Spaces:
Runtime error

Runtime error
Commit
•
d889137
1
Parent(s):
98f80c6
updated base model
Browse files- __pycache__/quantization.cpython-311.pyc +0 -0
- app.py +63 -38
- flagged/log.csv +2 -0
- flagged/throughput Comparison/49a4c8006ae895a1b75f/image.webp +0 -0
- mest.tar +0 -0
__pycache__/quantization.cpython-311.pyc
ADDED
|
Binary file (5.25 kB). View file
|
|
|
app.py
CHANGED
|
@@ -1,80 +1,105 @@
|
|
| 1 |
import gradio as gr
|
| 2 |
-
from transformers import pipeline
|
| 3 |
-
import numpy as np
|
| 4 |
-
from time import perf_counter
|
| 5 |
from setfit import SetFitModel
|
| 6 |
from optimum.onnxruntime import ORTModelForFeatureExtraction
|
| 7 |
from quantization import OnnxSetFitModel
|
| 8 |
-
|
| 9 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
| 10 |
|
| 11 |
-
|
|
|
|
| 12 |
ort_model = ORTModelForFeatureExtraction.from_pretrained("hsmashiana/optimized_model_hpml", file_name="model_quantized.onnx")
|
| 13 |
tokenizer = AutoTokenizer.from_pretrained("hsmashiana/optimized_model_hpml")
|
| 14 |
model3 = OnnxSetFitModel(ort_model, tokenizer, model1.model_head)
|
| 15 |
|
| 16 |
-
decode = {0:"World",1:"Sports",2:"Business",3:"Sci/Tech"}
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 17 |
|
| 18 |
def compare_models(text):
|
| 19 |
-
|
| 20 |
-
# result2 = model2(text)
|
| 21 |
-
# # Including model names in the results
|
| 22 |
-
# output1 = {"Model": "BERT Base Uncased", "Output": result1}
|
| 23 |
-
# output2 = {"Model": "RoBERTa Base", "Output": result2}
|
| 24 |
-
# return output1, output2
|
| 25 |
-
|
| 26 |
times = []
|
| 27 |
-
|
|
|
|
| 28 |
for _ in range(5):
|
| 29 |
model1([text])
|
|
|
|
| 30 |
# Measure the execution time of model predictions
|
| 31 |
for _ in range(20):
|
| 32 |
start = perf_counter()
|
| 33 |
out1 = model1([text])
|
| 34 |
end = perf_counter()
|
| 35 |
times.append(end - start)
|
| 36 |
-
# Calculate mean and standard deviation of latency
|
| 37 |
-
avg_latency_ms_model_1 = np.mean(times) * 1000
|
| 38 |
|
| 39 |
-
|
| 40 |
-
# # Warm-up phase to ensure fair timing
|
| 41 |
-
# for _ in range(5):
|
| 42 |
-
# model2([text])
|
| 43 |
-
# # Measure the execution time of model predictions
|
| 44 |
-
# for _ in range(20):
|
| 45 |
-
# start = perf_counter()
|
| 46 |
-
# out2 = model2([text])
|
| 47 |
-
# end = perf_counter()
|
| 48 |
-
# times.append(end - start)
|
| 49 |
-
# # Calculate mean and standard deviation of latency
|
| 50 |
-
# avg_latency_ms_model_2 = np.mean(times) * 1000
|
| 51 |
|
| 52 |
times = []
|
| 53 |
-
|
|
|
|
| 54 |
for _ in range(5):
|
| 55 |
model3.predict([text])
|
|
|
|
| 56 |
# Measure the execution time of model predictions
|
| 57 |
for _ in range(20):
|
| 58 |
start = perf_counter()
|
| 59 |
-
out3 = model3([text])
|
| 60 |
end = perf_counter()
|
| 61 |
times.append(end - start)
|
| 62 |
-
|
| 63 |
avg_latency_ms_model_3 = np.mean(times) * 1000
|
| 64 |
|
| 65 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 66 |
|
| 67 |
-
# Create a Gradio interface
|
| 68 |
iface = gr.Interface(
|
| 69 |
fn=compare_models,
|
| 70 |
inputs="text",
|
| 71 |
outputs=[
|
| 72 |
-
gr.components.JSON(label="Base
|
| 73 |
-
gr.components.JSON(label="
|
|
|
|
| 74 |
],
|
| 75 |
title="Compare Sentence Classification Models",
|
| 76 |
-
description="Enter a sentence to see how each model classifies it."
