Spaces:
Running

Running
Merge remote-tracking branch 'origin/main' into main
Browse files- app.py +3 -1
- examples.py +15 -1
- introduction.md +14 -5
- localization.py +178 -0
- requirements.txt +2 -1
- static/img/examples/child_on_slide.png +0 -0
- static/img/examples/due_gatti.png +0 -0
- static/img/examples/un_gatto.png +0 -0
- static/img/gatto_cane.png +0 -0
- static/img/image_to_text.png +0 -0
- static/img/text_to_image.png +0 -0
app.py
CHANGED
|
@@ -1,6 +1,7 @@
|
|
| 1 |
import streamlit as st
|
| 2 |
import image2text
|
| 3 |
import text2image
|
|
|
|
| 4 |
import home
|
| 5 |
import examples
|
| 6 |
from PIL import Image
|
|
@@ -9,7 +10,8 @@ PAGES = {
|
|
| 9 |
"Introduction": home,
|
| 10 |
"Text to Image": text2image,
|
| 11 |
"Image to Text": image2text,
|
| 12 |
-
"
|
|
|
|
| 13 |
}
|
| 14 |
|
| 15 |
st.sidebar.title("Explore our CLIP-Italian demo")
|
|
|
|
| 1 |
import streamlit as st
|
| 2 |
import image2text
|
| 3 |
import text2image
|
| 4 |
+
import localization
|
| 5 |
import home
|
| 6 |
import examples
|
| 7 |
from PIL import Image
|
|
|
|
| 10 |
"Introduction": home,
|
| 11 |
"Text to Image": text2image,
|
| 12 |
"Image to Text": image2text,
|
| 13 |
+
"Localization": localization,
|
| 14 |
+
"Gallery": examples,
|
| 15 |
}
|
| 16 |
|
| 17 |
st.sidebar.title("Explore our CLIP-Italian demo")
|
examples.py
CHANGED
|
@@ -3,7 +3,7 @@ import streamlit as st
|
|
| 3 |
|
| 4 |
|
| 5 |
def app():
|
| 6 |
-
st.title("
|
| 7 |
st.write(
|
| 8 |
"""
|
| 9 |
|
|
@@ -81,6 +81,20 @@ def app():
|
|
| 81 |
col2.markdown("*A rustic chair*")
|
| 82 |
col2.image("static/img/examples/sedia_rustica.jpeg", use_column_width=True)
|
| 83 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 84 |
st.markdown("## Image Classification")
|
| 85 |
st.markdown(
|
| 86 |
"We report this cool example provided by the "
|
|
|
|
| 3 |
|
| 4 |
|
| 5 |
def app():
|
| 6 |
+
st.title("Gallery")
|
| 7 |
st.write(
|
| 8 |
"""
|
| 9 |
|
|
|
|
| 81 |
col2.markdown("*A rustic chair*")
|
| 82 |
col2.image("static/img/examples/sedia_rustica.jpeg", use_column_width=True)
|
| 83 |
|
| 84 |
+
st.markdown("## Localization")
|
| 85 |
+
|
| 86 |
+
st.subheader("Un gatto")
|
| 87 |
+
st.markdown("*A cat*")
|
| 88 |
+
st.image("static/img/examples/un_gatto.png", use_column_width=True)
|
| 89 |
+
|
| 90 |
+
st.subheader("Un gatto")
|
| 91 |
+
st.markdown("*A cat*")
|
| 92 |
+
st.image("static/img/examples/due_gatti.png", use_column_width=True)
|
| 93 |
+
|
| 94 |
+
st.subheader("Un bambino")
|
| 95 |
+
st.markdown("*A child*")
|
| 96 |
+
st.image("static/img/examples/child_on_slide.png", use_column_width=True)
|
| 97 |
+
|
| 98 |
st.markdown("## Image Classification")
|
| 99 |
st.markdown(
|
| 100 |
"We report this cool example provided by the "
|
introduction.md
CHANGED
|
@@ -9,7 +9,7 @@ is built upon the pre-trained [Italian BERT](https://huggingface.co/dbmdz/bert-b
|
|
| 9 |
|
| 10 |
In building this project we kept in mind the following principles:
|
| 11 |
|
| 12 |
-
+ **Novel Contributions**: We created
|
| 13 |
+ **Scientific Validity**: Claim are easy, facts are hard. That's why validation is important to assess the real impact of a model. We thoroughly evaluated our models on two tasks and made the validation reproducible for everybody.
