Spaces:
Running

Running
Upload 12 files
Browse files- .gitignore +10 -0
- Dockerfile +21 -0
- Dockerfile.cpu +21 -0
- LICENSE +21 -0
- README.md +227 -11
- docker-compose.yml +40 -0
- icon.png +0 -0
- launcher.py +168 -0
- requirements.txt +10 -0
- subgen.env +6 -0
- subgen.py +1045 -0
- subgen.xml +56 -0
.gitignore
ADDED
|
@@ -0,0 +1,10 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
.vscode/*
|
| 2 |
+
|
| 3 |
+
# Local History for Visual Studio Code
|
| 4 |
+
.history/
|
| 5 |
+
|
| 6 |
+
# Built Visual Studio Code Extensions
|
| 7 |
+
*.vsix
|
| 8 |
+
|
| 9 |
+
#ignore our settings
|
| 10 |
+
subgen.env
|
Dockerfile
ADDED
|
@@ -0,0 +1,21 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
FROM nvidia/cuda:12.2.2-cudnn8-runtime-ubuntu22.04
|
| 2 |
+
|
| 3 |
+
WORKDIR /subgen
|
| 4 |
+
|
| 5 |
+
ADD https://raw.githubusercontent.com/McCloudS/subgen/main/requirements.txt /subgen/requirements.txt
|
| 6 |
+
|
| 7 |
+
RUN apt-get update \
|
| 8 |
+
&& apt-get install -y \
|
| 9 |
+
python3 \
|
| 10 |
+
python3-pip \
|
| 11 |
+
ffmpeg \
|
| 12 |
+
&& apt-get clean \
|
| 13 |
+
&& rm -rf /var/lib/apt/lists/* \
|
| 14 |
+
&& pip3 install -r requirements.txt
|
| 15 |
+
|
| 16 |
+
ENV PYTHONUNBUFFERED=1
|
| 17 |
+
|
| 18 |
+
ADD https://raw.githubusercontent.com/McCloudS/subgen/main/launcher.py /subgen/launcher.py
|
| 19 |
+
ADD https://raw.githubusercontent.com/McCloudS/subgen/main/subgen.py /subgen/subgen.py
|
| 20 |
+
|
| 21 |
+
CMD [ "bash", "-c", "python3 -u launcher.py" ]
|
Dockerfile.cpu
ADDED
|
@@ -0,0 +1,21 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
FROM python:3.11-slim-bullseye
|
| 2 |
+
|
| 3 |
+
WORKDIR /subgen
|
| 4 |
+
|
| 5 |
+
ADD https://raw.githubusercontent.com/McCloudS/subgen/main/requirements.txt /subgen/requirements.txt
|
| 6 |
+
|
| 7 |
+
RUN apt-get update \
|
| 8 |
+
&& apt-get install -y \
|
| 9 |
+
python3 \
|
| 10 |
+
python3-pip \
|
| 11 |
+
ffmpeg \
|
| 12 |
+
&& apt-get clean \
|
| 13 |
+
&& rm -rf /var/lib/apt/lists/* \
|
| 14 |
+
&& pip install -r requirements.txt
|
| 15 |
+
|
| 16 |
+
ENV PYTHONUNBUFFERED=1
|
| 17 |
+
|
| 18 |
+
ADD https://raw.githubusercontent.com/McCloudS/subgen/main/launcher.py /subgen/launcher.py
|
| 19 |
+
ADD https://raw.githubusercontent.com/McCloudS/subgen/main/subgen.py /subgen/subgen.py
|
| 20 |
+
|
| 21 |
+
CMD [ "bash", "-c", "python3 -u launcher.py" ]
|
LICENSE
ADDED
|
@@ -0,0 +1,21 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
MIT License
|
| 2 |
+
|
| 3 |
+
Copyright (c) 2023 McCloudS
|
| 4 |
+
|
| 5 |
+
Permission is hereby granted, free of charge, to any person obtaining a copy
|
| 6 |
+
of this software and associated documentation files (the "Software"), to deal
|
| 7 |
+
in the Software without restriction, including without limitation the rights
|
| 8 |
+
to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
|
| 9 |
+
copies of the Software, and to permit persons to whom the Software is
|
| 10 |
+
furnished to do so, subject to the following conditions:
|
| 11 |
+
|
| 12 |
+
The above copyright notice and this permission notice shall be included in all
|
| 13 |
+
copies or substantial portions of the Software.
|
| 14 |
+
|
| 15 |
+
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
|
| 16 |
+
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
|
| 17 |
+
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
|
| 18 |
+
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
|
| 19 |
+
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
|
| 20 |
+
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
|
| 21 |
+
SOFTWARE.
|
README.md
CHANGED
|
@@ -1,11 +1,227 @@
|
|
| 1 |
-
|
| 2 |
-
|
| 3 |
-
|
| 4 |
-
|
| 5 |
-
|
| 6 |
-
|
| 7 |
-
|
| 8 |
-
|
| 9 |
-
|
| 10 |
-
|
| 11 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
[](https://www.paypal.com/donate/?hosted_button_id=SU4QQP6LH5PF6)
|
| 2 |
+
<img src="https://raw.githubusercontent.com/McCloudS/subgen/main/icon.png" width="200">
|
| 3 |
+
|
| 4 |
+
<details>
|
| 5 |
+
<summary>Updates:</summary>
|
| 6 |
+
|
| 7 |
+
21 Apr 2024: Fixed queuing with thanks to https://github.com/xhzhu0628 @ https://github.com/McCloudS/subgen/pull/85. Bazarr intentionally doesn't follow `CONCURRENT_TRANSCRIPTIONS` because it needs a time sensitive response.
|
| 8 |
+
|
| 9 |
+
31 Mar 2024: Removed `/subsync` endpoint and general refactoring. Open an issue if you were using it!
|
| 10 |
+
|
| 11 |
+
24 Mar 2024: Added a 'webui' to configure environment variables. You can use this instead of manually editing the script or using Environment Variables in your OS or Docker (if you want). The config will prioritize OS Env Variables, then the .env file, then the defaults. You can access it at `http://subgen:9000/`
|
| 12 |
+
|
| 13 |
+
23 Mar 2024: Added `CUSTOM_REGROUP` to try to 'clean up' subtitles a bit.
|
| 14 |
+
|
| 15 |
+
22 Mar 2024: Added LRC capability via see: `'LRC_FOR_AUDIO_FILES' | True | Will generate LRC (instead of SRT) files for filetypes: '.mp3', '.flac', '.wav', '.alac', '.ape', '.ogg', '.wma', '.m4a', '.m4b', '.aac', '.aiff' |`
|
| 16 |
+
|
| 17 |
+
21 Mar 2024: Added a 'wizard' into the launcher that will help standalone users get common Bazarr variables configured. See below in Launcher section. Removed 'Transformers' as an option. While I usually don't like to remove features, I don't think anyone is using this and the results are wildly unpredictable and often cause out of memory errors. Added two new environment variables called `USE_MODEL_PROMPT` and `CUSTOM_MODEL_PROMPT`. If `USE_MODEL_PROMPT` is `True` it will use `CUSTOM_MODEL_PROMPT` if set, otherwise will default to using the pre-configured language pairings, such as: `"en": "Hello, welcome to my lecture.",
|
| 18 |
+
"zh": "你好,欢迎来到我的讲座。"` These pre-configurated translations are geared towards fixing some audio that may not have punctionation. We can prompt it to try to force the use of punctuation during transcription.
|
| 19 |
+
|
| 20 |
+
19 Mar 2024: Added a `MONITOR` environment variable. Will 'watch' or 'monitor' your `TRANSCRIBE_FOLDERS` for changes and run on them. Useful if you just want to paste files into a folder and get subtitles.
|
| 21 |
+
|
| 22 |
+
6 Mar 2024: Added a `/subsync` endpoint that can attempt to align/synchronize subtitles to a file. Takes audio_file, subtitle_file, language (2 letter code), and outputs an srt.
|
| 23 |
+
|
| 24 |
+
5 Mar 2024: Cleaned up logging. Added timestamps option (if Debug = True, timestamps will print in logs).
|
| 25 |
+
|
| 26 |
+
4 Mar 2024: Updated Dockerfile CUDA to 12.2.2 (From CTranslate2). Added endpoint `/status` to return Subgen version. Can also use distil models now! See variables below!
|
| 27 |
+
|
| 28 |
+
29 Feb 2024: Changed sefault port to align with whisper-asr and deconflict other consumers of the previous port.
|
| 29 |
+
|
| 30 |
+
11 Feb 2024: Added a 'launcher.py' file for Docker to prevent huge image downloads. Now set UPDATE to True if you want pull the latest version, otherwise it will default to what was in the image on build. Docker builds will still be auto-built on any commit. If you don't want to use the auto-update function, no action is needed on your part and continue to update docker images as before. Fixed bug where detect-langauge could return an empty result. Reduced useless debug output that was spamming logs and defaulted DEBUG to True. Added APPEND, which will add f"Transcribed by whisperAI with faster-whisper ({whisper_model}) on {datetime.now()}" at the end of a subtitle.
|
| 31 |
+
|
| 32 |
+
10 Feb 2024: Added some features from JaiZed's branch such as skipping if SDH subtitles are detected, functions updated to also be able to transcribe audio files, allow individual files to be manually transcribed, and a better implementation of forceLanguage. Added `/batch` endpoint (Thanks JaiZed). Allows you to navigate in a browser to http://subgen_ip:9000/docs and call the batch endpoint which can take a file or a folder to manually transcribe files. Added CLEAR_VRAM_ON_COMPLETE, HF_TRANSFORMERS, HF_BATCH_SIZE. Hugging Face Transformers boast '9x increase', but my limited testing shows it's comparable to faster-whisper or slightly slower. I also have an older 8gb GPU. Simplest way to persist HF Transformer models is to set "HF_HUB_CACHE" and set it to "/subgen/models" for Docker (assuming you have the matching volume).
|
| 33 |
+
|
| 34 |
+
8 Feb 2024: Added FORCE_DETECTED_LANGUAGE_TO to force a wrongly detected language. Fixed asr to actually use the language passed to it.
|
| 35 |
+
|
| 36 |
+
5 Feb 2024: General housekeeping, minor tweaks on the TRANSCRIBE_FOLDERS function.
|
| 37 |
+
|
| 38 |
+
28 Jan 2024: Fixed issue with ffmpeg python module not importing correctly. Removed separate GPU/CPU containers. Also removed the script from installing packages, which should help with odd updates I can't control (from other packages/modules). The image is a couple gigabytes larger, but allows easier maintenance.
|
| 39 |
+
|
| 40 |
+
19 Dec 2023: Added the ability for Plex and Jellyfin to automatically update metadata so the subtitles shows up properly on playback. (See https://github.com/McCloudS/subgen/pull/33 from Rikiar73574)
|
| 41 |
+
|
| 42 |
+
31 Oct 2023: Added Bazarr support via Whipser provider.
|
| 43 |
+
|
| 44 |
+
25 Oct 2023: Added Emby (IE http://192.168.1.111:9000/emby) support and TRANSCRIBE_FOLDERS, which will recurse through the provided folders and generate subtitles. It's geared towards attempting to transcribe existing media without using a webhook.
|
| 45 |
+
|
| 46 |
+
23 Oct 2023: There are now two docker images, ones for CPU (it's smaller): mccloud/subgen:latest, mccloud/subgen:cpu, the other is for cuda/GPU: mccloud/subgen:cuda. I also added Jellyfin support and considerable cleanup in the script. I also renamed the webhooks, so they will require new configuration/updates on your end. Instead of /webhook they are now /plex, /tautulli, and /jellyfin.
|
| 47 |
+
|
| 48 |
+
22 Oct 2023: The script should have backwards compability with previous envirionment settings, but just to be sure, look at the new options below. If you don't want to manually edit your environment variables, just edit the script manually. While I have added GPU support, I haven't tested it yet.
|
| 49 |
+
|
| 50 |
+
19 Oct 2023: And we're back! Uses faster-whisper and stable-ts. Shouldn't break anything from previous settings, but adds a couple new options that aren't documented at this point in time. As of now, this is not a docker image on dockerhub. The potential intent is to move this eventually to a pure python script, primarily to simplify my efforts. Quick and dirty to meet dependencies: pip or `pip3 install flask requests stable-ts faster-whisper`
|
| 51 |
+
|
| 52 |
+
This potentially has the ability to use CUDA/Nvidia GPU's, but I don't have one set up yet. Tesla T4 is in the mail!
|
| 53 |
+
|
| 54 |
+
2 Feb 2023: Added Tautulli webhooks back in. Didn't realize Plex webhooks was PlexPass only. See below for instructions to add it back in.
|
| 55 |
+
|
| 56 |
+
31 Jan 2023 : Rewrote the script substantially to remove Tautulli and fix some variable handling. For some reason my implementation requires the container to be in host mode. My Plex was giving "401 Unauthorized" when attempt to query from docker subnets during API calls. (**Fixed now, it can be in bridge**)
|
| 57 |
+
|
| 58 |
+
</details>
|
| 59 |
+
|
| 60 |
+
# What is this?
|
| 61 |
+
|
| 62 |
+
This will transcribe your personal media on a Plex, Emby, or Jellyfin server to create subtitles (.srt) from audio/video files with the following languages: https://github.com/McCloudS/subgen#audio-languages-supported-via-openai and transcribe or translate them into english. It can also be used as a Whisper provider in Bazarr (See below instructions). It technically has support to transcribe from a foreign langauge to itself (IE Japanese > Japanese, see [TRANSCRIBE_OR_TRANSLATE](https://github.com/McCloudS/subgen#variables)). It is currently reliant on webhooks from Jellyfin, Emby, Plex, or Tautulli. This uses stable-ts and faster-whisper which can use both Nvidia GPUs and CPUs.
|
| 63 |
+
|
| 64 |
+
# Why?
|
| 65 |
+
|
| 66 |
+
Honestly, I built this for me, but saw the utility in other people maybe using it. This works well for my use case. Since having children, I'm either deaf or wanting to have everything quiet. We watch EVERYTHING with subtitles now, and I feel like I can't even understand the show without them. I use Bazarr to auto-download, and gap fill with Plex's built-in capability. This is for everything else. Some shows just won't have subtitles available for some reason or another, or in some cases on my H265 media, they are wildly out of sync.
|
| 67 |
+
|
| 68 |
+
# What can it do?
|
| 69 |
+
|
| 70 |
+
* Create .srt subtitles when a media file is added or played which triggers off of Jellyfin, Plex, or Tautulli webhooks. It can also be called via the Whisper provider inside Bazarr.
|
| 71 |
+
|
| 72 |
+
# How do I set it up?
|
| 73 |
+
|
| 74 |
+
## Install/Setup
|
| 75 |
+
|
| 76 |
+
You can now configure all environment variables via `http://subgen:9000/` (fill in your appropriate IP and port). You can still use Docker variables or OS Env Variables if you prefer. A small snapshot of it below:
|
| 77 |
+

|
| 78 |
+
|
| 79 |
+
|
| 80 |
+
### Standalone/Without Docker
|
| 81 |
+
|
| 82 |
+
Install python3 and ffmpeg ~~and run `pip3 install numpy stable-ts fastapi requests faster-whisper uvicorn python-multipart python-ffmpeg whisper transformers optimum accelerate watchdog`~~. Then run it: `python3 launcher.py -u -i -s`. You need to have matching paths relative to your Plex server/folders, or use USE_PATH_MAPPING. Paths are not needed if you are only using Bazarr. You will need the appropriate NVIDIA drivers installed (12.2.0): https://developer.nvidia.com/cuda-12-2-0-download-archive?target_os=Windows&target_arch=x86_64
|
| 83 |
+
|
| 84 |
+
#### Using Launcher
|
| 85 |
+
|
| 86 |
+
launcher.py can launch subgen for you and automate the setup and can take the following options:
|
| 87 |
+

|
| 88 |
+
|
| 89 |
+
Using `-s` for Bazarr setup:
|
| 90 |
+

|
| 91 |
+
|
| 92 |
+
|
| 93 |
+
|
| 94 |
+
### Docker
|
| 95 |
+
|
| 96 |
+
The dockerfile is in the repo along with an example docker-compose file, and is also posted on dockerhub (mccloud/subgen).
