
This view is limited to 50 files because it contains too many changes.
See raw diff
- README.md +7 -9
- datid3d_gradio_app.py +357 -0
- datid3d_test.py +251 -0
- datid3d_train.py +105 -0
- eg3d/LICENSE.txt +99 -0
- eg3d/README.md +216 -0
- eg3d/calc_metrics.py +190 -0
- eg3d/camera_utils.py +149 -0
- eg3d/dataset_tool.py +458 -0
- eg3d/datid3d_data_gen.py +204 -0
- eg3d/dnnlib/__init__.py +11 -0
- eg3d/dnnlib/util.py +493 -0
- eg3d/docs/camera_conventions.md +2 -0
- eg3d/docs/camera_coordinate_conventions.jpg +0 -0
- eg3d/docs/models.md +71 -0
- eg3d/docs/teaser.jpeg +0 -0
- eg3d/docs/training_guide.md +165 -0
- eg3d/docs/visualizer.png +0 -0
- eg3d/docs/visualizer_guide.md +66 -0
- eg3d/gen_samples.py +280 -0
- eg3d/gen_videos.py +371 -0
- eg3d/gui_utils/__init__.py +11 -0
- eg3d/gui_utils/gl_utils.py +376 -0
- eg3d/gui_utils/glfw_window.py +231 -0
- eg3d/gui_utils/imgui_utils.py +171 -0
- eg3d/gui_utils/imgui_window.py +105 -0
- eg3d/gui_utils/text_utils.py +125 -0
- eg3d/legacy.py +325 -0
- eg3d/metrics/__init__.py +11 -0
- eg3d/metrics/equivariance.py +269 -0
- eg3d/metrics/frechet_inception_distance.py +43 -0
- eg3d/metrics/inception_score.py +40 -0
- eg3d/metrics/kernel_inception_distance.py +48 -0
- eg3d/metrics/metric_main.py +155 -0
- eg3d/metrics/metric_utils.py +281 -0
- eg3d/metrics/perceptual_path_length.py +127 -0
- eg3d/metrics/precision_recall.py +64 -0
- eg3d/projector/w_plus_projector.py +182 -0
- eg3d/projector/w_projector.py +177 -0
- eg3d/run_inversion.py +106 -0
- eg3d/shape_utils.py +124 -0
- eg3d/torch_utils/__init__.py +11 -0
- eg3d/torch_utils/custom_ops.py +159 -0
- eg3d/torch_utils/misc.py +268 -0
- eg3d/torch_utils/ops/__init__.py +11 -0
- eg3d/torch_utils/ops/bias_act.cpp +103 -0
- eg3d/torch_utils/ops/bias_act.cu +177 -0
- eg3d/torch_utils/ops/bias_act.h +42 -0
- eg3d/torch_utils/ops/bias_act.py +211 -0
- eg3d/torch_utils/ops/conv2d_gradfix.py +199 -0
README.md
CHANGED
|
@@ -1,13 +1,11 @@
|
|
| 1 |
---
|
| 2 |
-
title: DATID
|
| 3 |
-
emoji:
|
| 4 |
-
colorFrom:
|
| 5 |
-
colorTo:
|
| 6 |
sdk: gradio
|
| 7 |
-
sdk_version: 3.
|
| 8 |
-
app_file:
|
| 9 |
pinned: false
|
| 10 |
-
license:
|
| 11 |
---
|
| 12 |
-
|
| 13 |
-
Check out the configuration reference at https://huggingface.co/docs/hub/spaces-config-reference
|
|
|
|
| 1 |
---
|
| 2 |
+
title: DATID-3D
|
| 3 |
+
emoji: 🛋
|
| 4 |
+
colorFrom: gray
|
| 5 |
+
colorTo: yellow
|
| 6 |
sdk: gradio
|
| 7 |
+
sdk_version: 3.28.3
|
| 8 |
+
app_file: datid3d_gradio_app.py
|
| 9 |
pinned: false
|
| 10 |
+
license: mit
|
| 11 |
---
|
|
|
|
|
|
datid3d_gradio_app.py
ADDED
|
@@ -0,0 +1,357 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import argparse
|
| 2 |
+
import gradio as gr
|
| 3 |
+
import os
|
| 4 |
+
import shutil
|
| 5 |
+
from glob import glob
|
| 6 |
+
from PIL import Image
|
| 7 |
+
import numpy as np
|
| 8 |
+
import matplotlib.pyplot as plt
|
| 9 |
+
from torchvision.utils import make_grid, save_image
|
| 10 |
+
from torchvision.io import read_image
|
| 11 |
+
import torchvision.transforms.functional as F
|
| 12 |
+
from functools import partial
|
| 13 |
+
from datetime import datetime
|
| 14 |
+
|
| 15 |
+
|
| 16 |
+
|
| 17 |
+
plt.rcParams["savefig.bbox"] = 'tight'
|
| 18 |
+
|
| 19 |
+
def show(imgs):
|
| 20 |
+
if not isinstance(imgs, list):
|
| 21 |
+
imgs = [imgs]
|
| 22 |
+
fig, axs = plt.subplots(ncols=len(imgs), squeeze=False)
|
| 23 |
+
for i, img in enumerate(imgs):
|
| 24 |
+
img = F.to_pil_image(img.detach())
|
| 25 |
+
axs[0, i].imshow(np.asarray(img))
|
| 26 |
+
axs[0, i].set(xticklabels=[], yticklabels=[], xticks=[], yticks=[])
|
| 27 |
+
|
| 28 |
+
class Intermediate:
|
| 29 |
+
def __init__(self):
|
| 30 |
+
self.input_img = None
|
| 31 |
+
self.input_img_time = 0
|
| 32 |
+
|
| 33 |
+
|
| 34 |
+
model_ckpts = {"elf": "ffhq-elf.pkl",
|
| 35 |
+
"greek_statue": "ffhq-greek_statue.pkl",
|
| 36 |
+
"hobbit": "ffhq-hobbit.pkl",
|
| 37 |
+
"lego": "ffhq-lego.pkl",
|
| 38 |
+
"masquerade": "ffhq-masquerade.pkl",
|
| 39 |
+
"neanderthal": "ffhq-neanderthal.pkl",
|
| 40 |
+
"orc": "ffhq-orc.pkl",
|
| 41 |
+
"pixar": "ffhq-pixar.pkl",
|
| 42 |
+
"skeleton": "ffhq-skeleton.pkl",
|
| 43 |
+
"stone_golem": "ffhq-stone_golem.pkl",
|
| 44 |
+
"super_mario": "ffhq-super_mario.pkl",
|
| 45 |
+
"tekken": "ffhq-tekken.pkl",
|
| 46 |
+
"yoda": "ffhq-yoda.pkl",
|
| 47 |
+
"zombie": "ffhq-zombie.pkl",
|
| 48 |
+
"cat_in_Zootopia": "cat-cat_in_Zootopia.pkl",
|
| 49 |
+
"fox_in_Zootopia": "cat-fox_in_Zootopia.pkl",
|
| 50 |
+
"golden_aluminum_animal": "cat-golden_aluminum_animal.pkl",
|
| 51 |
+
}
|
| 52 |
+
|
| 53 |
+
manip_model_ckpts = {"super_mario": "ffhq-super_mario.pkl",
|
| 54 |
+
"lego": "ffhq-lego.pkl",
|
| 55 |
+
"neanderthal": "ffhq-neanderthal.pkl",
|
| 56 |
+
"orc": "ffhq-orc.pkl",
|
| 57 |
+
"pixar": "ffhq-pixar.pkl",
|
| 58 |
+
"skeleton": "ffhq-skeleton.pkl",
|
| 59 |
+
"stone_golem": "ffhq-stone_golem.pkl",
|
| 60 |
+
"tekken": "ffhq-tekken.pkl",
|
| 61 |
+
"greek_statue": "ffhq-greek_statue.pkl",
|
| 62 |
+
"yoda": "ffhq-yoda.pkl",
|
| 63 |
+
"zombie": "ffhq-zombie.pkl",
|
| 64 |
+
"elf": "ffhq-elf.pkl",
|
| 65 |
+
}
|
| 66 |
+
|
| 67 |
+
|
| 68 |
+
def TextGuidedImageTo3D(intermediate, img, model_name, num_inversion_steps, truncation):
|
| 69 |
+
if img != intermediate.input_img:
|
| 70 |
+
if os.path.exists('input_imgs_gradio'):
|
| 71 |
+
shutil.rmtree('input_imgs_gradio')
|
| 72 |
+
os.makedirs('input_imgs_gradio', exist_ok=True)
|
| 73 |
+
img.save('input_imgs_gradio/input.png')
|
| 74 |
+
intermediate.input_img = img
|
| 75 |
+
now = datetime.now()
|
| 76 |
+
intermediate.input_img_time = now.strftime('%Y-%m-%d_%H:%M:%S')
|
| 77 |
+
|
| 78 |
+
all_model_names = manip_model_ckpts.keys()
|
| 79 |
+
generator_type = 'ffhq'
|
| 80 |
+
|
| 81 |
+
if model_name == 'all':
|
| 82 |
+
_no_video_models = []
|
| 83 |
+
for _model_name in all_model_names:
|
| 84 |
+
if not os.path.exists(f'test_runs/manip_3D_recon_gradio_{intermediate.input_img_time}/4_manip_result/finetuned___{model_ckpts[_model_name]}__input_inv.mp4'):
|
| 85 |
+
print()
|
| 86 |
+
_no_video_models.append(_model_name)
|
| 87 |
+
|
| 88 |
+
model_names_command = ''
|
| 89 |
+
for _model_name in _no_video_models:
|
| 90 |
+
if not os.path.exists(f'finetuned/{model_ckpts[_model_name]}'):
|
| 91 |
+
command = f"""wget https://huggingface.co/gwang-kim/datid3d-finetuned-eg3d-models/resolve/main/finetuned_models/{model_ckpts[_model_name]} -O finetuned/{model_ckpts[_model_name]}
|
| 92 |
+
"""
|
| 93 |
+
os.system(command)
|
| 94 |
+
|
| 95 |
+
model_names_command += f"finetuned/{model_ckpts[_model_name]} "
|
| 96 |
+
|
| 97 |
+
w_pths = sorted(glob(f'test_runs/manip_3D_recon_gradio_{intermediate.input_img_time}/3_inversion_result/*.pt'))
|
| 98 |
+
if len(w_pths) == 0:
|
| 99 |
+
mode = 'manip'
|
| 100 |
+
else:
|
| 101 |
+
mode = 'manip_from_inv'
|
| 102 |
+
|
| 103 |
+
if len(_no_video_models) > 0:
|
| 104 |
+
command = f"""python datid3d_test.py --mode {mode} \
|
| 105 |
+
--indir='input_imgs_gradio' \
|
| 106 |
+
--generator_type={generator_type} \
|
| 107 |
+
--outdir='test_runs' \
|
| 108 |
+
--trunc={truncation} \
|
| 109 |
+
--network {model_names_command} \
|
| 110 |
+
--num_inv_steps={num_inversion_steps} \
|
| 111 |
+
--down_src_eg3d_from_nvidia=False \
|
| 112 |
+
--name_tag='_gradio_{intermediate.input_img_time}' \
|
| 113 |
+
--shape=False \
|
| 114 |
+
--w_frames 60
|
| 115 |
+
"""
|
| 116 |
+
print(command)
|
| 117 |
+
os.system(command)
|
| 118 |
+
|
| 119 |
+
aligned_img_pth = sorted(glob(f'test_runs/manip_3D_recon_gradio_{intermediate.input_img_time}/2_pose_result/*.png'))[0]
|
| 120 |
+
aligned_img = Image.open(aligned_img_pth)
|
| 121 |
+
|
| 122 |
+
result_imgs = []
|
| 123 |
+
for _model_name in all_model_names:
|
| 124 |
+
img_pth = f'test_runs/manip_3D_recon_gradio_{intermediate.input_img_time}/4_manip_result/finetuned___{model_ckpts[_model_name]}__input_inv.png'
|
| 125 |
+
result_imgs.append(read_image(img_pth))
|
| 126 |
+
|
| 127 |
+
result_grid_pt = make_grid(result_imgs, nrow=1)
|
| 128 |
+
result_img = F.to_pil_image(result_grid_pt)
|
| 129 |
+
else:
|
| 130 |
+
if not os.path.exists(f'finetuned/{model_ckpts[model_name]}'):
|
| 131 |
+
command = f"""wget https://huggingface.co/gwang-kim/datid3d-finetuned-eg3d-models/resolve/main/finetuned_models/{model_ckpts[model_name]} -O finetuned/{model_ckpts[model_name]}
|
| 132 |
+
"""
|
| 133 |
+
os.system(command)
|
| 134 |
+
|
| 135 |
+
if not os.path.exists(f'test_runs/manip_3D_recon_gradio_{intermediate.input_img_time}/4_manip_result/finetuned___{model_ckpts[model_name]}__input_inv.mp4'):
|
| 136 |
+
w_pths = sorted(glob(f'test_runs/manip_3D_recon_gradio_{intermediate.input_img_time}/3_inversion_result/*.pt'))
|
| 137 |
+
if len(w_pths) == 0:
|
| 138 |
+
mode = 'manip'
|
| 139 |
+
else:
|
| 140 |
+
mode = 'manip_from_inv'
|
| 141 |
+
|
| 142 |
+
command = f"""python datid3d_test.py --mode {mode} \
|
| 143 |
+
--indir='input_imgs_gradio' \
|
| 144 |
+
--generator_type={generator_type} \
|
| 145 |
+
--outdir='test_runs' \
|
| 146 |
+
--trunc={truncation} \
|
| 147 |
+
--network finetuned/{model_ckpts[model_name]} \
|
| 148 |
+
--num_inv_steps={num_inversion_steps} \
|
| 149 |
+
--down_src_eg3d_from_nvidia=0 \
|
| 150 |
+
--name_tag='_gradio_{intermediate.input_img_time}' \
|
| 151 |
+
--shape=False
|
| 152 |
+
--w_frames 60"""
|
| 153 |
+
print(command)
|
| 154 |
+
os.system(command)
|
| 155 |
+
|
| 156 |
+
aligned_img_pth = sorted(glob(f'test_runs/manip_3D_recon_gradio_{intermediate.input_img_time}/2_pose_result/*.png'))[0]
|
| 157 |
+
aligned_img = Image.open(aligned_img_pth)
|
| 158 |
+
|
| 159 |
+
result_img_pth = sorted(glob(f'test_runs/manip_3D_recon_gradio_{intermediate.input_img_time}/4_manip_result/*{model_ckpts[model_name]}*.png'))[0]
|
| 160 |
+
result_img = Image.open(result_img_pth)
|
| 161 |
+
|
| 162 |
+
|
| 163 |
+
|
| 164 |
+
|
| 165 |
+
if model_name=='all':
|
| 166 |
+
result_video_pth = f'test_runs/manip_3D_recon_gradio_{intermediate.input_img_time}/4_manip_result/finetuned___ffhq-all__input_inv.mp4'
|
| 167 |
+
if os.path.exists(result_video_pth):
|
| 168 |
+
os.remove(result_video_pth)
|
| 169 |
+
command = 'ffmpeg '
|
| 170 |
+
for _model_name in all_model_names:
|
| 171 |
+
command += f'-i test_runs/manip_3D_recon_gradio_{intermediate.input_img_time}/4_manip_result/finetuned___ffhq-{_model_name}.pkl__input_inv.mp4 '
|
| 172 |
+
command += '-filter_complex "[0:v]scale=2*iw:-1[v0];[1:v]scale=2*iw:-1[v1];[2:v]scale=2*iw:-1[v2];[3:v]scale=2*iw:-1[v3];[4:v]scale=2*iw:-1[v4];[5:v]scale=2*iw:-1[v5];[6:v]scale=2*iw:-1[v6];[7:v]scale=2*iw:-1[v7];[8:v]scale=2*iw:-1[v8];[9:v]scale=2*iw:-1[v9];[10:v]scale=2*iw:-1[v10];[11:v]scale=2*iw:-1[v11];[v0][v1][v2][v3][v4][v5][v6][v7][v8][v9][v10][v11]xstack=inputs=12:layout=0_0|w0_0|w0+w1_0|w0+w1+w2_0|0_h0|w4_h0|w4+w5_h0|w4+w5+w6_h0|0_h0+h4|w8_h0+h4|w8+w9_h0+h4|w8+w9+w10_h0+h4" '
|
| 173 |
+
command += f" -vcodec libx264 {result_video_pth}"
|
| 174 |
+
print()
|
| 175 |
+
print(command)
|
| 176 |
+
os.system(command)
|
| 177 |
+
|
| 178 |
+
else:
|
| 179 |
+
result_video_pth = sorted(glob(f'test_runs/manip_3D_recon_gradio_{intermediate.input_img_time}/4_manip_result/*{model_ckpts[model_name]}*.mp4'))[0]
|
| 180 |
+
|
| 181 |
+
return aligned_img, result_img, result_video_pth
|
| 182 |
+
|
| 183 |
+
|
| 184 |
+
def SampleImage(model_name, num_samples, truncation, seed):
|
| 185 |
+
seed_list = np.random.RandomState(seed).choice(np.arange(10000), num_samples).tolist()
|
| 186 |
+
seeds = ''
|
| 187 |
+
for seed in seed_list:
|
| 188 |
+
seeds += f'{seed},'
|
| 189 |
+
seeds = seeds[:-1]
|
| 190 |
+
|
| 191 |
+
if model_name in ["fox_in_Zootopia", "cat_in_Zootopia", "golden_aluminum_animal"]:
|
| 192 |
+
generator_type = 'cat'
|
| 193 |
+
else:
|
| 194 |
+
generator_type = 'ffhq'
|
| 195 |
+
|
| 196 |
+
if not os.path.exists(f'finetuned/{model_ckpts[model_name]}'):
|
| 197 |
+
command = f"""wget https://huggingface.co/gwang-kim/datid3d-finetuned-eg3d-models/resolve/main/finetuned_models/{model_ckpts[model_name]} -O finetuned/{model_ckpts[model_name]}
|
| 198 |
+
"""
|
| 199 |
+
os.system(command)
|
| 200 |
+
|
| 201 |
+
command = f"""python datid3d_test.py --mode image \
|
| 202 |
+
--generator_type={generator_type} \
|
| 203 |
+
--outdir='test_runs' \
|
| 204 |
+
--seeds={seeds} \
|
| 205 |
+
--trunc={truncation} \
|
| 206 |
+
--network=finetuned/{model_ckpts[model_name]} \
|
| 207 |
+
--shape=False"""
|
| 208 |
+
print(command)
|
| 209 |
+
os.system(command)
|
| 210 |
+
|
| 211 |
+
result_img_pths = sorted(glob(f'test_runs/image/*{model_ckpts[model_name]}*.png'))
|
| 212 |
+
result_imgs = []
|
| 213 |
+
for img_pth in result_img_pths:
|
| 214 |
+
result_imgs.append(read_image(img_pth))
|
| 215 |
+
|
| 216 |
+
result_grid_pt = make_grid(result_imgs, nrow=1)
|
| 217 |
+
result_grid_pil = F.to_pil_image(result_grid_pt)
|
| 218 |
+
return result_grid_pil
|
| 219 |
+
|
| 220 |
+
|
| 221 |
+
|
| 222 |
+
|
| 223 |
+
def SampleVideo(model_name, grid_height, truncation, seed):
|
| 224 |
+
seed_list = np.random.RandomState(seed).choice(np.arange(10000), grid_height**2).tolist()
|
| 225 |
+
seeds = ''
|
| 226 |
+
for seed in seed_list:
|
| 227 |
+
seeds += f'{seed},'
|
| 228 |
+
seeds = seeds[:-1]
|
| 229 |
+
|
| 230 |
+
if model_name in ["fox_in_Zootopia", "cat_in_Zootopia", "golden_aluminum_animal"]:
|
| 231 |
+
generator_type = 'cat'
|
| 232 |
+
else:
|
| 233 |
+
generator_type = 'ffhq'
|
| 234 |
+
|
| 235 |
+
if not os.path.exists(f'finetuned/{model_ckpts[model_name]}'):
|
| 236 |
+
command = f"""wget https://huggingface.co/gwang-kim/datid3d-finetuned-eg3d-models/resolve/main/finetuned_models/{model_ckpts[model_name]} -O finetuned/{model_ckpts[model_name]}
|
| 237 |
+
"""
|
| 238 |
+
os.system(command)
|
| 239 |
+
|
| 240 |
+
command = f"""python datid3d_test.py --mode video \
|
| 241 |
+
--generator_type={generator_type} \
|
| 242 |
+
--outdir='test_runs' \
|
| 243 |
+
--seeds={seeds} \
|
| 244 |
+
--trunc={truncation} \
|
| 245 |
+
--grid={grid_height}x{grid_height} \
|
| 246 |
+
--network=finetuned/{model_ckpts[model_name]} \
|
| 247 |
+
--shape=False"""
|
| 248 |
+
print(command)
|
| 249 |
+
os.system(command)
|
| 250 |
+
|
| 251 |
+
result_video_pth = sorted(glob(f'test_runs/video/*{model_ckpts[model_name]}*.mp4'))[0]
|
| 252 |
+
|
| 253 |
+
return result_video_pth
|
| 254 |
+
|
| 255 |
+
|
| 256 |
+
if __name__ == '__main__':
|
| 257 |
+
parser = argparse.ArgumentParser()
|
| 258 |
+
parser.add_argument('--share', action='store_true', help="public url")
|
| 259 |
+
args = parser.parse_args()
|
| 260 |
+
|
| 261 |
+
demo = gr.Blocks(title="DATID-3D Interactive Demo")
|
| 262 |
+
os.makedirs('finetuned', exist_ok=True)
|
| 263 |
+
intermediate = Intermediate()
|
| 264 |
+
with demo:
|
| 265 |
+
gr.Markdown("# DATID-3D Interactive Demo")
|
| 266 |
+
gr.Markdown(
|
| 267 |
+
"### Demo of the CVPR 2023 paper \"DATID-3D: Diversity-Preserved Domain Adaptation Using Text-to-Image Diffusion for 3D Generative Model\"")
|
| 268 |
+
|
| 269 |
+
with gr.Tab("Text-guided Manipulated 3D reconstruction"):
|
| 270 |
+
gr.Markdown("Text-guided Image-to-3D Translation")
|
| 271 |
+
with gr.Row():
|
| 272 |
+
with gr.Column(scale=1, variant='panel'):
|
| 273 |
+
t_image_input = gr.Image(source='upload', type="pil", interactive=True)
|
| 274 |
+
|
| 275 |
+
t_model_name = gr.Radio(["super_mario", "lego", "neanderthal", "orc",
|
| 276 |
+
"pixar", "skeleton", "stone_golem","tekken",
|
| 277 |
+
"greek_statue", "yoda", "zombie", "elf", "all"],
|
| 278 |
+
label="Model fine-tuned through DATID-3D",
|
| 279 |
+
value="super_mario", interactive=True)
|
| 280 |
+
with gr.Accordion("Advanced Options", open=False):
|
| 281 |
+
t_truncation = gr.Slider(label="Truncation psi", minimum=0, maximum=1.0, step=0.01, randomize=False, value=0.8)
|
| 282 |
+
t_num_inversion_steps = gr.Slider(200, 1000, value=200, step=1, label='Number of steps for the invresion')
|
| 283 |
+
with gr.Row():
|
| 284 |
+
t_button_gen_result = gr.Button("Generate Result", variant='primary')
|
| 285 |
+
# t_button_gen_video = gr.Button("Generate Video", variant='primary')
|
| 286 |
+
# t_button_gen_image = gr.Button("Generate Image", variant='secondary')
|
| 287 |
+
with gr.Row():
|
| 288 |
+
t_align_image_result = gr.Image(label="Alignment result", interactive=False)
|
| 289 |
+
with gr.Column(scale=1, variant='panel'):
|
| 290 |
+
with gr.Row():
|
| 291 |
+
t_video_result = gr.Video(label="Video result", interactive=False)
|
| 292 |
+
|
| 293 |
+
with gr.Row():
|
| 294 |
+
t_image_result = gr.Image(label="Image result", interactive=False)
|
| 295 |
+
|
| 296 |
+
|
| 297 |
+
with gr.Tab("Sample Images"):
|
| 298 |
+
with gr.Row():
|
| 299 |
+
with gr.Column(scale=1, variant='panel'):
|
| 300 |
+
i_model_name = gr.Radio(
|
| 301 |
+
["elf", "greek_statue", "hobbit", "lego", "masquerade", "neanderthal", "orc", "pixar",
|
| 302 |
+
"skeleton", "stone_golem", "super_mario", "tekken", "yoda", "zombie", "fox_in_Zootopia",
|
| 303 |
+
"cat_in_Zootopia", "golden_aluminum_animal"],
|
| 304 |
+
label="Model fine-tuned through DATID-3D",
|
| 305 |
+
value="super_mario", interactive=True)
|
| 306 |
+
i_num_samples = gr.Slider(0, 20, value=4, step=1, label='Number of samples')
|
| 307 |
+
i_seed = gr.Slider(label="Seed", minimum=0, maximum=1000000000, step=1, value=1235)
|
| 308 |
+
with gr.Accordion("Advanced Options", open=False):
|
| 309 |
+
i_truncation = gr.Slider(label="Truncation psi", minimum=0, maximum=1.0, step=0.01, randomize=False, value=0.8)
|
| 310 |
+
with gr.Row():
|
| 311 |
+
i_button_gen_image = gr.Button("Generate Image", variant='primary')
|
| 312 |
+
with gr.Column(scale=1, variant='panel'):
|
| 313 |
+
with gr.Row():
|
| 314 |
+
i_image_result = gr.Image(label="Image result", interactive=False)
|
| 315 |
+
|
| 316 |
+
|
| 317 |
+
with gr.Tab("Sample Videos"):
|
| 318 |
+
with gr.Row():
|
| 319 |
+
with gr.Column(scale=1, variant='panel'):
|
| 320 |
+
v_model_name = gr.Radio(
|
| 321 |
+
["elf", "greek_statue", "hobbit", "lego", "masquerade", "neanderthal", "orc", "pixar",
|
| 322 |
+
"skeleton", "stone_golem", "super_mario", "tekken", "yoda", "zombie", "fox_in_Zootopia",
|
| 323 |
+
"cat_in_Zootopia", "golden_aluminum_animal"],
|
| 324 |
+
label="Model fine-tuned through DATID-3D",
|
| 325 |
+
value="super_mario", interactive=True)
|
| 326 |
+
v_grid_height = gr.Slider(0, 5, value=2, step=1,label='Height of the grid')
|
| 327 |
+
v_seed = gr.Slider(label="Seed", minimum=0, maximum=1000000000, step=1, value=1235)
|
| 328 |
+
with gr.Accordion("Advanced Options", open=False):
|
| 329 |
+
v_truncation = gr.Slider(label="Truncation psi", minimum=0, maximum=1.0, step=0.01, randomize=False,
|
| 330 |
+
value=0.8)
|
| 331 |
+
|
| 332 |
+
with gr.Row():
|
| 333 |
+
v_button_gen_video = gr.Button("Generate Video", variant='primary')
|
| 334 |
+
|
| 335 |
+
with gr.Column(scale=1, variant='panel'):
|
| 336 |
+
|
| 337 |
+
with gr.Row():
|
| 338 |
+
v_video_result = gr.Video(label="Video result", interactive=False)
|
| 339 |
+
|
| 340 |
+
|
| 341 |
+
|
| 342 |
+
|
| 343 |
+
|
| 344 |
+
# functions
|
| 345 |
+
t_button_gen_result.click(fn=partial(TextGuidedImageTo3D, intermediate),
|
| 346 |
+
inputs=[t_image_input, t_model_name, t_num_inversion_steps, t_truncation],
|
| 347 |
+
outputs=[t_align_image_result, t_image_result, t_video_result])
|
| 348 |
+
i_button_gen_image.click(fn=SampleImage,
|
| 349 |
+
inputs=[i_model_name, i_num_samples, i_truncation, i_seed],
|
| 350 |
+
outputs=[i_image_result])
|
| 351 |
+
v_button_gen_video.click(fn=SampleVideo,
|
| 352 |
+
inputs=[i_model_name, v_grid_height, v_truncation, v_seed],
|
| 353 |
+
outputs=[v_video_result])
|
| 354 |
+
|
| 355 |
+
demo.queue(concurrency_count=1)
|
| 356 |
+
demo.launch(share=args.share)
|
| 357 |
+
|
datid3d_test.py
ADDED
|
@@ -0,0 +1,251 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import os
|
| 2 |
+
from os.path import join as opj
|
| 3 |
+
import argparse
|
| 4 |
+
from glob import glob
|
| 5 |
+
|
| 6 |
+
### Parameters
|
| 7 |
+
parser = argparse.ArgumentParser()
|
| 8 |
+
|
| 9 |
+
# For all
|
| 10 |
+
parser.add_argument('--mode', type=str, required=True, choices=['image', 'video', 'manip', 'manip_from_inv'],
|
| 11 |
+
help="image: Sample images and shapes, "
|
| 12 |
+
"video: Sample pose-controlled videos, "
|
| 13 |
+
"manip: Manipulated 3D reconstruction from images, "
|
| 14 |
+
"manip_from_inv: Manipulated 3D reconstruction from inverted latent")
|
| 15 |
+
parser.add_argument('--network', type=str, nargs='+', required=True)
|
| 16 |
+
parser.add_argument('--generator_type', default='ffhq', type=str, choices=['ffhq', 'cat']) # ffhq, cat
|
| 17 |
+
parser.add_argument('--outdir', type=str, default='test_runs')
|
| 18 |
+
parser.add_argument('--trunc', type=float, default=0.7)
|
| 19 |
+
parser.add_argument('--seeds', type=str, default='100-200')
|
| 20 |
+
parser.add_argument('--down_src_eg3d_from_nvidia', default=True)
|
| 21 |
+
parser.add_argument('--num_inv_steps', default=300, type=int)
|
| 22 |
+
# Manipulated 3D reconstruction
|
| 23 |
+
parser.add_argument('--indir', type=str, default='input_imgs')
|
| 24 |
+
parser.add_argument('--name_tag', type=str, default='')
|
| 25 |
+
# Sample images
|
| 26 |
+
parser.add_argument('--shape', default=True)
|
| 27 |
+
parser.add_argument('--shape_format', type=str, choices=['.mrc', '.ply'], default='.mrc')
|
| 28 |
+
parser.add_argument('--shape_only_first', type=bool, default=False)
|
| 29 |
+
# Sample pose-controlled videos
|
| 30 |
+
parser.add_argument('--grid', default='1x1')
|
| 31 |
+
parser.add_argument('--w_frames', type=int, default=120)
|
| 32 |
+
|
| 33 |
+
|
| 34 |
+
|
| 35 |
+
args = parser.parse_args()
|
| 36 |
+
os.makedirs(args.outdir, exist_ok=True)
|
| 37 |
+
print()
|
| 38 |
+
|
| 39 |
+
|
| 40 |
+
network_command = ''
|
| 41 |
+
for network_path in args.network:
|
| 42 |
+
network_command += f"--network {opj('..', network_path)} "
|
| 43 |
+
|
| 44 |
+
|
| 45 |
+
|
| 46 |
+
### Sample images
|
| 47 |
+
if args.mode == 'image':
|
| 48 |
+
image_path = opj(args.outdir, f'image{args.name_tag}')
|
| 49 |
+
os.makedirs(image_path, exist_ok=True)
|
| 50 |
+
|
| 51 |
+
os.chdir('eg3d')
|
| 52 |
+
command = f"""python gen_samples.py \
|
| 53 |
+
{network_command} \
|
| 54 |
+
--seeds={args.seeds} \
|
| 55 |
+
--generator_type={args.generator_type} \
|
| 56 |
+
--outdir={opj('..', image_path)} \
|
| 57 |
+
--shapes={args.shape} \
|
| 58 |
+
--shape_format={args.shape_format} \
|
| 59 |
+
--shape_only_first={args.shape_only_first} \
|
| 60 |
+
--trunc={args.trunc} \
|
| 61 |
+
"""
|
| 62 |
+
print(f"{command} \n")
|
| 63 |
+
os.system(command)
|
| 64 |
+
os.chdir('..')
|
| 65 |
+
|
| 66 |
+
|
| 67 |
+
|
| 68 |
+
|
| 69 |
+
|
| 70 |
+
### Sample pose-controlled videos
|
| 71 |
+
if args.mode == 'video':
|
| 72 |
+
video_path = opj(args.outdir, f'video{args.name_tag}')
|
| 73 |
+
os.makedirs(video_path, exist_ok=True)
|
| 74 |
+
|
| 75 |
+
os.chdir('eg3d')
|
| 76 |
+
command = f"""python gen_videos.py \
|
| 77 |
+
{network_command} \
|
| 78 |
+
--seeds={args.seeds} \
|
| 79 |
+
--generator_type={args.generator_type} \
|
| 80 |
+
--outdir={opj('..', video_path)} \
|
| 81 |
+
--shapes=False \
|
| 82 |
+
--trunc={args.trunc} \
|
| 83 |
+
--grid={args.grid} \
|
| 84 |
+
--w-frames={args.w_frames}
|
| 85 |
+
"""
|
| 86 |
+
print(f"{command} \n")
|
| 87 |
+
os.system(command)
|
| 88 |
+
os.chdir('..')
|
| 89 |
+
|
| 90 |
+
|
| 91 |
+
### Manipulated 3D reconstruction from images
|
| 92 |
+
if args.mode == 'manip':
|
| 93 |
+
input_path = opj(args.indir)
|
| 94 |
+
align_path = opj(args.outdir, f'manip_3D_recon{args.name_tag}', '1_align_result')
|
| 95 |
+
pose_path = opj(args.outdir, f'manip_3D_recon{args.name_tag}', '2_pose_result')
|
| 96 |
+
inversion_path = opj(args.outdir, f'manip_3D_recon{args.name_tag}', '3_inversion_result')
|
| 97 |
+
manip_path = opj(args.outdir, f'manip_3D_recon{args.name_tag}', '4_manip_result')
|
| 98 |
+
|
| 99 |
+
os.makedirs(opj(args.outdir, f'manip_3D_recon{args.name_tag}'), exist_ok=True)
|
| 100 |
+
os.makedirs(align_path, exist_ok=True)
|
| 101 |
+
os.makedirs(pose_path, exist_ok=True)
|
| 102 |
+
os.makedirs(inversion_path, exist_ok=True)
|
| 103 |
+
os.makedirs(manip_path, exist_ok=True)
|
| 104 |
+
|
| 105 |
+
os.chdir('eg3d')
|
| 106 |
+
if args.generator_type == 'cat':
|
| 107 |
+
generator_id = 'afhqcats512-128.pkl'
|
| 108 |
+
else:
|
| 109 |
+
generator_id = 'ffhqrebalanced512-128.pkl'
|
| 110 |
+
generator_path = f'pretrained/{generator_id}'
|
| 111 |
+
if not os.path.exists(generator_path):
|
| 112 |
+
os.makedirs(f'pretrained', exist_ok=True)
|
| 113 |
+
print("Pretrained EG3D model cannot be found. Downloading the pretrained EG3D models.")
|
| 114 |
+
if args.down_src_eg3d_from_nvidia == True:
|
| 115 |
+
os.system(f'wget -c https://api.ngc.nvidia.com/v2/models/nvidia/research/eg3d/versions/1/files/{generator_id} -O {generator_path}')
|
| 116 |
+
else:
|
| 117 |
+
os.system(f'wget https://huggingface.co/gwang-kim/datid3d-finetuned-eg3d-models/resolve/main/finetuned_models/nvidia_{generator_id} -O {generator_path}')
|
| 118 |
+
os.chdir('..')
|
| 119 |
+
|
| 120 |
+
## Align images and Pose extraction
|
| 121 |
+
os.chdir('pose_estimation')
|
| 122 |
+
if not os.path.exists('checkpoints/pretrained/epoch_20.pth') or not os.path.exists('BFM'):
|
| 123 |
+
print(f"BFM and pretrained DeepFaceRecon3D model cannot be found. Downloading the pretrained pose estimation model and BFM files, put epoch_20.pth in ./pose_estimation/checkpoints/pretrained/ and put unzip BFM.zip in ./pose_estimation/.")
|
| 124 |
+
|
| 125 |
+
try:
|
| 126 |
+
from gdown import download as drive_download
|
| 127 |
+
drive_download(f'https://drive.google.com/uc?id=1mdqkEUepHZROeOj99pXogAPJPqzBDN2G', './BFM.zip', quiet=False)
|
| 128 |
+
os.system('unzip BFM.zip')
|
| 129 |
+
drive_download(f'https://drive.google.com/uc?id=1zawY7jYDJlUGnSAXn1pgIHgIvJpiSmj5', './checkpoints/pretrained/epoch_20.pth', quiet=False)
|
| 130 |
+
except:
|
| 131 |
+
os.system("pip install -U --no-cache-dir gdown --pre")
|
| 132 |
+
from gdown import download as drive_download
|
| 133 |
+
drive_download(f'https://drive.google.com/uc?id=1mdqkEUepHZROeOj99pXogAPJPqzBDN2G', './BFM.zip', quiet=False)
|
| 134 |
+
os.system('unzip BFM.zip')
|
| 135 |
+
drive_download(f'https://drive.google.com/uc?id=1zawY7jYDJlUGnSAXn1pgIHgIvJpiSmj5', './checkpoints/pretrained/epoch_20.pth', quiet=False)
|
| 136 |
+
|
| 137 |
+
print()
|
| 138 |
+
command = f"""python extract_pose.py 0 \
|
| 139 |
+
{opj('..', input_path)} {opj('..', align_path)} {opj('..', pose_path)}
|
| 140 |
+
"""
|
| 141 |
+
print(f"{command} \n")
|
| 142 |
+
os.system(command)
|
| 143 |
+
os.chdir('..')
|
| 144 |
+
|
| 145 |
+
## Invert images to the latent space of 3D GANs
|
| 146 |
+
os.chdir('eg3d')
|
| 147 |
+
command = f"""python run_inversion.py \
|
| 148 |
+
--outdir={opj('..', inversion_path)} \
|
| 149 |
+
--latent_space_type=w_plus \
|
| 150 |
+
--network={generator_path} \
|
| 151 |
+
--image_path={opj('..', pose_path)} \
|
| 152 |
+
--num_steps={args.num_inv_steps}
|
| 153 |
+
"""
|
| 154 |
+
print(f"{command} \n")
|
| 155 |
+
os.system(command)
|
| 156 |
+
os.chdir('..')
|
| 157 |
+
|
| 158 |
+
## Generate videos, images and mesh
|
| 159 |
+
os.chdir('eg3d')
|
| 160 |
+
w_pths = sorted(glob(opj('..', inversion_path, '*.pt')))
|
| 161 |
+
if len(w_pths) == 0:
|
| 162 |
+
print("No inverted latent")
|
| 163 |
+
exit()
|
| 164 |
+
for w_pth in w_pths:
|
| 165 |
+
print(f"{w_pth} \n")
|
| 166 |
+
|
| 167 |
+
command = f"""python gen_samples.py \
|
| 168 |
+
{network_command} \
|
| 169 |
+
--w_pth={w_pth} \
|
| 170 |
+
--seeds='100-200' \
|
| 171 |
+
--generator_type={args.generator_type} \
|
| 172 |
+
--outdir={opj('..', manip_path)} \
|
| 173 |
+
--shapes={args.shape} \
|
| 174 |
+
--shape_format={args.shape_format} \
|
| 175 |
+
--shape_only_first={args.shape_only_first} \
|
| 176 |
+
--trunc={args.trunc} \
|
| 177 |
+
"""
|
| 178 |
+
print(f"{command} \n")
|
| 179 |
+
os.system(command)
|
| 180 |
+
|
| 181 |
+
command = f"""python gen_videos.py \
|
| 182 |
+
{network_command} \
|
| 183 |
+
--w_pth={w_pth} \
|
| 184 |
+
--seeds='100-200' \
|
| 185 |
+
--generator_type={args.generator_type} \
|
| 186 |
+
--outdir={opj('..', manip_path)} \
|
| 187 |
+
--shapes=False \
|
| 188 |
+
--trunc={args.trunc} \
|
| 189 |
+
--grid=1x1 \
|
| 190 |
+
--w-frames={args.w_frames}
|
| 191 |
+
"""
|
| 192 |
+
print(f"{command} \n")
|
| 193 |
+
os.system(command)
|
| 194 |
+
os.chdir('..')
|
| 195 |
+
|
| 196 |
+
|
| 197 |
+
|
| 198 |
+
|
| 199 |
+
|
| 200 |
+
### Manipulated 3D reconstruction from inverted latent
|
| 201 |
+
if args.mode == 'manip_from_inv':
|
| 202 |
+
input_path = opj(args.indir)
|
| 203 |
+
align_path = opj(args.outdir, f'manip_3D_recon{args.name_tag}', '1_align_result')
|
| 204 |
+
pose_path = opj(args.outdir, f'manip_3D_recon{args.name_tag}', '2_pose_result')
|
| 205 |
+
inversion_path = opj(args.outdir, f'manip_3D_recon{args.name_tag}', '3_inversion_result')
|
| 206 |
+
manip_path = opj(args.outdir, f'manip_3D_recon{args.name_tag}', '4_manip_result')
|
| 207 |
+
|
| 208 |
+
os.makedirs(opj(args.outdir, f'manip_3D_recon{args.name_tag}'), exist_ok=True)
|
| 209 |
+
os.makedirs(align_path, exist_ok=True)
|
| 210 |
+
os.makedirs(pose_path, exist_ok=True)
|
| 211 |
+
os.makedirs(inversion_path, exist_ok=True)
|
| 212 |
+
os.makedirs(manip_path, exist_ok=True)
|
| 213 |
+
|
| 214 |
+
## Generate videos, images and mesh
|
| 215 |
+
os.chdir('eg3d')
|
| 216 |
+
w_pths = sorted(glob(opj('..', inversion_path, '*.pt')))
|
| 217 |
+
if len(w_pths) == 0:
|
| 218 |
+
print("No inverted latent")
|
| 219 |
+
exit()
|
| 220 |
+
for w_pth in w_pths:
|
| 221 |
+
print(f"{w_pth} \n")
|
| 222 |
+
|
| 223 |
+
command = f"""python gen_samples.py \
|
| 224 |
+
{network_command} \
|
| 225 |
+
--w_pth={w_pth} \
|
| 226 |
+
--seeds='100-200' \
|
| 227 |
+
--generator_type={args.generator_type} \
|
| 228 |
+
--outdir={opj('..', manip_path)} \
|
| 229 |
+
--shapes={args.shape} \
|
| 230 |
+
--shape_format={args.shape_format} \
|
| 231 |
+
--shape_only_first={args.shape_only_first} \
|
| 232 |
+
--trunc={args.trunc} \
|
| 233 |
+
"""
|
| 234 |
+
print(f"{command} \n")
|
| 235 |
+
os.system(command)
|
| 236 |
+
|
| 237 |
+
command = f"""python gen_videos.py \
|
| 238 |
+
{network_command} \
|
| 239 |
+
--w_pth={w_pth} \
|
| 240 |
+
--seeds='100-200' \
|
| 241 |
+
--generator_type={args.generator_type} \
|
| 242 |
+
--outdir={opj('..', manip_path)} \
|
| 243 |
+
--shapes=False \
|
| 244 |
+
--trunc={args.trunc} \
|
| 245 |
+
--grid=1x1
|
| 246 |
+
"""
|
| 247 |
+
print(f"{command} \n")
|
| 248 |
+
os.system(command)
|
| 249 |
+
os.chdir('..')
|
| 250 |
+
|
| 251 |
+
|
datid3d_train.py
ADDED
|
@@ -0,0 +1,105 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import os
|
| 2 |
+
import argparse
|
| 3 |
+
|
| 4 |
+
### Parameters
|
| 5 |
+
parser = argparse.ArgumentParser()
|
| 6 |
+
|
| 7 |
+
# For all
|
| 8 |
+
parser.add_argument('--mode', type=str, required=True, choices=['pdg', 'ft', 'both'],
|
| 9 |
+
help="pdg: Pose-aware dataset generation, ft: Fine-tuning 3D generative models, both: Doing both")
|
| 10 |
+
parser.add_argument('--down_src_eg3d_from_nvidia', default=True)
|
| 11 |
+
# Pose-aware dataset generation
|
| 12 |
+
parser.add_argument('--pdg_prompt', type=str, required=True)
|
| 13 |
+
parser.add_argument('--pdg_generator_type', default='ffhq', type=str, choices=['ffhq', 'cat']) # ffhq, cat
|
| 14 |
+
parser.add_argument('--pdg_strength', default=0.7, type=float)
|
| 15 |
+
parser.add_argument('--pdg_guidance_scale', default=8, type=float)
|
| 16 |
+
parser.add_argument('--pdg_num_images', default=1000, type=int)
|
| 17 |
+
parser.add_argument('--pdg_sd_model_id', default='stabilityai/stable-diffusion-2-1-base', type=str)
|
| 18 |
+
parser.add_argument('--pdg_num_inference_steps', default=50, type=int)
|
| 19 |
+
parser.add_argument('--pdg_name_tag', default='', type=str)
|
| 20 |
+
parser.add_argument('--down_src_eg3d_from_nvidia', default=True)
|
| 21 |
+
# Fine-tuning 3D generative models
|
| 22 |
+
parser.add_argument('--ft_generator_type', default='same', help="None: The same type as pdg_generator_type", type=str, choices=['ffhq', 'cat', 'same'])
|
| 23 |
+
parser.add_argument('--ft_kimg', default=200, type=int)
|
| 24 |
+
parser.add_argument('--ft_batch', default=20, type=int)
|
| 25 |
+
parser.add_argument('--ft_tick', default=1, type=int)
|
| 26 |
+
parser.add_argument('--ft_snap', default=50, type=int)
|
| 27 |
+
parser.add_argument('--ft_outdir', default='../training_runs', type=str) #
|
| 28 |
+
parser.add_argument('--ft_gpus', default=1, type=str) #
|
| 29 |
+
parser.add_argument('--ft_workers', default=8, type=int) #
|
| 30 |
+
parser.add_argument('--ft_data_max_size', default=500000000, type=int) #
|
| 31 |
+
parser.add_argument('--ft_freeze_dec_sr', default=True, type=bool) #
|
| 32 |
+
|
| 33 |
+
args = parser.parse_args()
|
| 34 |
+
|
| 35 |
+
|
| 36 |
+
### Pose-aware target generation
|
| 37 |
+
if args.mode in ['pdg', 'both']:
|
| 38 |
+
os.chdir('eg3d')
|
| 39 |
+
if args.pdg_generator_type == 'cat':
|
| 40 |
+
pdg_generator_id = 'afhqcats512-128.pkl'
|
| 41 |
+
else:
|
| 42 |
+
pdg_generator_id = 'ffhqrebalanced512-128.pkl'
|
| 43 |
+
|
| 44 |
+
pdg_generator_path = f'pretrained/{pdg_generator_id}'
|
| 45 |
+
if not os.path.exists(pdg_generator_path):
|
| 46 |
+
os.makedirs(f'pretrained', exist_ok=True)
|
| 47 |
+
print("Pretrained EG3D model cannot be found. Downloading the pretrained EG3D models.")
|
| 48 |
+
if args.down_src_eg3d_from_nvidia == True:
|
| 49 |
+
os.system(f'wget -c https://api.ngc.nvidia.com/v2/models/nvidia/research/eg3d/versions/1/files/{pdg_generator_id} -O {pdg_generator_path}')
|
| 50 |
+
else:
|
| 51 |
+
os.system(f'wget https://huggingface.co/gwang-kim/datid3d-finetuned-eg3d-models/resolve/main/finetuned_models/nvidia_{pdg_generator_id} -O {pdg_generator_path}')
|
| 52 |
+
command = f"""python datid3d_data_gen.py \
|
| 53 |
+
--prompt="{args.pdg_prompt}" \
|
| 54 |
+
--data_type={args.pdg_generator_type} \
|
| 55 |
+
--strength={args.pdg_strength} \
|
| 56 |
+
--guidance_scale={args.pdg_guidance_scale} \
|
| 57 |
+
--num_images={args.pdg_num_images} \
|
| 58 |
+
--sd_model_id="{args.pdg_sd_model_id}" \
|
| 59 |
+
--num_inference_steps={args.pdg_num_inference_steps} \
|
| 60 |
+
--name_tag={args.pdg_name_tag}
|
| 61 |
+
"""
|
| 62 |
+
print(f"{command} \n")
|
| 63 |
+
os.system(command)
|
| 64 |
+
os.chdir('..')
|
| 65 |
+
|
| 66 |
+
### Filtering process
|
| 67 |
+
# TODO
|
| 68 |
+
|
| 69 |
+
|
| 70 |
+
### Fine-tuning 3D generative models
|
| 71 |
+
if args.mode in ['ft', 'both']:
|
| 72 |
+
os.chdir('eg3d')
|
| 73 |
+
if args.ft_generator_type == 'same':
|
| 74 |
+
args.ft_generator_type = args.pdg_generator_type
|
| 75 |
+
|
| 76 |
+
if args.ft_generator_type == 'cat':
|
| 77 |
+
ft_generator_id = 'afhqcats512-128.pkl'
|
| 78 |
+
else:
|
| 79 |
+
ft_generator_id = 'ffhqrebalanced512-128.pkl'
|
| 80 |
+
|
| 81 |
+
ft_generator_path = f'pretrained/{ft_generator_id}'
|
| 82 |
+
if not os.path.exists(ft_generator_path):
|
| 83 |
+
os.makedirs(f'pretrained', exist_ok=True)
|
| 84 |
+
print("Pretrained EG3D model cannot be found. Downloading the pretrained EG3D models.")
|
| 85 |
+
if args.down_src_eg3d_from_nvidia == True:
|
| 86 |
+
os.system(f'wget -c https://api.ngc.nvidia.com/v2/models/nvidia/research/eg3d/versions/1/files/{ft_generator_id} -O {ft_generator_path}')
|
| 87 |
+
else:
|
| 88 |
+
os.system(f'wget https://huggingface.co/gwang-kim/datid3d-finetuned-eg3d-models/resolve/main/finetuned_models/nvidia_{ft_generator_id} -O {ft_generator_path}')
|
| 89 |
+
|
| 90 |
+
dataset_id = f'data_{args.pdg_generator_type}_{args.pdg_prompt.replace(" ", "_")}{args.pdg_name_tag}'
|
| 91 |
+
dataset_path = f'./exp_data/{dataset_id}/{dataset_id}.zip'
|
| 92 |
+
|
| 93 |
+
|
| 94 |
+
command = f"""python train.py \
|
| 95 |
+
--outdir={args.ft_outdir} \
|
| 96 |
+
--cfg={args.ft_generator_type} \
|
| 97 |
+
--data="{dataset_path}" \
|
| 98 |
+
--resume={ft_generator_path} --freeze_dec_sr={args.ft_freeze_dec_sr} \
|
| 99 |
+
--batch={args.ft_batch} --workers={args.ft_workers} --gpus={args.ft_gpus} \
|
| 100 |
+
--tick={args.ft_tick} --snap={args.ft_snap} --data_max_size={args.ft_data_max_size} --kimg={args.ft_kimg} \
|
| 101 |
+
--gamma=5 --aug=ada --neural_rendering_resolution_final=128 --gen_pose_cond=True --gpc_reg_prob=0.8 --metrics=None
|
| 102 |
+
"""
|
| 103 |
+
print(f"{command} \n")
|
| 104 |
+
os.system(command)
|
| 105 |
+
os.chdir('..')
|
eg3d/LICENSE.txt
ADDED
|
@@ -0,0 +1,99 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
Copyright (c) 2021-2022, NVIDIA Corporation & affiliates. All rights
|
| 2 |
+
reserved.
|
| 3 |
+
|
| 4 |
+
|
| 5 |
+
NVIDIA Source Code License for EG3D
|
| 6 |
+
|
| 7 |
+
|
| 8 |
+
=======================================================================
|
| 9 |
+
|
| 10 |
+
1. Definitions
|
| 11 |
+
|
| 12 |
+
"Licensor" means any person or entity that distributes its Work.
|
| 13 |
+
|
| 14 |
+
"Software" means the original work of authorship made available under
|
| 15 |
+
this License.
|
| 16 |
+
|
| 17 |
+
"Work" means the Software and any additions to or derivative works of
|
| 18 |
+
the Software that are made available under this License.
|
| 19 |
+
|
| 20 |
+
The terms "reproduce," "reproduction," "derivative works," and
|
| 21 |
+
"distribution" have the meaning as provided under U.S. copyright law;
|
| 22 |
+
provided, however, that for the purposes of this License, derivative
|
| 23 |
+
works shall not include works that remain separable from, or merely
|
| 24 |
+
link (or bind by name) to the interfaces of, the Work.
|
| 25 |
+
|
| 26 |
+
Works, including the Software, are "made available" under this License
|
| 27 |
+
by including in or with the Work either (a) a copyright notice
|
| 28 |
+
referencing the applicability of this License to the Work, or (b) a
|
| 29 |
+
copy of this License.
|
| 30 |
+
|
| 31 |
+
2. License Grants
|
| 32 |
+
|
| 33 |
+
2.1 Copyright Grant. Subject to the terms and conditions of this
|
| 34 |
+
License, each Licensor grants to you a perpetual, worldwide,
|
| 35 |
+
non-exclusive, royalty-free, copyright license to reproduce,
|
| 36 |
+
prepare derivative works of, publicly display, publicly perform,
|
| 37 |
+
sublicense and distribute its Work and any resulting derivative
|
| 38 |
+
works in any form.
|
| 39 |
+
|
| 40 |
+
3. Limitations
|
| 41 |
+
|
| 42 |
+
3.1 Redistribution. You may reproduce or distribute the Work only
|
| 43 |
+
if (a) you do so under this License, (b) you include a complete
|
| 44 |
+
copy of this License with your distribution, and (c) you retain
|
| 45 |
+
without modification any copyright, patent, trademark, or
|
| 46 |
+
attribution notices that are present in the Work.
|
| 47 |
+
|
| 48 |
+
3.2 Derivative Works. You may specify that additional or different
|
| 49 |
+
terms apply to the use, reproduction, and distribution of your
|
| 50 |
+
derivative works of the Work ("Your Terms") only if (a) Your Terms
|
| 51 |
+
provide that the use limitation in Section 3.3 applies to your
|
| 52 |
+
derivative works, and (b) you identify the specific derivative
|
| 53 |
+
works that are subject to Your Terms. Notwithstanding Your Terms,
|
| 54 |
+
this License (including the redistribution requirements in Section
|
| 55 |
+
3.1) will continue to apply to the Work itself.
|
| 56 |
+
|
| 57 |
+
3.3 Use Limitation. The Work and any derivative works thereof only
|
| 58 |
+
may be used or intended for use non-commercially. The Work or
|
| 59 |
+
derivative works thereof may be used or intended for use by NVIDIA
|
| 60 |
+
or it’s affiliates commercially or non-commercially. As used
|
| 61 |
+
herein, "non-commercially" means for research or evaluation
|
| 62 |
+
purposes only and not for any direct or indirect monetary gain.
|
| 63 |
+
|
| 64 |
+
3.4 Patent Claims. If you bring or threaten to bring a patent claim
|
| 65 |
+
against any Licensor (including any claim, cross-claim or
|
| 66 |
+
counterclaim in a lawsuit) to enforce any patents that you allege
|
| 67 |
+
are infringed by any Work, then your rights under this License from
|
| 68 |
+
such Licensor (including the grants in Sections 2.1) will terminate
|
| 69 |
+
immediately.
|
| 70 |
+
|
| 71 |
+
3.5 Trademarks. This License does not grant any rights to use any
|
| 72 |
+
Licensor’s or its affiliates’ names, logos, or trademarks, except
|
| 73 |
+
as necessary to reproduce the notices described in this License.
|
| 74 |
+
|
| 75 |
+
3.6 Termination. If you violate any term of this License, then your
|
| 76 |
+
rights under this License (including the grants in Sections 2.1)
|
| 77 |
+
will terminate immediately.
|
| 78 |
+
|
| 79 |
+
4. Disclaimer of Warranty.
|
| 80 |
+
|
| 81 |
+
THE WORK IS PROVIDED "AS IS" WITHOUT WARRANTIES OR CONDITIONS OF ANY
|
| 82 |
+
KIND, EITHER EXPRESS OR IMPLIED, INCLUDING WARRANTIES OR CONDITIONS OF
|
| 83 |
+
MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE, TITLE OR
|
| 84 |
+
NON-INFRINGEMENT. YOU BEAR THE RISK OF UNDERTAKING ANY ACTIVITIES UNDER
|
| 85 |
+
THIS LICENSE.
|
| 86 |
+
|
| 87 |
+
5. Limitation of Liability.
|
| 88 |
+
|
| 89 |
+
EXCEPT AS PROHIBITED BY APPLICABLE LAW, IN NO EVENT AND UNDER NO LEGAL
|
| 90 |
+
THEORY, WHETHER IN TORT (INCLUDING NEGLIGENCE), CONTRACT, OR OTHERWISE
|
| 91 |
+
SHALL ANY LICENSOR BE LIABLE TO YOU FOR DAMAGES, INCLUDING ANY DIRECT,
|
| 92 |
+
INDIRECT, SPECIAL, INCIDENTAL, OR CONSEQUENTIAL DAMAGES ARISING OUT OF
|
| 93 |
+
OR RELATED TO THIS LICENSE, THE USE OR INABILITY TO USE THE WORK
|
| 94 |
+
(INCLUDING BUT NOT LIMITED TO LOSS OF GOODWILL, BUSINESS INTERRUPTION,
|
| 95 |
+
LOST PROFITS OR DATA, COMPUTER FAILURE OR MALFUNCTION, OR ANY OTHER
|
| 96 |
+
COMMERCIAL DAMAGES OR LOSSES), EVEN IF THE LICENSOR HAS BEEN ADVISED OF
|
| 97 |
+
THE POSSIBILITY OF SUCH DAMAGES.
|
| 98 |
+
|
| 99 |
+
=======================================================================
|
eg3d/README.md
ADDED
|
@@ -0,0 +1,216 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
## Efficient Geometry-aware 3D Generative Adversarial Networks (EG3D)<br><sub>Official PyTorch implementation of the CVPR 2022 paper</sub>
|
| 2 |
+
|
| 3 |
+

|
| 4 |
+
|
| 5 |
+
**Efficient Geometry-aware 3D Generative Adversarial Networks**<br>
|
| 6 |
+
Eric R. Chan*, Connor Z. Lin*, Matthew A. Chan*, Koki Nagano*, Boxiao Pan, Shalini De Mello, Orazio Gallo, Leonidas Guibas, Jonathan Tremblay, Sameh Khamis, Tero Karras, and Gordon Wetzstein<br>*\* equal contribution*<br>
|
| 7 |
+
<br>https://nvlabs.github.io/eg3d/<br>
|
| 8 |
+
|
| 9 |
+
Abstract: *Unsupervised generation of high-quality multi-view-consistent images and 3D shapes using only collections of single-view 2D photographs has been a long-standing challenge. Existing 3D GANs are either compute-intensive or make approximations that are not 3D-consistent; the former limits quality and resolution of the generated images and the latter adversely affects multi-view consistency and shape quality. In this work, we improve the computational efficiency and image quality of 3D GANs without overly relying on these approximations. We introduce an expressive hybrid explicit-implicit network architecture that, together with other design choices, synthesizes not only high-resolution multi-view-consistent images in real time but also produces high-quality 3D geometry. By decoupling feature generation and neural rendering, our framework is able to leverage state-of-the-art 2D CNN generators, such as StyleGAN2, and inherit their efficiency and expressiveness. We demonstrate state-of-the-art 3D-aware synthesis with FFHQ and AFHQ Cats, among other experiments.*
|
| 10 |
+
|
| 11 |
+
For business inquiries, please visit our website and submit the form: [NVIDIA Research Licensing](https://www.nvidia.com/en-us/research/inquiries/)
|
| 12 |
+
|
| 13 |
+
## Requirements
|
| 14 |
+
|
| 15 |
+
* We recommend Linux for performance and compatibility reasons.
|
| 16 |
+
* 1–8 high-end NVIDIA GPUs. We have done all testing and development using V100, RTX3090, and A100 GPUs.
|
| 17 |
+
* 64-bit Python 3.8 and PyTorch 1.11.0 (or later). See https://pytorch.org for PyTorch install instructions.
|
| 18 |
+
* CUDA toolkit 11.3 or later. (Why is a separate CUDA toolkit installation required? We use the custom CUDA extensions from the StyleGAN3 repo. Please see [Troubleshooting](https://github.com/NVlabs/stylegan3/blob/main/docs/troubleshooting.md#why-is-cuda-toolkit-installation-necessary)).
|
| 19 |
+
* Python libraries: see [environment.yml](../environment.yml) for exact library dependencies. You can use the following commands with Miniconda3 to create and activate your Python environment:
|
| 20 |
+
- `cd eg3d`
|
| 21 |
+
- `conda env create -f environment.yml`
|
| 22 |
+
- `conda activate eg3d`
|
| 23 |
+
|
| 24 |
+
## Getting started
|
| 25 |
+
|
| 26 |
+
Pre-trained networks are stored as `*.pkl` files that can be referenced using local filenames. See [Models](./docs/models.md) for download links to pre-trained checkpoints.
|
| 27 |
+
|
| 28 |
+
|
| 29 |
+
## Generating media
|
| 30 |
+
|
| 31 |
+
```.bash
|
| 32 |
+
# Generate videos using pre-trained model
|
| 33 |
+
|
| 34 |
+
python gen_videos.py --outdir=out --trunc=0.7 --seeds=0-3 --grid=2x2 \
|
| 35 |
+
--network=networks/network_snapshot.pkl
|
| 36 |
+
|
| 37 |
+
# Generate the same 4 seeds in an interpolation sequence
|
| 38 |
+
|
| 39 |
+
python gen_videos.py --outdir=out --trunc=0.7 --seeds=0-3 --grid=1x1 \
|
| 40 |
+
--network=networks/network_snapshot.pkl
|
| 41 |
+
```
|
| 42 |
+
|
| 43 |
+
```.bash
|
| 44 |
+
# Generate images and shapes (as .mrc files) using pre-trained model
|
| 45 |
+
|
| 46 |
+
python gen_samples.py --outdir=out --trunc=0.7 --shapes=true --seeds=0-3 \
|
| 47 |
+
--network=networks/network_snapshot.pkl
|
| 48 |
+
```
|
| 49 |
+
|
| 50 |
+
We visualize our .mrc shape files with [UCSF Chimerax](https://www.cgl.ucsf.edu/chimerax/).
|
| 51 |
+
|
| 52 |
+
To visualize a shape in ChimeraX do the following:
|
| 53 |
+
1. Import the `.mrc` file with `File > Open`
|
| 54 |
+
1. Find the selected shape in the Volume Viewer tool
|
| 55 |
+
1. The Volume Viewer tool is located under `Tools > Volume Data > Volume Viewer`
|
| 56 |
+
1. Change volume type to "Surface"
|
| 57 |
+
1. Change step size to 1
|
| 58 |
+
1. Change level set to 10
|
| 59 |
+
1. Note that the optimal level can vary by each object, but is usually between 2 and 20. Individual adjustment may make certain shapes slightly sharper
|
| 60 |
+
1. In the `Lighting` menu in the top bar, change lighting to "Full"
|
| 61 |
+
|
| 62 |
+
|
| 63 |
+
## Interactive visualization
|
| 64 |
+
|
| 65 |
+
This release contains an interactive model visualization tool that can be used to explore various characteristics of a trained model. To start it, run:
|
| 66 |
+
|
| 67 |
+
```.bash
|
| 68 |
+
python visualizer.py
|
| 69 |
+
```
|
| 70 |
+
|
| 71 |
+
See the [`Visualizer Guide`](./docs/visualizer_guide.md) for a description of important options.
