
Flavio de Oliveira
commited on
Commit
•
e411600
1
Parent(s):
db11cde
First commit
Browse files- .gitignore +6 -0
- README.md +2 -2
- app.py +224 -0
- assets/bullinger-digital.png +0 -0
- assets/uzh_logo.png +0 -0
- examples/6_00_r1l2.png +0 -0
- examples/6_00_r1l2.txt +1 -0
- examples/6_00_r1l4.png +0 -0
- examples/6_00_r1l4.txt +1 -0
- examples/6_00_r1l44.png +0 -0
- examples/6_00_r1l44.txt +1 -0
- examples/7_00_r1l5.png +0 -0
- examples/7_00_r1l5.txt +1 -0
- icon.png +0 -0
- requirements.txt +7 -0
.gitignore
ADDED
|
@@ -0,0 +1,6 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
__pycache__
|
| 2 |
+
.DS_Store
|
| 3 |
+
flagged/
|
| 4 |
+
tests/
|
| 5 |
+
*.yml
|
| 6 |
+
*.ipynb
|
README.md
CHANGED
|
@@ -1,6 +1,6 @@
|
|
| 1 |
---
|
| 2 |
-
title:
|
| 3 |
-
emoji:
|
| 4 |
colorFrom: indigo
|
| 5 |
colorTo: gray
|
| 6 |
sdk: gradio
|
|
|
|
| 1 |
---
|
| 2 |
+
title: TrOCR Bullinger HTR
|
| 3 |
+
emoji: ✍️
|
| 4 |
colorFrom: indigo
|
| 5 |
colorTo: gray
|
| 6 |
sdk: gradio
|
app.py
ADDED
|
@@ -0,0 +1,224 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import gradio as gr
|
| 2 |
+
import os
|
| 3 |
+
from PIL import Image
|
| 4 |
+
from transformers import TrOCRProcessor, VisionEncoderDecoderModel, AutoImageProcessor
|
| 5 |
+
# import utils
|
| 6 |
+
import base64
|
| 7 |
+
# from datasets import load_metric
|
| 8 |
+
import evaluate
|
| 9 |
+
import logging
|
| 10 |
+
|
| 11 |
+
# Only show log messages that are at the ERROR level or above, effectively filtering out any warnings
|
| 12 |
+
logging.getLogger('transformers').setLevel(logging.ERROR)
|
| 13 |
+
|
| 14 |
+
processor = TrOCRProcessor.from_pretrained("microsoft/trocr-base-handwritten")
|
| 15 |
+
image_processor = AutoImageProcessor.from_pretrained("pstroe/bullinger-general-model")
|
| 16 |
+
model = VisionEncoderDecoderModel.from_pretrained("pstroe/bullinger-general-model")
|
| 17 |
+
|
| 18 |
+
# Create examples
|
| 19 |
+
# Get images and respective transcriptions from the examples directory
|
| 20 |
+
def get_example_data(folder_path="./examples/"):
|
| 21 |
+
|
| 22 |
+
example_data = []
|
| 23 |
+
|
| 24 |
+
# Get list of all files in the folder
|
| 25 |
+
all_files = os.listdir(folder_path)
|
| 26 |
+
|
| 27 |
+
# Loop through the file list
|
| 28 |
+
for file_name in all_files:
|
| 29 |
+
|
| 30 |
+
file_path = os.path.join(folder_path, file_name)
|
| 31 |
+
|
| 32 |
+
# Check if the file is an image (.png)
|
| 33 |
+
if file_name.endswith(".png"):
|
| 34 |
+
|
| 35 |
+
# Construct the corresponding .txt filename (same name)
|
| 36 |
+
corresponding_text_file_name = file_name.replace(".png", ".txt")
|
| 37 |
+
corresponding_text_file_path = os.path.join(folder_path, corresponding_text_file_name)
|
| 38 |
+
|
| 39 |
+
# Initialize to a default value
|
| 40 |
+
transcription = "Transcription not found."
