Spaces:
Runtime error

Runtime error
Revert "update"
Browse filesThis reverts commit 9735a9a113298ae9a684f187a906816c063807c8.
- .gitattributes +31 -1
- .gitignore +2 -0
- README.md +13 -2
- app.py +28 -12
- data/tokyo_topics.csv +0 -131
- data/topics_tokyo.pickle +0 -0
- data/topics_tokyo_unclean.pickle +0 -0
- models/bertopic_model_tokyo_olympics_tweets_unclean +3 -0
- models/distilbart-mnli-12-1/README.md +59 -0
- models/distilbart-mnli-12-1/config.json +56 -0
- models/distilbart-mnli-12-1/merges.txt +0 -0
- models/distilbart-mnli-12-1/pytorch_model.bin +3 -0
- models/distilbart-mnli-12-1/special_tokens_map.json +1 -0
- models/distilbart-mnli-12-1/tokenizer_config.json +1 -0
- models/distilbart-mnli-12-1/vocab.json +0 -0
- models/distilbert-base-uncased-finetuned-sst-2-english/README.md +31 -0
- models/distilbert-base-uncased-finetuned-sst-2-english/config.json +31 -0
- models/distilbert-base-uncased-finetuned-sst-2-english/map.jpeg +0 -0
- models/distilbert-base-uncased-finetuned-sst-2-english/pytorch_model.bin +3 -0
- models/distilbert-base-uncased-finetuned-sst-2-english/tokenizer_config.json +1 -0
- models/distilbert-base-uncased-finetuned-sst-2-english/vocab.txt +0 -0
.gitattributes
CHANGED
|
@@ -1,2 +1,32 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
models/distilbart-mnli-12-1/pytorch_model.bin filter=lfs diff=lfs merge=lfs -text
|
| 2 |
-
models/distilbert-base-uncased-finetuned-sst-2-english/pytorch_model.bin filter=lfs diff=lfs merge=lfs -text
|
|
|
|
| 1 |
+
*.7z filter=lfs diff=lfs merge=lfs -text
|
| 2 |
+
*.arrow filter=lfs diff=lfs merge=lfs -text
|
| 3 |
+
*.bin filter=lfs diff=lfs merge=lfs -text
|
| 4 |
+
*.bz2 filter=lfs diff=lfs merge=lfs -text
|
| 5 |
+
*.ftz filter=lfs diff=lfs merge=lfs -text
|
| 6 |
+
*.gz filter=lfs diff=lfs merge=lfs -text
|
| 7 |
+
*.h5 filter=lfs diff=lfs merge=lfs -text
|
| 8 |
+
*.joblib filter=lfs diff=lfs merge=lfs -text
|
| 9 |
+
*.lfs.* filter=lfs diff=lfs merge=lfs -text
|
| 10 |
+
*.model filter=lfs diff=lfs merge=lfs -text
|
| 11 |
+
*.msgpack filter=lfs diff=lfs merge=lfs -text
|
| 12 |
+
*.onnx filter=lfs diff=lfs merge=lfs -text
|
| 13 |
+
*.ot filter=lfs diff=lfs merge=lfs -text
|
| 14 |
+
*.parquet filter=lfs diff=lfs merge=lfs -text
|
| 15 |
+
*.pb filter=lfs diff=lfs merge=lfs -text
|
| 16 |
+
*.pt filter=lfs diff=lfs merge=lfs -text
|
| 17 |
+
*.pth filter=lfs diff=lfs merge=lfs -text
|
| 18 |
+
*.rar filter=lfs diff=lfs merge=lfs -text
|
| 19 |
+
saved_model/**/* filter=lfs diff=lfs merge=lfs -text
|
| 20 |
+
*.tar.* filter=lfs diff=lfs merge=lfs -text
|
| 21 |
+
*.tflite filter=lfs diff=lfs merge=lfs -text
|
| 22 |
+
*.tgz filter=lfs diff=lfs merge=lfs -text
|
| 23 |
+
*.wasm filter=lfs diff=lfs merge=lfs -text
|
| 24 |
+
*.xz filter=lfs diff=lfs merge=lfs -text
|
| 25 |
+
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 26 |
+
*.zstandard filter=lfs diff=lfs merge=lfs -text
|
| 27 |
+
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
| 28 |
+
models/bertopic_model_tokyo_olympics_tweets filter=lfs diff=lfs merge=lfs -text
|
| 29 |
+
models/bertopic_model_tokyo_olympics_tweets_unclean filter=lfs diff=lfs merge=lfs -text
|
| 30 |
+
models/distilbart-mnli-12-1/flax_model.msgpack filter=lfs diff=lfs merge=lfs -text
|
| 31 |
models/distilbart-mnli-12-1/pytorch_model.bin filter=lfs diff=lfs merge=lfs -text
|
| 32 |
+
models/distilbert-base-uncased-finetuned-sst-2-english/pytorch_model.bin filter=lfs diff=lfs merge=lfs -text
|
.gitignore
CHANGED
|
@@ -1,5 +1,7 @@
|
|
| 1 |
# custom
|
| 2 |
survey_analytics.ipynb
|
|
|
|
|
|
|
| 3 |
|
| 4 |
# Byte-compiled / optimized / DLL files
|
| 5 |
__pycache__/
|
|
|
|
| 1 |
# custom
|
| 2 |
survey_analytics.ipynb
|
| 3 |
+
embeddings_unclean.pickle
|
| 4 |
+
embeddings.pickle
|
| 5 |
|
| 6 |
# Byte-compiled / optimized / DLL files
|
| 7 |
__pycache__/
|
README.md
CHANGED
|
