Spaces:
Running

Running
Avijit Ghosh
commited on
Commit
•
736eb2a
1
Parent(s):
0cbf125
added files
Browse files- .gitignore +2 -0
- BiasEvals.csv +45 -0
- Images/WEAT1.png +0 -0
- Images/WEAT2.png +0 -0
- app.py +178 -0
- css.py +17 -0
.gitignore
ADDED
|
@@ -0,0 +1,2 @@
|
|
|
|
|
|
|
|
|
|
| 1 |
+
temp/
|
| 2 |
+
.env
|
BiasEvals.csv
ADDED
|
@@ -0,0 +1,45 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
Modality,Suggested Evaluation,What it is evaluating,Considerations,Link,URL
|
| 2 |
+
Text,Word Embedding Association Test (WEAT),Associations and word embeddings based on Implicit Associations Test (IAT),"Although based in human associations, general societal attitudes do not always represent subgroups of people and cultures.",Semantics derived automatically from language corpora contain human-like biases,https://researchportal.bath.ac.uk/en/publications/semantics-derived-automatically-from-language-corpora-necessarily
|
| 3 |
+
Text,"Word Embedding Factual As
|
| 4 |
+
sociation Test (WEFAT)",Associations and word embeddings based on Implicit Associations Test (IAT),"Although based in human associations, general societal attitudes do not always represent subgroups of people and cultures.",Semantics derived automatically from language corpora contain human-like biases,https://researchportal.bath.ac.uk/en/publications/semantics-derived-automatically-from-language-corpora-necessarily
|
| 5 |
+
Text,Sentence Encoder Association Test (SEAT),Associations and word embeddings based on Implicit Associations Test (IAT),"Although based in human associations, general societal attitudes do not always represent subgroups of people and cultures.",[1903.10561] On Measuring Social Biases in Sentence Encoders,https://arxiv.org/abs/1903.10561
|
| 6 |
+
Text,Contextual Word Representation Association Tests for social and intersectional biases,Associations and word embeddings based on Implicit Associations Test (IAT),"Although based in human associations, general societal attitudes do not always represent subgroups of people and cultures.",Assessing social and intersectional biases in contextualized word representations | Proceedings of the 33rd International Conference on Neural Information Processing Systems,https://dl.acm.org/doi/abs/10.5555/3454287.3455472
|
| 7 |
+
Text,StereoSet,Protected class stereotypes,Automating stereotype detection makes distinguishing harmful stereotypes difficult. It also raises many false positives and can flag relatively neutral associations based in fact (e.g. population x has a high proportion of lactose intolerant people).,[2004.09456] StereoSet: Measuring stereotypical bias in pretrained language models,https://arxiv.org/abs/2004.09456
|
| 8 |
+
Text,Crow-S Pairs,Protected class stereotypes,Automating stereotype detection makes distinguishing harmful stereotypes difficult. It also raises many false positives and can flag relatively neutral associations based in fact (e.g. population x has a high proportion of lactose intolerant people).,[2010.00133] CrowS-Pairs: A Challenge Dataset for Measuring Social Biases in Masked Language Models,https://arxiv.org/abs/2010.00133
|
| 9 |
+
Text,HONEST: Measuring Hurtful Sentence Completion in Language Models,Protected class stereotypes and hurtful language,Automating stereotype detection makes distinguishing harmful stereotypes difficult. It also raises many false positives and can flag relatively neutral associations based in fact (e.g. population x has a high proportion of lactose intolerant people).,HONEST: Measuring Hurtful Sentence Completion in Language Models,https://aclanthology.org/2021.naacl-main.191.pdf
|
| 10 |
+
