Spaces:
Build error

Build error
modules to test the model
Browse files- .gitignore +2 -1
- app.py +25 -10
- data +1 -1
- inference.py +119 -0
- loss_main_plot.png +0 -0
- requirements.txt +7 -1
- run.sh +3 -0
- val_accuracy_plot.png +0 -0
.gitignore
CHANGED
|
@@ -2,4 +2,5 @@ data/*
|
|
| 2 |
gradio_queue.db
|
| 3 |
data
|
| 4 |
__pycache__/*
|
| 5 |
-
data_local/*
|
|
|
|
|
|
| 2 |
gradio_queue.db
|
| 3 |
data
|
| 4 |
__pycache__/*
|
| 5 |
+
data_local/*
|
| 6 |
+
afro-speech/__pycache__
|
app.py
CHANGED
|
@@ -11,8 +11,7 @@ from utils import *
|
|
| 11 |
import matplotlib.pyplot as plt
|
| 12 |
import scipy.io.wavfile as wavf
|
| 13 |
from huggingface_hub import Repository, upload_file
|
| 14 |
-
|
| 15 |
-
|
| 16 |
|
| 17 |
|
| 18 |
HF_TOKEN = os.environ.get("HF_TOKEN")
|
|
@@ -31,7 +30,6 @@ os.makedirs(LOCAL_DIR,exist_ok=True)
|
|
| 31 |
|
| 32 |
GENDER = ['Choose Gender','Male','Female','Other','Prefer not to say']
|
| 33 |
|
| 34 |
-
|
| 35 |
#------------------Work on Languages--------------------
|
| 36 |
DEFAULT_LANGS = {}
|
| 37 |
languages = read_json_lines('clean_languages.json')
|
|
@@ -50,8 +48,6 @@ repo.git_pull()
|
|
| 50 |
with open('app.css','r') as f:
|
| 51 |
BLOCK_CSS = f.read()
|
| 52 |
|
| 53 |
-
|
| 54 |
-
|
| 55 |
def save_record(language,text,record,number,age,gender,accent,number_history,current_number,country,email,done_recording):
|
| 56 |
# set default
|
| 57 |
number_history = number_history if number_history is not None else [0]
|
|
@@ -273,6 +269,7 @@ __Note:__ You should record all numbers shown till the end. It does not count i
|
|
| 273 |
PLOTS_FOR_GRADIO = []
|
| 274 |
FUNCTIONS_FOR_GRADIO = []
|
| 275 |
|
|
|
|
| 276 |
# Interface design begins
|
| 277 |
block = gr.Blocks(css=BLOCK_CSS)
|
| 278 |
with block:
|
|
@@ -366,12 +363,30 @@ with block:
|
|
| 366 |
|
| 367 |
#listen = gr.Button("Listen")
|
| 368 |
listen_tab.select(show_records,inputs=[],outputs=[display_html,plot]+PLOTS_FOR_GRADIO)
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 369 |
|
| 370 |
-
|
| 371 |
-
# Have a list of the languages. lang
|
| 372 |
-
# We want digits per language and gender per language
|
| 373 |
-
# for l in range(len(lang),step =4)
|
| 374 |
-
# with Row().... d
|
| 375 |
gr.Markdown(ARTICLE)
|
| 376 |
|
| 377 |
block.launch()
|
|
|
|
| 11 |
import matplotlib.pyplot as plt
|
| 12 |
import scipy.io.wavfile as wavf
|
| 13 |
from huggingface_hub import Repository, upload_file
|
| 14 |
+
from inference import make_inference
|
|
|
|
| 15 |
|
| 16 |
|
| 17 |
HF_TOKEN = os.environ.get("HF_TOKEN")
|
|
|
|
| 30 |
|
| 31 |
GENDER = ['Choose Gender','Male','Female','Other','Prefer not to say']
|
| 32 |
|
|
|
|
| 33 |
#------------------Work on Languages--------------------
|
| 34 |
DEFAULT_LANGS = {}
|
| 35 |
languages = read_json_lines('clean_languages.json')
|
|
|
|
| 48 |
with open('app.css','r') as f:
|
| 49 |
BLOCK_CSS = f.read()
|
| 50 |
|
|
|
|
|
|
|
| 51 |
def save_record(language,text,record,number,age,gender,accent,number_history,current_number,country,email,done_recording):
|
| 52 |
# set default
|
| 53 |
number_history = number_history if number_history is not None else [0]
|
|
|
|
| 269 |
PLOTS_FOR_GRADIO = []
|
| 270 |
FUNCTIONS_FOR_GRADIO = []
|
| 271 |
|
| 272 |
+
|
| 273 |
# Interface design begins
|
| 274 |
block = gr.Blocks(css=BLOCK_CSS)
|
| 275 |
with block:
|
|
|
|
| 363 |
|
| 364 |
#listen = gr.Button("Listen")
|
| 365 |
listen_tab.select(show_records,inputs=[],outputs=[display_html,plot]+PLOTS_FOR_GRADIO)
|
| 366 |
+
|
| 367 |
+
with gr.TabItem('Test Model') as listen_tab:
|
| 368 |
+
# Dropdown to choose a language from any of the 6
|
| 369 |
+
# When you choose, it will load the correponding model
|
| 370 |
+
# And then one can record a voice and get the model prediction
|
| 371 |
+
|
| 372 |
+
#Igbo - ibo
|
| 373 |
+
#Oshiwambo - kua
|
| 374 |
+
#Yoruba - yor
|
| 375 |
+
#Oromo (although note all of these audios are from female) - gax
|
| 376 |
+
#Shona (all male) - sna
|
| 377 |
+
#Rundi (all male) - run
|
| 378 |
+
|
| 379 |
+
gr.Markdown('''Here we are testing the models which we trained on the dataset collected.
