Spaces:
Build error

Build error
Upload 146 files
Browse filesThis view is limited to 50 files because it contains too many changes.
See raw diff
- Dockerfile +41 -0
- LICENSE +1347 -0
- README.md +231 -12
- assets/yolo_arch.png +0 -0
- assets/yolo_logo.png +0 -0
- configs/finetune_coco/README.md +26 -0
- configs/finetune_coco/yolo_world_l_dual_vlpan_2e-4_80e_8gpus_finetune_coco.py +179 -0
- configs/finetune_coco/yolo_world_l_dual_vlpan_2e-4_80e_8gpus_mask-refine_finetune_coco.py +181 -0
- configs/finetune_coco/yolo_world_l_efficient_neck_2e-4_80e_8gpus_mask-refine_finetune_coco.py +159 -0
- configs/finetune_coco/yolo_world_v2_l_efficient_neck_2e-4_80e_8gpus_mask-refine_finetune_coco.py +182 -0
- configs/finetune_coco/yolo_world_v2_l_vlpan_bn_2e-4_80e_8gpus_mask-refine_finetune_coco.py +181 -0
- configs/finetune_coco/yolo_world_v2_l_vlpan_bn_sgd_1e-3_40e_8gpus_finetune_coco.py +160 -0
- configs/finetune_coco/yolo_world_v2_l_vlpan_bn_sgd_1e-3_80e_8gpus_mask-refine_finetune_coco.py +161 -0
- configs/finetune_coco/yolo_world_v2_m_vlpan_bn_2e-4_80e_8gpus_mask-refine_finetune_coco.py +182 -0
- configs/finetune_coco/yolo_world_v2_s_vlpan_bn_2e-4_80e_8gpus_mask-refine_finetune_coco.py +184 -0
- configs/finetune_coco/yolo_world_v2_x_vlpan_bn_2e-4_80e_8gpus_mask-refine_finetune_coco.py +183 -0
- configs/finetune_coco/yolo_world_v2_xl_vlpan_bn_2e-4_80e_8gpus_mask-refine_finetune_coco.py +173 -0
- configs/pretrain/yolo_world_v2_l_clip_large_vlpan_bn_2e-3_100e_4x8gpus_obj365v1_goldg_train_800ft_lvis_minival.py +200 -0
- configs/pretrain/yolo_world_v2_l_clip_large_vlpan_bn_2e-3_100e_4x8gpus_obj365v1_goldg_train_lvis_minival.py +171 -0
- configs/pretrain/yolo_world_v2_l_vlpan_bn_2e-3_100e_4x8gpus_obj365v1_goldg_train_1280ft_lvis_minival.py +202 -0
- configs/pretrain/yolo_world_v2_l_vlpan_bn_2e-3_100e_4x8gpus_obj365v1_goldg_train_lvis_minival.py +171 -0
- configs/pretrain/yolo_world_v2_l_vlpan_bn_2e-3_100e_4x8gpus_obj365v1_goldg_train_lvis_val.py +171 -0
- configs/pretrain/yolo_world_v2_m_vlpan_bn_2e-3_100e_4x8gpus_obj365v1_goldg_train_1280ft_lvis_minival.py +198 -0
- configs/pretrain/yolo_world_v2_m_vlpan_bn_2e-3_100e_4x8gpus_obj365v1_goldg_train_lvis_minival.py +171 -0
- configs/pretrain/yolo_world_v2_m_vlpan_bn_noeinsum_2e-3_100e_4x8gpus_obj365v1_goldg_train_lvis_minival.py +176 -0
- configs/pretrain/yolo_world_v2_s_vlpan_bn_2e-3_100e_4x8gpus_obj365v1_goldg_train_1280ft_lvis_minival.py +195 -0
- configs/pretrain/yolo_world_v2_s_vlpan_bn_2e-3_100e_4x8gpus_obj365v1_goldg_train_lvis_minival.py +170 -0
- configs/pretrain/yolo_world_v2_x_vlpan_bn_2e-3_100e_4x8gpus_obj365v1_goldg_train_lvis_minival.py +171 -0
- configs/pretrain/yolo_world_v2_xl_vlpan_bn_2e-3_100e_4x8gpus_obj365v1_goldg_train_lvis_minival.py +185 -0
- configs/pretrain_v1/README.md +21 -0
- configs/pretrain_v1/yolo_world_l_dual_vlpan_l2norm_2e-3_100e_4x8gpus_obj365v1_goldg_train_lvis_minival.py +172 -0
- configs/pretrain_v1/yolo_world_l_dual_vlpan_l2norm_2e-3_100e_4x8gpus_obj365v1_goldg_train_lvis_val.py +172 -0
- configs/pretrain_v1/yolo_world_m_dual_vlpan_l2norm_2e-3_100e_4x8gpus_obj365v1_goldg_train_lvis_minival.py +172 -0
- configs/pretrain_v1/yolo_world_s_dual_vlpan_l2norm_2e-3_100e_4x8gpus_obj365v1_goldg_train_lvis_minival.py +172 -0
- configs/pretrain_v1/yolo_world_x_dual_vlpan_l2norm_2e-3_100e_4x8gpus_obj365v1_goldg_train_lvis_minival.py +172 -0
- configs/prompt_tuning_coco/READEME.md +12 -0
- configs/prompt_tuning_coco/yolo_world_v2_l_vlpan_bn_2e-4_80e_8gpus_all_fine_tuning_coco.py +118 -0
- configs/prompt_tuning_coco/yolo_world_v2_l_vlpan_bn_2e-4_80e_8gpus_all_fine_tuning_rmdecay_rmmosaic_coco.py +114 -0
- configs/prompt_tuning_coco/yolo_world_v2_l_vlpan_bn_2e-4_80e_8gpus_mask-refine_all_fine_tuning_coco.py +156 -0
- configs/prompt_tuning_coco/yolo_world_v2_l_vlpan_bn_2e-4_80e_8gpus_mask-refine_fine_prompt_tuning_coco.py +156 -0
- configs/prompt_tuning_coco/yolo_world_v2_l_vlpan_bn_2e-4_80e_8gpus_mask-refine_prompt_tuning_coco.py +161 -0
- configs/prompt_tuning_coco/yolo_world_v2_l_vlpan_bn_sgd_1e-3_20e_8gpus_all_fine_tuning_rmdecay_coco.py +113 -0
- configs/prompt_tuning_coco/yolo_world_v2_l_vlpan_bn_sgd_1e-3_40e_8gpus_all_fine_tuning_rmdecay_coco.py +111 -0
- configs/prompt_tuning_coco/yolo_world_v2_l_vlpan_bn_sgd_1e-3_80e_8gpus_all_fine_tuning_coco.py +109 -0
- configs/prompt_tuning_coco/yolo_world_v2_l_vlpan_bn_sgd_1e-3_80e_8gpus_all_fine_tuning_rmdecay_coco.py +113 -0
- configs/prompt_tuning_coco/yolo_world_v2_l_vlpan_bn_sgd_1e-3_80e_8gpus_all_fine_tuning_rmdecay_coco_fixed.py +111 -0
- configs/prompt_tuning_coco/yolo_world_v2_l_vlpan_bn_sgd_1e-4_80e_8gpus_all_fine_tuning_coco.py +109 -0
- configs/segmentation/README.md +27 -0
- configs/segmentation/yolo_world_seg_l_dual_vlpan_2e-4_80e_8gpus_allmodules_finetune_lvis.py +227 -0
- configs/segmentation/yolo_world_seg_l_dual_vlpan_2e-4_80e_8gpus_seghead_finetune_lvis.py +237 -0
Dockerfile
ADDED
|
@@ -0,0 +1,41 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
FROM nvidia/cuda:11.8.0-devel-ubuntu22.04
|
| 2 |
+
|
| 3 |
+
ARG MODEL="yolo_world_l_dual_vlpan_l2norm_2e-3_100e_4x8gpus_obj365v1_goldg_train_lvis_minival.py"
|
| 4 |
+
ARG WEIGHT="yolo_world_l_clip_base_dual_vlpan_2e-3adamw_32xb16_100e_o365_goldg_train_pretrained-0e566235.pth"
|
| 5 |
+
|
| 6 |
+
ENV FORCE_CUDA="1"
|
| 7 |
+
ENV MMCV_WITH_OPS=1
|
| 8 |
+
|
| 9 |
+
RUN apt-get update && apt-get install -y --no-install-recommends \
|
| 10 |
+
python3-pip \
|
| 11 |
+
libgl1-mesa-glx \
|
| 12 |
+
libsm6 \
|
| 13 |
+
libxext6 \
|
| 14 |
+
libxrender-dev \
|
| 15 |
+
libglib2.0-0 \
|
| 16 |
+
git \
|
| 17 |
+
python3-dev \
|
| 18 |
+
python3-wheel
|
| 19 |
+
|
| 20 |
+
RUN pip3 install --upgrade pip \
|
| 21 |
+
&& pip3 install \
|
| 22 |
+
gradio \
|
| 23 |
+
opencv-python \
|
| 24 |
+
supervision \
|
| 25 |
+
mmengine \
|
| 26 |
+
setuptools \
|
| 27 |
+
&& pip3 install --no-cache-dir --index-url https://download.pytorch.org/whl/cu118 \
|
| 28 |
+
wheel \
|
| 29 |
+
torch \
|
| 30 |
+
torchvision \
|
| 31 |
+
torchaudio
|
| 32 |
+
|
| 33 |
+
COPY . /yolo
|
| 34 |
+
WORKDIR /yolo
|
| 35 |
+
|
| 36 |
+
RUN pip3 install -e .
|
| 37 |
+
|
| 38 |
+
RUN curl -o weights/$WEIGHT -L https://huggingface.co/wondervictor/YOLO-World/resolve/main/$WEIGHT
|
| 39 |
+
|
| 40 |
+
ENTRYPOINT [ "python3", "demo.py" ]
|
| 41 |
+
CMD ["configs/pretrain/$MODEL", "weights/$WEIGHT"]
|
LICENSE
ADDED
|
@@ -0,0 +1,1347 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
GNU GENERAL PUBLIC LICENSE
|
| 2 |
+
Version 3, 29 June 2007
|
| 3 |
+
|
| 4 |
+
Copyright (C) 2007 Free Software Foundation, Inc. <https://fsf.org/>
|
| 5 |
+
Everyone is permitted to copy and distribute verbatim copies
|
| 6 |
+
of this license document, but changing it is not allowed.
|
| 7 |
+
|
| 8 |
+
Preamble
|
| 9 |
+
|
| 10 |
+
The GNU General Public License is a free, copyleft license for
|
| 11 |
+
software and other kinds of works.
|
| 12 |
+
|
| 13 |
+
The licenses for most software and other practical works are designed
|
| 14 |
+
to take away your freedom to share and change the works. By contrast,
|
| 15 |
+
the GNU General Public License is intended to guarantee your freedom to
|
| 16 |
+
share and change all versions of a program--to make sure it remains free
|
| 17 |
+
software for all its users. We, the Free Software Foundation, use the
|
| 18 |
+
GNU General Public License for most of our software; it applies also to
|
| 19 |
+
any other work released this way by its authors. You can apply it to
|
| 20 |
+
your programs, too.
|
| 21 |
+
|
| 22 |
+
When we speak of free software, we are referring to freedom, not
|
| 23 |
+
price. Our General Public Licenses are designed to make sure that you
|
| 24 |
+
have the freedom to distribute copies of free software (and charge for
|
| 25 |
+
them if you wish), that you receive source code or can get it if you
|
| 26 |
+
want it, that you can change the software or use pieces of it in new
|
| 27 |
+
free programs, and that you know you can do these things.
|
| 28 |
+
|
| 29 |
+
To protect your rights, we need to prevent others from denying you
|
| 30 |
+
these rights or asking you to surrender the rights. Therefore, you have
|
| 31 |
+
certain responsibilities if you distribute copies of the software, or if
|
| 32 |
+
you modify it: responsibilities to respect the freedom of others.
|
| 33 |
+
|
| 34 |
+
For example, if you distribute copies of such a program, whether
|
| 35 |
+
gratis or for a fee, you must pass on to the recipients the same
|
| 36 |
+
freedoms that you received. You must make sure that they, too, receive
|
| 37 |
+
or can get the source code. And you must show them these terms so they
|
| 38 |
+
know their rights.
|
| 39 |
+
|
| 40 |
+
Developers that use the GNU GPL protect your rights with two steps:
|
| 41 |
+
(1) assert copyright on the software, and (2) offer you this License
|
| 42 |
+
giving you legal permission to copy, distribute and/or modify it.
|
| 43 |
+
|
| 44 |
+
For the developers' and authors' protection, the GPL clearly explains
|
| 45 |
+
that there is no warranty for this free software. For both users' and
|
| 46 |
+
authors' sake, the GPL requires that modified versions be marked as
|
| 47 |
+
changed, so that their problems will not be attributed erroneously to
|
| 48 |
+
authors of previous versions.
|
| 49 |
+
|
| 50 |
+
Some devices are designed to deny users access to install or run
|
| 51 |
+
modified versions of the software inside them, although the manufacturer
|
| 52 |
+
can do so. This is fundamentally incompatible with the aim of
|
| 53 |
+
protecting users' freedom to change the software. The systematic
|
| 54 |
+
pattern of such abuse occurs in the area of products for individuals to
|
| 55 |
+
use, which is precisely where it is most unacceptable. Therefore, we
|
| 56 |
+
have designed this version of the GPL to prohibit the practice for those
|
| 57 |
+
products. If such problems arise substantially in other domains, we
|
| 58 |
+
stand ready to extend this provision to those domains in future versions
|
| 59 |
+
of the GPL, as needed to protect the freedom of users.
|
| 60 |
+
|
| 61 |
+
Finally, every program is threatened constantly by software patents.
|
| 62 |
+
States should not allow patents to restrict development and use of
|
| 63 |
+
software on general-purpose computers, but in those that do, we wish to
|
| 64 |
+
avoid the special danger that patents applied to a free program could
|
| 65 |
+
make it effectively proprietary. To prevent this, the GPL assures that
|
| 66 |
+
patents cannot be used to render the program non-free.
|
| 67 |
+
|
| 68 |
+
The precise terms and conditions for copying, distribution and
|
| 69 |
+
modification follow.
|
| 70 |
+
|
| 71 |
+
TERMS AND CONDITIONS
|
| 72 |
+
|
| 73 |
+
0. Definitions.
|
| 74 |
+
|
| 75 |
+
"This License" refers to version 3 of the GNU General Public License.
|
| 76 |
+
|
| 77 |
+
"Copyright" also means copyright-like laws that apply to other kinds of
|
| 78 |
+
works, such as semiconductor masks.
|
| 79 |
+
|
| 80 |
+
"The Program" refers to any copyrightable work licensed under this
|
| 81 |
+
License. Each licensee is addressed as "you". "Licensees" and
|
| 82 |
+
"recipients" may be individuals or organizations.
|
| 83 |
+
|
| 84 |
+
To "modify" a work means to copy from or adapt all or part of the work
|
| 85 |
+
in a fashion requiring copyright permission, other than the making of an
|
| 86 |
+
exact copy. The resulting work is called a "modified version" of the
|
| 87 |
+
earlier work or a work "based on" the earlier work.
|
| 88 |
+
|
| 89 |
+
A "covered work" means either the unmodified Program or a work based
|
| 90 |
+
on the Program.
|
| 91 |
+
|
| 92 |
+
To "propagate" a work means to do anything with it that, without
|
| 93 |
+
permission, would make you directly or secondarily liable for
|
| 94 |
+
infringement under applicable copyright law, except executing it on a
|
| 95 |
+
computer or modifying a private copy. Propagation includes copying,
|
| 96 |
+
distribution (with or without modification), making available to the
|
| 97 |
+
public, and in some countries other activities as well.
|
| 98 |
+
|
| 99 |
+
To "convey" a work means any kind of propagation that enables other
|
| 100 |
+
parties to make or receive copies. Mere interaction with a user through
|
| 101 |
+
a computer network, with no transfer of a copy, is not conveying.
|
| 102 |
+
|
| 103 |
+
An interactive user interface displays "Appropriate Legal Notices"
|
| 104 |
+
to the extent that it includes a convenient and prominently visible
|
| 105 |
+
feature that (1) displays an appropriate copyright notice, and (2)
|
| 106 |
+
tells the user that there is no warranty for the work (except to the
|
| 107 |
+
extent that warranties are provided), that licensees may convey the
|
| 108 |
+
work under this License, and how to view a copy of this License. If
|
| 109 |
+
the interface presents a list of user commands or options, such as a
|
| 110 |
+
menu, a prominent item in the list meets this criterion.
|
| 111 |
+
|
| 112 |
+
1. Source Code.
|
| 113 |
+
|
| 114 |
+
The "source code" for a work means the preferred form of the work
|
| 115 |
+
for making modifications to it. "Object code" means any non-source
|
| 116 |
+
form of a work.
|
| 117 |
+
|
| 118 |
+
A "Standard Interface" means an interface that either is an official
|
| 119 |
+
standard defined by a recognized standards body, or, in the case of
|
| 120 |
+
interfaces specified for a particular programming language, one that
|
| 121 |
+
is widely used among developers working in that language.
|
| 122 |
+
|
| 123 |
+
The "System Libraries" of an executable work include anything, other
|
| 124 |
+
than the work as a whole, that (a) is included in the normal form of
|
| 125 |
+
packaging a Major Component, but which is not part of that Major
|
| 126 |
+
Component, and (b) serves only to enable use of the work with that
|
| 127 |
+
Major Component, or to implement a Standard Interface for which an
|
| 128 |
+
implementation is available to the public in source code form. A
|
| 129 |
+
"Major Component", in this context, means a major essential component
|
| 130 |
+
(kernel, window system, and so on) of the specific operating system
|
| 131 |
+
(if any) on which the executable work runs, or a compiler used to
|
| 132 |
+
produce the work, or an object code interpreter used to run it.
|
| 133 |
+
|
| 134 |
+
The "Corresponding Source" for a work in object code form means all
|
| 135 |
+
the source code needed to generate, install, and (for an executable
|
| 136 |
+
work) run the object code and to modify the work, including scripts to
|
| 137 |
+
control those activities. However, it does not include the work's
|
| 138 |
+
System Libraries, or general-purpose tools or generally available free
|
| 139 |
+
programs which are used unmodified in performing those activities but
|
| 140 |
+
which are not part of the work. For example, Corresponding Source
|
| 141 |
+
includes interface definition files associated with source files for
|
| 142 |
+
the work, and the source code for shared libraries and dynamically
|
| 143 |
+
linked subprograms that the work is specifically designed to require,
|
| 144 |
+
such as by intimate data communication or control flow between those
|
| 145 |
+
subprograms and other parts of the work.
|
| 146 |
+
|
| 147 |
+
The Corresponding Source need not include anything that users
|
| 148 |
+
can regenerate automatically from other parts of the Corresponding
|
| 149 |
+
Source.
|
| 150 |
+
|
| 151 |
+
The Corresponding Source for a work in source code form is that
|
| 152 |
+
same work.
|
| 153 |
+
|
| 154 |
+
2. Basic Permissions.
|
| 155 |
+
|
| 156 |
+
All rights granted under this License are granted for the term of
|
| 157 |
+
copyright on the Program, and are irrevocable provided the stated
|
| 158 |
+
conditions are met. This License explicitly affirms your unlimited
|
| 159 |
+
permission to run the unmodified Program. The output from running a
|
| 160 |
+
covered work is covered by this License only if the output, given its
|
| 161 |
+
content, constitutes a covered work. This License acknowledges your
|
| 162 |
+
rights of fair use or other equivalent, as provided by copyright law.
|
| 163 |
+
|
| 164 |
+
You may make, run and propagate covered works that you do not
|
| 165 |
+
convey, without conditions so long as your license otherwise remains
|
| 166 |
+
in force. You may convey covered works to others for the sole purpose
|
| 167 |
+
of having them make modifications exclusively for you, or provide you
|
| 168 |
+
with facilities for running those works, provided that you comply with
|
| 169 |
+
the terms of this License in conveying all material for which you do
|
| 170 |
+
not control copyright. Those thus making or running the covered works
|
| 171 |
+
for you must do so exclusively on your behalf, under your direction
|
| 172 |
+
and control, on terms that prohibit them from making any copies of
|
| 173 |
+
your copyrighted material outside their relationship with you.
|
| 174 |
+
|
| 175 |
+
Conveying under any other circumstances is permitted solely under
|
| 176 |
+
the conditions stated below. Sublicensing is not allowed; section 10
|
| 177 |
+
makes it unnecessary.
|
| 178 |
+
|
| 179 |
+
3. Protecting Users' Legal Rights From Anti-Circumvention Law.
|
| 180 |
+
|
| 181 |
+
No covered work shall be deemed part of an effective technological
|
| 182 |
+
measure under any applicable law fulfilling obligations under article
|
| 183 |
+
11 of the WIPO copyright treaty adopted on 20 December 1996, or
|
| 184 |
+
similar laws prohibiting or restricting circumvention of such
|
| 185 |
+
measures.
|
| 186 |
+
|
| 187 |
+
When you convey a covered work, you waive any legal power to forbid
|
| 188 |
+
circumvention of technological measures to the extent such circumvention
|
| 189 |
+
is effected by exercising rights under this License with respect to
|
| 190 |
+
the covered work, and you disclaim any intention to limit operation or
|
| 191 |
+
modification of the work as a means of enforcing, against the work's
|
| 192 |
+
users, your or third parties' legal rights to forbid circumvention of
|
| 193 |
+
technological measures.
|
| 194 |
+
|
| 195 |
+
4. Conveying Verbatim Copies.
|
| 196 |
+
|
| 197 |
+
You may convey verbatim copies of the Program's source code as you
|
| 198 |
+
receive it, in any medium, provided that you conspicuously and
|
| 199 |
+
appropriately publish on each copy an appropriate copyright notice;
|
| 200 |
+
keep intact all notices stating that this License and any
|
| 201 |
+
non-permissive terms added in accord with section 7 apply to the code;
|
| 202 |
+
keep intact all notices of the absence of any warranty; and give all
|
| 203 |
+
recipients a copy of this License along with the Program.
|
| 204 |
+
|
| 205 |
+
You may charge any price or no price for each copy that you convey,
|
| 206 |
+
and you may offer support or warranty protection for a fee.
|
| 207 |
+
|
| 208 |
+
5. Conveying Modified Source Versions.
|
| 209 |
+
|
| 210 |
+
You may convey a work based on the Program, or the modifications to
|
| 211 |
+
produce it from the Program, in the form of source code under the
|
| 212 |
+
terms of section 4, provided that you also meet all of these conditions:
|
| 213 |
+
|
| 214 |
+
a) The work must carry prominent notices stating that you modified
|
| 215 |
+
it, and giving a relevant date.
|
| 216 |
+
|
| 217 |
+
b) The work must carry prominent notices stating that it is
|
| 218 |
+
released under this License and any conditions added under section
|
| 219 |
+
7. This requirement modifies the requirement in section 4 to
|
| 220 |
+
"keep intact all notices".
|
| 221 |
+
|
| 222 |
+
c) You must license the entire work, as a whole, under this
|
| 223 |
+
License to anyone who comes into possession of a copy. This
|
| 224 |
+
License will therefore apply, along with any applicable section 7
|
| 225 |
+
additional terms, to the whole of the work, and all its parts,
|
| 226 |
+
regardless of how they are packaged. This License gives no
|
| 227 |
+
permission to license the work in any other way, but it does not
|
| 228 |
+
invalidate such permission if you have separately received it.
|
| 229 |
+
|
| 230 |
+
d) If the work has interactive user interfaces, each must display
|
| 231 |
+
Appropriate Legal Notices; however, if the Program has interactive
|
| 232 |
+
interfaces that do not display Appropriate Legal Notices, your
|
| 233 |
+
work need not make them do so.
|
| 234 |
+
|
| 235 |
+
A compilation of a covered work with other separate and independent
|
| 236 |
+
works, which are not by their nature extensions of the covered work,
|
| 237 |
+
and which are not combined with it such as to form a larger program,
|
| 238 |
+
in or on a volume of a storage or distribution medium, is called an
|
| 239 |
+
"aggregate" if the compilation and its resulting copyright are not
|
| 240 |
+
used to limit the access or legal rights of the compilation's users
|
| 241 |
+
beyond what the individual works permit. Inclusion of a covered work
|
| 242 |
+
in an aggregate does not cause this License to apply to the other
|
| 243 |
+
parts of the aggregate.
|
| 244 |
+
|
| 245 |
+
6. Conveying Non-Source Forms.
|
| 246 |
+
|
| 247 |
+
You may convey a covered work in object code form under the terms
|
| 248 |
+
of sections 4 and 5, provided that you also convey the
|
| 249 |
+
machine-readable Corresponding Source under the terms of this License,
|
| 250 |
+
in one of these ways:
|
| 251 |
+
|
| 252 |
+
a) Convey the object code in, or embodied in, a physical product
|
| 253 |
+
(including a physical distribution medium), accompanied by the
|
| 254 |
+
Corresponding Source fixed on a durable physical medium
|
| 255 |
+
customarily used for software interchange.
|
| 256 |
+
|
| 257 |
+
b) Convey the object code in, or embodied in, a physical product
|
| 258 |
+
(including a physical distribution medium), accompanied by a
|
| 259 |
+
written offer, valid for at least three years and valid for as
|
| 260 |
+
long as you offer spare parts or customer support for that product
|
| 261 |
+
model, to give anyone who possesses the object code either (1) a
|
| 262 |
+
copy of the Corresponding Source for all the software in the
|
| 263 |
+
product that is covered by this License, on a durable physical
|
| 264 |
+
medium customarily used for software interchange, for a price no
|
| 265 |
+
more than your reasonable cost of physically performing this
|
| 266 |
+
conveying of source, or (2) access to copy the
|
| 267 |
+
Corresponding Source from a network server at no charge.
|
| 268 |
+
|
| 269 |
+
c) Convey individual copies of the object code with a copy of the
|
| 270 |
+
written offer to provide the Corresponding Source. This
|
| 271 |
+
alternative is allowed only occasionally and noncommercially, and
|
| 272 |
+
only if you received the object code with such an offer, in accord
|
| 273 |
+
with subsection 6b.
|
| 274 |
+
|
| 275 |
+
d) Convey the object code by offering access from a designated
|
| 276 |
+
place (gratis or for a charge), and offer equivalent access to the
|
| 277 |
+
Corresponding Source in the same way through the same place at no
|
| 278 |
+
further charge. You need not require recipients to copy the
|
| 279 |
+
Corresponding Source along with the object code. If the place to
|
| 280 |
+
copy the object code is a network server, the Corresponding Source
|
| 281 |
+
may be on a different server (operated by you or a third party)
|
| 282 |
+
that supports equivalent copying facilities, provided you maintain
|
| 283 |
+
clear directions next to the object code saying where to find the
|
| 284 |
+
Corresponding Source. Regardless of what server hosts the
|
| 285 |
+
Corresponding Source, you remain obligated to ensure that it is
|
| 286 |
+
available for as long as needed to satisfy these requirements.
|
| 287 |
+
|
| 288 |
+
e) Convey the object code using peer-to-peer transmission, provided
|
| 289 |
+
you inform other peers where the object code and Corresponding
|
| 290 |
+
Source of the work are being offered to the general public at no
|
| 291 |
+
charge under subsection 6d.
|
| 292 |
+
|
| 293 |
+
A separable portion of the object code, whose source code is excluded
|
| 294 |
+
from the Corresponding Source as a System Library, need not be
|
| 295 |
+
included in conveying the object code work.
|
| 296 |
+
|
| 297 |
+
A "User Product" is either (1) a "consumer product", which means any
|
| 298 |
+
tangible personal property which is normally used for personal, family,
|
| 299 |
+
or household purposes, or (2) anything designed or sold for incorporation
|
| 300 |
+
into a dwelling. In determining whether a product is a consumer product,
|
| 301 |
+
doubtful cases shall be resolved in favor of coverage. For a particular
|
| 302 |
+
product received by a particular user, "normally used" refers to a
|
| 303 |
+
typical or common use of that class of product, regardless of the status
|
| 304 |
+
of the particular user or of the way in which the particular user
|
| 305 |
+
actually uses, or expects or is expected to use, the product. A product
|
| 306 |
+
is a consumer product regardless of whether the product has substantial
|
| 307 |
+
commercial, industrial or non-consumer uses, unless such uses represent
|
| 308 |
+
the only significant mode of use of the product.
|
| 309 |
+
|
| 310 |
+
"Installation Information" for a User Product means any methods,
|
| 311 |
+
procedures, authorization keys, or other information required to install
|
| 312 |
+
and execute modified versions of a covered work in that User Product from
|
| 313 |
+
a modified version of its Corresponding Source. The information must
|
| 314 |
+
suffice to ensure that the continued functioning of the modified object
|
| 315 |
+
code is in no case prevented or interfered with solely because
|
| 316 |
+
modification has been made.
|
| 317 |
+
|
| 318 |
+
If you convey an object code work under this section in, or with, or
|
| 319 |
+
specifically for use in, a User Product, and the conveying occurs as
|
| 320 |
+
part of a transaction in which the right of possession and use of the
|
| 321 |
+
User Product is transferred to the recipient in perpetuity or for a
|
| 322 |
+
fixed term (regardless of how the transaction is characterized), the
|
| 323 |
+
Corresponding Source conveyed under this section must be accompanied
|
| 324 |
+
by the Installation Information. But this requirement does not apply
|
| 325 |
+
if neither you nor any third party retains the ability to install
|
| 326 |
+
modified object code on the User Product (for example, the work has
|
| 327 |
+
been installed in ROM).
|
| 328 |
+
|
| 329 |
+
The requirement to provide Installation Information does not include a
|
| 330 |
+
requirement to continue to provide support service, warranty, or updates
|
| 331 |
+
for a work that has been modified or installed by the recipient, or for
|
| 332 |
+
the User Product in which it has been modified or installed. Access to a
|
| 333 |
+
network may be denied when the modification itself materially and
|
| 334 |
+
adversely affects the operation of the network or violates the rules and
|
| 335 |
+
protocols for communication across the network.
|
| 336 |
+
|
| 337 |
+
Corresponding Source conveyed, and Installation Information provided,
|
| 338 |
+
in accord with this section must be in a format that is publicly
|
| 339 |
+
documented (and with an implementation available to the public in
|
| 340 |
+
source code form), and must require no special password or key for
|
| 341 |
+
unpacking, reading or copying.
|
| 342 |
+
|
| 343 |
+
7. Additional Terms.
|
| 344 |
+
|
| 345 |
+
"Additional permissions" are terms that supplement the terms of this
|
| 346 |
+
License by making exceptions from one or more of its conditions.
|
| 347 |
+
Additional permissions that are applicable to the entire Program shall
|
| 348 |
+
be treated as though they were included in this License, to the extent
|
| 349 |
+
that they are valid under applicable law. If additional permissions
|
| 350 |
+
apply only to part of the Program, that part may be used separately
|
| 351 |
+
under those permissions, but the entire Program remains governed by
|
| 352 |
+
this License without regard to the additional permissions.
|
| 353 |
+
|
| 354 |
+
When you convey a copy of a covered work, you may at your option
|
| 355 |
+
remove any additional permissions from that copy, or from any part of
|
| 356 |
+
it. (Additional permissions may be written to require their own
|
| 357 |
+
removal in certain cases when you modify the work.) You may place
|
| 358 |
+
additional permissions on material, added by you to a covered work,
|
| 359 |
+
for which you have or can give appropriate copyright permission.
|
| 360 |
+
|
| 361 |
+
Notwithstanding any other provision of this License, for material you
|
| 362 |
+
add to a covered work, you may (if authorized by the copyright holders of
|
| 363 |
+
that material) supplement the terms of this License with terms:
|
| 364 |
+
|
| 365 |
+
a) Disclaiming warranty or limiting liability differently from the
|
| 366 |
+
terms of sections 15 and 16 of this License; or
|
| 367 |
+
|
| 368 |
+
b) Requiring preservation of specified reasonable legal notices or
|
| 369 |
+
author attributions in that material or in the Appropriate Legal
|
| 370 |
+
Notices displayed by works containing it; or
|
| 371 |
+
|
| 372 |
+
c) Prohibiting misrepresentation of the origin of that material, or
|
| 373 |
+
requiring that modified versions of such material be marked in
|
| 374 |
+
reasonable ways as different from the original version; or
|
| 375 |
+
|
| 376 |
+
d) Limiting the use for publicity purposes of names of licensors or
|
| 377 |
+
authors of the material; or
|
| 378 |
+
|
| 379 |
+
e) Declining to grant rights under trademark law for use of some
|
| 380 |
+
trade names, trademarks, or service marks; or
|
| 381 |
+
|
| 382 |
+
f) Requiring indemnification of licensors and authors of that
|
| 383 |
+
material by anyone who conveys the material (or modified versions of
|
| 384 |
+
it) with contractual assumptions of liability to the recipient, for
|
| 385 |
+
any liability that these contractual assumptions directly impose on
|
| 386 |
+
those licensors and authors.
|
| 387 |
+
|
| 388 |
+
All other non-permissive additional terms are considered "further
|
| 389 |
+
restrictions" within the meaning of section 10. If the Program as you
|
| 390 |
+
received it, or any part of it, contains a notice stating that it is
|
| 391 |
+
governed by this License along with a term that is a further
|
| 392 |
+
restriction, you may remove that term. If a license document contains
|
| 393 |
+
a further restriction but permits relicensing or conveying under this
|
| 394 |
+
License, you may add to a covered work material governed by the terms
|
| 395 |
+
of that license document, provided that the further restriction does
|
| 396 |
+
not survive such relicensing or conveying.
|
| 397 |
+
|
| 398 |
+
If you add terms to a covered work in accord with this section, you
|
| 399 |
+
must place, in the relevant source files, a statement of the
|
| 400 |
+
additional terms that apply to those files, or a notice indicating
|
| 401 |
+
where to find the applicable terms.
|
| 402 |
+
|
| 403 |
+
Additional terms, permissive or non-permissive, may be stated in the
|
| 404 |
+
form of a separately written license, or stated as exceptions;
|
| 405 |
+
the above requirements apply either way.
|
| 406 |
+
|
| 407 |
+
8. Termination.
|
| 408 |
+
|
| 409 |
+
You may not propagate or modify a covered work except as expressly
|
| 410 |
+
provided under this License. Any attempt otherwise to propagate or
|
| 411 |
+
modify it is void, and will automatically terminate your rights under
|
| 412 |
+
this License (including any patent licenses granted under the third
|
| 413 |
+
paragraph of section 11).
|
| 414 |
+
|
| 415 |
+
However, if you cease all violation of this License, then your
|
| 416 |
+
license from a particular copyright holder is reinstated (a)
|
| 417 |
+
provisionally, unless and until the copyright holder explicitly and
|
| 418 |
+
finally terminates your license, and (b) permanently, if the copyright
|
| 419 |
+
holder fails to notify you of the violation by some reasonable means
|
| 420 |
+
prior to 60 days after the cessation.
|
| 421 |
+
|
| 422 |
+
Moreover, your license from a particular copyright holder is
|
| 423 |
+
reinstated permanently if the copyright holder notifies you of the
|
| 424 |
+
violation by some reasonable means, this is the first time you have
|
| 425 |
+
received notice of violation of this License (for any work) from that
|
| 426 |
+
copyright holder, and you cure the violation prior to 30 days after
|
| 427 |
+
your receipt of the notice.
|
| 428 |
+
|
| 429 |
+
Termination of your rights under this section does not terminate the
|
| 430 |
+
licenses of parties who have received copies or rights from you under
|
| 431 |
+
this License. If your rights have been terminated and not permanently
|
| 432 |
+
reinstated, you do not qualify to receive new licenses for the same
|
| 433 |
+
material under section 10.
|
| 434 |
+
|
| 435 |
+
9. Acceptance Not Required for Having Copies.
|
| 436 |
+
|
| 437 |
+
You are not required to accept this License in order to receive or
|
| 438 |
+
run a copy of the Program. Ancillary propagation of a covered work
|
| 439 |
+
occurring solely as a consequence of using peer-to-peer transmission
|
| 440 |
+
to receive a copy likewise does not require acceptance. However,
|
| 441 |
+
nothing other than this License grants you permission to propagate or
|
| 442 |
+
modify any covered work. These actions infringe copyright if you do
|
| 443 |
+
not accept this License. Therefore, by modifying or propagating a
|
| 444 |
+
covered work, you indicate your acceptance of this License to do so.
|
| 445 |
+
|
| 446 |
+
10. Automatic Licensing of Downstream Recipients.
|
| 447 |
+
|
| 448 |
+
Each time you convey a covered work, the recipient automatically
|
| 449 |
+
receives a license from the original licensors, to run, modify and
|
| 450 |
+
propagate that work, subject to this License. You are not responsible
|
| 451 |
+
for enforcing compliance by third parties with this License.
|
| 452 |
+
|
| 453 |
+
An "entity transaction" is a transaction transferring control of an
|
| 454 |
+
organization, or substantially all assets of one, or subdividing an
|
| 455 |
+
organization, or merging organizations. If propagation of a covered
|
| 456 |
+
work results from an entity transaction, each party to that
|
| 457 |
+
transaction who receives a copy of the work also receives whatever
|
| 458 |
+
licenses to the work the party's predecessor in interest had or could
|
| 459 |
+
give under the previous paragraph, plus a right to possession of the
|
| 460 |
+
Corresponding Source of the work from the predecessor in interest, if
|
| 461 |
+
the predecessor has it or can get it with reasonable efforts.
|
| 462 |
+
|
| 463 |
+
You may not impose any further restrictions on the exercise of the
|
| 464 |
+
rights granted or affirmed under this License. For example, you may
|
| 465 |
+
not impose a license fee, royalty, or other charge for exercise of
|
| 466 |
+
rights granted under this License, and you may not initiate litigation
|
| 467 |
+
(including a cross-claim or counterclaim in a lawsuit) alleging that
|
| 468 |
+
any patent claim is infringed by making, using, selling, offering for
|
| 469 |
+
sale, or importing the Program or any portion of it.
|
| 470 |
+
|
| 471 |
+
11. Patents.
|
| 472 |
+
|
| 473 |
+
A "contributor" is a copyright holder who authorizes use under this
|
| 474 |
+
License of the Program or a work on which the Program is based. The
|
| 475 |
+
work thus licensed is called the contributor's "contributor version".
|
| 476 |
+
|
| 477 |
+
A contributor's "essential patent claims" are all patent claims
|
| 478 |
+
owned or controlled by the contributor, whether already acquired or
|
| 479 |
+
hereafter acquired, that would be infringed by some manner, permitted
|
| 480 |
+
by this License, of making, using, or selling its contributor version,
|
| 481 |
+
but do not include claims that would be infringed only as a
|
| 482 |
+
consequence of further modification of the contributor version. For
|
| 483 |
+
purposes of this definition, "control" includes the right to grant
|
| 484 |
+
patent sublicenses in a manner consistent with the requirements of
|
| 485 |
+
this License.
|
| 486 |
+
|
| 487 |
+
Each contributor grants you a non-exclusive, worldwide, royalty-free
|
| 488 |
+
patent license under the contributor's essential patent claims, to
|
| 489 |
+
make, use, sell, offer for sale, import and otherwise run, modify and
|
| 490 |
+
propagate the contents of its contributor version.
|
| 491 |
+
|
| 492 |
+
In the following three paragraphs, a "patent license" is any express
|
| 493 |
+
agreement or commitment, however denominated, not to enforce a patent
|
| 494 |
+
(such as an express permission to practice a patent or covenant not to
|
| 495 |
+
sue for patent infringement). To "grant" such a patent license to a
|
| 496 |
+
party means to make such an agreement or commitment not to enforce a
|
| 497 |
+
patent against the party.
|
| 498 |
+
|
| 499 |
+
If you convey a covered work, knowingly relying on a patent license,
|
| 500 |
+
and the Corresponding Source of the work is not available for anyone
|
| 501 |
+
to copy, free of charge and under the terms of this License, through a
|
| 502 |
+
publicly available network server or other readily accessible means,
|
| 503 |
+
then you must either (1) cause the Corresponding Source to be so
|
| 504 |
+
available, or (2) arrange to deprive yourself of the benefit of the
|
| 505 |
+
patent license for this particular work, or (3) arrange, in a manner
|
| 506 |
+
consistent with the requirements of this License, to extend the patent
|
| 507 |
+
license to downstream recipients. "Knowingly relying" means you have
|
| 508 |
+
actual knowledge that, but for the patent license, your conveying the
|
| 509 |
+
covered work in a country, or your recipient's use of the covered work
|
| 510 |
+
in a country, would infringe one or more identifiable patents in that
|
| 511 |
+
country that you have reason to believe are valid.
|
| 512 |
+
|
| 513 |
+
If, pursuant to or in connection with a single transaction or
|
| 514 |
+
arrangement, you convey, or propagate by procuring conveyance of, a
|
| 515 |
+
covered work, and grant a patent license to some of the parties
|
| 516 |
+
receiving the covered work authorizing them to use, propagate, modify
|
| 517 |
+
or convey a specific copy of the covered work, then the patent license
|
| 518 |
+
you grant is automatically extended to all recipients of the covered
|
| 519 |
+
work and works based on it.
|
| 520 |
+
|
| 521 |
+
A patent license is "discriminatory" if it does not include within
|
| 522 |
+
the scope of its coverage, prohibits the exercise of, or is
|
| 523 |
+
conditioned on the non-exercise of one or more of the rights that are
|
| 524 |
+
specifically granted under this License. You may not convey a covered
|
| 525 |
+
work if you are a party to an arrangement with a third party that is
|
| 526 |
+
in the business of distributing software, under which you make payment
|
| 527 |
+
to the third party based on the extent of your activity of conveying
|
| 528 |
+
the work, and under which the third party grants, to any of the
|
| 529 |
+
parties who would receive the covered work from you, a discriminatory
|
| 530 |
+
patent license (a) in connection with copies of the covered work
|
| 531 |
+
conveyed by you (or copies made from those copies), or (b) primarily
|
| 532 |
+
for and in connection with specific products or compilations that
|
| 533 |
+
contain the covered work, unless you entered into that arrangement,
|
| 534 |
+
or that patent license was granted, prior to 28 March 2007.
|
| 535 |
+
|
| 536 |
+
Nothing in this License shall be construed as excluding or limiting
|
| 537 |
+
any implied license or other defenses to infringement that may
|
| 538 |
+
otherwise be available to you under applicable patent law.
|
| 539 |
+
|
| 540 |
+
12. No Surrender of Others' Freedom.
|
| 541 |
+
|
| 542 |
+
If conditions are imposed on you (whether by court order, agreement or
|
| 543 |
+
otherwise) that contradict the conditions of this License, they do not
|
| 544 |
+
excuse you from the conditions of this License. If you cannot convey a
|
| 545 |
+
covered work so as to satisfy simultaneously your obligations under this
|
| 546 |
+
License and any other pertinent obligations, then as a consequence you may
|
| 547 |
+
not convey it at all. For example, if you agree to terms that obligate you
|
| 548 |
+
to collect a royalty for further conveying from those to whom you convey
|
| 549 |
+
the Program, the only way you could satisfy both those terms and this
|
| 550 |
+
License would be to refrain entirely from conveying the Program.
|
| 551 |
+
|
| 552 |
+
13. Use with the GNU Affero General Public License.
|
| 553 |
+
|
| 554 |
+
Notwithstanding any other provision of this License, you have
|
| 555 |
+
permission to link or combine any covered work with a work licensed
|
| 556 |
+
under version 3 of the GNU Affero General Public License into a single
|
| 557 |
+
combined work, and to convey the resulting work. The terms of this
|
| 558 |
+
License will continue to apply to the part which is the covered work,
|
| 559 |
+
but the special requirements of the GNU Affero General Public License,
|
| 560 |
+
section 13, concerning interaction through a network will apply to the
|
| 561 |
+
combination as such.
|
| 562 |
+
|
| 563 |
+
14. Revised Versions of this License.
|
| 564 |
+
|
| 565 |
+
The Free Software Foundation may publish revised and/or new versions of
|
| 566 |
+
the GNU General Public License from time to time. Such new versions will
|
| 567 |
+
be similar in spirit to the present version, but may differ in detail to
|
| 568 |
+
address new problems or concerns.
|
| 569 |
+
|
| 570 |
+
Each version is given a distinguishing version number. If the
|
| 571 |
+
Program specifies that a certain numbered version of the GNU General
|
| 572 |
+
Public License "or any later version" applies to it, you have the
|
| 573 |
+
option of following the terms and conditions either of that numbered
|
| 574 |
+
version or of any later version published by the Free Software
|
| 575 |
+
Foundation. If the Program does not specify a version number of the
|
| 576 |
+
GNU General Public License, you may choose any version ever published
|
| 577 |
+
by the Free Software Foundation.
|
| 578 |
+
|
| 579 |
+
If the Program specifies that a proxy can decide which future
|
| 580 |
+
versions of the GNU General Public License can be used, that proxy's
|
| 581 |
+
public statement of acceptance of a version permanently authorizes you
|
| 582 |
+
to choose that version for the Program.
|
| 583 |
+
|
| 584 |
+
Later license versions may give you additional or different
|
| 585 |
+
permissions. However, no additional obligations are imposed on any
|
| 586 |
+
author or copyright holder as a result of your choosing to follow a
|
| 587 |
+
later version.
|
| 588 |
+
|
| 589 |
+
15. Disclaimer of Warranty.
|
| 590 |
+
|
| 591 |
+
THERE IS NO WARRANTY FOR THE PROGRAM, TO THE EXTENT PERMITTED BY
|
| 592 |
+
APPLICABLE LAW. EXCEPT WHEN OTHERWISE STATED IN WRITING THE COPYRIGHT
|
| 593 |
+
HOLDERS AND/OR OTHER PARTIES PROVIDE THE PROGRAM "AS IS" WITHOUT WARRANTY
|
| 594 |
+
OF ANY KIND, EITHER EXPRESSED OR IMPLIED, INCLUDING, BUT NOT LIMITED TO,
|
| 595 |
+
THE IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR
|
| 596 |
+
PURPOSE. THE ENTIRE RISK AS TO THE QUALITY AND PERFORMANCE OF THE PROGRAM
|
| 597 |
+
IS WITH YOU. SHOULD THE PROGRAM PROVE DEFECTIVE, YOU ASSUME THE COST OF
|
| 598 |
+
ALL NECESSARY SERVICING, REPAIR OR CORRECTION.
|
| 599 |
+
|
| 600 |
+
16. Limitation of Liability.
|
| 601 |
+
|
| 602 |
+
IN NO EVENT UNLESS REQUIRED BY APPLICABLE LAW OR AGREED TO IN WRITING
|
| 603 |
+
WILL ANY COPYRIGHT HOLDER, OR ANY OTHER PARTY WHO MODIFIES AND/OR CONVEYS
|
| 604 |
+
THE PROGRAM AS PERMITTED ABOVE, BE LIABLE TO YOU FOR DAMAGES, INCLUDING ANY
|
| 605 |
+
GENERAL, SPECIAL, INCIDENTAL OR CONSEQUENTIAL DAMAGES ARISING OUT OF THE
|
| 606 |
+
USE OR INABILITY TO USE THE PROGRAM (INCLUDING BUT NOT LIMITED TO LOSS OF
|
| 607 |
+
DATA OR DATA BEING RENDERED INACCURATE OR LOSSES SUSTAINED BY YOU OR THIRD
|
| 608 |
+
PARTIES OR A FAILURE OF THE PROGRAM TO OPERATE WITH ANY OTHER PROGRAMS),
|
| 609 |
+
EVEN IF SUCH HOLDER OR OTHER PARTY HAS BEEN ADVISED OF THE POSSIBILITY OF
|
| 610 |
+
SUCH DAMAGES.
|
| 611 |
+
|
| 612 |
+
17. Interpretation of Sections 15 and 16.
|
| 613 |
+
|
| 614 |
+
If the disclaimer of warranty and limitation of liability provided
|
| 615 |
+
above cannot be given local legal effect according to their terms,
|
| 616 |
+
reviewing courts shall apply local law that most closely approximates
|
| 617 |
+
an absolute waiver of all civil liability in connection with the
|
| 618 |
+
Program, unless a warranty or assumption of liability accompanies a
|
| 619 |
+
copy of the Program in return for a fee.
|
| 620 |
+
|
| 621 |
+
END OF TERMS AND CONDITIONS
|
| 622 |
+
|
| 623 |
+
How to Apply These Terms to Your New Programs
|
| 624 |
+
|
| 625 |
+
If you develop a new program, and you want it to be of the greatest
|
| 626 |
+
possible use to the public, the best way to achieve this is to make it
|
| 627 |
+
free software which everyone can redistribute and change under these terms.
|
| 628 |
+
|
| 629 |
+
To do so, attach the following notices to the program. It is safest
|
| 630 |
+
to attach them to the start of each source file to most effectively
|
| 631 |
+
state the exclusion of warranty; and each file should have at least
|
| 632 |
+
the "copyright" line and a pointer to where the full notice is found.
|
| 633 |
+
|
| 634 |
+
<one line to give the program's name and a brief idea of what it does.>
|
| 635 |
+
Copyright (C) <year> <name of author>
|
| 636 |
+
|
| 637 |
+
This program is free software: you can redistribute it and/or modify
|
| 638 |
+
it under the terms of the GNU General Public License as published by
|
| 639 |
+
the Free Software Foundation, either version 3 of the License, or
|
| 640 |
+
(at your option) any later version.
|
| 641 |
+
|
| 642 |
+
This program is distributed in the hope that it will be useful,
|
| 643 |
+
but WITHOUT ANY WARRANTY; without even the implied warranty of
|
| 644 |
+
MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
|
| 645 |
+
GNU General Public License for more details.
|
| 646 |
+
|
| 647 |
+
You should have received a copy of the GNU General Public License
|
| 648 |
+
along with this program. If not, see <https://www.gnu.org/licenses/>.
|
| 649 |
+
|
| 650 |
+
Also add information on how to contact you by electronic and paper mail.
|
| 651 |
+
|
| 652 |
+
If the program does terminal interaction, make it output a short
|
| 653 |
+
notice like this when it starts in an interactive mode:
|
| 654 |
+
|
| 655 |
+
<program> Copyright (C) <year> <name of author>
|
| 656 |
+
This program comes with ABSOLUTELY NO WARRANTY; for details type `show w'.
|
| 657 |
+
This is free software, and you are welcome to redistribute it
|
| 658 |
+
under certain conditions; type `show c' for details.
|
| 659 |
+
|
| 660 |
+
The hypothetical commands `show w' and `show c' should show the appropriate
|
| 661 |
+
parts of the General Public License. Of course, your program's commands
|
| 662 |
+
might be different; for a GUI interface, you would use an "about box".
|
| 663 |
+
|
| 664 |
+
You should also get your employer (if you work as a programmer) or school,
|
| 665 |
+
if any, to sign a "copyright disclaimer" for the program, if necessary.
|
| 666 |
+
For more information on this, and how to apply and follow the GNU GPL, see
|
| 667 |
+
<https://www.gnu.org/licenses/>.
|
| 668 |
+
|
| 669 |
+
The GNU General Public License does not permit incorporating your program
|
| 670 |
+
into proprietary programs. If your program is a subroutine library, you
|
| 671 |
+
may consider it more useful to permit linking proprietary applications with
|
| 672 |
+
the library. If this is what you want to do, use the GNU Lesser General
|
| 673 |
+
Public License instead of this License. But first, please read
|
| 674 |
+
<https://www.gnu.org/licenses/why-not-lgpl.html>. GNU GENERAL PUBLIC LICENSE
|
| 675 |
+
Version 3, 29 June 2007
|
| 676 |
+
|
| 677 |
+
Copyright (C) 2007 Free Software Foundation, Inc. <https://fsf.org/>
|
| 678 |
+
Everyone is permitted to copy and distribute verbatim copies
|
| 679 |
+
of this license document, but changing it is not allowed.
|
| 680 |
+
|
| 681 |
+
Preamble
|
| 682 |
+
|
| 683 |
+
The GNU General Public License is a free, copyleft license for
|
| 684 |
+
software and other kinds of works.
|
| 685 |
+
|
| 686 |
+
The licenses for most software and other practical works are designed
|
| 687 |
+
to take away your freedom to share and change the works. By contrast,
|
| 688 |
+
the GNU General Public License is intended to guarantee your freedom to
|
| 689 |
+
share and change all versions of a program--to make sure it remains free
|
| 690 |
+
software for all its users. We, the Free Software Foundation, use the
|
| 691 |
+
GNU General Public License for most of our software; it applies also to
|
| 692 |
+
any other work released this way by its authors. You can apply it to
|
| 693 |
+
your programs, too.
|
| 694 |
+
|
| 695 |
+
When we speak of free software, we are referring to freedom, not
|
| 696 |
+
price. Our General Public Licenses are designed to make sure that you
|
| 697 |
+
have the freedom to distribute copies of free software (and charge for
|
| 698 |
+
them if you wish), that you receive source code or can get it if you
|
| 699 |
+
want it, that you can change the software or use pieces of it in new
|
| 700 |
+
free programs, and that you know you can do these things.
|
| 701 |
+
|
| 702 |
+
To protect your rights, we need to prevent others from denying you
|
| 703 |
+
these rights or asking you to surrender the rights. Therefore, you have
|
| 704 |
+
certain responsibilities if you distribute copies of the software, or if
|
| 705 |
+
you modify it: responsibilities to respect the freedom of others.
|
| 706 |
+
|
| 707 |
+
For example, if you distribute copies of such a program, whether
|
| 708 |
+
gratis or for a fee, you must pass on to the recipients the same
|
| 709 |
+
freedoms that you received. You must make sure that they, too, receive
|
| 710 |
+
or can get the source code. And you must show them these terms so they
|
| 711 |
+
know their rights.
|
| 712 |
+
|
| 713 |
+
Developers that use the GNU GPL protect your rights with two steps:
|
| 714 |
+
(1) assert copyright on the software, and (2) offer you this License
|
| 715 |
+
giving you legal permission to copy, distribute and/or modify it.
|
| 716 |
+
|
| 717 |
+
For the developers' and authors' protection, the GPL clearly explains
|
| 718 |
+
that there is no warranty for this free software. For both users' and
|
| 719 |
+
authors' sake, the GPL requires that modified versions be marked as
|
| 720 |
+
changed, so that their problems will not be attributed erroneously to
|
| 721 |
+
authors of previous versions.
|
| 722 |
+
|
| 723 |
+
Some devices are designed to deny users access to install or run
|
| 724 |
+
modified versions of the software inside them, although the manufacturer
|
| 725 |
+
can do so. This is fundamentally incompatible with the aim of
|
| 726 |
+
protecting users' freedom to change the software. The systematic
|
| 727 |
+
pattern of such abuse occurs in the area of products for individuals to
|
| 728 |
+
use, which is precisely where it is most unacceptable. Therefore, we
|
| 729 |
+
have designed this version of the GPL to prohibit the practice for those
|
| 730 |
+
products. If such problems arise substantially in other domains, we
|
| 731 |
+
stand ready to extend this provision to those domains in future versions
|
| 732 |
+
of the GPL, as needed to protect the freedom of users.
|
| 733 |
+
|
| 734 |
+
Finally, every program is threatened constantly by software patents.
|
| 735 |
+
States should not allow patents to restrict development and use of
|
| 736 |
+
software on general-purpose computers, but in those that do, we wish to
|
| 737 |
+
avoid the special danger that patents applied to a free program could
|
| 738 |
+
make it effectively proprietary. To prevent this, the GPL assures that
|
| 739 |
+
patents cannot be used to render the program non-free.
|
| 740 |
+
|
| 741 |
+
The precise terms and conditions for copying, distribution and
|
| 742 |
+
modification follow.
|
| 743 |
+
|
| 744 |
+
TERMS AND CONDITIONS
|
| 745 |
+
|
| 746 |
+
0. Definitions.
|
| 747 |
+
|
| 748 |
+
"This License" refers to version 3 of the GNU General Public License.
|
| 749 |
+
|
| 750 |
+
"Copyright" also means copyright-like laws that apply to other kinds of
|
| 751 |
+
works, such as semiconductor masks.
|
| 752 |
+
|
| 753 |
+
"The Program" refers to any copyrightable work licensed under this
|
| 754 |
+
License. Each licensee is addressed as "you". "Licensees" and
|
| 755 |
+
"recipients" may be individuals or organizations.
|
| 756 |
+
|
| 757 |
+
To "modify" a work means to copy from or adapt all or part of the work
|
| 758 |
+
in a fashion requiring copyright permission, other than the making of an
|
| 759 |
+
exact copy. The resulting work is called a "modified version" of the
|
| 760 |
+
earlier work or a work "based on" the earlier work.
|
| 761 |
+
|
| 762 |
+
A "covered work" means either the unmodified Program or a work based
|
| 763 |
+
on the Program.
|
| 764 |
+
|
| 765 |
+
To "propagate" a work means to do anything with it that, without
|
| 766 |
+
permission, would make you directly or secondarily liable for
|
| 767 |
+
infringement under applicable copyright law, except executing it on a
|
| 768 |
+
computer or modifying a private copy. Propagation includes copying,
|
| 769 |
+
distribution (with or without modification), making available to the
|
| 770 |
+
public, and in some countries other activities as well.
|
| 771 |
+
|
| 772 |
+
To "convey" a work means any kind of propagation that enables other
|
| 773 |
+
parties to make or receive copies. Mere interaction with a user through
|
| 774 |
+
a computer network, with no transfer of a copy, is not conveying.
|
| 775 |
+
|
| 776 |
+
An interactive user interface displays "Appropriate Legal Notices"
|
| 777 |
+
to the extent that it includes a convenient and prominently visible
|
| 778 |
+
feature that (1) displays an appropriate copyright notice, and (2)
|
| 779 |
+
tells the user that there is no warranty for the work (except to the
|
| 780 |
+
extent that warranties are provided), that licensees may convey the
|
| 781 |
+
work under this License, and how to view a copy of this License. If
|
| 782 |
+
the interface presents a list of user commands or options, such as a
|
| 783 |
+
menu, a prominent item in the list meets this criterion.
|
| 784 |
+
|
| 785 |
+
1. Source Code.
|
| 786 |
+
|
| 787 |
+
The "source code" for a work means the preferred form of the work
|
| 788 |
+
for making modifications to it. "Object code" means any non-source
|
| 789 |
+
form of a work.
|
| 790 |
+
|
| 791 |
+
A "Standard Interface" means an interface that either is an official
|
| 792 |
+
standard defined by a recognized standards body, or, in the case of
|
| 793 |
+
interfaces specified for a particular programming language, one that
|
| 794 |
+
is widely used among developers working in that language.
|
| 795 |
+
|
| 796 |
+
The "System Libraries" of an executable work include anything, other
|
| 797 |
+
than the work as a whole, that (a) is included in the normal form of
|
| 798 |
+
packaging a Major Component, but which is not part of that Major
|
| 799 |
+
Component, and (b) serves only to enable use of the work with that
|
| 800 |
+
Major Component, or to implement a Standard Interface for which an
|
| 801 |
+
implementation is available to the public in source code form. A
|
| 802 |
+
"Major Component", in this context, means a major essential component
|
| 803 |
+
(kernel, window system, and so on) of the specific operating system
|
| 804 |
+
(if any) on which the executable work runs, or a compiler used to
|
| 805 |
+
produce the work, or an object code interpreter used to run it.
|
| 806 |
+
|
| 807 |
+
The "Corresponding Source" for a work in object code form means all
|
| 808 |
+
the source code needed to generate, install, and (for an executable
|
| 809 |
+
work) run the object code and to modify the work, including scripts to
|
| 810 |
+
control those activities. However, it does not include the work's
|
| 811 |
+
System Libraries, or general-purpose tools or generally available free
|
| 812 |
+
programs which are used unmodified in performing those activities but
|
| 813 |
+
which are not part of the work. For example, Corresponding Source
|
| 814 |
+
includes interface definition files associated with source files for
|
| 815 |
+
the work, and the source code for shared libraries and dynamically
|
| 816 |
+
linked subprograms that the work is specifically designed to require,
|
| 817 |
+
such as by intimate data communication or control flow between those
|
| 818 |
+
subprograms and other parts of the work.
|
| 819 |
+
|
| 820 |
+
The Corresponding Source need not include anything that users
|
| 821 |
+
can regenerate automatically from other parts of the Corresponding
|
| 822 |
+
Source.
|
| 823 |
+
|
| 824 |
+
The Corresponding Source for a work in source code form is that
|
| 825 |
+
same work.
|
| 826 |
+
|
| 827 |
+
2. Basic Permissions.
|
| 828 |
+
|
| 829 |
+
All rights granted under this License are granted for the term of
|
| 830 |
+
copyright on the Program, and are irrevocable provided the stated
|
| 831 |
+
conditions are met. This License explicitly affirms your unlimited
|
| 832 |
+
permission to run the unmodified Program. The output from running a
|
| 833 |
+
covered work is covered by this License only if the output, given its
|
| 834 |
+
content, constitutes a covered work. This License acknowledges your
|
| 835 |
+
rights of fair use or other equivalent, as provided by copyright law.
|
| 836 |
+
|
| 837 |
+
You may make, run and propagate covered works that you do not
|
| 838 |
+
convey, without conditions so long as your license otherwise remains
|
| 839 |
+
in force. You may convey covered works to others for the sole purpose
|
| 840 |
+
of having them make modifications exclusively for you, or provide you
|
| 841 |
+
with facilities for running those works, provided that you comply with
|
| 842 |
+
the terms of this License in conveying all material for which you do
|
| 843 |
+
not control copyright. Those thus making or running the covered works
|
| 844 |
+
for you must do so exclusively on your behalf, under your direction
|
| 845 |
+
and control, on terms that prohibit them from making any copies of
|
| 846 |
+
your copyrighted material outside their relationship with you.
|
| 847 |
+
|
| 848 |
+
Conveying under any other circumstances is permitted solely under
|
| 849 |
+
the conditions stated below. Sublicensing is not allowed; section 10
|
| 850 |
+
makes it unnecessary.
|
| 851 |
+
|
| 852 |
+
3. Protecting Users' Legal Rights From Anti-Circumvention Law.
|
| 853 |
+
|
| 854 |
+
No covered work shall be deemed part of an effective technological
|
| 855 |
+
measure under any applicable law fulfilling obligations under article
|
| 856 |
+
11 of the WIPO copyright treaty adopted on 20 December 1996, or
|
| 857 |
+
similar laws prohibiting or restricting circumvention of such
|
| 858 |
+
measures.
|
| 859 |
+
|
| 860 |
+
When you convey a covered work, you waive any legal power to forbid
|
| 861 |
+
circumvention of technological measures to the extent such circumvention
|
| 862 |
+
is effected by exercising rights under this License with respect to
|
| 863 |
+
the covered work, and you disclaim any intention to limit operation or
|
| 864 |
+
modification of the work as a means of enforcing, against the work's
|
| 865 |
+
users, your or third parties' legal rights to forbid circumvention of
|
| 866 |
+
technological measures.
|
| 867 |
+
|
| 868 |
+
4. Conveying Verbatim Copies.
|
| 869 |
+
|
| 870 |
+
You may convey verbatim copies of the Program's source code as you
|
| 871 |
+
receive it, in any medium, provided that you conspicuously and
|
| 872 |
+
appropriately publish on each copy an appropriate copyright notice;
|
| 873 |
+
keep intact all notices stating that this License and any
|
| 874 |
+
non-permissive terms added in accord with section 7 apply to the code;
|
| 875 |
+
keep intact all notices of the absence of any warranty; and give all
|
| 876 |
+
recipients a copy of this License along with the Program.
|
| 877 |
+
|
| 878 |
+
You may charge any price or no price for each copy that you convey,
|
| 879 |
+
and you may offer support or warranty protection for a fee.
|
| 880 |
+
|
| 881 |
+
5. Conveying Modified Source Versions.
|
| 882 |
+
|
| 883 |
+
You may convey a work based on the Program, or the modifications to
|
| 884 |
+
produce it from the Program, in the form of source code under the
|
| 885 |
+
terms of section 4, provided that you also meet all of these conditions:
|
| 886 |
+
|
| 887 |
+
a) The work must carry prominent notices stating that you modified
|
| 888 |
+
it, and giving a relevant date.
|
| 889 |
+
|
| 890 |
+
b) The work must carry prominent notices stating that it is
|
| 891 |
+
released under this License and any conditions added under section
|
| 892 |
+
7. This requirement modifies the requirement in section 4 to
|
| 893 |
+
"keep intact all notices".
|
| 894 |
+
|
| 895 |
+
c) You must license the entire work, as a whole, under this
|
| 896 |
+
License to anyone who comes into possession of a copy. This
|
| 897 |
+
License will therefore apply, along with any applicable section 7
|
| 898 |
+
additional terms, to the whole of the work, and all its parts,
|
| 899 |
+
regardless of how they are packaged. This License gives no
|
| 900 |
+
permission to license the work in any other way, but it does not
|
| 901 |
+
invalidate such permission if you have separately received it.
|
| 902 |
+
|
| 903 |
+
d) If the work has interactive user interfaces, each must display
|
| 904 |
+
Appropriate Legal Notices; however, if the Program has interactive
|
| 905 |
+
interfaces that do not display Appropriate Legal Notices, your
|
| 906 |
+
work need not make them do so.
|
| 907 |
+
|
| 908 |
+
A compilation of a covered work with other separate and independent
|
| 909 |
+
works, which are not by their nature extensions of the covered work,
|
| 910 |
+
and which are not combined with it such as to form a larger program,
|
| 911 |
+
in or on a volume of a storage or distribution medium, is called an
|
| 912 |
+
"aggregate" if the compilation and its resulting copyright are not
|
| 913 |
+
used to limit the access or legal rights of the compilation's users
|
| 914 |
+
beyond what the individual works permit. Inclusion of a covered work
|
| 915 |
+
in an aggregate does not cause this License to apply to the other
|
| 916 |
+
parts of the aggregate.
|
| 917 |
+
|
| 918 |
+
6. Conveying Non-Source Forms.
|
| 919 |
+
|
| 920 |
+
You may convey a covered work in object code form under the terms
|
| 921 |
+
of sections 4 and 5, provided that you also convey the
|
| 922 |
+
machine-readable Corresponding Source under the terms of this License,
|
| 923 |
+
in one of these ways:
|
| 924 |
+
|
| 925 |
+
a) Convey the object code in, or embodied in, a physical product
|
| 926 |
+
(including a physical distribution medium), accompanied by the
|
| 927 |
+
Corresponding Source fixed on a durable physical medium
|
| 928 |
+
customarily used for software interchange.
|
| 929 |
+
|
| 930 |
+
b) Convey the object code in, or embodied in, a physical product
|
| 931 |
+
(including a physical distribution medium), accompanied by a
|
| 932 |
+
written offer, valid for at least three years and valid for as
|
| 933 |
+
long as you offer spare parts or customer support for that product
|
| 934 |
+
model, to give anyone who possesses the object code either (1) a
|
| 935 |
+
copy of the Corresponding Source for all the software in the
|
| 936 |
+
product that is covered by this License, on a durable physical
|
| 937 |
+
medium customarily used for software interchange, for a price no
|
| 938 |
+
more than your reasonable cost of physically performing this
|
| 939 |
+
conveying of source, or (2) access to copy the
|
| 940 |
+
Corresponding Source from a network server at no charge.
|
| 941 |
+
|
| 942 |
+
c) Convey individual copies of the object code with a copy of the
|
| 943 |
+
written offer to provide the Corresponding Source. This
|
| 944 |
+
alternative is allowed only occasionally and noncommercially, and
|
| 945 |
+
only if you received the object code with such an offer, in accord
|
| 946 |
+
with subsection 6b.
|
| 947 |
+
|
| 948 |
+
d) Convey the object code by offering access from a designated
|
| 949 |
+
place (gratis or for a charge), and offer equivalent access to the
|
| 950 |
+
Corresponding Source in the same way through the same place at no
|
| 951 |
+
further charge. You need not require recipients to copy the
|
| 952 |
+
Corresponding Source along with the object code. If the place to
|
| 953 |
+
copy the object code is a network server, the Corresponding Source
|
| 954 |
+
may be on a different server (operated by you or a third party)
|
| 955 |
+
that supports equivalent copying facilities, provided you maintain
|
| 956 |
+
clear directions next to the object code saying where to find the
|
| 957 |
+
Corresponding Source. Regardless of what server hosts the
|
| 958 |
+
Corresponding Source, you remain obligated to ensure that it is
|
| 959 |
+
available for as long as needed to satisfy these requirements.
|
| 960 |
+
|
| 961 |
+
e) Convey the object code using peer-to-peer transmission, provided
|
| 962 |
+
you inform other peers where the object code and Corresponding
|
| 963 |
+
Source of the work are being offered to the general public at no
|
| 964 |
+
charge under subsection 6d.
|
| 965 |
+
|
| 966 |
+
A separable portion of the object code, whose source code is excluded
|
| 967 |
+
from the Corresponding Source as a System Library, need not be
|
| 968 |
+
included in conveying the object code work.
|
| 969 |
+
|
| 970 |
+
A "User Product" is either (1) a "consumer product", which means any
|
| 971 |
+
tangible personal property which is normally used for personal, family,
|
| 972 |
+
or household purposes, or (2) anything designed or sold for incorporation
|
| 973 |
+
into a dwelling. In determining whether a product is a consumer product,
|
| 974 |
+
doubtful cases shall be resolved in favor of coverage. For a particular
|
| 975 |
+
product received by a particular user, "normally used" refers to a
|
| 976 |
+
typical or common use of that class of product, regardless of the status
|
| 977 |
+
of the particular user or of the way in which the particular user
|
| 978 |
+
actually uses, or expects or is expected to use, the product. A product
|
| 979 |
+
is a consumer product regardless of whether the product has substantial
|
| 980 |
+
commercial, industrial or non-consumer uses, unless such uses represent
|
| 981 |
+
the only significant mode of use of the product.
