Spaces:
Runtime error
Runtime error

Commit
•
2e4274a
1
Parent(s):
663fe1d
add all application files
Browse files- LICENSE +201 -0
- README.md +48 -7
- apps/.DS_Store +0 -0
- apps/app.py +386 -0
- apps/app_utils.py +262 -0
- apps/data_utils.py +150 -0
- apps/visualization_utils.py +159 -0
- requirements.txt +10 -0
- scripts/download_models.py +70 -0
- scripts/install_dependencies.py +41 -0
- scripts/launch_app.py +41 -0
- setup.py +50 -0
- src/.DS_Store +0 -0
- src/__init__.py +0 -0
- src/content_preservation.py +366 -0
- src/style_classification.py +245 -0
- src/style_transfer.py +94 -0
- src/transformer_interpretability.py +148 -0
- static/images/app_screenshot.png +0 -0
- static/images/cldr-favicon.ico +0 -0
- static/images/ffllogo2@1x.png +0 -0
- tests/__init__.py +0 -0
- tests/test_model_classes.py +164 -0
LICENSE
ADDED
|
@@ -0,0 +1,201 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
Apache License
|
| 2 |
+
Version 2.0, January 2004
|
| 3 |
+
http://www.apache.org/licenses/
|
| 4 |
+
|
| 5 |
+
TERMS AND CONDITIONS FOR USE, REPRODUCTION, AND DISTRIBUTION
|
| 6 |
+
|
| 7 |
+
1. Definitions.
|
| 8 |
+
|
| 9 |
+
"License" shall mean the terms and conditions for use, reproduction,
|
| 10 |
+
and distribution as defined by Sections 1 through 9 of this document.
|
| 11 |
+
|
| 12 |
+
"Licensor" shall mean the copyright owner or entity authorized by
|
| 13 |
+
the copyright owner that is granting the License.
|
| 14 |
+
|
| 15 |
+
"Legal Entity" shall mean the union of the acting entity and all
|
| 16 |
+
other entities that control, are controlled by, or are under common
|
| 17 |
+
control with that entity. For the purposes of this definition,
|
| 18 |
+
"control" means (i) the power, direct or indirect, to cause the
|
| 19 |
+
direction or management of such entity, whether by contract or
|
| 20 |
+
otherwise, or (ii) ownership of fifty percent (50%) or more of the
|
| 21 |
+
outstanding shares, or (iii) beneficial ownership of such entity.
|
| 22 |
+
|
| 23 |
+
"You" (or "Your") shall mean an individual or Legal Entity
|
| 24 |
+
exercising permissions granted by this License.
|
| 25 |
+
|
| 26 |
+
"Source" form shall mean the preferred form for making modifications,
|
| 27 |
+
including but not limited to software source code, documentation
|
| 28 |
+
source, and configuration files.
|
| 29 |
+
|
| 30 |
+
"Object" form shall mean any form resulting from mechanical
|
| 31 |
+
transformation or translation of a Source form, including but
|
| 32 |
+
not limited to compiled object code, generated documentation,
|
| 33 |
+
and conversions to other media types.
|
| 34 |
+
|
| 35 |
+
"Work" shall mean the work of authorship, whether in Source or
|
| 36 |
+
Object form, made available under the License, as indicated by a
|
| 37 |
+
copyright notice that is included in or attached to the work
|
| 38 |
+
(an example is provided in the Appendix below).
|
| 39 |
+
|
| 40 |
+
"Derivative Works" shall mean any work, whether in Source or Object
|
| 41 |
+
form, that is based on (or derived from) the Work and for which the
|
| 42 |
+
editorial revisions, annotations, elaborations, or other modifications
|
| 43 |
+
represent, as a whole, an original work of authorship. For the purposes
|
| 44 |
+
of this License, Derivative Works shall not include works that remain
|
| 45 |
+
separable from, or merely link (or bind by name) to the interfaces of,
|
| 46 |
+
the Work and Derivative Works thereof.
|
| 47 |
+
|
| 48 |
+
"Contribution" shall mean any work of authorship, including
|
| 49 |
+
the original version of the Work and any modifications or additions
|
| 50 |
+
to that Work or Derivative Works thereof, that is intentionally
|
| 51 |
+
submitted to Licensor for inclusion in the Work by the copyright owner
|
| 52 |
+
or by an individual or Legal Entity authorized to submit on behalf of
|
| 53 |
+
the copyright owner. For the purposes of this definition, "submitted"
|
| 54 |
+
means any form of electronic, verbal, or written communication sent
|
| 55 |
+
to the Licensor or its representatives, including but not limited to
|
| 56 |
+
communication on electronic mailing lists, source code control systems,
|
| 57 |
+
and issue tracking systems that are managed by, or on behalf of, the
|
| 58 |
+
Licensor for the purpose of discussing and improving the Work, but
|
| 59 |
+
excluding communication that is conspicuously marked or otherwise
|
| 60 |
+
designated in writing by the copyright owner as "Not a Contribution."
|
| 61 |
+
|
| 62 |
+
"Contributor" shall mean Licensor and any individual or Legal Entity
|
| 63 |
+
on behalf of whom a Contribution has been received by Licensor and
|
| 64 |
+
subsequently incorporated within the Work.
|
| 65 |
+
|
| 66 |
+
2. Grant of Copyright License. Subject to the terms and conditions of
|
| 67 |
+
this License, each Contributor hereby grants to You a perpetual,
|
| 68 |
+
worldwide, non-exclusive, no-charge, royalty-free, irrevocable
|
| 69 |
+
copyright license to reproduce, prepare Derivative Works of,
|
| 70 |
+
publicly display, publicly perform, sublicense, and distribute the
|
| 71 |
+
Work and such Derivative Works in Source or Object form.
|
| 72 |
+
|
| 73 |
+
3. Grant of Patent License. Subject to the terms and conditions of
|
| 74 |
+
this License, each Contributor hereby grants to You a perpetual,
|
| 75 |
+
worldwide, non-exclusive, no-charge, royalty-free, irrevocable
|
| 76 |
+
(except as stated in this section) patent license to make, have made,
|
| 77 |
+
use, offer to sell, sell, import, and otherwise transfer the Work,
|
| 78 |
+
where such license applies only to those patent claims licensable
|
| 79 |
+
by such Contributor that are necessarily infringed by their
|
| 80 |
+
Contribution(s) alone or by combination of their Contribution(s)
|
| 81 |
+
with the Work to which such Contribution(s) was submitted. If You
|
| 82 |
+
institute patent litigation against any entity (including a
|
| 83 |
+
cross-claim or counterclaim in a lawsuit) alleging that the Work
|
| 84 |
+
or a Contribution incorporated within the Work constitutes direct
|
| 85 |
+
or contributory patent infringement, then any patent licenses
|
| 86 |
+
granted to You under this License for that Work shall terminate
|
| 87 |
+
as of the date such litigation is filed.
|
| 88 |
+
|
| 89 |
+
4. Redistribution. You may reproduce and distribute copies of the
|
| 90 |
+
Work or Derivative Works thereof in any medium, with or without
|
| 91 |
+
modifications, and in Source or Object form, provided that You
|
| 92 |
+
meet the following conditions:
|
| 93 |
+
|
| 94 |
+
(a) You must give any other recipients of the Work or
|
| 95 |
+
Derivative Works a copy of this License; and
|
| 96 |
+
|
| 97 |
+
(b) You must cause any modified files to carry prominent notices
|
| 98 |
+
stating that You changed the files; and
|
| 99 |
+
|
| 100 |
+
(c) You must retain, in the Source form of any Derivative Works
|
| 101 |
+
that You distribute, all copyright, patent, trademark, and
|
| 102 |
+
attribution notices from the Source form of the Work,
|
| 103 |
+
excluding those notices that do not pertain to any part of
|
| 104 |
+
the Derivative Works; and
|
| 105 |
+
|
| 106 |
+
(d) If the Work includes a "NOTICE" text file as part of its
|
| 107 |
+
distribution, then any Derivative Works that You distribute must
|
| 108 |
+
include a readable copy of the attribution notices contained
|
| 109 |
+
within such NOTICE file, excluding those notices that do not
|
| 110 |
+
pertain to any part of the Derivative Works, in at least one
|
| 111 |
+
of the following places: within a NOTICE text file distributed
|
| 112 |
+
as part of the Derivative Works; within the Source form or
|
| 113 |
+
documentation, if provided along with the Derivative Works; or,
|
| 114 |
+
within a display generated by the Derivative Works, if and
|
| 115 |
+
wherever such third-party notices normally appear. The contents
|
| 116 |
+
of the NOTICE file are for informational purposes only and
|
| 117 |
+
do not modify the License. You may add Your own attribution
|
| 118 |
+
notices within Derivative Works that You distribute, alongside
|
| 119 |
+
or as an addendum to the NOTICE text from the Work, provided
|
| 120 |
+
that such additional attribution notices cannot be construed
|
| 121 |
+
as modifying the License.
|
| 122 |
+
|
| 123 |
+
You may add Your own copyright statement to Your modifications and
|
| 124 |
+
may provide additional or different license terms and conditions
|
| 125 |
+
for use, reproduction, or distribution of Your modifications, or
|
| 126 |
+
for any such Derivative Works as a whole, provided Your use,
|
| 127 |
+
reproduction, and distribution of the Work otherwise complies with
|
| 128 |
+
the conditions stated in this License.
|
| 129 |
+
|
| 130 |
+
5. Submission of Contributions. Unless You explicitly state otherwise,
|
| 131 |
+
any Contribution intentionally submitted for inclusion in the Work
|
| 132 |
+
by You to the Licensor shall be under the terms and conditions of
|
| 133 |
+
this License, without any additional terms or conditions.
|
| 134 |
+
Notwithstanding the above, nothing herein shall supersede or modify
|
| 135 |
+
the terms of any separate license agreement you may have executed
|
| 136 |
+
with Licensor regarding such Contributions.
|
| 137 |
+
|
| 138 |
+
6. Trademarks. This License does not grant permission to use the trade
|
| 139 |
+
names, trademarks, service marks, or product names of the Licensor,
|
| 140 |
+
except as required for reasonable and customary use in describing the
|
| 141 |
+
origin of the Work and reproducing the content of the NOTICE file.
|
| 142 |
+
|
| 143 |
+
7. Disclaimer of Warranty. Unless required by applicable law or
|
| 144 |
+
agreed to in writing, Licensor provides the Work (and each
|
| 145 |
+
Contributor provides its Contributions) on an "AS IS" BASIS,
|
| 146 |
+
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or
|
| 147 |
+
implied, including, without limitation, any warranties or conditions
|
| 148 |
+
of TITLE, NON-INFRINGEMENT, MERCHANTABILITY, or FITNESS FOR A
|
| 149 |
+
PARTICULAR PURPOSE. You are solely responsible for determining the
|
| 150 |
+
appropriateness of using or redistributing the Work and assume any
|
| 151 |
+
risks associated with Your exercise of permissions under this License.
|
| 152 |
+
|
| 153 |
+
8. Limitation of Liability. In no event and under no legal theory,
|
| 154 |
+
whether in tort (including negligence), contract, or otherwise,
|
| 155 |
+
unless required by applicable law (such as deliberate and grossly
|
| 156 |
+
negligent acts) or agreed to in writing, shall any Contributor be
|
| 157 |
+
liable to You for damages, including any direct, indirect, special,
|
| 158 |
+
incidental, or consequential damages of any character arising as a
|
| 159 |
+
result of this License or out of the use or inability to use the
|
| 160 |
+
Work (including but not limited to damages for loss of goodwill,
|
| 161 |
+
work stoppage, computer failure or malfunction, or any and all
|
| 162 |
+
other commercial damages or losses), even if such Contributor
|
| 163 |
+
has been advised of the possibility of such damages.
|
| 164 |
+
|
| 165 |
+
9. Accepting Warranty or Additional Liability. While redistributing
|
| 166 |
+
the Work or Derivative Works thereof, You may choose to offer,
|
| 167 |
+
and charge a fee for, acceptance of support, warranty, indemnity,
|
| 168 |
+
or other liability obligations and/or rights consistent with this
|
| 169 |
+
License. However, in accepting such obligations, You may act only
|
| 170 |
+
on Your own behalf and on Your sole responsibility, not on behalf
|
| 171 |
+
of any other Contributor, and only if You agree to indemnify,
|
| 172 |
+
defend, and hold each Contributor harmless for any liability
|
| 173 |
+
incurred by, or claims asserted against, such Contributor by reason
|
| 174 |
+
of your accepting any such warranty or additional liability.
|
| 175 |
+
|
| 176 |
+
END OF TERMS AND CONDITIONS
|
| 177 |
+
|
| 178 |
+
APPENDIX: How to apply the Apache License to your work.
|
| 179 |
+
|
| 180 |
+
To apply the Apache License to your work, attach the following
|
| 181 |
+
boilerplate notice, with the fields enclosed by brackets "[]"
|
| 182 |
+
replaced with your own identifying information. (Don't include
|
| 183 |
+
the brackets!) The text should be enclosed in the appropriate
|
| 184 |
+
comment syntax for the file format. We also recommend that a
|
| 185 |
+
file or class name and description of purpose be included on the
|
| 186 |
+
same "printed page" as the copyright notice for easier
|
| 187 |
+
identification within third-party archives.
|
| 188 |
+
|
| 189 |
+
Copyright [yyyy] [name of copyright owner]
|
| 190 |
+
|
| 191 |
+
Licensed under the Apache License, Version 2.0 (the "License");
|
| 192 |
+
you may not use this file except in compliance with the License.
|
| 193 |
+
You may obtain a copy of the License at
|
| 194 |
+
|
| 195 |
+
http://www.apache.org/licenses/LICENSE-2.0
|
| 196 |
+
|
| 197 |
+
Unless required by applicable law or agreed to in writing, software
|
| 198 |
+
distributed under the License is distributed on an "AS IS" BASIS,
|
| 199 |
+
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
| 200 |
+
See the License for the specific language governing permissions and
|
| 201 |
+
limitations under the License.
|
README.md
CHANGED
|
@@ -1,13 +1,54 @@
|
|
| 1 |
---
|
| 2 |
-
title: Exploring Intelligent Writing Assistance
|
| 3 |
-
emoji:
|
| 4 |
-
colorFrom:
|
| 5 |
-
colorTo:
|
| 6 |
sdk: streamlit
|
| 7 |
sdk_version: 1.10.0
|
| 8 |
-
app_file: app.py
|
| 9 |
-
|
|
|
|
| 10 |
license: apache-2.0
|
| 11 |
---
|
| 12 |
|
| 13 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
---
|
| 2 |
+
title: Exploring Intelligent Writing Assistance with Text Style Transfer
|
| 3 |
+
emoji: :twisted_rightwards_arrows:
|
| 4 |
+
colorFrom: blue
|
| 5 |
+
colorTo: green
|
| 6 |
sdk: streamlit
|
| 7 |
sdk_version: 1.10.0
|
| 8 |
+
app_file: apps/app.py
|
| 9 |
+
models: ["sentence-transformers/all-MiniLM-L6-v2", "cffl/bert-base-styleclassification-subjective-neutral", "cffl/bart-base-styletransfer-subjective-to-neutral", "cointegrated/roberta-base-formality", "prithivida/informal_to_formal_styletransfer"]
|
| 10 |
+
pinned: true
|
| 11 |
license: apache-2.0
|
| 12 |
---
|
| 13 |
|
| 14 |
+
# Exploring Intelligent Writing Assistance
|
| 15 |
+
|
| 16 |
+
A demonstration of how the NLP task of _text style transfer_ can be applied to enhance the human writing experience using [HuggingFace Transformers](https://huggingface.co/) and [Streamlit](https://streamlit.io/).
|
| 17 |
+
|
| 18 |
+

|
| 19 |
+
|
| 20 |
+
> This repo accompanies Cloudera Fast Forward Labs' [blog series](https://blog.fastforwardlabs.com/2022/03/22/an-introduction-to-text-style-transfer.html) in which we explore the task of automatically neutralizing subjectivity bias in free text.
|
| 21 |
+
|
| 22 |
+
The goal of this application is to demonstrate how the NLP task of text style transfer can be applied to enhance the human writing experience. In this sense, we intend to peel back the curtains on how an intelligent writing assistant might function — walking through the logical steps needed to automatically re-style a piece of text (from informal-to-formal **or** subjective-to-neutral) while building up confidence in the model output.
|
| 23 |
+
|
| 24 |
+
Through the application, we emphasize the imperative for a human-in-the-loop user experience when designing natural language generation systems. We believe text style transfer has the potential to empower writers to better express themselves, but not by blindly generating text. Rather, generative models, in conjunction with interpretability methods, should be combined to help writers understand the nuances of linguistic style and suggest stylistic edits that may improve their writing.
|
| 25 |
+
|
| 26 |
+
## Project Structure
|
| 27 |
+
|
| 28 |
+
```
|
| 29 |
+
.