|
| 380 |
+
|
| 381 |
+
Choose a language from the dropdown, record your voice and select `Submit`.''')
|
| 382 |
+
|
| 383 |
+
with gr.Row():
|
| 384 |
+
language_choice = gr.Dropdown(["Choose language","Igbo", "Oshiwambo", "Yoruba","Oromo","Shona","Rundi","MULTILINGUAL"],label="Choose language",default="Choose language")
|
| 385 |
+
input_audio = gr.Audio(source="microphone",label='Record your voice',type='filepath')
|
| 386 |
+
output_pred = gr.Label(num_top_classes=5)
|
| 387 |
+
submit = gr.Button('Submit')
|
| 388 |
+
submit.click(make_inference, inputs = [language_choice,input_audio], outputs = [output_pred])
|
| 389 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 390 |
gr.Markdown(ARTICLE)
|
| 391 |
|
| 392 |
block.launch()
|
data
CHANGED
|
@@ -1 +1 @@
|
|
| 1 |
-
Subproject commit
|
|
|
|
| 1 |
+
Subproject commit ebedcd8c55c90d39fd27126d29d8484566cd27ca
|
inference.py
ADDED
|
@@ -0,0 +1,119 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import torch
|
| 2 |
+
import torchaudio
|
| 3 |
+
from torch import nn
|
| 4 |
+
from transformers import AutoFeatureExtractor,AutoModelForAudioClassification,pipeline
|
| 5 |
+
|
| 6 |
+
#Preprocessing the data
|
| 7 |
+
feature_extractor = AutoFeatureExtractor.from_pretrained("facebook/wav2vec2-base")
|
| 8 |
+
max_duration = 2.0 # seconds
|
| 9 |
+
|
| 10 |
+
|
| 11 |
+
if torch.cuda.is_available():
|
| 12 |
+
device = "cuda"
|
| 13 |
+
else:
|
| 14 |
+
device = "cpu"
|
| 15 |
+
|
| 16 |
+
softmax = nn.Softmax()
|
| 17 |
+
|
| 18 |
+
|
| 19 |
+
label2id, id2label = dict(), dict()
|
| 20 |
+
labels = ['0','1','2','3','4','5','6','7','8','9']