|
| 982 |
+
|
| 983 |
+
"Installation Information" for a User Product means any methods,
|
| 984 |
+
procedures, authorization keys, or other information required to install
|
| 985 |
+
and execute modified versions of a covered work in that User Product from
|
| 986 |
+
a modified version of its Corresponding Source. The information must
|
| 987 |
+
suffice to ensure that the continued functioning of the modified object
|
| 988 |
+
code is in no case prevented or interfered with solely because
|
| 989 |
+
modification has been made.
|
| 990 |
+
|
| 991 |
+
If you convey an object code work under this section in, or with, or
|
| 992 |
+
specifically for use in, a User Product, and the conveying occurs as
|
| 993 |
+
part of a transaction in which the right of possession and use of the
|
| 994 |
+
User Product is transferred to the recipient in perpetuity or for a
|
| 995 |
+
fixed term (regardless of how the transaction is characterized), the
|
| 996 |
+
Corresponding Source conveyed under this section must be accompanied
|
| 997 |
+
by the Installation Information. But this requirement does not apply
|
| 998 |
+
if neither you nor any third party retains the ability to install
|
| 999 |
+
modified object code on the User Product (for example, the work has
|
| 1000 |
+
been installed in ROM).
|
| 1001 |
+
|
| 1002 |
+
The requirement to provide Installation Information does not include a
|
| 1003 |
+
requirement to continue to provide support service, warranty, or updates
|
| 1004 |
+
for a work that has been modified or installed by the recipient, or for
|
| 1005 |
+
the User Product in which it has been modified or installed. Access to a
|
| 1006 |
+
network may be denied when the modification itself materially and
|
| 1007 |
+
adversely affects the operation of the network or violates the rules and
|
| 1008 |
+
protocols for communication across the network.
|
| 1009 |
+
|
| 1010 |
+
Corresponding Source conveyed, and Installation Information provided,
|
| 1011 |
+
in accord with this section must be in a format that is publicly
|
| 1012 |
+
documented (and with an implementation available to the public in
|
| 1013 |
+
source code form), and must require no special password or key for
|
| 1014 |
+
unpacking, reading or copying.
|
| 1015 |
+
|
| 1016 |
+
7. Additional Terms.
|
| 1017 |
+
|
| 1018 |
+
"Additional permissions" are terms that supplement the terms of this
|
| 1019 |
+
License by making exceptions from one or more of its conditions.
|
| 1020 |
+
Additional permissions that are applicable to the entire Program shall
|
| 1021 |
+
be treated as though they were included in this License, to the extent
|
| 1022 |
+
that they are valid under applicable law. If additional permissions
|
| 1023 |
+
apply only to part of the Program, that part may be used separately
|
| 1024 |
+
under those permissions, but the entire Program remains governed by
|
| 1025 |
+
this License without regard to the additional permissions.
|
| 1026 |
+
|
| 1027 |
+
When you convey a copy of a covered work, you may at your option
|
| 1028 |
+
remove any additional permissions from that copy, or from any part of
|
| 1029 |
+
it. (Additional permissions may be written to require their own
|
| 1030 |
+
removal in certain cases when you modify the work.) You may place
|
| 1031 |
+
additional permissions on material, added by you to a covered work,
|
| 1032 |
+
for which you have or can give appropriate copyright permission.
|
| 1033 |
+
|
| 1034 |
+
Notwithstanding any other provision of this License, for material you
|
| 1035 |
+
add to a covered work, you may (if authorized by the copyright holders of
|
| 1036 |
+
that material) supplement the terms of this License with terms:
|
| 1037 |
+
|
| 1038 |
+
a) Disclaiming warranty or limiting liability differently from the
|
| 1039 |
+
terms of sections 15 and 16 of this License; or
|
| 1040 |
+
|
| 1041 |
+
b) Requiring preservation of specified reasonable legal notices or
|
| 1042 |
+
author attributions in that material or in the Appropriate Legal
|
| 1043 |
+
Notices displayed by works containing it; or
|
| 1044 |
+
|
| 1045 |
+
c) Prohibiting misrepresentation of the origin of that material, or
|
| 1046 |
+
requiring that modified versions of such material be marked in
|
| 1047 |
+
reasonable ways as different from the original version; or
|
| 1048 |
+
|
| 1049 |
+
d) Limiting the use for publicity purposes of names of licensors or
|
| 1050 |
+
authors of the material; or
|
| 1051 |
+
|
| 1052 |
+
e) Declining to grant rights under trademark law for use of some
|
| 1053 |
+
trade names, trademarks, or service marks; or
|
| 1054 |
+
|
| 1055 |
+
f) Requiring indemnification of licensors and authors of that
|
| 1056 |
+
material by anyone who conveys the material (or modified versions of
|
| 1057 |
+
it) with contractual assumptions of liability to the recipient, for
|
| 1058 |
+
any liability that these contractual assumptions directly impose on
|
| 1059 |
+
those licensors and authors.
|
| 1060 |
+
|
| 1061 |
+
All other non-permissive additional terms are considered "further
|
| 1062 |
+
restrictions" within the meaning of section 10. If the Program as you
|
| 1063 |
+
received it, or any part of it, contains a notice stating that it is
|
| 1064 |
+
governed by this License along with a term that is a further
|
| 1065 |
+
restriction, you may remove that term. If a license document contains
|
| 1066 |
+
a further restriction but permits relicensing or conveying under this
|
| 1067 |
+
License, you may add to a covered work material governed by the terms
|
| 1068 |
+
of that license document, provided that the further restriction does
|
| 1069 |
+
not survive such relicensing or conveying.
|
| 1070 |
+
|
| 1071 |
+
If you add terms to a covered work in accord with this section, you
|
| 1072 |
+
must place, in the relevant source files, a statement of the
|
| 1073 |
+
additional terms that apply to those files, or a notice indicating
|
| 1074 |
+
where to find the applicable terms.
|
| 1075 |
+
|
| 1076 |
+
Additional terms, permissive or non-permissive, may be stated in the
|
| 1077 |
+
form of a separately written license, or stated as exceptions;
|
| 1078 |
+
the above requirements apply either way.
|
| 1079 |
+
|
| 1080 |
+
8. Termination.
|
| 1081 |
+
|
| 1082 |
+
You may not propagate or modify a covered work except as expressly
|
| 1083 |
+
provided under this License. Any attempt otherwise to propagate or
|
| 1084 |
+
modify it is void, and will automatically terminate your rights under
|
| 1085 |
+
this License (including any patent licenses granted under the third
|
| 1086 |
+
paragraph of section 11).
|
| 1087 |
+
|
| 1088 |
+
However, if you cease all violation of this License, then your
|
| 1089 |
+
license from a particular copyright holder is reinstated (a)
|
| 1090 |
+
provisionally, unless and until the copyright holder explicitly and
|
| 1091 |
+
finally terminates your license, and (b) permanently, if the copyright
|
| 1092 |
+
holder fails to notify you of the violation by some reasonable means
|
| 1093 |
+
prior to 60 days after the cessation.
|
| 1094 |
+
|
| 1095 |
+
Moreover, your license from a particular copyright holder is
|
| 1096 |
+
reinstated permanently if the copyright holder notifies you of the
|
| 1097 |
+
violation by some reasonable means, this is the first time you have
|
| 1098 |
+
received notice of violation of this License (for any work) from that
|
| 1099 |
+
copyright holder, and you cure the violation prior to 30 days after
|
| 1100 |
+
your receipt of the notice.
|
| 1101 |
+
|
| 1102 |
+
Termination of your rights under this section does not terminate the
|
| 1103 |
+
licenses of parties who have received copies or rights from you under
|
| 1104 |
+
this License. If your rights have been terminated and not permanently
|
| 1105 |
+
reinstated, you do not qualify to receive new licenses for the same
|
| 1106 |
+
material under section 10.
|
| 1107 |
+
|
| 1108 |
+
9. Acceptance Not Required for Having Copies.
|
| 1109 |
+
|
| 1110 |
+
You are not required to accept this License in order to receive or
|
| 1111 |
+
run a copy of the Program. Ancillary propagation of a covered work
|
| 1112 |
+
occurring solely as a consequence of using peer-to-peer transmission
|
| 1113 |
+
to receive a copy likewise does not require acceptance. However,
|
| 1114 |
+
nothing other than this License grants you permission to propagate or
|
| 1115 |
+
modify any covered work. These actions infringe copyright if you do
|
| 1116 |
+
not accept this License. Therefore, by modifying or propagating a
|
| 1117 |
+
covered work, you indicate your acceptance of this License to do so.
|
| 1118 |
+
|
| 1119 |
+
10. Automatic Licensing of Downstream Recipients.
|
| 1120 |
+
|
| 1121 |
+
Each time you convey a covered work, the recipient automatically
|
| 1122 |
+
receives a license from the original licensors, to run, modify and
|
| 1123 |
+
propagate that work, subject to this License. You are not responsible
|
| 1124 |
+
for enforcing compliance by third parties with this License.
|
| 1125 |
+
|
| 1126 |
+
An "entity transaction" is a transaction transferring control of an
|
| 1127 |
+
organization, or substantially all assets of one, or subdividing an
|
| 1128 |
+
organization, or merging organizations. If propagation of a covered
|
| 1129 |
+
work results from an entity transaction, each party to that
|
| 1130 |
+
transaction who receives a copy of the work also receives whatever
|
| 1131 |
+
licenses to the work the party's predecessor in interest had or could
|
| 1132 |
+
give under the previous paragraph, plus a right to possession of the
|
| 1133 |
+
Corresponding Source of the work from the predecessor in interest, if
|
| 1134 |
+
the predecessor has it or can get it with reasonable efforts.
|
| 1135 |
+
|
| 1136 |
+
You may not impose any further restrictions on the exercise of the
|
| 1137 |
+
rights granted or affirmed under this License. For example, you may
|
| 1138 |
+
not impose a license fee, royalty, or other charge for exercise of
|
| 1139 |
+
rights granted under this License, and you may not initiate litigation
|
| 1140 |
+
(including a cross-claim or counterclaim in a lawsuit) alleging that
|
| 1141 |
+
any patent claim is infringed by making, using, selling, offering for
|
| 1142 |
+
sale, or importing the Program or any portion of it.
|
| 1143 |
+
|
| 1144 |
+
11. Patents.
|
| 1145 |
+
|
| 1146 |
+
A "contributor" is a copyright holder who authorizes use under this
|
| 1147 |
+
License of the Program or a work on which the Program is based. The
|
| 1148 |
+
work thus licensed is called the contributor's "contributor version".
|
| 1149 |
+
|
| 1150 |
+
A contributor's "essential patent claims" are all patent claims
|
| 1151 |
+
owned or controlled by the contributor, whether already acquired or
|
| 1152 |
+
hereafter acquired, that would be infringed by some manner, permitted
|
| 1153 |
+
by this License, of making, using, or selling its contributor version,
|
| 1154 |
+
but do not include claims that would be infringed only as a
|
| 1155 |
+
consequence of further modification of the contributor version. For
|
| 1156 |
+
purposes of this definition, "control" includes the right to grant
|
| 1157 |
+
patent sublicenses in a manner consistent with the requirements of
|
| 1158 |
+
this License.
|
| 1159 |
+
|
| 1160 |
+
Each contributor grants you a non-exclusive, worldwide, royalty-free
|
| 1161 |
+
patent license under the contributor's essential patent claims, to
|
| 1162 |
+
make, use, sell, offer for sale, import and otherwise run, modify and
|
| 1163 |
+
propagate the contents of its contributor version.
|
| 1164 |
+
|
| 1165 |
+
In the following three paragraphs, a "patent license" is any express
|
| 1166 |
+
agreement or commitment, however denominated, not to enforce a patent
|
| 1167 |
+
(such as an express permission to practice a patent or covenant not to
|
| 1168 |
+
sue for patent infringement). To "grant" such a patent license to a
|
| 1169 |
+
party means to make such an agreement or commitment not to enforce a
|
| 1170 |
+
patent against the party.
|
| 1171 |
+
|
| 1172 |
+
If you convey a covered work, knowingly relying on a patent license,
|
| 1173 |
+
and the Corresponding Source of the work is not available for anyone
|
| 1174 |
+
to copy, free of charge and under the terms of this License, through a
|
| 1175 |
+
publicly available network server or other readily accessible means,
|
| 1176 |
+
then you must either (1) cause the Corresponding Source to be so
|
| 1177 |
+
available, or (2) arrange to deprive yourself of the benefit of the
|
| 1178 |
+
patent license for this particular work, or (3) arrange, in a manner
|
| 1179 |
+
consistent with the requirements of this License, to extend the patent
|
| 1180 |
+
license to downstream recipients. "Knowingly relying" means you have
|
| 1181 |
+
actual knowledge that, but for the patent license, your conveying the
|
| 1182 |
+
covered work in a country, or your recipient's use of the covered work
|
| 1183 |
+
in a country, would infringe one or more identifiable patents in that
|
| 1184 |
+
country that you have reason to believe are valid.
|
| 1185 |
+
|
| 1186 |
+
If, pursuant to or in connection with a single transaction or
|
| 1187 |
+
arrangement, you convey, or propagate by procuring conveyance of, a
|
| 1188 |
+
covered work, and grant a patent license to some of the parties
|
| 1189 |
+
receiving the covered work authorizing them to use, propagate, modify
|
| 1190 |
+
or convey a specific copy of the covered work, then the patent license
|
| 1191 |
+
you grant is automatically extended to all recipients of the covered
|
| 1192 |
+
work and works based on it.
|
| 1193 |
+
|
| 1194 |
+
A patent license is "discriminatory" if it does not include within
|
| 1195 |
+
the scope of its coverage, prohibits the exercise of, or is
|
| 1196 |
+
conditioned on the non-exercise of one or more of the rights that are
|
| 1197 |
+
specifically granted under this License. You may not convey a covered
|
| 1198 |
+
work if you are a party to an arrangement with a third party that is
|
| 1199 |
+
in the business of distributing software, under which you make payment
|
| 1200 |
+
to the third party based on the extent of your activity of conveying
|
| 1201 |
+
the work, and under which the third party grants, to any of the
|
| 1202 |
+
parties who would receive the covered work from you, a discriminatory
|
| 1203 |
+
patent license (a) in connection with copies of the covered work
|
| 1204 |
+
conveyed by you (or copies made from those copies), or (b) primarily
|
| 1205 |
+
for and in connection with specific products or compilations that
|
| 1206 |
+
contain the covered work, unless you entered into that arrangement,
|
| 1207 |
+
or that patent license was granted, prior to 28 March 2007.
|
| 1208 |
+
|
| 1209 |
+
Nothing in this License shall be construed as excluding or limiting
|
| 1210 |
+
any implied license or other defenses to infringement that may
|
| 1211 |
+
otherwise be available to you under applicable patent law.
|
| 1212 |
+
|
| 1213 |
+
12. No Surrender of Others' Freedom.
|
| 1214 |
+
|
| 1215 |
+
If conditions are imposed on you (whether by court order, agreement or
|
| 1216 |
+
otherwise) that contradict the conditions of this License, they do not
|
| 1217 |
+
excuse you from the conditions of this License. If you cannot convey a
|
| 1218 |
+
covered work so as to satisfy simultaneously your obligations under this
|
| 1219 |
+
License and any other pertinent obligations, then as a consequence you may
|
| 1220 |
+
not convey it at all. For example, if you agree to terms that obligate you
|
| 1221 |
+
to collect a royalty for further conveying from those to whom you convey
|
| 1222 |
+
the Program, the only way you could satisfy both those terms and this
|
| 1223 |
+
License would be to refrain entirely from conveying the Program.
|
| 1224 |
+
|
| 1225 |
+
13. Use with the GNU Affero General Public License.
|
| 1226 |
+
|
| 1227 |
+
Notwithstanding any other provision of this License, you have
|
| 1228 |
+
permission to link or combine any covered work with a work licensed
|
| 1229 |
+
under version 3 of the GNU Affero General Public License into a single
|
| 1230 |
+
combined work, and to convey the resulting work. The terms of this
|
| 1231 |
+
License will continue to apply to the part which is the covered work,
|
| 1232 |
+
but the special requirements of the GNU Affero General Public License,
|
| 1233 |
+
section 13, concerning interaction through a network will apply to the
|
| 1234 |
+
combination as such.
|
| 1235 |
+
|
| 1236 |
+
14. Revised Versions of this License.
|
| 1237 |
+
|
| 1238 |
+
The Free Software Foundation may publish revised and/or new versions of
|
| 1239 |
+
the GNU General Public License from time to time. Such new versions will
|
| 1240 |
+
be similar in spirit to the present version, but may differ in detail to
|
| 1241 |
+
address new problems or concerns.
|
| 1242 |
+
|
| 1243 |
+
Each version is given a distinguishing version number. If the
|
| 1244 |
+
Program specifies that a certain numbered version of the GNU General
|
| 1245 |
+
Public License "or any later version" applies to it, you have the
|
| 1246 |
+
option of following the terms and conditions either of that numbered
|
| 1247 |
+
version or of any later version published by the Free Software
|
| 1248 |
+
Foundation. If the Program does not specify a version number of the
|
| 1249 |
+
GNU General Public License, you may choose any version ever published
|
| 1250 |
+
by the Free Software Foundation.
|
| 1251 |
+
|
| 1252 |
+
If the Program specifies that a proxy can decide which future
|
| 1253 |
+
versions of the GNU General Public License can be used, that proxy's
|
| 1254 |
+
public statement of acceptance of a version permanently authorizes you
|
| 1255 |
+
to choose that version for the Program.
|
| 1256 |
+
|
| 1257 |
+
Later license versions may give you additional or different
|
| 1258 |
+
permissions. However, no additional obligations are imposed on any
|
| 1259 |
+
author or copyright holder as a result of your choosing to follow a
|
| 1260 |
+
later version.
|
| 1261 |
+
|
| 1262 |
+
15. Disclaimer of Warranty.
|
| 1263 |
+
|
| 1264 |
+
THERE IS NO WARRANTY FOR THE PROGRAM, TO THE EXTENT PERMITTED BY
|
| 1265 |
+
APPLICABLE LAW. EXCEPT WHEN OTHERWISE STATED IN WRITING THE COPYRIGHT
|
| 1266 |
+
HOLDERS AND/OR OTHER PARTIES PROVIDE THE PROGRAM "AS IS" WITHOUT WARRANTY
|
| 1267 |
+
OF ANY KIND, EITHER EXPRESSED OR IMPLIED, INCLUDING, BUT NOT LIMITED TO,
|
| 1268 |
+
THE IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR
|
| 1269 |
+
PURPOSE. THE ENTIRE RISK AS TO THE QUALITY AND PERFORMANCE OF THE PROGRAM
|
| 1270 |
+
IS WITH YOU. SHOULD THE PROGRAM PROVE DEFECTIVE, YOU ASSUME THE COST OF
|
| 1271 |
+
ALL NECESSARY SERVICING, REPAIR OR CORRECTION.
|
| 1272 |
+
|
| 1273 |
+
16. Limitation of Liability.
|
| 1274 |
+
|
| 1275 |
+
IN NO EVENT UNLESS REQUIRED BY APPLICABLE LAW OR AGREED TO IN WRITING
|
| 1276 |
+
WILL ANY COPYRIGHT HOLDER, OR ANY OTHER PARTY WHO MODIFIES AND/OR CONVEYS
|
| 1277 |
+
THE PROGRAM AS PERMITTED ABOVE, BE LIABLE TO YOU FOR DAMAGES, INCLUDING ANY
|
| 1278 |
+
GENERAL, SPECIAL, INCIDENTAL OR CONSEQUENTIAL DAMAGES ARISING OUT OF THE
|
| 1279 |
+
USE OR INABILITY TO USE THE PROGRAM (INCLUDING BUT NOT LIMITED TO LOSS OF
|
| 1280 |
+
DATA OR DATA BEING RENDERED INACCURATE OR LOSSES SUSTAINED BY YOU OR THIRD
|
| 1281 |
+
PARTIES OR A FAILURE OF THE PROGRAM TO OPERATE WITH ANY OTHER PROGRAMS),
|
| 1282 |
+
EVEN IF SUCH HOLDER OR OTHER PARTY HAS BEEN ADVISED OF THE POSSIBILITY OF
|
| 1283 |
+
SUCH DAMAGES.
|
| 1284 |
+
|
| 1285 |
+
17. Interpretation of Sections 15 and 16.
|
| 1286 |
+
|
| 1287 |
+
If the disclaimer of warranty and limitation of liability provided
|
| 1288 |
+
above cannot be given local legal effect according to their terms,
|
| 1289 |
+
reviewing courts shall apply local law that most closely approximates
|
| 1290 |
+
an absolute waiver of all civil liability in connection with the
|
| 1291 |
+
Program, unless a warranty or assumption of liability accompanies a
|
| 1292 |
+
copy of the Program in return for a fee.
|
| 1293 |
+
|
| 1294 |
+
END OF TERMS AND CONDITIONS
|
| 1295 |
+
|
| 1296 |
+
How to Apply These Terms to Your New Programs
|
| 1297 |
+
|
| 1298 |
+
If you develop a new program, and you want it to be of the greatest
|
| 1299 |
+
possible use to the public, the best way to achieve this is to make it
|
| 1300 |
+
free software which everyone can redistribute and change under these terms.
|
| 1301 |
+
|
| 1302 |
+
To do so, attach the following notices to the program. It is safest
|
| 1303 |
+
to attach them to the start of each source file to most effectively
|
| 1304 |
+
state the exclusion of warranty; and each file should have at least
|
| 1305 |
+
the "copyright" line and a pointer to where the full notice is found.
|
| 1306 |
+
|
| 1307 |
+
<one line to give the program's name and a brief idea of what it does.>
|
| 1308 |
+
Copyright (C) <year> <name of author>
|
| 1309 |
+
|
| 1310 |
+
This program is free software: you can redistribute it and/or modify
|
| 1311 |
+
it under the terms of the GNU General Public License as published by
|
| 1312 |
+
the Free Software Foundation, either version 3 of the License, or
|
| 1313 |
+
(at your option) any later version.
|
| 1314 |
+
|
| 1315 |
+
This program is distributed in the hope that it will be useful,
|
| 1316 |
+
but WITHOUT ANY WARRANTY; without even the implied warranty of
|
| 1317 |
+
MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
|
| 1318 |
+
GNU General Public License for more details.
|
| 1319 |
+
|
| 1320 |
+
You should have received a copy of the GNU General Public License
|
| 1321 |
+
along with this program. If not, see <https://www.gnu.org/licenses/>.
|
| 1322 |
+
|
| 1323 |
+
Also add information on how to contact you by electronic and paper mail.
|
| 1324 |
+
|
| 1325 |
+
If the program does terminal interaction, make it output a short
|
| 1326 |
+
notice like this when it starts in an interactive mode:
|
| 1327 |
+
|
| 1328 |
+
<program> Copyright (C) <year> <name of author>
|
| 1329 |
+
This program comes with ABSOLUTELY NO WARRANTY; for details type `show w'.
|
| 1330 |
+
This is free software, and you are welcome to redistribute it
|
| 1331 |
+
under certain conditions; type `show c' for details.
|
| 1332 |
+
|
| 1333 |
+
The hypothetical commands `show w' and `show c' should show the appropriate
|
| 1334 |
+
parts of the General Public License. Of course, your program's commands
|
| 1335 |
+
might be different; for a GUI interface, you would use an "about box".
|
| 1336 |
+
|
| 1337 |
+
You should also get your employer (if you work as a programmer) or school,
|
| 1338 |
+
if any, to sign a "copyright disclaimer" for the program, if necessary.
|
| 1339 |
+
For more information on this, and how to apply and follow the GNU GPL, see
|
| 1340 |
+
<https://www.gnu.org/licenses/>.
|
| 1341 |
+
|
| 1342 |
+
The GNU General Public License does not permit incorporating your program
|
| 1343 |
+
into proprietary programs. If your program is a subroutine library, you
|
| 1344 |
+
may consider it more useful to permit linking proprietary applications with
|
| 1345 |
+
the library. If this is what you want to do, use the GNU Lesser General
|
| 1346 |
+
Public License instead of this License. But first, please read
|
| 1347 |
+
<https://www.gnu.org/licenses/why-not-lgpl.html>.
|
README.md
CHANGED
|
@@ -1,12 +1,231 @@
|
|
| 1 |
-
|
| 2 |
-
|
| 3 |
-
|
| 4 |
-
|
| 5 |
-
|
| 6 |
-
|
| 7 |
-
|
| 8 |
-
|
| 9 |
-
|
| 10 |
-
|
| 11 |
-
|
| 12 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
<div align="center">
|
| 2 |
+
<img src="./assets/yolo_logo.png" width=60%>
|
| 3 |
+
<br>
|
| 4 |
+
<a href="https://scholar.google.com/citations?hl=zh-CN&user=PH8rJHYAAAAJ">Tianheng Cheng</a><sup><span>2,3,*</span></sup>,
|
| 5 |
+
<a href="https://linsong.info/">Lin Song</a><sup><span>1,📧,*</span></sup>,
|
| 6 |
+
<a href="https://yxgeee.github.io/">Yixiao Ge</a><sup><span>1,🌟,2</span></sup>,
|
| 7 |
+
<a href="http://eic.hust.edu.cn/professor/liuwenyu/"> Wenyu Liu</a><sup><span>3</span></sup>,
|
| 8 |
+
<a href="https://xwcv.github.io/">Xinggang Wang</a><sup><span>3,📧</span></sup>,
|
| 9 |
+
<a href="https://scholar.google.com/citations?user=4oXBp9UAAAAJ&hl=en">Ying Shan</a><sup><span>1,2</span></sup>
|
| 10 |
+
</br>
|
| 11 |
+
|
| 12 |
+
\* Equal contribution 🌟 Project lead 📧 Corresponding author
|
| 13 |
+
|
| 14 |
+
<sup>1</sup> Tencent AI Lab, <sup>2</sup> ARC Lab, Tencent PCG
|
| 15 |
+
<sup>3</sup> Huazhong University of Science and Technology
|
| 16 |
+
<br>
|
| 17 |
+
<div>
|
| 18 |
+
|
| 19 |
+
[](https://wondervictor.github.io/)
|
| 20 |
+
[](https://arxiv.org/abs/2401.17270)
|
| 21 |
+
<a href="https://colab.research.google.com/github/AILab-CVC/YOLO-World/blob/master/inference.ipynb"><img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"></a>
|
| 22 |
+
[](https://huggingface.co/spaces/stevengrove/YOLO-World)
|
| 23 |
+
[](https://replicate.com/zsxkib/yolo-world)
|
| 24 |
+
[](https://huggingface.co/papers/2401.17270)
|
| 25 |
+
[](LICENSE)
|
| 26 |
+
[](https://huggingface.co/spaces/SkalskiP/YOLO-World)
|
| 27 |
+
[](https://supervision.roboflow.com/develop/notebooks/zero-shot-object-detection-with-yolo-world)
|
| 28 |
+
[](https://inference.roboflow.com/foundation/yolo_world/)
|
| 29 |
+
|
| 30 |
+
</div>
|
| 31 |
+
</div>
|
| 32 |
+
|
| 33 |
+
## Notice
|
| 34 |
+
|
| 35 |
+
We recommend that everyone **use English to communicate on issues**, as this helps developers from around the world discuss, share experiences, and answer questions together.
|
| 36 |
+
|
| 37 |
+
## 🔥 Updates
|
| 38 |
+
`[2024-3-28]:` We provide: (1) more high-resolution pre-trained models (e.g., S, M, X) ([#142](https://github.com/AILab-CVC/YOLO-World/issues/142)); (2) pre-trained models with CLIP-Large text encoders. Most importantly, we preliminarily fix the **fine-tuning without `mask-refine`** and explore a new fine-tuning setting ([#160](https://github.com/AILab-CVC/YOLO-World/issues/160),[#76](https://github.com/AILab-CVC/YOLO-World/issues/76)). In addition, fine-tuning YOLO-World with `mask-refine` also obtains significant improvements, check more details in [configs/finetune_coco](./configs/finetune_coco/).
|
| 39 |
+
`[2024-3-16]:` We fix the bugs about the demo ([#110](https://github.com/AILab-CVC/YOLO-World/issues/110),[#94](https://github.com/AILab-CVC/YOLO-World/issues/94),[#129](https://github.com/AILab-CVC/YOLO-World/issues/129), [#125](https://github.com/AILab-CVC/YOLO-World/issues/125)) with visualizations of segmentation masks, and release [**YOLO-World with Embeddings**](./docs/prompt_yolo_world.md), which supports prompt tuning, text prompts and image prompts.
|
| 40 |
+
`[2024-3-3]:` We add the **high-resolution YOLO-World**, which supports `1280x1280` resolution with higher accuracy and better performance for small objects!
|
| 41 |
+
`[2024-2-29]:` We release the newest version of [ **YOLO-World-v2**](./docs/updates.md) with higher accuracy and faster speed! We hope the community can join us to improve YOLO-World!
|
| 42 |
+
`[2024-2-28]:` Excited to announce that YOLO-World has been accepted by **CVPR 2024**! We're continuing to make YOLO-World faster and stronger, as well as making it better to use for all.
|
| 43 |
+
`[2024-2-22]:` We sincerely thank [RoboFlow](https://roboflow.com/) and [@Skalskip92](https://twitter.com/skalskip92) for the [**Video Guide**](https://www.youtube.com/watch?v=X7gKBGVz4vs) about YOLO-World, nice work!
|
| 44 |
+
`[2024-2-18]:` We thank [@Skalskip92](https://twitter.com/skalskip92) for developing the wonderful segmentation demo via connecting YOLO-World and EfficientSAM. You can try it now at the [🤗 HuggingFace Spaces](https://huggingface.co/spaces/SkalskiP/YOLO-World).
|
| 45 |
+
`[2024-2-17]:` The largest model **X** of YOLO-World is released, which achieves better zero-shot performance!
|
| 46 |
+
`[2024-2-17]:` We release the code & models for **YOLO-World-Seg** now! YOLO-World now supports open-vocabulary / zero-shot object segmentation!
|
| 47 |
+
`[2024-2-15]:` The pre-traind YOLO-World-L with CC3M-Lite is released!
|
| 48 |
+
`[2024-2-14]:` We provide the [`image_demo`](demo.py) for inference on images or directories.
|
| 49 |
+
`[2024-2-10]:` We provide the [fine-tuning](./docs/finetuning.md) and [data](./docs/data.md) details for fine-tuning YOLO-World on the COCO dataset or the custom datasets!
|
| 50 |
+
`[2024-2-3]:` We support the `Gradio` demo now in the repo and you can build the YOLO-World demo on your own device!
|
| 51 |
+
`[2024-2-1]:` We've released the code and weights of YOLO-World now!
|
| 52 |
+
`[2024-2-1]:` We deploy the YOLO-World demo on [HuggingFace 🤗](https://huggingface.co/spaces/stevengrove/YOLO-World), you can try it now!
|
| 53 |
+
`[2024-1-31]:` We are excited to launch **YOLO-World**, a cutting-edge real-time open-vocabulary object detector.
|
| 54 |
+
|
| 55 |
+
|
| 56 |
+
## TODO
|
| 57 |
+
|
| 58 |
+
YOLO-World is under active development and please stay tuned ☕️!
|
| 59 |
+
If you have suggestions📃 or ideas💡,**we would love for you to bring them up in the [Roadmap](https://github.com/AILab-CVC/YOLO-World/issues/109)** ❤️!
|
| 60 |
+
> YOLO-World 目前正在积极开发中📃,如果你有建议或者想法💡,**我们非常希望您在 [Roadmap](https://github.com/AILab-CVC/YOLO-World/issues/109) 中提出来** ❤️!
|
| 61 |
+
|
| 62 |
+
## [FAQ (Frequently Asked Questions)](https://github.com/AILab-CVC/YOLO-World/discussions/149)
|
| 63 |
+
|
| 64 |
+
We have set up an FAQ about YOLO-World in the discussion on GitHub. We hope everyone can raise issues or solutions during use here, and we also hope that everyone can quickly find solutions from it.
|
| 65 |
+
|
| 66 |
+
> 我们在GitHub的discussion中建立了关于YOLO-World的常见问答,这里将收集一些常见问题,同时大家可以在此提出使用中的问题或者解决方案,也希望大家能够从中快速寻找到解决方案
|
| 67 |
+
|
| 68 |
+
|
| 69 |
+
## Highlights & Introduction
|
| 70 |
+
|
| 71 |
+
This repo contains the PyTorch implementation, pre-trained weights, and pre-training/fine-tuning code for YOLO-World.
|
| 72 |
+
|
| 73 |
+
* YOLO-World is pre-trained on large-scale datasets, including detection, grounding, and image-text datasets.
|
| 74 |
+
|
| 75 |
+
* YOLO-World is the next-generation YOLO detector, with a strong open-vocabulary detection capability and grounding ability.
|
| 76 |
+
|
| 77 |
+
* YOLO-World presents a *prompt-then-detect* paradigm for efficient user-vocabulary inference, which re-parameterizes vocabulary embeddings as parameters into the model and achieve superior inference speed. You can try to export your own detection model without extra training or fine-tuning in our [online demo](https://huggingface.co/spaces/stevengrove/YOLO-World)!
|
| 78 |
+
|
| 79 |
+
|
| 80 |
+
<center>
|
| 81 |
+
<img width=800px src="./assets/yolo_arch.png">
|
| 82 |
+
</center>
|
| 83 |
+
|
| 84 |
+
## Model Zoo
|
| 85 |
+
|
| 86 |
+
We've pre-trained YOLO-World-S/M/L from scratch and evaluate on the `LVIS val-1.0` and `LVIS minival`. We provide the pre-trained model weights and training logs for applications/research or re-producing the results.
|
| 87 |
+
|
| 88 |
+
### Zero-shot Inference on LVIS dataset
|
| 89 |
+
|
| 90 |
+
<div><font size=2>
|
| 91 |
+
|
| 92 |
+
| model | Pre-train Data | Size | AP<sup>mini</su> | AP<sub>r</sub> | AP<sub>c</sub> | AP<sub>f</sub> | AP<sup>val</su> | AP<sub>r</sub> | AP<sub>c</sub> | AP<sub>f</sub> | weights |
|
| 93 |
+
| :------------------------------------------------------------------------------------------------------------------- | :------------------- | :----------------- | :--------------: | :------------: | :------------: | :------------: | :-------------: | :------------: | :------------: | :------------: | :------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------: |
|
| 94 |
+
| [YOLO-Worldv2-S](./configs/pretrain/yolo_world_v2_s_vlpan_bn_2e-3_100e_4x8gpus_obj365v1_goldg_train_lvis_minival.py) | O365+GoldG | 640 | 22.7 | 16.3 | 20.8 | 25.5 | 17.3 | 11.3 | 14.9 | 22.7 |[HF Checkpoints 🤗](https://huggingface.co/wondervictor/YOLO-World/blob/main/yolo_world_v2_s_obj365v1_goldg_pretrain-55b943ea.pth)|
|
| 95 |
+
| [YOLO-Worldv2-S](./configs/pretrain/yolo_world_v2_s_vlpan_bn_2e-3_100e_4x8gpus_obj365v1_goldg_train_1280ft_lvis_minival.py) | O365+GoldG | 1280🔸 | 24.1 | 18.7 | 22.0 | 26.9 | 18.8 | 14.1 | 16.3 | 23.8 |[HF Checkpoints 🤗](https://huggingface.co/wondervictor/YOLO-World/blob/main/yolo_world_v2_s_obj365v1_goldg_pretrain_1280ft-fc4ff4f7.pth)|
|
| 96 |
+
| [YOLO-Worldv2-M](./configs/pretrain/yolo_world_v2_m_vlpan_bn_2e-3_100e_4x8gpus_obj365v1_goldg_train_lvis_minival.py) | O365+GoldG | 640 | 30.0 | 25.0 | 27.2 | 33.4 | 23.5 | 17.1 | 20.0 | 30.1 | [HF Checkpoints 🤗](https://huggingface.co/wondervictor/YOLO-World/blob/main/yolo_world_v2_m_obj365v1_goldg_pretrain-c6237d5b.pth)|
|
| 97 |
+
| [YOLO-Worldv2-M](./configs/pretrain/yolo_world_v2_m_vlpan_bn_2e-3_100e_4x8gpus_obj365v1_goldg_train_1280ft_lvis_minival.py) | O365+GoldG | 1280🔸 | 31.6 | 24.5 | 29.0 | 35.1 | 25.3 | 19.3 | 22.0 | 31.7 | [HF Checkpoints 🤗](https://huggingface.co/wondervictor/YOLO-World/blob/main/yolo_world_v2_m_obj365v1_goldg_pretrain_1280ft-77d0346d.pth)|
|
| 98 |
+
| [YOLO-Worldv2-L](./configs/pretrain/yolo_world_v2_l_vlpan_bn_2e-3_100e_4x8gpus_obj365v1_goldg_train_lvis_minival.py) | O365+GoldG | 640 | 33.0 | 22.6 | 32.0 | 35.8 | 26.0 | 18.6 | 23.0 | 32.6 | [HF Checkpoints 🤗](https://huggingface.co/wondervictor/YOLO-World/blob/main/yolo_world_v2_l_obj365v1_goldg_pretrain-a82b1fe3.pth)|
|
| 99 |
+
| [YOLO-Worldv2-L](./configs/pretrain/yolo_world_v2_l_vlpan_bn_2e-3_100e_4x8gpus_obj365v1_goldg_train_1280ft_lvis_minival.py) | O365+GoldG | 1280🔸 | 34.6 | 29.2 | 32.8 | 37.2 | 27.6 | 21.9 | 24.2 | 34.0 | [HF Checkpoints 🤗](https://huggingface.co/wondervictor/YOLO-World/blob/main/yolo_world_v2_l_obj365v1_goldg_pretrain_1280ft-9babe3f6.pth)|
|
| 100 |
+
| [YOLO-Worldv2-L (CLIP-Large)](./configs/pretrain/yolo_world_v2_l_clip_large_vlpan_bn_2e-3_100e_4x8gpus_obj365v1_goldg_train_lvis_minival.py) 🔥 | O365+GoldG | 640 | 34.0 | 22.0 | 32.6 | 37.4 | 27.1 | 19.9 | 23.9 | 33.9 | [HF Checkpoints 🤗](https://huggingface.co/wondervictor/YOLO-World/blob/main/yolo_world_v2_l_clip_large_o365v1_goldg_pretrain-8ff2e744.pth)|
|
| 101 |
+
| [YOLO-Worldv2-L (CLIP-Large)](./configs/pretrain/yolo_world_v2_l_clip_large_vlpan_bn_2e-3_100e_4x8gpus_obj365v1_goldg_train_800ft_lvis_minival.py) 🔥 | O365+GoldG | 800🔸 | 35.5 | 28.3 | 33.2 | 38.8 | 28.6 | 22.0 | 25.1 | 35.4 | [HF Checkpoints 🤗](https://huggingface.co/wondervictor/YOLO-World/blob/main/yolo_world_v2_l_clip_large_o365v1_goldg_pretrain_800ft-9df82e55.pth)|
|
| 102 |
+
| [YOLO-Worldv2-L](./configs/pretrain/yolo_world_v2_l_vlpan_bn_2e-3_100e_4x8gpus_obj365v1_goldg_train_lvis_minival.py) | O365+GoldG+CC3M-Lite | 640 | 32.9 | 25.3 | 31.1 | 35.8 | 26.1 | 20.6 | 22.6 | 32.3 | [HF Checkpoints 🤗](https://huggingface.co/wondervictor/YOLO-World/blob/main/yolo_world_v2_l_obj365v1_goldg_cc3mlite_pretrain-ca93cd1f.pth)|
|
| 103 |
+
| [YOLO-Worldv2-X](./configs/pretrain/yolo_world_v2_x_vlpan_bn_2e-3_100e_4x8gpus_obj365v1_goldg_train_lvis_minival.py) | O365+GoldG+CC3M-Lite | 640 | 35.4 | 28.7 | 32.9 | 38.7 | 28.4 | 20.6 | 25.6 | 35.0 | [HF Checkpoints 🤗](https://huggingface.co/wondervictor/YOLO-World/blob/main/yolo_world_v2_x_obj365v1_goldg_cc3mlite_pretrain-8698fbfa.pth) |
|
| 104 |
+
| [YOLO-Worldv2-XL](./configs/pretrain/yolo_world_v2_xl_vlpan_bn_2e-3_100e_4x8gpus_obj365v1_goldg_train_lvis_minival.py) | O365+GoldG+CC3M-Lite | 640 | 36.0 | 25.8 | 34.1 | 39.5 | 29.1 | 21.1 | 26.3 | 35.8 | [HF Checkpoints 🤗](https://huggingface.co/wondervictor/YOLO-World/blob/main/yolo_world_v2_x_obj365v1_goldg_cc3mlite_pretrain-8698fbfa.pth) |
|
| 105 |
+
|
| 106 |
+
</font>
|
| 107 |
+
</div>
|
| 108 |
+
|
| 109 |
+
**NOTE:**
|
| 110 |
+
1. AP<sup>mini</sup>: evaluated on LVIS `minival`.
|
| 111 |
+
3. AP<sup>val</sup>: evaluated on LVIS `val 1.0`.
|
| 112 |
+
4. [HuggingFace Mirror](https://hf-mirror.com/) provides the mirror of HuggingFace, which is a choice for users who are unable to reach.
|
| 113 |
+
5. 🔸: fine-tuning models with the pre-trained data.
|
| 114 |
+
|
| 115 |
+
**Pre-training Logs:**
|
| 116 |
+
|
| 117 |
+
We provide the pre-training logs of `YOLO-World-v2`. Due to the unexpected errors of the local machines, the training might be interrupted several times.
|
| 118 |
+
|
| 119 |
+
| Model | YOLO-World-v2-S | YOLO-World-v2-M | YOLO-World-v2-L | YOLO-World-v2-X |
|
| 120 |
+
| :--- | :-------------: | :--------------: | :-------------: | :-------------: |
|
| 121 |
+
|Pre-training Log | [Part-1](https://drive.google.com/file/d/1oib7pKfA2h1U_5-85H_s0Nz8jWd0R-WP/view?usp=drive_link), [Part-2](https://drive.google.com/file/d/11cZ6OZy80VTvBlZy3kzLAHCxx5Iix5-n/view?usp=drive_link) | [Part-1](https://drive.google.com/file/d/1E6vYSS8kBipGc8oQnsjAfeUAx8I9yOX7/view?usp=drive_link), [Part-2](https://drive.google.com/file/d/1fbM7vt2tgSeB8o_7tUDofWvpPNSViNj5/view?usp=drive_link) | [Part-1](https://drive.google.com/file/d/1Tola1QGJZTL6nGy3SBxKuknfNfREDm8J/view?usp=drive_link), [Part-2](https://drive.google.com/file/d/1mTBXniioUb0CdctCG4ckIU6idGo0NnH8/view?usp=drive_link) | [Final part](https://drive.google.com/file/d/1aEUA_EPQbXOrpxHTQYB6ieGXudb1PLpd/view?usp=drive_link)|
|
| 122 |
+
|
| 123 |
+
|
| 124 |
+
## Getting started
|
| 125 |
+
|
| 126 |
+
### 1. Installation
|
| 127 |
+
|
| 128 |
+
YOLO-World is developed based on `torch==1.11.0` `mmyolo==0.6.0` and `mmdetection==3.0.0`.
|
| 129 |
+
|
| 130 |
+
#### Clone Project
|
| 131 |
+
|
| 132 |
+
```bash
|
| 133 |
+
git clone --recursive https://github.com/AILab-CVC/YOLO-World.git
|
| 134 |
+
```
|
| 135 |
+
#### Install
|
| 136 |
+
|
| 137 |
+
```bash
|
| 138 |
+
pip install torch wheel -q
|
| 139 |
+
pip install -e .
|
| 140 |
+
```
|
| 141 |
+
|
| 142 |
+
### 2. Preparing Data
|
| 143 |
+
|
| 144 |
+
We provide the details about the pre-training data in [docs/data](./docs/data.md).
|
| 145 |
+
|
| 146 |
+
|
| 147 |
+
## Training & Evaluation
|
| 148 |
+
|
| 149 |
+
We adopt the default [training](./tools/train.py) or [evaluation](./tools/test.py) scripts of [mmyolo](https://github.com/open-mmlab/mmyolo).
|
| 150 |
+
We provide the configs for pre-training and fine-tuning in `configs/pretrain` and `configs/finetune_coco`.
|
| 151 |
+
Training YOLO-World is easy:
|
| 152 |
+
|
| 153 |
+
```bash
|
| 154 |
+
chmod +x tools/dist_train.sh
|
| 155 |
+
# sample command for pre-training, use AMP for mixed-precision training
|
| 156 |
+
./tools/dist_train.sh configs/pretrain/yolo_world_l_t2i_bn_2e-4_100e_4x8gpus_obj365v1_goldg_train_lvis_minival.py 8 --amp
|
| 157 |
+
```
|
| 158 |
+
**NOTE:** YOLO-World is pre-trained on 4 nodes with 8 GPUs per node (32 GPUs in total). For pre-training, the `node_rank` and `nnodes` for multi-node training should be specified.
|
| 159 |
+
|
| 160 |
+
Evaluating YOLO-World is also easy:
|
| 161 |
+
|
| 162 |
+
```bash
|
| 163 |
+
chmod +x tools/dist_test.sh
|
| 164 |
+
./tools/dist_test.sh path/to/config path/to/weights 8
|
| 165 |
+
```
|
| 166 |
+
|
| 167 |
+
**NOTE:** We mainly evaluate the performance on LVIS-minival for pre-training.
|
| 168 |
+
|
| 169 |
+
## Fine-tuning YOLO-World
|
| 170 |
+
|
| 171 |
+
We provide the details about fine-tuning YOLO-World in [docs/fine-tuning](./docs/finetuning.md).
|
| 172 |
+
|
| 173 |
+
## Deployment
|
| 174 |
+
|
| 175 |
+
We provide the details about deployment for downstream applications in [docs/deployment](./docs/deploy.md).
|
| 176 |
+
You can directly download the ONNX model through the online [demo](https://huggingface.co/spaces/stevengrove/YOLO-World) in Huggingface Spaces 🤗.
|
| 177 |
+
|
| 178 |
+
## Demo
|
| 179 |
+
|
| 180 |
+
### Gradio Demo
|
| 181 |
+
|
| 182 |
+
We provide the [Gradio](https://www.gradio.app/) demo for local devices:
|
| 183 |
+
|
| 184 |
+
```bash
|
| 185 |
+
pip install gradio==4.16.0
|
| 186 |
+
python demo.py path/to/config path/to/weights
|
| 187 |
+
```
|
| 188 |
+
|
| 189 |
+
Additionaly, you can use a Dockerfile to build an image with gradio. As a prerequisite, make sure you have respective drivers installed alongside [nvidia-container-runtime](https://stackoverflow.com/questions/59691207/docker-build-with-nvidia-runtime). Replace MODEL_NAME and WEIGHT_NAME with the respective values or ommit this and use default values from the [Dockerfile](Dockerfile#3)
|
| 190 |
+
|
| 191 |
+
```bash
|
| 192 |
+
docker build --build-arg="MODEL=MODEL_NAME" --build-arg="WEIGHT=WEIGHT_NAME" -t yolo_demo .
|
| 193 |
+
docker run --runtime nvidia -p 8080:8080
|
| 194 |
+
```
|
| 195 |
+
|
| 196 |
+
### Image Demo
|
| 197 |
+
|
| 198 |
+
We provide a simple image demo for inference on images with visualization outputs.
|
| 199 |
+
|
| 200 |
+
```bash
|
| 201 |
+
python image_demo.py path/to/config path/to/weights image/path/directory 'person,dog,cat' --topk 100 --threshold 0.005 --output-dir demo_outputs
|
| 202 |
+
```
|
| 203 |
+
|
| 204 |
+
**Notes:**
|
| 205 |
+
* The `image` can be a directory or a single image.
|
| 206 |
+
* The `texts` can be a string of categories (noun phrases) which is separated by a comma. We also support `txt` file in which each line contains a category ( noun phrases).
|
| 207 |
+
* The `topk` and `threshold` control the number of predictions and the confidence threshold.
|
| 208 |
+
|
| 209 |
+
### Google Golab Notebook
|
| 210 |
+
|
| 211 |
+
We sincerely thank [Onuralp](https://github.com/onuralpszr) for sharing the [Colab Demo](https://colab.research.google.com/drive/1F_7S5lSaFM06irBCZqjhbN7MpUXo6WwO?usp=sharing), you can have a try 😊!
|
| 212 |
+
|
| 213 |
+
|
| 214 |
+
## Acknowledgement
|
| 215 |
+
|
| 216 |
+
We sincerely thank [mmyolo](https://github.com/open-mmlab/mmyolo), [mmdetection](https://github.com/open-mmlab/mmdetection), [GLIP](https://github.com/microsoft/GLIP), and [transformers](https://github.com/huggingface/transformers) for providing their wonderful code to the community!
|
| 217 |
+
|
| 218 |
+
## Citations
|
| 219 |
+
If you find YOLO-World is useful in your research or applications, please consider giving us a star 🌟 and citing it.
|
| 220 |
+
|
| 221 |
+
```bibtex
|
| 222 |
+
@inproceedings{Cheng2024YOLOWorld,
|
| 223 |
+
title={YOLO-World: Real-Time Open-Vocabulary Object Detection},
|
| 224 |
+
author={Cheng, Tianheng and Song, Lin and Ge, Yixiao and Liu, Wenyu and Wang, Xinggang and Shan, Ying},
|
| 225 |
+
booktitle={Proc. IEEE Conf. Computer Vision and Pattern Recognition (CVPR)},
|
| 226 |
+
year={2024}
|
| 227 |
+
}
|
| 228 |
+
```
|
| 229 |
+
|
| 230 |
+
## Licence
|
| 231 |
+
YOLO-World is under the GPL-v3 Licence and is supported for comercial usage.
|
assets/yolo_arch.png
ADDED
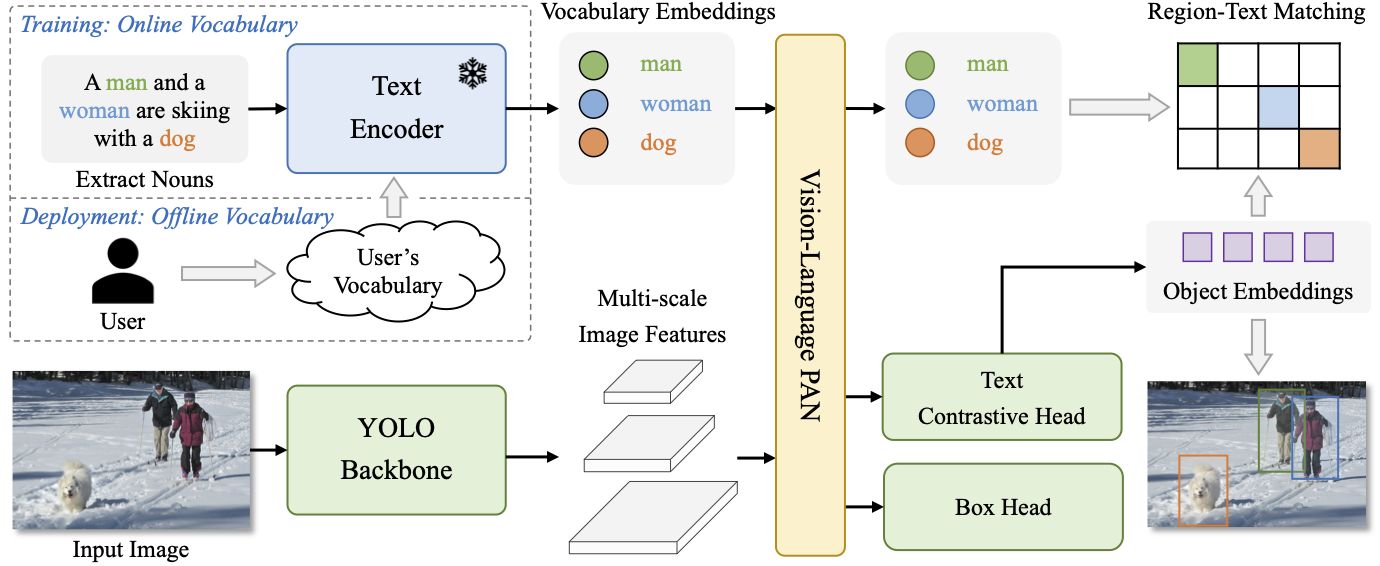
|
assets/yolo_logo.png
ADDED
|
|
configs/finetune_coco/README.md
ADDED
|
@@ -0,0 +1,26 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
## Fine-tune YOLO-World on MS-COCO
|
| 2 |
+
|
| 3 |
+
|
| 4 |
+
### Updates
|
| 5 |
+
|
| 6 |
+
1. [2024-3-27]: Considering that fine-tuning YOLO-World on COCO **without `mask-refine`** obtains bad results, e.g., YOLO-World-L obtains 48.6 AP without `mask-refine` compared to 53.3 AP with `mask-refine`, we rethink the training process and explore new training schemes for fine-tuning without `mask-refine`.
|
| 7 |
+
BTW, the COCO fine-tuning results are updated with higher performance (with `mask-refine`)!
|
| 8 |
+
|
| 9 |
+
|
| 10 |
+
### COCO Results and Checkpoints
|
| 11 |
+
|
| 12 |
+
**NOTE:**
|
| 13 |
+
1. AP<sup>ZS</sup>: AP evaluated in the zero-shot setting (w/o fine-tuning on COCO dataset).
|
| 14 |
+
2. `mask-refine`: refine the box annotations with masks, and add `CopyPaste` augmentation during training.