|
| 41 |
+
|
| 42 |
+
# Try to read the content from the .txt file
|
| 43 |
+
try:
|
| 44 |
+
with open(corresponding_text_file_path, "r") as f:
|
| 45 |
+
transcription = f.read().strip()
|
| 46 |
+
except FileNotFoundError:
|
| 47 |
+
pass # If the corresponding .txt file is not found, leave the default value
|
| 48 |
+
|
| 49 |
+
example_data.append([file_path, transcription])
|
| 50 |
+
|
| 51 |
+
return example_data
|
| 52 |
+
|
| 53 |
+
# From pstroe's script
|
| 54 |
+
# def compute_metrics(pred):
|
| 55 |
+
|
| 56 |
+
# labels_ids = pred.label_ids
|
| 57 |
+
# pred_ids = pred.predictions
|
| 58 |
+
|
| 59 |
+
# pred_str = processor.batch_decode(pred_ids, skip_special_tokens=True)
|
| 60 |
+
# labels_ids[labels_ids == -100] = processor.tokenizer.pad_token_id
|
| 61 |
+
# label_str = processor.batch_decode(labels_ids, skip_special_tokens=True)
|
| 62 |
+
|
| 63 |
+
# cer = cer_metric.compute(predictions=pred_str, references=label_str)
|
| 64 |
+
|
| 65 |
+
# return {"cer": cer}
|
| 66 |
+
|
| 67 |
+
def process_image(image, ground_truth):
|
| 68 |
+
|
| 69 |
+
cer = None
|
| 70 |
+
|
| 71 |
+
# prepare image
|
| 72 |
+
pixel_values = image_processor(image, return_tensors="pt").pixel_values
|
| 73 |
+
|
| 74 |
+
# generate (no beam search)
|
| 75 |
+
generated_ids = model.generate(pixel_values)
|
| 76 |
+
|
| 77 |
+
# decode
|
| 78 |
+
generated_text = processor.batch_decode(generated_ids, skip_special_tokens=True)[0]
|
| 79 |
+
|
| 80 |
+
if ground_truth is not None and ground_truth.strip() != "":
|
| 81 |
+
|
| 82 |
+
# Debug: Print lengths before computing metric
|
| 83 |
+
print("Number of predictions:", len(generated_text))
|
| 84 |
+
print("Number of references:", len(ground_truth))
|
| 85 |
+
|
| 86 |
+
# Check if lengths match
|
| 87 |
+
if len(generated_text) != len(ground_truth):
|
| 88 |
+
|
| 89 |
+
print("Mismatch in number of predictions and references.")
|
| 90 |
+
print("Predictions:", generated_text)
|
| 91 |
+
print("References:", ground_truth)
|
| 92 |
+
print("\n")
|
| 93 |
+
|
| 94 |
+
cer = cer_metric.compute(predictions=[generated_text], references=[ground_truth])
|
| 95 |
+
# cer = f"{cer:.3f}"
|
| 96 |
+
|
| 97 |
+
else:
|
| 98 |
+
|
| 99 |
+
cer = "Ground truth not provided"
|
| 100 |
+
|
| 101 |
+
return generated_text, cer
|
| 102 |
+
|
| 103 |
+
# One way to use .svg files
|
| 104 |
+
# logo_url = "https://www.bullinger-digital.ch/bullinger-digital.svg"
|
| 105 |
+
# logo_url = "https://www.cl.uzh.ch/docroot/logos/uzh_logo_e_pos.svg"
|
| 106 |
+
|
| 107 |
+
# header_html = "<img src='data:image/png;base64,{}' class='img-fluid' width='180px'>".format(
|
| 108 |
+
# utils.img_to_bytes(".uzh_logo_e_pos.svg")
|
| 109 |
+
# )
|
| 110 |
+
|
| 111 |
+
# Encode images
|
| 112 |
+
with open("assets/uzh_logo.png", "rb") as img_file:
|
| 113 |
+
logo_html = base64.b64encode(img_file.read()).decode('utf-8')
|
| 114 |
+
|
| 115 |
+
with open("assets/bullinger-digital.png", "rb") as img_file:
|
| 116 |
+
footer_html = base64.b64encode(img_file.read()).decode('utf-8')
|
| 117 |
+
|
| 118 |
+
# App header
|
| 119 |
+
title = """
|
| 120 |
+
<h1 style='text-align: center'> TrOCR: Bullinger Dataset</p>
|
| 121 |
+
"""
|
| 122 |
+
|
| 123 |
+
description = """
|
| 124 |
+
Use of Microsoft's [TrOCR](https://arxiv.org/abs/2109.10282), an encoder-decoder model consisting of an \
|
| 125 |
+
image Transformer encoder and a text Transformer decoder for state-of-the-art optical character recognition \
|
| 126 |
+
(OCR) on single-text line images. \
|
| 127 |
+
This particular model was fine-tuned on [Bullinger Dataset](https://github.com/pstroe/bullinger-htr) \
|
| 128 |
+
as part of the project [Bullinger Digital](https://www.bullinger-digital.ch)
|
| 129 |
+
([References](https://www.cl.uzh.ch/de/people/team/compling/pstroebel.html#Publications)).