@@ -1,2 +1,13 @@
|
|
| 1 |
-
|
| 2 |
-
Survey
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
title: Survey Analytics
|
| 3 |
+
emoji: 🐨
|
| 4 |
+
colorFrom: green
|
| 5 |
+
colorTo: indigo
|
| 6 |
+
sdk: streamlit
|
| 7 |
+
sdk_version: 1.10.0
|
| 8 |
+
app_file: app.py
|
| 9 |
+
pinned: false
|
| 10 |
+
license: gpl-3.0
|
| 11 |
+
---
|
| 12 |
+
|
| 13 |
+
Check out the configuration reference at https://huggingface.co/docs/hub/spaces-config-reference
|
app.py
CHANGED
|
@@ -9,7 +9,6 @@ import os
|
|
| 9 |
import matplotlib.pyplot as plt
|
| 10 |
import seaborn as sns
|
| 11 |
import plotly.express as px
|
| 12 |
-
import pickle
|
| 13 |
|
| 14 |
# factor analysis
|
| 15 |
from factor_analyzer import FactorAnalyzer
|
|
@@ -20,6 +19,7 @@ from scipy.stats import zscore
|
|
| 20 |
# nlp
|
| 21 |
from bertopic import BERTopic
|
| 22 |
from transformers import pipeline
|
|
|
|
| 23 |
|
| 24 |
# custom
|
| 25 |
import survey_analytics_library as LIB
|
|
@@ -40,10 +40,16 @@ def read_survey_data():
|
|
| 40 |
data_survey, data_questions = read_survey_data()
|
| 41 |
|
| 42 |
@st.cache
|
| 43 |
-
def
|
| 44 |
tokyo = pd.read_csv(data_path+'tokyo_olympics_tweets.csv')
|
| 45 |
return tokyo
|
| 46 |
-
tokyo =
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 47 |
|
| 48 |
@st.cache(allow_output_mutation=True)
|
| 49 |
def load_bertopic_model():
|
|
@@ -276,9 +282,14 @@ st.write('''
|
|
| 276 |
''')
|
| 277 |
st.write('\n')
|
| 278 |
|
| 279 |
-
#
|
| 280 |
-
|
| 281 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 282 |
st.plotly_chart(fig, use_container_width=True)
|
| 283 |
|
| 284 |
st.write('''
|
|
@@ -300,9 +311,14 @@ labelled_topics = [
|
|
| 300 |
'Vikas Krishan (Indian Boxer)',
|
| 301 |
]
|
| 302 |
|
| 303 |
-
#
|
| 304 |
-
|
| 305 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 306 |
st.plotly_chart(fig, use_container_width=True)
|
| 307 |
|
| 308 |
st.write('''
|
|
@@ -365,7 +381,7 @@ st.write(f'''
|
|
| 365 |
An an example, within the topic of 'Climate Change', we are interested in finance, politics, technology, and wildlife.
|
| 366 |
Using **Zero-shot Classification**, we can classify responses into one of these four categories.
|
| 367 |
As an added bonus, we can also find out how responders feel about the categories using **Sentiment Analysis**.
|
| 368 |
-
We'll use a different set of
|
| 369 |
''')
|
| 370 |
st.write('\n')
|
| 371 |
|
|
@@ -377,12 +393,12 @@ st.dataframe(sentiment_results[['Tweet']])
|
|
| 377 |
def load_transfomer_pipelines():
|
| 378 |
classifier_zero_shot = pipeline(
|
| 379 |
task='zero-shot-classification',
|
| 380 |
-
model='
|
| 381 |
return_all_scores=True
|
| 382 |
)
|
| 383 |
classifier_sentiment = pipeline(
|
| 384 |
task='sentiment-analysis',
|
| 385 |
-
model
|
| 386 |
return_all_scores=True
|
| 387 |
)
|
| 388 |
return classifier_zero_shot, classifier_sentiment
|
|
|
|
| 9 |
import matplotlib.pyplot as plt
|
| 10 |
import seaborn as sns
|
| 11 |
import plotly.express as px
|
|
|
|
| 12 |
|
| 13 |
# factor analysis
|
| 14 |
from factor_analyzer import FactorAnalyzer
|
|
|
|
| 19 |
# nlp
|
| 20 |
from bertopic import BERTopic
|
| 21 |
from transformers import pipeline
|
| 22 |
+
import transformers
|
| 23 |
|
| 24 |
# custom
|
| 25 |
import survey_analytics_library as LIB
|
|
|
|
| 40 |
data_survey, data_questions = read_survey_data()
|
| 41 |
|
| 42 |
@st.cache
|
| 43 |
+
def read_tweet_data():
|
| 44 |
tokyo = pd.read_csv(data_path+'tokyo_olympics_tweets.csv')
|
| 45 |
return tokyo
|
| 46 |
+
tokyo = read_tweet_data()
|
| 47 |
+
|
| 48 |
+
@st.cache(allow_output_mutation=True)
|
| 49 |
+
def load_bertopic_model_unclean():
|
| 50 |
+
topic_model = BERTopic.load(model_path+'bertopic_model_tokyo_olympics_tweets_unclean')
|
| 51 |
+
return topic_model
|
| 52 |
+
topic_model_unclean = load_bertopic_model_unclean()
|
| 53 |
|
| 54 |
