Spaces:
No application file

No application file

update
Browse filesThis view is limited to 50 files because it contains too many changes.
See raw diff
- .gitattributes +3 -0
- CLIP/CLIP.png +0 -0
- CLIP/LICENSE +22 -0
- CLIP/MANIFEST.in +1 -0
- CLIP/clip/__init__.py +1 -0
- CLIP/clip/__pycache__/__init__.cpython-38.pyc +0 -0
- CLIP/clip/__pycache__/clip.cpython-38.pyc +0 -0
- CLIP/clip/__pycache__/model.cpython-38.pyc +0 -0
- CLIP/clip/__pycache__/simple_tokenizer.cpython-38.pyc +0 -0
- CLIP/clip/bpe_simple_vocab_16e6.txt.gz +3 -0
- CLIP/clip/clip.py +200 -0
- CLIP/clip/model.py +439 -0
- CLIP/clip/simple_tokenizer.py +132 -0
- CLIP/math.json +98 -0
- CLIP/model-card.md +118 -0
- CLIP/notebooks/Interacting_with_CLIP.ipynb +0 -0
- CLIP/notebooks/Prompt_Engineering_for_ImageNet.ipynb +1188 -0
- CLIP/requirements.txt +5 -0
- CLIP/setup.py +21 -0
- CLIP/tests/test_consistency.py +25 -0
- GPT_eval_multi.py +144 -0
- LICENSE +201 -0
- README.md +227 -13
- VQ_eval.py +95 -0
- attack.py +182 -0
- dataset/dataset_TM_eval.py +241 -0
- dataset/dataset_TM_train.py +188 -0
- dataset/dataset_VQ.py +109 -0
- dataset/dataset_tokenize.py +136 -0
- dataset/prepare/download_extractor.sh +15 -0
- dataset/prepare/download_glove.sh +9 -0
- dataset/prepare/download_model.sh +12 -0
- dataset/prepare/download_smpl.sh +13 -0
- environment.yml +121 -0
- eval_trans_per.py +653 -0
- images/1 +1 -0
- images/example/1 +1 -0
- images/example/boot/1 +1 -0
- images/example/boot/gpt.gif +0 -0
- images/example/boot/mdm.gif +0 -0
- images/example/boot/momask.gif +0 -0
- images/example/boot/sato.gif +0 -0
- images/example/kick/1 +1 -0
- images/example/kick/gpt.gif +0 -0
- images/example/kick/mdm.gif +0 -0
- images/example/kick/momask.gif +0 -0
- images/example/kick/sato.gif +0 -0
- images/visualization/1 +1 -0
- images/visualization/circle/1 +1 -0
- images/visualization/circle/gpt.gif +0 -0
.gitattributes
CHANGED
|
@@ -33,3 +33,6 @@ saved_model/**/* filter=lfs diff=lfs merge=lfs -text
|
|
| 33 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
|
|
|
|
|
|
|
|
|
|
|
| 33 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
| 36 |
+
images/visualization/circle/mdm.gif filter=lfs diff=lfs merge=lfs -text
|
| 37 |
+
images/visualization/circle/sato.gif filter=lfs diff=lfs merge=lfs -text
|
| 38 |
+
images/visualization/loop/mdm.gif filter=lfs diff=lfs merge=lfs -text
|
CLIP/CLIP.png
ADDED
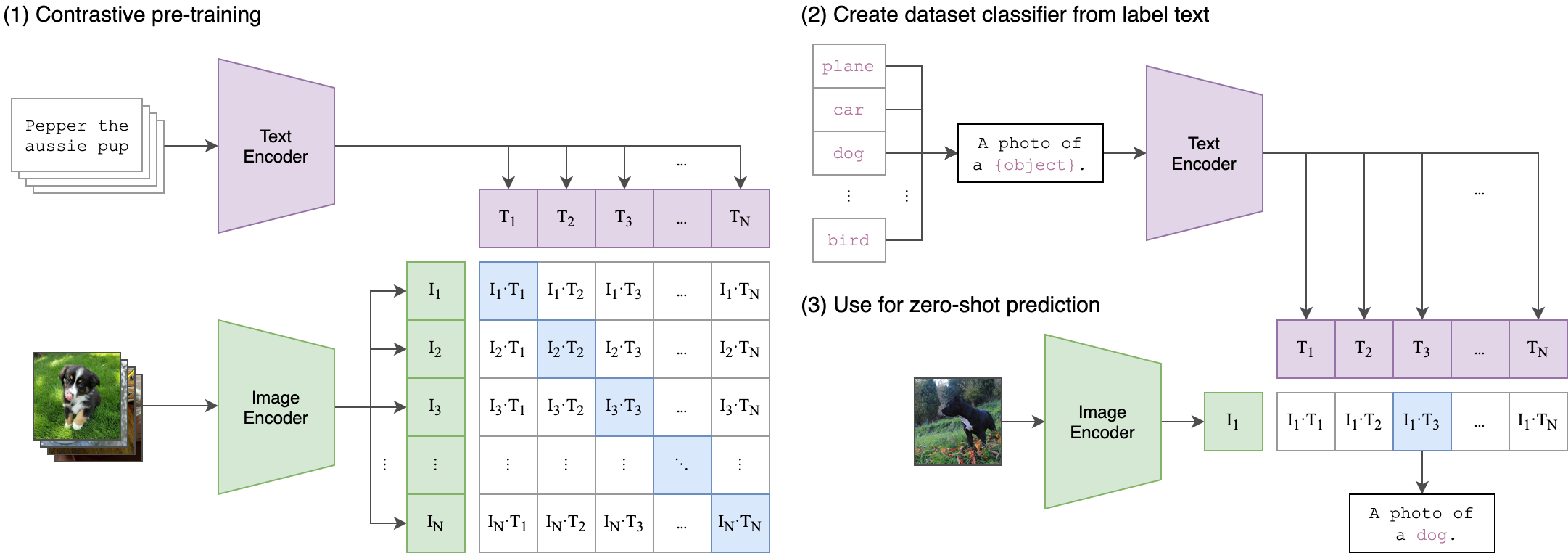
|
CLIP/LICENSE
ADDED
|
@@ -0,0 +1,22 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
MIT License
|
| 2 |
+
|
| 3 |
+
Copyright (c) 2021 OpenAI
|
| 4 |
+
|
| 5 |
+
Permission is hereby granted, free of charge, to any person obtaining a copy
|
| 6 |
+
of this software and associated documentation files (the "Software"), to deal
|
| 7 |
+
in the Software without restriction, including without limitation the rights
|
| 8 |
+
to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
|
| 9 |
+
copies of the Software, and to permit persons to whom the Software is
|
| 10 |
+
furnished to do so, subject to the following conditions:
|
| 11 |
+
|
| 12 |
+
The above copyright notice and this permission notice shall be included in all
|
| 13 |
+
copies or substantial portions of the Software.
|
| 14 |
+
|
| 15 |
+
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
|
| 16 |
+
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
|
| 17 |
+
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
|
| 18 |
+
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
|
| 19 |
+
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
|
| 20 |
+
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
|
| 21 |
+
SOFTWARE.
|
| 22 |
+
|
CLIP/MANIFEST.in
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
include clip/bpe_simple_vocab_16e6.txt.gz
|
CLIP/clip/__init__.py
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
from .clip import *
|
CLIP/clip/__pycache__/__init__.cpython-38.pyc
ADDED
|
Binary file (167 Bytes). View file
|
|
|
CLIP/clip/__pycache__/clip.cpython-38.pyc
ADDED
|
Binary file (6.81 kB). View file
|
|
|
CLIP/clip/__pycache__/model.cpython-38.pyc
ADDED
|
Binary file (15 kB). View file
|
|
|
CLIP/clip/__pycache__/simple_tokenizer.cpython-38.pyc
ADDED
|
Binary file (5.79 kB). View file
|
|
|
CLIP/clip/bpe_simple_vocab_16e6.txt.gz
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:924691ac288e54409236115652ad4aa250f48203de50a9e4722a6ecd48d6804a
|
| 3 |
+
size 1356917
|
CLIP/clip/clip.py
ADDED
|
@@ -0,0 +1,200 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import hashlib
|
| 2 |
+
import os
|
| 3 |
+
import urllib
|
| 4 |
+
import warnings
|
| 5 |
+
from typing import Union, List
|
| 6 |
+
|
| 7 |
+
import torch
|
| 8 |
+
from PIL import Image
|
| 9 |
+
from torchvision.transforms import Compose, Resize, CenterCrop, ToTensor, Normalize
|
| 10 |
+
from tqdm import tqdm
|
| 11 |
+
|
| 12 |
+
from .model import build_model
|
| 13 |
+
from .simple_tokenizer import SimpleTokenizer as _Tokenizer
|
| 14 |
+
|
| 15 |
+
__all__ = ["available_models", "load", "tokenize"]
|
| 16 |
+
_tokenizer = _Tokenizer()
|
| 17 |
+
|
| 18 |
+
_MODELS = {
|
| 19 |
+
"RN50": "https://openaipublic.azureedge.net/clip/models/afeb0e10f9e5a86da6080e35cf09123aca3b358a0c3e3b6c78a7b63bc04b6762/RN50.pt",
|
| 20 |
+
"ViT-B/32": "https://openaipublic.azureedge.net/clip/models/40d365715913c9da98579312b702a82c18be219cc2a73407c4526f58eba950af/ViT-B-32.pt",
|
| 21 |
+
}
|
| 22 |
+
|
| 23 |
+
|
| 24 |
+
def _download(url: str, root: str = os.path.expanduser("~/.cache/clip")):
|
| 25 |
+
os.makedirs(root, exist_ok=True)
|
| 26 |
+
filename = os.path.basename(url)
|
| 27 |
+
|
| 28 |
+
expected_sha256 = url.split("/")[-2]
|
| 29 |
+
download_target = os.path.join(root, filename)
|
| 30 |
+
|
| 31 |
+
if os.path.exists(download_target) and not os.path.isfile(download_target):
|
| 32 |
+
raise RuntimeError(f"{download_target} exists and is not a regular file")
|
| 33 |
+
|
| 34 |
+
if os.path.isfile(download_target):
|
| 35 |
+
if hashlib.sha256(open(download_target, "rb").read()).hexdigest() == expected_sha256:
|
| 36 |
+
return download_target
|
| 37 |
+
else:
|
| 38 |
+
warnings.warn(f"{download_target} exists, but the SHA256 checksum does not match; re-downloading the file")
|
| 39 |
+
|
| 40 |
+
with urllib.request.urlopen(url) as source, open(download_target, "wb") as output:
|
| 41 |
+
with tqdm(total=int(source.info().get("Content-Length")), ncols=80, unit='iB', unit_scale=True) as loop:
|
| 42 |
+
while True:
|
| 43 |
+
buffer = source.read(8192)
|
| 44 |
+
if not buffer:
|
| 45 |
+
break
|
| 46 |
+
|
| 47 |
+
output.write(buffer)
|
| 48 |
+
loop.update(len(buffer))
|
| 49 |
+
|
| 50 |
+
if hashlib.sha256(open(download_target, "rb").read()).hexdigest() != expected_sha256:
|
| 51 |
+
raise RuntimeError(f"Model has been downloaded but the SHA256 checksum does not not match")
|
| 52 |
+
|
| 53 |
+
return download_target
|
| 54 |
+
|
| 55 |
+
|
| 56 |
+
def _transform(n_px):
|
| 57 |
+
return Compose([
|
| 58 |
+
Resize(n_px, interpolation=Image.BICUBIC),
|
| 59 |
+
CenterCrop(n_px),
|
| 60 |
+
lambda image: image.convert("RGB"),
|
| 61 |
+
ToTensor(),
|
| 62 |
+
Normalize((0.48145466, 0.4578275, 0.40821073), (0.26862954, 0.26130258, 0.27577711)),
|
| 63 |
+
])
|
| 64 |
+
|
| 65 |
+
|
| 66 |
+
def available_models() -> List[str]:
|
| 67 |
+
"""Returns the names of available CLIP models"""
|
| 68 |
+
return list(_MODELS.keys())
|
| 69 |
+
|
| 70 |
+
|
| 71 |
+
def load(name: str, device: Union[str, torch.device] = "cuda" if torch.cuda.is_available() else "cpu", jit=True):
|
| 72 |
+
"""Load a CLIP model
|
| 73 |
+
|
| 74 |
+
Parameters
|
| 75 |
+
----------
|
| 76 |
+
name : str
|
| 77 |
+
A model name listed by `clip.available_models()`, or the path to a model checkpoint containing the state_dict
|
| 78 |
+
|
| 79 |
+
device : Union[str, torch.device]
|
| 80 |
+
The device to put the loaded model
|
| 81 |
+
|
| 82 |
+
jit : bool
|
| 83 |
+
Whether to load the optimized JIT model (default) or more hackable non-JIT model.
|
| 84 |
+
|
| 85 |
+
Returns
|
| 86 |
+
-------
|
| 87 |
+
model : torch.nn.Module
|
| 88 |
+
The CLIP model
|
| 89 |
+
|
| 90 |
+
preprocess : Callable[[PIL.Image], torch.Tensor]
|
| 91 |
+
A torchvision transform that converts a PIL image into a tensor that the returned model can take as its input
|
| 92 |
+
"""
|
| 93 |
+
if name in _MODELS:
|
| 94 |
+
model_path = _download(_MODELS[name])
|
| 95 |
+
elif os.path.isfile(name):
|
| 96 |
+
model_path = name
|
| 97 |
+
else:
|
| 98 |
+
raise RuntimeError(f"Model {name} not found; available models = {available_models()}")
|
| 99 |
+
|
| 100 |
+
try:
|
| 101 |
+
# loading JIT archive
|
| 102 |
+
model = torch.jit.load(model_path, map_location=device if jit else "cpu").eval()
|
| 103 |
+
state_dict = None
|
| 104 |
+
except RuntimeError:
|
| 105 |
+
# loading saved state dict
|
| 106 |
+
if jit:
|
| 107 |
+
warnings.warn(f"File {model_path} is not a JIT archive. Loading as a state dict instead")
|
| 108 |
+
jit = False
|
| 109 |
+
state_dict = torch.load(model_path, map_location="cpu")
|
| 110 |
+
|
| 111 |
+
if not jit:
|
| 112 |
+
model = build_model(state_dict or model.state_dict()).to(device)
|
| 113 |
+
if str(device) == "cpu":
|
| 114 |
+
model.float()
|
| 115 |
+
return model, _transform(model.visual.input_resolution)
|
| 116 |
+
|
| 117 |
+
# patch the device names
|
| 118 |
+
device_holder = torch.jit.trace(lambda: torch.ones([]).to(torch.device(device)), example_inputs=[])
|
| 119 |
+
device_node = [n for n in device_holder.graph.findAllNodes("prim::Constant") if "Device" in repr(n)][-1]
|
| 120 |
+
|
| 121 |
+
def patch_device(module):
|
| 122 |
+
graphs = [module.graph] if hasattr(module, "graph") else []
|
| 123 |
+
if hasattr(module, "forward1"):
|
| 124 |
+
graphs.append(module.forward1.graph)
|
| 125 |
+
|
| 126 |
+
for graph in graphs:
|
| 127 |
+
for node in graph.findAllNodes("prim::Constant"):
|
| 128 |
+
if "value" in node.attributeNames() and str(node["value"]).startswith("cuda"):
|
| 129 |
+
node.copyAttributes(device_node)
|
| 130 |
+
|
| 131 |
+
model.apply(patch_device)
|
| 132 |
+
patch_device(model.encode_image)
|
| 133 |
+
patch_device(model.encode_text)
|
| 134 |
+
|
| 135 |
+
# patch dtype to float32 on CPU
|
| 136 |
+
if str(device) == "cpu":
|
| 137 |
+
float_holder = torch.jit.trace(lambda: torch.ones([]).float(), example_inputs=[])
|
| 138 |
+
float_input = list(float_holder.graph.findNode("aten::to").inputs())[1]
|
| 139 |
+
float_node = float_input.node()
|
| 140 |
+
|
| 141 |
+
def patch_float(module):
|
| 142 |
+
graphs = [module.graph] if hasattr(module, "graph") else []
|
| 143 |
+
if hasattr(module, "forward1"):
|
| 144 |
+
graphs.append(module.forward1.graph)
|
| 145 |
+
|
| 146 |
+
for graph in graphs:
|
| 147 |
+
for node in graph.findAllNodes("aten::to"):
|
| 148 |
+
inputs = list(node.inputs())
|
| 149 |
+
for i in [1, 2]: # dtype can be the second or third argument to aten::to()
|
| 150 |
+
if inputs[i].node()["value"] == 5:
|
| 151 |
+
inputs[i].node().copyAttributes(float_node)
|
| 152 |
+
|
| 153 |
+
model.apply(patch_float)
|
| 154 |
+
patch_float(model.encode_image)
|
| 155 |
+
patch_float(model.encode_text)
|
| 156 |
+
|
| 157 |
+
model.float()
|
| 158 |
+
|
| 159 |
+
return model, _transform(model.input_resolution.item())
|
| 160 |
+
|
| 161 |
+
|
| 162 |
+
def tokenize(texts: Union[str, List[str]], context_length: int = 77, truncate: bool = False) -> torch.LongTensor:
|
| 163 |
+
"""
|
| 164 |
+
Returns the tokenized representation of given input string(s)
|
| 165 |
+
|
| 166 |
+
Parameters
|
| 167 |
+
----------
|
| 168 |
+
texts : Union[str, List[str]]
|
| 169 |
+
An input string or a list of input strings to tokenize
|
| 170 |
+
|
| 171 |
+
context_length : int
|
| 172 |
+
The context length to use; all CLIP models use 77 as the context length
|
| 173 |
+
|
| 174 |
+
Returns
|
| 175 |
+
-------
|
| 176 |
+
A two-dimensional tensor containing the resulting tokens, shape = [number of input strings, context_length]
|
| 177 |
+
"""
|
| 178 |
+
if isinstance(texts, str):
|
| 179 |
+
texts = [texts]
|
| 180 |
+
|
| 181 |
+
sot_token = _tokenizer.encoder["<|startoftext|>"]
|
| 182 |
+
eot_token = _tokenizer.encoder["<|endoftext|>"]
|
| 183 |
+
all_tokens = [[sot_token] + _tokenizer.encode(text) + [eot_token] for text in texts]
|
| 184 |
+
result = torch.zeros(len(all_tokens), context_length, dtype=torch.long)
|
| 185 |
+
|
| 186 |
+
for i, tokens in enumerate(all_tokens):
|
| 187 |
+
if len(tokens) > context_length:
|
| 188 |
+
if truncate:
|
| 189 |
+
tokens = tokens[:context_length]
|
| 190 |
+
tokens[-1] = eot_token
|
| 191 |
+
else:
|
| 192 |
+
raise RuntimeError(f"Input {texts[i]} is too long for context length {context_length}")
|
| 193 |
+
result[i, :len(tokens)] = torch.tensor(tokens)
|
| 194 |
+
# for i, tokens in enumerate(all_tokens):
|
| 195 |
+
# if len(tokens) > context_length:
|
| 196 |
+
# print('error: ', len(tokens), texts[i])
|
| 197 |
+
# raise RuntimeError(f"Input {texts[i]} is too long for context length {context_length}")
|
| 198 |
+
# result[i, :len(tokens)] = torch.tensor(tokens)
|
| 199 |
+
|
| 200 |
+
return result
|
CLIP/clip/model.py
ADDED
|
@@ -0,0 +1,439 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from collections import OrderedDict
|
| 2 |
+
from typing import Tuple, Union
|
| 3 |
+
|
| 4 |
+
import torch
|
| 5 |
+
import torch.nn.functional as F
|
| 6 |
+
from torch import nn
|
| 7 |
+
|
| 8 |
+
|
| 9 |
+
class Bottleneck(nn.Module):
|
| 10 |
+
expansion = 4
|
| 11 |
+
|
| 12 |
+
def __init__(self, inplanes, planes, stride=1):
|
| 13 |
+
super().__init__()
|
| 14 |
+
|
| 15 |
+
# all conv layers have stride 1. an avgpool is performed after the second convolution when stride > 1
|
| 16 |
+
self.conv1 = nn.Conv2d(inplanes, planes, 1, bias=False)
|
| 17 |
+
self.bn1 = nn.BatchNorm2d(planes)
|
| 18 |
+
|
| 19 |
+
self.conv2 = nn.Conv2d(planes, planes, 3, padding=1, bias=False)
|
| 20 |
+
self.bn2 = nn.BatchNorm2d(planes)
|
| 21 |
+
|
| 22 |
+
self.avgpool = nn.AvgPool2d(stride) if stride > 1 else nn.Identity()
|
| 23 |
+
|
| 24 |
+
self.conv3 = nn.Conv2d(planes, planes * self.expansion, 1, bias=False)
|
| 25 |
+
self.bn3 = nn.BatchNorm2d(planes * self.expansion)
|
| 26 |
+
|
| 27 |
+
self.relu = nn.ReLU(inplace=True)
|
| 28 |
+
self.downsample = None
|
| 29 |
+
self.stride = stride
|
| 30 |
+
|
| 31 |
+
if stride > 1 or inplanes != planes * Bottleneck.expansion:
|
| 32 |
+
# downsampling layer is prepended with an avgpool, and the subsequent convolution has stride 1
|
| 33 |
+
self.downsample = nn.Sequential(OrderedDict([
|
| 34 |
+
("-1", nn.AvgPool2d(stride)),
|
| 35 |
+
("0", nn.Conv2d(inplanes, planes * self.expansion, 1, stride=1, bias=False)),
|
| 36 |
+
("1", nn.BatchNorm2d(planes * self.expansion))
|
| 37 |
+
]))
|
| 38 |
+
|
| 39 |
+
def forward(self, x: torch.Tensor):
|
| 40 |
+
identity = x
|
| 41 |
+
|
| 42 |
+
out = self.relu(self.bn1(self.conv1(x)))
|
| 43 |
+
out = self.relu(self.bn2(self.conv2(out)))
|
| 44 |
+
out = self.avgpool(out)
|
| 45 |
+
out = self.bn3(self.conv3(out))
|
| 46 |
+
|
| 47 |
+
if self.downsample is not None:
|
| 48 |
+
identity = self.downsample(x)
|
| 49 |
+
|
| 50 |
+
out += identity
|
| 51 |
+
out = self.relu(out)
|
| 52 |
+
return out
|
| 53 |
+
|
| 54 |
+
|
| 55 |
+
class AttentionPool2d(nn.Module):
|
| 56 |
+
def __init__(self, spacial_dim: int, embed_dim: int, num_heads: int, output_dim: int = None):
|
| 57 |
+
super().__init__()
|
| 58 |
+
self.positional_embedding = nn.Parameter(torch.randn(spacial_dim ** 2 + 1, embed_dim) / embed_dim ** 0.5)
|
| 59 |
+
self.k_proj = nn.Linear(embed_dim, embed_dim)
|
| 60 |
+
self.q_proj = nn.Linear(embed_dim, embed_dim)
|
| 61 |
+
self.v_proj = nn.Linear(embed_dim, embed_dim)
|
| 62 |
+
self.c_proj = nn.Linear(embed_dim, output_dim or embed_dim)
|
| 63 |
+
self.num_heads = num_heads
|
| 64 |
+
|
| 65 |
+
def forward(self, x):
|
| 66 |
+
x = x.reshape(x.shape[0], x.shape[1], x.shape[2] * x.shape[3]).permute(2, 0, 1) # NCHW -> (HW)NC
|
| 67 |
+
x = torch.cat([x.mean(dim=0, keepdim=True), x], dim=0) # (HW+1)NC
|
| 68 |
+
x = x + self.positional_embedding[:, None, :].to(x.dtype) # (HW+1)NC
|
| 69 |
+
x, _ = F.multi_head_attention_forward(
|
| 70 |
+
query=x, key=x, value=x,
|
| 71 |
+
embed_dim_to_check=x.shape[-1],
|
| 72 |
+
num_heads=self.num_heads,
|
| 73 |
+
q_proj_weight=self.q_proj.weight,
|
| 74 |
+
k_proj_weight=self.k_proj.weight,
|
| 75 |
+
v_proj_weight=self.v_proj.weight,
|
| 76 |
+
in_proj_weight=None,
|
| 77 |
+
in_proj_bias=torch.cat([self.q_proj.bias, self.k_proj.bias, self.v_proj.bias]),
|
| 78 |
+
bias_k=None,
|
| 79 |
+
bias_v=None,
|
| 80 |
+
add_zero_attn=False,
|
| 81 |
+
dropout_p=0,
|
| 82 |
+
out_proj_weight=self.c_proj.weight,
|
| 83 |
+
out_proj_bias=self.c_proj.bias,
|
| 84 |
+
use_separate_proj_weight=True,
|
| 85 |
+
training=self.training,
|
| 86 |
+
need_weights=False
|
| 87 |
+
)
|
| 88 |
+
|
| 89 |
+
return x[0]
|
| 90 |
+
|
| 91 |
+
|
| 92 |
+
class ModifiedResNet(nn.Module):
|
| 93 |
+
"""
|
| 94 |
+
A ResNet class that is similar to torchvision's but contains the following changes:
|
| 95 |
+
- There are now 3 "stem" convolutions as opposed to 1, with an average pool instead of a max pool.
|
| 96 |
+
- Performs anti-aliasing strided convolutions, where an avgpool is prepended to convolutions with stride > 1
|
| 97 |
+
- The final pooling layer is a QKV attention instead of an average pool
|
| 98 |
+
"""
|
| 99 |
+
|
| 100 |
+
def __init__(self, layers, output_dim, heads, input_resolution=224, width=64):
|
| 101 |
+
super().__init__()
|
| 102 |
+
self.output_dim = output_dim
|
| 103 |
+
self.input_resolution = input_resolution
|
| 104 |
+
|
| 105 |
+
# the 3-layer stem
|
| 106 |
+
self.conv1 = nn.Conv2d(3, width // 2, kernel_size=3, stride=2, padding=1, bias=False)
|
| 107 |
+
self.bn1 = nn.BatchNorm2d(width // 2)
|
| 108 |
+
self.conv2 = nn.Conv2d(width // 2, width // 2, kernel_size=3, padding=1, bias=False)
|
| 109 |
+
self.bn2 = nn.BatchNorm2d(width // 2)
|
| 110 |
+
self.conv3 = nn.Conv2d(width // 2, width, kernel_size=3, padding=1, bias=False)
|
| 111 |
+
self.bn3 = nn.BatchNorm2d(width)
|
| 112 |
+
self.avgpool = nn.AvgPool2d(2)
|
| 113 |
+
self.relu = nn.ReLU(inplace=True)
|
| 114 |
+
|
| 115 |
+
# residual layers
|
| 116 |
+
self._inplanes = width # this is a *mutable* variable used during construction
|
| 117 |
+
self.layer1 = self._make_layer(width, layers[0])
|
| 118 |
+
self.layer2 = self._make_layer(width * 2, layers[1], stride=2)
|
| 119 |
+
self.layer3 = self._make_layer(width * 4, layers[2], stride=2)
|
| 120 |
+
self.layer4 = self._make_layer(width * 8, layers[3], stride=2)
|
| 121 |
+
|
| 122 |
+
embed_dim = width * 32 # the ResNet feature dimension
|
| 123 |
+
self.attnpool = AttentionPool2d(input_resolution // 32, embed_dim, heads, output_dim)
|
| 124 |
+
|
| 125 |
+
def _make_layer(self, planes, blocks, stride=1):
|
| 126 |
+
layers = [Bottleneck(self._inplanes, planes, stride)]
|
| 127 |
+
|
| 128 |
+
self._inplanes = planes * Bottleneck.expansion
|
| 129 |
+
for _ in range(1, blocks):
|
| 130 |
+
layers.append(Bottleneck(self._inplanes, planes))
|
| 131 |
+
|
| 132 |
+
return nn.Sequential(*layers)
|
| 133 |
+
|
| 134 |
+
def forward(self, x):
|
| 135 |
+
def stem(x):
|
| 136 |
+
for conv, bn in [(self.conv1, self.bn1), (self.conv2, self.bn2), (self.conv3, self.bn3)]:
|
| 137 |
+
x = self.relu(bn(conv(x)))
|
| 138 |
+
x = self.avgpool(x)
|
| 139 |
+
return x
|
| 140 |
+
|
| 141 |
+
x = x.type(self.conv1.weight.dtype)
|
| 142 |
+
x = stem(x)
|
| 143 |
+
x = self.layer1(x)
|
| 144 |
+
x = self.layer2(x)
|
| 145 |
+
x = self.layer3(x)
|
| 146 |
+
x = self.layer4(x)
|
| 147 |
+
x = self.attnpool(x)
|
| 148 |
+
|
| 149 |
+
return x
|
| 150 |
+
|
| 151 |
+
|
| 152 |
+
class LayerNorm(nn.LayerNorm):
|
| 153 |
+
"""Subclass torch's LayerNorm to handle fp16."""
|
| 154 |
+
|
| 155 |
+
def forward(self, x: torch.Tensor):
|
| 156 |
+
orig_type = x.dtype
|
| 157 |
+
ret = super().forward(x.type(torch.float32))
|
| 158 |
+
return ret.type(orig_type)
|
| 159 |
+
|
| 160 |
+
|
| 161 |
+
class QuickGELU(nn.Module):
|
| 162 |
+
def forward(self, x: torch.Tensor):
|
| 163 |
+
return x * torch.sigmoid(1.702 * x)
|
| 164 |
+
|
| 165 |
+
|
| 166 |
+
class ResidualAttentionBlock(nn.Module):
|
| 167 |
+
def __init__(self, d_model: int, n_head: int, attn_mask: torch.Tensor = None):
|
| 168 |
+
super().__init__()
|
| 169 |
+
|
| 170 |
+
self.attn = nn.MultiheadAttention(d_model, n_head)
|
| 171 |
+
self.ln_1 = LayerNorm(d_model)
|
| 172 |
+
self.mlp = nn.Sequential(OrderedDict([
|
| 173 |
+
("c_fc", nn.Linear(d_model, d_model * 4)),
|
| 174 |
+
("gelu", QuickGELU()),
|
| 175 |
+
("c_proj", nn.Linear(d_model * 4, d_model))
|
| 176 |
+
]))
|
| 177 |
+
self.ln_2 = LayerNorm(d_model)
|
| 178 |
+
self.attn_mask = attn_mask
|
| 179 |
+
|
| 180 |
+
def attention(self, x: torch.Tensor): # x--77,64,512
|
| 181 |
+
self.attn_mask = self.attn_mask.to(dtype=x.dtype, device=x.device) if self.attn_mask is not None else None
|
| 182 |
+
return self.attn(x, x, x, need_weights=True, attn_mask=self.attn_mask)
|
| 183 |
+
|
| 184 |
+
def forward(self, x: torch.Tensor):
|
| 185 |
+
attention_res = self.attention(self.ln_1(x))
|
| 186 |
+
x, weight = x+attention_res[0], attention_res[1]
|
| 187 |
+
x = x + self.mlp(self.ln_2(x))
|
| 188 |
+
return x, weight
|
| 189 |
+
|
| 190 |
+
|
| 191 |
+
class Transformer(nn.Module):
|
| 192 |
+
def __init__(self, width: int, layers: int, heads: int, attn_mask: torch.Tensor = None):
|
| 193 |
+
super().__init__()
|
| 194 |
+
self.width = width # 512
|
| 195 |
+
self.layers = layers # 12
|
| 196 |
+
self.resblocks = nn.Sequential(*[ResidualAttentionBlock(width, heads, attn_mask) for _ in range(layers)])
|
| 197 |
+
|
| 198 |
+
def forward(self, x: torch.Tensor):
|
| 199 |
+
weights = []
|
| 200 |
+
|
| 201 |
+
for block in self.resblocks:
|
| 202 |
+
x, weight = block(x)
|
| 203 |
+
weights.append(weight)
|
| 204 |
+
|
| 205 |
+
return x, weights
|
| 206 |
+
|
| 207 |
+
|
| 208 |
+
class VisualTransformer(nn.Module):
|
| 209 |
+
def __init__(self, input_resolution: int, patch_size: int, width: int, layers: int, heads: int, output_dim: int):
|
| 210 |
+
super().__init__()
|
| 211 |
+
self.input_resolution = input_resolution
|
| 212 |
+
self.output_dim = output_dim
|
| 213 |
+
self.conv1 = nn.Conv2d(in_channels=3, out_channels=width, kernel_size=patch_size, stride=patch_size, bias=False)
|
| 214 |
+
|
| 215 |
+
scale = width ** -0.5
|
| 216 |
+
self.class_embedding = nn.Parameter(scale * torch.randn(width))
|
| 217 |
+
self.positional_embedding = nn.Parameter(scale * torch.randn((input_resolution // patch_size) ** 2 + 1, width))
|
| 218 |
+
self.ln_pre = LayerNorm(width)
|
| 219 |
+
|
| 220 |
+
self.transformer = Transformer(width, layers, heads)
|
| 221 |
+
|
| 222 |
+
self.ln_post = LayerNorm(width)
|
| 223 |
+
self.proj = nn.Parameter(scale * torch.randn(width, output_dim))
|
| 224 |
+
|
| 225 |
+
def forward(self, x: torch.Tensor):
|
| 226 |
+
x = self.conv1(x) # shape = [*, width, grid, grid]
|
| 227 |
+
x = x.reshape(x.shape[0], x.shape[1], -1) # shape = [*, width, grid ** 2]
|
| 228 |
+
x = x.permute(0, 2, 1) # shape = [*, grid ** 2, width]
|
| 229 |
+
x = torch.cat([self.class_embedding.to(x.dtype) + torch.zeros(x.shape[0], 1, x.shape[-1], dtype=x.dtype, device=x.device), x], dim=1) # shape = [*, grid ** 2 + 1, width]
|
| 230 |
+
x = x + self.positional_embedding.to(x.dtype)
|
| 231 |
+
x = self.ln_pre(x)
|
| 232 |
+
|
| 233 |
+
x = x.permute(1, 0, 2) # NLD -> LND
|
| 234 |
+
x, weight = self.transformer(x)
|
| 235 |
+
x = x.permute(1, 0, 2) # LND -> NLD
|
| 236 |
+
|
| 237 |
+
x = self.ln_post(x[:, 0, :])
|
| 238 |
+
|
| 239 |
+
if self.proj is not None:
|
| 240 |
+
x = x @ self.proj
|
| 241 |
+
|
| 242 |
+
return x
|
| 243 |
+
|
| 244 |
+
|
| 245 |
+
class CLIP(nn.Module):
|
| 246 |
+
def __init__(self,
|
| 247 |
+
embed_dim: int,
|
| 248 |
+
# vision
|
| 249 |
+
image_resolution: int,
|
| 250 |
+
vision_layers: Union[Tuple[int, int, int, int], int],
|
| 251 |
+
vision_width: int,
|
| 252 |
+
vision_patch_size: int,
|
| 253 |
+
# text
|
| 254 |
+
context_length: int,
|
| 255 |
+
vocab_size: int,
|
| 256 |
+
transformer_width: int,
|
| 257 |
+
transformer_heads: int,
|
| 258 |
+
transformer_layers: int
|
| 259 |
+
):
|
| 260 |
+
super().__init__()
|
| 261 |
+
|
| 262 |
+
self.context_length = context_length
|
| 263 |
+
|
| 264 |
+
if isinstance(vision_layers, (tuple, list)):
|
| 265 |
+
vision_heads = vision_width * 32 // 64
|
| 266 |
+
self.visual = ModifiedResNet(
|
| 267 |
+
layers=vision_layers,
|
| 268 |
+
output_dim=embed_dim,
|
| 269 |
+
heads=vision_heads,
|
| 270 |
+
input_resolution=image_resolution,
|
| 271 |
+
width=vision_width
|
| 272 |
+
)
|
| 273 |
+
else:
|
| 274 |
+
vision_heads = vision_width // 64
|
| 275 |
+
self.visual = VisualTransformer(
|
| 276 |
+
input_resolution=image_resolution,
|
| 277 |
+
patch_size=vision_patch_size,
|
| 278 |
+
width=vision_width,
|
| 279 |
+
layers=vision_layers,
|
| 280 |
+
heads=vision_heads,
|
| 281 |
+
output_dim=embed_dim
|
| 282 |
+
)
|
| 283 |
+
|
| 284 |
+
self.transformer = Transformer(
|
| 285 |
+
width=transformer_width,
|
| 286 |
+
layers=transformer_layers,
|
| 287 |
+
heads=transformer_heads,
|
| 288 |
+
attn_mask=self.build_attention_mask()
|
| 289 |
+
)
|
| 290 |
+
|
| 291 |
+
self.vocab_size = vocab_size
|
| 292 |
+
self.token_embedding = nn.Embedding(vocab_size, transformer_width)
|
| 293 |
+
self.positional_embedding = nn.Parameter(torch.empty(self.context_length, transformer_width))
|
| 294 |
+
self.ln_final = LayerNorm(transformer_width)
|
| 295 |
+
|
| 296 |
+
self.text_projection = nn.Parameter(torch.empty(transformer_width, embed_dim))
|
| 297 |
+
self.logit_scale = nn.Parameter(torch.ones([]))
|
| 298 |
+
|
| 299 |
+
self.initialize_parameters()
|
| 300 |
+
|
| 301 |
+
def initialize_parameters(self):
|
| 302 |
+
nn.init.normal_(self.token_embedding.weight, std=0.02)
|
| 303 |
+
nn.init.normal_(self.positional_embedding, std=0.01)
|
| 304 |
+
|
| 305 |
+
if isinstance(self.visual, ModifiedResNet):
|
| 306 |
+
if self.visual.attnpool is not None:
|
| 307 |
+
std = self.visual.attnpool.c_proj.in_features ** -0.5
|
| 308 |
+
nn.init.normal_(self.visual.attnpool.q_proj.weight, std=std)
|
| 309 |
+
nn.init.normal_(self.visual.attnpool.k_proj.weight, std=std)
|
| 310 |
+
nn.init.normal_(self.visual.attnpool.v_proj.weight, std=std)
|
| 311 |
+
nn.init.normal_(self.visual.attnpool.c_proj.weight, std=std)
|
| 312 |
+
|
| 313 |
+
for resnet_block in [self.visual.layer1, self.visual.layer2, self.visual.layer3, self.visual.layer4]:
|
| 314 |
+
for name, param in resnet_block.named_parameters():
|
| 315 |
+
if name.endswith("bn3.weight"):
|
| 316 |
+
nn.init.zeros_(param)
|
| 317 |
+
|
| 318 |
+
proj_std = (self.transformer.width ** -0.5) * ((2 * self.transformer.layers) ** -0.5)
|
| 319 |
+
attn_std = self.transformer.width ** -0.5
|
| 320 |
+
fc_std = (2 * self.transformer.width) ** -0.5
|
| 321 |
+
for block in self.transformer.resblocks:
|
| 322 |
+
nn.init.normal_(block.attn.in_proj_weight, std=attn_std)
|
| 323 |
+
nn.init.normal_(block.attn.out_proj.weight, std=proj_std)
|
| 324 |
+
nn.init.normal_(block.mlp.c_fc.weight, std=fc_std)
|
| 325 |
+
nn.init.normal_(block.mlp.c_proj.weight, std=proj_std)
|
| 326 |
+
|
| 327 |
+
if self.text_projection is not None:
|
| 328 |
+
nn.init.normal_(self.text_projection, std=self.transformer.width ** -0.5)
|
| 329 |
+
|
| 330 |
+
def build_attention_mask(self):
|
| 331 |
+
# lazily create causal attention mask, with full attention between the vision tokens
|
| 332 |
+
# pytorch uses additive attention mask; fill with -inf
|
| 333 |
+
mask = torch.empty(self.context_length, self.context_length)
|
| 334 |
+
mask.fill_(float("-inf"))
|
| 335 |
+
mask.triu_(1) # zero out the lower diagonal
|
| 336 |
+
return mask
|
| 337 |
+
|
| 338 |
+
@property
|
| 339 |
+
def dtype(self):
|
| 340 |
+
return self.visual.conv1.weight.dtype
|
| 341 |
+
|
| 342 |
+
def encode_image(self, image):
|
| 343 |
+
return self.visual(image.type(self.dtype))
|
| 344 |
+
|
| 345 |
+
def encode_text(self, text):
|
| 346 |
+
x = self.token_embedding(text).type(self.dtype) # [batch_size, n_ctx, d_model]
|
| 347 |
+
|
| 348 |
+
x = x + self.positional_embedding.type(self.dtype)
|
| 349 |
+
|
| 350 |
+
x = x.permute(1, 0, 2) # NLD -> LND
|
| 351 |
+
x, weights = self.transformer(x)
|
| 352 |
+
x = x.permute(1, 0, 2) # LND -> NLD
|
| 353 |
+
x = self.ln_final(x).type(self.dtype)
|
| 354 |
+
|
| 355 |
+
# x.shape = [batch_size, n_ctx, transformer.width]
|
| 356 |
+
# take features from the eot embedding (eot_token is the highest number in each sequence)
|
| 357 |
+
x = x[torch.arange(x.shape[0]), text.argmax(dim=-1)] @ self.text_projection
|
| 358 |
+
|
| 359 |
+
return x, weights
|
| 360 |
+
|
| 361 |
+
def forward(self, image, text):
|
| 362 |
+
image_features = self.encode_image(image)
|
| 363 |
+
text_features = self.encode_text(text)
|
| 364 |
+
|
| 365 |
+
# normalized features
|
| 366 |
+
image_features = image_features / image_features.norm(dim=-1, keepdim=True)
|
| 367 |
+
text_features = text_features / text_features.norm(dim=-1, keepdim=True)
|
| 368 |
+
|
| 369 |
+
# cosine similarity as logits
|
| 370 |
+
logit_scale = self.logit_scale.exp()
|
| 371 |
+
logits_per_image = logit_scale * image_features @ text_features.t()
|
| 372 |
+
logits_per_text = logit_scale * text_features @ image_features.t()
|
| 373 |
+
|
| 374 |
+
# shape = [global_batch_size, global_batch_size]
|
| 375 |
+
return logits_per_image, logits_per_text
|
| 376 |
+
|
| 377 |
+
|
| 378 |
+
def convert_weights(model: nn.Module):
|
| 379 |
+
"""Convert applicable model parameters to fp16"""
|
| 380 |
+
|
| 381 |
+
def _convert_weights_to_fp16(l):
|
| 382 |
+
if isinstance(l, (nn.Conv1d, nn.Conv2d, nn.Linear)):
|
| 383 |
+
l.weight.data = l.weight.data.half()
|
| 384 |
+
if l.bias is not None:
|
| 385 |
+
l.bias.data = l.bias.data.half()
|
| 386 |
+
|
| 387 |
+
if isinstance(l, nn.MultiheadAttention):
|
| 388 |
+
for attr in [*[f"{s}_proj_weight" for s in ["in", "q", "k", "v"]], "in_proj_bias", "bias_k", "bias_v"]:
|
| 389 |
+
tensor = getattr(l, attr)
|
| 390 |
+
if tensor is not None:
|
| 391 |
+
tensor.data = tensor.data.half()
|
| 392 |
+
|
| 393 |
+
for name in ["text_projection", "proj"]:
|
| 394 |
+
if hasattr(l, name):
|
| 395 |
+
attr = getattr(l, name)
|
| 396 |
+
if attr is not None:
|
| 397 |
+
attr.data = attr.data.half()
|
| 398 |
+
|
| 399 |
+
model.apply(_convert_weights_to_fp16)
|
| 400 |
+
|
| 401 |
+
|
| 402 |
+
def build_model(state_dict: dict):
|
| 403 |
+
vit = "visual.proj" in state_dict
|
| 404 |
+
|
| 405 |
+
if vit:
|
| 406 |
+
vision_width = state_dict["visual.conv1.weight"].shape[0]
|
| 407 |
+
vision_layers = len([k for k in state_dict.keys() if k.startswith("visual.") and k.endswith(".attn.in_proj_weight")])
|
| 408 |
+
vision_patch_size = state_dict["visual.conv1.weight"].shape[-1]
|
| 409 |
+
grid_size = round((state_dict["visual.positional_embedding"].shape[0] - 1) ** 0.5)
|
| 410 |
+
image_resolution = vision_patch_size * grid_size
|
| 411 |
+
else:
|
| 412 |
+
counts: list = [len(set(k.split(".")[2] for k in state_dict if k.startswith(f"visual.layer{b}"))) for b in [1, 2, 3, 4]]
|
| 413 |
+
vision_layers = tuple(counts)
|
| 414 |
+
vision_width = state_dict["visual.layer1.0.conv1.weight"].shape[0]
|
| 415 |
+
output_width = round((state_dict["visual.attnpool.positional_embedding"].shape[0] - 1) ** 0.5)
|
| 416 |
+
vision_patch_size = None
|
| 417 |
+
assert output_width ** 2 + 1 == state_dict["visual.attnpool.positional_embedding"].shape[0]
|
| 418 |
+
image_resolution = output_width * 32
|
| 419 |
+
|
| 420 |
+
embed_dim = state_dict["text_projection"].shape[1]
|
| 421 |
+
context_length = state_dict["positional_embedding"].shape[0]
|
| 422 |
+
vocab_size = state_dict["token_embedding.weight"].shape[0]
|
| 423 |
+
transformer_width = state_dict["ln_final.weight"].shape[0]
|
| 424 |
+
transformer_heads = transformer_width // 64
|
| 425 |
+
transformer_layers = len(set(k.split(".")[2] for k in state_dict if k.startswith(f"transformer.resblocks")))
|
| 426 |
+
|
| 427 |
+
model = CLIP(
|
| 428 |
+
embed_dim,
|
| 429 |
+
image_resolution, vision_layers, vision_width, vision_patch_size,
|
| 430 |
+
context_length, vocab_size, transformer_width, transformer_heads, transformer_layers
|
| 431 |
+
)
|
| 432 |
+
|
| 433 |
+
for key in ["input_resolution", "context_length", "vocab_size"]:
|
| 434 |
+
if key in state_dict:
|
| 435 |
+
del state_dict[key]
|
| 436 |
+
|
| 437 |
+
convert_weights(model)
|
| 438 |
+
model.load_state_dict(state_dict)
|
| 439 |
+
return model.eval()
|
CLIP/clip/simple_tokenizer.py
ADDED
|
@@ -0,0 +1,132 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import gzip
|
| 2 |
+
import html
|
| 3 |
+
import os
|
| 4 |
+
from functools import lru_cache
|
| 5 |
+
|
| 6 |
+
import ftfy
|
| 7 |
+
import regex as re
|
| 8 |
+
|
| 9 |
+
|
| 10 |
+
@lru_cache()
|
| 11 |
+
def default_bpe():
|
| 12 |
+
return os.path.join(os.path.dirname(os.path.abspath(__file__)), "bpe_simple_vocab_16e6.txt.gz")
|
| 13 |
+
|
| 14 |
+
|
| 15 |
+
@lru_cache()
|
| 16 |
+
def bytes_to_unicode():
|
| 17 |
+
"""
|
| 18 |
+
Returns list of utf-8 byte and a corresponding list of unicode strings.
