
Commit
•
e9f47fc
1
Parent(s):
1160f7b
files Uploaded
Browse files- assets/model_prediction.png +0 -0
- assets/residual_plot.png +0 -0
- assets/test_data_forecast.png +0 -0
- assets/tsForecast.png +0 -0
- assets/tsHome.png +0 -0
- assets/tsResults.png +0 -0
- config/config.yaml +11 -0
- params.yaml +4 -0
- requirements.txt +15 -15
- tsForecaster/__init__.py +21 -0
- tsForecaster/components/__init__.py +0 -0
- tsForecaster/components/data_ingestion.py +44 -0
- tsForecaster/components/data_preprocessing.py +77 -0
- tsForecaster/components/model_evaluation.py +31 -0
- tsForecaster/components/model_training.py +46 -0
- tsForecaster/config/__init__.py +0 -0
- tsForecaster/config/configuration.py +44 -0
- tsForecaster/constants/__init__.py +4 -0
- tsForecaster/entity/__init__.py +0 -0
- tsForecaster/entity/config_entity.py +20 -0
- tsForecaster/pipeline/__init__.py +0 -0
- tsForecaster/pipeline/stage_01_data_ingestion.py +29 -0
- tsForecaster/pipeline/stage_02_data_preprocessing.py +36 -0
- tsForecaster/pipeline/stage_03_model_training.py +28 -0
- tsForecaster/pipeline/stage_04_model_evaluation.py +30 -0
- tsForecaster/utils/__init__.py +0 -0
- tsForecaster/utils/common.py +191 -0
assets/model_prediction.png
ADDED
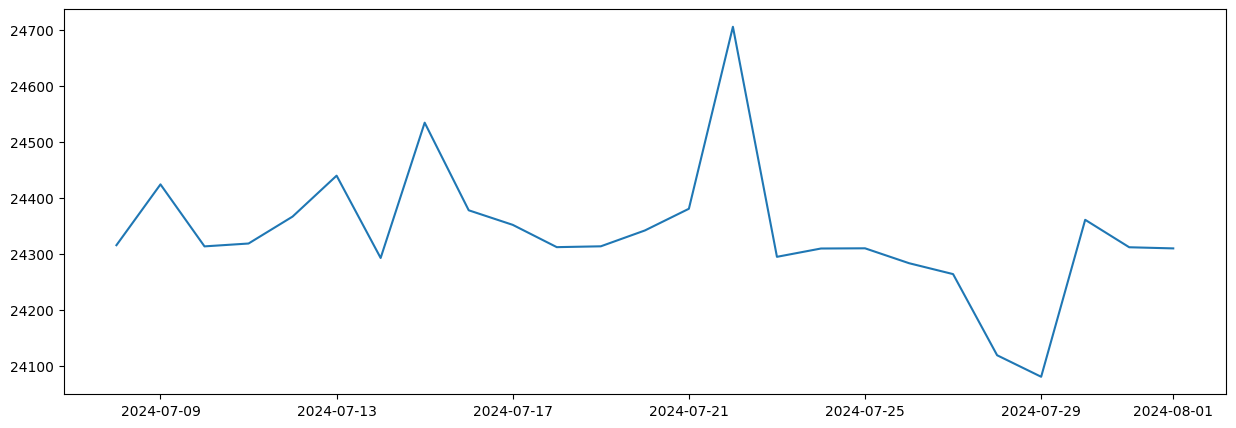
|
assets/residual_plot.png
ADDED

|
assets/test_data_forecast.png
ADDED

|
assets/tsForecast.png
ADDED

|
assets/tsHome.png
ADDED
|
assets/tsResults.png
ADDED

|
config/config.yaml
ADDED
|
@@ -0,0 +1,11 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
artifacts_root: artifacts
|
| 2 |
+
|
| 3 |
+
data_ingestion:
|
| 4 |
+
root_dir: artifacts/data_ingestion
|
| 5 |
+
source_url: https://drive.google.com/file/d/1kI7vnsPB46Z2grGq9GSaUCaQ3Y1ekI9a/view?usp=sharing
|
| 6 |
+
data_dir: artifacts/data_ingestion/
|
| 7 |
+
scaler_path: artifacts/data_preprocessing
|
| 8 |
+
|
| 9 |
+
model_training:
|
| 10 |
+
root_dir: artifacts/model_training
|
| 11 |
+
trained_model_path: artifacts/model_training/model.keras
|
params.yaml
ADDED
|
@@ -0,0 +1,4 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
EPOCHS: 300
|
| 2 |
+
BATCH_SIZE: 32
|
| 3 |
+
LEARNING_RATE: 0.001
|
| 4 |
+
TIME_STEPS: 60
|
requirements.txt
CHANGED
|
@@ -1,16 +1,16 @@
|
|
| 1 |
-
tensorflow==2.17.0
|
| 2 |
-
yfinance==0.2.40
|
| 3 |
-
pandas==2.2.2
|
| 4 |
-
numpy
|
| 5 |
-
matplotlib==3.9.1
|
| 6 |
-
seaborn==0.13.2
|
| 7 |
-
python-box==7.2.0
|
| 8 |
-
pyYAML==6.0.1
|
| 9 |
-
tqdm==4.66.4
|
| 10 |
-
ensure==1.0.4
|
| 11 |
-
joblib==1.4.2
|
| 12 |
-
types-PyYAML==6.0.12
|
| 13 |
-
fastapi==0.111.0
|
| 14 |
-
streamlit==1.36.0
|
| 15 |
-
plotly==5.22.0
|
| 16 |
scikit-learn
|
|
|
|
| 1 |
+
tensorflow==2.17.0
|
| 2 |
+
yfinance==0.2.40
|
| 3 |
+
pandas==2.2.2
|
| 4 |
+
numpy
|
| 5 |
+
matplotlib==3.9.1
|
| 6 |
+
seaborn==0.13.2
|
| 7 |
+
python-box==7.2.0
|
| 8 |
+
pyYAML==6.0.1
|
| 9 |
+
tqdm==4.66.4
|
| 10 |
+
ensure==1.0.4
|
| 11 |
+
joblib==1.4.2
|
| 12 |
+
types-PyYAML==6.0.12
|
| 13 |
+
fastapi==0.111.0
|
