Spaces:
Runtime error

Runtime error
Upload folder using huggingface_hub
Browse filesThis view is limited to 50 files because it contains too many changes.
See raw diff
- .gitignore +8 -0
- LICENSE +333 -0
- README.md +109 -8
- __pycache__/api.cpython-311.pyc +0 -0
- __pycache__/api.cpython-39.pyc +0 -0
- __pycache__/attentions.cpython-311.pyc +0 -0
- __pycache__/attentions.cpython-39.pyc +0 -0
- __pycache__/commons.cpython-311.pyc +0 -0
- __pycache__/commons.cpython-39.pyc +0 -0
- __pycache__/mel_processing.cpython-311.pyc +0 -0
- __pycache__/mel_processing.cpython-39.pyc +0 -0
- __pycache__/models.cpython-311.pyc +0 -0
- __pycache__/models.cpython-39.pyc +0 -0
- __pycache__/modules.cpython-311.pyc +0 -0
- __pycache__/modules.cpython-39.pyc +0 -0
- __pycache__/se_extractor.cpython-311.pyc +0 -0
- __pycache__/se_extractor.cpython-39.pyc +0 -0
- __pycache__/transforms.cpython-311.pyc +0 -0
- __pycache__/transforms.cpython-39.pyc +0 -0
- __pycache__/utils.cpython-311.pyc +0 -0
- __pycache__/utils.cpython-39.pyc +0 -0
- api.py +201 -0
- attentions.py +465 -0
- checkpoints/base_speakers/EN/checkpoint.pth +3 -0
- checkpoints/base_speakers/EN/config.json +145 -0
- checkpoints/base_speakers/EN/en_default_se.pth +3 -0
- checkpoints/base_speakers/EN/en_style_se.pth +3 -0
- checkpoints/base_speakers/ZH/checkpoint.pth +3 -0
- checkpoints/base_speakers/ZH/config.json +137 -0
- checkpoints/base_speakers/ZH/zh_default_se.pth +3 -0
- checkpoints/converter/checkpoint.pth +3 -0
- checkpoints/converter/config.json +57 -0
- checkpoints_1226.zip +3 -0
- commons.py +160 -0
- demo_part1.ipynb +236 -0
- demo_part2.ipynb +195 -0
- mel_processing.py +183 -0
- models.py +497 -0
- modules.py +598 -0
- openvoice_app.py +307 -0
- requirements.txt +15 -0
- resources/demo_speaker0.mp3 +0 -0
- resources/demo_speaker1.mp3 +0 -0
- resources/demo_speaker2.mp3 +0 -0
- resources/example_reference.mp3 +0 -0
- resources/framework-ipa.png +0 -0
- resources/framework.jpg +0 -0
- resources/lepton.jpg +0 -0
- resources/myshell.jpg +0 -0
- resources/openvoicelogo.jpg +0 -0
.gitignore
ADDED
|
@@ -0,0 +1,8 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
__pycache__/
|
| 2 |
+
.ipynb_checkpoints/
|
| 3 |
+
processed
|
| 4 |
+
outputs
|
| 5 |
+
checkpoints
|
| 6 |
+
trash
|
| 7 |
+
examples*
|
| 8 |
+
.env
|
LICENSE
ADDED
|
@@ -0,0 +1,333 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
Creative Commons Attribution-NonCommercial 4.0 International Public
|
| 2 |
+
License
|
| 3 |
+
|
| 4 |
+
By exercising the Licensed Rights (defined below), You accept and agree
|
| 5 |
+
to be bound by the terms and conditions of this Creative Commons
|
| 6 |
+
Attribution-NonCommercial 4.0 International Public License ("Public
|
| 7 |
+
License"). To the extent this Public License may be interpreted as a
|
| 8 |
+
contract, You are granted the Licensed Rights in consideration of Your
|
| 9 |
+
acceptance of these terms and conditions, and the Licensor grants You
|
| 10 |
+
such rights in consideration of benefits the Licensor receives from
|
| 11 |
+
making the Licensed Material available under these terms and
|
| 12 |
+
conditions.
|
| 13 |
+
|
| 14 |
+
|
| 15 |
+
Section 1 -- Definitions.
|
| 16 |
+
|
| 17 |
+
a. Adapted Material means material subject to Copyright and Similar
|
| 18 |
+
Rights that is derived from or based upon the Licensed Material
|
| 19 |
+
and in which the Licensed Material is translated, altered,
|
| 20 |
+
arranged, transformed, or otherwise modified in a manner requiring
|
| 21 |
+
permission under the Copyright and Similar Rights held by the
|
| 22 |
+
Licensor. For purposes of this Public License, where the Licensed
|
| 23 |
+
Material is a musical work, performance, or sound recording,
|
| 24 |
+
Adapted Material is always produced where the Licensed Material is
|
| 25 |
+
synched in timed relation with a moving image.
|
| 26 |
+
|
| 27 |
+
b. Adapter's License means the license You apply to Your Copyright
|
| 28 |
+
and Similar Rights in Your contributions to Adapted Material in
|
| 29 |
+
accordance with the terms and conditions of this Public License.
|
| 30 |
+
|
| 31 |
+
c. Copyright and Similar Rights means copyright and/or similar rights
|
| 32 |
+
closely related to copyright including, without limitation,
|
| 33 |
+
performance, broadcast, sound recording, and Sui Generis Database
|
| 34 |
+
Rights, without regard to how the rights are labeled or
|
| 35 |
+
categorized. For purposes of this Public License, the rights
|
| 36 |
+
specified in Section 2(b)(1)-(2) are not Copyright and Similar
|
| 37 |
+
Rights.
|
| 38 |
+
d. Effective Technological Measures means those measures that, in the
|
| 39 |
+
absence of proper authority, may not be circumvented under laws
|
| 40 |
+
fulfilling obligations under Article 11 of the WIPO Copyright
|
| 41 |
+
Treaty adopted on December 20, 1996, and/or similar international
|
| 42 |
+
agreements.
|
| 43 |
+
|
| 44 |
+
e. Exceptions and Limitations means fair use, fair dealing, and/or
|
| 45 |
+
any other exception or limitation to Copyright and Similar Rights
|
| 46 |
+
that applies to Your use of the Licensed Material.
|
| 47 |
+
|
| 48 |
+
f. Licensed Material means the artistic or literary work, database,
|
| 49 |
+
or other material to which the Licensor applied this Public
|
| 50 |
+
License.
|
| 51 |
+
|
| 52 |
+
g. Licensed Rights means the rights granted to You subject to the
|
| 53 |
+
terms and conditions of this Public License, which are limited to
|
| 54 |
+
all Copyright and Similar Rights that apply to Your use of the
|
| 55 |
+
Licensed Material and that the Licensor has authority to license.
|
| 56 |
+
|
| 57 |
+
h. Licensor means the individual(s) or entity(ies) granting rights
|
| 58 |
+
under this Public License.
|
| 59 |
+
|
| 60 |
+
i. NonCommercial means not primarily intended for or directed towards
|
| 61 |
+
commercial advantage or monetary compensation. For purposes of
|
| 62 |
+
this Public License, the exchange of the Licensed Material for
|
| 63 |
+
other material subject to Copyright and Similar Rights by digital
|
| 64 |
+
file-sharing or similar means is NonCommercial provided there is
|
| 65 |
+
no payment of monetary compensation in connection with the
|
| 66 |
+
exchange.
|
| 67 |
+
|
| 68 |
+
j. Share means to provide material to the public by any means or
|
| 69 |
+
process that requires permission under the Licensed Rights, such
|
| 70 |
+
as reproduction, public display, public performance, distribution,
|
| 71 |
+
dissemination, communication, or importation, and to make material
|
| 72 |
+
available to the public including in ways that members of the
|
| 73 |
+
public may access the material from a place and at a time
|
| 74 |
+
individually chosen by them.
|
| 75 |
+
|
| 76 |
+
k. Sui Generis Database Rights means rights other than copyright
|
| 77 |
+
resulting from Directive 96/9/EC of the European Parliament and of
|
| 78 |
+
the Council of 11 March 1996 on the legal protection of databases,
|
| 79 |
+
as amended and/or succeeded, as well as other essentially
|
| 80 |
+
equivalent rights anywhere in the world.
|
| 81 |
+
|
| 82 |
+
l. You means the individual or entity exercising the Licensed Rights
|
| 83 |
+
under this Public License. Your has a corresponding meaning.
|
| 84 |
+
|
| 85 |
+
|
| 86 |
+
Section 2 -- Scope.
|
| 87 |
+
|
| 88 |
+
a. License grant.
|
| 89 |
+
|
| 90 |
+
1. Subject to the terms and conditions of this Public License,
|
| 91 |
+
the Licensor hereby grants You a worldwide, royalty-free,
|
| 92 |
+
non-sublicensable, non-exclusive, irrevocable license to
|
| 93 |
+
exercise the Licensed Rights in the Licensed Material to:
|
| 94 |
+
|
| 95 |
+
a. reproduce and Share the Licensed Material, in whole or
|
| 96 |
+
in part, for NonCommercial purposes only; and
|
| 97 |
+
|
| 98 |
+
b. produce, reproduce, and Share Adapted Material for
|
| 99 |
+
NonCommercial purposes only.
|
| 100 |
+
|
| 101 |
+
2. Exceptions and Limitations. For the avoidance of doubt, where
|
| 102 |
+
Exceptions and Limitations apply to Your use, this Public
|
| 103 |
+
License does not apply, and You do not need to comply with
|
| 104 |
+
its terms and conditions.
|
| 105 |
+
|
| 106 |
+
3. Term. The term of this Public License is specified in Section
|
| 107 |
+
6(a).
|
| 108 |
+
|
| 109 |
+
4. Media and formats; technical modifications allowed. The
|
| 110 |
+
Licensor authorizes You to exercise the Licensed Rights in
|
| 111 |
+
all media and formats whether now known or hereafter created,
|
| 112 |
+
and to make technical modifications necessary to do so. The
|
| 113 |
+
Licensor waives and/or agrees not to assert any right or
|
| 114 |
+
authority to forbid You from making technical modifications
|
| 115 |
+
necessary to exercise the Licensed Rights, including
|
| 116 |
+
technical modifications necessary to circumvent Effective
|
| 117 |
+
Technological Measures. For purposes of this Public License,
|
| 118 |
+
simply making modifications authorized by this Section 2(a)
|
| 119 |
+
(4) never produces Adapted Material.
|
| 120 |
+
|
| 121 |
+
5. Downstream recipients.
|
| 122 |
+
|
| 123 |
+
a. Offer from the Licensor -- Licensed Material. Every
|
| 124 |
+
recipient of the Licensed Material automatically
|
| 125 |
+
receives an offer from the Licensor to exercise the
|
| 126 |
+
Licensed Rights under the terms and conditions of this
|
| 127 |
+
Public License.
|
| 128 |
+
|
| 129 |
+
b. No downstream restrictions. You may not offer or impose
|
| 130 |
+
any additional or different terms or conditions on, or
|
| 131 |
+
apply any Effective Technological Measures to, the
|
| 132 |
+
Licensed Material if doing so restricts exercise of the
|
| 133 |
+
Licensed Rights by any recipient of the Licensed
|
| 134 |
+
Material.
|
| 135 |
+
|
| 136 |
+
6. No endorsement. Nothing in this Public License constitutes or
|
| 137 |
+
may be construed as permission to assert or imply that You
|
| 138 |
+
are, or that Your use of the Licensed Material is, connected
|
| 139 |
+
with, or sponsored, endorsed, or granted official status by,
|
| 140 |
+
the Licensor or others designated to receive attribution as
|
| 141 |
+
provided in Section 3(a)(1)(A)(i).
|
| 142 |
+
|
| 143 |
+
b. Other rights.
|
| 144 |
+
|
| 145 |
+
1. Moral rights, such as the right of integrity, are not
|
| 146 |
+
licensed under this Public License, nor are publicity,
|
| 147 |
+
privacy, and/or other similar personality rights; however, to
|
| 148 |
+
the extent possible, the Licensor waives and/or agrees not to
|
| 149 |
+
assert any such rights held by the Licensor to the limited
|
| 150 |
+
extent necessary to allow You to exercise the Licensed
|
| 151 |
+
Rights, but not otherwise.
|
| 152 |
+
|
| 153 |
+
2. Patent and trademark rights are not licensed under this
|
| 154 |
+
Public License.
|
| 155 |
+
|
| 156 |
+
3. To the extent possible, the Licensor waives any right to
|
| 157 |
+
collect royalties from You for the exercise of the Licensed
|
| 158 |
+
Rights, whether directly or through a collecting society
|
| 159 |
+
under any voluntary or waivable statutory or compulsory
|
| 160 |
+
licensing scheme. In all other cases the Licensor expressly
|
| 161 |
+
reserves any right to collect such royalties, including when
|
| 162 |
+
the Licensed Material is used other than for NonCommercial
|
| 163 |
+
purposes.
|
| 164 |
+
|
| 165 |
+
|
| 166 |
+
Section 3 -- License Conditions.
|
| 167 |
+
|
| 168 |
+
Your exercise of the Licensed Rights is expressly made subject to the
|
| 169 |
+
following conditions.
|
| 170 |
+
|
| 171 |
+
a. Attribution.
|
| 172 |
+
|
| 173 |
+
1. If You Share the Licensed Material (including in modified
|
| 174 |
+
form), You must:
|
| 175 |
+
|
| 176 |
+
a. retain the following if it is supplied by the Licensor
|
| 177 |
+
with the Licensed Material:
|
| 178 |
+
|
| 179 |
+
i. identification of the creator(s) of the Licensed
|
| 180 |
+
Material and any others designated to receive
|
| 181 |
+
attribution, in any reasonable manner requested by
|
| 182 |
+
the Licensor (including by pseudonym if
|
| 183 |
+
designated);
|
| 184 |
+
|
| 185 |
+
ii. a copyright notice;
|
| 186 |
+
|
| 187 |
+
iii. a notice that refers to this Public License;
|
| 188 |
+
|
| 189 |
+
iv. a notice that refers to the disclaimer of
|
| 190 |
+
warranties;
|
| 191 |
+
|
| 192 |
+
v. a URI or hyperlink to the Licensed Material to the
|
| 193 |
+
extent reasonably practicable;
|
| 194 |
+
|
| 195 |
+
b. indicate if You modified the Licensed Material and
|
| 196 |
+
retain an indication of any previous modifications; and
|
| 197 |
+
|
| 198 |
+
c. indicate the Licensed Material is licensed under this
|
| 199 |
+
Public License, and include the text of, or the URI or
|
| 200 |
+
hyperlink to, this Public License.
|
| 201 |
+
|
| 202 |
+
2. You may satisfy the conditions in Section 3(a)(1) in any
|
| 203 |
+
reasonable manner based on the medium, means, and context in
|
| 204 |
+
which You Share the Licensed Material. For example, it may be
|
| 205 |
+
reasonable to satisfy the conditions by providing a URI or
|
| 206 |
+
hyperlink to a resource that includes the required
|
| 207 |
+
information.
|
| 208 |
+
|
| 209 |
+
3. If requested by the Licensor, You must remove any of the
|
| 210 |
+
information required by Section 3(a)(1)(A) to the extent
|
| 211 |
+
reasonably practicable.
|
| 212 |
+
|
| 213 |
+
4. If You Share Adapted Material You produce, the Adapter's
|
| 214 |
+
License You apply must not prevent recipients of the Adapted
|
| 215 |
+
Material from complying with this Public License.
|
| 216 |
+
|
| 217 |
+
|
| 218 |
+
Section 4 -- Sui Generis Database Rights.
|
| 219 |
+
|
| 220 |
+
Where the Licensed Rights include Sui Generis Database Rights that
|
| 221 |
+
apply to Your use of the Licensed Material:
|
| 222 |
+
|
| 223 |
+
a. for the avoidance of doubt, Section 2(a)(1) grants You the right
|
| 224 |
+
to extract, reuse, reproduce, and Share all or a substantial
|
| 225 |
+
portion of the contents of the database for NonCommercial purposes
|
| 226 |
+
only;
|
| 227 |
+
|
| 228 |
+
b. if You include all or a substantial portion of the database
|
| 229 |
+
contents in a database in which You have Sui Generis Database
|
| 230 |
+
Rights, then the database in which You have Sui Generis Database
|
| 231 |
+
Rights (but not its individual contents) is Adapted Material; and
|
| 232 |
+
|
| 233 |
+
c. You must comply with the conditions in Section 3(a) if You Share
|
| 234 |
+
all or a substantial portion of the contents of the database.
|
| 235 |
+
|
| 236 |
+
For the avoidance of doubt, this Section 4 supplements and does not
|
| 237 |
+
replace Your obligations under this Public License where the Licensed
|
| 238 |
+
Rights include other Copyright and Similar Rights.
|
| 239 |
+
|
| 240 |
+
|
| 241 |
+
Section 5 -- Disclaimer of Warranties and Limitation of Liability.
|
| 242 |
+
|
| 243 |
+
a. UNLESS OTHERWISE SEPARATELY UNDERTAKEN BY THE LICENSOR, TO THE
|
| 244 |
+
EXTENT POSSIBLE, THE LICENSOR OFFERS THE LICENSED MATERIAL AS-IS
|
| 245 |
+
AND AS-AVAILABLE, AND MAKES NO REPRESENTATIONS OR WARRANTIES OF
|
| 246 |
+
ANY KIND CONCERNING THE LICENSED MATERIAL, WHETHER EXPRESS,
|
| 247 |
+
IMPLIED, STATUTORY, OR OTHER. THIS INCLUDES, WITHOUT LIMITATION,
|
| 248 |
+
WARRANTIES OF TITLE, MERCHANTABILITY, FITNESS FOR A PARTICULAR
|
| 249 |
+
PURPOSE, NON-INFRINGEMENT, ABSENCE OF LATENT OR OTHER DEFECTS,
|
| 250 |
+
ACCURACY, OR THE PRESENCE OR ABSENCE OF ERRORS, WHETHER OR NOT
|
| 251 |
+
KNOWN OR DISCOVERABLE. WHERE DISCLAIMERS OF WARRANTIES ARE NOT
|
| 252 |
+
ALLOWED IN FULL OR IN PART, THIS DISCLAIMER MAY NOT APPLY TO YOU.
|
| 253 |
+
|
| 254 |
+
b. TO THE EXTENT POSSIBLE, IN NO EVENT WILL THE LICENSOR BE LIABLE
|
| 255 |
+
TO YOU ON ANY LEGAL THEORY (INCLUDING, WITHOUT LIMITATION,
|
| 256 |
+
NEGLIGENCE) OR OTHERWISE FOR ANY DIRECT, SPECIAL, INDIRECT,
|
| 257 |
+
INCIDENTAL, CONSEQUENTIAL, PUNITIVE, EXEMPLARY, OR OTHER LOSSES,
|
| 258 |
+
COSTS, EXPENSES, OR DAMAGES ARISING OUT OF THIS PUBLIC LICENSE OR
|
| 259 |
+
USE OF THE LICENSED MATERIAL, EVEN IF THE LICENSOR HAS BEEN
|
| 260 |
+
ADVISED OF THE POSSIBILITY OF SUCH LOSSES, COSTS, EXPENSES, OR
|
| 261 |
+
DAMAGES. WHERE A LIMITATION OF LIABILITY IS NOT ALLOWED IN FULL OR
|
| 262 |
+
IN PART, THIS LIMITATION MAY NOT APPLY TO YOU.
|
| 263 |
+
|
| 264 |
+
c. The disclaimer of warranties and limitation of liability provided
|
| 265 |
+
above shall be interpreted in a manner that, to the extent
|
| 266 |
+
possible, most closely approximates an absolute disclaimer and
|
| 267 |
+
waiver of all liability.
|
| 268 |
+
|
| 269 |
+
|
| 270 |
+
Section 6 -- Term and Termination.
|
| 271 |
+
|
| 272 |
+
a. This Public License applies for the term of the Copyright and
|
| 273 |
+
Similar Rights licensed here. However, if You fail to comply with
|
| 274 |
+
this Public License, then Your rights under this Public License
|
| 275 |
+
terminate automatically.
|
| 276 |
+
|
| 277 |
+
b. Where Your right to use the Licensed Material has terminated under
|
| 278 |
+
Section 6(a), it reinstates:
|
| 279 |
+
|
| 280 |
+
1. automatically as of the date the violation is cured, provided
|
| 281 |
+
it is cured within 30 days of Your discovery of the
|
| 282 |
+
violation; or
|
| 283 |
+
|
| 284 |
+
2. upon express reinstatement by the Licensor.
|
| 285 |
+
|
| 286 |
+
For the avoidance of doubt, this Section 6(b) does not affect any
|
| 287 |
+
right the Licensor may have to seek remedies for Your violations
|
| 288 |
+
of this Public License.
|
| 289 |
+
|
| 290 |
+
c. For the avoidance of doubt, the Licensor may also offer the
|
| 291 |
+
Licensed Material under separate terms or conditions or stop
|
| 292 |
+
distributing the Licensed Material at any time; however, doing so
|
| 293 |
+
will not terminate this Public License.
|
| 294 |
+
|
| 295 |
+
d. Sections 1, 5, 6, 7, and 8 survive termination of this Public
|
| 296 |
+
License.
|
| 297 |
+
|
| 298 |
+
|
| 299 |
+
Section 7 -- Other Terms and Conditions.
|
| 300 |
+
|
| 301 |
+
a. The Licensor shall not be bound by any additional or different
|
| 302 |
+
terms or conditions communicated by You unless expressly agreed.
|
| 303 |
+
|
| 304 |
+
b. Any arrangements, understandings, or agreements regarding the
|
| 305 |
+
Licensed Material not stated herein are separate from and
|
| 306 |
+
independent of the terms and conditions of this Public License.
|
| 307 |
+
|
| 308 |
+
|
| 309 |
+
Section 8 -- Interpretation.
|
| 310 |
+
|
| 311 |
+
a. For the avoidance of doubt, this Public License does not, and
|
| 312 |
+
shall not be interpreted to, reduce, limit, restrict, or impose
|
| 313 |
+
conditions on any use of the Licensed Material that could lawfully
|
| 314 |
+
be made without permission under this Public License.
|
| 315 |
+
|
| 316 |
+
b. To the extent possible, if any provision of this Public License is
|
| 317 |
+
deemed unenforceable, it shall be automatically reformed to the
|
| 318 |
+
minimum extent necessary to make it enforceable. If the provision
|
| 319 |
+
cannot be reformed, it shall be severed from this Public License
|
| 320 |
+
without affecting the enforceability of the remaining terms and
|
| 321 |
+
conditions.
|
| 322 |
+
|
| 323 |
+
c. No term or condition of this Public License will be waived and no
|
| 324 |
+
failure to comply consented to unless expressly agreed to by the
|
| 325 |
+
Licensor.
|
| 326 |
+
|
| 327 |
+
d. Nothing in this Public License constitutes or may be interpreted
|
| 328 |
+
as a limitation upon, or waiver of, any privileges and immunities
|
| 329 |
+
that apply to the Licensor or You, including from the legal
|
| 330 |
+
processes of any jurisdiction or authority.
|
| 331 |
+
|
| 332 |
+
=======================================================================
|
| 333 |
+
|
README.md
CHANGED
|
@@ -1,12 +1,113 @@
|
|
| 1 |
---
|
| 2 |
-
title: OpenVoice
|
| 3 |
-
|
| 4 |
-
colorFrom: red
|
| 5 |
-
colorTo: purple
|
| 6 |
sdk: gradio
|
| 7 |
-
sdk_version:
|
| 8 |
-
app_file: app.py
|
| 9 |
-
pinned: false
|
| 10 |
---
|
|
|
|
|
|
|
|
|
|
| 11 |
|
| 12 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
---
|
| 2 |
+
title: OpenVoice-main
|
| 3 |
+
app_file: openvoice_app.py
|
|
|
|
|
|
|
| 4 |
sdk: gradio
|
| 5 |
+
sdk_version: 3.50.2
|
|
|
|
|
|
|
| 6 |
---
|
| 7 |
+
<div align="center">
|
| 8 |
+
<div> </div>
|
| 9 |
+
<img src="resources/openvoicelogo.jpg" width="400"/>
|
| 10 |
|
| 11 |
+
[Paper](https://arxiv.org/abs/2312.01479) |
|
| 12 |
+
[Website](https://research.myshell.ai/open-voice)
|
| 13 |
+
|
| 14 |
+
</div>
|
| 15 |
+
|
| 16 |
+
## Join Our Community
|
| 17 |
+
|
| 18 |
+
Join our [Discord community](https://discord.gg/myshell) and select the `Developer` role upon joining to gain exclusive access to our developer-only channel! Don't miss out on valuable discussions and collaboration opportunities.
|
| 19 |
+
|
| 20 |
+
## Introduction
|
| 21 |
+
As we detailed in our [paper](https://arxiv.org/abs/2312.01479) and [website](https://research.myshell.ai/open-voice), the advantages of OpenVoice are three-fold:
|
| 22 |
+
|
| 23 |
+
**1. Accurate Tone Color Cloning.**
|
| 24 |
+
OpenVoice can accurately clone the reference tone color and generate speech in multiple languages and accents.
|
| 25 |
+
|
| 26 |
+
**2. Flexible Voice Style Control.**
|
| 27 |
+
OpenVoice enables granular control over voice styles, such as emotion and accent, as well as other style parameters including rhythm, pauses, and intonation.
|
| 28 |
+
|
| 29 |
+
**3. Zero-shot Cross-lingual Voice Cloning.**
|
| 30 |
+
Neither of the language of the generated speech nor the language of the reference speech needs to be presented in the massive-speaker multi-lingual training dataset.
|
| 31 |
+
|
| 32 |
+
[Video](https://github.com/myshell-ai/OpenVoice/assets/40556743/3cba936f-82bf-476c-9e52-09f0f417bb2f)
|
| 33 |
+
|
| 34 |
+
<div align="center">
|
| 35 |
+
<div> </div>
|
| 36 |
+
<img src="resources/framework-ipa.png" width="800"/>
|
| 37 |
+
<div> </div>
|
| 38 |
+
</div>
|
| 39 |
+
|
| 40 |
+
OpenVoice has been powering the instant voice cloning capability of [myshell.ai](https://app.myshell.ai/explore) since May 2023. Until Nov 2023, the voice cloning model has been used tens of millions of times by users worldwide, and witnessed the explosive user growth on the platform.