Text,TANGO: Towards Centering Transgender and Non-Binary Voices to Measure Biases in Open Language Generation,"Bias measurement for trans and nonbinary community via measuring gender non-affirmative language, specifically 1) misgendering 2), negative responses to gender disclosure","Based on automatic evaluations of the resulting open language generation, may be sensitive to the choice of evaluator. Would advice for a combination of perspective, detoxify, and regard metrics","Paper
|
| 11 |
+
Dataset",
|
| 12 |
+
Text,BBQ: A hand-built bias benchmark for question answering,Protected class stereotypes,,BBQ: A hand-built bias benchmark for question answering,https://aclanthology.org/2022.findings-acl.165.pdf
|
| 13 |
+
Text,"BBNLI, bias in NLI benchmark",Protected class stereotypes,,On Measuring Social Biases in Prompt-Based Multi-Task Learning,https://aclanthology.org/2022.findings-naacl.42.pdf
|
| 14 |
+
Text,WinoGender,Bias between gender and occupation,,Gender Bias in Coreference Resolution,https://arxiv.org/abs/1804.09301
|
| 15 |
+
Text,WinoQueer,"Bias between gender, sexuality",,Winoqueer,https://arxiv.org/abs/2306.15087
|
| 16 |
+
Text,Level of caricature,,,CoMPosT: Characterizing and Evaluating Caricature in LLM Simulations,https://arxiv.org/abs/2310.11501
|
| 17 |
+
Text,SeeGULL: A Stereotype Benchmark with Broad Geo-Cultural Coverage Leveraging Generative Models,,,[2305.11840] SeeGULL: A Stereotype Benchmark with Broad Geo-Cultural Coverage Leveraging Generative Models,https://arxiv.org/abs/2305.11840
|
| 18 |
+
Text,"Investigating Subtler Biases in LLMs:
|
| 19 |
+
Ageism, Beauty, Institutional, and Nationality Bias in Generative Models",,,https://arxiv.org/abs/2309.08902,https://arxiv.org/abs/2309.08902
|
| 20 |
+
Text,ROBBIE: Robust Bias Evaluation of Large Generative Language Models,,,[2311.18140] ROBBIE: Robust Bias Evaluation of Large Generative Language Models,https://arxiv.org/abs/2311.18140
|
| 21 |
+
Image,Image Embedding Association Test (iEAT),Embedding associations,,"Image Representations Learned With Unsupervised Pre-Training Contain Human-like Biases | Proceedings of the 2021 ACM Conference on Fairness, Accountability, and Transparency",https://dl.acm.org/doi/abs/10.1145/3442188.3445932
|
| 22 |
+
Image,Dataset leakage and model leakage,Gender and label bias,,[1811.08489] Balanced Datasets Are Not Enough: Estimating and Mitigating Gender Bias in Deep Image Representations,https://arxiv.org/abs/1811.08489
|
| 23 |
+
Image,Grounded-WEAT,Joint vision and language embeddings,,Measuring Social Biases in Grounded Vision and Language Embeddings - ACL Anthology,https://aclanthology.org/2021.naacl-main.78/
|
| 24 |
+
Image,Grounded-SEAT,,,,
|
| 25 |
+
Image,CLIP-based evaluation,"Gender and race and class associations with four attribute categories (profession, political, object, and other.)",,DALL-Eval: Probing the Reasoning Skills and Social Biases of Text-to-Image Generative Transformers,https://arxiv.org/abs/2202.04053
|
| 26 |
+
Image,Human evaluation,,,,
|
| 27 |
+
Image,,,,[2108.02818] Evaluating CLIP: Towards Characterization of Broader Capabilities and Downstream Implications,https://arxiv.org/abs/2108.02818
|
| 28 |
+
Image,,,,[2004.07173] Bias in Multimodal AI: Testbed for Fair Automatic Recruitment,https://arxiv.org/abs/2004.07173
|
| 29 |
+
Image,Characterizing the variation in generated images,,,Stable bias: Analyzing societal representations in diffusion models,https://arxiv.org/abs/2303.11408
|
| 30 |
+
Image,Stereotypical representation of professions,,,Editing Implicit Assumptions in Text-to-Image Diffusion Models see section 6,
|
| 31 |
+
