Spaces:
Runtime error

Runtime error

Commit
·
1b0a5d8
1
Parent(s):
2cf2fe6
Upload 8 files
Browse files- README.md +1 -1
- app.py +39 -0
- data/data_sample.csv +0 -0
- data/topics_info.csv +0 -0
- images/logo.png +0 -0
- images/map.png +0 -0
- images/map_prompt.html +0 -0
- images/pipeline.png +0 -0
README.md
CHANGED
|
@@ -10,4 +10,4 @@ pinned: false
|
|
| 10 |
license: apache-2.0
|
| 11 |
---
|
| 12 |
|
| 13 |
-
Check out the configuration reference at https://huggingface.co/docs/hub/spaces-config-reference
|
|
|
|
| 10 |
license: apache-2.0
|
| 11 |
---
|
| 12 |
|
| 13 |
+
Check out the configuration reference at <https://huggingface.co/docs/hub/spaces-config-reference>
|
app.py
ADDED
|
@@ -0,0 +1,39 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import streamlit as st
|
| 2 |
+
import pandas as pd
|
| 3 |
+
import streamlit.components.v1 as components
|
| 4 |
+
|
| 5 |
+
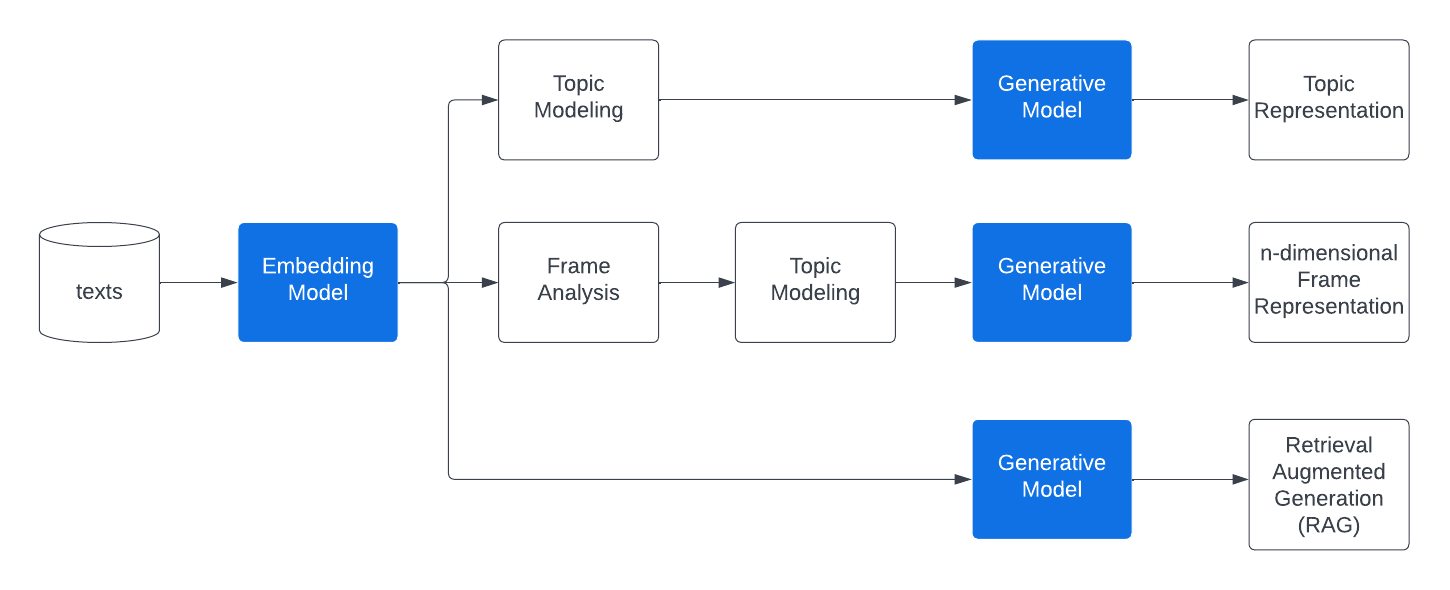
st.sidebar.image("images/logo.png", use_column_width=True)
|
| 6 |
+
st.sidebar.write("Bunka Summarizes & Visualizes Information as Maps using LLMs.")
|
| 7 |
+
st.sidebar.title("Github Page")
|
| 8 |
+
st.sidebar.write(
|
| 9 |
+
"Have a look at the following package on GitHub: https://github.com/charlesdedampierre/BunkaTopics"
|
| 10 |
+
)
|
| 11 |
+
st.sidebar.title("Dataset")
|
| 12 |
+
st.sidebar.write(
|
| 13 |
+
"We used a subset of Wikipedia dataset: https://huggingface.co/datasets/OpenAssistant/oasst2"
|
| 14 |
+
)
|
| 15 |
+
|
| 16 |
+
st.title("How to understand large textual datasets?")
|
| 17 |
+
|
| 18 |
+
df = pd.read_csv("data/data_sample.csv", index_col=[0])
|
| 19 |
+
df = df[["message_id", "text"]]
|
| 20 |
+
df = df.head(300)
|
| 21 |
+
st.dataframe(df, use_container_width=True)
|
| 22 |
+
st.title("Inside the OASST2 dataset")
|
| 23 |
+
element = open("images/map_prompt.html", "r", encoding="utf-8")
|
| 24 |
+
|
| 25 |
+
components.html(element.read(), height=900, width=900)
|
| 26 |
+
|
| 27 |
+
st.title("Some insights by territory")
|
| 28 |
+
df_info = pd.read_csv("data/topics_info.csv", index_col=[0])
|
| 29 |
+
df_info = df_info[["name", "size", "percent"]]
|
| 30 |
+
df_info["percent"] = df_info["percent"].apply(lambda x: str(int(x)) + "%")
|
| 31 |
+
df_info = df_info.reset_index(drop=True)
|
| 32 |
+
|
| 33 |
+
st.dataframe(df_info, use_container_width=True)
|
| 34 |
+
|
| 35 |
+
st.title("Bunka Exploration Engine")
|
| 36 |
+
st.image(
|
| 37 |
+
"images/pipeline.png",
|
| 38 |
+
use_column_width=True,
|
| 39 |
+
)
|
data/data_sample.csv
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
data/topics_info.csv
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
images/logo.png
ADDED
|
|
images/map.png
ADDED

|
images/map_prompt.html
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
images/pipeline.png
ADDED
|