|
| 41 |
+
|
| 42 |
+
## Main Contributors
|
| 43 |
+
|
| 44 |
+
- [Zengyi Qin](https://www.qinzy.tech) at MIT and MyShell
|
| 45 |
+
- [Wenliang Zhao](https://wl-zhao.github.io) at Tsinghua University
|
| 46 |
+
- [Xumin Yu](https://yuxumin.github.io) at Tsinghua University
|
| 47 |
+
- [Ethan Sun](https://twitter.com/ethan_myshell) at MyShell
|
| 48 |
+
|
| 49 |
+
## Live Demo
|
| 50 |
+
|
| 51 |
+
<div align="center">
|
| 52 |
+
<a href="https://www.lepton.ai/playground/openvoice"><img src="resources/lepton.jpg"></a>
|
| 53 |
+
|
| 54 |
+
<a href="https://app.myshell.ai/bot/z6Bvua/1702636181"><img src="resources/myshell.jpg"></a>
|
| 55 |
+
</div>
|
| 56 |
+
|
| 57 |
+
## Disclaimer
|
| 58 |
+
|
| 59 |
+
This is a implementation that approximates the performance of the internal voice clone technology of [myshell.ai](https://app.myshell.ai/explore). The online version in myshell.ai has better 1) audio quality, 2) voice cloning similarity, 3) speech naturalness and 4) computational efficiency.
|
| 60 |
+
|
| 61 |
+
## Installation
|
| 62 |
+
Clone this repo, and run
|
| 63 |
+
```
|
| 64 |
+
conda create -n openvoice python=3.9
|
| 65 |
+
conda activate openvoice
|
| 66 |
+
conda install pytorch==1.13.1 torchvision==0.14.1 torchaudio==0.13.1 pytorch-cuda=11.7 -c pytorch -c nvidia
|
| 67 |
+
pip install -r requirements.txt
|
| 68 |
+
```
|
| 69 |
+
Download the checkpoint from [here](https://myshell-public-repo-hosting.s3.amazonaws.com/checkpoints_1226.zip) and extract it to the `checkpoints` folder
|
| 70 |
+
|
| 71 |
+
## Usage
|
| 72 |
+
|
| 73 |
+
**1. Flexible Voice Style Control.**
|
| 74 |
+
Please see [`demo_part1.ipynb`](demo_part1.ipynb) for an example usage of how OpenVoice enables flexible style control over the cloned voice.
|
| 75 |
+
|
| 76 |
+
**2. Cross-Lingual Voice Cloning.**
|
| 77 |
+
Please see [`demo_part2.ipynb`](demo_part2.ipynb) for an example for languages seen or unseen in the MSML training set.
|
| 78 |
+
|
| 79 |
+
**3. Gradio Demo.**
|
| 80 |
+
Launch a local gradio demo with [`python -m openvoice_app --share`](openvoice_app.py).
|
| 81 |
+
|
| 82 |
+
**4. Advanced Usage.**
|
| 83 |
+
The base speaker model can be replaced with any model (in any language and style) that the user prefer. Please use the `se_extractor.get_se` function as demonstrated in the demo to extract the tone color embedding for the new base speaker.
|
| 84 |
+
|
| 85 |
+
**5. Tips to Generate Natural Speech.**
|
| 86 |
+
There are many single or multi-speaker TTS methods that can generate natural speech, and are readily available. By simply replacing the base speaker model with the model you prefer, you can push the speech naturalness to a level you desire.
|
| 87 |
+
|
| 88 |
+
## Roadmap
|
| 89 |
+
|
| 90 |
+
- [x] Inference code
|
| 91 |
+
- [x] Tone color converter model
|
| 92 |
+
- [x] Multi-style base speaker model
|
| 93 |
+
- [x] Multi-style and multi-lingual demo
|
| 94 |
+
- [x] Base speaker model in other languages
|
| 95 |
+
- [x] EN base speaker model with better naturalness
|
| 96 |
+
|
| 97 |
+
|
| 98 |
+
## Citation
|
| 99 |
+
```
|
| 100 |
+
@article{qin2023openvoice,
|
| 101 |
+
title={OpenVoice: Versatile Instant Voice Cloning},
|
| 102 |
+
author={Qin, Zengyi and Zhao, Wenliang and Yu, Xumin and Sun, Xin},
|
| 103 |
+
journal={arXiv preprint arXiv:2312.01479},
|
| 104 |
+
year={2023}
|
| 105 |
+
}
|
| 106 |
+
```
|
| 107 |
+
|
| 108 |
+
## License
|
| 109 |
+
This repository is licensed under a Creative Commons Attribution-NonCommercial 4.0 International License, which prohibits commercial usage. **MyShell reserves the ability to detect whether an audio is generated by OpenVoice**, no matter whether the watermark is added or not.
|
| 110 |
+
|
| 111 |
+
|
| 112 |
+
## Acknowledgements
|
| 113 |
+
This implementation is based on several excellent projects, [TTS](https://github.com/coqui-ai/TTS), [VITS](https://github.com/jaywalnut310/vits), and [VITS2](https://github.com/daniilrobnikov/vits2). Thanks for their awesome work!
|
__pycache__/api.cpython-311.pyc
ADDED
|
Binary file (15.4 kB). View file
|
|
|
__pycache__/api.cpython-39.pyc
ADDED
|
Binary file (7.16 kB). View file
|
|
|
__pycache__/attentions.cpython-311.pyc
ADDED
|
Binary file (23.4 kB). View file
|
|
|
__pycache__/attentions.cpython-39.pyc
ADDED
|
Binary file (11.1 kB). View file
|
|
|
__pycache__/commons.cpython-311.pyc
ADDED
|
Binary file (10.3 kB). View file
|
|
|
__pycache__/commons.cpython-39.pyc
ADDED
|
Binary file (5.76 kB). View file
|
|
|
__pycache__/mel_processing.cpython-311.pyc
ADDED
|
Binary file (9.16 kB). View file
|
|
|
__pycache__/mel_processing.cpython-39.pyc
ADDED
|
Binary file (4.16 kB). View file
|
|
|
__pycache__/models.cpython-311.pyc
ADDED
|
Binary file (27.2 kB). View file
|
|
|
__pycache__/models.cpython-39.pyc
ADDED
|
Binary file (12.6 kB). View file
|
|
|
__pycache__/modules.cpython-311.pyc
ADDED
|
Binary file (27.1 kB). View file
|
|
|
__pycache__/modules.cpython-39.pyc
ADDED
|
Binary file (13 kB). View file
|
|
|
__pycache__/se_extractor.cpython-311.pyc
ADDED
|
Binary file (7.62 kB). View file
|
|
|
__pycache__/se_extractor.cpython-39.pyc
ADDED
|
Binary file (3.74 kB). View file
|
|
|
__pycache__/transforms.cpython-311.pyc
ADDED
|
Binary file (7.6 kB). View file
|
|
|
__pycache__/transforms.cpython-39.pyc
ADDED
|
Binary file (3.91 kB). View file
|
|
|
__pycache__/utils.cpython-311.pyc
ADDED
|
Binary file (11.1 kB). View file
|
|
|
__pycache__/utils.cpython-39.pyc
ADDED
|
Binary file (6.24 kB). View file
|
|
|
api.py
ADDED
|
@@ -0,0 +1,201 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import torch
|
| 2 |
+
import numpy as np
|
| 3 |
+
import re
|
| 4 |
+
import soundfile
|
| 5 |
+
import utils
|
| 6 |
+
import commons
|
| 7 |
+
import os
|
| 8 |
+
import librosa
|
| 9 |
+
from text import text_to_sequence
|
| 10 |
+
from mel_processing import spectrogram_torch
|
| 11 |
+
from models import SynthesizerTrn
|
| 12 |
+
|
| 13 |
+
|
| 14 |
+
class OpenVoiceBaseClass(object):
|
| 15 |
+
def __init__(self,
|
| 16 |
+
config_path,
|
| 17 |
+
device='cuda:0'):
|
| 18 |
+
if 'cuda' in device:
|
| 19 |
+
assert torch.cuda.is_available()
|
| 20 |
+
|
| 21 |
+
hps = utils.get_hparams_from_file(config_path)
|
| 22 |
+
|
| 23 |
+
model = SynthesizerTrn(
|
| 24 |
+
len(getattr(hps, 'symbols', [])),
|
| 25 |
+
hps.data.filter_length // 2 + 1,
|
| 26 |
+
n_speakers=hps.data.n_speakers,
|
| 27 |
+
**hps.model,
|
| 28 |
+
).to(device)
|
| 29 |
+
|
| 30 |
+
model.eval()
|
| 31 |
+
self.model = model
|
| 32 |
+
self.hps = hps
|
| 33 |
+
self.device = device
|
| 34 |
+
|
| 35 |
+
def load_ckpt(self, ckpt_path):
|
| 36 |
+
checkpoint_dict = torch.load(ckpt_path, map_location=torch.device(self.device))
|
| 37 |
+
a, b = self.model.load_state_dict(checkpoint_dict['model'], strict=False)
|
| 38 |
+
print("Loaded checkpoint '{}'".format(ckpt_path))
|
| 39 |
+
print('missing/unexpected keys:', a, b)
|
| 40 |
+
|
| 41 |
+
|
| 42 |
+
class BaseSpeakerTTS(OpenVoiceBaseClass):
|
| 43 |
+
language_marks = {
|
| 44 |
+
"english": "EN",
|
| 45 |
+
"chinese": "ZH",
|
| 46 |
+
}
|
| 47 |
+
|
| 48 |
+
@staticmethod
|
| 49 |
+
def get_text(text, hps, is_symbol):
|
| 50 |
+
text_norm = text_to_sequence(text, hps.symbols, [] if is_symbol else hps.data.text_cleaners)
|
| 51 |
+
if hps.data.add_blank:
|
| 52 |
+
text_norm = commons.intersperse(text_norm, 0)
|
| 53 |
+
text_norm = torch.LongTensor(text_norm)
|
| 54 |
+
return text_norm
|
| 55 |
+
|
| 56 |
+
@staticmethod
|
| 57 |
+
def audio_numpy_concat(segment_data_list, sr, speed=1.):
|
| 58 |
+
audio_segments = []
|
| 59 |
+
for segment_data in segment_data_list:
|
| 60 |
+
audio_segments += segment_data.reshape(-1).tolist()
|
| 61 |
+
audio_segments += [0] * int((sr * 0.05)/speed)
|
| 62 |
+
audio_segments = np.array(audio_segments).astype(np.float32)
|
| 63 |
+
return audio_segments
|
| 64 |
+
|
| 65 |
+
@staticmethod
|
| 66 |
+
def split_sentences_into_pieces(text, language_str):
|
| 67 |
+
texts = utils.split_sentence(text, language_str=language_str)
|
| 68 |
+
print(" > Text splitted to sentences.")
|
| 69 |
+
print('\n'.join(texts))
|
| 70 |
+
print(" > ===========================")
|
| 71 |
+
return texts
|
| 72 |
+
|
| 73 |
+
def tts(self, text, output_path, speaker, language='English', speed=1.0):
|
| 74 |
+
mark = self.language_marks.get(language.lower(), None)
|
| 75 |
+
assert mark is not None, f"language {language} is not supported"
|
| 76 |
+
|
| 77 |
+
texts = self.split_sentences_into_pieces(text, mark)
|
| 78 |
+
|
| 79 |
+
audio_list = []
|
| 80 |
+
for t in texts:
|
| 81 |
+
t = re.sub(r'([a-z])([A-Z])', r'\1 \2', t)
|
| 82 |
+
t = f'[{mark}]{t}[{mark}]'
|
| 83 |
+
stn_tst = self.get_text(t, self.hps, False)
|
| 84 |
+
device = self.device
|
| 85 |
+
speaker_id = self.hps.speakers[speaker]
|
| 86 |
+
with torch.no_grad():
|
| 87 |
+
x_tst = stn_tst.unsqueeze(0).to(device)
|
| 88 |
+
x_tst_lengths = torch.LongTensor([stn_tst.size(0)]).to(device)
|
| 89 |
+
sid = torch.LongTensor([speaker_id]).to(device)
|
| 90 |
+
audio = self.model.infer(x_tst, x_tst_lengths, sid=sid, noise_scale=0.667, noise_scale_w=0.6,
|
| 91 |
+
length_scale=1.0 / speed)[0][0, 0].data.cpu().float().numpy()
|
| 92 |
+
audio_list.append(audio)
|
| 93 |
+
audio = self.audio_numpy_concat(audio_list, sr=self.hps.data.sampling_rate, speed=speed)
|
| 94 |
+
|
| 95 |
+
if output_path is None:
|
| 96 |
+
return audio
|
| 97 |
+
else:
|
| 98 |
+
soundfile.write(output_path, audio, self.hps.data.sampling_rate)
|
| 99 |
+
|
| 100 |
+
|
| 101 |
+
class ToneColorConverter(OpenVoiceBaseClass):
|
| 102 |
+
def __init__(self, *args, **kwargs):
|
| 103 |
+
super().__init__(*args, **kwargs)
|
| 104 |
+
|
| 105 |
+
if kwargs.get('enable_watermark', True):
|
| 106 |
+
import wavmark
|
| 107 |
+
self.watermark_model = wavmark.load_model().to(self.device)
|
| 108 |
+
else:
|
| 109 |
+
self.watermark_model = None
|
| 110 |
+
|
| 111 |
+
|
| 112 |
+
|
| 113 |
+
def extract_se(self, ref_wav_list, se_save_path=None):
|
| 114 |
+
if isinstance(ref_wav_list, str):
|
| 115 |
+
ref_wav_list = [ref_wav_list]
|
| 116 |
+
|
| 117 |
+
device = self.device
|
| 118 |
+
hps = self.hps
|
| 119 |
+
gs = []
|
| 120 |
+
|
| 121 |
+
for fname in ref_wav_list:
|
| 122 |
+
audio_ref, sr = librosa.load(fname, sr=hps.data.sampling_rate)
|
| 123 |
+
y = torch.FloatTensor(audio_ref)
|
| 124 |
+
y = y.to(device)
|
| 125 |
+
y = y.unsqueeze(0)
|
| 126 |
+
y = spectrogram_torch(y, hps.data.filter_length,
|
| 127 |
+
hps.data.sampling_rate, hps.data.hop_length, hps.data.win_length,
|
| 128 |
+
center=False).to(device)
|
| 129 |
+
with torch.no_grad():
|
| 130 |
+
g = self.model.ref_enc(y.transpose(1, 2)).unsqueeze(-1)
|
| 131 |
+
gs.append(g.detach())
|
| 132 |
+
gs = torch.stack(gs).mean(0)
|
| 133 |
+
|
| 134 |
+
if se_save_path is not None:
|
| 135 |
+
os.makedirs(os.path.dirname(se_save_path), exist_ok=True)
|
| 136 |
+
torch.save(gs.cpu(), se_save_path)
|
| 137 |
+
|
| 138 |
+
return gs
|
| 139 |
+
|
| 140 |
+
def convert(self, audio_src_path, src_se, tgt_se, output_path=None, tau=0.3, message="default"):
|
| 141 |
+
hps = self.hps
|
| 142 |
+
# load audio
|
| 143 |
+
audio, sample_rate = librosa.load(audio_src_path, sr=hps.data.sampling_rate)
|
| 144 |
+
audio = torch.tensor(audio).float()
|
| 145 |
+
|
| 146 |
+
with torch.no_grad():
|
| 147 |
+
y = torch.FloatTensor(audio).to(self.device)
|
| 148 |
+
y = y.unsqueeze(0)
|
| 149 |
+
spec = spectrogram_torch(y, hps.data.filter_length,
|
| 150 |
+
hps.data.sampling_rate, hps.data.hop_length, hps.data.win_length,
|
| 151 |
+
center=False).to(self.device)
|
| 152 |
+
spec_lengths = torch.LongTensor([spec.size(-1)]).to(self.device)
|
| 153 |
+
audio = self.model.voice_conversion(spec, spec_lengths, sid_src=src_se, sid_tgt=tgt_se, tau=tau)[0][
|
| 154 |
+
0, 0].data.cpu().float().numpy()
|
| 155 |
+
audio = self.add_watermark(audio, message)
|
| 156 |
+
if output_path is None:
|
| 157 |
+
return audio
|
| 158 |
+
else:
|
| 159 |
+
soundfile.write(output_path, audio, hps.data.sampling_rate)
|
| 160 |
+
|
| 161 |
+
def add_watermark(self, audio, message):
|
| 162 |
+
if self.watermark_model is None:
|
| 163 |
+
return audio
|
| 164 |
+
device = self.device
|
| 165 |
+
bits = utils.string_to_bits(message).reshape(-1)
|
| 166 |
+
n_repeat = len(bits) // 32
|
| 167 |
+
|
| 168 |
+
K = 16000
|
| 169 |
+
coeff = 2
|
| 170 |
+
for n in range(n_repeat):
|
| 171 |
+
trunck = audio[(coeff * n) * K: (coeff * n + 1) * K]
|
| 172 |
+
if len(trunck) != K:
|
| 173 |
+
print('Audio too short, fail to add watermark')
|
| 174 |
+
break
|
| 175 |
+
message_npy = bits[n * 32: (n + 1) * 32]
|
| 176 |
+
|
| 177 |
+
with torch.no_grad():
|
| 178 |
+
signal = torch.FloatTensor(trunck).to(device)[None]
|
| 179 |
+
message_tensor = torch.FloatTensor(message_npy).to(device)[None]
|
| 180 |
+
signal_wmd_tensor = self.watermark_model.encode(signal, message_tensor)
|
| 181 |
+
signal_wmd_npy = signal_wmd_tensor.detach().cpu().squeeze()
|
| 182 |
+
audio[(coeff * n) * K: (coeff * n + 1) * K] = signal_wmd_npy
|
| 183 |
+
return audio
|
| 184 |
+
|
| 185 |
+
def detect_watermark(self, audio, n_repeat):
|
| 186 |
+
bits = []
|
| 187 |
+
K = 16000
|
| 188 |
+
coeff = 2
|
| 189 |
+
for n in range(n_repeat):
|
| 190 |
+
trunck = audio[(coeff * n) * K: (coeff * n + 1) * K]
|
| 191 |
+
if len(trunck) != K:
|
| 192 |
+
print('Audio too short, fail to detect watermark')
|
| 193 |
+
return 'Fail'
|
| 194 |
+
with torch.no_grad():
|
| 195 |
+
signal = torch.FloatTensor(trunck).to(self.device).unsqueeze(0)
|
| 196 |
+
message_decoded_npy = (self.watermark_model.decode(signal) >= 0.5).int().detach().cpu().numpy().squeeze()
|
| 197 |
+
bits.append(message_decoded_npy)
|
| 198 |
+
bits = np.stack(bits).reshape(-1, 8)
|
| 199 |
+
message = utils.bits_to_string(bits)
|
| 200 |
+
return message
|
| 201 |
+
|
attentions.py
ADDED
|
@@ -0,0 +1,465 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import math
|
| 2 |
+
import torch
|
| 3 |
+
from torch import nn
|
| 4 |
+
from torch.nn import functional as F
|
| 5 |
+
|
| 6 |
+
import commons
|
| 7 |
+
import logging
|
| 8 |
+
|
| 9 |
+
logger = logging.getLogger(__name__)
|
| 10 |
+
|
| 11 |
+
|
| 12 |
+
class LayerNorm(nn.Module):
|
| 13 |
+
def __init__(self, channels, eps=1e-5):
|
| 14 |
+
super().__init__()
|
| 15 |
+
self.channels = channels
|
| 16 |
+
self.eps = eps
|
| 17 |
+
|
| 18 |
+
self.gamma = nn.Parameter(torch.ones(channels))
|
| 19 |
+
self.beta = nn.Parameter(torch.zeros(channels))
|
| 20 |
+
|
| 21 |
+
def forward(self, x):
|
| 22 |
+
x = x.transpose(1, -1)
|
| 23 |
+
x = F.layer_norm(x, (self.channels,), self.gamma, self.beta, self.eps)
|
| 24 |
+
return x.transpose(1, -1)
|
| 25 |
+
|
| 26 |
+
|
| 27 |
+
@torch.jit.script
|
| 28 |
+
def fused_add_tanh_sigmoid_multiply(input_a, input_b, n_channels):
|
| 29 |
+
n_channels_int = n_channels[0]
|
| 30 |
+
in_act = input_a + input_b
|
| 31 |
+
t_act = torch.tanh(in_act[:, :n_channels_int, :])
|
| 32 |
+
s_act = torch.sigmoid(in_act[:, n_channels_int:, :])
|
| 33 |
+
acts = t_act * s_act
|
| 34 |
+
return acts
|
| 35 |
+
|
| 36 |
+
|
| 37 |
+
class Encoder(nn.Module):
|
| 38 |
+
def __init__(
|
| 39 |
+
self,
|
| 40 |
+
hidden_channels,
|
| 41 |
+
filter_channels,
|
| 42 |
+
n_heads,
|
| 43 |
+
n_layers,
|
| 44 |
+
kernel_size=1,
|
| 45 |
+
p_dropout=0.0,
|
| 46 |
+
window_size=4,
|
| 47 |
+
isflow=True,
|
| 48 |
+
**kwargs
|
| 49 |
+
):
|
| 50 |
+
super().__init__()
|
| 51 |
+
self.hidden_channels = hidden_channels
|
| 52 |
+
self.filter_channels = filter_channels
|
| 53 |
+
self.n_heads = n_heads
|
| 54 |
+
self.n_layers = n_layers
|
| 55 |
+
self.kernel_size = kernel_size
|
| 56 |
+
self.p_dropout = p_dropout
|
| 57 |
+
self.window_size = window_size
|
| 58 |
+
# if isflow:
|
| 59 |
+
# cond_layer = torch.nn.Conv1d(256, 2*hidden_channels*n_layers, 1)
|
| 60 |
+
# self.cond_pre = torch.nn.Conv1d(hidden_channels, 2*hidden_channels, 1)
|
| 61 |
+
# self.cond_layer = weight_norm(cond_layer, name='weight')
|
| 62 |
+
# self.gin_channels = 256
|
| 63 |
+
self.cond_layer_idx = self.n_layers
|
| 64 |
+
if "gin_channels" in kwargs:
|
| 65 |
+
self.gin_channels = kwargs["gin_channels"]
|
| 66 |
+
if self.gin_channels != 0:
|
| 67 |
+
self.spk_emb_linear = nn.Linear(self.gin_channels, self.hidden_channels)
|
| 68 |
+
# vits2 says 3rd block, so idx is 2 by default
|
| 69 |
+
self.cond_layer_idx = (
|
| 70 |
+
kwargs["cond_layer_idx"] if "cond_layer_idx" in kwargs else 2
|
| 71 |
+
)
|
| 72 |
+
# logging.debug(self.gin_channels, self.cond_layer_idx)
|
| 73 |
+
assert (
|
| 74 |
+
self.cond_layer_idx < self.n_layers
|
| 75 |
+
), "cond_layer_idx should be less than n_layers"
|
| 76 |
+
self.drop = nn.Dropout(p_dropout)
|
| 77 |
+
self.attn_layers = nn.ModuleList()
|
| 78 |
+
self.norm_layers_1 = nn.ModuleList()
|
| 79 |
+
self.ffn_layers = nn.ModuleList()
|
| 80 |
+
self.norm_layers_2 = nn.ModuleList()
|
| 81 |
+
|
| 82 |
+
for i in range(self.n_layers):
|
| 83 |
+
self.attn_layers.append(
|
| 84 |
+
MultiHeadAttention(
|
| 85 |
+
hidden_channels,
|
| 86 |
+
hidden_channels,
|
| 87 |
+
n_heads,
|
| 88 |
+
p_dropout=p_dropout,
|
| 89 |
+
window_size=window_size,
|
| 90 |
+
)
|
| 91 |
+
)
|
| 92 |
+
self.norm_layers_1.append(LayerNorm(hidden_channels))
|
| 93 |
+
self.ffn_layers.append(
|
| 94 |
+
FFN(
|
| 95 |
+
hidden_channels,
|
| 96 |
+
hidden_channels,
|
| 97 |
+
filter_channels,
|
| 98 |
+
kernel_size,
|
| 99 |
+
p_dropout=p_dropout,
|
| 100 |
+
)
|
| 101 |
+
)
|
| 102 |
+
self.norm_layers_2.append(LayerNorm(hidden_channels))
|
| 103 |
+
|
| 104 |
+
def forward(self, x, x_mask, g=None):
|
| 105 |
+
attn_mask = x_mask.unsqueeze(2) * x_mask.unsqueeze(-1)
|
| 106 |
+
x = x * x_mask
|
| 107 |
+
for i in range(self.n_layers):
|
| 108 |
+
if i == self.cond_layer_idx and g is not None:
|
| 109 |
+
g = self.spk_emb_linear(g.transpose(1, 2))
|
| 110 |
+
g = g.transpose(1, 2)
|
| 111 |
+
x = x + g
|
| 112 |
+
x = x * x_mask
|
| 113 |
+
y = self.attn_layers[i](x, x, attn_mask)
|
| 114 |
+
y = self.drop(y)
|
| 115 |
+
x = self.norm_layers_1[i](x + y)
|
| 116 |
+
|
| 117 |
+
y = self.ffn_layers[i](x, x_mask)
|
| 118 |
+
y = self.drop(y)
|
| 119 |
+
x = self.norm_layers_2[i](x + y)
|
| 120 |
+
x = x * x_mask
|
| 121 |
+
return x
|
| 122 |
+
|
| 123 |
+
|
| 124 |
+
class Decoder(nn.Module):
|
| 125 |
+
def __init__(
|
| 126 |
+
self,
|
| 127 |
+
hidden_channels,
|
| 128 |
+
filter_channels,
|
| 129 |
+
n_heads,
|
| 130 |
+
n_layers,
|
| 131 |
+
kernel_size=1,
|
| 132 |
+
p_dropout=0.0,
|
| 133 |
+
proximal_bias=False,
|
| 134 |
+
proximal_init=True,
|
| 135 |
+
**kwargs
|
| 136 |
+
):
|
| 137 |
+
super().__init__()
|
| 138 |
+
self.hidden_channels = hidden_channels
|
| 139 |
+
self.filter_channels = filter_channels
|
| 140 |
+
self.n_heads = n_heads
|
| 141 |
+
self.n_layers = n_layers
|
| 142 |
+
self.kernel_size = kernel_size
|
| 143 |
+
self.p_dropout = p_dropout
|
| 144 |
+
self.proximal_bias = proximal_bias
|
| 145 |
+
self.proximal_init = proximal_init
|
| 146 |
+
|
| 147 |
+
self.drop = nn.Dropout(p_dropout)
|
| 148 |
+
self.self_attn_layers = nn.ModuleList()
|
| 149 |
+
self.norm_layers_0 = nn.ModuleList()
|
| 150 |
+
self.encdec_attn_layers = nn.ModuleList()
|
| 151 |
+
self.norm_layers_1 = nn.ModuleList()
|
| 152 |
+
self.ffn_layers = nn.ModuleList()
|
| 153 |
+
self.norm_layers_2 = nn.ModuleList()
|
| 154 |
+
for i in range(self.n_layers):
|
| 155 |
+
self.self_attn_layers.append(
|
| 156 |
+
MultiHeadAttention(
|
| 157 |
+
hidden_channels,
|
| 158 |
+
hidden_channels,
|
| 159 |
+
n_heads,
|
| 160 |
+
p_dropout=p_dropout,
|
| 161 |
+
proximal_bias=proximal_bias,
|
| 162 |
+
proximal_init=proximal_init,
|
| 163 |
+
)
|
| 164 |
+
)
|
| 165 |
+
self.norm_layers_0.append(LayerNorm(hidden_channels))
|
| 166 |
+
self.encdec_attn_layers.append(
|
| 167 |
+
MultiHeadAttention(
|
| 168 |
+
hidden_channels, hidden_channels, n_heads, p_dropout=p_dropout
|
| 169 |
+
)
|
| 170 |
+
)
|
| 171 |
+
self.norm_layers_1.append(LayerNorm(hidden_channels))
|
| 172 |
+
self.ffn_layers.append(
|
| 173 |
+
FFN(
|
| 174 |
+
hidden_channels,
|
| 175 |
+
hidden_channels,
|
| 176 |
+
filter_channels,
|
| 177 |
+
kernel_size,
|
| 178 |
+
p_dropout=p_dropout,
|
| 179 |
+
causal=True,
|
| 180 |
+
)
|
| 181 |
+
)
|
| 182 |
+
self.norm_layers_2.append(LayerNorm(hidden_channels))
|
| 183 |
+
|
| 184 |
+
def forward(self, x, x_mask, h, h_mask):
|
| 185 |
+
"""
|
| 186 |
+
x: decoder input
|
| 187 |
+
h: encoder output
|
| 188 |
+
"""
|
| 189 |
+
self_attn_mask = commons.subsequent_mask(x_mask.size(2)).to(
|
| 190 |
+
device=x.device, dtype=x.dtype
|
| 191 |
+
)
|
| 192 |
+
encdec_attn_mask = h_mask.unsqueeze(2) * x_mask.unsqueeze(-1)
|
| 193 |
+
x = x * x_mask
|
| 194 |
+
for i in range(self.n_layers):
|
| 195 |
+
y = self.self_attn_layers[i](x, x, self_attn_mask)
|
| 196 |
+
y = self.drop(y)
|
| 197 |
+
x = self.norm_layers_0[i](x + y)
|
| 198 |
+
|
| 199 |
+
y = self.encdec_attn_layers[i](x, h, encdec_attn_mask)
|
| 200 |
+
y = self.drop(y)
|
| 201 |
+
x = self.norm_layers_1[i](x + y)
|
| 202 |
+
|
| 203 |
+
y = self.ffn_layers[i](x, x_mask)
|
| 204 |
+
y = self.drop(y)
|
| 205 |
+
x = self.norm_layers_2[i](x + y)
|
| 206 |
+
x = x * x_mask
|
| 207 |
+
return x
|
| 208 |
+
|
| 209 |
+
|
| 210 |
+
class MultiHeadAttention(nn.Module):
|
| 211 |
+
def __init__(
|
| 212 |
+
self,
|
| 213 |
+
channels,
|
| 214 |
+
out_channels,
|
| 215 |
+
n_heads,
|
| 216 |
+
p_dropout=0.0,
|
| 217 |
+
window_size=None,
|
| 218 |
+
heads_share=True,
|
| 219 |
+
block_length=None,
|
| 220 |
+
proximal_bias=False,
|
| 221 |
+
proximal_init=False,
|
| 222 |
+
):
|
| 223 |
+
super().__init__()
|
| 224 |
+
assert channels % n_heads == 0
|
| 225 |
+
|
| 226 |
+
self.channels = channels
|
| 227 |
+
self.out_channels = out_channels
|
| 228 |
+
self.n_heads = n_heads
|
| 229 |
+
self.p_dropout = p_dropout
|
| 230 |
+
self.window_size = window_size
|
| 231 |
+
self.heads_share = heads_share
|
| 232 |
+
self.block_length = block_length
|
| 233 |
+
self.proximal_bias = proximal_bias
|
| 234 |
+
self.proximal_init = proximal_init
|
| 235 |
+
self.attn = None
|
| 236 |
+
|
| 237 |
+
self.k_channels = channels // n_heads
|
| 238 |
+
self.conv_q = nn.Conv1d(channels, channels, 1)
|
| 239 |
+
self.conv_k = nn.Conv1d(channels, channels, 1)
|
| 240 |
+
self.conv_v = nn.Conv1d(channels, channels, 1)
|
| 241 |
+
self.conv_o = nn.Conv1d(channels, out_channels, 1)
|
| 242 |
+
self.drop = nn.Dropout(p_dropout)
|
| 243 |
+
|
| 244 |
+
if window_size is not None:
|
| 245 |
+
n_heads_rel = 1 if heads_share else n_heads
|
| 246 |
+
rel_stddev = self.k_channels**-0.5
|
| 247 |
+
self.emb_rel_k = nn.Parameter(
|
| 248 |
+
torch.randn(n_heads_rel, window_size * 2 + 1, self.k_channels)
|
| 249 |
+
* rel_stddev
|
| 250 |
+
)
|
| 251 |
+
self.emb_rel_v = nn.Parameter(
|
| 252 |
+
torch.randn(n_heads_rel, window_size * 2 + 1, self.k_channels)
|
| 253 |
+
* rel_stddev
|
| 254 |
+
)
|
| 255 |
+
|
| 256 |
+
nn.init.xavier_uniform_(self.conv_q.weight)
|
| 257 |
+
nn.init.xavier_uniform_(self.conv_k.weight)
|
| 258 |
+
nn.init.xavier_uniform_(self.conv_v.weight)
|
| 259 |
+
if proximal_init:
|
| 260 |
+
with torch.no_grad():
|
| 261 |
+
self.conv_k.weight.copy_(self.conv_q.weight)
|
| 262 |
+
self.conv_k.bias.copy_(self.conv_q.bias)
|
| 263 |
+
|
| 264 |
+
def forward(self, x, c, attn_mask=None):
|
| 265 |
+
q = self.conv_q(x)
|
| 266 |
+
k = self.conv_k(c)
|
| 267 |
+
v = self.conv_v(c)
|
| 268 |
+
|
| 269 |
+
x, self.attn = self.attention(q, k, v, mask=attn_mask)
|
| 270 |
+
|
| 271 |
+
x = self.conv_o(x)
|
| 272 |
+
return x
|
| 273 |
+
|
| 274 |
+
def attention(self, query, key, value, mask=None):
|
| 275 |
+
# reshape [b, d, t] -> [b, n_h, t, d_k]
|
| 276 |
+
b, d, t_s, t_t = (*key.size(), query.size(2))
|
| 277 |
+
query = query.view(b, self.n_heads, self.k_channels, t_t).transpose(2, 3)
|
| 278 |
+
key = key.view(b, self.n_heads, self.k_channels, t_s).transpose(2, 3)
|
| 279 |
+
value = value.view(b, self.n_heads, self.k_channels, t_s).transpose(2, 3)
|
| 280 |
+
|
| 281 |
+
scores = torch.matmul(query / math.sqrt(self.k_channels), key.transpose(-2, -1))
|
| 282 |
+
if self.window_size is not None:
|
| 283 |
+
assert (
|
| 284 |
+
t_s == t_t
|
| 285 |
+
), "Relative attention is only available for self-attention."