|
| 97 |
+
|
| 98 |
+
If using Subgen without Bazarr, you MUST mount your media volumes in subgen the same way Plex (or your media server) sees them. For example, if Plex uses "/Share/media/TV:/tv" you must have that identical volume in subgen.
|
| 99 |
+
|
| 100 |
+
`"${APPDATA}/subgen/models:/subgen/models"` is just for storage of the language models. This isn't necessary, but you will have to redownload the models on any new image pulls if you don't use it.
|
| 101 |
+
|
| 102 |
+
`"${APPDATA}/subgen/subgen.py:/subgen/subgen.py"` If you want to control the version of subgen.py by yourself. Launcher.py can still be used to download a newer version.
|
| 103 |
+
|
| 104 |
+
If you want to use a GPU, you need to map it accordingly.
|
| 105 |
+
|
| 106 |
+
## Plex
|
| 107 |
+
|
| 108 |
+
Create a webhook in Plex that will call back to your subgen address, IE: http://192.168.1.111:9000/plex see: https://support.plex.tv/articles/115002267687-webhooks/ You will also need to generate the token to use it.
|
| 109 |
+
|
| 110 |
+
## Emby
|
| 111 |
+
|
| 112 |
+
All you need to do is create a webhook in Emby pointing to your subgen IE: http://192.168.154:9000/emby
|
| 113 |
+
|
| 114 |
+
Emby was really nice and provides good information in their responses, so we don't need to add an API token or server url to query for more information.
|
| 115 |
+
|
| 116 |
+
## Bazarr
|
| 117 |
+
|
| 118 |
+
You only need to confiure the Whisper Provider as shown below: <br>
|
| 119 |
+
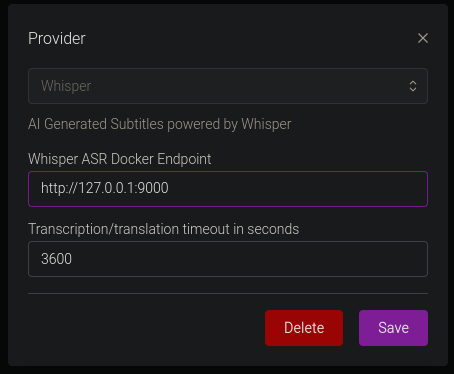 <br>
|
| 120 |
+
The Docker Endpoint is the ip address and port of your subgen container (IE http://192.168.1.111:9000) See https://wiki.bazarr.media/Additional-Configuration/Whisper-Provider/ for more info. I recomend not enabling this with other webhooks, or you will likely be generating duplicate subtitles. If you are using Bazarr, path mapping isn't necessary, as Bazarr sends the file over http.
|
| 121 |
+
|
| 122 |
+
## Tautulli
|
| 123 |
+
|
| 124 |
+
Create the webhooks in Tautulli with the following settings:
|
| 125 |
+
Webhook URL: http://yourdockerip:9000/tautulli
|
| 126 |
+
Webhook Method: Post
|
| 127 |
+
Triggers: Whatever you want, but you'll likely want "Playback Start" and "Recently Added"
|
| 128 |
+
Data: Under Playback Start, JSON Header will be:
|
| 129 |
+
```json
|
| 130 |
+
{ "source":"Tautulli" }
|
| 131 |
+
```
|
| 132 |
+
Data:
|
| 133 |
+
```json
|
| 134 |
+
{
|
| 135 |
+
"event":"played",
|
| 136 |
+
"file":"{file}",
|
| 137 |
+
"filename":"{filename}",
|
| 138 |
+
"mediatype":"{media_type}"
|
| 139 |
+
}
|
| 140 |
+
```
|
| 141 |
+
Similarly, under Recently Added, Header is:
|
| 142 |
+
```json
|
| 143 |
+
{ "source":"Tautulli" }
|
| 144 |
+
```
|
| 145 |
+
Data:
|
| 146 |
+
```json
|
| 147 |
+
{
|
| 148 |
+
"event":"added",
|
| 149 |
+
"file":"{file}",
|
| 150 |
+
"filename":"{filename}",
|
| 151 |
+
"mediatype":"{media_type}"
|
| 152 |
+
}
|
| 153 |
+
```
|
| 154 |
+
## Jellyfin
|
| 155 |
+
|
| 156 |
+
First, you need to install the Jellyfin webhooks plugin. Then you need to click "Add Generic Destination", name it anything you want, webhook url is your subgen info (IE http://192.168.1.154:9000/jellyfin). Next, check Item Added, Playback Start, and Send All Properties. Last, "Add Request Header" and add the Key: `Content-Type` Value: `application/json`<br><br>Click Save and you should be all set!
|
| 157 |
+
|
| 158 |
+
## Variables
|
| 159 |
+
|
| 160 |
+
You can define the port via environment variables, but the endpoints are static.
|
| 161 |
+
|
| 162 |
+
The following environment variables are available in Docker. They will default to the values listed below.
|
| 163 |
+
| Variable | Default Value | Description |
|
| 164 |
+
|---------------------------|------------------------|-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
|
| 165 |
+
| TRANSCRIBE_DEVICE | 'cpu' | Can transcribe via gpu (Cuda only) or cpu. Takes option of "cpu", "gpu", "cuda". |
|
| 166 |
+
| WHISPER_MODEL | 'medium' | Can be:'tiny', 'tiny.en', 'base', 'base.en', 'small', 'small.en', 'medium', 'medium.en', 'large-v1','large-v2', 'large-v3', 'large', 'distil-large-v2', 'distil-large-v3', 'distil-medium.en', 'distil-small.en' |
|
| 167 |
+
| CONCURRENT_TRANSCRIPTIONS | 2 | Number of files it will transcribe in parallel |
|
| 168 |
+
| WHISPER_THREADS | 4 | number of threads to use during computation |
|
| 169 |
+
| MODEL_PATH | './models' | This is where the WHISPER_MODEL will be stored. This defaults to placing it where you execute the script in the folder 'models' |
|
| 170 |
+
| PROCADDEDMEDIA | True | will gen subtitles for all media added regardless of existing external/embedded subtitles (based off of SKIPIFINTERNALSUBLANG) |
|
| 171 |
+
| PROCMEDIAONPLAY | True | will gen subtitles for all played media regardless of existing external/embedded subtitles (based off of SKIPIFINTERNALSUBLANG) |
|
| 172 |
+
| NAMESUBLANG | 'aa' | allows you to pick what it will name the subtitle. Instead of using EN, I'm using AA, so it doesn't mix with exiting external EN subs, and AA will populate higher on the list in Plex. |
|
| 173 |
+
| SKIPIFINTERNALSUBLANG | 'eng' | Will not generate a subtitle if the file has an internal sub matching the 3 letter code of this variable (See https://en.wikipedia.org/wiki/List_of_ISO_639-1_codes) |
|
| 174 |
+
| WORD_LEVEL_HIGHLIGHT | False | Highlights each words as it's spoken in the subtitle. See example video @ https://github.com/jianfch/stable-ts |
|
| 175 |
+
| PLEXSERVER | 'http://plex:32400' | This needs to be set to your local plex server address/port |
|
| 176 |
+
| PLEXTOKEN | 'token here' | This needs to be set to your plex token found by https://support.plex.tv/articles/204059436-finding-an-authentication-token-x-plex-token/ |
|
| 177 |
+
| JELLYFINSERVER | 'http://jellyfin:8096' | Set to your Jellyfin server address/port |
|
| 178 |
+
| JELLYFINTOKEN | 'token here' | Generate a token inside the Jellyfin interface |
|
| 179 |
+
| WEBHOOKPORT | 9000 | Change this if you need a different port for your webhook |
|
| 180 |
+
| USE_PATH_MAPPING | False | Similar to sonarr and radarr path mapping, this will attempt to replace paths on file systems that don't have identical paths. Currently only support for one path replacement. Examples below. |
|
| 181 |
+
| PATH_MAPPING_FROM | '/tv' | This is the path of my media relative to my Plex server |
|
| 182 |
+
| PATH_MAPPING_TO | '/Volumes/TV' | This is the path of that same folder relative to my Mac Mini that will run the script |
|
| 183 |
+
| TRANSCRIBE_FOLDERS | '' | Takes a pipe '\|' separated list (For example: /tv\|/movies\|/familyvideos) and iterates through and adds those files to be queued for subtitle generation if they don't have internal subtitles |
|
| 184 |
+
| TRANSCRIBE_OR_TRANSLATE | 'transcribe' | Takes either 'transcribe' or 'translate'. Transcribe will transcribe the audio in the same language as the input. Translate will transcribe and translate into English. |
|
| 185 |
+
| COMPUTE_TYPE | 'auto' | Set compute-type using the following information: https://github.com/OpenNMT/CTranslate2/blob/master/docs/quantization.md |
|
| 186 |
+
| DEBUG | True | Provides some debug data that can be helpful to troubleshoot path mapping and other issues. Fun fact, if this is set to true, any modifications to the script will auto-reload it (if it isn't actively transcoding). Useful to make small tweaks without re-downloading the whole file. |
|
| 187 |
+
| FORCE_DETECTED_LANGUAGE_TO | '' | This is to force the model to a language instead of the detected one, takes a 2 letter language code. For example, your audio is French but keeps detecting as English, you would set it to 'fr' |
|
| 188 |
+
| CLEAR_VRAM_ON_COMPLETE | True | This will delete the model and do garbage collection when queue is empty. Good if you need to use the VRAM for something else. |
|
| 189 |
+
| UPDATE | False | Will pull latest subgen.py from the repository if True. False will use the original subgen.py built into the Docker image. Standalone users can use this with launcher.py to get updates. |
|
| 190 |
+
| APPEND | False | Will add the following at the end of a subtitle: "Transcribed by whisperAI with faster-whisper ({whisper_model}) on {datetime.now()}"
|
| 191 |
+
| MONITOR | False | Will monitor `TRANSCRIBE_FOLDERS` for real-time changes to see if we need to generate subtitles |
|
| 192 |
+
| USE_MODEL_PROMPT | False | When set to `True`, will use the default prompt stored in greetings_translations "Hello, welcome to my lecture." to try and force the use of punctuation in transcriptions that don't. Automatic `CUSTOM_MODEL_PROMPT` will only work with ASR, but can still be set manually like so: `USE_MODEL_PROMPT=True and CUSTOM_MODEL_PROMPT=Hello, welcome to my lecture.` |
|
| 193 |
+
| CUSTOM_MODEL_PROMPT | '' | If `USE_MODEL_PROMPT` is `True`, you can override the default prompt (See: https://medium.com/axinc-ai/prompt-engineering-in-whisper-6bb18003562d for great examples). |
|
| 194 |
+
| LRC_FOR_AUDIO_FILES | True | Will generate LRC (instead of SRT) files for filetypes: '.mp3', '.flac', '.wav', '.alac', '.ape', '.ogg', '.wma', '.m4a', '.m4b', '.aac', '.aiff' |
|
| 195 |
+
| CUSTOM_REGROUP | 'cm_sl=84_sl=42++++++1' | Attempts to regroup some of the segments to make a cleaner looking subtitle. See https://github.com/McCloudS/subgen/issues/68 for discussion. Set to blank if you want to use Stable-TS default regroups algorithm of `cm_sp=,* /,_sg=.5_mg=.3+3_sp=.* /。/?/?` |
|
| 196 |
+
| DETECT_LANGUAGE_LENGTH | 30 | Detect language on the first x seconds of the audio. |
|
| 197 |
+
|
| 198 |
+
### Images:
|
| 199 |
+
`mccloud/subgen:latest` is GPU or CPU <br>
|
| 200 |
+
`mccloud/subgen:cpu` is for CPU only (slightly smaller image)
|
| 201 |
+
<br><br>
|
| 202 |
+
|
| 203 |
+
# What are the limitations/problems?
|
| 204 |
+
|
| 205 |
+
* I made it and know nothing about formal deployment for python coding.
|
| 206 |
+
* It's using trained AI models to transcribe, so it WILL mess up
|
| 207 |
+
|
| 208 |
+
# What's next?
|
| 209 |
+
|
| 210 |
+
Fix documentation and make it prettier!
|
| 211 |
+
|
| 212 |
+
# Audio Languages Supported (via OpenAI)
|
| 213 |
+
|
| 214 |
+
Afrikaans, Arabic, Armenian, Azerbaijani, Belarusian, Bosnian, Bulgarian, Catalan, Chinese, Croatian, Czech, Danish, Dutch, English, Estonian, Finnish, French, Galician, German, Greek, Hebrew, Hindi, Hungarian, Icelandic, Indonesian, Italian, Japanese, Kannada, Kazakh, Korean, Latvian, Lithuanian, Macedonian, Malay, Marathi, Maori, Nepali, Norwegian, Persian, Polish, Portuguese, Romanian, Russian, Serbian, Slovak, Slovenian, Spanish, Swahili, Swedish, Tagalog, Tamil, Thai, Turkish, Ukrainian, Urdu, Vietnamese, and Welsh.
|
| 215 |
+
|
| 216 |
+
# Additional reading:
|
| 217 |
+
|
| 218 |
+
* https://github.com/openai/whisper (Original OpenAI project)
|
| 219 |
+
* https://en.wikipedia.org/wiki/List_of_ISO_639-1_codes (2 letter subtitle codes)
|
| 220 |
+
|
| 221 |
+
# Credits:
|
| 222 |
+
* Whisper.cpp (https://github.com/ggerganov/whisper.cpp) for original implementation
|
| 223 |
+
* Google
|
| 224 |
+
* ffmpeg
|
| 225 |
+
* https://github.com/jianfch/stable-ts
|
| 226 |
+
* https://github.com/guillaumekln/faster-whisper
|
| 227 |
+
* Whipser ASR Webservice (https://github.com/ahmetoner/whisper-asr-webservice) for how to implement Bazarr webhooks.
|
docker-compose.yml
ADDED
|
@@ -0,0 +1,40 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
#docker-compose.yml
|
| 2 |
+
version: '2'
|
| 3 |
+
services:
|
| 4 |
+
subgen:
|
| 5 |
+
container_name: subgen
|
| 6 |
+
tty: true
|
| 7 |
+
image: mccloud/subgen
|
| 8 |
+
environment:
|
| 9 |
+
- "WHISPER_MODEL=medium"
|
| 10 |
+
- "WHISPER_THREADS=4"
|
| 11 |
+
- "PROCADDEDMEDIA=True"
|
| 12 |
+
- "PROCMEDIAONPLAY=False"
|
| 13 |
+
- "NAMESUBLANG=aa"
|
| 14 |
+
- "SKIPIFINTERNALSUBLANG=eng"
|
| 15 |
+
- "PLEXTOKEN=plextoken"
|
| 16 |
+
- "PLEXSERVER=http://plexserver:32400"
|
| 17 |
+
- "JELLYFINTOKEN=token here"
|
| 18 |
+
- "JELLYFINSERVER=http://jellyfin:8096"
|
| 19 |
+
- "WEBHOOKPORT=9000"
|
| 20 |
+
- "CONCURRENT_TRANSCRIPTIONS=2"
|
| 21 |
+
- "WORD_LEVEL_HIGHLIGHT=False"
|
| 22 |
+
- "DEBUG=True"
|
| 23 |
+
- "USE_PATH_MAPPING=False"
|
| 24 |
+
- "PATH_MAPPING_FROM=/tv"
|
| 25 |
+
- "PATH_MAPPING_TO=/Volumes/TV"
|
| 26 |
+
- "TRANSCRIBE_DEVICE=cpu"
|
| 27 |
+
- "CLEAR_VRAM_ON_COMPLETE=True"
|
| 28 |
+
- "MODEL_PATH=./models"
|
| 29 |
+
- "UPDATE=False"
|
| 30 |
+
- "APPEND=False"
|
| 31 |
+
- "USE_MODEL_PROMPT=False"
|
| 32 |
+
- "CUSTOM_MODEL_PROMPT="
|
| 33 |
+
- "LRC_FOR_AUDIO_FILES=True"
|
| 34 |
+
- "CUSTOM_REGROUP=cm_sl=84_sl=42++++++1"
|
| 35 |
+
volumes:
|
| 36 |
+
- "${TV}:/tv"
|
| 37 |
+
- "${MOVIES}:/movies"
|
| 38 |
+
- "${APPDATA}/subgen/models:/subgen/models"
|
| 39 |
+
ports:
|
| 40 |
+
- "9000:9000"
|
icon.png
ADDED
|
|
launcher.py
ADDED
|
@@ -0,0 +1,168 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import os
|
| 2 |
+
import sys
|
| 3 |
+
import urllib.request
|
| 4 |
+
import subprocess
|
| 5 |
+
import argparse
|
| 6 |
+
|
| 7 |
+
def convert_to_bool(in_bool):
|
| 8 |
+
# Convert the input to string and lower case, then check against true values
|
| 9 |
+
return str(in_bool).lower() in ('true', 'on', '1', 'y', 'yes')
|
| 10 |
+
|
| 11 |
+
def install_packages_from_requirements(requirements_file):
|
| 12 |
+
try:
|
| 13 |
+
# Try installing with pip3
|
| 14 |
+
subprocess.run(['pip3', 'install', '-r', requirements_file, '--upgrade'], check=True)
|
| 15 |
+
print("Packages installed successfully using pip3.")
