling `result["depth"]`.
|
| 32 |
+
```
|
| 33 |
+
|
| 34 |
+
## Useful Resources
|
| 35 |
+
|
| 36 |
+
- [Monocular depth estimation task guide](https://huggingface.co/docs/transformers/tasks/monocular_depth_estimation)
|
packages/tasks/src/depth-estimation/data.ts
ADDED
|
@@ -0,0 +1,52 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import type { TaskDataCustom } from "../Types";
|
| 2 |
+
|
| 3 |
+
const taskData: TaskDataCustom = {
|
| 4 |
+
datasets: [
|
| 5 |
+
{
|
| 6 |
+
description: "NYU Depth V2 Dataset: Video dataset containing both RGB and depth sensor data",
|
| 7 |
+
id: "sayakpaul/nyu_depth_v2",
|
| 8 |
+
},
|
| 9 |
+
],
|
| 10 |
+
demo: {
|
| 11 |
+
inputs: [
|
| 12 |
+
{
|
| 13 |
+
filename: "depth-estimation-input.jpg",
|
| 14 |
+
type: "img",
|
| 15 |
+
},
|
| 16 |
+
],
|
| 17 |
+
outputs: [
|
| 18 |
+
{
|
| 19 |
+
filename: "depth-estimation-output.png",
|
| 20 |
+
type: "img",
|
| 21 |
+
},
|
| 22 |
+
],
|
| 23 |
+
},
|
| 24 |
+
metrics: [],
|
| 25 |
+
models: [
|
| 26 |
+
{
|
| 27 |
+
// TO DO: write description
|
| 28 |
+
description: "Strong Depth Estimation model trained on 1.4 million images.",
|
| 29 |
+
id: "Intel/dpt-large",
|
| 30 |
+
},
|
| 31 |
+
{
|
| 32 |
+
// TO DO: write description
|
| 33 |
+
description: "Strong Depth Estimation model trained on the KITTI dataset.",
|
| 34 |
+
id: "vinvino02/glpn-kitti",
|
| 35 |
+
},
|
| 36 |
+
],
|
| 37 |
+
spaces: [
|
| 38 |
+
{
|
| 39 |
+
description: "An application that predicts the depth of an image and then reconstruct the 3D model as voxels.",
|
| 40 |
+
id: "radames/dpt-depth-estimation-3d-voxels",
|
| 41 |
+
},
|
| 42 |
+
{
|
| 43 |
+
description: "An application that can estimate the depth in a given image.",
|
| 44 |
+
id: "keras-io/Monocular-Depth-Estimation",
|
| 45 |
+
},
|
| 46 |
+
],
|
| 47 |
+
summary: "Depth estimation is the task of predicting depth of the objects present in an image.",
|
| 48 |
+
widgetModels: [""],
|
| 49 |
+
youtubeId: "",
|
| 50 |
+
};
|
| 51 |
+
|
| 52 |
+
export default taskData;
|
packages/tasks/src/document-question-answering/about.md
ADDED
|
@@ -0,0 +1,53 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
## Use Cases
|
| 2 |
+
|
| 3 |
+
Document Question Answering models can be used to answer natural language questions about documents. Typically, document QA models consider textual, layout and potentially visual information. This is useful when the question requires some understanding of the visual aspects of the document.
|
| 4 |
+
Nevertheless, certain document QA models can work without document images. Hence the task is not limited to visually-rich documents and allows users to ask questions based on spreadsheets, text PDFs, etc!
|
| 5 |
+
|
| 6 |
+
### Document Parsing
|
| 7 |
+
|
| 8 |
+
One of the most popular use cases of document question answering models is the parsing of structured documents. For example, you can extract the name, address, and other information from a form. You can also use the model to extract information from a table, or even a resume.
|
| 9 |
+
|
| 10 |
+
### Invoice Information Extraction
|
| 11 |
+
|
| 12 |
+
Another very popular use case is invoice information extraction. For example, you can extract the invoice number, the invoice date, the total amount, the VAT number, and the invoice recipient.
|
| 13 |
+
|
| 14 |
+
## Inference
|
| 15 |
+
|
| 16 |
+
You can infer with Document QA models with the 🤗 Transformers library using the [`document-question-answering` pipeline](https://huggingface.co/docs/transformers/en/main_classes/pipelines#transformers.DocumentQuestionAnsweringPipeline). If no model checkpoint is given, the pipeline will be initialized with [`impira/layoutlm-document-qa`](https://huggingface.co/impira/layoutlm-document-qa). This pipeline takes question(s) and document(s) as input, and returns the answer.
|
| 17 |
+
👉 Note that the question answering task solved here is extractive: the model extracts the answer from a context (the document).
|
| 18 |
+
|
| 19 |
+
```python
|
| 20 |
+
from transformers import pipeline
|
| 21 |
+
from PIL import Image
|
| 22 |
+
|
| 23 |
+
pipe = pipeline("document-question-answering", model="naver-clova-ix/donut-base-finetuned-docvqa")
|
| 24 |
+
|
| 25 |
+
question = "What is the purchase amount?"
|
| 26 |
+
image = Image.open("your-document.png")
|
| 27 |
+
|
| 28 |
+
pipe(image=image, question=question)
|
| 29 |
+
|
| 30 |
+
## [{'answer': '20,000$'}]
|
| 31 |
+
```
|
| 32 |
+
|
| 33 |
+
## Useful Resources
|
| 34 |
+
|
| 35 |
+
Would you like to learn more about Document QA? Awesome! Here are some curated resources that you may find helpful!
|
| 36 |
+
|
| 37 |
+
- [Document Visual Question Answering (DocVQA) challenge](https://rrc.cvc.uab.es/?ch=17)
|
| 38 |
+
- [DocVQA: A Dataset for Document Visual Question Answering](https://arxiv.org/abs/2007.00398) (Dataset paper)
|
| 39 |
+
- [ICDAR 2021 Competition on Document Visual Question Answering](https://lilianweng.github.io/lil-log/2020/10/29/open-domain-question-answering.html) (Conference paper)
|
| 40 |
+
- [HuggingFace's Document Question Answering pipeline](https://huggingface.co/docs/transformers/en/main_classes/pipelines#transformers.DocumentQuestionAnsweringPipeline)
|
| 41 |
+
- [Github repo: DocQuery - Document Query Engine Powered by Large Language Models](https://github.com/impira/docquery)
|
| 42 |
+
|
| 43 |
+
### Notebooks
|
| 44 |
+
|
| 45 |
+
- [Fine-tuning Donut on DocVQA dataset](https://github.com/NielsRogge/Transformers-Tutorials/tree/0ea77f29d01217587d7e32a848f3691d9c15d6ab/Donut/DocVQA)
|
| 46 |
+
- [Fine-tuning LayoutLMv2 on DocVQA dataset](https://github.com/NielsRogge/Transformers-Tutorials/tree/1b4bad710c41017d07a8f63b46a12523bfd2e835/LayoutLMv2/DocVQA)
|
| 47 |
+
- [Accelerating Document AI](https://huggingface.co/blog/document-ai)
|
| 48 |
+
|
| 49 |
+
### Documentation
|
| 50 |
+
|
| 51 |
+
- [Document question answering task guide](https://huggingface.co/docs/transformers/tasks/document_question_answering)
|
| 52 |
+
|
| 53 |
+
The contents of this page are contributed by [Eliott Zemour](https://huggingface.co/eliolio) and reviewed by [Kwadwo Agyapon-Ntra](https://huggingface.co/KayO) and [Ankur Goyal](https://huggingface.co/ankrgyl).
|
packages/tasks/src/document-question-answering/data.ts
ADDED
|
@@ -0,0 +1,70 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import type { TaskDataCustom } from "../Types";
|
| 2 |
+
|
| 3 |
+
const taskData: TaskDataCustom = {
|
| 4 |
+
datasets: [
|
| 5 |
+
{
|
| 6 |
+
// TODO write proper description
|
| 7 |
+
description:
|
| 8 |
+
"Dataset from the 2020 DocVQA challenge. The documents are taken from the UCSF Industry Documents Library.",
|
| 9 |
+
id: "eliolio/docvqa",
|
| 10 |
+
},
|
| 11 |
+
],
|
| 12 |
+
demo: {
|
| 13 |
+
inputs: [
|
| 14 |
+
{
|
| 15 |
+
label: "Question",
|
| 16 |
+
content: "What is the idea behind the consumer relations efficiency team?",
|
| 17 |
+
type: "text",
|
| 18 |
+
},
|
| 19 |
+
{
|
| 20 |
+
filename: "document-question-answering-input.png",
|
| 21 |
+
type: "img",
|
| 22 |
+
},
|
| 23 |
+
],
|
| 24 |
+
outputs: [
|
| 25 |
+
{
|
| 26 |
+
label: "Answer",
|
| 27 |
+
content: "Balance cost efficiency with quality customer service",
|
| 28 |
+
type: "text",
|
| 29 |
+
},
|
| 30 |
+
],
|
| 31 |
+
},
|
| 32 |
+
metrics: [
|
| 33 |
+
{
|
| 34 |
+
description:
|
| 35 |
+
"The evaluation metric for the DocVQA challenge is the Average Normalized Levenshtein Similarity (ANLS). This metric is flexible to character regognition errors and compares the predicted answer with the ground truth answer.",
|
| 36 |
+
id: "anls",
|
| 37 |
+
},
|
| 38 |
+
{
|
| 39 |
+
description:
|
| 40 |
+
"Exact Match is a metric based on the strict character match of the predicted answer and the right answer. For answers predicted correctly, the Exact Match will be 1. Even if only one character is different, Exact Match will be 0",
|
| 41 |
+
id: "exact-match",
|
| 42 |
+
},
|
| 43 |
+
],
|
| 44 |
+
models: [
|
| 45 |
+
{
|
| 46 |
+
description: "A LayoutLM model for the document QA task, fine-tuned on DocVQA and SQuAD2.0.",
|
| 47 |
+
id: "impira/layoutlm-document-qa",
|
| 48 |
+
},
|
| 49 |
+
{
|
| 50 |
+
description: "A special model for OCR-free Document QA task. Donut model fine-tuned on DocVQA.",
|
| 51 |
+
id: "naver-clova-ix/donut-base-finetuned-docvqa",
|
| 52 |
+
},
|
| 53 |
+
],
|
| 54 |
+
spaces: [
|
| 55 |
+
{
|
| 56 |
+
description: "A robust document question answering application.",
|
| 57 |
+
id: "impira/docquery",
|
| 58 |
+
},
|
| 59 |
+
{
|
| 60 |
+
description: "An application that can answer questions from invoices.",
|
| 61 |
+
id: "impira/invoices",
|
| 62 |
+
},
|
| 63 |
+
],
|
| 64 |
+
summary:
|
| 65 |
+
"Document Question Answering (also known as Document Visual Question Answering) is the task of answering questions on document images. Document question answering models take a (document, question) pair as input and return an answer in natural language. Models usually rely on multi-modal features, combining text, position of words (bounding-boxes) and image.",
|
| 66 |
+
widgetModels: ["impira/layoutlm-document-qa"],
|
| 67 |
+
youtubeId: "",
|
| 68 |
+
};
|
| 69 |
+
|
| 70 |
+
export default taskData;
|
packages/tasks/src/feature-extraction/about.md
ADDED
|
@@ -0,0 +1,34 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
## About the Task
|
| 2 |
+
|
| 3 |
+
Feature extraction is the task of building features intended to be informative from a given dataset,
|
| 4 |
+
facilitating the subsequent learning and generalization steps in various domains of machine learning.
|
| 5 |
+
|
| 6 |
+
## Use Cases
|
| 7 |
+
|
| 8 |
+
Feature extraction can be used to do transfer learning in natural language processing, computer vision and audio models.
|
| 9 |
+
|
| 10 |
+
## Inference
|
| 11 |
+
|
| 12 |
+
#### Feature Extraction
|
| 13 |
+
|
| 14 |
+
```python
|
| 15 |
+
from transformers import pipeline
|
| 16 |
+
checkpoint = "facebook/bart-base"
|
| 17 |
+
feature_extractor = pipeline("feature-extraction",framework="pt",model=checkpoint)
|
| 18 |
+
text = "Transformers is an awesome library!"
|
| 19 |
+
|
| 20 |
+
#Reducing along the first dimension to get a 768 dimensional array
|
| 21 |
+
feature_extractor(text,return_tensors = "pt")[0].numpy().mean(axis=0)
|
| 22 |
+
|
| 23 |
+
'''tensor([[[ 2.5834, 2.7571, 0.9024, ..., 1.5036, -0.0435, -0.8603],
|
| 24 |
+
[-1.2850, -1.0094, -2.0826, ..., 1.5993, -0.9017, 0.6426],
|
| 25 |
+
[ 0.9082, 0.3896, -0.6843, ..., 0.7061, 0.6517, 1.0550],
|
| 26 |
+
...,
|
| 27 |
+
[ 0.6919, -1.1946, 0.2438, ..., 1.3646, -1.8661, -0.1642],
|
| 28 |
+
[-0.1701, -2.0019, -0.4223, ..., 0.3680, -1.9704, -0.0068],
|
| 29 |
+
[ 0.2520, -0.6869, -1.0582, ..., 0.5198, -2.2106, 0.4547]]])'''
|
| 30 |
+
```
|
| 31 |
+
|
| 32 |
+
## Useful resources
|
| 33 |
+
|
| 34 |
+
- [Documentation for feature extractor of 🤗Transformers](https://huggingface.co/docs/transformers/main_classes/feature_extractor)
|
packages/tasks/src/feature-extraction/data.ts
ADDED
|
@@ -0,0 +1,54 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import type { TaskDataCustom } from "../Types";
|
| 2 |
+
|
| 3 |
+
const taskData: TaskDataCustom = {
|
| 4 |
+
datasets: [
|
| 5 |
+
{
|
| 6 |
+
description:
|
| 7 |
+
"Wikipedia dataset containing cleaned articles of all languages. Can be used to train `feature-extraction` models.",
|
| 8 |
+
id: "wikipedia",
|
| 9 |
+
},
|
| 10 |
+
],
|
| 11 |
+
demo: {
|
| 12 |
+
inputs: [
|
| 13 |
+
{
|
| 14 |
+
label: "Input",
|
| 15 |
+
content: "India, officially the Republic of India, is a country in South Asia.",
|
| 16 |
+
type: "text",
|
| 17 |
+
},
|
| 18 |
+
],
|
| 19 |
+
outputs: [
|
| 20 |
+
{
|
| 21 |
+
table: [
|
| 22 |
+
["Dimension 1", "Dimension 2", "Dimension 3"],
|
| 23 |
+
["2.583383083343506", "2.757075071334839", "0.9023529887199402"],
|
| 24 |
+
["8.29393482208252", "1.1071064472198486", "2.03399395942688"],
|
| 25 |
+
["-0.7754912972450256", "-1.647324562072754", "-0.6113331913948059"],
|
| 26 |
+
["0.07087723910808563", "1.5942802429199219", "1.4610432386398315"],
|
| 27 |
+
],
|
| 28 |
+
type: "tabular",
|
| 29 |
+
},
|
| 30 |
+
],
|
| 31 |
+
},
|
| 32 |
+
metrics: [
|
| 33 |
+
{
|
| 34 |
+
description: "",
|
| 35 |
+
id: "",
|
| 36 |
+
},
|
| 37 |
+
],
|
| 38 |
+
models: [
|
| 39 |
+
{
|
| 40 |
+
description: "A powerful feature extraction model for natural language processing tasks.",
|
| 41 |
+
id: "facebook/bart-base",
|
| 42 |
+
},
|
| 43 |
+
{
|
| 44 |
+
description: "A strong feature extraction model for coding tasks.",
|
| 45 |
+
id: "microsoft/codebert-base",
|
| 46 |
+
},
|
| 47 |
+
],
|
| 48 |
+
spaces: [],
|
| 49 |
+
summary:
|
| 50 |
+
"Feature extraction refers to the process of transforming raw data into numerical features that can be processed while preserving the information in the original dataset.",
|
| 51 |
+
widgetModels: ["facebook/bart-base"],
|
| 52 |
+
};
|
| 53 |
+
|
| 54 |
+
export default taskData;
|
packages/tasks/src/fill-mask/about.md
ADDED
|
@@ -0,0 +1,51 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
## Use Cases
|
| 2 |
+
|
| 3 |
+
### Domain Adaptation 👩⚕️
|
| 4 |
+
|
| 5 |
+
Masked language models do not require labelled data! They are trained by masking a couple of words in sentences and the model is expected to guess the masked word. This makes it very practical!
|
| 6 |
+
|
| 7 |
+
For example, masked language modeling is used to train large models for domain-specific problems. If you have to work on a domain-specific task, such as retrieving information from medical research papers, you can train a masked language model using those papers. 📄
|
| 8 |
+
|
| 9 |
+
The resulting model has a statistical understanding of the language used in medical research papers, and can be further trained in a process called fine-tuning to solve different tasks, such as [Text Classification](/tasks/text-classification) or [Question Answering](/tasks/question-answering) to build a medical research papers information extraction system. 👩⚕️ Pre-training on domain-specific data tends to yield better results (see [this paper](https://arxiv.org/abs/2007.15779) for an example).
|
| 10 |
+
|
| 11 |
+
If you don't have the data to train a masked language model, you can also use an existing [domain-specific masked language model](https://huggingface.co/microsoft/BiomedNLP-PubMedBERT-base-uncased-abstract-fulltext) from the Hub and fine-tune it with your smaller task dataset. That's the magic of Open Source and sharing your work! 🎉
|
| 12 |
+
|
| 13 |
+
## Inference with Fill-Mask Pipeline
|
| 14 |
+
|
| 15 |
+
You can use the 🤗 Transformers library `fill-mask` pipeline to do inference with masked language models. If a model name is not provided, the pipeline will be initialized with [distilroberta-base](/distilroberta-base). You can provide masked text and it will return a list of possible mask values ranked according to the score.
