Spaces:
Configuration error

Configuration error
Upload 18 files
Browse files- README.md +6 -11
- __pycache__/funcoes_modelos.cpython-38.pyc +0 -0
- __pycache__/streamlit_app.cpython-38.pyc +0 -0
- __pycache__/tscv.cpython-38.pyc +0 -0
- data/comparacao_cv_30.csv +3 -0
- diagnostics.py +123 -0
- experiments.py +164 -0
- images/acf.png +0 -0
- images/acfdiff.png +0 -0
- images/pacf.png +0 -0
- images/pacfdiff.png +0 -0
- images/sarima_diags.png +0 -0
- models/model_sarima_summary.pickle +3 -0
- predict_model.py +97 -0
- requirements.txt +2 -1
- streamlit_app.py +267 -0
- tscv.py +106 -0
README.md
CHANGED
|
@@ -1,12 +1,7 @@
|
|
| 1 |
-
|
| 2 |
-
title: Trabalho Series Temporais
|
| 3 |
-
emoji: 🐨
|
| 4 |
-
colorFrom: green
|
| 5 |
-
colorTo: purple
|
| 6 |
-
sdk: streamlit
|
| 7 |
-
sdk_version: 1.21.0
|
| 8 |
-
app_file: app.py
|
| 9 |
-
pinned: false
|
| 10 |
-
---
|
| 11 |
|
| 12 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Trabalho Séries Temporais - 1S 2023
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 2 |
|
| 3 |
+
### Esse repositório armazena os principais códigos responsáveis pela análise, modelagem e diagóstico de uma série temporal.
|
| 4 |
+
|
| 5 |
+
Esses dados foram coletados a partir da biblioteca meteostat, do python, que fornece informações acerca do clima de diversos pontos do mundo. Nesse caso a cidade escolhida foi Vancouver, por conta da quantidade de dados disponíveis e ausência de falhas na coleta (como apresntadas em Campinas em São Paulo).
|
| 6 |
+
|
| 7 |
+
O foco do trabalho é predizer a temperatura média do dia seguinte, usando as temperaturas anteriores e com auxílio da variável precipitação. Outras variáveis não foram consideradas ou por se mostrarem ineficiêntes, ou por possuírem muitos valores faltantes.
|
__pycache__/funcoes_modelos.cpython-38.pyc
ADDED
|
Binary file (3.14 kB). View file
|
|
|
__pycache__/streamlit_app.cpython-38.pyc
ADDED
|
Binary file (5.57 kB). View file
|
|
|
__pycache__/tscv.cpython-38.pyc
ADDED
|
Binary file (3.53 kB). View file
|
|
|
data/comparacao_cv_30.csv
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
,11,12,4,10,1,2,3,9,0,6,8,7,5
|
| 2 |
+
Model,sarima,ARIMAX-precp,AutoARIMA,Seu ARIMA,Naive,Drift,ExpSmo,ARIMA-GARCH,Media,ARCH2,GARCH22,GARCH11,ARCH1
|
| 3 |
+
m5_rmse,1.4216997766664468,1.4405214459890654,1.4867429183071361,1.4931783954737987,1.671428442001343,1.671835810797555,1.7179135731288364,3.0421461080979126,5.066647263935635,6.231218099889622,6.2312442352950255,6.231574173609016,6.231589827422044
|
diagnostics.py
ADDED
|
@@ -0,0 +1,123 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
|
| 2 |
+
import streamlit as st
|
| 3 |
+
import pandas as pd
|
| 4 |
+
import numpy as np
|
| 5 |
+
import urllib.request
|
| 6 |
+
import json
|
| 7 |
+
import plotly.express as px
|
| 8 |
+
import matplotlib.pyplot as plt
|
| 9 |
+
import yfinance as yf
|
| 10 |
+
import pandas as pd
|
| 11 |
+
import numpy as np
|
| 12 |
+
import matplotlib.pyplot as plt
|
| 13 |
+
import seaborn as sns
|
| 14 |
+
from datetime import datetime
|
| 15 |
+
import statsmodels.api as sm
|
| 16 |
+
|
| 17 |
+
from sklearn.linear_model import LinearRegression
|
| 18 |
+
from statsmodels.tsa.seasonal import seasonal_decompose
|
| 19 |
+
from sklearn.model_selection import TimeSeriesSplit
|
| 20 |
+
from sklearn.metrics import mean_squared_error
|
| 21 |
+
|
| 22 |
+
from statsforecast.models import HistoricAverage
|
| 23 |
+
from statsforecast.models import Naive
|
| 24 |
+
from statsforecast.models import RandomWalkWithDrift
|
| 25 |
+
from statsforecast.models import SeasonalNaive
|
| 26 |
+
from statsforecast.models import SimpleExponentialSmoothing
|
| 27 |
+
from statsforecast.models import HoltWinters
|
| 28 |
+
from statsforecast.models import AutoARIMA
|
| 29 |
+
from statsforecast.models import ARIMA
|
| 30 |
+
from statsforecast.models import GARCH
|
| 31 |
+
from statsforecast.models import ARCH
|
| 32 |
+
|
| 33 |
+
from statsmodels.graphics.tsaplots import plot_pacf
|
| 34 |
+
from statsmodels.graphics.tsaplots import plot_acf
|
| 35 |
+
|
| 36 |
+
from scipy.stats import shapiro
|
| 37 |
+
from datetime import datetime
|
| 38 |
+
import matplotlib.pyplot as plt
|
| 39 |
+
from meteostat import Point, Daily
|
| 40 |
+
|
| 41 |
+
from statsmodels.graphics.tsaplots import plot_pacf
|
| 42 |
+
from statsmodels.graphics.tsaplots import plot_acf
|
| 43 |
+
