
Upload 5 files
Browse files- LICENSE +21 -0
- README.md +50 -13
- download_model.py +21 -0
- inference.py +79 -0
- requirements.txt +2 -0
LICENSE
ADDED
|
@@ -0,0 +1,21 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
MIT License
|
| 2 |
+
|
| 3 |
+
Copyright (c) 2023 Anton Bacaj
|
| 4 |
+
|
| 5 |
+
Permission is hereby granted, free of charge, to any person obtaining a copy
|
| 6 |
+
of this software and associated documentation files (the "Software"), to deal
|
| 7 |
+
in the Software without restriction, including without limitation the rights
|
| 8 |
+
to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
|
| 9 |
+
copies of the Software, and to permit persons to whom the Software is
|
| 10 |
+
furnished to do so, subject to the following conditions:
|
| 11 |
+
|
| 12 |
+
The above copyright notice and this permission notice shall be included in all
|
| 13 |
+
copies or substantial portions of the Software.
|
| 14 |
+
|
| 15 |
+
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
|
| 16 |
+
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
|
| 17 |
+
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
|
| 18 |
+
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
|
| 19 |
+
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
|
| 20 |
+
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
|
| 21 |
+
SOFTWARE.
|
README.md
CHANGED
|
@@ -1,13 +1,50 @@
|
|
| 1 |
-
|
| 2 |
-
|
| 3 |
-
|
| 4 |
-
|
| 5 |
-
|
| 6 |
-
|
| 7 |
-
|
| 8 |
-
|
| 9 |
-
|
| 10 |
-
|
| 11 |
-
|
| 12 |
-
|
| 13 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# MPT 30B inference code using CPU
|
| 2 |
+
|
| 3 |
+
Run inference on the latest MPT-30B model using your CPU. This inference code uses a [ggml](https://github.com/ggerganov/ggml) quantized model. To run the model we'll use a library called [ctransformers](https://github.com/marella/ctransformers) that has bindings to ggml in python.
|
| 4 |
+
|
| 5 |
+
Turn style with history on latest commit:
|
| 6 |
+
|
| 7 |
+
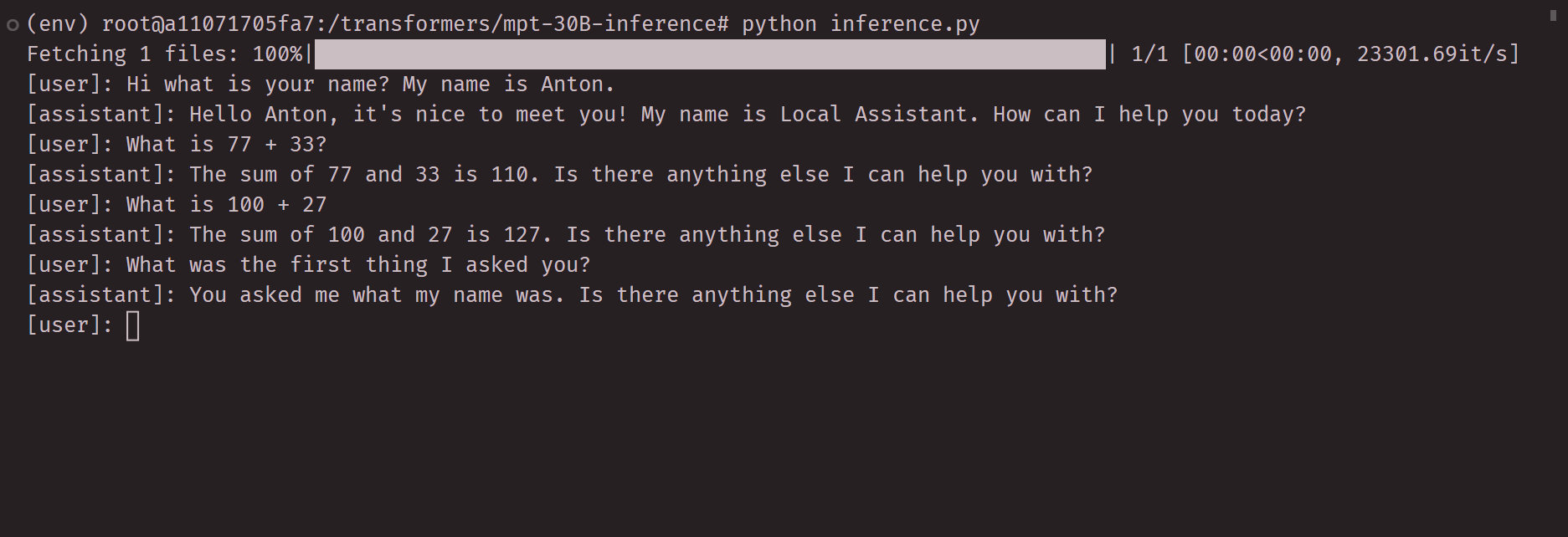
|
| 8 |
+
|
| 9 |
+
Video of initial demo:
|
| 10 |
+
|
| 11 |
+
[Inference Demo](https://github.com/abacaj/mpt-30B-inference/assets/7272343/486fc9b1-8216-43cc-93c3-781677235502)
|
| 12 |
+
|
| 13 |
+
## Requirements
|
| 14 |
+
|
| 15 |
+
I recommend you use docker for this model, it will make everything easier for you. Minimum specs system with 32GB of ram. Recommend to use `python 3.10`.