|
| 14 |
+ **Broader Outlook**: We always kept in mind which are the possible usages and limitations of this model.
|
| 15 |
|
|
@@ -21,14 +21,23 @@ Thank you for this amazing opportunity, we hope you will like the results! :hear
|
|
| 21 |
|
| 22 |
In this demo, we present two tasks:
|
| 23 |
|
| 24 |
-
+
|
| 25 |
compute the similarity between this string of text with respect to a set of images. The webapp is going to display the images that
|
| 26 |
have the highest similarity with the text query.
|
| 27 |
|
| 28 |
-
|
|
|
|
|
|
|
| 29 |
is going to compute the similarity between the image and each label. The webapp is going to display a probability distribution over the captions.
|
| 30 |
|
| 31 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 32 |
different applications that can start from here.
|
| 33 |
|
| 34 |
# Novel Contributions
|
|
@@ -247,7 +256,7 @@ labels most probably had an impact on the final scores.
|
|
| 247 |
|
| 248 |
We hereby show some interesting properties of the model. One is its ability to detect colors,
|
| 249 |
then there is its (partial) counting ability and finally the ability of understanding more complex queries. You can find
|
| 250 |
-
more examples in the "*
|
| 251 |
|
| 252 |
To our own surprise, many of the answers the model gives make a lot of sense! Note that the model, in this case,
|
| 253 |
is searching the right image from a set of 25K images from an Unsplash dataset.
|
|
|
|
| 9 |
|
| 10 |
In building this project we kept in mind the following principles:
|
| 11 |
|
| 12 |
+
+ **Novel Contributions**: We created an impressive dataset of ~1.4 million Italian image-text pairs (**that we will share with the community**) and, to the best of our knowledge, we trained the best Italian CLIP model currently in existence;
|
| 13 |
+ **Scientific Validity**: Claim are easy, facts are hard. That's why validation is important to assess the real impact of a model. We thoroughly evaluated our models on two tasks and made the validation reproducible for everybody.
|
| 14 |
+ **Broader Outlook**: We always kept in mind which are the possible usages and limitations of this model.
|
| 15 |
|
|
|
|
| 21 |
|
| 22 |
In this demo, we present two tasks:
|
| 23 |
|
| 24 |
+
+ **Text to Image**: This task is essentially an image retrieval task. The user is asked to input a string of text and CLIP is going to
|
| 25 |
compute the similarity between this string of text with respect to a set of images. The webapp is going to display the images that
|
| 26 |
have the highest similarity with the text query.