Image,Effect of different scripts on text-to-image generation,"It evaluates generated images for cultural stereotypes, when using different scripts (homoglyphs). It somewhat measures the suceptibility of a model to produce cultural stereotypes by simply switching the script",,Exploiting Cultural Biases via Homoglyphs in Text-to-Image Synthesis,https://arxiv.org/pdf/2209.08891.pdf
|
| 32 |
+
Image,Automatic classification of the immorality of images,,,Ensuring Visual Commonsense Morality for Text-to-Image Generation,https://arxiv.org/pdf/2209.08891.pdf
|
| 33 |
+
Image,"ENTIGEN: effect on the
|
| 34 |
+
diversity of the generated images when adding
|
| 35 |
+
ethical intervention",,,"How well can Text-to-Image Generative Models understand Ethical
|
| 36 |
+
Natural Language Interventions?",
|
| 37 |
+
Image,Evaluating text-to-image models for (complex) biases,,,Easily accessible text-to-image generation amplifies demographic stereotypes at large scale,https://dl.acm.org/doi/abs/10.1145/3593013.3594095
|
| 38 |
+
Image,,,,FACET: Fairness in Computer Vision Evaluation Benchmark,https://openaccess.thecvf.com/content/ICCV2023/html/Gustafson_FACET_Fairness_in_Computer_Vision_Evaluation_Benchmark_ICCV_2023_paper.html
|
| 39 |
+
Image,Evaluating text-to-image models for occupation-gender biases from source to output,"Measuring bias from source to output (dataset, model and outcome). Using different prompts to search dataset and to generate images. Evaluate them in turn for stereotypes.","Evaluating for social attributes that one self-identifies for, e.g. gender, is challenging in computer- generated images.",Fair Diffusion: Instructing Text-to-Image Generation Models on Fairness,https://arxiv.org/abs/2302.10893
|
| 40 |
+
Image,Evaluating text-to-image models for gender biases in a multilingual setting,Using different prompts in different languages to generate images and evaluate them in turn for stereotypes.,,Multilingual Text-to-Image Generation Magnifies Gender Stereotypes and Prompt Engineering May Not Help You,
|
| 41 |
+
Image,Evaluating text-to-image models for biases when multiple people are generated,This work focuses on generating images depicting multiple people. This puts the evaluation on a higher level beyond portrait evaluation.,Same as for the other evaluations of social attributes + evaluating for location in image is difficult as the models have no inherent spatial understanding.,The Male CEO and the Female Assistant: Probing Gender Biases in Text-To-Image Models Through Paired Stereotype Test,https://arxiv.org/abs/2402.11089
|
| 42 |
+
Image,Multimodal Composite Association Score: Measuring Gender Bias in Generative Multimodal Models,Measure association between concepts in multi-modal settings (image and text),,,
|
| 43 |
+
Image,VisoGender,"This work measures gender-occupation biases in image-to-text models by evaluating: (1) their ability to correctly resolve the pronouns of individuals in scenes, and (2) the perceived gender of individuals in images retrieved for gender-neutral search queries.",Relies on annotators’ perceptions of binary gender. Could better control for the fact that models generally struggle with captioning any scene that involves interactions between two or more individuals.,VisoGender: A dataset for benchmarking gender bias in image-text pronoun resolution,https://proceedings.neurips.cc/paper_files/paper/2023/hash/c93f26b1381b17693055a611a513f1e9-Abstract-Datasets_and_Benchmarks.html
|
| 44 |
+
Audio,Not My Voice! A Taxonomy of Ethical and Safety Harms of Speech Generators,Lists harms of audio/speech generators,Not necessarily evaluation but a good source of taxonomy. We can use this to point readers towards high-level evaluations,https://arxiv.org/pdf/2402.01708.pdf,https://arxiv.org/pdf/2402.01708.pdf
|
| 45 |
+