|
| 16 |
+
|
| 17 |
+
## Tested working on
|
| 18 |
+
|
| 19 |
+
Will post some numbers for these two later.
|
| 20 |
+
|
| 21 |
+
- AMD Epyc 7003 series CPU
|
| 22 |
+
- AMD Ryzen 5950x CPU
|
| 23 |
+
|
| 24 |
+
## Setup
|
| 25 |
+
|
| 26 |
+
First create a venv.
|
| 27 |
+
|
| 28 |
+
```sh
|
| 29 |
+
python -m venv env && source env/bin/activate
|
| 30 |
+
```
|
| 31 |
+
|
| 32 |
+
Next install dependencies.
|
| 33 |
+
|
| 34 |
+
```sh
|
| 35 |
+
pip install -r requirements.txt
|
| 36 |
+
```
|
| 37 |
+
|
| 38 |
+
Next download the quantized model weights (about 19GB).
|
| 39 |
+
|
| 40 |
+
```sh
|
| 41 |
+
python download_model.py
|
| 42 |
+
```
|
| 43 |
+
|
| 44 |
+
Ready to rock, run inference.
|
| 45 |
+
|
| 46 |
+
```sh
|
| 47 |
+
python inference.py
|
| 48 |
+
```
|
| 49 |
+
|
| 50 |
+
Next modify inference script prompt and generation parameters.
|
download_model.py
ADDED
|
@@ -0,0 +1,21 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import os
|
| 2 |
+
from huggingface_hub import hf_hub_download
|
| 3 |
+
|
| 4 |
+
|
| 5 |
+
def download_mpt_quant(destination_folder: str, repo_id: str, model_filename: str):
|
| 6 |
+
local_path = os.path.abspath(destination_folder)
|
| 7 |
+
return hf_hub_download(
|
| 8 |
+
repo_id=repo_id,
|
| 9 |
+
filename=model_filename,
|
| 10 |
+
local_dir=local_path,
|
| 11 |
+
local_dir_use_symlinks=True
|
| 12 |
+
)
|
| 13 |
+
|
| 14 |
+
|
| 15 |
+
if __name__ == "__main__":
|
| 16 |
+
"""full url: https://huggingface.co/TheBloke/mpt-30B-chat-GGML/blob/main/mpt-30b-chat.ggmlv0.q4_1.bin"""
|
| 17 |
+
|
| 18 |
+
repo_id = "TheBloke/mpt-30B-chat-GGML"
|
| 19 |
+
model_filename = "mpt-30b-chat.ggmlv0.q4_1.bin"
|
| 20 |
+
destination_folder = "models"
|
| 21 |
+
download_mpt_quant(destination_folder, repo_id, model_filename)
|
inference.py
ADDED
|
@@ -0,0 +1,79 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import os
|
| 2 |
+
from dataclasses import dataclass, asdict
|
| 3 |
+
from ctransformers import AutoModelForCausalLM, AutoConfig
|
| 4 |
+
|
| 5 |
+
|
| 6 |
+
@dataclass
|
| 7 |
+
class GenerationConfig:
|
| 8 |
+
temperature: float
|
| 9 |
+
top_k: int
|
| 10 |
+
top_p: float
|
| 11 |
+
repetition_penalty: float
|
| 12 |
+
max_new_tokens: int
|
| 13 |
+
seed: int
|
| 14 |
+
reset: bool
|
| 15 |
+
stream: bool
|
| 16 |
+
threads: int
|
| 17 |
+
stop: list[str]
|
| 18 |
+
|
| 19 |
+
|
| 20 |
+