|
| 16 |
+
|
| 17 |
+
```python
|
| 18 |
+
from transformers import pipeline
|
| 19 |
+
|
| 20 |
+
classifier = pipeline("fill-mask")
|
| 21 |
+
classifier("Paris is the <mask> of France.")
|
| 22 |
+
|
| 23 |
+
# [{'score': 0.7, 'sequence': 'Paris is the capital of France.'},
|
| 24 |
+
# {'score': 0.2, 'sequence': 'Paris is the birthplace of France.'},
|
| 25 |
+
# {'score': 0.1, 'sequence': 'Paris is the heart of France.'}]
|
| 26 |
+
```
|
| 27 |
+
|
| 28 |
+
## Useful Resources
|
| 29 |
+
|
| 30 |
+
Would you like to learn more about the topic? Awesome! Here you can find some curated resources that can be helpful to you!
|
| 31 |
+
|
| 32 |
+
- [Course Chapter on Fine-tuning a Masked Language Model](https://huggingface.co/course/chapter7/3?fw=pt)
|
| 33 |
+
- [Workshop on Pretraining Language Models and CodeParrot](https://www.youtube.com/watch?v=ExUR7w6xe94)
|
| 34 |
+
- [BERT 101: State Of The Art NLP Model Explained](https://huggingface.co/blog/bert-101)
|
| 35 |
+
- [Nyströmformer: Approximating self-attention in linear time and memory via the Nyström method](https://huggingface.co/blog/nystromformer)
|
| 36 |
+
|
| 37 |
+
### Notebooks
|
| 38 |
+
|
| 39 |
+
- [Pre-training an MLM for JAX/Flax](https://github.com/huggingface/notebooks/blob/master/examples/masked_language_modeling_flax.ipynb)
|
| 40 |
+
- [Masked language modeling in TensorFlow](https://github.com/huggingface/notebooks/blob/master/examples/language_modeling-tf.ipynb)
|
| 41 |
+
- [Masked language modeling in PyTorch](https://github.com/huggingface/notebooks/blob/master/examples/language_modeling.ipynb)
|
| 42 |
+
|
| 43 |
+
### Scripts for training
|
| 44 |
+
|
| 45 |
+
- [PyTorch](https://github.com/huggingface/transformers/tree/main/examples/pytorch/language-modeling)
|
| 46 |
+
- [Flax](https://github.com/huggingface/transformers/tree/main/examples/flax/language-modeling)
|
| 47 |
+
- [TensorFlow](https://github.com/huggingface/transformers/tree/main/examples/tensorflow/language-modeling)
|
| 48 |
+
|
| 49 |
+
### Documentation
|
| 50 |
+
|
| 51 |
+
- [Masked language modeling task guide](https://huggingface.co/docs/transformers/tasks/masked_language_modeling)
|
packages/tasks/src/fill-mask/data.ts
ADDED
|
@@ -0,0 +1,79 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import type { TaskDataCustom } from "../Types";
|
| 2 |
+
|
| 3 |
+
const taskData: TaskDataCustom = {
|
| 4 |
+
datasets: [
|
| 5 |
+
{
|
| 6 |
+
description: "A common dataset that is used to train models for many languages.",
|
| 7 |
+
id: "wikipedia",
|
| 8 |
+
},
|
| 9 |
+
{
|
| 10 |
+
description: "A large English dataset with text crawled from the web.",
|
| 11 |
+
id: "c4",
|
| 12 |
+
},
|
| 13 |
+
],
|
| 14 |
+
demo: {
|
| 15 |
+
inputs: [
|
| 16 |
+
{
|
| 17 |
+
label: "Input",
|
| 18 |
+
content: "The <mask> barked at me",
|
| 19 |
+
type: "text",
|
| 20 |
+
},
|
| 21 |
+
],
|
| 22 |
+
outputs: [
|
| 23 |
+
{
|
| 24 |
+
type: "chart",
|
| 25 |
+
data: [
|
| 26 |
+
{
|
| 27 |
+
label: "wolf",
|
| 28 |
+
score: 0.487,
|
| 29 |
+
},
|
| 30 |
+
{
|
| 31 |
+
label: "dog",
|
| 32 |
+
score: 0.061,
|
| 33 |
+
},
|
| 34 |
+
{
|
| 35 |
+
label: "cat",
|
| 36 |
+
score: 0.058,
|
| 37 |
+
},
|
| 38 |
+
{
|
| 39 |
+
label: "fox",
|
| 40 |
+
score: 0.047,
|
| 41 |
+
},
|
| 42 |
+
{
|
| 43 |
+
label: "squirrel",
|
| 44 |
+
score: 0.025,
|
| 45 |
+
},
|
| 46 |
+
],
|
| 47 |
+
},
|
| 48 |
+
],
|
| 49 |
+
},
|
| 50 |
+
metrics: [
|
| 51 |
+
{
|
| 52 |
+
description:
|
| 53 |
+
"Cross Entropy is a metric that calculates the difference between two probability distributions. Each probability distribution is the distribution of predicted words",
|
| 54 |
+
id: "cross_entropy",
|
| 55 |
+
},
|
| 56 |
+
{
|
| 57 |
+
description:
|
| 58 |
+
"Perplexity is the exponential of the cross-entropy loss. It evaluates the probabilities assigned to the next word by the model. Lower perplexity indicates better performance",
|
| 59 |
+
id: "perplexity",
|
| 60 |
+
},
|
| 61 |
+
],
|
| 62 |
+
models: [
|
| 63 |
+
{
|
| 64 |
+
description: "A faster and smaller model than the famous BERT model.",
|
| 65 |
+
id: "distilbert-base-uncased",
|
| 66 |
+
},
|
| 67 |
+
{
|
| 68 |
+
description: "A multilingual model trained on 100 languages.",
|
| 69 |
+
id: "xlm-roberta-base",
|
| 70 |
+
},
|
| 71 |
+
],
|
| 72 |
+
spaces: [],
|
| 73 |
+
summary:
|
| 74 |
+
"Masked language modeling is the task of masking some of the words in a sentence and predicting which words should replace those masks. These models are useful when we want to get a statistical understanding of the language in which the model is trained in.",
|
| 75 |
+
widgetModels: ["distilroberta-base"],
|
| 76 |
+
youtubeId: "mqElG5QJWUg",
|
| 77 |
+
};
|
| 78 |
+
|
| 79 |
+
export default taskData;
|
packages/tasks/src/image-classification/about.md
ADDED
|
@@ -0,0 +1,50 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
## Use Cases
|
| 2 |
+
|
| 3 |
+
Image classification models can be used when we are not interested in specific instances of objects with location information or their shape.
|
| 4 |
+
|
| 5 |
+
### Keyword Classification
|
| 6 |
+
|
| 7 |
+
Image classification models are used widely in stock photography to assign each image a keyword.
|
| 8 |
+
|
| 9 |
+
### Image Search
|
| 10 |
+
|
| 11 |
+
Models trained in image classification can improve user experience by organizing and categorizing photo galleries on the phone or in the cloud, on multiple keywords or tags.
|
| 12 |
+
|
| 13 |
+
## Inference
|
| 14 |
+
|
| 15 |
+
With the `transformers` library, you can use the `image-classification` pipeline to infer with image classification models. You can initialize the pipeline with a model id from the Hub. If you do not provide a model id it will initialize with [google/vit-base-patch16-224](https://huggingface.co/google/vit-base-patch16-224) by default. When calling the pipeline you just need to specify a path, http link or an image loaded in PIL. You can also provide a `top_k` parameter which determines how many results it should return.
|
| 16 |
+
|
| 17 |
+
```python
|
| 18 |
+
from transformers import pipeline
|
| 19 |
+
clf = pipeline("image-classification")
|
| 20 |
+
clf("path_to_a_cat_image")
|
| 21 |
+
|
| 22 |
+
[{'label': 'tabby cat', 'score': 0.731},
|
| 23 |
+
...
|
| 24 |
+
]
|
| 25 |
+
```
|
| 26 |
+
|
| 27 |
+
You can use [huggingface.js](https://github.com/huggingface/huggingface.js) to classify images using models on Hugging Face Hub.
|
| 28 |
+
|
| 29 |
+
```javascript
|
| 30 |
+
import { HfInference } from "@huggingface/inference";
|
| 31 |
+
|
| 32 |
+
const inference = new HfInference(HF_ACCESS_TOKEN);
|
| 33 |
+
await inference.imageClassification({
|
| 34 |
+
data: await (await fetch("https://picsum.photos/300/300")).blob(),
|
| 35 |
+
model: "microsoft/resnet-50",
|
| 36 |
+
});
|
| 37 |
+
```
|
| 38 |
+
|
| 39 |
+
## Useful Resources
|
| 40 |
+
|
| 41 |
+
- [Let's Play Pictionary with Machine Learning!](https://www.youtube.com/watch?v=LS9Y2wDVI0k)
|
| 42 |
+
- [Fine-Tune ViT for Image Classification with 🤗Transformers](https://huggingface.co/blog/fine-tune-vit)
|
| 43 |
+
- [Walkthrough of Computer Vision Ecosystem in Hugging Face - CV Study Group](https://www.youtube.com/watch?v=oL-xmufhZM8)
|
| 44 |
+
- [Computer Vision Study Group: Swin Transformer](https://www.youtube.com/watch?v=Ngikt-K1Ecc)
|
| 45 |
+
- [Computer Vision Study Group: Masked Autoencoders Paper Walkthrough](https://www.youtube.com/watch?v=Ngikt-K1Ecc)
|
| 46 |
+
- [Image classification task guide](https://huggingface.co/docs/transformers/tasks/image_classification)
|
| 47 |
+
|
| 48 |
+
### Creating your own image classifier in just a few minutes
|
| 49 |
+
|
| 50 |
+
With [HuggingPics](https://github.com/nateraw/huggingpics), you can fine-tune Vision Transformers for anything using images found on the web. This project downloads images of classes defined by you, trains a model, and pushes it to the Hub. You even get to try out the model directly with a working widget in the browser, ready to be shared with all your friends!
|
packages/tasks/src/image-classification/data.ts
ADDED
|
@@ -0,0 +1,88 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import type { TaskDataCustom } from "../Types";
|
| 2 |
+
|
| 3 |
+
const taskData: TaskDataCustom = {
|
| 4 |
+
datasets: [
|
| 5 |
+
{
|
| 6 |
+
// TODO write proper description
|
| 7 |
+
description: "Benchmark dataset used for image classification with images that belong to 100 classes.",
|
| 8 |
+
id: "cifar100",
|
| 9 |
+
},
|
| 10 |
+
{
|
| 11 |
+
// TODO write proper description
|
| 12 |
+
description: "Dataset consisting of images of garments.",
|
| 13 |
+
id: "fashion_mnist",
|
| 14 |
+
},
|
| 15 |
+
],
|
| 16 |
+
demo: {
|
| 17 |
+
inputs: [
|
| 18 |
+
{
|
| 19 |
+
filename: "image-classification-input.jpeg",
|
| 20 |
+
type: "img",
|
| 21 |
+
},
|
| 22 |
+
],
|
| 23 |
+
outputs: [
|
| 24 |
+
{
|
| 25 |
+
type: "chart",
|
| 26 |
+
data: [
|
| 27 |
+
{
|
| 28 |
+
label: "Egyptian cat",
|
| 29 |
+
score: 0.514,
|
| 30 |
+
},
|
| 31 |
+
{
|
| 32 |
+
label: "Tabby cat",
|
| 33 |
+
score: 0.193,
|
| 34 |
+
},
|
| 35 |
+
{
|
| 36 |
+
label: "Tiger cat",
|
| 37 |
+
score: 0.068,
|
| 38 |
+
},
|
| 39 |
+
],
|
| 40 |
+
},
|
| 41 |
+
],
|
| 42 |
+
},
|
| 43 |
+
metrics: [
|
| 44 |
+
{
|
| 45 |
+
description: "",
|
| 46 |
+
id: "accuracy",
|
| 47 |
+
},
|
| 48 |
+
{
|
| 49 |
+
description: "",
|
| 50 |
+
id: "recall",
|
| 51 |
+
},
|
| 52 |
+
{
|
| 53 |
+
description: "",
|
| 54 |
+
id: "precision",
|
| 55 |
+
},
|
| 56 |
+
{
|
| 57 |
+
description: "",
|
| 58 |
+
id: "f1",
|
| 59 |
+
},
|
| 60 |
+
],
|
| 61 |
+
models: [
|
| 62 |
+
{
|
| 63 |
+
description: "A strong image classification model.",
|
| 64 |
+
id: "google/vit-base-patch16-224",
|
| 65 |
+
},
|
| 66 |
+
{
|
| 67 |
+
description: "A robust image classification model.",
|
| 68 |
+
id: "facebook/deit-base-distilled-patch16-224",
|
| 69 |
+
},
|
| 70 |
+
{
|
| 71 |
+
description: "A strong image classification model.",
|
| 72 |
+
id: "facebook/convnext-large-224",
|
| 73 |
+
},
|
| 74 |
+
],
|
| 75 |
+
spaces: [
|
| 76 |
+
{
|
| 77 |
+
// TO DO: write description
|
| 78 |
+
description: "An application that classifies what a given image is about.",
|
| 79 |
+
id: "nielsr/perceiver-image-classification",
|
| 80 |
+
},
|
| 81 |
+
],
|
| 82 |
+
summary:
|
| 83 |
+
"Image classification is the task of assigning a label or class to an entire image. Images are expected to have only one class for each image. Image classification models take an image as input and return a prediction about which class the image belongs to.",
|
| 84 |
+
widgetModels: ["google/vit-base-patch16-224"],
|
| 85 |
+
youtubeId: "tjAIM7BOYhw",
|
| 86 |
+
};
|
| 87 |
+
|
| 88 |
+
export default taskData;
|
packages/tasks/src/image-segmentation/about.md
ADDED
|
@@ -0,0 +1,63 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
## Use Cases
|
| 2 |
+
|
| 3 |
+
### Autonomous Driving
|
| 4 |
+
|
| 5 |
+
Segmentation models are used to identify road patterns such as lanes and obstacles for safer driving.
|
| 6 |
+
|
| 7 |
+
### Background Removal
|
| 8 |
+
|
| 9 |
+
Image Segmentation models are used in cameras to erase the background of certain objects and apply filters to them.
|
| 10 |
+
|
| 11 |
+
### Medical Imaging
|
| 12 |
+
|
| 13 |
+
Image Segmentation models are used to distinguish organs or tissues, improving medical imaging workflows. Models are used to segment dental instances, analyze X-Ray scans or even segment cells for pathological diagnosis. This [dataset](https://github.com/v7labs/covid-19-xray-dataset) contains images of lungs of healthy patients and patients with COVID-19 segmented with masks. Another [segmentation dataset](https://ivdm3seg.weebly.com/data.html) contains segmented MRI data of the lower spine to analyze the effect of spaceflight simulation.
|
| 14 |
+
|
| 15 |
+
## Task Variants
|
| 16 |
+
|
| 17 |
+
### Semantic Segmentation
|
| 18 |
+
|
| 19 |
+
Semantic Segmentation is the task of segmenting parts of an image that belong to the same class. Semantic Segmentation models make predictions for each pixel and return the probabilities of the classes for each pixel. These models are evaluated on Mean Intersection Over Union (Mean IoU).
|
| 20 |
+
|
| 21 |
+
### Instance Segmentation
|
| 22 |
+
|
| 23 |
+
Instance Segmentation is the variant of Image Segmentation where every distinct object is segmented, instead of one segment per class.
|
| 24 |
+
|
| 25 |
+
### Panoptic Segmentation
|
| 26 |
+
|
| 27 |
+
Panoptic Segmentation is the Image Segmentation task that segments the image both by instance and by class, assigning each pixel a different instance of the class.
|
| 28 |
+
|
| 29 |
+
## Inference
|
| 30 |
+
|
| 31 |
+
You can infer with Image Segmentation models using the `image-segmentation` pipeline. You need to install [timm](https://github.com/rwightman/pytorch-image-models) first.
|
| 32 |
+
|
| 33 |
+
```python
|
| 34 |
+
!pip install timm
|
| 35 |
+
model = pipeline("image-segmentation")
|
| 36 |
+
model("cat.png")
|
| 37 |
+
#[{'label': 'cat',
|
| 38 |
+
# 'mask': mask_code,
|
| 39 |
+
# 'score': 0.999}
|
| 40 |
+
# ...]
|
| 41 |
+
```
|
| 42 |
+
|
| 43 |
+
You can use [huggingface.js](https://github.com/huggingface/huggingface.js) to infer image segmentation models on Hugging Face Hub.
|
| 44 |
+
|
| 45 |
+
```javascript
|
| 46 |
+
import { HfInference } from "@huggingface/inference";
|
| 47 |
+
|
| 48 |
+
const inference = new HfInference(HF_ACCESS_TOKEN);
|
| 49 |
+
await inference.imageSegmentation({
|
| 50 |
+
data: await (await fetch("https://picsum.photos/300/300")).blob(),
|
| 51 |
+
model: "facebook/detr-resnet-50-panoptic",
|
| 52 |
+
});
|
| 53 |
+
```
|
| 54 |
+
|
| 55 |
+
## Useful Resources
|
| 56 |
+
|
| 57 |
+
Would you like to learn more about image segmentation? Great! Here you can find some curated resources that you may find helpful!
