
Commit
·
704ce7b
1
Parent(s):
58e928c
functional w dags
Browse files- .gitignore +1 -0
- app.py +372 -0
- non_well_spec.png +0 -0
- well_spec.png +0 -0
.gitignore
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
venv*
|
app.py
ADDED
|
@@ -0,0 +1,372 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# !pip install gradio -q
|
| 2 |
+
# !pip install transformers -q
|
| 3 |
+
|
| 4 |
+
# %%
|
| 5 |
+
import gradio as gr
|
| 6 |
+
import matplotlib.pyplot as plt
|
| 7 |
+
import numpy as np
|
| 8 |
+
import pandas as pd
|
| 9 |
+
import random
|
| 10 |
+
from matplotlib.ticker import MaxNLocator
|
| 11 |
+
from transformers import pipeline
|
| 12 |
+
|
| 13 |
+
# %%
|
| 14 |
+
MODEL_NAMES = [
|
| 15 |
+
"bert-base-uncased",
|
| 16 |
+
"roberta-base",
|
| 17 |
+
"bert-large-uncased",
|
| 18 |
+
"roberta-large",
|
| 19 |
+
]
|
| 20 |
+
OWN_MODEL_NAME = "add-a-model"
|
| 21 |
+
|
| 22 |
+
DECIMAL_PLACES = 1
|
| 23 |
+
EPS = 1e-5 # to avoid /0 errors
|
| 24 |
+
# %%
|
| 25 |
+
|
| 26 |
+
# Fire up the models
|
| 27 |
+
models = dict()
|
| 28 |
+
|
| 29 |
+
for bert_like in MODEL_NAMES:
|
| 30 |
+
models[bert_like] = pipeline("fill-mask", model=bert_like)
|
| 31 |
+
|
| 32 |
+
# %%
|
| 33 |
+
|
| 34 |
+
def clean_tokens(tokens):
|
| 35 |
+
return [token.strip() for token in tokens]
|
| 36 |
+
|
| 37 |
+
|
| 38 |
+
def prepare_text_for_masking(input_text, mask_token, gendered_tokens, split_key):
|
| 39 |
+
text_w_masks_list = [
|
| 40 |
+
mask_token if word.lower() in gendered_tokens else word
|
| 41 |
+
for word in input_text.split()
|
| 42 |
+
]
|
| 43 |
+
num_masks = len([m for m in text_w_masks_list if m == mask_token])
|
| 44 |
+
|
| 45 |
+
text_portions = " ".join(text_w_masks_list).split(split_key)
|
| 46 |
+
return text_portions, num_masks
|
| 47 |
+
|
| 48 |
+
|
| 49 |
+
def get_avg_prob_from_pipeline_outputs(mask_filled_text, gendered_token, num_preds):
|
| 50 |
+
pronoun_preds = [
|
| 51 |
+
sum(
|
| 52 |
+
[
|
| 53 |
+
pronoun["score"]
|
| 54 |
+
if pronoun["token_str"].strip().lower() in gendered_token
|
| 55 |
+
else 0.0
|
| 56 |
+
for pronoun in top_preds
|
| 57 |
+
]
|
| 58 |
+
)
|
| 59 |
+
for top_preds in mask_filled_text
|
| 60 |
+
]
|
| 61 |
+
return round(sum(pronoun_preds) / (EPS + num_preds) * 100, DECIMAL_PLACES)
|
| 62 |
+
|
| 63 |
+
|
| 64 |
+
|
| 65 |
+
|
| 66 |
+
def get_figure(df, gender, n_fit=1):
|
| 67 |
+
df = df.set_index("x-axis")
|
| 68 |
+
cols = df.columns
|
| 69 |
+
xs = list(range(len(df)))
|
| 70 |
+
ys = df[cols[0]]
|
| 71 |
+
