Spaces:
Runtime error


Runtime error

files
Browse files- app.py +170 -50
- clipseg/LICENSE +21 -0
- clipseg/Quickstart.ipynb +107 -0
- clipseg/Readme.md +84 -0
- clipseg/Tables.ipynb +349 -0
- clipseg/Visual_Feature_Engineering.ipynb +366 -0
- clipseg/datasets/coco_wrapper.py +99 -0
- clipseg/datasets/pascal_classes.json +1 -0
- clipseg/datasets/pascal_zeroshot.py +60 -0
- clipseg/datasets/pfe_dataset.py +129 -0
- clipseg/datasets/phrasecut.py +335 -0
- clipseg/datasets/utils.py +68 -0
- clipseg/environment.yml +15 -0
- clipseg/evaluation_utils.py +292 -0
- clipseg/example_image.jpg +0 -0
- clipseg/experiments/ablation.yaml +84 -0
- clipseg/experiments/coco.yaml +101 -0
- clipseg/experiments/pascal_1shot.yaml +101 -0
- clipseg/experiments/phrasecut.yaml +80 -0
- clipseg/general_utils.py +272 -0
- clipseg/metrics.py +271 -0
- clipseg/models/clipseg.py +552 -0
- clipseg/models/vitseg.py +286 -0
- clipseg/overview.png +0 -0
- clipseg/score.py +453 -0
- clipseg/setup.py +30 -0
- clipseg/training.py +266 -0
- clipseg/weights/rd64-uni.pth +3 -0
- init_image.png +0 -0
- inpainting.py +194 -0
- mask_image.png +0 -0
app.py
CHANGED
|
@@ -1,54 +1,174 @@
|
|
| 1 |
-
from diffusers import StableDiffusionInpaintPipeline
|
| 2 |
import gradio as gr
|
| 3 |
-
|
| 4 |
-
import imageio
|
| 5 |
-
from PIL import Image
|
| 6 |
from io import BytesIO
|
|
|
|
|
|
|
|
|
|
|
|
|
| 7 |
import os
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 8 |
|
| 9 |
-
|
| 10 |
-
|
| 11 |
-
|
| 12 |
-
|
| 13 |
-
|
| 14 |
-
|
| 15 |
-
|
| 16 |
-
|
| 17 |
-
|
| 18 |
-
|
| 19 |
-
|
| 20 |
-
|
| 21 |
-
|
| 22 |
-
|
| 23 |
-
|
| 24 |
-
|
| 25 |
-
|
| 26 |
-
|
| 27 |
-
|
| 28 |
-
|
| 29 |
-
|
| 30 |
-
|
| 31 |
-
|
| 32 |
-
|
| 33 |
-
|
| 34 |
-
|
| 35 |
-
|
| 36 |
-
|
| 37 |
-
|
| 38 |
-
|
| 39 |
-
|
| 40 |
-
|
| 41 |
-
|
| 42 |
-
|
| 43 |
-
|
| 44 |
-
|
| 45 |
-
|
| 46 |
-
|
| 47 |
-
|
| 48 |
-
|
| 49 |
-
|
| 50 |
-
|
| 51 |
-
|
| 52 |
-
|
| 53 |
-
|
| 54 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
import gradio as gr
|
| 2 |
+
|
|
|
|
|
|
|
| 3 |
from io import BytesIO
|
| 4 |
+
import requests
|
| 5 |
+
import PIL
|
| 6 |
+
from PIL import Image
|
| 7 |
+
import numpy as np
|
| 8 |
import os
|
| 9 |
+
import uuid
|
| 10 |
+
import torch
|
| 11 |
+
from torch import autocast
|
| 12 |
+
import cv2
|
| 13 |
+
from matplotlib import pyplot as plt
|
| 14 |
+
from inpainting import StableDiffusionInpaintingPipeline
|
| 15 |
+
from torchvision import transforms
|
| 16 |
+
from clipseg.models.clipseg import CLIPDensePredT
|
| 17 |
+
|
| 18 |
+
auth_token = os.environ.get("API_TOKEN") or True
|
| 19 |
+
|
| 20 |
+
def download_image(url):
|
| 21 |
+
response = requests.get(url)
|
| 22 |
+
return PIL.Image.open(BytesIO(response.content)).convert("RGB")
|
| 23 |
+
|
| 24 |
+
device = "cuda" if torch.cuda.is_available() else "cpu"
|
| 25 |
+
pipe = StableDiffusionInpaintingPipeline.from_pretrained(
|
| 26 |
+
"CompVis/stable-diffusion-v1-4",
|
| 27 |
+
revision="fp16",
|
| 28 |
+
torch_dtype=torch.float16,
|
| 29 |
+
use_auth_token=auth_token,
|
| 30 |
+
).to(device)
|
| 31 |
+
|
| 32 |
+
model = CLIPDensePredT(version='ViT-B/16', reduce_dim=64)
|
| 33 |
+
model.eval()
|
| 34 |
+
model.load_state_dict(torch.load('./clipseg/weights/rd64-uni.pth', map_location=torch.device('cuda')), strict=False)
|
| 35 |
+
|
| 36 |
+
transform = transforms.Compose([
|
| 37 |
+
transforms.ToTensor(),
|
| 38 |
+
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]),
|
| 39 |
+
transforms.Resize((512, 512)),
|
| 40 |
+
])
|
| 41 |
+
|
| 42 |
+
def predict(radio, dict, word_mask, prompt=""):
|
| 43 |
+
if(radio == "draw a mask above"):
|
| 44 |
+
with autocast("cuda"):
|
| 45 |
+
init_image = dict["image"].convert("RGB").resize((512, 512))
|
| 46 |
+
mask = dict["mask"].convert("RGB").resize((512, 512))
|
| 47 |
+
else:
|
| 48 |
+
img = transform(dict["image"]).unsqueeze(0)
|
| 49 |
+
word_masks = [word_mask]
|
| 50 |
+
with torch.no_grad():
|
| 51 |
+
preds = model(img.repeat(len(word_masks),1,1,1), word_masks)[0]
|
| 52 |
+
init_image = dict['image'].convert('RGB').resize((512, 512))
|
| 53 |
+
filename = f"{uuid.uuid4()}.png"
|
| 54 |
+
plt.imsave(filename,torch.sigmoid(preds[0][0]))
|
| 55 |
+
img2 = cv2.imread(filename)
|
| 56 |
+
gray_image = cv2.cvtColor(img2, cv2.COLOR_BGR2GRAY)
|
| 57 |
+
(thresh, bw_image) = cv2.threshold(gray_image, 100, 255, cv2.THRESH_BINARY)
|
| 58 |
+
cv2.cvtColor(bw_image, cv2.COLOR_BGR2RGB)
|
| 59 |
+
mask = Image.fromarray(np.uint8(bw_image)).convert('RGB')
|
| 60 |
+
os.remove(filename)
|
| 61 |
+
with autocast("cuda"):
|
| 62 |
+
images = pipe(prompt = prompt, init_image=init_image, mask_image=mask, strength=0.8)["sample"]
|
| 63 |
+
return images[0]
|
| 64 |
+
|
| 65 |
+
# examples = [[dict(image="init_image.png", mask="mask_image.png"), "A panda sitting on a bench"]]
|
| 66 |
+
css = '''
|
| 67 |
+
.container {max-width: 1150px;margin: auto;padding-top: 1.5rem}
|
| 68 |
+
#image_upload{min-height:400px}
|
| 69 |
+
#image_upload [data-testid="image"], #image_upload [data-testid="image"] > div{min-height: 400px}
|
| 70 |
+
#mask_radio .gr-form{background:transparent; border: none}
|
| 71 |
+
#word_mask{margin-top: .75em !important}
|
| 72 |
+
#word_mask textarea:disabled{opacity: 0.3}
|
| 73 |
+
.footer {margin-bottom: 45px;margin-top: 35px;text-align: center;border-bottom: 1px solid #e5e5e5}
|
| 74 |
+
.footer>p {font-size: .8rem; display: inline-block; padding: 0 10px;transform: translateY(10px);background: white}
|
| 75 |
+
.dark .footer {border-color: #303030}
|
| 76 |
+
.dark .footer>p {background: #0b0f19}
|
| 77 |
+
.acknowledgments h4{margin: 1.25em 0 .25em 0;font-weight: bold;font-size: 115%}
|
| 78 |
+
#image_upload .touch-none{display: flex}
|
| 79 |
+
'''
|
| 80 |
+
def swap_word_mask(radio_option):
|
| 81 |
+
if(radio_option == "type what to mask below"):
|
| 82 |
+
return gr.update(interactive=True, placeholder="A cat")
|
| 83 |
+
else:
|
| 84 |
+
return gr.update(interactive=False, placeholder="Disabled")
|
| 85 |
|
| 86 |
+
image_blocks = gr.Blocks(css=css)
|
| 87 |
+
with image_blocks as demo:
|
| 88 |
+
gr.HTML(
|
| 89 |
+
"""
|
| 90 |
+
<div style="text-align: center; max-width: 650px; margin: 0 auto;">
|
| 91 |
+
<div
|
| 92 |
+
style="
|
| 93 |
+
display: inline-flex;
|
| 94 |
+
align-items: center;
|
| 95 |
+
gap: 0.8rem;
|
| 96 |
+
font-size: 1.75rem;
|
| 97 |
+
"
|
| 98 |
+
>
|
| 99 |
+
<svg
|
| 100 |
+
width="0.65em"
|
| 101 |
+
height="0.65em"
|
| 102 |
+
viewBox="0 0 115 115"
|
| 103 |
+
fill="none"
|
| 104 |
+
xmlns="http://www.w3.org/2000/svg"
|
| 105 |
+
>
|
| 106 |
+
<rect width="23" height="23" fill="white"></rect>
|
| 107 |
+
<rect y="69" width="23" height="23" fill="white"></rect>
|
| 108 |
+
<rect x="23" width="23" height="23" fill="#AEAEAE"></rect>
|
| 109 |
+
<rect x="23" y="69" width="23" height="23" fill="#AEAEAE"></rect>
|
| 110 |
+
<rect x="46" width="23" height="23" fill="white"></rect>
|
| 111 |
+
<rect x="46" y="69" width="23" height="23" fill="white"></rect>
|
| 112 |
+
<rect x="69" width="23" height="23" fill="black"></rect>
|
| 113 |
+
<rect x="69" y="69" width="23" height="23" fill="black"></rect>
|
| 114 |
+
<rect x="92" width="23" height="23" fill="#D9D9D9"></rect>
|
| 115 |
+
<rect x="92" y="69" width="23" height="23" fill="#AEAEAE"></rect>
|
| 116 |
+
<rect x="115" y="46" width="23" height="23" fill="white"></rect>
|
| 117 |
+
<rect x="115" y="115" width="23" height="23" fill="white"></rect>
|
| 118 |
+
<rect x="115" y="69" width="23" height="23" fill="#D9D9D9"></rect>
|
| 119 |
+
<rect x="92" y="46" width="23" height="23" fill="#AEAEAE"></rect>
|
| 120 |
+
<rect x="92" y="115" width="23" height="23" fill="#AEAEAE"></rect>
|
| 121 |
+
<rect x="92" y="69" width="23" height="23" fill="white"></rect>
|
| 122 |
+
<rect x="69" y="46" width="23" height="23" fill="white"></rect>
|
| 123 |
+
<rect x="69" y="115" width="23" height="23" fill="white"></rect>
|
| 124 |
+
<rect x="69" y="69" width="23" height="23" fill="#D9D9D9"></rect>
|
| 125 |
+
<rect x="46" y="46" width="23" height="23" fill="black"></rect>
|
| 126 |
+
<rect x="46" y="115" width="23" height="23" fill="black"></rect>
|
| 127 |
+
<rect x="46" y="69" width="23" height="23" fill="black"></rect>
|
| 128 |
+
<rect x="23" y="46" width="23" height="23" fill="#D9D9D9"></rect>
|
| 129 |
+
<rect x="23" y="115" width="23" height="23" fill="#AEAEAE"></rect>
|
| 130 |
+
<rect x="23" y="69" width="23" height="23" fill="black"></rect>
|
| 131 |
+
</svg>
|
| 132 |
+
<h1 style="font-weight: 900; margin-bottom: 7px;">
|
| 133 |
+
Stable Diffusion Multi Inpainting
|
| 134 |
+
</h1>
|
| 135 |
+
</div>
|
| 136 |
+
<p style="margin-bottom: 10px; font-size: 94%">
|
| 137 |
+
Inpaint Stable Diffusion by either drawing a mask or typing what to replace
|
| 138 |
+
</p>
|
| 139 |
+
</div>
|
| 140 |
+
"""
|
| 141 |
+
)
|
| 142 |
+
with gr.Row():
|
| 143 |
+
with gr.Column():
|
| 144 |
+
image = gr.Image(source='upload', tool='sketch', elem_id="image_upload", type="pil", label="Upload").style(height=400)
|
| 145 |
+
with gr.Box(elem_id="mask_radio").style(border=False):
|
| 146 |
+
radio = gr.Radio(["draw a mask above", "type what to mask below"], value="draw a mask above", show_label=False, interactive=True).style(container=False)
|
| 147 |
+
word_mask = gr.Textbox(label = "What to find in your image", interactive=False, elem_id="word_mask", placeholder="Disabled").style(container=False)
|
| 148 |
+
prompt = gr.Textbox(label = 'Your prompt (what you want to add in place of what you are removing)')
|
| 149 |
+
radio.change(fn=swap_word_mask, inputs=radio, outputs=word_mask,show_progress=False)
|
| 150 |
+
radio.change(None, inputs=[], outputs=image_blocks, _js = """
|
| 151 |
+
() => {
|
| 152 |
+
css_style = document.styleSheets[document.styleSheets.length - 1]
|
| 153 |
+
last_item = css_style.cssRules[css_style.cssRules.length - 1]
|
| 154 |
+
last_item.style.display = ["flex", ""].includes(last_item.style.display) ? "none" : "flex";
|
| 155 |
+
}""")
|
| 156 |
+
btn = gr.Button("Run")
|
| 157 |
+
with gr.Column():
|
| 158 |
+
result = gr.Image(label="Result")
|
| 159 |
+
btn.click(fn=predict, inputs=[radio, image, word_mask, prompt], outputs=result)
|
| 160 |
+
gr.HTML(
|
| 161 |
+
"""
|
| 162 |
+
<div class="footer">
|
| 163 |
+
<p>Model by <a href="https://huggingface.co/CompVis" style="text-decoration: underline;" target="_blank">CompVis</a> and <a href="https://huggingface.co/stabilityai" style="text-decoration: underline;" target="_blank">Stability AI</a> - Inpainting by <a href="https://github.com/nagolinc" style="text-decoration: underline;" target="_blank">nagolinc</a> and <a href="https://github.com/patil-suraj" style="text-decoration: underline;">patil-suraj</a>, inpainting with words by <a href="https://twitter.com/yvrjsharma/" style="text-decoration: underline;" target="_blank">@yvrjsharma</a> and <a href="https://twitter.com/1littlecoder" style="text-decoration: underline;">@1littlecoder</a> - Gradio Demo by 🤗 Hugging Face
|
| 164 |
+
</p>
|
| 165 |
+
</div>
|
| 166 |
+
<div class="acknowledgments">
|
| 167 |
+
<p><h4>LICENSE</h4>
|
| 168 |
+
The model is licensed with a <a href="https://huggingface.co/spaces/CompVis/stable-diffusion-license" style="text-decoration: underline;" target="_blank">CreativeML Open RAIL-M</a> license. The authors claim no rights on the outputs you generate, you are free to use them and are accountable for their use which must not go against the provisions set in this license. The license forbids you from sharing any content that violates any laws, produce any harm to a person, disseminate any personal information that would be meant for harm, spread misinformation and target vulnerable groups. For the full list of restrictions please <a href="https://huggingface.co/spaces/CompVis/stable-diffusion-license" target="_blank" style="text-decoration: underline;" target="_blank">read the license</a></p>
|
| 169 |
+
<p><h4>Biases and content acknowledgment</h4>
|
| 170 |
+
Despite how impressive being able to turn text into image is, beware to the fact that this model may output content that reinforces or exacerbates societal biases, as well as realistic faces, pornography and violence. The model was trained on the <a href="https://laion.ai/blog/laion-5b/" style="text-decoration: underline;" target="_blank">LAION-5B dataset</a>, which scraped non-curated image-text-pairs from the internet (the exception being the removal of illegal content) and is meant for research purposes. You can read more in the <a href="https://huggingface.co/CompVis/stable-diffusion-v1-4" style="text-decoration: underline;" target="_blank">model card</a></p>
|
| 171 |
+
</div>
|
| 172 |
+
"""
|
| 173 |
+
)
|
| 174 |
+
demo.launch()
|
clipseg/LICENSE
ADDED
|
@@ -0,0 +1,21 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
MIT License
|
| 2 |
+
|
| 3 |
+
This license does not apply to the model weights.
|
| 4 |
+
|
| 5 |
+
Permission is hereby granted, free of charge, to any person obtaining a copy
|
| 6 |
+
of this software and associated documentation files (the "Software"), to deal
|
| 7 |
+
in the Software without restriction, including without limitation the rights
|
| 8 |
+
to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
|
| 9 |
+
copies of the Software, and to permit persons to whom the Software is
|
| 10 |
+
furnished to do so, subject to the following conditions:
|
| 11 |
+
|
| 12 |
+
The above copyright notice and this permission notice shall be included in all
|
| 13 |
+
copies or substantial portions of the Software.
|
| 14 |
+
|
| 15 |
+
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
|
| 16 |
+
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
|
| 17 |
+
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
|
| 18 |
+
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
|
| 19 |
+
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
|
| 20 |
+
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
|
| 21 |
+
SOFTWARE.
|
clipseg/Quickstart.ipynb
ADDED
|
@@ -0,0 +1,107 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"cells": [
|
| 3 |
+
{
|
| 4 |
+
"cell_type": "code",
|
| 5 |
+
"execution_count": null,
|
| 6 |
+
"metadata": {},
|
| 7 |
+
"outputs": [],
|
| 8 |
+
"source": [
|
| 9 |
+
"import torch\n",
|
| 10 |
+
"import requests\n",
|
| 11 |
+
"\n",
|
| 12 |
+
"! wget https://owncloud.gwdg.de/index.php/s/ioHbRzFx6th32hn/download -O weights.zip\n",
|
| 13 |
+
"! unzip -d weights -j weights.zip\n",
|
| 14 |
+
"from models.clipseg import CLIPDensePredT\n",
|
| 15 |
+
"from PIL import Image\n",
|
| 16 |
+
"from torchvision import transforms\n",
|
| 17 |
+
"from matplotlib import pyplot as plt\n",
|
| 18 |
+
"\n",
|
| 19 |
+
"# load model\n",
|
| 20 |
+
"model = CLIPDensePredT(version='ViT-B/16', reduce_dim=64)\n",
|
| 21 |
+
"model.eval();\n",
|
| 22 |
+
"\n",
|
| 23 |
+
"# non-strict, because we only stored decoder weights (not CLIP weights)\n",
|
| 24 |
+
"model.load_state_dict(torch.load('weights/rd64-uni.pth', map_location=torch.device('cpu')), strict=False);"
|
| 25 |
+
]
|
| 26 |
+
},
|
| 27 |
+
{
|
| 28 |
+
"cell_type": "markdown",
|
| 29 |
+
"metadata": {},
|
| 30 |
+
"source": [
|
| 31 |
+
"Load and normalize `example_image.jpg`. You can also load through an URL."
|
| 32 |
+
]
|
| 33 |
+
},
|
| 34 |
+
{
|
| 35 |
+
"cell_type": "code",
|
| 36 |
+
"execution_count": null,
|
| 37 |
+
"metadata": {},
|
| 38 |
+
"outputs": [],
|
| 39 |
+
"source": [
|
| 40 |
+
"# load and normalize image\n",
|
| 41 |
+
"input_image = Image.open('example_image.jpg')\n",
|
| 42 |
+
"\n",
|
| 43 |
+
"# or load from URL...\n",
|
| 44 |
+
"# image_url = 'https://farm5.staticflickr.com/4141/4856248695_03475782dc_z.jpg'\n",
|
| 45 |
+
"# input_image = Image.open(requests.get(image_url, stream=True).raw)\n",
|
| 46 |
+
"\n",
|
| 47 |
+
"transform = transforms.Compose([\n",
|
| 48 |
+
" transforms.ToTensor(),\n",
|
| 49 |
+
" transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]),\n",
|
| 50 |
+
" transforms.Resize((352, 352)),\n",
|
| 51 |
+
"])\n",
|
| 52 |
+
"img = transform(input_image).unsqueeze(0)"
|
| 53 |
+
]
|
| 54 |
+
},
|
| 55 |
+
{
|
| 56 |
+
"cell_type": "markdown",
|
| 57 |
+
"metadata": {},
|
| 58 |
+
"source": [
|
| 59 |
+
"Predict and visualize (this might take a few seconds if running without GPU support)"
|
| 60 |
+
]
|
| 61 |
+
},
|
| 62 |
+
{
|
| 63 |
+
"cell_type": "code",
|
| 64 |
+
"execution_count": null,
|
| 65 |
+
"metadata": {},
|
| 66 |
+
"outputs": [],
|
| 67 |
+
"source": [
|
| 68 |
+
"prompts = ['a glass', 'something to fill', 'wood', 'a jar']\n",
|
| 69 |
+
"\n",
|
| 70 |
+
"# predict\n",
|
| 71 |
+
"with torch.no_grad():\n",
|
| 72 |
+
" preds = model(img.repeat(4,1,1,1), prompts)[0]\n",
|
| 73 |
+
"\n",
|
| 74 |
+
"# visualize prediction\n",
|
| 75 |
+
"_, ax = plt.subplots(1, 5, figsize=(15, 4))\n",
|
| 76 |
+
"[a.axis('off') for a in ax.flatten()]\n",
|
| 77 |
+
"ax[0].imshow(input_image)\n",
|
| 78 |
+
"[ax[i+1].imshow(torch.sigmoid(preds[i][0])) for i in range(4)];\n",
|
| 79 |
+
"[ax[i+1].text(0, -15, prompts[i]) for i in range(4)];"
|
| 80 |
+
]
|
| 81 |
+
}
|
| 82 |
+
],
|
| 83 |
+
"metadata": {
|
| 84 |
+
"interpreter": {
|
| 85 |
+
"hash": "800ed241f7db2bd3aa6942aa3be6809cdb30ee6b0a9e773dfecfa9fef1f4c586"
|
| 86 |
+
},
|
| 87 |
+
"kernelspec": {
|
| 88 |
+
"display_name": "Python 3",
|
| 89 |
+
"language": "python",
|
| 90 |
+
"name": "python3"
|
| 91 |
+
},
|
| 92 |
+
"language_info": {
|
| 93 |
+
"codemirror_mode": {
|
| 94 |
+
"name": "ipython",
|
| 95 |
+
"version": 3
|
| 96 |
+
},
|
| 97 |
+
"file_extension": ".py",
|
| 98 |
+
"mimetype": "text/x-python",
|
| 99 |
+
"name": "python",
|
| 100 |
+
"nbconvert_exporter": "python",
|
| 101 |
+
"pygments_lexer": "ipython3",
|
| 102 |
+
"version": "3.8.10"
|
| 103 |
+
}
|
| 104 |
+
},
|
| 105 |
+
"nbformat": 4,
|
| 106 |
+
"nbformat_minor": 4
|
| 107 |
+
}
|
clipseg/Readme.md
ADDED
|
@@ -0,0 +1,84 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Image Segmentation Using Text and Image Prompts
|
| 2 |
+
This repository contains the code used in the paper ["Image Segmentation Using Text and Image Prompts"](https://arxiv.org/abs/2112.10003).
|
| 3 |
+
|
| 4 |
+
**The Paper has been accepted to CVPR 2022!**
|
| 5 |
+
|
| 6 |
+
<img src="overview.png" alt="drawing" height="200em"/>
|
| 7 |
+
|
| 8 |
+
The systems allows to create segmentation models without training based on:
|
| 9 |
+
- An arbitrary text query
|
| 10 |
+
- Or an image with a mask highlighting stuff or an object.
|
| 11 |
+
|
| 12 |
+
### Quick Start
|
| 13 |
+
|
| 14 |
+
In the `Quickstart.ipynb` notebook we provide the code for using a pre-trained CLIPSeg model. If you run the notebook locally, make sure you downloaded the `rd64-uni.pth` weights, either manually or via git lfs extension.
|
| 15 |
+
It can also be used interactively using [MyBinder](https://mybinder.org/v2/gh/timojl/clipseg/HEAD?labpath=Quickstart.ipynb)
|
| 16 |
+
(please note that the VM does not use a GPU, thus inference takes a few seconds).
|
| 17 |
+
|
| 18 |
+
|
| 19 |
+
### Dependencies
|
| 20 |
+
This code base depends on pytorch, torchvision and clip (`pip install git+https://github.com/openai/CLIP.git`).
|
| 21 |
+
Additional dependencies are hidden for double blind review.
|
| 22 |
+
|
| 23 |
+
|
| 24 |
+
### Datasets
|
| 25 |
+
|
| 26 |
+
* `PhraseCut` and `PhraseCutPlus`: Referring expression dataset
|
| 27 |
+
* `PFEPascalWrapper`: Wrapper class for PFENet's Pascal-5i implementation
|
| 28 |
+
* `PascalZeroShot`: Wrapper class for PascalZeroShot
|
| 29 |
+
* `COCOWrapper`: Wrapper class for COCO.
|
| 30 |
+
|
| 31 |
+
### Models
|
| 32 |
+
|
| 33 |
+
* `CLIPDensePredT`: CLIPSeg model with transformer-based decoder.
|
| 34 |
+
* `ViTDensePredT`: CLIPSeg model with transformer-based decoder.
|
| 35 |
+
|
| 36 |
+
### Third Party Dependencies
|
| 37 |
+
For some of the datasets third party dependencies are required. Run the following commands in the `third_party` folder.
|
| 38 |
+
```bash
|
| 39 |
+
git clone https://github.com/cvlab-yonsei/JoEm
|
| 40 |
+
git clone https://github.com/Jia-Research-Lab/PFENet.git
|
| 41 |
+
git clone https://github.com/ChenyunWu/PhraseCutDataset.git
|
| 42 |
+
git clone https://github.com/juhongm999/hsnet.git
|
| 43 |
+
```
|
| 44 |
+
|
| 45 |
+
### Weights
|
| 46 |
+
|
| 47 |
+
The MIT license does not apply to these weights.
|
| 48 |
+
|
| 49 |
+
We provide two model weights, for D=64 (4.1MB) and D=16 (1.1MB).
|
| 50 |
+
```
|
| 51 |
+
wget https://owncloud.gwdg.de/index.php/s/ioHbRzFx6th32hn/download -O weights.zip
|
| 52 |
+
unzip -d weights -j weights.zip
|
| 53 |
+
```
|
| 54 |
+
|
| 55 |
+
|
| 56 |
+
### Training and Evaluation
|
| 57 |
+
|
| 58 |
+
To train use the `training.py` script with experiment file and experiment id parameters. E.g. `python training.py phrasecut.yaml 0` will train the first phrasecut experiment which is defined by the `configuration` and first `individual_configurations` parameters. Model weights will be written in `logs/`.
|
| 59 |
+
|
| 60 |
+
For evaluation use `score.py`. E.g. `python score.py phrasecut.yaml 0 0` will train the first phrasecut experiment of `test_configuration` and the first configuration in `individual_configurations`.
|
| 61 |
+
|
| 62 |
+
|
| 63 |
+
### Usage of PFENet Wrappers
|
| 64 |
+
|
| 65 |
+
In order to use the dataset and model wrappers for PFENet, the PFENet repository needs to be cloned to the root folder.
|
| 66 |
+
`git clone https://github.com/Jia-Research-Lab/PFENet.git `
|
| 67 |
+
|
| 68 |
+
|
| 69 |
+
### License
|
| 70 |
+
|
| 71 |
+
The source code files in this repository (excluding model weights) are released under MIT license.