|
| 15 |
+
|
| 16 |
+
| model | Schedule | `mask-refine` | efficient neck | AP<sup>ZS</sup>| AP | AP<sub>50</sub> | AP<sub>75</sub> | weights | log |
|
| 17 |
+
| :---- | :-------: | :----------: |:-------------: | :------------: | :-: | :--------------:| :-------------: |:------: | :-: |
|
| 18 |
+
| [YOLO-World-v2-S](./yolo_world_v2_s_vlpan_bn_2e-4_80e_8gpus_mask-refine_finetune_coco.py) | AdamW, 2e-4, 80e | ✔️ | ✖️ | 37.5 | 46.1 | 62.0 | 49.9 | [HF Checkpoints](https://huggingface.co/wondervictor/YOLO-World/blob/main/yolo_world_v2_s_vlpan_bn_2e-4_80e_8gpus_mask-refine_finetune_coco_ep80-492dc329.pth) | [log](https://huggingface.co/wondervictor/YOLO-World/blob/main/yolo_world_v2_s_vlpan_bn_2e-4_80e_8gpus_mask-refine_finetune_coco_20240327_110411.log) |
|
| 19 |
+
| [YOLO-World-v2-M](./yolo_world_v2_m_vlpan_bn_2e-4_80e_8gpus_mask-refine_finetune_coco.py) | AdamW, 2e-4, 80e | ✔️ | ✖️ | 42.8 | 51.0 | 67.5 | 55.2 | [HF Checkpoints](https://huggingface.co/wondervictor/YOLO-World/blob/main/yolo_world_v2_m_vlpan_bn_2e-4_80e_8gpus_mask-refine_finetune_coco_ep80-69c27ac7.pth) | [log](https://huggingface.co/wondervictor/YOLO-World/blob/main/yolo_world_v2_m_vlpan_bn_2e-4_80e_8gpus_mask-refine_finetune_coco_20240327_110411.log) |
|
| 20 |
+
| [YOLO-World-v2-L](./yolo_world_v2_l_vlpan_bn_2e-4_80e_8gpus_mask-refine_finetune_coco.py) | AdamW, 2e-4, 80e | ✔️ | ✖️ | 45.1 | 53.9 | 70.9 | 58.8 | [HF Checkpoints](https://huggingface.co/wondervictor/YOLO-World/blob/main/yolo_world_v2_l_vlpan_bn_2e-4_80e_8gpus_mask-refine_finetune_coco_ep80-81c701ee.pth) | [log](https://huggingface.co/wondervictor/YOLO-World/blob/main/yolo_world_v2_l_vlpan_bn_2e-4_80e_8gpus_mask-refine_finetune_coco_20240326_160313.log) |
|
| 21 |
+
| [YOLO-World-v2-L](./yolo_world_v2_l_efficient_neck_2e-4_80e_8gpus_mask-refine_finetune_coco.py) | AdamW, 2e-4, 80e | ✔️ | ✔️ | 45.1 | | | | [HF Checkpoints]() | [log]() |
|
| 22 |
+
| [YOLO-World-v2-X](./yolo_world_v2_x_vlpan_bn_2e-4_80e_8gpus_mask-refine_finetune_coco.py) | AdamW, 2e-4, 80e | ✔️ | ✖️ | 46.8 | 54.7 | 71.6 | 59.6 | [HF Checkpoints](https://huggingface.co/wondervictor/YOLO-World/blob/main/yolo_world_v2_x_vlpan_bn_2e-4_80e_8gpus_mask-refine_finetune_coco_ep80-76bc0cbd.pth) | [log](https://huggingface.co/wondervictor/YOLO-World/blob/main/yolo_world_v2_x_vlpan_bn_2e-4_80e_8gpus_mask-refine_finetune_coco_20240322_181232.log) |
|
| 23 |
+
| [YOLO-World-v2-L](./yolo_world_v2_l_vlpan_bn_sgd_1e-3_40e_8gpus_finetune_coco.py) 🔥 | SGD, 1e-3, 40e | ✖️ | ✖️ | 45.1 | 52.8 | 69.5 | 57.8 | [HF Checkpoints](https://huggingface.co/wondervictor/YOLO-World/blob/main/yolo_world_v2_l_vlpan_bn_sgd_1e-3_40e_8gpus_finetune_coco_ep80-e1288152.pth) | [log](https://huggingface.co/wondervictor/YOLO-World/blob/main/yolo_world_v2_l_vlpan_bn_sgd_1e-3_40e_8gpus_finetuning_coco_20240327_014902.log) |
|
| 24 |
+
|
| 25 |
+
|
| 26 |
+
|
configs/finetune_coco/yolo_world_l_dual_vlpan_2e-4_80e_8gpus_finetune_coco.py
ADDED
|
@@ -0,0 +1,179 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
_base_ = (
|
| 2 |
+
'../../third_party/mmyolo/configs/yolov8/'
|
| 3 |
+
'yolov8_l_syncbn_fast_8xb16-500e_coco.py')
|
| 4 |
+
custom_imports = dict(
|
| 5 |
+
imports=['yolo_world'],
|
| 6 |
+
allow_failed_imports=False)
|
| 7 |
+
|
| 8 |
+
# hyper-parameters
|
| 9 |
+
num_classes = 80
|
| 10 |
+
num_training_classes = 80
|
| 11 |
+
max_epochs = 80 # Maximum training epochs
|
| 12 |
+
close_mosaic_epochs = 10
|
| 13 |
+
save_epoch_intervals = 5
|
| 14 |
+
text_channels = 512
|
| 15 |
+
neck_embed_channels = [128, 256, _base_.last_stage_out_channels // 2]
|
| 16 |
+
neck_num_heads = [4, 8, _base_.last_stage_out_channels // 2 // 32]
|
| 17 |
+
base_lr = 2e-4
|
| 18 |
+
weight_decay = 0.05
|
| 19 |
+
train_batch_size_per_gpu = 16
|
| 20 |
+
load_from='pretrained_models/yolo_world_l_clip_base_dual_vlpan_2e-3adamw_32xb16_100e_o365_goldg_train_pretrained-0e566235.pth'
|
| 21 |
+
persistent_workers = False
|
| 22 |
+
|
| 23 |
+
# model settings
|
| 24 |
+
model = dict(
|
| 25 |
+
type='YOLOWorldDetector',
|
| 26 |
+
mm_neck=True,
|
| 27 |
+
num_train_classes=num_training_classes,
|
| 28 |
+
num_test_classes=num_classes,
|
| 29 |
+
data_preprocessor=dict(type='YOLOWDetDataPreprocessor'),
|
| 30 |
+
backbone=dict(
|
| 31 |
+
_delete_=True,
|
| 32 |
+
type='MultiModalYOLOBackbone',
|
| 33 |
+
image_model={{_base_.model.backbone}},
|
| 34 |
+
text_model=dict(
|
| 35 |
+
type='HuggingCLIPLanguageBackbone',
|
| 36 |
+
model_name='openai/clip-vit-base-patch32',
|
| 37 |
+
frozen_modules=['all'])),
|
| 38 |
+
neck=dict(type='YOLOWorldDualPAFPN',
|
| 39 |
+
guide_channels=text_channels,
|
| 40 |
+
embed_channels=neck_embed_channels,
|
| 41 |
+
num_heads=neck_num_heads,
|
| 42 |
+
block_cfg=dict(type='MaxSigmoidCSPLayerWithTwoConv'),
|
| 43 |
+
text_enhancder=dict(type='ImagePoolingAttentionModule',
|
| 44 |
+
embed_channels=256,
|
| 45 |
+
num_heads=8)),
|
| 46 |
+
bbox_head=dict(type='YOLOWorldHead',
|
| 47 |
+
head_module=dict(type='YOLOWorldHeadModule',
|
| 48 |
+
embed_dims=text_channels,
|
| 49 |
+
num_classes=num_training_classes)),
|
| 50 |
+
train_cfg=dict(assigner=dict(num_classes=num_training_classes)))
|
| 51 |
+
|
| 52 |
+
# dataset settings
|
| 53 |
+
text_transform = [
|
| 54 |
+
dict(type='RandomLoadText',
|
| 55 |
+
num_neg_samples=(num_classes, num_classes),
|
| 56 |
+
max_num_samples=num_training_classes,
|
| 57 |
+
padding_to_max=True,
|
| 58 |
+
padding_value=''),
|
| 59 |
+
dict(type='mmdet.PackDetInputs',
|
| 60 |
+
meta_keys=('img_id', 'img_path', 'ori_shape', 'img_shape', 'flip',
|
| 61 |
+
'flip_direction', 'texts'))
|
| 62 |
+
]
|
| 63 |
+
mosaic_affine_transform = [
|
| 64 |
+
dict(
|
| 65 |
+
type='MultiModalMosaic',
|
| 66 |
+
img_scale=_base_.img_scale,
|
| 67 |
+
pad_val=114.0,
|
| 68 |
+
pre_transform=_base_.pre_transform),
|
| 69 |
+
dict(
|
| 70 |
+
type='YOLOv5RandomAffine',
|
| 71 |
+
max_rotate_degree=0.0,
|
| 72 |
+
max_shear_degree=0.0,
|
| 73 |
+
max_aspect_ratio=100.,
|
| 74 |
+
scaling_ratio_range=(1 - _base_.affine_scale,
|
| 75 |
+
1 + _base_.affine_scale),
|
| 76 |
+
# img_scale is (width, height)
|
| 77 |
+
border=(-_base_.img_scale[0] // 2, -_base_.img_scale[1] // 2),
|
| 78 |
+
border_val=(114, 114, 114))
|
| 79 |
+
]
|
| 80 |
+
train_pipeline = [
|
| 81 |
+
*_base_.pre_transform,
|
| 82 |
+
*mosaic_affine_transform,
|
| 83 |
+
dict(
|
| 84 |
+
type='YOLOv5MultiModalMixUp',
|
| 85 |
+
prob=_base_.mixup_prob,
|
| 86 |
+
pre_transform=[*_base_.pre_transform,
|
| 87 |
+
*mosaic_affine_transform]),
|
| 88 |
+
*_base_.last_transform[:-1],
|
| 89 |
+
*text_transform
|
| 90 |
+
]
|
| 91 |
+
train_pipeline_stage2 = [
|
| 92 |
+
*_base_.train_pipeline_stage2[:-1],
|
| 93 |
+
*text_transform
|
| 94 |
+
]
|
| 95 |
+
coco_train_dataset = dict(
|
| 96 |
+
_delete_=True,
|
| 97 |
+
type='MultiModalDataset',
|
| 98 |
+
dataset=dict(
|
| 99 |
+
type='YOLOv5CocoDataset',
|
| 100 |
+
data_root='data/coco',
|
| 101 |
+
ann_file='annotations/instances_train2017.json',
|
| 102 |
+
data_prefix=dict(img='train2017/'),
|
| 103 |
+
filter_cfg=dict(filter_empty_gt=False, min_size=32)),
|
| 104 |
+
class_text_path='data/texts/coco_class_texts.json',
|
| 105 |
+
pipeline=train_pipeline)
|
| 106 |
+
|
| 107 |
+
train_dataloader = dict(
|
| 108 |
+
persistent_workers=persistent_workers,
|
| 109 |
+
batch_size=train_batch_size_per_gpu,
|
| 110 |
+
collate_fn=dict(type='yolow_collate'),
|
| 111 |
+
dataset=coco_train_dataset)
|
| 112 |
+
test_pipeline = [
|
| 113 |
+
*_base_.test_pipeline[:-1],
|
| 114 |
+
dict(type='LoadText'),
|
| 115 |
+
dict(
|
| 116 |
+
type='mmdet.PackDetInputs',
|
| 117 |
+
meta_keys=('img_id', 'img_path', 'ori_shape', 'img_shape',
|
| 118 |
+
'scale_factor', 'pad_param', 'texts'))
|
| 119 |
+
]
|
| 120 |
+
coco_val_dataset = dict(
|
| 121 |
+
_delete_=True,
|
| 122 |
+
type='MultiModalDataset',
|
| 123 |
+
dataset=dict(
|
| 124 |
+
type='YOLOv5CocoDataset',
|
| 125 |
+
data_root='data/coco',
|
| 126 |
+
ann_file='annotations/instances_val2017.json',
|
| 127 |
+
data_prefix=dict(img='val2017/'),
|
| 128 |
+
filter_cfg=dict(filter_empty_gt=False, min_size=32)),
|
| 129 |
+
class_text_path='data/texts/coco_class_texts.json',
|
| 130 |
+
pipeline=test_pipeline)
|
| 131 |
+
val_dataloader = dict(dataset=coco_val_dataset)
|
| 132 |
+
test_dataloader = val_dataloader
|
| 133 |
+
# training settings
|
| 134 |
+
default_hooks = dict(
|
| 135 |
+
param_scheduler=dict(
|
| 136 |
+
scheduler_type='linear',
|
| 137 |
+
lr_factor=0.01,
|
| 138 |
+
max_epochs=max_epochs),
|
| 139 |
+
checkpoint=dict(
|
| 140 |
+
max_keep_ckpts=-1,
|
| 141 |
+
save_best=None,
|
| 142 |
+
interval=save_epoch_intervals))
|
| 143 |
+
custom_hooks = [
|
| 144 |
+
dict(
|
| 145 |
+
type='EMAHook',
|
| 146 |
+
ema_type='ExpMomentumEMA',
|
| 147 |
+
momentum=0.0001,
|
| 148 |
+
update_buffers=True,
|
| 149 |
+
strict_load=False,
|
| 150 |
+
priority=49),
|
| 151 |
+
dict(
|
| 152 |
+
type='mmdet.PipelineSwitchHook',
|
| 153 |
+
switch_epoch=max_epochs - close_mosaic_epochs,
|
| 154 |
+
switch_pipeline=train_pipeline_stage2)
|
| 155 |
+
]
|
| 156 |
+
train_cfg = dict(
|
| 157 |
+
max_epochs=max_epochs,
|
| 158 |
+
val_interval=5,
|
| 159 |
+
dynamic_intervals=[((max_epochs - close_mosaic_epochs),
|
| 160 |
+
_base_.val_interval_stage2)])
|
| 161 |
+
optim_wrapper = dict(
|
| 162 |
+
optimizer=dict(
|
| 163 |
+
_delete_=True,
|
| 164 |
+
type='AdamW',
|
| 165 |
+
lr=base_lr,
|
| 166 |
+
weight_decay=weight_decay,
|
| 167 |
+
batch_size_per_gpu=train_batch_size_per_gpu),
|
| 168 |
+
paramwise_cfg=dict(
|
| 169 |
+
custom_keys={'backbone.text_model': dict(lr_mult=0.01),
|
| 170 |
+
'logit_scale': dict(weight_decay=0.0)}),
|
| 171 |
+
constructor='YOLOWv5OptimizerConstructor')
|
| 172 |
+
|
| 173 |
+
# evaluation settings
|
| 174 |
+
val_evaluator = dict(
|
| 175 |
+
_delete_=True,
|
| 176 |
+
type='mmdet.CocoMetric',
|
| 177 |
+
proposal_nums=(100, 1, 10),
|
| 178 |
+
ann_file='data/coco/annotations/instances_val2017.json',
|
| 179 |
+
metric='bbox')
|
configs/finetune_coco/yolo_world_l_dual_vlpan_2e-4_80e_8gpus_mask-refine_finetune_coco.py
ADDED
|
@@ -0,0 +1,181 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
_base_ = (
|
| 2 |
+
'../../third_party/mmyolo/configs/yolov8/'
|
| 3 |
+
'yolov8_l_mask-refine_syncbn_fast_8xb16-500e_coco.py')
|
| 4 |
+
custom_imports = dict(
|
| 5 |
+
imports=['yolo_world'],
|
| 6 |
+
allow_failed_imports=False)
|
| 7 |
+
|
| 8 |
+
# hyper-parameters
|
| 9 |
+
num_classes = 80
|
| 10 |
+
num_training_classes = 80
|
| 11 |
+
max_epochs = 80 # Maximum training epochs
|
| 12 |
+
close_mosaic_epochs = 10
|
| 13 |
+
save_epoch_intervals = 5
|
| 14 |
+
text_channels = 512
|
| 15 |
+
neck_embed_channels = [128, 256, _base_.last_stage_out_channels // 2]
|
| 16 |
+
neck_num_heads = [4, 8, _base_.last_stage_out_channels // 2 // 32]
|
| 17 |
+
base_lr = 2e-4
|
| 18 |
+
weight_decay = 0.05
|
| 19 |
+
train_batch_size_per_gpu = 16
|
| 20 |
+
load_from='pretrained_models/yolo_world_l_clip_base_dual_vlpan_2e-3adamw_32xb16_100e_o365_goldg_train_pretrained-0e566235.pth'
|
| 21 |
+
persistent_workers = False
|
| 22 |
+
|
| 23 |
+
# model settings
|
| 24 |
+
model = dict(
|
| 25 |
+
type='YOLOWorldDetector',
|
| 26 |
+
mm_neck=True,
|
| 27 |
+
num_train_classes=num_training_classes,
|
| 28 |
+
num_test_classes=num_classes,
|
| 29 |
+
data_preprocessor=dict(type='YOLOWDetDataPreprocessor'),
|
| 30 |
+
backbone=dict(
|
| 31 |
+
_delete_=True,
|
| 32 |
+
type='MultiModalYOLOBackbone',
|
| 33 |
+
image_model={{_base_.model.backbone}},
|
| 34 |
+
text_model=dict(
|
| 35 |
+
type='HuggingCLIPLanguageBackbone',
|
| 36 |
+
model_name='openai/clip-vit-base-patch32',
|
| 37 |
+
frozen_modules=['all'])),
|
| 38 |
+
neck=dict(type='YOLOWorldDualPAFPN',
|
| 39 |
+
guide_channels=text_channels,
|
| 40 |
+
embed_channels=neck_embed_channels,
|
| 41 |
+
num_heads=neck_num_heads,
|
| 42 |
+
block_cfg=dict(type='MaxSigmoidCSPLayerWithTwoConv'),
|
| 43 |
+
text_enhancder=dict(type='ImagePoolingAttentionModule',
|
| 44 |
+
embed_channels=256,
|
| 45 |
+
num_heads=8)),
|
| 46 |
+
bbox_head=dict(type='YOLOWorldHead',
|
| 47 |
+
head_module=dict(type='YOLOWorldHeadModule',
|
| 48 |
+
embed_dims=text_channels,
|
| 49 |
+
num_classes=num_training_classes)),
|
| 50 |
+
train_cfg=dict(assigner=dict(num_classes=num_training_classes)))
|
| 51 |
+
|
| 52 |
+
# dataset settings
|
| 53 |
+
text_transform = [
|
| 54 |
+
dict(type='RandomLoadText',
|
| 55 |
+
num_neg_samples=(num_classes, num_classes),
|
| 56 |
+
max_num_samples=num_training_classes,
|
| 57 |
+
padding_to_max=True,
|
| 58 |
+
padding_value=''),
|
| 59 |
+
dict(type='mmdet.PackDetInputs',
|
| 60 |
+
meta_keys=('img_id', 'img_path', 'ori_shape', 'img_shape', 'flip',
|
| 61 |
+
'flip_direction', 'texts'))
|
| 62 |
+
]
|
| 63 |
+
mosaic_affine_transform = [
|
| 64 |
+
dict(
|
| 65 |
+
type='MultiModalMosaic',
|
| 66 |
+
img_scale=_base_.img_scale,
|
| 67 |
+
pad_val=114.0,
|
| 68 |
+
pre_transform=_base_.pre_transform),
|
| 69 |
+
dict(type='YOLOv5CopyPaste', prob=_base_.copypaste_prob),
|
| 70 |
+
dict(
|
| 71 |
+
type='YOLOv5RandomAffine',
|
| 72 |
+
max_rotate_degree=0.0,
|
| 73 |
+
max_shear_degree=0.0,
|
| 74 |
+
max_aspect_ratio=100.,
|
| 75 |
+
scaling_ratio_range=(1 - _base_.affine_scale,
|
| 76 |
+
1 + _base_.affine_scale),
|
| 77 |
+
# img_scale is (width, height)
|
| 78 |
+
border=(-_base_.img_scale[0] // 2, -_base_.img_scale[1] // 2),
|
| 79 |
+
border_val=(114, 114, 114),
|
| 80 |
+
min_area_ratio=_base_.min_area_ratio,
|
| 81 |
+
use_mask_refine=_base_.use_mask2refine)
|
| 82 |
+
]
|
| 83 |
+
train_pipeline = [
|
| 84 |
+
*_base_.pre_transform,
|
| 85 |
+
*mosaic_affine_transform,
|
| 86 |
+
dict(
|
| 87 |
+
type='YOLOv5MultiModalMixUp',
|
| 88 |
+
prob=_base_.mixup_prob,
|
| 89 |
+
pre_transform=[*_base_.pre_transform,
|
| 90 |
+
*mosaic_affine_transform]),
|
| 91 |
+
*_base_.last_transform[:-1],
|
| 92 |
+
*text_transform
|
| 93 |
+
]
|
| 94 |
+
train_pipeline_stage2 = [
|
| 95 |
+
*_base_.train_pipeline_stage2[:-1],
|
| 96 |
+
*text_transform
|
| 97 |
+
]
|
| 98 |
+
coco_train_dataset = dict(
|
| 99 |
+
_delete_=True,
|
| 100 |
+
type='MultiModalDataset',
|
| 101 |
+
dataset=dict(
|
| 102 |
+
type='YOLOv5CocoDataset',
|
| 103 |
+
data_root='data/coco',
|
| 104 |
+
ann_file='annotations/instances_train2017.json',
|
| 105 |
+
data_prefix=dict(img='train2017/'),
|
| 106 |
+
filter_cfg=dict(filter_empty_gt=False, min_size=32)),
|
| 107 |
+
class_text_path='data/texts/coco_class_texts.json',
|
| 108 |
+
pipeline=train_pipeline)
|
| 109 |
+
|
| 110 |
+
train_dataloader = dict(
|
| 111 |
+
persistent_workers=persistent_workers,
|
| 112 |
+
batch_size=train_batch_size_per_gpu,
|
| 113 |
+
collate_fn=dict(type='yolow_collate'),
|
| 114 |
+
dataset=coco_train_dataset)
|
| 115 |
+
test_pipeline = [
|
| 116 |
+
*_base_.test_pipeline[:-1],
|
| 117 |
+
dict(type='LoadText'),
|
| 118 |
+
dict(
|
| 119 |
+
type='mmdet.PackDetInputs',
|
| 120 |
+
meta_keys=('img_id', 'img_path', 'ori_shape', 'img_shape',
|
| 121 |
+
'scale_factor', 'pad_param', 'texts'))
|
| 122 |
+
]
|
| 123 |
+
coco_val_dataset = dict(
|
| 124 |
+
_delete_=True,
|
| 125 |
+
type='MultiModalDataset',
|
| 126 |
+
dataset=dict(
|
| 127 |
+
type='YOLOv5CocoDataset',
|
| 128 |
+
data_root='data/coco',
|
| 129 |
+
ann_file='annotations/instances_val2017.json',
|
| 130 |
+
data_prefix=dict(img='val2017/'),
|
| 131 |
+
filter_cfg=dict(filter_empty_gt=False, min_size=32)),
|
| 132 |
+
class_text_path='data/texts/coco_class_texts.json',
|
| 133 |
+
pipeline=test_pipeline)
|
| 134 |
+
val_dataloader = dict(dataset=coco_val_dataset)
|
| 135 |
+
test_dataloader = val_dataloader
|
| 136 |
+
# training settings
|
| 137 |
+
default_hooks = dict(
|
| 138 |
+
param_scheduler=dict(
|
| 139 |
+
scheduler_type='linear',
|
| 140 |
+
lr_factor=0.01,
|
| 141 |
+
max_epochs=max_epochs),
|
| 142 |
+
checkpoint=dict(
|
| 143 |
+
max_keep_ckpts=-1,
|
| 144 |
+
save_best=None,
|
| 145 |
+
interval=save_epoch_intervals))
|
| 146 |
+
custom_hooks = [
|
| 147 |
+
dict(
|
| 148 |
+
type='EMAHook',
|
| 149 |
+
ema_type='ExpMomentumEMA',
|
| 150 |
+
momentum=0.0001,
|
| 151 |
+
update_buffers=True,
|
| 152 |
+
strict_load=False,
|
| 153 |
+
priority=49),
|
| 154 |
+
dict(
|
| 155 |
+
type='mmdet.PipelineSwitchHook',
|
| 156 |
+
switch_epoch=max_epochs - close_mosaic_epochs,
|
| 157 |
+
switch_pipeline=train_pipeline_stage2)
|
| 158 |
+
]
|
| 159 |
+
train_cfg = dict(
|
| 160 |
+
max_epochs=max_epochs,
|
| 161 |
+
val_interval=5,
|
| 162 |
+
dynamic_intervals=[((max_epochs - close_mosaic_epochs),
|
| 163 |
+
_base_.val_interval_stage2)])
|
| 164 |
+
optim_wrapper = dict(
|
| 165 |
+
optimizer=dict(
|
| 166 |
+
_delete_=True,
|
| 167 |
+
type='AdamW',
|
| 168 |
+
lr=base_lr,
|
| 169 |
+
weight_decay=weight_decay,
|
| 170 |
+
batch_size_per_gpu=train_batch_size_per_gpu),
|
| 171 |
+
paramwise_cfg=dict(
|
| 172 |
+
custom_keys={'backbone.text_model': dict(lr_mult=0.01),
|
| 173 |
+
'logit_scale': dict(weight_decay=0.0)}),
|
| 174 |
+
constructor='YOLOWv5OptimizerConstructor')
|
| 175 |
+
# evaluation settings
|
| 176 |
+
val_evaluator = dict(
|
| 177 |
+
_delete_=True,
|
| 178 |
+
type='mmdet.CocoMetric',
|
| 179 |
+
proposal_nums=(100, 1, 10),
|
| 180 |
+
ann_file='data/coco/annotations/instances_val2017.json',
|
| 181 |
+
metric='bbox')
|
configs/finetune_coco/yolo_world_l_efficient_neck_2e-4_80e_8gpus_mask-refine_finetune_coco.py
ADDED
|
@@ -0,0 +1,159 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
_base_ = ('../../third_party/mmyolo/configs/yolov8/'
|
| 2 |
+
'yolov8_l_mask-refine_syncbn_fast_8xb16-500e_coco.py')
|
| 3 |
+
custom_imports = dict(imports=['yolo_world'], allow_failed_imports=False)
|
| 4 |
+
|
| 5 |
+
# hyper-parameters
|
| 6 |
+
num_classes = 80
|
| 7 |
+
num_training_classes = 80
|
| 8 |
+
max_epochs = 80 # Maximum training epochs
|
| 9 |
+
close_mosaic_epochs = 10
|
| 10 |
+
save_epoch_intervals = 5
|
| 11 |
+
text_channels = 512
|
| 12 |
+
neck_embed_channels = [128, 256, _base_.last_stage_out_channels // 2]
|
| 13 |
+
neck_num_heads = [4, 8, _base_.last_stage_out_channels // 2 // 32]
|
| 14 |
+
base_lr = 2e-4
|
| 15 |
+
weight_decay = 0.05
|
| 16 |
+
train_batch_size_per_gpu = 16
|
| 17 |
+
load_from = 'pretrained_models/yolo_world_l_clip_base_dual_vlpan_2e-3adamw_32xb16_100e_o365_goldg_train_pretrained-0e566235.pth'
|
| 18 |
+
# huggingface text model
|
| 19 |
+
text_model_name = 'openai/clip-vit-base-patch32'
|
| 20 |
+
persistent_workers = False
|
| 21 |
+
|
| 22 |
+
# model settings
|
| 23 |
+
model = dict(
|
| 24 |
+
type='YOLOWorldDetector',
|
| 25 |
+
mm_neck=True,
|
| 26 |
+
num_train_classes=num_training_classes,
|
| 27 |
+
num_test_classes=num_classes,
|
| 28 |
+
data_preprocessor=dict(type='YOLOWDetDataPreprocessor'),
|
| 29 |
+
backbone=dict(
|
| 30 |
+
_delete_=True,
|
| 31 |
+
type='MultiModalYOLOBackbone',
|
| 32 |
+
image_model={{_base_.model.backbone}},
|
| 33 |
+
text_model=dict(
|
| 34 |
+
type='HuggingCLIPLanguageBackbone',
|
| 35 |
+
model_name=text_model_name,
|
| 36 |
+
frozen_modules=['all'])),
|
| 37 |
+
neck=dict(type='YOLOWorldPAFPN',
|
| 38 |
+
guide_channels=text_channels,
|
| 39 |
+
embed_channels=neck_embed_channels,
|
| 40 |
+
num_heads=neck_num_heads,
|
| 41 |
+
block_cfg=dict(type='EfficientCSPLayerWithTwoConv')),
|
| 42 |
+
bbox_head=dict(type='YOLOWorldHead',
|
| 43 |
+
head_module=dict(type='YOLOWorldHeadModule',
|
| 44 |
+
embed_dims=text_channels,
|
| 45 |
+
num_classes=num_training_classes)),
|
| 46 |
+
train_cfg=dict(assigner=dict(num_classes=num_training_classes)))
|
| 47 |
+
|
| 48 |
+
# dataset settings
|
| 49 |
+
text_transform = [
|
| 50 |
+
dict(type='RandomLoadText',
|
| 51 |
+
num_neg_samples=(num_classes, num_classes),
|
| 52 |
+
max_num_samples=num_training_classes,
|
| 53 |
+
padding_to_max=True,
|
| 54 |
+
padding_value=''),
|
| 55 |
+
dict(type='mmdet.PackDetInputs',
|
| 56 |
+
meta_keys=('img_id', 'img_path', 'ori_shape', 'img_shape', 'flip',
|
| 57 |
+
'flip_direction', 'texts'))
|
| 58 |
+
]
|
| 59 |
+
mosaic_affine_transform = [
|
| 60 |
+
dict(type='MultiModalMosaic',
|
| 61 |
+
img_scale=_base_.img_scale,
|
| 62 |
+
pad_val=114.0,
|
| 63 |
+
pre_transform=_base_.pre_transform),
|
| 64 |
+
dict(type='YOLOv5CopyPaste', prob=_base_.copypaste_prob),
|
| 65 |
+
dict(
|
| 66 |
+
type='YOLOv5RandomAffine',
|
| 67 |
+
max_rotate_degree=0.0,
|
| 68 |
+
max_shear_degree=0.0,
|
| 69 |
+
max_aspect_ratio=100.,
|
| 70 |
+
scaling_ratio_range=(1 - _base_.affine_scale, 1 + _base_.affine_scale),
|
| 71 |
+
# img_scale is (width, height)
|
| 72 |
+
border=(-_base_.img_scale[0] // 2, -_base_.img_scale[1] // 2),
|
| 73 |
+
border_val=(114, 114, 114),
|
| 74 |
+
min_area_ratio=_base_.min_area_ratio,
|
| 75 |
+
use_mask_refine=_base_.use_mask2refine)
|
| 76 |
+
]
|
| 77 |
+
train_pipeline = [
|
| 78 |
+
*_base_.pre_transform, *mosaic_affine_transform,
|
| 79 |
+
dict(type='YOLOv5MultiModalMixUp',
|
| 80 |
+
prob=_base_.mixup_prob,
|
| 81 |
+
pre_transform=[*_base_.pre_transform, *mosaic_affine_transform]),
|
| 82 |
+
*_base_.last_transform[:-1], *text_transform
|
| 83 |
+
]
|
| 84 |
+
train_pipeline_stage2 = [*_base_.train_pipeline_stage2[:-1], *text_transform]
|
| 85 |
+
coco_train_dataset = dict(_delete_=True,
|
| 86 |
+
type='MultiModalDataset',
|
| 87 |
+
dataset=dict(
|
| 88 |
+
type='YOLOv5CocoDataset',
|
| 89 |
+
data_root='data/coco',
|
| 90 |
+
ann_file='annotations/instances_train2017.json',
|
| 91 |
+
data_prefix=dict(img='train2017/'),
|
| 92 |
+
filter_cfg=dict(filter_empty_gt=False,
|
| 93 |
+
min_size=32)),
|
| 94 |
+
class_text_path='data/texts/coco_class_texts.json',
|
| 95 |
+
pipeline=train_pipeline)
|
| 96 |
+
|
| 97 |
+
train_dataloader = dict(persistent_workers=persistent_workers,
|
| 98 |
+
batch_size=train_batch_size_per_gpu,
|
| 99 |
+
collate_fn=dict(type='yolow_collate'),
|
| 100 |
+
dataset=coco_train_dataset)
|
| 101 |
+
test_pipeline = [
|
| 102 |
+
*_base_.test_pipeline[:-1],
|
| 103 |
+
dict(type='LoadText'),
|
| 104 |
+
dict(type='mmdet.PackDetInputs',
|
| 105 |
+
meta_keys=('img_id', 'img_path', 'ori_shape', 'img_shape',
|
| 106 |
+
'scale_factor', 'pad_param', 'texts'))
|
| 107 |
+
]
|
| 108 |
+
coco_val_dataset = dict(
|
| 109 |
+
_delete_=True,
|
| 110 |
+
type='MultiModalDataset',
|
| 111 |
+
dataset=dict(type='YOLOv5CocoDataset',
|
| 112 |
+
data_root='data/coco',
|
| 113 |
+
ann_file='annotations/instances_val2017.json',
|
| 114 |
+
data_prefix=dict(img='val2017/'),
|
| 115 |
+
filter_cfg=dict(filter_empty_gt=False, min_size=32)),
|
| 116 |
+
class_text_path='data/texts/coco_class_texts.json',
|
| 117 |
+
pipeline=test_pipeline)
|
| 118 |
+
val_dataloader = dict(dataset=coco_val_dataset)
|
| 119 |
+
test_dataloader = val_dataloader
|
| 120 |
+
# training settings
|
| 121 |
+
default_hooks = dict(param_scheduler=dict(scheduler_type='linear',
|
| 122 |
+
lr_factor=0.01,
|
| 123 |
+
max_epochs=max_epochs),
|
| 124 |
+
checkpoint=dict(max_keep_ckpts=-1,
|
| 125 |
+
save_best=None,
|
| 126 |
+
interval=save_epoch_intervals))
|
| 127 |
+
custom_hooks = [
|
| 128 |
+
dict(type='EMAHook',
|
| 129 |
+
ema_type='ExpMomentumEMA',
|
| 130 |
+
momentum=0.0001,
|
| 131 |
+
update_buffers=True,
|
| 132 |
+
strict_load=False,
|
| 133 |
+
priority=49),
|
| 134 |
+
dict(type='mmdet.PipelineSwitchHook',
|
| 135 |
+
switch_epoch=max_epochs - close_mosaic_epochs,
|
| 136 |
+
switch_pipeline=train_pipeline_stage2)
|
| 137 |
+
]
|
| 138 |
+
train_cfg = dict(max_epochs=max_epochs,
|
| 139 |
+
val_interval=5,
|
| 140 |
+
dynamic_intervals=[((max_epochs - close_mosaic_epochs),
|
| 141 |
+
_base_.val_interval_stage2)])
|
| 142 |
+
optim_wrapper = dict(
|
| 143 |
+
optimizer=dict(
|
| 144 |
+
_delete_=True,
|
| 145 |
+
type='AdamW',
|
| 146 |
+
lr=base_lr,
|
| 147 |
+
weight_decay=weight_decay,
|
| 148 |
+
batch_size_per_gpu=train_batch_size_per_gpu),
|
| 149 |
+
paramwise_cfg=dict(
|
| 150 |
+
custom_keys={'backbone.text_model': dict(lr_mult=0.01),
|
| 151 |
+
'logit_scale': dict(weight_decay=0.0)}),
|
| 152 |
+
constructor='YOLOWv5OptimizerConstructor')
|
| 153 |
+
|
| 154 |
+
# evaluation settings
|
| 155 |
+
val_evaluator = dict(_delete_=True,
|
| 156 |
+
type='mmdet.CocoMetric',
|
| 157 |
+
proposal_nums=(100, 1, 10),
|
| 158 |
+
ann_file='data/coco/annotations/instances_val2017.json',
|
| 159 |
+
metric='bbox')
|
configs/finetune_coco/yolo_world_v2_l_efficient_neck_2e-4_80e_8gpus_mask-refine_finetune_coco.py
ADDED
|
@@ -0,0 +1,182 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
_base_ = (
|
| 2 |
+
'../../third_party/mmyolo/configs/yolov8/'
|
| 3 |
+
'yolov8_l_mask-refine_syncbn_fast_8xb16-500e_coco.py')
|
| 4 |
+
custom_imports = dict(
|
| 5 |
+
imports=['yolo_world'],
|
| 6 |
+
allow_failed_imports=False)
|
| 7 |
+
|
| 8 |
+
# hyper-parameters
|
| 9 |
+
num_classes = 80
|
| 10 |
+
num_training_classes = 80
|
| 11 |
+
max_epochs = 80 # Maximum training epochs
|
| 12 |
+
close_mosaic_epochs = 10
|
| 13 |
+
save_epoch_intervals = 5
|
| 14 |
+
text_channels = 512
|
| 15 |
+
neck_embed_channels = [128, 256, _base_.last_stage_out_channels // 2]
|
| 16 |
+
neck_num_heads = [4, 8, _base_.last_stage_out_channels // 2 // 32]
|
| 17 |
+
base_lr = 2e-4
|
| 18 |
+
weight_decay = 0.05
|
| 19 |
+
train_batch_size_per_gpu = 16
|
| 20 |
+
load_from = 'pretrained_models/yolo_world_l_clip_t2i_bn_2e-3adamw_32xb16-100e_obj365v1_goldg_cc3mlite_train-ca93cd1f.pth'
|
| 21 |
+
text_model_name = '../pretrained_models/clip-vit-base-patch32-projection'
|
| 22 |
+
# text_model_name = 'openai/clip-vit-base-patch32'
|
| 23 |
+
persistent_workers = False
|
| 24 |
+
|
| 25 |
+
# model settings
|
| 26 |
+
model = dict(
|
| 27 |
+
type='YOLOWorldDetector',
|
| 28 |
+
mm_neck=True,
|
| 29 |
+
num_train_classes=num_training_classes,
|
| 30 |
+
num_test_classes=num_classes,
|
| 31 |
+
data_preprocessor=dict(type='YOLOWDetDataPreprocessor'),
|
| 32 |
+
backbone=dict(
|
| 33 |
+
_delete_=True,
|
| 34 |
+
type='MultiModalYOLOBackbone',
|
| 35 |
+
image_model={{_base_.model.backbone}},
|
| 36 |
+
text_model=dict(
|
| 37 |
+
type='HuggingCLIPLanguageBackbone',
|
| 38 |
+
model_name=text_model_name,
|
| 39 |
+
frozen_modules=['all'])),
|
| 40 |
+
neck=dict(type='YOLOWorldPAFPN',
|
| 41 |
+
guide_channels=text_channels,
|
| 42 |
+
embed_channels=neck_embed_channels,
|
| 43 |
+
num_heads=neck_num_heads,
|
| 44 |
+
block_cfg=dict(type='EfficientCSPLayerWithTwoConv')),
|
| 45 |
+
bbox_head=dict(type='YOLOWorldHead',
|
| 46 |
+
head_module=dict(type='YOLOWorldHeadModule',
|
| 47 |
+
use_bn_head=True,
|
| 48 |
+
embed_dims=text_channels,
|
| 49 |
+
num_classes=num_training_classes)),
|
| 50 |
+
train_cfg=dict(assigner=dict(num_classes=num_training_classes)))
|
| 51 |
+
|
| 52 |
+
# dataset settings
|
| 53 |
+
text_transform = [
|
| 54 |
+
dict(type='RandomLoadText',
|
| 55 |
+
num_neg_samples=(num_classes, num_classes),
|
| 56 |
+
max_num_samples=num_training_classes,
|
| 57 |
+
padding_to_max=True,
|
| 58 |
+
padding_value=''),
|
| 59 |
+
dict(type='mmdet.PackDetInputs',
|
| 60 |
+
meta_keys=('img_id', 'img_path', 'ori_shape', 'img_shape', 'flip',
|
| 61 |
+
'flip_direction', 'texts'))
|
| 62 |
+
]
|
| 63 |
+
mosaic_affine_transform = [
|
| 64 |
+
dict(
|
| 65 |
+
type='MultiModalMosaic',
|
| 66 |
+
img_scale=_base_.img_scale,
|
| 67 |
+
pad_val=114.0,
|
| 68 |
+
pre_transform=_base_.pre_transform),
|
| 69 |
+
dict(type='YOLOv5CopyPaste', prob=_base_.copypaste_prob),
|
| 70 |
+
dict(
|
| 71 |
+
type='YOLOv5RandomAffine',
|
| 72 |
+
max_rotate_degree=0.0,
|
| 73 |
+
max_shear_degree=0.0,
|
| 74 |
+
max_aspect_ratio=100.,
|
| 75 |
+
scaling_ratio_range=(1 - _base_.affine_scale,
|
| 76 |
+
1 + _base_.affine_scale),
|
| 77 |
+
# img_scale is (width, height)
|
| 78 |
+
border=(-_base_.img_scale[0] // 2, -_base_.img_scale[1] // 2),
|
| 79 |
+
border_val=(114, 114, 114),
|
| 80 |
+
min_area_ratio=_base_.min_area_ratio,
|
| 81 |
+
use_mask_refine=_base_.use_mask2refine)
|
| 82 |
+
]
|
| 83 |
+
train_pipeline = [
|
| 84 |
+
*_base_.pre_transform,
|
| 85 |
+
*mosaic_affine_transform,
|
| 86 |
+
dict(
|
| 87 |
+
type='YOLOv5MultiModalMixUp',
|
| 88 |
+
prob=_base_.mixup_prob,
|
| 89 |
+
pre_transform=[*_base_.pre_transform,
|
| 90 |
+
*mosaic_affine_transform]),
|
| 91 |
+
*_base_.last_transform[:-1],
|
| 92 |
+
*text_transform
|
| 93 |
+
]
|
| 94 |
+
train_pipeline_stage2 = [
|
| 95 |
+
*_base_.train_pipeline_stage2[:-1],
|
| 96 |
+
*text_transform
|
| 97 |
+
]
|
| 98 |
+
coco_train_dataset = dict(
|
| 99 |
+
_delete_=True,
|
| 100 |
+
type='MultiModalDataset',
|
| 101 |
+
dataset=dict(
|
| 102 |
+
type='YOLOv5CocoDataset',
|
| 103 |
+
data_root='data/coco',
|
| 104 |
+
ann_file='annotations/instances_train2017.json',
|
| 105 |
+
data_prefix=dict(img='train2017/'),
|
| 106 |
+
filter_cfg=dict(filter_empty_gt=False, min_size=32)),
|
| 107 |
+
class_text_path='data/texts/coco_class_texts.json',
|
| 108 |
+
pipeline=train_pipeline)
|
| 109 |
+
|
| 110 |
+
train_dataloader = dict(
|
| 111 |
+
persistent_workers=persistent_workers,
|
| 112 |
+
batch_size=train_batch_size_per_gpu,
|
| 113 |
+
collate_fn=dict(type='yolow_collate'),
|
| 114 |
+
dataset=coco_train_dataset)
|
| 115 |
+
test_pipeline = [
|
| 116 |
+
*_base_.test_pipeline[:-1],
|
| 117 |
+
dict(type='LoadText'),
|
| 118 |
+
dict(
|
| 119 |
+
type='mmdet.PackDetInputs',
|
| 120 |
+
meta_keys=('img_id', 'img_path', 'ori_shape', 'img_shape',
|
| 121 |
+
'scale_factor', 'pad_param', 'texts'))
|
| 122 |
+
]
|
| 123 |
+
coco_val_dataset = dict(
|
| 124 |
+
_delete_=True,
|
| 125 |
+
type='MultiModalDataset',
|
| 126 |
+
dataset=dict(
|
| 127 |
+
type='YOLOv5CocoDataset',
|
| 128 |
+
data_root='data/coco',
|
| 129 |
+
ann_file='annotations/instances_val2017.json',
|
| 130 |
+
data_prefix=dict(img='val2017/'),
|
| 131 |
+
filter_cfg=dict(filter_empty_gt=False, min_size=32)),
|
| 132 |
+
class_text_path='data/texts/coco_class_texts.json',
|
| 133 |
+
pipeline=test_pipeline)
|
| 134 |
+
val_dataloader = dict(dataset=coco_val_dataset)
|
| 135 |
+
test_dataloader = val_dataloader
|
| 136 |
+
# training settings
|
| 137 |
+
default_hooks = dict(
|
| 138 |
+
param_scheduler=dict(
|
| 139 |
+
scheduler_type='linear',
|
| 140 |
+
lr_factor=0.01,
|
| 141 |
+
max_epochs=max_epochs),
|
| 142 |
+
checkpoint=dict(
|
| 143 |
+
max_keep_ckpts=-1,
|
| 144 |
+
save_best=None,
|
| 145 |
+
interval=save_epoch_intervals))
|
| 146 |
+
custom_hooks = [
|
| 147 |
+
dict(
|
| 148 |
+
type='EMAHook',
|
| 149 |
+
ema_type='ExpMomentumEMA',
|
| 150 |
+
momentum=0.0001,
|
| 151 |
+
update_buffers=True,
|
| 152 |
+
strict_load=False,
|
| 153 |
+
priority=49),
|
| 154 |
+
dict(
|
| 155 |
+
type='mmdet.PipelineSwitchHook',
|
| 156 |
+
switch_epoch=max_epochs - close_mosaic_epochs,
|
| 157 |
+
switch_pipeline=train_pipeline_stage2)
|
| 158 |
+
]
|
| 159 |
+
train_cfg = dict(
|
| 160 |
+
max_epochs=max_epochs,
|
| 161 |
+
val_interval=5,
|
| 162 |
+
dynamic_intervals=[((max_epochs - close_mosaic_epochs),
|
| 163 |
+
_base_.val_interval_stage2)])
|
| 164 |
+
optim_wrapper = dict(
|
| 165 |
+
optimizer=dict(
|
| 166 |
+
_delete_=True,
|
| 167 |
+
type='AdamW',
|
| 168 |
+
lr=base_lr,
|
| 169 |
+
weight_decay=weight_decay,
|
| 170 |
+
batch_size_per_gpu=train_batch_size_per_gpu),
|
| 171 |
+
paramwise_cfg=dict(
|
| 172 |
+
custom_keys={'backbone.text_model': dict(lr_mult=0.01),
|
| 173 |
+
'logit_scale': dict(weight_decay=0.0)}),
|
| 174 |
+
constructor='YOLOWv5OptimizerConstructor')
|
| 175 |
+
|
| 176 |
+
# evaluation settings
|
| 177 |
+
val_evaluator = dict(
|
| 178 |
+
_delete_=True,
|
| 179 |
+
type='mmdet.CocoMetric',
|
| 180 |
+
proposal_nums=(100, 1, 10),
|
| 181 |
+
ann_file='data/coco/annotations/instances_val2017.json',
|
| 182 |
+
metric='bbox')
|
configs/finetune_coco/yolo_world_v2_l_vlpan_bn_2e-4_80e_8gpus_mask-refine_finetune_coco.py
ADDED
|
@@ -0,0 +1,181 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
_base_ = (
|
| 2 |
+
'../../third_party/mmyolo/configs/yolov8/'
|
| 3 |
+
'yolov8_l_mask-refine_syncbn_fast_8xb16-500e_coco.py')
|
| 4 |
+
custom_imports = dict(
|
| 5 |
+
imports=['yolo_world'],
|
| 6 |
+
allow_failed_imports=False)
|
| 7 |
+
|
| 8 |
+
# hyper-parameters
|
| 9 |
+
num_classes = 80
|
| 10 |
+
num_training_classes = 80
|
| 11 |
+
max_epochs = 80 # Maximum training epochs
|
| 12 |
+
close_mosaic_epochs = 10
|
| 13 |
+
save_epoch_intervals = 5
|
| 14 |
+
text_channels = 512
|
| 15 |
+
neck_embed_channels = [128, 256, _base_.last_stage_out_channels // 2]
|
| 16 |
+
neck_num_heads = [4, 8, _base_.last_stage_out_channels // 2 // 32]
|
| 17 |
+
base_lr = 2e-4
|
| 18 |
+
weight_decay = 0.05
|
| 19 |
+
train_batch_size_per_gpu = 16
|
| 20 |
+
load_from = 'pretrained_models/yolo_world_l_clip_t2i_bn_2e-3adamw_32xb16-100e_obj365v1_goldg_cc3mlite_train-ca93cd1f.pth'
|
| 21 |
+
# text_model_name = '../pretrained_models/clip-vit-base-patch32-projection'
|
| 22 |
+
text_model_name = 'openai/clip-vit-base-patch32'
|
| 23 |
+
persistent_workers = False
|
| 24 |
+
|
| 25 |
+
# model settings
|
| 26 |
+
model = dict(
|
| 27 |
+
type='YOLOWorldDetector',
|
| 28 |
+
mm_neck=True,
|
| 29 |
+
num_train_classes=num_training_classes,
|
| 30 |
+
num_test_classes=num_classes,
|
| 31 |
+
data_preprocessor=dict(type='YOLOWDetDataPreprocessor'),
|
| 32 |
+
backbone=dict(
|
| 33 |
+
_delete_=True,
|
| 34 |
+
type='MultiModalYOLOBackbone',
|
| 35 |
+
image_model={{_base_.model.backbone}},
|
| 36 |
+
text_model=dict(
|
| 37 |
+
type='HuggingCLIPLanguageBackbone',
|
| 38 |
+
model_name=text_model_name,
|
| 39 |
+
frozen_modules=['all'])),
|
| 40 |
+
neck=dict(type='YOLOWorldPAFPN',
|
| 41 |
+
guide_channels=text_channels,
|
| 42 |
+
embed_channels=neck_embed_channels,
|
| 43 |
+
num_heads=neck_num_heads,
|
| 44 |
+
block_cfg=dict(type='MaxSigmoidCSPLayerWithTwoConv')),
|
| 45 |
+
bbox_head=dict(type='YOLOWorldHead',
|
| 46 |
+
head_module=dict(type='YOLOWorldHeadModule',
|
| 47 |
+
use_bn_head=True,
|
| 48 |
+
embed_dims=text_channels,
|
| 49 |
+
num_classes=num_training_classes)),
|
| 50 |
+
train_cfg=dict(assigner=dict(num_classes=num_training_classes)))
|
| 51 |
+
|
| 52 |
+
# dataset settings
|
| 53 |
+
text_transform = [
|
| 54 |
+
dict(type='RandomLoadText',
|
| 55 |
+
num_neg_samples=(num_classes, num_classes),
|
| 56 |
+
max_num_samples=num_training_classes,
|
| 57 |
+
padding_to_max=True,
|
| 58 |
+
padding_value=''),
|
| 59 |
+
dict(type='mmdet.PackDetInputs',
|
| 60 |
+
meta_keys=('img_id', 'img_path', 'ori_shape', 'img_shape', 'flip',
|
| 61 |
+
'flip_direction', 'texts'))
|
| 62 |
+
]
|
| 63 |
+
mosaic_affine_transform = [
|
| 64 |
+
dict(
|
| 65 |
+
type='MultiModalMosaic',
|
| 66 |
+
img_scale=_base_.img_scale,
|
| 67 |
+
pad_val=114.0,
|
| 68 |
+
pre_transform=_base_.pre_transform),
|
| 69 |
+
dict(type='YOLOv5CopyPaste', prob=_base_.copypaste_prob),
|
| 70 |
+
dict(
|
| 71 |
+
type='YOLOv5RandomAffine',
|
| 72 |
+
max_rotate_degree=0.0,
|
| 73 |
+
max_shear_degree=0.0,
|
| 74 |
+
max_aspect_ratio=100.,
|
| 75 |
+
scaling_ratio_range=(1 - _base_.affine_scale,
|
| 76 |
+
1 + _base_.affine_scale),
|
| 77 |
+
# img_scale is (width, height)
|
| 78 |
+
border=(-_base_.img_scale[0] // 2, -_base_.img_scale[1] // 2),
|
| 79 |
+
border_val=(114, 114, 114),
|
| 80 |
+
min_area_ratio=_base_.min_area_ratio,
|
| 81 |
+
use_mask_refine=_base_.use_mask2refine)
|
| 82 |
+
]
|
| 83 |
+
train_pipeline = [
|
| 84 |
+
*_base_.pre_transform,
|
| 85 |
+
*mosaic_affine_transform,
|
| 86 |
+
dict(
|
| 87 |
+
type='YOLOv5MultiModalMixUp',
|
| 88 |
+
prob=_base_.mixup_prob,
|
| 89 |
+
pre_transform=[*_base_.pre_transform,
|
| 90 |
+
*mosaic_affine_transform]),
|
| 91 |
+
*_base_.last_transform[:-1],
|
| 92 |
+
*text_transform
|
| 93 |
+
]
|
| 94 |
+
train_pipeline_stage2 = [
|
| 95 |
+
*_base_.train_pipeline_stage2[:-1],
|
| 96 |
+
*text_transform
|
| 97 |
+
]
|
| 98 |
+
coco_train_dataset = dict(
|
| 99 |
+
_delete_=True,
|
| 100 |
+
type='MultiModalDataset',
|
| 101 |
+
dataset=dict(
|
| 102 |
+
type='YOLOv5CocoDataset',
|
| 103 |
+
data_root='data/coco',
|
| 104 |
+
ann_file='annotations/instances_train2017.json',
|
| 105 |
+
data_prefix=dict(img='train2017/'),
|
| 106 |
+
filter_cfg=dict(filter_empty_gt=False, min_size=32)),
|
| 107 |
+
class_text_path='data/texts/coco_class_texts.json',
|
| 108 |
+
pipeline=train_pipeline)
|
| 109 |
+
|
| 110 |
+
train_dataloader = dict(
|
| 111 |
+
persistent_workers=persistent_workers,
|
| 112 |
+
batch_size=train_batch_size_per_gpu,
|
| 113 |
+
collate_fn=dict(type='yolow_collate'),
|
| 114 |
+
dataset=coco_train_dataset)
|
| 115 |
+
test_pipeline = [
|
| 116 |
+
*_base_.test_pipeline[:-1],
|
| 117 |
+
dict(type='LoadText'),
|
| 118 |
+
dict(
|
| 119 |
+
type='mmdet.PackDetInputs',
|
| 120 |
+
meta_keys=('img_id', 'img_path', 'ori_shape', 'img_shape',
|
| 121 |
+
'scale_factor', 'pad_param', 'texts'))
|
| 122 |
+
]
|
| 123 |
+
coco_val_dataset = dict(
|
| 124 |
+
_delete_=True,
|
| 125 |
+
type='MultiModalDataset',
|
| 126 |
+
dataset=dict(
|
| 127 |
+
type='YOLOv5CocoDataset',
|
| 128 |
+
data_root='data/coco',
|
| 129 |
+
ann_file='annotations/instances_val2017.json',
|
| 130 |
+
data_prefix=dict(img='val2017/'),
|
| 131 |
+
filter_cfg=dict(filter_empty_gt=False, min_size=32)),
|
| 132 |
+
class_text_path='data/texts/coco_class_texts.json',
|
| 133 |
+
pipeline=test_pipeline)
|
| 134 |
+
val_dataloader = dict(dataset=coco_val_dataset)
|
| 135 |
+
test_dataloader = val_dataloader
|
| 136 |
+
# training settings
|
| 137 |
+
default_hooks = dict(
|
| 138 |
+
param_scheduler=dict(
|
| 139 |
+
scheduler_type='linear',
|
| 140 |
+
lr_factor=0.01,
|
| 141 |
+
max_epochs=max_epochs),
|
| 142 |
+
checkpoint=dict(
|
| 143 |
+
max_keep_ckpts=-1,
|
| 144 |
+
save_best=None,
|
| 145 |
+
interval=save_epoch_intervals))
|
| 146 |
+
custom_hooks = [
|
| 147 |
+
dict(
|
| 148 |
+
type='EMAHook',
|
| 149 |
+
ema_type='ExpMomentumEMA',
|
| 150 |
+
momentum=0.0001,
|
| 151 |
+
update_buffers=True,
|
| 152 |
+
strict_load=False,
|
| 153 |
+
priority=49),
|
| 154 |
+
dict(
|
| 155 |
+
type='mmdet.PipelineSwitchHook',
|
| 156 |
+
switch_epoch=max_epochs - close_mosaic_epochs,
|
| 157 |
+
switch_pipeline=train_pipeline_stage2)
|
| 158 |
+
]
|
| 159 |
+
train_cfg = dict(
|
| 160 |
+
max_epochs=max_epochs,
|
| 161 |
+
val_interval=5,
|
| 162 |
+
dynamic_intervals=[((max_epochs - close_mosaic_epochs),
|
| 163 |
+
_base_.val_interval_stage2)])
|
| 164 |
+
optim_wrapper = dict(
|
| 165 |
+
optimizer=dict(
|
| 166 |
+
_delete_=True,
|
| 167 |
+
type='AdamW',
|
| 168 |
+
lr=base_lr,
|
| 169 |
+
weight_decay=weight_decay,
|
| 170 |
+
batch_size_per_gpu=train_batch_size_per_gpu),
|
| 171 |
+
paramwise_cfg=dict(
|
| 172 |
+
custom_keys={'backbone.text_model': dict(lr_mult=0.01),
|
| 173 |
+
'logit_scale': dict(weight_decay=0.0)}),
|
| 174 |
+
constructor='YOLOWv5OptimizerConstructor')
|
| 175 |
+
# evaluation settings
|
| 176 |
+
val_evaluator = dict(
|
| 177 |
+
_delete_=True,
|
| 178 |
+
type='mmdet.CocoMetric',
|
| 179 |
+
proposal_nums=(100, 1, 10),
|
| 180 |
+
ann_file='data/coco/annotations/instances_val2017.json',
|
| 181 |
+
metric='bbox')
|
configs/finetune_coco/yolo_world_v2_l_vlpan_bn_sgd_1e-3_40e_8gpus_finetune_coco.py
ADDED
|
@@ -0,0 +1,160 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
_base_ = ('../../third_party/mmyolo/configs/yolov8/'
|
| 2 |
+
'yolov8_l_syncbn_fast_8xb16-500e_coco.py')
|
| 3 |
+
custom_imports = dict(imports=['yolo_world'], allow_failed_imports=False)
|
| 4 |
+
|
| 5 |
+
# hyper-parameters
|
| 6 |
+
num_classes = 80
|
| 7 |
+
num_training_classes = 80
|
| 8 |
+
max_epochs = 40 # Maximum training epochs
|
| 9 |
+
close_mosaic_epochs = 30
|
| 10 |
+
save_epoch_intervals = 5
|
| 11 |
+
text_channels = 512
|
| 12 |
+
neck_embed_channels = [128, 256, _base_.last_stage_out_channels // 2]
|
| 13 |
+
neck_num_heads = [4, 8, _base_.last_stage_out_channels // 2 // 32]
|
| 14 |
+
base_lr = 1e-3
|
| 15 |
+
weight_decay = 0.0005
|
| 16 |
+
train_batch_size_per_gpu = 16
|
| 17 |
+
load_from = 'pretrained_models/yolo_world_l_clip_t2i_bn_2e-3adamw_32xb16-100e_obj365v1_goldg_cc3mlite_train-ca93cd1f.pth'
|
| 18 |
+
text_model_name = '../pretrained_models/clip-vit-base-patch32-projection'
|
| 19 |
+
# text_model_name = 'openai/clip-vit-base-patch32'
|
| 20 |
+
persistent_workers = False
|
| 21 |
+
|
| 22 |
+
# model settings
|
| 23 |
+
model = dict(type='YOLOWorldDetector',
|
| 24 |
+
mm_neck=True,
|
| 25 |
+
num_train_classes=num_training_classes,
|
| 26 |
+
num_test_classes=num_classes,
|
| 27 |
+
data_preprocessor=dict(type='YOLOWDetDataPreprocessor'),
|
| 28 |
+
backbone=dict(_delete_=True,
|
| 29 |
+
type='MultiModalYOLOBackbone',
|
| 30 |
+
image_model={{_base_.model.backbone}},
|
| 31 |
+
text_model=dict(type='HuggingCLIPLanguageBackbone',
|
| 32 |
+
model_name=text_model_name,
|
| 33 |
+
frozen_modules=['all'])),
|
| 34 |
+
neck=dict(type='YOLOWorldPAFPN',
|
| 35 |
+
guide_channels=text_channels,
|
| 36 |
+
embed_channels=neck_embed_channels,
|
| 37 |
+
num_heads=neck_num_heads,
|
| 38 |
+
block_cfg=dict(type='MaxSigmoidCSPLayerWithTwoConv')),
|
| 39 |
+
bbox_head=dict(type='YOLOWorldHead',
|
| 40 |
+
head_module=dict(
|
| 41 |
+
type='YOLOWorldHeadModule',
|
| 42 |
+
use_bn_head=True,
|
| 43 |
+
embed_dims=text_channels,
|
| 44 |
+
num_classes=num_training_classes)),
|
| 45 |
+
train_cfg=dict(assigner=dict(num_classes=num_training_classes)))
|
| 46 |
+
|
| 47 |
+
# dataset settings
|
| 48 |
+
text_transform = [
|
| 49 |
+
dict(type='RandomLoadText',
|
| 50 |
+
num_neg_samples=(num_classes, num_classes),
|
| 51 |
+
max_num_samples=num_training_classes,
|
| 52 |
+
padding_to_max=True,
|
| 53 |
+
padding_value=''),
|
| 54 |
+
dict(type='mmdet.PackDetInputs',
|
| 55 |
+
meta_keys=('img_id', 'img_path', 'ori_shape', 'img_shape', 'flip',
|
| 56 |
+
'flip_direction', 'texts'))
|
| 57 |
+
]
|
| 58 |
+
mosaic_affine_transform = [
|
| 59 |
+
dict(type='MultiModalMosaic',
|
| 60 |
+
img_scale=_base_.img_scale,
|
| 61 |
+
pad_val=114.0,
|
| 62 |
+
pre_transform=_base_.pre_transform),
|
| 63 |
+
dict(
|
| 64 |
+
type='YOLOv5RandomAffine',
|
| 65 |
+
max_rotate_degree=0.0,
|
| 66 |
+
max_shear_degree=0.0,
|
| 67 |
+
max_aspect_ratio=100.,
|
| 68 |
+
scaling_ratio_range=(1 - _base_.affine_scale, 1 + _base_.affine_scale),
|
| 69 |
+
# img_scale is (width, height)
|
| 70 |
+
border=(-_base_.img_scale[0] // 2, -_base_.img_scale[1] // 2),
|
| 71 |
+
border_val=(114, 114, 114))
|
| 72 |
+
]
|
| 73 |
+
|
| 74 |
+
train_pipeline = [
|
| 75 |
+
*_base_.pre_transform, *mosaic_affine_transform,
|
| 76 |
+
dict(type='YOLOv5MultiModalMixUp',
|
| 77 |
+
prob=_base_.mixup_prob,
|
| 78 |
+
pre_transform=[*_base_.pre_transform, *mosaic_affine_transform]),
|
| 79 |
+
*_base_.last_transform[:-1], *text_transform
|
| 80 |
+
]
|
| 81 |
+
train_pipeline_stage2 = [*_base_.train_pipeline_stage2[:-1], *text_transform]
|
| 82 |
+
|
| 83 |
+
coco_train_dataset = dict(_delete_=True,
|
| 84 |
+
type='MultiModalDataset',
|
| 85 |
+
dataset=dict(
|
| 86 |
+
type='YOLOv5CocoDataset',
|
| 87 |
+
data_root='data/coco',
|
| 88 |
+
ann_file='annotations/instances_train2017.json',
|
| 89 |
+
data_prefix=dict(img='train2017/'),
|
| 90 |
+
filter_cfg=dict(filter_empty_gt=False,
|
| 91 |
+
min_size=32)),
|
| 92 |
+
class_text_path='data/texts/coco_class_texts.json',
|
| 93 |
+
pipeline=train_pipeline)
|
| 94 |
+
|
| 95 |
+
train_dataloader = dict(persistent_workers=persistent_workers,
|
| 96 |
+
batch_size=train_batch_size_per_gpu,
|
| 97 |
+
collate_fn=dict(type='yolow_collate'),
|
| 98 |
+
dataset=coco_train_dataset)
|
| 99 |
+
test_pipeline = [
|
| 100 |
+
*_base_.test_pipeline[:-1],
|
| 101 |
+
dict(type='LoadText'),
|
| 102 |
+
dict(type='mmdet.PackDetInputs',
|
| 103 |
+
meta_keys=('img_id', 'img_path', 'ori_shape', 'img_shape',
|
| 104 |
+
'scale_factor', 'pad_param', 'texts'))
|
| 105 |
+
]
|
| 106 |
+
coco_val_dataset = dict(
|
| 107 |
+
_delete_=True,
|
| 108 |
+
type='MultiModalDataset',
|
| 109 |
+
dataset=dict(type='YOLOv5CocoDataset',
|
| 110 |
+
data_root='data/coco',
|
| 111 |
+
ann_file='annotations/instances_val2017.json',
|
| 112 |
+
data_prefix=dict(img='val2017/'),
|
| 113 |
+
filter_cfg=dict(filter_empty_gt=False, min_size=32)),
|
| 114 |
+
class_text_path='data/texts/coco_class_texts.json',
|
| 115 |
+
pipeline=test_pipeline)
|
| 116 |
+
val_dataloader = dict(dataset=coco_val_dataset)
|
| 117 |
+
test_dataloader = val_dataloader
|
| 118 |
+
# training settings
|
| 119 |
+
default_hooks = dict(param_scheduler=dict(scheduler_type='linear',
|
| 120 |
+
lr_factor=0.01,
|
| 121 |
+
max_epochs=max_epochs),
|
| 122 |
+
checkpoint=dict(max_keep_ckpts=-1,
|
| 123 |
+
save_best=None,
|
| 124 |
+
interval=save_epoch_intervals))
|
| 125 |
+
custom_hooks = [
|
| 126 |
+
dict(type='EMAHook',
|
| 127 |
+
ema_type='ExpMomentumEMA',
|
| 128 |
+
momentum=0.0001,
|
| 129 |
+
update_buffers=True,
|
| 130 |
+
strict_load=False,
|
| 131 |
+
priority=49),
|
| 132 |
+
dict(type='mmdet.PipelineSwitchHook',
|
| 133 |
+
switch_epoch=max_epochs - close_mosaic_epochs,
|
| 134 |
+
switch_pipeline=train_pipeline_stage2)
|
| 135 |
+
]
|
| 136 |
+
train_cfg = dict(max_epochs=max_epochs,
|
| 137 |
+
val_interval=5,
|
| 138 |
+
dynamic_intervals=[((max_epochs - close_mosaic_epochs),
|
| 139 |
+
_base_.val_interval_stage2)])
|
| 140 |
+
optim_wrapper = dict(optimizer=dict(
|
| 141 |
+
_delete_=True,
|
| 142 |
+
type='SGD',
|
| 143 |
+
lr=base_lr,
|
| 144 |
+
momentum=0.937,
|
| 145 |
+
nesterov=True,
|
| 146 |
+
weight_decay=weight_decay,
|
| 147 |
+
batch_size_per_gpu=train_batch_size_per_gpu),
|
| 148 |
+
paramwise_cfg=dict(
|
| 149 |
+
custom_keys={
|
| 150 |
+
'backbone.text_model': dict(lr_mult=0.01),
|
| 151 |
+
'logit_scale': dict(weight_decay=0.0)
|
| 152 |
+
}),
|
| 153 |
+
constructor='YOLOWv5OptimizerConstructor')
|
| 154 |
+
|
| 155 |
+
# evaluation settings
|
| 156 |
+
val_evaluator = dict(_delete_=True,
|
| 157 |
+
type='mmdet.CocoMetric',
|
| 158 |
+
proposal_nums=(100, 1, 10),
|
| 159 |
+
ann_file='data/coco/annotations/instances_val2017.json',
|
| 160 |
+
metric='bbox')
|
configs/finetune_coco/yolo_world_v2_l_vlpan_bn_sgd_1e-3_80e_8gpus_mask-refine_finetune_coco.py
ADDED
|
@@ -0,0 +1,161 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
_base_ = ('../../third_party/mmyolo/configs/yolov8/'
|
| 2 |
+
'yolov8_l_mask-refine_syncbn_fast_8xb16-500e_coco.py')
|
| 3 |
+
custom_imports = dict(imports=['yolo_world'], allow_failed_imports=False)
|
| 4 |
+
|
| 5 |
+
# hyper-parameters
|
| 6 |
+
num_classes = 80
|
| 7 |
+
num_training_classes = 80
|
| 8 |
+
max_epochs = 80 # Maximum training epochs
|
| 9 |
+
close_mosaic_epochs = 10
|
| 10 |
+
save_epoch_intervals = 5
|
| 11 |
+
text_channels = 512
|
| 12 |
+
neck_embed_channels = [128, 256, _base_.last_stage_out_channels // 2]
|
| 13 |
+
neck_num_heads = [4, 8, _base_.last_stage_out_channels // 2 // 32]
|
| 14 |
+
base_lr = 1e-3
|
| 15 |
+
weight_decay = 0.0005
|
| 16 |
+
train_batch_size_per_gpu = 16
|
| 17 |
+
load_from = 'pretrained_models/yolo_world_l_clip_t2i_bn_2e-3adamw_32xb16-100e_obj365v1_goldg_cc3mlite_train-ca93cd1f.pth'
|
| 18 |
+
text_model_name = '../pretrained_models/clip-vit-base-patch32-projection'
|
| 19 |
+
# text_model_name = 'openai/clip-vit-base-patch32'
|
| 20 |
+
persistent_workers = False
|
| 21 |
+
|
| 22 |
+
# model settings
|
| 23 |
+
model = dict(type='YOLOWorldDetector',
|
| 24 |
+
mm_neck=True,
|
| 25 |
+
num_train_classes=num_training_classes,
|
| 26 |
+
num_test_classes=num_classes,
|
| 27 |
+
data_preprocessor=dict(type='YOLOWDetDataPreprocessor'),
|
| 28 |
+
backbone=dict(_delete_=True,
|
| 29 |
+
type='MultiModalYOLOBackbone',
|
| 30 |
+
image_model={{_base_.model.backbone}},
|
| 31 |
+
text_model=dict(type='HuggingCLIPLanguageBackbone',
|
| 32 |
+
model_name=text_model_name,
|
| 33 |
+
frozen_modules=['all'])),
|
| 34 |
+
neck=dict(type='YOLOWorldPAFPN',
|
| 35 |
+
guide_channels=text_channels,
|
| 36 |
+
embed_channels=neck_embed_channels,
|
| 37 |
+
num_heads=neck_num_heads,
|
| 38 |
+
block_cfg=dict(type='MaxSigmoidCSPLayerWithTwoConv')),
|
| 39 |
+
bbox_head=dict(type='YOLOWorldHead',
|
| 40 |
+
head_module=dict(
|
| 41 |
+
type='YOLOWorldHeadModule',
|
| 42 |
+
use_bn_head=True,
|
| 43 |
+
embed_dims=text_channels,
|
| 44 |
+
num_classes=num_training_classes)),
|
| 45 |
+
train_cfg=dict(assigner=dict(num_classes=num_training_classes)))
|
| 46 |
+
|
| 47 |
+
# dataset settings
|
| 48 |
+
text_transform = [
|
| 49 |
+
dict(type='RandomLoadText',
|
| 50 |
+
num_neg_samples=(num_classes, num_classes),
|
| 51 |
+
max_num_samples=num_training_classes,
|
| 52 |
+
padding_to_max=True,
|
| 53 |
+
padding_value=''),
|
| 54 |
+
dict(type='mmdet.PackDetInputs',
|
| 55 |
+
meta_keys=('img_id', 'img_path', 'ori_shape', 'img_shape', 'flip',
|
| 56 |
+
'flip_direction', 'texts'))
|
| 57 |
+
]
|
| 58 |
+
mosaic_affine_transform = [
|
| 59 |
+
dict(type='MultiModalMosaic',
|
| 60 |
+
img_scale=_base_.img_scale,
|
| 61 |
+
pad_val=114.0,
|
| 62 |
+
pre_transform=_base_.pre_transform),
|
| 63 |
+
dict(type='YOLOv5CopyPaste', prob=_base_.copypaste_prob),
|
| 64 |
+
dict(
|
| 65 |
+
type='YOLOv5RandomAffine',
|
| 66 |
+
max_rotate_degree=0.0,
|
| 67 |
+
max_shear_degree=0.0,
|
| 68 |
+
max_aspect_ratio=100.,
|
| 69 |
+
scaling_ratio_range=(1 - _base_.affine_scale, 1 + _base_.affine_scale),
|
| 70 |
+
# img_scale is (width, height)
|
| 71 |
+
border=(-_base_.img_scale[0] // 2, -_base_.img_scale[1] // 2),
|
| 72 |
+
border_val=(114, 114, 114),
|
| 73 |
+
min_area_ratio=_base_.min_area_ratio,
|
| 74 |
+
use_mask_refine=_base_.use_mask2refine)
|
| 75 |
+
]
|
| 76 |
+
train_pipeline = [
|
| 77 |
+
*_base_.pre_transform, *mosaic_affine_transform,
|
| 78 |
+
dict(type='YOLOv5MultiModalMixUp',
|
| 79 |
+
prob=_base_.mixup_prob,
|
| 80 |
+
pre_transform=[*_base_.pre_transform, *mosaic_affine_transform]),
|
| 81 |
+
*_base_.last_transform[:-1], *text_transform
|
| 82 |
+
]
|
| 83 |
+
train_pipeline_stage2 = [*_base_.train_pipeline_stage2[:-1], *text_transform]
|
| 84 |
+
coco_train_dataset = dict(_delete_=True,
|
| 85 |
+
type='MultiModalDataset',
|
| 86 |
+
dataset=dict(
|
| 87 |
+
type='YOLOv5CocoDataset',
|
| 88 |
+
data_root='data/coco',
|
| 89 |
+
ann_file='annotations/instances_train2017.json',
|
| 90 |
+
data_prefix=dict(img='train2017/'),
|
| 91 |
+
filter_cfg=dict(filter_empty_gt=False,
|
| 92 |
+
min_size=32)),
|
| 93 |
+
class_text_path='data/texts/coco_class_texts.json',
|
| 94 |
+
pipeline=train_pipeline)
|
| 95 |
+
|
| 96 |
+
train_dataloader = dict(persistent_workers=persistent_workers,
|
| 97 |
+
batch_size=train_batch_size_per_gpu,
|
| 98 |
+
collate_fn=dict(type='yolow_collate'),
|
| 99 |
+
dataset=coco_train_dataset)
|
| 100 |
+
test_pipeline = [
|
| 101 |
+
*_base_.test_pipeline[:-1],
|
| 102 |
+
dict(type='LoadText'),
|
| 103 |
+
dict(type='mmdet.PackDetInputs',
|
| 104 |
+
meta_keys=('img_id', 'img_path', 'ori_shape', 'img_shape',
|
| 105 |
+
'scale_factor', 'pad_param', 'texts'))
|
| 106 |
+
]
|
| 107 |
+
coco_val_dataset = dict(
|
| 108 |
+
_delete_=True,
|
| 109 |
+
type='MultiModalDataset',
|
| 110 |
+
dataset=dict(type='YOLOv5CocoDataset',
|
| 111 |
+
data_root='data/coco',
|
| 112 |
+
ann_file='annotations/instances_val2017.json',
|
| 113 |
+
data_prefix=dict(img='val2017/'),
|
| 114 |
+
filter_cfg=dict(filter_empty_gt=False, min_size=32)),
|
| 115 |
+
class_text_path='data/texts/coco_class_texts.json',
|
| 116 |
+
pipeline=test_pipeline)
|
| 117 |
+
val_dataloader = dict(dataset=coco_val_dataset)
|
| 118 |
+
test_dataloader = val_dataloader
|
| 119 |
+
# training settings
|
| 120 |
+
default_hooks = dict(param_scheduler=dict(scheduler_type='linear',
|
| 121 |
+
lr_factor=0.01,
|
| 122 |
+
max_epochs=max_epochs),
|
| 123 |
+
checkpoint=dict(max_keep_ckpts=-1,
|
| 124 |
+
save_best=None,
|
| 125 |
+
interval=save_epoch_intervals))
|
| 126 |
+
custom_hooks = [
|
| 127 |
+
dict(type='EMAHook',
|
| 128 |
+
ema_type='ExpMomentumEMA',
|
| 129 |
+
momentum=0.0001,
|
| 130 |
+
update_buffers=True,
|
| 131 |
+
strict_load=False,
|
| 132 |
+
priority=49),
|
| 133 |
+
dict(type='mmdet.PipelineSwitchHook',
|
| 134 |
+
switch_epoch=max_epochs - close_mosaic_epochs,
|
| 135 |
+
switch_pipeline=train_pipeline_stage2)
|
| 136 |
+
]
|
| 137 |
+
train_cfg = dict(max_epochs=max_epochs,
|
| 138 |
+
val_interval=5,
|
| 139 |
+
dynamic_intervals=[((max_epochs - close_mosaic_epochs),
|
| 140 |
+
_base_.val_interval_stage2)])
|
| 141 |
+
optim_wrapper = dict(optimizer=dict(
|
| 142 |
+
_delete_=True,
|
| 143 |
+
type='SGD',
|
| 144 |
+
lr=base_lr,
|
| 145 |
+
momentum=0.937,
|
| 146 |
+
nesterov=True,
|
| 147 |
+
weight_decay=weight_decay,
|
| 148 |
+
batch_size_per_gpu=train_batch_size_per_gpu),
|
| 149 |
+
paramwise_cfg=dict(
|
| 150 |
+
custom_keys={
|
| 151 |
+
'backbone.text_model': dict(lr_mult=0.01),
|
| 152 |
+
'logit_scale': dict(weight_decay=0.0)
|
| 153 |
+
}),
|
| 154 |
+
constructor='YOLOWv5OptimizerConstructor')
|
| 155 |
+
|
| 156 |
+
# evaluation settings
|
| 157 |
+
val_evaluator = dict(_delete_=True,
|
| 158 |
+
type='mmdet.CocoMetric',
|
| 159 |
+
proposal_nums=(100, 1, 10),
|
| 160 |
+
ann_file='data/coco/annotations/instances_val2017.json',
|
| 161 |
+
metric='bbox')
|
configs/finetune_coco/yolo_world_v2_m_vlpan_bn_2e-4_80e_8gpus_mask-refine_finetune_coco.py
ADDED
|
@@ -0,0 +1,182 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
_base_ = (
|
| 2 |
+
'../../third_party/mmyolo/configs/yolov8/'
|
| 3 |
+
'yolov8_m_mask-refine_syncbn_fast_8xb16-500e_coco.py')
|
| 4 |
+
custom_imports = dict(
|
| 5 |
+
imports=['yolo_world'],
|
| 6 |
+
allow_failed_imports=False)
|
| 7 |
+
|
| 8 |
+
# hyper-parameters
|
| 9 |
+
num_classes = 80
|
| 10 |
+
num_training_classes = 80
|