@st.cache(allow_output_mutation=True)
|
| 55 |
def load_bertopic_model():
|
|
|
|
| 282 |
''')
|
| 283 |
st.write('\n')
|
| 284 |
|
| 285 |
+
# plot topics using unclean data
|
| 286 |
+
fig = LIB.visualize_barchart_titles(
|
| 287 |
+
topic_model=topic_model_unclean,
|
| 288 |
+
subplot_titles=None,
|
| 289 |
+
n_words=5,
|
| 290 |
+
top_n_topics=8,
|
| 291 |
+
height=300
|
| 292 |
+
)
|
| 293 |
st.plotly_chart(fig, use_container_width=True)
|
| 294 |
|
| 295 |
st.write('''
|
|
|
|
| 311 |
'Vikas Krishan (Indian Boxer)',
|
| 312 |
]
|
| 313 |
|
| 314 |
+
# plot topics using clean data with stopwords removed
|
| 315 |
+
fig = LIB.visualize_barchart_titles(
|
| 316 |
+
topic_model=topic_model,
|
| 317 |
+
subplot_titles=labelled_topics,
|
| 318 |
+
n_words=5,
|
| 319 |
+
top_n_topics=8,
|
| 320 |
+
height=300
|
| 321 |
+
)
|
| 322 |
st.plotly_chart(fig, use_container_width=True)
|
| 323 |
|
| 324 |
st.write('''
|
|
|
|
| 381 |
An an example, within the topic of 'Climate Change', we are interested in finance, politics, technology, and wildlife.
|
| 382 |
Using **Zero-shot Classification**, we can classify responses into one of these four categories.
|
| 383 |
As an added bonus, we can also find out how responders feel about the categories using **Sentiment Analysis**.
|
| 384 |
+
We'll use a different set of 10,000 tweets related to climate change.
|
| 385 |
''')
|
| 386 |
st.write('\n')
|
| 387 |
|
|
|
|
| 393 |
def load_transfomer_pipelines():
|
| 394 |
classifier_zero_shot = pipeline(
|
| 395 |
task='zero-shot-classification',
|
| 396 |
+
model=model_path+'distilbart-mnli-12-1',
|
| 397 |
return_all_scores=True
|
| 398 |
)
|
| 399 |
classifier_sentiment = pipeline(
|
| 400 |
task='sentiment-analysis',
|
| 401 |
+
model=model_path+'distilbert-base-uncased-finetuned-sst-2-english',
|
| 402 |
return_all_scores=True
|
| 403 |
)
|
| 404 |
return classifier_zero_shot, classifier_sentiment
|
data/tokyo_topics.csv
DELETED
|
@@ -1,131 +0,0 @@
|
|
| 1 |
-
Topic,Count,Name
|
| 2 |
-
-1,2624,-1_silver_medal_proud_mirabaichanu
|
| 3 |
-
0,428,0_banda_zambia_barbra_barbra banda
|
| 4 |
-
1,356,1_india_proud_indians_moment
|
| 5 |
-
2,296,2_sutirtha_mukherjee_sutirtha mukherjee_tabletennis
|
| 6 |
-
3,287,3_mirabaichanu hearty_lifting womens_mirabaichanu lifting_hearty congratulations
|
| 7 |
-
4,248,4_race_road_road race_carapaz
|
| 8 |
-
5,210,5_japan_volleyball_venezuela_flag
|
| 9 |
-
6,195,6_kerr_sam_sam kerr_matildas
|
| 10 |
-
7,183,7_vikas_boxing_krishan_vikas krishan
|
| 11 |
-
8,163,8_gymnastics_mens gymnastics_max_whitlock
|
| 12 |
-
9,148,9_tennis_murray_singles_nagal
|
| 13 |
-
10,121,10_bbc_coverage_live_bbcsport
|
| 14 |
-
11,120,11_ina_facebook_action_officialvkyadav
|
| 15 |
-
12,115,12_puneethrajkumar cheer4india_dvitva james_dvitva_james puneethrajkumar
|
| 16 |
-
13,113,13_hockey_south africa_gbhockey_africa
|
| 17 |
-
14,100,14_judo_takato_gold_japans
|
| 18 |
-
15,97,15_chanu_mirabai chanu_chanu wins_mirabai
|
| 19 |
-
16,92,16_swimming_swimming swimming_aquatics_finals
|
| 20 |
-
17,89,17_medal weightlifting_mirabaichanu winning_ace indian_congratulations ace
|
| 21 |
-
18,87,18_q2_canwnt_corner_follow live
|
| 22 |
-
19,85,19_winning medal_indias medal_medal india_medal
|
| 23 |
-
20,84,20_basketball_3x3_3x3 basketball_usa
|
| 24 |
-
21,80,21_butterfly_100m_heat_100m butterfly
|
| 25 |
-
22,78,22_weightlifter_weightlifter mirabai_chanu_mirabai chanu
|
| 26 |
-
23,78,23_kosovo_distria_krasniqi_distria krasniqi
|
| 27 |
-
24,77,24_swevaus_damn_furniture_swevaus fuck
|
| 28 |
-
25,75,25_yulo_carlos_carlos yulo_rings
|
| 29 |
-
26,71,26_ceremony_opening ceremony_opening_drones
|
| 30 |
-
27,69,27_medal ongoing_ongoing_winning indias_indias medal
|
| 31 |
-
28,64,28_teamgb_gb_come_team gb
|
| 32 |
-
29,62,29_sweden_swedes_swevaus_swedish
|
| 33 |
-
30,61,30_sweden_australia_rolfo_fridolina
|
| 34 |