|
| 16 |
+
except subprocess.CalledProcessError:
|
| 17 |
+
try:
|
| 18 |
+
# If pip3 fails, try installing with pip
|
| 19 |
+
subprocess.run(['pip', 'install', '-r', requirements_file, '--upgrade'], check=True)
|
| 20 |
+
print("Packages installed successfully using pip.")
|
| 21 |
+
except subprocess.CalledProcessError:
|
| 22 |
+
print("Failed to install packages using both pip3 and pip.")
|
| 23 |
+
|
| 24 |
+
def download_from_github(url, output_file):
|
| 25 |
+
try:
|
| 26 |
+
with urllib.request.urlopen(url) as response, open(output_file, 'wb') as out_file:
|
| 27 |
+
data = response.read() # a `bytes` object
|
| 28 |
+
out_file.write(data)
|
| 29 |
+
print(f"File downloaded successfully to {output_file}")
|
| 30 |
+
except urllib.error.HTTPError as e:
|
| 31 |
+
print(f"Failed to download file from {url}. HTTP Error Code: {e.code}")
|
| 32 |
+
except urllib.error.URLError as e:
|
| 33 |
+
print(f"URL Error: {e.reason}")
|
| 34 |
+
except Exception as e:
|
| 35 |
+
print(f"An error occurred: {e}")
|
| 36 |
+
|
| 37 |
+
def prompt_and_save_bazarr_env_variables():
|
| 38 |
+
"""
|
| 39 |
+
Prompts the user for Bazarr related environment variables with descriptions and saves them to a file.
|
| 40 |
+
If the user does not input anything, default values are used.
|
| 41 |
+
"""
|
| 42 |
+
# Instructions for the user
|
| 43 |
+
instructions = (
|
| 44 |
+
"You will be prompted for several configuration values.\n"
|
| 45 |
+
"If you wish to use the default value for any of them, simply press Enter without typing anything.\n"
|
| 46 |
+
"The default values are shown in brackets [] next to the prompts.\n"
|
| 47 |
+
"Items can be the value of true, on, 1, y, yes, false, off, 0, n, no, or an appropriate text response.\n"
|
| 48 |
+
)
|
| 49 |
+
print(instructions)
|
| 50 |
+
env_vars = {
|
| 51 |
+
'WHISPER_MODEL': ('Whisper Model', 'Enter the Whisper model you want to run: tiny, tiny.en, base, base.en, small, small.en, medium, medium.en, large, distil-large-v2, distil-medium.en, distil-small.en', 'medium'),
|
| 52 |
+
'WEBHOOKPORT': ('Webhook Port', 'Default listening port for subgen.py', '9000'),
|
| 53 |
+
'TRANSCRIBE_DEVICE': ('Transcribe Device', 'Set as cpu or gpu', 'gpu'),
|
| 54 |
+
'DEBUG': ('Debug', 'Enable debug logging', 'True'),
|
| 55 |
+
'CLEAR_VRAM_ON_COMPLETE': ('Clear VRAM', 'Attempt to clear VRAM when complete (Windows users may need to set this to False)', 'False'),
|
| 56 |
+
'APPEND': ('Append', 'Append \'Transcribed by whisper\' to generated subtitle', 'False'),
|
| 57 |
+
}
|
| 58 |
+
|
| 59 |
+
# Dictionary to hold the user's input
|
| 60 |
+
user_input = {}
|
| 61 |
+
|
| 62 |
+
# Prompt the user for each environment variable and write to .env file
|
| 63 |
+
with open('subgen.env', 'w') as file:
|
| 64 |
+
for var, (description, prompt, default) in env_vars.items():
|
| 65 |
+
value = input(f"{prompt} [{default}]: ") or default
|
| 66 |
+
file.write(f"{var}={value}\n")
|
| 67 |
+
|
| 68 |
+
print("Environment variables have been saved to subgen.env")
|
| 69 |
+
|
| 70 |
+
def load_env_variables(env_filename='subgen.env'):
|
| 71 |
+
"""
|
| 72 |
+
Loads environment variables from a specified .env file and sets them.
|
| 73 |
+
"""
|
| 74 |
+
try:
|
| 75 |
+
with open(env_filename, 'r') as file:
|
| 76 |
+
for line in file:
|
| 77 |
+
var, value = line.strip().split('=', 1)
|
| 78 |
+
os.environ[var] = value
|
| 79 |
+
|
| 80 |
+
print(f"Environment variables have been loaded from {env_filename}")
|
| 81 |
+
|
| 82 |
+
except FileNotFoundError:
|
| 83 |
+
print(f"{env_filename} file not found. Please run prompt_and_save_env_variables() first.")
|
| 84 |
+
|
| 85 |
+
def main():
|
| 86 |
+
# Check if the script is run with 'python' or 'python3'
|
| 87 |
+
if 'python3' in sys.executable:
|
| 88 |
+
python_cmd = 'python3'
|
| 89 |
+
elif 'python' in sys.executable:
|
| 90 |
+
python_cmd = 'python'
|
| 91 |
+
else:
|
| 92 |
+
print("Script started with an unknown command")
|
| 93 |
+
sys.exit(1)
|
| 94 |
+
if sys.version_info[0] < 3:
|
| 95 |
+
print(f"This script requires Python 3 or higher, you are running {sys.version}")
|
| 96 |
+
sys.exit(1) # Terminate the script
|
| 97 |
+
|
| 98 |
+
#Make sure we're saving subgen.py and subgen.env in the right folder
|
| 99 |
+
os.chdir(os.path.dirname(os.path.abspath(__file__)))
|
| 100 |
+
|
| 101 |
+
# Construct the argument parser
|
| 102 |
+
parser = argparse.ArgumentParser(prog="python launcher.py", formatter_class=argparse.ArgumentDefaultsHelpFormatter)
|
| 103 |
+
parser.add_argument('-d', '--debug', default=False, action='store_true', help="Enable console debugging")
|
| 104 |
+
parser.add_argument('-i', '--install', default=False, action='store_true', help="Install/update all necessary packages")
|
| 105 |
+
parser.add_argument('-a', '--append', default=False, action='store_true', help="Append 'Transcribed by whisper' to generated subtitle")
|
| 106 |
+
parser.add_argument('-u', '--update', default=False, action='store_true', help="Update Subgen")
|
| 107 |
+
parser.add_argument('-x', '--exit-early', default=False, action='store_true', help="Exit without running subgen.py")
|
| 108 |
+
parser.add_argument('-s', '--setup-bazarr', default=False, action='store_true', help="Prompt for common Bazarr setup parameters and save them for future runs")
|
| 109 |
+
parser.add_argument('-b', '--branch', type=str, default='main', help='Specify the branch to download from')
|
| 110 |
+
parser.add_argument('-l', '--launcher-update', default=False, action='store_true', help="Update launcher.py and re-launch")
|
| 111 |
+
|
| 112 |
+
args = parser.parse_args()
|
| 113 |
+
|
| 114 |
+
# Get the branch name from the BRANCH environment variable or default to 'main'
|
| 115 |
+
branch_name = args.branch if args.branch != 'main' else os.getenv('BRANCH', 'main')
|
| 116 |
+
# Determine the script name based on the branch name
|
| 117 |
+
script_name = f"-{branch_name}.py" if branch_name != "main" else ".py"
|
| 118 |
+
# Check we need to update the launcher
|
| 119 |
+
|
| 120 |
+
if args.launcher_update or convert_to_bool(os.getenv('LAUNCHER_UPDATE')):
|
| 121 |
+
print(f"Updating launcher.py from GitHub branch {branch_name}...")
|
| 122 |
+
download_from_github(f"https://raw.githubusercontent.com/McCloudS/subgen/{branch_name}/launcher.py", f'launcher{script_name}')
|
| 123 |
+
|
| 124 |
+
# Prepare the arguments to exclude update triggers
|
| 125 |
+
excluded_args = ['--launcher-update', '-l']
|
| 126 |
+
new_args = [arg for arg in sys.argv[1:] if arg not in excluded_args]
|
| 127 |
+
if branch_name == 'main' and args.launcher_update:
|
| 128 |
+
print("Running launcher.py for the 'main' branch.")
|
| 129 |
+
os.execl(sys.executable, sys.executable, "launcher.py", *new_args)
|
| 130 |
+
elif args.launcher_update:
|
| 131 |
+
print(f"Running launcher-{branch_name}.py for the '{branch_name}' branch.")
|
| 132 |
+
os.execl(sys.executable, sys.executable, f"launcher{script_name}", *new_args)
|
| 133 |
+
|
| 134 |
+
# Set environment variables based on the parsed arguments
|
| 135 |
+
os.environ['DEBUG'] = str(args.debug)
|
| 136 |
+
os.environ['APPEND'] = str(args.append)
|
| 137 |
+
|
| 138 |
+
if args.setup_bazarr:
|
| 139 |
+
prompt_and_save_bazarr_env_variables()
|
| 140 |
+
load_env_variables()
|
| 141 |
+
|
| 142 |
+
# URL to the requirements.txt file on GitHub
|
| 143 |
+
requirements_url = "https://raw.githubusercontent.com/McCloudS/subgen/main/requirements.txt"
|
| 144 |
+
requirements_file = "requirements.txt"
|
| 145 |
+
|
| 146 |
+
# Install packages from requirements.txt if the install or packageupdate argument is True
|
| 147 |
+
if args.install:
|
| 148 |
+
download_from_github(requirements_url, requirements_file)
|
| 149 |
+
install_packages_from_requirements(requirements_file)
|
| 150 |
+
|
| 151 |
+
# Check if the script exists or if the UPDATE environment variable is set to True
|
| 152 |
+
if not os.path.exists(f'subgen{script_name}') or args.update or convert_to_bool(os.getenv('UPDATE')):
|
| 153 |
+
print(f"Downloading subgen.py from GitHub branch {branch_name}...")
|
| 154 |
+
download_from_github(f"https://raw.githubusercontent.com/McCloudS/subgen/{branch_name}/subgen.py", f'subgen{script_name}')
|
| 155 |
+
else:
|
| 156 |
+
print("subgen.py exists and UPDATE is set to False, skipping download.")
|
| 157 |
+
|
| 158 |
+
if not args.exit_early:
|
| 159 |
+
print(f'Launching subgen{script_name}')
|
| 160 |
+
if branch_name != 'main':
|
| 161 |
+
subprocess.run([f'{python_cmd}', '-u', f'subgen{script_name}'], check=True)
|
| 162 |
+
else:
|
| 163 |
+
subprocess.run([f'{python_cmd}', '-u', 'subgen.py'], check=True)
|
| 164 |
+
else:
|
| 165 |
+
print("Not running subgen.py: -x or --exit-early set")
|
| 166 |
+
|
| 167 |
+
if __name__ == "__main__":
|
| 168 |
+
main()
|
requirements.txt
ADDED
|
@@ -0,0 +1,10 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
numpy
|
| 2 |
+
stable-ts
|
| 3 |
+
fastapi
|
| 4 |
+
requests
|
| 5 |
+
faster-whisper
|
| 6 |
+
uvicorn
|
| 7 |
+
python-multipart
|
| 8 |
+
python-ffmpeg
|
| 9 |
+
whisper
|
| 10 |
+
watchdog
|
subgen.env
ADDED
|
@@ -0,0 +1,6 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
WHISPER_MODEL=medium
|
| 2 |
+
WEBHOOKPORT=9000
|
| 3 |
+
TRANSCRIBE_DEVICE=gpu
|
| 4 |
+
DEBUG=True
|
| 5 |
+
CLEAR_VRAM_ON_COMPLETE=False
|
| 6 |
+
APPEND=False
|
subgen.py
ADDED
|
@@ -0,0 +1,1045 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
subgen_version = '2024.5.15.78'
|
| 2 |
+
|
| 3 |
+
from datetime import datetime
|
| 4 |
+
import subprocess
|
| 5 |
+
import os
|
| 6 |
+
import json
|
| 7 |
+
import xml.etree.ElementTree as ET
|
| 8 |
+
import threading
|
| 9 |
+
import sys
|
| 10 |
+
import time
|
| 11 |
+
import queue
|
| 12 |
+
import logging
|
| 13 |
+
import gc
|
| 14 |
+
import io
|
| 15 |
+
import random
|
| 16 |
+
from typing import BinaryIO, Union, Any
|
| 17 |
+
from fastapi import FastAPI, File, UploadFile, Query, Header, Body, Form, Request
|
| 18 |
+
from fastapi.responses import StreamingResponse, RedirectResponse, HTMLResponse
|
| 19 |
+
import numpy as np
|
| 20 |
+
import stable_whisper
|
| 21 |
+
from stable_whisper import Segment
|
| 22 |
+
import requests
|
| 23 |
+
import av
|
| 24 |
+
import ffmpeg
|
| 25 |
+
import whisper
|
| 26 |
+
import re
|
| 27 |
+
from watchdog.observers.polling import PollingObserver as Observer
|
| 28 |
+
from watchdog.events import FileSystemEventHandler
|
| 29 |
+
import faster_whisper
|
| 30 |
+
|
| 31 |
+
def get_key_by_value(d, value):
|
| 32 |
+
reverse_dict = {v: k for k, v in d.items()}
|
| 33 |
+
return reverse_dict.get(value)
|
| 34 |
+
|
| 35 |
+
def convert_to_bool(in_bool):
|
| 36 |
+
# Convert the input to string and lower case, then check against true values
|
| 37 |
+
return str(in_bool).lower() in ('true', 'on', '1', 'y', 'yes')
|
| 38 |
+
|
| 39 |
+
# Function to read environment variables from a file and return them as a dictionary
|
| 40 |
+
def get_env_variables_from_file(filename):
|
| 41 |
+
env_vars = {}
|
| 42 |
+
try:
|
| 43 |
+
with open(filename, 'r') as file:
|
| 44 |
+
for line in file:
|
| 45 |
+
if line.strip() and not line.startswith('#'):
|
| 46 |
+
key, value = line.strip().split('=', 1)
|
| 47 |
+
env_vars[key.strip()] = value.strip()
|
| 48 |
+
except FileNotFoundError:
|
| 49 |
+
print(f"File {filename} not found. Using default values.")
|
| 50 |
+
return env_vars
|
| 51 |
+
|
| 52 |
+
def set_env_variables(filename):
|
| 53 |
+
try:
|
| 54 |
+
with open(filename, 'r') as file:
|
| 55 |
+
for line in file:
|
| 56 |
+
if line.strip() and not line.startswith('#'):
|
| 57 |
+
key, value = line.strip().split('=', 1)
|
| 58 |
+
os.environ[key.strip()] = value.strip().strip('\"').strip("'")
|
| 59 |
+
except FileNotFoundError:
|
| 60 |
+
print(f"File {filename} not found. Environment variables not set.")