| 11 |
+
max_epochs = 80 # Maximum training epochs
|
| 12 |
+
close_mosaic_epochs = 10
|
| 13 |
+
save_epoch_intervals = 5
|
| 14 |
+
text_channels = 512
|
| 15 |
+
neck_embed_channels = [128, 256, _base_.last_stage_out_channels // 2]
|
| 16 |
+
neck_num_heads = [4, 8, _base_.last_stage_out_channels // 2 // 32]
|
| 17 |
+
base_lr = 2e-4
|
| 18 |
+
weight_decay = 0.05
|
| 19 |
+
train_batch_size_per_gpu = 16
|
| 20 |
+
load_from = 'pretrained_models/yolo_world_m_clip_t2i_bn_2e-3adamw_32xb16-100e_obj365v1_goldg_train-c6237d5b.pth'
|
| 21 |
+
# text_model_name = '../pretrained_models/clip-vit-base-patch32-projection'
|
| 22 |
+
text_model_name = 'openai/clip-vit-base-patch32'
|
| 23 |
+
persistent_workers = False
|
| 24 |
+
|
| 25 |
+
# model settings
|
| 26 |
+
model = dict(
|
| 27 |
+
type='YOLOWorldDetector',
|
| 28 |
+
mm_neck=True,
|
| 29 |
+
num_train_classes=num_training_classes,
|
| 30 |
+
num_test_classes=num_classes,
|
| 31 |
+
data_preprocessor=dict(type='YOLOWDetDataPreprocessor'),
|
| 32 |
+
backbone=dict(
|
| 33 |
+
_delete_=True,
|
| 34 |
+
type='MultiModalYOLOBackbone',
|
| 35 |
+
image_model={{_base_.model.backbone}},
|
| 36 |
+
text_model=dict(
|
| 37 |
+
type='HuggingCLIPLanguageBackbone',
|
| 38 |
+
model_name=text_model_name,
|
| 39 |
+
frozen_modules=['all'])),
|
| 40 |
+
neck=dict(type='YOLOWorldPAFPN',
|
| 41 |
+
guide_channels=text_channels,
|
| 42 |
+
embed_channels=neck_embed_channels,
|
| 43 |
+
num_heads=neck_num_heads,
|
| 44 |
+
block_cfg=dict(type='MaxSigmoidCSPLayerWithTwoConv')),
|
| 45 |
+
bbox_head=dict(type='YOLOWorldHead',
|
| 46 |
+
head_module=dict(type='YOLOWorldHeadModule',
|
| 47 |
+
use_bn_head=True,
|
| 48 |
+
embed_dims=text_channels,
|
| 49 |
+
num_classes=num_training_classes)),
|
| 50 |
+
train_cfg=dict(assigner=dict(num_classes=num_training_classes)))
|
| 51 |
+
|
| 52 |
+
# dataset settings
|
| 53 |
+
text_transform = [
|
| 54 |
+
dict(type='RandomLoadText',
|
| 55 |
+
num_neg_samples=(num_classes, num_classes),
|
| 56 |
+
max_num_samples=num_training_classes,
|
| 57 |
+
padding_to_max=True,
|
| 58 |
+
padding_value=''),
|
| 59 |
+
dict(type='mmdet.PackDetInputs',
|
| 60 |
+
meta_keys=('img_id', 'img_path', 'ori_shape', 'img_shape', 'flip',
|
| 61 |
+
'flip_direction', 'texts'))
|
| 62 |
+
]
|
| 63 |
+
mosaic_affine_transform = [
|
| 64 |
+
dict(
|
| 65 |
+
type='MultiModalMosaic',
|
| 66 |
+
img_scale=_base_.img_scale,
|
| 67 |
+
pad_val=114.0,
|
| 68 |
+
pre_transform=_base_.pre_transform),
|
| 69 |
+
dict(type='YOLOv5CopyPaste', prob=_base_.copypaste_prob),
|
| 70 |
+
dict(
|
| 71 |
+
type='YOLOv5RandomAffine',
|
| 72 |
+
max_rotate_degree=0.0,
|
| 73 |
+
max_shear_degree=0.0,
|
| 74 |
+
max_aspect_ratio=100.,
|
| 75 |
+
scaling_ratio_range=(1 - _base_.affine_scale,
|
| 76 |
+
1 + _base_.affine_scale),
|
| 77 |
+
# img_scale is (width, height)
|
| 78 |
+
border=(-_base_.img_scale[0] // 2, -_base_.img_scale[1] // 2),
|
| 79 |
+
border_val=(114, 114, 114),
|
| 80 |
+
min_area_ratio=_base_.min_area_ratio,
|
| 81 |
+
use_mask_refine=_base_.use_mask2refine)
|
| 82 |
+
]
|
| 83 |
+
train_pipeline = [
|
| 84 |
+
*_base_.pre_transform,
|
| 85 |
+
*mosaic_affine_transform,
|
| 86 |
+
dict(
|
| 87 |
+
type='YOLOv5MultiModalMixUp',
|
| 88 |
+
prob=_base_.mixup_prob,
|
| 89 |
+
pre_transform=[*_base_.pre_transform,
|
| 90 |
+
*mosaic_affine_transform]),
|
| 91 |
+
*_base_.last_transform[:-1],
|
| 92 |
+
*text_transform
|
| 93 |
+
]
|
| 94 |
+
train_pipeline_stage2 = [
|
| 95 |
+
*_base_.train_pipeline_stage2[:-1],
|
| 96 |
+
*text_transform
|
| 97 |
+
]
|
| 98 |
+
coco_train_dataset = dict(
|
| 99 |
+
_delete_=True,
|
| 100 |
+
type='MultiModalDataset',
|
| 101 |
+
dataset=dict(
|
| 102 |
+
type='YOLOv5CocoDataset',
|
| 103 |
+
data_root='data/coco',
|
| 104 |
+
ann_file='annotations/instances_train2017.json',
|
| 105 |
+
data_prefix=dict(img='train2017/'),
|
| 106 |
+
filter_cfg=dict(filter_empty_gt=False, min_size=32)),
|
| 107 |
+
class_text_path='data/texts/coco_class_texts.json',
|
| 108 |
+
pipeline=train_pipeline)
|
| 109 |
+
|
| 110 |
+
train_dataloader = dict(
|
| 111 |
+
persistent_workers=persistent_workers,
|
| 112 |
+
batch_size=train_batch_size_per_gpu,
|
| 113 |
+
collate_fn=dict(type='yolow_collate'),
|
| 114 |
+
dataset=coco_train_dataset)
|
| 115 |
+
test_pipeline = [
|
| 116 |
+
*_base_.test_pipeline[:-1],
|
| 117 |
+
dict(type='LoadText'),
|
| 118 |
+
dict(
|
| 119 |
+
type='mmdet.PackDetInputs',
|
| 120 |
+
meta_keys=('img_id', 'img_path', 'ori_shape', 'img_shape',
|
| 121 |
+
'scale_factor', 'pad_param', 'texts'))
|
| 122 |
+
]
|
| 123 |
+
coco_val_dataset = dict(
|
| 124 |
+
_delete_=True,
|
| 125 |
+
type='MultiModalDataset',
|
| 126 |
+
dataset=dict(
|
| 127 |
+
type='YOLOv5CocoDataset',
|
| 128 |
+
data_root='data/coco',
|
| 129 |
+
ann_file='annotations/instances_val2017.json',
|
| 130 |
+
data_prefix=dict(img='val2017/'),
|
| 131 |
+
filter_cfg=dict(filter_empty_gt=False, min_size=32)),
|
| 132 |
+
class_text_path='data/texts/coco_class_texts.json',
|
| 133 |
+
pipeline=test_pipeline)
|
| 134 |
+
val_dataloader = dict(dataset=coco_val_dataset)
|
| 135 |
+
test_dataloader = val_dataloader
|
| 136 |
+
# training settings
|
| 137 |
+
default_hooks = dict(
|
| 138 |
+
param_scheduler=dict(
|
| 139 |
+
scheduler_type='linear',
|
| 140 |
+
lr_factor=0.01,
|
| 141 |
+
max_epochs=max_epochs),
|
| 142 |
+
checkpoint=dict(
|
| 143 |
+
max_keep_ckpts=-1,
|
| 144 |
+
save_best=None,
|
| 145 |
+
interval=save_epoch_intervals))
|
| 146 |
+
custom_hooks = [
|
| 147 |
+
dict(
|
| 148 |
+
type='EMAHook',
|
| 149 |
+
ema_type='ExpMomentumEMA',
|
| 150 |
+
momentum=0.0001,
|
| 151 |
+
update_buffers=True,
|
| 152 |
+
strict_load=False,
|
| 153 |
+
priority=49),
|
| 154 |
+
dict(
|
| 155 |
+
type='mmdet.PipelineSwitchHook',
|
| 156 |
+
switch_epoch=max_epochs - close_mosaic_epochs,
|
| 157 |
+
switch_pipeline=train_pipeline_stage2)
|
| 158 |
+
]
|
| 159 |
+
train_cfg = dict(
|
| 160 |
+
max_epochs=max_epochs,
|
| 161 |
+
val_interval=5,
|
| 162 |
+
dynamic_intervals=[((max_epochs - close_mosaic_epochs),
|
| 163 |
+
_base_.val_interval_stage2)])
|
| 164 |
+
optim_wrapper = dict(
|
| 165 |
+
optimizer=dict(
|
| 166 |
+
_delete_=True,
|
| 167 |
+
type='AdamW',
|
| 168 |
+
lr=base_lr,
|
| 169 |
+
weight_decay=weight_decay,
|
| 170 |
+
batch_size_per_gpu=train_batch_size_per_gpu),
|
| 171 |
+
paramwise_cfg=dict(
|
| 172 |
+
custom_keys={'backbone.text_model': dict(lr_mult=0.01),
|
| 173 |
+
'logit_scale': dict(weight_decay=0.0)}),
|
| 174 |
+
constructor='YOLOWv5OptimizerConstructor')
|
| 175 |
+
|
| 176 |
+
# evaluation settings
|
| 177 |
+
val_evaluator = dict(
|
| 178 |
+
_delete_=True,
|
| 179 |
+
type='mmdet.CocoMetric',
|
| 180 |
+
proposal_nums=(100, 1, 10),
|
| 181 |
+
ann_file='data/coco/annotations/instances_val2017.json',
|
| 182 |
+
metric='bbox')
|
configs/finetune_coco/yolo_world_v2_s_vlpan_bn_2e-4_80e_8gpus_mask-refine_finetune_coco.py
ADDED
|
@@ -0,0 +1,184 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
_base_ = (
|
| 2 |
+
'../../third_party/mmyolo/configs/yolov8/'
|
| 3 |
+
'yolov8_s_mask-refine_syncbn_fast_8xb16-500e_coco.py')
|
| 4 |
+
custom_imports = dict(
|
| 5 |
+
imports=['yolo_world'],
|
| 6 |
+
allow_failed_imports=False)
|
| 7 |
+
|
| 8 |
+
# hyper-parameters
|
| 9 |
+
num_classes = 80
|
| 10 |
+
num_training_classes = 80
|
| 11 |
+
max_epochs = 80 # Maximum training epochs
|
| 12 |
+
close_mosaic_epochs = 10
|
| 13 |
+
save_epoch_intervals = 5
|
| 14 |
+
text_channels = 512
|
| 15 |
+
neck_embed_channels = [128, 256, _base_.last_stage_out_channels // 2]
|
| 16 |
+
neck_num_heads = [4, 8, _base_.last_stage_out_channels // 2 // 32]
|
| 17 |
+
base_lr = 2e-4
|
| 18 |
+
weight_decay = 0.05
|
| 19 |
+
train_batch_size_per_gpu = 16
|
| 20 |
+
load_from = 'pretrained_models/yolo_world_s_clip_t2i_bn_2e-3adamw_32xb16-100e_obj365v1_goldg_train-55b943ea.pth'
|
| 21 |
+
# text_model_name = '../pretrained_models/clip-vit-base-patch32-projection'
|
| 22 |
+
text_model_name = 'openai/clip-vit-base-patch32'
|
| 23 |
+
persistent_workers = False
|
| 24 |
+
mixup_prob = 0.15
|
| 25 |
+
copypaste_prob = 0.3
|
| 26 |
+
|
| 27 |
+
# model settings
|
| 28 |
+
model = dict(
|
| 29 |
+
type='YOLOWorldDetector',
|
| 30 |
+
mm_neck=True,
|
| 31 |
+
num_train_classes=num_training_classes,
|
| 32 |
+
num_test_classes=num_classes,
|
| 33 |
+
data_preprocessor=dict(type='YOLOWDetDataPreprocessor'),
|
| 34 |
+
backbone=dict(
|
| 35 |
+
_delete_=True,
|
| 36 |
+
type='MultiModalYOLOBackbone',
|
| 37 |
+
image_model={{_base_.model.backbone}},
|
| 38 |
+
text_model=dict(
|
| 39 |
+
type='HuggingCLIPLanguageBackbone',
|
| 40 |
+
model_name=text_model_name,
|
| 41 |
+
frozen_modules=['all'])),
|
| 42 |
+
neck=dict(type='YOLOWorldPAFPN',
|
| 43 |
+
guide_channels=text_channels,
|
| 44 |
+
embed_channels=neck_embed_channels,
|
| 45 |
+
num_heads=neck_num_heads,
|
| 46 |
+
block_cfg=dict(type='MaxSigmoidCSPLayerWithTwoConv')),
|
| 47 |
+
bbox_head=dict(type='YOLOWorldHead',
|
| 48 |
+
head_module=dict(type='YOLOWorldHeadModule',
|
| 49 |
+
use_bn_head=True,
|
| 50 |
+
embed_dims=text_channels,
|
| 51 |
+
num_classes=num_training_classes)),
|
| 52 |
+
train_cfg=dict(assigner=dict(num_classes=num_training_classes)))
|
| 53 |
+
|
| 54 |
+
# dataset settings
|
| 55 |
+
text_transform = [
|
| 56 |
+
dict(type='RandomLoadText',
|
| 57 |
+
num_neg_samples=(num_classes, num_classes),
|
| 58 |
+
max_num_samples=num_training_classes,
|
| 59 |
+
padding_to_max=True,
|
| 60 |
+
padding_value=''),
|
| 61 |
+
dict(type='mmdet.PackDetInputs',
|
| 62 |
+
meta_keys=('img_id', 'img_path', 'ori_shape', 'img_shape', 'flip',
|
| 63 |
+
'flip_direction', 'texts'))
|
| 64 |
+
]
|
| 65 |
+
mosaic_affine_transform = [
|
| 66 |
+
dict(
|
| 67 |
+
type='MultiModalMosaic',
|
| 68 |
+
img_scale=_base_.img_scale,
|
| 69 |
+
pad_val=114.0,
|
| 70 |
+
pre_transform=_base_.pre_transform),
|
| 71 |
+
dict(type='YOLOv5CopyPaste', prob=copypaste_prob),
|
| 72 |
+
dict(
|
| 73 |
+
type='YOLOv5RandomAffine',
|
| 74 |
+
max_rotate_degree=0.0,
|
| 75 |
+
max_shear_degree=0.0,
|
| 76 |
+
max_aspect_ratio=100.,
|
| 77 |
+
scaling_ratio_range=(1 - _base_.affine_scale,
|
| 78 |
+
1 + _base_.affine_scale),
|
| 79 |
+
# img_scale is (width, height)
|
| 80 |
+
border=(-_base_.img_scale[0] // 2, -_base_.img_scale[1] // 2),
|
| 81 |
+
border_val=(114, 114, 114),
|
| 82 |
+
min_area_ratio=_base_.min_area_ratio,
|
| 83 |
+
use_mask_refine=_base_.use_mask2refine)
|
| 84 |
+
]
|
| 85 |
+
train_pipeline = [
|
| 86 |
+
*_base_.pre_transform,
|
| 87 |
+
*mosaic_affine_transform,
|
| 88 |
+
dict(
|
| 89 |
+
type='YOLOv5MultiModalMixUp',
|
| 90 |
+
prob=mixup_prob,
|
| 91 |
+
pre_transform=[*_base_.pre_transform,
|
| 92 |
+
*mosaic_affine_transform]),
|
| 93 |
+
*_base_.last_transform[:-1],
|
| 94 |
+
*text_transform
|
| 95 |
+
]
|
| 96 |
+
train_pipeline_stage2 = [
|
| 97 |
+
*_base_.train_pipeline_stage2[:-1],
|
| 98 |
+
*text_transform
|
| 99 |
+
]
|
| 100 |
+
coco_train_dataset = dict(
|
| 101 |
+
_delete_=True,
|
| 102 |
+
type='MultiModalDataset',
|
| 103 |
+
dataset=dict(
|
| 104 |
+
type='YOLOv5CocoDataset',
|
| 105 |
+
data_root='data/coco',
|
| 106 |
+
ann_file='annotations/instances_train2017.json',
|
| 107 |
+
data_prefix=dict(img='train2017/'),
|
| 108 |
+
filter_cfg=dict(filter_empty_gt=False, min_size=32)),
|
| 109 |
+
class_text_path='data/texts/coco_class_texts.json',
|
| 110 |
+
pipeline=train_pipeline)
|
| 111 |
+
|
| 112 |
+
train_dataloader = dict(
|
| 113 |
+
persistent_workers=persistent_workers,
|
| 114 |
+
batch_size=train_batch_size_per_gpu,
|
| 115 |
+
collate_fn=dict(type='yolow_collate'),
|
| 116 |
+
dataset=coco_train_dataset)
|
| 117 |
+
test_pipeline = [
|
| 118 |
+
*_base_.test_pipeline[:-1],
|
| 119 |
+
dict(type='LoadText'),
|
| 120 |
+
dict(
|
| 121 |
+
type='mmdet.PackDetInputs',
|
| 122 |
+
meta_keys=('img_id', 'img_path', 'ori_shape', 'img_shape',
|
| 123 |
+
'scale_factor', 'pad_param', 'texts'))
|
| 124 |
+
]
|
| 125 |
+
coco_val_dataset = dict(
|
| 126 |
+
_delete_=True,
|
| 127 |
+
type='MultiModalDataset',
|
| 128 |
+
dataset=dict(
|
| 129 |
+
type='YOLOv5CocoDataset',
|
| 130 |
+
data_root='data/coco',
|
| 131 |
+
ann_file='annotations/instances_val2017.json',
|
| 132 |
+
data_prefix=dict(img='val2017/'),
|
| 133 |
+
filter_cfg=dict(filter_empty_gt=False, min_size=32)),
|
| 134 |
+
class_text_path='data/texts/coco_class_texts.json',
|
| 135 |
+
pipeline=test_pipeline)
|
| 136 |
+
val_dataloader = dict(dataset=coco_val_dataset)
|
| 137 |
+
test_dataloader = val_dataloader
|
| 138 |
+
# training settings
|
| 139 |
+
default_hooks = dict(
|
| 140 |
+
param_scheduler=dict(
|
| 141 |
+
scheduler_type='linear',
|
| 142 |
+
lr_factor=0.01,
|
| 143 |
+
max_epochs=max_epochs),
|
| 144 |
+
checkpoint=dict(
|
| 145 |
+
max_keep_ckpts=-1,
|
| 146 |
+
save_best=None,
|
| 147 |
+
interval=save_epoch_intervals))
|
| 148 |
+
custom_hooks = [
|
| 149 |
+
dict(
|
| 150 |
+
type='EMAHook',
|
| 151 |
+
ema_type='ExpMomentumEMA',
|
| 152 |
+
momentum=0.0001,
|
| 153 |
+
update_buffers=True,
|
| 154 |
+
strict_load=False,
|
| 155 |
+
priority=49),
|
| 156 |
+
dict(
|
| 157 |
+
type='mmdet.PipelineSwitchHook',
|
| 158 |
+
switch_epoch=max_epochs - close_mosaic_epochs,
|
| 159 |
+
switch_pipeline=train_pipeline_stage2)
|
| 160 |
+
]
|
| 161 |
+
train_cfg = dict(
|
| 162 |
+
max_epochs=max_epochs,
|
| 163 |
+
val_interval=5,
|
| 164 |
+
dynamic_intervals=[((max_epochs - close_mosaic_epochs),
|
| 165 |
+
_base_.val_interval_stage2)])
|
| 166 |
+
optim_wrapper = dict(
|
| 167 |
+
optimizer=dict(
|
| 168 |
+
_delete_=True,
|
| 169 |
+
type='AdamW',
|
| 170 |
+
lr=base_lr,
|
| 171 |
+
weight_decay=weight_decay,
|
| 172 |
+
batch_size_per_gpu=train_batch_size_per_gpu),
|
| 173 |
+
paramwise_cfg=dict(
|
| 174 |
+
custom_keys={'backbone.text_model': dict(lr_mult=0.01),
|
| 175 |
+
'logit_scale': dict(weight_decay=0.0)}),
|
| 176 |
+
constructor='YOLOWv5OptimizerConstructor')
|
| 177 |
+
|
| 178 |
+
# evaluation settings
|
| 179 |
+
val_evaluator = dict(
|
| 180 |
+
_delete_=True,
|
| 181 |
+
type='mmdet.CocoMetric',
|
| 182 |
+
proposal_nums=(100, 1, 10),
|
| 183 |
+
ann_file='data/coco/annotations/instances_val2017.json',
|
| 184 |
+
metric='bbox')
|
configs/finetune_coco/yolo_world_v2_x_vlpan_bn_2e-4_80e_8gpus_mask-refine_finetune_coco.py
ADDED
|
@@ -0,0 +1,183 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
_base_ = (
|
| 2 |
+
'../../third_party/mmyolo/configs/yolov8/'
|
| 3 |
+
'yolov8_x_mask-refine_syncbn_fast_8xb16-500e_coco.py')
|
| 4 |
+
custom_imports = dict(
|
| 5 |
+
imports=['yolo_world'],
|
| 6 |
+
allow_failed_imports=False)
|
| 7 |
+
|
| 8 |
+
# hyper-parameters
|
| 9 |
+
num_classes = 80
|
| 10 |
+
num_training_classes = 80
|
| 11 |
+
max_epochs = 80 # Maximum training epochs
|
| 12 |
+
close_mosaic_epochs = 10
|
| 13 |
+
save_epoch_intervals = 5
|
| 14 |
+
text_channels = 512
|
| 15 |
+
neck_embed_channels = [128, 256, _base_.last_stage_out_channels // 2]
|
| 16 |
+
neck_num_heads = [4, 8, _base_.last_stage_out_channels // 2 // 32]
|
| 17 |
+
base_lr = 2e-4
|
| 18 |
+
weight_decay = 0.05
|
| 19 |
+
train_batch_size_per_gpu = 16
|
| 20 |
+
load_from = 'pretrained_models/yolo_world_x_clip_t2i_bn_2e-3adamw_32xb16-100e_obj365v1_goldg_cc250k_train_lviseval-8698fbfa.pth'
|
| 21 |
+
text_model_name = '../pretrained_models/clip-vit-base-patch32-projection'
|
| 22 |
+
# text_model_name = 'openai/clip-vit-base-patch32'
|
| 23 |
+
persistent_workers = False
|
| 24 |
+
|
| 25 |
+
# model settings
|
| 26 |
+
model = dict(
|
| 27 |
+
type='YOLOWorldDetector',
|
| 28 |
+
mm_neck=True,
|
| 29 |
+
num_train_classes=num_training_classes,
|
| 30 |
+
num_test_classes=num_classes,
|
| 31 |
+
data_preprocessor=dict(type='YOLOWDetDataPreprocessor'),
|
| 32 |
+
backbone=dict(
|
| 33 |
+
_delete_=True,
|
| 34 |
+
type='MultiModalYOLOBackbone',
|
| 35 |
+
image_model={{_base_.model.backbone}},
|
| 36 |
+
text_model=dict(
|
| 37 |
+
type='HuggingCLIPLanguageBackbone',
|
| 38 |
+
model_name=text_model_name,
|
| 39 |
+
frozen_modules=['all'])),
|
| 40 |
+
neck=dict(type='YOLOWorldPAFPN',
|
| 41 |
+
guide_channels=text_channels,
|
| 42 |
+
embed_channels=neck_embed_channels,
|
| 43 |
+
num_heads=neck_num_heads,
|
| 44 |
+
block_cfg=dict(type='MaxSigmoidCSPLayerWithTwoConv')),
|
| 45 |
+
bbox_head=dict(type='YOLOWorldHead',
|
| 46 |
+
head_module=dict(type='YOLOWorldHeadModule',
|
| 47 |
+
use_bn_head=True,
|
| 48 |
+
embed_dims=text_channels,
|
| 49 |
+
num_classes=num_training_classes)),
|
| 50 |
+
train_cfg=dict(assigner=dict(num_classes=num_training_classes)))
|
| 51 |
+
|
| 52 |
+
# dataset settings
|
| 53 |
+
text_transform = [
|
| 54 |
+
dict(type='RandomLoadText',
|
| 55 |
+
num_neg_samples=(num_classes, num_classes),
|
| 56 |
+
max_num_samples=num_training_classes,
|
| 57 |
+
padding_to_max=True,
|
| 58 |
+
padding_value=''),
|
| 59 |
+
dict(type='mmdet.PackDetInputs',
|
| 60 |
+
meta_keys=('img_id', 'img_path', 'ori_shape', 'img_shape', 'flip',
|
| 61 |
+
'flip_direction', 'texts'))
|
| 62 |
+
]
|
| 63 |
+
mosaic_affine_transform = [
|
| 64 |
+
dict(
|
| 65 |
+
type='MultiModalMosaic',
|
| 66 |
+
img_scale=_base_.img_scale,
|
| 67 |
+
pad_val=114.0,
|
| 68 |
+
pre_transform=_base_.pre_transform),
|
| 69 |
+
dict(type='YOLOv5CopyPaste', prob=_base_.copypaste_prob),
|
| 70 |
+
dict(
|
| 71 |
+
type='YOLOv5RandomAffine',
|
| 72 |
+
max_rotate_degree=0.0,
|
| 73 |
+
max_shear_degree=0.0,
|
| 74 |
+
max_aspect_ratio=100.,
|
| 75 |
+
scaling_ratio_range=(1 - _base_.affine_scale,
|
| 76 |
+
1 + _base_.affine_scale),
|
| 77 |
+
# img_scale is (width, height)
|
| 78 |
+
border=(-_base_.img_scale[0] // 2, -_base_.img_scale[1] // 2),
|
| 79 |
+
border_val=(114, 114, 114),
|
| 80 |
+
min_area_ratio=_base_.min_area_ratio,
|
| 81 |
+
use_mask_refine=_base_.use_mask2refine)
|
| 82 |
+
]
|
| 83 |
+
train_pipeline = [
|
| 84 |
+
*_base_.pre_transform,
|
| 85 |
+
*mosaic_affine_transform,
|
| 86 |
+
dict(
|
| 87 |
+
type='YOLOv5MultiModalMixUp',
|
| 88 |
+
prob=_base_.mixup_prob,
|
| 89 |
+
pre_transform=[*_base_.pre_transform,
|
| 90 |
+
*mosaic_affine_transform]),
|
| 91 |
+
*_base_.last_transform[:-1],
|
| 92 |
+
*text_transform
|
| 93 |
+
]
|
| 94 |
+
train_pipeline_stage2 = [
|
| 95 |
+
*_base_.train_pipeline_stage2[:-1],
|
| 96 |
+
*text_transform
|
| 97 |
+
]
|
| 98 |
+
coco_train_dataset = dict(
|
| 99 |
+
_delete_=True,
|
| 100 |
+
type='MultiModalDataset',
|
| 101 |
+
dataset=dict(
|
| 102 |
+
type='YOLOv5CocoDataset',
|
| 103 |
+
data_root='data/coco',
|
| 104 |
+
ann_file='annotations/instances_train2017.json',
|
| 105 |
+
data_prefix=dict(img='train2017/'),
|
| 106 |
+
filter_cfg=dict(filter_empty_gt=False, min_size=32)),
|
| 107 |
+
class_text_path='data/texts/coco_class_texts.json',
|
| 108 |
+
pipeline=train_pipeline)
|
| 109 |
+
|
| 110 |
+
train_dataloader = dict(
|
| 111 |
+
persistent_workers=persistent_workers,
|
| 112 |
+
batch_size=train_batch_size_per_gpu,
|
| 113 |
+
collate_fn=dict(type='yolow_collate'),
|
| 114 |
+
dataset=coco_train_dataset)
|
| 115 |
+
|
| 116 |
+
test_pipeline = [
|
| 117 |
+
*_base_.test_pipeline[:-1],
|
| 118 |
+
dict(type='LoadText'),
|
| 119 |
+
dict(
|
| 120 |
+
type='mmdet.PackDetInputs',
|
| 121 |
+
meta_keys=('img_id', 'img_path', 'ori_shape', 'img_shape',
|
| 122 |
+
'scale_factor', 'pad_param', 'texts'))
|
| 123 |
+
]
|
| 124 |
+
|
| 125 |
+
coco_val_dataset = dict(
|
| 126 |
+
_delete_=True,
|
| 127 |
+
type='MultiModalDataset',
|
| 128 |
+
dataset=dict(
|
| 129 |
+
type='YOLOv5CocoDataset',
|
| 130 |
+
data_root='data/coco',
|
| 131 |
+
ann_file='annotations/instances_val2017.json',
|
| 132 |
+
data_prefix=dict(img='val2017/'),
|
| 133 |
+
filter_cfg=dict(filter_empty_gt=False, min_size=32)),
|
| 134 |
+
class_text_path='data/texts/coco_class_texts.json',
|
| 135 |
+
pipeline=test_pipeline)
|
| 136 |
+
val_dataloader = dict(dataset=coco_val_dataset)
|
| 137 |
+
test_dataloader = val_dataloader
|
| 138 |
+
# training settings
|
| 139 |
+
default_hooks = dict(
|
| 140 |
+
param_scheduler=dict(
|
| 141 |
+
scheduler_type='linear',
|
| 142 |
+
lr_factor=0.01,
|
| 143 |
+
max_epochs=max_epochs),
|
| 144 |
+
checkpoint=dict(
|
| 145 |
+
max_keep_ckpts=-1,
|
| 146 |
+
save_best=None,
|
| 147 |
+
interval=save_epoch_intervals))
|
| 148 |
+
custom_hooks = [
|
| 149 |
+
dict(
|
| 150 |
+
type='EMAHook',
|
| 151 |
+
ema_type='ExpMomentumEMA',
|
| 152 |
+
momentum=0.0001,
|
| 153 |
+
update_buffers=True,
|
| 154 |
+
strict_load=False,
|
| 155 |
+
priority=49),
|
| 156 |
+
dict(
|
| 157 |
+
type='mmdet.PipelineSwitchHook',
|
| 158 |
+
switch_epoch=max_epochs - close_mosaic_epochs,
|
| 159 |
+
switch_pipeline=train_pipeline_stage2)
|
| 160 |
+
]
|
| 161 |
+
train_cfg = dict(
|
| 162 |
+
max_epochs=max_epochs,
|
| 163 |
+
val_interval=5,
|
| 164 |
+
dynamic_intervals=[((max_epochs - close_mosaic_epochs),
|
| 165 |
+
_base_.val_interval_stage2)])
|
| 166 |
+
optim_wrapper = dict(
|
| 167 |
+
optimizer=dict(
|
| 168 |
+
_delete_=True,
|
| 169 |
+
type='AdamW',
|
| 170 |
+
lr=base_lr,
|
| 171 |
+
weight_decay=weight_decay,
|
| 172 |
+
batch_size_per_gpu=train_batch_size_per_gpu),
|
| 173 |
+
paramwise_cfg=dict(
|
| 174 |
+
custom_keys={'backbone.text_model': dict(lr_mult=0.01),
|
| 175 |
+
'logit_scale': dict(weight_decay=0.0)}),
|
| 176 |
+
constructor='YOLOWv5OptimizerConstructor')
|
| 177 |
+
# evaluation settings
|
| 178 |
+
val_evaluator = dict(
|
| 179 |
+
_delete_=True,
|
| 180 |
+
type='mmdet.CocoMetric',
|
| 181 |
+
proposal_nums=(100, 1, 10),
|
| 182 |
+
ann_file='data/coco/annotations/instances_val2017.json',
|
| 183 |
+
metric='bbox')
|
configs/finetune_coco/yolo_world_v2_xl_vlpan_bn_2e-4_80e_8gpus_mask-refine_finetune_coco.py
ADDED
|
@@ -0,0 +1,173 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
_base_ = ('../../third_party/mmyolo/configs/yolov8/'
|
| 2 |
+
'yolov8_x_mask-refine_syncbn_fast_8xb16-500e_coco.py')
|
| 3 |
+
custom_imports = dict(imports=['yolo_world'], allow_failed_imports=False)
|
| 4 |
+
|
| 5 |
+
# hyper-parameters
|
| 6 |
+
num_classes = 80
|
| 7 |
+
num_training_classes = 80
|
| 8 |
+
max_epochs = 80 # Maximum training epochs
|
| 9 |
+
close_mosaic_epochs = 10
|
| 10 |
+
save_epoch_intervals = 5
|
| 11 |
+
text_channels = 512
|
| 12 |
+
neck_embed_channels = [128, 256, _base_.last_stage_out_channels // 2]
|
| 13 |
+
neck_num_heads = [4, 8, _base_.last_stage_out_channels // 2 // 32]
|
| 14 |
+
base_lr = 2e-4
|
| 15 |
+
weight_decay = 0.05
|
| 16 |
+
train_batch_size_per_gpu = 16
|
| 17 |
+
text_model_name = '../pretrained_models/clip-vit-base-patch32-projection'
|
| 18 |
+
# text_model_name = 'openai/clip-vit-base-patch32'
|
| 19 |
+
persistent_workers = False
|
| 20 |
+
|
| 21 |
+
# scaling model from X to XL
|
| 22 |
+
deepen_factor = 1.0
|
| 23 |
+
widen_factor = 1.5
|
| 24 |
+
|
| 25 |
+
backbone = _base_.model.backbone
|
| 26 |
+
backbone.update(deepen_factor=deepen_factor, widen_factor=widen_factor)
|
| 27 |
+
|
| 28 |
+
# model settings
|
| 29 |
+
model = dict(type='YOLOWorldDetector',
|
| 30 |
+
mm_neck=True,
|
| 31 |
+
num_train_classes=num_training_classes,
|
| 32 |
+
num_test_classes=num_classes,
|
| 33 |
+
data_preprocessor=dict(type='YOLOWDetDataPreprocessor'),
|
| 34 |
+
backbone=dict(_delete_=True,
|
| 35 |
+
type='MultiModalYOLOBackbone',
|
| 36 |
+
image_model=backbone,
|
| 37 |
+
text_model=dict(type='HuggingCLIPLanguageBackbone',
|
| 38 |
+
model_name=text_model_name,
|
| 39 |
+
frozen_modules=['all'])),
|
| 40 |
+
neck=dict(type='YOLOWorldPAFPN',
|
| 41 |
+
deepen_factor=deepen_factor,
|
| 42 |
+
widen_factor=widen_factor,
|
| 43 |
+
guide_channels=text_channels,
|
| 44 |
+
embed_channels=neck_embed_channels,
|
| 45 |
+
num_heads=neck_num_heads,
|
| 46 |
+
block_cfg=dict(type='MaxSigmoidCSPLayerWithTwoConv')),
|
| 47 |
+
bbox_head=dict(type='YOLOWorldHead',
|
| 48 |
+
head_module=dict(
|
| 49 |
+
type='YOLOWorldHeadModule',
|
| 50 |
+
widen_factor=widen_factor,
|
| 51 |
+
use_bn_head=True,
|
| 52 |
+
embed_dims=text_channels,
|
| 53 |
+
num_classes=num_training_classes)),
|
| 54 |
+
train_cfg=dict(assigner=dict(num_classes=num_training_classes)))
|
| 55 |
+
|
| 56 |
+
# dataset settings
|
| 57 |
+
text_transform = [
|
| 58 |
+
dict(type='RandomLoadText',
|
| 59 |
+
num_neg_samples=(num_classes, num_classes),
|
| 60 |
+
max_num_samples=num_training_classes,
|
| 61 |
+
padding_to_max=True,
|
| 62 |
+
padding_value=''),
|
| 63 |
+
dict(type='mmdet.PackDetInputs',
|
| 64 |
+
meta_keys=('img_id', 'img_path', 'ori_shape', 'img_shape', 'flip',
|
| 65 |
+
'flip_direction', 'texts'))
|
| 66 |
+
]
|
| 67 |
+
mosaic_affine_transform = [
|
| 68 |
+
dict(type='MultiModalMosaic',
|
| 69 |
+
img_scale=_base_.img_scale,
|
| 70 |
+
pad_val=114.0,
|
| 71 |
+
pre_transform=_base_.pre_transform),
|
| 72 |
+
dict(type='YOLOv5CopyPaste', prob=_base_.copypaste_prob),
|
| 73 |
+
dict(
|
| 74 |
+
type='YOLOv5RandomAffine',
|
| 75 |
+
max_rotate_degree=0.0,
|
| 76 |
+
max_shear_degree=0.0,
|
| 77 |
+
max_aspect_ratio=100.,
|
| 78 |
+
scaling_ratio_range=(1 - _base_.affine_scale, 1 + _base_.affine_scale),
|
| 79 |
+
# img_scale is (width, height)
|
| 80 |
+
border=(-_base_.img_scale[0] // 2, -_base_.img_scale[1] // 2),
|
| 81 |
+
border_val=(114, 114, 114),
|
| 82 |
+
min_area_ratio=_base_.min_area_ratio,
|
| 83 |
+
use_mask_refine=_base_.use_mask2refine)
|
| 84 |
+
]
|
| 85 |
+
train_pipeline = [
|
| 86 |
+
*_base_.pre_transform, *mosaic_affine_transform,
|
| 87 |
+
dict(type='YOLOv5MultiModalMixUp',
|
| 88 |
+
prob=_base_.mixup_prob,
|
| 89 |
+
pre_transform=[*_base_.pre_transform, *mosaic_affine_transform]),
|
| 90 |
+
*_base_.last_transform[:-1], *text_transform
|
| 91 |
+
]
|
| 92 |
+
train_pipeline_stage2 = [*_base_.train_pipeline_stage2[:-1], *text_transform]
|
| 93 |
+
coco_train_dataset = dict(_delete_=True,
|
| 94 |
+
type='MultiModalDataset',
|
| 95 |
+
dataset=dict(
|
| 96 |
+
type='YOLOv5CocoDataset',
|
| 97 |
+
data_root='data/coco',
|
| 98 |
+
ann_file='annotations/instances_train2017.json',
|
| 99 |
+
data_prefix=dict(img='train2017/'),
|
| 100 |
+
filter_cfg=dict(filter_empty_gt=False,
|
| 101 |
+
min_size=32)),
|
| 102 |
+
class_text_path='data/texts/coco_class_texts.json',
|
| 103 |
+
pipeline=train_pipeline)
|
| 104 |
+
|
| 105 |
+
train_dataloader = dict(persistent_workers=persistent_workers,
|
| 106 |
+
batch_size=train_batch_size_per_gpu,
|
| 107 |
+
collate_fn=dict(type='yolow_collate'),
|
| 108 |
+
dataset=coco_train_dataset)
|
| 109 |
+
|
| 110 |
+
test_pipeline = [
|
| 111 |
+
*_base_.test_pipeline[:-1],
|
| 112 |
+
dict(type='LoadText'),
|
| 113 |
+
dict(type='mmdet.PackDetInputs',
|
| 114 |
+
meta_keys=('img_id', 'img_path', 'ori_shape', 'img_shape',
|
| 115 |
+
'scale_factor', 'pad_param', 'texts'))
|
| 116 |
+
]
|
| 117 |
+
|
| 118 |
+
coco_val_dataset = dict(
|
| 119 |
+
_delete_=True,
|
| 120 |
+
type='MultiModalDataset',
|
| 121 |
+
dataset=dict(type='YOLOv5CocoDataset',
|
| 122 |
+
data_root='data/coco',
|
| 123 |
+
ann_file='annotations/instances_val2017.json',
|
| 124 |
+
data_prefix=dict(img='val2017/'),
|
| 125 |
+
filter_cfg=dict(filter_empty_gt=False, min_size=32)),
|
| 126 |
+
class_text_path='data/texts/coco_class_texts.json',
|
| 127 |
+
pipeline=test_pipeline)
|
| 128 |
+
val_dataloader = dict(dataset=coco_val_dataset)
|
| 129 |
+
test_dataloader = val_dataloader
|
| 130 |
+
# training settings
|
| 131 |
+
default_hooks = dict(param_scheduler=dict(scheduler_type='linear',
|
| 132 |
+
lr_factor=0.01,
|
| 133 |
+
max_epochs=max_epochs),
|
| 134 |
+
checkpoint=dict(max_keep_ckpts=-1,
|
| 135 |
+
save_best=None,
|
| 136 |
+
interval=save_epoch_intervals))
|
| 137 |
+
custom_hooks = [
|
| 138 |
+
dict(type='EMAHook',
|
| 139 |
+
ema_type='ExpMomentumEMA',
|
| 140 |
+
momentum=0.0001,
|
| 141 |
+
update_buffers=True,
|
| 142 |
+
strict_load=False,
|
| 143 |
+
priority=49),
|
| 144 |
+
dict(type='mmdet.PipelineSwitchHook',
|
| 145 |
+
switch_epoch=max_epochs - close_mosaic_epochs,
|
| 146 |
+
switch_pipeline=train_pipeline_stage2)
|
| 147 |
+
]
|
| 148 |
+
train_cfg = dict(max_epochs=max_epochs,
|
| 149 |
+
val_interval=5,
|
| 150 |
+
dynamic_intervals=[((max_epochs - close_mosaic_epochs),
|
| 151 |
+
_base_.val_interval_stage2)])
|
| 152 |
+
optim_wrapper = dict(optimizer=dict(
|
| 153 |
+
_delete_=True,
|
| 154 |
+
type='AdamW',
|
| 155 |
+
lr=base_lr,
|
| 156 |
+
weight_decay=weight_decay,
|
| 157 |
+
batch_size_per_gpu=train_batch_size_per_gpu),
|
| 158 |
+
paramwise_cfg=dict(bias_decay_mult=0.0,
|
| 159 |
+
norm_decay_mult=0.0,
|
| 160 |
+
custom_keys={
|
| 161 |
+
'backbone.text_model':
|
| 162 |
+
dict(lr_mult=0.01),
|
| 163 |
+
'logit_scale':
|
| 164 |
+
dict(weight_decay=0.0)
|
| 165 |
+
}),
|
| 166 |
+
constructor='YOLOWv5OptimizerConstructor')
|
| 167 |
+
|
| 168 |
+
# evaluation settings
|
| 169 |
+
val_evaluator = dict(_delete_=True,
|
| 170 |
+
type='mmdet.CocoMetric',
|
| 171 |
+
proposal_nums=(100, 1, 10),
|
| 172 |
+
ann_file='data/coco/annotations/instances_val2017.json',
|
| 173 |
+
metric='bbox')
|
configs/pretrain/yolo_world_v2_l_clip_large_vlpan_bn_2e-3_100e_4x8gpus_obj365v1_goldg_train_800ft_lvis_minival.py
ADDED
|
@@ -0,0 +1,200 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
_base_ = ('../../third_party/mmyolo/configs/yolov8/'
|
| 2 |
+
'yolov8_l_syncbn_fast_8xb16-500e_coco.py')
|
| 3 |
+
custom_imports = dict(imports=['yolo_world'],
|
| 4 |
+
allow_failed_imports=False)
|
| 5 |
+
|
| 6 |
+
# hyper-parameters
|
| 7 |
+
num_classes = 1203
|
| 8 |
+
num_training_classes = 80
|
| 9 |
+
max_epochs = 100 # Maximum training epochs
|
| 10 |
+
close_mosaic_epochs = 2
|
| 11 |
+
save_epoch_intervals = 2
|
| 12 |
+
text_channels = 768
|
| 13 |
+
neck_embed_channels = [128, 256, _base_.last_stage_out_channels // 2]
|
| 14 |
+
neck_num_heads = [4, 8, _base_.last_stage_out_channels // 2 // 32]
|
| 15 |
+
base_lr = 2e-3
|
| 16 |
+
weight_decay = 0.0125
|
| 17 |
+
train_batch_size_per_gpu = 16
|
| 18 |
+
# text_model_name = '../pretrained_models/clip-vit-large-patch14-336'
|
| 19 |
+
text_model_name = 'openai/clip-vit-large-patch14-336'
|
| 20 |
+
img_scale = (800, 800)
|
| 21 |
+
|
| 22 |
+
# model settings
|
| 23 |
+
model = dict(
|
| 24 |
+
type='YOLOWorldDetector',
|
| 25 |
+
mm_neck=True,
|
| 26 |
+
num_train_classes=num_training_classes,
|
| 27 |
+
num_test_classes=num_classes,
|
| 28 |
+
data_preprocessor=dict(type='YOLOWDetDataPreprocessor'),
|
| 29 |
+
backbone=dict(
|
| 30 |
+
_delete_=True,
|
| 31 |
+
type='MultiModalYOLOBackbone',
|
| 32 |
+
image_model={{_base_.model.backbone}},
|
| 33 |
+
text_model=dict(
|
| 34 |
+
type='HuggingCLIPLanguageBackbone',
|
| 35 |
+
model_name=text_model_name,
|
| 36 |
+
frozen_modules=['all'])),
|
| 37 |
+
neck=dict(type='YOLOWorldPAFPN',
|
| 38 |
+
guide_channels=text_channels,
|
| 39 |
+
embed_channels=neck_embed_channels,
|
| 40 |
+
num_heads=neck_num_heads,
|
| 41 |
+
block_cfg=dict(type='MaxSigmoidCSPLayerWithTwoConv')),
|
| 42 |
+
bbox_head=dict(type='YOLOWorldHead',
|
| 43 |
+
head_module=dict(type='YOLOWorldHeadModule',
|
| 44 |
+
use_bn_head=True,
|
| 45 |
+
embed_dims=text_channels,
|
| 46 |
+
num_classes=num_training_classes)),
|
| 47 |
+
train_cfg=dict(assigner=dict(num_classes=num_training_classes)))
|
| 48 |
+
|
| 49 |
+
# dataset settings
|
| 50 |
+
text_transform = [
|
| 51 |
+
dict(type='RandomLoadText',
|
| 52 |
+
num_neg_samples=(num_classes, num_classes),
|
| 53 |
+
max_num_samples=num_training_classes,
|
| 54 |
+
padding_to_max=True,
|
| 55 |
+
padding_value=''),
|
| 56 |
+
dict(type='mmdet.PackDetInputs',
|
| 57 |
+
meta_keys=('img_id', 'img_path', 'ori_shape', 'img_shape', 'flip',
|
| 58 |
+
'flip_direction', 'texts'))
|
| 59 |
+
]
|
| 60 |
+
train_pipeline = [
|
| 61 |
+
*_base_.pre_transform,
|
| 62 |
+
dict(type='MultiModalMosaic',
|
| 63 |
+
img_scale=img_scale,
|
| 64 |
+
pad_val=114.0,
|
| 65 |
+
pre_transform=_base_.pre_transform),
|
| 66 |
+
dict(
|
| 67 |
+
type='YOLOv5RandomAffine',
|
| 68 |
+
max_rotate_degree=0.0,
|
| 69 |
+
max_shear_degree=0.0,
|
| 70 |
+
scaling_ratio_range=(1 - _base_.affine_scale, 1 + _base_.affine_scale),
|
| 71 |
+
max_aspect_ratio=_base_.max_aspect_ratio,
|
| 72 |
+
border=(-img_scale[0] // 2, -img_scale[1] // 2),
|
| 73 |
+
border_val=(114, 114, 114)),
|
| 74 |
+
*_base_.last_transform[:-1],
|
| 75 |
+
*text_transform,
|
| 76 |
+
]
|
| 77 |
+
|
| 78 |
+
train_pipeline_stage2 = [
|
| 79 |
+
*_base_.pre_transform,
|
| 80 |
+
dict(type='YOLOv5KeepRatioResize', scale=img_scale),
|
| 81 |
+
dict(
|
| 82 |
+
type='LetterResize',
|
| 83 |
+
scale=img_scale,
|
| 84 |
+
allow_scale_up=True,
|
| 85 |
+
pad_val=dict(img=114.0)),
|
| 86 |
+
dict(
|
| 87 |
+
type='YOLOv5RandomAffine',
|
| 88 |
+
max_rotate_degree=0.0,
|
| 89 |
+
max_shear_degree=0.0,
|
| 90 |
+
scaling_ratio_range=(1 - _base_.affine_scale, 1 + _base_.affine_scale),
|
| 91 |
+
max_aspect_ratio=_base_.max_aspect_ratio,
|
| 92 |
+
border_val=(114, 114, 114)),
|
| 93 |
+
*_base_.last_transform[:-1],
|
| 94 |
+
*text_transform
|
| 95 |
+
]
|
| 96 |
+
|
| 97 |
+
obj365v1_train_dataset = dict(
|
| 98 |
+
type='MultiModalDataset',
|
| 99 |
+
dataset=dict(
|
| 100 |
+
type='YOLOv5Objects365V1Dataset',
|
| 101 |
+
data_root='data/objects365v1/',
|
| 102 |
+
ann_file='annotations/objects365_train.json',
|
| 103 |
+
data_prefix=dict(img='train/'),
|
| 104 |
+
filter_cfg=dict(filter_empty_gt=False, min_size=32)),
|
| 105 |
+
class_text_path='data/texts/obj365v1_class_texts.json',
|
| 106 |
+
pipeline=train_pipeline)
|
| 107 |
+
|
| 108 |
+
mg_train_dataset = dict(type='YOLOv5MixedGroundingDataset',
|
| 109 |
+
data_root='data/mixed_grounding/',
|
| 110 |
+
ann_file='annotations/final_mixed_train_no_coco.json',
|
| 111 |
+
data_prefix=dict(img='gqa/images/'),
|
| 112 |
+
filter_cfg=dict(filter_empty_gt=False, min_size=32),
|
| 113 |
+
pipeline=train_pipeline)
|
| 114 |
+
|
| 115 |
+
flickr_train_dataset = dict(
|
| 116 |
+
type='YOLOv5MixedGroundingDataset',
|
| 117 |
+
data_root='data/flickr/',
|
| 118 |
+
ann_file='annotations/final_flickr_separateGT_train.json',
|
| 119 |
+
data_prefix=dict(img='full_images/'),
|
| 120 |
+
filter_cfg=dict(filter_empty_gt=True, min_size=32),
|
| 121 |
+
pipeline=train_pipeline)
|
| 122 |
+
|
| 123 |
+
train_dataloader = dict(batch_size=train_batch_size_per_gpu,
|
| 124 |
+
collate_fn=dict(type='yolow_collate'),
|
| 125 |
+
dataset=dict(_delete_=True,
|
| 126 |
+
type='ConcatDataset',
|
| 127 |
+
datasets=[
|
| 128 |
+
obj365v1_train_dataset,
|
| 129 |
+
flickr_train_dataset, mg_train_dataset
|
| 130 |
+
],
|
| 131 |
+
ignore_keys=['classes', 'palette']))
|
| 132 |
+
|
| 133 |
+
test_pipeline = [
|
| 134 |
+
dict(type='LoadImageFromFile'),
|
| 135 |
+
dict(type='YOLOv5KeepRatioResize', scale=img_scale),
|
| 136 |
+
dict(
|
| 137 |
+
type='LetterResize',
|
| 138 |
+
scale=img_scale,
|
| 139 |
+
allow_scale_up=False,
|
| 140 |
+
pad_val=dict(img=114)),
|
| 141 |
+
dict(type='LoadAnnotations', with_bbox=True, _scope_='mmdet'),
|
| 142 |
+
dict(type='LoadText'),
|
| 143 |
+
dict(type='mmdet.PackDetInputs',
|
| 144 |
+
meta_keys=('img_id', 'img_path', 'ori_shape', 'img_shape',
|
| 145 |
+
'scale_factor', 'pad_param', 'texts'))
|
| 146 |
+
]
|
| 147 |
+
|
| 148 |
+
coco_val_dataset = dict(
|
| 149 |
+
_delete_=True,
|
| 150 |
+
type='MultiModalDataset',
|
| 151 |
+
dataset=dict(type='YOLOv5LVISV1Dataset',
|
| 152 |
+
data_root='data/coco/',
|
| 153 |
+
test_mode=True,
|
| 154 |
+
ann_file='lvis/lvis_v1_minival_inserted_image_name.json',
|
| 155 |
+
data_prefix=dict(img=''),
|
| 156 |
+
batch_shapes_cfg=None),
|
| 157 |
+
class_text_path='data/texts/lvis_v1_class_texts.json',
|
| 158 |
+
pipeline=test_pipeline)
|
| 159 |
+
val_dataloader = dict(dataset=coco_val_dataset)
|
| 160 |
+
test_dataloader = val_dataloader
|
| 161 |
+
|
| 162 |
+
val_evaluator = dict(type='mmdet.LVISMetric',
|
| 163 |
+
ann_file='data/coco/lvis/lvis_v1_minival_inserted_image_name.json',
|
| 164 |
+
metric='bbox')
|
| 165 |
+
test_evaluator = val_evaluator
|
| 166 |
+
|
| 167 |
+
# training settings
|
| 168 |
+
default_hooks = dict(param_scheduler=dict(max_epochs=max_epochs),
|
| 169 |
+
checkpoint=dict(interval=save_epoch_intervals,
|
| 170 |
+
rule='greater'))
|
| 171 |
+
custom_hooks = [
|
| 172 |
+
dict(type='EMAHook',
|
| 173 |
+
ema_type='ExpMomentumEMA',
|
| 174 |
+
momentum=0.0001,
|
| 175 |
+
update_buffers=True,
|
| 176 |
+
strict_load=False,
|
| 177 |
+
priority=49),
|
| 178 |
+
dict(type='mmdet.PipelineSwitchHook',
|
| 179 |
+
switch_epoch=max_epochs - close_mosaic_epochs,
|
| 180 |
+
switch_pipeline=train_pipeline_stage2)
|
| 181 |
+
]
|
| 182 |
+
train_cfg = dict(max_epochs=max_epochs,
|
| 183 |
+
val_interval=10,
|
| 184 |
+
dynamic_intervals=[((max_epochs - close_mosaic_epochs),
|
| 185 |
+
_base_.val_interval_stage2)])
|
| 186 |
+
optim_wrapper = dict(optimizer=dict(
|
| 187 |
+
_delete_=True,
|
| 188 |
+
type='AdamW',
|
| 189 |
+
lr=base_lr,
|
| 190 |
+
weight_decay=weight_decay,
|
| 191 |
+
batch_size_per_gpu=train_batch_size_per_gpu),
|
| 192 |
+
paramwise_cfg=dict(bias_decay_mult=0.0,
|
| 193 |
+
norm_decay_mult=0.0,
|
| 194 |
+
custom_keys={
|
| 195 |
+
'backbone.text_model':
|
| 196 |
+
dict(lr_mult=0.01),
|
| 197 |
+
'logit_scale':
|
| 198 |
+
dict(weight_decay=0.0)
|
| 199 |
+
}),
|
| 200 |
+
constructor='YOLOWv5OptimizerConstructor')
|
configs/pretrain/yolo_world_v2_l_clip_large_vlpan_bn_2e-3_100e_4x8gpus_obj365v1_goldg_train_lvis_minival.py
ADDED
|
@@ -0,0 +1,171 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
_base_ = ('../../third_party/mmyolo/configs/yolov8/'
|
| 2 |
+
'yolov8_l_syncbn_fast_8xb16-500e_coco.py')
|
| 3 |
+
custom_imports = dict(imports=['yolo_world'],
|
| 4 |
+
allow_failed_imports=False)
|
| 5 |
+
|
| 6 |
+
# hyper-parameters
|
| 7 |
+
num_classes = 1203
|
| 8 |
+
num_training_classes = 80
|
| 9 |
+
max_epochs = 100 # Maximum training epochs
|
| 10 |
+
close_mosaic_epochs = 2
|
| 11 |
+
save_epoch_intervals = 2
|
| 12 |
+
text_channels = 768
|
| 13 |
+
neck_embed_channels = [128, 256, _base_.last_stage_out_channels // 2]
|
| 14 |
+
neck_num_heads = [4, 8, _base_.last_stage_out_channels // 2 // 32]
|
| 15 |
+
base_lr = 2e-3
|
| 16 |
+
weight_decay = 0.0125
|
| 17 |
+
train_batch_size_per_gpu = 16
|
| 18 |
+
# text_model_name = '../pretrained_models/clip-vit-large-patch14-336'
|
| 19 |
+
text_model_name = 'openai/clip-vit-large-patch14-336'
|
| 20 |
+
# model settings
|
| 21 |
+
model = dict(
|
| 22 |
+
type='YOLOWorldDetector',
|
| 23 |
+
mm_neck=True,
|
| 24 |
+
num_train_classes=num_training_classes,
|
| 25 |
+
num_test_classes=num_classes,
|
| 26 |
+
data_preprocessor=dict(type='YOLOWDetDataPreprocessor'),
|
| 27 |
+
backbone=dict(
|
| 28 |
+
_delete_=True,
|
| 29 |
+
type='MultiModalYOLOBackbone',
|
| 30 |
+
image_model={{_base_.model.backbone}},
|
| 31 |
+
text_model=dict(
|
| 32 |
+
type='HuggingCLIPLanguageBackbone',
|
| 33 |
+
model_name=text_model_name,
|
| 34 |
+
frozen_modules=['all'])),
|
| 35 |
+
neck=dict(type='YOLOWorldPAFPN',
|
| 36 |
+
guide_channels=text_channels,
|
| 37 |
+
embed_channels=neck_embed_channels,
|
| 38 |
+
num_heads=neck_num_heads,
|
| 39 |
+
block_cfg=dict(type='MaxSigmoidCSPLayerWithTwoConv')),
|
| 40 |
+
bbox_head=dict(type='YOLOWorldHead',
|
| 41 |
+
head_module=dict(type='YOLOWorldHeadModule',
|
| 42 |
+
use_bn_head=True,
|
| 43 |
+
embed_dims=text_channels,
|
| 44 |
+
num_classes=num_training_classes)),
|
| 45 |
+
train_cfg=dict(assigner=dict(num_classes=num_training_classes)))
|
| 46 |
+
|
| 47 |
+
# dataset settings
|
| 48 |
+
text_transform = [
|
| 49 |
+
dict(type='RandomLoadText',
|
| 50 |
+
num_neg_samples=(num_classes, num_classes),
|
| 51 |
+
max_num_samples=num_training_classes,
|
| 52 |
+
padding_to_max=True,
|
| 53 |
+
padding_value=''),
|
| 54 |
+
dict(type='mmdet.PackDetInputs',
|
| 55 |
+
meta_keys=('img_id', 'img_path', 'ori_shape', 'img_shape', 'flip',
|
| 56 |
+
'flip_direction', 'texts'))
|
| 57 |
+
]
|
| 58 |
+
train_pipeline = [
|
| 59 |
+
*_base_.pre_transform,
|
| 60 |
+
dict(type='MultiModalMosaic',
|
| 61 |
+
img_scale=_base_.img_scale,
|
| 62 |
+
pad_val=114.0,
|
| 63 |
+
pre_transform=_base_.pre_transform),
|
| 64 |
+
dict(
|
| 65 |
+
type='YOLOv5RandomAffine',
|
| 66 |
+
max_rotate_degree=0.0,
|
| 67 |
+
max_shear_degree=0.0,
|
| 68 |
+
scaling_ratio_range=(1 - _base_.affine_scale, 1 + _base_.affine_scale),
|
| 69 |
+
max_aspect_ratio=_base_.max_aspect_ratio,
|
| 70 |
+
border=(-_base_.img_scale[0] // 2, -_base_.img_scale[1] // 2),
|
| 71 |
+
border_val=(114, 114, 114)),
|
| 72 |
+
*_base_.last_transform[:-1],
|
| 73 |
+
*text_transform,
|
| 74 |
+
]
|
| 75 |
+
train_pipeline_stage2 = [*_base_.train_pipeline_stage2[:-1], *text_transform]
|
| 76 |
+
obj365v1_train_dataset = dict(
|
| 77 |
+
type='MultiModalDataset',
|
| 78 |
+
dataset=dict(
|
| 79 |
+
type='YOLOv5Objects365V1Dataset',
|
| 80 |
+
data_root='data/objects365v1/',
|
| 81 |
+
ann_file='annotations/objects365_train.json',
|
| 82 |
+
data_prefix=dict(img='train/'),
|
| 83 |
+
filter_cfg=dict(filter_empty_gt=False, min_size=32)),
|
| 84 |
+
class_text_path='data/texts/obj365v1_class_texts.json',
|
| 85 |
+
pipeline=train_pipeline)
|
| 86 |
+
|
| 87 |
+
mg_train_dataset = dict(type='YOLOv5MixedGroundingDataset',
|
| 88 |
+
data_root='data/mixed_grounding/',
|
| 89 |
+
ann_file='annotations/final_mixed_train_no_coco.json',
|
| 90 |
+
data_prefix=dict(img='gqa/images/'),
|
| 91 |
+
filter_cfg=dict(filter_empty_gt=False, min_size=32),
|
| 92 |
+
pipeline=train_pipeline)
|
| 93 |
+
|
| 94 |
+
flickr_train_dataset = dict(
|
| 95 |
+
type='YOLOv5MixedGroundingDataset',
|
| 96 |
+
data_root='data/flickr/',
|
| 97 |
+
ann_file='annotations/final_flickr_separateGT_train.json',
|
| 98 |
+
data_prefix=dict(img='full_images/'),
|
| 99 |
+
filter_cfg=dict(filter_empty_gt=True, min_size=32),
|
| 100 |
+
pipeline=train_pipeline)
|
| 101 |
+
|
| 102 |
+
train_dataloader = dict(batch_size=train_batch_size_per_gpu,
|
| 103 |
+
collate_fn=dict(type='yolow_collate'),
|
| 104 |
+
dataset=dict(_delete_=True,
|
| 105 |
+
type='ConcatDataset',
|
| 106 |
+
datasets=[
|
| 107 |
+
obj365v1_train_dataset,
|
| 108 |
+
flickr_train_dataset, mg_train_dataset
|
| 109 |
+
],
|
| 110 |
+
ignore_keys=['classes', 'palette']))
|
| 111 |
+
|
| 112 |
+
test_pipeline = [
|
| 113 |
+
*_base_.test_pipeline[:-1],
|
| 114 |
+
dict(type='LoadText'),
|
| 115 |
+
dict(type='mmdet.PackDetInputs',
|
| 116 |
+
meta_keys=('img_id', 'img_path', 'ori_shape', 'img_shape',
|
| 117 |
+
'scale_factor', 'pad_param', 'texts'))
|
| 118 |
+
]
|
| 119 |
+
coco_val_dataset = dict(
|
| 120 |
+
_delete_=True,
|
| 121 |
+
type='MultiModalDataset',
|
| 122 |
+
dataset=dict(type='YOLOv5LVISV1Dataset',
|
| 123 |
+
data_root='data/coco/',
|
| 124 |
+
test_mode=True,
|
| 125 |
+
ann_file='lvis/lvis_v1_minival_inserted_image_name.json',
|
| 126 |
+
data_prefix=dict(img=''),
|
| 127 |
+
batch_shapes_cfg=None),
|
| 128 |
+
class_text_path='data/texts/lvis_v1_class_texts.json',
|
| 129 |
+
pipeline=test_pipeline)
|
| 130 |
+
val_dataloader = dict(dataset=coco_val_dataset)
|
| 131 |
+
test_dataloader = val_dataloader
|
| 132 |
+
|
| 133 |
+
val_evaluator = dict(type='mmdet.LVISMetric',
|
| 134 |
+
ann_file='data/coco/lvis/lvis_v1_minival_inserted_image_name.json',
|
| 135 |
+
metric='bbox')
|
| 136 |
+
test_evaluator = val_evaluator
|
| 137 |
+
|
| 138 |
+
# training settings
|
| 139 |
+
default_hooks = dict(param_scheduler=dict(max_epochs=max_epochs),
|
| 140 |
+
checkpoint=dict(interval=save_epoch_intervals,
|
| 141 |
+
rule='greater'))
|
| 142 |
+
custom_hooks = [
|
| 143 |
+
dict(type='EMAHook',
|
| 144 |
+
ema_type='ExpMomentumEMA',
|
| 145 |
+
momentum=0.0001,
|
| 146 |
+
update_buffers=True,
|
| 147 |
+
strict_load=False,
|
| 148 |
+
priority=49),
|
| 149 |
+
dict(type='mmdet.PipelineSwitchHook',
|
| 150 |
+
switch_epoch=max_epochs - close_mosaic_epochs,
|
| 151 |
+
switch_pipeline=train_pipeline_stage2)
|
| 152 |
+
]
|
| 153 |
+
train_cfg = dict(max_epochs=max_epochs,
|
| 154 |
+
val_interval=10,
|
| 155 |
+
dynamic_intervals=[((max_epochs - close_mosaic_epochs),
|
| 156 |
+
_base_.val_interval_stage2)])
|
| 157 |
+
optim_wrapper = dict(optimizer=dict(
|
| 158 |
+
_delete_=True,
|
| 159 |
+
type='AdamW',
|
| 160 |
+
lr=base_lr,
|
| 161 |
+
weight_decay=weight_decay,
|
| 162 |
+
batch_size_per_gpu=train_batch_size_per_gpu),
|
| 163 |
+
paramwise_cfg=dict(bias_decay_mult=0.0,
|
| 164 |
+
norm_decay_mult=0.0,
|
| 165 |
+
custom_keys={
|
| 166 |
+
'backbone.text_model':
|
| 167 |
+
dict(lr_mult=0.01),
|
| 168 |
+
'logit_scale':
|
| 169 |
+
dict(weight_decay=0.0)
|
| 170 |
+
}),
|
| 171 |
+
constructor='YOLOWv5OptimizerConstructor')
|
configs/pretrain/yolo_world_v2_l_vlpan_bn_2e-3_100e_4x8gpus_obj365v1_goldg_train_1280ft_lvis_minival.py
ADDED
|
@@ -0,0 +1,202 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
_base_ = ('../../third_party/mmyolo/configs/yolov8/'
|
| 2 |
+
'yolov8_l_syncbn_fast_8xb16-500e_coco.py')
|
| 3 |
+
custom_imports = dict(imports=['yolo_world'],
|
| 4 |
+
allow_failed_imports=False)
|
| 5 |
+
|
| 6 |
+
# hyper-parameters
|
| 7 |
+
num_classes = 1203
|
| 8 |
+
num_training_classes = 80
|
| 9 |
+
max_epochs = 20 # Maximum training epochs
|
| 10 |
+
close_mosaic_epochs = 2
|
| 11 |
+
save_epoch_intervals = 2
|
| 12 |
+
text_channels = 512
|
| 13 |
+
neck_embed_channels = [128, 256, _base_.last_stage_out_channels // 2]
|
| 14 |
+
neck_num_heads = [4, 8, _base_.last_stage_out_channels // 2 // 32]
|
| 15 |
+
base_lr = 2e-4
|
| 16 |
+
weight_decay = 0.025
|
| 17 |
+
train_batch_size_per_gpu = 4
|
| 18 |
+
load_from = "pretrained_models/yolo_world_v2_l_obj365v1_goldg_pretrain-a82b1fe3.pth"
|
| 19 |
+
# text_model_name = '../pretrained_models/clip-vit-base-patch32-projection'
|
| 20 |
+
text_model_name = 'openai/clip-vit-base-patch32'
|
| 21 |
+
img_scale = (1280, 1280)
|
| 22 |
+
|
| 23 |
+
# model settings
|
| 24 |
+
model = dict(
|
| 25 |
+
type='YOLOWorldDetector',
|
| 26 |
+
mm_neck=True,
|
| 27 |
+
num_train_classes=num_training_classes,
|
| 28 |
+
num_test_classes=num_classes,
|
| 29 |
+
data_preprocessor=dict(type='YOLOWDetDataPreprocessor'),
|
| 30 |
+
backbone=dict(
|
| 31 |
+
_delete_=True,
|
| 32 |
+
type='MultiModalYOLOBackbone',
|
| 33 |
+
image_model={{_base_.model.backbone}},
|
| 34 |
+
text_model=dict(
|
| 35 |
+
type='HuggingCLIPLanguageBackbone',
|
| 36 |
+
model_name=text_model_name,
|
| 37 |
+
frozen_modules=['all'])),
|
| 38 |
+
neck=dict(type='YOLOWorldPAFPN',
|
| 39 |
+
guide_channels=text_channels,
|
| 40 |
+
embed_channels=neck_embed_channels,
|
| 41 |
+
num_heads=neck_num_heads,
|
| 42 |
+
block_cfg=dict(type='MaxSigmoidCSPLayerWithTwoConv')),
|
| 43 |
+
bbox_head=dict(type='YOLOWorldHead',
|
| 44 |
+
head_module=dict(type='YOLOWorldHeadModule',
|
| 45 |
+
use_bn_head=True,
|
| 46 |
+
embed_dims=text_channels,
|
| 47 |
+
num_classes=num_training_classes)),
|
| 48 |
+
train_cfg=dict(assigner=dict(num_classes=num_training_classes)))
|
| 49 |
+
|
| 50 |
+
# dataset settings
|
| 51 |
+
text_transform = [
|
| 52 |
+
dict(type='RandomLoadText',
|
| 53 |
+
num_neg_samples=(num_classes, num_classes),
|
| 54 |
+
max_num_samples=num_training_classes,
|
| 55 |
+
padding_to_max=True,
|
| 56 |
+
padding_value=''),
|
| 57 |
+
dict(type='mmdet.PackDetInputs',
|
| 58 |
+
meta_keys=('img_id', 'img_path', 'ori_shape', 'img_shape', 'flip',
|
| 59 |
+
'flip_direction', 'texts'))
|
| 60 |
+
]
|
| 61 |
+
train_pipeline = [
|
| 62 |
+
*_base_.pre_transform,
|
| 63 |
+
dict(type='MultiModalMosaic',
|
| 64 |
+
img_scale=img_scale,
|
| 65 |
+
pad_val=114.0,
|
| 66 |
+
pre_transform=_base_.pre_transform),
|
| 67 |
+
dict(
|
| 68 |
+
type='YOLOv5RandomAffine',
|
| 69 |
+
max_rotate_degree=0.0,
|
| 70 |
+
max_shear_degree=0.0,
|
| 71 |
+
scaling_ratio_range=(1 - _base_.affine_scale, 1 + _base_.affine_scale),
|
| 72 |
+
max_aspect_ratio=_base_.max_aspect_ratio,
|
| 73 |
+
border=(-img_scale[0] // 2, -img_scale[1] // 2),
|
| 74 |
+
border_val=(114, 114, 114)),
|
| 75 |
+
*_base_.last_transform[:-1],
|
| 76 |
+
*text_transform,
|
| 77 |
+
]
|
| 78 |
+
|
| 79 |
+
train_pipeline_stage2 = [
|
| 80 |
+
*_base_.pre_transform,
|
| 81 |
+
dict(type='YOLOv5KeepRatioResize', scale=img_scale),
|
| 82 |
+
dict(
|
| 83 |
+
type='LetterResize',
|
| 84 |
+
scale=img_scale,
|
| 85 |
+
allow_scale_up=True,
|
| 86 |
+
pad_val=dict(img=114.0)),
|
| 87 |
+
dict(
|
| 88 |
+
type='YOLOv5RandomAffine',
|
| 89 |
+
max_rotate_degree=0.0,
|
| 90 |
+
max_shear_degree=0.0,
|
| 91 |
+
scaling_ratio_range=(1 - _base_.affine_scale, 1 + _base_.affine_scale),
|
| 92 |
+
max_aspect_ratio=_base_.max_aspect_ratio,
|
| 93 |
+
border_val=(114, 114, 114)),
|
| 94 |
+
*_base_.last_transform[:-1],
|
| 95 |
+
*text_transform
|
| 96 |
+
]
|
| 97 |
+
|
| 98 |
+
obj365v1_train_dataset = dict(
|
| 99 |
+
type='MultiModalDataset',
|
| 100 |
+
dataset=dict(
|
| 101 |
+
type='YOLOv5Objects365V1Dataset',
|
| 102 |
+
data_root='data/objects365v1/',
|
| 103 |
+
ann_file='annotations/objects365_train.json',
|
| 104 |
+
data_prefix=dict(img='train/'),
|
| 105 |
+
filter_cfg=dict(filter_empty_gt=False, min_size=32)),
|
| 106 |
+
class_text_path='data/texts/obj365v1_class_texts.json',
|
| 107 |
+
pipeline=train_pipeline)
|
| 108 |
+
|
| 109 |
+
mg_train_dataset = dict(type='YOLOv5MixedGroundingDataset',
|
| 110 |
+
data_root='data/mixed_grounding/',
|
| 111 |
+
ann_file='annotations/final_mixed_train_no_coco.json',
|
| 112 |
+
data_prefix=dict(img='gqa/images/'),
|
| 113 |
+
filter_cfg=dict(filter_empty_gt=False, min_size=32),
|
| 114 |
+
pipeline=train_pipeline)
|
| 115 |
+
|
| 116 |
+
flickr_train_dataset = dict(
|
| 117 |
+
type='YOLOv5MixedGroundingDataset',
|
| 118 |
+
data_root='data/flickr/',
|
| 119 |
+
ann_file='annotations/final_flickr_separateGT_train.json',
|
| 120 |
+
data_prefix=dict(img='full_images/'),
|
| 121 |
+
filter_cfg=dict(filter_empty_gt=True, min_size=32),
|
| 122 |
+
pipeline=train_pipeline)
|
| 123 |
+
|
| 124 |
+
train_dataloader = dict(batch_size=train_batch_size_per_gpu,
|
| 125 |
+
collate_fn=dict(type='yolow_collate'),
|
| 126 |
+
dataset=dict(_delete_=True,
|
| 127 |
+
type='ConcatDataset',
|
| 128 |
+
datasets=[
|
| 129 |
+
obj365v1_train_dataset,
|
| 130 |
+
flickr_train_dataset, mg_train_dataset
|
| 131 |
+
],
|
| 132 |
+
ignore_keys=['classes', 'palette']))
|
| 133 |
+
|
| 134 |
+
test_pipeline = [
|
| 135 |
+
dict(type='LoadImageFromFile'),
|
| 136 |
+
dict(type='YOLOv5KeepRatioResize', scale=img_scale),
|
| 137 |
+
dict(
|
| 138 |
+
type='LetterResize',
|
| 139 |
+
scale=img_scale,
|
| 140 |
+
allow_scale_up=False,
|
| 141 |
+
pad_val=dict(img=114)),
|
| 142 |
+
dict(type='LoadAnnotations', with_bbox=True, _scope_='mmdet'),
|
| 143 |
+
dict(type='LoadText'),
|
| 144 |
+
dict(type='mmdet.PackDetInputs',
|
| 145 |
+
meta_keys=('img_id', 'img_path', 'ori_shape', 'img_shape',
|
| 146 |
+
'scale_factor', 'pad_param', 'texts'))
|
| 147 |
+
]
|
| 148 |
+
|
| 149 |
+
coco_val_dataset = dict(
|
| 150 |
+
_delete_=True,
|
| 151 |
+
type='MultiModalDataset',
|
| 152 |
+
dataset=dict(type='YOLOv5LVISV1Dataset',
|
| 153 |
+
data_root='data/coco/',
|
| 154 |
+
test_mode=True,
|
| 155 |
+
ann_file='lvis/lvis_v1_minival_inserted_image_name.json',
|
| 156 |
+
data_prefix=dict(img=''),
|
| 157 |
+
batch_shapes_cfg=None),
|
| 158 |
+
class_text_path='data/texts/lvis_v1_class_texts.json',
|
| 159 |
+
pipeline=test_pipeline)
|
| 160 |
+
val_dataloader = dict(dataset=coco_val_dataset)
|
| 161 |
+
test_dataloader = val_dataloader
|
| 162 |
+
|
| 163 |
+
val_evaluator = dict(type='mmdet.LVISMetric',
|
| 164 |
+
ann_file='data/coco/lvis/lvis_v1_minival_inserted_image_name.json',
|
| 165 |
+
metric='bbox')
|
| 166 |
+
test_evaluator = val_evaluator
|
| 167 |
+
|
| 168 |
+
# training settings
|
| 169 |
+
default_hooks = dict(param_scheduler=dict(max_epochs=max_epochs),
|
| 170 |
+
checkpoint=dict(interval=save_epoch_intervals,
|
| 171 |
+
rule='greater'))
|
| 172 |
+
custom_hooks = [
|
| 173 |
+
dict(type='EMAHook',
|
| 174 |
+
ema_type='ExpMomentumEMA',
|
| 175 |
+
momentum=0.0001,
|
| 176 |
+
update_buffers=True,
|
| 177 |
+
strict_load=False,
|
| 178 |
+
priority=49),
|
| 179 |
+
dict(type='mmdet.PipelineSwitchHook',
|
| 180 |
+
switch_epoch=max_epochs - close_mosaic_epochs,
|
| 181 |
+
switch_pipeline=train_pipeline_stage2)
|
| 182 |
+
]
|
| 183 |
+
train_cfg = dict(max_epochs=max_epochs,
|
| 184 |
+
val_interval=10,
|
| 185 |
+
dynamic_intervals=[((max_epochs - close_mosaic_epochs),
|
| 186 |
+
_base_.val_interval_stage2)])
|
| 187 |
+
|
| 188 |
+
optim_wrapper = dict(optimizer=dict(
|
| 189 |
+
_delete_=True,
|
| 190 |
+
type='AdamW',
|
| 191 |
+
lr=base_lr,
|
| 192 |
+
weight_decay=weight_decay,
|
| 193 |
+
batch_size_per_gpu=train_batch_size_per_gpu),
|
| 194 |
+
paramwise_cfg=dict(bias_decay_mult=0.0,
|
| 195 |
+
norm_decay_mult=0.0,
|
| 196 |
+
custom_keys={
|
| 197 |
+
'backbone.text_model':
|
| 198 |
+
dict(lr_mult=0.01),
|
| 199 |
+
'logit_scale':
|
| 200 |
+
dict(weight_decay=0.0)
|
| 201 |
+
}),
|
| 202 |
+
constructor='YOLOWv5OptimizerConstructor')
|
configs/pretrain/yolo_world_v2_l_vlpan_bn_2e-3_100e_4x8gpus_obj365v1_goldg_train_lvis_minival.py
ADDED
|
@@ -0,0 +1,171 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
_base_ = ('../../third_party/mmyolo/configs/yolov8/'
|
| 2 |
+
'yolov8_l_syncbn_fast_8xb16-500e_coco.py')
|
| 3 |
+
custom_imports = dict(imports=['yolo_world'],
|
| 4 |
+
allow_failed_imports=False)
|
| 5 |
+
|
| 6 |
+
# hyper-parameters
|
| 7 |
+
num_classes = 1203
|
| 8 |
+
num_training_classes = 80
|
| 9 |
+
max_epochs = 100 # Maximum training epochs
|
| 10 |
+
close_mosaic_epochs = 2
|
| 11 |
+
save_epoch_intervals = 2
|
| 12 |
+
text_channels = 512
