Spaces:
Runtime error

Runtime error
Submission
Browse files- app.py +10 -0
- churn.csv +0 -0
- churn.png +0 -0
- customer_churn.h5 +3 -0
- eda.py +153 -0
- final_pipeline.pkl +3 -0
- main.py +10 -0
- model.png +0 -0
- prediction.py +97 -0
- requirements.txt +11 -0
app.py
ADDED
|
@@ -0,0 +1,10 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import streamlit as st
|
| 2 |
+
import eda
|
| 3 |
+
import prediction
|
| 4 |
+
|
| 5 |
+
navigation = st.sidebar.selectbox('Choose Page : ', ('EDA', 'Churn Customer Prediction'))
|
| 6 |
+
|
| 7 |
+
if navigation == 'EDA':
|
| 8 |
+
eda.run()
|
| 9 |
+
else:
|
| 10 |
+
prediction.run()
|
churn.csv
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
churn.png
ADDED

|
customer_churn.h5
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:0f48cc86f0c3a4c763f9f92a5c0d7e9af5ecb50fe6567aab95e827ba07b0860f
|
| 3 |
+
size 66352
|
eda.py
ADDED
|
@@ -0,0 +1,153 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import streamlit as st
|
| 2 |
+
import pandas as pd
|
| 3 |
+
import seaborn as sns
|
| 4 |
+
import matplotlib.pyplot as plt
|
| 5 |
+
import plotly.express as px
|
| 6 |
+
from PIL import Image
|
| 7 |
+
|
| 8 |
+
# Melebarkan visualisasi untuk memaksimalkan browser
|
| 9 |
+
st.set_page_config(
|
| 10 |
+
page_title='Churn Customer',
|
| 11 |
+
layout='wide',
|
| 12 |
+
initial_sidebar_state='expanded'
|
| 13 |
+
)
|
| 14 |
+
|
| 15 |
+
def run():
|
| 16 |
+
# Membuat title
|
| 17 |
+
st.title('Churn Customer Prediction')
|
| 18 |
+
st.write('### by Fadya Ulya Salsabila')
|
| 19 |
+
|
| 20 |
+
# Menambahkan Gambar
|
| 21 |
+
image = Image.open('churn.png')
|
| 22 |
+
st.image(image, caption='Illustration of Churn Customer')
|
| 23 |
+
|
| 24 |
+
# Menambahkan Deskripsi
|
| 25 |
+
st.write('## Background')
|
| 26 |
+
st.write("""
|
| 27 |
+
A make-up company "Sister" wants to minimize the risk of a customer stopping using their product.
|
| 28 |
+
The company then analyzes the history of its customers in making purchases based on time and frequency. Then, this company also looks at the feedback that customers have given it.
|
| 29 |
+
This is intended to determine customer predictions whether to stop using their product or not.
|
| 30 |
+
Because if many customers stop, the company will evaluate product sales and marketing to customers. In addition, the company will also provide discounts and special offers to loyal customers.
|
| 31 |
+
|
| 32 |
+
The objectives from this analysis and modeling in this dataset are:
|
| 33 |
+
1. Find out the customer prediction, whether customer churn or not.
|
| 34 |
+
2. Find out the best model prediction using Artificial Neural Network (ANN).""")
|
| 35 |
+
|
| 36 |
+
st.write('## Dataset')
|
| 37 |
+
st.write("""
|
| 38 |
+
The dataset is from Github Milestones 1 Hacktiv8 `churn.csv` that contains 22 columns.