| 14 |
+
streamlit==1.36.0
|
| 15 |
+
plotly==5.22.0
|
| 16 |
scikit-learn
|
tsForecaster/__init__.py
ADDED
|
@@ -0,0 +1,21 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import os
|
| 2 |
+
import sys
|
| 3 |
+
import logging
|
| 4 |
+
|
| 5 |
+
logging_str = "[%(asctime)s: %(levelname)s: %(module)s: %(message)s]"
|
| 6 |
+
|
| 7 |
+
log_dir = "logs"
|
| 8 |
+
log_filepath = os.path.join(log_dir, "running_logs.log")
|
| 9 |
+
os.makedirs(log_dir, exist_ok=True)
|
| 10 |
+
|
| 11 |
+
logging.basicConfig(
|
| 12 |
+
level=logging.INFO,
|
| 13 |
+
format=logging_str,
|
| 14 |
+
|
| 15 |
+
handlers=[
|
| 16 |
+
logging.FileHandler(log_filepath),
|
| 17 |
+
logging.StreamHandler(sys.stdout)
|
| 18 |
+
]
|
| 19 |
+
)
|
| 20 |
+
|
| 21 |
+
logger = logging.getLogger("tsForecasterLogger")
|
tsForecaster/components/__init__.py
ADDED
|
File without changes
|
tsForecaster/components/data_ingestion.py
ADDED
|
@@ -0,0 +1,44 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import os
|
| 2 |
+
import opendatasets as od
|
| 3 |
+
import yfinance as yf
|
| 4 |
+
import pandas as pd
|
| 5 |
+
from tsForecaster.entity.config_entity import DataIngestionConfig
|
| 6 |
+
from tsForecaster import logger
|
| 7 |
+
|
| 8 |
+
class DataIngestion:
|
| 9 |
+
def __init__(self, config:DataIngestionConfig) -> None:
|
| 10 |
+
self.config = config
|
| 11 |
+
|
| 12 |
+
def download_file(self) ->None:
|
| 13 |
+
try:
|
| 14 |
+
download_dir = self.config.data_dir
|
| 15 |
+
dataset_url = self.config.source_url
|
| 16 |
+
os.makedirs(download_dir, exist_ok=True)
|
| 17 |
+
logger.info(f"Downloading data from {dataset_url} into file {download_dir}")
|
| 18 |
+
od.download(dataset_url, data_dir=download_dir)
|
| 19 |
+
logger.info(f"Downloaded data from {dataset_url} into file {download_dir}")
|
| 20 |
+
except Exception as e:
|
| 21 |
+
raise e
|
| 22 |
+
|
| 23 |
+
def update_file(self) ->None:
|
| 24 |
+
try:
|
| 25 |
+
download_dir = self.config.data_dir
|
| 26 |
+
ticker = yf.Ticker("^NSEI")
|
| 27 |
+
history = ticker.history(start='2024-07-08', interval='1d')
|
| 28 |
+
history.drop(columns=['Volume', 'Dividends', 'Stock Splits'], inplace=True)
|
| 29 |
+
history = round(history, 2)
|
| 30 |
+
history['Index Name'] = "NIFTY 50"
|
| 31 |
+
history.reset_index(inplace=True)
|
| 32 |
+
history['Date'] = history['Date'].dt.strftime('%d %b %Y')
|
| 33 |
+
history = history[['Index Name', 'Date', 'Open', 'High', 'Low', 'Close']]
|
| 34 |
+
history = history.sort_values(by=['Date'], ascending=False)
|
| 35 |
+
df = pd.read_csv(os.path.join(download_dir ,"NIFTY 50_Historical.csv"))
|
| 36 |
+
df = pd.concat([history, df], ignore_index=True)
|
| 37 |
+
df = df[['Index Name', 'Date', 'Open', 'High', 'Low', 'Close']]
|
| 38 |
+
df['Date'] = pd.to_datetime(df['Date'])
|
| 39 |
+
df = df.drop_duplicates(subset=['Date'])
|
| 40 |
+
df.to_csv(os.path.join(download_dir ,"NIFTY 50_Historical.csv"))
|
| 41 |
+
|
| 42 |
+
except Exception as e:
|
| 43 |