|
| 21 |
+
num_labels = 10
|
| 22 |
+
|
| 23 |
+
for i, label in enumerate(labels):
|
| 24 |
+
label2id[label] = str(i)
|
| 25 |
+
id2label[str(i)] = label
|
| 26 |
+
|
| 27 |
+
|
| 28 |
+
def get_pipeline(model_name):
|
| 29 |
+
if model_name.split('-')[-1].strip()!='ibo':
|
| 30 |
+
return None
|
| 31 |
+
return pipeline(task="audio-classification", model=model_name)
|
| 32 |
+
|
| 33 |
+
|
| 34 |
+
def load_model(model_checkpoint):
|
| 35 |
+
#if model_checkpoint.split('-')[-1].strip()!='ibo': #This is for DEBUGGING
|
| 36 |
+
# return None, None
|
| 37 |
+
|
| 38 |
+
# construct model and assign it to device
|
| 39 |
+
model = AutoModelForAudioClassification.from_pretrained(
|
| 40 |
+
model_checkpoint,
|
| 41 |
+
num_labels=num_labels,
|
| 42 |
+
label2id=label2id,
|
| 43 |
+
id2label=id2label,
|
| 44 |
+
).to(device)
|
| 45 |
+
|
| 46 |
+
return model
|
| 47 |
+
|
| 48 |
+
language_dict = {
|
| 49 |
+
"Igbo":'ibo',
|
| 50 |
+
"Oshiwambo":'kua',
|
| 51 |
+
"Yoruba":'yor',
|
| 52 |
+
"Oromo":'gax',
|
| 53 |
+
"Shona":'sna',
|
| 54 |
+
"Rundi":'run',
|
| 55 |
+
"Choose language":'none',
|
| 56 |
+
"MULTILINGUAL":'all'
|
| 57 |
+
}
|
| 58 |
+
|
| 59 |
+
AUDIO_CLASSIFICATION_MODELS= {'ibo':load_model('chrisjay/afrospeech-wav2vec-ibo'),
|
| 60 |
+
'kua':load_model('chrisjay/afrospeech-wav2vec-kua'),
|
| 61 |
+
'sna':load_model('chrisjay/afrospeech-wav2vec-sna'),
|
| 62 |
+
'yor':load_model('chrisjay/afrospeech-wav2vec-yor'),
|
| 63 |
+
'gax':load_model('chrisjay/afrospeech-wav2vec-gax'),
|
| 64 |
+
'run':load_model('chrisjay/afrospeech-wav2vec-run'),
|
| 65 |
+