|
| 19 |
+
The reversible bpe codes work on unicode strings.
|
| 20 |
+
This means you need a large # of unicode characters in your vocab if you want to avoid UNKs.
|
| 21 |
+
When you're at something like a 10B token dataset you end up needing around 5K for decent coverage.
|
| 22 |
+
This is a signficant percentage of your normal, say, 32K bpe vocab.
|
| 23 |
+
To avoid that, we want lookup tables between utf-8 bytes and unicode strings.
|
| 24 |
+
And avoids mapping to whitespace/control characters the bpe code barfs on.
|
| 25 |
+
"""
|
| 26 |
+
bs = list(range(ord("!"), ord("~")+1))+list(range(ord("¡"), ord("¬")+1))+list(range(ord("®"), ord("ÿ")+1))
|
| 27 |
+
cs = bs[:]
|
| 28 |
+
n = 0
|
| 29 |
+
for b in range(2**8):
|
| 30 |
+
if b not in bs:
|
| 31 |
+
bs.append(b)
|
| 32 |
+
cs.append(2**8+n)
|
| 33 |
+
n += 1
|
| 34 |
+
cs = [chr(n) for n in cs]
|
| 35 |
+
return dict(zip(bs, cs))
|
| 36 |
+
|
| 37 |
+
|
| 38 |
+
def get_pairs(word):
|
| 39 |
+
"""Return set of symbol pairs in a word.
|
| 40 |
+
Word is represented as tuple of symbols (symbols being variable-length strings).
|
| 41 |
+
"""
|
| 42 |
+
pairs = set()
|
| 43 |
+
prev_char = word[0]
|
| 44 |
+
for char in word[1:]:
|
| 45 |
+
pairs.add((prev_char, char))
|
| 46 |
+
prev_char = char
|
| 47 |
+
return pairs
|
| 48 |
+
|
| 49 |
+
|
| 50 |
+
def basic_clean(text):
|
| 51 |
+
text = ftfy.fix_text(text)
|
| 52 |
+
text = html.unescape(html.unescape(text))
|
| 53 |
+
return text.strip()
|
| 54 |
+
|
| 55 |
+
|
| 56 |
+
def whitespace_clean(text):
|
| 57 |
+
text = re.sub(r'\s+', ' ', text)
|
| 58 |
+
text = text.strip()
|
| 59 |
+
return text
|
| 60 |
+
|
| 61 |
+
|
| 62 |
+
class SimpleTokenizer(object):
|
| 63 |
+
def __init__(self, bpe_path: str = default_bpe()):
|
| 64 |
+
self.byte_encoder = bytes_to_unicode()
|
| 65 |
+
self.byte_decoder = {v: k for k, v in self.byte_encoder.items()}
|
| 66 |
+
merges = gzip.open(bpe_path).read().decode("utf-8").split('\n')
|
| 67 |
+
merges = merges[1:49152-256-2+1]
|
| 68 |
+
merges = [tuple(merge.split()) for merge in merges]
|
| 69 |
+
vocab = list(bytes_to_unicode().values())
|
| 70 |
+
vocab = vocab + [v+'</w>' for v in vocab]
|
| 71 |
+
for merge in merges:
|
| 72 |
+
vocab.append(''.join(merge))
|
| 73 |
+
vocab.extend(['<|startoftext|>', '<|endoftext|>'])
|
| 74 |
+
self.encoder = dict(zip(vocab, range(len(vocab))))
|
| 75 |
+
self.decoder = {v: k for k, v in self.encoder.items()}
|
| 76 |
+
self.bpe_ranks = dict(zip(merges, range(len(merges))))
|
| 77 |
+
self.cache = {'<|startoftext|>': '<|startoftext|>', '<|endoftext|>': '<|endoftext|>'}
|
| 78 |
+
self.pat = re.compile(r"""<\|startoftext\|>|<\|endoftext\|>|'s|'t|'re|'ve|'m|'ll|'d|[\p{L}]+|[\p{N}]|[^\s\p{L}\p{N}]+""", re.IGNORECASE)
|
| 79 |
+
|
| 80 |
+
def bpe(self, token):
|
| 81 |
+
if token in self.cache:
|
| 82 |
+
return self.cache[token]
|
| 83 |
+
word = tuple(token[:-1]) + ( token[-1] + '</w>',)
|
| 84 |
+
pairs = get_pairs(word)
|
| 85 |
+
|
| 86 |
+
if not pairs:
|
| 87 |
+
return token+'</w>'
|
| 88 |
+
|
| 89 |
+
while True:
|
| 90 |
+
bigram = min(pairs, key = lambda pair: self.bpe_ranks.get(pair, float('inf')))
|
| 91 |
+
if bigram not in self.bpe_ranks:
|
| 92 |
+
break
|
| 93 |
+
first, second = bigram
|
| 94 |
+
new_word = []
|
| 95 |
+
i = 0
|
| 96 |
+
while i < len(word):
|
| 97 |
+
try:
|
| 98 |
+
j = word.index(first, i)
|
| 99 |
+
new_word.extend(word[i:j])
|
| 100 |
+
i = j
|
| 101 |
+
except:
|
| 102 |
+
new_word.extend(word[i:])
|
| 103 |
+
break
|
| 104 |
+
|
| 105 |
+
if word[i] == first and i < len(word)-1 and word[i+1] == second:
|
| 106 |
+
new_word.append(first+second)
|
| 107 |
+
i += 2
|
| 108 |
+
else:
|
| 109 |
+
new_word.append(word[i])
|
| 110 |
+
i += 1
|
| 111 |
+
new_word = tuple(new_word)
|
| 112 |
+
word = new_word
|
| 113 |
+
if len(word) == 1:
|
| 114 |
+
break
|
| 115 |
+
else:
|
| 116 |
+
pairs = get_pairs(word)
|
| 117 |
+
word = ' '.join(word)
|
| 118 |
+
self.cache[token] = word
|
| 119 |
+
return word
|
| 120 |
+
|
| 121 |
+
def encode(self, text):
|
| 122 |
+
bpe_tokens = []
|
| 123 |
+
text = whitespace_clean(basic_clean(text)).lower()
|
| 124 |
+
for token in re.findall(self.pat, text):
|
| 125 |
+
token = ''.join(self.byte_encoder[b] for b in token.encode('utf-8'))
|
| 126 |
+
bpe_tokens.extend(self.encoder[bpe_token] for bpe_token in self.bpe(token).split(' '))
|
| 127 |
+
return bpe_tokens
|
| 128 |
+
|
| 129 |
+
def decode(self, tokens):
|
| 130 |
+
text = ''.join([self.decoder[token] for token in tokens])
|
| 131 |
+
text = bytearray([self.byte_decoder[c] for c in text]).decode('utf-8', errors="replace").replace('</w>', ' ')
|
| 132 |
+
return text
|
CLIP/math.json
ADDED
|
@@ -0,0 +1,98 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
[
|
| 2 |
+
{
|
| 3 |
+
"conversation": [
|
| 4 |
+
{
|
| 5 |
+
"input": "The endpoints of a diameter of circle $M$ are $(-1,-4)$ and $(-7,6)$. What are the coordinates of the center of circle $M$? Express your answer as an ordered pair.",
|
| 6 |
+
"output": "The midpoint of a diameter of a circle is its center. Thus, $M$ is the midpoint of the segment from $(-1,-4)$ to $(-7,6),$ so $M$ has coordinates \\[\\left(\\frac{-1+(-7)}{2},\\frac{-4+6}{2} \\right)=\\boxed{(-4,1)}.\\]"
|
| 7 |
+
}
|
| 8 |
+
]
|
| 9 |
+
},
|
| 10 |
+
{
|
| 11 |
+
"conversation": [
|
| 12 |
+
{
|
| 13 |
+
"input": "In triangle $ABC$,\n\\[2a^2 + 4b^2 + c^2 = 4ab + 2ac.\\]Compute the numerical value of $\\cos B.$",
|
| 14 |
+
"output": "Moving everything to one side, we get\n\\[2a^2 + 4b^2 + c^2 - 4ab - 2ac = 0.\\]We can write this equation as\n\\[(a - 2b)^2 + (a - c)^2 = 0,\\]so $b = \\frac{a}{2}$ and $a = c.$ Then by the Law of Cosines,\n\\[\\cos B = \\frac{a^2 + c^2 - b^2}{2ac} = \\frac{a^2 + a^2 - \\frac{a^2}{4}}{2a^2} = \\boxed{\\frac{7}{8}}.\\]"
|
| 15 |
+
}
|
| 16 |
+
]
|
| 17 |
+
},
|
| 18 |
+
{
|
| 19 |
+
"conversation": [
|
| 20 |
+
{
|
| 21 |
+
"input": "Find the smallest positive integer $N$ with the following property: of the three numbers $N$, $N+1$, and $N+2$, one of them is divisible by $2^2$, one of them is divisible by $3^2$, one is divisible by $5^2$, and one is divisible by $7^2$.",
|
| 22 |
+
"output": "The most efficient means of searching for this trio of integers is to begin with the multiples of $7^2$. The first such number is 49, which almost works, since 50 is divisible by $5^2$ and 48 is divisible by $2^2$. But none of the nearby numbers is divisible by $3^2$, so we move on to the next multiple of $7^2$, which is 98. To our delight we discover that $3^2$ divides 99, while $2^2$ and $5^2$ divide 100. Hence we should take $N=\\boxed{98}$."
|
| 23 |
+
}
|
| 24 |
+
]
|
| 25 |
+
},
|
| 26 |
+
{
|
| 27 |
+
"conversation": [
|
| 28 |
+
{
|
| 29 |
+
"input": "Using the letters $A$ and $B$, the following two-letter code words can be formed: $AA$, $AB$, $BB$, $BA$. Using the letters $A$, $B$, and $C$, how many different three-letter code words can be formed?",
|
| 30 |
+
"output": "Make a tree-diagram for all three-letter code words starting with $A$. Each path from the top to the bottom contains 3 letters, which is one of the code words beginning with $A$. There are 9 such code words. Clearly, there are 9 code words starting with $B$ and 9 starting with $C$. In all, there are $\\boxed{27}$ code words.\n\n[asy]\n\ndraw((-10,-8)--(0,0)--(10,-8));\nlabel(\"$A$\",(0,0),N);\n\ndraw((-12,-18)--(-10,-12)--(-10,-18));\ndraw((-10,-12)--(-8,-18));\n\nlabel(\"$A$\",(-10,-10));\nlabel(\"$A$\",(-12,-18),S);\nlabel(\"$B$\",(-10,-18),S);\nlabel(\"$C$\",(-8,-18),S);\n\ndraw((0,0)--(0,-8));\n\ndraw((-2,-18)--(0,-12)--(0,-18));\ndraw((0,-12)--(2,-18));\n\nlabel(\"$B$\",(0,-10));\nlabel(\"$A$\",(-2,-18),S);\nlabel(\"$B$\",(0,-18),S);\nlabel(\"$C$\",(2,-18),S);\n\ndraw((8,-18)--(10,-12)--(10,-18));\ndraw((10,-12)--(12,-18));\n\nlabel(\"$C$\",(10,-10));\nlabel(\"$A$\",(8,-18),S);\nlabel(\"$B$\",(10,-18),S);\nlabel(\"$C$\",(12,-18),S);\n\n[/asy]"
|
| 31 |
+
}
|
| 32 |
+
]
|
| 33 |
+
},
|
| 34 |
+
{
|
| 35 |
+
"conversation": [
|
| 36 |
+
{
|
| 37 |
+
"input": "Steve has an isosceles triangle with base 8 inches and height 10 inches. He wants to cut it into eight pieces that have equal areas, as shown below. To the nearest hundredth of an inch what is the number of inches in the greatest perimeter among the eight pieces? [asy]\nsize(150);\ndefaultpen(linewidth(0.7));\ndraw((0,0)--(8,0));\nfor(int i = 0; i < 9; ++i){\ndraw((4,10)--(i,0));\n}\ndraw((0,-0.5)--(8,-0.5),Bars(5));\nlabel(\"$8''$\",(0,-0.5)--(8,-0.5),S);\n[/asy]",
|
| 38 |
+
"output": "To make the $8$ triangles have the same area, the base must be divided into $8$ segments of length $1$ inch each. Define points $A$, $B_0$, $B_1$, $B_2$, $B_3$, and $B_4$ as in the figure. For $0\\leq k\\leq 3$, the perimeter $P(k)$ of triangle $A B_k B_{k+1}$ in inches is \\[\nP(k)=1+\\sqrt{10^2+k^2}+\\sqrt{10^2+(k+1)^2},\n\\]where each distance $A B_k$ is calculated by applying the Pythagorean theorem to right triangle $A B_0 B_k$. Since $P(k)$ increases as $k$ increases, its largest value is $P(3)=1+\\sqrt{100+3^2}+\\sqrt{100+4^2}$, which to the nearest hundredth is $\\boxed{22.21}$ inches. [asy]\nsize(200);\ndefaultpen(linewidth(0.7)+fontsize(10));\ndraw((0,0)--(8,0));\nfor(int i = 0; i < 9; ++i){\ndraw((4,10)--(i,0));\nif(i>=4)\n\nlabel(\"$B_\"+string(i-4)+\"$\",(i,0),S);\n}\nlabel(\"$A$\",(4,10),N);\n[/asy]"
|
| 39 |
+
}
|
| 40 |
+
]
|
| 41 |
+
},
|
| 42 |
+
{
|
| 43 |
+
"conversation": [
|
| 44 |
+
{
|
| 45 |
+
"input": "\\lim {x \\rightarrow+\\infty} \\frac{x^{3}+x^{2}+1}{\\mathrm{e}^{x}+x^{3}}(\\sin x+\\cos x)=",
|
| 46 |
+
"output": "0 \\\\ 解: 由于\\\\\\lim _{x \\rightarrow+\\infty} \\frac{x^{3}+x^{2}+1}{\\mathrm{e}^{x}+x^{3}}=\\lim _{x \\rightarrow+\\infty} \\frac{3 x^{2}+2 x}{\\mathrm{e}^{x}+3 x^{2}}=\\lim _{x \\rightarrow+\\infty} \\frac{6 x+2}{\\mathrm{e}^{x}+6 x}=\\lim _{x \\rightarrow+\\infty} \\frac{6}{\\mathrm{e}^{x}+6}=0,\\\\\\且 |\\sin x+\\cos x| \\leqslant 2, 即有界, 故原式 =0.\\【注】当 x \\rightarrow+\\infty 时, \\mathrm{e}^{x} 是比 x^{3} 高阶的无穷大, 则 \\lim _{x \\rightarrow+\\infty} \\frac{x^{3}+x^{2}+1}{\\mathrm{e}^{x}+x^{3}}=0."
|
| 47 |
+
}
|
| 48 |
+
]
|
| 49 |
+
},
|
| 50 |
+
{
|
| 51 |
+
"conversation": [
|
| 52 |
+
{
|
| 53 |
+
"input": "In how many ways can a President and a Vice-President be chosen from a group of 5 people (assuming that the President and the Vice-President cannot be the same person)?",
|
| 54 |
+
"output": "There are 5 choices for President, and then 4 choices (the remaining four people) for Vice-President, so there are $5 \\times 4 = \\boxed{20}$ choices for the two officers."
|
| 55 |
+
}
|
| 56 |
+
]
|
| 57 |
+
},
|
| 58 |
+
{
|
| 59 |
+
"conversation": [
|
| 60 |
+
{
|
| 61 |
+
"input": "Let $a_1,$ $a_2,$ $\\dots$ be a sequence of real numbers such that for all positive integers $n,$\n\\[\\sum_{k = 1}^n a_k \\left( \\frac{k}{n} \\right)^2 = 1.\\]Find the smallest $n$ such that $a_n < \\frac{1}{2018}.$",
|
| 62 |
+
"output": "For $n = 1,$ we get $a_1 = 1.$ Otherwise,\n\\[\\sum_{k = 1}^n k^2 a_k = n^2.\\]Also,\n\\[\\sum_{k = 1}^{n - 1} k^2 a_k = (n - 1)^2.\\]Subtracting these equations, we get\n\\[n^2 a_n = n^2 - (n - 1)^2 = 2n - 1,\\]so $a_n = \\frac{2n - 1}{n^2} = \\frac{2}{n} - \\frac{1}{n^2}.$ Note that $a_n = 1 - \\frac{n^2 - 2n + 1}{n^2} = 1 - \\left( \\frac{n - 1}{n} \\right)^2$ is a decreasing function of $n.$\n\nAlso,\n\\[a_{4035} - \\frac{1}{2018} = \\frac{2}{4035} - \\frac{1}{4035^2} - \\frac{1}{2018} = \\frac{1}{4035 \\cdot 2018} - \\frac{1}{4035^2} > 0,\\]and\n\\[a_{4036} < \\frac{2}{4036} = \\frac{1}{2018}.\\]Thus, the smallest such $n$ is $\\boxed{4036}.$"
|
| 63 |
+
}
|
| 64 |
+
]
|
| 65 |
+
},
|
| 66 |
+
{
|
| 67 |
+
"conversation": [
|
| 68 |
+
{
|
| 69 |
+
"input": "A right, rectangular prism has three faces with areas of $6,8$ and $12$ square inches. What is the volume of the prism, in cubic inches?",
|
| 70 |
+
"output": "If $l$, $w$, and $h$ represent the dimensions of the rectangular prism, we look for the volume $lwh$. We arbitrarily set $lw=6$, $wh=8$, and $lh=12$. Now notice that if we multiply all three equations, we get $l^2w^2h^2=6\\cdot8\\cdot12=3\\cdot2\\cdot2^3\\cdot2^2\\cdot3=2^6\\cdot3^2$. To get the volume, we take the square root of each side and get $lwh=2^3\\cdot3=\\boxed{24}$ cubic inches."
|
| 71 |
+
}
|
| 72 |
+
]
|
| 73 |
+
},
|
| 74 |
+
{
|
| 75 |
+
"conversation": [
|
| 76 |
+
{
|
| 77 |
+
"input": "Given that the diagonals of a rhombus are always perpendicular bisectors of each other, what is the area of a rhombus with side length $\\sqrt{89}$ units and diagonals that differ by 6 units?",
|
| 78 |
+
"output": "Because the diagonals of a rhombus are perpendicular bisectors of each other, they divide the rhombus into four congruent right triangles. Let $x$ be half of the length of the shorter diagonal of the rhombus. Then $x+3$ is half of the length of the longer diagonal. Also, $x$ and $x+3$ are the lengths of the legs of each of the right triangles. By the Pythagorean theorem, \\[\nx^2+(x+3)^2=\\left(\\sqrt{89}\\right)^2.\n\\] Expanding $(x+3)^2$ as $x^2+6x+9$ and moving every term to the left-hand side, the equation simplifies to $2x^2+6x-80=0$. The expression $2x^2+6x-80$ factors as $2(x-5)(x+8)$, so we find $x=5$ and $x=-8$. Discarding the negative solution, we calculate the area of the rhombus by multiplying the area of one of the right triangles by 4. The area of the rhombus is $4\\cdot\\left(\\frac{1}{2}\\cdot 5(5+3)\\right)=\\boxed{80}$ square units.\n\n[asy]\nunitsize(3mm);\ndefaultpen(linewidth(0.7pt)+fontsize(11pt));\ndotfactor=3;\npair A=(8,0), B=(0,5), C=(-8,0), D=(0,-5), Ep = (0,0);\ndraw(A--B--C--D--cycle);\ndraw(A--C);\ndraw(B--D);\nlabel(\"$x$\",midpoint(Ep--B),W);\nlabel(\"$x+3$\",midpoint(Ep--A),S);\nlabel(\"$\\sqrt{89}$\",midpoint(A--B),NE);[/asy]"
|
| 79 |
+
}
|
| 80 |
+
]
|
| 81 |
+
},
|
| 82 |
+
{
|
| 83 |
+
"conversation": [
|
| 84 |
+
{
|
| 85 |
+
"input": "A large sphere has a volume of $288\\pi$ cubic units. A smaller sphere has a volume which is $12.5\\%$ of the volume of the larger sphere. What is the ratio of the radius of the smaller sphere to the radius of the larger sphere? Express your answer as a common fraction.",
|
| 86 |
+
"output": "We know that the two spheres are similar (in the same sense that triangles are similar) because corresponding parts are in proportion. We will prove that for two spheres that are similar in the ratio $1:k$, their volumes have the ratio $1:k^3$. Let the radius of the first sphere be $r$, so the radius of the other sphere is $kr$. The volume of the first sphere is $\\frac{4}{3}\\pi r^3$ and the volume of the second sphere is $\\frac{4}{3}\\pi (kr)^3$. The ratio between the two volumes is \\[\\frac{\\frac{4}{3}\\pi r^3}{\\frac{4}{3}\\pi (kr)^3}=\\frac{r^3}{k^3r^3}=\\frac{1}{k^3}\\] Thus, the ratio of the volumes of the two spheres is $1:k^3$.\n\nIn this problem, since the smaller sphere has $12.5\\%=\\frac{1}{8}$ of the volume of the larger sphere, the radius is $\\sqrt[3]{\\frac{1}{8}}=\\frac{1}{2}$ that of the larger sphere. Thus, the ratio between the two radii is $\\boxed{\\frac{1}{2}}$.\n\n(In general, the ratio of the volumes of two similar 3-D shapes is the cube of the ratio of the lengths of corresponding sides.)"
|
| 87 |
+
}
|
| 88 |
+
]
|
| 89 |
+
},
|
| 90 |
+
{
|
| 91 |
+
"conversation": [
|
| 92 |
+
{
|
| 93 |
+
"input": "A drawer contains 3 white balls and 6 black balls. Two balls are drawn out of the box at random. What is the probability that they both are white?",
|
| 94 |
+
"output": "There are $\\binom{9}{2} = 36$ combinations of two balls that can be drawn. There are $\\binom{3}{2} = 3$ combinations of two white balls that can be drawn. So the probability that two balls pulled out are both white is $\\dfrac{3}{36} = \\boxed{\\dfrac{1}{12}}$."
|
| 95 |
+
}
|
| 96 |
+
]
|
| 97 |
+
}
|
| 98 |
+
]
|
CLIP/model-card.md
ADDED
|
@@ -0,0 +1,118 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Model Card: CLIP
|
| 2 |
+
|
| 3 |
+
Inspired by [Model Cards for Model Reporting (Mitchell et al.)](https://arxiv.org/abs/1810.03993) and [Lessons from Archives (Jo & Gebru)](https://arxiv.org/pdf/1912.10389.pdf), we’re providing some accompanying information about the multimodal model.
|
| 4 |
+
|
| 5 |
+
## Model Details
|
| 6 |
+
|
| 7 |
+
The CLIP model was developed by researchers at OpenAI to learn about what contributes to robustness in computer vision tasks. The model was also developed to test the ability of models to generalize to arbitrary image classification tasks in a zero-shot manner. It was not developed for general model deployment - to deploy models like CLIP, researchers will first need to carefully study their capabilities in relation to the specific context they’re being deployed within.
|
| 8 |
+
|
| 9 |
+
### Model Date
|
| 10 |
+
|
| 11 |
+
January 2021
|
| 12 |
+
|
| 13 |
+
### Model Type
|
| 14 |
+
|
| 15 |
+
The base model uses a ResNet50 with several modifications as an image encoder and uses a masked self-attention Transformer as a text encoder. These encoders are trained to maximize the similarity of (image, text) pairs via a contrastive loss. There is also a variant of the model where the ResNet image encoder is replaced with a Vision Transformer.
|
| 16 |
+
|
| 17 |
+
### Model Version
|
| 18 |
+
|
| 19 |
+
Initially we’ve released one CLIP model based on the Vision Transformer architecture equivalent to ViT-B/32
|
| 20 |
+
|
| 21 |
+
Please see the paper linked below for further details about their specification.
|
| 22 |
+
|
| 23 |
+
### Documents
|
| 24 |
+
|
| 25 |
+
- [Blog Post](https://openai.com/blog/clip/)
|
| 26 |
+
- [CLIP Paper](https://cdn.openai.com/papers/Learning_Transferable_Visual_Models_From_Natural_Language_Supervision.pdf)
|
| 27 |
+
|
| 28 |
+
|
| 29 |
+
|
| 30 |
+
## Model Use
|
| 31 |
+
|
| 32 |
+
### Intended Use
|
| 33 |
+
|
| 34 |
+
The model is intended as a research output for research communities. We hope that this model will enable researchers to better understand and explore zero-shot, arbitrary image classification. We also hope it can be used for interdisciplinary studies of the potential impact of such models - the CLIP paper includes a discussion of potential downstream impacts to provide an example for this sort of analysis.
|
| 35 |
+
|
| 36 |
+
#### Primary intended uses
|
| 37 |
+
|
| 38 |
+
The primary intended users of these models are AI researchers.
|
| 39 |
+
|
| 40 |
+
We primarily imagine the model will be used by researchers to better understand robustness, generalization, and other capabilities, biases, and constraints of computer vision models.
|
| 41 |
+
|
| 42 |
+
### Out-of-Scope Use Cases
|
| 43 |
+
|
| 44 |
+
**Any** deployed use case of the model - whether commercial or not - is currently out of scope. Non-deployed use cases such as image search in a constrained environment, are also not recommended unless there is thorough in-domain testing of the model with a specific, fixed class taxonomy. This is because our safety assessment demonstrated a high need for task specific testing especially given the variability of CLIP’s performance with different class taxonomies. This makes untested and unconstrained deployment of the model in any use case currently potentially harmful.
|
| 45 |
+
|
| 46 |
+
Certain use cases which would fall under the domain of surveillance and facial recognition are always out-of-scope regardless of performance of the model. This is because the use of artificial intelligence for tasks such as these can be premature currently given the lack of testing norms and checks to ensure its fair use.
|
| 47 |
+
|
| 48 |
+
Since the model has not been purposefully trained in or evaluated on any languages other than English, its use should be limited to English language use cases.
|
| 49 |
+
|
| 50 |
+
|
| 51 |
+
|
| 52 |
+
## Data
|
| 53 |
+
|
| 54 |
+
The model was trained on publicly available image-caption data. This was done through a combination of crawling a handful of websites and using commonly-used pre-existing image datasets such as [YFCC100M](http://projects.dfki.uni-kl.de/yfcc100m/). A large portion of the data comes from our crawling of the internet. This means that the data is more representative of people and societies most connected to the internet which tend to skew towards more developed nations, and younger, male users.
|
| 55 |
+
|
| 56 |
+
### Data Mission Statement
|
| 57 |
+
|
| 58 |
+
Our goal with building this dataset was to test out robustness and generalizability in computer vision tasks. As a result, the focus was on gathering large quantities of data from different publicly-available internet data sources. The data was gathered in a mostly non-interventionist manner. However, we only crawled websites that had policies against excessively violent and adult images and allowed us to filter out such content. We do not intend for this dataset to be used as the basis for any commercial or deployed model and will not be releasing the dataset.
|
| 59 |
+
|
| 60 |
+
|
| 61 |
+
|
| 62 |
+
## Performance and Limitations
|
| 63 |
+
|
| 64 |
+
### Performance
|
| 65 |
+
|
| 66 |
+
We have evaluated the performance of CLIP on a wide range of benchmarks across a variety of computer vision datasets such as OCR to texture recognition to fine-grained classification. The paper describes model performance on the following datasets:
|
| 67 |
+
|
| 68 |
+
- Food101
|
| 69 |
+
- CIFAR10
|
| 70 |
+
- CIFAR100
|
| 71 |
+
- Birdsnap
|
| 72 |
+
- SUN397
|
| 73 |
+
- Stanford Cars
|
| 74 |
+
- FGVC Aircraft
|
| 75 |
+
- VOC2007
|
| 76 |
+
- DTD
|
| 77 |
+
- Oxford-IIIT Pet dataset
|
| 78 |
+
- Caltech101
|
| 79 |
+
- Flowers102
|
| 80 |
+
- MNIST
|
| 81 |
+
- SVHN
|
| 82 |
+
- IIIT5K
|
| 83 |
+
- Hateful Memes
|
| 84 |
+
- SST-2
|
| 85 |
+
- UCF101
|
| 86 |
+
- Kinetics700
|
| 87 |
+
- Country211
|
| 88 |
+
- CLEVR Counting
|
| 89 |
+
- KITTI Distance
|
| 90 |
+
- STL-10
|
| 91 |
+
- RareAct
|
| 92 |
+
- Flickr30
|
| 93 |
+
- MSCOCO
|
| 94 |
+
- ImageNet
|
| 95 |
+
- ImageNet-A
|
| 96 |
+
- ImageNet-R
|
| 97 |
+
- ImageNet Sketch
|
| 98 |
+
- ObjectNet (ImageNet Overlap)
|
| 99 |
+
- Youtube-BB
|
| 100 |
+
- ImageNet-Vid
|
| 101 |
+
|
| 102 |
+
## Limitations
|
| 103 |
+
|
| 104 |
+
CLIP and our analysis of it have a number of limitations. CLIP currently struggles with respect to certain tasks such as fine grained classification and counting objects. CLIP also poses issues with regards to fairness and bias which we discuss in the paper and briefly in the next section. Additionally, our approach to testing CLIP also has an important limitation- in many cases we have used linear probes to evaluate the performance of CLIP and there is evidence suggesting that linear probes can underestimate model performance.
|
| 105 |
+
|
| 106 |
+
### Bias and Fairness
|
| 107 |
+
|
| 108 |
+
We find that the performance of CLIP - and the specific biases it exhibits - can depend significantly on class design and the choices one makes for categories to include and exclude. We tested the risk of certain kinds of denigration with CLIP by classifying images of people from [Fairface](https://arxiv.org/abs/1908.04913) into crime-related and non-human animal categories. We found significant disparities with respect to race and gender. Additionally, we found that these disparities could shift based on how the classes were constructed. (Details captured in the Broader Impacts Section in the paper).
|
| 109 |
+
|
| 110 |
+
We also tested the performance of CLIP on gender, race and age classification using the Fairface dataset (We default to using race categories as they are constructed in the Fairface dataset.) in order to assess quality of performance across different demographics. We found accuracy >96% across all races for gender classification with ‘Middle Eastern’ having the highest accuracy (98.4%) and ‘White’ having the lowest (96.5%). Additionally, CLIP averaged ~93% for racial classification and ~63% for age classification. Our use of evaluations to test for gender, race and age classification as well as denigration harms is simply to evaluate performance of the model across people and surface potential risks and not to demonstrate an endorsement/enthusiasm for such tasks.