|
| 58 |
+
|
| 59 |
+
- [Fine-Tune a Semantic Segmentation Model with a Custom Dataset](https://huggingface.co/blog/fine-tune-segformer)
|
| 60 |
+
- [Walkthrough of Computer Vision Ecosystem in Hugging Face - CV Study Group](https://www.youtube.com/watch?v=oL-xmufhZM8)
|
| 61 |
+
- [A Guide on Universal Image Segmentation with Mask2Former and OneFormer](https://huggingface.co/blog/mask2former)
|
| 62 |
+
- [Zero-shot image segmentation with CLIPSeg](https://huggingface.co/blog/clipseg-zero-shot)
|
| 63 |
+
- [Semantic segmentation task guide](https://huggingface.co/docs/transformers/tasks/semantic_segmentation)
|
packages/tasks/src/image-segmentation/data.ts
ADDED
|
@@ -0,0 +1,99 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import type { TaskDataCustom } from "../Types";
|
| 2 |
+
|
| 3 |
+
const taskData: TaskDataCustom = {
|
| 4 |
+
datasets: [
|
| 5 |
+
{
|
| 6 |
+
description: "Scene segmentation dataset.",
|
| 7 |
+
id: "scene_parse_150",
|
| 8 |
+
},
|
| 9 |
+
],
|
| 10 |
+
demo: {
|
| 11 |
+
inputs: [
|
| 12 |
+
{
|
| 13 |
+
filename: "image-segmentation-input.jpeg",
|
| 14 |
+
type: "img",
|
| 15 |
+
},
|
| 16 |
+
],
|
| 17 |
+
outputs: [
|
| 18 |
+
{
|
| 19 |
+
filename: "image-segmentation-output.png",
|
| 20 |
+
type: "img",
|
| 21 |
+
},
|
| 22 |
+
],
|
| 23 |
+
},
|
| 24 |
+
metrics: [
|
| 25 |
+
{
|
| 26 |
+
description:
|
| 27 |
+
"Average Precision (AP) is the Area Under the PR Curve (AUC-PR). It is calculated for each semantic class separately",
|
| 28 |
+
id: "Average Precision",
|
| 29 |
+
},
|
| 30 |
+
{
|
| 31 |
+
description: "Mean Average Precision (mAP) is the overall average of the AP values",
|
| 32 |
+
id: "Mean Average Precision",
|
| 33 |
+
},
|
| 34 |
+
{
|
| 35 |
+
description:
|
| 36 |
+
"Intersection over Union (IoU) is the overlap of segmentation masks. Mean IoU is the average of the IoU of all semantic classes",
|
| 37 |
+
id: "Mean Intersection over Union",
|
| 38 |
+
},
|
| 39 |
+
{
|
| 40 |
+
description: "APα is the Average Precision at the IoU threshold of a α value, for example, AP50 and AP75",
|
| 41 |
+
id: "APα",
|
| 42 |
+
},
|
| 43 |
+
],
|
| 44 |
+
models: [
|
| 45 |
+
{
|
| 46 |
+
// TO DO: write description
|
| 47 |
+
description: "Solid panoptic segmentation model trained on the COCO 2017 benchmark dataset.",
|
| 48 |
+
id: "facebook/detr-resnet-50-panoptic",
|
| 49 |
+
},
|
| 50 |
+
{
|
| 51 |
+
description: "Semantic segmentation model trained on ADE20k benchmark dataset.",
|
| 52 |
+
id: "microsoft/beit-large-finetuned-ade-640-640",
|
| 53 |
+
},
|
| 54 |
+
{
|
| 55 |
+
description: "Semantic segmentation model trained on ADE20k benchmark dataset with 512x512 resolution.",
|
| 56 |
+
id: "nvidia/segformer-b0-finetuned-ade-512-512",
|
| 57 |
+
},
|
| 58 |
+
{
|
| 59 |
+
description: "Semantic segmentation model trained Cityscapes dataset.",
|
| 60 |
+
id: "facebook/mask2former-swin-large-cityscapes-semantic",
|
| 61 |
+
},
|
| 62 |
+
{
|
| 63 |
+
description: "Panoptic segmentation model trained COCO (common objects) dataset.",
|
| 64 |
+
id: "facebook/mask2former-swin-large-coco-panoptic",
|
| 65 |
+
},
|
| 66 |
+
],
|
| 67 |
+
spaces: [
|
| 68 |
+
{
|
| 69 |
+
description: "A semantic segmentation application that can predict unseen instances out of the box.",
|
| 70 |
+
id: "facebook/ov-seg",
|
| 71 |
+
},
|
| 72 |
+
{
|
| 73 |
+
description: "One of the strongest segmentation applications.",
|
| 74 |
+
id: "jbrinkma/segment-anything",
|
| 75 |
+
},
|
| 76 |
+
{
|
| 77 |
+
description: "A semantic segmentation application that predicts human silhouettes.",
|
| 78 |
+
id: "keras-io/Human-Part-Segmentation",
|
| 79 |
+
},
|
| 80 |
+
{
|
| 81 |
+
description: "An instance segmentation application to predict neuronal cell types from microscopy images.",
|
| 82 |
+
id: "rashmi/sartorius-cell-instance-segmentation",
|
| 83 |
+
},
|
| 84 |
+
{
|
| 85 |
+
description: "An application that segments videos.",
|
| 86 |
+
id: "ArtGAN/Segment-Anything-Video",
|
| 87 |
+
},
|
| 88 |
+
{
|
| 89 |
+
description: "An panoptic segmentation application built for outdoor environments.",
|
| 90 |
+
id: "segments/panoptic-segment-anything",
|
| 91 |
+
},
|
| 92 |
+
],
|
| 93 |
+
summary:
|
| 94 |
+
"Image Segmentation divides an image into segments where each pixel in the image is mapped to an object. This task has multiple variants such as instance segmentation, panoptic segmentation and semantic segmentation.",
|
| 95 |
+
widgetModels: ["facebook/detr-resnet-50-panoptic"],
|
| 96 |
+
youtubeId: "dKE8SIt9C-w",
|
| 97 |
+
};
|
| 98 |
+
|
| 99 |
+
export default taskData;
|
packages/tasks/src/image-to-image/about.md
ADDED
|
@@ -0,0 +1,79 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
## Use Cases
|
| 2 |
+
|
| 3 |
+
### Style transfer
|
| 4 |
+
|
| 5 |
+
One of the most popular use cases of image to image is the style transfer. Style transfer models can convert a regular photography into a painting in the style of a famous painter.
|
| 6 |
+
|
| 7 |
+
## Task Variants
|
| 8 |
+
|
| 9 |
+
### Image inpainting
|
| 10 |
+
|
| 11 |
+
Image inpainting is widely used during photography editing to remove unwanted objects, such as poles, wires or sensor
|
| 12 |
+
dust.
|
| 13 |
+
|
| 14 |
+
### Image colorization
|
| 15 |
+
|
| 16 |
+
Old, black and white images can be brought up to life using an image colorization model.
|
| 17 |
+
|
| 18 |
+
### Super Resolution
|
| 19 |
+
|
| 20 |
+
Super resolution models increase the resolution of an image, allowing for higher quality viewing and printing.
|
| 21 |
+
|
| 22 |
+
## Inference
|
| 23 |
+
|
| 24 |
+
You can use pipelines for image-to-image in 🧨diffusers library to easily use image-to-image models. See an example for `StableDiffusionImg2ImgPipeline` below.
|
| 25 |
+
|
| 26 |
+
```python
|
| 27 |
+
from PIL import Image
|
| 28 |
+
from diffusers import StableDiffusionImg2ImgPipeline
|
| 29 |
+
|
| 30 |
+
model_id_or_path = "runwayml/stable-diffusion-v1-5"
|
| 31 |
+
pipe = StableDiffusionImg2ImgPipeline.from_pretrained(model_id_or_path, torch_dtype=torch.float16)
|
| 32 |
+
pipe = pipe.to(cuda)
|
| 33 |
+
|
| 34 |
+
init_image = Image.open("mountains_image.jpeg").convert("RGB").resize((768, 512))
|
| 35 |
+
prompt = "A fantasy landscape, trending on artstation"
|
| 36 |
+
|
| 37 |
+
images = pipe(prompt=prompt, image=init_image, strength=0.75, guidance_scale=7.5).images
|
| 38 |
+
images[0].save("fantasy_landscape.png")
|
| 39 |
+
```
|
| 40 |
+
|
| 41 |
+
You can use [huggingface.js](https://github.com/huggingface/huggingface.js) to infer image-to-image models on Hugging Face Hub.
|
| 42 |
+
|
| 43 |
+
```javascript
|
| 44 |
+
import { HfInference } from "@huggingface/inference";
|
| 45 |
+
|
| 46 |
+
const inference = new HfInference(HF_ACCESS_TOKEN);
|
| 47 |
+
await inference.imageToImage({
|
| 48 |
+
data: await (await fetch("image")).blob(),
|
| 49 |
+
model: "timbrooks/instruct-pix2pix",
|
| 50 |
+
parameters: {
|
| 51 |
+
prompt: "Deblur this image",
|
| 52 |
+
},
|
| 53 |
+
});
|
| 54 |
+
```
|
| 55 |
+
|
| 56 |
+
## ControlNet
|
| 57 |
+
|
| 58 |
+
Controlling outputs of diffusion models only with a text prompt is a challenging problem. ControlNet is a neural network type that provides an image based control to diffusion models. These controls can be edges or landmarks in an image.
|
| 59 |
+
|
| 60 |
+
Many ControlNet models were trained in our community event, JAX Diffusers sprint. You can see the full list of the ControlNet models available [here](https://huggingface.co/spaces/jax-diffusers-event/leaderboard).
|
| 61 |
+
|
| 62 |
+
## Most Used Model for the Task
|
| 63 |
+
|
| 64 |
+
Pix2Pix is a popular model used for image to image translation tasks. It is based on a conditional-GAN (generative adversarial network) where instead of a noise vector a 2D image is given as input. More information about Pix2Pix can be retrieved from this [link](https://phillipi.github.io/pix2pix/) where the associated paper and the GitHub repository can be found.
|
| 65 |
+
|
| 66 |
+
Below images show some of the examples shared in the paper that can be obtained using Pix2Pix. There are various cases this model can be applied on. It is capable of relatively simpler things, e.g. converting a grayscale image to its colored version. But more importantly, it can generate realistic pictures from rough sketches (can be seen in the purse example) or from painting-like images (can be seen in the street and facade examples below).
|
| 67 |
+
|
| 68 |
+
|
| 69 |
+
|
| 70 |
+
## Useful Resources
|
| 71 |
+
|
| 72 |
+
- [Train your ControlNet with diffusers 🧨](https://huggingface.co/blog/train-your-controlnet)
|
| 73 |
+
- [Ultra fast ControlNet with 🧨 Diffusers](https://huggingface.co/blog/controlnet)
|
| 74 |
+
|
| 75 |
+
## References
|
| 76 |
+
|
| 77 |
+
[1] P. Isola, J. -Y. Zhu, T. Zhou and A. A. Efros, "Image-to-Image Translation with Conditional Adversarial Networks," 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2017, pp. 5967-5976, doi: 10.1109/CVPR.2017.632.
|
| 78 |
+
|
| 79 |
+
This page was made possible thanks to the efforts of [Paul Gafton](https://github.com/Paul92) and [Osman Alenbey](https://huggingface.co/osman93).
|
packages/tasks/src/image-to-image/data.ts
ADDED
|
@@ -0,0 +1,101 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import type { TaskDataCustom } from "../Types";
|
| 2 |
+
|
| 3 |
+
const taskData: TaskDataCustom = {
|
| 4 |
+
datasets: [
|
| 5 |
+
{
|
| 6 |
+
description: "Synthetic dataset, for image relighting",
|
| 7 |
+
id: "VIDIT",
|
| 8 |
+
},
|
| 9 |
+
{
|
| 10 |
+
description: "Multiple images of celebrities, used for facial expression translation",
|
| 11 |
+
id: "huggan/CelebA-faces",
|
| 12 |
+
},
|
| 13 |
+
],
|
| 14 |
+
demo: {
|
| 15 |
+
inputs: [
|
| 16 |
+
{
|
| 17 |
+
filename: "image-to-image-input.jpeg",
|
| 18 |
+
type: "img",
|
| 19 |
+
},
|
| 20 |
+
],
|
| 21 |
+
outputs: [
|
| 22 |
+
{
|
| 23 |
+
filename: "image-to-image-output.png",
|
| 24 |
+
type: "img",
|
| 25 |
+
},
|
| 26 |
+
],
|
| 27 |
+
},
|
| 28 |
+
isPlaceholder: false,
|
| 29 |
+
metrics: [
|
| 30 |
+
{
|
| 31 |
+
description:
|
| 32 |
+
"Peak Signal to Noise Ratio (PSNR) is an approximation of the human perception, considering the ratio of the absolute intensity with respect to the variations. Measured in dB, a high value indicates a high fidelity.",
|
| 33 |
+
id: "PSNR",
|
| 34 |
+
},
|
| 35 |
+
{
|
| 36 |
+
description:
|
| 37 |
+
"Structural Similarity Index (SSIM) is a perceptual metric which compares the luminance, contrast and structure of two images. The values of SSIM range between -1 and 1, and higher values indicate closer resemblance to the original image.",
|
| 38 |
+
id: "SSIM",
|
| 39 |
+
},
|
| 40 |
+
{
|
| 41 |
+
description:
|
| 42 |
+
"Inception Score (IS) is an analysis of the labels predicted by an image classification model when presented with a sample of the generated images.",
|
| 43 |
+
id: "IS",
|
| 44 |
+
},
|
| 45 |
+
],
|
| 46 |
+
models: [
|
| 47 |
+
{
|
| 48 |
+
description: "A model that enhances images captured in low light conditions.",
|
| 49 |
+
id: "keras-io/low-light-image-enhancement",
|
| 50 |
+
},
|
| 51 |
+
{
|
| 52 |
+
description: "A model that increases the resolution of an image.",
|
| 53 |
+
id: "keras-io/super-resolution",
|
| 54 |
+
},
|
| 55 |
+
{
|
| 56 |
+
description:
|
| 57 |
+
"A model that creates a set of variations of the input image in the style of DALL-E using Stable Diffusion.",
|
| 58 |
+
id: "lambdalabs/sd-image-variations-diffusers",
|
| 59 |
+
},
|
| 60 |
+
{
|
| 61 |
+
description: "A model that generates images based on segments in the input image and the text prompt.",
|
| 62 |
+
id: "mfidabel/controlnet-segment-anything",
|
| 63 |
+
},
|
| 64 |
+
{
|
| 65 |
+
description: "A model that takes an image and an instruction to edit the image.",
|
| 66 |
+
id: "timbrooks/instruct-pix2pix",
|
| 67 |
+
},
|
| 68 |
+
],
|
| 69 |
+
spaces: [
|
| 70 |
+
{
|
| 71 |
+
description: "Image enhancer application for low light.",
|
| 72 |
+
id: "keras-io/low-light-image-enhancement",
|
| 73 |
+
},
|
| 74 |
+
{
|
| 75 |
+
description: "Style transfer application.",
|
| 76 |
+
id: "keras-io/neural-style-transfer",
|
| 77 |
+
},
|
| 78 |
+
{
|
| 79 |
+
description: "An application that generates images based on segment control.",
|
| 80 |
+
id: "mfidabel/controlnet-segment-anything",
|
| 81 |
+
},
|
| 82 |
+
{
|
| 83 |
+
description: "Image generation application that takes image control and text prompt.",
|
| 84 |
+
id: "hysts/ControlNet",
|
| 85 |
+
},
|
| 86 |
+
{
|
| 87 |
+
description: "Colorize any image using this app.",
|
| 88 |
+
id: "ioclab/brightness-controlnet",
|
| 89 |
+
},
|
| 90 |
+
{
|
| 91 |
+
description: "Edit images with instructions.",
|
| 92 |
+
id: "timbrooks/instruct-pix2pix",
|
| 93 |
+
},
|
| 94 |
+
],
|
| 95 |
+
summary:
|
| 96 |
+
"Image-to-image is the task of transforming a source image to match the characteristics of a target image or a target image domain. Any image manipulation and enhancement is possible with image to image models.",
|
| 97 |
+
widgetModels: ["lllyasviel/sd-controlnet-canny"],
|
| 98 |
+
youtubeId: "",
|
| 99 |
+
};
|
| 100 |
+
|
| 101 |
+
export default taskData;
|
packages/tasks/src/image-to-text/about.md
ADDED
|
@@ -0,0 +1,65 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
## Use Cases
|
| 2 |
+
|
| 3 |
+
### Image Captioning
|
| 4 |
+
|
| 5 |
+
Image Captioning is the process of generating textual description of an image.
|
| 6 |
+
This can help the visually impaired people to understand what's happening in their surroundings.
|
| 7 |
+
|
| 8 |
+
### Optical Character Recognition (OCR)
|
| 9 |
+
|
| 10 |
+
OCR models convert the text present in an image, e.g. a scanned document, to text.
|
| 11 |
+
|
| 12 |
+
## Pix2Struct
|
| 13 |
+
|
| 14 |
+
Pix2Struct is a state-of-the-art model built and released by Google AI. The model itself has to be trained on a downstream task to be used. These tasks include, captioning UI components, images including text, visual questioning infographics, charts, scientific diagrams and more. You can find these models on recommended models of this page.
|
| 15 |
+
|
| 16 |
+
## Inference
|
| 17 |
+
|
| 18 |
+
### Image Captioning
|
| 19 |
+
|
| 20 |
+
You can use the 🤗 Transformers library's `image-to-text` pipeline to generate caption for the Image input.