|
| 72 |
+
|
| 73 |
+
|
| 74 |
+
## Using networks from Python
|
| 75 |
+
|
| 76 |
+
You can use pre-trained networks in your own Python code as follows:
|
| 77 |
+
|
| 78 |
+
```.python
|
| 79 |
+
with open('ffhq.pkl', 'rb') as f:
|
| 80 |
+
G = pickle.load(f)['G_ema'].cuda() # torch.nn.Module
|
| 81 |
+
z = torch.randn([1, G.z_dim]).cuda() # latent codes
|
| 82 |
+
c = torch.cat([cam2world_pose.reshape(-1, 16), intrinsics.reshape(-1, 9)], 1) # camera parameters
|
| 83 |
+
img = G(z, c)['image'] # NCHW, float32, dynamic range [-1, +1], no truncation
|
| 84 |
+
```
|
| 85 |
+
|
| 86 |
+
The above code requires `torch_utils` and `dnnlib` to be accessible via `PYTHONPATH`. It does not need source code for the networks themselves — their class definitions are loaded from the pickle via `torch_utils.persistence`.
|
| 87 |
+
|
| 88 |
+
The pickle contains three networks. `'G'` and `'D'` are instantaneous snapshots taken during training, and `'G_ema'` represents a moving average of the generator weights over several training steps. The networks are regular instances of `torch.nn.Module`, with all of their parameters and buffers placed on the CPU at import and gradient computation disabled by default.
|
| 89 |
+
|
| 90 |
+
The generator consists of two submodules, `G.mapping` and `G.synthesis`, that can be executed separately. They also support various additional options:
|
| 91 |
+
|
| 92 |
+
```.python
|
| 93 |
+
w = G.mapping(z, conditioning_params, truncation_psi=0.5, truncation_cutoff=8)
|
| 94 |
+
img = G.synthesis(w, camera_params)['image]
|
| 95 |
+
```
|
| 96 |
+
|
| 97 |
+
Please refer to [`gen_samples.py`](gen_samples.py) for complete code example.
|
| 98 |
+
|
| 99 |
+
## Preparing datasets
|
| 100 |
+
|
| 101 |
+
Datasets are stored as uncompressed ZIP archives containing uncompressed PNG files and a metadata file `dataset.json` for labels. Each label is a 25-length list of floating point numbers, which is the concatenation of the flattened 4x4 camera extrinsic matrix and flattened 3x3 camera intrinsic matrix. Custom datasets can be created from a folder containing images; see `python dataset_tool.py --help` for more information. Alternatively, the folder can also be used directly as a dataset, without running it through `dataset_tool.py` first, but doing so may lead to suboptimal performance.
|
| 102 |
+
|
| 103 |
+
**FFHQ**: Download and process the [Flickr-Faces-HQ dataset](https://github.com/NVlabs/ffhq-dataset) using the following commands.
|
| 104 |
+
|
| 105 |
+
1. Ensure the [Deep3DFaceRecon_pytorch](https://github.com/sicxu/Deep3DFaceRecon_pytorch/tree/6ba3d22f84bf508f0dde002da8fff277196fef21) submodule is properly initialized
|
| 106 |
+
```.bash
|
| 107 |
+
git submodule update --init --recursive
|
| 108 |
+
```
|
| 109 |
+
|
| 110 |
+
2. Run the following commands
|
| 111 |
+
```.bash
|
| 112 |
+
cd dataset_preprocessing/ffhq
|
| 113 |
+
python runme.py
|
| 114 |
+
```
|
| 115 |
+
|
| 116 |
+
Optional: preprocessing in-the-wild portrait images.
|
| 117 |
+
In case you want to crop in-the-wild face images and extract poses using [Deep3DFaceRecon_pytorch](https://github.com/sicxu/Deep3DFaceRecon_pytorch/tree/6ba3d22f84bf508f0dde002da8fff277196fef21) in a way that align with the FFHQ data above and the checkpoint, run the following commands
|
| 118 |
+
```.bash
|
| 119 |
+
cd dataset_preprocessing/ffhq
|
| 120 |
+
python preprocess_in_the_wild.py --indir=INPUT_IMAGE_FOLDER
|
| 121 |
+
```
|
| 122 |
+
|
| 123 |
+
|
| 124 |
+
**AFHQv2**: Download and process the [AFHQv2 dataset](https://github.com/clovaai/stargan-v2/blob/master/README.md#animal-faces-hq-dataset-afhq) with the following.
|
| 125 |
+
|
| 126 |
+
1. Download the AFHQv2 images zipfile from the [StarGAN V2 repository](https://github.com/clovaai/stargan-v2/)
|
| 127 |
+
2. Run the following commands:
|
| 128 |
+
```.bash
|
| 129 |
+
cd dataset_preprocessing/afhq
|
| 130 |
+
python runme.py "path/to/downloaded/afhq.zip"
|
| 131 |
+
```
|
| 132 |
+
|
| 133 |
+
**ShapeNet Cars**: Download and process renderings of the cars category of [ShapeNet](https://shapenet.org/) using the following commands.
|
| 134 |
+
NOTE: the following commands download renderings of the ShapeNet cars from the [Scene Representation Networks repository](https://www.vincentsitzmann.com/srns/).
|
| 135 |
+
|
| 136 |
+
```.bash
|
| 137 |
+
cd dataset_preprocessing/shapenet
|
| 138 |
+
python runme.py
|
| 139 |
+
```
|
| 140 |
+
|
| 141 |
+
## Training
|
| 142 |
+
|
| 143 |
+
You can train new networks using `train.py`. For example:
|
| 144 |
+
|
| 145 |
+
```.bash
|
| 146 |
+
# Train with FFHQ from scratch with raw neural rendering resolution=64, using 8 GPUs.
|
| 147 |
+
python train.py --outdir=~/training-runs --cfg=ffhq --data=~/datasets/FFHQ_512.zip \
|
| 148 |
+
--gpus=8 --batch=32 --gamma=1 --gen_pose_cond=True
|
| 149 |
+
|
| 150 |
+
# Second stage finetuning of FFHQ to 128 neural rendering resolution (optional).
|
| 151 |
+
python train.py --outdir=~/training-runs --cfg=ffhq --data=~/datasets/FFHQ_512.zip \
|
| 152 |
+
--resume=~/training-runs/ffhq_experiment_dir/network-snapshot-025000.pkl \
|
| 153 |
+
--gpus=8 --batch=32 --gamma=1 --gen_pose_cond=True --neural_rendering_resolution_final=128
|
| 154 |
+
|
| 155 |
+
# Train with Shapenet from scratch, using 8 GPUs.
|
| 156 |
+
python train.py --outdir=~/training-runs --cfg=shapenet --data=~/datasets/cars_train.zip \
|
| 157 |
+
--gpus=8 --batch=32 --gamma=0.3
|
| 158 |
+
|
| 159 |
+
# Train with AFHQ, finetuning from FFHQ with ADA, using 8 GPUs.
|
| 160 |
+
python train.py --outdir=~/training-runs --cfg=afhq --data=~/datasets/afhq.zip \
|
| 161 |
+
--gpus=8 --batch=32 --gamma=5 --aug=ada --neural_rendering_resolution_final=128 --gen_pose_cond=True --gpc_reg_prob=0.8
|
| 162 |
+
```
|
| 163 |
+
|
| 164 |
+
Please see the [Training Guide](./docs/training_guide.md) for a guide to setting up a training run on your own data.
|
| 165 |
+
|
| 166 |
+
Please see [Models](./docs/models.md) for recommended training configurations and download links for pre-trained checkpoints.
|
| 167 |
+
|
| 168 |
+
|
| 169 |
+
The results of each training run are saved to a newly created directory, for example `~/training-runs/00000-ffhq-ffhq512-gpus8-batch32-gamma1`. The training loop exports network pickles (`network-snapshot-<KIMG>.pkl`) and random image grids (`fakes<KIMG>.png`) at regular intervals (controlled by `--snap`). For each exported pickle, it evaluates FID (controlled by `--metrics`) and logs the result in `metric-fid50k_full.jsonl`. It also records various statistics in `training_stats.jsonl`, as well as `*.tfevents` if TensorBoard is installed.
|
| 170 |
+
|
| 171 |
+
## Quality metrics
|
| 172 |
+
|
| 173 |
+
By default, `train.py` automatically computes FID for each network pickle exported during training. We recommend inspecting `metric-fid50k_full.jsonl` (or TensorBoard) at regular intervals to monitor the training progress. When desired, the automatic computation can be disabled with `--metrics=none` to speed up the training slightly.
|
| 174 |
+
|
| 175 |
+
Additional quality metrics can also be computed after the training:
|
| 176 |
+
|
| 177 |
+
```.bash
|
| 178 |
+
# Previous training run: look up options automatically, save result to JSONL file.
|
| 179 |
+
python calc_metrics.py --metrics=fid50k_full \
|
| 180 |
+
--network=~/training-runs/network-snapshot-000000.pkl
|
| 181 |
+
|
| 182 |
+
# Pre-trained network pickle: specify dataset explicitly, print result to stdout.
|
| 183 |
+
python calc_metrics.py --metrics=fid50k_full --data=~/datasets/ffhq_512.zip \
|
| 184 |
+
--network=ffhq-128.pkl
|
| 185 |
+
```
|
| 186 |
+
|
| 187 |
+
Note that the metrics can be quite expensive to compute (up to 1h), and many of them have an additional one-off cost for each new dataset (up to 30min). Also note that the evaluation is done using a different random seed each time, so the results will vary if the same metric is computed multiple times.
|
| 188 |
+
|
| 189 |
+
References:
|
| 190 |
+
1. [GANs Trained by a Two Time-Scale Update Rule Converge to a Local Nash Equilibrium](https://arxiv.org/abs/1706.08500), Heusel et al. 2017
|
| 191 |
+
2. [Demystifying MMD GANs](https://arxiv.org/abs/1801.01401), Bińkowski et al. 2018
|
| 192 |
+
|
| 193 |
+
<!-- ## License
|
| 194 |
+
|
| 195 |
+
Copyright © 2021, NVIDIA Corporation & affiliates. All rights reserved.
|
| 196 |
+
|
| 197 |
+
This work is made available under the [Nvidia Source Code License](https://github.com/NVlabs/stylegan3/blob/main/LICENSE.txt). -->
|
| 198 |
+
|
| 199 |
+
## Citation
|
| 200 |
+
|
| 201 |
+
```
|
| 202 |
+
@inproceedings{Chan2022,
|
| 203 |
+
author = {Eric R. Chan and Connor Z. Lin and Matthew A. Chan and Koki Nagano and Boxiao Pan and Shalini De Mello and Orazio Gallo and Leonidas Guibas and Jonathan Tremblay and Sameh Khamis and Tero Karras and Gordon Wetzstein},
|
| 204 |
+
title = {Efficient Geometry-aware {3D} Generative Adversarial Networks},
|
| 205 |
+
booktitle = {CVPR},
|
| 206 |
+
year = {2022}
|
| 207 |
+
}
|
| 208 |
+
```
|
| 209 |
+
|
| 210 |
+
## Development
|
| 211 |
+
|
| 212 |
+
This is a research reference implementation and is treated as a one-time code drop. As such, we do not accept outside code contributions in the form of pull requests.
|
| 213 |
+
|
| 214 |
+
## Acknowledgements
|
| 215 |
+
|
| 216 |
+
We thank David Luebke, Jan Kautz, Jaewoo Seo, Jonathan Granskog, Simon Yuen, Alex Evans, Stan Birchfield, Alexander Bergman, and Joy Hsu for feedback on drafts, Alex Chan, Giap Nguyen, and Trevor Chan for help with diagrams, and Colette Kress and Bryan Catanzaro for allowing use of their photographs. This project was in part supported by Stanford HAI and a Samsung GRO. Koki Nagano and Eric Chan were partially supported by DARPA’s Semantic Forensics (SemaFor) contract (HR0011-20-3-0005). The views and conclusions contained in this document are those of the authors and should not be interpreted as representing the official policies, either expressed or implied, of the U.S. Government. Distribution Statement "A" (Approved for Public Release, Distribution Unlimited).
|
eg3d/calc_metrics.py
ADDED
|
@@ -0,0 +1,190 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# SPDX-FileCopyrightText: Copyright (c) 2021-2022 NVIDIA CORPORATION & AFFILIATES. All rights reserved.
|
| 2 |
+
# SPDX-License-Identifier: LicenseRef-NvidiaProprietary
|
| 3 |
+
#
|
| 4 |
+
# NVIDIA CORPORATION, its affiliates and licensors retain all intellectual
|
| 5 |
+
# property and proprietary rights in and to this material, related
|
| 6 |
+
# documentation and any modifications thereto. Any use, reproduction,
|
| 7 |
+
# disclosure or distribution of this material and related documentation
|
| 8 |
+
# without an express license agreement from NVIDIA CORPORATION or
|
| 9 |
+
# its affiliates is strictly prohibited.
|
| 10 |
+
|
| 11 |
+
"""Calculate quality metrics for previous training run or pretrained network pickle."""
|
| 12 |
+
|
| 13 |
+
import os
|
| 14 |
+
import click
|
| 15 |
+
import json
|
| 16 |
+
import tempfile
|
| 17 |
+
import copy
|
| 18 |
+
import torch
|
| 19 |
+
|
| 20 |
+
import dnnlib
|
| 21 |
+
import legacy
|
| 22 |
+
from metrics import metric_main
|
| 23 |
+
from metrics import metric_utils
|
| 24 |
+
from torch_utils import training_stats
|
| 25 |
+
from torch_utils import custom_ops
|
| 26 |
+
from torch_utils import misc
|
| 27 |
+
from torch_utils.ops import conv2d_gradfix
|
| 28 |
+
|
| 29 |
+
#----------------------------------------------------------------------------
|
| 30 |
+
|
| 31 |
+
def subprocess_fn(rank, args, temp_dir):
|
| 32 |
+
dnnlib.util.Logger(should_flush=True)
|
| 33 |
+
|
| 34 |
+
# Init torch.distributed.
|
| 35 |
+
if args.num_gpus > 1:
|
| 36 |
+
init_file = os.path.abspath(os.path.join(temp_dir, '.torch_distributed_init'))
|
| 37 |
+
if os.name == 'nt':
|
| 38 |
+
init_method = 'file:///' + init_file.replace('\\', '/')
|
| 39 |
+
torch.distributed.init_process_group(backend='gloo', init_method=init_method, rank=rank, world_size=args.num_gpus)
|
| 40 |
+
else:
|
| 41 |
+
init_method = f'file://{init_file}'
|
| 42 |
+
torch.distributed.init_process_group(backend='nccl', init_method=init_method, rank=rank, world_size=args.num_gpus)
|
| 43 |
+
|
| 44 |
+
# Init torch_utils.
|
| 45 |
+
sync_device = torch.device('cuda', rank) if args.num_gpus > 1 else None
|
| 46 |
+
training_stats.init_multiprocessing(rank=rank, sync_device=sync_device)
|
| 47 |
+
if rank != 0 or not args.verbose:
|
| 48 |
+
custom_ops.verbosity = 'none'
|
| 49 |
+
|
| 50 |
+
# Configure torch.
|
| 51 |
+
device = torch.device('cuda', rank)
|
| 52 |
+
torch.backends.cuda.matmul.allow_tf32 = False
|
| 53 |
+
torch.backends.cudnn.allow_tf32 = False
|
| 54 |
+
conv2d_gradfix.enabled = True
|
| 55 |
+
|
| 56 |
+
# Print network summary.
|
| 57 |
+
G = copy.deepcopy(args.G).eval().requires_grad_(False).to(device)
|
| 58 |
+
if rank == 0 and args.verbose:
|
| 59 |
+
z = torch.empty([1, G.z_dim], device=device)
|
| 60 |
+
c = torch.empty([1, G.c_dim], device=device)
|
| 61 |
+
misc.print_module_summary(G, [z, c])
|
| 62 |
+
|
| 63 |
+
# Calculate each metric.
|
| 64 |
+
for metric in args.metrics:
|
| 65 |
+
if rank == 0 and args.verbose:
|
| 66 |
+
print(f'Calculating {metric}...')
|
| 67 |
+
progress = metric_utils.ProgressMonitor(verbose=args.verbose)
|
| 68 |
+
result_dict = metric_main.calc_metric(metric=metric, G=G, dataset_kwargs=args.dataset_kwargs,
|
| 69 |
+
num_gpus=args.num_gpus, rank=rank, device=device, progress=progress)
|
| 70 |
+
if rank == 0:
|
| 71 |
+
metric_main.report_metric(result_dict, run_dir=args.run_dir, snapshot_pkl=args.network_pkl)
|
| 72 |
+
if rank == 0 and args.verbose:
|
| 73 |
+
print()
|
| 74 |
+
|
| 75 |
+
# Done.
|
| 76 |
+
if rank == 0 and args.verbose:
|
| 77 |
+
print('Exiting...')
|
| 78 |
+
|
| 79 |
+
#----------------------------------------------------------------------------
|
| 80 |
+
|
| 81 |
+
def parse_comma_separated_list(s):
|
| 82 |
+
if isinstance(s, list):
|
| 83 |
+
return s
|
| 84 |
+
if s is None or s.lower() == 'none' or s == '':
|
| 85 |
+
return []
|
| 86 |
+
return s.split(',')
|
| 87 |
+
|
| 88 |
+
#----------------------------------------------------------------------------
|
| 89 |
+
|
| 90 |
+
@click.command()
|
| 91 |
+
@click.pass_context
|
| 92 |
+
@click.option('network_pkl', '--network', help='Network pickle filename or URL', metavar='PATH', required=True)
|
| 93 |
+
@click.option('--metrics', help='Quality metrics', metavar='[NAME|A,B,C|none]', type=parse_comma_separated_list, default='fid50k_full', show_default=True)
|
| 94 |
+
@click.option('--data', help='Dataset to evaluate against [default: look up]', metavar='[ZIP|DIR]')
|
| 95 |
+
@click.option('--mirror', help='Enable dataset x-flips [default: look up]', type=bool, metavar='BOOL')
|
| 96 |
+
@click.option('--gpus', help='Number of GPUs to use', type=int, default=1, metavar='INT', show_default=True)
|
| 97 |
+
@click.option('--verbose', help='Print optional information', type=bool, default=True, metavar='BOOL', show_default=True)
|
| 98 |
+
|
| 99 |
+
def calc_metrics(ctx, network_pkl, metrics, data, mirror, gpus, verbose):
|
| 100 |
+
"""Calculate quality metrics for previous training run or pretrained network pickle.
|
| 101 |
+
|
| 102 |
+
Examples:
|
| 103 |
+
|
| 104 |
+
\b
|
| 105 |
+
# Previous training run: look up options automatically, save result to JSONL file.
|
| 106 |
+
python calc_metrics.py --metrics=eqt50k_int,eqr50k \\
|
| 107 |
+
--network=~/training-runs/00000-stylegan3-r-mydataset/network-snapshot-000000.pkl
|
| 108 |
+
|
| 109 |
+
\b
|
| 110 |
+
# Pre-trained network pickle: specify dataset explicitly, print result to stdout.
|
| 111 |
+
python calc_metrics.py --metrics=fid50k_full --data=~/datasets/ffhq-1024x1024.zip --mirror=1 \\
|
| 112 |
+
--network=https://api.ngc.nvidia.com/v2/models/nvidia/research/stylegan3/versions/1/files/stylegan3-t-ffhq-1024x1024.pkl
|
| 113 |
+
|
| 114 |
+
\b
|
| 115 |
+
Recommended metrics:
|
| 116 |
+
fid50k_full Frechet inception distance against the full dataset.
|
| 117 |
+
kid50k_full Kernel inception distance against the full dataset.
|
| 118 |
+
pr50k3_full Precision and recall againt the full dataset.
|
| 119 |
+
ppl2_wend Perceptual path length in W, endpoints, full image.
|
| 120 |
+
eqt50k_int Equivariance w.r.t. integer translation (EQ-T).
|
| 121 |
+
eqt50k_frac Equivariance w.r.t. fractional translation (EQ-T_frac).
|
| 122 |
+
eqr50k Equivariance w.r.t. rotation (EQ-R).
|
| 123 |
+
|
| 124 |
+
\b
|
| 125 |
+
Legacy metrics:
|
| 126 |
+
fid50k Frechet inception distance against 50k real images.
|
| 127 |
+
kid50k Kernel inception distance against 50k real images.
|
| 128 |
+
pr50k3 Precision and recall against 50k real images.
|
| 129 |
+
is50k Inception score for CIFAR-10.
|
| 130 |
+
"""
|
| 131 |
+
dnnlib.util.Logger(should_flush=True)
|
| 132 |
+
|
| 133 |
+
# Validate arguments.
|
| 134 |
+
args = dnnlib.EasyDict(metrics=metrics, num_gpus=gpus, network_pkl=network_pkl, verbose=verbose)
|
| 135 |
+
if not all(metric_main.is_valid_metric(metric) for metric in args.metrics):
|
| 136 |
+
ctx.fail('\n'.join(['--metrics can only contain the following values:'] + metric_main.list_valid_metrics()))
|
| 137 |
+
if not args.num_gpus >= 1:
|
| 138 |
+
ctx.fail('--gpus must be at least 1')
|
| 139 |
+
|
| 140 |
+
# Load network.
|
| 141 |
+
if not dnnlib.util.is_url(network_pkl, allow_file_urls=True) and not os.path.isfile(network_pkl):
|
| 142 |
+
ctx.fail('--network must point to a file or URL')
|
| 143 |
+
if args.verbose:
|
| 144 |
+
print(f'Loading network from "{network_pkl}"...')
|
| 145 |
+
with dnnlib.util.open_url(network_pkl, verbose=args.verbose) as f:
|
| 146 |
+
network_dict = legacy.load_network_pkl(f)
|
| 147 |
+
args.G = network_dict['G_ema'] # subclass of torch.nn.Module
|
| 148 |
+
|
| 149 |
+
# Initialize dataset options.
|
| 150 |
+
if data is not None:
|
| 151 |
+
args.dataset_kwargs = dnnlib.EasyDict(class_name='training.dataset.ImageFolderDataset', path=data)
|
| 152 |
+
elif network_dict['training_set_kwargs'] is not None:
|
| 153 |
+
args.dataset_kwargs = dnnlib.EasyDict(network_dict['training_set_kwargs'])
|
| 154 |
+
else:
|
| 155 |
+
ctx.fail('Could not look up dataset options; please specify --data')
|
| 156 |
+
|
| 157 |
+
# Finalize dataset options.
|
| 158 |
+
args.dataset_kwargs.resolution = args.G.img_resolution
|
| 159 |
+
args.dataset_kwargs.use_labels = (args.G.c_dim != 0)
|
| 160 |
+
if mirror is not None:
|
| 161 |
+
args.dataset_kwargs.xflip = mirror
|
| 162 |
+
|
| 163 |
+
# Print dataset options.
|
| 164 |
+
if args.verbose:
|
| 165 |
+
print('Dataset options:')
|
| 166 |
+
print(json.dumps(args.dataset_kwargs, indent=2))
|
| 167 |
+
|
| 168 |
+
# Locate run dir.
|
| 169 |
+
args.run_dir = None
|
| 170 |
+
if os.path.isfile(network_pkl):
|
| 171 |
+
pkl_dir = os.path.dirname(network_pkl)
|
| 172 |
+
if os.path.isfile(os.path.join(pkl_dir, 'training_options.json')):
|
| 173 |
+
args.run_dir = pkl_dir
|
| 174 |
+
|
| 175 |
+
# Launch processes.
|
| 176 |
+
if args.verbose:
|
| 177 |
+
print('Launching processes...')
|
| 178 |
+
torch.multiprocessing.set_start_method('spawn')
|
| 179 |
+
with tempfile.TemporaryDirectory() as temp_dir:
|
| 180 |
+
if args.num_gpus == 1:
|
| 181 |
+
subprocess_fn(rank=0, args=args, temp_dir=temp_dir)
|
| 182 |
+
else:
|
| 183 |
+
torch.multiprocessing.spawn(fn=subprocess_fn, args=(args, temp_dir), nprocs=args.num_gpus)
|
| 184 |
+
|
| 185 |
+
#----------------------------------------------------------------------------
|
| 186 |
+
|
| 187 |
+
if __name__ == "__main__":
|
| 188 |
+
calc_metrics() # pylint: disable=no-value-for-parameter
|
| 189 |
+
|
| 190 |
+
#----------------------------------------------------------------------------
|
eg3d/camera_utils.py
ADDED
|
@@ -0,0 +1,149 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# SPDX-FileCopyrightText: Copyright (c) 2021-2022 NVIDIA CORPORATION & AFFILIATES. All rights reserved.
|
| 2 |
+
# SPDX-License-Identifier: LicenseRef-NvidiaProprietary
|
| 3 |
+
#
|
| 4 |
+
# NVIDIA CORPORATION, its affiliates and licensors retain all intellectual
|
| 5 |
+
# property and proprietary rights in and to this material, related
|
| 6 |
+
# documentation and any modifications thereto. Any use, reproduction,
|
| 7 |
+
# disclosure or distribution of this material and related documentation
|
| 8 |
+
# without an express license agreement from NVIDIA CORPORATION or
|
| 9 |
+
# its affiliates is strictly prohibited.
|
| 10 |
+
|
| 11 |
+
"""
|
| 12 |
+
Helper functions for constructing camera parameter matrices. Primarily used in visualization and inference scripts.
|
| 13 |
+
"""
|
| 14 |
+
|
| 15 |
+
import math
|
| 16 |
+
|
| 17 |
+
import torch
|
| 18 |
+
import torch.nn as nn
|
| 19 |
+
|
| 20 |
+
from training.volumetric_rendering import math_utils
|
| 21 |
+
|
| 22 |
+
class GaussianCameraPoseSampler:
|
| 23 |
+
"""
|
| 24 |
+
Samples pitch and yaw from a Gaussian distribution and returns a camera pose.
|
| 25 |
+
Camera is specified as looking at the origin.
|
| 26 |
+
If horizontal and vertical stddev (specified in radians) are zero, gives a
|
| 27 |
+
deterministic camera pose with yaw=horizontal_mean, pitch=vertical_mean.
|
| 28 |
+
The coordinate system is specified with y-up, z-forward, x-left.
|
| 29 |
+
Horizontal mean is the azimuthal angle (rotation around y axis) in radians,
|
| 30 |
+
vertical mean is the polar angle (angle from the y axis) in radians.
|
| 31 |
+
A point along the z-axis has azimuthal_angle=0, polar_angle=pi/2.
|
| 32 |
+
|
| 33 |
+
Example:
|
| 34 |
+
For a camera pose looking at the origin with the camera at position [0, 0, 1]:
|
| 35 |
+
cam2world = GaussianCameraPoseSampler.sample(math.pi/2, math.pi/2, radius=1)
|
| 36 |
+
"""
|
| 37 |
+
|
| 38 |
+
@staticmethod
|
| 39 |
+
def sample(horizontal_mean, vertical_mean, horizontal_stddev=0, vertical_stddev=0, radius=1, batch_size=1, device='cpu'):
|
| 40 |
+
h = torch.randn((batch_size, 1), device=device) * horizontal_stddev + horizontal_mean
|
| 41 |
+
v = torch.randn((batch_size, 1), device=device) * vertical_stddev + vertical_mean
|
| 42 |
+
v = torch.clamp(v, 1e-5, math.pi - 1e-5)
|
| 43 |
+
|
| 44 |
+
theta = h
|
| 45 |
+
v = v / math.pi
|
| 46 |
+
phi = torch.arccos(1 - 2*v)
|
| 47 |
+
|
| 48 |
+
camera_origins = torch.zeros((batch_size, 3), device=device)
|
| 49 |
+
|
| 50 |
+
camera_origins[:, 0:1] = radius*torch.sin(phi) * torch.cos(math.pi-theta)
|
| 51 |
+
camera_origins[:, 2:3] = radius*torch.sin(phi) * torch.sin(math.pi-theta)
|
| 52 |
+
camera_origins[:, 1:2] = radius*torch.cos(phi)
|
| 53 |
+
|
| 54 |
+
forward_vectors = math_utils.normalize_vecs(-camera_origins)
|
| 55 |
+
return create_cam2world_matrix(forward_vectors, camera_origins)
|
| 56 |
+
|
| 57 |
+
|
| 58 |
+
class LookAtPoseSampler:
|
| 59 |
+
"""
|
| 60 |
+
Same as GaussianCameraPoseSampler, except the
|
| 61 |
+
camera is specified as looking at 'lookat_position', a 3-vector.
|
| 62 |
+
|
| 63 |
+
Example:
|
| 64 |
+
For a camera pose looking at the origin with the camera at position [0, 0, 1]:
|
| 65 |
+
cam2world = LookAtPoseSampler.sample(math.pi/2, math.pi/2, torch.tensor([0, 0, 0]), radius=1)
|
| 66 |
+
"""
|
| 67 |
+
|
| 68 |
+
@staticmethod
|
| 69 |
+
def sample(horizontal_mean, vertical_mean, lookat_position, horizontal_stddev=0, vertical_stddev=0, radius=1, batch_size=1, device='cpu'):
|
| 70 |
+
h = torch.randn((batch_size, 1), device=device) * horizontal_stddev + horizontal_mean
|
| 71 |
+
v = torch.randn((batch_size, 1), device=device) * vertical_stddev + vertical_mean
|
| 72 |
+
v = torch.clamp(v, 1e-5, math.pi - 1e-5)
|
| 73 |
+
|
| 74 |
+
theta = h
|
| 75 |
+
v = v / math.pi
|
| 76 |
+
phi = torch.arccos(1 - 2*v)
|
| 77 |
+
|
| 78 |
+
camera_origins = torch.zeros((batch_size, 3), device=device)
|
| 79 |
+
|
| 80 |
+
camera_origins[:, 0:1] = radius*torch.sin(phi) * torch.cos(math.pi-theta)
|
| 81 |
+
camera_origins[:, 2:3] = radius*torch.sin(phi) * torch.sin(math.pi-theta)
|
| 82 |
+
camera_origins[:, 1:2] = radius*torch.cos(phi)
|
| 83 |
+
|
| 84 |
+
# forward_vectors = math_utils.normalize_vecs(-camera_origins)
|
| 85 |
+
forward_vectors = math_utils.normalize_vecs(lookat_position - camera_origins)
|
| 86 |
+
return create_cam2world_matrix(forward_vectors, camera_origins)
|
| 87 |
+
|
| 88 |
+
class UniformCameraPoseSampler:
|
| 89 |
+
"""
|
| 90 |
+
Same as GaussianCameraPoseSampler, except the
|
| 91 |
+
pose is sampled from a uniform distribution with range +-[horizontal/vertical]_stddev.
|
| 92 |
+
|
| 93 |
+
Example:
|
| 94 |
+
For a batch of random camera poses looking at the origin with yaw sampled from [-pi/2, +pi/2] radians:
|
| 95 |
+
|
| 96 |
+
cam2worlds = UniformCameraPoseSampler.sample(math.pi/2, math.pi/2, horizontal_stddev=math.pi/2, radius=1, batch_size=16)
|
| 97 |
+
"""
|
| 98 |
+
|
| 99 |
+
@staticmethod
|
| 100 |
+
def sample(horizontal_mean, vertical_mean, horizontal_stddev=0, vertical_stddev=0, radius=1, batch_size=1, device='cpu'):
|
| 101 |
+
h = (torch.rand((batch_size, 1), device=device) * 2 - 1) * horizontal_stddev + horizontal_mean
|
| 102 |
+
v = (torch.rand((batch_size, 1), device=device) * 2 - 1) * vertical_stddev + vertical_mean
|
| 103 |
+
v = torch.clamp(v, 1e-5, math.pi - 1e-5)
|
| 104 |
+
|
| 105 |
+
theta = h
|
| 106 |
+
v = v / math.pi
|
| 107 |
+
phi = torch.arccos(1 - 2*v)
|
| 108 |
+
|
| 109 |
+
camera_origins = torch.zeros((batch_size, 3), device=device)
|
| 110 |
+
|
| 111 |
+
camera_origins[:, 0:1] = radius*torch.sin(phi) * torch.cos(math.pi-theta)
|
| 112 |
+
camera_origins[:, 2:3] = radius*torch.sin(phi) * torch.sin(math.pi-theta)
|
| 113 |
+
camera_origins[:, 1:2] = radius*torch.cos(phi)
|
| 114 |
+
|
| 115 |
+
forward_vectors = math_utils.normalize_vecs(-camera_origins)
|
| 116 |
+
return create_cam2world_matrix(forward_vectors, camera_origins)
|
| 117 |
+
|
| 118 |
+
def create_cam2world_matrix(forward_vector, origin):
|
| 119 |
+
"""
|
| 120 |
+
Takes in the direction the camera is pointing and the camera origin and returns a cam2world matrix.
|
| 121 |
+
Works on batches of forward_vectors, origins. Assumes y-axis is up and that there is no camera roll.
|
| 122 |
+
"""
|
| 123 |
+
|
| 124 |
+
forward_vector = math_utils.normalize_vecs(forward_vector)
|
| 125 |
+
up_vector = torch.tensor([0, 1, 0], dtype=torch.float, device=origin.device).expand_as(forward_vector)
|
| 126 |
+
|
| 127 |
+
right_vector = -math_utils.normalize_vecs(torch.cross(up_vector, forward_vector, dim=-1))
|
| 128 |
+
up_vector = math_utils.normalize_vecs(torch.cross(forward_vector, right_vector, dim=-1))
|
| 129 |
+
|
| 130 |
+
rotation_matrix = torch.eye(4, device=origin.device).unsqueeze(0).repeat(forward_vector.shape[0], 1, 1)
|
| 131 |
+
rotation_matrix[:, :3, :3] = torch.stack((right_vector, up_vector, forward_vector), axis=-1)
|
| 132 |
+
|
| 133 |
+
translation_matrix = torch.eye(4, device=origin.device).unsqueeze(0).repeat(forward_vector.shape[0], 1, 1)
|
| 134 |
+
translation_matrix[:, :3, 3] = origin
|
| 135 |
+
cam2world = (translation_matrix @ rotation_matrix)[:, :, :]
|
| 136 |
+
assert(cam2world.shape[1:] == (4, 4))
|
| 137 |
+
return cam2world
|
| 138 |
+
|
| 139 |
+
|
| 140 |
+
def FOV_to_intrinsics(fov_degrees, device='cpu'):
|
| 141 |
+
"""
|
| 142 |
+
Creates a 3x3 camera intrinsics matrix from the camera field of view, specified in degrees.
|
| 143 |
+
Note the intrinsics are returned as normalized by image size, rather than in pixel units.
|
| 144 |
+
Assumes principal point is at image center.
|
| 145 |
+
"""
|
| 146 |
+
|
| 147 |
+
focal_length = float(1 / (math.tan(fov_degrees * 3.14159 / 360) * 1.414))
|
| 148 |
+
intrinsics = torch.tensor([[focal_length, 0, 0.5], [0, focal_length, 0.5], [0, 0, 1]], device=device)
|
| 149 |
+
return intrinsics
|
eg3d/dataset_tool.py
ADDED
|
@@ -0,0 +1,458 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# SPDX-FileCopyrightText: Copyright (c) 2021-2022 NVIDIA CORPORATION & AFFILIATES. All rights reserved.
|
| 2 |
+
# SPDX-License-Identifier: LicenseRef-NvidiaProprietary
|
| 3 |
+
#
|
| 4 |
+
# NVIDIA CORPORATION, its affiliates and licensors retain all intellectual
|
| 5 |
+
# property and proprietary rights in and to this material, related
|
| 6 |
+
# documentation and any modifications thereto. Any use, reproduction,
|
| 7 |
+
# disclosure or distribution of this material and related documentation
|
| 8 |
+
# without an express license agreement from NVIDIA CORPORATION or
|
| 9 |
+
# its affiliates is strictly prohibited.
|
| 10 |
+
|
| 11 |
+
"""Tool for creating ZIP/PNG based datasets."""
|
| 12 |
+
|
| 13 |
+
import functools
|
| 14 |
+
import gzip
|
| 15 |
+
import io
|
| 16 |
+
import json
|
| 17 |
+
import os
|
| 18 |
+
import pickle
|
| 19 |
+
import re
|
| 20 |
+
import sys
|
| 21 |
+
import tarfile
|
| 22 |
+
import zipfile
|
| 23 |
+
from pathlib import Path
|
| 24 |
+
from typing import Callable, Optional, Tuple, Union
|
| 25 |
+
|
| 26 |
+
import click
|
| 27 |
+
import numpy as np
|
| 28 |
+
import PIL.Image
|
| 29 |
+
from tqdm import tqdm
|
| 30 |
+
|
| 31 |
+
#----------------------------------------------------------------------------
|
| 32 |
+
|
| 33 |
+
def error(msg):
|
| 34 |
+
print('Error: ' + msg)
|
| 35 |
+
sys.exit(1)
|
| 36 |
+
|
| 37 |
+
#----------------------------------------------------------------------------
|
| 38 |
+
|
| 39 |
+
def parse_tuple(s: str) -> Tuple[int, int]:
|
| 40 |
+
'''Parse a 'M,N' or 'MxN' integer tuple.
|
| 41 |
+
|
| 42 |
+
Example:
|
| 43 |
+
'4x2' returns (4,2)
|
| 44 |
+
'0,1' returns (0,1)
|
| 45 |
+
'''
|
| 46 |
+
if m := re.match(r'^(\d+)[x,](\d+)$', s):
|
| 47 |
+
return (int(m.group(1)), int(m.group(2)))
|
| 48 |
+
raise ValueError(f'cannot parse tuple {s}')
|
| 49 |
+
|
| 50 |
+
#----------------------------------------------------------------------------
|
| 51 |
+
|
| 52 |
+
def maybe_min(a: int, b: Optional[int]) -> int:
|
| 53 |
+
if b is not None:
|
| 54 |
+
return min(a, b)
|
| 55 |
+
return a
|
| 56 |
+
|
| 57 |
+
#----------------------------------------------------------------------------
|
| 58 |
+
|
| 59 |
+
def file_ext(name: Union[str, Path]) -> str:
|
| 60 |
+
return str(name).split('.')[-1]
|
| 61 |
+
|
| 62 |
+
#----------------------------------------------------------------------------
|
| 63 |
+
|
| 64 |
+
def is_image_ext(fname: Union[str, Path]) -> bool:
|
| 65 |
+
ext = file_ext(fname).lower()
|
| 66 |
+
return f'.{ext}' in PIL.Image.EXTENSION # type: ignore
|
| 67 |
+
|
| 68 |
+
#----------------------------------------------------------------------------
|
| 69 |
+
|
| 70 |
+
def open_image_folder(source_dir, *, max_images: Optional[int]):
|
| 71 |
+
input_images = [str(f) for f in sorted(Path(source_dir).rglob('*')) if is_image_ext(f) and os.path.isfile(f)]
|
| 72 |
+
|
| 73 |
+
# Load labels.
|
| 74 |
+
labels = {}
|
| 75 |
+
meta_fname = os.path.join(source_dir, 'dataset.json')
|
| 76 |
+
if os.path.isfile(meta_fname):
|
| 77 |
+
with open(meta_fname, 'r') as file:
|
| 78 |
+
labels = json.load(file)['labels']
|
| 79 |
+
if labels is not None:
|
| 80 |
+
labels = { x[0]: x[1] for x in labels }
|
| 81 |
+
else:
|
| 82 |
+
labels = {}
|
| 83 |
+
|
| 84 |
+
max_idx = maybe_min(len(input_images), max_images)
|
| 85 |
+
|
| 86 |
+
def iterate_images():
|
| 87 |
+
for idx, fname in enumerate(input_images):
|
| 88 |
+
arch_fname = os.path.relpath(fname, source_dir)
|
| 89 |
+
arch_fname = arch_fname.replace('\\', '/')
|
| 90 |
+
img = np.array(PIL.Image.open(fname))
|
| 91 |
+
yield dict(img=img, label=labels.get(arch_fname))
|
| 92 |
+
if idx >= max_idx-1:
|
| 93 |
+
break
|
| 94 |
+
return max_idx, iterate_images()
|
| 95 |
+
|
| 96 |
+
#----------------------------------------------------------------------------
|
| 97 |
+
|
| 98 |
+
def open_image_zip(source, *, max_images: Optional[int]):
|
| 99 |
+
with zipfile.ZipFile(source, mode='r') as z:
|
| 100 |
+
input_images = [str(f) for f in sorted(z.namelist()) if is_image_ext(f)]
|
| 101 |
+
|
| 102 |
+
# Load labels.
|
| 103 |
+
labels = {}
|
| 104 |
+
if 'dataset.json' in z.namelist():
|
| 105 |
+
with z.open('dataset.json', 'r') as file:
|
| 106 |
+
labels = json.load(file)['labels']
|
| 107 |
+
if labels is not None:
|
| 108 |
+
labels = { x[0]: x[1] for x in labels }
|
| 109 |
+
else:
|
| 110 |
+
labels = {}
|
| 111 |
+
|
| 112 |
+
max_idx = maybe_min(len(input_images), max_images)
|
| 113 |
+
|
| 114 |
+
def iterate_images():
|
| 115 |
+
with zipfile.ZipFile(source, mode='r') as z:
|
| 116 |
+
for idx, fname in enumerate(input_images):
|
| 117 |
+
with z.open(fname, 'r') as file:
|
| 118 |
+
img = PIL.Image.open(file) # type: ignore
|
| 119 |
+
img = np.array(img)
|
| 120 |
+
yield dict(img=img, label=labels.get(fname))
|
| 121 |
+
if idx >= max_idx-1:
|
| 122 |
+
break
|
| 123 |
+
return max_idx, iterate_images()
|
| 124 |
+
|
| 125 |
+
#----------------------------------------------------------------------------
|
| 126 |
+
|
| 127 |
+
def open_lmdb(lmdb_dir: str, *, max_images: Optional[int]):
|
| 128 |
+
import cv2 # pip install opencv-python # pylint: disable=import-error
|
| 129 |
+
import lmdb # pip install lmdb # pylint: disable=import-error
|
| 130 |
+
|
| 131 |
+
with lmdb.open(lmdb_dir, readonly=True, lock=False).begin(write=False) as txn:
|
| 132 |
+
max_idx = maybe_min(txn.stat()['entries'], max_images)
|
| 133 |
+
|
| 134 |
+
def iterate_images():
|
| 135 |
+
with lmdb.open(lmdb_dir, readonly=True, lock=False).begin(write=False) as txn:
|
| 136 |
+
for idx, (_key, value) in enumerate(txn.cursor()):
|
| 137 |
+
try:
|
| 138 |
+
try:
|
| 139 |
+
img = cv2.imdecode(np.frombuffer(value, dtype=np.uint8), 1)
|
| 140 |
+
if img is None:
|
| 141 |
+
raise IOError('cv2.imdecode failed')
|
| 142 |
+
img = img[:, :, ::-1] # BGR => RGB
|
| 143 |
+
except IOError:
|
| 144 |
+
img = np.array(PIL.Image.open(io.BytesIO(value)))
|
| 145 |
+
yield dict(img=img, label=None)
|
| 146 |
+
if idx >= max_idx-1:
|
| 147 |
+
break
|
| 148 |
+
except:
|
| 149 |
+
print(sys.exc_info()[1])
|
| 150 |
+
|
| 151 |
+
return max_idx, iterate_images()
|
| 152 |
+
|
| 153 |
+
#----------------------------------------------------------------------------
|
| 154 |
+
|
| 155 |
+
def open_cifar10(tarball: str, *, max_images: Optional[int]):
|
| 156 |
+
images = []
|
| 157 |
+
labels = []
|
| 158 |
+
|
| 159 |
+
with tarfile.open(tarball, 'r:gz') as tar:
|
| 160 |
+
for batch in range(1, 6):
|
| 161 |
+
member = tar.getmember(f'cifar-10-batches-py/data_batch_{batch}')
|
| 162 |
+
with tar.extractfile(member) as file:
|
| 163 |
+
data = pickle.load(file, encoding='latin1')
|
| 164 |
+
images.append(data['data'].reshape(-1, 3, 32, 32))
|
| 165 |
+
labels.append(data['labels'])
|
| 166 |
+
|
| 167 |
+
images = np.concatenate(images)
|
| 168 |
+
labels = np.concatenate(labels)
|
| 169 |
+
images = images.transpose([0, 2, 3, 1]) # NCHW -> NHWC
|
| 170 |
+
assert images.shape == (50000, 32, 32, 3) and images.dtype == np.uint8
|
| 171 |
+
assert labels.shape == (50000,) and labels.dtype in [np.int32, np.int64]
|
| 172 |
+
assert np.min(images) == 0 and np.max(images) == 255
|
| 173 |
+
assert np.min(labels) == 0 and np.max(labels) == 9
|
| 174 |
+
|
| 175 |
+
max_idx = maybe_min(len(images), max_images)
|
| 176 |
+
|
| 177 |
+
def iterate_images():
|
| 178 |
+
for idx, img in enumerate(images):
|
| 179 |
+
yield dict(img=img, label=int(labels[idx]))
|
| 180 |
+
if idx >= max_idx-1:
|
| 181 |
+
break
|
| 182 |
+
|
| 183 |
+
return max_idx, iterate_images()
|
| 184 |
+
|
| 185 |
+
#----------------------------------------------------------------------------
|
| 186 |
+
|
| 187 |
+
def open_mnist(images_gz: str, *, max_images: Optional[int]):
|
| 188 |
+
labels_gz = images_gz.replace('-images-idx3-ubyte.gz', '-labels-idx1-ubyte.gz')
|
| 189 |
+
assert labels_gz != images_gz
|
| 190 |
+
images = []
|
| 191 |
+
labels = []
|
| 192 |
+
|
| 193 |
+
with gzip.open(images_gz, 'rb') as f:
|
| 194 |
+
images = np.frombuffer(f.read(), np.uint8, offset=16)
|
| 195 |
+
with gzip.open(labels_gz, 'rb') as f:
|
| 196 |
+
labels = np.frombuffer(f.read(), np.uint8, offset=8)
|
| 197 |
+
|
| 198 |
+
images = images.reshape(-1, 28, 28)
|
| 199 |
+
images = np.pad(images, [(0,0), (2,2), (2,2)], 'constant', constant_values=0)
|
| 200 |
+
assert images.shape == (60000, 32, 32) and images.dtype == np.uint8
|
| 201 |
+
assert labels.shape == (60000,) and labels.dtype == np.uint8
|
| 202 |
+
assert np.min(images) == 0 and np.max(images) == 255
|
| 203 |
+
assert np.min(labels) == 0 and np.max(labels) == 9
|
| 204 |
+
|
| 205 |
+
max_idx = maybe_min(len(images), max_images)
|
| 206 |
+
|
| 207 |
+
def iterate_images():
|
| 208 |
+
for idx, img in enumerate(images):
|
| 209 |
+
yield dict(img=img, label=int(labels[idx]))
|
| 210 |
+
if idx >= max_idx-1:
|
| 211 |
+
break
|
| 212 |
+
|
| 213 |
+
return max_idx, iterate_images()
|
| 214 |
+
|
| 215 |
+
#----------------------------------------------------------------------------
|
| 216 |
+
|
| 217 |
+
def make_transform(
|
| 218 |
+
transform: Optional[str],
|
| 219 |
+
output_width: Optional[int],
|
| 220 |
+
output_height: Optional[int]
|
| 221 |
+
) -> Callable[[np.ndarray], Optional[np.ndarray]]:
|
| 222 |
+
def scale(width, height, img):
|
| 223 |
+
w = img.shape[1]
|
| 224 |
+
h = img.shape[0]
|
| 225 |
+
if width == w and height == h:
|
| 226 |
+
return img
|
| 227 |
+
img = PIL.Image.fromarray(img)
|
| 228 |
+
ww = width if width is not None else w
|
| 229 |
+
hh = height if height is not None else h
|
| 230 |
+
img = img.resize((ww, hh), PIL.Image.LANCZOS)
|
| 231 |
+
return np.array(img)
|
| 232 |
+
|
| 233 |
+
def center_crop(width, height, img):
|
| 234 |
+
crop = np.min(img.shape[:2])
|
| 235 |
+
img = img[(img.shape[0] - crop) // 2 : (img.shape[0] + crop) // 2, (img.shape[1] - crop) // 2 : (img.shape[1] + crop) // 2]
|
| 236 |
+
img = PIL.Image.fromarray(img, 'RGB')
|
| 237 |
+
img = img.resize((width, height), PIL.Image.LANCZOS)
|
| 238 |
+
return np.array(img)
|
| 239 |
+
|
| 240 |
+
def center_crop_wide(width, height, img):
|
| 241 |
+
ch = int(np.round(width * img.shape[0] / img.shape[1]))
|
| 242 |
+
if img.shape[1] < width or ch < height:
|
| 243 |
+
return None
|
| 244 |
+
|
| 245 |
+
img = img[(img.shape[0] - ch) // 2 : (img.shape[0] + ch) // 2]
|
| 246 |
+
img = PIL.Image.fromarray(img, 'RGB')
|
| 247 |
+
img = img.resize((width, height), PIL.Image.LANCZOS)
|
| 248 |
+
img = np.array(img)
|
| 249 |
+
|
| 250 |
+
canvas = np.zeros([width, width, 3], dtype=np.uint8)
|
| 251 |
+
canvas[(width - height) // 2 : (width + height) // 2, :] = img
|
| 252 |
+
return canvas
|
| 253 |
+
|
| 254 |
+
if transform is None:
|
| 255 |
+
return functools.partial(scale, output_width, output_height)
|
| 256 |
+
if transform == 'center-crop':
|
| 257 |
+
if (output_width is None) or (output_height is None):
|
| 258 |
+
error ('must specify --resolution=WxH when using ' + transform + 'transform')
|
| 259 |
+
return functools.partial(center_crop, output_width, output_height)
|
| 260 |
+
if transform == 'center-crop-wide':
|
| 261 |
+
if (output_width is None) or (output_height is None):
|
| 262 |
+
error ('must specify --resolution=WxH when using ' + transform + ' transform')
|
| 263 |
+
return functools.partial(center_crop_wide, output_width, output_height)
|
| 264 |
+
assert False, 'unknown transform'
|
| 265 |
+
|
| 266 |
+
#----------------------------------------------------------------------------
|
| 267 |
+
|
| 268 |
+
def open_dataset(source, *, max_images: Optional[int]):
|
| 269 |
+
if os.path.isdir(source):
|
| 270 |
+
if source.rstrip('/').endswith('_lmdb'):
|
| 271 |
+
return open_lmdb(source, max_images=max_images)
|
| 272 |
+
else:
|
| 273 |
+
return open_image_folder(source, max_images=max_images)
|
| 274 |
+
elif os.path.isfile(source):
|
| 275 |
+
if os.path.basename(source) == 'cifar-10-python.tar.gz':
|
| 276 |
+
return open_cifar10(source, max_images=max_images)
|
| 277 |
+
elif os.path.basename(source) == 'train-images-idx3-ubyte.gz':
|
| 278 |
+
return open_mnist(source, max_images=max_images)
|
| 279 |
+
elif file_ext(source) == 'zip':
|
| 280 |
+
return open_image_zip(source, max_images=max_images)
|
| 281 |
+
else:
|
| 282 |
+
assert False, 'unknown archive type'
|
| 283 |
+
else:
|
| 284 |
+
error(f'Missing input file or directory: {source}')
|
| 285 |
+
|
| 286 |
+
#----------------------------------------------------------------------------
|
| 287 |
+
|
| 288 |
+
def open_dest(dest: str) -> Tuple[str, Callable[[str, Union[bytes, str]], None], Callable[[], None]]:
|
| 289 |
+
dest_ext = file_ext(dest)
|
| 290 |
+
|
| 291 |
+
if dest_ext == 'zip':
|
| 292 |
+
if os.path.dirname(dest) != '':
|
| 293 |
+
os.makedirs(os.path.dirname(dest), exist_ok=True)
|
| 294 |
+
zf = zipfile.ZipFile(file=dest, mode='w', compression=zipfile.ZIP_STORED)
|
| 295 |
+
def zip_write_bytes(fname: str, data: Union[bytes, str]):
|
| 296 |
+
zf.writestr(fname, data)
|
| 297 |
+
return '', zip_write_bytes, zf.close
|
| 298 |
+
else:
|
| 299 |
+
# If the output folder already exists, check that is is
|
| 300 |
+
# empty.
|
| 301 |
+
#
|
| 302 |
+
# Note: creating the output directory is not strictly
|
| 303 |
+
# necessary as folder_write_bytes() also mkdirs, but it's better
|
| 304 |
+
# to give an error message earlier in case the dest folder
|
| 305 |
+
# somehow cannot be created.
|
| 306 |
+
if os.path.isdir(dest) and len(os.listdir(dest)) != 0:
|
| 307 |
+
error('--dest folder must be empty')
|
| 308 |
+
os.makedirs(dest, exist_ok=True)
|
| 309 |
+
|
| 310 |
+
def folder_write_bytes(fname: str, data: Union[bytes, str]):
|
| 311 |
+
os.makedirs(os.path.dirname(fname), exist_ok=True)
|
| 312 |
+
with open(fname, 'wb') as fout:
|
| 313 |
+
if isinstance(data, str):
|
| 314 |
+
data = data.encode('utf8')
|
| 315 |
+
fout.write(data)
|
| 316 |
+
return dest, folder_write_bytes, lambda: None
|
| 317 |
+
|
| 318 |
+
#----------------------------------------------------------------------------
|
| 319 |
+
|
| 320 |
+
@click.command()
|
| 321 |
+
@click.pass_context
|
| 322 |
+
@click.option('--source', help='Directory or archive name for input dataset', required=True, metavar='PATH')
|
| 323 |
+
@click.option('--dest', help='Output directory or archive name for output dataset', required=True, metavar='PATH')
|
| 324 |
+
@click.option('--max-images', help='Output only up to `max-images` images', type=int, default=None)
|
| 325 |
+
@click.option('--transform', help='Input crop/resize mode', type=click.Choice(['center-crop', 'center-crop-wide']))
|
| 326 |
+
@click.option('--resolution', help='Output resolution (e.g., \'512x512\')', metavar='WxH', type=parse_tuple)
|
| 327 |
+
def convert_dataset(
|
| 328 |
+
ctx: click.Context,
|
| 329 |
+
source: str,
|
| 330 |
+
dest: str,
|
| 331 |
+
max_images: Optional[int],
|
| 332 |
+
transform: Optional[str],
|
| 333 |
+
resolution: Optional[Tuple[int, int]]
|
| 334 |
+
):
|
| 335 |
+
"""Convert an image dataset into a dataset archive usable with StyleGAN2 ADA PyTorch.
|
| 336 |
+
|
| 337 |
+
The input dataset format is guessed from the --source argument:
|
| 338 |
+
|
| 339 |
+
\b
|
| 340 |
+
--source *_lmdb/ Load LSUN dataset
|
| 341 |
+
--source cifar-10-python.tar.gz Load CIFAR-10 dataset
|
| 342 |
+
--source train-images-idx3-ubyte.gz Load MNIST dataset
|
| 343 |
+
--source path/ Recursively load all images from path/
|
| 344 |
+
--source dataset.zip Recursively load all images from dataset.zip
|
| 345 |
+
|
| 346 |
+
Specifying the output format and path:
|
| 347 |
+
|
| 348 |
+
\b
|
| 349 |
+
--dest /path/to/dir Save output files under /path/to/dir
|
| 350 |
+
--dest /path/to/dataset.zip Save output files into /path/to/dataset.zip
|
| 351 |
+
|
| 352 |
+
The output dataset format can be either an image folder or an uncompressed zip archive.
|
| 353 |
+
Zip archives makes it easier to move datasets around file servers and clusters, and may
|
| 354 |
+
offer better training performance on network file systems.
|
| 355 |
+
|
| 356 |
+
Images within the dataset archive will be stored as uncompressed PNG.
|
| 357 |
+
Uncompressed PNGs can be efficiently decoded in the training loop.
|
| 358 |
+
|
| 359 |
+
Class labels are stored in a file called 'dataset.json' that is stored at the
|
| 360 |
+
dataset root folder. This file has the following structure:
|
| 361 |
+
|
| 362 |
+
\b
|
| 363 |
+
{
|
| 364 |
+
"labels": [
|
| 365 |
+
["00000/img00000000.png",6],
|
| 366 |
+
["00000/img00000001.png",9],
|
| 367 |
+
... repeated for every image in the dataset
|
| 368 |
+
["00049/img00049999.png",1]
|
| 369 |
+
]
|
| 370 |
+
}
|
| 371 |
+
|
| 372 |
+
If the 'dataset.json' file cannot be found, the dataset is interpreted as
|
| 373 |
+
not containing class labels.
|
| 374 |
+
|
| 375 |
+
Image scale/crop and resolution requirements:
|
| 376 |
+
|
| 377 |
+
Output images must be square-shaped and they must all have the same power-of-two
|
| 378 |
+
dimensions.
|
| 379 |
+
|
| 380 |
+
To scale arbitrary input image size to a specific width and height, use the
|
| 381 |
+
--resolution option. Output resolution will be either the original
|
| 382 |
+
input resolution (if resolution was not specified) or the one specified with
|
| 383 |
+
--resolution option.
|
| 384 |
+
|
| 385 |
+
Use the --transform=center-crop or --transform=center-crop-wide options to apply a
|
| 386 |
+
center crop transform on the input image. These options should be used with the
|
| 387 |
+
--resolution option. For example:
|
| 388 |
+
|
| 389 |
+
\b
|
| 390 |
+
python dataset_tool.py --source LSUN/raw/cat_lmdb --dest /tmp/lsun_cat \\
|
| 391 |
+
--transform=center-crop-wide --resolution=512x384
|
| 392 |
+
"""
|
| 393 |
+
|
| 394 |
+
PIL.Image.init() # type: ignore
|
| 395 |
+
|
| 396 |
+
if dest == '':
|
| 397 |
+
ctx.fail('--dest output filename or directory must not be an empty string')
|
| 398 |
+
|
| 399 |
+
num_files, input_iter = open_dataset(source, max_images=max_images)
|
| 400 |
+
archive_root_dir, save_bytes, close_dest = open_dest(dest)
|
| 401 |
+
|
| 402 |
+
if resolution is None: resolution = (None, None)
|
| 403 |
+
transform_image = make_transform(transform, *resolution)
|
| 404 |
+
|
| 405 |
+
dataset_attrs = None
|
| 406 |
+
|
| 407 |
+
labels = []
|
| 408 |
+
for idx, image in tqdm(enumerate(input_iter), total=num_files):
|
| 409 |
+
idx_str = f'{idx:08d}'
|
| 410 |
+
archive_fname = f'{idx_str[:5]}/img{idx_str}.png'
|
| 411 |
+
|
| 412 |
+
# Apply crop and resize.
|
| 413 |
+
img = transform_image(image['img'])
|
| 414 |
+
|
| 415 |
+
# Transform may drop images.
|
| 416 |
+
if img is None:
|
| 417 |
+
continue
|
| 418 |
+
|
| 419 |
+
# Error check to require uniform image attributes across
|
| 420 |
+
# the whole dataset.
|
| 421 |
+
channels = img.shape[2] if img.ndim == 3 else 1
|
| 422 |
+
cur_image_attrs = {
|
| 423 |
+
'width': img.shape[1],
|
| 424 |
+
'height': img.shape[0],
|
| 425 |
+
'channels': channels
|
| 426 |
+
}
|
| 427 |
+
if dataset_attrs is None:
|
| 428 |
+
dataset_attrs = cur_image_attrs
|
| 429 |
+
width = dataset_attrs['width']
|
| 430 |
+
height = dataset_attrs['height']
|
| 431 |
+
if width != height:
|
| 432 |
+
error(f'Image dimensions after scale and crop are required to be square. Got {width}x{height}')
|
| 433 |
+
if dataset_attrs['channels'] not in [1, 3, 4]:
|
| 434 |
+
error('Input images must be stored as RGB or grayscale')
|
| 435 |
+
if width != 2 ** int(np.floor(np.log2(width))):
|
| 436 |
+
error('Image width/height after scale and crop are required to be power-of-two')
|
| 437 |
+
elif dataset_attrs != cur_image_attrs:
|
| 438 |
+
err = [f' dataset {k}/cur image {k}: {dataset_attrs[k]}/{cur_image_attrs[k]}' for k in dataset_attrs.keys()] # pylint: disable=unsubscriptable-object
|
| 439 |
+
error(f'Image {archive_fname} attributes must be equal across all images of the dataset. Got:\n' + '\n'.join(err))
|
| 440 |
+
|
| 441 |
+
# Save the image as an uncompressed PNG.
|
| 442 |
+
img = PIL.Image.fromarray(img, { 1: 'L', 3: 'RGB', 4: 'RGBA'}[channels])
|
| 443 |
+
if channels == 4: img = img.convert('RGB')
|
| 444 |
+
image_bits = io.BytesIO()
|
| 445 |
+
img.save(image_bits, format='png', compress_level=0, optimize=False)
|
| 446 |
+
save_bytes(os.path.join(archive_root_dir, archive_fname), image_bits.getbuffer())
|
| 447 |
+
labels.append([archive_fname, image['label']] if image['label'] is not None else None)
|
| 448 |
+
|
| 449 |
+
metadata = {
|
| 450 |
+
'labels': labels if all(x is not None for x in labels) else None
|
| 451 |
+
}
|
| 452 |
+
save_bytes(os.path.join(archive_root_dir, 'dataset.json'), json.dumps(metadata))
|
| 453 |
+
close_dest()
|
| 454 |
+
|
| 455 |
+
#----------------------------------------------------------------------------
|
| 456 |
+
|
| 457 |
+
if __name__ == "__main__":
|
| 458 |
+
convert_dataset() # pylint: disable=no-value-for-parameter
|
eg3d/datid3d_data_gen.py
ADDED
|
@@ -0,0 +1,204 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
|
| 2 |
+
import sys, os
|
| 3 |
+
sys.path.append(os.getcwd())
|
| 4 |
+
from os.path import join as opj
|
| 5 |
+
import zipfile
|
| 6 |
+
import json
|
| 7 |
+
import pickle
|
| 8 |
+
from tqdm import tqdm
|
| 9 |
+
import argparse
|
| 10 |
+
|
| 11 |
+
import numpy as np
|
| 12 |
+
import torch
|
| 13 |
+
import torch.nn.functional as F
|
| 14 |
+
from torch import autocast
|
| 15 |
+
from torchvision.transforms import ToPILImage
|
| 16 |
+
from diffusers import StableDiffusionImg2ImgPipeline, PNDMScheduler
|
| 17 |
+
from camera_utils import LookAtPoseSampler, FOV_to_intrinsics
|
| 18 |
+
|
| 19 |
+
|
| 20 |
+
|
| 21 |
+
def parse_args():
|
| 22 |
+
"""Parse input arguments."""