|
| 39 |
+
1. `user_id`: ID of a customer
|
| 40 |
+
2. `age`: Age of a customer
|
| 41 |
+
3. `gender`: Gender of a customer
|
| 42 |
+
4. `region_category`: Region that a customer belongs to
|
| 43 |
+
5. `membership_category`: Category of the membership that a customer is using
|
| 44 |
+
6. `joining_date`: Date when a customer became a member
|
| 45 |
+
7. `joined_through_referral`: Whether a customer joined using any referral code or ID
|
| 46 |
+
8. `preferred_offer_types`: Type of offer that a customer prefers
|
| 47 |
+
9. `medium_of_operation`: Medium of operation that a customer uses for transactions
|
| 48 |
+
10. `internet_option`: Type of internet service a customer uses
|
| 49 |
+
11. `last_visit_time`: The last time a customer visited the website
|
| 50 |
+
12. `days_since_last_login`: Number of days since a customer last logged into the website
|
| 51 |
+
13. `avg_time_spent`: Average time spent by a customer on the website
|
| 52 |
+
14. `avg_transaction_value`: Average transaction value of a customer
|
| 53 |
+
15. `avg_frequency_login_days`: Number of times a customer has logged in to the website
|
| 54 |
+
16. `points_in_wallet`: Points awarded to a customer on each transaction
|
| 55 |
+
17. `used_special_discount`: Whether a customer uses special discounts offered
|
| 56 |
+
18. `offer_application_preference`: Whether a customer prefers offers
|
| 57 |
+
19. `past_complaint`: Whether a customer has raised any complaints
|
| 58 |
+
20. `complaint_status`: Whether the complaints raised by a customer was resolved
|
| 59 |
+
21. `feedback`: Feedback provided by a customer
|
| 60 |
+
22. `churn_risk_score`: Churn score (0 : Not churn, 1 : Churn)""")
|
| 61 |
+
|
| 62 |
+
# Membuat Garis Lurus
|
| 63 |
+
st.markdown('---')
|
| 64 |
+
|
| 65 |
+
# Membuat Sub Headrer
|
| 66 |
+
st.subheader('EDA for Churn Customer')
|
| 67 |
+
|
| 68 |
+
# Magic Syntax
|
| 69 |
+
st.write(
|
| 70 |
+
' On this page, the author will do a simple exploration.'
|
| 71 |
+
' The dataset used is the Churn Custimer dataset.'
|
| 72 |
+
' This dataset comes from Github Project Hacktiv8.')
|
| 73 |
+
|
| 74 |
+
# Show DataFrame
|
| 75 |
+
df1 = pd.read_csv('churn.csv')
|
| 76 |
+
st.dataframe(df1)
|
| 77 |
+
|
| 78 |
+
# Membuat Barplot
|
| 79 |
+
st.write('#### Churn Risk Plot')
|
| 80 |
+
fig = plt.figure(figsize=(10,7))
|
| 81 |
+
sns.countplot(x='churn_risk_score', data=df1, palette="PuRd")
|
| 82 |
+
st.pyplot(fig)
|
| 83 |
+
st.write('The target data is balanced.')
|
| 84 |
+
|
| 85 |
+
st.write('#### Gender Based on Churn Risk')
|
| 86 |
+
fig1, ax1 = plt.subplots(figsize=(15, 8))
|
| 87 |
+
sns.countplot(x='gender', hue='churn_risk_score', data=df1, ax=ax1)
|
| 88 |
+
st.pyplot(fig1)
|
| 89 |
+
st.write('Gender distribution is normal between men and women.')
|
| 90 |
+
|
| 91 |
+
# Mengelompokkan Usia
|
| 92 |
+
bins = [8, 20, 30, 40, 50, 60, 120]
|
| 93 |
+
labels = ['10-19', '20-29', '30-39', '40-49', '50-59', '60-69']
|
| 94 |
+
df1['agerange'] = pd.cut(df1.age, bins, labels = labels,include_lowest = True)
|
| 95 |
+
|
| 96 |
+
# Menampilkan visualisasi usia berdasarkan churn risk
|
| 97 |
+
st.write('#### Age Based on Churn Risk')
|
| 98 |
+
fig2, ax2 = plt.subplots(figsize=(10,7))
|
| 99 |
+
sns.countplot(x='agerange', data=df1, hue="churn_risk_score", ax=ax2)
|
| 100 |
+
st.pyplot(fig2)
|
| 101 |
+
st.write('Customers in this company varies greatly, ranging from 10-64 years old. ')
|
| 102 |
+
|
| 103 |
+
# Membuat heatmap correlation
|
| 104 |
+
st.write('#### Heatmap Correlation')
|
| 105 |
+
fig = plt.figure(figsize = (15,8))
|
| 106 |
+
sns.heatmap(df1.corr(), annot = True, square = True)
|
| 107 |
+
st.pyplot(fig)
|
| 108 |
+
st.write("""
|
| 109 |
+
The heatmap correlation above shows that the column that has a very high relationship with churn risk is the `avg_freqeuncy_login_days` column with score `0.11`. This column shows how many customers log in in a day.
