
Commit
•
7877864
1
Parent(s):
6cf198b
Upload 17 files
Browse files- .gitattributes +1 -0
- app.py +99 -0
- clf-1.png +0 -0
- clf-2.png +0 -0
- clf-3.png +0 -0
- clf-4.png +0 -0
- knn_model.joblib +3 -0
- label_encoder.joblib +3 -0
- nca_model.joblib +3 -0
- requirements.txt +67 -0
- rnk-1.png +0 -0
- rnk-2.png +0 -0
- rnk-3.png +0 -0
- rnk-4.png +0 -0
- tfidf_vectorizer.joblib +3 -0
- train_classifier.py +102 -0
- utils.py +602 -0
- wiki-news-300d-1M-subword.vec +3 -0
.gitattributes
CHANGED
|
@@ -33,3 +33,4 @@ saved_model/**/* filter=lfs diff=lfs merge=lfs -text
|
|
| 33 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
|
|
|
|
|
| 33 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
| 36 |
+
wiki-news-300d-1M-subword.vec filter=lfs diff=lfs merge=lfs -text
|
app.py
ADDED
|
@@ -0,0 +1,99 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import pandas as pd
|
| 2 |
+
import streamlit as st
|
| 3 |
+
|
| 4 |
+
from utils import *
|
| 5 |
+
|
| 6 |
+
backgroundPattern = """
|
| 7 |
+
<style>
|
| 8 |
+
[data-testid="stAppViewContainer"] {
|
| 9 |
+
background-color: #0E1117;
|
| 10 |
+
opacity: 1;
|
| 11 |
+
background-image: radial-gradient(#282C34 0.75px, #0E1117 0.75px);
|
| 12 |
+
background-size: 15px 15px;
|
| 13 |
+
}
|
| 14 |
+
</style>
|
| 15 |
+
"""
|
| 16 |
+
|
| 17 |
+
# backgroundPattern = """
|
| 18 |
+
# <style>
|
| 19 |
+
# [data-testid="stAppViewContainer"] {
|
| 20 |
+
# background-color: #FFFFFF;
|
| 21 |
+
# opacity: 1;
|
| 22 |
+
# background-image: radial-gradient(#D1D1D1 0.75px, #FFFFFF 0.75px);
|
| 23 |
+
# background-size: 15px 15px;
|
| 24 |
+
# }
|
| 25 |
+
# </style>
|
| 26 |
+
# """
|
| 27 |
+
|
| 28 |
+
st.markdown(backgroundPattern, unsafe_allow_html=True)
|
| 29 |
+
|
| 30 |
+
st.write("""
|
| 31 |
+
# Resume Screening & Classification
|
| 32 |
+
""")
|
| 33 |
+
st.caption("""
|
| 34 |
+
Using K-Nearest Neighbors (KNN) algorithm and Cosine Similarity
|
| 35 |
+
######
|
| 36 |
+
""")
|
| 37 |
+
|
| 38 |
+
tab1, tab2, tab3 = st.tabs(['Getting Started', 'Classify', 'Rank'])
|
| 39 |
+
|
| 40 |
+
with tab1:
|
| 41 |
+
writeGettingStarted()
|
| 42 |
+
|
| 43 |
+
with tab2:
|
| 44 |
+
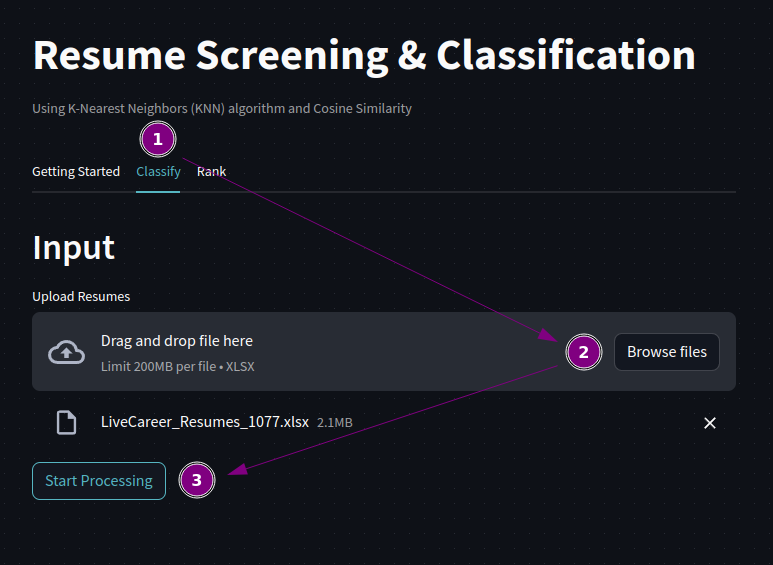
st.header('Input')
|
| 45 |
+
uploadedResumeClf = st.file_uploader('Upload Resumes', type = 'xlsx', key = 'upload-resume-clf')
|
| 46 |
+
|
| 47 |
+
if uploadedResumeClf is not None:
|
| 48 |
+
isButtonDisabledClf = False
|
| 49 |
+
else:
|
| 50 |
+
st.session_state.processClf = False
|
| 51 |
+
isButtonDisabledClf = True
|
| 52 |
+
|
| 53 |
+
if 'processClf' not in st.session_state:
|
| 54 |
+
st.session_state.processClf = False
|
| 55 |
+
|
| 56 |
+
st.button('Start Processing', on_click = clickClassify, disabled = isButtonDisabledClf, key = 'process-clf')
|
| 57 |
+
|
| 58 |
+
if st.session_state.processClf:
|
| 59 |
+
st.divider()
|
| 60 |
+
st.header('Output')
|
| 61 |
+
resumeClf = pd.read_excel(uploadedResumeClf)
|
| 62 |
+
resumeClf = classifyResumes(resumeClf)
|
| 63 |
+
with st.expander('View Bar Chart'):
|
| 64 |
+
barChart = createBarChart(resumeClf)
|
| 65 |
+
st.altair_chart(barChart, use_container_width = True)
|
| 66 |
+
currentClf = filterDataframeClf(resumeClf)
|
| 67 |
+
st.dataframe(currentClf, use_container_width = True, hide_index = True)
|
| 68 |
+
xlsxClf = convertDfToXlsx(currentClf)
|
| 69 |
+
st.download_button(label='Save Current Output as XLSX', data = xlsxClf, file_name = 'Resumes_categorized.xlsx')
|
| 70 |
+
|
| 71 |
+
with tab3:
|
| 72 |
+
st.header('Input')
|
| 73 |
+
uploadedJobDescriptionRnk = st.file_uploader('Upload Job Description', type = 'txt', key = 'upload-jd-rnk')
|
| 74 |
+
uploadedResumeRnk = st.file_uploader('Upload Resumes', type = 'xlsx', key = 'upload-resume-rnk')
|
| 75 |
+
|
| 76 |
+
if all([uploadedJobDescriptionRnk, uploadedResumeRnk]):
|
| 77 |
+
isButtonDisabledRnk = False
|
| 78 |
+
else:
|
| 79 |
+
st.session_state.processRank = False
|
| 80 |
+
isButtonDisabledRnk = True
|
| 81 |
+
|
| 82 |
+
if 'processRank' not in st.session_state:
|
| 83 |
+
st.session_state.processRank = False
|
| 84 |
+
|
| 85 |
+
st.button('Start Processing', on_click = clickRank, disabled = isButtonDisabledRnk, key = 'process-rnk')
|
| 86 |
+
|
| 87 |
+
if st.session_state.processRank:
|
| 88 |
+
st.divider()
|
| 89 |
+
st.header('Output')
|
| 90 |
+
jobDescriptionRnk = uploadedJobDescriptionRnk.read().decode('utf-8')
|
| 91 |
+
resumeRnk = pd.read_excel(uploadedResumeRnk)
|
| 92 |
+
resumeRnk = rankResumes(jobDescriptionRnk, resumeRnk)
|
| 93 |
+
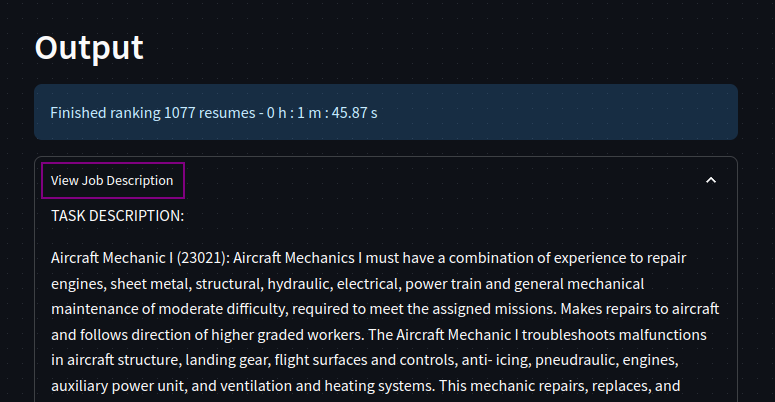
with st.expander('View Job Description'):
|
| 94 |
+
st.write(jobDescriptionRnk)
|
| 95 |
+
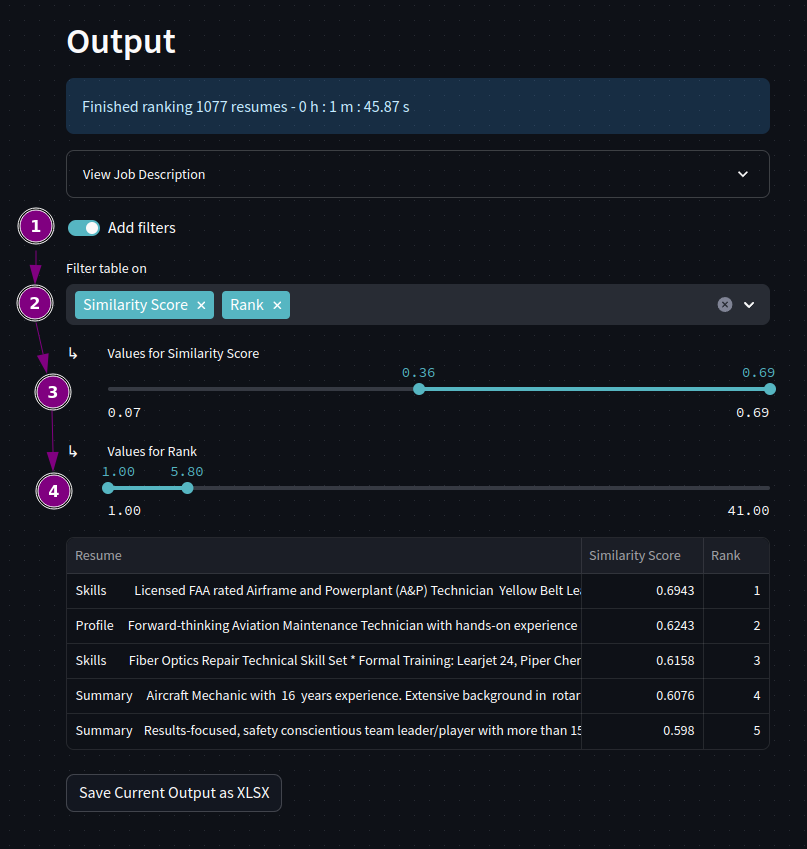
currentRnk = filterDataframeRnk(resumeRnk)
|
| 96 |
+
st.dataframe(currentRnk, use_container_width = True, hide_index = True)
|
| 97 |
+
xlsxRnk = convertDfToXlsx(currentRnk)
|
| 98 |
+
st.download_button(label='Save Current Output as XLSX', data = xlsxRnk, file_name = 'Resumes_ranked.xlsx')