from statsmodels.tsa.statespace.sarimax import SARIMAX
|
| 44 |
+
from statsmodels.tsa.holtwinters import ExponentialSmoothing
|
| 45 |
+
from statsmodels.tsa.stattools import adfuller
|
| 46 |
+
import matplotlib.pyplot as plt
|
| 47 |
+
from tqdm import tqdm_notebook
|
| 48 |
+
from itertools import product
|
| 49 |
+
|
| 50 |
+
from PIL import Image
|
| 51 |
+
|
| 52 |
+
from funcoes_modelos import montar_dataframe_temp
|
| 53 |
+
from funcoes_modelos import predict_ARIMA_GARCH
|
| 54 |
+
from funcoes_modelos import return_exog
|
| 55 |
+
|
| 56 |
+
import warnings
|
| 57 |
+
warnings.filterwarnings('ignore')
|
| 58 |
+
|
| 59 |
+
from tscv import TimeBasedCV
|
| 60 |
+
|
| 61 |
+
import pickle
|
| 62 |
+
|
| 63 |
+
|
| 64 |
+
#########################################################################
|
| 65 |
+
def read_data():
|
| 66 |
+
# Set time period
|
| 67 |
+
start = datetime(2010, 1, 1)
|
| 68 |
+
end = pd.to_datetime(datetime.now().strftime("%Y-%m-%d"))
|
| 69 |
+
# Create Point for Vancouver, BC
|
| 70 |
+
vancouver = Point(49.2497, -123.1193, 70)
|
| 71 |
+
#campinas = Point(-22.9056, -47.0608, 686)
|
| 72 |
+
#saopaulo = Point(-23.5475, -46.6361, 769)
|
| 73 |
+
|
| 74 |
+
# Get daily data for 2018
|
| 75 |
+
data = Daily(vancouver, start, end)
|
| 76 |
+
data = data.fetch()
|
| 77 |
+
data = data[['tavg', 'prcp']]
|
| 78 |
+
|
| 79 |
+
return data
|
| 80 |
+
|
| 81 |
+
|
| 82 |
+
data = read_data()
|
| 83 |
+
returns = data['tavg']
|
| 84 |
+
|
| 85 |
+
#plot_acf(returns, lags = 400, zero = False)
|
| 86 |
+
#plt.show()
|
| 87 |
+
#plot_pacf(returns, lags = 400, zero = False)
|
| 88 |
+
#plt.show()
|
| 89 |
+
#plot_acf(returns.diff(1).dropna(), lags = 400, zero = False)
|
| 90 |
+
#plt.show()
|
| 91 |
+
#plot_pacf(returns.diff(1).dropna(), lags = 400, zero = False)
|
| 92 |
+
#plt.show()
|
| 93 |
+
|
| 94 |
+
model = sm.tsa.statespace.SARIMAX(returns , order=(1,1,3), seasonal_order=(0,1,1,7),
|
| 95 |
+
enforce_stationarity=False, enforce_invertibility=False, freq='D')
|
| 96 |
+
model = model.fit()
|
| 97 |
+
|
| 98 |
+
|
| 99 |
+
pred = model.forecast(1)
|
| 100 |
+
|
| 101 |
+
model.plot_diagnostics(figsize=(15, 12))
|
| 102 |
+
#plt.show()
|
| 103 |
+
|
| 104 |
+
print(shapiro(model.resid))
|
| 105 |
+
|
| 106 |
+
print(sm.stats.acorr_ljungbox(model.resid, return_df=True, boxpierce = True))
|
| 107 |
+
|
| 108 |
+
with open('./models/model_sarima_summary.pickle', 'wb') as file:
|
| 109 |
+
f = pickle.dump(model.summary(), file)
|
| 110 |
+
|
| 111 |
+
|
| 112 |
+
|
| 113 |
+
|
| 114 |
+
|
| 115 |
+
|
| 116 |
+
|
| 117 |
+
|
| 118 |
+
|
| 119 |
+
|
| 120 |
+
|
| 121 |
+
|
| 122 |
+
|
| 123 |
+
|
experiments.py
ADDED
|
@@ -0,0 +1,164 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
|
| 2 |
+
import streamlit as st
|
| 3 |
+
import pandas as pd
|
| 4 |
+
import numpy as np
|
| 5 |
+
import urllib.request
|
| 6 |
+
import json
|
| 7 |
+
import plotly.express as px
|
| 8 |
+
import matplotlib.pyplot as plt
|
| 9 |
+
import yfinance as yf
|
| 10 |
+
import pandas as pd
|
| 11 |
+
import numpy as np
|
| 12 |
+
import matplotlib.pyplot as plt
|
| 13 |
+
import seaborn as sns
|
| 14 |
+
from datetime import datetime
|
| 15 |
+
import statsmodels.api as sm
|
| 16 |
+
|
| 17 |
+
from sklearn.linear_model import LinearRegression
|
| 18 |
+
from statsmodels.tsa.seasonal import seasonal_decompose
|
| 19 |
+
from sklearn.model_selection import TimeSeriesSplit
|
| 20 |
+
from sklearn.metrics import mean_squared_error
|
| 21 |
+
|
| 22 |
+
from statsforecast.models import HistoricAverage
|
| 23 |
+
from statsforecast.models import Naive
|
| 24 |
+
from statsforecast.models import RandomWalkWithDrift
|
| 25 |
+
from statsforecast.models import SeasonalNaive
|
| 26 |
+
from statsforecast.models import SimpleExponentialSmoothing
|
| 27 |
+
from statsforecast.models import HoltWinters
|
| 28 |
+
from statsforecast.models import AutoARIMA
|
| 29 |
+
from statsforecast.models import ARIMA
|
| 30 |
+
from statsforecast.models import GARCH
|
| 31 |
+
from statsforecast.models import ARCH
|
| 32 |
+
|
| 33 |
+
from statsmodels.graphics.tsaplots import plot_pacf
|
| 34 |
+
from statsmodels.graphics.tsaplots import plot_acf
|
| 35 |
+
|
| 36 |
+
from scipy.stats import shapiro
|
| 37 |
+
from datetime import datetime
|
| 38 |
+
import matplotlib.pyplot as plt
|
| 39 |
+
from meteostat import Point, Daily
|
| 40 |
+
|
| 41 |
+