|
| 111 |
+
|
| 112 |
+
|
| 113 |
+
|
| 114 |
+
## Feedback
|
| 115 |
+
|
| 116 |
+
### Where to send questions or comments about the model
|
| 117 |
+
|
| 118 |
+
Please use [this Google Form](https://forms.gle/Uv7afRH5dvY34ZEs9)
|
CLIP/notebooks/Interacting_with_CLIP.ipynb
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
CLIP/notebooks/Prompt_Engineering_for_ImageNet.ipynb
ADDED
|
@@ -0,0 +1,1188 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"nbformat": 4,
|
| 3 |
+
"nbformat_minor": 0,
|
| 4 |
+
"metadata": {
|
| 5 |
+
"colab": {
|
| 6 |
+
"name": "Prompt Engineering for ImageNet.ipynb",
|
| 7 |
+
"provenance": [],
|
| 8 |
+
"collapsed_sections": []
|
| 9 |
+
},
|
| 10 |
+
"kernelspec": {
|
| 11 |
+
"name": "python3",
|
| 12 |
+
"display_name": "Python 3"
|
| 13 |
+
},
|
| 14 |
+
"accelerator": "GPU",
|
| 15 |
+
"widgets": {
|
| 16 |
+
"application/vnd.jupyter.widget-state+json": {
|
| 17 |
+
"4e3a3f83649f45f8bef3434980634664": {
|
| 18 |
+
"model_module": "@jupyter-widgets/controls",
|
| 19 |
+
"model_name": "HBoxModel",
|
| 20 |
+
"state": {
|
| 21 |
+
"_view_name": "HBoxView",
|
| 22 |
+
"_dom_classes": [],
|
| 23 |
+
"_model_name": "HBoxModel",
|
| 24 |
+
"_view_module": "@jupyter-widgets/controls",
|
| 25 |
+
"_model_module_version": "1.5.0",
|
| 26 |
+
"_view_count": null,
|
| 27 |
+
"_view_module_version": "1.5.0",
|
| 28 |
+
"box_style": "",
|
| 29 |
+
"layout": "IPY_MODEL_f066bdb766664c788ba1e9de8d311e22",
|
| 30 |
+
"_model_module": "@jupyter-widgets/controls",
|
| 31 |
+
"children": [
|
| 32 |
+
"IPY_MODEL_4e7a7427d28a4ae684e0be4548eb9944",
|
| 33 |
+
"IPY_MODEL_cc9dc019c1334a46b2558ffa6c0dd6e6"
|
| 34 |
+
]
|
| 35 |
+
}
|
| 36 |
+
},
|
| 37 |
+
"f066bdb766664c788ba1e9de8d311e22": {
|
| 38 |
+
"model_module": "@jupyter-widgets/base",
|
| 39 |
+
"model_name": "LayoutModel",
|
| 40 |
+
"state": {
|
| 41 |
+
"_view_name": "LayoutView",
|
| 42 |
+
"grid_template_rows": null,
|
| 43 |
+
"right": null,
|
| 44 |
+
"justify_content": null,
|
| 45 |
+
"_view_module": "@jupyter-widgets/base",
|
| 46 |
+
"overflow": null,
|
| 47 |
+
"_model_module_version": "1.2.0",
|
| 48 |
+
"_view_count": null,
|
| 49 |
+
"flex_flow": null,
|
| 50 |
+
"width": null,
|
| 51 |
+
"min_width": null,
|
| 52 |
+
"border": null,
|
| 53 |
+
"align_items": null,
|
| 54 |
+
"bottom": null,
|
| 55 |
+
"_model_module": "@jupyter-widgets/base",
|
| 56 |
+
"top": null,
|
| 57 |
+
"grid_column": null,
|
| 58 |
+
"overflow_y": null,
|
| 59 |
+
"overflow_x": null,
|
| 60 |
+
"grid_auto_flow": null,
|
| 61 |
+
"grid_area": null,
|
| 62 |
+
"grid_template_columns": null,
|
| 63 |
+
"flex": null,
|
| 64 |
+
"_model_name": "LayoutModel",
|
| 65 |
+
"justify_items": null,
|
| 66 |
+
"grid_row": null,
|
| 67 |
+
"max_height": null,
|
| 68 |
+
"align_content": null,
|
| 69 |
+
"visibility": null,
|
| 70 |
+
"align_self": null,
|
| 71 |
+
"height": null,
|
| 72 |
+
"min_height": null,
|
| 73 |
+
"padding": null,
|
| 74 |
+
"grid_auto_rows": null,
|
| 75 |
+
"grid_gap": null,
|
| 76 |
+
"max_width": null,
|
| 77 |
+
"order": null,
|
| 78 |
+
"_view_module_version": "1.2.0",
|
| 79 |
+
"grid_template_areas": null,
|
| 80 |
+
"object_position": null,
|
| 81 |
+
"object_fit": null,
|
| 82 |
+
"grid_auto_columns": null,
|
| 83 |
+
"margin": null,
|
| 84 |
+
"display": null,
|
| 85 |
+
"left": null
|
| 86 |
+
}
|
| 87 |
+
},
|
| 88 |
+
"4e7a7427d28a4ae684e0be4548eb9944": {
|
| 89 |
+
"model_module": "@jupyter-widgets/controls",
|
| 90 |
+
"model_name": "FloatProgressModel",
|
| 91 |
+
"state": {
|
| 92 |
+
"_view_name": "ProgressView",
|
| 93 |
+
"style": "IPY_MODEL_285c877d4f644f3a8a58c4eb5948101c",
|
| 94 |
+
"_dom_classes": [],
|
| 95 |
+
"description": "100%",
|
| 96 |
+
"_model_name": "FloatProgressModel",
|
| 97 |
+
"bar_style": "success",
|
| 98 |
+
"max": 1000,
|
| 99 |
+
"_view_module": "@jupyter-widgets/controls",
|
| 100 |
+
"_model_module_version": "1.5.0",
|
| 101 |
+
"value": 1000,
|
| 102 |
+
"_view_count": null,
|
| 103 |
+
"_view_module_version": "1.5.0",
|
| 104 |
+
"orientation": "horizontal",
|
| 105 |
+
"min": 0,
|
| 106 |
+
"description_tooltip": null,
|
| 107 |
+
"_model_module": "@jupyter-widgets/controls",
|
| 108 |
+
"layout": "IPY_MODEL_075d6545e02e419ca565589eb5ffc318"
|
| 109 |
+
}
|
| 110 |
+
},
|
| 111 |
+
"cc9dc019c1334a46b2558ffa6c0dd6e6": {
|
| 112 |
+
"model_module": "@jupyter-widgets/controls",
|
| 113 |
+
"model_name": "HTMLModel",
|
| 114 |
+
"state": {
|
| 115 |
+
"_view_name": "HTMLView",
|
| 116 |
+
"style": "IPY_MODEL_53f9106c80e84d5b8c3ec96162d1db98",
|
| 117 |
+
"_dom_classes": [],
|
| 118 |
+
"description": "",
|
| 119 |
+
"_model_name": "HTMLModel",
|
| 120 |
+
"placeholder": "",
|
| 121 |
+
"_view_module": "@jupyter-widgets/controls",
|
| 122 |
+
"_model_module_version": "1.5.0",
|
| 123 |
+
"value": " 1000/1000 [01:09<00:00, 14.35it/s]",
|
| 124 |
+
"_view_count": null,
|
| 125 |
+
"_view_module_version": "1.5.0",
|
| 126 |
+
"description_tooltip": null,
|
| 127 |
+
"_model_module": "@jupyter-widgets/controls",
|
| 128 |
+
"layout": "IPY_MODEL_19c57d99e7c44cbda508ce558fde435d"
|
| 129 |
+
}
|
| 130 |
+
},
|
| 131 |
+
"285c877d4f644f3a8a58c4eb5948101c": {
|
| 132 |
+
"model_module": "@jupyter-widgets/controls",
|
| 133 |
+
"model_name": "ProgressStyleModel",
|
| 134 |
+
"state": {
|
| 135 |
+
"_view_name": "StyleView",
|
| 136 |
+
"_model_name": "ProgressStyleModel",
|
| 137 |
+
"description_width": "initial",
|
| 138 |
+
"_view_module": "@jupyter-widgets/base",
|
| 139 |
+
"_model_module_version": "1.5.0",
|
| 140 |
+
"_view_count": null,
|
| 141 |
+
"_view_module_version": "1.2.0",
|
| 142 |
+
"bar_color": null,
|
| 143 |
+
"_model_module": "@jupyter-widgets/controls"
|
| 144 |
+
}
|
| 145 |
+
},
|
| 146 |
+
"075d6545e02e419ca565589eb5ffc318": {
|
| 147 |
+
"model_module": "@jupyter-widgets/base",
|
| 148 |
+
"model_name": "LayoutModel",
|
| 149 |
+
"state": {
|
| 150 |
+
"_view_name": "LayoutView",
|
| 151 |
+
"grid_template_rows": null,
|
| 152 |
+
"right": null,
|
| 153 |
+
"justify_content": null,
|
| 154 |
+
"_view_module": "@jupyter-widgets/base",
|
| 155 |
+
"overflow": null,
|
| 156 |
+
"_model_module_version": "1.2.0",
|
| 157 |
+
"_view_count": null,
|
| 158 |
+
"flex_flow": null,
|
| 159 |
+
"width": null,
|
| 160 |
+
"min_width": null,
|
| 161 |
+
"border": null,
|
| 162 |
+
"align_items": null,
|
| 163 |
+
"bottom": null,
|
| 164 |
+
"_model_module": "@jupyter-widgets/base",
|
| 165 |
+
"top": null,
|
| 166 |
+
"grid_column": null,
|
| 167 |
+
"overflow_y": null,
|
| 168 |
+
"overflow_x": null,
|
| 169 |
+
"grid_auto_flow": null,
|
| 170 |
+
"grid_area": null,
|
| 171 |
+
"grid_template_columns": null,
|
| 172 |
+
"flex": null,
|
| 173 |
+
"_model_name": "LayoutModel",
|
| 174 |
+
"justify_items": null,
|
| 175 |
+
"grid_row": null,
|
| 176 |
+
"max_height": null,
|
| 177 |
+
"align_content": null,
|
| 178 |
+
"visibility": null,
|
| 179 |
+
"align_self": null,
|
| 180 |
+
"height": null,
|
| 181 |
+
"min_height": null,
|
| 182 |
+
"padding": null,
|
| 183 |
+
"grid_auto_rows": null,
|
| 184 |
+
"grid_gap": null,
|
| 185 |
+
"max_width": null,
|
| 186 |
+
"order": null,
|
| 187 |
+
"_view_module_version": "1.2.0",
|
| 188 |
+
"grid_template_areas": null,
|
| 189 |
+
"object_position": null,
|
| 190 |
+
"object_fit": null,
|
| 191 |
+
"grid_auto_columns": null,
|
| 192 |
+
"margin": null,
|
| 193 |
+
"display": null,
|
| 194 |
+
"left": null
|
| 195 |
+
}
|
| 196 |
+
},
|
| 197 |
+
"53f9106c80e84d5b8c3ec96162d1db98": {
|
| 198 |
+
"model_module": "@jupyter-widgets/controls",
|
| 199 |
+
"model_name": "DescriptionStyleModel",
|
| 200 |
+
"state": {
|
| 201 |
+
"_view_name": "StyleView",
|
| 202 |
+
"_model_name": "DescriptionStyleModel",
|
| 203 |
+
"description_width": "",
|
| 204 |
+
"_view_module": "@jupyter-widgets/base",
|
| 205 |
+
"_model_module_version": "1.5.0",
|
| 206 |
+
"_view_count": null,
|
| 207 |
+
"_view_module_version": "1.2.0",
|
| 208 |
+
"_model_module": "@jupyter-widgets/controls"
|
| 209 |
+
}
|
| 210 |
+
},
|
| 211 |
+
"19c57d99e7c44cbda508ce558fde435d": {
|
| 212 |
+
"model_module": "@jupyter-widgets/base",
|
| 213 |
+
"model_name": "LayoutModel",
|
| 214 |
+
"state": {
|
| 215 |
+
"_view_name": "LayoutView",
|
| 216 |
+
"grid_template_rows": null,
|
| 217 |
+
"right": null,
|
| 218 |
+
"justify_content": null,
|
| 219 |
+
"_view_module": "@jupyter-widgets/base",
|
| 220 |
+
"overflow": null,
|
| 221 |
+
"_model_module_version": "1.2.0",
|
| 222 |
+
"_view_count": null,
|
| 223 |
+
"flex_flow": null,
|
| 224 |
+
"width": null,
|
| 225 |
+
"min_width": null,
|
| 226 |
+
"border": null,
|
| 227 |
+
"align_items": null,
|
| 228 |
+
"bottom": null,
|
| 229 |
+
"_model_module": "@jupyter-widgets/base",
|
| 230 |
+
"top": null,
|
| 231 |
+
"grid_column": null,
|
| 232 |
+
"overflow_y": null,
|
| 233 |
+
"overflow_x": null,
|
| 234 |
+
"grid_auto_flow": null,
|
| 235 |
+
"grid_area": null,
|
| 236 |
+
"grid_template_columns": null,
|
| 237 |
+
"flex": null,
|
| 238 |
+
"_model_name": "LayoutModel",
|
| 239 |
+
"justify_items": null,
|
| 240 |
+
"grid_row": null,
|
| 241 |
+
"max_height": null,
|
| 242 |
+
"align_content": null,
|
| 243 |
+
"visibility": null,
|
| 244 |
+
"align_self": null,
|
| 245 |
+
"height": null,
|
| 246 |
+
"min_height": null,
|
| 247 |
+
"padding": null,
|
| 248 |
+
"grid_auto_rows": null,
|
| 249 |
+
"grid_gap": null,
|
| 250 |
+
"max_width": null,
|
| 251 |
+
"order": null,
|
| 252 |
+
"_view_module_version": "1.2.0",
|
| 253 |
+
"grid_template_areas": null,
|
| 254 |
+
"object_position": null,
|
| 255 |
+
"object_fit": null,
|
| 256 |
+
"grid_auto_columns": null,
|
| 257 |
+
"margin": null,
|
| 258 |
+
"display": null,
|
| 259 |
+
"left": null
|
| 260 |
+
}
|
| 261 |
+
},
|
| 262 |
+
"fbb2b937b22049f5987f39f48c652a86": {
|
| 263 |
+
"model_module": "@jupyter-widgets/controls",
|
| 264 |
+
"model_name": "HBoxModel",
|
| 265 |
+
"state": {
|
| 266 |
+
"_view_name": "HBoxView",
|
| 267 |
+
"_dom_classes": [],
|
| 268 |
+
"_model_name": "HBoxModel",
|
| 269 |
+
"_view_module": "@jupyter-widgets/controls",
|
| 270 |
+
"_model_module_version": "1.5.0",
|
| 271 |
+
"_view_count": null,
|
| 272 |
+
"_view_module_version": "1.5.0",
|
| 273 |
+
"box_style": "",
|
| 274 |
+
"layout": "IPY_MODEL_0a1b6b76984349ccb36ca2fc4a4a0208",
|
| 275 |
+
"_model_module": "@jupyter-widgets/controls",
|
| 276 |
+
"children": [
|
| 277 |
+
"IPY_MODEL_c136afb47aa14ac2832093ee415c6f3e",
|
| 278 |
+
"IPY_MODEL_467a151e73744eccb199fe72aa352e5b"
|
| 279 |
+
]
|
| 280 |
+
}
|
| 281 |
+
},
|
| 282 |
+
"0a1b6b76984349ccb36ca2fc4a4a0208": {
|
| 283 |
+
"model_module": "@jupyter-widgets/base",
|
| 284 |
+
"model_name": "LayoutModel",
|
| 285 |
+
"state": {
|
| 286 |
+
"_view_name": "LayoutView",
|
| 287 |
+
"grid_template_rows": null,
|
| 288 |
+
"right": null,
|
| 289 |
+
"justify_content": null,
|
| 290 |
+
"_view_module": "@jupyter-widgets/base",
|
| 291 |
+
"overflow": null,
|
| 292 |
+
"_model_module_version": "1.2.0",
|
| 293 |
+
"_view_count": null,
|
| 294 |
+
"flex_flow": null,
|
| 295 |
+
"width": null,
|
| 296 |
+
"min_width": null,
|
| 297 |
+
"border": null,
|
| 298 |
+
"align_items": null,
|
| 299 |
+
"bottom": null,
|
| 300 |
+
"_model_module": "@jupyter-widgets/base",
|
| 301 |
+
"top": null,
|
| 302 |
+
"grid_column": null,
|
| 303 |
+
"overflow_y": null,
|
| 304 |
+
"overflow_x": null,
|
| 305 |
+
"grid_auto_flow": null,
|
| 306 |
+
"grid_area": null,
|
| 307 |
+
"grid_template_columns": null,
|
| 308 |
+
"flex": null,
|
| 309 |
+
"_model_name": "LayoutModel",
|
| 310 |
+
"justify_items": null,
|
| 311 |
+
"grid_row": null,
|
| 312 |
+
"max_height": null,
|
| 313 |
+
"align_content": null,
|
| 314 |
+
"visibility": null,
|
| 315 |
+
"align_self": null,
|
| 316 |
+
"height": null,
|
| 317 |
+
"min_height": null,
|
| 318 |
+
"padding": null,
|
| 319 |
+
"grid_auto_rows": null,
|
| 320 |
+
"grid_gap": null,
|
| 321 |
+
"max_width": null,
|
| 322 |
+
"order": null,
|
| 323 |
+
"_view_module_version": "1.2.0",
|
| 324 |
+
"grid_template_areas": null,
|
| 325 |
+
"object_position": null,
|
| 326 |
+
"object_fit": null,
|
| 327 |
+
"grid_auto_columns": null,
|
| 328 |
+
"margin": null,
|
| 329 |
+
"display": null,
|
| 330 |
+
"left": null
|
| 331 |
+
}
|
| 332 |
+
},
|
| 333 |
+
"c136afb47aa14ac2832093ee415c6f3e": {
|
| 334 |
+
"model_module": "@jupyter-widgets/controls",
|
| 335 |
+
"model_name": "FloatProgressModel",
|
| 336 |
+
"state": {
|
| 337 |
+
"_view_name": "ProgressView",
|
| 338 |
+
"style": "IPY_MODEL_f6d637c3fc3c46928d023441227130e5",
|
| 339 |
+
"_dom_classes": [],
|
| 340 |
+
"description": "100%",
|
| 341 |
+
"_model_name": "FloatProgressModel",
|
| 342 |
+
"bar_style": "success",
|
| 343 |
+
"max": 313,
|
| 344 |
+
"_view_module": "@jupyter-widgets/controls",
|
| 345 |
+
"_model_module_version": "1.5.0",
|
| 346 |
+
"value": 313,
|
| 347 |
+
"_view_count": null,
|
| 348 |
+
"_view_module_version": "1.5.0",
|
| 349 |
+
"orientation": "horizontal",
|
| 350 |
+
"min": 0,
|
| 351 |
+
"description_tooltip": null,
|
| 352 |
+
"_model_module": "@jupyter-widgets/controls",
|
| 353 |
+
"layout": "IPY_MODEL_029e6eadacb8480193aab52ff073be8f"
|
| 354 |
+
}
|
| 355 |
+
},
|
| 356 |
+
"467a151e73744eccb199fe72aa352e5b": {
|
| 357 |
+
"model_module": "@jupyter-widgets/controls",
|
| 358 |
+
"model_name": "HTMLModel",
|
| 359 |
+
"state": {
|
| 360 |
+
"_view_name": "HTMLView",
|
| 361 |
+
"style": "IPY_MODEL_30178355f76742898d37966b3875ef0a",
|
| 362 |
+
"_dom_classes": [],
|
| 363 |
+
"description": "",
|
| 364 |
+
"_model_name": "HTMLModel",
|
| 365 |
+
"placeholder": "",
|
| 366 |
+
"_view_module": "@jupyter-widgets/controls",
|
| 367 |
+
"_model_module_version": "1.5.0",
|
| 368 |
+
"value": " 313/313 [01:26<00:00, 3.62it/s]",
|
| 369 |
+
"_view_count": null,
|
| 370 |
+
"_view_module_version": "1.5.0",
|
| 371 |
+
"description_tooltip": null,
|
| 372 |
+
"_model_module": "@jupyter-widgets/controls",
|
| 373 |
+
"layout": "IPY_MODEL_2e62544c03d64d6d92b94fcfaca2fc90"
|
| 374 |
+
}
|
| 375 |
+
},
|
| 376 |
+
"f6d637c3fc3c46928d023441227130e5": {
|
| 377 |
+
"model_module": "@jupyter-widgets/controls",
|
| 378 |
+
"model_name": "ProgressStyleModel",
|
| 379 |
+
"state": {
|
| 380 |
+
"_view_name": "StyleView",
|
| 381 |
+
"_model_name": "ProgressStyleModel",
|
| 382 |
+
"description_width": "initial",
|
| 383 |
+
"_view_module": "@jupyter-widgets/base",
|
| 384 |
+
"_model_module_version": "1.5.0",
|
| 385 |
+
"_view_count": null,
|
| 386 |
+
"_view_module_version": "1.2.0",
|
| 387 |
+
"bar_color": null,
|
| 388 |
+
"_model_module": "@jupyter-widgets/controls"
|
| 389 |
+
}
|
| 390 |
+
},
|
| 391 |
+
"029e6eadacb8480193aab52ff073be8f": {
|
| 392 |
+
"model_module": "@jupyter-widgets/base",
|
| 393 |
+
"model_name": "LayoutModel",
|
| 394 |
+
"state": {
|
| 395 |
+
"_view_name": "LayoutView",
|
| 396 |
+
"grid_template_rows": null,
|
| 397 |
+
"right": null,
|
| 398 |
+
"justify_content": null,
|
| 399 |
+
"_view_module": "@jupyter-widgets/base",
|
| 400 |
+
"overflow": null,
|
| 401 |
+
"_model_module_version": "1.2.0",
|
| 402 |
+
"_view_count": null,
|
| 403 |
+
"flex_flow": null,
|
| 404 |
+
"width": null,
|
| 405 |
+
"min_width": null,
|
| 406 |
+
"border": null,
|
| 407 |
+
"align_items": null,
|
| 408 |
+
"bottom": null,
|
| 409 |
+
"_model_module": "@jupyter-widgets/base",
|
| 410 |
+
"top": null,
|
| 411 |
+
"grid_column": null,
|
| 412 |
+
"overflow_y": null,
|
| 413 |
+
"overflow_x": null,
|
| 414 |
+
"grid_auto_flow": null,
|
| 415 |
+
"grid_area": null,
|
| 416 |
+
"grid_template_columns": null,
|
| 417 |
+
"flex": null,
|
| 418 |
+
"_model_name": "LayoutModel",
|
| 419 |
+
"justify_items": null,
|
| 420 |
+
"grid_row": null,
|
| 421 |
+
"max_height": null,
|
| 422 |
+
"align_content": null,
|
| 423 |
+
"visibility": null,
|
| 424 |
+
"align_self": null,
|
| 425 |
+
"height": null,
|
| 426 |
+
"min_height": null,
|
| 427 |
+
"padding": null,
|
| 428 |
+
"grid_auto_rows": null,
|
| 429 |
+
"grid_gap": null,
|
| 430 |
+
"max_width": null,
|
| 431 |
+
"order": null,
|
| 432 |
+
"_view_module_version": "1.2.0",
|
| 433 |
+
"grid_template_areas": null,
|
| 434 |
+
"object_position": null,
|
| 435 |
+
"object_fit": null,
|
| 436 |
+
"grid_auto_columns": null,
|
| 437 |
+
"margin": null,
|
| 438 |
+
"display": null,
|
| 439 |
+
"left": null
|
| 440 |
+
}
|
| 441 |
+
},
|
| 442 |
+
"30178355f76742898d37966b3875ef0a": {
|
| 443 |
+
"model_module": "@jupyter-widgets/controls",
|
| 444 |
+
"model_name": "DescriptionStyleModel",
|
| 445 |
+
"state": {
|
| 446 |
+
"_view_name": "StyleView",
|
| 447 |
+
"_model_name": "DescriptionStyleModel",
|
| 448 |
+
"description_width": "",
|
| 449 |
+
"_view_module": "@jupyter-widgets/base",
|
| 450 |
+
"_model_module_version": "1.5.0",
|
| 451 |
+
"_view_count": null,
|
| 452 |
+
"_view_module_version": "1.2.0",
|
| 453 |
+
"_model_module": "@jupyter-widgets/controls"
|
| 454 |
+
}
|
| 455 |
+
},
|
| 456 |
+
"2e62544c03d64d6d92b94fcfaca2fc90": {
|
| 457 |
+
"model_module": "@jupyter-widgets/base",
|
| 458 |
+
"model_name": "LayoutModel",
|
| 459 |
+
"state": {
|
| 460 |
+
"_view_name": "LayoutView",
|
| 461 |
+
"grid_template_rows": null,
|
| 462 |
+
"right": null,
|
| 463 |
+
"justify_content": null,
|
| 464 |
+
"_view_module": "@jupyter-widgets/base",
|
| 465 |
+
"overflow": null,
|
| 466 |
+
"_model_module_version": "1.2.0",
|
| 467 |
+
"_view_count": null,
|
| 468 |
+
"flex_flow": null,
|
| 469 |
+
"width": null,
|
| 470 |
+
"min_width": null,
|
| 471 |
+
"border": null,
|
| 472 |
+
"align_items": null,
|
| 473 |
+
"bottom": null,
|
| 474 |
+
"_model_module": "@jupyter-widgets/base",
|
| 475 |
+
"top": null,
|
| 476 |
+
"grid_column": null,
|
| 477 |
+
"overflow_y": null,
|
| 478 |
+
"overflow_x": null,
|
| 479 |
+
"grid_auto_flow": null,
|
| 480 |
+
"grid_area": null,
|
| 481 |
+
"grid_template_columns": null,
|
| 482 |
+
"flex": null,
|
| 483 |
+
"_model_name": "LayoutModel",
|
| 484 |
+
"justify_items": null,
|
| 485 |
+
"grid_row": null,
|
| 486 |
+
"max_height": null,
|
| 487 |
+
"align_content": null,
|
| 488 |
+
"visibility": null,
|
| 489 |
+
"align_self": null,
|
| 490 |
+
"height": null,
|
| 491 |
+
"min_height": null,
|
| 492 |
+
"padding": null,
|
| 493 |
+
"grid_auto_rows": null,
|
| 494 |
+
"grid_gap": null,
|
| 495 |
+
"max_width": null,
|
| 496 |
+
"order": null,
|
| 497 |
+
"_view_module_version": "1.2.0",
|
| 498 |
+
"grid_template_areas": null,
|
| 499 |
+
"object_position": null,
|
| 500 |
+
"object_fit": null,
|
| 501 |
+
"grid_auto_columns": null,
|
| 502 |
+
"margin": null,
|
| 503 |
+
"display": null,
|
| 504 |
+
"left": null
|
| 505 |
+
}
|
| 506 |
+
}
|
| 507 |
+
}
|
| 508 |
+
}
|
| 509 |
+
},
|
| 510 |
+
"cells": [
|
| 511 |
+
{
|
| 512 |
+
"cell_type": "markdown",
|
| 513 |
+
"metadata": {
|
| 514 |
+
"id": "53N4k0pj_9qL"
|
| 515 |
+
},
|
| 516 |
+
"source": [
|
| 517 |
+
"# Preparation for Colab\n",
|
| 518 |
+
"\n",
|
| 519 |
+
"Make sure you're running a GPU runtime; if not, select \"GPU\" as the hardware accelerator in Runtime > Change Runtime Type in the menu. The next cells will print the CUDA version of the runtime if it has a GPU, and install PyTorch 1.7.1."
|
| 520 |
+
]
|
| 521 |
+
},
|
| 522 |
+
{
|
| 523 |
+
"cell_type": "code",
|
| 524 |
+
"metadata": {
|
| 525 |
+
"colab": {
|
| 526 |
+
"base_uri": "https://localhost:8080/"
|
| 527 |
+
},
|
| 528 |
+
"id": "0BpdJkdBssk9",
|
| 529 |
+
"outputId": "dc75b5f9-17c7-4856-ac79-8047fa609500"
|
| 530 |
+
},
|
| 531 |
+
"source": [
|
| 532 |
+
"import subprocess\n",
|
| 533 |
+
"\n",
|
| 534 |
+
"CUDA_version = [s for s in subprocess.check_output([\"nvcc\", \"--version\"]).decode(\"UTF-8\").split(\", \") if s.startswith(\"release\")][0].split(\" \")[-1]\n",
|
| 535 |
+
"print(\"CUDA version:\", CUDA_version)\n",
|
| 536 |
+
"\n",
|
| 537 |
+
"if CUDA_version == \"10.0\":\n",
|
| 538 |
+
" torch_version_suffix = \"+cu100\"\n",
|
| 539 |
+
"elif CUDA_version == \"10.1\":\n",
|
| 540 |
+
" torch_version_suffix = \"+cu101\"\n",
|
| 541 |
+
"elif CUDA_version == \"10.2\":\n",
|
| 542 |
+
" torch_version_suffix = \"\"\n",
|
| 543 |
+
"else:\n",
|
| 544 |
+
" torch_version_suffix = \"+cu110\""
|
| 545 |
+
],
|
| 546 |
+
"execution_count": 1,
|
| 547 |
+
"outputs": [
|
| 548 |
+
{
|
| 549 |
+
"output_type": "stream",
|
| 550 |
+
"text": [
|
| 551 |
+
"CUDA version: 10.1\n"
|
| 552 |
+
],
|
| 553 |
+
"name": "stdout"
|
| 554 |
+
}
|
| 555 |
+
]
|
| 556 |
+
},
|
| 557 |
+
{
|
| 558 |
+
"cell_type": "code",
|
| 559 |
+
"metadata": {
|
| 560 |
+
"colab": {
|
| 561 |
+
"base_uri": "https://localhost:8080/"
|
| 562 |
+
},
|
| 563 |
+
"id": "RBVr18E5tse8",
|
| 564 |
+
"outputId": "404230c1-0f78-451d-8816-19d4109d579e"
|
| 565 |
+
},
|
| 566 |
+
"source": [
|
| 567 |
+
"! pip install torch==1.7.1{torch_version_suffix} torchvision==0.8.2{torch_version_suffix} -f https://download.pytorch.org/whl/torch_stable.html ftfy regex"
|
| 568 |
+
],
|
| 569 |
+
"execution_count": 2,
|
| 570 |
+
"outputs": [
|
| 571 |
+
{
|
| 572 |
+
"output_type": "stream",
|
| 573 |
+
"text": [
|
| 574 |
+
"Looking in links: https://download.pytorch.org/whl/torch_stable.html\n",
|
| 575 |
+
"Collecting torch==1.7.1+cu101\n",
|
| 576 |
+
"\u001b[?25l Downloading https://download.pytorch.org/whl/cu101/torch-1.7.1%2Bcu101-cp36-cp36m-linux_x86_64.whl (735.4MB)\n",
|
| 577 |
+
"\u001b[K |████████████████████████████████| 735.4MB 25kB/s \n",
|
| 578 |
+
"\u001b[?25hCollecting torchvision==0.8.2+cu101\n",
|
| 579 |
+
"\u001b[?25l Downloading https://download.pytorch.org/whl/cu101/torchvision-0.8.2%2Bcu101-cp36-cp36m-linux_x86_64.whl (12.8MB)\n",
|
| 580 |
+
"\u001b[K |████████████████████████████████| 12.8MB 248kB/s \n",
|
| 581 |
+
"\u001b[?25hCollecting ftfy\n",
|
| 582 |
+
"\u001b[?25l Downloading https://files.pythonhosted.org/packages/ff/e2/3b51c53dffb1e52d9210ebc01f1fb9f2f6eba9b3201fa971fd3946643c71/ftfy-5.8.tar.gz (64kB)\n",
|
| 583 |
+
"\u001b[K |████████████████████████████████| 71kB 5.6MB/s \n",
|
| 584 |
+
"\u001b[?25hRequirement already satisfied: regex in /usr/local/lib/python3.6/dist-packages (2019.12.20)\n",
|
| 585 |
+
"Requirement already satisfied: typing-extensions in /usr/local/lib/python3.6/dist-packages (from torch==1.7.1+cu101) (3.7.4.3)\n",
|
| 586 |
+
"Requirement already satisfied: numpy in /usr/local/lib/python3.6/dist-packages (from torch==1.7.1+cu101) (1.19.5)\n",
|
| 587 |
+
"Requirement already satisfied: dataclasses; python_version < \"3.7\" in /usr/local/lib/python3.6/dist-packages (from torch==1.7.1+cu101) (0.8)\n",
|
| 588 |
+
"Requirement already satisfied: pillow>=4.1.1 in /usr/local/lib/python3.6/dist-packages (from torchvision==0.8.2+cu101) (7.0.0)\n",
|
| 589 |
+
"Requirement already satisfied: wcwidth in /usr/local/lib/python3.6/dist-packages (from ftfy) (0.2.5)\n",
|
| 590 |
+
"Building wheels for collected packages: ftfy\n",
|
| 591 |
+
" Building wheel for ftfy (setup.py) ... \u001b[?25l\u001b[?25hdone\n",
|
| 592 |
+
" Created wheel for ftfy: filename=ftfy-5.8-cp36-none-any.whl size=45613 sha256=73a94b51b7fe03350783d5b9dd638801a904c618d3b0dc7237ce77f401f33404\n",
|
| 593 |
+
" Stored in directory: /root/.cache/pip/wheels/ba/c0/ef/f28c4da5ac84a4e06ac256ca9182fc34fa57fefffdbc68425b\n",
|
| 594 |
+
"Successfully built ftfy\n",
|
| 595 |
+
"Installing collected packages: torch, torchvision, ftfy\n",
|
| 596 |
+
" Found existing installation: torch 1.7.0+cu101\n",
|
| 597 |
+
" Uninstalling torch-1.7.0+cu101:\n",
|
| 598 |
+
" Successfully uninstalled torch-1.7.0+cu101\n",
|
| 599 |
+
" Found existing installation: torchvision 0.8.1+cu101\n",
|
| 600 |
+
" Uninstalling torchvision-0.8.1+cu101:\n",
|
| 601 |
+
" Successfully uninstalled torchvision-0.8.1+cu101\n",
|
| 602 |
+
"Successfully installed ftfy-5.8 torch-1.7.1+cu101 torchvision-0.8.2+cu101\n"
|
| 603 |
+
],
|
| 604 |
+
"name": "stdout"
|
| 605 |
+
}
|
| 606 |
+
]
|
| 607 |
+
},
|
| 608 |
+
{
|
| 609 |
+
"cell_type": "markdown",
|
| 610 |
+
"metadata": {
|
| 611 |
+
"id": "zGm7TwfbDLgu"
|
| 612 |
+
},
|
| 613 |
+
"source": [
|
| 614 |
+
"The following command installs the `clip` module from its source:"
|
| 615 |
+
]
|
| 616 |
+
},
|
| 617 |
+
{
|
| 618 |
+
"cell_type": "code",
|
| 619 |
+
"metadata": {
|
| 620 |
+
"colab": {
|
| 621 |
+
"base_uri": "https://localhost:8080/"
|
| 622 |
+
},
|
| 623 |
+
"id": "QAFjXlGdEMQM",
|
| 624 |
+
"outputId": "859da71b-00c8-44d1-84d0-7965c20411b4"
|
| 625 |
+
},
|
| 626 |
+
"source": [
|
| 627 |
+
"! pip install git+https://github.com/openai/CLIP.git"
|
| 628 |
+
],
|
| 629 |
+
"execution_count": 3,
|
| 630 |
+
"outputs": [
|
| 631 |
+
{
|
| 632 |
+
"output_type": "stream",
|
| 633 |
+
"text": [
|
| 634 |
+
"Collecting git+https://github.com/openai/CLIP.git\n",
|
| 635 |
+
" Cloning https://github.com/openai/CLIP.git to /tmp/pip-req-build-ewapt31c\n",
|
| 636 |
+
" Running command git clone -q https://github.com/openai/CLIP.git /tmp/pip-req-build-ewapt31c\n",
|
| 637 |
+
"Requirement already satisfied: ftfy in /usr/local/lib/python3.6/dist-packages (from clip==1.0) (5.8)\n",
|
| 638 |
+
"Requirement already satisfied: regex in /usr/local/lib/python3.6/dist-packages (from clip==1.0) (2019.12.20)\n",
|
| 639 |
+
"Requirement already satisfied: tqdm in /usr/local/lib/python3.6/dist-packages (from clip==1.0) (4.41.1)\n",
|
| 640 |
+
"Requirement already satisfied: torch~=1.7.1 in /usr/local/lib/python3.6/dist-packages (from clip==1.0) (1.7.1+cu101)\n",
|
| 641 |
+
"Requirement already satisfied: torchvision~=0.8.2 in /usr/local/lib/python3.6/dist-packages (from clip==1.0) (0.8.2+cu101)\n",
|
| 642 |
+
"Requirement already satisfied: wcwidth in /usr/local/lib/python3.6/dist-packages (from ftfy->clip==1.0) (0.2.5)\n",
|
| 643 |
+
"Requirement already satisfied: dataclasses; python_version < \"3.7\" in /usr/local/lib/python3.6/dist-packages (from torch~=1.7.1->clip==1.0) (0.8)\n",
|
| 644 |
+
"Requirement already satisfied: typing-extensions in /usr/local/lib/python3.6/dist-packages (from torch~=1.7.1->clip==1.0) (3.7.4.3)\n",
|
| 645 |
+
"Requirement already satisfied: numpy in /usr/local/lib/python3.6/dist-packages (from torch~=1.7.1->clip==1.0) (1.19.5)\n",
|
| 646 |
+
"Requirement already satisfied: pillow>=4.1.1 in /usr/local/lib/python3.6/dist-packages (from torchvision~=0.8.2->clip==1.0) (7.0.0)\n",
|
| 647 |
+
"Building wheels for collected packages: clip\n",
|
| 648 |
+
" Building wheel for clip (setup.py) ... \u001b[?25l\u001b[?25hdone\n",
|
| 649 |
+
" Created wheel for clip: filename=clip-1.0-cp36-none-any.whl size=1367993 sha256=1839a2f0b015f75579b578ebfa15bcbe8ebab1ff535127c9357c5b26f8473de3\n",
|
| 650 |
+
" Stored in directory: /tmp/pip-ephem-wheel-cache-jwymwzm4/wheels/79/51/d7/69f91d37121befe21d9c52332e04f592e17d1cabc7319b3e09\n",
|
| 651 |
+
"Successfully built clip\n",
|
| 652 |
+
"Installing collected packages: clip\n",
|
| 653 |
+
"Successfully installed clip-1.0\n"
|
| 654 |
+
],
|
| 655 |
+
"name": "stdout"
|
| 656 |
+
}
|
| 657 |
+
]
|
| 658 |
+
},
|
| 659 |
+
{
|
| 660 |
+
"cell_type": "code",
|
| 661 |
+
"metadata": {
|
| 662 |
+
"id": "C1hkDT38hSaP",
|
| 663 |
+
"colab": {
|
| 664 |
+
"base_uri": "https://localhost:8080/"
|
| 665 |
+
},
|
| 666 |
+
"outputId": "6cd33e12-aed4-4950-e32f-6f1113eb3ade"
|
| 667 |
+
},
|
| 668 |
+
"source": [
|
| 669 |
+
"import numpy as np\n",
|
| 670 |
+
"import torch\n",
|
| 671 |
+
"import clip\n",
|
| 672 |
+
"from tqdm.notebook import tqdm\n",
|
| 673 |
+
"\n",
|
| 674 |
+
"print(\"Torch version:\", torch.__version__)"
|
| 675 |
+
],
|
| 676 |
+
"execution_count": 4,
|
| 677 |
+
"outputs": [
|
| 678 |
+
{
|
| 679 |
+
"output_type": "stream",
|
| 680 |
+
"text": [
|
| 681 |
+
"Torch version: 1.7.1+cu101\n"
|
| 682 |
+
],
|
| 683 |
+
"name": "stdout"
|
| 684 |
+
}
|
| 685 |
+
]
|
| 686 |
+
},
|
| 687 |
+
{
|
| 688 |
+
"cell_type": "markdown",
|
| 689 |
+
"metadata": {
|
| 690 |
+
"id": "eFxgLV5HAEEw"
|
| 691 |
+
},
|
| 692 |
+
"source": [
|
| 693 |
+
"# Loading the model\n",
|
| 694 |
+
"\n",
|
| 695 |
+
"Download and instantiate a CLIP model using the `clip` module that we just installed."
|
| 696 |
+
]
|
| 697 |
+
},
|
| 698 |
+
{
|
| 699 |
+
"cell_type": "code",
|
| 700 |
+
"metadata": {
|
| 701 |
+
"id": "uLFS29hnhlY4",
|
| 702 |
+
"colab": {
|
| 703 |
+
"base_uri": "https://localhost:8080/"
|
| 704 |
+
},
|
| 705 |
+
"outputId": "3148f942-0226-42a3-e5d8-4b9bc6c7c4f8"
|
| 706 |
+
},
|
| 707 |
+
"source": [
|
| 708 |
+
"clip.available_models()"
|
| 709 |
+
],
|
| 710 |
+
"execution_count": 5,
|
| 711 |
+
"outputs": [
|
| 712 |
+
{
|
| 713 |
+
"output_type": "execute_result",
|
| 714 |
+
"data": {
|
| 715 |
+
"text/plain": [
|
| 716 |
+
"['RN50', 'ViT-B/32']"
|
| 717 |
+
]
|
| 718 |
+
},
|
| 719 |
+
"metadata": {
|
| 720 |
+
"tags": []
|
| 721 |
+
},
|
| 722 |
+
"execution_count": 5
|
| 723 |
+
}
|
| 724 |
+
]
|
| 725 |
+
},
|
| 726 |
+
{
|
| 727 |
+
"cell_type": "code",
|
| 728 |
+
"metadata": {
|
| 729 |
+
"id": "cboKZocQlSYX",
|
| 730 |
+
"colab": {
|
| 731 |
+
"base_uri": "https://localhost:8080/"
|
| 732 |
+
},
|
| 733 |
+
"outputId": "58e644d4-6e23-43b5-964e-1e9e8540d22e"
|
| 734 |
+
},
|
| 735 |
+
"source": [
|
| 736 |
+
"model, preprocess = clip.load(\"ViT-B/32\")"
|
| 737 |
+
],
|
| 738 |
+
"execution_count": 6,
|
| 739 |
+
"outputs": [
|
| 740 |
+
{
|
| 741 |
+
"output_type": "stream",
|
| 742 |
+
"text": [
|
| 743 |
+
"100%|██████████████████████| 353976522/353976522 [00:01<00:00, 188872424.30it/s]\n"
|
| 744 |
+
],
|
| 745 |
+
"name": "stderr"
|
| 746 |
+
}
|
| 747 |
+
]
|
| 748 |
+
},
|
| 749 |
+
{
|
| 750 |
+
"cell_type": "code",
|
| 751 |
+
"metadata": {
|
| 752 |
+
"colab": {
|
| 753 |
+
"base_uri": "https://localhost:8080/"
|
| 754 |
+
},
|
| 755 |
+
"id": "IBRVTY9lbGm8",
|
| 756 |
+
"outputId": "58641dc2-919d-40ae-b71a-7b7b47830f77"
|
| 757 |
+
},
|
| 758 |
+
"source": [
|
| 759 |
+
"input_resolution = model.input_resolution.item()\n",
|
| 760 |
+
"context_length = model.context_length.item()\n",
|
| 761 |
+
"vocab_size = model.vocab_size.item()\n",
|
| 762 |
+
"\n",
|
| 763 |
+
"print(\"Model parameters:\", f\"{np.sum([int(np.prod(p.shape)) for p in model.parameters()]):,}\")\n",
|
| 764 |
+
"print(\"Input resolution:\", input_resolution)\n",
|
| 765 |
+
"print(\"Context length:\", context_length)\n",
|
| 766 |
+
"print(\"Vocab size:\", vocab_size)"
|
| 767 |
+
],
|
| 768 |
+
"execution_count": 7,
|
| 769 |
+
"outputs": [
|
| 770 |
+
{
|
| 771 |
+
"output_type": "stream",
|
| 772 |
+
"text": [
|
| 773 |
+
"Model parameters: 151,277,313\n",
|
| 774 |
+
"Input resolution: 224\n",
|
| 775 |
+
"Context length: 77\n",
|
| 776 |
+
"Vocab size: 49408\n"
|
| 777 |
+
],
|
| 778 |
+
"name": "stdout"
|
| 779 |
+
}
|
| 780 |
+
]
|
| 781 |
+
},
|
| 782 |
+
{
|
| 783 |
+
"cell_type": "markdown",
|
| 784 |
+
"metadata": {
|
| 785 |
+
"id": "LhO3OtOmF8M4"
|
| 786 |
+
},
|
| 787 |
+
"source": [
|
| 788 |
+
"# Preparing ImageNet labels and prompts\n",
|
| 789 |
+
"\n",
|
| 790 |
+
"The following cell contains the 1,000 labels for the ImageNet dataset, followed by the text templates we'll use as \"prompt engineering\"."