|
| 99 |
+
|
clf-1.png
ADDED
|
clf-2.png
ADDED

|
clf-3.png
ADDED

|
clf-4.png
ADDED

|
knn_model.joblib
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:69d9b5be2223b9acb49fe7cf16a6df47daa312ed35b21e2a9341b9ae97575c60
|
| 3 |
+
size 4223478
|
label_encoder.joblib
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:b0ed5884fd4a68001090ffe82fda74566574d5b9aed8654eec48c19cc4585f1b
|
| 3 |
+
size 715
|
nca_model.joblib
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:4fd5ab8d8adb40ead5421e8d90e36c99004f2af426be6659e7add2f0c58893e7
|
| 3 |
+
size 43294492
|
requirements.txt
ADDED
|
@@ -0,0 +1,67 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
altair==5.1.1
|
| 2 |
+
attrs==23.1.0
|
| 3 |
+
blinker==1.6.2
|
| 4 |
+
cachetools==5.3.1
|
| 5 |
+
certifi==2023.7.22
|
| 6 |
+
charset-normalizer==3.2.0
|
| 7 |
+
click==8.1.7
|
| 8 |
+
contourpy==1.1.1
|
| 9 |
+
cycler==0.11.0
|
| 10 |
+
et-xmlfile==1.1.0
|
| 11 |
+
fonttools==4.42.1
|
| 12 |
+
gensim==4.3.2
|
| 13 |
+
gitdb==4.0.10
|
| 14 |
+
GitPython==3.1.37
|
| 15 |
+
idna==3.4
|
| 16 |
+
importlib-metadata==6.8.0
|
| 17 |
+
Jinja2==3.1.2
|
| 18 |
+
joblib==1.3.2
|
| 19 |
+
jsonschema==4.19.1
|
| 20 |
+
jsonschema-specifications==2023.7.1
|
| 21 |
+
kiwisolver==1.4.5
|
| 22 |
+
markdown-it-py==3.0.0
|
| 23 |
+
MarkupSafe==2.1.3
|
| 24 |
+
matplotlib==3.8.0
|
| 25 |
+
mdurl==0.1.2
|
| 26 |
+
nltk==3.8.1
|
| 27 |
+
numpy==1.26.0
|
| 28 |
+
openpyxl==3.1.2
|
| 29 |
+
packaging==23.1
|
| 30 |
+
pandas==2.1.1
|
| 31 |
+
Pillow==9.5.0
|
| 32 |
+
protobuf==4.24.3
|
| 33 |
+
pyarrow==13.0.0
|
| 34 |
+
pydeck==0.8.1b0
|
| 35 |
+
Pygments==2.16.1
|
| 36 |
+
pyparsing==3.1.1
|
| 37 |
+
PyQt5==5.15.9
|
| 38 |
+
PyQt5-Qt5==5.15.2
|
| 39 |
+
PyQt5-sip==12.12.2
|
| 40 |
+
python-dateutil==2.8.2
|
| 41 |
+
pytz==2023.3.post1
|
| 42 |
+
referencing==0.30.2
|
| 43 |
+
regex==2023.8.8
|
| 44 |
+
requests==2.31.0
|
| 45 |
+
rich==13.5.3
|
| 46 |
+
rpds-py==0.10.3
|
| 47 |
+
scikit-learn==1.3.1
|
| 48 |
+
scipy==1.11.2
|
| 49 |
+
seaborn==0.12.2
|
| 50 |
+
six==1.16.0
|
| 51 |
+
smart-open==6.4.0
|
| 52 |
+
smmap==5.0.1
|
| 53 |
+
streamlit==1.27.0
|
| 54 |
+
tenacity==8.2.3
|
| 55 |
+
threadpoolctl==3.2.0
|
| 56 |
+
toml==0.10.2
|
| 57 |
+
toolz==0.12.0
|
| 58 |
+
tornado==6.3.3
|
| 59 |
+
tqdm==4.66.1
|
| 60 |
+
typing_extensions==4.8.0
|
| 61 |
+
tzdata==2023.3
|
| 62 |
+
tzlocal==5.0.1
|
| 63 |
+
urllib3==2.0.5
|
| 64 |
+
validators==0.22.0
|
| 65 |
+
watchdog==3.0.0
|
| 66 |
+
XlsxWriter==3.1.4
|
| 67 |
+
zipp==3.17.0
|
rnk-1.png
ADDED

|
rnk-2.png
ADDED
|
rnk-3.png
ADDED
|
rnk-4.png
ADDED

|
tfidf_vectorizer.joblib
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:986d302aa10cddb969608ad2afe08fade436d19afd812ba508a0c8b4f1498a2b
|
| 3 |
+
size 794455
|
train_classifier.py
ADDED
|
@@ -0,0 +1,102 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import joblib
|
| 2 |
+
import matplotlib.pyplot as plt
|
| 3 |
+
import pandas as pd
|
| 4 |
+
import re
|
| 5 |
+
import seaborn as sns
|
| 6 |
+
from nltk.corpus import stopwords
|
| 7 |
+
from nltk.stem import PorterStemmer
|
| 8 |
+
from sklearn import metrics
|
| 9 |
+
from sklearn.feature_extraction.text import TfidfVectorizer
|
| 10 |
+
from sklearn.model_selection import train_test_split, GridSearchCV
|
| 11 |
+
from sklearn.neighbors import KNeighborsClassifier, NeighborhoodComponentsAnalysis
|
| 12 |
+
from sklearn.preprocessing import LabelEncoder
|
| 13 |
+
|
| 14 |
+
file_path = '~/Projects/hau/csstudy/resume-screening-and-classification/knn-trial/datasets/dataset_hr_edited.csv'
|
| 15 |
+
|
| 16 |
+
resumeDataSet = pd.read_csv(file_path)
|
| 17 |
+
|
| 18 |
+
stop_words = set(stopwords.words('english'))
|
| 19 |
+
stemmer = PorterStemmer()
|
| 20 |
+
|
| 21 |
+
print (resumeDataSet['Category'].value_counts())
|
| 22 |
+
|
| 23 |
+
def cleanResume(resumeText):
|
| 24 |
+
resumeText = re.sub('http\S+\s*', ' ', resumeText) # remove URLs
|
| 25 |
+
resumeText = re.sub('RT|cc', ' ', resumeText) # remove RT and cc
|
| 26 |
+
resumeText = re.sub('#\S+', '', resumeText) # remove hashtags
|
| 27 |
+
resumeText = re.sub('@\S+', ' ', resumeText) # remove mentions
|
| 28 |
+
resumeText = re.sub('[%s]' % re.escape("""!"#$%&'()*+,-./:;<=>?@[\]^_`{|}~"""), ' ', resumeText) # remove punctuations
|
| 29 |
+
resumeText = re.sub(r'[^\x00-\x7f]',r' ', resumeText)
|
| 30 |
+
resumeText = re.sub('\s+', ' ', resumeText) # remove extra whitespace
|
| 31 |
+
|
| 32 |
+
words = resumeText.split()
|
| 33 |
+
words = [word for word in words if word.lower() not in stop_words]
|
| 34 |
+
words = [stemmer.stem(word.lower()) for word in words if word.lower() not in stop_words]
|
| 35 |
+
resumeText = ' '.join(words)
|
| 36 |
+
return resumeText
|
| 37 |
+
|
| 38 |
+
resumeDataSet['cleaned_resume'] = resumeDataSet.Resume.apply(lambda x: cleanResume(x))
|
| 39 |
+
|
| 40 |
+
le = LabelEncoder()
|
| 41 |
+
resumeDataSet['Category'] = le.fit_transform(resumeDataSet['Category'])
|
| 42 |
+