from statsmodels.graphics.tsaplots import plot_pacf
|
| 42 |
+
from statsmodels.graphics.tsaplots import plot_acf
|
| 43 |
+
from statsmodels.tsa.statespace.sarimax import SARIMAX
|
| 44 |
+
from statsmodels.tsa.holtwinters import ExponentialSmoothing
|
| 45 |
+
from statsmodels.tsa.stattools import adfuller
|
| 46 |
+
import matplotlib.pyplot as plt
|
| 47 |
+
from tqdm import tqdm_notebook
|
| 48 |
+
from itertools import product
|
| 49 |
+
|
| 50 |
+
from funcoes_modelos import montar_dataframe_temp
|
| 51 |
+
from funcoes_modelos import predict_ARIMA_GARCH
|
| 52 |
+
from funcoes_modelos import return_exog
|
| 53 |
+
|
| 54 |
+
import warnings
|
| 55 |
+
warnings.filterwarnings('ignore')
|
| 56 |
+
|
| 57 |
+
from tscv import TimeBasedCV
|
| 58 |
+
|
| 59 |
+
|
| 60 |
+
#########################################################################
|
| 61 |
+
def read_data():
|
| 62 |
+
# Set time period
|
| 63 |
+
start = datetime(2010, 1, 1)
|
| 64 |
+
end = pd.to_datetime(datetime.now().strftime("%Y-%m-%d"))
|
| 65 |
+
# Create Point for Vancouver, BC
|
| 66 |
+
vancouver = Point(49.2497, -123.1193, 70)
|
| 67 |
+
#campinas = Point(-22.9056, -47.0608, 686)
|
| 68 |
+
#saopaulo = Point(-23.5475, -46.6361, 769)
|
| 69 |
+
|
| 70 |
+
# Get daily data for 2018
|
| 71 |
+
data = Daily(vancouver, start, end)
|
| 72 |
+
data = data.fetch()
|
| 73 |
+
data = data[['tavg', 'prcp']]
|
| 74 |
+
|
| 75 |
+
return data
|
| 76 |
+
|
| 77 |
+
data = read_data()
|
| 78 |
+
returns = data['tavg']
|
| 79 |
+
|
| 80 |
+
|
| 81 |
+
modelos = [HistoricAverage(),
|
| 82 |
+
Naive(),
|
| 83 |
+
# SeasonalNaive(365),
|
| 84 |
+
# SeasonalNaive(30),
|
| 85 |
+
RandomWalkWithDrift(),
|
| 86 |
+
SimpleExponentialSmoothing(0.9),
|
| 87 |
+
#HoltWinters(season_length=180, error_type='A'),
|
| 88 |
+
#HoltWinters(season_length=30, error_type='A') ,
|
| 89 |
+
AutoARIMA(),
|
| 90 |
+
ARCH(p = 1),
|
| 91 |
+
ARCH(p = 2),
|
| 92 |
+
GARCH(1,1),
|
| 93 |
+
GARCH(2,2),
|
| 94 |
+
[AutoARIMA(), GARCH(2, 2)],
|
| 95 |
+
#SARIMAX(returns.values, order=(1,1,1), seasonal_order=(1,1,1, 365)),
|
| 96 |
+
ARIMA(order = (1,1, 1)),
|
| 97 |
+
ARIMA(order = (1,1,3), seasonal_order = (0,1,1), season_length = 7)
|
| 98 |
+
]
|
| 99 |
+
|
| 100 |
+
|
| 101 |
+
model_names = ['Media', 'Naive', 'Drift','ExpSmo', #'HoltWin180','HoltWin30',
|
| 102 |
+
'AutoARIMA','ARCH1','ARCH2', 'GARCH11', 'GARCH22', 'ARIMA-GARCH',
|
| 103 |
+
'Seu ARIMA', 'sarima']
|
| 104 |
+
|
| 105 |
+
modelos.append('ourmodel')
|
| 106 |
+
model_names.append('ARIMAX-precp')
|
| 107 |
+
|
| 108 |
+
|
| 109 |
+
|
| 110 |
+
datatrain = data.reset_index()[['time', 'tavg']]
|
| 111 |
+
datatrain['time'] = pd.to_datetime(datatrain['time'])
|
| 112 |
+
|
| 113 |
+
from tscv import TimeBasedCV
|
| 114 |
+
n_cv = 5
|
| 115 |
+
|
| 116 |
+
#tscv = TimeSeriesSplit(n_splits = n_cv, max_train_size= 740, )
|
| 117 |
+
tscv = TimeBasedCV(train_period= len(data) - n_cv,
|
| 118 |
+
test_period=1,
|
| 119 |
+
freq='days')
|
| 120 |
+
erros = pd.DataFrame(columns = ['Model', 'm5_rmse'])
|
| 121 |
+
n = 1
|
| 122 |
+
|
| 123 |
+
for i, model in enumerate(modelos):
|
| 124 |
+
|
| 125 |
+
model_name = model_names[i]
|
| 126 |
+
rmse = []
|
| 127 |
+
for train_index, test_index in tscv.split(data = datatrain , date_column='time'):
|
| 128 |
+
cv_train, cv_test = returns.iloc[train_index], returns.iloc[test_index]
|
| 129 |
+
|
| 130 |
+
if model_name == 'ARIMA-GARCH':
|
| 131 |
+
|
| 132 |
+
temp_train = montar_dataframe_temp(cv_train)
|
| 133 |
+
|
| 134 |
+
predictions = predict_ARIMA_GARCH(model, temp_train, n)
|
| 135 |
+
|
| 136 |
+
elif model_name == 'ARIMAX-precp':
|
| 137 |
+
|
| 138 |
+
temp_train = montar_dataframe_temp(cv_train)
|
| 139 |
+
|
| 140 |
+
sarimax = sm.tsa.statespace.SARIMAX(temp_train['tavg'] , order=(3,0,1), exog = temp_train[['precip_ontem', 'precip_media_semana']],
|
| 141 |
+
enforce_stationarity=False, enforce_invertibility=False, freq='D', simple_differencing=True).fit(low_memory=True, cov_type='none')
|
| 142 |
+
|
| 143 |
+
#mod = sm.tsa.arima.ARIMA(temp_train['tavg'], order=(3, 0, 1), seasonal_order=(0,1,0,365))
|
| 144 |
+
#res = mod.fit(method='innovations_mle', low_memory=True, cov_type='none')
|
| 145 |
+
|
| 146 |
+
predictions = sarimax.forecast(n, exog = return_exog(temp_train, n).values).values
|
| 147 |
+
#predictions = res.forecast(n).values
|
| 148 |
+
else:
|
| 149 |
+
model = model.fit(cv_train.values)
