Spaces:
Build error

Build error
updates to afro speech
Browse files- app.css +38 -0
- app.py +160 -85
- number/0.jpg +0 -0
- number/1.jpg +0 -0
- number/2.jpg +0 -0
- number/3.jpg +0 -0
- number/4.jpg +0 -0
- number/5.jpg +0 -0
- number/6.jpg +0 -0
- number/7.jpg +0 -0
- number/8.jpg +0 -0
- number/9.jpg +0 -0
- number/best.gif +3 -0
- utils.py +44 -0
app.css
ADDED
|
@@ -0,0 +1,38 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
|
| 2 |
+
.infoPoint h1 {
|
| 3 |
+
font-size: 30px;
|
| 4 |
+
text-decoration: bold;
|
| 5 |
+
|
| 6 |
+
}
|
| 7 |
+
|
| 8 |
+
a {
|
| 9 |
+
text-decoration: underline;
|
| 10 |
+
color: #1f3b54 ;
|
| 11 |
+
}
|
| 12 |
+
|
| 13 |
+
.finished {
|
| 14 |
+
color:rgb(9, 102, 169);
|
| 15 |
+
font-size:13px
|
| 16 |
+
}
|
| 17 |
+
|
| 18 |
+
table {
|
| 19 |
+
|
| 20 |
+
margin: 25px 0;
|
| 21 |
+
font-size: 0.9em;
|
| 22 |
+
font-family: sans-serif;
|
| 23 |
+
min-width: 400px;
|
| 24 |
+
max-width: 400px;
|
| 25 |
+
box-shadow: 0 0 20px rgba(0, 0, 0, 0.15);
|
| 26 |
+
}
|
| 27 |
+
|
| 28 |
+
table th,
|
| 29 |
+
table td {
|
| 30 |
+
padding: 12px 15px;
|
| 31 |
+
}
|
| 32 |
+
|
| 33 |
+
tr {
|
| 34 |
+
text-align: left;
|
| 35 |
+
}
|
| 36 |
+
thead tr {
|
| 37 |
+
text-align: left;
|
| 38 |
+
}
|
app.py
CHANGED
|
@@ -1,144 +1,219 @@
|
|
|
|
|
| 1 |
import os
|
| 2 |
import csv
|
|
|
|
| 3 |
import pandas as pd
|
| 4 |
import gradio as gr
|
| 5 |
-
import
|
| 6 |
import scipy.io.wavfile as wavf
|
| 7 |
-
from huggingface_hub import Repository
|
|
|
|
|
|
|
|
|
|
| 8 |
|
| 9 |
HF_TOKEN = os.environ.get("HF_TOKEN")
|
| 10 |
|
|
|
|
|
|
|
|
|
|
| 11 |
|
| 12 |
DATASET_REPO_URL = "https://huggingface.co/datasets/chrisjay/crowd-speech-africa"
|
| 13 |
-
|
| 14 |
-
|
| 15 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 16 |
|
| 17 |
-
|
| 18 |
-
|
|
|
|
|
|
|
| 19 |
|
| 20 |
repo = Repository(
|
| 21 |
local_dir="data", clone_from=DATASET_REPO_URL, use_auth_token=HF_TOKEN
|
| 22 |
)
|
| 23 |
-
repo.git_pull()
|
| 24 |
|
| 25 |
-
|
|
|
|
| 26 |
|
| 27 |
|
| 28 |
-
def push_record():
|
| 29 |
-
# Push the wav to a folder and reference the location
|
| 30 |
-
commit_url = repo.push_to_hub()
|
| 31 |
-
output = f'Recordings successfully pushed!'