fig, ax = plt.subplots()
|
| 72 |
+
# Trying small fig due to rendering issues on HF, not on VS Code
|
| 73 |
+
fig.set_figheight(3)
|
| 74 |
+
fig.set_figwidth(9)
|
| 75 |
+
|
| 76 |
+
# find stackoverflow reference
|
| 77 |
+
p, C_p = np.polyfit(xs, ys, n_fit, cov=1)
|
| 78 |
+
t = np.linspace(min(xs)-1, max(xs)+1, 10*len(xs))
|
| 79 |
+
TT = np.vstack([t**(n_fit-i) for i in range(n_fit+1)]).T
|
| 80 |
+
|
| 81 |
+
# matrix multiplication calculates the polynomial values
|
| 82 |
+
yi = np.dot(TT, p)
|
| 83 |
+
C_yi = np.dot(TT, np.dot(C_p, TT.T)) # C_y = TT*C_z*TT.T
|
| 84 |
+
sig_yi = np.sqrt(np.diag(C_yi)) # Standard deviations are sqrt of diagonal
|
| 85 |
+
|
| 86 |
+
ax.fill_between(t, yi+sig_yi, yi-sig_yi, alpha=.25)
|
| 87 |
+
ax.plot(t, yi, '-')
|
| 88 |
+
ax.plot(df, "ro")
|
| 89 |
+
ax.legend(list(df.columns))
|
| 90 |
+
|
| 91 |
+
ax.axis("tight")
|
| 92 |
+
ax.set_xlabel("Value injected into input text")
|
| 93 |
+
ax.set_title(f"Probability of predicting {gender} tokens.")
|
| 94 |
+
ax.set_ylabel(f"Softmax prob")
|
| 95 |
+
ax.tick_params(axis="x", labelrotation=5)
|
| 96 |
+
ax.set_ylim(0, 100)
|
| 97 |
+
return fig
|
| 98 |
+
|
| 99 |
+
|
| 100 |
+
|
| 101 |
+
# %%
|
| 102 |
+
def predict_masked_tokens(
|
| 103 |
+
model_name,
|
| 104 |
+
own_model_name,
|
| 105 |
+
group_a_tokens,
|
| 106 |
+
group_b_tokens,
|
| 107 |
+
indie_vars,
|
| 108 |
+
split_key,
|
| 109 |
+
normalizing,
|
| 110 |
+
n_fit,
|
| 111 |
+
input_text,
|
| 112 |
+
):
|
| 113 |
+
"""Run inference on input_text for each model type, returning df and plots of percentage
|
| 114 |
+
of gender pronouns predicted as female and male in each target text.
|
| 115 |
+
"""
|
| 116 |
+
if model_name not in MODEL_NAMES:
|
| 117 |
+
model = pipeline("fill-mask", model=own_model_name)
|
| 118 |
+
else:
|
| 119 |
+
model = models[model_name]
|
| 120 |
+
|
| 121 |
+
mask_token = model.tokenizer.mask_token
|
| 122 |
+
|
| 123 |
+
indie_vars_list = indie_vars.split(",")
|
| 124 |
+
|
| 125 |
+
group_a_tokens = clean_tokens(group_a_tokens.split(","))
|
| 126 |
+
group_b_tokens = clean_tokens(group_b_tokens.split(","))
|
| 127 |
+
|
| 128 |
+
text_segments, num_preds = prepare_text_for_masking(
|
| 129 |
+
input_text, mask_token, group_b_tokens + group_a_tokens, split_key
|
| 130 |
+
)
|
| 131 |
+
|
| 132 |
+
male_pronoun_preds = []
|
| 133 |
+
female_pronoun_preds = []
|
| 134 |
+
for indie_var in indie_vars_list:
|
| 135 |
+
target_text = f"{indie_var}".join(text_segments)
|
| 136 |
+
mask_filled_text = model(target_text)