+
raise e
|
| 44 |
+
|
tsForecaster/components/data_preprocessing.py
ADDED
|
@@ -0,0 +1,77 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import os
|
| 2 |
+
from pathlib import Path
|
| 3 |
+
import joblib
|
| 4 |
+
import numpy as np
|
| 5 |
+
import pandas as pd
|
| 6 |
+
from sklearn.preprocessing import MinMaxScaler
|
| 7 |
+
from tsForecaster.entity.config_entity import DataIngestionConfig
|
| 8 |
+
from tsForecaster import logger
|
| 9 |
+
|
| 10 |
+
class DataPreProcessing:
|
| 11 |
+
def __init__(self, config: DataIngestionConfig) -> None:
|
| 12 |
+
self.config = config
|
| 13 |
+
|
| 14 |
+
def process_csv(self) -> pd.DataFrame:
|
| 15 |
+
logger.info("Processing data from CSV to DataFrame")
|
| 16 |
+
df_path = Path(self.config.data_dir) / "NIFTY 50_Historical.csv"
|
| 17 |
+
df = pd.read_csv(df_path, index_col=[0])
|
| 18 |
+
df.drop(columns=['Index Name', 'Open', 'High', 'Low'], inplace=True)
|
| 19 |
+
df['Date'] = pd.to_datetime(df['Date'])
|
| 20 |
+
|
| 21 |
+
start_date = '1990-07-03'
|
| 22 |
+
end_date = pd.Timestamp.today().strftime('%Y-%m-%d')
|
| 23 |
+
date_range = pd.date_range(start=start_date, end=end_date, freq='D')
|
| 24 |
+
date_df = pd.DataFrame(date_range, columns=['Date'])
|
| 25 |
+
df = pd.merge(date_df, df, how='left', on='Date')
|
| 26 |
+
df = df.ffill()
|
| 27 |
+
|
| 28 |
+
df['Close%'] = ((df['Close'] / df['Close'].shift(1)) - 1) * 100
|
| 29 |
+
for period, days in {
|
| 30 |
+
'1D': 1, '2D': 2, '3D': 3, '1W': 7, '2W': 14, '1M': 30, '2M': 60,
|
| 31 |
+
'3M': 90, '6M': 180, '1Y': 365, '2Y': 730, '3Y': 1095, '5Y': 1825,
|
| 32 |
+
'7Y': 2555, '10Y': 3650
|
| 33 |
+
}.items():
|
| 34 |
+
df[f'Close_{period}_ago'] = df['Close%'].shift(days)
|
| 35 |
+
|
| 36 |
+
df.dropna(inplace=True)
|
| 37 |
+
df.reset_index(drop=True, inplace=True)
|
| 38 |
+
df.set_index('Date', inplace=True)
|
| 39 |
+
|
| 40 |
+
logger.info("Done processing data from CSV to DataFrame")
|
| 41 |
+
return df
|
| 42 |
+
|
| 43 |
+
def scaling_data(self, df: pd.DataFrame):
|
| 44 |
+
logger.info("Scaling data...")
|
| 45 |
+
scaler = MinMaxScaler()
|
| 46 |
+
df_scaled = pd.DataFrame(scaler.fit_transform(df), columns=df.columns, index=df.index)
|
| 47 |
+
joblib.dump(scaler, Path(os.path.join(self.config.scaler_path, 'scaler.pkl')))
|
| 48 |
+
logger.info("Data scaling done")
|
| 49 |
+
return df_scaled
|
| 50 |
+
|
| 51 |
+
def create_sequences(self, df: pd.DataFrame, time_steps: int):
|
| 52 |
+
logger.info("Creating X, y sequences...")
|
| 53 |
+
X, y = [], []
|
| 54 |
+
for i in range(len(df) - time_steps):
|
| 55 |
+
X.append(df.iloc[i: i + time_steps, 1:].values)
|
| 56 |
+
y.append(df.iloc[i, 0])
|
| 57 |
+
dates = df.index[time_steps:]
|
| 58 |
+
logger.info("X, y sequences created")
|
| 59 |
+
return np.array(X), np.array(y), dates
|
| 60 |
+
|
| 61 |
+
def train_test_split(self, X, y, dates, train_len=0.8, val_len=0.1, test_len=0.1):
|
| 62 |
+
logger.info("Splitting train, val, test data...")