|
| 61 |
+
|
| 62 |
+
def update_env_variables():
|
| 63 |
+
global plextoken, plexserver, jellyfintoken, jellyfinserver, whisper_model, whisper_threads
|
| 64 |
+
global concurrent_transcriptions, transcribe_device, procaddedmedia, procmediaonplay
|
| 65 |
+
global namesublang, skipifinternalsublang, webhookport, word_level_highlight, debug
|
| 66 |
+
global use_path_mapping, path_mapping_from, path_mapping_to, model_location, monitor
|
| 67 |
+
global transcribe_folders, transcribe_or_translate, force_detected_language_to
|
| 68 |
+
global clear_vram_on_complete, compute_type, append, reload_script_on_change
|
| 69 |
+
global model_prompt, custom_model_prompt, lrc_for_audio_files, custom_regroup
|
| 70 |
+
global subextension, subextensionSDH, detect_language_length
|
| 71 |
+
|
| 72 |
+
plextoken = os.getenv('PLEXTOKEN', 'token here')
|
| 73 |
+
plexserver = os.getenv('PLEXSERVER', 'http://192.168.1.111:32400')
|
| 74 |
+
jellyfintoken = os.getenv('JELLYFINTOKEN', 'token here')
|
| 75 |
+
jellyfinserver = os.getenv('JELLYFINSERVER', 'http://192.168.1.111:8096')
|
| 76 |
+
whisper_model = os.getenv('WHISPER_MODEL', 'medium')
|
| 77 |
+
whisper_threads = int(os.getenv('WHISPER_THREADS', 4))
|
| 78 |
+
concurrent_transcriptions = int(os.getenv('CONCURRENT_TRANSCRIPTIONS', 2))
|
| 79 |
+
transcribe_device = os.getenv('TRANSCRIBE_DEVICE', 'cpu')
|
| 80 |
+
procaddedmedia = convert_to_bool(os.getenv('PROCADDEDMEDIA', True))
|
| 81 |
+
procmediaonplay = convert_to_bool(os.getenv('PROCMEDIAONPLAY', True))
|
| 82 |
+
namesublang = os.getenv('NAMESUBLANG', 'aa')
|
| 83 |
+
skipifinternalsublang = os.getenv('SKIPIFINTERNALSUBLANG', 'eng')
|
| 84 |
+
webhookport = int(os.getenv('WEBHOOKPORT', 9000))
|
| 85 |
+
word_level_highlight = convert_to_bool(os.getenv('WORD_LEVEL_HIGHLIGHT', False))
|
| 86 |
+
debug = convert_to_bool(os.getenv('DEBUG', True))
|
| 87 |
+
use_path_mapping = convert_to_bool(os.getenv('USE_PATH_MAPPING', False))
|
| 88 |
+
path_mapping_from = os.getenv('PATH_MAPPING_FROM', r'/tv')
|
| 89 |
+
path_mapping_to = os.getenv('PATH_MAPPING_TO', r'/Volumes/TV')
|
| 90 |
+
model_location = os.getenv('MODEL_PATH', './models')
|
| 91 |
+
monitor = convert_to_bool(os.getenv('MONITOR', False))
|
| 92 |
+
transcribe_folders = os.getenv('TRANSCRIBE_FOLDERS', '')
|
| 93 |
+
transcribe_or_translate = os.getenv('TRANSCRIBE_OR_TRANSLATE', 'transcribe')
|
| 94 |
+
force_detected_language_to = os.getenv('FORCE_DETECTED_LANGUAGE_TO', '').lower()
|
| 95 |
+
clear_vram_on_complete = convert_to_bool(os.getenv('CLEAR_VRAM_ON_COMPLETE', True))
|
| 96 |
+
compute_type = os.getenv('COMPUTE_TYPE', 'auto')
|
| 97 |
+
append = convert_to_bool(os.getenv('APPEND', False))
|
| 98 |
+
reload_script_on_change = convert_to_bool(os.getenv('RELOAD_SCRIPT_ON_CHANGE', False))
|
| 99 |
+
model_prompt = os.getenv('USE_MODEL_PROMPT', 'False')
|
| 100 |
+
custom_model_prompt = os.getenv('CUSTOM_MODEL_PROMPT', '')
|
| 101 |
+
lrc_for_audio_files = convert_to_bool(os.getenv('LRC_FOR_AUDIO_FILES', True))
|
| 102 |
+
custom_regroup = os.getenv('CUSTOM_REGROUP', 'cm_sl=84_sl=42++++++1')
|
| 103 |
+
detect_language_length = os.getenv('DETECT_LANGUAGE_LENGTH', 30)
|
| 104 |
+
|
| 105 |
+
set_env_variables('subgen.env')
|
| 106 |
+
|
| 107 |
+
if transcribe_device == "gpu":
|
| 108 |
+
transcribe_device = "cuda"
|
| 109 |
+
|
| 110 |
+
subextension = f".subgen.{whisper_model.split('.')[0]}.{namesublang}.srt"
|
| 111 |
+
subextensionSDH = f".subgen.{whisper_model.split('.')[0]}.{namesublang}.sdh.srt"
|
| 112 |
+
|
| 113 |
+
update_env_variables()
|
| 114 |
+
|
| 115 |
+
app = FastAPI()
|
| 116 |
+
model = None
|
| 117 |
+
|
| 118 |
+
in_docker = os.path.exists('/.dockerenv')
|
| 119 |
+
docker_status = "Docker" if in_docker else "Standalone"
|
| 120 |
+
last_print_time = None
|
| 121 |
+
|
| 122 |
+
#start queue
|
| 123 |
+
global task_queue
|
| 124 |
+
task_queue = queue.Queue()
|
| 125 |
+
|
| 126 |
+
def transcription_worker():
|
| 127 |
+
while True:
|
| 128 |
+
task = task_queue.get()
|
| 129 |
+
if 'Bazarr-' in task['path']:
|
| 130 |
+
logging.info(f"{task['path']} is being handled handled by ASR.")
|
| 131 |
+
else:
|
| 132 |
+
gen_subtitles(task['path'], task['transcribe_or_translate'], task['force_language'])
|
| 133 |
+
task_queue.task_done()
|
| 134 |
+
# show queue
|
| 135 |
+
logging.debug(f"There are {task_queue.qsize()} tasks left in the queue.")
|
| 136 |
+
|
| 137 |
+
for _ in range(concurrent_transcriptions):
|
| 138 |
+
threading.Thread(target=transcription_worker, daemon=True).start()
|
| 139 |
+
|
| 140 |
+
# Define a filter class
|
| 141 |
+
class MultiplePatternsFilter(logging.Filter):
|
| 142 |
+
def filter(self, record):
|
| 143 |
+
# Define the patterns to search for
|
| 144 |
+
patterns = [
|
| 145 |
+
"Compression ratio threshold is not met",
|
| 146 |
+
"Processing segment at",
|
| 147 |
+
"Log probability threshold is",
|
| 148 |
+
"Reset prompt",
|
| 149 |
+
"Attempting to release",
|
| 150 |
+
"released on ",
|
| 151 |
+
"Attempting to acquire",
|
| 152 |
+
"acquired on",
|
| 153 |
+
"header parsing failed",
|
| 154 |
+
"timescale not set",
|
| 155 |
+
"misdetection possible",
|
| 156 |
+
"srt was added",
|
| 157 |
+
"doesn't have any audio to transcribe",
|
| 158 |
+
]
|
| 159 |
+
# Return False if any of the patterns are found, True otherwise
|
| 160 |
+
return not any(pattern in record.getMessage() for pattern in patterns)
|
| 161 |
+
|
| 162 |
+
# Configure logging
|
| 163 |
+
if debug:
|
| 164 |
+
level = logging.DEBUG
|
| 165 |
+
logging.basicConfig(stream=sys.stderr, level=level, format="%(asctime)s %(levelname)s: %(message)s")
|
| 166 |
+
else:
|
| 167 |
+
level = logging.INFO
|
| 168 |
+
logging.basicConfig(stream=sys.stderr, level=level)
|
| 169 |
+
|
| 170 |
+
# Get the root logger
|
| 171 |
+
logger = logging.getLogger()
|
| 172 |
+
logger.setLevel(level) # Set the logger level
|
| 173 |
+
|
| 174 |
+
for handler in logger.handlers:
|
| 175 |
+
handler.addFilter(MultiplePatternsFilter())
|
| 176 |
+
|
| 177 |
+
logging.getLogger("multipart").setLevel(logging.WARNING)
|
| 178 |
+
logging.getLogger("urllib3").setLevel(logging.WARNING)
|
| 179 |
+
logging.getLogger("asyncio").setLevel(logging.WARNING)
|
| 180 |
+
logging.getLogger("watchfiles").setLevel(logging.WARNING)
|
| 181 |
+
|
| 182 |
+
#This forces a flush to print progress correctly
|
| 183 |
+
def progress(seek, total):
|
| 184 |
+
sys.stdout.flush()
|
| 185 |
+
sys.stderr.flush()
|
| 186 |
+
if(docker_status) == 'Docker':
|
| 187 |
+
global last_print_time
|
| 188 |
+
# Get the current time
|
| 189 |
+
current_time = time.time()
|
| 190 |
+
|
| 191 |
+
# Check if 5 seconds have passed since the last print
|
| 192 |
+
if last_print_time is None or (current_time - last_print_time) >= 5:
|
| 193 |
+
# Update the last print time
|
| 194 |
+
last_print_time = current_time
|
| 195 |
+
# Log the message
|
| 196 |
+
logging.info("Force Update...")
|
| 197 |
+
|
| 198 |
+
TIME_OFFSET = 5
|
| 199 |
+
|
| 200 |
+
def appendLine(result):
|
| 201 |
+
if append:
|
| 202 |
+
lastSegment = result.segments[-1]
|
| 203 |
+
date_time_str = datetime.now().strftime("%d %b %Y - %H:%M:%S")
|
| 204 |
+
appended_text = f"Transcribed by whisperAI with faster-whisper ({whisper_model}) on {date_time_str}"
|
| 205 |
+
|
| 206 |
+
# Create a new segment with the updated information
|
| 207 |
+
newSegment = Segment(
|
| 208 |
+
start=lastSegment.start + TIME_OFFSET,
|
| 209 |
+
end=lastSegment.end + TIME_OFFSET,
|
| 210 |
+
text=appended_text,
|
| 211 |
+
words=[], # Empty list for words
|
| 212 |
+
id=lastSegment.id + 1
|
| 213 |
+
)
|
| 214 |
+
|
| 215 |
+
# Append the new segment to the result's segments
|
| 216 |
+
result.segments.append(newSegment)
|
| 217 |
+
|
| 218 |
+
@app.get("/plex")
|
| 219 |
+
@app.get("/webhook")
|
| 220 |
+
@app.get("/jellyfin")
|
| 221 |
+
@app.get("/asr")
|
| 222 |
+
@app.get("/emby")
|
| 223 |
+
@app.get("/detect-language")
|
| 224 |
+
@app.get("/tautulli")
|
| 225 |
+
def handle_get_request(request: Request):
|
| 226 |
+
return {"You accessed this request incorrectly via a GET request. See https://github.com/McCloudS/subgen for proper configuration"}
|
| 227 |
+
|
| 228 |
+
@app.get("/status")
|
| 229 |
+
def status():
|
| 230 |
+
return {"version" : f"Subgen {subgen_version}, stable-ts {stable_whisper.__version__}, faster-whisper {faster_whisper.__version__} ({docker_status})"}
|
| 231 |
+
|
| 232 |
+
# Function to generate HTML form with values filled from the environment file
|
| 233 |
+
@app.get("/", response_class=HTMLResponse)
|
| 234 |
+
def form_get():
|
| 235 |
+
# Read the environment variables from the file
|
| 236 |
+
env_values = get_env_variables_from_file('subgen.env')
|
| 237 |
+
html_content = "<html><head><title>Subgen settings!</title></head><body>"
|
| 238 |
+
html_content += '<img src="https://raw.githubusercontent.com/McCloudS/subgen/main/icon.png" alt="Header Image" style="display: block; margin-left: auto; margin-right: auto; width: 10%;">'
|
| 239 |
+
html_content += "<html><body><form action=\"/submit\" method=\"post\">"
|
| 240 |
+
|
| 241 |
+
for var_name, var_info in env_variables.items():
|
| 242 |
+
value = os.getenv(var_name, env_values.get(var_name, var_info['default'])) if not isinstance(var_info['default'], bool) else convert_to_bool(os.getenv(var_name, env_values.get(var_name, var_info['default'])))
|
| 243 |
+
# Generate the HTML content
|
| 244 |
+
html_content += f"<br><div><strong>{var_name}</strong>: {var_info['description']} (<strong>default: {var_info['default']}</strong>)<br>"
|
| 245 |
+
if var_name == "TRANSCRIBE_OR_TRANSLATE":
|
| 246 |
+
html_content += f"<select name=\"{var_name}\">"
|
| 247 |
+
html_content += f"<option value=\"transcribe\"{' selected' if value == 'transcribe' else ''}>Transcribe</option>"
|
| 248 |
+
html_content += f"<option value=\"translate\"{' selected' if value == 'translate' else ''}>Translate</option>"
|
| 249 |
+
html_content += "</select><br>"
|
| 250 |
+
elif isinstance(var_info['default'], bool):
|
| 251 |
+
html_content += f"<select name=\"{var_name}\">"
|
| 252 |
+
html_content += f"<option value=\"True\"{' selected' if value else ''}>True</option>"
|
| 253 |
+
html_content += f"<option value=\"False\"{' selected' if not value else ''}>False</option>"
|
| 254 |
+
html_content += "</select><br>"
|
| 255 |
+
else:
|
| 256 |
+
value = value if value != var_info['default'] else ''
|
| 257 |
+
html_content += f"<input type=\"text\" name=\"{var_name}\" value=\"{value}\" placeholder=\"{var_info['default']}\" style=\"width: 200px;\"/></div>"
|
| 258 |
+
|
| 259 |
+
html_content += "<br><input type=\"submit\" value=\"Save as subgen.env and reload\"/></form></body></html>"
|
| 260 |
+
return html_content
|
| 261 |
+
|
| 262 |
+
|
| 263 |
+
@app.post("/submit")
|
| 264 |
+
async def form_post(request: Request):
|
| 265 |
+
env_path = 'subgen.env'
|
| 266 |
+
form_data = await request.form()
|
| 267 |
+
# Read the existing content of the file
|
| 268 |
+
try:
|
| 269 |
+
with open(env_path, "r") as file:
|
| 270 |
+
lines = file.readlines()
|
| 271 |
+
except FileNotFoundError:
|
| 272 |
+
lines = []
|
| 273 |
+
|
| 274 |
+
# Create a dictionary of existing variables
|
| 275 |
+
existing_vars = {}
|
| 276 |
+
for line in lines:
|
| 277 |
+
if "=" in line:
|
| 278 |
+
var, val = line.split("=", 1)
|
| 279 |
+
existing_vars[var.strip()] = val.strip()
|
| 280 |
+
|
| 281 |
+
# Update the file with new values from the form
|
| 282 |
+
with open(env_path, "w") as file:
|
| 283 |
+
for key, value in form_data.items():
|
| 284 |
+
# Normalize the key to uppercase
|
| 285 |
+
key = key.upper()
|
| 286 |
+
# Convert the value to the correct type (boolean or string)
|
| 287 |
+
value = value.strip() if not isinstance(env_variables[key]["default"], bool) else convert_to_bool(value.strip())
|
| 288 |
+
# Retrieve the current environment variable value
|
| 289 |
+
env_value = os.getenv(key)
|
| 290 |
+
if key in os.environ:
|
| 291 |
+
del os.environ[key]
|
| 292 |
+
# Write to file only if the value is different from the os.getenv and has a value
|
| 293 |
+
if env_value != value and (value is not None and value != '') and (env_variables[key]["default"] != value):
|
| 294 |
+
# Update the existing variable with the new value
|
| 295 |
+
existing_vars[key] = str(value)
|
| 296 |
+
# Update the environment variable
|
| 297 |
+
os.environ[key] = str(value)
|
| 298 |
+
|
| 299 |
+
# Write the updated variables to the file
|
| 300 |
+
for var, val in existing_vars.items():
|
| 301 |
+
file.write(f"{var}={val}\n")
|
| 302 |
+
|
| 303 |
+
update_env_variables()
|
| 304 |
+
return f"Configuration saved to {env_path}, reloading your subgen with your new values!"