|
| 150 |
+
|
| 151 |
+
predictions = model.predict(n)
|
| 152 |
+
predictions = predictions['mean']#[0]
|
| 153 |
+
|
| 154 |
+
|
| 155 |
+
true_values = cv_test.values[0:n]
|
| 156 |
+
rmse.append(np.sqrt(mean_squared_error(true_values, predictions)))
|
| 157 |
+
|
| 158 |
+
|
| 159 |
+
erros = pd.concat([erros, pd.DataFrame([{'Model': model_name,'m5_rmse': np.mean(rmse)}])],
|
| 160 |
+
ignore_index = True)
|
| 161 |
+
|
| 162 |
+
|
| 163 |
+
print(erros.sort_values('m5_rmse').T)
|
| 164 |
+
erros.sort_values('m5_rmse').T.to_csv(f'comparacao_cv_{n_cv}.csv')
|
images/acf.png
ADDED
|
images/acfdiff.png
ADDED

|
images/pacf.png
ADDED

|
images/pacfdiff.png
ADDED

|
images/sarima_diags.png
ADDED

|
models/model_sarima_summary.pickle
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:15ceef30812813136f63ab93011f371affa7e88d606cc3b901213194bc1dec2e
|
| 3 |
+
size 7876
|
predict_model.py
ADDED
|
@@ -0,0 +1,97 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
|
| 2 |
+
import streamlit as st
|
| 3 |
+
import pandas as pd
|
| 4 |
+
import numpy as np
|
| 5 |
+
import urllib.request
|
| 6 |
+
import json
|
| 7 |
+
import plotly.express as px
|
| 8 |
+
import matplotlib.pyplot as plt
|
| 9 |
+
import yfinance as yf
|
| 10 |
+
import pandas as pd
|
| 11 |
+
import numpy as np
|
| 12 |
+
import matplotlib.pyplot as plt
|
| 13 |
+
import seaborn as sns
|
| 14 |
+
from datetime import datetime
|
| 15 |
+
import statsmodels.api as sm
|
| 16 |
+
import pickle
|
| 17 |
+
|
| 18 |
+
from sklearn.linear_model import LinearRegression
|
| 19 |
+
from statsmodels.tsa.seasonal import seasonal_decompose
|
| 20 |
+
from sklearn.model_selection import TimeSeriesSplit
|
| 21 |
+
from sklearn.metrics import mean_squared_error
|
| 22 |
+
|
| 23 |
+
from statsforecast.models import HistoricAverage
|
| 24 |
+
from statsforecast.models import Naive
|
| 25 |
+
from statsforecast.models import RandomWalkWithDrift
|
| 26 |
+
from statsforecast.models import SeasonalNaive
|
| 27 |
+
from statsforecast.models import SimpleExponentialSmoothing
|
| 28 |
+
from statsforecast.models import HoltWinters
|
| 29 |
+
from statsforecast.models import AutoARIMA
|
| 30 |
+
from statsforecast.models import ARIMA
|
| 31 |
+
from statsforecast.models import GARCH
|
| 32 |
+
from statsforecast.models import ARCH
|
| 33 |
+
|
| 34 |
+
from statsmodels.graphics.tsaplots import plot_pacf
|
| 35 |
+
from statsmodels.graphics.tsaplots import plot_acf
|
| 36 |
+
|
| 37 |
+
from scipy.stats import shapiro
|
| 38 |
+
from datetime import datetime
|
| 39 |
+
import matplotlib.pyplot as plt
|
| 40 |
+
from meteostat import Point, Daily
|
| 41 |
+
|
| 42 |
+
from statsmodels.graphics.tsaplots import plot_pacf
|
| 43 |
+
from statsmodels.graphics.tsaplots import plot_acf
|
| 44 |
+
from statsmodels.tsa.statespace.sarimax import SARIMAX
|
| 45 |
+
from statsmodels.tsa.holtwinters import ExponentialSmoothing
|
| 46 |
+
from statsmodels.tsa.stattools import adfuller
|
| 47 |
+
import matplotlib.pyplot as plt
|
| 48 |
+
from tqdm import tqdm_notebook
|
| 49 |
+
from itertools import product
|
| 50 |
+
|
| 51 |
+
from PIL import Image
|
| 52 |
+
|
| 53 |
+
from funcoes_modelos import montar_dataframe_temp
|
| 54 |
+
from funcoes_modelos import predict_ARIMA_GARCH
|
| 55 |
+
from funcoes_modelos import return_exog
|
| 56 |
+
|
| 57 |
+
import warnings
|
| 58 |
+
warnings.filterwarnings('ignore')
|
| 59 |
+
|
| 60 |
+
from tscv import TimeBasedCV
|
| 61 |
+
|
| 62 |
+
|
| 63 |
+
#########################################################################
|
| 64 |
+
def read_data():
|
| 65 |
+
# Set time period
|
| 66 |
+
start = datetime(2010, 1, 1)
|
| 67 |
+
end = pd.to_datetime(datetime.now().strftime("%Y-%m-%d"))
|
| 68 |
+
# Create Point for Vancouver, BC
|
| 69 |
+
vancouver = Point(49.2497, -123.1193, 70)
|
| 70 |
+
#campinas = Point(-22.9056, -47.0608, 686)
|
| 71 |
+
#saopaulo = Point(-23.5475, -46.6361, 769)
|
| 72 |
+
|
| 73 |
+
# Get daily data for 2018
|
| 74 |
+
data = Daily(vancouver, start, end)
|
| 75 |
+
data = data.fetch()
|
| 76 |
+
data = data[['tavg', 'prcp']]
|
| 77 |
+
|
| 78 |
+
return data
|
| 79 |
+
|
| 80 |
+
data = read_data()
|
| 81 |
+
returns = data['tavg']
|
| 82 |
+
print(returns.tail(1))
|
| 83 |
+
|
| 84 |
+
model = sm.tsa.statespace.SARIMAX(returns , order=(1,1,3), seasonal_order=(0,1,1,7),
|
| 85 |
+
enforce_stationarity=False, enforce_invertibility=False, freq='D')