|
| 791 |
+
]
|
| 792 |
+
},
|
| 793 |
+
{
|
| 794 |
+
"cell_type": "code",
|
| 795 |
+
"metadata": {
|
| 796 |
+
"id": "R2HbOZrqa0jF"
|
| 797 |
+
},
|
| 798 |
+
"source": [
|
| 799 |
+
"imagenet_classes = [\"tench\", \"goldfish\", \"great white shark\", \"tiger shark\", \"hammerhead shark\", \"electric ray\", \"stingray\", \"rooster\", \"hen\", \"ostrich\", \"brambling\", \"goldfinch\", \"house finch\", \"junco\", \"indigo bunting\", \"American robin\", \"bulbul\", \"jay\", \"magpie\", \"chickadee\", \"American dipper\", \"kite (bird of prey)\", \"bald eagle\", \"vulture\", \"great grey owl\", \"fire salamander\", \"smooth newt\", \"newt\", \"spotted salamander\", \"axolotl\", \"American bullfrog\", \"tree frog\", \"tailed frog\", \"loggerhead sea turtle\", \"leatherback sea turtle\", \"mud turtle\", \"terrapin\", \"box turtle\", \"banded gecko\", \"green iguana\", \"Carolina anole\", \"desert grassland whiptail lizard\", \"agama\", \"frilled-necked lizard\", \"alligator lizard\", \"Gila monster\", \"European green lizard\", \"chameleon\", \"Komodo dragon\", \"Nile crocodile\", \"American alligator\", \"triceratops\", \"worm snake\", \"ring-necked snake\", \"eastern hog-nosed snake\", \"smooth green snake\", \"kingsnake\", \"garter snake\", \"water snake\", \"vine snake\", \"night snake\", \"boa constrictor\", \"African rock python\", \"Indian cobra\", \"green mamba\", \"sea snake\", \"Saharan horned viper\", \"eastern diamondback rattlesnake\", \"sidewinder rattlesnake\", \"trilobite\", \"harvestman\", \"scorpion\", \"yellow garden spider\", \"barn spider\", \"European garden spider\", \"southern black widow\", \"tarantula\", \"wolf spider\", \"tick\", \"centipede\", \"black grouse\", \"ptarmigan\", \"ruffed grouse\", \"prairie grouse\", \"peafowl\", \"quail\", \"partridge\", \"african grey parrot\", \"macaw\", \"sulphur-crested cockatoo\", \"lorikeet\", \"coucal\", \"bee eater\", \"hornbill\", \"hummingbird\", \"jacamar\", \"toucan\", \"duck\", \"red-breasted merganser\", \"goose\", \"black swan\", \"tusker\", \"echidna\", \"platypus\", \"wallaby\", \"koala\", \"wombat\", \"jellyfish\", \"sea anemone\", \"brain coral\", \"flatworm\", \"nematode\", \"conch\", \"snail\", \"slug\", \"sea slug\", \"chiton\", \"chambered nautilus\", \"Dungeness crab\", \"rock crab\", \"fiddler crab\", \"red king crab\", \"American lobster\", \"spiny lobster\", \"crayfish\", \"hermit crab\", \"isopod\", \"white stork\", \"black stork\", \"spoonbill\", \"flamingo\", \"little blue heron\", \"great egret\", \"bittern bird\", \"crane bird\", \"limpkin\", \"common gallinule\", \"American coot\", \"bustard\", \"ruddy turnstone\", \"dunlin\", \"common redshank\", \"dowitcher\", \"oystercatcher\", \"pelican\", \"king penguin\", \"albatross\", \"grey whale\", \"killer whale\", \"dugong\", \"sea lion\", \"Chihuahua\", \"Japanese Chin\", \"Maltese\", \"Pekingese\", \"Shih Tzu\", \"King Charles Spaniel\", \"Papillon\", \"toy terrier\", \"Rhodesian Ridgeback\", \"Afghan Hound\", \"Basset Hound\", \"Beagle\", \"Bloodhound\", \"Bluetick Coonhound\", \"Black and Tan Coonhound\", \"Treeing Walker Coonhound\", \"English foxhound\", \"Redbone Coonhound\", \"borzoi\", \"Irish Wolfhound\", \"Italian Greyhound\", \"Whippet\", \"Ibizan Hound\", \"Norwegian Elkhound\", \"Otterhound\", \"Saluki\", \"Scottish Deerhound\", \"Weimaraner\", \"Staffordshire Bull Terrier\", \"American Staffordshire Terrier\", \"Bedlington Terrier\", \"Border Terrier\", \"Kerry Blue Terrier\", \"Irish Terrier\", \"Norfolk Terrier\", \"Norwich Terrier\", \"Yorkshire Terrier\", \"Wire Fox Terrier\", \"Lakeland Terrier\", \"Sealyham Terrier\", \"Airedale Terrier\", \"Cairn Terrier\", \"Australian Terrier\", \"Dandie Dinmont Terrier\", \"Boston Terrier\", \"Miniature Schnauzer\", \"Giant Schnauzer\", \"Standard Schnauzer\", \"Scottish Terrier\", \"Tibetan Terrier\", \"Australian Silky Terrier\", \"Soft-coated Wheaten Terrier\", \"West Highland White Terrier\", \"Lhasa Apso\", \"Flat-Coated Retriever\", \"Curly-coated Retriever\", \"Golden Retriever\", \"Labrador Retriever\", \"Chesapeake Bay Retriever\", \"German Shorthaired Pointer\", \"Vizsla\", \"English Setter\", \"Irish Setter\", \"Gordon Setter\", \"Brittany dog\", \"Clumber Spaniel\", \"English Springer Spaniel\", \"Welsh Springer Spaniel\", \"Cocker Spaniel\", \"Sussex Spaniel\", \"Irish Water Spaniel\", \"Kuvasz\", \"Schipperke\", \"Groenendael dog\", \"Malinois\", \"Briard\", \"Australian Kelpie\", \"Komondor\", \"Old English Sheepdog\", \"Shetland Sheepdog\", \"collie\", \"Border Collie\", \"Bouvier des Flandres dog\", \"Rottweiler\", \"German Shepherd Dog\", \"Dobermann\", \"Miniature Pinscher\", \"Greater Swiss Mountain Dog\", \"Bernese Mountain Dog\", \"Appenzeller Sennenhund\", \"Entlebucher Sennenhund\", \"Boxer\", \"Bullmastiff\", \"Tibetan Mastiff\", \"French Bulldog\", \"Great Dane\", \"St. Bernard\", \"husky\", \"Alaskan Malamute\", \"Siberian Husky\", \"Dalmatian\", \"Affenpinscher\", \"Basenji\", \"pug\", \"Leonberger\", \"Newfoundland dog\", \"Great Pyrenees dog\", \"Samoyed\", \"Pomeranian\", \"Chow Chow\", \"Keeshond\", \"brussels griffon\", \"Pembroke Welsh Corgi\", \"Cardigan Welsh Corgi\", \"Toy Poodle\", \"Miniature Poodle\", \"Standard Poodle\", \"Mexican hairless dog (xoloitzcuintli)\", \"grey wolf\", \"Alaskan tundra wolf\", \"red wolf or maned wolf\", \"coyote\", \"dingo\", \"dhole\", \"African wild dog\", \"hyena\", \"red fox\", \"kit fox\", \"Arctic fox\", \"grey fox\", \"tabby cat\", \"tiger cat\", \"Persian cat\", \"Siamese cat\", \"Egyptian Mau\", \"cougar\", \"lynx\", \"leopard\", \"snow leopard\", \"jaguar\", \"lion\", \"tiger\", \"cheetah\", \"brown bear\", \"American black bear\", \"polar bear\", \"sloth bear\", \"mongoose\", \"meerkat\", \"tiger beetle\", \"ladybug\", \"ground beetle\", \"longhorn beetle\", \"leaf beetle\", \"dung beetle\", \"rhinoceros beetle\", \"weevil\", \"fly\", \"bee\", \"ant\", \"grasshopper\", \"cricket insect\", \"stick insect\", \"cockroach\", \"praying mantis\", \"cicada\", \"leafhopper\", \"lacewing\", \"dragonfly\", \"damselfly\", \"red admiral butterfly\", \"ringlet butterfly\", \"monarch butterfly\", \"small white butterfly\", \"sulphur butterfly\", \"gossamer-winged butterfly\", \"starfish\", \"sea urchin\", \"sea cucumber\", \"cottontail rabbit\", \"hare\", \"Angora rabbit\", \"hamster\", \"porcupine\", \"fox squirrel\", \"marmot\", \"beaver\", \"guinea pig\", \"common sorrel horse\", \"zebra\", \"pig\", \"wild boar\", \"warthog\", \"hippopotamus\", \"ox\", \"water buffalo\", \"bison\", \"ram (adult male sheep)\", \"bighorn sheep\", \"Alpine ibex\", \"hartebeest\", \"impala (antelope)\", \"gazelle\", \"arabian camel\", \"llama\", \"weasel\", \"mink\", \"European polecat\", \"black-footed ferret\", \"otter\", \"skunk\", \"badger\", \"armadillo\", \"three-toed sloth\", \"orangutan\", \"gorilla\", \"chimpanzee\", \"gibbon\", \"siamang\", \"guenon\", \"patas monkey\", \"baboon\", \"macaque\", \"langur\", \"black-and-white colobus\", \"proboscis monkey\", \"marmoset\", \"white-headed capuchin\", \"howler monkey\", \"titi monkey\", \"Geoffroy's spider monkey\", \"common squirrel monkey\", \"ring-tailed lemur\", \"indri\", \"Asian elephant\", \"African bush elephant\", \"red panda\", \"giant panda\", \"snoek fish\", \"eel\", \"silver salmon\", \"rock beauty fish\", \"clownfish\", \"sturgeon\", \"gar fish\", \"lionfish\", \"pufferfish\", \"abacus\", \"abaya\", \"academic gown\", \"accordion\", \"acoustic guitar\", \"aircraft carrier\", \"airliner\", \"airship\", \"altar\", \"ambulance\", \"amphibious vehicle\", \"analog clock\", \"apiary\", \"apron\", \"trash can\", \"assault rifle\", \"backpack\", \"bakery\", \"balance beam\", \"balloon\", \"ballpoint pen\", \"Band-Aid\", \"banjo\", \"baluster / handrail\", \"barbell\", \"barber chair\", \"barbershop\", \"barn\", \"barometer\", \"barrel\", \"wheelbarrow\", \"baseball\", \"basketball\", \"bassinet\", \"bassoon\", \"swimming cap\", \"bath towel\", \"bathtub\", \"station wagon\", \"lighthouse\", \"beaker\", \"military hat (bearskin or shako)\", \"beer bottle\", \"beer glass\", \"bell tower\", \"baby bib\", \"tandem bicycle\", \"bikini\", \"ring binder\", \"binoculars\", \"birdhouse\", \"boathouse\", \"bobsleigh\", \"bolo tie\", \"poke bonnet\", \"bookcase\", \"bookstore\", \"bottle cap\", \"hunting bow\", \"bow tie\", \"brass memorial plaque\", \"bra\", \"breakwater\", \"breastplate\", \"broom\", \"bucket\", \"buckle\", \"bulletproof vest\", \"high-speed train\", \"butcher shop\", \"taxicab\", \"cauldron\", \"candle\", \"cannon\", \"canoe\", \"can opener\", \"cardigan\", \"car mirror\", \"carousel\", \"tool kit\", \"cardboard box / carton\", \"car wheel\", \"automated teller machine\", \"cassette\", \"cassette player\", \"castle\", \"catamaran\", \"CD player\", \"cello\", \"mobile phone\", \"chain\", \"chain-link fence\", \"chain mail\", \"chainsaw\", \"storage chest\", \"chiffonier\", \"bell or wind chime\", \"china cabinet\", \"Christmas stocking\", \"church\", \"movie theater\", \"cleaver\", \"cliff dwelling\", \"cloak\", \"clogs\", \"cocktail shaker\", \"coffee mug\", \"coffeemaker\", \"spiral or coil\", \"combination lock\", \"computer keyboard\", \"candy store\", \"container ship\", \"convertible\", \"corkscrew\", \"cornet\", \"cowboy boot\", \"cowboy hat\", \"cradle\", \"construction crane\", \"crash helmet\", \"crate\", \"infant bed\", \"Crock Pot\", \"croquet ball\", \"crutch\", \"cuirass\", \"dam\", \"desk\", \"desktop computer\", \"rotary dial telephone\", \"diaper\", \"digital clock\", \"digital watch\", \"dining table\", \"dishcloth\", \"dishwasher\", \"disc brake\", \"dock\", \"dog sled\", \"dome\", \"doormat\", \"drilling rig\", \"drum\", \"drumstick\", \"dumbbell\", \"Dutch oven\", \"electric fan\", \"electric guitar\", \"electric locomotive\", \"entertainment center\", \"envelope\", \"espresso machine\", \"face powder\", \"feather boa\", \"filing cabinet\", \"fireboat\", \"fire truck\", \"fire screen\", \"flagpole\", \"flute\", \"folding chair\", \"football helmet\", \"forklift\", \"fountain\", \"fountain pen\", \"four-poster bed\", \"freight car\", \"French horn\", \"frying pan\", \"fur coat\", \"garbage truck\", \"gas mask or respirator\", \"gas pump\", \"goblet\", \"go-kart\", \"golf ball\", \"golf cart\", \"gondola\", \"gong\", \"gown\", \"grand piano\", \"greenhouse\", \"radiator grille\", \"grocery store\", \"guillotine\", \"hair clip\", \"hair spray\", \"half-track\", \"hammer\", \"hamper\", \"hair dryer\", \"hand-held computer\", \"handkerchief\", \"hard disk drive\", \"harmonica\", \"harp\", \"combine harvester\", \"hatchet\", \"holster\", \"home theater\", \"honeycomb\", \"hook\", \"hoop skirt\", \"gymnastic horizontal bar\", \"horse-drawn vehicle\", \"hourglass\", \"iPod\", \"clothes iron\", \"carved pumpkin\", \"jeans\", \"jeep\", \"T-shirt\", \"jigsaw puzzle\", \"rickshaw\", \"joystick\", \"kimono\", \"knee pad\", \"knot\", \"lab coat\", \"ladle\", \"lampshade\", \"laptop computer\", \"lawn mower\", \"lens cap\", \"letter opener\", \"library\", \"lifeboat\", \"lighter\", \"limousine\", \"ocean liner\", \"lipstick\", \"slip-on shoe\", \"lotion\", \"music speaker\", \"loupe magnifying glass\", \"sawmill\", \"magnetic compass\", \"messenger bag\", \"mailbox\", \"tights\", \"one-piece bathing suit\", \"manhole cover\", \"maraca\", \"marimba\", \"mask\", \"matchstick\", \"maypole\", \"maze\", \"measuring cup\", \"medicine cabinet\", \"megalith\", \"microphone\", \"microwave oven\", \"military uniform\", \"milk can\", \"minibus\", \"miniskirt\", \"minivan\", \"missile\", \"mitten\", \"mixing bowl\", \"mobile home\", \"ford model t\", \"modem\", \"monastery\", \"monitor\", \"moped\", \"mortar and pestle\", \"graduation cap\", \"mosque\", \"mosquito net\", \"vespa\", \"mountain bike\", \"tent\", \"computer mouse\", \"mousetrap\", \"moving van\", \"muzzle\", \"metal nail\", \"neck brace\", \"necklace\", \"baby pacifier\", \"notebook computer\", \"obelisk\", \"oboe\", \"ocarina\", \"odometer\", \"oil filter\", \"pipe organ\", \"oscilloscope\", \"overskirt\", \"bullock cart\", \"oxygen mask\", \"product packet / packaging\", \"paddle\", \"paddle wheel\", \"padlock\", \"paintbrush\", \"pajamas\", \"palace\", \"pan flute\", \"paper towel\", \"parachute\", \"parallel bars\", \"park bench\", \"parking meter\", \"railroad car\", \"patio\", \"payphone\", \"pedestal\", \"pencil case\", \"pencil sharpener\", \"perfume\", \"Petri dish\", \"photocopier\", \"plectrum\", \"Pickelhaube\", \"picket fence\", \"pickup truck\", \"pier\", \"piggy bank\", \"pill bottle\", \"pillow\", \"ping-pong ball\", \"pinwheel\", \"pirate ship\", \"drink pitcher\", \"block plane\", \"planetarium\", \"plastic bag\", \"plate rack\", \"farm plow\", \"plunger\", \"Polaroid camera\", \"pole\", \"police van\", \"poncho\", \"pool table\", \"soda bottle\", \"plant pot\", \"potter's wheel\", \"power drill\", \"prayer rug\", \"printer\", \"prison\", \"missile\", \"projector\", \"hockey puck\", \"punching bag\", \"purse\", \"quill\", \"quilt\", \"race car\", \"racket\", \"radiator\", \"radio\", \"radio telescope\", \"rain barrel\", \"recreational vehicle\", \"fishing casting reel\", \"reflex camera\", \"refrigerator\", \"remote control\", \"restaurant\", \"revolver\", \"rifle\", \"rocking chair\", \"rotisserie\", \"eraser\", \"rugby ball\", \"ruler measuring stick\", \"sneaker\", \"safe\", \"safety pin\", \"salt shaker\", \"sandal\", \"sarong\", \"saxophone\", \"scabbard\", \"weighing scale\", \"school bus\", \"schooner\", \"scoreboard\", \"CRT monitor\", \"screw\", \"screwdriver\", \"seat belt\", \"sewing machine\", \"shield\", \"shoe store\", \"shoji screen / room divider\", \"shopping basket\", \"shopping cart\", \"shovel\", \"shower cap\", \"shower curtain\", \"ski\", \"balaclava ski mask\", \"sleeping bag\", \"slide rule\", \"sliding door\", \"slot machine\", \"snorkel\", \"snowmobile\", \"snowplow\", \"soap dispenser\", \"soccer ball\", \"sock\", \"solar thermal collector\", \"sombrero\", \"soup bowl\", \"keyboard space bar\", \"space heater\", \"space shuttle\", \"spatula\", \"motorboat\", \"spider web\", \"spindle\", \"sports car\", \"spotlight\", \"stage\", \"steam locomotive\", \"through arch bridge\", \"steel drum\", \"stethoscope\", \"scarf\", \"stone wall\", \"stopwatch\", \"stove\", \"strainer\", \"tram\", \"stretcher\", \"couch\", \"stupa\", \"submarine\", \"suit\", \"sundial\", \"sunglasses\", \"sunglasses\", \"sunscreen\", \"suspension bridge\", \"mop\", \"sweatshirt\", \"swim trunks / shorts\", \"swing\", \"electrical switch\", \"syringe\", \"table lamp\", \"tank\", \"tape player\", \"teapot\", \"teddy bear\", \"television\", \"tennis ball\", \"thatched roof\", \"front curtain\", \"thimble\", \"threshing machine\", \"throne\", \"tile roof\", \"toaster\", \"tobacco shop\", \"toilet seat\", \"torch\", \"totem pole\", \"tow truck\", \"toy store\", \"tractor\", \"semi-trailer truck\", \"tray\", \"trench coat\", \"tricycle\", \"trimaran\", \"tripod\", \"triumphal arch\", \"trolleybus\", \"trombone\", \"hot tub\", \"turnstile\", \"typewriter keyboard\", \"umbrella\", \"unicycle\", \"upright piano\", \"vacuum cleaner\", \"vase\", \"vaulted or arched ceiling\", \"velvet fabric\", \"vending machine\", \"vestment\", \"viaduct\", \"violin\", \"volleyball\", \"waffle iron\", \"wall clock\", \"wallet\", \"wardrobe\", \"military aircraft\", \"sink\", \"washing machine\", \"water bottle\", \"water jug\", \"water tower\", \"whiskey jug\", \"whistle\", \"hair wig\", \"window screen\", \"window shade\", \"Windsor tie\", \"wine bottle\", \"airplane wing\", \"wok\", \"wooden spoon\", \"wool\", \"split-rail fence\", \"shipwreck\", \"sailboat\", \"yurt\", \"website\", \"comic book\", \"crossword\", \"traffic or street sign\", \"traffic light\", \"dust jacket\", \"menu\", \"plate\", \"guacamole\", \"consomme\", \"hot pot\", \"trifle\", \"ice cream\", \"popsicle\", \"baguette\", \"bagel\", \"pretzel\", \"cheeseburger\", \"hot dog\", \"mashed potatoes\", \"cabbage\", \"broccoli\", \"cauliflower\", \"zucchini\", \"spaghetti squash\", \"acorn squash\", \"butternut squash\", \"cucumber\", \"artichoke\", \"bell pepper\", \"cardoon\", \"mushroom\", \"Granny Smith apple\", \"strawberry\", \"orange\", \"lemon\", \"fig\", \"pineapple\", \"banana\", \"jackfruit\", \"cherimoya (custard apple)\", \"pomegranate\", \"hay\", \"carbonara\", \"chocolate syrup\", \"dough\", \"meatloaf\", \"pizza\", \"pot pie\", \"burrito\", \"red wine\", \"espresso\", \"tea cup\", \"eggnog\", \"mountain\", \"bubble\", \"cliff\", \"coral reef\", \"geyser\", \"lakeshore\", \"promontory\", \"sandbar\", \"beach\", \"valley\", \"volcano\", \"baseball player\", \"bridegroom\", \"scuba diver\", \"rapeseed\", \"daisy\", \"yellow lady's slipper\", \"corn\", \"acorn\", \"rose hip\", \"horse chestnut seed\", \"coral fungus\", \"agaric\", \"gyromitra\", \"stinkhorn mushroom\", \"earth star fungus\", \"hen of the woods mushroom\", \"bolete\", \"corn cob\", \"toilet paper\"]"
|
| 800 |
+
],
|
| 801 |
+
"execution_count": 8,
|
| 802 |
+
"outputs": []
|
| 803 |
+
},
|
| 804 |
+
{
|
| 805 |
+
"cell_type": "markdown",
|
| 806 |
+
"metadata": {
|
| 807 |
+
"id": "eMQSCuBta2G6"
|
| 808 |
+
},
|
| 809 |
+
"source": [
|
| 810 |
+
"A subset of these class names are modified from the default ImageNet class names sourced from Anish Athalye's imagenet-simple-labels.\n",
|
| 811 |
+
"\n",
|
| 812 |
+
"These edits were made via trial and error and concentrated on the lowest performing classes according to top_1 and top_5 accuracy on the ImageNet training set for the RN50, RN101, and RN50x4 models. These tweaks improve top_1 by 1.5% on ViT-B/32 over using the default class names. Alec got bored somewhere along the way as gains started to diminish and never finished updating / tweaking the list. He also didn't revisit this with the better performing RN50x16, RN50x64, or any of the ViT models. He thinks it's likely another 0.5% to 1% top_1 could be gained from further work here. It'd be interesting to more rigorously study / understand this.\n",
|
| 813 |
+
"\n",
|
| 814 |
+
"Some examples beyond the crane/crane -> construction crane / bird crane issue mentioned in Section 3.1.4 of the paper include:\n",
|
| 815 |
+
"\n",
|
| 816 |
+
"- CLIP interprets \"nail\" as \"fingernail\" so we changed the label to \"metal nail\".\n",
|
| 817 |
+
"- ImageNet kite class refers to the bird of prey, not the flying toy, so we changed \"kite\" to \"kite (bird of prey)\"\n",
|
| 818 |
+
"- The ImageNet class for red wolf seems to include a lot of mislabeled maned wolfs so we changed \"red wolf\" to \"red wolf or maned wolf\""
|
| 819 |
+
]
|
| 820 |
+
},
|
| 821 |
+
{
|
| 822 |
+
"cell_type": "code",
|
| 823 |
+
"metadata": {
|
| 824 |
+
"id": "toGtcd-Ji_MD",
|
| 825 |
+
"colab": {
|
| 826 |
+
"base_uri": "https://localhost:8080/"
|
| 827 |
+
},
|
| 828 |
+
"outputId": "46bcc85f-3968-4836-f3c6-e48848e944c4"
|
| 829 |
+
},
|
| 830 |
+
"source": [
|
| 831 |
+
"imagenet_templates = [\n",
|
| 832 |
+
" 'a bad photo of a {}.',\n",
|
| 833 |
+
" 'a photo of many {}.',\n",
|
| 834 |
+
" 'a sculpture of a {}.',\n",
|
| 835 |
+
" 'a photo of the hard to see {}.',\n",
|
| 836 |
+
" 'a low resolution photo of the {}.',\n",
|
| 837 |
+
" 'a rendering of a {}.',\n",
|
| 838 |
+
" 'graffiti of a {}.',\n",
|
| 839 |
+
" 'a bad photo of the {}.',\n",
|
| 840 |
+
" 'a cropped photo of the {}.',\n",
|
| 841 |
+
" 'a tattoo of a {}.',\n",
|
| 842 |
+
" 'the embroidered {}.',\n",
|
| 843 |
+
" 'a photo of a hard to see {}.',\n",
|
| 844 |
+
" 'a bright photo of a {}.',\n",
|
| 845 |
+
" 'a photo of a clean {}.',\n",
|
| 846 |
+
" 'a photo of a dirty {}.',\n",
|
| 847 |
+
" 'a dark photo of the {}.',\n",
|
| 848 |
+
" 'a drawing of a {}.',\n",
|
| 849 |
+
" 'a photo of my {}.',\n",
|
| 850 |
+
" 'the plastic {}.',\n",
|
| 851 |
+
" 'a photo of the cool {}.',\n",
|
| 852 |
+
" 'a close-up photo of a {}.',\n",
|
| 853 |
+
" 'a black and white photo of the {}.',\n",
|
| 854 |
+
" 'a painting of the {}.',\n",
|
| 855 |
+
" 'a painting of a {}.',\n",
|
| 856 |
+
" 'a pixelated photo of the {}.',\n",
|
| 857 |
+
" 'a sculpture of the {}.',\n",
|
| 858 |
+
" 'a bright photo of the {}.',\n",
|
| 859 |
+
" 'a cropped photo of a {}.',\n",
|
| 860 |
+
" 'a plastic {}.',\n",
|
| 861 |
+
" 'a photo of the dirty {}.',\n",
|
| 862 |
+
" 'a jpeg corrupted photo of a {}.',\n",
|
| 863 |
+
" 'a blurry photo of the {}.',\n",
|
| 864 |
+
" 'a photo of the {}.',\n",
|
| 865 |
+
" 'a good photo of the {}.',\n",
|
| 866 |
+
" 'a rendering of the {}.',\n",
|
| 867 |
+
" 'a {} in a video game.',\n",
|
| 868 |
+
" 'a photo of one {}.',\n",
|
| 869 |
+
" 'a doodle of a {}.',\n",
|
| 870 |
+
" 'a close-up photo of the {}.',\n",
|
| 871 |
+
" 'a photo of a {}.',\n",
|
| 872 |
+
" 'the origami {}.',\n",
|
| 873 |
+
" 'the {} in a video game.',\n",
|
| 874 |
+
" 'a sketch of a {}.',\n",
|
| 875 |
+
" 'a doodle of the {}.',\n",
|
| 876 |
+
" 'a origami {}.',\n",
|
| 877 |
+
" 'a low resolution photo of a {}.',\n",
|
| 878 |
+
" 'the toy {}.',\n",
|
| 879 |
+
" 'a rendition of the {}.',\n",
|
| 880 |
+
" 'a photo of the clean {}.',\n",
|
| 881 |
+
" 'a photo of a large {}.',\n",
|
| 882 |
+
" 'a rendition of a {}.',\n",
|
| 883 |
+
" 'a photo of a nice {}.',\n",
|
| 884 |
+
" 'a photo of a weird {}.',\n",
|
| 885 |
+
" 'a blurry photo of a {}.',\n",
|
| 886 |
+
" 'a cartoon {}.',\n",
|
| 887 |
+
" 'art of a {}.',\n",
|
| 888 |
+
" 'a sketch of the {}.',\n",
|
| 889 |
+
" 'a embroidered {}.',\n",
|
| 890 |
+
" 'a pixelated photo of a {}.',\n",
|
| 891 |
+
" 'itap of the {}.',\n",
|
| 892 |
+
" 'a jpeg corrupted photo of the {}.',\n",
|
| 893 |
+
" 'a good photo of a {}.',\n",
|
| 894 |
+
" 'a plushie {}.',\n",
|
| 895 |
+
" 'a photo of the nice {}.',\n",
|
| 896 |
+
" 'a photo of the small {}.',\n",
|
| 897 |
+
" 'a photo of the weird {}.',\n",
|
| 898 |
+
" 'the cartoon {}.',\n",
|
| 899 |
+
" 'art of the {}.',\n",
|
| 900 |
+
" 'a drawing of the {}.',\n",
|
| 901 |
+
" 'a photo of the large {}.',\n",
|
| 902 |
+
" 'a black and white photo of a {}.',\n",
|
| 903 |
+
" 'the plushie {}.',\n",
|
| 904 |
+
" 'a dark photo of a {}.',\n",
|
| 905 |
+
" 'itap of a {}.',\n",
|
| 906 |
+
" 'graffiti of the {}.',\n",
|
| 907 |
+
" 'a toy {}.',\n",
|
| 908 |
+
" 'itap of my {}.',\n",
|
| 909 |
+
" 'a photo of a cool {}.',\n",
|
| 910 |
+
" 'a photo of a small {}.',\n",
|
| 911 |
+
" 'a tattoo of the {}.',\n",
|
| 912 |
+
"]\n",
|
| 913 |
+
"\n",
|
| 914 |
+
"print(f\"{len(imagenet_classes)} classes, {len(imagenet_templates)} templates\")"
|
| 915 |
+
],
|
| 916 |
+
"execution_count": 9,
|
| 917 |
+
"outputs": [
|
| 918 |
+
{
|
| 919 |
+
"output_type": "stream",
|
| 920 |
+
"text": [
|
| 921 |
+
"1000 classes, 80 templates\n"
|
| 922 |
+
],
|
| 923 |
+
"name": "stdout"
|
| 924 |
+
}
|
| 925 |
+
]
|
| 926 |
+
},
|
| 927 |
+
{
|
| 928 |
+
"cell_type": "markdown",
|
| 929 |
+
"metadata": {
|
| 930 |
+
"id": "aRB5OzgpHwqQ"
|
| 931 |
+
},
|
| 932 |
+
"source": [
|
| 933 |
+
"A similar, intuition-guided trial and error based on the ImageNet training set was used for templates. This list is pretty haphazard and was gradually made / expanded over the course of about a year of the project and was revisited / tweaked every few months. A surprising / weird thing was adding templates intended to help ImageNet-R performance (specifying different possible renditions of an object) improved standard ImageNet accuracy too.\n",
|
| 934 |
+
"\n",
|
| 935 |
+
"After the 80 templates were \"locked\" for the paper, we ran sequential forward selection over the list of 80 templates. The search terminated after ensembling 7 templates and selected them in the order below.\n",
|
| 936 |
+
"\n",
|
| 937 |
+
"1. itap of a {}.\n",
|
| 938 |
+
"2. a bad photo of the {}.\n",
|
| 939 |
+
"3. a origami {}.\n",
|
| 940 |
+
"4. a photo of the large {}.\n",
|
| 941 |
+
"5. a {} in a video game.\n",
|
| 942 |
+
"6. art of the {}.\n",
|
| 943 |
+
"7. a photo of the small {}.\n",
|
| 944 |
+
"\n",
|
| 945 |
+
"Speculating, we think it's interesting to see different scales (large and small), a difficult view (a bad photo), and \"abstract\" versions (origami, video game, art), were all selected for, but we haven't studied this in any detail. This subset performs a bit better than the full 80 ensemble reported in the paper, especially for the smaller models."