|
| 32 |
-
output_string = "<html> <body> <div class='output' style='color:green; font-size:13px'>"+output+"</div> </body> </html>"
|
| 33 |
-
return output_string
|
| 34 |
-
|
| 35 |
|
|
|
|
|
|
|
| 36 |
|
| 37 |
-
def save_record(language,text,record):
|
| 38 |
# Save text and its corresponding record to flag
|
| 39 |
-
|
| 40 |
-
if
|
| 41 |
-
|
| 42 |
-
|
| 43 |
-
|
| 44 |
-
|
| 45 |
-
|
| 46 |
-
|
| 47 |
-
|
| 48 |
-
|
| 49 |
-
|
| 50 |
-
|
| 51 |
-
|
| 52 |
-
|
| 53 |
-
|
| 54 |
-
|
| 55 |
-
|
| 56 |
-
|
| 57 |
-
|
| 58 |
-
|
| 59 |
-
|
| 60 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 61 |
|
| 62 |
-
|
| 63 |
-
|
| 64 |
-
|
| 65 |
-
|
| 66 |
-
|
| 67 |
-
|
| 68 |
-
|
| 69 |
-
|
| 70 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 71 |
|
| 72 |
def display_records():
|
| 73 |
-
|
| 74 |
-
|
| 75 |
-
|
| 76 |
-
|
| 77 |
-
|
| 78 |
-
|
| 79 |
-
|
| 80 |
-
|
| 81 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 82 |
<tr>
|
| 83 |
<th>language</th>
|
| 84 |
<th>audio</th>
|
|
|
|
| 85 |
<th>text</th>
|
| 86 |
</tr>"""
|
| 87 |
-
for lang, audio, text in zip(langs,audios,texts):
|
| 88 |
html+= f"""<tr>
|
| 89 |
<td>{lang}</td>
|
| 90 |
<td><audio controls><source src="{audio}" type="audio/wav"> </audio></td>
|
|
|
|
| 91 |
<td>{text}</td>
|
| 92 |
</tr>"""
|
| 93 |
html+="</table></div>"
|
| 94 |
return html
|
| 95 |
|
| 96 |
|
|
|
|
| 97 |
|
| 98 |
|
| 99 |
-
title = 'African Crowdsource Speech'
|
| 100 |
-
description = 'A platform to contribute to your African language by recording your voice'
|
| 101 |
-
|
| 102 |
-
markdown = """# Africa Crowdsource Speech
|
| 103 |
|
| 104 |
-
|
|
|
|
| 105 |
|
| 106 |
|
| 107 |
-
GENDER = ['Choose Gender','Male','Female','Other','Prefer not to say']
|
| 108 |
-
NUMBERS = [i for i in range(21)]
|
| 109 |
-
|
| 110 |
# Interface design begins
|
| 111 |
-
block = gr.Blocks()
|
| 112 |
with block:
|
| 113 |
gr.Markdown(markdown)
|
| 114 |
with gr.Tabs():
|
| 115 |
|
| 116 |
with gr.TabItem('Record'):
|
| 117 |
-
#with gr.Row():
|
| 118 |
-
language = gr.inputs.Dropdown(choices = list(DEFAULT_LANGS.keys()),label="Choose language",default="Choose language")
|
| 119 |
-
|
| 120 |
with gr.Row():
|
| 121 |
-
|
| 122 |
-
|
| 123 |
-
|
| 124 |
-
|
| 125 |
-
|
| 126 |
-
|
| 127 |
-
|
| 128 |
-
|
| 129 |
|
| 130 |
output_result = gr.outputs.HTML()
|
| 131 |
-
|
| 132 |
-
|
| 133 |
-
|
|
|
|
|
|
|
| 134 |
|
| 135 |
-
save.click(save_record, inputs=[language,text,record],outputs=output_result)
|
| 136 |
-
push.click(push_record, inputs=[],outputs=output_result)
|
| 137 |
|
| 138 |
with gr.TabItem('Listen') as listen_tab:
|
| 139 |
gr.Markdown("Listen to the recordings contributed. You can find them <a href='https://huggingface.co/datasets/chrisjay/crowd-speech-africa' target='blank'>here</a>.")