|
| 130 |
+
* HF `model card`: [pstroe/bullinger-general-model](https://huggingface.co/pstroe/bullinger-general-model) | \
|
| 131 |
+
[Flexible Techniques for Automatic Text Recognition of Historical Documents](https://doi.org/10.5167/uzh-234886)
|
| 132 |
+
"""
|
| 133 |
+
|
| 134 |
+
# articles = """
|
| 135 |
+
# <p style='text-align: center'><a href='https://arxiv.org/abs/2109.10282'>TrOCR: Transformer-based Optical Character Recognition with Pre-trained Models</a><br>
|
| 136 |
+
# <a href='https://doi.org/10.5167/uzh-234886'>Flexible Techniques for Automatic Text Recognition of Historical Documents</a><br>
|
| 137 |
+
# <a href='https://zenodo.org/record/7715357'>Bullingers Briefwechsel zugänglich machen: Stand der Handschriftenerkennung</a></p>
|
| 138 |
+
# """
|
| 139 |
+
|
| 140 |
+
# Read .png and the respective .txt files
|
| 141 |
+
examples = get_example_data()
|
| 142 |
+
|
| 143 |
+
# load_metric() is deprecated
|
| 144 |
+
# cer_metric = load_metric("cer")
|
| 145 |
+
# pip install evaluate
|
| 146 |
+
cer_metric = evaluate.load("cer")
|
| 147 |
+
|
| 148 |
+
with gr.Blocks(
|
| 149 |
+
theme=gr.themes.Soft(),
|
| 150 |
+
title="TrOCR Bullinger",
|
| 151 |
+
) as demo:
|
| 152 |
+
|
| 153 |
+
gr.HTML(
|
| 154 |
+
f"""
|
| 155 |
+
<div style='display: flex; justify-content: left; width: 100%;'>
|
| 156 |
+
<img src='data:image/png;base64,{logo_html}' class='img-fluid' width='200px'>
|
| 157 |
+
</div>
|
| 158 |
+
"""
|
| 159 |
+
)
|
| 160 |
+
|
| 161 |
+
#174x60
|
| 162 |
+
|
| 163 |
+
title = gr.HTML(title)
|
| 164 |
+
description = gr.Markdown(description)
|
| 165 |
+
|
| 166 |
+
with gr.Row():
|
| 167 |
+
|
| 168 |
+
with gr.Column(variant="panel"):
|
| 169 |
+
|
| 170 |
+
input = gr.components.Image(type="pil", label="Input image:")
|
| 171 |
+
|
| 172 |
+
with gr.Row():
|
| 173 |
+
|
| 174 |
+
btn_clear = gr.Button(value="Clear")
|
| 175 |
+
button = gr.Button(value="Submit")
|
| 176 |
+
|
| 177 |
+
with gr.Column(variant="panel"):
|
| 178 |
+
|
| 179 |
+
output = gr.components.Textbox(label="Generated text:")
|
| 180 |
+
ground_truth = gr.components.Textbox(value="", placeholder="Provide the ground truth, if available.", label="Ground truth:")
|
| 181 |
+
cer_output = gr.components.Textbox(label="CER:")
|
| 182 |
+
|
| 183 |
+
with gr.Row():
|
| 184 |
+
|
| 185 |
+
with gr.Accordion(label="Choose an example from test set:", open=False):
|
| 186 |
+
|
| 187 |
+
gr.Examples(
|