|
| 27 |
|
| 28 |
+
<img src="https://huggingface.co/spaces/clip-italian/clip-italian-demo/raw/main/static/img/text_to_image.png" alt="drawing" width="95%"/>
|
| 29 |
+
|
| 30 |
+
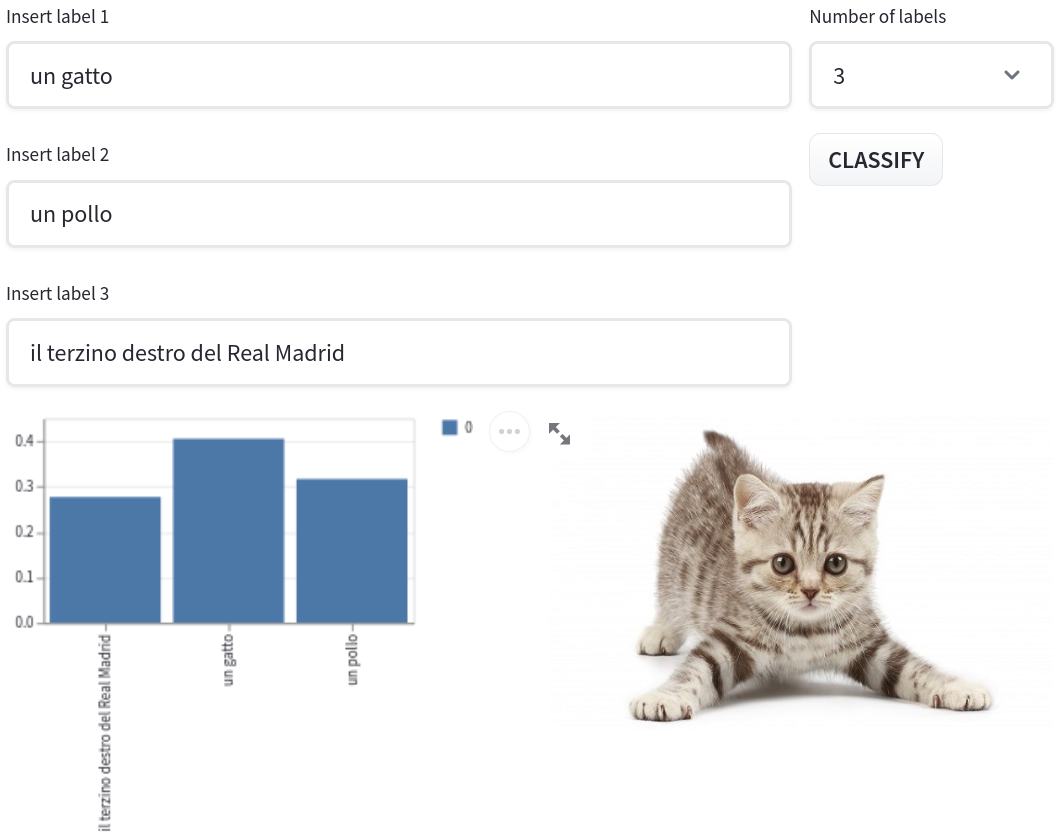
+ **Image to Text**: This task is essentially a zero-shot image classification task. The user is asked for an image and for a set of captions/labels and CLIP
|
| 31 |
is going to compute the similarity between the image and each label. The webapp is going to display a probability distribution over the captions.
|
| 32 |
|
| 33 |
+
<img src="https://huggingface.co/spaces/clip-italian/clip-italian-demo/raw/main/static/img/image_to_text.png" alt="drawing" width="95%"/>
|
| 34 |
+
|
| 35 |
+
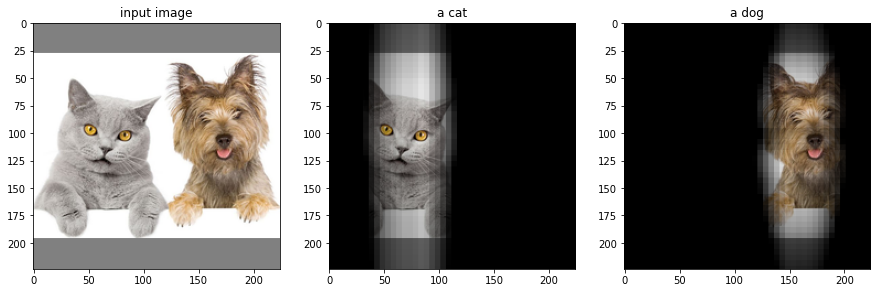
+ **Localization**: This is a **very cool** feature :sunglasses: and at the best of our knowledge, it is a novel contribution. We can use CLIP
|
| 36 |
+
to find where "something" (like a "cat") is an image. The location of the object is computed by masking different areas of the image and looking at how the similarity to the image description changes.