|
|
|
|
| 77 |
)
|
| 78 |
|
| 79 |
-
# Run the interface
|
| 80 |
iface.launch()
|
|
|
|
| 1 |
import gradio as gr
|
| 2 |
+
from transformers import pipeline, AutoTokenizer
|
|
|
|
|
|
|
| 3 |
from setfit import SetFitModel
|
| 4 |
from optimum.onnxruntime import ORTModelForFeatureExtraction
|
| 5 |
from quantization import OnnxSetFitModel
|
| 6 |
+
import numpy as np
|
| 7 |
+
from time import perf_counter
|
| 8 |
+
import matplotlib.pyplot as plt
|
| 9 |
+
from io import BytesIO
|
| 10 |
+
from PIL import Image
|
| 11 |
+
import io
|
| 12 |
|
| 13 |
+
# Load the models
|
| 14 |
+
model1 = SetFitModel.from_pretrained("hsmashiana/basemodel_hpml")
|
| 15 |
ort_model = ORTModelForFeatureExtraction.from_pretrained("hsmashiana/optimized_model_hpml", file_name="model_quantized.onnx")
|
| 16 |
tokenizer = AutoTokenizer.from_pretrained("hsmashiana/optimized_model_hpml")
|
| 17 |
model3 = OnnxSetFitModel(ort_model, tokenizer, model1.model_head)
|
| 18 |
|
| 19 |
+
decode = {0: "World", 1: "Sports", 2: "Business", 3: "Sci/Tech"}
|
| 20 |
+
|
| 21 |
+
def plot_throughput_bar_chart(throughput_model1, throughput_model2):
|
| 22 |
+
labels = ['Base model', 'Optimized model']
|
| 23 |
+
throughputs = [throughput_model1, throughput_model2]
|
| 24 |
+
|
| 25 |
+
plt.figure(figsize=(8, 6))
|
| 26 |
+
plt.bar(labels, throughputs, color=['blue', 'navy'])
|
| 27 |
+
plt.xlabel('Models')
|
| 28 |
+
plt.ylabel('Throughput (tokens/second)')
|
| 29 |
+
plt.title('Model Throughput Comparison')
|
| 30 |
+
plt.tight_layout()
|
| 31 |
+
|
| 32 |
+
# Create a PIL Image from the plot
|
| 33 |
+
buf = io.BytesIO()
|
| 34 |
+
plt.savefig(buf, format='png')
|
| 35 |
+
buf.seek(0)
|
| 36 |
+
img = Image.open(buf)
|
| 37 |
+
plt.close()
|
| 38 |
+
return img
|
| 39 |
|
| 40 |
def compare_models(text):
|
| 41 |
+
inputs = tokenizer(text, return_tensors="pt")
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 42 |
times = []
|
| 43 |
+
|
| 44 |
+
# Warm-up phase to ensure fair timing
|
| 45 |
for _ in range(5):
|
| 46 |
model1([text])
|
| 47 |
+
|
| 48 |
# Measure the execution time of model predictions
|
| 49 |
for _ in range(20):
|
| 50 |
start = perf_counter()
|
| 51 |
out1 = model1([text])
|
| 52 |
end = perf_counter()
|
| 53 |
times.append(end - start)
|
|
|
|
|
|
|
| 54 |
|
| 55 |
+
avg_latency_ms_model_1 = np.mean(times) * 1000
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 56 |
|
| 57 |
times = []
|
| 58 |
+
|
| 59 |
+
# Warm-up phase to ensure fair timing
|