|
| 23 |
+
parser = argparse.ArgumentParser(description='Pose-aware dataset generation')
|
| 24 |
+
parser.add_argument('--strength', default=0.7, type=float)
|
| 25 |
+
parser.add_argument('--prompt', type=str)
|
| 26 |
+
parser.add_argument('--data_type', default='ffhq', type=str) # ffhq, cat
|
| 27 |
+
parser.add_argument('--guidance_scale', default=8, type=float)
|
| 28 |
+
parser.add_argument('--num_images', default=1000, type=int)
|
| 29 |
+
parser.add_argument('--sd_model_id', default='stabilityai/stable-diffusion-2-1-base', type=str)
|
| 30 |
+
parser.add_argument('--num_inference_steps', default=30, type=int)
|
| 31 |
+
parser.add_argument('--ffhq_eg3d_path', default='pretrained/ffhqrebalanced512-128.pkl', type=str)
|
| 32 |
+
parser.add_argument('--cat_eg3d_path', default='pretrained/afhqcats512-128.pkl', type=str)
|
| 33 |
+
parser.add_argument('--ffhq_pivot', default=0.2, type=float)
|
| 34 |
+
parser.add_argument('--cat_pivot', default=0.05, type=float)
|
| 35 |
+
parser.add_argument('--pitch_range', default=0.3, type=float)
|
| 36 |
+
parser.add_argument('--yaw_range', default=0.3, type=float)
|
| 37 |
+
parser.add_argument('--name_tag', default='', type=str)
|
| 38 |
+
parser.add_argument('--seed', default=15, type=int)
|
| 39 |
+
|
| 40 |
+
args = parser.parse_args()
|
| 41 |
+
return args
|
| 42 |
+
|
| 43 |
+
def make_zip(base_dir, prompt, data_type='ffhq', name_tag=''):
|
| 44 |
+
base_dir = os.path.abspath(base_dir)
|
| 45 |
+
|
| 46 |
+
owd = os.path.abspath(os.getcwd())
|
| 47 |
+
os.chdir(base_dir)
|
| 48 |
+
|
| 49 |
+
json_path = opj(base_dir, "dataset.json")
|
| 50 |
+
|
| 51 |
+
zip_path = opj(base_dir, f'data_{data_type}_{prompt.replace(" ", "_")}{name_tag}.zip')
|
| 52 |
+
zip_file = zipfile.ZipFile(zip_path, "w")
|
| 53 |
+
|
| 54 |
+
with open(json_path, 'r') as file:
|
| 55 |
+
data = json.load(file)
|
| 56 |
+
zip_file.write(os.path.relpath(json_path, base_dir), compress_type=zipfile.ZIP_STORED)
|
| 57 |
+
|
| 58 |
+
for label in data['labels']:
|
| 59 |
+
trg_img_path = label[0]
|
| 60 |
+
zip_file.write(trg_img_path, compress_type=zipfile.ZIP_STORED)
|
| 61 |
+
|
| 62 |
+
zip_file.close()
|
| 63 |
+
os.chdir(owd)
|
| 64 |
+
|
| 65 |
+
def pts2pil(pts):
|
| 66 |
+
pts = (pts + 1) / 2
|
| 67 |
+
pts[pts > 1] = 1
|
| 68 |
+
pts[pts < 0] = 0
|
| 69 |
+
return ToPILImage()(pts[0])
|
| 70 |
+
|
| 71 |
+
if __name__ == '__main__':
|
| 72 |
+
args = parse_args()
|
| 73 |
+
|
| 74 |
+
device = "cuda"
|
| 75 |
+
torch.manual_seed(args.seed)
|
| 76 |
+
np.random.seed(args.seed)
|
| 77 |
+
|
| 78 |
+
data_type = args.data_type
|
| 79 |
+
prompt = args.prompt
|
| 80 |
+
strength = args.strength
|
| 81 |
+
guidance_scale = args.guidance_scale
|
| 82 |
+
num_inference_steps = args.num_inference_steps
|
| 83 |
+
num_images = args.num_images
|
| 84 |
+
name_tag = args.name_tag
|
| 85 |
+
|
| 86 |
+
# 3DG options
|
| 87 |
+
ffhq_eg3d_path = args.ffhq_eg3d_path
|
| 88 |
+
cat_eg3d_path = args.cat_eg3d_path
|
| 89 |
+
cat_pivot = args.cat_pivot
|
| 90 |
+
ffhq_pivot = args.ffhq_pivot
|
| 91 |
+
pitch_range = args.pitch_range
|
| 92 |
+
yaw_range = args.yaw_range
|
| 93 |
+
num_frames = 240
|
| 94 |
+
truncation_psi = 0.7
|
| 95 |
+
truncation_cutoff = 14
|
| 96 |
+
fov_deg = 18.837
|
| 97 |
+
ft_img_size = 512
|
| 98 |
+
|
| 99 |
+
# Load 3DG
|
| 100 |
+
eg3d_path = None
|
| 101 |
+
if data_type == 'ffhq':
|
| 102 |
+
eg3d_path = args.ffhq_eg3d_path
|
| 103 |
+
pivot = ffhq_pivot
|
| 104 |
+
elif data_type == 'cat':
|
| 105 |
+
eg3d_path = args.cat_eg3d_path
|
| 106 |
+
pivot = cat_pivot
|
| 107 |
+
|
| 108 |
+
with open(eg3d_path, 'rb') as f:
|
| 109 |
+
G = pickle.load(f)['G_ema'].to(device) # torch.nn.Module
|
| 110 |
+
G.train()
|
| 111 |
+
for param in G.parameters():
|
| 112 |
+
param.requires_grad_(True)
|
| 113 |
+
|
| 114 |
+
# SD options
|
| 115 |
+
model_id = args.sd_model_id
|
| 116 |
+
negative_prompt = None
|
| 117 |
+
eta = 0.0
|
| 118 |
+
batch_size = 1
|
| 119 |
+
model_inversion = False
|
| 120 |
+
|
| 121 |
+
# Load SD
|
| 122 |
+
pipe = StableDiffusionImg2ImgPipeline.from_pretrained(
|
| 123 |
+
model_id,
|
| 124 |
+
revision="fp16",
|
| 125 |
+
torch_dtype=torch.float16,
|
| 126 |
+
use_auth_token=True,
|
| 127 |
+
scheduler=PNDMScheduler(beta_start=0.00085, beta_end=0.012, beta_schedule="scaled_linear",
|
| 128 |
+
num_train_timesteps=1000, set_alpha_to_one=False, steps_offset=1, skip_prk_steps=1),
|
| 129 |
+
).to(device)
|
| 130 |
+
pipe.safety_checker = None
|
| 131 |
+
print('SD model is loaded')
|
| 132 |
+
|
| 133 |
+
# Outputs directory
|
| 134 |
+
base_dir = opj(f'./exp_data/data_{data_type}_{prompt.replace(" ", "_")}{name_tag}')
|
| 135 |
+
|
| 136 |
+
src_img_dir = opj(base_dir, "src_imgs")
|
| 137 |
+
trg_img_dir = opj(base_dir, "trg_imgs")
|
| 138 |
+
|
| 139 |
+
os.makedirs('exp_data', exist_ok=True)
|
| 140 |
+
os.makedirs(base_dir, exist_ok=True)
|
| 141 |
+
os.makedirs(src_img_dir, exist_ok=True)
|
| 142 |
+
os.makedirs(trg_img_dir, exist_ok=True)
|
| 143 |
+
labels = []
|
| 144 |
+
|
| 145 |
+
# Fine-tuning 3D generator
|
| 146 |
+
for i in tqdm(range(num_images)):
|
| 147 |
+
G.eval()
|
| 148 |
+
z = torch.from_numpy(np.random.randn(batch_size, G.z_dim)).to(device)
|
| 149 |
+
intrinsics = FOV_to_intrinsics(fov_deg, device=device)
|
| 150 |
+
|
| 151 |
+
with torch.no_grad():
|
| 152 |
+
yaw_idx = np.random.randint(num_frames)
|
| 153 |
+
pitch_idx = np.random.randint(num_frames)
|
| 154 |
+
|
| 155 |
+
cam_pivot = torch.tensor([0, 0, pivot], device=device)
|
| 156 |
+
cam_radius = G.rendering_kwargs.get('avg_camera_radius', 2.7)
|
| 157 |
+
cam2world_pose = LookAtPoseSampler.sample(np.pi / 2 + yaw_range * np.sin(2 * np.pi * yaw_idx / num_frames),
|
| 158 |
+
np.pi / 2 - 0.05 + pitch_range * np.cos(
|
| 159 |
+
2 * np.pi * pitch_idx / num_frames),
|
| 160 |
+
cam_pivot, radius=cam_radius, device=device,
|
| 161 |
+
batch_size=batch_size)
|
| 162 |
+
conditioning_cam2world_pose = LookAtPoseSampler.sample(np.pi / 2, np.pi / 2, cam_pivot, radius=cam_radius,
|
| 163 |
+
device=device, batch_size=batch_size)
|
| 164 |
+
camera_params = torch.cat([cam2world_pose.reshape(-1, 16), intrinsics.reshape(-1, 9).repeat(batch_size, 1)],
|
| 165 |
+
1)
|
| 166 |
+
conditioning_params = torch.cat(
|
| 167 |
+
[conditioning_cam2world_pose.reshape(-1, 16), intrinsics.reshape(-1, 9).repeat(batch_size, 1)], 1)
|
| 168 |
+
|
| 169 |
+
ws = G.mapping(z, conditioning_params, truncation_psi=truncation_psi, truncation_cutoff=truncation_cutoff)
|
| 170 |
+
|
| 171 |
+
img_pts = G.synthesis(ws, camera_params)['image']
|
| 172 |
+
|
| 173 |
+
src_img_pts = img_pts.detach()
|
| 174 |
+
src_img_pts = F.interpolate(src_img_pts, (ft_img_size, ft_img_size), mode='bilinear', align_corners=False)
|
| 175 |
+
with autocast("cuda"):
|
| 176 |
+
trg_img_pil = pipe(prompt=prompt,
|
| 177 |
+
image=src_img_pts,
|
| 178 |
+
strength=strength,
|
| 179 |
+
guidance_scale=guidance_scale,
|
| 180 |
+
num_inference_steps=num_inference_steps,
|
| 181 |
+
)['images'][0]
|
| 182 |
+
|
| 183 |
+
src_idx = f'{i:05d}_src.png'
|
| 184 |
+
trg_idx = f'{i:05d}_trg.png'
|
| 185 |
+
|
| 186 |
+
src_img_pil_path = opj(src_img_dir, src_idx)
|
| 187 |
+
trg_img_pil_path = opj(trg_img_dir, trg_idx)
|
| 188 |
+
|
| 189 |
+
src_img_pil = pts2pil(src_img_pts.cpu())
|
| 190 |
+
|
| 191 |
+
src_img_pil.save(src_img_pil_path)
|
| 192 |
+
trg_img_pil.save(trg_img_pil_path)
|
| 193 |
+
|
| 194 |
+
label = [trg_img_pil_path.replace(base_dir, '').replace('/trg_', 'trg_'), camera_params[0].tolist()]
|
| 195 |
+
|
| 196 |
+
labels.append(label)
|
| 197 |
+
|
| 198 |
+
|
| 199 |
+
json_path = opj(base_dir, "dataset.json")
|
| 200 |
+
json_data = {'labels': labels}
|
| 201 |
+
with open(json_path, 'w') as outfile:
|
| 202 |
+
json.dump(json_data, outfile, indent=4)
|
| 203 |
+
|
| 204 |
+
make_zip(base_dir, prompt, data_type, name_tag)
|
eg3d/dnnlib/__init__.py
ADDED
|
@@ -0,0 +1,11 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# SPDX-FileCopyrightText: Copyright (c) 2021-2022 NVIDIA CORPORATION & AFFILIATES. All rights reserved.
|
| 2 |
+
# SPDX-License-Identifier: LicenseRef-NvidiaProprietary
|
| 3 |
+
#
|
| 4 |
+
# NVIDIA CORPORATION, its affiliates and licensors retain all intellectual
|
| 5 |
+
# property and proprietary rights in and to this material, related
|
| 6 |
+
# documentation and any modifications thereto. Any use, reproduction,
|
| 7 |
+
# disclosure or distribution of this material and related documentation
|
| 8 |
+
# without an express license agreement from NVIDIA CORPORATION or
|
| 9 |
+
# its affiliates is strictly prohibited.
|
| 10 |
+
|
| 11 |
+
from .util import EasyDict, make_cache_dir_path
|
eg3d/dnnlib/util.py
ADDED
|
@@ -0,0 +1,493 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# SPDX-FileCopyrightText: Copyright (c) 2021-2022 NVIDIA CORPORATION & AFFILIATES. All rights reserved.
|
| 2 |
+
# SPDX-License-Identifier: LicenseRef-NvidiaProprietary
|
| 3 |
+
#
|
| 4 |
+
# NVIDIA CORPORATION, its affiliates and licensors retain all intellectual
|
| 5 |
+
# property and proprietary rights in and to this material, related
|
| 6 |
+
# documentation and any modifications thereto. Any use, reproduction,
|
| 7 |
+
# disclosure or distribution of this material and related documentation
|
| 8 |
+
# without an express license agreement from NVIDIA CORPORATION or
|
| 9 |
+
# its affiliates is strictly prohibited.
|
| 10 |
+
|
| 11 |
+
"""Miscellaneous utility classes and functions."""
|
| 12 |
+
|
| 13 |
+
import ctypes
|
| 14 |
+
import fnmatch
|
| 15 |
+
import importlib
|
| 16 |
+
import inspect
|
| 17 |
+
import numpy as np
|
| 18 |
+
import os
|
| 19 |
+
import shutil
|
| 20 |
+
import sys
|
| 21 |
+
import types
|
| 22 |
+
import io
|
| 23 |
+
import pickle
|
| 24 |
+
import re
|
| 25 |
+
import requests
|
| 26 |
+
import html
|
| 27 |
+
import hashlib
|
| 28 |
+
import glob
|
| 29 |
+
import tempfile
|
| 30 |
+
import urllib
|
| 31 |
+
import urllib.request
|
| 32 |
+
import uuid
|
| 33 |
+
|
| 34 |
+
from distutils.util import strtobool
|
| 35 |
+
from typing import Any, List, Tuple, Union
|
| 36 |
+
|
| 37 |
+
|
| 38 |
+
# Util classes
|
| 39 |
+
# ------------------------------------------------------------------------------------------
|
| 40 |
+
|
| 41 |
+
|
| 42 |
+
class EasyDict(dict):
|
| 43 |
+
"""Convenience class that behaves like a dict but allows access with the attribute syntax."""
|
| 44 |
+
|
| 45 |
+
def __getattr__(self, name: str) -> Any:
|
| 46 |
+
try:
|
| 47 |
+
return self[name]
|
| 48 |
+
except KeyError:
|
| 49 |
+
raise AttributeError(name)
|
| 50 |
+
|
| 51 |
+
def __setattr__(self, name: str, value: Any) -> None:
|
| 52 |
+
self[name] = value
|
| 53 |
+
|
| 54 |
+
def __delattr__(self, name: str) -> None:
|
| 55 |
+
del self[name]
|
| 56 |
+
|
| 57 |
+
|
| 58 |
+
class Logger(object):
|
| 59 |
+
"""Redirect stderr to stdout, optionally print stdout to a file, and optionally force flushing on both stdout and the file."""
|
| 60 |
+
|
| 61 |
+
def __init__(self, file_name: str = None, file_mode: str = "w", should_flush: bool = True):
|
| 62 |
+
self.file = None
|
| 63 |
+
|
| 64 |
+
if file_name is not None:
|
| 65 |
+
self.file = open(file_name, file_mode)
|
| 66 |
+
|
| 67 |
+
self.should_flush = should_flush
|
| 68 |
+
self.stdout = sys.stdout
|
| 69 |
+
self.stderr = sys.stderr
|
| 70 |
+
|
| 71 |
+
sys.stdout = self
|
| 72 |
+
sys.stderr = self
|
| 73 |
+
|
| 74 |
+
def __enter__(self) -> "Logger":
|
| 75 |
+
return self
|
| 76 |
+
|
| 77 |
+
def __exit__(self, exc_type: Any, exc_value: Any, traceback: Any) -> None:
|
| 78 |
+
self.close()
|
| 79 |
+
|
| 80 |
+
def write(self, text: Union[str, bytes]) -> None:
|
| 81 |
+
"""Write text to stdout (and a file) and optionally flush."""
|
| 82 |
+
if isinstance(text, bytes):
|
| 83 |
+
text = text.decode()
|
| 84 |
+
if len(text) == 0: # workaround for a bug in VSCode debugger: sys.stdout.write(''); sys.stdout.flush() => crash
|
| 85 |
+
return
|
| 86 |
+
|
| 87 |
+
if self.file is not None:
|
| 88 |
+
self.file.write(text)
|
| 89 |
+
|
| 90 |
+
self.stdout.write(text)
|
| 91 |
+
|
| 92 |
+
if self.should_flush:
|
| 93 |
+
self.flush()
|
| 94 |
+
|
| 95 |
+
def flush(self) -> None:
|
| 96 |
+
"""Flush written text to both stdout and a file, if open."""
|
| 97 |
+
if self.file is not None:
|
| 98 |
+
self.file.flush()
|
| 99 |
+
|
| 100 |
+
self.stdout.flush()
|
| 101 |
+
|
| 102 |
+
def close(self) -> None:
|
| 103 |
+
"""Flush, close possible files, and remove stdout/stderr mirroring."""
|
| 104 |
+
self.flush()
|
| 105 |
+
|
| 106 |
+
# if using multiple loggers, prevent closing in wrong order
|
| 107 |
+
if sys.stdout is self:
|
| 108 |
+
sys.stdout = self.stdout
|
| 109 |
+
if sys.stderr is self:
|
| 110 |
+
sys.stderr = self.stderr
|
| 111 |
+
|
| 112 |
+
if self.file is not None:
|
| 113 |
+
self.file.close()
|
| 114 |
+
self.file = None
|
| 115 |
+
|
| 116 |
+
|
| 117 |
+
# Cache directories
|
| 118 |
+
# ------------------------------------------------------------------------------------------
|
| 119 |
+
|
| 120 |
+
_dnnlib_cache_dir = None
|
| 121 |
+
|
| 122 |
+
def set_cache_dir(path: str) -> None:
|
| 123 |
+
global _dnnlib_cache_dir
|
| 124 |
+
_dnnlib_cache_dir = path
|
| 125 |
+
|
| 126 |
+
def make_cache_dir_path(*paths: str) -> str:
|
| 127 |
+
if _dnnlib_cache_dir is not None:
|
| 128 |
+
return os.path.join(_dnnlib_cache_dir, *paths)
|
| 129 |
+
if 'DNNLIB_CACHE_DIR' in os.environ:
|
| 130 |
+
return os.path.join(os.environ['DNNLIB_CACHE_DIR'], *paths)
|
| 131 |
+
if 'HOME' in os.environ:
|
| 132 |
+
return os.path.join(os.environ['HOME'], '.cache', 'dnnlib', *paths)
|
| 133 |
+
if 'USERPROFILE' in os.environ:
|
| 134 |
+
return os.path.join(os.environ['USERPROFILE'], '.cache', 'dnnlib', *paths)
|
| 135 |
+
return os.path.join(tempfile.gettempdir(), '.cache', 'dnnlib', *paths)
|
| 136 |
+
|
| 137 |
+
# Small util functions
|
| 138 |
+
# ------------------------------------------------------------------------------------------
|
| 139 |
+
|
| 140 |
+
|
| 141 |
+
def format_time(seconds: Union[int, float]) -> str:
|
| 142 |
+
"""Convert the seconds to human readable string with days, hours, minutes and seconds."""
|
| 143 |
+
s = int(np.rint(seconds))
|
| 144 |
+
|
| 145 |
+
if s < 60:
|
| 146 |
+
return "{0}s".format(s)
|
| 147 |
+
elif s < 60 * 60:
|
| 148 |
+
return "{0}m {1:02}s".format(s // 60, s % 60)
|
| 149 |
+
elif s < 24 * 60 * 60:
|
| 150 |
+
return "{0}h {1:02}m {2:02}s".format(s // (60 * 60), (s // 60) % 60, s % 60)
|
| 151 |
+
else:
|
| 152 |
+
return "{0}d {1:02}h {2:02}m".format(s // (24 * 60 * 60), (s // (60 * 60)) % 24, (s // 60) % 60)
|
| 153 |
+
|
| 154 |
+
|
| 155 |
+
def format_time_brief(seconds: Union[int, float]) -> str:
|
| 156 |
+
"""Convert the seconds to human readable string with days, hours, minutes and seconds."""
|
| 157 |
+
s = int(np.rint(seconds))
|
| 158 |
+
|
| 159 |
+
if s < 60:
|
| 160 |
+
return "{0}s".format(s)
|
| 161 |
+
elif s < 60 * 60:
|
| 162 |
+
return "{0}m {1:02}s".format(s // 60, s % 60)
|
| 163 |
+
elif s < 24 * 60 * 60:
|
| 164 |
+
return "{0}h {1:02}m".format(s // (60 * 60), (s // 60) % 60)
|
| 165 |
+
else:
|
| 166 |
+
return "{0}d {1:02}h".format(s // (24 * 60 * 60), (s // (60 * 60)) % 24)
|
| 167 |
+
|
| 168 |
+
|
| 169 |
+
def ask_yes_no(question: str) -> bool:
|
| 170 |
+
"""Ask the user the question until the user inputs a valid answer."""
|
| 171 |
+
while True:
|
| 172 |
+
try:
|
| 173 |
+
print("{0} [y/n]".format(question))
|
| 174 |
+
return strtobool(input().lower())
|
| 175 |
+
except ValueError:
|
| 176 |
+
pass
|
| 177 |
+
|
| 178 |
+
|
| 179 |
+
def tuple_product(t: Tuple) -> Any:
|
| 180 |
+
"""Calculate the product of the tuple elements."""
|
| 181 |
+
result = 1
|
| 182 |
+
|
| 183 |
+
for v in t:
|
| 184 |
+
result *= v
|
| 185 |
+
|
| 186 |
+
return result
|
| 187 |
+
|
| 188 |
+
|
| 189 |
+
_str_to_ctype = {
|
| 190 |
+
"uint8": ctypes.c_ubyte,
|
| 191 |
+
"uint16": ctypes.c_uint16,
|
| 192 |
+
"uint32": ctypes.c_uint32,
|
| 193 |
+
"uint64": ctypes.c_uint64,
|
| 194 |
+
"int8": ctypes.c_byte,
|
| 195 |
+
"int16": ctypes.c_int16,
|
| 196 |
+
"int32": ctypes.c_int32,
|
| 197 |
+
"int64": ctypes.c_int64,
|
| 198 |
+
"float32": ctypes.c_float,
|
| 199 |
+
"float64": ctypes.c_double
|
| 200 |
+
}
|
| 201 |
+
|
| 202 |
+
|
| 203 |
+
def get_dtype_and_ctype(type_obj: Any) -> Tuple[np.dtype, Any]:
|
| 204 |
+
"""Given a type name string (or an object having a __name__ attribute), return matching Numpy and ctypes types that have the same size in bytes."""
|
| 205 |
+
type_str = None
|
| 206 |
+
|
| 207 |
+
if isinstance(type_obj, str):
|
| 208 |
+
type_str = type_obj
|
| 209 |
+
elif hasattr(type_obj, "__name__"):
|
| 210 |
+
type_str = type_obj.__name__
|
| 211 |
+
elif hasattr(type_obj, "name"):
|
| 212 |
+
type_str = type_obj.name
|
| 213 |
+
else:
|
| 214 |
+
raise RuntimeError("Cannot infer type name from input")
|
| 215 |
+
|
| 216 |
+
assert type_str in _str_to_ctype.keys()
|
| 217 |
+
|
| 218 |
+
my_dtype = np.dtype(type_str)
|
| 219 |
+
my_ctype = _str_to_ctype[type_str]
|
| 220 |
+
|
| 221 |
+
assert my_dtype.itemsize == ctypes.sizeof(my_ctype)
|
| 222 |
+
|
| 223 |
+
return my_dtype, my_ctype
|
| 224 |
+
|
| 225 |
+
|
| 226 |
+
def is_pickleable(obj: Any) -> bool:
|
| 227 |
+
try:
|
| 228 |
+
with io.BytesIO() as stream:
|
| 229 |
+
pickle.dump(obj, stream)
|
| 230 |
+
return True
|
| 231 |
+
except:
|
| 232 |
+
return False
|
| 233 |
+
|
| 234 |
+
|
| 235 |
+
# Functionality to import modules/objects by name, and call functions by name
|
| 236 |
+
# ------------------------------------------------------------------------------------------
|
| 237 |
+
|
| 238 |
+
def get_module_from_obj_name(obj_name: str) -> Tuple[types.ModuleType, str]:
|
| 239 |
+
"""Searches for the underlying module behind the name to some python object.
|
| 240 |
+
Returns the module and the object name (original name with module part removed)."""
|
| 241 |
+
|
| 242 |
+
# allow convenience shorthands, substitute them by full names
|
| 243 |
+
obj_name = re.sub("^np.", "numpy.", obj_name)
|
| 244 |
+
obj_name = re.sub("^tf.", "tensorflow.", obj_name)
|
| 245 |
+
|
| 246 |
+
# list alternatives for (module_name, local_obj_name)
|
| 247 |
+
parts = obj_name.split(".")
|
| 248 |
+
name_pairs = [(".".join(parts[:i]), ".".join(parts[i:])) for i in range(len(parts), 0, -1)]
|
| 249 |
+
|
| 250 |
+
# try each alternative in turn
|
| 251 |
+
for module_name, local_obj_name in name_pairs:
|
| 252 |
+
try:
|
| 253 |
+
module = importlib.import_module(module_name) # may raise ImportError
|
| 254 |
+
get_obj_from_module(module, local_obj_name) # may raise AttributeError
|
| 255 |
+
return module, local_obj_name
|
| 256 |
+
except:
|
| 257 |
+
pass
|
| 258 |
+
|
| 259 |
+
# maybe some of the modules themselves contain errors?
|
| 260 |
+
for module_name, _local_obj_name in name_pairs:
|
| 261 |
+
try:
|
| 262 |
+
importlib.import_module(module_name) # may raise ImportError
|
| 263 |
+
except ImportError:
|
| 264 |
+
if not str(sys.exc_info()[1]).startswith("No module named '" + module_name + "'"):
|
| 265 |
+
raise
|
| 266 |
+
|
| 267 |
+
# maybe the requested attribute is missing?
|
| 268 |
+
for module_name, local_obj_name in name_pairs:
|
| 269 |
+
try:
|
| 270 |
+
module = importlib.import_module(module_name) # may raise ImportError
|
| 271 |
+
get_obj_from_module(module, local_obj_name) # may raise AttributeError
|
| 272 |
+
except ImportError:
|
| 273 |
+
pass
|
| 274 |
+
|
| 275 |
+
# we are out of luck, but we have no idea why
|
| 276 |
+
raise ImportError(obj_name)
|
| 277 |
+
|
| 278 |
+
|
| 279 |
+
def get_obj_from_module(module: types.ModuleType, obj_name: str) -> Any:
|
| 280 |
+
"""Traverses the object name and returns the last (rightmost) python object."""
|
| 281 |
+
if obj_name == '':
|
| 282 |
+
return module
|
| 283 |
+
obj = module
|
| 284 |
+
for part in obj_name.split("."):
|
| 285 |
+
obj = getattr(obj, part)
|
| 286 |
+
return obj
|
| 287 |
+
|
| 288 |
+
|
| 289 |
+
def get_obj_by_name(name: str) -> Any:
|
| 290 |
+
"""Finds the python object with the given name."""
|
| 291 |
+
module, obj_name = get_module_from_obj_name(name)
|
| 292 |
+
return get_obj_from_module(module, obj_name)
|
| 293 |
+
|
| 294 |
+
|
| 295 |
+
def call_func_by_name(*args, func_name: str = None, **kwargs) -> Any:
|
| 296 |
+
"""Finds the python object with the given name and calls it as a function."""
|
| 297 |
+
assert func_name is not None
|
| 298 |
+
func_obj = get_obj_by_name(func_name)
|
| 299 |
+
assert callable(func_obj)
|
| 300 |
+
return func_obj(*args, **kwargs)
|
| 301 |
+
|
| 302 |
+
|
| 303 |
+
def construct_class_by_name(*args, class_name: str = None, **kwargs) -> Any:
|
| 304 |
+
"""Finds the python class with the given name and constructs it with the given arguments."""
|
| 305 |
+
return call_func_by_name(*args, func_name=class_name, **kwargs)
|
| 306 |
+
|
| 307 |
+
|
| 308 |
+
def get_module_dir_by_obj_name(obj_name: str) -> str:
|
| 309 |
+
"""Get the directory path of the module containing the given object name."""
|
| 310 |
+
module, _ = get_module_from_obj_name(obj_name)
|
| 311 |
+
return os.path.dirname(inspect.getfile(module))
|
| 312 |
+
|
| 313 |
+
|
| 314 |
+
def is_top_level_function(obj: Any) -> bool:
|
| 315 |
+
"""Determine whether the given object is a top-level function, i.e., defined at module scope using 'def'."""
|
| 316 |
+
return callable(obj) and obj.__name__ in sys.modules[obj.__module__].__dict__
|
| 317 |
+
|
| 318 |
+
|
| 319 |
+
def get_top_level_function_name(obj: Any) -> str:
|
| 320 |
+
"""Return the fully-qualified name of a top-level function."""
|
| 321 |
+
assert is_top_level_function(obj)
|
| 322 |
+
module = obj.__module__
|
| 323 |
+
if module == '__main__':
|
| 324 |
+
module = os.path.splitext(os.path.basename(sys.modules[module].__file__))[0]
|
| 325 |
+
return module + "." + obj.__name__
|
| 326 |
+
|
| 327 |
+
|
| 328 |
+
# File system helpers
|
| 329 |
+
# ------------------------------------------------------------------------------------------
|
| 330 |
+
|
| 331 |
+
def list_dir_recursively_with_ignore(dir_path: str, ignores: List[str] = None, add_base_to_relative: bool = False) -> List[Tuple[str, str]]:
|
| 332 |
+
"""List all files recursively in a given directory while ignoring given file and directory names.
|
| 333 |
+
Returns list of tuples containing both absolute and relative paths."""
|
| 334 |
+
assert os.path.isdir(dir_path)
|
| 335 |
+
base_name = os.path.basename(os.path.normpath(dir_path))
|
| 336 |
+
|
| 337 |
+
if ignores is None:
|
| 338 |
+
ignores = []
|
| 339 |
+
|
| 340 |
+
result = []
|
| 341 |
+
|
| 342 |
+
for root, dirs, files in os.walk(dir_path, topdown=True):
|
| 343 |
+
for ignore_ in ignores:
|
| 344 |
+
dirs_to_remove = [d for d in dirs if fnmatch.fnmatch(d, ignore_)]
|
| 345 |
+
|
| 346 |
+
# dirs need to be edited in-place
|
| 347 |
+
for d in dirs_to_remove:
|
| 348 |
+
dirs.remove(d)
|
| 349 |
+
|
| 350 |
+
files = [f for f in files if not fnmatch.fnmatch(f, ignore_)]
|
| 351 |
+
|
| 352 |
+
absolute_paths = [os.path.join(root, f) for f in files]
|
| 353 |
+
relative_paths = [os.path.relpath(p, dir_path) for p in absolute_paths]
|
| 354 |
+
|
| 355 |
+
if add_base_to_relative:
|
| 356 |
+
relative_paths = [os.path.join(base_name, p) for p in relative_paths]
|
| 357 |
+
|
| 358 |
+
assert len(absolute_paths) == len(relative_paths)
|
| 359 |
+
result += zip(absolute_paths, relative_paths)
|
| 360 |
+
|
| 361 |
+
return result
|
| 362 |
+
|
| 363 |
+
|
| 364 |
+
def copy_files_and_create_dirs(files: List[Tuple[str, str]]) -> None:
|
| 365 |
+
"""Takes in a list of tuples of (src, dst) paths and copies files.
|
| 366 |
+
Will create all necessary directories."""
|
| 367 |
+
for file in files:
|
| 368 |
+
target_dir_name = os.path.dirname(file[1])
|
| 369 |
+
|
| 370 |
+
# will create all intermediate-level directories
|
| 371 |
+
if not os.path.exists(target_dir_name):
|
| 372 |
+
os.makedirs(target_dir_name)
|
| 373 |
+
|
| 374 |
+
shutil.copyfile(file[0], file[1])
|
| 375 |
+
|
| 376 |
+
|
| 377 |
+
# URL helpers
|
| 378 |
+
# ------------------------------------------------------------------------------------------
|
| 379 |
+
|
| 380 |
+
def is_url(obj: Any, allow_file_urls: bool = False) -> bool:
|
| 381 |
+
"""Determine whether the given object is a valid URL string."""
|
| 382 |
+
if not isinstance(obj, str) or not "://" in obj:
|
| 383 |
+
return False
|
| 384 |
+
if allow_file_urls and obj.startswith('file://'):
|
| 385 |
+
return True
|
| 386 |
+
try:
|
| 387 |
+
res = requests.compat.urlparse(obj)
|
| 388 |
+
if not res.scheme or not res.netloc or not "." in res.netloc:
|
| 389 |
+
return False
|
| 390 |
+
res = requests.compat.urlparse(requests.compat.urljoin(obj, "/"))
|
| 391 |
+
if not res.scheme or not res.netloc or not "." in res.netloc:
|
| 392 |
+
return False
|
| 393 |
+
except:
|
| 394 |
+
return False
|
| 395 |
+
return True
|
| 396 |
+
|
| 397 |
+
|
| 398 |
+
def open_url(url: str, cache_dir: str = None, num_attempts: int = 10, verbose: bool = True, return_filename: bool = False, cache: bool = True) -> Any:
|
| 399 |
+
"""Download the given URL and return a binary-mode file object to access the data."""
|
| 400 |
+
assert num_attempts >= 1
|
| 401 |
+
assert not (return_filename and (not cache))
|
| 402 |
+
|
| 403 |
+
# Doesn't look like an URL scheme so interpret it as a local filename.
|
| 404 |
+
if not re.match('^[a-z]+://', url):
|
| 405 |
+
return url if return_filename else open(url, "rb")
|
| 406 |
+
|
| 407 |
+
# Handle file URLs. This code handles unusual file:// patterns that
|
| 408 |
+
# arise on Windows:
|
| 409 |
+
#
|
| 410 |
+
# file:///c:/foo.txt
|
| 411 |
+
#
|
| 412 |
+
# which would translate to a local '/c:/foo.txt' filename that's
|
| 413 |
+
# invalid. Drop the forward slash for such pathnames.
|
| 414 |
+
#
|
| 415 |
+
# If you touch this code path, you should test it on both Linux and
|
| 416 |
+
# Windows.
|
| 417 |
+
#
|
| 418 |
+
# Some internet resources suggest using urllib.request.url2pathname() but
|
| 419 |
+
# but that converts forward slashes to backslashes and this causes
|
| 420 |
+
# its own set of problems.
|
| 421 |
+
if url.startswith('file://'):
|
| 422 |
+
filename = urllib.parse.urlparse(url).path
|
| 423 |
+
if re.match(r'^/[a-zA-Z]:', filename):
|
| 424 |
+
filename = filename[1:]
|
| 425 |
+
return filename if return_filename else open(filename, "rb")
|
| 426 |
+
|
| 427 |
+
assert is_url(url)
|
| 428 |
+
|
| 429 |
+
# Lookup from cache.
|
| 430 |
+
if cache_dir is None:
|
| 431 |
+
cache_dir = make_cache_dir_path('downloads')
|
| 432 |
+
|
| 433 |
+
url_md5 = hashlib.md5(url.encode("utf-8")).hexdigest()
|
| 434 |
+
if cache:
|
| 435 |
+
cache_files = glob.glob(os.path.join(cache_dir, url_md5 + "_*"))
|
| 436 |
+
if len(cache_files) == 1:
|
| 437 |
+
filename = cache_files[0]
|
| 438 |
+
return filename if return_filename else open(filename, "rb")
|
| 439 |
+
|
| 440 |
+
# Download.
|
| 441 |
+
url_name = None
|
| 442 |
+
url_data = None
|
| 443 |
+
with requests.Session() as session:
|
| 444 |
+
if verbose:
|
| 445 |
+
print("Downloading %s ..." % url, end="", flush=True)
|
| 446 |
+
for attempts_left in reversed(range(num_attempts)):
|
| 447 |
+
try:
|
| 448 |
+
with session.get(url) as res:
|
| 449 |
+
res.raise_for_status()
|
| 450 |
+
if len(res.content) == 0:
|
| 451 |
+
raise IOError("No data received")
|
| 452 |
+
|
| 453 |
+
if len(res.content) < 8192:
|
| 454 |
+
content_str = res.content.decode("utf-8")
|
| 455 |
+
if "download_warning" in res.headers.get("Set-Cookie", ""):
|
| 456 |
+
links = [html.unescape(link) for link in content_str.split('"') if "export=download" in link]
|
| 457 |
+
if len(links) == 1:
|
| 458 |
+
url = requests.compat.urljoin(url, links[0])
|
| 459 |
+
raise IOError("Google Drive virus checker nag")
|
| 460 |
+
if "Google Drive - Quota exceeded" in content_str:
|
| 461 |
+
raise IOError("Google Drive download quota exceeded -- please try again later")
|
| 462 |
+
|
| 463 |
+
match = re.search(r'filename="([^"]*)"', res.headers.get("Content-Disposition", ""))
|
| 464 |
+
url_name = match[1] if match else url
|
| 465 |
+
url_data = res.content
|
| 466 |
+
if verbose:
|
| 467 |
+
print(" done")
|
| 468 |
+
break
|
| 469 |
+
except KeyboardInterrupt:
|
| 470 |
+
raise
|
| 471 |
+
except:
|
| 472 |
+
if not attempts_left:
|
| 473 |
+
if verbose:
|
| 474 |
+
print(" failed")
|
| 475 |
+
raise
|
| 476 |
+
if verbose:
|
| 477 |
+
print(".", end="", flush=True)
|
| 478 |
+
|
| 479 |
+
# Save to cache.
|
| 480 |
+
if cache:
|
| 481 |
+
safe_name = re.sub(r"[^0-9a-zA-Z-._]", "_", url_name)
|
| 482 |
+
cache_file = os.path.join(cache_dir, url_md5 + "_" + safe_name)
|
| 483 |
+
temp_file = os.path.join(cache_dir, "tmp_" + uuid.uuid4().hex + "_" + url_md5 + "_" + safe_name)
|
| 484 |
+
os.makedirs(cache_dir, exist_ok=True)
|
| 485 |
+
with open(temp_file, "wb") as f:
|
| 486 |
+
f.write(url_data)
|
| 487 |
+
os.replace(temp_file, cache_file) # atomic
|
| 488 |
+
if return_filename:
|
| 489 |
+
return cache_file
|
| 490 |
+
|
| 491 |
+
# Return data as file object.
|
| 492 |
+
assert not return_filename
|
| 493 |
+
return io.BytesIO(url_data)
|
eg3d/docs/camera_conventions.md
ADDED
|
@@ -0,0 +1,2 @@
|
|
|
|
|
|
|
|
|
|
| 1 |
+
Camera poses are in OpenCV Cam2World format.
|
| 2 |
+
Intrinsics are normalized.
|
eg3d/docs/camera_coordinate_conventions.jpg
ADDED
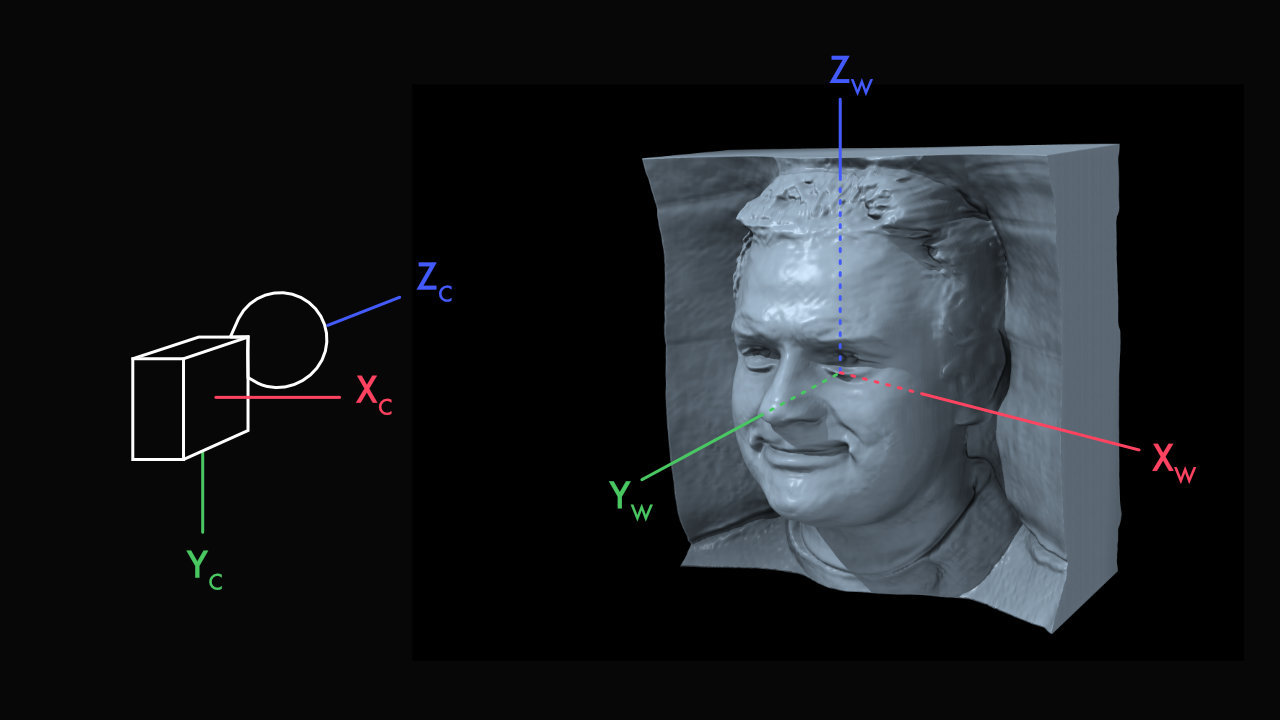
|
eg3d/docs/models.md
ADDED
|
@@ -0,0 +1,71 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
Pre-trained checkpoints can be found on the [NGC Catalog](https://catalog.ngc.nvidia.com/orgs/nvidia/teams/research/models/eg3d).
|
| 2 |
+
|
| 3 |
+
Brief descriptions of models and the commands used to train them are found below.
|
| 4 |
+
|
| 5 |
+
---
|
| 6 |
+
|
| 7 |
+
# FFHQ
|
| 8 |
+
|
| 9 |
+
**ffhq512-64.pkl**
|
| 10 |
+
|
| 11 |
+
FFHQ 512, trained with neural rendering resolution of 64x64.
|
| 12 |
+
|
| 13 |
+
```.bash
|
| 14 |
+
# Train with FFHQ from scratch with raw neural rendering resolution=64, using 8 GPUs.
|
| 15 |
+
python train.py --outdir=~/training-runs --cfg=ffhq --data=~/datasets/FFHQ_512.zip \
|
| 16 |
+
--gpus=8 --batch=32 --gamma=1 --gen_pose_cond=True
|
| 17 |
+
```
|
| 18 |
+
|
| 19 |
+
**ffhq512-128.pkl**
|
| 20 |
+
|
| 21 |
+
Fine-tune FFHQ 512, with neural rendering resolution of 128x128.
|
| 22 |
+
|
| 23 |
+
```.bash
|
| 24 |
+
# Second stage finetuning of FFHQ to 128 neural rendering resolution.
|
| 25 |
+
python train.py --outdir=~/training-runs --cfg=ffhq --data=~/datasets/FFHQ_512.zip \
|
| 26 |
+
--resume=ffhq-64.pkl \
|
| 27 |
+
--gpus=8 --batch=32 --gamma=1 --gen_pose_cond=True --neural_rendering_resolution_final=128 --kimg=2000
|
| 28 |
+
```
|
| 29 |
+
|
| 30 |
+
## FFHQ Rebalanced
|
| 31 |
+
|
| 32 |
+
Same as the models above, but fine-tuned using a rebalanced version of FFHQ that has a more uniform pose distribution. Compared to models trained on standard FFHQ, these models should produce better 3D shapes and better renderings from steep angles.
|
| 33 |
+
|
| 34 |
+
**ffhqrebalanced512-64.pkl**
|
| 35 |
+
|
| 36 |
+
```.bash
|
| 37 |
+
# Finetune with rebalanced FFHQ at rendering resolution 64.
|
| 38 |
+
python train.py --outdir=~/training-runs --cfg=ffhq --data=~/datasets/FFHQ_rebalanced_512.zip \
|
| 39 |
+
--resume=ffhq-64.pkl \
|
| 40 |
+
--gpus=8 --batch=32 --gamma=1 --gen_pose_cond=True --gpc_reg_prob=0.8
|
| 41 |
+
```
|
| 42 |
+
|
| 43 |
+
**ffhqrebalanced512-128.pkl**
|
| 44 |
+
```.bash
|
| 45 |
+
# Finetune with rebalanced FFHQ at 128 neural rendering resolution.
|
| 46 |
+
python train.py --outdir=~/training-runs --cfg=ffhq --data=~/datasets/FFHQ_rebalanced_512.zip \
|
| 47 |
+
--resume=ffhq-rebalanced-64.pkl \
|
| 48 |
+
--gpus=8 --batch=32 --gamma=1 --gen_pose_cond=True --gpc_reg_prob=0.8 --neural_rendering_resolution_final=128
|
| 49 |
+
```
|
| 50 |
+
|
| 51 |
+
# AFHQ Cats
|
| 52 |
+
|
| 53 |
+
**afhqcats512-128.pkl**
|
| 54 |
+
|
| 55 |
+
```.bash
|
| 56 |
+
# Train with AFHQ, finetuning from FFHQ with ADA, using 8 GPUs.
|
| 57 |
+
python train.py --outdir=~/training-runs --cfg=afhq --data=~/datasets/afhq.zip \
|
| 58 |
+
--resume=ffhq-64.pkl \
|
| 59 |
+
--gpus=8 --batch=32 --gamma=5 --aug=ada --gen_pose_cond=True --gpc_reg_prob=0.8 --neural_rendering_resolution_final=128
|
| 60 |
+
```
|
| 61 |
+
|
| 62 |
+
|
| 63 |
+
# Shapenet
|
| 64 |
+
|
| 65 |
+
**shapenetcars128-64.pkl**
|
| 66 |
+
|
| 67 |
+
```.bash
|
| 68 |
+
# Train with Shapenet from scratch, using 8 GPUs.
|
| 69 |
+
python train.py --outdir=~/training-runs --cfg=shapenet --data=~/datasets/cars_train.zip \
|
| 70 |
+
--gpus=8 --batch=32 --gamma=0.3
|
| 71 |
+
```
|
eg3d/docs/teaser.jpeg
ADDED

|
eg3d/docs/training_guide.md
ADDED
|
@@ -0,0 +1,165 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
## Guide to Training
|
| 2 |
+
|
| 3 |
+
Tips and tricks for setting up your own training runs. This guide looks at the most important options when setting up a training run with new data.
|
| 4 |
+
|
| 5 |
+
---
|
| 6 |
+
|
| 7 |
+
## Preparing your data
|
| 8 |
+
|
| 9 |
+
Your dataset should be a directory that includes your images and a dataset.json file that fits the following format:
|
| 10 |
+
|
| 11 |
+
```
|
| 12 |
+
{
|
| 13 |
+
'labels': [
|
| 14 |
+
["img_0000.png", [0.1, 0.2, -0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.8, 0.9, 1.0, 1.1, 1.2, 1.3, 1.4, -1.5, 1.6, 1.7, 1.8, -1.9, 2.0, 2.1, -2.2, 2.3, 2.4, -2.5]]
|
| 15 |
+
]
|
| 16 |
+
}
|
| 17 |
+
```
|
| 18 |
+
Each entry of the 'labels' list contains the relative filename and a 25-length camera parameters vector. The first 16 entries of the camera parameters are the 4x4 OpenCV Cam2World extrinsics matrix. The last 9 parameters are the 3x3 intrinsics matrix normalized by image size.
|
| 19 |
+
|
| 20 |
+
## Camera Conventions
|
| 21 |
+
|
| 22 |
+

|
| 23 |
+
|
| 24 |
+
### Intrinsics
|
| 25 |
+
We use normalized intrinsics so we can ignore image size during training. You can easily normalize intrinsics by dividing by your image size in number of pixels. For a camera intrinsics matrix with focal length f_x, f_y, principal point offset x_0, y_0, axis skew s, and image size (in pixels) size_x, size_y:
|
| 26 |
+
|
| 27 |
+
```
|
| 28 |
+
unnormalized normalized
|
| 29 |
+
|
| 30 |
+
[[ f_x, s, x_0] [[ f_x/size_x, s, x_0/size_x]
|
| 31 |
+
[ 0, f_y, y_0] -> [ 0, f_y/size_y, y_0/size_y]
|
| 32 |
+
[ 0, 0, 1 ]] [ 0, 0, 1 ]]
|
| 33 |
+
```
|
| 34 |
+
|
| 35 |
+
As a sanity check, after normalization, your principal point should be close to 0.5, 0.5.
|
| 36 |
+
|
| 37 |
+
## Mirrored Data
|
| 38 |
+
|
| 39 |
+
We recommend you mirror data manually by duplicating images and creating a duplicate camera pose label in your dataset.json file. See the FFHQ dataset preprocessing scripts for an example.
|
| 40 |
+
|
| 41 |
+
## Uncompressed Zip
|
| 42 |
+
|
| 43 |
+
While you can train with simply a directory of images and the dataset.json file, it's sometimes easier to zip the directory into an archive for more efficient transfer on networked systems. We use uncompressed .zip archives so that reading from the archive is as efficient as possible.
|
| 44 |
+
|
| 45 |
+
```
|
| 46 |
+
cd my_dataset
|
| 47 |
+
zip -0 -r ../my_dataset.zip *
|
| 48 |
+
```
|
| 49 |
+
|
| 50 |
+
## Examples
|
| 51 |
+
|
| 52 |
+
Please see the dataset_preprocessing directory for example scripts for preparing FFHQ, AFHQ, ShapeNet datasets.
|
| 53 |
+
|
| 54 |
+
---
|
| 55 |
+
|
| 56 |
+
## Basic Training and Rendering Parameters
|
| 57 |
+
|
| 58 |
+
### Finetuning
|
| 59 |
+
|
| 60 |
+
`--resume=my_pretrained_model.pkl`
|
| 61 |
+
|
| 62 |
+
Once you have your data, it's time to start some training runs. If possible, we highly recommend using finetuning off of a pre-trained model. Doing so dramatically improves the rate of convergence, so you can get better results in much less time. If your new dataset is front-facing, FFHQ is a great choice. If your dataset is imaged from 360 degrees, ShapeNet is going to be a better option.
|
| 63 |
+
|
| 64 |
+
### Batch Size
|
| 65 |
+
|
| 66 |
+
`--gpus=8 --batch=32`
|
| 67 |
+
|
| 68 |
+
If possible, use 8 gpus and a batch size of 32; these were our defaults for all of our major experiments. However, good results have also been obtained with small batch sizes on one or two GPUs, especially when finetuning is used. The batch size you specify is split evenly across the number of GPUs. If your batch size is small, use stronger R1 regularization (higher gamma).
|
| 69 |
+
|
| 70 |
+
### Gamma
|
| 71 |
+
|
| 72 |
+
`--gamma=5`
|
| 73 |
+
|
| 74 |
+
The strength of R1 regularization is an important hyperparameter for ensuring stability of GAN training. The best value of gamma may vary widely between datasets. If you have nothing to go on, ```--gamma=5``` is a safe choice. If training seems stable, and your model starts to produce diverse and reasonable outputs, you can try lowering gamma. If you experience training instability or mode collapse, try increasing gamma. In general, if your batch size is small, or if your images are large, you will need more regularization (higher gamma).
|
| 75 |
+
|
| 76 |
+
Finding the optimal value of gamma is important for maximizing your image quality.
|
| 77 |
+
|
| 78 |
+
### Generator Pose Conditioning
|
| 79 |
+
|
| 80 |
+
`--gen_pose_cond=True --gpc_reg_prob=0.8`
|
| 81 |
+
|
| 82 |
+
Generator pose conditioning (GPC) is when we condition the generator on the rendering camera pose. In doing so, we allow the camera pose to influence the identity of the scene, which is important for modelling pose-appearance correlations.
|
| 83 |
+
|
| 84 |
+
The above options control the presence and strength of GPC. `--gpc_reg_prob` adjusts probability of swapping regularization—when instead of conditioning on the rendering camera pose, we instead condition with a random camera pose. A high (close to 1) swapping regularization makes the conditioning vector "unreliable" and the effect of GPC weaker; a low (close to 0) swapping regularization means the effect of GPC is stronger but may introduce artifacts.
|
| 85 |
+
|
| 86 |
+
Our recommendation when starting with a new dataset is to train *without* generator pose conditioning by setting `--gen_pose_cond=False`. Whether you should use GPC is dependent on your dataset. If you use synthetic data, and know that all of your scenes are sampled randomly, you probably won't need it; by contrast, if you know your dataset has clear pose-appearance biases, turning on GPC may improve your image quality. After obtaining reasonable results without generator pose conditioning, you can try turning it on. Try setting your `--gpc_reg_prob` to somewhere between `0.5` and `0.8`.
|
| 87 |
+
|
| 88 |
+
|
| 89 |
+
### Neural Rendering Resolution
|
| 90 |
+
|
| 91 |
+
`--neural_rendering_resolution_final=128`
|
| 92 |
+
|
| 93 |
+
Neural rendering resolution is the resolution at which we volumetrically render, and it is independent of your output image size. In general, low neural rendering resolutions (e.g. 64) are faster at training and at inference. Higher neural rendering resolutions (e.g. 128) are more compute intensive but have less aliasing, produce more detailed shapes, and more view-consistent 3D renderings. For most models, we train at neural rendering resolution of 64 and optionally continue training with a neural rendering resolution of 128. **For the best quality and multi-view consistency, we strongly recommend fine-tuning at the 128 neural rendering resolution.**
|
| 94 |
+
|
| 95 |
+
To train with a static neural rendering resolution of 64:
|
| 96 |
+
```.bash
|
| 97 |
+
python train.py \
|
| 98 |
+
--neural_rendering_resolution_initial=64 \
|
| 99 |
+
...
|
| 100 |
+
```
|
| 101 |
+
|
| 102 |
+
To train with a neural rendering resolution that changes gradually increases from 64 to 128 over 1 million images:
|
| 103 |
+
```.bash
|
| 104 |
+
python train.py \
|
| 105 |
+
--neural_rendering_resolution_initial=64 \
|
| 106 |
+
--neural_rendering_resolution_final=128 \
|
| 107 |
+
--neural_rendering_resolution_fade_kimg=1000 \
|
| 108 |
+
...
|
| 109 |
+
```
|
| 110 |
+
|
| 111 |
+
Please see **Two-stage training** (Section 3 of the supplemental) for additional details.
|
| 112 |
+
|
| 113 |
+
### Adaptive Discriminator Augmentation
|
| 114 |
+
|
| 115 |
+
With small datasets, the discriminator can memorize the real images and destabilize training. Enable ADA by setting `--aug=ada`. Note that for small datasets, you'll see the largest benefit if you use both ADA as well as finetuning.
|
| 116 |
+
|
| 117 |
+
### Discriminator Pose Conditioning Regularization
|
| 118 |
+
|
| 119 |
+
We condition the discriminator on the rendering camera pose in order to aid convergence to accurate 3D objects. However, it's sometimes possible for discriminator pose conditioning to hurt training stability. If your input poses are accurate and unique, e.g. if they were generated synthetically with random camera poses, it's possible for the discriminator to memorize which poses must be paired with which images. We can regularize this effect by corrupting these poses with Gaussian noise before they are seen by the discriminator. To add 1 standard deviation of Gaussian noise, set `--disc_c_noise=1`.
|
| 120 |
+
|
| 121 |
+
---
|
| 122 |
+
|
| 123 |
+
## Rendering Config
|
| 124 |
+
|
| 125 |
+
```
|
| 126 |
+
if opts.cfg == 'shapenet':
|
| 127 |
+
rendering_options.update({
|
| 128 |
+
'depth_resolution': 64,
|
| 129 |
+
'depth_resolution_importance': 64,
|
| 130 |
+
'ray_start': 'auto',
|
| 131 |
+
'ray_end': 'auto',
|
| 132 |
+
'box_warp': 1.6,
|
| 133 |
+
'white_back': True,
|
| 134 |
+
'avg_camera_radius': 1.7,
|
| 135 |
+
'avg_camera_pivot': [0, 0, 0],
|
| 136 |
+
})
|
| 137 |
+
```
|
| 138 |
+
|
| 139 |
+
The last step before training a model is to set up a rendering config, which you can do in the `train.py` script.
|
| 140 |
+
|
| 141 |
+
**depth_resolution:** How many uniformly spaced samples to take along each ray.
|
| 142 |
+
|
| 143 |
+
**depth_resolution_importance:** How many importance samples to take along each ray.
|
| 144 |
+
|
| 145 |
+
**ray_start:** The distance between the camera origin and the first depth sample along the ray. Can be a float, e.g. `0.1` or `'auto'`, if you want to use the ray-box intersection of the volume to set ray bounds.
|
| 146 |
+
|
| 147 |
+
**ray_end:** The distance between the camera origin and the last depth sample along the ray. Can be a float, e.g. `1.5` or `'auto'`, if you want to use the ray-box intersection of the volume to set ray bounds.
|
| 148 |
+
|
| 149 |
+
**box_warp:** The side length of the cube spanned by the tri-planes. The box is axis-aligned, centered at the origin, and has limits [-box_warp/2, -box_warp/2, -box_warp/2] - [box_warp/2, box_warp/2, box_warp/2]. If `box_warp=1.8`, it has vertices at [0.9, 0.9, 0.9], [0.9, 0.9, -0.9], ...
|
| 150 |
+
|
| 151 |
+
**white_back:** Controls the color of rays that pass through the volume without encountering any solid objects. Set to True if your background is white; set to false if the background is black.
|
| 152 |
+
|
| 153 |
+
**avg_camera_radius:** The average radius of the camera, assuming it rotates on a sphere about the origin. This option is unused at training—it is used only to specify the camera path in the visualizer.
|
| 154 |
+
|
| 155 |
+
**avg_camera_pivot:** The point at which the camera looks, assuming it rotates on a sphere about the origin. This option is unused at training—it is used only to specify the camera path in the visualizer.
|
| 156 |
+
|
| 157 |
+
---
|
| 158 |
+
|
| 159 |
+
Taking all of the above into account, you'll likely have a command that is similar to this one:
|
| 160 |
+
|
| 161 |
+
`python train.py --data=/data/mydata.zip --gpus=2 --batch=8 --cfg=myconfig --gamma=5 --resume=shapenet.pkl --outdir=training_runs`
|
| 162 |
+
|
| 163 |
+
For the training commands used to create the supplied pre-trained models, see [Models](models.md).
|
| 164 |
+
|
| 165 |
+
Good luck!
|
eg3d/docs/visualizer.png
ADDED
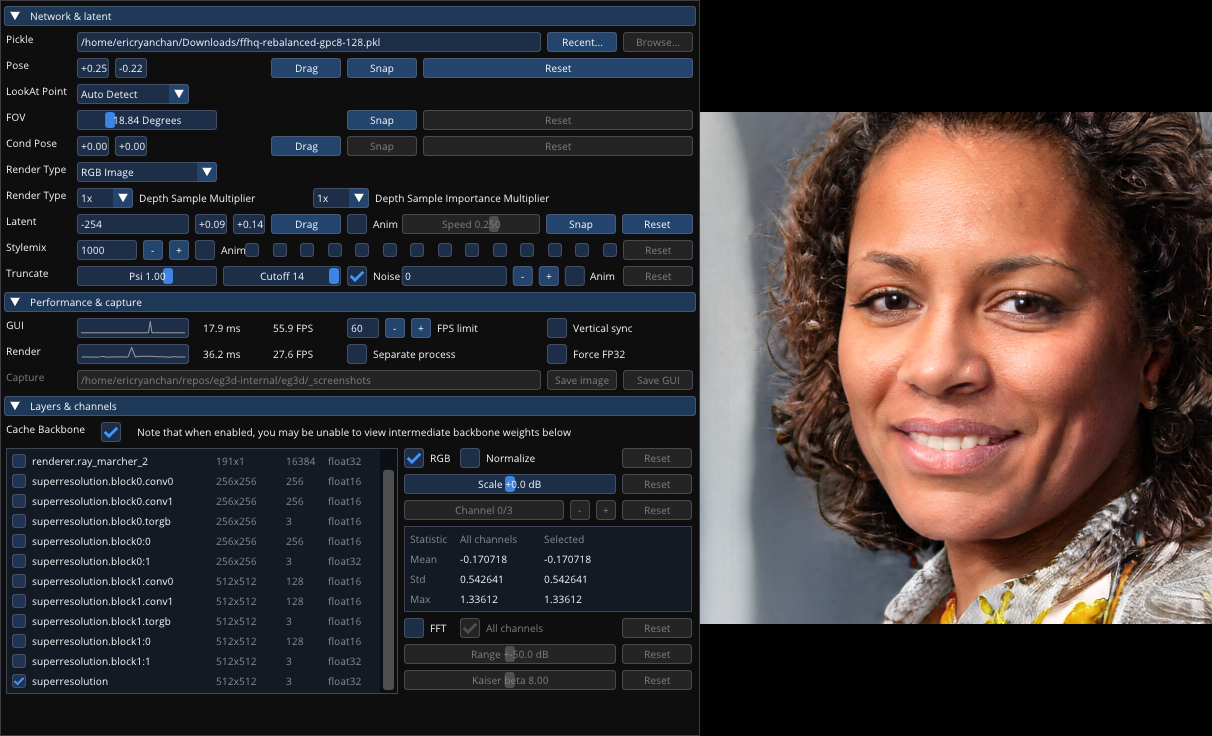
|
eg3d/docs/visualizer_guide.md
ADDED
|
@@ -0,0 +1,66 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
## Guide to the Visualizer
|
| 2 |
+
|
| 3 |
+

|
| 4 |
+
|
| 5 |
+
We include a 3D visualizer that is based on the amazing tool introduced in StyleGAN3. The following document describes important options and sliders of the visualizer UI.
|
| 6 |
+
|
| 7 |
+
TLDR:
|
| 8 |
+
1. Press the "Pickle/Recent" button to select a pretrained EG3D model.
|
| 9 |
+
2. Click and drag the "Latent/Drag" button to sweep latent codes and change the scene identity.
|
| 10 |
+
3. Click and drag the rendering on the right to move the camera.
|
| 11 |
+
|
| 12 |
+
---
|
| 13 |
+
|
| 14 |
+
## Network & Latent
|
| 15 |
+
|
| 16 |
+
### Pickle
|
| 17 |
+
Specify the path of the model checkpoint to visualize. You have a few options:
|
| 18 |
+
1. Drag and drop the .pkl file from your file browser into the visualizer window
|
| 19 |
+
1. Type the path (or url) of your .pkl file into the text field
|
| 20 |
+
1. Press the recent box to access a list of recently used checkpoints
|
| 21 |
+
|
| 22 |
+
### Pose
|
| 23 |
+
Control the pitch and yaw of the camera by clicking and dragging the rendering on the right. By default, the camera rotates on a sphere with fixed radius, pointed at the origin.
|
| 24 |
+
|
| 25 |
+
### FOV
|
| 26 |
+
Control the field of view of the camera with this slider to zoom the camera in and out. For FFHQ, 18 degrees is about right; for ShapeNet, use a FOV of 45 degrees.
|
| 27 |
+
|
| 28 |
+
### Cond Pose
|
| 29 |
+
The pose with which we condition the generator (see Generator Pose Conditioning in Sec. 4.4). By default, we condition on the fixed frontal camera pose. For models trained without generator pose conditioning, this will have no effect.
|
| 30 |
+
|
| 31 |
+
### Render Type
|
| 32 |
+
Toggle between the final super-resolved output (RGB image), a depth map (Depth image) or the raw neural rendering without super resolution (Neural rendering).
|
| 33 |
+
|
| 34 |
+
### Depth Sample Multiplier / Depth Sample Importance Multiplier
|
| 35 |
+
Adjust the number of depth samples taken per ray. By increasing the number of depth samples, we reduce flickering artifacts caused by depth aliasing, which leads to more temporally-consistent videos. However, the tradeoff is slower rendering and slightly blurrier images. At 1X / 1X, render in the visualizer with the same number of depth samples as at training; at 2X / 2X, take double the uniformly spaced and double the importance samples per ray. As an example: we train FFHQ with 48 uniformly spaced depth samples and 48 importance samples per ray. Using 2X / 2X, we instead take 96 uniformly spaced depth samples and 96 importance samples (192 total).
|
| 36 |
+
|
| 37 |
+
### Latent
|
| 38 |
+
The seed for the latent code, *z*, that is the input to the generator. Click and drag the "drag" button to sweep between scene identities. Press the "Anim" checkbox to play an animation sweeping through latent codes.
|
| 39 |
+
|
| 40 |
+
### Stylemix
|
| 41 |
+
The seed for a second latent code for style mixing. Check the boxes on the right to select which layers should be conditioned by this second code.
|
| 42 |
+
|
| 43 |
+
### Truncate
|
| 44 |
+
Apply the truncation trick in *w*-space to trade off fidelity for diversity. Psi=1 means no truncation. Psi=0 gives the "average" scene learned by the generator. A Psi between 0 and 1, e.g. 0.7 is a compromise that reduces diversity somewhat but improves the overall consistency in quality. (See the Truncation Trick in StyleGAN for more info.)