|
| 30 |
+
├── LICENSE
|
| 31 |
+
├── README.md
|
| 32 |
+
├── apps
|
| 33 |
+
│ ├── app.py
|
| 34 |
+
│ ├── app_utils.py
|
| 35 |
+
│ ├── data_utils.py
|
| 36 |
+
│ └── visualization_utils.py
|
| 37 |
+
├── requirements.txt
|
| 38 |
+
├── scripts
|
| 39 |
+
│ ├── download_models.py
|
| 40 |
+
│ ├── install_dependencies.py
|
| 41 |
+
│ └── launch_app.py
|
| 42 |
+
├── setup.py
|
| 43 |
+
├── src
|
| 44 |
+
│ ├── __init__.py
|
| 45 |
+
│ ├── content_preservation.py
|
| 46 |
+
│ ├── style_classification.py
|
| 47 |
+
│ ├── style_transfer.py
|
| 48 |
+
│ └── transformer_interpretability.py
|
| 49 |
+
├── static
|
| 50 |
+
│ └── images
|
| 51 |
+
└── tests
|
| 52 |
+
├── __init__.py
|
| 53 |
+
└── test_model_classes.py
|
| 54 |
+
```
|
apps/.DS_Store
ADDED
|
Binary file (6.15 kB). View file
|
|
|
apps/app.py
ADDED
|
@@ -0,0 +1,386 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# ###########################################################################
|
| 2 |
+
#
|
| 3 |
+
# CLOUDERA APPLIED MACHINE LEARNING PROTOTYPE (AMP)
|
| 4 |
+
# (C) Cloudera, Inc. 2022
|
| 5 |
+
# All rights reserved.
|
| 6 |
+
#
|
| 7 |
+
# Applicable Open Source License: Apache 2.0
|
| 8 |
+
#
|
| 9 |
+
# NOTE: Cloudera open source products are modular software products
|
| 10 |
+
# made up of hundreds of individual components, each of which was
|
| 11 |
+
# individually copyrighted. Each Cloudera open source product is a
|
| 12 |
+
# collective work under U.S. Copyright Law. Your license to use the
|
| 13 |
+
# collective work is as provided in your written agreement with
|
| 14 |
+
# Cloudera. Used apart from the collective work, this file is
|
| 15 |
+
# licensed for your use pursuant to the open source license
|
| 16 |
+
# identified above.
|
| 17 |
+
#
|
| 18 |
+
# This code is provided to you pursuant a written agreement with
|
| 19 |
+
# (i) Cloudera, Inc. or (ii) a third-party authorized to distribute
|
| 20 |
+
# this code. If you do not have a written agreement with Cloudera nor
|
| 21 |
+
# with an authorized and properly licensed third party, you do not
|
| 22 |
+
# have any rights to access nor to use this code.
|
| 23 |
+
#
|
| 24 |
+
# Absent a written agreement with Cloudera, Inc. (“Cloudera”) to the
|
| 25 |
+
# contrary, A) CLOUDERA PROVIDES THIS CODE TO YOU WITHOUT WARRANTIES OF ANY
|
| 26 |
+
# KIND; (B) CLOUDERA DISCLAIMS ANY AND ALL EXPRESS AND IMPLIED
|
| 27 |
+
# WARRANTIES WITH RESPECT TO THIS CODE, INCLUDING BUT NOT LIMITED TO
|
| 28 |
+
# IMPLIED WARRANTIES OF TITLE, NON-INFRINGEMENT, MERCHANTABILITY AND
|
| 29 |
+
# FITNESS FOR A PARTICULAR PURPOSE; (C) CLOUDERA IS NOT LIABLE TO YOU,
|
| 30 |
+
# AND WILL NOT DEFEND, INDEMNIFY, NOR HOLD YOU HARMLESS FOR ANY CLAIMS
|
| 31 |
+
# ARISING FROM OR RELATED TO THE CODE; AND (D)WITH RESPECT TO YOUR EXERCISE
|
| 32 |
+
# OF ANY RIGHTS GRANTED TO YOU FOR THE CODE, CLOUDERA IS NOT LIABLE FOR ANY
|
| 33 |
+
# DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, PUNITIVE OR
|
| 34 |
+
# CONSEQUENTIAL DAMAGES INCLUDING, BUT NOT LIMITED TO, DAMAGES
|
| 35 |
+
# RELATED TO LOST REVENUE, LOST PROFITS, LOSS OF INCOME, LOSS OF
|
| 36 |
+
# BUSINESS ADVANTAGE OR UNAVAILABILITY, OR LOSS OR CORRUPTION OF
|
| 37 |
+
# DATA.
|
| 38 |
+
#
|
| 39 |
+
# ###########################################################################
|
| 40 |
+
|
| 41 |
+
import pandas as pd
|
| 42 |
+
from PIL import Image
|
| 43 |
+
import streamlit as st
|
| 44 |
+
import streamlit.components.v1 as components
|
| 45 |
+
|
| 46 |
+
from apps.data_utils import (
|
| 47 |
+
DATA_PACKET,
|
| 48 |
+
format_classification_results,
|
| 49 |
+
)
|
| 50 |
+
from apps.app_utils import (
|
| 51 |
+
DisableableButton,
|
| 52 |
+
reset_page_progress_state,
|
| 53 |
+
get_cached_style_intensity_classifier,
|
| 54 |
+
get_cached_word_attributions,
|
| 55 |
+
get_sti_metric,
|
| 56 |
+
get_cps_metric,
|
| 57 |
+
generate_style_transfer,
|
| 58 |
+
)
|
| 59 |
+
from apps.visualization_utils import build_altair_classification_plot
|
| 60 |
+
|
| 61 |
+
# SESSION STATE UTILS
|
| 62 |
+
if "page_progress" not in st.session_state:
|
| 63 |
+
st.session_state.page_progress = 1
|
| 64 |
+
|
| 65 |
+
if "st_result" not in st.session_state:
|
| 66 |
+
st.session_state.st_result = False
|
| 67 |
+
|
| 68 |
+
|
| 69 |
+
# PAGE CONFIG
|
| 70 |
+
ffl_favicon = Image.open("static/images/cldr-favicon.ico")
|
| 71 |
+
st.set_page_config(
|
| 72 |
+
page_title="CFFL: Text Style Transfer",
|
| 73 |
+
page_icon=ffl_favicon,
|
| 74 |
+
layout="centered",
|
| 75 |
+
initial_sidebar_state="expanded",
|
| 76 |
+
)
|
| 77 |
+
|
| 78 |
+
# SIDEBAR
|
| 79 |
+
ffl_logo = Image.open("static/images/ffllogo2@1x.png")
|
| 80 |
+
st.sidebar.image(ffl_logo)
|
| 81 |
+
|
| 82 |
+
st.sidebar.write(
|
| 83 |
+
"This prototype accompanies our [Text Style Transfer](https://blog.fastforwardlabs.com/2022/03/22/an-introduction-to-text-style-transfer.html)\
|
| 84 |
+
blog series in which we explore the task of automatically neutralizing subjectivity bias in free text."
|
| 85 |
+
)
|
| 86 |
+
|
| 87 |
+
st.sidebar.markdown("## Select a style attribute")
|
| 88 |
+
style_attribute = st.sidebar.selectbox(
|
| 89 |
+
"What style would you like to transfer between?", options=DATA_PACKET.keys()
|
| 90 |
+
)
|
| 91 |
+
STYLE_ATTRIBUTE_DATA = DATA_PACKET[style_attribute]
|
| 92 |
+
|
| 93 |
+
st.sidebar.markdown("## Start over")
|
| 94 |
+
st.sidebar.caption(
|
| 95 |
+
"This application is intended to be run sequentially from top to bottom. If you wish to alter selections after \
|
| 96 |
+
advancing through the app, push the button below to start fresh from the beginning."
|
| 97 |
+
)
|
| 98 |
+
st.sidebar.button("Restart from beginning", on_click=reset_page_progress_state)
|
| 99 |
+
|
| 100 |
+
# MAIN CONTENT
|
| 101 |
+
st.markdown("# Exploring Intelligent Writing Assistance")
|
| 102 |
+
|
| 103 |
+
st.write(
|
| 104 |
+
"""
|
| 105 |
+
The goal of this application is to demonstrate how the NLP task of _text style transfer_ can be applied to enhance the human writing experience.
|
| 106 |
+
In this sense, we intend to peel back the curtains on how an intelligent writing assistant might function — walking through the logical steps needed to
|
| 107 |
+
automatically re-style a piece of text while building up confidence in the model output.
|
| 108 |
+
|
| 109 |
+
We emphasize the imperative for a human-in-the-loop user experience when designing natural language generation systems. We believe text style
|
| 110 |
+
transfer has the potential to empower writers to better express themselves, but not by blindly generating text. Rather, generative models, in conjunction with
|
| 111 |
+
interpretability methods, should be combined to help writers understand the nuances of linguistic style and suggest stylistic edits that _may_ improve their writing.
|
| 112 |
+
|
| 113 |
+
Select a style attribute from the sidebar and enter some text below to get started!
|
| 114 |
+
"""
|
| 115 |
+
)
|
| 116 |
+
|
| 117 |
+
## 1. INPUT EXAMPLE
|
| 118 |
+
if st.session_state.page_progress > 0:
|
| 119 |
+
st.write("### 1. Input some text")
|
| 120 |
+
|
| 121 |
+
with st.container():
|
| 122 |
+
|
| 123 |
+
col1_1, col1_2 = st.columns([1, 3])
|
| 124 |
+
with col1_1:
|
| 125 |
+
input_type = st.radio(
|
| 126 |
+
"Type your own or choose from a preset example",
|
| 127 |
+
("Choose preset", "Enter text"),
|
| 128 |
+
horizontal=False,
|
| 129 |
+
)
|
| 130 |
+
with col1_2:
|
| 131 |
+
if input_type == "Enter text":
|
| 132 |
+
text_sample = st.text_input(
|
| 133 |
+
f"Enter some text to modify style from {style_attribute}",
|
| 134 |
+
help="You can also select one of our preset examples by toggling the radio button to the left.",
|
| 135 |
+
)
|
| 136 |
+
else:
|
| 137 |
+
option = st.selectbox(
|
| 138 |
+
f"Select a preset example to modify style from {style_attribute}",
|
| 139 |
+
[
|
| 140 |
+
f"Example {i+1}"
|
| 141 |
+
for i in range(len(STYLE_ATTRIBUTE_DATA.examples))
|
| 142 |
+
],
|
| 143 |
+
help="You can also enter your own text by toggling the radio button to the left.",
|
| 144 |
+
)
|
| 145 |
+
|
| 146 |
+
idx_key = int(option.split(" ")[-1]) - 1
|
| 147 |
+
text_sample = STYLE_ATTRIBUTE_DATA.examples[idx_key]
|
| 148 |
+
|
| 149 |
+
st.text_area(
|
| 150 |
+
"Preview Text",
|
| 151 |
+
value=text_sample,
|
| 152 |
+
placeholder="Enter some text above or toggle to choose a preset!",
|
| 153 |
+
disabled=True,
|
| 154 |
+
)
|
| 155 |
+
|
| 156 |
+
if text_sample != "":
|
| 157 |
+
db1 = DisableableButton(1, "Let's go!")
|
| 158 |
+
db1.create_enabled_button()
|
| 159 |
+
|
| 160 |
+
## 2. CLASSIFY INPUT
|
| 161 |
+
if st.session_state.page_progress > 1:
|
| 162 |
+
db1.disable()
|
| 163 |
+
|
| 164 |
+
st.write("### 2. Detect style")
|
| 165 |
+
st.write(
|
| 166 |
+
f"""
|
| 167 |
+
Before we can transfer style, we need to ensure the input text isn't already of the target style! To do so,
|
| 168 |
+
we classify the sample text with a model that has been fine-tuned to differentiate between
|
| 169 |
+
{STYLE_ATTRIBUTE_DATA.attribute_AND_string} tones.
|
| 170 |
+
|
| 171 |
+
In a product setting, you could imagine this style detection process running continuously inside your favorite word processor as you write,
|
| 172 |
+
prompting you for action when it detects language that is at odds with your desired tone of voice.
|
| 173 |
+
"""
|
| 174 |
+
)
|
| 175 |
+
|
| 176 |
+
with st.spinner("Detecting style, hang tight!"):
|
| 177 |
+
|
| 178 |
+
sic = get_cached_style_intensity_classifier(style_data=STYLE_ATTRIBUTE_DATA)
|
| 179 |
+
cls_result = sic.score(text_sample)
|
| 180 |
+
|
| 181 |
+
cls_result_df = pd.DataFrame(
|
| 182 |
+
cls_result[0]["distribution"],
|
| 183 |
+
columns=["Score"],
|
| 184 |
+
index=[v for k, v in sic.pipeline.model.config.id2label.items()],
|
| 185 |
+
)
|
| 186 |
+
|
| 187 |
+
with st.container():
|
| 188 |
+
|
| 189 |
+
format_cls_result = format_classification_results(
|
| 190 |
+
id2label=sic.pipeline.model.config.id2label, cls_result=cls_result
|
| 191 |
+
)
|
| 192 |
+
st.markdown("##### Distribution Between Style Classes")
|
| 193 |
+
chart = build_altair_classification_plot(format_cls_result)
|
| 194 |
+
st.altair_chart(chart.interactive(), use_container_width=True)
|
| 195 |
+
|
| 196 |
+
st.markdown(
|
| 197 |
+
f"""
|
| 198 |
+
- **:hugging_face: Model:** [{STYLE_ATTRIBUTE_DATA.cls_model_path}]({STYLE_ATTRIBUTE_DATA.build_model_url("cls")})
|
| 199 |
+
- **Input Text:** *"{text_sample}"*
|
| 200 |
+
- **Classification Result:** \t {cls_result[0]["label"].capitalize()} ({round(cls_result[0]["score"]*100, 2)}%)
|
| 201 |
+
"""
|
| 202 |
+
)
|
| 203 |
+
st.write(" ")
|
| 204 |
+
|
| 205 |
+
if cls_result[0]["label"].lower() != STYLE_ATTRIBUTE_DATA.target_attribute:
|
| 206 |
+
st.info(
|
| 207 |
+
f"""
|
| 208 |
+
**Looks like we have room for improvement!**
|
| 209 |
+
|
| 210 |
+
The distribution of classification scores suggests that the input text is more {STYLE_ATTRIBUTE_DATA.attribute_THAN_string}. Therefore,
|
| 211 |
+
an automated style transfer may improve our intended tone of voice."""
|
| 212 |
+
)
|
| 213 |
+
db2 = DisableableButton(2, "Let's see why")
|
| 214 |
+
db2.create_enabled_button()
|
| 215 |
+
else:
|
| 216 |
+
st.success(
|
| 217 |
+
f"""**No work to be done!** \n\n\n The distribution of classification scores suggests that the input text is less \
|
| 218 |
+
{STYLE_ATTRIBUTE_DATA.attribute_THAN_string}. Therefore, there's no need to transfer style. \
|
| 219 |
+
Enter a different text prompt or select one of the preset examples to re-run the analysis with."""
|
| 220 |
+
)
|
| 221 |
+
|
| 222 |
+
## 3. Here's why
|
| 223 |
+
if st.session_state.page_progress > 2:
|
| 224 |
+
db2.disable()
|
| 225 |
+
st.write("### 3. Interpret the classification result")
|
| 226 |
+
st.write(
|
| 227 |
+
f"""
|
| 228 |
+
Interpreting our model's output is a crucial practice that helps build trust and justify taking real-world action from the
|
| 229 |
+
model predictions. In this case, we apply a popular model interpretability technique called [Integrated Gradients](https://arxiv.org/pdf/1703.01365.pdf)
|
| 230 |
+
to the Transformer-based classifier to explain the model's prediction in terms of its features."""
|
| 231 |
+
)
|
| 232 |
+
|
| 233 |
+
with st.spinner("Interpreting the prediction, hang tight!"):
|
| 234 |
+
word_attributions_visual = get_cached_word_attributions(
|
| 235 |
+
text_sample=text_sample, style_data=STYLE_ATTRIBUTE_DATA
|
| 236 |
+
)
|
| 237 |
+
components.html(html=word_attributions_visual, height=200, scrolling=True)
|
| 238 |
+
|
| 239 |
+
st.write(
|
| 240 |
+
f"""
|
| 241 |
+
The visual above displays word attributions using the [Transformers Interpret](https://github.com/cdpierse/transformers-interpret) library.
|
| 242 |
+
Positive attribution values (green) indicate tokens that contribute positively towards the
|
| 243 |
+
predicted class ({STYLE_ATTRIBUTE_DATA.source_attribute}), while negative values (red) indicate tokens that contribute negatively towards the predicted class.
|
| 244 |
+
|
| 245 |
+
Visualizing word attributions is a helpful way to build intuition about what makes the input text _{STYLE_ATTRIBUTE_DATA.source_attribute}_!"""
|
| 246 |
+
)
|
| 247 |
+
db3 = DisableableButton(3, "Next")
|
| 248 |
+
db3.create_enabled_button()
|
| 249 |
+
|
| 250 |
+
|
| 251 |
+
## 4. SUGGEST GENERATED EDIT
|
| 252 |
+
if st.session_state.page_progress > 3:
|
| 253 |
+
db3.disable()
|
| 254 |
+
|
| 255 |
+
st.write("### 4. Generate a suggestion")
|
| 256 |
+
st.write(
|
| 257 |
+
f"Now that we've verified the input text is in fact *{STYLE_ATTRIBUTE_DATA.source_attribute}* and understand why that's the case, we can utilize a \
|
| 258 |
+
text style transfer model to generate a suggested replacement that retains the same semantic meaning, but achieves the *{STYLE_ATTRIBUTE_DATA.target_attribute}* target style.\
|
| 259 |
+
\n\n Expand the accordian below to toggle generation parameters, then click the button to transfer style!"
|
| 260 |
+
)
|
| 261 |
+
|
| 262 |
+
with st.expander("Toggle generation parameters"):
|
| 263 |
+
|
| 264 |
+
# st.markdown("##### Text generation parameters")
|
| 265 |
+
st.write("**max_gen_length**")
|
| 266 |
+
max_gen_length = st.slider(
|
| 267 |
+
"Whats the maximum generation length desired?", 1, 250, 200, 10
|
| 268 |
+
)
|
| 269 |
+
st.write("**num_beams**")
|
| 270 |
+
num_beams = st.slider(
|
| 271 |
+
"How many beams to use for beam-search decoding?", 1, 8, 4
|
| 272 |
+
)
|
| 273 |
+
st.write("**temperature**")
|
| 274 |
+
temperature = st.slider(
|
| 275 |
+
"What sensitivity value to model next token probabilities?",
|
| 276 |
+
0.0,
|
| 277 |
+
1.0,
|
| 278 |
+
1.0,
|
| 279 |
+
)
|
| 280 |
+
|
| 281 |
+
st.markdown(
|
| 282 |
+
f"""
|
| 283 |
+
**:hugging_face: Model:** [{STYLE_ATTRIBUTE_DATA.seq2seq_model_path}]({STYLE_ATTRIBUTE_DATA.build_model_url("seq2seq")})
|
| 284 |
+
"""
|
| 285 |
+
)
|
| 286 |
+
|
| 287 |
+
col4_1, col4_2, col4_3 = st.columns([1, 5, 4])
|
| 288 |
+
with col4_2:
|
| 289 |
+
st.markdown(
|
| 290 |
+
f"""
|
| 291 |
+
- **Max Generation Length:** {max_gen_length}
|
| 292 |
+
- **Number of Beams:** {num_beams}
|
| 293 |
+
- **Temperature:** {temperature}
|
| 294 |
+
"""
|
| 295 |
+
)
|
| 296 |
+
with col4_3:
|
| 297 |
+
with st.container():
|
| 298 |
+
st.write("")
|
| 299 |
+
st.button(
|
| 300 |
+
"Generate style transfer",
|
| 301 |
+
key="generate_text",
|
| 302 |
+
on_click=generate_style_transfer,
|
| 303 |
+
kwargs={
|
| 304 |
+
"text_sample": text_sample,
|
| 305 |
+
"style_data": STYLE_ATTRIBUTE_DATA,
|
| 306 |
+
"max_gen_length": max_gen_length,
|
| 307 |
+
"num_beams": num_beams,
|
| 308 |
+
"temperature": temperature,
|
| 309 |
+
},
|
| 310 |
+
)
|
| 311 |
+
|
| 312 |
+
if st.session_state.st_result:
|
| 313 |
+
st.warning(
|
| 314 |
+
f"""**{STYLE_ATTRIBUTE_DATA.source_attribute.capitalize()} Input:** "{text_sample}" """
|
| 315 |
+
)
|
| 316 |
+
st.info(
|
| 317 |
+
f"""
|
| 318 |
+
**{STYLE_ATTRIBUTE_DATA.target_attribute.capitalize()} Suggestion:** "{st.session_state.st_result[0]}" """
|
| 319 |
+
)
|
| 320 |
+
db4 = DisableableButton(4, "Next")
|
| 321 |
+
db4.create_enabled_button()
|
| 322 |
+
|
| 323 |
+
## 5. EVALUATE THE SUGGESTION
|
| 324 |
+
if st.session_state.page_progress > 4:
|
| 325 |
+
db4.disable()
|
| 326 |
+
st.write("### 5. Evaluate the suggestion")
|
| 327 |
+
st.markdown(
|
| 328 |
+
"""
|
| 329 |
+
Blindly prompting a writer with style suggestions without first checking quality would make for a noisy, error-prone product
|
| 330 |
+
with a poor user experience. Ultimately, we only want to suggest high quality edits. But what makes for a suggestion-worthy edit?