|
| 63 |
+
total_len = train_len + val_len + test_len
|
| 64 |
+
if total_len != 1.0:
|
| 65 |
+
logger.error("Error splitting train, val, test data: Total length is not equal to 1")
|
| 66 |
+
raise ValueError("Aggregate length of train, validation, and test lengths should be equal to 1")
|
| 67 |
+
|
| 68 |
+
total_size = len(y)
|
| 69 |
+
train_size = int(total_size * train_len)
|
| 70 |
+
val_size = int(total_size * val_len)
|
| 71 |
+
|
| 72 |
+
X_train, X_val, X_test = X[:train_size], X[train_size:train_size+val_size], X[train_size+val_size:]
|
| 73 |
+
y_train, y_val, y_test = y[:train_size], y[train_size:train_size+val_size], y[train_size+val_size:]
|
| 74 |
+
dates_train, dates_val, dates_test = dates[:train_size], dates[train_size:train_size+val_size], dates[train_size+val_size:]
|
| 75 |
+
|
| 76 |
+
logger.info("Done splitting train, val, test data")
|
| 77 |
+
return X_train, X_val, X_test, y_train, y_val, y_test, dates_train, dates_val, dates_test
|
tsForecaster/components/model_evaluation.py
ADDED
|
@@ -0,0 +1,31 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from pathlib import Path
|
| 2 |
+
from matplotlib import pyplot as plt
|
| 3 |
+
import tensorflow as tf
|
| 4 |
+
from tsForecaster.entity.config_entity import ModelTrainingConfig
|
| 5 |
+
from sklearn.metrics import mean_absolute_error, mean_squared_error, r2_score
|
| 6 |
+
|
| 7 |
+
|
| 8 |
+
class ModelEvaluation:
|
| 9 |
+
def __init__(self, config:ModelTrainingConfig) -> None:
|
| 10 |
+
self.config = config
|
| 11 |
+
|
| 12 |
+
@staticmethod
|
| 13 |
+
def load_model(path: Path) -> tf.keras.Model:
|
| 14 |
+
return tf.keras.models.load_model(path)
|
| 15 |
+
|
| 16 |
+
def evaluation(self, X, y, dates):
|
| 17 |
+
self.model = self.load_model(self.config.training_model_path)
|
| 18 |
+
y_pred = self.model.predict(X).flatten()
|
| 19 |
+
|
| 20 |
+
plt.figure(figsize=(15, 5))
|
| 21 |
+
plt.plot(dates, y)
|
| 22 |
+
plt.plot(dates, y_pred)
|
| 23 |
+
plt.legend(['y-true', 'y-pred'])
|
| 24 |
+
plt.show()
|
| 25 |
+
|
| 26 |
+
mae = mean_absolute_error(y, y_pred)
|
| 27 |
+
mse = mean_squared_error(y, y_pred)
|
| 28 |
+
rmse = mean_squared_error(y, y_pred, squared=False)
|
| 29 |
+
r2 = r2_score(y, y_pred)
|
| 30 |
+
|
| 31 |
+
return mae, mse, rmse, r2
|
tsForecaster/components/model_training.py
ADDED
|
@@ -0,0 +1,46 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import tensorflow as tf
|
| 2 |
+
from pathlib import Path
|
| 3 |
+
from tsForecaster.entity.config_entity import ModelTrainingConfig
|
| 4 |
+
from tsForecaster.utils.common import create_directories
|
| 5 |
+
|
| 6 |
+
|
| 7 |
+
class ModelTraining:
|
| 8 |
+
def __init__(self, config: ModelTrainingConfig) -> None:
|
| 9 |
+
self.config = config
|
| 10 |
+
self.model = self.create_model()
|
| 11 |
+
|
| 12 |
+
create_directories([config.root_dir])
|
| 13 |
+
|
| 14 |
+
@staticmethod
|
| 15 |
+
def save_model(path: Path, model: tf.keras.Model):
|
| 16 |
+
model.save(path)
|
| 17 |
+
|
| 18 |
+
def create_model(self) -> tf.keras.Model:
|
| 19 |
+
model = tf.keras.models.Sequential([
|
| 20 |
+
tf.keras.layers.Input((self.config.params_time_steps, 15)),
|
| 21 |
+
tf.keras.layers.GRU(128, return_sequences=True),
|
| 22 |
+
tf.keras.layers.GRU(128, return_sequences=False),
|
| 23 |
+
tf.keras.layers.Dense(64, activation='relu'),
|
| 24 |
+
tf.keras.layers.Dense(64, activation='relu'),
|
| 25 |
+
tf.keras.layers.Dense(64, activation='relu'),
|
| 26 |
+
tf.keras.layers.Dense(1)
|
| 27 |
+
])
|
| 28 |
+
|
| 29 |
+
model.compile(loss='mse', optimizer=tf.keras.optimizers.Adam(learning_rate=self.config.params_learning_rate), metrics=['mean_squared_error'])
|
| 30 |
+
|
| 31 |
+
model.summary()
|
| 32 |
+
|
| 33 |
+
return model
|
| 34 |
+
|
| 35 |
+
def train(self, X_train, y_train, X_val, y_val):
|
| 36 |
+
early_stop = tf.keras.callbacks.EarlyStopping(monitor='loss', patience=10, restore_best_weights=True)