|
| 286 |
+
key_relative_embeddings = self._get_relative_embeddings(self.emb_rel_k, t_s)
|
| 287 |
+
rel_logits = self._matmul_with_relative_keys(
|
| 288 |
+
query / math.sqrt(self.k_channels), key_relative_embeddings
|
| 289 |
+
)
|
| 290 |
+
scores_local = self._relative_position_to_absolute_position(rel_logits)
|
| 291 |
+
scores = scores + scores_local
|
| 292 |
+
if self.proximal_bias:
|
| 293 |
+
assert t_s == t_t, "Proximal bias is only available for self-attention."
|
| 294 |
+
scores = scores + self._attention_bias_proximal(t_s).to(
|
| 295 |
+
device=scores.device, dtype=scores.dtype
|
| 296 |
+
)
|
| 297 |
+
if mask is not None:
|
| 298 |
+
scores = scores.masked_fill(mask == 0, -1e4)
|
| 299 |
+
if self.block_length is not None:
|
| 300 |
+
assert (
|
| 301 |
+
t_s == t_t
|
| 302 |
+
), "Local attention is only available for self-attention."
|
| 303 |
+
block_mask = (
|
| 304 |
+
torch.ones_like(scores)
|
| 305 |
+
.triu(-self.block_length)
|
| 306 |
+
.tril(self.block_length)
|
| 307 |
+
)
|
| 308 |
+
scores = scores.masked_fill(block_mask == 0, -1e4)
|
| 309 |
+
p_attn = F.softmax(scores, dim=-1) # [b, n_h, t_t, t_s]
|
| 310 |
+
p_attn = self.drop(p_attn)
|
| 311 |
+
output = torch.matmul(p_attn, value)
|
| 312 |
+
if self.window_size is not None:
|
| 313 |
+
relative_weights = self._absolute_position_to_relative_position(p_attn)
|
| 314 |
+
value_relative_embeddings = self._get_relative_embeddings(
|
| 315 |
+
self.emb_rel_v, t_s
|
| 316 |
+
)
|
| 317 |
+
output = output + self._matmul_with_relative_values(
|
| 318 |
+
relative_weights, value_relative_embeddings
|
| 319 |
+
)
|
| 320 |
+
output = (
|
| 321 |
+
output.transpose(2, 3).contiguous().view(b, d, t_t)
|
| 322 |
+
) # [b, n_h, t_t, d_k] -> [b, d, t_t]
|
| 323 |
+
return output, p_attn
|
| 324 |
+
|
| 325 |
+
def _matmul_with_relative_values(self, x, y):
|
| 326 |
+
"""
|
| 327 |
+
x: [b, h, l, m]
|
| 328 |
+
y: [h or 1, m, d]
|
| 329 |
+
ret: [b, h, l, d]
|
| 330 |
+
"""
|
| 331 |
+
ret = torch.matmul(x, y.unsqueeze(0))
|
| 332 |
+
return ret
|
| 333 |
+
|
| 334 |
+
def _matmul_with_relative_keys(self, x, y):
|
| 335 |
+
"""
|
| 336 |
+
x: [b, h, l, d]
|
| 337 |
+
y: [h or 1, m, d]
|
| 338 |
+
ret: [b, h, l, m]
|
| 339 |
+
"""
|
| 340 |
+
ret = torch.matmul(x, y.unsqueeze(0).transpose(-2, -1))
|
| 341 |
+
return ret
|
| 342 |
+
|
| 343 |
+
def _get_relative_embeddings(self, relative_embeddings, length):
|
| 344 |
+
2 * self.window_size + 1
|
| 345 |
+
# Pad first before slice to avoid using cond ops.
|
| 346 |
+
pad_length = max(length - (self.window_size + 1), 0)
|
| 347 |
+
slice_start_position = max((self.window_size + 1) - length, 0)
|
| 348 |
+
slice_end_position = slice_start_position + 2 * length - 1
|
| 349 |
+
if pad_length > 0:
|
| 350 |
+
padded_relative_embeddings = F.pad(
|
| 351 |
+
relative_embeddings,
|
| 352 |
+
commons.convert_pad_shape([[0, 0], [pad_length, pad_length], [0, 0]]),
|
| 353 |
+
)
|
| 354 |
+
else:
|
| 355 |
+
padded_relative_embeddings = relative_embeddings
|
| 356 |
+
used_relative_embeddings = padded_relative_embeddings[
|
| 357 |
+
:, slice_start_position:slice_end_position
|
| 358 |
+
]
|
| 359 |
+
return used_relative_embeddings
|
| 360 |
+
|
| 361 |
+
def _relative_position_to_absolute_position(self, x):
|
| 362 |
+
"""
|
| 363 |
+
x: [b, h, l, 2*l-1]
|
| 364 |
+
ret: [b, h, l, l]
|
| 365 |
+
"""
|
| 366 |
+
batch, heads, length, _ = x.size()
|
| 367 |
+
# Concat columns of pad to shift from relative to absolute indexing.
|
| 368 |
+
x = F.pad(x, commons.convert_pad_shape([[0, 0], [0, 0], [0, 0], [0, 1]]))
|
| 369 |
+
|
| 370 |
+
# Concat extra elements so to add up to shape (len+1, 2*len-1).
|
| 371 |
+
x_flat = x.view([batch, heads, length * 2 * length])
|
| 372 |
+
x_flat = F.pad(
|
| 373 |
+
x_flat, commons.convert_pad_shape([[0, 0], [0, 0], [0, length - 1]])
|
| 374 |
+
)
|
| 375 |
+
|
| 376 |
+
# Reshape and slice out the padded elements.
|
| 377 |
+
x_final = x_flat.view([batch, heads, length + 1, 2 * length - 1])[
|
| 378 |
+
:, :, :length, length - 1 :
|
| 379 |
+
]
|
| 380 |
+
return x_final
|
| 381 |
+
|
| 382 |
+
def _absolute_position_to_relative_position(self, x):
|
| 383 |
+
"""
|
| 384 |
+
x: [b, h, l, l]
|
| 385 |
+
ret: [b, h, l, 2*l-1]
|
| 386 |
+
"""
|
| 387 |
+
batch, heads, length, _ = x.size()
|
| 388 |
+
# pad along column
|
| 389 |
+
x = F.pad(
|
| 390 |
+
x, commons.convert_pad_shape([[0, 0], [0, 0], [0, 0], [0, length - 1]])
|
| 391 |
+
)
|
| 392 |
+
x_flat = x.view([batch, heads, length**2 + length * (length - 1)])
|
| 393 |
+
# add 0's in the beginning that will skew the elements after reshape
|
| 394 |
+
x_flat = F.pad(x_flat, commons.convert_pad_shape([[0, 0], [0, 0], [length, 0]]))
|
| 395 |
+
x_final = x_flat.view([batch, heads, length, 2 * length])[:, :, :, 1:]
|
| 396 |
+
return x_final
|
| 397 |
+
|
| 398 |
+
def _attention_bias_proximal(self, length):
|
| 399 |
+
"""Bias for self-attention to encourage attention to close positions.
|
| 400 |
+
Args:
|
| 401 |
+
length: an integer scalar.
|
| 402 |
+
Returns:
|
| 403 |
+
a Tensor with shape [1, 1, length, length]
|
| 404 |
+
"""
|
| 405 |
+
r = torch.arange(length, dtype=torch.float32)
|
| 406 |
+
diff = torch.unsqueeze(r, 0) - torch.unsqueeze(r, 1)
|
| 407 |
+
return torch.unsqueeze(torch.unsqueeze(-torch.log1p(torch.abs(diff)), 0), 0)
|
| 408 |
+
|
| 409 |
+
|
| 410 |
+
class FFN(nn.Module):
|
| 411 |
+
def __init__(
|
| 412 |
+
self,
|
| 413 |
+
in_channels,
|
| 414 |
+
out_channels,
|
| 415 |
+
filter_channels,
|
| 416 |
+
kernel_size,
|
| 417 |
+
p_dropout=0.0,
|
| 418 |
+
activation=None,
|
| 419 |
+
causal=False,
|
| 420 |
+
):
|
| 421 |
+
super().__init__()
|
| 422 |
+
self.in_channels = in_channels
|
| 423 |
+
self.out_channels = out_channels
|
| 424 |
+
self.filter_channels = filter_channels
|
| 425 |
+
self.kernel_size = kernel_size
|
| 426 |
+
self.p_dropout = p_dropout
|
| 427 |
+
self.activation = activation
|
| 428 |
+
self.causal = causal
|
| 429 |
+
|
| 430 |
+
if causal:
|
| 431 |
+
self.padding = self._causal_padding
|
| 432 |
+
else:
|
| 433 |
+
self.padding = self._same_padding
|
| 434 |
+
|
| 435 |
+
self.conv_1 = nn.Conv1d(in_channels, filter_channels, kernel_size)
|
| 436 |
+
self.conv_2 = nn.Conv1d(filter_channels, out_channels, kernel_size)
|
| 437 |
+
self.drop = nn.Dropout(p_dropout)
|
| 438 |
+
|
| 439 |
+
def forward(self, x, x_mask):
|
| 440 |
+
x = self.conv_1(self.padding(x * x_mask))
|
| 441 |
+
if self.activation == "gelu":
|
| 442 |
+
x = x * torch.sigmoid(1.702 * x)
|
| 443 |
+
else:
|
| 444 |
+
x = torch.relu(x)
|
| 445 |
+
x = self.drop(x)
|
| 446 |
+
x = self.conv_2(self.padding(x * x_mask))
|
| 447 |
+
return x * x_mask
|
| 448 |
+
|
| 449 |
+
def _causal_padding(self, x):
|
| 450 |
+
if self.kernel_size == 1:
|
| 451 |
+
return x
|
| 452 |
+
pad_l = self.kernel_size - 1
|
| 453 |
+
pad_r = 0
|
| 454 |
+
padding = [[0, 0], [0, 0], [pad_l, pad_r]]
|
| 455 |
+
x = F.pad(x, commons.convert_pad_shape(padding))
|
| 456 |
+
return x
|
| 457 |
+
|
| 458 |
+
def _same_padding(self, x):
|
| 459 |
+
if self.kernel_size == 1:
|
| 460 |
+
return x
|
| 461 |
+
pad_l = (self.kernel_size - 1) // 2
|
| 462 |
+
pad_r = self.kernel_size // 2
|
| 463 |
+
padding = [[0, 0], [0, 0], [pad_l, pad_r]]
|
| 464 |
+
x = F.pad(x, commons.convert_pad_shape(padding))
|
| 465 |
+
return x
|
checkpoints/base_speakers/EN/checkpoint.pth
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:1db1ae1a5c8ded049bd1536051489aefbfad4a5077c01c2257e9e88fa1bb8422
|
| 3 |
+
size 160467309
|
checkpoints/base_speakers/EN/config.json
ADDED
|
@@ -0,0 +1,145 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"data": {
|
| 3 |
+
"text_cleaners": [
|
| 4 |
+
"cjke_cleaners2"
|
| 5 |
+
],
|
| 6 |
+
"sampling_rate": 22050,
|
| 7 |
+
"filter_length": 1024,
|
| 8 |
+
"hop_length": 256,
|
| 9 |
+
"win_length": 1024,
|
| 10 |
+
"n_mel_channels": 80,
|
| 11 |
+
"add_blank": true,
|
| 12 |
+
"cleaned_text": true,
|
| 13 |
+
"n_speakers": 10
|
| 14 |
+
},
|
| 15 |
+
"model": {
|
| 16 |
+
"inter_channels": 192,
|
| 17 |
+
"hidden_channels": 192,
|
| 18 |
+
"filter_channels": 768,
|
| 19 |
+
"n_heads": 2,
|
| 20 |
+
"n_layers": 6,
|
| 21 |
+
"n_layers_trans_flow": 3,
|
| 22 |
+
"kernel_size": 3,
|
| 23 |
+
"p_dropout": 0.1,
|
| 24 |
+
"resblock": "1",
|
| 25 |
+
"resblock_kernel_sizes": [
|
| 26 |
+
3,
|
| 27 |
+
7,
|
| 28 |
+
11
|
| 29 |
+
],
|
| 30 |
+
"resblock_dilation_sizes": [
|
| 31 |
+
[
|
| 32 |
+
1,
|
| 33 |
+
3,
|
| 34 |
+
5
|
| 35 |
+
],
|
| 36 |
+
[
|
| 37 |
+
1,
|
| 38 |
+
3,
|
| 39 |
+
5
|
| 40 |
+
],
|
| 41 |
+
[
|
| 42 |
+
1,
|
| 43 |
+
3,
|
| 44 |
+
5
|
| 45 |
+
]
|
| 46 |
+
],
|
| 47 |
+
"upsample_rates": [
|
| 48 |
+
8,
|
| 49 |
+
8,
|
| 50 |
+
2,
|
| 51 |
+
2
|
| 52 |
+
],
|
| 53 |
+
"upsample_initial_channel": 512,
|
| 54 |
+
"upsample_kernel_sizes": [
|
| 55 |
+
16,
|
| 56 |
+
16,
|
| 57 |
+
4,
|
| 58 |
+
4
|
| 59 |
+
],
|
| 60 |
+
"n_layers_q": 3,
|
| 61 |
+
"use_spectral_norm": false,
|
| 62 |
+
"gin_channels": 256
|
| 63 |
+
},
|
| 64 |
+
"symbols": [
|
| 65 |
+
"_",
|
| 66 |
+
",",
|
| 67 |
+
".",
|
| 68 |
+
"!",
|
| 69 |
+
"?",
|
| 70 |
+
"-",
|
| 71 |
+
"~",
|
| 72 |
+
"\u2026",
|
| 73 |
+
"N",
|
| 74 |
+
"Q",
|
| 75 |
+
"a",
|
| 76 |
+
"b",
|
| 77 |
+
"d",
|
| 78 |
+
"e",
|
| 79 |
+
"f",
|
| 80 |
+
"g",
|
| 81 |
+
"h",
|
| 82 |
+
"i",
|
| 83 |
+
"j",
|
| 84 |
+
"k",
|
| 85 |
+
"l",
|
| 86 |
+
"m",
|
| 87 |
+
"n",
|
| 88 |
+
"o",
|
| 89 |
+
"p",
|
| 90 |
+
"s",
|
| 91 |
+
"t",
|
| 92 |
+
"u",
|
| 93 |
+
"v",
|
| 94 |
+
"w",
|
| 95 |
+
"x",
|
| 96 |
+
"y",
|
| 97 |
+
"z",
|
| 98 |
+
"\u0251",
|
| 99 |
+
"\u00e6",
|
| 100 |
+
"\u0283",
|
| 101 |
+
"\u0291",
|
| 102 |
+
"\u00e7",
|
| 103 |
+
"\u026f",
|
| 104 |
+
"\u026a",
|
| 105 |
+
"\u0254",
|
| 106 |
+
"\u025b",
|
| 107 |
+
"\u0279",
|
| 108 |
+
"\u00f0",
|
| 109 |
+
"\u0259",
|
| 110 |
+
"\u026b",
|
| 111 |
+
"\u0265",
|
| 112 |
+
"\u0278",
|
| 113 |
+
"\u028a",
|
| 114 |
+
"\u027e",
|
| 115 |
+
"\u0292",
|
| 116 |
+
"\u03b8",
|
| 117 |
+
"\u03b2",
|
| 118 |
+
"\u014b",
|
| 119 |
+
"\u0266",
|
| 120 |
+
"\u207c",
|
| 121 |
+
"\u02b0",
|
| 122 |
+
"`",
|
| 123 |
+
"^",
|
| 124 |
+
"#",
|
| 125 |
+
"*",
|
| 126 |
+
"=",
|
| 127 |
+
"\u02c8",
|
| 128 |
+
"\u02cc",
|
| 129 |
+
"\u2192",
|
| 130 |
+
"\u2193",
|
| 131 |
+
"\u2191",
|
| 132 |
+
" "
|
| 133 |
+
],
|
| 134 |
+
"speakers": {
|
| 135 |
+
"default": 1,
|
| 136 |
+
"whispering": 2,
|
| 137 |
+
"shouting": 3,
|
| 138 |
+
"excited": 4,
|
| 139 |
+
"cheerful": 5,
|
| 140 |
+
"terrified": 6,
|
| 141 |
+
"angry": 7,
|
| 142 |
+
"sad": 8,
|
| 143 |
+
"friendly": 9
|
| 144 |
+
}
|
| 145 |
+
}
|
checkpoints/base_speakers/EN/en_default_se.pth
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:9cab24002eec738d0fe72cb73a34e57fbc3999c1bd4a1670a7b56ee4e3590ac9
|
| 3 |
+
size 1789
|
checkpoints/base_speakers/EN/en_style_se.pth
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:6f698153be5004b90a8642d1157c89cae7dd296752a3276450ced6a17b8b98a9
|
| 3 |
+
size 1783
|
checkpoints/base_speakers/ZH/checkpoint.pth
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:de9fb0eb749f3254130fe0172fcbb20e75f88a9b16b54dd0b73cac0dc40da7d9
|
| 3 |
+
size 160467309
|
checkpoints/base_speakers/ZH/config.json
ADDED
|
@@ -0,0 +1,137 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"data": {
|
| 3 |
+
"text_cleaners": [
|
| 4 |
+
"cjke_cleaners2"
|
| 5 |
+
],
|
| 6 |
+
"sampling_rate": 22050,
|
| 7 |
+
"filter_length": 1024,
|
| 8 |
+
"hop_length": 256,
|
| 9 |
+
"win_length": 1024,
|
| 10 |
+
"n_mel_channels": 80,
|
| 11 |
+
"add_blank": true,
|
| 12 |
+
"cleaned_text": true,
|
| 13 |
+
"n_speakers": 10
|
| 14 |
+
},
|
| 15 |
+
"model": {
|
| 16 |
+
"inter_channels": 192,
|
| 17 |
+
"hidden_channels": 192,
|
| 18 |
+
"filter_channels": 768,
|
| 19 |
+
"n_heads": 2,
|
| 20 |
+
"n_layers": 6,
|
| 21 |
+
"n_layers_trans_flow": 3,
|
| 22 |
+
"kernel_size": 3,
|
| 23 |
+
"p_dropout": 0.1,
|
| 24 |
+
"resblock": "1",
|
| 25 |
+
"resblock_kernel_sizes": [
|
| 26 |
+
3,
|
| 27 |
+
7,
|
| 28 |
+
11
|
| 29 |
+
],
|
| 30 |
+
"resblock_dilation_sizes": [
|
| 31 |
+
[
|
| 32 |
+
1,
|
| 33 |
+
3,
|
| 34 |
+
5
|
| 35 |
+
],
|
| 36 |
+
[
|
| 37 |
+
1,
|
| 38 |
+
3,
|
| 39 |
+
5
|
| 40 |
+
],
|
| 41 |
+
[
|
| 42 |
+
1,
|
| 43 |
+
3,
|
| 44 |
+
5
|
| 45 |
+
]
|
| 46 |
+
],
|
| 47 |
+
"upsample_rates": [
|
| 48 |
+
8,
|
| 49 |
+
8,
|
| 50 |
+
2,
|
| 51 |
+
2
|
| 52 |
+
],
|
| 53 |
+
"upsample_initial_channel": 512,
|
| 54 |
+
"upsample_kernel_sizes": [
|
| 55 |
+
16,
|
| 56 |
+
16,
|
| 57 |
+
4,
|
| 58 |
+
4
|
| 59 |
+
],
|
| 60 |
+
"n_layers_q": 3,
|
| 61 |
+
"use_spectral_norm": false,
|
| 62 |
+
"gin_channels": 256
|
| 63 |
+
},
|
| 64 |
+
"symbols": [
|
| 65 |
+
"_",
|
| 66 |
+
",",
|
| 67 |
+
".",
|
| 68 |
+
"!",
|
| 69 |
+
"?",
|
| 70 |
+
"-",
|
| 71 |
+
"~",
|
| 72 |
+
"\u2026",
|
| 73 |
+
"N",
|
| 74 |
+
"Q",
|
| 75 |
+
"a",
|
| 76 |
+
"b",
|
| 77 |
+
"d",
|
| 78 |
+
"e",
|
| 79 |
+
"f",
|
| 80 |
+
"g",
|
| 81 |
+
"h",
|
| 82 |
+
"i",
|
| 83 |
+
"j",
|
| 84 |
+
"k",
|
| 85 |
+
"l",
|
| 86 |
+
"m",
|
| 87 |
+
"n",
|
| 88 |
+
"o",
|
| 89 |
+
"p",
|
| 90 |
+
"s",
|
| 91 |
+
"t",
|
| 92 |
+
"u",
|
| 93 |
+
"v",
|
| 94 |
+
"w",
|
| 95 |
+
"x",
|
| 96 |
+
"y",
|
| 97 |
+
"z",
|
| 98 |
+
"\u0251",
|
| 99 |
+
"\u00e6",
|
| 100 |
+
"\u0283",
|
| 101 |
+
"\u0291",
|
| 102 |
+
"\u00e7",
|
| 103 |
+
"\u026f",
|
| 104 |
+
"\u026a",
|
| 105 |
+
"\u0254",
|
| 106 |
+
"\u025b",
|
| 107 |
+
"\u0279",
|
| 108 |
+
"\u00f0",
|
| 109 |
+
"\u0259",
|
| 110 |
+
"\u026b",
|
| 111 |
+
"\u0265",
|
| 112 |
+
"\u0278",
|
| 113 |
+
"\u028a",
|
| 114 |
+
"\u027e",
|
| 115 |
+
"\u0292",
|
| 116 |
+
"\u03b8",
|
| 117 |
+
"\u03b2",
|
| 118 |
+
"\u014b",
|
| 119 |
+
"\u0266",
|
| 120 |
+
"\u207c",
|
| 121 |
+
"\u02b0",
|
| 122 |
+
"`",
|
| 123 |
+
"^",
|
| 124 |
+
"#",
|
| 125 |
+
"*",
|
| 126 |
+
"=",
|
| 127 |
+
"\u02c8",
|
| 128 |
+
"\u02cc",
|
| 129 |
+
"\u2192",
|
| 130 |
+
"\u2193",
|
| 131 |
+
"\u2191",
|
| 132 |
+
" "
|
| 133 |
+
],
|
| 134 |
+
"speakers": {
|
| 135 |
+
"default": 0
|
| 136 |
+
}
|
| 137 |
+
}
|
checkpoints/base_speakers/ZH/zh_default_se.pth
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:3b62e8264962059b8a84dd00b29e2fcccc92f5d3be90eec67dfa082c0cf58ccf
|
| 3 |
+
size 1789
|
checkpoints/converter/checkpoint.pth
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:89ae83aa4e3668fef64b388b789ff7b0ce0def9f801069edfc18a00ea420748d
|
| 3 |
+
size 131327338
|
checkpoints/converter/config.json
ADDED
|
@@ -0,0 +1,57 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"data": {
|
| 3 |
+
"sampling_rate": 22050,
|
| 4 |
+
"filter_length": 1024,
|
| 5 |
+
"hop_length": 256,
|
| 6 |
+
"win_length": 1024,
|
| 7 |
+
"n_speakers": 0
|
| 8 |
+
},
|
| 9 |
+
"model": {
|
| 10 |
+
"inter_channels": 192,
|
| 11 |
+
"hidden_channels": 192,
|
| 12 |
+
"filter_channels": 768,
|
| 13 |
+
"n_heads": 2,
|
| 14 |
+
"n_layers": 6,
|
| 15 |
+
"kernel_size": 3,
|
| 16 |
+
"p_dropout": 0.1,
|
| 17 |
+
"resblock": "1",
|
| 18 |
+
"resblock_kernel_sizes": [
|
| 19 |
+
3,
|
| 20 |
+
7,
|
| 21 |
+
11
|
| 22 |
+
],
|
| 23 |
+
"resblock_dilation_sizes": [
|
| 24 |
+
[
|
| 25 |
+
1,
|
| 26 |
+
3,
|
| 27 |
+
5
|
| 28 |
+
],
|
| 29 |
+
[
|
| 30 |
+
1,
|
| 31 |
+
3,
|
| 32 |
+
5
|
| 33 |
+
],
|
| 34 |
+
[
|
| 35 |
+
1,
|
| 36 |
+
3,
|
| 37 |
+
5
|
| 38 |
+
]
|
| 39 |
+
],
|
| 40 |
+
"upsample_rates": [