|
| 72 |
+
|
| 73 |
+
### Citation
|
| 74 |
+
```
|
| 75 |
+
@InProceedings{lueddecke22_cvpr,
|
| 76 |
+
author = {L\"uddecke, Timo and Ecker, Alexander},
|
| 77 |
+
title = {Image Segmentation Using Text and Image Prompts},
|
| 78 |
+
booktitle = {Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
|
| 79 |
+
month = {June},
|
| 80 |
+
year = {2022},
|
| 81 |
+
pages = {7086-7096}
|
| 82 |
+
}
|
| 83 |
+
|
| 84 |
+
```
|
clipseg/Tables.ipynb
ADDED
|
@@ -0,0 +1,349 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"cells": [
|
| 3 |
+
{
|
| 4 |
+
"cell_type": "code",
|
| 5 |
+
"execution_count": null,
|
| 6 |
+
"metadata": {},
|
| 7 |
+
"outputs": [],
|
| 8 |
+
"source": [
|
| 9 |
+
"%load_ext autoreload\n",
|
| 10 |
+
"%autoreload 2\n",
|
| 11 |
+
"\n",
|
| 12 |
+
"import clip\n",
|
| 13 |
+
"from evaluation_utils import norm, denorm\n",
|
| 14 |
+
"from general_utils import *\n",
|
| 15 |
+
"from datasets.lvis_oneshot3 import LVIS_OneShot3, LVIS_OneShot"
|
| 16 |
+
]
|
| 17 |
+
},
|
| 18 |
+
{
|
| 19 |
+
"cell_type": "markdown",
|
| 20 |
+
"metadata": {},
|
| 21 |
+
"source": [
|
| 22 |
+
"# PhraseCut"
|
| 23 |
+
]
|
| 24 |
+
},
|
| 25 |
+
{
|
| 26 |
+
"cell_type": "code",
|
| 27 |
+
"execution_count": null,
|
| 28 |
+
"metadata": {},
|
| 29 |
+
"outputs": [],
|
| 30 |
+
"source": [
|
| 31 |
+
"pc = experiment('experiments/phrasecut.yaml', nums=':6').dataframe()"
|
| 32 |
+
]
|
| 33 |
+
},
|
| 34 |
+
{
|
| 35 |
+
"cell_type": "code",
|
| 36 |
+
"execution_count": null,
|
| 37 |
+
"metadata": {},
|
| 38 |
+
"outputs": [],
|
| 39 |
+
"source": [
|
| 40 |
+
"tab1 = pc[['name', 'pc_miou_best', 'pc_fgiou_best', 'pc_ap']]"
|
| 41 |
+
]
|
| 42 |
+
},
|
| 43 |
+
{
|
| 44 |
+
"cell_type": "code",
|
| 45 |
+
"execution_count": null,
|
| 46 |
+
"metadata": {},
|
| 47 |
+
"outputs": [],
|
| 48 |
+
"source": [
|
| 49 |
+
"cols = ['pc_miou_0.3', 'pc_fgiou_0.3', 'pc_ap']\n",
|
| 50 |
+
"tab1 = pc[['name'] + cols]\n",
|
| 51 |
+
"for k in cols:\n",
|
| 52 |
+
" tab1.loc[:, k] = (100 * tab1.loc[:, k]).round(1)\n",
|
| 53 |
+
"tab1.loc[:, 'name'] = ['CLIPSeg (PC+)', 'CLIPSeg (PC, $D=128$)', 'CLIPSeg (PC)', 'CLIP-Deconv', 'ViTSeg (PC+)', 'ViTSeg (PC)']\n",
|
| 54 |
+
"tab1.insert(1, 't', [0.3]*tab1.shape[0])\n",
|
| 55 |
+
"print(tab1.to_latex(header=False, index=False))"
|
| 56 |
+
]
|
| 57 |
+
},
|
| 58 |
+
{
|
| 59 |
+
"cell_type": "markdown",
|
| 60 |
+
"metadata": {},
|
| 61 |
+
"source": [
|
| 62 |
+
"For 0.1 threshold"
|
| 63 |
+
]
|
| 64 |
+
},
|
| 65 |
+
{
|
| 66 |
+
"cell_type": "code",
|
| 67 |
+
"execution_count": null,
|
| 68 |
+
"metadata": {},
|
| 69 |
+
"outputs": [],
|
| 70 |
+
"source": [
|
| 71 |
+
"cols = ['pc_miou_0.1', 'pc_fgiou_0.1', 'pc_ap']\n",
|
| 72 |
+
"tab1 = pc[['name'] + cols]\n",
|
| 73 |
+
"for k in cols:\n",
|
| 74 |
+
" tab1.loc[:, k] = (100 * tab1.loc[:, k]).round(1)\n",
|
| 75 |
+
"tab1.loc[:, 'name'] = ['CLIPSeg (PC+)', 'CLIPSeg (PC, $D=128$)', 'CLIPSeg (PC)', 'CLIP-Deconv', 'ViTSeg (PC+)', 'ViTSeg (PC)']\n",
|
| 76 |
+
"tab1.insert(1, 't', [0.1]*tab1.shape[0])\n",
|
| 77 |
+
"print(tab1.to_latex(header=False, index=False))"
|
| 78 |
+
]
|
| 79 |
+
},
|
| 80 |
+
{
|
| 81 |
+
"cell_type": "markdown",
|
| 82 |
+
"metadata": {},
|
| 83 |
+
"source": [
|
| 84 |
+
"# One-shot"
|
| 85 |
+
]
|
| 86 |
+
},
|
| 87 |
+
{
|
| 88 |
+
"cell_type": "markdown",
|
| 89 |
+
"metadata": {},
|
| 90 |
+
"source": [
|
| 91 |
+
"### Pascal"
|
| 92 |
+
]
|
| 93 |
+
},
|
| 94 |
+
{
|
| 95 |
+
"cell_type": "code",
|
| 96 |
+
"execution_count": null,
|
| 97 |
+
"metadata": {},
|
| 98 |
+
"outputs": [],
|
| 99 |
+
"source": [
|
| 100 |
+
"pas = experiment('experiments/pascal_1shot.yaml', nums=':19').dataframe()"
|
| 101 |
+
]
|
| 102 |
+
},
|
| 103 |
+
{
|
| 104 |
+
"cell_type": "code",
|
| 105 |
+
"execution_count": null,
|
| 106 |
+
"metadata": {},
|
| 107 |
+
"outputs": [],
|
| 108 |
+
"source": [
|
| 109 |
+
"pas[['name', 'pas_h2_miou_0.3', 'pas_h2_biniou_0.3', 'pas_h2_ap', 'pas_h2_fgiou_ct']]"
|
| 110 |
+
]
|
| 111 |
+
},
|
| 112 |
+
{
|
| 113 |
+
"cell_type": "code",
|
| 114 |
+
"execution_count": null,
|
| 115 |
+
"metadata": {},
|
| 116 |
+
"outputs": [],
|
| 117 |
+
"source": [
|
| 118 |
+
"pas = experiment('experiments/pascal_1shot.yaml', nums=':8').dataframe()\n",
|
| 119 |
+
"tab1 = pas[['pas_h2_miou_0.3', 'pas_h2_biniou_0.3', 'pas_h2_ap']]\n",
|
| 120 |
+
"print('CLIPSeg (PC+) & 0.3 & CLIP & ' + ' & '.join(f'{x*100:.1f}' for x in tab1[0:4].mean(0).values), '\\\\\\\\')\n",
|
| 121 |
+
"print('CLIPSeg (PC) & 0.3 & CLIP & ' + ' & '.join(f'{x*100:.1f}' for x in tab1[4:8].mean(0).values), '\\\\\\\\')\n",
|
| 122 |
+
"\n",
|
| 123 |
+
"pas = experiment('experiments/pascal_1shot.yaml', nums='12:16').dataframe()\n",
|
| 124 |
+
"tab1 = pas[['pas_h2_miou_0.2', 'pas_h2_biniou_0.2', 'pas_h2_ap']]\n",
|
| 125 |
+
"print('CLIP-Deconv (PC+) & 0.2 & CLIP & ' + ' & '.join(f'{x*100:.1f}' for x in tab1[0:4].mean(0).values), '\\\\\\\\')\n",
|
| 126 |
+
"\n",
|
| 127 |
+
"pas = experiment('experiments/pascal_1shot.yaml', nums='16:20').dataframe()\n",
|
| 128 |
+
"tab1 = pas[['pas_t_miou_0.2', 'pas_t_biniou_0.2', 'pas_t_ap']]\n",
|
| 129 |
+
"print('ViTSeg (PC+) & 0.2 & CLIP & ' + ' & '.join(f'{x*100:.1f}' for x in tab1[0:4].mean(0).values), '\\\\\\\\')"
|
| 130 |
+
]
|
| 131 |
+
},
|
| 132 |
+
{
|
| 133 |
+
"cell_type": "markdown",
|
| 134 |
+
"metadata": {},
|
| 135 |
+
"source": [
|
| 136 |
+
"#### Pascal Zero-shot (in one-shot setting)\n",
|
| 137 |
+
"\n",
|
| 138 |
+
"Using the same setting as one-shot (hence different from the other zero-shot benchmark)"
|
| 139 |
+
]
|
| 140 |
+
},
|
| 141 |
+
{
|
| 142 |
+
"cell_type": "code",
|
| 143 |
+
"execution_count": null,
|
| 144 |
+
"metadata": {},
|
| 145 |
+
"outputs": [],
|
| 146 |
+
"source": [
|
| 147 |
+
"pas = experiment('experiments/pascal_1shot.yaml', nums=':8').dataframe()\n",
|
| 148 |
+
"tab1 = pas[['pas_t_miou_0.3', 'pas_t_biniou_0.3', 'pas_t_ap']]\n",
|
| 149 |
+
"print('CLIPSeg (PC+) & 0.3 & CLIP & ' + ' & '.join(f'{x*100:.1f}' for x in tab1[0:4].mean(0).values), '\\\\\\\\')\n",
|
| 150 |
+
"print('CLIPSeg (PC) & 0.3 & CLIP & ' + ' & '.join(f'{x*100:.1f}' for x in tab1[4:8].mean(0).values), '\\\\\\\\')\n",
|
| 151 |
+
"\n",
|
| 152 |
+
"pas = experiment('experiments/pascal_1shot.yaml', nums='12:16').dataframe()\n",
|
| 153 |
+
"tab1 = pas[['pas_t_miou_0.3', 'pas_t_biniou_0.3', 'pas_t_ap']]\n",
|
| 154 |
+
"print('CLIP-Deconv (PC+) & 0.3 & CLIP & ' + ' & '.join(f'{x*100:.1f}' for x in tab1[0:4].mean(0).values), '\\\\\\\\')\n",
|
| 155 |
+
"\n",
|
| 156 |
+
"pas = experiment('experiments/pascal_1shot.yaml', nums='16:20').dataframe()\n",
|
| 157 |
+
"tab1 = pas[['pas_t_miou_0.2', 'pas_t_biniou_0.2', 'pas_t_ap']]\n",
|
| 158 |
+
"print('ViTSeg (PC+) & 0.2 & CLIP & ' + ' & '.join(f'{x*100:.1f}' for x in tab1[0:4].mean(0).values), '\\\\\\\\')"
|
| 159 |
+
]
|
| 160 |
+
},
|
| 161 |
+
{
|
| 162 |
+
"cell_type": "code",
|
| 163 |
+
"execution_count": null,
|
| 164 |
+
"metadata": {},
|
| 165 |
+
"outputs": [],
|
| 166 |
+
"source": [
|
| 167 |
+
"# without fixed thresholds...\n",
|
| 168 |
+
"\n",
|
| 169 |
+
"pas = experiment('experiments/pascal_1shot.yaml', nums=':8').dataframe()\n",
|
| 170 |
+
"tab1 = pas[['pas_t_best_miou', 'pas_t_best_biniou', 'pas_t_ap']]\n",
|
| 171 |
+
"print('CLIPSeg (PC+) & CLIP & ' + ' & '.join(f'{x*100:.1f}' for x in tab1[0:4].mean(0).values), '\\\\\\\\')\n",
|
| 172 |
+
"print('CLIPSeg (PC) & CLIP & ' + ' & '.join(f'{x*100:.1f}' for x in tab1[4:8].mean(0).values), '\\\\\\\\')\n",
|
| 173 |
+
"\n",
|
| 174 |
+
"pas = experiment('experiments/pascal_1shot.yaml', nums='12:16').dataframe()\n",
|
| 175 |
+
"tab1 = pas[['pas_t_best_miou', 'pas_t_best_biniou', 'pas_t_ap']]\n",
|
| 176 |
+
"print('CLIP-Deconv (PC+) & CLIP & ' + ' & '.join(f'{x*100:.1f}' for x in tab1[0:4].mean(0).values), '\\\\\\\\')"
|
| 177 |
+
]
|
| 178 |
+
},
|
| 179 |
+
{
|
| 180 |
+
"cell_type": "markdown",
|
| 181 |
+
"metadata": {},
|
| 182 |
+
"source": [
|
| 183 |
+
"### COCO"
|
| 184 |
+
]
|
| 185 |
+
},
|
| 186 |
+
{
|
| 187 |
+
"cell_type": "code",
|
| 188 |
+
"execution_count": null,
|
| 189 |
+
"metadata": {},
|
| 190 |
+
"outputs": [],
|
| 191 |
+
"source": [
|
| 192 |
+
"coco = experiment('experiments/coco.yaml', nums=':29').dataframe()"
|
| 193 |
+
]
|
| 194 |
+
},
|
| 195 |
+
{
|
| 196 |
+
"cell_type": "code",
|
| 197 |
+
"execution_count": null,
|
| 198 |
+
"metadata": {},
|
| 199 |
+
"outputs": [],
|
| 200 |
+
"source": [
|
| 201 |
+
"tab1 = coco[['coco_h2_miou_0.1', 'coco_h2_biniou_0.1', 'coco_h2_ap']]\n",
|
| 202 |
+
"tab2 = coco[['coco_h2_miou_0.2', 'coco_h2_biniou_0.2', 'coco_h2_ap']]\n",
|
| 203 |
+
"tab3 = coco[['coco_h2_miou_best', 'coco_h2_biniou_best', 'coco_h2_ap']]\n",
|
| 204 |
+
"print('CLIPSeg (COCO) & 0.1 & CLIP & ' + ' & '.join(f'{x*100:.1f}' for x in tab1[:4].mean(0).values), '\\\\\\\\')\n",
|
| 205 |
+
"print('CLIPSeg (COCO+N) & 0.1 & CLIP & ' + ' & '.join(f'{x*100:.1f}' for x in tab1[4:8].mean(0).values), '\\\\\\\\')\n",
|
| 206 |
+
"print('CLIP-Deconv (COCO+N) & 0.1 & CLIP & ' + ' & '.join(f'{x*100:.1f}' for x in tab1[12:16].mean(0).values), '\\\\\\\\')\n",
|
| 207 |
+
"print('ViTSeg (COCO) & 0.1 & CLIP & ' + ' & '.join(f'{x*100:.1f}' for x in tab1[8:12].mean(0).values), '\\\\\\\\')"
|
| 208 |
+
]
|
| 209 |
+
},
|
| 210 |
+
{
|
| 211 |
+
"cell_type": "markdown",
|
| 212 |
+
"metadata": {},
|
| 213 |
+
"source": [
|
| 214 |
+
"# Zero-shot"
|
| 215 |
+
]
|
| 216 |
+
},
|
| 217 |
+
{
|
| 218 |
+
"cell_type": "code",
|
| 219 |
+
"execution_count": null,
|
| 220 |
+
"metadata": {},
|
| 221 |
+
"outputs": [],
|
| 222 |
+
"source": [
|
| 223 |
+
"zs = experiment('experiments/pascal_0shot.yaml', nums=':11').dataframe()"
|
| 224 |
+
]
|
| 225 |
+
},
|
| 226 |
+
{
|
| 227 |
+
"cell_type": "code",
|
| 228 |
+
"execution_count": null,
|
| 229 |
+
"metadata": {},
|
| 230 |
+
"outputs": [],
|
| 231 |
+
"source": [
|
| 232 |
+
"\n",
|
| 233 |
+
"tab1 = zs[['pas_zs_seen', 'pas_zs_unseen']]\n",
|
| 234 |
+
"print('CLIPSeg (PC+) & CLIP & ' + ' & '.join(f'{x*100:.1f}' for x in tab1[8:9].values[0].tolist() + tab1[10:11].values[0].tolist()), '\\\\\\\\')\n",
|
| 235 |
+
"print('CLIP-Deconv & CLIP & ' + ' & '.join(f'{x*100:.1f}' for x in tab1[2:3].values[0].tolist() + tab1[3:4].values[0].tolist()), '\\\\\\\\')\n",
|
| 236 |
+
"print('ViTSeg & ImageNet-1K & ' + ' & '.join(f'{x*100:.1f}' for x in tab1[4:5].values[0].tolist() + tab1[5:6].values[0].tolist()), '\\\\\\\\')"
|
| 237 |
+
]
|
| 238 |
+
},
|
| 239 |
+
{
|
| 240 |
+
"cell_type": "markdown",
|
| 241 |
+
"metadata": {},
|
| 242 |
+
"source": [
|
| 243 |
+
"# Ablation"
|
| 244 |
+
]
|
| 245 |
+
},
|
| 246 |
+
{
|
| 247 |
+
"cell_type": "code",
|
| 248 |
+
"execution_count": null,
|
| 249 |
+
"metadata": {},
|
| 250 |
+
"outputs": [],
|
| 251 |
+
"source": [
|
| 252 |
+
"ablation = experiment('experiments/ablation.yaml', nums=':8').dataframe()"
|
| 253 |
+
]
|
| 254 |
+
},
|
| 255 |
+
{
|
| 256 |
+
"cell_type": "code",
|
| 257 |
+
"execution_count": null,
|
| 258 |
+
"metadata": {},
|
| 259 |
+
"outputs": [],
|
| 260 |
+
"source": [
|
| 261 |
+
"tab1 = ablation[['name', 'pc_miou_best', 'pc_ap', 'pc-vis_miou_best', 'pc-vis_ap']]\n",
|
| 262 |
+
"for k in ['pc_miou_best', 'pc_ap', 'pc-vis_miou_best', 'pc-vis_ap']:\n",
|
| 263 |
+
" tab1.loc[:, k] = (100 * tab1.loc[:, k]).round(1)\n",
|
| 264 |
+
"tab1.loc[:, 'name'] = ['CLIPSeg', 'no CLIP pre-training', 'no-negatives', '50% negatives', 'no visual', '$D=16$', 'only layer 3', 'highlight mask']"
|
| 265 |
+
]
|
| 266 |
+
},
|
| 267 |
+
{
|
| 268 |
+
"cell_type": "code",
|
| 269 |
+
"execution_count": null,
|
| 270 |
+
"metadata": {},
|
| 271 |
+
"outputs": [],
|
| 272 |
+
"source": [
|
| 273 |
+
"print(tab1.loc[[0,1,4,5,6,7],:].to_latex(header=False, index=False))"
|
| 274 |
+
]
|
| 275 |
+
},
|
| 276 |
+
{
|
| 277 |
+
"cell_type": "code",
|
| 278 |
+
"execution_count": null,
|
| 279 |
+
"metadata": {},
|
| 280 |
+
"outputs": [],
|
| 281 |
+
"source": [
|
| 282 |
+
"print(tab1.loc[[0,1,4,5,6,7],:].to_latex(header=False, index=False))"
|
| 283 |
+
]
|
| 284 |
+
},
|
| 285 |
+
{
|
| 286 |
+
"cell_type": "markdown",
|
| 287 |
+
"metadata": {},
|
| 288 |
+
"source": [
|
| 289 |
+
"# Generalization"
|
| 290 |
+
]
|
| 291 |
+
},
|
| 292 |
+
{
|
| 293 |
+
"cell_type": "code",
|
| 294 |
+
"execution_count": null,
|
| 295 |
+
"metadata": {},
|
| 296 |
+
"outputs": [],
|
| 297 |
+
"source": [
|
| 298 |
+
"generalization = experiment('experiments/generalize.yaml').dataframe()"
|
| 299 |
+
]
|
| 300 |
+
},
|
| 301 |
+
{
|
| 302 |
+
"cell_type": "code",
|
| 303 |
+
"execution_count": null,
|
| 304 |
+
"metadata": {},
|
| 305 |
+
"outputs": [],
|
| 306 |
+
"source": [
|
| 307 |
+
"gen = generalization[['aff_best_fgiou', 'aff_ap', 'ability_best_fgiou', 'ability_ap', 'part_best_fgiou', 'part_ap']].values"
|
| 308 |
+
]
|
| 309 |
+
},
|
| 310 |
+
{
|
| 311 |
+
"cell_type": "code",
|
| 312 |
+
"execution_count": null,
|
| 313 |
+
"metadata": {},
|
| 314 |
+
"outputs": [],
|
| 315 |
+
"source": [
|
| 316 |
+
"print(\n",
|
| 317 |
+
" 'CLIPSeg (PC+) & ' + ' & '.join(f'{x*100:.1f}' for x in gen[1]) + ' \\\\\\\\ \\n' + \\\n",
|
| 318 |
+
" 'CLIPSeg (LVIS) & ' + ' & '.join(f'{x*100:.1f}' for x in gen[0]) + ' \\\\\\\\ \\n' + \\\n",
|
| 319 |
+
" 'CLIP-Deconv & ' + ' & '.join(f'{x*100:.1f}' for x in gen[2]) + ' \\\\\\\\ \\n' + \\\n",
|
| 320 |
+
" 'VITSeg & ' + ' & '.join(f'{x*100:.1f}' for x in gen[3]) + ' \\\\\\\\'\n",
|
| 321 |
+
")"
|
| 322 |
+
]
|
| 323 |
+
}
|
| 324 |
+
],
|
| 325 |
+
"metadata": {
|
| 326 |
+
"interpreter": {
|
| 327 |
+
"hash": "800ed241f7db2bd3aa6942aa3be6809cdb30ee6b0a9e773dfecfa9fef1f4c586"
|
| 328 |
+
},
|
| 329 |
+
"kernelspec": {
|
| 330 |
+
"display_name": "env2",
|
| 331 |
+
"language": "python",
|
| 332 |
+
"name": "env2"
|
| 333 |
+
},
|
| 334 |
+
"language_info": {
|
| 335 |
+
"codemirror_mode": {
|
| 336 |
+
"name": "ipython",
|
| 337 |
+
"version": 3
|
| 338 |
+
},
|
| 339 |
+
"file_extension": ".py",
|
| 340 |
+
"mimetype": "text/x-python",
|
| 341 |
+
"name": "python",
|
| 342 |
+
"nbconvert_exporter": "python",
|
| 343 |
+
"pygments_lexer": "ipython3",
|
| 344 |
+
"version": "3.8.8"
|
| 345 |
+
}
|
| 346 |
+
},
|
| 347 |
+
"nbformat": 4,
|
| 348 |
+
"nbformat_minor": 4
|
| 349 |
+
}
|
clipseg/Visual_Feature_Engineering.ipynb
ADDED
|
@@ -0,0 +1,366 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"cells": [
|
| 3 |
+
{
|
| 4 |
+
"cell_type": "markdown",
|
| 5 |
+
"metadata": {},
|
| 6 |
+
"source": [
|
| 7 |
+
"# Systematic"
|
| 8 |
+
]
|
| 9 |
+
},
|
| 10 |
+
{
|
| 11 |
+
"cell_type": "code",
|
| 12 |
+
"execution_count": null,
|
| 13 |
+
"metadata": {},
|
| 14 |
+
"outputs": [],
|
| 15 |
+
"source": [
|
| 16 |
+
"%load_ext autoreload\n",
|
| 17 |
+
"%autoreload 2\n",
|
| 18 |
+
"\n",
|
| 19 |
+
"import clip\n",
|
| 20 |
+
"from evaluation_utils import norm, denorm\n",
|
| 21 |
+
"from general_utils import *\n",
|
| 22 |
+
"from datasets.lvis_oneshot3 import LVIS_OneShot3\n",
|
| 23 |
+
"\n",
|
| 24 |
+
"clip_device = 'cuda'\n",
|
| 25 |
+
"clip_model, preprocess = clip.load(\"ViT-B/16\", device=clip_device)\n",
|
| 26 |
+
"clip_model.eval();\n",
|
| 27 |
+
"\n",
|
| 28 |
+
"from models.clipseg import CLIPDensePredTMasked\n",
|
| 29 |
+
"\n",
|
| 30 |
+
"clip_mask_model = CLIPDensePredTMasked(version='ViT-B/16').to(clip_device)\n",
|
| 31 |
+
"clip_mask_model.eval();"
|
| 32 |
+
]
|
| 33 |
+
},
|
| 34 |
+
{
|
| 35 |
+
"cell_type": "code",
|
| 36 |
+
"execution_count": null,
|
| 37 |
+
"metadata": {},
|
| 38 |
+
"outputs": [],
|
| 39 |
+
"source": [
|
| 40 |
+
"lvis = LVIS_OneShot3('train_fixed', mask='separate', normalize=True, with_class_label=True, add_bar=False, \n",
|
| 41 |
+
" text_class_labels=True, image_size=352, min_area=0.1,\n",
|
| 42 |
+
" min_frac_s=0.05, min_frac_q=0.05, fix_find_crop=True)"
|
| 43 |
+
]
|
| 44 |
+
},
|
| 45 |
+
{
|
| 46 |
+
"cell_type": "code",
|
| 47 |
+
"execution_count": null,
|
| 48 |
+
"metadata": {},
|
| 49 |
+
"outputs": [],
|
| 50 |
+
"source": [
|
| 51 |
+
"plot_data(lvis)"
|
| 52 |
+
]
|
| 53 |
+
},
|
| 54 |
+
{
|
| 55 |
+
"cell_type": "code",
|
| 56 |
+
"execution_count": null,
|
| 57 |
+
"metadata": {},
|
| 58 |
+
"outputs": [],
|
| 59 |
+
"source": [
|
| 60 |
+
"from collections import defaultdict\n",
|
| 61 |
+
"import json\n",
|
| 62 |
+
"\n",
|
| 63 |
+
"lvis_raw = json.load(open(expanduser('~/datasets/LVIS/lvis_v1_train.json')))\n",
|
| 64 |
+
"lvis_val_raw = json.load(open(expanduser('~/datasets/LVIS/lvis_v1_val.json')))\n",
|
| 65 |
+
"\n",
|
| 66 |
+
"objects_per_image = defaultdict(lambda : set())\n",
|
| 67 |
+
"for ann in lvis_raw['annotations']:\n",
|
| 68 |
+
" objects_per_image[ann['image_id']].add(ann['category_id'])\n",
|
| 69 |
+
" \n",
|
| 70 |
+
"for ann in lvis_val_raw['annotations']:\n",
|
| 71 |
+
" objects_per_image[ann['image_id']].add(ann['category_id']) \n",
|
| 72 |
+
" \n",
|
| 73 |
+
"objects_per_image = {o: [lvis.category_names[o] for o in v] for o, v in objects_per_image.items()}\n",
|
| 74 |
+
"\n",
|
| 75 |
+
"del lvis_raw, lvis_val_raw"
|
| 76 |
+
]
|
| 77 |
+
},
|
| 78 |
+
{
|
| 79 |
+
"cell_type": "code",
|
| 80 |
+
"execution_count": null,
|
| 81 |
+
"metadata": {},
|
| 82 |
+
"outputs": [],
|
| 83 |
+
"source": [
|
| 84 |
+
"#bs = 32\n",
|
| 85 |
+
"#batches = [get_batch(lvis, i*bs, (i+1)*bs, cuda=True) for i in range(10)]"
|
| 86 |
+
]
|
| 87 |
+
},
|
| 88 |
+
{
|
| 89 |
+
"cell_type": "code",
|
| 90 |
+
"execution_count": null,
|
| 91 |
+
"metadata": {},
|
| 92 |
+
"outputs": [],
|
| 93 |
+
"source": [
|
| 94 |
+
"from general_utils import get_batch\n",
|
| 95 |
+
"from functools import partial\n",
|
| 96 |
+
"from evaluation_utils import img_preprocess\n",
|
| 97 |
+
"import torch\n",
|
| 98 |
+
"\n",
|
| 99 |
+
"def get_similarities(batches_or_dataset, process, mask=lambda x: None, clipmask=False):\n",
|
| 100 |
+
"\n",
|
| 101 |
+
" # base_words = [f'a photo of {x}' for x in ['a person', 'an animal', 'a knife', 'a cup']]\n",
|
| 102 |
+
"\n",
|
| 103 |
+
" all_prompts = []\n",
|
| 104 |
+
" \n",
|
| 105 |
+
" with torch.no_grad():\n",
|
| 106 |
+
" valid_sims = []\n",
|
| 107 |
+
" torch.manual_seed(571)\n",
|
| 108 |
+
" \n",
|
| 109 |
+
" if type(batches_or_dataset) == list:\n",
|
| 110 |
+
" loader = batches_or_dataset # already loaded\n",
|
| 111 |
+
" max_iter = float('inf')\n",
|
| 112 |
+
" else:\n",
|
| 113 |
+
" loader = DataLoader(batches_or_dataset, shuffle=False, batch_size=32)\n",
|
| 114 |
+
" max_iter = 50\n",
|
| 115 |
+
" \n",
|
| 116 |
+
" global batch\n",
|
| 117 |
+
" for i_batch, (batch, batch_y) in enumerate(loader):\n",
|
| 118 |
+
" \n",
|
| 119 |
+
" if i_batch >= max_iter: break\n",
|
| 120 |
+
" \n",
|
| 121 |
+
" processed_batch = process(batch)\n",
|
| 122 |
+
" if type(processed_batch) == dict:\n",
|
| 123 |
+
" \n",
|
| 124 |
+
" # processed_batch = {k: v.to(clip_device) for k, v in processed_batch.items()}\n",
|
| 125 |
+
" image_features = clip_mask_model.visual_forward(**processed_batch)[0].to(clip_device).half()\n",
|
| 126 |
+
" else:\n",
|
| 127 |
+
" processed_batch = process(batch).to(clip_device)\n",
|
| 128 |
+
" processed_batch = nnf.interpolate(processed_batch, (224, 224), mode='bilinear')\n",
|
| 129 |
+
" #image_features = clip_model.encode_image(processed_batch.to(clip_device)) \n",
|
| 130 |
+
" image_features = clip_mask_model.visual_forward(processed_batch)[0].to(clip_device).half()\n",
|
| 131 |
+
" \n",
|
| 132 |
+
" image_features = image_features / image_features.norm(dim=-1, keepdim=True)\n",
|
| 133 |
+
" bs = len(batch[0])\n",
|
| 134 |
+
" for j in range(bs):\n",
|
| 135 |
+
" \n",
|
| 136 |
+
" c, _, sid, qid = lvis.sample_ids[bs * i_batch + j]\n",
|
| 137 |
+
" support_image = basename(lvis.samples[c][sid])\n",
|
| 138 |
+
" \n",
|
| 139 |
+
" img_objs = [o for o in objects_per_image[int(support_image)]]\n",
|
| 140 |
+
" img_objs = [o.replace('_', ' ') for o in img_objs]\n",
|
| 141 |
+
" \n",
|
| 142 |
+
" other_words = [f'a photo of a {o.replace(\"_\", \" \")}' for o in img_objs \n",
|
| 143 |
+
" if o != batch_y[2][j]]\n",
|
| 144 |
+
" \n",
|
| 145 |
+
" prompts = [f'a photo of a {batch_y[2][j]}'] + other_words\n",
|
| 146 |
+
" all_prompts += [prompts]\n",
|
| 147 |
+
" \n",
|
| 148 |
+
" text_cond = clip_model.encode_text(clip.tokenize(prompts).to(clip_device))\n",
|
| 149 |
+
" text_cond = text_cond / text_cond.norm(dim=-1, keepdim=True) \n",
|
| 150 |
+
"\n",
|
| 151 |
+
" global logits\n",
|
| 152 |
+
" logits = clip_model.logit_scale.exp() * image_features[j] @ text_cond.T\n",
|
| 153 |
+
"\n",
|
| 154 |
+
" global sim\n",
|
| 155 |
+
" sim = torch.softmax(logits, dim=-1)\n",
|
| 156 |
+
" \n",
|
| 157 |
+
" valid_sims += [sim]\n",
|
| 158 |
+
" \n",
|
| 159 |
+
" #valid_sims = torch.stack(valid_sims)\n",
|
| 160 |
+
" return valid_sims, all_prompts\n",
|
| 161 |
+
" \n",
|
| 162 |
+
"\n",
|
| 163 |
+
"def new_img_preprocess(x):\n",
|
| 164 |
+
" return {'x_inp': x[1], 'mask': (11, 'cls_token', x[2])}\n",
|
| 165 |
+
" \n",
|
| 166 |
+
"#get_similarities(lvis, partial(img_preprocess, center_context=0.5));\n",
|
| 167 |
+
"get_similarities(lvis, lambda x: x[1]);"
|
| 168 |
+
]
|
| 169 |
+
},
|
| 170 |
+
{
|
| 171 |
+
"cell_type": "code",
|
| 172 |
+
"execution_count": null,
|
| 173 |
+
"metadata": {},
|
| 174 |
+
"outputs": [],
|
| 175 |
+
"source": [
|
| 176 |
+
"preprocessing_functions = [\n",
|
| 177 |
+
"# ['clip mask CLS L11', lambda x: {'x_inp': x[1].cuda(), 'mask': (11, 'cls_token', x[2].cuda())}],\n",
|
| 178 |
+
"# ['clip mask CLS all', lambda x: {'x_inp': x[1].cuda(), 'mask': ('all', 'cls_token', x[2].cuda())}],\n",
|
| 179 |
+
"# ['clip mask all all', lambda x: {'x_inp': x[1].cuda(), 'mask': ('all', 'all', x[2].cuda())}],\n",
|
| 180 |
+
"# ['colorize object red', partial(img_preprocess, colorize=True)],\n",
|
| 181 |
+
"# ['add red outline', partial(img_preprocess, outline=True)],\n",
|
| 182 |
+
" \n",
|
| 183 |
+
"# ['BG brightness 50%', partial(img_preprocess, bg_fac=0.5)],\n",
|
| 184 |
+
"# ['BG brightness 10%', partial(img_preprocess, bg_fac=0.1)],\n",
|
| 185 |
+
"# ['BG brightness 0%', partial(img_preprocess, bg_fac=0.0)],\n",
|
| 186 |
+
"# ['BG blur', partial(img_preprocess, blur=3)],\n",
|
| 187 |
+
"# ['BG blur & intensity 10%', partial(img_preprocess, blur=3, bg_fac=0.1)],\n",
|
| 188 |
+
" \n",
|
| 189 |
+
"# ['crop large context', partial(img_preprocess, center_context=0.5)],\n",
|
| 190 |
+
"# ['crop small context', partial(img_preprocess, center_context=0.1)],\n",
|
| 191 |
+
" ['crop & background blur', partial(img_preprocess, blur=3, center_context=0.5)],\n",
|
| 192 |
+
" ['crop & intensity 10%', partial(img_preprocess, blur=3, bg_fac=0.1)],\n",
|
| 193 |
+
"# ['crop & background blur & intensity 10%', partial(img_preprocess, blur=3, center_context=0.1, bg_fac=0.1)],\n",
|
| 194 |
+
"]\n",
|
| 195 |
+
"\n",
|
| 196 |
+
"preprocessing_functions = preprocessing_functions\n",
|
| 197 |
+
"\n",
|
| 198 |
+
"base, base_p = get_similarities(lvis, lambda x: x[1])\n",
|
| 199 |
+
"outs = [get_similarities(lvis, fun) for _, fun in preprocessing_functions]"
|
| 200 |
+
]
|
| 201 |
+
},
|
| 202 |
+
{
|
| 203 |
+
"cell_type": "code",
|
| 204 |
+
"execution_count": null,
|
| 205 |
+
"metadata": {},
|
| 206 |
+
"outputs": [],
|
| 207 |
+
"source": [
|
| 208 |
+
"outs2 = [get_similarities(lvis, fun) for _, fun in [['BG brightness 0%', partial(img_preprocess, bg_fac=0.0)]]]"
|
| 209 |
+
]
|
| 210 |
+
},
|
| 211 |
+
{
|
| 212 |
+
"cell_type": "code",
|
| 213 |
+
"execution_count": null,
|
| 214 |
+
"metadata": {},
|
| 215 |
+
"outputs": [],
|
| 216 |
+
"source": [
|
| 217 |
+
"for j in range(1):\n",
|
| 218 |
+
" print(np.mean([outs2[j][0][i][0].cpu() - base[i][0].cpu() for i in range(len(base)) if len(base_p[i]) >= 3]))"
|
| 219 |
+
]
|
| 220 |
+
},
|
| 221 |
+
{
|
| 222 |
+
"cell_type": "code",
|
| 223 |
+
"execution_count": null,
|
| 224 |
+
"metadata": {},
|
| 225 |
+
"outputs": [],
|
| 226 |
+
"source": [
|
| 227 |
+
"from pandas import DataFrame\n",
|
| 228 |
+
"tab = dict()\n",
|
| 229 |
+
"for j, (name, _) in enumerate(preprocessing_functions):\n",
|
| 230 |
+
" tab[name] = np.mean([outs[j][0][i][0].cpu() - base[i][0].cpu() for i in range(len(base)) if len(base_p[i]) >= 3])\n",
|
| 231 |
+
" \n",
|
| 232 |
+
" \n",
|
| 233 |
+
"print('\\n'.join(f'{k} & {v*100:.2f} \\\\\\\\' for k,v in tab.items())) "
|
| 234 |
+
]
|
| 235 |
+
},
|
| 236 |