-
31,60,31_japan_britain_great britain_japan great
|
| 35 |
-
32,59,32_rule_remedy_remedy rule_butterfly
|
| 36 |
-
33,55,33_silver medal_winning silver_silver_mirabaichanu winning
|
| 37 |
-
34,52,34_mirabaichanu proud_proud_proud mirabaichanu_mirabaichanu
|
| 38 |
-
35,51,35_chile_canada_beckie_janine
|
| 39 |
-
36,51,36_mediasai_virenrasquinha imrahultrehan_iosindiaoff virenrasquinha_iosindiaoff
|
| 40 |
-
37,49,37_clareburt_lewis_lewis clareburt_kalisz
|
| 41 |
-
38,49,38_dressage_equestrian_horse_equestrian dressage
|
| 42 |
-
39,47,39_mirabaichanu wins_49kg category_category_india snatches
|
| 43 |
-
40,47,40_imrahultrehan congratulations_mirabaichanu mediasai_railminindia_iosindiaoff
|
| 44 |
-
41,47,41_silver medal_tally_silver_medals tally
|
| 45 |
-
42,47,42_penalty_penalty china_ref_referee
|
| 46 |
-
43,45,43_country proud_medal country_country_winning silver
|
| 47 |
-
44,45,44_teammalaysia_teamindia_teamina_congrats teammalaysia
|
| 48 |
-
45,44,45_daddies_badminton_daddies badminton_ina
|
| 49 |
-
46,44,46_chirag_rankireddy_shetty_chirag shetty
|
| 50 |
-
47,44,47_countrys medal_bringing glory_glory medal_countrys
|
| 51 |
-
48,43,48_medals_1001_medals won_1001 1001
|
| 52 |
-
49,43,49_badminton_badmintonmalaysia_ina_wooi yik
|
| 53 |
-
50,42,50_achieving medal_mirabaichanu achieving_achieving_medal india
|
| 54 |
-
51,41,51_badminton_malaysia_double_sokongmalaysia
|
| 55 |
-
52,41,52_sleep_saturday_hours_watch
|
| 56 |
-
53,41,53_cheer4india_teamindia_da boys_teamindia best
|
| 57 |
-
54,40,54_sweaus_sweaus football_swe_aus
|
| 58 |
-
55,40,55_pistol_10m_air pistol_air
|
| 59 |
-
56,39,56_medal weightlifting_winning silver_weightlifting_silver medal
|
| 60 |
-
57,38,57_silver india_silver_india_mirabaichanu silver
|
| 61 |
-
58,37,58_flying start_flying_start huge_huge congratulations
|
| 62 |
-
59,36,59_archery_mixed team_korea_mixed
|
| 63 |
-
60,35,60_covid19_covid_paralympics_test
|
| 64 |
-
61,35,61_athletes_olympians_proud athletes_congratulations joebrier99
|
| 65 |
-
62,35,62_penalty_swevaus_penalty swevaus_swevaus penalty
|
| 66 |
-
63,35,63_pakistan_uae_athletes_afghanistan
|
| 67 |
-
64,34,64_asked_asked happier_india elated_happier start
|
| 68 |
-
65,34,65_smith_brendon_brendon smith_swim
|
| 69 |
-
66,33,66_matildas_sweden_matildas sweden_attacking
|
| 70 |
-
67,32,67_mirabaichanu cheer4india_cheer4india_cheer4india mirabaichanu_mirabaichanu congratulations
|
| 71 |
-
68,32,68_day mirabaichanu_indias 1st_medal day_weightlifting india
|
| 72 |
-
69,31,69_boxing_boxers_welterweights_delante
|
| 73 |
-
70,31,70_loving_let party_officially held_waiting gymnastics
|
| 74 |
-
71,31,71_400m_mens 400m_heat_400
|
| 75 |
-
72,30,72_malaysia_malaysiaboleh_malaysiaboleh congrats_malaysia malaysia
|
| 76 |
-
73,30,73_time india_india clinches_clinches medal_day hearty
|
| 77 |
-
74,30,74_silver medal_medal india_silver_india
|
| 78 |
-
75,30,75_mirabai chanu_mirabai_chanu_saikhom mirabai
|
| 79 |
-
76,30,76_football_womens football_soccer_women
|
| 80 |
-
77,30,77_mcgrail_peter mcgrail_peter_butdee
|
| 81 |
-
78,29,78_display weightlifting_amazing display_absolutely amazing_display
|
| 82 |
-
79,29,79_cheer4india_medal cheer4india_indias mirabaichanu_medal medal
|
| 83 |
-
80,29,80_mirabaichanu teamindia_teamindia_teamindia mirabaichanu_proud teamindia
|
| 84 |
-
81,29,81_spain_waterpolo_water polo_polo
|
| 85 |
-
82,29,82_daddies_daddies daddies_daddies victory_mantap daddies
|
| 86 |
-
83,28,83_pen_pen swevaus_swevaus pen_swevaus
|
| 87 |
-
84,28,84_mirabaichanu mirabaichanu_mirabaichanu_congratulations mirabaichanu_power
|
| 88 |
-
85,27,85_congratulations mirabai_chanu winning_mirabai chanu_49 kg
|
| 89 |
-
86,27,86_silver weightlifting_huge congratulations_huge_winning silver
|
| 90 |
-
87,27,87_qian_yang qian_yang_chinas
|
| 91 |
-
88,27,88_medal womens_category_49kg_winning silver
