Spaces:
Runtime error

Runtime error
Alexander Seifert
commited on
Commit
·
c8d36ae
1
Parent(s):
7a75a86
add stuff for vis2
Browse files- .gitignore +1 -0
- Makefile +8 -0
- README.md +0 -20
- html/index.md +102 -0
- html/screenshot.jpg +0 -0
- presentation.pdf +0 -0
- requirements.txt +1 -0
- src/app.py +7 -0
- src/data.py +4 -3
- src/subpages/attention.py +4 -1
- src/subpages/find_duplicates.py +1 -0
- src/subpages/hidden_states.py +3 -0
- src/subpages/inspect.py +1 -0
- src/subpages/losses.py +1 -0
- src/subpages/lossy_samples.py +1 -0
- src/subpages/metrics.py +3 -0
- src/subpages/misclassified.py +1 -0
- src/subpages/probing.py +3 -0
- src/subpages/random_samples.py +1 -0
- src/subpages/raw_data.py +1 -0
.gitignore
CHANGED
|
@@ -163,3 +163,4 @@ cache_dir/
|
|
| 163 |
outputs/
|
| 164 |
models/
|
| 165 |
runs/
|
|
|
|
|
|
| 163 |
outputs/
|
| 164 |
models/
|
| 165 |
runs/
|
| 166 |
+
.vscode/
|
Makefile
ADDED
|
@@ -0,0 +1,8 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
doc:
|
| 2 |
+
pdoc --docformat google src -o doc
|
| 3 |
+
|
| 4 |
+
vis2: doc
|
| 5 |
+
pandoc html/index.md -s -o html/index.html
|
| 6 |
+
|
| 7 |
+
run:
|
| 8 |
+
python -m streamlit run src/app.py
|
README.md
CHANGED
|
@@ -14,26 +14,6 @@ pinned: true
|
|
| 14 |
|
| 15 |
Error Analysis is an important but often overlooked part of the data science project lifecycle, for which there is still very little tooling available. Practitioners tend to write throwaway code or, worse, skip this crucial step of understanding their models' errors altogether. This project tries to provide an extensive toolkit to probe any NER model/dataset combination, find labeling errors and understand the models' and datasets' limitations, leading the user on her way to further improvements.
|
| 16 |
|
| 17 |
-
|
| 18 |
-
Some interesting visualization techniques:
|
| 19 |
-
|
| 20 |
-
* customizable visualization of neural network activation, based on the embedding layer and the feed-forward layers of the selected transformer model. (https://aclanthology.org/2021.acl-demo.30/)
|
| 21 |
-
* customizable similarity map of a 2d projection of the model's final layer's hidden states, using various algorithms (a bit like the [Tensorflow Embedding Projector](https://projector.tensorflow.org/))
|
| 22 |
-
* inline HTML representation of samples with token-level prediction + labels (my own; see 'Samples by loss' page for more info)
|
| 23 |
-
* automatic selection of foreground-color (black/white) for a user-selected background-color
|
| 24 |
-
* some fancy pandas styling here and there
|
| 25 |
-
|
| 26 |
-
|
| 27 |
-
Libraries important to this project:
|
| 28 |
-
|
| 29 |
-
* `streamlit` for demoing (custom multi-page feature hacked in, also using session state)
|
| 30 |
-
* `plotly` and `matplotlib` for charting
|
| 31 |
-
* `transformers` for providing the models, and `datasets` for, well, the datasets
|
| 32 |
-
* a forked, slightly modified version of [`ecco`](https://github.com/jalammar/ecco) for visualizing the neural net activations
|
| 33 |
-
* `sentence_transformers` for finding potential duplicates
|
| 34 |
-
* `scikit-learn` for TruncatedSVD & PCA, `umap-learn` for UMAP
|
| 35 |
-
|
| 36 |
-
|
| 37 |
## Sections
|
| 38 |
|
| 39 |
|
|
|
|
| 14 |
|
| 15 |
Error Analysis is an important but often overlooked part of the data science project lifecycle, for which there is still very little tooling available. Practitioners tend to write throwaway code or, worse, skip this crucial step of understanding their models' errors altogether. This project tries to provide an extensive toolkit to probe any NER model/dataset combination, find labeling errors and understand the models' and datasets' limitations, leading the user on her way to further improvements.