|
| 946 |
+
]
|
| 947 |
+
},
|
| 948 |
+
{
|
| 949 |
+
"cell_type": "markdown",
|
| 950 |
+
"metadata": {
|
| 951 |
+
"id": "4W8ARJVqBJXs"
|
| 952 |
+
},
|
| 953 |
+
"source": [
|
| 954 |
+
"# Loading the Images\n",
|
| 955 |
+
"\n",
|
| 956 |
+
"The ILSVRC2012 datasets are no longer available for download publicly. We instead download the ImageNet-V2 dataset by [Recht et al.](https://arxiv.org/abs/1902.10811).\n",
|
| 957 |
+
"\n",
|
| 958 |
+
"If you have the ImageNet dataset downloaded, you can replace the dataset with the official torchvision loader, e.g.:\n",
|
| 959 |
+
"\n",
|
| 960 |
+
"```python\n",
|
| 961 |
+
"images = torchvision.datasets.ImageNet(\"path/to/imagenet\", split='val', transform=preprocess)\n",
|
| 962 |
+
"```"
|
| 963 |
+
]
|
| 964 |
+
},
|
| 965 |
+
{
|
| 966 |
+
"cell_type": "code",
|
| 967 |
+
"metadata": {
|
| 968 |
+
"colab": {
|
| 969 |
+
"base_uri": "https://localhost:8080/"
|
| 970 |
+
},
|
| 971 |
+
"id": "moHR4UlHKsDc",
|
| 972 |
+
"outputId": "178f6d0d-9a34-4cbc-c9c1-e7ce09927980"
|
| 973 |
+
},
|
| 974 |
+
"source": [
|
| 975 |
+
"! pip install git+https://github.com/modestyachts/ImageNetV2_pytorch\n",
|
| 976 |
+
"\n",
|
| 977 |
+
"from imagenetv2_pytorch import ImageNetV2Dataset\n",
|
| 978 |
+
"\n",
|
| 979 |
+
"images = ImageNetV2Dataset(transform=preprocess)\n",
|
| 980 |
+
"loader = torch.utils.data.DataLoader(images, batch_size=32, num_workers=16)"
|
| 981 |
+
],
|
| 982 |
+
"execution_count": 10,
|
| 983 |
+
"outputs": [
|
| 984 |
+
{
|
| 985 |
+
"output_type": "stream",
|
| 986 |
+
"text": [
|
| 987 |
+
"Collecting git+https://github.com/modestyachts/ImageNetV2_pytorch\n",
|
| 988 |
+
" Cloning https://github.com/modestyachts/ImageNetV2_pytorch to /tmp/pip-req-build-2fnslbyv\n",
|
| 989 |
+
" Running command git clone -q https://github.com/modestyachts/ImageNetV2_pytorch /tmp/pip-req-build-2fnslbyv\n",
|
| 990 |
+
"Building wheels for collected packages: imagenetv2-pytorch\n",
|
| 991 |
+
" Building wheel for imagenetv2-pytorch (setup.py) ... \u001b[?25l\u001b[?25hdone\n",
|
| 992 |
+
" Created wheel for imagenetv2-pytorch: filename=imagenetv2_pytorch-0.1-cp36-none-any.whl size=2665 sha256=0978fc64026ab86ace52a9f3ebcef53331c43288433173c450a4b5ddcc197f31\n",
|
| 993 |
+
" Stored in directory: /tmp/pip-ephem-wheel-cache-4eewuaap/wheels/f7/09/0d/03ded955ce95b04c9590b999ae9be076bb5d8f389650aa2147\n",
|
| 994 |
+
"Successfully built imagenetv2-pytorch\n",
|
| 995 |
+
"Installing collected packages: imagenetv2-pytorch\n",
|
| 996 |
+
"Successfully installed imagenetv2-pytorch-0.1\n",
|
| 997 |
+
"Dataset matched-frequency not found on disk, downloading....\n"
|
| 998 |
+
],
|
| 999 |
+
"name": "stdout"
|
| 1000 |
+
},
|
| 1001 |
+
{
|
| 1002 |
+
"output_type": "stream",
|
| 1003 |
+
"text": [
|
| 1004 |
+
"100%|██████████| 1.26G/1.26G [00:35<00:00, 35.7MiB/s]\n"
|
| 1005 |
+
],
|
| 1006 |
+
"name": "stderr"
|
| 1007 |
+
},
|
| 1008 |
+
{
|
| 1009 |
+
"output_type": "stream",
|
| 1010 |
+
"text": [
|
| 1011 |
+
"Extracting....\n"
|
| 1012 |
+
],
|
| 1013 |
+
"name": "stdout"
|
| 1014 |
+
}
|
| 1015 |
+
]
|
| 1016 |
+
},
|
| 1017 |
+
{
|
| 1018 |
+
"cell_type": "markdown",
|
| 1019 |
+
"metadata": {
|
| 1020 |
+
"id": "fz6D-F-Wbrtp"
|
| 1021 |
+
},
|
| 1022 |
+
"source": [
|
| 1023 |
+
"# Creating zero-shot classifier weights"
|
| 1024 |
+
]
|
| 1025 |
+
},
|
| 1026 |
+
{
|
| 1027 |
+
"cell_type": "code",
|
| 1028 |
+
"metadata": {
|
| 1029 |
+
"colab": {
|
| 1030 |
+
"base_uri": "https://localhost:8080/",
|
| 1031 |
+
"height": 66,
|
| 1032 |
+
"referenced_widgets": [
|
| 1033 |
+
"4e3a3f83649f45f8bef3434980634664",
|
| 1034 |
+
"f066bdb766664c788ba1e9de8d311e22",
|
| 1035 |
+
"4e7a7427d28a4ae684e0be4548eb9944",
|
| 1036 |
+
"cc9dc019c1334a46b2558ffa6c0dd6e6",
|
| 1037 |
+
"285c877d4f644f3a8a58c4eb5948101c",
|
| 1038 |
+
"075d6545e02e419ca565589eb5ffc318",
|
| 1039 |
+
"53f9106c80e84d5b8c3ec96162d1db98",
|
| 1040 |
+
"19c57d99e7c44cbda508ce558fde435d"
|
| 1041 |
+
]
|
| 1042 |
+
},
|
| 1043 |
+
"id": "sRqDoz1Gbsii",
|
| 1044 |
+
"outputId": "5ab6c001-8a5e-42c9-ab46-4477a693229c"
|
| 1045 |
+
},
|
| 1046 |
+
"source": [
|
| 1047 |
+
"def zeroshot_classifier(classnames, templates):\n",
|
| 1048 |
+
" with torch.no_grad():\n",
|
| 1049 |
+
" zeroshot_weights = []\n",
|
| 1050 |
+
" for classname in tqdm(classnames):\n",
|
| 1051 |
+
" texts = [template.format(classname) for template in templates] #format with class\n",
|
| 1052 |
+
" texts = clip.tokenize(texts).cuda() #tokenize\n",
|
| 1053 |
+
" class_embeddings = model.encode_text(texts) #embed with text encoder\n",
|
| 1054 |
+
" class_embeddings /= class_embeddings.norm(dim=-1, keepdim=True)\n",
|
| 1055 |
+
" class_embedding = class_embeddings.mean(dim=0)\n",
|
| 1056 |
+
" class_embedding /= class_embedding.norm()\n",
|
| 1057 |
+
" zeroshot_weights.append(class_embedding)\n",
|
| 1058 |
+
" zeroshot_weights = torch.stack(zeroshot_weights, dim=1).cuda()\n",
|
| 1059 |
+
" return zeroshot_weights\n",
|
| 1060 |
+
"\n",
|
| 1061 |
+
"\n",
|
| 1062 |
+
"zeroshot_weights = zeroshot_classifier(imagenet_classes, imagenet_templates)"
|
| 1063 |
+
],
|
| 1064 |
+
"execution_count": 11,
|
| 1065 |
+
"outputs": [
|
| 1066 |
+
{
|
| 1067 |
+
"output_type": "display_data",
|
| 1068 |
+
"data": {
|
| 1069 |
+
"application/vnd.jupyter.widget-view+json": {
|
| 1070 |
+
"model_id": "4e3a3f83649f45f8bef3434980634664",
|
| 1071 |
+
"version_minor": 0,
|
| 1072 |
+
"version_major": 2
|
| 1073 |
+
},
|
| 1074 |
+
"text/plain": [
|
| 1075 |
+
"HBox(children=(FloatProgress(value=0.0, max=1000.0), HTML(value='')))"
|
| 1076 |
+
]
|
| 1077 |
+
},
|
| 1078 |
+
"metadata": {
|
| 1079 |
+
"tags": []
|
| 1080 |
+
}
|
| 1081 |
+
},
|
| 1082 |
+
{
|
| 1083 |
+
"output_type": "stream",
|
| 1084 |
+
"text": [
|
| 1085 |
+
"\n"
|
| 1086 |
+
],
|
| 1087 |
+
"name": "stdout"
|
| 1088 |
+
}
|
| 1089 |
+
]
|
| 1090 |
+
},
|
| 1091 |
+
{
|
| 1092 |
+
"cell_type": "markdown",
|
| 1093 |
+
"metadata": {
|
| 1094 |
+
"id": "1fZo7hG8iJP5"
|
| 1095 |
+
},
|
| 1096 |
+
"source": [
|
| 1097 |
+
"# Zero-shot prediction"
|
| 1098 |
+
]
|
| 1099 |
+
},
|
| 1100 |
+
{
|
| 1101 |
+
"cell_type": "code",
|
| 1102 |
+
"metadata": {
|
| 1103 |
+
"id": "j4kPSZoShQxN"
|
| 1104 |
+
},
|
| 1105 |
+
"source": [
|
| 1106 |
+
"def accuracy(output, target, topk=(1,)):\n",
|
| 1107 |
+
" pred = output.topk(max(topk), 1, True, True)[1].t()\n",
|
| 1108 |
+
" correct = pred.eq(target.view(1, -1).expand_as(pred))\n",
|
| 1109 |
+
" return [float(correct[:k].reshape(-1).float().sum(0, keepdim=True).cpu().numpy()) for k in topk]"
|
| 1110 |
+
],
|
| 1111 |
+
"execution_count": 12,
|
| 1112 |
+
"outputs": []
|
| 1113 |
+
},
|
| 1114 |
+
{
|
| 1115 |
+
"cell_type": "code",
|
| 1116 |
+
"metadata": {
|
| 1117 |
+
"colab": {
|
| 1118 |
+
"base_uri": "https://localhost:8080/",
|
| 1119 |
+
"height": 100,
|
| 1120 |
+
"referenced_widgets": [
|
| 1121 |
+
"fbb2b937b22049f5987f39f48c652a86",
|
| 1122 |
+
"0a1b6b76984349ccb36ca2fc4a4a0208",
|
| 1123 |
+
"c136afb47aa14ac2832093ee415c6f3e",
|
| 1124 |
+
"467a151e73744eccb199fe72aa352e5b",
|
| 1125 |
+
"f6d637c3fc3c46928d023441227130e5",
|
| 1126 |
+
"029e6eadacb8480193aab52ff073be8f",
|
| 1127 |
+
"30178355f76742898d37966b3875ef0a",
|
| 1128 |
+
"2e62544c03d64d6d92b94fcfaca2fc90"
|
| 1129 |
+
]
|
| 1130 |
+
},
|
| 1131 |
+
"id": "wKJ7YsdlkDXo",
|
| 1132 |
+
"outputId": "90e084fd-86bc-4a52-a06e-61bff7aa86e0"
|
| 1133 |
+
},
|
| 1134 |
+
"source": [
|
| 1135 |
+
"with torch.no_grad():\n",
|
| 1136 |
+
" top1, top5, n = 0., 0., 0.\n",
|
| 1137 |
+
" for i, (images, target) in enumerate(tqdm(loader)):\n",
|
| 1138 |
+
" images = images.cuda()\n",
|
| 1139 |
+
" target = target.cuda()\n",
|
| 1140 |
+
" \n",
|
| 1141 |
+
" # predict\n",
|
| 1142 |
+
" image_features = model.encode_image(images)\n",
|
| 1143 |
+
" image_features /= image_features.norm(dim=-1, keepdim=True)\n",
|
| 1144 |
+
" logits = 100. * image_features @ zeroshot_weights\n",
|
| 1145 |
+
"\n",
|
| 1146 |
+
" # measure accuracy\n",
|
| 1147 |
+
" acc1, acc5 = accuracy(logits, target, topk=(1, 5))\n",
|
| 1148 |
+
" top1 += acc1\n",
|
| 1149 |
+
" top5 += acc5\n",
|
| 1150 |
+
" n += images.size(0)\n",
|
| 1151 |
+
"\n",
|
| 1152 |
+
"top1 = (top1 / n) * 100\n",
|
| 1153 |
+
"top5 = (top5 / n) * 100 \n",
|
| 1154 |
+
"\n",
|
| 1155 |
+
"print(f\"Top-1 accuracy: {top1:.2f}\")\n",
|
| 1156 |
+
"print(f\"Top-5 accuracy: {top5:.2f}\")"
|
| 1157 |
+
],
|
| 1158 |
+
"execution_count": 13,
|
| 1159 |
+
"outputs": [
|
| 1160 |
+
{
|
| 1161 |
+
"output_type": "display_data",
|
| 1162 |
+
"data": {
|
| 1163 |
+
"application/vnd.jupyter.widget-view+json": {
|
| 1164 |
+
"model_id": "fbb2b937b22049f5987f39f48c652a86",
|
| 1165 |
+
"version_minor": 0,
|
| 1166 |
+
"version_major": 2
|
| 1167 |
+
},
|
| 1168 |
+
"text/plain": [
|
| 1169 |
+
"HBox(children=(FloatProgress(value=0.0, max=313.0), HTML(value='')))"
|
| 1170 |
+
]
|
| 1171 |
+
},
|
| 1172 |
+
"metadata": {
|
| 1173 |
+
"tags": []
|
| 1174 |
+
}
|
| 1175 |
+
},
|
| 1176 |
+
{
|
| 1177 |
+
"output_type": "stream",
|
| 1178 |
+
"text": [
|
| 1179 |
+
"\n",
|
| 1180 |
+
"Top-1 accuracy: 55.73\n",
|
| 1181 |
+
"Top-5 accuracy: 83.45\n"
|
| 1182 |
+
],
|
| 1183 |
+
"name": "stdout"
|
| 1184 |
+
}
|
| 1185 |
+
]
|
| 1186 |
+
}
|
| 1187 |
+
]
|
| 1188 |
+
}
|
CLIP/requirements.txt
ADDED
|
@@ -0,0 +1,5 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
ftfy
|
| 2 |
+
regex
|
| 3 |
+
tqdm
|
| 4 |
+
torch~=1.7.1
|
| 5 |
+
torchvision~=0.8.2
|
CLIP/setup.py
ADDED
|
@@ -0,0 +1,21 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import os
|
| 2 |
+
|
| 3 |
+
import pkg_resources
|
| 4 |
+
from setuptools import setup, find_packages
|
| 5 |
+
|
| 6 |
+
setup(
|
| 7 |
+
name="clip",
|
| 8 |
+
py_modules=["clip"],
|
| 9 |
+
version="1.0",
|
| 10 |
+
description="",
|
| 11 |
+
author="OpenAI",
|
| 12 |
+
packages=find_packages(exclude=["tests*"]),
|
| 13 |
+
install_requires=[
|
| 14 |
+
str(r)
|
| 15 |
+
for r in pkg_resources.parse_requirements(
|
| 16 |
+
open(os.path.join(os.path.dirname(__file__), "requirements.txt"))
|
| 17 |
+
)
|
| 18 |
+
],
|
| 19 |
+
include_package_data=True,
|
| 20 |
+
extras_require={'dev': ['pytest']},
|
| 21 |
+
)
|
CLIP/tests/test_consistency.py
ADDED
|
@@ -0,0 +1,25 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import numpy as np
|
| 2 |
+
import pytest
|
| 3 |
+
import torch
|
| 4 |
+
from PIL import Image
|
| 5 |
+
|
| 6 |
+
import clip
|
| 7 |
+
|
| 8 |
+
|
| 9 |
+
@pytest.mark.parametrize('model_name', clip.available_models())
|
| 10 |
+
def test_consistency(model_name):
|
| 11 |
+
device = "cpu"
|
| 12 |
+
jit_model, transform = clip.load(model_name, device=device)
|
| 13 |
+
py_model, _ = clip.load(model_name, device=device, jit=False)
|
| 14 |
+
|
| 15 |
+
image = transform(Image.open("CLIP.png")).unsqueeze(0).to(device)
|
| 16 |
+
text = clip.tokenize(["a diagram", "a dog", "a cat"]).to(device)
|
| 17 |
+
|
| 18 |
+
with torch.no_grad():
|
| 19 |
+
logits_per_image, _ = jit_model(image, text)
|
| 20 |
+
jit_probs = logits_per_image.softmax(dim=-1).cpu().numpy()
|
| 21 |
+
|
| 22 |
+
logits_per_image, _ = py_model(image, text)
|
| 23 |
+
py_probs = logits_per_image.softmax(dim=-1).cpu().numpy()
|
| 24 |
+
|
| 25 |
+
assert np.allclose(jit_probs, py_probs, atol=0.01, rtol=0.1)
|
GPT_eval_multi.py
ADDED
|
@@ -0,0 +1,144 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import os
|
| 2 |
+
import torch
|
| 3 |
+
import numpy as np
|
| 4 |
+
from torch.utils.tensorboard import SummaryWriter
|
| 5 |
+
import json
|
| 6 |
+
# import clip
|
| 7 |
+
from CLIP import clip
|
| 8 |
+
|
| 9 |
+
import options.option_transformer as option_trans
|
| 10 |
+
import models.vqvae as vqvae
|
| 11 |
+
import utils.utils_model as utils_model
|
| 12 |
+
import eval_trans_per as eval_trans
|
| 13 |
+
from dataset import dataset_TM_eval
|
| 14 |
+
import models.t2m_trans as trans
|
| 15 |
+
from options.get_eval_option import get_opt
|
| 16 |
+
from models.evaluator_wrapper import EvaluatorModelWrapper
|
| 17 |
+
import warnings
|
| 18 |
+
from tqdm import trange
|
| 19 |
+
warnings.filterwarnings('ignore')
|
| 20 |
+
|
| 21 |
+
##### ---- Exp dirs ---- #####
|
| 22 |
+
os.chdir('/root/autodl-tmp/SATO')
|
| 23 |
+
args = option_trans.get_args_parser()
|
| 24 |
+
torch.manual_seed(args.seed)
|
| 25 |
+
|
| 26 |
+
args.out_dir = os.path.join(args.out_dir, f'{args.exp_name}')
|
| 27 |
+
os.makedirs(args.out_dir, exist_ok = True)
|
| 28 |
+
|
| 29 |
+
##### ---- Logger ---- #####
|
| 30 |
+
logger = utils_model.get_logger(args.out_dir)
|
| 31 |
+
writer = SummaryWriter(args.out_dir)
|
| 32 |
+
logger.info(json.dumps(vars(args), indent=4, sort_keys=True))
|
| 33 |
+
|
| 34 |
+
from utils.word_vectorizer import WordVectorizer
|
| 35 |
+
w_vectorizer = WordVectorizer('./glove', 'our_vab')
|
| 36 |
+
val_loader = dataset_TM_eval.DATALoader(args.dataname, True, 32, w_vectorizer)
|
| 37 |
+
|
| 38 |
+
dataset_opt_path = 'checkpoints/kit/Comp_v6_KLD005/opt.txt' if args.dataname == 'kit' else 'checkpoints/t2m/Comp_v6_KLD005/opt.txt'
|
| 39 |
+
|
| 40 |
+
wrapper_opt = get_opt(dataset_opt_path, torch.device('cuda'))
|
| 41 |
+
eval_wrapper = EvaluatorModelWrapper(wrapper_opt)
|
| 42 |
+
|
| 43 |
+
##### ---- Network ---- #####
|
| 44 |
+
|
| 45 |
+
## load clip model and datasets
|
| 46 |
+
|
| 47 |
+
clip_model, clip_preprocess = clip.load(args.clip_path, device=torch.device('cuda'), jit=False) # Must set jit=False for training
|
| 48 |
+
clip.model.convert_weights(clip_model) # Actually this line is unnecessary since clip by default already on float16
|
| 49 |
+
clip_model.eval()
|
| 50 |
+
for p in clip_model.parameters():
|
| 51 |
+
p.requires_grad = False
|
| 52 |
+
|
| 53 |
+
net = vqvae.HumanVQVAE(args, ## use args to define different parameters in different quantizers
|
| 54 |
+
args.nb_code,
|
| 55 |
+
args.code_dim,
|
| 56 |
+
args.output_emb_width,
|
| 57 |
+
args.down_t,
|
| 58 |
+
args.stride_t,
|
| 59 |
+
args.width,
|
| 60 |
+
args.depth,
|
| 61 |
+
args.dilation_growth_rate)
|
| 62 |
+
|
| 63 |
+
|
| 64 |
+
trans_encoder = trans.Text2Motion_Transformer(num_vq=args.nb_code,
|
| 65 |
+
embed_dim=args.embed_dim_gpt,
|
| 66 |
+
clip_dim=args.clip_dim,
|
| 67 |
+
block_size=args.block_size,
|
| 68 |
+
num_layers=args.num_layers,
|
| 69 |
+
n_head=args.n_head_gpt,
|
| 70 |
+
drop_out_rate=args.drop_out_rate,
|
| 71 |
+
fc_rate=args.ff_rate)
|
| 72 |
+
|
| 73 |
+
|
| 74 |
+
print ('loading checkpoint from {}'.format(args.resume_pth))
|
| 75 |
+
ckpt = torch.load(args.resume_pth, map_location='cpu')
|
| 76 |
+
net.load_state_dict(ckpt['net'], strict=True)
|
| 77 |
+
net.eval()
|
| 78 |
+
net.cuda()
|
| 79 |
+
|
| 80 |
+
if args.resume_trans is not None:
|
| 81 |
+
print ('loading transformer checkpoint from {}'.format(args.resume_trans))
|
| 82 |
+
ckpt = torch.load(args.resume_trans, map_location='cpu')
|
| 83 |
+
trans_encoder.load_state_dict(ckpt['trans'], strict=True)
|
| 84 |
+
trans_encoder.train()
|
| 85 |
+
trans_encoder.cuda()
|
| 86 |
+
print('checkpoints loading successfully')
|
| 87 |
+
|
| 88 |
+
fid = []
|
| 89 |
+
fid_per=[]
|
| 90 |
+
div = []
|
| 91 |
+
top1 = []
|
| 92 |
+
top2 = []
|
| 93 |
+
top3 = []
|
| 94 |
+
matching = []
|
| 95 |
+
multi = []
|
| 96 |
+
repeat_time = 20
|
| 97 |
+
fid_word_perb=[]
|
| 98 |
+
|
| 99 |
+
for i in range(repeat_time):
|
| 100 |
+
print('repeat_time: ',i)
|
| 101 |
+
best_fid,best_fid_word_perb,best_fid_per, best_iter, best_div, best_top1, best_top2, best_top3, best_matching, best_multi, writer, logger = eval_trans.evaluation_transformer_test(args.out_dir, val_loader, net, trans_encoder, logger, writer, 0, best_fid=1000,best_fid_word_perb=1000,best_fid_perturbation=1000, best_iter=0, best_div=100, best_top1=0, best_top2=0, best_top3=0, best_matching=100, best_multi=0, clip_model=clip_model, eval_wrapper=eval_wrapper, draw=False, savegif=False, save=False, savenpy=(i==0))
|
| 102 |
+
fid.append(best_fid)
|
| 103 |
+
fid_word_perb.append(best_fid_word_perb)
|
| 104 |
+
fid_per.append(best_fid_per)
|
| 105 |
+
div.append(best_div)
|
| 106 |
+
top1.append(best_top1)
|
| 107 |
+
top2.append(best_top2)
|
| 108 |
+
top3.append(best_top3)
|
| 109 |
+
matching.append(best_matching)
|
| 110 |
+
multi.append(best_multi)
|
| 111 |
+
|
| 112 |
+
# print('fid: ', sum(fid)/(i+1))
|
| 113 |
+
# print('fid_per',sum(fid_per)/(i+1))
|
| 114 |
+
# print('div: ', sum(div)/(i+1))
|
| 115 |
+
# print('top1: ', sum(top1)/(i+1))
|
| 116 |
+
# print('top2: ', sum(top2)/(i+1))
|
| 117 |
+
# print('top3: ', sum(top3)/(i+1))
|
| 118 |
+
# print('matching: ', sum(matching)/(i+1))
|
| 119 |
+
# print('multi: ', sum(multi)/(i+1))
|
| 120 |
+
|
| 121 |
+
|
| 122 |
+
print('final result:')
|
| 123 |
+
print('fid: ', sum(fid)/repeat_time)
|
| 124 |
+
print('fid_word_perb',sum(fid_word_perb)/repeat_time)
|
| 125 |
+
print('fid_per',sum(fid_per)/repeat_time)
|
| 126 |
+
print('div: ', sum(div)/repeat_time)
|
| 127 |
+
print('top1: ', sum(top1)/repeat_time)
|
| 128 |
+
print('top2: ', sum(top2)/repeat_time)
|
| 129 |
+
print('top3: ', sum(top3)/repeat_time)
|
| 130 |
+
print('matching: ', sum(matching)/repeat_time)
|
| 131 |
+
# print('multi: ', sum(multi)/repeat_time)
|
| 132 |
+
|
| 133 |
+
fid = np.array(fid)
|
| 134 |
+
fid_word_perb=np.array(fid_word_perb)
|
| 135 |
+
fid_per=np.array(fid_per)
|
| 136 |
+
div = np.array(div)
|
| 137 |
+
top1 = np.array(top1)
|
| 138 |
+
top2 = np.array(top2)
|
| 139 |
+
top3 = np.array(top3)
|
| 140 |
+
matching = np.array(matching)
|
| 141 |
+
# multi = np.array(multi)
|
| 142 |
+
# msg_final = f"FID. {np.mean(fid):.3f}, FID_PERB.{np.mean(fid_per):.3f}conf. {np.std(fid)*1.96/np.sqrt(repeat_time):.3f}, Diversity. {np.mean(div):.3f}, conf. {np.std(div)*1.96/np.sqrt(repeat_time):.3f}, TOP1. {np.mean(top1):.3f}, conf. {np.std(top1)*1.96/np.sqrt(repeat_time):.3f}, TOP2. {np.mean(top2):.3f}, conf. {np.std(top2)*1.96/np.sqrt(repeat_time):.3f}, TOP3. {np.mean(top3):.3f}, conf. {np.std(top3)*1.96/np.sqrt(repeat_time):.3f}, Matching. {np.mean(matching):.3f}, conf. {np.std(matching)*1.96/np.sqrt(repeat_time):.3f}, Multi. {np.mean(multi):.3f}, conf. {np.std(multi)*1.96/np.sqrt(repeat_time):.3f}"
|
| 143 |
+
msg_final = f"FID. {np.mean(fid):.3f}, {np.std(fid)*1.96/np.sqrt(repeat_time):.3f}, FID_word_perb.{np.mean(fid_word_perb):.3f}, {np.std(fid_word_perb)*1.96/np.sqrt(repeat_time):.3f},FID_PERB.{np.mean(fid_per):.3f}, conf. {np.std(fid)*1.96/np.sqrt(repeat_time):.3f}, Diversity. {np.mean(div):.3f}, conf. {np.std(div)*1.96/np.sqrt(repeat_time):.3f}, TOP1. {np.mean(top1):.3f}, conf. {np.std(top1)*1.96/np.sqrt(repeat_time):.3f}, TOP2. {np.mean(top2):.3f}, conf. {np.std(top2)*1.96/np.sqrt(repeat_time):.3f}, TOP3. {np.mean(top3):.3f}, conf. {np.std(top3)*1.96/np.sqrt(repeat_time):.3f}, Matching. {np.mean(matching):.3f}, conf. {np.std(matching)*1.96/np.sqrt(repeat_time):.3f}, conf. {np.std(multi)*1.96/np.sqrt(repeat_time):.3f}"
|
| 144 |
+
logger.info(msg_final)
|
LICENSE
ADDED
|
@@ -0,0 +1,201 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
Apache License
|
| 2 |
+
Version 2.0, January 2004
|
| 3 |
+
http://www.apache.org/licenses/
|
| 4 |
+
|
| 5 |
+
TERMS AND CONDITIONS FOR USE, REPRODUCTION, AND DISTRIBUTION
|
| 6 |
+
|
| 7 |
+
1. Definitions.
|
| 8 |
+
|
| 9 |
+
"License" shall mean the terms and conditions for use, reproduction,
|
| 10 |
+
and distribution as defined by Sections 1 through 9 of this document.
|
| 11 |
+
|
| 12 |
+
"Licensor" shall mean the copyright owner or entity authorized by
|
| 13 |
+
the copyright owner that is granting the License.
|
| 14 |
+
|
| 15 |
+
"Legal Entity" shall mean the union of the acting entity and all
|
| 16 |
+
other entities that control, are controlled by, or are under common
|
| 17 |
+
control with that entity. For the purposes of this definition,
|
| 18 |
+
"control" means (i) the power, direct or indirect, to cause the
|
| 19 |
+
direction or management of such entity, whether by contract or
|
| 20 |
+
otherwise, or (ii) ownership of fifty percent (50%) or more of the
|
| 21 |
+
outstanding shares, or (iii) beneficial ownership of such entity.
|
| 22 |
+
|
| 23 |
+
"You" (or "Your") shall mean an individual or Legal Entity
|
| 24 |
+
exercising permissions granted by this License.
|
| 25 |
+
|
| 26 |
+
"Source" form shall mean the preferred form for making modifications,
|
| 27 |
+
including but not limited to software source code, documentation
|
| 28 |
+
source, and configuration files.
|
| 29 |
+
|
| 30 |
+
"Object" form shall mean any form resulting from mechanical
|
| 31 |
+
transformation or translation of a Source form, including but
|
| 32 |
+
not limited to compiled object code, generated documentation,
|
| 33 |
+
and conversions to other media types.
|
| 34 |
+
|
| 35 |
+
"Work" shall mean the work of authorship, whether in Source or
|
| 36 |
+
Object form, made available under the License, as indicated by a
|
| 37 |
+
copyright notice that is included in or attached to the work
|
| 38 |
+
(an example is provided in the Appendix below).
|
| 39 |
+
|
| 40 |
+
"Derivative Works" shall mean any work, whether in Source or Object
|
| 41 |
+
form, that is based on (or derived from) the Work and for which the
|
| 42 |
+
editorial revisions, annotations, elaborations, or other modifications
|
| 43 |
+
represent, as a whole, an original work of authorship. For the purposes
|
| 44 |
+
of this License, Derivative Works shall not include works that remain
|
| 45 |
+
separable from, or merely link (or bind by name) to the interfaces of,
|
| 46 |
+
the Work and Derivative Works thereof.
|
| 47 |
+
|
| 48 |
+
"Contribution" shall mean any work of authorship, including
|
| 49 |
+
the original version of the Work and any modifications or additions
|
| 50 |
+
to that Work or Derivative Works thereof, that is intentionally
|
| 51 |
+
submitted to Licensor for inclusion in the Work by the copyright owner
|
| 52 |
+
or by an individual or Legal Entity authorized to submit on behalf of
|
| 53 |
+
the copyright owner. For the purposes of this definition, "submitted"
|
| 54 |
+
means any form of electronic, verbal, or written communication sent
|
| 55 |
+
to the Licensor or its representatives, including but not limited to
|
| 56 |
+
communication on electronic mailing lists, source code control systems,
|
| 57 |
+
and issue tracking systems that are managed by, or on behalf of, the
|
| 58 |
+
Licensor for the purpose of discussing and improving the Work, but
|
| 59 |
+
excluding communication that is conspicuously marked or otherwise
|
| 60 |
+
designated in writing by the copyright owner as "Not a Contribution."
|
| 61 |
+
|
| 62 |
+
"Contributor" shall mean Licensor and any individual or Legal Entity
|
| 63 |
+
on behalf of whom a Contribution has been received by Licensor and
|
| 64 |
+
subsequently incorporated within the Work.
|
| 65 |
+
|
| 66 |
+
2. Grant of Copyright License. Subject to the terms and conditions of
|
| 67 |
+
this License, each Contributor hereby grants to You a perpetual,
|
| 68 |
+
worldwide, non-exclusive, no-charge, royalty-free, irrevocable
|
| 69 |
+
copyright license to reproduce, prepare Derivative Works of,
|
| 70 |
+
publicly display, publicly perform, sublicense, and distribute the
|
| 71 |
+
Work and such Derivative Works in Source or Object form.
|
| 72 |
+
|
| 73 |
+
3. Grant of Patent License. Subject to the terms and conditions of
|
| 74 |
+
this License, each Contributor hereby grants to You a perpetual,
|
| 75 |
+
worldwide, non-exclusive, no-charge, royalty-free, irrevocable
|
| 76 |
+
(except as stated in this section) patent license to make, have made,
|
| 77 |
+
use, offer to sell, sell, import, and otherwise transfer the Work,
|
| 78 |
+
where such license applies only to those patent claims licensable
|
| 79 |
+
by such Contributor that are necessarily infringed by their
|
| 80 |
+
Contribution(s) alone or by combination of their Contribution(s)
|
| 81 |
+
with the Work to which such Contribution(s) was submitted. If You
|
| 82 |
+
institute patent litigation against any entity (including a
|
| 83 |
+
cross-claim or counterclaim in a lawsuit) alleging that the Work
|
| 84 |
+
or a Contribution incorporated within the Work constitutes direct
|
| 85 |
+
or contributory patent infringement, then any patent licenses
|
| 86 |
+
granted to You under this License for that Work shall terminate
|
| 87 |
+
as of the date such litigation is filed.
|
| 88 |
+
|
| 89 |
+
4. Redistribution. You may reproduce and distribute copies of the
|
| 90 |
+
Work or Derivative Works thereof in any medium, with or without
|
| 91 |
+
modifications, and in Source or Object form, provided that You
|
| 92 |
+
meet the following conditions:
|
| 93 |
+
|
| 94 |
+
(a) You must give any other recipients of the Work or
|
| 95 |
+
Derivative Works a copy of this License; and
|
| 96 |
+
|
| 97 |
+
(b) You must cause any modified files to carry prominent notices
|
| 98 |
+
stating that You changed the files; and
|
| 99 |
+
|
| 100 |
+
(c) You must retain, in the Source form of any Derivative Works
|
| 101 |
+
that You distribute, all copyright, patent, trademark, and
|
| 102 |
+
attribution notices from the Source form of the Work,
|
| 103 |
+
excluding those notices that do not pertain to any part of
|
| 104 |
+
the Derivative Works; and
|
| 105 |
+
|
| 106 |
+
(d) If the Work includes a "NOTICE" text file as part of its
|
| 107 |
+
distribution, then any Derivative Works that You distribute must
|
| 108 |
+
include a readable copy of the attribution notices contained
|
| 109 |
+
within such NOTICE file, excluding those notices that do not
|
| 110 |
+
pertain to any part of the Derivative Works, in at least one
|
| 111 |
+
of the following places: within a NOTICE text file distributed
|
| 112 |
+
as part of the Derivative Works; within the Source form or
|
| 113 |
+
documentation, if provided along with the Derivative Works; or,
|
| 114 |
+
within a display generated by the Derivative Works, if and
|
| 115 |
+
wherever such third-party notices normally appear. The contents
|
| 116 |
+
of the NOTICE file are for informational purposes only and
|
| 117 |
+
do not modify the License. You may add Your own attribution
|
| 118 |
+
notices within Derivative Works that You distribute, alongside
|
| 119 |
+
or as an addendum to the NOTICE text from the Work, provided
|
| 120 |
+
that such additional attribution notices cannot be construed
|
| 121 |
+
as modifying the License.
|
| 122 |
+
|
| 123 |
+
You may add Your own copyright statement to Your modifications and
|
| 124 |
+
may provide additional or different license terms and conditions
|
| 125 |
+
for use, reproduction, or distribution of Your modifications, or
|
| 126 |
+
for any such Derivative Works as a whole, provided Your use,
|
| 127 |
+
reproduction, and distribution of the Work otherwise complies with
|
| 128 |
+
the conditions stated in this License.
|
| 129 |
+
|
| 130 |
+
5. Submission of Contributions. Unless You explicitly state otherwise,
|
| 131 |
+
any Contribution intentionally submitted for inclusion in the Work
|
| 132 |
+
by You to the Licensor shall be under the terms and conditions of
|
| 133 |
+
this License, without any additional terms or conditions.
|
| 134 |
+
Notwithstanding the above, nothing herein shall supersede or modify
|
| 135 |
+
the terms of any separate license agreement you may have executed
|
| 136 |
+
with Licensor regarding such Contributions.
|
| 137 |
+
|
| 138 |
+
6. Trademarks. This License does not grant permission to use the trade
|
| 139 |
+
names, trademarks, service marks, or product names of the Licensor,
|
| 140 |
+
except as required for reasonable and customary use in describing the
|
| 141 |
+
origin of the Work and reproducing the content of the NOTICE file.
|
| 142 |
+
|
| 143 |
+
7. Disclaimer of Warranty. Unless required by applicable law or
|
| 144 |
+
agreed to in writing, Licensor provides the Work (and each
|
| 145 |
+
Contributor provides its Contributions) on an "AS IS" BASIS,
|
| 146 |
+
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or
|
| 147 |
+
implied, including, without limitation, any warranties or conditions
|
| 148 |
+
of TITLE, NON-INFRINGEMENT, MERCHANTABILITY, or FITNESS FOR A
|
| 149 |
+
PARTICULAR PURPOSE. You are solely responsible for determining the
|
| 150 |
+
appropriateness of using or redistributing the Work and assume any
|
| 151 |
+
risks associated with Your exercise of permissions under this License.
|
| 152 |
+
|
| 153 |
+
8. Limitation of Liability. In no event and under no legal theory,
|
| 154 |
+
whether in tort (including negligence), contract, or otherwise,
|
| 155 |
+
unless required by applicable law (such as deliberate and grossly
|
| 156 |
+
negligent acts) or agreed to in writing, shall any Contributor be
|
| 157 |
+
liable to You for damages, including any direct, indirect, special,
|
| 158 |
+
incidental, or consequential damages of any character arising as a
|
| 159 |
+
result of this License or out of the use or inability to use the
|
| 160 |
+
Work (including but not limited to damages for loss of goodwill,
|
| 161 |
+
work stoppage, computer failure or malfunction, or any and all
|
| 162 |
+
other commercial damages or losses), even if such Contributor
|
| 163 |
+
has been advised of the possibility of such damages.
|
| 164 |
+
|
| 165 |
+
9. Accepting Warranty or Additional Liability. While redistributing
|
| 166 |
+
the Work or Derivative Works thereof, You may choose to offer,
|
| 167 |
+
and charge a fee for, acceptance of support, warranty, indemnity,
|
| 168 |
+
or other liability obligations and/or rights consistent with this
|
| 169 |
+
License. However, in accepting such obligations, You may act only
|
| 170 |
+
on Your own behalf and on Your sole responsibility, not on behalf
|
| 171 |
+
of any other Contributor, and only if You agree to indemnify,
|
| 172 |
+
defend, and hold each Contributor harmless for any liability
|
| 173 |
+
incurred by, or claims asserted against, such Contributor by reason
|
| 174 |
+
of your accepting any such warranty or additional liability.
|
| 175 |
+
|
| 176 |
+
END OF TERMS AND CONDITIONS
|
| 177 |
+
|
| 178 |
+
APPENDIX: How to apply the Apache License to your work.
|
| 179 |
+
|
| 180 |
+
To apply the Apache License to your work, attach the following
|
| 181 |
+
boilerplate notice, with the fields enclosed by brackets "[]"
|
| 182 |
+
replaced with your own identifying information. (Don't include
|
| 183 |
+
the brackets!) The text should be enclosed in the appropriate
|
| 184 |
+
comment syntax for the file format. We also recommend that a
|
| 185 |
+
file or class name and description of purpose be included on the
|
| 186 |
+
same "printed page" as the copyright notice for easier
|
| 187 |
+
identification within third-party archives.
|
| 188 |
+
|
| 189 |
+
Copyright 2023 tencent
|
| 190 |
+
|
| 191 |
+
Licensed under the Apache License, Version 2.0 (the "License");
|
| 192 |
+
you may not use this file except in compliance with the License.
|
| 193 |
+
You may obtain a copy of the License at
|
| 194 |
+
|
| 195 |
+
http://www.apache.org/licenses/LICENSE-2.0
|
| 196 |
+
|
| 197 |
+
Unless required by applicable law or agreed to in writing, software
|
| 198 |
+
distributed under the License is distributed on an "AS IS" BASIS,
|
| 199 |
+
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
| 200 |
+
See the License for the specific language governing permissions and
|
| 201 |
+
limitations under the License.
|
README.md
CHANGED
|
@@ -1,13 +1,227 @@
|
|
| 1 |
-
|
| 2 |
-
|
| 3 |
-
|
| 4 |
-
|
| 5 |
-
|
| 6 |
-
|
| 7 |
-
|
| 8 |
-
|
| 9 |
-
|
| 10 |
-
|
| 11 |
-
|
| 12 |
-
|
| 13 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# SATO: Stable Text-to-Motion Framework
|
| 2 |
+
|
| 3 |
+
[Wenshuo chen*](https://github.com/shurdy123), [Hongru Xiao*](https://github.com/Hongru0306), [Erhang Zhang*](https://github.com/zhangerhang), [Lijie Hu](https://sites.google.com/view/lijiehu/homepage), [Lei Wang](https://leiwangr.github.io/), [Mengyuan Liu](), [Chen Chen](https://www.crcv.ucf.edu/chenchen/)
|
| 4 |
+
|
| 5 |
+
[](https://sato-team.github.io/Stable-Text-to-Motion-Framework/) []() []()
|
| 6 |
+
## Existing Challenges
|
| 7 |
+
A fundamental challenge inherent in text-to-motion tasks stems from the variability of textual inputs. Even when conveying similar or the same meanings and intentions, texts can exhibit considerable variations in vocabulary and structure due to individual user preferences or linguistic nuances. Despite the considerable advancements made in these models, we find a notable weakness: all of them demonstrate instability in prediction when encountering minor textual perturbations, such as synonym substitutions. In the following demonstration, we showcase the instability of predictions generated by the previous method when presented with different user inputs conveying identical semantic meaning.
|
| 8 |
+
<!-- <div style="display:flex;">
|
| 9 |
+
<img src="assets/run_lola.gif" width="45%" style="margin-right: 1%;">
|
| 10 |
+
<img src="assets/yt_solo.gif" width="45%">
|
| 11 |
+
</div> -->
|
| 12 |
+
|
| 13 |
+
<p align="center">
|
| 14 |
+
<table align="center">
|
| 15 |
+
<tr>
|
| 16 |
+
<th colspan="4">Original text: A man kicks something or someone with his left leg.</th>
|
| 17 |
+
</tr>
|
| 18 |
+
<tr>
|
| 19 |
+
<th align="center"><u><a href="https://github.com/Mael-zys/T2M-GPT"><nobr>T2M-GPT</nobr> </a></u></th>
|
| 20 |
+
<th align="center"><u><a href="https://guytevet.github.io/mdm-page/"><nobr>MDM</nobr> </a></u></th>
|
| 21 |
+
<th align="center"><u><a href="https://github.com/EricGuo5513/momask-codes"><nobr>MoMask</nobr> </a></u></th>
|
| 22 |
+
</tr>
|
| 23 |
+
|
| 24 |
+
<tr>
|
| 25 |
+
<td width="250" align="center"><img src="images/example/kick/gpt.gif" width="150px" height="150px" alt="gif"></td>
|
| 26 |
+
<td width="250" align="center"><img src="images/example/kick/mdm.gif" width="150px" height="150px" alt="gif"></td>
|
| 27 |
+
<td width="250" align="center"><img src="images/example/kick/momask.gif" width="150px" height="150px" alt="gif"></td>
|
| 28 |
+
</tr>
|
| 29 |
+
|
| 30 |
+
<tr>
|
| 31 |
+
<th colspan="4" >Perturbed text: A human boots something or someone with his left leg.</th>
|
| 32 |
+
</tr>
|
| 33 |
+
<tr>
|
| 34 |
+
<th align="center"><u><a href="https://github.com/Mael-zys/T2M-GPT"><nobr>T2M-GPT</nobr> </a></u></th>
|
| 35 |
+
<th align="center"><u><a href="https://guytevet.github.io/mdm-page/"><nobr>MDM</nobr> </a></u></th>
|
| 36 |
+
<th align="center"><u><a href="https://github.com/EricGuo5513/momask-codes"><nobr>MoMask</nobr> </a></u></th>
|
| 37 |
+
</tr>
|
| 38 |
+
|
| 39 |
+
<tr>
|
| 40 |
+
<td width="250" align="center"><img src="images/example/boot/gpt.gif" width="150px" height="150px" alt="gif"></td>
|
| 41 |
+
<td width="250" align="center"><img src="images/example/boot/mdm.gif" width="150px" height="150px" alt="gif"></td>
|
| 42 |
+
<td width="250" align="center"><img src="images/example/boot/momask.gif" width="150px" height="150px" alt="gif"></td>
|
| 43 |
+
</tr>
|
| 44 |
+
</table>
|
| 45 |
+
</p>
|
| 46 |
+
|
| 47 |
+
## Motivation
|
| 48 |
+

|
| 49 |
+
The model's inconsistent outputs are accompanied by unstable attention patterns. We further elucidate the aforementioned experimental findings: When perturbed text is inputted, the model exhibits unstable attention, often neglecting critical text elements necessary for accurate motion prediction. This instability further complicates the encoding of text into consistent embeddings, leading to a cascade of consecutive temporal motion generation errors.
