Spaces:
Runtime error

Runtime error
Soufiane
commited on
Commit
·
8a6a4ae
1
Parent(s):
8565879
added table extraction
Browse files- app.py +6 -7
- invoice.py +21 -10
- invoices/facture.png +0 -0
- invoices/facture1.png +0 -0
- invoices/facture2.webp +0 -0
- invoices/facture3.png +0 -0
- invoices/facture4.webp +0 -0
- invoices/facture5.png +0 -0
- invoices/facture6.jpg +0 -0
- invoices/pdf/facture.pdf +0 -0
- invoices/pdf/facture1.pdf +0 -0
- invoices/pdf/facture2.pdf +0 -0
- invoices/pdf/releve de compte.pdf +0 -0
- requirements.txt +11 -0
- tables/Fgwf1.png +0 -0
- tables/article with tables.pdf +0 -0
- tables/facture_table.png +0 -0
- utils.py +140 -0
app.py
CHANGED
|
@@ -1,9 +1,9 @@
|
|
| 1 |
import streamlit as st
|
| 2 |
-
from PIL import Image
|
| 3 |
import pandas as pd
|
| 4 |
import numpy as np
|
| 5 |
from invoice import extract_data, extract_tables, INVOICE
|
| 6 |
-
|
| 7 |
|
| 8 |
|
| 9 |
|
|
@@ -21,8 +21,9 @@ def main():
|
|
| 21 |
st.image(uploaded_image, caption="Uploaded Image", use_column_width=True)
|
| 22 |
|
| 23 |
lang = st.selectbox("Select Language", ["french", "english", "arabic"])
|
|
|
|
|
|
|
| 24 |
|
| 25 |
-
# UI for adding elements to extract list
|
| 26 |
st.write("Add elements to extract:")
|
| 27 |
extract_input = st.text_input("Add elements")
|
| 28 |
extract_list = st.session_state.get("extract_list", INVOICE)
|
|
@@ -36,8 +37,7 @@ def main():
|
|
| 36 |
st.write(f"`{item}`", unsafe_allow_html=True)
|
| 37 |
|
| 38 |
if st.button("Extract information"):
|
| 39 |
-
|
| 40 |
-
numpy_image = np.array(pil_image)
|
| 41 |
image_info = process_image(lang, extract_list, numpy_image)
|
| 42 |
|
| 43 |
df = pd.DataFrame(list(image_info.items()), columns=["Field", "Value"])
|
|
@@ -45,8 +45,7 @@ def main():
|
|
| 45 |
st.dataframe(df)
|
| 46 |
|
| 47 |
if st.button("Extract Tables"):
|
| 48 |
-
|
| 49 |
-
csv = df.to_csv(index=False, header=False)
|
| 50 |
st.download_button(label="Download CSV", data=csv, file_name='data.csv', mime='text/csv')
|
| 51 |
|
| 52 |
|
|
|
|
| 1 |
import streamlit as st
|
| 2 |
+
from PIL import Image
|
| 3 |
import pandas as pd
|
| 4 |
import numpy as np
|
| 5 |
from invoice import extract_data, extract_tables, INVOICE
|
| 6 |
+
|
| 7 |
|
| 8 |
|
| 9 |
|
|
|
|
| 21 |
st.image(uploaded_image, caption="Uploaded Image", use_column_width=True)
|
| 22 |
|
| 23 |
lang = st.selectbox("Select Language", ["french", "english", "arabic"])
|
| 24 |
+
pil_image = Image.open(uploaded_image).convert('RGB')
|
| 25 |
+
numpy_image = np.array(pil_image)
|
| 26 |
|
|
|
|
| 27 |
st.write("Add elements to extract:")
|
| 28 |
extract_input = st.text_input("Add elements")
|
| 29 |
extract_list = st.session_state.get("extract_list", INVOICE)
|
|
|
|
| 37 |
st.write(f"`{item}`", unsafe_allow_html=True)
|
| 38 |
|
| 39 |
if st.button("Extract information"):
|
| 40 |
+
|
|
|
|
| 41 |
image_info = process_image(lang, extract_list, numpy_image)
|
| 42 |
|
| 43 |
df = pd.DataFrame(list(image_info.items()), columns=["Field", "Value"])
|
|
|
|
| 45 |
st.dataframe(df)
|
| 46 |
|
| 47 |
if st.button("Extract Tables"):
|
| 48 |
+
csv = extract_tables(lang, numpy_image)
|
|
|
|
| 49 |
st.download_button(label="Download CSV", data=csv, file_name='data.csv', mime='text/csv')
|
| 50 |
|
| 51 |
|
invoice.py
CHANGED
|
@@ -1,7 +1,7 @@
|
|
| 1 |
import cv2
|
| 2 |
from PIL import Image
|
| 3 |
-
|
| 4 |
-
|
| 5 |
import pandas as pd
|
| 6 |
import numpy as np
|
| 7 |
import easyocr
|
|
@@ -9,13 +9,13 @@ from utils import *
|
|
| 9 |
|
| 10 |
INVOICE = ["Numéro de facture", "Date", "Numéro de commande", "Echéance", "Total"]
|
| 11 |
|
| 12 |
-
|
| 13 |
-
|
| 14 |
-
|
| 15 |
-
|
| 16 |
-
|
| 17 |
|
| 18 |
-
|
| 19 |
|
| 20 |
|
| 21 |
def detect_tables(image):
|
|
@@ -94,13 +94,24 @@ def intersection(box1, box2):
|
|
| 94 |
return {'xmin': xmin, 'ymin': ymin, 'xmax': xmax, 'ymax': ymax}
|
| 95 |
|
| 96 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 97 |
def extract_tables(lang, image):
|
| 98 |
reader = easyocr.Reader([langs[lang]])
|
| 99 |
tables = detect_tables(image)
|
| 100 |
-
|
| 101 |
for i in range(len(tables)):
|
| 102 |
df = rec_table(tables[i], reader)
|
| 103 |
-
df.