|
| 16 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 17 |
## Sections
|
| 18 |
|
| 19 |
|
html/index.md
ADDED
|
@@ -0,0 +1,102 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
title: "🏷️ ExplaiNER"
|
| 3 |
+
subtitle: "Error Analysis for NER models & datasets"
|
| 4 |
+
---
|
| 5 |
+
|
| 6 |
+
Error Analysis is an important but often overlooked part of the data science project lifecycle, for which there is still very little tooling available. Practitioners tend to write throwaway code or, worse, skip this crucial step of understanding their models' errors altogether. This project tries to provide an extensive toolkit to probe any NER model/dataset combination, find labeling errors and understand the models' and datasets' limitations, leading the user on her way to further improvements.
|
| 7 |
+
|
| 8 |
+
[Documentation](../doc/index.html) | [Slides](../presentation.pdf)
|
| 9 |
+
|
| 10 |
+
## Getting started
|
| 11 |
+
|
| 12 |
+
```bash
|
| 13 |
+
# Install requirements
|
| 14 |
+
pip install -r requirements.txt # you'll need Python 3.9+
|
| 15 |
+
|
| 16 |
+
# Run
|
| 17 |
+
make run
|
| 18 |
+
```
|
| 19 |
+
|
| 20 |
+
## ExplaiNER's features
|
| 21 |
+
|
| 22 |
+

|
| 23 |
+
|
| 24 |
+
|
| 25 |
+
Some interesting visualization techniques contained in this project:
|
| 26 |
+
|
| 27 |
+
* customizable visualization of neural network activation, based on the embedding layer and the feed-forward layers of the selected transformer model. (https://aclanthology.org/2021.acl-demo.30/)
|
| 28 |
+
* customizable similarity map of a 2d projection of the model's final layer's hidden states, using various algorithms (a bit like the [Tensorflow Embedding Projector](https://projector.tensorflow.org/))
|
| 29 |
+
* inline HTML representation of samples with token-level prediction + labels (my own; see 'Samples by loss' page for more info)
|
| 30 |
+
|
| 31 |
+
|
| 32 |
+
Libraries important to this project:
|
| 33 |
+
|
| 34 |
+
* `streamlit` for demoing (custom multi-page feature hacked in, also using session state)
|
| 35 |
+
* `plotly` and `matplotlib` for charting
|
| 36 |
+
* `transformers` for providing the models, and `datasets` for, well, the datasets
|
| 37 |
+
* a forked, slightly modified version of [`ecco`](https://github.com/jalammar/ecco) for visualizing the neural net activations
|
| 38 |
+
* `sentence_transformers` for finding potential duplicates
|
| 39 |
+
* `scikit-learn` for TruncatedSVD & PCA, `umap-learn` for UMAP
|
| 40 |
+
|
| 41 |
+
|
| 42 |
+
## Application Sections
|
| 43 |
+
|
| 44 |
+
|
| 45 |
+
### Activations
|
| 46 |
+
|
| 47 |
+
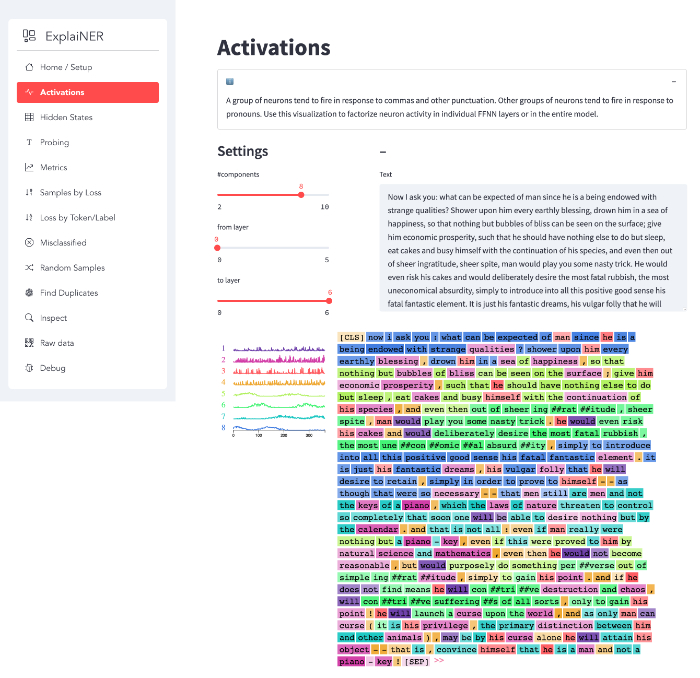
A group of neurons tend to fire in response to commas and other punctuation. Other groups of neurons tend to fire in response to pronouns. Use this visualization to factorize neuron activity in individual FFNN layers or in the entire model.