le_filename = f'label_encoder.joblib'
|
| 43 |
+
joblib.dump(le, le_filename)
|
| 44 |
+
|
| 45 |
+
requiredText = resumeDataSet['cleaned_resume'].values
|
| 46 |
+
requiredTarget = resumeDataSet['Category'].values
|
| 47 |
+
|
| 48 |
+
word_vectorizer = TfidfVectorizer(
|
| 49 |
+
stop_words='english',
|
| 50 |
+
sublinear_tf=True,
|
| 51 |
+
max_features=18038
|
| 52 |
+
)
|
| 53 |
+
|
| 54 |
+
word_vectorizer.fit(requiredText)
|
| 55 |
+
joblib.dump(word_vectorizer, 'tfidf_vectorizer.joblib')
|
| 56 |
+
WordFeatures = word_vectorizer.transform(requiredText)
|
| 57 |
+
|
| 58 |
+
nca = NeighborhoodComponentsAnalysis(n_components=300, random_state=42)
|
| 59 |
+
WordFeatures = nca.fit_transform(WordFeatures.toarray(), requiredTarget)
|
| 60 |
+
nca_filename = f'nca_model.joblib'
|
| 61 |
+
joblib.dump(nca, nca_filename)
|
| 62 |
+
|
| 63 |
+
X_train,X_test,y_train,y_test = train_test_split(WordFeatures,requiredTarget,random_state=42, test_size=0.2,shuffle=True, stratify=requiredTarget)
|
| 64 |
+
print(X_train.shape)
|
| 65 |
+
print(X_test.shape)
|
| 66 |
+
|
| 67 |
+
# n_neighbors_values = [1, 3, 5, 7, 9, 11, 13, 15, 17, 19, 21, 23, 25, 27, 29, 31, 33, 35, 37, 39, 41, 43, 45, 47, 49, 51, 53, 55, 57, 59, 61, 63, 65, 67, 69, 71, 73, 75, 77, 79, 81, 83, 85, 87, 89, 91, 93, 95, 97, 99]
|
| 68 |
+
# weights = ["uniform", "distance"]
|
| 69 |
+
# metric = ["euclidean", "manhattan", "minkowski", "cosine"]
|
| 70 |
+
# algorithm = ['ball_tree', 'kd_tree', 'brute', 'auto']
|
| 71 |
+
# param_grid = dict(n_neighbors=n_neighbors_values, weights=weights, metric=metric, algorithm=algorithm)
|
| 72 |
+
# knn = KNeighborsClassifier()
|
| 73 |
+
# gs = GridSearchCV(estimator=knn, param_grid=param_grid, scoring="accuracy", verbose=1, cv=10, n_jobs=3)
|
| 74 |
+
# grid_search = gs.fit(X_train, y_train)
|
| 75 |
+
# best_score = grid_search.best_score_
|
| 76 |
+
# best_parameters = grid_search.best_params_
|
| 77 |
+
# print("Best Score:", best_score)
|
| 78 |
+
# print("Best Parameters:", best_parameters)
|
| 79 |
+
|
| 80 |
+
knn = KNeighborsClassifier(n_neighbors=1,
|
| 81 |
+
metric='manhattan',
|
| 82 |
+
weights='uniform',
|
| 83 |
+
algorithm='ball_tree',
|
| 84 |
+
)
|
| 85 |
+
knn.fit(X_train, y_train)
|
| 86 |
+
|
| 87 |
+
knnModel_filename = f'knn_model.joblib'
|
| 88 |
+
joblib.dump(knn, knnModel_filename)
|
| 89 |
+
|
| 90 |
+
prediction = knn.predict(X_test)
|
| 91 |
+
print('Accuracy of KNeighbors Classifier on training set: {:.2f}'.format(knn.score(X_train, y_train)))
|
| 92 |
+
print('Accuracy of KNeighbors Classifier on test set: {:.2f}'.format(knn.score(X_test, y_test)))
|
| 93 |
+
print("\n Classification report for classifier %s:\n%s\n" % (knn, metrics.classification_report(y_test, prediction)))
|
| 94 |
+
|
| 95 |
+
confusion_matrix = metrics.confusion_matrix(y_test, prediction)
|
| 96 |
+
|
| 97 |
+
plt.figure(figsize=(10, 10))
|
| 98 |
+
sns.heatmap(confusion_matrix, annot=True, fmt='d', cmap='Blues', xticklabels=le.classes_, yticklabels=le.classes_)
|
| 99 |
+
plt.xlabel('Predicted')
|
| 100 |
+
plt.ylabel('True')
|
| 101 |
+
plt.title('Confusion Matrix')
|
| 102 |
+
plt.show()
|
utils.py
ADDED
|
@@ -0,0 +1,602 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import altair as alt
|
| 2 |
+
# import datetime
|
| 3 |
+
import joblib
|
| 4 |
+
import nltk
|
| 5 |
+
import numpy as np
|
| 6 |
+
import pandas as pd
|
| 7 |
+
import re
|
| 8 |
+
import streamlit as st
|
| 9 |
+
import time
|
| 10 |
+
|
| 11 |
+
from gensim.corpora import Dictionary
|
| 12 |
+
from gensim.models import KeyedVectors, TfidfModel
|
| 13 |
+
from gensim.similarities import SoftCosineSimilarity, SparseTermSimilarityMatrix, WordEmbeddingSimilarityIndex
|
| 14 |
+
from io import BytesIO
|
| 15 |
+
from nltk import pos_tag, word_tokenize
|
| 16 |
+
from nltk.corpus import stopwords, wordnet
|
| 17 |
+
from nltk.stem import PorterStemmer, WordNetLemmatizer
|
| 18 |
+
from pandas.api.types import is_categorical_dtype, is_numeric_dtype
|
| 19 |
+
from PIL import Image
|
| 20 |
+
from scipy.sparse import csr_matrix, hstack
|
| 21 |
+
|
| 22 |
+
nltk.download('averaged_perceptron_tagger')
|
| 23 |
+
nltk.download('punkt')
|
| 24 |
+
nltk.download('stopwords')
|
| 25 |
+
|
| 26 |
+
stop_words = set(stopwords.words('english'))
|
| 27 |
+
lemmatizer = WordNetLemmatizer()
|
| 28 |
+
stemmer = PorterStemmer()
|
| 29 |
+
|
| 30 |
+
def addZeroFeatures(matrix):
|
| 31 |
+
maxFeatures = 18038
|
| 32 |
+
numDocs, numTerms = matrix.shape
|
| 33 |
+
missingFeatures = maxFeatures - numTerms
|
| 34 |
+
if missingFeatures > 0:
|
| 35 |
+
zeroFeatures = csr_matrix((numDocs, missingFeatures), dtype=np.float64)
|
| 36 |
+
matrix = hstack([matrix, zeroFeatures])
|
| 37 |
+
return matrix
|
| 38 |
+
|
| 39 |
+
@st.cache_data(max_entries = 1, show_spinner = False)
|
| 40 |
+
def classifyResumes(df):
|
| 41 |
+
# WITH PROGRESS BAR
|
| 42 |
+
progressBar = st.progress(0)
|
| 43 |
+
progressBar.progress(0, text = "Preprocessing data ...")