def format_prompt(system_prompt: str, user_prompt: str):
|
| 21 |
+
"""format prompt based on: https://huggingface.co/spaces/mosaicml/mpt-30b-chat/blob/main/app.py"""
|
| 22 |
+
|
| 23 |
+
system_prompt = f"<|im_start|>system\n{system_prompt}<|im_end|>\n"
|
| 24 |
+
user_prompt = f"<|im_start|>user\n{user_prompt}<|im_end|>\n"
|
| 25 |
+
assistant_prompt = f"<|im_start|>assistant\n"
|
| 26 |
+
|
| 27 |
+
return f"{system_prompt}{user_prompt}{assistant_prompt}"
|
| 28 |
+
|
| 29 |
+
|
| 30 |
+
def generate(
|
| 31 |
+
llm: AutoModelForCausalLM,
|
| 32 |
+
generation_config: GenerationConfig,
|
| 33 |
+
system_prompt: str,
|
| 34 |
+
user_prompt: str,
|
| 35 |
+
):
|
| 36 |
+
"""run model inference, will return a Generator if streaming is true"""
|
| 37 |
+
|
| 38 |
+
return llm(
|
| 39 |
+
format_prompt(
|
| 40 |
+
system_prompt,
|
| 41 |
+
user_prompt,
|
| 42 |
+
),
|
| 43 |
+
**asdict(generation_config),
|
| 44 |
+
)
|
| 45 |
+
|
| 46 |
+
|
| 47 |
+
if __name__ == "__main__":
|
| 48 |
+
config = AutoConfig.from_pretrained("mosaicml/mpt-30b-chat", context_length=8192)
|
| 49 |
+
llm = AutoModelForCausalLM.from_pretrained(
|
| 50 |
+
os.path.abspath("models/mpt-30b-chat.ggmlv0.q4_1.bin"),
|
| 51 |
+
model_type="mpt",
|
| 52 |
+
config=config,
|
| 53 |
+
)
|
| 54 |
+
|
| 55 |
+
system_prompt = "A conversation between a user and an LLM-based AI assistant named Local Assistant. Local Assistant gives helpful and honest answers."
|
| 56 |
+
|
| 57 |
+
generation_config = GenerationConfig(
|
| 58 |
+
temperature=0.2,
|
| 59 |
+
top_k=0,
|
| 60 |
+
top_p=0.9,
|
| 61 |
+
repetition_penalty=1.0,
|
| 62 |
+
max_new_tokens=512, # adjust as needed
|
| 63 |
+
seed=42,
|
| 64 |
+
reset=False, # reset history (cache)
|
| 65 |
+
stream=True, # streaming per word/token
|
| 66 |
+
threads=int(os.cpu_count() / 2), # adjust for your CPU
|
| 67 |
+
stop=["<|im_end|>", "|<"],
|
| 68 |
+
)
|
| 69 |
+
|
| 70 |
+
user_prefix = "[user]: "
|
| 71 |
+
assistant_prefix = f"[assistant]:"
|
| 72 |
+
|
| 73 |
+
while True:
|
| 74 |
+
user_prompt = input(user_prefix)
|
| 75 |
+
generator = generate(llm, generation_config, system_prompt, user_prompt.strip())
|
| 76 |
+
print(assistant_prefix, end=" ", flush=True)
|
| 77 |
+
for word in generator:
|
| 78 |
+
print(word, end="", flush=True)
|
| 79 |
+
print("")
|
requirements.txt
ADDED
|
@@ -0,0 +1,2 @@
|
|
|
|
|
|
|
|
|
|
| 1 |
+
ctransformers==0.2.10
|
| 2 |
+
transformers==4.30.2
|