|
| 110 |
+
It means they are still interested in the product in this company. Meanwhile, `avg_transaction_value` have a strong negative correlation with churn risk witn score `-0.22`.
|
| 111 |
+
This shows that the number of purchase transactions on this product has no significant effect on customer churn.""")
|
| 112 |
+
|
| 113 |
+
# Membuat internet option berdasarkan churn risk
|
| 114 |
+
st.write('#### Internet Option Based on Churn Risk')
|
| 115 |
+
fig3, ax3 = plt.subplots(figsize=(10,7))
|
| 116 |
+
sns.countplot(x='internet_option', data=df1, hue="churn_risk_score", ax=ax3, palette="Blues")
|
| 117 |
+
st.pyplot(fig3)
|
| 118 |
+
st.write("""
|
| 119 |
+
Bar plot visualization above, shows that the `internet option` of customers doesn't have a strong correlation with churn risk.
|
| 120 |
+
Distribution of internet option data almost have the same number of values and there is no significant difference.
|
| 121 |
+
Customers who use the internet with Wi-Fi, Fiber Optic, and Mobile Data are almost the same.""")
|
| 122 |
+
|
| 123 |
+
# Membuat region category berdasarkan churn risk
|
| 124 |
+
st.write('#### Region Category Based on Churn Risk')
|
| 125 |
+
fig4, ax4 = plt.subplots(figsize=(10,7))
|
| 126 |
+
sns.countplot(x='region_category', data=df1, hue="churn_risk_score", ax=ax4, palette="Blues")
|
| 127 |
+
st.pyplot(fig4)
|
| 128 |
+
st.write("""
|
| 129 |
+
Based on customer region, there is no significant correlation with churn risk.
|
| 130 |
+
It's just that many customers of this product live in town areas compared to villages and cities.""")
|
| 131 |
+
|
| 132 |
+
# Membuat membership category berdasarkan churn risk
|
| 133 |
+
st.write('#### Membership Category on Churn Risk')
|
| 134 |
+
fig5, ax5 = plt.subplots(figsize=(10,7))
|
| 135 |
+
sns.countplot(y='membership_category', data=df1, hue="churn_risk_score", ax=ax5, palette="Blues")
|
| 136 |
+
st.pyplot(fig5)
|
| 137 |
+
st.write("""
|
| 138 |
+
In `membership_category` column, customers which include in `No Membership` dan `Basic Membership` are customers with the highest churn risk.
|
| 139 |
+
This can happen because the customer is deemed not a loyal customer so the risk of stopping the transaction is high.
|
| 140 |
+
In contrast to silver, premium, gold, and platinum members where customers are considered loyal to product transactions.
|
| 141 |
+
""")
|
| 142 |
+
|
| 143 |
+
# Membuat Histogram Berdasarkan Input User
|
| 144 |
+
st.write('#### Histogram Based On User Input')
|
| 145 |
+
pilihan = st.selectbox('Choose Column : ', ('age', 'gender', 'days_since_last_login', 'avg_time_spent',
|
| 146 |
+
'avg_transaction_value', 'avg_frequency_login_days',
|
| 147 |
+
'points_in_wallet'))
|
| 148 |
+
fig = plt.figure(figsize=(15,5))
|
| 149 |
+
sns.histplot(df1[pilihan], bins=30, kde=True)
|
| 150 |
+
st.pyplot(fig)
|
| 151 |
+
|
| 152 |
+
if __name__ == '__main__':
|
| 153 |
+
run()
|
final_pipeline.pkl