|
|
|
|
|
|
|
|
|
|
| 104 |
|
| 105 |
if __name__ == '__main__':
|
| 106 |
lang = "french"
|
|
|
|
| 1 |
import cv2
|
| 2 |
from PIL import Image
|
| 3 |
+
from ultralyticsplus import YOLO
|
| 4 |
+
from transformers import pipeline
|
| 5 |
import pandas as pd
|
| 6 |
import numpy as np
|
| 7 |
import easyocr
|
|
|
|
| 9 |
|
| 10 |
INVOICE = ["Numéro de facture", "Date", "Numéro de commande", "Echéance", "Total"]
|
| 11 |
|
| 12 |
+
model = YOLO('keremberke/yolov8s-table-extraction')
|
| 13 |
+
model.overrides['conf'] = 0.25 # NMS confidence threshold
|
| 14 |
+
model.overrides['iou'] = 0.45 # NMS IoU threshold
|
| 15 |
+
model.overrides['agnostic_nms'] = False # NMS class-agnostic
|
| 16 |
+
model.overrides['max_det'] = 1000 # maximum number of detections per image
|
| 17 |
|
| 18 |
+
pipe = pipeline("object-detection", model="bilguun/table-transformer-structure-recognition")
|
| 19 |
|
| 20 |
|
| 21 |
def detect_tables(image):
|
|
|
|
| 94 |
return {'xmin': xmin, 'ymin': ymin, 'xmax': xmax, 'ymax': ymax}
|
| 95 |
|
| 96 |
|
| 97 |
+
# def extract_tables(lang, image):
|
| 98 |
+
# reader = easyocr.Reader([langs[lang]])
|
| 99 |
+
# tables = detect_tables(image)
|
| 100 |
+
|
| 101 |
+
# for i in range(len(tables)):
|
| 102 |
+
# df = rec_table(tables[i], reader)
|
| 103 |
+
# df.to_excel(f'table_{i+1}.xlsx', index=False, header=False)
|
| 104 |
+
|
| 105 |
def extract_tables(lang, image):
|
| 106 |
reader = easyocr.Reader([langs[lang]])
|
| 107 |
tables = detect_tables(image)
|
| 108 |
+
csvs = []
|
| 109 |
for i in range(len(tables)):
|
| 110 |
df = rec_table(tables[i], reader)
|
| 111 |
+
csv = df.to_csv(index=False, header=False)
|
| 112 |
+
csvs.append(csvs)
|
| 113 |
+
|
| 114 |
+
return csvs[0]
|
| 115 |
|
| 116 |
if __name__ == '__main__':
|
| 117 |
lang = "french"
|
invoices/facture.png
ADDED

|
invoices/facture1.png
ADDED
|
invoices/facture2.webp
ADDED

|
invoices/facture3.png
ADDED

|
invoices/facture4.webp
ADDED
|
invoices/facture5.png
ADDED
|
invoices/facture6.jpg
ADDED
|
invoices/pdf/facture.pdf
ADDED
|
Binary file (104 kB). View file
|
|
|
invoices/pdf/facture1.pdf
ADDED
|
Binary file (37.9 kB). View file
|
|
|
invoices/pdf/facture2.pdf
ADDED
|
Binary file (24 kB). View file
|
|
|
invoices/pdf/releve de compte.pdf
ADDED
|
Binary file (42.7 kB). View file
|
|
|
requirements.txt
ADDED
|
@@ -0,0 +1,11 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
easyocr
|
| 2 |
+
json
|
| 3 |
+
opencv-python
|
| 4 |
+
google-generativeai
|
| 5 |
+
streamlit
|
| 6 |
+
Pillow
|
| 7 |
+
pandas
|
| 8 |
+
numpy
|
| 9 |
+
base64
|
| 10 |