+
{
|
| 237 |
+
"cell_type": "markdown",
|
| 238 |
+
"metadata": {},
|
| 239 |
+
"source": [
|
| 240 |
+
"# Visual"
|
| 241 |
+
]
|
| 242 |
+
},
|
| 243 |
+
{
|
| 244 |
+
"cell_type": "code",
|
| 245 |
+
"execution_count": null,
|
| 246 |
+
"metadata": {},
|
| 247 |
+
"outputs": [],
|
| 248 |
+
"source": [
|
| 249 |
+
"from evaluation_utils import denorm, norm"
|
| 250 |
+
]
|
| 251 |
+
},
|
| 252 |
+
{
|
| 253 |
+
"cell_type": "code",
|
| 254 |
+
"execution_count": null,
|
| 255 |
+
"metadata": {},
|
| 256 |
+
"outputs": [],
|
| 257 |
+
"source": [
|
| 258 |
+
"def load_sample(filename, filename2):\n",
|
| 259 |
+
" from os.path import join\n",
|
| 260 |
+
" bp = expanduser('~/cloud/resources/sample_images')\n",
|
| 261 |
+
" tf = transforms.Compose([\n",
|
| 262 |
+
" transforms.ToTensor(),\n",
|
| 263 |
+
" transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]),\n",
|
| 264 |
+
" transforms.Resize(224),\n",
|
| 265 |
+
" transforms.CenterCrop(224)\n",
|
| 266 |
+
" ])\n",
|
| 267 |
+
" tf2 = transforms.Compose([\n",
|
| 268 |
+
" transforms.ToTensor(),\n",
|
| 269 |
+
" transforms.Resize(224),\n",
|
| 270 |
+
" transforms.CenterCrop(224)\n",
|
| 271 |
+
" ])\n",
|
| 272 |
+
" inp1 = [None, tf(Image.open(join(bp, filename))), tf2(Image.open(join(bp, filename2)))]\n",
|
| 273 |
+
" inp1[1] = inp1[1].unsqueeze(0)\n",
|
| 274 |
+
" inp1[2] = inp1[2][:1] \n",
|
| 275 |
+
" return inp1\n",
|
| 276 |
+
"\n",
|
| 277 |
+
"def all_preprocessing(inp1):\n",
|
| 278 |
+
" return [\n",
|
| 279 |
+
" img_preprocess(inp1),\n",
|
| 280 |
+
" img_preprocess(inp1, colorize=True),\n",
|
| 281 |
+
" img_preprocess(inp1, outline=True), \n",
|
| 282 |
+
" img_preprocess(inp1, blur=3),\n",
|
| 283 |
+
" img_preprocess(inp1, bg_fac=0.1),\n",
|
| 284 |
+
" #img_preprocess(inp1, bg_fac=0.5),\n",
|
| 285 |
+
" #img_preprocess(inp1, blur=3, bg_fac=0.5), \n",
|
| 286 |
+
" img_preprocess(inp1, blur=3, bg_fac=0.5, center_context=0.5),\n",
|
| 287 |
+
" ]\n",
|
| 288 |
+
"\n"
|
| 289 |
+
]
|
| 290 |
+
},
|
| 291 |
+
{
|
| 292 |
+
"cell_type": "code",
|
| 293 |
+
"execution_count": null,
|
| 294 |
+
"metadata": {},
|
| 295 |
+
"outputs": [],
|
| 296 |
+
"source": [
|
| 297 |
+
"from torchvision import transforms\n",
|
| 298 |
+
"from PIL import Image\n",
|
| 299 |
+
"from matplotlib import pyplot as plt\n",
|
| 300 |
+
"from evaluation_utils import img_preprocess\n",
|
| 301 |
+
"import clip\n",
|
| 302 |
+
"\n",
|
| 303 |
+
"images_queries = [\n",
|
| 304 |
+
" [load_sample('things1.jpg', 'things1_jar.png'), ['jug', 'knife', 'car', 'animal', 'sieve', 'nothing']],\n",
|
| 305 |
+
" [load_sample('own_photos/IMG_2017s_square.jpg', 'own_photos/IMG_2017s_square_trash_can.png'), ['trash bin', 'house', 'car', 'bike', 'window', 'nothing']],\n",
|
| 306 |
+
"]\n",
|
| 307 |
+
"\n",
|
| 308 |
+
"\n",
|
| 309 |
+
"_, ax = plt.subplots(2 * len(images_queries), 6, figsize=(14, 4.5 * len(images_queries)))\n",
|
| 310 |
+
"\n",
|
| 311 |
+
"for j, (images, objects) in enumerate(images_queries):\n",
|
| 312 |
+
" \n",
|
| 313 |
+
" joint_image = all_preprocessing(images)\n",
|
| 314 |
+
" \n",
|
| 315 |
+
" joint_image = torch.stack(joint_image)[:,0]\n",
|
| 316 |
+
" clip_model, preprocess = clip.load(\"ViT-B/16\", device='cpu')\n",
|
| 317 |
+
" image_features = clip_model.encode_image(joint_image)\n",
|
| 318 |
+
" image_features = image_features / image_features.norm(dim=-1, keepdim=True)\n",
|
| 319 |
+
" \n",
|
| 320 |
+
" prompts = [f'a photo of a {obj}'for obj in objects]\n",
|
| 321 |
+
" text_cond = clip_model.encode_text(clip.tokenize(prompts))\n",
|
| 322 |
+
" text_cond = text_cond / text_cond.norm(dim=-1, keepdim=True)\n",
|
| 323 |
+
" logits = clip_model.logit_scale.exp() * image_features @ text_cond.T\n",
|
| 324 |
+
" sim = torch.softmax(logits, dim=-1).detach().cpu()\n",
|
| 325 |
+
"\n",
|
| 326 |
+
" for i, img in enumerate(joint_image):\n",
|
| 327 |
+
" ax[2*j, i].axis('off')\n",
|
| 328 |
+
" \n",
|
| 329 |
+
" ax[2*j, i].imshow(torch.clamp(denorm(joint_image[i]).permute(1,2,0), 0, 1))\n",
|
| 330 |
+
" ax[2*j+ 1, i].grid(True)\n",
|
| 331 |
+
" \n",
|
| 332 |
+
" ax[2*j + 1, i].set_ylim(0,1)\n",
|
| 333 |
+
" ax[2*j + 1, i].set_yticklabels([])\n",
|
| 334 |
+
" ax[2*j + 1, i].set_xticks([]) # set_xticks(range(len(prompts)))\n",
|
| 335 |
+
"# ax[1, i].set_xticklabels(objects, rotation=90)\n",
|
| 336 |
+
" for k in range(len(sim[i])):\n",
|
| 337 |
+
" ax[2*j + 1, i].bar(k, sim[i][k], color=plt.cm.tab20(1) if k!=0 else plt.cm.tab20(3))\n",
|
| 338 |
+
" ax[2*j + 1, i].text(k, 0.07, objects[k], rotation=90, ha='center', fontsize=15)\n",
|
| 339 |
+
"\n",
|
| 340 |
+
"plt.tight_layout()\n",
|
| 341 |
+
"plt.savefig('figures/prompt_engineering.pdf', bbox_inches='tight')"
|
| 342 |
+
]
|
| 343 |
+
}
|
| 344 |
+
],
|
| 345 |
+
"metadata": {
|
| 346 |
+
"kernelspec": {
|
| 347 |
+
"display_name": "env2",
|
| 348 |
+
"language": "python",
|
| 349 |
+
"name": "env2"
|
| 350 |
+
},
|
| 351 |
+
"language_info": {
|
| 352 |
+
"codemirror_mode": {
|
| 353 |
+
"name": "ipython",
|
| 354 |
+
"version": 3
|
| 355 |
+
},
|
| 356 |
+
"file_extension": ".py",
|
| 357 |
+
"mimetype": "text/x-python",
|
| 358 |
+
"name": "python",
|
| 359 |
+
"nbconvert_exporter": "python",
|
| 360 |
+
"pygments_lexer": "ipython3",
|
| 361 |
+
"version": "3.8.8"
|
| 362 |
+
}
|
| 363 |
+
},
|
| 364 |
+
"nbformat": 4,
|
| 365 |
+
"nbformat_minor": 4
|
| 366 |
+
}
|
clipseg/datasets/coco_wrapper.py
ADDED
|
@@ -0,0 +1,99 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import pickle
|
| 2 |
+
from types import new_class
|
| 3 |
+
import torch
|
| 4 |
+
import numpy as np
|
| 5 |
+
import os
|
| 6 |
+
import json
|
| 7 |
+
|
| 8 |
+
from os.path import join, dirname, isdir, isfile, expanduser, realpath, basename
|
| 9 |
+
from random import shuffle, seed as set_seed
|
| 10 |
+
from PIL import Image
|
| 11 |
+
|
| 12 |
+
from itertools import combinations
|
| 13 |
+
from torchvision import transforms
|
| 14 |
+
from torchvision.transforms.transforms import Resize
|
| 15 |
+
|
| 16 |
+
from datasets.utils import blend_image_segmentation
|
| 17 |
+
from general_utils import get_from_repository
|
| 18 |
+
|
| 19 |
+
COCO_CLASSES = {0: 'person', 1: 'bicycle', 2: 'car', 3: 'motorcycle', 4: 'airplane', 5: 'bus', 6: 'train', 7: 'truck', 8: 'boat', 9: 'traffic light', 10: 'fire hydrant', 11: 'stop sign', 12: 'parking meter', 13: 'bench', 14: 'bird', 15: 'cat', 16: 'dog', 17: 'horse', 18: 'sheep', 19: 'cow', 20: 'elephant', 21: 'bear', 22: 'zebra', 23: 'giraffe', 24: 'backpack', 25: 'umbrella', 26: 'handbag', 27: 'tie', 28: 'suitcase', 29: 'frisbee', 30: 'skis', 31: 'snowboard', 32: 'sports ball', 33: 'kite', 34: 'baseball bat', 35: 'baseball glove', 36: 'skateboard', 37: 'surfboard', 38: 'tennis racket', 39: 'bottle', 40: 'wine glass', 41: 'cup', 42: 'fork', 43: 'knife', 44: 'spoon', 45: 'bowl', 46: 'banana', 47: 'apple', 48: 'sandwich', 49: 'orange', 50: 'broccoli', 51: 'carrot', 52: 'hot dog', 53: 'pizza', 54: 'donut', 55: 'cake', 56: 'chair', 57: 'couch', 58: 'potted plant', 59: 'bed', 60: 'dining table', 61: 'toilet', 62: 'tv', 63: 'laptop', 64: 'mouse', 65: 'remote', 66: 'keyboard', 67: 'cell phone', 68: 'microwave', 69: 'oven', 70: 'toaster', 71: 'sink', 72: 'refrigerator', 73: 'book', 74: 'clock', 75: 'vase', 76: 'scissors', 77: 'teddy bear', 78: 'hair drier', 79: 'toothbrush'}
|
| 20 |
+
|
| 21 |
+
class COCOWrapper(object):
|
| 22 |
+
|
| 23 |
+
def __init__(self, split, fold=0, image_size=400, aug=None, mask='separate', negative_prob=0,
|
| 24 |
+
with_class_label=False):
|
| 25 |
+
super().__init__()
|
| 26 |
+
|
| 27 |
+
self.mask = mask
|
| 28 |
+
self.with_class_label = with_class_label
|
| 29 |
+
self.negative_prob = negative_prob
|
| 30 |
+
|
| 31 |
+
from third_party.hsnet.data.coco import DatasetCOCO
|
| 32 |
+
|
| 33 |
+
get_from_repository('COCO-20i', ['COCO-20i.tar'])
|
| 34 |
+
|
| 35 |
+
foldpath = join(dirname(__file__), '../third_party/hsnet/data/splits/coco/%s/fold%d.pkl')
|
| 36 |
+
|
| 37 |
+
def build_img_metadata_classwise(self):
|
| 38 |
+
with open(foldpath % (self.split, self.fold), 'rb') as f:
|
| 39 |
+
img_metadata_classwise = pickle.load(f)
|
| 40 |
+
return img_metadata_classwise
|
| 41 |
+
|
| 42 |
+
|
| 43 |
+
DatasetCOCO.build_img_metadata_classwise = build_img_metadata_classwise
|
| 44 |
+
# DatasetCOCO.read_mask = read_mask
|
| 45 |
+
|
| 46 |
+
mean = [0.485, 0.456, 0.406]
|
| 47 |
+
std = [0.229, 0.224, 0.225]
|
| 48 |
+
transform = transforms.Compose([
|
| 49 |
+
transforms.Resize((image_size, image_size)),
|
| 50 |
+
transforms.ToTensor(),
|
| 51 |
+
transforms.Normalize(mean, std)
|
| 52 |
+
])
|
| 53 |
+
|
| 54 |
+
self.coco = DatasetCOCO(expanduser('~/datasets/COCO-20i/'), fold, transform, split, 1, False)
|
| 55 |
+
|
| 56 |
+
self.all_classes = [self.coco.class_ids]
|
| 57 |
+
self.coco.base_path = join(expanduser('~/datasets/COCO-20i'))
|
| 58 |
+
|
| 59 |
+
def __len__(self):
|
| 60 |
+
return len(self.coco)
|
| 61 |
+
|
| 62 |
+
def __getitem__(self, i):
|
| 63 |
+
sample = self.coco[i]
|
| 64 |
+
|
| 65 |
+
label_name = COCO_CLASSES[int(sample['class_id'])]
|
| 66 |
+
|
| 67 |
+
img_s, seg_s = sample['support_imgs'][0], sample['support_masks'][0]
|
| 68 |
+
|
| 69 |
+
if self.negative_prob > 0 and torch.rand(1).item() < self.negative_prob:
|
| 70 |
+
new_class_id = sample['class_id']
|
| 71 |
+
while new_class_id == sample['class_id']:
|
| 72 |
+
sample2 = self.coco[torch.randint(0, len(self), (1,)).item()]
|
| 73 |
+
new_class_id = sample2['class_id']
|
| 74 |
+
img_s = sample2['support_imgs'][0]
|
| 75 |
+
seg_s = torch.zeros_like(seg_s)
|
| 76 |
+
|
| 77 |
+
mask = self.mask
|
| 78 |
+
if mask == 'separate':
|
| 79 |
+
supp = (img_s, seg_s)
|
| 80 |
+
elif mask == 'text_label':
|
| 81 |
+
# DEPRECATED
|
| 82 |
+
supp = [int(sample['class_id'])]
|
| 83 |
+
elif mask == 'text':
|
| 84 |
+
supp = [label_name]
|
| 85 |
+
else:
|
| 86 |
+
if mask.startswith('text_and_'):
|
| 87 |
+
mask = mask[9:]
|
| 88 |
+
label_add = [label_name]
|
| 89 |
+
else:
|
| 90 |
+
label_add = []
|
| 91 |
+
|
| 92 |
+
supp = label_add + blend_image_segmentation(img_s, seg_s, mode=mask)
|
| 93 |
+
|
| 94 |
+
if self.with_class_label:
|
| 95 |
+
label = (torch.zeros(0), sample['class_id'],)
|
| 96 |
+
else:
|
| 97 |
+
label = (torch.zeros(0), )
|
| 98 |
+
|
| 99 |
+
return (sample['query_img'],) + tuple(supp), (sample['query_mask'].unsqueeze(0),) + label
|
clipseg/datasets/pascal_classes.json
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
[{"id": 1, "synonyms": ["aeroplane"]}, {"id": 2, "synonyms": ["bicycle"]}, {"id": 3, "synonyms": ["bird"]}, {"id": 4, "synonyms": ["boat"]}, {"id": 5, "synonyms": ["bottle"]}, {"id": 6, "synonyms": ["bus"]}, {"id": 7, "synonyms": ["car"]}, {"id": 8, "synonyms": ["cat"]}, {"id": 9, "synonyms": ["chair"]}, {"id": 10, "synonyms": ["cow"]}, {"id": 11, "synonyms": ["diningtable"]}, {"id": 12, "synonyms": ["dog"]}, {"id": 13, "synonyms": ["horse"]}, {"id": 14, "synonyms": ["motorbike"]}, {"id": 15, "synonyms": ["person"]}, {"id": 16, "synonyms": ["pottedplant"]}, {"id": 17, "synonyms": ["sheep"]}, {"id": 18, "synonyms": ["sofa"]}, {"id": 19, "synonyms": ["train"]}, {"id": 20, "synonyms": ["tvmonitor"]}]
|
clipseg/datasets/pascal_zeroshot.py
ADDED
|
@@ -0,0 +1,60 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from os.path import expanduser
|
| 2 |
+
import torch
|
| 3 |
+
import json
|
| 4 |
+
import torchvision
|
| 5 |
+
from general_utils import get_from_repository
|
| 6 |
+
from general_utils import log
|
| 7 |
+
from torchvision import transforms
|
| 8 |
+
|
| 9 |
+
PASCAL_VOC_CLASSES_ZS = [['cattle.n.01', 'motorcycle.n.01'], ['aeroplane.n.01', 'sofa.n.01'],
|
| 10 |
+
['cat.n.01', 'television.n.03'], ['train.n.01', 'bottle.n.01'],
|
| 11 |
+
['chair.n.01', 'pot_plant.n.01']]
|
| 12 |
+
|
| 13 |
+
|
| 14 |
+
class PascalZeroShot(object):
|
| 15 |
+
|
| 16 |
+
def __init__(self, split, n_unseen, image_size=224) -> None:
|
| 17 |
+
super().__init__()
|
| 18 |
+
|
| 19 |
+
import sys
|
| 20 |
+
sys.path.append('third_party/JoEm')
|
| 21 |
+
from third_party.JoEm.data_loader.dataset import VOCSegmentation
|
| 22 |
+
from third_party.JoEm.data_loader import get_seen_idx, get_unseen_idx, VOC
|
| 23 |
+
|
| 24 |
+
self.pascal_classes = VOC
|
| 25 |
+
self.image_size = image_size
|
| 26 |
+
|
| 27 |
+
self.transform = transforms.Compose([
|
| 28 |
+
transforms.Resize((image_size, image_size)),
|
| 29 |
+
])
|
| 30 |
+
|
| 31 |
+
if split == 'train':
|
| 32 |
+
self.voc = VOCSegmentation(get_unseen_idx(n_unseen), get_seen_idx(n_unseen),
|
| 33 |
+
split=split, transform=True, transform_args=dict(base_size=312, crop_size=312),
|
| 34 |
+
ignore_bg=False, ignore_unseen=False, remv_unseen_img=True)
|
| 35 |
+
elif split == 'val':
|
| 36 |
+
self.voc = VOCSegmentation(get_unseen_idx(n_unseen), get_seen_idx(n_unseen),
|
| 37 |
+
split=split, transform=False,
|
| 38 |
+
ignore_bg=False, ignore_unseen=False)
|
| 39 |
+
|
| 40 |
+
self.unseen_idx = get_unseen_idx(n_unseen)
|
| 41 |
+
|
| 42 |
+
def __len__(self):
|
| 43 |
+
return len(self.voc)
|
| 44 |
+
|
| 45 |
+
def __getitem__(self, i):
|
| 46 |
+
|
| 47 |
+
sample = self.voc[i]
|
| 48 |
+
label = sample['label'].long()
|
| 49 |
+
all_labels = [l for l in torch.where(torch.bincount(label.flatten())>0)[0].numpy().tolist() if l != 255]
|
| 50 |
+
class_indices = [l for l in all_labels]
|
| 51 |
+
class_names = [self.pascal_classes[l] for l in all_labels]
|
| 52 |
+
|
| 53 |
+
image = self.transform(sample['image'])
|
| 54 |
+
|
| 55 |
+
label = transforms.Resize((self.image_size, self.image_size),
|
| 56 |
+
interpolation=torchvision.transforms.InterpolationMode.NEAREST)(label.unsqueeze(0))[0]
|
| 57 |
+
|
| 58 |
+
return (image,), (label, )
|
| 59 |
+
|
| 60 |
+
|
clipseg/datasets/pfe_dataset.py
ADDED
|
@@ -0,0 +1,129 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from os.path import expanduser
|
| 2 |
+
import torch
|
| 3 |
+
import json
|
| 4 |
+
from general_utils import get_from_repository
|
| 5 |
+
from datasets.lvis_oneshot3 import blend_image_segmentation
|
| 6 |
+
from general_utils import log
|
| 7 |
+
|
| 8 |
+
PASCAL_CLASSES = {a['id']: a['synonyms'] for a in json.load(open('datasets/pascal_classes.json'))}
|
| 9 |
+
|
| 10 |
+
|
| 11 |
+
class PFEPascalWrapper(object):
|
| 12 |
+
|
| 13 |
+
def __init__(self, mode, split, mask='separate', image_size=473, label_support=None, size=None, p_negative=0, aug=None):
|
| 14 |
+
import sys
|
| 15 |
+
# sys.path.append(expanduser('~/projects/new_one_shot'))
|
| 16 |
+
from third_party.PFENet.util.dataset import SemData
|
| 17 |
+
|
| 18 |
+
get_from_repository('PascalVOC2012', ['Pascal5i.tar'])
|
| 19 |
+
|
| 20 |
+
self.p_negative = p_negative
|
| 21 |
+
self.size = size
|
| 22 |
+
self.mode = mode
|
| 23 |
+
self.image_size = image_size
|
| 24 |
+
|
| 25 |
+
if label_support in {True, False}:
|
| 26 |
+
log.warning('label_support argument is deprecated. Use mask instead.')
|
| 27 |
+
#raise ValueError()
|
| 28 |
+
|
| 29 |
+
self.mask = mask
|
| 30 |
+
|
| 31 |
+
value_scale = 255
|
| 32 |
+
mean = [0.485, 0.456, 0.406]
|
| 33 |
+
mean = [item * value_scale for item in mean]
|
| 34 |
+
std = [0.229, 0.224, 0.225]
|
| 35 |
+
std = [item * value_scale for item in std]
|
| 36 |
+
|
| 37 |
+
import third_party.PFENet.util.transform as transform
|
| 38 |
+
|
| 39 |
+
if mode == 'val':
|
| 40 |
+
data_list = expanduser('~/projects/old_one_shot/PFENet/lists/pascal/val.txt')
|
| 41 |
+
|
| 42 |
+
data_transform = [transform.test_Resize(size=image_size)] if image_size != 'original' else []
|
| 43 |
+
data_transform += [
|
| 44 |
+
transform.ToTensor(),
|
| 45 |
+
transform.Normalize(mean=mean, std=std)
|
| 46 |
+
]
|
| 47 |
+
|
| 48 |
+
|
| 49 |
+
elif mode == 'train':
|
| 50 |
+
data_list = expanduser('~/projects/old_one_shot/PFENet/lists/pascal/voc_sbd_merge_noduplicate.txt')
|
| 51 |
+
|
| 52 |
+
assert image_size != 'original'
|
| 53 |
+
|
| 54 |
+
data_transform = [
|
| 55 |
+
transform.RandScale([0.9, 1.1]),
|
| 56 |
+
transform.RandRotate([-10, 10], padding=mean, ignore_label=255),
|
| 57 |
+
transform.RandomGaussianBlur(),
|
| 58 |
+
transform.RandomHorizontalFlip(),
|
| 59 |
+
transform.Crop((image_size, image_size), crop_type='rand', padding=mean, ignore_label=255),
|
| 60 |
+
transform.ToTensor(),
|
| 61 |
+
transform.Normalize(mean=mean, std=std)
|
| 62 |
+
]
|
| 63 |
+
|
| 64 |
+
data_transform = transform.Compose(data_transform)
|
| 65 |
+
|
| 66 |
+
self.dataset = SemData(split=split, mode=mode, data_root=expanduser('~/datasets/PascalVOC2012/VOC2012'),
|
| 67 |
+
data_list=data_list, shot=1, transform=data_transform, use_coco=False, use_split_coco=False)
|
| 68 |
+
|
| 69 |
+
self.class_list = self.dataset.sub_val_list if mode == 'val' else self.dataset.sub_list
|
| 70 |
+
|
| 71 |
+
# verify that subcls_list always has length 1
|
| 72 |
+
# assert len(set([len(d[4]) for d in self.dataset])) == 1
|
| 73 |
+
|
| 74 |
+
print('actual length', len(self.dataset.data_list))
|
| 75 |
+
|
| 76 |
+
def __len__(self):
|
| 77 |
+
if self.mode == 'val':
|
| 78 |
+
return len(self.dataset.data_list)
|
| 79 |
+
else:
|
| 80 |
+
return len(self.dataset.data_list)
|
| 81 |
+
|
| 82 |
+
def __getitem__(self, index):
|
| 83 |
+
if self.dataset.mode == 'train':
|
| 84 |
+
image, label, s_x, s_y, subcls_list = self.dataset[index % len(self.dataset.data_list)]
|
| 85 |
+
elif self.dataset.mode == 'val':
|
| 86 |
+
image, label, s_x, s_y, subcls_list, ori_label = self.dataset[index % len(self.dataset.data_list)]
|
| 87 |
+
ori_label = torch.from_numpy(ori_label).unsqueeze(0)
|
| 88 |
+
|
| 89 |
+
if self.image_size != 'original':
|
| 90 |
+
longerside = max(ori_label.size(1), ori_label.size(2))
|
| 91 |
+
backmask = torch.ones(ori_label.size(0), longerside, longerside).cuda()*255
|
| 92 |
+
backmask[0, :ori_label.size(1), :ori_label.size(2)] = ori_label
|
| 93 |
+
label = backmask.clone().long()
|
| 94 |
+
else:
|
| 95 |
+
label = label.unsqueeze(0)
|
| 96 |
+
|
| 97 |
+
# assert label.shape == (473, 473)
|
| 98 |
+
|
| 99 |
+
if self.p_negative > 0:
|
| 100 |
+
if torch.rand(1).item() < self.p_negative:
|
| 101 |
+
while True:
|
| 102 |
+
idx = torch.randint(0, len(self.dataset.data_list), (1,)).item()
|
| 103 |
+
_, _, s_x, s_y, subcls_list_tmp, _ = self.dataset[idx]
|
| 104 |
+
if subcls_list[0] != subcls_list_tmp[0]:
|
| 105 |
+
break
|
| 106 |
+
|
| 107 |
+
s_x = s_x[0]
|
| 108 |
+
s_y = (s_y == 1)[0]
|
| 109 |
+
label_fg = (label == 1).float()
|
| 110 |
+
val_mask = (label != 255).float()
|
| 111 |
+
|
| 112 |
+
class_id = self.class_list[subcls_list[0]]
|
| 113 |
+
|
| 114 |
+
label_name = PASCAL_CLASSES[class_id][0]
|
| 115 |
+
label_add = ()
|
| 116 |
+
mask = self.mask
|
| 117 |
+
|
| 118 |
+
if mask == 'text':
|
| 119 |
+
support = ('a photo of a ' + label_name + '.',)
|
| 120 |
+
elif mask == 'separate':
|
| 121 |
+
support = (s_x, s_y)
|
| 122 |
+
else:
|
| 123 |
+
if mask.startswith('text_and_'):
|
| 124 |
+
label_add = (label_name,)
|
| 125 |
+
mask = mask[9:]
|
| 126 |
+
|
| 127 |
+
support = (blend_image_segmentation(s_x, s_y.float(), mask)[0],)
|
| 128 |
+
|
| 129 |
+
return (image,) + label_add + support, (label_fg.unsqueeze(0), val_mask.unsqueeze(0), subcls_list[0])
|
clipseg/datasets/phrasecut.py
ADDED
|
@@ -0,0 +1,335 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
|
| 2 |
+
import torch
|
| 3 |
+
import numpy as np
|
| 4 |
+
import os
|
| 5 |
+
|
| 6 |
+
from os.path import join, isdir, isfile, expanduser
|
| 7 |
+
from PIL import Image
|
| 8 |
+
|
| 9 |
+
from torchvision import transforms
|
| 10 |
+
from torchvision.transforms.transforms import Resize
|
| 11 |
+
|
| 12 |
+
from torch.nn import functional as nnf
|
| 13 |
+
from general_utils import get_from_repository
|
| 14 |
+
|
| 15 |
+
from skimage.draw import polygon2mask
|
| 16 |
+
|
| 17 |
+
|
| 18 |
+
|
| 19 |
+
def random_crop_slices(origin_size, target_size):
|
| 20 |
+
"""Gets slices of a random crop. """
|
| 21 |
+
assert origin_size[0] >= target_size[0] and origin_size[1] >= target_size[1], f'actual size: {origin_size}, target size: {target_size}'
|
| 22 |
+
|
| 23 |
+
offset_y = torch.randint(0, origin_size[0] - target_size[0] + 1, (1,)).item() # range: 0 <= value < high
|
| 24 |
+
offset_x = torch.randint(0, origin_size[1] - target_size[1] + 1, (1,)).item()
|
| 25 |
+
|
| 26 |
+
return slice(offset_y, offset_y + target_size[0]), slice(offset_x, offset_x + target_size[1])
|
| 27 |
+
|
| 28 |
+
|
| 29 |
+
def find_crop(seg, image_size, iterations=1000, min_frac=None, best_of=None):
|
| 30 |
+
|
| 31 |
+
|
| 32 |
+
best_crops = []
|
| 33 |
+
best_crop_not_ok = float('-inf'), None, None
|
| 34 |
+
min_sum = 0
|
| 35 |
+
|
| 36 |
+
seg = seg.astype('bool')
|
| 37 |
+
|
| 38 |
+
if min_frac is not None:
|
| 39 |
+
#min_sum = seg.sum() * min_frac
|
| 40 |
+
min_sum = seg.shape[0] * seg.shape[1] * min_frac
|
| 41 |
+
|
| 42 |
+
for iteration in range(iterations):
|
| 43 |
+
sl_y, sl_x = random_crop_slices(seg.shape, image_size)
|
| 44 |
+
seg_ = seg[sl_y, sl_x]
|
| 45 |
+
sum_seg_ = seg_.sum()
|
| 46 |
+
|
| 47 |
+
if sum_seg_ > min_sum:
|
| 48 |
+
|
| 49 |
+
if best_of is None:
|
| 50 |
+
return sl_y, sl_x, False
|
| 51 |
+
else:
|
| 52 |
+
best_crops += [(sum_seg_, sl_y, sl_x)]
|
| 53 |
+
if len(best_crops) >= best_of:
|
| 54 |
+
best_crops.sort(key=lambda x:x[0], reverse=True)
|
| 55 |
+
sl_y, sl_x = best_crops[0][1:]
|
| 56 |
+
|
| 57 |
+
return sl_y, sl_x, False
|
| 58 |
+
|
| 59 |
+
else:
|
| 60 |
+
if sum_seg_ > best_crop_not_ok[0]:
|
| 61 |
+
best_crop_not_ok = sum_seg_, sl_y, sl_x
|
| 62 |
+
|
| 63 |
+
else:
|
| 64 |
+
# return best segmentation found
|
| 65 |
+
return best_crop_not_ok[1:] + (best_crop_not_ok[0] <= min_sum,)
|
| 66 |
+
|
| 67 |
+
|
| 68 |
+
class PhraseCut(object):
|
| 69 |
+
|
| 70 |
+
def __init__(self, split, image_size=400, negative_prob=0, aug=None, aug_color=False, aug_crop=True,
|
| 71 |
+
min_size=0, remove_classes=None, with_visual=False, only_visual=False, mask=None):
|
| 72 |
+
super().__init__()
|
| 73 |
+
|
| 74 |
+
self.negative_prob = negative_prob
|
| 75 |
+
self.image_size = image_size
|
| 76 |
+
self.with_visual = with_visual
|
| 77 |
+
self.only_visual = only_visual
|
| 78 |
+
self.phrase_form = '{}'
|
| 79 |
+
self.mask = mask
|
| 80 |
+
self.aug_crop = aug_crop
|
| 81 |
+
|
| 82 |
+
if aug_color:
|
| 83 |
+
self.aug_color = transforms.Compose([
|
| 84 |
+
transforms.ColorJitter(0.5, 0.5, 0.2, 0.05),
|
| 85 |
+
])
|
| 86 |
+
else:
|
| 87 |
+
self.aug_color = None
|
| 88 |
+
|
| 89 |
+
get_from_repository('PhraseCut', ['PhraseCut.tar'], integrity_check=lambda local_dir: all([
|
| 90 |
+
isdir(join(local_dir, 'VGPhraseCut_v0')),
|
| 91 |
+
isdir(join(local_dir, 'VGPhraseCut_v0', 'images')),
|
| 92 |
+
isfile(join(local_dir, 'VGPhraseCut_v0', 'refer_train.json')),
|
| 93 |
+
len(os.listdir(join(local_dir, 'VGPhraseCut_v0', 'images'))) in {108250, 108249}
|
| 94 |
+
]))
|
| 95 |
+
|
| 96 |
+
from third_party.PhraseCutDataset.utils.refvg_loader import RefVGLoader
|
| 97 |
+
self.refvg_loader = RefVGLoader(split=split)
|
| 98 |
+
|
| 99 |
+
# img_ids where the size in the annotations does not match actual size
|
| 100 |
+
invalid_img_ids = set([150417, 285665, 498246, 61564, 285743, 498269, 498010, 150516, 150344, 286093, 61530,
|
| 101 |
+
150333, 286065, 285814, 498187, 285761, 498042])
|
| 102 |
+
|
| 103 |
+
mean = [0.485, 0.456, 0.406]
|
| 104 |
+
std = [0.229, 0.224, 0.225]
|
| 105 |
+
self.normalize = transforms.Normalize(mean, std)
|
| 106 |
+
|
| 107 |
+
self.sample_ids = [(i, j)
|
| 108 |
+
for i in self.refvg_loader.img_ids
|
| 109 |
+
for j in range(len(self.refvg_loader.get_img_ref_data(i)['phrases']))
|
| 110 |
+
if i not in invalid_img_ids]
|
| 111 |
+
|
| 112 |
+
|
| 113 |
+
# self.all_phrases = list(set([p for i in self.refvg_loader.img_ids for p in self.refvg_loader.get_img_ref_data(i)['phrases']]))
|
| 114 |
+
|
| 115 |
+
from nltk.stem import WordNetLemmatizer
|
| 116 |
+
wnl = WordNetLemmatizer()
|
| 117 |
+
|
| 118 |
+
# Filter by class (if remove_classes is set)
|
| 119 |
+
if remove_classes is None:
|
| 120 |
+
pass
|
| 121 |
+
else:
|
| 122 |
+
from datasets.generate_lvis_oneshot import PASCAL_SYNSETS, traverse_lemmas, traverse_lemmas_hypo
|
| 123 |
+
from nltk.corpus import wordnet
|
| 124 |
+
|
| 125 |
+
print('remove pascal classes...')