|
| 86 |
+
model = model.fit()
|
| 87 |
+
|
| 88 |
+
|
| 89 |
+
pred = model.forecast(1)
|
| 90 |
+
print(returns.tail(1))
|
| 91 |
+
print(pred)
|
| 92 |
+
|
| 93 |
+
#model.save('./models/model_sarima.pickle')
|
| 94 |
+
|
| 95 |
+
|
| 96 |
+
#print(model.test_normality('jarquebera'))
|
| 97 |
+
#print(model.test_serial_correlation('ljungbox', 10))
|
requirements.txt
CHANGED
|
@@ -11,4 +11,5 @@ scikit-learn
|
|
| 11 |
statsforecast
|
| 12 |
scipy
|
| 13 |
meteostat
|
| 14 |
-
tqdm
|
|
|
|
|
|
| 11 |
statsforecast
|
| 12 |
scipy
|
| 13 |
meteostat
|
| 14 |
+
tqdm
|
| 15 |
+
pickle
|
streamlit_app.py
ADDED
|
@@ -0,0 +1,267 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
#import altair as alt
|
| 2 |
+
#import pandas as pd
|
| 3 |
+
#import streamlit as st
|
| 4 |
+
#
|
| 5 |
+
#st.set_page_config(
|
| 6 |
+
# page_title="Trabalho Final Séries Temporais - 2s 2023", page_icon="⬇", layout="centered"
|
| 7 |
+
#)
|
| 8 |
+
#
|
| 9 |
+
#
|
| 10 |
+
#st.title("Trabalho final Séries Temporais")
|
| 11 |
+
#
|
| 12 |
+
#st.write("Começo dos testes para criação do DashBoard")
|
| 13 |
+
import pickle
|
| 14 |
+
import streamlit as st
|
| 15 |
+
import pandas as pd
|
| 16 |
+
import numpy as np
|
| 17 |
+
import urllib.request
|
| 18 |
+
import json
|
| 19 |
+
import plotly.express as px
|
| 20 |
+
import matplotlib.pyplot as plt
|
| 21 |
+
import yfinance as yf
|
| 22 |
+
import pandas as pd
|
| 23 |
+
import numpy as np
|
| 24 |
+
import matplotlib.pyplot as plt
|
| 25 |
+
import seaborn as sns
|
| 26 |
+
from datetime import datetime
|
| 27 |
+
import statsmodels.api as sm
|
| 28 |
+
|
| 29 |
+
from sklearn.linear_model import LinearRegression
|
| 30 |
+
from statsmodels.tsa.seasonal import seasonal_decompose
|
| 31 |
+
from sklearn.model_selection import TimeSeriesSplit
|
| 32 |
+
from sklearn.metrics import mean_squared_error
|
| 33 |
+
|
| 34 |
+
from statsforecast.models import HistoricAverage
|
| 35 |
+
from statsforecast.models import Naive
|
| 36 |
+
from statsforecast.models import RandomWalkWithDrift
|
| 37 |
+
from statsforecast.models import SeasonalNaive
|
| 38 |
+
from statsforecast.models import SimpleExponentialSmoothing
|
| 39 |
+
from statsforecast.models import HoltWinters
|
| 40 |
+
from statsforecast.models import AutoARIMA
|
| 41 |
+
from statsforecast.models import ARIMA
|
| 42 |
+
from statsforecast.models import GARCH
|
| 43 |
+
from statsforecast.models import ARCH
|
| 44 |
+
|
| 45 |
+
from statsmodels.graphics.tsaplots import plot_pacf
|
| 46 |
+
from statsmodels.graphics.tsaplots import plot_acf
|
| 47 |
+
|
| 48 |
+
from scipy.stats import shapiro
|
| 49 |
+
from datetime import datetime
|
| 50 |
+
import matplotlib.pyplot as plt
|
| 51 |
+
from meteostat import Point, Daily
|
| 52 |
+
|
| 53 |
+
from statsmodels.graphics.tsaplots import plot_pacf
|
| 54 |
+
from statsmodels.graphics.tsaplots import plot_acf
|
| 55 |
+
from statsmodels.tsa.statespace.sarimax import SARIMAX
|
| 56 |
+
from statsmodels.tsa.holtwinters import ExponentialSmoothing
|
| 57 |
+
from statsmodels.tsa.stattools import adfuller
|
| 58 |
+
import matplotlib.pyplot as plt
|
| 59 |
+
from tqdm import tqdm_notebook
|
| 60 |
+
from itertools import product
|
| 61 |
+
|
| 62 |
+
from funcoes_modelos import montar_dataframe_temp
|
| 63 |
+
from funcoes_modelos import predict_ARIMA_GARCH
|
| 64 |
+
from funcoes_modelos import return_exog
|
| 65 |
+
|
| 66 |
+
from PIL import Image
|
| 67 |
+
import plotly.graph_objects as go
|
| 68 |
+
|
| 69 |
+
|
| 70 |
+
import warnings
|
| 71 |
+
warnings.filterwarnings('ignore')
|
| 72 |
+
|
| 73 |
+
|
| 74 |
+
st.set_page_config('Séries Tempoais', page_icon= ':chart_with_upwards_trend:')
|
| 75 |
+
|
| 76 |
+
with st.sidebar:
|
| 77 |
+
st.markdown("# ME607")
|
| 78 |
+
st.markdown("A seguir podem ser encontrados alguns links útis referente ao trabalho aqui apresentado:")
|
| 79 |
+
st.markdown('[Github](https://github.com/GabrielTalasso/trabalho-series)')
|
| 80 |
+
|
| 81 |
+
st.title(':chart_with_upwards_trend: Trabalho Final Séries Temporais' )
|
| 82 |
+
st.error('Aguarde o simbolo de "Running" no canto superior para a visualização completa.')
|
| 83 |
+
st.markdown('Grupo: Gabriel Ukstin Talasso - 235078 ; Tiago Henrique Silva Monteiro - 217517....')
|
| 84 |
+
st.markdown("## Visão geral dos dados")
|
| 85 |
+
st.markdown("### Alterne entre as abas para as visualizações!")