|
| 48 |
+
|
| 49 |
+
|
| 50 |
+
### Hidden States
|
| 51 |
+
|
| 52 |
+
For every token in the dataset, we take its hidden state and project it onto a two-dimensional plane. Data points are colored by label/prediction, with mislabeled examples marked by a small black border.
|
| 53 |
+
|
| 54 |
+
|
| 55 |
+
### Probing
|
| 56 |
+
|
| 57 |
+
A very direct and interactive way to test your model is by providing it with a list of text inputs and then inspecting the model outputs. The application features a multiline text field so the user can input multiple texts separated by newlines. For each text, the app will show a data frame containing the tokenized string, token predictions, probabilities and a visual indicator for low probability predictions -- these are the ones you should inspect first for prediction errors.
|
| 58 |
+
|
| 59 |
+
|
| 60 |
+
### Metrics
|
| 61 |
+
|
| 62 |
+
The metrics page contains precision, recall and f-score metrics as well as a confusion matrix over all the classes. By default, the confusion matrix is normalized. There's an option to zero out the diagonal, leaving only prediction errors (here it makes sense to turn off normalization, so you get raw error counts).
|
| 63 |
+
|
| 64 |
+
|
| 65 |
+
### Misclassified
|
| 66 |
+
|
| 67 |
+
This page contains all misclassified examples and allows filtering by specific error types.
|
| 68 |
+
|
| 69 |
+
|
| 70 |
+
### Loss by Token/Label
|
| 71 |
+
|
| 72 |
+
Show count, mean and median loss per token and label.
|
| 73 |
+
|
| 74 |
+
|
| 75 |
+
### Samples by Loss
|
| 76 |
+
|
| 77 |
+
Show every example sorted by loss (descending) for close inspection.
|
| 78 |
+
|
| 79 |
+
|
| 80 |
+
### Random Samples
|
| 81 |
+
|
| 82 |
+
Show random samples. Simple method, but it often turns up interesting things.
|
| 83 |
+
|
| 84 |
+
|
| 85 |
+
### Find Duplicates
|
| 86 |
+
|
| 87 |
+
Find potential duplicates in the data using cosine similarity.
|
| 88 |
+
|
| 89 |
+
|
| 90 |
+
### Inspect
|
| 91 |
+
|
| 92 |
+
Inspect your whole dataset, either unfiltered or by id.
|
| 93 |
+
|
| 94 |
+
|
| 95 |
+
### Raw data
|
| 96 |
+
|
| 97 |
+
See the data as seen by your model.
|
| 98 |
+
|
| 99 |
+
|
| 100 |
+
### Debug
|
| 101 |
+
|
| 102 |
+
Debug info.
|
html/screenshot.jpg
ADDED
|
presentation.pdf
ADDED
|
Binary file (693 kB). View file
|
|
|
requirements.txt
CHANGED
|
@@ -12,4 +12,5 @@ matplotlib
|
|
| 12 |
seqeval
|
| 13 |
streamlit-aggrid
|
| 14 |
streamlit_option_menu
|
|
|
|
| 15 |
git+https://github.com/aseifert/ecco.git@streamlit
|
|
|
|
| 12 |
seqeval
|
| 13 |
streamlit-aggrid
|
| 14 |
streamlit_option_menu
|
| 15 |
+
pdoc
|
| 16 |
git+https://github.com/aseifert/ecco.git@streamlit
|
src/app.py
CHANGED
|
@@ -1,3 +1,9 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
import pandas as pd
|
| 2 |
import streamlit as st
|
| 3 |
from streamlit_option_menu import option_menu
|
|
@@ -69,6 +75,7 @@ def _write_color_legend(context):
|
|
| 69 |
|
| 70 |
|
| 71 |
def main():
|
|
|
|
| 72 |
pages: list[Page] = [
|
| 73 |
HomePage(),
|
| 74 |
AttentionPage(),
|
|
|
|
| 1 |
+
"""The App module is the main entry point for the application.
|
| 2 |
+
|
| 3 |
+
Run `streamlit run app.py` to start the app.
|
| 4 |
+
|
| 5 |
+
"""
|
| 6 |
+
|
| 7 |
import pandas as pd
|
| 8 |
import streamlit as st
|
| 9 |
from streamlit_option_menu import option_menu
|
|
|
|
| 75 |
|
| 76 |
|
| 77 |
def main():
|
| 78 |
+
"""The main entry point for the application."""