|
| 126 |
+
|
| 127 |
+
get_data = self.refvg_loader.get_img_ref_data # shortcut
|
| 128 |
+
keep_sids = None
|
| 129 |
+
|
| 130 |
+
if remove_classes[0] == 'pas5i':
|
| 131 |
+
subset_id = remove_classes[1]
|
| 132 |
+
from datasets.generate_lvis_oneshot import PASCAL_5I_SYNSETS_ORDERED, PASCAL_5I_CLASS_IDS
|
| 133 |
+
avoid = [PASCAL_5I_SYNSETS_ORDERED[i] for i in range(20) if i+1 not in PASCAL_5I_CLASS_IDS[subset_id]]
|
| 134 |
+
|
| 135 |
+
|
| 136 |
+
elif remove_classes[0] == 'zs':
|
| 137 |
+
stop = remove_classes[1]
|
| 138 |
+
|
| 139 |
+
from datasets.pascal_zeroshot import PASCAL_VOC_CLASSES_ZS
|
| 140 |
+
|
| 141 |
+
avoid = [c for class_set in PASCAL_VOC_CLASSES_ZS[:stop] for c in class_set]
|
| 142 |
+
print(avoid)
|
| 143 |
+
|
| 144 |
+
elif remove_classes[0] == 'aff':
|
| 145 |
+
# avoid = ['drink.v.01', 'sit.v.01', 'ride.v.02']
|
| 146 |
+
# all_lemmas = set(['drink', 'sit', 'ride'])
|
| 147 |
+
avoid = ['drink', 'drinks', 'drinking', 'sit', 'sits', 'sitting',
|
| 148 |
+
'ride', 'rides', 'riding',
|
| 149 |
+
'fly', 'flies', 'flying', 'drive', 'drives', 'driving', 'driven',
|
| 150 |
+
'swim', 'swims', 'swimming',
|
| 151 |
+
'wheels', 'wheel', 'legs', 'leg', 'ear', 'ears']
|
| 152 |
+
keep_sids = [(i, j) for i, j in self.sample_ids if
|
| 153 |
+
all(x not in avoid for x in get_data(i)['phrases'][j].split(' '))]
|
| 154 |
+
|
| 155 |
+
print('avoid classes:', avoid)
|
| 156 |
+
|
| 157 |
+
|
| 158 |
+
if keep_sids is None:
|
| 159 |
+
all_lemmas = [s for ps in avoid for s in traverse_lemmas_hypo(wordnet.synset(ps), max_depth=None)]
|
| 160 |
+
all_lemmas = list(set(all_lemmas))
|
| 161 |
+
all_lemmas = [h.replace('_', ' ').lower() for h in all_lemmas]
|
| 162 |
+
all_lemmas = set(all_lemmas)
|
| 163 |
+
|
| 164 |
+
# divide into multi word and single word
|
| 165 |
+
all_lemmas_s = set(l for l in all_lemmas if ' ' not in l)
|
| 166 |
+
all_lemmas_m = set(l for l in all_lemmas if l not in all_lemmas_s)
|
| 167 |
+
|
| 168 |
+
# new3
|
| 169 |
+
phrases = [get_data(i)['phrases'][j] for i, j in self.sample_ids]
|
| 170 |
+
remove_sids = set((i,j) for (i,j), phrase in zip(self.sample_ids, phrases)
|
| 171 |
+
if any(l in phrase for l in all_lemmas_m) or
|
| 172 |
+
len(set(wnl.lemmatize(w) for w in phrase.split(' ')).intersection(all_lemmas_s)) > 0
|
| 173 |
+
)
|
| 174 |
+
keep_sids = [(i, j) for i, j in self.sample_ids if (i,j) not in remove_sids]
|
| 175 |
+
|
| 176 |
+
print(f'Reduced to {len(keep_sids) / len(self.sample_ids):.3f}')
|
| 177 |
+
removed_ids = set(self.sample_ids) - set(keep_sids)
|
| 178 |
+
|
| 179 |
+
print('Examples of removed', len(removed_ids))
|
| 180 |
+
for i, j in list(removed_ids)[:20]:
|
| 181 |
+
print(i, get_data(i)['phrases'][j])
|
| 182 |
+
|
| 183 |
+
self.sample_ids = keep_sids
|
| 184 |
+
|
| 185 |
+
from itertools import groupby
|
| 186 |
+
samples_by_phrase = [(self.refvg_loader.get_img_ref_data(i)['phrases'][j], (i, j))
|
| 187 |
+
for i, j in self.sample_ids]
|
| 188 |
+
samples_by_phrase = sorted(samples_by_phrase)
|
| 189 |
+
samples_by_phrase = groupby(samples_by_phrase, key=lambda x: x[0])
|
| 190 |
+
|
| 191 |
+
self.samples_by_phrase = {prompt: [s[1] for s in prompt_sample_ids] for prompt, prompt_sample_ids in samples_by_phrase}
|
| 192 |
+
|
| 193 |
+
self.all_phrases = list(set(self.samples_by_phrase.keys()))
|
| 194 |
+
|
| 195 |
+
|
| 196 |
+
if self.only_visual:
|
| 197 |
+
assert self.with_visual
|
| 198 |
+
self.sample_ids = [(i, j) for i, j in self.sample_ids
|
| 199 |
+
if len(self.samples_by_phrase[self.refvg_loader.get_img_ref_data(i)['phrases'][j]]) > 1]
|
| 200 |
+
|
| 201 |
+
# Filter by size (if min_size is set)
|
| 202 |
+
sizes = [self.refvg_loader.get_img_ref_data(i)['gt_boxes'][j] for i, j in self.sample_ids]
|
| 203 |
+
image_sizes = [self.refvg_loader.get_img_ref_data(i)['width'] * self.refvg_loader.get_img_ref_data(i)['height'] for i, j in self.sample_ids]
|
| 204 |
+
#self.sizes = [sum([(s[2] - s[0]) * (s[3] - s[1]) for s in size]) for size in sizes]
|
| 205 |
+
self.sizes = [sum([s[2] * s[3] for s in size]) / img_size for size, img_size in zip(sizes, image_sizes)]
|
| 206 |
+
|
| 207 |
+
if min_size:
|
| 208 |
+
print('filter by size')
|
| 209 |
+
|
| 210 |
+
self.sample_ids = [self.sample_ids[i] for i in range(len(self.sample_ids)) if self.sizes[i] > min_size]
|
| 211 |
+
|
| 212 |
+
self.base_path = join(expanduser('~/datasets/PhraseCut/VGPhraseCut_v0/images/'))
|
| 213 |
+
|
| 214 |
+
def __len__(self):
|
| 215 |
+
return len(self.sample_ids)
|
| 216 |
+
|
| 217 |
+
|
| 218 |
+
def load_sample(self, sample_i, j):
|
| 219 |
+
|
| 220 |
+
img_ref_data = self.refvg_loader.get_img_ref_data(sample_i)
|
| 221 |
+
|
| 222 |
+
polys_phrase0 = img_ref_data['gt_Polygons'][j]
|
| 223 |
+
phrase = img_ref_data['phrases'][j]
|
| 224 |
+
phrase = self.phrase_form.format(phrase)
|
| 225 |
+
|
| 226 |
+
masks = []
|
| 227 |
+
for polys in polys_phrase0:
|
| 228 |
+
for poly in polys:
|
| 229 |
+
poly = [p[::-1] for p in poly] # swap x,y
|
| 230 |
+
masks += [polygon2mask((img_ref_data['height'], img_ref_data['width']), poly)]
|
| 231 |
+
|
| 232 |
+
seg = np.stack(masks).max(0)
|
| 233 |
+
img = np.array(Image.open(join(self.base_path, str(img_ref_data['image_id']) + '.jpg')))
|
| 234 |
+
|
| 235 |
+
min_shape = min(img.shape[:2])
|
| 236 |
+
|
| 237 |
+
if self.aug_crop:
|
| 238 |
+
sly, slx, exceed = find_crop(seg, (min_shape, min_shape), iterations=50, min_frac=0.05)
|
| 239 |
+
else:
|
| 240 |
+
sly, slx = slice(0, None), slice(0, None)
|
| 241 |
+
|
| 242 |
+
seg = seg[sly, slx]
|
| 243 |
+
img = img[sly, slx]
|
| 244 |
+
|
| 245 |
+
seg = seg.astype('uint8')
|
| 246 |
+
seg = torch.from_numpy(seg).view(1, 1, *seg.shape)
|
| 247 |
+
|
| 248 |
+
if img.ndim == 2:
|
| 249 |
+
img = np.dstack([img] * 3)
|
| 250 |
+
|
| 251 |
+
img = torch.from_numpy(img).permute(2,0,1).unsqueeze(0).float()
|
| 252 |
+
|
| 253 |
+
seg = nnf.interpolate(seg, (self.image_size, self.image_size), mode='nearest')[0,0]
|
| 254 |
+
img = nnf.interpolate(img, (self.image_size, self.image_size), mode='bilinear', align_corners=True)[0]
|
| 255 |
+
|
| 256 |
+
# img = img.permute([2,0, 1])
|
| 257 |
+
img = img / 255.0
|
| 258 |
+
|
| 259 |
+
if self.aug_color is not None:
|
| 260 |
+
img = self.aug_color(img)
|
| 261 |
+
|
| 262 |
+
img = self.normalize(img)
|
| 263 |
+
|
| 264 |
+
|
| 265 |
+
|
| 266 |
+
return img, seg, phrase
|
| 267 |
+
|
| 268 |
+
def __getitem__(self, i):
|
| 269 |
+
|
| 270 |
+
sample_i, j = self.sample_ids[i]
|
| 271 |
+
|
| 272 |
+
img, seg, phrase = self.load_sample(sample_i, j)
|
| 273 |
+
|
| 274 |
+
if self.negative_prob > 0:
|
| 275 |
+
if torch.rand((1,)).item() < self.negative_prob:
|
| 276 |
+
|
| 277 |
+
new_phrase = None
|
| 278 |
+
while new_phrase is None or new_phrase == phrase:
|
| 279 |
+
idx = torch.randint(0, len(self.all_phrases), (1,)).item()
|
| 280 |
+
new_phrase = self.all_phrases[idx]
|
| 281 |
+
phrase = new_phrase
|
| 282 |
+
seg = torch.zeros_like(seg)
|
| 283 |
+
|
| 284 |
+
if self.with_visual:
|
| 285 |
+
# find a corresponding visual image
|
| 286 |
+
if phrase in self.samples_by_phrase and len(self.samples_by_phrase[phrase]) > 1:
|
| 287 |
+
idx = torch.randint(0, len(self.samples_by_phrase[phrase]), (1,)).item()
|
| 288 |
+
other_sample = self.samples_by_phrase[phrase][idx]
|
| 289 |
+
#print(other_sample)
|
| 290 |
+
img_s, seg_s, _ = self.load_sample(*other_sample)
|
| 291 |
+
|
| 292 |
+
from datasets.utils import blend_image_segmentation
|
| 293 |
+
|
| 294 |
+
if self.mask in {'separate', 'text_and_separate'}:
|
| 295 |
+
# assert img.shape[1:] == img_s.shape[1:] == seg_s.shape == seg.shape[1:]
|
| 296 |
+
add_phrase = [phrase] if self.mask == 'text_and_separate' else []
|
| 297 |
+
vis_s = add_phrase + [img_s, seg_s, True]
|
| 298 |
+
else:
|
| 299 |
+
if self.mask.startswith('text_and_'):
|
| 300 |
+
mask_mode = self.mask[9:]
|
| 301 |
+
label_add = [phrase]
|
| 302 |
+
else:
|
| 303 |
+
mask_mode = self.mask
|
| 304 |
+
label_add = []
|
| 305 |
+
|
| 306 |
+
masked_img_s = torch.from_numpy(blend_image_segmentation(img_s, seg_s, mode=mask_mode, image_size=self.image_size)[0])
|
| 307 |
+
vis_s = label_add + [masked_img_s, True]
|
| 308 |
+
|
| 309 |
+
else:
|
| 310 |
+
# phrase is unique
|
| 311 |
+
vis_s = torch.zeros_like(img)
|
| 312 |
+
|
| 313 |
+
if self.mask in {'separate', 'text_and_separate'}:
|
| 314 |
+
add_phrase = [phrase] if self.mask == 'text_and_separate' else []
|
| 315 |
+
vis_s = add_phrase + [vis_s, torch.zeros(*vis_s.shape[1:], dtype=torch.uint8), False]
|
| 316 |
+
elif self.mask.startswith('text_and_'):
|
| 317 |
+
vis_s = [phrase, vis_s, False]
|
| 318 |
+
else:
|
| 319 |
+
vis_s = [vis_s, False]
|
| 320 |
+
else:
|
| 321 |
+
assert self.mask == 'text'
|
| 322 |
+
vis_s = [phrase]
|
| 323 |
+
|
| 324 |
+
seg = seg.unsqueeze(0).float()
|
| 325 |
+
|
| 326 |
+
data_x = (img,) + tuple(vis_s)
|
| 327 |
+
|
| 328 |
+
return data_x, (seg, torch.zeros(0), i)
|
| 329 |
+
|
| 330 |
+
|
| 331 |
+
class PhraseCutPlus(PhraseCut):
|
| 332 |
+
|
| 333 |
+
def __init__(self, split, image_size=400, aug=None, aug_color=False, aug_crop=True, min_size=0, remove_classes=None, only_visual=False, mask=None):
|
| 334 |
+
super().__init__(split, image_size=image_size, negative_prob=0.2, aug=aug, aug_color=aug_color, aug_crop=aug_crop, min_size=min_size,
|
| 335 |
+
remove_classes=remove_classes, with_visual=True, only_visual=only_visual, mask=mask)
|
clipseg/datasets/utils.py
ADDED
|
@@ -0,0 +1,68 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
|
| 2 |
+
import numpy as np
|
| 3 |
+
import torch
|
| 4 |
+
|
| 5 |
+
|
| 6 |
+
def blend_image_segmentation(img, seg, mode, image_size=224):
|
| 7 |
+
|
| 8 |
+
|
| 9 |
+
if mode in {'blur_highlight', 'blur3_highlight', 'blur3_highlight01', 'blur_highlight_random', 'crop'}:
|
| 10 |
+
if isinstance(img, np.ndarray):
|
| 11 |
+
img = torch.from_numpy(img)
|
| 12 |
+
|
| 13 |
+
if isinstance(seg, np.ndarray):
|
| 14 |
+
seg = torch.from_numpy(seg)
|
| 15 |
+
|
| 16 |
+
if mode == 'overlay':
|
| 17 |
+
out = img * seg
|
| 18 |
+
out = [out.astype('float32')]
|
| 19 |
+
elif mode == 'highlight':
|
| 20 |
+
out = img * seg[None, :, :] * 0.85 + 0.15 * img
|
| 21 |
+
out = [out.astype('float32')]
|
| 22 |
+
elif mode == 'highlight2':
|
| 23 |
+
img = img / 2
|
| 24 |
+
out = (img+0.1) * seg[None, :, :] + 0.3 * img
|
| 25 |
+
out = [out.astype('float32')]
|
| 26 |
+
elif mode == 'blur_highlight':
|
| 27 |
+
from evaluation_utils import img_preprocess
|
| 28 |
+
out = [img_preprocess((None, [img], [seg]), blur=1, bg_fac=0.5).numpy()[0] - 0.01]
|
| 29 |
+
elif mode == 'blur3_highlight':
|
| 30 |
+
from evaluation_utils import img_preprocess
|
| 31 |
+
out = [img_preprocess((None, [img], [seg]), blur=3, bg_fac=0.5).numpy()[0] - 0.01]
|
| 32 |
+
elif mode == 'blur3_highlight01':
|
| 33 |
+
from evaluation_utils import img_preprocess
|
| 34 |
+
out = [img_preprocess((None, [img], [seg]), blur=3, bg_fac=0.1).numpy()[0] - 0.01]
|
| 35 |
+
elif mode == 'blur_highlight_random':
|
| 36 |
+
from evaluation_utils import img_preprocess
|
| 37 |
+
out = [img_preprocess((None, [img], [seg]), blur=0 + torch.randint(0, 3, (1,)).item(), bg_fac=0.1 + 0.8*torch.rand(1).item()).numpy()[0] - 0.01]
|
| 38 |
+
elif mode == 'crop':
|
| 39 |
+
from evaluation_utils import img_preprocess
|
| 40 |
+
out = [img_preprocess((None, [img], [seg]), blur=1, center_context=0.1, image_size=image_size)[0].numpy()]
|
| 41 |
+
elif mode == 'crop_blur_highlight':
|
| 42 |
+
from evaluation_utils import img_preprocess
|
| 43 |
+
out = [img_preprocess((None, [img], [seg]), blur=3, center_context=0.1, bg_fac=0.1, image_size=image_size)[0].numpy()]
|
| 44 |
+
elif mode == 'crop_blur_highlight352':
|
| 45 |
+
from evaluation_utils import img_preprocess
|
| 46 |
+
out = [img_preprocess((None, [img], [seg]), blur=3, center_context=0.1, bg_fac=0.1, image_size=352)[0].numpy()]
|
| 47 |
+
elif mode == 'shape':
|
| 48 |
+
out = [np.stack([seg[:, :]]*3).astype('float32')]
|
| 49 |
+
elif mode == 'concat':
|
| 50 |
+
out = [np.concatenate([img, seg[None, :, :]]).astype('float32')]
|
| 51 |
+
elif mode == 'image_only':
|
| 52 |
+
out = [img.astype('float32')]
|
| 53 |
+
elif mode == 'image_black':
|
| 54 |
+
out = [img.astype('float32')*0]
|
| 55 |
+
elif mode is None:
|
| 56 |
+
out = [img.astype('float32')]
|
| 57 |
+
elif mode == 'separate':
|
| 58 |
+
out = [img.astype('float32'), seg.astype('int64')]
|
| 59 |
+
elif mode == 'separate_img_black':
|
| 60 |
+
out = [img.astype('float32')*0, seg.astype('int64')]
|
| 61 |
+
elif mode == 'separate_seg_ones':
|
| 62 |
+
out = [img.astype('float32'), np.ones_like(seg).astype('int64')]
|
| 63 |
+
elif mode == 'separate_both_black':
|
| 64 |
+
out = [img.astype('float32')*0, seg.astype('int64')*0]
|
| 65 |
+
else:
|
| 66 |
+
raise ValueError(f'invalid mode: {mode}')
|
| 67 |
+
|
| 68 |
+
return out
|
clipseg/environment.yml
ADDED
|
@@ -0,0 +1,15 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
name: clipseg-environment
|
| 2 |
+
channels:
|
| 3 |
+
- conda-forge
|
| 4 |
+
- pytorch
|
| 5 |
+
dependencies:
|
| 6 |
+
- numpy
|
| 7 |
+
- scipy
|
| 8 |
+
- matplotlib-base
|
| 9 |
+
- pip
|
| 10 |
+
- pip:
|
| 11 |
+
- --find-links https://download.pytorch.org/whl/torch_stable.html
|
| 12 |
+
- torch==1.10.0+cpu
|
| 13 |
+
- torchvision==0.11.1+cpu
|
| 14 |
+
- opencv-python
|
| 15 |
+
- git+https://github.com/openai/CLIP.git
|
clipseg/evaluation_utils.py
ADDED
|
@@ -0,0 +1,292 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from torch.functional import Tensor
|
| 2 |
+
from general_utils import load_model
|
| 3 |
+
from torch.utils.data import DataLoader
|
| 4 |
+
import torch
|
| 5 |
+
import numpy as np
|
| 6 |
+
|
| 7 |
+
def denorm(img):
|
| 8 |
+
|
| 9 |
+
np_input = False
|
| 10 |
+
if isinstance(img, np.ndarray):
|
| 11 |
+
img = torch.from_numpy(img)
|
| 12 |
+
np_input = True
|
| 13 |
+
|
| 14 |
+
mean = torch.Tensor([0.485, 0.456, 0.406])
|
| 15 |
+
std = torch.Tensor([0.229, 0.224, 0.225])
|
| 16 |
+
|
| 17 |
+
img_denorm = (img*std[:,None,None]) + mean[:,None,None]
|
| 18 |
+
|
| 19 |
+
if np_input:
|
| 20 |
+
img_denorm = np.clip(img_denorm.numpy(), 0, 1)
|
| 21 |
+
else:
|
| 22 |
+
img_denorm = torch.clamp(img_denorm, 0, 1)
|
| 23 |
+
|
| 24 |
+
return img_denorm
|
| 25 |
+
|
| 26 |
+
|
| 27 |
+
def norm(img):
|
| 28 |
+
mean = torch.Tensor([0.485, 0.456, 0.406])
|
| 29 |
+
std = torch.Tensor([0.229, 0.224, 0.225])
|
| 30 |
+
return (img - mean[:,None,None]) / std[:,None,None]
|
| 31 |
+
|
| 32 |
+
|
| 33 |
+
def fast_iou_curve(p, g):
|
| 34 |
+
|
| 35 |
+
g = g[p.sort().indices]
|
| 36 |
+
p = torch.sigmoid(p.sort().values)
|
| 37 |
+
|
| 38 |
+
scores = []
|
| 39 |
+
vals = np.linspace(0, 1, 50)
|
| 40 |
+
|
| 41 |
+
for q in vals:
|
| 42 |
+
|
| 43 |
+
n = int(len(g) * q)
|
| 44 |
+
|
| 45 |
+
valid = torch.where(p > q)[0]
|
| 46 |
+
if len(valid) > 0:
|
| 47 |
+
n = int(valid[0])
|
| 48 |
+
else:
|
| 49 |
+
n = len(g)
|
| 50 |
+
|
| 51 |
+
fn = g[:n].sum()
|
| 52 |
+
tn = n - fn
|
| 53 |
+
tp = g[n:].sum()
|
| 54 |
+
fp = len(g) - n - tp
|
| 55 |
+
|
| 56 |
+
iou = tp / (tp + fn + fp)
|
| 57 |
+
|
| 58 |
+
precision = tp / (tp + fp)
|
| 59 |
+
recall = tp / (tp + fn)
|
| 60 |
+
|
| 61 |
+
scores += [iou]
|
| 62 |
+
|
| 63 |
+
return vals, scores
|
| 64 |
+
|
| 65 |
+
|
| 66 |
+
def fast_rp_curve(p, g):
|
| 67 |
+
|
| 68 |
+
g = g[p.sort().indices]
|
| 69 |
+
p = torch.sigmoid(p.sort().values)
|
| 70 |
+
|
| 71 |
+
precisions, recalls = [], []
|
| 72 |
+
vals = np.linspace(p.min(), p.max(), 250)
|
| 73 |
+
|
| 74 |
+
for q in p[::100000]:
|
| 75 |
+
|
| 76 |
+
n = int(len(g) * q)
|
| 77 |
+
|
| 78 |
+
valid = torch.where(p > q)[0]
|
| 79 |
+
if len(valid) > 0:
|
| 80 |
+
n = int(valid[0])
|
| 81 |
+
else:
|
| 82 |
+
n = len(g)
|
| 83 |
+
|
| 84 |
+
fn = g[:n].sum()
|
| 85 |
+
tn = n - fn
|
| 86 |
+
tp = g[n:].sum()
|
| 87 |
+
fp = len(g) - n - tp
|
| 88 |
+
|
| 89 |
+
iou = tp / (tp + fn + fp)
|
| 90 |
+
|
| 91 |
+
precision = tp / (tp + fp)
|
| 92 |
+
recall = tp / (tp + fn)
|
| 93 |
+
|
| 94 |
+
precisions += [precision]
|
| 95 |
+
recalls += [recall]
|
| 96 |
+
|
| 97 |
+
return recalls, precisions
|
| 98 |
+
|
| 99 |
+
|
| 100 |
+
# Image processing
|
| 101 |
+
|
| 102 |
+
def img_preprocess(batch, blur=0, grayscale=False, center_context=None, rect=False, rect_color=(255,0,0), rect_width=2,
|
| 103 |
+
brightness=1.0, bg_fac=1, colorize=False, outline=False, image_size=224):
|
| 104 |
+
import cv2
|
| 105 |
+
|
| 106 |
+
rw = rect_width
|
| 107 |
+
|
| 108 |
+
out = []
|
| 109 |
+
for img, mask in zip(batch[1], batch[2]):
|
| 110 |
+
|
| 111 |
+
img = img.cpu() if isinstance(img, torch.Tensor) else torch.from_numpy(img)
|
| 112 |
+
mask = mask.cpu() if isinstance(mask, torch.Tensor) else torch.from_numpy(mask)
|
| 113 |
+
|
| 114 |
+
img *= brightness
|
| 115 |
+
img_bl = img
|
| 116 |
+
if blur > 0: # best 5
|
| 117 |
+
img_bl = torch.from_numpy(cv2.GaussianBlur(img.permute(1,2,0).numpy(), (15, 15), blur)).permute(2,0,1)
|
| 118 |
+
|
| 119 |
+
if grayscale:
|
| 120 |
+
img_bl = img_bl[1][None]
|
| 121 |
+
|
| 122 |
+
#img_inp = img_ratio*img*mask + (1-img_ratio)*img_bl
|
| 123 |
+
# img_inp = img_ratio*img*mask + (1-img_ratio)*img_bl * (1-mask)
|
| 124 |
+
img_inp = img*mask + (bg_fac) * img_bl * (1-mask)
|
| 125 |
+
|
| 126 |
+
if rect:
|
| 127 |
+
_, bbox = crop_mask(img, mask, context=0.1)
|
| 128 |
+
img_inp[:, bbox[2]: bbox[3], max(0, bbox[0]-rw):bbox[0]+rw] = torch.tensor(rect_color)[:,None,None]
|
| 129 |
+
img_inp[:, bbox[2]: bbox[3], max(0, bbox[1]-rw):bbox[1]+rw] = torch.tensor(rect_color)[:,None,None]
|
| 130 |
+
img_inp[:, max(0, bbox[2]-1): bbox[2]+rw, bbox[0]:bbox[1]] = torch.tensor(rect_color)[:,None,None]
|
| 131 |
+
img_inp[:, max(0, bbox[3]-1): bbox[3]+rw, bbox[0]:bbox[1]] = torch.tensor(rect_color)[:,None,None]
|
| 132 |
+
|
| 133 |
+
|
| 134 |
+
if center_context is not None:
|
| 135 |
+
img_inp = object_crop(img_inp, mask, context=center_context, image_size=image_size)
|
| 136 |
+
|
| 137 |
+
if colorize:
|
| 138 |
+
img_gray = denorm(img)
|
| 139 |
+
img_gray = cv2.cvtColor(img_gray.permute(1,2,0).numpy(), cv2.COLOR_RGB2GRAY)
|
| 140 |
+
img_gray = torch.stack([torch.from_numpy(img_gray)]*3)
|
| 141 |
+
img_inp = torch.tensor([1,0.2,0.2])[:,None,None] * img_gray * mask + bg_fac * img_gray * (1-mask)
|
| 142 |
+
img_inp = norm(img_inp)
|
| 143 |
+
|
| 144 |
+
if outline:
|
| 145 |
+
cont = cv2.findContours(mask.byte().numpy(), cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
|
| 146 |
+
outline_img = np.zeros(mask.shape, dtype=np.uint8)
|
| 147 |
+
cv2.drawContours(outline_img, cont[0], -1, thickness=5, color=(255, 255, 255))
|
| 148 |
+
outline_img = torch.stack([torch.from_numpy(outline_img)]*3).float() / 255.
|
| 149 |
+
img_inp = torch.tensor([1,0,0])[:,None,None] * outline_img + denorm(img_inp) * (1- outline_img)
|
| 150 |
+
img_inp = norm(img_inp)
|
| 151 |
+
|
| 152 |
+
out += [img_inp]
|
| 153 |
+
|
| 154 |
+
return torch.stack(out)
|
| 155 |
+
|
| 156 |
+
|
| 157 |
+
def object_crop(img, mask, context=0.0, square=False, image_size=224):
|
| 158 |
+
img_crop, bbox = crop_mask(img, mask, context=context, square=square)
|
| 159 |
+
img_crop = pad_to_square(img_crop, channel_dim=0)
|
| 160 |
+
img_crop = torch.nn.functional.interpolate(img_crop.unsqueeze(0), (image_size, image_size)).squeeze(0)
|
| 161 |
+
return img_crop
|
| 162 |
+
|
| 163 |
+
|
| 164 |
+
def crop_mask(img, mask, context=0.0, square=False):
|
| 165 |
+
|
| 166 |
+
assert img.shape[1:] == mask.shape
|
| 167 |
+
|
| 168 |
+
bbox = [mask.max(0).values.argmax(), mask.size(0) - mask.max(0).values.flip(0).argmax()]
|
| 169 |
+
bbox += [mask.max(1).values.argmax(), mask.size(1) - mask.max(1).values.flip(0).argmax()]
|
| 170 |
+
bbox = [int(x) for x in bbox]
|
| 171 |
+
|
| 172 |
+
width, height = (bbox[3] - bbox[2]), (bbox[1] - bbox[0])
|
| 173 |
+
|
| 174 |
+
# square mask
|
| 175 |
+
if square:
|
| 176 |
+
bbox[0] = int(max(0, bbox[0] - context * height))
|
| 177 |
+
bbox[1] = int(min(mask.size(0), bbox[1] + context * height))
|
| 178 |
+
bbox[2] = int(max(0, bbox[2] - context * width))
|
| 179 |
+
bbox[3] = int(min(mask.size(1), bbox[3] + context * width))
|
| 180 |
+
|
| 181 |
+
width, height = (bbox[3] - bbox[2]), (bbox[1] - bbox[0])
|
| 182 |
+
if height > width:
|
| 183 |
+
bbox[2] = int(max(0, (bbox[2] - 0.5*height)))
|
| 184 |
+
bbox[3] = bbox[2] + height
|
| 185 |
+
else:
|
| 186 |
+
bbox[0] = int(max(0, (bbox[0] - 0.5*width)))
|
| 187 |
+
bbox[1] = bbox[0] + width
|
| 188 |
+
else:
|
| 189 |
+
bbox[0] = int(max(0, bbox[0] - context * height))
|
| 190 |
+
bbox[1] = int(min(mask.size(0), bbox[1] + context * height))
|
| 191 |
+
bbox[2] = int(max(0, bbox[2] - context * width))
|
| 192 |
+
bbox[3] = int(min(mask.size(1), bbox[3] + context * width))
|
| 193 |
+
|
| 194 |
+
width, height = (bbox[3] - bbox[2]), (bbox[1] - bbox[0])
|
| 195 |
+
img_crop = img[:, bbox[2]: bbox[3], bbox[0]: bbox[1]]
|
| 196 |
+
return img_crop, bbox
|
| 197 |
+
|
| 198 |
+
|
| 199 |
+
def pad_to_square(img, channel_dim=2, fill=0):
|
| 200 |
+
"""
|
| 201 |
+
|
| 202 |
+
|
| 203 |
+
add padding such that a squared image is returned """
|
| 204 |
+
|
| 205 |
+
from torchvision.transforms.functional import pad
|
| 206 |
+
|
| 207 |
+
if channel_dim == 2:
|
| 208 |
+
img = img.permute(2, 0, 1)
|
| 209 |
+
elif channel_dim == 0:
|
| 210 |
+
pass
|
| 211 |
+
else:
|
| 212 |
+
raise ValueError('invalid channel_dim')
|
| 213 |
+
|
| 214 |
+
h, w = img.shape[1:]
|
| 215 |
+
pady1 = pady2 = padx1 = padx2 = 0
|
| 216 |
+
|
| 217 |
+
if h > w:
|
| 218 |
+
padx1 = (h - w) // 2
|
| 219 |
+
padx2 = h - w - padx1
|
| 220 |
+
elif w > h:
|
| 221 |
+
pady1 = (w - h) // 2
|
| 222 |
+
pady2 = w - h - pady1
|
| 223 |
+
|
| 224 |
+
img_padded = pad(img, padding=(padx1, pady1, padx2, pady2), padding_mode='constant')
|
| 225 |
+
|
| 226 |
+
if channel_dim == 2:
|
| 227 |
+
img_padded = img_padded.permute(1, 2, 0)
|
| 228 |
+
|
| 229 |
+
return img_padded
|
| 230 |
+
|
| 231 |
+
|
| 232 |
+
# qualitative
|
| 233 |
+
|
| 234 |
+
def split_sentence(inp, limit=9):
|
| 235 |
+
t_new, current_len = [], 0
|
| 236 |
+
for k, t in enumerate(inp.split(' ')):
|
| 237 |
+
current_len += len(t) + 1
|
| 238 |
+
t_new += [t+' ']
|
| 239 |
+
# not last
|
| 240 |
+
if current_len > limit and k != len(inp.split(' ')) - 1:
|
| 241 |
+
current_len = 0
|
| 242 |
+
t_new += ['\n']
|
| 243 |
+
|
| 244 |
+
t_new = ''.join(t_new)
|
| 245 |
+
return t_new
|
| 246 |
+
|
| 247 |
+
|
| 248 |
+
from matplotlib import pyplot as plt
|
| 249 |
+
|
| 250 |
+
|
| 251 |
+
def plot(imgs, *preds, labels=None, scale=1, cmap=plt.cm.magma, aps=None, gt_labels=None, vmax=None):
|
| 252 |
+
|
| 253 |
+
row_off = 0 if labels is None else 1
|
| 254 |
+
_, ax = plt.subplots(len(imgs) + row_off, 1 + len(preds), figsize=(scale * float(1 + 2*len(preds)), scale * float(len(imgs)*2)))
|
| 255 |
+
[a.axis('off') for a in ax.flatten()]
|
| 256 |
+
|
| 257 |
+
if labels is not None:
|
| 258 |
+
for j in range(len(labels)):
|
| 259 |
+
t_new = split_sentence(labels[j], limit=6)
|
| 260 |
+
ax[0, 1+ j].text(0.5, 0.1, t_new, ha='center', fontsize=3+ 10*scale)
|
| 261 |
+
|
| 262 |
+
|
| 263 |
+
for i in range(len(imgs)):
|
| 264 |
+
ax[i + row_off,0].imshow(imgs[i])
|
| 265 |
+
for j in range(len(preds)):
|
| 266 |
+
img = preds[j][i][0].detach().cpu().numpy()
|
| 267 |
+
|
| 268 |
+
if gt_labels is not None and labels[j] == gt_labels[i]:
|
| 269 |
+
print(j, labels[j], gt_labels[i])
|
| 270 |
+
edgecolor = 'red'
|
| 271 |
+
if aps is not None:
|
| 272 |
+
ax[i + row_off, 1 + j].text(30, 70, f'AP: {aps[i]:.3f}', color='red', fontsize=8)
|
| 273 |
+
else:
|
| 274 |
+
edgecolor = 'k'
|
| 275 |
+
|
| 276 |
+
rect = plt.Rectangle([0,0], img.shape[0], img.shape[1], facecolor="none",
|
| 277 |
+
edgecolor=edgecolor, linewidth=3)
|
| 278 |
+
ax[i + row_off,1 + j].add_patch(rect)
|
| 279 |
+
|
| 280 |
+
if vmax is None:
|
| 281 |
+
this_vmax = 1
|
| 282 |
+
elif vmax == 'per_prompt':
|
| 283 |
+
this_vmax = max([preds[j][_i][0].max() for _i in range(len(imgs))])
|
| 284 |
+
elif vmax == 'per_image':
|
| 285 |
+
this_vmax = max([preds[_j][i][0].max() for _j in range(len(preds))])
|
| 286 |
+
|
| 287 |
+
ax[i + row_off,1 + j].imshow(img, vmin=0, vmax=this_vmax, cmap=cmap)
|
| 288 |
+
|
| 289 |
+
|
| 290 |
+
# ax[i,1 + j].imshow(preds[j][i][0].detach().cpu().numpy(), vmin=preds[j].min(), vmax=preds[j].max())
|
| 291 |
+
plt.tight_layout()
|
| 292 |
+
plt.subplots_adjust(wspace=0.05, hspace=0.05)
|
clipseg/example_image.jpg
ADDED

|
clipseg/experiments/ablation.yaml
ADDED
|
@@ -0,0 +1,84 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
configuration:
|
| 2 |
+
batch_size: 64
|
| 3 |
+
optimizer: torch.optim.AdamW
|
| 4 |
+
|
| 5 |
+
lr: 0.001
|
| 6 |
+
|
| 7 |
+
trainer: experiment_setup.train_loop
|
| 8 |
+
scorer: experiment_setup.score
|
| 9 |
+
model: models.clipseg.CLIPDensePredT
|
| 10 |
+
|
| 11 |
+
lr_scheduler: cosine
|
| 12 |
+
T_max: 20000
|
| 13 |
+
eta_min: 0.0001
|
| 14 |
+
|
| 15 |
+
max_iterations: 20000 # <-##########################################
|
| 16 |
+
val_interval: null
|
| 17 |
+
|
| 18 |
+
# dataset
|
| 19 |
+
dataset: datasets.phrasecut.PhraseCut # <-----------------
|
| 20 |
+
split_mode: pascal_test
|
| 21 |
+
split: train
|
| 22 |
+
mask: text_and_crop_blur_highlight352
|
| 23 |
+
image_size: 352
|
| 24 |
+
negative_prob: 0.2
|
| 25 |
+
mix_text_max: 0.5
|
| 26 |
+
|
| 27 |
+
# general
|
| 28 |
+
mix: True # <-----------------
|
| 29 |
+
prompt: shuffle+
|
| 30 |
+
norm_cond: True
|
| 31 |
+
mix_text_min: 0.0
|
| 32 |
+
with_visual: True
|
| 33 |
+
|
| 34 |
+
# model
|
| 35 |
+
version: 'ViT-B/16'
|
| 36 |
+
extract_layers: [3, 7, 9]
|
| 37 |
+
reduce_dim: 64
|
| 38 |
+
depth: 3
|
| 39 |
+
fix_shift: False # <-##########################################
|
| 40 |
+
|
| 41 |
+
loss: torch.nn.functional.binary_cross_entropy_with_logits
|
| 42 |
+
amp: True
|
| 43 |
+
|
| 44 |
+
test_configuration_common:
|
| 45 |
+
normalize: True
|
| 46 |
+
image_size: 352
|
| 47 |
+
batch_size: 32
|
| 48 |
+
sigmoid: True
|
| 49 |
+
split: test
|
| 50 |
+
label_support: True
|
| 51 |
+
|
| 52 |
+
test_configuration:
|
| 53 |
+
|
| 54 |
+
-
|
| 55 |
+
name: pc
|
| 56 |
+
metric: metrics.FixedIntervalMetrics
|
| 57 |
+
test_dataset: phrasecut
|
| 58 |
+
mask: text
|
| 59 |
+
|
| 60 |
+
-
|
| 61 |
+
name: pc-vis
|
| 62 |
+
metric: metrics.FixedIntervalMetrics
|
| 63 |
+
test_dataset: phrasecut
|
| 64 |
+
mask: crop_blur_highlight352
|
| 65 |
+
with_visual: True
|
| 66 |
+
visual_only: True
|
| 67 |
+
|
| 68 |
+
|
| 69 |
+
columns: [name,
|
| 70 |
+
pc_fgiou_best, pc_miou_best, pc_fgiou_0.5,
|
| 71 |
+
pc-vis_fgiou_best, pc-vis_miou_best, pc-vis_fgiou_0.5,
|
| 72 |
+
duration]
|
| 73 |
+
|
| 74 |
+
|
| 75 |
+
individual_configurations:
|
| 76 |
+
|
| 77 |
+
- {name: rd64-uni}
|
| 78 |
+
- {name: rd64-no-pretrain, not_pretrained: True, lr: 0.0003}
|
| 79 |
+
- {name: rd64-no-negatives, negative_prob: 0.0}
|
| 80 |
+
- {name: rd64-neg0.5, negative_prob: 0.5}
|
| 81 |
+
- {name: rd64-no-visual, with_visual: False, mix: False}
|
| 82 |
+
- {name: rd16-uni, reduce_dim: 16}
|
| 83 |
+
- {name: rd64-layer3, extract_layers: [3], depth: 1}
|
| 84 |
+
- {name: rd64-blur-highlight, mask: text_and_blur_highlight, test_configuration: {mask: blur_highlight}}
|
clipseg/experiments/coco.yaml
ADDED
|
@@ -0,0 +1,101 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
configuration:
|
| 2 |
+
batch_size: 64
|
| 3 |
+
optimizer: torch.optim.AdamW
|
| 4 |
+
|
| 5 |
+
lr: 0.001
|
| 6 |
+
|
| 7 |
+
trainer: experiment_setup.train_loop
|
| 8 |
+
scorer: experiment_setup.score
|
| 9 |
+
model: models.clipseg.CLIPDensePredT
|
| 10 |
+
|
| 11 |
+
lr_scheduler: cosine
|
| 12 |
+
T_max: 20000
|
| 13 |
+
eta_min: 0.0001
|
| 14 |
+
|
| 15 |
+
max_iterations: 20000
|
| 16 |
+
val_interval: null
|
| 17 |
+
|
| 18 |
+
# dataset
|
| 19 |
+
dataset: datasets.coco_wrapper.COCOWrapper
|
| 20 |
+
# split_mode: pascal_test
|
| 21 |
+
split: train
|
| 22 |
+
mask: text_and_blur3_highlight01
|
| 23 |
+
image_size: 352
|
| 24 |
+
normalize: True
|
| 25 |
+
pre_crop_image_size: [sample, 1, 1.5]
|
| 26 |
+
aug: 1new
|
| 27 |
+
|
| 28 |
+
# general
|
| 29 |
+
mix: True
|
| 30 |
+
prompt: shuffle+
|
| 31 |
+
norm_cond: True
|
| 32 |
+
mix_text_min: 0.0
|
| 33 |
+
|
| 34 |
+
# model
|
| 35 |
+
out: 1
|
| 36 |
+
extract_layers: [3, 7, 9]
|
| 37 |
+
reduce_dim: 64
|
| 38 |
+
depth: 3
|
| 39 |
+
fix_shift: False
|
| 40 |
+
|
| 41 |
+
loss: torch.nn.functional.binary_cross_entropy_with_logits
|
| 42 |
+
amp: True
|
| 43 |
+
|
| 44 |
+
test_configuration_common:
|
| 45 |
+
normalize: True
|
| 46 |
+
image_size: 352
|
| 47 |
+
# max_iterations: 10
|
| 48 |
+
batch_size: 8
|
| 49 |
+
sigmoid: True
|
| 50 |
+
test_dataset: coco
|
| 51 |
+
metric: metrics.FixedIntervalMetrics
|
| 52 |
+
|
| 53 |
+
test_configuration:
|
| 54 |
+
|
| 55 |
+
-
|
| 56 |
+
name: coco_t
|
| 57 |
+
mask: text
|
| 58 |
+
|
| 59 |
+
-
|
| 60 |
+
name: coco_h
|
| 61 |
+
mask: blur3_highlight01
|
| 62 |
+
|
| 63 |
+
-
|
| 64 |
+
name: coco_h2
|
| 65 |
+
mask: crop_blur_highlight352
|
| 66 |
+
|
| 67 |
+
|
| 68 |
+
columns: [i, name,
|
| 69 |
+
coco_t_fgiou_best, coco_t_miou_best, coco_t_fgiou_0.5,
|
| 70 |
+
coco_h_fgiou_best, coco_h_miou_best, coco_h_fgiou_0.5,
|
| 71 |
+
coco_h2_fgiou_best, coco_h2_miou_best, coco_h2_fgiou_0.5, coco_h2_fgiou_best_t,
|
| 72 |
+
train_loss, duration, date
|
| 73 |
+
]
|
| 74 |
+
|
| 75 |
+
individual_configurations:
|
| 76 |
+
|
| 77 |
+
|
| 78 |
+
- {name: rd64-7K-vit16-cbh-coco-0, version: 'ViT-B/16', fold: 0, reduce_dim: 64, mask: text_and_crop_blur_highlight352, T_max: 7000, max_iterations: 7000}
|
| 79 |
+
- {name: rd64-7K-vit16-cbh-coco-1, version: 'ViT-B/16', fold: 1, reduce_dim: 64, mask: text_and_crop_blur_highlight352, T_max: 7000, max_iterations: 7000}
|
| 80 |
+
- {name: rd64-7K-vit16-cbh-coco-2, version: 'ViT-B/16', fold: 2, reduce_dim: 64, mask: text_and_crop_blur_highlight352, T_max: 7000, max_iterations: 7000}
|
| 81 |
+
- {name: rd64-7K-vit16-cbh-coco-3, version: 'ViT-B/16', fold: 3, reduce_dim: 64, mask: text_and_crop_blur_highlight352, T_max: 7000, max_iterations: 7000}
|
| 82 |
+
|
| 83 |
+
|
| 84 |
+
- {name: rd64-7K-vit16-cbh-neg0.2-coco-0, version: 'ViT-B/16', negative_prob: 0.2, fold: 0, reduce_dim: 64, mask: text_and_crop_blur_highlight352, T_max: 7000, max_iterations: 7000}
|
| 85 |
+
- {name: rd64-7K-vit16-cbh-neg0.2-coco-1, version: 'ViT-B/16', negative_prob: 0.2, fold: 1, reduce_dim: 64, mask: text_and_crop_blur_highlight352, T_max: 7000, max_iterations: 7000}
|
| 86 |
+
- {name: rd64-7K-vit16-cbh-neg0.2-coco-2, version: 'ViT-B/16', negative_prob: 0.2, fold: 2, reduce_dim: 64, mask: text_and_crop_blur_highlight352, T_max: 7000, max_iterations: 7000}
|
| 87 |
+
- {name: rd64-7K-vit16-cbh-neg0.2-coco-3, version: 'ViT-B/16', negative_prob: 0.2, fold: 3, reduce_dim: 64, mask: text_and_crop_blur_highlight352, T_max: 7000, max_iterations: 7000}
|
| 88 |
+
|
| 89 |
+
|
| 90 |
+
# ViT
|
| 91 |
+
- {name: vit64-7K-vit16-cbh-coco-0, version: 'ViT-B/16', model: models.vitseg.VITDensePredT, fold: 0, reduce_dim: 64, mask: text_and_crop_blur_highlight352, T_max: 7000, max_iterations: 7000, lr: 0.0001}
|
| 92 |
+
- {name: vit64-7K-vit16-cbh-coco-1, version: 'ViT-B/16', model: models.vitseg.VITDensePredT, fold: 1, reduce_dim: 64, mask: text_and_crop_blur_highlight352, T_max: 7000, max_iterations: 7000, lr: 0.0001}
|
| 93 |
+
- {name: vit64-7K-vit16-cbh-coco-2, version: 'ViT-B/16', model: models.vitseg.VITDensePredT, fold: 2, reduce_dim: 64, mask: text_and_crop_blur_highlight352, T_max: 7000, max_iterations: 7000, lr: 0.0001}
|
| 94 |
+
- {name: vit64-7K-vit16-cbh-coco-3, version: 'ViT-B/16', model: models.vitseg.VITDensePredT, fold: 3, reduce_dim: 64, mask: text_and_crop_blur_highlight352, T_max: 7000, max_iterations: 7000, lr: 0.0001}
|
| 95 |
+
|
| 96 |
+
|
| 97 |
+
# BASELINE
|
| 98 |
+
- {name: bl64-7K-vit16-cbh-neg0.2-coco-0, model: models.clipseg.CLIPDenseBaseline, reduce2_dim: 64, version: 'ViT-B/16', negative_prob: 0.2, fold: 0, reduce_dim: 64, mask: text_and_crop_blur_highlight352, T_max: 7000, max_iterations: 7000}
|
| 99 |
+
- {name: bl64-7K-vit16-cbh-neg0.2-coco-1, model: models.clipseg.CLIPDenseBaseline, reduce2_dim: 64, version: 'ViT-B/16', negative_prob: 0.2, fold: 1, reduce_dim: 64, mask: text_and_crop_blur_highlight352, T_max: 7000, max_iterations: 7000}
|
| 100 |
+
- {name: bl64-7K-vit16-cbh-neg0.2-coco-2, model: models.clipseg.CLIPDenseBaseline, reduce2_dim: 64, version: 'ViT-B/16', negative_prob: 0.2, fold: 2, reduce_dim: 64, mask: text_and_crop_blur_highlight352, T_max: 7000, max_iterations: 7000}
|
| 101 |
+
- {name: bl64-7K-vit16-cbh-neg0.2-coco-3, model: models.clipseg.CLIPDenseBaseline, reduce2_dim: 64, version: 'ViT-B/16', negative_prob: 0.2, fold: 3, reduce_dim: 64, mask: text_and_crop_blur_highlight352, T_max: 7000, max_iterations: 7000}