'all':load_model('chrisjay/afrospeech-wav2vec-all-6') }
|
| 66 |
+
|
| 67 |
+
|
| 68 |
+
def cut_if_necessary(signal,num_samples):
|
| 69 |
+
if signal.shape[1] > num_samples:
|
| 70 |
+
signal = signal[:, :num_samples]
|
| 71 |
+
return signal
|
| 72 |
+
|
| 73 |
+
def right_pad_if_necessary(signal,num_samples):
|
| 74 |
+
length_signal = signal.shape[1]
|
| 75 |
+
if length_signal < num_samples:
|
| 76 |
+
num_missing_samples = num_samples - length_signal
|
| 77 |
+
last_dim_padding = (0, num_missing_samples)
|
| 78 |
+
signal = torch.nn.functional.pad(signal, last_dim_padding)
|
| 79 |
+
return signal
|
| 80 |
+
|
| 81 |
+
def resample_if_necessary(signal, sr,target_sample_rate,device):
|
| 82 |
+
if sr != target_sample_rate:
|
| 83 |
+
resampler = torchaudio.transforms.Resample(sr, target_sample_rate).to(device)
|
| 84 |
+
signal = resampler(signal)
|
| 85 |
+
return signal
|
| 86 |
+
|
| 87 |
+
def mix_down_if_necessary(signal):
|
| 88 |
+
if signal.shape[0] > 1:
|
| 89 |
+
signal = torch.mean(signal, dim=0, keepdim=True)
|
| 90 |
+
return signal
|
| 91 |
+
|
| 92 |
+
|
| 93 |
+
|
| 94 |
+
def preprocess_audio(waveform,sample_rate,feature_extractor):
|
| 95 |
+
|
| 96 |
+
waveform = resample_if_necessary(waveform, sample_rate,16000,device)
|
| 97 |
+
waveform = mix_down_if_necessary(waveform)
|
| 98 |
+
waveform = cut_if_necessary(waveform,16000)
|
| 99 |
+
waveform = right_pad_if_necessary(waveform,16000)
|
| 100 |
+
transformed = feature_extractor(waveform,sampling_rate=feature_extractor.sampling_rate, max_length=16000, truncation=True)
|
| 101 |
+
return transformed
|
| 102 |