|
| 140 |
-
|
| 141 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 142 |
|
| 143 |
|
| 144 |
block.launch()
|
|
|
|
| 1 |
+
from email.policy import default
|
| 2 |
import os
|
| 3 |
import csv
|
| 4 |
+
import random
|
| 5 |
import pandas as pd
|
| 6 |
import gradio as gr
|
| 7 |
+
from utils import *
|
| 8 |
import scipy.io.wavfile as wavf
|
| 9 |
+
from huggingface_hub import Repository, upload_file
|
| 10 |
+
|
| 11 |
+
|
| 12 |
+
|
| 13 |
|
| 14 |
HF_TOKEN = os.environ.get("HF_TOKEN")
|
| 15 |
|
| 16 |
+
NUMBER_DIR = './number'
|
| 17 |
+
number_files = [f.name for f in os.scandir(NUMBER_DIR)]
|
| 18 |
+
|
| 19 |
|
| 20 |
DATASET_REPO_URL = "https://huggingface.co/datasets/chrisjay/crowd-speech-africa"
|
| 21 |
+
REPOSITORY_DIR = "data"
|
| 22 |
+
LOCAL_DIR = 'data_local'
|
| 23 |
+
os.makedirs(LOCAL_DIR,exist_ok=True)
|
| 24 |
+
#DEFAULT_LANGS = {'Igbo':'ibo','Yoruba':'yor','Hausa':'hau'}
|
| 25 |
+
|
| 26 |
+
GENDER = ['Choose Gender','Male','Female','Other','Prefer not to say']
|
| 27 |
+
|
| 28 |
+
|
| 29 |
+
#------------------Work on Languages--------------------
|
| 30 |
+
DEFAULT_LANGS = {}
|
| 31 |
+
languages = read_json_lines('clean_languages.json')
|
| 32 |
+
languages_lower=[l for l in languages]
|
| 33 |
|
| 34 |
+
_ = [DEFAULT_LANGS.update({l['full'].lower():l['id'].lower()}) for l in languages_lower]
|
| 35 |
+
#_ = [DEFAULT_LANGS.update({l_other.lower():[l['id'].lower()]}) for l in languages_lower for l_other in l['others'] if l_other.lower()!=l['full'].lower()]
|
| 36 |
+
|
| 37 |
+
#------------------Work on Languages--------------------
|
| 38 |
|
| 39 |
repo = Repository(
|
| 40 |
local_dir="data", clone_from=DATASET_REPO_URL, use_auth_token=HF_TOKEN
|
| 41 |
)
|
| 42 |
+
#repo.git_pull()
|
| 43 |
|
| 44 |
+
with open('app.css','r') as f:
|
| 45 |
+
BLOCK_CSS = f.read()
|
| 46 |
|
| 47 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 48 |
|
| 49 |
+
def save_record(language,text,record,number,age,gender,accent,number_history,current_number,done_recording):
|
| 50 |
+
number_history = number_history or [0]
|
| 51 |
|
|
|
|
| 52 |
# Save text and its corresponding record to flag
|
| 53 |
+
speaker_metadata={}
|
| 54 |
+
speaker_metadata['gender'] = gender if gender!=GENDER[0] else ''
|
| 55 |
+
speaker_metadata['age'] = age if age !='' else ''
|
| 56 |
+
speaker_metadata['accent'] = accent if accent!='' else ''
|
| 57 |
+
if not done_recording:
|
| 58 |
+
if language!=None and language!='Choose language' and record is not None and number is not None:
|
| 59 |
+
language = language.lower()
|
| 60 |
+
lang_id = DEFAULT_LANGS[language]
|
| 61 |
+
text =text.strip()
|
| 62 |
+
|
| 63 |
+
# Write audio to file
|
| 64 |
+
audio_name = get_unique_name()
|
| 65 |
+
SAVE_FILE_DIR = os.path.join(LOCAL_DIR,audio_name)
|
| 66 |
+
os.makedirs(SAVE_FILE_DIR,exist_ok=True)
|
| 67 |
+
audio_output_filename = os.path.join(SAVE_FILE_DIR,'audio.wav')
|
| 68 |
+