|
| 21 |
+
|
| 22 |
+
```python
|
| 23 |
+
from transformers import pipeline
|
| 24 |
+
|
| 25 |
+
captioner = pipeline("image-to-text",model="Salesforce/blip-image-captioning-base")
|
| 26 |
+
captioner("https://huggingface.co/datasets/Narsil/image_dummy/resolve/main/parrots.png")
|
| 27 |
+
## [{'generated_text': 'two birds are standing next to each other '}]
|
| 28 |
+
```
|
| 29 |
+
|
| 30 |
+
### OCR
|
| 31 |
+
|
| 32 |
+
This code snippet uses Microsoft’s TrOCR, an encoder-decoder model consisting of an image Transformer encoder and a text Transformer decoder for state-of-the-art optical character recognition (OCR) on single-text line images.
|
| 33 |
+
|
| 34 |
+
```python
|
| 35 |
+
from transformers import TrOCRProcessor, VisionEncoderDecoderModel
|
| 36 |
+
|
| 37 |
+
processor = TrOCRProcessor.from_pretrained('microsoft/trocr-base-handwritten')
|
| 38 |
+
model = VisionEncoderDecoderModel.from_pretrained('microsoft/trocr-base-handwritten')
|
| 39 |
+
pixel_values = processor(images="image.jpeg", return_tensors="pt").pixel_values
|
| 40 |
+
|
| 41 |
+
generated_ids = model.generate(pixel_values)
|
| 42 |
+
generated_text = processor.batch_decode(generated_ids, skip_special_tokens=True)[0]
|
| 43 |
+
|
| 44 |
+
```
|
| 45 |
+
|
| 46 |
+
You can use [huggingface.js](https://github.com/huggingface/huggingface.js) to infer image-to-text models on Hugging Face Hub.
|
| 47 |
+
|
| 48 |
+
```javascript
|
| 49 |
+
import { HfInference } from "@huggingface/inference";
|
| 50 |
+
|
| 51 |
+
const inference = new HfInference(HF_ACCESS_TOKEN);
|
| 52 |
+
await inference.imageToText({
|
| 53 |
+
data: await (await fetch("https://picsum.photos/300/300")).blob(),
|
| 54 |
+
model: "Salesforce/blip-image-captioning-base",
|
| 55 |
+
});
|
| 56 |
+
```
|
| 57 |
+
|
| 58 |
+
## Useful Resources
|
| 59 |
+
|
| 60 |
+
- [Image Captioning](https://huggingface.co/docs/transformers/main/en/tasks/image_captioning)
|
| 61 |
+
- [Image captioning use case](https://blog.google/outreach-initiatives/accessibility/get-image-descriptions/)
|
| 62 |
+
- [Train Image Captioning model on your dataset](https://github.com/NielsRogge/Transformers-Tutorials/blob/master/GIT/Fine_tune_GIT_on_an_image_captioning_dataset.ipynb)
|
| 63 |
+
- [Train OCR model on your dataset ](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/TrOCR)
|
| 64 |
+
|
| 65 |
+
This page was made possible thanks to efforts of [Sukesh Perla](https://huggingface.co/hitchhiker3010) and [Johannes Kolbe](https://huggingface.co/johko).
|
packages/tasks/src/image-to-text/data.ts
ADDED
|
@@ -0,0 +1,86 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import type { TaskDataCustom } from "../Types";
|
| 2 |
+
|
| 3 |
+
const taskData: TaskDataCustom = {
|
| 4 |
+
datasets: [
|
| 5 |
+
{
|
| 6 |
+
// TODO write proper description
|
| 7 |
+
description: "Dataset from 12M image-text of Reddit",
|
| 8 |
+
id: "red_caps",
|
| 9 |
+
},
|
| 10 |
+
{
|
| 11 |
+
// TODO write proper description
|
| 12 |
+
description: "Dataset from 3.3M images of Google",
|
| 13 |
+
id: "datasets/conceptual_captions",
|
| 14 |
+
},
|
| 15 |
+
],
|
| 16 |
+
demo: {
|
| 17 |
+
inputs: [
|
| 18 |
+
{
|
| 19 |
+
filename: "savanna.jpg",
|
| 20 |
+
type: "img",
|
| 21 |
+
},
|
| 22 |
+
],
|
| 23 |
+
outputs: [
|
| 24 |
+
{
|
| 25 |
+
label: "Detailed description",
|
| 26 |
+
content: "a herd of giraffes and zebras grazing in a field",
|
| 27 |
+
type: "text",
|
| 28 |
+
},
|
| 29 |
+
],
|
| 30 |
+
},
|
| 31 |
+
metrics: [],
|
| 32 |
+
models: [
|
| 33 |
+
{
|
| 34 |
+
description: "A robust image captioning model.",
|
| 35 |
+
id: "Salesforce/blip-image-captioning-large",
|
| 36 |
+
},
|
| 37 |
+
{
|
| 38 |
+
description: "A strong image captioning model.",
|
| 39 |
+
id: "nlpconnect/vit-gpt2-image-captioning",
|
| 40 |
+
},
|
| 41 |
+
{
|
| 42 |
+
description: "A strong optical character recognition model.",
|
| 43 |
+
id: "microsoft/trocr-base-printed",
|
| 44 |
+
},
|
| 45 |
+
{
|
| 46 |
+
description: "A strong visual question answering model for scientific diagrams.",
|
| 47 |
+
id: "google/pix2struct-ai2d-base",
|
| 48 |
+
},
|
| 49 |
+
{
|
| 50 |
+
description: "A strong captioning model for UI components.",
|
| 51 |
+
id: "google/pix2struct-widget-captioning-base",
|
| 52 |
+
},
|
| 53 |
+
{
|
| 54 |
+
description: "A captioning model for images that contain text.",
|
| 55 |
+
id: "google/pix2struct-textcaps-base",
|
| 56 |
+
},
|
| 57 |
+
],
|
| 58 |
+
spaces: [
|
| 59 |
+
{
|
| 60 |
+
description: "A robust image captioning application.",
|
| 61 |
+
id: "flax-community/image-captioning",
|
| 62 |
+
},
|
| 63 |
+
{
|
| 64 |
+
description: "An application that transcribes handwritings into text.",
|
| 65 |
+
id: "nielsr/TrOCR-handwritten",
|
| 66 |
+
},
|
| 67 |
+
{
|
| 68 |
+
description: "An application that can caption images and answer questions about a given image.",
|
| 69 |
+
id: "Salesforce/BLIP",
|
| 70 |
+
},
|
| 71 |
+
{
|
| 72 |
+
description: "An application that can caption images and answer questions with a conversational agent.",
|
| 73 |
+
id: "Salesforce/BLIP2",
|
| 74 |
+
},
|
| 75 |
+
{
|
| 76 |
+
description: "An image captioning application that demonstrates the effect of noise on captions.",
|
| 77 |
+
id: "johko/capdec-image-captioning",
|
| 78 |
+
},
|
| 79 |
+
],
|
| 80 |
+
summary:
|
| 81 |
+
"Image to text models output a text from a given image. Image captioning or optical character recognition can be considered as the most common applications of image to text.",
|
| 82 |
+
widgetModels: ["Salesforce/blip-image-captioning-base"],
|
| 83 |
+
youtubeId: "",
|
| 84 |
+
};
|
| 85 |
+
|
| 86 |
+
export default taskData;
|
packages/tasks/src/index.ts
ADDED
|
@@ -0,0 +1,13 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
export type { TaskData, TaskDemo, TaskDemoEntry, ExampleRepo } from "./Types";
|
| 2 |
+
export { TASKS_DATA } from "./tasksData";
|
| 3 |
+
export {
|
| 4 |
+
PIPELINE_DATA,
|
| 5 |
+
PIPELINE_TYPES,
|
| 6 |
+
type PipelineType,
|
| 7 |
+
type PipelineData,
|
| 8 |
+
type Modality,
|
| 9 |
+
MODALITIES,
|
| 10 |
+
MODALITY_LABELS,
|
| 11 |
+
} from "./pipelines";
|
| 12 |
+
export { ModelLibrary } from "./modelLibraries";
|
| 13 |
+
export type { ModelLibraryKey } from "./modelLibraries";
|
packages/tasks/src/modelLibraries.ts
ADDED
|
@@ -0,0 +1,43 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
/**
|
| 2 |
+
* Add your new library here.
|
| 3 |
+
*
|
| 4 |
+
* This is for modeling (= architectures) libraries, not for file formats (like ONNX, etc).
|
| 5 |
+
* File formats live in an enum inside the internal codebase.
|
| 6 |
+
*/
|
| 7 |
+
export enum ModelLibrary {
|
| 8 |
+
"adapter-transformers" = "Adapter Transformers",
|
| 9 |
+
"allennlp" = "allenNLP",
|
| 10 |
+
"asteroid" = "Asteroid",
|
| 11 |
+
"bertopic" = "BERTopic",
|
| 12 |
+
"diffusers" = "Diffusers",
|
| 13 |
+
"doctr" = "docTR",
|
| 14 |
+
"espnet" = "ESPnet",
|
| 15 |
+
"fairseq" = "Fairseq",
|
| 16 |
+
"flair" = "Flair",
|
| 17 |
+
"keras" = "Keras",
|
| 18 |
+
"k2" = "K2",
|
| 19 |
+
"nemo" = "NeMo",
|
| 20 |
+
"open_clip" = "OpenCLIP",
|
| 21 |
+
"paddlenlp" = "PaddleNLP",
|
| 22 |
+
"peft" = "PEFT",
|
| 23 |
+
"pyannote-audio" = "pyannote.audio",
|
| 24 |
+
"sample-factory" = "Sample Factory",
|
| 25 |
+
"sentence-transformers" = "Sentence Transformers",
|
| 26 |
+
"sklearn" = "Scikit-learn",
|
| 27 |
+
"spacy" = "spaCy",
|
| 28 |
+
"span-marker" = "SpanMarker",
|
| 29 |
+
"speechbrain" = "speechbrain",
|
| 30 |
+
"tensorflowtts" = "TensorFlowTTS",
|
| 31 |
+
"timm" = "Timm",
|
| 32 |
+
"fastai" = "fastai",
|
| 33 |
+
"transformers" = "Transformers",
|
| 34 |
+
"transformers.js" = "Transformers.js",
|
| 35 |
+
"stanza" = "Stanza",
|
| 36 |
+
"fasttext" = "fastText",
|
| 37 |
+
"stable-baselines3" = "Stable-Baselines3",
|
| 38 |
+
"ml-agents" = "ML-Agents",
|
| 39 |
+
"pythae" = "Pythae",
|
| 40 |
+
"mindspore" = "MindSpore",
|
| 41 |
+
}
|
| 42 |
+
|
| 43 |
+
export type ModelLibraryKey = keyof typeof ModelLibrary;
|
packages/tasks/src/object-detection/about.md
ADDED
|
@@ -0,0 +1,37 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
## Use Cases
|
| 2 |
+
|
| 3 |
+
### Autonomous Driving
|
| 4 |
+
|
| 5 |
+
Object Detection is widely used in computer vision for autonomous driving. Self-driving cars use Object Detection models to detect pedestrians, bicycles, traffic lights and road signs to decide which step to take.
|
| 6 |
+
|
| 7 |
+
### Object Tracking in Matches
|
| 8 |
+
|
| 9 |
+
Object Detection models are widely used in sports where the ball or a player is tracked for monitoring and refereeing during matches.
|
| 10 |
+
|
| 11 |
+
### Image Search
|
| 12 |
+
|
| 13 |
+
Object Detection models are widely used in image search. Smartphones use Object Detection models to detect entities (such as specific places or objects) and allow the user to search for the entity on the Internet.
|
| 14 |
+
|
| 15 |
+
### Object Counting
|
| 16 |
+
|
| 17 |
+
Object Detection models are used to count instances of objects in a given image, this can include counting the objects in warehouses or stores, or counting the number of visitors in a store. They are also used to manage crowds at events to prevent disasters.
|
| 18 |
+
|
| 19 |
+
## Inference
|
| 20 |
+
|
| 21 |
+
You can infer with Object Detection models through the `object-detection` pipeline. When calling the pipeline you just need to specify a path or http link to an image.
|
| 22 |
+
|
| 23 |
+
```python
|
| 24 |
+
model = pipeline("object-detection")
|
| 25 |
+
|
| 26 |
+
model("path_to_cat_image")
|
| 27 |
+
|
| 28 |
+
# [{'label': 'blanket',
|
| 29 |
+
# 'mask': mask_string,
|
| 30 |
+
# 'score': 0.917},
|
| 31 |
+
#...]
|
| 32 |
+
```
|
| 33 |
+
|
| 34 |
+
# Useful Resources
|
| 35 |
+
|
| 36 |
+
- [Walkthrough of Computer Vision Ecosystem in Hugging Face - CV Study Group](https://www.youtube.com/watch?v=oL-xmufhZM8)
|
| 37 |
+
- [Object detection task guide](https://huggingface.co/docs/transformers/tasks/object_detection)
|
packages/tasks/src/object-detection/data.ts
ADDED
|
@@ -0,0 +1,76 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import type { TaskDataCustom } from "../Types";
|
| 2 |
+
|
| 3 |
+
const taskData: TaskDataCustom = {
|
| 4 |
+
datasets: [
|
| 5 |
+
{
|
| 6 |
+
// TODO write proper description
|
| 7 |
+
description: "Widely used benchmark dataset for multiple Vision tasks.",
|
| 8 |
+
id: "merve/coco2017",
|
| 9 |
+
},
|
| 10 |
+
],
|
| 11 |
+
demo: {
|
| 12 |
+
inputs: [
|
| 13 |
+
{
|
| 14 |
+
filename: "object-detection-input.jpg",
|
| 15 |
+
type: "img",
|
| 16 |
+
},
|
| 17 |
+
],
|
| 18 |
+
outputs: [
|
| 19 |
+
{
|
| 20 |
+
filename: "object-detection-output.jpg",
|
| 21 |
+
type: "img",
|
| 22 |
+
},
|
| 23 |
+
],
|
| 24 |
+
},
|
| 25 |
+
metrics: [
|
| 26 |
+
{
|
| 27 |
+
description:
|
| 28 |
+
"The Average Precision (AP) metric is the Area Under the PR Curve (AUC-PR). It is calculated for each class separately",
|
| 29 |
+
id: "Average Precision",
|
| 30 |
+
},
|
| 31 |
+
{
|
| 32 |
+
description: "The Mean Average Precision (mAP) metric is the overall average of the AP values",
|
| 33 |
+
id: "Mean Average Precision",
|
| 34 |
+
},
|
| 35 |
+
{
|
| 36 |
+
description:
|
| 37 |
+
"The APα metric is the Average Precision at the IoU threshold of a α value, for example, AP50 and AP75",
|
| 38 |
+
id: "APα",
|
| 39 |
+
},
|
| 40 |
+
],
|
| 41 |
+
models: [
|
| 42 |
+
{
|
| 43 |
+
// TO DO: write description
|
| 44 |
+
description: "Solid object detection model trained on the benchmark dataset COCO 2017.",
|
| 45 |
+
id: "facebook/detr-resnet-50",
|
| 46 |
+
},
|
| 47 |
+
{
|
| 48 |
+
description: "Strong object detection model trained on ImageNet-21k dataset.",
|
| 49 |
+
id: "microsoft/beit-base-patch16-224-pt22k-ft22k",
|
| 50 |
+
},
|
| 51 |
+
],
|
| 52 |
+
spaces: [
|
| 53 |
+
{
|
| 54 |
+
description: "An object detection application that can detect unseen objects out of the box.",
|
| 55 |
+
id: "adirik/OWL-ViT",
|
| 56 |
+
},
|
| 57 |
+
{
|
| 58 |
+
description: "An application that contains various object detection models to try from.",
|
| 59 |
+
id: "Gradio-Blocks/Object-Detection-With-DETR-and-YOLOS",
|
| 60 |
+
},
|
| 61 |
+
{
|
| 62 |
+
description: "An application that shows multiple cutting edge techniques for object detection and tracking.",
|
| 63 |
+
id: "kadirnar/torchyolo",
|
| 64 |
+
},
|
| 65 |
+
{
|
| 66 |
+
description: "An object tracking, segmentation and inpainting application.",
|
| 67 |
+
id: "VIPLab/Track-Anything",
|
| 68 |
+
},
|
| 69 |
+
],
|
| 70 |
+
summary:
|
| 71 |
+
"Object Detection models allow users to identify objects of certain defined classes. Object detection models receive an image as input and output the images with bounding boxes and labels on detected objects.",
|
| 72 |
+
widgetModels: ["facebook/detr-resnet-50"],
|
| 73 |
+
youtubeId: "WdAeKSOpxhw",
|
| 74 |
+
};
|
| 75 |
+
|
| 76 |
+
export default taskData;
|
packages/tasks/src/pipelines.ts
ADDED
|
@@ -0,0 +1,619 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
export const MODALITIES = ["cv", "nlp", "audio", "tabular", "multimodal", "rl", "other"] as const;
|
| 2 |
+
|
| 3 |
+
export type Modality = (typeof MODALITIES)[number];
|
| 4 |
+
|
| 5 |
+
export const MODALITY_LABELS = {
|
| 6 |
+
multimodal: "Multimodal",
|
| 7 |
+
nlp: "Natural Language Processing",
|
| 8 |
+
audio: "Audio",
|
| 9 |
+
cv: "Computer Vision",
|
| 10 |
+
rl: "Reinforcement Learning",
|
| 11 |
+
tabular: "Tabular",
|
| 12 |
+
other: "Other",
|
| 13 |
+
} satisfies Record<Modality, string>;
|
| 14 |
+
|
| 15 |
+
/**
|
| 16 |
+
* Public interface for a sub task.
|
| 17 |
+
*
|
| 18 |
+
* This can be used in a model card's `model-index` metadata.
|
| 19 |
+
* and is more granular classification that can grow significantly
|
| 20 |
+
* over time as new tasks are added.