|
| 331 |
+
|
| 332 |
+
A comprehensive quality evaluation for text style transfer output should consider three criteria:
|
| 333 |
+
1. **Style strength** - To what degree does the generated text achieve the target style?
|
| 334 |
+
2. **Content preservation** - To what degree does the generated text retain the semantic meaning of the source text?
|
| 335 |
+
3. **Fluency** - To what degree does the generated text appear as if it were produced naturally by a human?
|
| 336 |
+
|
| 337 |
+
Below, we apply automated evaluation metrics - _Style Transfer Intensity (STI)_ & _Content Preservation Score (CPS)_ - to
|
| 338 |
+
measure the first two of these criteria by comparing the input text to the generated suggestion.
|
| 339 |
+
"""
|
| 340 |
+
)
|
| 341 |
+
|
| 342 |
+
with st.spinner("Evaluating text style transfer, hang tight!"):
|
| 343 |
+
|
| 344 |
+
sti = get_sti_metric(
|
| 345 |
+
input_text=text_sample,
|
| 346 |
+
output_text=st.session_state.st_result[0],
|
| 347 |
+
style_data=STYLE_ATTRIBUTE_DATA,
|
| 348 |
+
)
|
| 349 |
+
cps = get_cps_metric(
|
| 350 |
+
input_text=text_sample,
|
| 351 |
+
output_text=st.session_state.st_result[0],
|
| 352 |
+
style_data=STYLE_ATTRIBUTE_DATA,
|
| 353 |
+
)
|
| 354 |
+
|
| 355 |
+
st.markdown(
|
| 356 |
+
"""<hr style="height:2px;border:none;color:#333;background-color:#333;" /> """,
|
| 357 |
+
unsafe_allow_html=True,
|
| 358 |
+
)
|
| 359 |
+
|
| 360 |
+
col5_1, col5_2, col5_3 = st.columns([3, 1, 3])
|
| 361 |
+
|
| 362 |
+
with col5_1:
|
| 363 |
+
st.metric(
|
| 364 |
+
label="Style Transfer Intensity (STI)",
|
| 365 |
+
value=f"{round(sti[0]*100,2)}%",
|
| 366 |
+
)
|
| 367 |
+
st.caption(
|
| 368 |
+
f"""
|
| 369 |
+
STI compares the style class distributions (determined by the [style classifier]({STYLE_ATTRIBUTE_DATA.build_model_url("cls")}))
|
| 370 |
+
between the input text and generated suggestion using Earth Mover's Distance. Therefore, STI can be thought of as the percentage of the possible target style distribution
|
| 371 |
+
that was captured during the transfer.
|
| 372 |
+
"""
|
| 373 |
+
)
|
| 374 |
+
|
| 375 |
+
with col5_3:
|
| 376 |
+
st.metric(
|
| 377 |
+
label="Content Preservation Score (CPS)",
|
| 378 |
+
value=f"{round(cps[0]*100,2)}%",
|
| 379 |
+
)
|
| 380 |
+
st.caption(
|
| 381 |
+
f"""
|
| 382 |
+
CPS compares the latent space embeddings (determined by [SentenceBERT]({STYLE_ATTRIBUTE_DATA.build_model_url("sbert")}))
|
| 383 |
+
between the input text and generated suggestion using cosine similarity. Therefore, CPS can be thought of as the percentage of content that was perserved
|
| 384 |
+
during the style transfer.
|
| 385 |
+
"""
|
| 386 |
+
)
|
apps/app_utils.py
ADDED
|
@@ -0,0 +1,262 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# ###########################################################################
|
| 2 |
+
#
|
| 3 |
+
# CLOUDERA APPLIED MACHINE LEARNING PROTOTYPE (AMP)
|
| 4 |
+
# (C) Cloudera, Inc. 2022
|
| 5 |
+
# All rights reserved.
|
| 6 |
+
#
|
| 7 |
+
# Applicable Open Source License: Apache 2.0
|
| 8 |
+
#
|
| 9 |
+
# NOTE: Cloudera open source products are modular software products
|
| 10 |
+
# made up of hundreds of individual components, each of which was
|
| 11 |
+
# individually copyrighted. Each Cloudera open source product is a
|
| 12 |
+
# collective work under U.S. Copyright Law. Your license to use the
|
| 13 |
+
# collective work is as provided in your written agreement with
|
| 14 |
+
# Cloudera. Used apart from the collective work, this file is
|
| 15 |
+
# licensed for your use pursuant to the open source license
|
| 16 |
+
# identified above.
|
| 17 |
+
#
|
| 18 |
+
# This code is provided to you pursuant a written agreement with
|
| 19 |
+
# (i) Cloudera, Inc. or (ii) a third-party authorized to distribute
|
| 20 |
+
# this code. If you do not have a written agreement with Cloudera nor
|
| 21 |
+
# with an authorized and properly licensed third party, you do not
|
| 22 |
+
# have any rights to access nor to use this code.
|
| 23 |
+
#
|
| 24 |
+
# Absent a written agreement with Cloudera, Inc. (“Cloudera”) to the
|
| 25 |
+
# contrary, A) CLOUDERA PROVIDES THIS CODE TO YOU WITHOUT WARRANTIES OF ANY
|
| 26 |
+
# KIND; (B) CLOUDERA DISCLAIMS ANY AND ALL EXPRESS AND IMPLIED
|
| 27 |
+
# WARRANTIES WITH RESPECT TO THIS CODE, INCLUDING BUT NOT LIMITED TO
|
| 28 |
+
# IMPLIED WARRANTIES OF TITLE, NON-INFRINGEMENT, MERCHANTABILITY AND
|
| 29 |
+
# FITNESS FOR A PARTICULAR PURPOSE; (C) CLOUDERA IS NOT LIABLE TO YOU,
|
| 30 |
+
# AND WILL NOT DEFEND, INDEMNIFY, NOR HOLD YOU HARMLESS FOR ANY CLAIMS
|
| 31 |
+
# ARISING FROM OR RELATED TO THE CODE; AND (D)WITH RESPECT TO YOUR EXERCISE
|
| 32 |
+
# OF ANY RIGHTS GRANTED TO YOU FOR THE CODE, CLOUDERA IS NOT LIABLE FOR ANY
|
| 33 |
+
# DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, PUNITIVE OR
|
| 34 |
+
# CONSEQUENTIAL DAMAGES INCLUDING, BUT NOT LIMITED TO, DAMAGES
|
| 35 |
+
# RELATED TO LOST REVENUE, LOST PROFITS, LOSS OF INCOME, LOSS OF
|
| 36 |
+
# BUSINESS ADVANTAGE OR UNAVAILABILITY, OR LOSS OR CORRUPTION OF
|
| 37 |
+
# DATA.
|
| 38 |
+
#
|
| 39 |
+
# ###########################################################################
|
| 40 |
+
|
| 41 |
+
from typing import List
|
| 42 |
+
|
| 43 |
+
import tokenizers
|
| 44 |
+
import streamlit as st
|
| 45 |
+
|
| 46 |
+
from src.style_transfer import StyleTransfer
|
| 47 |
+
from src.style_classification import StyleIntensityClassifier
|
| 48 |
+
from src.content_preservation import ContentPreservationScorer
|
| 49 |
+
from src.transformer_interpretability import InterpretTransformer
|
| 50 |
+
from apps.data_utils import StyleAttributeData, string_to_list_string
|
| 51 |
+
|
| 52 |
+
# CALLBACKS
|
| 53 |
+
def increment_page_progress():
|
| 54 |
+
st.session_state.page_progress += 1
|
| 55 |
+
|
| 56 |
+
|
| 57 |
+
def reset_page_progress_state():
|
| 58 |
+
del st.session_state.st_result
|
| 59 |
+
st.session_state.page_progress = 1
|
| 60 |
+
|
| 61 |
+
|
| 62 |
+
# UTILITY CLASSES
|
| 63 |
+
class DisableableButton:
|
| 64 |
+
"""
|
| 65 |
+
Utility class for creating "disable-able" buttons upon click.
|
| 66 |
+
|
| 67 |
+
We initialize an empty container, then update that container with buttons
|
| 68 |
+
upon calling `create_enabled_button` and `disable` methods where clicking
|
| 69 |
+
is enabled and then disabled, respectively.
|
| 70 |
+
|
| 71 |
+
"""
|
| 72 |
+
|
| 73 |
+
def __init__(self, button_number, button_text):
|
| 74 |
+
self.button_number = button_number
|
| 75 |
+
self.button_text = button_text
|
| 76 |
+
|
| 77 |
+
def _init_placeholder_container(self):
|
| 78 |
+
self.ph = st.empty()
|
| 79 |
+
|
| 80 |
+
def create_enabled_button(self):
|
| 81 |
+
self._init_placeholder_container()
|
| 82 |
+
self.ph.button(
|
| 83 |
+
self.button_text,
|
| 84 |
+
on_click=increment_page_progress,
|
| 85 |
+
key=f"ph{self.button_number}_before",
|
| 86 |
+
disabled=False,
|
| 87 |
+
)
|
| 88 |
+
|
| 89 |
+
def disable(self):
|
| 90 |
+
self.ph.button(
|
| 91 |
+
self.button_text, key=f"ph{self.button_number}_after", disabled=True
|
| 92 |
+
)
|
| 93 |
+
|
| 94 |
+
|
| 95 |
+
# CACHED FUNCTIONS
|
| 96 |
+
@st.cache(
|
| 97 |
+
hash_funcs={tokenizers.Tokenizer: lambda _: None},
|
| 98 |
+
allow_output_mutation=True,
|
| 99 |
+
show_spinner=False,
|
| 100 |
+
)
|
| 101 |
+
def get_cached_style_intensity_classifier(
|
| 102 |
+
style_data: StyleAttributeData,
|
| 103 |
+
) -> StyleIntensityClassifier:
|
| 104 |
+
"""
|
| 105 |
+
Return a cached style classifier.
|
| 106 |
+
|
| 107 |
+
This function overwrites the existing model's config values for
|
| 108 |
+
`id2label` and `label2id`.
|
| 109 |
+
|
| 110 |
+
Args:
|
| 111 |
+
style_data (StyleAttributeData)
|
| 112 |
+
|
| 113 |
+
Returns:
|
| 114 |
+
StyleIntensityClassifier
|
| 115 |
+
"""
|
| 116 |
+
sic = StyleIntensityClassifier(style_data.cls_model_path)
|
| 117 |
+
|
| 118 |
+
# create or overwrite id-label lookup in model config
|
| 119 |
+
sic.pipeline.model.config.__dict__["id2label"] = {
|
| 120 |
+
i: a
|
| 121 |
+
for i, a in enumerate(
|
| 122 |
+
[
|
| 123 |
+
style_data.source_attribute.capitalize(),
|
| 124 |
+
style_data.target_attribute.capitalize(),
|
| 125 |
+
]
|
| 126 |
+
)
|
| 127 |
+
}
|
| 128 |
+
sic.pipeline.model.config.__dict__["label2id"] = {
|
| 129 |
+
v: k for k, v in sic.pipeline.model.config.__dict__["id2label"].items()
|
| 130 |
+
}
|
| 131 |
+
|
| 132 |
+
return sic
|
| 133 |
+
|
| 134 |
+
|
| 135 |
+
@st.cache(
|
| 136 |
+
hash_funcs={tokenizers.Tokenizer: lambda _: None},
|
| 137 |
+
allow_output_mutation=True,
|
| 138 |
+
show_spinner=False,
|
| 139 |
+
)
|
| 140 |
+
def get_cached_word_attributions(
|
| 141 |
+
text_sample: str, style_data: StyleAttributeData
|
| 142 |
+
) -> str:
|
| 143 |
+
"""
|
| 144 |
+
Calculated word attributions and return HTML visual.
|
| 145 |
+
|
| 146 |
+
This function overwrites the existing model's config values for
|
| 147 |
+
`id2label` and `label2id`.
|
| 148 |
+
|
| 149 |
+
Args:
|
| 150 |
+
text_sample (str)
|
| 151 |
+
style_data (StyleAttributeData)
|
| 152 |
+
|
| 153 |
+
Returns:
|
| 154 |
+
str
|
| 155 |
+
"""
|
| 156 |
+
it = InterpretTransformer(cls_model_identifier=style_data.cls_model_path)
|
| 157 |
+
|
| 158 |
+
# create or overwrite id-label lookup in model config
|
| 159 |
+
it.explainer.id2label = {
|
| 160 |
+
i: a
|
| 161 |
+
for i, a in enumerate(
|
| 162 |
+
[
|
| 163 |
+
style_data.source_attribute.capitalize(),
|
| 164 |
+
style_data.target_attribute.capitalize(),
|
| 165 |
+
]
|
| 166 |
+
)
|
| 167 |
+
}
|
| 168 |
+
it.explainer.label2id = {v: k for k, v in it.explainer.id2label.items()}
|
| 169 |
+
return it.visualize_feature_attribution_scores(text_sample).data
|
| 170 |
+
|
| 171 |
+
|
| 172 |
+
@st.cache(
|
| 173 |
+
hash_funcs={tokenizers.Tokenizer: lambda _: None},
|
| 174 |
+
allow_output_mutation=True,
|
| 175 |
+
show_spinner=False,
|
| 176 |
+
)
|
| 177 |
+
def get_sti_metric(
|
| 178 |
+
input_text: str, output_text: str, style_data: StyleAttributeData
|
| 179 |
+
) -> List[float]:
|
| 180 |
+
"""
|
| 181 |
+
Calculate Style Transfer Intensity (STI)
|
| 182 |
+
|
| 183 |
+
Args:
|
| 184 |
+
input_text (str)
|
| 185 |
+
output_text (str)
|
| 186 |
+
style_data (StyleAttributeData)
|
| 187 |
+
|
| 188 |
+
Returns:
|
| 189 |
+
List[float]
|
| 190 |
+
"""
|
| 191 |
+
sti = StyleIntensityClassifier(
|
| 192 |
+
model_identifier=style_data.cls_model_path,
|
| 193 |
+
)
|
| 194 |
+
return sti.calculate_transfer_intensity_fraction(
|
| 195 |
+
string_to_list_string(input_text), string_to_list_string(output_text)
|
| 196 |
+
)
|
| 197 |
+
|
| 198 |
+
|
| 199 |
+
@st.cache(
|
| 200 |
+
hash_funcs={tokenizers.Tokenizer: lambda _: None},
|
| 201 |
+
allow_output_mutation=True,
|
| 202 |
+
show_spinner=False,
|
| 203 |
+
)
|
| 204 |
+
def get_cps_metric(
|
| 205 |
+
input_text: str, output_text: str, style_data: StyleAttributeData
|
| 206 |
+
) -> List[float]:
|
| 207 |
+
"""
|
| 208 |
+
Calculate Content Preservation Score (CPS)
|
| 209 |
+
|
| 210 |
+
Args:
|
| 211 |
+
input_text (str)
|
| 212 |
+
output_text (str)
|
| 213 |
+
style_data (StyleAttributeData)
|
| 214 |
+
|
| 215 |
+
Returns:
|
| 216 |
+
List[float]
|
| 217 |
+
"""
|
| 218 |
+
cps = ContentPreservationScorer(
|
| 219 |
+
cls_model_identifier=style_data.cls_model_path,
|
| 220 |
+
sbert_model_identifier=style_data.sbert_model_path,
|
| 221 |
+
)
|
| 222 |
+
return cps.calculate_content_preservation_score(
|
| 223 |
+
string_to_list_string(input_text),
|
| 224 |
+
string_to_list_string(output_text),
|
| 225 |
+
mask_type="none",
|
| 226 |
+
)
|
| 227 |
+
|
| 228 |
+
|
| 229 |
+
def generate_style_transfer(
|
| 230 |
+
text_sample: str,
|
| 231 |
+
style_data: StyleAttributeData,
|
| 232 |
+
max_gen_length: int,
|
| 233 |
+
num_beams: int,
|
| 234 |
+
temperature: int,
|
| 235 |
+
):
|
| 236 |
+
"""
|
| 237 |
+
Run inference on seq2seq model and persist result to
|
| 238 |
+
`session_state` varaible.
|
| 239 |
+
|
| 240 |
+
Args:
|
| 241 |
+
text_sample (str): _description_
|
| 242 |
+
style_data (StyleAttributeData): _description_
|
| 243 |
+
max_gen_length (int): _description_
|
| 244 |
+
num_beams (int): _description_
|
| 245 |
+
temperature (int): _description_
|
| 246 |
+
"""
|
| 247 |
+
with st.spinner("Transferring style, hang tight!"):
|
| 248 |
+
|
| 249 |
+
generate_kwargs = {
|
| 250 |
+
"max_gen_length": max_gen_length,
|
| 251 |
+
"num_beams": num_beams,
|
| 252 |
+
"temperature": temperature,
|
| 253 |
+
}
|
| 254 |
+
|
| 255 |
+
st_class = StyleTransfer(
|
| 256 |
+
model_identifier=style_data.seq2seq_model_path,
|
| 257 |
+
**generate_kwargs,
|
| 258 |
+
)
|
| 259 |
+
|
| 260 |
+
st_result = st_class.transfer(text_sample)
|
| 261 |
+
|
| 262 |
+
st.session_state.st_result = st_result
|
apps/data_utils.py
ADDED
|
@@ -0,0 +1,150 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# ###########################################################################