|
| 44 |
+
startTime = time.time()
|
| 45 |
+
df['cleanedResume'] = df.Resume.apply(lambda x: performStemming(x))
|
| 46 |
+
resumeText = df['cleanedResume'].values
|
| 47 |
+
progressBar.progress(20, text = "Extracting features ...")
|
| 48 |
+
vectorizer = loadTfidfVectorizer()
|
| 49 |
+
wordFeatures = vectorizer.transform(resumeText)
|
| 50 |
+
wordFeaturesWithZeros = addZeroFeatures(wordFeatures)
|
| 51 |
+
progressBar.progress(40, text = "Reducing dimensionality ...")
|
| 52 |
+
finalFeatures = dimensionalityReduction(wordFeaturesWithZeros)
|
| 53 |
+
progressBar.progress(60, text = "Predicting categories ...")
|
| 54 |
+
knn = loadKnnModel()
|
| 55 |
+
predictedCategories = knn.predict(finalFeatures)
|
| 56 |
+
progressBar.progress(80, text = "Finishing touches ...")
|
| 57 |
+
le = loadLabelEncoder()
|
| 58 |
+
df['Industry Category'] = le.inverse_transform(predictedCategories)
|
| 59 |
+
df['Industry Category'] = pd.Categorical(df['Industry Category'])
|
| 60 |
+
df.drop(columns = ['cleanedResume'], inplace = True)
|
| 61 |
+
endTime = time.time()
|
| 62 |
+
elapsedSeconds = endTime - startTime
|
| 63 |
+
hours, remainder = divmod(int(elapsedSeconds), 3600)
|
| 64 |
+
minutes, _ = divmod(remainder, 60)
|
| 65 |
+
secondsWithDecimals = '{:.2f}'.format(elapsedSeconds % 60)
|
| 66 |
+
elapsedTimeStr = f'{hours} h : {minutes} m : {secondsWithDecimals} s'
|
| 67 |
+
progressBar.progress(100, text = f'Classification Complete!')
|
| 68 |
+
time.sleep(1)
|
| 69 |
+
progressBar.empty()
|
| 70 |
+
st.info(f'Finished classifying {len(resumeText)} resumes - {elapsedTimeStr}')
|
| 71 |
+
return df
|
| 72 |
+
|
| 73 |
+
# NO LOADING WIDGET
|
| 74 |
+
# startTime = time.time()
|
| 75 |
+
# df['cleanedResume'] = df.Resume.apply(lambda x: performStemming(x))
|
| 76 |
+
# resumeText = df['cleanedResume'].values
|
| 77 |
+
# vectorizer = loadTfidfVectorizer()
|
| 78 |
+
# wordFeatures = vectorizer.transform(resumeText)
|
| 79 |
+
# wordFeaturesWithZeros = addZeroFeatures(wordFeatures)
|
| 80 |
+
# finalFeatures = dimensionalityReduction(wordFeaturesWithZeros)
|
| 81 |
+
# knn = loadKnnModel()
|
| 82 |
+
# predictedCategories = knn.predict(finalFeatures)
|
| 83 |
+
# le = loadLabelEncoder()
|
| 84 |
+
# df['Industry Category'] = le.inverse_transform(predictedCategories)
|
| 85 |
+
# df['Industry Category'] = pd.Categorical(df['Industry Category'])
|
| 86 |
+
# df.drop(columns = ['cleanedResume'], inplace = True)
|
| 87 |
+
# endTime = time.time()
|
| 88 |
+
# elapsedSeconds = endTime - startTime
|
| 89 |
+
# elapsedTime = datetime.timedelta(seconds = elapsedSeconds)
|
| 90 |
+
# hours, remainder = divmod(elapsedTime.seconds, 3600)
|
| 91 |
+
# minutes, seconds = divmod(remainder, 60)
|
| 92 |
+
# elapsedTimeStr = f"{hours} hr {minutes} min {seconds} sec"
|
| 93 |
+
# st.info(f'Finished in {elapsedTimeStr}')
|
| 94 |
+
# return df
|
| 95 |
+
|
| 96 |
+
def clickClassify():
|
| 97 |
+
st.session_state.processClf = True
|
| 98 |
+
|
| 99 |
+
def clickRank():
|
| 100 |
+
st.session_state.processRank = True
|
| 101 |
+
|
| 102 |
+
def convertDfToXlsx(df):
|
| 103 |
+
output = BytesIO()
|
| 104 |
+
writer = pd.ExcelWriter(output, engine = 'xlsxwriter')
|
| 105 |
+
df.to_excel(writer, index = False, sheet_name = 'Sheet1')
|
| 106 |
+
workbook = writer.book
|
| 107 |
+
worksheet = writer.sheets['Sheet1']
|
| 108 |
+
format1 = workbook.add_format({'num_format': '0.00'})
|
| 109 |
+
worksheet.set_column('A:A', None, format1)
|
| 110 |
+
writer.close()
|
| 111 |
+
processedData = output.getvalue()
|
| 112 |
+
return processedData
|
| 113 |
+
|
| 114 |
+
def createBarChart(df):
|
| 115 |
+
valueCounts = df['Industry Category'].value_counts().reset_index()
|
| 116 |
+
valueCounts.columns = ['Industry Category', 'Count']
|
| 117 |
+
newDataframe = pd.DataFrame(valueCounts)
|
| 118 |
+
barChart = alt.Chart(newDataframe,
|
| 119 |
+
).mark_bar(
|
| 120 |
+
color = '#56B6C2',
|
| 121 |
+
size = 13
|
| 122 |
+
).encode(
|
| 123 |
+
x = alt.X('Count:Q', axis = alt.Axis(format = 'd'), title = 'Number of Resumes'),
|
| 124 |
+
y = alt.Y('Industry Category:N', title = 'Category'),
|
| 125 |
+
tooltip = ['Industry Category', 'Count']
|
| 126 |
+
).properties(
|
| 127 |
+
title = 'Number of Resumes per Category',
|
| 128 |
+
)
|
| 129 |
+
return barChart
|
| 130 |
+
|
| 131 |
+
def dimensionalityReduction(features):
|
| 132 |
+
nca = joblib.load('nca_model.joblib')
|
| 133 |
+
features = nca.transform(features.toarray())
|
| 134 |
+
return features
|
| 135 |
+
|
| 136 |
+
def filterDataframeClf(df: pd.DataFrame) -> pd.DataFrame:
|
| 137 |
+
modify = st.toggle("Add filters", key = 'filter-clf-1')
|
| 138 |
+
if not modify:
|
| 139 |
+
return df
|
| 140 |
+
df = df.copy()
|
| 141 |
+
modificationContainer = st.container()
|
| 142 |
+
with modificationContainer:
|
| 143 |
+
toFilterColumns = st.multiselect("Filter table on", df.columns, key = 'filter-clf-2')
|
| 144 |
+
for column in toFilterColumns:
|
| 145 |
+
left, right = st.columns((1, 20))
|
| 146 |
+
left.write("↳")
|
| 147 |
+
widgetKey = f'filter-clf-{toFilterColumns.index(column)}-{column}'
|
| 148 |
+
if is_categorical_dtype(df[column]):
|
| 149 |
+
userCatInput = right.multiselect(
|
| 150 |
+
f'Values for {column}',
|
| 151 |
+
df[column].unique(),
|
| 152 |
+
default = list(df[column].unique()),
|
| 153 |
+
key = widgetKey
|
| 154 |
+
)
|
| 155 |