|
| 21 |
+
*/
|
| 22 |
+
export interface SubTask {
|
| 23 |
+
/**
|
| 24 |
+
* type of the task (e.g. audio-source-separation)
|
| 25 |
+
*/
|
| 26 |
+
type: string;
|
| 27 |
+
/**
|
| 28 |
+
* displayed name of the task (e.g. Audio Source Separation)
|
| 29 |
+
*/
|
| 30 |
+
name: string;
|
| 31 |
+
}
|
| 32 |
+
|
| 33 |
+
/**
|
| 34 |
+
* Public interface for a PipelineData.
|
| 35 |
+
*
|
| 36 |
+
* This information corresponds to a pipeline type (aka task)
|
| 37 |
+
* in the Hub.
|
| 38 |
+
*/
|
| 39 |
+
export interface PipelineData {
|
| 40 |
+
/**
|
| 41 |
+
* displayed name of the task (e.g. Text Classification)
|
| 42 |
+
*/
|
| 43 |
+
name: string;
|
| 44 |
+
subtasks?: SubTask[];
|
| 45 |
+
modality: Modality;
|
| 46 |
+
/**
|
| 47 |
+
* color for the tag icon.
|
| 48 |
+
*/
|
| 49 |
+
color: "blue" | "green" | "indigo" | "orange" | "red" | "yellow";
|
| 50 |
+
/**
|
| 51 |
+
* whether to hide in /models filters
|
| 52 |
+
*/
|
| 53 |
+
hideInModels?: boolean;
|
| 54 |
+
/**
|
| 55 |
+
* whether to hide in /datasets filters
|
| 56 |
+
*/
|
| 57 |
+
hideInDatasets?: boolean;
|
| 58 |
+
}
|
| 59 |
+
|
| 60 |
+
/// Coarse-grained taxonomy of tasks
|
| 61 |
+
///
|
| 62 |
+
/// This type is used in multiple places in the Hugging Face
|
| 63 |
+
/// ecosystem:
|
| 64 |
+
/// - To determine which widget to show.
|
| 65 |
+
/// - To determine which endpoint of Inference API to use.
|
| 66 |
+
/// - As filters at the left of models and datasets page.
|
| 67 |
+
///
|
| 68 |
+
/// Note that this is sensitive to order.
|
| 69 |
+
/// For each domain, the order should be of decreasing specificity.
|
| 70 |
+
/// This will impact the default pipeline tag of a model when not
|
| 71 |
+
/// specified.
|
| 72 |
+
export const PIPELINE_DATA = {
|
| 73 |
+
"text-classification": {
|
| 74 |
+
name: "Text Classification",
|
| 75 |
+
subtasks: [
|
| 76 |
+
{
|
| 77 |
+
type: "acceptability-classification",
|
| 78 |
+
name: "Acceptability Classification",
|
| 79 |
+
},
|
| 80 |
+
{
|
| 81 |
+
type: "entity-linking-classification",
|
| 82 |
+
name: "Entity Linking Classification",
|
| 83 |
+
},
|
| 84 |
+
{
|
| 85 |
+
type: "fact-checking",
|
| 86 |
+
name: "Fact Checking",
|
| 87 |
+
},
|
| 88 |
+
{
|
| 89 |
+
type: "intent-classification",
|
| 90 |
+
name: "Intent Classification",
|
| 91 |
+
},
|
| 92 |
+
{
|
| 93 |
+
type: "language-identification",
|
| 94 |
+
name: "Language Identification",
|
| 95 |
+
},
|
| 96 |
+
{
|
| 97 |
+
type: "multi-class-classification",
|
| 98 |
+
name: "Multi Class Classification",
|
| 99 |
+
},
|
| 100 |
+
{
|
| 101 |
+
type: "multi-label-classification",
|
| 102 |
+
name: "Multi Label Classification",
|
| 103 |
+
},
|
| 104 |
+
{
|
| 105 |
+
type: "multi-input-text-classification",
|
| 106 |
+
name: "Multi-input Text Classification",
|
| 107 |
+
},
|
| 108 |
+
{
|
| 109 |
+
type: "natural-language-inference",
|
| 110 |
+
name: "Natural Language Inference",
|
| 111 |
+
},
|
| 112 |
+
{
|
| 113 |
+
type: "semantic-similarity-classification",
|
| 114 |
+
name: "Semantic Similarity Classification",
|
| 115 |
+
},
|
| 116 |
+
{
|
| 117 |
+
type: "sentiment-classification",
|
| 118 |
+
name: "Sentiment Classification",
|
| 119 |
+
},
|
| 120 |
+
{
|
| 121 |
+
type: "topic-classification",
|
| 122 |
+
name: "Topic Classification",
|
| 123 |
+
},
|
| 124 |
+
{
|
| 125 |
+
type: "semantic-similarity-scoring",
|
| 126 |
+
name: "Semantic Similarity Scoring",
|
| 127 |
+
},
|
| 128 |
+
{
|
| 129 |
+
type: "sentiment-scoring",
|
| 130 |
+
name: "Sentiment Scoring",
|
| 131 |
+
},
|
| 132 |
+
{
|
| 133 |
+
type: "sentiment-analysis",
|
| 134 |
+
name: "Sentiment Analysis",
|
| 135 |
+
},
|
| 136 |
+
{
|
| 137 |
+
type: "hate-speech-detection",
|
| 138 |
+
name: "Hate Speech Detection",
|
| 139 |
+
},
|
| 140 |
+
{
|
| 141 |
+
type: "text-scoring",
|
| 142 |
+
name: "Text Scoring",
|
| 143 |
+
},
|
| 144 |
+
],
|
| 145 |
+
modality: "nlp",
|
| 146 |
+
color: "orange",
|
| 147 |
+
},
|
| 148 |
+
"token-classification": {
|
| 149 |
+
name: "Token Classification",
|
| 150 |
+
subtasks: [
|
| 151 |
+
{
|
| 152 |
+
type: "named-entity-recognition",
|
| 153 |
+
name: "Named Entity Recognition",
|
| 154 |
+
},
|
| 155 |
+
{
|
| 156 |
+
type: "part-of-speech",
|
| 157 |
+
name: "Part of Speech",
|
| 158 |
+
},
|
| 159 |
+
{
|
| 160 |
+
type: "parsing",
|
| 161 |
+
name: "Parsing",
|
| 162 |
+
},
|
| 163 |
+
{
|
| 164 |
+
type: "lemmatization",
|
| 165 |
+
name: "Lemmatization",
|
| 166 |
+
},
|
| 167 |
+
{
|
| 168 |
+
type: "word-sense-disambiguation",
|
| 169 |
+
name: "Word Sense Disambiguation",
|
| 170 |
+
},
|
| 171 |
+
{
|
| 172 |
+
type: "coreference-resolution",
|
| 173 |
+
name: "Coreference-resolution",
|
| 174 |
+
},
|
| 175 |
+
],
|
| 176 |
+
modality: "nlp",
|
| 177 |
+
color: "blue",
|
| 178 |
+
},
|
| 179 |
+
"table-question-answering": {
|
| 180 |
+
name: "Table Question Answering",
|
| 181 |
+
modality: "nlp",
|
| 182 |
+
color: "green",
|
| 183 |
+
},
|
| 184 |
+
"question-answering": {
|
| 185 |
+
name: "Question Answering",
|
| 186 |
+
subtasks: [
|
| 187 |
+
{
|
| 188 |
+
type: "extractive-qa",
|
| 189 |
+
name: "Extractive QA",
|
| 190 |
+
},
|
| 191 |
+
{
|
| 192 |
+
type: "open-domain-qa",
|
| 193 |
+
name: "Open Domain QA",
|
| 194 |
+
},
|
| 195 |
+
{
|
| 196 |
+
type: "closed-domain-qa",
|
| 197 |
+
name: "Closed Domain QA",
|
| 198 |
+
},
|
| 199 |
+
],
|
| 200 |
+
modality: "nlp",
|
| 201 |
+
color: "blue",
|
| 202 |
+
},
|
| 203 |
+
"zero-shot-classification": {
|
| 204 |
+
name: "Zero-Shot Classification",
|
| 205 |
+
modality: "nlp",
|
| 206 |
+
color: "yellow",
|
| 207 |
+
},
|
| 208 |
+
translation: {
|
| 209 |
+
name: "Translation",
|
| 210 |
+
modality: "nlp",
|
| 211 |
+
color: "green",
|
| 212 |
+
},
|
| 213 |
+
summarization: {
|
| 214 |
+
name: "Summarization",
|
| 215 |
+
subtasks: [
|
| 216 |
+
{
|
| 217 |
+
type: "news-articles-summarization",
|
| 218 |
+
name: "News Articles Summarization",
|
| 219 |
+
},
|
| 220 |
+
{
|
| 221 |
+
type: "news-articles-headline-generation",
|
| 222 |
+
name: "News Articles Headline Generation",
|
| 223 |
+
},
|
| 224 |
+
],
|
| 225 |
+
modality: "nlp",
|
| 226 |
+
color: "indigo",
|
| 227 |
+
},
|
| 228 |
+
conversational: {
|
| 229 |
+
name: "Conversational",
|
| 230 |
+
subtasks: [
|
| 231 |
+
{
|
| 232 |
+
type: "dialogue-generation",
|
| 233 |
+
name: "Dialogue Generation",
|
| 234 |
+
},
|
| 235 |
+
],
|
| 236 |
+
modality: "nlp",
|
| 237 |
+
color: "green",
|
| 238 |
+
},
|
| 239 |
+
"feature-extraction": {
|
| 240 |
+
name: "Feature Extraction",
|
| 241 |
+
modality: "multimodal",
|
| 242 |
+
color: "red",
|
| 243 |
+
},
|
| 244 |
+
"text-generation": {
|
| 245 |
+
name: "Text Generation",
|
| 246 |
+
subtasks: [
|
| 247 |
+
{
|
| 248 |
+
type: "dialogue-modeling",
|
| 249 |
+
name: "Dialogue Modeling",
|
| 250 |
+
},
|
| 251 |
+
{
|
| 252 |
+
type: "language-modeling",
|
| 253 |
+
name: "Language Modeling",
|
| 254 |
+
},
|
| 255 |
+
],
|
| 256 |
+
modality: "nlp",
|
| 257 |
+
color: "indigo",
|
| 258 |
+
},
|
| 259 |
+
"text2text-generation": {
|
| 260 |
+
name: "Text2Text Generation",
|
| 261 |
+
subtasks: [
|
| 262 |
+
{
|
| 263 |
+
type: "text-simplification",
|
| 264 |
+
name: "Text simplification",
|
| 265 |
+
},
|
| 266 |
+
{
|
| 267 |
+
type: "explanation-generation",
|
| 268 |
+
name: "Explanation Generation",
|
| 269 |
+
},
|
| 270 |
+
{
|
| 271 |
+
type: "abstractive-qa",
|
| 272 |
+
name: "Abstractive QA",
|
| 273 |
+
},
|
| 274 |
+
{
|
| 275 |
+
type: "open-domain-abstractive-qa",
|
| 276 |
+
name: "Open Domain Abstractive QA",
|
| 277 |
+
},
|
| 278 |
+
{
|
| 279 |
+
type: "closed-domain-qa",
|
| 280 |
+
name: "Closed Domain QA",
|
| 281 |
+
},
|
| 282 |
+
{
|
| 283 |
+
type: "open-book-qa",
|
| 284 |
+
name: "Open Book QA",
|
| 285 |
+
},
|
| 286 |
+
{
|
| 287 |
+
type: "closed-book-qa",
|
| 288 |
+
name: "Closed Book QA",
|
| 289 |
+
},
|
| 290 |
+
],
|
| 291 |
+
modality: "nlp",
|
| 292 |
+
color: "indigo",
|
| 293 |
+
},
|
| 294 |
+
"fill-mask": {
|
| 295 |
+
name: "Fill-Mask",
|
| 296 |
+
subtasks: [
|
| 297 |
+
{
|
| 298 |
+
type: "slot-filling",
|
| 299 |
+
name: "Slot Filling",
|
| 300 |
+
},
|
| 301 |
+
{
|
| 302 |
+
type: "masked-language-modeling",
|
| 303 |
+
name: "Masked Language Modeling",
|
| 304 |
+
},
|
| 305 |
+
],
|
| 306 |
+
modality: "nlp",
|
| 307 |
+
color: "red",
|
| 308 |
+
},
|
| 309 |
+
"sentence-similarity": {
|
| 310 |
+
name: "Sentence Similarity",
|
| 311 |
+
modality: "nlp",
|
| 312 |
+
color: "yellow",
|
| 313 |
+
},
|
| 314 |
+
"text-to-speech": {
|
| 315 |
+
name: "Text-to-Speech",
|
| 316 |
+
modality: "audio",
|
| 317 |
+
color: "yellow",
|
| 318 |
+
},
|
| 319 |
+
"text-to-audio": {
|
| 320 |
+
name: "Text-to-Audio",
|
| 321 |
+
modality: "audio",
|
| 322 |
+
color: "yellow",
|
| 323 |
+
},
|
| 324 |
+
"automatic-speech-recognition": {
|
| 325 |
+
name: "Automatic Speech Recognition",
|
| 326 |
+
modality: "audio",
|
| 327 |
+
color: "yellow",
|
| 328 |
+
},
|
| 329 |
+
"audio-to-audio": {
|
| 330 |
+
name: "Audio-to-Audio",
|
| 331 |
+
modality: "audio",
|
| 332 |
+
color: "blue",
|
| 333 |
+
},
|
| 334 |
+
"audio-classification": {
|
| 335 |
+
name: "Audio Classification",
|
| 336 |
+
subtasks: [
|
| 337 |
+
{
|
| 338 |
+
type: "keyword-spotting",
|
| 339 |
+
name: "Keyword Spotting",
|
| 340 |
+
},
|
| 341 |
+
{
|
| 342 |
+
type: "speaker-identification",
|
| 343 |
+
name: "Speaker Identification",
|
| 344 |
+
},
|
| 345 |
+
{
|
| 346 |
+
type: "audio-intent-classification",
|
| 347 |
+
name: "Audio Intent Classification",
|
| 348 |
+
},
|
| 349 |
+
{
|
| 350 |
+
type: "audio-emotion-recognition",
|
| 351 |
+
name: "Audio Emotion Recognition",
|
| 352 |
+
},
|
| 353 |
+
{
|
| 354 |
+
type: "audio-language-identification",
|
| 355 |
+
name: "Audio Language Identification",
|
| 356 |
+
},
|
| 357 |
+
],
|
| 358 |
+
modality: "audio",
|
| 359 |
+
color: "green",
|
| 360 |
+
},
|
| 361 |
+
"voice-activity-detection": {
|
| 362 |
+
name: "Voice Activity Detection",
|
| 363 |
+
modality: "audio",
|
| 364 |
+
color: "red",
|
| 365 |
+
},
|
| 366 |
+
"depth-estimation": {
|
| 367 |
+
name: "Depth Estimation",
|
| 368 |
+
modality: "cv",
|
| 369 |
+
color: "yellow",
|
| 370 |
+
},
|
| 371 |
+
"image-classification": {
|
| 372 |
+
name: "Image Classification",
|
| 373 |
+
subtasks: [
|
| 374 |
+
{
|
| 375 |
+
type: "multi-label-image-classification",
|
| 376 |
+
name: "Multi Label Image Classification",
|
| 377 |
+
},
|
| 378 |
+
{
|
| 379 |
+
type: "multi-class-image-classification",
|
| 380 |
+
name: "Multi Class Image Classification",
|
| 381 |
+
},
|
| 382 |
+
],
|
| 383 |
+
modality: "cv",
|
| 384 |
+
color: "blue",
|
| 385 |
+
},
|
| 386 |
+
"object-detection": {
|
| 387 |
+
name: "Object Detection",
|
| 388 |
+
subtasks: [
|
| 389 |
+
{
|
| 390 |
+
type: "face-detection",
|
| 391 |
+
name: "Face Detection",
|
| 392 |
+
},
|
| 393 |
+
{
|
| 394 |
+
type: "vehicle-detection",
|
| 395 |
+
name: "Vehicle Detection",
|
| 396 |
+
},
|
| 397 |
+
],
|
| 398 |
+
modality: "cv",
|
| 399 |
+
color: "yellow",
|
| 400 |
+
},
|
| 401 |
+
"image-segmentation": {
|
| 402 |
+
name: "Image Segmentation",
|
| 403 |
+
subtasks: [
|
| 404 |
+
{
|
| 405 |
+
type: "instance-segmentation",
|
| 406 |
+
name: "Instance Segmentation",
|
| 407 |
+
},
|
| 408 |
+
{
|
| 409 |
+
type: "semantic-segmentation",
|
| 410 |
+
name: "Semantic Segmentation",
|
| 411 |
+
},
|
| 412 |
+
{
|
| 413 |
+
type: "panoptic-segmentation",
|
| 414 |
+
name: "Panoptic Segmentation",
|
| 415 |
+
},
|
| 416 |
+
],
|
| 417 |
+
modality: "cv",
|
| 418 |
+
color: "green",
|
| 419 |
+
},
|
| 420 |
+
"text-to-image": {
|
| 421 |
+
name: "Text-to-Image",
|
| 422 |
+
modality: "multimodal",
|
| 423 |
+
color: "yellow",
|
| 424 |
+
},
|
| 425 |
+
"image-to-text": {
|
| 426 |
+
name: "Image-to-Text",
|
| 427 |
+
subtasks: [
|
| 428 |
+
{
|
| 429 |
+
type: "image-captioning",
|
| 430 |
+
name: "Image Captioning",
|
| 431 |
+
},
|
| 432 |
+
],
|
| 433 |
+
modality: "multimodal",
|
| 434 |
+
color: "red",
|
| 435 |
+
},
|
| 436 |
+
"image-to-image": {
|
| 437 |
+
name: "Image-to-Image",
|
| 438 |
+
modality: "cv",
|
| 439 |
+
color: "indigo",
|
| 440 |
+
},
|
| 441 |
+
"unconditional-image-generation": {
|
| 442 |
+
name: "Unconditional Image Generation",
|
| 443 |
+
modality: "cv",
|
| 444 |
+
color: "green",
|
| 445 |
+
},
|
| 446 |
+
"video-classification": {
|
| 447 |
+
name: "Video Classification",
|
| 448 |
+
modality: "cv",
|
| 449 |
+
color: "blue",
|
| 450 |
+
},
|
| 451 |
+
"reinforcement-learning": {
|
| 452 |
+
name: "Reinforcement Learning",
|
| 453 |
+
modality: "rl",
|
| 454 |
+
color: "red",
|
| 455 |
+
},
|
| 456 |
+
robotics: {
|
| 457 |
+
name: "Robotics",
|
| 458 |
+
modality: "rl",
|
| 459 |
+
subtasks: [
|
| 460 |
+
{
|
| 461 |
+
type: "grasping",
|
| 462 |
+
name: "Grasping",
|
| 463 |
+
},
|
| 464 |
+
{
|
| 465 |
+
type: "task-planning",
|
| 466 |
+
name: "Task Planning",
|
| 467 |
+
},
|
| 468 |
+
],
|
| 469 |
+
color: "blue",
|
| 470 |
+
},
|
| 471 |
+
"tabular-classification": {
|
| 472 |
+
name: "Tabular Classification",
|
| 473 |
+