|
| 2 |
+
#
|
| 3 |
+
# CLOUDERA APPLIED MACHINE LEARNING PROTOTYPE (AMP)
|
| 4 |
+
# (C) Cloudera, Inc. 2022
|
| 5 |
+
# All rights reserved.
|
| 6 |
+
#
|
| 7 |
+
# Applicable Open Source License: Apache 2.0
|
| 8 |
+
#
|
| 9 |
+
# NOTE: Cloudera open source products are modular software products
|
| 10 |
+
# made up of hundreds of individual components, each of which was
|
| 11 |
+
# individually copyrighted. Each Cloudera open source product is a
|
| 12 |
+
# collective work under U.S. Copyright Law. Your license to use the
|
| 13 |
+
# collective work is as provided in your written agreement with
|
| 14 |
+
# Cloudera. Used apart from the collective work, this file is
|
| 15 |
+
# licensed for your use pursuant to the open source license
|
| 16 |
+
# identified above.
|
| 17 |
+
#
|
| 18 |
+
# This code is provided to you pursuant a written agreement with
|
| 19 |
+
# (i) Cloudera, Inc. or (ii) a third-party authorized to distribute
|
| 20 |
+
# this code. If you do not have a written agreement with Cloudera nor
|
| 21 |
+
# with an authorized and properly licensed third party, you do not
|
| 22 |
+
# have any rights to access nor to use this code.
|
| 23 |
+
#
|
| 24 |
+
# Absent a written agreement with Cloudera, Inc. (“Cloudera”) to the
|
| 25 |
+
# contrary, A) CLOUDERA PROVIDES THIS CODE TO YOU WITHOUT WARRANTIES OF ANY
|
| 26 |
+
# KIND; (B) CLOUDERA DISCLAIMS ANY AND ALL EXPRESS AND IMPLIED
|
| 27 |
+
# WARRANTIES WITH RESPECT TO THIS CODE, INCLUDING BUT NOT LIMITED TO
|
| 28 |
+
# IMPLIED WARRANTIES OF TITLE, NON-INFRINGEMENT, MERCHANTABILITY AND
|
| 29 |
+
# FITNESS FOR A PARTICULAR PURPOSE; (C) CLOUDERA IS NOT LIABLE TO YOU,
|
| 30 |
+
# AND WILL NOT DEFEND, INDEMNIFY, NOR HOLD YOU HARMLESS FOR ANY CLAIMS
|
| 31 |
+
# ARISING FROM OR RELATED TO THE CODE; AND (D)WITH RESPECT TO YOUR EXERCISE
|
| 32 |
+
# OF ANY RIGHTS GRANTED TO YOU FOR THE CODE, CLOUDERA IS NOT LIABLE FOR ANY
|
| 33 |
+
# DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, PUNITIVE OR
|
| 34 |
+
# CONSEQUENTIAL DAMAGES INCLUDING, BUT NOT LIMITED TO, DAMAGES
|
| 35 |
+
# RELATED TO LOST REVENUE, LOST PROFITS, LOSS OF INCOME, LOSS OF
|
| 36 |
+
# BUSINESS ADVANTAGE OR UNAVAILABILITY, OR LOSS OR CORRUPTION OF
|
| 37 |
+
# DATA.
|
| 38 |
+
#
|
| 39 |
+
# ###########################################################################
|
| 40 |
+
|
| 41 |
+
import os
|
| 42 |
+
from typing import List
|
| 43 |
+
from collections import defaultdict
|
| 44 |
+
from dataclasses import dataclass
|
| 45 |
+
|
| 46 |
+
import numpy as np
|
| 47 |
+
|
| 48 |
+
|
| 49 |
+
@dataclass
|
| 50 |
+
class StyleAttributeData:
|
| 51 |
+
source_attribute: str
|
| 52 |
+
target_attribute: str
|
| 53 |
+
examples: List[str]
|
| 54 |
+
cls_model_path: str
|
| 55 |
+
seq2seq_model_path: str
|
| 56 |
+
sbert_model_path: str = "sentence-transformers/all-MiniLM-L6-v2"
|
| 57 |
+
hf_base_url: str = "https://huggingface.co/"
|
| 58 |
+
|
| 59 |
+
def __post_init__(self):
|
| 60 |
+
self._make_attribute_selection_string()
|
| 61 |
+
self._make_attribute_AND_string()
|
| 62 |
+
self._make_attribute_THAN_string()
|
| 63 |
+
|
| 64 |
+
def _make_attribute_selection_string(self):
|
| 65 |
+
self.attribute_selecting_string = (
|
| 66 |
+
f"{self.source_attribute}-{self.target_attribute}"
|
| 67 |
+
)
|
| 68 |
+
|
| 69 |
+
def _make_attribute_AND_string(self):
|
| 70 |
+
self.attribute_AND_string = (
|
| 71 |
+
f"**{self.source_attribute}** and **{self.target_attribute}**"
|
| 72 |
+
)
|
| 73 |
+
|
| 74 |
+
def _make_attribute_THAN_string(self):
|
| 75 |
+
self.attribute_THAN_string = (
|
| 76 |
+
f"**{self.source_attribute}** than **{self.target_attribute}**"
|
| 77 |
+
)
|
| 78 |
+
|
| 79 |
+
def build_model_url(self, model_type: str):
|
| 80 |
+
"""
|
| 81 |
+
Build a complete HuggingFace url for the given `model_type`.
|
| 82 |
+
|
| 83 |
+
Args:
|
| 84 |
+
model_type (str): "cls", "seq2seq", "sbert"
|
| 85 |
+
"""
|
| 86 |
+
attr_name = f"{model_type}_model_path"
|
| 87 |
+
return os.path.join(self.hf_base_url, getattr(self, attr_name))
|
| 88 |
+
|
| 89 |
+
|
| 90 |
+
# instantiate data classes & collect all data class instances
|
| 91 |
+
DATA_PACKET = {
|
| 92 |
+
"subjective-to-neutral": StyleAttributeData(
|
| 93 |
+
source_attribute="subjective",
|
| 94 |
+
target_attribute="neutral",
|
| 95 |
+
examples=[
|
| 96 |
+
"another strikingly elegant four-door design for the bentley s3 continental came from james.",
|
| 97 |
+
"the band plays an engaging and contagious rhythm known as brega pop and calypso.",
|
| 98 |
+
"chemical abstracts service (cas), a prominent division of the american chemical society, is the world's leading source of chemical information.",
|
| 99 |
+
"the final fight scene is with the martial arts great, master ninja sho kosugi.",
|
| 100 |
+
],
|
| 101 |
+
cls_model_path="cffl/bert-base-styleclassification-subjective-neutral",
|
| 102 |
+
seq2seq_model_path="cffl/bart-base-styletransfer-subjective-to-neutral",
|
| 103 |
+
),
|
| 104 |
+
"informal-to-formal": StyleAttributeData(
|
| 105 |
+
source_attribute="informal",
|
| 106 |
+
target_attribute="formal",
|
| 107 |
+
examples=[
|
| 108 |
+
"that was funny LOL",
|
| 109 |
+
"btw - ur avatar looks familiar",
|
| 110 |
+
"i loooooooooooooooooooooooove going to the movies.",
|
| 111 |
+
"haha, thatd be dope",
|
| 112 |
+
],
|
| 113 |
+
cls_model_path="cointegrated/roberta-base-formality",
|
| 114 |
+
seq2seq_model_path="prithivida/informal_to_formal_styletransfer",
|
| 115 |
+
),
|
| 116 |
+
}
|
| 117 |
+
|
| 118 |
+
|
| 119 |
+
def format_classification_results(id2label: dict, cls_result):
|
| 120 |
+
"""
|
| 121 |
+
Formats classification output to be plotted using Altair.
|
| 122 |
+
|
| 123 |
+
Args:
|
| 124 |
+
id2label (dict): Transformer model's label dictionary
|
| 125 |
+
cls_result (List): Classification pipeline output
|
| 126 |
+
"""
|
| 127 |
+
|
| 128 |
+
labels = [v for k, v in id2label.items()]
|
| 129 |
+
|
| 130 |
+
format_cls_result = []
|
| 131 |
+
|
| 132 |
+
for i in range(len(labels)):
|
| 133 |
+
temp = defaultdict()
|
| 134 |
+
temp["type"] = labels[i].capitalize()
|
| 135 |
+
temp["value"] = round(cls_result[0]["distribution"][i], 4)
|
| 136 |
+
|
| 137 |
+
if i == 0:
|
| 138 |
+
temp["percentage_start"] = 0
|
| 139 |
+
temp["percentage_end"] = temp["value"]
|
| 140 |
+
else:
|
| 141 |
+
temp["percentage_start"] = 1 - temp["value"]
|
| 142 |
+
temp["percentage_end"] = 1
|
| 143 |
+
|
| 144 |
+
format_cls_result.append(temp)
|
| 145 |
+
|
| 146 |
+
return format_cls_result
|
| 147 |
+
|
| 148 |
+
|
| 149 |
+
def string_to_list_string(text: str):
|
| 150 |
+
return np.expand_dims(np.array(text), axis=0).tolist()
|
apps/visualization_utils.py
ADDED
|
@@ -0,0 +1,159 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# ###########################################################################
|
| 2 |
+
#
|
| 3 |
+
# CLOUDERA APPLIED MACHINE LEARNING PROTOTYPE (AMP)
|
| 4 |
+
# (C) Cloudera, Inc. 2022
|
| 5 |
+
# All rights reserved.
|
| 6 |
+
#
|
| 7 |
+
# Applicable Open Source License: Apache 2.0
|
| 8 |
+
#
|
| 9 |
+
# NOTE: Cloudera open source products are modular software products
|
| 10 |
+
# made up of hundreds of individual components, each of which was
|
| 11 |
+
# individually copyrighted. Each Cloudera open source product is a
|
| 12 |
+
# collective work under U.S. Copyright Law. Your license to use the
|
| 13 |
+
# collective work is as provided in your written agreement with
|
| 14 |
+
# Cloudera. Used apart from the collective work, this file is
|
| 15 |
+
# licensed for your use pursuant to the open source license
|
| 16 |
+
# identified above.
|
| 17 |
+
#
|
| 18 |
+
# This code is provided to you pursuant a written agreement with
|
| 19 |
+
# (i) Cloudera, Inc. or (ii) a third-party authorized to distribute
|
| 20 |
+
# this code. If you do not have a written agreement with Cloudera nor
|
| 21 |
+
# with an authorized and properly licensed third party, you do not
|
| 22 |
+
# have any rights to access nor to use this code.
|
| 23 |
+
#
|
| 24 |
+
# Absent a written agreement with Cloudera, Inc. (“Cloudera”) to the
|
| 25 |
+
# contrary, A) CLOUDERA PROVIDES THIS CODE TO YOU WITHOUT WARRANTIES OF ANY
|
| 26 |
+
# KIND; (B) CLOUDERA DISCLAIMS ANY AND ALL EXPRESS AND IMPLIED
|
| 27 |
+
# WARRANTIES WITH RESPECT TO THIS CODE, INCLUDING BUT NOT LIMITED TO
|
| 28 |
+
# IMPLIED WARRANTIES OF TITLE, NON-INFRINGEMENT, MERCHANTABILITY AND
|
| 29 |
+
# FITNESS FOR A PARTICULAR PURPOSE; (C) CLOUDERA IS NOT LIABLE TO YOU,
|
| 30 |
+
# AND WILL NOT DEFEND, INDEMNIFY, NOR HOLD YOU HARMLESS FOR ANY CLAIMS
|
| 31 |
+
# ARISING FROM OR RELATED TO THE CODE; AND (D)WITH RESPECT TO YOUR EXERCISE
|
| 32 |
+
# OF ANY RIGHTS GRANTED TO YOU FOR THE CODE, CLOUDERA IS NOT LIABLE FOR ANY
|
| 33 |
+
# DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, PUNITIVE OR
|
| 34 |
+
# CONSEQUENTIAL DAMAGES INCLUDING, BUT NOT LIMITED TO, DAMAGES
|
| 35 |
+
# RELATED TO LOST REVENUE, LOST PROFITS, LOSS OF INCOME, LOSS OF
|
| 36 |
+
# BUSINESS ADVANTAGE OR UNAVAILABILITY, OR LOSS OR CORRUPTION OF
|
| 37 |
+
# DATA.
|
| 38 |
+
#
|
| 39 |
+
# ###########################################################################
|
| 40 |
+
|
| 41 |
+
from typing import Iterable
|
| 42 |
+
|
| 43 |
+
import altair as alt
|
| 44 |
+
from captum.attr._utils.visualization import (
|
| 45 |
+
VisualizationDataRecord,
|
| 46 |
+
format_word_importances,
|
| 47 |
+
_get_color,
|
| 48 |
+
)
|
| 49 |
+
|
| 50 |
+
try:
|
| 51 |
+
from IPython.display import display, HTML
|
| 52 |
+
|
| 53 |
+
HAS_IPYTHON = True
|
| 54 |
+
except ImportError:
|
| 55 |
+
HAS_IPYTHON = False
|
| 56 |
+
|
| 57 |
+
def format_classname(classname):
|
| 58 |
+
return f'<td>{classname}</td>'
|
| 59 |
+
|
| 60 |
+
def visualize_text(
|
| 61 |
+
datarecords: Iterable[VisualizationDataRecord], legend: bool = True
|
| 62 |
+
) -> "HTML": # In quotes because this type doesn't exist in standalone mode
|
| 63 |
+
assert HAS_IPYTHON, (
|
| 64 |
+
"IPython must be available to visualize text. "
|
| 65 |
+
"Please run 'pip install ipython'."
|
| 66 |
+
)
|
| 67 |
+
|
| 68 |
+
dom = []
|
| 69 |
+
dom.append(
|
| 70 |
+
'<head><link rel="stylesheet" href="https://cdn.jsdelivr.net/npm/bootstrap@4.0.0/dist/css/bootstrap.min.css" integrity="sha384-Gn5384xqQ1aoWXA+058RXPxPg6fy4IWvTNh0E263XmFcJlSAwiGgFAW/dAiS6JXm" crossorigin="anonymous"></head>'
|
| 71 |
+
)
|
| 72 |
+
dom.append("""<table width:100; class="table">""")
|
| 73 |
+
rows = [
|
| 74 |
+
"<thead>"
|
| 75 |
+
"<tr>"
|
| 76 |
+
"<th scope='col'><span class='text-nowrap'>Predicted Label</span></th>"
|
| 77 |
+
"<th scope='col'><span class='text-nowrap'>Attribution Score</span></th>"
|
| 78 |
+
"<th scope='col'><span class='text-nowrap'>Feature Importance</span></th>"
|
| 79 |
+
"</tr>"
|
| 80 |
+
"</thead>"
|
| 81 |
+
]
|
| 82 |
+
for datarecord in datarecords:
|
| 83 |
+
rows.append(
|
| 84 |
+
"".join(
|
| 85 |
+
[
|
| 86 |
+
"<tbody>",
|
| 87 |
+
"<tr>",
|
| 88 |
+
format_classname(
|
| 89 |
+
f"{datarecord.pred_class.capitalize()}"
|
| 90 |
+
),
|
| 91 |
+
format_classname(f"{round(datarecord.attr_score.item(), 2)}"),
|
| 92 |
+
format_word_importances(
|
| 93 |
+
datarecord.raw_input_ids, datarecord.word_attributions
|
| 94 |
+
),
|
| 95 |
+
"<tr>",
|
| 96 |
+
"</tbody>",
|
| 97 |
+
]
|
| 98 |
+
)
|
| 99 |
+
)
|
| 100 |
+
|
| 101 |
+
dom.append("".join(rows))
|
| 102 |
+
dom.append("</table>")
|
| 103 |
+
|
| 104 |
+
if legend:
|
| 105 |
+
dom.append("<div class='row'>")
|
| 106 |
+
dom.append("<div class='col-6'>")
|
| 107 |
+
dom.append("<b>Legend: </b>")
|
| 108 |
+
|
| 109 |
+
for value, label in zip([-1, 0, 1], ["Negative", "Neutral", "Positive"]):
|
| 110 |
+
dom.append(
|
| 111 |
+
'<span style="display: inline-block; width: 10px; height: 10px; \
|
| 112 |
+
border: 1px solid; background-color: \
|
| 113 |
+
{value}"></span> {label} '.format(
|
| 114 |
+
value=_get_color(value), label=label
|
| 115 |
+
)
|
| 116 |
+
)
|
| 117 |
+
dom.append("</div>")
|
| 118 |
+
dom.append("<div class='col-6'></div>")
|
| 119 |
+
|
| 120 |
+
dom.append("</div>")
|
| 121 |
+
|
| 122 |
+
html = HTML("".join(dom))
|
| 123 |
+
display(html)
|
| 124 |
+
|
| 125 |
+
return html
|
| 126 |
+
|
| 127 |
+
|
| 128 |
+
def build_altair_classification_plot(format_cls_result):
|
| 129 |
+
"""
|
| 130 |
+
Builds Altair bar chart for classification results.
|
| 131 |
+
|
| 132 |
+
Args:
|
| 133 |
+
format_cls_result (List): Output from `format_classification_results()`
|
| 134 |
+
"""
|
| 135 |
+
source = alt.pd.DataFrame(format_cls_result)
|
| 136 |
+
|
| 137 |
+
color_scale = alt.Scale(
|
| 138 |
+
domain=[record["type"] for record in format_cls_result],
|
| 139 |
+
range=["#00A3AF", "#F96702"],
|
| 140 |
+
)
|
| 141 |
+
|
| 142 |
+
c = (
|
| 143 |
+
alt.Chart(source)
|
| 144 |
+
.mark_bar(size=50)
|
| 145 |
+
.encode(
|
| 146 |
+
x=alt.X(
|
| 147 |
+
"percentage_start:Q", axis=alt.Axis(title="Style Distribution (%)")
|
| 148 |
+
),
|
| 149 |
+
x2=alt.X2("percentage_end:Q"),
|
| 150 |
+
color=alt.Color(
|
| 151 |
+
"type:N",
|
| 152 |
+
legend=alt.Legend(title="Attribute"),
|
| 153 |
+
scale=color_scale,
|
| 154 |
+
),
|
| 155 |
+
)
|
| 156 |
+
.properties(height=150)
|
| 157 |
+
)
|
| 158 |
+
|
| 159 |
+
return c
|
requirements.txt
ADDED
|
@@ -0,0 +1,10 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
torch==1.12.0
|
| 2 |
+
transformers==4.20.1
|
| 3 |
+
pyemd==0.5.1
|
| 4 |
+
streamlit==1.10.0
|
| 5 |
+
attrs==21.4.0
|
| 6 |
+
jinja2==3.1.2
|
| 7 |
+
jsonschema==4.7.2
|
| 8 |
+
pyrsistent==0.18.1
|
| 9 |
+
transformers-interpret==0.7.2
|
| 10 |
+
-e .