|
| 137 |
+
# Quick hack as realized return type based on how many MASKs in text.
|
| 138 |
+
if type(mask_filled_text[0]) is not list:
|
| 139 |
+
mask_filled_text = [mask_filled_text]
|
| 140 |
+
|
| 141 |
+
female_pronoun_preds.append(
|
| 142 |
+
get_avg_prob_from_pipeline_outputs(
|
| 143 |
+
mask_filled_text, group_a_tokens, num_preds
|
| 144 |
+
)
|
| 145 |
+
)
|
| 146 |
+
male_pronoun_preds.append(
|
| 147 |
+
get_avg_prob_from_pipeline_outputs(
|
| 148 |
+
mask_filled_text, group_b_tokens, num_preds
|
| 149 |
+
)
|
| 150 |
+
)
|
| 151 |
+
|
| 152 |
+
if normalizing:
|
| 153 |
+
total_gendered_probs = np.add(female_pronoun_preds, male_pronoun_preds)
|
| 154 |
+
female_pronoun_preds = np.around(
|
| 155 |
+
np.divide(female_pronoun_preds, total_gendered_probs + EPS) * 100,
|
| 156 |
+
decimals=DECIMAL_PLACES,
|
| 157 |
+
)
|
| 158 |
+
male_pronoun_preds = np.around(
|
| 159 |
+
np.divide(male_pronoun_preds, total_gendered_probs + EPS) * 100,
|
| 160 |
+
decimals=DECIMAL_PLACES,
|
| 161 |
+
)
|
| 162 |
+
|
| 163 |
+
results_df = pd.DataFrame({"x-axis": indie_vars_list})
|
| 164 |
+
results_df["group_a"] = female_pronoun_preds
|
| 165 |
+
results_df["group_b"] = male_pronoun_preds
|
| 166 |
+
female_fig = get_figure(
|
| 167 |
+
results_df.drop("group_b", axis=1),
|
| 168 |
+
"group_a",
|
| 169 |
+
n_fit,
|
| 170 |
+
)
|
| 171 |
+
male_fig = get_figure(
|
| 172 |
+
results_df.drop("group_a", axis=1),
|
| 173 |
+
"group_b",
|
| 174 |
+
n_fit,
|
| 175 |
+
)
|
| 176 |
+
display_text = f"{random.choice(indie_vars_list)}".join(text_segments)
|
| 177 |
+
|
| 178 |
+
return (
|
| 179 |
+
display_text,
|
| 180 |
+
female_fig,
|
| 181 |
+
male_fig,
|
| 182 |
+
results_df,
|
| 183 |
+
)
|
| 184 |
+
|
| 185 |
+
|
| 186 |
+
truck_fn_example = [
|
| 187 |
+
MODEL_NAMES[2],
|
| 188 |
+
'',
|
| 189 |
+
', '.join(['truck', 'pickup']),
|
| 190 |
+
', '.join(['car', 'sedan']),
|
| 191 |
+
', '.join(['city','neighborhood','farm']),
|
| 192 |
+
'PLACE',
|
| 193 |
+
"True",
|
| 194 |
+
1,
|
| 195 |
+
]
|
| 196 |
+
def truck_1_fn():
|
| 197 |
+
return truck_fn_example + [
|
| 198 |
+
'He loaded up his truck and drove to the PLACE.'
|
| 199 |
+
]
|
| 200 |
+
|
| 201 |
+
def truck_2_fn():
|
| 202 |
+
return truck_fn_example + [
|
| 203 |
+
'He loaded up the bed of his truck and drove to the PLACE.'
|
| 204 |
+
]
|
| 205 |
+
|
| 206 |
+
|
| 207 |
+
# # %%
|
| 208 |
+
|
| 209 |
+
|
| 210 |
+
|
| 211 |
+
demo = gr.Blocks()
|
| 212 |
+
with demo:
|
| 213 |
+
gr.Markdown("# Spurious Correlation Evaluation for Pre-trained LLMs")
|
| 214 |
+
|
| 215 |
+
|
| 216 |
+
gr.Markdown("## Instructions for this Demo")
|
| 217 |
+
gr.Markdown(
|
| 218 |
+
"1) Click on one of the examples below to pre-populate the input fields."