|
| 41 |
+
8,
|
| 42 |
+
8,
|
| 43 |
+
2,
|
| 44 |
+
2
|
| 45 |
+
],
|
| 46 |
+
"upsample_initial_channel": 512,
|
| 47 |
+
"upsample_kernel_sizes": [
|
| 48 |
+
16,
|
| 49 |
+
16,
|
| 50 |
+
4,
|
| 51 |
+
4
|
| 52 |
+
],
|
| 53 |
+
"n_layers_q": 3,
|
| 54 |
+
"use_spectral_norm": false,
|
| 55 |
+
"gin_channels": 256
|
| 56 |
+
}
|
| 57 |
+
}
|
checkpoints_1226.zip
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:d86a78fd96caca7e2e9d79c7724391b39581b861d332619a9aaa8de31ad954b7
|
| 3 |
+
size 420616031
|
commons.py
ADDED
|
@@ -0,0 +1,160 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import math
|
| 2 |
+
import torch
|
| 3 |
+
from torch.nn import functional as F
|
| 4 |
+
|
| 5 |
+
|
| 6 |
+
def init_weights(m, mean=0.0, std=0.01):
|
| 7 |
+
classname = m.__class__.__name__
|
| 8 |
+
if classname.find("Conv") != -1:
|
| 9 |
+
m.weight.data.normal_(mean, std)
|
| 10 |
+
|
| 11 |
+
|
| 12 |
+
def get_padding(kernel_size, dilation=1):
|
| 13 |
+
return int((kernel_size * dilation - dilation) / 2)
|
| 14 |
+
|
| 15 |
+
|
| 16 |
+
def convert_pad_shape(pad_shape):
|
| 17 |
+
layer = pad_shape[::-1]
|
| 18 |
+
pad_shape = [item for sublist in layer for item in sublist]
|
| 19 |
+
return pad_shape
|
| 20 |
+
|
| 21 |
+
|
| 22 |
+
def intersperse(lst, item):
|
| 23 |
+
result = [item] * (len(lst) * 2 + 1)
|
| 24 |
+
result[1::2] = lst
|
| 25 |
+
return result
|
| 26 |
+
|
| 27 |
+
|
| 28 |
+
def kl_divergence(m_p, logs_p, m_q, logs_q):
|
| 29 |
+
"""KL(P||Q)"""
|
| 30 |
+
kl = (logs_q - logs_p) - 0.5
|
| 31 |
+
kl += (
|
| 32 |
+
0.5 * (torch.exp(2.0 * logs_p) + ((m_p - m_q) ** 2)) * torch.exp(-2.0 * logs_q)
|
| 33 |
+
)
|
| 34 |
+
return kl
|
| 35 |
+
|
| 36 |
+
|
| 37 |
+
def rand_gumbel(shape):
|
| 38 |
+
"""Sample from the Gumbel distribution, protect from overflows."""
|
| 39 |
+
uniform_samples = torch.rand(shape) * 0.99998 + 0.00001
|
| 40 |
+
return -torch.log(-torch.log(uniform_samples))
|
| 41 |
+
|
| 42 |
+
|
| 43 |
+
def rand_gumbel_like(x):
|
| 44 |
+
g = rand_gumbel(x.size()).to(dtype=x.dtype, device=x.device)
|
| 45 |
+
return g
|
| 46 |
+
|
| 47 |
+
|
| 48 |
+
def slice_segments(x, ids_str, segment_size=4):
|
| 49 |
+
ret = torch.zeros_like(x[:, :, :segment_size])
|
| 50 |
+
for i in range(x.size(0)):
|
| 51 |
+
idx_str = ids_str[i]
|
| 52 |
+
idx_end = idx_str + segment_size
|
| 53 |
+
ret[i] = x[i, :, idx_str:idx_end]
|
| 54 |
+
return ret
|
| 55 |
+
|
| 56 |
+
|
| 57 |
+
def rand_slice_segments(x, x_lengths=None, segment_size=4):
|
| 58 |
+
b, d, t = x.size()
|
| 59 |
+
if x_lengths is None:
|
| 60 |
+
x_lengths = t
|
| 61 |
+
ids_str_max = x_lengths - segment_size + 1
|
| 62 |
+
ids_str = (torch.rand([b]).to(device=x.device) * ids_str_max).to(dtype=torch.long)
|
| 63 |
+
ret = slice_segments(x, ids_str, segment_size)
|
| 64 |
+
return ret, ids_str
|
| 65 |
+
|
| 66 |
+
|
| 67 |
+
def get_timing_signal_1d(length, channels, min_timescale=1.0, max_timescale=1.0e4):
|
| 68 |
+
position = torch.arange(length, dtype=torch.float)
|
| 69 |
+
num_timescales = channels // 2
|
| 70 |
+
log_timescale_increment = math.log(float(max_timescale) / float(min_timescale)) / (
|
| 71 |
+
num_timescales - 1
|
| 72 |
+
)
|
| 73 |
+
inv_timescales = min_timescale * torch.exp(
|
| 74 |
+
torch.arange(num_timescales, dtype=torch.float) * -log_timescale_increment
|
| 75 |
+
)
|
| 76 |
+
scaled_time = position.unsqueeze(0) * inv_timescales.unsqueeze(1)
|
| 77 |
+
signal = torch.cat([torch.sin(scaled_time), torch.cos(scaled_time)], 0)
|
| 78 |
+
signal = F.pad(signal, [0, 0, 0, channels % 2])
|
| 79 |
+
signal = signal.view(1, channels, length)
|
| 80 |
+
return signal
|
| 81 |
+
|
| 82 |
+
|
| 83 |
+
def add_timing_signal_1d(x, min_timescale=1.0, max_timescale=1.0e4):
|
| 84 |
+
b, channels, length = x.size()
|
| 85 |
+
signal = get_timing_signal_1d(length, channels, min_timescale, max_timescale)
|
| 86 |
+
return x + signal.to(dtype=x.dtype, device=x.device)
|
| 87 |
+
|
| 88 |
+
|
| 89 |
+
def cat_timing_signal_1d(x, min_timescale=1.0, max_timescale=1.0e4, axis=1):
|
| 90 |
+
b, channels, length = x.size()
|
| 91 |
+
signal = get_timing_signal_1d(length, channels, min_timescale, max_timescale)
|
| 92 |
+
return torch.cat([x, signal.to(dtype=x.dtype, device=x.device)], axis)
|
| 93 |
+
|
| 94 |
+
|
| 95 |
+
def subsequent_mask(length):
|
| 96 |
+
mask = torch.tril(torch.ones(length, length)).unsqueeze(0).unsqueeze(0)
|
| 97 |
+
return mask
|
| 98 |
+
|
| 99 |
+
|
| 100 |
+
@torch.jit.script
|
| 101 |
+
def fused_add_tanh_sigmoid_multiply(input_a, input_b, n_channels):
|
| 102 |
+
n_channels_int = n_channels[0]
|
| 103 |
+
in_act = input_a + input_b
|
| 104 |
+
t_act = torch.tanh(in_act[:, :n_channels_int, :])
|
| 105 |
+
s_act = torch.sigmoid(in_act[:, n_channels_int:, :])
|
| 106 |
+
acts = t_act * s_act
|
| 107 |
+
return acts
|
| 108 |
+
|
| 109 |
+
|
| 110 |
+
def convert_pad_shape(pad_shape):
|
| 111 |
+
layer = pad_shape[::-1]
|
| 112 |
+
pad_shape = [item for sublist in layer for item in sublist]
|
| 113 |
+
return pad_shape
|
| 114 |
+
|
| 115 |
+
|
| 116 |
+
def shift_1d(x):
|
| 117 |
+
x = F.pad(x, convert_pad_shape([[0, 0], [0, 0], [1, 0]]))[:, :, :-1]
|
| 118 |
+
return x
|
| 119 |
+
|
| 120 |
+
|
| 121 |
+
def sequence_mask(length, max_length=None):
|
| 122 |
+
if max_length is None:
|
| 123 |
+
max_length = length.max()
|
| 124 |
+
x = torch.arange(max_length, dtype=length.dtype, device=length.device)
|
| 125 |
+
return x.unsqueeze(0) < length.unsqueeze(1)
|
| 126 |
+
|
| 127 |
+
|
| 128 |
+
def generate_path(duration, mask):
|
| 129 |
+
"""
|
| 130 |
+
duration: [b, 1, t_x]
|
| 131 |
+
mask: [b, 1, t_y, t_x]
|
| 132 |
+
"""
|
| 133 |
+
|
| 134 |
+
b, _, t_y, t_x = mask.shape
|
| 135 |
+
cum_duration = torch.cumsum(duration, -1)
|
| 136 |
+
|
| 137 |
+
cum_duration_flat = cum_duration.view(b * t_x)
|
| 138 |
+
path = sequence_mask(cum_duration_flat, t_y).to(mask.dtype)
|
| 139 |
+
path = path.view(b, t_x, t_y)
|
| 140 |
+
path = path - F.pad(path, convert_pad_shape([[0, 0], [1, 0], [0, 0]]))[:, :-1]
|
| 141 |
+
path = path.unsqueeze(1).transpose(2, 3) * mask
|
| 142 |
+
return path
|
| 143 |
+
|
| 144 |
+
|
| 145 |
+
def clip_grad_value_(parameters, clip_value, norm_type=2):
|
| 146 |
+
if isinstance(parameters, torch.Tensor):
|
| 147 |
+
parameters = [parameters]
|
| 148 |
+
parameters = list(filter(lambda p: p.grad is not None, parameters))
|
| 149 |
+
norm_type = float(norm_type)
|
| 150 |
+
if clip_value is not None:
|
| 151 |
+
clip_value = float(clip_value)
|
| 152 |
+
|
| 153 |
+
total_norm = 0
|
| 154 |
+
for p in parameters:
|
| 155 |
+
param_norm = p.grad.data.norm(norm_type)
|
| 156 |
+
total_norm += param_norm.item() ** norm_type
|
| 157 |
+
if clip_value is not None:
|
| 158 |
+
p.grad.data.clamp_(min=-clip_value, max=clip_value)
|
| 159 |
+
total_norm = total_norm ** (1.0 / norm_type)
|
| 160 |
+
return total_norm
|
demo_part1.ipynb
ADDED
|
@@ -0,0 +1,236 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"cells": [
|
| 3 |
+
{
|
| 4 |
+
"cell_type": "markdown",
|
| 5 |
+
"id": "b6ee1ede",
|
| 6 |
+
"metadata": {},
|
| 7 |
+
"source": [
|
| 8 |
+
"## Voice Style Control Demo"
|
| 9 |
+
]
|
| 10 |
+
},
|
| 11 |
+
{
|
| 12 |
+
"cell_type": "code",
|
| 13 |
+
"execution_count": null,
|
| 14 |
+
"id": "b7f043ee",
|
| 15 |
+
"metadata": {},
|
| 16 |
+
"outputs": [],
|
| 17 |
+
"source": [
|
| 18 |
+
"import os\n",
|
| 19 |
+
"import torch\n",
|
| 20 |
+
"import se_extractor\n",
|
| 21 |
+
"from api import BaseSpeakerTTS, ToneColorConverter"
|
| 22 |
+
]
|
| 23 |
+
},
|
| 24 |
+
{
|
| 25 |
+
"cell_type": "markdown",
|
| 26 |
+
"id": "15116b59",
|
| 27 |
+
"metadata": {},
|
| 28 |
+
"source": [
|
| 29 |
+
"### Initialization"
|
| 30 |
+
]
|
| 31 |
+
},
|
| 32 |
+
{
|
| 33 |
+
"cell_type": "code",
|
| 34 |
+
"execution_count": null,
|
| 35 |
+
"id": "aacad912",
|
| 36 |
+
"metadata": {},
|
| 37 |
+
"outputs": [],
|
| 38 |
+
"source": [
|
| 39 |
+
"ckpt_base = 'checkpoints/base_speakers/EN'\n",
|
| 40 |
+
"ckpt_converter = 'checkpoints/converter'\n",
|
| 41 |
+
"device = 'cuda:0'\n",
|
| 42 |
+
"output_dir = 'outputs'\n",
|
| 43 |
+
"\n",
|
| 44 |
+
"base_speaker_tts = BaseSpeakerTTS(f'{ckpt_base}/config.json', device=device)\n",
|
| 45 |
+
"base_speaker_tts.load_ckpt(f'{ckpt_base}/checkpoint.pth')\n",
|
| 46 |
+
"\n",
|
| 47 |
+
"tone_color_converter = ToneColorConverter(f'{ckpt_converter}/config.json', device=device)\n",
|
| 48 |
+
"tone_color_converter.load_ckpt(f'{ckpt_converter}/checkpoint.pth')\n",
|
| 49 |
+
"\n",
|
| 50 |
+
"os.makedirs(output_dir, exist_ok=True)"
|
| 51 |
+
]
|
| 52 |
+
},
|
| 53 |
+
{
|
| 54 |
+
"cell_type": "markdown",
|
| 55 |
+
"id": "7f67740c",
|
| 56 |
+
"metadata": {},
|
| 57 |
+
"source": [
|
| 58 |
+
"### Obtain Tone Color Embedding"
|
| 59 |
+
]
|
| 60 |
+
},
|
| 61 |
+
{
|
| 62 |
+
"cell_type": "markdown",
|
| 63 |
+
"id": "f8add279",
|
| 64 |
+
"metadata": {},
|
| 65 |
+
"source": [
|
| 66 |
+
"The `source_se` is the tone color embedding of the base speaker. \n",
|
| 67 |
+
"It is an average of multiple sentences generated by the base speaker. We directly provide the result here but\n",
|
| 68 |
+
"the readers feel free to extract `source_se` by themselves."
|
| 69 |
+
]
|
| 70 |
+
},
|
| 71 |
+
{
|
| 72 |
+
"cell_type": "code",
|
| 73 |
+
"execution_count": null,
|
| 74 |
+
"id": "63ff6273",
|
| 75 |
+
"metadata": {},
|
| 76 |
+
"outputs": [],
|
| 77 |
+
"source": [
|
| 78 |
+
"source_se = torch.load(f'{ckpt_base}/en_default_se.pth').to(device)"
|
| 79 |
+
]
|
| 80 |
+
},
|
| 81 |
+
{
|
| 82 |
+
"cell_type": "markdown",
|
| 83 |
+
"id": "4f71fcc3",
|
| 84 |
+
"metadata": {},
|
| 85 |
+
"source": [
|
| 86 |
+
"The `reference_speaker.mp3` below points to the short audio clip of the reference whose voice we want to clone. We provide an example here. If you use your own reference speakers, please **make sure each speaker has a unique filename.** The `se_extractor` will save the `targeted_se` using the filename of the audio and **will not automatically overwrite.**"
|
| 87 |
+
]
|
| 88 |
+
},
|
| 89 |
+
{
|
| 90 |
+
"cell_type": "code",
|
| 91 |
+
"execution_count": null,
|
| 92 |
+
"id": "55105eae",
|
| 93 |
+
"metadata": {},
|
| 94 |
+
"outputs": [],
|
| 95 |
+
"source": [
|
| 96 |
+
"reference_speaker = 'resources/example_reference.mp3'\n",
|
| 97 |
+
"target_se, audio_name = se_extractor.get_se(reference_speaker, tone_color_converter, target_dir='processed', vad=True)"
|
| 98 |
+
]
|
| 99 |
+
},
|
| 100 |
+
{
|
| 101 |
+
"cell_type": "markdown",
|
| 102 |
+
"id": "a40284aa",
|
| 103 |
+
"metadata": {},
|
| 104 |
+
"source": [
|
| 105 |
+
"### Inference"
|
| 106 |
+
]
|
| 107 |
+
},
|
| 108 |
+
{
|
| 109 |
+
"cell_type": "code",
|
| 110 |
+
"execution_count": null,
|
| 111 |
+
"id": "73dc1259",
|
| 112 |
+
"metadata": {},
|
| 113 |
+
"outputs": [],
|
| 114 |
+
"source": [
|
| 115 |
+
"save_path = f'{output_dir}/output_en_default.wav'\n",
|
| 116 |
+
"\n",
|
| 117 |
+
"# Run the base speaker tts\n",
|
| 118 |
+
"text = \"This audio is generated by OpenVoice.\"\n",
|
| 119 |
+
"src_path = f'{output_dir}/tmp.wav'\n",
|
| 120 |
+
"base_speaker_tts.tts(text, src_path, speaker='default', language='English', speed=1.0)\n",
|
| 121 |
+
"\n",
|
| 122 |
+
"# Run the tone color converter\n",
|
| 123 |
+
"encode_message = \"@MyShell\"\n",
|
| 124 |
+
"tone_color_converter.convert(\n",
|
| 125 |
+
" audio_src_path=src_path, \n",
|
| 126 |
+
" src_se=source_se, \n",
|
| 127 |
+
" tgt_se=target_se, \n",
|
| 128 |
+
" output_path=save_path,\n",
|
| 129 |
+
" message=encode_message)"
|
| 130 |
+
]
|
| 131 |
+
},
|
| 132 |
+
{
|
| 133 |
+
"cell_type": "markdown",
|
| 134 |
+
"id": "6e3ea28a",
|
| 135 |
+
"metadata": {},
|
| 136 |
+
"source": [
|
| 137 |
+
"**Try with different styles and speed.** The style can be controlled by the `speaker` parameter in the `base_speaker_tts.tts` method. Available choices: friendly, cheerful, excited, sad, angry, terrified, shouting, whispering. Note that the tone color embedding need to be updated. The speed can be controlled by the `speed` parameter. Let's try whispering with speed 0.9."
|
| 138 |
+
]
|
| 139 |
+
},
|
| 140 |
+
{
|
| 141 |
+
"cell_type": "code",
|
| 142 |
+
"execution_count": null,
|
| 143 |
+
"id": "fd022d38",
|
| 144 |
+
"metadata": {},
|
| 145 |
+
"outputs": [],
|
| 146 |
+
"source": [
|
| 147 |
+
"source_se = torch.load(f'{ckpt_base}/en_style_se.pth').to(device)\n",
|
| 148 |
+
"save_path = f'{output_dir}/output_whispering.wav'\n",
|
| 149 |
+
"\n",
|
| 150 |
+
"# Run the base speaker tts\n",
|
| 151 |
+
"text = \"This audio is generated by OpenVoice with a half-performance model.\"\n",
|
| 152 |
+
"src_path = f'{output_dir}/tmp.wav'\n",
|
| 153 |
+
"base_speaker_tts.tts(text, src_path, speaker='whispering', language='English', speed=0.9)\n",
|
| 154 |
+
"\n",
|
| 155 |
+
"# Run the tone color converter\n",
|
| 156 |
+
"encode_message = \"@MyShell\"\n",
|
| 157 |
+
"tone_color_converter.convert(\n",
|
| 158 |
+
" audio_src_path=src_path, \n",
|
| 159 |
+
" src_se=source_se, \n",
|
| 160 |
+
" tgt_se=target_se, \n",
|
| 161 |
+
" output_path=save_path,\n",
|
| 162 |
+
" message=encode_message)"
|
| 163 |
+
]
|
| 164 |
+
},
|
| 165 |
+
{
|
| 166 |
+
"cell_type": "markdown",
|
| 167 |
+
"id": "5fcfc70b",
|
| 168 |
+
"metadata": {},
|
| 169 |
+
"source": [
|
| 170 |
+
"**Try with different languages.** OpenVoice can achieve multi-lingual voice cloning by simply replace the base speaker. We provide an example with a Chinese base speaker here and we encourage the readers to try `demo_part2.ipynb` for a detailed demo."
|
| 171 |
+
]
|
| 172 |
+
},
|
| 173 |
+
{
|
| 174 |
+
"cell_type": "code",
|
| 175 |
+
"execution_count": null,
|
| 176 |
+
"id": "a71d1387",
|
| 177 |
+
"metadata": {},
|
| 178 |
+
"outputs": [],
|
| 179 |
+
"source": [
|
| 180 |
+
"\n",
|
| 181 |
+
"ckpt_base = 'checkpoints/base_speakers/ZH'\n",
|
| 182 |
+
"base_speaker_tts = BaseSpeakerTTS(f'{ckpt_base}/config.json', device=device)\n",
|
| 183 |
+
"base_speaker_tts.load_ckpt(f'{ckpt_base}/checkpoint.pth')\n",
|
| 184 |
+
"\n",
|
| 185 |
+
"source_se = torch.load(f'{ckpt_base}/zh_default_se.pth').to(device)\n",
|
| 186 |
+
"save_path = f'{output_dir}/output_chinese.wav'\n",
|
| 187 |
+
"\n",
|
| 188 |
+
"# Run the base speaker tts\n",
|
| 189 |
+
"text = \"今天天气真好,我们一起出去吃饭吧。\"\n",
|
| 190 |
+
"src_path = f'{output_dir}/tmp.wav'\n",
|
| 191 |
+
"base_speaker_tts.tts(text, src_path, speaker='default', language='Chinese', speed=1.0)\n",
|
| 192 |
+
"\n",
|
| 193 |
+
"# Run the tone color converter\n",
|
| 194 |
+
"encode_message = \"@MyShell\"\n",
|
| 195 |
+
"tone_color_converter.convert(\n",
|
| 196 |
+
" audio_src_path=src_path, \n",
|
| 197 |
+
" src_se=source_se, \n",
|
| 198 |
+
" tgt_se=target_se, \n",
|
| 199 |
+
" output_path=save_path,\n",
|
| 200 |
+
" message=encode_message)"
|
| 201 |
+
]
|
| 202 |
+
},
|
| 203 |
+
{
|
| 204 |
+
"cell_type": "markdown",
|
| 205 |
+
"id": "8e513094",
|
| 206 |
+
"metadata": {},
|
| 207 |
+
"source": [
|
| 208 |
+
"**Tech for good.** For people who will deploy OpenVoice for public usage: We offer you the option to add watermark to avoid potential misuse. Please see the ToneColorConverter class. **MyShell reserves the ability to detect whether an audio is generated by OpenVoice**, no matter whether the watermark is added or not."