|
| 86 |
+
|
| 87 |
+
@st.cache_data # 👈 Add the caching decorator
|
| 88 |
+
def read_data():
|
| 89 |
+
# Set time period
|
| 90 |
+
start = datetime(2010, 1, 1)
|
| 91 |
+
end = pd.to_datetime(datetime.now().strftime("%Y-%m-%d"))
|
| 92 |
+
# Create Point for Vancouver, BC
|
| 93 |
+
vancouver = Point(49.2497, -123.1193, 70)
|
| 94 |
+
#campinas = Point(-22.9056, -47.0608, 686)
|
| 95 |
+
#saopaulo = Point(-23.5475, -46.6361, 769)
|
| 96 |
+
|
| 97 |
+
# Get daily data for 2018
|
| 98 |
+
data = Daily(vancouver, start, end)
|
| 99 |
+
data = data.fetch()
|
| 100 |
+
data = data[['tavg', 'prcp']]
|
| 101 |
+
|
| 102 |
+
return data
|
| 103 |
+
|
| 104 |
+
data = read_data()
|
| 105 |
+
|
| 106 |
+
returns = data['tavg']
|
| 107 |
+
|
| 108 |
+
if data not in st.session_state:
|
| 109 |
+
st.session_state['df'] = data
|
| 110 |
+
|
| 111 |
+
st.markdown("#### :mostly_sunny: Visão geral -Temperaturas média diária - Vancouver")
|
| 112 |
+
|
| 113 |
+
tab1, tab2, tab3 = st.tabs([ "Grafico da Série",
|
| 114 |
+
"Grafico Diferenciada",
|
| 115 |
+
"Tabela dos dados"])
|
| 116 |
+
|
| 117 |
+
with tab1:
|
| 118 |
+
fig = px.line(returns, title='Temperatura Média Diária - Vancouver',
|
| 119 |
+
labels=({'value':'Temperatura Média', 'time':'Data'}))
|
| 120 |
+
fig.update_layout(showlegend=False)
|
| 121 |
+
st.plotly_chart(fig)
|
| 122 |
+
|
| 123 |
+
with tab2:
|
| 124 |
+
fig = px.line(returns.diff(1).dropna(), title='Temperatura Média Diária - Vancouver - Diferenciada',
|
| 125 |
+
labels = {'value':'Diferença da temperatura', 'time':'Data'})
|
| 126 |
+
fig.update_layout(showlegend=False)
|
| 127 |
+
st.plotly_chart(fig)
|
| 128 |
+
|
| 129 |
+
with tab3:
|
| 130 |
+
st.write(data.tail(10))
|
| 131 |
+
|
| 132 |
+
st.markdown("#### :bar_chart: Médias móveis -Temperaturas média diária - Vancouver")
|
| 133 |
+
|
| 134 |
+
|
| 135 |
+
tab1, tab2, tab3 = st.tabs(['Média Móvel 7', 'Média Móvel 30', 'Média Móvel 300'] )
|
| 136 |
+
with tab1:
|
| 137 |
+
fig = px.scatter(returns, trendline="rolling", title = 'Média Móvel de 3 dias da temperatura média.',
|
| 138 |
+
trendline_options=dict(window=7),
|
| 139 |
+
trendline_color_override="red")
|
| 140 |
+
fig.update_layout(showlegend=False)
|
| 141 |
+
st.plotly_chart(fig)
|
| 142 |
+
|
| 143 |
+
with tab2:
|
| 144 |
+
fig = px.scatter(returns, trendline="rolling",title = 'Média Móvel de 30 dias da temperatura média.',
|
| 145 |
+
trendline_options=dict(window=30),
|
| 146 |
+
trendline_color_override="red")
|
| 147 |
+
fig.update_layout(showlegend=False)
|
| 148 |
+
st.plotly_chart(fig)
|
| 149 |
+
|
| 150 |
+
|
| 151 |
+
with tab3:
|
| 152 |
+
fig = px.scatter(returns, trendline="rolling", title = 'Média Móvel de 300 dias da temperatura média.',
|
| 153 |
+
trendline_options=dict(window=300),
|
| 154 |
+
trendline_color_override="red")
|
| 155 |
+
fig.update_layout(showlegend=False)
|
| 156 |
+
st.plotly_chart(fig)
|
| 157 |
+
|
| 158 |
+
|
| 159 |
+
st.markdown("#### :umbrella_with_rain_drops: Visão geral - Precipitação diária - Vancouver")
|
| 160 |
+
|
| 161 |
+
|
| 162 |
+
tab1, tab2= st.tabs([ "Grafico da Série",
|
| 163 |
+
"Matriz de correlação"])
|
| 164 |
+
with tab1:
|
| 165 |
+
fig = px.line(data['prcp'], title='Precipitação diária - Vancouver',
|
| 166 |
+
labels=({'value':'Precipitação diária', 'time':'Data'}))
|
| 167 |
+
fig.update_layout(showlegend=False)
|
| 168 |
+
st.plotly_chart(fig)
|
| 169 |
+
|
| 170 |
+
with tab2:
|
| 171 |
+
df_corr = data.corr()
|
| 172 |
+
fig = go.Figure()
|
| 173 |
+
fig.add_trace(
|
| 174 |
+
go.Heatmap(
|
| 175 |
+
x = df_corr.columns,
|
| 176 |
+
y = df_corr.index,
|
| 177 |
+
z = np.array(df_corr),
|
| 178 |
+
text=df_corr.values,
|
| 179 |
+
texttemplate='%{text:.2f}'
|
| 180 |
+
)
|
| 181 |
+
)
|
| 182 |
+
fig.update_layout(showlegend=False)
|
| 183 |
+
st.plotly_chart(fig)
|
| 184 |
+
|
| 185 |
+
|
| 186 |
+
|
| 187 |
+
c0 = st.checkbox('Mais informações sobre os dados.', help = 'Clique para saber mais sobre os dados do projeto.')
|
| 188 |
+
|
| 189 |
+
if c0:
|
| 190 |
+
|
| 191 |
+
st.markdown('Esses dados foram coletados a partir da biblioteca meteostat, do python, que fornece informações acerca do clima de diversos pontos do mundo.')
|
| 192 |
+
st.markdown('Nesse caso a cidade escolhida foi Vancouver, por conta da quantidade de dados disponíveis e ausência de falahas na coleta (como apresntadas em Campinas em São Paulo).')
|
| 193 |
+
st.markdown('O foco do trabalho é predizer a temperatura média do dia seguinte, usando as temperaturas anteriores e com auxílio da variável precipitação. Outras variáveis não foram consideradas ou por se mostrarem ineficiẽntes, ou por possírem muitos valores faltantes.')