|
| 219 |
+
)
|
| 220 |
+
gr.Markdown(
|
| 221 |
+
"2) Check out the pre-populated fields as you scroll down to the ['Hit Submit...'] button!"
|
| 222 |
+
)
|
| 223 |
+
gr.Markdown(
|
| 224 |
+
"3) Repeat steps (1) and (2) with more pre-populated inputs or with your own values in the input fields!"
|
| 225 |
+
)
|
| 226 |
+
|
| 227 |
+
|
| 228 |
+
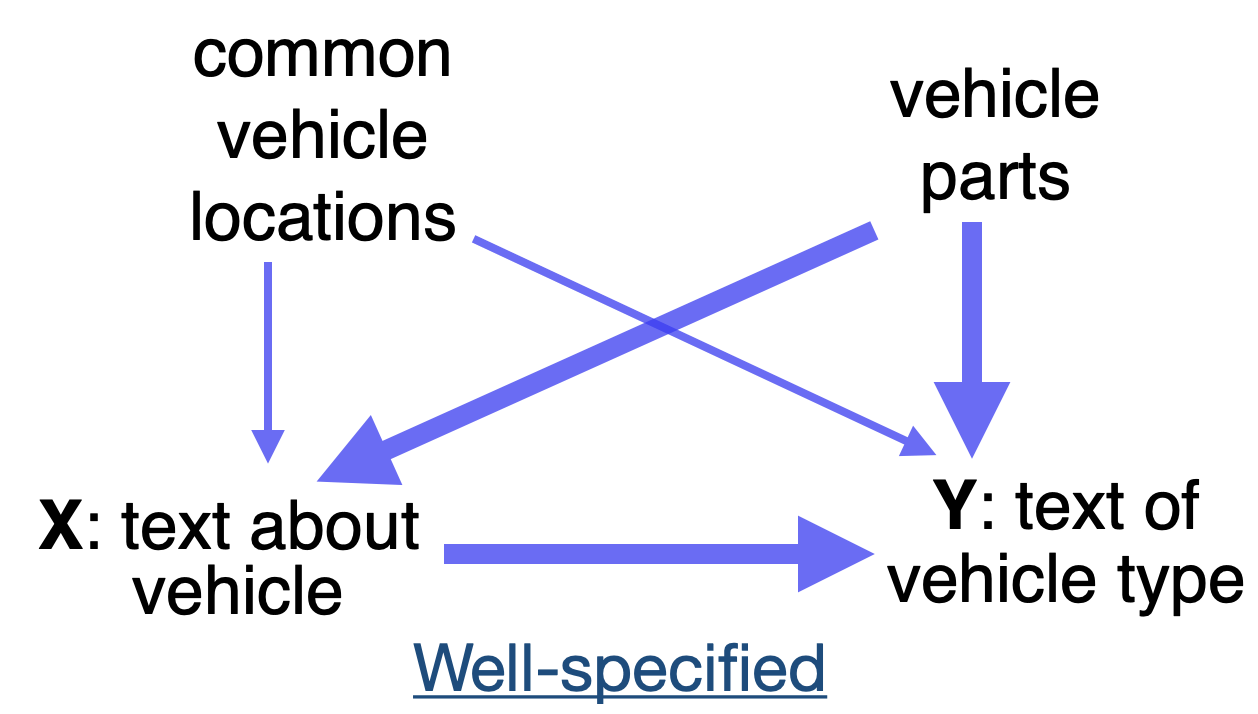
gr.Markdown("""The pre-populated inputs below are for a demo example of a location-vs-vehicle-type spurious correlation.
|
| 229 |
+
We can see this spurious correlation largely disappears in the well-specified example text.