|
| 50 |
+
|
| 51 |
+
|
| 52 |
+
## Visualization
|
| 53 |
+
<p align="center">
|
| 54 |
+
<table align="center">
|
| 55 |
+
<tr>
|
| 56 |
+
<th colspan="4">Original text: person is walking normally in a circle.</th>
|
| 57 |
+
</tr>
|
| 58 |
+
<tr>
|
| 59 |
+
<th align="center"><u><a href="https://github.com/Mael-zys/T2M-GPT"><nobr>T2M-GPT</nobr> </a></u></th>
|
| 60 |
+
<th align="center"><u><a href="https://guytevet.github.io/mdm-page/"><nobr>MDM</nobr> </a></u></th>
|
| 61 |
+
<th align="center"><u><a href="https://github.com/EricGuo5513/momask-codes"><nobr>MoMask</nobr> </a></u></th>
|
| 62 |
+
<th align="center"><nobr>SATO</nobr> </th>
|
| 63 |
+
</tr>
|
| 64 |
+
|
| 65 |
+
<tr>
|
| 66 |
+
<td width="250" align="center"><img src="images/visualization/circle/gpt.gif" width="150px" height="150px" alt="gif"></td>
|
| 67 |
+
<td width="250" align="center"><img src="images/visualization/circle/mdm.gif" width="150px" height="150px" alt="gif"></td>
|
| 68 |
+
<td width="250" align="center"><img src="images/visualization/circle/momask.gif" width="150px" height="150px" alt="gif"></td>
|
| 69 |
+
<td width="250" align="center"><img src="images/visualization/circle/sato.gif" width="150px" height="150px" alt="gif"></td>
|
| 70 |
+
</tr>
|
| 71 |
+
|
| 72 |
+
<tr>
|
| 73 |
+
<th colspan="4" >Perturbed text: <span style="color: red;">human</span> is walking <span style="color: red;">usually</span> in a <span style="color: red;">loop.</th>
|
| 74 |
+
</tr>
|
| 75 |
+
<tr>
|
| 76 |
+
<th align="center"><u><a href="https://github.com/Mael-zys/T2M-GPT"><nobr>T2M-GPT</nobr> </a></u></th>
|
| 77 |
+
<th align="center"><u><a href="https://guytevet.github.io/mdm-page/"><nobr>MDM</nobr> </a></u></th>
|
| 78 |
+
<th align="center"><u><a href="https://github.com/EricGuo5513/momask-codes"><nobr>MoMask</nobr> </a></u></th>
|
| 79 |
+
<th align="center"><nobr>SATO</nobr> </th>
|
| 80 |
+
</tr>
|
| 81 |
+
|
| 82 |
+
<tr>
|
| 83 |
+
<td width="250" align="center"><img src="images/visualization/loop/gpt.gif" width="150px" height="150px" alt="gif"></td>
|
| 84 |
+
<td width="250" align="center"><img src="images/visualization/loop/mdm.gif" width="150px" height="150px" alt="gif"></td>
|
| 85 |
+
<td width="250" align="center"><img src="images/visualization/loop/momask.gif" width="150px" height="150px" alt="gif"></td>
|
| 86 |
+
<td width="250" align="center"><img src="images/visualization/loop/sato.gif" width="150px" height="150px" alt="gif"></td>
|
| 87 |
+
</tr>
|
| 88 |
+
</table>
|
| 89 |
+
</p>
|
| 90 |
+
<center>
|
| 91 |
+
<h3>
|
| 92 |
+
<p style="color: blue;">Explanation: T2M-GPT, MDM, and MoMask all don't walk in a loop.</p>
|
| 93 |
+
</h3>
|
| 94 |
+
|
| 95 |
+
<p align="center">
|
| 96 |
+
<table align="center">
|
| 97 |
+
<tr>
|
| 98 |
+
<th colspan="4">Original text: a person uses his right arm to help himself to stand up.</th>
|
| 99 |
+
</tr>
|
| 100 |
+
<tr>
|
| 101 |
+
<th align="center"><u><a href="https://github.com/Mael-zys/T2M-GPT"><nobr>T2M-GPT</nobr> </a></u></th>
|
| 102 |
+
<th align="center"><u><a href="https://guytevet.github.io/mdm-page/"><nobr>MDM</nobr> </a></u></th>
|
| 103 |
+
<th align="center"><u><a href="https://github.com/EricGuo5513/momask-codes"><nobr>MoMask</nobr> </a></u></th>
|
| 104 |
+
<th align="center"><nobr>SATO</nobr> </th>
|
| 105 |
+
</tr>
|
| 106 |
+
|
| 107 |
+
<tr>
|
| 108 |
+
<td width="250" align="center"><img src="images/visualization/use/gpt.gif" width="150px" height="150px" alt="gif"></td>
|
| 109 |
+
<td width="250" align="center"><img src="images/visualization/use/mdm.gif" width="150px" height="150px" alt="gif"></td>
|
| 110 |
+
<td width="250" align="center"><img src="images/visualization/use/momask.gif" width="150px" height="150px" alt="gif"></td>
|
| 111 |
+
<td width="250" align="center"><img src="images/visualization/use/sato.gif" width="150px" height="150px" alt="gif"></td>
|
| 112 |
+
</tr>
|
| 113 |
+
|
| 114 |
+
<tr>
|
| 115 |
+
<th colspan="4" >Perturbed text: A human <span style="color: red;">utilizes</span> his right arm to help himself to stand up.</th>
|
| 116 |
+
</tr>
|
| 117 |
+
<tr>
|
| 118 |
+
<th align="center"><u><a href="https://github.com/Mael-zys/T2M-GPT"><nobr>T2M-GPT</nobr> </a></u></th>
|
| 119 |
+
<th align="center"><u><a href="https://guytevet.github.io/mdm-page/"><nobr>MDM</nobr> </a></u></th>
|
| 120 |
+
<th align="center"><u><a href="https://github.com/EricGuo5513/momask-codes"><nobr>MoMask</nobr> </a></u></th>
|
| 121 |
+
<th align="center"><nobr>SATO</nobr> </th>
|
| 122 |
+
</tr>
|
| 123 |
+
|
| 124 |
+
<tr>
|
| 125 |
+
<td width="250" align="center"><img src="images/visualization/utilize/gpt.gif" width="150px" height="150px" alt="gif"></td>
|
| 126 |
+
<td width="250" align="center"><img src="images/visualization/utilize/mdm.gif" width="150px" height="150px" alt="gif"></td>
|
| 127 |
+
<td width="250" align="center"><img src="images/visualization/utilize/momask.gif" width="150px" height="150px" alt="gif"></td>
|
| 128 |
+
<td width="250" align="center"><img src="images/visualization/utilize/sato.gif" width="150px" height="150px" alt="gif"></td>
|
| 129 |
+
</tr>
|
| 130 |
+
</table>
|
| 131 |
+
</p>
|
| 132 |
+
<center>
|
| 133 |
+
<h3>
|
| 134 |
+
<p style="color: blue;">Explanation: T2M-GPT, MDM, and MoMask all lack the action of transitioning from squatting to standing up, resulting in a catastrophic error.</p>
|
| 135 |
+
</h3>
|
| 136 |
+
|
| 137 |
+
|
| 138 |
+
## How to Use the Code
|
| 139 |
+
|
| 140 |
+
* [1. Setup and Installation](#setup)
|
| 141 |
+
|
| 142 |
+
* [2.Dependencies](#Dependencies)
|
| 143 |
+
|
| 144 |
+
* [3. Quick Start](#quickstart)
|
| 145 |
+
|
| 146 |
+
* [4. Datasets](#datasets)
|
| 147 |
+
|
| 148 |
+
* [4. Train](#train)
|
| 149 |
+
|
| 150 |
+
* [5. Evaluation](#eval)
|
| 151 |
+
|
| 152 |
+
* [6. Acknowledgments](#acknowledgements)
|
| 153 |
+
|
| 154 |
+
|
| 155 |
+
## Setup and Installation <a name="setup"></a>
|
| 156 |
+
|
| 157 |
+
Clone the repository:
|
| 158 |
+
|
| 159 |
+
```shell
|
| 160 |
+
git clone https://github.com/sato-team/Stable-Text-to-motion-Framework.git
|
| 161 |
+
```
|
| 162 |
+
|
| 163 |
+
Create fresh conda environment and install all the dependencies:
|
| 164 |
+
|
| 165 |
+
```
|
| 166 |
+
conda env create -f environment.yml
|
| 167 |
+
conda activate SATO
|
| 168 |
+
```
|
| 169 |
+
|
| 170 |
+
The code was tested on Python 3.8 and PyTorch 1.8.1.
|
| 171 |
+
|
| 172 |
+
## Dependencies<a name="Dependencies"></a>
|
| 173 |
+
|
| 174 |
+
```shell
|
| 175 |
+
bash dataset/prepare/download_extractor.sh
|
| 176 |
+
bash dataset/prepare/download_glove.sh
|
| 177 |
+
```
|
| 178 |
+
|
| 179 |
+
## **Quick Start**<a name="quickstart"></a>
|
| 180 |
+
|
| 181 |
+
A quick reference guide for using our code is provided in quickstart.ipynb.
|
| 182 |
+
|
| 183 |
+
## Datasets<a name="datasets"></a>
|
| 184 |
+
|
| 185 |
+
We are using two 3D human motion-language dataset: HumanML3D and KIT-ML. For both datasets, you could find the details as well as download [link](https://github.com/EricGuo5513/HumanML3D).
|
| 186 |
+
We perturbed the input texts based on the two datasets mentioned. You can access the perturbed text dataset through the following [link](https://drive.google.com/file/d/1XLvu2jfG1YKyujdANhYHV_NfFTyOJPvP/view?usp=sharing).
|
| 187 |
+
Take HumanML3D for an example, the dataset structure should look like this:
|
| 188 |
+
```
|
| 189 |
+
./dataset/HumanML3D/
|
| 190 |
+
├── new_joint_vecs/
|
| 191 |
+
├── texts/ # You need to replace the 'texts' folder in the original dataset with the 'texts' folder from our dataset.
|
| 192 |
+
├── Mean.npy
|
| 193 |
+
├── Std.npy
|
| 194 |
+
├── train.txt
|
| 195 |
+
├── val.txt
|
| 196 |
+
├── test.txt
|
| 197 |
+
├── train_val.txt
|
| 198 |
+
└── all.txt
|
| 199 |
+
```
|
| 200 |
+
### **Train**<a name="train"></a>
|
| 201 |
+
|
| 202 |
+
We will release the training code soon.
|
| 203 |
+
|
| 204 |
+
### **Evaluation**<a name="eval"></a>
|
| 205 |
+
|
| 206 |
+
You can download the pretrained models in this [link](https://drive.google.com/drive/folders/1rs8QPJ3UPzLW4H3vWAAX9hJn4ln7m_ts?usp=sharing).
|
| 207 |
+
|
| 208 |
+
```shell
|
| 209 |
+
python eval_t2m.py --resume-pth pretrained/net_best_fid.pth --clip_path pretrained/clip_best_fid.pth
|
| 210 |
+
```
|
| 211 |
+
|
| 212 |
+
## Acknowledgements<a name="acknowledgements"></a>
|
| 213 |
+
|
| 214 |
+
We appreciate helps from :
|
| 215 |
+
|
| 216 |
+
- Open Source Code:[T2M-GPT](https://github.com/Mael-zys/T2M-GPT), [MoMask ](https://github.com/EricGuo5513/momask-codes), [MDM](https://guytevet.github.io/mdm-page/), etc.
|
| 217 |
+
- [Hongru Xiao](https://github.com/Hongru0306), [Erhang Zhang](https://github.com/zhangerhang), [Lijie Hu](https://sites.google.com/view/lijiehu/homepage), [Lei Wang](https://leiwangr.github.io/), [Mengyuan Liu](), [Chen Chen](https://www.crcv.ucf.edu/chenchen/) for discussions and guidance throughout the project, which has been instrumental to our work.
|
| 218 |
+
- [Zhen Zhao](https://github.com/Zanebla) for project website.
|
| 219 |
+
- If you find our work helpful, we would appreciate it if you could give our project a star!
|
| 220 |
+
## Citing<a name="citing"></a>
|
| 221 |
+
|
| 222 |
+
If you find this code useful for your research, please consider citing the following paper:
|
| 223 |
+
|
| 224 |
+
```bibtex
|
| 225 |
+
|
| 226 |
+
```
|
| 227 |
+
|
VQ_eval.py
ADDED
|
@@ -0,0 +1,95 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import os
|
| 2 |
+
import json
|
| 3 |
+
|
| 4 |
+
import torch
|
| 5 |
+
from torch.utils.tensorboard import SummaryWriter
|
| 6 |
+
import numpy as np
|
| 7 |
+
import models.vqvae as vqvae
|
| 8 |
+
import options.option_vq as option_vq
|
| 9 |
+
import utils.utils_model as utils_model
|
| 10 |
+
from dataset import dataset_TM_eval
|
| 11 |
+
import utils.eval_trans as eval_trans
|
| 12 |
+
from options.get_eval_option import get_opt
|
| 13 |
+
from models.evaluator_wrapper import EvaluatorModelWrapper
|
| 14 |
+
import warnings
|
| 15 |
+
warnings.filterwarnings('ignore')
|
| 16 |
+
import numpy as np
|
| 17 |
+
##### ---- Exp dirs ---- #####
|
| 18 |
+
args = option_vq.get_args_parser()
|
| 19 |
+
torch.manual_seed(args.seed)
|
| 20 |
+
|
| 21 |
+
args.out_dir = os.path.join(args.out_dir, f'{args.exp_name}')
|
| 22 |
+
os.makedirs(args.out_dir, exist_ok = True)
|
| 23 |
+
|
| 24 |
+
##### ---- Logger ---- #####
|
| 25 |
+
logger = utils_model.get_logger(args.out_dir)
|
| 26 |
+
writer = SummaryWriter(args.out_dir)
|
| 27 |
+
logger.info(json.dumps(vars(args), indent=4, sort_keys=True))
|
| 28 |
+
|
| 29 |
+
|
| 30 |
+
from utils.word_vectorizer import WordVectorizer
|
| 31 |
+
w_vectorizer = WordVectorizer('./glove', 'our_vab')
|
| 32 |
+
|
| 33 |
+
|
| 34 |
+
dataset_opt_path = 'checkpoints/kit/Comp_v6_KLD005/opt.txt' if args.dataname == 'kit' else 'checkpoints/t2m/Comp_v6_KLD005/opt.txt'
|
| 35 |
+
|
| 36 |
+
wrapper_opt = get_opt(dataset_opt_path, torch.device('cuda'))
|
| 37 |
+
eval_wrapper = EvaluatorModelWrapper(wrapper_opt)
|
| 38 |
+
|
| 39 |
+
|
| 40 |
+
##### ---- Dataloader ---- #####
|
| 41 |
+
args.nb_joints = 21 if args.dataname == 'kit' else 22
|
| 42 |
+
|
| 43 |
+
val_loader = dataset_TM_eval.DATALoader(args.dataname, True, 32, w_vectorizer, unit_length=2**args.down_t)
|
| 44 |
+
|
| 45 |
+
##### ---- Network ---- #####
|
| 46 |
+
net = vqvae.HumanVQVAE(args, ## use args to define different parameters in different quantizers
|
| 47 |
+
args.nb_code,
|
| 48 |
+
args.code_dim,
|
| 49 |
+
args.output_emb_width,
|
| 50 |
+
args.down_t,
|
| 51 |
+
args.stride_t,
|
| 52 |
+
args.width,
|
| 53 |
+
args.depth,
|
| 54 |
+
args.dilation_growth_rate,
|
| 55 |
+
args.vq_act,
|
| 56 |
+
args.vq_norm)
|
| 57 |
+
|
| 58 |
+
if args.resume_pth :
|
| 59 |
+
logger.info('loading checkpoint from {}'.format(args.resume_pth))
|
| 60 |
+
ckpt = torch.load(args.resume_pth, map_location='cpu')
|
| 61 |
+
net.load_state_dict(ckpt['net'], strict=True)
|
| 62 |
+
net.train()
|
| 63 |
+
net.cuda()
|
| 64 |
+
|
| 65 |
+
fid = []
|
| 66 |
+
div = []
|
| 67 |
+
top1 = []
|
| 68 |
+
top2 = []
|
| 69 |
+
top3 = []
|
| 70 |
+
matching = []
|
| 71 |
+
repeat_time = 20
|
| 72 |
+
for i in range(repeat_time):
|
| 73 |
+
best_fid, best_iter, best_div, best_top1, best_top2, best_top3, best_matching, writer, logger = eval_trans.evaluation_vqvae(args.out_dir, val_loader, net, logger, writer, 0, best_fid=1000, best_iter=0, best_div=100, best_top1=0, best_top2=0, best_top3=0, best_matching=100, eval_wrapper=eval_wrapper, draw=False, save=False, savenpy=(i==0))
|
| 74 |
+
fid.append(best_fid)
|
| 75 |
+
div.append(best_div)
|
| 76 |
+
top1.append(best_top1)
|
| 77 |
+
top2.append(best_top2)
|
| 78 |
+
top3.append(best_top3)
|
| 79 |
+
matching.append(best_matching)
|
| 80 |
+
print('final result:')
|
| 81 |
+
print('fid: ', sum(fid)/repeat_time)
|
| 82 |
+
print('div: ', sum(div)/repeat_time)
|
| 83 |
+
print('top1: ', sum(top1)/repeat_time)
|
| 84 |
+
print('top2: ', sum(top2)/repeat_time)
|
| 85 |
+
print('top3: ', sum(top3)/repeat_time)
|
| 86 |
+
print('matching: ', sum(matching)/repeat_time)
|
| 87 |
+
|
| 88 |
+
fid = np.array(fid)
|
| 89 |
+
div = np.array(div)
|
| 90 |
+
top1 = np.array(top1)
|
| 91 |
+
top2 = np.array(top2)
|
| 92 |
+
top3 = np.array(top3)
|
| 93 |
+
matching = np.array(matching)
|
| 94 |
+
msg_final = f"FID. {np.mean(fid):.3f}, conf. {np.std(fid)*1.96/np.sqrt(repeat_time):.3f}, Diversity. {np.mean(div):.3f}, conf. {np.std(div)*1.96/np.sqrt(repeat_time):.3f}, TOP1. {np.mean(top1):.3f}, conf. {np.std(top1)*1.96/np.sqrt(repeat_time):.3f}, TOP2. {np.mean(top2):.3f}, conf. {np.std(top2)*1.96/np.sqrt(repeat_time):.3f}, TOP3. {np.mean(top3):.3f}, conf. {np.std(top3)*1.96/np.sqrt(repeat_time):.3f}, Matching. {np.mean(matching):.3f}, conf. {np.std(matching)*1.96/np.sqrt(repeat_time):.3f}"
|
| 95 |
+
logger.info(msg_final)
|
attack.py
ADDED
|
@@ -0,0 +1,182 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import torch
|
| 2 |
+
import numpy as np
|
| 3 |
+
# device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
|
| 4 |
+
|
| 5 |
+
class PGDAttacker():
|
| 6 |
+
def __init__(self, radius, steps, step_size, random_start, norm_type, ascending=True):
|
| 7 |
+
self.radius = radius # attack radius
|
| 8 |
+
self.steps = steps # how many step to conduct pgd
|
| 9 |
+
self.step_size = step_size # coefficient of PGD
|
| 10 |
+
self.random_start = random_start
|
| 11 |
+
self.norm_type = norm_type # which norm of your noise
|
| 12 |
+
self.ascending = ascending # perform gradient ascending, i.e, to maximum the loss
|
| 13 |
+
|
| 14 |
+
def output(self, x, model, tokens_lens, text_token):
|
| 15 |
+
|
| 16 |
+
x = x + model.positional_embedding.type(model.dtype)
|
| 17 |
+
|
| 18 |
+
x = x.permute(1, 0, 2) # NLD -> LND
|
| 19 |
+
x, weight = model.transformer(x)
|
| 20 |
+
x = x.permute(1, 0, 2) # LND -> NLD
|
| 21 |
+
x = model.ln_final(x).type(model.dtype)
|
| 22 |
+
x = x[torch.arange(x.shape[0]), text_token.argmax(dim=-1)] @ model.text_projection
|
| 23 |
+
|
| 24 |
+
attention_weights_all = []
|
| 25 |
+
for i in range(len(tokens_lens)):
|
| 26 |
+
attention_weights = weight[-1][i][min(76, tokens_lens[i])][:1+min(75, max(tokens_lens))][1:][:-1]
|
| 27 |
+
attention_weights_all.append(attention_weights)
|
| 28 |
+
attention_weights = torch.stack(attention_weights_all, dim=0)
|
| 29 |
+
|
| 30 |
+
return x, attention_weights
|
| 31 |
+
|
| 32 |
+
def perturb(self, device, m_tokens_len, bs, criterion, x, y,a_indices,encoder, tokens_lens=None, model=None, text_token=None):
|
| 33 |
+
if self.steps==0 or self.radius==0:
|
| 34 |
+
return x.clone()
|
| 35 |
+
|
| 36 |
+
adv_x = x.clone()
|
| 37 |
+
|
| 38 |
+
if self.random_start:
|
| 39 |
+
if self.norm_type == 'l-infty':
|
| 40 |
+
adv_x += 2 * (torch.rand_like(x) - 0.5) * self.radius
|
| 41 |
+
else:
|
| 42 |
+
adv_x += 2 * (torch.rand_like(x) - 0.5) * self.radius / self.steps
|
| 43 |
+
self._clip_(adv_x, x)
|
| 44 |
+
|
| 45 |
+
''' temporarily shutdown autograd of model to improve pgd efficiency '''
|
| 46 |
+
# adv_x, attention_weights = self.output(adv_x, model, tokens_lens, text_token)
|
| 47 |
+
|
| 48 |
+
# model.eval()
|
| 49 |
+
encoder.eval()
|
| 50 |
+
for pp in encoder.parameters():
|
| 51 |
+
pp.requires_grad = False
|
| 52 |
+
|
| 53 |
+
for step in range(self.steps):
|
| 54 |
+
adv_x_o = adv_x.clone()
|
| 55 |
+
adv_x.requires_grad_()
|
| 56 |
+
_y = encoder(a_indices,adv_x)
|
| 57 |
+
loss = criterion(y.to(device), _y, m_tokens_len, bs)
|
| 58 |
+
grad = torch.autograd.grad(loss, [adv_x])[0]
|
| 59 |
+
|
| 60 |
+
with torch.no_grad():
|
| 61 |
+
if not self.ascending: grad.mul_(-1)
|
| 62 |
+
|
| 63 |
+
if self.norm_type == 'l-infty':
|
| 64 |
+
adv_x.add_(torch.sign(grad), alpha=self.step_size)
|
| 65 |
+
else:
|
| 66 |
+
if self.norm_type == 'l2':
|
| 67 |
+
grad_norm = (grad.reshape(grad.shape[0],-1)**2).sum(dim=1).sqrt()
|
| 68 |
+
elif self.norm_type == 'l1':
|
| 69 |
+
grad_norm = grad.reshape(grad.shape[0],-1).abs().sum(dim=1)
|
| 70 |
+
grad_norm = grad_norm.reshape( -1, *( [1] * (len(x.shape)-1) ) )
|
| 71 |
+
scaled_grad = grad / (grad_norm + 1e-10)
|
| 72 |
+
adv_x.add_(scaled_grad, alpha=self.step_size)
|
| 73 |
+
|
| 74 |
+
self._clip_(adv_x, adv_x_o)
|
| 75 |
+
|
| 76 |
+
''' reopen autograd of model after pgd '''
|
| 77 |
+
# decoder.trian()
|
| 78 |
+
for pp in encoder.parameters():
|
| 79 |
+
pp.requires_grad = True
|
| 80 |
+
|
| 81 |
+
return adv_x # , attention_weights
|
| 82 |
+
|
| 83 |
+
def perturb_random(self, criterion, x, data, decoder,y,target_model,encoder=None):
|
| 84 |
+
if self.steps==0 or self.radius==0:
|
| 85 |
+
return x.clone()
|
| 86 |
+
adv_x = x.clone()
|
| 87 |
+
if self.norm_type == 'l-infty':
|
| 88 |
+
adv_x += 2 * (torch.rand_like(x) - 0.5) * self.radius
|
| 89 |
+
else:
|
| 90 |
+
adv_x += 2 * (torch.rand_like(x) - 0.5) * self.radius / self.steps
|
| 91 |
+
self._clip_(adv_x, x)
|
| 92 |
+
return adv_x.data
|
| 93 |
+
|
| 94 |
+
def perturb_iat(self, criterion, x, data, decoder,y,target_model,encoder=None):
|
| 95 |
+
if self.steps==0 or self.radius==0:
|
| 96 |
+
return x.clone()
|
| 97 |
+
|
| 98 |
+
B = x.shape[0]
|
| 99 |
+
L = x.shape[1]
|
| 100 |
+
H = x.shape[2]
|
| 101 |
+
nb_num = 8
|
| 102 |
+
|
| 103 |
+
alpha = torch.rand(B,L,nb_num,1).to(device)
|
| 104 |
+
|
| 105 |
+
A_1 = x.unsqueeze(2).expand(B,L,nb_num,H)
|
| 106 |
+
A_2 = x.unsqueeze(1).expand(B,L,L,H)
|
| 107 |
+
rand_idx = []
|
| 108 |
+
for i in range(L):
|
| 109 |
+
rand_idx.append(np.random.choice(L,nb_num,replace=False))
|
| 110 |
+
rand_idx = np.array(rand_idx)
|
| 111 |
+
rand_idx = torch.tensor(rand_idx).long().reshape(1,L,1,nb_num).expand(B,L,H,nb_num).to(device)
|
| 112 |
+
# A_2 = A_2[:,np.arange(0,L), rand_idx,:]
|
| 113 |
+
A_2 = torch.gather(A_2.reshape(B,L,H,L),-1,rand_idx).reshape(B,L,nb_num, H)
|
| 114 |
+
A_e = A_1 - A_2
|
| 115 |
+
# A_e
|
| 116 |
+
# adv_x = (A_e * alpha).sum(dim=-1) + x.clone()
|
| 117 |
+
|
| 118 |
+
adv_x = x.clone()
|
| 119 |
+
|
| 120 |
+
if self.random_start:
|
| 121 |
+
if self.norm_type == 'l-infty':
|
| 122 |
+
adv_x += 2 * (torch.rand_like(x) - 0.5) * self.radius
|
| 123 |
+
else:
|
| 124 |
+
adv_x += 2 * (torch.rand_like(x) - 0.5) * self.radius / self.steps
|
| 125 |
+
self._clip_(adv_x, x)
|
| 126 |
+
|
| 127 |
+
# assert adv_x.shape[0] == 8
|
| 128 |
+
|
| 129 |
+
''' temporarily shutdown autograd of model to improve pgd efficiency '''
|
| 130 |
+
# model.eval()
|
| 131 |
+
decoder.eval()
|
| 132 |
+
for pp in decoder.parameters():
|
| 133 |
+
pp.requires_grad = False
|
| 134 |
+
|
| 135 |
+
adv_x = x.clone()
|
| 136 |
+
|
| 137 |
+
alpha.requires_grad_()
|
| 138 |
+
|
| 139 |
+
for step in range(self.steps):
|
| 140 |
+
alpha.requires_grad_()
|
| 141 |
+
dot_Ae_alpha = (A_e * alpha).sum(dim=-2)
|
| 142 |
+
# print("dot_Ae_alpha:", dot_Ae_alpha.shape)
|
| 143 |
+
|
| 144 |
+
adv_x.add_(torch.sign(dot_Ae_alpha), alpha=self.step_size)
|
| 145 |
+
|
| 146 |
+
self._clip_(adv_x, x)
|
| 147 |
+
|
| 148 |
+
if encoder is None:
|
| 149 |
+
adv_x_input = adv_x.squeeze(-1)
|
| 150 |
+
else:
|
| 151 |
+
adv_x_input = adv_x
|
| 152 |
+
|
| 153 |
+
_y = target_model(adv_x_input, data,decoder,encoder)
|
| 154 |
+
loss = criterion(y.to(device), _y)
|
| 155 |
+
grad = torch.autograd.grad(loss, [alpha],retain_graph=True)[0]
|
| 156 |
+
# with torch.no_grad():
|
| 157 |
+
with torch.no_grad():
|
| 158 |
+
if not self.ascending: grad.mul_(-1)
|
| 159 |
+
assert self.norm_type == 'l-infty'
|
| 160 |
+
alpha = alpha.detach()+ grad * 0.01
|
| 161 |
+
|
| 162 |
+
''' reopen autograd of model after pgd '''
|
| 163 |
+
# decoder.trian()
|
| 164 |
+
for pp in decoder.parameters():
|
| 165 |
+
pp.requires_grad = True
|
| 166 |
+
|
| 167 |
+
return adv_x.data
|
| 168 |
+
|
| 169 |
+
def _clip_(self, adv_x, x):
|
| 170 |
+
adv_x -= x
|
| 171 |
+
if self.norm_type == 'l-infty':
|
| 172 |
+
adv_x.clamp_(-self.radius, self.radius)
|
| 173 |
+
else:
|
| 174 |
+
if self.norm_type == 'l2':
|
| 175 |
+
norm = (adv_x.reshape(adv_x.shape[0],-1)**2).sum(dim=1).sqrt()
|
| 176 |
+
elif self.norm_type == 'l1':
|
| 177 |
+
norm = adv_x.reshape(adv_x.shape[0],-1).abs().sum(dim=1)
|
| 178 |
+
norm = norm.reshape( -1, *( [1] * (len(x.shape)-1) ) )
|
| 179 |
+
adv_x /= (norm + 1e-10)
|
| 180 |
+
adv_x *= norm.clamp(max=self.radius)
|
| 181 |
+
adv_x += x
|
| 182 |
+
adv_x.clamp_(0, 1)
|
dataset/dataset_TM_eval.py
ADDED
|
@@ -0,0 +1,241 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import torch
|
| 2 |
+
from torch.utils import data
|
| 3 |
+
import numpy as np
|
| 4 |
+
from os.path import join as pjoin
|
| 5 |
+
import random
|
| 6 |
+
import codecs as cs
|
| 7 |
+
from tqdm import tqdm
|
| 8 |
+
|
| 9 |
+
import utils.paramUtil as paramUtil
|
| 10 |
+
from torch.utils.data._utils.collate import default_collate
|
| 11 |
+
|
| 12 |
+
|
| 13 |
+
def collate_fn(batch):
|
| 14 |
+
batch.sort(key=lambda x: x[3], reverse=True)
|
| 15 |
+
return default_collate(batch)
|
| 16 |
+
|
| 17 |
+
|
| 18 |
+
'''For use of training text-2-motion generative model'''
|
| 19 |
+
class Text2MotionDataset(data.Dataset):
|
| 20 |
+
def __init__(self, dataset_name, is_test, w_vectorizer, feat_bias = 5, max_text_len = 20, unit_length = 4):
|
| 21 |
+
|
| 22 |
+
self.max_length = 20
|
| 23 |
+
self.pointer = 0
|
| 24 |
+
self.dataset_name = dataset_name
|
| 25 |
+
self.is_test = is_test
|
| 26 |
+
self.max_text_len = max_text_len
|
| 27 |
+
self.unit_length = unit_length
|
| 28 |
+
self.w_vectorizer = w_vectorizer
|
| 29 |
+
if dataset_name == 't2m':
|
| 30 |
+
self.data_root = './dataset/HumanML3D'
|
| 31 |
+
self.motion_dir = pjoin(self.data_root, 'new_joint_vecs')
|
| 32 |
+
self.text_dir = pjoin(self.data_root, 'texts')
|
| 33 |
+
self.joints_num = 22
|
| 34 |
+
radius = 4
|
| 35 |
+
fps = 20
|
| 36 |
+
self.max_motion_length = 196
|
| 37 |
+
dim_pose = 263
|
| 38 |
+
kinematic_chain = paramUtil.t2m_kinematic_chain
|
| 39 |
+
self.meta_dir = 'checkpoints/t2m/VQVAEV3_CB1024_CMT_H1024_NRES3/meta'
|
| 40 |
+
elif dataset_name == 'kit':
|
| 41 |
+
self.data_root = './dataset/KIT-ML'
|
| 42 |
+
self.motion_dir = pjoin(self.data_root, 'new_joint_vecs')
|
| 43 |
+
self.text_dir = pjoin(self.data_root, 'texts')
|
| 44 |
+
self.joints_num = 21
|
| 45 |
+
radius = 240 * 8
|
| 46 |
+
fps = 12.5
|
| 47 |
+
dim_pose = 251
|
| 48 |
+
self.max_motion_length = 196
|
| 49 |
+
kinematic_chain = paramUtil.kit_kinematic_chain
|
| 50 |
+
self.meta_dir = 'checkpoints/kit/VQVAEV3_CB1024_CMT_H1024_NRES3/meta'
|
| 51 |
+
|
| 52 |
+
|
| 53 |
+
mean = np.load(pjoin(self.meta_dir, 'mean.npy'))
|
| 54 |
+
std = np.load(pjoin(self.meta_dir, 'std.npy'))
|
| 55 |
+
|
| 56 |
+
if is_test:
|
| 57 |
+
split_file = pjoin(self.data_root, 'test.txt') # test.txt
|
| 58 |
+
else:
|
| 59 |
+
split_file = pjoin(self.data_root, 'val.txt')
|
| 60 |
+
|
| 61 |
+
min_motion_len = 40 if self.dataset_name =='t2m' else 24
|
| 62 |
+
# min_motion_len = 64
|
| 63 |
+
|
| 64 |
+
joints_num = self.joints_num
|
| 65 |
+
|
| 66 |
+
data_dict = {}
|
| 67 |
+
id_list = []
|
| 68 |
+
with cs.open(split_file, 'r') as f:
|
| 69 |
+
for line in f.readlines():
|
| 70 |
+
id_list.append(line.strip())
|
| 71 |
+
|
| 72 |
+
new_name_list = []
|
| 73 |
+
length_list = []
|
| 74 |
+
for name in tqdm(id_list):
|
| 75 |
+
try:
|
| 76 |
+
motion = np.load(pjoin(self.motion_dir, name + '.npy'))
|
| 77 |
+
if (len(motion)) < min_motion_len or (len(motion) >= 200):
|
| 78 |
+
continue
|
| 79 |
+
text_data = []
|
| 80 |
+
flag = False
|
| 81 |
+
|
| 82 |
+
with cs.open(pjoin(self.text_dir, name + '.txt')) as f:
|
| 83 |
+
for line in f.readlines():
|
| 84 |
+
text_dict = {}
|
| 85 |
+
line_split = line.strip().split('#')
|
| 86 |
+
caption = line_split[0]
|
| 87 |
+
txt_perb = line_split[-1]
|
| 88 |
+
tokens = line_split[1].split(' ')
|
| 89 |
+
f_tag = float(line_split[2])
|
| 90 |
+
to_tag = float(line_split[3])
|
| 91 |
+
f_tag = 0.0 if np.isnan(f_tag) else f_tag
|
| 92 |
+
to_tag = 0.0 if np.isnan(to_tag) else to_tag
|
| 93 |
+
|
| 94 |
+
text_dict['caption'] = caption
|
| 95 |
+
text_dict['caption_perb'] = txt_perb
|
| 96 |
+
text_dict['tokens'] = tokens
|
| 97 |
+
if f_tag == 0.0 and to_tag == 0.0:
|
| 98 |
+
flag = True
|
| 99 |
+
text_data.append(text_dict)
|
| 100 |
+
else:
|
| 101 |
+
try:
|
| 102 |
+
n_motion = motion[int(f_tag*fps) : int(to_tag*fps)]
|
| 103 |
+
if (len(n_motion)) < min_motion_len or (len(n_motion) >= 200):
|
| 104 |
+
continue
|
| 105 |
+
new_name = random.choice('ABCDEFGHIJKLMNOPQRSTUVW') + '_' + name
|
| 106 |
+
while new_name in data_dict:
|
| 107 |
+
new_name = random.choice('ABCDEFGHIJKLMNOPQRSTUVW') + '_' + name
|
| 108 |
+
data_dict[new_name] = {'motion': n_motion,
|
| 109 |
+
'length': len(n_motion),
|
| 110 |
+
'text':[text_dict]}
|
| 111 |
+
new_name_list.append(new_name)
|
| 112 |
+
length_list.append(len(n_motion))
|
| 113 |
+
except:
|
| 114 |
+
print(line_split)
|
| 115 |
+
print(line_split[2], line_split[3], f_tag, to_tag, name)
|
| 116 |
+
# break
|
| 117 |
+
|
| 118 |
+
if flag:
|
| 119 |
+
data_dict[name] = {'motion': motion,
|
| 120 |
+
'length': len(motion),
|
| 121 |
+
'text': text_data}
|
| 122 |
+
new_name_list.append(name)
|
| 123 |
+
length_list.append(len(motion))
|
| 124 |
+
except Exception as e:
|
| 125 |
+
# print(e)
|
| 126 |
+
pass
|
| 127 |
+
|
| 128 |
+
name_list, length_list = zip(*sorted(zip(new_name_list, length_list), key=lambda x: x[1]))
|
| 129 |
+
self.mean = mean
|
| 130 |
+
self.std = std
|
| 131 |
+
self.length_arr = np.array(length_list)
|
| 132 |
+
self.data_dict = data_dict
|
| 133 |
+
self.name_list = name_list
|
| 134 |
+
self.reset_max_len(self.max_length)
|
| 135 |
+
|
| 136 |
+
def reset_max_len(self, length):
|
| 137 |
+
assert length <= self.max_motion_length
|
| 138 |
+
self.pointer = np.searchsorted(self.length_arr, length)
|
| 139 |
+
print("Pointer Pointing at %d"%self.pointer)
|
| 140 |
+
self.max_length = length
|
| 141 |
+
|
| 142 |
+
def inv_transform(self, data):
|
| 143 |
+
return data * self.std + self.mean
|
| 144 |
+
|
| 145 |
+
def forward_transform(self, data):
|
| 146 |
+
return (data - self.mean) / self.std
|
| 147 |
+
|
| 148 |
+
def __len__(self):
|
| 149 |
+
return len(self.data_dict) - self.pointer
|
| 150 |
+
|
| 151 |
+
def __getitem__(self, item):
|
| 152 |
+
idx = self.pointer + item
|
| 153 |
+
name = self.name_list[idx]
|
| 154 |
+
data = self.data_dict[name]
|
| 155 |
+
# data = self.data_dict[self.name_list[idx]]
|
| 156 |
+
motion, m_length, text_list = data['motion'], data['length'], data['text']
|
| 157 |
+
# Randomly select a caption
|
| 158 |
+
text_data = random.choice(text_list)
|
| 159 |
+
caption, tokens, caption_perb = text_data['caption'], text_data['tokens'], text_data['caption_perb']
|
| 160 |
+
|
| 161 |
+
if len(tokens) < self.max_text_len:
|
| 162 |
+
# pad with "unk"
|
| 163 |
+
tokens = ['sos/OTHER'] + tokens + ['eos/OTHER']
|
| 164 |
+
sent_len = len(tokens)
|
| 165 |
+
tokens = tokens + ['unk/OTHER'] * (self.max_text_len + 2 - sent_len)
|
| 166 |
+
else:
|
| 167 |
+
# crop
|
| 168 |
+
tokens = tokens[:self.max_text_len]
|
| 169 |
+
tokens = ['sos/OTHER'] + tokens + ['eos/OTHER']
|
| 170 |
+
sent_len = len(tokens)
|
| 171 |
+
pos_one_hots = []
|
| 172 |
+
word_embeddings = []
|
| 173 |
+
for token in tokens:
|
| 174 |
+
word_emb, pos_oh = self.w_vectorizer[token]
|
| 175 |
+
pos_one_hots.append(pos_oh[None, :])
|
| 176 |
+
word_embeddings.append(word_emb[None, :])
|
| 177 |
+
pos_one_hots = np.concatenate(pos_one_hots, axis=0)
|
| 178 |
+
word_embeddings = np.concatenate(word_embeddings, axis=0)
|
| 179 |
+
|
| 180 |
+
if self.unit_length < 10:
|
| 181 |
+
coin2 = np.random.choice(['single', 'single', 'double'])
|
| 182 |
+
else:
|
| 183 |
+
coin2 = 'single'
|
| 184 |
+
|
| 185 |
+
if coin2 == 'double':
|
| 186 |
+
m_length = (m_length // self.unit_length - 1) * self.unit_length
|
| 187 |
+
elif coin2 == 'single':
|
| 188 |
+
m_length = (m_length // self.unit_length) * self.unit_length
|
| 189 |
+
idx = random.randint(0, len(motion) - m_length)
|
| 190 |
+
motion = motion[idx:idx+m_length]
|
| 191 |
+
|
| 192 |
+
"Z Normalization"
|
| 193 |
+
motion = (motion - self.mean) / self.std
|
| 194 |
+
|
| 195 |
+
if m_length < self.max_motion_length:
|
| 196 |
+
motion = np.concatenate([motion,
|
| 197 |
+
np.zeros((self.max_motion_length - m_length, motion.shape[1]))
|
| 198 |
+
], axis=0)
|
| 199 |
+
|
| 200 |
+
return word_embeddings, pos_one_hots, caption, caption_perb, sent_len, motion, m_length, '_'.join(tokens), name
|
| 201 |
+
|
| 202 |
+
|
| 203 |
+
|
| 204 |
+
|
| 205 |
+
def DATALoader(dataset_name, is_test,
|
| 206 |
+
batch_size, w_vectorizer,
|
| 207 |
+