+
ultralyticsplus
|
| 11 |
+
transformers
|
tables/Fgwf1.png
ADDED
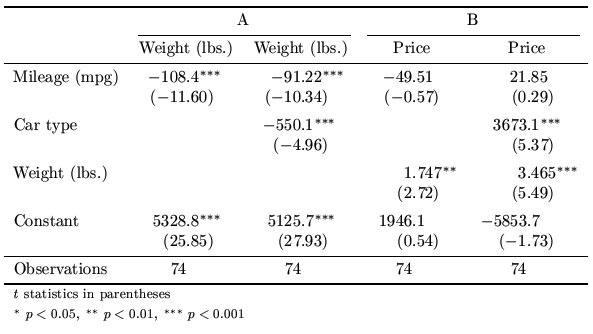
|
tables/article with tables.pdf
ADDED
|
Binary file (296 kB). View file
|
|
|
tables/facture_table.png
ADDED
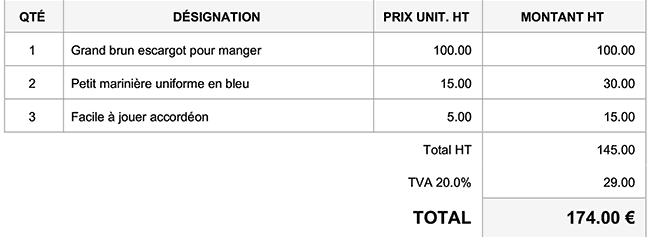
|
utils.py
ADDED
|
@@ -0,0 +1,140 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import easyocr
|
| 2 |
+
import json
|
| 3 |
+
import re
|
| 4 |
+
import cv2
|
| 5 |
+
import easyocr
|
| 6 |
+
import google.generativeai as genai
|
| 7 |
+
|
| 8 |
+
|
| 9 |
+
langs = {'french': 'fr', 'english': 'en', 'arabic': 'ar'}
|
| 10 |
+
|
| 11 |
+
|
| 12 |
+
GOOGLE_API_KEY = "AIzaSyC6NXwTrucSl2JkY23YWsucFZPMBDoaqJw"
|
| 13 |
+
genai.configure(api_key=GOOGLE_API_KEY)
|
| 14 |
+
model = genai.GenerativeModel('gemini-pro')
|
| 15 |
+
|
| 16 |
+
def get_ocr(image,reader):
|
| 17 |
+
result = reader.readtext(image)
|
| 18 |
+
return result
|
| 19 |
+
|
| 20 |
+
|
| 21 |
+
def get_input(result, sep = " "):
|
| 22 |
+
a = {}
|
| 23 |
+
for (bbox, text, prob) in result:
|
| 24 |
+
if prob<0.3:
|
| 25 |
+
continue
|
| 26 |
+
k = True
|
| 27 |
+
for row in a:
|
| 28 |
+
if abs(bbox[0][1] - row)<=5:
|
| 29 |
+
k = False
|
| 30 |
+
a[row]+= sep
|
| 31 |
+
a[row]+= text
|
| 32 |
+
|
| 33 |
+
if k:
|
| 34 |
+
a[bbox[0][1]] = text
|
| 35 |
+
|
| 36 |
+
inputt = ""
|
| 37 |
+
for row in a:
|
| 38 |
+
inputt+= a[row]
|
| 39 |
+
inputt+= "\n"
|
| 40 |
+
|
| 41 |
+
return inputt
|
| 42 |
+
|
| 43 |
+
|
| 44 |
+
def imp_ocr(result, image, reader):
|
| 45 |
+
v_exp_rate = 0.2
|
| 46 |
+
h_exp_rate = 0.3
|
| 47 |
+
imp_result = []
|
| 48 |
+
for i in range(len(result)):
|
| 49 |
+
prob = result[i][2]
|
| 50 |
+
if prob < 0.1:
|
| 51 |
+
continue
|
| 52 |
+
if prob < 0.9:
|
| 53 |
+
bbox = result[i][0]
|
| 54 |
+
x = int(bbox[0][0] - (bbox[2][0] - bbox[0][0])*h_exp_rate/2)
|
| 55 |
+
x_h = int(bbox[2][0] + (bbox[2][0] - bbox[0][0])*h_exp_rate/2)
|
| 56 |
+
y = int(bbox[0][1] - (bbox[2][1] - bbox[0][1])*v_exp_rate/2)
|
| 57 |
+
y_h = int(bbox[2][1] + (bbox[2][1] - bbox[0][1])*v_exp_rate/2)
|
| 58 |
+
|
| 59 |
+
x = max(x, 0)
|
| 60 |
+
x_h = min(x_h, image.shape[1])
|
| 61 |
+
y = max(y, 0)
|
| 62 |
+
y_h = min(y_h, image.shape[0])
|
| 63 |
+
|
| 64 |
+
sub_img = image[y:y_h, x:x_h]
|
| 65 |
+
res = get_ocr(sub_img,reader)
|
| 66 |
+
if not res:
|
| 67 |
+
imp_result.append(result[i])
|
| 68 |
+
continue
|
| 69 |
+
if len(res)>1:
|
| 70 |
+
res = sorted(res, key=lambda x: x[2], reverse=True)
|
| 71 |
+
|
| 72 |
+
if res[0][2] >= prob:
|
| 73 |
+
imp_result.append((result[i][0], res[0][1], res[0][2]))
|
| 74 |
+