|
scripts/download_models.py
ADDED
|
@@ -0,0 +1,70 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# ###########################################################################
|
| 2 |
+
#
|
| 3 |
+
# CLOUDERA APPLIED MACHINE LEARNING PROTOTYPE (AMP)
|
| 4 |
+
# (C) Cloudera, Inc. 2022
|
| 5 |
+
# All rights reserved.
|
| 6 |
+
#
|
| 7 |
+
# Applicable Open Source License: Apache 2.0
|
| 8 |
+
#
|
| 9 |
+
# NOTE: Cloudera open source products are modular software products
|
| 10 |
+
# made up of hundreds of individual components, each of which was
|
| 11 |
+
# individually copyrighted. Each Cloudera open source product is a
|
| 12 |
+
# collective work under U.S. Copyright Law. Your license to use the
|
| 13 |
+
# collective work is as provided in your written agreement with
|
| 14 |
+
# Cloudera. Used apart from the collective work, this file is
|
| 15 |
+
# licensed for your use pursuant to the open source license
|
| 16 |
+
# identified above.
|
| 17 |
+
#
|
| 18 |
+
# This code is provided to you pursuant a written agreement with
|
| 19 |
+
# (i) Cloudera, Inc. or (ii) a third-party authorized to distribute
|
| 20 |
+
# this code. If you do not have a written agreement with Cloudera nor
|
| 21 |
+
# with an authorized and properly licensed third party, you do not
|
| 22 |
+
# have any rights to access nor to use this code.
|
| 23 |
+
#
|
| 24 |
+
# Absent a written agreement with Cloudera, Inc. (“Cloudera”) to the
|
| 25 |
+
# contrary, A) CLOUDERA PROVIDES THIS CODE TO YOU WITHOUT WARRANTIES OF ANY
|
| 26 |
+
# KIND; (B) CLOUDERA DISCLAIMS ANY AND ALL EXPRESS AND IMPLIED
|
| 27 |
+
# WARRANTIES WITH RESPECT TO THIS CODE, INCLUDING BUT NOT LIMITED TO
|
| 28 |
+
# IMPLIED WARRANTIES OF TITLE, NON-INFRINGEMENT, MERCHANTABILITY AND
|
| 29 |
+
# FITNESS FOR A PARTICULAR PURPOSE; (C) CLOUDERA IS NOT LIABLE TO YOU,
|
| 30 |
+
# AND WILL NOT DEFEND, INDEMNIFY, NOR HOLD YOU HARMLESS FOR ANY CLAIMS
|
| 31 |
+
# ARISING FROM OR RELATED TO THE CODE; AND (D)WITH RESPECT TO YOUR EXERCISE
|
| 32 |
+
# OF ANY RIGHTS GRANTED TO YOU FOR THE CODE, CLOUDERA IS NOT LIABLE FOR ANY
|
| 33 |
+
# DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, PUNITIVE OR
|
| 34 |
+
# CONSEQUENTIAL DAMAGES INCLUDING, BUT NOT LIMITED TO, DAMAGES
|
| 35 |
+
# RELATED TO LOST REVENUE, LOST PROFITS, LOSS OF INCOME, LOSS OF
|
| 36 |
+
# BUSINESS ADVANTAGE OR UNAVAILABILITY, OR LOSS OR CORRUPTION OF
|
| 37 |
+
# DATA.
|
| 38 |
+
#
|
| 39 |
+
# ###########################################################################
|
| 40 |
+
|
| 41 |
+
from apps.data_utils import DATA_PACKET
|
| 42 |
+
from src.style_transfer import StyleTransfer
|
| 43 |
+
from src.style_classification import StyleIntensityClassifier
|
| 44 |
+
from src.content_preservation import ContentPreservationScorer
|
| 45 |
+
|
| 46 |
+
|
| 47 |
+
def load_and_cache_HF_models(style_data_packet):
|
| 48 |
+
"""
|
| 49 |
+
This utility function is used to download and cache models needed for all style
|
| 50 |
+
attributes in `apps.data_utils.DATA_PACKET`
|
| 51 |
+
|
| 52 |
+
Args:
|
| 53 |
+
style_data_packet (dict)
|
| 54 |
+
"""
|
| 55 |
+
|
| 56 |
+
for style_data in style_data_packet.keys():
|
| 57 |
+
try:
|
| 58 |
+
st = StyleTransfer(model_identifier=style_data.seq2seq_model_path)
|
| 59 |
+
sic = StyleIntensityClassifier(style_data.cls_model_path)
|
| 60 |
+
cps = ContentPreservationScorer(
|
| 61 |
+
cls_model_identifier=style_data.cls_model_path,
|
| 62 |
+
sbert_model_identifier=style_data.sbert_model_path,
|
| 63 |
+
)
|
| 64 |
+
|
| 65 |
+
del st, sic, cps
|
| 66 |
+
except Exception as e:
|
| 67 |
+
print(e)
|
| 68 |
+
|
| 69 |
+
if __name__=="__main__":
|
| 70 |
+
load_and_cache_HF_models(DATA_PACKET)
|
scripts/install_dependencies.py
ADDED
|
@@ -0,0 +1,41 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# ###########################################################################
|
| 2 |
+
#
|
| 3 |
+
# CLOUDERA APPLIED MACHINE LEARNING PROTOTYPE (AMP)
|
| 4 |
+
# (C) Cloudera, Inc. 2022
|
| 5 |
+
# All rights reserved.
|
| 6 |
+
#
|
| 7 |
+
# Applicable Open Source License: Apache 2.0
|
| 8 |
+
#
|
| 9 |
+
# NOTE: Cloudera open source products are modular software products
|
| 10 |
+
# made up of hundreds of individual components, each of which was
|
| 11 |
+
# individually copyrighted. Each Cloudera open source product is a
|
| 12 |
+
# collective work under U.S. Copyright Law. Your license to use the
|
| 13 |
+
# collective work is as provided in your written agreement with
|
| 14 |
+
# Cloudera. Used apart from the collective work, this file is
|
| 15 |
+
# licensed for your use pursuant to the open source license
|
| 16 |
+
# identified above.
|
| 17 |
+
#
|
| 18 |
+
# This code is provided to you pursuant a written agreement with
|
| 19 |
+
# (i) Cloudera, Inc. or (ii) a third-party authorized to distribute
|
| 20 |
+
# this code. If you do not have a written agreement with Cloudera nor
|
| 21 |
+
# with an authorized and properly licensed third party, you do not
|
| 22 |
+
# have any rights to access nor to use this code.
|
| 23 |
+
#
|
| 24 |
+
# Absent a written agreement with Cloudera, Inc. (“Cloudera”) to the
|
| 25 |
+
# contrary, A) CLOUDERA PROVIDES THIS CODE TO YOU WITHOUT WARRANTIES OF ANY
|
| 26 |
+
# KIND; (B) CLOUDERA DISCLAIMS ANY AND ALL EXPRESS AND IMPLIED
|
| 27 |
+
# WARRANTIES WITH RESPECT TO THIS CODE, INCLUDING BUT NOT LIMITED TO
|
| 28 |
+
# IMPLIED WARRANTIES OF TITLE, NON-INFRINGEMENT, MERCHANTABILITY AND
|
| 29 |
+
# FITNESS FOR A PARTICULAR PURPOSE; (C) CLOUDERA IS NOT LIABLE TO YOU,
|
| 30 |
+
# AND WILL NOT DEFEND, INDEMNIFY, NOR HOLD YOU HARMLESS FOR ANY CLAIMS
|
| 31 |
+
# ARISING FROM OR RELATED TO THE CODE; AND (D)WITH RESPECT TO YOUR EXERCISE
|
| 32 |
+
# OF ANY RIGHTS GRANTED TO YOU FOR THE CODE, CLOUDERA IS NOT LIABLE FOR ANY
|
| 33 |
+
# DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, PUNITIVE OR
|
| 34 |
+
# CONSEQUENTIAL DAMAGES INCLUDING, BUT NOT LIMITED TO, DAMAGES
|
| 35 |
+
# RELATED TO LOST REVENUE, LOST PROFITS, LOSS OF INCOME, LOSS OF
|
| 36 |
+
# BUSINESS ADVANTAGE OR UNAVAILABILITY, OR LOSS OR CORRUPTION OF
|
| 37 |
+
# DATA.
|
| 38 |
+
#
|
| 39 |
+
# ###########################################################################
|
| 40 |
+
|
| 41 |
+
!pip3 install -r requirements.txt && python3 scripts/download_models.py
|
scripts/launch_app.py
ADDED
|
@@ -0,0 +1,41 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# ###########################################################################
|
| 2 |
+
#
|
| 3 |
+
# CLOUDERA APPLIED MACHINE LEARNING PROTOTYPE (AMP)
|
| 4 |
+
# (C) Cloudera, Inc. 2022
|
| 5 |
+
# All rights reserved.
|
| 6 |
+
#
|
| 7 |
+
# Applicable Open Source License: Apache 2.0
|
| 8 |
+
#
|
| 9 |
+
# NOTE: Cloudera open source products are modular software products
|
| 10 |
+
# made up of hundreds of individual components, each of which was
|
| 11 |
+
# individually copyrighted. Each Cloudera open source product is a
|
| 12 |
+
# collective work under U.S. Copyright Law. Your license to use the
|
| 13 |
+
# collective work is as provided in your written agreement with
|
| 14 |
+
# Cloudera. Used apart from the collective work, this file is
|
| 15 |
+
# licensed for your use pursuant to the open source license
|
| 16 |
+
# identified above.
|
| 17 |
+
#
|
| 18 |
+
# This code is provided to you pursuant a written agreement with
|
| 19 |
+
# (i) Cloudera, Inc. or (ii) a third-party authorized to distribute
|
| 20 |
+
# this code. If you do not have a written agreement with Cloudera nor
|
| 21 |
+
# with an authorized and properly licensed third party, you do not
|
| 22 |
+
# have any rights to access nor to use this code.
|
| 23 |
+
#
|
| 24 |
+
# Absent a written agreement with Cloudera, Inc. (“Cloudera”) to the
|
| 25 |
+
# contrary, A) CLOUDERA PROVIDES THIS CODE TO YOU WITHOUT WARRANTIES OF ANY
|
| 26 |
+
# KIND; (B) CLOUDERA DISCLAIMS ANY AND ALL EXPRESS AND IMPLIED
|
| 27 |
+
# WARRANTIES WITH RESPECT TO THIS CODE, INCLUDING BUT NOT LIMITED TO
|
| 28 |
+
# IMPLIED WARRANTIES OF TITLE, NON-INFRINGEMENT, MERCHANTABILITY AND
|
| 29 |
+
# FITNESS FOR A PARTICULAR PURPOSE; (C) CLOUDERA IS NOT LIABLE TO YOU,
|
| 30 |
+
# AND WILL NOT DEFEND, INDEMNIFY, NOR HOLD YOU HARMLESS FOR ANY CLAIMS
|
| 31 |
+
# ARISING FROM OR RELATED TO THE CODE; AND (D)WITH RESPECT TO YOUR EXERCISE
|
| 32 |
+
# OF ANY RIGHTS GRANTED TO YOU FOR THE CODE, CLOUDERA IS NOT LIABLE FOR ANY
|
| 33 |
+
# DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, PUNITIVE OR
|
| 34 |
+
# CONSEQUENTIAL DAMAGES INCLUDING, BUT NOT LIMITED TO, DAMAGES
|
| 35 |
+
# RELATED TO LOST REVENUE, LOST PROFITS, LOSS OF INCOME, LOSS OF
|
| 36 |
+
# BUSINESS ADVANTAGE OR UNAVAILABILITY, OR LOSS OR CORRUPTION OF
|
| 37 |
+
# DATA.
|
| 38 |
+
#
|
| 39 |
+
# ###########################################################################
|
| 40 |
+
|
| 41 |
+
!streamlit run apps/app.py --server.port $CDSW_APP_PORT --server.address 127.0.0.1
|
setup.py
ADDED
|
@@ -0,0 +1,50 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# ###########################################################################
|
| 2 |
+
#
|
| 3 |
+
# CLOUDERA APPLIED MACHINE LEARNING PROTOTYPE (AMP)
|
| 4 |
+
# (C) Cloudera, Inc. 2022
|
| 5 |
+
# All rights reserved.
|
| 6 |
+
#
|
| 7 |
+
# Applicable Open Source License: Apache 2.0
|
| 8 |
+
#
|
| 9 |
+
# NOTE: Cloudera open source products are modular software products
|
| 10 |
+
# made up of hundreds of individual components, each of which was
|
| 11 |
+
# individually copyrighted. Each Cloudera open source product is a
|
| 12 |
+
# collective work under U.S. Copyright Law. Your license to use the
|
| 13 |
+
# collective work is as provided in your written agreement with
|
| 14 |
+
# Cloudera. Used apart from the collective work, this file is
|
| 15 |
+
# licensed for your use pursuant to the open source license
|
| 16 |
+
# identified above.
|
| 17 |
+
#
|
| 18 |
+
# This code is provided to you pursuant a written agreement with
|
| 19 |
+
# (i) Cloudera, Inc. or (ii) a third-party authorized to distribute
|
| 20 |
+
# this code. If you do not have a written agreement with Cloudera nor
|
| 21 |
+
# with an authorized and properly licensed third party, you do not
|
| 22 |
+
# have any rights to access nor to use this code.
|
| 23 |
+
#
|
| 24 |
+
# Absent a written agreement with Cloudera, Inc. (“Cloudera”) to the
|
| 25 |
+
# contrary, A) CLOUDERA PROVIDES THIS CODE TO YOU WITHOUT WARRANTIES OF ANY
|
| 26 |
+
# KIND; (B) CLOUDERA DISCLAIMS ANY AND ALL EXPRESS AND IMPLIED
|
| 27 |
+
# WARRANTIES WITH RESPECT TO THIS CODE, INCLUDING BUT NOT LIMITED TO
|
| 28 |
+
# IMPLIED WARRANTIES OF TITLE, NON-INFRINGEMENT, MERCHANTABILITY AND
|
| 29 |
+
# FITNESS FOR A PARTICULAR PURPOSE; (C) CLOUDERA IS NOT LIABLE TO YOU,
|
| 30 |
+
# AND WILL NOT DEFEND, INDEMNIFY, NOR HOLD YOU HARMLESS FOR ANY CLAIMS
|
| 31 |
+
# ARISING FROM OR RELATED TO THE CODE; AND (D)WITH RESPECT TO YOUR EXERCISE
|
| 32 |
+
# OF ANY RIGHTS GRANTED TO YOU FOR THE CODE, CLOUDERA IS NOT LIABLE FOR ANY
|
| 33 |
+
# DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, PUNITIVE OR
|
| 34 |
+
# CONSEQUENTIAL DAMAGES INCLUDING, BUT NOT LIMITED TO, DAMAGES
|
| 35 |
+
# RELATED TO LOST REVENUE, LOST PROFITS, LOSS OF INCOME, LOSS OF
|
| 36 |
+
# BUSINESS ADVANTAGE OR UNAVAILABILITY, OR LOSS OR CORRUPTION OF
|
| 37 |
+
# DATA.
|
| 38 |
+
#
|
| 39 |
+
# ###########################################################################
|
| 40 |
+
|
| 41 |
+
from setuptools import setup, find_packages
|
| 42 |
+
|
| 43 |
+
setup(
|
| 44 |
+
name="text-style-transfer",
|
| 45 |
+
version="0.1.0",
|
| 46 |
+
description="A library and demo application for the NLP task of text style transfer.",
|
| 47 |
+
author="Andrew Reed",
|
| 48 |
+
author_email="andrew.reed.r@gmail.com",
|
| 49 |
+
packages=find_packages(),
|
| 50 |
+
)
|
src/.DS_Store
ADDED
|
Binary file (6.15 kB). View file
|
|
|
src/__init__.py
ADDED
|
File without changes
|
src/content_preservation.py
ADDED
|
@@ -0,0 +1,366 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# ###########################################################################
|
| 2 |
+
#
|
| 3 |
+
# CLOUDERA APPLIED MACHINE LEARNING PROTOTYPE (AMP)
|
| 4 |
+
# (C) Cloudera, Inc. 2022
|
| 5 |
+
# All rights reserved.
|
| 6 |
+
#
|
| 7 |
+
# Applicable Open Source License: Apache 2.0
|
| 8 |
+
#
|
| 9 |
+
# NOTE: Cloudera open source products are modular software products
|
| 10 |
+
# made up of hundreds of individual components, each of which was
|
| 11 |
+
# individually copyrighted. Each Cloudera open source product is a
|
| 12 |
+
# collective work under U.S. Copyright Law. Your license to use the
|
| 13 |
+
# collective work is as provided in your written agreement with
|
| 14 |
+
# Cloudera. Used apart from the collective work, this file is
|
| 15 |
+
# licensed for your use pursuant to the open source license
|
| 16 |
+
# identified above.
|
| 17 |
+
#
|
| 18 |
+
# This code is provided to you pursuant a written agreement with
|
| 19 |
+
# (i) Cloudera, Inc. or (ii) a third-party authorized to distribute
|
| 20 |
+
# this code. If you do not have a written agreement with Cloudera nor
|
| 21 |
+
# with an authorized and properly licensed third party, you do not
|
| 22 |
+
# have any rights to access nor to use this code.
|
| 23 |
+
#
|
| 24 |
+
# Absent a written agreement with Cloudera, Inc. (“Cloudera”) to the
|
| 25 |
+
# contrary, A) CLOUDERA PROVIDES THIS CODE TO YOU WITHOUT WARRANTIES OF ANY
|
| 26 |
+
# KIND; (B) CLOUDERA DISCLAIMS ANY AND ALL EXPRESS AND IMPLIED
|
| 27 |
+
# WARRANTIES WITH RESPECT TO THIS CODE, INCLUDING BUT NOT LIMITED TO
|
| 28 |
+
# IMPLIED WARRANTIES OF TITLE, NON-INFRINGEMENT, MERCHANTABILITY AND
|
| 29 |
+
# FITNESS FOR A PARTICULAR PURPOSE; (C) CLOUDERA IS NOT LIABLE TO YOU,
|
| 30 |
+
# AND WILL NOT DEFEND, INDEMNIFY, NOR HOLD YOU HARMLESS FOR ANY CLAIMS
|
| 31 |
+
# ARISING FROM OR RELATED TO THE CODE; AND (D)WITH RESPECT TO YOUR EXERCISE
|
| 32 |
+
# OF ANY RIGHTS GRANTED TO YOU FOR THE CODE, CLOUDERA IS NOT LIABLE FOR ANY
|
| 33 |
+
# DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, PUNITIVE OR
|
| 34 |
+
# CONSEQUENTIAL DAMAGES INCLUDING, BUT NOT LIMITED TO, DAMAGES
|
| 35 |
+
# RELATED TO LOST REVENUE, LOST PROFITS, LOSS OF INCOME, LOSS OF
|
| 36 |
+
# BUSINESS ADVANTAGE OR UNAVAILABILITY, OR LOSS OR CORRUPTION OF
|
| 37 |
+
# DATA.
|
| 38 |
+
#
|
| 39 |
+
# ###########################################################################
|
| 40 |
+
|
| 41 |
+
from typing import List
|
| 42 |
+
|
| 43 |
+
import torch
|
| 44 |
+
import pandas as pd
|
| 45 |
+
from transformers import (
|
| 46 |
+
AutoTokenizer,
|
| 47 |
+
AutoModel,
|
| 48 |
+
AutoModelForSequenceClassification,
|
| 49 |
+
)
|
| 50 |
+
|
| 51 |
+
|
| 52 |
+
class ContentPreservationScorer:
|
| 53 |
+
"""
|
| 54 |
+
Utility for calculating Content Preservation Score between
|
| 55 |
+
two pieces of text (i.e. input and output of TST model).
|
| 56 |
+
|
| 57 |
+
This custom evaluation metric aims to quantify content preservation by
|
| 58 |
+
first modifying text to remove all style-related tokens leaving just
|
| 59 |
+
content related tokens behind. Style tokens are determind on a
|
| 60 |
+
sentence-by-sentence basis by extracting out salient token attributions
|
| 61 |
+
from a trained Style Classifier (BERT) so contextual information is
|
| 62 |
+
perserved in the attribution scores. Style tokens are then masked/removed
|
| 63 |
+
from the text. We pass the style-less sentences through a pre-trained,
|
| 64 |
+
but not fine-tuned SentenceBert model to compute sentence embeddings.
|
| 65 |
+
Cosine similarity on the embeddings produces a score that should represent
|
| 66 |
+
content preservation.
|
| 67 |
+
|
| 68 |
+
PSUEDO-CODE: (higher score is better preservation)
|
| 69 |
+
1. mask out style tokens for input and output text (1str)
|
| 70 |
+
2. get SBERT embedddings for each (multi)
|
| 71 |
+
3. calculate cosine similarity (multi pairs)
|
| 72 |
+
|
| 73 |
+
Attributes:
|
| 74 |
+
cls_model_identifier (str)
|
| 75 |
+
sbert_model_identifier (str)
|
| 76 |
+
|
| 77 |
+
"""
|
| 78 |
+
|
| 79 |
+
def __init__(self, cls_model_identifier: str, sbert_model_identifier: str):
|
| 80 |
+
|
| 81 |
+
self.cls_model_identifier = cls_model_identifier
|
| 82 |
+
self.sbert_model_identifier = sbert_model_identifier
|
| 83 |
+
self.device = (
|
| 84 |
+
torch.cuda.current_device() if torch.cuda.is_available() else "cpu"
|
| 85 |
+
)
|
| 86 |
+
|
| 87 |
+
self._initialize_hf_artifacts()
|
| 88 |
+
|
| 89 |
+
def _initialize_hf_artifacts(self):
|
| 90 |
+
"""
|
| 91 |
+
Initialize a HuggingFace artifacts (tokenizer and model) according
|
| 92 |
+
to the provided identifiers for both SBert and the classification model.