+
df = df[df[column].isin(userCatInput)]
|
| 156 |
+
elif is_numeric_dtype(df[column]):
|
| 157 |
+
_min = float(df[column].min())
|
| 158 |
+
_max = float(df[column].max())
|
| 159 |
+
step = (_max - _min) / 100
|
| 160 |
+
userNumInput = right.slider(
|
| 161 |
+
f'Values for {column}',
|
| 162 |
+
min_value = _min,
|
| 163 |
+
max_value = _max,
|
| 164 |
+
value = (_min, _max),
|
| 165 |
+
step = step,
|
| 166 |
+
key = widgetKey
|
| 167 |
+
)
|
| 168 |
+
df = df[df[column].between(*userNumInput)]
|
| 169 |
+
else:
|
| 170 |
+
userTextInput = right.text_input(
|
| 171 |
+
f'Substring or regex in {column}',
|
| 172 |
+
key = widgetKey
|
| 173 |
+
)
|
| 174 |
+
if userTextInput:
|
| 175 |
+
userTextInput = userTextInput.lower()
|
| 176 |
+
df = df[df[column].astype(str).str.lower().str.contains(userTextInput)]
|
| 177 |
+
return df
|
| 178 |
+
|
| 179 |
+
def filterDataframeRnk(df: pd.DataFrame) -> pd.DataFrame:
|
| 180 |
+
modify = st.toggle("Add filters", key = 'filter-rnk-1')
|
| 181 |
+
if not modify:
|
| 182 |
+
return df
|
| 183 |
+
df = df.copy()
|
| 184 |
+
modificationContainer = st.container()
|
| 185 |
+
with modificationContainer:
|
| 186 |
+
toFilterColumns = st.multiselect("Filter table on", df.columns, key = 'filter-rnk-2')
|
| 187 |
+
for column in toFilterColumns:
|
| 188 |
+
left, right = st.columns((1, 20))
|
| 189 |
+
left.write("↳")
|
| 190 |
+
widgetKey = f'filter-rnk-{toFilterColumns.index(column)}-{column}'
|
| 191 |
+
if is_categorical_dtype(df[column]):
|
| 192 |
+
userCatInput = right.multiselect(
|
| 193 |
+
f'Values for {column}',
|
| 194 |
+
df[column].unique(),
|
| 195 |
+
default = list(df[column].unique()),
|
| 196 |
+
key = widgetKey
|
| 197 |
+
)
|
| 198 |
+
df = df[df[column].isin(userCatInput)]
|
| 199 |
+
elif is_numeric_dtype(df[column]):
|
| 200 |
+
_min = float(df[column].min())
|
| 201 |
+
_max = float(df[column].max())
|
| 202 |
+
step = (_max - _min) / 100
|
| 203 |
+
userNumInput = right.slider(
|
| 204 |
+
f'Values for {column}',
|
| 205 |
+
min_value = _min,
|
| 206 |
+
max_value = _max,
|
| 207 |
+
value = (_min, _max),
|
| 208 |
+
step = step,
|
| 209 |
+
key = widgetKey
|
| 210 |
+
)
|
| 211 |
+
df = df[df[column].between(*userNumInput)]
|
| 212 |
+
else:
|
| 213 |
+
userTextInput = right.text_input(
|
| 214 |
+
f'Substring or regex in {column}',
|
| 215 |
+
key = widgetKey
|
| 216 |
+
)
|
| 217 |
+
if userTextInput:
|
| 218 |
+
userTextInput = userTextInput.lower()
|
| 219 |
+
df = df[df[column].astype(str).str.lower().str.contains(userTextInput)]
|
| 220 |
+
return df
|
| 221 |
+
|
| 222 |
+
def getWordnetPos(tag):
|
| 223 |
+
if tag.startswith('J'):
|
| 224 |
+
return wordnet.ADJ
|
| 225 |
+
elif tag.startswith('V'):
|
| 226 |
+
return wordnet.VERB
|
| 227 |
+
elif tag.startswith('N'):
|
| 228 |
+
return wordnet.NOUN
|
| 229 |
+
elif tag.startswith('R'):
|
| 230 |
+
return wordnet.ADV
|
| 231 |
+
else:
|
| 232 |
+
return wordnet.NOUN
|
| 233 |
+
|
| 234 |
+
def loadKnnModel():
|
| 235 |
+
knnModelFileName = f'knn_model.joblib'
|
| 236 |
+
return joblib.load(knnModelFileName)
|
| 237 |
+
|
| 238 |
+
def loadLabelEncoder():
|
| 239 |
+
labelEncoderFileName = f'label_encoder.joblib'
|
| 240 |
+
return joblib.load(labelEncoderFileName)
|
| 241 |
+
|
| 242 |
+
def loadTfidfVectorizer():
|
| 243 |
+
tfidfVectorizerFileName = f'tfidf_vectorizer.joblib'
|
| 244 |
+
return joblib.load(tfidfVectorizerFileName)
|
| 245 |
+
|
| 246 |
+
def performLemmatization(text):
|
| 247 |
+
text = re.sub('http\S+\s*', ' ', text)
|
| 248 |
+
text = re.sub('RT|cc', ' ', text)
|
| 249 |
+
text = re.sub('#\S+', '', text)
|
| 250 |
+
text = re.sub('@\S+', ' ', text)
|
| 251 |
+
text = re.sub('[%s]' % re.escape("""!"#$%&'()*+,-./:;<=>?@[\]^_`{|}~"""), ' ', text)
|
| 252 |
+
text = re.sub(r'[^\x00-\x7f]',r' ', text)
|
| 253 |
+
text = re.sub('\s+', ' ', text)
|
| 254 |
+
words = word_tokenize(text)
|
| 255 |
+
words = [
|
| 256 |
+
lemmatizer.lemmatize(word.lower(), pos = getWordnetPos(pos))
|
| 257 |
+
for word, pos in pos_tag(words) if word.lower() not in stop_words
|
| 258 |
+
]
|
| 259 |
+
return words
|
| 260 |
+
|
| 261 |
+
def performStemming(text):
|
| 262 |
+
text = re.sub('http\S+\s*', ' ', text)
|
| 263 |
+
text = re.sub('RT|cc', ' ', text)
|
| 264 |
+
text = re.sub('#\S+', '', text)
|
| 265 |
+
text = re.sub('@\S+', ' ', text)
|
| 266 |
+
text = re.sub('[%s]' % re.escape("""!"#$%&'()*+,-./:;<=>?@[\]^_`{|}~"""), ' ', text)
|
| 267 |
+
text = re.sub(r'[^\x00-\x7f]',r' ', text)
|
| 268 |
+
text = re.sub('\s+', ' ', text)
|
| 269 |
+
words = word_tokenize(text)
|
| 270 |
+
words = [stemmer.stem(word.lower()) for word in words if word.lower() not in stop_words]
|
| 271 |
+
text = ' '.join(words)
|
| 272 |
+
return text
|
| 273 |
+
|
| 274 |
+
@st.cache_data
|
| 275 |
+
def loadModel():
|
| 276 |
+
# model_path = '~/Projects/hau/csstudy/final-csstudy/wiki-news-300d-1M-subword.vec'
|
| 277 |
+
model_path = 'wiki-news-300d-1M-subword.vec'
|
| 278 |
+
model = KeyedVectors.load_word2vec_format(model_path, limit = 100000)
|
| 279 |
+
return model
|
| 280 |
+
|
| 281 |
+
model = loadModel()
|
| 282 |
+
|
| 283 |
+
@st.cache_data(max_entries = 1, show_spinner = False)
|
| 284 |
+
def rankResumes(text, df):
|
| 285 |
+
# WITH PROGRESS BAR
|
| 286 |
+
progressBar = st.progress(0)
|
| 287 |
+
progressBar.progress(0, text = "Preprocessing data ...")