|
| 305 |
+
|
| 306 |
+
|
| 307 |
+
@app.post("/tautulli")
|
| 308 |
+
def receive_tautulli_webhook(
|
| 309 |
+
source: Union[str, None] = Header(None),
|
| 310 |
+
event: str = Body(None),
|
| 311 |
+
file: str = Body(None),
|
| 312 |
+
):
|
| 313 |
+
if source == "Tautulli":
|
| 314 |
+
logging.debug(f"Tautulli event detected is: {event}")
|
| 315 |
+
if((event == "added" and procaddedmedia) or (event == "played" and procmediaonplay)):
|
| 316 |
+
fullpath = file
|
| 317 |
+
logging.debug("Path of file: " + fullpath)
|
| 318 |
+
|
| 319 |
+
gen_subtitles_queue(path_mapping(fullpath), transcribe_or_translate)
|
| 320 |
+
else:
|
| 321 |
+
return {
|
| 322 |
+
"message": "This doesn't appear to be a properly configured Tautulli webhook, please review the instructions again!"}
|
| 323 |
+
|
| 324 |
+
return ""
|
| 325 |
+
|
| 326 |
+
|
| 327 |
+
@app.post("/plex")
|
| 328 |
+
def receive_plex_webhook(
|
| 329 |
+
user_agent: Union[str] = Header(None),
|
| 330 |
+
payload: Union[str] = Form(),
|
| 331 |
+
):
|
| 332 |
+
try:
|
| 333 |
+
plex_json = json.loads(payload)
|
| 334 |
+
logging.debug(f"Raw response: {payload}")
|
| 335 |
+
|
| 336 |
+
if "PlexMediaServer" not in user_agent:
|
| 337 |
+
return {"message": "This doesn't appear to be a properly configured Plex webhook, please review the instructions again"}
|
| 338 |
+
|
| 339 |
+
event = plex_json["event"]
|
| 340 |
+
logging.debug(f"Plex event detected is: {event}")
|
| 341 |
+
|
| 342 |
+
if (event in ["library.new", "media.play"] and (procaddedmedia or procmediaonplay)):
|
| 343 |
+
fullpath = get_plex_file_name(plex_json['Metadata']['ratingKey'], plexserver, plextoken)
|
| 344 |
+
logging.debug("Path of file: " + fullpath)
|
| 345 |
+
|
| 346 |
+
gen_subtitles_queue(path_mapping(fullpath), transcribe_or_translate)
|
| 347 |
+
refresh_plex_metadata(plex_json['Metadata']['ratingKey'], plexserver, plextoken)
|
| 348 |
+
logging.info(f"Metadata for item {plex_json['Metadata']['ratingKey']} refreshed successfully.")
|
| 349 |
+
except Exception as e:
|
| 350 |
+
logging.error(f"Failed to process Plex webhook: {e}")
|
| 351 |
+
|
| 352 |
+
return ""
|
| 353 |
+
|
| 354 |
+
|
| 355 |
+
@app.post("/jellyfin")
|
| 356 |
+
def receive_jellyfin_webhook(
|
| 357 |
+
user_agent: str = Header(None),
|
| 358 |
+
NotificationType: str = Body(None),
|
| 359 |
+
file: str = Body(None),
|
| 360 |
+
ItemId: str = Body(None),
|
| 361 |
+
):
|
| 362 |
+
if "Jellyfin-Server" in user_agent:
|
| 363 |
+
logging.debug(f"Jellyfin event detected is: {NotificationType}")
|
| 364 |
+
logging.debug(f"itemid is: {ItemId}")
|
| 365 |
+
|
| 366 |
+
if (NotificationType == "ItemAdded" and procaddedmedia) or (
|
| 367 |
+
NotificationType == "PlaybackStart" and procmediaonplay):
|
| 368 |
+
fullpath = get_jellyfin_file_name(ItemId, jellyfinserver, jellyfintoken)
|
| 369 |
+
logging.debug(f"Path of file: {fullpath}")
|
| 370 |
+
|
| 371 |
+
gen_subtitles_queue(path_mapping(fullpath), transcribe_or_translate)
|
| 372 |
+
try:
|
| 373 |
+
refresh_jellyfin_metadata(ItemId, jellyfinserver, jellyfintoken)
|
| 374 |
+
logging.info(f"Metadata for item {ItemId} refreshed successfully.")
|
| 375 |
+
except Exception as e:
|
| 376 |
+
logging.error(f"Failed to refresh metadata for item {ItemId}: {e}")
|
| 377 |
+
else:
|
| 378 |
+
return {
|
| 379 |
+
"message": "This doesn't appear to be a properly configured Jellyfin webhook, please review the instructions again!"}
|
| 380 |
+
|
| 381 |
+
return ""
|
| 382 |
+
|
| 383 |
+
|
| 384 |
+
@app.post("/emby")
|
| 385 |
+
def receive_emby_webhook(
|
| 386 |
+
user_agent: Union[str, None] = Header(None),
|
| 387 |
+
data: Union[str, None] = Form(None),
|
| 388 |
+
):
|
| 389 |
+
logging.debug("Raw response: %s", data)
|
| 390 |
+
|
| 391 |
+
if "Emby Server" not in user_agent:
|
| 392 |
+
return {"This doesn't appear to be a properly configured Emby webhook, please review the instructions again!"}
|
| 393 |
+
|
| 394 |
+
if not data:
|
| 395 |
+
return ""
|
| 396 |
+
|
| 397 |
+
data_dict = json.loads(data)
|
| 398 |
+
fullpath = data_dict['Item']['Path']
|
| 399 |
+
event = data_dict['Event']
|
| 400 |
+
logging.debug("Emby event detected is: " + event)
|
| 401 |
+
|
| 402 |
+
if event == "library.new" and procaddedmedia or event == "playback.start" and procmediaonplay:
|
| 403 |
+
logging.debug("Path of file: " + fullpath)
|
| 404 |
+
gen_subtitles_queue(path_mapping(fullpath), transcribe_or_translate)
|
| 405 |
+
|
| 406 |
+
return ""
|
| 407 |
+
|
| 408 |
+
@app.post("/batch")
|
| 409 |
+
def batch(
|
| 410 |
+
directory: Union[str, None] = Query(default=None),
|
| 411 |
+
forceLanguage: Union[str, None] = Query(default=None)
|
| 412 |
+
):
|
| 413 |
+
transcribe_existing(directory, forceLanguage)
|
| 414 |
+
|
| 415 |
+
# idea and some code for asr and detect language from https://github.com/ahmetoner/whisper-asr-webservice
|
| 416 |
+
@app.post("//asr")
|
| 417 |
+
@app.post("/asr")
|
| 418 |
+
def asr(
|
| 419 |
+
task: Union[str, None] = Query(default="transcribe", enum=["transcribe", "translate"]),
|
| 420 |
+
language: Union[str, None] = Query(default=None),
|
| 421 |
+
initial_prompt: Union[str, None] = Query(default=None), #not used by Bazarr
|
| 422 |
+
audio_file: UploadFile = File(...),
|
| 423 |
+
encode: bool = Query(default=True, description="Encode audio first through ffmpeg"), #not used by Bazarr/always False
|
| 424 |
+
output: Union[str, None] = Query(default="srt", enum=["txt", "vtt", "srt", "tsv", "json"]),
|
| 425 |
+
word_timestamps: bool = Query(default=False, description="Word level timestamps") #not used by Bazarr
|
| 426 |
+
):
|
| 427 |
+
try:
|
| 428 |
+
logging.info(f"Transcribing file from Bazarr/ASR webhook")
|
| 429 |
+
result = None
|
| 430 |
+
random_name = ''.join(random.choices("abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ1234567890", k=6))
|
| 431 |
+
|
| 432 |
+
if force_detected_language_to:
|
| 433 |
+
language = force_detected_language_to
|
| 434 |
+
|
| 435 |
+
start_time = time.time()
|
| 436 |
+
start_model()
|
| 437 |
+
|
| 438 |
+
task_id = { 'path': f"Bazarr-asr-{random_name}" }
|
| 439 |
+
task_queue.put(task_id)
|
| 440 |
+
|
| 441 |
+
audio_data = np.frombuffer(audio_file.file.read(), np.int16).flatten().astype(np.float32) / 32768.0
|
| 442 |
+
if model_prompt:
|
| 443 |
+
custom_prompt = greetings_translations.get(language, '') or custom_model_prompt
|
| 444 |
+
if custom_regroup:
|
| 445 |
+
result = model.transcribe_stable(audio_data, task=task, input_sr=16000, language=language, progress_callback=progress, initial_prompt=custom_prompt, regroup=custom_regroup)
|
| 446 |
+
else:
|
| 447 |
+
result = model.transcribe_stable(audio_data, task=task, input_sr=16000, language=language, progress_callback=progress, initial_prompt=custom_prompt)
|
| 448 |
+
appendLine(result)
|
| 449 |
+
elapsed_time = time.time() - start_time
|
| 450 |
+
minutes, seconds = divmod(int(elapsed_time), 60)
|
| 451 |
+
logging.info(f"Bazarr transcription is completed, it took {minutes} minutes and {seconds} seconds to complete.")
|
| 452 |
+
except Exception as e:
|
| 453 |
+
logging.info(f"Error processing or transcribing Bazarr {audio_file.filename}: {e}")
|
| 454 |
+
finally:
|
| 455 |
+
task_queue.task_done()
|
| 456 |
+
delete_model()
|
| 457 |
+
if result:
|
| 458 |
+
return StreamingResponse(
|
| 459 |
+
iter(result.to_srt_vtt(filepath = None, word_level=word_level_highlight)),
|
| 460 |
+
media_type="text/plain",
|
| 461 |
+
headers={
|
| 462 |
+
'Source': 'Transcribed using stable-ts from Subgen!',
|
| 463 |
+
})
|
| 464 |
+
else:
|
| 465 |
+
return
|
| 466 |
+
|
| 467 |
+
@app.post("//detect-language")
|
| 468 |
+
@app.post("/detect-language")
|
| 469 |
+
def detect_language(
|
| 470 |
+
audio_file: UploadFile = File(...),
|
| 471 |
+
#encode: bool = Query(default=True, description="Encode audio first through ffmpeg") # This is always false from Bazarr
|
| 472 |
+
):
|
| 473 |
+
detected_language = "" # Initialize with an empty string
|
| 474 |
+
language_code = "" # Initialize with an empty string
|
| 475 |
+
if int(detect_language_length) != 30:
|
| 476 |
+
logging.info(f"Detect language is set to detect on the first {detect_language_length} seconds of the audio.")
|
| 477 |
+
try:
|
| 478 |
+
start_model()
|
| 479 |
+
random_name = ''.join(random.choices("abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ1234567890", k=6))
|
| 480 |
+
|
| 481 |
+
task_id = { 'path': f"Bazarr-detect-language-{random_name}" }
|
| 482 |
+
task_queue.put(task_id)
|
| 483 |
+
|
| 484 |
+
audio_data = np.frombuffer(audio_file.file.read(), np.int16).flatten().astype(np.float32) / 32768.0
|
| 485 |
+
detected_language = model.transcribe_stable(whisper.pad_or_trim(audio_data, int(detect_language_length) * 16000), input_sr=16000).language
|
| 486 |
+
# reverse lookup of language -> code, ex: "english" -> "en", "nynorsk" -> "nn", ...
|
| 487 |
+
language_code = get_key_by_value(whisper_languages, detected_language)
|
| 488 |
+
|
| 489 |
+
except Exception as e:
|
| 490 |
+
logging.info(f"Error processing or transcribing Bazarr {audio_file.filename}: {e}")
|
| 491 |
+
|
| 492 |
+
finally:
|
| 493 |
+
task_queue.task_done()
|
| 494 |
+
delete_model()
|
| 495 |
+
|
| 496 |
+
return {"detected_language": detected_language, "language_code": language_code}
|
| 497 |
+
|
| 498 |
+
def start_model():
|
| 499 |
+
global model
|
| 500 |
+
if model is None:
|
| 501 |
+
logging.debug("Model was purged, need to re-create")
|
| 502 |
+
model = stable_whisper.load_faster_whisper(whisper_model, download_root=model_location, device=transcribe_device, cpu_threads=whisper_threads, num_workers=concurrent_transcriptions, compute_type=compute_type)
|
| 503 |
+
|
| 504 |
+
def delete_model():
|
| 505 |
+
if clear_vram_on_complete and task_queue.qsize() == 0:
|
| 506 |
+
global model
|
| 507 |
+
logging.debug("Queue is empty, clearing/releasing VRAM")
|
| 508 |
+
model = None
|
| 509 |
+
gc.collect()
|
| 510 |
+
|
| 511 |
+
def isAudioFileExtension(file_extension):
|
| 512 |
+
return file_extension.casefold() in \
|
| 513 |
+
[ '.mp3', '.flac', '.wav', '.alac', '.ape', '.ogg', '.wma', '.m4a', '.m4b', '.aac', '.aiff' ]
|
| 514 |
+
|
| 515 |
+
def write_lrc(result, file_path):
|
| 516 |
+
with open(file_path, "w") as file:
|
| 517 |
+
for segment in result.segments:
|
| 518 |
+
minutes, seconds = divmod(int(segment.start), 60)
|
| 519 |
+
fraction = int((segment.start - int(segment.start)) * 100)
|
| 520 |
+
file.write(f"[{minutes:02d}:{seconds:02d}.{fraction:02d}] {segment.text}\n")
|
| 521 |
+
|
| 522 |
+
def gen_subtitles(file_path: str, transcription_type: str, force_language=None) -> None:
|
| 523 |
+
"""Generates subtitles for a video file.
|
| 524 |
+
|
| 525 |
+
Args:
|
| 526 |
+
file_path: str - The path to the video file.
|
| 527 |
+
transcription_type: str - The type of transcription or translation to perform.
|
| 528 |
+
force_language: str - The language to force for transcription or translation. Default is None.
|
| 529 |
+
"""
|
| 530 |
+
|
| 531 |
+
try:
|
| 532 |
+
logging.info(f"Added {os.path.basename(file_path)} for transcription.")
|
| 533 |
+
logging.info(f"Transcribing file: {os.path.basename(file_path)}")
|
| 534 |
+
|
| 535 |
+
start_time = time.time()
|
| 536 |
+
start_model()
|
| 537 |
+
|
| 538 |
+
if force_detected_language_to:
|
| 539 |
+
force_language = force_detected_language_to
|
| 540 |
+
logging.info(f"Forcing language to {force_language}")
|
| 541 |
+
|
| 542 |
+
if custom_regroup:
|
| 543 |
+
result = model.transcribe_stable(file_path, language=force_language, task=transcription_type,
|
| 544 |
+
progress_callback=progress, initial_prompt=custom_model_prompt,
|
| 545 |
+
regroup=custom_regroup)
|
| 546 |
+
else:
|
| 547 |
+
result = model.transcribe_stable(file_path, language=force_language, task=transcription_type,
|
| 548 |
+
progress_callback=progress, initial_prompt=custom_model_prompt)
|
| 549 |
+
|
| 550 |
+
appendLine(result)
|
| 551 |
+
file_name, file_extension = os.path.splitext(file_path)
|
| 552 |
+
|
| 553 |
+
if isAudioFileExtension(file_extension) and lrc_for_audio_files:
|
| 554 |
+
write_lrc(result, file_name + '.lrc')
|
| 555 |
+
else:
|
| 556 |
+
result.to_srt_vtt(file_name + subextension, word_level=word_level_highlight)
|
| 557 |
+
|
| 558 |
+
elapsed_time = time.time() - start_time
|
| 559 |
+
minutes, seconds = divmod(int(elapsed_time), 60)
|
| 560 |
+
logging.info(
|
| 561 |
+
f"Transcription of {os.path.basename(file_path)} is completed, it took {minutes} minutes and {seconds} seconds to complete.")