|
| 92 |
-
89,27,89_potential_massive potential_long term_term quick
|
| 93 |
-
90,26,90_matildas_fark_pen matildas_matildas matildas
|
| 94 |
-
91,26,91_grande_carapaz_hispanos_grande carapaz
|
| 95 |
-
92,25,92_gift selflove_mensfashion_selflove_selfie mensfashion
|
| 96 |
-
93,24,93_matildas_matildas swevaus_swevaus_swevaus matildas
|
| 97 |
-
94,24,94_49_womens 49_49 kgs_kgs
|
| 98 |
-
95,24,95_thematildas_goaustralia_thematildas samkerr1_goaustralia thematildas
|
| 99 |
-
96,23,96_new zealand_zealand_hockey_new
|
| 100 |
-
97,23,97_chanu secured_secured medal_secured_country winning
|
| 101 |
-
98,23,98_weightlifting lets_lets cheer_cheer india_cheer
|
| 102 |
-
99,23,99_raymondcupid kyereminator_kyereminator daterush_watch hisbella4_kyereminator
|
| 103 |
-
100,22,100_mirabaichanu silver_silver_silver mirabaichanu_mam silver
|
| 104 |
-
101,22,101_nigeria_ghana_team_ghanas
|
| 105 |
-
102,22,102_aus_ausvswe_aussies_australia
|
| 106 |
-
103,22,103_winning silver_mirabaichanu winning_weightlifting medal_silver weightlifting
|
| 107 |
-
104,22,104_teamindia 49kg_silver medal_mirabaichanu won_medal radiant
|
| 108 |
-
105,21,105_swimming_bbcsport_bbc_swimming heats
|
| 109 |
-
106,21,106_mirabaichanu weightlifting_weightlifting_india mirabaichanu_india
|
| 110 |
-
107,21,107_mirabaichanu weightlifting_weightlifting_spirits_bow
|
| 111 |
-
108,21,108_history mirabai_teamindia mirabaichanu_chanu won_medal teamindia
|
| 112 |
-
109,21,109_giochiolimpici_forzaazzurri_olimpiadi forzaazzurri_olimpiadi
|
| 113 |
-
110,21,110_handball_portugal_egypt_esp
|
| 114 |
-
111,21,111_seto_daiya_daiya seto_shock
|
| 115 |
-
112,21,112_congratulations mirabai_chanu winning_chanu_mirabai
|
| 116 |
-
113,21,113_brazil_netherlands_netherlands brazil_brazil womens
|
| 117 |
-
114,20,114_mohanlal_mirabaichanu congratulations_mohanlal mirabaichanu_winning indias
|
| 118 |
-
115,20,115_day congratulations_congratulations saikhom_49kg weightlift_weightlift
|
| 119 |
-
116,20,116_saikhom_saikhom mirabai_congratulations saikhom_chanu winning
|
| 120 |
-
117,20,117_dreams_criticism blood_sacrifice_criticism
|
| 121 |
-
118,20,118_peaty_adam_adam peaty_adampeaty
|
| 122 |
-
119,19,119_actor_medal winner_favourite actor_winner mirabaichanu
|
| 123 |
-
120,19,120_peng_ying_chan peng_chan
|
| 124 |
-
121,19,121_taekwondo_jin_barbosa_kurt
|
| 125 |
-
122,18,122_fencing_samele fencing_samele_2nd round
|
| 126 |
-
123,18,123_congratulated winning_mirabaichanu congratulated_congratulated_spoke
|
| 127 |
-
124,18,124_strikes medal_india strikes_strikes_medal 49
|
| 128 |
-
125,17,125_mirabaichanu comes_comes india_mohanlal mirabaichanu_mohanlal
|
| 129 |
-
126,15,126_carrying_moment_proud moment_proud
|
| 130 |
-
127,15,127_cheer4india_country cheer4india_teamindia_medal teamindia
|
| 131 |
-
128,15,128_medal mirabai_kg womens_medal 49_womens weightlifting
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
data/topics_tokyo.pickle
DELETED
|
Binary file (9.44 kB)
|
|
|
data/topics_tokyo_unclean.pickle
DELETED
|
Binary file (9.34 kB)
|
|
|
models/bertopic_model_tokyo_olympics_tweets_unclean
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:0de856ed231c12e7baeaff15eb3159e1a5ef7c5512b459f915f46712f6d203a3
|
| 3 |
+
size 71961846
|
models/distilbart-mnli-12-1/README.md
ADDED
|
@@ -0,0 +1,59 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
datasets:
|
| 3 |
+
- mnli
|
| 4 |
+
tags:
|
| 5 |
+
- distilbart
|
| 6 |
+
- distilbart-mnli
|
| 7 |
+
pipeline_tag: zero-shot-classification
|
| 8 |
+
---
|
| 9 |
+
|
| 10 |
+
# DistilBart-MNLI
|
| 11 |
+
|
| 12 |
+
distilbart-mnli is the distilled version of bart-large-mnli created using the **No Teacher Distillation** technique proposed for BART summarisation by Huggingface, [here](https://github.com/huggingface/transformers/tree/master/examples/seq2seq#distilbart).