|
| 93 |
+
Then initialize the word attribution explainer with the HF model+tokenizer.
|
| 94 |
+
|
| 95 |
+
"""
|
| 96 |
+
|
| 97 |
+
# sbert
|
| 98 |
+
self.sbert_tokenizer = AutoTokenizer.from_pretrained(
|
| 99 |
+
self.sbert_model_identifier
|
| 100 |
+
)
|
| 101 |
+
self.sbert_model = AutoModel.from_pretrained(self.sbert_model_identifier)
|
| 102 |
+
|
| 103 |
+
# classifer
|
| 104 |
+
self.cls_tokenizer = AutoTokenizer.from_pretrained(self.cls_model_identifier)
|
| 105 |
+
self.cls_model = AutoModelForSequenceClassification.from_pretrained(
|
| 106 |
+
self.cls_model_identifier
|
| 107 |
+
)
|
| 108 |
+
self.cls_model.to(self.device)
|
| 109 |
+
|
| 110 |
+
def compute_sentence_embeddings(self, input_text: List[str]) -> torch.Tensor:
|
| 111 |
+
"""
|
| 112 |
+
Compute sentence embeddings for each sentence provided a list of text strings.
|
| 113 |
+
|
| 114 |
+
Args:
|
| 115 |
+
input_text (List[str]) - list of input sentences to encode
|
| 116 |
+
|
| 117 |
+
Returns:
|
| 118 |
+
sentence_embeddings (torch.Tensor)
|
| 119 |
+
|
| 120 |
+
"""
|
| 121 |
+
# tokenize sentences
|
| 122 |
+
encoded_input = self.sbert_tokenizer(
|
| 123 |
+
input_text,
|
| 124 |
+
padding=True,
|
| 125 |
+
truncation=True,
|
| 126 |
+
max_length=256,
|
| 127 |
+
return_tensors="pt",
|
| 128 |
+
)
|
| 129 |
+
|
| 130 |
+
# to device
|
| 131 |
+
self.sbert_model.eval()
|
| 132 |
+
self.sbert_model.to(self.device)
|
| 133 |
+
encoded_input = {k: v.to(self.device) for k, v in encoded_input.items()}
|
| 134 |
+
|
| 135 |
+
# compute token embeddings
|
| 136 |
+
with torch.no_grad():
|
| 137 |
+
model_output = self.sbert_model(**encoded_input)
|
| 138 |
+
|
| 139 |
+
return (
|
| 140 |
+
self.mean_pooling(model_output, encoded_input["attention_mask"])
|
| 141 |
+
.detach()
|
| 142 |
+
.cpu()
|
| 143 |
+
)
|
| 144 |
+
|
| 145 |
+
def calculate_content_preservation_score(
|
| 146 |
+
self,
|
| 147 |
+
input_text: List[str],
|
| 148 |
+
output_text: List[str],
|
| 149 |
+
threshold: float = 0.3,
|
| 150 |
+
mask_type: str = "pad",
|
| 151 |
+
return_all: bool = False,
|
| 152 |
+
) -> List[float]:
|
| 153 |
+
"""
|
| 154 |
+
Calcualates the content preservation score (CPS) between two pieces of text.
|
| 155 |
+
|
| 156 |
+
Args:
|
| 157 |
+
input_text (list) - list of input texts with indicies corresponding
|
| 158 |
+
to counterpart in output_text
|
| 159 |
+
ouptput_text (list) - list of output texts with indicies corresponding
|
| 160 |
+
to counterpart in input_text
|
| 161 |
+
return_all (bool) - If true, return dict containing intermediate
|
| 162 |
+
text with style masking applied, along with scores
|
| 163 |
+
mask_type (str) - "pad", "remove", or "none"
|
| 164 |
+
|
| 165 |
+
Returns:
|
| 166 |
+
A list of floats with corresponding content preservation scores.
|
| 167 |
+
|
| 168 |
+
PSUEDO-CODE: (higher score is better preservation)
|
| 169 |
+
1. mask out style tokens for input and output text (1str)
|
| 170 |
+
2. get SBERT embedddings for each (multi)
|
| 171 |
+
3. calculate cosine similarity (multi pairs)
|
| 172 |
+
"""
|
| 173 |
+
if len(input_text) != len(output_text):
|
| 174 |
+
raise ValueError(
|
| 175 |
+
"input_text and output_text must be of same length with corresponding items"
|
| 176 |
+
)
|
| 177 |
+
|
| 178 |
+
if mask_type != "none":
|
| 179 |
+
# Mask out style tokens
|
| 180 |
+
masked_input_text = [
|
| 181 |
+
self.mask_style_tokens(text, mask_type=mask_type, threshold=threshold)
|
| 182 |
+
for text in input_text
|
| 183 |
+
]
|
| 184 |
+
masked_output_text = [
|
| 185 |
+
self.mask_style_tokens(text, mask_type=mask_type, threshold=threshold)
|
| 186 |
+
for text in output_text
|
| 187 |
+
]
|
| 188 |
+
|
| 189 |
+
# Compute SBert embeddings
|
| 190 |
+
input_embeddings = self.compute_sentence_embeddings(masked_input_text)
|
| 191 |
+
output_embeddings = self.compute_sentence_embeddings(masked_output_text)
|
| 192 |
+
else:
|
| 193 |
+
# Compute SBert embeddings on unmasked text
|
| 194 |
+
input_embeddings = self.compute_sentence_embeddings(input_text)
|
| 195 |
+
output_embeddings = self.compute_sentence_embeddings(output_text)
|
| 196 |
+
|
| 197 |
+
# Calculate cosine similarity
|
| 198 |
+
scores = self.cosine_similarity(input_embeddings, output_embeddings)
|
| 199 |
+
|
| 200 |
+
if return_all:
|
| 201 |
+
output = {
|
| 202 |
+
"scores": scores,
|
| 203 |
+
"masked_input_text": masked_input_text
|
| 204 |
+
if mask_type != "none"
|
| 205 |
+
else input_text,
|
| 206 |
+
"masked_output_text": masked_output_text
|
| 207 |
+
if mask_type != "none"
|
| 208 |
+
else output_text,
|
| 209 |
+
}
|
| 210 |
+
return output
|
| 211 |
+
else:
|
| 212 |
+
return scores
|
| 213 |
+
|
| 214 |
+
def calculate_feature_attribution_scores(
|
| 215 |
+
self, text: str, class_index: int = 0, as_norm: bool = False
|
| 216 |
+
) -> List[tuple]:
|
| 217 |
+
"""
|
| 218 |
+
Calcualte feature attributions using integrated gradients by passing
|
| 219 |
+
a string of text as input.
|
| 220 |
+
|
| 221 |
+
Args:
|
| 222 |
+
text (str) - text to get attributions for
|
| 223 |
+
class_index (int) - Optional output index to provide attributions for
|
| 224 |
+
|
| 225 |
+
"""
|
| 226 |
+
attributions = self.explainer(text, index=class_index)
|
| 227 |
+
|
| 228 |
+
if as_norm:
|
| 229 |
+
return self.format_feature_attribution_scores(attributions)
|
| 230 |
+
|
| 231 |
+
return attributions
|
| 232 |
+
|
| 233 |
+
def mask_style_tokens(
|
| 234 |
+
self,
|
| 235 |
+
text: str,
|
| 236 |
+
threshold: float = 0.3,
|
| 237 |
+
mask_type: str = "pad",
|
| 238 |
+
class_index: int = 0,
|
| 239 |
+
) -> str:
|
| 240 |
+
"""
|
| 241 |
+
Utility function to mask out style tokens from a given string of text.
|
| 242 |
+
|
| 243 |
+
Style tokens are determined by first calculating feature importances (via
|
| 244 |
+
word attributions from trained StyleClassifer) for each token in the input sentence.
|
| 245 |
+
We then normalize the absolute values of attributions scores to see how much each token
|
| 246 |
+
contributes as a percentage overall style classification and rank those in descending order.
|
| 247 |
+
|
| 248 |
+
We then select the top N tokens that account for the cumulative _threshold_ amount (%) of
|
| 249 |
+
total styleattribution. By using cumulative percentages, N is not a fixed number and we
|
| 250 |
+
ultimately take however many tokens are needed to account for _threshold_ % of the overall
|
| 251 |
+
style.
|
| 252 |
+
|
| 253 |
+
We can optionally return a string with these style tokens padded out or completely removed
|
| 254 |
+
by toggling _mask_type_ between "pad" and "remove".
|
| 255 |
+
|
| 256 |
+
Args:
|
| 257 |
+
text (str)
|
| 258 |
+
threshold (float) - percentage of style attribution as cutoff for masking selection.
|
| 259 |
+
mask_type (str) - "pad" or "remove", indicates how to handle style tokens
|
| 260 |
+
class_index (str)
|
| 261 |
+
|
| 262 |
+
Returns:
|
| 263 |
+
text (str)
|
| 264 |
+
|
| 265 |
+
"""
|
| 266 |
+
|
| 267 |
+
# get attributions and format as sorted dataframe
|
| 268 |
+
attributions = self.calculate_feature_attribution_scores(
|
| 269 |
+
text, class_index=class_index, as_norm=False
|
| 270 |
+
)
|
| 271 |
+
attributions_df = self.format_feature_attribution_scores(attributions)
|
| 272 |
+
|
| 273 |
+
# select tokens to mask
|
| 274 |
+
token_idxs_to_mask = []
|
| 275 |
+
|
| 276 |
+
# If the first token accounts for more than the set
|
| 277 |
+
# threshold, take just that token to mask. Otherwise,
|
| 278 |
+
# take all tokens up to the threshold
|
| 279 |
+
if attributions_df.iloc[0]["cumulative"] > threshold:
|
| 280 |
+
token_idxs_to_mask.append(attributions_df.index[0])
|
| 281 |
+
else:
|
| 282 |
+
token_idxs_to_mask.extend(
|
| 283 |
+
attributions_df[
|
| 284 |
+
attributions_df["cumulative"] <= threshold
|
| 285 |
+
].index.to_list()
|
| 286 |
+
)
|
| 287 |
+
|
| 288 |
+
# Build text sequence with tokens masked out
|
| 289 |
+
mask_map = {"pad": "[PAD]", "remove": ""}
|
| 290 |
+
toks = [token for token, score in attributions]
|
| 291 |
+
for idx in token_idxs_to_mask:
|
| 292 |
+
toks[idx] = mask_map[mask_type]
|
| 293 |
+
|
| 294 |
+
if mask_type == "remove":
|
| 295 |
+
toks = [token for token in toks if token != ""]
|
| 296 |
+
|
| 297 |
+
# Decode that sequence
|
| 298 |
+
masked_text = self.explainer.tokenizer.decode(
|
| 299 |
+
self.explainer.tokenizer.convert_tokens_to_ids(toks),
|
| 300 |
+
skip_special_tokens=False,
|
| 301 |
+
)
|
| 302 |
+
|
| 303 |
+
# Remove special characters other than [PAD]
|
| 304 |
+
for special_token in self.explainer.tokenizer.all_special_tokens:
|
| 305 |
+
if special_token != "[PAD]":
|
| 306 |
+
masked_text = masked_text.replace(special_token, "")
|
| 307 |
+
|
| 308 |
+
return masked_text.strip()
|
| 309 |
+
|
| 310 |
+
@staticmethod
|
| 311 |
+
def format_feature_attribution_scores(attributions: List[tuple]) -> pd.DataFrame:
|
| 312 |
+
"""
|
| 313 |
+
Utility for formatting attribution scores for style token mask selection
|
| 314 |
+
|
| 315 |
+
Sorts a given List[tuple] where tuples represent (token, score) by the
|
| 316 |
+
normalized absolute value of each token score.
|
| 317 |
+
|
| 318 |
+
"""
|
| 319 |
+
|
| 320 |
+
df = pd.DataFrame(attributions, columns=["token", "score"])
|
| 321 |
+
df["abs_norm"] = df["score"].abs() / df["score"].abs().sum()
|
| 322 |
+
df = df.sort_values(by="abs_norm", ascending=False)
|
| 323 |
+
df["cumulative"] = df["abs_norm"].cumsum()
|
| 324 |
+
return df
|
| 325 |
+
|
| 326 |
+
@staticmethod
|
| 327 |
+
def cosine_similarity(tensor1: torch.Tensor, tensor2: torch.Tensor) -> List[float]:
|
| 328 |
+
"""
|
| 329 |
+
Calculate cosine similarity on pairs of embedddings.
|
| 330 |
+
|
| 331 |
+
Can handle 1D Tensor for single pair or 2D Tensors with corresponding indicies
|
| 332 |
+
for matrix operation on multiple pairs.
|
| 333 |
+
|
| 334 |
+
"""
|
| 335 |
+
|
| 336 |
+
assert tensor1.shape == tensor2.shape
|
| 337 |
+
|
| 338 |
+
# ensure 2D tensor
|
| 339 |
+
if tensor1.ndim == 1:
|
| 340 |
+
tensor1 = tensor1.unsqueeze(0)
|
| 341 |
+
tensor2 = tensor2.unsqueeze(0)
|
| 342 |
+
|
| 343 |
+
cos_sim = torch.nn.CosineSimilarity(dim=1, eps=1e-6)
|
| 344 |
+
return [round(val, 4) for val in cos_sim(tensor1, tensor2).tolist()]
|
| 345 |
+
|
| 346 |
+
@staticmethod
|
| 347 |
+
def mean_pooling(model_output, attention_mask):
|
| 348 |
+
"""
|
| 349 |
+
Peform mean pooling over token embeddings to create sentence embedding. Here we take
|
| 350 |
+
the attention mask into account for correct averaging on active token positions.
|
| 351 |
+
|
| 352 |
+
CODE BORROWED FROM:
|
| 353 |
+
https://www.sbert.net/examples/applications/computing-embeddings/README.html#sentence-embeddings-with-transformers
|
| 354 |
+
|
| 355 |
+
"""
|
| 356 |
+
|
| 357 |
+
token_embeddings = model_output[
|
| 358 |
+
0
|
| 359 |
+
] # First element of model_output contains all token embeddings
|
| 360 |
+
input_mask_expanded = (
|
| 361 |
+
attention_mask.unsqueeze(-1).expand(token_embeddings.size()).float()
|
| 362 |
+
)
|
| 363 |
+
sum_embeddings = torch.sum(token_embeddings * input_mask_expanded, 1)
|
| 364 |
+
sum_mask = torch.clamp(input_mask_expanded.sum(1), min=1e-9)
|
| 365 |
+
|
| 366 |
+
return sum_embeddings / sum_mask
|
src/style_classification.py
ADDED
|
@@ -0,0 +1,245 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# ###########################################################################
|
| 2 |
+
#
|
| 3 |
+
# CLOUDERA APPLIED MACHINE LEARNING PROTOTYPE (AMP)
|
| 4 |
+
# (C) Cloudera, Inc. 2022
|
| 5 |
+
# All rights reserved.
|
| 6 |
+
#
|
| 7 |
+
# Applicable Open Source License: Apache 2.0
|
| 8 |
+
#
|
| 9 |
+
# NOTE: Cloudera open source products are modular software products
|
| 10 |
+
# made up of hundreds of individual components, each of which was
|
| 11 |
+
# individually copyrighted. Each Cloudera open source product is a
|
| 12 |
+
# collective work under U.S. Copyright Law. Your license to use the
|
| 13 |
+
# collective work is as provided in your written agreement with
|
| 14 |
+
# Cloudera. Used apart from the collective work, this file is
|
| 15 |
+
# licensed for your use pursuant to the open source license
|
| 16 |
+
# identified above.
|
| 17 |
+
#
|
| 18 |
+
# This code is provided to you pursuant a written agreement with
|
| 19 |
+
# (i) Cloudera, Inc. or (ii) a third-party authorized to distribute
|
| 20 |
+
# this code. If you do not have a written agreement with Cloudera nor
|
| 21 |
+
# with an authorized and properly licensed third party, you do not
|
| 22 |
+
# have any rights to access nor to use this code.
|
| 23 |
+
#
|
| 24 |
+
# Absent a written agreement with Cloudera, Inc. (“Cloudera”) to the
|
| 25 |
+
# contrary, A) CLOUDERA PROVIDES THIS CODE TO YOU WITHOUT WARRANTIES OF ANY
|
| 26 |
+
# KIND; (B) CLOUDERA DISCLAIMS ANY AND ALL EXPRESS AND IMPLIED
|
| 27 |
+
# WARRANTIES WITH RESPECT TO THIS CODE, INCLUDING BUT NOT LIMITED TO
|
| 28 |
+
# IMPLIED WARRANTIES OF TITLE, NON-INFRINGEMENT, MERCHANTABILITY AND
|
| 29 |
+
# FITNESS FOR A PARTICULAR PURPOSE; (C) CLOUDERA IS NOT LIABLE TO YOU,
|
| 30 |
+
# AND WILL NOT DEFEND, INDEMNIFY, NOR HOLD YOU HARMLESS FOR ANY CLAIMS
|
| 31 |
+
# ARISING FROM OR RELATED TO THE CODE; AND (D)WITH RESPECT TO YOUR EXERCISE
|
| 32 |
+
# OF ANY RIGHTS GRANTED TO YOU FOR THE CODE, CLOUDERA IS NOT LIABLE FOR ANY
|
| 33 |
+
# DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, PUNITIVE OR
|
| 34 |
+
# CONSEQUENTIAL DAMAGES INCLUDING, BUT NOT LIMITED TO, DAMAGES
|
| 35 |
+
# RELATED TO LOST REVENUE, LOST PROFITS, LOSS OF INCOME, LOSS OF
|
| 36 |
+
# BUSINESS ADVANTAGE OR UNAVAILABILITY, OR LOSS OR CORRUPTION OF
|
| 37 |
+
# DATA.
|
| 38 |
+
#
|
| 39 |
+
# ###########################################################################
|
| 40 |
+
|
| 41 |
+
from typing import List, Union
|
| 42 |
+
|
| 43 |
+
import torch
|
| 44 |
+
import numpy as np
|
| 45 |
+
from pyemd import emd
|
| 46 |
+
from transformers import pipeline
|
| 47 |
+
|
| 48 |
+
|
| 49 |
+
class StyleIntensityClassifier:
|
| 50 |
+
"""
|
| 51 |
+
Utility for classifying style and calculating Style Transfer Intensity between
|
| 52 |
+
two pieces of text (i.e. input and output of TST model).
|
| 53 |
+
|
| 54 |
+
This custom evaluation metric aims to quantify the magnitude of transferred
|
| 55 |
+
style between two texts. To accomplish this, we pass input and output texts
|
| 56 |
+
through a trained style classifier to produce two distributions. We then
|
| 57 |
+
utilize Earth Movers Distance (EMD) to calculate the minimum "cost"/"work"
|
| 58 |
+
required to turn the input distribution into the output distribution. This
|
| 59 |
+
metric allows us to capture a more nuanced, per-example measure of style
|
| 60 |
+
transfer when compared to simply aggregating binary classifications over
|
| 61 |
+
records in a dataset.