modality: "tabular",
|
| 474 |
+
subtasks: [
|
| 475 |
+
{
|
| 476 |
+
type: "tabular-multi-class-classification",
|
| 477 |
+
name: "Tabular Multi Class Classification",
|
| 478 |
+
},
|
| 479 |
+
{
|
| 480 |
+
type: "tabular-multi-label-classification",
|
| 481 |
+
name: "Tabular Multi Label Classification",
|
| 482 |
+
},
|
| 483 |
+
],
|
| 484 |
+
color: "blue",
|
| 485 |
+
},
|
| 486 |
+
"tabular-regression": {
|
| 487 |
+
name: "Tabular Regression",
|
| 488 |
+
modality: "tabular",
|
| 489 |
+
subtasks: [
|
| 490 |
+
{
|
| 491 |
+
type: "tabular-single-column-regression",
|
| 492 |
+
name: "Tabular Single Column Regression",
|
| 493 |
+
},
|
| 494 |
+
],
|
| 495 |
+
color: "blue",
|
| 496 |
+
},
|
| 497 |
+
"tabular-to-text": {
|
| 498 |
+
name: "Tabular to Text",
|
| 499 |
+
modality: "tabular",
|
| 500 |
+
subtasks: [
|
| 501 |
+
{
|
| 502 |
+
type: "rdf-to-text",
|
| 503 |
+
name: "RDF to text",
|
| 504 |
+
},
|
| 505 |
+
],
|
| 506 |
+
color: "blue",
|
| 507 |
+
hideInModels: true,
|
| 508 |
+
},
|
| 509 |
+
"table-to-text": {
|
| 510 |
+
name: "Table to Text",
|
| 511 |
+
modality: "nlp",
|
| 512 |
+
color: "blue",
|
| 513 |
+
hideInModels: true,
|
| 514 |
+
},
|
| 515 |
+
"multiple-choice": {
|
| 516 |
+
name: "Multiple Choice",
|
| 517 |
+
subtasks: [
|
| 518 |
+
{
|
| 519 |
+
type: "multiple-choice-qa",
|
| 520 |
+
name: "Multiple Choice QA",
|
| 521 |
+
},
|
| 522 |
+
{
|
| 523 |
+
type: "multiple-choice-coreference-resolution",
|
| 524 |
+
name: "Multiple Choice Coreference Resolution",
|
| 525 |
+
},
|
| 526 |
+
],
|
| 527 |
+
modality: "nlp",
|
| 528 |
+
color: "blue",
|
| 529 |
+
hideInModels: true,
|
| 530 |
+
},
|
| 531 |
+
"text-retrieval": {
|
| 532 |
+
name: "Text Retrieval",
|
| 533 |
+
subtasks: [
|
| 534 |
+
{
|
| 535 |
+
type: "document-retrieval",
|
| 536 |
+
name: "Document Retrieval",
|
| 537 |
+
},
|
| 538 |
+
{
|
| 539 |
+
type: "utterance-retrieval",
|
| 540 |
+
name: "Utterance Retrieval",
|
| 541 |
+
},
|
| 542 |
+
{
|
| 543 |
+
type: "entity-linking-retrieval",
|
| 544 |
+
name: "Entity Linking Retrieval",
|
| 545 |
+
},
|
| 546 |
+
{
|
| 547 |
+
type: "fact-checking-retrieval",
|
| 548 |
+
name: "Fact Checking Retrieval",
|
| 549 |
+
},
|
| 550 |
+
],
|
| 551 |
+
modality: "nlp",
|
| 552 |
+
color: "indigo",
|
| 553 |
+
hideInModels: true,
|
| 554 |
+
},
|
| 555 |
+
"time-series-forecasting": {
|
| 556 |
+
name: "Time Series Forecasting",
|
| 557 |
+
modality: "tabular",
|
| 558 |
+
subtasks: [
|
| 559 |
+
{
|
| 560 |
+
type: "univariate-time-series-forecasting",
|
| 561 |
+
name: "Univariate Time Series Forecasting",
|
| 562 |
+
},
|
| 563 |
+
{
|
| 564 |
+
type: "multivariate-time-series-forecasting",
|
| 565 |
+
name: "Multivariate Time Series Forecasting",
|
| 566 |
+
},
|
| 567 |
+
],
|
| 568 |
+
color: "blue",
|
| 569 |
+
hideInModels: true,
|
| 570 |
+
},
|
| 571 |
+
"text-to-video": {
|
| 572 |
+
name: "Text-to-Video",
|
| 573 |
+
modality: "multimodal",
|
| 574 |
+
color: "green",
|
| 575 |
+
},
|
| 576 |
+
"visual-question-answering": {
|
| 577 |
+
name: "Visual Question Answering",
|
| 578 |
+
subtasks: [
|
| 579 |
+
{
|
| 580 |
+
type: "visual-question-answering",
|
| 581 |
+
name: "Visual Question Answering",
|
| 582 |
+
},
|
| 583 |
+
],
|
| 584 |
+
modality: "multimodal",
|
| 585 |
+
color: "red",
|
| 586 |
+
},
|
| 587 |
+
"document-question-answering": {
|
| 588 |
+
name: "Document Question Answering",
|
| 589 |
+
subtasks: [
|
| 590 |
+
{
|
| 591 |
+
type: "document-question-answering",
|
| 592 |
+
name: "Document Question Answering",
|
| 593 |
+
},
|
| 594 |
+
],
|
| 595 |
+
modality: "multimodal",
|
| 596 |
+
color: "blue",
|
| 597 |
+
hideInDatasets: true,
|
| 598 |
+
},
|
| 599 |
+
"zero-shot-image-classification": {
|
| 600 |
+
name: "Zero-Shot Image Classification",
|
| 601 |
+
modality: "cv",
|
| 602 |
+
color: "yellow",
|
| 603 |
+
},
|
| 604 |
+
"graph-ml": {
|
| 605 |
+
name: "Graph Machine Learning",
|
| 606 |
+
modality: "multimodal",
|
| 607 |
+
color: "green",
|
| 608 |
+
},
|
| 609 |
+
other: {
|
| 610 |
+
name: "Other",
|
| 611 |
+
modality: "other",
|
| 612 |
+
color: "blue",
|
| 613 |
+
hideInModels: true,
|
| 614 |
+
hideInDatasets: true,
|
| 615 |
+
},
|
| 616 |
+
} satisfies Record<string, PipelineData>;
|
| 617 |
+
|
| 618 |
+
export type PipelineType = keyof typeof PIPELINE_DATA;
|
| 619 |
+
export const PIPELINE_TYPES = Object.keys(PIPELINE_DATA) as PipelineType[];
|
packages/tasks/src/placeholder/about.md
ADDED
|
@@ -0,0 +1,15 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
## Use Cases
|
| 2 |
+
|
| 3 |
+
You can contribute this area with common use cases of the task!
|
| 4 |
+
|
| 5 |
+
## Task Variants
|
| 6 |
+
|
| 7 |
+
This place can be filled with variants of this task if there's any.
|
| 8 |
+
|
| 9 |
+
## Inference
|
| 10 |
+
|
| 11 |
+
This section should have useful information about how to pull a model from Hugging Face Hub that is a part of a library specialized in a task and use it.
|
| 12 |
+
|
| 13 |
+
## Useful Resources
|
| 14 |
+
|
| 15 |
+
In this area, you can insert useful resources about how to train or use a model for this task.
|
packages/tasks/src/placeholder/data.ts
ADDED
|
@@ -0,0 +1,18 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import type { TaskDataCustom } from "../Types";
|
| 2 |
+
|
| 3 |
+
const taskData: TaskDataCustom = {
|
| 4 |
+
datasets: [],
|
| 5 |
+
demo: {
|
| 6 |
+
inputs: [],
|
| 7 |
+
outputs: [],
|
| 8 |
+
},
|
| 9 |
+
isPlaceholder: true,
|
| 10 |
+
metrics: [],
|
| 11 |
+
models: [],
|
| 12 |
+
spaces: [],
|
| 13 |
+
summary: "",
|
| 14 |
+
widgetModels: [],
|
| 15 |
+
youtubeId: undefined,
|
| 16 |
+
};
|
| 17 |
+
|
| 18 |
+
export default taskData;
|
packages/tasks/src/question-answering/about.md
ADDED
|
@@ -0,0 +1,56 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
## Use Cases
|
| 2 |
+
|
| 3 |
+
### Frequently Asked Questions
|
| 4 |
+
|
| 5 |
+
You can use Question Answering (QA) models to automate the response to frequently asked questions by using a knowledge base (documents) as context. Answers to customer questions can be drawn from those documents.
|
| 6 |
+
|
| 7 |
+
⚡⚡ If you’d like to save inference time, you can first use [passage ranking models](/tasks/sentence-similarity) to see which document might contain the answer to the question and iterate over that document with the QA model instead.
|
| 8 |
+
|
| 9 |
+
## Task Variants
|
| 10 |
+
There are different QA variants based on the inputs and outputs:
|
| 11 |
+
|
| 12 |
+
- **Extractive QA:** The model **extracts** the answer from a context. The context here could be a provided text, a table or even HTML! This is usually solved with BERT-like models.
|
| 13 |
+
- **Open Generative QA:** The model **generates** free text directly based on the context. You can learn more about the Text Generation task in [its page](/tasks/text-generation).
|
| 14 |
+
- **Closed Generative QA:** In this case, no context is provided. The answer is completely generated by a model.
|
| 15 |
+
|
| 16 |
+
The schema above illustrates extractive, open book QA. The model takes a context and the question and extracts the answer from the given context.
|
| 17 |
+
|
| 18 |
+
You can also differentiate QA models depending on whether they are open-domain or closed-domain. Open-domain models are not restricted to a specific domain, while closed-domain models are restricted to a specific domain (e.g. legal, medical documents).
|
| 19 |
+
|
| 20 |
+
## Inference
|
| 21 |
+
|
| 22 |
+
You can infer with QA models with the 🤗 Transformers library using the `question-answering` pipeline. If no model checkpoint is given, the pipeline will be initialized with `distilbert-base-cased-distilled-squad`. This pipeline takes a question and a context from which the answer will be extracted and returned.
|
| 23 |
+
|
| 24 |
+
```python
|
| 25 |
+
from transformers import pipeline
|
| 26 |
+
|
| 27 |
+
qa_model = pipeline("question-answering")
|
| 28 |
+
question = "Where do I live?"
|
| 29 |
+
context = "My name is Merve and I live in İstanbul."
|
| 30 |
+
qa_model(question = question, context = context)
|
| 31 |
+
## {'answer': 'İstanbul', 'end': 39, 'score': 0.953, 'start': 31}
|
| 32 |
+
```
|
| 33 |
+
|
| 34 |
+
## Useful Resources
|
| 35 |
+
|
| 36 |
+
Would you like to learn more about QA? Awesome! Here are some curated resources that you may find helpful!
|
| 37 |
+
|
| 38 |
+
- [Course Chapter on Question Answering](https://huggingface.co/course/chapter7/7?fw=pt)
|
| 39 |
+
- [Question Answering Workshop](https://www.youtube.com/watch?v=Ihgk8kGLpIE&ab_channel=HuggingFace)
|
| 40 |
+
- [How to Build an Open-Domain Question Answering System?](https://lilianweng.github.io/lil-log/2020/10/29/open-domain-question-answering.html)
|
| 41 |
+
- [Blog Post: ELI5 A Model for Open Domain Long Form Question Answering](https://yjernite.github.io/lfqa.html)
|
| 42 |
+
|
| 43 |
+
### Notebooks
|
| 44 |
+
|
| 45 |
+
- [PyTorch](https://github.com/huggingface/notebooks/blob/master/examples/question_answering.ipynb)
|
| 46 |
+
- [TensorFlow](https://github.com/huggingface/notebooks/blob/main/examples/question_answering-tf.ipynb)
|
| 47 |
+
|
| 48 |
+
### Scripts for training
|
| 49 |
+
|
| 50 |
+
- [PyTorch](https://github.com/huggingface/transformers/tree/main/examples/pytorch/question-answering)
|
| 51 |
+
- [TensorFlow](https://github.com/huggingface/transformers/tree/main/examples/tensorflow/question-answering)
|
| 52 |
+
- [Flax](https://github.com/huggingface/transformers/tree/main/examples/flax/question-answering)
|
| 53 |
+
|
| 54 |
+
### Documentation
|
| 55 |
+
|
| 56 |
+
- [Question answering task guide](https://huggingface.co/docs/transformers/tasks/question_answering)
|
packages/tasks/src/question-answering/data.ts
ADDED
|
@@ -0,0 +1,71 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import type { TaskDataCustom } from "../Types";
|
| 2 |
+
|
| 3 |
+
const taskData: TaskDataCustom = {
|
| 4 |
+
datasets: [
|
| 5 |
+
{
|
| 6 |
+
// TODO write proper description
|
| 7 |
+
description: "A famous question answering dataset based on English articles from Wikipedia.",
|
| 8 |
+
id: "squad_v2",
|
| 9 |
+
},
|
| 10 |
+
{
|
| 11 |
+
// TODO write proper description
|
| 12 |
+
description: "A dataset of aggregated anonymized actual queries issued to the Google search engine.",
|
| 13 |
+
id: "natural_questions",
|
| 14 |
+
},
|
| 15 |
+
],
|
| 16 |
+
demo: {
|
| 17 |
+
inputs: [
|
| 18 |
+
{
|
| 19 |
+
label: "Question",
|
| 20 |
+
content: "Which name is also used to describe the Amazon rainforest in English?",
|
| 21 |
+
type: "text",
|
| 22 |
+
},
|
| 23 |
+
{
|
| 24 |
+
label: "Context",
|
| 25 |
+
content: "The Amazon rainforest, also known in English as Amazonia or the Amazon Jungle",
|
| 26 |
+
type: "text",
|
| 27 |
+
},
|
| 28 |
+
],
|
| 29 |
+
outputs: [
|
| 30 |
+
{
|
| 31 |
+
label: "Answer",
|
| 32 |
+
content: "Amazonia",
|
| 33 |
+
type: "text",
|
| 34 |
+
},
|
| 35 |
+
],
|
| 36 |
+
},
|
| 37 |
+
metrics: [
|
| 38 |
+
{
|
| 39 |
+
description:
|
| 40 |
+
"Exact Match is a metric based on the strict character match of the predicted answer and the right answer. For answers predicted correctly, the Exact Match will be 1. Even if only one character is different, Exact Match will be 0",
|
| 41 |
+
id: "exact-match",
|
| 42 |
+
},
|
| 43 |
+
{
|
| 44 |
+
description:
|
| 45 |
+
" The F1-Score metric is useful if we value both false positives and false negatives equally. The F1-Score is calculated on each word in the predicted sequence against the correct answer",
|
| 46 |
+
id: "f1",
|
| 47 |
+
},
|
| 48 |
+
],
|
| 49 |
+
models: [
|
| 50 |
+
{
|
| 51 |
+
description: "A robust baseline model for most question answering domains.",
|
| 52 |
+
id: "deepset/roberta-base-squad2",
|
| 53 |
+
},
|
| 54 |
+
{
|
| 55 |
+
description: "A special model that can answer questions from tables!",
|
| 56 |
+
id: "google/tapas-base-finetuned-wtq",
|
| 57 |
+
},
|
| 58 |
+
],
|
| 59 |
+
spaces: [
|
| 60 |
+
{
|
| 61 |
+
description: "An application that can answer a long question from Wikipedia.",
|
| 62 |
+
id: "deepset/wikipedia-assistant",
|
| 63 |
+
},
|
| 64 |
+
],
|
| 65 |
+
summary:
|
| 66 |
+
"Question Answering models can retrieve the answer to a question from a given text, which is useful for searching for an answer in a document. Some question answering models can generate answers without context!",
|
| 67 |
+
widgetModels: ["deepset/roberta-base-squad2"],
|
| 68 |
+
youtubeId: "ajPx5LwJD-I",
|
| 69 |
+
};
|
| 70 |
+
|
| 71 |
+
export default taskData;
|
packages/tasks/src/reinforcement-learning/about.md
ADDED
|
@@ -0,0 +1,167 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
## Use Cases
|
| 2 |
+
|
| 3 |
+
### Gaming
|
| 4 |
+
|
| 5 |
+
Reinforcement learning is known for its application to video games. Since the games provide a safe environment for the agent to be trained in the sense that it is perfectly defined and controllable, this makes them perfect candidates for experimentation and will help a lot to learn about the capabilities and limitations of various RL algorithms.