|
| 13 |
+
|
| 14 |
+
We just copy alternating layers from `bart-large-mnli` and finetune more on the same data.
|
| 15 |
+
|
| 16 |
+
|
| 17 |
+
| | matched acc | mismatched acc |
|
| 18 |
+
| ------------------------------------------------------------------------------------ | ----------- | -------------- |
|
| 19 |
+
| [bart-large-mnli](https://huggingface.co/facebook/bart-large-mnli) (baseline, 12-12) | 89.9 | 90.01 |
|
| 20 |
+
| [distilbart-mnli-12-1](https://huggingface.co/valhalla/distilbart-mnli-12-1) | 87.08 | 87.5 |
|
| 21 |
+
| [distilbart-mnli-12-3](https://huggingface.co/valhalla/distilbart-mnli-12-3) | 88.1 | 88.19 |
|
| 22 |
+
| [distilbart-mnli-12-6](https://huggingface.co/valhalla/distilbart-mnli-12-6) | 89.19 | 89.01 |
|
| 23 |
+
| [distilbart-mnli-12-9](https://huggingface.co/valhalla/distilbart-mnli-12-9) | 89.56 | 89.52 |
|
| 24 |
+
|
| 25 |
+
|
| 26 |
+
This is a very simple and effective technique, as we can see the performance drop is very little.
|
| 27 |
+
|
| 28 |
+
Detailed performace trade-offs will be posted in this [sheet](https://docs.google.com/spreadsheets/d/1dQeUvAKpScLuhDV1afaPJRRAE55s2LpIzDVA5xfqxvk/edit?usp=sharing).
|
| 29 |
+
|
| 30 |
+
|
| 31 |
+
## Fine-tuning
|
| 32 |
+
If you want to train these models yourself, clone the [distillbart-mnli repo](https://github.com/patil-suraj/distillbart-mnli) and follow the steps below
|
| 33 |
+
|
| 34 |
+
Clone and install transformers from source
|
| 35 |
+
```bash
|
| 36 |
+
git clone https://github.com/huggingface/transformers.git
|
| 37 |
+
pip install -qqq -U ./transformers
|
| 38 |
+
```
|
| 39 |
+
|
| 40 |
+
Download MNLI data
|
| 41 |
+
```bash
|
| 42 |
+
python transformers/utils/download_glue_data.py --data_dir glue_data --tasks MNLI
|
| 43 |
+
```
|
| 44 |
+
|
| 45 |
+
Create student model
|
| 46 |
+
```bash
|
| 47 |
+
python create_student.py \
|
| 48 |
+
--teacher_model_name_or_path facebook/bart-large-mnli \
|
| 49 |
+
--student_encoder_layers 12 \
|
| 50 |
+
--student_decoder_layers 6 \
|
| 51 |
+
--save_path student-bart-mnli-12-6 \
|
| 52 |
+
```
|
| 53 |
+
|
| 54 |
+
Start fine-tuning
|
| 55 |
+
```bash
|
| 56 |
+
python run_glue.py args.json
|
| 57 |
+
```
|
| 58 |
+
|
| 59 |
+
You can find the logs of these trained models in this [wandb project](https://wandb.ai/psuraj/distilbart-mnli).