|
| 13 |
+
neck_embed_channels = [128, 256, _base_.last_stage_out_channels // 2]
|
| 14 |
+
neck_num_heads = [4, 8, _base_.last_stage_out_channels // 2 // 32]
|
| 15 |
+
base_lr = 2e-3
|
| 16 |
+
weight_decay = 0.05 / 2
|
| 17 |
+
train_batch_size_per_gpu = 16
|
| 18 |
+
# text_model_name = '../pretrained_models/clip-vit-base-patch32-projection'
|
| 19 |
+
text_model_name = 'openai/clip-vit-base-patch32'
|
| 20 |
+
# model settings
|
| 21 |
+
model = dict(
|
| 22 |
+
type='YOLOWorldDetector',
|
| 23 |
+
mm_neck=True,
|
| 24 |
+
num_train_classes=num_training_classes,
|
| 25 |
+
num_test_classes=num_classes,
|
| 26 |
+
data_preprocessor=dict(type='YOLOWDetDataPreprocessor'),
|
| 27 |
+
backbone=dict(
|
| 28 |
+
_delete_=True,
|
| 29 |
+
type='MultiModalYOLOBackbone',
|
| 30 |
+
image_model={{_base_.model.backbone}},
|
| 31 |
+
text_model=dict(
|
| 32 |
+
type='HuggingCLIPLanguageBackbone',
|
| 33 |
+
model_name=text_model_name,
|
| 34 |
+
frozen_modules=['all'])),
|
| 35 |
+
neck=dict(type='YOLOWorldPAFPN',
|
| 36 |
+
guide_channels=text_channels,
|
| 37 |
+
embed_channels=neck_embed_channels,
|
| 38 |
+
num_heads=neck_num_heads,
|
| 39 |
+
block_cfg=dict(type='MaxSigmoidCSPLayerWithTwoConv')),
|
| 40 |
+
bbox_head=dict(type='YOLOWorldHead',
|
| 41 |
+
head_module=dict(type='YOLOWorldHeadModule',
|
| 42 |
+
use_bn_head=True,
|
| 43 |
+
embed_dims=text_channels,
|
| 44 |
+
num_classes=num_training_classes)),
|
| 45 |
+
train_cfg=dict(assigner=dict(num_classes=num_training_classes)))
|
| 46 |
+
|
| 47 |
+
# dataset settings
|
| 48 |
+
text_transform = [
|
| 49 |
+
dict(type='RandomLoadText',
|
| 50 |
+
num_neg_samples=(num_classes, num_classes),
|
| 51 |
+
max_num_samples=num_training_classes,
|
| 52 |
+
padding_to_max=True,
|
| 53 |
+
padding_value=''),
|
| 54 |
+
dict(type='mmdet.PackDetInputs',
|
| 55 |
+
meta_keys=('img_id', 'img_path', 'ori_shape', 'img_shape', 'flip',
|
| 56 |
+
'flip_direction', 'texts'))
|
| 57 |
+
]
|
| 58 |
+
train_pipeline = [
|
| 59 |
+
*_base_.pre_transform,
|
| 60 |
+
dict(type='MultiModalMosaic',
|
| 61 |
+
img_scale=_base_.img_scale,
|
| 62 |
+
pad_val=114.0,
|
| 63 |
+
pre_transform=_base_.pre_transform),
|
| 64 |
+
dict(
|
| 65 |
+
type='YOLOv5RandomAffine',
|
| 66 |
+
max_rotate_degree=0.0,
|
| 67 |
+
max_shear_degree=0.0,
|
| 68 |
+
scaling_ratio_range=(1 - _base_.affine_scale, 1 + _base_.affine_scale),
|
| 69 |
+
max_aspect_ratio=_base_.max_aspect_ratio,
|
| 70 |
+
border=(-_base_.img_scale[0] // 2, -_base_.img_scale[1] // 2),
|
| 71 |
+
border_val=(114, 114, 114)),
|
| 72 |
+
*_base_.last_transform[:-1],
|
| 73 |
+
*text_transform,
|
| 74 |
+
]
|
| 75 |
+
train_pipeline_stage2 = [*_base_.train_pipeline_stage2[:-1], *text_transform]
|
| 76 |
+
obj365v1_train_dataset = dict(
|
| 77 |
+
type='MultiModalDataset',
|
| 78 |
+
dataset=dict(
|
| 79 |
+
type='YOLOv5Objects365V1Dataset',
|
| 80 |
+
data_root='data/objects365v1/',
|
| 81 |
+
ann_file='annotations/objects365_train.json',
|
| 82 |
+
data_prefix=dict(img='train/'),
|
| 83 |
+
filter_cfg=dict(filter_empty_gt=False, min_size=32)),
|
| 84 |
+
class_text_path='data/texts/obj365v1_class_texts.json',
|
| 85 |
+
pipeline=train_pipeline)
|
| 86 |
+
|
| 87 |
+
mg_train_dataset = dict(type='YOLOv5MixedGroundingDataset',
|
| 88 |
+
data_root='data/mixed_grounding/',
|
| 89 |
+
ann_file='annotations/final_mixed_train_no_coco.json',
|
| 90 |
+
data_prefix=dict(img='gqa/images/'),
|
| 91 |
+
filter_cfg=dict(filter_empty_gt=False, min_size=32),
|
| 92 |
+
pipeline=train_pipeline)
|
| 93 |
+
|
| 94 |
+
flickr_train_dataset = dict(
|
| 95 |
+
type='YOLOv5MixedGroundingDataset',
|
| 96 |
+
data_root='data/flickr/',
|
| 97 |
+
ann_file='annotations/final_flickr_separateGT_train.json',
|
| 98 |
+
data_prefix=dict(img='full_images/'),
|
| 99 |
+
filter_cfg=dict(filter_empty_gt=True, min_size=32),
|
| 100 |
+
pipeline=train_pipeline)
|
| 101 |
+
|
| 102 |
+
train_dataloader = dict(batch_size=train_batch_size_per_gpu,
|
| 103 |
+
collate_fn=dict(type='yolow_collate'),
|
| 104 |
+
dataset=dict(_delete_=True,
|
| 105 |
+
type='ConcatDataset',
|
| 106 |
+
datasets=[
|
| 107 |
+
obj365v1_train_dataset,
|
| 108 |
+
flickr_train_dataset, mg_train_dataset
|
| 109 |
+
],
|
| 110 |
+
ignore_keys=['classes', 'palette']))
|
| 111 |
+
|
| 112 |
+
test_pipeline = [
|
| 113 |
+
*_base_.test_pipeline[:-1],
|
| 114 |
+
dict(type='LoadText'),
|
| 115 |
+
dict(type='mmdet.PackDetInputs',
|
| 116 |
+
meta_keys=('img_id', 'img_path', 'ori_shape', 'img_shape',
|
| 117 |
+
'scale_factor', 'pad_param', 'texts'))
|
| 118 |
+
]
|
| 119 |
+
coco_val_dataset = dict(
|
| 120 |
+
_delete_=True,
|
| 121 |
+
type='MultiModalDataset',
|
| 122 |
+
dataset=dict(type='YOLOv5LVISV1Dataset',
|
| 123 |
+
data_root='data/coco/',
|
| 124 |
+
test_mode=True,
|
| 125 |
+
ann_file='lvis/lvis_v1_minival_inserted_image_name.json',
|
| 126 |
+
data_prefix=dict(img=''),
|
| 127 |
+
batch_shapes_cfg=None),
|
| 128 |
+
class_text_path='data/texts/lvis_v1_class_texts.json',
|
| 129 |
+
pipeline=test_pipeline)
|
| 130 |
+
val_dataloader = dict(dataset=coco_val_dataset)
|
| 131 |
+
test_dataloader = val_dataloader
|
| 132 |
+
|
| 133 |
+
val_evaluator = dict(type='mmdet.LVISMetric',
|
| 134 |
+
ann_file='data/coco/lvis/lvis_v1_minival_inserted_image_name.json',
|
| 135 |
+
metric='bbox')
|
| 136 |
+
test_evaluator = val_evaluator
|
| 137 |
+
|
| 138 |
+
# training settings
|
| 139 |
+
default_hooks = dict(param_scheduler=dict(max_epochs=max_epochs),
|
| 140 |
+
checkpoint=dict(interval=save_epoch_intervals,
|
| 141 |
+
rule='greater'))
|
| 142 |
+
custom_hooks = [
|
| 143 |
+
dict(type='EMAHook',
|
| 144 |
+
ema_type='ExpMomentumEMA',
|
| 145 |
+
momentum=0.0001,
|
| 146 |
+
update_buffers=True,
|
| 147 |
+
strict_load=False,
|
| 148 |
+
priority=49),
|
| 149 |
+
dict(type='mmdet.PipelineSwitchHook',
|
| 150 |
+
switch_epoch=max_epochs - close_mosaic_epochs,
|
| 151 |
+
switch_pipeline=train_pipeline_stage2)
|
| 152 |
+
]
|
| 153 |
+
train_cfg = dict(max_epochs=max_epochs,
|
| 154 |
+
val_interval=10,
|
| 155 |
+
dynamic_intervals=[((max_epochs - close_mosaic_epochs),
|
| 156 |
+
_base_.val_interval_stage2)])
|
| 157 |
+
optim_wrapper = dict(optimizer=dict(
|
| 158 |
+
_delete_=True,
|
| 159 |
+
type='AdamW',
|
| 160 |
+
lr=base_lr,
|
| 161 |
+
weight_decay=weight_decay,
|
| 162 |
+
batch_size_per_gpu=train_batch_size_per_gpu),
|
| 163 |
+
paramwise_cfg=dict(bias_decay_mult=0.0,
|
| 164 |
+
norm_decay_mult=0.0,
|
| 165 |
+
custom_keys={
|
| 166 |
+
'backbone.text_model':
|
| 167 |
+
dict(lr_mult=0.01),
|
| 168 |
+
'logit_scale':
|
| 169 |
+
dict(weight_decay=0.0)
|
| 170 |
+
}),
|
| 171 |
+
constructor='YOLOWv5OptimizerConstructor')
|
configs/pretrain/yolo_world_v2_l_vlpan_bn_2e-3_100e_4x8gpus_obj365v1_goldg_train_lvis_val.py
ADDED
|
@@ -0,0 +1,171 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
_base_ = ('../../third_party/mmyolo/configs/yolov8/'
|
| 2 |
+
'yolov8_l_syncbn_fast_8xb16-500e_coco.py')
|
| 3 |
+
custom_imports = dict(imports=['yolo_world'],
|
| 4 |
+
allow_failed_imports=False)
|
| 5 |
+
|
| 6 |
+
# hyper-parameters
|
| 7 |
+
num_classes = 1203
|
| 8 |
+
num_training_classes = 80
|
| 9 |
+
max_epochs = 100 # Maximum training epochs
|
| 10 |
+
close_mosaic_epochs = 2
|
| 11 |
+
save_epoch_intervals = 2
|
| 12 |
+
text_channels = 512
|
| 13 |
+
neck_embed_channels = [128, 256, _base_.last_stage_out_channels // 2]
|
| 14 |
+
neck_num_heads = [4, 8, _base_.last_stage_out_channels // 2 // 32]
|
| 15 |
+
base_lr = 2e-3
|
| 16 |
+
weight_decay = 0.05 / 2
|
| 17 |
+
train_batch_size_per_gpu = 16
|
| 18 |
+
# text_model_name = '../pretrained_models/clip-vit-base-patch32-projection'
|
| 19 |
+
text_model_name = 'openai/clip-vit-base-patch32'
|
| 20 |
+
# model settings
|
| 21 |
+
model = dict(
|
| 22 |
+
type='YOLOWorldDetector',
|
| 23 |
+
mm_neck=True,
|
| 24 |
+
num_train_classes=num_training_classes,
|
| 25 |
+
num_test_classes=num_classes,
|
| 26 |
+
data_preprocessor=dict(type='YOLOWDetDataPreprocessor'),
|
| 27 |
+
backbone=dict(
|
| 28 |
+
_delete_=True,
|
| 29 |
+
type='MultiModalYOLOBackbone',
|
| 30 |
+
image_model={{_base_.model.backbone}},
|
| 31 |
+
text_model=dict(
|
| 32 |
+
type='HuggingCLIPLanguageBackbone',
|
| 33 |
+
model_name=text_model_name,
|
| 34 |
+
frozen_modules=['all'])),
|
| 35 |
+
neck=dict(type='YOLOWorldPAFPN',
|
| 36 |
+
guide_channels=text_channels,
|
| 37 |
+
embed_channels=neck_embed_channels,
|
| 38 |
+
num_heads=neck_num_heads,
|
| 39 |
+
block_cfg=dict(type='MaxSigmoidCSPLayerWithTwoConv')),
|
| 40 |
+
bbox_head=dict(type='YOLOWorldHead',
|
| 41 |
+
head_module=dict(type='YOLOWorldHeadModule',
|
| 42 |
+
use_bn_head=True,
|
| 43 |
+
embed_dims=text_channels,
|
| 44 |
+
num_classes=num_training_classes)),
|
| 45 |
+
train_cfg=dict(assigner=dict(num_classes=num_training_classes)))
|
| 46 |
+
|
| 47 |
+
# dataset settings
|
| 48 |
+
text_transform = [
|
| 49 |
+
dict(type='RandomLoadText',
|
| 50 |
+
num_neg_samples=(num_classes, num_classes),
|
| 51 |
+
max_num_samples=num_training_classes,
|
| 52 |
+
padding_to_max=True,
|
| 53 |
+
padding_value=''),
|
| 54 |
+
dict(type='mmdet.PackDetInputs',
|
| 55 |
+
meta_keys=('img_id', 'img_path', 'ori_shape', 'img_shape', 'flip',
|
| 56 |
+
'flip_direction', 'texts'))
|
| 57 |
+
]
|
| 58 |
+
train_pipeline = [
|
| 59 |
+
*_base_.pre_transform,
|
| 60 |
+
dict(type='MultiModalMosaic',
|
| 61 |
+
img_scale=_base_.img_scale,
|
| 62 |
+
pad_val=114.0,
|
| 63 |
+
pre_transform=_base_.pre_transform),
|
| 64 |
+
dict(
|
| 65 |
+
type='YOLOv5RandomAffine',
|
| 66 |
+
max_rotate_degree=0.0,
|
| 67 |
+
max_shear_degree=0.0,
|
| 68 |
+
scaling_ratio_range=(1 - _base_.affine_scale, 1 + _base_.affine_scale),
|
| 69 |
+
max_aspect_ratio=_base_.max_aspect_ratio,
|
| 70 |
+
border=(-_base_.img_scale[0] // 2, -_base_.img_scale[1] // 2),
|
| 71 |
+
border_val=(114, 114, 114)),
|
| 72 |
+
*_base_.last_transform[:-1],
|
| 73 |
+
*text_transform,
|
| 74 |
+
]
|
| 75 |
+
train_pipeline_stage2 = [*_base_.train_pipeline_stage2[:-1], *text_transform]
|
| 76 |
+
obj365v1_train_dataset = dict(
|
| 77 |
+
type='MultiModalDataset',
|
| 78 |
+
dataset=dict(
|
| 79 |
+
type='YOLOv5Objects365V1Dataset',
|
| 80 |
+
data_root='data/objects365v1/',
|
| 81 |
+
ann_file='annotations/objects365_train.json',
|
| 82 |
+
data_prefix=dict(img='train/'),
|
| 83 |
+
filter_cfg=dict(filter_empty_gt=False, min_size=32)),
|
| 84 |
+
class_text_path='data/texts/obj365v1_class_texts.json',
|
| 85 |
+
pipeline=train_pipeline)
|
| 86 |
+
|
| 87 |
+
mg_train_dataset = dict(type='YOLOv5MixedGroundingDataset',
|
| 88 |
+
data_root='data/mixed_grounding/',
|
| 89 |
+
ann_file='annotations/final_mixed_train_no_coco.json',
|
| 90 |
+
data_prefix=dict(img='gqa/images/'),
|
| 91 |
+
filter_cfg=dict(filter_empty_gt=False, min_size=32),
|
| 92 |
+
pipeline=train_pipeline)
|
| 93 |
+
|
| 94 |
+
flickr_train_dataset = dict(
|
| 95 |
+
type='YOLOv5MixedGroundingDataset',
|
| 96 |
+
data_root='data/flickr/',
|
| 97 |
+
ann_file='annotations/final_flickr_separateGT_train.json',
|
| 98 |
+
data_prefix=dict(img='full_images/'),
|
| 99 |
+
filter_cfg=dict(filter_empty_gt=True, min_size=32),
|
| 100 |
+
pipeline=train_pipeline)
|
| 101 |
+
|
| 102 |
+
train_dataloader = dict(batch_size=train_batch_size_per_gpu,
|
| 103 |
+
collate_fn=dict(type='yolow_collate'),
|
| 104 |
+
dataset=dict(_delete_=True,
|
| 105 |
+
type='ConcatDataset',
|
| 106 |
+
datasets=[
|
| 107 |
+
obj365v1_train_dataset,
|
| 108 |
+
flickr_train_dataset, mg_train_dataset
|
| 109 |
+
],
|
| 110 |
+
ignore_keys=['classes', 'palette']))
|
| 111 |
+
|
| 112 |
+
test_pipeline = [
|
| 113 |
+
*_base_.test_pipeline[:-1],
|
| 114 |
+
dict(type='LoadText'),
|
| 115 |
+
dict(type='mmdet.PackDetInputs',
|
| 116 |
+
meta_keys=('img_id', 'img_path', 'ori_shape', 'img_shape',
|
| 117 |
+
'scale_factor', 'pad_param', 'texts'))
|
| 118 |
+
]
|
| 119 |
+
coco_val_dataset = dict(
|
| 120 |
+
_delete_=True,
|
| 121 |
+
type='MultiModalDataset',
|
| 122 |
+
dataset=dict(type='YOLOv5LVISV1Dataset',
|
| 123 |
+
data_root='data/coco/',
|
| 124 |
+
test_mode=True,
|
| 125 |
+
ann_file='lvis/lvis_v1_val.json',
|
| 126 |
+
data_prefix=dict(img=''),
|
| 127 |
+
batch_shapes_cfg=None),
|
| 128 |
+
class_text_path='data/texts/lvis_v1_class_texts.json',
|
| 129 |
+
pipeline=test_pipeline)
|
| 130 |
+
val_dataloader = dict(dataset=coco_val_dataset)
|
| 131 |
+
test_dataloader = val_dataloader
|
| 132 |
+
|
| 133 |
+
val_evaluator = dict(type='mmdet.LVISMetric',
|
| 134 |
+
ann_file='data/coco/lvis/lvis_v1_val.json',
|
| 135 |
+
metric='bbox')
|
| 136 |
+
test_evaluator = val_evaluator
|
| 137 |
+
|
| 138 |
+
# training settings
|
| 139 |
+
default_hooks = dict(param_scheduler=dict(max_epochs=max_epochs),
|
| 140 |
+
checkpoint=dict(interval=save_epoch_intervals,
|
| 141 |
+
rule='greater'))
|
| 142 |
+
custom_hooks = [
|
| 143 |
+
dict(type='EMAHook',
|
| 144 |
+
ema_type='ExpMomentumEMA',
|
| 145 |
+
momentum=0.0001,
|
| 146 |
+
update_buffers=True,
|
| 147 |
+
strict_load=False,
|
| 148 |
+
priority=49),
|
| 149 |
+
dict(type='mmdet.PipelineSwitchHook',
|
| 150 |
+
switch_epoch=max_epochs - close_mosaic_epochs,
|
| 151 |
+
switch_pipeline=train_pipeline_stage2)
|
| 152 |
+
]
|
| 153 |
+
train_cfg = dict(max_epochs=max_epochs,
|
| 154 |
+
val_interval=10,
|
| 155 |
+
dynamic_intervals=[((max_epochs - close_mosaic_epochs),
|
| 156 |
+
_base_.val_interval_stage2)])
|
| 157 |
+
optim_wrapper = dict(optimizer=dict(
|
| 158 |
+
_delete_=True,
|
| 159 |
+
type='AdamW',
|
| 160 |
+
lr=base_lr,
|
| 161 |
+
weight_decay=weight_decay,
|
| 162 |
+
batch_size_per_gpu=train_batch_size_per_gpu),
|
| 163 |
+
paramwise_cfg=dict(bias_decay_mult=0.0,
|
| 164 |
+
norm_decay_mult=0.0,
|
| 165 |
+
custom_keys={
|
| 166 |
+
'backbone.text_model':
|
| 167 |
+
dict(lr_mult=0.01),
|
| 168 |
+
'logit_scale':
|
| 169 |
+
dict(weight_decay=0.0)
|
| 170 |
+
}),
|
| 171 |
+
constructor='YOLOWv5OptimizerConstructor')
|
configs/pretrain/yolo_world_v2_m_vlpan_bn_2e-3_100e_4x8gpus_obj365v1_goldg_train_1280ft_lvis_minival.py
ADDED
|
@@ -0,0 +1,198 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
_base_ = ('../../third_party/mmyolo/configs/yolov8/'
|
| 2 |
+
'yolov8_m_syncbn_fast_8xb16-500e_coco.py')
|
| 3 |
+
custom_imports = dict(imports=['yolo_world'],
|
| 4 |
+
allow_failed_imports=False)
|
| 5 |
+
|
| 6 |
+
# hyper-parameters
|
| 7 |
+
num_classes = 1203
|
| 8 |
+
num_training_classes = 80
|
| 9 |
+
max_epochs = 100 # Maximum training epochs
|
| 10 |
+
close_mosaic_epochs = 2
|
| 11 |
+
save_epoch_intervals = 2
|
| 12 |
+
text_channels = 512
|
| 13 |
+
neck_embed_channels = [128, 256, _base_.last_stage_out_channels // 2]
|
| 14 |
+
neck_num_heads = [4, 8, _base_.last_stage_out_channels // 2 // 32]
|
| 15 |
+
base_lr = 2e-3
|
| 16 |
+
weight_decay = 0.05 / 2
|
| 17 |
+
train_batch_size_per_gpu = 16
|
| 18 |
+
text_model_name = '../pretrained_models/clip-vit-base-patch32-projection'
|
| 19 |
+
img_scale = (1280, 1280)
|
| 20 |
+
|
| 21 |
+
# text_model_name = 'openai/clip-vit-base-patch32'
|
| 22 |
+
# model settings
|
| 23 |
+
model = dict(
|
| 24 |
+
type='YOLOWorldDetector',
|
| 25 |
+
mm_neck=True,
|
| 26 |
+
num_train_classes=num_training_classes,
|
| 27 |
+
num_test_classes=num_classes,
|
| 28 |
+
data_preprocessor=dict(type='YOLOWDetDataPreprocessor'),
|
| 29 |
+
backbone=dict(
|
| 30 |
+
_delete_=True,
|
| 31 |
+
type='MultiModalYOLOBackbone',
|
| 32 |
+
image_model={{_base_.model.backbone}},
|
| 33 |
+
text_model=dict(
|
| 34 |
+
type='HuggingCLIPLanguageBackbone',
|
| 35 |
+
model_name=text_model_name,
|
| 36 |
+
frozen_modules=['all'])),
|
| 37 |
+
neck=dict(type='YOLOWorldPAFPN',
|
| 38 |
+
guide_channels=text_channels,
|
| 39 |
+
embed_channels=neck_embed_channels,
|
| 40 |
+
num_heads=neck_num_heads,
|
| 41 |
+
block_cfg=dict(type='MaxSigmoidCSPLayerWithTwoConv')),
|
| 42 |
+
bbox_head=dict(type='YOLOWorldHead',
|
| 43 |
+
head_module=dict(type='YOLOWorldHeadModule',
|
| 44 |
+
use_bn_head=True,
|
| 45 |
+
embed_dims=text_channels,
|
| 46 |
+
num_classes=num_training_classes)),
|
| 47 |
+
train_cfg=dict(assigner=dict(num_classes=num_training_classes)))
|
| 48 |
+
|
| 49 |
+
# dataset settings
|
| 50 |
+
text_transform = [
|
| 51 |
+
dict(type='RandomLoadText',
|
| 52 |
+
num_neg_samples=(num_classes, num_classes),
|
| 53 |
+
max_num_samples=num_training_classes,
|
| 54 |
+
padding_to_max=True,
|
| 55 |
+
padding_value=''),
|
| 56 |
+
dict(type='mmdet.PackDetInputs',
|
| 57 |
+
meta_keys=('img_id', 'img_path', 'ori_shape', 'img_shape', 'flip',
|
| 58 |
+
'flip_direction', 'texts'))
|
| 59 |
+
]
|
| 60 |
+
train_pipeline = [
|
| 61 |
+
*_base_.pre_transform,
|
| 62 |
+
dict(type='MultiModalMosaic',
|
| 63 |
+
img_scale=img_scale,
|
| 64 |
+
pad_val=114.0,
|
| 65 |
+
pre_transform=_base_.pre_transform),
|
| 66 |
+
dict(
|
| 67 |
+
type='YOLOv5RandomAffine',
|
| 68 |
+
max_rotate_degree=0.0,
|
| 69 |
+
max_shear_degree=0.0,
|
| 70 |
+
scaling_ratio_range=(1 - _base_.affine_scale, 1 + _base_.affine_scale),
|
| 71 |
+
max_aspect_ratio=_base_.max_aspect_ratio,
|
| 72 |
+
border=(-img_scale[0] // 2, -img_scale[1] // 2),
|
| 73 |
+
border_val=(114, 114, 114)),
|
| 74 |
+
*_base_.last_transform[:-1],
|
| 75 |
+
*text_transform,
|
| 76 |
+
]
|
| 77 |
+
|
| 78 |
+
train_pipeline_stage2 = [
|
| 79 |
+
*_base_.pre_transform,
|
| 80 |
+
dict(type='YOLOv5KeepRatioResize', scale=img_scale),
|
| 81 |
+
dict(
|
| 82 |
+
type='LetterResize',
|
| 83 |
+
scale=img_scale,
|
| 84 |
+
allow_scale_up=True,
|
| 85 |
+
pad_val=dict(img=114.0)),
|
| 86 |
+
dict(
|
| 87 |
+
type='YOLOv5RandomAffine',
|
| 88 |
+
max_rotate_degree=0.0,
|
| 89 |
+
max_shear_degree=0.0,
|
| 90 |
+
scaling_ratio_range=(1 - _base_.affine_scale, 1 + _base_.affine_scale),
|
| 91 |
+
max_aspect_ratio=_base_.max_aspect_ratio,
|
| 92 |
+
border_val=(114, 114, 114)),
|
| 93 |
+
*_base_.last_transform[:-1],
|
| 94 |
+
*text_transform
|
| 95 |
+
]
|
| 96 |
+
obj365v1_train_dataset = dict(
|
| 97 |
+
type='MultiModalDataset',
|
| 98 |
+
dataset=dict(
|
| 99 |
+
type='YOLOv5Objects365V1Dataset',
|
| 100 |
+
data_root='data/objects365v1/',
|
| 101 |
+
ann_file='annotations/objects365_train.json',
|
| 102 |
+
data_prefix=dict(img='train/'),
|
| 103 |
+
filter_cfg=dict(filter_empty_gt=False, min_size=32)),
|
| 104 |
+
class_text_path='data/texts/obj365v1_class_texts.json',
|
| 105 |
+
pipeline=train_pipeline)
|
| 106 |
+
|
| 107 |
+
mg_train_dataset = dict(type='YOLOv5MixedGroundingDataset',
|
| 108 |
+
data_root='data/mixed_grounding/',
|
| 109 |
+
ann_file='annotations/final_mixed_train_no_coco.json',
|
| 110 |
+
data_prefix=dict(img='gqa/images/'),
|
| 111 |
+
filter_cfg=dict(filter_empty_gt=False, min_size=32),
|
| 112 |
+
pipeline=train_pipeline)
|
| 113 |
+
|
| 114 |
+
flickr_train_dataset = dict(
|
| 115 |
+
type='YOLOv5MixedGroundingDataset',
|
| 116 |
+
data_root='data/flickr/',
|
| 117 |
+
ann_file='annotations/final_flickr_separateGT_train.json',
|
| 118 |
+
data_prefix=dict(img='full_images/'),
|
| 119 |
+
filter_cfg=dict(filter_empty_gt=True, min_size=32),
|
| 120 |
+
pipeline=train_pipeline)
|
| 121 |
+
|
| 122 |
+
train_dataloader = dict(batch_size=train_batch_size_per_gpu,
|
| 123 |
+
collate_fn=dict(type='yolow_collate'),
|
| 124 |
+
dataset=dict(_delete_=True,
|
| 125 |
+
type='ConcatDataset',
|
| 126 |
+
datasets=[
|
| 127 |
+
obj365v1_train_dataset,
|
| 128 |
+
flickr_train_dataset, mg_train_dataset
|
| 129 |
+
],
|
| 130 |
+
ignore_keys=['classes', 'palette']))
|
| 131 |
+
|
| 132 |
+
test_pipeline = [
|
| 133 |
+
dict(type='LoadImageFromFile'),
|
| 134 |
+
dict(type='YOLOv5KeepRatioResize', scale=img_scale),
|
| 135 |
+
dict(
|
| 136 |
+
type='LetterResize',
|
| 137 |
+
scale=img_scale,
|
| 138 |
+
allow_scale_up=False,
|
| 139 |
+
pad_val=dict(img=114)),
|
| 140 |
+
dict(type='LoadAnnotations', with_bbox=True, _scope_='mmdet'),
|
| 141 |
+
dict(type='LoadText'),
|
| 142 |
+
dict(type='mmdet.PackDetInputs',
|
| 143 |
+
meta_keys=('img_id', 'img_path', 'ori_shape', 'img_shape',
|
| 144 |
+
'scale_factor', 'pad_param', 'texts'))
|
| 145 |
+
]
|
| 146 |
+
coco_val_dataset = dict(
|
| 147 |
+
_delete_=True,
|
| 148 |
+
type='MultiModalDataset',
|
| 149 |
+
dataset=dict(type='YOLOv5LVISV1Dataset',
|
| 150 |
+
data_root='data/coco/',
|
| 151 |
+
test_mode=True,
|
| 152 |
+
ann_file='lvis/lvis_v1_minival_inserted_image_name.json',
|
| 153 |
+
data_prefix=dict(img=''),
|
| 154 |
+
batch_shapes_cfg=None),
|
| 155 |
+
class_text_path='data/texts/lvis_v1_class_texts.json',
|
| 156 |
+
pipeline=test_pipeline)
|
| 157 |
+
val_dataloader = dict(dataset=coco_val_dataset)
|
| 158 |
+
test_dataloader = val_dataloader
|
| 159 |
+
|
| 160 |
+
val_evaluator = dict(type='mmdet.LVISMetric',
|
| 161 |
+
ann_file='data/coco/lvis/lvis_v1_minival_inserted_image_name.json',
|
| 162 |
+
metric='bbox')
|
| 163 |
+
test_evaluator = val_evaluator
|
| 164 |
+
|
| 165 |
+
# training settings
|
| 166 |
+
default_hooks = dict(param_scheduler=dict(max_epochs=max_epochs),
|
| 167 |
+
checkpoint=dict(interval=save_epoch_intervals,
|
| 168 |
+
rule='greater'))
|
| 169 |
+
custom_hooks = [
|
| 170 |
+
dict(type='EMAHook',
|
| 171 |
+
ema_type='ExpMomentumEMA',
|
| 172 |
+
momentum=0.0001,
|
| 173 |
+
update_buffers=True,
|
| 174 |
+
strict_load=False,
|
| 175 |
+
priority=49),
|
| 176 |
+
dict(type='mmdet.PipelineSwitchHook',
|
| 177 |
+
switch_epoch=max_epochs - close_mosaic_epochs,
|
| 178 |
+
switch_pipeline=train_pipeline_stage2)
|
| 179 |
+
]
|
| 180 |
+
train_cfg = dict(max_epochs=max_epochs,
|
| 181 |
+
val_interval=10,
|
| 182 |
+
dynamic_intervals=[((max_epochs - close_mosaic_epochs),
|
| 183 |
+
_base_.val_interval_stage2)])
|
| 184 |
+
optim_wrapper = dict(optimizer=dict(
|
| 185 |
+
_delete_=True,
|
| 186 |
+
type='AdamW',
|
| 187 |
+
lr=base_lr,
|
| 188 |
+
weight_decay=weight_decay,
|
| 189 |
+
batch_size_per_gpu=train_batch_size_per_gpu),
|
| 190 |
+
paramwise_cfg=dict(bias_decay_mult=0.0,
|
| 191 |
+
norm_decay_mult=0.0,
|
| 192 |
+
custom_keys={
|
| 193 |
+
'backbone.text_model':
|
| 194 |
+
dict(lr_mult=0.01),
|
| 195 |
+
'logit_scale':
|
| 196 |
+
dict(weight_decay=0.0)
|
| 197 |
+
}),
|
| 198 |
+
constructor='YOLOWv5OptimizerConstructor')
|
configs/pretrain/yolo_world_v2_m_vlpan_bn_2e-3_100e_4x8gpus_obj365v1_goldg_train_lvis_minival.py
ADDED
|
@@ -0,0 +1,171 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
_base_ = ('../../third_party/mmyolo/configs/yolov8/'
|
| 2 |
+
'yolov8_m_syncbn_fast_8xb16-500e_coco.py')
|
| 3 |
+
custom_imports = dict(imports=['yolo_world'],
|
| 4 |
+
allow_failed_imports=False)
|
| 5 |
+
|
| 6 |
+
# hyper-parameters
|
| 7 |
+
num_classes = 1203
|
| 8 |
+
num_training_classes = 80
|
| 9 |
+
max_epochs = 100 # Maximum training epochs
|
| 10 |
+
close_mosaic_epochs = 2
|
| 11 |
+
save_epoch_intervals = 2
|
| 12 |
+
text_channels = 512
|
| 13 |
+
neck_embed_channels = [128, 256, _base_.last_stage_out_channels // 2]
|
| 14 |
+
neck_num_heads = [4, 8, _base_.last_stage_out_channels // 2 // 32]
|
| 15 |
+
base_lr = 2e-3
|
| 16 |
+
weight_decay = 0.05 / 2
|
| 17 |
+
train_batch_size_per_gpu = 16
|
| 18 |
+
text_model_name = '../pretrained_models/clip-vit-base-patch32-projection'
|
| 19 |
+
# text_model_name = 'openai/clip-vit-base-patch32'
|
| 20 |
+
# model settings
|
| 21 |
+
model = dict(
|
| 22 |
+
type='YOLOWorldDetector',
|
| 23 |
+
mm_neck=True,
|
| 24 |
+
num_train_classes=num_training_classes,
|
| 25 |
+
num_test_classes=num_classes,
|
| 26 |
+
data_preprocessor=dict(type='YOLOWDetDataPreprocessor'),
|
| 27 |
+
backbone=dict(
|
| 28 |
+
_delete_=True,
|
| 29 |
+
type='MultiModalYOLOBackbone',
|
| 30 |
+
image_model={{_base_.model.backbone}},
|
| 31 |
+
text_model=dict(
|
| 32 |
+
type='HuggingCLIPLanguageBackbone',
|
| 33 |
+
model_name=text_model_name,
|
| 34 |
+
frozen_modules=['all'])),
|
| 35 |
+
neck=dict(type='YOLOWorldPAFPN',
|
| 36 |
+
guide_channels=text_channels,
|
| 37 |
+
embed_channels=neck_embed_channels,
|
| 38 |
+
num_heads=neck_num_heads,
|
| 39 |
+
block_cfg=dict(type='MaxSigmoidCSPLayerWithTwoConv')),
|
| 40 |
+
bbox_head=dict(type='YOLOWorldHead',
|
| 41 |
+
head_module=dict(type='YOLOWorldHeadModule',
|
| 42 |
+
use_bn_head=True,
|
| 43 |
+
embed_dims=text_channels,
|
| 44 |
+
num_classes=num_training_classes)),
|
| 45 |
+
train_cfg=dict(assigner=dict(num_classes=num_training_classes)))
|
| 46 |
+
|
| 47 |
+
# dataset settings
|
| 48 |
+
text_transform = [
|
| 49 |
+
dict(type='RandomLoadText',
|
| 50 |
+
num_neg_samples=(num_classes, num_classes),
|
| 51 |
+
max_num_samples=num_training_classes,
|
| 52 |
+
padding_to_max=True,
|
| 53 |
+
padding_value=''),
|
| 54 |
+
dict(type='mmdet.PackDetInputs',
|
| 55 |
+
meta_keys=('img_id', 'img_path', 'ori_shape', 'img_shape', 'flip',
|
| 56 |
+
'flip_direction', 'texts'))
|
| 57 |
+
]
|
| 58 |
+
train_pipeline = [
|
| 59 |
+
*_base_.pre_transform,
|
| 60 |
+
dict(type='MultiModalMosaic',
|
| 61 |
+
img_scale=_base_.img_scale,
|
| 62 |
+
pad_val=114.0,
|
| 63 |
+
pre_transform=_base_.pre_transform),
|
| 64 |
+
dict(
|
| 65 |
+
type='YOLOv5RandomAffine',
|
| 66 |
+
max_rotate_degree=0.0,
|
| 67 |
+
max_shear_degree=0.0,
|
| 68 |
+
scaling_ratio_range=(1 - _base_.affine_scale, 1 + _base_.affine_scale),
|
| 69 |
+
max_aspect_ratio=_base_.max_aspect_ratio,
|
| 70 |
+
border=(-_base_.img_scale[0] // 2, -_base_.img_scale[1] // 2),
|
| 71 |
+
border_val=(114, 114, 114)),
|
| 72 |
+
*_base_.last_transform[:-1],
|
| 73 |
+
*text_transform,
|
| 74 |
+
]
|
| 75 |
+
train_pipeline_stage2 = [*_base_.train_pipeline_stage2[:-1], *text_transform]
|
| 76 |
+
obj365v1_train_dataset = dict(
|
| 77 |
+
type='MultiModalDataset',
|
| 78 |
+
dataset=dict(
|
| 79 |
+
type='YOLOv5Objects365V1Dataset',
|
| 80 |
+
data_root='data/objects365v1/',
|
| 81 |
+
ann_file='annotations/objects365_train.json',
|
| 82 |
+
data_prefix=dict(img='train/'),
|
| 83 |
+
filter_cfg=dict(filter_empty_gt=False, min_size=32)),
|
| 84 |
+
class_text_path='data/texts/obj365v1_class_texts.json',
|
| 85 |
+
pipeline=train_pipeline)
|
| 86 |
+
|
| 87 |
+
mg_train_dataset = dict(type='YOLOv5MixedGroundingDataset',
|
| 88 |
+
data_root='data/mixed_grounding/',
|
| 89 |
+
ann_file='annotations/final_mixed_train_no_coco.json',
|
| 90 |
+
data_prefix=dict(img='gqa/images/'),
|
| 91 |
+
filter_cfg=dict(filter_empty_gt=False, min_size=32),
|
| 92 |
+
pipeline=train_pipeline)
|
| 93 |
+
|
| 94 |
+
flickr_train_dataset = dict(
|
| 95 |
+
type='YOLOv5MixedGroundingDataset',
|
| 96 |
+
data_root='data/flickr/',
|
| 97 |
+
ann_file='annotations/final_flickr_separateGT_train.json',
|
| 98 |
+
data_prefix=dict(img='full_images/'),
|
| 99 |
+
filter_cfg=dict(filter_empty_gt=True, min_size=32),
|
| 100 |
+
pipeline=train_pipeline)
|
| 101 |
+
|
| 102 |
+
train_dataloader = dict(batch_size=train_batch_size_per_gpu,
|
| 103 |
+
collate_fn=dict(type='yolow_collate'),
|
| 104 |
+
dataset=dict(_delete_=True,
|
| 105 |
+
type='ConcatDataset',
|
| 106 |
+
datasets=[
|
| 107 |
+
obj365v1_train_dataset,
|
| 108 |
+
flickr_train_dataset, mg_train_dataset
|
| 109 |
+
],
|
| 110 |
+
ignore_keys=['classes', 'palette']))
|
| 111 |
+
|
| 112 |
+
test_pipeline = [
|
| 113 |
+
*_base_.test_pipeline[:-1],
|
| 114 |
+
dict(type='LoadText'),
|
| 115 |
+
dict(type='mmdet.PackDetInputs',
|
| 116 |
+
meta_keys=('img_id', 'img_path', 'ori_shape', 'img_shape',
|
| 117 |
+
'scale_factor', 'pad_param', 'texts'))
|
| 118 |
+
]
|
| 119 |
+
coco_val_dataset = dict(
|
| 120 |
+
_delete_=True,
|
| 121 |
+
type='MultiModalDataset',
|
| 122 |
+
dataset=dict(type='YOLOv5LVISV1Dataset',
|
| 123 |
+
data_root='data/coco/',
|
| 124 |
+
test_mode=True,
|
| 125 |
+
ann_file='lvis/lvis_v1_minival_inserted_image_name.json',
|
| 126 |
+
data_prefix=dict(img=''),
|
| 127 |
+
batch_shapes_cfg=None),
|
| 128 |
+
class_text_path='data/texts/lvis_v1_class_texts.json',
|
| 129 |
+
pipeline=test_pipeline)
|
| 130 |
+
val_dataloader = dict(dataset=coco_val_dataset)
|
| 131 |
+
test_dataloader = val_dataloader
|
| 132 |
+
|
| 133 |
+
val_evaluator = dict(type='mmdet.LVISMetric',
|
| 134 |
+
ann_file='data/coco/lvis/lvis_v1_minival_inserted_image_name.json',
|
| 135 |
+
metric='bbox')
|
| 136 |
+
test_evaluator = val_evaluator
|
| 137 |
+
|
| 138 |
+
# training settings
|
| 139 |
+
default_hooks = dict(param_scheduler=dict(max_epochs=max_epochs),
|
| 140 |
+
checkpoint=dict(interval=save_epoch_intervals,
|
| 141 |
+
rule='greater'))
|
| 142 |
+
custom_hooks = [
|
| 143 |
+
dict(type='EMAHook',
|
| 144 |
+
ema_type='ExpMomentumEMA',
|
| 145 |
+
momentum=0.0001,
|
| 146 |
+
update_buffers=True,
|
| 147 |
+
strict_load=False,
|
| 148 |
+
priority=49),
|
| 149 |
+
dict(type='mmdet.PipelineSwitchHook',
|
| 150 |
+
switch_epoch=max_epochs - close_mosaic_epochs,
|
| 151 |
+
switch_pipeline=train_pipeline_stage2)
|
| 152 |
+
]
|
| 153 |
+
train_cfg = dict(max_epochs=max_epochs,
|
| 154 |
+
val_interval=10,
|
| 155 |
+
dynamic_intervals=[((max_epochs - close_mosaic_epochs),
|
| 156 |
+
_base_.val_interval_stage2)])
|
| 157 |
+
optim_wrapper = dict(optimizer=dict(
|
| 158 |
+
_delete_=True,
|
| 159 |
+
type='AdamW',
|
| 160 |
+
lr=base_lr,
|
| 161 |
+
weight_decay=weight_decay,
|
| 162 |
+
batch_size_per_gpu=train_batch_size_per_gpu),
|
| 163 |
+
paramwise_cfg=dict(bias_decay_mult=0.0,
|
| 164 |
+
norm_decay_mult=0.0,
|
| 165 |
+
custom_keys={
|
| 166 |
+
'backbone.text_model':
|
| 167 |
+
dict(lr_mult=0.01),
|
| 168 |
+
'logit_scale':
|
| 169 |
+
dict(weight_decay=0.0)
|
| 170 |
+
}),
|
| 171 |
+
constructor='YOLOWv5OptimizerConstructor')
|
configs/pretrain/yolo_world_v2_m_vlpan_bn_noeinsum_2e-3_100e_4x8gpus_obj365v1_goldg_train_lvis_minival.py
ADDED
|
@@ -0,0 +1,176 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
_base_ = ('../../third_party/mmyolo/configs/yolov8/'
|
| 2 |
+
'yolov8_m_syncbn_fast_8xb16-500e_coco.py')
|
| 3 |
+
custom_imports = dict(imports=['yolo_world'],
|
| 4 |
+
allow_failed_imports=False)
|
| 5 |
+
|
| 6 |
+
# hyper-parameters
|
| 7 |
+
num_classes = 1203
|
| 8 |
+
num_training_classes = 80
|
| 9 |
+
max_epochs = 100 # Maximum training epochs
|
| 10 |
+
close_mosaic_epochs = 2
|
| 11 |
+
save_epoch_intervals = 2
|
| 12 |
+
text_channels = 512
|
| 13 |
+
neck_embed_channels = [128, 256, _base_.last_stage_out_channels // 2]
|
| 14 |
+
neck_num_heads = [4, 8, _base_.last_stage_out_channels // 2 // 32]
|
| 15 |
+
base_lr = 2e-3
|
| 16 |
+
weight_decay = 0.05 / 2
|
| 17 |
+
train_batch_size_per_gpu = 16
|
| 18 |
+
text_model_name = '../pretrained_models/clip-vit-base-patch32-projection'
|
| 19 |
+
# text_model_name = 'openai/clip-vit-base-patch32'
|
| 20 |
+
# model settings
|
| 21 |
+
model = dict(
|
| 22 |
+
type='YOLOWorldDetector',
|
| 23 |
+
mm_neck=True,
|
| 24 |
+
num_train_classes=num_training_classes,
|
| 25 |
+
num_test_classes=num_classes,
|
| 26 |
+
data_preprocessor=dict(type='YOLOWDetDataPreprocessor'),
|
| 27 |
+
backbone=dict(
|
| 28 |
+
_delete_=True,
|
| 29 |
+
type='MultiModalYOLOBackbone',
|
| 30 |
+
image_model={{_base_.model.backbone}},
|
| 31 |
+
text_model=dict(
|
| 32 |
+
type='HuggingCLIPLanguageBackbone',
|
| 33 |
+
model_name=text_model_name,
|
| 34 |
+
frozen_modules=['all'])),
|
| 35 |
+
neck=dict(type='YOLOWorldPAFPN',
|
| 36 |
+
guide_channels=text_channels,
|
| 37 |
+
embed_channels=neck_embed_channels,
|
| 38 |
+
num_heads=neck_num_heads,
|
| 39 |
+
block_cfg=dict(type='MaxSigmoidCSPLayerWithTwoConv',
|
| 40 |
+
use_einsum=False)),
|
| 41 |
+
bbox_head=dict(type='YOLOWorldHead',
|
| 42 |
+
head_module=dict(type='YOLOWorldHeadModule',
|
| 43 |
+
use_bn_head=True,
|
| 44 |
+
embed_dims=text_channels,
|
| 45 |
+
num_classes=num_training_classes,
|
| 46 |
+
use_einsum=False)),
|
| 47 |
+
train_cfg=dict(assigner=dict(num_classes=num_training_classes)))
|
| 48 |
+
|
| 49 |
+
# dataset settings
|
| 50 |
+
text_transform = [
|
| 51 |
+
dict(type='RandomLoadText',
|
| 52 |
+
num_neg_samples=(num_classes, num_classes),
|
| 53 |
+
max_num_samples=num_training_classes,
|
| 54 |
+
padding_to_max=True,
|
| 55 |
+
padding_value=''),
|
| 56 |
+
dict(type='mmdet.PackDetInputs',
|
| 57 |
+
meta_keys=('img_id', 'img_path', 'ori_shape', 'img_shape', 'flip',
|
| 58 |
+
'flip_direction', 'texts'))
|
| 59 |
+
]
|
| 60 |
+
|
| 61 |
+
train_pipeline = [
|
| 62 |
+
*_base_.pre_transform,
|
| 63 |
+
dict(type='MultiModalMosaic',
|
| 64 |
+
img_scale=_base_.img_scale,
|
| 65 |
+
pad_val=114.0,
|
| 66 |
+
pre_transform=_base_.pre_transform),
|
| 67 |
+
dict(
|
| 68 |
+
type='YOLOv5RandomAffine',
|
| 69 |
+
max_rotate_degree=0.0,
|
| 70 |
+
max_shear_degree=0.0,
|
| 71 |
+
scaling_ratio_range=(1 - _base_.affine_scale, 1 + _base_.affine_scale),
|
| 72 |
+
max_aspect_ratio=_base_.max_aspect_ratio,
|
| 73 |
+
border=(-_base_.img_scale[0] // 2, -_base_.img_scale[1] // 2),
|
| 74 |
+
border_val=(114, 114, 114)),
|
| 75 |
+
*_base_.last_transform[:-1],
|
| 76 |
+
*text_transform,
|
| 77 |
+
]
|
| 78 |
+
|
| 79 |
+
train_pipeline_stage2 = [*_base_.train_pipeline_stage2[:-1], *text_transform]
|
| 80 |
+
obj365v1_train_dataset = dict(
|
| 81 |
+
type='MultiModalDataset',
|
| 82 |
+
dataset=dict(
|
| 83 |
+
type='YOLOv5Objects365V1Dataset',
|
| 84 |
+
data_root='data/objects365v1/',
|
| 85 |
+
ann_file='annotations/objects365_train.json',
|
| 86 |
+
data_prefix=dict(img='train/'),
|
| 87 |
+
filter_cfg=dict(filter_empty_gt=False, min_size=32)),
|
| 88 |
+
class_text_path='data/texts/obj365v1_class_texts.json',
|
| 89 |
+
pipeline=train_pipeline)
|
| 90 |
+
|
| 91 |
+
mg_train_dataset = dict(type='YOLOv5MixedGroundingDataset',
|
| 92 |
+
data_root='data/mixed_grounding/',
|
| 93 |
+
ann_file='annotations/final_mixed_train_no_coco.json',
|
| 94 |
+
data_prefix=dict(img='gqa/images/'),
|
| 95 |
+
filter_cfg=dict(filter_empty_gt=False, min_size=32),
|
| 96 |
+
pipeline=train_pipeline)
|
| 97 |
+
|
| 98 |
+
flickr_train_dataset = dict(
|
| 99 |
+
type='YOLOv5MixedGroundingDataset',
|
| 100 |
+
data_root='data/flickr/',
|
| 101 |
+
ann_file='annotations/final_flickr_separateGT_train.json',
|
| 102 |
+
data_prefix=dict(img='full_images/'),
|
| 103 |
+
filter_cfg=dict(filter_empty_gt=True, min_size=32),
|
| 104 |
+
pipeline=train_pipeline)
|
| 105 |
+
|
| 106 |
+
train_dataloader = dict(batch_size=train_batch_size_per_gpu,
|
| 107 |
+
collate_fn=dict(type='yolow_collate'),
|
| 108 |
+
dataset=dict(_delete_=True,
|
| 109 |
+
type='ConcatDataset',
|
| 110 |
+
datasets=[
|
| 111 |
+
obj365v1_train_dataset,
|
| 112 |
+
flickr_train_dataset, mg_train_dataset
|
| 113 |
+
],
|
| 114 |
+
ignore_keys=['classes', 'palette']))
|
| 115 |
+
|
| 116 |
+
test_pipeline = [
|
| 117 |
+
*_base_.test_pipeline[:-1],
|
| 118 |
+
dict(type='LoadText'),
|
| 119 |
+
dict(type='mmdet.PackDetInputs',
|
| 120 |
+
meta_keys=('img_id', 'img_path', 'ori_shape', 'img_shape',
|
| 121 |
+
'scale_factor', 'pad_param', 'texts'))
|
| 122 |
+
]
|
| 123 |
+
|
| 124 |
+
coco_val_dataset = dict(
|
| 125 |
+
_delete_=True,
|
| 126 |
+
type='MultiModalDataset',
|
| 127 |
+
dataset=dict(type='YOLOv5LVISV1Dataset',
|
| 128 |
+
data_root='data/coco/',
|
| 129 |
+
test_mode=True,
|
| 130 |
+
ann_file='lvis/lvis_v1_minival_inserted_image_name.json',
|
| 131 |
+
data_prefix=dict(img=''),
|
| 132 |
+
batch_shapes_cfg=None),
|
| 133 |
+
class_text_path='data/texts/lvis_v1_class_texts.json',
|
| 134 |
+
pipeline=test_pipeline)
|
| 135 |
+
val_dataloader = dict(dataset=coco_val_dataset)
|
| 136 |
+
test_dataloader = val_dataloader
|
| 137 |
+
|
| 138 |
+
val_evaluator = dict(type='mmdet.LVISMetric',
|
| 139 |
+
ann_file='data/coco/lvis/lvis_v1_minival_inserted_image_name.json',
|
| 140 |
+
metric='bbox')
|
| 141 |
+
test_evaluator = val_evaluator
|
| 142 |
+
|
| 143 |
+
# training settings
|
| 144 |
+
default_hooks = dict(param_scheduler=dict(max_epochs=max_epochs),
|
| 145 |
+
checkpoint=dict(interval=save_epoch_intervals,
|
| 146 |
+
rule='greater'))
|
| 147 |
+
custom_hooks = [
|
| 148 |
+
dict(type='EMAHook',
|
| 149 |
+
ema_type='ExpMomentumEMA',
|
| 150 |
+
momentum=0.0001,
|
| 151 |
+
update_buffers=True,
|
| 152 |
+
strict_load=False,
|
| 153 |
+
priority=49),
|
| 154 |
+
dict(type='mmdet.PipelineSwitchHook',
|
| 155 |
+
switch_epoch=max_epochs - close_mosaic_epochs,
|
| 156 |
+
switch_pipeline=train_pipeline_stage2)
|
| 157 |
+
]
|
| 158 |
+
train_cfg = dict(max_epochs=max_epochs,
|
| 159 |
+
val_interval=10,
|
| 160 |
+
dynamic_intervals=[((max_epochs - close_mosaic_epochs),
|
| 161 |
+
_base_.val_interval_stage2)])
|
| 162 |
+
optim_wrapper = dict(optimizer=dict(
|
| 163 |
+
_delete_=True,
|
| 164 |
+
type='AdamW',
|
| 165 |
+
lr=base_lr,
|
| 166 |
+
weight_decay=weight_decay,
|
| 167 |
+
batch_size_per_gpu=train_batch_size_per_gpu),
|
| 168 |
+
paramwise_cfg=dict(bias_decay_mult=0.0,
|
| 169 |
+
norm_decay_mult=0.0,
|
| 170 |
+
custom_keys={
|
| 171 |
+
'backbone.text_model':
|
| 172 |
+
dict(lr_mult=0.01),
|
| 173 |
+
'logit_scale':
|
| 174 |
+
dict(weight_decay=0.0)
|
| 175 |
+
}),
|
| 176 |
+
constructor='YOLOWv5OptimizerConstructor')
|
configs/pretrain/yolo_world_v2_s_vlpan_bn_2e-3_100e_4x8gpus_obj365v1_goldg_train_1280ft_lvis_minival.py
ADDED
|
@@ -0,0 +1,195 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
_base_ = ('../../third_party/mmyolo/configs/yolov8/'
|
| 2 |
+
'yolov8_s_syncbn_fast_8xb16-500e_coco.py')
|
| 3 |
+
custom_imports = dict(imports=['yolo_world'],
|
| 4 |
+
allow_failed_imports=False)
|
| 5 |
+
|
| 6 |
+
# hyper-parameters
|
| 7 |
+
num_classes = 1203
|
| 8 |
+
num_training_classes = 80
|
| 9 |
+
max_epochs = 100 # Maximum training epochs
|
| 10 |
+
close_mosaic_epochs = 2
|
| 11 |
+
save_epoch_intervals = 2
|
| 12 |
+
text_channels = 512
|
| 13 |
+
neck_embed_channels = [128, 256, _base_.last_stage_out_channels // 2]
|
| 14 |
+
neck_num_heads = [4, 8, _base_.last_stage_out_channels // 2 // 32]
|
| 15 |
+
base_lr = 2e-4
|
| 16 |
+
weight_decay = 0.025
|
| 17 |
+
train_batch_size_per_gpu = 4
|
| 18 |
+
img_scale = (1280, 1280)
|
| 19 |
+
|
| 20 |
+
# model settings
|
| 21 |
+
model = dict(
|
| 22 |
+
type='YOLOWorldDetector',
|
| 23 |
+
mm_neck=True,
|
| 24 |
+
num_train_classes=num_training_classes,
|
| 25 |
+
num_test_classes=num_classes,
|
| 26 |
+
data_preprocessor=dict(type='YOLOWDetDataPreprocessor'),
|
| 27 |
+
backbone=dict(
|
| 28 |
+
_delete_=True,
|
| 29 |
+
type='MultiModalYOLOBackbone',
|
| 30 |
+
image_model={{_base_.model.backbone}},
|
| 31 |
+
text_model=dict(
|
| 32 |
+
type='HuggingCLIPLanguageBackbone',
|
| 33 |
+
model_name='openai/clip-vit-base-patch32',
|
| 34 |
+
frozen_modules=['all'])),
|
| 35 |
+
neck=dict(type='YOLOWorldPAFPN',
|
| 36 |
+
guide_channels=text_channels,
|
| 37 |
+
embed_channels=neck_embed_channels,
|
| 38 |
+
num_heads=neck_num_heads,
|
| 39 |
+
block_cfg=dict(type='MaxSigmoidCSPLayerWithTwoConv')),
|
| 40 |
+
bbox_head=dict(type='YOLOWorldHead',
|
| 41 |
+
head_module=dict(type='YOLOWorldHeadModule',
|
| 42 |
+
use_bn_head=True,
|
| 43 |
+
embed_dims=text_channels,
|
| 44 |
+
num_classes=num_training_classes)),
|
| 45 |
+
train_cfg=dict(assigner=dict(num_classes=num_training_classes)))
|
| 46 |
+
|
| 47 |
+
# dataset settings
|
| 48 |
+
text_transform = [
|
| 49 |
+
dict(type='RandomLoadText',
|
| 50 |
+
num_neg_samples=(num_classes, num_classes),
|
| 51 |
+
max_num_samples=num_training_classes,
|
| 52 |
+
padding_to_max=True,
|
| 53 |
+
padding_value=''),
|
| 54 |
+
dict(type='mmdet.PackDetInputs',
|
| 55 |
+
meta_keys=('img_id', 'img_path', 'ori_shape', 'img_shape', 'flip',
|
| 56 |
+
'flip_direction', 'texts'))
|
| 57 |
+
]
|
| 58 |
+
train_pipeline = [
|
| 59 |
+
*_base_.pre_transform,
|
| 60 |
+
dict(type='MultiModalMosaic',
|
| 61 |
+
img_scale=img_scale,
|
| 62 |
+
pad_val=114.0,
|
| 63 |
+
pre_transform=_base_.pre_transform),
|
| 64 |
+
dict(
|
| 65 |
+
type='YOLOv5RandomAffine',
|
| 66 |
+
max_rotate_degree=0.0,
|
| 67 |
+
max_shear_degree=0.0,
|
| 68 |
+
scaling_ratio_range=(1 - _base_.affine_scale, 1 + _base_.affine_scale),
|
| 69 |
+
max_aspect_ratio=_base_.max_aspect_ratio,
|
| 70 |
+
border=(-img_scale[0] // 2, -img_scale[1] // 2),
|
| 71 |
+
border_val=(114, 114, 114)),
|
| 72 |
+
*_base_.last_transform[:-1],
|
| 73 |
+
*text_transform,
|
| 74 |
+
]
|
| 75 |
+
train_pipeline_stage2 = [
|
| 76 |
+
*_base_.pre_transform,
|
| 77 |
+
dict(type='YOLOv5KeepRatioResize', scale=img_scale),
|
| 78 |
+
dict(
|
| 79 |
+
type='LetterResize',
|
| 80 |
+
scale=img_scale,
|
| 81 |
+
allow_scale_up=True,
|
| 82 |
+
pad_val=dict(img=114.0)),
|
| 83 |
+
dict(
|
| 84 |
+
type='YOLOv5RandomAffine',
|
| 85 |
+
max_rotate_degree=0.0,
|
| 86 |
+
max_shear_degree=0.0,
|
| 87 |
+
scaling_ratio_range=(1 - _base_.affine_scale, 1 + _base_.affine_scale),
|
| 88 |
+
max_aspect_ratio=_base_.max_aspect_ratio,
|
| 89 |
+
border_val=(114, 114, 114)),
|
| 90 |
+
*_base_.last_transform[:-1],
|
| 91 |
+
*text_transform
|
| 92 |
+
]
|
| 93 |
+
obj365v1_train_dataset = dict(
|
| 94 |
+
type='MultiModalDataset',
|
| 95 |
+
dataset=dict(
|
| 96 |
+
type='YOLOv5Objects365V1Dataset',
|
| 97 |
+
data_root='data/objects365v1/',
|
| 98 |
+
ann_file='annotations/objects365_train.json',
|
| 99 |
+
data_prefix=dict(img='train/'),
|
| 100 |
+
filter_cfg=dict(filter_empty_gt=False, min_size=32)),
|
| 101 |
+
class_text_path='data/texts/obj365v1_class_texts.json',
|
| 102 |
+
pipeline=train_pipeline)
|
| 103 |
+
|
| 104 |
+
mg_train_dataset = dict(type='YOLOv5MixedGroundingDataset',
|
| 105 |
+
data_root='data/mixed_grounding/',
|
| 106 |
+
ann_file='annotations/final_mixed_train_no_coco.json',
|
| 107 |
+
data_prefix=dict(img='gqa/images/'),
|
| 108 |
+
filter_cfg=dict(filter_empty_gt=False, min_size=32),
|
| 109 |
+
pipeline=train_pipeline)
|
| 110 |
+
|
| 111 |
+
flickr_train_dataset = dict(
|
| 112 |
+
type='YOLOv5MixedGroundingDataset',
|
| 113 |
+
data_root='data/flickr/',
|
| 114 |
+
ann_file='annotations/final_flickr_separateGT_train.json',
|
| 115 |
+
data_prefix=dict(img='full_images/'),
|
| 116 |
+
filter_cfg=dict(filter_empty_gt=True, min_size=32),
|
| 117 |
+
pipeline=train_pipeline)
|
| 118 |
+
|
| 119 |
+
train_dataloader = dict(batch_size=train_batch_size_per_gpu,
|
| 120 |
+
collate_fn=dict(type='yolow_collate'),
|
| 121 |
+
dataset=dict(_delete_=True,
|
| 122 |
+
type='ConcatDataset',
|
| 123 |
+
datasets=[
|
| 124 |
+
obj365v1_train_dataset,
|
| 125 |
+
flickr_train_dataset, mg_train_dataset
|
| 126 |
+
],
|
| 127 |
+
ignore_keys=['classes', 'palette']))
|
| 128 |
+
test_pipeline = [
|
| 129 |
+
dict(type='LoadImageFromFile'),
|
| 130 |
+
dict(type='YOLOv5KeepRatioResize', scale=img_scale),
|
| 131 |
+
dict(
|
| 132 |
+
type='LetterResize',
|
| 133 |
+
scale=img_scale,
|
| 134 |
+
allow_scale_up=False,
|
| 135 |
+
pad_val=dict(img=114)),
|
| 136 |
+
dict(type='LoadAnnotations', with_bbox=True, _scope_='mmdet'),
|
| 137 |
+
dict(type='LoadText'),
|
| 138 |
+
dict(type='mmdet.PackDetInputs',
|
| 139 |
+
meta_keys=('img_id', 'img_path', 'ori_shape', 'img_shape',
|
| 140 |
+
'scale_factor', 'pad_param', 'texts'))
|
| 141 |
+
]
|
| 142 |
+
|
| 143 |
+
coco_val_dataset = dict(
|
| 144 |
+
_delete_=True,
|
| 145 |
+
type='MultiModalDataset',
|
| 146 |
+
dataset=dict(type='YOLOv5LVISV1Dataset',
|
| 147 |
+
data_root='data/coco/',
|
| 148 |
+
test_mode=True,
|
| 149 |
+
ann_file='lvis/lvis_v1_minival_inserted_image_name.json',
|
| 150 |
+
data_prefix=dict(img=''),
|
| 151 |
+
batch_shapes_cfg=None),
|
| 152 |
+
class_text_path='data/texts/lvis_v1_class_texts.json',
|
| 153 |
+
pipeline=test_pipeline)
|
| 154 |
+
val_dataloader = dict(dataset=coco_val_dataset)
|
| 155 |
+
test_dataloader = val_dataloader
|
| 156 |
+
|
| 157 |
+
val_evaluator = dict(type='mmdet.LVISMetric',
|
| 158 |
+
ann_file='data/coco/lvis/lvis_v1_minival_inserted_image_name.json',
|
| 159 |
+
metric='bbox')
|
| 160 |
+
test_evaluator = val_evaluator
|
| 161 |
+
|
| 162 |
+
# training settings
|
| 163 |
+
default_hooks = dict(param_scheduler=dict(max_epochs=max_epochs),
|
| 164 |
+
checkpoint=dict(interval=save_epoch_intervals,
|
| 165 |
+
rule='greater'))
|
| 166 |
+
custom_hooks = [
|
| 167 |
+
dict(type='EMAHook',
|
| 168 |
+
ema_type='ExpMomentumEMA',
|
| 169 |
+
momentum=0.0001,
|
| 170 |
+
update_buffers=True,
|
| 171 |
+
strict_load=False,
|
| 172 |
+
priority=49),
|
| 173 |
+
dict(type='mmdet.PipelineSwitchHook',
|
| 174 |
+
switch_epoch=max_epochs - close_mosaic_epochs,
|
| 175 |
+
switch_pipeline=train_pipeline_stage2)
|
| 176 |
+
]
|
| 177 |
+
train_cfg = dict(max_epochs=max_epochs,
|
| 178 |
+
val_interval=10,
|
| 179 |
+
dynamic_intervals=[((max_epochs - close_mosaic_epochs),
|
| 180 |
+
_base_.val_interval_stage2)])
|
| 181 |
+
optim_wrapper = dict(optimizer=dict(
|
| 182 |
+
_delete_=True,
|
| 183 |
+
type='AdamW',
|
| 184 |
+
lr=base_lr,
|
| 185 |
+
weight_decay=weight_decay,
|
| 186 |
+
batch_size_per_gpu=train_batch_size_per_gpu),
|
| 187 |
+
paramwise_cfg=dict(bias_decay_mult=0.0,
|
| 188 |
+
norm_decay_mult=0.0,
|
| 189 |
+
custom_keys={
|
| 190 |
+
'backbone.text_model':
|
| 191 |
+
dict(lr_mult=0.01),
|
| 192 |
+
'logit_scale':
|
| 193 |
+
dict(weight_decay=0.0)
|
| 194 |
+
}),
|
| 195 |
+
constructor='YOLOWv5OptimizerConstructor')
|
configs/pretrain/yolo_world_v2_s_vlpan_bn_2e-3_100e_4x8gpus_obj365v1_goldg_train_lvis_minival.py
ADDED
|
@@ -0,0 +1,170 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
_base_ = ('../../third_party/mmyolo/configs/yolov8/'
|
| 2 |
+
'yolov8_s_syncbn_fast_8xb16-500e_coco.py')
|
| 3 |
+
custom_imports = dict(imports=['yolo_world'],
|
| 4 |
+
allow_failed_imports=False)
|
| 5 |
+
|
| 6 |
+
# hyper-parameters
|
| 7 |
+
num_classes = 1203
|
| 8 |
+
num_training_classes = 80
|
| 9 |
+
max_epochs = 100 # Maximum training epochs
|
| 10 |
+
close_mosaic_epochs = 2
|
| 11 |
+
save_epoch_intervals = 2
|
| 12 |
+
text_channels = 512
|
| 13 |
+
neck_embed_channels = [128, 256, _base_.last_stage_out_channels // 2]
|
| 14 |
+
neck_num_heads = [4, 8, _base_.last_stage_out_channels // 2 // 32]
|
| 15 |
+
base_lr = 2e-3
|
| 16 |
+
weight_decay = 0.05 / 2
|
| 17 |
+
train_batch_size_per_gpu = 16
|
| 18 |
+
|
| 19 |
+
# model settings
|
| 20 |
+
model = dict(
|
| 21 |
+
type='YOLOWorldDetector',
|
| 22 |
+
mm_neck=True,
|
| 23 |
+
num_train_classes=num_training_classes,
|
| 24 |
+
num_test_classes=num_classes,
|
| 25 |
+
data_preprocessor=dict(type='YOLOWDetDataPreprocessor'),
|
| 26 |
+
backbone=dict(
|
| 27 |
+
_delete_=True,
|
| 28 |
+
type='MultiModalYOLOBackbone',
|
| 29 |
+
image_model={{_base_.model.backbone}},
|
| 30 |
+
text_model=dict(
|
| 31 |
+
type='HuggingCLIPLanguageBackbone',
|
| 32 |
+
model_name='openai/clip-vit-base-patch32',
|
| 33 |
+
frozen_modules=['all'])),
|
| 34 |
+
neck=dict(type='YOLOWorldPAFPN',
|
| 35 |
+
guide_channels=text_channels,
|
| 36 |
+
embed_channels=neck_embed_channels,
|
| 37 |
+
num_heads=neck_num_heads,
|
| 38 |
+
block_cfg=dict(type='MaxSigmoidCSPLayerWithTwoConv')),
|
| 39 |
+
bbox_head=dict(type='YOLOWorldHead',
|
| 40 |
+
head_module=dict(type='YOLOWorldHeadModule',
|
| 41 |
+
use_bn_head=True,
|
| 42 |
+
embed_dims=text_channels,
|
| 43 |
+
num_classes=num_training_classes)),
|
| 44 |
+
train_cfg=dict(assigner=dict(num_classes=num_training_classes)))
|
| 45 |
+
|
| 46 |
+
# dataset settings
|
| 47 |
+
text_transform = [
|
| 48 |
+
dict(type='RandomLoadText',
|
| 49 |
+
num_neg_samples=(num_classes, num_classes),
|
| 50 |
+
max_num_samples=num_training_classes,
|
| 51 |
+
padding_to_max=True,
|
| 52 |
+
padding_value=''),
|
| 53 |
+
dict(type='mmdet.PackDetInputs',
|
| 54 |
+
meta_keys=('img_id', 'img_path', 'ori_shape', 'img_shape', 'flip',
|
| 55 |
+
'flip_direction', 'texts'))
|
| 56 |
+
]
|
| 57 |
+
train_pipeline = [
|
| 58 |
+
*_base_.pre_transform,
|
| 59 |
+
dict(type='MultiModalMosaic',
|
| 60 |
+
img_scale=_base_.img_scale,
|
| 61 |
+
pad_val=114.0,
|
| 62 |
+
pre_transform=_base_.pre_transform),
|
| 63 |
+
dict(
|
| 64 |
+
type='YOLOv5RandomAffine',
|
| 65 |
+
max_rotate_degree=0.0,
|
| 66 |
+
max_shear_degree=0.0,
|
| 67 |
+
scaling_ratio_range=(1 - _base_.affine_scale, 1 + _base_.affine_scale),
|
| 68 |
+
max_aspect_ratio=_base_.max_aspect_ratio,
|
| 69 |
+
border=(-_base_.img_scale[0] // 2, -_base_.img_scale[1] // 2),
|
| 70 |
+
border_val=(114, 114, 114)),
|
| 71 |
+
*_base_.last_transform[:-1],
|
| 72 |
+
*text_transform,
|
| 73 |
+
]
|
| 74 |
+
train_pipeline_stage2 = [*_base_.train_pipeline_stage2[:-1], *text_transform]
|
| 75 |
+
obj365v1_train_dataset = dict(
|
| 76 |
+
type='MultiModalDataset',
|
| 77 |
+
dataset=dict(
|
| 78 |
+
type='YOLOv5Objects365V1Dataset',
|
| 79 |
+
data_root='data/objects365v1/',
|
| 80 |
+
ann_file='annotations/objects365_train.json',
|
| 81 |
+
data_prefix=dict(img='train/'),
|
| 82 |
+
filter_cfg=dict(filter_empty_gt=False, min_size=32)),
|
| 83 |
+
class_text_path='data/texts/obj365v1_class_texts.json',
|
| 84 |
+
pipeline=train_pipeline)
|
| 85 |
+
|
| 86 |
+
mg_train_dataset = dict(type='YOLOv5MixedGroundingDataset',
|
| 87 |
+
data_root='data/mixed_grounding/',
|
| 88 |
+
ann_file='annotations/final_mixed_train_no_coco.json',
|
| 89 |
+
data_prefix=dict(img='gqa/images/'),
|
| 90 |
+
filter_cfg=dict(filter_empty_gt=False, min_size=32),
|
| 91 |
+
pipeline=train_pipeline)
|
| 92 |
+
|
| 93 |
+
flickr_train_dataset = dict(
|
| 94 |
+
type='YOLOv5MixedGroundingDataset',
|
| 95 |
+
data_root='data/flickr/',
|
| 96 |
+
ann_file='annotations/final_flickr_separateGT_train.json',
|
| 97 |
+
data_prefix=dict(img='full_images/'),
|
| 98 |
+
filter_cfg=dict(filter_empty_gt=True, min_size=32),
|
| 99 |
+
pipeline=train_pipeline)
|
| 100 |
+
|
| 101 |
+
train_dataloader = dict(batch_size=train_batch_size_per_gpu,
|
| 102 |
+
collate_fn=dict(type='yolow_collate'),
|
| 103 |
+
dataset=dict(_delete_=True,
|
| 104 |
+
type='ConcatDataset',
|
| 105 |
+
datasets=[
|
| 106 |
+
obj365v1_train_dataset,
|
| 107 |
+
flickr_train_dataset, mg_train_dataset
|
| 108 |
+
],
|
| 109 |
+
ignore_keys=['classes', 'palette']))
|
| 110 |
+
|
| 111 |
+
test_pipeline = [
|
| 112 |
+
*_base_.test_pipeline[:-1],
|
| 113 |
+
dict(type='LoadText'),
|
| 114 |
+
dict(type='mmdet.PackDetInputs',
|
| 115 |
+
meta_keys=('img_id', 'img_path', 'ori_shape', 'img_shape',
|
| 116 |
+
'scale_factor', 'pad_param', 'texts'))
|
| 117 |
+
]
|
| 118 |
+
coco_val_dataset = dict(
|
| 119 |
+
_delete_=True,
|
| 120 |
+
type='MultiModalDataset',
|
| 121 |
+
dataset=dict(type='YOLOv5LVISV1Dataset',
|
| 122 |
+
data_root='data/coco/',
|
| 123 |
+
test_mode=True,
|
| 124 |
+
ann_file='lvis/lvis_v1_minival_inserted_image_name.json',
|
| 125 |
+
data_prefix=dict(img=''),
|
| 126 |
+
batch_shapes_cfg=None),
|
| 127 |
+
class_text_path='data/texts/lvis_v1_class_texts.json',
|
| 128 |
+
pipeline=test_pipeline)
|
| 129 |
+
val_dataloader = dict(dataset=coco_val_dataset)
|
| 130 |
+
test_dataloader = val_dataloader
|
| 131 |
+
|
| 132 |
+
val_evaluator = dict(type='mmdet.LVISMetric',
|
| 133 |
+
ann_file='data/coco/lvis/lvis_v1_minival_inserted_image_name.json',
|
| 134 |
+
metric='bbox')
|
| 135 |
+
test_evaluator = val_evaluator
|
| 136 |
+
|
| 137 |
+
# training settings
|
| 138 |
+
default_hooks = dict(param_scheduler=dict(max_epochs=max_epochs),
|
| 139 |
+
checkpoint=dict(interval=save_epoch_intervals,
|
| 140 |
+
rule='greater'))
|
| 141 |
+
custom_hooks = [
|
| 142 |
+
dict(type='EMAHook',
|
| 143 |
+
ema_type='ExpMomentumEMA',
|
| 144 |
+
momentum=0.0001,
|
| 145 |
+
update_buffers=True,
|
| 146 |
+
strict_load=False,
|
| 147 |
+
priority=49),
|
| 148 |
+
dict(type='mmdet.PipelineSwitchHook',
|
| 149 |
+
switch_epoch=max_epochs - close_mosaic_epochs,
|
| 150 |
+
switch_pipeline=train_pipeline_stage2)
|
| 151 |
+
]
|
| 152 |
+
train_cfg = dict(max_epochs=max_epochs,
|
| 153 |
+
val_interval=10,
|
| 154 |
+
dynamic_intervals=[((max_epochs - close_mosaic_epochs),
|
| 155 |
+
_base_.val_interval_stage2)])
|
| 156 |
+
optim_wrapper = dict(optimizer=dict(
|
| 157 |
+
_delete_=True,
|
| 158 |
+
type='AdamW',
|
| 159 |
+
lr=base_lr,
|
| 160 |
+
weight_decay=weight_decay,
|
| 161 |
+
batch_size_per_gpu=train_batch_size_per_gpu),
|
| 162 |
+
paramwise_cfg=dict(bias_decay_mult=0.0,
|
| 163 |
+
norm_decay_mult=0.0,
|
| 164 |
+
custom_keys={
|
| 165 |
+
'backbone.text_model':
|
| 166 |
+
dict(lr_mult=0.01),
|
| 167 |
+
'logit_scale':
|
| 168 |
+
dict(weight_decay=0.0)
|
| 169 |
+
}),
|
| 170 |
+
constructor='YOLOWv5OptimizerConstructor')
|
configs/pretrain/yolo_world_v2_x_vlpan_bn_2e-3_100e_4x8gpus_obj365v1_goldg_train_lvis_minival.py
ADDED
|
@@ -0,0 +1,171 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
_base_ = ('../../third_party/mmyolo/configs/yolov8/'
|
| 2 |
+
'yolov8_x_syncbn_fast_8xb16-500e_coco.py')
|
| 3 |
+
custom_imports = dict(imports=['yolo_world'],
|
| 4 |
+
allow_failed_imports=False)
|
| 5 |
+
|
| 6 |
+
# hyper-parameters
|
| 7 |
+
num_classes = 1203
|
| 8 |
+
num_training_classes = 80
|
| 9 |
+
max_epochs = 100 # Maximum training epochs
|
| 10 |
+
close_mosaic_epochs = 2
|
| 11 |
+
save_epoch_intervals = 2
|
| 12 |
+
text_channels = 512
|
| 13 |
+
neck_embed_channels = [128, 256, _base_.last_stage_out_channels // 2]
|
| 14 |
+
neck_num_heads = [4, 8, _base_.last_stage_out_channels // 2 // 32]
|
| 15 |
+
base_lr = 2e-3
|
| 16 |
+
weight_decay = 0.05 / 2
|
| 17 |
+
train_batch_size_per_gpu = 16
|
| 18 |
+
# text_model_name = '../pretrained_models/clip-vit-base-patch32-projection'
|
| 19 |
+
text_model_name = 'openai/clip-vit-base-patch32'
|
| 20 |
+
# model settings
|
| 21 |
+
model = dict(
|
| 22 |
+
type='YOLOWorldDetector',
|
| 23 |
+
mm_neck=True,
|
| 24 |
+
num_train_classes=num_training_classes,
|
| 25 |
+
num_test_classes=num_classes,
|
| 26 |
+
data_preprocessor=dict(type='YOLOWDetDataPreprocessor'),
|
| 27 |
+
backbone=dict(
|
| 28 |
+
_delete_=True,