|
| 209 |
+
]
|
| 210 |
+
}
|
| 211 |
+
],
|
| 212 |
+
"metadata": {
|
| 213 |
+
"interpreter": {
|
| 214 |
+
"hash": "9d70c38e1c0b038dbdffdaa4f8bfa1f6767c43760905c87a9fbe7800d18c6c35"
|
| 215 |
+
},
|
| 216 |
+
"kernelspec": {
|
| 217 |
+
"display_name": "Python 3.9.18 ('openvoice')",
|
| 218 |
+
"language": "python",
|
| 219 |
+
"name": "python3"
|
| 220 |
+
},
|
| 221 |
+
"language_info": {
|
| 222 |
+
"codemirror_mode": {
|
| 223 |
+
"name": "ipython",
|
| 224 |
+
"version": 3
|
| 225 |
+
},
|
| 226 |
+
"file_extension": ".py",
|
| 227 |
+
"mimetype": "text/x-python",
|
| 228 |
+
"name": "python",
|
| 229 |
+
"nbconvert_exporter": "python",
|
| 230 |
+
"pygments_lexer": "ipython3",
|
| 231 |
+
"version": "3.9.18"
|
| 232 |
+
}
|
| 233 |
+
},
|
| 234 |
+
"nbformat": 4,
|
| 235 |
+
"nbformat_minor": 5
|
| 236 |
+
}
|
demo_part2.ipynb
ADDED
|
@@ -0,0 +1,195 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"cells": [
|
| 3 |
+
{
|
| 4 |
+
"cell_type": "markdown",
|
| 5 |
+
"id": "b6ee1ede",
|
| 6 |
+
"metadata": {},
|
| 7 |
+
"source": [
|
| 8 |
+
"## Cross-Lingual Voice Clone Demo"
|
| 9 |
+
]
|
| 10 |
+
},
|
| 11 |
+
{
|
| 12 |
+
"cell_type": "code",
|
| 13 |
+
"execution_count": null,
|
| 14 |
+
"id": "b7f043ee",
|
| 15 |
+
"metadata": {},
|
| 16 |
+
"outputs": [],
|
| 17 |
+
"source": [
|
| 18 |
+
"import os\n",
|
| 19 |
+
"import torch\n",
|
| 20 |
+
"import se_extractor\n",
|
| 21 |
+
"from api import ToneColorConverter"
|
| 22 |
+
]
|
| 23 |
+
},
|
| 24 |
+
{
|
| 25 |
+
"cell_type": "markdown",
|
| 26 |
+
"id": "15116b59",
|
| 27 |
+
"metadata": {},
|
| 28 |
+
"source": [
|
| 29 |
+
"### Initialization"
|
| 30 |
+
]
|
| 31 |
+
},
|
| 32 |
+
{
|
| 33 |
+
"cell_type": "code",
|
| 34 |
+
"execution_count": null,
|
| 35 |
+
"id": "aacad912",
|
| 36 |
+
"metadata": {},
|
| 37 |
+
"outputs": [],
|
| 38 |
+
"source": [
|
| 39 |
+
"ckpt_converter = 'checkpoints/converter'\n",
|
| 40 |
+
"device = 'cuda:0'\n",
|
| 41 |
+
"output_dir = 'outputs'\n",
|
| 42 |
+
"\n",
|
| 43 |
+
"tone_color_converter = ToneColorConverter(f'{ckpt_converter}/config.json', device=device)\n",
|
| 44 |
+
"tone_color_converter.load_ckpt(f'{ckpt_converter}/checkpoint.pth')\n",
|
| 45 |
+
"\n",
|
| 46 |
+
"os.makedirs(output_dir, exist_ok=True)"
|
| 47 |
+
]
|
| 48 |
+
},
|
| 49 |
+
{
|
| 50 |
+
"cell_type": "markdown",
|
| 51 |
+
"id": "3db80fcf",
|
| 52 |
+
"metadata": {},
|
| 53 |
+
"source": [
|
| 54 |
+
"In this demo, we will use OpenAI TTS as the base speaker to produce multi-lingual speech audio. The users can flexibly change the base speaker according to their own needs. Please create a file named `.env` and place OpenAI key as `OPENAI_API_KEY=xxx`. We have also provided a Chinese base speaker model (see `demo_part1.ipynb`)."
|
| 55 |
+
]
|
| 56 |
+
},
|
| 57 |
+
{
|
| 58 |
+
"cell_type": "code",
|
| 59 |
+
"execution_count": null,
|
| 60 |
+
"id": "3b245ca3",
|
| 61 |
+
"metadata": {},
|
| 62 |
+
"outputs": [],
|
| 63 |
+
"source": [
|
| 64 |
+
"from openai import OpenAI\n",
|
| 65 |
+
"from dotenv import load_dotenv\n",
|
| 66 |
+
"\n",
|
| 67 |
+
"# Please create a file named .env and place your\n",
|
| 68 |
+
"# OpenAI key as OPENAI_API_KEY=xxx\n",
|
| 69 |
+
"load_dotenv() \n",
|
| 70 |
+
"\n",
|
| 71 |
+
"client = OpenAI(api_key=os.environ.get(\"OPENAI_API_KEY\"))\n",
|
| 72 |
+
"\n",
|
| 73 |
+
"response = client.audio.speech.create(\n",
|
| 74 |
+
" model=\"tts-1\",\n",
|
| 75 |
+
" voice=\"nova\",\n",
|
| 76 |
+
" input=\"This audio will be used to extract the base speaker tone color embedding. \" + \\\n",
|
| 77 |
+
" \"Typically a very short audio should be sufficient, but increasing the audio \" + \\\n",
|
| 78 |
+
" \"length will also improve the output audio quality.\"\n",
|
| 79 |
+
")\n",
|
| 80 |
+
"\n",
|
| 81 |
+
"response.stream_to_file(f\"{output_dir}/openai_source_output.mp3\")"
|
| 82 |
+
]
|
| 83 |
+
},
|
| 84 |
+
{
|
| 85 |
+
"cell_type": "markdown",
|
| 86 |
+
"id": "7f67740c",
|
| 87 |
+
"metadata": {},
|
| 88 |
+
"source": [
|
| 89 |
+
"### Obtain Tone Color Embedding"
|
| 90 |
+
]
|
| 91 |
+
},
|
| 92 |
+
{
|
| 93 |
+
"cell_type": "markdown",
|
| 94 |
+
"id": "f8add279",
|
| 95 |
+
"metadata": {},
|
| 96 |
+
"source": [
|
| 97 |
+
"The `source_se` is the tone color embedding of the base speaker. \n",
|
| 98 |
+
"It is an average for multiple sentences with multiple emotions\n",
|
| 99 |
+
"of the base speaker. We directly provide the result here but\n",
|
| 100 |
+
"the readers feel free to extract `source_se` by themselves."
|
| 101 |
+
]
|
| 102 |
+
},
|
| 103 |
+
{
|
| 104 |
+
"cell_type": "code",
|
| 105 |
+
"execution_count": null,
|
| 106 |
+
"id": "63ff6273",
|
| 107 |
+
"metadata": {},
|
| 108 |
+
"outputs": [],
|
| 109 |
+
"source": [
|
| 110 |
+
"base_speaker = f\"{output_dir}/openai_source_output.mp3\"\n",
|
| 111 |
+
"source_se, audio_name = se_extractor.get_se(base_speaker, tone_color_converter, vad=True)\n",
|
| 112 |
+
"\n",
|
| 113 |
+
"reference_speaker = 'resources/example_reference.mp3'\n",
|
| 114 |
+
"target_se, audio_name = se_extractor.get_se(reference_speaker, tone_color_converter, vad=True)"
|
| 115 |
+
]
|
| 116 |
+
},
|
| 117 |
+
{
|
| 118 |
+
"cell_type": "markdown",
|
| 119 |
+
"id": "a40284aa",
|
| 120 |
+
"metadata": {},
|
| 121 |
+
"source": [
|
| 122 |
+
"### Inference"
|
| 123 |
+
]
|
| 124 |
+
},
|
| 125 |
+
{
|
| 126 |
+
"cell_type": "code",
|
| 127 |
+
"execution_count": null,
|
| 128 |
+
"id": "73dc1259",
|
| 129 |
+
"metadata": {},
|
| 130 |
+
"outputs": [],
|
| 131 |
+
"source": [
|
| 132 |
+
"# Run the base speaker tts\n",
|
| 133 |
+
"text = [\n",
|
| 134 |
+
" \"MyShell is a decentralized and comprehensive platform for discovering, creating, and staking AI-native apps.\",\n",
|
| 135 |
+
" \"MyShell es una plataforma descentralizada y completa para descubrir, crear y apostar por aplicaciones nativas de IA.\",\n",
|
| 136 |
+
" \"MyShell est une plateforme décentralisée et complète pour découvrir, créer et miser sur des applications natives d'IA.\",\n",
|
| 137 |
+
" \"MyShell ist eine dezentralisierte und umfassende Plattform zum Entdecken, Erstellen und Staken von KI-nativen Apps.\",\n",
|
| 138 |
+
" \"MyShell è una piattaforma decentralizzata e completa per scoprire, creare e scommettere su app native di intelligenza artificiale.\",\n",
|
| 139 |
+
" \"MyShellは、AIネイティブアプリの発見、作成、およびステーキングのための分散型かつ包括的なプラットフォームです。\",\n",
|
| 140 |
+
" \"MyShell — это децентрализованная и всеобъемлющая платформа для обнаружения, создания и стейкинга AI-ориентированных приложений.\",\n",
|
| 141 |
+
" \"MyShell هي منصة لامركزية وشاملة لاكتشاف وإنشاء ورهان تطبيقات الذكاء الاصطناعي الأصلية.\",\n",
|
| 142 |
+
" \"MyShell是一个去中心化且全面的平台,用于发现、创建和投资AI原生应用程序。\",\n",
|
| 143 |
+
" \"MyShell एक विकेंद्रीकृत और व्यापक मंच है, जो AI-मूल ऐप्स की खोज, सृजन और स्टेकिंग के लिए है।\",\n",
|
| 144 |
+
" \"MyShell é uma plataforma descentralizada e abrangente para descobrir, criar e apostar em aplicativos nativos de IA.\"\n",
|
| 145 |
+
"]\n",
|
| 146 |
+
"src_path = f'{output_dir}/tmp.wav'\n",
|
| 147 |
+
"\n",
|
| 148 |
+
"for i, t in enumerate(text):\n",
|
| 149 |
+
"\n",
|
| 150 |
+
" response = client.audio.speech.create(\n",
|
| 151 |
+
" model=\"tts-1\",\n",
|
| 152 |
+
" voice=\"alloy\",\n",
|
| 153 |
+
" input=t,\n",
|
| 154 |
+
" )\n",
|
| 155 |
+
"\n",
|
| 156 |
+
" response.stream_to_file(src_path)\n",
|
| 157 |
+
"\n",
|
| 158 |
+
" save_path = f'{output_dir}/output_crosslingual_{i}.wav'\n",
|
| 159 |
+
"\n",
|
| 160 |
+
" # Run the tone color converter\n",
|
| 161 |
+
" encode_message = \"@MyShell\"\n",
|
| 162 |
+
" tone_color_converter.convert(\n",
|
| 163 |
+
" audio_src_path=src_path, \n",
|
| 164 |
+
" src_se=source_se, \n",
|
| 165 |
+
" tgt_se=target_se, \n",
|
| 166 |
+
" output_path=save_path,\n",
|
| 167 |
+
" message=encode_message)"
|
| 168 |
+
]
|
| 169 |
+
}
|
| 170 |
+
],
|
| 171 |
+
"metadata": {
|
| 172 |
+
"interpreter": {
|
| 173 |
+
"hash": "9d70c38e1c0b038dbdffdaa4f8bfa1f6767c43760905c87a9fbe7800d18c6c35"
|
| 174 |
+
},
|
| 175 |
+
"kernelspec": {
|
| 176 |
+
"display_name": "Python 3.9.18 ('openvoice')",
|
| 177 |
+
"language": "python",
|
| 178 |
+
"name": "python3"
|
| 179 |
+
},
|
| 180 |
+
"language_info": {
|
| 181 |
+
"codemirror_mode": {
|
| 182 |
+
"name": "ipython",
|
| 183 |
+
"version": 3
|
| 184 |
+
},
|
| 185 |
+
"file_extension": ".py",
|
| 186 |
+
"mimetype": "text/x-python",
|
| 187 |
+
"name": "python",
|
| 188 |
+
"nbconvert_exporter": "python",
|
| 189 |
+
"pygments_lexer": "ipython3",
|
| 190 |
+
"version": "3.9.18"
|
| 191 |
+
}
|
| 192 |
+
},
|
| 193 |
+
"nbformat": 4,
|
| 194 |
+
"nbformat_minor": 5
|
| 195 |
+
}
|
mel_processing.py
ADDED
|
@@ -0,0 +1,183 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import torch
|
| 2 |
+
import torch.utils.data
|
| 3 |
+
from librosa.filters import mel as librosa_mel_fn
|
| 4 |
+
|
| 5 |
+
MAX_WAV_VALUE = 32768.0
|
| 6 |
+
|
| 7 |
+
|
| 8 |
+
def dynamic_range_compression_torch(x, C=1, clip_val=1e-5):
|
| 9 |
+
"""
|
| 10 |
+
PARAMS
|
| 11 |
+
------
|
| 12 |
+
C: compression factor
|
| 13 |
+
"""
|
| 14 |
+
return torch.log(torch.clamp(x, min=clip_val) * C)
|
| 15 |
+
|
| 16 |
+
|
| 17 |
+
def dynamic_range_decompression_torch(x, C=1):
|
| 18 |
+
"""
|
| 19 |
+
PARAMS
|
| 20 |
+
------
|
| 21 |
+
C: compression factor used to compress
|
| 22 |
+
"""
|
| 23 |
+
return torch.exp(x) / C
|
| 24 |
+
|
| 25 |
+
|
| 26 |
+
def spectral_normalize_torch(magnitudes):
|
| 27 |
+
output = dynamic_range_compression_torch(magnitudes)
|
| 28 |
+
return output
|
| 29 |
+
|
| 30 |
+
|
| 31 |
+
def spectral_de_normalize_torch(magnitudes):
|
| 32 |
+
output = dynamic_range_decompression_torch(magnitudes)
|
| 33 |
+
return output
|
| 34 |
+
|
| 35 |
+
|
| 36 |
+
mel_basis = {}
|
| 37 |
+
hann_window = {}
|
| 38 |
+
|
| 39 |
+
|
| 40 |
+
def spectrogram_torch(y, n_fft, sampling_rate, hop_size, win_size, center=False):
|
| 41 |
+
if torch.min(y) < -1.1:
|
| 42 |
+
print("min value is ", torch.min(y))
|
| 43 |
+
if torch.max(y) > 1.1:
|
| 44 |
+
print("max value is ", torch.max(y))
|
| 45 |
+
|
| 46 |
+
global hann_window
|
| 47 |
+
dtype_device = str(y.dtype) + "_" + str(y.device)
|
| 48 |
+
wnsize_dtype_device = str(win_size) + "_" + dtype_device
|
| 49 |
+
if wnsize_dtype_device not in hann_window:
|
| 50 |
+
hann_window[wnsize_dtype_device] = torch.hann_window(win_size).to(
|
| 51 |
+
dtype=y.dtype, device=y.device
|
| 52 |
+
)
|
| 53 |
+
|
| 54 |
+
y = torch.nn.functional.pad(
|
| 55 |
+
y.unsqueeze(1),
|
| 56 |
+
(int((n_fft - hop_size) / 2), int((n_fft - hop_size) / 2)),
|
| 57 |
+
mode="reflect",
|
| 58 |
+
)
|
| 59 |
+
y = y.squeeze(1)
|
| 60 |
+
|
| 61 |
+
spec = torch.stft(
|
| 62 |
+
y,
|
| 63 |
+
n_fft,
|
| 64 |
+
hop_length=hop_size,
|
| 65 |
+
win_length=win_size,
|
| 66 |
+
window=hann_window[wnsize_dtype_device],
|
| 67 |
+
center=center,
|
| 68 |
+
pad_mode="reflect",
|
| 69 |
+
normalized=False,
|
| 70 |
+
onesided=True,
|
| 71 |
+
return_complex=False,
|
| 72 |
+
)
|
| 73 |
+
|
| 74 |
+
spec = torch.sqrt(spec.pow(2).sum(-1) + 1e-6)
|
| 75 |
+
return spec
|
| 76 |
+
|
| 77 |
+
|
| 78 |
+
def spectrogram_torch_conv(y, n_fft, sampling_rate, hop_size, win_size, center=False):
|
| 79 |
+
# if torch.min(y) < -1.:
|
| 80 |
+
# print('min value is ', torch.min(y))
|
| 81 |
+
# if torch.max(y) > 1.:
|
| 82 |
+
# print('max value is ', torch.max(y))
|
| 83 |
+
|
| 84 |
+
global hann_window
|
| 85 |
+
dtype_device = str(y.dtype) + '_' + str(y.device)
|
| 86 |
+
wnsize_dtype_device = str(win_size) + '_' + dtype_device
|
| 87 |
+
if wnsize_dtype_device not in hann_window:
|
| 88 |
+
hann_window[wnsize_dtype_device] = torch.hann_window(win_size).to(dtype=y.dtype, device=y.device)
|
| 89 |
+
|
| 90 |
+
y = torch.nn.functional.pad(y.unsqueeze(1), (int((n_fft-hop_size)/2), int((n_fft-hop_size)/2)), mode='reflect')
|
| 91 |
+
|
| 92 |
+
# ******************** original ************************#
|
| 93 |
+
# y = y.squeeze(1)
|
| 94 |
+
# spec1 = torch.stft(y, n_fft, hop_length=hop_size, win_length=win_size, window=hann_window[wnsize_dtype_device],
|
| 95 |
+
# center=center, pad_mode='reflect', normalized=False, onesided=True, return_complex=False)
|
| 96 |
+
|
| 97 |
+
# ******************** ConvSTFT ************************#
|
| 98 |
+
freq_cutoff = n_fft // 2 + 1
|
| 99 |
+
fourier_basis = torch.view_as_real(torch.fft.fft(torch.eye(n_fft)))
|
| 100 |
+
forward_basis = fourier_basis[:freq_cutoff].permute(2, 0, 1).reshape(-1, 1, fourier_basis.shape[1])
|
| 101 |
+
forward_basis = forward_basis * torch.as_tensor(librosa.util.pad_center(torch.hann_window(win_size), size=n_fft)).float()
|
| 102 |
+
|
| 103 |
+
import torch.nn.functional as F
|
| 104 |
+
|
| 105 |
+
# if center:
|
| 106 |
+
# signal = F.pad(y[:, None, None, :], (n_fft // 2, n_fft // 2, 0, 0), mode = 'reflect').squeeze(1)
|
| 107 |
+
assert center is False
|
| 108 |
+
|
| 109 |
+
forward_transform_squared = F.conv1d(y, forward_basis.to(y.device), stride = hop_size)
|
| 110 |
+
spec2 = torch.stack([forward_transform_squared[:, :freq_cutoff, :], forward_transform_squared[:, freq_cutoff:, :]], dim = -1)
|
| 111 |
+
|
| 112 |
+
|
| 113 |
+
# ******************** Verification ************************#
|
| 114 |
+
spec1 = torch.stft(y.squeeze(1), n_fft, hop_length=hop_size, win_length=win_size, window=hann_window[wnsize_dtype_device],
|
| 115 |
+
center=center, pad_mode='reflect', normalized=False, onesided=True, return_complex=False)
|
| 116 |
+
assert torch.allclose(spec1, spec2, atol=1e-4)
|
| 117 |
+
|
| 118 |
+
spec = torch.sqrt(spec2.pow(2).sum(-1) + 1e-6)
|
| 119 |
+
return spec
|
| 120 |
+
|
| 121 |
+
|
| 122 |
+
def spec_to_mel_torch(spec, n_fft, num_mels, sampling_rate, fmin, fmax):
|
| 123 |
+
global mel_basis
|
| 124 |
+
dtype_device = str(spec.dtype) + "_" + str(spec.device)
|
| 125 |
+
fmax_dtype_device = str(fmax) + "_" + dtype_device
|
| 126 |
+
if fmax_dtype_device not in mel_basis:
|
| 127 |
+
mel = librosa_mel_fn(sampling_rate, n_fft, num_mels, fmin, fmax)
|
| 128 |
+
mel_basis[fmax_dtype_device] = torch.from_numpy(mel).to(
|
| 129 |
+
dtype=spec.dtype, device=spec.device
|
| 130 |
+
)
|
| 131 |
+
spec = torch.matmul(mel_basis[fmax_dtype_device], spec)
|
| 132 |
+
spec = spectral_normalize_torch(spec)
|
| 133 |
+
return spec
|
| 134 |
+
|
| 135 |
+
|
| 136 |
+
def mel_spectrogram_torch(
|
| 137 |
+
y, n_fft, num_mels, sampling_rate, hop_size, win_size, fmin, fmax, center=False
|
| 138 |
+
):
|
| 139 |
+
if torch.min(y) < -1.0:
|
| 140 |
+
print("min value is ", torch.min(y))
|
| 141 |
+
if torch.max(y) > 1.0:
|
| 142 |
+
print("max value is ", torch.max(y))
|
| 143 |
+
|
| 144 |
+
global mel_basis, hann_window
|
| 145 |
+
dtype_device = str(y.dtype) + "_" + str(y.device)
|
| 146 |
+
fmax_dtype_device = str(fmax) + "_" + dtype_device
|
| 147 |
+
wnsize_dtype_device = str(win_size) + "_" + dtype_device
|
| 148 |
+
if fmax_dtype_device not in mel_basis:
|
| 149 |
+
mel = librosa_mel_fn(sampling_rate, n_fft, num_mels, fmin, fmax)
|
| 150 |
+
mel_basis[fmax_dtype_device] = torch.from_numpy(mel).to(
|
| 151 |
+
dtype=y.dtype, device=y.device
|
| 152 |
+
)
|
| 153 |
+
if wnsize_dtype_device not in hann_window:
|
| 154 |
+
hann_window[wnsize_dtype_device] = torch.hann_window(win_size).to(
|
| 155 |
+
dtype=y.dtype, device=y.device
|
| 156 |
+
)
|
| 157 |
+
|
| 158 |
+
y = torch.nn.functional.pad(
|
| 159 |
+
y.unsqueeze(1),
|
| 160 |
+
(int((n_fft - hop_size) / 2), int((n_fft - hop_size) / 2)),
|
| 161 |
+
mode="reflect",
|
| 162 |
+
)
|
| 163 |
+
y = y.squeeze(1)
|
| 164 |
+
|
| 165 |
+
spec = torch.stft(
|
| 166 |
+
y,
|
| 167 |
+
n_fft,
|
| 168 |
+
hop_length=hop_size,
|
| 169 |
+
win_length=win_size,
|
| 170 |
+
window=hann_window[wnsize_dtype_device],
|
| 171 |
+
center=center,
|
| 172 |
+
pad_mode="reflect",
|
| 173 |
+
normalized=False,
|
| 174 |
+
onesided=True,
|
| 175 |
+
return_complex=False,
|
| 176 |
+
)
|
| 177 |
+
|
| 178 |
+
spec = torch.sqrt(spec.pow(2).sum(-1) + 1e-6)
|
| 179 |
+
|
| 180 |
+
spec = torch.matmul(mel_basis[fmax_dtype_device], spec)
|
| 181 |
+
spec = spectral_normalize_torch(spec)
|
| 182 |
+
|
| 183 |
+
return spec
|
models.py
ADDED
|
@@ -0,0 +1,497 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import math
|
| 2 |
+
import torch
|
| 3 |
+
from torch import nn
|
| 4 |
+
from torch.nn import functional as F
|
| 5 |
+
|
| 6 |
+
import commons
|
| 7 |
+
import modules
|
| 8 |
+
import attentions
|
| 9 |
+
|
| 10 |
+
from torch.nn import Conv1d, ConvTranspose1d, Conv2d
|
| 11 |
+
from torch.nn.utils import weight_norm, remove_weight_norm, spectral_norm
|
| 12 |
+
|
| 13 |
+
from commons import init_weights, get_padding
|
| 14 |
+
|
| 15 |
+
|
| 16 |
+
class TextEncoder(nn.Module):
|
| 17 |
+
def __init__(self,
|
| 18 |
+
n_vocab,
|
| 19 |
+
out_channels,
|
| 20 |
+
hidden_channels,
|
| 21 |
+
filter_channels,
|
| 22 |
+
n_heads,
|
| 23 |
+
n_layers,
|
| 24 |
+
kernel_size,
|
| 25 |
+
p_dropout):
|
| 26 |
+
super().__init__()
|
| 27 |
+
self.n_vocab = n_vocab
|
| 28 |
+
self.out_channels = out_channels
|
| 29 |
+
self.hidden_channels = hidden_channels
|
| 30 |
+
self.filter_channels = filter_channels
|
| 31 |
+
self.n_heads = n_heads
|
| 32 |
+
self.n_layers = n_layers
|
| 33 |
+
self.kernel_size = kernel_size
|
| 34 |
+
self.p_dropout = p_dropout
|
| 35 |
+
|
| 36 |
+
self.emb = nn.Embedding(n_vocab, hidden_channels)
|
| 37 |
+
nn.init.normal_(self.emb.weight, 0.0, hidden_channels**-0.5)
|
| 38 |
+
|
| 39 |
+
self.encoder = attentions.Encoder(
|
| 40 |
+
hidden_channels,
|
| 41 |
+
filter_channels,
|
| 42 |
+
n_heads,
|
| 43 |
+
n_layers,
|
| 44 |
+
kernel_size,
|
| 45 |
+
p_dropout)
|
| 46 |
+
self.proj= nn.Conv1d(hidden_channels, out_channels * 2, 1)
|
| 47 |
+
|
| 48 |
+
def forward(self, x, x_lengths):
|
| 49 |
+
x = self.emb(x) * math.sqrt(self.hidden_channels) # [b, t, h]
|
| 50 |
+
x = torch.transpose(x, 1, -1) # [b, h, t]
|
| 51 |
+
x_mask = torch.unsqueeze(commons.sequence_mask(x_lengths, x.size(2)), 1).to(x.dtype)
|
| 52 |
+
|
| 53 |
+
x = self.encoder(x * x_mask, x_mask)
|
| 54 |
+
stats = self.proj(x) * x_mask
|
| 55 |
+
|
| 56 |
+
m, logs = torch.split(stats, self.out_channels, dim=1)
|
| 57 |
+
return x, m, logs, x_mask
|
| 58 |
+
|
| 59 |
+
|
| 60 |
+
class DurationPredictor(nn.Module):
|
| 61 |
+
def __init__(
|
| 62 |
+
self, in_channels, filter_channels, kernel_size, p_dropout, gin_channels=0
|
| 63 |
+
):
|
| 64 |
+
super().__init__()
|
| 65 |
+
|
| 66 |
+
self.in_channels = in_channels
|
| 67 |
+
self.filter_channels = filter_channels
|
| 68 |
+
self.kernel_size = kernel_size
|
| 69 |
+
self.p_dropout = p_dropout
|
| 70 |
+
self.gin_channels = gin_channels
|
| 71 |
+
|
| 72 |
+
self.drop = nn.Dropout(p_dropout)
|
| 73 |
+
self.conv_1 = nn.Conv1d(
|
| 74 |
+
in_channels, filter_channels, kernel_size, padding=kernel_size // 2
|
| 75 |
+
)
|
| 76 |
+
self.norm_1 = modules.LayerNorm(filter_channels)
|
| 77 |
+
self.conv_2 = nn.Conv1d(
|
| 78 |
+
filter_channels, filter_channels, kernel_size, padding=kernel_size // 2
|
| 79 |
+
)
|
| 80 |
+
self.norm_2 = modules.LayerNorm(filter_channels)
|
| 81 |
+
self.proj = nn.Conv1d(filter_channels, 1, 1)
|
| 82 |
+
|
| 83 |
+
if gin_channels != 0:
|
| 84 |
+
self.cond = nn.Conv1d(gin_channels, in_channels, 1)
|
| 85 |
+
|
| 86 |
+
def forward(self, x, x_mask, g=None):
|
| 87 |
+
x = torch.detach(x)
|
| 88 |
+
if g is not None:
|
| 89 |
+
g = torch.detach(g)
|
| 90 |
+
x = x + self.cond(g)
|
| 91 |
+
x = self.conv_1(x * x_mask)
|
| 92 |
+
x = torch.relu(x)
|
| 93 |
+
x = self.norm_1(x)
|
| 94 |
+
x = self.drop(x)
|
| 95 |
+
x = self.conv_2(x * x_mask)
|
| 96 |
+
x = torch.relu(x)
|
| 97 |
+
x = self.norm_2(x)
|
| 98 |
+
x = self.drop(x)
|
| 99 |
+
x = self.proj(x * x_mask)
|
| 100 |
+
return x * x_mask
|
| 101 |
+
|
| 102 |
+
class StochasticDurationPredictor(nn.Module):
|
| 103 |
+
def __init__(self, in_channels, filter_channels, kernel_size, p_dropout, n_flows=4, gin_channels=0):
|
| 104 |
+
super().__init__()
|
| 105 |
+
filter_channels = in_channels # it needs to be removed from future version.