|
models/distilbart-mnli-12-1/config.json
ADDED
|
@@ -0,0 +1,56 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"_num_labels": 3,
|
| 3 |
+
"activation_dropout": 0.0,
|
| 4 |
+
"activation_function": "gelu",
|
| 5 |
+
"add_bias_logits": false,
|
| 6 |
+
"add_final_layer_norm": false,
|
| 7 |
+
"architectures": [
|
| 8 |
+
"BartForSequenceClassification"
|
| 9 |
+
],
|
| 10 |
+
"attention_dropout": 0.1,
|
| 11 |
+
"bos_token_id": 0,
|
| 12 |
+
"classif_dropout": 0.0,
|
| 13 |
+
"classifier_dropout": 0.0,
|
| 14 |
+
"d_model": 1024,
|
| 15 |
+
"decoder_attention_heads": 16,
|
| 16 |
+
"decoder_ffn_dim": 4096,
|
| 17 |
+
"decoder_layerdrop": 0.0,
|
| 18 |
+
"decoder_layers": 1,
|
| 19 |
+
"decoder_start_token_id": 2,
|
| 20 |
+
"dropout": 0.1,
|
| 21 |
+
"encoder_attention_heads": 16,
|
| 22 |
+
"encoder_ffn_dim": 4096,
|
| 23 |
+
"encoder_layerdrop": 0.0,
|
| 24 |
+
"encoder_layers": 12,
|
| 25 |
+
"eos_token_id": 2,
|
| 26 |
+
"extra_pos_embeddings": 2,
|
| 27 |
+
"finetuning_task": "mnli",
|
| 28 |
+
"force_bos_token_to_be_generated": false,
|
| 29 |
+
"forced_eos_token_id": 2,
|
| 30 |
+
"gradient_checkpointing": false,
|
| 31 |
+
"id2label": {
|
| 32 |
+
"0": "contradiction",
|
| 33 |
+
"1": "neutral",
|
| 34 |
+
"2": "entailment"
|
| 35 |
+
},
|
| 36 |
+
"init_std": 0.02,
|
| 37 |
+
"is_encoder_decoder": true,
|
| 38 |
+
"label2id": {
|
| 39 |
+
"contradiction": 0,
|
| 40 |
+
"entailment": 2,
|
| 41 |
+
"neutral": 1
|
| 42 |
+
},
|
| 43 |
+
"max_position_embeddings": 1024,
|
| 44 |
+
"model_type": "bart",
|
| 45 |
+
"normalize_before": false,
|
| 46 |
+
"normalize_embedding": true,
|
| 47 |
+
"num_hidden_layers": 12,
|
| 48 |
+
"output_past": false,
|
| 49 |
+
"pad_token_id": 1,
|
| 50 |
+
"scale_embedding": false,
|
| 51 |
+
"static_position_embeddings": false,
|
| 52 |
+
"total_flos": 153130534133111808,
|
| 53 |
+
"transformers_version": "4.7.0.dev0",
|
| 54 |
+
"use_cache": true,
|
| 55 |
+
"vocab_size": 50265
|
| 56 |
+
}
|
models/distilbart-mnli-12-1/merges.txt
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
models/distilbart-mnli-12-1/pytorch_model.bin
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:aa79ff59084a5036b07a9cffeaa1b1b7c1aa5edeb1885416a734c001a09aa046
|
| 3 |
+
size 890410947
|
models/distilbart-mnli-12-1/special_tokens_map.json
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
{"bos_token": {"content": "<s>", "single_word": false, "lstrip": false, "rstrip": false, "normalized": true}, "eos_token": {"content": "</s>", "single_word": false, "lstrip": false, "rstrip": false, "normalized": true}, "unk_token": {"content": "<unk>", "single_word": false, "lstrip": false, "rstrip": false, "normalized": true}, "sep_token": {"content": "</s>", "single_word": false, "lstrip": false, "rstrip": false, "normalized": true}, "pad_token": {"content": "<pad>", "single_word": false, "lstrip": false, "rstrip": false, "normalized": true}, "cls_token": {"content": "<s>", "single_word": false, "lstrip": false, "rstrip": false, "normalized": true}, "mask_token": {"content": "<mask>", "single_word": false, "lstrip": true, "rstrip": false, "normalized": true}}
|
models/distilbart-mnli-12-1/tokenizer_config.json
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
{"model_max_length": 1024}
|
models/distilbart-mnli-12-1/vocab.json
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
models/distilbert-base-uncased-finetuned-sst-2-english/README.md
ADDED
|
@@ -0,0 +1,31 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
language: en
|
| 3 |
+
license: apache-2.0
|
| 4 |
+
datasets:
|
| 5 |
+
- sst-2
|
| 6 |
+
---
|
| 7 |
+
|
| 8 |
+
# DistilBERT base uncased finetuned SST-2
|
| 9 |
+
|
| 10 |
+
This model is a fine-tune checkpoint of [DistilBERT-base-uncased](https://huggingface.co/distilbert-base-uncased), fine-tuned on SST-2.
|
| 11 |
+
This model reaches an accuracy of 91.3 on the dev set (for comparison, Bert bert-base-uncased version reaches an accuracy of 92.7).
|
| 12 |
+
|
| 13 |
+
For more details about DistilBERT, we encourage users to check out [this model card](https://huggingface.co/distilbert-base-uncased).
|
| 14 |
+
|
| 15 |
+
# Fine-tuning hyper-parameters
|
| 16 |
+
|
| 17 |
+
- learning_rate = 1e-5
|
| 18 |
+
- batch_size = 32
|
| 19 |
+
- warmup = 600
|
| 20 |
+
- max_seq_length = 128
|
| 21 |
+
- num_train_epochs = 3.0
|
| 22 |
+
|
| 23 |
+
# Bias
|
| 24 |
+
|
| 25 |
+
Based on a few experimentations, we observed that this model could produce biased predictions that target underrepresented populations.