|
| 37 |
+
history = self.model.fit(
|
| 38 |
+
X_train,
|
| 39 |
+
y_train,
|
| 40 |
+
validation_data=(X_val, y_val),
|
| 41 |
+
epochs=self.config.params_epochs,
|
| 42 |
+
batch_size=self.config.params_batch_size,
|
| 43 |
+
callbacks=[early_stop]
|
| 44 |
+
)
|
| 45 |
+
self.save_model(path=self.config.training_model_path, model=self.model)
|
| 46 |
+
return history
|
tsForecaster/config/__init__.py
ADDED
|
File without changes
|
tsForecaster/config/configuration.py
ADDED
|
@@ -0,0 +1,44 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import os
|
| 2 |
+
from pathlib import Path
|
| 3 |
+
from tsForecaster.constants import CONFIG_FILE_PATH, PARAMS_FILE_PATH
|
| 4 |
+
from tsForecaster.utils.common import read_yaml, create_directories
|
| 5 |
+
from tsForecaster.entity.config_entity import DataIngestionConfig, ModelTrainingConfig
|
| 6 |
+
|
| 7 |
+
class ConfigurationManager:
|
| 8 |
+
def __init__(self, config_file_path=CONFIG_FILE_PATH, params_file_path=PARAMS_FILE_PATH) -> None:
|
| 9 |
+
self.config = read_yaml(config_file_path)
|
| 10 |
+
self.params = read_yaml(params_file_path)
|
| 11 |
+
|
| 12 |
+
create_directories([self.config.artifacts_root])
|
| 13 |
+
|
| 14 |
+
def get_data_ingestion_config(self) -> DataIngestionConfig:
|
| 15 |
+
config = self.config.data_ingestion
|
| 16 |
+
|
| 17 |
+
create_directories([config.root_dir])
|
| 18 |
+
|
| 19 |
+
data_ingestion_config = DataIngestionConfig(
|
| 20 |
+
root_dir=config.root_dir,
|
| 21 |
+
source_url=config.source_url,
|
| 22 |
+
data_dir=config.data_dir,
|
| 23 |
+
scaler_path=config.scaler_path
|
| 24 |
+
)
|
| 25 |
+
|
| 26 |
+
return data_ingestion_config
|
| 27 |
+
|
| 28 |
+
def get_model_training_config(self) -> ModelTrainingConfig:
|
| 29 |
+
model_training = self.config.model_training
|
| 30 |
+
params = self.params
|
| 31 |
+
|
| 32 |
+
create_directories([model_training.root_dir])
|
| 33 |
+
|
| 34 |
+
model_training_config = ModelTrainingConfig(
|
| 35 |
+
root_dir=Path(model_training.root_dir),
|
| 36 |
+
training_model_path=Path(model_training.trained_model_path),
|
| 37 |
+
training_data_path=Path(self.config.data_ingestion.data_dir),
|
| 38 |
+
params_epochs=params.EPOCHS,
|
| 39 |
+
params_batch_size=params.BATCH_SIZE,
|
| 40 |
+
params_learning_rate=params.LEARNING_RATE,
|
| 41 |
+
params_time_steps=params.TIME_STEPS
|
| 42 |
+
)
|
| 43 |
+
|
| 44 |
+
return model_training_config
|
tsForecaster/constants/__init__.py
ADDED
|
@@ -0,0 +1,4 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from pathlib import Path
|
| 2 |
+
|
| 3 |
+
CONFIG_FILE_PATH = Path("config/config.yaml")
|
| 4 |
+
PARAMS_FILE_PATH = Path("params.yaml")
|
tsForecaster/entity/__init__.py
ADDED
|
File without changes
|
tsForecaster/entity/config_entity.py
ADDED
|
@@ -0,0 +1,20 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from dataclasses import dataclass
|
| 2 |
+
from pathlib import Path
|
| 3 |
+
|
| 4 |
+
@dataclass(frozen=True)
|
| 5 |
+
class DataIngestionConfig:
|
| 6 |
+
root_dir: Path
|
| 7 |
+
source_url: Path
|
| 8 |
+
data_dir: Path
|
| 9 |
+
scaler_path: Path
|
| 10 |
+
|
| 11 |
+
@dataclass(frozen=True)
|
| 12 |
+
class ModelTrainingConfig:
|
| 13 |
+
root_dir: Path
|
| 14 |
+
training_model_path: Path
|
| 15 |
+
training_data_path: Path
|
| 16 |
+
params_time_steps: int
|
| 17 |
+
params_epochs: int
|
| 18 |
+
params_batch_size: int
|
| 19 |
+
params_learning_rate: float
|
| 20 |
+
|
tsForecaster/pipeline/__init__.py
ADDED
|
File without changes
|
tsForecaster/pipeline/stage_01_data_ingestion.py
ADDED
|
@@ -0,0 +1,29 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from tsForecaster.components.data_ingestion import DataIngestion
|
| 2 |
+
from tsForecaster.config.configuration import ConfigurationManager
|
| 3 |
+
from tsForecaster import logger
|
| 4 |
+
|
| 5 |
+
STAGE_NAME = "Data Ingestion Stage"
|
| 6 |
+
|
| 7 |
+
class DataIngestionPipeline:
|