|
| 194 |
+
|
| 195 |
+
st.markdown('### :calendar: Para um vislumbre da dinâmica dos dados, a seguir podemos ver os seguintes gráficos:')
|
| 196 |
+
|
| 197 |
+
tab1, tab2, tab3, tab4 = st.tabs([ "ACF - Original",
|
| 198 |
+
"PACF - Original",
|
| 199 |
+
"ACF - Diferenciada",
|
| 200 |
+
"PACF - DIferenciada"])
|
| 201 |
+
with tab1:
|
| 202 |
+
image = Image.open('images/acf.png')
|
| 203 |
+
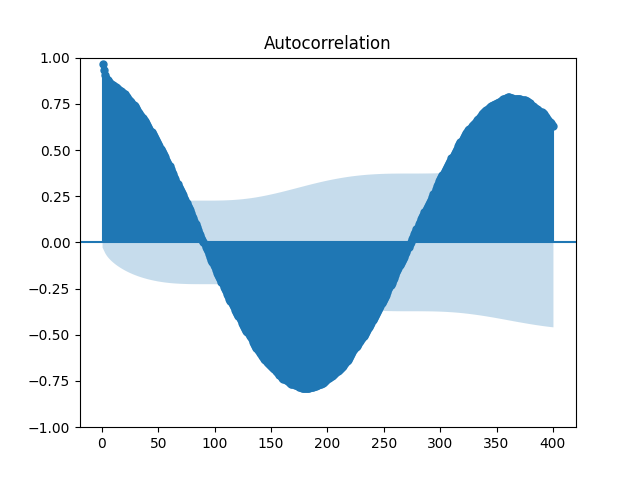
st.image(image = image, caption='ACF. Teste de Ljung-Box rejeita que são não correlacionados.')
|
| 204 |
+
with tab2:
|
| 205 |
+
image = Image.open('images/pacf.png')
|
| 206 |
+
st.image(image = image)
|
| 207 |
+
|
| 208 |
+
with tab3:
|
| 209 |
+
image = Image.open('images/acfdiff.png')
|
| 210 |
+
st.image(image = image, caption='ACF. Teste de Ljung-Box rejeita que são não correlacionados. ')
|
| 211 |
+
with tab4:
|
| 212 |
+
image = Image.open('images/pacfdiff.png')
|
| 213 |
+
st.image(image = image)
|
| 214 |
+
|
| 215 |
+
st.markdown('### :computer: Modelagem')
|
| 216 |
+
st.markdown(' A seguir podemos ver o resulado do teste de diversos modelos, comparados atravez de uma validação cruzada de janela deslizante.')
|
| 217 |
+
st.markdown(' Cada modelo foi testado 30 vezes, predizedo sempre um passo a frente a raiz do erro quadratico médio (RMSE) de cada um pode ser visto na tabela abaixo')
|
| 218 |
+
|
| 219 |
+
results = pd.read_csv('data/comparacao_cv_30.csv').T
|
| 220 |
+
results = results.replace({'Seu ARIMA': 'ARIMA111', 'm5_rmse':'RMSE', 'sarima': 'SARIMA'})
|
| 221 |
+
results.columns = results.iloc[0]
|
| 222 |
+
results = results.drop(results.index[0])
|
| 223 |
+
results = results.set_index('Model')
|
| 224 |
+
results['RMSE'] = results['RMSE'].apply(lambda x: round(float(x), 3))
|
| 225 |
+
|
| 226 |
+
col1, col2, col3 = st.columns(3)
|
| 227 |
+
|
| 228 |
+
with col1:
|
| 229 |
+
st.write(' ')
|
| 230 |
+
|
| 231 |
+
with col2:
|
| 232 |
+
st.write(results)
|
| 233 |
+
|
| 234 |
+
with col3:
|
| 235 |
+
st.write(' ')
|
| 236 |
+
|
| 237 |
+
c1 = st.checkbox('Mostrar mais sobre os testes.', help = 'Clique para mais informações a cerca dos experimentos para testes de modelos.')
|
| 238 |
+
if c1:
|
| 239 |
+
st.write('O melhor modelo encontrado foi um SARIMA(1,1,3)(0,1,1)7, que desempenhou melhor nos nossos testes. '+
|
| 240 |
+
'Além disso, o segundo melhor modelo foi um ARIMAX(1,0,1), usando a precipitação do dia anterior e a média da precipitação semanal como covariáveis.')
|
| 241 |
+
st.markdown('OBS: Outros modelos também foram testados mas não mostrados na tabela, os apresentados são os modelos de cada tipo que tiveram melhor desempenho nos testes realizados. Modelos com período sazonal 365 dias ou não bateram os baselines ou demoravam horas para rodar, por isso foram descartados de uma anpalise diária.')
|
| 242 |
+
|
| 243 |
+
st.markdown('### :white_check_mark: Diagnóstico do modelo: SARIMA(1,1,3)(0,1,1)7')
|
| 244 |
+
|
| 245 |
+
image = Image.open('images/sarima_diags.png')
|
| 246 |
+
st.image(image = image, caption='Diagnóstico do modelo. Rejeita-se normalidade dos resíduos à 5%.')
|
| 247 |
+
|
| 248 |
+
c2 = st.checkbox('Mostrar mais sobre o diagnóstico.', help = 'Clique para mais informações a cerca do diagnóstico do modelo.')
|
| 249 |
+
|
| 250 |
+
if c2:
|
| 251 |
+
st.markdown('Mesmo esse sendo o melhor modelo nos testes visualmente adequado nos gráficos. Ainda rejeitamos a normalidade dos resíduos, ou seja, o modelo ainda ainda não capturou complemente a dinâmica dos dados. Porém o modelo não rejeita que os resíduos são descorrelacionados, o que é um bom sinal de ajuste.')
|
| 252 |
+
st.markdown('OBS: Por se tratar de um problema complexo e que envolve muitas variáveis não disponíveis, nenhum dos modelos testados obteve resíduos normais.')
|
| 253 |
+
|
| 254 |
+
|
| 255 |
+
st.markdown('### :clipboard: Informações ténicas sobre o modelo.')
|
| 256 |
+
|
| 257 |
+
with open('./models/model_sarima_summary.pickle', 'rb') as file:
|
| 258 |
+
f = pickle.load(file)
|
| 259 |
+
|
| 260 |
+
st.write(f)
|
| 261 |
+
|
| 262 |
+
c3 = st.checkbox('Mais informações sobre os parâmetros do modelo.')