num_workers = 8, unit_length = 4) :
|
| 208 |
+
|
| 209 |
+
val_loader = torch.utils.data.DataLoader(Text2MotionDataset(dataset_name, is_test, w_vectorizer, unit_length=unit_length),
|
| 210 |
+
batch_size,
|
| 211 |
+
shuffle = True,
|
| 212 |
+
num_workers=num_workers,
|
| 213 |
+
collate_fn=collate_fn,
|
| 214 |
+
drop_last = True)
|
| 215 |
+
return val_loader
|
| 216 |
+
|
| 217 |
+
|
| 218 |
+
from torch.utils.data.distributed import DistributedSampler
|
| 219 |
+
|
| 220 |
+
def DATALoader_ddp(dataset_name, is_test,
|
| 221 |
+
batch_size, w_vectorizer,
|
| 222 |
+
num_workers = 8, unit_length = 4):
|
| 223 |
+
|
| 224 |
+
|
| 225 |
+
val_dataset = Text2MotionDataset(dataset_name, is_test, w_vectorizer, unit_length=unit_length)
|
| 226 |
+
|
| 227 |
+
val_sampler = DistributedSampler(val_dataset)
|
| 228 |
+
|
| 229 |
+
val_loader = torch.utils.data.DataLoader(val_dataset,
|
| 230 |
+
batch_size,
|
| 231 |
+
num_workers=num_workers,
|
| 232 |
+
collate_fn=collate_fn,
|
| 233 |
+
drop_last = True,
|
| 234 |
+
sampler=val_sampler)
|
| 235 |
+
return val_loader
|
| 236 |
+
|
| 237 |
+
|
| 238 |
+
def cycle(iterable):
|
| 239 |
+
while True:
|
| 240 |
+
for x in iterable:
|
| 241 |
+
yield x
|
dataset/dataset_TM_train.py
ADDED
|
@@ -0,0 +1,188 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import torch
|
| 2 |
+
from torch.utils import data
|
| 3 |
+
import numpy as np
|
| 4 |
+
from os.path import join as pjoin
|
| 5 |
+
import random
|
| 6 |
+
import codecs as cs
|
| 7 |
+
from tqdm import tqdm
|
| 8 |
+
import utils.paramUtil as paramUtil
|
| 9 |
+
from torch.utils.data._utils.collate import default_collate
|
| 10 |
+
import options.option_transformer as option_trans
|
| 11 |
+
args = option_trans.get_args_parser()
|
| 12 |
+
|
| 13 |
+
def collate_fn(batch):
|
| 14 |
+
batch.sort(key=lambda x: x[3], reverse=True)
|
| 15 |
+
return default_collate(batch)
|
| 16 |
+
|
| 17 |
+
|
| 18 |
+
'''For use of training text-2-motion generative model'''
|
| 19 |
+
class Text2MotionDataset(data.Dataset):
|
| 20 |
+
def __init__(self, dataset_name, feat_bias = 5, unit_length = 4, codebook_size = 1024, tokenizer_name=None,method=None):
|
| 21 |
+
|
| 22 |
+
self.max_length = 64
|
| 23 |
+
self.pointer = 0
|
| 24 |
+
self.dataset_name = dataset_name
|
| 25 |
+
|
| 26 |
+
self.unit_length = unit_length
|
| 27 |
+
# self.mot_start_idx = codebook_size
|
| 28 |
+
self.mot_end_idx = codebook_size
|
| 29 |
+
self.mot_pad_idx = codebook_size + 1
|
| 30 |
+
self.method=method
|
| 31 |
+
if dataset_name == 't2m':
|
| 32 |
+
self.data_root = './dataset/HumanML3D'
|
| 33 |
+
self.motion_dir = pjoin(self.data_root, 'new_joint_vecs')
|
| 34 |
+
self.text_dir = pjoin(self.data_root, 'texts')
|
| 35 |
+
self.joints_num = 22
|
| 36 |
+
radius = 4
|
| 37 |
+
fps = 20
|
| 38 |
+
self.max_motion_length = 26 if unit_length == 8 else 51
|
| 39 |
+
dim_pose = 263
|
| 40 |
+
kinematic_chain = paramUtil.t2m_kinematic_chain
|
| 41 |
+
elif dataset_name == 'kit':
|
| 42 |
+
self.data_root = './dataset/KIT-ML'
|
| 43 |
+
self.motion_dir = pjoin(self.data_root, 'new_joint_vecs')
|
| 44 |
+
self.text_dir = pjoin(self.data_root, 'texts')
|
| 45 |
+
self.joints_num = 21
|
| 46 |
+
radius = 240 * 8
|
| 47 |
+
fps = 12.5
|
| 48 |
+
dim_pose = 251
|
| 49 |
+
self.max_motion_length = 26 if unit_length == 8 else 51
|
| 50 |
+
kinematic_chain = paramUtil.kit_kinematic_chain
|
| 51 |
+
|
| 52 |
+
split_file = pjoin(self.data_root, 'train.txt')
|
| 53 |
+
|
| 54 |
+
|
| 55 |
+
id_list = []
|
| 56 |
+
with cs.open(split_file, 'r') as f:
|
| 57 |
+
for line in f.readlines():
|
| 58 |
+
id_list.append(line.strip())
|
| 59 |
+
|
| 60 |
+
new_name_list = []
|
| 61 |
+
data_dict = {}
|
| 62 |
+
if self.method=='adv':
|
| 63 |
+
|
| 64 |
+
pass
|
| 65 |
+
for name in tqdm(id_list):
|
| 66 |
+
try:
|
| 67 |
+
m_token_list = np.load(pjoin(self.data_root, tokenizer_name, '%s.npy'%name))
|
| 68 |
+
|
| 69 |
+
# Read text
|
| 70 |
+
with cs.open(pjoin(self.text_dir, name + '.txt')) as f:
|
| 71 |
+
text_data = []
|
| 72 |
+
flag = False
|
| 73 |
+
lines = f.readlines()
|
| 74 |
+
|
| 75 |
+
for line in lines:
|
| 76 |
+
try:
|
| 77 |
+
text_dict = {}
|
| 78 |
+
line_split = line.strip().split('#')
|
| 79 |
+
caption = line_split[0]
|
| 80 |
+
txt_perb = line_split[-1]
|
| 81 |
+
t_tokens = line_split[1].split(' ')
|
| 82 |
+
f_tag = float(line_split[2])
|
| 83 |
+
to_tag = float(line_split[3])
|
| 84 |
+
f_tag = 0.0 if np.isnan(f_tag) else f_tag
|
| 85 |
+
to_tag = 0.0 if np.isnan(to_tag) else to_tag
|
| 86 |
+
|
| 87 |
+
text_dict['caption'] = caption
|
| 88 |
+
text_dict['tokens'] = t_tokens
|
| 89 |
+
text_dict['caption_perb'] = txt_perb
|
| 90 |
+
|
| 91 |
+
if f_tag == 0.0 and to_tag == 0.0:
|
| 92 |
+
flag = True
|
| 93 |
+
text_data.append(text_dict)
|
| 94 |
+
else:
|
| 95 |
+
m_token_list_new = [tokens[int(f_tag*fps/unit_length) : int(to_tag*fps/unit_length)] for tokens in m_token_list if int(f_tag*fps/unit_length) < int(to_tag*fps/unit_length)]
|
| 96 |
+
|
| 97 |
+
if len(m_token_list_new) == 0:
|
| 98 |
+
continue
|
| 99 |
+
new_name = '%s_%f_%f'%(name, f_tag, to_tag)
|
| 100 |
+
|
| 101 |
+
data_dict[new_name] = {'m_token_list': m_token_list_new,
|
| 102 |
+
'text':[text_dict]}
|
| 103 |
+
new_name_list.append(new_name)
|
| 104 |
+
except:
|
| 105 |
+
pass
|
| 106 |
+
|
| 107 |
+
if flag:
|
| 108 |
+
data_dict[name] = {'m_token_list': m_token_list,
|
| 109 |
+
'text':text_data}
|
| 110 |
+
new_name_list.append(name)
|
| 111 |
+
except:
|
| 112 |
+
pass
|
| 113 |
+
self.data_dict = data_dict
|
| 114 |
+
self.name_list = new_name_list
|
| 115 |
+
|
| 116 |
+
def __len__(self):
|
| 117 |
+
return len(self.data_dict)
|
| 118 |
+
|
| 119 |
+
def __getitem__(self, item):
|
| 120 |
+
data = self.data_dict[self.name_list[item]]
|
| 121 |
+
m_token_list, text_list = data['m_token_list'], data['text']
|
| 122 |
+
m_tokens = random.choice(m_token_list)
|
| 123 |
+
|
| 124 |
+
text_data = random.choice(text_list)
|
| 125 |
+
caption,caption_perb= text_data['caption'], text_data['caption_perb']
|
| 126 |
+
|
| 127 |
+
|
| 128 |
+
coin = np.random.choice([False, False, True])
|
| 129 |
+
# print(len(m_tokens))
|
| 130 |
+
if coin:
|
| 131 |
+
# drop one token at the head or tail
|
| 132 |
+
coin2 = np.random.choice([True, False])
|
| 133 |
+
if coin2:
|
| 134 |
+
m_tokens = m_tokens[:-1]
|
| 135 |
+
else:
|
| 136 |
+
m_tokens = m_tokens[1:]
|
| 137 |
+
m_tokens_len = m_tokens.shape[0]
|
| 138 |
+
|
| 139 |
+
if m_tokens_len+1 < self.max_motion_length:
|
| 140 |
+
m_tokens = np.concatenate([m_tokens, np.ones((1), dtype=int) * self.mot_end_idx, np.ones((self.max_motion_length-1-m_tokens_len), dtype=int) * self.mot_pad_idx], axis=0)
|
| 141 |
+
else:
|
| 142 |
+
m_tokens = np.concatenate([m_tokens, np.ones((1), dtype=int) * self.mot_end_idx], axis=0)
|
| 143 |
+
|
| 144 |
+
return caption,caption_perb, m_tokens.reshape(-1), m_tokens_len
|
| 145 |
+
|
| 146 |
+
|
| 147 |
+
|
| 148 |
+
|
| 149 |
+
def DATALoader(dataset_name,
|
| 150 |
+
batch_size, codebook_size, tokenizer_name, unit_length=4,
|
| 151 |
+
num_workers = 0) :
|
| 152 |
+
|
| 153 |
+
train_loader = torch.utils.data.DataLoader(Text2MotionDataset(dataset_name, codebook_size = codebook_size, tokenizer_name = tokenizer_name, unit_length=unit_length),
|
| 154 |
+
batch_size,
|
| 155 |
+
shuffle=False,
|
| 156 |
+
num_workers=num_workers,
|
| 157 |
+
#collate_fn=collate_fn,
|
| 158 |
+
drop_last = True)
|
| 159 |
+
|
| 160 |
+
|
| 161 |
+
return train_loader
|
| 162 |
+
|
| 163 |
+
|
| 164 |
+
from torch.utils.data.distributed import DistributedSampler
|
| 165 |
+
|
| 166 |
+
def DATALoader_ddp(dataset_name,
|
| 167 |
+
batch_size, codebook_size, tokenizer_name, unit_length=4,
|
| 168 |
+
num_workers = 0) :
|
| 169 |
+
|
| 170 |
+
dataset = Text2MotionDataset(dataset_name, codebook_size = codebook_size, tokenizer_name = tokenizer_name, unit_length=unit_length)
|
| 171 |
+
train_sampler = DistributedSampler(dataset)
|
| 172 |
+
train_loader = torch.utils.data.DataLoader(dataset,
|
| 173 |
+
batch_size,
|
| 174 |
+
num_workers=num_workers,
|
| 175 |
+
#collate_fn=collate_fn,
|
| 176 |
+
drop_last = True,
|
| 177 |
+
sampler=train_sampler)
|
| 178 |
+
|
| 179 |
+
|
| 180 |
+
return train_loader
|
| 181 |
+
|
| 182 |
+
|
| 183 |
+
def cycle(iterable):
|
| 184 |
+
while True:
|
| 185 |
+
for x in iterable:
|
| 186 |
+
yield x
|
| 187 |
+
|
| 188 |
+
|
dataset/dataset_VQ.py
ADDED
|
@@ -0,0 +1,109 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import torch
|
| 2 |
+
from torch.utils import data
|
| 3 |
+
import numpy as np
|
| 4 |
+
from os.path import join as pjoin
|
| 5 |
+
import random
|
| 6 |
+
import codecs as cs
|
| 7 |
+
from tqdm import tqdm
|
| 8 |
+
|
| 9 |
+
|
| 10 |
+
|
| 11 |
+
class VQMotionDataset(data.Dataset):
|
| 12 |
+
def __init__(self, dataset_name, window_size = 64, unit_length = 4):
|
| 13 |
+
self.window_size = window_size
|
| 14 |
+
self.unit_length = unit_length
|
| 15 |
+
self.dataset_name = dataset_name
|
| 16 |
+
|
| 17 |
+
if dataset_name == 't2m':
|
| 18 |
+
self.data_root = './dataset/HumanML3D'
|
| 19 |
+
self.motion_dir = pjoin(self.data_root, 'new_joint_vecs')
|
| 20 |
+
self.text_dir = pjoin(self.data_root, 'texts')
|
| 21 |
+
self.joints_num = 22
|
| 22 |
+
self.max_motion_length = 196
|
| 23 |
+
self.meta_dir = 'checkpoints/t2m/VQVAEV3_CB1024_CMT_H1024_NRES3/meta'
|
| 24 |
+
|
| 25 |
+
elif dataset_name == 'kit':
|
| 26 |
+
self.data_root = './dataset/KIT-ML'
|
| 27 |
+
self.motion_dir = pjoin(self.data_root, 'new_joint_vecs')
|
| 28 |
+
self.text_dir = pjoin(self.data_root, 'texts')
|
| 29 |
+
self.joints_num = 21
|
| 30 |
+
|
| 31 |
+
self.max_motion_length = 196
|
| 32 |
+
self.meta_dir = 'checkpoints/kit/VQVAEV3_CB1024_CMT_H1024_NRES3/meta'
|
| 33 |
+
|
| 34 |
+
joints_num = self.joints_num
|
| 35 |
+
|
| 36 |
+
mean = np.load(pjoin(self.meta_dir, 'mean.npy'))
|
| 37 |
+
std = np.load(pjoin(self.meta_dir, 'std.npy'))
|
| 38 |
+
|
| 39 |
+
split_file = pjoin(self.data_root, 'train.txt')
|
| 40 |
+
|
| 41 |
+
self.data = []
|
| 42 |
+
self.lengths = []
|
| 43 |
+
id_list = []
|
| 44 |
+
with cs.open(split_file, 'r') as f:
|
| 45 |
+
for line in f.readlines():
|
| 46 |
+
id_list.append(line.strip())
|
| 47 |
+
|
| 48 |
+
for name in tqdm(id_list):
|
| 49 |
+
try:
|
| 50 |
+
motion = np.load(pjoin(self.motion_dir, name + '.npy'))
|
| 51 |
+
if motion.shape[0] < self.window_size:
|
| 52 |
+
continue
|
| 53 |
+
self.lengths.append(motion.shape[0] - self.window_size)
|
| 54 |
+
self.data.append(motion)
|
| 55 |
+
except:
|
| 56 |
+
# Some motion may not exist in KIT dataset
|
| 57 |
+
pass
|
| 58 |
+
|
| 59 |
+
|
| 60 |
+
self.mean = mean
|
| 61 |
+
self.std = std
|
| 62 |
+
print("Total number of motions {}".format(len(self.data)))
|
| 63 |
+
|
| 64 |
+
def inv_transform(self, data):
|
| 65 |
+
return data * self.std + self.mean
|
| 66 |
+
|
| 67 |
+
def compute_sampling_prob(self) :
|
| 68 |
+
|
| 69 |
+
prob = np.array(self.lengths, dtype=np.float32)
|
| 70 |
+
prob /= np.sum(prob)
|
| 71 |
+
return prob
|
| 72 |
+
|
| 73 |
+
def __len__(self):
|
| 74 |
+
return len(self.data)
|
| 75 |
+
|
| 76 |
+
def __getitem__(self, item):
|
| 77 |
+
motion = self.data[item]
|
| 78 |
+
|
| 79 |
+
idx = random.randint(0, len(motion) - self.window_size)
|
| 80 |
+
|
| 81 |
+
motion = motion[idx:idx+self.window_size]
|
| 82 |
+
"Z Normalization"
|
| 83 |
+
motion = (motion - self.mean) / self.std
|
| 84 |
+
|
| 85 |
+
return motion
|
| 86 |
+
|
| 87 |
+
def DATALoader(dataset_name,
|
| 88 |
+
batch_size,
|
| 89 |
+
num_workers = 8,
|
| 90 |
+
window_size = 64,
|
| 91 |
+
unit_length = 4):
|
| 92 |
+
|
| 93 |
+
trainSet = VQMotionDataset(dataset_name, window_size=window_size, unit_length=unit_length)
|
| 94 |
+
prob = trainSet.compute_sampling_prob()
|
| 95 |
+
sampler = torch.utils.data.WeightedRandomSampler(prob, num_samples = len(trainSet) * 1000, replacement=True)
|
| 96 |
+
train_loader = torch.utils.data.DataLoader(trainSet,
|
| 97 |
+
batch_size,
|
| 98 |
+
shuffle=True,
|
| 99 |
+
#sampler=sampler,
|
| 100 |
+
num_workers=num_workers,
|
| 101 |
+
#collate_fn=collate_fn,
|
| 102 |
+
drop_last = True)
|
| 103 |
+
|
| 104 |
+
return train_loader
|
| 105 |
+
|
| 106 |
+
def cycle(iterable):
|
| 107 |
+
while True:
|
| 108 |
+
for x in iterable:
|
| 109 |
+
yield x
|
dataset/dataset_tokenize.py
ADDED
|
@@ -0,0 +1,136 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import torch
|
| 2 |
+
from torch.utils import data
|
| 3 |
+
import numpy as np
|
| 4 |
+
from os.path import join as pjoin
|
| 5 |
+
import random
|
| 6 |
+
import codecs as cs
|
| 7 |
+
from tqdm import tqdm
|
| 8 |
+
|
| 9 |
+
|
| 10 |
+
|
| 11 |
+
class VQMotionDataset(data.Dataset):
|
| 12 |
+
def __init__(self, dataset_name, feat_bias = 5, window_size = 64, unit_length = 8):
|
| 13 |
+
self.window_size = window_size
|
| 14 |
+
self.unit_length = unit_length
|
| 15 |
+
self.feat_bias = feat_bias
|
| 16 |
+
|
| 17 |
+
self.dataset_name = dataset_name
|
| 18 |
+
min_motion_len = 40 if dataset_name =='t2m' else 24
|
| 19 |
+
|
| 20 |
+
if dataset_name == 't2m':
|
| 21 |
+
self.data_root = './dataset/HumanML3D'
|
| 22 |
+
self.motion_dir = pjoin(self.data_root, 'new_joint_vecs')
|
| 23 |
+
self.text_dir = pjoin(self.data_root, 'texts')
|
| 24 |
+
self.joints_num = 22
|
| 25 |
+
radius = 4
|
| 26 |
+
fps = 20
|
| 27 |
+
self.max_motion_length = 196
|
| 28 |
+
dim_pose = 263
|
| 29 |
+
self.meta_dir = './checkpoints/t2m/VQVAEV3_CB1024_CMT_H1024_NRES3/meta'
|
| 30 |
+
#kinematic_chain = paramUtil.t2m_kinematic_chain
|
| 31 |
+
elif dataset_name == 'kit':
|
| 32 |
+
self.data_root = './dataset/KIT-ML'
|
| 33 |
+
self.motion_dir = pjoin(self.data_root, 'new_joint_vecs')
|
| 34 |
+
self.text_dir = pjoin(self.data_root, 'texts')
|
| 35 |
+
self.joints_num = 21
|
| 36 |
+
radius = 240 * 8
|
| 37 |
+
fps = 12.5
|
| 38 |
+
dim_pose = 251
|
| 39 |
+
self.max_motion_length = 196
|
| 40 |
+
self.meta_dir = './checkpoints/kit/VQVAEV3_CB1024_CMT_H1024_NRES3/meta'
|
| 41 |
+
#kinematic_chain = paramUtil.kit_kinematic_chain
|
| 42 |
+
|
| 43 |
+
joints_num = self.joints_num
|
| 44 |
+
|
| 45 |
+
mean = np.load(pjoin(self.meta_dir, 'mean.npy'))
|
| 46 |
+
std = np.load(pjoin(self.meta_dir, 'std.npy'))
|
| 47 |
+
|
| 48 |
+
split_file = pjoin(self.data_root, 'train.txt')
|
| 49 |
+
|
| 50 |
+
data_dict = {}
|
| 51 |
+
id_list = []
|
| 52 |
+
with cs.open(split_file, 'r') as f:
|
| 53 |
+
for line in f.readlines():
|
| 54 |
+
id_list.append(line.strip())
|
| 55 |
+
|
| 56 |
+
new_name_list = []
|
| 57 |
+
length_list = []
|
| 58 |
+
for name in tqdm(id_list):
|
| 59 |
+
try:
|
| 60 |
+
motion = np.load(pjoin(self.motion_dir, name + '.npy'))
|
| 61 |
+
if (len(motion)) < min_motion_len or (len(motion) >= 200):
|
| 62 |
+
|
| 63 |
+
continue
|
| 64 |
+
|
| 65 |
+
data_dict[name] = {'motion': motion,
|
| 66 |
+
'length': len(motion),
|
| 67 |
+
'name': name}
|
| 68 |
+
new_name_list.append(name)
|
| 69 |
+
length_list.append(len(motion))
|
| 70 |
+
except:
|
| 71 |
+
# Some motion may not exist in KIT dataset
|
| 72 |
+
pass
|
| 73 |
+
|
| 74 |
+
|
| 75 |
+
self.mean = mean
|
| 76 |
+
self.std = std
|
| 77 |
+
self.length_arr = np.array(length_list)
|
| 78 |
+
self.data_dict = data_dict
|
| 79 |
+
self.name_list = new_name_list
|
| 80 |
+
|
| 81 |
+
def inv_transform(self, data):
|
| 82 |
+
return data * self.std + self.mean
|
| 83 |
+
|
| 84 |
+
def __len__(self):
|
| 85 |
+
return len(self.data_dict)
|
| 86 |
+
|
| 87 |
+
def __getitem__(self, item):
|
| 88 |
+
name = self.name_list[item]
|
| 89 |
+
data = self.data_dict[name]
|
| 90 |
+
motion, m_length = data['motion'], data['length']
|
| 91 |
+
|
| 92 |
+
m_length = (m_length // self.unit_length) * self.unit_length
|
| 93 |
+
|
| 94 |
+
idx = random.randint(0, len(motion) - m_length)
|
| 95 |
+
motion = motion[idx:idx+m_length]
|
| 96 |
+
|
| 97 |
+
"Z Normalization"
|
| 98 |
+
motion = (motion - self.mean) / self.std
|
| 99 |
+
|
| 100 |
+
return motion, name
|
| 101 |
+
|
| 102 |
+
def DATALoader(dataset_name,
|
| 103 |
+
batch_size = 4,
|
| 104 |
+
num_workers = 8, unit_length = 4) :
|
| 105 |
+
|
| 106 |
+
train_loader = torch.utils.data.DataLoader(VQMotionDataset(dataset_name, unit_length=unit_length),
|
| 107 |
+
batch_size,
|
| 108 |
+
shuffle=True,
|
| 109 |
+
num_workers=num_workers,
|
| 110 |
+
#collate_fn=collate_fn,
|
| 111 |
+
drop_last = True)
|
| 112 |
+
|
| 113 |
+
return train_loader
|
| 114 |
+
|
| 115 |
+
from torch.utils.data.distributed import DistributedSampler
|
| 116 |
+
|
| 117 |
+
# def DATALoader_ddp(dataset_name,
|
| 118 |
+
# batch_size = 4,
|
| 119 |
+
# num_workers = 8, unit_length = 4) :
|
| 120 |
+
|
| 121 |
+
|
| 122 |
+
# dataset = VQMotionDataset(dataset_name, unit_length=unit_length)
|
| 123 |
+
# train_sampler = DistributedSampler(dataset)
|
| 124 |
+
|
| 125 |
+
# train_loader = torch.utils.data.DataLoader(dataset,
|
| 126 |
+
# batch_size=batch_size,
|
| 127 |
+
# shuffle=False,
|
| 128 |
+
# num_workers=num_workers,
|
| 129 |
+
# sampler=train_sampler)
|
| 130 |
+
|
| 131 |
+
# return train_loader
|
| 132 |
+
|
| 133 |
+
def cycle(iterable):
|
| 134 |
+
while True:
|
| 135 |
+
for x in iterable:
|
| 136 |
+
yield x
|
dataset/prepare/download_extractor.sh
ADDED
|
@@ -0,0 +1,15 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
rm -rf checkpoints
|
| 2 |
+
mkdir checkpoints
|
| 3 |
+
cd checkpoints
|
| 4 |
+
echo -e "Downloading extractors"
|
| 5 |
+
gdown --fuzzy https://drive.google.com/file/d/1o7RTDQcToJjTm9_mNWTyzvZvjTWpZfug/view
|
| 6 |
+
gdown --fuzzy https://drive.google.com/file/d/1KNU8CsMAnxFrwopKBBkC8jEULGLPBHQp/view
|
| 7 |
+
|
| 8 |
+
|
| 9 |
+
unzip t2m.zip
|
| 10 |
+
unzip kit.zip
|
| 11 |
+
|
| 12 |
+
echo -e "Cleaning\n"
|
| 13 |
+
rm t2m.zip
|
| 14 |
+
rm kit.zip
|
| 15 |
+
echo -e "Downloading done!"
|
dataset/prepare/download_glove.sh
ADDED
|
@@ -0,0 +1,9 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
echo -e "Downloading glove (in use by the evaluators)"
|
| 2 |
+
gdown --fuzzy https://drive.google.com/file/d/1bCeS6Sh_mLVTebxIgiUHgdPrroW06mb6/view?usp=sharing
|
| 3 |
+
rm -rf glove
|
| 4 |
+
|
| 5 |
+
unzip glove.zip
|
| 6 |
+
echo -e "Cleaning\n"
|
| 7 |
+
rm glove.zip
|
| 8 |
+
|
| 9 |
+
echo -e "Downloading done!"
|
dataset/prepare/download_model.sh
ADDED
|
@@ -0,0 +1,12 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
|
| 2 |
+
mkdir -p pretrained
|
| 3 |
+
cd pretrained/
|
| 4 |
+
|
| 5 |
+
echo -e "The pretrained model files will be stored in the 'pretrained' folder\n"
|
| 6 |
+
gdown 1LaOvwypF-jM2Axnq5dc-Iuvv3w_G-WDE
|
| 7 |
+
|
| 8 |
+
unzip VQTrans_pretrained.zip
|
| 9 |
+
echo -e "Cleaning\n"
|
| 10 |
+
rm VQTrans_pretrained.zip
|
| 11 |
+
|
| 12 |
+
echo -e "Downloading done!"
|
dataset/prepare/download_smpl.sh
ADDED
|
@@ -0,0 +1,13 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
|
| 2 |
+
mkdir -p body_models
|
| 3 |
+
cd body_models/
|
| 4 |
+
|
| 5 |
+
echo -e "The smpl files will be stored in the 'body_models/smpl/' folder\n"
|
| 6 |
+
gdown 1INYlGA76ak_cKGzvpOV2Pe6RkYTlXTW2
|
| 7 |
+
rm -rf smpl
|
| 8 |
+
|
| 9 |
+
unzip smpl.zip
|
| 10 |
+
echo -e "Cleaning\n"
|
| 11 |
+
rm smpl.zip
|
| 12 |
+
|
| 13 |
+
echo -e "Downloading done!"
|
environment.yml
ADDED
|
@@ -0,0 +1,121 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
name: SATO
|
| 2 |
+
channels:
|
| 3 |
+
- pytorch
|
| 4 |
+
- defaults
|
| 5 |
+
dependencies:
|
| 6 |
+
- _libgcc_mutex=0.1=main
|
| 7 |
+
- _openmp_mutex=4.5=1_gnu
|
| 8 |
+
- blas=1.0=mkl
|
| 9 |
+
- bzip2=1.0.8=h7b6447c_0
|
| 10 |
+
- ca-certificates=2021.7.5=h06a4308_1
|
| 11 |
+
- certifi=2021.5.30=py38h06a4308_0
|
| 12 |
+
- cudatoolkit=10.1.243=h6bb024c_0
|
| 13 |
+
- ffmpeg=4.3=hf484d3e_0
|
| 14 |
+
- freetype=2.10.4=h5ab3b9f_0
|
| 15 |
+
- gmp=6.2.1=h2531618_2
|
| 16 |
+
- gnutls=3.6.15=he1e5248_0
|
| 17 |
+
- intel-openmp=2021.3.0=h06a4308_3350
|
| 18 |
+
- jpeg=9b=h024ee3a_2
|
| 19 |
+
- lame=3.100=h7b6447c_0
|
| 20 |
+
- lcms2=2.12=h3be6417_0
|
| 21 |
+
- ld_impl_linux-64=2.35.1=h7274673_9
|
| 22 |
+
- libffi=3.3=he6710b0_2
|
| 23 |
+
- libgcc-ng=9.3.0=h5101ec6_17
|
| 24 |
+
- libgomp=9.3.0=h5101ec6_17
|
| 25 |
+
- libiconv=1.15=h63c8f33_5
|
| 26 |
+
- libidn2=2.3.2=h7f8727e_0
|
| 27 |
+
- libpng=1.6.37=hbc83047_0
|
| 28 |
+
- libstdcxx-ng=9.3.0=hd4cf53a_17
|
| 29 |
+
- libtasn1=4.16.0=h27cfd23_0
|
| 30 |
+
- libtiff=4.2.0=h85742a9_0
|
| 31 |
+
- libunistring=0.9.10=h27cfd23_0
|
| 32 |
+
- libuv=1.40.0=h7b6447c_0
|
| 33 |
+
- libwebp-base=1.2.0=h27cfd23_0
|
| 34 |
+
- lz4-c=1.9.3=h295c915_1
|
| 35 |
+
- mkl=2021.3.0=h06a4308_520
|
| 36 |
+
- mkl-service=2.4.0=py38h7f8727e_0
|
| 37 |
+
- mkl_fft=1.3.0=py38h42c9631_2
|
| 38 |
+
- mkl_random=1.2.2=py38h51133e4_0
|
| 39 |
+
- ncurses=6.2=he6710b0_1
|
| 40 |
+
- nettle=3.7.3=hbbd107a_1
|
| 41 |
+
- ninja=1.10.2=hff7bd54_1
|
| 42 |
+
- numpy=1.20.3=py38hf144106_0
|
| 43 |
+
- numpy-base=1.20.3=py38h74d4b33_0
|
| 44 |
+
- olefile=0.46=py_0
|
| 45 |
+
- openh264=2.1.0=hd408876_0
|
| 46 |
+
- openjpeg=2.3.0=h05c96fa_1
|
| 47 |
+
- openssl=1.1.1k=h27cfd23_0
|
| 48 |
+
- pillow=8.3.1=py38h2c7a002_0
|
| 49 |
+
- pip=21.0.1=py38h06a4308_0
|
| 50 |
+
- python=3.8.11=h12debd9_0_cpython
|
| 51 |
+
- pytorch=1.8.1=py3.8_cuda10.1_cudnn7.6.3_0
|
| 52 |
+
- readline=8.1=h27cfd23_0
|
| 53 |
+
- setuptools=52.0.0=py38h06a4308_0
|
| 54 |
+
- six=1.16.0=pyhd3eb1b0_0
|
| 55 |
+
- sqlite=3.36.0=hc218d9a_0
|
| 56 |
+
- tk=8.6.10=hbc83047_0
|
| 57 |
+
- torchaudio=0.8.1=py38
|
| 58 |
+
- torchvision=0.9.1=py38_cu101
|
| 59 |
+
- typing_extensions=3.10.0.0=pyh06a4308_0
|
| 60 |
+
- wheel=0.37.0=pyhd3eb1b0_0
|
| 61 |
+
- xz=5.2.5=h7b6447c_0
|
| 62 |
+
- zlib=1.2.11=h7b6447c_3
|
| 63 |
+
- zstd=1.4.9=haebb681_0
|
| 64 |
+
- pip:
|
| 65 |
+
- absl-py==0.13.0
|
| 66 |
+
- backcall==0.2.0
|
| 67 |
+
- cachetools==4.2.2
|
| 68 |
+
- charset-normalizer==2.0.4
|
| 69 |
+
- chumpy==0.70
|
| 70 |
+
- cycler==0.10.0
|
| 71 |
+
- decorator==5.0.9
|
| 72 |
+
- google-auth==1.35.0
|
| 73 |
+
- google-auth-oauthlib==0.4.5
|
| 74 |
+
- grpcio==1.39.0
|
| 75 |
+
- idna==3.2
|
| 76 |
+
- imageio==2.9.0
|
| 77 |
+
- ipdb==0.13.9
|
| 78 |
+
- ipython==7.26.0
|
| 79 |
+
- ipython-genutils==0.2.0
|
| 80 |
+
- jedi==0.18.0
|
| 81 |
+
- joblib==1.0.1
|
| 82 |
+
- kiwisolver==1.3.1
|
| 83 |
+
- markdown==3.3.4
|
| 84 |
+
- matplotlib==3.4.3
|
| 85 |
+
- matplotlib-inline==0.1.2
|
| 86 |
+
- oauthlib==3.1.1
|
| 87 |
+
- pandas==1.3.2
|
| 88 |
+
- parso==0.8.2
|
| 89 |
+
- pexpect==4.8.0
|
| 90 |
+
- pickleshare==0.7.5
|
| 91 |
+
- prompt-toolkit==3.0.20
|
| 92 |
+
- protobuf==3.17.3
|
| 93 |
+
- ptyprocess==0.7.0
|
| 94 |
+
- pyasn1==0.4.8
|
| 95 |
+
- pyasn1-modules==0.2.8
|
| 96 |
+
- pygments==2.10.0
|
| 97 |
+
- pyparsing==2.4.7
|
| 98 |
+
- python-dateutil==2.8.2
|
| 99 |
+
- pytz==2021.1
|
| 100 |
+
- pyyaml==5.4.1
|
| 101 |
+
- requests==2.26.0
|
| 102 |
+
- requests-oauthlib==1.3.0
|
| 103 |
+
- rsa==4.7.2
|
| 104 |
+
- scikit-learn==0.24.2
|
| 105 |
+
- scipy==1.7.1
|
| 106 |
+
- sklearn==0.0
|
| 107 |
+
- smplx==0.1.28
|
| 108 |
+
- tensorboard==2.6.0
|
| 109 |
+
- tensorboard-data-server==0.6.1
|
| 110 |
+
- tensorboard-plugin-wit==1.8.0
|
| 111 |
+
- threadpoolctl==2.2.0
|
| 112 |
+
- toml==0.10.2
|
| 113 |
+
- tqdm==4.62.2
|
| 114 |
+
- traitlets==5.0.5
|
| 115 |
+
- urllib3==1.26.6
|
| 116 |
+
- wcwidth==0.2.5
|
| 117 |
+
- werkzeug==2.0.1
|
| 118 |
+
- git+https://github.com/openai/CLIP.git
|
| 119 |
+
- git+https://github.com/nghorbani/human_body_prior
|
| 120 |
+
- gdown
|
| 121 |
+
- moviepy
|
eval_trans_per.py
ADDED
|
@@ -0,0 +1,653 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import os
|
| 2 |
+
|
| 3 |
+
# import clip
|
| 4 |
+
from CLIP.clip import clip
|
| 5 |
+
import numpy as np
|
| 6 |
+
import torch
|
| 7 |
+
from scipy import linalg
|
| 8 |
+
from tqdm import tqdm
|
| 9 |
+
import visualization.plot_3d_global as plot_3d
|
| 10 |
+
from utils.motion_process import recover_from_ric
|
| 11 |
+
from tqdm import trange
|
| 12 |
+
|
| 13 |
+
def tensorborad_add_video_xyz(writer, xyz, nb_iter, tag, nb_vis=4, title_batch=None, outname=None):
|
| 14 |
+
xyz = xyz[:1]
|
| 15 |
+
bs, seq = xyz.shape[:2]
|
| 16 |
+
xyz = xyz.reshape(bs, seq, -1, 3)
|
| 17 |
+
plot_xyz = plot_3d.draw_to_batch(xyz.cpu().numpy(),title_batch, outname)
|
| 18 |
+
plot_xyz =np.transpose(plot_xyz, (0, 1, 4, 2, 3))
|
| 19 |
+
writer.add_video(tag, plot_xyz, nb_iter, fps = 20)
|
| 20 |
+
|
| 21 |
+
@torch.no_grad()
|
| 22 |
+
def evaluation_vqvae(out_dir, val_loader, net, logger, writer, nb_iter, best_fid, best_iter, best_div, best_top1, best_top2, best_top3, best_matching, eval_wrapper, draw = True, save = True, savegif=False, savenpy=False) :
|
| 23 |
+
net.eval()
|
| 24 |
+
nb_sample = 0
|
| 25 |
+
|
| 26 |
+
draw_org = []
|
| 27 |
+
draw_pred = []
|
| 28 |
+
draw_text = []
|
| 29 |
+
|
| 30 |
+
|
| 31 |
+
motion_annotation_list = []
|
| 32 |
+
motion_pred_list = []
|
| 33 |
+
|
| 34 |
+
R_precision_real = 0
|
| 35 |
+
R_precision = 0
|
| 36 |
+
|
| 37 |
+
nb_sample = 0
|
| 38 |
+
matching_score_real = 0
|
| 39 |
+
matching_score_pred = 0
|
| 40 |
+
for batch in val_loader:
|
| 41 |
+
word_embeddings, pos_one_hots, caption, sent_len, motion, m_length, token, name = batch
|
| 42 |
+
|
| 43 |
+
motion = motion.cuda()
|
| 44 |
+
et, em = eval_wrapper.get_co_embeddings(word_embeddings, pos_one_hots, sent_len, motion, m_length)
|
| 45 |
+
bs, seq = motion.shape[0], motion.shape[1]
|
| 46 |
+
|
| 47 |
+
num_joints = 21 if motion.shape[-1] == 251 else 22
|
| 48 |
+
|
| 49 |
+
pred_pose_eval = torch.zeros((bs, seq, motion.shape[-1])).cuda()
|
| 50 |
+
|
| 51 |
+
for i in range(bs):
|
| 52 |
+
pose = val_loader.dataset.inv_transform(motion[i:i+1, :m_length[i], :].detach().cpu().numpy())
|
| 53 |
+
pose_xyz = recover_from_ric(torch.from_numpy(pose).float().cuda(), num_joints)
|
| 54 |
+
|
| 55 |
+
|
| 56 |
+
pred_pose, loss_commit, perplexity = net(motion[i:i+1, :m_length[i]])
|
| 57 |
+
pred_denorm = val_loader.dataset.inv_transform(pred_pose.detach().cpu().numpy())
|
| 58 |
+
pred_xyz = recover_from_ric(torch.from_numpy(pred_denorm).float().cuda(), num_joints)
|
| 59 |
+
|
| 60 |
+
if savenpy:
|
| 61 |
+
np.save(os.path.join(out_dir, name[i]+'_gt.npy'), pose_xyz[:, :m_length[i]].cpu().numpy())
|
| 62 |
+
np.save(os.path.join(out_dir, name[i]+'_pred.npy'), pred_xyz.detach().cpu().numpy())
|
| 63 |
+
|
| 64 |
+
pred_pose_eval[i:i+1,:m_length[i],:] = pred_pose
|
| 65 |
+
|
| 66 |
+
if i < min(4, bs):
|
| 67 |
+
draw_org.append(pose_xyz)
|
| 68 |
+
draw_pred.append(pred_xyz)
|
| 69 |
+
draw_text.append(caption[i])
|
| 70 |
+
|
| 71 |
+
et_pred, em_pred = eval_wrapper.get_co_embeddings(word_embeddings, pos_one_hots, sent_len, pred_pose_eval, m_length)
|
| 72 |
+
|
| 73 |
+
motion_pred_list.append(em_pred)
|
| 74 |
+
motion_annotation_list.append(em)
|
| 75 |
+
|
| 76 |
+
temp_R, temp_match = calculate_R_precision(et.cpu().numpy(), em.cpu().numpy(), top_k=3, sum_all=True)
|
| 77 |
+
R_precision_real += temp_R
|
| 78 |
+
matching_score_real += temp_match
|
| 79 |
+
temp_R, temp_match = calculate_R_precision(et_pred.cpu().numpy(), em_pred.cpu().numpy(), top_k=3, sum_all=True)
|
| 80 |
+
R_precision += temp_R
|
| 81 |
+
matching_score_pred += temp_match
|
| 82 |
+
|
| 83 |
+
nb_sample += bs
|
| 84 |
+
|
| 85 |
+
motion_annotation_np = torch.cat(motion_annotation_list, dim=0).cpu().numpy()
|
| 86 |
+
motion_pred_np = torch.cat(motion_pred_list, dim=0).cpu().numpy()
|
| 87 |
+
gt_mu, gt_cov = calculate_activation_statistics(motion_annotation_np)
|
| 88 |
+
mu, cov= calculate_activation_statistics(motion_pred_np)
|
| 89 |
+
|
| 90 |
+
diversity_real = calculate_diversity(motion_annotation_np, 300 if nb_sample > 300 else 100)
|
| 91 |
+
diversity = calculate_diversity(motion_pred_np, 300 if nb_sample > 300 else 100)
|
| 92 |
+
|
| 93 |
+
R_precision_real = R_precision_real / nb_sample
|
| 94 |
+
R_precision = R_precision / nb_sample
|
| 95 |
+
|
| 96 |
+
matching_score_real = matching_score_real / nb_sample
|
| 97 |
+
matching_score_pred = matching_score_pred / nb_sample
|
| 98 |
+
|
| 99 |
+
fid = calculate_frechet_distance(gt_mu, gt_cov, mu, cov)
|
| 100 |
+
|
| 101 |
+
msg = f"--> \t Eva. Iter {nb_iter} :, FID. {fid:.4f}, Diversity Real. {diversity_real:.4f}, Diversity. {diversity:.4f}, R_precision_real. {R_precision_real}, R_precision. {R_precision}, matching_score_real. {matching_score_real}, matching_score_pred. {matching_score_pred}"
|
| 102 |
+
logger.info(msg)
|
| 103 |
+
|
| 104 |
+
if draw:
|
| 105 |
+
writer.add_scalar('./Test/FID', fid, nb_iter)
|
| 106 |
+
writer.add_scalar('./Test/Diversity', diversity, nb_iter)
|
| 107 |
+
writer.add_scalar('./Test/top1', R_precision[0], nb_iter)
|
| 108 |
+
writer.add_scalar('./Test/top2', R_precision[1], nb_iter)
|
| 109 |
+
writer.add_scalar('./Test/top3', R_precision[2], nb_iter)
|
| 110 |
+
writer.add_scalar('./Test/matching_score', matching_score_pred, nb_iter)
|
| 111 |
+
|
| 112 |
+
|
| 113 |
+
if nb_iter % 5000 == 0 :
|
| 114 |
+
for ii in range(4):
|
| 115 |
+
tensorborad_add_video_xyz(writer, draw_org[ii], nb_iter, tag='./Vis/org_eval'+str(ii), nb_vis=1, title_batch=[draw_text[ii]], outname=[os.path.join(out_dir, 'gt'+str(ii)+'.gif')] if savegif else None)
|
| 116 |
+
|
| 117 |
+
if nb_iter % 5000 == 0 :
|
| 118 |
+
for ii in range(4):
|
| 119 |
+
tensorborad_add_video_xyz(writer, draw_pred[ii], nb_iter, tag='./Vis/pred_eval'+str(ii), nb_vis=1, title_batch=[draw_text[ii]], outname=[os.path.join(out_dir, 'pred'+str(ii)+'.gif')] if savegif else None)
|
| 120 |
+
|
| 121 |
+
|
| 122 |
+
if fid < best_fid :
|
| 123 |
+
print(fid,best_fid)
|
| 124 |
+
|
| 125 |
+
msg = f"--> --> \t FID Improved from {best_fid:.5f} to {fid:.5f} !!!"