|
clipseg/experiments/pascal_1shot.yaml
ADDED
|
@@ -0,0 +1,101 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
configuration:
|
| 2 |
+
batch_size: 64
|
| 3 |
+
optimizer: torch.optim.AdamW
|
| 4 |
+
|
| 5 |
+
lr: 0.001
|
| 6 |
+
|
| 7 |
+
trainer: experiment_setup.train_loop
|
| 8 |
+
scorer: experiment_setup.score
|
| 9 |
+
model: models.clipseg.CLIPDensePredT
|
| 10 |
+
|
| 11 |
+
lr_scheduler: cosine
|
| 12 |
+
T_max: 20000
|
| 13 |
+
eta_min: 0.0001
|
| 14 |
+
|
| 15 |
+
max_iterations: 20000 # <-##########################################
|
| 16 |
+
val_interval: null
|
| 17 |
+
|
| 18 |
+
# dataset
|
| 19 |
+
dataset: datasets.phrasecut.PhraseCut
|
| 20 |
+
split_mode: pascal_test
|
| 21 |
+
mode: train
|
| 22 |
+
mask: text_and_crop_blur_highlight352
|
| 23 |
+
image_size: 352
|
| 24 |
+
normalize: True
|
| 25 |
+
pre_crop_image_size: [sample, 1, 1.5]
|
| 26 |
+
aug: 1new
|
| 27 |
+
with_visual: True
|
| 28 |
+
split: train
|
| 29 |
+
|
| 30 |
+
# general
|
| 31 |
+
mix: True
|
| 32 |
+
prompt: shuffle+
|
| 33 |
+
norm_cond: True
|
| 34 |
+
mix_text_min: 0.0
|
| 35 |
+
|
| 36 |
+
# model
|
| 37 |
+
out: 1
|
| 38 |
+
version: 'ViT-B/16'
|
| 39 |
+
extract_layers: [3, 7, 9]
|
| 40 |
+
reduce_dim: 64
|
| 41 |
+
depth: 3
|
| 42 |
+
|
| 43 |
+
loss: torch.nn.functional.binary_cross_entropy_with_logits
|
| 44 |
+
amp: True
|
| 45 |
+
|
| 46 |
+
test_configuration_common:
|
| 47 |
+
normalize: True
|
| 48 |
+
image_size: 352
|
| 49 |
+
metric: metrics.FixedIntervalMetrics
|
| 50 |
+
batch_size: 1
|
| 51 |
+
test_dataset: pascal
|
| 52 |
+
sigmoid: True
|
| 53 |
+
# max_iterations: 250
|
| 54 |
+
|
| 55 |
+
test_configuration:
|
| 56 |
+
|
| 57 |
+
-
|
| 58 |
+
name: pas_t
|
| 59 |
+
mask: text
|
| 60 |
+
|
| 61 |
+
-
|
| 62 |
+
name: pas_h
|
| 63 |
+
mask: blur3_highlight01
|
| 64 |
+
|
| 65 |
+
-
|
| 66 |
+
name: pas_h2
|
| 67 |
+
mask: crop_blur_highlight352
|
| 68 |
+
|
| 69 |
+
|
| 70 |
+
columns: [name,
|
| 71 |
+
pas_t_fgiou_best, pas_t_miou_best, pas_t_fgiou_ct,
|
| 72 |
+
pas_h_fgiou_best, pas_h_miou_best, pas_h_fgiou_ct,
|
| 73 |
+
pas_h2_fgiou_best, pas_h2_miou_best, pas_h2_fgiou_ct, pas_h2_fgiou_best_t,
|
| 74 |
+
train_loss, duration, date
|
| 75 |
+
]
|
| 76 |
+
|
| 77 |
+
individual_configurations:
|
| 78 |
+
|
| 79 |
+
- {name: rd64-uni-phrasepas5i-0, remove_classes: [pas5i, 0], negative_prob: 0.2, mix_text_max: 0.5, test_configuration: {splits: [0], custom_threshold: 0.24}}
|
| 80 |
+
- {name: rd64-uni-phrasepas5i-1, remove_classes: [pas5i, 1], negative_prob: 0.2, mix_text_max: 0.5, test_configuration: {splits: [1], custom_threshold: 0.24}}
|
| 81 |
+
- {name: rd64-uni-phrasepas5i-2, remove_classes: [pas5i, 2], negative_prob: 0.2, mix_text_max: 0.5, test_configuration: {splits: [2], custom_threshold: 0.24}}
|
| 82 |
+
- {name: rd64-uni-phrasepas5i-3, remove_classes: [pas5i, 3], negative_prob: 0.2, mix_text_max: 0.5, test_configuration: {splits: [3], custom_threshold: 0.24}}
|
| 83 |
+
|
| 84 |
+
|
| 85 |
+
- {name: rd64-phrasepas5i-0, remove_classes: [pas5i, 0], negative_prob: 0.0, test_configuration: {splits: [0], custom_threshold: 0.28}}
|
| 86 |
+
- {name: rd64-phrasepas5i-1, remove_classes: [pas5i, 1], negative_prob: 0.0, test_configuration: {splits: [1], custom_threshold: 0.28}}
|
| 87 |
+
- {name: rd64-phrasepas5i-2, remove_classes: [pas5i, 2], negative_prob: 0.0, test_configuration: {splits: [2], custom_threshold: 0.28}}
|
| 88 |
+
- {name: rd64-phrasepas5i-3, remove_classes: [pas5i, 3], negative_prob: 0.0, test_configuration: {splits: [3], custom_threshold: 0.28}}
|
| 89 |
+
|
| 90 |
+
|
| 91 |
+
# baseline
|
| 92 |
+
- {name: bl64-phrasepas5i-0, model: models.clipseg.CLIPDenseBaseline, remove_classes: [pas5i, 0], reduce2_dim: 64, negative_prob: 0.0, test_configuration: {splits: [0], custom_threshold: 0.24}}
|
| 93 |
+
- {name: bl64-phrasepas5i-1, model: models.clipseg.CLIPDenseBaseline, remove_classes: [pas5i, 1], reduce2_dim: 64, negative_prob: 0.0, test_configuration: {splits: [1], custom_threshold: 0.24}}
|
| 94 |
+
- {name: bl64-phrasepas5i-2, model: models.clipseg.CLIPDenseBaseline, remove_classes: [pas5i, 2], reduce2_dim: 64, negative_prob: 0.0, test_configuration: {splits: [2], custom_threshold: 0.24}}
|
| 95 |
+
- {name: bl64-phrasepas5i-3, model: models.clipseg.CLIPDenseBaseline, remove_classes: [pas5i, 3], reduce2_dim: 64, negative_prob: 0.0, test_configuration: {splits: [3], custom_threshold: 0.24}}
|
| 96 |
+
|
| 97 |
+
# ViT
|
| 98 |
+
- {name: vit64-uni-phrasepas5i-0, remove_classes: [pas5i, 0], model: models.vitseg.VITDensePredT, negative_prob: 0.2, mix_text_max: 0.5, lr: 0.0001, test_configuration: {splits: [0], custom_threshold: 0.02}}
|
| 99 |
+
- {name: vit64-uni-phrasepas5i-1, remove_classes: [pas5i, 1], model: models.vitseg.VITDensePredT, negative_prob: 0.2, mix_text_max: 0.5, lr: 0.0001, test_configuration: {splits: [1], custom_threshold: 0.02}}
|
| 100 |
+
- {name: vit64-uni-phrasepas5i-2, remove_classes: [pas5i, 2], model: models.vitseg.VITDensePredT, negative_prob: 0.2, mix_text_max: 0.5, lr: 0.0001, test_configuration: {splits: [2], custom_threshold: 0.02}}
|
| 101 |
+
- {name: vit64-uni-phrasepas5i-3, remove_classes: [pas5i, 3], model: models.vitseg.VITDensePredT, negative_prob: 0.2, mix_text_max: 0.5, lr: 0.0001, test_configuration: {splits: [3], custom_threshold: 0.02}}
|
clipseg/experiments/phrasecut.yaml
ADDED
|
@@ -0,0 +1,80 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
configuration:
|
| 2 |
+
batch_size: 64
|
| 3 |
+
optimizer: torch.optim.AdamW
|
| 4 |
+
|
| 5 |
+
lr: 0.001
|
| 6 |
+
|
| 7 |
+
trainer: experiment_setup.train_loop
|
| 8 |
+
scorer: experiment_setup.score
|
| 9 |
+
model: models.clipseg.CLIPDensePredT
|
| 10 |
+
|
| 11 |
+
lr_scheduler: cosine
|
| 12 |
+
T_max: 20000
|
| 13 |
+
eta_min: 0.0001
|
| 14 |
+
|
| 15 |
+
max_iterations: 20000
|
| 16 |
+
val_interval: null
|
| 17 |
+
|
| 18 |
+
# dataset
|
| 19 |
+
dataset: datasets.phrasecut.PhraseCut # <-----------------
|
| 20 |
+
split_mode: pascal_test
|
| 21 |
+
split: train
|
| 22 |
+
mask: text_and_crop_blur_highlight352
|
| 23 |
+
image_size: 352
|
| 24 |
+
normalize: True
|
| 25 |
+
pre_crop_image_size: [sample, 1, 1.5]
|
| 26 |
+
aug: 1new
|
| 27 |
+
|
| 28 |
+
# general
|
| 29 |
+
mix: False # <-----------------
|
| 30 |
+
prompt: shuffle+
|
| 31 |
+
norm_cond: True
|
| 32 |
+
mix_text_min: 0.0
|
| 33 |
+
|
| 34 |
+
# model
|
| 35 |
+
out: 1
|
| 36 |
+
extract_layers: [3, 7, 9]
|
| 37 |
+
reduce_dim: 64
|
| 38 |
+
depth: 3
|
| 39 |
+
fix_shift: False
|
| 40 |
+
|
| 41 |
+
loss: torch.nn.functional.binary_cross_entropy_with_logits
|
| 42 |
+
amp: True
|
| 43 |
+
|
| 44 |
+
test_configuration_common:
|
| 45 |
+
normalize: True
|
| 46 |
+
image_size: 352
|
| 47 |
+
batch_size: 32
|
| 48 |
+
# max_iterations: 5
|
| 49 |
+
# max_iterations: 150
|
| 50 |
+
|
| 51 |
+
test_configuration:
|
| 52 |
+
|
| 53 |
+
-
|
| 54 |
+
name: pc # old: phrasecut
|
| 55 |
+
metric: metrics.FixedIntervalMetrics
|
| 56 |
+
test_dataset: phrasecut
|
| 57 |
+
split: test
|
| 58 |
+
mask: text
|
| 59 |
+
label_support: True
|
| 60 |
+
sigmoid: True
|
| 61 |
+
|
| 62 |
+
|
| 63 |
+
columns: [i, name, pc_miou_0.3, pc_fgiou_0.3, pc_fgiou_0.5, pc_ap, duration, date]
|
| 64 |
+
|
| 65 |
+
|
| 66 |
+
individual_configurations:
|
| 67 |
+
|
| 68 |
+
# important ones
|
| 69 |
+
|
| 70 |
+
|
| 71 |
+
- {name: rd64-uni, version: 'ViT-B/16', reduce_dim: 64, with_visual: True, negative_prob: 0.2, mix: True, mix_text_max: 0.5}
|
| 72 |
+
|
| 73 |
+
# this was accedentally trained using old mask
|
| 74 |
+
- {name: rd128-vit16-phrasecut, version: 'ViT-B/16', reduce_dim: 128, mask: text_and_blur3_highlight01}
|
| 75 |
+
- {name: rd64-uni-novis, version: 'ViT-B/16', reduce_dim: 64, with_visual: False, negative_prob: 0.2, mix: False}
|
| 76 |
+
# this was accedentally trained using old mask
|
| 77 |
+
- {name: baseline3-vit16-phrasecut, model: models.clipseg.CLIPDenseBaseline, version: 'ViT-B/16', reduce_dim: 64, reduce2_dim: 64, mask: text_and_blur3_highlight01}
|
| 78 |
+
|
| 79 |
+
- {name: vit64-uni, version: 'ViT-B/16', model: models.vitseg.VITDensePredT, reduce_dim: 64, with_visual: True, only_visual: True, negative_prob: 0.2, mask: crop_blur_highlight352, lr: 0.0003}
|
| 80 |
+
- {name: vit64-uni-novis, version: 'ViT-B/16', model: models.vitseg.VITDensePredT, with_visual: False, reduce_dim: 64, lr: 0.0001}
|
clipseg/general_utils.py
ADDED
|
@@ -0,0 +1,272 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import json
|
| 2 |
+
import inspect
|
| 3 |
+
import torch
|
| 4 |
+
import os
|
| 5 |
+
import sys
|
| 6 |
+
import yaml
|
| 7 |
+
from shutil import copy, copytree
|
| 8 |
+
from os.path import join, dirname, realpath, expanduser, isfile, isdir, basename
|
| 9 |
+
|
| 10 |
+
|
| 11 |
+
class Logger(object):
|
| 12 |
+
|
| 13 |
+
def __getattr__(self, k):
|
| 14 |
+
return print
|
| 15 |
+
|
| 16 |
+
log = Logger()
|
| 17 |
+
|
| 18 |
+
def training_config_from_cli_args():
|
| 19 |
+
experiment_name = sys.argv[1]
|
| 20 |
+
experiment_id = int(sys.argv[2])
|
| 21 |
+
|
| 22 |
+
yaml_config = yaml.load(open(f'experiments/{experiment_name}'), Loader=yaml.SafeLoader)
|
| 23 |
+
|
| 24 |
+
config = yaml_config['configuration']
|
| 25 |
+
config = {**config, **yaml_config['individual_configurations'][experiment_id]}
|
| 26 |
+
config = AttributeDict(config)
|
| 27 |
+
return config
|
| 28 |
+
|
| 29 |
+
|
| 30 |
+
def score_config_from_cli_args():
|
| 31 |
+
experiment_name = sys.argv[1]
|
| 32 |
+
experiment_id = int(sys.argv[2])
|
| 33 |
+
|
| 34 |
+
|
| 35 |
+
yaml_config = yaml.load(open(f'experiments/{experiment_name}'), Loader=yaml.SafeLoader)
|
| 36 |
+
|
| 37 |
+
config = yaml_config['test_configuration_common']
|
| 38 |
+
|
| 39 |
+
if type(yaml_config['test_configuration']) == list:
|
| 40 |
+
test_id = int(sys.argv[3])
|
| 41 |
+
config = {**config, **yaml_config['test_configuration'][test_id]}
|
| 42 |
+
else:
|
| 43 |
+
config = {**config, **yaml_config['test_configuration']}
|
| 44 |
+
|
| 45 |
+
if 'test_configuration' in yaml_config['individual_configurations'][experiment_id]:
|
| 46 |
+
config = {**config, **yaml_config['individual_configurations'][experiment_id]['test_configuration']}
|
| 47 |
+
|
| 48 |
+
train_checkpoint_id = yaml_config['individual_configurations'][experiment_id]['name']
|
| 49 |
+
|
| 50 |
+
config = AttributeDict(config)
|
| 51 |
+
return config, train_checkpoint_id
|
| 52 |
+
|
| 53 |
+
|
| 54 |
+
def get_from_repository(local_name, repo_files, integrity_check=None, repo_dir='~/dataset_repository',
|
| 55 |
+
local_dir='~/datasets'):
|
| 56 |
+
""" copies files from repository to local folder.
|
| 57 |
+
|
| 58 |
+
repo_files: list of filenames or list of tuples [filename, target path]
|
| 59 |
+
|
| 60 |
+
e.g. get_from_repository('MyDataset', [['data/dataset1.tar', 'other/path/ds03.tar'])
|
| 61 |
+
will create a folder 'MyDataset' in local_dir, and extract the content of
|
| 62 |
+
'<repo_dir>/data/dataset1.tar' to <local_dir>/MyDataset/other/path.
|
| 63 |
+
"""
|
| 64 |
+
|
| 65 |
+
local_dir = realpath(join(expanduser(local_dir), local_name))
|
| 66 |
+
|
| 67 |
+
dataset_exists = True
|
| 68 |
+
|
| 69 |
+
# check if folder is available
|
| 70 |
+
if not isdir(local_dir):
|
| 71 |
+
dataset_exists = False
|
| 72 |
+
|
| 73 |
+
if integrity_check is not None:
|
| 74 |
+
try:
|
| 75 |
+
integrity_ok = integrity_check(local_dir)
|
| 76 |
+
except BaseException:
|
| 77 |
+
integrity_ok = False
|
| 78 |
+
|
| 79 |
+
if integrity_ok:
|
| 80 |
+
log.hint('Passed custom integrity check')
|
| 81 |
+
else:
|
| 82 |
+
log.hint('Custom integrity check failed')
|
| 83 |
+
|
| 84 |
+
dataset_exists = dataset_exists and integrity_ok
|
| 85 |
+
|
| 86 |
+
if not dataset_exists:
|
| 87 |
+
|
| 88 |
+
repo_dir = realpath(expanduser(repo_dir))
|
| 89 |
+
|
| 90 |
+
for i, filename in enumerate(repo_files):
|
| 91 |
+
|
| 92 |
+
if type(filename) == str:
|
| 93 |
+
origin, target = filename, filename
|
| 94 |
+
archive_target = join(local_dir, basename(origin))
|
| 95 |
+
extract_target = join(local_dir)
|
| 96 |
+
else:
|
| 97 |
+
origin, target = filename
|
| 98 |
+
archive_target = join(local_dir, dirname(target), basename(origin))
|
| 99 |
+
extract_target = join(local_dir, dirname(target))
|
| 100 |
+
|
| 101 |
+
archive_origin = join(repo_dir, origin)
|
| 102 |
+
|
| 103 |
+
log.hint(f'copy: {archive_origin} to {archive_target}')
|
| 104 |
+
|
| 105 |
+
# make sure the path exists
|
| 106 |
+
os.makedirs(dirname(archive_target), exist_ok=True)
|
| 107 |
+
|
| 108 |
+
if os.path.isfile(archive_target):
|
| 109 |
+
# only copy if size differs
|
| 110 |
+
if os.path.getsize(archive_target) != os.path.getsize(archive_origin):
|
| 111 |
+
log.hint(f'file exists but filesize differs: target {os.path.getsize(archive_target)} vs. origin {os.path.getsize(archive_origin)}')
|
| 112 |
+
copy(archive_origin, archive_target)
|
| 113 |
+
else:
|
| 114 |
+
copy(archive_origin, archive_target)
|
| 115 |
+
|
| 116 |
+
extract_archive(archive_target, extract_target, noarchive_ok=True)
|
| 117 |
+
|
| 118 |
+
# concurrent processes might have deleted the file
|
| 119 |
+
if os.path.isfile(archive_target):
|
| 120 |
+
os.remove(archive_target)
|
| 121 |
+
|
| 122 |
+
|
| 123 |
+
def extract_archive(filename, target_folder=None, noarchive_ok=False):
|
| 124 |
+
from subprocess import run, PIPE
|
| 125 |
+
|
| 126 |
+
if filename.endswith('.tgz') or filename.endswith('.tar'):
|
| 127 |
+
command = f'tar -xf {filename}'
|
| 128 |
+
command += f' -C {target_folder}' if target_folder is not None else ''
|
| 129 |
+
elif filename.endswith('.tar.gz'):
|
| 130 |
+
command = f'tar -xzf {filename}'
|
| 131 |
+
command += f' -C {target_folder}' if target_folder is not None else ''
|
| 132 |
+
elif filename.endswith('zip'):
|
| 133 |
+
command = f'unzip {filename}'
|
| 134 |
+
command += f' -d {target_folder}' if target_folder is not None else ''
|
| 135 |
+
else:
|
| 136 |
+
if noarchive_ok:
|
| 137 |
+
return
|
| 138 |
+
else:
|
| 139 |
+
raise ValueError(f'unsuppored file ending of {filename}')
|
| 140 |
+
|
| 141 |
+
log.hint(command)
|
| 142 |
+
result = run(command.split(), stdout=PIPE, stderr=PIPE)
|
| 143 |
+
if result.returncode != 0:
|
| 144 |
+
print(result.stdout, result.stderr)
|
| 145 |
+
|
| 146 |
+
|
| 147 |
+
class AttributeDict(dict):
|
| 148 |
+
"""
|
| 149 |
+
An extended dictionary that allows access to elements as atttributes and counts
|
| 150 |
+
these accesses. This way, we know if some attributes were never used.
|
| 151 |
+
"""
|
| 152 |
+
|
| 153 |
+
def __init__(self, *args, **kwargs):
|
| 154 |
+
from collections import Counter
|
| 155 |
+
super().__init__(*args, **kwargs)
|
| 156 |
+
self.__dict__['counter'] = Counter()
|
| 157 |
+
|
| 158 |
+
def __getitem__(self, k):
|
| 159 |
+
self.__dict__['counter'][k] += 1
|
| 160 |
+
return super().__getitem__(k)
|
| 161 |
+
|
| 162 |
+
def __getattr__(self, k):
|
| 163 |
+
self.__dict__['counter'][k] += 1
|
| 164 |
+
return super().get(k)
|
| 165 |
+
|
| 166 |
+
def __setattr__(self, k, v):
|
| 167 |
+
return super().__setitem__(k, v)
|
| 168 |
+
|
| 169 |
+
def __delattr__(self, k, v):
|
| 170 |
+
return super().__delitem__(k, v)
|
| 171 |
+
|
| 172 |
+
def unused_keys(self, exceptions=()):
|
| 173 |
+
return [k for k in super().keys() if self.__dict__['counter'][k] == 0 and k not in exceptions]
|
| 174 |
+
|
| 175 |
+
def assume_no_unused_keys(self, exceptions=()):
|
| 176 |
+
if len(self.unused_keys(exceptions=exceptions)) > 0:
|
| 177 |
+
log.warning('Unused keys:', self.unused_keys(exceptions=exceptions))
|
| 178 |
+
|
| 179 |
+
|
| 180 |
+
def get_attribute(name):
|
| 181 |
+
import importlib
|
| 182 |
+
|
| 183 |
+
if name is None:
|
| 184 |
+
raise ValueError('The provided attribute is None')
|
| 185 |
+
|
| 186 |
+
name_split = name.split('.')
|
| 187 |
+
mod = importlib.import_module('.'.join(name_split[:-1]))
|
| 188 |
+
return getattr(mod, name_split[-1])
|
| 189 |
+
|
| 190 |
+
|
| 191 |
+
|
| 192 |
+
def filter_args(input_args, default_args):
|
| 193 |
+
|
| 194 |
+
updated_args = {k: input_args[k] if k in input_args else v for k, v in default_args.items()}
|
| 195 |
+
used_args = {k: v for k, v in input_args.items() if k in default_args}
|
| 196 |
+
unused_args = {k: v for k, v in input_args.items() if k not in default_args}
|
| 197 |
+
|
| 198 |
+
return AttributeDict(updated_args), AttributeDict(used_args), AttributeDict(unused_args)
|
| 199 |
+
|
| 200 |
+
|
| 201 |
+
def load_model(checkpoint_id, weights_file=None, strict=True, model_args='from_config', with_config=False):
|
| 202 |
+
|
| 203 |
+
config = json.load(open(join('logs', checkpoint_id, 'config.json')))
|
| 204 |
+
|
| 205 |
+
if model_args != 'from_config' and type(model_args) != dict:
|
| 206 |
+
raise ValueError('model_args must either be "from_config" or a dictionary of values')
|
| 207 |
+
|
| 208 |
+
model_cls = get_attribute(config['model'])
|
| 209 |
+
|
| 210 |
+
# load model
|
| 211 |
+
if model_args == 'from_config':
|
| 212 |
+
_, model_args, _ = filter_args(config, inspect.signature(model_cls).parameters)
|
| 213 |
+
|
| 214 |
+
model = model_cls(**model_args)
|
| 215 |
+
|
| 216 |
+
if weights_file is None:
|
| 217 |
+
weights_file = realpath(join('logs', checkpoint_id, 'weights.pth'))
|
| 218 |
+
else:
|
| 219 |
+
weights_file = realpath(join('logs', checkpoint_id, weights_file))
|
| 220 |
+
|
| 221 |
+
if isfile(weights_file):
|
| 222 |
+
weights = torch.load(weights_file)
|
| 223 |
+
for _, w in weights.items():
|
| 224 |
+
assert not torch.any(torch.isnan(w)), 'weights contain NaNs'
|
| 225 |
+
model.load_state_dict(weights, strict=strict)
|
| 226 |
+
else:
|
| 227 |
+
raise FileNotFoundError(f'model checkpoint {weights_file} was not found')
|
| 228 |
+
|
| 229 |
+
if with_config:
|
| 230 |
+
return model, config
|
| 231 |
+
|
| 232 |
+
return model
|
| 233 |
+
|
| 234 |
+
|
| 235 |
+
class TrainingLogger(object):
|
| 236 |
+
|
| 237 |
+
def __init__(self, model, log_dir, config=None, *args):
|
| 238 |
+
super().__init__()
|
| 239 |
+
self.model = model
|
| 240 |
+
self.base_path = join(f'logs/{log_dir}') if log_dir is not None else None
|
| 241 |
+
|
| 242 |
+
os.makedirs('logs/', exist_ok=True)
|
| 243 |
+
os.makedirs(self.base_path, exist_ok=True)
|
| 244 |
+
|
| 245 |
+
if config is not None:
|
| 246 |
+
json.dump(config, open(join(self.base_path, 'config.json'), 'w'))
|
| 247 |
+
|
| 248 |
+
def iter(self, i, **kwargs):
|
| 249 |
+
if i % 100 == 0 and 'loss' in kwargs:
|
| 250 |
+
loss = kwargs['loss']
|
| 251 |
+
print(f'iteration {i}: loss {loss:.4f}')
|
| 252 |
+
|
| 253 |
+
def save_weights(self, only_trainable=False, weight_file='weights.pth'):
|
| 254 |
+
if self.model is None:
|
| 255 |
+
raise AttributeError('You need to provide a model reference when initializing TrainingTracker to save weights.')
|
| 256 |
+
|
| 257 |
+
weights_path = join(self.base_path, weight_file)
|
| 258 |
+
|
| 259 |
+
weight_dict = self.model.state_dict()
|
| 260 |
+
|
| 261 |
+
if only_trainable:
|
| 262 |
+
weight_dict = {n: weight_dict[n] for n, p in self.model.named_parameters() if p.requires_grad}
|
| 263 |
+
|
| 264 |
+
torch.save(weight_dict, weights_path)
|
| 265 |
+
log.info(f'Saved weights to {weights_path}')
|
| 266 |
+
|
| 267 |
+
def __enter__(self):
|
| 268 |
+
return self
|
| 269 |
+
|
| 270 |
+
def __exit__(self, type, value, traceback):
|
| 271 |
+
""" automatically stop processes if used in a context manager """
|
| 272 |
+
pass
|
clipseg/metrics.py
ADDED
|
@@ -0,0 +1,271 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from torch.functional import Tensor
|
| 2 |
+
from general_utils import log
|
| 3 |
+
from collections import defaultdict
|
| 4 |
+
import numpy as np
|
| 5 |
+
|
| 6 |
+
import torch
|
| 7 |
+
from torch.nn import functional as nnf
|
| 8 |
+
|
| 9 |
+
|
| 10 |
+
class BaseMetric(object):
|
| 11 |
+
|
| 12 |
+
def __init__(self, metric_names, pred_range=None, gt_index=0, pred_index=0, eval_intermediate=True,
|
| 13 |
+
eval_validation=True):
|
| 14 |
+
self._names = tuple(metric_names)
|
| 15 |
+
self._eval_intermediate = eval_intermediate
|
| 16 |
+
self._eval_validation = eval_validation
|
| 17 |
+
|
| 18 |
+
self._pred_range = pred_range
|
| 19 |
+
self._pred_index = pred_index
|
| 20 |
+
self._gt_index = gt_index
|
| 21 |
+
|
| 22 |
+
self.predictions = []
|
| 23 |
+
self.ground_truths = []
|
| 24 |
+
|
| 25 |
+
def eval_intermediate(self):
|
| 26 |
+
return self._eval_intermediate
|
| 27 |
+
|
| 28 |
+
def eval_validation(self):
|
| 29 |
+
return self._eval_validation
|
| 30 |
+
|
| 31 |
+
def names(self):
|
| 32 |
+
return self._names
|
| 33 |
+
|
| 34 |
+
def add(self, predictions, ground_truth):
|
| 35 |
+
raise NotImplementedError
|
| 36 |
+
|
| 37 |
+
def value(self):
|
| 38 |
+
raise NotImplementedError
|
| 39 |
+
|
| 40 |
+
def scores(self):
|
| 41 |
+
# similar to value but returns dict
|
| 42 |
+
value = self.value()
|
| 43 |
+
if type(value) == dict:
|
| 44 |
+
return value
|
| 45 |
+
else:
|
| 46 |
+
assert type(value) in {list, tuple}
|
| 47 |
+
return list(zip(self.names(), self.value()))
|
| 48 |
+
|
| 49 |
+
def _get_pred_gt(self, predictions, ground_truth):
|
| 50 |
+
pred = predictions[self._pred_index]
|
| 51 |
+
gt = ground_truth[self._gt_index]
|
| 52 |
+
|
| 53 |
+
if self._pred_range is not None:
|
| 54 |
+
pred = pred[:, self._pred_range[0]: self._pred_range[1]]
|
| 55 |
+
|
| 56 |
+
return pred, gt
|
| 57 |
+
|
| 58 |
+
|
| 59 |
+
class FixedIntervalMetrics(BaseMetric):
|
| 60 |
+
|
| 61 |
+
def __init__(self, sigmoid=False, ignore_mask=False, resize_to=None,
|
| 62 |
+
resize_pred=None, n_values=51, custom_threshold=None):
|
| 63 |
+
|
| 64 |
+
|
| 65 |
+
super().__init__(('ap', 'best_fgiou', 'best_miou', 'fgiou0.5', 'fgiou0.1', 'mean_iou_0p5', 'mean_iou_0p1', 'best_biniou', 'biniou_0.5', 'fgiou_thresh'))
|
| 66 |
+
self.intersections = []
|
| 67 |
+
self.unions = []
|
| 68 |
+
# self.threshold = threshold
|
| 69 |
+
self.sigmoid = sigmoid
|
| 70 |
+
self.resize_to = resize_to
|
| 71 |
+
self.resize_pred = resize_pred # resize prediction to match ground truth
|
| 72 |
+
self.class_count = defaultdict(lambda: 0)
|
| 73 |
+
self.per_class = defaultdict(lambda : [0,0])
|
| 74 |
+
self.ignore_mask = ignore_mask
|
| 75 |
+
self.custom_threshold = custom_threshold
|
| 76 |
+
|
| 77 |
+
self.scores_ap = []
|
| 78 |
+
self.scores_iou = []
|
| 79 |
+
self.gts, self.preds = [], []
|
| 80 |
+
self.classes = []
|
| 81 |
+
|
| 82 |
+
# [1:-1] ignores 0 and 1
|
| 83 |
+
self.threshold_values = np.linspace(0, 1, n_values)[1:-1]
|
| 84 |
+
|
| 85 |
+
self.metrics = dict(tp=[], fp=[], fn=[], tn=[])
|
| 86 |
+
|
| 87 |
+
def add(self, pred, gt):
|
| 88 |
+
|
| 89 |
+
pred_batch = pred[0].cpu()
|
| 90 |
+
|
| 91 |
+
if self.sigmoid:
|
| 92 |
+
pred_batch = torch.sigmoid(pred_batch)
|
| 93 |
+
|
| 94 |
+
gt_batch = gt[0].cpu()
|
| 95 |
+
mask_batch = gt[1] if len(gt) > 1 and not self.ignore_mask and gt[1].numel() > 0 else ([None] * len(pred_batch))
|
| 96 |
+
cls_batch = gt[2] if len(gt) > 2 else [None] * len(pred_batch)
|
| 97 |
+
|
| 98 |
+
if self.resize_to is not None:
|
| 99 |
+
gt_batch = nnf.interpolate(gt_batch, self.resize_to, mode='nearest')
|
| 100 |
+
pred_batch = nnf.interpolate(pred_batch, self.resize_to, mode='bilinear', align_corners=False)
|
| 101 |
+
|
| 102 |
+
if isinstance(cls_batch, torch.Tensor):
|
| 103 |
+
cls_batch = cls_batch.cpu().numpy().tolist()
|
| 104 |
+
|
| 105 |
+
assert len(gt_batch) == len(pred_batch) == len(cls_batch), f'{len(gt_batch)} {len(pred_batch)} {len(cls_batch)}'
|
| 106 |
+
|
| 107 |
+
for predictions, ground_truth, mask, cls in zip(pred_batch, gt_batch, mask_batch, cls_batch):
|
| 108 |
+
|
| 109 |
+
if self.resize_pred:
|
| 110 |
+
predictions = nnf.interpolate(predictions.unsqueeze(0).float(), size=ground_truth.size()[-2:], mode='bilinear', align_corners=True)
|
| 111 |
+
|
| 112 |
+
p = predictions.flatten()
|
| 113 |
+
g = ground_truth.flatten()
|
| 114 |
+
|
| 115 |
+
assert len(p) == len(g)
|
| 116 |
+
|
| 117 |
+
if mask is not None:
|
| 118 |
+
m = mask.flatten().bool()
|
| 119 |
+
p = p[m]
|
| 120 |
+
g = g[m]
|
| 121 |
+
|
| 122 |
+
p_sorted = p.sort()
|
| 123 |
+
p = p_sorted.values
|
| 124 |
+
g = g[p_sorted.indices]
|
| 125 |
+
|
| 126 |
+
tps, fps, fns, tns = [], [], [], []
|
| 127 |
+
for thresh in self.threshold_values:
|
| 128 |
+
|
| 129 |
+
valid = torch.where(p > thresh)[0]
|
| 130 |
+
if len(valid) > 0:
|
| 131 |
+
n = int(valid[0])
|
| 132 |
+
else:
|
| 133 |
+
n = len(g)
|
| 134 |
+
|
| 135 |
+
fn = int(g[:n].sum())
|
| 136 |
+
tp = int(g[n:].sum())
|
| 137 |
+
fns += [fn]
|
| 138 |
+
tns += [n - fn]
|
| 139 |
+
tps += [tp]
|
| 140 |
+
fps += [len(g) - n - tp]
|
| 141 |
+
|
| 142 |
+
self.metrics['tp'] += [tps]
|
| 143 |
+
self.metrics['fp'] += [fps]
|
| 144 |
+
self.metrics['fn'] += [fns]
|
| 145 |
+
self.metrics['tn'] += [tns]
|
| 146 |
+
|
| 147 |
+
self.classes += [cls.item() if isinstance(cls, torch.Tensor) else cls]
|
| 148 |
+
|
| 149 |
+
def value(self):
|
| 150 |
+
|
| 151 |
+
import time
|
| 152 |
+
t_start = time.time()
|
| 153 |
+
|
| 154 |
+
if set(self.classes) == set([None]):
|
| 155 |
+
all_classes = None
|
| 156 |
+
log.warning('classes were not provided, cannot compute mIoU')
|
| 157 |
+
else:
|
| 158 |
+
all_classes = set(int(c) for c in self.classes)
|
| 159 |
+
# log.info(f'compute metrics for {len(all_classes)} classes')
|
| 160 |
+
|
| 161 |
+
summed = {k: [sum([self.metrics[k][i][j]
|
| 162 |
+
for i in range(len(self.metrics[k]))])
|
| 163 |
+
for j in range(len(self.threshold_values))]
|
| 164 |
+
for k in self.metrics.keys()}
|
| 165 |
+
|
| 166 |
+
if all_classes is not None:
|
| 167 |
+
|
| 168 |
+
assert len(self.classes) == len(self.metrics['tp']) == len(self.metrics['fn'])
|
| 169 |
+
# group by class
|
| 170 |
+
metrics_by_class = {c: {k: [] for k in self.metrics.keys()} for c in all_classes}
|
| 171 |
+
for i in range(len(self.metrics['tp'])):
|
| 172 |
+
for k in self.metrics.keys():
|
| 173 |
+
metrics_by_class[self.classes[i]][k] += [self.metrics[k][i]]
|
| 174 |
+
|
| 175 |
+
# sum over all instances within the classes
|
| 176 |
+
summed_by_cls = {k: {c: np.array(metrics_by_class[c][k]).sum(0).tolist() for c in all_classes} for k in self.metrics.keys()}
|
| 177 |
+
|
| 178 |
+
|
| 179 |
+
# Compute average precision
|
| 180 |
+
|
| 181 |
+
assert (np.array(summed['fp']) + np.array(summed['tp']) ).sum(), 'no predictions is made'
|
| 182 |
+
|
| 183 |
+
# only consider values where a prediction is made
|
| 184 |
+
precisions = [summed['tp'][j] / (1 + summed['tp'][j] + summed['fp'][j]) for j in range(len(self.threshold_values))
|
| 185 |
+
if summed['tp'][j] + summed['fp'][j] > 0]
|
| 186 |
+
recalls = [summed['tp'][j] / (1 + summed['tp'][j] + summed['fn'][j]) for j in range(len(self.threshold_values))
|
| 187 |
+
if summed['tp'][j] + summed['fp'][j] > 0]
|
| 188 |
+
|
| 189 |
+
# remove duplicate recall-precision-pairs (and sort by recall value)
|
| 190 |
+
recalls, precisions = zip(*sorted(list(set(zip(recalls, precisions))), key=lambda x: x[0]))
|
| 191 |
+
|
| 192 |
+
from scipy.integrate import simps
|
| 193 |
+
ap = simps(precisions, recalls)
|
| 194 |
+
|
| 195 |
+
# Compute best IoU
|
| 196 |
+
fgiou_scores = [summed['tp'][j] / (1 + summed['tp'][j] + summed['fp'][j] + summed['fn'][j]) for j in range(len(self.threshold_values))]
|
| 197 |
+
|
| 198 |
+
biniou_scores = [
|
| 199 |
+
0.5*(summed['tp'][j] / (1 + summed['tp'][j] + summed['fp'][j] + summed['fn'][j])) +
|
| 200 |
+
0.5*(summed['tn'][j] / (1 + summed['tn'][j] + summed['fn'][j] + summed['fp'][j]))
|
| 201 |
+
for j in range(len(self.threshold_values))
|
| 202 |
+
]
|
| 203 |
+
|
| 204 |
+
index_0p5 = self.threshold_values.tolist().index(0.5)
|
| 205 |
+
index_0p1 = self.threshold_values.tolist().index(0.1)
|
| 206 |
+
index_0p2 = self.threshold_values.tolist().index(0.2)
|
| 207 |
+
index_0p3 = self.threshold_values.tolist().index(0.3)
|
| 208 |
+
|
| 209 |
+
if self.custom_threshold is not None:
|
| 210 |
+
index_ct = self.threshold_values.tolist().index(self.custom_threshold)
|
| 211 |
+
|
| 212 |
+
if all_classes is not None:
|
| 213 |
+
# mean IoU
|
| 214 |
+
mean_ious = [np.mean([summed_by_cls['tp'][c][j] / (1 + summed_by_cls['tp'][c][j] + summed_by_cls['fp'][c][j] + summed_by_cls['fn'][c][j])
|
| 215 |
+
for c in all_classes])
|
| 216 |
+
for j in range(len(self.threshold_values))]
|
| 217 |
+
|
| 218 |
+
mean_iou_dict = {
|
| 219 |
+
'miou_best': max(mean_ious) if all_classes is not None else None,
|
| 220 |
+
'miou_0.5': mean_ious[index_0p5] if all_classes is not None else None,
|
| 221 |
+
'miou_0.1': mean_ious[index_0p1] if all_classes is not None else None,
|
| 222 |
+
'miou_0.2': mean_ious[index_0p2] if all_classes is not None else None,
|
| 223 |
+
'miou_0.3': mean_ious[index_0p3] if all_classes is not None else None,
|
| 224 |
+
'miou_best_t': self.threshold_values[np.argmax(mean_ious)],
|
| 225 |
+
'mean_iou_ct': mean_ious[index_ct] if all_classes is not None and self.custom_threshold is not None else None,
|
| 226 |
+
'mean_iou_scores': mean_ious,
|
| 227 |
+
}
|
| 228 |
+
|
| 229 |
+
print(f'metric computation on {(len(all_classes) if all_classes is not None else "no")} classes took {time.time() - t_start:.1f}s')
|
| 230 |
+
|
| 231 |
+
return {
|
| 232 |
+
'ap': ap,
|
| 233 |
+
|
| 234 |
+
# fgiou
|
| 235 |
+
'fgiou_best': max(fgiou_scores),
|
| 236 |
+
'fgiou_0.5': fgiou_scores[index_0p5],
|
| 237 |
+
'fgiou_0.1': fgiou_scores[index_0p1],
|
| 238 |
+
'fgiou_0.2': fgiou_scores[index_0p2],
|
| 239 |
+
'fgiou_0.3': fgiou_scores[index_0p3],
|
| 240 |
+
'fgiou_best_t': self.threshold_values[np.argmax(fgiou_scores)],
|
| 241 |
+
|
| 242 |
+
# mean iou
|
| 243 |
+
|
| 244 |
+
|
| 245 |
+
# biniou
|
| 246 |
+
'biniou_best': max(biniou_scores),
|
| 247 |
+
'biniou_0.5': biniou_scores[index_0p5],
|
| 248 |
+
'biniou_0.1': biniou_scores[index_0p1],
|
| 249 |
+
'biniou_0.2': biniou_scores[index_0p2],
|
| 250 |
+
'biniou_0.3': biniou_scores[index_0p3],
|
| 251 |
+
'biniou_best_t': self.threshold_values[np.argmax(biniou_scores)],
|
| 252 |
+
|
| 253 |
+
# custom threshold
|
| 254 |
+
'fgiou_ct': fgiou_scores[index_ct] if self.custom_threshold is not None else None,
|
| 255 |
+
'biniou_ct': biniou_scores[index_ct] if self.custom_threshold is not None else None,
|
| 256 |
+
'ct': self.custom_threshold,
|
| 257 |
+
|
| 258 |
+
# statistics
|
| 259 |
+
'fgiou_scores': fgiou_scores,
|
| 260 |
+
'biniou_scores': biniou_scores,
|
| 261 |
+
'precision_recall_curve': sorted(list(set(zip(recalls, precisions)))),
|
| 262 |
+
'summed_statistics': summed,
|
| 263 |
+
'summed_by_cls_statistics': summed_by_cls,
|
| 264 |
+
|
| 265 |
+
**mean_iou_dict
|
| 266 |
+
}
|
| 267 |
+
|
| 268 |
+
# ('ap', 'best_fgiou', 'best_miou', 'fgiou0.5', 'fgiou0.1', 'mean_iou_0p5', 'mean_iou_0p1', 'best_biniou', 'biniou_0.5', 'fgiou_thresh'
|
| 269 |
+
|
| 270 |
+
# return ap, best_fgiou, best_mean_iou, iou_0p5, iou_0p1, mean_iou_0p5, mean_iou_0p1, best_biniou, biniou0p5, best_fgiou_thresh, {'summed': summed, 'summed_by_cls': summed_by_cls}
|
| 271 |
+
|
clipseg/models/clipseg.py
ADDED
|
@@ -0,0 +1,552 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import math
|
| 2 |
+
from os.path import basename, dirname, join, isfile
|
| 3 |
+
import torch
|
| 4 |
+
from torch import nn
|
| 5 |
+
from torch.nn import functional as nnf
|
| 6 |
+
from torch.nn.modules.activation import ReLU
|
| 7 |
+
|
| 8 |
+
|
| 9 |
+
def precompute_clip_vectors():
|
| 10 |
+
|
| 11 |
+
from trails.initialization import init_dataset
|
| 12 |
+
lvis = init_dataset('LVIS_OneShot3', split='train', mask='text_label', image_size=224, aug=1, normalize=True,
|
| 13 |
+
reduce_factor=None, add_bar=False, negative_prob=0.5)
|
| 14 |
+
|
| 15 |
+
all_names = list(lvis.category_names.values())
|
| 16 |
+
|
| 17 |
+
import clip
|
| 18 |
+
from models.clip_prompts import imagenet_templates
|
| 19 |
+
clip_model = clip.load("ViT-B/32", device='cuda', jit=False)[0]
|
| 20 |
+
prompt_vectors = {}
|
| 21 |
+
for name in all_names[:100]:
|
| 22 |
+
with torch.no_grad():
|
| 23 |
+
conditionals = [t.format(name).replace('_', ' ') for t in imagenet_templates]
|
| 24 |
+
text_tokens = clip.tokenize(conditionals).cuda()
|
| 25 |
+
cond = clip_model.encode_text(text_tokens).cpu()
|
| 26 |
+
|
| 27 |
+
for cond, vec in zip(conditionals, cond):
|
| 28 |
+
prompt_vectors[cond] = vec.cpu()
|
| 29 |
+
|
| 30 |
+
import pickle
|
| 31 |
+
|
| 32 |
+
pickle.dump(prompt_vectors, open('precomputed_prompt_vectors.pickle', 'wb'))
|
| 33 |
+
|
| 34 |
+
|
| 35 |
+
def get_prompt_list(prompt):
|
| 36 |
+
if prompt == 'plain':
|
| 37 |
+
return ['{}']
|
| 38 |
+
elif prompt == 'fixed':
|
| 39 |
+
return ['a photo of a {}.']