| 8 |
+
def __init__(self) -> None:
|
| 9 |
+
pass
|
| 10 |
+
|
| 11 |
+
def main(self):
|
| 12 |
+
try:
|
| 13 |
+
config = ConfigurationManager()
|
| 14 |
+
data_ingestion_config = config.get_data_ingestion_config()
|
| 15 |
+
data_ingestion = DataIngestion(config=data_ingestion_config)
|
| 16 |
+
data_ingestion.download_file()
|
| 17 |
+
data_ingestion.update_file()
|
| 18 |
+
except Exception as e:
|
| 19 |
+
raise e
|
| 20 |
+
|
| 21 |
+
if __name__ == '__main__':
|
| 22 |
+
try:
|
| 23 |
+
logger.info(f">>>>> stage {STAGE_NAME} started <<<<<")
|
| 24 |
+
obj = DataIngestionPipeline()
|
| 25 |
+
obj.main()
|
| 26 |
+
logger.info(f">>>>> stage {STAGE_NAME} completed <<<<<")
|
| 27 |
+
except Exception as e:
|
| 28 |
+
logger.exception(e)
|
| 29 |
+
raise e
|
tsForecaster/pipeline/stage_02_data_preprocessing.py
ADDED
|
@@ -0,0 +1,36 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from tsForecaster.components.data_preprocessing import DataPreProcessing
|
| 2 |
+
from tsForecaster import logger
|
| 3 |
+
from tsForecaster.config.configuration import ConfigurationManager
|
| 4 |
+
|
| 5 |
+
STAGE_NAME = "Data Pre-Processing Stage"
|
| 6 |
+
|
| 7 |
+
class DataPreProcessingPipeline:
|
| 8 |
+
def __init__(self) -> None:
|
| 9 |
+
pass
|
| 10 |
+
|
| 11 |
+
def main(self):
|
| 12 |
+
try:
|
| 13 |
+
config = ConfigurationManager()
|
| 14 |
+
data_ingestion_config = config.get_data_ingestion_config()
|
| 15 |
+
data_preprocessing = DataPreProcessing(config=data_ingestion_config)
|
| 16 |
+
df = data_preprocessing.process_csv()
|
| 17 |
+
close_df = df['Close']
|
| 18 |
+
df.drop(columns=['Close'], inplace=True)
|
| 19 |
+
scaled_df = data_preprocessing.scaling_data(df)
|
| 20 |
+
time_steps = 60
|
| 21 |
+
X, y, dates = data_preprocessing.create_sequences(scaled_df, time_steps)
|
| 22 |
+
X_train, X_val, X_test, y_train, y_val, y_test, dates_train, dates_val, dates_test = data_preprocessing.train_test_split(X, y, dates, train_len=0.8, val_len=0.1, test_len=0.1)
|
| 23 |
+
|
| 24 |
+
return X_train, X_val, X_test, y_train, y_val, y_test, dates_train, dates_val, dates_test, close_df
|
| 25 |
+
except Exception as e:
|
| 26 |
+
raise e
|
| 27 |
+
|
| 28 |
+
if __name__ == '__main__':
|
| 29 |
+
try:
|
| 30 |
+
logger.info(f">>>>> stage {STAGE_NAME} started <<<<<")
|
| 31 |
+
obj = DataPreProcessingPipeline()
|
| 32 |
+
obj.main()
|
| 33 |
+
logger.info(f">>>>> stage {STAGE_NAME} completed <<<<<")
|
| 34 |
+
except Exception as e:
|
| 35 |
+
logger.exception(e)
|
| 36 |
+
raise e
|
tsForecaster/pipeline/stage_03_model_training.py
ADDED
|
@@ -0,0 +1,28 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from tsForecaster.components.model_training import ModelTraining
|
| 2 |
+
from tsForecaster.config.configuration import ConfigurationManager
|
| 3 |
+
from tsForecaster import logger
|
| 4 |
+
|
| 5 |
+
STAGE_NAME = "Model Training"
|
| 6 |
+
|
| 7 |
+
class ModelTrainingPipeline:
|
| 8 |
+
def __init__(self) -> None:
|
| 9 |
+
pass
|
| 10 |
+
|
| 11 |
+
def main(self, X_train, y_train, X_val, y_val):
|
| 12 |
+
try:
|
| 13 |
+
config = ConfigurationManager()
|
| 14 |
+
model_training_config = config.get_model_training_config()
|
| 15 |
+
model_training = ModelTraining(config=model_training_config)
|
| 16 |
+
model_training.train(X_train, y_train, X_val, y_val)
|
| 17 |
+
except Exception as e:
|
| 18 |
+
raise e
|
| 19 |
+
|
| 20 |
+
if __name__ == '__main__':
|
| 21 |
+
try:
|
| 22 |
+
logger.info(f">>>>> stage {STAGE_NAME} started <<<<<")
|
| 23 |
+
obj = ModelTrainingPipeline()
|
| 24 |
+
history = obj.main()
|
| 25 |
+
logger.info(f">>>>> stage {STAGE_NAME} completed <<<<<")
|
| 26 |
+
except Exception as e:
|
| 27 |
+
logger.exception(e)
|
| 28 |
+
raise e
|
tsForecaster/pipeline/stage_04_model_evaluation.py
ADDED
|
@@ -0,0 +1,30 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import os
|
| 2 |
+
from tsForecaster import logger
|
| 3 |
+