|
| 29 |
+
type='MultiModalYOLOBackbone',
|
| 30 |
+
image_model={{_base_.model.backbone}},
|
| 31 |
+
text_model=dict(
|
| 32 |
+
type='HuggingCLIPLanguageBackbone',
|
| 33 |
+
model_name=text_model_name,
|
| 34 |
+
frozen_modules=['all'])),
|
| 35 |
+
neck=dict(type='YOLOWorldPAFPN',
|
| 36 |
+
guide_channels=text_channels,
|
| 37 |
+
embed_channels=neck_embed_channels,
|
| 38 |
+
num_heads=neck_num_heads,
|
| 39 |
+
block_cfg=dict(type='MaxSigmoidCSPLayerWithTwoConv')),
|
| 40 |
+
bbox_head=dict(type='YOLOWorldHead',
|
| 41 |
+
head_module=dict(type='YOLOWorldHeadModule',
|
| 42 |
+
use_bn_head=True,
|
| 43 |
+
embed_dims=text_channels,
|
| 44 |
+
num_classes=num_training_classes)),
|
| 45 |
+
train_cfg=dict(assigner=dict(num_classes=num_training_classes)))
|
| 46 |
+
|
| 47 |
+
# dataset settings
|
| 48 |
+
text_transform = [
|
| 49 |
+
dict(type='RandomLoadText',
|
| 50 |
+
num_neg_samples=(num_classes, num_classes),
|
| 51 |
+
max_num_samples=num_training_classes,
|
| 52 |
+
padding_to_max=True,
|
| 53 |
+
padding_value=''),
|
| 54 |
+
dict(type='mmdet.PackDetInputs',
|
| 55 |
+
meta_keys=('img_id', 'img_path', 'ori_shape', 'img_shape', 'flip',
|
| 56 |
+
'flip_direction', 'texts'))
|
| 57 |
+
]
|
| 58 |
+
train_pipeline = [
|
| 59 |
+
*_base_.pre_transform,
|
| 60 |
+
dict(type='MultiModalMosaic',
|
| 61 |
+
img_scale=_base_.img_scale,
|
| 62 |
+
pad_val=114.0,
|
| 63 |
+
pre_transform=_base_.pre_transform),
|
| 64 |
+
dict(
|
| 65 |
+
type='YOLOv5RandomAffine',
|
| 66 |
+
max_rotate_degree=0.0,
|
| 67 |
+
max_shear_degree=0.0,
|
| 68 |
+
scaling_ratio_range=(1 - _base_.affine_scale, 1 + _base_.affine_scale),
|
| 69 |
+
max_aspect_ratio=_base_.max_aspect_ratio,
|
| 70 |
+
border=(-_base_.img_scale[0] // 2, -_base_.img_scale[1] // 2),
|
| 71 |
+
border_val=(114, 114, 114)),
|
| 72 |
+
*_base_.last_transform[:-1],
|
| 73 |
+
*text_transform,
|
| 74 |
+
]
|
| 75 |
+
train_pipeline_stage2 = [*_base_.train_pipeline_stage2[:-1], *text_transform]
|
| 76 |
+
obj365v1_train_dataset = dict(
|
| 77 |
+
type='MultiModalDataset',
|
| 78 |
+
dataset=dict(
|
| 79 |
+
type='YOLOv5Objects365V1Dataset',
|
| 80 |
+
data_root='data/objects365v1/',
|
| 81 |
+
ann_file='annotations/objects365_train.json',
|
| 82 |
+
data_prefix=dict(img='train/'),
|
| 83 |
+
filter_cfg=dict(filter_empty_gt=False, min_size=32)),
|
| 84 |
+
class_text_path='data/texts/obj365v1_class_texts.json',
|
| 85 |
+
pipeline=train_pipeline)
|
| 86 |
+
|
| 87 |
+
mg_train_dataset = dict(type='YOLOv5MixedGroundingDataset',
|
| 88 |
+
data_root='data/mixed_grounding/',
|
| 89 |
+
ann_file='annotations/final_mixed_train_no_coco.json',
|
| 90 |
+
data_prefix=dict(img='gqa/images/'),
|
| 91 |
+
filter_cfg=dict(filter_empty_gt=False, min_size=32),
|
| 92 |
+
pipeline=train_pipeline)
|
| 93 |
+
|
| 94 |
+
flickr_train_dataset = dict(
|
| 95 |
+
type='YOLOv5MixedGroundingDataset',
|
| 96 |
+
data_root='data/flickr/',
|
| 97 |
+
ann_file='annotations/final_flickr_separateGT_train.json',
|
| 98 |
+
data_prefix=dict(img='full_images/'),
|
| 99 |
+
filter_cfg=dict(filter_empty_gt=True, min_size=32),
|
| 100 |
+
pipeline=train_pipeline)
|
| 101 |
+
|
| 102 |
+
train_dataloader = dict(batch_size=train_batch_size_per_gpu,
|
| 103 |
+
collate_fn=dict(type='yolow_collate'),
|
| 104 |
+
dataset=dict(_delete_=True,
|
| 105 |
+
type='ConcatDataset',
|
| 106 |
+
datasets=[
|
| 107 |
+
obj365v1_train_dataset,
|
| 108 |
+
flickr_train_dataset, mg_train_dataset
|
| 109 |
+
],
|
| 110 |
+
ignore_keys=['classes', 'palette']))
|
| 111 |
+
|
| 112 |
+
test_pipeline = [
|
| 113 |
+
*_base_.test_pipeline[:-1],
|
| 114 |
+
dict(type='LoadText'),
|
| 115 |
+
dict(type='mmdet.PackDetInputs',
|
| 116 |
+
meta_keys=('img_id', 'img_path', 'ori_shape', 'img_shape',
|
| 117 |
+
'scale_factor', 'pad_param', 'texts'))
|
| 118 |
+
]
|
| 119 |
+
coco_val_dataset = dict(
|
| 120 |
+
_delete_=True,
|
| 121 |
+
type='MultiModalDataset',
|
| 122 |
+
dataset=dict(type='YOLOv5LVISV1Dataset',
|
| 123 |
+
data_root='data/coco/',
|
| 124 |
+
test_mode=True,
|
| 125 |
+
ann_file='lvis/lvis_v1_minival_inserted_image_name.json',
|
| 126 |
+
data_prefix=dict(img=''),
|
| 127 |
+
batch_shapes_cfg=None),
|
| 128 |
+
class_text_path='data/texts/lvis_v1_class_texts.json',
|
| 129 |
+
pipeline=test_pipeline)
|
| 130 |
+
val_dataloader = dict(dataset=coco_val_dataset)
|
| 131 |
+
test_dataloader = val_dataloader
|
| 132 |
+
|
| 133 |
+
val_evaluator = dict(type='mmdet.LVISMetric',
|
| 134 |
+
ann_file='data/coco/lvis/lvis_v1_minival_inserted_image_name.json',
|
| 135 |
+
metric='bbox')
|
| 136 |
+
test_evaluator = val_evaluator
|
| 137 |
+
|
| 138 |
+
# training settings
|
| 139 |
+
default_hooks = dict(param_scheduler=dict(max_epochs=max_epochs),
|
| 140 |
+
checkpoint=dict(interval=save_epoch_intervals,
|
| 141 |
+
rule='greater'))
|
| 142 |
+
custom_hooks = [
|
| 143 |
+
dict(type='EMAHook',
|
| 144 |
+
ema_type='ExpMomentumEMA',
|
| 145 |
+
momentum=0.0001,
|
| 146 |
+
update_buffers=True,
|
| 147 |
+
strict_load=False,
|
| 148 |
+
priority=49),
|
| 149 |
+
dict(type='mmdet.PipelineSwitchHook',
|
| 150 |
+
switch_epoch=max_epochs - close_mosaic_epochs,
|
| 151 |
+
switch_pipeline=train_pipeline_stage2)
|
| 152 |
+
]
|
| 153 |
+
train_cfg = dict(max_epochs=max_epochs,
|
| 154 |
+
val_interval=10,
|
| 155 |
+
dynamic_intervals=[((max_epochs - close_mosaic_epochs),
|
| 156 |
+
_base_.val_interval_stage2)])
|
| 157 |
+
optim_wrapper = dict(optimizer=dict(
|
| 158 |
+
_delete_=True,
|
| 159 |
+
type='AdamW',
|
| 160 |
+
lr=base_lr,
|
| 161 |
+
weight_decay=weight_decay,
|
| 162 |
+
batch_size_per_gpu=train_batch_size_per_gpu),
|
| 163 |
+
paramwise_cfg=dict(bias_decay_mult=0.0,
|
| 164 |
+
norm_decay_mult=0.0,
|
| 165 |
+
custom_keys={
|
| 166 |
+
'backbone.text_model':
|
| 167 |
+
dict(lr_mult=0.01),
|
| 168 |
+
'logit_scale':
|
| 169 |
+
dict(weight_decay=0.0)
|
| 170 |
+
}),
|
| 171 |
+
constructor='YOLOWv5OptimizerConstructor')
|
configs/pretrain/yolo_world_v2_xl_vlpan_bn_2e-3_100e_4x8gpus_obj365v1_goldg_train_lvis_minival.py
ADDED
|
@@ -0,0 +1,185 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
_base_ = ('../../third_party/mmyolo/configs/yolov8/'
|
| 2 |
+
'yolov8_x_syncbn_fast_8xb16-500e_coco.py')
|
| 3 |
+
custom_imports = dict(imports=['yolo_world'],
|
| 4 |
+
allow_failed_imports=False)
|
| 5 |
+
|
| 6 |
+
# hyper-parameters
|
| 7 |
+
num_classes = 1203
|
| 8 |
+
num_training_classes = 80
|
| 9 |
+
max_epochs = 100 # Maximum training epochs
|
| 10 |
+
close_mosaic_epochs = 2
|
| 11 |
+
save_epoch_intervals = 2
|
| 12 |
+
text_channels = 512
|
| 13 |
+
neck_embed_channels = [128, 256, _base_.last_stage_out_channels // 2]
|
| 14 |
+
neck_num_heads = [4, 8, _base_.last_stage_out_channels // 2 // 32]
|
| 15 |
+
base_lr = 2e-3
|
| 16 |
+
weight_decay = 0.05 / 2
|
| 17 |
+
train_batch_size_per_gpu = 16
|
| 18 |
+
text_model_name = '../pretrained_models/clip-vit-base-patch32-projection'
|
| 19 |
+
# text_model_name = 'openai/clip-vit-base-patch32'
|
| 20 |
+
|
| 21 |
+
# scaling model from X to XL
|
| 22 |
+
deepen_factor = 1.0
|
| 23 |
+
widen_factor = 1.5
|
| 24 |
+
|
| 25 |
+
backbone = _base_.model.backbone
|
| 26 |
+
backbone.update(
|
| 27 |
+
deepen_factor=deepen_factor,
|
| 28 |
+
widen_factor=widen_factor
|
| 29 |
+
)
|
| 30 |
+
|
| 31 |
+
# model settings
|
| 32 |
+
model = dict(
|
| 33 |
+
type='YOLOWorldDetector',
|
| 34 |
+
mm_neck=True,
|
| 35 |
+
num_train_classes=num_training_classes,
|
| 36 |
+
num_test_classes=num_classes,
|
| 37 |
+
data_preprocessor=dict(type='YOLOWDetDataPreprocessor'),
|
| 38 |
+
backbone=dict(
|
| 39 |
+
_delete_=True,
|
| 40 |
+
type='MultiModalYOLOBackbone',
|
| 41 |
+
image_model=backbone,
|
| 42 |
+
text_model=dict(
|
| 43 |
+
type='HuggingCLIPLanguageBackbone',
|
| 44 |
+
model_name=text_model_name,
|
| 45 |
+
frozen_modules=['all'])),
|
| 46 |
+
neck=dict(type='YOLOWorldPAFPN',
|
| 47 |
+
deepen_factor=deepen_factor,
|
| 48 |
+
widen_factor=widen_factor,
|
| 49 |
+
guide_channels=text_channels,
|
| 50 |
+
embed_channels=neck_embed_channels,
|
| 51 |
+
num_heads=neck_num_heads,
|
| 52 |
+
block_cfg=dict(type='MaxSigmoidCSPLayerWithTwoConv')),
|
| 53 |
+
bbox_head=dict(type='YOLOWorldHead',
|
| 54 |
+
head_module=dict(type='YOLOWorldHeadModule',
|
| 55 |
+
widen_factor=widen_factor,
|
| 56 |
+
use_bn_head=True,
|
| 57 |
+
embed_dims=text_channels,
|
| 58 |
+
num_classes=num_training_classes)),
|
| 59 |
+
train_cfg=dict(assigner=dict(num_classes=num_training_classes)))
|
| 60 |
+
|
| 61 |
+
# dataset settings
|
| 62 |
+
text_transform = [
|
| 63 |
+
dict(type='RandomLoadText',
|
| 64 |
+
num_neg_samples=(num_classes, num_classes),
|
| 65 |
+
max_num_samples=num_training_classes,
|
| 66 |
+
padding_to_max=True,
|
| 67 |
+
padding_value=''),
|
| 68 |
+
dict(type='mmdet.PackDetInputs',
|
| 69 |
+
meta_keys=('img_id', 'img_path', 'ori_shape', 'img_shape', 'flip',
|
| 70 |
+
'flip_direction', 'texts'))
|
| 71 |
+
]
|
| 72 |
+
train_pipeline = [
|
| 73 |
+
*_base_.pre_transform,
|
| 74 |
+
dict(type='MultiModalMosaic',
|
| 75 |
+
img_scale=_base_.img_scale,
|
| 76 |
+
pad_val=114.0,
|
| 77 |
+
pre_transform=_base_.pre_transform),
|
| 78 |
+
dict(
|
| 79 |
+
type='YOLOv5RandomAffine',
|
| 80 |
+
max_rotate_degree=0.0,
|
| 81 |
+
max_shear_degree=0.0,
|
| 82 |
+
scaling_ratio_range=(1 - _base_.affine_scale, 1 + _base_.affine_scale),
|
| 83 |
+
max_aspect_ratio=_base_.max_aspect_ratio,
|
| 84 |
+
border=(-_base_.img_scale[0] // 2, -_base_.img_scale[1] // 2),
|
| 85 |
+
border_val=(114, 114, 114)),
|
| 86 |
+
*_base_.last_transform[:-1],
|
| 87 |
+
*text_transform,
|
| 88 |
+
]
|
| 89 |
+
train_pipeline_stage2 = [*_base_.train_pipeline_stage2[:-1], *text_transform]
|
| 90 |
+
obj365v1_train_dataset = dict(
|
| 91 |
+
type='MultiModalDataset',
|
| 92 |
+
dataset=dict(
|
| 93 |
+
type='YOLOv5Objects365V1Dataset',
|
| 94 |
+
data_root='data/objects365v1/',
|
| 95 |
+
ann_file='annotations/objects365_train.json',
|
| 96 |
+
data_prefix=dict(img='train/'),
|
| 97 |
+
filter_cfg=dict(filter_empty_gt=False, min_size=32)),
|
| 98 |
+
class_text_path='data/texts/obj365v1_class_texts.json',
|
| 99 |
+
pipeline=train_pipeline)
|
| 100 |
+
|
| 101 |
+
mg_train_dataset = dict(type='YOLOv5MixedGroundingDataset',
|
| 102 |
+
data_root='data/mixed_grounding/',
|
| 103 |
+
ann_file='annotations/final_mixed_train_no_coco.json',
|
| 104 |
+
data_prefix=dict(img='gqa/images/'),
|
| 105 |
+
filter_cfg=dict(filter_empty_gt=False, min_size=32),
|
| 106 |
+
pipeline=train_pipeline)
|
| 107 |
+
|
| 108 |
+
flickr_train_dataset = dict(
|
| 109 |
+
type='YOLOv5MixedGroundingDataset',
|
| 110 |
+
data_root='data/flickr/',
|
| 111 |
+
ann_file='annotations/final_flickr_separateGT_train.json',
|
| 112 |
+
data_prefix=dict(img='full_images/'),
|
| 113 |
+
filter_cfg=dict(filter_empty_gt=True, min_size=32),
|
| 114 |
+
pipeline=train_pipeline)
|
| 115 |
+
|
| 116 |
+
train_dataloader = dict(batch_size=train_batch_size_per_gpu,
|
| 117 |
+
collate_fn=dict(type='yolow_collate'),
|
| 118 |
+
dataset=dict(_delete_=True,
|
| 119 |
+
type='ConcatDataset',
|
| 120 |
+
datasets=[
|
| 121 |
+
obj365v1_train_dataset,
|
| 122 |
+
flickr_train_dataset, mg_train_dataset
|
| 123 |
+
],
|
| 124 |
+
ignore_keys=['classes', 'palette']))
|
| 125 |
+
|
| 126 |
+
test_pipeline = [
|
| 127 |
+
*_base_.test_pipeline[:-1],
|
| 128 |
+
dict(type='LoadText'),
|
| 129 |
+
dict(type='mmdet.PackDetInputs',
|
| 130 |
+
meta_keys=('img_id', 'img_path', 'ori_shape', 'img_shape',
|
| 131 |
+
'scale_factor', 'pad_param', 'texts'))
|
| 132 |
+
]
|
| 133 |
+
coco_val_dataset = dict(
|
| 134 |
+
_delete_=True,
|
| 135 |
+
type='MultiModalDataset',
|
| 136 |
+
dataset=dict(type='YOLOv5LVISV1Dataset',
|
| 137 |
+
data_root='data/coco/',
|
| 138 |
+
test_mode=True,
|
| 139 |
+
ann_file='lvis/lvis_v1_minival_inserted_image_name.json',
|
| 140 |
+
data_prefix=dict(img=''),
|
| 141 |
+
batch_shapes_cfg=None),
|
| 142 |
+
class_text_path='data/texts/lvis_v1_class_texts.json',
|
| 143 |
+
pipeline=test_pipeline)
|
| 144 |
+
val_dataloader = dict(dataset=coco_val_dataset)
|
| 145 |
+
test_dataloader = val_dataloader
|
| 146 |
+
|
| 147 |
+
val_evaluator = dict(type='mmdet.LVISMetric',
|
| 148 |
+
ann_file='data/coco/lvis/lvis_v1_minival_inserted_image_name.json',
|
| 149 |
+
metric='bbox')
|
| 150 |
+
test_evaluator = val_evaluator
|
| 151 |
+
|
| 152 |
+
# training settings
|
| 153 |
+
default_hooks = dict(param_scheduler=dict(max_epochs=max_epochs),
|
| 154 |
+
checkpoint=dict(interval=save_epoch_intervals,
|
| 155 |
+
rule='greater'))
|
| 156 |
+
custom_hooks = [
|
| 157 |
+
dict(type='EMAHook',
|
| 158 |
+
ema_type='ExpMomentumEMA',
|
| 159 |
+
momentum=0.0001,
|
| 160 |
+
update_buffers=True,
|
| 161 |
+
strict_load=False,
|
| 162 |
+
priority=49),
|
| 163 |
+
dict(type='mmdet.PipelineSwitchHook',
|
| 164 |
+
switch_epoch=max_epochs - close_mosaic_epochs,
|
| 165 |
+
switch_pipeline=train_pipeline_stage2)
|
| 166 |
+
]
|
| 167 |
+
train_cfg = dict(max_epochs=max_epochs,
|
| 168 |
+
val_interval=10,
|
| 169 |
+
dynamic_intervals=[((max_epochs - close_mosaic_epochs),
|
| 170 |
+
_base_.val_interval_stage2)])
|
| 171 |
+
optim_wrapper = dict(optimizer=dict(
|
| 172 |
+
_delete_=True,
|
| 173 |
+
type='AdamW',
|
| 174 |
+
lr=base_lr,
|
| 175 |
+
weight_decay=weight_decay,
|
| 176 |
+
batch_size_per_gpu=train_batch_size_per_gpu),
|
| 177 |
+
paramwise_cfg=dict(bias_decay_mult=0.0,
|
| 178 |
+
norm_decay_mult=0.0,
|
| 179 |
+
custom_keys={
|
| 180 |
+
'backbone.text_model':
|
| 181 |
+
dict(lr_mult=0.01),
|
| 182 |
+
'logit_scale':
|
| 183 |
+
dict(weight_decay=0.0)
|
| 184 |
+
}),
|
| 185 |
+
constructor='YOLOWv5OptimizerConstructor')
|
configs/pretrain_v1/README.md
ADDED
|
@@ -0,0 +1,21 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
## Pre-training YOLO-World-v1
|
| 2 |
+
|
| 3 |
+
> The YOLO-World-v1 is an initial version, and now is nearly deprecated! We strongly suggest you use the [latest version](../pretrain/).
|
| 4 |
+
|
| 5 |
+
|
| 6 |
+
|
| 7 |
+
### Zero-shot Inference on LVIS dataset
|
| 8 |
+
|
| 9 |
+
| model | Pre-train Data | Size | AP<sup>mini</su> | AP<sub>r</sub> | AP<sub>c</sub> | AP<sub>f</sub> | AP<sup>val</su> | AP<sub>r</sub> | AP<sub>c</sub> | AP<sub>f</sub> | weights |
|
| 10 |
+
| :------------------------------------------------------------------------------------------------------------------- | :------------------- | :----------------- | :--------------: | :------------: | :------------: | :------------: | :-------------: | :------------: | :------------: | :------------: | :------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------: |
|
| 11 |
+
| [YOLO-World-S](./yolo_world_s_dual_vlpan_l2norm_2e-3_100e_4x8gpus_obj365v1_goldg_train_lvis_minival.py) | O365+GoldG | 640 | 24.3 | 16.6 | 22.1 | 27.7 | 17.8 | 11.0 | 14.8 | 24.0 | [HF Checkpoints 🤗](https://huggingface.co/wondervictor/YOLO-World/resolve/main/yolo_world_s_clip_base_dual_vlpan_2e-3adamw_32xb16_100e_o365_goldg_train_pretrained-18bea4d2.pth) |
|
| 12 |
+
| [YOLO-World-M](./yolo_world_m_dual_l2norm_2e-4_100e_4x8gpus_obj365v1_goldg_train_lvis_minival.py) | O365+GoldG | 640 | 28.6 | 19.7 | 26.6 | 31.9 | 22.3 | 16.2 | 19.0 | 28.7 | [HF Checkpoints 🤗](https://huggingface.co/wondervictor/YOLO-World/resolve/main/yolo_world_m_clip_base_dual_vlpan_2e-3adamw_32xb16_100e_o365_goldg_train_pretrained-2b7bd1be.pth) |
|
| 13 |
+
| [YOLO-World-L](./yolo_world_l_dual_vlpan_l2norm_2e-3_100e_4x8gpus_obj365v1_goldg_train_lvis_minival.py) | O365+GoldG | 640 | 32.5 | 22.3 | 30.6 | 36.1 | 24.8 | 17.8 | 22.4 | 32.5 | [HF Checkpoints 🤗](https://huggingface.co/wondervictor/YOLO-World/resolve/main/yolo_world_l_clip_base_dual_vlpan_2e-3adamw_32xb16_100e_o365_goldg_train_pretrained-0e566235.pth) |
|
| 14 |
+
| [YOLO-World-L](./yolo_world_l_dual_vlpan_l2norm_2e-3_100e_4x8gpus_obj365v1_goldg_train_lvis_minival.py) | O365+GoldG+CC3M-Lite | 640 | 33.0 | 23.6 | 32.0 | 35.5 | 25.3 | 18.0 | 22.1 | 32.1 | [HF Checkpoints 🤗](https://huggingface.co/wondervictor/YOLO-World/blob/main/yolo_world_l_clip_base_dual_vlpan_2e-3adamw_32xb16_100e_o365_goldg_cc3mlite_train_pretrained-7a5eea3b.pth) |
|
| 15 |
+
| [YOLO-World-X](./yolo_world_x_dual_vlpan_l2norm_2e-3_100e_4x8gpus_obj365v1_goldg_train_lvis_minival.py) | O365+GoldG+CC3M-Lite | 640 | 33.4 | 24.4 | 31.6 | 36.6 | 26.6 | 19.2 | 23.5 | 33.2 | [HF Checkpoints 🤗](https://huggingface.co/wondervictor/YOLO-World/blob/main/yolo_world_x_clip_base_dual_vlpan_2e-3adamw_32xb16_100e_o365_goldg_cc3mlite_train_pretrained-8cf6b025.pth) |
|
| 16 |
+
|
| 17 |
+
|
| 18 |
+
**NOTE:**
|
| 19 |
+
1. AP<sup>mini</sup>: evaluated on LVIS `minival`.
|
| 20 |
+
3. AP<sup>val</sup>: evaluated on LVIS `val 1.0`.
|
| 21 |
+
4. [HuggingFace Mirror](https://hf-mirror.com/) provides the mirror of HuggingFace, which is a choice for users who are unable to reach.
|
configs/pretrain_v1/yolo_world_l_dual_vlpan_l2norm_2e-3_100e_4x8gpus_obj365v1_goldg_train_lvis_minival.py
ADDED
|
@@ -0,0 +1,172 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
_base_ = ('../../third_party/mmyolo/configs/yolov8/'
|
| 2 |
+
'yolov8_l_syncbn_fast_8xb16-500e_coco.py')
|
| 3 |
+
custom_imports = dict(imports=['yolo_world'],
|
| 4 |
+
allow_failed_imports=False)
|
| 5 |
+
|
| 6 |
+
# hyper-parameters
|
| 7 |
+
num_classes = 1203
|
| 8 |
+
num_training_classes = 80
|
| 9 |
+
max_epochs = 100 # Maximum training epochs
|
| 10 |
+
close_mosaic_epochs = 2
|
| 11 |
+
save_epoch_intervals = 2
|
| 12 |
+
text_channels = 512
|
| 13 |
+
neck_embed_channels = [128, 256, _base_.last_stage_out_channels // 2]
|
| 14 |
+
neck_num_heads = [4, 8, _base_.last_stage_out_channels // 2 // 32]
|
| 15 |
+
base_lr = 2e-3
|
| 16 |
+
weight_decay = 0.05 / 2
|
| 17 |
+
train_batch_size_per_gpu = 16
|
| 18 |
+
|
| 19 |
+
# model settings
|
| 20 |
+
model = dict(
|
| 21 |
+
type='YOLOWorldDetector',
|
| 22 |
+
mm_neck=True,
|
| 23 |
+
num_train_classes=num_training_classes,
|
| 24 |
+
num_test_classes=num_classes,
|
| 25 |
+
data_preprocessor=dict(type='YOLOWDetDataPreprocessor'),
|
| 26 |
+
backbone=dict(
|
| 27 |
+
_delete_=True,
|
| 28 |
+
type='MultiModalYOLOBackbone',
|
| 29 |
+
image_model={{_base_.model.backbone}},
|
| 30 |
+
text_model=dict(
|
| 31 |
+
type='HuggingCLIPLanguageBackbone',
|
| 32 |
+
model_name='openai/clip-vit-base-patch32',
|
| 33 |
+
frozen_modules=['all'])),
|
| 34 |
+
neck=dict(type='YOLOWorldDualPAFPN',
|
| 35 |
+
guide_channels=text_channels,
|
| 36 |
+
embed_channels=neck_embed_channels,
|
| 37 |
+
num_heads=neck_num_heads,
|
| 38 |
+
block_cfg=dict(type='MaxSigmoidCSPLayerWithTwoConv'),
|
| 39 |
+
text_enhancder=dict(type='ImagePoolingAttentionModule',
|
| 40 |
+
embed_channels=256,
|
| 41 |
+
num_heads=8)),
|
| 42 |
+
bbox_head=dict(type='YOLOWorldHead',
|
| 43 |
+
head_module=dict(type='YOLOWorldHeadModule',
|
| 44 |
+
embed_dims=text_channels,
|
| 45 |
+
num_classes=num_training_classes)),
|
| 46 |
+
train_cfg=dict(assigner=dict(num_classes=num_training_classes)))
|
| 47 |
+
|
| 48 |
+
# dataset settings
|
| 49 |
+
text_transform = [
|
| 50 |
+
dict(type='RandomLoadText',
|
| 51 |
+
num_neg_samples=(num_classes, num_classes),
|
| 52 |
+
max_num_samples=num_training_classes,
|
| 53 |
+
padding_to_max=True,
|
| 54 |
+
padding_value=''),
|
| 55 |
+
dict(type='mmdet.PackDetInputs',
|
| 56 |
+
meta_keys=('img_id', 'img_path', 'ori_shape', 'img_shape', 'flip',
|
| 57 |
+
'flip_direction', 'texts'))
|
| 58 |
+
]
|
| 59 |
+
train_pipeline = [
|
| 60 |
+
*_base_.pre_transform,
|
| 61 |
+
dict(type='MultiModalMosaic',
|
| 62 |
+
img_scale=_base_.img_scale,
|
| 63 |
+
pad_val=114.0,
|
| 64 |
+
pre_transform=_base_.pre_transform),
|
| 65 |
+
dict(
|
| 66 |
+
type='YOLOv5RandomAffine',
|
| 67 |
+
max_rotate_degree=0.0,
|
| 68 |
+
max_shear_degree=0.0,
|
| 69 |
+
scaling_ratio_range=(1 - _base_.affine_scale, 1 + _base_.affine_scale),
|
| 70 |
+
max_aspect_ratio=_base_.max_aspect_ratio,
|
| 71 |
+
border=(-_base_.img_scale[0] // 2, -_base_.img_scale[1] // 2),
|
| 72 |
+
border_val=(114, 114, 114)),
|
| 73 |
+
*_base_.last_transform[:-1],
|
| 74 |
+
*text_transform,
|
| 75 |
+
]
|
| 76 |
+
train_pipeline_stage2 = [*_base_.train_pipeline_stage2[:-1], *text_transform]
|
| 77 |
+
obj365v1_train_dataset = dict(
|
| 78 |
+
type='MultiModalDataset',
|
| 79 |
+
dataset=dict(
|
| 80 |
+
type='YOLOv5Objects365V1Dataset',
|
| 81 |
+
data_root='data/objects365v1/',
|
| 82 |
+
ann_file='annotations/objects365_train.json',
|
| 83 |
+
data_prefix=dict(img='train/'),
|
| 84 |
+
filter_cfg=dict(filter_empty_gt=False, min_size=32)),
|
| 85 |
+
class_text_path='data/texts/obj365v1_class_texts.json',
|
| 86 |
+
pipeline=train_pipeline)
|
| 87 |
+
|
| 88 |
+
mg_train_dataset = dict(type='YOLOv5MixedGroundingDataset',
|
| 89 |
+
data_root='data/mixed_grounding/',
|
| 90 |
+
ann_file='annotations/final_mixed_train_no_coco.json',
|
| 91 |
+
data_prefix=dict(img='gqa/images/'),
|
| 92 |
+
filter_cfg=dict(filter_empty_gt=False, min_size=32),
|
| 93 |
+
pipeline=train_pipeline)
|
| 94 |
+
|
| 95 |
+
flickr_train_dataset = dict(
|
| 96 |
+
type='YOLOv5MixedGroundingDataset',
|
| 97 |
+
data_root='data/flickr/',
|
| 98 |
+
ann_file='annotations/final_flickr_separateGT_train.json',
|
| 99 |
+
data_prefix=dict(img='full_images/'),
|
| 100 |
+
filter_cfg=dict(filter_empty_gt=True, min_size=32),
|
| 101 |
+
pipeline=train_pipeline)
|
| 102 |
+
|
| 103 |
+
train_dataloader = dict(batch_size=train_batch_size_per_gpu,
|
| 104 |
+
collate_fn=dict(type='yolow_collate'),
|
| 105 |
+
dataset=dict(_delete_=True,
|
| 106 |
+
type='ConcatDataset',
|
| 107 |
+
datasets=[
|
| 108 |
+
obj365v1_train_dataset,
|
| 109 |
+
flickr_train_dataset, mg_train_dataset
|
| 110 |
+
],
|
| 111 |
+
ignore_keys=['classes', 'palette']))
|
| 112 |
+
|
| 113 |
+
test_pipeline = [
|
| 114 |
+
*_base_.test_pipeline[:-1],
|
| 115 |
+
dict(type='LoadText'),
|
| 116 |
+
dict(type='mmdet.PackDetInputs',
|
| 117 |
+
meta_keys=('img_id', 'img_path', 'ori_shape', 'img_shape',
|
| 118 |
+
'scale_factor', 'pad_param', 'texts'))
|
| 119 |
+
]
|
| 120 |
+
coco_val_dataset = dict(
|
| 121 |
+
_delete_=True,
|
| 122 |
+
type='MultiModalDataset',
|
| 123 |
+
dataset=dict(type='YOLOv5LVISV1Dataset',
|
| 124 |
+
data_root='data/coco/',
|
| 125 |
+
test_mode=True,
|
| 126 |
+
ann_file='lvis/lvis_v1_minival_inserted_image_name.json',
|
| 127 |
+
data_prefix=dict(img=''),
|
| 128 |
+
batch_shapes_cfg=None),
|
| 129 |
+
class_text_path='data/texts/lvis_v1_class_texts.json',
|
| 130 |
+
pipeline=test_pipeline)
|
| 131 |
+
val_dataloader = dict(dataset=coco_val_dataset)
|
| 132 |
+
test_dataloader = val_dataloader
|
| 133 |
+
|
| 134 |
+
val_evaluator = dict(type='mmdet.LVISMetric',
|
| 135 |
+
ann_file='data/coco/lvis/lvis_v1_minival_inserted_image_name.json',
|
| 136 |
+
metric='bbox')
|
| 137 |
+
test_evaluator = val_evaluator
|
| 138 |
+
|
| 139 |
+
# training settings
|
| 140 |
+
default_hooks = dict(param_scheduler=dict(max_epochs=max_epochs),
|
| 141 |
+
checkpoint=dict(interval=save_epoch_intervals,
|
| 142 |
+
rule='greater'))
|
| 143 |
+
custom_hooks = [
|
| 144 |
+
dict(type='EMAHook',
|
| 145 |
+
ema_type='ExpMomentumEMA',
|
| 146 |
+
momentum=0.0001,
|
| 147 |
+
update_buffers=True,
|
| 148 |
+
strict_load=False,
|
| 149 |
+
priority=49),
|
| 150 |
+
dict(type='mmdet.PipelineSwitchHook',
|
| 151 |
+
switch_epoch=max_epochs - close_mosaic_epochs,
|
| 152 |
+
switch_pipeline=train_pipeline_stage2)
|
| 153 |
+
]
|
| 154 |
+
train_cfg = dict(max_epochs=max_epochs,
|
| 155 |
+
val_interval=10,
|
| 156 |
+
dynamic_intervals=[((max_epochs - close_mosaic_epochs),
|
| 157 |
+
_base_.val_interval_stage2)])
|
| 158 |
+
optim_wrapper = dict(optimizer=dict(
|
| 159 |
+
_delete_=True,
|
| 160 |
+
type='AdamW',
|
| 161 |
+
lr=base_lr,
|
| 162 |
+
weight_decay=weight_decay,
|
| 163 |
+
batch_size_per_gpu=train_batch_size_per_gpu),
|
| 164 |
+
paramwise_cfg=dict(bias_decay_mult=0.0,
|
| 165 |
+
norm_decay_mult=0.0,
|
| 166 |
+
custom_keys={
|
| 167 |
+
'backbone.text_model':
|
| 168 |
+
dict(lr_mult=0.01),
|
| 169 |
+
'logit_scale':
|
| 170 |
+
dict(weight_decay=0.0)
|
| 171 |
+
}),
|
| 172 |
+
constructor='YOLOWv5OptimizerConstructor')
|
configs/pretrain_v1/yolo_world_l_dual_vlpan_l2norm_2e-3_100e_4x8gpus_obj365v1_goldg_train_lvis_val.py
ADDED
|
@@ -0,0 +1,172 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
_base_ = ('../../third_party/mmyolo/configs/yolov8/'
|
| 2 |
+
'yolov8_l_syncbn_fast_8xb16-500e_coco.py')
|
| 3 |
+
custom_imports = dict(imports=['yolo_world'],
|
| 4 |
+
allow_failed_imports=False)
|
| 5 |
+
|
| 6 |
+
# hyper-parameters
|
| 7 |
+
num_classes = 1203
|
| 8 |
+
num_training_classes = 80
|
| 9 |
+
max_epochs = 100 # Maximum training epochs
|
| 10 |
+
close_mosaic_epochs = 2
|
| 11 |
+
save_epoch_intervals = 2
|
| 12 |
+
text_channels = 512
|
| 13 |
+
neck_embed_channels = [128, 256, _base_.last_stage_out_channels // 2]
|
| 14 |
+
neck_num_heads = [4, 8, _base_.last_stage_out_channels // 2 // 32]
|
| 15 |
+
base_lr = 2e-3
|
| 16 |
+
weight_decay = 0.05 / 2
|
| 17 |
+
train_batch_size_per_gpu = 16
|
| 18 |
+
|
| 19 |
+
# model settings
|
| 20 |
+
model = dict(
|
| 21 |
+
type='YOLOWorldDetector',
|
| 22 |
+
mm_neck=True,
|
| 23 |
+
num_train_classes=num_training_classes,
|
| 24 |
+
num_test_classes=num_classes,
|
| 25 |
+
data_preprocessor=dict(type='YOLOWDetDataPreprocessor'),
|
| 26 |
+
backbone=dict(
|
| 27 |
+
_delete_=True,
|
| 28 |
+
type='MultiModalYOLOBackbone',
|
| 29 |
+
image_model={{_base_.model.backbone}},
|
| 30 |
+
text_model=dict(
|
| 31 |
+
type='HuggingCLIPLanguageBackbone',
|
| 32 |
+
model_name='openai/clip-vit-base-patch32',
|
| 33 |
+
frozen_modules=['all'])),
|
| 34 |
+
neck=dict(type='YOLOWorldDualPAFPN',
|
| 35 |
+
guide_channels=text_channels,
|
| 36 |
+
embed_channels=neck_embed_channels,
|
| 37 |
+
num_heads=neck_num_heads,
|
| 38 |
+
block_cfg=dict(type='MaxSigmoidCSPLayerWithTwoConv'),
|
| 39 |
+
text_enhancder=dict(type='ImagePoolingAttentionModule',
|
| 40 |
+
embed_channels=256,
|
| 41 |
+
num_heads=8)),
|
| 42 |
+
bbox_head=dict(type='YOLOWorldHead',
|
| 43 |
+
head_module=dict(type='YOLOWorldHeadModule',
|
| 44 |
+
embed_dims=text_channels,
|
| 45 |
+
num_classes=num_training_classes)),
|
| 46 |
+
train_cfg=dict(assigner=dict(num_classes=num_training_classes)))
|
| 47 |
+
|
| 48 |
+
# dataset settings
|
| 49 |
+
text_transform = [
|
| 50 |
+
dict(type='RandomLoadText',
|
| 51 |
+
num_neg_samples=(num_classes, num_classes),
|
| 52 |
+
max_num_samples=num_training_classes,
|
| 53 |
+
padding_to_max=True,
|
| 54 |
+
padding_value=''),
|
| 55 |
+
dict(type='mmdet.PackDetInputs',
|
| 56 |
+
meta_keys=('img_id', 'img_path', 'ori_shape', 'img_shape', 'flip',
|
| 57 |
+
'flip_direction', 'texts'))
|
| 58 |
+
]
|
| 59 |
+
train_pipeline = [
|
| 60 |
+
*_base_.pre_transform,
|
| 61 |
+
dict(type='MultiModalMosaic',
|
| 62 |
+
img_scale=_base_.img_scale,
|
| 63 |
+
pad_val=114.0,
|
| 64 |
+
pre_transform=_base_.pre_transform),
|
| 65 |
+
dict(
|
| 66 |
+
type='YOLOv5RandomAffine',
|
| 67 |
+
max_rotate_degree=0.0,
|
| 68 |
+
max_shear_degree=0.0,
|
| 69 |
+
scaling_ratio_range=(1 - _base_.affine_scale, 1 + _base_.affine_scale),
|
| 70 |
+
max_aspect_ratio=_base_.max_aspect_ratio,
|
| 71 |
+
border=(-_base_.img_scale[0] // 2, -_base_.img_scale[1] // 2),
|
| 72 |
+
border_val=(114, 114, 114)),
|
| 73 |
+
*_base_.last_transform[:-1],
|
| 74 |
+
*text_transform,
|
| 75 |
+
]
|
| 76 |
+
train_pipeline_stage2 = [*_base_.train_pipeline_stage2[:-1], *text_transform]
|
| 77 |
+
obj365v1_train_dataset = dict(
|
| 78 |
+
type='MultiModalDataset',
|
| 79 |
+
dataset=dict(
|
| 80 |
+
type='YOLOv5Objects365V1Dataset',
|
| 81 |
+
data_root='data/objects365v1/',
|
| 82 |
+
ann_file='annotations/objects365_train.json',
|
| 83 |
+
data_prefix=dict(img='train/'),
|
| 84 |
+
filter_cfg=dict(filter_empty_gt=False, min_size=32)),
|
| 85 |
+
class_text_path='data/texts/obj365v1_class_texts.json',
|
| 86 |
+
pipeline=train_pipeline)
|
| 87 |
+
|
| 88 |
+
mg_train_dataset = dict(type='YOLOv5MixedGroundingDataset',
|
| 89 |
+
data_root='data/mixed_grounding/',
|
| 90 |
+
ann_file='annotations/final_mixed_train_no_coco.json',
|
| 91 |
+
data_prefix=dict(img='gqa/images/'),
|
| 92 |
+
filter_cfg=dict(filter_empty_gt=False, min_size=32),
|
| 93 |
+
pipeline=train_pipeline)
|
| 94 |
+
|
| 95 |
+
flickr_train_dataset = dict(
|
| 96 |
+
type='YOLOv5MixedGroundingDataset',
|
| 97 |
+
data_root='data/flickr/',
|
| 98 |
+
ann_file='annotations/final_flickr_separateGT_train.json',
|
| 99 |
+
data_prefix=dict(img='full_images/'),
|
| 100 |
+
filter_cfg=dict(filter_empty_gt=True, min_size=32),
|
| 101 |
+
pipeline=train_pipeline)
|
| 102 |
+
|
| 103 |
+
train_dataloader = dict(batch_size=train_batch_size_per_gpu,
|
| 104 |
+
collate_fn=dict(type='yolow_collate'),
|
| 105 |
+
dataset=dict(_delete_=True,
|
| 106 |
+
type='ConcatDataset',
|
| 107 |
+
datasets=[
|
| 108 |
+
obj365v1_train_dataset,
|
| 109 |
+
flickr_train_dataset, mg_train_dataset
|
| 110 |
+
],
|
| 111 |
+
ignore_keys=['classes', 'palette']))
|
| 112 |
+
|
| 113 |
+
test_pipeline = [
|
| 114 |
+
*_base_.test_pipeline[:-1],
|
| 115 |
+
dict(type='LoadText'),
|
| 116 |
+
dict(type='mmdet.PackDetInputs',
|
| 117 |
+
meta_keys=('img_id', 'img_path', 'ori_shape', 'img_shape',
|
| 118 |
+
'scale_factor', 'pad_param', 'texts'))
|
| 119 |
+
]
|
| 120 |
+
coco_val_dataset = dict(
|
| 121 |
+
_delete_=True,
|
| 122 |
+
type='MultiModalDataset',
|
| 123 |
+
dataset=dict(type='YOLOv5LVISV1Dataset',
|
| 124 |
+
data_root='data/coco/',
|
| 125 |
+
test_mode=True,
|
| 126 |
+
ann_file='lvis/lvis_v1_val.json',
|
| 127 |
+
data_prefix=dict(img=''),
|
| 128 |
+
batch_shapes_cfg=None),
|
| 129 |
+
class_text_path='data/texts/lvis_v1_class_texts.json',
|
| 130 |
+
pipeline=test_pipeline)
|
| 131 |
+
val_dataloader = dict(dataset=coco_val_dataset)
|
| 132 |
+
test_dataloader = val_dataloader
|
| 133 |
+
|
| 134 |
+
val_evaluator = dict(type='mmdet.LVISMetric',
|
| 135 |
+
ann_file='data/coco/lvis/lvis_v1_val.json',
|
| 136 |
+
metric='bbox')
|
| 137 |
+
test_evaluator = val_evaluator
|
| 138 |
+
|
| 139 |
+
# training settings
|
| 140 |
+
default_hooks = dict(param_scheduler=dict(max_epochs=max_epochs),
|
| 141 |
+
checkpoint=dict(interval=save_epoch_intervals,
|
| 142 |
+
rule='greater'))
|
| 143 |
+
custom_hooks = [
|
| 144 |
+
dict(type='EMAHook',
|
| 145 |
+
ema_type='ExpMomentumEMA',
|
| 146 |
+
momentum=0.0001,
|
| 147 |
+
update_buffers=True,
|
| 148 |
+
strict_load=False,
|
| 149 |
+
priority=49),
|
| 150 |
+
dict(type='mmdet.PipelineSwitchHook',
|
| 151 |
+
switch_epoch=max_epochs - close_mosaic_epochs,
|
| 152 |
+
switch_pipeline=train_pipeline_stage2)
|
| 153 |
+
]
|
| 154 |
+
train_cfg = dict(max_epochs=max_epochs,
|
| 155 |
+
val_interval=10,
|
| 156 |
+
dynamic_intervals=[((max_epochs - close_mosaic_epochs),
|
| 157 |
+
_base_.val_interval_stage2)])
|
| 158 |
+
optim_wrapper = dict(optimizer=dict(
|
| 159 |
+
_delete_=True,
|
| 160 |
+
type='AdamW',
|
| 161 |
+
lr=base_lr,
|
| 162 |
+
weight_decay=weight_decay,
|
| 163 |
+
batch_size_per_gpu=train_batch_size_per_gpu),
|
| 164 |
+
paramwise_cfg=dict(bias_decay_mult=0.0,
|
| 165 |
+
norm_decay_mult=0.0,
|
| 166 |
+
custom_keys={
|
| 167 |
+
'backbone.text_model':
|
| 168 |
+
dict(lr_mult=0.01),
|
| 169 |
+
'logit_scale':
|
| 170 |
+
dict(weight_decay=0.0)
|
| 171 |
+
}),
|
| 172 |
+
constructor='YOLOWv5OptimizerConstructor')
|
configs/pretrain_v1/yolo_world_m_dual_vlpan_l2norm_2e-3_100e_4x8gpus_obj365v1_goldg_train_lvis_minival.py
ADDED
|
@@ -0,0 +1,172 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
_base_ = ('../../third_party/mmyolo/configs/yolov8/'
|
| 2 |
+
'yolov8_m_syncbn_fast_8xb16-500e_coco.py')
|
| 3 |
+
custom_imports = dict(imports=['yolo_world'],
|
| 4 |
+
allow_failed_imports=False)
|
| 5 |
+
|
| 6 |
+
# hyper-parameters
|
| 7 |
+
num_classes = 1203
|
| 8 |
+
num_training_classes = 80
|
| 9 |
+
max_epochs = 100 # Maximum training epochs
|
| 10 |
+
close_mosaic_epochs = 2
|
| 11 |
+
save_epoch_intervals = 2
|
| 12 |
+
text_channels = 512
|
| 13 |
+
neck_embed_channels = [128, 256, _base_.last_stage_out_channels // 2]
|
| 14 |
+
neck_num_heads = [4, 8, _base_.last_stage_out_channels // 2 // 32]
|
| 15 |
+
base_lr = 2e-3
|
| 16 |
+
weight_decay = 0.05 / 2
|
| 17 |
+
train_batch_size_per_gpu = 16
|
| 18 |
+
|
| 19 |
+
# model settings
|
| 20 |
+
model = dict(
|
| 21 |
+
type='YOLOWorldDetector',
|
| 22 |
+
mm_neck=True,
|
| 23 |
+
num_train_classes=num_training_classes,
|
| 24 |
+
num_test_classes=num_classes,
|
| 25 |
+
data_preprocessor=dict(type='YOLOWDetDataPreprocessor'),
|
| 26 |
+
backbone=dict(
|
| 27 |
+
_delete_=True,
|
| 28 |
+
type='MultiModalYOLOBackbone',
|
| 29 |
+
image_model={{_base_.model.backbone}},
|
| 30 |
+
text_model=dict(
|
| 31 |
+
type='HuggingCLIPLanguageBackbone',
|
| 32 |
+
model_name='openai/clip-vit-base-patch32',
|
| 33 |
+
frozen_modules=['all'])),
|
| 34 |
+
neck=dict(type='YOLOWorldDualPAFPN',
|
| 35 |
+
guide_channels=text_channels,
|
| 36 |
+
embed_channels=neck_embed_channels,
|
| 37 |
+
num_heads=neck_num_heads,
|
| 38 |
+
block_cfg=dict(type='MaxSigmoidCSPLayerWithTwoConv'),
|
| 39 |
+
text_enhancder=dict(type='ImagePoolingAttentionModule',
|
| 40 |
+
embed_channels=256,
|
| 41 |
+
num_heads=8)),
|
| 42 |
+
bbox_head=dict(type='YOLOWorldHead',
|
| 43 |
+
head_module=dict(type='YOLOWorldHeadModule',
|
| 44 |
+
embed_dims=text_channels,
|
| 45 |
+
num_classes=num_training_classes)),
|
| 46 |
+
train_cfg=dict(assigner=dict(num_classes=num_training_classes)))
|
| 47 |
+
|
| 48 |
+
# dataset settings
|
| 49 |
+
text_transform = [
|
| 50 |
+
dict(type='RandomLoadText',
|
| 51 |
+
num_neg_samples=(num_classes, num_classes),
|
| 52 |
+
max_num_samples=num_training_classes,
|
| 53 |
+
padding_to_max=True,
|
| 54 |
+
padding_value=''),
|
| 55 |
+
dict(type='mmdet.PackDetInputs',
|
| 56 |
+
meta_keys=('img_id', 'img_path', 'ori_shape', 'img_shape', 'flip',
|
| 57 |
+
'flip_direction', 'texts'))
|
| 58 |
+
]
|
| 59 |
+
train_pipeline = [
|
| 60 |
+
*_base_.pre_transform,
|
| 61 |
+
dict(type='MultiModalMosaic',
|
| 62 |
+
img_scale=_base_.img_scale,
|
| 63 |
+
pad_val=114.0,
|
| 64 |
+
pre_transform=_base_.pre_transform),
|
| 65 |
+
dict(
|
| 66 |
+
type='YOLOv5RandomAffine',
|
| 67 |
+
max_rotate_degree=0.0,
|
| 68 |
+
max_shear_degree=0.0,
|
| 69 |
+
scaling_ratio_range=(1 - _base_.affine_scale, 1 + _base_.affine_scale),
|
| 70 |
+
max_aspect_ratio=_base_.max_aspect_ratio,
|
| 71 |
+
border=(-_base_.img_scale[0] // 2, -_base_.img_scale[1] // 2),
|
| 72 |
+
border_val=(114, 114, 114)),
|
| 73 |
+
*_base_.last_transform[:-1],
|
| 74 |
+
*text_transform,
|
| 75 |
+
]
|
| 76 |
+
train_pipeline_stage2 = [*_base_.train_pipeline_stage2[:-1], *text_transform]
|
| 77 |
+
obj365v1_train_dataset = dict(
|
| 78 |
+
type='MultiModalDataset',
|
| 79 |
+
dataset=dict(
|
| 80 |
+
type='YOLOv5Objects365V1Dataset',
|
| 81 |
+
data_root='data/objects365v1/',
|
| 82 |
+
ann_file='annotations/objects365_train.json',
|
| 83 |
+
data_prefix=dict(img='train/'),
|
| 84 |
+
filter_cfg=dict(filter_empty_gt=False, min_size=32)),
|
| 85 |
+
class_text_path='data/texts/obj365v1_class_texts.json',
|
| 86 |
+
pipeline=train_pipeline)
|
| 87 |
+
|
| 88 |
+
mg_train_dataset = dict(type='YOLOv5MixedGroundingDataset',
|
| 89 |
+
data_root='data/mixed_grounding/',
|
| 90 |
+
ann_file='annotations/final_mixed_train_no_coco.json',
|
| 91 |
+
data_prefix=dict(img='gqa/images/'),
|
| 92 |
+
filter_cfg=dict(filter_empty_gt=False, min_size=32),
|
| 93 |
+
pipeline=train_pipeline)
|
| 94 |
+
|
| 95 |
+
flickr_train_dataset = dict(
|
| 96 |
+
type='YOLOv5MixedGroundingDataset',
|
| 97 |
+
data_root='data/flickr/',
|
| 98 |
+
ann_file='annotations/final_flickr_separateGT_train.json',
|
| 99 |
+
data_prefix=dict(img='full_images/'),
|
| 100 |
+
filter_cfg=dict(filter_empty_gt=True, min_size=32),
|
| 101 |
+
pipeline=train_pipeline)
|
| 102 |
+
|
| 103 |
+
train_dataloader = dict(batch_size=train_batch_size_per_gpu,
|
| 104 |
+
collate_fn=dict(type='yolow_collate'),
|
| 105 |
+
dataset=dict(_delete_=True,
|
| 106 |
+
type='ConcatDataset',
|
| 107 |
+
datasets=[
|
| 108 |
+
obj365v1_train_dataset,
|
| 109 |
+
flickr_train_dataset, mg_train_dataset
|
| 110 |
+
],
|
| 111 |
+
ignore_keys=['classes', 'palette']))
|
| 112 |
+
|
| 113 |
+
test_pipeline = [
|
| 114 |
+
*_base_.test_pipeline[:-1],
|
| 115 |
+
dict(type='LoadText'),
|
| 116 |
+
dict(type='mmdet.PackDetInputs',
|
| 117 |
+
meta_keys=('img_id', 'img_path', 'ori_shape', 'img_shape',
|
| 118 |
+
'scale_factor', 'pad_param', 'texts'))
|
| 119 |
+
]
|
| 120 |
+
coco_val_dataset = dict(
|
| 121 |
+
_delete_=True,
|
| 122 |
+
type='MultiModalDataset',
|
| 123 |
+
dataset=dict(type='YOLOv5LVISV1Dataset',
|
| 124 |
+
data_root='data/coco/',
|
| 125 |
+
test_mode=True,
|
| 126 |
+
ann_file='lvis/lvis_v1_minival_inserted_image_name.json',
|
| 127 |
+
data_prefix=dict(img=''),
|
| 128 |
+
batch_shapes_cfg=None),
|
| 129 |
+
class_text_path='data/texts/lvis_v1_class_texts.json',
|
| 130 |
+
pipeline=test_pipeline)
|
| 131 |
+
val_dataloader = dict(dataset=coco_val_dataset)
|
| 132 |
+
test_dataloader = val_dataloader
|
| 133 |
+
|
| 134 |
+
val_evaluator = dict(type='mmdet.LVISMetric',
|
| 135 |
+
ann_file='data/coco/lvis/lvis_v1_minival_inserted_image_name.json',
|
| 136 |
+
metric='bbox')
|
| 137 |
+
test_evaluator = val_evaluator
|
| 138 |
+
|
| 139 |
+
# training settings
|
| 140 |
+
default_hooks = dict(param_scheduler=dict(max_epochs=max_epochs),
|
| 141 |
+
checkpoint=dict(interval=save_epoch_intervals,
|
| 142 |
+
rule='greater'))
|
| 143 |
+
custom_hooks = [
|
| 144 |
+
dict(type='EMAHook',
|
| 145 |
+
ema_type='ExpMomentumEMA',
|
| 146 |
+
momentum=0.0001,
|
| 147 |
+
update_buffers=True,
|
| 148 |
+
strict_load=False,
|
| 149 |
+
priority=49),
|
| 150 |
+
dict(type='mmdet.PipelineSwitchHook',
|
| 151 |
+
switch_epoch=max_epochs - close_mosaic_epochs,
|
| 152 |
+
switch_pipeline=train_pipeline_stage2)
|
| 153 |
+
]
|
| 154 |
+
train_cfg = dict(max_epochs=max_epochs,
|
| 155 |
+
val_interval=10,
|
| 156 |
+
dynamic_intervals=[((max_epochs - close_mosaic_epochs),
|
| 157 |
+
_base_.val_interval_stage2)])
|
| 158 |
+
optim_wrapper = dict(optimizer=dict(
|
| 159 |
+
_delete_=True,
|
| 160 |
+
type='AdamW',
|
| 161 |
+
lr=base_lr,
|
| 162 |
+
weight_decay=weight_decay,
|
| 163 |
+
batch_size_per_gpu=train_batch_size_per_gpu),
|
| 164 |
+
paramwise_cfg=dict(bias_decay_mult=0.0,
|
| 165 |
+
norm_decay_mult=0.0,
|
| 166 |
+
custom_keys={
|
| 167 |
+
'backbone.text_model':
|
| 168 |
+
dict(lr_mult=0.01),
|
| 169 |
+
'logit_scale':
|
| 170 |
+
dict(weight_decay=0.0)
|
| 171 |
+
}),
|
| 172 |
+
constructor='YOLOWv5OptimizerConstructor')
|
configs/pretrain_v1/yolo_world_s_dual_vlpan_l2norm_2e-3_100e_4x8gpus_obj365v1_goldg_train_lvis_minival.py
ADDED
|
@@ -0,0 +1,172 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
_base_ = ('../../third_party/mmyolo/configs/yolov8/'
|
| 2 |
+
'yolov8_s_syncbn_fast_8xb16-500e_coco.py')
|
| 3 |
+
custom_imports = dict(imports=['yolo_world'],
|
| 4 |
+
allow_failed_imports=False)
|
| 5 |
+
|
| 6 |
+
# hyper-parameters
|
| 7 |
+
num_classes = 1203
|
| 8 |
+
num_training_classes = 80
|
| 9 |
+
max_epochs = 100 # Maximum training epochs
|
| 10 |
+
close_mosaic_epochs = 2
|
| 11 |
+
save_epoch_intervals = 2
|
| 12 |
+
text_channels = 512
|
| 13 |
+
neck_embed_channels = [128, 256, _base_.last_stage_out_channels // 2]
|
| 14 |
+
neck_num_heads = [4, 8, _base_.last_stage_out_channels // 2 // 32]
|
| 15 |
+
base_lr = 2e-3
|
| 16 |
+
weight_decay = 0.05 / 2
|
| 17 |
+
train_batch_size_per_gpu = 16
|
| 18 |
+
|
| 19 |
+
# model settings
|
| 20 |
+
model = dict(
|
| 21 |
+
type='YOLOWorldDetector',
|
| 22 |
+
mm_neck=True,
|
| 23 |
+
num_train_classes=num_training_classes,
|
| 24 |
+
num_test_classes=num_classes,
|
| 25 |
+
data_preprocessor=dict(type='YOLOWDetDataPreprocessor'),
|
| 26 |
+
backbone=dict(
|
| 27 |
+
_delete_=True,
|
| 28 |
+
type='MultiModalYOLOBackbone',
|
| 29 |
+
image_model={{_base_.model.backbone}},
|
| 30 |
+
text_model=dict(
|
| 31 |
+
type='HuggingCLIPLanguageBackbone',
|
| 32 |
+
model_name='openai/clip-vit-base-patch32',
|
| 33 |
+
frozen_modules=['all'])),
|
| 34 |
+
neck=dict(type='YOLOWorldDualPAFPN',
|
| 35 |
+
guide_channels=text_channels,
|
| 36 |
+
embed_channels=neck_embed_channels,
|
| 37 |
+
num_heads=neck_num_heads,
|
| 38 |
+
block_cfg=dict(type='MaxSigmoidCSPLayerWithTwoConv'),
|
| 39 |
+
text_enhancder=dict(type='ImagePoolingAttentionModule',
|
| 40 |
+
embed_channels=256,
|
| 41 |
+
num_heads=8)),
|
| 42 |
+
bbox_head=dict(type='YOLOWorldHead',
|
| 43 |
+
head_module=dict(type='YOLOWorldHeadModule',
|
| 44 |
+
embed_dims=text_channels,
|
| 45 |
+
num_classes=num_training_classes)),
|
| 46 |
+
train_cfg=dict(assigner=dict(num_classes=num_training_classes)))
|
| 47 |
+
|
| 48 |
+
# dataset settings
|
| 49 |
+
text_transform = [
|
| 50 |
+
dict(type='RandomLoadText',
|
| 51 |
+
num_neg_samples=(num_classes, num_classes),
|
| 52 |
+
max_num_samples=num_training_classes,
|
| 53 |
+
padding_to_max=True,
|
| 54 |
+
padding_value=''),
|
| 55 |
+
dict(type='mmdet.PackDetInputs',
|
| 56 |
+
meta_keys=('img_id', 'img_path', 'ori_shape', 'img_shape', 'flip',
|
| 57 |
+
'flip_direction', 'texts'))
|
| 58 |
+
]
|
| 59 |
+
train_pipeline = [
|
| 60 |
+
*_base_.pre_transform,
|
| 61 |
+
dict(type='MultiModalMosaic',
|
| 62 |
+
img_scale=_base_.img_scale,
|
| 63 |
+
pad_val=114.0,
|
| 64 |
+
pre_transform=_base_.pre_transform),
|
| 65 |
+
dict(
|
| 66 |
+
type='YOLOv5RandomAffine',
|
| 67 |
+
max_rotate_degree=0.0,
|
| 68 |
+
max_shear_degree=0.0,
|
| 69 |
+
scaling_ratio_range=(1 - _base_.affine_scale, 1 + _base_.affine_scale),
|
| 70 |
+
max_aspect_ratio=_base_.max_aspect_ratio,
|
| 71 |
+
border=(-_base_.img_scale[0] // 2, -_base_.img_scale[1] // 2),
|
| 72 |
+
border_val=(114, 114, 114)),
|
| 73 |
+
*_base_.last_transform[:-1],
|
| 74 |
+
*text_transform,
|
| 75 |
+
]
|
| 76 |
+
train_pipeline_stage2 = [*_base_.train_pipeline_stage2[:-1], *text_transform]
|
| 77 |
+
obj365v1_train_dataset = dict(
|
| 78 |
+
type='MultiModalDataset',
|
| 79 |
+
dataset=dict(
|
| 80 |
+
type='YOLOv5Objects365V1Dataset',
|
| 81 |
+
data_root='data/objects365v1/',
|
| 82 |
+
ann_file='annotations/objects365_train.json',
|
| 83 |
+
data_prefix=dict(img='train/'),
|
| 84 |
+
filter_cfg=dict(filter_empty_gt=False, min_size=32)),
|
| 85 |
+
class_text_path='data/texts/obj365v1_class_texts.json',
|
| 86 |
+
pipeline=train_pipeline)
|
| 87 |
+
|
| 88 |
+
mg_train_dataset = dict(type='YOLOv5MixedGroundingDataset',
|
| 89 |
+
data_root='data/mixed_grounding/',
|
| 90 |
+
ann_file='annotations/final_mixed_train_no_coco.json',
|
| 91 |
+
data_prefix=dict(img='gqa/images/'),
|
| 92 |
+
filter_cfg=dict(filter_empty_gt=False, min_size=32),
|
| 93 |
+
pipeline=train_pipeline)
|
| 94 |
+
|
| 95 |
+
flickr_train_dataset = dict(
|
| 96 |
+
type='YOLOv5MixedGroundingDataset',
|
| 97 |
+
data_root='data/flickr/',
|
| 98 |
+
ann_file='annotations/final_flickr_separateGT_train.json',
|
| 99 |
+
data_prefix=dict(img='full_images/'),
|
| 100 |
+
filter_cfg=dict(filter_empty_gt=True, min_size=32),
|
| 101 |
+
pipeline=train_pipeline)
|
| 102 |
+
|
| 103 |
+
train_dataloader = dict(batch_size=train_batch_size_per_gpu,
|
| 104 |
+
collate_fn=dict(type='yolow_collate'),
|
| 105 |
+
dataset=dict(_delete_=True,
|
| 106 |
+
type='ConcatDataset',
|
| 107 |
+
datasets=[
|
| 108 |
+
obj365v1_train_dataset,
|
| 109 |
+
flickr_train_dataset, mg_train_dataset
|
| 110 |
+
],
|
| 111 |
+
ignore_keys=['classes', 'palette']))
|
| 112 |
+
|
| 113 |
+
test_pipeline = [
|
| 114 |
+
*_base_.test_pipeline[:-1],
|
| 115 |
+
dict(type='LoadText'),
|
| 116 |
+
dict(type='mmdet.PackDetInputs',
|
| 117 |
+
meta_keys=('img_id', 'img_path', 'ori_shape', 'img_shape',
|
| 118 |
+
'scale_factor', 'pad_param', 'texts'))
|
| 119 |
+
]
|
| 120 |
+
coco_val_dataset = dict(
|
| 121 |
+
_delete_=True,
|
| 122 |
+
type='MultiModalDataset',
|
| 123 |
+
dataset=dict(type='YOLOv5LVISV1Dataset',
|
| 124 |
+
data_root='data/coco/',
|
| 125 |
+
test_mode=True,
|
| 126 |
+
ann_file='lvis/lvis_v1_minival_inserted_image_name.json',
|
| 127 |
+
data_prefix=dict(img=''),
|
| 128 |
+
batch_shapes_cfg=None),
|
| 129 |
+
class_text_path='data/texts/lvis_v1_class_texts.json',
|
| 130 |
+
pipeline=test_pipeline)
|
| 131 |
+
val_dataloader = dict(dataset=coco_val_dataset)
|
| 132 |
+
test_dataloader = val_dataloader
|
| 133 |
+
|
| 134 |
+
val_evaluator = dict(type='mmdet.LVISMetric',
|
| 135 |
+
ann_file='data/coco/lvis/lvis_v1_minival_inserted_image_name.json',
|
| 136 |
+
metric='bbox')
|
| 137 |
+
test_evaluator = val_evaluator
|
| 138 |
+
|
| 139 |
+
# training settings
|
| 140 |
+
default_hooks = dict(param_scheduler=dict(max_epochs=max_epochs),
|
| 141 |
+
checkpoint=dict(interval=save_epoch_intervals,
|
| 142 |
+
rule='greater'))
|
| 143 |
+
custom_hooks = [
|
| 144 |
+
dict(type='EMAHook',
|
| 145 |
+
ema_type='ExpMomentumEMA',
|
| 146 |
+
momentum=0.0001,
|
| 147 |
+
update_buffers=True,
|
| 148 |
+
strict_load=False,
|
| 149 |
+
priority=49),
|
| 150 |
+
dict(type='mmdet.PipelineSwitchHook',
|
| 151 |
+
switch_epoch=max_epochs - close_mosaic_epochs,
|
| 152 |
+
switch_pipeline=train_pipeline_stage2)
|
| 153 |
+
]
|
| 154 |
+
train_cfg = dict(max_epochs=max_epochs,
|
| 155 |
+
val_interval=10,
|
| 156 |
+
dynamic_intervals=[((max_epochs - close_mosaic_epochs),
|
| 157 |
+
_base_.val_interval_stage2)])
|
| 158 |
+
optim_wrapper = dict(optimizer=dict(
|
| 159 |
+
_delete_=True,
|
| 160 |
+
type='AdamW',
|
| 161 |
+
lr=base_lr,
|
| 162 |
+
weight_decay=weight_decay,
|
| 163 |
+
batch_size_per_gpu=train_batch_size_per_gpu),
|
| 164 |
+
paramwise_cfg=dict(bias_decay_mult=0.0,
|
| 165 |
+
norm_decay_mult=0.0,
|
| 166 |
+
custom_keys={
|
| 167 |
+
'backbone.text_model':
|
| 168 |
+
dict(lr_mult=0.01),
|
| 169 |
+
'logit_scale':
|
| 170 |
+
dict(weight_decay=0.0)
|
| 171 |
+
}),
|
| 172 |
+
constructor='YOLOWv5OptimizerConstructor')
|
configs/pretrain_v1/yolo_world_x_dual_vlpan_l2norm_2e-3_100e_4x8gpus_obj365v1_goldg_train_lvis_minival.py
ADDED
|
@@ -0,0 +1,172 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
_base_ = ('../../third_party/mmyolo/configs/yolov8/'
|
| 2 |
+
'yolov8_x_syncbn_fast_8xb16-500e_coco.py')
|
| 3 |
+
custom_imports = dict(imports=['yolo_world'],
|
| 4 |
+
allow_failed_imports=False)
|
| 5 |
+
|
| 6 |
+
# hyper-parameters
|
| 7 |
+
num_classes = 1203
|
| 8 |
+
num_training_classes = 80
|
| 9 |
+
max_epochs = 100 # Maximum training epochs
|
| 10 |
+
close_mosaic_epochs = 2
|
| 11 |
+
save_epoch_intervals = 2
|
| 12 |
+
text_channels = 512
|
| 13 |
+
neck_embed_channels = [128, 256, _base_.last_stage_out_channels // 2]
|
| 14 |
+
neck_num_heads = [4, 8, _base_.last_stage_out_channels // 2 // 32]
|
| 15 |
+
base_lr = 2e-3
|
| 16 |
+
weight_decay = 0.05 / 2
|
| 17 |
+
train_batch_size_per_gpu = 16
|
| 18 |
+
|
| 19 |
+
# model settings
|
| 20 |
+
model = dict(
|
| 21 |
+
type='YOLOWorldDetector',
|
| 22 |
+
mm_neck=True,
|
| 23 |
+
num_train_classes=num_training_classes,
|
| 24 |
+
num_test_classes=num_classes,
|
| 25 |
+
data_preprocessor=dict(type='YOLOWDetDataPreprocessor'),
|
| 26 |
+
backbone=dict(
|
| 27 |
+
_delete_=True,
|
| 28 |
+
type='MultiModalYOLOBackbone',
|
| 29 |
+
image_model={{_base_.model.backbone}},
|
| 30 |
+
text_model=dict(
|
| 31 |
+
type='HuggingCLIPLanguageBackbone',
|
| 32 |
+
model_name='openai/clip-vit-base-patch32',
|
| 33 |
+
frozen_modules=['all'])),
|
| 34 |
+
neck=dict(type='YOLOWorldDualPAFPN',
|
| 35 |
+
guide_channels=text_channels,
|
| 36 |
+
embed_channels=neck_embed_channels,
|
| 37 |
+
num_heads=neck_num_heads,
|
| 38 |
+
block_cfg=dict(type='MaxSigmoidCSPLayerWithTwoConv'),
|
| 39 |
+
text_enhancder=dict(type='ImagePoolingAttentionModule',
|
| 40 |
+
embed_channels=256,
|
| 41 |
+
num_heads=8)),
|
| 42 |
+
bbox_head=dict(type='YOLOWorldHead',
|
| 43 |
+
head_module=dict(type='YOLOWorldHeadModule',
|
| 44 |
+
embed_dims=text_channels,
|
| 45 |
+
num_classes=num_training_classes)),
|
| 46 |
+
train_cfg=dict(assigner=dict(num_classes=num_training_classes)))
|
| 47 |
+
|
| 48 |
+
# dataset settings
|
| 49 |
+
text_transform = [
|
| 50 |
+
dict(type='RandomLoadText',
|
| 51 |
+
num_neg_samples=(num_classes, num_classes),
|
| 52 |
+
max_num_samples=num_training_classes,
|
| 53 |
+
padding_to_max=True,
|
| 54 |
+
padding_value=''),
|
| 55 |
+
dict(type='mmdet.PackDetInputs',
|
| 56 |
+
meta_keys=('img_id', 'img_path', 'ori_shape', 'img_shape', 'flip',
|
| 57 |
+
'flip_direction', 'texts'))
|
| 58 |
+
]
|
| 59 |
+
train_pipeline = [
|
| 60 |
+
*_base_.pre_transform,
|
| 61 |
+
dict(type='MultiModalMosaic',
|
| 62 |
+
img_scale=_base_.img_scale,
|
| 63 |
+
pad_val=114.0,
|
| 64 |
+
pre_transform=_base_.pre_transform),
|
| 65 |
+
dict(
|
| 66 |
+
type='YOLOv5RandomAffine',
|
| 67 |
+
max_rotate_degree=0.0,
|
| 68 |
+
max_shear_degree=0.0,
|
| 69 |
+
scaling_ratio_range=(1 - _base_.affine_scale, 1 + _base_.affine_scale),
|
| 70 |
+
max_aspect_ratio=_base_.max_aspect_ratio,
|
| 71 |
+
border=(-_base_.img_scale[0] // 2, -_base_.img_scale[1] // 2),
|
| 72 |
+
border_val=(114, 114, 114)),
|
| 73 |
+
*_base_.last_transform[:-1],
|
| 74 |
+
*text_transform,
|
| 75 |
+
]
|
| 76 |
+
train_pipeline_stage2 = [*_base_.train_pipeline_stage2[:-1], *text_transform]
|
| 77 |
+
obj365v1_train_dataset = dict(
|
| 78 |
+
type='MultiModalDataset',
|
| 79 |
+
dataset=dict(
|
| 80 |
+
type='YOLOv5Objects365V1Dataset',
|
| 81 |
+
data_root='data/objects365v1/',
|
| 82 |
+
ann_file='annotations/objects365_train.json',
|
| 83 |
+
data_prefix=dict(img='train/'),
|
| 84 |
+
filter_cfg=dict(filter_empty_gt=False, min_size=32)),
|
| 85 |
+
class_text_path='data/texts/obj365v1_class_texts.json',
|
| 86 |
+
pipeline=train_pipeline)
|
| 87 |
+
|
| 88 |
+
mg_train_dataset = dict(type='YOLOv5MixedGroundingDataset',
|
| 89 |
+
data_root='data/mixed_grounding/',
|
| 90 |
+
ann_file='annotations/final_mixed_train_no_coco.json',
|
| 91 |
+
data_prefix=dict(img='gqa/images/'),
|
| 92 |
+
filter_cfg=dict(filter_empty_gt=False, min_size=32),
|
| 93 |
+
pipeline=train_pipeline)
|
| 94 |
+
|
| 95 |
+
flickr_train_dataset = dict(
|
| 96 |
+
type='YOLOv5MixedGroundingDataset',
|
| 97 |
+
data_root='data/flickr/',
|
| 98 |
+
ann_file='annotations/final_flickr_separateGT_train.json',
|
| 99 |
+
data_prefix=dict(img='full_images/'),
|
| 100 |
+
filter_cfg=dict(filter_empty_gt=True, min_size=32),
|
| 101 |
+
pipeline=train_pipeline)
|
| 102 |
+
|
| 103 |
+
train_dataloader = dict(batch_size=train_batch_size_per_gpu,
|
| 104 |
+
collate_fn=dict(type='yolow_collate'),
|
| 105 |
+
dataset=dict(_delete_=True,
|
| 106 |
+
type='ConcatDataset',
|
| 107 |
+
datasets=[
|
| 108 |
+
obj365v1_train_dataset,
|
| 109 |
+
flickr_train_dataset, mg_train_dataset
|
| 110 |
+
],
|
| 111 |
+
ignore_keys=['classes', 'palette']))
|
| 112 |
+
|
| 113 |
+
test_pipeline = [
|
| 114 |
+
*_base_.test_pipeline[:-1],
|
| 115 |
+
dict(type='LoadText'),
|
| 116 |
+
dict(type='mmdet.PackDetInputs',
|
| 117 |
+
meta_keys=('img_id', 'img_path', 'ori_shape', 'img_shape',
|
| 118 |
+
'scale_factor', 'pad_param', 'texts'))
|
| 119 |
+
]
|
| 120 |
+
coco_val_dataset = dict(
|
| 121 |
+
_delete_=True,
|
| 122 |
+
type='MultiModalDataset',
|
| 123 |
+
dataset=dict(type='YOLOv5LVISV1Dataset',
|
| 124 |
+
data_root='data/coco/',
|
| 125 |
+
test_mode=True,
|
| 126 |
+
ann_file='lvis/lvis_v1_minival_inserted_image_name.json',
|
| 127 |
+
data_prefix=dict(img=''),
|
| 128 |
+
batch_shapes_cfg=None),
|
| 129 |
+
class_text_path='data/texts/lvis_v1_class_texts.json',
|
| 130 |
+
pipeline=test_pipeline)
|
| 131 |
+
val_dataloader = dict(dataset=coco_val_dataset)
|
| 132 |
+
test_dataloader = val_dataloader
|
| 133 |
+
|
| 134 |
+
val_evaluator = dict(type='mmdet.LVISMetric',
|
| 135 |
+
ann_file='data/coco/lvis/lvis_v1_minival_inserted_image_name.json',
|
| 136 |
+
metric='bbox')
|
| 137 |
+
test_evaluator = val_evaluator
|
| 138 |
+
|
| 139 |
+
# training settings
|
| 140 |
+
default_hooks = dict(param_scheduler=dict(max_epochs=max_epochs),
|
| 141 |
+
checkpoint=dict(interval=save_epoch_intervals,
|
| 142 |
+
rule='greater'))
|
| 143 |
+
custom_hooks = [
|
| 144 |
+
dict(type='EMAHook',
|
| 145 |
+
ema_type='ExpMomentumEMA',
|
| 146 |
+
momentum=0.0001,
|
| 147 |
+
update_buffers=True,
|
| 148 |
+
strict_load=False,
|
| 149 |
+
priority=49),
|
| 150 |
+
dict(type='mmdet.PipelineSwitchHook',
|
| 151 |
+
switch_epoch=max_epochs - close_mosaic_epochs,
|
| 152 |
+
switch_pipeline=train_pipeline_stage2)
|
| 153 |
+
]
|
| 154 |
+
train_cfg = dict(max_epochs=max_epochs,
|
| 155 |
+
val_interval=10,
|
| 156 |
+
dynamic_intervals=[((max_epochs - close_mosaic_epochs),
|
| 157 |
+
_base_.val_interval_stage2)])
|
| 158 |
+
optim_wrapper = dict(optimizer=dict(
|
| 159 |
+
_delete_=True,
|
| 160 |
+
type='AdamW',
|
| 161 |
+
lr=base_lr,
|
| 162 |
+
weight_decay=weight_decay,
|
| 163 |
+
batch_size_per_gpu=train_batch_size_per_gpu),
|
| 164 |
+
paramwise_cfg=dict(bias_decay_mult=0.0,
|
| 165 |
+
norm_decay_mult=0.0,
|
| 166 |
+
custom_keys={
|
| 167 |
+
'backbone.text_model':
|
| 168 |
+
dict(lr_mult=0.01),
|
| 169 |
+
'logit_scale':
|
| 170 |
+
dict(weight_decay=0.0)
|
| 171 |
+
}),
|
| 172 |
+
constructor='YOLOWv5OptimizerConstructor')
|
configs/prompt_tuning_coco/READEME.md
ADDED
|
@@ -0,0 +1,12 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
## Prompt Tuning for YOLO-World
|
| 2 |
+
|
| 3 |
+
### NOTE:
|
| 4 |
+
|
| 5 |
+
This folder contains many experimental config files, which will be removed later!!