|
| 562 |
+
|
| 563 |
+
except Exception as e:
|
| 564 |
+
logging.info(f"Error processing or transcribing {file_path}: {e}")
|
| 565 |
+
|
| 566 |
+
finally:
|
| 567 |
+
delete_model()
|
| 568 |
+
|
| 569 |
+
def gen_subtitles_queue(file_path: str, transcription_type: str, force_language=None) -> None:
|
| 570 |
+
global task_queue
|
| 571 |
+
|
| 572 |
+
if not has_audio(file_path):
|
| 573 |
+
logging.debug(f"{file_path} doesn't have any audio to transcribe!")
|
| 574 |
+
return
|
| 575 |
+
|
| 576 |
+
message = None
|
| 577 |
+
if has_subtitle_language(file_path, skipifinternalsublang):
|
| 578 |
+
message = f"{file_path} already has an internal subtitle we want, skipping generation"
|
| 579 |
+
elif os.path.exists(file_path.rsplit('.', 1)[0] + subextension):
|
| 580 |
+
message = f"{file_path} already has a subtitle created for this, skipping it"
|
| 581 |
+
elif os.path.exists(file_path.rsplit('.', 1)[0] + subextensionSDH):
|
| 582 |
+
message = f"{file_path} already has a SDH subtitle created for this, skipping it"
|
| 583 |
+
if message:
|
| 584 |
+
logging.info(message)
|
| 585 |
+
return
|
| 586 |
+
|
| 587 |
+
task = {
|
| 588 |
+
'path': file_path,
|
| 589 |
+
'transcribe_or_translate': transcription_type,
|
| 590 |
+
'force_language':force_language
|
| 591 |
+
}
|
| 592 |
+
task_queue.put(task)
|
| 593 |
+
|
| 594 |
+
def get_file_name_without_extension(file_path):
|
| 595 |
+
file_name, file_extension = os.path.splitext(file_path)
|
| 596 |
+
return file_name
|
| 597 |
+
|
| 598 |
+
def has_subtitle_language(video_file, target_language):
|
| 599 |
+
try:
|
| 600 |
+
with av.open(video_file) as container:
|
| 601 |
+
subtitle_stream = next((stream for stream in container.streams if stream.type == 'subtitle' and 'language' in stream.metadata and stream.metadata['language'] == target_language), None)
|
| 602 |
+
|
| 603 |
+
if subtitle_stream:
|
| 604 |
+
logging.debug(f"Subtitles in '{target_language}' language found in the video.")
|
| 605 |
+
return True
|
| 606 |
+
else:
|
| 607 |
+
logging.debug(f"No subtitles in '{target_language}' language found in the video.")
|
| 608 |
+
except Exception as e:
|
| 609 |
+
logging.info(f"An error occurred: {e}")
|
| 610 |
+
return False
|
| 611 |
+
|
| 612 |
+
def get_plex_file_name(itemid: str, server_ip: str, plex_token: str) -> str:
|
| 613 |
+
"""Gets the full path to a file from the Plex server.
|
| 614 |
+
|
| 615 |
+
Args:
|
| 616 |
+
itemid: The ID of the item in the Plex library.
|
| 617 |
+
server_ip: The IP address of the Plex server.
|
| 618 |
+
plex_token: The Plex token.
|
| 619 |
+
|
| 620 |
+
Returns:
|
| 621 |
+
The full path to the file.
|
| 622 |
+
"""
|
| 623 |
+
|
| 624 |
+
url = f"{server_ip}/library/metadata/{itemid}"
|
| 625 |
+
|
| 626 |
+
headers = {
|
| 627 |
+
"X-Plex-Token": plex_token,
|
| 628 |
+
}
|
| 629 |
+
|
| 630 |
+
response = requests.get(url, headers=headers)
|
| 631 |
+
|
| 632 |
+
if response.status_code == 200:
|
| 633 |
+
root = ET.fromstring(response.content)
|
| 634 |
+
fullpath = root.find(".//Part").attrib['file']
|
| 635 |
+
return fullpath
|
| 636 |
+
else:
|
| 637 |
+
raise Exception(f"Error: {response.status_code}")
|
| 638 |
+
|
| 639 |
+
def refresh_plex_metadata(itemid: str, server_ip: str, plex_token: str) -> None:
|
| 640 |
+
"""
|
| 641 |
+
Refreshes the metadata of a Plex library item.
|
| 642 |
+
|
| 643 |
+
Args:
|
| 644 |
+
itemid: The ID of the item in the Plex library whose metadata needs to be refreshed.
|
| 645 |
+
server_ip: The IP address of the Plex server.
|
| 646 |
+
plex_token: The Plex token used for authentication.
|
| 647 |
+
|
| 648 |
+
Raises:
|
| 649 |
+
Exception: If the server does not respond with a successful status code.
|
| 650 |
+
"""
|
| 651 |
+
|
| 652 |
+
# Plex API endpoint to refresh metadata for a specific item
|
| 653 |
+
url = f"{server_ip}/library/metadata/{itemid}/refresh"
|
| 654 |
+
|
| 655 |
+
# Headers to include the Plex token for authentication
|
| 656 |
+
headers = {
|
| 657 |
+
"X-Plex-Token": plex_token,
|
| 658 |
+
}
|
| 659 |
+
|
| 660 |
+
# Sending the PUT request to refresh metadata
|
| 661 |
+
response = requests.put(url, headers=headers)
|
| 662 |
+
|
| 663 |
+
# Check if the request was successful
|
| 664 |
+
if response.status_code == 200:
|
| 665 |
+
logging.info("Metadata refresh initiated successfully.")
|
| 666 |
+
else:
|
| 667 |
+
raise Exception(f"Error refreshing metadata: {response.status_code}")
|
| 668 |
+
|
| 669 |
+
def refresh_jellyfin_metadata(itemid: str, server_ip: str, jellyfin_token: str) -> None:
|
| 670 |
+
"""
|
| 671 |
+
Refreshes the metadata of a Jellyfin library item.
|
| 672 |
+
|
| 673 |
+
Args:
|
| 674 |
+
itemid: The ID of the item in the Jellyfin library whose metadata needs to be refreshed.
|
| 675 |
+
server_ip: The IP address of the Jellyfin server.
|
| 676 |
+
jellyfin_token: The Jellyfin token used for authentication.
|
| 677 |
+
|
| 678 |
+
Raises:
|
| 679 |
+
Exception: If the server does not respond with a successful status code.
|
| 680 |
+
"""
|
| 681 |
+
|
| 682 |
+
# Jellyfin API endpoint to refresh metadata for a specific item
|
| 683 |
+
url = f"{server_ip}/Items/{itemid}/Refresh"
|
| 684 |
+
|
| 685 |
+
# Headers to include the Jellyfin token for authentication
|
| 686 |
+
headers = {
|
| 687 |
+
"Authorization": f"MediaBrowser Token={jellyfin_token}",
|
| 688 |
+
}
|
| 689 |
+
|
| 690 |
+
# Cheap way to get the admin user id, and save it for later use.
|
| 691 |
+
users = json.loads(requests.get(f"{server_ip}/Users", headers=headers).content)
|
| 692 |
+
jellyfin_admin = get_jellyfin_admin(users)
|
| 693 |
+
|
| 694 |
+
response = requests.get(f"{server_ip}/Users/{jellyfin_admin}/Items/{itemid}/Refresh", headers=headers)
|
| 695 |
+
|
| 696 |
+
# Sending the PUT request to refresh metadata
|
| 697 |
+
response = requests.post(url, headers=headers)
|
| 698 |
+
|
| 699 |
+
# Check if the request was successful
|
| 700 |
+
if response.status_code == 204:
|
| 701 |
+
logging.info("Metadata refresh queued successfully.")
|
| 702 |
+
else:
|
| 703 |
+
raise Exception(f"Error refreshing metadata: {response.status_code}")
|
| 704 |
+
|
| 705 |
+
|
| 706 |
+
def get_jellyfin_file_name(item_id: str, jellyfin_url: str, jellyfin_token: str) -> str:
|
| 707 |
+
"""Gets the full path to a file from the Jellyfin server.
|
| 708 |
+
|
| 709 |
+
Args:
|
| 710 |
+
jellyfin_url: The URL of the Jellyfin server.
|
| 711 |
+
jellyfin_token: The Jellyfin token.
|
| 712 |
+
item_id: The ID of the item in the Jellyfin library.
|
| 713 |
+
|
| 714 |
+
Returns:
|
| 715 |
+
The full path to the file.
|
| 716 |
+
"""
|
| 717 |
+
|
| 718 |
+
headers = {
|
| 719 |
+
"Authorization": f"MediaBrowser Token={jellyfin_token}",
|
| 720 |
+
}
|
| 721 |
+
|
| 722 |
+
# Cheap way to get the admin user id, and save it for later use.
|
| 723 |
+
users = json.loads(requests.get(f"{jellyfin_url}/Users", headers=headers).content)
|
| 724 |
+
jellyfin_admin = get_jellyfin_admin(users)
|
| 725 |
+
|
| 726 |
+
response = requests.get(f"{jellyfin_url}/Users/{jellyfin_admin}/Items/{item_id}", headers=headers)
|
| 727 |
+
|
| 728 |
+
if response.status_code == 200:
|
| 729 |
+
file_name = json.loads(response.content)['Path']
|
| 730 |
+
return file_name
|
| 731 |
+
else:
|
| 732 |
+
raise Exception(f"Error: {response.status_code}")
|
| 733 |
+
|
| 734 |
+
def get_jellyfin_admin(users):
|
| 735 |
+
for user in users:
|
| 736 |
+
if user["Policy"]["IsAdministrator"]:
|
| 737 |
+
return user["Id"]
|
| 738 |
+
|
| 739 |
+
raise Exception("Unable to find administrator user in Jellyfin")
|
| 740 |
+
|
| 741 |
+
def has_audio(file_path):
|
| 742 |
+
try:
|
| 743 |
+
with av.open(file_path) as container:
|
| 744 |
+
return any(stream.type == 'audio' for stream in container.streams)
|
| 745 |
+
except (av.AVError, UnicodeDecodeError):
|
| 746 |
+
return False
|
| 747 |
+
|
| 748 |
+
def path_mapping(fullpath):
|
| 749 |
+
if use_path_mapping:
|
| 750 |
+
logging.debug("Updated path: " + fullpath.replace(path_mapping_from, path_mapping_to))
|
| 751 |
+
return fullpath.replace(path_mapping_from, path_mapping_to)
|
| 752 |
+
return fullpath
|
| 753 |
+
|
| 754 |
+
if monitor:
|
| 755 |
+
# Define a handler class that will process new files
|
| 756 |
+
class NewFileHandler(FileSystemEventHandler):
|
| 757 |
+
def create_subtitle(self, event):
|
| 758 |
+
# Only process if it's a file
|
| 759 |
+
if not event.is_directory:
|
| 760 |
+
file_path = event.src_path
|
| 761 |
+
if has_audio(file_path):
|
| 762 |
+
# Call the gen_subtitles function
|
| 763 |
+
logging.info(f"File: {path_mapping(file_path)} was added")
|
| 764 |
+
gen_subtitles_queue(path_mapping(file_path), transcribe_or_translate)
|
| 765 |
+
def on_created(self, event):
|
| 766 |
+
self.create_subtitle(event)
|
| 767 |
+
def on_modified(self, event):
|
| 768 |
+
self.create_subtitle(event)
|
| 769 |
+
|
| 770 |
+
def transcribe_existing(transcribe_folders, forceLanguage=None):
|
| 771 |
+
transcribe_folders = transcribe_folders.split("|")
|
| 772 |
+
logging.info("Starting to search folders to see if we need to create subtitles.")
|
| 773 |
+
logging.debug("The folders are:")
|
| 774 |
+
for path in transcribe_folders:
|
| 775 |
+
logging.debug(path)
|
| 776 |
+
for root, dirs, files in os.walk(path):
|
| 777 |
+
for file in files:
|
| 778 |
+
file_path = os.path.join(root, file)
|
| 779 |
+
gen_subtitles_queue(path_mapping(file_path), transcribe_or_translate, forceLanguage)
|
| 780 |
+
# if the path specified was actually a single file and not a folder, process it
|
| 781 |
+
if os.path.isfile(path):
|
| 782 |
+
if has_audio(path):
|
| 783 |
+
gen_subtitles_queue(path_mapping(path), transcribe_or_translate, forceLanguage)
|
| 784 |
+
# Set up the observer to watch for new files
|
| 785 |
+
if monitor:
|
| 786 |
+
observer = Observer()
|
| 787 |
+
for path in transcribe_folders:
|
| 788 |
+
if os.path.isdir(path):
|
| 789 |
+
handler = NewFileHandler()
|
| 790 |
+
observer.schedule(handler, path, recursive=True)
|
| 791 |
+
observer.start()
|
| 792 |
+
logging.info("Finished searching and queueing files for transcription. Now watching for new files.")