|
| 45 |
+
|
| 46 |
+
---
|
| 47 |
+
|
| 48 |
+
## Performance & capture
|
| 49 |
+
|
| 50 |
+
### Render
|
| 51 |
+
|
| 52 |
+
Displays the framerate of rendering. On an RTX 3090, with neural rendering resolution of 128, and with 48 uniform and 48 importance depth samples, we get 25-30 FPS.
|
| 53 |
+
|
| 54 |
+
### Capture
|
| 55 |
+
|
| 56 |
+
Save screenshots to the directory specified by the text field. Save image saves just the rendering; Save GUI saves the complete pane including the user interface.
|
| 57 |
+
|
| 58 |
+
---
|
| 59 |
+
|
| 60 |
+
## Layers & channels
|
| 61 |
+
|
| 62 |
+
### Cache backbone
|
| 63 |
+
For rendering where the scene identity (the latent code *z* and conditioning pose) remain static, but rendering parameters (the camera pose, fov, render type, etc...) change, we can enable 'backbone caching' which will enable us to cache and reuse the existing triplanes computed by the convolutional backbone. Backbone caching slightly improves rendering speed.
|
| 64 |
+
|
| 65 |
+
### Layer viewer
|
| 66 |
+
View and analyze the intermediate weights and layers of the generator. Scroll through the network and select a layer using the checkbox. Use the "Channel" slider on the right to view different activations. Do note that when 'cache backbone' is enabled, you will be unable to view the intermediate weights of the convolutional backbone/triplanes.
|
eg3d/gen_samples.py
ADDED
|
@@ -0,0 +1,280 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# SPDX-FileCopyrightText: Copyright (c) 2021-2022 NVIDIA CORPORATION & AFFILIATES. All rights reserved.
|
| 2 |
+
# SPDX-License-Identifier: LicenseRef-NvidiaProprietary
|
| 3 |
+
#
|
| 4 |
+
# NVIDIA CORPORATION, its affiliates and licensors retain all intellectual
|
| 5 |
+
# property and proprietary rights in and to this material, related
|
| 6 |
+
# documentation and any modifications thereto. Any use, reproduction,
|
| 7 |
+
# disclosure or distribution of this material and related documentation
|
| 8 |
+
# without an express license agreement from NVIDIA CORPORATION or
|
| 9 |
+
# its affiliates is strictly prohibited.
|
| 10 |
+
|
| 11 |
+
"""Generate images and shapes using pretrained network pickle."""
|
| 12 |
+
|
| 13 |
+
import os
|
| 14 |
+
import re
|
| 15 |
+
from typing import List, Optional, Tuple, Union
|
| 16 |
+
|
| 17 |
+
import click
|
| 18 |
+
import dnnlib
|
| 19 |
+
import numpy as np
|
| 20 |
+
import PIL.Image
|
| 21 |
+
import torch
|
| 22 |
+
from tqdm import tqdm
|
| 23 |
+
import mrcfile
|
| 24 |
+
|
| 25 |
+
|
| 26 |
+
import legacy
|
| 27 |
+
from camera_utils import LookAtPoseSampler, FOV_to_intrinsics
|
| 28 |
+
from torch_utils import misc
|
| 29 |
+
from training.triplane import TriPlaneGenerator
|
| 30 |
+
|
| 31 |
+
|
| 32 |
+
#----------------------------------------------------------------------------
|
| 33 |
+
|
| 34 |
+
def parse_range(s: Union[str, List]) -> List[int]:
|
| 35 |
+
'''Parse a comma separated list of numbers or ranges and return a list of ints.
|
| 36 |
+
|
| 37 |
+
Example: '1,2,5-10' returns [1, 2, 5, 6, 7]
|
| 38 |
+
'''
|
| 39 |
+
if isinstance(s, list): return s
|
| 40 |
+
ranges = []
|
| 41 |
+
range_re = re.compile(r'^(\d+)-(\d+)$')
|
| 42 |
+
for p in s.split(','):
|
| 43 |
+
if m := range_re.match(p):
|
| 44 |
+
ranges.extend(range(int(m.group(1)), int(m.group(2))+1))
|
| 45 |
+
else:
|
| 46 |
+
ranges.append(int(p))
|
| 47 |
+
return ranges
|
| 48 |
+
|
| 49 |
+
#----------------------------------------------------------------------------
|
| 50 |
+
|
| 51 |
+
def parse_vec2(s: Union[str, Tuple[float, float]]) -> Tuple[float, float]:
|
| 52 |
+
'''Parse a floating point 2-vector of syntax 'a,b'.
|
| 53 |
+
|
| 54 |
+
Example:
|
| 55 |
+
'0,1' returns (0,1)
|
| 56 |
+
'''
|
| 57 |
+
if isinstance(s, tuple): return s
|
| 58 |
+
parts = s.split(',')
|
| 59 |
+
if len(parts) == 2:
|
| 60 |
+
return (float(parts[0]), float(parts[1]))
|
| 61 |
+
raise ValueError(f'cannot parse 2-vector {s}')
|
| 62 |
+
|
| 63 |
+
#----------------------------------------------------------------------------
|
| 64 |
+
|
| 65 |
+
def make_transform(translate: Tuple[float,float], angle: float):
|
| 66 |
+
m = np.eye(3)
|
| 67 |
+
s = np.sin(angle/360.0*np.pi*2)
|
| 68 |
+
c = np.cos(angle/360.0*np.pi*2)
|
| 69 |
+
m[0][0] = c
|
| 70 |
+
m[0][1] = s
|
| 71 |
+
m[0][2] = translate[0]
|
| 72 |
+
m[1][0] = -s
|
| 73 |
+
m[1][1] = c
|
| 74 |
+
m[1][2] = translate[1]
|
| 75 |
+
return m
|
| 76 |
+
|
| 77 |
+
#----------------------------------------------------------------------------
|
| 78 |
+
|
| 79 |
+
def create_samples(N=256, voxel_origin=[0, 0, 0], cube_length=2.0):
|
| 80 |
+
# NOTE: the voxel_origin is actually the (bottom, left, down) corner, not the middle
|
| 81 |
+
voxel_origin = np.array(voxel_origin) - cube_length/2
|
| 82 |
+
voxel_size = cube_length / (N - 1)
|
| 83 |
+
|
| 84 |
+
overall_index = torch.arange(0, N ** 3, 1, out=torch.LongTensor())
|
| 85 |
+
samples = torch.zeros(N ** 3, 3)
|
| 86 |
+
|
| 87 |
+
# transform first 3 columns
|
| 88 |
+
# to be the x, y, z index
|
| 89 |
+
samples[:, 2] = overall_index % N
|
| 90 |
+
samples[:, 1] = (overall_index.float() / N) % N
|
| 91 |
+
samples[:, 0] = ((overall_index.float() / N) / N) % N
|
| 92 |
+
|
| 93 |
+
# transform first 3 columns
|
| 94 |
+
# to be the x, y, z coordinate
|
| 95 |
+
samples[:, 0] = (samples[:, 0] * voxel_size) + voxel_origin[2]
|
| 96 |
+
samples[:, 1] = (samples[:, 1] * voxel_size) + voxel_origin[1]
|
| 97 |
+
samples[:, 2] = (samples[:, 2] * voxel_size) + voxel_origin[0]
|
| 98 |
+
|
| 99 |
+
num_samples = N ** 3
|
| 100 |
+
|
| 101 |
+
return samples.unsqueeze(0), voxel_origin, voxel_size
|
| 102 |
+
|
| 103 |
+
#----------------------------------------------------------------------------
|
| 104 |
+
|
| 105 |
+
@click.command()
|
| 106 |
+
@click.option('--network', help='Network path', multiple=True, required=True)
|
| 107 |
+
@click.option('--w_pth', help='latent path')
|
| 108 |
+
@click.option('--generator_type', help='Generator type', type=click.Choice(['ffhq', 'cat']), required=False, metavar='STR', default='ffhq', show_default=True)
|
| 109 |
+
@click.option('--model_is_state_dict', type=bool, default=False)
|
| 110 |
+
@click.option('--seeds', type=parse_range, help='List of random seeds (e.g., \'0,1,4-6\')', required=True)
|
| 111 |
+
@click.option('--trunc', 'truncation_psi', type=float, help='Truncation psi', default=1, show_default=True)
|
| 112 |
+
@click.option('--trunc-cutoff', 'truncation_cutoff', type=int, help='Truncation cutoff', default=14, show_default=True)
|
| 113 |
+
@click.option('--outdir', help='Where to save the output images', type=str, required=True, metavar='DIR')
|
| 114 |
+
@click.option('--shapes', help='Export shapes as .mrc files viewable in ChimeraX', type=bool, required=False, metavar='BOOL', default=False, show_default=True)
|
| 115 |
+
@click.option('--shape-res', help='', type=int, required=False, metavar='int', default=512, show_default=True)
|
| 116 |
+
@click.option('--shape_only_first', type=bool, default=False)
|
| 117 |
+
@click.option('--fov-deg', help='Field of View of camera in degrees', type=int, required=False, metavar='float', default=18.837, show_default=True)
|
| 118 |
+
@click.option('--shape_format', help='Shape Format', type=click.Choice(['.mrc', '.ply']), default='.mrc')
|
| 119 |
+
def generate_images(
|
| 120 |
+
network: List[str],
|
| 121 |
+
w_pth: str,
|
| 122 |
+
generator_type: str,
|
| 123 |
+
seeds: List[int],
|
| 124 |
+
truncation_psi: float,
|
| 125 |
+
truncation_cutoff: int,
|
| 126 |
+
outdir: str,
|
| 127 |
+
shapes: bool,
|
| 128 |
+
shape_res: int,
|
| 129 |
+
fov_deg: float,
|
| 130 |
+
shape_format: str,
|
| 131 |
+
model_is_state_dict: bool,
|
| 132 |
+
shape_only_first: bool,
|
| 133 |
+
):
|
| 134 |
+
|
| 135 |
+
|
| 136 |
+
if not os.path.exists(outdir):
|
| 137 |
+
os.makedirs(outdir, exist_ok=True)
|
| 138 |
+
|
| 139 |
+
device = torch.device('cuda')
|
| 140 |
+
|
| 141 |
+
if generator_type == 'ffhq':
|
| 142 |
+
network_pkl_tmp = 'pretrained/ffhqrebalanced512-128.pkl'
|
| 143 |
+
elif generator_type == 'cat':
|
| 144 |
+
network_pkl_tmp = 'pretrained/afhqcats512-128.pkl'
|
| 145 |
+
else:
|
| 146 |
+
NotImplementedError()
|
| 147 |
+
|
| 148 |
+
G_list = []
|
| 149 |
+
outputs = []
|
| 150 |
+
for network_path in network:
|
| 151 |
+
print('Loading networks from "%s"...' % network_path)
|
| 152 |
+
dir_label = network_path.split('/')[-2] + '___' + network_path.split('/')[-1]
|
| 153 |
+
output = os.path.join(outdir, dir_label)
|
| 154 |
+
outputs.append(output)
|
| 155 |
+
if model_is_state_dict:
|
| 156 |
+
with dnnlib.util.open_url(network_pkl_tmp) as f:
|
| 157 |
+
G = legacy.load_network_pkl(f)['G_ema'].to(device) # type: ignore
|
| 158 |
+
ckpt = torch.load(network_path)
|
| 159 |
+
G.load_state_dict(ckpt, strict=False)
|
| 160 |
+
else:
|
| 161 |
+
with dnnlib.util.open_url(network_path) as f:
|
| 162 |
+
G = legacy.load_network_pkl(f)['G_ema'].to(device) # type: ignore
|
| 163 |
+
|
| 164 |
+
G.rendering_kwargs['depth_resolution'] = int(G.rendering_kwargs['depth_resolution'])
|
| 165 |
+
G.rendering_kwargs['depth_resolution_importance'] = int(
|
| 166 |
+
G.rendering_kwargs['depth_resolution_importance'])
|
| 167 |
+
|
| 168 |
+
if generator_type == 'cat':
|
| 169 |
+
G.rendering_kwargs['avg_camera_pivot'] = [0, 0, -0.06]
|
| 170 |
+
elif generator_type == 'ffhq':
|
| 171 |
+
G.rendering_kwargs['avg_camera_pivot'] = [0, 0, 0.2]
|
| 172 |
+
|
| 173 |
+
G_list.append(G)
|
| 174 |
+
|
| 175 |
+
if truncation_cutoff == 0:
|
| 176 |
+
truncation_psi = 1.0 # truncation cutoff of 0 means no truncation anyways
|
| 177 |
+
if truncation_psi == 1.0:
|
| 178 |
+
truncation_cutoff = 14 # no truncation so doesn't matter where we cutoff
|
| 179 |
+
|
| 180 |
+
if w_pth is not None:
|
| 181 |
+
seeds = [0]
|
| 182 |
+
seed_idx = ''
|
| 183 |
+
for i, seed in enumerate(seeds):
|
| 184 |
+
if i < len(seeds) - 1:
|
| 185 |
+
seed_idx += f'{seed}_'
|
| 186 |
+
else:
|
| 187 |
+
seed_idx += f'{seed}'
|
| 188 |
+
|
| 189 |
+
intrinsics = FOV_to_intrinsics(fov_deg, device=device)
|
| 190 |
+
|
| 191 |
+
print(seeds)
|
| 192 |
+
|
| 193 |
+
# Generate images.
|
| 194 |
+
for G, output in zip(G_list, outputs):
|
| 195 |
+
for seed_idx, seed in enumerate(seeds):
|
| 196 |
+
print('Generating image for seed %d (%d/%d) ...' % (seed, seed_idx, len(seeds)))
|
| 197 |
+
|
| 198 |
+
z = torch.from_numpy(np.random.RandomState(seed).randn(1, G.z_dim)).to(device)
|
| 199 |
+
|
| 200 |
+
imgs = []
|
| 201 |
+
angle_p = -0.2
|
| 202 |
+
for angle_y, angle_p in [(.4, angle_p), (0, angle_p), (-.4, angle_p)]:
|
| 203 |
+
cam_pivot = torch.tensor(G.rendering_kwargs.get('avg_camera_pivot', [0, 0, 0]), device=device)
|
| 204 |
+
cam_radius = G.rendering_kwargs.get('avg_camera_radius', 2.7)
|
| 205 |
+
cam2world_pose = LookAtPoseSampler.sample(np.pi/2 + angle_y, np.pi/2 + angle_p, cam_pivot, radius=cam_radius, device=device)
|
| 206 |
+
conditioning_cam2world_pose = LookAtPoseSampler.sample(np.pi/2, np.pi/2, cam_pivot, radius=cam_radius, device=device)
|
| 207 |
+
camera_params = torch.cat([cam2world_pose.reshape(-1, 16), intrinsics.reshape(-1, 9)], 1)
|
| 208 |
+
conditioning_params = torch.cat([conditioning_cam2world_pose.reshape(-1, 16), intrinsics.reshape(-1, 9)], 1)
|
| 209 |
+
|
| 210 |
+
if w_pth is not None:
|
| 211 |
+
ws = torch.load(w_pth).cuda()
|
| 212 |
+
w_given_id = os.path.split(w_pth)[-1].split('.')[-2]
|
| 213 |
+
output_img = output + f'__{w_given_id}.png'
|
| 214 |
+
output_shape = output + f'__{w_given_id}.mrc'
|
| 215 |
+
else:
|
| 216 |
+
ws = G.mapping(z, conditioning_params, truncation_psi=truncation_psi, truncation_cutoff=truncation_cutoff)
|
| 217 |
+
output_img = output + f'__{seed_idx:05d}.png'
|
| 218 |
+
output_shape = output + f'__{seed_idx:05d}.mrc'
|
| 219 |
+
|
| 220 |
+
|
| 221 |
+
img = G.synthesis(ws, camera_params)['image']
|
| 222 |
+
|
| 223 |
+
img = (img.permute(0, 2, 3, 1) * 127.5 + 128).clamp(0, 255).to(torch.uint8)
|
| 224 |
+
imgs.append(img)
|
| 225 |
+
|
| 226 |
+
img = torch.cat(imgs, dim=2)
|
| 227 |
+
|
| 228 |
+
PIL.Image.fromarray(img[0].cpu().numpy(), 'RGB').save(output_img)
|
| 229 |
+
if shape_only_first and seed_idx != 0:
|
| 230 |
+
continue
|
| 231 |
+
|
| 232 |
+
|
| 233 |
+
if shapes:
|
| 234 |
+
# extract a shape.mrc with marching cubes. You can view the .mrc file using ChimeraX from UCSF.
|
| 235 |
+
max_batch=1000000
|
| 236 |
+
|
| 237 |
+
samples, voxel_origin, voxel_size = create_samples(N=shape_res, voxel_origin=[0, 0, 0], cube_length=G.rendering_kwargs['box_warp'] * 1)#.reshape(1, -1, 3)
|
| 238 |
+
samples = samples.to(z.device)
|
| 239 |
+
sigmas = torch.zeros((samples.shape[0], samples.shape[1], 1), device=z.device)
|
| 240 |
+
transformed_ray_directions_expanded = torch.zeros((samples.shape[0], max_batch, 3), device=z.device)
|
| 241 |
+
transformed_ray_directions_expanded[..., -1] = -1
|
| 242 |
+
|
| 243 |
+
head = 0
|
| 244 |
+
with tqdm(total = samples.shape[1]) as pbar:
|
| 245 |
+
with torch.no_grad():
|
| 246 |
+
while head < samples.shape[1]:
|
| 247 |
+
torch.manual_seed(0)
|
| 248 |
+
sigma = G.sample(samples[:, head:head+max_batch], transformed_ray_directions_expanded[:, :samples.shape[1]-head], z, conditioning_params, truncation_psi=truncation_psi, truncation_cutoff=truncation_cutoff, noise_mode='const')['sigma']
|
| 249 |
+
sigmas[:, head:head+max_batch] = sigma
|
| 250 |
+
head += max_batch
|
| 251 |
+
pbar.update(max_batch)
|
| 252 |
+
|
| 253 |
+
sigmas = sigmas.reshape((shape_res, shape_res, shape_res)).cpu().numpy()
|
| 254 |
+
sigmas = np.flip(sigmas, 0)
|
| 255 |
+
|
| 256 |
+
# Trim the border of the extracted cube
|
| 257 |
+
pad = int(30 * shape_res / 256)
|
| 258 |
+
pad_value = -1000
|
| 259 |
+
sigmas[:pad] = pad_value
|
| 260 |
+
sigmas[-pad:] = pad_value
|
| 261 |
+
sigmas[:, :pad] = pad_value
|
| 262 |
+
sigmas[:, -pad:] = pad_value
|
| 263 |
+
sigmas[:, :, :pad] = pad_value
|
| 264 |
+
sigmas[:, :, -pad:] = pad_value
|
| 265 |
+
|
| 266 |
+
|
| 267 |
+
if shape_format == '.ply':
|
| 268 |
+
from shape_utils import convert_sdf_samples_to_ply
|
| 269 |
+
convert_sdf_samples_to_ply(np.transpose(sigmas, (2, 1, 0)), [0, 0, 0], 1, output_shape.replace('.mrc','.ply'), level=10)
|
| 270 |
+
elif shape_format == '.mrc': # output mrc
|
| 271 |
+
with mrcfile.new_mmap(output_shape, overwrite=True, shape=sigmas.shape, mrc_mode=2) as mrc:
|
| 272 |
+
mrc.data[:] = sigmas
|
| 273 |
+
|
| 274 |
+
|
| 275 |
+
#----------------------------------------------------------------------------
|
| 276 |
+
|
| 277 |
+
if __name__ == "__main__":
|
| 278 |
+
generate_images() # pylint: disable=no-value-for-parameter
|
| 279 |
+
|
| 280 |
+
#----------------------------------------------------------------------------
|
eg3d/gen_videos.py
ADDED
|
@@ -0,0 +1,371 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# SPDX-FileCopyrightText: Copyright (c) 2021-2022 NVIDIA CORPORATION & AFFILIATES. All rights reserved.
|
| 2 |
+
# SPDX-License-Identifier: LicenseRef-NvidiaProprietary
|
| 3 |
+
#
|
| 4 |
+
# NVIDIA CORPORATION, its affiliates and licensors retain all intellectual
|
| 5 |
+
# property and proprietary rights in and to this material, related
|
| 6 |
+
# documentation and any modifications thereto. Any use, reproduction,
|
| 7 |
+
# disclosure or distribution of this material and related documentation
|
| 8 |
+
# without an express license agreement from NVIDIA CORPORATION or
|
| 9 |
+
# its affiliates is strictly prohibited.
|
| 10 |
+
|
| 11 |
+
"""Generate lerp videos using pretrained network pickle."""
|
| 12 |
+
|
| 13 |
+
import os
|
| 14 |
+
import re
|
| 15 |
+
from typing import List, Optional, Tuple, Union
|
| 16 |
+
|
| 17 |
+
import click
|
| 18 |
+
import dnnlib
|
| 19 |
+
import imageio
|
| 20 |
+
import numpy as np
|
| 21 |
+
import scipy.interpolate
|
| 22 |
+
import torch
|
| 23 |
+
from tqdm import tqdm
|
| 24 |
+
import mrcfile
|
| 25 |
+
|
| 26 |
+
import legacy
|
| 27 |
+
|
| 28 |
+
from camera_utils import LookAtPoseSampler
|
| 29 |
+
from torch_utils import misc
|
| 30 |
+
#----------------------------------------------------------------------------
|
| 31 |
+
|
| 32 |
+
def layout_grid(img, grid_w=None, grid_h=1, float_to_uint8=True, chw_to_hwc=True, to_numpy=True):
|
| 33 |
+
batch_size, channels, img_h, img_w = img.shape
|
| 34 |
+
if grid_w is None:
|
| 35 |
+
grid_w = batch_size // grid_h
|
| 36 |
+
assert batch_size == grid_w * grid_h
|
| 37 |
+
if float_to_uint8:
|
| 38 |
+
img = (img * 127.5 + 128).clamp(0, 255).to(torch.uint8)
|
| 39 |
+
img = img.reshape(grid_h, grid_w, channels, img_h, img_w)
|
| 40 |
+
img = img.permute(2, 0, 3, 1, 4)
|
| 41 |
+
img = img.reshape(channels, grid_h * img_h, grid_w * img_w)
|
| 42 |
+
if chw_to_hwc:
|
| 43 |
+
img = img.permute(1, 2, 0)
|
| 44 |
+
if to_numpy:
|
| 45 |
+
img = img.cpu().numpy()
|
| 46 |
+
return img
|
| 47 |
+
|
| 48 |
+
def create_samples(N=256, voxel_origin=[0, 0, 0], cube_length=2.0):
|
| 49 |
+
# NOTE: the voxel_origin is actually the (bottom, left, down) corner, not the middle
|
| 50 |
+
voxel_origin = np.array(voxel_origin) - cube_length/2
|
| 51 |
+
voxel_size = cube_length / (N - 1)
|
| 52 |
+
|
| 53 |
+
overall_index = torch.arange(0, N ** 3, 1, out=torch.LongTensor())
|
| 54 |
+
samples = torch.zeros(N ** 3, 3)
|
| 55 |
+
|
| 56 |
+
# transform first 3 columns
|
| 57 |
+
# to be the x, y, z index
|
| 58 |
+
samples[:, 2] = overall_index % N
|
| 59 |
+
samples[:, 1] = (overall_index.float() / N) % N
|
| 60 |
+
samples[:, 0] = ((overall_index.float() / N) / N) % N
|
| 61 |
+
|
| 62 |
+
# transform first 3 columns
|
| 63 |
+
# to be the x, y, z coordinate
|
| 64 |
+
samples[:, 0] = (samples[:, 0] * voxel_size) + voxel_origin[2]
|
| 65 |
+
samples[:, 1] = (samples[:, 1] * voxel_size) + voxel_origin[1]
|
| 66 |
+
samples[:, 2] = (samples[:, 2] * voxel_size) + voxel_origin[0]
|
| 67 |
+
|
| 68 |
+
num_samples = N ** 3
|
| 69 |
+
|
| 70 |
+
return samples.unsqueeze(0), voxel_origin, voxel_size
|
| 71 |
+
|
| 72 |
+
#----------------------------------------------------------------------------
|
| 73 |
+
|
| 74 |
+
def gen_interp_video(G, w_given, mp4: str, seeds, shuffle_seed=None, w_frames=60*4, kind='cubic', grid_dims=(1,1), num_keyframes=None, wraps=2, psi=1., truncation_cutoff=14, generator_type='ffhq', image_mode='image', gen_shapes=False, device=torch.device('cuda'), **video_kwargs):
|
| 75 |
+
grid_w = grid_dims[0]
|
| 76 |
+
grid_h = grid_dims[1]
|
| 77 |
+
|
| 78 |
+
if num_keyframes is None:
|
| 79 |
+
if len(seeds) % (grid_w*grid_h) != 0:
|
| 80 |
+
raise ValueError('Number of input seeds must be divisible by grid W*H')
|
| 81 |
+
num_keyframes = len(seeds) // (grid_w*grid_h)
|
| 82 |
+
|
| 83 |
+
all_seeds = np.zeros(num_keyframes*grid_h*grid_w, dtype=np.int64)
|
| 84 |
+
for idx in range(num_keyframes*grid_h*grid_w):
|
| 85 |
+
all_seeds[idx] = seeds[idx % len(seeds)]
|
| 86 |
+
|
| 87 |
+
if shuffle_seed is not None:
|
| 88 |
+
rng = np.random.RandomState(seed=shuffle_seed)
|
| 89 |
+
rng.shuffle(all_seeds)
|
| 90 |
+
|
| 91 |
+
camera_lookat_point = torch.tensor(G.rendering_kwargs['avg_camera_pivot'], device=device)
|
| 92 |
+
zs = torch.from_numpy(np.stack([np.random.RandomState(seed).randn(G.z_dim) for seed in all_seeds])).to(device)
|
| 93 |
+
cam2world_pose = LookAtPoseSampler.sample(3.14/2, 3.14/2, camera_lookat_point, radius=G.rendering_kwargs['avg_camera_radius'], device=device)
|
| 94 |
+
focal_length = 4.2647 #if generator_type != 'Shapenet' else 1.7074 # shapenet has higher FOV
|
| 95 |
+
intrinsics = torch.tensor([[focal_length, 0, 0.5], [0, focal_length, 0.5], [0, 0, 1]], device=device)
|
| 96 |
+
c = torch.cat([cam2world_pose.reshape(-1, 16), intrinsics.reshape(-1, 9)], 1)
|
| 97 |
+
c = c.repeat(len(zs), 1)
|
| 98 |
+
|
| 99 |
+
if w_given is not None:
|
| 100 |
+
ws = w_given
|
| 101 |
+
if ws.shape[1] != G.backbone.mapping.num_ws:
|
| 102 |
+
ws = ws.repeat([1, G.backbone.mapping.num_ws, 1])
|
| 103 |
+
else:
|
| 104 |
+
ws = G.mapping(z=zs, c=c, truncation_psi=psi, truncation_cutoff=truncation_cutoff)
|
| 105 |
+
# _ = G.synthesis(ws[:1], c[:1]) # warm up
|
| 106 |
+
ws = ws.reshape(grid_h, grid_w, num_keyframes, *ws.shape[1:])
|
| 107 |
+
|
| 108 |
+
# Interpolation.
|
| 109 |
+
grid = []
|
| 110 |
+
for yi in range(grid_h):
|
| 111 |
+
row = []
|
| 112 |
+
for xi in range(grid_w):
|
| 113 |
+
x = np.arange(-num_keyframes * wraps, num_keyframes * (wraps + 1))
|
| 114 |
+
y = np.tile(ws[yi][xi].cpu().numpy(), [wraps * 2 + 1, 1, 1])
|
| 115 |
+
interp = scipy.interpolate.interp1d(x, y, kind=kind, axis=0)
|
| 116 |
+
row.append(interp)
|
| 117 |
+
grid.append(row)
|
| 118 |
+
|
| 119 |
+
# Render video.
|
| 120 |
+
max_batch = 10000000
|
| 121 |
+
voxel_resolution = 512
|
| 122 |
+
video_out = imageio.get_writer(mp4, mode='I', fps=60, codec='libx264', **video_kwargs)
|
| 123 |
+
|
| 124 |
+
if gen_shapes:
|
| 125 |
+
outdir = 'interpolation_{}_{}/'.format(all_seeds[0], all_seeds[1])
|
| 126 |
+
os.makedirs(outdir, exist_ok=True)
|
| 127 |
+
all_poses = []
|
| 128 |
+
for frame_idx in tqdm(range(num_keyframes * w_frames)):
|
| 129 |
+
imgs = []
|
| 130 |
+
for yi in range(grid_h):
|
| 131 |
+
for xi in range(grid_w):
|
| 132 |
+
pitch_range = 0.25
|
| 133 |
+
yaw_range = 0.35
|
| 134 |
+
cam2world_pose = LookAtPoseSampler.sample(3.14/2 + yaw_range * np.sin(2 * 3.14 * frame_idx / (num_keyframes * w_frames)),
|
| 135 |
+
3.14/2 -0.05 + pitch_range * np.cos(2 * 3.14 * frame_idx / (num_keyframes * w_frames)),
|
| 136 |
+
camera_lookat_point, radius=G.rendering_kwargs['avg_camera_radius'], device=device)
|
| 137 |
+
all_poses.append(cam2world_pose.squeeze().cpu().numpy())
|
| 138 |
+
focal_length = 4.2647 if generator_type != 'Shapenet' else 1.7074 # shapenet has higher FOV
|
| 139 |
+
intrinsics = torch.tensor([[focal_length, 0, 0.5], [0, focal_length, 0.5], [0, 0, 1]], device=device)
|
| 140 |
+
c = torch.cat([cam2world_pose.reshape(-1, 16), intrinsics.reshape(-1, 9)], 1)
|
| 141 |
+
|
| 142 |
+
interp = grid[yi][xi]
|
| 143 |
+
w = torch.from_numpy(interp(frame_idx / w_frames)).to(device)
|
| 144 |
+
|
| 145 |
+
entangle = 'camera'
|
| 146 |
+
if entangle == 'conditioning':
|
| 147 |
+
c_forward = torch.cat([LookAtPoseSampler.sample(3.14/2,
|
| 148 |
+
3.14/2,
|
| 149 |
+
camera_lookat_point,
|
| 150 |
+
radius=G.rendering_kwargs['avg_camera_radius'], device=device).reshape(-1, 16), intrinsics.reshape(-1, 9)], 1)
|
| 151 |
+
w_c = G.mapping(z=zs[0:1], c=c[0:1], truncation_psi=psi, truncation_cutoff=truncation_cutoff)
|
| 152 |
+
img = G.synthesis(ws=w_c, c=c_forward, noise_mode='const')[image_mode][0]
|
| 153 |
+
elif entangle == 'camera':
|
| 154 |
+
img = G.synthesis(ws=w.unsqueeze(0), c=c[0:1], noise_mode='const')[image_mode][0]
|
| 155 |
+
# img = G.synthesis(ws=ws[yi, xi], c=c[0:1], noise_mode='const')[image_mode][0]
|
| 156 |
+
elif entangle == 'both':
|
| 157 |
+
w_c = G.mapping(z=zs[0:1], c=c[0:1], truncation_psi=psi, truncation_cutoff=truncation_cutoff)
|
| 158 |
+
img = G.synthesis(ws=w_c, c=c[0:1], noise_mode='const')[image_mode][0]
|
| 159 |
+
|
| 160 |
+
if image_mode == 'image_depth':
|
| 161 |
+
img = -img
|
| 162 |
+
img = (img - img.min()) / (img.max() - img.min()) * 2 - 1
|
| 163 |
+
|
| 164 |
+
imgs.append(img)
|
| 165 |
+
|
| 166 |
+
if gen_shapes:
|
| 167 |
+
# generate shapes
|
| 168 |
+
print('Generating shape for frame %d / %d ...' % (frame_idx, num_keyframes * w_frames))
|
| 169 |
+
|
| 170 |
+
samples, voxel_origin, voxel_size = create_samples(N=voxel_resolution, voxel_origin=[0, 0, 0], cube_length=G.rendering_kwargs['box_warp'])
|
| 171 |
+
samples = samples.to(device)
|
| 172 |
+
sigmas = torch.zeros((samples.shape[0], samples.shape[1], 1), device=device)
|
| 173 |
+
transformed_ray_directions_expanded = torch.zeros((samples.shape[0], max_batch, 3), device=device)
|
| 174 |
+
transformed_ray_directions_expanded[..., -1] = -1
|
| 175 |
+
|
| 176 |
+
head = 0
|
| 177 |
+
with tqdm(total = samples.shape[1]) as pbar:
|
| 178 |
+
with torch.no_grad():
|
| 179 |
+
while head < samples.shape[1]:
|
| 180 |
+
torch.manual_seed(0)
|
| 181 |
+
sigma = G.sample_mixed(samples[:, head:head+max_batch], transformed_ray_directions_expanded[:, :samples.shape[1]-head], w.unsqueeze(0), truncation_psi=psi, noise_mode='const')['sigma']
|
| 182 |
+
sigmas[:, head:head+max_batch] = sigma
|
| 183 |
+
head += max_batch
|
| 184 |
+
pbar.update(max_batch)
|
| 185 |
+
|
| 186 |
+
sigmas = sigmas.reshape((voxel_resolution, voxel_resolution, voxel_resolution)).cpu().numpy()
|
| 187 |
+
sigmas = np.flip(sigmas, 0)
|
| 188 |
+
|
| 189 |
+
pad = int(30 * voxel_resolution / 256)
|
| 190 |
+
pad_top = int(38 * voxel_resolution / 256)
|
| 191 |
+
sigmas[:pad] = 0
|
| 192 |
+
sigmas[-pad:] = 0
|
| 193 |
+
sigmas[:, :pad] = 0
|
| 194 |
+
sigmas[:, -pad_top:] = 0
|
| 195 |
+
sigmas[:, :, :pad] = 0
|
| 196 |
+
sigmas[:, :, -pad:] = 0
|
| 197 |
+
|
| 198 |
+
output_ply = False
|
| 199 |
+
if output_ply:
|
| 200 |
+
try:
|
| 201 |
+
from shape_utils import convert_sdf_samples_to_ply
|
| 202 |
+
convert_sdf_samples_to_ply(np.transpose(sigmas, (2, 1, 0)), [0, 0, 0], 1, os.path.join(outdir, f'{frame_idx:04d}_shape.ply'), level=10)
|
| 203 |
+
except:
|
| 204 |
+
pass
|
| 205 |
+
else: # output mrc
|
| 206 |
+
with mrcfile.new_mmap(outdir + f'{frame_idx:04d}_shape.mrc', overwrite=True, shape=sigmas.shape, mrc_mode=2) as mrc:
|
| 207 |
+
mrc.data[:] = sigmas
|
| 208 |
+
|
| 209 |
+
video_out.append_data(layout_grid(torch.stack(imgs), grid_w=grid_w, grid_h=grid_h))
|
| 210 |
+
video_out.close()
|
| 211 |
+
all_poses = np.stack(all_poses)
|
| 212 |
+
|
| 213 |
+
if gen_shapes:
|
| 214 |
+
print(all_poses.shape)
|
| 215 |
+
with open(mp4.replace('.mp4', '_trajectory.npy'), 'wb') as f:
|
| 216 |
+
np.save(f, all_poses)
|
| 217 |
+
|
| 218 |
+
#----------------------------------------------------------------------------
|
| 219 |
+
|
| 220 |
+
def parse_range(s: Union[str, List[int]]) -> List[int]:
|
| 221 |
+
'''Parse a comma separated list of numbers or ranges and return a list of ints.
|
| 222 |
+
|
| 223 |
+
Example: '1,2,5-10' returns [1, 2, 5, 6, 7]
|
| 224 |
+
'''
|
| 225 |
+
if isinstance(s, list): return s
|
| 226 |
+
ranges = []
|
| 227 |
+
range_re = re.compile(r'^(\d+)-(\d+)$')
|
| 228 |
+
for p in s.split(','):
|
| 229 |
+
if m := range_re.match(p):
|
| 230 |
+
ranges.extend(range(int(m.group(1)), int(m.group(2))+1))
|
| 231 |
+
else:
|
| 232 |
+
ranges.append(int(p))
|
| 233 |
+
return ranges
|
| 234 |
+
|
| 235 |
+
#----------------------------------------------------------------------------
|
| 236 |
+
|
| 237 |
+
def parse_tuple(s: Union[str, Tuple[int,int]]) -> Tuple[int, int]:
|
| 238 |
+
'''Parse a 'M,N' or 'MxN' integer tuple.
|
| 239 |
+
|
| 240 |
+
Example:
|
| 241 |
+
'4x2' returns (4,2)
|
| 242 |
+
'0,1' returns (0,1)
|
| 243 |
+
'''
|
| 244 |
+
if isinstance(s, tuple): return s
|
| 245 |
+
if m := re.match(r'^(\d+)[x,](\d+)$', s):
|
| 246 |
+
return (int(m.group(1)), int(m.group(2)))
|
| 247 |
+
raise ValueError(f'cannot parse tuple {s}')
|
| 248 |
+
|
| 249 |
+
#----------------------------------------------------------------------------
|
| 250 |
+
|
| 251 |
+
@click.command()
|
| 252 |
+
@click.option('--network', help='Network path',multiple=True, required=True)
|
| 253 |
+
@click.option('--w_pth', help='latent path')
|
| 254 |
+
@click.option('--generator_type', help='Generator type', type=click.Choice(['ffhq', 'cat']), required=False, metavar='STR', default='ffhq', show_default=True)
|
| 255 |
+
@click.option('--model_is_state_dict', type=bool, default=False)
|
| 256 |
+
@click.option('--seeds', type=parse_range, help='List of random seeds', required=True)
|
| 257 |
+
@click.option('--shuffle-seed', type=int, help='Random seed to use for shuffling seed order', default=None)
|
| 258 |
+
@click.option('--grid', type=parse_tuple, help='Grid width/height, e.g. \'4x3\' (default: 1x1)', default=(1,1))
|
| 259 |
+
@click.option('--num-keyframes', type=int, help='Number of seeds to interpolate through. If not specified, determine based on the length of the seeds array given by --seeds.', default=None)
|
| 260 |
+
@click.option('--w-frames', type=int, help='Number of frames to interpolate between latents', default=120)
|
| 261 |
+
@click.option('--trunc', 'truncation_psi', type=float, help='Truncation psi', default=1, show_default=True)
|
| 262 |
+
@click.option('--trunc-cutoff', 'truncation_cutoff', type=int, help='Truncation cutoff', default=14, show_default=True)
|
| 263 |
+
@click.option('--outdir', help='Output directory', type=str, default='../test_runs/manip_3D_recon/4_manip_result', metavar='DIR')
|
| 264 |
+
@click.option('--image_mode', help='Image mode', type=click.Choice(['image', 'image_depth', 'image_raw']), required=False, metavar='STR', default='image', show_default=True)
|
| 265 |
+
@click.option('--sample_mult', 'sampling_multiplier', type=float, help='Multiplier for depth sampling in volume rendering', default=2, show_default=True)
|
| 266 |
+
@click.option('--nrr', type=int, help='Neural rendering resolution override', default=None, show_default=True)
|
| 267 |
+
@click.option('--shapes', type=bool, help='Gen shapes for shape interpolation', default=False, show_default=True)
|
| 268 |
+
|
| 269 |
+
def generate_images(
|
| 270 |
+
network: List[str],
|
| 271 |
+
w_pth: str,
|
| 272 |
+
seeds: List[int],
|
| 273 |
+
shuffle_seed: Optional[int],
|
| 274 |
+
truncation_psi: float,
|
| 275 |
+
truncation_cutoff: int,
|
| 276 |
+
grid: Tuple[int,int],
|
| 277 |
+
num_keyframes: Optional[int],
|
| 278 |
+
w_frames: int,
|
| 279 |
+
outdir: str,
|
| 280 |
+
generator_type: str,
|
| 281 |
+
image_mode: str,
|
| 282 |
+
sampling_multiplier: float,
|
| 283 |
+
nrr: Optional[int],
|
| 284 |
+
shapes: bool,
|
| 285 |
+
model_is_state_dict: bool,
|
| 286 |
+
):
|
| 287 |
+
|
| 288 |
+
if not os.path.exists(outdir):
|
| 289 |
+
os.makedirs(outdir, exist_ok=True)
|
| 290 |
+
|
| 291 |
+
device = torch.device('cuda')
|
| 292 |
+
|
| 293 |
+
if generator_type == 'ffhq':
|
| 294 |
+
network_pkl_tmp = 'pretrained/ffhqrebalanced512-128.pkl'
|
| 295 |
+
elif generator_type == 'cat':
|
| 296 |
+
network_pkl_tmp = 'pretrained/afhqcats512-128.pkl'
|
| 297 |
+
else:
|
| 298 |
+
NotImplementedError()
|
| 299 |
+
|
| 300 |
+
G_list = []
|
| 301 |
+
outputs = []
|
| 302 |
+
for network_path in network:
|
| 303 |
+
print('Loading networks from "%s"...' % network_path)
|
| 304 |
+
dir_label = network_path.split('/')[-2] + '___' + network_path.split('/')[-1]
|
| 305 |
+
output = os.path.join(outdir, dir_label)
|
| 306 |
+
outputs.append(output)
|
| 307 |
+
if model_is_state_dict:
|
| 308 |
+
with dnnlib.util.open_url(network_pkl_tmp) as f:
|
| 309 |
+
G = legacy.load_network_pkl(f)['G_ema'].to(device) # type: ignore
|
| 310 |
+
ckpt = torch.load(network_path)
|
| 311 |
+
G.load_state_dict(ckpt, strict=False)
|
| 312 |
+
else:
|
| 313 |
+
with dnnlib.util.open_url(network_path) as f:
|
| 314 |
+
G = legacy.load_network_pkl(f)['G_ema'].to(device) # type: ignore
|
| 315 |
+
|
| 316 |
+
G.rendering_kwargs['depth_resolution'] = int(G.rendering_kwargs['depth_resolution'] * sampling_multiplier)
|
| 317 |
+
G.rendering_kwargs['depth_resolution_importance'] = int(G.rendering_kwargs['depth_resolution_importance'] * sampling_multiplier)
|
| 318 |
+
|
| 319 |
+
if generator_type == 'cat':
|
| 320 |
+
G.rendering_kwargs['avg_camera_pivot'] = [0, 0, -0.06]
|
| 321 |
+
elif generator_type == 'ffhq':
|
| 322 |
+
G.rendering_kwargs['avg_camera_pivot'] = [0, 0, 0.2]
|
| 323 |
+
|
| 324 |
+
if nrr is not None: G.neural_rendering_resolution = nrr
|
| 325 |
+
G_list.append(G)
|
| 326 |
+
|
| 327 |
+
|
| 328 |
+
if truncation_cutoff == 0:
|
| 329 |
+
truncation_psi = 1.0 # truncation cutoff of 0 means no truncation anyways
|
| 330 |
+
if truncation_psi == 1.0:
|
| 331 |
+
truncation_cutoff = 14 # no truncation so doesn't matter where we cutoff
|
| 332 |
+
|
| 333 |
+
grid_w, grid_h = grid
|
| 334 |
+
seeds = seeds[:grid_w * grid_h]
|
| 335 |
+
|
| 336 |
+
seed_idx = ''
|
| 337 |
+
|
| 338 |
+
for i, seed in enumerate(seeds):
|
| 339 |
+
if i < len(seeds) - 1:
|
| 340 |
+
seed_idx += f'{seed}_'
|
| 341 |
+
else:
|
| 342 |
+
seed_idx += f'{seed}'
|
| 343 |
+
|
| 344 |
+
|
| 345 |
+
for G, output in zip(G_list, outputs):
|
| 346 |
+
if w_pth is not None:
|
| 347 |
+
grid = (1, 1)
|
| 348 |
+
w_given = torch.load(w_pth).cuda()
|
| 349 |
+
w_given_id = os.path.split(w_pth)[-1].split('.')[-2]
|
| 350 |
+
output = output + f'__{w_given_id}.mp4'
|
| 351 |
+
gen_interp_video(G=G, w_given=w_given, mp4=output, bitrate='10M', grid_dims=grid, num_keyframes=num_keyframes,
|
| 352 |
+
w_frames=w_frames,
|
| 353 |
+
seeds=seeds, shuffle_seed=shuffle_seed, psi=truncation_psi,
|
| 354 |
+
truncation_cutoff=truncation_cutoff, generator_type=generator_type, image_mode=image_mode,
|
| 355 |
+
gen_shapes=shapes)
|
| 356 |
+
|
| 357 |
+
else:
|
| 358 |
+
output = output + f'__{seed_idx}.mp4'
|
| 359 |
+
gen_interp_video(G=G, w_given=None, mp4=output, bitrate='10M', grid_dims=grid, num_keyframes=num_keyframes,
|
| 360 |
+
w_frames=w_frames,
|
| 361 |
+
seeds=seeds, shuffle_seed=shuffle_seed, psi=truncation_psi,
|
| 362 |
+
truncation_cutoff=truncation_cutoff, generator_type=generator_type, image_mode=image_mode,
|
| 363 |
+
gen_shapes=shapes)
|
| 364 |
+
|
| 365 |
+
|
| 366 |
+
#----------------------------------------------------------------------------
|
| 367 |
+
|
| 368 |
+
if __name__ == "__main__":
|
| 369 |
+
generate_images() # pylint: disable=no-value-for-parameter
|
| 370 |
+
|
| 371 |
+
#----------------------------------------------------------------------------
|
eg3d/gui_utils/__init__.py
ADDED
|
@@ -0,0 +1,11 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# SPDX-FileCopyrightText: Copyright (c) 2021-2022 NVIDIA CORPORATION & AFFILIATES. All rights reserved.
|
| 2 |
+
# SPDX-License-Identifier: LicenseRef-NvidiaProprietary
|
| 3 |
+
#
|
| 4 |
+
# NVIDIA CORPORATION, its affiliates and licensors retain all intellectual
|
| 5 |
+
# property and proprietary rights in and to this material, related
|
| 6 |
+
# documentation and any modifications thereto. Any use, reproduction,
|
| 7 |
+
# disclosure or distribution of this material and related documentation
|
| 8 |
+
# without an express license agreement from NVIDIA CORPORATION or
|
| 9 |
+
# its affiliates is strictly prohibited.
|
| 10 |
+
|
| 11 |
+
# empty
|
eg3d/gui_utils/gl_utils.py
ADDED
|
@@ -0,0 +1,376 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# SPDX-FileCopyrightText: Copyright (c) 2021-2022 NVIDIA CORPORATION & AFFILIATES. All rights reserved.
|
| 2 |
+
# SPDX-License-Identifier: LicenseRef-NvidiaProprietary
|
| 3 |
+
#
|
| 4 |
+
# NVIDIA CORPORATION, its affiliates and licensors retain all intellectual
|
| 5 |
+
# property and proprietary rights in and to this material, related
|
| 6 |
+
# documentation and any modifications thereto. Any use, reproduction,
|
| 7 |
+
# disclosure or distribution of this material and related documentation
|
| 8 |
+
# without an express license agreement from NVIDIA CORPORATION or
|
| 9 |
+
# its affiliates is strictly prohibited.
|
| 10 |
+
|
| 11 |
+
import os
|
| 12 |
+
import functools
|
| 13 |
+
import contextlib
|
| 14 |
+
import numpy as np
|
| 15 |
+
import OpenGL.GL as gl
|
| 16 |
+
import OpenGL.GL.ARB.texture_float
|
| 17 |
+
import dnnlib
|
| 18 |
+
|
| 19 |
+
#----------------------------------------------------------------------------
|
| 20 |
+
|
| 21 |
+
def init_egl():
|
| 22 |
+
assert os.environ['PYOPENGL_PLATFORM'] == 'egl' # Must be set before importing OpenGL.
|
| 23 |
+
import OpenGL.EGL as egl
|
| 24 |
+
import ctypes
|
| 25 |
+
|
| 26 |
+
# Initialize EGL.
|
| 27 |
+
display = egl.eglGetDisplay(egl.EGL_DEFAULT_DISPLAY)
|
| 28 |
+
assert display != egl.EGL_NO_DISPLAY
|
| 29 |
+
major = ctypes.c_int32()
|
| 30 |
+
minor = ctypes.c_int32()
|
| 31 |
+
ok = egl.eglInitialize(display, major, minor)
|
| 32 |
+
assert ok
|
| 33 |
+
assert major.value * 10 + minor.value >= 14
|
| 34 |
+
|
| 35 |
+
# Choose config.
|
| 36 |
+
config_attribs = [
|
| 37 |
+
egl.EGL_RENDERABLE_TYPE, egl.EGL_OPENGL_BIT,
|
| 38 |
+
egl.EGL_SURFACE_TYPE, egl.EGL_PBUFFER_BIT,
|
| 39 |
+
egl.EGL_NONE
|
| 40 |
+
]
|
| 41 |
+
configs = (ctypes.c_int32 * 1)()
|
| 42 |
+
num_configs = ctypes.c_int32()
|
| 43 |
+
ok = egl.eglChooseConfig(display, config_attribs, configs, 1, num_configs)
|
| 44 |
+
assert ok
|
| 45 |
+
assert num_configs.value == 1
|
| 46 |
+
config = configs[0]
|
| 47 |
+
|
| 48 |
+
# Create dummy pbuffer surface.
|
| 49 |
+
surface_attribs = [
|
| 50 |
+
egl.EGL_WIDTH, 1,
|
| 51 |
+
egl.EGL_HEIGHT, 1,
|
| 52 |
+
egl.EGL_NONE
|
| 53 |
+
]
|
| 54 |
+
surface = egl.eglCreatePbufferSurface(display, config, surface_attribs)
|
| 55 |
+
assert surface != egl.EGL_NO_SURFACE
|
| 56 |
+
|
| 57 |
+
# Setup GL context.
|
| 58 |
+
ok = egl.eglBindAPI(egl.EGL_OPENGL_API)
|
| 59 |
+
assert ok
|
| 60 |
+
context = egl.eglCreateContext(display, config, egl.EGL_NO_CONTEXT, None)
|
| 61 |
+
assert context != egl.EGL_NO_CONTEXT
|
| 62 |
+
ok = egl.eglMakeCurrent(display, surface, surface, context)
|
| 63 |
+
assert ok
|
| 64 |
+
|
| 65 |
+
#----------------------------------------------------------------------------
|
| 66 |
+
|
| 67 |
+
_texture_formats = {
|
| 68 |
+
('uint8', 1): dnnlib.EasyDict(type=gl.GL_UNSIGNED_BYTE, format=gl.GL_LUMINANCE, internalformat=gl.GL_LUMINANCE8),
|
| 69 |
+
('uint8', 2): dnnlib.EasyDict(type=gl.GL_UNSIGNED_BYTE, format=gl.GL_LUMINANCE_ALPHA, internalformat=gl.GL_LUMINANCE8_ALPHA8),
|
| 70 |
+
('uint8', 3): dnnlib.EasyDict(type=gl.GL_UNSIGNED_BYTE, format=gl.GL_RGB, internalformat=gl.GL_RGB8),
|
| 71 |
+
('uint8', 4): dnnlib.EasyDict(type=gl.GL_UNSIGNED_BYTE, format=gl.GL_RGBA, internalformat=gl.GL_RGBA8),
|
| 72 |
+
('float32', 1): dnnlib.EasyDict(type=gl.GL_FLOAT, format=gl.GL_LUMINANCE, internalformat=OpenGL.GL.ARB.texture_float.GL_LUMINANCE32F_ARB),
|
| 73 |
+
('float32', 2): dnnlib.EasyDict(type=gl.GL_FLOAT, format=gl.GL_LUMINANCE_ALPHA, internalformat=OpenGL.GL.ARB.texture_float.GL_LUMINANCE_ALPHA32F_ARB),
|
| 74 |
+
('float32', 3): dnnlib.EasyDict(type=gl.GL_FLOAT, format=gl.GL_RGB, internalformat=gl.GL_RGB32F),
|
| 75 |
+
('float32', 4): dnnlib.EasyDict(type=gl.GL_FLOAT, format=gl.GL_RGBA, internalformat=gl.GL_RGBA32F),
|
| 76 |
+
}
|
| 77 |
+
|
| 78 |
+
def get_texture_format(dtype, channels):
|
| 79 |
+
return _texture_formats[(np.dtype(dtype).name, int(channels))]
|
| 80 |
+
|
| 81 |
+
#----------------------------------------------------------------------------
|
| 82 |
+
|
| 83 |
+
def prepare_texture_data(image):
|
| 84 |
+
image = np.asarray(image)
|
| 85 |
+
if image.ndim == 2:
|
| 86 |
+
image = image[:, :, np.newaxis]
|
| 87 |
+
if image.dtype.name == 'float64':
|
| 88 |
+
image = image.astype('float32')
|
| 89 |
+
return image
|
| 90 |
+
|
| 91 |
+
#----------------------------------------------------------------------------
|
| 92 |
+
|
| 93 |
+
def draw_pixels(image, *, pos=0, zoom=1, align=0, rint=True):
|
| 94 |
+
pos = np.broadcast_to(np.asarray(pos, dtype='float32'), [2])
|
| 95 |
+
zoom = np.broadcast_to(np.asarray(zoom, dtype='float32'), [2])
|
| 96 |
+
align = np.broadcast_to(np.asarray(align, dtype='float32'), [2])
|
| 97 |
+
image = prepare_texture_data(image)
|
| 98 |
+
height, width, channels = image.shape
|
| 99 |
+
size = zoom * [width, height]
|
| 100 |
+
pos = pos - size * align
|
| 101 |
+
if rint:
|
| 102 |
+
pos = np.rint(pos)
|
| 103 |
+
fmt = get_texture_format(image.dtype, channels)
|
| 104 |
+
|
| 105 |
+
gl.glPushAttrib(gl.GL_CURRENT_BIT | gl.GL_PIXEL_MODE_BIT)
|
| 106 |
+
gl.glPushClientAttrib(gl.GL_CLIENT_PIXEL_STORE_BIT)
|
| 107 |
+
gl.glRasterPos2f(pos[0], pos[1])
|
| 108 |
+
gl.glPixelZoom(zoom[0], -zoom[1])
|
| 109 |
+
gl.glPixelStorei(gl.GL_UNPACK_ALIGNMENT, 1)
|
| 110 |
+
gl.glDrawPixels(width, height, fmt.format, fmt.type, image)
|
| 111 |
+
gl.glPopClientAttrib()
|
| 112 |
+
gl.glPopAttrib()
|
| 113 |
+
|
| 114 |
+
#----------------------------------------------------------------------------
|
| 115 |
+
|
| 116 |
+
def read_pixels(width, height, *, pos=0, dtype='uint8', channels=3):
|
| 117 |
+
pos = np.broadcast_to(np.asarray(pos, dtype='float32'), [2])
|
| 118 |
+
dtype = np.dtype(dtype)
|
| 119 |
+
fmt = get_texture_format(dtype, channels)
|
| 120 |
+
image = np.empty([height, width, channels], dtype=dtype)
|
| 121 |
+
|
| 122 |
+
gl.glPushClientAttrib(gl.GL_CLIENT_PIXEL_STORE_BIT)
|
| 123 |
+
gl.glPixelStorei(gl.GL_PACK_ALIGNMENT, 1)
|
| 124 |
+
gl.glReadPixels(int(np.round(pos[0])), int(np.round(pos[1])), width, height, fmt.format, fmt.type, image)
|
| 125 |
+
gl.glPopClientAttrib()
|
| 126 |
+
return np.flipud(image)
|
| 127 |
+
|
| 128 |
+
#----------------------------------------------------------------------------
|
| 129 |
+
|
| 130 |
+
class Texture:
|
| 131 |
+
def __init__(self, *, image=None, width=None, height=None, channels=None, dtype=None, bilinear=True, mipmap=True):
|
| 132 |
+
self.gl_id = None
|
| 133 |
+
self.bilinear = bilinear
|
| 134 |
+
self.mipmap = mipmap
|
| 135 |
+
|
| 136 |
+
# Determine size and dtype.
|
| 137 |
+
if image is not None:
|
| 138 |
+
image = prepare_texture_data(image)
|
| 139 |
+
self.height, self.width, self.channels = image.shape
|
| 140 |
+
self.dtype = image.dtype
|
| 141 |
+
else:
|
| 142 |
+
assert width is not None and height is not None
|
| 143 |
+
self.width = width
|
| 144 |
+
self.height = height
|
| 145 |
+
self.channels = channels if channels is not None else 3
|
| 146 |
+
self.dtype = np.dtype(dtype) if dtype is not None else np.uint8
|
| 147 |
+
|
| 148 |
+
# Validate size and dtype.
|
| 149 |
+
assert isinstance(self.width, int) and self.width >= 0
|
| 150 |
+
assert isinstance(self.height, int) and self.height >= 0
|
| 151 |
+
assert isinstance(self.channels, int) and self.channels >= 1
|
| 152 |
+
assert self.is_compatible(width=width, height=height, channels=channels, dtype=dtype)
|
| 153 |
+
|
| 154 |
+
# Create texture object.
|
| 155 |
+
self.gl_id = gl.glGenTextures(1)
|
| 156 |
+
with self.bind():
|
| 157 |
+
gl.glTexParameterf(gl.GL_TEXTURE_2D, gl.GL_TEXTURE_WRAP_S, gl.GL_CLAMP_TO_EDGE)
|
| 158 |
+
gl.glTexParameterf(gl.GL_TEXTURE_2D, gl.GL_TEXTURE_WRAP_T, gl.GL_CLAMP_TO_EDGE)
|
| 159 |
+
gl.glTexParameterf(gl.GL_TEXTURE_2D, gl.GL_TEXTURE_MAG_FILTER, gl.GL_LINEAR if self.bilinear else gl.GL_NEAREST)
|
| 160 |
+
gl.glTexParameterf(gl.GL_TEXTURE_2D, gl.GL_TEXTURE_MIN_FILTER, gl.GL_LINEAR_MIPMAP_LINEAR if self.mipmap else gl.GL_NEAREST)
|
| 161 |
+
self.update(image)
|
| 162 |
+
|
| 163 |
+
def delete(self):
|
| 164 |
+
if self.gl_id is not None:
|
| 165 |
+
gl.glDeleteTextures([self.gl_id])
|
| 166 |
+
self.gl_id = None
|
| 167 |
+
|
| 168 |
+
def __del__(self):
|
| 169 |
+
try:
|
| 170 |
+
self.delete()
|
| 171 |
+
except:
|
| 172 |
+
pass
|
| 173 |
+
|
| 174 |
+
@contextlib.contextmanager
|
| 175 |
+
def bind(self):
|
| 176 |
+
prev_id = gl.glGetInteger(gl.GL_TEXTURE_BINDING_2D)
|
| 177 |
+
gl.glBindTexture(gl.GL_TEXTURE_2D, self.gl_id)
|
| 178 |
+
yield
|
| 179 |
+
gl.glBindTexture(gl.GL_TEXTURE_2D, prev_id)
|
| 180 |
+
|
| 181 |
+
def update(self, image):
|
| 182 |
+
if image is not None:
|
| 183 |
+
image = prepare_texture_data(image)
|
| 184 |
+
assert self.is_compatible(image=image)
|
| 185 |
+
with self.bind():
|
| 186 |
+
fmt = get_texture_format(self.dtype, self.channels)
|
| 187 |
+
gl.glPushClientAttrib(gl.GL_CLIENT_PIXEL_STORE_BIT)
|
| 188 |
+
gl.glPixelStorei(gl.GL_UNPACK_ALIGNMENT, 1)
|
| 189 |
+
gl.glTexImage2D(gl.GL_TEXTURE_2D, 0, fmt.internalformat, self.width, self.height, 0, fmt.format, fmt.type, image)
|
| 190 |
+
if self.mipmap:
|
| 191 |
+
gl.glGenerateMipmap(gl.GL_TEXTURE_2D)
|
| 192 |
+
gl.glPopClientAttrib()
|
| 193 |
+
|
| 194 |
+
def draw(self, *, pos=0, zoom=1, align=0, rint=False, color=1, alpha=1, rounding=0):
|
| 195 |
+
zoom = np.broadcast_to(np.asarray(zoom, dtype='float32'), [2])
|
| 196 |
+
size = zoom * [self.width, self.height]
|
| 197 |
+
with self.bind():
|
| 198 |
+
gl.glPushAttrib(gl.GL_ENABLE_BIT)
|
| 199 |
+
gl.glEnable(gl.GL_TEXTURE_2D)
|
| 200 |
+
draw_rect(pos=pos, size=size, align=align, rint=rint, color=color, alpha=alpha, rounding=rounding)
|
| 201 |
+
gl.glPopAttrib()
|
| 202 |
+
|
| 203 |
+
def is_compatible(self, *, image=None, width=None, height=None, channels=None, dtype=None): # pylint: disable=too-many-return-statements
|
| 204 |
+
if image is not None:
|
| 205 |
+
if image.ndim != 3:
|
| 206 |
+
return False
|
| 207 |
+
ih, iw, ic = image.shape
|
| 208 |
+
if not self.is_compatible(width=iw, height=ih, channels=ic, dtype=image.dtype):
|
| 209 |
+
return False
|
| 210 |
+
if width is not None and self.width != width:
|
| 211 |
+
return False
|
| 212 |
+
if height is not None and self.height != height:
|
| 213 |
+
return False
|
| 214 |
+
if channels is not None and self.channels != channels:
|
| 215 |
+
return False
|
| 216 |
+
if dtype is not None and self.dtype != dtype:
|
| 217 |
+
return False
|
| 218 |
+
return True
|
| 219 |
+
|
| 220 |
+
#----------------------------------------------------------------------------
|
| 221 |
+
|
| 222 |
+
class Framebuffer:
|
| 223 |
+
def __init__(self, *, texture=None, width=None, height=None, channels=None, dtype=None, msaa=0):
|
| 224 |
+
self.texture = texture
|
| 225 |
+
self.gl_id = None
|
| 226 |
+
self.gl_color = None
|
| 227 |
+
self.gl_depth_stencil = None
|
| 228 |
+
self.msaa = msaa
|
| 229 |
+
|
| 230 |
+
# Determine size and dtype.
|
| 231 |
+
if texture is not None:
|
| 232 |
+
assert isinstance(self.texture, Texture)
|
| 233 |
+
self.width = texture.width
|
| 234 |
+
self.height = texture.height
|
| 235 |
+
self.channels = texture.channels
|
| 236 |
+
self.dtype = texture.dtype
|
| 237 |
+
else:
|
| 238 |
+
assert width is not None and height is not None
|
| 239 |
+
self.width = width
|
| 240 |
+
self.height = height
|
| 241 |
+
self.channels = channels if channels is not None else 4
|
| 242 |
+
self.dtype = np.dtype(dtype) if dtype is not None else np.float32
|
| 243 |
+
|
| 244 |
+
# Validate size and dtype.
|
| 245 |
+
assert isinstance(self.width, int) and self.width >= 0
|
| 246 |
+
assert isinstance(self.height, int) and self.height >= 0
|
| 247 |
+
assert isinstance(self.channels, int) and self.channels >= 1
|
| 248 |
+
assert width is None or width == self.width
|
| 249 |
+
assert height is None or height == self.height
|
| 250 |
+
assert channels is None or channels == self.channels
|
| 251 |
+
assert dtype is None or dtype == self.dtype
|
| 252 |
+
|
| 253 |
+
# Create framebuffer object.
|
| 254 |
+
self.gl_id = gl.glGenFramebuffers(1)
|
| 255 |
+
with self.bind():
|
| 256 |
+
|
| 257 |
+
# Setup color buffer.
|
| 258 |
+
if self.texture is not None:
|
| 259 |
+
assert self.msaa == 0
|
| 260 |
+
gl.glFramebufferTexture2D(gl.GL_FRAMEBUFFER, gl.GL_COLOR_ATTACHMENT0, gl.GL_TEXTURE_2D, self.texture.gl_id, 0)
|
| 261 |
+
else:
|
| 262 |
+
fmt = get_texture_format(self.dtype, self.channels)
|
| 263 |
+
self.gl_color = gl.glGenRenderbuffers(1)
|
| 264 |
+
gl.glBindRenderbuffer(gl.GL_RENDERBUFFER, self.gl_color)
|
| 265 |
+
gl.glRenderbufferStorageMultisample(gl.GL_RENDERBUFFER, self.msaa, fmt.internalformat, self.width, self.height)
|
| 266 |
+
gl.glFramebufferRenderbuffer(gl.GL_FRAMEBUFFER, gl.GL_COLOR_ATTACHMENT0, gl.GL_RENDERBUFFER, self.gl_color)
|
| 267 |
+
|
| 268 |
+
# Setup depth/stencil buffer.
|
| 269 |
+
self.gl_depth_stencil = gl.glGenRenderbuffers(1)
|
| 270 |
+
gl.glBindRenderbuffer(gl.GL_RENDERBUFFER, self.gl_depth_stencil)
|
| 271 |
+
gl.glRenderbufferStorageMultisample(gl.GL_RENDERBUFFER, self.msaa, gl.GL_DEPTH24_STENCIL8, self.width, self.height)
|
| 272 |
+
gl.glFramebufferRenderbuffer(gl.GL_FRAMEBUFFER, gl.GL_DEPTH_STENCIL_ATTACHMENT, gl.GL_RENDERBUFFER, self.gl_depth_stencil)
|
| 273 |
+
|
| 274 |
+
def delete(self):
|
| 275 |
+
if self.gl_id is not None:
|
| 276 |
+
gl.glDeleteFramebuffers([self.gl_id])
|
| 277 |
+
self.gl_id = None
|
| 278 |
+
if self.gl_color is not None:
|
| 279 |
+
gl.glDeleteRenderbuffers(1, [self.gl_color])
|
| 280 |
+
self.gl_color = None
|
| 281 |
+
if self.gl_depth_stencil is not None:
|
| 282 |
+
gl.glDeleteRenderbuffers(1, [self.gl_depth_stencil])
|
| 283 |
+
self.gl_depth_stencil = None
|
| 284 |
+
|
| 285 |
+
def __del__(self):
|
| 286 |
+
try:
|
| 287 |
+
self.delete()
|
| 288 |
+
except:
|
| 289 |
+
pass
|
| 290 |
+
|
| 291 |
+
@contextlib.contextmanager
|
| 292 |
+
def bind(self):
|
| 293 |
+
prev_fbo = gl.glGetInteger(gl.GL_FRAMEBUFFER_BINDING)
|
| 294 |
+
prev_rbo = gl.glGetInteger(gl.GL_RENDERBUFFER_BINDING)
|
| 295 |
+
gl.glBindFramebuffer(gl.GL_FRAMEBUFFER, self.gl_id)
|
| 296 |
+
if self.width is not None and self.height is not None:
|
| 297 |
+
gl.glViewport(0, 0, self.width, self.height)
|
| 298 |
+
yield
|
| 299 |
+
gl.glBindFramebuffer(gl.GL_FRAMEBUFFER, prev_fbo)
|
| 300 |
+
gl.glBindRenderbuffer(gl.GL_RENDERBUFFER, prev_rbo)
|
| 301 |
+
|
| 302 |
+
def blit(self, dst=None):
|
| 303 |
+
assert dst is None or isinstance(dst, Framebuffer)
|
| 304 |
+
with self.bind():
|
| 305 |
+
gl.glBindFramebuffer(gl.GL_DRAW_FRAMEBUFFER, 0 if dst is None else dst.fbo)
|
| 306 |
+
gl.glBlitFramebuffer(0, 0, self.width, self.height, 0, 0, self.width, self.height, gl.GL_COLOR_BUFFER_BIT, gl.GL_NEAREST)
|
| 307 |
+
|
| 308 |
+
#----------------------------------------------------------------------------
|
| 309 |
+
|
| 310 |
+
def draw_shape(vertices, *, mode=gl.GL_TRIANGLE_FAN, pos=0, size=1, color=1, alpha=1):
|
| 311 |
+
assert vertices.ndim == 2 and vertices.shape[1] == 2
|
| 312 |
+
pos = np.broadcast_to(np.asarray(pos, dtype='float32'), [2])
|
| 313 |
+
size = np.broadcast_to(np.asarray(size, dtype='float32'), [2])
|
| 314 |
+
color = np.broadcast_to(np.asarray(color, dtype='float32'), [3])
|
| 315 |
+
alpha = np.clip(np.broadcast_to(np.asarray(alpha, dtype='float32'), []), 0, 1)
|
| 316 |
+
|
| 317 |
+
gl.glPushClientAttrib(gl.GL_CLIENT_VERTEX_ARRAY_BIT)
|
| 318 |
+
gl.glPushAttrib(gl.GL_CURRENT_BIT | gl.GL_TRANSFORM_BIT)
|
| 319 |
+
gl.glMatrixMode(gl.GL_MODELVIEW)
|
| 320 |
+
gl.glPushMatrix()
|
| 321 |
+
|
| 322 |
+
gl.glEnableClientState(gl.GL_VERTEX_ARRAY)
|
| 323 |
+
gl.glEnableClientState(gl.GL_TEXTURE_COORD_ARRAY)
|
| 324 |
+
gl.glVertexPointer(2, gl.GL_FLOAT, 0, vertices)
|
| 325 |
+
gl.glTexCoordPointer(2, gl.GL_FLOAT, 0, vertices)
|
| 326 |
+
gl.glTranslate(pos[0], pos[1], 0)
|
| 327 |
+
gl.glScale(size[0], size[1], 1)
|
| 328 |
+
gl.glColor4f(color[0] * alpha, color[1] * alpha, color[2] * alpha, alpha)
|
| 329 |
+
gl.glDrawArrays(mode, 0, vertices.shape[0])
|
| 330 |
+
|
| 331 |
+
gl.glPopMatrix()
|
| 332 |
+
gl.glPopAttrib()
|
| 333 |
+
gl.glPopClientAttrib()
|
| 334 |
+
|
| 335 |
+
#----------------------------------------------------------------------------
|
| 336 |
+
|
| 337 |
+
def draw_rect(*, pos=0, pos2=None, size=None, align=0, rint=False, color=1, alpha=1, rounding=0):
|
| 338 |
+
assert pos2 is None or size is None
|
| 339 |
+
pos = np.broadcast_to(np.asarray(pos, dtype='float32'), [2])
|
| 340 |
+
pos2 = np.broadcast_to(np.asarray(pos2, dtype='float32'), [2]) if pos2 is not None else None
|
| 341 |
+
size = np.broadcast_to(np.asarray(size, dtype='float32'), [2]) if size is not None else None
|
| 342 |
+
size = size if size is not None else pos2 - pos if pos2 is not None else np.array([1, 1], dtype='float32')
|
| 343 |
+
pos = pos - size * align
|
| 344 |
+
if rint:
|
| 345 |
+
pos = np.rint(pos)
|
| 346 |
+
rounding = np.broadcast_to(np.asarray(rounding, dtype='float32'), [2])
|
| 347 |
+
rounding = np.minimum(np.abs(rounding) / np.maximum(np.abs(size), 1e-8), 0.5)
|
| 348 |
+
if np.min(rounding) == 0:
|
| 349 |
+
rounding *= 0
|
| 350 |
+
vertices = _setup_rect(float(rounding[0]), float(rounding[1]))
|
| 351 |
+
draw_shape(vertices, mode=gl.GL_TRIANGLE_FAN, pos=pos, size=size, color=color, alpha=alpha)
|
| 352 |
+
|
| 353 |
+
@functools.lru_cache(maxsize=10000)
|
| 354 |
+
def _setup_rect(rx, ry):
|
| 355 |
+
t = np.linspace(0, np.pi / 2, 1 if max(rx, ry) == 0 else 64)
|
| 356 |
+
s = 1 - np.sin(t); c = 1 - np.cos(t)
|
| 357 |
+
x = [c * rx, 1 - s * rx, 1 - c * rx, s * rx]
|
| 358 |
+
y = [s * ry, c * ry, 1 - s * ry, 1 - c * ry]
|
| 359 |
+
v = np.stack([x, y], axis=-1).reshape(-1, 2)
|
| 360 |
+
return v.astype('float32')
|
| 361 |
+
|
| 362 |
+
#----------------------------------------------------------------------------
|
| 363 |
+
|
| 364 |
+
def draw_circle(*, center=0, radius=100, hole=0, color=1, alpha=1):
|
| 365 |
+
hole = np.broadcast_to(np.asarray(hole, dtype='float32'), [])
|
| 366 |
+
vertices = _setup_circle(float(hole))
|
| 367 |
+
draw_shape(vertices, mode=gl.GL_TRIANGLE_STRIP, pos=center, size=radius, color=color, alpha=alpha)
|
| 368 |
+
|
| 369 |
+
@functools.lru_cache(maxsize=10000)
|
| 370 |
+
def _setup_circle(hole):
|
| 371 |
+
t = np.linspace(0, np.pi * 2, 128)
|
| 372 |
+
s = np.sin(t); c = np.cos(t)
|
| 373 |
+
v = np.stack([c, s, c * hole, s * hole], axis=-1).reshape(-1, 2)
|
| 374 |
+
return v.astype('float32')
|
| 375 |
+
|
| 376 |
+
#----------------------------------------------------------------------------
|
eg3d/gui_utils/glfw_window.py
ADDED
|
@@ -0,0 +1,231 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# SPDX-FileCopyrightText: Copyright (c) 2021-2022 NVIDIA CORPORATION & AFFILIATES. All rights reserved.