|
| 37 |
+
|
| 38 |
+
<img src="https://huggingface.co/spaces/clip-italian/clip-italian-demo/raw/main/static/img/gatto_cane.png" alt="drawing" width="95%"/>
|
| 39 |
+
|
| 40 |
+
+ **Gallery**: This page showcases some interesting results we got from the model, we believe that there are
|
| 41 |
different applications that can start from here.
|
| 42 |
|
| 43 |
# Novel Contributions
|
|
|
|
| 256 |
|
| 257 |
We hereby show some interesting properties of the model. One is its ability to detect colors,
|
| 258 |
then there is its (partial) counting ability and finally the ability of understanding more complex queries. You can find
|
| 259 |
+
more examples in the "*Gallery*" section of this demo.
|
| 260 |
|
| 261 |
To our own surprise, many of the answers the model gives make a lot of sense! Note that the model, in this case,
|
| 262 |
is searching the right image from a set of 25K images from an Unsplash dataset.
|
localization.py
ADDED
|
@@ -0,0 +1,178 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import streamlit as st
|
| 2 |
+
from text2image import get_model, get_tokenizer, get_image_transform
|
| 3 |
+
from utils import text_encoder
|
| 4 |
+
from torchvision import transforms
|
| 5 |
+
from PIL import Image
|
| 6 |
+
from jax import numpy as jnp
|
| 7 |
+
import pandas as pd
|
| 8 |
+
import numpy as np
|
| 9 |
+
import requests
|
| 10 |
+
import psutil
|
| 11 |
+
import time
|
| 12 |
+
import jax
|
| 13 |
+
import gc
|
| 14 |
+
|
| 15 |
+
|
| 16 |
+
preprocess = transforms.Compose([
|
| 17 |
+
transforms.ToTensor(),
|
| 18 |
+
transforms.Normalize((0.48145466, 0.4578275, 0.40821073), (0.26862954, 0.26130258, 0.27577711)),
|
| 19 |
+
])
|
| 20 |
+
|
| 21 |
+
|
| 22 |
+
def pad_to_square(image, size=224):
|
| 23 |
+
ratio = float(size) / max(image.size)
|
| 24 |
+
new_size = tuple([int(x * ratio) for x in image.size])
|
| 25 |
+
image = image.resize(new_size, Image.ANTIALIAS)
|
| 26 |
+
new_image = Image.new("RGB", size=(size, size), color=(128, 128, 128))
|
| 27 |
+
new_image.paste(image, ((size - new_size[0]) // 2, (size - new_size[1]) // 2))
|
| 28 |
+
return new_image
|
| 29 |
+
|
| 30 |
+
|
| 31 |
+
def image_encoder(image, model):
|
| 32 |
+
image = np.transpose(image, (0, 2, 3, 1))
|
| 33 |
+
features = model.get_image_features(image)
|
| 34 |
+
features /= jnp.linalg.norm(features, keepdims=True)
|
| 35 |
+
return features
|
| 36 |
+
|
| 37 |
+
|
| 38 |
+
def gen_image_batch(image_url, image_size=224, pixel_size=10):
|
| 39 |
+
n_pixels = image_size // pixel_size + 1
|
| 40 |
+
|
| 41 |
+
image_batch = []
|
| 42 |
+
masks = []
|
| 43 |
+
image_raw = requests.get(image_url, stream=True).raw
|
| 44 |
+
image = Image.open(image_raw).convert("RGB")
|
| 45 |
+
image = pad_to_square(image, size=image_size)
|
| 46 |
+
gray = np.ones_like(image) * 128
|
| 47 |
+
mask = np.ones_like(image)
|
| 48 |
+
|
| 49 |
+
image_batch.append(image)
|
| 50 |
+
masks.append(mask)
|
| 51 |
+
|
| 52 |
+
for i in range(0, n_pixels):
|
| 53 |
+
for j in range(i+1, n_pixels):