|
| 288 |
+
startTime = time.time()
|
| 289 |
+
jobDescriptionText = performLemmatization(text)
|
| 290 |
+
df['cleanedResume'] = df['Resume'].apply(lambda x: performLemmatization(x))
|
| 291 |
+
documents = [jobDescriptionText] + df['cleanedResume'].tolist()
|
| 292 |
+
progressBar.progress(13, text = "Creating a dictionary ...")
|
| 293 |
+
dictionary = Dictionary(documents)
|
| 294 |
+
progressBar.progress(25, text = "Creating a TF-IDF model ...")
|
| 295 |
+
tfidf = TfidfModel(dictionary = dictionary)
|
| 296 |
+
progressBar.progress(38, text = "Creating a Similarity Index...")
|
| 297 |
+
similarityIndex = WordEmbeddingSimilarityIndex(model)
|
| 298 |
+
progressBar.progress(50, text = "Creating a Similarity Matrix...")
|
| 299 |
+
similarityMatrix = SparseTermSimilarityMatrix(similarityIndex, dictionary, tfidf)
|
| 300 |
+
progressBar.progress(63, text = "Setting up job description as the query ...")
|
| 301 |
+
query = tfidf[dictionary.doc2bow(jobDescriptionText)]
|
| 302 |
+
progressBar.progress(75, text = "Calculating semantic similarities ...")
|
| 303 |
+
index = SoftCosineSimilarity(
|
| 304 |
+
tfidf[[dictionary.doc2bow(resume) for resume in df['cleanedResume']]],
|
| 305 |
+
similarityMatrix
|
| 306 |
+
)
|
| 307 |
+
similarities = index[query]
|
| 308 |
+
progressBar.progress(88, text = "Finishing touches ...")
|
| 309 |
+
df['Similarity Score'] = similarities
|
| 310 |
+
df['Rank'] = df['Similarity Score'].rank(ascending=False, method='dense').astype(int)
|
| 311 |
+
df.sort_values(by='Rank', inplace=True)
|
| 312 |
+
df.drop(columns = ['cleanedResume'], inplace = True)
|
| 313 |
+
endTime = time.time()
|
| 314 |
+
elapsedSeconds = endTime - startTime
|
| 315 |
+
hours, remainder = divmod(int(elapsedSeconds), 3600)
|
| 316 |
+
minutes, _ = divmod(remainder, 60)
|
| 317 |
+
secondsWithDecimals = '{:.2f}'.format(elapsedSeconds % 60)
|
| 318 |
+
elapsedTimeStr = f'{hours} h : {minutes} m : {secondsWithDecimals} s'
|
| 319 |
+
progressBar.progress(100, text = f'Classification Complete!')
|
| 320 |
+
time.sleep(1)
|
| 321 |
+
progressBar.empty()
|
| 322 |
+
st.info(f'Finished ranking {len(df)} resumes - {elapsedTimeStr}')
|
| 323 |
+
return df
|
| 324 |
+
|
| 325 |
+
# NO LOADING WIDGET
|
| 326 |
+
# startTime = time.time()
|
| 327 |
+
# jobDescriptionText = performLemmatization(text)
|
| 328 |
+
# df['cleanedResume'] = df['Resume'].apply(lambda x: performLemmatization(x))
|
| 329 |
+
# documents = [jobDescriptionText] + df['cleanedResume'].tolist()
|
| 330 |
+
# dictionary = Dictionary(documents)
|
| 331 |
+
# tfidf = TfidfModel(dictionary = dictionary)
|
| 332 |
+
# similarityIndex = WordEmbeddingSimilarityIndex(model)
|
| 333 |
+
# similarityMatrix = SparseTermSimilarityMatrix(similarityIndex, dictionary, tfidf)
|
| 334 |
+
# query = tfidf[dictionary.doc2bow(jobDescriptionText)]
|
| 335 |
+
# index = SoftCosineSimilarity(
|
| 336 |
+
# tfidf[[dictionary.doc2bow(resume) for resume in df['cleanedResume']]],
|
| 337 |
+
# similarityMatrix
|
| 338 |
+
# )
|
| 339 |
+
# similarities = index[query]
|
| 340 |
+
# df['Similarity Score'] = similarities
|
| 341 |
+
# df.sort_values(by = 'Similarity Score', ascending = False, inplace = True)
|
| 342 |
+
# df.drop(columns = ['cleanedResume'], inplace = True)
|
| 343 |
+
# endTime = time.time()
|
| 344 |
+
# elapsedSeconds = endTime - startTime
|
| 345 |
+
# elapsedTime = datetime.timedelta(seconds = elapsedSeconds)
|
| 346 |
+
# hours, remainder = divmod(elapsedTime.seconds, 3600)
|
| 347 |
+
# minutes, seconds = divmod(remainder, 60)
|
| 348 |
+
# elapsedTimeStr = f"{hours} hr {minutes} min {seconds} sec"
|
| 349 |
+
# st.info(f'Finished in {elapsedTimeStr}')
|
| 350 |
+
# return df
|
| 351 |
+
|
| 352 |
+
# TF-IDF + LSA + COSSIM
|
| 353 |
+
# from sklearn.decomposition import TruncatedSVD
|
| 354 |
+
# import math
|
| 355 |
+
# def resumesRank(jobDescriptionRnk, resumeRnk):
|
| 356 |
+
# jobDescriptionRnk = preprocessing(jobDescriptionRnk)
|
| 357 |
+
# resumeRnk['cleanedResume'] = resumeRnk.Resume.apply(lambda x: preprocessing(x))
|
| 358 |
+
# resumes = resumeRnk['cleanedResume'].values
|
| 359 |
+
# # tfidfVectorizer = TfidfVectorizer(sublinear_tf = True, stop_words = 'english')
|
| 360 |
+
# # tfidfVectorizer = TfidfVectorizer(sublinear_tf = True)
|
| 361 |
+
# # tfidfVectorizer = TfidfVectorizer(stop_words = 'english')
|
| 362 |
+
# tfidfVectorizer = TfidfVectorizer()
|
| 363 |
+
# tfidfMatrix = tfidfVectorizer.fit_transform([jobDescriptionRnk] + list(resumes))
|
| 364 |
+
# num_features = len(tfidfVectorizer.get_feature_names_out())
|
| 365 |
+
# st.write(f"Number of TF-IDF Features: {num_features}")
|
| 366 |
+
# nComponents = math.ceil(len(resumes) * 0.55)
|
| 367 |
+
# # nComponents = math.ceil(num_features * 0.01)
|
| 368 |
+
# # nComponents = 5
|
| 369 |
+
# st.write(nComponents)
|
| 370 |
+
# # nComponents = len(resumes)
|
| 371 |
+
# lsa = TruncatedSVD(n_components=nComponents)
|
| 372 |
+
# lsaMatrix = lsa.fit_transform(tfidfMatrix)
|
| 373 |
+
# similarityScores = cosine_similarity(lsaMatrix[0:1], lsaMatrix[1:])
|
| 374 |
+
# resumeRnk['Similarity Score (%)'] = similarityScores[0] * 100
|
| 375 |
+
# resumeRnk = resumeRnk.sort_values(by='Similarity Score (%)', ascending=False)
|
| 376 |
+
# del resumeRnk['cleanedResume']
|
| 377 |
+
# return resumeRnk
|
| 378 |
+
|
| 379 |
+
# 1 BY 1 SOFT COSSIM
|
| 380 |
+
# def resumesRank(jobDescriptionRnk, resumeRnk):
|
| 381 |
+
# jobDescriptionText = preprocessing2(jobDescriptionRnk)
|
| 382 |
+
# resumeRnk['cleanedResume'] = resumeRnk['Resume'].apply(lambda x: preprocessing2(x))
|
| 383 |
+
# similarityscore = []
|