|
| 263 |
+
|
| 264 |
+
if c3:
|
| 265 |
+
st.markdown('Acima podemos ver as as estimativas para todos os parâmetros do modelo, além disso é possível visualizar também as principais métricas de performance do modelo estudado, assim os testes comentados anteriormente.')
|
| 266 |
+
st.markdown('Apesar de parte MA sasonal não se mostrar significativa, ela melhorou a desenpenho do modelo ns testes e por isso for mantida. Lembrando que esse p-valor apresentado se refere a significância da variável dado que todas outras já foram colocadas no modelo.')
|
| 267 |
+
|
tscv.py
ADDED
|
@@ -0,0 +1,106 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import pandas as pd
|
| 2 |
+
import datetime
|
| 3 |
+
from datetime import datetime as dt
|
| 4 |
+
from dateutil.relativedelta import *
|
| 5 |
+
|
| 6 |
+
class TimeBasedCV(object):
|
| 7 |
+
'''
|
| 8 |
+
Parameters
|
| 9 |
+
----------
|
| 10 |
+
train_period: int
|
| 11 |
+
number of time units to include in each train set
|
| 12 |
+
default is 30
|
| 13 |
+
test_period: int
|
| 14 |
+
number of time units to include in each test set
|
| 15 |
+
default is 7
|
| 16 |
+
freq: string
|
| 17 |
+
frequency of input parameters. possible values are: days, months, years, weeks, hours, minutes, seconds
|
| 18 |
+
possible values designed to be used by dateutil.relativedelta class
|
| 19 |
+
deafault is days
|
| 20 |
+
'''
|
| 21 |
+
|
| 22 |
+
|
| 23 |
+
def __init__(self, train_period=30, test_period=7, freq='days'):
|
| 24 |
+
self.train_period = train_period
|
| 25 |
+
self.test_period = test_period
|
| 26 |
+
self.freq = freq
|
| 27 |
+
|
| 28 |
+
|
| 29 |
+
|
| 30 |
+
def split(self, data, validation_split_date=None, date_column='record_date', gap=0):
|
| 31 |
+
'''
|
| 32 |
+
Generate indices to split data into training and test set
|
| 33 |
+
|
| 34 |
+
Parameters
|
| 35 |
+
----------
|
| 36 |
+
data: pandas DataFrame
|
| 37 |
+
your data, contain one column for the record date
|
| 38 |
+
validation_split_date: datetime.date()
|
| 39 |
+
first date to perform the splitting on.
|
| 40 |
+
if not provided will set to be the minimum date in the data after the first training set
|
| 41 |
+
date_column: string, deafult='record_date'
|
| 42 |
+
date of each record
|
| 43 |
+
gap: int, default=0
|
| 44 |
+
for cases the test set does not come right after the train set,
|
| 45 |
+
*gap* days are left between train and test sets
|
| 46 |
+
|
| 47 |
+
Returns
|
| 48 |
+
-------
|
| 49 |
+
train_index ,test_index:
|
| 50 |
+
list of tuples (train index, test index) similar to sklearn model selection
|
| 51 |
+
'''
|
| 52 |
+
|
| 53 |
+
# check that date_column exist in the data:
|
| 54 |
+
try:
|
| 55 |
+
data[date_column]
|
| 56 |
+
except:
|
| 57 |
+
raise KeyError(date_column)
|
| 58 |
+
|
| 59 |
+
train_indices_list = []
|
| 60 |
+
test_indices_list = []
|
| 61 |
+
|
| 62 |
+
if validation_split_date==None:
|
| 63 |
+
validation_split_date = data[date_column].min().date() + eval('relativedelta('+self.freq+'=self.train_period)')
|
| 64 |
+
|
| 65 |
+
start_train = validation_split_date - eval('relativedelta('+self.freq+'=self.train_period)')
|
| 66 |
+
end_train = start_train + eval('relativedelta('+self.freq+'=self.train_period)')
|
| 67 |
+
start_test = end_train + eval('relativedelta('+self.freq+'=gap)')
|
| 68 |
+
end_test = start_test + eval('relativedelta('+self.freq+'=self.test_period)')
|
| 69 |
+
|
| 70 |
+
while end_test < data[date_column].max().date():
|
| 71 |
+
# train indices:
|
| 72 |
+
cur_train_indices = list(data[(data[date_column].dt.date>=start_train) &
|
| 73 |
+
(data[date_column].dt.date<end_train)].index)
|
| 74 |
+
|
| 75 |
+
# test indices:
|
| 76 |
+
cur_test_indices = list(data[(data[date_column].dt.date>=start_test) &
|
| 77 |
+
(data[date_column].dt.date<end_test)].index)
|
| 78 |
+
|
| 79 |
+
print("Train period:",start_train,"-" , end_train, ", Test period", start_test, "-", end_test,
|
| 80 |
+
"# train records", len(cur_train_indices), ", # test records", len(cur_test_indices))
|
| 81 |
+
|
| 82 |
+
train_indices_list.append(cur_train_indices)
|
| 83 |
+
test_indices_list.append(cur_test_indices)
|
| 84 |
+
|
| 85 |
+
# update dates:
|
| 86 |
+
start_train = start_train + eval('relativedelta('+self.freq+'=self.test_period)')
|
| 87 |
+
end_train = start_train + eval('relativedelta('+self.freq+'=self.train_period)')
|
| 88 |
+
start_test = end_train + eval('relativedelta('+self.freq+'=gap)')
|
| 89 |
+
end_test = start_test + eval('relativedelta('+self.freq+'=self.test_period)')
|
| 90 |
+
|
| 91 |
+
# mimic sklearn output
|
| 92 |
+
index_output = [(train,test) for train,test in zip(train_indices_list,test_indices_list)]
|
| 93 |
+
|
| 94 |
+
self.n_splits = len(index_output)
|
| 95 |
+
|
| 96 |
+
return index_output
|
| 97 |
+
|
| 98 |
+
|
| 99 |
+
def get_n_splits(self):
|
| 100 |
+
"""Returns the number of splitting iterations in the cross-validator
|
| 101 |
+
Returns
|
| 102 |
+
-------
|
| 103 |
+
n_splits : int
|
| 104 |
+
Returns the number of splitting iterations in the cross-validator.
|
| 105 |
+
"""
|
| 106 |
+
return self.n_splits
|