from tsForecaster.components.model_evaluation import ModelEvaluation
|
| 4 |
+
from tsForecaster.config.configuration import ConfigurationManager
|
| 5 |
+
|
| 6 |
+
STAGE_NAME = "Model Evaluation Stage"
|
| 7 |
+
|
| 8 |
+
class ModelEvaluationPipeline:
|
| 9 |
+
def __init__(self) -> None:
|
| 10 |
+
|
| 11 |
+
pass
|
| 12 |
+
|
| 13 |
+
def main(self, X, y, dates):
|
| 14 |
+
try:
|
| 15 |
+
config = ConfigurationManager()
|
| 16 |
+
eval_config = config.get_model_training_config()
|
| 17 |
+
eval = ModelEvaluation(eval_config)
|
| 18 |
+
eval.evaluation(X, y, dates)
|
| 19 |
+
except Exception as e:
|
| 20 |
+
raise e
|
| 21 |
+
|
| 22 |
+
if __name__ == '__main__':
|
| 23 |
+
try:
|
| 24 |
+
logger.info(f">>>>> stage {STAGE_NAME} started <<<<<")
|
| 25 |
+
obj = ModelEvaluationPipeline()
|
| 26 |
+
obj.main()
|
| 27 |
+
logger.info(f">>>>> stage {STAGE_NAME} completed <<<<<")
|
| 28 |
+
except Exception as e:
|
| 29 |
+
logger.exception(e)
|
| 30 |
+
raise e
|
tsForecaster/utils/__init__.py
ADDED
|
File without changes
|
tsForecaster/utils/common.py
ADDED
|
@@ -0,0 +1,191 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import os
|
| 2 |
+
from box.exceptions import BoxValueError
|
| 3 |
+
import yaml
|
| 4 |
+
from tsForecaster import logger
|
| 5 |
+
import json
|
| 6 |
+
import joblib
|
| 7 |
+
from ensure import ensure_annotations
|
| 8 |
+
from box import ConfigBox
|
| 9 |
+
from pathlib import Path
|
| 10 |
+
from typing import Any
|
| 11 |
+
import base64
|
| 12 |
+
|
| 13 |
+
@ensure_annotations
|
| 14 |
+
def read_yaml(path_to_yaml: Path) -> ConfigBox:
|
| 15 |
+
"""
|
| 16 |
+
Read and load data from a YAML file.
|
| 17 |
+
|
| 18 |
+
Args:
|
| 19 |
+
path_to_yaml (Path): Path to the YAML file.
|
| 20 |
+
|
| 21 |
+
Returns:
|
| 22 |
+
Box: A Box object containing the YAML file data.
|
| 23 |
+
|
| 24 |
+
Raises:
|
| 25 |
+
ValueError: If the YAML file is empty or cannot be loaded.
|
| 26 |
+
Exception: For any other unexpected errors during file reading or parsing.
|
| 27 |
+
"""
|
| 28 |
+
try:
|
| 29 |
+
with open(path_to_yaml) as yaml_file:
|
| 30 |
+
content = yaml.safe_load(yaml_file)
|
| 31 |
+
logger.info(f"yaml file {path_to_yaml} loaded successfully")
|
| 32 |
+
return ConfigBox(content)
|
| 33 |
+
except BoxValueError:
|
| 34 |
+
raise ValueError("Yaml file is empty")
|
| 35 |
+
except Exception as e:
|
| 36 |
+
raise e
|
| 37 |
+
|
| 38 |
+
@ensure_annotations
|
| 39 |
+
def create_directories(path_to_directories: list, verbose: bool=True):
|
| 40 |
+
"""
|
| 41 |
+
Create directories specified in the list.
|
| 42 |
+
|
| 43 |
+
Args:
|
| 44 |
+
path_to_directories (list): List of directory paths to create.
|
| 45 |
+
verbose (bool, optional): Whether to log directory creation (default is True).
|
| 46 |
+
|
| 47 |
+
Raises:
|
| 48 |
+
Exception: For any unexpected errors during directory creation.
|
| 49 |
+
"""
|
| 50 |
+
try:
|
| 51 |
+
for dirs in path_to_directories:
|
| 52 |
+
os.makedirs(dirs, exist_ok=True)
|
| 53 |
+
if verbose:
|
| 54 |
+
logger.info(f"Created directory at: {path_to_directories}")
|
| 55 |
+
except Exception as e:
|
| 56 |
+
raise e
|
| 57 |
+
|
| 58 |
+
@ensure_annotations
|
| 59 |
+
def save_json(path: Path, data: dict):
|
| 60 |
+
"""
|
| 61 |
+
Save JSON data to a file.
|
| 62 |
+
|
| 63 |
+
Args:
|
| 64 |
+
path (Path): Path to the JSON file.
|
| 65 |
+
data (dict): Dictionary containing JSON serializable data.
|
| 66 |
+
|
| 67 |
+
Raises:
|
| 68 |
+
Exception: For any unexpected errors during file saving.
|
| 69 |
+
"""
|
| 70 |
+
try:
|
| 71 |
+
with open(path, 'w') as f:
|
| 72 |
+
json.dump(data, f, indent=4)
|
| 73 |
+
logger.info(f"Json saved at: {path}")
|
| 74 |
+
except Exception as e:
|
| 75 |
+
raise e
|
| 76 |
+
|
| 77 |
+
@ensure_annotations
|
| 78 |
+
def load_json(path: Path) -> ConfigBox:
|
| 79 |
+
"""
|
| 80 |
+
Load JSON data from a file and return as a Box object.