|
| 793 |
+
|
| 794 |
+
whisper_languages = {
|
| 795 |
+
"en": "english",
|
| 796 |
+
"zh": "chinese",
|
| 797 |
+
"de": "german",
|
| 798 |
+
"es": "spanish",
|
| 799 |
+
"ru": "russian",
|
| 800 |
+
"ko": "korean",
|
| 801 |
+
"fr": "french",
|
| 802 |
+
"ja": "japanese",
|
| 803 |
+
"pt": "portuguese",
|
| 804 |
+
"tr": "turkish",
|
| 805 |
+
"pl": "polish",
|
| 806 |
+
"ca": "catalan",
|
| 807 |
+
"nl": "dutch",
|
| 808 |
+
"ar": "arabic",
|
| 809 |
+
"sv": "swedish",
|
| 810 |
+
"it": "italian",
|
| 811 |
+
"id": "indonesian",
|
| 812 |
+
"hi": "hindi",
|
| 813 |
+
"fi": "finnish",
|
| 814 |
+
"vi": "vietnamese",
|
| 815 |
+
"he": "hebrew",
|
| 816 |
+
"uk": "ukrainian",
|
| 817 |
+
"el": "greek",
|
| 818 |
+
"ms": "malay",
|
| 819 |
+
"cs": "czech",
|
| 820 |
+
"ro": "romanian",
|
| 821 |
+
"da": "danish",
|
| 822 |
+
"hu": "hungarian",
|
| 823 |
+
"ta": "tamil",
|
| 824 |
+
"no": "norwegian",
|
| 825 |
+
"th": "thai",
|
| 826 |
+
"ur": "urdu",
|
| 827 |
+
"hr": "croatian",
|
| 828 |
+
"bg": "bulgarian",
|
| 829 |
+
"lt": "lithuanian",
|
| 830 |
+
"la": "latin",
|
| 831 |
+
"mi": "maori",
|
| 832 |
+
"ml": "malayalam",
|
| 833 |
+
"cy": "welsh",
|
| 834 |
+
"sk": "slovak",
|
| 835 |
+
"te": "telugu",
|
| 836 |
+
"fa": "persian",
|
| 837 |
+
"lv": "latvian",
|
| 838 |
+
"bn": "bengali",
|
| 839 |
+
"sr": "serbian",
|
| 840 |
+
"az": "azerbaijani",
|
| 841 |
+
"sl": "slovenian",
|
| 842 |
+
"kn": "kannada",
|
| 843 |
+
"et": "estonian",
|
| 844 |
+
"mk": "macedonian",
|
| 845 |
+
"br": "breton",
|
| 846 |
+
"eu": "basque",
|
| 847 |
+
"is": "icelandic",
|
| 848 |
+
"hy": "armenian",
|
| 849 |
+
"ne": "nepali",
|
| 850 |
+
"mn": "mongolian",
|
| 851 |
+
"bs": "bosnian",
|
| 852 |
+
"kk": "kazakh",
|
| 853 |
+
"sq": "albanian",
|
| 854 |
+
"sw": "swahili",
|
| 855 |
+
"gl": "galician",
|
| 856 |
+
"mr": "marathi",
|
| 857 |
+
"pa": "punjabi",
|
| 858 |
+
"si": "sinhala",
|
| 859 |
+
"km": "khmer",
|
| 860 |
+
"sn": "shona",
|
| 861 |
+
"yo": "yoruba",
|
| 862 |
+
"so": "somali",
|
| 863 |
+
"af": "afrikaans",
|
| 864 |
+
"oc": "occitan",
|
| 865 |
+
"ka": "georgian",
|
| 866 |
+
"be": "belarusian",
|
| 867 |
+
"tg": "tajik",
|
| 868 |
+
"sd": "sindhi",
|
| 869 |
+
"gu": "gujarati",
|
| 870 |
+
"am": "amharic",
|
| 871 |
+
"yi": "yiddish",
|
| 872 |
+
"lo": "lao",
|
| 873 |
+
"uz": "uzbek",
|
| 874 |
+
"fo": "faroese",
|
| 875 |
+
"ht": "haitian creole",
|
| 876 |
+
"ps": "pashto",
|
| 877 |
+
"tk": "turkmen",
|
| 878 |
+
"nn": "nynorsk",
|
| 879 |
+
"mt": "maltese",
|
| 880 |
+
"sa": "sanskrit",
|
| 881 |
+
"lb": "luxembourgish",
|
| 882 |
+
"my": "myanmar",
|
| 883 |
+
"bo": "tibetan",
|
| 884 |
+
"tl": "tagalog",
|
| 885 |
+
"mg": "malagasy",
|
| 886 |
+
"as": "assamese",
|
| 887 |
+
"tt": "tatar",
|
| 888 |
+
"haw": "hawaiian",
|
| 889 |
+
"ln": "lingala",
|
| 890 |
+
"ha": "hausa",
|
| 891 |
+
"ba": "bashkir",
|
| 892 |
+
"jw": "javanese",
|
| 893 |
+
"su": "sundanese",
|
| 894 |
+
}
|
| 895 |
+
|
| 896 |
+
greetings_translations = {
|
| 897 |
+
"en": "Hello, welcome to my lecture.",
|
| 898 |
+
"zh": "你好,欢迎来到我的讲座。",
|
| 899 |
+
"de": "Hallo, willkommen zu meiner Vorlesung.",
|
| 900 |
+
"es": "Hola, bienvenido a mi conferencia.",
|
| 901 |
+
"ru": "Привет, добро пожаловать на мою лекцию.",
|
| 902 |
+
"ko": "안녕하세요, 제 강의에 오신 것을 환영합니다.",
|
| 903 |
+
"fr": "Bonjour, bienvenue à mon cours.",
|
| 904 |
+
"ja": "こんにちは、私の講義へようこそ。",
|
| 905 |
+
"pt": "Olá, bem-vindo à minha palestra.",
|
| 906 |
+
"tr": "Merhaba, dersime hoş geldiniz.",
|
| 907 |
+
"pl": "Cześć, witaj na mojej wykładzie.",
|
| 908 |
+
"ca": "Hola, benvingut a la meva conferència.",
|
| 909 |
+
"nl": "Hallo, welkom bij mijn lezing.",
|
| 910 |
+
"ar": "مرحبًا، مرحبًا بك في محاضرتي.",
|
| 911 |
+
"sv": "Hej, välkommen till min föreläsning.",
|
| 912 |
+
"it": "Ciao, benvenuto alla mia conferenza.",
|
| 913 |
+
"id": "Halo, selamat datang di kuliah saya.",
|
| 914 |
+
"hi": "नमस्ते, मेरे व्याख्यान में आपका स्वागत है।",
|
| 915 |
+
"fi": "Hei, tervetuloa luentooni.",
|
| 916 |
+
"vi": "Xin chào, chào mừng bạn đến với bài giảng của tôi.",
|
| 917 |
+
"he": "שלום, ברוך הבא להרצאתי.",
|
| 918 |
+
"uk": "Привіт, ласкаво просимо на мою лекцію.",
|
| 919 |
+
"el": "Γεια σας, καλώς ήλθατε στη διάλεξή μου.",
|
| 920 |
+
"ms": "Halo, selamat datang ke kuliah saya.",
|
| 921 |
+
"cs": "Ahoj, vítejte na mé přednášce.",
|
| 922 |
+
"ro": "Bună, bun venit la cursul meu.",
|
| 923 |
+
"da": "Hej, velkommen til min forelæsning.",
|
| 924 |
+
"hu": "Helló, üdvözöllek az előadásomon.",
|
| 925 |
+
"ta": "வணக்கம், என் பாடத்திற்கு வரவேற்கிறேன்.",
|
| 926 |
+
"no": "Hei, velkommen til foredraget mitt.",
|
| 927 |
+
"th": "สวัสดีครับ ยินดีต้อนรับสู่การบรรยายของฉัน",
|
| 928 |
+
"ur": "ہیلو، میری لیکچر میں خوش آمدید۔",
|
| 929 |
+
"hr": "Pozdrav, dobrodošli na moje predavanje.",
|
| 930 |
+
"bg": "Здравейте, добре дошли на моята лекция.",
|
| 931 |
+
"lt": "Sveiki, sveiki atvykę į mano paskaitą.",
|
| 932 |
+
"la": "Salve, gratias vobis pro eo quod meam lectionem excipitis.",
|
| 933 |
+
"mi": "Kia ora, nau mai ki aku rorohiko.",
|
| 934 |
+
"ml": "ഹലോ, എന്റെ പാഠത്തിലേക്ക് സ്വാഗതം.",
|
| 935 |
+
"cy": "Helo, croeso i fy narlith.",
|
| 936 |
+
"sk": "Ahoj, vitajte na mojej prednáške.",
|
| 937 |
+
"te": "హలో, నా పాఠానికి స్వాగతం.",
|
| 938 |
+
"fa": "سلام، خوش آمدید به سخنرانی من.",
|
| 939 |
+
"lv": "Sveiki, laipni lūdzam uz manu lekciju.",
|
| 940 |
+
"bn": "হ্যালো, আমার লেকচারে আপনাকে স্বাগতম।",
|
| 941 |
+
"sr": "Здраво, добродошли на моје предавање.",
|
| 942 |
+
"az": "Salam, mənim dərsimə xoş gəlmisiniz.",
|
| 943 |
+
"sl": "Pozdravljeni, dobrodošli na moje predavanje.",
|
| 944 |
+
"kn": "ಹಲೋ, ನನ್ನ ಭಾಷಣಕ್ಕೆ ಸುಸ್ವಾಗತ.",
|
| 945 |
+
"et": "Tere, tere tulemast minu loengusse.",
|
| 946 |
+
"mk": "Здраво, добредојдовте на мојата предавање.",
|
| 947 |
+
"br": "Demat, kroget e oa d'an daol-labour.",
|
| 948 |
+
"eu": "Kaixo, ongi etorri nire hitzaldi.",
|
| 949 |
+
"is": "Halló, velkomin á fyrirlestur minn.",
|
| 950 |
+
"hy": "Բարեւ, ողջույն եկավ իմ դասընթացի.",
|
| 951 |
+
"ne": "नमस्ते, मेरो प्रवचनमा स्वागत छ।",
|
| 952 |
+
"mn": "Сайн байна уу, миний хичээлд тавтай морилно уу.",
|
| 953 |
+
"bs": "Zdravo, dobrodošli na moje predavanje.",
|
| 954 |
+
"kk": "Сәлеметсіз бе, оқу сабағыма қош келдіңіз.",
|
| 955 |
+
"sq": "Përshëndetje, mirësevini në ligjëratën time.",
|
| 956 |
+
"sw": "Habari, karibu kwenye hotuba yangu.",
|
| 957 |
+
"gl": "Ola, benvido á miña conferencia.",
|
| 958 |
+
"mr": "नमस्कार, माझ्या व्याख्यानात आपले स्वागत आहे.",
|
| 959 |
+
"pa": "ਸਤ ਸ੍ਰੀ ਅਕਾਲ, ਮੇਰੀ ਵਾਰਤਾ ਵਿੱਚ ਤੁਹਾਨੂੰ ਜੀ ਆਇਆ ਨੂੰ ਸੁਆਗਤ ਹੈ।",
|
| 960 |
+
"si": "හෙලෝ, මගේ වාර්තාවට ඔබේ ස්වාදයට සාමාජිකත්වයක්.",
|
| 961 |
+
"km": "សួស្តី, សូមស្វាគមន៍មកកាន់អារម្មណ៍របស់ខ្ញុំ។",
|
| 962 |
+
"sn": "Mhoro, wakaribisha kumusoro wangu.",
|
| 963 |
+
"yo": "Bawo, ku isoro si wa orin mi.",
|
| 964 |
+
"so": "Soo dhawoow, soo dhawoow marka laga hadlo kulambanayaashaaga.",
|
| 965 |
+
"af": "Hallo, welkom by my lesing.",
|
| 966 |
+
"oc": "Bonjorn, benvenguda a ma conferéncia.",
|
| 967 |
+
"ka": "გამარჯობა, მესწა��მეტყველება ჩემი ლექციაზე.",
|
| 968 |
+
"be": "Прывітанне, запрашаем на маю лекцыю.",
|
| 969 |
+
"tg": "Салом, ба лаҳзаи мавзӯъати ман хуш омадед.",
|
| 970 |
+
"sd": "هيلو، ميري ليڪڪي ۾ خوش آيو.",
|
| 971 |
+
"gu": "નમસ્તે, મારી પાઠશાળામાં આપનું સ્વાગત છે.",
|
| 972 |
+
"am": "ሰላም፣ ለአንድነት የተመረጠን ትምህርት በመሆን እናመሰግናለን።",
|
| 973 |
+
"yi": "העלאָ, ווילקומן צו מיין לעקטשער.",
|
| 974 |
+
"lo": "ສະບາຍດີ, ຍິນດີນາງຂອງຂ້ອຍໄດ້ຍິນດີ.",
|
| 975 |
+
"uz": "Salom, darsimda xush kelibsiz.",
|
| 976 |
+
"fo": "Halló, vælkomin til mína fyrilestrar.",
|
| 977 |
+
"ht": "Bonjou, byenveni nan leson mwen.",
|
| 978 |
+
"ps": "سلام، مې لومړۍ کې خوش آمدید.",
|
| 979 |
+
"tk": "Salam, dersimiňe hoş geldiňiz.",
|
| 980 |
+
"nn": "Hei, velkomen til førelesinga mi.",
|
| 981 |
+
"mt": "Hello, merħba għall-lezzjoni tiegħi.",
|
| 982 |
+
"sa": "नमस्ते, मम उपन्यासे स्वागतं.",
|
| 983 |
+
"lb": "Hallo, wëllkomm zu menger Lektioun.",
|
| 984 |
+
"my": "မင်္ဂလာပါ၊ ကျေးဇူးတင်သည့်ကိစ္စသည်။",
|
| 985 |
+
"bo": "བཀྲ་ཤིས་བདེ་ལེགས་འབད་བཅོས། ངའི་འཛིན་གྱི་སློབ་མའི་མིང་གི་འཕྲོད།",
|
| 986 |
+
"tl": "Kamusta, maligayang pagdating sa aking leksyon.",
|
| 987 |
+
"mg": "Manao ahoana, tonga soa sy tonga soa eto amin'ny lesona.",
|
| 988 |
+
"as": "নমস্কাৰ, মোৰ পাঠলৈ আপোনাক স্বাগতম।",
|
| 989 |
+
"tt": "Сәлам, лекциямга рәхмәт киләсез.",
|
| 990 |
+
"haw": "Aloha, welina me ke kipa ana i ko'u ha'i 'ōlelo.",
|
| 991 |
+
"ln": "Mbote, tango na zongisa mwa kilela yandi.",
|
| 992 |
+
"ha": "Sannu, ka ci gaba da tattalin arziki na.",
|
| 993 |
+
"ba": "Сәләм, лекцияғыма ҡуш тиңләгәнһүҙ.",
|
| 994 |
+
"jw": "Halo, sugeng datang marang kulawargané.",
|
| 995 |
+
"su": "Wilujeng, hatur nuhun ka lékturing abdi.",
|
| 996 |
+
}
|
| 997 |
+
|
| 998 |
+
env_variables = {
|
| 999 |
+
"TRANSCRIBE_DEVICE": {"description": "Can transcribe via gpu (Cuda only) or cpu. Takes option of 'cpu', 'gpu', 'cuda'.", "default": "cpu", "value": ""},
|
| 1000 |
+
"WHISPER_MODEL": {"description": "Can be: 'tiny', 'tiny.en', 'base', 'base.en', 'small', 'small.en', 'medium', 'medium.en', 'large-v1','large-v2', 'large-v3', 'large', 'distil-large-v2', 'distil-medium.en', 'distil-small.en'", "default": "medium", "value": ""},
|
| 1001 |
+
"CONCURRENT_TRANSCRIPTIONS": {"description": "Number of files it will transcribe in parallel", "default": "2", "value": ""},
|
| 1002 |
+
"WHISPER_THREADS": {"description": "Number of threads to use during computation", "default": "4", "value": ""},
|
| 1003 |
+
"MODEL_PATH": {"description": "This is where the WHISPER_MODEL will be stored. This defaults to placing it where you execute the script in the folder 'models'", "default": "./models", "value": ""},
|
| 1004 |
+
"PROCADDEDMEDIA": {"description": "Will gen subtitles for all media added regardless of existing external/embedded subtitles (based off of SKIPIFINTERNALSUBLANG)", "default": True, "value": ""},
|
| 1005 |
+
"PROCMEDIAONPLAY": {"description": "Will gen subtitles for all played media regardless of existing external/embedded subtitles (based off of SKIPIFINTERNALSUBLANG)", "default": True, "value": ""},
|
| 1006 |
+
"NAMESUBLANG": {"description": "Allows you to pick what it will name the subtitle. Instead of using EN, I'm using AA, so it doesn't mix with existing external EN subs, and AA will populate higher on the list in Plex.", "default": "aa", "value": ""},
|
| 1007 |
+
"SKIPIFINTERNALSUBLANG": {"description": "Will not generate a subtitle if the file has an internal sub matching the 3 letter code of this variable", "default": "eng", "value": ""},
|
| 1008 |
+
"WORD_LEVEL_HIGHLIGHT": {"description": "Highlights each word as it's spoken in the subtitle.", "default": False, "value": ""},
|
| 1009 |
+
"PLEXSERVER": {"description": "This needs to be set to your local plex server address/port", "default": "http://plex:32400", "value": ""},
|
| 1010 |
+
"PLEXTOKEN": {"description": "This needs to be set to your plex token", "default": "token here", "value": ""},
|
| 1011 |
+
"JELLYFINSERVER": {"description": "Set to your Jellyfin server address/port", "default": "http://jellyfin:8096", "value": ""},
|
| 1012 |
+
"JELLYFINTOKEN": {"description": "Generate a token inside the Jellyfin interface", "default": "token here", "value": ""},
|
| 1013 |
+
"WEBHOOKPORT": {"description": "Change this if you need a different port for your webhook", "default": "9000", "value": ""},
|
| 1014 |
+
"USE_PATH_MAPPING": {"description": "Similar to sonarr and radarr path mapping, this will attempt to replace paths on file systems that don't have identical paths. Currently only support for one path replacement.", "default": False, "value": ""},
|
| 1015 |
+
"PATH_MAPPING_FROM": {"description": "This is the path of my media relative to my Plex server", "default": "/tv", "value": ""},
|
| 1016 |
+
"PATH_MAPPING_TO": {"description": "This is the path of that same folder relative to my Mac Mini that will run the script", "default": "/Volumes/TV", "value": ""},
|
| 1017 |
+
"TRANSCRIBE_FOLDERS": {"description": "Takes a pipe '|' separated list and iterates through and adds those files to be queued for subtitle generation if they don't have internal subtitles", "default": "", "value": ""},
|
| 1018 |
+
"TRANSCRIBE_OR_TRANSLATE": {"description": "Takes either 'transcribe' or 'translate'. Transcribe will transcribe the audio in the same language as the input. Translate will transcribe and translate into English.", "default": "transcribe", "value": ""},
|
| 1019 |
+
"COMPUTE_TYPE": {"description": "Set compute-type using the following information: https://github.com/OpenNMT/CTranslate2/blob/master/docs/quantization.md", "default": "auto", "value": ""},
|
| 1020 |
+
"DEBUG": {"description": "Provides some debug data that can be helpful to troubleshoot path mapping and other issues. If set to true, any modifications to the script will auto-reload it (if it isn't actively transcoding). Useful to make small tweaks without re-downloading the whole file.", "default": True, "value": ""},
|
| 1021 |
+
"FORCE_DETECTED_LANGUAGE_TO": {"description": "This is to force the model to a language instead of the detected one, takes a 2 letter language code.", "default": "", "value": ""},
|
| 1022 |
+
"CLEAR_VRAM_ON_COMPLETE": {"description": "This will delete the model and do garbage collection when queue is empty. Good if you need to use the VRAM for something else.", "default": True, "value": ""},
|
| 1023 |
+
"UPDATE": {"description": "Will pull latest subgen.py from the repository if True. False will use the original subgen.py built into the Docker image. Standalone users can use this with launcher.py to get updates.","default": False,"value": ""},
|
| 1024 |
+
"APPEND": {"description": "Will add the following at the end of a subtitle: 'Transcribed by whisperAI with faster-whisper ({whisper_model}) on {datetime.now()}'","default": False,"value": ""},
|
| 1025 |
+
"MONITOR": {"description": "Will monitor TRANSCRIBE_FOLDERS for real-time changes to see if we need to generate subtitles","default": False,"value": ""},
|
| 1026 |
+
"USE_MODEL_PROMPT": {"description": "When set to True, will use the default prompt stored in greetings_translations 'Hello, welcome to my lecture.' to try and force the use of punctuation in transcriptions that don't.","default": False,"value": ""},
|
| 1027 |
+
"CUSTOM_MODEL_PROMPT": {"description": "If USE_MODEL_PROMPT is True, you can override the default prompt (See: [prompt engineering in whisper](https://medium.com/axinc-ai/prompt-engineering-in-whisper-6bb18003562d%29) for great examples).","default": "","value": ""},
|
| 1028 |
+
"LRC_FOR_AUDIO_FILES": {"description": "Will generate LRC (instead of SRT) files for filetypes: '.mp3', '.flac', '.wav', '.alac', '.ape', '.ogg', '.wma', '.m4a', '.m4b', '.aac', '.aiff'","default": True,"value": ""},
|
| 1029 |
+
"CUSTOM_REGROUP": {"description": "Attempts to regroup some of the segments to make a cleaner looking subtitle. See #68 for discussion. Set to blank if you want to use Stable-TS default regroups algorithm of cm_sp=,* /,_sg=.5_mg=.3+3_sp=.* /。/?/?","default": "cm_sl=84_sl=42++++++1","value": ""},
|
| 1030 |
+
"DETECT_LANGUAGE_LENGTH": {"description": "Detect language on the first x seconds of the audio.","default": 30,"value": ""},
|
| 1031 |
+
}
|
| 1032 |
+
|
| 1033 |
+
if __name__ == "__main__":
|
| 1034 |
+
import uvicorn
|
| 1035 |
+
update_env_variables()
|
| 1036 |
+
logging.info(f"Subgen v{subgen_version}")
|
| 1037 |
+
logging.info("Starting Subgen with listening webhooks!")