|
| 2 |
+
# SPDX-License-Identifier: LicenseRef-NvidiaProprietary
|
| 3 |
+
#
|
| 4 |
+
# NVIDIA CORPORATION, its affiliates and licensors retain all intellectual
|
| 5 |
+
# property and proprietary rights in and to this material, related
|
| 6 |
+
# documentation and any modifications thereto. Any use, reproduction,
|
| 7 |
+
# disclosure or distribution of this material and related documentation
|
| 8 |
+
# without an express license agreement from NVIDIA CORPORATION or
|
| 9 |
+
# its affiliates is strictly prohibited.
|
| 10 |
+
|
| 11 |
+
import time
|
| 12 |
+
import glfw
|
| 13 |
+
import OpenGL.GL as gl
|
| 14 |
+
from . import gl_utils
|
| 15 |
+
|
| 16 |
+
#----------------------------------------------------------------------------
|
| 17 |
+
|
| 18 |
+
class GlfwWindow: # pylint: disable=too-many-public-methods
|
| 19 |
+
def __init__(self, *, title='GlfwWindow', window_width=1920, window_height=1080, deferred_show=True, close_on_esc=True):
|
| 20 |
+
self._glfw_window = None
|
| 21 |
+
self._drawing_frame = False
|
| 22 |
+
self._frame_start_time = None
|
| 23 |
+
self._frame_delta = 0
|
| 24 |
+
self._fps_limit = None
|
| 25 |
+
self._vsync = None
|
| 26 |
+
self._skip_frames = 0
|
| 27 |
+
self._deferred_show = deferred_show
|
| 28 |
+
self._close_on_esc = close_on_esc
|
| 29 |
+
self._esc_pressed = False
|
| 30 |
+
self._drag_and_drop_paths = None
|
| 31 |
+
self._capture_next_frame = False
|
| 32 |
+
self._captured_frame = None
|
| 33 |
+
|
| 34 |
+
# Create window.
|
| 35 |
+
glfw.init()
|
| 36 |
+
glfw.window_hint(glfw.VISIBLE, False)
|
| 37 |
+
self._glfw_window = glfw.create_window(width=window_width, height=window_height, title=title, monitor=None, share=None)
|
| 38 |
+
self._attach_glfw_callbacks()
|
| 39 |
+
self.make_context_current()
|
| 40 |
+
|
| 41 |
+
# Adjust window.
|
| 42 |
+
self.set_vsync(False)
|
| 43 |
+
self.set_window_size(window_width, window_height)
|
| 44 |
+
if not self._deferred_show:
|
| 45 |
+
glfw.show_window(self._glfw_window)
|
| 46 |
+
|
| 47 |
+
def close(self):
|
| 48 |
+
if self._drawing_frame:
|
| 49 |
+
self.end_frame()
|
| 50 |
+
if self._glfw_window is not None:
|
| 51 |
+
glfw.destroy_window(self._glfw_window)
|
| 52 |
+
self._glfw_window = None
|
| 53 |
+
#glfw.terminate() # Commented out to play it nice with other glfw clients.
|
| 54 |
+
|
| 55 |
+
def __del__(self):
|
| 56 |
+
try:
|
| 57 |
+
self.close()
|
| 58 |
+
except:
|
| 59 |
+
pass
|
| 60 |
+
|
| 61 |
+
@property
|
| 62 |
+
def window_width(self):
|
| 63 |
+
return self.content_width
|
| 64 |
+
|
| 65 |
+
@property
|
| 66 |
+
def window_height(self):
|
| 67 |
+
return self.content_height + self.title_bar_height
|
| 68 |
+
|
| 69 |
+
@property
|
| 70 |
+
def content_width(self):
|
| 71 |
+
width, _height = glfw.get_window_size(self._glfw_window)
|
| 72 |
+
return width
|
| 73 |
+
|
| 74 |
+
@property
|
| 75 |
+
def content_height(self):
|
| 76 |
+
_width, height = glfw.get_window_size(self._glfw_window)
|
| 77 |
+
return height
|
| 78 |
+
|
| 79 |
+
@property
|
| 80 |
+
def title_bar_height(self):
|
| 81 |
+
_left, top, _right, _bottom = glfw.get_window_frame_size(self._glfw_window)
|
| 82 |
+
return top
|
| 83 |
+
|
| 84 |
+
@property
|
| 85 |
+
def monitor_width(self):
|
| 86 |
+
_, _, width, _height = glfw.get_monitor_workarea(glfw.get_primary_monitor())
|
| 87 |
+
return width
|
| 88 |
+
|
| 89 |
+
@property
|
| 90 |
+
def monitor_height(self):
|
| 91 |
+
_, _, _width, height = glfw.get_monitor_workarea(glfw.get_primary_monitor())
|
| 92 |
+
return height
|
| 93 |
+
|
| 94 |
+
@property
|
| 95 |
+
def frame_delta(self):
|
| 96 |
+
return self._frame_delta
|
| 97 |
+
|
| 98 |
+
def set_title(self, title):
|
| 99 |
+
glfw.set_window_title(self._glfw_window, title)
|
| 100 |
+
|
| 101 |
+
def set_window_size(self, width, height):
|
| 102 |
+
width = min(width, self.monitor_width)
|
| 103 |
+
height = min(height, self.monitor_height)
|
| 104 |
+
glfw.set_window_size(self._glfw_window, width, max(height - self.title_bar_height, 0))
|
| 105 |
+
if width == self.monitor_width and height == self.monitor_height:
|
| 106 |
+
self.maximize()
|
| 107 |
+
|
| 108 |
+
def set_content_size(self, width, height):
|
| 109 |
+
self.set_window_size(width, height + self.title_bar_height)
|
| 110 |
+
|
| 111 |
+
def maximize(self):
|
| 112 |
+
glfw.maximize_window(self._glfw_window)
|
| 113 |
+
|
| 114 |
+
def set_position(self, x, y):
|
| 115 |
+
glfw.set_window_pos(self._glfw_window, x, y + self.title_bar_height)
|
| 116 |
+
|
| 117 |
+
def center(self):
|
| 118 |
+
self.set_position((self.monitor_width - self.window_width) // 2, (self.monitor_height - self.window_height) // 2)
|
| 119 |
+
|
| 120 |
+
def set_vsync(self, vsync):
|
| 121 |
+
vsync = bool(vsync)
|
| 122 |
+
if vsync != self._vsync:
|
| 123 |
+
glfw.swap_interval(1 if vsync else 0)
|
| 124 |
+
self._vsync = vsync
|
| 125 |
+
|
| 126 |
+
def set_fps_limit(self, fps_limit):
|
| 127 |
+
self._fps_limit = int(fps_limit)
|
| 128 |
+
|
| 129 |
+
def should_close(self):
|
| 130 |
+
return glfw.window_should_close(self._glfw_window) or (self._close_on_esc and self._esc_pressed)
|
| 131 |
+
|
| 132 |
+
def skip_frame(self):
|
| 133 |
+
self.skip_frames(1)
|
| 134 |
+
|
| 135 |
+
def skip_frames(self, num): # Do not update window for the next N frames.
|
| 136 |
+
self._skip_frames = max(self._skip_frames, int(num))
|
| 137 |
+
|
| 138 |
+
def is_skipping_frames(self):
|
| 139 |
+
return self._skip_frames > 0
|
| 140 |
+
|
| 141 |
+
def capture_next_frame(self):
|
| 142 |
+
self._capture_next_frame = True
|
| 143 |
+
|
| 144 |
+
def pop_captured_frame(self):
|
| 145 |
+
frame = self._captured_frame
|
| 146 |
+
self._captured_frame = None
|
| 147 |
+
return frame
|
| 148 |
+
|
| 149 |
+
def pop_drag_and_drop_paths(self):
|
| 150 |
+
paths = self._drag_and_drop_paths
|
| 151 |
+
self._drag_and_drop_paths = None
|
| 152 |
+
return paths
|
| 153 |
+
|
| 154 |
+
def draw_frame(self): # To be overridden by subclass.
|
| 155 |
+
self.begin_frame()
|
| 156 |
+
# Rendering code goes here.
|
| 157 |
+
self.end_frame()
|
| 158 |
+
|
| 159 |
+
def make_context_current(self):
|
| 160 |
+
if self._glfw_window is not None:
|
| 161 |
+
glfw.make_context_current(self._glfw_window)
|
| 162 |
+
|
| 163 |
+
def begin_frame(self):
|
| 164 |
+
# End previous frame.
|
| 165 |
+
if self._drawing_frame:
|
| 166 |
+
self.end_frame()
|
| 167 |
+
|
| 168 |
+
# Apply FPS limit.
|
| 169 |
+
if self._frame_start_time is not None and self._fps_limit is not None:
|
| 170 |
+
delay = self._frame_start_time - time.perf_counter() + 1 / self._fps_limit
|
| 171 |
+
if delay > 0:
|
| 172 |
+
time.sleep(delay)
|
| 173 |
+
cur_time = time.perf_counter()
|
| 174 |
+
if self._frame_start_time is not None:
|
| 175 |
+
self._frame_delta = cur_time - self._frame_start_time
|
| 176 |
+
self._frame_start_time = cur_time
|
| 177 |
+
|
| 178 |
+
# Process events.
|
| 179 |
+
glfw.poll_events()
|
| 180 |
+
|
| 181 |
+
# Begin frame.
|
| 182 |
+
self._drawing_frame = True
|
| 183 |
+
self.make_context_current()
|
| 184 |
+
|
| 185 |
+
# Initialize GL state.
|
| 186 |
+
gl.glViewport(0, 0, self.content_width, self.content_height)
|
| 187 |
+
gl.glMatrixMode(gl.GL_PROJECTION)
|
| 188 |
+
gl.glLoadIdentity()
|
| 189 |
+
gl.glTranslate(-1, 1, 0)
|
| 190 |
+
gl.glScale(2 / max(self.content_width, 1), -2 / max(self.content_height, 1), 1)
|
| 191 |
+
gl.glMatrixMode(gl.GL_MODELVIEW)
|
| 192 |
+
gl.glLoadIdentity()
|
| 193 |
+
gl.glEnable(gl.GL_BLEND)
|
| 194 |
+
gl.glBlendFunc(gl.GL_ONE, gl.GL_ONE_MINUS_SRC_ALPHA) # Pre-multiplied alpha.
|
| 195 |
+
|
| 196 |
+
# Clear.
|
| 197 |
+
gl.glClearColor(0, 0, 0, 1)
|
| 198 |
+
gl.glClear(gl.GL_COLOR_BUFFER_BIT | gl.GL_DEPTH_BUFFER_BIT)
|
| 199 |
+
|
| 200 |
+
def end_frame(self):
|
| 201 |
+
assert self._drawing_frame
|
| 202 |
+
self._drawing_frame = False
|
| 203 |
+
|
| 204 |
+
# Skip frames if requested.
|
| 205 |
+
if self._skip_frames > 0:
|
| 206 |
+
self._skip_frames -= 1
|
| 207 |
+
return
|
| 208 |
+
|
| 209 |
+
# Capture frame if requested.
|
| 210 |
+
if self._capture_next_frame:
|
| 211 |
+
self._captured_frame = gl_utils.read_pixels(self.content_width, self.content_height)
|
| 212 |
+
self._capture_next_frame = False
|
| 213 |
+
|
| 214 |
+
# Update window.
|
| 215 |
+
if self._deferred_show:
|
| 216 |
+
glfw.show_window(self._glfw_window)
|
| 217 |
+
self._deferred_show = False
|
| 218 |
+
glfw.swap_buffers(self._glfw_window)
|
| 219 |
+
|
| 220 |
+
def _attach_glfw_callbacks(self):
|
| 221 |
+
glfw.set_key_callback(self._glfw_window, self._glfw_key_callback)
|
| 222 |
+
glfw.set_drop_callback(self._glfw_window, self._glfw_drop_callback)
|
| 223 |
+
|
| 224 |
+
def _glfw_key_callback(self, _window, key, _scancode, action, _mods):
|
| 225 |
+
if action == glfw.PRESS and key == glfw.KEY_ESCAPE:
|
| 226 |
+
self._esc_pressed = True
|
| 227 |
+
|
| 228 |
+
def _glfw_drop_callback(self, _window, paths):
|
| 229 |
+
self._drag_and_drop_paths = paths
|
| 230 |
+
|
| 231 |
+
#----------------------------------------------------------------------------
|
eg3d/gui_utils/imgui_utils.py
ADDED
|
@@ -0,0 +1,171 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# SPDX-FileCopyrightText: Copyright (c) 2021-2022 NVIDIA CORPORATION & AFFILIATES. All rights reserved.
|
| 2 |
+
# SPDX-License-Identifier: LicenseRef-NvidiaProprietary
|
| 3 |
+
#
|
| 4 |
+
# NVIDIA CORPORATION, its affiliates and licensors retain all intellectual
|
| 5 |
+
# property and proprietary rights in and to this material, related
|
| 6 |
+
# documentation and any modifications thereto. Any use, reproduction,
|
| 7 |
+
# disclosure or distribution of this material and related documentation
|
| 8 |
+
# without an express license agreement from NVIDIA CORPORATION or
|
| 9 |
+
# its affiliates is strictly prohibited.
|
| 10 |
+
|
| 11 |
+
import contextlib
|
| 12 |
+
import imgui
|
| 13 |
+
|
| 14 |
+
#----------------------------------------------------------------------------
|
| 15 |
+
|
| 16 |
+
def set_default_style(color_scheme='dark', spacing=9, indent=23, scrollbar=27):
|
| 17 |
+
s = imgui.get_style()
|
| 18 |
+
s.window_padding = [spacing, spacing]
|
| 19 |
+
s.item_spacing = [spacing, spacing]
|
| 20 |
+
s.item_inner_spacing = [spacing, spacing]
|
| 21 |
+
s.columns_min_spacing = spacing
|
| 22 |
+
s.indent_spacing = indent
|
| 23 |
+
s.scrollbar_size = scrollbar
|
| 24 |
+
s.frame_padding = [4, 3]
|
| 25 |
+
s.window_border_size = 1
|
| 26 |
+
s.child_border_size = 1
|
| 27 |
+
s.popup_border_size = 1
|
| 28 |
+
s.frame_border_size = 1
|
| 29 |
+
s.window_rounding = 0
|
| 30 |
+
s.child_rounding = 0
|
| 31 |
+
s.popup_rounding = 3
|
| 32 |
+
s.frame_rounding = 3
|
| 33 |
+
s.scrollbar_rounding = 3
|
| 34 |
+
s.grab_rounding = 3
|
| 35 |
+
|
| 36 |
+
getattr(imgui, f'style_colors_{color_scheme}')(s)
|
| 37 |
+
c0 = s.colors[imgui.COLOR_MENUBAR_BACKGROUND]
|
| 38 |
+
c1 = s.colors[imgui.COLOR_FRAME_BACKGROUND]
|
| 39 |
+
s.colors[imgui.COLOR_POPUP_BACKGROUND] = [x * 0.7 + y * 0.3 for x, y in zip(c0, c1)][:3] + [1]
|
| 40 |
+
|
| 41 |
+
#----------------------------------------------------------------------------
|
| 42 |
+
|
| 43 |
+
@contextlib.contextmanager
|
| 44 |
+
def grayed_out(cond=True):
|
| 45 |
+
if cond:
|
| 46 |
+
s = imgui.get_style()
|
| 47 |
+
text = s.colors[imgui.COLOR_TEXT_DISABLED]
|
| 48 |
+
grab = s.colors[imgui.COLOR_SCROLLBAR_GRAB]
|
| 49 |
+
back = s.colors[imgui.COLOR_MENUBAR_BACKGROUND]
|
| 50 |
+
imgui.push_style_color(imgui.COLOR_TEXT, *text)
|
| 51 |
+
imgui.push_style_color(imgui.COLOR_CHECK_MARK, *grab)
|
| 52 |
+
imgui.push_style_color(imgui.COLOR_SLIDER_GRAB, *grab)
|
| 53 |
+
imgui.push_style_color(imgui.COLOR_SLIDER_GRAB_ACTIVE, *grab)
|
| 54 |
+
imgui.push_style_color(imgui.COLOR_FRAME_BACKGROUND, *back)
|
| 55 |
+
imgui.push_style_color(imgui.COLOR_FRAME_BACKGROUND_HOVERED, *back)
|
| 56 |
+
imgui.push_style_color(imgui.COLOR_FRAME_BACKGROUND_ACTIVE, *back)
|
| 57 |
+
imgui.push_style_color(imgui.COLOR_BUTTON, *back)
|
| 58 |
+
imgui.push_style_color(imgui.COLOR_BUTTON_HOVERED, *back)
|
| 59 |
+
imgui.push_style_color(imgui.COLOR_BUTTON_ACTIVE, *back)
|
| 60 |
+
imgui.push_style_color(imgui.COLOR_HEADER, *back)
|
| 61 |
+
imgui.push_style_color(imgui.COLOR_HEADER_HOVERED, *back)
|
| 62 |
+
imgui.push_style_color(imgui.COLOR_HEADER_ACTIVE, *back)
|
| 63 |
+
imgui.push_style_color(imgui.COLOR_POPUP_BACKGROUND, *back)
|
| 64 |
+
yield
|
| 65 |
+
imgui.pop_style_color(14)
|
| 66 |
+
else:
|
| 67 |
+
yield
|
| 68 |
+
|
| 69 |
+
#----------------------------------------------------------------------------
|
| 70 |
+
|
| 71 |
+
@contextlib.contextmanager
|
| 72 |
+
def item_width(width=None):
|
| 73 |
+
if width is not None:
|
| 74 |
+
imgui.push_item_width(width)
|
| 75 |
+
yield
|
| 76 |
+
imgui.pop_item_width()
|
| 77 |
+
else:
|
| 78 |
+
yield
|
| 79 |
+
|
| 80 |
+
#----------------------------------------------------------------------------
|
| 81 |
+
|
| 82 |
+
def scoped_by_object_id(method):
|
| 83 |
+
def decorator(self, *args, **kwargs):
|
| 84 |
+
imgui.push_id(str(id(self)))
|
| 85 |
+
res = method(self, *args, **kwargs)
|
| 86 |
+
imgui.pop_id()
|
| 87 |
+
return res
|
| 88 |
+
return decorator
|
| 89 |
+
|
| 90 |
+
#----------------------------------------------------------------------------
|
| 91 |
+
|
| 92 |
+
def button(label, width=0, enabled=True):
|
| 93 |
+
with grayed_out(not enabled):
|
| 94 |
+
clicked = imgui.button(label, width=width)
|
| 95 |
+
clicked = clicked and enabled
|
| 96 |
+
return clicked
|
| 97 |
+
|
| 98 |
+
#----------------------------------------------------------------------------
|
| 99 |
+
|
| 100 |
+
def collapsing_header(text, visible=None, flags=0, default=False, enabled=True, show=True):
|
| 101 |
+
expanded = False
|
| 102 |
+
if show:
|
| 103 |
+
if default:
|
| 104 |
+
flags |= imgui.TREE_NODE_DEFAULT_OPEN
|
| 105 |
+
if not enabled:
|
| 106 |
+
flags |= imgui.TREE_NODE_LEAF
|
| 107 |
+
with grayed_out(not enabled):
|
| 108 |
+
expanded, visible = imgui.collapsing_header(text, visible=visible, flags=flags)
|
| 109 |
+
expanded = expanded and enabled
|
| 110 |
+
return expanded, visible
|
| 111 |
+
|
| 112 |
+
#----------------------------------------------------------------------------
|
| 113 |
+
|
| 114 |
+
def popup_button(label, width=0, enabled=True):
|
| 115 |
+
if button(label, width, enabled):
|
| 116 |
+
imgui.open_popup(label)
|
| 117 |
+
opened = imgui.begin_popup(label)
|
| 118 |
+
return opened
|
| 119 |
+
|
| 120 |
+
#----------------------------------------------------------------------------
|
| 121 |
+
|
| 122 |
+
def input_text(label, value, buffer_length, flags, width=None, help_text=''):
|
| 123 |
+
old_value = value
|
| 124 |
+
color = list(imgui.get_style().colors[imgui.COLOR_TEXT])
|
| 125 |
+
if value == '':
|
| 126 |
+
color[-1] *= 0.5
|
| 127 |
+
with item_width(width):
|
| 128 |
+
imgui.push_style_color(imgui.COLOR_TEXT, *color)
|
| 129 |
+
value = value if value != '' else help_text
|
| 130 |
+
changed, value = imgui.input_text(label, value, buffer_length, flags)
|
| 131 |
+
value = value if value != help_text else ''
|
| 132 |
+
imgui.pop_style_color(1)
|
| 133 |
+
if not flags & imgui.INPUT_TEXT_ENTER_RETURNS_TRUE:
|
| 134 |
+
changed = (value != old_value)
|
| 135 |
+
return changed, value
|
| 136 |
+
|
| 137 |
+
#----------------------------------------------------------------------------
|
| 138 |
+
|
| 139 |
+
def drag_previous_control(enabled=True):
|
| 140 |
+
dragging = False
|
| 141 |
+
dx = 0
|
| 142 |
+
dy = 0
|
| 143 |
+
if imgui.begin_drag_drop_source(imgui.DRAG_DROP_SOURCE_NO_PREVIEW_TOOLTIP):
|
| 144 |
+
if enabled:
|
| 145 |
+
dragging = True
|
| 146 |
+
dx, dy = imgui.get_mouse_drag_delta()
|
| 147 |
+
imgui.reset_mouse_drag_delta()
|
| 148 |
+
imgui.end_drag_drop_source()
|
| 149 |
+
return dragging, dx, dy
|
| 150 |
+
|
| 151 |
+
#----------------------------------------------------------------------------
|
| 152 |
+
|
| 153 |
+
def drag_button(label, width=0, enabled=True):
|
| 154 |
+
clicked = button(label, width=width, enabled=enabled)
|
| 155 |
+
dragging, dx, dy = drag_previous_control(enabled=enabled)
|
| 156 |
+
return clicked, dragging, dx, dy
|
| 157 |
+
|
| 158 |
+
#----------------------------------------------------------------------------
|
| 159 |
+
|
| 160 |
+
def drag_hidden_window(label, x, y, width, height, enabled=True):
|
| 161 |
+
imgui.push_style_color(imgui.COLOR_WINDOW_BACKGROUND, 0, 0, 0, 0)
|
| 162 |
+
imgui.push_style_color(imgui.COLOR_BORDER, 0, 0, 0, 0)
|
| 163 |
+
imgui.set_next_window_position(x, y)
|
| 164 |
+
imgui.set_next_window_size(width, height)
|
| 165 |
+
imgui.begin(label, closable=False, flags=(imgui.WINDOW_NO_TITLE_BAR | imgui.WINDOW_NO_RESIZE | imgui.WINDOW_NO_MOVE))
|
| 166 |
+
dragging, dx, dy = drag_previous_control(enabled=enabled)
|
| 167 |
+
imgui.end()
|
| 168 |
+
imgui.pop_style_color(2)
|
| 169 |
+
return dragging, dx, dy
|
| 170 |
+
|
| 171 |
+
#----------------------------------------------------------------------------
|
eg3d/gui_utils/imgui_window.py
ADDED
|
@@ -0,0 +1,105 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# SPDX-FileCopyrightText: Copyright (c) 2021-2022 NVIDIA CORPORATION & AFFILIATES. All rights reserved.
|
| 2 |
+
# SPDX-License-Identifier: LicenseRef-NvidiaProprietary
|
| 3 |
+
#
|
| 4 |
+
# NVIDIA CORPORATION, its affiliates and licensors retain all intellectual
|
| 5 |
+
# property and proprietary rights in and to this material, related
|
| 6 |
+
# documentation and any modifications thereto. Any use, reproduction,
|
| 7 |
+
# disclosure or distribution of this material and related documentation
|
| 8 |
+
# without an express license agreement from NVIDIA CORPORATION or
|
| 9 |
+
# its affiliates is strictly prohibited.
|
| 10 |
+
|
| 11 |
+
import os
|
| 12 |
+
import imgui
|
| 13 |
+
import imgui.integrations.glfw
|
| 14 |
+
|
| 15 |
+
from . import glfw_window
|
| 16 |
+
from . import imgui_utils
|
| 17 |
+
from . import text_utils
|
| 18 |
+
|
| 19 |
+
#----------------------------------------------------------------------------
|
| 20 |
+
|
| 21 |
+
class ImguiWindow(glfw_window.GlfwWindow):
|
| 22 |
+
def __init__(self, *, title='ImguiWindow', font=None, font_sizes=range(14,24), **glfw_kwargs):
|
| 23 |
+
if font is None:
|
| 24 |
+
font = text_utils.get_default_font()
|
| 25 |
+
font_sizes = {int(size) for size in font_sizes}
|
| 26 |
+
super().__init__(title=title, **glfw_kwargs)
|
| 27 |
+
|
| 28 |
+
# Init fields.
|
| 29 |
+
self._imgui_context = None
|
| 30 |
+
self._imgui_renderer = None
|
| 31 |
+
self._imgui_fonts = None
|
| 32 |
+
self._cur_font_size = max(font_sizes)
|
| 33 |
+
|
| 34 |
+
# Delete leftover imgui.ini to avoid unexpected behavior.
|
| 35 |
+
if os.path.isfile('imgui.ini'):
|
| 36 |
+
os.remove('imgui.ini')
|
| 37 |
+
|
| 38 |
+
# Init ImGui.
|
| 39 |
+
self._imgui_context = imgui.create_context()
|
| 40 |
+
self._imgui_renderer = _GlfwRenderer(self._glfw_window)
|
| 41 |
+
self._attach_glfw_callbacks()
|
| 42 |
+
imgui.get_io().ini_saving_rate = 0 # Disable creating imgui.ini at runtime.
|
| 43 |
+
imgui.get_io().mouse_drag_threshold = 0 # Improve behavior with imgui_utils.drag_custom().
|
| 44 |
+
self._imgui_fonts = {size: imgui.get_io().fonts.add_font_from_file_ttf(font, size) for size in font_sizes}
|
| 45 |
+
self._imgui_renderer.refresh_font_texture()
|
| 46 |
+
|
| 47 |
+
def close(self):
|
| 48 |
+
self.make_context_current()
|
| 49 |
+
self._imgui_fonts = None
|
| 50 |
+
if self._imgui_renderer is not None:
|
| 51 |
+
self._imgui_renderer.shutdown()
|
| 52 |
+
self._imgui_renderer = None
|
| 53 |
+
if self._imgui_context is not None:
|
| 54 |
+
#imgui.destroy_context(self._imgui_context) # Commented out to avoid creating imgui.ini at the end.
|
| 55 |
+
self._imgui_context = None
|
| 56 |
+
super().close()
|
| 57 |
+
|
| 58 |
+
def _glfw_key_callback(self, *args):
|
| 59 |
+
super()._glfw_key_callback(*args)
|
| 60 |
+
self._imgui_renderer.keyboard_callback(*args)
|
| 61 |
+
|
| 62 |
+
@property
|
| 63 |
+
def font_size(self):
|
| 64 |
+
return self._cur_font_size
|
| 65 |
+
|
| 66 |
+
@property
|
| 67 |
+
def spacing(self):
|
| 68 |
+
return round(self._cur_font_size * 0.4)
|
| 69 |
+
|
| 70 |
+
def set_font_size(self, target): # Applied on next frame.
|
| 71 |
+
self._cur_font_size = min((abs(key - target), key) for key in self._imgui_fonts.keys())[1]
|
| 72 |
+
|
| 73 |
+
def begin_frame(self):
|
| 74 |
+
# Begin glfw frame.
|
| 75 |
+
super().begin_frame()
|
| 76 |
+
|
| 77 |
+
# Process imgui events.
|
| 78 |
+
self._imgui_renderer.mouse_wheel_multiplier = self._cur_font_size / 10
|
| 79 |
+
if self.content_width > 0 and self.content_height > 0:
|
| 80 |
+
self._imgui_renderer.process_inputs()
|
| 81 |
+
|
| 82 |
+
# Begin imgui frame.
|
| 83 |
+
imgui.new_frame()
|
| 84 |
+
imgui.push_font(self._imgui_fonts[self._cur_font_size])
|
| 85 |
+
imgui_utils.set_default_style(spacing=self.spacing, indent=self.font_size, scrollbar=self.font_size+4)
|
| 86 |
+
|
| 87 |
+
def end_frame(self):
|
| 88 |
+
imgui.pop_font()
|
| 89 |
+
imgui.render()
|
| 90 |
+
imgui.end_frame()
|
| 91 |
+
self._imgui_renderer.render(imgui.get_draw_data())
|
| 92 |
+
super().end_frame()
|
| 93 |
+
|
| 94 |
+
#----------------------------------------------------------------------------
|
| 95 |
+
# Wrapper class for GlfwRenderer to fix a mouse wheel bug on Linux.
|
| 96 |
+
|
| 97 |
+
class _GlfwRenderer(imgui.integrations.glfw.GlfwRenderer):
|
| 98 |
+
def __init__(self, *args, **kwargs):
|
| 99 |
+
super().__init__(*args, **kwargs)
|
| 100 |
+
self.mouse_wheel_multiplier = 1
|
| 101 |
+
|
| 102 |
+
def scroll_callback(self, window, x_offset, y_offset):
|
| 103 |
+
self.io.mouse_wheel += y_offset * self.mouse_wheel_multiplier
|
| 104 |
+
|
| 105 |
+
#----------------------------------------------------------------------------
|
eg3d/gui_utils/text_utils.py
ADDED
|
@@ -0,0 +1,125 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# SPDX-FileCopyrightText: Copyright (c) 2021-2022 NVIDIA CORPORATION & AFFILIATES. All rights reserved.
|
| 2 |
+
# SPDX-License-Identifier: LicenseRef-NvidiaProprietary
|
| 3 |
+
#
|
| 4 |
+
# NVIDIA CORPORATION, its affiliates and licensors retain all intellectual
|
| 5 |
+
# property and proprietary rights in and to this material, related
|
| 6 |
+
# documentation and any modifications thereto. Any use, reproduction,
|
| 7 |
+
# disclosure or distribution of this material and related documentation
|
| 8 |
+
# without an express license agreement from NVIDIA CORPORATION or
|
| 9 |
+
# its affiliates is strictly prohibited.
|
| 10 |
+
|
| 11 |
+
import functools
|
| 12 |
+
from typing import Optional
|
| 13 |
+
|
| 14 |
+
import dnnlib
|
| 15 |
+
import numpy as np
|
| 16 |
+
import PIL.Image
|
| 17 |
+
import PIL.ImageFont
|
| 18 |
+
import scipy.ndimage
|
| 19 |
+
|
| 20 |
+
from . import gl_utils
|
| 21 |
+
|
| 22 |
+
#----------------------------------------------------------------------------
|
| 23 |
+
|
| 24 |
+
def get_default_font():
|
| 25 |
+
url = 'http://fonts.gstatic.com/s/opensans/v17/mem8YaGs126MiZpBA-U1UpcaXcl0Aw.ttf' # Open Sans regular
|
| 26 |
+
return dnnlib.util.open_url(url, return_filename=True)
|
| 27 |
+
|
| 28 |
+
#----------------------------------------------------------------------------
|
| 29 |
+
|
| 30 |
+
@functools.lru_cache(maxsize=None)
|
| 31 |
+
def get_pil_font(font=None, size=32):
|
| 32 |
+
if font is None:
|
| 33 |
+
font = get_default_font()
|
| 34 |
+
return PIL.ImageFont.truetype(font=font, size=size)
|
| 35 |
+
|
| 36 |
+
#----------------------------------------------------------------------------
|
| 37 |
+
|
| 38 |
+
def get_array(string, *, dropshadow_radius: int=None, **kwargs):
|
| 39 |
+
if dropshadow_radius is not None:
|
| 40 |
+
offset_x = int(np.ceil(dropshadow_radius*2/3))
|
| 41 |
+
offset_y = int(np.ceil(dropshadow_radius*2/3))
|
| 42 |
+
return _get_array_priv(string, dropshadow_radius=dropshadow_radius, offset_x=offset_x, offset_y=offset_y, **kwargs)
|
| 43 |
+
else:
|
| 44 |
+
return _get_array_priv(string, **kwargs)
|
| 45 |
+
|
| 46 |
+
@functools.lru_cache(maxsize=10000)
|
| 47 |
+
def _get_array_priv(
|
| 48 |
+
string: str, *,
|
| 49 |
+
size: int = 32,
|
| 50 |
+
max_width: Optional[int]=None,
|
| 51 |
+
max_height: Optional[int]=None,
|
| 52 |
+
min_size=10,
|
| 53 |
+
shrink_coef=0.8,
|
| 54 |
+
dropshadow_radius: int=None,
|
| 55 |
+
offset_x: int=None,
|
| 56 |
+
offset_y: int=None,
|
| 57 |
+
**kwargs
|
| 58 |
+
):
|
| 59 |
+
cur_size = size
|
| 60 |
+
array = None
|
| 61 |
+
while True:
|
| 62 |
+
if dropshadow_radius is not None:
|
| 63 |
+
# separate implementation for dropshadow text rendering
|
| 64 |
+
array = _get_array_impl_dropshadow(string, size=cur_size, radius=dropshadow_radius, offset_x=offset_x, offset_y=offset_y, **kwargs)
|
| 65 |
+
else:
|
| 66 |
+
array = _get_array_impl(string, size=cur_size, **kwargs)
|
| 67 |
+
height, width, _ = array.shape
|
| 68 |
+
if (max_width is None or width <= max_width) and (max_height is None or height <= max_height) or (cur_size <= min_size):
|
| 69 |
+
break
|
| 70 |
+
cur_size = max(int(cur_size * shrink_coef), min_size)
|
| 71 |
+
return array
|
| 72 |
+
|
| 73 |
+
#----------------------------------------------------------------------------
|
| 74 |
+
|
| 75 |
+
@functools.lru_cache(maxsize=10000)
|
| 76 |
+
def _get_array_impl(string, *, font=None, size=32, outline=0, outline_pad=3, outline_coef=3, outline_exp=2, line_pad: int=None):
|
| 77 |
+
pil_font = get_pil_font(font=font, size=size)
|
| 78 |
+
lines = [pil_font.getmask(line, 'L') for line in string.split('\n')]
|
| 79 |
+
lines = [np.array(line, dtype=np.uint8).reshape([line.size[1], line.size[0]]) for line in lines]
|
| 80 |
+
width = max(line.shape[1] for line in lines)
|
| 81 |
+
lines = [np.pad(line, ((0, 0), (0, width - line.shape[1])), mode='constant') for line in lines]
|
| 82 |
+
line_spacing = line_pad if line_pad is not None else size // 2
|
| 83 |
+
lines = [np.pad(line, ((0, line_spacing), (0, 0)), mode='constant') for line in lines[:-1]] + lines[-1:]
|
| 84 |
+
mask = np.concatenate(lines, axis=0)
|
| 85 |
+
alpha = mask
|
| 86 |
+
if outline > 0:
|
| 87 |
+
mask = np.pad(mask, int(np.ceil(outline * outline_pad)), mode='constant', constant_values=0)
|
| 88 |
+
alpha = mask.astype(np.float32) / 255
|
| 89 |
+
alpha = scipy.ndimage.gaussian_filter(alpha, outline)
|
| 90 |
+
alpha = 1 - np.maximum(1 - alpha * outline_coef, 0) ** outline_exp
|
| 91 |
+
alpha = (alpha * 255 + 0.5).clip(0, 255).astype(np.uint8)
|
| 92 |
+
alpha = np.maximum(alpha, mask)
|
| 93 |
+
return np.stack([mask, alpha], axis=-1)
|
| 94 |
+
|
| 95 |
+
#----------------------------------------------------------------------------
|
| 96 |
+
|
| 97 |
+
@functools.lru_cache(maxsize=10000)
|
| 98 |
+
def _get_array_impl_dropshadow(string, *, font=None, size=32, radius: int, offset_x: int, offset_y: int, line_pad: int=None, **kwargs):
|
| 99 |
+
assert (offset_x > 0) and (offset_y > 0)
|
| 100 |
+
pil_font = get_pil_font(font=font, size=size)
|
| 101 |
+
lines = [pil_font.getmask(line, 'L') for line in string.split('\n')]
|
| 102 |
+
lines = [np.array(line, dtype=np.uint8).reshape([line.size[1], line.size[0]]) for line in lines]
|
| 103 |
+
width = max(line.shape[1] for line in lines)
|
| 104 |
+
lines = [np.pad(line, ((0, 0), (0, width - line.shape[1])), mode='constant') for line in lines]
|
| 105 |
+
line_spacing = line_pad if line_pad is not None else size // 2
|
| 106 |
+
lines = [np.pad(line, ((0, line_spacing), (0, 0)), mode='constant') for line in lines[:-1]] + lines[-1:]
|
| 107 |
+
mask = np.concatenate(lines, axis=0)
|
| 108 |
+
alpha = mask
|
| 109 |
+
|
| 110 |
+
mask = np.pad(mask, 2*radius + max(abs(offset_x), abs(offset_y)), mode='constant', constant_values=0)
|
| 111 |
+
alpha = mask.astype(np.float32) / 255
|
| 112 |
+
alpha = scipy.ndimage.gaussian_filter(alpha, radius)
|
| 113 |
+
alpha = 1 - np.maximum(1 - alpha * 1.5, 0) ** 1.4
|
| 114 |
+
alpha = (alpha * 255 + 0.5).clip(0, 255).astype(np.uint8)
|
| 115 |
+
alpha = np.pad(alpha, [(offset_y, 0), (offset_x, 0)], mode='constant')[:-offset_y, :-offset_x]
|
| 116 |
+
alpha = np.maximum(alpha, mask)
|
| 117 |
+
return np.stack([mask, alpha], axis=-1)
|
| 118 |
+
|
| 119 |
+
#----------------------------------------------------------------------------
|
| 120 |
+
|
| 121 |
+
@functools.lru_cache(maxsize=10000)
|
| 122 |
+
def get_texture(string, bilinear=True, mipmap=True, **kwargs):
|
| 123 |
+
return gl_utils.Texture(image=get_array(string, **kwargs), bilinear=bilinear, mipmap=mipmap)
|
| 124 |
+
|
| 125 |
+
#----------------------------------------------------------------------------
|
eg3d/legacy.py
ADDED
|
@@ -0,0 +1,325 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# SPDX-FileCopyrightText: Copyright (c) 2021-2022 NVIDIA CORPORATION & AFFILIATES. All rights reserved.
|
| 2 |
+
# SPDX-License-Identifier: LicenseRef-NvidiaProprietary
|
| 3 |
+
#
|
| 4 |
+
# NVIDIA CORPORATION, its affiliates and licensors retain all intellectual
|
| 5 |
+
# property and proprietary rights in and to this material, related
|
| 6 |
+
# documentation and any modifications thereto. Any use, reproduction,
|
| 7 |
+
# disclosure or distribution of this material and related documentation
|
| 8 |
+
# without an express license agreement from NVIDIA CORPORATION or
|
| 9 |
+
# its affiliates is strictly prohibited.
|
| 10 |
+
|
| 11 |
+
"""Converting legacy network pickle into the new format."""
|
| 12 |
+
|
| 13 |
+
import click
|
| 14 |
+
import pickle
|
| 15 |
+
import re
|
| 16 |
+
import copy
|
| 17 |
+
import numpy as np
|
| 18 |
+
import torch
|
| 19 |
+
import dnnlib
|
| 20 |
+
from torch_utils import misc
|
| 21 |
+
|
| 22 |
+
#----------------------------------------------------------------------------
|
| 23 |
+
|
| 24 |
+
def load_network_pkl(f, force_fp16=False):
|
| 25 |
+
data = _LegacyUnpickler(f).load()
|
| 26 |
+
|
| 27 |
+
# Legacy TensorFlow pickle => convert.
|
| 28 |
+
if isinstance(data, tuple) and len(data) == 3 and all(isinstance(net, _TFNetworkStub) for net in data):
|
| 29 |
+
tf_G, tf_D, tf_Gs = data
|
| 30 |
+
G = convert_tf_generator(tf_G)
|
| 31 |
+
D = convert_tf_discriminator(tf_D)
|
| 32 |
+
G_ema = convert_tf_generator(tf_Gs)
|
| 33 |
+
data = dict(G=G, D=D, G_ema=G_ema)
|
| 34 |
+
|
| 35 |
+
# Add missing fields.
|
| 36 |
+
if 'training_set_kwargs' not in data:
|
| 37 |
+
data['training_set_kwargs'] = None
|
| 38 |
+
if 'augment_pipe' not in data:
|
| 39 |
+
data['augment_pipe'] = None
|
| 40 |
+
|
| 41 |
+
# Validate contents.
|
| 42 |
+
assert isinstance(data['G'], torch.nn.Module)
|
| 43 |
+
assert isinstance(data['D'], torch.nn.Module)
|
| 44 |
+
assert isinstance(data['G_ema'], torch.nn.Module)
|
| 45 |
+
assert isinstance(data['training_set_kwargs'], (dict, type(None)))
|
| 46 |
+
assert isinstance(data['augment_pipe'], (torch.nn.Module, type(None)))
|
| 47 |
+
|
| 48 |
+
# Force FP16.
|
| 49 |
+
if force_fp16:
|
| 50 |
+
for key in ['G', 'D', 'G_ema']:
|
| 51 |
+
old = data[key]
|
| 52 |
+
kwargs = copy.deepcopy(old.init_kwargs)
|
| 53 |
+
fp16_kwargs = kwargs.get('synthesis_kwargs', kwargs)
|
| 54 |
+
fp16_kwargs.num_fp16_res = 4
|
| 55 |
+
fp16_kwargs.conv_clamp = 256
|
| 56 |
+
if kwargs != old.init_kwargs:
|
| 57 |
+
new = type(old)(**kwargs).eval().requires_grad_(False)
|
| 58 |
+
misc.copy_params_and_buffers(old, new, require_all=True)
|
| 59 |
+
data[key] = new
|
| 60 |
+
return data
|
| 61 |
+
|
| 62 |
+
#----------------------------------------------------------------------------
|
| 63 |
+
|
| 64 |
+
class _TFNetworkStub(dnnlib.EasyDict):
|
| 65 |
+
pass
|
| 66 |
+
|
| 67 |
+
class _LegacyUnpickler(pickle.Unpickler):
|
| 68 |
+
def find_class(self, module, name):
|
| 69 |
+
if module == 'dnnlib.tflib.network' and name == 'Network':
|
| 70 |
+
return _TFNetworkStub
|
| 71 |
+
return super().find_class(module, name)
|
| 72 |
+
|
| 73 |
+
#----------------------------------------------------------------------------
|
| 74 |
+
|
| 75 |
+
def _collect_tf_params(tf_net):
|
| 76 |
+
# pylint: disable=protected-access
|
| 77 |
+
tf_params = dict()
|
| 78 |
+
def recurse(prefix, tf_net):
|
| 79 |
+
for name, value in tf_net.variables:
|
| 80 |
+
tf_params[prefix + name] = value
|
| 81 |
+
for name, comp in tf_net.components.items():
|
| 82 |
+
recurse(prefix + name + '/', comp)
|
| 83 |
+
recurse('', tf_net)
|
| 84 |
+
return tf_params
|
| 85 |
+
|
| 86 |
+
#----------------------------------------------------------------------------
|
| 87 |
+
|
| 88 |
+
def _populate_module_params(module, *patterns):
|
| 89 |
+
for name, tensor in misc.named_params_and_buffers(module):
|
| 90 |
+
found = False
|
| 91 |
+
value = None
|
| 92 |
+
for pattern, value_fn in zip(patterns[0::2], patterns[1::2]):
|
| 93 |
+
match = re.fullmatch(pattern, name)
|
| 94 |
+
if match:
|
| 95 |
+
found = True
|
| 96 |
+
if value_fn is not None:
|
| 97 |
+
value = value_fn(*match.groups())
|
| 98 |
+
break
|
| 99 |
+
try:
|
| 100 |
+
assert found
|
| 101 |
+
if value is not None:
|
| 102 |
+
tensor.copy_(torch.from_numpy(np.array(value)))
|
| 103 |
+
except:
|
| 104 |
+
print(name, list(tensor.shape))
|
| 105 |
+
raise
|
| 106 |
+
|
| 107 |
+
#----------------------------------------------------------------------------
|
| 108 |
+
|
| 109 |
+
def convert_tf_generator(tf_G):
|
| 110 |
+
if tf_G.version < 4:
|
| 111 |
+
raise ValueError('TensorFlow pickle version too low')
|
| 112 |
+
|
| 113 |
+
# Collect kwargs.
|
| 114 |
+
tf_kwargs = tf_G.static_kwargs
|
| 115 |
+
known_kwargs = set()
|
| 116 |
+
def kwarg(tf_name, default=None, none=None):
|
| 117 |
+
known_kwargs.add(tf_name)
|
| 118 |
+
val = tf_kwargs.get(tf_name, default)
|
| 119 |
+
return val if val is not None else none
|
| 120 |
+
|
| 121 |
+
# Convert kwargs.
|
| 122 |
+
from training import networks_stylegan2
|
| 123 |
+
network_class = networks_stylegan2.Generator
|
| 124 |
+
kwargs = dnnlib.EasyDict(
|
| 125 |
+
z_dim = kwarg('latent_size', 512),
|
| 126 |
+
c_dim = kwarg('label_size', 0),
|
| 127 |
+
w_dim = kwarg('dlatent_size', 512),
|
| 128 |
+
img_resolution = kwarg('resolution', 1024),
|
| 129 |
+
img_channels = kwarg('num_channels', 3),
|
| 130 |
+
channel_base = kwarg('fmap_base', 16384) * 2,
|
| 131 |
+
channel_max = kwarg('fmap_max', 512),
|
| 132 |
+
num_fp16_res = kwarg('num_fp16_res', 0),
|
| 133 |
+
conv_clamp = kwarg('conv_clamp', None),
|
| 134 |
+
architecture = kwarg('architecture', 'skip'),
|
| 135 |
+
resample_filter = kwarg('resample_kernel', [1,3,3,1]),
|
| 136 |
+
use_noise = kwarg('use_noise', True),
|
| 137 |
+
activation = kwarg('nonlinearity', 'lrelu'),
|
| 138 |
+
mapping_kwargs = dnnlib.EasyDict(
|
| 139 |
+
num_layers = kwarg('mapping_layers', 8),
|
| 140 |
+
embed_features = kwarg('label_fmaps', None),
|
| 141 |
+
layer_features = kwarg('mapping_fmaps', None),
|
| 142 |
+
activation = kwarg('mapping_nonlinearity', 'lrelu'),
|
| 143 |
+
lr_multiplier = kwarg('mapping_lrmul', 0.01),
|
| 144 |
+
w_avg_beta = kwarg('w_avg_beta', 0.995, none=1),
|
| 145 |
+
),
|
| 146 |
+
)
|
| 147 |
+
|
| 148 |
+
# Check for unknown kwargs.
|
| 149 |
+
kwarg('truncation_psi')
|
| 150 |
+
kwarg('truncation_cutoff')
|
| 151 |
+
kwarg('style_mixing_prob')
|
| 152 |
+
kwarg('structure')
|
| 153 |
+
kwarg('conditioning')
|
| 154 |
+
kwarg('fused_modconv')
|
| 155 |
+
unknown_kwargs = list(set(tf_kwargs.keys()) - known_kwargs)
|
| 156 |
+
if len(unknown_kwargs) > 0:
|
| 157 |
+
raise ValueError('Unknown TensorFlow kwarg', unknown_kwargs[0])
|
| 158 |
+
|
| 159 |
+
# Collect params.
|
| 160 |
+
tf_params = _collect_tf_params(tf_G)
|
| 161 |
+
for name, value in list(tf_params.items()):
|
| 162 |
+
match = re.fullmatch(r'ToRGB_lod(\d+)/(.*)', name)
|
| 163 |
+
if match:
|
| 164 |
+
r = kwargs.img_resolution // (2 ** int(match.group(1)))
|
| 165 |
+
tf_params[f'{r}x{r}/ToRGB/{match.group(2)}'] = value
|
| 166 |
+
kwargs.synthesis.kwargs.architecture = 'orig'
|
| 167 |
+
#for name, value in tf_params.items(): print(f'{name:<50s}{list(value.shape)}')
|
| 168 |
+
|
| 169 |
+
# Convert params.
|
| 170 |
+
G = network_class(**kwargs).eval().requires_grad_(False)
|
| 171 |
+
# pylint: disable=unnecessary-lambda
|
| 172 |
+
# pylint: disable=f-string-without-interpolation
|
| 173 |
+
_populate_module_params(G,
|
| 174 |
+
r'mapping\.w_avg', lambda: tf_params[f'dlatent_avg'],
|
| 175 |
+
r'mapping\.embed\.weight', lambda: tf_params[f'mapping/LabelEmbed/weight'].transpose(),
|
| 176 |
+
r'mapping\.embed\.bias', lambda: tf_params[f'mapping/LabelEmbed/bias'],
|
| 177 |
+
r'mapping\.fc(\d+)\.weight', lambda i: tf_params[f'mapping/Dense{i}/weight'].transpose(),
|
| 178 |
+
r'mapping\.fc(\d+)\.bias', lambda i: tf_params[f'mapping/Dense{i}/bias'],
|
| 179 |
+
r'synthesis\.b4\.const', lambda: tf_params[f'synthesis/4x4/Const/const'][0],
|
| 180 |
+
r'synthesis\.b4\.conv1\.weight', lambda: tf_params[f'synthesis/4x4/Conv/weight'].transpose(3, 2, 0, 1),
|
| 181 |
+
r'synthesis\.b4\.conv1\.bias', lambda: tf_params[f'synthesis/4x4/Conv/bias'],
|
| 182 |
+
r'synthesis\.b4\.conv1\.noise_const', lambda: tf_params[f'synthesis/noise0'][0, 0],
|
| 183 |
+
r'synthesis\.b4\.conv1\.noise_strength', lambda: tf_params[f'synthesis/4x4/Conv/noise_strength'],
|
| 184 |
+
r'synthesis\.b4\.conv1\.affine\.weight', lambda: tf_params[f'synthesis/4x4/Conv/mod_weight'].transpose(),
|
| 185 |
+
r'synthesis\.b4\.conv1\.affine\.bias', lambda: tf_params[f'synthesis/4x4/Conv/mod_bias'] + 1,
|
| 186 |
+
r'synthesis\.b(\d+)\.conv0\.weight', lambda r: tf_params[f'synthesis/{r}x{r}/Conv0_up/weight'][::-1, ::-1].transpose(3, 2, 0, 1),
|
| 187 |
+
r'synthesis\.b(\d+)\.conv0\.bias', lambda r: tf_params[f'synthesis/{r}x{r}/Conv0_up/bias'],
|
| 188 |
+
r'synthesis\.b(\d+)\.conv0\.noise_const', lambda r: tf_params[f'synthesis/noise{int(np.log2(int(r)))*2-5}'][0, 0],
|
| 189 |
+
r'synthesis\.b(\d+)\.conv0\.noise_strength', lambda r: tf_params[f'synthesis/{r}x{r}/Conv0_up/noise_strength'],
|
| 190 |
+
r'synthesis\.b(\d+)\.conv0\.affine\.weight', lambda r: tf_params[f'synthesis/{r}x{r}/Conv0_up/mod_weight'].transpose(),
|
| 191 |
+
r'synthesis\.b(\d+)\.conv0\.affine\.bias', lambda r: tf_params[f'synthesis/{r}x{r}/Conv0_up/mod_bias'] + 1,
|
| 192 |
+
r'synthesis\.b(\d+)\.conv1\.weight', lambda r: tf_params[f'synthesis/{r}x{r}/Conv1/weight'].transpose(3, 2, 0, 1),
|
| 193 |
+
r'synthesis\.b(\d+)\.conv1\.bias', lambda r: tf_params[f'synthesis/{r}x{r}/Conv1/bias'],
|
| 194 |
+
r'synthesis\.b(\d+)\.conv1\.noise_const', lambda r: tf_params[f'synthesis/noise{int(np.log2(int(r)))*2-4}'][0, 0],
|
| 195 |
+
r'synthesis\.b(\d+)\.conv1\.noise_strength', lambda r: tf_params[f'synthesis/{r}x{r}/Conv1/noise_strength'],
|
| 196 |
+
r'synthesis\.b(\d+)\.conv1\.affine\.weight', lambda r: tf_params[f'synthesis/{r}x{r}/Conv1/mod_weight'].transpose(),
|
| 197 |
+
r'synthesis\.b(\d+)\.conv1\.affine\.bias', lambda r: tf_params[f'synthesis/{r}x{r}/Conv1/mod_bias'] + 1,
|
| 198 |
+
r'synthesis\.b(\d+)\.torgb\.weight', lambda r: tf_params[f'synthesis/{r}x{r}/ToRGB/weight'].transpose(3, 2, 0, 1),
|
| 199 |
+
r'synthesis\.b(\d+)\.torgb\.bias', lambda r: tf_params[f'synthesis/{r}x{r}/ToRGB/bias'],
|
| 200 |
+
r'synthesis\.b(\d+)\.torgb\.affine\.weight', lambda r: tf_params[f'synthesis/{r}x{r}/ToRGB/mod_weight'].transpose(),
|
| 201 |
+
r'synthesis\.b(\d+)\.torgb\.affine\.bias', lambda r: tf_params[f'synthesis/{r}x{r}/ToRGB/mod_bias'] + 1,
|
| 202 |
+
r'synthesis\.b(\d+)\.skip\.weight', lambda r: tf_params[f'synthesis/{r}x{r}/Skip/weight'][::-1, ::-1].transpose(3, 2, 0, 1),
|
| 203 |
+
r'.*\.resample_filter', None,
|
| 204 |
+
r'.*\.act_filter', None,
|
| 205 |
+
)
|
| 206 |
+
return G
|
| 207 |
+
|
| 208 |
+
#----------------------------------------------------------------------------
|
| 209 |
+
|
| 210 |
+
def convert_tf_discriminator(tf_D):
|
| 211 |
+
if tf_D.version < 4:
|
| 212 |
+
raise ValueError('TensorFlow pickle version too low')
|
| 213 |
+
|
| 214 |
+
# Collect kwargs.
|
| 215 |
+
tf_kwargs = tf_D.static_kwargs
|
| 216 |
+
known_kwargs = set()
|
| 217 |
+
def kwarg(tf_name, default=None):
|
| 218 |
+
known_kwargs.add(tf_name)
|
| 219 |
+
return tf_kwargs.get(tf_name, default)
|
| 220 |
+
|
| 221 |
+
# Convert kwargs.
|
| 222 |
+
kwargs = dnnlib.EasyDict(
|
| 223 |
+
c_dim = kwarg('label_size', 0),
|
| 224 |
+
img_resolution = kwarg('resolution', 1024),
|
| 225 |
+
img_channels = kwarg('num_channels', 3),
|
| 226 |
+
architecture = kwarg('architecture', 'resnet'),
|
| 227 |
+
channel_base = kwarg('fmap_base', 16384) * 2,
|
| 228 |
+
channel_max = kwarg('fmap_max', 512),
|
| 229 |
+
num_fp16_res = kwarg('num_fp16_res', 0),
|
| 230 |
+
conv_clamp = kwarg('conv_clamp', None),
|
| 231 |
+
cmap_dim = kwarg('mapping_fmaps', None),
|
| 232 |
+
block_kwargs = dnnlib.EasyDict(
|
| 233 |
+
activation = kwarg('nonlinearity', 'lrelu'),
|
| 234 |
+
resample_filter = kwarg('resample_kernel', [1,3,3,1]),
|
| 235 |
+
freeze_layers = kwarg('freeze_layers', 0),
|
| 236 |
+
),
|
| 237 |
+
mapping_kwargs = dnnlib.EasyDict(
|
| 238 |
+
num_layers = kwarg('mapping_layers', 0),
|
| 239 |
+
embed_features = kwarg('mapping_fmaps', None),
|
| 240 |
+
layer_features = kwarg('mapping_fmaps', None),
|
| 241 |
+
activation = kwarg('nonlinearity', 'lrelu'),
|
| 242 |
+
lr_multiplier = kwarg('mapping_lrmul', 0.1),
|
| 243 |
+
),
|
| 244 |
+
epilogue_kwargs = dnnlib.EasyDict(
|
| 245 |
+
mbstd_group_size = kwarg('mbstd_group_size', None),
|
| 246 |
+
mbstd_num_channels = kwarg('mbstd_num_features', 1),
|
| 247 |
+
activation = kwarg('nonlinearity', 'lrelu'),
|
| 248 |
+
),
|
| 249 |
+
)
|
| 250 |
+
|
| 251 |
+
# Check for unknown kwargs.
|
| 252 |
+
kwarg('structure')
|
| 253 |
+
kwarg('conditioning')
|
| 254 |
+
unknown_kwargs = list(set(tf_kwargs.keys()) - known_kwargs)
|
| 255 |
+
if len(unknown_kwargs) > 0:
|
| 256 |
+
raise ValueError('Unknown TensorFlow kwarg', unknown_kwargs[0])
|
| 257 |
+
|
| 258 |
+
# Collect params.
|
| 259 |
+
tf_params = _collect_tf_params(tf_D)
|
| 260 |
+
for name, value in list(tf_params.items()):
|
| 261 |
+
match = re.fullmatch(r'FromRGB_lod(\d+)/(.*)', name)
|
| 262 |
+
if match:
|
| 263 |
+
r = kwargs.img_resolution // (2 ** int(match.group(1)))
|
| 264 |
+
tf_params[f'{r}x{r}/FromRGB/{match.group(2)}'] = value
|
| 265 |
+
kwargs.architecture = 'orig'
|
| 266 |
+
#for name, value in tf_params.items(): print(f'{name:<50s}{list(value.shape)}')
|
| 267 |
+
|
| 268 |
+
# Convert params.
|
| 269 |
+
from training import networks_stylegan2
|
| 270 |
+
D = networks_stylegan2.Discriminator(**kwargs).eval().requires_grad_(False)
|
| 271 |
+
# pylint: disable=unnecessary-lambda
|
| 272 |
+
# pylint: disable=f-string-without-interpolation
|
| 273 |
+
_populate_module_params(D,
|
| 274 |
+
r'b(\d+)\.fromrgb\.weight', lambda r: tf_params[f'{r}x{r}/FromRGB/weight'].transpose(3, 2, 0, 1),
|
| 275 |
+
r'b(\d+)\.fromrgb\.bias', lambda r: tf_params[f'{r}x{r}/FromRGB/bias'],
|
| 276 |
+
r'b(\d+)\.conv(\d+)\.weight', lambda r, i: tf_params[f'{r}x{r}/Conv{i}{["","_down"][int(i)]}/weight'].transpose(3, 2, 0, 1),
|
| 277 |
+
r'b(\d+)\.conv(\d+)\.bias', lambda r, i: tf_params[f'{r}x{r}/Conv{i}{["","_down"][int(i)]}/bias'],
|
| 278 |
+
r'b(\d+)\.skip\.weight', lambda r: tf_params[f'{r}x{r}/Skip/weight'].transpose(3, 2, 0, 1),
|
| 279 |
+
r'mapping\.embed\.weight', lambda: tf_params[f'LabelEmbed/weight'].transpose(),
|
| 280 |
+
r'mapping\.embed\.bias', lambda: tf_params[f'LabelEmbed/bias'],
|
| 281 |
+
r'mapping\.fc(\d+)\.weight', lambda i: tf_params[f'Mapping{i}/weight'].transpose(),
|
| 282 |
+
r'mapping\.fc(\d+)\.bias', lambda i: tf_params[f'Mapping{i}/bias'],
|
| 283 |
+
r'b4\.conv\.weight', lambda: tf_params[f'4x4/Conv/weight'].transpose(3, 2, 0, 1),
|
| 284 |
+
r'b4\.conv\.bias', lambda: tf_params[f'4x4/Conv/bias'],
|
| 285 |
+
r'b4\.fc\.weight', lambda: tf_params[f'4x4/Dense0/weight'].transpose(),
|
| 286 |
+
r'b4\.fc\.bias', lambda: tf_params[f'4x4/Dense0/bias'],
|
| 287 |
+
r'b4\.out\.weight', lambda: tf_params[f'Output/weight'].transpose(),
|
| 288 |
+
r'b4\.out\.bias', lambda: tf_params[f'Output/bias'],
|
| 289 |
+
r'.*\.resample_filter', None,
|
| 290 |
+
)
|
| 291 |
+
return D
|
| 292 |
+
|
| 293 |
+
#----------------------------------------------------------------------------
|
| 294 |
+
|
| 295 |
+
@click.command()
|
| 296 |
+
@click.option('--source', help='Input pickle', required=True, metavar='PATH')
|
| 297 |
+
@click.option('--dest', help='Output pickle', required=True, metavar='PATH')
|
| 298 |
+
@click.option('--force-fp16', help='Force the networks to use FP16', type=bool, default=False, metavar='BOOL', show_default=True)
|
| 299 |
+
def convert_network_pickle(source, dest, force_fp16):
|
| 300 |
+
"""Convert legacy network pickle into the native PyTorch format.