|
| 106 |
+
self.in_channels = in_channels
|
| 107 |
+
self.filter_channels = filter_channels
|
| 108 |
+
self.kernel_size = kernel_size
|
| 109 |
+
self.p_dropout = p_dropout
|
| 110 |
+
self.n_flows = n_flows
|
| 111 |
+
self.gin_channels = gin_channels
|
| 112 |
+
|
| 113 |
+
self.log_flow = modules.Log()
|
| 114 |
+
self.flows = nn.ModuleList()
|
| 115 |
+
self.flows.append(modules.ElementwiseAffine(2))
|
| 116 |
+
for i in range(n_flows):
|
| 117 |
+
self.flows.append(modules.ConvFlow(2, filter_channels, kernel_size, n_layers=3))
|
| 118 |
+
self.flows.append(modules.Flip())
|
| 119 |
+
|
| 120 |
+
self.post_pre = nn.Conv1d(1, filter_channels, 1)
|
| 121 |
+
self.post_proj = nn.Conv1d(filter_channels, filter_channels, 1)
|
| 122 |
+
self.post_convs = modules.DDSConv(filter_channels, kernel_size, n_layers=3, p_dropout=p_dropout)
|
| 123 |
+
self.post_flows = nn.ModuleList()
|
| 124 |
+
self.post_flows.append(modules.ElementwiseAffine(2))
|
| 125 |
+
for i in range(4):
|
| 126 |
+
self.post_flows.append(modules.ConvFlow(2, filter_channels, kernel_size, n_layers=3))
|
| 127 |
+
self.post_flows.append(modules.Flip())
|
| 128 |
+
|
| 129 |
+
self.pre = nn.Conv1d(in_channels, filter_channels, 1)
|
| 130 |
+
self.proj = nn.Conv1d(filter_channels, filter_channels, 1)
|
| 131 |
+
self.convs = modules.DDSConv(filter_channels, kernel_size, n_layers=3, p_dropout=p_dropout)
|
| 132 |
+
if gin_channels != 0:
|
| 133 |
+
self.cond = nn.Conv1d(gin_channels, filter_channels, 1)
|
| 134 |
+
|
| 135 |
+
def forward(self, x, x_mask, w=None, g=None, reverse=False, noise_scale=1.0):
|
| 136 |
+
x = torch.detach(x)
|
| 137 |
+
x = self.pre(x)
|
| 138 |
+
if g is not None:
|
| 139 |
+
g = torch.detach(g)
|
| 140 |
+
x = x + self.cond(g)
|
| 141 |
+
x = self.convs(x, x_mask)
|
| 142 |
+
x = self.proj(x) * x_mask
|
| 143 |
+
|
| 144 |
+
if not reverse:
|
| 145 |
+
flows = self.flows
|
| 146 |
+
assert w is not None
|
| 147 |
+
|
| 148 |
+
logdet_tot_q = 0
|
| 149 |
+
h_w = self.post_pre(w)
|
| 150 |
+
h_w = self.post_convs(h_w, x_mask)
|
| 151 |
+
h_w = self.post_proj(h_w) * x_mask
|
| 152 |
+
e_q = torch.randn(w.size(0), 2, w.size(2)).to(device=x.device, dtype=x.dtype) * x_mask
|
| 153 |
+
z_q = e_q
|
| 154 |
+
for flow in self.post_flows:
|
| 155 |
+
z_q, logdet_q = flow(z_q, x_mask, g=(x + h_w))
|
| 156 |
+
logdet_tot_q += logdet_q
|
| 157 |
+
z_u, z1 = torch.split(z_q, [1, 1], 1)
|
| 158 |
+
u = torch.sigmoid(z_u) * x_mask
|
| 159 |
+
z0 = (w - u) * x_mask
|
| 160 |
+
logdet_tot_q += torch.sum((F.logsigmoid(z_u) + F.logsigmoid(-z_u)) * x_mask, [1,2])
|
| 161 |
+
logq = torch.sum(-0.5 * (math.log(2*math.pi) + (e_q**2)) * x_mask, [1,2]) - logdet_tot_q
|
| 162 |
+
|
| 163 |
+
logdet_tot = 0
|
| 164 |
+
z0, logdet = self.log_flow(z0, x_mask)
|
| 165 |
+
logdet_tot += logdet
|
| 166 |
+
z = torch.cat([z0, z1], 1)
|
| 167 |
+
for flow in flows:
|
| 168 |
+
z, logdet = flow(z, x_mask, g=x, reverse=reverse)
|
| 169 |
+
logdet_tot = logdet_tot + logdet
|
| 170 |
+
nll = torch.sum(0.5 * (math.log(2*math.pi) + (z**2)) * x_mask, [1,2]) - logdet_tot
|
| 171 |
+
return nll + logq # [b]
|
| 172 |
+
else:
|
| 173 |
+
flows = list(reversed(self.flows))
|
| 174 |
+
flows = flows[:-2] + [flows[-1]] # remove a useless vflow
|
| 175 |
+
z = torch.randn(x.size(0), 2, x.size(2)).to(device=x.device, dtype=x.dtype) * noise_scale
|
| 176 |
+
for flow in flows:
|
| 177 |
+
z = flow(z, x_mask, g=x, reverse=reverse)
|
| 178 |
+
z0, z1 = torch.split(z, [1, 1], 1)
|
| 179 |
+
logw = z0
|
| 180 |
+
return logw
|
| 181 |
+
|
| 182 |
+
class PosteriorEncoder(nn.Module):
|
| 183 |
+
def __init__(
|
| 184 |
+
self,
|
| 185 |
+
in_channels,
|
| 186 |
+
out_channels,
|
| 187 |
+
hidden_channels,
|
| 188 |
+
kernel_size,
|
| 189 |
+
dilation_rate,
|
| 190 |
+
n_layers,
|
| 191 |
+
gin_channels=0,
|
| 192 |
+
):
|
| 193 |
+
super().__init__()
|
| 194 |
+
self.in_channels = in_channels
|
| 195 |
+
self.out_channels = out_channels
|
| 196 |
+
self.hidden_channels = hidden_channels
|
| 197 |
+
self.kernel_size = kernel_size
|
| 198 |
+
self.dilation_rate = dilation_rate
|
| 199 |
+
self.n_layers = n_layers
|
| 200 |
+
self.gin_channels = gin_channels
|
| 201 |
+
|
| 202 |
+
self.pre = nn.Conv1d(in_channels, hidden_channels, 1)
|
| 203 |
+
self.enc = modules.WN(
|
| 204 |
+
hidden_channels,
|
| 205 |
+
kernel_size,
|
| 206 |
+
dilation_rate,
|
| 207 |
+
n_layers,
|
| 208 |
+
gin_channels=gin_channels,
|
| 209 |
+
)
|
| 210 |
+
self.proj = nn.Conv1d(hidden_channels, out_channels * 2, 1)
|
| 211 |
+
|
| 212 |
+
def forward(self, x, x_lengths, g=None, tau=1.0):
|
| 213 |
+
x_mask = torch.unsqueeze(commons.sequence_mask(x_lengths, x.size(2)), 1).to(
|
| 214 |
+
x.dtype
|
| 215 |
+
)
|
| 216 |
+
x = self.pre(x) * x_mask
|
| 217 |
+
x = self.enc(x, x_mask, g=g)
|
| 218 |
+
stats = self.proj(x) * x_mask
|
| 219 |
+
m, logs = torch.split(stats, self.out_channels, dim=1)
|
| 220 |
+
z = (m + torch.randn_like(m) * tau * torch.exp(logs)) * x_mask
|
| 221 |
+
return z, m, logs, x_mask
|
| 222 |
+
|
| 223 |
+
|
| 224 |
+
class Generator(torch.nn.Module):
|
| 225 |
+
def __init__(
|
| 226 |
+
self,
|
| 227 |
+
initial_channel,
|
| 228 |
+
resblock,
|
| 229 |
+
resblock_kernel_sizes,
|
| 230 |
+
resblock_dilation_sizes,
|
| 231 |
+
upsample_rates,
|
| 232 |
+
upsample_initial_channel,
|
| 233 |
+
upsample_kernel_sizes,
|
| 234 |
+
gin_channels=0,
|
| 235 |
+
):
|
| 236 |
+
super(Generator, self).__init__()
|
| 237 |
+
self.num_kernels = len(resblock_kernel_sizes)
|
| 238 |
+
self.num_upsamples = len(upsample_rates)
|
| 239 |
+
self.conv_pre = Conv1d(
|
| 240 |
+
initial_channel, upsample_initial_channel, 7, 1, padding=3
|
| 241 |
+
)
|
| 242 |
+
resblock = modules.ResBlock1 if resblock == "1" else modules.ResBlock2
|
| 243 |
+
|
| 244 |
+
self.ups = nn.ModuleList()
|
| 245 |
+
for i, (u, k) in enumerate(zip(upsample_rates, upsample_kernel_sizes)):
|
| 246 |
+
self.ups.append(
|
| 247 |
+
weight_norm(
|
| 248 |
+
ConvTranspose1d(
|
| 249 |
+
upsample_initial_channel // (2**i),
|
| 250 |
+
upsample_initial_channel // (2 ** (i + 1)),
|
| 251 |
+
k,
|
| 252 |
+
u,
|
| 253 |
+
padding=(k - u) // 2,
|
| 254 |
+
)
|
| 255 |
+
)
|
| 256 |
+
)
|
| 257 |
+
|
| 258 |
+
self.resblocks = nn.ModuleList()
|
| 259 |
+
for i in range(len(self.ups)):
|
| 260 |
+
ch = upsample_initial_channel // (2 ** (i + 1))
|
| 261 |
+
for j, (k, d) in enumerate(
|
| 262 |
+
zip(resblock_kernel_sizes, resblock_dilation_sizes)
|
| 263 |
+
):
|
| 264 |
+
self.resblocks.append(resblock(ch, k, d))
|
| 265 |
+
|
| 266 |
+
self.conv_post = Conv1d(ch, 1, 7, 1, padding=3, bias=False)
|
| 267 |
+
self.ups.apply(init_weights)
|
| 268 |
+
|
| 269 |
+
if gin_channels != 0:
|
| 270 |
+
self.cond = nn.Conv1d(gin_channels, upsample_initial_channel, 1)
|
| 271 |
+
|
| 272 |
+
def forward(self, x, g=None):
|
| 273 |
+
x = self.conv_pre(x)
|
| 274 |
+
if g is not None:
|
| 275 |
+
x = x + self.cond(g)
|
| 276 |
+
|
| 277 |
+
for i in range(self.num_upsamples):
|
| 278 |
+
x = F.leaky_relu(x, modules.LRELU_SLOPE)
|
| 279 |
+
x = self.ups[i](x)
|
| 280 |
+
xs = None
|
| 281 |
+
for j in range(self.num_kernels):
|
| 282 |
+
if xs is None:
|
| 283 |
+
xs = self.resblocks[i * self.num_kernels + j](x)
|
| 284 |
+
else:
|
| 285 |
+
xs += self.resblocks[i * self.num_kernels + j](x)
|
| 286 |
+
x = xs / self.num_kernels
|
| 287 |
+
x = F.leaky_relu(x)
|
| 288 |
+
x = self.conv_post(x)
|
| 289 |
+
x = torch.tanh(x)
|
| 290 |
+
|
| 291 |
+
return x
|
| 292 |
+
|
| 293 |
+
def remove_weight_norm(self):
|
| 294 |
+
print("Removing weight norm...")
|
| 295 |
+
for layer in self.ups:
|
| 296 |
+
remove_weight_norm(layer)
|
| 297 |
+
for layer in self.resblocks:
|
| 298 |
+
layer.remove_weight_norm()
|
| 299 |
+
|
| 300 |
+
|
| 301 |
+
class ReferenceEncoder(nn.Module):
|
| 302 |
+
"""
|
| 303 |
+
inputs --- [N, Ty/r, n_mels*r] mels
|
| 304 |
+
outputs --- [N, ref_enc_gru_size]
|
| 305 |
+
"""
|
| 306 |
+
|
| 307 |
+
def __init__(self, spec_channels, gin_channels=0, layernorm=True):
|
| 308 |
+
super().__init__()
|
| 309 |
+
self.spec_channels = spec_channels
|
| 310 |
+
ref_enc_filters = [32, 32, 64, 64, 128, 128]
|
| 311 |
+
K = len(ref_enc_filters)
|
| 312 |
+
filters = [1] + ref_enc_filters
|
| 313 |
+
convs = [
|
| 314 |
+
weight_norm(
|
| 315 |
+
nn.Conv2d(
|
| 316 |
+
in_channels=filters[i],
|
| 317 |
+
out_channels=filters[i + 1],
|
| 318 |
+
kernel_size=(3, 3),
|
| 319 |
+
stride=(2, 2),
|
| 320 |
+
padding=(1, 1),
|
| 321 |
+
)
|
| 322 |
+
)
|
| 323 |
+
for i in range(K)
|
| 324 |
+
]
|
| 325 |
+
self.convs = nn.ModuleList(convs)
|
| 326 |
+
|
| 327 |
+
out_channels = self.calculate_channels(spec_channels, 3, 2, 1, K)
|
| 328 |
+
self.gru = nn.GRU(
|
| 329 |
+
input_size=ref_enc_filters[-1] * out_channels,
|
| 330 |
+
hidden_size=256 // 2,
|
| 331 |
+
batch_first=True,
|
| 332 |
+
)
|
| 333 |
+
self.proj = nn.Linear(128, gin_channels)
|
| 334 |
+
if layernorm:
|
| 335 |
+
self.layernorm = nn.LayerNorm(self.spec_channels)
|
| 336 |
+
else:
|
| 337 |
+
self.layernorm = None
|
| 338 |
+
|
| 339 |
+
def forward(self, inputs, mask=None):
|
| 340 |
+
N = inputs.size(0)
|
| 341 |
+
|
| 342 |
+
out = inputs.view(N, 1, -1, self.spec_channels) # [N, 1, Ty, n_freqs]
|
| 343 |
+
if self.layernorm is not None:
|
| 344 |
+
out = self.layernorm(out)
|
| 345 |
+
|
| 346 |
+
for conv in self.convs:
|
| 347 |
+
out = conv(out)
|
| 348 |
+
# out = wn(out)
|
| 349 |
+
out = F.relu(out) # [N, 128, Ty//2^K, n_mels//2^K]
|
| 350 |
+
|
| 351 |
+
out = out.transpose(1, 2) # [N, Ty//2^K, 128, n_mels//2^K]
|
| 352 |
+
T = out.size(1)
|
| 353 |
+
N = out.size(0)
|
| 354 |
+
out = out.contiguous().view(N, T, -1) # [N, Ty//2^K, 128*n_mels//2^K]
|
| 355 |
+
|
| 356 |
+
self.gru.flatten_parameters()
|
| 357 |
+
memory, out = self.gru(out) # out --- [1, N, 128]
|
| 358 |
+
|
| 359 |
+
return self.proj(out.squeeze(0))
|
| 360 |
+
|
| 361 |
+
def calculate_channels(self, L, kernel_size, stride, pad, n_convs):
|
| 362 |
+
for i in range(n_convs):
|
| 363 |
+
L = (L - kernel_size + 2 * pad) // stride + 1
|
| 364 |
+
return L
|
| 365 |
+
|
| 366 |
+
|
| 367 |
+
class ResidualCouplingBlock(nn.Module):
|
| 368 |
+
def __init__(self,
|
| 369 |
+
channels,
|
| 370 |
+
hidden_channels,
|
| 371 |
+
kernel_size,
|
| 372 |
+
dilation_rate,
|
| 373 |
+
n_layers,
|
| 374 |
+
n_flows=4,
|
| 375 |
+
gin_channels=0):
|
| 376 |
+
super().__init__()
|
| 377 |
+
self.channels = channels
|
| 378 |
+
self.hidden_channels = hidden_channels
|
| 379 |
+
self.kernel_size = kernel_size
|
| 380 |
+
self.dilation_rate = dilation_rate
|
| 381 |
+
self.n_layers = n_layers
|
| 382 |
+
self.n_flows = n_flows
|
| 383 |
+
self.gin_channels = gin_channels
|
| 384 |
+
|
| 385 |
+
self.flows = nn.ModuleList()
|
| 386 |
+
for i in range(n_flows):
|
| 387 |
+
self.flows.append(modules.ResidualCouplingLayer(channels, hidden_channels, kernel_size, dilation_rate, n_layers, gin_channels=gin_channels, mean_only=True))
|
| 388 |
+
self.flows.append(modules.Flip())
|
| 389 |
+
|
| 390 |
+
def forward(self, x, x_mask, g=None, reverse=False):
|
| 391 |
+
if not reverse:
|
| 392 |
+
for flow in self.flows:
|
| 393 |
+
x, _ = flow(x, x_mask, g=g, reverse=reverse)
|
| 394 |
+
else:
|
| 395 |
+
for flow in reversed(self.flows):
|
| 396 |
+
x = flow(x, x_mask, g=g, reverse=reverse)
|
| 397 |
+
return x
|
| 398 |
+
|
| 399 |
+
class SynthesizerTrn(nn.Module):
|
| 400 |
+
"""
|
| 401 |
+
Synthesizer for Training
|
| 402 |
+
"""
|
| 403 |
+
|
| 404 |
+
def __init__(
|
| 405 |
+
self,
|
| 406 |
+
n_vocab,
|
| 407 |
+
spec_channels,
|
| 408 |
+
inter_channels,
|
| 409 |
+
hidden_channels,
|
| 410 |
+
filter_channels,
|
| 411 |
+
n_heads,
|
| 412 |
+
n_layers,
|
| 413 |
+
kernel_size,
|
| 414 |
+
p_dropout,
|
| 415 |
+
resblock,
|
| 416 |
+
resblock_kernel_sizes,
|
| 417 |
+
resblock_dilation_sizes,
|
| 418 |
+
upsample_rates,
|
| 419 |
+
upsample_initial_channel,
|
| 420 |
+
upsample_kernel_sizes,
|
| 421 |
+
n_speakers=256,
|
| 422 |
+
gin_channels=256,
|
| 423 |
+
**kwargs
|
| 424 |
+
):
|
| 425 |
+
super().__init__()
|
| 426 |
+
|
| 427 |
+
self.dec = Generator(
|
| 428 |
+
inter_channels,
|
| 429 |
+
resblock,
|
| 430 |
+
resblock_kernel_sizes,
|
| 431 |
+
resblock_dilation_sizes,
|
| 432 |
+
upsample_rates,
|
| 433 |
+
upsample_initial_channel,
|
| 434 |
+
upsample_kernel_sizes,
|
| 435 |
+
gin_channels=gin_channels,
|
| 436 |
+
)
|
| 437 |
+
self.enc_q = PosteriorEncoder(
|
| 438 |
+
spec_channels,
|
| 439 |
+
inter_channels,
|
| 440 |
+
hidden_channels,
|
| 441 |
+
5,
|
| 442 |
+
1,
|
| 443 |
+
16,
|
| 444 |
+
gin_channels=gin_channels,
|
| 445 |
+
)
|
| 446 |
+
|
| 447 |
+
self.flow = ResidualCouplingBlock(inter_channels, hidden_channels, 5, 1, 4, gin_channels=gin_channels)
|
| 448 |
+
|
| 449 |
+
self.n_speakers = n_speakers
|
| 450 |
+
if n_speakers == 0:
|
| 451 |
+
self.ref_enc = ReferenceEncoder(spec_channels, gin_channels)
|
| 452 |
+
else:
|
| 453 |
+
self.enc_p = TextEncoder(n_vocab,
|
| 454 |
+
inter_channels,
|
| 455 |
+
hidden_channels,
|
| 456 |
+
filter_channels,
|
| 457 |
+
n_heads,
|
| 458 |
+
n_layers,
|
| 459 |
+
kernel_size,
|
| 460 |
+
p_dropout)
|
| 461 |
+
self.sdp = StochasticDurationPredictor(hidden_channels, 192, 3, 0.5, 4, gin_channels=gin_channels)
|
| 462 |
+
self.dp = DurationPredictor(hidden_channels, 256, 3, 0.5, gin_channels=gin_channels)
|
| 463 |
+
self.emb_g = nn.Embedding(n_speakers, gin_channels)
|
| 464 |
+
|
| 465 |
+
def infer(self, x, x_lengths, sid=None, noise_scale=1, length_scale=1, noise_scale_w=1., sdp_ratio=0.2, max_len=None):
|
| 466 |
+
x, m_p, logs_p, x_mask = self.enc_p(x, x_lengths)
|
| 467 |
+
if self.n_speakers > 0:
|
| 468 |
+
g = self.emb_g(sid).unsqueeze(-1) # [b, h, 1]
|
| 469 |
+
else:
|
| 470 |
+
g = None
|
| 471 |
+
|
| 472 |
+
logw = self.sdp(x, x_mask, g=g, reverse=True, noise_scale=noise_scale_w) * sdp_ratio \
|
| 473 |
+
+ self.dp(x, x_mask, g=g) * (1 - sdp_ratio)
|
| 474 |
+
|
| 475 |
+
w = torch.exp(logw) * x_mask * length_scale
|
| 476 |
+
w_ceil = torch.ceil(w)
|
| 477 |
+
y_lengths = torch.clamp_min(torch.sum(w_ceil, [1, 2]), 1).long()
|
| 478 |
+
y_mask = torch.unsqueeze(commons.sequence_mask(y_lengths, None), 1).to(x_mask.dtype)
|
| 479 |
+
attn_mask = torch.unsqueeze(x_mask, 2) * torch.unsqueeze(y_mask, -1)
|
| 480 |
+
attn = commons.generate_path(w_ceil, attn_mask)
|
| 481 |
+
|
| 482 |
+
m_p = torch.matmul(attn.squeeze(1), m_p.transpose(1, 2)).transpose(1, 2) # [b, t', t], [b, t, d] -> [b, d, t']
|
| 483 |
+
logs_p = torch.matmul(attn.squeeze(1), logs_p.transpose(1, 2)).transpose(1, 2) # [b, t', t], [b, t, d] -> [b, d, t']
|
| 484 |
+
|
| 485 |
+
z_p = m_p + torch.randn_like(m_p) * torch.exp(logs_p) * noise_scale
|
| 486 |
+
z = self.flow(z_p, y_mask, g=g, reverse=True)
|
| 487 |
+
o = self.dec((z * y_mask)[:,:,:max_len], g=g)
|
| 488 |
+
return o, attn, y_mask, (z, z_p, m_p, logs_p)
|
| 489 |
+
|
| 490 |
+
def voice_conversion(self, y, y_lengths, sid_src, sid_tgt, tau=1.0):
|
| 491 |
+
g_src = sid_src
|
| 492 |
+
g_tgt = sid_tgt
|
| 493 |
+
z, m_q, logs_q, y_mask = self.enc_q(y, y_lengths, g=g_src, tau=tau)
|
| 494 |
+
z_p = self.flow(z, y_mask, g=g_src)
|
| 495 |
+
z_hat = self.flow(z_p, y_mask, g=g_tgt, reverse=True)
|
| 496 |
+
o_hat = self.dec(z_hat * y_mask, g=g_tgt)
|
| 497 |
+
return o_hat, y_mask, (z, z_p, z_hat)
|
modules.py
ADDED
|
@@ -0,0 +1,598 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import math
|
| 2 |
+
import torch
|
| 3 |
+
from torch import nn
|
| 4 |
+
from torch.nn import functional as F
|
| 5 |
+
|
| 6 |
+
from torch.nn import Conv1d
|
| 7 |
+
from torch.nn.utils import weight_norm, remove_weight_norm
|
| 8 |
+
|
| 9 |
+
import commons
|
| 10 |
+
from commons import init_weights, get_padding
|
| 11 |
+
from transforms import piecewise_rational_quadratic_transform
|
| 12 |
+
from attentions import Encoder
|
| 13 |
+
|
| 14 |
+
LRELU_SLOPE = 0.1
|
| 15 |
+
|
| 16 |
+
|
| 17 |
+
class LayerNorm(nn.Module):
|
| 18 |
+
def __init__(self, channels, eps=1e-5):
|
| 19 |
+
super().__init__()
|
| 20 |
+
self.channels = channels
|
| 21 |
+
self.eps = eps
|
| 22 |
+
|
| 23 |
+
self.gamma = nn.Parameter(torch.ones(channels))
|
| 24 |
+
self.beta = nn.Parameter(torch.zeros(channels))
|
| 25 |
+
|
| 26 |
+
def forward(self, x):
|
| 27 |
+
x = x.transpose(1, -1)
|
| 28 |
+
x = F.layer_norm(x, (self.channels,), self.gamma, self.beta, self.eps)
|
| 29 |
+
return x.transpose(1, -1)
|
| 30 |
+
|
| 31 |
+
|
| 32 |
+
class ConvReluNorm(nn.Module):
|
| 33 |
+
def __init__(
|
| 34 |
+
self,
|
| 35 |
+
in_channels,
|
| 36 |
+
hidden_channels,
|
| 37 |
+
out_channels,
|
| 38 |
+
kernel_size,
|
| 39 |
+
n_layers,
|
| 40 |
+
p_dropout,
|
| 41 |
+
):
|
| 42 |
+
super().__init__()
|
| 43 |
+
self.in_channels = in_channels
|
| 44 |
+
self.hidden_channels = hidden_channels
|
| 45 |
+
self.out_channels = out_channels
|
| 46 |
+
self.kernel_size = kernel_size
|
| 47 |
+
self.n_layers = n_layers
|
| 48 |
+
self.p_dropout = p_dropout
|
| 49 |
+
assert n_layers > 1, "Number of layers should be larger than 0."