|
| 1038 |
+
logging.info(f"Transcriptions are limited to running {str(concurrent_transcriptions)} at a time")
|
| 1039 |
+
logging.info(f"Running {str(whisper_threads)} threads per transcription")
|
| 1040 |
+
logging.info(f"Using {transcribe_device} to encode")
|
| 1041 |
+
logging.info(f"Using faster-whisper")
|
| 1042 |
+
os.environ["KMP_DUPLICATE_LIB_OK"]="TRUE"
|
| 1043 |
+
if transcribe_folders:
|
| 1044 |
+
transcribe_existing(transcribe_folders)
|
| 1045 |
+
uvicorn.run("__main__:app", host="0.0.0.0", port=int(webhookport), reload=reload_script_on_change, use_colors=True)
|
subgen.xml
ADDED
|
@@ -0,0 +1,56 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
<?xml version="1.0"?>
|
| 2 |
+
<Container version="2">
|
| 3 |
+
<Name>subgen</Name>
|
| 4 |
+
<ExtraParams>--gpus all</ExtraParams>
|
| 5 |
+
<Beta>false</Beta>
|
| 6 |
+
<Category>CATEGORY:</Category>
|
| 7 |
+
<Repository>mccloud/subgen</Repository>
|
| 8 |
+
<Registry>https://github.com/McCloudS/subgen</Registry>
|
| 9 |
+
<DonateText>If you appreciate my work, then please consider donating</DonateText>
|
| 10 |
+
<DonateLink>https://www.paypal.com/donate/?hosted_button_id=SU4QQP6LH5PF6</DonateLink>
|
| 11 |
+
<DonateImg>https://www.paypal.com/en_US/i/btn/btn_donate_SM.gif</DonateImg>
|
| 12 |
+
<Network>bridge</Network>
|
| 13 |
+
<Privileged>false</Privileged>
|
| 14 |
+
<Support>https://github.com/McCloudS/subgen/issues</Support>
|
| 15 |
+
<Shell>bash</Shell>
|
| 16 |
+
<GitHub>https://github.com/McCloudS/subgen</GitHub>
|
| 17 |
+
<ReadMe>https://github.com/McCloudS/subgen/blob/main/README.md</ReadMe>
|
| 18 |
+
<Project>https://github.com/McCloudS/subgen</Project>
|
| 19 |
+
<Overview>subgen will transcribe your personal media on a Plex, Emby, or Jellyfin server to create subtitles (.srt) from audio/video files, it can also be used as a Whisper Provider in Bazarr</Overview>
|
| 20 |
+
<WebUI>http://[IP]:[PORT:9000]/docs</WebUI>
|
| 21 |
+
<TemplateURL>https://github.com/McCloudS/subgen/blob/main/subgen.xml</TemplateURL>
|
| 22 |
+
<Icon>https://raw.githubusercontent.com/McCloudS/subgen/main/icon.png</Icon>
|
| 23 |
+
<Date>2024-03-23</Date>
|
| 24 |
+
<Changes></Changes>
|
| 25 |
+
<Config Name="Port: Webhook Port" Target="9000" Default="9000" Mode="tcp" Description="This is the port for the webhook" Type="Port" Display="always" Required="true" Mask="false"/>
|
| 26 |
+
<Config Name="Path: /subgen" Target="/subgen" Default="/mnt/user/appdata/subgen" Mode="rw" Description="This is the container path to your configuration files." Type="Path" Display="always" Required="true" Mask="false"/>
|
| 27 |
+
<Config Name="Variable: TRANSCRIBE_DEVICE" Target="TRANSCRIBE_DEVICE" Default="gpu" Description="Can transcribe via gpu (Cuda only) or cpu. Takes option of 'cpu', 'gpu', 'cuda'." Type="Variable" Display="always" Required="false" Mask="false"/>
|
| 28 |
+
<Config Name="Variable: WHISPER_MODEL" Target="WHISPER_MODEL" Default="medium" Description="Can be:'tiny', 'tiny.en', 'base', 'base.en', 'small', 'small.en', 'medium', 'medium.en', 'large-v1','large-v2', 'large-v3', 'large', 'distil-large-v2', 'distil-medium.en', 'distil-small.en'" Type="Variable" Display="always" Required="false" Mask="false"/>
|
| 29 |
+
<Config Name="Variable: CONCURRENT_TRANSCRIPTIONS" Target="CONCURRENT_TRANSCRIPTIONS" Default="2" Description="Number of files it will transcribe in parallel" Type="Variable" Display="advanced" Required="false" Mask="false"/>
|
| 30 |
+
<Config Name="Variable: WHISPER_THREADS" Target="WHISPER_THREADS" Default="4" Description="number of threads to use during computation" Type="Variable" Display="advanced" Required="false" Mask="false"/>
|
| 31 |
+
<Config Name="Variable: MODEL_PATH" Target="MODEL_PATH" Default="./models" Description="This is where the WHISPER_MODEL will be stored. This defaults to placing it where you execute the script in the folder 'models'" Type="Variable" Display="advanced" Required="false" Mask="false"/>
|
| 32 |
+
<Config Name="Variable: PROCADDEDMEDIA" Target="PROCADDEDMEDIA" Default="True" Description="will gen subtitles for all media added regardless of existing external/embedded subtitles (based off of SKIPIFINTERNALSUBLANG)" Type="Variable" Display="advanced" Required="false" Mask="false"/>
|
| 33 |
+
<Config Name="Variable: PROCMEDIAONPLAY" Target="PROCMEDIAONPLAY" Default="True" Description="will gen subtitles for all played media regardless of existing external/embedded subtitles (based off of SKIPIFINTERNALSUBLANG)" Type="Variable" Display="advanced" Required="false" Mask="false"/>
|
| 34 |
+
<Config Name="Variable: NAMESUBLANG" Target="NAMESUBLANG" Default="aa" Description="allows you to pick what it will name the subtitle. Instead of using EN, I'm using AA, so it doesn't mix with exiting external EN subs, and AA will populate higher on the list in Plex." Type="Variable" Display="advanced" Required="false" Mask="false"/>
|
| 35 |
+
<Config Name="Variable: SKIPIFINTERNALSUBLANG" Target="SKIPIFINTERNALSUBLANG" Default="eng" Description="Will not generate a subtitle if the file has an internal sub matching the 3 letter code of this variable (See https://en.wikipedia.org/wiki/List_of_ISO_639-1_codes)" Type="Variable" Display="advanced" Required="false" Mask="false"/>
|
| 36 |
+
<Config Name="Variable: WORD_LEVEL_HIGHLIGHT" Target="WORD_LEVEL_HIGHLIGHT" Default="False" Description="Highlights each words as it's spoken in the subtitle. See example video @ https://github.com/jianfch/stable-ts" Type="Variable" Display="advanced" Required="false" Mask="false"/>
|
| 37 |
+
<Config Name="Variable: PLEXSERVER" Target="PLEXSERVER" Default="http://plex:32400" Description="This needs to be set to your local plex server address/port" Type="Variable" Display="advanced" Required="false" Mask="false"/>
|
| 38 |
+
<Config Name="Variable: PLEXTOKEN" Target="PLEXTOKEN" Default="token here" Description="This needs to be set to your plex token found by https://support.plex.tv/articles/204059436-finding-an-authentication-token-x-plex-token/" Type="Variable" Display="advanced" Required="false" Mask="false"/>
|
| 39 |
+
<Config Name="Variable: JELLYFINSERVER" Target="JELLYFINSERVER" Default="http://jellyfin:8096" Description="Set to your Jellyfin server address/port" Type="Variable" Display="advanced" Required="false" Mask="false"/>
|
| 40 |
+
<Config Name="Variable: JELLYFINTOKEN" Target="JELLYFINTOKEN" Default="token here" Description="Generate a token inside the Jellyfin interface" Type="Variable" Display="advanced" Required="false" Mask="false"/>
|
| 41 |
+
<Config Name="Variable: WEBHOOKPORT" Target="WEBHOOKPORT" Default="9000" Description="Change this if you need a different port for your webhook" Type="Variable" Display="advanced" Required="false" Mask="false"/>
|
| 42 |
+
<Config Name="Variable: TRANSCRIBE_FOLDERS" Target="TRANSCRIBE_FOLDERS" Default="" Description="Takes a pipe '|' separated list (For example: /tv|/movies|/familyvideos) and iterates through and adds those files to be queued for subtitle generation if they don't have internal subtitles" Type="Variable" Display="advanced" Required="false" Mask="false"/>
|
| 43 |
+
<Config Name="Variable: TRANSCRIBE_OR_TRANSLATE" Target="TRANSCRIBE_OR_TRANSLATE" Default="transcribe" Description="Takes either 'transcribe' or 'translate'. Transcribe will transcribe the audio in the same language as the input. Translate will transcribe and translate into English." Type="Variable" Display="advanced" Required="false" Mask="false"/>
|
| 44 |
+
<Config Name="Variable: COMPUTE_TYPE" Target="COMPUTE_TYPE" Default="auto" Description="Set compute-type using the following information: https://github.com/OpenNMT/CTranslate2/blob/master/docs/quantization.md" Type="Variable" Display="advanced" Required="false" Mask="false"/>
|
| 45 |
+
<Config Name="Variable: DEBUG" Target="DEBUG" Default="True" Description="Provides some debug data that can be helpful to troubleshoot path mapping and other issues." Type="Variable" Display="advanced" Required="false" Mask="false"/>
|
| 46 |
+
<Config Name="Variable: FORCE_DETECTED_LANGUAGE_TO" Target="FORCE_DETECTED_LANGUAGE_TO" Default="" Description="This is to force the model to a language instead of the detected one, takes a 2 letter language code. For example, your audio is French but keeps detecting as English, you would set it to 'fr'" Type="Variable" Display="advanced" Required="false" Mask="false"/>
|
| 47 |
+
<Config Name="Variable: CLEAR_VRAM_ON_COMPLETE" Target="CLEAR_VRAM_ON_COMPLETE" Default="False" Description="This will delete the model and do garbage collection when queue is empty. Good if you need to use the VRAM for something else." Type="Variable" Display="advanced" Required="false" Mask="false"/>
|
| 48 |
+
<Config Name="Variable: UPDATE" Target="UPDATE" Default="True" Description="Will pull latest subgen.py from the repository if True. False will use the original subgen.py built into the Docker image. Standalone users can use this with launcher.py to get updates." Type="Variable" Display="always" Required="false" Mask="false"/>
|
| 49 |
+
<Config Name="Variable: APPEND" Target="APPEND" Default="False" Description="Will add the following at the end of a subtitle: 'Transcribed by whisperAI with faster-whisper ({whisper_model}) on {datetime.now()}'" Type="Variable" Display="advanced" Required="false" Mask="false"/>
|
| 50 |
+
<Config Name="Variable: MONITOR" Target="MONITOR" Default="False" Description="Will monitor TRANSCRIBE_FOLDERS for real-time changes to see if we need to generate subtitles" Type="Variable" Display="advanced" Required="false" Mask="false"/>
|
| 51 |
+
<Config Name="Variable: USE_MODEL_PROMPT" Target="USE_MODEL_PROMPT" Default="False" Description="When set to True, will use the default prompt stored in greetings_translations 'Hello, welcome to my lecture.' to try and force the use of punctuation in transcriptions that don't." Type="Variable" Display="advanced" Required="false" Mask="false"/>
|
| 52 |
+
<Config Name="Variable: CUSTOM_MODEL_PROMPT" Target="CUSTOM_MODEL_PROMPT" Default="" Description="If USE_MODEL_PROMPT is True, you can override the default prompt (See: https://medium.com/axinc-ai/prompt-engineering-in-whisper-6bb18003562d for great examples)." Type="Variable" Display="advanced" Required="false" Mask="false"/>
|
| 53 |
+
<Config Name="Variable: LRC_FOR_AUDIO_FILES" Target="LRC_FOR_AUDIO_FILES" Default="True" Description="Will generate LRC (instead of SRT) files for filetypes: '.mp3', '.flac', '.wav', '.alac', '.ape', '.ogg', '.wma', '.m4a', '.m4b', '.aac', '.aiff'" Type="Variable" Display="advanced" Required="false" Mask="false"/>
|
| 54 |
+
<Config Name="Variable: CUSTOM_REGROUP" Target="CUSTOM_REGROUP" Default="cm_sl=84_sl=42++++++1" Description="Attempts to regroup some of the segments to make a cleaner looking subtitle. See Issue #68 for discussion. Set to blank if you want to use Stable-TS default regroups algorithm of cm_sp=,* /,_sg=.5_mg=.3+3_sp=.* /。/?/?'" Type="Variable" Display="advanced" Required="false" Mask="false"/>
|
| 55 |
+
|
| 56 |
+
</Container>
|