|
| 79 |
pages: list[Page] = [
|
| 80 |
HomePage(),
|
| 81 |
AttentionPage(),
|
src/data.py
CHANGED
|
@@ -12,8 +12,9 @@ from src.utils import device, tokenizer_hash_funcs
|
|
| 12 |
|
| 13 |
@st.cache(allow_output_mutation=True)
|
| 14 |
def get_data(ds_name: str, config_name: str, split_name: str, split_sample_size: int) -> Dataset:
|
| 15 |
-
"""Loads
|
| 16 |
-
|
|
|
|
| 17 |
|
| 18 |
Args:
|
| 19 |
ds_name (str): Path or name of the dataset.
|
|
@@ -34,7 +35,7 @@ def get_data(ds_name: str, config_name: str, split_name: str, split_sample_size:
|
|
| 34 |
hash_funcs=tokenizer_hash_funcs,
|
| 35 |
)
|
| 36 |
def get_collator(tokenizer) -> DataCollatorForTokenClassification:
|
| 37 |
-
"""
|
| 38 |
|
| 39 |
Args:
|
| 40 |
tokenizer ([PreTrainedTokenizer] or [PreTrainedTokenizerFast]): The tokenizer used for encoding the data.
|
|
|
|
| 12 |
|
| 13 |
@st.cache(allow_output_mutation=True)
|
| 14 |
def get_data(ds_name: str, config_name: str, split_name: str, split_sample_size: int) -> Dataset:
|
| 15 |
+
"""Loads a Dataset from the HuggingFace hub (if not already loaded).
|
| 16 |
+
|
| 17 |
+
Uses `datasets.load_dataset` to load the dataset (see its documentation for additional details).
|
| 18 |
|
| 19 |
Args:
|
| 20 |
ds_name (str): Path or name of the dataset.
|
|
|
|
| 35 |
hash_funcs=tokenizer_hash_funcs,
|
| 36 |
)
|
| 37 |
def get_collator(tokenizer) -> DataCollatorForTokenClassification:
|
| 38 |
+
"""Returns a DataCollator that will dynamically pad the inputs received, as well as the labels.
|
| 39 |
|
| 40 |
Args:
|
| 41 |
tokenizer ([PreTrainedTokenizer] or [PreTrainedTokenizerFast]): The tokenizer used for encoding the data.
|
src/subpages/attention.py
CHANGED
|
@@ -1,3 +1,6 @@
|
|
|
|
|
|
|
|
|
|
|
| 1 |
import ecco
|
| 2 |
import streamlit as st
|
| 3 |
from streamlit.components.v1 import html
|
|
@@ -151,7 +154,7 @@ class AttentionPage(Page):
|
|
| 151 |
)
|
| 152 |
with col2:
|
| 153 |
st.subheader("–")
|
| 154 |
-
text = st.text_area("Text", key="act_default_text")
|
| 155 |
|
| 156 |
inputs = lm.tokenizer([text], return_tensors="pt")
|
| 157 |
output = lm(inputs)
|
|
|
|
| 1 |
+
"""
|
| 2 |
+
A group of neurons tend to fire in response to commas and other punctuation. Other groups of neurons tend to fire in response to pronouns. Use this visualization to factorize neuron activity in individual FFNN layers or in the entire model.
|
| 3 |
+
"""
|
| 4 |
import ecco
|
| 5 |
import streamlit as st
|
| 6 |
from streamlit.components.v1 import html
|
|
|
|
| 154 |
)
|
| 155 |
with col2:
|
| 156 |
st.subheader("–")
|
| 157 |
+
text = st.text_area("Text", key="act_default_text", height=240)
|
| 158 |
|
| 159 |
inputs = lm.tokenizer([text], return_tensors="pt")
|
| 160 |
output = lm(inputs)
|
src/subpages/find_duplicates.py
CHANGED
|
@@ -1,3 +1,4 @@
|
|
|
|
|
| 1 |
import streamlit as st
|
| 2 |
from sentence_transformers.util import cos_sim
|
| 3 |
|
|
|
|
| 1 |
+
"""Find potential duplicates in the data using cosine similarity."""
|
| 2 |
import streamlit as st
|
| 3 |
from sentence_transformers.util import cos_sim
|
| 4 |
|
src/subpages/hidden_states.py
CHANGED
|
@@ -1,3 +1,6 @@
|
|
|
|
|
|
|
|
|
|
|
| 1 |
import numpy as np
|
| 2 |
import plotly.express as px
|
| 3 |
import plotly.graph_objects as go
|
|
|
|
| 1 |
+
"""
|
| 2 |
+
For every token in the dataset, we take its hidden state and project it onto a two-dimensional plane. Data points are colored by label/prediction, with mislabeled examples marked by a small black border.