|
| 54 |
+
m = mask.copy()
|
| 55 |
+
m[:min(i*pixel_size, image_size) + 1, :] = 0
|
| 56 |
+
m[min(j*pixel_size, image_size) + 1:, :] = 0
|
| 57 |
+
neg_m = 1 - m
|
| 58 |
+
image_batch.append(image * m + gray * neg_m)
|
| 59 |
+
masks.append(m)
|
| 60 |
+
|
| 61 |
+
for i in range(0, n_pixels+1):
|
| 62 |
+
for j in range(i+1, n_pixels+1):
|
| 63 |
+
m = mask.copy()
|
| 64 |
+
m[:, :min(i*pixel_size + 1, image_size)] = 0
|
| 65 |
+
m[:, min(j*pixel_size + 1, image_size):] = 0
|
| 66 |
+
neg_m = 1 - m
|
| 67 |
+
image_batch.append(image * m + gray * neg_m)
|
| 68 |
+
masks.append(m)
|
| 69 |
+
|
| 70 |
+
return image_batch, masks
|
| 71 |
+
|
| 72 |
+
|
| 73 |
+
def get_heatmap(image_url, text, pixel_size=10, iterations=3):
|
| 74 |
+
tokenizer = get_tokenizer()
|
| 75 |
+
model = get_model()
|
| 76 |
+
image_size = model.config.vision_config.image_size
|
| 77 |
+
text_embedding = text_encoder(text, model, tokenizer)
|
| 78 |
+
images, masks = gen_image_batch(image_url, image_size=image_size, pixel_size=pixel_size)
|
| 79 |
+
|
| 80 |
+
input_image = images[0].copy()
|
| 81 |
+
images = np.stack([preprocess(image) for image in images], axis=0)
|
| 82 |
+
image_embeddings = jnp.asarray(image_encoder(images, model))
|
| 83 |
+
|
| 84 |
+
sims = []
|
| 85 |
+
scores = []
|
| 86 |
+
mask_val = jnp.zeros_like(masks[0])
|
| 87 |
+
|
| 88 |
+
for e, m in zip(image_embeddings, masks):
|
| 89 |
+
sim = jnp.matmul(e, text_embedding.T)
|
| 90 |
+
sims.append(sim)
|
| 91 |
+
if len(sims) > 1:
|
| 92 |
+
scores.append(sim * m)
|
| 93 |
+
mask_val += 1 - m
|
| 94 |
+
|
| 95 |
+
score = jnp.mean(jnp.clip(jnp.array(scores) - sims[0], 0, jnp.inf), axis=0)
|
| 96 |
+
for i in range(iterations):
|
| 97 |
+
score = jnp.clip(score - jnp.mean(score), 0, jnp.inf)
|
| 98 |
+
score = (score - jnp.min(score)) / (jnp.max(score) - jnp.min(score))
|
| 99 |
+
return np.asarray(score), input_image
|
| 100 |
+
|
| 101 |
+
|
| 102 |
+
def app():
|
| 103 |
+
st.title("Zero-Shot Localization")
|
| 104 |
+
st.markdown(
|
| 105 |
+
"""
|
| 106 |
+
|
| 107 |
+
### 👋 Ciao!
|
| 108 |
+
|
| 109 |
+
Here you can find an example for zero shot localization that will show you where in an image the model sees an object.
|
| 110 |
+
|
| 111 |
+
The location of the object is computed by masking different areas of the image and looking at
|
| 112 |
+
how the similarity to the image description changes. If you want to have a look at the implementation in details
|
| 113 |
+
you can find it in [this Colab](https://colab.research.google.com/drive/10neENr1DEAFq_GzsLqBDo0gZ50hOhkOr?usp=sharing).
|
| 114 |
+
|
| 115 |
+
On the two parameters: the pixel size defines the resolution of the localization map. A pixel size of 15 means
|
| 116 |
+
that 15 pixels in the original image will form 1 pixel in the heatmap. The refinement
|
| 117 |
+
iterations are just a cheap operation to reduce background noise. Too few iterations will leave a lot of noise.
|
| 118 |
+
Too many will shrink the heatmap too much.