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:9069967f38a72a08cead02e6165a6a92ca62ac04e38e25557416f5b1cdbef61c
|
| 3 |
+
size 3546
|
main.py
ADDED
|
@@ -0,0 +1,10 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import streamlit as st
|
| 2 |
+
import eda
|
| 3 |
+
import prediction
|
| 4 |
+
|
| 5 |
+
navigation = st.sidebar.selectbox('Choose Page : ', ('EDA', 'Churn Customer Prediction'))
|
| 6 |
+
|
| 7 |
+
if navigation == 'EDA':
|
| 8 |
+
eda.run()
|
| 9 |
+
else:
|
| 10 |
+
prediction.run()
|
model.png
ADDED
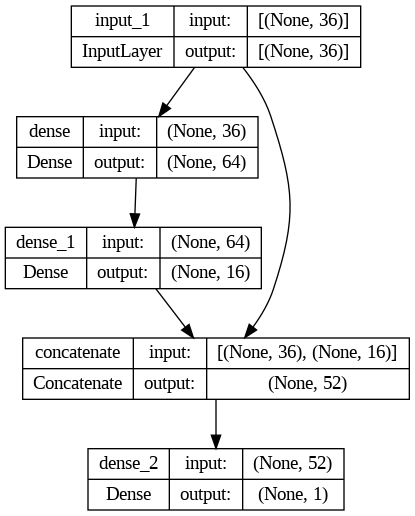
|
prediction.py
ADDED
|
@@ -0,0 +1,97 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import streamlit as st
|
| 2 |
+
import pickle
|
| 3 |
+
from tensorflow.keras.models import load_model
|
| 4 |
+
import pandas as pd
|
| 5 |
+
import numpy as np
|
| 6 |
+
|
| 7 |
+
# Load All Files
|
| 8 |
+
|
| 9 |
+
with open('final_pipeline.pkl', 'rb') as file_1:
|
| 10 |
+
model_pipeline = pickle.load(file_1)
|
| 11 |
+
|
| 12 |
+
model_ann = load_model('customer_churn.h5')
|
| 13 |
+
|
| 14 |
+
def run():
|
| 15 |
+
with st.form(key='Churn_Customer_Prediction'):
|
| 16 |
+
churn_risk_score = st.selectbox('Churn Risk', (0, 1), index=1)
|
| 17 |
+
age = st.number_input('Age', min_value=23, max_value=65, value=23)
|
| 18 |
+
gender = st.selectbox('Gender', ('Male', 'Female'), index=1)
|
| 19 |
+
days_since_last_login = st.number_input('Last Login', min_value=0, max_value=26, value=0)
|
| 20 |
+
avg_time_spent = st.number_input('Avg. Time Spent', min_value=0, max_value=3236, value=0)
|
| 21 |
+
avg_transaction_value = st.number_input('Avg. Transaction Value', min_value=800, max_value=99915, value=29271)
|
| 22 |
+
avg_frequency_login_days = st.number_input('Avg. Frequency Login Days', min_value=0, max_value=73, value=0)
|
| 23 |
+
points_in_wallet = st.number_input('Points in Wallet', min_value=0, max_value=2070, value=0)
|
| 24 |
+
joining_date = st.date_input("Select Join Date")
|
| 25 |
+
last_visit_time = st.time_input('Last Visit Time')
|
| 26 |
+
st.markdown('---')
|
| 27 |
+
|
| 28 |
+
region_category = st.selectbox('Region Category', ('Village', 'Town', 'City'), index=1)
|
| 29 |
+
membership_category = st.selectbox('Membership Category', ('No Membership', 'Basic Membership',
|
| 30 |
+
'Silver Membership', 'Premium Membership',
|
| 31 |
+
'Gold Membership', 'Platinum Membership'), index=1)
|
| 32 |
+
preferred_offer_types = st.selectbox('Preffered Offer', ('Without Offers', 'Credit/Debit Card Offers',
|
| 33 |
+
'Gift Vouchers/Coupons'), index=1)
|
| 34 |
+
medium_of_operation = st.selectbox('Medium Ops', ('Desktop', 'Mobile', 'Both'
|
| 35 |
+
'Gift Vouchers/Coupons'), index=1)
|
| 36 |
+
internet_option = st.selectbox('Internet Ops', ('Wi-Fi', 'Fiber_Optic', 'Mobile-Data'), index=1)
|
| 37 |
+
feedback = st.selectbox('Feedback', ('Poor Website', 'Poor Customer Service', 'Poor Product Quality',
|
| 38 |
+
'Too many ads', 'No reason specified', 'Products always in Stock',