| 188 |
+
examples=examples,
|
| 189 |
+
inputs = [input, ground_truth],
|
| 190 |
+
label=None,
|
| 191 |
+
)
|
| 192 |
+
|
| 193 |
+
with gr.Row():
|
| 194 |
+
|
| 195 |
+
gr.HTML(
|
| 196 |
+
f"""
|
| 197 |
+
<div style="display: flex; align-items: center; justify-content: center">
|
| 198 |
+
<img src="data:image/png;base64,{footer_html}" style="width: 150px; height: 60px; object-fit: contain; margin-right: 5px; margin-bottom: 5px">
|
| 199 |
+
<p style="font-size: 13px">
|
| 200 |
+
| Institut für Computerlinguistik, Universität Zürich, 2023
|
| 201 |
+
</p>
|
| 202 |
+
</div>
|
| 203 |
+
"""
|
| 204 |
+
)
|
| 205 |
+
|
| 206 |
+
#383x85
|
| 207 |
+
|
| 208 |
+
button.click(process_image, inputs=[input, ground_truth], outputs=[output, cer_output])
|
| 209 |
+
btn_clear.click(lambda: [None, "", "", ""], outputs=[input, output, ground_truth, cer_output])
|
| 210 |
+
|
| 211 |
+
# Try to force light mode
|
| 212 |
+
js = """
|
| 213 |
+
function () {
|
| 214 |
+
gradioURL = window.location.href
|
| 215 |
+
if (!gradioURL.endsWith('?__theme=light')) {
|
| 216 |
+
window.location.replace(gradioURL + '?__theme=light');
|
| 217 |
+
}
|
| 218 |
+
}"""
|
| 219 |
+
|
| 220 |
+
demo.load(_js=js)
|
| 221 |
+
|
| 222 |
+
if __name__ == "__main__":
|
| 223 |
+
|
| 224 |
+
demo.launch(favicon_path="icon.png")
|
assets/bullinger-digital.png
ADDED

|
assets/uzh_logo.png
ADDED
|
|
examples/6_00_r1l2.png
ADDED
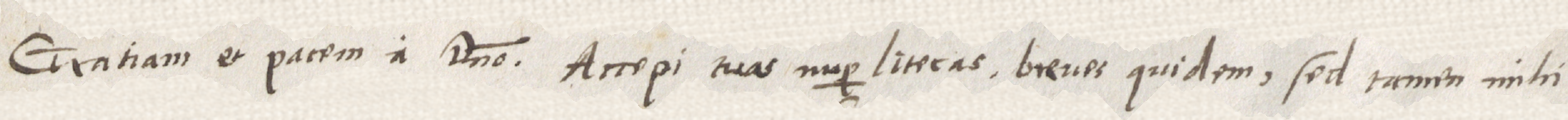
|
examples/6_00_r1l2.txt
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
Gratiam et pacem a domino. Accepi tuas nuper literas, breves quidem, sed tamen mihi
|
examples/6_00_r1l4.png
ADDED

|
examples/6_00_r1l4.txt
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
et recte quidem, ne temere, ad quos legittime sim vocatus, deseram: non equidem
|
examples/6_00_r1l44.png
ADDED

|
examples/6_00_r1l44.txt
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
zuͦ einem zeichen der dankbarkeit; so ich köndte und vermöchte, wolt
|
examples/7_00_r1l5.png
ADDED

|
examples/7_00_r1l5.txt
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
gethon, wytters nichts zugeschriben, an solchem haben
|
icon.png
ADDED
|
|
requirements.txt
ADDED
|
@@ -0,0 +1,7 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
gradio==3.42.0
|
| 2 |
+
torch==2.0.1
|
| 3 |
+
pillow==9.4.0
|
| 4 |
+
transformers==4.33.0
|
| 5 |
+
datasets==2.14.4
|
| 6 |
+
jiwer==3.0.3
|
| 7 |
+
evaluate==0.4.0
|