|
| 62 |
+
|
| 63 |
+
Attributes:
|
| 64 |
+
model_identifier (str)
|
| 65 |
+
|
| 66 |
+
"""
|
| 67 |
+
|
| 68 |
+
def __init__(self, model_identifier: str):
|
| 69 |
+
self.model_identifier = model_identifier
|
| 70 |
+
self.device = torch.cuda.current_device() if torch.cuda.is_available() else -1
|
| 71 |
+
self._build_pipeline()
|
| 72 |
+
|
| 73 |
+
def _build_pipeline(self):
|
| 74 |
+
|
| 75 |
+
self.pipeline = pipeline(
|
| 76 |
+
task="text-classification",
|
| 77 |
+
model=self.model_identifier,
|
| 78 |
+
device=self.device,
|
| 79 |
+
return_all_scores=True,
|
| 80 |
+
)
|
| 81 |
+
|
| 82 |
+
def score(self, input_text: Union[str, List[str]]):
|
| 83 |
+
"""
|
| 84 |
+
Classify a given input text using the model initialized by the class.
|
| 85 |
+
|
| 86 |
+
Args:
|
| 87 |
+
input_text (`str` or `List[str]`) - Input text for classification
|
| 88 |
+
|
| 89 |
+
Returns:
|
| 90 |
+
classification (dict) - a dictionary containing the label, score, and
|
| 91 |
+
distribution between classes
|
| 92 |
+
|
| 93 |
+
"""
|
| 94 |
+
if isinstance(input_text, str):
|
| 95 |
+
tmp = list()
|
| 96 |
+
tmp.append(input_text)
|
| 97 |
+
input_text = tmp
|
| 98 |
+
|
| 99 |
+
result = self.pipeline(input_text)
|
| 100 |
+
distributions = np.array(
|
| 101 |
+
[[label["score"] for label in item] for item in result]
|
| 102 |
+
)
|
| 103 |
+
return [
|
| 104 |
+
{
|
| 105 |
+
"label": self.pipeline.model.config.id2label[scores.argmax()],
|
| 106 |
+
"score": round(scores.max(), 4),
|
| 107 |
+
"distribution": scores.tolist(),
|
| 108 |
+
}
|
| 109 |
+
for scores in distributions
|
| 110 |
+
]
|
| 111 |
+
|
| 112 |
+
def calculate_transfer_intensity(
|
| 113 |
+
self, input_text: List[str], output_text: List[str], target_class_idx: int = 1
|
| 114 |
+
) -> List[float]:
|
| 115 |
+
"""
|
| 116 |
+
Calcualates the style transfer intensity (STI) between two pieces of text.
|
| 117 |
+
|
| 118 |
+
Args:
|
| 119 |
+
input_text (list) - list of input texts with indicies corresponding
|
| 120 |
+
to counterpart in output_text
|
| 121 |
+
ouptput_text (list) - list of output texts with indicies corresponding
|
| 122 |
+
to counterpart in input_text
|
| 123 |
+
target_class_idx (int) - index of the target style class used for directional
|
| 124 |
+
score correction
|
| 125 |
+
|
| 126 |
+
Returns:
|
| 127 |
+
A list of floats with corresponding style transfer intensity scores.
|
| 128 |
+
|
| 129 |
+
"""
|
| 130 |
+
|
| 131 |
+
if len(input_text) != len(output_text):
|
| 132 |
+
raise ValueError(
|
| 133 |
+
"input_text and output_text must be of same length with corresponding items"
|
| 134 |
+
)
|
| 135 |
+
|
| 136 |
+
input_dist = [item["distribution"] for item in self.score(input_text)]
|
| 137 |
+
output_dist = [item["distribution"] for item in self.score(output_text)]
|
| 138 |
+
|
| 139 |
+
return [
|
| 140 |
+
self.calculate_emd(input_dist[i], output_dist[i], target_class_idx)
|
| 141 |
+
for i in range(len(input_dist))
|
| 142 |
+
]
|
| 143 |
+
|
| 144 |
+
def calculate_transfer_intensity_fraction(
|
| 145 |
+
self, input_text: List[str], output_text: List[str], target_class_idx: int = 1
|
| 146 |
+
) -> List[float]:
|
| 147 |
+
"""
|
| 148 |
+
Calcualates the style transfer intensity (STI) _fraction_ between two pieces of text.
|
| 149 |
+
See `calcualte_sti_fraction()` for details.
|
| 150 |
+
|
| 151 |
+
Args:
|
| 152 |
+
input_text (list) - list of input texts with indicies corresponding
|
| 153 |
+
to counterpart in output_text
|
| 154 |
+
ouptput_text (list) - list of output texts with indicies corresponding
|
| 155 |
+
to counterpart in input_text
|
| 156 |
+
target_class_idx (int) - index of the target style class used for directional
|
| 157 |
+
score correction
|
| 158 |
+
|
| 159 |
+
Returns:
|
| 160 |
+
A list of floats with corresponding style transfer intensity scores.
|
| 161 |
+
|
| 162 |
+
"""
|
| 163 |
+
|
| 164 |
+
if len(input_text) != len(output_text):
|
| 165 |
+
raise ValueError(
|
| 166 |
+
"input_text and output_text must be of same length with corresponding items"
|
| 167 |
+
)
|
| 168 |
+
|
| 169 |
+
input_dist = [item["distribution"] for item in self.score(input_text)]
|
| 170 |
+
output_dist = [item["distribution"] for item in self.score(output_text)]
|
| 171 |
+
|
| 172 |
+
return [
|
| 173 |
+
self.calculate_sti_fraction(
|
| 174 |
+
input_dist[i],
|
| 175 |
+
output_dist[i],
|
| 176 |
+
ideal_dist=[0.0, 1.0],
|
| 177 |
+
target_class_idx=target_class_idx,
|
| 178 |
+
)
|
| 179 |
+
for i in range(len(input_dist))
|
| 180 |
+
]
|
| 181 |
+
|
| 182 |
+
def calculate_sti_fraction(
|
| 183 |
+
self, input_dist, output_dist, ideal_dist=[0.0, 1.0], target_class_idx=1
|
| 184 |
+
):
|
| 185 |
+
"""
|
| 186 |
+
Calculate the direction-corrected style transfer intensity fraction between
|
| 187 |
+
two style distributions of equal length.
|
| 188 |
+
|
| 189 |
+
If output_dist moves closer towards target style class, the metric represents the percentage of
|
| 190 |
+
the possible _target_ style distribution that was captured during the transfer. If output_dist
|
| 191 |
+
moves further from the target style class, the metric represents the percentage of the possible
|
| 192 |
+
_source_ style distribution that was captured.
|
| 193 |
+
|
| 194 |
+
Args:
|
| 195 |
+
input_dist (list) - probabilities assigned to the style classes
|
| 196 |
+
from the input text to style transfer model
|
| 197 |
+
output_dist (list) - probabilities assigned to the style classes
|
| 198 |
+
from the outut text of the style transfer model
|
| 199 |
+
ideal_dist (list, optional): The maximum possibly distribution. Defaults to [0.0, 1.0].
|
| 200 |
+
target_class_idx (int, optional)
|
| 201 |
+
|
| 202 |
+
Returns:
|
| 203 |
+
sti_fraction (float)
|
| 204 |
+
"""
|
| 205 |
+
|
| 206 |
+
sti = self.calculate_emd(input_dist, output_dist, target_class_idx)
|
| 207 |
+
|
| 208 |
+
if sti > 0:
|
| 209 |
+
potential = self.calculate_emd(input_dist, ideal_dist, target_class_idx)
|
| 210 |
+
else:
|
| 211 |
+
potential = self.calculate_emd(
|
| 212 |
+
input_dist, ideal_dist[::-1], target_class_idx
|
| 213 |
+
)
|
| 214 |
+
|
| 215 |
+
return sti / potential
|
| 216 |
+
|
| 217 |
+
@staticmethod
|
| 218 |
+
def calculate_emd(input_dist, output_dist, target_class_idx):
|
| 219 |
+
"""
|
| 220 |
+
Calculate the direction-corrected Earth Mover's Distance (aka Wasserstein distance)
|
| 221 |
+
between two distributions of equal length. Here we penalize the EMD score if
|
| 222 |
+
the output text style moved further away from the target style.
|
| 223 |
+
|
| 224 |
+
Reference: https://github.com/passeul/style-transfer-model-evaluation/blob/master/code/style_transfer_intensity.py
|
| 225 |
+
|
| 226 |
+
Args:
|
| 227 |
+
input_dist (list) - probabilities assigned to the style classes
|
| 228 |
+
from the input text to style transfer model
|
| 229 |
+
output_dist (list) - probabilities assigned to the style classes
|
| 230 |
+
from the outut text of the style transfer model
|
| 231 |
+
|
| 232 |
+
Returns:
|
| 233 |
+
emd (float) - Earth Movers Distance between the two distributions
|
| 234 |
+
|
| 235 |
+
"""
|
| 236 |
+
|
| 237 |
+
N = len(input_dist)
|
| 238 |
+
distance_matrix = np.ones((N, N))
|
| 239 |
+
dist = emd(np.array(input_dist), np.array(output_dist), distance_matrix)
|
| 240 |
+
|
| 241 |
+
transfer_direction_correction = (
|
| 242 |
+
1 if output_dist[target_class_idx] >= input_dist[target_class_idx] else -1
|
| 243 |
+
)
|
| 244 |
+
|
| 245 |
+
return round(dist * transfer_direction_correction, 4)
|
src/style_transfer.py
ADDED
|
@@ -0,0 +1,94 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# ###########################################################################
|
| 2 |
+
#
|
| 3 |
+
# CLOUDERA APPLIED MACHINE LEARNING PROTOTYPE (AMP)
|
| 4 |
+
# (C) Cloudera, Inc. 2022
|
| 5 |
+
# All rights reserved.
|
| 6 |
+
#
|
| 7 |
+
# Applicable Open Source License: Apache 2.0
|
| 8 |
+
#
|
| 9 |
+
# NOTE: Cloudera open source products are modular software products
|
| 10 |
+
# made up of hundreds of individual components, each of which was
|
| 11 |
+
# individually copyrighted. Each Cloudera open source product is a
|
| 12 |
+
# collective work under U.S. Copyright Law. Your license to use the
|
| 13 |
+
# collective work is as provided in your written agreement with
|
| 14 |
+
# Cloudera. Used apart from the collective work, this file is
|
| 15 |
+
# licensed for your use pursuant to the open source license
|
| 16 |
+
# identified above.
|
| 17 |
+
#
|
| 18 |
+
# This code is provided to you pursuant a written agreement with
|
| 19 |
+
# (i) Cloudera, Inc. or (ii) a third-party authorized to distribute
|
| 20 |
+
# this code. If you do not have a written agreement with Cloudera nor
|
| 21 |
+
# with an authorized and properly licensed third party, you do not
|
| 22 |
+
# have any rights to access nor to use this code.
|
| 23 |
+
#
|
| 24 |
+
# Absent a written agreement with Cloudera, Inc. (“Cloudera”) to the
|
| 25 |
+
# contrary, A) CLOUDERA PROVIDES THIS CODE TO YOU WITHOUT WARRANTIES OF ANY
|
| 26 |
+
# KIND; (B) CLOUDERA DISCLAIMS ANY AND ALL EXPRESS AND IMPLIED
|
| 27 |
+
# WARRANTIES WITH RESPECT TO THIS CODE, INCLUDING BUT NOT LIMITED TO
|
| 28 |
+
# IMPLIED WARRANTIES OF TITLE, NON-INFRINGEMENT, MERCHANTABILITY AND
|
| 29 |
+
# FITNESS FOR A PARTICULAR PURPOSE; (C) CLOUDERA IS NOT LIABLE TO YOU,
|
| 30 |
+
# AND WILL NOT DEFEND, INDEMNIFY, NOR HOLD YOU HARMLESS FOR ANY CLAIMS
|
| 31 |
+
# ARISING FROM OR RELATED TO THE CODE; AND (D)WITH RESPECT TO YOUR EXERCISE
|
| 32 |
+
# OF ANY RIGHTS GRANTED TO YOU FOR THE CODE, CLOUDERA IS NOT LIABLE FOR ANY
|
| 33 |
+
# DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, PUNITIVE OR
|
| 34 |
+
# CONSEQUENTIAL DAMAGES INCLUDING, BUT NOT LIMITED TO, DAMAGES
|
| 35 |
+
# RELATED TO LOST REVENUE, LOST PROFITS, LOSS OF INCOME, LOSS OF
|
| 36 |
+
# BUSINESS ADVANTAGE OR UNAVAILABILITY, OR LOSS OR CORRUPTION OF
|
| 37 |
+
# DATA.
|
| 38 |
+
#
|
| 39 |
+
# ###########################################################################
|
| 40 |
+
|
| 41 |
+
from typing import List, Union
|
| 42 |
+
|
| 43 |
+
import torch
|
| 44 |
+
from transformers import pipeline
|
| 45 |
+
|
| 46 |
+
|
| 47 |
+
class StyleTransfer:
|
| 48 |
+
"""
|
| 49 |
+
Model wrapper for a Text2TextGeneration pipeline used to transfer a style attribute on a given piece of text.
|
| 50 |
+
|
| 51 |
+
Attributes:
|
| 52 |
+
model_identifier (str) - Path to the model that will be used by the pipeline to make predictions
|
| 53 |
+
max_gen_length (int) - Upper limit on number of tokens the model can generate as output
|
| 54 |
+
|
| 55 |
+
"""
|
| 56 |
+
|
| 57 |
+
def __init__(
|
| 58 |
+
self,
|
| 59 |
+
model_identifier: str,
|
| 60 |
+
max_gen_length: int = 200,
|
| 61 |
+
num_beams=4,
|
| 62 |
+
temperature=1,
|
| 63 |
+
):
|
| 64 |
+
self.model_identifier = model_identifier
|
| 65 |
+
self.max_gen_length = max_gen_length
|
| 66 |
+
self.num_beams = num_beams
|
| 67 |
+
self.temperature = temperature
|
| 68 |
+
self.device = torch.cuda.current_device() if torch.cuda.is_available() else -1
|
| 69 |
+
self._build_pipeline()
|
| 70 |
+
|
| 71 |
+
def _build_pipeline(self):
|
| 72 |
+
|
| 73 |
+
self.pipeline = pipeline(
|
| 74 |
+
task="text2text-generation",
|
| 75 |
+
model=self.model_identifier,
|
| 76 |
+
device=self.device,
|
| 77 |
+
max_length=self.max_gen_length,
|
| 78 |
+
num_beams=self.num_beams,
|
| 79 |
+
temperature=self.temperature,
|
| 80 |
+
)
|
| 81 |
+
|
| 82 |
+
def transfer(self, input_text: Union[str, List[str]]) -> List[str]:
|
| 83 |
+
"""
|
| 84 |
+
Transfer the style attribute on a given piece of text using the
|
| 85 |
+
initialized `model_identifier`.
|
| 86 |
+
|
| 87 |
+
Args:
|
| 88 |
+
input_text (`str` or `List[str]`) - Input text for style transfer
|
| 89 |
+
|
| 90 |
+
Returns:
|
| 91 |
+
generated_text (`List[str]`) - The generated text outputs
|
| 92 |
+
|
| 93 |
+
"""
|
| 94 |
+
return [item["generated_text"] for item in self.pipeline(input_text)]
|
src/transformer_interpretability.py
ADDED
|
@@ -0,0 +1,148 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# ###########################################################################
|
| 2 |
+
#
|
| 3 |
+
# CLOUDERA APPLIED MACHINE LEARNING PROTOTYPE (AMP)
|
| 4 |
+
# (C) Cloudera, Inc. 2022
|
| 5 |
+
# All rights reserved.
|
| 6 |
+
#
|
| 7 |
+
# Applicable Open Source License: Apache 2.0
|
| 8 |
+
#
|
| 9 |
+
# NOTE: Cloudera open source products are modular software products
|
| 10 |
+
# made up of hundreds of individual components, each of which was
|
| 11 |
+
# individually copyrighted. Each Cloudera open source product is a
|
| 12 |
+
# collective work under U.S. Copyright Law. Your license to use the
|
| 13 |
+
# collective work is as provided in your written agreement with
|
| 14 |
+
# Cloudera. Used apart from the collective work, this file is
|
| 15 |
+
# licensed for your use pursuant to the open source license
|
| 16 |
+
# identified above.
|
| 17 |
+
#
|
| 18 |
+
# This code is provided to you pursuant a written agreement with
|
| 19 |
+
# (i) Cloudera, Inc. or (ii) a third-party authorized to distribute
|
| 20 |
+
# this code. If you do not have a written agreement with Cloudera nor
|
| 21 |
+
# with an authorized and properly licensed third party, you do not
|
| 22 |
+
# have any rights to access nor to use this code.
|
| 23 |
+
#
|
| 24 |
+
# Absent a written agreement with Cloudera, Inc. (“Cloudera”) to the
|
| 25 |
+
# contrary, A) CLOUDERA PROVIDES THIS CODE TO YOU WITHOUT WARRANTIES OF ANY
|
| 26 |
+
# KIND; (B) CLOUDERA DISCLAIMS ANY AND ALL EXPRESS AND IMPLIED
|
| 27 |
+
# WARRANTIES WITH RESPECT TO THIS CODE, INCLUDING BUT NOT LIMITED TO
|
| 28 |
+
# IMPLIED WARRANTIES OF TITLE, NON-INFRINGEMENT, MERCHANTABILITY AND
|
| 29 |
+
# FITNESS FOR A PARTICULAR PURPOSE; (C) CLOUDERA IS NOT LIABLE TO YOU,
|
| 30 |
+
# AND WILL NOT DEFEND, INDEMNIFY, NOR HOLD YOU HARMLESS FOR ANY CLAIMS
|
| 31 |
+
# ARISING FROM OR RELATED TO THE CODE; AND (D)WITH RESPECT TO YOUR EXERCISE
|
| 32 |
+
# OF ANY RIGHTS GRANTED TO YOU FOR THE CODE, CLOUDERA IS NOT LIABLE FOR ANY
|
| 33 |
+
# DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, PUNITIVE OR
|
| 34 |
+
# CONSEQUENTIAL DAMAGES INCLUDING, BUT NOT LIMITED TO, DAMAGES
|
| 35 |
+
# RELATED TO LOST REVENUE, LOST PROFITS, LOSS OF INCOME, LOSS OF
|
| 36 |
+
# BUSINESS ADVANTAGE OR UNAVAILABILITY, OR LOSS OR CORRUPTION OF
|
| 37 |
+
# DATA.
|
| 38 |
+
#
|
| 39 |
+
# ###########################################################################
|
| 40 |
+
|
| 41 |
+
import torch
|
| 42 |
+
from transformers_interpret import SequenceClassificationExplainer
|
| 43 |
+
from transformers import (
|
| 44 |
+
AutoTokenizer,
|
| 45 |
+
AutoModelForSequenceClassification,
|
| 46 |
+
)
|
| 47 |
+
|
| 48 |
+
from apps.visualization_utils import visualize_text
|
| 49 |
+
|
| 50 |
+
class CustomSequenceClassificationExplainer(SequenceClassificationExplainer):
|
| 51 |
+
"""
|
| 52 |
+
Subclassing to replace `visualize()` method with custom styling.
|
| 53 |
+
|
| 54 |
+
Namely, removing a few columns, styling fonts, and re-arrangning legend position.
|
| 55 |
+
"""
|
| 56 |
+
|
| 57 |
+
def visualize(self, html_filepath: str = None, true_class: str = None):
|
| 58 |
+
"""
|
| 59 |
+
Visualizes word attributions. If in a notebook table will be displayed inline.