|
| 39 |
+
'Reasonable Price', 'Quality Customer Care', 'User Friendly Website'), index=1)
|
| 40 |
+
complaint_status = st.selectbox('Complaint Status', ('No Information Available', 'Not Aplicable', 'Unsolved',
|
| 41 |
+
'Solved', 'Solved in Follow-up'), index=1)
|
| 42 |
+
|
| 43 |
+
st.markdown('---')
|
| 44 |
+
|
| 45 |
+
joined_through_referral = st.selectbox('Join Through Referral', ('Yes', 'No'), index=1)
|
| 46 |
+
used_special_discount = st.selectbox('Use Special Discount', ('Yes', 'No'), index=1)
|
| 47 |
+
offer_application_preference = st.selectbox('Offer Application Preference', ('Yes', 'No'), index=1)
|
| 48 |
+
past_complaint = st.selectbox('Past Complaint', ('Yes', 'No'), index=1)
|
| 49 |
+
|
| 50 |
+
submitted = st.form_submit_button('Predict')
|
| 51 |
+
|
| 52 |
+
data_inf = {
|
| 53 |
+
'age': age,
|
| 54 |
+
'gender': gender,
|
| 55 |
+
'region_category': region_category,
|
| 56 |
+
'membership_category': membership_category,
|
| 57 |
+
'joining_date': joining_date,
|
| 58 |
+
'joined_through_referral': joined_through_referral,
|
| 59 |
+
'preferred_offer_types': preferred_offer_types,
|
| 60 |
+
'medium_of_operation': medium_of_operation,
|
| 61 |
+
'internet_option': internet_option,
|
| 62 |
+
'last_visit_time': last_visit_time,
|
| 63 |
+
'days_since_last_login': days_since_last_login,
|
| 64 |
+
'avg_time_spent': avg_time_spent,
|
| 65 |
+
'avg_transaction_value': avg_transaction_value,
|
| 66 |
+
'avg_frequency_login_days': avg_frequency_login_days,
|
| 67 |
+
'points_in_wallet': points_in_wallet,
|
| 68 |
+
'used_special_discount': used_special_discount,
|
| 69 |
+
'offer_application_preference': offer_application_preference,
|
| 70 |
+
'past_complaint': past_complaint,
|
| 71 |
+
'complaint_status': complaint_status,
|
| 72 |
+
'feedback': feedback,
|
| 73 |
+
'churn_risk_score': churn_risk_score
|
| 74 |
+
}
|
| 75 |
+
|
| 76 |
+
data_inf = pd.DataFrame([data_inf])
|
| 77 |
+
data_inf_transform = model_pipeline.transform(data_inf)
|
| 78 |
+
|
| 79 |
+
a = st.dataframe(data_inf_transform)
|
| 80 |
+
b = ''
|
| 81 |
+
|
| 82 |
+
if len(data_inf_transform) == 0:
|
| 83 |
+
b = 'Not Churn'
|
| 84 |
+
else:
|
| 85 |
+
# Predict using ANN: Sequential API
|
| 86 |
+
y_pred_inf = model_ann.predict(data_inf_transform)
|
| 87 |
+
y_pred_inf = np.where(y_pred_inf >= 0.5, 1, 0)
|
| 88 |
+
if y_pred_inf == 0:
|
| 89 |
+
b = 'Not Churn'
|
| 90 |
+
else:
|
| 91 |
+
b = 'Churn'
|
| 92 |
+
|
| 93 |
+
if submitted:
|
| 94 |
+
st.write('# Prediction : ', b)
|
| 95 |
+
|
| 96 |
+
if __name__ == '__main__':
|
| 97 |
+
run()
|
requirements.txt
ADDED
|
@@ -0,0 +1,11 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Berisi daftar library yang kita butuhkan
|
| 2 |
+
|
| 3 |
+
streamlit
|
| 4 |
+
pandas
|
| 5 |
+
seaborn
|
| 6 |
+
matplotlib
|
| 7 |
+
numpy
|
| 8 |
+
scikit-learn==1.2.1
|
| 9 |
+
plotly
|
| 10 |
+
tensorflow-cpu==2.12.0
|
| 11 |
+
protobuf==3.20.1
|