|
| 81 |
+
|
| 82 |
+
Args:
|
| 83 |
+
path (Path): Path to the JSON file.
|
| 84 |
+
|
| 85 |
+
Returns:
|
| 86 |
+
Box: A Box object containing the JSON data.
|
| 87 |
+
|
| 88 |
+
Raises:
|
| 89 |
+
Exception: For any unexpected errors during file loading.
|
| 90 |
+
"""
|
| 91 |
+
try:
|
| 92 |
+
with open(path, 'r') as f:
|
| 93 |
+
content = json.load(f)
|
| 94 |
+
logger.info(f"Successfully loaded json from: {path}")
|
| 95 |
+
return ConfigBox(content)
|
| 96 |
+
except Exception as e:
|
| 97 |
+
raise e
|
| 98 |
+
|
| 99 |
+
@ensure_annotations
|
| 100 |
+
def save_bin(data: Any, path: Path) -> None:
|
| 101 |
+
"""
|
| 102 |
+
Save binary data using joblib.
|
| 103 |
+
|
| 104 |
+
Args:
|
| 105 |
+
data (Any): Data to be saved.
|
| 106 |
+
path (Path): Path to save the binary file.
|
| 107 |
+
|
| 108 |
+
Raises:
|
| 109 |
+
Exception: For any unexpected errors during file saving.
|
| 110 |
+
"""
|
| 111 |
+
try:
|
| 112 |
+
joblib.dump(value=data, filename=path)
|
| 113 |
+
logger.info(f"Binary file saved at: {path}")
|
| 114 |
+
except Exception as e:
|
| 115 |
+
raise e
|
| 116 |
+
|
| 117 |
+
@ensure_annotations
|
| 118 |
+
def load_bin(path: Path):
|
| 119 |
+
"""
|
| 120 |
+
Load binary data using joblib.
|
| 121 |
+
|
| 122 |
+
Args:
|
| 123 |
+
path (Path): Path to the binary file.
|
| 124 |
+
|
| 125 |
+
Returns:
|
| 126 |
+
Any: Loaded binary data.
|
| 127 |
+
|
| 128 |
+
Raises:
|
| 129 |
+
Exception: For any unexpected errors during file loading.
|
| 130 |
+
"""
|
| 131 |
+
joblib.load(filename=path)
|
| 132 |
+
logger.info(f"Successfully loaded binary from: {path}")
|
| 133 |
+
|
| 134 |
+
@ensure_annotations
|
| 135 |
+
def get_size(path: Path) -> str:
|
| 136 |
+
"""
|
| 137 |
+
Get the size of a file in kilobytes.
|
| 138 |
+
|
| 139 |
+
Args:
|
| 140 |
+
path (Path): Path to the file.
|
| 141 |
+
|
| 142 |
+
Returns:
|
| 143 |
+
str: Size of the file in kilobytes formatted as "{size} kb".
|
| 144 |
+
|
| 145 |
+
Raises:
|
| 146 |
+
Exception: For any unexpected errors during file size retrieval.
|
| 147 |
+
"""
|
| 148 |
+
try:
|
| 149 |
+
size_in_kb = round(os.path.getsize(path)/1024, 2)
|
| 150 |
+
return f"{size_in_kb} kb"
|
| 151 |
+
except Exception as e:
|
| 152 |
+
raise e
|
| 153 |
+
|
| 154 |
+
def decodeImage(imgString, fileName) -> None:
|
| 155 |
+
"""
|
| 156 |
+
Decode base64 encoded image data and save it to a file.
|
| 157 |
+
|
| 158 |
+
Args:
|
| 159 |
+
imgString (str): Base64 encoded image data.
|
| 160 |
+
fileName (str): Name of the file to save the decoded image data.
|
| 161 |
+
|
| 162 |
+
Raises:
|
| 163 |
+
Exception: For any unexpected errors during decoding or file writing.
|
| 164 |
+
"""
|
| 165 |
+
try:
|
| 166 |
+
imgData = base64.b64decode(imgString)
|
| 167 |
+
with open(fileName, 'wb') as f:
|
| 168 |
+
f.write(imgData)
|
| 169 |
+
f.close
|
| 170 |
+
except Exception as e:
|
| 171 |
+
raise e
|
| 172 |
+
|
| 173 |
+
def encodeImage(imagePath) -> bytes:
|
| 174 |
+
"""
|
| 175 |
+
Encode an image file to base64 bytes.
|
| 176 |
+
|
| 177 |
+
Args:
|
| 178 |
+
imagePath (str): Path to the image file.
|
| 179 |
+
|
| 180 |
+
Returns:
|
| 181 |
+
bytes: Base64 encoded bytes of the image data.
|
| 182 |
+
|
| 183 |
+
Raises:
|
| 184 |
+
Exception: For any unexpected errors during encoding or file reading.
|
| 185 |
+
"""
|
| 186 |
+
try:
|
| 187 |
+
with open(imagePath, 'rb') as f:
|
| 188 |
+
imgData = f.read()
|
| 189 |
+
return base64.b64encode(imgData)
|
| 190 |
+
except Exception as e:
|
| 191 |
+
raise e
|