| 60 |
for _ in range(5):
|
| 61 |
model3.predict([text])
|
| 62 |
+
|
| 63 |
# Measure the execution time of model predictions
|
| 64 |
for _ in range(20):
|
| 65 |
start = perf_counter()
|
| 66 |
+
out3 = model3.predict([text])
|
| 67 |
end = perf_counter()
|
| 68 |
times.append(end - start)
|
| 69 |
+
|
| 70 |
avg_latency_ms_model_3 = np.mean(times) * 1000
|
| 71 |
|
| 72 |
+
throughput_tokens_per_sec1 = inputs['input_ids'].size(1) / (avg_latency_ms_model_1 / 1000)
|
| 73 |
+
throughput_tokens_per_sec2 = inputs['input_ids'].size(1) / (avg_latency_ms_model_3 / 1000)
|
| 74 |
+
|
| 75 |
+
plot_data = plot_throughput_bar_chart(throughput_tokens_per_sec1, throughput_tokens_per_sec2)
|
| 76 |
+
|
| 77 |
+
result1 = {
|
| 78 |
+
"Base Model": {
|
| 79 |
+
"answer": decode[out1.numpy()[0]],
|
| 80 |
+
"average time (ms)": avg_latency_ms_model_1,
|
| 81 |
+
"throughput (tokens/sec)": throughput_tokens_per_sec1
|
| 82 |
+
}}
|
| 83 |
+
result2 = {
|
| 84 |
+
"Optimized Model": {
|
| 85 |
+
"answer": decode[out3[0]],
|
| 86 |
+
"average time (ms)": avg_latency_ms_model_3,
|
| 87 |
+
"throughput (tokens/sec)": throughput_tokens_per_sec2
|
| 88 |
+
}}
|
| 89 |
+
|
| 90 |
+
return result1, result2, plot_data
|
| 91 |
|
|
|
|
| 92 |
iface = gr.Interface(
|
| 93 |
fn=compare_models,
|
| 94 |
inputs="text",
|
| 95 |
outputs=[
|
| 96 |
+
gr.components.JSON(label="Base Model"),
|
| 97 |
+
gr.components.JSON(label="Optimized Model"),
|
| 98 |
+
gr.components.Image(label="throughput Comparison")
|
| 99 |
],
|
| 100 |
title="Compare Sentence Classification Models",
|
| 101 |
+
description="Enter a sentence to see how each model classifies it and their throughputs.",
|
| 102 |
+
allow_flagging="never"
|
| 103 |
)
|
| 104 |
|
|
|
|
| 105 |
iface.launch()
|
flagged/log.csv
ADDED
|
@@ -0,0 +1,2 @@
|
|
|
|
|
|
|
|
|
|
| 1 |
+
text,Base Model,Optimized Model,throughput Comparison,flag,username,timestamp
|
| 2 |
+
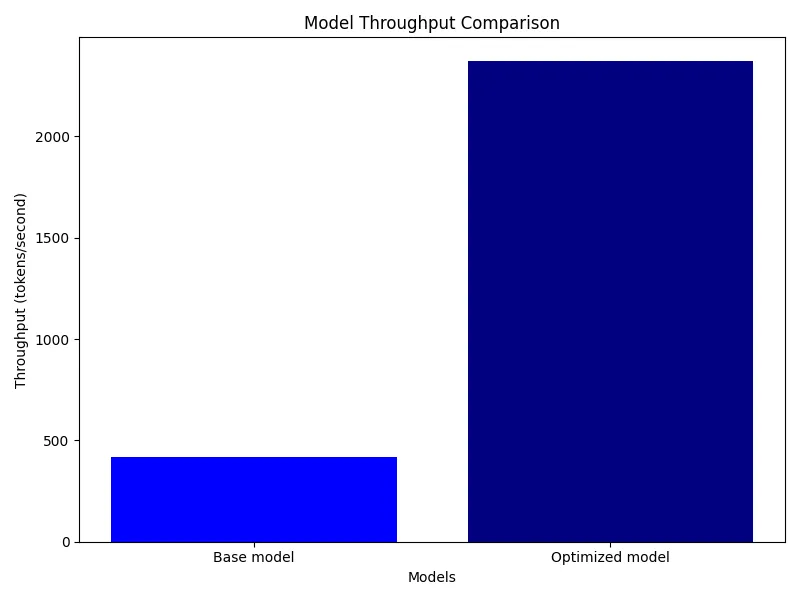
hellool,"{""Base Model"": {""answer"": ""Business"", ""average time (ms)"": 9.624537501076702, ""throughput (tokens/sec)"": 415.60438613829683}}","{""Optimized Model"": {""answer"": ""Business"", ""average time (ms)"": 1.6875000983418431, ""throughput (tokens/sec)"": 2370.370232233139}}",flagged/throughput Comparison/49a4c8006ae895a1b75f/image.webp,,,2024-05-04 20:48:16.264716
|
flagged/throughput Comparison/49a4c8006ae895a1b75f/image.webp
ADDED
|
mest.tar
ADDED
|
Binary file (1.02 kB). View file
|
|
|