|
| 6 |
+
|
| 7 |
+
There are many videos on the Internet where a game-playing reinforcement learning agent starts with a terrible gaming strategy due to random initialization of its settings, but over iterations, the agent gets better and better with each episode of the training. This [paper](https://arxiv.org/abs/1912.10944) mainly investigates the performance of RL in popular games such as Minecraft or Dota2. The agent's performance can exceed a human player's, although there are still some challenges mainly related to efficiency in constructing the gaming policy of the reinforcement learning agent.
|
| 8 |
+
|
| 9 |
+
### Trading and Finance
|
| 10 |
+
|
| 11 |
+
Reinforcement learning is the science to train computers to make decisions and thus has a novel use in trading and finance. All time-series models are helpful in predicting prices, volume and future sales of a product or a stock. Reinforcement based automated agents can decide to sell, buy or hold a stock. It shifts the impact of AI in this field to real time decision making rather than just prediction of prices. The glossary given below will clear some parameters to as to how we can train a model to take these decisions.
|
| 12 |
+
|
| 13 |
+
## Task Variants
|
| 14 |
+
|
| 15 |
+
### Model Based RL
|
| 16 |
+
|
| 17 |
+
In model based reinforcement learning techniques intend to create a model of the environment, learn the state transition probabilities and the reward function, to find the optimal action. Some typical examples for model based reinforcement learning algorithms are dynamic programming, value iteration and policy iteration.
|
| 18 |
+
|
| 19 |
+
### Model Free RL
|
| 20 |
+
|
| 21 |
+
In model free reinforcement learning, agent decides on optimal actions based on its experience in the environment and the reward it collects from it. This is one of the most commonly used algorithms beneficial in complex environments, where modeling of state transition probabilities and reward functions are difficult. Some of the examples of model free reinforcement learning are SARSA, Q-Learning, actor-critic and proximal policy optimization (PPO) algorithms.
|
| 22 |
+
|
| 23 |
+
## Glossary
|
| 24 |
+
|
| 25 |
+
<!--  TODO: Uncomment image for visual understanding if it fits within the page-->
|
| 26 |
+
|
| 27 |
+
**Agent:** The learner and the decision maker.
|
| 28 |
+
|
| 29 |
+
**Environment:** The part of the world the agent interacts, comprising everything outside the agent.
|
| 30 |
+
|
| 31 |
+
Observations and states are the information our agent gets from the environment. In the case of a video game, it can be a frame (a screenshot). In the case of the trading agent, it can be the value of a certain stock.
|
| 32 |
+
|
| 33 |
+
**State:** Complete description of the state of the environment with no hidden information.
|
| 34 |
+
|
| 35 |
+
**Observation:** Partial description of the state, in a partially observed environment.
|
| 36 |
+
|
| 37 |
+
**Action:** The decision taken by the agent.
|
| 38 |
+
|
| 39 |
+
**Reward:** The numerical feedback signal that the agent receives from the environment based on the chosen action.
|
| 40 |
+
|
| 41 |
+
**Return:** Cumulative Reward. In the simplest case, the return is the sum of the rewards.
|
| 42 |
+
|
| 43 |
+
**Episode:** For some applications there is a natural notion of final time step. In this case, there is a starting point and an ending point (a terminal state). This creates an episode: a list of States, Actions, Rewards, and new States. For instance, think about Chess: an episode begins at the initial board position and ends when the game is over.
|
| 44 |
+
|
| 45 |
+
**Policy:** The Policy is the brain of the Agent, it’s the function that tells what action to take given the state. So it defines the agent’s behavior at a given time. Reinforcement learning methods specify how the agent’s policy is changed as a result of its experience.
|
| 46 |
+
|
| 47 |
+
## Inference
|
| 48 |
+
|
| 49 |
+
Inference in reinforcement learning differs from other modalities, in which there's a model and test data. In reinforcement learning, once you have trained an agent in an environment, you try to run the trained agent for additional steps to get the average reward.
|
| 50 |
+
|
| 51 |
+
A typical training cycle consists of gathering experience from the environment, training the agent, and running the agent on a test environment to obtain average reward. Below there's a snippet on how you can interact with the environment using the `gymnasium` library, train an agent using `stable-baselines3`, evalute the agent on test environment and infer actions from the trained agent.
|
| 52 |
+
|
| 53 |
+
```python
|
| 54 |
+
# Here we are running 20 episodes of CartPole-v1 environment, taking random actions
|
| 55 |
+
import gymnasium as gym
|
| 56 |
+
|
| 57 |
+
env = gym.make("CartPole-v1")
|
| 58 |
+
observation, info = env.reset()
|
| 59 |
+
|
| 60 |
+
for _ in range(20):
|
| 61 |
+
action = env.action_space.sample() # samples random action from action sample space
|
| 62 |
+
|
| 63 |
+
# the agent takes the action
|
| 64 |
+
observation, reward, terminated, truncated, info = env.step(action)
|
| 65 |
+
|
| 66 |
+
|
| 67 |
+
# if the agent reaches terminal state, we reset the environment
|
| 68 |
+
if terminated or truncated:
|
| 69 |
+
|
| 70 |
+
print("Environment is reset")
|
| 71 |
+
observation = env.reset()
|
| 72 |
+
|
| 73 |
+
env.close()
|
| 74 |
+
```
|
| 75 |
+
|
| 76 |
+
Below snippet shows how to train a PPO model on LunarLander-v2 environment using `stable-baselines3` library and saving the model
|
| 77 |
+
|
| 78 |
+
```python
|
| 79 |
+
from stable_baselines3 import PPO
|
| 80 |
+
|
| 81 |
+
# initialize the environment
|
| 82 |
+
|
| 83 |
+
env = gym.make("LunarLander-v2")
|
| 84 |
+
|
| 85 |
+
# initialize the model
|
| 86 |
+
|
| 87 |
+
model = PPO(policy = "MlpPolicy",
|
| 88 |
+
env = env,
|
| 89 |
+
n_steps = 1024,
|
| 90 |
+
batch_size = 64,
|
| 91 |
+
n_epochs = 4,
|
| 92 |
+
verbose = 1)
|
| 93 |
+
|
| 94 |
+
# train the model for 1000 time steps
|
| 95 |
+
model.learn(total_timesteps = 1000)
|
| 96 |
+
|
| 97 |
+
# Saving the model in desired directory
|
| 98 |
+
model_name = "PPO-LunarLander-v2"
|
| 99 |
+
model.save(model_name)
|
| 100 |
+
```
|
| 101 |
+
|
| 102 |
+
Below code shows how to evaluate an agent trained using `stable-baselines3`
|
| 103 |
+
|
| 104 |
+
```python
|
| 105 |
+
# Loading a saved model and evaluating the model for 10 episodes
|
| 106 |
+
from stable_baselines3.common.evaluation import evaluate_policy
|
| 107 |
+
from stable_baselines3 import PPO
|
| 108 |
+
|
| 109 |
+
|
| 110 |
+
env = gym.make("LunarLander-v2")
|
| 111 |
+
# Loading the saved model
|
| 112 |
+
model = PPO.load("PPO-LunarLander-v2",env=env)
|
| 113 |
+
|
| 114 |
+
# Initializating the evaluation environment
|
| 115 |
+
eval_env = gym.make("LunarLander-v2")
|
| 116 |
+
|
| 117 |
+
# Running the trained agent on eval_env for 10 time steps and getting the mean reward
|
| 118 |
+
mean_reward, std_reward = evaluate_policy(model, eval_env, n_eval_episodes = 10,
|
| 119 |
+
deterministic=True)
|
| 120 |
+
|
| 121 |
+
print(f"mean_reward={mean_reward:.2f} +/- {std_reward}")
|
| 122 |
+
```
|
| 123 |
+
|
| 124 |
+
Below code snippet shows how to infer actions from an agent trained using `stable-baselines3`
|
| 125 |
+
|
| 126 |
+
```python
|
| 127 |
+
from stable_baselines3.common.evaluation import evaluate_policy
|
| 128 |
+
from stable_baselines3 import PPO
|
| 129 |
+
|
| 130 |
+
# Loading the saved model
|
| 131 |
+
model = PPO.load("PPO-LunarLander-v2",env=env)
|
| 132 |
+
|
| 133 |
+
# Getting the environment from the trained agent
|
| 134 |
+
env = model.get_env()
|
| 135 |
+
|
| 136 |
+
obs = env.reset()
|
| 137 |
+
for i in range(1000):
|
| 138 |
+
# getting action predictions from the trained agent
|
| 139 |
+
action, _states = model.predict(obs, deterministic=True)
|
| 140 |
+
|
| 141 |
+
# taking the predicted action in the environment to observe next state and rewards
|
| 142 |
+
obs, rewards, dones, info = env.step(action)
|
| 143 |
+
```
|
| 144 |
+
|
| 145 |
+
For more information, you can check out the documentations of the respective libraries.
|
| 146 |
+
|
| 147 |
+
[Gymnasium Documentation](https://gymnasium.farama.org/)
|
| 148 |
+
[Stable Baselines Documentation](https://stable-baselines3.readthedocs.io/en/master/)
|
| 149 |
+
|
| 150 |
+
## Useful Resources
|
| 151 |
+
|
| 152 |
+
Would you like to learn more about the topic? Awesome! Here you can find some curated resources that you may find helpful!
|
| 153 |
+
|
| 154 |
+
- [HuggingFace Deep Reinforcement Learning Class](https://github.com/huggingface/deep-rl-class)
|
| 155 |
+
- [Introduction to Deep Reinforcement Learning](https://huggingface.co/blog/deep-rl-intro)
|
| 156 |
+
- [Stable Baselines Integration with HuggingFace](https://huggingface.co/blog/sb3)
|
| 157 |
+
- Learn how reinforcement learning is used in conversational agents in this blog: [Illustrating Reinforcement Learning from Human Feedback (RLHF)](https://huggingface.co/blog/rlhf)
|
| 158 |
+
- [Reinforcement Learning from Human Feedback From Zero to ChatGPT](https://www.youtube.com/watch?v=EAd4oQtEJOM)
|
| 159 |
+
- [Guide on Multi-Agent Competition Systems](https://huggingface.co/blog/aivsai)
|
| 160 |
+
|
| 161 |
+
### Notebooks
|
| 162 |
+
|
| 163 |
+
- [Train a Deep Reinforcement Learning lander agent to land correctly on the Moon 🌕 using Stable-Baselines3](https://github.com/huggingface/deep-rl-class/blob/main/notebooks/unit1/unit1.ipynb)
|
| 164 |
+
- [Introduction to Unity MLAgents](https://github.com/huggingface/deep-rl-class/blob/main/notebooks/unit5/unit5.ipynb)
|
| 165 |
+
- [Training Decision Transformers with 🤗 transformers](https://github.com/huggingface/blog/blob/main/notebooks/101_train-decision-transformers.ipynb)
|
| 166 |
+
|
| 167 |
+
This page was made possible thanks to the efforts of [Ram Ananth](https://huggingface.co/RamAnanth1), [Emilio Lehoucq](https://huggingface.co/emiliol), [Sagar Mathpal](https://huggingface.co/sagarmathpal) and [Osman Alenbey](https://huggingface.co/osman93).
|
packages/tasks/src/reinforcement-learning/data.ts
ADDED
|
@@ -0,0 +1,75 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import type { TaskDataCustom } from "../Types";
|
| 2 |
+
|
| 3 |
+
const taskData: TaskDataCustom = {
|
| 4 |
+
datasets: [
|
| 5 |
+
{
|
| 6 |
+
description: "A curation of widely used datasets for Data Driven Deep Reinforcement Learning (D4RL)",
|
| 7 |
+
id: "edbeeching/decision_transformer_gym_replay",
|
| 8 |
+
},
|
| 9 |
+
],
|
| 10 |
+
demo: {
|
| 11 |
+
inputs: [
|
| 12 |
+
{
|
| 13 |
+
label: "State",
|
| 14 |
+
content: "Red traffic light, pedestrians are about to pass.",
|
| 15 |
+
type: "text",
|
| 16 |
+
},
|
| 17 |
+
],
|
| 18 |
+
outputs: [
|
| 19 |
+
{
|
| 20 |
+
label: "Action",
|
| 21 |
+
content: "Stop the car.",
|
| 22 |
+
type: "text",
|
| 23 |
+
},
|
| 24 |
+
{
|
| 25 |
+
label: "Next State",
|
| 26 |
+
content: "Yellow light, pedestrians have crossed.",
|
| 27 |
+
type: "text",
|
| 28 |
+
},
|
| 29 |
+
],
|
| 30 |
+
},
|
| 31 |
+
metrics: [
|
| 32 |
+
{
|
| 33 |
+
description:
|
| 34 |
+
"Accumulated reward across all time steps discounted by a factor that ranges between 0 and 1 and determines how much the agent optimizes for future relative to immediate rewards. Measures how good is the policy ultimately found by a given algorithm considering uncertainty over the future.",
|
| 35 |
+
id: "Discounted Total Reward",
|
| 36 |
+
},
|
| 37 |
+
{
|
| 38 |
+
description:
|
| 39 |
+
"Average return obtained after running the policy for a certain number of evaluation episodes. As opposed to total reward, mean reward considers how much reward a given algorithm receives while learning.",
|
| 40 |
+
id: "Mean Reward",
|
| 41 |
+
},
|
| 42 |
+
{
|
| 43 |
+
description:
|
| 44 |
+
"Measures how good a given algorithm is after a predefined time. Some algorithms may be guaranteed to converge to optimal behavior across many time steps. However, an agent that reaches an acceptable level of optimality after a given time horizon may be preferable to one that ultimately reaches optimality but takes a long time.",
|
| 45 |
+
id: "Level of Performance After Some Time",
|
| 46 |
+
},
|
| 47 |
+
],
|
| 48 |
+
models: [
|
| 49 |
+
{
|
| 50 |
+
description: "A Reinforcement Learning model trained on expert data from the Gym Hopper environment",
|
| 51 |
+
|
| 52 |
+
id: "edbeeching/decision-transformer-gym-hopper-expert",
|
| 53 |
+
},
|
| 54 |
+
{
|
| 55 |
+
description: "A PPO agent playing seals/CartPole-v0 using the stable-baselines3 library and the RL Zoo.",
|
| 56 |
+
id: "HumanCompatibleAI/ppo-seals-CartPole-v0",
|
| 57 |
+
},
|
| 58 |
+
],
|
| 59 |
+
spaces: [
|
| 60 |
+
{
|
| 61 |
+
description: "An application for a cute puppy agent learning to catch a stick.",
|
| 62 |
+
id: "ThomasSimonini/Huggy",
|
| 63 |
+
},
|
| 64 |
+
{
|
| 65 |
+
description: "An application to play Snowball Fight with a reinforcement learning agent.",
|
| 66 |
+
id: "ThomasSimonini/SnowballFight",
|
| 67 |
+
},
|
| 68 |
+
],
|
| 69 |
+
summary:
|
| 70 |
+
"Reinforcement learning is the computational approach of learning from action by interacting with an environment through trial and error and receiving rewards (negative or positive) as feedback",
|
| 71 |
+
widgetModels: [],
|
| 72 |
+
youtubeId: "q0BiUn5LiBc",
|
| 73 |
+
};
|
| 74 |
+
|
| 75 |
+
export default taskData;
|
packages/tasks/src/sentence-similarity/about.md
ADDED
|
@@ -0,0 +1,97 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
## Use Cases 🔍
|
| 2 |
+
|
| 3 |
+
### Information Retrieval
|
| 4 |
+
|
| 5 |
+
You can extract information from documents using Sentence Similarity models. The first step is to rank documents using Passage Ranking models. You can then get to the top ranked document and search it with Sentence Similarity models by selecting the sentence that has the most similarity to the input query.
|
| 6 |
+
|
| 7 |
+
## The Sentence Transformers library
|
| 8 |
+
|
| 9 |
+
The [Sentence Transformers](https://www.sbert.net/) library is very powerful for calculating embeddings of sentences, paragraphs, and entire documents. An embedding is just a vector representation of a text and is useful for finding how similar two texts are.
|
| 10 |
+
|
| 11 |
+
You can find and use [hundreds of Sentence Transformers](https://huggingface.co/models?library=sentence-transformers&sort=downloads) models from the Hub by directly using the library, playing with the widgets in the browser or using the Inference API.
|
| 12 |
+
|
| 13 |
+
## Task Variants
|
| 14 |
+
|
| 15 |
+
### Passage Ranking
|
| 16 |
+
|
| 17 |
+
Passage Ranking is the task of ranking documents based on their relevance to a given query. The task is evaluated on Mean Reciprocal Rank. These models take one query and multiple documents and return ranked documents according to the relevancy to the query. 📄
|
| 18 |
+
|
| 19 |
+
You can infer with Passage Ranking models using the [Inference API](https://huggingface.co/inference-api). The Passage Ranking model inputs are a query for which we look for relevancy in the documents and the documents we want to search. The model will return scores according to the relevancy of these documents for the query.