|
| 301 |
+
|
| 302 |
+
The tool is able to load the main network configurations exported using the TensorFlow version of StyleGAN2 or StyleGAN2-ADA.
|
| 303 |
+
It does not support e.g. StyleGAN2-ADA comparison methods, StyleGAN2 configs A-D, or StyleGAN1 networks.
|
| 304 |
+
|
| 305 |
+
Example:
|
| 306 |
+
|
| 307 |
+
\b
|
| 308 |
+
python legacy.py \\
|
| 309 |
+
--source=https://nvlabs-fi-cdn.nvidia.com/stylegan2/networks/stylegan2-cat-config-f.pkl \\
|
| 310 |
+
--dest=stylegan2-cat-config-f.pkl
|
| 311 |
+
"""
|
| 312 |
+
print(f'Loading "{source}"...')
|
| 313 |
+
with dnnlib.util.open_url(source) as f:
|
| 314 |
+
data = load_network_pkl(f, force_fp16=force_fp16)
|
| 315 |
+
print(f'Saving "{dest}"...')
|
| 316 |
+
with open(dest, 'wb') as f:
|
| 317 |
+
pickle.dump(data, f)
|
| 318 |
+
print('Done.')
|
| 319 |
+
|
| 320 |
+
#----------------------------------------------------------------------------
|
| 321 |
+
|
| 322 |
+
if __name__ == "__main__":
|
| 323 |
+
convert_network_pickle() # pylint: disable=no-value-for-parameter
|
| 324 |
+
|
| 325 |
+
#----------------------------------------------------------------------------
|
eg3d/metrics/__init__.py
ADDED
|
@@ -0,0 +1,11 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# SPDX-FileCopyrightText: Copyright (c) 2021-2022 NVIDIA CORPORATION & AFFILIATES. All rights reserved.
|
| 2 |
+
# SPDX-License-Identifier: LicenseRef-NvidiaProprietary
|
| 3 |
+
#
|
| 4 |
+
# NVIDIA CORPORATION, its affiliates and licensors retain all intellectual
|
| 5 |
+
# property and proprietary rights in and to this material, related
|
| 6 |
+
# documentation and any modifications thereto. Any use, reproduction,
|
| 7 |
+
# disclosure or distribution of this material and related documentation
|
| 8 |
+
# without an express license agreement from NVIDIA CORPORATION or
|
| 9 |
+
# its affiliates is strictly prohibited.
|
| 10 |
+
|
| 11 |
+
# empty
|
eg3d/metrics/equivariance.py
ADDED
|
@@ -0,0 +1,269 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# SPDX-FileCopyrightText: Copyright (c) 2021-2022 NVIDIA CORPORATION & AFFILIATES. All rights reserved.
|
| 2 |
+
# SPDX-License-Identifier: LicenseRef-NvidiaProprietary
|
| 3 |
+
#
|
| 4 |
+
# NVIDIA CORPORATION, its affiliates and licensors retain all intellectual
|
| 5 |
+
# property and proprietary rights in and to this material, related
|
| 6 |
+
# documentation and any modifications thereto. Any use, reproduction,
|
| 7 |
+
# disclosure or distribution of this material and related documentation
|
| 8 |
+
# without an express license agreement from NVIDIA CORPORATION or
|
| 9 |
+
# its affiliates is strictly prohibited.
|
| 10 |
+
|
| 11 |
+
"""Equivariance metrics (EQ-T, EQ-T_frac, and EQ-R) from the paper
|
| 12 |
+
"Alias-Free Generative Adversarial Networks"."""
|
| 13 |
+
|
| 14 |
+
import copy
|
| 15 |
+
import numpy as np
|
| 16 |
+
import torch
|
| 17 |
+
import torch.fft
|
| 18 |
+
from torch_utils.ops import upfirdn2d
|
| 19 |
+
from . import metric_utils
|
| 20 |
+
|
| 21 |
+
#----------------------------------------------------------------------------
|
| 22 |
+
# Utilities.
|
| 23 |
+
|
| 24 |
+
def sinc(x):
|
| 25 |
+
y = (x * np.pi).abs()
|
| 26 |
+
z = torch.sin(y) / y.clamp(1e-30, float('inf'))
|
| 27 |
+
return torch.where(y < 1e-30, torch.ones_like(x), z)
|
| 28 |
+
|
| 29 |
+
def lanczos_window(x, a):
|
| 30 |
+
x = x.abs() / a
|
| 31 |
+
return torch.where(x < 1, sinc(x), torch.zeros_like(x))
|
| 32 |
+
|
| 33 |
+
def rotation_matrix(angle):
|
| 34 |
+
angle = torch.as_tensor(angle).to(torch.float32)
|
| 35 |
+
mat = torch.eye(3, device=angle.device)
|
| 36 |
+
mat[0, 0] = angle.cos()
|
| 37 |
+
mat[0, 1] = angle.sin()
|
| 38 |
+
mat[1, 0] = -angle.sin()
|
| 39 |
+
mat[1, 1] = angle.cos()
|
| 40 |
+
return mat
|
| 41 |
+
|
| 42 |
+
#----------------------------------------------------------------------------
|
| 43 |
+
# Apply integer translation to a batch of 2D images. Corresponds to the
|
| 44 |
+
# operator T_x in Appendix E.1.
|
| 45 |
+
|
| 46 |
+
def apply_integer_translation(x, tx, ty):
|
| 47 |
+
_N, _C, H, W = x.shape
|
| 48 |
+
tx = torch.as_tensor(tx * W).to(dtype=torch.float32, device=x.device)
|
| 49 |
+
ty = torch.as_tensor(ty * H).to(dtype=torch.float32, device=x.device)
|
| 50 |
+
ix = tx.round().to(torch.int64)
|
| 51 |
+
iy = ty.round().to(torch.int64)
|
| 52 |
+
|
| 53 |
+
z = torch.zeros_like(x)
|
| 54 |
+
m = torch.zeros_like(x)
|
| 55 |
+
if abs(ix) < W and abs(iy) < H:
|
| 56 |
+
y = x[:, :, max(-iy,0) : H+min(-iy,0), max(-ix,0) : W+min(-ix,0)]
|
| 57 |
+
z[:, :, max(iy,0) : H+min(iy,0), max(ix,0) : W+min(ix,0)] = y
|
| 58 |
+
m[:, :, max(iy,0) : H+min(iy,0), max(ix,0) : W+min(ix,0)] = 1
|
| 59 |
+
return z, m
|
| 60 |
+
|
| 61 |
+
#----------------------------------------------------------------------------
|
| 62 |
+
# Apply integer translation to a batch of 2D images. Corresponds to the
|
| 63 |
+
# operator T_x in Appendix E.2.
|
| 64 |
+
|
| 65 |
+
def apply_fractional_translation(x, tx, ty, a=3):
|
| 66 |
+
_N, _C, H, W = x.shape
|
| 67 |
+
tx = torch.as_tensor(tx * W).to(dtype=torch.float32, device=x.device)
|
| 68 |
+
ty = torch.as_tensor(ty * H).to(dtype=torch.float32, device=x.device)
|
| 69 |
+
ix = tx.floor().to(torch.int64)
|
| 70 |
+
iy = ty.floor().to(torch.int64)
|
| 71 |
+
fx = tx - ix
|
| 72 |
+
fy = ty - iy
|
| 73 |
+
b = a - 1
|
| 74 |
+
|
| 75 |
+
z = torch.zeros_like(x)
|
| 76 |
+
zx0 = max(ix - b, 0)
|
| 77 |
+
zy0 = max(iy - b, 0)
|
| 78 |
+
zx1 = min(ix + a, 0) + W
|
| 79 |
+
zy1 = min(iy + a, 0) + H
|
| 80 |
+
if zx0 < zx1 and zy0 < zy1:
|
| 81 |
+
taps = torch.arange(a * 2, device=x.device) - b
|
| 82 |
+
filter_x = (sinc(taps - fx) * sinc((taps - fx) / a)).unsqueeze(0)
|
| 83 |
+
filter_y = (sinc(taps - fy) * sinc((taps - fy) / a)).unsqueeze(1)
|
| 84 |
+
y = x
|
| 85 |
+
y = upfirdn2d.filter2d(y, filter_x / filter_x.sum(), padding=[b,a,0,0])
|
| 86 |
+
y = upfirdn2d.filter2d(y, filter_y / filter_y.sum(), padding=[0,0,b,a])
|
| 87 |
+
y = y[:, :, max(b-iy,0) : H+b+a+min(-iy-a,0), max(b-ix,0) : W+b+a+min(-ix-a,0)]
|
| 88 |
+
z[:, :, zy0:zy1, zx0:zx1] = y
|
| 89 |
+
|
| 90 |
+
m = torch.zeros_like(x)
|
| 91 |
+
mx0 = max(ix + a, 0)
|
| 92 |
+
my0 = max(iy + a, 0)
|
| 93 |
+
mx1 = min(ix - b, 0) + W
|
| 94 |
+
my1 = min(iy - b, 0) + H
|
| 95 |
+
if mx0 < mx1 and my0 < my1:
|
| 96 |
+
m[:, :, my0:my1, mx0:mx1] = 1
|
| 97 |
+
return z, m
|
| 98 |
+
|
| 99 |
+
#----------------------------------------------------------------------------
|
| 100 |
+
# Construct an oriented low-pass filter that applies the appropriate
|
| 101 |
+
# bandlimit with respect to the input and output of the given affine 2D
|
| 102 |
+
# image transformation.
|
| 103 |
+
|
| 104 |
+
def construct_affine_bandlimit_filter(mat, a=3, amax=16, aflt=64, up=4, cutoff_in=1, cutoff_out=1):
|
| 105 |
+
assert a <= amax < aflt
|
| 106 |
+
mat = torch.as_tensor(mat).to(torch.float32)
|
| 107 |
+
|
| 108 |
+
# Construct 2D filter taps in input & output coordinate spaces.
|
| 109 |
+
taps = ((torch.arange(aflt * up * 2 - 1, device=mat.device) + 1) / up - aflt).roll(1 - aflt * up)
|
| 110 |
+
yi, xi = torch.meshgrid(taps, taps)
|
| 111 |
+
xo, yo = (torch.stack([xi, yi], dim=2) @ mat[:2, :2].t()).unbind(2)
|
| 112 |
+
|
| 113 |
+
# Convolution of two oriented 2D sinc filters.
|
| 114 |
+
fi = sinc(xi * cutoff_in) * sinc(yi * cutoff_in)
|
| 115 |
+
fo = sinc(xo * cutoff_out) * sinc(yo * cutoff_out)
|
| 116 |
+
f = torch.fft.ifftn(torch.fft.fftn(fi) * torch.fft.fftn(fo)).real
|
| 117 |
+
|
| 118 |
+
# Convolution of two oriented 2D Lanczos windows.
|
| 119 |
+
wi = lanczos_window(xi, a) * lanczos_window(yi, a)
|
| 120 |
+
wo = lanczos_window(xo, a) * lanczos_window(yo, a)
|
| 121 |
+
w = torch.fft.ifftn(torch.fft.fftn(wi) * torch.fft.fftn(wo)).real
|
| 122 |
+
|
| 123 |
+
# Construct windowed FIR filter.
|
| 124 |
+
f = f * w
|
| 125 |
+
|
| 126 |
+
# Finalize.
|
| 127 |
+
c = (aflt - amax) * up
|
| 128 |
+
f = f.roll([aflt * up - 1] * 2, dims=[0,1])[c:-c, c:-c]
|
| 129 |
+
f = torch.nn.functional.pad(f, [0, 1, 0, 1]).reshape(amax * 2, up, amax * 2, up)
|
| 130 |
+
f = f / f.sum([0,2], keepdim=True) / (up ** 2)
|
| 131 |
+
f = f.reshape(amax * 2 * up, amax * 2 * up)[:-1, :-1]
|
| 132 |
+
return f
|
| 133 |
+
|
| 134 |
+
#----------------------------------------------------------------------------
|
| 135 |
+
# Apply the given affine transformation to a batch of 2D images.
|
| 136 |
+
|
| 137 |
+
def apply_affine_transformation(x, mat, up=4, **filter_kwargs):
|
| 138 |
+
_N, _C, H, W = x.shape
|
| 139 |
+
mat = torch.as_tensor(mat).to(dtype=torch.float32, device=x.device)
|
| 140 |
+
|
| 141 |
+
# Construct filter.
|
| 142 |
+
f = construct_affine_bandlimit_filter(mat, up=up, **filter_kwargs)
|
| 143 |
+
assert f.ndim == 2 and f.shape[0] == f.shape[1] and f.shape[0] % 2 == 1
|
| 144 |
+
p = f.shape[0] // 2
|
| 145 |
+
|
| 146 |
+
# Construct sampling grid.
|
| 147 |
+
theta = mat.inverse()
|
| 148 |
+
theta[:2, 2] *= 2
|
| 149 |
+
theta[0, 2] += 1 / up / W
|
| 150 |
+
theta[1, 2] += 1 / up / H
|
| 151 |
+
theta[0, :] *= W / (W + p / up * 2)
|
| 152 |
+
theta[1, :] *= H / (H + p / up * 2)
|
| 153 |
+
theta = theta[:2, :3].unsqueeze(0).repeat([x.shape[0], 1, 1])
|
| 154 |
+
g = torch.nn.functional.affine_grid(theta, x.shape, align_corners=False)
|
| 155 |
+
|
| 156 |
+
# Resample image.
|
| 157 |
+
y = upfirdn2d.upsample2d(x=x, f=f, up=up, padding=p)
|
| 158 |
+
z = torch.nn.functional.grid_sample(y, g, mode='bilinear', padding_mode='zeros', align_corners=False)
|
| 159 |
+
|
| 160 |
+
# Form mask.
|
| 161 |
+
m = torch.zeros_like(y)
|
| 162 |
+
c = p * 2 + 1
|
| 163 |
+
m[:, :, c:-c, c:-c] = 1
|
| 164 |
+
m = torch.nn.functional.grid_sample(m, g, mode='nearest', padding_mode='zeros', align_corners=False)
|
| 165 |
+
return z, m
|
| 166 |
+
|
| 167 |
+
#----------------------------------------------------------------------------
|
| 168 |
+
# Apply fractional rotation to a batch of 2D images. Corresponds to the
|
| 169 |
+
# operator R_\alpha in Appendix E.3.
|
| 170 |
+
|
| 171 |
+
def apply_fractional_rotation(x, angle, a=3, **filter_kwargs):
|
| 172 |
+
angle = torch.as_tensor(angle).to(dtype=torch.float32, device=x.device)
|
| 173 |
+
mat = rotation_matrix(angle)
|
| 174 |
+
return apply_affine_transformation(x, mat, a=a, amax=a*2, **filter_kwargs)
|
| 175 |
+
|
| 176 |
+
#----------------------------------------------------------------------------
|
| 177 |
+
# Modify the frequency content of a batch of 2D images as if they had undergo
|
| 178 |
+
# fractional rotation -- but without actually rotating them. Corresponds to
|
| 179 |
+
# the operator R^*_\alpha in Appendix E.3.
|
| 180 |
+
|
| 181 |
+
def apply_fractional_pseudo_rotation(x, angle, a=3, **filter_kwargs):
|
| 182 |
+
angle = torch.as_tensor(angle).to(dtype=torch.float32, device=x.device)
|
| 183 |
+
mat = rotation_matrix(-angle)
|
| 184 |
+
f = construct_affine_bandlimit_filter(mat, a=a, amax=a*2, up=1, **filter_kwargs)
|
| 185 |
+
y = upfirdn2d.filter2d(x=x, f=f)
|
| 186 |
+
m = torch.zeros_like(y)
|
| 187 |
+
c = f.shape[0] // 2
|
| 188 |
+
m[:, :, c:-c, c:-c] = 1
|
| 189 |
+
return y, m
|
| 190 |
+
|
| 191 |
+
#----------------------------------------------------------------------------
|
| 192 |
+
# Compute the selected equivariance metrics for the given generator.
|
| 193 |
+
|
| 194 |
+
def compute_equivariance_metrics(opts, num_samples, batch_size, translate_max=0.125, rotate_max=1, compute_eqt_int=False, compute_eqt_frac=False, compute_eqr=False):
|
| 195 |
+
assert compute_eqt_int or compute_eqt_frac or compute_eqr
|
| 196 |
+
|
| 197 |
+
# Setup generator and labels.
|
| 198 |
+
G = copy.deepcopy(opts.G).eval().requires_grad_(False).to(opts.device)
|
| 199 |
+
I = torch.eye(3, device=opts.device)
|
| 200 |
+
M = getattr(getattr(getattr(G, 'synthesis', None), 'input', None), 'transform', None)
|
| 201 |
+
if M is None:
|
| 202 |
+
raise ValueError('Cannot compute equivariance metrics; the given generator does not support user-specified image transformations')
|
| 203 |
+
c_iter = metric_utils.iterate_random_labels(opts=opts, batch_size=batch_size)
|
| 204 |
+
|
| 205 |
+
# Sampling loop.
|
| 206 |
+
sums = None
|
| 207 |
+
progress = opts.progress.sub(tag='eq sampling', num_items=num_samples)
|
| 208 |
+
for batch_start in range(0, num_samples, batch_size * opts.num_gpus):
|
| 209 |
+
progress.update(batch_start)
|
| 210 |
+
s = []
|
| 211 |
+
|
| 212 |
+
# Randomize noise buffers, if any.
|
| 213 |
+
for name, buf in G.named_buffers():
|
| 214 |
+
if name.endswith('.noise_const'):
|
| 215 |
+
buf.copy_(torch.randn_like(buf))
|
| 216 |
+
|
| 217 |
+
# Run mapping network.
|
| 218 |
+
z = torch.randn([batch_size, G.z_dim], device=opts.device)
|
| 219 |
+
c = next(c_iter)
|
| 220 |
+
ws = G.mapping(z=z, c=c)
|
| 221 |
+
|
| 222 |
+
# Generate reference image.
|
| 223 |
+
M[:] = I
|
| 224 |
+
orig = G.synthesis(ws=ws, noise_mode='const', **opts.G_kwargs)
|
| 225 |
+
|
| 226 |
+
# Integer translation (EQ-T).
|
| 227 |
+
if compute_eqt_int:
|
| 228 |
+
t = (torch.rand(2, device=opts.device) * 2 - 1) * translate_max
|
| 229 |
+
t = (t * G.img_resolution).round() / G.img_resolution
|
| 230 |
+
M[:] = I
|
| 231 |
+
M[:2, 2] = -t
|
| 232 |
+
img = G.synthesis(ws=ws, noise_mode='const', **opts.G_kwargs)
|
| 233 |
+
ref, mask = apply_integer_translation(orig, t[0], t[1])
|
| 234 |
+
s += [(ref - img).square() * mask, mask]
|
| 235 |
+
|
| 236 |
+
# Fractional translation (EQ-T_frac).
|
| 237 |
+
if compute_eqt_frac:
|
| 238 |
+
t = (torch.rand(2, device=opts.device) * 2 - 1) * translate_max
|
| 239 |
+
M[:] = I
|
| 240 |
+
M[:2, 2] = -t
|
| 241 |
+
img = G.synthesis(ws=ws, noise_mode='const', **opts.G_kwargs)
|
| 242 |
+
ref, mask = apply_fractional_translation(orig, t[0], t[1])
|
| 243 |
+
s += [(ref - img).square() * mask, mask]
|
| 244 |
+
|
| 245 |
+
# Rotation (EQ-R).
|
| 246 |
+
if compute_eqr:
|
| 247 |
+
angle = (torch.rand([], device=opts.device) * 2 - 1) * (rotate_max * np.pi)
|
| 248 |
+
M[:] = rotation_matrix(-angle)
|
| 249 |
+
img = G.synthesis(ws=ws, noise_mode='const', **opts.G_kwargs)
|
| 250 |
+
ref, ref_mask = apply_fractional_rotation(orig, angle)
|
| 251 |
+
pseudo, pseudo_mask = apply_fractional_pseudo_rotation(img, angle)
|
| 252 |
+
mask = ref_mask * pseudo_mask
|
| 253 |
+
s += [(ref - pseudo).square() * mask, mask]
|
| 254 |
+
|
| 255 |
+
# Accumulate results.
|
| 256 |
+
s = torch.stack([x.to(torch.float64).sum() for x in s])
|
| 257 |
+
sums = sums + s if sums is not None else s
|
| 258 |
+
progress.update(num_samples)
|
| 259 |
+
|
| 260 |
+
# Compute PSNRs.
|
| 261 |
+
if opts.num_gpus > 1:
|
| 262 |
+
torch.distributed.all_reduce(sums)
|
| 263 |
+
sums = sums.cpu()
|
| 264 |
+
mses = sums[0::2] / sums[1::2]
|
| 265 |
+
psnrs = np.log10(2) * 20 - mses.log10() * 10
|
| 266 |
+
psnrs = tuple(psnrs.numpy())
|
| 267 |
+
return psnrs[0] if len(psnrs) == 1 else psnrs
|
| 268 |
+
|
| 269 |
+
#----------------------------------------------------------------------------
|
eg3d/metrics/frechet_inception_distance.py
ADDED
|
@@ -0,0 +1,43 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# SPDX-FileCopyrightText: Copyright (c) 2021-2022 NVIDIA CORPORATION & AFFILIATES. All rights reserved.
|
| 2 |
+
# SPDX-License-Identifier: LicenseRef-NvidiaProprietary
|
| 3 |
+
#
|
| 4 |
+
# NVIDIA CORPORATION, its affiliates and licensors retain all intellectual
|
| 5 |
+
# property and proprietary rights in and to this material, related
|
| 6 |
+
# documentation and any modifications thereto. Any use, reproduction,
|
| 7 |
+
# disclosure or distribution of this material and related documentation
|
| 8 |
+
# without an express license agreement from NVIDIA CORPORATION or
|
| 9 |
+
# its affiliates is strictly prohibited.
|
| 10 |
+
|
| 11 |
+
"""Frechet Inception Distance (FID) from the paper
|
| 12 |
+
"GANs trained by a two time-scale update rule converge to a local Nash
|
| 13 |
+
equilibrium". Matches the original implementation by Heusel et al. at
|
| 14 |
+
https://github.com/bioinf-jku/TTUR/blob/master/fid.py"""
|
| 15 |
+
|
| 16 |
+
import numpy as np
|
| 17 |
+
import scipy.linalg
|
| 18 |
+
from . import metric_utils
|
| 19 |
+
|
| 20 |
+
#----------------------------------------------------------------------------
|
| 21 |
+
|
| 22 |
+
def compute_fid(opts, max_real, num_gen):
|
| 23 |
+
# Direct TorchScript translation of http://download.tensorflow.org/models/image/imagenet/inception-2015-12-05.tgz
|
| 24 |
+
detector_url = 'https://api.ngc.nvidia.com/v2/models/nvidia/research/stylegan3/versions/1/files/metrics/inception-2015-12-05.pkl'
|
| 25 |
+
detector_kwargs = dict(return_features=True) # Return raw features before the softmax layer.
|
| 26 |
+
|
| 27 |
+
mu_real, sigma_real = metric_utils.compute_feature_stats_for_dataset(
|
| 28 |
+
opts=opts, detector_url=detector_url, detector_kwargs=detector_kwargs,
|
| 29 |
+
rel_lo=0, rel_hi=0, capture_mean_cov=True, max_items=max_real).get_mean_cov()
|
| 30 |
+
|
| 31 |
+
mu_gen, sigma_gen = metric_utils.compute_feature_stats_for_generator(
|
| 32 |
+
opts=opts, detector_url=detector_url, detector_kwargs=detector_kwargs,
|
| 33 |
+
rel_lo=0, rel_hi=1, capture_mean_cov=True, max_items=num_gen).get_mean_cov()
|
| 34 |
+
|
| 35 |
+
if opts.rank != 0:
|
| 36 |
+
return float('nan')
|
| 37 |
+
|
| 38 |
+
m = np.square(mu_gen - mu_real).sum()
|
| 39 |
+
s, _ = scipy.linalg.sqrtm(np.dot(sigma_gen, sigma_real), disp=False) # pylint: disable=no-member
|
| 40 |
+
fid = np.real(m + np.trace(sigma_gen + sigma_real - s * 2))
|
| 41 |
+
return float(fid)
|
| 42 |
+
|
| 43 |
+
#----------------------------------------------------------------------------
|
eg3d/metrics/inception_score.py
ADDED
|
@@ -0,0 +1,40 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# SPDX-FileCopyrightText: Copyright (c) 2021-2022 NVIDIA CORPORATION & AFFILIATES. All rights reserved.
|
| 2 |
+
# SPDX-License-Identifier: LicenseRef-NvidiaProprietary
|
| 3 |
+
#
|
| 4 |
+
# NVIDIA CORPORATION, its affiliates and licensors retain all intellectual
|
| 5 |
+
# property and proprietary rights in and to this material, related
|
| 6 |
+
# documentation and any modifications thereto. Any use, reproduction,
|
| 7 |
+
# disclosure or distribution of this material and related documentation
|
| 8 |
+
# without an express license agreement from NVIDIA CORPORATION or
|
| 9 |
+
# its affiliates is strictly prohibited.
|
| 10 |
+
|
| 11 |
+
"""Inception Score (IS) from the paper "Improved techniques for training
|
| 12 |
+
GANs". Matches the original implementation by Salimans et al. at
|
| 13 |
+
https://github.com/openai/improved-gan/blob/master/inception_score/model.py"""
|
| 14 |
+
|
| 15 |
+
import numpy as np
|
| 16 |
+
from . import metric_utils
|
| 17 |
+
|
| 18 |
+
#----------------------------------------------------------------------------
|
| 19 |
+
|
| 20 |
+
def compute_is(opts, num_gen, num_splits):
|
| 21 |
+
# Direct TorchScript translation of http://download.tensorflow.org/models/image/imagenet/inception-2015-12-05.tgz
|
| 22 |
+
detector_url = 'https://api.ngc.nvidia.com/v2/models/nvidia/research/stylegan3/versions/1/files/metrics/inception-2015-12-05.pkl'
|
| 23 |
+
detector_kwargs = dict(no_output_bias=True) # Match the original implementation by not applying bias in the softmax layer.
|
| 24 |
+
|
| 25 |
+
gen_probs = metric_utils.compute_feature_stats_for_generator(
|
| 26 |
+
opts=opts, detector_url=detector_url, detector_kwargs=detector_kwargs,
|
| 27 |
+
capture_all=True, max_items=num_gen).get_all()
|
| 28 |
+
|
| 29 |
+
if opts.rank != 0:
|
| 30 |
+
return float('nan'), float('nan')
|
| 31 |
+
|
| 32 |
+
scores = []
|
| 33 |
+
for i in range(num_splits):
|
| 34 |
+
part = gen_probs[i * num_gen // num_splits : (i + 1) * num_gen // num_splits]
|
| 35 |
+
kl = part * (np.log(part) - np.log(np.mean(part, axis=0, keepdims=True)))
|
| 36 |
+
kl = np.mean(np.sum(kl, axis=1))
|
| 37 |
+
scores.append(np.exp(kl))
|
| 38 |
+
return float(np.mean(scores)), float(np.std(scores))
|
| 39 |
+
|
| 40 |
+
#----------------------------------------------------------------------------
|
eg3d/metrics/kernel_inception_distance.py
ADDED
|
@@ -0,0 +1,48 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# SPDX-FileCopyrightText: Copyright (c) 2021-2022 NVIDIA CORPORATION & AFFILIATES. All rights reserved.
|
| 2 |
+
# SPDX-License-Identifier: LicenseRef-NvidiaProprietary
|
| 3 |
+
#
|
| 4 |
+
# NVIDIA CORPORATION, its affiliates and licensors retain all intellectual
|
| 5 |
+
# property and proprietary rights in and to this material, related
|
| 6 |
+
# documentation and any modifications thereto. Any use, reproduction,
|
| 7 |
+
# disclosure or distribution of this material and related documentation
|
| 8 |
+
# without an express license agreement from NVIDIA CORPORATION or
|
| 9 |
+
# its affiliates is strictly prohibited.
|
| 10 |
+
|
| 11 |
+
"""Kernel Inception Distance (KID) from the paper "Demystifying MMD
|
| 12 |
+
GANs". Matches the original implementation by Binkowski et al. at
|
| 13 |
+
https://github.com/mbinkowski/MMD-GAN/blob/master/gan/compute_scores.py"""
|
| 14 |
+
|
| 15 |
+
import numpy as np
|
| 16 |
+
from . import metric_utils
|
| 17 |
+
|
| 18 |
+
#----------------------------------------------------------------------------
|
| 19 |
+
|
| 20 |
+
def compute_kid(opts, max_real, num_gen, num_subsets, max_subset_size):
|
| 21 |
+
# Direct TorchScript translation of http://download.tensorflow.org/models/image/imagenet/inception-2015-12-05.tgz
|
| 22 |
+
detector_url = 'https://api.ngc.nvidia.com/v2/models/nvidia/research/stylegan3/versions/1/files/metrics/inception-2015-12-05.pkl'
|
| 23 |
+
detector_kwargs = dict(return_features=True) # Return raw features before the softmax layer.
|
| 24 |
+
|
| 25 |
+
real_features = metric_utils.compute_feature_stats_for_dataset(
|
| 26 |
+
opts=opts, detector_url=detector_url, detector_kwargs=detector_kwargs,
|
| 27 |
+
rel_lo=0, rel_hi=0, capture_all=True, max_items=max_real).get_all()
|
| 28 |
+
|
| 29 |
+
gen_features = metric_utils.compute_feature_stats_for_generator(
|
| 30 |
+
opts=opts, detector_url=detector_url, detector_kwargs=detector_kwargs,
|
| 31 |
+
rel_lo=0, rel_hi=1, capture_all=True, max_items=num_gen).get_all()
|
| 32 |
+
|
| 33 |
+
if opts.rank != 0:
|
| 34 |
+
return float('nan')
|
| 35 |
+
|
| 36 |
+
n = real_features.shape[1]
|
| 37 |
+
m = min(min(real_features.shape[0], gen_features.shape[0]), max_subset_size)
|
| 38 |
+
t = 0
|
| 39 |
+
for _subset_idx in range(num_subsets):
|
| 40 |
+
x = gen_features[np.random.choice(gen_features.shape[0], m, replace=False)]
|
| 41 |
+
y = real_features[np.random.choice(real_features.shape[0], m, replace=False)]
|
| 42 |
+
a = (x @ x.T / n + 1) ** 3 + (y @ y.T / n + 1) ** 3
|
| 43 |
+
b = (x @ y.T / n + 1) ** 3
|
| 44 |
+
t += (a.sum() - np.diag(a).sum()) / (m - 1) - b.sum() * 2 / m
|
| 45 |
+
kid = t / num_subsets / m
|
| 46 |
+
return float(kid)
|
| 47 |
+
|
| 48 |
+
#----------------------------------------------------------------------------
|
eg3d/metrics/metric_main.py
ADDED
|
@@ -0,0 +1,155 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# SPDX-FileCopyrightText: Copyright (c) 2021-2022 NVIDIA CORPORATION & AFFILIATES. All rights reserved.
|
| 2 |
+
# SPDX-License-Identifier: LicenseRef-NvidiaProprietary
|
| 3 |
+
#
|
| 4 |
+
# NVIDIA CORPORATION, its affiliates and licensors retain all intellectual
|
| 5 |
+
# property and proprietary rights in and to this material, related
|
| 6 |
+
# documentation and any modifications thereto. Any use, reproduction,
|
| 7 |
+
# disclosure or distribution of this material and related documentation
|
| 8 |
+
# without an express license agreement from NVIDIA CORPORATION or
|
| 9 |
+
# its affiliates is strictly prohibited.
|
| 10 |
+
|
| 11 |
+
"""Main API for computing and reporting quality metrics."""
|
| 12 |
+
|
| 13 |
+
import os
|
| 14 |
+
import time
|
| 15 |
+
import json
|
| 16 |
+
import torch
|
| 17 |
+
import dnnlib
|
| 18 |
+
|
| 19 |
+
from . import metric_utils
|
| 20 |
+
from . import frechet_inception_distance
|
| 21 |
+
from . import kernel_inception_distance
|
| 22 |
+
from . import precision_recall
|
| 23 |
+
from . import perceptual_path_length
|
| 24 |
+
from . import inception_score
|
| 25 |
+
from . import equivariance
|
| 26 |
+
|
| 27 |
+
#----------------------------------------------------------------------------
|
| 28 |
+
|
| 29 |
+
_metric_dict = dict() # name => fn
|
| 30 |
+
|
| 31 |
+
def register_metric(fn):
|
| 32 |
+
assert callable(fn)
|
| 33 |
+
_metric_dict[fn.__name__] = fn
|
| 34 |
+
return fn
|
| 35 |
+
|
| 36 |
+
def is_valid_metric(metric):
|
| 37 |
+
return metric in _metric_dict
|
| 38 |
+
|
| 39 |
+
def list_valid_metrics():
|
| 40 |
+
return list(_metric_dict.keys())
|
| 41 |
+
|
| 42 |
+
#----------------------------------------------------------------------------
|
| 43 |
+
|
| 44 |
+
def calc_metric(metric, **kwargs): # See metric_utils.MetricOptions for the full list of arguments.
|
| 45 |
+
assert is_valid_metric(metric)
|
| 46 |
+
opts = metric_utils.MetricOptions(**kwargs)
|
| 47 |
+
|
| 48 |
+
# Calculate.
|
| 49 |
+
start_time = time.time()
|
| 50 |
+
results = _metric_dict[metric](opts)
|
| 51 |
+
total_time = time.time() - start_time
|
| 52 |
+
|
| 53 |
+
# Broadcast results.
|
| 54 |
+
for key, value in list(results.items()):
|
| 55 |
+
if opts.num_gpus > 1:
|
| 56 |
+
value = torch.as_tensor(value, dtype=torch.float64, device=opts.device)
|
| 57 |
+
torch.distributed.broadcast(tensor=value, src=0)
|
| 58 |
+
value = float(value.cpu())
|
| 59 |
+
results[key] = value
|
| 60 |
+
|
| 61 |
+
# Decorate with metadata.
|
| 62 |
+
return dnnlib.EasyDict(
|
| 63 |
+
results = dnnlib.EasyDict(results),
|
| 64 |
+
metric = metric,
|
| 65 |
+
total_time = total_time,
|
| 66 |
+
total_time_str = dnnlib.util.format_time(total_time),
|
| 67 |
+
num_gpus = opts.num_gpus,
|
| 68 |
+
)
|
| 69 |
+
|
| 70 |
+
#----------------------------------------------------------------------------
|
| 71 |
+
|
| 72 |
+
def report_metric(result_dict, run_dir=None, snapshot_pkl=None):
|
| 73 |
+
metric = result_dict['metric']
|
| 74 |
+
assert is_valid_metric(metric)
|
| 75 |
+
if run_dir is not None and snapshot_pkl is not None:
|
| 76 |
+
snapshot_pkl = os.path.relpath(snapshot_pkl, run_dir)
|
| 77 |
+
|
| 78 |
+
jsonl_line = json.dumps(dict(result_dict, snapshot_pkl=snapshot_pkl, timestamp=time.time()))
|
| 79 |
+
print(jsonl_line)
|
| 80 |
+
if run_dir is not None and os.path.isdir(run_dir):
|
| 81 |
+
with open(os.path.join(run_dir, f'metric-{metric}.jsonl'), 'at') as f:
|
| 82 |
+
f.write(jsonl_line + '\n')
|
| 83 |
+
|
| 84 |
+
#----------------------------------------------------------------------------
|
| 85 |
+
# Recommended metrics.
|
| 86 |
+
|
| 87 |
+
@register_metric
|
| 88 |
+
def fid50k_full(opts):
|
| 89 |
+
opts.dataset_kwargs.update(max_size=None, xflip=False)
|
| 90 |
+
fid = frechet_inception_distance.compute_fid(opts, max_real=None, num_gen=50000)
|
| 91 |
+
return dict(fid50k_full=fid)
|
| 92 |
+
|
| 93 |
+
@register_metric
|
| 94 |
+
def kid50k_full(opts):
|
| 95 |
+
opts.dataset_kwargs.update(max_size=None, xflip=False)
|
| 96 |
+
kid = kernel_inception_distance.compute_kid(opts, max_real=1000000, num_gen=50000, num_subsets=100, max_subset_size=1000)
|
| 97 |
+
return dict(kid50k_full=kid)
|
| 98 |
+
|
| 99 |
+
@register_metric
|
| 100 |
+
def pr50k3_full(opts):
|
| 101 |
+
opts.dataset_kwargs.update(max_size=None, xflip=False)
|
| 102 |
+
precision, recall = precision_recall.compute_pr(opts, max_real=200000, num_gen=50000, nhood_size=3, row_batch_size=10000, col_batch_size=10000)
|
| 103 |
+
return dict(pr50k3_full_precision=precision, pr50k3_full_recall=recall)
|
| 104 |
+
|
| 105 |
+
@register_metric
|
| 106 |
+
def ppl2_wend(opts):
|
| 107 |
+
ppl = perceptual_path_length.compute_ppl(opts, num_samples=50000, epsilon=1e-4, space='w', sampling='end', crop=False, batch_size=2)
|
| 108 |
+
return dict(ppl2_wend=ppl)
|
| 109 |
+
|
| 110 |
+
@register_metric
|
| 111 |
+
def eqt50k_int(opts):
|
| 112 |
+
opts.G_kwargs.update(force_fp32=True)
|
| 113 |
+
psnr = equivariance.compute_equivariance_metrics(opts, num_samples=50000, batch_size=4, compute_eqt_int=True)
|
| 114 |
+
return dict(eqt50k_int=psnr)
|
| 115 |
+
|
| 116 |
+
@register_metric
|
| 117 |
+
def eqt50k_frac(opts):
|
| 118 |
+
opts.G_kwargs.update(force_fp32=True)
|
| 119 |
+
psnr = equivariance.compute_equivariance_metrics(opts, num_samples=50000, batch_size=4, compute_eqt_frac=True)
|
| 120 |
+
return dict(eqt50k_frac=psnr)
|
| 121 |
+
|
| 122 |
+
@register_metric
|
| 123 |
+
def eqr50k(opts):
|
| 124 |
+
opts.G_kwargs.update(force_fp32=True)
|
| 125 |
+
psnr = equivariance.compute_equivariance_metrics(opts, num_samples=50000, batch_size=4, compute_eqr=True)
|
| 126 |
+
return dict(eqr50k=psnr)
|
| 127 |
+
|
| 128 |
+
#----------------------------------------------------------------------------
|
| 129 |
+
# Legacy metrics.
|
| 130 |
+
|
| 131 |
+
@register_metric
|
| 132 |
+
def fid50k(opts):
|
| 133 |
+
opts.dataset_kwargs.update(max_size=None)
|
| 134 |
+
fid = frechet_inception_distance.compute_fid(opts, max_real=50000, num_gen=50000)
|
| 135 |
+
return dict(fid50k=fid)
|
| 136 |
+
|
| 137 |
+
@register_metric
|
| 138 |
+
def kid50k(opts):
|
| 139 |
+
opts.dataset_kwargs.update(max_size=None)
|
| 140 |
+
kid = kernel_inception_distance.compute_kid(opts, max_real=50000, num_gen=50000, num_subsets=100, max_subset_size=1000)
|
| 141 |
+
return dict(kid50k=kid)
|
| 142 |
+
|
| 143 |
+
@register_metric
|
| 144 |
+
def pr50k3(opts):
|
| 145 |
+
opts.dataset_kwargs.update(max_size=None)
|
| 146 |
+
precision, recall = precision_recall.compute_pr(opts, max_real=50000, num_gen=50000, nhood_size=3, row_batch_size=10000, col_batch_size=10000)
|
| 147 |
+
return dict(pr50k3_precision=precision, pr50k3_recall=recall)
|
| 148 |
+
|
| 149 |
+
@register_metric
|
| 150 |
+
def is50k(opts):
|
| 151 |
+
opts.dataset_kwargs.update(max_size=None, xflip=False)
|
| 152 |
+
mean, std = inception_score.compute_is(opts, num_gen=50000, num_splits=10)
|
| 153 |
+
return dict(is50k_mean=mean, is50k_std=std)
|
| 154 |
+
|
| 155 |
+
#----------------------------------------------------------------------------
|
eg3d/metrics/metric_utils.py
ADDED
|
@@ -0,0 +1,281 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# SPDX-FileCopyrightText: Copyright (c) 2021-2022 NVIDIA CORPORATION & AFFILIATES. All rights reserved.
|
| 2 |
+
# SPDX-License-Identifier: LicenseRef-NvidiaProprietary
|
| 3 |
+
#
|
| 4 |
+
# NVIDIA CORPORATION, its affiliates and licensors retain all intellectual
|
| 5 |
+
# property and proprietary rights in and to this material, related
|
| 6 |
+
# documentation and any modifications thereto. Any use, reproduction,
|
| 7 |
+
# disclosure or distribution of this material and related documentation
|
| 8 |
+
# without an express license agreement from NVIDIA CORPORATION or
|
| 9 |
+
# its affiliates is strictly prohibited.
|
| 10 |
+
|
| 11 |
+
"""Miscellaneous utilities used internally by the quality metrics."""
|
| 12 |
+
|
| 13 |
+
import os
|
| 14 |
+
import time
|
| 15 |
+
import hashlib
|
| 16 |
+
import pickle
|
| 17 |
+
import copy
|
| 18 |
+
import uuid
|
| 19 |
+
import numpy as np
|
| 20 |
+
import torch
|
| 21 |
+
import dnnlib
|
| 22 |
+
|
| 23 |
+
#----------------------------------------------------------------------------
|
| 24 |
+
|
| 25 |
+
class MetricOptions:
|
| 26 |
+
def __init__(self, G=None, G_kwargs={}, dataset_kwargs={}, num_gpus=1, rank=0, device=None, progress=None, cache=True):
|
| 27 |
+
assert 0 <= rank < num_gpus
|
| 28 |
+
self.G = G
|
| 29 |
+
self.G_kwargs = dnnlib.EasyDict(G_kwargs)
|
| 30 |
+
self.dataset_kwargs = dnnlib.EasyDict(dataset_kwargs)
|
| 31 |
+
self.num_gpus = num_gpus
|
| 32 |
+
self.rank = rank
|
| 33 |
+
self.device = device if device is not None else torch.device('cuda', rank)
|
| 34 |
+
self.progress = progress.sub() if progress is not None and rank == 0 else ProgressMonitor()
|
| 35 |
+
self.cache = cache
|
| 36 |
+
|
| 37 |
+
#----------------------------------------------------------------------------
|
| 38 |
+
|
| 39 |
+
_feature_detector_cache = dict()
|
| 40 |
+
|
| 41 |
+
def get_feature_detector_name(url):
|
| 42 |
+
return os.path.splitext(url.split('/')[-1])[0]
|
| 43 |
+
|
| 44 |
+
def get_feature_detector(url, device=torch.device('cpu'), num_gpus=1, rank=0, verbose=False):
|
| 45 |
+
assert 0 <= rank < num_gpus
|
| 46 |
+
key = (url, device)
|
| 47 |
+
if key not in _feature_detector_cache:
|
| 48 |
+
is_leader = (rank == 0)
|
| 49 |
+
if not is_leader and num_gpus > 1:
|
| 50 |
+
torch.distributed.barrier() # leader goes first
|
| 51 |
+
with dnnlib.util.open_url(url, verbose=(verbose and is_leader)) as f:
|
| 52 |
+
_feature_detector_cache[key] = pickle.load(f).to(device)
|
| 53 |
+
if is_leader and num_gpus > 1:
|
| 54 |
+
torch.distributed.barrier() # others follow
|
| 55 |
+
return _feature_detector_cache[key]
|
| 56 |
+
|
| 57 |
+
#----------------------------------------------------------------------------
|
| 58 |
+
|
| 59 |
+
def iterate_random_labels(opts, batch_size):
|
| 60 |
+
if opts.G.c_dim == 0:
|
| 61 |
+
c = torch.zeros([batch_size, opts.G.c_dim], device=opts.device)
|
| 62 |
+
while True:
|
| 63 |
+
yield c
|
| 64 |
+
else:
|
| 65 |
+
dataset = dnnlib.util.construct_class_by_name(**opts.dataset_kwargs)
|
| 66 |
+
while True:
|
| 67 |
+
c = [dataset.get_label(np.random.randint(len(dataset))) for _i in range(batch_size)]
|
| 68 |
+
c = torch.from_numpy(np.stack(c)).pin_memory().to(opts.device)
|
| 69 |
+
yield c
|
| 70 |
+
|
| 71 |
+
#----------------------------------------------------------------------------
|
| 72 |
+
|
| 73 |
+
class FeatureStats:
|
| 74 |
+
def __init__(self, capture_all=False, capture_mean_cov=False, max_items=None):
|
| 75 |
+
self.capture_all = capture_all
|
| 76 |
+
self.capture_mean_cov = capture_mean_cov
|
| 77 |
+
self.max_items = max_items
|
| 78 |
+
self.num_items = 0
|
| 79 |
+
self.num_features = None
|
| 80 |
+
self.all_features = None
|
| 81 |
+
self.raw_mean = None
|
| 82 |
+
self.raw_cov = None
|
| 83 |
+
|
| 84 |
+
def set_num_features(self, num_features):
|
| 85 |
+
if self.num_features is not None:
|
| 86 |
+
assert num_features == self.num_features
|
| 87 |
+
else:
|
| 88 |
+
self.num_features = num_features
|
| 89 |
+
self.all_features = []
|
| 90 |
+
self.raw_mean = np.zeros([num_features], dtype=np.float64)
|
| 91 |
+
self.raw_cov = np.zeros([num_features, num_features], dtype=np.float64)
|
| 92 |
+
|
| 93 |
+
def is_full(self):
|
| 94 |
+
return (self.max_items is not None) and (self.num_items >= self.max_items)
|
| 95 |
+
|
| 96 |
+
def append(self, x):
|
| 97 |
+
x = np.asarray(x, dtype=np.float32)
|
| 98 |
+
assert x.ndim == 2
|
| 99 |
+
if (self.max_items is not None) and (self.num_items + x.shape[0] > self.max_items):
|
| 100 |
+
if self.num_items >= self.max_items:
|
| 101 |
+
return
|
| 102 |
+
x = x[:self.max_items - self.num_items]
|
| 103 |
+
|
| 104 |
+
self.set_num_features(x.shape[1])
|
| 105 |
+
self.num_items += x.shape[0]
|
| 106 |
+
if self.capture_all:
|
| 107 |
+
self.all_features.append(x)
|
| 108 |
+
if self.capture_mean_cov:
|
| 109 |
+
x64 = x.astype(np.float64)
|
| 110 |
+
self.raw_mean += x64.sum(axis=0)
|
| 111 |
+
self.raw_cov += x64.T @ x64
|
| 112 |
+
|
| 113 |
+
def append_torch(self, x, num_gpus=1, rank=0):
|
| 114 |
+
assert isinstance(x, torch.Tensor) and x.ndim == 2
|
| 115 |
+
assert 0 <= rank < num_gpus
|
| 116 |
+
if num_gpus > 1:
|
| 117 |
+
ys = []
|
| 118 |
+
for src in range(num_gpus):
|
| 119 |
+
y = x.clone()
|
| 120 |
+
torch.distributed.broadcast(y, src=src)
|
| 121 |
+
ys.append(y)
|
| 122 |
+
x = torch.stack(ys, dim=1).flatten(0, 1) # interleave samples
|
| 123 |
+
self.append(x.cpu().numpy())
|
| 124 |
+
|
| 125 |
+
def get_all(self):
|
| 126 |
+
assert self.capture_all
|
| 127 |
+
return np.concatenate(self.all_features, axis=0)
|
| 128 |
+
|
| 129 |
+
def get_all_torch(self):
|
| 130 |
+
return torch.from_numpy(self.get_all())
|
| 131 |
+
|
| 132 |
+
def get_mean_cov(self):
|
| 133 |
+
assert self.capture_mean_cov
|
| 134 |
+
mean = self.raw_mean / self.num_items
|
| 135 |
+
cov = self.raw_cov / self.num_items
|
| 136 |
+
cov = cov - np.outer(mean, mean)
|
| 137 |
+
return mean, cov
|
| 138 |
+
|
| 139 |
+
def save(self, pkl_file):
|
| 140 |
+
with open(pkl_file, 'wb') as f:
|
| 141 |
+
pickle.dump(self.__dict__, f)
|
| 142 |
+
|
| 143 |
+
@staticmethod
|
| 144 |
+
def load(pkl_file):
|
| 145 |
+
with open(pkl_file, 'rb') as f:
|
| 146 |
+
s = dnnlib.EasyDict(pickle.load(f))
|
| 147 |
+
obj = FeatureStats(capture_all=s.capture_all, max_items=s.max_items)
|
| 148 |
+
obj.__dict__.update(s)
|
| 149 |
+
return obj
|
| 150 |
+
|
| 151 |
+
#----------------------------------------------------------------------------
|
| 152 |
+
|
| 153 |
+
class ProgressMonitor:
|
| 154 |
+
def __init__(self, tag=None, num_items=None, flush_interval=1000, verbose=False, progress_fn=None, pfn_lo=0, pfn_hi=1000, pfn_total=1000):
|
| 155 |
+
self.tag = tag
|
| 156 |
+
self.num_items = num_items
|
| 157 |
+
self.verbose = verbose
|
| 158 |
+
self.flush_interval = flush_interval
|
| 159 |
+
self.progress_fn = progress_fn
|
| 160 |
+
self.pfn_lo = pfn_lo
|
| 161 |
+
self.pfn_hi = pfn_hi
|
| 162 |
+
self.pfn_total = pfn_total
|
| 163 |
+
self.start_time = time.time()
|
| 164 |
+
self.batch_time = self.start_time
|
| 165 |
+
self.batch_items = 0
|
| 166 |
+
if self.progress_fn is not None:
|
| 167 |
+
self.progress_fn(self.pfn_lo, self.pfn_total)
|
| 168 |
+
|
| 169 |
+
def update(self, cur_items):
|
| 170 |
+
assert (self.num_items is None) or (cur_items <= self.num_items)
|
| 171 |
+
if (cur_items < self.batch_items + self.flush_interval) and (self.num_items is None or cur_items < self.num_items):
|
| 172 |
+
return
|
| 173 |
+
cur_time = time.time()
|
| 174 |
+
total_time = cur_time - self.start_time
|
| 175 |
+
time_per_item = (cur_time - self.batch_time) / max(cur_items - self.batch_items, 1)
|
| 176 |
+
if (self.verbose) and (self.tag is not None):
|
| 177 |
+
print(f'{self.tag:<19s} items {cur_items:<7d} time {dnnlib.util.format_time(total_time):<12s} ms/item {time_per_item*1e3:.2f}')
|
| 178 |
+
self.batch_time = cur_time
|
| 179 |
+
self.batch_items = cur_items
|
| 180 |
+
|
| 181 |
+
if (self.progress_fn is not None) and (self.num_items is not None):
|
| 182 |
+
self.progress_fn(self.pfn_lo + (self.pfn_hi - self.pfn_lo) * (cur_items / self.num_items), self.pfn_total)
|
| 183 |
+
|
| 184 |
+
def sub(self, tag=None, num_items=None, flush_interval=1000, rel_lo=0, rel_hi=1):
|
| 185 |
+
return ProgressMonitor(
|
| 186 |
+
tag = tag,
|
| 187 |
+
num_items = num_items,
|
| 188 |
+
flush_interval = flush_interval,
|
| 189 |
+
verbose = self.verbose,
|
| 190 |
+
progress_fn = self.progress_fn,
|
| 191 |
+
pfn_lo = self.pfn_lo + (self.pfn_hi - self.pfn_lo) * rel_lo,
|
| 192 |
+
pfn_hi = self.pfn_lo + (self.pfn_hi - self.pfn_lo) * rel_hi,
|
| 193 |
+
pfn_total = self.pfn_total,
|
| 194 |
+
)
|
| 195 |
+
|
| 196 |
+
#----------------------------------------------------------------------------
|
| 197 |
+
|
| 198 |
+
def compute_feature_stats_for_dataset(opts, detector_url, detector_kwargs, rel_lo=0, rel_hi=1, batch_size=64, data_loader_kwargs=None, max_items=None, **stats_kwargs):
|
| 199 |
+
dataset = dnnlib.util.construct_class_by_name(**opts.dataset_kwargs)
|
| 200 |
+
if data_loader_kwargs is None:
|
| 201 |
+
data_loader_kwargs = dict(pin_memory=True, num_workers=3, prefetch_factor=2)
|
| 202 |
+
|
| 203 |
+
# Try to lookup from cache.
|
| 204 |
+
cache_file = None
|
| 205 |
+
if opts.cache:
|
| 206 |
+
# Choose cache file name.
|
| 207 |
+
args = dict(dataset_kwargs=opts.dataset_kwargs, detector_url=detector_url, detector_kwargs=detector_kwargs, stats_kwargs=stats_kwargs)
|
| 208 |
+
md5 = hashlib.md5(repr(sorted(args.items())).encode('utf-8'))
|
| 209 |
+
cache_tag = f'{dataset.name}-{get_feature_detector_name(detector_url)}-{md5.hexdigest()}'
|
| 210 |
+
cache_file = dnnlib.make_cache_dir_path('gan-metrics', cache_tag + '.pkl')
|
| 211 |
+
|
| 212 |
+
# Check if the file exists (all processes must agree).
|
| 213 |
+
flag = os.path.isfile(cache_file) if opts.rank == 0 else False
|
| 214 |
+
if opts.num_gpus > 1:
|
| 215 |
+
flag = torch.as_tensor(flag, dtype=torch.float32, device=opts.device)
|
| 216 |
+
torch.distributed.broadcast(tensor=flag, src=0)
|
| 217 |
+
flag = (float(flag.cpu()) != 0)
|
| 218 |
+
|
| 219 |
+
# Load.
|
| 220 |
+
if flag:
|
| 221 |
+
return FeatureStats.load(cache_file)
|
| 222 |
+
|
| 223 |
+
# Initialize.
|
| 224 |
+
num_items = len(dataset)
|
| 225 |
+
if max_items is not None:
|
| 226 |
+
num_items = min(num_items, max_items)
|
| 227 |
+
stats = FeatureStats(max_items=num_items, **stats_kwargs)
|
| 228 |
+
progress = opts.progress.sub(tag='dataset features', num_items=num_items, rel_lo=rel_lo, rel_hi=rel_hi)
|
| 229 |
+
detector = get_feature_detector(url=detector_url, device=opts.device, num_gpus=opts.num_gpus, rank=opts.rank, verbose=progress.verbose)
|
| 230 |
+
|
| 231 |
+
# Main loop.
|
| 232 |
+
item_subset = [(i * opts.num_gpus + opts.rank) % num_items for i in range((num_items - 1) // opts.num_gpus + 1)]
|
| 233 |
+
for images, _labels in torch.utils.data.DataLoader(dataset=dataset, sampler=item_subset, batch_size=batch_size, **data_loader_kwargs):
|
| 234 |
+
if images.shape[1] == 1:
|
| 235 |
+
images = images.repeat([1, 3, 1, 1])
|
| 236 |
+
features = detector(images.to(opts.device), **detector_kwargs)
|
| 237 |
+
stats.append_torch(features, num_gpus=opts.num_gpus, rank=opts.rank)
|
| 238 |
+
progress.update(stats.num_items)
|
| 239 |
+
|
| 240 |
+
# Save to cache.
|
| 241 |
+
if cache_file is not None and opts.rank == 0:
|
| 242 |
+
os.makedirs(os.path.dirname(cache_file), exist_ok=True)
|
| 243 |
+
temp_file = cache_file + '.' + uuid.uuid4().hex
|
| 244 |
+
stats.save(temp_file)
|
| 245 |
+
os.replace(temp_file, cache_file) # atomic
|
| 246 |
+
return stats
|
| 247 |
+
|
| 248 |
+
#----------------------------------------------------------------------------
|
| 249 |
+
|
| 250 |
+
def compute_feature_stats_for_generator(opts, detector_url, detector_kwargs, rel_lo=0, rel_hi=1, batch_size=64, batch_gen=None, **stats_kwargs):
|
| 251 |
+
if batch_gen is None:
|
| 252 |
+
batch_gen = min(batch_size, 4)
|
| 253 |
+
assert batch_size % batch_gen == 0
|
| 254 |
+
|
| 255 |
+
# Setup generator and labels.
|
| 256 |
+
G = copy.deepcopy(opts.G).eval().requires_grad_(False).to(opts.device)
|
| 257 |
+
c_iter = iterate_random_labels(opts=opts, batch_size=batch_gen)
|
| 258 |
+
|
| 259 |
+
# Initialize.
|
| 260 |
+
stats = FeatureStats(**stats_kwargs)
|
| 261 |
+
assert stats.max_items is not None
|
| 262 |
+
progress = opts.progress.sub(tag='generator features', num_items=stats.max_items, rel_lo=rel_lo, rel_hi=rel_hi)
|
| 263 |
+
detector = get_feature_detector(url=detector_url, device=opts.device, num_gpus=opts.num_gpus, rank=opts.rank, verbose=progress.verbose)
|
| 264 |
+
|
| 265 |
+
# Main loop.
|
| 266 |
+
while not stats.is_full():
|
| 267 |
+
images = []
|
| 268 |
+
for _i in range(batch_size // batch_gen):
|
| 269 |
+
z = torch.randn([batch_gen, G.z_dim], device=opts.device)
|
| 270 |
+
img = G(z=z, c=next(c_iter), **opts.G_kwargs)['image']
|
| 271 |
+
img = (img * 127.5 + 128).clamp(0, 255).to(torch.uint8)
|
| 272 |
+
images.append(img)
|
| 273 |
+
images = torch.cat(images)
|
| 274 |
+
if images.shape[1] == 1:
|
| 275 |
+
images = images.repeat([1, 3, 1, 1])
|
| 276 |
+
features = detector(images, **detector_kwargs)
|
| 277 |
+
stats.append_torch(features, num_gpus=opts.num_gpus, rank=opts.rank)
|
| 278 |
+
progress.update(stats.num_items)
|
| 279 |
+
return stats
|
| 280 |
+
|
| 281 |
+
#----------------------------------------------------------------------------
|
eg3d/metrics/perceptual_path_length.py
ADDED
|
@@ -0,0 +1,127 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# SPDX-FileCopyrightText: Copyright (c) 2021-2022 NVIDIA CORPORATION & AFFILIATES. All rights reserved.