wavf.write(audio_output_filename,record[0],record[1])
|
| 69 |
+
|
| 70 |
+
# Write metadata.json to file
|
| 71 |
+
json_file_path = os.path.join(SAVE_FILE_DIR,'metadata.jsonl')
|
| 72 |
+
metadata= {'id':audio_name,'file_name':'audio.wav',
|
| 73 |
+
'language_name':language,'language_id':lang_id,
|
| 74 |
+
'number':current_number, 'text':text,'frequency':record[0],
|
| 75 |
+
'age': speaker_metadata['age'],'gender': speaker_metadata['gender'],
|
| 76 |
+
'accent': speaker_metadata['accent']
|
| 77 |
+
}
|
| 78 |
+
|
| 79 |
+
dump_json(metadata,json_file_path)
|
| 80 |
+
|
| 81 |
+
# Simply upload the audio file and metadata using the hub's upload_file
|
| 82 |
+
# Upload the audio
|
| 83 |
+
repo_audio_path = os.path.join(REPOSITORY_DIR,os.path.join(audio_name,'audio.wav'))
|
| 84 |
+
|
| 85 |
+
_ = upload_file(path_or_fileobj = audio_output_filename,
|
| 86 |
+
path_in_repo =repo_audio_path,
|
| 87 |
+
repo_id='chrisjay/crowd-speech-africa',
|
| 88 |
+
repo_type='dataset',
|
| 89 |
+
token=HF_TOKEN
|
| 90 |
+
)
|
| 91 |
+
|
| 92 |
+
# Upload the metadata
|
| 93 |
+
repo_json_path = os.path.join(REPOSITORY_DIR,os.path.join(audio_name,'metadata.jsonl'))
|
| 94 |
+
_ = upload_file(path_or_fileobj = json_file_path,
|
| 95 |
+
path_in_repo =repo_json_path,
|
| 96 |
+
repo_id='chrisjay/crowd-speech-africa',
|
| 97 |
+
repo_type='dataset',
|
| 98 |
+
token=HF_TOKEN
|
| 99 |
+
)
|
| 100 |
+
|
| 101 |
+
output = f'Recording successfully saved!'
|
| 102 |
+
|
| 103 |
+
# Choose the next number
|
| 104 |
+
number_history.append(current_number)
|
| 105 |
+
number_choices = [num for num in [i for i in range(10)] if num not in number_history]
|
| 106 |
+
if number_choices!=[]:
|
| 107 |
+
next_number = random.choice(number_choices)
|
| 108 |
+
|
| 109 |
+
next_number_image = f'number/{next_number}.jpg'
|
| 110 |
+
else:
|
| 111 |
+
done_recording=True
|
| 112 |
+
next_number = 0 # the default number
|
| 113 |
+
next_number_image = f'number/best.gif'
|
| 114 |
+
output_string = "<html> <body> <div class='output' style='color:green; font-size:13px'>"+output+"</div> </body> </html>"
|
| 115 |
+
return output_string,next_number_image,number_history,next_number,done_recording
|
| 116 |
|
| 117 |
+
if number is None:
|
| 118 |
+
output = "Number must be specified!"
|
| 119 |
+
if record is None:
|
| 120 |
+
output="No recording found!"
|
| 121 |
+
if language is None or language=='Choose language':
|
| 122 |
+
output = 'Language must be specified!'
|
| 123 |
+
output_string = "<html> <body> <div class='output' style='color:green; font-size:13px'>"+output+"</div> </body> </html>"
|
| 124 |
+
|
| 125 |
+
# return output_string, previous image and state
|
| 126 |
+
return output_string, number,number_history,current_number,done_recording
|
| 127 |
+
else:
|
| 128 |
+
# Stop submitting recording (best.gif is displaying)
|
| 129 |
+
output = '🙌 You have finished all recording! Thank You. You can reload to start again (maybe in another language).'