|
| 50 |
+
|
| 51 |
+
self.conv_layers = nn.ModuleList()
|
| 52 |
+
self.norm_layers = nn.ModuleList()
|
| 53 |
+
self.conv_layers.append(
|
| 54 |
+
nn.Conv1d(
|
| 55 |
+
in_channels, hidden_channels, kernel_size, padding=kernel_size // 2
|
| 56 |
+
)
|
| 57 |
+
)
|
| 58 |
+
self.norm_layers.append(LayerNorm(hidden_channels))
|
| 59 |
+
self.relu_drop = nn.Sequential(nn.ReLU(), nn.Dropout(p_dropout))
|
| 60 |
+
for _ in range(n_layers - 1):
|
| 61 |
+
self.conv_layers.append(
|
| 62 |
+
nn.Conv1d(
|
| 63 |
+
hidden_channels,
|
| 64 |
+
hidden_channels,
|
| 65 |
+
kernel_size,
|
| 66 |
+
padding=kernel_size // 2,
|
| 67 |
+
)
|
| 68 |
+
)
|
| 69 |
+
self.norm_layers.append(LayerNorm(hidden_channels))
|
| 70 |
+
self.proj = nn.Conv1d(hidden_channels, out_channels, 1)
|
| 71 |
+
self.proj.weight.data.zero_()
|
| 72 |
+
self.proj.bias.data.zero_()
|
| 73 |
+
|
| 74 |
+
def forward(self, x, x_mask):
|
| 75 |
+
x_org = x
|
| 76 |
+
for i in range(self.n_layers):
|
| 77 |
+
x = self.conv_layers[i](x * x_mask)
|
| 78 |
+
x = self.norm_layers[i](x)
|
| 79 |
+
x = self.relu_drop(x)
|
| 80 |
+
x = x_org + self.proj(x)
|
| 81 |
+
return x * x_mask
|
| 82 |
+
|
| 83 |
+
|
| 84 |
+
class DDSConv(nn.Module):
|
| 85 |
+
"""
|
| 86 |
+
Dilated and Depth-Separable Convolution
|
| 87 |
+
"""
|
| 88 |
+
|
| 89 |
+
def __init__(self, channels, kernel_size, n_layers, p_dropout=0.0):
|
| 90 |
+
super().__init__()
|
| 91 |
+
self.channels = channels
|
| 92 |
+
self.kernel_size = kernel_size
|
| 93 |
+
self.n_layers = n_layers
|
| 94 |
+
self.p_dropout = p_dropout
|
| 95 |
+
|
| 96 |
+
self.drop = nn.Dropout(p_dropout)
|
| 97 |
+
self.convs_sep = nn.ModuleList()
|
| 98 |
+
self.convs_1x1 = nn.ModuleList()
|
| 99 |
+
self.norms_1 = nn.ModuleList()
|
| 100 |
+
self.norms_2 = nn.ModuleList()
|
| 101 |
+
for i in range(n_layers):
|
| 102 |
+
dilation = kernel_size**i
|
| 103 |
+
padding = (kernel_size * dilation - dilation) // 2
|
| 104 |
+
self.convs_sep.append(
|
| 105 |
+
nn.Conv1d(
|
| 106 |
+
channels,
|
| 107 |
+
channels,
|
| 108 |
+
kernel_size,
|
| 109 |
+
groups=channels,
|
| 110 |
+
dilation=dilation,
|
| 111 |
+
padding=padding,
|
| 112 |
+
)
|
| 113 |
+
)
|
| 114 |
+
self.convs_1x1.append(nn.Conv1d(channels, channels, 1))
|
| 115 |
+
self.norms_1.append(LayerNorm(channels))
|
| 116 |
+
self.norms_2.append(LayerNorm(channels))
|
| 117 |
+
|
| 118 |
+
def forward(self, x, x_mask, g=None):
|
| 119 |
+
if g is not None:
|
| 120 |
+
x = x + g
|
| 121 |
+
for i in range(self.n_layers):
|
| 122 |
+
y = self.convs_sep[i](x * x_mask)
|
| 123 |
+
y = self.norms_1[i](y)
|
| 124 |
+
y = F.gelu(y)
|
| 125 |
+
y = self.convs_1x1[i](y)
|
| 126 |
+
y = self.norms_2[i](y)
|
| 127 |
+
y = F.gelu(y)
|
| 128 |
+
y = self.drop(y)
|
| 129 |
+
x = x + y
|
| 130 |
+
return x * x_mask
|
| 131 |
+
|
| 132 |
+
|
| 133 |
+
class WN(torch.nn.Module):
|
| 134 |
+
def __init__(
|
| 135 |
+
self,
|
| 136 |
+
hidden_channels,
|
| 137 |
+
kernel_size,
|
| 138 |
+
dilation_rate,
|
| 139 |
+
n_layers,
|
| 140 |
+
gin_channels=0,
|
| 141 |
+
p_dropout=0,
|
| 142 |
+
):
|
| 143 |
+
super(WN, self).__init__()
|
| 144 |
+
assert kernel_size % 2 == 1
|
| 145 |
+
self.hidden_channels = hidden_channels
|
| 146 |
+
self.kernel_size = (kernel_size,)
|
| 147 |
+
self.dilation_rate = dilation_rate
|
| 148 |
+
self.n_layers = n_layers
|
| 149 |
+
self.gin_channels = gin_channels
|
| 150 |
+
self.p_dropout = p_dropout
|
| 151 |
+
|
| 152 |
+
self.in_layers = torch.nn.ModuleList()
|
| 153 |
+
self.res_skip_layers = torch.nn.ModuleList()
|
| 154 |
+
self.drop = nn.Dropout(p_dropout)
|
| 155 |
+
|
| 156 |
+
if gin_channels != 0:
|
| 157 |
+
cond_layer = torch.nn.Conv1d(
|
| 158 |
+
gin_channels, 2 * hidden_channels * n_layers, 1
|
| 159 |
+
)
|
| 160 |
+
self.cond_layer = torch.nn.utils.weight_norm(cond_layer, name="weight")
|
| 161 |
+
|
| 162 |
+
for i in range(n_layers):
|
| 163 |
+
dilation = dilation_rate**i
|
| 164 |
+
padding = int((kernel_size * dilation - dilation) / 2)
|
| 165 |
+
in_layer = torch.nn.Conv1d(
|
| 166 |
+
hidden_channels,
|
| 167 |
+
2 * hidden_channels,
|
| 168 |
+
kernel_size,
|
| 169 |
+
dilation=dilation,
|
| 170 |
+
padding=padding,
|
| 171 |
+
)
|
| 172 |
+
in_layer = torch.nn.utils.weight_norm(in_layer, name="weight")
|
| 173 |
+
self.in_layers.append(in_layer)
|
| 174 |
+
|
| 175 |
+
# last one is not necessary
|
| 176 |
+
if i < n_layers - 1:
|
| 177 |
+
res_skip_channels = 2 * hidden_channels
|
| 178 |
+
else:
|
| 179 |
+
res_skip_channels = hidden_channels
|
| 180 |
+
|
| 181 |
+
res_skip_layer = torch.nn.Conv1d(hidden_channels, res_skip_channels, 1)
|
| 182 |
+
res_skip_layer = torch.nn.utils.weight_norm(res_skip_layer, name="weight")
|
| 183 |
+
self.res_skip_layers.append(res_skip_layer)
|
| 184 |
+
|
| 185 |
+
def forward(self, x, x_mask, g=None, **kwargs):
|
| 186 |
+
output = torch.zeros_like(x)
|
| 187 |
+
n_channels_tensor = torch.IntTensor([self.hidden_channels])
|
| 188 |
+
|
| 189 |
+
if g is not None:
|
| 190 |
+
g = self.cond_layer(g)
|
| 191 |
+
|
| 192 |
+
for i in range(self.n_layers):
|
| 193 |
+
x_in = self.in_layers[i](x)
|
| 194 |
+
if g is not None:
|
| 195 |
+
cond_offset = i * 2 * self.hidden_channels
|
| 196 |
+
g_l = g[:, cond_offset : cond_offset + 2 * self.hidden_channels, :]
|
| 197 |
+
else:
|
| 198 |
+
g_l = torch.zeros_like(x_in)
|
| 199 |
+
|
| 200 |
+
acts = commons.fused_add_tanh_sigmoid_multiply(x_in, g_l, n_channels_tensor)
|
| 201 |
+
acts = self.drop(acts)
|
| 202 |
+
|
| 203 |
+
res_skip_acts = self.res_skip_layers[i](acts)
|
| 204 |
+
if i < self.n_layers - 1:
|
| 205 |
+
res_acts = res_skip_acts[:, : self.hidden_channels, :]
|
| 206 |
+
x = (x + res_acts) * x_mask
|
| 207 |
+
output = output + res_skip_acts[:, self.hidden_channels :, :]
|
| 208 |
+
else:
|
| 209 |
+
output = output + res_skip_acts
|
| 210 |
+
return output * x_mask
|
| 211 |
+
|
| 212 |
+
def remove_weight_norm(self):
|
| 213 |
+
if self.gin_channels != 0:
|
| 214 |
+
torch.nn.utils.remove_weight_norm(self.cond_layer)
|
| 215 |
+
for l in self.in_layers:
|
| 216 |
+
torch.nn.utils.remove_weight_norm(l)
|
| 217 |
+
for l in self.res_skip_layers:
|
| 218 |
+
torch.nn.utils.remove_weight_norm(l)
|
| 219 |
+
|
| 220 |
+
|
| 221 |
+
class ResBlock1(torch.nn.Module):
|
| 222 |
+
def __init__(self, channels, kernel_size=3, dilation=(1, 3, 5)):
|
| 223 |
+
super(ResBlock1, self).__init__()
|
| 224 |
+
self.convs1 = nn.ModuleList(
|
| 225 |
+
[
|
| 226 |
+
weight_norm(
|
| 227 |
+
Conv1d(
|
| 228 |
+
channels,
|
| 229 |
+
channels,
|
| 230 |
+
kernel_size,
|
| 231 |
+
1,
|
| 232 |
+
dilation=dilation[0],
|
| 233 |
+
padding=get_padding(kernel_size, dilation[0]),
|
| 234 |
+
)
|
| 235 |
+
),
|
| 236 |
+
weight_norm(
|
| 237 |
+
Conv1d(
|
| 238 |
+
channels,
|
| 239 |
+
channels,
|
| 240 |
+
kernel_size,
|
| 241 |
+
1,
|
| 242 |
+
dilation=dilation[1],
|
| 243 |
+
padding=get_padding(kernel_size, dilation[1]),
|
| 244 |
+
)
|
| 245 |
+
),
|
| 246 |
+
weight_norm(
|
| 247 |
+
Conv1d(
|
| 248 |
+
channels,
|
| 249 |
+
channels,
|
| 250 |
+
kernel_size,
|
| 251 |
+
1,
|
| 252 |
+
dilation=dilation[2],
|
| 253 |
+
padding=get_padding(kernel_size, dilation[2]),
|
| 254 |
+
)
|
| 255 |
+
),
|
| 256 |
+
]
|
| 257 |
+
)
|
| 258 |
+
self.convs1.apply(init_weights)
|
| 259 |
+
|
| 260 |
+
self.convs2 = nn.ModuleList(
|
| 261 |
+
[
|
| 262 |
+
weight_norm(
|
| 263 |
+
Conv1d(
|
| 264 |
+
channels,
|
| 265 |
+
channels,
|
| 266 |
+
kernel_size,
|
| 267 |
+
1,
|
| 268 |
+
dilation=1,
|
| 269 |
+
padding=get_padding(kernel_size, 1),
|
| 270 |
+
)
|
| 271 |
+
),
|
| 272 |
+
weight_norm(
|
| 273 |
+
Conv1d(
|
| 274 |
+
channels,
|
| 275 |
+
channels,
|
| 276 |
+
kernel_size,
|
| 277 |
+
1,
|
| 278 |
+
dilation=1,
|
| 279 |
+
padding=get_padding(kernel_size, 1),
|
| 280 |
+
)
|
| 281 |
+
),
|
| 282 |
+
weight_norm(
|
| 283 |
+
Conv1d(
|
| 284 |
+
channels,
|
| 285 |
+
channels,
|
| 286 |
+
kernel_size,
|
| 287 |
+
1,
|
| 288 |
+
dilation=1,
|
| 289 |
+
padding=get_padding(kernel_size, 1),
|
| 290 |
+
)
|
| 291 |
+
),
|
| 292 |
+
]
|
| 293 |
+
)
|
| 294 |
+
self.convs2.apply(init_weights)
|
| 295 |
+
|
| 296 |
+
def forward(self, x, x_mask=None):
|
| 297 |
+
for c1, c2 in zip(self.convs1, self.convs2):
|
| 298 |
+
xt = F.leaky_relu(x, LRELU_SLOPE)
|
| 299 |
+
if x_mask is not None:
|
| 300 |
+
xt = xt * x_mask
|
| 301 |
+
xt = c1(xt)
|
| 302 |
+
xt = F.leaky_relu(xt, LRELU_SLOPE)
|
| 303 |
+
if x_mask is not None:
|
| 304 |
+
xt = xt * x_mask
|
| 305 |
+
xt = c2(xt)
|
| 306 |
+
x = xt + x
|
| 307 |
+
if x_mask is not None:
|
| 308 |
+
x = x * x_mask
|
| 309 |
+
return x
|
| 310 |
+
|
| 311 |
+
def remove_weight_norm(self):
|
| 312 |
+
for l in self.convs1:
|
| 313 |
+
remove_weight_norm(l)
|
| 314 |
+
for l in self.convs2:
|
| 315 |
+
remove_weight_norm(l)
|
| 316 |
+
|
| 317 |
+
|
| 318 |
+
class ResBlock2(torch.nn.Module):
|
| 319 |
+
def __init__(self, channels, kernel_size=3, dilation=(1, 3)):
|
| 320 |
+
super(ResBlock2, self).__init__()
|
| 321 |
+
self.convs = nn.ModuleList(
|
| 322 |
+
[
|
| 323 |
+
weight_norm(
|
| 324 |
+
Conv1d(
|
| 325 |
+
channels,
|
| 326 |
+
channels,
|
| 327 |
+
kernel_size,
|
| 328 |
+
1,
|
| 329 |
+
dilation=dilation[0],
|
| 330 |
+
padding=get_padding(kernel_size, dilation[0]),
|
| 331 |
+
)
|
| 332 |
+
),
|
| 333 |
+
weight_norm(
|
| 334 |
+
Conv1d(
|
| 335 |
+
channels,
|
| 336 |
+
channels,
|
| 337 |
+
kernel_size,
|
| 338 |
+
1,
|
| 339 |
+
dilation=dilation[1],
|
| 340 |
+
padding=get_padding(kernel_size, dilation[1]),
|
| 341 |
+
)
|
| 342 |
+
),
|
| 343 |
+
]
|
| 344 |
+
)
|
| 345 |
+
self.convs.apply(init_weights)
|
| 346 |
+
|
| 347 |
+
def forward(self, x, x_mask=None):
|
| 348 |
+
for c in self.convs:
|
| 349 |
+
xt = F.leaky_relu(x, LRELU_SLOPE)
|
| 350 |
+
if x_mask is not None:
|
| 351 |
+
xt = xt * x_mask
|
| 352 |
+
xt = c(xt)
|
| 353 |
+
x = xt + x
|
| 354 |
+
if x_mask is not None:
|
| 355 |
+
x = x * x_mask
|
| 356 |
+
return x
|
| 357 |
+
|
| 358 |
+
def remove_weight_norm(self):
|
| 359 |
+
for l in self.convs:
|
| 360 |
+
remove_weight_norm(l)
|
| 361 |
+
|
| 362 |
+
|
| 363 |
+
class Log(nn.Module):
|
| 364 |
+
def forward(self, x, x_mask, reverse=False, **kwargs):
|
| 365 |
+
if not reverse:
|
| 366 |
+
y = torch.log(torch.clamp_min(x, 1e-5)) * x_mask
|
| 367 |
+
logdet = torch.sum(-y, [1, 2])
|
| 368 |
+
return y, logdet
|
| 369 |
+
else:
|
| 370 |
+
x = torch.exp(x) * x_mask
|
| 371 |
+
return x
|
| 372 |
+
|
| 373 |
+
|
| 374 |
+
class Flip(nn.Module):
|
| 375 |
+
def forward(self, x, *args, reverse=False, **kwargs):
|
| 376 |
+
x = torch.flip(x, [1])
|
| 377 |
+
if not reverse:
|
| 378 |
+
logdet = torch.zeros(x.size(0)).to(dtype=x.dtype, device=x.device)
|
| 379 |
+
return x, logdet
|
| 380 |
+
else:
|
| 381 |
+
return x
|
| 382 |
+
|
| 383 |
+
|
| 384 |
+
class ElementwiseAffine(nn.Module):
|
| 385 |
+
def __init__(self, channels):
|
| 386 |
+
super().__init__()
|
| 387 |
+
self.channels = channels
|
| 388 |
+
self.m = nn.Parameter(torch.zeros(channels, 1))
|
| 389 |
+
self.logs = nn.Parameter(torch.zeros(channels, 1))
|
| 390 |
+
|
| 391 |
+
def forward(self, x, x_mask, reverse=False, **kwargs):
|
| 392 |
+
if not reverse:
|
| 393 |
+
y = self.m + torch.exp(self.logs) * x
|
| 394 |
+
y = y * x_mask
|
| 395 |
+
logdet = torch.sum(self.logs * x_mask, [1, 2])
|
| 396 |
+
return y, logdet
|
| 397 |
+
else:
|
| 398 |
+
x = (x - self.m) * torch.exp(-self.logs) * x_mask
|
| 399 |
+
return x
|
| 400 |
+
|
| 401 |
+
|
| 402 |
+
class ResidualCouplingLayer(nn.Module):
|
| 403 |
+
def __init__(
|
| 404 |
+
self,
|
| 405 |
+
channels,
|
| 406 |
+
hidden_channels,
|
| 407 |
+
kernel_size,
|
| 408 |
+
dilation_rate,
|
| 409 |
+
n_layers,
|
| 410 |
+
p_dropout=0,
|
| 411 |
+
gin_channels=0,
|
| 412 |
+
mean_only=False,
|
| 413 |
+
):
|
| 414 |
+
assert channels % 2 == 0, "channels should be divisible by 2"
|
| 415 |
+
super().__init__()
|
| 416 |
+
self.channels = channels
|
| 417 |
+
self.hidden_channels = hidden_channels
|
| 418 |
+
self.kernel_size = kernel_size
|
| 419 |
+
self.dilation_rate = dilation_rate
|
| 420 |
+
self.n_layers = n_layers
|
| 421 |
+
self.half_channels = channels // 2
|
| 422 |
+
self.mean_only = mean_only
|
| 423 |
+
|
| 424 |
+
self.pre = nn.Conv1d(self.half_channels, hidden_channels, 1)
|
| 425 |
+
self.enc = WN(
|
| 426 |
+
hidden_channels,
|
| 427 |
+
kernel_size,
|
| 428 |
+
dilation_rate,
|
| 429 |
+
n_layers,
|
| 430 |
+
p_dropout=p_dropout,
|
| 431 |
+
gin_channels=gin_channels,
|
| 432 |
+
)
|
| 433 |
+
self.post = nn.Conv1d(hidden_channels, self.half_channels * (2 - mean_only), 1)
|
| 434 |
+
self.post.weight.data.zero_()
|
| 435 |
+
self.post.bias.data.zero_()
|
| 436 |
+
|
| 437 |
+
def forward(self, x, x_mask, g=None, reverse=False):
|
| 438 |
+
x0, x1 = torch.split(x, [self.half_channels] * 2, 1)
|
| 439 |
+
h = self.pre(x0) * x_mask
|
| 440 |
+
h = self.enc(h, x_mask, g=g)
|
| 441 |
+
stats = self.post(h) * x_mask
|
| 442 |
+
if not self.mean_only:
|
| 443 |
+
m, logs = torch.split(stats, [self.half_channels] * 2, 1)
|
| 444 |
+
else:
|
| 445 |
+
m = stats
|
| 446 |
+
logs = torch.zeros_like(m)
|
| 447 |
+
|
| 448 |
+
if not reverse:
|
| 449 |
+
x1 = m + x1 * torch.exp(logs) * x_mask
|
| 450 |
+
x = torch.cat([x0, x1], 1)
|
| 451 |
+
logdet = torch.sum(logs, [1, 2])
|
| 452 |
+
return x, logdet
|
| 453 |
+
else:
|
| 454 |
+
x1 = (x1 - m) * torch.exp(-logs) * x_mask
|
| 455 |
+
x = torch.cat([x0, x1], 1)
|
| 456 |
+
return x
|
| 457 |
+
|
| 458 |
+
|
| 459 |
+
class ConvFlow(nn.Module):
|
| 460 |
+
def __init__(
|
| 461 |
+
self,
|
| 462 |
+
in_channels,
|
| 463 |
+
filter_channels,
|
| 464 |
+
kernel_size,
|
| 465 |
+
n_layers,
|
| 466 |
+
num_bins=10,
|
| 467 |
+
tail_bound=5.0,
|
| 468 |
+
):
|
| 469 |
+
super().__init__()
|
| 470 |
+
self.in_channels = in_channels
|
| 471 |
+
self.filter_channels = filter_channels
|
| 472 |
+
self.kernel_size = kernel_size
|
| 473 |
+
self.n_layers = n_layers
|
| 474 |
+
self.num_bins = num_bins
|
| 475 |
+
self.tail_bound = tail_bound
|
| 476 |
+
self.half_channels = in_channels // 2
|
| 477 |
+
|
| 478 |
+
self.pre = nn.Conv1d(self.half_channels, filter_channels, 1)
|
| 479 |
+
self.convs = DDSConv(filter_channels, kernel_size, n_layers, p_dropout=0.0)
|
| 480 |
+
self.proj = nn.Conv1d(
|
| 481 |
+
filter_channels, self.half_channels * (num_bins * 3 - 1), 1
|
| 482 |
+
)
|
| 483 |
+
self.proj.weight.data.zero_()
|
| 484 |
+
self.proj.bias.data.zero_()
|
| 485 |
+
|
| 486 |
+
def forward(self, x, x_mask, g=None, reverse=False):
|
| 487 |
+
x0, x1 = torch.split(x, [self.half_channels] * 2, 1)
|
| 488 |
+
h = self.pre(x0)
|
| 489 |
+
h = self.convs(h, x_mask, g=g)
|
| 490 |
+
h = self.proj(h) * x_mask
|
| 491 |
+
|
| 492 |
+
b, c, t = x0.shape
|
| 493 |
+
h = h.reshape(b, c, -1, t).permute(0, 1, 3, 2) # [b, cx?, t] -> [b, c, t, ?]