|
| 2 |
+
# SPDX-License-Identifier: LicenseRef-NvidiaProprietary
|
| 3 |
+
#
|
| 4 |
+
# NVIDIA CORPORATION, its affiliates and licensors retain all intellectual
|
| 5 |
+
# property and proprietary rights in and to this material, related
|
| 6 |
+
# documentation and any modifications thereto. Any use, reproduction,
|
| 7 |
+
# disclosure or distribution of this material and related documentation
|
| 8 |
+
# without an express license agreement from NVIDIA CORPORATION or
|
| 9 |
+
# its affiliates is strictly prohibited.
|
| 10 |
+
|
| 11 |
+
"""Perceptual Path Length (PPL) from the paper "A Style-Based Generator
|
| 12 |
+
Architecture for Generative Adversarial Networks". Matches the original
|
| 13 |
+
implementation by Karras et al. at
|
| 14 |
+
https://github.com/NVlabs/stylegan/blob/master/metrics/perceptual_path_length.py"""
|
| 15 |
+
|
| 16 |
+
import copy
|
| 17 |
+
import numpy as np
|
| 18 |
+
import torch
|
| 19 |
+
from . import metric_utils
|
| 20 |
+
|
| 21 |
+
#----------------------------------------------------------------------------
|
| 22 |
+
|
| 23 |
+
# Spherical interpolation of a batch of vectors.
|
| 24 |
+
def slerp(a, b, t):
|
| 25 |
+
a = a / a.norm(dim=-1, keepdim=True)
|
| 26 |
+
b = b / b.norm(dim=-1, keepdim=True)
|
| 27 |
+
d = (a * b).sum(dim=-1, keepdim=True)
|
| 28 |
+
p = t * torch.acos(d)
|
| 29 |
+
c = b - d * a
|
| 30 |
+
c = c / c.norm(dim=-1, keepdim=True)
|
| 31 |
+
d = a * torch.cos(p) + c * torch.sin(p)
|
| 32 |
+
d = d / d.norm(dim=-1, keepdim=True)
|
| 33 |
+
return d
|
| 34 |
+
|
| 35 |
+
#----------------------------------------------------------------------------
|
| 36 |
+
|
| 37 |
+
class PPLSampler(torch.nn.Module):
|
| 38 |
+
def __init__(self, G, G_kwargs, epsilon, space, sampling, crop, vgg16):
|
| 39 |
+
assert space in ['z', 'w']
|
| 40 |
+
assert sampling in ['full', 'end']
|
| 41 |
+
super().__init__()
|
| 42 |
+
self.G = copy.deepcopy(G)
|
| 43 |
+
self.G_kwargs = G_kwargs
|
| 44 |
+
self.epsilon = epsilon
|
| 45 |
+
self.space = space
|
| 46 |
+
self.sampling = sampling
|
| 47 |
+
self.crop = crop
|
| 48 |
+
self.vgg16 = copy.deepcopy(vgg16)
|
| 49 |
+
|
| 50 |
+
def forward(self, c):
|
| 51 |
+
# Generate random latents and interpolation t-values.
|
| 52 |
+
t = torch.rand([c.shape[0]], device=c.device) * (1 if self.sampling == 'full' else 0)
|
| 53 |
+
z0, z1 = torch.randn([c.shape[0] * 2, self.G.z_dim], device=c.device).chunk(2)
|
| 54 |
+
|
| 55 |
+
# Interpolate in W or Z.
|
| 56 |
+
if self.space == 'w':
|
| 57 |
+
w0, w1 = self.G.mapping(z=torch.cat([z0,z1]), c=torch.cat([c,c])).chunk(2)
|
| 58 |
+
wt0 = w0.lerp(w1, t.unsqueeze(1).unsqueeze(2))
|
| 59 |
+
wt1 = w0.lerp(w1, t.unsqueeze(1).unsqueeze(2) + self.epsilon)
|
| 60 |
+
else: # space == 'z'
|
| 61 |
+
zt0 = slerp(z0, z1, t.unsqueeze(1))
|
| 62 |
+
zt1 = slerp(z0, z1, t.unsqueeze(1) + self.epsilon)
|
| 63 |
+
wt0, wt1 = self.G.mapping(z=torch.cat([zt0,zt1]), c=torch.cat([c,c])).chunk(2)
|
| 64 |
+
|
| 65 |
+
# Randomize noise buffers.
|
| 66 |
+
for name, buf in self.G.named_buffers():
|
| 67 |
+
if name.endswith('.noise_const'):
|
| 68 |
+
buf.copy_(torch.randn_like(buf))
|
| 69 |
+
|
| 70 |
+
# Generate images.
|
| 71 |
+
img = self.G.synthesis(ws=torch.cat([wt0,wt1]), noise_mode='const', force_fp32=True, **self.G_kwargs)
|
| 72 |
+
|
| 73 |
+
# Center crop.
|
| 74 |
+
if self.crop:
|
| 75 |
+
assert img.shape[2] == img.shape[3]
|
| 76 |
+
c = img.shape[2] // 8
|
| 77 |
+
img = img[:, :, c*3 : c*7, c*2 : c*6]
|
| 78 |
+
|
| 79 |
+
# Downsample to 256x256.
|
| 80 |
+
factor = self.G.img_resolution // 256
|
| 81 |
+
if factor > 1:
|
| 82 |
+
img = img.reshape([-1, img.shape[1], img.shape[2] // factor, factor, img.shape[3] // factor, factor]).mean([3, 5])
|
| 83 |
+
|
| 84 |
+
# Scale dynamic range from [-1,1] to [0,255].
|
| 85 |
+
img = (img + 1) * (255 / 2)
|
| 86 |
+
if self.G.img_channels == 1:
|
| 87 |
+
img = img.repeat([1, 3, 1, 1])
|
| 88 |
+
|
| 89 |
+
# Evaluate differential LPIPS.
|
| 90 |
+
lpips_t0, lpips_t1 = self.vgg16(img, resize_images=False, return_lpips=True).chunk(2)
|
| 91 |
+
dist = (lpips_t0 - lpips_t1).square().sum(1) / self.epsilon ** 2
|
| 92 |
+
return dist
|
| 93 |
+
|
| 94 |
+
#----------------------------------------------------------------------------
|
| 95 |
+
|
| 96 |
+
def compute_ppl(opts, num_samples, epsilon, space, sampling, crop, batch_size):
|
| 97 |
+
vgg16_url = 'https://api.ngc.nvidia.com/v2/models/nvidia/research/stylegan3/versions/1/files/metrics/vgg16.pkl'
|
| 98 |
+
vgg16 = metric_utils.get_feature_detector(vgg16_url, num_gpus=opts.num_gpus, rank=opts.rank, verbose=opts.progress.verbose)
|
| 99 |
+
|
| 100 |
+
# Setup sampler and labels.
|
| 101 |
+
sampler = PPLSampler(G=opts.G, G_kwargs=opts.G_kwargs, epsilon=epsilon, space=space, sampling=sampling, crop=crop, vgg16=vgg16)
|
| 102 |
+
sampler.eval().requires_grad_(False).to(opts.device)
|
| 103 |
+
c_iter = metric_utils.iterate_random_labels(opts=opts, batch_size=batch_size)
|
| 104 |
+
|
| 105 |
+
# Sampling loop.
|
| 106 |
+
dist = []
|
| 107 |
+
progress = opts.progress.sub(tag='ppl sampling', num_items=num_samples)
|
| 108 |
+
for batch_start in range(0, num_samples, batch_size * opts.num_gpus):
|
| 109 |
+
progress.update(batch_start)
|
| 110 |
+
x = sampler(next(c_iter))
|
| 111 |
+
for src in range(opts.num_gpus):
|
| 112 |
+
y = x.clone()
|
| 113 |
+
if opts.num_gpus > 1:
|
| 114 |
+
torch.distributed.broadcast(y, src=src)
|
| 115 |
+
dist.append(y)
|
| 116 |
+
progress.update(num_samples)
|
| 117 |
+
|
| 118 |
+
# Compute PPL.
|
| 119 |
+
if opts.rank != 0:
|
| 120 |
+
return float('nan')
|
| 121 |
+
dist = torch.cat(dist)[:num_samples].cpu().numpy()
|
| 122 |
+
lo = np.percentile(dist, 1, interpolation='lower')
|
| 123 |
+
hi = np.percentile(dist, 99, interpolation='higher')
|
| 124 |
+
ppl = np.extract(np.logical_and(dist >= lo, dist <= hi), dist).mean()
|
| 125 |
+
return float(ppl)
|
| 126 |
+
|
| 127 |
+
#----------------------------------------------------------------------------
|
eg3d/metrics/precision_recall.py
ADDED
|
@@ -0,0 +1,64 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# SPDX-FileCopyrightText: Copyright (c) 2021-2022 NVIDIA CORPORATION & AFFILIATES. All rights reserved.
|
| 2 |
+
# SPDX-License-Identifier: LicenseRef-NvidiaProprietary
|
| 3 |
+
#
|
| 4 |
+
# NVIDIA CORPORATION, its affiliates and licensors retain all intellectual
|
| 5 |
+
# property and proprietary rights in and to this material, related
|
| 6 |
+
# documentation and any modifications thereto. Any use, reproduction,
|
| 7 |
+
# disclosure or distribution of this material and related documentation
|
| 8 |
+
# without an express license agreement from NVIDIA CORPORATION or
|
| 9 |
+
# its affiliates is strictly prohibited.
|
| 10 |
+
|
| 11 |
+
"""Precision/Recall (PR) from the paper "Improved Precision and Recall
|
| 12 |
+
Metric for Assessing Generative Models". Matches the original implementation
|
| 13 |
+
by Kynkaanniemi et al. at
|
| 14 |
+
https://github.com/kynkaat/improved-precision-and-recall-metric/blob/master/precision_recall.py"""
|
| 15 |
+
|
| 16 |
+
import torch
|
| 17 |
+
from . import metric_utils
|
| 18 |
+
|
| 19 |
+
#----------------------------------------------------------------------------
|
| 20 |
+
|
| 21 |
+
def compute_distances(row_features, col_features, num_gpus, rank, col_batch_size):
|
| 22 |
+
assert 0 <= rank < num_gpus
|
| 23 |
+
num_cols = col_features.shape[0]
|
| 24 |
+
num_batches = ((num_cols - 1) // col_batch_size // num_gpus + 1) * num_gpus
|
| 25 |
+
col_batches = torch.nn.functional.pad(col_features, [0, 0, 0, -num_cols % num_batches]).chunk(num_batches)
|
| 26 |
+
dist_batches = []
|
| 27 |
+
for col_batch in col_batches[rank :: num_gpus]:
|
| 28 |
+
dist_batch = torch.cdist(row_features.unsqueeze(0), col_batch.unsqueeze(0))[0]
|
| 29 |
+
for src in range(num_gpus):
|
| 30 |
+
dist_broadcast = dist_batch.clone()
|
| 31 |
+
if num_gpus > 1:
|
| 32 |
+
torch.distributed.broadcast(dist_broadcast, src=src)
|
| 33 |
+
dist_batches.append(dist_broadcast.cpu() if rank == 0 else None)
|
| 34 |
+
return torch.cat(dist_batches, dim=1)[:, :num_cols] if rank == 0 else None
|
| 35 |
+
|
| 36 |
+
#----------------------------------------------------------------------------
|
| 37 |
+
|
| 38 |
+
def compute_pr(opts, max_real, num_gen, nhood_size, row_batch_size, col_batch_size):
|
| 39 |
+
detector_url = 'https://api.ngc.nvidia.com/v2/models/nvidia/research/stylegan3/versions/1/files/metrics/vgg16.pkl'
|
| 40 |
+
detector_kwargs = dict(return_features=True)
|
| 41 |
+
|
| 42 |
+
real_features = metric_utils.compute_feature_stats_for_dataset(
|
| 43 |
+
opts=opts, detector_url=detector_url, detector_kwargs=detector_kwargs,
|
| 44 |
+
rel_lo=0, rel_hi=0, capture_all=True, max_items=max_real).get_all_torch().to(torch.float16).to(opts.device)
|
| 45 |
+
|
| 46 |
+
gen_features = metric_utils.compute_feature_stats_for_generator(
|
| 47 |
+
opts=opts, detector_url=detector_url, detector_kwargs=detector_kwargs,
|
| 48 |
+
rel_lo=0, rel_hi=1, capture_all=True, max_items=num_gen).get_all_torch().to(torch.float16).to(opts.device)
|
| 49 |
+
|
| 50 |
+
results = dict()
|
| 51 |
+
for name, manifold, probes in [('precision', real_features, gen_features), ('recall', gen_features, real_features)]:
|
| 52 |
+
kth = []
|
| 53 |
+
for manifold_batch in manifold.split(row_batch_size):
|
| 54 |
+
dist = compute_distances(row_features=manifold_batch, col_features=manifold, num_gpus=opts.num_gpus, rank=opts.rank, col_batch_size=col_batch_size)
|
| 55 |
+
kth.append(dist.to(torch.float32).kthvalue(nhood_size + 1).values.to(torch.float16) if opts.rank == 0 else None)
|
| 56 |
+
kth = torch.cat(kth) if opts.rank == 0 else None
|
| 57 |
+
pred = []
|
| 58 |
+
for probes_batch in probes.split(row_batch_size):
|
| 59 |
+
dist = compute_distances(row_features=probes_batch, col_features=manifold, num_gpus=opts.num_gpus, rank=opts.rank, col_batch_size=col_batch_size)
|
| 60 |
+
pred.append((dist <= kth).any(dim=1) if opts.rank == 0 else None)
|
| 61 |
+
results[name] = float(torch.cat(pred).to(torch.float32).mean() if opts.rank == 0 else 'nan')
|
| 62 |
+
return results['precision'], results['recall']
|
| 63 |
+
|
| 64 |
+
#----------------------------------------------------------------------------
|
eg3d/projector/w_plus_projector.py
ADDED
|
@@ -0,0 +1,182 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright (c) 2021, NVIDIA CORPORATION. All rights reserved.
|
| 2 |
+
#
|
| 3 |
+
# NVIDIA CORPORATION and its licensors retain all intellectual property
|
| 4 |
+
# and proprietary rights in and to this software, related documentation
|
| 5 |
+
# and any modifications thereto. Any use, reproduction, disclosure or
|
| 6 |
+
# distribution of this software and related documentation without an express
|
| 7 |
+
# license agreement from NVIDIA CORPORATION is strictly prohibited.
|
| 8 |
+
|
| 9 |
+
"""Project given image to the latent space of pretrained network pickle."""
|
| 10 |
+
|
| 11 |
+
import copy
|
| 12 |
+
import os
|
| 13 |
+
import numpy as np
|
| 14 |
+
import torch
|
| 15 |
+
import torch.nn.functional as F
|
| 16 |
+
from tqdm import tqdm
|
| 17 |
+
import dnnlib
|
| 18 |
+
import PIL
|
| 19 |
+
from camera_utils import LookAtPoseSampler
|
| 20 |
+
|
| 21 |
+
def project(
|
| 22 |
+
G,
|
| 23 |
+
c,
|
| 24 |
+
outdir,
|
| 25 |
+
target: torch.Tensor, # [C,H,W] and dynamic range [0,255], W & H must match G output resolution
|
| 26 |
+
*,
|
| 27 |
+
num_steps=1000,
|
| 28 |
+
w_avg_samples=10000,
|
| 29 |
+
initial_learning_rate=0.01,
|
| 30 |
+
initial_noise_factor=0.05,
|
| 31 |
+
lr_rampdown_length=0.25,
|
| 32 |
+
lr_rampup_length=0.05,
|
| 33 |
+
noise_ramp_length=0.75,
|
| 34 |
+
regularize_noise_weight=1e5,
|
| 35 |
+
verbose=False,
|
| 36 |
+
device: torch.device,
|
| 37 |
+
initial_w=None,
|
| 38 |
+
image_log_step=100,
|
| 39 |
+
w_name: str
|
| 40 |
+
):
|
| 41 |
+
os.makedirs(f'{outdir}/{w_name}_w_plus', exist_ok=True)
|
| 42 |
+
outdir = f'{outdir}/{w_name}_w_plus'
|
| 43 |
+
assert target.shape == (G.img_channels, G.img_resolution, G.img_resolution)
|
| 44 |
+
|
| 45 |
+
def logprint(*args):
|
| 46 |
+
if verbose:
|
| 47 |
+
print(*args)
|
| 48 |
+
|
| 49 |
+
G = copy.deepcopy(G).eval().requires_grad_(False).to(device).float() # type: ignore
|
| 50 |
+
|
| 51 |
+
# Compute w stats.
|
| 52 |
+
w_avg_path = './w_avg.npy'
|
| 53 |
+
w_std_path = './w_std.npy'
|
| 54 |
+
if (not os.path.exists(w_avg_path)) or (not os.path.exists(w_std_path)):
|
| 55 |
+
print(f'Computing W midpoint and stddev using {w_avg_samples} samples...')
|
| 56 |
+
z_samples = np.random.RandomState(123).randn(w_avg_samples, G.z_dim)
|
| 57 |
+
# c_samples = c.repeat(w_avg_samples, 1)
|
| 58 |
+
|
| 59 |
+
# use avg look at point
|
| 60 |
+
|
| 61 |
+
camera_lookat_point = torch.tensor(G.rendering_kwargs['avg_camera_pivot'], device=device)
|
| 62 |
+
cam2world_pose = LookAtPoseSampler.sample(3.14 / 2, 3.14 / 2, camera_lookat_point,
|
| 63 |
+
radius=G.rendering_kwargs['avg_camera_radius'], device=device)
|
| 64 |
+
focal_length = 4.2647 # FFHQ's FOV
|
| 65 |
+
intrinsics = torch.tensor([[focal_length, 0, 0.5], [0, focal_length, 0.5], [0, 0, 1]], device=device)
|
| 66 |
+
c_samples = torch.cat([cam2world_pose.reshape(-1, 16), intrinsics.reshape(-1, 9)], 1)
|
| 67 |
+
c_samples = c_samples.repeat(w_avg_samples, 1)
|
| 68 |
+
|
| 69 |
+
w_samples = G.mapping(torch.from_numpy(z_samples).to(device), c_samples) # [N, L, C]
|
| 70 |
+
w_samples = w_samples[:, :1, :].cpu().numpy().astype(np.float32) # [N, 1, C]
|
| 71 |
+
w_avg = np.mean(w_samples, axis=0, keepdims=True) # [1, 1, C]
|
| 72 |
+
# print('save w_avg to ./w_avg.npy')
|
| 73 |
+
# np.save('./w_avg.npy',w_avg)
|
| 74 |
+
w_avg_tensor = torch.from_numpy(w_avg).cuda()
|
| 75 |
+
w_std = (np.sum((w_samples - w_avg) ** 2) / w_avg_samples) ** 0.5
|
| 76 |
+
|
| 77 |
+
# np.save(w_avg_path, w_avg)
|
| 78 |
+
# np.save(w_std_path, w_std)
|
| 79 |
+
else:
|
| 80 |
+
# w_avg = np.load(w_avg_path)
|
| 81 |
+
# w_std = np.load(w_std_path)
|
| 82 |
+
raise Exception(' ')
|
| 83 |
+
|
| 84 |
+
# z_samples = np.random.RandomState(123).randn(w_avg_samples, G.z_dim)
|
| 85 |
+
# c_samples = c.repeat(w_avg_samples, 1)
|
| 86 |
+
# w_samples = G.mapping(torch.from_numpy(z_samples).to(device), c_samples) # [N, L, C]
|
| 87 |
+
# w_samples = w_samples[:, :1, :].cpu().numpy().astype(np.float32) # [N, 1, C]
|
| 88 |
+
# w_avg = np.mean(w_samples, axis=0, keepdims=True) # [1, 1, C]
|
| 89 |
+
# w_avg_tensor = torch.from_numpy(w_avg).cuda()
|
| 90 |
+
# w_std = (np.sum((w_samples - w_avg) ** 2) / w_avg_samples) ** 0.5
|
| 91 |
+
|
| 92 |
+
start_w = initial_w if initial_w is not None else w_avg
|
| 93 |
+
|
| 94 |
+
# Setup noise inputs.
|
| 95 |
+
noise_bufs = {name: buf for (name, buf) in G.backbone.synthesis.named_buffers() if 'noise_const' in name}
|
| 96 |
+
|
| 97 |
+
# Load VGG16 feature detector.
|
| 98 |
+
url = 'https://nvlabs-fi-cdn.nvidia.com/stylegan2-ada-pytorch/pretrained/metrics/vgg16.pt'
|
| 99 |
+
# url = './networks/vgg16.pt'
|
| 100 |
+
with dnnlib.util.open_url(url) as f:
|
| 101 |
+
vgg16 = torch.jit.load(f).eval().to(device)
|
| 102 |
+
|
| 103 |
+
# Features for target image.
|
| 104 |
+
target_images = target.unsqueeze(0).to(device).to(torch.float32)
|
| 105 |
+
if target_images.shape[2] > 256:
|
| 106 |
+
target_images = F.interpolate(target_images, size=(256, 256), mode='area')
|
| 107 |
+
target_features = vgg16(target_images, resize_images=False, return_lpips=True)
|
| 108 |
+
|
| 109 |
+
start_w = np.repeat(start_w, G.backbone.mapping.num_ws, axis=1)
|
| 110 |
+
w_opt = torch.tensor(start_w, dtype=torch.float32, device=device,
|
| 111 |
+
requires_grad=True) # pylint: disable=not-callable
|
| 112 |
+
|
| 113 |
+
optimizer = torch.optim.Adam([w_opt] + list(noise_bufs.values()), betas=(0.9, 0.999),
|
| 114 |
+
lr=0.1)
|
| 115 |
+
|
| 116 |
+
# Init noise.
|
| 117 |
+
for buf in noise_bufs.values():
|
| 118 |
+
buf[:] = torch.randn_like(buf)
|
| 119 |
+
buf.requires_grad = True
|
| 120 |
+
|
| 121 |
+
for step in tqdm(range(num_steps), position=0, leave=True):
|
| 122 |
+
|
| 123 |
+
# Learning rate schedule.
|
| 124 |
+
t = step / num_steps
|
| 125 |
+
w_noise_scale = w_std * initial_noise_factor * max(0.0, 1.0 - t / noise_ramp_length) ** 2
|
| 126 |
+
lr_ramp = min(1.0, (1.0 - t) / lr_rampdown_length)
|
| 127 |
+
lr_ramp = 0.5 - 0.5 * np.cos(lr_ramp * np.pi)
|
| 128 |
+
lr_ramp = lr_ramp * min(1.0, t / lr_rampup_length)
|
| 129 |
+
lr = initial_learning_rate * lr_ramp
|
| 130 |
+
for param_group in optimizer.param_groups:
|
| 131 |
+
param_group['lr'] = lr
|
| 132 |
+
|
| 133 |
+
# Synth images from opt_w.
|
| 134 |
+
w_noise = torch.randn_like(w_opt) * w_noise_scale
|
| 135 |
+
ws = (w_opt + w_noise)
|
| 136 |
+
synth_images = G.synthesis(ws,c, noise_mode='const')['image']
|
| 137 |
+
|
| 138 |
+
if step % image_log_step == 0:
|
| 139 |
+
with torch.no_grad():
|
| 140 |
+
vis_img = (synth_images.permute(0, 2, 3, 1) * 127.5 + 128).clamp(0, 255).to(torch.uint8)
|
| 141 |
+
|
| 142 |
+
PIL.Image.fromarray(vis_img[0].cpu().numpy(), 'RGB').save(f'{outdir}/{step}.png')
|
| 143 |
+
|
| 144 |
+
# Downsample image to 256x256 if it's larger than that. VGG was built for 224x224 images.
|
| 145 |
+
synth_images = (synth_images + 1) * (255 / 2)
|
| 146 |
+
if synth_images.shape[2] > 256:
|
| 147 |
+
synth_images = F.interpolate(synth_images, size=(256, 256), mode='area')
|
| 148 |
+
|
| 149 |
+
# Features for synth images.
|
| 150 |
+
synth_features = vgg16(synth_images, resize_images=False, return_lpips=True)
|
| 151 |
+
dist = (target_features - synth_features).square().sum()
|
| 152 |
+
|
| 153 |
+
# Noise regularization.
|
| 154 |
+
reg_loss = 0.0
|
| 155 |
+
for v in noise_bufs.values():
|
| 156 |
+
noise = v[None, None, :, :] # must be [1,1,H,W] for F.avg_pool2d()
|
| 157 |
+
while True:
|
| 158 |
+
reg_loss += (noise * torch.roll(noise, shifts=1, dims=3)).mean() ** 2
|
| 159 |
+
reg_loss += (noise * torch.roll(noise, shifts=1, dims=2)).mean() ** 2
|
| 160 |
+
if noise.shape[2] <= 8:
|
| 161 |
+
break
|
| 162 |
+
noise = F.avg_pool2d(noise, kernel_size=2)
|
| 163 |
+
loss = dist + reg_loss * regularize_noise_weight
|
| 164 |
+
|
| 165 |
+
# if step % 10 == 0:
|
| 166 |
+
# with torch.no_grad():
|
| 167 |
+
# print({f'step {step}, first projection _{w_name}': loss.detach().cpu()})
|
| 168 |
+
|
| 169 |
+
# Step
|
| 170 |
+
optimizer.zero_grad(set_to_none=True)
|
| 171 |
+
loss.backward()
|
| 172 |
+
optimizer.step()
|
| 173 |
+
logprint(f'step {step + 1:>4d}/{num_steps}: dist {dist:<4.2f} loss {float(loss):<5.2f}')
|
| 174 |
+
|
| 175 |
+
# Normalize noise.
|
| 176 |
+
with torch.no_grad():
|
| 177 |
+
for buf in noise_bufs.values():
|
| 178 |
+
buf -= buf.mean()
|
| 179 |
+
buf *= buf.square().mean().rsqrt()
|
| 180 |
+
|
| 181 |
+
del G
|
| 182 |
+
return w_opt
|
eg3d/projector/w_projector.py
ADDED
|
@@ -0,0 +1,177 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright (c) 2021, NVIDIA CORPORATION. All rights reserved.
|
| 2 |
+
#
|
| 3 |
+
# NVIDIA CORPORATION and its licensors retain all intellectual property
|
| 4 |
+
# and proprietary rights in and to this software, related documentation
|
| 5 |
+
# and any modifications thereto. Any use, reproduction, disclosure or
|
| 6 |
+
# distribution of this software and related documentation without an express
|
| 7 |
+
# license agreement from NVIDIA CORPORATION is strictly prohibited.
|
| 8 |
+
|
| 9 |
+
"""Project given image to the latent space of pretrained network pickle."""
|
| 10 |
+
|
| 11 |
+
import copy
|
| 12 |
+
import os
|
| 13 |
+
import numpy as np
|
| 14 |
+
import torch
|
| 15 |
+
import torch.nn.functional as F
|
| 16 |
+
from tqdm import tqdm
|
| 17 |
+
import dnnlib
|
| 18 |
+
import PIL
|
| 19 |
+
from camera_utils import LookAtPoseSampler
|
| 20 |
+
def project(
|
| 21 |
+
G,
|
| 22 |
+
c,
|
| 23 |
+
outdir,
|
| 24 |
+
target: torch.Tensor, # [C,H,W] and dynamic range [0,255], W & H must match G output resolution
|
| 25 |
+
*,
|
| 26 |
+
num_steps=1000,
|
| 27 |
+
w_avg_samples=10000,
|
| 28 |
+
initial_learning_rate=0.01,
|
| 29 |
+
initial_noise_factor=0.05,
|
| 30 |
+
lr_rampdown_length=0.25,
|
| 31 |
+
lr_rampup_length=0.05,
|
| 32 |
+
noise_ramp_length=0.75,
|
| 33 |
+
regularize_noise_weight=1e5,
|
| 34 |
+
verbose=False,
|
| 35 |
+
device: torch.device,
|
| 36 |
+
initial_w=None,
|
| 37 |
+
image_log_step=100,
|
| 38 |
+
w_name: str
|
| 39 |
+
):
|
| 40 |
+
os.makedirs(f'{outdir}/{w_name}_w',exist_ok=True)
|
| 41 |
+
outdir = f'{outdir}/{w_name}_w'
|
| 42 |
+
assert target.shape == (G.img_channels, G.img_resolution, G.img_resolution)
|
| 43 |
+
|
| 44 |
+
def logprint(*args):
|
| 45 |
+
if verbose:
|
| 46 |
+
print(*args)
|
| 47 |
+
|
| 48 |
+
G = copy.deepcopy(G).eval().requires_grad_(False).to(device).float() # type: ignore
|
| 49 |
+
|
| 50 |
+
# Compute w stats.
|
| 51 |
+
|
| 52 |
+
w_avg_path = './w_avg.npy'
|
| 53 |
+
w_std_path = './w_std.npy'
|
| 54 |
+
if (not os.path.exists(w_avg_path)) or (not os.path.exists(w_std_path)):
|
| 55 |
+
print(f'Computing W midpoint and stddev using {w_avg_samples} samples...')
|
| 56 |
+
z_samples = np.random.RandomState(123).randn(w_avg_samples, G.z_dim)
|
| 57 |
+
#c_samples = c.repeat(w_avg_samples, 1)
|
| 58 |
+
|
| 59 |
+
# use avg look at point
|
| 60 |
+
|
| 61 |
+
camera_lookat_point = torch.tensor(G.rendering_kwargs['avg_camera_pivot'], device=device)
|
| 62 |
+
cam2world_pose = LookAtPoseSampler.sample(3.14 / 2, 3.14 / 2, camera_lookat_point,
|
| 63 |
+
radius=G.rendering_kwargs['avg_camera_radius'], device=device)
|
| 64 |
+
focal_length = 4.2647 # FFHQ's FOV
|
| 65 |
+
intrinsics = torch.tensor([[focal_length, 0, 0.5], [0, focal_length, 0.5], [0, 0, 1]], device=device)
|
| 66 |
+
c_samples = torch.cat([cam2world_pose.reshape(-1, 16), intrinsics.reshape(-1, 9)], 1)
|
| 67 |
+
c_samples = c_samples.repeat(w_avg_samples, 1)
|
| 68 |
+
|
| 69 |
+
|
| 70 |
+
|
| 71 |
+
w_samples = G.mapping(torch.from_numpy(z_samples).to(device), c_samples) # [N, L, C]
|
| 72 |
+
w_samples = w_samples[:, :1, :].cpu().numpy().astype(np.float32) # [N, 1, C]
|
| 73 |
+
w_avg = np.mean(w_samples, axis=0, keepdims=True) # [1, 1, C]
|
| 74 |
+
# print('save w_avg to ./w_avg.npy')
|
| 75 |
+
# np.save('./w_avg.npy',w_avg)
|
| 76 |
+
w_avg_tensor = torch.from_numpy(w_avg).cuda()
|
| 77 |
+
w_std = (np.sum((w_samples - w_avg) ** 2) / w_avg_samples) ** 0.5
|
| 78 |
+
|
| 79 |
+
# np.save(w_avg_path, w_avg)
|
| 80 |
+
# np.save(w_std_path, w_std)
|
| 81 |
+
else:
|
| 82 |
+
# w_avg = np.load(w_avg_path)
|
| 83 |
+
# w_std = np.load(w_std_path)
|
| 84 |
+
raise Exception(' ')
|
| 85 |
+
|
| 86 |
+
start_w = initial_w if initial_w is not None else w_avg
|
| 87 |
+
|
| 88 |
+
# Setup noise inputs.
|
| 89 |
+
noise_bufs = {name: buf for (name, buf) in G.backbone.synthesis.named_buffers() if 'noise_const' in name}
|
| 90 |
+
|
| 91 |
+
# Load VGG16 feature detector.
|
| 92 |
+
url = 'https://nvlabs-fi-cdn.nvidia.com/stylegan2-ada-pytorch/pretrained/metrics/vgg16.pt'
|
| 93 |
+
# url = './networks/vgg16.pt'
|
| 94 |
+
with dnnlib.util.open_url(url) as f:
|
| 95 |
+
vgg16 = torch.jit.load(f).eval().to(device)
|
| 96 |
+
|
| 97 |
+
# Features for target image.
|
| 98 |
+
target_images = target.unsqueeze(0).to(device).to(torch.float32)
|
| 99 |
+
if target_images.shape[2] > 256:
|
| 100 |
+
target_images = F.interpolate(target_images, size=(256, 256), mode='area')
|
| 101 |
+
target_features = vgg16(target_images, resize_images=False, return_lpips=True)
|
| 102 |
+
|
| 103 |
+
w_opt = torch.tensor(start_w, dtype=torch.float32, device=device,
|
| 104 |
+
requires_grad=True) # pylint: disable=not-callable
|
| 105 |
+
print('w_opt shape: ',w_opt.shape)
|
| 106 |
+
|
| 107 |
+
optimizer = torch.optim.Adam([w_opt] + list(noise_bufs.values()), betas=(0.9, 0.999),
|
| 108 |
+
lr=0.1)
|
| 109 |
+
|
| 110 |
+
# Init noise.
|
| 111 |
+
for buf in noise_bufs.values():
|
| 112 |
+
buf[:] = torch.randn_like(buf)
|
| 113 |
+
buf.requires_grad = True
|
| 114 |
+
|
| 115 |
+
for step in tqdm(range(num_steps), position=0, leave=True):
|
| 116 |
+
|
| 117 |
+
# Learning rate schedule.
|
| 118 |
+
t = step / num_steps
|
| 119 |
+
w_noise_scale = w_std * initial_noise_factor * max(0.0, 1.0 - t / noise_ramp_length) ** 2
|
| 120 |
+
lr_ramp = min(1.0, (1.0 - t) / lr_rampdown_length)
|
| 121 |
+
lr_ramp = 0.5 - 0.5 * np.cos(lr_ramp * np.pi)
|
| 122 |
+
lr_ramp = lr_ramp * min(1.0, t / lr_rampup_length)
|
| 123 |
+
lr = initial_learning_rate * lr_ramp
|
| 124 |
+
for param_group in optimizer.param_groups:
|
| 125 |
+
param_group['lr'] = lr
|
| 126 |
+
|
| 127 |
+
# Synth images from opt_w.
|
| 128 |
+
w_noise = torch.randn_like(w_opt) * w_noise_scale
|
| 129 |
+
ws = (w_opt + w_noise).repeat([1, G.backbone.mapping.num_ws, 1])
|
| 130 |
+
synth_images = G.synthesis(ws,c, noise_mode='const')['image']
|
| 131 |
+
|
| 132 |
+
if step % image_log_step == 0:
|
| 133 |
+
with torch.no_grad():
|
| 134 |
+
vis_img = (synth_images.permute(0, 2, 3, 1) * 127.5 + 128).clamp(0, 255).to(torch.uint8)
|
| 135 |
+
|
| 136 |
+
PIL.Image.fromarray(vis_img[0].cpu().numpy(), 'RGB').save(f'{outdir}/{step}.png')
|
| 137 |
+
|
| 138 |
+
# Downsample image to 256x256 if it's larger than that. VGG was built for 224x224 images.
|
| 139 |
+
synth_images = (synth_images + 1) * (255 / 2)
|
| 140 |
+
if synth_images.shape[2] > 256:
|
| 141 |
+
synth_images = F.interpolate(synth_images, size=(256, 256), mode='area')
|
| 142 |
+
|
| 143 |
+
# Features for synth images.
|
| 144 |
+
synth_features = vgg16(synth_images, resize_images=False, return_lpips=True)
|
| 145 |
+
dist = (target_features - synth_features).square().sum()
|
| 146 |
+
|
| 147 |
+
# Noise regularization.
|
| 148 |
+
reg_loss = 0.0
|
| 149 |
+
for v in noise_bufs.values():
|
| 150 |
+
noise = v[None, None, :, :] # must be [1,1,H,W] for F.avg_pool2d()
|
| 151 |
+
while True:
|
| 152 |
+
reg_loss += (noise * torch.roll(noise, shifts=1, dims=3)).mean() ** 2
|
| 153 |
+
reg_loss += (noise * torch.roll(noise, shifts=1, dims=2)).mean() ** 2
|
| 154 |
+
if noise.shape[2] <= 8:
|
| 155 |
+
break
|
| 156 |
+
noise = F.avg_pool2d(noise, kernel_size=2)
|
| 157 |
+
loss = dist + reg_loss * regularize_noise_weight
|
| 158 |
+
|
| 159 |
+
# if step % 10 == 0:
|
| 160 |
+
# with torch.no_grad():
|
| 161 |
+
# print({f'step {step } first projection _{w_name}': loss.detach().cpu()})
|
| 162 |
+
|
| 163 |
+
# Step
|
| 164 |
+
optimizer.zero_grad(set_to_none=True)
|
| 165 |
+
loss.backward()
|
| 166 |
+
optimizer.step()
|
| 167 |
+
logprint(f'step {step + 1:>4d}/{num_steps}: dist {dist:<4.2f} loss {float(loss):<5.2f}')
|
| 168 |
+
|
| 169 |
+
# Normalize noise.
|
| 170 |
+
with torch.no_grad():
|
| 171 |
+
for buf in noise_bufs.values():
|
| 172 |
+
buf -= buf.mean()
|
| 173 |
+
buf *= buf.square().mean().rsqrt()
|
| 174 |
+
|
| 175 |
+
|
| 176 |
+
return w_opt.repeat([1, G.backbone.mapping.num_ws, 1])
|
| 177 |
+
del G
|
eg3d/run_inversion.py
ADDED
|
@@ -0,0 +1,106 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
|
| 2 |
+
# SPDX-FileCopyrightText: Copyright (c) 2021-2022 NVIDIA CORPORATION & AFFILIATES. All rights reserved.
|
| 3 |
+
# SPDX-License-Identifier: LicenseRef-NvidiaProprietary
|
| 4 |
+
#
|
| 5 |
+
# NVIDIA CORPORATION, its affiliates and licensors retain all intellectual
|
| 6 |
+
# property and proprietary rights in and to this material, related
|
| 7 |
+
# documentation and any modifications thereto. Any use, reproduction,
|
| 8 |
+
# disclosure or distribution of this material and related documentation
|
| 9 |
+
# without an express license agreement from NVIDIA CORPORATION or
|
| 10 |
+
# its affiliates is strictly prohibited.
|
| 11 |
+
|
| 12 |
+
"""Generate lerp videos using pretrained network pickle."""
|
| 13 |
+
|
| 14 |
+
import os
|
| 15 |
+
import re
|
| 16 |
+
from typing import List, Optional, Tuple, Union
|
| 17 |
+
|
| 18 |
+
import click
|
| 19 |
+
import dnnlib
|
| 20 |
+
import numpy as np
|
| 21 |
+
import torch
|
| 22 |
+
import legacy
|
| 23 |
+
from torchvision.transforms import transforms
|
| 24 |
+
from projector import w_projector,w_plus_projector
|
| 25 |
+
from PIL import Image
|
| 26 |
+
from glob import glob
|
| 27 |
+
from os.path import join as opj
|
| 28 |
+
|
| 29 |
+
@click.command()
|
| 30 |
+
@click.option('--image_path', help='path of image file or image directory', type=str, required=True, metavar='STR', show_default=True)
|
| 31 |
+
@click.option('--c_path', help='camera parameters path', type=str, required=True, default='test-runs', metavar='STR', show_default=True)
|
| 32 |
+
@click.option('--network', 'network_pkl', help='Network pickle filename', required=True)
|
| 33 |
+
@click.option('--outdir', help='Output directory', type=str, required=True, metavar='DIR')
|
| 34 |
+
@click.option('--latent_space_type', help='latent_space_type', type=click.Choice(['w', 'w_plus']), required=False, metavar='STR',
|
| 35 |
+
default='w', show_default=True)
|
| 36 |
+
@click.option('--num_steps', 'num_steps', type=int,
|
| 37 |
+
help='Multiplier for depth sampling in volume rendering', default=500, show_default=True)
|
| 38 |
+
@click.option('--sample_mult', 'sampling_multiplier', type=float,
|
| 39 |
+
help='Multiplier for depth sampling in volume rendering', default=2, show_default=True)
|
| 40 |
+
@click.option('--nrr', type=int, help='Neural rendering resolution override', default=None, show_default=True)
|
| 41 |
+
def run(
|
| 42 |
+
network_pkl: str,
|
| 43 |
+
outdir: str,
|
| 44 |
+
sampling_multiplier: float,
|
| 45 |
+
nrr: Optional[int],
|
| 46 |
+
latent_space_type:str,
|
| 47 |
+
image_path:str,
|
| 48 |
+
c_path:str,
|
| 49 |
+
num_steps:int
|
| 50 |
+
):
|
| 51 |
+
os.makedirs(outdir, exist_ok=True)
|
| 52 |
+
print('Loading networks from "%s"...' % network_pkl)
|
| 53 |
+
device = torch.device('cuda')
|
| 54 |
+
with dnnlib.util.open_url(network_pkl) as f:
|
| 55 |
+
G = legacy.load_network_pkl(f)['G_ema']
|
| 56 |
+
|
| 57 |
+
G = G.to(device)
|
| 58 |
+
G.rendering_kwargs['depth_resolution'] = int(G.rendering_kwargs['depth_resolution'] * sampling_multiplier)
|
| 59 |
+
G.rendering_kwargs['depth_resolution_importance'] = int(
|
| 60 |
+
G.rendering_kwargs['depth_resolution_importance'] * sampling_multiplier)
|
| 61 |
+
if nrr is not None: G.neural_rendering_resolution = nrr
|
| 62 |
+
|
| 63 |
+
|
| 64 |
+
if os.path.isdir(image_path):
|
| 65 |
+
img_paths = sorted(glob(opj(image_path,"*.png")))
|
| 66 |
+
else:
|
| 67 |
+
img_paths = [image_path]
|
| 68 |
+
|
| 69 |
+
trans = transforms.Compose([
|
| 70 |
+
transforms.ToTensor(),
|
| 71 |
+
transforms.Normalize([0.5, 0.5, 0.5], [0.5, 0.5, 0.5]),
|
| 72 |
+
transforms.Resize((512, 512))
|
| 73 |
+
])
|
| 74 |
+
|
| 75 |
+
|
| 76 |
+
for img_path in img_paths:
|
| 77 |
+
img = Image.open(img_path).convert('RGB')
|
| 78 |
+
img_id = os.path.split(img_path)[-1].split('.')[0]
|
| 79 |
+
img.save(f'{outdir}/{img_id}_orig.png')
|
| 80 |
+
c = np.load(img_path.replace('png','npy'))
|
| 81 |
+
c = np.reshape(c,(1,25))
|
| 82 |
+
c = torch.FloatTensor(c).cuda()
|
| 83 |
+
|
| 84 |
+
from_im = trans(img).cuda()
|
| 85 |
+
id_image = torch.squeeze((from_im.cuda() + 1) / 2) * 255
|
| 86 |
+
|
| 87 |
+
if latent_space_type == 'w':
|
| 88 |
+
w = w_projector.project(G, c, outdir,id_image, device=torch.device('cuda'), w_avg_samples=600, num_steps = num_steps, w_name=img_id)
|
| 89 |
+
else:
|
| 90 |
+
w = w_plus_projector.project(G, c,outdir, id_image, device=torch.device('cuda'), w_avg_samples=600, w_name=img_id, num_steps = num_steps )
|
| 91 |
+
|
| 92 |
+
result_img = G.synthesis(w, c, noise_mode='const')['image']
|
| 93 |
+
vis_img = (result_img.permute(0, 2, 3, 1) * 127.5 + 128).clamp(0, 255).to(torch.uint8)
|
| 94 |
+
Image.fromarray(vis_img[0].cpu().numpy(), 'RGB').save(f'{outdir}/{img_id}_inv.png')
|
| 95 |
+
|
| 96 |
+
torch.save(w.detach().cpu(), f'{outdir}/{img_id}_inv.pt')
|
| 97 |
+
|
| 98 |
+
# ----------------------------------------------------------------------------
|
| 99 |
+
|
| 100 |
+
if __name__ == "__main__":
|
| 101 |
+
run() # pylint: disable=no-value-for-parameter
|
| 102 |
+
|
| 103 |
+
# ----------------------------------------------------------------------------
|
| 104 |
+
|
| 105 |
+
|
| 106 |
+
|
eg3d/shape_utils.py
ADDED
|
@@ -0,0 +1,124 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# SPDX-FileCopyrightText: Copyright (c) 2021-2022 NVIDIA CORPORATION & AFFILIATES. All rights reserved.
|
| 2 |
+
# SPDX-License-Identifier: LicenseRef-NvidiaProprietary
|
| 3 |
+
#
|
| 4 |
+
# NVIDIA CORPORATION, its affiliates and licensors retain all intellectual
|
| 5 |
+
# property and proprietary rights in and to this material, related
|
| 6 |
+
# documentation and any modifications thereto. Any use, reproduction,
|
| 7 |
+
# disclosure or distribution of this material and related documentation
|
| 8 |
+
# without an express license agreement from NVIDIA CORPORATION or
|
| 9 |
+
# its affiliates is strictly prohibited.
|
| 10 |
+
|
| 11 |
+
|
| 12 |
+
"""
|
| 13 |
+
Utils for extracting 3D shapes using marching cubes. Based on code from DeepSDF (Park et al.)
|
| 14 |
+
|
| 15 |
+
Takes as input an .mrc file and extracts a mesh.
|
| 16 |
+
|
| 17 |
+
Ex.
|
| 18 |
+
python shape_utils.py my_shape.mrc
|
| 19 |
+
Ex.
|
| 20 |
+
python shape_utils.py myshapes_directory --level=12
|
| 21 |
+
"""
|
| 22 |
+
|
| 23 |
+
|
| 24 |
+
import time
|
| 25 |
+
import plyfile
|
| 26 |
+
import glob
|
| 27 |
+
import logging
|
| 28 |
+
import numpy as np
|
| 29 |
+
import os
|
| 30 |
+
import random
|
| 31 |
+
import torch
|
| 32 |
+
import torch.utils.data
|
| 33 |
+
import trimesh
|
| 34 |
+
import skimage.measure
|
| 35 |
+
import argparse
|
| 36 |
+
import mrcfile
|
| 37 |
+
from tqdm import tqdm
|
| 38 |
+
|
| 39 |
+
|
| 40 |
+
def convert_sdf_samples_to_ply(
|
| 41 |
+
numpy_3d_sdf_tensor,
|
| 42 |
+
voxel_grid_origin,
|
| 43 |
+
voxel_size,
|
| 44 |
+
ply_filename_out,
|
| 45 |
+
offset=None,
|
| 46 |
+
scale=None,
|
| 47 |
+
level=0.0
|
| 48 |
+
):
|
| 49 |
+
"""
|
| 50 |
+
Convert sdf samples to .ply
|
| 51 |
+
:param pytorch_3d_sdf_tensor: a torch.FloatTensor of shape (n,n,n)
|
| 52 |
+
:voxel_grid_origin: a list of three floats: the bottom, left, down origin of the voxel grid
|
| 53 |
+
:voxel_size: float, the size of the voxels
|
| 54 |
+
:ply_filename_out: string, path of the filename to save to
|
| 55 |
+
This function adapted from: https://github.com/RobotLocomotion/spartan
|
| 56 |
+
"""
|
| 57 |
+
start_time = time.time()
|
| 58 |
+
|
| 59 |
+
verts, faces, normals, values = np.zeros((0, 3)), np.zeros((0, 3)), np.zeros((0, 3)), np.zeros(0)
|
| 60 |
+
# try:
|
| 61 |
+
verts, faces, normals, values = skimage.measure.marching_cubes(
|
| 62 |
+
numpy_3d_sdf_tensor, level=level, spacing=[voxel_size] * 3
|
| 63 |
+
)
|
| 64 |
+
# except:
|
| 65 |
+
# pass
|
| 66 |
+
|
| 67 |
+
# transform from voxel coordinates to camera coordinates
|
| 68 |
+
# note x and y are flipped in the output of marching_cubes
|
| 69 |
+
mesh_points = np.zeros_like(verts)
|
| 70 |
+
mesh_points[:, 0] = voxel_grid_origin[0] + verts[:, 0]
|
| 71 |
+
mesh_points[:, 1] = voxel_grid_origin[1] + verts[:, 1]
|
| 72 |
+
mesh_points[:, 2] = voxel_grid_origin[2] + verts[:, 2]
|
| 73 |
+
|
| 74 |
+
# apply additional offset and scale
|
| 75 |
+
if scale is not None:
|
| 76 |
+
mesh_points = mesh_points / scale
|
| 77 |
+
if offset is not None:
|
| 78 |
+
mesh_points = mesh_points - offset
|
| 79 |
+
|
| 80 |
+
# try writing to the ply file
|
| 81 |
+
|
| 82 |
+
num_verts = verts.shape[0]
|
| 83 |
+
num_faces = faces.shape[0]
|
| 84 |
+
|
| 85 |
+
verts_tuple = np.zeros((num_verts,), dtype=[("x", "f4"), ("y", "f4"), ("z", "f4")])
|
| 86 |
+
|
| 87 |
+
for i in range(0, num_verts):
|
| 88 |
+
verts_tuple[i] = tuple(mesh_points[i, :])
|
| 89 |
+
|
| 90 |
+
faces_building = []
|
| 91 |
+
for i in range(0, num_faces):
|
| 92 |
+
faces_building.append(((faces[i, :].tolist(),)))
|
| 93 |
+
faces_tuple = np.array(faces_building, dtype=[("vertex_indices", "i4", (3,))])
|
| 94 |
+
|
| 95 |
+
el_verts = plyfile.PlyElement.describe(verts_tuple, "vertex")
|
| 96 |
+
el_faces = plyfile.PlyElement.describe(faces_tuple, "face")
|
| 97 |
+
|
| 98 |
+
ply_data = plyfile.PlyData([el_verts, el_faces])
|
| 99 |
+
ply_data.write(ply_filename_out)
|
| 100 |
+
print(f"wrote to {ply_filename_out}")
|
| 101 |
+
|
| 102 |
+
|
| 103 |
+
def convert_mrc(input_filename, output_filename, isosurface_level=1):
|
| 104 |
+
with mrcfile.open(input_filename) as mrc:
|
| 105 |
+
convert_sdf_samples_to_ply(np.transpose(mrc.data, (2, 1, 0)), [0, 0, 0], 1, output_filename, level=isosurface_level)
|
| 106 |
+
|
| 107 |
+
if __name__ == '__main__':
|
| 108 |
+
start_time = time.time()
|
| 109 |
+
parser = argparse.ArgumentParser()
|
| 110 |
+
parser.add_argument('input_mrc_path')
|
| 111 |
+
parser.add_argument('--level', type=float, default=10, help="The isosurface level for marching cubes")
|
| 112 |
+
args = parser.parse_args()
|
| 113 |
+
|
| 114 |
+
if os.path.isfile(args.input_mrc_path) and args.input_mrc_path.split('.')[-1] == 'ply':
|
| 115 |
+
output_obj_path = args.input_mrc_path.split('.mrc')[0] + '.ply'
|
| 116 |
+
convert_mrc(args.input_mrc_path, output_obj_path, isosurface_level=1)
|
| 117 |
+
|
| 118 |
+
print(f"{time.time() - start_time:02f} s")
|
| 119 |
+
else:
|
| 120 |
+
assert os.path.isdir(args.input_mrc_path)
|
| 121 |
+
|
| 122 |
+
for mrc_path in tqdm(glob.glob(os.path.join(args.input_mrc_path, '*.mrc'))):
|
| 123 |
+
output_obj_path = mrc_path.split('.mrc')[0] + '.ply'
|
| 124 |
+
convert_mrc(mrc_path, output_obj_path, isosurface_level=args.level)
|
eg3d/torch_utils/__init__.py
ADDED
|
@@ -0,0 +1,11 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# SPDX-FileCopyrightText: Copyright (c) 2021-2022 NVIDIA CORPORATION & AFFILIATES. All rights reserved.
|
| 2 |
+
# SPDX-License-Identifier: LicenseRef-NvidiaProprietary
|
| 3 |
+
#
|
| 4 |
+
# NVIDIA CORPORATION, its affiliates and licensors retain all intellectual
|
| 5 |
+
# property and proprietary rights in and to this material, related
|
| 6 |
+
# documentation and any modifications thereto. Any use, reproduction,
|
| 7 |
+
# disclosure or distribution of this material and related documentation
|
| 8 |
+
# without an express license agreement from NVIDIA CORPORATION or
|
| 9 |
+
# its affiliates is strictly prohibited.
|
| 10 |
+
|
| 11 |
+
# empty
|
eg3d/torch_utils/custom_ops.py
ADDED
|
@@ -0,0 +1,159 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# SPDX-FileCopyrightText: Copyright (c) 2021-2022 NVIDIA CORPORATION & AFFILIATES. All rights reserved.
|
| 2 |
+
# SPDX-License-Identifier: LicenseRef-NvidiaProprietary
|
| 3 |
+
#
|
| 4 |
+
# NVIDIA CORPORATION, its affiliates and licensors retain all intellectual
|
| 5 |
+
# property and proprietary rights in and to this material, related
|
| 6 |
+
# documentation and any modifications thereto. Any use, reproduction,
|
| 7 |
+
# disclosure or distribution of this material and related documentation
|
| 8 |
+
# without an express license agreement from NVIDIA CORPORATION or
|
| 9 |
+
# its affiliates is strictly prohibited.
|
| 10 |
+
|
| 11 |
+
import glob
|
| 12 |
+
import hashlib
|
| 13 |
+
import importlib
|
| 14 |
+
import os
|
| 15 |
+
import re
|
| 16 |
+
import shutil
|
| 17 |
+
import uuid
|
| 18 |
+
|
| 19 |
+
import torch
|
| 20 |
+
import torch.utils.cpp_extension
|
| 21 |
+
from torch.utils.file_baton import FileBaton
|
| 22 |
+
|
| 23 |
+
#----------------------------------------------------------------------------
|
| 24 |
+
# Global options.
|
| 25 |
+
|
| 26 |
+
verbosity = 'brief' # Verbosity level: 'none', 'brief', 'full'
|
| 27 |
+
|
| 28 |
+
#----------------------------------------------------------------------------
|
| 29 |
+
# Internal helper funcs.
|
| 30 |
+
|
| 31 |
+
def _find_compiler_bindir():
|
| 32 |
+
patterns = [
|
| 33 |
+
'C:/Program Files (x86)/Microsoft Visual Studio/*/Professional/VC/Tools/MSVC/*/bin/Hostx64/x64',
|
| 34 |
+
'C:/Program Files (x86)/Microsoft Visual Studio/*/BuildTools/VC/Tools/MSVC/*/bin/Hostx64/x64',
|
| 35 |
+
'C:/Program Files (x86)/Microsoft Visual Studio/*/Community/VC/Tools/MSVC/*/bin/Hostx64/x64',
|
| 36 |
+
'C:/Program Files (x86)/Microsoft Visual Studio */vc/bin',
|
| 37 |
+
]
|
| 38 |
+
for pattern in patterns:
|
| 39 |
+
matches = sorted(glob.glob(pattern))
|
| 40 |
+
if len(matches):
|
| 41 |
+
return matches[-1]
|
| 42 |
+
return None
|
| 43 |
+
|
| 44 |
+
#----------------------------------------------------------------------------
|
| 45 |
+
|
| 46 |
+
def _get_mangled_gpu_name():
|
| 47 |
+
name = torch.cuda.get_device_name().lower()
|
| 48 |
+
out = []
|
| 49 |
+
for c in name:
|
| 50 |
+
if re.match('[a-z0-9_-]+', c):
|
| 51 |
+
out.append(c)
|
| 52 |
+
else:
|
| 53 |
+
out.append('-')
|
| 54 |
+
return ''.join(out)
|
| 55 |
+
|
| 56 |
+
#----------------------------------------------------------------------------
|
| 57 |
+
# Main entry point for compiling and loading C++/CUDA plugins.
|
| 58 |
+
|
| 59 |
+
_cached_plugins = dict()
|
| 60 |
+
|
| 61 |
+
def get_plugin(module_name, sources, headers=None, source_dir=None, **build_kwargs):
|
| 62 |
+
assert verbosity in ['none', 'brief', 'full']
|
| 63 |
+
if headers is None:
|
| 64 |
+
headers = []
|
| 65 |
+
if source_dir is not None:
|
| 66 |
+
sources = [os.path.join(source_dir, fname) for fname in sources]
|
| 67 |
+
headers = [os.path.join(source_dir, fname) for fname in headers]
|
| 68 |
+
|
| 69 |
+
# Already cached?
|
| 70 |
+
if module_name in _cached_plugins:
|
| 71 |
+
return _cached_plugins[module_name]
|
| 72 |
+
|
| 73 |
+
# Print status.
|
| 74 |
+
if verbosity == 'full':
|
| 75 |
+
print(f'Setting up PyTorch plugin "{module_name}"...')
|
| 76 |
+
elif verbosity == 'brief':
|
| 77 |
+
print(f'Setting up PyTorch plugin "{module_name}"... ', end='', flush=True)
|
| 78 |
+
verbose_build = (verbosity == 'full')
|
| 79 |
+
|
| 80 |
+
# Compile and load.
|
| 81 |
+
try: # pylint: disable=too-many-nested-blocks
|
| 82 |
+
# Make sure we can find the necessary compiler binaries.
|
| 83 |
+
if os.name == 'nt' and os.system("where cl.exe >nul 2>nul") != 0:
|
| 84 |
+
compiler_bindir = _find_compiler_bindir()
|
| 85 |
+
if compiler_bindir is None:
|
| 86 |
+
raise RuntimeError(f'Could not find MSVC/GCC/CLANG installation on this computer. Check _find_compiler_bindir() in "{__file__}".')
|
| 87 |
+
os.environ['PATH'] += ';' + compiler_bindir
|
| 88 |
+
|
| 89 |
+
# Some containers set TORCH_CUDA_ARCH_LIST to a list that can either
|
| 90 |
+
# break the build or unnecessarily restrict what's available to nvcc.
|
| 91 |
+
# Unset it to let nvcc decide based on what's available on the
|
| 92 |
+
# machine.
|
| 93 |
+
os.environ['TORCH_CUDA_ARCH_LIST'] = ''
|
| 94 |
+
|
| 95 |
+
# Incremental build md5sum trickery. Copies all the input source files
|
| 96 |
+
# into a cached build directory under a combined md5 digest of the input
|
| 97 |
+
# source files. Copying is done only if the combined digest has changed.
|
| 98 |
+
# This keeps input file timestamps and filenames the same as in previous
|
| 99 |
+
# extension builds, allowing for fast incremental rebuilds.
|
| 100 |
+
#
|
| 101 |
+
# This optimization is done only in case all the source files reside in
|
| 102 |
+
# a single directory (just for simplicity) and if the TORCH_EXTENSIONS_DIR
|
| 103 |
+
# environment variable is set (we take this as a signal that the user
|
| 104 |
+
# actually cares about this.)
|
| 105 |
+
#
|
| 106 |
+
# EDIT: We now do it regardless of TORCH_EXTENSIOS_DIR, in order to work
|
| 107 |
+
# around the *.cu dependency bug in ninja config.
|
| 108 |
+
#
|
| 109 |
+
all_source_files = sorted(sources + headers)
|
| 110 |
+
all_source_dirs = set(os.path.dirname(fname) for fname in all_source_files)
|
| 111 |
+
if len(all_source_dirs) == 1: # and ('TORCH_EXTENSIONS_DIR' in os.environ):
|
| 112 |
+
|
| 113 |
+
# Compute combined hash digest for all source files.
|
| 114 |
+
hash_md5 = hashlib.md5()
|
| 115 |
+
for src in all_source_files:
|
| 116 |
+
with open(src, 'rb') as f:
|
| 117 |
+
hash_md5.update(f.read())
|
| 118 |
+
|
| 119 |
+
# Select cached build directory name.
|
| 120 |
+
source_digest = hash_md5.hexdigest()
|
| 121 |
+
build_top_dir = torch.utils.cpp_extension._get_build_directory(module_name, verbose=verbose_build) # pylint: disable=protected-access
|
| 122 |
+
cached_build_dir = os.path.join(build_top_dir, f'{source_digest}-{_get_mangled_gpu_name()}')
|
| 123 |
+
|
| 124 |
+
if not os.path.isdir(cached_build_dir):
|
| 125 |
+
tmpdir = f'{build_top_dir}/srctmp-{uuid.uuid4().hex}'
|
| 126 |
+
os.makedirs(tmpdir)
|
| 127 |
+
for src in all_source_files:
|
| 128 |
+
shutil.copyfile(src, os.path.join(tmpdir, os.path.basename(src)))
|
| 129 |
+
try:
|
| 130 |
+
os.replace(tmpdir, cached_build_dir) # atomic
|
| 131 |
+
except OSError:
|
| 132 |
+
# source directory already exists, delete tmpdir and its contents.
|
| 133 |
+
shutil.rmtree(tmpdir)
|
| 134 |
+
if not os.path.isdir(cached_build_dir): raise
|
| 135 |
+
|
| 136 |
+
# Compile.
|
| 137 |
+
cached_sources = [os.path.join(cached_build_dir, os.path.basename(fname)) for fname in sources]
|
| 138 |
+
torch.utils.cpp_extension.load(name=module_name, build_directory=cached_build_dir,
|
| 139 |
+
verbose=verbose_build, sources=cached_sources, **build_kwargs)
|
| 140 |
+
else:
|
| 141 |
+
torch.utils.cpp_extension.load(name=module_name, verbose=verbose_build, sources=sources, **build_kwargs)
|
| 142 |
+
|
| 143 |
+
# Load.
|
| 144 |
+
module = importlib.import_module(module_name)
|
| 145 |
+
|
| 146 |
+
except:
|
| 147 |
+
if verbosity == 'brief':
|
| 148 |
+
print('Failed!')
|
| 149 |
+
raise
|
| 150 |
+
|
| 151 |
+
# Print status and add to cache dict.
|
| 152 |
+
if verbosity == 'full':
|
| 153 |
+
print(f'Done setting up PyTorch plugin "{module_name}".')
|
| 154 |
+
elif verbosity == 'brief':
|
| 155 |
+
print('Done.')
|
| 156 |
+
_cached_plugins[module_name] = module
|
| 157 |
+
return module
|
| 158 |
+
|
| 159 |
+
#----------------------------------------------------------------------------
|
eg3d/torch_utils/misc.py
ADDED
|
@@ -0,0 +1,268 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# SPDX-FileCopyrightText: Copyright (c) 2021-2022 NVIDIA CORPORATION & AFFILIATES. All rights reserved.