+
|
| 103 |
+
|
| 104 |
+
|
| 105 |
+
def make_inference(drop_down,audio):
|
| 106 |
+
waveform, sample_rate = torchaudio.load(audio)
|
| 107 |
+
preprocessed_audio = preprocess_audio(waveform,sample_rate,feature_extractor)
|
| 108 |
+
language_code_chosen = language_dict[drop_down]
|
| 109 |
+
model = AUDIO_CLASSIFICATION_MODELS[language_code_chosen]
|
| 110 |
+
model.eval()
|
| 111 |
+
torch_preprocessed_audio = torch.from_numpy(preprocessed_audio.input_values[0])
|
| 112 |
+
# make prediction
|
| 113 |
+
prediction = softmax(model(torch_preprocessed_audio).logits)
|
| 114 |
+
|
| 115 |
+
sorted_prediction = torch.sort(prediction,descending=True)
|
| 116 |
+
confidences={}
|
| 117 |
+
for s,v in zip(sorted_prediction.indices.detach().numpy().tolist()[0],sorted_prediction.values.detach().numpy().tolist()[0]):
|
| 118 |
+
confidences.update({s:v})
|
| 119 |
+
return confidences
|
loss_main_plot.png
ADDED
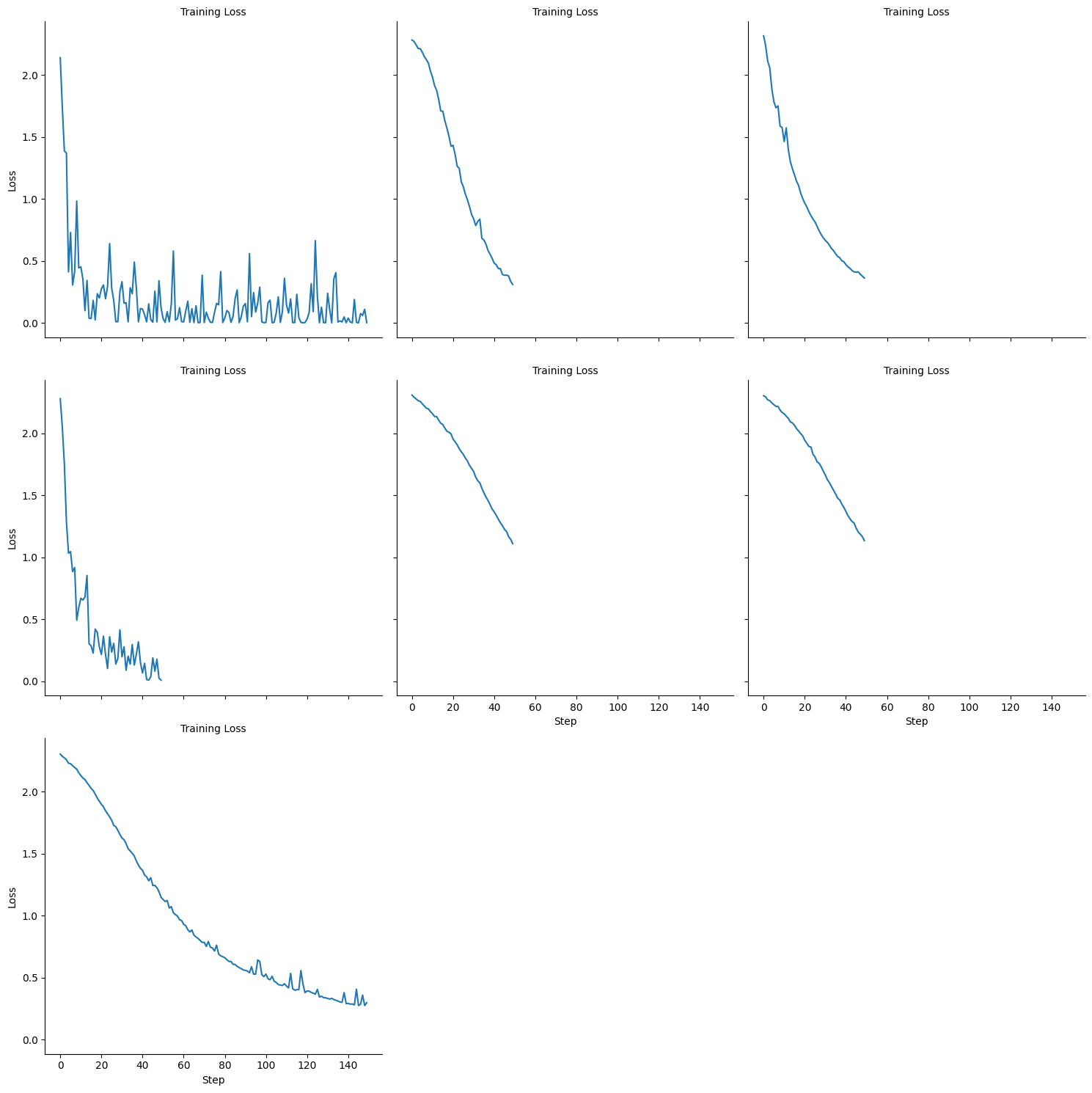
|
requirements.txt
CHANGED
|
@@ -2,4 +2,10 @@ pandas
|
|
| 2 |
scipy
|
| 3 |
pycountry
|
| 4 |
numpy
|
| 5 |
-
matplotlib
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 2 |
scipy
|
| 3 |
pycountry
|
| 4 |
numpy
|
| 5 |
+
matplotlib
|
| 6 |
+
datasets==1.14
|
| 7 |
+
transformers
|
| 8 |
+
librosa
|
| 9 |
+
torch
|
| 10 |
+
huggingface-hub
|
| 11 |
+
torchaudio
|
run.sh
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
#!/bin/bash
|
| 2 |
+
#cd afro-speech
|
| 3 |
+
export HF_TOKEN=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 && python -m pdb app.py
|
val_accuracy_plot.png
ADDED
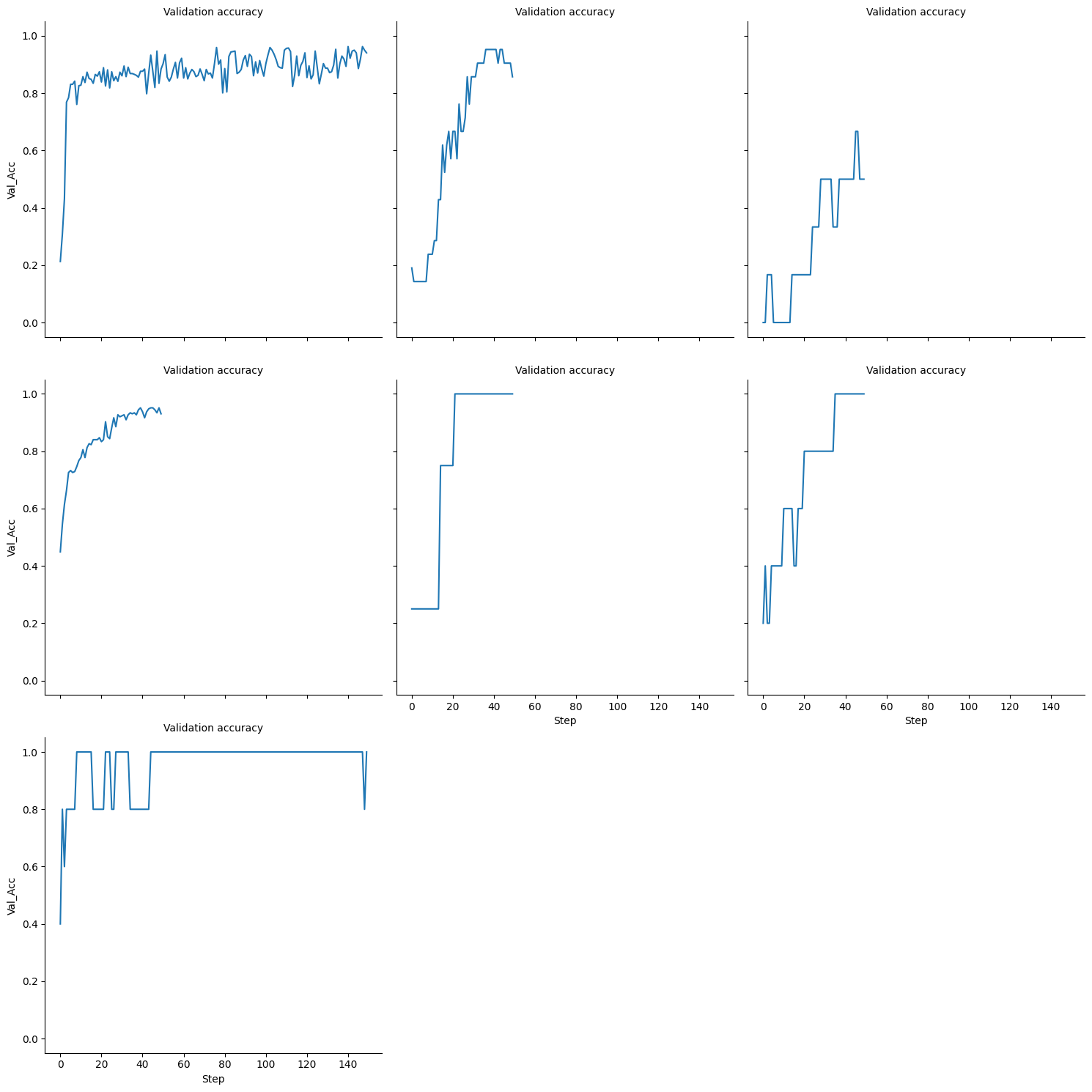
|