|
| 20 |
+
|
| 21 |
+
```python
|
| 22 |
+
import json
|
| 23 |
+
import requests
|
| 24 |
+
|
| 25 |
+
API_URL = "https://api-inference.huggingface.co/models/sentence-transformers/msmarco-distilbert-base-tas-b"
|
| 26 |
+
headers = {"Authorization": f"Bearer {api_token}"}
|
| 27 |
+
|
| 28 |
+
def query(payload):
|
| 29 |
+
response = requests.post(API_URL, headers=headers, json=payload)
|
| 30 |
+
return response.json()
|
| 31 |
+
|
| 32 |
+
data = query(
|
| 33 |
+
{
|
| 34 |
+
"inputs": {
|
| 35 |
+
"source_sentence": "That is a happy person",
|
| 36 |
+
"sentences": [
|
| 37 |
+
"That is a happy dog",
|
| 38 |
+
"That is a very happy person",
|
| 39 |
+
"Today is a sunny day"
|
| 40 |
+
]
|
| 41 |
+
}
|
| 42 |
+
}
|
| 43 |
+
## [0.853, 0.981, 0.655]
|
| 44 |
+
```
|
| 45 |
+
|
| 46 |
+
### Semantic Textual Similarity
|
| 47 |
+
|
| 48 |
+
Semantic Textual Similarity is the task of evaluating how similar two texts are in terms of meaning. These models take a source sentence and a list of sentences in which we will look for similarities and will return a list of similarity scores. The benchmark dataset is the [Semantic Textual Similarity Benchmark](http://ixa2.si.ehu.eus/stswiki/index.php/STSbenchmark). The task is evaluated on Pearson’s Rank Correlation.
|
| 49 |
+
|
| 50 |
+
```python
|
| 51 |
+
import json
|
| 52 |
+
import requests
|
| 53 |
+
|
| 54 |
+
API_URL = "https://api-inference.huggingface.co/models/sentence-transformers/all-MiniLM-L6-v2"
|
| 55 |
+
headers = {"Authorization": f"Bearer {api_token}"}
|
| 56 |
+
|
| 57 |
+
def query(payload):
|
| 58 |
+
response = requests.post(API_URL, headers=headers, json=payload)
|
| 59 |
+
return response.json()
|
| 60 |
+
|
| 61 |
+
data = query(
|
| 62 |
+
{
|
| 63 |
+
"inputs": {
|
| 64 |
+
"source_sentence": "I'm very happy",
|
| 65 |
+
"sentences":["I'm filled with happiness", "I'm happy"]
|
| 66 |
+
}
|
| 67 |
+
})
|
| 68 |
+
|
| 69 |
+
## [0.605, 0.894]
|
| 70 |
+
```
|
| 71 |
+
|
| 72 |
+
You can also infer with the models in the Hub using Sentence Transformer models.
|
| 73 |
+
|
| 74 |
+
```python
|
| 75 |
+
pip install -U sentence-transformers
|
| 76 |
+
|
| 77 |
+
from sentence_transformers import SentenceTransformer, util
|
| 78 |
+
sentences = ["I'm happy", "I'm full of happiness"]
|
| 79 |
+
|
| 80 |
+
model = SentenceTransformer('sentence-transformers/all-MiniLM-L6-v2')
|
| 81 |
+
|
| 82 |
+
#Compute embedding for both lists
|
| 83 |
+
embedding_1= model.encode(sentences[0], convert_to_tensor=True)
|
| 84 |
+
embedding_2 = model.encode(sentences[1], convert_to_tensor=True)
|
| 85 |
+
|
| 86 |
+
util.pytorch_cos_sim(embedding_1, embedding_2)
|
| 87 |
+
## tensor([[0.6003]])
|
| 88 |
+
```
|
| 89 |
+
|
| 90 |
+
## Useful Resources
|
| 91 |
+
|
| 92 |
+
Would you like to learn more about Sentence Transformers and Sentence Similarity? Awesome! Here you can find some curated resources that you may find helpful!
|
| 93 |
+
|
| 94 |
+
- [Sentence Transformers Documentation](https://www.sbert.net/)
|
| 95 |
+
- [Sentence Transformers in the Hub](https://huggingface.co/blog/sentence-transformers-in-the-hub)
|
| 96 |
+
- [Building a Playlist Generator with Sentence Transformers](https://huggingface.co/blog/playlist-generator)
|
| 97 |
+
- [Getting Started With Embeddings](https://huggingface.co/blog/getting-started-with-embeddings)
|
packages/tasks/src/sentence-similarity/data.ts
ADDED
|
@@ -0,0 +1,101 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import type { TaskDataCustom } from "../Types";
|
| 2 |
+
|
| 3 |
+
const taskData: TaskDataCustom = {
|
| 4 |
+
datasets: [
|
| 5 |
+
{
|
| 6 |
+
description: "Bing queries with relevant passages from various web sources.",
|
| 7 |
+
id: "ms_marco",
|
| 8 |
+
},
|
| 9 |
+
],
|
| 10 |
+
demo: {
|
| 11 |
+
inputs: [
|
| 12 |
+
{
|
| 13 |
+
label: "Source sentence",
|
| 14 |
+
content: "Machine learning is so easy.",
|
| 15 |
+
type: "text",
|
| 16 |
+
},
|
| 17 |
+
{
|
| 18 |
+
label: "Sentences to compare to",
|
| 19 |
+
content: "Deep learning is so straightforward.",
|
| 20 |
+
type: "text",
|
| 21 |
+
},
|
| 22 |
+
{
|
| 23 |
+
label: "",
|
| 24 |
+
content: "This is so difficult, like rocket science.",
|
| 25 |
+
type: "text",
|
| 26 |
+
},
|
| 27 |
+
{
|
| 28 |
+
label: "",
|
| 29 |
+
content: "I can't believe how much I struggled with this.",
|
| 30 |
+
type: "text",
|
| 31 |
+
},
|
| 32 |
+
],
|
| 33 |
+
outputs: [
|
| 34 |
+
{
|
| 35 |
+
type: "chart",
|
| 36 |
+
data: [
|
| 37 |
+
{
|
| 38 |
+
label: "Deep learning is so straightforward.",
|
| 39 |
+
score: 0.623,
|
| 40 |
+
},
|
| 41 |
+
{
|
| 42 |
+
label: "This is so difficult, like rocket science.",
|
| 43 |
+
score: 0.413,
|
| 44 |
+
},
|
| 45 |
+
{
|
| 46 |
+
label: "I can't believe how much I struggled with this.",
|
| 47 |
+
score: 0.256,
|
| 48 |
+
},
|
| 49 |
+
],
|
| 50 |
+
},
|
| 51 |
+
],
|
| 52 |
+
},
|
| 53 |
+
metrics: [
|
| 54 |
+
{
|
| 55 |
+
description:
|
| 56 |
+
"Reciprocal Rank is a measure used to rank the relevancy of documents given a set of documents. Reciprocal Rank is the reciprocal of the rank of the document retrieved, meaning, if the rank is 3, the Reciprocal Rank is 0.33. If the rank is 1, the Reciprocal Rank is 1",
|
| 57 |
+
id: "Mean Reciprocal Rank",
|
| 58 |
+
},
|
| 59 |
+
{
|
| 60 |
+
description:
|
| 61 |
+
"The similarity of the embeddings is evaluated mainly on cosine similarity. It is calculated as the cosine of the angle between two vectors. It is particularly useful when your texts are not the same length",
|
| 62 |
+
id: "Cosine Similarity",
|
| 63 |
+
},
|
| 64 |
+
],
|
| 65 |
+
models: [
|
| 66 |
+
{
|
| 67 |
+
description:
|
| 68 |
+
"This model works well for sentences and paragraphs and can be used for clustering/grouping and semantic searches.",
|
| 69 |
+
id: "sentence-transformers/all-mpnet-base-v2",
|
| 70 |
+
},
|
| 71 |
+
{
|
| 72 |
+
description: "A multilingual model trained for FAQ retrieval.",
|
| 73 |
+
id: "clips/mfaq",
|
| 74 |
+
},
|
| 75 |
+
],
|
| 76 |
+
spaces: [
|
| 77 |
+
{
|
| 78 |
+
description: "An application that leverages sentence similarity to answer questions from YouTube videos.",
|
| 79 |
+
id: "Gradio-Blocks/Ask_Questions_To_YouTube_Videos",
|
| 80 |
+
},
|
| 81 |
+
{
|
| 82 |
+
description:
|
| 83 |
+
"An application that retrieves relevant PubMed abstracts for a given online article which can be used as further references.",
|
| 84 |
+
id: "Gradio-Blocks/pubmed-abstract-retriever",
|
| 85 |
+
},
|
| 86 |
+
{
|
| 87 |
+
description: "An application that leverages sentence similarity to summarize text.",
|
| 88 |
+
id: "nickmuchi/article-text-summarizer",
|
| 89 |
+
},
|
| 90 |
+
{
|
| 91 |
+
description: "A guide that explains how Sentence Transformers can be used for semantic search.",
|
| 92 |
+
id: "sentence-transformers/Sentence_Transformers_for_semantic_search",
|
| 93 |
+
},
|
| 94 |
+
],
|
| 95 |
+
summary:
|
| 96 |
+
"Sentence Similarity is the task of determining how similar two texts are. Sentence similarity models convert input texts into vectors (embeddings) that capture semantic information and calculate how close (similar) they are between them. This task is particularly useful for information retrieval and clustering/grouping.",
|
| 97 |
+
widgetModels: ["sentence-transformers/all-MiniLM-L6-v2"],
|
| 98 |
+
youtubeId: "VCZq5AkbNEU",
|
| 99 |
+
};
|
| 100 |
+
|
| 101 |
+
export default taskData;
|
packages/tasks/src/summarization/about.md
ADDED
|
@@ -0,0 +1,58 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
## Use Cases
|
| 2 |
+
|
| 3 |
+
### Research Paper Summarization 🧐
|
| 4 |
+
|
| 5 |
+
Research papers can be summarized to allow researchers to spend less time selecting which articles to read. There are several approaches you can take for a task like this:
|
| 6 |
+
|
| 7 |
+
1. Use an existing extractive summarization model on the Hub to do inference.
|
| 8 |
+
2. Pick an existing language model trained for academic papers. This model can then be trained in a process called fine-tuning so it can solve the summarization task.
|
| 9 |
+
3. Use a sequence-to-sequence model like [T5](https://huggingface.co/docs/transformers/model_doc/t5) for abstractive text summarization.
|
| 10 |
+
|
| 11 |
+
## Inference
|
| 12 |
+
|
| 13 |
+
You can use the 🤗 Transformers library `summarization` pipeline to infer with existing Summarization models. If no model name is provided the pipeline will be initialized with [sshleifer/distilbart-cnn-12-6](https://huggingface.co/sshleifer/distilbart-cnn-12-6).
|
| 14 |
+
|
| 15 |
+
```python
|
| 16 |
+
from transformers import pipeline
|
| 17 |
+
|
| 18 |
+
classifier = pipeline("summarization")
|
| 19 |
+
classifier("Paris is the capital and most populous city of France, with an estimated population of 2,175,601 residents as of 2018, in an area of more than 105 square kilometres (41 square miles). The City of Paris is the centre and seat of government of the region and province of Île-de-France, or Paris Region, which has an estimated population of 12,174,880, or about 18 percent of the population of France as of 2017.")
|
| 20 |
+
## [{ "summary_text": " Paris is the capital and most populous city of France..." }]
|
| 21 |
+
```
|
| 22 |
+
|
| 23 |
+
You can use [huggingface.js](https://github.com/huggingface/huggingface.js) to infer summarization models on Hugging Face Hub.
|
| 24 |
+
|
| 25 |
+
```javascript
|
| 26 |
+
import { HfInference } from "@huggingface/inference";
|
| 27 |
+
|
| 28 |
+
const inference = new HfInference(HF_ACCESS_TOKEN);
|
| 29 |
+
const inputs =
|
| 30 |
+
"Paris is the capital and most populous city of France, with an estimated population of 2,175,601 residents as of 2018, in an area of more than 105 square kilometres (41 square miles). The City of Paris is the centre and seat of government of the region and province of Île-de-France, or Paris Region, which has an estimated population of 12,174,880, or about 18 percent of the population of France as of 2017.";
|
| 31 |
+
|
| 32 |
+
await inference.summarization({
|
| 33 |
+
model: "sshleifer/distilbart-cnn-12-6",
|
| 34 |
+
inputs,
|
| 35 |
+
});
|
| 36 |
+
```
|
| 37 |
+
|
| 38 |
+
## Useful Resources
|
| 39 |
+
|
| 40 |
+
Would you like to learn more about the topic? Awesome! Here you can find some curated resources that you may find helpful!
|
| 41 |
+
|
| 42 |
+
- [Course Chapter on Summarization](https://huggingface.co/course/chapter7/5?fw=pt)
|
| 43 |
+
- [Distributed Training: Train BART/T5 for Summarization using 🤗 Transformers and Amazon SageMaker](https://huggingface.co/blog/sagemaker-distributed-training-seq2seq)
|
| 44 |
+
|
| 45 |
+
### Notebooks
|
| 46 |
+
|
| 47 |
+
- [PyTorch](https://github.com/huggingface/notebooks/blob/master/examples/summarization.ipynb)
|
| 48 |
+
- [TensorFlow](https://github.com/huggingface/notebooks/blob/master/examples/summarization-tf.ipynb)
|
| 49 |
+
|
| 50 |
+
### Scripts for training
|
| 51 |
+
|
| 52 |
+
- [PyTorch](https://github.com/huggingface/transformers/tree/main/examples/pytorch/summarization)
|
| 53 |
+
- [TensorFlow](https://github.com/huggingface/transformers/tree/main/examples/tensorflow/summarization)
|
| 54 |
+
- [Flax](https://github.com/huggingface/transformers/tree/main/examples/flax/summarization)
|
| 55 |
+
|
| 56 |
+
### Documentation
|
| 57 |
+
|
| 58 |
+
- [Summarization task guide](https://huggingface.co/docs/transformers/tasks/summarization)
|
packages/tasks/src/summarization/data.ts
ADDED
|
@@ -0,0 +1,75 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import type { TaskDataCustom } from "../Types";
|
| 2 |
+
|
| 3 |
+
const taskData: TaskDataCustom = {
|
| 4 |
+
datasets: [
|
| 5 |
+
{
|
| 6 |
+
description:
|
| 7 |
+
"News articles in five different languages along with their summaries. Widely used for benchmarking multilingual summarization models.",
|
| 8 |
+
id: "mlsum",
|
| 9 |
+
},
|
| 10 |
+
{
|
| 11 |
+
description: "English conversations and their summaries. Useful for benchmarking conversational agents.",
|
| 12 |
+
id: "samsum",
|
| 13 |
+
},
|
| 14 |
+
],
|
| 15 |
+
demo: {
|
| 16 |
+
inputs: [
|
| 17 |
+
{
|
| 18 |
+
label: "Input",
|
| 19 |
+
content:
|
| 20 |
+
"The tower is 324 metres (1,063 ft) tall, about the same height as an 81-storey building, and the tallest structure in Paris. Its base is square, measuring 125 metres (410 ft) on each side. It was the first structure to reach a height of 300 metres. Excluding transmitters, the Eiffel Tower is the second tallest free-standing structure in France after the Millau Viaduct.",
|
| 21 |
+
type: "text",
|
| 22 |
+
},
|
| 23 |
+
],
|
| 24 |
+
outputs: [
|
| 25 |
+
{
|
| 26 |
+
label: "Output",
|
| 27 |
+
content:
|
| 28 |
+
"The tower is 324 metres (1,063 ft) tall, about the same height as an 81-storey building. It was the first structure to reach a height of 300 metres.",
|
| 29 |
+
type: "text",
|
| 30 |
+
},
|
| 31 |
+
],
|
| 32 |
+
},
|
| 33 |
+
metrics: [
|
| 34 |
+
{
|
| 35 |
+
description:
|
| 36 |
+
"The generated sequence is compared against its summary, and the overlap of tokens are counted. ROUGE-N refers to overlap of N subsequent tokens, ROUGE-1 refers to overlap of single tokens and ROUGE-2 is the overlap of two subsequent tokens.",
|
| 37 |
+
id: "rouge",
|
| 38 |
+
},
|
| 39 |
+
],
|
| 40 |
+
models: [
|
| 41 |
+
{
|
| 42 |
+
description:
|
| 43 |
+
"A strong summarization model trained on English news articles. Excels at generating factual summaries.",
|
| 44 |
+
id: "facebook/bart-large-cnn",
|
| 45 |
+
},
|
| 46 |
+
{
|
| 47 |
+
description: "A summarization model trained on medical articles.",
|
| 48 |
+
id: "google/bigbird-pegasus-large-pubmed",
|
| 49 |
+
},
|
| 50 |
+
],
|
| 51 |
+
spaces: [
|
| 52 |
+
{
|
| 53 |
+
description: "An application that can summarize long paragraphs.",
|
| 54 |
+
id: "pszemraj/summarize-long-text",
|
| 55 |
+
},
|
| 56 |
+
{
|
| 57 |
+
description: "A much needed summarization application for terms and conditions.",
|
| 58 |
+
id: "ml6team/distilbart-tos-summarizer-tosdr",
|
| 59 |
+
},
|
| 60 |
+
{
|
| 61 |
+
description: "An application that summarizes long documents.",
|
| 62 |
+
id: "pszemraj/document-summarization",
|
| 63 |
+
},
|
| 64 |
+
{
|
| 65 |
+
description: "An application that can detect errors in abstractive summarization.",
|
| 66 |
+
id: "ml6team/post-processing-summarization",
|
| 67 |
+
},
|
| 68 |
+
],
|
| 69 |
+
summary:
|
| 70 |
+
"Summarization is the task of producing a shorter version of a document while preserving its important information. Some models can extract text from the original input, while other models can generate entirely new text.",
|
| 71 |
+
widgetModels: ["sshleifer/distilbart-cnn-12-6"],
|
| 72 |
+
youtubeId: "yHnr5Dk2zCI",
|
| 73 |
+
};
|
| 74 |
+
|
| 75 |
+
export default taskData;
|