|
| 230 |
+
|
| 231 |
+
<p align="center">
|
| 232 |
+
<img src="file/non_well_spec.png" alt="results" width="300"/>
|
| 233 |
+
</p>
|
| 234 |
+
|
| 235 |
+
|
| 236 |
+
<p align="center">
|
| 237 |
+
<img src="file/well_spec.png" alt="results" width="300"/>
|
| 238 |
+
</p>
|
| 239 |
+
""")
|
| 240 |
+
|
| 241 |
+
gr.Markdown("## Example inputs")
|
| 242 |
+
gr.Markdown(
|
| 243 |
+
"Click a button below to pre-populate input fields with example values. Then scroll down to Hit Submit to generate predictions."
|
| 244 |
+
)
|
| 245 |
+
with gr.Row():
|
| 246 |
+
truck_1_gen = gr.Button("Click for non-well-specified(?) vehicle-type example inputs")
|
| 247 |
+
gr.Markdown("<-- Multiple solutions with low training error. LLM sensitive to spurious(?) correlations.")
|
| 248 |
+
|
| 249 |
+
truck_2_gen = gr.Button("Click for well-specified vehicle-type example inputs")
|
| 250 |
+
gr.Markdown("<-- Fewer solutions with low training error. LLM less sensitive to spurious(?) correlations.")
|
| 251 |
+
|
| 252 |
+
gr.Markdown("## Input fields")
|
| 253 |
+
gr.Markdown(
|
| 254 |
+
f"A) Pick a spectrum of comma separated values for text injection and x-axis."
|
| 255 |
+
)
|
| 256 |
+
|
| 257 |
+
with gr.Row():
|
| 258 |
+
group_a_tokens = gr.Textbox(
|
| 259 |
+
type="text",
|
| 260 |
+
lines=3,
|
| 261 |
+
label="A) To-MASK tokens A: Comma separated words that account for accumulated group A softmax probs",
|
| 262 |
+
)
|
| 263 |
+
|
| 264 |
+
group_b_tokens = gr.Textbox(
|
| 265 |
+
type="text",
|
| 266 |
+
lines=3,
|
| 267 |
+
label="B) To-MASK tokens B: Comma separated words that account for accumulated group B softmax probs",
|
| 268 |
+
)
|
| 269 |
+
|
| 270 |
+
with gr.Row():
|
| 271 |
+
x_axis = gr.Textbox(
|
| 272 |
+
type="text",
|
| 273 |
+
lines=3,
|
| 274 |
+
label="C) Comma separated values for text injection and x-axis",
|
| 275 |
+
)
|
| 276 |
+
|
| 277 |
+
gr.Markdown("D) Pick a pre-loaded BERT-family model of interest on the right.")
|
| 278 |
+
gr.Markdown(
|
| 279 |
+
f"Or E) select `{OWN_MODEL_NAME}`, then add the mame of any other Hugging Face model that supports the [fill-mask](https://huggingface.co/models?pipeline_tag=fill-mask) task on the right (note: this may take some time to load)."
|
| 280 |
+
)
|
| 281 |
+
|
| 282 |
+
with gr.Row():
|
| 283 |
+
model_name = gr.Radio(
|
| 284 |
+
MODEL_NAMES + [OWN_MODEL_NAME],
|
| 285 |
+
type="value",
|
| 286 |
+
label="D) BERT-like model.",
|
| 287 |
+
)
|
| 288 |
+
own_model_name = gr.Textbox(
|
| 289 |
+
label="E) If you selected an 'add-a-model' model, put any Hugging Face pipeline model name (that supports the fill-mask task) here.",
|
| 290 |
+
)
|
| 291 |
+
|
| 292 |
+
gr.Markdown(
|
| 293 |
+
"F) Pick if you want to the predictions normalied to only those from group A or B."
|
| 294 |
+
)
|
| 295 |
+
gr.Markdown(
|
| 296 |
+
"G) Also tell the demo what special token you will use in your input text, that you would like replaced with the spectrum of values you listed above."