|
| 126 |
+
logger.info(msg)
|
| 127 |
+
best_fid, best_iter = fid, nb_iter
|
| 128 |
+
if save:
|
| 129 |
+
torch.save({'net' : net.state_dict()}, os.path.join(out_dir, 'net_best_fid.pth'))
|
| 130 |
+
|
| 131 |
+
if abs(diversity_real - diversity) < abs(diversity_real - best_div) :
|
| 132 |
+
msg = f"--> --> \t Diversity Improved from {best_div:.5f} to {diversity:.5f} !!!"
|
| 133 |
+
logger.info(msg)
|
| 134 |
+
best_div = diversity
|
| 135 |
+
if save:
|
| 136 |
+
torch.save({'net' : net.state_dict()}, os.path.join(out_dir, 'net_best_div.pth'))
|
| 137 |
+
|
| 138 |
+
if R_precision[0] > best_top1 :
|
| 139 |
+
msg = f"--> --> \t Top1 Improved from {best_top1:.4f} to {R_precision[0]:.4f} !!!"
|
| 140 |
+
logger.info(msg)
|
| 141 |
+
best_top1 = R_precision[0]
|
| 142 |
+
if save:
|
| 143 |
+
torch.save({'net' : net.state_dict()}, os.path.join(out_dir, 'net_best_top1.pth'))
|
| 144 |
+
|
| 145 |
+
if R_precision[1] > best_top2 :
|
| 146 |
+
msg = f"--> --> \t Top2 Improved from {best_top2:.4f} to {R_precision[1]:.4f} !!!"
|
| 147 |
+
logger.info(msg)
|
| 148 |
+
best_top2 = R_precision[1]
|
| 149 |
+
|
| 150 |
+
if R_precision[2] > best_top3 :
|
| 151 |
+
msg = f"--> --> \t Top3 Improved from {best_top3:.4f} to {R_precision[2]:.4f} !!!"
|
| 152 |
+
logger.info(msg)
|
| 153 |
+
best_top3 = R_precision[2]
|
| 154 |
+
|
| 155 |
+
if matching_score_pred < best_matching :
|
| 156 |
+
msg = f"--> --> \t matching_score Improved from {best_matching:.5f} to {matching_score_pred:.5f} !!!"
|
| 157 |
+
logger.info(msg)
|
| 158 |
+
best_matching = matching_score_pred
|
| 159 |
+
if save:
|
| 160 |
+
torch.save({'net' : net.state_dict()}, os.path.join(out_dir, 'net_best_matching.pth'))
|
| 161 |
+
|
| 162 |
+
if save:
|
| 163 |
+
torch.save({'net' : net.state_dict()}, os.path.join(out_dir, 'net_last.pth'))
|
| 164 |
+
|
| 165 |
+
net.train()
|
| 166 |
+
return best_fid, best_iter, best_div, best_top1, best_top2, best_top3, best_matching, writer, logger
|
| 167 |
+
|
| 168 |
+
|
| 169 |
+
@torch.no_grad()
|
| 170 |
+
def evaluation_transformer(out_dir, val_loader, net, trans, logger, writer, nb_iter, best_fid, best_fid_syn,best_fid_perturbation,best_iter, best_div, best_top1, best_top2, best_top3, best_matching, clip_model, eval_wrapper, draw = True, save = True, savegif=False,PGD=None,crit=None) :
|
| 171 |
+
|
| 172 |
+
trans.eval()
|
| 173 |
+
#这里是不是应该clip也eval()
|
| 174 |
+
nb_sample = 0
|
| 175 |
+
|
| 176 |
+
draw_org = []
|
| 177 |
+
draw_pred = []
|
| 178 |
+
draw_text = []
|
| 179 |
+
draw_text_pred = []
|
| 180 |
+
|
| 181 |
+
motion_annotation_list = []
|
| 182 |
+
motion_pred_list = []
|
| 183 |
+
motion_pred_per_list = []
|
| 184 |
+
R_precision_real = 0
|
| 185 |
+
R_precision = 0
|
| 186 |
+
matching_score_real = 0
|
| 187 |
+
matching_score_pred = 0
|
| 188 |
+
|
| 189 |
+
nb_sample = 0
|
| 190 |
+
for i in range(1):
|
| 191 |
+
for batch in tqdm(val_loader):
|
| 192 |
+
word_embeddings, pos_one_hots, clip_text, clip_text_perb, sent_len, pose, m_length, token, name = batch
|
| 193 |
+
|
| 194 |
+
bs, seq = pose.shape[:2]
|
| 195 |
+
num_joints = 21 if pose.shape[-1] == 251 else 22
|
| 196 |
+
|
| 197 |
+
text = clip.tokenize(clip_text, truncate=True).cuda()
|
| 198 |
+
text_perb = clip.tokenize(clip_text_perb, truncate=True).cuda()
|
| 199 |
+
|
| 200 |
+
|
| 201 |
+
feat_clip_text = clip_model.encode_text(text)[0].float()
|
| 202 |
+
feat_clip_text_per = clip_model.encode_text(text_perb)[0].float()
|
| 203 |
+
|
| 204 |
+
|
| 205 |
+
pred_pose_eval = torch.zeros((bs, seq, pose.shape[-1])).cuda()
|
| 206 |
+
pred_pose_eval_per = torch.zeros((bs, seq, pose.shape[-1])).cuda()
|
| 207 |
+
pred_len = torch.ones(bs).long()
|
| 208 |
+
pred_len_per = torch.ones(bs).long()
|
| 209 |
+
|
| 210 |
+
for k in range(bs):
|
| 211 |
+
try:
|
| 212 |
+
index_motion = trans.sample(feat_clip_text[k:k+1], False)
|
| 213 |
+
index_motion_per = trans.sample(feat_clip_text_per[k:k+1], False)
|
| 214 |
+
except:
|
| 215 |
+
# print('---------------------')
|
| 216 |
+
index_motion = torch.ones(1,1).cuda().long()
|
| 217 |
+
index_motion_per = torch.ones(1,1).cuda().long()
|
| 218 |
+
|
| 219 |
+
pred_pose = net.forward_decoder(index_motion)
|
| 220 |
+
pred_pose_per = net.forward_decoder(index_motion_per)
|
| 221 |
+
|
| 222 |
+
cur_len = pred_pose.shape[1]
|
| 223 |
+
cur_len_per = pred_pose_per.shape[1]
|
| 224 |
+
|
| 225 |
+
pred_len[k] = min(cur_len, seq)
|
| 226 |
+
pred_len_per[k] = min(cur_len_per, seq)
|
| 227 |
+
pred_pose_eval[k:k+1, :cur_len] = pred_pose[:, :seq]
|
| 228 |
+
pred_pose_eval_per[k:k+1, :cur_len_per] = pred_pose_per[:, :seq]
|
| 229 |
+
|
| 230 |
+
if draw:
|
| 231 |
+
pred_denorm = val_loader.dataset.inv_transform(pred_pose.detach().cpu().numpy())
|
| 232 |
+
pred_xyz = recover_from_ric(torch.from_numpy(pred_denorm).float().cuda(), num_joints)
|
| 233 |
+
|
| 234 |
+
if i == 0 and k < 4:
|
| 235 |
+
draw_pred.append(pred_xyz)
|
| 236 |
+
draw_text_pred.append(clip_text[k])
|
| 237 |
+
|
| 238 |
+
et_pred, em_pred = eval_wrapper.get_co_embeddings(word_embeddings, pos_one_hots, sent_len, pred_pose_eval, pred_len)
|
| 239 |
+
et_pred_per, em_pred_per = eval_wrapper.get_co_embeddings(word_embeddings, pos_one_hots, sent_len, pred_pose_eval_per, pred_len_per)
|
| 240 |
+
|
| 241 |
+
if i == 0:
|
| 242 |
+
pose = pose.cuda().float()
|
| 243 |
+
|
| 244 |
+
et, em = eval_wrapper.get_co_embeddings(word_embeddings, pos_one_hots, sent_len, pose, m_length)
|
| 245 |
+
motion_annotation_list.append(em)
|
| 246 |
+
motion_pred_list.append(em_pred)
|
| 247 |
+
motion_pred_per_list.append(em_pred_per)
|
| 248 |
+
|
| 249 |
+
if draw:
|
| 250 |
+
pose = val_loader.dataset.inv_transform(pose.detach().cpu().numpy())
|
| 251 |
+
pose_xyz = recover_from_ric(torch.from_numpy(pose).float().cuda(), num_joints)
|
| 252 |
+
|
| 253 |
+
|
| 254 |
+
for j in range(min(4, bs)):
|
| 255 |
+
draw_org.append(pose_xyz[j][:m_length[j]].unsqueeze(0))
|
| 256 |
+
draw_text.append(clip_text[j])
|
| 257 |
+
|
| 258 |
+
temp_R, temp_match = calculate_R_precision(et.cpu().numpy(), em.cpu().numpy(), top_k=3, sum_all=True)
|
| 259 |
+
R_precision_real += temp_R
|
| 260 |
+
matching_score_real += temp_match
|
| 261 |
+
temp_R, temp_match = calculate_R_precision(et_pred.cpu().numpy(), em_pred.cpu().numpy(), top_k=3, sum_all=True)
|
| 262 |
+
R_precision += temp_R
|
| 263 |
+
matching_score_pred += temp_match
|
| 264 |
+
|
| 265 |
+
nb_sample += bs
|
| 266 |
+
|
| 267 |
+
motion_annotation_np = torch.cat(motion_annotation_list, dim=0).cpu().numpy()
|
| 268 |
+
motion_pred_np = torch.cat(motion_pred_list, dim=0).cpu().numpy()
|
| 269 |
+
motion_pred_per_np = torch.cat(motion_pred_per_list, dim=0).cpu().numpy()
|
| 270 |
+
gt_mu, gt_cov = calculate_activation_statistics(motion_annotation_np)
|
| 271 |
+
mu, cov= calculate_activation_statistics(motion_pred_np)
|
| 272 |
+
mu_per, cov_per= calculate_activation_statistics(motion_pred_per_np)
|
| 273 |
+
|
| 274 |
+
diversity_real = calculate_diversity(motion_annotation_np, 300 if nb_sample > 300 else 100)
|
| 275 |
+
diversity = calculate_diversity(motion_pred_np, 300 if nb_sample > 300 else 100)
|
| 276 |
+
|
| 277 |
+
R_precision_real = R_precision_real / nb_sample
|
| 278 |
+
R_precision = R_precision / nb_sample
|
| 279 |
+
|
| 280 |
+
matching_score_real = matching_score_real / nb_sample
|
| 281 |
+
matching_score_pred = matching_score_pred / nb_sample
|
| 282 |
+
|
| 283 |
+
|
| 284 |
+
fid = calculate_frechet_distance(gt_mu, gt_cov, mu, cov)
|
| 285 |
+
fid_syn = calculate_frechet_distance(gt_mu,gt_cov,mu_per,cov_per)
|
| 286 |
+
fid_perturbation = calculate_frechet_distance(mu_per, cov_per, mu, cov)
|
| 287 |
+
|
| 288 |
+
msg = f"--> \t Eva. Iter {nb_iter} :, FID. {fid:.4f},FID_syn{fid_syn:.5f},FID_perturbation_and_origin.{fid_perturbation:.5f} Diversity Real. {diversity_real:.4f}, Diversity. {diversity:.4f}, R_precision_real. {R_precision_real}, R_precision. {R_precision}, matching_score_real. {matching_score_real}, matching_score_pred. {matching_score_pred}"
|
| 289 |
+
logger.info(msg)
|
| 290 |
+
|
| 291 |
+
|
| 292 |
+
if draw:
|
| 293 |
+
writer.add_scalar('./Test/FID', fid, nb_iter)
|
| 294 |
+
writer.add_scalar('./Test/FID_perturbation_and_origin', fid_perturbation, nb_iter)
|
| 295 |
+
writer.add_scalar('./Test/FID_syn', fid_syn, nb_iter)
|
| 296 |
+
writer.add_scalar('./Test/Diversity', diversity, nb_iter)
|
| 297 |
+
writer.add_scalar('./Test/top1', R_precision[0], nb_iter)
|
| 298 |
+
writer.add_scalar('./Test/top2', R_precision[1], nb_iter)
|
| 299 |
+
writer.add_scalar('./Test/top3', R_precision[2], nb_iter)
|
| 300 |
+
writer.add_scalar('./Test/matching_score', matching_score_pred, nb_iter)
|
| 301 |
+
|
| 302 |
+
|
| 303 |
+
# if nb_iter % 10000 == 0 :
|
| 304 |
+
# for ii in range(4):
|
| 305 |
+
# tensorborad_add_video_xyz(writer, draw_org[ii], nb_iter, tag='./Vis/org_eval'+str(ii), nb_vis=1, title_batch=[draw_text[ii]], outname=[os.path.join(out_dir, 'gt'+str(ii)+'.gif')] if savegif else None)
|
| 306 |
+
|
| 307 |
+
# if nb_iter % 10000 == 0 :
|
| 308 |
+
# for ii in range(4):
|
| 309 |
+
# tensorborad_add_video_xyz(writer, draw_pred[ii], nb_iter, tag='./Vis/pred_eval'+str(ii), nb_vis=1, title_batch=[draw_text_pred[ii]], outname=[os.path.join(out_dir, 'pred'+str(ii)+'.gif')] if savegif else None)
|
| 310 |
+
|
| 311 |
+
if isinstance(best_fid, tuple):
|
| 312 |
+
best_fid=best_fid[0]
|
| 313 |
+
if isinstance(best_fid_perturbation, tuple):
|
| 314 |
+
best_fid_perturbation=best_fid_perturbation[0]
|
| 315 |
+
if fid < best_fid :
|
| 316 |
+
msg = f"--> --> \t FID Improved from {best_fid:.5f} to {fid:.5f} !!!"
|
| 317 |
+
logger.info(msg)
|
| 318 |
+
best_fid, best_iter = fid, nb_iter
|
| 319 |
+
if save:
|
| 320 |
+
state_dict = clip_model.state_dict()
|
| 321 |
+
torch.save(state_dict, os.path.join(out_dir, 'clip_best.pth'))
|
| 322 |
+
torch.save({'trans' : trans.state_dict()}, os.path.join(out_dir, 'net_best_fid.pth'))
|
| 323 |
+
msg = f"--> --> \t Current FID is {fid:.5f} !!!"
|
| 324 |
+
logger.info(msg)
|
| 325 |
+
if fid_syn < best_fid_syn:
|
| 326 |
+
msg = f"--> --> \t FID_syn {best_fid_syn:.5f} to {fid_syn:.5f} !!!"
|
| 327 |
+
logger.info(msg)
|
| 328 |
+
best_fid_syn = fid_syn
|
| 329 |
+
|
| 330 |
+
if fid_perturbation < best_fid_perturbation :
|
| 331 |
+
msg = f"--> --> \t FID_perturbation_and_origin {best_fid_perturbation:.5f} to {fid_perturbation:.5f} !!!"
|
| 332 |
+
logger.info(msg)
|
| 333 |
+
best_fid_perturbation = fid_perturbation
|
| 334 |
+
|
| 335 |
+
if matching_score_pred < best_matching :
|
| 336 |
+
msg = f"--> --> \t matching_score Improved from {best_matching:.5f} to {matching_score_pred:.5f} !!!"
|
| 337 |
+
logger.info(msg)
|
| 338 |
+
best_matching = matching_score_pred
|
| 339 |
+
|
| 340 |
+
if abs(diversity_real - diversity) < abs(diversity_real - best_div) :
|
| 341 |
+
msg = f"--> --> \t Diversity Improved from {best_div:.5f} to {diversity:.5f} !!!"
|
| 342 |
+
logger.info(msg)
|
| 343 |
+
best_div = diversity
|
| 344 |
+
|
| 345 |
+
if R_precision[0] > best_top1 :
|
| 346 |
+
msg = f"--> --> \t Top1 Improved from {best_top1:.4f} to {R_precision[0]:.4f} !!!"
|
| 347 |
+
logger.info(msg)
|
| 348 |
+
best_top1 = R_precision[0]
|
| 349 |
+
|
| 350 |
+
if R_precision[1] > best_top2 :
|
| 351 |
+
msg = f"--> --> \t Top2 Improved from {best_top2:.4f} to {R_precision[1]:.4f} !!!"
|
| 352 |
+
logger.info(msg)
|
| 353 |
+
best_top2 = R_precision[1]
|
| 354 |
+
|
| 355 |
+
if R_precision[2] > best_top3 :
|
| 356 |
+
msg = f"--> --> \t Top3 Improved from {best_top3:.4f} to {R_precision[2]:.4f} !!!"
|
| 357 |
+
logger.info(msg)
|
| 358 |
+
best_top3 = R_precision[2]
|
| 359 |
+
|
| 360 |
+
if save:
|
| 361 |
+
state_dict = clip_model.state_dict()
|
| 362 |
+
torch.save(state_dict, os.path.join(out_dir, 'clip_last.pth'))
|
| 363 |
+
torch.save({'trans' : trans.state_dict()}, os.path.join(out_dir, 'net_last.pth'))
|
| 364 |
+
|
| 365 |
+
trans.train()
|
| 366 |
+
return best_fid, best_fid_syn, best_fid_perturbation, best_iter, best_div, best_top1, best_top2, best_top3, best_matching, writer, logger
|
| 367 |
+
|
| 368 |
+
|
| 369 |
+
@torch.no_grad()
|
| 370 |
+
def evaluation_transformer_test(out_dir, val_loader, net, trans, logger, writer, nb_iter, best_fid,best_fid_word_perb,best_fid_perturbation, best_iter, best_div, best_top1, best_top2, best_top3, best_matching, best_multi, clip_model, eval_wrapper, draw = True, save = True, savegif=False, savenpy=False) :
|
| 371 |
+
|
| 372 |
+
trans.eval()
|
| 373 |
+
nb_sample = 0
|
| 374 |
+
|
| 375 |
+
draw_org = []
|
| 376 |
+
draw_pred = []
|
| 377 |
+
draw_text = []
|
| 378 |
+
draw_text_pred = []
|
| 379 |
+
draw_name = []
|
| 380 |
+
|
| 381 |
+
motion_annotation_list = []
|
| 382 |
+
motion_pred_list = []
|
| 383 |
+
motion_pred_per_list = []
|
| 384 |
+
|
| 385 |
+
motion_multimodality = []
|
| 386 |
+
R_precision_real = 0
|
| 387 |
+
R_precision = 0
|
| 388 |
+
matching_score_real = 0
|
| 389 |
+
matching_score_pred = 0
|
| 390 |
+
|
| 391 |
+
nb_sample = 0
|
| 392 |
+
|
| 393 |
+
for batch in tqdm(val_loader, desc="Validation Progress"):
|
| 394 |
+
|
| 395 |
+
word_embeddings, pos_one_hots, clip_text, clip_text_perb, sent_len, pose, m_length, token, name = batch
|
| 396 |
+
bs, seq = pose.shape[:2]
|
| 397 |
+
num_joints = 21 if pose.shape[-1] == 251 else 22
|
| 398 |
+
|
| 399 |
+
text = clip.tokenize(clip_text, truncate=True).cuda()
|
| 400 |
+
text_perb = clip.tokenize(clip_text_perb, truncate=True).cuda()
|
| 401 |
+
feat_clip_text = clip_model.encode_text(text)[0].float()
|
| 402 |
+
feat_clip_text_per = clip_model.encode_text(text_perb)[0].float()
|
| 403 |
+
|
| 404 |
+
|
| 405 |
+
motion_multimodality_batch = []
|
| 406 |
+
for i in range(1):
|
| 407 |
+
pred_pose_eval = torch.zeros((bs, seq, pose.shape[-1])).cuda()
|
| 408 |
+
pred_pose_eval_per = torch.zeros((bs, seq, pose.shape[-1])).cuda()
|
| 409 |
+
|
| 410 |
+
pred_len = torch.ones(bs).long()
|
| 411 |
+
pred_len_per = torch.ones(bs).long()
|
| 412 |
+
|
| 413 |
+
for k in range(bs):
|
| 414 |
+
try:
|
| 415 |
+
index_motion = trans.sample(feat_clip_text[k:k+1], True)
|
| 416 |
+
index_motion_per = trans.sample(feat_clip_text_per[k:k+1], True)
|
| 417 |
+
except:
|
| 418 |
+
index_motion = torch.ones(1,1).cuda().long()
|
| 419 |
+
index_motion_per = torch.ones(1,1).cuda().long()
|
| 420 |
+
|
| 421 |
+
pred_pose = net.forward_decoder(index_motion)
|
| 422 |
+
pred_pose_per = net.forward_decoder(index_motion_per)
|
| 423 |
+
cur_len = pred_pose.shape[1]
|
| 424 |
+
cur_len_per = pred_pose_per.shape[1]
|
| 425 |
+
|
| 426 |
+
pred_len[k] = min(cur_len, seq)
|
| 427 |
+
pred_len_per[k] = min(cur_len_per, seq)
|
| 428 |
+
|
| 429 |
+
pred_pose_eval[k:k+1, :cur_len] = pred_pose[:, :seq]
|
| 430 |
+
pred_pose_eval_per[k:k+1, :cur_len_per] = pred_pose_per[:, :seq]
|
| 431 |
+
|
| 432 |
+
if i == 0 and (draw or savenpy):
|
| 433 |
+
pred_denorm = val_loader.dataset.inv_transform(pred_pose.detach().cpu().numpy())
|
| 434 |
+
pred_xyz = recover_from_ric(torch.from_numpy(pred_denorm).float().cuda(), num_joints)
|
| 435 |
+
|
| 436 |
+
if savenpy:
|
| 437 |
+
np.save(os.path.join(out_dir, name[k]+'_pred.npy'), pred_xyz.detach().cpu().numpy())
|
| 438 |
+
|
| 439 |
+
if draw:
|
| 440 |
+
if i == 0:
|
| 441 |
+
draw_pred.append(pred_xyz)
|
| 442 |
+
draw_text_pred.append(clip_text[k])
|
| 443 |
+
draw_name.append(name[k])
|
| 444 |
+
|
| 445 |
+
et_pred, em_pred = eval_wrapper.get_co_embeddings(word_embeddings, pos_one_hots, sent_len, pred_pose_eval, pred_len)
|
| 446 |
+
et_pred_per, em_pred_per = eval_wrapper.get_co_embeddings(word_embeddings, pos_one_hots, sent_len, pred_pose_eval_per, pred_len_per)
|
| 447 |
+
|
| 448 |
+
# motion_multimodality_batch.append(em_pred.reshape(bs, 1, -1))
|
| 449 |
+
|
| 450 |
+
if i == 0:
|
| 451 |
+
pose = pose.cuda().float()
|
| 452 |
+
|
| 453 |
+
et, em = eval_wrapper.get_co_embeddings(word_embeddings, pos_one_hots, sent_len, pose, m_length)
|
| 454 |
+
motion_annotation_list.append(em)
|
| 455 |
+
motion_pred_list.append(em_pred)
|
| 456 |
+
motion_pred_per_list.append(em_pred_per)
|
| 457 |
+
|
| 458 |
+
if draw or savenpy:
|
| 459 |
+
pose = val_loader.dataset.inv_transform(pose.detach().cpu().numpy())
|
| 460 |
+
pose_xyz = recover_from_ric(torch.from_numpy(pose).float().cuda(), num_joints)
|
| 461 |
+
|
| 462 |
+
if savenpy:
|
| 463 |
+
for j in range(bs):
|
| 464 |
+
np.save(os.path.join(out_dir, name[j]+'_gt.npy'), pose_xyz[j][:m_length[j]].unsqueeze(0).cpu().numpy())
|
| 465 |
+
|
| 466 |
+
if draw:
|
| 467 |
+
for j in range(bs):
|
| 468 |
+
draw_org.append(pose_xyz[j][:m_length[j]].unsqueeze(0))
|
| 469 |
+
draw_text.append(clip_text[j])
|
| 470 |
+
|
| 471 |
+
temp_R, temp_match = calculate_R_precision(et.cpu().numpy(), em.cpu().numpy(), top_k=3, sum_all=True)
|
| 472 |
+
R_precision_real += temp_R
|
| 473 |
+
matching_score_real += temp_match
|
| 474 |
+
temp_R, temp_match = calculate_R_precision(et_pred.cpu().numpy(), em_pred.cpu().numpy(), top_k=3, sum_all=True)
|
| 475 |
+
R_precision += temp_R
|
| 476 |
+
matching_score_pred += temp_match
|
| 477 |
+
|
| 478 |
+
nb_sample += bs
|
| 479 |
+
|
| 480 |
+
# motion_multimodality.append(torch.cat(motion_multimodality_batch, dim=1))
|
| 481 |
+
|
| 482 |
+
motion_annotation_np = torch.cat(motion_annotation_list, dim=0).cpu().numpy()
|
| 483 |
+
motion_pred_np = torch.cat(motion_pred_list, dim=0).cpu().numpy()
|
| 484 |
+
motion_pred_per_np = torch.cat(motion_pred_per_list, dim=0).cpu().numpy()
|
| 485 |
+
gt_mu, gt_cov = calculate_activation_statistics(motion_annotation_np)
|
| 486 |
+
mu, cov= calculate_activation_statistics(motion_pred_np) # mu cov使用的是motion_perb_np
|
| 487 |
+
mu_per, cov_per= calculate_activation_statistics(motion_pred_per_np)
|
| 488 |
+
gt_mu[np.isnan(gt_mu) | np.isinf(gt_mu)] = 0.0
|
| 489 |
+
gt_cov[np.isnan(gt_cov) | np.isinf(gt_cov)] = 0.0
|
| 490 |
+
mu[np.isnan(mu) | np.isinf(mu)] = 0.0
|
| 491 |
+
cov[np.isnan(cov) | np.isinf(cov)] = 0.0
|
| 492 |
+
mu_per[np.isnan(mu_per) | np.isinf(mu_per)] = 0.0
|
| 493 |
+
cov_per[np.isnan(cov_per) | np.isinf(cov_per)] = 0.0
|
| 494 |
+
diversity_real = calculate_diversity(motion_annotation_np, 300 if nb_sample > 300 else 100)
|
| 495 |
+
diversity = calculate_diversity(motion_pred_np, 300 if nb_sample > 300 else 100)
|
| 496 |
+
|
| 497 |
+
R_precision_real = R_precision_real / nb_sample
|
| 498 |
+
R_precision = R_precision / nb_sample
|
| 499 |
+
|
| 500 |
+
matching_score_real = matching_score_real / nb_sample
|
| 501 |
+
matching_score_pred = matching_score_pred / nb_sample
|
| 502 |
+
|
| 503 |
+
multimodality = 0
|
| 504 |
+
# motion_multimodality = torch.cat(motion_multimodality, dim=0).cpu().numpy()
|
| 505 |
+
# multimodality = calculate_multimodality(motion_multimodality, 10)
|
| 506 |
+
try:
|
| 507 |
+
fid = calculate_frechet_distance(gt_mu, gt_cov, mu, cov)
|
| 508 |
+
fid_perturbation = calculate_frechet_distance(mu_per, cov_per, mu, cov)
|
| 509 |
+
fid_word_perb = calculate_frechet_distance(gt_mu,gt_cov,mu_per,cov_per)
|
| 510 |
+
except:
|
| 511 |
+
print('数据有问题!!')
|
| 512 |
+
msg = f"--> \t Eva. Iter {nb_iter} :, FID. {fid:.4f}, FID_syn. {fid_word_perb:.5f}, FID_Perturbation. {fid_perturbation:.4f}, Diversity Real. {diversity_real:.4f}, Diversity. {diversity:.4f}, R_precision_real. {R_precision_real}, R_precision. {R_precision}, matching_score_real. {matching_score_real}, matching_score_pred. {matching_score_pred}, multimodality. {multimodality:.4f}"
|
| 513 |
+
logger.info(msg)
|
| 514 |
+
|
| 515 |
+
|
| 516 |
+
if draw:
|
| 517 |
+
for ii in range(len(draw_org)):
|
| 518 |
+
tensorborad_add_video_xyz(writer, draw_org[ii], nb_iter, tag='./Vis/'+draw_name[ii]+'_org', nb_vis=1, title_batch=[draw_text[ii]], outname=[os.path.join(out_dir, draw_name[ii]+'_skel_gt.gif')] if savegif else None)
|
| 519 |
+
|
| 520 |
+
tensorborad_add_video_xyz(writer, draw_pred[ii], nb_iter, tag='./Vis/'+draw_name[ii]+'_pred', nb_vis=1, title_batch=[draw_text_pred[ii]], outname=[os.path.join(out_dir, draw_name[ii]+'_skel_pred.gif')] if savegif else None)
|
| 521 |
+
|
| 522 |
+
trans.train()
|
| 523 |
+
return fid,fid_word_perb,fid_perturbation, best_iter, diversity, R_precision[0], R_precision[1], R_precision[2], matching_score_pred, multimodality, writer, logger
|
| 524 |
+
|
| 525 |
+
# (X - X_train)*(X - X_train) = -2X*X_train + X*X + X_train*X_train
|
| 526 |
+
def euclidean_distance_matrix(matrix1, matrix2):
|
| 527 |
+
"""
|
| 528 |
+
Params:
|
| 529 |
+
-- matrix1: N1 x D
|
| 530 |
+
-- matrix2: N2 x D
|
| 531 |
+
Returns:
|
| 532 |
+
-- dist: N1 x N2
|
| 533 |
+
dist[i, j] == distance(matrix1[i], matrix2[j])
|
| 534 |
+
"""
|
| 535 |
+
assert matrix1.shape[1] == matrix2.shape[1]
|
| 536 |
+
d1 = -2 * np.dot(matrix1, matrix2.T) # shape (num_test, num_train)
|
| 537 |
+
d2 = np.sum(np.square(matrix1), axis=1, keepdims=True) # shape (num_test, 1)
|
| 538 |
+
d3 = np.sum(np.square(matrix2), axis=1) # shape (num_train, )
|
| 539 |
+
dists = np.sqrt(d1 + d2 + d3) # broadcasting
|
| 540 |
+
return dists
|
| 541 |
+
|
| 542 |
+
|
| 543 |
+
|
| 544 |
+
def calculate_top_k(mat, top_k):
|
| 545 |
+
size = mat.shape[0]
|
| 546 |
+
gt_mat = np.expand_dims(np.arange(size), 1).repeat(size, 1)
|
| 547 |
+
bool_mat = (mat == gt_mat)
|
| 548 |
+
correct_vec = False
|
| 549 |
+
top_k_list = []
|
| 550 |
+
for i in range(top_k):
|
| 551 |
+
# print(correct_vec, bool_mat[:, i])
|
| 552 |
+
correct_vec = (correct_vec | bool_mat[:, i])
|
| 553 |
+
# print(correct_vec)
|
| 554 |
+
top_k_list.append(correct_vec[:, None])
|
| 555 |
+
top_k_mat = np.concatenate(top_k_list, axis=1)
|
| 556 |
+
return top_k_mat
|
| 557 |
+
|
| 558 |
+
|
| 559 |
+
def calculate_R_precision(embedding1, embedding2, top_k, sum_all=False):
|
| 560 |
+
dist_mat = euclidean_distance_matrix(embedding1, embedding2)
|
| 561 |
+
matching_score = dist_mat.trace()
|
| 562 |
+
argmax = np.argsort(dist_mat, axis=1)
|
| 563 |
+
top_k_mat = calculate_top_k(argmax, top_k)
|
| 564 |
+
if sum_all:
|
| 565 |
+
return top_k_mat.sum(axis=0), matching_score
|
| 566 |
+
else:
|
| 567 |
+
return top_k_mat, matching_score
|
| 568 |
+
|
| 569 |
+
def calculate_multimodality(activation, multimodality_times):
|
| 570 |
+
assert len(activation.shape) == 3
|
| 571 |
+
assert activation.shape[1] > multimodality_times
|
| 572 |
+
num_per_sent = activation.shape[1]
|
| 573 |
+
|
| 574 |
+
first_dices = np.random.choice(num_per_sent, multimodality_times, replace=False)
|
| 575 |
+
second_dices = np.random.choice(num_per_sent, multimodality_times, replace=False)
|
| 576 |
+
dist = linalg.norm(activation[:, first_dices] - activation[:, second_dices], axis=2)
|
| 577 |
+
return dist.mean()
|
| 578 |
+
|
| 579 |
+
|
| 580 |
+
def calculate_diversity(activation, diversity_times):
|
| 581 |
+
assert len(activation.shape) == 2
|
| 582 |
+
assert activation.shape[0] > diversity_times
|
| 583 |
+
num_samples = activation.shape[0]
|
| 584 |
+
|
| 585 |
+
first_indices = np.random.choice(num_samples, diversity_times, replace=False)
|
| 586 |
+
second_indices = np.random.choice(num_samples, diversity_times, replace=False)
|
| 587 |
+
dist = linalg.norm(activation[first_indices] - activation[second_indices], axis=1)
|
| 588 |
+
return dist.mean()
|
| 589 |
+
|
| 590 |
+
|
| 591 |
+
|
| 592 |
+
def calculate_frechet_distance(mu1, sigma1, mu2, sigma2, eps=1e-6):
|
| 593 |
+
|
| 594 |
+
mu1 = np.atleast_1d(mu1)
|
| 595 |
+
mu2 = np.atleast_1d(mu2)
|
| 596 |
+
|
| 597 |
+
sigma1 = np.atleast_2d(sigma1)
|
| 598 |
+
sigma2 = np.atleast_2d(sigma2)
|
| 599 |
+
|
| 600 |
+
assert mu1.shape == mu2.shape, \
|
| 601 |
+
'Training and test mean vectors have different lengths'
|
| 602 |
+
assert sigma1.shape == sigma2.shape, \
|
| 603 |
+
'Training and test covariances have different dimensions'
|
| 604 |
+
|
| 605 |
+
diff = mu1 - mu2
|
| 606 |
+
|
| 607 |
+
# Product might be almost singular
|
| 608 |
+
covmean, _ = linalg.sqrtm(sigma1.dot(sigma2), disp=False)
|
| 609 |
+
if not np.isfinite(covmean).all():
|
| 610 |
+
msg = ('fid calculation produces singular product; '
|
| 611 |
+
'adding %s to diagonal of cov estimates') % eps
|
| 612 |
+
print(msg)
|
| 613 |
+
offset = np.eye(sigma1.shape[0]) * eps
|
| 614 |
+
covmean = linalg.sqrtm((sigma1 + offset).dot(sigma2 + offset))
|
| 615 |
+
|
| 616 |
+
# Numerical error might give slight imaginary component
|
| 617 |
+
if np.iscomplexobj(covmean):
|
| 618 |
+
if not np.allclose(np.diagonal(covmean).imag, 0, atol=1e-3):
|
| 619 |
+
m = np.max(np.abs(covmean.imag))
|
| 620 |
+
raise ValueError('Imaginary component {}'.format(m))
|
| 621 |
+
covmean = covmean.real
|
| 622 |
+
|
| 623 |
+
tr_covmean = np.trace(covmean)
|
| 624 |
+
|
| 625 |
+
return (diff.dot(diff) + np.trace(sigma1)
|
| 626 |
+
+ np.trace(sigma2) - 2 * tr_covmean)
|
| 627 |
+
|
| 628 |
+
|
| 629 |
+
|
| 630 |
+
def calculate_activation_statistics(activations):
|
| 631 |
+
|
| 632 |
+
mu = np.mean(activations, axis=0)
|
| 633 |
+
cov = np.cov(activations, rowvar=False)
|
| 634 |
+
return mu, cov
|
| 635 |
+
|
| 636 |
+
|
| 637 |
+
def calculate_frechet_feature_distance(feature_list1, feature_list2):
|
| 638 |
+
feature_list1 = np.stack(feature_list1)
|
| 639 |
+
feature_list2 = np.stack(feature_list2)
|
| 640 |
+
|
| 641 |
+
# normalize the scale
|
| 642 |
+
mean = np.mean(feature_list1, axis=0)
|
| 643 |
+
std = np.std(feature_list1, axis=0) + 1e-10
|
| 644 |
+
feature_list1 = (feature_list1 - mean) / std
|
| 645 |
+
feature_list2 = (feature_list2 - mean) / std
|
| 646 |
+
|
| 647 |
+
dist = calculate_frechet_distance(
|
| 648 |
+
mu1=np.mean(feature_list1, axis=0),
|
| 649 |
+
sigma1=np.cov(feature_list1, rowvar=False),
|
| 650 |
+
mu2=np.mean(feature_list2, axis=0),
|
| 651 |
+
sigma2=np.cov(feature_list2, rowvar=False),
|
| 652 |
+
)
|
| 653 |
+
return dist
|
images/1
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
|
images/example/1
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
|
images/example/boot/1
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
|
images/example/boot/gpt.gif
ADDED
|
images/example/boot/mdm.gif
ADDED
|
images/example/boot/momask.gif
ADDED
|
images/example/boot/sato.gif
ADDED
|
images/example/kick/1
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
|
images/example/kick/gpt.gif
ADDED
|
images/example/kick/mdm.gif
ADDED
|
images/example/kick/momask.gif
ADDED
|
images/example/kick/sato.gif
ADDED
|
images/visualization/1
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
|
images/visualization/circle/1
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
|
images/visualization/circle/gpt.gif
ADDED
|