Video,Diverse Misinformation: Impacts of Human Biases on Detection of Deepfakes on Networks,Human led evaluations of deepfakes to understand susceptibility and representational harms (including political violence),"Repr. harm, incite violence",https://arxiv.org/abs/2210.10026,https://arxiv.org/abs/2210.10026
|
Images/WEAT1.png
ADDED

|
Images/WEAT2.png
ADDED
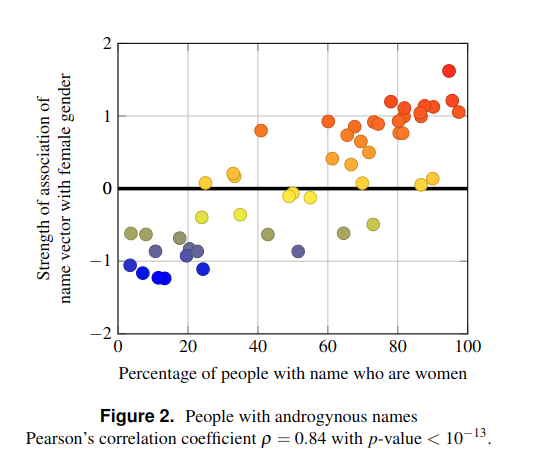
|
app.py
ADDED
|
@@ -0,0 +1,178 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import gradio as gr
|
| 2 |
+
from css import custom_css
|
| 3 |
+
import pandas as pd
|
| 4 |
+
from gradio_modal import Modal
|
| 5 |
+
|
| 6 |
+
|
| 7 |
+
|
| 8 |
+
# create a gradio page with tabs and accordions
|
| 9 |
+
|
| 10 |
+
# Path: taxonomy.py
|
| 11 |
+
|
| 12 |
+
metadatadict = {}
|
| 13 |
+
|
| 14 |
+
def loadtable(path):
|
| 15 |
+
rawdf = pd.read_csv(path)
|
| 16 |
+
for i, row in rawdf.iterrows():
|
| 17 |
+
metadatadict['<u>'+str(row['Link'])+'</u>'] = '['+str(row['Link'])+']('+str(row['URL'])+')'
|
| 18 |
+
#rawdf['Link'] = '['+rawdf['Link']+']('+rawdf['URL']+')'
|
| 19 |
+
rawdf['Link'] = '<u>'+rawdf['Link']+'</u>'
|
| 20 |
+
rawdf = rawdf.drop(columns=['URL'])
|
| 21 |
+
return rawdf
|
| 22 |
+
|
| 23 |
+
def filter_bias_table(fulltable, modality_filter):
|
| 24 |
+
filteredtable = fulltable[fulltable['Modality'].isin(modality_filter)]
|
| 25 |
+
return filteredtable
|
| 26 |
+
|
| 27 |
+
def showmodal(evt: gr.SelectData):
|
| 28 |
+
print(evt.value, evt.index, evt.target)
|
| 29 |
+
modal = Modal(visible=False)
|
| 30 |
+
md = gr.Markdown("")
|
| 31 |
+
if evt.index[1] == 4:
|
| 32 |
+
modal = Modal(visible=True)
|
| 33 |
+
md = gr.Markdown('# '+metadatadict[evt.value])
|
| 34 |
+
return [modal,md]
|
| 35 |
+
|
| 36 |
+
with gr.Blocks(title = "Social Impact Measurement V2", css=custom_css) as demo: #theme=gr.themes.Soft(),
|
| 37 |
+
# create tabs for the app, moving the current table to one titled "rewardbench" and the benchmark_text to a tab called "About"
|
| 38 |
+
with gr.Row():
|
| 39 |
+
gr.Markdown("""
|
| 40 |
+
# Social Impact Measurement
|
| 41 |
+
## A taxonomy of the social impacts of AI models and measurement techniques.
|
| 42 |
+
""")
|
| 43 |
+
with gr.Row():
|
| 44 |
+
gr.Markdown("""
|
| 45 |
+
#### A: Technical Base System Evaluations:
|
| 46 |
+
|
| 47 |
+
Below we list the aspects possible to evaluate in a generative system. Context-absent evaluations only provide narrow insights into the described aspects of the type of generative AI system. The depth of literature and research on evaluations differ by modality with some modalities having sparse or no relevant literature, but the themes for evaluations can be applied to most systems.
|
| 48 |
+
|
| 49 |
+
The following categories are high-level, non-exhaustive, and present a synthesis of the findings across different modalities. They refer solely to what can be evaluated in a base technical system:
|
| 50 |
+
|
| 51 |
+
""")
|
| 52 |
+
with gr.Tabs(elem_classes="tab-buttons") as tabs1:
|
| 53 |
+
with gr.TabItem("Bias/Stereotypes"):
|
| 54 |
+
fulltable = loadtable('BiasEvals.csv')
|
| 55 |
+
gr.Markdown("""
|
| 56 |
+
Generative AI systems can perpetuate harmful biases from various sources, including systemic, human, and statistical biases. These biases, also known as "fairness" considerations, can manifest in the final system due to choices made throughout the development process. They include harmful associations and stereotypes related to protected classes, such as race, gender, and sexuality. Evaluating biases involves assessing correlations, co-occurrences, sentiment, and toxicity across different modalities, both within the model itself and in the outputs of downstream tasks.