| 384 |
+
# for resume in resumeRnk['cleanedResume']:
|
| 385 |
+
# documents = [jobDescriptionText, resume]
|
| 386 |
+
# dictionary = Dictionary(documents)
|
| 387 |
+
# documentBow = [dictionary.doc2bow(doc) for doc in documents]
|
| 388 |
+
# tfidf = TfidfModel(documentBow, dictionary=dictionary)
|
| 389 |
+
# similarityIndex = WordEmbeddingSimilarityIndex(model)
|
| 390 |
+
# similarityMatrix = SparseTermSimilarityMatrix(similarityIndex, dictionary, tfidf)
|
| 391 |
+
# # similarityMatrix = SparseTermSimilarityMatrix(similarityIndex, dictionary)
|
| 392 |
+
# value = tfidf[dictionary.doc2bow(resume)]
|
| 393 |
+
# # value = dictionary.doc2bow(jobDescriptionText)
|
| 394 |
+
# index = SoftCosineSimilarity(
|
| 395 |
+
# # tfidf[[dictionary.doc2bow(resume)]],
|
| 396 |
+
# tfidf[[dictionary.doc2bow(jobDescriptionText)]],
|
| 397 |
+
# # [dictionary.doc2bow(resume) for resume in resumeRnk['cleanedResume']],
|
| 398 |
+
# similarityMatrix,
|
| 399 |
+
# )
|
| 400 |
+
# similarities = index[value]
|
| 401 |
+
# similarityscore.append(similarities)
|
| 402 |
+
# print(similarityscore)
|
| 403 |
+
# resumeRnk['Similarity Score'] = similarityscore
|
| 404 |
+
# resumeRnk.sort_values(by='Similarity Score', ascending=False, inplace=True)
|
| 405 |
+
# resumeRnk.drop(columns=['cleanedResume'], inplace=True)
|
| 406 |
+
# return resumeRnk
|
| 407 |
+
#
|
| 408 |
+
# TF-IDF SCORE + WORD EMBEDDINGS SCORE
|
| 409 |
+
# def resumesRank(jobDescriptionRnk, resumeRnk):
|
| 410 |
+
# def get_word_embedding(text):
|
| 411 |
+
# words = text.split()
|
| 412 |
+
# valid_words = [word for word in text.split() if word in model]
|
| 413 |
+
# if valid_words:
|
| 414 |
+
# return np.mean([model[word] for word in valid_words], axis=0)
|
| 415 |
+
# else:
|
| 416 |
+
# return np.zeros(model.vector_size)
|
| 417 |
+
# jobDescriptionRnk = preprocessing2(jobDescriptionRnk)
|
| 418 |
+
# resumeRnk['cleanedResume'] = resumeRnk.Resume.apply(lambda x: preprocessing2(x))
|
| 419 |
+
# tfidfVectorizer = TfidfVectorizer(sublinear_tf = True, stop_words='english')
|
| 420 |
+
# jobTfidf = tfidfVectorizer.fit_transform([jobDescriptionRnk])
|
| 421 |
+
# jobDescriptionEmbedding = get_word_embedding(jobDescriptionRnk)
|
| 422 |
+
# resumeSimilarities = []
|
| 423 |
+
# for resumeContent in resumeRnk['cleanedResume']:
|
| 424 |
+
# resumeEmbedding = get_word_embedding(resumeContent)
|
| 425 |
+
# similarityFastText = cosine_similarity([jobDescriptionEmbedding], [resumeEmbedding])[0][0]
|
| 426 |
+
# similarityTFIDF = cosine_similarity(jobTfidf, tfidfVectorizer.transform([resumeContent]))[0][0]
|
| 427 |
+
# similarity = (0.6 * similarityTFIDF) + (0.4 * similarityFastText)
|
| 428 |
+
# final_similarity = similarity * 100
|
| 429 |
+
# resumeSimilarities.append(final_similarity)
|
| 430 |
+
# resumeRnk['Similarity Score (%)'] = resumeSimilarities
|
| 431 |
+
# resumeRnk = resumeRnk.sort_values(by='Similarity Score (%)', ascending=False)
|
| 432 |
+
# del resumeRnk['cleanedResume']
|
| 433 |
+
# return resumeRnk
|
| 434 |
+
|
| 435 |
+
# WORD EMBEDDINGS + COSSIM
|
| 436 |
+
# def resumesRank(jobDescriptionRnk, resumeRnk):
|
| 437 |
+
# def get_word_embedding(text):
|
| 438 |
+
# words = text.split()
|
| 439 |
+
# valid_words = [word for word in text.split() if word in model]
|
| 440 |
+
# if valid_words:
|
| 441 |
+
# return np.mean([model[word] for word in valid_words], axis=0)
|
| 442 |
+
# else:
|
| 443 |
+
# return np.zeros(model.vector_size)
|
| 444 |
+
# jobDescriptionRnk = preprocessing2(jobDescriptionRnk)
|
| 445 |
+
# jobDescriptionEmbedding = get_word_embedding(jobDescriptionRnk)
|
| 446 |
+
# resumeRnk['cleanedResume'] = resumeRnk.Resume.apply(lambda x: preprocessing2(x))
|
| 447 |
+
# resumeSimilarities = []
|
| 448 |
+
# for resumeContent in resumeRnk['cleanedResume']:
|
| 449 |
+
# resumeEmbedding = get_word_embedding(resumeContent)
|
| 450 |
+
# similarity = cosine_similarity([jobDescriptionEmbedding], [resumeEmbedding])[0][0]
|
| 451 |
+
# percentageSimilarity = similarity * 100
|
| 452 |
+
# resumeSimilarities.append(percentageSimilarity)
|
| 453 |
+
# resumeRnk['Similarity Score (%)'] = resumeSimilarities
|
| 454 |
+
# resumeRnk = resumeRnk.sort_values(by='Similarity Score (%)', ascending=False)
|
| 455 |
+
# del resumeRnk['cleanedResume']
|
| 456 |
+
# return resumeRnk
|
| 457 |
+
|
| 458 |
+
# TF-IDF + COSSIM
|
| 459 |
+
# def resumesRank(jobDescriptionRnk, resumeRnk):
|
| 460 |
+
# jobDescriptionRnk = preprocessing2(jobDescriptionRnk)
|
| 461 |
+
# resumeRnk['cleanedResume'] = resumeRnk.Resume.apply(lambda x: preprocessing2(x))
|
| 462 |
+
# tfidfVectorizer = TfidfVectorizer(sublinear_tf = True, stop_words='english')
|
| 463 |
+
# jobTfidf = tfidfVectorizer.fit_transform([jobDescriptionRnk])
|
| 464 |
+
# resumeSimilarities = []
|
| 465 |
+
# for resumeContent in resumeRnk['cleanedResume']:
|
| 466 |
+
# resumeTfidf = tfidfVectorizer.transform([resumeContent])
|
| 467 |
+
# similarity = cosine_similarity(jobTfidf, resumeTfidf)
|
| 468 |
+
# percentageSimilarity = (similarity[0][0] * 100)
|
| 469 |
+
# resumeSimilarities.append(percentageSimilarity)
|
| 470 |
+
# resumeRnk['Similarity Score (%)'] = resumeSimilarities
|
| 471 |
+
# resumeRnk = resumeRnk.sort_values(by='Similarity Score (%)', ascending=False)
|
| 472 |
+
# del resumeRnk['cleanedResume']
|
| 473 |
+
# return resumeRnk
|
| 474 |
+
|
| 475 |
+
def writeGettingStarted():
|
| 476 |
+
st.write("""
|
| 477 |
+
## Hello, Welcome!
|
| 478 |
+
In today's competitive job market, the process of manually screening resumes has become a daunting task for recruiters and hiring managers.