|
| 119 |
+
|
| 120 |
+
|
| 121 |
+
🤌 Italian mode on! 🤌
|
| 122 |
+
|
| 123 |
+
For example, try typing "gatto" (cat) or "cane" (dog) in the space for label and click "locate"!
|
| 124 |
+
|
| 125 |
+
"""
|
| 126 |
+
)
|
| 127 |
+
|
| 128 |
+
image_url = st.text_input(
|
| 129 |
+
"You can input the URL of an image here...",
|
| 130 |
+
value="https://www.tuttosuigatti.it/files/styles/full_width/public/images/featured/205/cani-e-gatti.jpg?itok=WAAiTGS6",
|
| 131 |
+
)
|
| 132 |
+
|
| 133 |
+
MAX_ITER = 1
|
| 134 |
+
|
| 135 |
+
|
| 136 |
+
col1, col2 = st.beta_columns([3, 1])
|
| 137 |
+
|
| 138 |
+
with col2:
|
| 139 |
+
pixel_size = st.selectbox(
|
| 140 |
+
"Pixel Size", options=range(10, 21, 5), index=0
|
| 141 |
+
)
|
| 142 |
+
|
| 143 |
+
iterations = st.selectbox(
|
| 144 |
+
"Refinement Steps", options=range(3, 30, 3), index=0
|
| 145 |
+
)
|
| 146 |
+
|
| 147 |
+
compute = st.button("LOCATE")
|
| 148 |
+
|
| 149 |
+
with col1:
|
| 150 |
+
caption = st.text_input(f"Insert label...")
|
| 151 |
+
|
| 152 |
+
if compute:
|
| 153 |
+
|
| 154 |
+
with st.spinner('Waiting for resources...'):
|
| 155 |
+
sleep_time = 5
|
| 156 |
+
print('CPU_load', psutil.cpu_percent())
|
| 157 |
+
while psutil.cpu_percent() > 60:
|
| 158 |
+
time.sleep(sleep_time)
|
| 159 |
+
|
| 160 |
+
|
| 161 |
+
if not caption or not image_url:
|
| 162 |
+
st.error("Please choose one image and at least one label")
|
| 163 |
+
else:
|
| 164 |
+
with st.spinner("Computing... This might take up to a few minutes depending on the current load 😕 \n"
|
| 165 |
+
"[Colab Link](https://colab.research.google.com/drive/10neENr1DEAFq_GzsLqBDo0gZ50hOhkOr?usp=sharing)"):
|
| 166 |
+
heatmap, image = get_heatmap(image_url, caption, pixel_size, iterations)
|
| 167 |
+
|
| 168 |
+
with col1:
|
| 169 |
+
st.image(image, use_column_width=True)
|
| 170 |
+
st.image(heatmap, use_column_width=True)
|
| 171 |
+
st.image(np.asarray(image) / 255.0 * heatmap, use_column_width=True)
|
| 172 |
+
gc.collect()
|
| 173 |
+
|
| 174 |
+
elif image_url:
|
| 175 |
+
image_raw = requests.get(image_url, stream=True, ).raw
|
| 176 |
+
image = Image.open(image_raw).convert("RGB")
|
| 177 |
+
with col1:
|
| 178 |
+
st.image(image)
|
requirements.txt
CHANGED
|
@@ -6,4 +6,5 @@ torchvision
|
|
| 6 |
natsort
|
| 7 |
stqdm
|
| 8 |
pandas
|
| 9 |
-
requests
|
|
|
|
|
|
| 6 |
natsort
|
| 7 |
stqdm
|
| 8 |
pandas
|
| 9 |
+
requests
|
| 10 |
+
psutil
|
static/img/examples/child_on_slide.png
ADDED

|
static/img/examples/due_gatti.png
ADDED

|
static/img/examples/un_gatto.png
ADDED

|
static/img/gatto_cane.png
ADDED
|
static/img/image_to_text.png
ADDED
|
static/img/text_to_image.png
ADDED
|