Spaces:
Runtime error

Runtime error

Commit
•
f82fbe0
1
Parent(s):
7fe8d4e
first draft
Browse files- misc/Multilingual-IC.png +0 -0
- sections/acknowledgements.md +6 -0
- sections/challenges.md +10 -0
- sections/future_scope.md +4 -0
- sections/intro.md +6 -0
- sections/social_impact.md +4 -0
misc/Multilingual-IC.png
ADDED
|
sections/acknowledgements.md
CHANGED
|
@@ -0,0 +1,6 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
## Acknowledgements
|
| 2 |
+
We'd like to thank [Abheesht Sharma](https://huggingface.co/abheesht) for helping in the discussions in the initial phases. [Luke Melas](https://github.com/lukemelas) helped us get the cleaned CC-12M data on our TPU-VMs and we are very grateful to him.
|
| 3 |
+
|
| 4 |
+
This project would not be possible without the help of [Patrick](https://huggingface.co/patrickvonplaten) and [Suraj](https://huggingface.co/valhalla) who met with us and helped us review our approach and guided us throughout the project.
|
| 5 |
+
|
| 6 |
+
Last but not the least, we thank the Google Team for helping answer our queries on the Slack channel, and for providing us TPU-VMs.
|
sections/challenges.md
CHANGED
|
@@ -0,0 +1,10 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
## Challenges and Technical Difficulties
|
| 2 |
+
Training image captioning that too multilingual was a daunting task and we faced challenges at almost every point of this process.
|
| 3 |
+
|
| 4 |
+
- Dataset- Our initial plan was to translate ConceptualCaptions 12M using mTranslate or Yandex but they turned out to be too slow even with multiprocessing. Not having proper translation could lead to poor performance of the trained image-caption model. Then, we translated the whole dataset using MBart50 for all languages which took around 3-4 days. An ideal way would have been to use one model trained on a specific language but at that time no such models were available for specific languages (now Marian is available for the same).
|
| 5 |
+
|
| 6 |
+
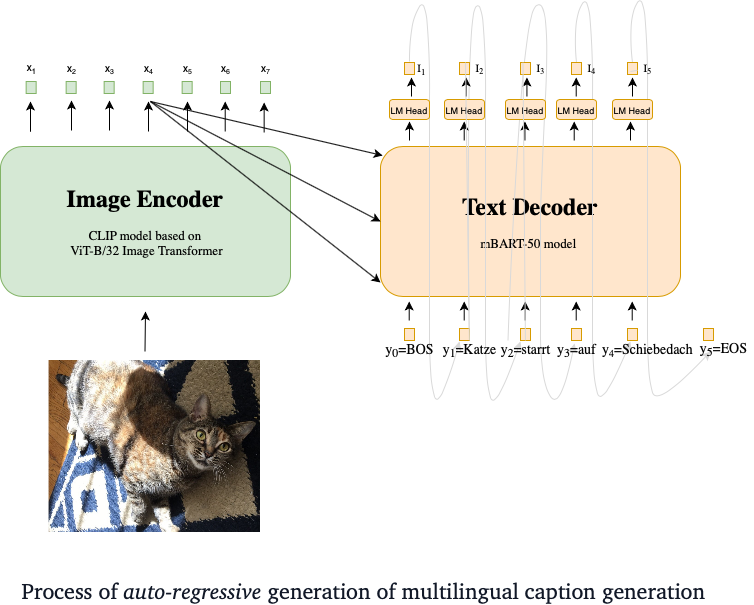
- We prepared the model and config classes for our model from scratch, basing it on `CLIP model based on ViT-B/32 Image Transformer` and `mBART50` implementations in FLAX. The CLIP embeddings were to be used inside the mBART50 embeddings class, which was the major challenge here.
|
| 7 |
+
|
| 8 |
+
- RAM issues- Loading and training 10M image-caption dataset led to huge amount of RAM consumption on TPU (~200GB in the first few steps) because of which we had to optimize the script, use less data, and use less `num_workers` in order to avoid this issue.
|
| 9 |
+
|
| 10 |
+
- We were only able to get around 2 days of training time on TPUs due to aformentioned challenges. We were unable to perform hyperparameter tuning. Our [loss curves on the pre-training model](https://huggingface.co/flax-community/multilingual-image-captioning-5M/tensorboard) show that the training hasn't converged, and we could see further improvement in the loss.
|
sections/future_scope.md
ADDED
|
@@ -0,0 +1,4 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Future scope of work
|
| 2 |
+
We hope to improve this in the future by using:
|
| 3 |
+
- Better translating options. Better translators (for e.g. Google Translate API, Large pre-trained seq2seq models for translation) to get more multilingual data, especially in low-resource languages.
|
| 4 |
+
- More training time: We found that training image captioning model for a single model takes a lot of compute time and if we want
|
sections/intro.md
ADDED
|
@@ -0,0 +1,6 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
|
| 2 |
+
This demo uses [CLIP-mBART50 model checkpoint](https://huggingface.co/flax-community/multilingual-image-captioning-5M/) to predict caption for a given image in 4 languages (English, French, German, Spanish). Training was done using image encoder and text decoder with approximately 5 million image-text pairs taken from the [Conceptual 12M dataset](https://github.com/google-research-datasets/conceptual-12m) translated using [MBart](https://huggingface.co/transformers/model_doc/mbart.html).
|
| 3 |
+
|
| 4 |
+
The model predicts one out of 3129 classes in English which can be found [here](https://huggingface.co/spaces/flax-community/Multilingual-VQA/blob/main/answer_reverse_mapping.json), and then the translated versions are provided based on the language chosen as `Answer Language`. The question can be present or written in any of the following: English, French, German and Spanish.
|
| 5 |
+
|
| 6 |
+
For more details, click on `Usage` or `Article` 🤗 below.
|
sections/social_impact.md
CHANGED
|
@@ -0,0 +1,4 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
## Social Impact
|
| 2 |
+
Being able to automatically describe the content of an image using properly formed sentences in any language is a challenging task, but it could have great impact by helping visually impaired people better understand their surroundings.
|
| 3 |
+
|
| 4 |
+
Our plan was to include 4 high-resource and 4 low-resource languages (Marathi, Bengali, Urdu, Telegu) in our training data. However, the existing translations do not perform as well and we would have received poor labels, not to mention, with a longer training time. We strongly believe that there should be no barriers in accessing
|