|
| 6 |
+
|
| 7 |
+
### Experimental Results
|
| 8 |
+
|
| 9 |
+
| Model | Config | AP | AP50 | AP75 | APS | APM | APL |
|
| 10 |
+
| :---- | :----: | :--: | :--: | :---: | :-: | :-: | :-: |
|
| 11 |
+
| YOLO-World-v2-L | Zero-shot | 45.7 | 61.6 | 49.8 | 29.9 | 50.0 | 60.8 |
|
| 12 |
+
| [YOLO-World-v2-L](./../configs/prompt_tuning_coco/yolo_world_v2_l_vlpan_bn_2e-4_80e_8gpus_mask-refine_prompt_tuning_coco.py) | Prompt tuning | 47.9 | 64.3 | 52.5 | 31.9 | 52.6 | 61.3 |
|
configs/prompt_tuning_coco/yolo_world_v2_l_vlpan_bn_2e-4_80e_8gpus_all_fine_tuning_coco.py
ADDED
|
@@ -0,0 +1,118 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
_base_ = ('../../third_party/mmyolo/configs/yolov8/'
|
| 2 |
+
'yolov8_l_syncbn_fast_8xb16-500e_coco.py')
|
| 3 |
+
custom_imports = dict(imports=['yolo_world'], allow_failed_imports=False)
|
| 4 |
+
|
| 5 |
+
# hyper-parameters
|
| 6 |
+
num_classes = 80
|
| 7 |
+
num_training_classes = 80
|
| 8 |
+
max_epochs = 80 # Maximum training epochs
|
| 9 |
+
close_mosaic_epochs = 10
|
| 10 |
+
save_epoch_intervals = 5
|
| 11 |
+
text_channels = 512
|
| 12 |
+
neck_embed_channels = [128, 256, _base_.last_stage_out_channels // 2]
|
| 13 |
+
neck_num_heads = [4, 8, _base_.last_stage_out_channels // 2 // 32]
|
| 14 |
+
base_lr = 2e-4
|
| 15 |
+
weight_decay = 0.05
|
| 16 |
+
train_batch_size_per_gpu = 16
|
| 17 |
+
load_from = 'pretrained_models/yolo_world_l_clip_t2i_bn_2e-3adamw_32xb16-100e_obj365v1_goldg_cc3mlite_train-ca93cd1f.pth'
|
| 18 |
+
persistent_workers = False
|
| 19 |
+
|
| 20 |
+
# model settings
|
| 21 |
+
model = dict(type='YOLOWorldPromptDetector',
|
| 22 |
+
mm_neck=True,
|
| 23 |
+
num_train_classes=num_training_classes,
|
| 24 |
+
num_test_classes=num_classes,
|
| 25 |
+
embedding_path='embeddings/clip_vit_b32_coco_80_embeddings.npy',
|
| 26 |
+
prompt_dim=text_channels,
|
| 27 |
+
num_prompts=80,
|
| 28 |
+
freeze_prompt=True,
|
| 29 |
+
data_preprocessor=dict(type='YOLOv5DetDataPreprocessor'),
|
| 30 |
+
backbone=dict(_delete_=True,
|
| 31 |
+
type='MultiModalYOLOBackbone',
|
| 32 |
+
text_model=None,
|
| 33 |
+
image_model={{_base_.model.backbone}},
|
| 34 |
+
with_text_model=False),
|
| 35 |
+
neck=dict(type='YOLOWorldPAFPN',
|
| 36 |
+
freeze_all=False,
|
| 37 |
+
guide_channels=text_channels,
|
| 38 |
+
embed_channels=neck_embed_channels,
|
| 39 |
+
num_heads=neck_num_heads,
|
| 40 |
+
block_cfg=dict(type='MaxSigmoidCSPLayerWithTwoConv')),
|
| 41 |
+
bbox_head=dict(type='YOLOWorldHead',
|
| 42 |
+
head_module=dict(
|
| 43 |
+
type='YOLOWorldHeadModule',
|
| 44 |
+
freeze_all=False,
|
| 45 |
+
use_bn_head=True,
|
| 46 |
+
embed_dims=text_channels,
|
| 47 |
+
num_classes=num_training_classes)),
|
| 48 |
+
train_cfg=dict(assigner=dict(num_classes=num_training_classes)))
|
| 49 |
+
|
| 50 |
+
# dataset settings
|
| 51 |
+
coco_train_dataset = dict(type='YOLOv5CocoDataset',
|
| 52 |
+
data_root='data/coco',
|
| 53 |
+
ann_file='annotations/instances_train2017.json',
|
| 54 |
+
data_prefix=dict(img='train2017/'),
|
| 55 |
+
filter_cfg=dict(filter_empty_gt=False, min_size=32),
|
| 56 |
+
pipeline=_base_.train_pipeline)
|
| 57 |
+
|
| 58 |
+
train_dataloader = dict(persistent_workers=persistent_workers,
|
| 59 |
+
batch_size=train_batch_size_per_gpu,
|
| 60 |
+
collate_fn=dict(type='yolow_collate'),
|
| 61 |
+
dataset=coco_train_dataset)
|
| 62 |
+
|
| 63 |
+
coco_val_dataset = dict(type='YOLOv5CocoDataset',
|
| 64 |
+
data_root='data/coco',
|
| 65 |
+
ann_file='annotations/instances_val2017.json',
|
| 66 |
+
data_prefix=dict(img='val2017/'),
|
| 67 |
+
filter_cfg=dict(filter_empty_gt=False, min_size=32),
|
| 68 |
+
pipeline=_base_.test_pipeline)
|
| 69 |
+
|
| 70 |
+
val_dataloader = dict(dataset=coco_val_dataset)
|
| 71 |
+
test_dataloader = val_dataloader
|
| 72 |
+
# training settings
|
| 73 |
+
default_hooks = dict(param_scheduler=dict(scheduler_type='linear',
|
| 74 |
+
lr_factor=0.01,
|
| 75 |
+
max_epochs=max_epochs),
|
| 76 |
+
checkpoint=dict(max_keep_ckpts=-1,
|
| 77 |
+
save_best=None,
|
| 78 |
+
interval=save_epoch_intervals))
|
| 79 |
+
custom_hooks = [
|
| 80 |
+
dict(type='EMAHook',
|
| 81 |
+
ema_type='ExpMomentumEMA',
|
| 82 |
+
momentum=0.0001,
|
| 83 |
+
update_buffers=True,
|
| 84 |
+
strict_load=False,
|
| 85 |
+
priority=49),
|
| 86 |
+
dict(type='mmdet.PipelineSwitchHook',
|
| 87 |
+
switch_epoch=max_epochs - close_mosaic_epochs,
|
| 88 |
+
switch_pipeline=_base_.train_pipeline_stage2)
|
| 89 |
+
]
|
| 90 |
+
train_cfg = dict(max_epochs=max_epochs,
|
| 91 |
+
val_interval=5,
|
| 92 |
+
dynamic_intervals=[((max_epochs - close_mosaic_epochs),
|
| 93 |
+
_base_.val_interval_stage2)])
|
| 94 |
+
|
| 95 |
+
optim_wrapper = dict(optimizer=dict(
|
| 96 |
+
_delete_=True,
|
| 97 |
+
type='AdamW',
|
| 98 |
+
lr=base_lr,
|
| 99 |
+
weight_decay=weight_decay,
|
| 100 |
+
batch_size_per_gpu=train_batch_size_per_gpu),
|
| 101 |
+
paramwise_cfg=dict(bias_decay_mult=0.0,
|
| 102 |
+
norm_decay_mult=0.0,
|
| 103 |
+
custom_keys={
|
| 104 |
+
'backbone.text_model':
|
| 105 |
+
dict(lr_mult=0.01),
|
| 106 |
+
'logit_scale':
|
| 107 |
+
dict(weight_decay=0.0),
|
| 108 |
+
'embeddings':
|
| 109 |
+
dict(weight_decay=0.0)
|
| 110 |
+
}),
|
| 111 |
+
constructor='YOLOWv5OptimizerConstructor')
|
| 112 |
+
|
| 113 |
+
# evaluation settings
|
| 114 |
+
val_evaluator = dict(_delete_=True,
|
| 115 |
+
type='mmdet.CocoMetric',
|
| 116 |
+
proposal_nums=(100, 1, 10),
|
| 117 |
+
ann_file='data/coco/annotations/instances_val2017.json',
|
| 118 |
+
metric='bbox')
|
configs/prompt_tuning_coco/yolo_world_v2_l_vlpan_bn_2e-4_80e_8gpus_all_fine_tuning_rmdecay_rmmosaic_coco.py
ADDED
|
@@ -0,0 +1,114 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
_base_ = ('../../third_party/mmyolo/configs/yolov8/'
|
| 2 |
+
'yolov8_l_syncbn_fast_8xb16-500e_coco.py')
|
| 3 |
+
custom_imports = dict(imports=['yolo_world'], allow_failed_imports=False)
|
| 4 |
+
|
| 5 |
+
# hyper-parameters
|
| 6 |
+
num_classes = 80
|
| 7 |
+
num_training_classes = 80
|
| 8 |
+
max_epochs = 80 # Maximum training epochs
|
| 9 |
+
close_mosaic_epochs = 70
|
| 10 |
+
save_epoch_intervals = 5
|
| 11 |
+
text_channels = 512
|
| 12 |
+
neck_embed_channels = [128, 256, _base_.last_stage_out_channels // 2]
|
| 13 |
+
neck_num_heads = [4, 8, _base_.last_stage_out_channels // 2 // 32]
|
| 14 |
+
base_lr = 2e-4
|
| 15 |
+
weight_decay = 0.05
|
| 16 |
+
train_batch_size_per_gpu = 16
|
| 17 |
+
load_from = 'pretrained_models/yolo_world_l_clip_t2i_bn_2e-3adamw_32xb16-100e_obj365v1_goldg_cc3mlite_train-ca93cd1f.pth'
|
| 18 |
+
persistent_workers = False
|
| 19 |
+
|
| 20 |
+
# model settings
|
| 21 |
+
model = dict(type='YOLOWorldPromptDetector',
|
| 22 |
+
mm_neck=True,
|
| 23 |
+
num_train_classes=num_training_classes,
|
| 24 |
+
num_test_classes=num_classes,
|
| 25 |
+
embedding_path='embeddings/clip_vit_b32_coco_80_embeddings.npy',
|
| 26 |
+
prompt_dim=text_channels,
|
| 27 |
+
num_prompts=80,
|
| 28 |
+
freeze_prompt=True,
|
| 29 |
+
data_preprocessor=dict(type='YOLOv5DetDataPreprocessor'),
|
| 30 |
+
backbone=dict(_delete_=True,
|
| 31 |
+
type='MultiModalYOLOBackbone',
|
| 32 |
+
text_model=None,
|
| 33 |
+
image_model={{_base_.model.backbone}},
|
| 34 |
+
with_text_model=False),
|
| 35 |
+
neck=dict(type='YOLOWorldPAFPN',
|
| 36 |
+
freeze_all=False,
|
| 37 |
+
guide_channels=text_channels,
|
| 38 |
+
embed_channels=neck_embed_channels,
|
| 39 |
+
num_heads=neck_num_heads,
|
| 40 |
+
block_cfg=dict(type='MaxSigmoidCSPLayerWithTwoConv')),
|
| 41 |
+
bbox_head=dict(type='YOLOWorldHead',
|
| 42 |
+
head_module=dict(
|
| 43 |
+
type='YOLOWorldHeadModule',
|
| 44 |
+
freeze_all=False,
|
| 45 |
+
use_bn_head=True,
|
| 46 |
+
embed_dims=text_channels,
|
| 47 |
+
num_classes=num_training_classes)),
|
| 48 |
+
train_cfg=dict(assigner=dict(num_classes=num_training_classes)))
|
| 49 |
+
|
| 50 |
+
# dataset settings
|
| 51 |
+
coco_train_dataset = dict(type='YOLOv5CocoDataset',
|
| 52 |
+
data_root='data/coco',
|
| 53 |
+
ann_file='annotations/instances_train2017.json',
|
| 54 |
+
data_prefix=dict(img='train2017/'),
|
| 55 |
+
filter_cfg=dict(filter_empty_gt=False, min_size=32),
|
| 56 |
+
pipeline=_base_.train_pipeline)
|
| 57 |
+
|
| 58 |
+
train_dataloader = dict(persistent_workers=persistent_workers,
|
| 59 |
+
batch_size=train_batch_size_per_gpu,
|
| 60 |
+
collate_fn=dict(type='yolow_collate'),
|
| 61 |
+
dataset=coco_train_dataset)
|
| 62 |
+
|
| 63 |
+
coco_val_dataset = dict(type='YOLOv5CocoDataset',
|
| 64 |
+
data_root='data/coco',
|
| 65 |
+
ann_file='annotations/instances_val2017.json',
|
| 66 |
+
data_prefix=dict(img='val2017/'),
|
| 67 |
+
filter_cfg=dict(filter_empty_gt=False, min_size=32),
|
| 68 |
+
pipeline=_base_.test_pipeline)
|
| 69 |
+
|
| 70 |
+
val_dataloader = dict(dataset=coco_val_dataset)
|
| 71 |
+
test_dataloader = val_dataloader
|
| 72 |
+
# training settings
|
| 73 |
+
default_hooks = dict(param_scheduler=dict(scheduler_type='linear',
|
| 74 |
+
lr_factor=0.01,
|
| 75 |
+
max_epochs=max_epochs),
|
| 76 |
+
checkpoint=dict(max_keep_ckpts=-1,
|
| 77 |
+
save_best=None,
|
| 78 |
+
interval=save_epoch_intervals))
|
| 79 |
+
custom_hooks = [
|
| 80 |
+
dict(type='EMAHook',
|
| 81 |
+
ema_type='ExpMomentumEMA',
|
| 82 |
+
momentum=0.0001,
|
| 83 |
+
update_buffers=True,
|
| 84 |
+
strict_load=False,
|
| 85 |
+
priority=49),
|
| 86 |
+
dict(type='mmdet.PipelineSwitchHook',
|
| 87 |
+
switch_epoch=max_epochs - close_mosaic_epochs,
|
| 88 |
+
switch_pipeline=_base_.train_pipeline_stage2)
|
| 89 |
+
]
|
| 90 |
+
train_cfg = dict(max_epochs=max_epochs,
|
| 91 |
+
val_interval=5,
|
| 92 |
+
dynamic_intervals=[((max_epochs - close_mosaic_epochs),
|
| 93 |
+
_base_.val_interval_stage2)])
|
| 94 |
+
|
| 95 |
+
optim_wrapper = dict(optimizer=dict(
|
| 96 |
+
_delete_=True,
|
| 97 |
+
type='AdamW',
|
| 98 |
+
lr=base_lr,
|
| 99 |
+
weight_decay=weight_decay,
|
| 100 |
+
batch_size_per_gpu=train_batch_size_per_gpu),
|
| 101 |
+
paramwise_cfg=dict(
|
| 102 |
+
custom_keys={
|
| 103 |
+
'backbone.text_model': dict(lr_mult=0.01),
|
| 104 |
+
'logit_scale': dict(weight_decay=0.0),
|
| 105 |
+
'embeddings': dict(weight_decay=0.0)
|
| 106 |
+
}),
|
| 107 |
+
constructor='YOLOWv5OptimizerConstructor')
|
| 108 |
+
|
| 109 |
+
# evaluation settings
|
| 110 |
+
val_evaluator = dict(_delete_=True,
|
| 111 |
+
type='mmdet.CocoMetric',
|
| 112 |
+
proposal_nums=(100, 1, 10),
|
| 113 |
+
ann_file='data/coco/annotations/instances_val2017.json',
|
| 114 |
+
metric='bbox')
|
configs/prompt_tuning_coco/yolo_world_v2_l_vlpan_bn_2e-4_80e_8gpus_mask-refine_all_fine_tuning_coco.py
ADDED
|
@@ -0,0 +1,156 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
_base_ = ('../../third_party/mmyolo/configs/yolov8/'
|
| 2 |
+
'yolov8_l_mask-refine_syncbn_fast_8xb16-500e_coco.py')
|
| 3 |
+
custom_imports = dict(imports=['yolo_world'], allow_failed_imports=False)
|
| 4 |
+
|
| 5 |
+
# hyper-parameters
|
| 6 |
+
num_classes = 80
|
| 7 |
+
num_training_classes = 80
|
| 8 |
+
max_epochs = 80 # Maximum training epochs
|
| 9 |
+
close_mosaic_epochs = 10
|
| 10 |
+
save_epoch_intervals = 5
|
| 11 |
+
text_channels = 512
|
| 12 |
+
neck_embed_channels = [128, 256, _base_.last_stage_out_channels // 2]
|
| 13 |
+
neck_num_heads = [4, 8, _base_.last_stage_out_channels // 2 // 32]
|
| 14 |
+
base_lr = 2e-4
|
| 15 |
+
weight_decay = 0.05
|
| 16 |
+
train_batch_size_per_gpu = 16
|
| 17 |
+
load_from = 'pretrained_models/yolo_world_l_clip_t2i_bn_2e-3adamw_32xb16-100e_obj365v1_goldg_cc3mlite_train-ca93cd1f.pth'
|
| 18 |
+
persistent_workers = False
|
| 19 |
+
|
| 20 |
+
# model settings
|
| 21 |
+
model = dict(type='YOLOWorldPromptDetector',
|
| 22 |
+
mm_neck=True,
|
| 23 |
+
num_train_classes=num_training_classes,
|
| 24 |
+
num_test_classes=num_classes,
|
| 25 |
+
embedding_path='embeddings/clip_vit_b32_coco_80_embeddings.npy',
|
| 26 |
+
prompt_dim=text_channels,
|
| 27 |
+
num_prompts=80,
|
| 28 |
+
freeze_prompt=True,
|
| 29 |
+
data_preprocessor=dict(type='YOLOv5DetDataPreprocessor'),
|
| 30 |
+
backbone=dict(_delete_=True,
|
| 31 |
+
type='MultiModalYOLOBackbone',
|
| 32 |
+
text_model=None,
|
| 33 |
+
image_model={{_base_.model.backbone}},
|
| 34 |
+
with_text_model=False),
|
| 35 |
+
neck=dict(type='YOLOWorldPAFPN',
|
| 36 |
+
freeze_all=False,
|
| 37 |
+
guide_channels=text_channels,
|
| 38 |
+
embed_channels=neck_embed_channels,
|
| 39 |
+
num_heads=neck_num_heads,
|
| 40 |
+
block_cfg=dict(type='MaxSigmoidCSPLayerWithTwoConv')),
|
| 41 |
+
bbox_head=dict(type='YOLOWorldHead',
|
| 42 |
+
head_module=dict(
|
| 43 |
+
type='YOLOWorldHeadModule',
|
| 44 |
+
freeze_all=False,
|
| 45 |
+
use_bn_head=True,
|
| 46 |
+
embed_dims=text_channels,
|
| 47 |
+
num_classes=num_training_classes)),
|
| 48 |
+
train_cfg=dict(assigner=dict(num_classes=num_training_classes)))
|
| 49 |
+
|
| 50 |
+
# dataset settings
|
| 51 |
+
final_transform = [
|
| 52 |
+
dict(type='mmdet.PackDetInputs',
|
| 53 |
+
meta_keys=('img_id', 'img_path', 'ori_shape', 'img_shape', 'flip',
|
| 54 |
+
'flip_direction'))
|
| 55 |
+
]
|
| 56 |
+
mosaic_affine_transform = [
|
| 57 |
+
dict(type='Mosaic',
|
| 58 |
+
img_scale=_base_.img_scale,
|
| 59 |
+
pad_val=114.0,
|
| 60 |
+
pre_transform=_base_.pre_transform),
|
| 61 |
+
dict(type='YOLOv5CopyPaste', prob=_base_.copypaste_prob),
|
| 62 |
+
dict(
|
| 63 |
+
type='YOLOv5RandomAffine',
|
| 64 |
+
max_rotate_degree=0.0,
|
| 65 |
+
max_shear_degree=0.0,
|
| 66 |
+
max_aspect_ratio=100.,
|
| 67 |
+
scaling_ratio_range=(1 - _base_.affine_scale, 1 + _base_.affine_scale),
|
| 68 |
+
# img_scale is (width, height)
|
| 69 |
+
border=(-_base_.img_scale[0] // 2, -_base_.img_scale[1] // 2),
|
| 70 |
+
border_val=(114, 114, 114),
|
| 71 |
+
min_area_ratio=_base_.min_area_ratio,
|
| 72 |
+
use_mask_refine=_base_.use_mask2refine)
|
| 73 |
+
]
|
| 74 |
+
train_pipeline = [
|
| 75 |
+
*_base_.pre_transform, *mosaic_affine_transform,
|
| 76 |
+
dict(type='YOLOv5MixUp',
|
| 77 |
+
prob=_base_.mixup_prob,
|
| 78 |
+
pre_transform=[*_base_.pre_transform, *mosaic_affine_transform]),
|
| 79 |
+
*_base_.last_transform[:-1], *final_transform
|
| 80 |
+
]
|
| 81 |
+
|
| 82 |
+
train_pipeline_stage2 = [*_base_.train_pipeline_stage2[:-1], *final_transform]
|
| 83 |
+
|
| 84 |
+
coco_train_dataset = dict(type='YOLOv5CocoDataset',
|
| 85 |
+
data_root='data/coco',
|
| 86 |
+
ann_file='annotations/instances_train2017.json',
|
| 87 |
+
data_prefix=dict(img='train2017/'),
|
| 88 |
+
filter_cfg=dict(filter_empty_gt=False, min_size=32),
|
| 89 |
+
pipeline=train_pipeline)
|
| 90 |
+
|
| 91 |
+
train_dataloader = dict(persistent_workers=persistent_workers,
|
| 92 |
+
batch_size=train_batch_size_per_gpu,
|
| 93 |
+
collate_fn=dict(type='yolow_collate'),
|
| 94 |
+
dataset=coco_train_dataset)
|
| 95 |
+
|
| 96 |
+
test_pipeline = [
|
| 97 |
+
*_base_.test_pipeline[:-1],
|
| 98 |
+
dict(type='mmdet.PackDetInputs',
|
| 99 |
+
meta_keys=('img_id', 'img_path', 'ori_shape', 'img_shape',
|
| 100 |
+
'scale_factor', 'pad_param'))
|
| 101 |
+
]
|
| 102 |
+
coco_val_dataset = dict(type='YOLOv5CocoDataset',
|
| 103 |
+
data_root='data/coco',
|
| 104 |
+
ann_file='annotations/instances_val2017.json',
|
| 105 |
+
data_prefix=dict(img='val2017/'),
|
| 106 |
+
filter_cfg=dict(filter_empty_gt=False, min_size=32),
|
| 107 |
+
pipeline=test_pipeline)
|
| 108 |
+
|
| 109 |
+
val_dataloader = dict(dataset=coco_val_dataset)
|
| 110 |
+
test_dataloader = val_dataloader
|
| 111 |
+
# training settings
|
| 112 |
+
default_hooks = dict(param_scheduler=dict(scheduler_type='linear',
|
| 113 |
+
lr_factor=0.01,
|
| 114 |
+
max_epochs=max_epochs),
|
| 115 |
+
checkpoint=dict(max_keep_ckpts=-1,
|
| 116 |
+
save_best=None,
|
| 117 |
+
interval=save_epoch_intervals))
|
| 118 |
+
custom_hooks = [
|
| 119 |
+
dict(type='EMAHook',
|
| 120 |
+
ema_type='ExpMomentumEMA',
|
| 121 |
+
momentum=0.0001,
|
| 122 |
+
update_buffers=True,
|
| 123 |
+
strict_load=False,
|
| 124 |
+
priority=49),
|
| 125 |
+
dict(type='mmdet.PipelineSwitchHook',
|
| 126 |
+
switch_epoch=max_epochs - close_mosaic_epochs,
|
| 127 |
+
switch_pipeline=train_pipeline_stage2)
|
| 128 |
+
]
|
| 129 |
+
train_cfg = dict(max_epochs=max_epochs,
|
| 130 |
+
val_interval=5,
|
| 131 |
+
dynamic_intervals=[((max_epochs - close_mosaic_epochs),
|
| 132 |
+
_base_.val_interval_stage2)])
|
| 133 |
+
optim_wrapper = dict(optimizer=dict(
|
| 134 |
+
_delete_=True,
|
| 135 |
+
type='AdamW',
|
| 136 |
+
lr=base_lr,
|
| 137 |
+
weight_decay=weight_decay,
|
| 138 |
+
batch_size_per_gpu=train_batch_size_per_gpu),
|
| 139 |
+
paramwise_cfg=dict(bias_decay_mult=0.0,
|
| 140 |
+
norm_decay_mult=0.0,
|
| 141 |
+
custom_keys={
|
| 142 |
+
'backbone.text_model':
|
| 143 |
+
dict(lr_mult=0.01),
|
| 144 |
+
'logit_scale':
|
| 145 |
+
dict(weight_decay=0.0),
|
| 146 |
+
'embeddings':
|
| 147 |
+
dict(weight_decay=0.0)
|
| 148 |
+
}),
|
| 149 |
+
constructor='YOLOWv5OptimizerConstructor')
|
| 150 |
+
|
| 151 |
+
# evaluation settings
|
| 152 |
+
val_evaluator = dict(_delete_=True,
|
| 153 |
+
type='mmdet.CocoMetric',
|
| 154 |
+
proposal_nums=(100, 1, 10),
|
| 155 |
+
ann_file='data/coco/annotations/instances_val2017.json',
|
| 156 |
+
metric='bbox')
|
configs/prompt_tuning_coco/yolo_world_v2_l_vlpan_bn_2e-4_80e_8gpus_mask-refine_fine_prompt_tuning_coco.py
ADDED
|
@@ -0,0 +1,156 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
_base_ = ('../../third_party/mmyolo/configs/yolov8/'
|
| 2 |
+
'yolov8_l_mask-refine_syncbn_fast_8xb16-500e_coco.py')
|
| 3 |
+
custom_imports = dict(imports=['yolo_world'], allow_failed_imports=False)
|
| 4 |
+
|
| 5 |
+
# hyper-parameters
|
| 6 |
+
num_classes = 80
|
| 7 |
+
num_training_classes = 80
|
| 8 |
+
max_epochs = 80 # Maximum training epochs
|
| 9 |
+
close_mosaic_epochs = 10
|
| 10 |
+
save_epoch_intervals = 5
|
| 11 |
+
text_channels = 512
|
| 12 |
+
neck_embed_channels = [128, 256, _base_.last_stage_out_channels // 2]
|
| 13 |
+
neck_num_heads = [4, 8, _base_.last_stage_out_channels // 2 // 32]
|
| 14 |
+
base_lr = 2e-4
|
| 15 |
+
weight_decay = 0.05
|
| 16 |
+
train_batch_size_per_gpu = 16
|
| 17 |
+
load_from = 'pretrained_models/yolo_world_l_clip_t2i_bn_2e-3adamw_32xb16-100e_obj365v1_goldg_cc3mlite_train-ca93cd1f.pth'
|
| 18 |
+
persistent_workers = False
|
| 19 |
+
|
| 20 |
+
# model settings
|
| 21 |
+
model = dict(type='YOLOWorldPromptDetector',
|
| 22 |
+
mm_neck=True,
|
| 23 |
+
num_train_classes=num_training_classes,
|
| 24 |
+
num_test_classes=num_classes,
|
| 25 |
+
embedding_path='embeddings/clip_vit_b32_coco_80_embeddings.npy',
|
| 26 |
+
prompt_dim=text_channels,
|
| 27 |
+
num_prompts=80,
|
| 28 |
+
freeze_prompt=False,
|
| 29 |
+
data_preprocessor=dict(type='YOLOv5DetDataPreprocessor'),
|
| 30 |
+
backbone=dict(_delete_=True,
|
| 31 |
+
type='MultiModalYOLOBackbone',
|
| 32 |
+
text_model=None,
|
| 33 |
+
image_model={{_base_.model.backbone}},
|
| 34 |
+
with_text_model=False),
|
| 35 |
+
neck=dict(type='YOLOWorldPAFPN',
|
| 36 |
+
freeze_all=False,
|
| 37 |
+
guide_channels=text_channels,
|
| 38 |
+
embed_channels=neck_embed_channels,
|
| 39 |
+
num_heads=neck_num_heads,
|
| 40 |
+
block_cfg=dict(type='MaxSigmoidCSPLayerWithTwoConv')),
|
| 41 |
+
bbox_head=dict(type='YOLOWorldHead',
|
| 42 |
+
head_module=dict(
|
| 43 |
+
type='YOLOWorldHeadModule',
|
| 44 |
+
freeze_all=False,
|
| 45 |
+
use_bn_head=True,
|
| 46 |
+
embed_dims=text_channels,
|
| 47 |
+
num_classes=num_training_classes)),
|
| 48 |
+
train_cfg=dict(assigner=dict(num_classes=num_training_classes)))
|
| 49 |
+
|
| 50 |
+
# dataset settings
|
| 51 |
+
final_transform = [
|
| 52 |
+
dict(type='mmdet.PackDetInputs',
|
| 53 |
+
meta_keys=('img_id', 'img_path', 'ori_shape', 'img_shape', 'flip',
|
| 54 |
+
'flip_direction'))
|
| 55 |
+
]
|
| 56 |
+
mosaic_affine_transform = [
|
| 57 |
+
dict(type='Mosaic',
|
| 58 |
+
img_scale=_base_.img_scale,
|
| 59 |
+
pad_val=114.0,
|
| 60 |
+
pre_transform=_base_.pre_transform),
|
| 61 |
+
dict(type='YOLOv5CopyPaste', prob=_base_.copypaste_prob),
|
| 62 |
+
dict(
|
| 63 |
+
type='YOLOv5RandomAffine',
|
| 64 |
+
max_rotate_degree=0.0,
|
| 65 |
+
max_shear_degree=0.0,
|
| 66 |
+
max_aspect_ratio=100.,
|
| 67 |
+
scaling_ratio_range=(1 - _base_.affine_scale, 1 + _base_.affine_scale),
|
| 68 |
+
# img_scale is (width, height)
|
| 69 |
+
border=(-_base_.img_scale[0] // 2, -_base_.img_scale[1] // 2),
|
| 70 |
+
border_val=(114, 114, 114),
|
| 71 |
+
min_area_ratio=_base_.min_area_ratio,
|
| 72 |
+
use_mask_refine=_base_.use_mask2refine)
|
| 73 |
+
]
|
| 74 |
+
train_pipeline = [
|
| 75 |
+
*_base_.pre_transform, *mosaic_affine_transform,
|
| 76 |
+
dict(type='YOLOv5MixUp',
|
| 77 |
+
prob=_base_.mixup_prob,
|
| 78 |
+
pre_transform=[*_base_.pre_transform, *mosaic_affine_transform]),
|
| 79 |
+
*_base_.last_transform[:-1], *final_transform
|
| 80 |
+
]
|
| 81 |
+
|
| 82 |
+
train_pipeline_stage2 = [*_base_.train_pipeline_stage2[:-1], *final_transform]
|
| 83 |
+
|
| 84 |
+
coco_train_dataset = dict(type='YOLOv5CocoDataset',
|
| 85 |
+
data_root='data/coco',
|
| 86 |
+
ann_file='annotations/instances_train2017.json',
|
| 87 |
+
data_prefix=dict(img='train2017/'),
|
| 88 |
+
filter_cfg=dict(filter_empty_gt=False, min_size=32),
|
| 89 |
+
pipeline=train_pipeline)
|
| 90 |
+
|
| 91 |
+
train_dataloader = dict(persistent_workers=persistent_workers,
|
| 92 |
+
batch_size=train_batch_size_per_gpu,
|
| 93 |
+
collate_fn=dict(type='yolow_collate'),
|
| 94 |
+
dataset=coco_train_dataset)
|
| 95 |
+
|
| 96 |
+
test_pipeline = [
|
| 97 |
+
*_base_.test_pipeline[:-1],
|
| 98 |
+
dict(type='mmdet.PackDetInputs',
|
| 99 |
+
meta_keys=('img_id', 'img_path', 'ori_shape', 'img_shape',
|
| 100 |
+
'scale_factor', 'pad_param'))
|
| 101 |
+
]
|
| 102 |
+
coco_val_dataset = dict(type='YOLOv5CocoDataset',
|
| 103 |
+
data_root='data/coco',
|
| 104 |
+
ann_file='annotations/instances_val2017.json',
|
| 105 |
+
data_prefix=dict(img='val2017/'),
|
| 106 |
+
filter_cfg=dict(filter_empty_gt=False, min_size=32),
|
| 107 |
+
pipeline=test_pipeline)
|
| 108 |
+
|
| 109 |
+
val_dataloader = dict(dataset=coco_val_dataset)
|
| 110 |
+
test_dataloader = val_dataloader
|
| 111 |
+
# training settings
|
| 112 |
+
default_hooks = dict(param_scheduler=dict(scheduler_type='linear',
|
| 113 |
+
lr_factor=0.01,
|
| 114 |
+
max_epochs=max_epochs),
|
| 115 |
+
checkpoint=dict(max_keep_ckpts=-1,
|
| 116 |
+
save_best=None,
|
| 117 |
+
interval=save_epoch_intervals))
|
| 118 |
+
custom_hooks = [
|
| 119 |
+
dict(type='EMAHook',
|
| 120 |
+
ema_type='ExpMomentumEMA',
|
| 121 |
+
momentum=0.0001,
|
| 122 |
+
update_buffers=True,
|
| 123 |
+
strict_load=False,
|
| 124 |
+
priority=49),
|
| 125 |
+
dict(type='mmdet.PipelineSwitchHook',
|
| 126 |
+
switch_epoch=max_epochs - close_mosaic_epochs,
|
| 127 |
+
switch_pipeline=train_pipeline_stage2)
|
| 128 |
+
]
|
| 129 |
+
train_cfg = dict(max_epochs=max_epochs,
|
| 130 |
+
val_interval=5,
|
| 131 |
+
dynamic_intervals=[((max_epochs - close_mosaic_epochs),
|
| 132 |
+
_base_.val_interval_stage2)])
|
| 133 |
+
optim_wrapper = dict(optimizer=dict(
|
| 134 |
+
_delete_=True,
|
| 135 |
+
type='AdamW',
|
| 136 |
+
lr=base_lr,
|
| 137 |
+
weight_decay=weight_decay,
|
| 138 |
+
batch_size_per_gpu=train_batch_size_per_gpu),
|
| 139 |
+
paramwise_cfg=dict(bias_decay_mult=0.0,
|
| 140 |
+
norm_decay_mult=0.0,
|
| 141 |
+
custom_keys={
|
| 142 |
+
'backbone.text_model':
|
| 143 |
+
dict(lr_mult=0.01),
|
| 144 |
+
'logit_scale':
|
| 145 |
+
dict(weight_decay=0.0),
|
| 146 |
+
'embeddings':
|
| 147 |
+
dict(weight_decay=0.0)
|
| 148 |
+
}),
|
| 149 |
+
constructor='YOLOWv5OptimizerConstructor')
|
| 150 |
+
|
| 151 |
+
# evaluation settings
|
| 152 |
+
val_evaluator = dict(_delete_=True,
|
| 153 |
+
type='mmdet.CocoMetric',
|
| 154 |
+
proposal_nums=(100, 1, 10),
|
| 155 |
+
ann_file='data/coco/annotations/instances_val2017.json',
|
| 156 |
+
metric='bbox')
|
configs/prompt_tuning_coco/yolo_world_v2_l_vlpan_bn_2e-4_80e_8gpus_mask-refine_prompt_tuning_coco.py
ADDED
|
@@ -0,0 +1,161 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
_base_ = ('../../third_party/mmyolo/configs/yolov8/'
|
| 2 |
+
'yolov8_l_mask-refine_syncbn_fast_8xb16-500e_coco.py')
|
| 3 |
+
custom_imports = dict(imports=['yolo_world'], allow_failed_imports=False)
|
| 4 |
+
|
| 5 |
+
# hyper-parameters
|
| 6 |
+
num_classes = 80
|
| 7 |
+
num_training_classes = 80
|
| 8 |
+
max_epochs = 80 # Maximum training epochs
|
| 9 |
+
close_mosaic_epochs = 10
|
| 10 |
+
save_epoch_intervals = 5
|
| 11 |
+
text_channels = 512
|
| 12 |
+
neck_embed_channels = [128, 256, _base_.last_stage_out_channels // 2]
|
| 13 |
+
neck_num_heads = [4, 8, _base_.last_stage_out_channels // 2 // 32]
|
| 14 |
+
base_lr = 2e-3
|
| 15 |
+
weight_decay = 0.05
|
| 16 |
+
train_batch_size_per_gpu = 16
|
| 17 |
+
load_from = 'pretrained_models/yolo_world_l_clip_t2i_bn_2e-3adamw_32xb16-100e_obj365v1_goldg_cc3mlite_train-ca93cd1f.pth'
|
| 18 |
+
persistent_workers = False
|
| 19 |
+
|
| 20 |
+
# model settings
|
| 21 |
+
model = dict(type='YOLOWorldPromptDetector',
|
| 22 |
+
mm_neck=True,
|
| 23 |
+
num_train_classes=num_training_classes,
|
| 24 |
+
num_test_classes=num_classes,
|
| 25 |
+
embedding_path='embeddings/clip_vit_b32_coco_80_embeddings.npy',
|
| 26 |
+
prompt_dim=text_channels,
|
| 27 |
+
num_prompts=80,
|
| 28 |
+
data_preprocessor=dict(type='YOLOv5DetDataPreprocessor'),
|
| 29 |
+
backbone=dict(_delete_=True,
|
| 30 |
+
type='MultiModalYOLOBackbone',
|
| 31 |
+
text_model=None,
|
| 32 |
+
image_model={{_base_.model.backbone}},
|
| 33 |
+
frozen_stages=4,
|
| 34 |
+
with_text_model=False),
|
| 35 |
+
neck=dict(type='YOLOWorldPAFPN',
|
| 36 |
+
freeze_all=True,
|
| 37 |
+
guide_channels=text_channels,
|
| 38 |
+
embed_channels=neck_embed_channels,
|
| 39 |
+
num_heads=neck_num_heads,
|
| 40 |
+
block_cfg=dict(type='MaxSigmoidCSPLayerWithTwoConv')),
|
| 41 |
+
bbox_head=dict(type='YOLOWorldHead',
|
| 42 |
+
head_module=dict(
|
| 43 |
+
type='YOLOWorldHeadModule',
|
| 44 |
+
freeze_all=True,
|
| 45 |
+
use_bn_head=True,
|
| 46 |
+
embed_dims=text_channels,
|
| 47 |
+
num_classes=num_training_classes)),
|
| 48 |
+
train_cfg=dict(assigner=dict(num_classes=num_training_classes)))
|
| 49 |
+
|
| 50 |
+
# dataset settings
|
| 51 |
+
final_transform = [
|
| 52 |
+
dict(type='mmdet.PackDetInputs',
|
| 53 |
+
meta_keys=('img_id', 'img_path', 'ori_shape', 'img_shape', 'flip',
|
| 54 |
+
'flip_direction'))
|
| 55 |
+
]
|
| 56 |
+
mosaic_affine_transform = [
|
| 57 |
+
dict(type='Mosaic',
|
| 58 |
+
img_scale=_base_.img_scale,
|
| 59 |
+
pad_val=114.0,
|
| 60 |
+
pre_transform=_base_.pre_transform),
|
| 61 |
+
dict(type='YOLOv5CopyPaste', prob=_base_.copypaste_prob),
|
| 62 |
+
dict(
|
| 63 |
+
type='YOLOv5RandomAffine',
|
| 64 |
+
max_rotate_degree=0.0,
|
| 65 |
+
max_shear_degree=0.0,
|
| 66 |
+
max_aspect_ratio=100.,
|
| 67 |
+
scaling_ratio_range=(1 - _base_.affine_scale, 1 + _base_.affine_scale),
|
| 68 |
+
# img_scale is (width, height)
|
| 69 |
+
border=(-_base_.img_scale[0] // 2, -_base_.img_scale[1] // 2),
|
| 70 |
+
border_val=(114, 114, 114),
|
| 71 |
+
min_area_ratio=_base_.min_area_ratio,
|
| 72 |
+
use_mask_refine=_base_.use_mask2refine)
|
| 73 |
+
]
|
| 74 |
+
train_pipeline = [
|
| 75 |
+
*_base_.pre_transform, *mosaic_affine_transform,
|
| 76 |
+
dict(type='YOLOv5MixUp',
|
| 77 |
+
prob=_base_.mixup_prob,
|
| 78 |
+
pre_transform=[*_base_.pre_transform, *mosaic_affine_transform]),
|
| 79 |
+
*_base_.last_transform[:-1], *final_transform
|
| 80 |
+
]
|
| 81 |
+
|
| 82 |
+
train_pipeline_stage2 = [*_base_.train_pipeline_stage2[:-1], *final_transform]
|
| 83 |
+
|
| 84 |
+
coco_train_dataset = dict(type='YOLOv5CocoDataset',
|
| 85 |
+
data_root='data/coco',
|
| 86 |
+
ann_file='annotations/instances_train2017.json',
|
| 87 |
+
data_prefix=dict(img='train2017/'),
|
| 88 |
+
filter_cfg=dict(filter_empty_gt=False, min_size=32),
|
| 89 |
+
pipeline=train_pipeline)
|
| 90 |
+
|
| 91 |
+
train_dataloader = dict(persistent_workers=persistent_workers,
|
| 92 |
+
batch_size=train_batch_size_per_gpu,
|
| 93 |
+
collate_fn=dict(type='yolow_collate'),
|
| 94 |
+
dataset=coco_train_dataset)
|
| 95 |
+
|
| 96 |
+
train_dataloader = dict(persistent_workers=persistent_workers,
|
| 97 |
+
batch_size=train_batch_size_per_gpu,
|
| 98 |
+
collate_fn=dict(type='yolow_collate'),
|
| 99 |
+
dataset=coco_train_dataset)
|
| 100 |
+
test_pipeline = [
|
| 101 |
+
*_base_.test_pipeline[:-1],
|
| 102 |
+
dict(type='mmdet.PackDetInputs',
|
| 103 |
+
meta_keys=('img_id', 'img_path', 'ori_shape', 'img_shape',
|
| 104 |
+
'scale_factor', 'pad_param'))
|
| 105 |
+
]
|
| 106 |
+
coco_val_dataset = dict(type='YOLOv5CocoDataset',
|
| 107 |
+
data_root='data/coco',
|
| 108 |
+
ann_file='annotations/instances_val2017.json',
|
| 109 |
+
data_prefix=dict(img='val2017/'),
|
| 110 |
+
filter_cfg=dict(filter_empty_gt=False, min_size=32),
|
| 111 |
+
pipeline=test_pipeline)
|
| 112 |
+
|
| 113 |
+
val_dataloader = dict(dataset=coco_val_dataset)
|
| 114 |
+
test_dataloader = val_dataloader
|
| 115 |
+
# training settings
|
| 116 |
+
default_hooks = dict(param_scheduler=dict(scheduler_type='linear',
|
| 117 |
+
lr_factor=0.01,
|
| 118 |
+
max_epochs=max_epochs),
|
| 119 |
+
checkpoint=dict(max_keep_ckpts=-1,
|
| 120 |
+
save_best=None,
|
| 121 |
+
interval=save_epoch_intervals))
|
| 122 |
+
custom_hooks = [
|
| 123 |
+
dict(type='EMAHook',
|
| 124 |
+
ema_type='ExpMomentumEMA',
|
| 125 |
+
momentum=0.0001,
|
| 126 |
+
update_buffers=True,
|
| 127 |
+
strict_load=False,
|
| 128 |
+
priority=49),
|
| 129 |
+
dict(type='mmdet.PipelineSwitchHook',
|
| 130 |
+
switch_epoch=max_epochs - close_mosaic_epochs,
|
| 131 |
+
switch_pipeline=train_pipeline_stage2)
|
| 132 |
+
]
|
| 133 |
+
train_cfg = dict(max_epochs=max_epochs,
|
| 134 |
+
val_interval=5,
|
| 135 |
+
dynamic_intervals=[((max_epochs - close_mosaic_epochs),
|
| 136 |
+
_base_.val_interval_stage2)])
|
| 137 |
+
optim_wrapper = dict(optimizer=dict(
|
| 138 |
+
_delete_=True,
|
| 139 |
+
type='AdamW',
|
| 140 |
+
lr=base_lr,
|
| 141 |
+
weight_decay=weight_decay,
|
| 142 |
+
batch_size_per_gpu=train_batch_size_per_gpu),
|
| 143 |
+
paramwise_cfg=dict(bias_decay_mult=0.0,
|
| 144 |
+
norm_decay_mult=0.0,
|
| 145 |
+
custom_keys={
|
| 146 |
+
'backbone.text_model':
|
| 147 |
+
dict(lr_mult=0.01),
|
| 148 |
+
'logit_scale':
|
| 149 |
+
dict(weight_decay=0.0),
|
| 150 |
+
'embeddings':
|
| 151 |
+
dict(weight_decay=0.0)
|
| 152 |
+
}),
|
| 153 |
+
constructor='YOLOWv5OptimizerConstructor')
|
| 154 |
+
|
| 155 |
+
# evaluation settings
|
| 156 |
+
val_evaluator = dict(_delete_=True,
|
| 157 |
+
type='mmdet.CocoMetric',
|
| 158 |
+
proposal_nums=(100, 1, 10),
|
| 159 |
+
ann_file='data/coco/annotations/instances_val2017.json',
|
| 160 |
+
metric='bbox')
|
| 161 |
+
find_unused_parameters = True
|
configs/prompt_tuning_coco/yolo_world_v2_l_vlpan_bn_sgd_1e-3_20e_8gpus_all_fine_tuning_rmdecay_coco.py
ADDED
|
@@ -0,0 +1,113 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
_base_ = ('../../third_party/mmyolo/configs/yolov8/'
|
| 2 |
+
'yolov8_l_syncbn_fast_8xb16-500e_coco.py')
|
| 3 |
+
custom_imports = dict(imports=['yolo_world'], allow_failed_imports=False)
|
| 4 |
+
|
| 5 |
+
# hyper-parameters
|
| 6 |
+
num_classes = 80
|
| 7 |
+
num_training_classes = 80
|
| 8 |
+
max_epochs = 20 # Maximum training epochs
|
| 9 |
+
close_mosaic_epochs = 10
|
| 10 |
+
save_epoch_intervals = 5
|
| 11 |
+
text_channels = 512
|
| 12 |
+
neck_embed_channels = [128, 256, _base_.last_stage_out_channels // 2]
|
| 13 |
+
neck_num_heads = [4, 8, _base_.last_stage_out_channels // 2 // 32]
|
| 14 |
+
base_lr = 1e-3
|
| 15 |
+
weight_decay = 0.0005
|
| 16 |
+
train_batch_size_per_gpu = 16
|
| 17 |
+
load_from = 'pretrained_models/yolo_world_l_clip_t2i_bn_2e-3adamw_32xb16-100e_obj365v1_goldg_cc3mlite_train-ca93cd1f.pth'
|
| 18 |
+
persistent_workers = False
|
| 19 |
+
|
| 20 |
+
# model settings
|
| 21 |
+
model = dict(type='YOLOWorldPromptDetector',
|
| 22 |
+
mm_neck=True,
|
| 23 |
+
num_train_classes=num_training_classes,
|
| 24 |
+
num_test_classes=num_classes,
|
| 25 |
+
embedding_path='embeddings/clip_vit_b32_coco_80_embeddings.npy',
|
| 26 |
+
prompt_dim=text_channels,
|
| 27 |
+
num_prompts=80,
|
| 28 |
+
freeze_prompt=True,
|
| 29 |
+
data_preprocessor=dict(type='YOLOv5DetDataPreprocessor'),
|
| 30 |
+
backbone=dict(_delete_=True,
|
| 31 |
+
type='MultiModalYOLOBackbone',
|
| 32 |
+
text_model=None,
|
| 33 |
+
image_model={{_base_.model.backbone}},
|
| 34 |
+
with_text_model=False),
|
| 35 |
+
neck=dict(type='YOLOWorldPAFPN',
|
| 36 |
+
freeze_all=False,
|
| 37 |
+
guide_channels=text_channels,
|
| 38 |
+
embed_channels=neck_embed_channels,
|
| 39 |
+
num_heads=neck_num_heads,
|
| 40 |
+
block_cfg=dict(type='MaxSigmoidCSPLayerWithTwoConv')),
|
| 41 |
+
bbox_head=dict(type='YOLOWorldHead',
|
| 42 |
+
head_module=dict(
|
| 43 |
+
type='YOLOWorldHeadModule',
|
| 44 |
+
freeze_all=False,
|
| 45 |
+
use_bn_head=True,
|
| 46 |
+
embed_dims=text_channels,
|
| 47 |
+
num_classes=num_training_classes)),
|
| 48 |
+
train_cfg=dict(assigner=dict(num_classes=num_training_classes)))
|
| 49 |
+
|
| 50 |
+
# dataset settings
|
| 51 |
+
coco_train_dataset = dict(type='YOLOv5CocoDataset',
|
| 52 |
+
data_root='data/coco',
|
| 53 |
+
ann_file='annotations/instances_train2017.json',
|
| 54 |
+
data_prefix=dict(img='train2017/'),
|
| 55 |
+
filter_cfg=dict(filter_empty_gt=False, min_size=32),
|
| 56 |
+
pipeline=_base_.train_pipeline)
|
| 57 |
+
|
| 58 |
+
train_dataloader = dict(persistent_workers=persistent_workers,
|
| 59 |
+
batch_size=train_batch_size_per_gpu,
|
| 60 |
+
collate_fn=dict(type='yolow_collate'),
|
| 61 |
+
dataset=coco_train_dataset)
|
| 62 |
+
|
| 63 |
+
coco_val_dataset = dict(type='YOLOv5CocoDataset',
|
| 64 |
+
data_root='data/coco',
|
| 65 |
+
ann_file='annotations/instances_val2017.json',
|
| 66 |
+
data_prefix=dict(img='val2017/'),
|
| 67 |
+
filter_cfg=dict(filter_empty_gt=False, min_size=32),
|
| 68 |
+
pipeline=_base_.test_pipeline)
|
| 69 |
+
|
| 70 |
+
val_dataloader = dict(dataset=coco_val_dataset)
|
| 71 |
+
test_dataloader = val_dataloader
|
| 72 |
+
# training settings
|
| 73 |
+
default_hooks = dict(param_scheduler=dict(scheduler_type='linear',
|
| 74 |
+
lr_factor=0.01,
|
| 75 |
+
max_epochs=max_epochs),
|
| 76 |
+
checkpoint=dict(max_keep_ckpts=-1,
|
| 77 |
+
save_best=None,
|
| 78 |
+
interval=save_epoch_intervals))
|
| 79 |
+
custom_hooks = [
|
| 80 |
+
dict(type='EMAHook',
|
| 81 |
+
ema_type='ExpMomentumEMA',
|
| 82 |
+
momentum=0.0001,
|
| 83 |
+
update_buffers=True,
|
| 84 |
+
strict_load=False,
|
| 85 |
+
priority=49),
|
| 86 |
+
dict(type='mmdet.PipelineSwitchHook',
|
| 87 |
+
switch_epoch=max_epochs - close_mosaic_epochs,
|
| 88 |
+
switch_pipeline=_base_.train_pipeline_stage2)
|
| 89 |
+
]
|
| 90 |
+
train_cfg = dict(max_epochs=max_epochs,
|
| 91 |
+
val_interval=5,
|
| 92 |
+
dynamic_intervals=[((max_epochs - close_mosaic_epochs),
|
| 93 |
+
_base_.val_interval_stage2)])
|
| 94 |
+
|
| 95 |
+
optim_wrapper = dict(
|
| 96 |
+
optimizer=dict(_delete_=True,
|
| 97 |
+
type='SGD',
|
| 98 |
+
lr=base_lr,
|
| 99 |
+
momentum=0.937,
|
| 100 |
+
nesterov=True,
|
| 101 |
+
weight_decay=weight_decay,
|
| 102 |
+
batch_size_per_gpu=train_batch_size_per_gpu),
|
| 103 |
+
paramwise_cfg=dict(bias_decay_mult=0.0,
|
| 104 |
+
norm_decay_mult=0.0,
|
| 105 |
+
custom_keys={'logit_scale': dict(weight_decay=0.0)}),
|
| 106 |
+
constructor='YOLOWv5OptimizerConstructor')
|
| 107 |
+
|
| 108 |
+
# evaluation settings
|
| 109 |
+
val_evaluator = dict(_delete_=True,
|
| 110 |
+
type='mmdet.CocoMetric',
|
| 111 |
+
proposal_nums=(100, 1, 10),
|
| 112 |
+
ann_file='data/coco/annotations/instances_val2017.json',
|
| 113 |
+
metric='bbox')
|
configs/prompt_tuning_coco/yolo_world_v2_l_vlpan_bn_sgd_1e-3_40e_8gpus_all_fine_tuning_rmdecay_coco.py
ADDED
|
@@ -0,0 +1,111 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
_base_ = ('../../third_party/mmyolo/configs/yolov8/'
|
| 2 |
+
'yolov8_l_syncbn_fast_8xb16-500e_coco.py')
|
| 3 |
+
custom_imports = dict(imports=['yolo_world'], allow_failed_imports=False)
|
| 4 |
+
|
| 5 |
+
# hyper-parameters
|
| 6 |
+
num_classes = 80
|
| 7 |
+
num_training_classes = 80
|
| 8 |
+
max_epochs = 40 # Maximum training epochs
|
| 9 |
+
close_mosaic_epochs = 30
|
| 10 |
+
save_epoch_intervals = 5
|
| 11 |
+
text_channels = 512
|
| 12 |
+
neck_embed_channels = [128, 256, _base_.last_stage_out_channels // 2]
|
| 13 |
+
neck_num_heads = [4, 8, _base_.last_stage_out_channels // 2 // 32]
|
| 14 |
+
base_lr = 1e-3
|
| 15 |
+
weight_decay = 0.0005
|
| 16 |
+
train_batch_size_per_gpu = 16
|
| 17 |
+
load_from = 'pretrained_models/yolo_world_l_clip_t2i_bn_2e-3adamw_32xb16-100e_obj365v1_goldg_cc3mlite_train-ca93cd1f.pth'
|
| 18 |
+
persistent_workers = False
|
| 19 |
+
|
| 20 |
+
# model settings
|
| 21 |
+
model = dict(type='YOLOWorldPromptDetector',
|
| 22 |
+
mm_neck=True,
|
| 23 |
+
num_train_classes=num_training_classes,
|
| 24 |
+
num_test_classes=num_classes,
|
| 25 |
+
embedding_path='embeddings/clip_vit_b32_coco_80_embeddings.npy',
|
| 26 |
+
prompt_dim=text_channels,
|
| 27 |
+
num_prompts=80,
|
| 28 |
+
freeze_prompt=True,
|
| 29 |
+
data_preprocessor=dict(type='YOLOv5DetDataPreprocessor'),
|
| 30 |
+
backbone=dict(_delete_=True,
|
| 31 |
+
type='MultiModalYOLOBackbone',
|
| 32 |
+
text_model=None,
|
| 33 |
+
image_model={{_base_.model.backbone}},
|
| 34 |
+
with_text_model=False),
|
| 35 |
+
neck=dict(type='YOLOWorldPAFPN',
|
| 36 |
+
freeze_all=False,
|
| 37 |
+
guide_channels=text_channels,
|
| 38 |
+
embed_channels=neck_embed_channels,
|
| 39 |
+
num_heads=neck_num_heads,
|
| 40 |
+
block_cfg=dict(type='MaxSigmoidCSPLayerWithTwoConv')),
|
| 41 |
+
bbox_head=dict(type='YOLOWorldHead',
|
| 42 |
+
head_module=dict(
|
| 43 |
+
type='YOLOWorldHeadModule',
|
| 44 |
+
freeze_all=False,
|
| 45 |
+
use_bn_head=True,
|
| 46 |
+
embed_dims=text_channels,
|
| 47 |
+
num_classes=num_training_classes)),
|
| 48 |
+
train_cfg=dict(assigner=dict(num_classes=num_training_classes)))
|
| 49 |
+
|
| 50 |
+
# dataset settings
|
| 51 |
+
coco_train_dataset = dict(type='YOLOv5CocoDataset',
|
| 52 |
+
data_root='data/coco',
|
| 53 |
+
ann_file='annotations/instances_train2017.json',
|
| 54 |
+
data_prefix=dict(img='train2017/'),
|
| 55 |
+
filter_cfg=dict(filter_empty_gt=False, min_size=32),
|
| 56 |
+
pipeline=_base_.train_pipeline)
|
| 57 |
+
|
| 58 |
+
train_dataloader = dict(persistent_workers=persistent_workers,
|
| 59 |
+
batch_size=train_batch_size_per_gpu,
|
| 60 |
+
collate_fn=dict(type='yolow_collate'),
|
| 61 |
+
dataset=coco_train_dataset)
|
| 62 |
+
|
| 63 |
+
coco_val_dataset = dict(type='YOLOv5CocoDataset',
|
| 64 |
+
data_root='data/coco',
|
| 65 |
+
ann_file='annotations/instances_val2017.json',
|
| 66 |
+
data_prefix=dict(img='val2017/'),
|
| 67 |
+
filter_cfg=dict(filter_empty_gt=False, min_size=32),
|
| 68 |
+
pipeline=_base_.test_pipeline)
|
| 69 |
+
|
| 70 |
+
val_dataloader = dict(dataset=coco_val_dataset)
|
| 71 |
+
test_dataloader = val_dataloader
|
| 72 |
+
# training settings
|
| 73 |
+
default_hooks = dict(param_scheduler=dict(scheduler_type='linear',
|
| 74 |
+
lr_factor=0.01,
|
| 75 |
+
max_epochs=max_epochs),
|
| 76 |
+
checkpoint=dict(max_keep_ckpts=-1,
|
| 77 |
+
save_best=None,
|
| 78 |
+
interval=save_epoch_intervals))
|
| 79 |
+
custom_hooks = [
|
| 80 |
+
dict(type='EMAHook',
|
| 81 |
+
ema_type='ExpMomentumEMA',
|
| 82 |
+
momentum=0.0001,
|
| 83 |
+
update_buffers=True,
|
| 84 |
+
strict_load=False,
|
| 85 |
+
priority=49),
|
| 86 |
+
dict(type='mmdet.PipelineSwitchHook',
|
| 87 |
+
switch_epoch=max_epochs - close_mosaic_epochs,
|
| 88 |
+
switch_pipeline=_base_.train_pipeline_stage2)
|
| 89 |
+
]
|
| 90 |
+
train_cfg = dict(max_epochs=max_epochs,
|
| 91 |
+
val_interval=5,
|
| 92 |
+
dynamic_intervals=[((max_epochs - close_mosaic_epochs),
|
| 93 |
+
_base_.val_interval_stage2)])
|
| 94 |
+
|
| 95 |
+
optim_wrapper = dict(
|
| 96 |
+
optimizer=dict(_delete_=True,
|
| 97 |
+
type='SGD',
|
| 98 |
+
lr=base_lr,
|
| 99 |
+
momentum=0.937,
|
| 100 |
+
nesterov=True,
|
| 101 |
+
weight_decay=weight_decay,
|
| 102 |
+
batch_size_per_gpu=train_batch_size_per_gpu),
|
| 103 |
+
paramwise_cfg=dict(custom_keys={'logit_scale': dict(weight_decay=0.0)}),
|
| 104 |
+
constructor='YOLOWv5OptimizerConstructor')
|
| 105 |
+
|
| 106 |
+
# evaluation settings
|
| 107 |
+
val_evaluator = dict(_delete_=True,
|
| 108 |
+
type='mmdet.CocoMetric',
|
| 109 |
+
proposal_nums=(100, 1, 10),
|
| 110 |
+
ann_file='data/coco/annotations/instances_val2017.json',
|
| 111 |
+
metric='bbox')
|
configs/prompt_tuning_coco/yolo_world_v2_l_vlpan_bn_sgd_1e-3_80e_8gpus_all_fine_tuning_coco.py
ADDED
|
@@ -0,0 +1,109 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
_base_ = ('../../third_party/mmyolo/configs/yolov8/'
|
| 2 |
+
'yolov8_l_syncbn_fast_8xb16-500e_coco.py')
|
| 3 |
+
custom_imports = dict(imports=['yolo_world'], allow_failed_imports=False)
|
| 4 |
+
|
| 5 |
+
# hyper-parameters
|
| 6 |
+
num_classes = 80
|
| 7 |
+
num_training_classes = 80
|
| 8 |
+
max_epochs = 80 # Maximum training epochs
|
| 9 |
+