|
| 479 |
+
The sheer volume of applications received for a single job posting can make it extremely time-consuming to identify the most suitable candidates efficiently.
|
| 480 |
+
This often leads to missed opportunities and the potential loss of top-tier talent.
|
| 481 |
+
|
| 482 |
+
The ***Resume Screening & Classification*** website application aims to help alleviate the challenges posed by manual resume screening.
|
| 483 |
+
The main objectives are:
|
| 484 |
+
- To classify the resumes into their most suitable job industry category
|
| 485 |
+
- To compare the resumes to the job description and rank them by similarity
|
| 486 |
+
""")
|
| 487 |
+
st.divider()
|
| 488 |
+
st.write("""
|
| 489 |
+
## Input Guide
|
| 490 |
+
#### For the Job Description:
|
| 491 |
+
Ensure the job description is saved in a text (.txt) file.
|
| 492 |
+
Kindly outline the responsibilities, qualifications, and skills associated with the position.
|
| 493 |
+
|
| 494 |
+
#### For the Resumes:
|
| 495 |
+
Resumes must be compiled in an excel (.xlsx) file.
|
| 496 |
+
The organization of columns is up to you but ensure that the "Resume" column is present.
|
| 497 |
+
The values under this column should include all the relevant details for each resume.
|
| 498 |
+
""")
|
| 499 |
+
st.divider()
|
| 500 |
+
st.write("""
|
| 501 |
+
## Demo Walkthrough
|
| 502 |
+
#### Classify Tab:
|
| 503 |
+
The web app will classify the resumes into their most suitable job industry category.
|
| 504 |
+
Currently the Category Scope consists of the following:
|
| 505 |
+
""")
|
| 506 |
+
column1, column2 = st.columns(2)
|
| 507 |
+
with column1:
|
| 508 |
+
st.write("""
|
| 509 |
+
- Aviation
|
| 510 |
+
- Business development
|
| 511 |
+
- Culinary
|
| 512 |
+
- Education
|
| 513 |
+
- Engineering
|
| 514 |
+
- Finance
|
| 515 |
+
""")
|
| 516 |
+
with column2:
|
| 517 |
+
st.write("""
|
| 518 |
+
- Fitness
|
| 519 |
+
- Healthcare
|
| 520 |
+
- HR
|
| 521 |
+
- Information Technology
|
| 522 |
+
- Public relations
|
| 523 |
+
""")
|
| 524 |
+
with st.expander('Classification Steps'):
|
| 525 |
+
st.write("""
|
| 526 |
+
##### Upload Resumes & Start Processing:
|
| 527 |
+
- Navigate to the "Classify" tab.
|
| 528 |
+
- Click the "Upload Resumes" button.
|
| 529 |
+
- Select the Excel file (.xlsx) containing the resumes you want to classify. Ensure that your Excel file has the "Resume" column with the resume text and any necessary columns for filtering or additional information.
|
| 530 |
+
- Click the "Start Processing" button.
|
| 531 |
+
- The app will analyze the resumes and categorize them into job industry categories.
|
| 532 |
+
######
|
| 533 |
+
""")
|
| 534 |
+
imgClf1 = Image.open('clf-1.png')
|
| 535 |
+
st.image(imgClf1, use_column_width = True, output_format = "PNG")
|
| 536 |
+
st.write("""
|
| 537 |
+
##### View Bar Chart:
|
| 538 |
+
- A bar chart will appear, showing the number of resumes per category, helping you visualize the distribution.
|
| 539 |
+
######
|
| 540 |
+
""")
|
| 541 |
+
imgClf2 = Image.open('clf-2.png')
|
| 542 |
+
st.image(imgClf2, use_column_width = True, output_format = "PNG")
|
| 543 |
+
st.write("""
|
| 544 |
+
##### Add Filters:
|
| 545 |
+
- You can apply filters to the dataframe to narrow down your results.
|
| 546 |
+
######
|
| 547 |
+
""")
|
| 548 |
+
imgClf3 = Image.open('clf-3.png')
|
| 549 |
+
st.image(imgClf3, use_column_width = True, output_format = "PNG")
|
| 550 |
+
st.write("""
|
| 551 |
+
##### Donwload Results:
|
| 552 |
+
- Once you've applied filters or are satisfied with the results, you can download the current dataframe as an Excel file by clicking the "Save Current Output as XLSX" button.
|
| 553 |
+
####
|
| 554 |
+
""")
|
| 555 |
+
imgClf4 = Image.open('clf-4.png')
|
| 556 |
+
st.image(imgClf4, use_column_width = True, output_format = "PNG")
|
| 557 |
+
st.write("""
|
| 558 |
+
#### Rank Tab:
|
| 559 |
+
The web app will rank the resumes based on their semantic similarity to the job description.
|
| 560 |
+
The similarity score ranges from -1 to 1.
|
| 561 |
+
A score of 1 is achieved when Document A and Document B are identical.
|
| 562 |
+
|
| 563 |
+
##### **Kindly take note:**
|
| 564 |
+
|
| 565 |
+
It's important to note that these scores are not absolute and may change when more resumes are added in the comparison.
|
| 566 |
+
The ranking algorithm dynamically adjusts its results based on the entire set of uploaded resumes.
|
| 567 |
+
We recommend considering the scores as a relative measure rather than an absolute determination.
|
| 568 |
+
""")
|
| 569 |
+
with st.expander('Ranking Steps'):
|
| 570 |
+
st.write("""
|
| 571 |
+
##### Upload Files & Start Processing:
|
| 572 |
+
- Navigate to the "Rank" tab.
|
| 573 |
+
- Upload the job description as a text file. This file should contain the description of the job you want to compare resumes against.
|
| 574 |
+
- Upload the Excel file that contains the resumes you want to rank.
|
| 575 |
+
- Click the "Start Processing" button.
|
| 576 |
+
- The app will analyze the job description and rank the resumes based on their similarity to the job description.
|
| 577 |
+
######
|
| 578 |
+
""")
|
| 579 |
+
imgRnk1 = Image.open('rnk-1.png')
|
| 580 |
+
st.image(imgRnk1, use_column_width = True, output_format = "PNG")
|
| 581 |
+
st.write("""
|
| 582 |
+
##### View Job Description:
|
| 583 |
+
- The output will display the contents of the job description for reference.
|
| 584 |
+
######
|
| 585 |
+
""")
|
| 586 |
+
imgRnk2 = Image.open('rnk-2.png')
|
| 587 |
+
st.image(imgRnk2, use_column_width = True, output_format = "PNG")
|
| 588 |
+
st.write("""
|
| 589 |
+
##### Add Filters:
|
| 590 |
+
- You can apply filters to the dataframe to narrow down your results.
|
| 591 |
+
######
|
| 592 |
+
""")
|
| 593 |
+
imgRnk3 = Image.open('rnk-3.png')
|
| 594 |
+
st.image(imgRnk3, use_column_width = True, output_format = "PNG")
|
| 595 |
+
st.write("""
|
| 596 |
+
##### Donwload Results:
|
| 597 |
+
- Once you've applied filters or are satisfied with the results, you can download the current dataframe as an Excel file by clicking the "Save Current Output as XLSX" button.
|
| 598 |
+
####
|
| 599 |
+
""")
|
| 600 |
+
imgRnk4 = Image.open('rnk-4.png')
|
| 601 |
+
st.image(imgRnk4, use_column_width = True, output_format = "PNG")
|
| 602 |
+
|
wiki-news-300d-1M-subword.vec
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:47e336cc848c697486273a9cb761ad30a3bf741d4ab26e779435bfa51491730e
|
| 3 |
+
size 2256858740
|