|
| 40 |
+
elif prompt == 'shuffle':
|
| 41 |
+
return ['a photo of a {}.', 'a photograph of a {}.', 'an image of a {}.', '{}.']
|
| 42 |
+
elif prompt == 'shuffle+':
|
| 43 |
+
return ['a photo of a {}.', 'a photograph of a {}.', 'an image of a {}.', '{}.',
|
| 44 |
+
'a cropped photo of a {}.', 'a good photo of a {}.', 'a photo of one {}.',
|
| 45 |
+
'a bad photo of a {}.', 'a photo of the {}.']
|
| 46 |
+
elif prompt == 'shuffle_clip':
|
| 47 |
+
from models.clip_prompts import imagenet_templates
|
| 48 |
+
return imagenet_templates
|
| 49 |
+
else:
|
| 50 |
+
raise ValueError('Invalid value for prompt')
|
| 51 |
+
|
| 52 |
+
|
| 53 |
+
def forward_multihead_attention(x, b, with_aff=False, attn_mask=None):
|
| 54 |
+
"""
|
| 55 |
+
Simplified version of multihead attention (taken from torch source code but without tons of if clauses).
|
| 56 |
+
The mlp and layer norm come from CLIP.
|
| 57 |
+
x: input.
|
| 58 |
+
b: multihead attention module.
|
| 59 |
+
"""
|
| 60 |
+
|
| 61 |
+
x_ = b.ln_1(x)
|
| 62 |
+
q, k, v = nnf.linear(x_, b.attn.in_proj_weight, b.attn.in_proj_bias).chunk(3, dim=-1)
|
| 63 |
+
tgt_len, bsz, embed_dim = q.size()
|
| 64 |
+
|
| 65 |
+
head_dim = embed_dim // b.attn.num_heads
|
| 66 |
+
scaling = float(head_dim) ** -0.5
|
| 67 |
+
|
| 68 |
+
q = q.contiguous().view(tgt_len, bsz * b.attn.num_heads, b.attn.head_dim).transpose(0, 1)
|
| 69 |
+
k = k.contiguous().view(-1, bsz * b.attn.num_heads, b.attn.head_dim).transpose(0, 1)
|
| 70 |
+
v = v.contiguous().view(-1, bsz * b.attn.num_heads, b.attn.head_dim).transpose(0, 1)
|
| 71 |
+
|
| 72 |
+
q = q * scaling
|
| 73 |
+
|
| 74 |
+
attn_output_weights = torch.bmm(q, k.transpose(1, 2)) # n_heads * batch_size, tokens^2, tokens^2
|
| 75 |
+
if attn_mask is not None:
|
| 76 |
+
|
| 77 |
+
|
| 78 |
+
attn_mask_type, attn_mask = attn_mask
|
| 79 |
+
n_heads = attn_output_weights.size(0) // attn_mask.size(0)
|
| 80 |
+
attn_mask = attn_mask.repeat(n_heads, 1)
|
| 81 |
+
|
| 82 |
+
if attn_mask_type == 'cls_token':
|
| 83 |
+
# the mask only affects similarities compared to the readout-token.
|
| 84 |
+
attn_output_weights[:, 0, 1:] = attn_output_weights[:, 0, 1:] * attn_mask[None,...]
|
| 85 |
+
# attn_output_weights[:, 0, 0] = 0*attn_output_weights[:, 0, 0]
|
| 86 |
+
|
| 87 |
+
if attn_mask_type == 'all':
|
| 88 |
+
# print(attn_output_weights.shape, attn_mask[:, None].shape)
|
| 89 |
+
attn_output_weights[:, 1:, 1:] = attn_output_weights[:, 1:, 1:] * attn_mask[:, None]
|
| 90 |
+
|
| 91 |
+
|
| 92 |
+
attn_output_weights = torch.softmax(attn_output_weights, dim=-1)
|
| 93 |
+
|
| 94 |
+
attn_output = torch.bmm(attn_output_weights, v)
|
| 95 |
+
attn_output = attn_output.transpose(0, 1).contiguous().view(tgt_len, bsz, embed_dim)
|
| 96 |
+
attn_output = b.attn.out_proj(attn_output)
|
| 97 |
+
|
| 98 |
+
x = x + attn_output
|
| 99 |
+
x = x + b.mlp(b.ln_2(x))
|
| 100 |
+
|
| 101 |
+
if with_aff:
|
| 102 |
+
return x, attn_output_weights
|
| 103 |
+
else:
|
| 104 |
+
return x
|
| 105 |
+
|
| 106 |
+
|
| 107 |
+
class CLIPDenseBase(nn.Module):
|
| 108 |
+
|
| 109 |
+
def __init__(self, version, reduce_cond, reduce_dim, prompt, n_tokens):
|
| 110 |
+
super().__init__()
|
| 111 |
+
|
| 112 |
+
import clip
|
| 113 |
+
|
| 114 |
+
# prec = torch.FloatTensor
|
| 115 |
+
self.clip_model, _ = clip.load(version, device='cpu', jit=False)
|
| 116 |
+
self.model = self.clip_model.visual
|
| 117 |
+
|
| 118 |
+
# if not None, scale conv weights such that we obtain n_tokens.
|
| 119 |
+
self.n_tokens = n_tokens
|
| 120 |
+
|
| 121 |
+
for p in self.clip_model.parameters():
|
| 122 |
+
p.requires_grad_(False)
|
| 123 |
+
|
| 124 |
+
# conditional
|
| 125 |
+
if reduce_cond is not None:
|
| 126 |
+
self.reduce_cond = nn.Linear(512, reduce_cond)
|
| 127 |
+
for p in self.reduce_cond.parameters():
|
| 128 |
+
p.requires_grad_(False)
|
| 129 |
+
else:
|
| 130 |
+
self.reduce_cond = None
|
| 131 |
+
|
| 132 |
+
self.film_mul = nn.Linear(512 if reduce_cond is None else reduce_cond, reduce_dim)
|
| 133 |
+
self.film_add = nn.Linear(512 if reduce_cond is None else reduce_cond, reduce_dim)
|
| 134 |
+
|
| 135 |
+
self.reduce = nn.Linear(768, reduce_dim)
|
| 136 |
+
|
| 137 |
+
self.prompt_list = get_prompt_list(prompt)
|
| 138 |
+
|
| 139 |
+
# precomputed prompts
|
| 140 |
+
import pickle
|
| 141 |
+
if isfile('precomputed_prompt_vectors.pickle'):
|
| 142 |
+
precomp = pickle.load(open('precomputed_prompt_vectors.pickle', 'rb'))
|
| 143 |
+
self.precomputed_prompts = {k: torch.from_numpy(v) for k, v in precomp.items()}
|
| 144 |
+
else:
|
| 145 |
+
self.precomputed_prompts = dict()
|
| 146 |
+
|
| 147 |
+
def rescaled_pos_emb(self, new_size):
|
| 148 |
+
assert len(new_size) == 2
|
| 149 |
+
|
| 150 |
+
a = self.model.positional_embedding[1:].T.view(1, 768, *self.token_shape)
|
| 151 |
+
b = nnf.interpolate(a, new_size, mode='bicubic', align_corners=False).squeeze(0).view(768, new_size[0]*new_size[1]).T
|
| 152 |
+
return torch.cat([self.model.positional_embedding[:1], b])
|
| 153 |
+
|
| 154 |
+
def visual_forward(self, x_inp, extract_layers=(), skip=False, mask=None):
|
| 155 |
+
|
| 156 |
+
|
| 157 |
+
with torch.no_grad():
|
| 158 |
+
|
| 159 |
+
inp_size = x_inp.shape[2:]
|
| 160 |
+
|
| 161 |
+
if self.n_tokens is not None:
|
| 162 |
+
stride2 = x_inp.shape[2] // self.n_tokens
|
| 163 |
+
conv_weight2 = nnf.interpolate(self.model.conv1.weight, (stride2, stride2), mode='bilinear', align_corners=True)
|
| 164 |
+
x = nnf.conv2d(x_inp, conv_weight2, bias=self.model.conv1.bias, stride=stride2, dilation=self.model.conv1.dilation)
|
| 165 |
+
else:
|
| 166 |
+
x = self.model.conv1(x_inp) # shape = [*, width, grid, grid]
|
| 167 |
+
|
| 168 |
+
x = x.reshape(x.shape[0], x.shape[1], -1) # shape = [*, width, grid ** 2]
|
| 169 |
+
x = x.permute(0, 2, 1) # shape = [*, grid ** 2, width]
|
| 170 |
+
|
| 171 |
+
x = torch.cat([self.model.class_embedding.to(x.dtype) + torch.zeros(x.shape[0], 1, x.shape[-1], dtype=x.dtype, device=x.device), x], dim=1) # shape = [*, grid ** 2 + 1, width]
|
| 172 |
+
|
| 173 |
+
standard_n_tokens = 50 if self.model.conv1.kernel_size[0] == 32 else 197
|
| 174 |
+
|
| 175 |
+
if x.shape[1] != standard_n_tokens:
|
| 176 |
+
new_shape = int(math.sqrt(x.shape[1]-1))
|
| 177 |
+
x = x + self.rescaled_pos_emb((new_shape, new_shape)).to(x.dtype)[None,:,:]
|
| 178 |
+
else:
|
| 179 |
+
x = x + self.model.positional_embedding.to(x.dtype)
|
| 180 |
+
|
| 181 |
+
x = self.model.ln_pre(x)
|
| 182 |
+
|
| 183 |
+
x = x.permute(1, 0, 2) # NLD -> LND
|
| 184 |
+
|
| 185 |
+
activations, affinities = [], []
|
| 186 |
+
for i, res_block in enumerate(self.model.transformer.resblocks):
|
| 187 |
+
|
| 188 |
+
if mask is not None:
|
| 189 |
+
mask_layer, mask_type, mask_tensor = mask
|
| 190 |
+
if mask_layer == i or mask_layer == 'all':
|
| 191 |
+
# import ipdb; ipdb.set_trace()
|
| 192 |
+
size = int(math.sqrt(x.shape[0] - 1))
|
| 193 |
+
|
| 194 |
+
attn_mask = (mask_type, nnf.interpolate(mask_tensor.unsqueeze(1).float(), (size, size)).view(mask_tensor.shape[0], size * size))
|
| 195 |
+
|
| 196 |
+
else:
|
| 197 |
+
attn_mask = None
|
| 198 |
+
else:
|
| 199 |
+
attn_mask = None
|
| 200 |
+
|
| 201 |
+
x, aff_per_head = forward_multihead_attention(x, res_block, with_aff=True, attn_mask=attn_mask)
|
| 202 |
+
|
| 203 |
+
if i in extract_layers:
|
| 204 |
+
affinities += [aff_per_head]
|
| 205 |
+
|
| 206 |
+
#if self.n_tokens is not None:
|
| 207 |
+
# activations += [nnf.interpolate(x, inp_size, mode='bilinear', align_corners=True)]
|
| 208 |
+
#else:
|
| 209 |
+
activations += [x]
|
| 210 |
+
|
| 211 |
+
if len(extract_layers) > 0 and i == max(extract_layers) and skip:
|
| 212 |
+
print('early skip')
|
| 213 |
+
break
|
| 214 |
+
|
| 215 |
+
x = x.permute(1, 0, 2) # LND -> NLD
|
| 216 |
+
x = self.model.ln_post(x[:, 0, :])
|
| 217 |
+
|
| 218 |
+
if self.model.proj is not None:
|
| 219 |
+
x = x @ self.model.proj
|
| 220 |
+
|
| 221 |
+
return x, activations, affinities
|
| 222 |
+
|
| 223 |
+
def sample_prompts(self, words, prompt_list=None):
|
| 224 |
+
|
| 225 |
+
prompt_list = prompt_list if prompt_list is not None else self.prompt_list
|
| 226 |
+
|
| 227 |
+
prompt_indices = torch.multinomial(torch.ones(len(prompt_list)), len(words), replacement=True)
|
| 228 |
+
prompts = [prompt_list[i] for i in prompt_indices]
|
| 229 |
+
return [promt.format(w) for promt, w in zip(prompts, words)]
|
| 230 |
+
|
| 231 |
+
def get_cond_vec(self, conditional, batch_size):
|
| 232 |
+
# compute conditional from a single string
|
| 233 |
+
if conditional is not None and type(conditional) == str:
|
| 234 |
+
cond = self.compute_conditional(conditional)
|
| 235 |
+
cond = cond.repeat(batch_size, 1)
|
| 236 |
+
|
| 237 |
+
# compute conditional from string list/tuple
|
| 238 |
+
elif conditional is not None and type(conditional) in {list, tuple} and type(conditional[0]) == str:
|
| 239 |
+
assert len(conditional) == batch_size
|
| 240 |
+
cond = self.compute_conditional(conditional)
|
| 241 |
+
|
| 242 |
+
# use conditional directly
|
| 243 |
+
elif conditional is not None and type(conditional) == torch.Tensor and conditional.ndim == 2:
|
| 244 |
+
cond = conditional
|
| 245 |
+
|
| 246 |
+
# compute conditional from image
|
| 247 |
+
elif conditional is not None and type(conditional) == torch.Tensor:
|
| 248 |
+
with torch.no_grad():
|
| 249 |
+
cond, _, _ = self.visual_forward(conditional)
|
| 250 |
+
else:
|
| 251 |
+
raise ValueError('invalid conditional')
|
| 252 |
+
return cond
|
| 253 |
+
|
| 254 |
+
def compute_conditional(self, conditional):
|
| 255 |
+
import clip
|
| 256 |
+
|
| 257 |
+
dev = next(self.parameters()).device
|
| 258 |
+
|
| 259 |
+
if type(conditional) in {list, tuple}:
|
| 260 |
+
text_tokens = clip.tokenize(conditional).to(dev)
|
| 261 |
+
cond = self.clip_model.encode_text(text_tokens)
|
| 262 |
+
else:
|
| 263 |
+
if conditional in self.precomputed_prompts:
|
| 264 |
+
cond = self.precomputed_prompts[conditional].float().to(dev)
|
| 265 |
+
else:
|
| 266 |
+
text_tokens = clip.tokenize([conditional]).to(dev)
|
| 267 |
+
cond = self.clip_model.encode_text(text_tokens)[0]
|
| 268 |
+
|
| 269 |
+
if self.shift_vector is not None:
|
| 270 |
+
return cond + self.shift_vector
|
| 271 |
+
else:
|
| 272 |
+
return cond
|
| 273 |
+
|
| 274 |
+
|
| 275 |
+
def clip_load_untrained(version):
|
| 276 |
+
assert version == 'ViT-B/16'
|
| 277 |
+
from clip.model import CLIP
|
| 278 |
+
from clip.clip import _MODELS, _download
|
| 279 |
+
model = torch.jit.load(_download(_MODELS['ViT-B/16'])).eval()
|
| 280 |
+
state_dict = model.state_dict()
|
| 281 |
+
|
| 282 |
+
vision_width = state_dict["visual.conv1.weight"].shape[0]
|
| 283 |
+
vision_layers = len([k for k in state_dict.keys() if k.startswith("visual.") and k.endswith(".attn.in_proj_weight")])
|
| 284 |
+
vision_patch_size = state_dict["visual.conv1.weight"].shape[-1]
|
| 285 |
+
grid_size = round((state_dict["visual.positional_embedding"].shape[0] - 1) ** 0.5)
|
| 286 |
+
image_resolution = vision_patch_size * grid_size
|
| 287 |
+
embed_dim = state_dict["text_projection"].shape[1]
|
| 288 |
+
context_length = state_dict["positional_embedding"].shape[0]
|
| 289 |
+
vocab_size = state_dict["token_embedding.weight"].shape[0]
|
| 290 |
+
transformer_width = state_dict["ln_final.weight"].shape[0]
|
| 291 |
+
transformer_heads = transformer_width // 64
|
| 292 |
+
transformer_layers = len(set(k.split(".")[2] for k in state_dict if k.startswith(f"transformer.resblocks")))
|
| 293 |
+
|
| 294 |
+
return CLIP(embed_dim, image_resolution, vision_layers, vision_width, vision_patch_size,
|
| 295 |
+
context_length, vocab_size, transformer_width, transformer_heads, transformer_layers)
|
| 296 |
+
|
| 297 |
+
|
| 298 |
+
class CLIPDensePredT(CLIPDenseBase):
|
| 299 |
+
|
| 300 |
+
def __init__(self, version='ViT-B/32', extract_layers=(3, 6, 9), cond_layer=0, reduce_dim=128, n_heads=4, prompt='fixed',
|
| 301 |
+
extra_blocks=0, reduce_cond=None, fix_shift=False,
|
| 302 |
+
learn_trans_conv_only=False, limit_to_clip_only=False, upsample=False,
|
| 303 |
+
add_calibration=False, rev_activations=False, trans_conv=None, n_tokens=None):
|
| 304 |
+
|
| 305 |
+
super().__init__(version, reduce_cond, reduce_dim, prompt, n_tokens)
|
| 306 |
+
# device = 'cpu'
|
| 307 |
+
|
| 308 |
+
self.extract_layers = extract_layers
|
| 309 |
+
self.cond_layer = cond_layer
|
| 310 |
+
self.limit_to_clip_only = limit_to_clip_only
|
| 311 |
+
self.process_cond = None
|
| 312 |
+
self.rev_activations = rev_activations
|
| 313 |
+
|
| 314 |
+
depth = len(extract_layers)
|
| 315 |
+
|
| 316 |
+
if add_calibration:
|
| 317 |
+
self.calibration_conds = 1
|
| 318 |
+
|
| 319 |
+
self.upsample_proj = nn.Conv2d(reduce_dim, 1, kernel_size=1) if upsample else None
|
| 320 |
+
|
| 321 |
+
self.add_activation1 = True
|
| 322 |
+
|
| 323 |
+
self.version = version
|
| 324 |
+
|
| 325 |
+
self.token_shape = {'ViT-B/32': (7, 7), 'ViT-B/16': (14, 14)}[version]
|
| 326 |
+
|
| 327 |
+
if fix_shift:
|
| 328 |
+
# self.shift_vector = nn.Parameter(torch.load(join(dirname(basename(__file__)), 'clip_text_shift_vector.pth')), requires_grad=False)
|
| 329 |
+
self.shift_vector = nn.Parameter(torch.load(join(dirname(basename(__file__)), 'shift_text_to_vis.pth')), requires_grad=False)
|
| 330 |
+
# self.shift_vector = nn.Parameter(-1*torch.load(join(dirname(basename(__file__)), 'shift2.pth')), requires_grad=False)
|
| 331 |
+
else:
|
| 332 |
+
self.shift_vector = None
|
| 333 |
+
|
| 334 |
+
if trans_conv is None:
|
| 335 |
+
trans_conv_ks = {'ViT-B/32': (32, 32), 'ViT-B/16': (16, 16)}[version]
|
| 336 |
+
else:
|
| 337 |
+
# explicitly define transposed conv kernel size
|
| 338 |
+
trans_conv_ks = (trans_conv, trans_conv)
|
| 339 |
+
|
| 340 |
+
self.trans_conv = nn.ConvTranspose2d(reduce_dim, 1, trans_conv_ks, stride=trans_conv_ks)
|
| 341 |
+
|
| 342 |
+
assert len(self.extract_layers) == depth
|
| 343 |
+
|
| 344 |
+
self.reduces = nn.ModuleList([nn.Linear(768, reduce_dim) for _ in range(depth)])
|
| 345 |
+
self.blocks = nn.ModuleList([nn.TransformerEncoderLayer(d_model=reduce_dim, nhead=n_heads) for _ in range(len(self.extract_layers))])
|
| 346 |
+
self.extra_blocks = nn.ModuleList([nn.TransformerEncoderLayer(d_model=reduce_dim, nhead=n_heads) for _ in range(extra_blocks)])
|
| 347 |
+
|
| 348 |
+
# refinement and trans conv
|
| 349 |
+
|
| 350 |
+
if learn_trans_conv_only:
|
| 351 |
+
for p in self.parameters():
|
| 352 |
+
p.requires_grad_(False)
|
| 353 |
+
|
| 354 |
+
for p in self.trans_conv.parameters():
|
| 355 |
+
p.requires_grad_(True)
|
| 356 |
+
|
| 357 |
+
self.prompt_list = get_prompt_list(prompt)
|
| 358 |
+
|
| 359 |
+
|
| 360 |
+
def forward(self, inp_image, conditional=None, return_features=False, mask=None):
|
| 361 |
+
|
| 362 |
+
assert type(return_features) == bool
|
| 363 |
+
|
| 364 |
+
inp_image = inp_image.to(self.model.positional_embedding.device)
|
| 365 |
+
|
| 366 |
+
if mask is not None:
|
| 367 |
+
raise ValueError('mask not supported')
|
| 368 |
+
|
| 369 |
+
# x_inp = normalize(inp_image)
|
| 370 |
+
x_inp = inp_image
|
| 371 |
+
|
| 372 |
+
bs, dev = inp_image.shape[0], x_inp.device
|
| 373 |
+
|
| 374 |
+
cond = self.get_cond_vec(conditional, bs)
|
| 375 |
+
|
| 376 |
+
visual_q, activations, _ = self.visual_forward(x_inp, extract_layers=[0] + list(self.extract_layers))
|
| 377 |
+
|
| 378 |
+
activation1 = activations[0]
|
| 379 |
+
activations = activations[1:]
|
| 380 |
+
|
| 381 |
+
_activations = activations[::-1] if not self.rev_activations else activations
|
| 382 |
+
|
| 383 |
+
a = None
|
| 384 |
+
for i, (activation, block, reduce) in enumerate(zip(_activations, self.blocks, self.reduces)):
|
| 385 |
+
|
| 386 |
+
if a is not None:
|
| 387 |
+
a = reduce(activation) + a
|
| 388 |
+
else:
|
| 389 |
+
a = reduce(activation)
|
| 390 |
+
|
| 391 |
+
if i == self.cond_layer:
|
| 392 |
+
if self.reduce_cond is not None:
|
| 393 |
+
cond = self.reduce_cond(cond)
|
| 394 |
+
|
| 395 |
+
a = self.film_mul(cond) * a + self.film_add(cond)
|
| 396 |
+
|
| 397 |
+
a = block(a)
|
| 398 |
+
|
| 399 |
+
for block in self.extra_blocks:
|
| 400 |
+
a = a + block(a)
|
| 401 |
+
|
| 402 |
+
a = a[1:].permute(1, 2, 0) # rm cls token and -> BS, Feats, Tokens
|
| 403 |
+
|
| 404 |
+
size = int(math.sqrt(a.shape[2]))
|
| 405 |
+
|
| 406 |
+
a = a.view(bs, a.shape[1], size, size)
|
| 407 |
+
|
| 408 |
+
a = self.trans_conv(a)
|
| 409 |
+
|
| 410 |
+
if self.n_tokens is not None:
|
| 411 |
+
a = nnf.interpolate(a, x_inp.shape[2:], mode='bilinear', align_corners=True)
|
| 412 |
+
|
| 413 |
+
if self.upsample_proj is not None:
|
| 414 |
+
a = self.upsample_proj(a)
|
| 415 |
+
a = nnf.interpolate(a, x_inp.shape[2:], mode='bilinear')
|
| 416 |
+
|
| 417 |
+
if return_features:
|
| 418 |
+
return a, visual_q, cond, [activation1] + activations
|
| 419 |
+
else:
|
| 420 |
+
return a,
|
| 421 |
+
|
| 422 |
+
|
| 423 |
+
|
| 424 |
+
class CLIPDensePredTMasked(CLIPDensePredT):
|
| 425 |
+
|
| 426 |
+
def __init__(self, version='ViT-B/32', extract_layers=(3, 6, 9), cond_layer=0, reduce_dim=128, n_heads=4,
|
| 427 |
+
prompt='fixed', extra_blocks=0, reduce_cond=None, fix_shift=False, learn_trans_conv_only=False,
|
| 428 |
+
refine=None, limit_to_clip_only=False, upsample=False, add_calibration=False, n_tokens=None):
|
| 429 |
+
|
| 430 |
+
super().__init__(version=version, extract_layers=extract_layers, cond_layer=cond_layer, reduce_dim=reduce_dim,
|
| 431 |
+
n_heads=n_heads, prompt=prompt, extra_blocks=extra_blocks, reduce_cond=reduce_cond,
|
| 432 |
+
fix_shift=fix_shift, learn_trans_conv_only=learn_trans_conv_only,
|
| 433 |
+
limit_to_clip_only=limit_to_clip_only, upsample=upsample, add_calibration=add_calibration,
|
| 434 |
+
n_tokens=n_tokens)
|
| 435 |
+
|
| 436 |
+
def visual_forward_masked(self, img_s, seg_s):
|
| 437 |
+
return super().visual_forward(img_s, mask=('all', 'cls_token', seg_s))
|
| 438 |
+
|
| 439 |
+
def forward(self, img_q, cond_or_img_s, seg_s=None, return_features=False):
|
| 440 |
+
|
| 441 |
+
if seg_s is None:
|
| 442 |
+
cond = cond_or_img_s
|
| 443 |
+
else:
|
| 444 |
+
img_s = cond_or_img_s
|
| 445 |
+
|
| 446 |
+
with torch.no_grad():
|
| 447 |
+
cond, _, _ = self.visual_forward_masked(img_s, seg_s)
|
| 448 |
+
|
| 449 |
+
return super().forward(img_q, cond, return_features=return_features)
|
| 450 |
+
|
| 451 |
+
|
| 452 |
+
|
| 453 |
+
class CLIPDenseBaseline(CLIPDenseBase):
|
| 454 |
+
|
| 455 |
+
def __init__(self, version='ViT-B/32', cond_layer=0,
|
| 456 |
+
extract_layer=9, reduce_dim=128, reduce2_dim=None, prompt='fixed',
|
| 457 |
+
reduce_cond=None, limit_to_clip_only=False, n_tokens=None):
|
| 458 |
+
|
| 459 |
+
super().__init__(version, reduce_cond, reduce_dim, prompt, n_tokens)
|
| 460 |
+
device = 'cpu'
|
| 461 |
+
|
| 462 |
+
# self.cond_layer = cond_layer
|
| 463 |
+
self.extract_layer = extract_layer
|
| 464 |
+
self.limit_to_clip_only = limit_to_clip_only
|
| 465 |
+
self.shift_vector = None
|
| 466 |
+
|
| 467 |
+
self.token_shape = {'ViT-B/32': (7, 7), 'ViT-B/16': (14, 14)}[version]
|
| 468 |
+
|
| 469 |
+
assert reduce2_dim is not None
|
| 470 |
+
|
| 471 |
+
self.reduce2 = nn.Sequential(
|
| 472 |
+
nn.Linear(reduce_dim, reduce2_dim),
|
| 473 |
+
nn.ReLU(),
|
| 474 |
+
nn.Linear(reduce2_dim, reduce_dim)
|
| 475 |
+
)
|
| 476 |
+
|
| 477 |
+
trans_conv_ks = {'ViT-B/32': (32, 32), 'ViT-B/16': (16, 16)}[version]
|
| 478 |
+
self.trans_conv = nn.ConvTranspose2d(reduce_dim, 1, trans_conv_ks, stride=trans_conv_ks)
|
| 479 |
+
|
| 480 |
+
|
| 481 |
+
def forward(self, inp_image, conditional=None, return_features=False):
|
| 482 |
+
|
| 483 |
+
inp_image = inp_image.to(self.model.positional_embedding.device)
|
| 484 |
+
|
| 485 |
+
# x_inp = normalize(inp_image)
|
| 486 |
+
x_inp = inp_image
|
| 487 |
+
|
| 488 |
+
bs, dev = inp_image.shape[0], x_inp.device
|
| 489 |
+
|
| 490 |
+
cond = self.get_cond_vec(conditional, bs)
|
| 491 |
+
|
| 492 |
+
visual_q, activations, affinities = self.visual_forward(x_inp, extract_layers=[self.extract_layer])
|
| 493 |
+
|
| 494 |
+
a = activations[0]
|
| 495 |
+
a = self.reduce(a)
|
| 496 |
+
a = self.film_mul(cond) * a + self.film_add(cond)
|
| 497 |
+
|
| 498 |
+
if self.reduce2 is not None:
|
| 499 |
+
a = self.reduce2(a)
|
| 500 |
+
|
| 501 |
+
# the original model would execute a transformer block here
|
| 502 |
+
|
| 503 |
+
a = a[1:].permute(1, 2, 0) # rm cls token and -> BS, Feats, Tokens
|
| 504 |
+
|
| 505 |
+
size = int(math.sqrt(a.shape[2]))
|
| 506 |
+
|
| 507 |
+
a = a.view(bs, a.shape[1], size, size)
|
| 508 |
+
a = self.trans_conv(a)
|
| 509 |
+
|
| 510 |
+
if return_features:
|
| 511 |
+
return a, visual_q, cond, activations
|
| 512 |
+
else:
|
| 513 |
+
return a,
|
| 514 |
+
|
| 515 |
+
|
| 516 |
+
class CLIPSegMultiLabel(nn.Module):
|
| 517 |
+
|
| 518 |
+
def __init__(self, model) -> None:
|
| 519 |
+
super().__init__()
|
| 520 |
+
|
| 521 |
+
from third_party.JoEm.data_loader import get_seen_idx, get_unseen_idx, VOC
|
| 522 |
+
|
| 523 |
+
self.pascal_classes = VOC
|
| 524 |
+
|
| 525 |
+
from models.clipseg import CLIPDensePredT
|
| 526 |
+
from general_utils import load_model
|
| 527 |
+
# self.clipseg = load_model('rd64-vit16-neg0.2-phrasecut', strict=False)
|
| 528 |
+
self.clipseg = load_model(model, strict=False)
|
| 529 |
+
|
| 530 |
+
self.clipseg.eval()
|
| 531 |
+
|
| 532 |
+
def forward(self, x):
|
| 533 |
+
|
| 534 |
+
bs = x.shape[0]
|
| 535 |
+
out = torch.ones(21, bs, 352, 352).to(x.device) * -10
|
| 536 |
+
|
| 537 |
+
for class_id, class_name in enumerate(self.pascal_classes):
|
| 538 |
+
|
| 539 |
+
fac = 3 if class_name == 'background' else 1
|
| 540 |
+
|
| 541 |
+