|
| 26 |
+
|
| 27 |
+
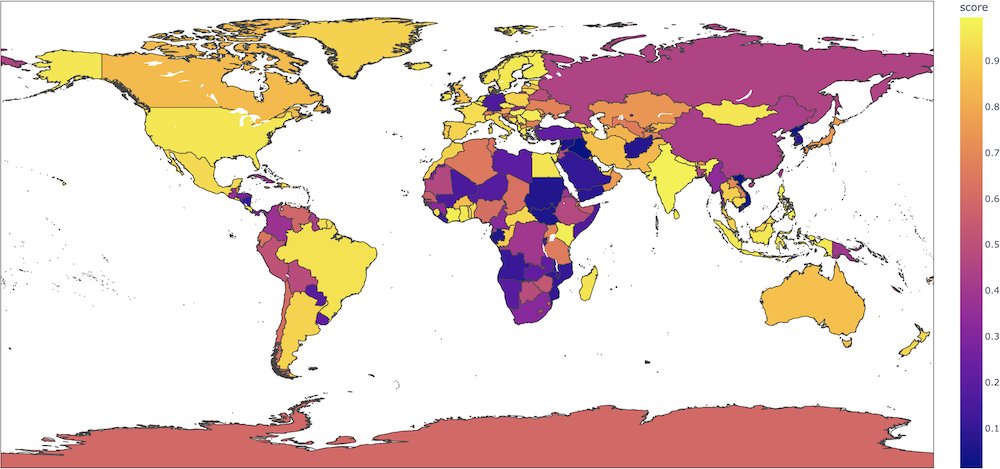
For instance, for sentences like `This film was filmed in COUNTRY`, this binary classification model will give radically different probabilities for the positive label depending on the country (0.89 if the country is France, but 0.08 if the country is Afghanistan) when nothing in the input indicates such a strong semantic shift. In this [colab](https://colab.research.google.com/gist/ageron/fb2f64fb145b4bc7c49efc97e5f114d3/biasmap.ipynb), [Aurélien Géron](https://twitter.com/aureliengeron) made an interesting map plotting these probabilities for each country.
|
| 28 |
+
|
| 29 |
+
<img src="https://huggingface.co/distilbert-base-uncased-finetuned-sst-2-english/resolve/main/map.jpeg" alt="Map of positive probabilities per country." width="500"/>
|
| 30 |
+
|
| 31 |
+
We strongly advise users to thoroughly probe these aspects on their use-cases in order to evaluate the risks of this model. We recommend looking at the following bias evaluation datasets as a place to start: [WinoBias](https://huggingface.co/datasets/wino_bias), [WinoGender](https://huggingface.co/datasets/super_glue), [Stereoset](https://huggingface.co/datasets/stereoset).
|
models/distilbert-base-uncased-finetuned-sst-2-english/config.json
ADDED
|
@@ -0,0 +1,31 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"activation": "gelu",
|
| 3 |
+
"architectures": [
|
| 4 |
+
"DistilBertForSequenceClassification"
|
| 5 |
+
],
|
| 6 |
+
"attention_dropout": 0.1,
|
| 7 |
+
"dim": 768,
|
| 8 |
+
"dropout": 0.1,
|
| 9 |
+
"finetuning_task": "sst-2",
|
| 10 |
+
"hidden_dim": 3072,
|
| 11 |
+
"id2label": {
|
| 12 |
+
"0": "NEGATIVE",
|
| 13 |
+
"1": "POSITIVE"
|
| 14 |
+
},
|
| 15 |
+
"initializer_range": 0.02,
|
| 16 |
+
"label2id": {
|
| 17 |
+
"NEGATIVE": 0,
|
| 18 |
+
"POSITIVE": 1
|
| 19 |
+
},
|
| 20 |
+
"max_position_embeddings": 512,
|
| 21 |
+
"model_type": "distilbert",
|
| 22 |
+
"n_heads": 12,
|
| 23 |
+
"n_layers": 6,
|
| 24 |
+
"output_past": true,
|
| 25 |
+
"pad_token_id": 0,
|
| 26 |
+
"qa_dropout": 0.1,
|
| 27 |
+
"seq_classif_dropout": 0.2,
|
| 28 |
+
"sinusoidal_pos_embds": false,
|
| 29 |
+
"tie_weights_": true,
|
| 30 |
+
"vocab_size": 30522
|
| 31 |
+
}
|
models/distilbert-base-uncased-finetuned-sst-2-english/map.jpeg
ADDED
|
models/distilbert-base-uncased-finetuned-sst-2-english/pytorch_model.bin
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:60554cbd7781b09d87f1ececbea8c064b94e49a7f03fd88e8775bfe6cc3d9f88
|
| 3 |
+
size 267844284
|
models/distilbert-base-uncased-finetuned-sst-2-english/tokenizer_config.json
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
{"model_max_length": 512, "do_lower_case": true}
|
models/distilbert-base-uncased-finetuned-sst-2-english/vocab.txt
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|