|
| 3 |
+
"""
|
| 4 |
import numpy as np
|
| 5 |
import plotly.express as px
|
| 6 |
import plotly.graph_objects as go
|
src/subpages/inspect.py
CHANGED
|
@@ -1,3 +1,4 @@
|
|
|
|
|
| 1 |
import streamlit as st
|
| 2 |
|
| 3 |
from src.subpages.page import Context, Page
|
|
|
|
| 1 |
+
"""Inspect your whole dataset, either unfiltered or by id."""
|
| 2 |
import streamlit as st
|
| 3 |
|
| 4 |
from src.subpages.page import Context, Page
|
src/subpages/losses.py
CHANGED
|
@@ -1,3 +1,4 @@
|
|
|
|
|
| 1 |
import streamlit as st
|
| 2 |
|
| 3 |
from src.subpages.page import Context, Page
|
|
|
|
| 1 |
+
"""Show count, mean and median loss per token and label."""
|
| 2 |
import streamlit as st
|
| 3 |
|
| 4 |
from src.subpages.page import Context, Page
|
src/subpages/lossy_samples.py
CHANGED
|
@@ -1,3 +1,4 @@
|
|
|
|
|
| 1 |
import pandas as pd
|
| 2 |
import streamlit as st
|
| 3 |
|
|
|
|
| 1 |
+
"""Show every example sorted by loss (descending) for close inspection."""
|
| 2 |
import pandas as pd
|
| 3 |
import streamlit as st
|
| 4 |
|
src/subpages/metrics.py
CHANGED
|
@@ -1,3 +1,6 @@
|
|
|
|
|
|
|
|
|
|
|
| 1 |
import re
|
| 2 |
|
| 3 |
import matplotlib.pyplot as plt
|
|
|
|
| 1 |
+
"""
|
| 2 |
+
The metrics page contains precision, recall and f-score metrics as well as a confusion matrix over all the classes. By default, the confusion matrix is normalized. There's an option to zero out the diagonal, leaving only prediction errors (here it makes sense to turn off normalization, so you get raw error counts).
|
| 3 |
+
"""
|
| 4 |
import re
|
| 5 |
|
| 6 |
import matplotlib.pyplot as plt
|
src/subpages/misclassified.py
CHANGED
|
@@ -1,3 +1,4 @@
|
|
|
|
|
| 1 |
from collections import defaultdict
|
| 2 |
|
| 3 |
import pandas as pd
|
|
|
|
| 1 |
+
"""This page contains all misclassified examples and allows filtering by specific error types."""
|
| 2 |
from collections import defaultdict
|
| 3 |
|
| 4 |
import pandas as pd
|
src/subpages/probing.py
CHANGED
|
@@ -1,3 +1,6 @@
|
|
|
|
|
|
|
|
|
|
|
| 1 |
import streamlit as st
|
| 2 |
|
| 3 |
from src.subpages.page import Context, Page
|
|
|
|
| 1 |
+
"""
|
| 2 |
+
A very direct and interactive way to test your model is by providing it with a list of text inputs and then inspecting the model outputs. The application features a multiline text field so the user can input multiple texts separated by newlines. For each text, the app will show a data frame containing the tokenized string, token predictions, probabilities and a visual indicator for low probability predictions -- these are the ones you should inspect first for prediction errors.
|
| 3 |
+
"""
|
| 4 |
import streamlit as st
|
| 5 |
|
| 6 |
from src.subpages.page import Context, Page
|
src/subpages/random_samples.py
CHANGED
|
@@ -1,3 +1,4 @@
|
|
|
|
|
| 1 |
import pandas as pd
|
| 2 |
import streamlit as st
|
| 3 |
|
|
|
|
| 1 |
+
"""Show random samples. Simple method, but it often turns up interesting things."""
|
| 2 |
import pandas as pd
|
| 3 |
import streamlit as st
|
| 4 |
|
src/subpages/raw_data.py
CHANGED
|
@@ -1,3 +1,4 @@
|
|
|
|
|
| 1 |
import pandas as pd
|
| 2 |
import streamlit as st
|
| 3 |
|
|
|
|
| 1 |
+
"""See the data as seen by your model."""
|
| 2 |
import pandas as pd
|
| 3 |
import streamlit as st
|
| 4 |
|