|
| 60 |
+
Otherwise pass a valid path to `html_filepath` and the visualization will be saved
|
| 61 |
+
as a html file.
|
| 62 |
+
If the true class is known for the text that can be passed to `true_class`
|
| 63 |
+
"""
|
| 64 |
+
tokens = [token.replace("Ġ", "") for token in self.decode(self.input_ids)]
|
| 65 |
+
attr_class = self.id2label[self.selected_index]
|
| 66 |
+
|
| 67 |
+
if self._single_node_output:
|
| 68 |
+
if true_class is None:
|
| 69 |
+
true_class = round(float(self.pred_probs))
|
| 70 |
+
predicted_class = round(float(self.pred_probs))
|
| 71 |
+
attr_class = round(float(self.pred_probs))
|
| 72 |
+
else:
|
| 73 |
+
if true_class is None:
|
| 74 |
+
true_class = self.selected_index
|
| 75 |
+
predicted_class = self.predicted_class_name
|
| 76 |
+
|
| 77 |
+
score_viz = self.attributions.visualize_attributions( # type: ignore
|
| 78 |
+
self.pred_probs,
|
| 79 |
+
predicted_class,
|
| 80 |
+
true_class,
|
| 81 |
+
attr_class,
|
| 82 |
+
tokens,
|
| 83 |
+
)
|
| 84 |
+
|
| 85 |
+
# NOTE: here is the overwritten function
|
| 86 |
+
html = visualize_text([score_viz])
|
| 87 |
+
|
| 88 |
+
if html_filepath:
|
| 89 |
+
if not html_filepath.endswith(".html"):
|
| 90 |
+
html_filepath = html_filepath + ".html"
|
| 91 |
+
with open(html_filepath, "w") as html_file:
|
| 92 |
+
html_file.write(html.data)
|
| 93 |
+
|
| 94 |
+
return html
|
| 95 |
+
|
| 96 |
+
|
| 97 |
+
class InterpretTransformer:
|
| 98 |
+
"""
|
| 99 |
+
Utility for visualizing word attribution scores from Transformer models.
|
| 100 |
+
|
| 101 |
+
This class utilizes the [Transformers Interpret](https://github.com/cdpierse/transformers-interpret)
|
| 102 |
+
libary to calculate word attributions using a techinique called Integrated Gradients.
|
| 103 |
+
|
| 104 |
+
Attributes:
|
| 105 |
+
cls_model_identifier (str)
|
| 106 |
+
|
| 107 |
+
"""
|
| 108 |
+
|
| 109 |
+
def __init__(self, cls_model_identifier: str):
|
| 110 |
+
|
| 111 |
+
self.cls_model_identifier = cls_model_identifier
|
| 112 |
+
self.device = (
|
| 113 |
+
torch.cuda.current_device() if torch.cuda.is_available() else "cpu"
|
| 114 |
+
)
|
| 115 |
+
|
| 116 |
+
self._initialize_hf_artifacts()
|
| 117 |
+
|
| 118 |
+
def _initialize_hf_artifacts(self):
|
| 119 |
+
"""
|
| 120 |
+
Initialize a HuggingFace artifacts (tokenizer and model) according
|
| 121 |
+
to the provided identifiers for both SBert and the classification model.
|
| 122 |
+
Then initialize the word attribution explainer with the HF model+tokenizer.
|
| 123 |
+
|
| 124 |
+
"""
|
| 125 |
+
|
| 126 |
+
# classifer
|
| 127 |
+
self.cls_tokenizer = AutoTokenizer.from_pretrained(self.cls_model_identifier)
|
| 128 |
+
self.cls_model = AutoModelForSequenceClassification.from_pretrained(
|
| 129 |
+
self.cls_model_identifier
|
| 130 |
+
)
|
| 131 |
+
self.cls_model.to(self.device)
|
| 132 |
+
|
| 133 |
+
# transformers interpret
|
| 134 |
+
self.explainer = CustomSequenceClassificationExplainer(
|
| 135 |
+
self.cls_model, self.cls_tokenizer
|
| 136 |
+
)
|
| 137 |
+
|
| 138 |
+
def visualize_feature_attribution_scores(self, text: str, class_index: int = 0):
|
| 139 |
+
"""
|
| 140 |
+
Calculates and visualizes feature attributions using integrated gradients.
|
| 141 |
+
|
| 142 |
+
Args:
|
| 143 |
+
text (str) - text to get attributions for
|
| 144 |
+
class_index (int) - Optional output index to provide attributions for
|
| 145 |
+
|
| 146 |
+
"""
|
| 147 |
+
self.explainer(text, index=class_index)
|
| 148 |
+
return self.explainer.visualize()
|
static/images/app_screenshot.png
ADDED
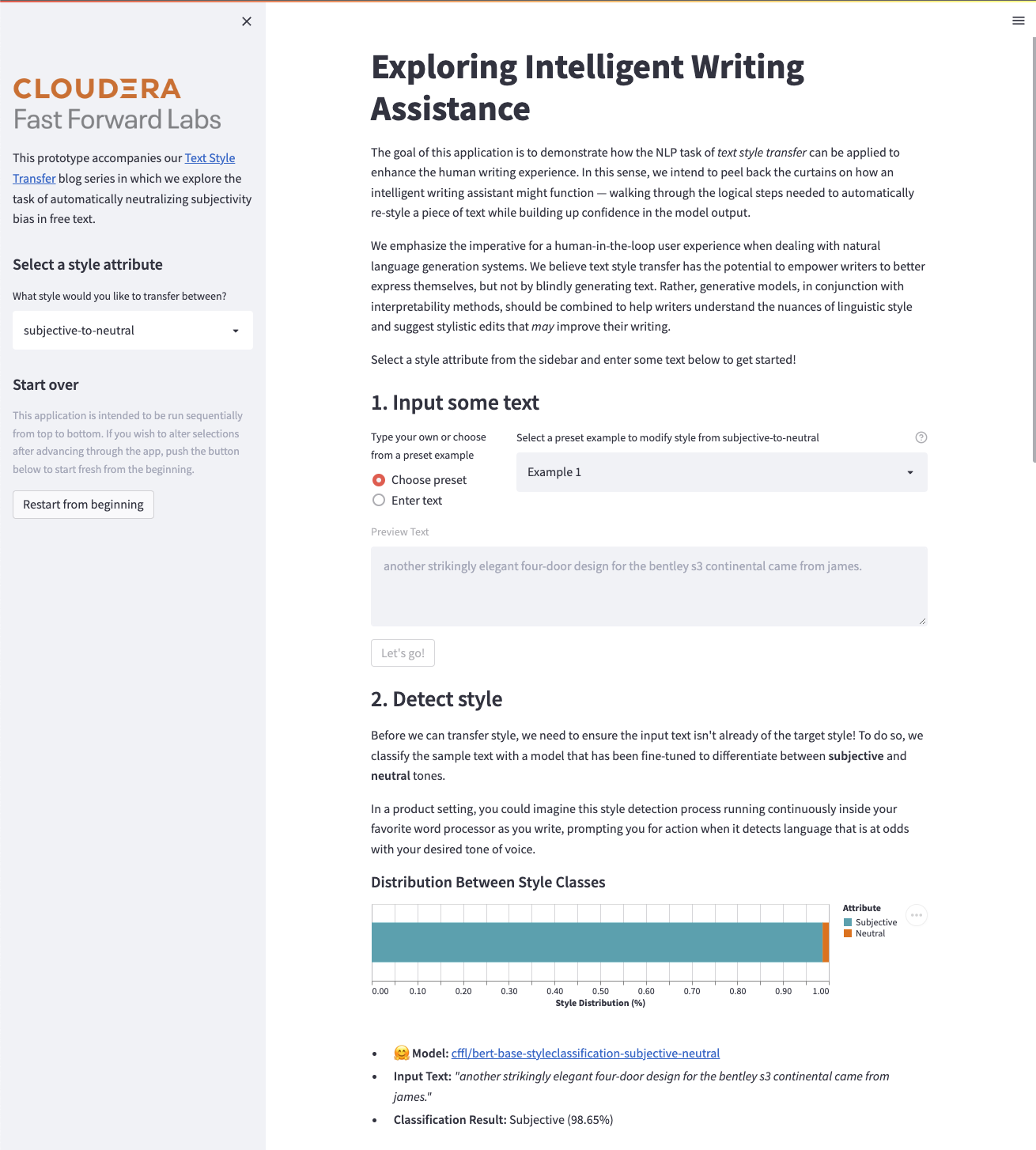
|
static/images/cldr-favicon.ico
ADDED

|
static/images/ffllogo2@1x.png
ADDED

|
tests/__init__.py
ADDED
|
File without changes
|
tests/test_model_classes.py
ADDED
|
@@ -0,0 +1,164 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# ###########################################################################
|
| 2 |
+
#
|
| 3 |
+
# CLOUDERA APPLIED MACHINE LEARNING PROTOTYPE (AMP)
|
| 4 |
+
# (C) Cloudera, Inc. 2022
|
| 5 |
+
# All rights reserved.
|
| 6 |
+
#
|
| 7 |
+
# Applicable Open Source License: Apache 2.0
|
| 8 |
+
#
|
| 9 |
+
# NOTE: Cloudera open source products are modular software products
|
| 10 |
+
# made up of hundreds of individual components, each of which was
|
| 11 |
+
# individually copyrighted. Each Cloudera open source product is a
|
| 12 |
+
# collective work under U.S. Copyright Law. Your license to use the
|
| 13 |
+
# collective work is as provided in your written agreement with
|
| 14 |
+
# Cloudera. Used apart from the collective work, this file is
|
| 15 |
+
# licensed for your use pursuant to the open source license
|
| 16 |
+
# identified above.
|
| 17 |
+
#
|
| 18 |
+
# This code is provided to you pursuant a written agreement with
|
| 19 |
+
# (i) Cloudera, Inc. or (ii) a third-party authorized to distribute
|
| 20 |
+
# this code. If you do not have a written agreement with Cloudera nor
|
| 21 |
+
# with an authorized and properly licensed third party, you do not
|
| 22 |
+
# have any rights to access nor to use this code.
|
| 23 |
+
#
|
| 24 |
+
# Absent a written agreement with Cloudera, Inc. (“Cloudera”) to the
|
| 25 |
+
# contrary, A) CLOUDERA PROVIDES THIS CODE TO YOU WITHOUT WARRANTIES OF ANY
|
| 26 |
+
# KIND; (B) CLOUDERA DISCLAIMS ANY AND ALL EXPRESS AND IMPLIED
|
| 27 |
+
# WARRANTIES WITH RESPECT TO THIS CODE, INCLUDING BUT NOT LIMITED TO
|
| 28 |
+
# IMPLIED WARRANTIES OF TITLE, NON-INFRINGEMENT, MERCHANTABILITY AND
|
| 29 |
+
# FITNESS FOR A PARTICULAR PURPOSE; (C) CLOUDERA IS NOT LIABLE TO YOU,
|
| 30 |
+
# AND WILL NOT DEFEND, INDEMNIFY, NOR HOLD YOU HARMLESS FOR ANY CLAIMS
|
| 31 |
+
# ARISING FROM OR RELATED TO THE CODE; AND (D)WITH RESPECT TO YOUR EXERCISE
|
| 32 |
+
# OF ANY RIGHTS GRANTED TO YOU FOR THE CODE, CLOUDERA IS NOT LIABLE FOR ANY
|
| 33 |
+
# DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, PUNITIVE OR
|
| 34 |
+
# CONSEQUENTIAL DAMAGES INCLUDING, BUT NOT LIMITED TO, DAMAGES
|
| 35 |
+
# RELATED TO LOST REVENUE, LOST PROFITS, LOSS OF INCOME, LOSS OF
|
| 36 |
+
# BUSINESS ADVANTAGE OR UNAVAILABILITY, OR LOSS OR CORRUPTION OF
|
| 37 |
+
# DATA.
|
| 38 |
+
#
|
| 39 |
+
# ###########################################################################
|
| 40 |
+
|
| 41 |
+
import pytest
|
| 42 |
+
import transformers
|
| 43 |
+
|
| 44 |
+
from src.style_transfer import StyleTransfer
|
| 45 |
+
from src.style_classification import StyleIntensityClassifier
|
| 46 |
+
from src.content_preservation import ContentPreservationScorer
|
| 47 |
+
from src.transformer_interpretability import InterpretTransformer
|
| 48 |
+
|
| 49 |
+
|
| 50 |
+
@pytest.fixture
|
| 51 |
+
def subjectivity_example_data():
|
| 52 |
+
examples = [
|
| 53 |
+
"""there is an iconic roadhouse, named "spud's roadhouse", which sells fuel and general shop items , has great meals and has accommodation.""",
|
| 54 |
+
"chemical abstracts service (cas), a prominent division of the american chemical society, is the world's leading source of chemical information.",
|
| 55 |
+
"the most serious scandal was the iran-contra affair.",
|
| 56 |
+
"another strikingly elegant four-door saloon for the s3 continental came from james young.",
|
| 57 |
+
"other ambassadors also sent their messages of condolence following her passing.",
|
| 58 |
+
]
|
| 59 |
+
|
| 60 |
+
ground_truth = [
|
| 61 |
+
'there is a roadhouse, named "spud\'s roadhouse", which sells fuel and general shop items and has accommodation.',
|
| 62 |
+
"chemical abstracts service (cas), a division of the american chemical society, is a source of chemical information.",
|
| 63 |
+
"one controversy was the iran-contra affair.",
|
| 64 |
+
"another four-door saloon for the s3 continental came from james young.",
|
| 65 |
+
"other ambassadors also sent their messages of condolence following her death.",
|
| 66 |
+
]
|
| 67 |
+
|
| 68 |
+
return {"examples": examples, "ground_truth": ground_truth}
|
| 69 |
+
|
| 70 |
+
|
| 71 |
+
@pytest.fixture
|
| 72 |
+
def subjectivity_styletransfer():
|
| 73 |
+
MODEL_PATH = "cffl/bart-base-styletransfer-subjective-to-neutral"
|
| 74 |
+
return StyleTransfer(model_identifier=MODEL_PATH, max_gen_length=200)
|
| 75 |
+
|
| 76 |
+
|
| 77 |
+
@pytest.fixture
|
| 78 |
+
def subjectivity_styleintensityclassifier():
|
| 79 |
+
CLS_MODEL_PATH = "cffl/bert-base-styleclassification-subjective-neutral"
|
| 80 |
+
return StyleIntensityClassifier(model_identifier=CLS_MODEL_PATH)
|
| 81 |
+
|
| 82 |
+
|
| 83 |
+
@pytest.fixture
|
| 84 |
+
def subjectivity_contentpreservationscorer():
|
| 85 |
+
CLS_MODEL_PATH = "cffl/bert-base-styleclassification-subjective-neutral"
|
| 86 |
+
SBERT_MODEL_PATH = "sentence-transformers/all-MiniLM-L6-v2"
|
| 87 |
+
return ContentPreservationScorer(
|
| 88 |
+
cls_model_identifier=CLS_MODEL_PATH, sbert_model_identifier=SBERT_MODEL_PATH
|
| 89 |
+
)
|
| 90 |
+
|
| 91 |
+
|
| 92 |
+
@pytest.fixture
|
| 93 |
+
def subjectivity_interprettransformer():
|
| 94 |
+
CLS_MODEL_PATH = "cffl/bert-base-styleclassification-subjective-neutral"
|
| 95 |
+
return InterpretTransformer(cls_model_identifier=CLS_MODEL_PATH)
|
| 96 |
+
|
| 97 |
+
|
| 98 |
+
# test class initialization
|
| 99 |
+
def test_StyleTransfer_init(subjectivity_styletransfer):
|
| 100 |
+
assert isinstance(
|
| 101 |
+
subjectivity_styletransfer.pipeline,
|
| 102 |
+
transformers.pipelines.text2text_generation.Text2TextGenerationPipeline,
|
| 103 |
+
)
|
| 104 |
+
|
| 105 |
+
|
| 106 |
+
def test_StyleIntensityClassifier_init(subjectivity_styleintensityclassifier):
|
| 107 |
+
assert isinstance(
|
| 108 |
+
subjectivity_styleintensityclassifier.pipeline,
|
| 109 |
+
transformers.pipelines.text_classification.TextClassificationPipeline,
|
| 110 |
+
)
|
| 111 |
+
|
| 112 |
+
|
| 113 |
+
def test_ContentPreservationScorer_init(subjectivity_contentpreservationscorer):
|
| 114 |
+
assert isinstance(
|
| 115 |
+
subjectivity_contentpreservationscorer.cls_model,
|
| 116 |
+
transformers.models.bert.modeling_bert.BertForSequenceClassification,
|
| 117 |
+
)
|
| 118 |
+
assert isinstance(
|
| 119 |
+
subjectivity_contentpreservationscorer.sbert_model,
|
| 120 |
+
transformers.models.bert.modeling_bert.BertModel,
|
| 121 |
+
)
|
| 122 |
+
|
| 123 |
+
|
| 124 |
+
def test_InterpretTransformer_init(subjectivity_interprettransformer):
|
| 125 |
+
assert isinstance(
|
| 126 |
+
subjectivity_interprettransformer.cls_model,
|
| 127 |
+
transformers.models.bert.modeling_bert.BertForSequenceClassification,
|
| 128 |
+
)
|
| 129 |
+
|
| 130 |
+
|
| 131 |
+
# test class functionality
|
| 132 |
+
def test_StyleTransfer_transfer(subjectivity_styletransfer, subjectivity_example_data):
|
| 133 |
+
assert subjectivity_example_data[
|
| 134 |
+
"ground_truth"
|
| 135 |
+
] == subjectivity_styletransfer.transfer(subjectivity_example_data["examples"])
|
| 136 |
+
|
| 137 |
+
|
| 138 |
+
def test_StyleIntensityClassifier_calculate_transfer_intensity_fraction(
|
| 139 |
+
subjectivity_styleintensityclassifier, subjectivity_example_data
|
| 140 |
+
):
|
| 141 |
+
sti_frac = (
|
| 142 |
+
subjectivity_styleintensityclassifier.calculate_transfer_intensity_fraction(
|
| 143 |
+
input_text=subjectivity_example_data["examples"],
|
| 144 |
+
output_text=subjectivity_example_data["ground_truth"],
|
| 145 |
+
)
|
| 146 |
+
)
|
| 147 |
+
assert sti_frac == [
|
| 148 |
+
0.9891820847234861,
|
| 149 |
+
0.9808499743983614,
|
| 150 |
+
0.8070009460737938,
|
| 151 |
+
0.9913705583756346,
|
| 152 |
+
0.9611679711017459,
|
| 153 |
+
]
|
| 154 |
+
|
| 155 |
+
|
| 156 |
+
def test_ContentPreservationScorer_calculate_content_preservation_score(
|
| 157 |
+
subjectivity_contentpreservationscorer, subjectivity_example_data
|
| 158 |
+
):
|
| 159 |
+
cps = subjectivity_contentpreservationscorer.calculate_content_preservation_score(
|
| 160 |
+
input_text=subjectivity_example_data["examples"],
|
| 161 |
+
output_text=subjectivity_example_data["ground_truth"],
|
| 162 |
+
mask_type="none",
|
| 163 |
+
)
|
| 164 |
+
assert cps == [0.9369, 0.9856, 0.7328, 0.9718, 0.9709]
|