with torch.no_grad():
|
| 542 |
+
pred = torch.sigmoid(self.clipseg(x, class_name)[0][:,0]) * fac
|
| 543 |
+
|
| 544 |
+
out[class_id] += pred
|
| 545 |
+
|
| 546 |
+
|
| 547 |
+
out = out.permute(1, 0, 2, 3)
|
| 548 |
+
|
| 549 |
+
return out
|
| 550 |
+
|
| 551 |
+
# construct output tensor
|
| 552 |
+
|
clipseg/models/vitseg.py
ADDED
|
@@ -0,0 +1,286 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import math
|
| 2 |
+
from posixpath import basename, dirname, join
|
| 3 |
+
# import clip
|
| 4 |
+
from clip.model import convert_weights
|
| 5 |
+
import torch
|
| 6 |
+
import json
|
| 7 |
+
from torch import nn
|
| 8 |
+
from torch.nn import functional as nnf
|
| 9 |
+
from torch.nn.modules import activation
|
| 10 |
+
from torch.nn.modules.activation import ReLU
|
| 11 |
+
from torchvision import transforms
|
| 12 |
+
|
| 13 |
+
normalize = transforms.Normalize(mean=(0.48145466, 0.4578275, 0.40821073), std=(0.26862954, 0.26130258, 0.27577711))
|
| 14 |
+
|
| 15 |
+
from torchvision.models import ResNet
|
| 16 |
+
|
| 17 |
+
|
| 18 |
+
def process_prompts(conditional, prompt_list, conditional_map):
|
| 19 |
+
# DEPRECATED
|
| 20 |
+
|
| 21 |
+
# randomly sample a synonym
|
| 22 |
+
words = [conditional_map[int(i)] for i in conditional]
|
| 23 |
+
words = [syns[torch.multinomial(torch.ones(len(syns)), 1, replacement=True).item()] for syns in words]
|
| 24 |
+
words = [w.replace('_', ' ') for w in words]
|
| 25 |
+
|
| 26 |
+
if prompt_list is not None:
|
| 27 |
+
prompt_indices = torch.multinomial(torch.ones(len(prompt_list)), len(words), replacement=True)
|
| 28 |
+
prompts = [prompt_list[i] for i in prompt_indices]
|
| 29 |
+
else:
|
| 30 |
+
prompts = ['a photo of {}'] * (len(words))
|
| 31 |
+
|
| 32 |
+
return [promt.format(w) for promt, w in zip(prompts, words)]
|
| 33 |
+
|
| 34 |
+
|
| 35 |
+
class VITDenseBase(nn.Module):
|
| 36 |
+
|
| 37 |
+
def rescaled_pos_emb(self, new_size):
|
| 38 |
+
assert len(new_size) == 2
|
| 39 |
+
|
| 40 |
+
a = self.model.positional_embedding[1:].T.view(1, 768, *self.token_shape)
|
| 41 |
+
b = nnf.interpolate(a, new_size, mode='bicubic', align_corners=False).squeeze(0).view(768, new_size[0]*new_size[1]).T
|
| 42 |
+
return torch.cat([self.model.positional_embedding[:1], b])
|
| 43 |
+
|
| 44 |
+
def visual_forward(self, x_inp, extract_layers=(), skip=False, mask=None):
|
| 45 |
+
|
| 46 |
+
with torch.no_grad():
|
| 47 |
+
|
| 48 |
+
x_inp = nnf.interpolate(x_inp, (384, 384))
|
| 49 |
+
|
| 50 |
+
x = self.model.patch_embed(x_inp)
|
| 51 |
+
cls_token = self.model.cls_token.expand(x.shape[0], -1, -1) # stole cls_tokens impl from Phil Wang, thanks
|
| 52 |
+
if self.model.dist_token is None:
|
| 53 |
+
x = torch.cat((cls_token, x), dim=1)
|
| 54 |
+
else:
|
| 55 |
+
x = torch.cat((cls_token, self.model.dist_token.expand(x.shape[0], -1, -1), x), dim=1)
|
| 56 |
+
x = self.model.pos_drop(x + self.model.pos_embed)
|
| 57 |
+
|
| 58 |
+
activations = []
|
| 59 |
+
for i, block in enumerate(self.model.blocks):
|
| 60 |
+
x = block(x)
|
| 61 |
+
|
| 62 |
+
if i in extract_layers:
|
| 63 |
+
# permute to be compatible with CLIP
|
| 64 |
+
activations += [x.permute(1,0,2)]
|
| 65 |
+
|
| 66 |
+
x = self.model.norm(x)
|
| 67 |
+
x = self.model.head(self.model.pre_logits(x[:, 0]))
|
| 68 |
+
|
| 69 |
+
# again for CLIP compatibility
|
| 70 |
+
# x = x.permute(1, 0, 2)
|
| 71 |
+
|
| 72 |
+
return x, activations, None
|
| 73 |
+
|
| 74 |
+
def sample_prompts(self, words, prompt_list=None):
|
| 75 |
+
|
| 76 |
+
prompt_list = prompt_list if prompt_list is not None else self.prompt_list
|
| 77 |
+
|
| 78 |
+
prompt_indices = torch.multinomial(torch.ones(len(prompt_list)), len(words), replacement=True)
|
| 79 |
+
prompts = [prompt_list[i] for i in prompt_indices]
|
| 80 |
+
return [promt.format(w) for promt, w in zip(prompts, words)]
|
| 81 |
+
|
| 82 |
+
def get_cond_vec(self, conditional, batch_size):
|
| 83 |
+
# compute conditional from a single string
|
| 84 |
+
if conditional is not None and type(conditional) == str:
|
| 85 |
+
cond = self.compute_conditional(conditional)
|
| 86 |
+
cond = cond.repeat(batch_size, 1)
|
| 87 |
+
|
| 88 |
+
# compute conditional from string list/tuple
|
| 89 |
+
elif conditional is not None and type(conditional) in {list, tuple} and type(conditional[0]) == str:
|
| 90 |
+
assert len(conditional) == batch_size
|
| 91 |
+
cond = self.compute_conditional(conditional)
|
| 92 |
+
|
| 93 |
+
# use conditional directly
|
| 94 |
+
elif conditional is not None and type(conditional) == torch.Tensor and conditional.ndim == 2:
|
| 95 |
+
cond = conditional
|
| 96 |
+
|
| 97 |
+
# compute conditional from image
|
| 98 |
+
elif conditional is not None and type(conditional) == torch.Tensor:
|
| 99 |
+
with torch.no_grad():
|
| 100 |
+
cond, _, _ = self.visual_forward(conditional)
|
| 101 |
+
else:
|
| 102 |
+
raise ValueError('invalid conditional')
|
| 103 |
+
return cond
|
| 104 |
+
|
| 105 |
+
def compute_conditional(self, conditional):
|
| 106 |
+
import clip
|
| 107 |
+
|
| 108 |
+
dev = next(self.parameters()).device
|
| 109 |
+
|
| 110 |
+
if type(conditional) in {list, tuple}:
|
| 111 |
+
text_tokens = clip.tokenize(conditional).to(dev)
|
| 112 |
+
cond = self.clip_model.encode_text(text_tokens)
|
| 113 |
+
else:
|
| 114 |
+
if conditional in self.precomputed_prompts:
|
| 115 |
+
cond = self.precomputed_prompts[conditional].float().to(dev)
|
| 116 |
+
else:
|
| 117 |
+
text_tokens = clip.tokenize([conditional]).to(dev)
|
| 118 |
+
cond = self.clip_model.encode_text(text_tokens)[0]
|
| 119 |
+
|
| 120 |
+
return cond
|
| 121 |
+
|
| 122 |
+
|
| 123 |
+
class VITDensePredT(VITDenseBase):
|
| 124 |
+
|
| 125 |
+
def __init__(self, extract_layers=(3, 6, 9), cond_layer=0, reduce_dim=128, n_heads=4, prompt='fixed',
|
| 126 |
+
depth=3, extra_blocks=0, reduce_cond=None, fix_shift=False,
|
| 127 |
+
learn_trans_conv_only=False, refine=None, limit_to_clip_only=False, upsample=False,
|
| 128 |
+
add_calibration=False, process_cond=None, not_pretrained=False):
|
| 129 |
+
super().__init__()
|
| 130 |
+
# device = 'cpu'
|
| 131 |
+
|
| 132 |
+
self.extract_layers = extract_layers
|
| 133 |
+
self.cond_layer = cond_layer
|
| 134 |
+
self.limit_to_clip_only = limit_to_clip_only
|
| 135 |
+
self.process_cond = None
|
| 136 |
+
|
| 137 |
+
if add_calibration:
|
| 138 |
+
self.calibration_conds = 1
|
| 139 |
+
|
| 140 |
+
self.upsample_proj = nn.Conv2d(reduce_dim, 1, kernel_size=1) if upsample else None
|
| 141 |
+
|
| 142 |
+
self.add_activation1 = True
|
| 143 |
+
|
| 144 |
+
import timm
|
| 145 |
+
self.model = timm.create_model('vit_base_patch16_384', pretrained=True)
|
| 146 |
+
self.model.head = nn.Linear(768, 512 if reduce_cond is None else reduce_cond)
|
| 147 |
+
|
| 148 |
+
for p in self.model.parameters():
|
| 149 |
+
p.requires_grad_(False)
|
| 150 |
+
|
| 151 |
+
import clip
|
| 152 |
+
self.clip_model, _ = clip.load('ViT-B/16', device='cpu', jit=False)
|
| 153 |
+
# del self.clip_model.visual
|
| 154 |
+
|
| 155 |
+
|
| 156 |
+
self.token_shape = (14, 14)
|
| 157 |
+
|
| 158 |
+
# conditional
|
| 159 |
+
if reduce_cond is not None:
|
| 160 |
+
self.reduce_cond = nn.Linear(512, reduce_cond)
|
| 161 |
+
for p in self.reduce_cond.parameters():
|
| 162 |
+
p.requires_grad_(False)
|
| 163 |
+
else:
|
| 164 |
+
self.reduce_cond = None
|
| 165 |
+
|
| 166 |
+
# self.film = AVAILABLE_BLOCKS['film'](512, 128)
|
| 167 |
+
self.film_mul = nn.Linear(512 if reduce_cond is None else reduce_cond, reduce_dim)
|
| 168 |
+
self.film_add = nn.Linear(512 if reduce_cond is None else reduce_cond, reduce_dim)
|
| 169 |
+
|
| 170 |
+
# DEPRECATED
|
| 171 |
+
# self.conditional_map = {c['id']: c['synonyms'] for c in json.load(open(cond_map))}
|
| 172 |
+
|
| 173 |
+
assert len(self.extract_layers) == depth
|
| 174 |
+
|
| 175 |
+
self.reduces = nn.ModuleList([nn.Linear(768, reduce_dim) for _ in range(depth)])
|
| 176 |
+
self.blocks = nn.ModuleList([nn.TransformerEncoderLayer(d_model=reduce_dim, nhead=n_heads) for _ in range(len(self.extract_layers))])
|
| 177 |
+
self.extra_blocks = nn.ModuleList([nn.TransformerEncoderLayer(d_model=reduce_dim, nhead=n_heads) for _ in range(extra_blocks)])
|
| 178 |
+
|
| 179 |
+
trans_conv_ks = (16, 16)
|
| 180 |
+
self.trans_conv = nn.ConvTranspose2d(reduce_dim, 1, trans_conv_ks, stride=trans_conv_ks)
|
| 181 |
+
|
| 182 |
+
# refinement and trans conv
|
| 183 |
+
|
| 184 |
+
if learn_trans_conv_only:
|
| 185 |
+
for p in self.parameters():
|
| 186 |
+
p.requires_grad_(False)
|
| 187 |
+
|
| 188 |
+
for p in self.trans_conv.parameters():
|
| 189 |
+
p.requires_grad_(True)
|
| 190 |
+
|
| 191 |
+
if prompt == 'fixed':
|
| 192 |
+
self.prompt_list = ['a photo of a {}.']
|
| 193 |
+
elif prompt == 'shuffle':
|
| 194 |
+
self.prompt_list = ['a photo of a {}.', 'a photograph of a {}.', 'an image of a {}.', '{}.']
|
| 195 |
+
elif prompt == 'shuffle+':
|
| 196 |
+
self.prompt_list = ['a photo of a {}.', 'a photograph of a {}.', 'an image of a {}.', '{}.',
|
| 197 |
+
'a cropped photo of a {}.', 'a good photo of a {}.', 'a photo of one {}.',
|
| 198 |
+
'a bad photo of a {}.', 'a photo of the {}.']
|
| 199 |
+
elif prompt == 'shuffle_clip':
|
| 200 |
+
from models.clip_prompts import imagenet_templates
|
| 201 |
+
self.prompt_list = imagenet_templates
|
| 202 |
+
|
| 203 |
+
if process_cond is not None:
|
| 204 |
+
if process_cond == 'clamp' or process_cond[0] == 'clamp':
|
| 205 |
+
|
| 206 |
+
val = process_cond[1] if type(process_cond) in {list, tuple} else 0.2
|
| 207 |
+
|
| 208 |
+
def clamp_vec(x):
|
| 209 |
+
return torch.clamp(x, -val, val)
|
| 210 |
+
|
| 211 |
+
self.process_cond = clamp_vec
|
| 212 |
+
|
| 213 |
+
elif process_cond.endswith('.pth'):
|
| 214 |
+
|
| 215 |
+
shift = torch.load(process_cond)
|
| 216 |
+
def add_shift(x):
|
| 217 |
+
return x + shift.to(x.device)
|
| 218 |
+
|
| 219 |
+
self.process_cond = add_shift
|
| 220 |
+
|
| 221 |
+
import pickle
|
| 222 |
+
precomp = pickle.load(open('precomputed_prompt_vectors.pickle', 'rb'))
|
| 223 |
+
self.precomputed_prompts = {k: torch.from_numpy(v) for k, v in precomp.items()}
|
| 224 |
+
|
| 225 |
+
|
| 226 |
+
def forward(self, inp_image, conditional=None, return_features=False, mask=None):
|
| 227 |
+
|
| 228 |
+
assert type(return_features) == bool
|
| 229 |
+
|
| 230 |
+
# inp_image = inp_image.to(self.model.positional_embedding.device)
|
| 231 |
+
|
| 232 |
+
if mask is not None:
|
| 233 |
+
raise ValueError('mask not supported')
|
| 234 |
+
|
| 235 |
+
# x_inp = normalize(inp_image)
|
| 236 |
+
x_inp = inp_image
|
| 237 |
+
|
| 238 |
+
bs, dev = inp_image.shape[0], x_inp.device
|
| 239 |
+
|
| 240 |
+
inp_image_size = inp_image.shape[2:]
|
| 241 |
+
|
| 242 |
+
cond = self.get_cond_vec(conditional, bs)
|
| 243 |
+
|
| 244 |
+
visual_q, activations, _ = self.visual_forward(x_inp, extract_layers=[0] + list(self.extract_layers))
|
| 245 |
+
|
| 246 |
+
activation1 = activations[0]
|
| 247 |
+
activations = activations[1:]
|
| 248 |
+
|
| 249 |
+
a = None
|
| 250 |
+
for i, (activation, block, reduce) in enumerate(zip(activations[::-1], self.blocks, self.reduces)):
|
| 251 |
+
|
| 252 |
+
if a is not None:
|
| 253 |
+
a = reduce(activation) + a
|
| 254 |
+
else:
|
| 255 |
+
a = reduce(activation)
|
| 256 |
+
|
| 257 |
+
if i == self.cond_layer:
|
| 258 |
+
if self.reduce_cond is not None:
|
| 259 |
+
cond = self.reduce_cond(cond)
|
| 260 |
+
|
| 261 |
+
a = self.film_mul(cond) * a + self.film_add(cond)
|
| 262 |
+
|
| 263 |
+
a = block(a)
|
| 264 |
+
|
| 265 |
+
for block in self.extra_blocks:
|
| 266 |
+
a = a + block(a)
|
| 267 |
+
|
| 268 |
+
a = a[1:].permute(1, 2, 0) # rm cls token and -> BS, Feats, Tokens
|
| 269 |
+
|
| 270 |
+
size = int(math.sqrt(a.shape[2]))
|
| 271 |
+
|
| 272 |
+
a = a.view(bs, a.shape[1], size, size)
|
| 273 |
+
|
| 274 |
+
if self.trans_conv is not None:
|
| 275 |
+
a = self.trans_conv(a)
|
| 276 |
+
|
| 277 |
+
if self.upsample_proj is not None:
|
| 278 |
+
a = self.upsample_proj(a)
|
| 279 |
+
a = nnf.interpolate(a, x_inp.shape[2:], mode='bilinear')
|
| 280 |
+
|
| 281 |
+
a = nnf.interpolate(a, inp_image_size)
|
| 282 |
+
|
| 283 |
+
if return_features:
|
| 284 |
+
return a, visual_q, cond, [activation1] + activations
|
| 285 |
+
else:
|
| 286 |
+
return a,
|
clipseg/overview.png
ADDED
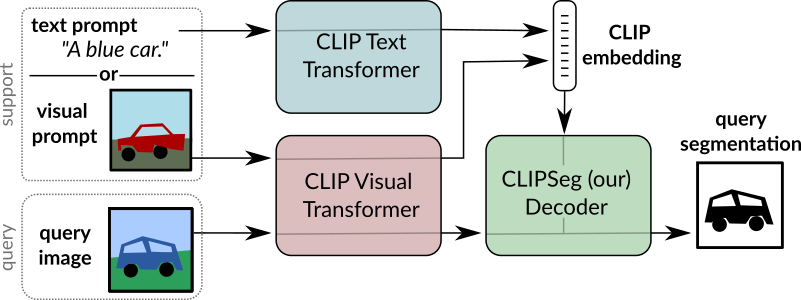
|
clipseg/score.py
ADDED
|
@@ -0,0 +1,453 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from torch.functional import Tensor
|
| 2 |
+
|
| 3 |
+
import torch
|
| 4 |
+
import inspect
|
| 5 |
+
import json
|
| 6 |
+
import yaml
|
| 7 |
+
import time
|
| 8 |
+
import sys
|
| 9 |
+
|
| 10 |
+
from general_utils import log
|
| 11 |
+
|
| 12 |
+
import numpy as np
|
| 13 |
+
from os.path import expanduser, join, isfile, realpath
|
| 14 |
+
|
| 15 |
+
from torch.utils.data import DataLoader
|
| 16 |
+
|
| 17 |
+
from metrics import FixedIntervalMetrics
|
| 18 |
+
|
| 19 |
+
from general_utils import load_model, log, score_config_from_cli_args, AttributeDict, get_attribute, filter_args
|
| 20 |
+
|
| 21 |
+
|
| 22 |
+
DATASET_CACHE = dict()
|
| 23 |
+
|
| 24 |
+
def load_model(checkpoint_id, weights_file=None, strict=True, model_args='from_config', with_config=False, ignore_weights=False):
|
| 25 |
+
|
| 26 |
+
config = json.load(open(join('logs', checkpoint_id, 'config.json')))
|
| 27 |
+
|
| 28 |
+
if model_args != 'from_config' and type(model_args) != dict:
|
| 29 |
+
raise ValueError('model_args must either be "from_config" or a dictionary of values')
|
| 30 |
+
|
| 31 |
+
model_cls = get_attribute(config['model'])
|
| 32 |
+
|
| 33 |
+
# load model
|
| 34 |
+
if model_args == 'from_config':
|
| 35 |
+
_, model_args, _ = filter_args(config, inspect.signature(model_cls).parameters)
|
| 36 |
+
|
| 37 |
+
model = model_cls(**model_args)
|
| 38 |
+
|
| 39 |
+
if weights_file is None:
|
| 40 |
+
weights_file = realpath(join('logs', checkpoint_id, 'weights.pth'))
|
| 41 |
+
else:
|
| 42 |
+
weights_file = realpath(join('logs', checkpoint_id, weights_file))
|
| 43 |
+
|
| 44 |
+
if isfile(weights_file) and not ignore_weights:
|
| 45 |
+
weights = torch.load(weights_file)
|
| 46 |
+
for _, w in weights.items():
|
| 47 |
+
assert not torch.any(torch.isnan(w)), 'weights contain NaNs'
|
| 48 |
+
model.load_state_dict(weights, strict=strict)
|
| 49 |
+
else:
|
| 50 |
+
if not ignore_weights:
|
| 51 |
+
raise FileNotFoundError(f'model checkpoint {weights_file} was not found')
|
| 52 |
+
|
| 53 |
+
if with_config:
|
| 54 |
+
return model, config
|
| 55 |
+
|
| 56 |
+
return model
|
| 57 |
+
|
| 58 |
+
|
| 59 |
+
def compute_shift2(model, datasets, seed=123, repetitions=1):
|
| 60 |
+
""" computes shift """
|
| 61 |
+
|
| 62 |
+
model.eval()
|
| 63 |
+
model.cuda()
|
| 64 |
+
|
| 65 |
+
import random
|
| 66 |
+
random.seed(seed)
|
| 67 |
+
|
| 68 |
+
preds, gts = [], []
|
| 69 |
+
for i_dataset, dataset in enumerate(datasets):
|
| 70 |
+
|
| 71 |
+
loader = DataLoader(dataset, batch_size=1, num_workers=0, shuffle=False, drop_last=False)
|
| 72 |
+
|
| 73 |
+
max_iterations = int(repetitions * len(dataset.dataset.data_list))
|
| 74 |
+
|
| 75 |
+
with torch.no_grad():
|
| 76 |
+
|
| 77 |
+
i, losses = 0, []
|
| 78 |
+
for i_all, (data_x, data_y) in enumerate(loader):
|
| 79 |
+
|
| 80 |
+
data_x = [v.cuda(non_blocking=True) if v is not None else v for v in data_x]
|
| 81 |
+
data_y = [v.cuda(non_blocking=True) if v is not None else v for v in data_y]
|
| 82 |
+
|
| 83 |
+
pred, = model(data_x[0], data_x[1], data_x[2])
|
| 84 |
+
preds += [pred.detach()]
|
| 85 |
+
gts += [data_y]
|
| 86 |
+
|
| 87 |
+
i += 1
|
| 88 |
+
if max_iterations and i >= max_iterations:
|
| 89 |
+
break
|
| 90 |
+
|
| 91 |
+
from metrics import FixedIntervalMetrics
|
| 92 |
+
n_values = 51
|
| 93 |
+
thresholds = np.linspace(0, 1, n_values)[1:-1]
|
| 94 |
+
metric = FixedIntervalMetrics(resize_pred=True, sigmoid=True, n_values=n_values)
|
| 95 |
+
|
| 96 |
+
for p, y in zip(preds, gts):
|
| 97 |
+
metric.add(p.unsqueeze(1), y)
|
| 98 |
+
|
| 99 |
+
best_idx = np.argmax(metric.value()['fgiou_scores'])
|
| 100 |
+
best_thresh = thresholds[best_idx]
|
| 101 |
+
|
| 102 |
+
return best_thresh
|
| 103 |
+
|
| 104 |
+
|
| 105 |
+
def get_cached_pascal_pfe(split, config):
|
| 106 |
+
from datasets.pfe_dataset import PFEPascalWrapper
|
| 107 |
+
try:
|
| 108 |
+
dataset = DATASET_CACHE[(split, config.image_size, config.label_support, config.mask)]
|
| 109 |
+
except KeyError:
|
| 110 |
+
dataset = PFEPascalWrapper(mode='val', split=split, mask=config.mask, image_size=config.image_size, label_support=config.label_support)
|
| 111 |
+
DATASET_CACHE[(split, config.image_size, config.label_support, config.mask)] = dataset
|
| 112 |
+
return dataset
|
| 113 |
+
|
| 114 |
+
|
| 115 |
+
|
| 116 |
+
|
| 117 |
+
def main():
|
| 118 |
+
config, train_checkpoint_id = score_config_from_cli_args()
|
| 119 |
+
|
| 120 |
+
metrics = score(config, train_checkpoint_id, None)
|
| 121 |
+
|
| 122 |
+
for dataset in metrics.keys():
|
| 123 |
+
for k in metrics[dataset]:
|
| 124 |
+
if type(metrics[dataset][k]) in {float, int}:
|
| 125 |
+
print(dataset, f'{k:<16} {metrics[dataset][k]:.3f}')
|
| 126 |
+
|
| 127 |
+
|
| 128 |
+
def score(config, train_checkpoint_id, train_config):
|
| 129 |
+
|
| 130 |
+
config = AttributeDict(config)
|
| 131 |
+
|
| 132 |
+
print(config)
|
| 133 |
+
|
| 134 |
+
# use training dataset and loss
|
| 135 |
+
train_config = AttributeDict(json.load(open(f'logs/{train_checkpoint_id}/config.json')))
|
| 136 |
+
|
| 137 |
+
cp_str = f'_{config.iteration_cp}' if config.iteration_cp is not None else ''
|
| 138 |
+
|
| 139 |
+
|
| 140 |
+
model_cls = get_attribute(train_config['model'])
|
| 141 |
+
|
| 142 |
+
_, model_args, _ = filter_args(train_config, inspect.signature(model_cls).parameters)
|
| 143 |
+
|
| 144 |
+
model_args = {**model_args, **{k: config[k] for k in ['process_cond', 'fix_shift'] if k in config}}
|
| 145 |
+
|
| 146 |
+
strict_models = {'ConditionBase4', 'PFENetWrapper'}
|
| 147 |
+
model = load_model(train_checkpoint_id, strict=model_cls.__name__ in strict_models, model_args=model_args,
|
| 148 |
+
weights_file=f'weights{cp_str}.pth', )
|
| 149 |
+
|
| 150 |
+
|
| 151 |
+
model.eval()
|
| 152 |
+
model.cuda()
|
| 153 |
+
|
| 154 |
+
metric_args = dict()
|
| 155 |
+
|
| 156 |
+
if 'threshold' in config:
|
| 157 |
+
if config.metric.split('.')[-1] == 'SkLearnMetrics':
|
| 158 |
+
metric_args['threshold'] = config.threshold
|
| 159 |
+
|
| 160 |
+
if 'resize_to' in config:
|
| 161 |
+
metric_args['resize_to'] = config.resize_to
|
| 162 |
+
|
| 163 |
+
if 'sigmoid' in config:
|
| 164 |
+
metric_args['sigmoid'] = config.sigmoid
|
| 165 |
+
|
| 166 |
+
if 'custom_threshold' in config:
|
| 167 |
+
metric_args['custom_threshold'] = config.custom_threshold
|
| 168 |
+
|
| 169 |
+
if config.test_dataset == 'pascal':
|
| 170 |
+
|
| 171 |
+
loss_fn = get_attribute(train_config.loss)
|
| 172 |
+
# assume that if no split is specified in train_config, test on all splits,
|
| 173 |
+
|
| 174 |
+
if 'splits' in config:
|
| 175 |
+
splits = config.splits
|
| 176 |
+
else:
|
| 177 |
+
if 'split' in train_config and type(train_config.split) == int:
|
| 178 |
+
# unless train_config has a split set, in that case assume train mode in training
|
| 179 |
+
splits = [train_config.split]
|
| 180 |
+
assert train_config.mode == 'train'
|
| 181 |
+
else:
|
| 182 |
+
splits = [0,1,2,3]
|
| 183 |
+
|
| 184 |
+
log.info('Test on these splits', splits)
|
| 185 |
+
|
| 186 |
+
scores = dict()
|
| 187 |
+
for split in splits:
|
| 188 |
+
|
| 189 |
+
shift = config.shift if 'shift' in config else 0
|
| 190 |
+
|
| 191 |
+
# automatic shift
|
| 192 |
+
if shift == 'auto':
|
| 193 |
+
shift_compute_t = time.time()
|
| 194 |
+
shift = compute_shift2(model, [get_cached_pascal_pfe(s, config) for s in range(4) if s != split], repetitions=config.compute_shift_fac)
|
| 195 |
+
log.info(f'Best threshold is {shift}, computed on splits: {[s for s in range(4) if s != split]}, took {time.time() - shift_compute_t:.1f}s')
|
| 196 |
+
|
| 197 |
+
dataset = get_cached_pascal_pfe(split, config)
|
| 198 |
+
|
| 199 |
+
eval_start_t = time.time()
|
| 200 |
+
|
| 201 |
+
loader = DataLoader(dataset, batch_size=1, num_workers=0, shuffle=False, drop_last=False)
|
| 202 |
+
|
| 203 |
+
assert config.batch_size is None or config.batch_size == 1, 'When PFE Dataset is used, batch size must be 1'
|
| 204 |
+
|
| 205 |
+
metric = FixedIntervalMetrics(resize_pred=True, sigmoid=True, custom_threshold=shift, **metric_args)
|
| 206 |
+
|
| 207 |
+
with torch.no_grad():
|
| 208 |
+
|
| 209 |
+
i, losses = 0, []
|
| 210 |
+
for i_all, (data_x, data_y) in enumerate(loader):
|
| 211 |
+
|
| 212 |
+
data_x = [v.cuda(non_blocking=True) if isinstance(v, torch.Tensor) else v for v in data_x]
|
| 213 |
+
data_y = [v.cuda(non_blocking=True) if isinstance(v, torch.Tensor) else v for v in data_y]
|
| 214 |
+
|
| 215 |
+
if config.mask == 'separate': # for old CondBase model
|
| 216 |
+
pred, = model(data_x[0], data_x[1], data_x[2])
|
| 217 |
+
else:
|
| 218 |
+
# assert config.mask in {'text', 'highlight'}
|
| 219 |
+
pred, _, _, _ = model(data_x[0], data_x[1], return_features=True)
|
| 220 |
+
|
| 221 |
+
# loss = loss_fn(pred, data_y[0])
|
| 222 |
+
metric.add(pred.unsqueeze(1) + shift, data_y)
|
| 223 |
+
|
| 224 |
+
# losses += [float(loss)]
|
| 225 |
+
|
| 226 |
+
i += 1
|
| 227 |
+
if config.max_iterations and i >= config.max_iterations:
|
| 228 |
+
break
|
| 229 |
+
|
| 230 |
+
#scores[split] = {m: s for m, s in zip(metric.names(), metric.value())}
|
| 231 |
+
|
| 232 |
+
log.info(f'Dataset length: {len(dataset)}, took {time.time() - eval_start_t:.1f}s to evaluate.')