|
| 494 |
+
|
| 495 |
+
unnormalized_widths = h[..., : self.num_bins] / math.sqrt(self.filter_channels)
|
| 496 |
+
unnormalized_heights = h[..., self.num_bins : 2 * self.num_bins] / math.sqrt(
|
| 497 |
+
self.filter_channels
|
| 498 |
+
)
|
| 499 |
+
unnormalized_derivatives = h[..., 2 * self.num_bins :]
|
| 500 |
+
|
| 501 |
+
x1, logabsdet = piecewise_rational_quadratic_transform(
|
| 502 |
+
x1,
|
| 503 |
+
unnormalized_widths,
|
| 504 |
+
unnormalized_heights,
|
| 505 |
+
unnormalized_derivatives,
|
| 506 |
+
inverse=reverse,
|
| 507 |
+
tails="linear",
|
| 508 |
+
tail_bound=self.tail_bound,
|
| 509 |
+
)
|
| 510 |
+
|
| 511 |
+
x = torch.cat([x0, x1], 1) * x_mask
|
| 512 |
+
logdet = torch.sum(logabsdet * x_mask, [1, 2])
|
| 513 |
+
if not reverse:
|
| 514 |
+
return x, logdet
|
| 515 |
+
else:
|
| 516 |
+
return x
|
| 517 |
+
|
| 518 |
+
|
| 519 |
+
class TransformerCouplingLayer(nn.Module):
|
| 520 |
+
def __init__(
|
| 521 |
+
self,
|
| 522 |
+
channels,
|
| 523 |
+
hidden_channels,
|
| 524 |
+
kernel_size,
|
| 525 |
+
n_layers,
|
| 526 |
+
n_heads,
|
| 527 |
+
p_dropout=0,
|
| 528 |
+
filter_channels=0,
|
| 529 |
+
mean_only=False,
|
| 530 |
+
wn_sharing_parameter=None,
|
| 531 |
+
gin_channels=0,
|
| 532 |
+
):
|
| 533 |
+
assert n_layers == 3, n_layers
|
| 534 |
+
assert channels % 2 == 0, "channels should be divisible by 2"
|
| 535 |
+
super().__init__()
|
| 536 |
+
self.channels = channels
|
| 537 |
+
self.hidden_channels = hidden_channels
|
| 538 |
+
self.kernel_size = kernel_size
|
| 539 |
+
self.n_layers = n_layers
|
| 540 |
+
self.half_channels = channels // 2
|
| 541 |
+
self.mean_only = mean_only
|
| 542 |
+
|
| 543 |
+
self.pre = nn.Conv1d(self.half_channels, hidden_channels, 1)
|
| 544 |
+
self.enc = (
|
| 545 |
+
Encoder(
|
| 546 |
+
hidden_channels,
|
| 547 |
+
filter_channels,
|
| 548 |
+
n_heads,
|
| 549 |
+
n_layers,
|
| 550 |
+
kernel_size,
|
| 551 |
+
p_dropout,
|
| 552 |
+
isflow=True,
|
| 553 |
+
gin_channels=gin_channels,
|
| 554 |
+
)
|
| 555 |
+
if wn_sharing_parameter is None
|
| 556 |
+
else wn_sharing_parameter
|
| 557 |
+
)
|
| 558 |
+
self.post = nn.Conv1d(hidden_channels, self.half_channels * (2 - mean_only), 1)
|
| 559 |
+
self.post.weight.data.zero_()
|
| 560 |
+
self.post.bias.data.zero_()
|
| 561 |
+
|
| 562 |
+
def forward(self, x, x_mask, g=None, reverse=False):
|
| 563 |
+
x0, x1 = torch.split(x, [self.half_channels] * 2, 1)
|
| 564 |
+
h = self.pre(x0) * x_mask
|
| 565 |
+
h = self.enc(h, x_mask, g=g)
|
| 566 |
+
stats = self.post(h) * x_mask
|
| 567 |
+
if not self.mean_only:
|
| 568 |
+
m, logs = torch.split(stats, [self.half_channels] * 2, 1)
|
| 569 |
+
else:
|
| 570 |
+
m = stats
|
| 571 |
+
logs = torch.zeros_like(m)
|
| 572 |
+
|
| 573 |
+
if not reverse:
|
| 574 |
+
x1 = m + x1 * torch.exp(logs) * x_mask
|
| 575 |
+
x = torch.cat([x0, x1], 1)
|
| 576 |
+
logdet = torch.sum(logs, [1, 2])
|
| 577 |
+
return x, logdet
|
| 578 |
+
else:
|
| 579 |
+
x1 = (x1 - m) * torch.exp(-logs) * x_mask
|
| 580 |
+
x = torch.cat([x0, x1], 1)
|
| 581 |
+
return x
|
| 582 |
+
|
| 583 |
+
x1, logabsdet = piecewise_rational_quadratic_transform(
|
| 584 |
+
x1,
|
| 585 |
+
unnormalized_widths,
|
| 586 |
+
unnormalized_heights,
|
| 587 |
+
unnormalized_derivatives,
|
| 588 |
+
inverse=reverse,
|
| 589 |
+
tails="linear",
|
| 590 |
+
tail_bound=self.tail_bound,
|
| 591 |
+
)
|
| 592 |
+
|
| 593 |
+
x = torch.cat([x0, x1], 1) * x_mask
|
| 594 |
+
logdet = torch.sum(logabsdet * x_mask, [1, 2])
|
| 595 |
+
if not reverse:
|
| 596 |
+
return x, logdet
|
| 597 |
+
else:
|
| 598 |
+
return x
|
openvoice_app.py
ADDED
|
@@ -0,0 +1,307 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import os
|
| 2 |
+
import torch
|
| 3 |
+
import argparse
|
| 4 |
+
import gradio as gr
|
| 5 |
+
from zipfile import ZipFile
|
| 6 |
+
import langid
|
| 7 |
+
import se_extractor
|
| 8 |
+
from api import BaseSpeakerTTS, ToneColorConverter
|
| 9 |
+
|
| 10 |
+
parser = argparse.ArgumentParser()
|
| 11 |
+
parser.add_argument("--share", action='store_true', default=False, help="make link public")
|
| 12 |
+
args = parser.parse_args()
|
| 13 |
+
|
| 14 |
+
en_ckpt_base = 'checkpoints/base_speakers/EN'
|
| 15 |
+
zh_ckpt_base = 'checkpoints/base_speakers/ZH'
|
| 16 |
+
ckpt_converter = 'checkpoints/converter'
|
| 17 |
+
device = 'cuda' if torch.cuda.is_available() else 'cpu'
|
| 18 |
+
output_dir = 'outputs'
|
| 19 |
+
os.makedirs(output_dir, exist_ok=True)
|
| 20 |
+
|
| 21 |
+
# load models
|
| 22 |
+
en_base_speaker_tts = BaseSpeakerTTS(f'{en_ckpt_base}/config.json', device=device)
|
| 23 |
+
en_base_speaker_tts.load_ckpt(f'{en_ckpt_base}/checkpoint.pth')
|
| 24 |
+
zh_base_speaker_tts = BaseSpeakerTTS(f'{zh_ckpt_base}/config.json', device=device)
|
| 25 |
+
zh_base_speaker_tts.load_ckpt(f'{zh_ckpt_base}/checkpoint.pth')
|
| 26 |
+
tone_color_converter = ToneColorConverter(f'{ckpt_converter}/config.json', device=device)
|
| 27 |
+
tone_color_converter.load_ckpt(f'{ckpt_converter}/checkpoint.pth')
|
| 28 |
+
|
| 29 |
+
# load speaker embeddings
|
| 30 |
+
en_source_default_se = torch.load(f'{en_ckpt_base}/en_default_se.pth').to(device)
|
| 31 |
+
en_source_style_se = torch.load(f'{en_ckpt_base}/en_style_se.pth').to(device)
|
| 32 |
+
zh_source_se = torch.load(f'{zh_ckpt_base}/zh_default_se.pth').to(device)
|
| 33 |
+
|
| 34 |
+
# This online demo mainly supports English and Chinese
|
| 35 |
+
supported_languages = ['zh', 'en']
|
| 36 |
+
|
| 37 |
+
def predict(prompt, style, audio_file_pth, mic_file_path, use_mic, agree):
|
| 38 |
+
# initialize a empty info
|
| 39 |
+
text_hint = ''
|
| 40 |
+
# agree with the terms
|
| 41 |
+
if agree == False:
|
| 42 |
+
text_hint += '[ERROR] Please accept the Terms & Condition!\n'
|
| 43 |
+
gr.Warning("Please accept the Terms & Condition!")
|
| 44 |
+
return (
|
| 45 |
+
text_hint,
|
| 46 |
+
None,
|
| 47 |
+
None,
|
| 48 |
+
)
|
| 49 |
+
|
| 50 |
+
# first detect the input language
|
| 51 |
+
language_predicted = langid.classify(prompt)[0].strip()
|
| 52 |
+
print(f"Detected language:{language_predicted}")
|
| 53 |
+
|
| 54 |
+
if language_predicted not in supported_languages:
|
| 55 |
+
text_hint += f"[ERROR] The detected language {language_predicted} for your input text is not in our Supported Languages: {supported_languages}\n"
|
| 56 |
+
gr.Warning(
|
| 57 |
+
f"The detected language {language_predicted} for your input text is not in our Supported Languages: {supported_languages}"
|
| 58 |
+
)
|
| 59 |
+
|
| 60 |
+
return (
|
| 61 |
+
text_hint,
|
| 62 |
+
None,
|
| 63 |
+
None,
|
| 64 |
+
)
|
| 65 |
+
|
| 66 |
+
if language_predicted == "zh":
|
| 67 |
+
tts_model = zh_base_speaker_tts
|
| 68 |
+
source_se = zh_source_se
|
| 69 |
+
language = 'Chinese'
|
| 70 |
+
if style not in ['default']:
|
| 71 |
+
text_hint += f"[ERROR] The style {style} is not supported for Chinese, which should be in ['default']\n"
|
| 72 |
+
gr.Warning(f"The style {style} is not supported for Chinese, which should be in ['default']")
|
| 73 |
+
return (
|
| 74 |
+
text_hint,
|
| 75 |
+
None,
|
| 76 |
+
None,
|
| 77 |
+
)
|
| 78 |
+
|
| 79 |
+
else:
|
| 80 |
+
tts_model = en_base_speaker_tts
|
| 81 |
+
if style == 'default':
|
| 82 |
+
source_se = en_source_default_se
|
| 83 |
+
else:
|
| 84 |
+
source_se = en_source_style_se
|
| 85 |
+
language = 'English'
|
| 86 |
+
if style not in ['default', 'whispering', 'shouting', 'excited', 'cheerful', 'terrified', 'angry', 'sad', 'friendly']:
|
| 87 |
+
text_hint += f"[ERROR] The style {style} is not supported for English, which should be in ['default', 'whispering', 'shouting', 'excited', 'cheerful', 'terrified', 'angry', 'sad', 'friendly']\n"
|
| 88 |
+
gr.Warning(f"The style {style} is not supported for English, which should be in ['default', 'whispering', 'shouting', 'excited', 'cheerful', 'terrified', 'angry', 'sad', 'friendly']")
|
| 89 |
+
return (
|
| 90 |
+
text_hint,
|
| 91 |
+
None,
|
| 92 |
+
None,
|
| 93 |
+
)
|
| 94 |
+
|
| 95 |
+
if use_mic == True:
|
| 96 |
+
if mic_file_path is not None:
|
| 97 |
+
speaker_wav = mic_file_path
|
| 98 |
+
else:
|
| 99 |
+
text_hint += f"[ERROR] Please record your voice with Microphone, or uncheck Use Microphone to use reference audios\n"
|
| 100 |
+
gr.Warning(
|
| 101 |
+
"Please record your voice with Microphone, or uncheck Use Microphone to use reference audios"
|
| 102 |
+
)
|
| 103 |
+
return (
|
| 104 |
+
text_hint,
|
| 105 |
+
None,
|
| 106 |
+
None,
|
| 107 |
+
)
|
| 108 |
+
|
| 109 |
+
else:
|
| 110 |
+
speaker_wav = audio_file_pth
|
| 111 |
+
|
| 112 |
+
if len(prompt) < 2:
|
| 113 |
+
text_hint += f"[ERROR] Please give a longer prompt text \n"
|
| 114 |
+
gr.Warning("Please give a longer prompt text")
|
| 115 |
+
return (
|
| 116 |
+
text_hint,
|
| 117 |
+
None,
|
| 118 |
+
None,
|
| 119 |
+
)
|
| 120 |
+
if len(prompt) > 200:
|
| 121 |
+
text_hint += f"[ERROR] Text length limited to 200 characters for this demo, please try shorter text. You can clone our open-source repo and try for your usage \n"
|
| 122 |
+
gr.Warning(
|
| 123 |
+
"Text length limited to 200 characters for this demo, please try shorter text. You can clone our open-source repo for your usage"
|
| 124 |
+
)
|
| 125 |
+
return (
|
| 126 |
+
text_hint,
|
| 127 |
+
None,
|
| 128 |
+
None,
|
| 129 |
+
)
|
| 130 |
+
|
| 131 |
+
# note diffusion_conditioning not used on hifigan (default mode), it will be empty but need to pass it to model.inference
|
| 132 |
+
try:
|
| 133 |
+
target_se, audio_name = se_extractor.get_se(speaker_wav, tone_color_converter, target_dir='processed', vad=True)
|
| 134 |
+
except Exception as e:
|
| 135 |
+
text_hint += f"[ERROR] Get target tone color error {str(e)} \n"
|
| 136 |
+
gr.Warning(
|
| 137 |
+
"[ERROR] Get target tone color error {str(e)} \n"
|
| 138 |
+
)
|
| 139 |
+
return (
|
| 140 |
+
text_hint,
|
| 141 |
+
None,
|
| 142 |
+
None,
|
| 143 |
+
)
|
| 144 |
+
|
| 145 |
+
src_path = f'{output_dir}/tmp.wav'
|
| 146 |
+
tts_model.tts(prompt, src_path, speaker=style, language=language)
|
| 147 |
+
|
| 148 |
+
save_path = f'{output_dir}/output.wav'
|
| 149 |
+
# Run the tone color converter
|
| 150 |
+
encode_message = "@MyShell"
|
| 151 |
+
tone_color_converter.convert(
|
| 152 |
+
audio_src_path=src_path,
|
| 153 |
+
src_se=source_se,
|
| 154 |
+
tgt_se=target_se,
|
| 155 |
+
output_path=save_path,
|
| 156 |
+
message=encode_message)
|
| 157 |
+
|
| 158 |
+
text_hint += f'''Get response successfully \n'''
|
| 159 |
+
|
| 160 |
+
return (
|
| 161 |
+
text_hint,
|
| 162 |
+
save_path,
|
| 163 |
+
speaker_wav,
|
| 164 |
+
)
|
| 165 |
+
|
| 166 |
+
|
| 167 |
+
|
| 168 |
+
title = "MyShell OpenVoice"
|
| 169 |
+
|
| 170 |
+
description = """
|
| 171 |
+
We introduce OpenVoice, a versatile instant voice cloning approach that requires only a short audio clip from the reference speaker to replicate their voice and generate speech in multiple languages. OpenVoice enables granular control over voice styles, including emotion, accent, rhythm, pauses, and intonation, in addition to replicating the tone color of the reference speaker. OpenVoice also achieves zero-shot cross-lingual voice cloning for languages not included in the massive-speaker training set.
|
| 172 |
+
"""
|
| 173 |
+
|
| 174 |
+
markdown_table = """
|
| 175 |
+
<div align="center" style="margin-bottom: 10px;">
|
| 176 |
+
|
| 177 |
+
| | | |
|
| 178 |
+
| :-----------: | :-----------: | :-----------: |
|
| 179 |
+
| **OpenSource Repo** | **Project Page** | **Join the Community** |
|
| 180 |
+
| <div style='text-align: center;'><a style="display:inline-block,align:center" href='https://github.com/myshell-ai/OpenVoice'><img src='https://img.shields.io/github/stars/myshell-ai/OpenVoice?style=social' /></a></div> | [OpenVoice](https://research.myshell.ai/open-voice) | [](https://discord.gg/myshell) |
|
| 181 |
+
|
| 182 |
+
</div>
|
| 183 |
+
"""
|
| 184 |
+
|
| 185 |
+
markdown_table_v2 = """
|
| 186 |
+
<div align="center" style="margin-bottom: 2px;">
|
| 187 |
+
|
| 188 |
+
| | | | |
|
| 189 |
+
| :-----------: | :-----------: | :-----------: | :-----------: |
|
| 190 |
+
| **OpenSource Repo** | <div style='text-align: center;'><a style="display:inline-block,align:center" href='https://github.com/myshell-ai/OpenVoice'><img src='https://img.shields.io/github/stars/myshell-ai/OpenVoice?style=social' /></a></div> | **Project Page** | [OpenVoice](https://research.myshell.ai/open-voice) |
|
| 191 |
+
|
| 192 |
+
| | |
|
| 193 |
+
| :-----------: | :-----------: |
|
| 194 |
+
**Join the Community** | [](https://discord.gg/myshell) |
|
| 195 |
+
|
| 196 |
+
</div>
|
| 197 |
+
"""
|
| 198 |
+
content = """
|
| 199 |
+
<div>
|
| 200 |
+
<strong>For multi-lingual & cross-lingual examples, please refer to <a href='https://github.com/myshell-ai/OpenVoice/blob/main/demo_part2.ipynb'>this jupyter notebook</a>.</strong>
|
| 201 |
+
This online demo mainly supports <strong>English</strong>. The <em>default</em> style also supports <strong>Chinese</strong>. But OpenVoice can adapt to any other language as long as a base speaker is provided.
|
| 202 |
+
</div>
|
| 203 |
+
"""
|
| 204 |
+
wrapped_markdown_content = f"<div style='border: 1px solid #000; padding: 10px;'>{content}</div>"
|
| 205 |
+
|
| 206 |
+
|
| 207 |
+
examples = [
|
| 208 |
+
[
|
| 209 |
+
"今天天气真好,我们一起出去吃饭吧。",
|
| 210 |
+
'default',
|
| 211 |
+
"resources/demo_speaker0.mp3",
|
| 212 |
+
None,
|
| 213 |
+
False,
|
| 214 |
+
True,
|
| 215 |
+
],[
|
| 216 |
+
"This audio is generated by open voice with a half-performance model.",
|
| 217 |
+
'whispering',
|
| 218 |
+
"resources/demo_speaker1.mp3",
|
| 219 |
+
None,
|
| 220 |
+
False,
|
| 221 |
+
True,
|
| 222 |
+
],
|
| 223 |
+
[
|
| 224 |
+
"He hoped there would be stew for dinner, turnips and carrots and bruised potatoes and fat mutton pieces to be ladled out in thick, peppered, flour-fattened sauce.",
|
| 225 |
+
'sad',
|
| 226 |
+
"resources/demo_speaker2.mp3",
|
| 227 |
+
None,
|
| 228 |
+
False,
|
| 229 |
+
True,
|
| 230 |
+
],
|
| 231 |
+
]
|
| 232 |
+
|
| 233 |
+
with gr.Blocks(analytics_enabled=False) as demo:
|
| 234 |
+
|
| 235 |
+
with gr.Row():
|
| 236 |
+
with gr.Column():
|
| 237 |
+
with gr.Row():
|
| 238 |
+
gr.Markdown(
|
| 239 |
+
"""
|
| 240 |
+
## <img src="https://huggingface.co/spaces/myshell-ai/OpenVoice/raw/main/logo.jpg" height="40"/>
|
| 241 |
+
"""
|
| 242 |
+
)
|
| 243 |
+
with gr.Row():
|
| 244 |
+
gr.Markdown(markdown_table_v2)
|
| 245 |
+
with gr.Row():
|
| 246 |
+
gr.Markdown(description)
|
| 247 |
+
with gr.Column():
|
| 248 |
+
gr.Video('https://github.com/myshell-ai/OpenVoice/assets/40556743/3cba936f-82bf-476c-9e52-09f0f417bb2f', autoplay=True)
|
| 249 |
+
|
| 250 |
+
with gr.Row():
|
| 251 |
+
gr.HTML(wrapped_markdown_content)
|
| 252 |
+
|
| 253 |
+
with gr.Row():
|
| 254 |
+
with gr.Column():
|
| 255 |
+
input_text_gr = gr.Textbox(
|
| 256 |
+
label="Text Prompt",
|
| 257 |
+
info="One or two sentences at a time is better. Up to 200 text characters.",
|
| 258 |
+
value="He hoped there would be stew for dinner, turnips and carrots and bruised potatoes and fat mutton pieces to be ladled out in thick, peppered, flour-fattened sauce.",
|
| 259 |
+
)
|
| 260 |
+
style_gr = gr.Dropdown(
|
| 261 |
+
label="Style",
|
| 262 |
+
info="Select a style of output audio for the synthesised speech. (Chinese only support 'default' now)",
|
| 263 |
+
choices=['default', 'whispering', 'cheerful', 'terrified', 'angry', 'sad', 'friendly'],
|
| 264 |
+
max_choices=1,
|
| 265 |
+
value="default",
|
| 266 |
+
)
|
| 267 |
+
ref_gr = gr.Audio(
|
| 268 |
+
label="Reference Audio",
|
| 269 |
+
info="Click on the ✎ button to upload your own target speaker audio",
|
| 270 |
+
type="filepath",
|
| 271 |
+
value="resources/demo_speaker0.mp3",
|
| 272 |
+
)
|
| 273 |
+
mic_gr = gr.Audio(
|
| 274 |
+
source="microphone",
|
| 275 |
+
type="filepath",
|
| 276 |
+
info="Use your microphone to record audio",
|
| 277 |
+
label="Use Microphone for Reference",
|
| 278 |
+
)
|
| 279 |
+
use_mic_gr = gr.Checkbox(
|
| 280 |
+
label="Use Microphone",
|
| 281 |
+
value=False,
|
| 282 |
+
info="Notice: Microphone input may not work properly under traffic",
|
| 283 |
+
)
|
| 284 |
+
tos_gr = gr.Checkbox(
|
| 285 |
+
label="Agree",
|
| 286 |
+
value=False,
|
| 287 |
+
info="I agree to the terms of the cc-by-nc-4.0 license-: https://github.com/myshell-ai/OpenVoice/blob/main/LICENSE",
|
| 288 |
+
)
|
| 289 |
+
|
| 290 |
+
tts_button = gr.Button("Send", elem_id="send-btn", visible=True)
|
| 291 |
+
|
| 292 |
+
|
| 293 |
+
with gr.Column():
|
| 294 |
+
out_text_gr = gr.Text(label="Info")
|
| 295 |
+
audio_gr = gr.Audio(label="Synthesised Audio", autoplay=True)
|
| 296 |
+
ref_audio_gr = gr.Audio(label="Reference Audio Used")
|
| 297 |
+
|
| 298 |
+
gr.Examples(examples,
|
| 299 |
+
label="Examples",
|
| 300 |
+
inputs=[input_text_gr, style_gr, ref_gr, mic_gr, use_mic_gr, tos_gr],
|
| 301 |
+
outputs=[out_text_gr, audio_gr, ref_audio_gr],
|
| 302 |
+
fn=predict,
|
| 303 |
+
cache_examples=False,)
|
| 304 |
+
tts_button.click(predict, [input_text_gr, style_gr, ref_gr, mic_gr, use_mic_gr, tos_gr], outputs=[out_text_gr, audio_gr, ref_audio_gr])
|
| 305 |
+
|
| 306 |
+
demo.queue()
|
| 307 |
+
demo.launch(debug=True, show_api=True, share=args.share)
|
requirements.txt
ADDED
|
@@ -0,0 +1,15 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
librosa==0.9.1
|
| 2 |
+
faster-whisper==0.9.0
|
| 3 |
+
pydub==0.25.1
|
| 4 |
+
wavmark==0.0.2
|
| 5 |
+
numpy==1.22.0
|
| 6 |
+
eng_to_ipa==0.0.2
|
| 7 |
+
inflect==7.0.0
|
| 8 |
+
unidecode==1.3.7
|
| 9 |
+
whisper-timestamped==1.14.2
|
| 10 |
+
openai
|
| 11 |
+
python-dotenv
|
| 12 |
+
pypinyin==0.50.0
|
| 13 |
+
cn2an==0.5.22
|
| 14 |
+
jieba==0.42.1
|
| 15 |
+
gradio
|
resources/demo_speaker0.mp3
ADDED
|
Binary file (309 kB). View file
|
|
|
resources/demo_speaker1.mp3
ADDED
|
Binary file (729 kB). View file
|
|
|
resources/demo_speaker2.mp3
ADDED
|
Binary file (472 kB). View file
|
|
|
resources/example_reference.mp3
ADDED
|
Binary file (117 kB). View file
|
|
|
resources/framework-ipa.png
ADDED
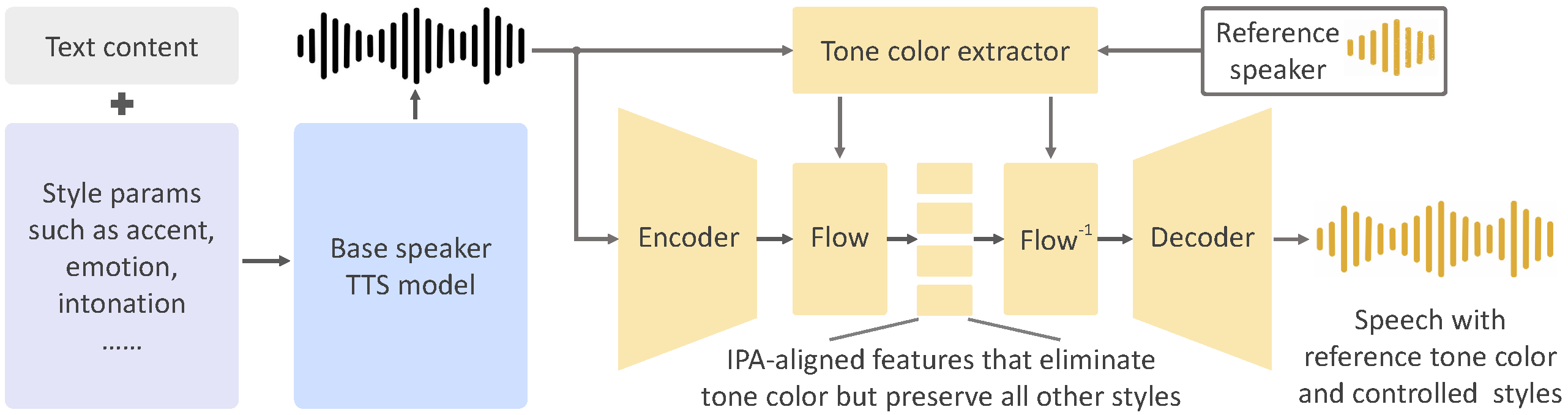
|
resources/framework.jpg
ADDED
|
resources/lepton.jpg
ADDED

|
resources/myshell.jpg
ADDED

|
resources/openvoicelogo.jpg
ADDED

|