|
| 57 |
+
""")
|
| 58 |
+
with gr.Row():
|
| 59 |
+
modality_filter = gr.CheckboxGroup(["Text", "Image", "Audio", "Video"],
|
| 60 |
+
value=["Text", "Image", "Audio", "Video"],
|
| 61 |
+
label="Modality",
|
| 62 |
+
show_label=True,
|
| 63 |
+
# info="Which modality to show."
|
| 64 |
+
)
|
| 65 |
+
with gr.Row():
|
| 66 |
+
biastable_full = gr.DataFrame(value=fulltable, wrap=True, datatype="markdown", visible=False)
|
| 67 |
+
biastable_filtered = gr.DataFrame(value=fulltable, wrap=True, datatype="markdown", visible=True)
|
| 68 |
+
modality_filter.change(filter_bias_table, inputs=[biastable_full, modality_filter], outputs=biastable_filtered)
|
| 69 |
+
with Modal(visible=False) as modal:
|
| 70 |
+
md = gr.Markdown("Test 1")
|
| 71 |
+
gr.Markdown('### Aylin Caliskan, Joanna J. Bryson, and Arvind Narayanan')
|
| 72 |
+
tags = ['Bias', 'Word Association', 'Embedding', 'NLP']
|
| 73 |
+
tagmd = ''
|
| 74 |
+
for tag in tags:
|
| 75 |
+
tagmd += '<span class="tag">#'+tag+'</span> '
|
| 76 |
+
gr.Markdown(tagmd)
|
| 77 |
+
gr.Markdown('''
|
| 78 |
+
Artificial intelligence and machine learning are in a period of astounding growth. However, there are concerns that these
|
| 79 |
+
technologies may be used, either with or without intention, to perpetuate the prejudice and unfairness that unfortunately
|
| 80 |
+
characterizes many human institutions. Here we show for the first time that human-like semantic biases result from the
|
| 81 |
+
application of standard machine learning to ordinary language—the same sort of language humans are exposed to every
|
| 82 |
+
day. We replicate a spectrum of standard human biases as exposed by the Implicit Association Test and other well-known
|
| 83 |
+
psychological studies. We replicate these using a widely used, purely statistical machine-learning model—namely, the GloVe
|
| 84 |
+
word embedding—trained on a corpus of text from the Web. Our results indicate that language itself contains recoverable and
|
| 85 |
+
accurate imprints of our historic biases, whether these are morally neutral as towards insects or flowers, problematic as towards
|
| 86 |
+
race or gender, or even simply veridical, reflecting the status quo for the distribution of gender with respect to careers or first
|
| 87 |
+
names. These regularities are captured by machine learning along with the rest of semantics. In addition to our empirical
|
| 88 |
+
findings concerning language, we also contribute new methods for evaluating bias in text, the Word Embedding Association
|
| 89 |
+
Test (WEAT) and the Word Embedding Factual Association Test (WEFAT). Our results have implications not only for AI and
|
| 90 |
+
machine learning, but also for the fields of psychology, sociology, and human ethics, since they raise the possibility that mere
|
| 91 |
+
exposure to everyday language can account for the biases we replicate here.
|
| 92 |
+
''')
|
| 93 |
+
gr.Gallery(['Images/WEAT1.png', 'Images/WEAT2.png'])
|
| 94 |
+
biastable_filtered.select(showmodal, None, [modal,md])
|
| 95 |
+
|
| 96 |
+
|
| 97 |
+
|
| 98 |
+
with gr.TabItem("Cultural Values/Sensitive Content"):
|
| 99 |
+
with gr.Row():
|
| 100 |
+
gr.Image()
|
| 101 |
+
|
| 102 |
+
with gr.TabItem("Disparate Performance"):
|
| 103 |
+
with gr.Row():
|
| 104 |
+
gr.Image()
|
| 105 |
+
|
| 106 |
+
with gr.TabItem("Privacy/Data Protection"):
|
| 107 |
+
with gr.Row():
|
| 108 |
+
gr.Image()
|
| 109 |
+
|
| 110 |
+
with gr.TabItem("Financial Costs"):
|
| 111 |
+
with gr.Row():
|
| 112 |
+
gr.Image()
|
| 113 |
+
|
| 114 |
+
with gr.TabItem("Environmental Costs"):
|
| 115 |
+
with gr.Row():
|
| 116 |
+
gr.Image()
|
| 117 |
+
|
| 118 |
+
with gr.TabItem("Data and Content Moderation Labor"):
|
| 119 |
+
with gr.Row():
|
| 120 |
+
gr.Image()
|
| 121 |
+
|
| 122 |
+
with gr.Row():
|
| 123 |
+
gr.Markdown("""
|
| 124 |
+
#### B: People and Society Impact Evaluations:
|
| 125 |
+
|
| 126 |
+
Long-term effects of systems embedded in society, such as economic or labor impact, largely require ideation of generative AI systems’ possible use cases and have fewer available general evaluations. The following categories heavily depend on how generative AI systems are deployed, including sector and application. In the broader ecosystem, methods of deployment affect social impact.