|
| 233 |
+
|
| 234 |
+
print(metric.value()['mean_iou_scores'])
|
| 235 |
+
|
| 236 |
+
scores[split] = metric.scores()
|
| 237 |
+
|
| 238 |
+
log.info(f'Completed split {split}')
|
| 239 |
+
|
| 240 |
+
key_prefix = config['name'] if 'name' in config else 'pas'
|
| 241 |
+
|
| 242 |
+
all_keys = set.intersection(*[set(v.keys()) for v in scores.values()])
|
| 243 |
+
|
| 244 |
+
valid_keys = [k for k in all_keys if all(v[k] is not None and isinstance(v[k], (int, float, np.float)) for v in scores.values())]
|
| 245 |
+
|
| 246 |
+
return {key_prefix: {k: np.mean([s[k] for s in scores.values()]) for k in valid_keys}}
|
| 247 |
+
|
| 248 |
+
|
| 249 |
+
if config.test_dataset == 'coco':
|
| 250 |
+
from datasets.coco_wrapper import COCOWrapper
|
| 251 |
+
|
| 252 |
+
coco_dataset = COCOWrapper('test', fold=train_config.fold, image_size=train_config.image_size, mask=config.mask,
|
| 253 |
+
with_class_label=True)
|
| 254 |
+
|
| 255 |
+
log.info('Dataset length', len(coco_dataset))
|
| 256 |
+
loader = DataLoader(coco_dataset, batch_size=config.batch_size, num_workers=2, shuffle=False, drop_last=False)
|
| 257 |
+
|
| 258 |
+
metric = get_attribute(config.metric)(resize_pred=True, **metric_args)
|
| 259 |
+
|
| 260 |
+
shift = config.shift if 'shift' in config else 0
|
| 261 |
+
|
| 262 |
+
with torch.no_grad():
|
| 263 |
+
|
| 264 |
+
i, losses = 0, []
|
| 265 |
+
for i_all, (data_x, data_y) in enumerate(loader):
|
| 266 |
+
data_x = [v.cuda(non_blocking=True) if isinstance(v, torch.Tensor) else v for v in data_x]
|
| 267 |
+
data_y = [v.cuda(non_blocking=True) if isinstance(v, torch.Tensor) else v for v in data_y]
|
| 268 |
+
|
| 269 |
+
if config.mask == 'separate': # for old CondBase model
|
| 270 |
+
pred, = model(data_x[0], data_x[1], data_x[2])
|
| 271 |
+
else:
|
| 272 |
+
# assert config.mask in {'text', 'highlight'}
|
| 273 |
+
pred, _, _, _ = model(data_x[0], data_x[1], return_features=True)
|
| 274 |
+
|
| 275 |
+
metric.add([pred + shift], data_y)
|
| 276 |
+
|
| 277 |
+
i += 1
|
| 278 |
+
if config.max_iterations and i >= config.max_iterations:
|
| 279 |
+
break
|
| 280 |
+
|
| 281 |
+
key_prefix = config['name'] if 'name' in config else 'coco'
|
| 282 |
+
return {key_prefix: metric.scores()}
|
| 283 |
+
#return {key_prefix: {k: v for k, v in zip(metric.names(), metric.value())}}
|
| 284 |
+
|
| 285 |
+
|
| 286 |
+
if config.test_dataset == 'phrasecut':
|
| 287 |
+
from datasets.phrasecut import PhraseCut
|
| 288 |
+
|
| 289 |
+
only_visual = config.only_visual is not None and config.only_visual
|
| 290 |
+
with_visual = config.with_visual is not None and config.with_visual
|
| 291 |
+
|
| 292 |
+
dataset = PhraseCut('test',
|
| 293 |
+
image_size=train_config.image_size,
|
| 294 |
+
mask=config.mask,
|
| 295 |
+
with_visual=with_visual, only_visual=only_visual, aug_crop=False,
|
| 296 |
+
aug_color=False)
|
| 297 |
+
|
| 298 |
+
loader = DataLoader(dataset, batch_size=config.batch_size, num_workers=2, shuffle=False, drop_last=False)
|
| 299 |
+
metric = get_attribute(config.metric)(resize_pred=True, **metric_args)
|
| 300 |
+
|
| 301 |
+
shift = config.shift if 'shift' in config else 0
|
| 302 |
+
|
| 303 |
+
|
| 304 |
+
with torch.no_grad():
|
| 305 |
+
|
| 306 |
+
i, losses = 0, []
|
| 307 |
+
for i_all, (data_x, data_y) in enumerate(loader):
|
| 308 |
+
data_x = [v.cuda(non_blocking=True) if isinstance(v, torch.Tensor) else v for v in data_x]
|
| 309 |
+
data_y = [v.cuda(non_blocking=True) if isinstance(v, torch.Tensor) else v for v in data_y]
|
| 310 |
+
|
| 311 |
+
pred, _, _, _ = model(data_x[0], data_x[1], return_features=True)
|
| 312 |
+
metric.add([pred + shift], data_y)
|
| 313 |
+
|
| 314 |
+
i += 1
|
| 315 |
+
if config.max_iterations and i >= config.max_iterations:
|
| 316 |
+
break
|
| 317 |
+
|
| 318 |
+
key_prefix = config['name'] if 'name' in config else 'phrasecut'
|
| 319 |
+
return {key_prefix: metric.scores()}
|
| 320 |
+
#return {key_prefix: {k: v for k, v in zip(metric.names(), metric.value())}}
|
| 321 |
+
|
| 322 |
+
if config.test_dataset == 'pascal_zs':
|
| 323 |
+
from third_party.JoEm.model.metric import Evaluator
|
| 324 |
+
from third_party.JoEm.data_loader import get_seen_idx, get_unseen_idx, VOC
|
| 325 |
+
from datasets.pascal_zeroshot import PascalZeroShot, PASCAL_VOC_CLASSES_ZS
|
| 326 |
+
|
| 327 |
+
from models.clipseg import CLIPSegMultiLabel
|
| 328 |
+
|
| 329 |
+
n_unseen = train_config.remove_classes[1]
|
| 330 |
+
|
| 331 |
+
pz = PascalZeroShot('val', n_unseen, image_size=352)
|
| 332 |
+
m = CLIPSegMultiLabel(model=train_config.name).cuda()
|
| 333 |
+
m.eval();
|
| 334 |
+
|
| 335 |
+
print(len(pz), n_unseen)
|
| 336 |
+
print('training removed', [c for class_set in PASCAL_VOC_CLASSES_ZS[:n_unseen // 2] for c in class_set])
|
| 337 |
+
|
| 338 |
+
print('unseen', [VOC[i] for i in get_unseen_idx(n_unseen)])
|
| 339 |
+
print('seen', [VOC[i] for i in get_seen_idx(n_unseen)])
|
| 340 |
+
|
| 341 |
+
loader = DataLoader(pz, batch_size=8)
|
| 342 |
+
evaluator = Evaluator(21, get_unseen_idx(n_unseen), get_seen_idx(n_unseen))
|
| 343 |
+
|
| 344 |
+
for i, (data_x, data_y) in enumerate(loader):
|
| 345 |
+
pred = m(data_x[0].cuda())
|
| 346 |
+
evaluator.add_batch(data_y[0].numpy(), pred.argmax(1).cpu().detach().numpy())
|
| 347 |
+
|
| 348 |
+
if config.max_iter is not None and i > config.max_iter:
|
| 349 |
+
break
|
| 350 |
+
|
| 351 |
+
scores = evaluator.Mean_Intersection_over_Union()
|
| 352 |
+
key_prefix = config['name'] if 'name' in config else 'pas_zs'
|
| 353 |
+
|
| 354 |
+
return {key_prefix: {k: scores[k] for k in ['seen', 'unseen', 'harmonic', 'overall']}}
|
| 355 |
+
|
| 356 |
+
elif config.test_dataset in {'same_as_training', 'affordance'}:
|
| 357 |
+
loss_fn = get_attribute(train_config.loss)
|
| 358 |
+
|
| 359 |
+
metric_cls = get_attribute(config.metric)
|
| 360 |
+
metric = metric_cls(**metric_args)
|
| 361 |
+
|
| 362 |
+
if config.test_dataset == 'same_as_training':
|
| 363 |
+
dataset_cls = get_attribute(train_config.dataset)
|
| 364 |
+
elif config.test_dataset == 'affordance':
|
| 365 |
+
dataset_cls = get_attribute('datasets.lvis_oneshot3.LVIS_Affordance')
|
| 366 |
+
dataset_name = 'aff'
|
| 367 |
+
else:
|
| 368 |
+
dataset_cls = get_attribute('datasets.lvis_oneshot3.LVIS_OneShot')
|
| 369 |
+
dataset_name = 'lvis'
|
| 370 |
+
|
| 371 |
+
_, dataset_args, _ = filter_args(config, inspect.signature(dataset_cls).parameters)
|
| 372 |
+
|
| 373 |
+
dataset_args['image_size'] = train_config.image_size # explicitly use training image size for evaluation
|
| 374 |
+
|
| 375 |
+
if model.__class__.__name__ == 'PFENetWrapper':
|
| 376 |
+
dataset_args['image_size'] = config.image_size
|
| 377 |
+
|
| 378 |
+
log.info('init dataset', str(dataset_cls))
|
| 379 |
+
dataset = dataset_cls(**dataset_args)
|
| 380 |
+
|
| 381 |
+
log.info(f'Score on {model.__class__.__name__} on {dataset_cls.__name__}')
|
| 382 |
+
|
| 383 |
+
data_loader = torch.utils.data.DataLoader(dataset, batch_size=config.batch_size, shuffle=config.shuffle)
|
| 384 |
+
|
| 385 |
+
# explicitly set prompts
|
| 386 |
+
if config.prompt == 'plain':
|
| 387 |
+
model.prompt_list = ['{}']
|
| 388 |
+
elif config.prompt == 'fixed':
|
| 389 |
+
model.prompt_list = ['a photo of a {}.']
|
| 390 |
+
elif config.prompt == 'shuffle':
|
| 391 |
+
model.prompt_list = ['a photo of a {}.', 'a photograph of a {}.', 'an image of a {}.', '{}.']
|
| 392 |
+
elif config.prompt == 'shuffle_clip':
|
| 393 |
+
from models.clip_prompts import imagenet_templates
|
| 394 |
+
model.prompt_list = imagenet_templates
|
| 395 |
+
|
| 396 |
+
config.assume_no_unused_keys(exceptions=['max_iterations'])
|
| 397 |
+
|
| 398 |
+
t_start = time.time()
|
| 399 |
+
|
| 400 |
+
with torch.no_grad(): # TODO: switch to inference_mode (torch 1.9)
|
| 401 |
+
i, losses = 0, []
|
| 402 |
+
for data_x, data_y in data_loader:
|
| 403 |
+
|
| 404 |
+
data_x = [x.cuda() if isinstance(x, torch.Tensor) else x for x in data_x]
|
| 405 |
+
data_y = [x.cuda() if isinstance(x, torch.Tensor) else x for x in data_y]
|
| 406 |
+
|
| 407 |
+
if model.__class__.__name__ in {'ConditionBase4', 'PFENetWrapper'}:
|
| 408 |
+
pred, = model(data_x[0], data_x[1], data_x[2])
|
| 409 |
+
visual_q = None
|
| 410 |
+
else:
|
| 411 |
+
pred, visual_q, _, _ = model(data_x[0], data_x[1], return_features=True)
|
| 412 |
+
|
| 413 |
+
loss = loss_fn(pred, data_y[0])
|
| 414 |
+
|
| 415 |
+
metric.add([pred], data_y)
|
| 416 |
+
|
| 417 |
+
losses += [float(loss)]
|
| 418 |
+
|
| 419 |
+
i += 1
|
| 420 |
+
if config.max_iterations and i >= config.max_iterations:
|
| 421 |
+
break
|
| 422 |
+
|
| 423 |
+
# scores = {m: s for m, s in zip(metric.names(), metric.value())}
|
| 424 |
+
scores = metric.scores()
|
| 425 |
+
|
| 426 |
+
keys = set(scores.keys())
|
| 427 |
+
if dataset.negative_prob > 0 and 'mIoU' in keys:
|
| 428 |
+
keys.remove('mIoU')
|
| 429 |
+
|
| 430 |
+
name_mask = dataset.mask.replace('text_label', 'txt')[:3]
|
| 431 |
+
name_neg = '' if dataset.negative_prob == 0 else '_' + str(dataset.negative_prob)
|
| 432 |
+
|
| 433 |
+
score_name = config.name if 'name' in config else f'{dataset_name}_{name_mask}{name_neg}'
|
| 434 |
+
|
| 435 |
+
scores = {score_name: {k: v for k,v in scores.items() if k in keys}}
|
| 436 |
+
scores[score_name].update({'test_loss': np.mean(losses)})
|
| 437 |
+
|
| 438 |
+
log.info(f'Evaluation took {time.time() - t_start:.1f}s')
|
| 439 |
+
|
| 440 |
+
return scores
|
| 441 |
+
else:
|
| 442 |
+
raise ValueError('invalid test dataset')
|
| 443 |
+
|
| 444 |
+
|
| 445 |
+
|
| 446 |
+
|
| 447 |
+
|
| 448 |
+
|
| 449 |
+
|
| 450 |
+
|
| 451 |
+
|
| 452 |
+
if __name__ == '__main__':
|
| 453 |
+
main()
|
clipseg/setup.py
ADDED
|
@@ -0,0 +1,30 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from setuptools import setup
|
| 2 |
+
|
| 3 |
+
with open("README.md", "r", encoding="utf-8") as readme_file:
|
| 4 |
+
readme = readme_file.read()
|
| 5 |
+
|
| 6 |
+
requirements = [
|
| 7 |
+
"numpy",
|
| 8 |
+
"scipy",
|
| 9 |
+
"matplotlib",
|
| 10 |
+
"torch",
|
| 11 |
+
"torchvision",
|
| 12 |
+
"opencv-python",
|
| 13 |
+
"CLIP @ git+https://github.com/openai/CLIP.git"
|
| 14 |
+
]
|
| 15 |
+
|
| 16 |
+
setup(
|
| 17 |
+
name='clipseg',
|
| 18 |
+
packages=['clipseg'],
|
| 19 |
+
package_dir={'clipseg': 'models'},
|
| 20 |
+
package_data={'clipseg': [
|
| 21 |
+
"../weights/*.pth",
|
| 22 |
+
]},
|
| 23 |
+
version='0.0.1',
|
| 24 |
+
url='https://github.com/timojl/clipseg',
|
| 25 |
+
python_requires='>=3.9',
|
| 26 |
+
install_requires=requirements,
|
| 27 |
+
description='This repository contains the code used in the paper "Image Segmentation Using Text and Image Prompts".',
|
| 28 |
+
long_description=readme,
|
| 29 |
+
long_description_content_type="text/markdown",
|
| 30 |
+
)
|
clipseg/training.py
ADDED
|
@@ -0,0 +1,266 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import torch
|
| 2 |
+
import inspect
|
| 3 |
+
import json
|
| 4 |
+
import yaml
|
| 5 |
+
import math
|
| 6 |
+
import os
|
| 7 |
+
import sys
|
| 8 |
+
|
| 9 |
+
from general_utils import log
|
| 10 |
+
|
| 11 |
+
import numpy as np
|
| 12 |
+
from functools import partial
|
| 13 |
+
from os.path import expanduser, join, isfile, basename
|
| 14 |
+
|
| 15 |
+
from torch.cuda.amp import autocast, GradScaler
|
| 16 |
+
from torch.optim.lr_scheduler import LambdaLR
|
| 17 |
+
from contextlib import nullcontext
|
| 18 |
+
from torch.utils.data import DataLoader
|
| 19 |
+
|
| 20 |
+
from general_utils import TrainingLogger, get_attribute, filter_args, log, training_config_from_cli_args
|
| 21 |
+
|
| 22 |
+
|
| 23 |
+
def cosine_warmup_lr(i, warmup=10, max_iter=90):
|
| 24 |
+
""" Cosine LR with Warmup """
|
| 25 |
+
if i < warmup:
|
| 26 |
+
return (i+1)/(warmup+1)
|
| 27 |
+
else:
|
| 28 |
+
return 0.5 + 0.5*math.cos(math.pi*(((i-warmup)/(max_iter- warmup))))
|
| 29 |
+
|
| 30 |
+
|
| 31 |
+
def validate(model, dataset, config):
|
| 32 |
+
data_loader = torch.utils.data.DataLoader(dataset, batch_size=4, shuffle=False)
|
| 33 |
+
|
| 34 |
+
metric_class, use_metric = config.val_metric_class, config.use_val_metric
|
| 35 |
+
loss_fn = get_attribute(config.loss)
|
| 36 |
+
|
| 37 |
+
model.eval()
|
| 38 |
+
model.cuda()
|
| 39 |
+
|
| 40 |
+
if metric_class is not None:
|
| 41 |
+
metric = get_attribute(metric_class)()
|
| 42 |
+
|
| 43 |
+
with torch.no_grad():
|
| 44 |
+
|
| 45 |
+
i, losses = 0, []
|
| 46 |
+
for data_x, data_y in data_loader:
|
| 47 |
+
|
| 48 |
+
data_x = [x.cuda() if isinstance(x, torch.Tensor) else x for x in data_x]
|
| 49 |
+
data_y = [x.cuda() if isinstance(x, torch.Tensor) else x for x in data_y]
|
| 50 |
+
|
| 51 |
+
prompts = model.sample_prompts(data_x[1], prompt_list=('a photo of a {}',))
|
| 52 |
+
pred, visual_q, _, _ = model(data_x[0], prompts, return_features=True)
|
| 53 |
+
|
| 54 |
+
if metric_class is not None:
|
| 55 |
+
metric.add([pred], data_y)
|
| 56 |
+
|
| 57 |
+
# pred = model(data_x[0], prompts)
|
| 58 |
+
# loss = loss_fn(pred[0], data_y[0])
|
| 59 |
+
loss = loss_fn(pred, data_y[0])
|
| 60 |
+
losses += [float(loss)]
|
| 61 |
+
|
| 62 |
+
i += 1
|
| 63 |
+
|
| 64 |
+
if config.val_max_iterations is not None and i > config.val_max_iterations:
|
| 65 |
+
break
|
| 66 |
+
|
| 67 |
+
if use_metric is None:
|
| 68 |
+
return np.mean(losses), {}, False
|
| 69 |
+
else:
|
| 70 |
+
metric_scores = {m: s for m, s in zip(metric.names(), metric.value())} if metric is not None else {}
|
| 71 |
+
return np.mean(losses), metric_scores, True
|
| 72 |
+
|
| 73 |
+
|
| 74 |
+
def main():
|
| 75 |
+
|
| 76 |
+
config = training_config_from_cli_args()
|
| 77 |
+
|
| 78 |
+
val_interval, best_val_loss, best_val_score = config.val_interval, float('inf'), float('-inf')
|
| 79 |
+
|
| 80 |
+
model_cls = get_attribute(config.model)
|
| 81 |
+
_, model_args, _ = filter_args(config, inspect.signature(model_cls).parameters)
|
| 82 |
+
model = model_cls(**model_args).cuda()
|
| 83 |
+
|
| 84 |
+
dataset_cls = get_attribute(config.dataset)
|
| 85 |
+
_, dataset_args, _ = filter_args(config, inspect.signature(dataset_cls).parameters)
|
| 86 |
+
|
| 87 |
+
dataset = dataset_cls(**dataset_args)
|
| 88 |
+
|
| 89 |
+
log.info(f'Train dataset {dataset.__class__.__name__} (length: {len(dataset)})')
|
| 90 |
+
|
| 91 |
+
if val_interval is not None:
|
| 92 |
+
dataset_val_args = {k[4:]: v for k,v in config.items() if k.startswith('val_') and k != 'val_interval'}
|
| 93 |
+
_, dataset_val_args, _ = filter_args(dataset_val_args, inspect.signature(dataset_cls).parameters)
|
| 94 |
+
print('val args', {**dataset_args, **{'split': 'val', 'aug': 0}, **dataset_val_args})
|
| 95 |
+
|
| 96 |
+
dataset_val = dataset_cls(**{**dataset_args, **{'split': 'val', 'aug': 0}, **dataset_val_args})
|
| 97 |
+
|
| 98 |
+
# optimizer
|
| 99 |
+
opt_cls = get_attribute(config.optimizer)
|
| 100 |
+
if config.optimize == 'torch.optim.SGD':
|
| 101 |
+
opt_args = {'momentum': config.momentum if 'momentum' in config else 0}
|
| 102 |
+
else:
|
| 103 |
+
opt_args = {}
|
| 104 |
+
opt = opt_cls(model.parameters(), lr=config.lr, **opt_args)
|
| 105 |
+
|
| 106 |
+
if config.lr_scheduler == 'cosine':
|
| 107 |
+
assert config.T_max is not None and config.eta_min is not None
|
| 108 |
+
lr_scheduler = torch.optim.lr_scheduler.CosineAnnealingLR(opt, config.T_max, config.eta_min)
|
| 109 |
+
elif config.lr_scheduler == 'warmup_cosine':
|
| 110 |
+
lr_scheduler = LambdaLR(opt, partial(cosine_warmup_lr, max_iter=(config.max_iterations), warmup=config.warmup))
|
| 111 |
+
else:
|
| 112 |
+
lr_scheduler = None
|
| 113 |
+
|
| 114 |
+
batch_size, max_iterations = config.batch_size, config.max_iterations
|
| 115 |
+
|
| 116 |
+
loss_fn = get_attribute(config.loss)
|
| 117 |
+
|
| 118 |
+
if config.amp:
|
| 119 |
+
log.info('Using AMP')
|
| 120 |
+
autocast_fn = autocast
|
| 121 |
+
scaler = GradScaler()
|
| 122 |
+
else:
|
| 123 |
+
autocast_fn, scaler = nullcontext, None
|
| 124 |
+
|
| 125 |
+
|
| 126 |
+
save_only_trainable = True
|
| 127 |
+
data_loader = DataLoader(dataset, batch_size=batch_size, num_workers=4)
|
| 128 |
+
|
| 129 |
+
# disable config when hyperparam. opt. to avoid writing logs.
|
| 130 |
+
tracker_config = config if not config.hyperparameter_optimization else None
|
| 131 |
+
|
| 132 |
+
with TrainingLogger(log_dir=config.name, model=model, config=tracker_config) as logger:
|
| 133 |
+
|
| 134 |
+
i = 0
|
| 135 |
+
while True:
|
| 136 |
+
for data_x, data_y in data_loader:
|
| 137 |
+
|
| 138 |
+
# between caption and output feature.
|
| 139 |
+
# 1. Sample random captions
|
| 140 |
+
# 2. Check alignment with CLIP
|
| 141 |
+
|
| 142 |
+
# randomly mix text and visual support conditionals
|
| 143 |
+
if config.mix:
|
| 144 |
+
|
| 145 |
+
assert config.mask.startswith('text_and')
|
| 146 |
+
|
| 147 |
+
with autocast_fn():
|
| 148 |
+
# data_x[1] = text label
|
| 149 |
+
prompts = model.sample_prompts(data_x[1])
|
| 150 |
+
|
| 151 |
+
# model.clip_model()
|
| 152 |
+
|
| 153 |
+
text_cond = model.compute_conditional(prompts)
|
| 154 |
+
if model.__class__.__name__ == 'CLIPDensePredTMasked':
|
| 155 |
+
# when mask=='separate'
|
| 156 |
+
visual_s_cond, _, _ = model.visual_forward_masked(data_x[2].cuda(), data_x[3].cuda())
|
| 157 |
+
else:
|
| 158 |
+
# data_x[2] = visual prompt
|
| 159 |
+
visual_s_cond, _, _ = model.visual_forward(data_x[2].cuda())
|
| 160 |
+
|
| 161 |
+
max_txt = config.mix_text_max if config.mix_text_max is not None else 1
|
| 162 |
+
batch_size = text_cond.shape[0]
|
| 163 |
+
|
| 164 |
+
# sample weights for each element in batch
|
| 165 |
+
text_weights = torch.distributions.Uniform(config.mix_text_min, max_txt).sample((batch_size,))[:, None]
|
| 166 |
+
text_weights = text_weights.cuda()
|
| 167 |
+
|
| 168 |
+
if dataset.__class__.__name__ == 'PhraseCut':
|
| 169 |
+
# give full weight to text where support_image is invalid
|
| 170 |
+
visual_is_valid = data_x[4] if model.__class__.__name__ == 'CLIPDensePredTMasked' else data_x[3]
|
| 171 |
+
text_weights = torch.max(text_weights[:,0], 1 - visual_is_valid.float().cuda()).unsqueeze(1)
|
| 172 |
+
|
| 173 |
+
cond = text_cond * text_weights + visual_s_cond * (1 - text_weights)
|
| 174 |
+
|
| 175 |
+
else:
|
| 176 |
+
# no mix
|
| 177 |
+
|
| 178 |
+
if model.__class__.__name__ == 'CLIPDensePredTMasked':
|
| 179 |
+
# compute conditional vector using CLIP masking
|
| 180 |
+
with autocast_fn():
|
| 181 |
+
assert config.mask == 'separate'
|
| 182 |
+
cond, _, _ = model.visual_forward_masked(data_x[1].cuda(), data_x[2].cuda())
|
| 183 |
+
else:
|
| 184 |
+
cond = data_x[1]
|
| 185 |
+
if isinstance(cond, torch.Tensor):
|
| 186 |
+
cond = cond.cuda()
|
| 187 |
+
|
| 188 |
+
with autocast_fn():
|
| 189 |
+
visual_q = None
|
| 190 |
+
|
| 191 |
+
pred, visual_q, _, _ = model(data_x[0].cuda(), cond, return_features=True)
|
| 192 |
+
|
| 193 |
+
loss = loss_fn(pred, data_y[0].cuda())
|
| 194 |
+
|
| 195 |
+
if torch.isnan(loss) or torch.isinf(loss):
|
| 196 |
+
# skip if loss is nan
|
| 197 |
+
log.warning('Training stopped due to inf/nan loss.')
|
| 198 |
+
sys.exit(-1)
|
| 199 |
+
|
| 200 |
+
extra_loss = 0
|
| 201 |
+
loss += extra_loss
|
| 202 |
+
|
| 203 |
+
opt.zero_grad()
|
| 204 |
+
|
| 205 |
+
if scaler is None:
|
| 206 |
+
loss.backward()
|
| 207 |
+
opt.step()
|
| 208 |
+
else:
|
| 209 |
+
scaler.scale(loss).backward()
|
| 210 |
+
scaler.step(opt)
|
| 211 |
+
scaler.update()
|
| 212 |
+
|
| 213 |
+
if lr_scheduler is not None:
|
| 214 |
+
lr_scheduler.step()
|
| 215 |
+
if i % 2000 == 0:
|
| 216 |
+
current_lr = [g['lr'] for g in opt.param_groups][0]
|
| 217 |
+
log.info(f'current lr: {current_lr:.5f} ({len(opt.param_groups)} parameter groups)')
|
| 218 |
+
|
| 219 |
+
logger.iter(i=i, loss=loss)
|
| 220 |
+
i += 1
|
| 221 |
+
|
| 222 |
+
if i >= max_iterations:
|
| 223 |
+
|
| 224 |
+
if not isfile(join(logger.base_path, 'weights.pth')):
|
| 225 |
+
# only write if no weights were already written
|
| 226 |
+
logger.save_weights(only_trainable=save_only_trainable)
|
| 227 |
+
|
| 228 |
+
sys.exit(0)
|
| 229 |
+
|
| 230 |
+
|
| 231 |
+
if config.checkpoint_iterations is not None and i in config.checkpoint_iterations:
|
| 232 |
+
logger.save_weights(only_trainable=save_only_trainable, weight_file=f'weights_{i}.pth')
|
| 233 |
+
|
| 234 |
+
|
| 235 |
+
if val_interval is not None and i % val_interval == val_interval - 1:
|
| 236 |
+
|
| 237 |
+
val_loss, val_scores, maximize = validate(model, dataset_val, config)
|
| 238 |
+
|
| 239 |
+
if len(val_scores) > 0:
|
| 240 |
+
|
| 241 |
+
score_str = f', scores: ' + ', '.join(f'{k}: {v}' for k, v in val_scores.items())
|
| 242 |
+
|
| 243 |
+
if maximize and val_scores[config.use_val_metric] > best_val_score:
|
| 244 |
+
logger.save_weights(only_trainable=save_only_trainable)
|
| 245 |
+
best_val_score = val_scores[config.use_val_metric]
|
| 246 |
+
|
| 247 |
+
elif not maximize and val_scores[config.use_val_metric] < best_val_score:
|
| 248 |
+
logger.save_weights(only_trainable=save_only_trainable)
|
| 249 |
+
best_val_score = val_scores[config.use_val_metric]
|
| 250 |
+
|
| 251 |
+
else:
|
| 252 |
+
score_str = ''
|
| 253 |
+
# if no score is used, fall back to loss
|
| 254 |
+
if val_loss < best_val_loss:
|
| 255 |
+
logger.save_weights(only_trainable=save_only_trainable)
|
| 256 |
+
best_val_loss = val_loss
|
| 257 |
+
|
| 258 |
+
log.info(f'Validation loss: {val_loss}' + score_str)
|
| 259 |
+
logger.iter(i=i, val_loss=val_loss, extra_loss=float(extra_loss), **val_scores)
|
| 260 |
+
model.train()
|
| 261 |
+
|
| 262 |
+
print('epoch complete')
|
| 263 |
+
|
| 264 |
+
|
| 265 |
+
if __name__ == '__main__':
|
| 266 |
+
main()
|
clipseg/weights/rd64-uni.pth
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:13845f6cee4d54ca46f62ee19dd354822094a26e0efccc64e606be93d6a7e26f
|
| 3 |
+
size 4306645
|
init_image.png
ADDED

|
inpainting.py
ADDED
|
@@ -0,0 +1,194 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import inspect
|
| 2 |
+
from typing import List, Optional, Union
|
| 3 |
+
|
| 4 |
+
import numpy as np
|
| 5 |
+
import torch
|
| 6 |
+
|
| 7 |
+
import PIL
|
| 8 |
+
from diffusers import AutoencoderKL, DDIMScheduler, DiffusionPipeline, PNDMScheduler, UNet2DConditionModel
|
| 9 |
+
from diffusers.pipelines.stable_diffusion import StableDiffusionSafetyChecker
|
| 10 |
+
from tqdm.auto import tqdm
|
| 11 |
+
from transformers import CLIPFeatureExtractor, CLIPTextModel, CLIPTokenizer
|
| 12 |
+
|
| 13 |
+
|
| 14 |
+
def preprocess_image(image):
|
| 15 |
+
w, h = image.size
|
| 16 |
+
w, h = map(lambda x: x - x % 32, (w, h)) # resize to integer multiple of 32
|
| 17 |
+
image = image.resize((w, h), resample=PIL.Image.LANCZOS)
|
| 18 |
+
image = np.array(image).astype(np.float32) / 255.0
|
| 19 |
+
image = image[None].transpose(0, 3, 1, 2)
|
| 20 |
+
image = torch.from_numpy(image)
|
| 21 |
+
return 2.0 * image - 1.0
|
| 22 |
+
|
| 23 |
+
|
| 24 |
+
def preprocess_mask(mask):
|
| 25 |
+
mask = mask.convert("L")
|
| 26 |
+
w, h = mask.size
|
| 27 |
+
w, h = map(lambda x: x - x % 32, (w, h)) # resize to integer multiple of 32
|
| 28 |
+
mask = mask.resize((w // 8, h // 8), resample=PIL.Image.NEAREST)
|
| 29 |
+
mask = np.array(mask).astype(np.float32) / 255.0
|
| 30 |
+
mask = np.tile(mask, (4, 1, 1))
|
| 31 |
+
mask = mask[None].transpose(0, 1, 2, 3) # what does this step do?
|
| 32 |
+
mask = 1 - mask # repaint white, keep black
|
| 33 |
+
mask = torch.from_numpy(mask)
|
| 34 |
+
return mask
|
| 35 |
+
|
| 36 |
+
class StableDiffusionInpaintingPipeline(DiffusionPipeline):
|
| 37 |
+
def __init__(
|
| 38 |
+
self,
|
| 39 |
+
vae: AutoencoderKL,
|
| 40 |
+
text_encoder: CLIPTextModel,
|
| 41 |
+
tokenizer: CLIPTokenizer,
|
| 42 |
+
unet: UNet2DConditionModel,
|
| 43 |
+
scheduler: Union[DDIMScheduler, PNDMScheduler],
|
| 44 |
+
safety_checker: StableDiffusionSafetyChecker,
|
| 45 |
+
feature_extractor: CLIPFeatureExtractor,
|
| 46 |
+
):
|
| 47 |
+
super().__init__()
|
| 48 |
+
scheduler = scheduler.set_format("pt")
|
| 49 |
+
self.register_modules(
|
| 50 |
+
vae=vae,
|
| 51 |
+
text_encoder=text_encoder,
|
| 52 |
+
tokenizer=tokenizer,
|
| 53 |
+
unet=unet,
|
| 54 |
+
scheduler=scheduler,
|
| 55 |
+
safety_checker=safety_checker,
|
| 56 |
+
feature_extractor=feature_extractor,
|
| 57 |
+
)
|
| 58 |
+
|
| 59 |
+
@torch.no_grad()
|
| 60 |
+
def __call__(
|
| 61 |
+
self,
|
| 62 |
+
prompt: Union[str, List[str]],
|
| 63 |
+
init_image: torch.FloatTensor,
|
| 64 |
+
mask_image: torch.FloatTensor,
|
| 65 |
+
strength: float = 0.8,
|
| 66 |
+
num_inference_steps: Optional[int] = 50,
|
| 67 |
+
guidance_scale: Optional[float] = 7.5,
|
| 68 |
+
eta: Optional[float] = 0.0,
|
| 69 |
+
generator: Optional[torch.Generator] = None,
|
| 70 |
+
output_type: Optional[str] = "pil",
|
| 71 |
+
):
|
| 72 |
+
|
| 73 |
+
if isinstance(prompt, str):
|
| 74 |
+
batch_size = 1
|
| 75 |
+
elif isinstance(prompt, list):
|
| 76 |
+
batch_size = len(prompt)
|
| 77 |
+
else:
|
| 78 |
+
raise ValueError(f"`prompt` has to be of type `str` or `list` but is {type(prompt)}")
|
| 79 |
+
|
| 80 |
+
if strength < 0 or strength > 1:
|
| 81 |
+
raise ValueError(f"The value of strength should in [0.0, 1.0] but is {strength}")
|
| 82 |
+
|
| 83 |
+
# set timesteps
|
| 84 |
+
accepts_offset = "offset" in set(inspect.signature(self.scheduler.set_timesteps).parameters.keys())
|
| 85 |
+
extra_set_kwargs = {}
|
| 86 |
+
offset = 0
|
| 87 |
+
if accepts_offset:
|
| 88 |
+
offset = 1
|
| 89 |
+
extra_set_kwargs["offset"] = 1
|
| 90 |
+
|
| 91 |
+
self.scheduler.set_timesteps(num_inference_steps, **extra_set_kwargs)
|
| 92 |
+
|
| 93 |
+
# preprocess image
|
| 94 |
+
init_image = preprocess_image(init_image).to(self.device)
|
| 95 |
+
|
| 96 |
+
# encode the init image into latents and scale the latents
|
| 97 |
+
init_latent_dist = self.vae.encode(init_image).latent_dist
|
| 98 |
+
init_latents = init_latent_dist.sample(generator=generator)
|
| 99 |
+
init_latents = 0.18215 * init_latents
|
| 100 |
+
|
| 101 |
+
# prepare init_latents noise to latents
|
| 102 |
+
init_latents = torch.cat([init_latents] * batch_size)
|
| 103 |
+
init_latents_orig = init_latents
|
| 104 |
+
|
| 105 |
+
# preprocess mask
|
| 106 |
+
mask = preprocess_mask(mask_image).to(self.device)
|
| 107 |
+
mask = torch.cat([mask] * batch_size)
|
| 108 |
+
|
| 109 |
+
# check sizes
|
| 110 |
+
if not mask.shape == init_latents.shape:
|
| 111 |
+
raise ValueError(f"The mask and init_image should be the same size!")
|
| 112 |
+
|
| 113 |
+
# get the original timestep using init_timestep
|
| 114 |
+
init_timestep = int(num_inference_steps * strength) + offset
|
| 115 |
+
init_timestep = min(init_timestep, num_inference_steps)
|
| 116 |
+
timesteps = self.scheduler.timesteps[-init_timestep]
|
| 117 |
+
timesteps = torch.tensor([timesteps] * batch_size, dtype=torch.long, device=self.device)
|
| 118 |
+
|
| 119 |
+
# add noise to latents using the timesteps
|
| 120 |
+
noise = torch.randn(init_latents.shape, generator=generator, device=self.device)
|
| 121 |
+
init_latents = self.scheduler.add_noise(init_latents, noise, timesteps)
|
| 122 |
+
|
| 123 |
+
# get prompt text embeddings
|
| 124 |
+
text_input = self.tokenizer(
|
| 125 |
+
prompt,
|
| 126 |
+
padding="max_length",
|
| 127 |
+
max_length=self.tokenizer.model_max_length,
|
| 128 |
+
truncation=True,
|
| 129 |
+
return_tensors="pt",
|
| 130 |
+
)
|
| 131 |
+
text_embeddings = self.text_encoder(text_input.input_ids.to(self.device))[0]
|
| 132 |
+
|
| 133 |
+
# here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
|
| 134 |
+
# of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
|
| 135 |
+
# corresponds to doing no classifier free guidance.
|
| 136 |
+
do_classifier_free_guidance = guidance_scale > 1.0
|
| 137 |
+
# get unconditional embeddings for classifier free guidance
|
| 138 |
+
if do_classifier_free_guidance:
|
| 139 |
+
max_length = text_input.input_ids.shape[-1]
|
| 140 |
+
uncond_input = self.tokenizer(
|
| 141 |
+
[""] * batch_size, padding="max_length", max_length=max_length, return_tensors="pt"
|
| 142 |
+
)
|
| 143 |
+
uncond_embeddings = self.text_encoder(uncond_input.input_ids.to(self.device))[0]
|
| 144 |
+
|
| 145 |
+
# For classifier free guidance, we need to do two forward passes.
|
| 146 |
+
# Here we concatenate the unconditional and text embeddings into a single batch
|
| 147 |
+
# to avoid doing two forward passes
|
| 148 |
+
text_embeddings = torch.cat([uncond_embeddings, text_embeddings])
|
| 149 |
+
|
| 150 |
+
# prepare extra kwargs for the scheduler step, since not all schedulers have the same signature
|
| 151 |
+
# eta (η) is only used with the DDIMScheduler, it will be ignored for other schedulers.
|
| 152 |
+
# eta corresponds to η in DDIM paper: https://arxiv.org/abs/2010.02502
|
| 153 |
+
# and should be between [0, 1]
|
| 154 |
+
accepts_eta = "eta" in set(inspect.signature(self.scheduler.step).parameters.keys())
|
| 155 |
+
extra_step_kwargs = {}
|
| 156 |
+
if accepts_eta:
|
| 157 |
+
extra_step_kwargs["eta"] = eta
|
| 158 |
+
|
| 159 |
+
latents = init_latents
|
| 160 |
+
t_start = max(num_inference_steps - init_timestep + offset, 0)
|
| 161 |
+
for i, t in tqdm(enumerate(self.scheduler.timesteps[t_start:])):
|
| 162 |
+
# expand the latents if we are doing classifier free guidance
|
| 163 |
+
latent_model_input = torch.cat([latents] * 2) if do_classifier_free_guidance else latents
|
| 164 |
+
|
| 165 |
+
# predict the noise residual
|
| 166 |
+
noise_pred = self.unet(latent_model_input, t, encoder_hidden_states=text_embeddings)["sample"]
|
| 167 |
+
|
| 168 |
+
# perform guidance
|
| 169 |
+
if do_classifier_free_guidance:
|
| 170 |
+
noise_pred_uncond, noise_pred_text = noise_pred.chunk(2)
|
| 171 |
+
noise_pred = noise_pred_uncond + guidance_scale * (noise_pred_text - noise_pred_uncond)
|
| 172 |
+
|
| 173 |
+
# compute the previous noisy sample x_t -> x_t-1
|
| 174 |
+
latents = self.scheduler.step(noise_pred, t, latents, **extra_step_kwargs)["prev_sample"]
|
| 175 |
+
|
| 176 |
+
# masking
|
| 177 |
+
init_latents_proper = self.scheduler.add_noise(init_latents_orig, noise, t)
|
| 178 |
+
latents = (init_latents_proper * mask) + (latents * (1 - mask))
|
| 179 |
+
|
| 180 |
+
# scale and decode the image latents with vae
|
| 181 |
+
latents = 1 / 0.18215 * latents
|
| 182 |
+
image = self.vae.decode(latents).sample
|
| 183 |
+
|
| 184 |
+
image = (image / 2 + 0.5).clamp(0, 1)
|
| 185 |
+
image = image.cpu().permute(0, 2, 3, 1).numpy()
|
| 186 |
+
|
| 187 |
+
# run safety checker
|
| 188 |
+
safety_cheker_input = self.feature_extractor(self.numpy_to_pil(image), return_tensors="pt").to(self.device)
|
| 189 |
+
image, has_nsfw_concept = self.safety_checker(images=image, clip_input=safety_cheker_input.pixel_values)
|
| 190 |
+
|
| 191 |
+
if output_type == "pil":
|
| 192 |
+
image = self.numpy_to_pil(image)
|
| 193 |
+
|
| 194 |
+
return {"sample": image, "nsfw_content_detected": has_nsfw_concept}
|
mask_image.png
ADDED

|