|
| 130 |
+
output_string = "<div class='finished'>"+output+"</div>"
|
| 131 |
+
next_number = 0 # the default number
|
| 132 |
+
next_number_image = f'number/best.gif'
|
| 133 |
+
return output_string,next_number_image,number_history,next_number,done_recording
|
| 134 |
|
| 135 |
def display_records():
|
| 136 |
+
repo.git_pull()
|
| 137 |
+
REPOSITORY_DATA_DIR = os.path.join(REPOSITORY_DIR,'data')
|
| 138 |
+
repo_recordings = [os.path.join(REPOSITORY_DATA_DIR,f.name) for f in os.scandir(REPOSITORY_DATA_DIR)] if os.path.isdir(REPOSITORY_DATA_DIR) else []
|
| 139 |
+
|
| 140 |
+
audio_repo = [os.path.join(f,'audio.wav') for f in repo_recordings]
|
| 141 |
+
audio_repo = [a.replace('data/data/','https://huggingface.co/datasets/chrisjay/crowd-speech-africa/resolve/main/data/') for a in audio_repo]
|
| 142 |
+
metadata_repo = [read_json_lines(os.path.join(f,'metadata.jsonl'))[0] for f in repo_recordings]
|
| 143 |
+
audios_all = audio_repo
|
| 144 |
+
metadata_all = metadata_repo
|
| 145 |
+
|
| 146 |
+
|
| 147 |
+
langs=[m['language_name'] for m in metadata_all]
|
| 148 |
+
audios = [a for a in audios_all]
|
| 149 |
+
texts = [m['text'] for m in metadata_all]
|
| 150 |
+
numbers = [m['number'] for m in metadata_all]
|
| 151 |
+
|
| 152 |
+
|
| 153 |
+
html = f"""<div class="infoPoint">
|
| 154 |
+
<h1> Hooray! We have collected {len(metadata_all)} samples!</h1>
|
| 155 |
+
<table style="width:100%; text-align:center">
|
| 156 |
<tr>
|
| 157 |
<th>language</th>
|
| 158 |
<th>audio</th>
|
| 159 |
+
<th>number</th>
|
| 160 |
<th>text</th>
|
| 161 |
</tr>"""
|
| 162 |
+
for lang, audio, text,num_ in zip(langs,audios,texts,numbers):
|
| 163 |
html+= f"""<tr>
|
| 164 |
<td>{lang}</td>
|
| 165 |
<td><audio controls><source src="{audio}" type="audio/wav"> </audio></td>
|
| 166 |
+
<td>{num_}</td>
|
| 167 |
<td>{text}</td>
|
| 168 |
</tr>"""
|
| 169 |
html+="</table></div>"
|
| 170 |
return html
|
| 171 |
|
| 172 |
|
| 173 |
+
# NUMBERS = [{'image':os.path.join(NUMBER_DIR,f),'number':int(f.split('.')[0])} for f in number_files]
|
| 174 |
|
| 175 |
|
|
|
|
|
|
|
|
|
|
|
|
|
| 176 |
|
| 177 |
+
markdown = """<div style="text-align: center"><p style="font-size: 40px"> Africa Crowdsource Speech </p> <br>
|
| 178 |
+
This is a platform to contribute to your African language by recording your voice </div>"""
|
| 179 |
|
| 180 |
|
|
|
|
|
|
|
|
|
|
| 181 |
# Interface design begins
|
| 182 |
+
block = gr.Blocks(css=BLOCK_CSS)
|
| 183 |
with block:
|
| 184 |
gr.Markdown(markdown)
|
| 185 |
with gr.Tabs():
|
| 186 |
|
| 187 |
with gr.TabItem('Record'):
|
|
|
|
|
|
|
|
|
|
| 188 |
with gr.Row():
|
| 189 |
+
language = gr.inputs.Dropdown(choices = sorted([lang_.title() for lang_ in list(DEFAULT_LANGS.keys())]),label="Choose language",default="Choose language")
|
| 190 |
+
age = gr.inputs.Textbox(placeholder='e.g. 21',label="Your age (optional)",default='')
|
| 191 |
+
gender = gr.inputs.Dropdown(choices=GENDER, type="value", default=None, label="Gender (optional)")
|
| 192 |
+
accent = gr.inputs.Textbox(label="Accent (optional)",default='')
|
| 193 |
+
|
| 194 |
+
number = gr.Image('number/0.jpg',image_mode="L")
|
| 195 |
+
text = gr.inputs.Textbox(placeholder='e.g. `one` is `otu` in Igbo or `ọkan` in Yoruba',label="Number in your language")
|
| 196 |
+
record = gr.inputs.Audio(source="microphone",label='Record your voice')
|
| 197 |
|
| 198 |
output_result = gr.outputs.HTML()
|
| 199 |
+
state = gr.Variable(default_value=[0])
|
| 200 |
+
current_number = gr.Variable(default_value=0)
|
| 201 |
+
done_recording = gr.Variable(default_value=False) # Signifies when to stop submitting records even if `submit`` is clicked
|
| 202 |
+
save = gr.Button("Submit")
|
| 203 |
+
|
| 204 |
|
| 205 |
+
save.click(save_record, inputs=[language,text,record,number,age,gender,accent,state,current_number,done_recording],outputs=[output_result,number,state,current_number,done_recording])
|
|
|
|
| 206 |
|
| 207 |
with gr.TabItem('Listen') as listen_tab:
|
| 208 |
gr.Markdown("Listen to the recordings contributed. You can find them <a href='https://huggingface.co/datasets/chrisjay/crowd-speech-africa' target='blank'>here</a>.")