else:
|
| 75 |
+
imp_result.append(result[i])
|
| 76 |
+
else:
|
| 77 |
+
imp_result.append(result[i])
|
| 78 |
+
return imp_result
|
| 79 |
+
|
| 80 |
+
|
| 81 |
+
def extract_data(lang, to_be_extracted, image):
|
| 82 |
+
reader = easyocr.Reader([langs[lang]])
|
| 83 |
+
ocr_result = get_ocr(image,reader)
|
| 84 |
+
imp_result = imp_ocr(ocr_result, image, reader)
|
| 85 |
+
inputt = get_input(imp_result, sep = " ")
|
| 86 |
+
return get_output(inputt, to_be_extracted, lang)
|
| 87 |
+
|
| 88 |
+
def get_output(inputt, to_be_extracted, lang):
|
| 89 |
+
prompt = f"""
|
| 90 |
+
Bellow is the ouptut text of an OCR system. The text is in {lang}.
|
| 91 |
+
Your job is:
|
| 92 |
+
1. Format the output in a python dictionary format with the following keys :
|
| 93 |
+
{to_be_extracted}.
|
| 94 |
+
2. correct any mistakes such as date formating (should be dd/mm/yyyy) or spelling mistakes (this is important).
|
| 95 |
+
|
| 96 |
+
here is your input:
|
| 97 |
+
{inputt}
|
| 98 |
+
"""
|
| 99 |
+
response = model.generate_content(prompt)
|
| 100 |
+
data = extract_json(response.text)
|
| 101 |
+
return data
|
| 102 |
+
|
| 103 |
+
def extract_json(text_response):
|
| 104 |
+
# This pattern matches a string that starts with '{' and ends with '}'
|
| 105 |
+
pattern = r'\{[^{}]*\}'
|
| 106 |
+
matches = re.finditer(pattern, text_response)
|
| 107 |
+
json_objects = []
|
| 108 |
+
for match in matches:
|
| 109 |
+
json_str = match.group(0)
|
| 110 |
+
try:
|
| 111 |
+
# Validate if the extracted string is valid JSON
|
| 112 |
+
json_obj = eval(json_str)
|
| 113 |
+
json_objects.append(json_obj)
|
| 114 |
+
except json.JSONDecodeError:
|
| 115 |
+
# Extend the search for nested structures
|
| 116 |
+
extended_json_str = extend_search(text_response, match.span())
|
| 117 |
+
try:
|
| 118 |
+
json_obj = eval(extended_json_str)
|
| 119 |
+
json_objects.append(json_obj)
|
| 120 |
+
except json.JSONDecodeError:
|
| 121 |
+
# Handle cases where the extraction is not valid JSON
|
| 122 |
+
continue
|
| 123 |
+
if json_objects:
|
| 124 |
+
return json_objects[0]
|
| 125 |
+
else:
|
| 126 |
+
return {}
|
| 127 |
+
|
| 128 |
+
|
| 129 |
+
def extend_search(text, span):
|
| 130 |
+
# Extend the search to try to capture nested structures
|
| 131 |
+
start, end = span
|
| 132 |
+
nest_count = 0
|
| 133 |
+
for i in range(start, len(text)):
|
| 134 |
+
if text[i] == '{':
|
| 135 |
+
nest_count += 1
|
| 136 |
+
elif text[i] == '}':
|
| 137 |
+
nest_count -= 1
|
| 138 |
+
if nest_count == 0:
|
| 139 |
+
return text[start:i+1]
|
| 140 |
+
return text[start:end]
|