close_mosaic_epochs = 10
|
| 10 |
+
save_epoch_intervals = 5
|
| 11 |
+
text_channels = 512
|
| 12 |
+
neck_embed_channels = [128, 256, _base_.last_stage_out_channels // 2]
|
| 13 |
+
neck_num_heads = [4, 8, _base_.last_stage_out_channels // 2 // 32]
|
| 14 |
+
base_lr = 1e-3
|
| 15 |
+
weight_decay = 0.0005
|
| 16 |
+
train_batch_size_per_gpu = 16
|
| 17 |
+
load_from = 'pretrained_models/yolo_world_l_clip_t2i_bn_2e-3adamw_32xb16-100e_obj365v1_goldg_cc3mlite_train-ca93cd1f.pth'
|
| 18 |
+
persistent_workers = False
|
| 19 |
+
|
| 20 |
+
# model settings
|
| 21 |
+
model = dict(type='YOLOWorldPromptDetector',
|
| 22 |
+
mm_neck=True,
|
| 23 |
+
num_train_classes=num_training_classes,
|
| 24 |
+
num_test_classes=num_classes,
|
| 25 |
+
embedding_path='embeddings/clip_vit_b32_coco_80_embeddings.npy',
|
| 26 |
+
prompt_dim=text_channels,
|
| 27 |
+
num_prompts=80,
|
| 28 |
+
freeze_prompt=True,
|
| 29 |
+
data_preprocessor=dict(type='YOLOv5DetDataPreprocessor'),
|
| 30 |
+
backbone=dict(_delete_=True,
|
| 31 |
+
type='MultiModalYOLOBackbone',
|
| 32 |
+
text_model=None,
|
| 33 |
+
image_model={{_base_.model.backbone}},
|
| 34 |
+
with_text_model=False),
|
| 35 |
+
neck=dict(type='YOLOWorldPAFPN',
|
| 36 |
+
freeze_all=False,
|
| 37 |
+
guide_channels=text_channels,
|
| 38 |
+
embed_channels=neck_embed_channels,
|
| 39 |
+
num_heads=neck_num_heads,
|
| 40 |
+
block_cfg=dict(type='MaxSigmoidCSPLayerWithTwoConv')),
|
| 41 |
+
bbox_head=dict(type='YOLOWorldHead',
|
| 42 |
+
head_module=dict(
|
| 43 |
+
type='YOLOWorldHeadModule',
|
| 44 |
+
freeze_all=False,
|
| 45 |
+
use_bn_head=True,
|
| 46 |
+
embed_dims=text_channels,
|
| 47 |
+
num_classes=num_training_classes)),
|
| 48 |
+
train_cfg=dict(assigner=dict(num_classes=num_training_classes)))
|
| 49 |
+
|
| 50 |
+
# dataset settings
|
| 51 |
+
coco_train_dataset = dict(type='YOLOv5CocoDataset',
|
| 52 |
+
data_root='data/coco',
|
| 53 |
+
ann_file='annotations/instances_train2017.json',
|
| 54 |
+
data_prefix=dict(img='train2017/'),
|
| 55 |
+
filter_cfg=dict(filter_empty_gt=False, min_size=32),
|
| 56 |
+
pipeline=_base_.train_pipeline)
|
| 57 |
+
|
| 58 |
+
train_dataloader = dict(persistent_workers=persistent_workers,
|
| 59 |
+
batch_size=train_batch_size_per_gpu,
|
| 60 |
+
collate_fn=dict(type='yolow_collate'),
|
| 61 |
+
dataset=coco_train_dataset)
|
| 62 |
+
|
| 63 |
+
coco_val_dataset = dict(type='YOLOv5CocoDataset',
|
| 64 |
+
data_root='data/coco',
|
| 65 |
+
ann_file='annotations/instances_val2017.json',
|
| 66 |
+
data_prefix=dict(img='val2017/'),
|
| 67 |
+
filter_cfg=dict(filter_empty_gt=False, min_size=32),
|
| 68 |
+
pipeline=_base_.test_pipeline)
|
| 69 |
+
|
| 70 |
+
val_dataloader = dict(dataset=coco_val_dataset)
|
| 71 |
+
test_dataloader = val_dataloader
|
| 72 |
+
# training settings
|
| 73 |
+
default_hooks = dict(param_scheduler=dict(scheduler_type='linear',
|
| 74 |
+
lr_factor=0.01,
|
| 75 |
+
max_epochs=max_epochs),
|
| 76 |
+
checkpoint=dict(max_keep_ckpts=-1,
|
| 77 |
+
save_best=None,
|
| 78 |
+
interval=save_epoch_intervals))
|
| 79 |
+
custom_hooks = [
|
| 80 |
+
dict(type='EMAHook',
|
| 81 |
+
ema_type='ExpMomentumEMA',
|
| 82 |
+
momentum=0.0001,
|
| 83 |
+
update_buffers=True,
|
| 84 |
+
strict_load=False,
|
| 85 |
+
priority=49),
|
| 86 |
+
dict(type='mmdet.PipelineSwitchHook',
|
| 87 |
+
switch_epoch=max_epochs - close_mosaic_epochs,
|
| 88 |
+
switch_pipeline=_base_.train_pipeline_stage2)
|
| 89 |
+
]
|
| 90 |
+
train_cfg = dict(max_epochs=max_epochs,
|
| 91 |
+
val_interval=5,
|
| 92 |
+
dynamic_intervals=[((max_epochs - close_mosaic_epochs),
|
| 93 |
+
_base_.val_interval_stage2)])
|
| 94 |
+
|
| 95 |
+
optim_wrapper = dict(optimizer=dict(
|
| 96 |
+
_delete_=True,
|
| 97 |
+
type='SGD',
|
| 98 |
+
lr=base_lr,
|
| 99 |
+
momentum=0.937,
|
| 100 |
+
nesterov=True,
|
| 101 |
+
weight_decay=weight_decay,
|
| 102 |
+
batch_size_per_gpu=train_batch_size_per_gpu))
|
| 103 |
+
|
| 104 |
+
# evaluation settings
|
| 105 |
+
val_evaluator = dict(_delete_=True,
|
| 106 |
+
type='mmdet.CocoMetric',
|
| 107 |
+
proposal_nums=(100, 1, 10),
|
| 108 |
+
ann_file='data/coco/annotations/instances_val2017.json',
|
| 109 |
+
metric='bbox')
|
configs/prompt_tuning_coco/yolo_world_v2_l_vlpan_bn_sgd_1e-3_80e_8gpus_all_fine_tuning_rmdecay_coco.py
ADDED
|
@@ -0,0 +1,113 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
_base_ = ('../../third_party/mmyolo/configs/yolov8/'
|
| 2 |
+
'yolov8_l_syncbn_fast_8xb16-500e_coco.py')
|
| 3 |
+
custom_imports = dict(imports=['yolo_world'], allow_failed_imports=False)
|
| 4 |
+
|
| 5 |
+
# hyper-parameters
|
| 6 |
+
num_classes = 80
|
| 7 |
+
num_training_classes = 80
|
| 8 |
+
max_epochs = 80 # Maximum training epochs
|
| 9 |
+
close_mosaic_epochs = 10
|
| 10 |
+
save_epoch_intervals = 5
|
| 11 |
+
text_channels = 512
|
| 12 |
+
neck_embed_channels = [128, 256, _base_.last_stage_out_channels // 2]
|
| 13 |
+
neck_num_heads = [4, 8, _base_.last_stage_out_channels // 2 // 32]
|
| 14 |
+
base_lr = 1e-3
|
| 15 |
+
weight_decay = 0.0005
|
| 16 |
+
train_batch_size_per_gpu = 16
|
| 17 |
+
load_from = 'pretrained_models/yolo_world_l_clip_t2i_bn_2e-3adamw_32xb16-100e_obj365v1_goldg_cc3mlite_train-ca93cd1f.pth'
|
| 18 |
+
persistent_workers = False
|
| 19 |
+
|
| 20 |
+
# model settings
|
| 21 |
+
model = dict(type='YOLOWorldPromptDetector',
|
| 22 |
+
mm_neck=True,
|
| 23 |
+
num_train_classes=num_training_classes,
|
| 24 |
+
num_test_classes=num_classes,
|
| 25 |
+
embedding_path='embeddings/clip_vit_b32_coco_80_embeddings.npy',
|
| 26 |
+
prompt_dim=text_channels,
|
| 27 |
+
num_prompts=80,
|
| 28 |
+
freeze_prompt=True,
|
| 29 |
+
data_preprocessor=dict(type='YOLOv5DetDataPreprocessor'),
|
| 30 |
+
backbone=dict(_delete_=True,
|
| 31 |
+
type='MultiModalYOLOBackbone',
|
| 32 |
+
text_model=None,
|
| 33 |
+
image_model={{_base_.model.backbone}},
|
| 34 |
+
with_text_model=False),
|
| 35 |
+
neck=dict(type='YOLOWorldPAFPN',
|
| 36 |
+
freeze_all=False,
|
| 37 |
+
guide_channels=text_channels,
|
| 38 |
+
embed_channels=neck_embed_channels,
|
| 39 |
+
num_heads=neck_num_heads,
|
| 40 |
+
block_cfg=dict(type='MaxSigmoidCSPLayerWithTwoConv')),
|
| 41 |
+
bbox_head=dict(type='YOLOWorldHead',
|
| 42 |
+
head_module=dict(
|
| 43 |
+
type='YOLOWorldHeadModule',
|
| 44 |
+
freeze_all=False,
|
| 45 |
+
use_bn_head=True,
|
| 46 |
+
embed_dims=text_channels,
|
| 47 |
+
num_classes=num_training_classes)),
|
| 48 |
+
train_cfg=dict(assigner=dict(num_classes=num_training_classes)))
|
| 49 |
+
|
| 50 |
+
# dataset settings
|
| 51 |
+
coco_train_dataset = dict(type='YOLOv5CocoDataset',
|
| 52 |
+
data_root='data/coco',
|
| 53 |
+
ann_file='annotations/instances_train2017.json',
|
| 54 |
+
data_prefix=dict(img='train2017/'),
|
| 55 |
+
filter_cfg=dict(filter_empty_gt=False, min_size=32),
|
| 56 |
+
pipeline=_base_.train_pipeline)
|
| 57 |
+
|
| 58 |
+
train_dataloader = dict(persistent_workers=persistent_workers,
|
| 59 |
+
batch_size=train_batch_size_per_gpu,
|
| 60 |
+
collate_fn=dict(type='yolow_collate'),
|
| 61 |
+
dataset=coco_train_dataset)
|
| 62 |
+
|
| 63 |
+
coco_val_dataset = dict(type='YOLOv5CocoDataset',
|
| 64 |
+
data_root='data/coco',
|
| 65 |
+
ann_file='annotations/instances_val2017.json',
|
| 66 |
+
data_prefix=dict(img='val2017/'),
|
| 67 |
+
filter_cfg=dict(filter_empty_gt=False, min_size=32),
|
| 68 |
+
pipeline=_base_.test_pipeline)
|
| 69 |
+
|
| 70 |
+
val_dataloader = dict(dataset=coco_val_dataset)
|
| 71 |
+
test_dataloader = val_dataloader
|
| 72 |
+
# training settings
|
| 73 |
+
default_hooks = dict(param_scheduler=dict(scheduler_type='linear',
|
| 74 |
+
lr_factor=0.01,
|
| 75 |
+
max_epochs=max_epochs),
|
| 76 |
+
checkpoint=dict(max_keep_ckpts=-1,
|
| 77 |
+
save_best=None,
|
| 78 |
+
interval=save_epoch_intervals))
|
| 79 |
+
custom_hooks = [
|
| 80 |
+
dict(type='EMAHook',
|
| 81 |
+
ema_type='ExpMomentumEMA',
|
| 82 |
+
momentum=0.0001,
|
| 83 |
+
update_buffers=True,
|
| 84 |
+
strict_load=False,
|
| 85 |
+
priority=49),
|
| 86 |
+
dict(type='mmdet.PipelineSwitchHook',
|
| 87 |
+
switch_epoch=max_epochs - close_mosaic_epochs,
|
| 88 |
+
switch_pipeline=_base_.train_pipeline_stage2)
|
| 89 |
+
]
|
| 90 |
+
train_cfg = dict(max_epochs=max_epochs,
|
| 91 |
+
val_interval=5,
|
| 92 |
+
dynamic_intervals=[((max_epochs - close_mosaic_epochs),
|
| 93 |
+
_base_.val_interval_stage2)])
|
| 94 |
+
|
| 95 |
+
optim_wrapper = dict(
|
| 96 |
+
optimizer=dict(_delete_=True,
|
| 97 |
+
type='SGD',
|
| 98 |
+
lr=base_lr,
|
| 99 |
+
momentum=0.937,
|
| 100 |
+
nesterov=True,
|
| 101 |
+
weight_decay=weight_decay,
|
| 102 |
+
batch_size_per_gpu=train_batch_size_per_gpu),
|
| 103 |
+
paramwise_cfg=dict(bias_decay_mult=0.0,
|
| 104 |
+
norm_decay_mult=0.0,
|
| 105 |
+
custom_keys={'logit_scale': dict(weight_decay=0.0)}),
|
| 106 |
+
constructor='YOLOWv5OptimizerConstructor')
|
| 107 |
+
|
| 108 |
+
# evaluation settings
|
| 109 |
+
val_evaluator = dict(_delete_=True,
|
| 110 |
+
type='mmdet.CocoMetric',
|
| 111 |
+
proposal_nums=(100, 1, 10),
|
| 112 |
+
ann_file='data/coco/annotations/instances_val2017.json',
|
| 113 |
+
metric='bbox')
|
configs/prompt_tuning_coco/yolo_world_v2_l_vlpan_bn_sgd_1e-3_80e_8gpus_all_fine_tuning_rmdecay_coco_fixed.py
ADDED
|
@@ -0,0 +1,111 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
_base_ = ('../../third_party/mmyolo/configs/yolov8/'
|
| 2 |
+
'yolov8_l_syncbn_fast_8xb16-500e_coco.py')
|
| 3 |
+
custom_imports = dict(imports=['yolo_world'], allow_failed_imports=False)
|
| 4 |
+
|
| 5 |
+
# hyper-parameters
|
| 6 |
+
num_classes = 80
|
| 7 |
+
num_training_classes = 80
|
| 8 |
+
max_epochs = 80 # Maximum training epochs
|
| 9 |
+
close_mosaic_epochs = 70
|
| 10 |
+
save_epoch_intervals = 5
|
| 11 |
+
text_channels = 512
|
| 12 |
+
neck_embed_channels = [128, 256, _base_.last_stage_out_channels // 2]
|
| 13 |
+
neck_num_heads = [4, 8, _base_.last_stage_out_channels // 2 // 32]
|
| 14 |
+
base_lr = 1e-3
|
| 15 |
+
weight_decay = 0.0005
|
| 16 |
+
train_batch_size_per_gpu = 16
|
| 17 |
+
load_from = 'pretrained_models/yolo_world_l_clip_t2i_bn_2e-3adamw_32xb16-100e_obj365v1_goldg_cc3mlite_train-ca93cd1f.pth'
|
| 18 |
+
persistent_workers = False
|
| 19 |
+
|
| 20 |
+
# model settings
|
| 21 |
+
model = dict(type='YOLOWorldPromptDetector',
|
| 22 |
+
mm_neck=True,
|
| 23 |
+
num_train_classes=num_training_classes,
|
| 24 |
+
num_test_classes=num_classes,
|
| 25 |
+
embedding_path='embeddings/clip_vit_b32_coco_80_embeddings.npy',
|
| 26 |
+
prompt_dim=text_channels,
|
| 27 |
+
num_prompts=80,
|
| 28 |
+
freeze_prompt=True,
|
| 29 |
+
data_preprocessor=dict(type='YOLOv5DetDataPreprocessor'),
|
| 30 |
+
backbone=dict(_delete_=True,
|
| 31 |
+
type='MultiModalYOLOBackbone',
|
| 32 |
+
text_model=None,
|
| 33 |
+
image_model={{_base_.model.backbone}},
|
| 34 |
+
with_text_model=False),
|
| 35 |
+
neck=dict(type='YOLOWorldPAFPN',
|
| 36 |
+
freeze_all=False,
|
| 37 |
+
guide_channels=text_channels,
|
| 38 |
+
embed_channels=neck_embed_channels,
|
| 39 |
+
num_heads=neck_num_heads,
|
| 40 |
+
block_cfg=dict(type='MaxSigmoidCSPLayerWithTwoConv')),
|
| 41 |
+
bbox_head=dict(type='YOLOWorldHead',
|
| 42 |
+
head_module=dict(
|
| 43 |
+
type='YOLOWorldHeadModule',
|
| 44 |
+
freeze_all=False,
|
| 45 |
+
use_bn_head=True,
|
| 46 |
+
embed_dims=text_channels,
|
| 47 |
+
num_classes=num_training_classes)),
|
| 48 |
+
train_cfg=dict(assigner=dict(num_classes=num_training_classes)))
|
| 49 |
+
|
| 50 |
+
# dataset settings
|
| 51 |
+
coco_train_dataset = dict(type='YOLOv5CocoDataset',
|
| 52 |
+
data_root='data/coco',
|
| 53 |
+
ann_file='annotations/instances_train2017.json',
|
| 54 |
+
data_prefix=dict(img='train2017/'),
|
| 55 |
+
filter_cfg=dict(filter_empty_gt=False, min_size=32),
|
| 56 |
+
pipeline=_base_.train_pipeline)
|
| 57 |
+
|
| 58 |
+
train_dataloader = dict(persistent_workers=persistent_workers,
|
| 59 |
+
batch_size=train_batch_size_per_gpu,
|
| 60 |
+
collate_fn=dict(type='yolow_collate'),
|
| 61 |
+
dataset=coco_train_dataset)
|
| 62 |
+
|
| 63 |
+
coco_val_dataset = dict(type='YOLOv5CocoDataset',
|
| 64 |
+
data_root='data/coco',
|
| 65 |
+
ann_file='annotations/instances_val2017.json',
|
| 66 |
+
data_prefix=dict(img='val2017/'),
|
| 67 |
+
filter_cfg=dict(filter_empty_gt=False, min_size=32),
|
| 68 |
+
pipeline=_base_.test_pipeline)
|
| 69 |
+
|
| 70 |
+
val_dataloader = dict(dataset=coco_val_dataset)
|
| 71 |
+
test_dataloader = val_dataloader
|
| 72 |
+
# training settings
|
| 73 |
+
default_hooks = dict(param_scheduler=dict(scheduler_type='linear',
|
| 74 |
+
lr_factor=0.01,
|
| 75 |
+
max_epochs=max_epochs),
|
| 76 |
+
checkpoint=dict(max_keep_ckpts=-1,
|
| 77 |
+
save_best=None,
|
| 78 |
+
interval=save_epoch_intervals))
|
| 79 |
+
custom_hooks = [
|
| 80 |
+
dict(type='EMAHook',
|
| 81 |
+
ema_type='ExpMomentumEMA',
|
| 82 |
+
momentum=0.0001,
|
| 83 |
+
update_buffers=True,
|
| 84 |
+
strict_load=False,
|
| 85 |
+
priority=49),
|
| 86 |
+
dict(type='mmdet.PipelineSwitchHook',
|
| 87 |
+
switch_epoch=max_epochs - close_mosaic_epochs,
|
| 88 |
+
switch_pipeline=_base_.train_pipeline_stage2)
|
| 89 |
+
]
|
| 90 |
+
train_cfg = dict(max_epochs=max_epochs,
|
| 91 |
+
val_interval=5,
|
| 92 |
+
dynamic_intervals=[((max_epochs - close_mosaic_epochs),
|
| 93 |
+
_base_.val_interval_stage2)])
|
| 94 |
+
|
| 95 |
+
optim_wrapper = dict(
|
| 96 |
+
optimizer=dict(_delete_=True,
|
| 97 |
+
type='SGD',
|
| 98 |
+
lr=base_lr,
|
| 99 |
+
momentum=0.937,
|
| 100 |
+
nesterov=True,
|
| 101 |
+
weight_decay=weight_decay,
|
| 102 |
+
batch_size_per_gpu=train_batch_size_per_gpu),
|
| 103 |
+
paramwise_cfg=dict(custom_keys={'logit_scale': dict(weight_decay=0.0)}),
|
| 104 |
+
constructor='YOLOWv5OptimizerConstructor')
|
| 105 |
+
|
| 106 |
+
# evaluation settings
|
| 107 |
+
val_evaluator = dict(_delete_=True,
|
| 108 |
+
type='mmdet.CocoMetric',
|
| 109 |
+
proposal_nums=(100, 1, 10),
|
| 110 |
+
ann_file='data/coco/annotations/instances_val2017.json',
|
| 111 |
+
metric='bbox')
|
configs/prompt_tuning_coco/yolo_world_v2_l_vlpan_bn_sgd_1e-4_80e_8gpus_all_fine_tuning_coco.py
ADDED
|
@@ -0,0 +1,109 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
_base_ = ('../../third_party/mmyolo/configs/yolov8/'
|
| 2 |
+
'yolov8_l_syncbn_fast_8xb16-500e_coco.py')
|
| 3 |
+
custom_imports = dict(imports=['yolo_world'], allow_failed_imports=False)
|
| 4 |
+
|
| 5 |
+
# hyper-parameters
|
| 6 |
+
num_classes = 80
|
| 7 |
+
num_training_classes = 80
|
| 8 |
+
max_epochs = 80 # Maximum training epochs
|
| 9 |
+
close_mosaic_epochs = 10
|
| 10 |
+
save_epoch_intervals = 5
|
| 11 |
+
text_channels = 512
|
| 12 |
+
neck_embed_channels = [128, 256, _base_.last_stage_out_channels // 2]
|
| 13 |
+
neck_num_heads = [4, 8, _base_.last_stage_out_channels // 2 // 32]
|
| 14 |
+
base_lr = 1e-3
|
| 15 |
+
weight_decay = 0.0005
|
| 16 |
+
train_batch_size_per_gpu = 16
|
| 17 |
+
load_from = 'pretrained_models/yolo_world_l_clip_t2i_bn_2e-3adamw_32xb16-100e_obj365v1_goldg_cc3mlite_train-ca93cd1f.pth'
|
| 18 |
+
persistent_workers = False
|
| 19 |
+
|
| 20 |
+
# model settings
|
| 21 |
+
model = dict(type='YOLOWorldPromptDetector',
|
| 22 |
+
mm_neck=True,
|
| 23 |
+
num_train_classes=num_training_classes,
|
| 24 |
+
num_test_classes=num_classes,
|
| 25 |
+
embedding_path='embeddings/clip_vit_b32_coco_80_embeddings.npy',
|
| 26 |
+
prompt_dim=text_channels,
|
| 27 |
+
num_prompts=80,
|
| 28 |
+
freeze_prompt=True,
|
| 29 |
+
data_preprocessor=dict(type='YOLOv5DetDataPreprocessor'),
|
| 30 |
+
backbone=dict(_delete_=True,
|
| 31 |
+
type='MultiModalYOLOBackbone',
|
| 32 |
+
text_model=None,
|
| 33 |
+
image_model={{_base_.model.backbone}},
|
| 34 |
+
with_text_model=False),
|
| 35 |
+
neck=dict(type='YOLOWorldPAFPN',
|
| 36 |
+
freeze_all=False,
|
| 37 |
+
guide_channels=text_channels,
|
| 38 |
+
embed_channels=neck_embed_channels,
|
| 39 |
+
num_heads=neck_num_heads,
|
| 40 |
+
block_cfg=dict(type='MaxSigmoidCSPLayerWithTwoConv')),
|
| 41 |
+
bbox_head=dict(type='YOLOWorldHead',
|
| 42 |
+
head_module=dict(
|
| 43 |
+
type='YOLOWorldHeadModule',
|
| 44 |
+
freeze_all=False,
|
| 45 |
+
use_bn_head=True,
|
| 46 |
+
embed_dims=text_channels,
|
| 47 |
+
num_classes=num_training_classes)),
|
| 48 |
+
train_cfg=dict(assigner=dict(num_classes=num_training_classes)))
|
| 49 |
+
|
| 50 |
+
# dataset settings
|
| 51 |
+
coco_train_dataset = dict(type='YOLOv5CocoDataset',
|
| 52 |
+
data_root='data/coco',
|
| 53 |
+
ann_file='annotations/instances_train2017.json',
|
| 54 |
+
data_prefix=dict(img='train2017/'),
|
| 55 |
+
filter_cfg=dict(filter_empty_gt=False, min_size=32),
|
| 56 |
+
pipeline=_base_.train_pipeline)
|
| 57 |
+
|
| 58 |
+
train_dataloader = dict(persistent_workers=persistent_workers,
|
| 59 |
+
batch_size=train_batch_size_per_gpu,
|
| 60 |
+
collate_fn=dict(type='yolow_collate'),
|
| 61 |
+
dataset=coco_train_dataset)
|
| 62 |
+
|
| 63 |
+
coco_val_dataset = dict(type='YOLOv5CocoDataset',
|
| 64 |
+
data_root='data/coco',
|
| 65 |
+
ann_file='annotations/instances_val2017.json',
|
| 66 |
+
data_prefix=dict(img='val2017/'),
|
| 67 |
+
filter_cfg=dict(filter_empty_gt=False, min_size=32),
|
| 68 |
+
pipeline=_base_.test_pipeline)
|
| 69 |
+
|
| 70 |
+
val_dataloader = dict(dataset=coco_val_dataset)
|
| 71 |
+
test_dataloader = val_dataloader
|
| 72 |
+
# training settings
|
| 73 |
+
default_hooks = dict(param_scheduler=dict(scheduler_type='linear',
|
| 74 |
+
lr_factor=0.01,
|
| 75 |
+
max_epochs=max_epochs),
|
| 76 |
+
checkpoint=dict(max_keep_ckpts=-1,
|
| 77 |
+
save_best=None,
|
| 78 |
+
interval=save_epoch_intervals))
|
| 79 |
+
custom_hooks = [
|
| 80 |
+
dict(type='EMAHook',
|
| 81 |
+
ema_type='ExpMomentumEMA',
|
| 82 |
+
momentum=0.0001,
|
| 83 |
+
update_buffers=True,
|
| 84 |
+
strict_load=False,
|
| 85 |
+
priority=49),
|
| 86 |
+
dict(type='mmdet.PipelineSwitchHook',
|
| 87 |
+
switch_epoch=max_epochs - close_mosaic_epochs,
|
| 88 |
+
switch_pipeline=_base_.train_pipeline_stage2)
|
| 89 |
+
]
|
| 90 |
+
train_cfg = dict(max_epochs=max_epochs,
|
| 91 |
+
val_interval=5,
|
| 92 |
+
dynamic_intervals=[((max_epochs - close_mosaic_epochs),
|
| 93 |
+
_base_.val_interval_stage2)])
|
| 94 |
+
|
| 95 |
+
optim_wrapper = dict(optimizer=dict(
|
| 96 |
+
_delete_=True,
|
| 97 |
+
type='SGD',
|
| 98 |
+
lr=base_lr,
|
| 99 |
+
momentum=0.937,
|
| 100 |
+
nesterov=True,
|
| 101 |
+
weight_decay=weight_decay,
|
| 102 |
+
batch_size_per_gpu=train_batch_size_per_gpu))
|
| 103 |
+
|
| 104 |
+
# evaluation settings
|
| 105 |
+
val_evaluator = dict(_delete_=True,
|
| 106 |
+
type='mmdet.CocoMetric',
|
| 107 |
+
proposal_nums=(100, 1, 10),
|
| 108 |
+
ann_file='data/coco/annotations/instances_val2017.json',
|
| 109 |
+
metric='bbox')
|
configs/segmentation/README.md
ADDED
|
@@ -0,0 +1,27 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
## Fine-tuning YOLO-World for Instance Segmentation
|
| 2 |
+
|
| 3 |
+
|
| 4 |
+
### Models
|
| 5 |
+
|
| 6 |
+
We fine-tune YOLO-World on LVIS (`LVIS-Base`) with mask annotations for open-vocabulary (zero-shot) instance segmentation.
|
| 7 |
+
|
| 8 |
+
We provide two fine-tuning strategies YOLO-World towards open-vocabulary instance segmentation:
|
| 9 |
+
|
| 10 |
+
* fine-tuning `all modules`: leads to better LVIS segmentation accuracy but affects the zero-shot performance.
|
| 11 |
+
|
| 12 |
+
* fine-tuning the `segmentation head`: maintains the zero-shot performanc but lowers LVIS segmentation accuracy.
|
| 13 |
+
|
| 14 |
+
| Model | Fine-tuning Data | Fine-tuning Modules| AP<sup>mask</su> | AP<sub>r</sub> | AP<sub>c</sub> | AP<sub>f</sub> | Weights |
|
| 15 |
+
| :---- | :--------------- | :----------------: | :--------------: | :------------: | :------------: | :------------: | :-----: |
|
| 16 |
+
| [YOLO-World-Seg-M](./yolo_world_seg_m_dual_vlpan_2e-4_80e_8gpus_allmodules_finetune_lvis.py) | `LVIS-Base` | `all modules` | 25.9 | 13.4 | 24.9 | 32.6 | [HF Checkpoints 🤗](https://huggingface.co/wondervictor/YOLO-World/blob/main/yolo_world_seg_m_dual_vlpan_2e-4_80e_8gpus_allmodules_finetune_lvis-ca465825.pth) |
|
| 17 |
+
| [YOLO-World-v2-Seg-M](./yolo_world_seg_m_dual_vlpan_2e-4_80e_8gpus_allmodules_finetune_lvis.py) | `LVIS-Base` | `all modules` | 25.9 | 13.4 | 24.9 | 32.6 | [HF Checkpoints 🤗]() |
|
| 18 |
+
| [YOLO-World-Seg-L](./yolo_world_seg_l_dual_vlpan_2e-4_80e_8gpus_allmodules_finetune_lvis.py) | `LVIS-Base` | `all modules` | 28.7 | 15.0 | 28.3 | 35.2| [HF Checkpoints 🤗](https://huggingface.co/wondervictor/YOLO-World/blob/main/yolo_world_seg_l_dual_vlpan_2e-4_80e_8gpus_allmodules_finetune_lvis-8c58c916.pth) |
|
| 19 |
+
| [YOLO-World-v2-Seg-L](./yolo_world_seg_l_dual_vlpan_2e-4_80e_8gpus_allmodules_finetune_lvis.py) | `LVIS-Base` | `all modules` | 28.7 | 15.0 | 28.3 | 35.2| [HF Checkpoints 🤗]() |
|
| 20 |
+
| [YOLO-World-Seg-M](./yolo_seg_world_m_dual_vlpan_2e-4_80e_8gpus_seghead_finetune_lvis.py) | `LVIS-Base` | `seg head` | 16.7 | 12.6 | 14.6 | 20.8 | [HF Checkpoints 🤗](https://huggingface.co/wondervictor/YOLO-World/blob/main/yolo_world_seg_m_dual_vlpan_2e-4_80e_8gpus_seghead_finetune_lvis-7bca59a7.pth) |
|
| 21 |
+
| [YOLO-World-v2-Seg-M](./yolo_world_v2_seg_m_vlpan_bn_2e-4_80e_8gpus_seghead_finetune_lvis.py) | `LVIS-Base` | `seg head` | 17.8 | 13.9 | 15.5 | 22.0 | [HF Checkpoints 🤗]() |
|
| 22 |
+
| [YOLO-World-Seg-L](yolo_seg_world_l_dual_vlpan_2e-4_80e_8gpus_seghead_finetune_lvis.py) | `LVIS-Base` | `seg head` | 19.1 | 14.2 | 17.2 | 23.5 | [HF Checkpoints 🤗](https://huggingface.co/wondervictor/YOLO-World/blob/main/yolo_world_seg_l_dual_vlpan_2e-4_80e_8gpus_seghead_finetune_lvis-5a642d30.pth) |
|
| 23 |
+
| [YOLO-World-v2-Seg-L](./yolo_world_v2_seg_l_vlpan_bn_2e-4_80e_8gpus_seghead_finetune_lvis.py) | `LVIS-Base` | `seg head` | 19.8 | 17.2 | 17.5 | 23.6 | [HF Checkpoints 🤗]() |
|
| 24 |
+
**NOTE:**
|
| 25 |
+
1. The mask AP are evaluated on the LVIS `val 1.0`.
|
| 26 |
+
2. All models are fine-tuned for 80 epochs on `LVIS-Base` (866 categories, `common + frequent`).
|
| 27 |
+
3. The YOLO-World-Seg with only `seg head` fine-tuned maintains the original zero-shot detection capability and segments objects.
|
configs/segmentation/yolo_world_seg_l_dual_vlpan_2e-4_80e_8gpus_allmodules_finetune_lvis.py
ADDED
|
@@ -0,0 +1,227 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
_base_ = (
|
| 2 |
+
'../../third_party/mmyolo/configs/yolov8/yolov8_l_mask-refine_syncbn_fast_8xb16-500e_coco.py'
|
| 3 |
+
)
|
| 4 |
+
custom_imports = dict(imports=['yolo_world'], allow_failed_imports=False)
|
| 5 |
+
# hyper-parameters
|
| 6 |
+
num_classes = 1203
|
| 7 |
+
num_training_classes = 80
|
| 8 |
+
max_epochs = 80 # Maximum training epochs
|
| 9 |
+
close_mosaic_epochs = 10
|
| 10 |
+
save_epoch_intervals = 5
|
| 11 |
+
text_channels = 512
|
| 12 |
+
neck_embed_channels = [128, 256, _base_.last_stage_out_channels // 2]
|
| 13 |
+
neck_num_heads = [4, 8, _base_.last_stage_out_channels // 2 // 32]
|
| 14 |
+
base_lr = 2e-4
|
| 15 |
+
|
| 16 |
+
weight_decay = 0.05
|
| 17 |
+
train_batch_size_per_gpu = 8
|
| 18 |
+
load_from = 'pretrained_models/yolo_world_l_clip_base_dual_vlpan_2e-3adamw_32xb16_100e_o365_goldg_train_pretrained-0e566235.pth'
|
| 19 |
+
persistent_workers = False
|
| 20 |
+
text_model_name = '../pretrained_models/clip-vit-base-patch32-projection'
|
| 21 |
+
# text_model_name = 'openai/clip-vit-base-patch32'
|
| 22 |
+
# Polygon2Mask
|
| 23 |
+
downsample_ratio = 4
|
| 24 |
+
mask_overlap = False
|
| 25 |
+
use_mask2refine = True
|
| 26 |
+
max_aspect_ratio = 100
|
| 27 |
+
min_area_ratio = 0.01
|
| 28 |
+
|
| 29 |
+
# model settings
|
| 30 |
+
model = dict(
|
| 31 |
+
type='YOLOWorldDetector',
|
| 32 |
+
mm_neck=True,
|
| 33 |
+
num_train_classes=num_training_classes,
|
| 34 |
+
num_test_classes=num_classes,
|
| 35 |
+
data_preprocessor=dict(type='YOLOWDetDataPreprocessor'),
|
| 36 |
+
backbone=dict(
|
| 37 |
+
_delete_=True,
|
| 38 |
+
type='MultiModalYOLOBackbone',
|
| 39 |
+
image_model={{_base_.model.backbone}},
|
| 40 |
+
text_model=dict(
|
| 41 |
+
type='HuggingCLIPLanguageBackbone',
|
| 42 |
+
model_name=text_model_name,
|
| 43 |
+
frozen_modules=[])),
|
| 44 |
+
neck=dict(type='YOLOWorldDualPAFPN',
|
| 45 |
+
guide_channels=text_channels,
|
| 46 |
+
embed_channels=neck_embed_channels,
|
| 47 |
+
num_heads=neck_num_heads,
|
| 48 |
+
block_cfg=dict(type='MaxSigmoidCSPLayerWithTwoConv'),
|
| 49 |
+
text_enhancder=dict(type='ImagePoolingAttentionModule',
|
| 50 |
+
embed_channels=256,
|
| 51 |
+
num_heads=8)),
|
| 52 |
+
bbox_head=dict(type='YOLOWorldSegHead',
|
| 53 |
+
head_module=dict(type='YOLOWorldSegHeadModule',
|
| 54 |
+
embed_dims=text_channels,
|
| 55 |
+
num_classes=num_training_classes,
|
| 56 |
+
mask_channels=32,
|
| 57 |
+
proto_channels=256),
|
| 58 |
+
mask_overlap=mask_overlap,
|
| 59 |
+
loss_mask=dict(type='mmdet.CrossEntropyLoss',
|
| 60 |
+
use_sigmoid=True,
|
| 61 |
+
reduction='none'),
|
| 62 |
+
loss_mask_weight=1.0),
|
| 63 |
+
train_cfg=dict(assigner=dict(num_classes=num_training_classes)),
|
| 64 |
+
test_cfg=dict(mask_thr_binary=0.5, fast_test=True))
|
| 65 |
+
|
| 66 |
+
pre_transform = [
|
| 67 |
+
dict(type='LoadImageFromFile', backend_args=_base_.backend_args),
|
| 68 |
+
dict(type='LoadAnnotations',
|
| 69 |
+
with_bbox=True,
|
| 70 |
+
with_mask=True,
|
| 71 |
+
mask2bbox=True)
|
| 72 |
+
]
|
| 73 |
+
|
| 74 |
+
last_transform = [
|
| 75 |
+
dict(type='mmdet.Albu',
|
| 76 |
+
transforms=_base_.albu_train_transforms,
|
| 77 |
+
bbox_params=dict(type='BboxParams',
|
| 78 |
+
format='pascal_voc',
|
| 79 |
+
label_fields=['gt_bboxes_labels',
|
| 80 |
+
'gt_ignore_flags']),
|
| 81 |
+
keymap={
|
| 82 |
+
'img': 'image',
|
| 83 |
+
'gt_bboxes': 'bboxes'
|
| 84 |
+
}),
|
| 85 |
+
dict(type='YOLOv5HSVRandomAug'),
|
| 86 |
+
dict(type='mmdet.RandomFlip', prob=0.5),
|
| 87 |
+
dict(type='Polygon2Mask',
|
| 88 |
+
downsample_ratio=downsample_ratio,
|
| 89 |
+
mask_overlap=mask_overlap),
|
| 90 |
+
]
|
| 91 |
+
|
| 92 |
+
# dataset settings
|
| 93 |
+
text_transform = [
|
| 94 |
+
dict(type='RandomLoadText',
|
| 95 |
+
num_neg_samples=(num_classes, num_classes),
|
| 96 |
+
max_num_samples=num_training_classes,
|
| 97 |
+
padding_to_max=True,
|
| 98 |
+
padding_value=''),
|
| 99 |
+
dict(type='PackDetInputs',
|
| 100 |
+
meta_keys=('img_id', 'img_path', 'ori_shape', 'img_shape', 'flip',
|
| 101 |
+
'flip_direction', 'texts'))
|
| 102 |
+
]
|
| 103 |
+
mosaic_affine_transform = [
|
| 104 |
+
dict(type='MultiModalMosaic',
|
| 105 |
+
img_scale=_base_.img_scale,
|
| 106 |
+
pad_val=114.0,
|
| 107 |
+
pre_transform=pre_transform),
|
| 108 |
+
dict(type='YOLOv5CopyPaste', prob=_base_.copypaste_prob),
|
| 109 |
+
dict(
|
| 110 |
+
type='YOLOv5RandomAffine',
|
| 111 |
+
max_rotate_degree=0.0,
|
| 112 |
+
max_shear_degree=0.0,
|
| 113 |
+
max_aspect_ratio=100.,
|
| 114 |
+
scaling_ratio_range=(1 - _base_.affine_scale, 1 + _base_.affine_scale),
|
| 115 |
+
# img_scale is (width, height)
|
| 116 |
+
border=(-_base_.img_scale[0] // 2, -_base_.img_scale[1] // 2),
|
| 117 |
+
border_val=(114, 114, 114),
|
| 118 |
+
min_area_ratio=_base_.min_area_ratio,
|
| 119 |
+
use_mask_refine=True)
|
| 120 |
+
]
|
| 121 |
+
train_pipeline = [
|
| 122 |
+
*pre_transform, *mosaic_affine_transform,
|
| 123 |
+
dict(type='YOLOv5MultiModalMixUp',
|
| 124 |
+
prob=_base_.mixup_prob,
|
| 125 |
+
pre_transform=[*pre_transform, *mosaic_affine_transform]),
|
| 126 |
+
*last_transform, *text_transform
|
| 127 |
+
]
|
| 128 |
+
|
| 129 |
+
_train_pipeline_stage2 = [
|
| 130 |
+
*pre_transform,
|
| 131 |
+
dict(type='YOLOv5KeepRatioResize', scale=_base_.img_scale),
|
| 132 |
+
dict(type='LetterResize',
|
| 133 |
+
scale=_base_.img_scale,
|
| 134 |
+
allow_scale_up=True,
|
| 135 |
+
pad_val=dict(img=114.0)),
|
| 136 |
+
dict(type='YOLOv5RandomAffine',
|
| 137 |
+
max_rotate_degree=0.0,
|
| 138 |
+
max_shear_degree=0.0,
|
| 139 |
+
scaling_ratio_range=(1 - _base_.affine_scale,
|
| 140 |
+
1 + _base_.affine_scale),
|
| 141 |
+
max_aspect_ratio=_base_.max_aspect_ratio,
|
| 142 |
+
border_val=(114, 114, 114),
|
| 143 |
+
min_area_ratio=min_area_ratio,
|
| 144 |
+
use_mask_refine=use_mask2refine), *last_transform
|
| 145 |
+
]
|
| 146 |
+
train_pipeline_stage2 = [*_train_pipeline_stage2, *text_transform]
|
| 147 |
+
coco_train_dataset = dict(
|
| 148 |
+
_delete_=True,
|
| 149 |
+
type='MultiModalDataset',
|
| 150 |
+
dataset=dict(type='YOLOv5LVISV1Dataset',
|
| 151 |
+
data_root='data/coco',
|
| 152 |
+
ann_file='lvis/lvis_v1_train_base.json',
|
| 153 |
+
data_prefix=dict(img=''),
|
| 154 |
+
filter_cfg=dict(filter_empty_gt=True, min_size=32)),
|
| 155 |
+
class_text_path='data/texts/lvis_v1_base_class_texts.json',
|
| 156 |
+
pipeline=train_pipeline)
|
| 157 |
+
train_dataloader = dict(persistent_workers=persistent_workers,
|
| 158 |
+
batch_size=train_batch_size_per_gpu,
|
| 159 |
+
collate_fn=dict(type='yolow_collate'),
|
| 160 |
+
dataset=coco_train_dataset)
|
| 161 |
+
|
| 162 |
+
test_pipeline = [
|
| 163 |
+
*_base_.test_pipeline[:-1],
|
| 164 |
+
dict(type='LoadText'),
|
| 165 |
+
dict(type='mmdet.PackDetInputs',
|
| 166 |
+
meta_keys=('img_id', 'img_path', 'ori_shape', 'img_shape',
|
| 167 |
+
'scale_factor', 'pad_param', 'texts'))
|
| 168 |
+
]
|
| 169 |
+
|
| 170 |
+
# training settings
|
| 171 |
+
default_hooks = dict(param_scheduler=dict(scheduler_type='linear',
|
| 172 |
+
lr_factor=0.01,
|
| 173 |
+
max_epochs=max_epochs),
|
| 174 |
+
checkpoint=dict(max_keep_ckpts=-1,
|
| 175 |
+
save_best=None,
|
| 176 |
+
interval=save_epoch_intervals))
|
| 177 |
+
custom_hooks = [
|
| 178 |
+
dict(type='EMAHook',
|
| 179 |
+
ema_type='ExpMomentumEMA',
|
| 180 |
+
momentum=0.0001,
|
| 181 |
+
update_buffers=True,
|
| 182 |
+
strict_load=False,
|
| 183 |
+
priority=49),
|
| 184 |
+
dict(type='mmdet.PipelineSwitchHook',
|
| 185 |
+
switch_epoch=max_epochs - close_mosaic_epochs,
|
| 186 |
+
switch_pipeline=train_pipeline_stage2)
|
| 187 |
+
]
|
| 188 |
+
train_cfg = dict(max_epochs=max_epochs,
|
| 189 |
+
val_interval=5,
|
| 190 |
+
dynamic_intervals=[((max_epochs - close_mosaic_epochs),
|
| 191 |
+
_base_.val_interval_stage2)])
|
| 192 |
+
optim_wrapper = dict(optimizer=dict(
|
| 193 |
+
_delete_=True,
|
| 194 |
+
type='AdamW',
|
| 195 |
+
lr=base_lr,
|
| 196 |
+
weight_decay=weight_decay,
|
| 197 |
+
batch_size_per_gpu=train_batch_size_per_gpu),
|
| 198 |
+
paramwise_cfg=dict(bias_decay_mult=0.0,
|
| 199 |
+
norm_decay_mult=0.0,
|
| 200 |
+
custom_keys={
|
| 201 |
+
'backbone.text_model':
|
| 202 |
+
dict(lr_mult=0.01),
|
| 203 |
+
'logit_scale':
|
| 204 |
+
dict(weight_decay=0.0),
|
| 205 |
+
}),
|
| 206 |
+
constructor='YOLOWv5OptimizerConstructor')
|
| 207 |
+
|
| 208 |
+
# evaluation settings
|
| 209 |
+
coco_val_dataset = dict(
|
| 210 |
+
_delete_=True,
|
| 211 |
+
type='MultiModalDataset',
|
| 212 |
+
dataset=dict(type='YOLOv5LVISV1Dataset',
|
| 213 |
+
data_root='data/coco/',
|
| 214 |
+
test_mode=True,
|
| 215 |
+
ann_file='lvis/lvis_v1_val.json',
|
| 216 |
+
data_prefix=dict(img=''),
|
| 217 |
+
batch_shapes_cfg=None),
|
| 218 |
+
class_text_path='data/captions/lvis_v1_class_captions.json',
|
| 219 |
+
pipeline=test_pipeline)
|
| 220 |
+
val_dataloader = dict(dataset=coco_val_dataset)
|
| 221 |
+
test_dataloader = val_dataloader
|
| 222 |
+
|
| 223 |
+
val_evaluator = dict(type='mmdet.LVISMetric',
|
| 224 |
+
ann_file='data/coco/lvis/lvis_v1_val.json',
|
| 225 |
+
metric=['bbox', 'segm'])
|
| 226 |
+
test_evaluator = val_evaluator
|
| 227 |
+
find_unused_parameters = True
|
configs/segmentation/yolo_world_seg_l_dual_vlpan_2e-4_80e_8gpus_seghead_finetune_lvis.py
ADDED
|
@@ -0,0 +1,237 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
_base_ = (
|
| 2 |
+
'../../third_party/mmyolo/configs/yolov8/yolov8_l_mask-refine_syncbn_fast_8xb16-500e_coco.py'
|
| 3 |
+
)
|
| 4 |
+
custom_imports = dict(imports=['yolo_world'], allow_failed_imports=False)
|
| 5 |
+
# hyper-parameters
|
| 6 |
+
num_classes = 1203
|
| 7 |
+
num_training_classes = 80
|
| 8 |
+
max_epochs = 80 # Maximum training epochs
|
| 9 |
+
close_mosaic_epochs = 10
|
| 10 |
+
save_epoch_intervals = 5
|
| 11 |
+
text_channels = 512
|
| 12 |
+
neck_embed_channels = [128, 256, _base_.last_stage_out_channels // 2]
|
| 13 |
+
neck_num_heads = [4, 8, _base_.last_stage_out_channels // 2 // 32]
|
| 14 |
+
base_lr = 2e-4
|
| 15 |
+
|
| 16 |
+
weight_decay = 0.05
|
| 17 |
+
train_batch_size_per_gpu = 8
|
| 18 |
+
load_from = 'pretrained_models/yolo_world_l_clip_base_dual_vlpan_2e-3adamw_32xb16_100e_o365_goldg_train_pretrained-0e566235.pth'
|
| 19 |
+
persistent_workers = False
|
| 20 |
+
|
| 21 |
+
# Polygon2Mask
|
| 22 |
+
downsample_ratio = 4
|
| 23 |
+
mask_overlap = False
|
| 24 |
+
use_mask2refine = True
|
| 25 |
+
max_aspect_ratio = 100
|
| 26 |
+
min_area_ratio = 0.01
|
| 27 |
+
|
| 28 |
+
# model settings
|
| 29 |
+
model = dict(
|
| 30 |
+
type='YOLOWorldDetector',
|
| 31 |
+
mm_neck=True,
|
| 32 |
+
num_train_classes=num_training_classes,
|
| 33 |
+
num_test_classes=num_classes,
|
| 34 |
+
data_preprocessor=dict(type='YOLOWDetDataPreprocessor'),
|
| 35 |
+
backbone=dict(
|
| 36 |
+
_delete_=True,
|
| 37 |
+
type='MultiModalYOLOBackbone',
|
| 38 |
+
image_model={{_base_.model.backbone}},
|
| 39 |
+
frozen_stages=4, # frozen the image backbone
|
| 40 |
+
text_model=dict(
|
| 41 |
+
type='HuggingCLIPLanguageBackbone',
|
| 42 |
+
model_name='openai/clip-vit-base-patch32',
|
| 43 |
+
frozen_modules=['all'])),
|
| 44 |
+
neck=dict(type='YOLOWorldDualPAFPN',
|
| 45 |
+
freeze_all=True,
|
| 46 |
+
guide_channels=text_channels,
|
| 47 |
+
embed_channels=neck_embed_channels,
|
| 48 |
+
num_heads=neck_num_heads,
|
| 49 |
+
block_cfg=dict(type='MaxSigmoidCSPLayerWithTwoConv'),
|
| 50 |
+
text_enhancder=dict(type='ImagePoolingAttentionModule',
|
| 51 |
+
embed_channels=256,
|
| 52 |
+
num_heads=8)),
|
| 53 |
+
bbox_head=dict(type='YOLOWorldSegHead',
|
| 54 |
+
head_module=dict(type='YOLOWorldSegHeadModule',
|
| 55 |
+
embed_dims=text_channels,
|
| 56 |
+
num_classes=num_training_classes,
|
| 57 |
+
mask_channels=32,
|
| 58 |
+
proto_channels=256,
|
| 59 |
+
freeze_bbox=True),
|
| 60 |
+
mask_overlap=mask_overlap,
|
| 61 |
+
loss_mask=dict(type='mmdet.CrossEntropyLoss',
|
| 62 |
+
use_sigmoid=True,
|
| 63 |
+
reduction='none'),
|
| 64 |
+
loss_mask_weight=1.0),
|
| 65 |
+
train_cfg=dict(assigner=dict(num_classes=num_training_classes)),
|
| 66 |
+
test_cfg=dict(mask_thr_binary=0.5, fast_test=True))
|
| 67 |
+
|
| 68 |
+
pre_transform = [
|
| 69 |
+
dict(type='LoadImageFromFile', backend_args=_base_.backend_args),
|
| 70 |
+
dict(type='LoadAnnotations',
|
| 71 |
+
with_bbox=True,
|
| 72 |
+
with_mask=True,
|
| 73 |
+
mask2bbox=True)
|
| 74 |
+
]
|
| 75 |
+
|
| 76 |
+
last_transform = [
|
| 77 |
+
dict(type='mmdet.Albu',
|
| 78 |
+
transforms=_base_.albu_train_transforms,
|
| 79 |
+
bbox_params=dict(type='BboxParams',
|
| 80 |
+
format='pascal_voc',
|
| 81 |
+
label_fields=['gt_bboxes_labels',
|
| 82 |
+
'gt_ignore_flags']),
|
| 83 |
+
keymap={
|
| 84 |
+
'img': 'image',
|
| 85 |
+
'gt_bboxes': 'bboxes'
|
| 86 |
+
}),
|
| 87 |
+
dict(type='YOLOv5HSVRandomAug'),
|
| 88 |
+
dict(type='mmdet.RandomFlip', prob=0.5),
|
| 89 |
+
dict(type='Polygon2Mask',
|
| 90 |
+
downsample_ratio=downsample_ratio,
|
| 91 |
+
mask_overlap=mask_overlap),
|
| 92 |
+
]
|
| 93 |
+
|
| 94 |
+
# dataset settings
|
| 95 |
+
text_transform = [
|
| 96 |
+
dict(type='RandomLoadText',
|
| 97 |
+
num_neg_samples=(num_classes, num_classes),
|
| 98 |
+
max_num_samples=num_training_classes,
|
| 99 |
+
padding_to_max=True,
|
| 100 |
+
padding_value=''),
|
| 101 |
+
dict(type='PackDetInputs',
|
| 102 |
+
meta_keys=('img_id', 'img_path', 'ori_shape', 'img_shape', 'flip',
|
| 103 |
+
'flip_direction', 'texts'))
|
| 104 |
+
]
|
| 105 |
+
mosaic_affine_transform = [
|
| 106 |
+
dict(type='MultiModalMosaic',
|
| 107 |
+
img_scale=_base_.img_scale,
|
| 108 |
+
pad_val=114.0,
|
| 109 |
+
pre_transform=pre_transform),
|
| 110 |
+
dict(type='YOLOv5CopyPaste', prob=_base_.copypaste_prob),
|
| 111 |
+
dict(
|
| 112 |
+
type='YOLOv5RandomAffine',
|
| 113 |
+
max_rotate_degree=0.0,
|
| 114 |
+
max_shear_degree=0.0,
|
| 115 |
+
max_aspect_ratio=100.,
|
| 116 |
+
scaling_ratio_range=(1 - _base_.affine_scale, 1 + _base_.affine_scale),
|
| 117 |
+
# img_scale is (width, height)
|
| 118 |
+
border=(-_base_.img_scale[0] // 2, -_base_.img_scale[1] // 2),
|
| 119 |
+
border_val=(114, 114, 114),
|
| 120 |
+
min_area_ratio=_base_.min_area_ratio,
|
| 121 |
+
use_mask_refine=True)
|
| 122 |
+
]
|
| 123 |
+
train_pipeline = [
|
| 124 |
+
*pre_transform, *mosaic_affine_transform,
|
| 125 |
+
dict(type='YOLOv5MultiModalMixUp',
|
| 126 |
+
prob=_base_.mixup_prob,
|
| 127 |
+
pre_transform=[*pre_transform, *mosaic_affine_transform]),
|
| 128 |
+
*last_transform, *text_transform
|
| 129 |
+
]
|
| 130 |
+
|
| 131 |
+
_train_pipeline_stage2 = [
|
| 132 |
+
*pre_transform,
|
| 133 |
+
dict(type='YOLOv5KeepRatioResize', scale=_base_.img_scale),
|
| 134 |
+
dict(type='LetterResize',
|
| 135 |
+
scale=_base_.img_scale,
|
| 136 |
+
allow_scale_up=True,
|
| 137 |
+
pad_val=dict(img=114.0)),
|
| 138 |
+
dict(type='YOLOv5RandomAffine',
|
| 139 |
+
max_rotate_degree=0.0,
|
| 140 |
+
max_shear_degree=0.0,
|
| 141 |
+
scaling_ratio_range=(1 - _base_.affine_scale,
|
| 142 |
+
1 + _base_.affine_scale),
|
| 143 |
+
max_aspect_ratio=_base_.max_aspect_ratio,
|
| 144 |
+
border_val=(114, 114, 114),
|
| 145 |
+
min_area_ratio=min_area_ratio,
|
| 146 |
+
use_mask_refine=use_mask2refine), *last_transform
|
| 147 |
+
]
|
| 148 |
+
train_pipeline_stage2 = [*_train_pipeline_stage2, *text_transform]
|
| 149 |
+
coco_train_dataset = dict(
|
| 150 |
+
_delete_=True,
|
| 151 |
+
type='MultiModalDataset',
|
| 152 |
+
dataset=dict(type='YOLOv5LVISV1Dataset',
|
| 153 |
+
data_root='data/coco',
|
| 154 |
+
ann_file='lvis/lvis_v1_train_base.json',
|
| 155 |
+
data_prefix=dict(img=''),
|
| 156 |
+
filter_cfg=dict(filter_empty_gt=True, min_size=32)),
|
| 157 |
+
class_text_path='data/texts/lvis_v1_base_class_texts.json',
|
| 158 |
+
pipeline=train_pipeline)
|
| 159 |
+
train_dataloader = dict(persistent_workers=persistent_workers,
|
| 160 |
+
batch_size=train_batch_size_per_gpu,
|
| 161 |
+
collate_fn=dict(type='yolow_collate'),
|
| 162 |
+
dataset=coco_train_dataset)
|
| 163 |
+
|
| 164 |
+
test_pipeline = [
|
| 165 |
+
*_base_.test_pipeline[:-1],
|
| 166 |
+
dict(type='LoadText'),
|
| 167 |
+
dict(type='mmdet.PackDetInputs',
|
| 168 |
+
meta_keys=('img_id', 'img_path', 'ori_shape', 'img_shape',
|
| 169 |
+
'scale_factor', 'pad_param', 'texts'))
|
| 170 |
+
]
|
| 171 |
+
|
| 172 |
+
# training settings
|
| 173 |
+
default_hooks = dict(param_scheduler=dict(scheduler_type='linear',
|
| 174 |
+
lr_factor=0.01,
|
| 175 |
+
max_epochs=max_epochs),
|
| 176 |
+
checkpoint=dict(max_keep_ckpts=-1,
|
| 177 |
+
save_best=None,
|
| 178 |
+
interval=save_epoch_intervals))
|
| 179 |
+
custom_hooks = [
|
| 180 |
+
dict(type='EMAHook',
|
| 181 |
+
ema_type='ExpMomentumEMA',
|
| 182 |
+
momentum=0.0001,
|
| 183 |
+
update_buffers=True,
|
| 184 |
+
strict_load=False,
|
| 185 |
+
priority=49),
|
| 186 |
+
dict(type='mmdet.PipelineSwitchHook',
|
| 187 |
+
switch_epoch=max_epochs - close_mosaic_epochs,
|
| 188 |
+
switch_pipeline=train_pipeline_stage2)
|
| 189 |
+
]
|
| 190 |
+
train_cfg = dict(max_epochs=max_epochs,
|
| 191 |
+
val_interval=5,
|
| 192 |
+
dynamic_intervals=[((max_epochs - close_mosaic_epochs),
|
| 193 |
+
_base_.val_interval_stage2)])
|
| 194 |
+
optim_wrapper = dict(optimizer=dict(
|
| 195 |
+
_delete_=True,
|
| 196 |
+
type='AdamW',
|
| 197 |
+
lr=base_lr,
|
| 198 |
+
weight_decay=weight_decay,
|
| 199 |
+
batch_size_per_gpu=train_batch_size_per_gpu),
|
| 200 |
+
paramwise_cfg=dict(bias_decay_mult=0.0,
|
| 201 |
+
norm_decay_mult=0.0,
|
| 202 |
+
custom_keys={
|
| 203 |
+
'backbone.text_model':
|
| 204 |
+
dict(lr_mult=0.01),
|
| 205 |
+
'logit_scale':
|
| 206 |
+
dict(weight_decay=0.0),
|
| 207 |
+
'neck':
|
| 208 |
+
dict(lr_mult=0.0),
|
| 209 |
+
'head.head_module.reg_preds':
|
| 210 |
+
dict(lr_mult=0.0),
|
| 211 |
+
'head.head_module.cls_preds':
|
| 212 |
+
dict(lr_mult=0.0),
|
| 213 |
+
'head.head_module.cls_contrasts':
|
| 214 |
+
dict(lr_mult=0.0)
|
| 215 |
+
}),
|
| 216 |
+
constructor='YOLOWv5OptimizerConstructor')
|
| 217 |
+
|
| 218 |
+
# evaluation settings
|
| 219 |
+
coco_val_dataset = dict(
|
| 220 |
+
_delete_=True,
|
| 221 |
+
type='MultiModalDataset',
|
| 222 |
+
dataset=dict(type='YOLOv5LVISV1Dataset',
|
| 223 |
+
data_root='data/coco/',
|
| 224 |
+
test_mode=True,
|
| 225 |
+
ann_file='lvis/lvis_v1_val.json',
|
| 226 |
+
data_prefix=dict(img=''),
|
| 227 |
+
batch_shapes_cfg=None),
|
| 228 |
+
class_text_path='data/captions/lvis_v1_class_captions.json',
|
| 229 |
+
pipeline=test_pipeline)
|
| 230 |
+
val_dataloader = dict(dataset=coco_val_dataset)
|
| 231 |
+
test_dataloader = val_dataloader
|
| 232 |
+
|
| 233 |
+
val_evaluator = dict(type='mmdet.LVISMetric',
|
| 234 |
+
ann_file='data/coco/lvis/lvis_v1_val.json',
|
| 235 |
+
metric=['bbox', 'segm'])
|
| 236 |
+
test_evaluator = val_evaluator
|
| 237 |
+
find_unused_parameters = True
|