|
| 209 |
+
display_html = gr.HTML("""<div style="color: green">
|
| 210 |
+
<p> ⌛ Please wait. Loading dataset... </p>
|
| 211 |
+
</div>
|
| 212 |
+
""")
|
| 213 |
+
|
| 214 |
+
|
| 215 |
+
#listen = gr.Button("Listen")
|
| 216 |
+
listen_tab.select(display_records,inputs=[],outputs=display_html)
|
| 217 |
|
| 218 |
|
| 219 |
block.launch()
|
number/0.jpg
ADDED

|
number/1.jpg
ADDED

|
number/2.jpg
ADDED

|
number/3.jpg
ADDED

|
number/4.jpg
ADDED
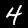
|
number/5.jpg
ADDED

|
number/6.jpg
ADDED

|
number/7.jpg
ADDED

|
number/8.jpg
ADDED

|
number/9.jpg
ADDED
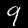
|
number/best.gif
ADDED

|
Git LFS Details
|
utils.py
ADDED
|
@@ -0,0 +1,44 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
|
| 2 |
+
import json
|
| 3 |
+
import hashlib
|
| 4 |
+
import random
|
| 5 |
+
import string
|
| 6 |
+
|
| 7 |
+
|
| 8 |
+
|
| 9 |
+
def get_unique_name():
|
| 10 |
+
return ''.join([random.choice(string.ascii_letters
|
| 11 |
+
+ string.digits) for n in range(32)])
|
| 12 |
+
|
| 13 |
+
|
| 14 |
+
def read_json_lines(file):
|
| 15 |
+
with open(file,'r',encoding="utf8") as f:
|
| 16 |
+
lines = f.readlines()
|
| 17 |
+
data=[]
|
| 18 |
+
for l in lines:
|
| 19 |
+
data.append(json.loads(l))
|
| 20 |
+
return data
|
| 21 |
+
|
| 22 |
+
|
| 23 |
+
def json_dump(thing):
|
| 24 |
+
return json.dumps(thing,
|
| 25 |
+
ensure_ascii=False,
|
| 26 |
+
sort_keys=True,
|
| 27 |
+
indent=None,
|
| 28 |
+
separators=(',', ':'))
|
| 29 |
+
|
| 30 |
+
def get_hash(thing): # stable-hashing
|
| 31 |
+
return str(hashlib.md5(json_dump(thing).encode('utf-8')).hexdigest())
|
| 32 |
+
|
| 33 |
+
|
| 34 |
+
def dump_json(thing,file):
|
| 35 |
+
with open(file,'w+',encoding="utf8") as f:
|
| 36 |
+
json.dump(thing,f)
|
| 37 |
+
|
| 38 |
+
def read_json_lines(file):
|
| 39 |
+
with open(file,'r',encoding="utf8") as f:
|
| 40 |
+
lines = f.readlines()
|
| 41 |
+
data=[]
|
| 42 |
+
for l in lines:
|
| 43 |
+
data.append(json.loads(l))
|
| 44 |
+
return data
|