|
| 2 |
+
# SPDX-License-Identifier: LicenseRef-NvidiaProprietary
|
| 3 |
+
#
|
| 4 |
+
# NVIDIA CORPORATION, its affiliates and licensors retain all intellectual
|
| 5 |
+
# property and proprietary rights in and to this material, related
|
| 6 |
+
# documentation and any modifications thereto. Any use, reproduction,
|
| 7 |
+
# disclosure or distribution of this material and related documentation
|
| 8 |
+
# without an express license agreement from NVIDIA CORPORATION or
|
| 9 |
+
# its affiliates is strictly prohibited.
|
| 10 |
+
|
| 11 |
+
import re
|
| 12 |
+
import contextlib
|
| 13 |
+
import numpy as np
|
| 14 |
+
import torch
|
| 15 |
+
import warnings
|
| 16 |
+
import dnnlib
|
| 17 |
+
|
| 18 |
+
#----------------------------------------------------------------------------
|
| 19 |
+
# Cached construction of constant tensors. Avoids CPU=>GPU copy when the
|
| 20 |
+
# same constant is used multiple times.
|
| 21 |
+
|
| 22 |
+
_constant_cache = dict()
|
| 23 |
+
|
| 24 |
+
def constant(value, shape=None, dtype=None, device=None, memory_format=None):
|
| 25 |
+
value = np.asarray(value)
|
| 26 |
+
if shape is not None:
|
| 27 |
+
shape = tuple(shape)
|
| 28 |
+
if dtype is None:
|
| 29 |
+
dtype = torch.get_default_dtype()
|
| 30 |
+
if device is None:
|
| 31 |
+
device = torch.device('cpu')
|
| 32 |
+
if memory_format is None:
|
| 33 |
+
memory_format = torch.contiguous_format
|
| 34 |
+
|
| 35 |
+
key = (value.shape, value.dtype, value.tobytes(), shape, dtype, device, memory_format)
|
| 36 |
+
tensor = _constant_cache.get(key, None)
|
| 37 |
+
if tensor is None:
|
| 38 |
+
tensor = torch.as_tensor(value.copy(), dtype=dtype, device=device)
|
| 39 |
+
if shape is not None:
|
| 40 |
+
tensor, _ = torch.broadcast_tensors(tensor, torch.empty(shape))
|
| 41 |
+
tensor = tensor.contiguous(memory_format=memory_format)
|
| 42 |
+
_constant_cache[key] = tensor
|
| 43 |
+
return tensor
|
| 44 |
+
|
| 45 |
+
#----------------------------------------------------------------------------
|
| 46 |
+
# Replace NaN/Inf with specified numerical values.
|
| 47 |
+
|
| 48 |
+
try:
|
| 49 |
+
nan_to_num = torch.nan_to_num # 1.8.0a0
|
| 50 |
+
except AttributeError:
|
| 51 |
+
def nan_to_num(input, nan=0.0, posinf=None, neginf=None, *, out=None): # pylint: disable=redefined-builtin
|
| 52 |
+
assert isinstance(input, torch.Tensor)
|
| 53 |
+
if posinf is None:
|
| 54 |
+
posinf = torch.finfo(input.dtype).max
|
| 55 |
+
if neginf is None:
|
| 56 |
+
neginf = torch.finfo(input.dtype).min
|
| 57 |
+
assert nan == 0
|
| 58 |
+
return torch.clamp(input.unsqueeze(0).nansum(0), min=neginf, max=posinf, out=out)
|
| 59 |
+
|
| 60 |
+
#----------------------------------------------------------------------------
|
| 61 |
+
# Symbolic assert.
|
| 62 |
+
|
| 63 |
+
try:
|
| 64 |
+
symbolic_assert = torch._assert # 1.8.0a0 # pylint: disable=protected-access
|
| 65 |
+
except AttributeError:
|
| 66 |
+
symbolic_assert = torch.Assert # 1.7.0
|
| 67 |
+
|
| 68 |
+
#----------------------------------------------------------------------------
|
| 69 |
+
# Context manager to temporarily suppress known warnings in torch.jit.trace().
|
| 70 |
+
# Note: Cannot use catch_warnings because of https://bugs.python.org/issue29672
|
| 71 |
+
|
| 72 |
+
@contextlib.contextmanager
|
| 73 |
+
def suppress_tracer_warnings():
|
| 74 |
+
flt = ('ignore', None, torch.jit.TracerWarning, None, 0)
|
| 75 |
+
warnings.filters.insert(0, flt)
|
| 76 |
+
yield
|
| 77 |
+
warnings.filters.remove(flt)
|
| 78 |
+
|
| 79 |
+
#----------------------------------------------------------------------------
|
| 80 |
+
# Assert that the shape of a tensor matches the given list of integers.
|
| 81 |
+
# None indicates that the size of a dimension is allowed to vary.
|
| 82 |
+
# Performs symbolic assertion when used in torch.jit.trace().
|
| 83 |
+
|
| 84 |
+
def assert_shape(tensor, ref_shape):
|
| 85 |
+
if tensor.ndim != len(ref_shape):
|
| 86 |
+
raise AssertionError(f'Wrong number of dimensions: got {tensor.ndim}, expected {len(ref_shape)}')
|
| 87 |
+
for idx, (size, ref_size) in enumerate(zip(tensor.shape, ref_shape)):
|
| 88 |
+
if ref_size is None:
|
| 89 |
+
pass
|
| 90 |
+
elif isinstance(ref_size, torch.Tensor):
|
| 91 |
+
with suppress_tracer_warnings(): # as_tensor results are registered as constants
|
| 92 |
+
symbolic_assert(torch.equal(torch.as_tensor(size), ref_size), f'Wrong size for dimension {idx}')
|
| 93 |
+
elif isinstance(size, torch.Tensor):
|
| 94 |
+
with suppress_tracer_warnings(): # as_tensor results are registered as constants
|
| 95 |
+
symbolic_assert(torch.equal(size, torch.as_tensor(ref_size)), f'Wrong size for dimension {idx}: expected {ref_size}')
|
| 96 |
+
elif size != ref_size:
|
| 97 |
+
raise AssertionError(f'Wrong size for dimension {idx}: got {size}, expected {ref_size}')
|
| 98 |
+
|
| 99 |
+
#----------------------------------------------------------------------------
|
| 100 |
+
# Function decorator that calls torch.autograd.profiler.record_function().
|
| 101 |
+
|
| 102 |
+
def profiled_function(fn):
|
| 103 |
+
def decorator(*args, **kwargs):
|
| 104 |
+
with torch.autograd.profiler.record_function(fn.__name__):
|
| 105 |
+
return fn(*args, **kwargs)
|
| 106 |
+
decorator.__name__ = fn.__name__
|
| 107 |
+
return decorator
|
| 108 |
+
|
| 109 |
+
#----------------------------------------------------------------------------
|
| 110 |
+
# Sampler for torch.utils.data.DataLoader that loops over the dataset
|
| 111 |
+
# indefinitely, shuffling items as it goes.
|
| 112 |
+
|
| 113 |
+
class InfiniteSampler(torch.utils.data.Sampler):
|
| 114 |
+
def __init__(self, dataset, rank=0, num_replicas=1, shuffle=True, seed=0, window_size=0.5):
|
| 115 |
+
assert len(dataset) > 0
|
| 116 |
+
assert num_replicas > 0
|
| 117 |
+
assert 0 <= rank < num_replicas
|
| 118 |
+
assert 0 <= window_size <= 1
|
| 119 |
+
super().__init__(dataset)
|
| 120 |
+
self.dataset = dataset
|
| 121 |
+
self.rank = rank
|
| 122 |
+
self.num_replicas = num_replicas
|
| 123 |
+
self.shuffle = shuffle
|
| 124 |
+
self.seed = seed
|
| 125 |
+
self.window_size = window_size
|
| 126 |
+
|
| 127 |
+
def __iter__(self):
|
| 128 |
+
order = np.arange(len(self.dataset))
|
| 129 |
+
rnd = None
|
| 130 |
+
window = 0
|
| 131 |
+
if self.shuffle:
|
| 132 |
+
rnd = np.random.RandomState(self.seed)
|
| 133 |
+
rnd.shuffle(order)
|
| 134 |
+
window = int(np.rint(order.size * self.window_size))
|
| 135 |
+
|
| 136 |
+
idx = 0
|
| 137 |
+
while True:
|
| 138 |
+
i = idx % order.size
|
| 139 |
+
if idx % self.num_replicas == self.rank:
|
| 140 |
+
yield order[i]
|
| 141 |
+
if window >= 2:
|
| 142 |
+
j = (i - rnd.randint(window)) % order.size
|
| 143 |
+
order[i], order[j] = order[j], order[i]
|
| 144 |
+
idx += 1
|
| 145 |
+
|
| 146 |
+
#----------------------------------------------------------------------------
|
| 147 |
+
# Utilities for operating with torch.nn.Module parameters and buffers.
|
| 148 |
+
|
| 149 |
+
def params_and_buffers(module):
|
| 150 |
+
assert isinstance(module, torch.nn.Module)
|
| 151 |
+
return list(module.parameters()) + list(module.buffers())
|
| 152 |
+
|
| 153 |
+
def named_params_and_buffers(module):
|
| 154 |
+
assert isinstance(module, torch.nn.Module)
|
| 155 |
+
return list(module.named_parameters()) + list(module.named_buffers())
|
| 156 |
+
|
| 157 |
+
def copy_params_and_buffers(src_module, dst_module, require_all=False):
|
| 158 |
+
assert isinstance(src_module, torch.nn.Module)
|
| 159 |
+
assert isinstance(dst_module, torch.nn.Module)
|
| 160 |
+
src_tensors = dict(named_params_and_buffers(src_module))
|
| 161 |
+
for name, tensor in named_params_and_buffers(dst_module):
|
| 162 |
+
assert (name in src_tensors) or (not require_all)
|
| 163 |
+
if name in src_tensors:
|
| 164 |
+
tensor.copy_(src_tensors[name].detach()).requires_grad_(tensor.requires_grad)
|
| 165 |
+
|
| 166 |
+
#----------------------------------------------------------------------------
|
| 167 |
+
# Context manager for easily enabling/disabling DistributedDataParallel
|
| 168 |
+
# synchronization.
|
| 169 |
+
|
| 170 |
+
@contextlib.contextmanager
|
| 171 |
+
def ddp_sync(module, sync):
|
| 172 |
+
assert isinstance(module, torch.nn.Module)
|
| 173 |
+
if sync or not isinstance(module, torch.nn.parallel.DistributedDataParallel):
|
| 174 |
+
yield
|
| 175 |
+
else:
|
| 176 |
+
with module.no_sync():
|
| 177 |
+
yield
|
| 178 |
+
|
| 179 |
+
#----------------------------------------------------------------------------
|
| 180 |
+
# Check DistributedDataParallel consistency across processes.
|
| 181 |
+
|
| 182 |
+
def check_ddp_consistency(module, ignore_regex=None):
|
| 183 |
+
assert isinstance(module, torch.nn.Module)
|
| 184 |
+
for name, tensor in named_params_and_buffers(module):
|
| 185 |
+
fullname = type(module).__name__ + '.' + name
|
| 186 |
+
if ignore_regex is not None and re.fullmatch(ignore_regex, fullname):
|
| 187 |
+
continue
|
| 188 |
+
tensor = tensor.detach()
|
| 189 |
+
if tensor.is_floating_point():
|
| 190 |
+
tensor = nan_to_num(tensor)
|
| 191 |
+
other = tensor.clone()
|
| 192 |
+
torch.distributed.broadcast(tensor=other, src=0)
|
| 193 |
+
assert (tensor == other).all(), fullname
|
| 194 |
+
|
| 195 |
+
#----------------------------------------------------------------------------
|
| 196 |
+
# Print summary table of module hierarchy.
|
| 197 |
+
|
| 198 |
+
def print_module_summary(module, inputs, max_nesting=3, skip_redundant=True):
|
| 199 |
+
assert isinstance(module, torch.nn.Module)
|
| 200 |
+
assert not isinstance(module, torch.jit.ScriptModule)
|
| 201 |
+
assert isinstance(inputs, (tuple, list))
|
| 202 |
+
|
| 203 |
+
# Register hooks.
|
| 204 |
+
entries = []
|
| 205 |
+
nesting = [0]
|
| 206 |
+
def pre_hook(_mod, _inputs):
|
| 207 |
+
nesting[0] += 1
|
| 208 |
+
def post_hook(mod, _inputs, outputs):
|
| 209 |
+
nesting[0] -= 1
|
| 210 |
+
if nesting[0] <= max_nesting:
|
| 211 |
+
outputs = list(outputs) if isinstance(outputs, (tuple, list)) else [outputs]
|
| 212 |
+
outputs = [t for t in outputs if isinstance(t, torch.Tensor)]
|
| 213 |
+
entries.append(dnnlib.EasyDict(mod=mod, outputs=outputs))
|
| 214 |
+
hooks = [mod.register_forward_pre_hook(pre_hook) for mod in module.modules()]
|
| 215 |
+
hooks += [mod.register_forward_hook(post_hook) for mod in module.modules()]
|
| 216 |
+
|
| 217 |
+
# Run module.
|
| 218 |
+
outputs = module(*inputs)
|
| 219 |
+
for hook in hooks:
|
| 220 |
+
hook.remove()
|
| 221 |
+
|
| 222 |
+
# Identify unique outputs, parameters, and buffers.
|
| 223 |
+
tensors_seen = set()
|
| 224 |
+
for e in entries:
|
| 225 |
+
e.unique_params = [t for t in e.mod.parameters() if id(t) not in tensors_seen]
|
| 226 |
+
e.unique_buffers = [t for t in e.mod.buffers() if id(t) not in tensors_seen]
|
| 227 |
+
e.unique_outputs = [t for t in e.outputs if id(t) not in tensors_seen]
|
| 228 |
+
tensors_seen |= {id(t) for t in e.unique_params + e.unique_buffers + e.unique_outputs}
|
| 229 |
+
|
| 230 |
+
# Filter out redundant entries.
|
| 231 |
+
if skip_redundant:
|
| 232 |
+
entries = [e for e in entries if len(e.unique_params) or len(e.unique_buffers) or len(e.unique_outputs)]
|
| 233 |
+
|
| 234 |
+
# Construct table.
|
| 235 |
+
rows = [[type(module).__name__, 'Parameters', 'Buffers', 'Output shape', 'Datatype']]
|
| 236 |
+
rows += [['---'] * len(rows[0])]
|
| 237 |
+
param_total = 0
|
| 238 |
+
buffer_total = 0
|
| 239 |
+
submodule_names = {mod: name for name, mod in module.named_modules()}
|
| 240 |
+
for e in entries:
|
| 241 |
+
name = '<top-level>' if e.mod is module else submodule_names[e.mod]
|
| 242 |
+
param_size = sum(t.numel() for t in e.unique_params)
|
| 243 |
+
buffer_size = sum(t.numel() for t in e.unique_buffers)
|
| 244 |
+
output_shapes = [str(list(t.shape)) for t in e.outputs]
|
| 245 |
+
output_dtypes = [str(t.dtype).split('.')[-1] for t in e.outputs]
|
| 246 |
+
rows += [[
|
| 247 |
+
name + (':0' if len(e.outputs) >= 2 else ''),
|
| 248 |
+
str(param_size) if param_size else '-',
|
| 249 |
+
str(buffer_size) if buffer_size else '-',
|
| 250 |
+
(output_shapes + ['-'])[0],
|
| 251 |
+
(output_dtypes + ['-'])[0],
|
| 252 |
+
]]
|
| 253 |
+
for idx in range(1, len(e.outputs)):
|
| 254 |
+
rows += [[name + f':{idx}', '-', '-', output_shapes[idx], output_dtypes[idx]]]
|
| 255 |
+
param_total += param_size
|
| 256 |
+
buffer_total += buffer_size
|
| 257 |
+
rows += [['---'] * len(rows[0])]
|
| 258 |
+
rows += [['Total', str(param_total), str(buffer_total), '-', '-']]
|
| 259 |
+
|
| 260 |
+
# Print table.
|
| 261 |
+
widths = [max(len(cell) for cell in column) for column in zip(*rows)]
|
| 262 |
+
print()
|
| 263 |
+
for row in rows:
|
| 264 |
+
print(' '.join(cell + ' ' * (width - len(cell)) for cell, width in zip(row, widths)))
|
| 265 |
+
print()
|
| 266 |
+
return outputs
|
| 267 |
+
|
| 268 |
+
#----------------------------------------------------------------------------
|
eg3d/torch_utils/ops/__init__.py
ADDED
|
@@ -0,0 +1,11 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# SPDX-FileCopyrightText: Copyright (c) 2021-2022 NVIDIA CORPORATION & AFFILIATES. All rights reserved.
|
| 2 |
+
# SPDX-License-Identifier: LicenseRef-NvidiaProprietary
|
| 3 |
+
#
|
| 4 |
+
# NVIDIA CORPORATION, its affiliates and licensors retain all intellectual
|
| 5 |
+
# property and proprietary rights in and to this material, related
|
| 6 |
+
# documentation and any modifications thereto. Any use, reproduction,
|
| 7 |
+
# disclosure or distribution of this material and related documentation
|
| 8 |
+
# without an express license agreement from NVIDIA CORPORATION or
|
| 9 |
+
# its affiliates is strictly prohibited.
|
| 10 |
+
|
| 11 |
+
# empty
|
eg3d/torch_utils/ops/bias_act.cpp
ADDED
|
@@ -0,0 +1,103 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
/*
|
| 2 |
+
* SPDX-FileCopyrightText: Copyright (c) 2021-2022 NVIDIA CORPORATION & AFFILIATES. All rights reserved.
|
| 3 |
+
* SPDX-License-Identifier: LicenseRef-NvidiaProprietary
|
| 4 |
+
*
|
| 5 |
+
* NVIDIA CORPORATION, its affiliates and licensors retain all intellectual
|
| 6 |
+
* property and proprietary rights in and to this material, related
|
| 7 |
+
* documentation and any modifications thereto. Any use, reproduction,
|
| 8 |
+
* disclosure or distribution of this material and related documentation
|
| 9 |
+
* without an express license agreement from NVIDIA CORPORATION or
|
| 10 |
+
* its affiliates is strictly prohibited.
|
| 11 |
+
*/
|
| 12 |
+
|
| 13 |
+
#include <torch/extension.h>
|
| 14 |
+
#include <ATen/cuda/CUDAContext.h>
|
| 15 |
+
#include <c10/cuda/CUDAGuard.h>
|
| 16 |
+
#include "bias_act.h"
|
| 17 |
+
|
| 18 |
+
//------------------------------------------------------------------------
|
| 19 |
+
|
| 20 |
+
static bool has_same_layout(torch::Tensor x, torch::Tensor y)
|
| 21 |
+
{
|
| 22 |
+
if (x.dim() != y.dim())
|
| 23 |
+
return false;
|
| 24 |
+
for (int64_t i = 0; i < x.dim(); i++)
|
| 25 |
+
{
|
| 26 |
+
if (x.size(i) != y.size(i))
|
| 27 |
+
return false;
|
| 28 |
+
if (x.size(i) >= 2 && x.stride(i) != y.stride(i))
|
| 29 |
+
return false;
|
| 30 |
+
}
|
| 31 |
+
return true;
|
| 32 |
+
}
|
| 33 |
+
|
| 34 |
+
//------------------------------------------------------------------------
|
| 35 |
+
|
| 36 |
+
static torch::Tensor bias_act(torch::Tensor x, torch::Tensor b, torch::Tensor xref, torch::Tensor yref, torch::Tensor dy, int grad, int dim, int act, float alpha, float gain, float clamp)
|
| 37 |
+
{
|
| 38 |
+
// Validate arguments.
|
| 39 |
+
TORCH_CHECK(x.is_cuda(), "x must reside on CUDA device");
|
| 40 |
+
TORCH_CHECK(b.numel() == 0 || (b.dtype() == x.dtype() && b.device() == x.device()), "b must have the same dtype and device as x");
|
| 41 |
+
TORCH_CHECK(xref.numel() == 0 || (xref.sizes() == x.sizes() && xref.dtype() == x.dtype() && xref.device() == x.device()), "xref must have the same shape, dtype, and device as x");
|
| 42 |
+
TORCH_CHECK(yref.numel() == 0 || (yref.sizes() == x.sizes() && yref.dtype() == x.dtype() && yref.device() == x.device()), "yref must have the same shape, dtype, and device as x");
|
| 43 |
+
TORCH_CHECK(dy.numel() == 0 || (dy.sizes() == x.sizes() && dy.dtype() == x.dtype() && dy.device() == x.device()), "dy must have the same dtype and device as x");
|
| 44 |
+
TORCH_CHECK(x.numel() <= INT_MAX, "x is too large");
|
| 45 |
+
TORCH_CHECK(b.dim() == 1, "b must have rank 1");
|
| 46 |
+
TORCH_CHECK(b.numel() == 0 || (dim >= 0 && dim < x.dim()), "dim is out of bounds");
|
| 47 |
+
TORCH_CHECK(b.numel() == 0 || b.numel() == x.size(dim), "b has wrong number of elements");
|
| 48 |
+
TORCH_CHECK(grad >= 0, "grad must be non-negative");
|
| 49 |
+
|
| 50 |
+
// Validate layout.
|
| 51 |
+
TORCH_CHECK(x.is_non_overlapping_and_dense(), "x must be non-overlapping and dense");
|
| 52 |
+
TORCH_CHECK(b.is_contiguous(), "b must be contiguous");
|
| 53 |
+
TORCH_CHECK(xref.numel() == 0 || has_same_layout(xref, x), "xref must have the same layout as x");
|
| 54 |
+
TORCH_CHECK(yref.numel() == 0 || has_same_layout(yref, x), "yref must have the same layout as x");
|
| 55 |
+
TORCH_CHECK(dy.numel() == 0 || has_same_layout(dy, x), "dy must have the same layout as x");
|
| 56 |
+
|
| 57 |
+
// Create output tensor.
|
| 58 |
+
const at::cuda::OptionalCUDAGuard device_guard(device_of(x));
|
| 59 |
+
torch::Tensor y = torch::empty_like(x);
|
| 60 |
+
TORCH_CHECK(has_same_layout(y, x), "y must have the same layout as x");
|
| 61 |
+
|
| 62 |
+
// Initialize CUDA kernel parameters.
|
| 63 |
+
bias_act_kernel_params p;
|
| 64 |
+
p.x = x.data_ptr();
|
| 65 |
+
p.b = (b.numel()) ? b.data_ptr() : NULL;
|
| 66 |
+
p.xref = (xref.numel()) ? xref.data_ptr() : NULL;
|
| 67 |
+
p.yref = (yref.numel()) ? yref.data_ptr() : NULL;
|
| 68 |
+
p.dy = (dy.numel()) ? dy.data_ptr() : NULL;
|
| 69 |
+
p.y = y.data_ptr();
|
| 70 |
+
p.grad = grad;
|
| 71 |
+
p.act = act;
|
| 72 |
+
p.alpha = alpha;
|
| 73 |
+
p.gain = gain;
|
| 74 |
+
p.clamp = clamp;
|
| 75 |
+
p.sizeX = (int)x.numel();
|
| 76 |
+
p.sizeB = (int)b.numel();
|
| 77 |
+
p.stepB = (b.numel()) ? (int)x.stride(dim) : 1;
|
| 78 |
+
|
| 79 |
+
// Choose CUDA kernel.
|
| 80 |
+
void* kernel;
|
| 81 |
+
AT_DISPATCH_FLOATING_TYPES_AND_HALF(x.scalar_type(), "upfirdn2d_cuda", [&]
|
| 82 |
+
{
|
| 83 |
+
kernel = choose_bias_act_kernel<scalar_t>(p);
|
| 84 |
+
});
|
| 85 |
+
TORCH_CHECK(kernel, "no CUDA kernel found for the specified activation func");
|
| 86 |
+
|
| 87 |
+
// Launch CUDA kernel.
|
| 88 |
+
p.loopX = 4;
|
| 89 |
+
int blockSize = 4 * 32;
|
| 90 |
+
int gridSize = (p.sizeX - 1) / (p.loopX * blockSize) + 1;
|
| 91 |
+
void* args[] = {&p};
|
| 92 |
+
AT_CUDA_CHECK(cudaLaunchKernel(kernel, gridSize, blockSize, args, 0, at::cuda::getCurrentCUDAStream()));
|
| 93 |
+
return y;
|
| 94 |
+
}
|
| 95 |
+
|
| 96 |
+
//------------------------------------------------------------------------
|
| 97 |
+
|
| 98 |
+
PYBIND11_MODULE(TORCH_EXTENSION_NAME, m)
|
| 99 |
+
{
|
| 100 |
+
m.def("bias_act", &bias_act);
|
| 101 |
+
}
|
| 102 |
+
|
| 103 |
+
//------------------------------------------------------------------------
|
eg3d/torch_utils/ops/bias_act.cu
ADDED
|
@@ -0,0 +1,177 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
/*
|
| 2 |
+
* SPDX-FileCopyrightText: Copyright (c) 2021-2022 NVIDIA CORPORATION & AFFILIATES. All rights reserved.
|
| 3 |
+
* SPDX-License-Identifier: LicenseRef-NvidiaProprietary
|
| 4 |
+
*
|
| 5 |
+
* NVIDIA CORPORATION, its affiliates and licensors retain all intellectual
|
| 6 |
+
* property and proprietary rights in and to this material, related
|
| 7 |
+
* documentation and any modifications thereto. Any use, reproduction,
|
| 8 |
+
* disclosure or distribution of this material and related documentation
|
| 9 |
+
* without an express license agreement from NVIDIA CORPORATION or
|
| 10 |
+
* its affiliates is strictly prohibited.
|
| 11 |
+
*/
|
| 12 |
+
|
| 13 |
+
#include <c10/util/Half.h>
|
| 14 |
+
#include "bias_act.h"
|
| 15 |
+
|
| 16 |
+
//------------------------------------------------------------------------
|
| 17 |
+
// Helpers.
|
| 18 |
+
|
| 19 |
+
template <class T> struct InternalType;
|
| 20 |
+
template <> struct InternalType<double> { typedef double scalar_t; };
|
| 21 |
+
template <> struct InternalType<float> { typedef float scalar_t; };
|
| 22 |
+
template <> struct InternalType<c10::Half> { typedef float scalar_t; };
|
| 23 |
+
|
| 24 |
+
//------------------------------------------------------------------------
|
| 25 |
+
// CUDA kernel.
|
| 26 |
+
|
| 27 |
+
template <class T, int A>
|
| 28 |
+
__global__ void bias_act_kernel(bias_act_kernel_params p)
|
| 29 |
+
{
|
| 30 |
+
typedef typename InternalType<T>::scalar_t scalar_t;
|
| 31 |
+
int G = p.grad;
|
| 32 |
+
scalar_t alpha = (scalar_t)p.alpha;
|
| 33 |
+
scalar_t gain = (scalar_t)p.gain;
|
| 34 |
+
scalar_t clamp = (scalar_t)p.clamp;
|
| 35 |
+
scalar_t one = (scalar_t)1;
|
| 36 |
+
scalar_t two = (scalar_t)2;
|
| 37 |
+
scalar_t expRange = (scalar_t)80;
|
| 38 |
+
scalar_t halfExpRange = (scalar_t)40;
|
| 39 |
+
scalar_t seluScale = (scalar_t)1.0507009873554804934193349852946;
|
| 40 |
+
scalar_t seluAlpha = (scalar_t)1.6732632423543772848170429916717;
|
| 41 |
+
|
| 42 |
+
// Loop over elements.
|
| 43 |
+
int xi = blockIdx.x * p.loopX * blockDim.x + threadIdx.x;
|
| 44 |
+
for (int loopIdx = 0; loopIdx < p.loopX && xi < p.sizeX; loopIdx++, xi += blockDim.x)
|
| 45 |
+
{
|
| 46 |
+
// Load.
|
| 47 |
+
scalar_t x = (scalar_t)((const T*)p.x)[xi];
|
| 48 |
+
scalar_t b = (p.b) ? (scalar_t)((const T*)p.b)[(xi / p.stepB) % p.sizeB] : 0;
|
| 49 |
+
scalar_t xref = (p.xref) ? (scalar_t)((const T*)p.xref)[xi] : 0;
|
| 50 |
+
scalar_t yref = (p.yref) ? (scalar_t)((const T*)p.yref)[xi] : 0;
|
| 51 |
+
scalar_t dy = (p.dy) ? (scalar_t)((const T*)p.dy)[xi] : one;
|
| 52 |
+
scalar_t yy = (gain != 0) ? yref / gain : 0;
|
| 53 |
+
scalar_t y = 0;
|
| 54 |
+
|
| 55 |
+
// Apply bias.
|
| 56 |
+
((G == 0) ? x : xref) += b;
|
| 57 |
+
|
| 58 |
+
// linear
|
| 59 |
+
if (A == 1)
|
| 60 |
+
{
|
| 61 |
+
if (G == 0) y = x;
|
| 62 |
+
if (G == 1) y = x;
|
| 63 |
+
}
|
| 64 |
+
|
| 65 |
+
// relu
|
| 66 |
+
if (A == 2)
|
| 67 |
+
{
|
| 68 |
+
if (G == 0) y = (x > 0) ? x : 0;
|
| 69 |
+
if (G == 1) y = (yy > 0) ? x : 0;
|
| 70 |
+
}
|
| 71 |
+
|
| 72 |
+
// lrelu
|
| 73 |
+
if (A == 3)
|
| 74 |
+
{
|
| 75 |
+
if (G == 0) y = (x > 0) ? x : x * alpha;
|
| 76 |
+
if (G == 1) y = (yy > 0) ? x : x * alpha;
|
| 77 |
+
}
|
| 78 |
+
|
| 79 |
+
// tanh
|
| 80 |
+
if (A == 4)
|
| 81 |
+
{
|
| 82 |
+
if (G == 0) { scalar_t c = exp(x); scalar_t d = one / c; y = (x < -expRange) ? -one : (x > expRange) ? one : (c - d) / (c + d); }
|
| 83 |
+
if (G == 1) y = x * (one - yy * yy);
|
| 84 |
+
if (G == 2) y = x * (one - yy * yy) * (-two * yy);
|
| 85 |
+
}
|
| 86 |
+
|
| 87 |
+
// sigmoid
|
| 88 |
+
if (A == 5)
|
| 89 |
+
{
|
| 90 |
+
if (G == 0) y = (x < -expRange) ? 0 : one / (exp(-x) + one);
|
| 91 |
+
if (G == 1) y = x * yy * (one - yy);
|
| 92 |
+
if (G == 2) y = x * yy * (one - yy) * (one - two * yy);
|
| 93 |
+
}
|
| 94 |
+
|
| 95 |
+
// elu
|
| 96 |
+
if (A == 6)
|
| 97 |
+
{
|
| 98 |
+
if (G == 0) y = (x >= 0) ? x : exp(x) - one;
|
| 99 |
+
if (G == 1) y = (yy >= 0) ? x : x * (yy + one);
|
| 100 |
+
if (G == 2) y = (yy >= 0) ? 0 : x * (yy + one);
|
| 101 |
+
}
|
| 102 |
+
|
| 103 |
+
// selu
|
| 104 |
+
if (A == 7)
|
| 105 |
+
{
|
| 106 |
+
if (G == 0) y = (x >= 0) ? seluScale * x : (seluScale * seluAlpha) * (exp(x) - one);
|
| 107 |
+
if (G == 1) y = (yy >= 0) ? x * seluScale : x * (yy + seluScale * seluAlpha);
|
| 108 |
+
if (G == 2) y = (yy >= 0) ? 0 : x * (yy + seluScale * seluAlpha);
|
| 109 |
+
}
|
| 110 |
+
|
| 111 |
+
// softplus
|
| 112 |
+
if (A == 8)
|
| 113 |
+
{
|
| 114 |
+
if (G == 0) y = (x > expRange) ? x : log(exp(x) + one);
|
| 115 |
+
if (G == 1) y = x * (one - exp(-yy));
|
| 116 |
+
if (G == 2) { scalar_t c = exp(-yy); y = x * c * (one - c); }
|
| 117 |
+
}
|
| 118 |
+
|
| 119 |
+
// swish
|
| 120 |
+
if (A == 9)
|
| 121 |
+
{
|
| 122 |
+
if (G == 0)
|
| 123 |
+
y = (x < -expRange) ? 0 : x / (exp(-x) + one);
|
| 124 |
+
else
|
| 125 |
+
{
|
| 126 |
+
scalar_t c = exp(xref);
|
| 127 |
+
scalar_t d = c + one;
|
| 128 |
+
if (G == 1)
|
| 129 |
+
y = (xref > halfExpRange) ? x : x * c * (xref + d) / (d * d);
|
| 130 |
+
else
|
| 131 |
+
y = (xref > halfExpRange) ? 0 : x * c * (xref * (two - d) + two * d) / (d * d * d);
|
| 132 |
+
yref = (xref < -expRange) ? 0 : xref / (exp(-xref) + one) * gain;
|
| 133 |
+
}
|
| 134 |
+
}
|
| 135 |
+
|
| 136 |
+
// Apply gain.
|
| 137 |
+
y *= gain * dy;
|
| 138 |
+
|
| 139 |
+
// Clamp.
|
| 140 |
+
if (clamp >= 0)
|
| 141 |
+
{
|
| 142 |
+
if (G == 0)
|
| 143 |
+
y = (y > -clamp & y < clamp) ? y : (y >= 0) ? clamp : -clamp;
|
| 144 |
+
else
|
| 145 |
+
y = (yref > -clamp & yref < clamp) ? y : 0;
|
| 146 |
+
}
|
| 147 |
+
|
| 148 |
+
// Store.
|
| 149 |
+
((T*)p.y)[xi] = (T)y;
|
| 150 |
+
}
|
| 151 |
+
}
|
| 152 |
+
|
| 153 |
+
//------------------------------------------------------------------------
|
| 154 |
+
// CUDA kernel selection.
|
| 155 |
+
|
| 156 |
+
template <class T> void* choose_bias_act_kernel(const bias_act_kernel_params& p)
|
| 157 |
+
{
|
| 158 |
+
if (p.act == 1) return (void*)bias_act_kernel<T, 1>;
|
| 159 |
+
if (p.act == 2) return (void*)bias_act_kernel<T, 2>;
|
| 160 |
+
if (p.act == 3) return (void*)bias_act_kernel<T, 3>;
|
| 161 |
+
if (p.act == 4) return (void*)bias_act_kernel<T, 4>;
|
| 162 |
+
if (p.act == 5) return (void*)bias_act_kernel<T, 5>;
|
| 163 |
+
if (p.act == 6) return (void*)bias_act_kernel<T, 6>;
|
| 164 |
+
if (p.act == 7) return (void*)bias_act_kernel<T, 7>;
|
| 165 |
+
if (p.act == 8) return (void*)bias_act_kernel<T, 8>;
|
| 166 |
+
if (p.act == 9) return (void*)bias_act_kernel<T, 9>;
|
| 167 |
+
return NULL;
|
| 168 |
+
}
|
| 169 |
+
|
| 170 |
+
//------------------------------------------------------------------------
|
| 171 |
+
// Template specializations.
|
| 172 |
+
|
| 173 |
+
template void* choose_bias_act_kernel<double> (const bias_act_kernel_params& p);
|
| 174 |
+
template void* choose_bias_act_kernel<float> (const bias_act_kernel_params& p);
|
| 175 |
+
template void* choose_bias_act_kernel<c10::Half> (const bias_act_kernel_params& p);
|
| 176 |
+
|
| 177 |
+
//------------------------------------------------------------------------
|
eg3d/torch_utils/ops/bias_act.h
ADDED
|
@@ -0,0 +1,42 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
/*
|
| 2 |
+
* SPDX-FileCopyrightText: Copyright (c) 2021-2022 NVIDIA CORPORATION & AFFILIATES. All rights reserved.
|
| 3 |
+
* SPDX-License-Identifier: LicenseRef-NvidiaProprietary
|
| 4 |
+
*
|
| 5 |
+
* NVIDIA CORPORATION, its affiliates and licensors retain all intellectual
|
| 6 |
+
* property and proprietary rights in and to this material, related
|
| 7 |
+
* documentation and any modifications thereto. Any use, reproduction,
|
| 8 |
+
* disclosure or distribution of this material and related documentation
|
| 9 |
+
* without an express license agreement from NVIDIA CORPORATION or
|
| 10 |
+
* its affiliates is strictly prohibited.
|
| 11 |
+
*/
|
| 12 |
+
|
| 13 |
+
//------------------------------------------------------------------------
|
| 14 |
+
// CUDA kernel parameters.
|
| 15 |
+
|
| 16 |
+
struct bias_act_kernel_params
|
| 17 |
+
{
|
| 18 |
+
const void* x; // [sizeX]
|
| 19 |
+
const void* b; // [sizeB] or NULL
|
| 20 |
+
const void* xref; // [sizeX] or NULL
|
| 21 |
+
const void* yref; // [sizeX] or NULL
|
| 22 |
+
const void* dy; // [sizeX] or NULL
|
| 23 |
+
void* y; // [sizeX]
|
| 24 |
+
|
| 25 |
+
int grad;
|
| 26 |
+
int act;
|
| 27 |
+
float alpha;
|
| 28 |
+
float gain;
|
| 29 |
+
float clamp;
|
| 30 |
+
|
| 31 |
+
int sizeX;
|
| 32 |
+
int sizeB;
|
| 33 |
+
int stepB;
|
| 34 |
+
int loopX;
|
| 35 |
+
};
|
| 36 |
+
|
| 37 |
+
//------------------------------------------------------------------------
|
| 38 |
+
// CUDA kernel selection.
|
| 39 |
+
|
| 40 |
+
template <class T> void* choose_bias_act_kernel(const bias_act_kernel_params& p);
|
| 41 |
+
|
| 42 |
+
//------------------------------------------------------------------------
|
eg3d/torch_utils/ops/bias_act.py
ADDED
|
@@ -0,0 +1,211 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# SPDX-FileCopyrightText: Copyright (c) 2021-2022 NVIDIA CORPORATION & AFFILIATES. All rights reserved.
|
| 2 |
+
# SPDX-License-Identifier: LicenseRef-NvidiaProprietary
|
| 3 |
+
#
|
| 4 |
+
# NVIDIA CORPORATION, its affiliates and licensors retain all intellectual
|
| 5 |
+
# property and proprietary rights in and to this material, related
|
| 6 |
+
# documentation and any modifications thereto. Any use, reproduction,
|
| 7 |
+
# disclosure or distribution of this material and related documentation
|
| 8 |
+
# without an express license agreement from NVIDIA CORPORATION or
|
| 9 |
+
# its affiliates is strictly prohibited.
|
| 10 |
+
|
| 11 |
+
"""Custom PyTorch ops for efficient bias and activation."""
|
| 12 |
+
|
| 13 |
+
import os
|
| 14 |
+
import numpy as np
|
| 15 |
+
import torch
|
| 16 |
+
import dnnlib
|
| 17 |
+
|
| 18 |
+
from .. import custom_ops
|
| 19 |
+
from .. import misc
|
| 20 |
+
|
| 21 |
+
#----------------------------------------------------------------------------
|
| 22 |
+
|
| 23 |
+
activation_funcs = {
|
| 24 |
+
'linear': dnnlib.EasyDict(func=lambda x, **_: x, def_alpha=0, def_gain=1, cuda_idx=1, ref='', has_2nd_grad=False),
|
| 25 |
+
'relu': dnnlib.EasyDict(func=lambda x, **_: torch.nn.functional.relu(x), def_alpha=0, def_gain=np.sqrt(2), cuda_idx=2, ref='y', has_2nd_grad=False),
|
| 26 |
+
'lrelu': dnnlib.EasyDict(func=lambda x, alpha, **_: torch.nn.functional.leaky_relu(x, alpha), def_alpha=0.2, def_gain=np.sqrt(2), cuda_idx=3, ref='y', has_2nd_grad=False),
|
| 27 |
+
'tanh': dnnlib.EasyDict(func=lambda x, **_: torch.tanh(x), def_alpha=0, def_gain=1, cuda_idx=4, ref='y', has_2nd_grad=True),
|
| 28 |
+
'sigmoid': dnnlib.EasyDict(func=lambda x, **_: torch.sigmoid(x), def_alpha=0, def_gain=1, cuda_idx=5, ref='y', has_2nd_grad=True),
|
| 29 |
+
'elu': dnnlib.EasyDict(func=lambda x, **_: torch.nn.functional.elu(x), def_alpha=0, def_gain=1, cuda_idx=6, ref='y', has_2nd_grad=True),
|
| 30 |
+
'selu': dnnlib.EasyDict(func=lambda x, **_: torch.nn.functional.selu(x), def_alpha=0, def_gain=1, cuda_idx=7, ref='y', has_2nd_grad=True),
|
| 31 |
+
'softplus': dnnlib.EasyDict(func=lambda x, **_: torch.nn.functional.softplus(x), def_alpha=0, def_gain=1, cuda_idx=8, ref='y', has_2nd_grad=True),
|
| 32 |
+
'swish': dnnlib.EasyDict(func=lambda x, **_: torch.sigmoid(x) * x, def_alpha=0, def_gain=np.sqrt(2), cuda_idx=9, ref='x', has_2nd_grad=True),
|
| 33 |
+
}
|
| 34 |
+
|
| 35 |
+
#----------------------------------------------------------------------------
|
| 36 |
+
|
| 37 |
+
_plugin = None
|
| 38 |
+
_null_tensor = torch.empty([0])
|
| 39 |
+
|
| 40 |
+
def _init():
|
| 41 |
+
global _plugin
|
| 42 |
+
if _plugin is None:
|
| 43 |
+
_plugin = custom_ops.get_plugin(
|
| 44 |
+
module_name='bias_act_plugin',
|
| 45 |
+
sources=['bias_act.cpp', 'bias_act.cu'],
|
| 46 |
+
headers=['bias_act.h'],
|
| 47 |
+
source_dir=os.path.dirname(__file__),
|
| 48 |
+
extra_cuda_cflags=['--use_fast_math'],
|
| 49 |
+
)
|
| 50 |
+
return True
|
| 51 |
+
|
| 52 |
+
#----------------------------------------------------------------------------
|
| 53 |
+
|
| 54 |
+
def bias_act(x, b=None, dim=1, act='linear', alpha=None, gain=None, clamp=None, impl='cuda'):
|
| 55 |
+
r"""Fused bias and activation function.
|
| 56 |
+
|
| 57 |
+
Adds bias `b` to activation tensor `x`, evaluates activation function `act`,
|
| 58 |
+
and scales the result by `gain`. Each of the steps is optional. In most cases,
|
| 59 |
+
the fused op is considerably more efficient than performing the same calculation
|
| 60 |
+
using standard PyTorch ops. It supports first and second order gradients,
|
| 61 |
+
but not third order gradients.
|
| 62 |
+
|
| 63 |
+
Args:
|
| 64 |
+
x: Input activation tensor. Can be of any shape.
|
| 65 |
+
b: Bias vector, or `None` to disable. Must be a 1D tensor of the same type
|
| 66 |
+
as `x`. The shape must be known, and it must match the dimension of `x`
|
| 67 |
+
corresponding to `dim`.
|
| 68 |
+
dim: The dimension in `x` corresponding to the elements of `b`.
|
| 69 |
+
The value of `dim` is ignored if `b` is not specified.
|
| 70 |
+
act: Name of the activation function to evaluate, or `"linear"` to disable.
|
| 71 |
+
Can be e.g. `"relu"`, `"lrelu"`, `"tanh"`, `"sigmoid"`, `"swish"`, etc.
|
| 72 |
+
See `activation_funcs` for a full list. `None` is not allowed.
|
| 73 |
+
alpha: Shape parameter for the activation function, or `None` to use the default.
|
| 74 |
+
gain: Scaling factor for the output tensor, or `None` to use default.
|
| 75 |
+
See `activation_funcs` for the default scaling of each activation function.
|
| 76 |
+
If unsure, consider specifying 1.
|
| 77 |
+
clamp: Clamp the output values to `[-clamp, +clamp]`, or `None` to disable
|
| 78 |
+
the clamping (default).
|
| 79 |
+
impl: Name of the implementation to use. Can be `"ref"` or `"cuda"` (default).
|
| 80 |
+
|
| 81 |
+
Returns:
|
| 82 |
+
Tensor of the same shape and datatype as `x`.
|
| 83 |
+
"""
|
| 84 |
+
assert isinstance(x, torch.Tensor)
|
| 85 |
+
assert impl in ['ref', 'cuda']
|
| 86 |
+
if impl == 'cuda' and x.device.type == 'cuda' and _init():
|
| 87 |
+
return _bias_act_cuda(dim=dim, act=act, alpha=alpha, gain=gain, clamp=clamp).apply(x, b)
|
| 88 |
+
return _bias_act_ref(x=x, b=b, dim=dim, act=act, alpha=alpha, gain=gain, clamp=clamp)
|
| 89 |
+
|
| 90 |
+
#----------------------------------------------------------------------------
|
| 91 |
+
|
| 92 |
+
@misc.profiled_function
|
| 93 |
+
def _bias_act_ref(x, b=None, dim=1, act='linear', alpha=None, gain=None, clamp=None):
|
| 94 |
+
"""Slow reference implementation of `bias_act()` using standard TensorFlow ops.
|
| 95 |
+
"""
|
| 96 |
+
assert isinstance(x, torch.Tensor)
|
| 97 |
+
assert clamp is None or clamp >= 0
|
| 98 |
+
spec = activation_funcs[act]
|
| 99 |
+
alpha = float(alpha if alpha is not None else spec.def_alpha)
|
| 100 |
+
gain = float(gain if gain is not None else spec.def_gain)
|
| 101 |
+
clamp = float(clamp if clamp is not None else -1)
|
| 102 |
+
|
| 103 |
+
# Add bias.
|
| 104 |
+
if b is not None:
|
| 105 |
+
assert isinstance(b, torch.Tensor) and b.ndim == 1
|
| 106 |
+
assert 0 <= dim < x.ndim
|
| 107 |
+
assert b.shape[0] == x.shape[dim]
|
| 108 |
+
x = x + b.reshape([-1 if i == dim else 1 for i in range(x.ndim)])
|
| 109 |
+
|
| 110 |
+
# Evaluate activation function.
|
| 111 |
+
alpha = float(alpha)
|
| 112 |
+
x = spec.func(x, alpha=alpha)
|
| 113 |
+
|
| 114 |
+
# Scale by gain.
|
| 115 |
+
gain = float(gain)
|
| 116 |
+
if gain != 1:
|
| 117 |
+
x = x * gain
|
| 118 |
+
|
| 119 |
+
# Clamp.
|
| 120 |
+
if clamp >= 0:
|
| 121 |
+
x = x.clamp(-clamp, clamp) # pylint: disable=invalid-unary-operand-type
|
| 122 |
+
return x
|
| 123 |
+
|
| 124 |
+
#----------------------------------------------------------------------------
|
| 125 |
+
|
| 126 |
+
_bias_act_cuda_cache = dict()
|
| 127 |
+
|
| 128 |
+
def _bias_act_cuda(dim=1, act='linear', alpha=None, gain=None, clamp=None):
|
| 129 |
+
"""Fast CUDA implementation of `bias_act()` using custom ops.
|
| 130 |
+
"""
|
| 131 |
+
# Parse arguments.
|
| 132 |
+
assert clamp is None or clamp >= 0
|
| 133 |
+
spec = activation_funcs[act]
|
| 134 |
+
alpha = float(alpha if alpha is not None else spec.def_alpha)
|
| 135 |
+
gain = float(gain if gain is not None else spec.def_gain)
|
| 136 |
+
clamp = float(clamp if clamp is not None else -1)
|
| 137 |
+
|
| 138 |
+
# Lookup from cache.
|
| 139 |
+
key = (dim, act, alpha, gain, clamp)
|
| 140 |
+
if key in _bias_act_cuda_cache:
|
| 141 |
+
return _bias_act_cuda_cache[key]
|
| 142 |
+
|
| 143 |
+
# Forward op.
|
| 144 |
+
class BiasActCuda(torch.autograd.Function):
|
| 145 |
+
@staticmethod
|
| 146 |
+
def forward(ctx, x, b): # pylint: disable=arguments-differ
|
| 147 |
+
ctx.memory_format = torch.channels_last if x.ndim > 2 and x.stride(1) == 1 else torch.contiguous_format
|
| 148 |
+
x = x.contiguous(memory_format=ctx.memory_format)
|
| 149 |
+
b = b.contiguous() if b is not None else _null_tensor
|
| 150 |
+
y = x
|
| 151 |
+
if act != 'linear' or gain != 1 or clamp >= 0 or b is not _null_tensor:
|
| 152 |
+
y = _plugin.bias_act(x, b, _null_tensor, _null_tensor, _null_tensor, 0, dim, spec.cuda_idx, alpha, gain, clamp)
|
| 153 |
+
ctx.save_for_backward(
|
| 154 |
+
x if 'x' in spec.ref or spec.has_2nd_grad else _null_tensor,
|
| 155 |
+
b if 'x' in spec.ref or spec.has_2nd_grad else _null_tensor,
|
| 156 |
+
y if 'y' in spec.ref else _null_tensor)
|
| 157 |
+
return y
|
| 158 |
+
|
| 159 |
+
@staticmethod
|
| 160 |
+
def backward(ctx, dy): # pylint: disable=arguments-differ
|
| 161 |
+
dy = dy.contiguous(memory_format=ctx.memory_format)
|
| 162 |
+
x, b, y = ctx.saved_tensors
|
| 163 |
+
dx = None
|
| 164 |
+
db = None
|
| 165 |
+
|
| 166 |
+
if ctx.needs_input_grad[0] or ctx.needs_input_grad[1]:
|
| 167 |
+
dx = dy
|
| 168 |
+
if act != 'linear' or gain != 1 or clamp >= 0:
|
| 169 |
+
dx = BiasActCudaGrad.apply(dy, x, b, y)
|
| 170 |
+
|
| 171 |
+
if ctx.needs_input_grad[1]:
|
| 172 |
+
db = dx.sum([i for i in range(dx.ndim) if i != dim])
|
| 173 |
+
|
| 174 |
+
return dx, db
|
| 175 |
+
|
| 176 |
+
# Backward op.
|
| 177 |
+
class BiasActCudaGrad(torch.autograd.Function):
|
| 178 |
+
@staticmethod
|
| 179 |
+
def forward(ctx, dy, x, b, y): # pylint: disable=arguments-differ
|
| 180 |
+
ctx.memory_format = torch.channels_last if dy.ndim > 2 and dy.stride(1) == 1 else torch.contiguous_format
|
| 181 |
+
dx = _plugin.bias_act(dy, b, x, y, _null_tensor, 1, dim, spec.cuda_idx, alpha, gain, clamp)
|
| 182 |
+
ctx.save_for_backward(
|
| 183 |
+
dy if spec.has_2nd_grad else _null_tensor,
|
| 184 |
+
x, b, y)
|
| 185 |
+
return dx
|
| 186 |
+
|
| 187 |
+
@staticmethod
|
| 188 |
+
def backward(ctx, d_dx): # pylint: disable=arguments-differ
|
| 189 |
+
d_dx = d_dx.contiguous(memory_format=ctx.memory_format)
|
| 190 |
+
dy, x, b, y = ctx.saved_tensors
|
| 191 |
+
d_dy = None
|
| 192 |
+
d_x = None
|
| 193 |
+
d_b = None
|
| 194 |
+
d_y = None
|
| 195 |
+
|
| 196 |
+
if ctx.needs_input_grad[0]:
|
| 197 |
+
d_dy = BiasActCudaGrad.apply(d_dx, x, b, y)
|
| 198 |
+
|
| 199 |
+
if spec.has_2nd_grad and (ctx.needs_input_grad[1] or ctx.needs_input_grad[2]):
|
| 200 |
+
d_x = _plugin.bias_act(d_dx, b, x, y, dy, 2, dim, spec.cuda_idx, alpha, gain, clamp)
|
| 201 |
+
|
| 202 |
+
if spec.has_2nd_grad and ctx.needs_input_grad[2]:
|
| 203 |
+
d_b = d_x.sum([i for i in range(d_x.ndim) if i != dim])
|
| 204 |
+
|
| 205 |
+
return d_dy, d_x, d_b, d_y
|
| 206 |
+
|
| 207 |
+
# Add to cache.
|
| 208 |
+
_bias_act_cuda_cache[key] = BiasActCuda
|
| 209 |
+
return BiasActCuda
|
| 210 |
+
|
| 211 |
+
#----------------------------------------------------------------------------
|
eg3d/torch_utils/ops/conv2d_gradfix.py
ADDED
|
@@ -0,0 +1,199 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# SPDX-FileCopyrightText: Copyright (c) 2021-2022 NVIDIA CORPORATION & AFFILIATES. All rights reserved.
|
| 2 |
+
# SPDX-License-Identifier: LicenseRef-NvidiaProprietary
|
| 3 |
+
#
|
| 4 |
+
# NVIDIA CORPORATION, its affiliates and licensors retain all intellectual
|
| 5 |
+
# property and proprietary rights in and to this material, related
|
| 6 |
+
# documentation and any modifications thereto. Any use, reproduction,
|
| 7 |
+
# disclosure or distribution of this material and related documentation
|
| 8 |
+
# without an express license agreement from NVIDIA CORPORATION or
|
| 9 |
+
# its affiliates is strictly prohibited.
|
| 10 |
+
|
| 11 |
+
"""Custom replacement for `torch.nn.functional.conv2d` that supports
|
| 12 |
+
arbitrarily high order gradients with zero performance penalty."""
|
| 13 |
+
|
| 14 |
+
import contextlib
|
| 15 |
+
import torch
|
| 16 |
+
|
| 17 |
+
# pylint: disable=redefined-builtin
|
| 18 |
+
# pylint: disable=arguments-differ
|
| 19 |
+
# pylint: disable=protected-access
|
| 20 |
+
|
| 21 |
+
#----------------------------------------------------------------------------
|
| 22 |
+
|
| 23 |
+
enabled = False # Enable the custom op by setting this to true.
|
| 24 |
+
weight_gradients_disabled = False # Forcefully disable computation of gradients with respect to the weights.
|
| 25 |
+
|
| 26 |
+
@contextlib.contextmanager
|
| 27 |
+
def no_weight_gradients(disable=True):
|
| 28 |
+
global weight_gradients_disabled
|
| 29 |
+
old = weight_gradients_disabled
|
| 30 |
+
if disable:
|
| 31 |
+
weight_gradients_disabled = True
|
| 32 |
+
yield
|
| 33 |
+
weight_gradients_disabled = old
|
| 34 |
+
|
| 35 |
+
#----------------------------------------------------------------------------
|
| 36 |
+
|
| 37 |
+
def conv2d(input, weight, bias=None, stride=1, padding=0, dilation=1, groups=1):
|
| 38 |
+
if _should_use_custom_op(input):
|
| 39 |
+
return _conv2d_gradfix(transpose=False, weight_shape=weight.shape, stride=stride, padding=padding, output_padding=0, dilation=dilation, groups=groups).apply(input, weight, bias)
|
| 40 |
+
return torch.nn.functional.conv2d(input=input, weight=weight, bias=bias, stride=stride, padding=padding, dilation=dilation, groups=groups)
|
| 41 |
+
|
| 42 |
+
def conv_transpose2d(input, weight, bias=None, stride=1, padding=0, output_padding=0, groups=1, dilation=1):
|
| 43 |
+
if _should_use_custom_op(input):
|
| 44 |
+
return _conv2d_gradfix(transpose=True, weight_shape=weight.shape, stride=stride, padding=padding, output_padding=output_padding, groups=groups, dilation=dilation).apply(input, weight, bias)
|
| 45 |
+
return torch.nn.functional.conv_transpose2d(input=input, weight=weight, bias=bias, stride=stride, padding=padding, output_padding=output_padding, groups=groups, dilation=dilation)
|
| 46 |
+
|
| 47 |
+
#----------------------------------------------------------------------------
|
| 48 |
+
|
| 49 |
+
def _should_use_custom_op(input):
|
| 50 |
+
assert isinstance(input, torch.Tensor)
|
| 51 |
+
if (not enabled) or (not torch.backends.cudnn.enabled):
|
| 52 |
+
return False
|
| 53 |
+
if input.device.type != 'cuda':
|
| 54 |
+
return False
|
| 55 |
+
return True
|
| 56 |
+
|
| 57 |
+
def _tuple_of_ints(xs, ndim):
|
| 58 |
+
xs = tuple(xs) if isinstance(xs, (tuple, list)) else (xs,) * ndim
|
| 59 |
+
assert len(xs) == ndim
|
| 60 |
+
assert all(isinstance(x, int) for x in xs)
|
| 61 |
+
return xs
|
| 62 |
+
|
| 63 |
+
#----------------------------------------------------------------------------
|
| 64 |
+
|
| 65 |
+
_conv2d_gradfix_cache = dict()
|
| 66 |
+
_null_tensor = torch.empty([0])
|
| 67 |
+
|
| 68 |
+
def _conv2d_gradfix(transpose, weight_shape, stride, padding, output_padding, dilation, groups):
|
| 69 |
+
# Parse arguments.
|
| 70 |
+
ndim = 2
|
| 71 |
+
weight_shape = tuple(weight_shape)
|
| 72 |
+
stride = _tuple_of_ints(stride, ndim)
|
| 73 |
+
padding = _tuple_of_ints(padding, ndim)
|
| 74 |
+
output_padding = _tuple_of_ints(output_padding, ndim)
|
| 75 |
+
dilation = _tuple_of_ints(dilation, ndim)
|
| 76 |
+
|
| 77 |
+
# Lookup from cache.
|
| 78 |
+
key = (transpose, weight_shape, stride, padding, output_padding, dilation, groups)
|
| 79 |
+
if key in _conv2d_gradfix_cache:
|
| 80 |
+
return _conv2d_gradfix_cache[key]
|
| 81 |
+
|
| 82 |
+
# Validate arguments.
|
| 83 |
+
assert groups >= 1
|
| 84 |
+
assert len(weight_shape) == ndim + 2
|
| 85 |
+
assert all(stride[i] >= 1 for i in range(ndim))
|
| 86 |
+
assert all(padding[i] >= 0 for i in range(ndim))
|
| 87 |
+
assert all(dilation[i] >= 0 for i in range(ndim))
|
| 88 |
+
if not transpose:
|
| 89 |
+
assert all(output_padding[i] == 0 for i in range(ndim))
|
| 90 |
+
else: # transpose
|
| 91 |
+
assert all(0 <= output_padding[i] < max(stride[i], dilation[i]) for i in range(ndim))
|
| 92 |
+
|
| 93 |
+
# Helpers.
|
| 94 |
+
common_kwargs = dict(stride=stride, padding=padding, dilation=dilation, groups=groups)
|
| 95 |
+
def calc_output_padding(input_shape, output_shape):
|
| 96 |
+
if transpose:
|
| 97 |
+
return [0, 0]
|
| 98 |
+
return [
|
| 99 |
+
input_shape[i + 2]
|
| 100 |
+
- (output_shape[i + 2] - 1) * stride[i]
|
| 101 |
+
- (1 - 2 * padding[i])
|
| 102 |
+
- dilation[i] * (weight_shape[i + 2] - 1)
|
| 103 |
+
for i in range(ndim)
|
| 104 |
+
]
|
| 105 |
+
|
| 106 |
+
# Forward & backward.
|
| 107 |
+
class Conv2d(torch.autograd.Function):
|
| 108 |
+
@staticmethod
|
| 109 |
+
def forward(ctx, input, weight, bias):
|
| 110 |
+
assert weight.shape == weight_shape
|
| 111 |
+
ctx.save_for_backward(
|
| 112 |
+
input if weight.requires_grad else _null_tensor,
|
| 113 |
+
weight if input.requires_grad else _null_tensor,
|
| 114 |
+
)
|
| 115 |
+
ctx.input_shape = input.shape
|
| 116 |
+
|
| 117 |
+
# Simple 1x1 convolution => cuBLAS (only on Volta, not on Ampere).
|
| 118 |
+
if weight_shape[2:] == stride == dilation == (1, 1) and padding == (0, 0) and torch.cuda.get_device_capability(input.device) < (8, 0):
|
| 119 |
+
a = weight.reshape(groups, weight_shape[0] // groups, weight_shape[1])
|
| 120 |
+
b = input.reshape(input.shape[0], groups, input.shape[1] // groups, -1)
|
| 121 |
+
c = (a.transpose(1, 2) if transpose else a) @ b.permute(1, 2, 0, 3).flatten(2)
|
| 122 |
+
c = c.reshape(-1, input.shape[0], *input.shape[2:]).transpose(0, 1)
|
| 123 |
+
c = c if bias is None else c + bias.unsqueeze(0).unsqueeze(2).unsqueeze(3)
|
| 124 |
+
return c.contiguous(memory_format=(torch.channels_last if input.stride(1) == 1 else torch.contiguous_format))
|
| 125 |
+
|
| 126 |
+
# General case => cuDNN.
|
| 127 |
+
if transpose:
|
| 128 |
+
return torch.nn.functional.conv_transpose2d(input=input, weight=weight, bias=bias, output_padding=output_padding, **common_kwargs)
|
| 129 |
+
return torch.nn.functional.conv2d(input=input, weight=weight, bias=bias, **common_kwargs)
|
| 130 |
+
|
| 131 |
+
@staticmethod
|
| 132 |
+
def backward(ctx, grad_output):
|
| 133 |
+
input, weight = ctx.saved_tensors
|
| 134 |
+
input_shape = ctx.input_shape
|
| 135 |
+
grad_input = None
|
| 136 |
+
grad_weight = None
|
| 137 |
+
grad_bias = None
|
| 138 |
+
|
| 139 |
+
if ctx.needs_input_grad[0]:
|
| 140 |
+
p = calc_output_padding(input_shape=input_shape, output_shape=grad_output.shape)
|
| 141 |
+
op = _conv2d_gradfix(transpose=(not transpose), weight_shape=weight_shape, output_padding=p, **common_kwargs)
|
| 142 |
+
grad_input = op.apply(grad_output, weight, None)
|
| 143 |
+
assert grad_input.shape == input_shape
|
| 144 |
+
|
| 145 |
+
if ctx.needs_input_grad[1] and not weight_gradients_disabled:
|
| 146 |
+
grad_weight = Conv2dGradWeight.apply(grad_output, input, weight)
|
| 147 |
+
assert grad_weight.shape == weight_shape
|
| 148 |
+
|
| 149 |
+
if ctx.needs_input_grad[2]:
|
| 150 |
+
grad_bias = grad_output.sum([0, 2, 3])
|
| 151 |
+
|
| 152 |
+
return grad_input, grad_weight, grad_bias
|
| 153 |
+
|
| 154 |
+
# Gradient with respect to the weights.
|
| 155 |
+
class Conv2dGradWeight(torch.autograd.Function):
|
| 156 |
+
@staticmethod
|
| 157 |
+
def forward(ctx, grad_output, input, weight):
|
| 158 |
+
ctx.save_for_backward(
|
| 159 |
+
grad_output if input.requires_grad else _null_tensor,
|
| 160 |
+
input if grad_output.requires_grad else _null_tensor,
|
| 161 |
+
)
|
| 162 |
+
ctx.grad_output_shape = grad_output.shape
|
| 163 |
+
ctx.input_shape = input.shape
|
| 164 |
+
|
| 165 |
+
# Simple 1x1 convolution => cuBLAS (on both Volta and Ampere).
|
| 166 |
+
if weight_shape[2:] == stride == dilation == (1, 1) and padding == (0, 0):
|
| 167 |
+
a = grad_output.reshape(grad_output.shape[0], groups, grad_output.shape[1] // groups, -1).permute(1, 2, 0, 3).flatten(2)
|
| 168 |
+
b = input.reshape(input.shape[0], groups, input.shape[1] // groups, -1).permute(1, 2, 0, 3).flatten(2)
|
| 169 |
+
c = (b @ a.transpose(1, 2) if transpose else a @ b.transpose(1, 2)).reshape(weight_shape)
|
| 170 |
+
return c.contiguous(memory_format=(torch.channels_last if input.stride(1) == 1 else torch.contiguous_format))
|
| 171 |
+
|
| 172 |
+
# General case => cuDNN.
|
| 173 |
+
return torch.ops.aten.convolution_backward(grad_output=grad_output, input=input, weight=weight, bias_sizes=None, stride=stride, padding=padding, dilation=dilation, transposed=transpose, output_padding=output_padding, groups=groups, output_mask=[False, True, False])[1]
|
| 174 |
+
|
| 175 |
+
|
| 176 |
+
@staticmethod
|
| 177 |
+
def backward(ctx, grad2_grad_weight):
|
| 178 |
+
grad_output, input = ctx.saved_tensors
|
| 179 |
+
grad_output_shape = ctx.grad_output_shape
|
| 180 |
+
input_shape = ctx.input_shape
|
| 181 |
+
grad2_grad_output = None
|
| 182 |
+
grad2_input = None
|
| 183 |
+
|
| 184 |
+
if ctx.needs_input_grad[0]:
|
| 185 |
+
grad2_grad_output = Conv2d.apply(input, grad2_grad_weight, None)
|
| 186 |
+
assert grad2_grad_output.shape == grad_output_shape
|
| 187 |
+
|
| 188 |
+
if ctx.needs_input_grad[1]:
|
| 189 |
+
p = calc_output_padding(input_shape=input_shape, output_shape=grad_output_shape)
|
| 190 |
+
op = _conv2d_gradfix(transpose=(not transpose), weight_shape=weight_shape, output_padding=p, **common_kwargs)
|
| 191 |
+
grad2_input = op.apply(grad_output, grad2_grad_weight, None)
|
| 192 |
+
assert grad2_input.shape == input_shape
|
| 193 |
+
|
| 194 |
+
return grad2_grad_output, grad2_input
|
| 195 |
+
|
| 196 |
+
_conv2d_gradfix_cache[key] = Conv2d
|
| 197 |
+
return Conv2d
|
| 198 |
+
|
| 199 |
+
#----------------------------------------------------------------------------
|