|
| 297 |
+
)
|
| 298 |
+
gr.Markdown(
|
| 299 |
+
"And H) the degree of polynomial fit used for high-lighting potential spurious association."
|
| 300 |
+
)
|
| 301 |
+
|
| 302 |
+
with gr.Row():
|
| 303 |
+
to_normalize = gr.Dropdown(
|
| 304 |
+
["False", "True"],
|
| 305 |
+
label="D) Normalize model's predictions?",
|
| 306 |
+
type="index",
|
| 307 |
+
)
|
| 308 |
+
place_holder = gr.Textbox(
|
| 309 |
+
label="E) Special token place-holder",
|
| 310 |
+
)
|
| 311 |
+
n_fit = gr.Dropdown(
|
| 312 |
+
list(range(1, 5)),
|
| 313 |
+
label="F) Degree of polynomial fit",
|
| 314 |
+
type="value",
|
| 315 |
+
)
|
| 316 |
+
|
| 317 |
+
gr.Markdown(
|
| 318 |
+
"I) Finally, add input text that includes at least one of the '`To-MASK`' tokens from (A) or (B) and one place-holder token from (G)."
|
| 319 |
+
)
|
| 320 |
+
|
| 321 |
+
with gr.Row():
|
| 322 |
+
input_text = gr.Textbox(
|
| 323 |
+
lines=2,
|
| 324 |
+
label="I) Input text with a '`To-MASK`' and place-holder token",
|
| 325 |
+
)
|
| 326 |
+
|
| 327 |
+
gr.Markdown("## Outputs!")
|
| 328 |
+
with gr.Row():
|
| 329 |
+
btn = gr.Button("Hit submit to generate predictions!")
|
| 330 |
+
|
| 331 |
+
with gr.Row():
|
| 332 |
+
sample_text = gr.Textbox(
|
| 333 |
+
type="text", label="Output text: Sample of text fed to model"
|
| 334 |
+
)
|
| 335 |
+
with gr.Row():
|
| 336 |
+
female_fig = gr.Plot(type="auto")
|
| 337 |
+
male_fig = gr.Plot(type="auto")
|
| 338 |
+
with gr.Row():
|
| 339 |
+
df = gr.Dataframe(
|
| 340 |
+
show_label=True,
|
| 341 |
+
overflow_row_behaviour="show_ends",
|
| 342 |
+
label="Table of softmax probability for grouped predictions",
|
| 343 |
+
)
|
| 344 |
+
|
| 345 |
+
with gr.Row():
|
| 346 |
+
truck_1_gen.click(truck_1_fn, inputs=[], outputs=[model_name, own_model_name, group_a_tokens, group_b_tokens,
|
| 347 |
+
x_axis, place_holder, to_normalize, n_fit, input_text])
|
| 348 |
+
|
| 349 |
+
truck_2_gen.click(truck_2_fn, inputs=[], outputs=[model_name, own_model_name, group_a_tokens, group_b_tokens,
|
| 350 |
+
x_axis, place_holder, to_normalize, n_fit, input_text])
|
| 351 |
+
|
| 352 |
+
btn.click(
|
| 353 |
+
predict_masked_tokens,
|
| 354 |
+
inputs=[
|
| 355 |
+
model_name,
|
| 356 |
+
own_model_name,
|
| 357 |
+
group_a_tokens,
|
| 358 |
+
group_b_tokens,
|
| 359 |
+
x_axis,
|
| 360 |
+
place_holder,
|
| 361 |
+
to_normalize,
|
| 362 |
+
n_fit,
|
| 363 |
+
input_text,
|
| 364 |
+
],
|
| 365 |
+
outputs=[sample_text, female_fig, male_fig, df],
|
| 366 |
+
)
|
| 367 |
+
|
| 368 |
+
demo.launch(debug=True, share=True)
|
| 369 |
+
|
| 370 |
+
# %%
|
| 371 |
+
|
| 372 |
+
|
non_well_spec.png
ADDED

|
well_spec.png
ADDED
|