|
| 127 |
+
|
| 128 |
+
The following categories are high-level, non-exhaustive, and present a synthesis of the findings across different modalities. They refer solely to what can be evaluated in people and society:
|
| 129 |
+
""")
|
| 130 |
+
|
| 131 |
+
with gr.Tabs(elem_classes="tab-buttons") as tabs2:
|
| 132 |
+
with gr.TabItem("Trustworthiness and Autonomy"):
|
| 133 |
+
with gr.Accordion("Trust in Media and Information", open=False):
|
| 134 |
+
gr.Image()
|
| 135 |
+
with gr.Accordion("Overreliance on Outputs", open=False):
|
| 136 |
+
gr.Image()
|
| 137 |
+
with gr.Accordion("Personal Privacy and Sense of Self", open=False):
|
| 138 |
+
gr.Image()
|
| 139 |
+
|
| 140 |
+
with gr.TabItem("Inequality, Marginalization, and Violence"):
|
| 141 |
+
with gr.Accordion("Community Erasure", open=False):
|
| 142 |
+
gr.Image()
|
| 143 |
+
with gr.Accordion("Long-term Amplifying Marginalization by Exclusion (and Inclusion)", open=False):
|
| 144 |
+
gr.Image()
|
| 145 |
+
with gr.Accordion("Abusive or Violent Content", open=False):
|
| 146 |
+
gr.Image()
|
| 147 |
+
|
| 148 |
+
with gr.TabItem("Concentration of Authority"):
|
| 149 |
+
with gr.Accordion("Militarization, Surveillance, and Weaponization", open=False):
|
| 150 |
+
gr.Image()
|
| 151 |
+
with gr.Accordion("Imposing Norms and Values", open=False):
|
| 152 |
+
gr.Image()
|
| 153 |
+
|
| 154 |
+
with gr.TabItem("Labor and Creativity"):
|
| 155 |
+
with gr.Accordion("Intellectual Property and Ownership", open=False):
|
| 156 |
+
gr.Image()
|
| 157 |
+
with gr.Accordion("Economy and Labor Market", open=False):
|
| 158 |
+
gr.Image()
|
| 159 |
+
|
| 160 |
+
with gr.TabItem("Ecosystem and Environment"):
|
| 161 |
+
with gr.Accordion("Widening Resource Gaps", open=False):
|
| 162 |
+
gr.Image()
|
| 163 |
+
with gr.Accordion("Environmental Impacts", open=False):
|
| 164 |
+
gr.Image()
|
| 165 |
+
|
| 166 |
+
|
| 167 |
+
with gr.Row():
|
| 168 |
+
with gr.Accordion("📚 Citation", open=False):
|
| 169 |
+
citation_button = gr.Textbox(
|
| 170 |
+
value=r"""BOOK CHAPTER CITE GOES HERE""",
|
| 171 |
+
lines=7,
|
| 172 |
+
label="Copy the following to cite this work.",
|
| 173 |
+
elem_id="citation-button",
|
| 174 |
+
show_copy_button=True,
|
| 175 |
+
)
|
| 176 |
+
|
| 177 |
+
|
| 178 |
+
demo.launch(debug=True)
|
css.py
ADDED
|
@@ -0,0 +1,17 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
custom_css = """
|
| 2 |
+
/* Full width space */
|
| 3 |
+
a {
|
| 4 |
+
text-decoration: underline;
|
| 5 |
+
# text-decoration-style: dotted;
|
| 6 |
+
}
|
| 7 |
+
|
| 8 |
+
h1, h2, h3, h4, h5, h6 {
|
| 9 |
+
margin: 0;
|
| 10 |
+
}
|
| 11 |
+
|
| 12 |
+
.tag {
|
| 13 |
+
padding: .1em .3em;
|
| 14 |
+
background-color: lightgrey;
|
| 15 |
+
border-radius: 12px;
|
| 16 |
+
}
|
| 17 |
+
"""
|