Spaces:
Runtime error

Runtime error

Commit
·
701f8ff
1
Parent(s):
cad936e
Upload 5 files
Browse files- images/Browse.png +0 -0
- images/Search.png +0 -0
- pages/0_📙_Dictionary_(Search).py +220 -0
- pages/1_📙_Dictionary_(Browse).py +79 -0
- style.css +4 -0
images/Browse.png
ADDED
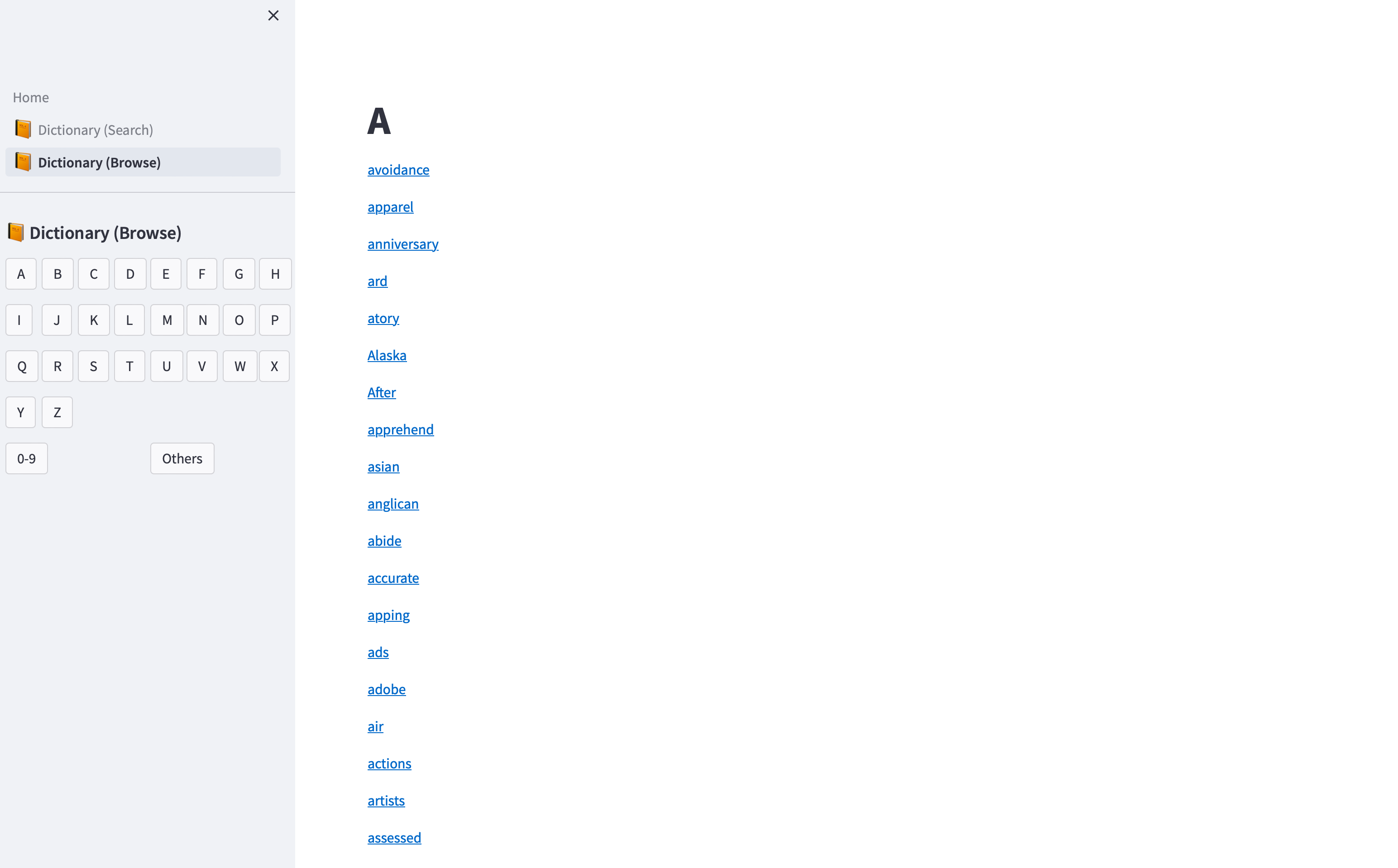
|
images/Search.png
ADDED
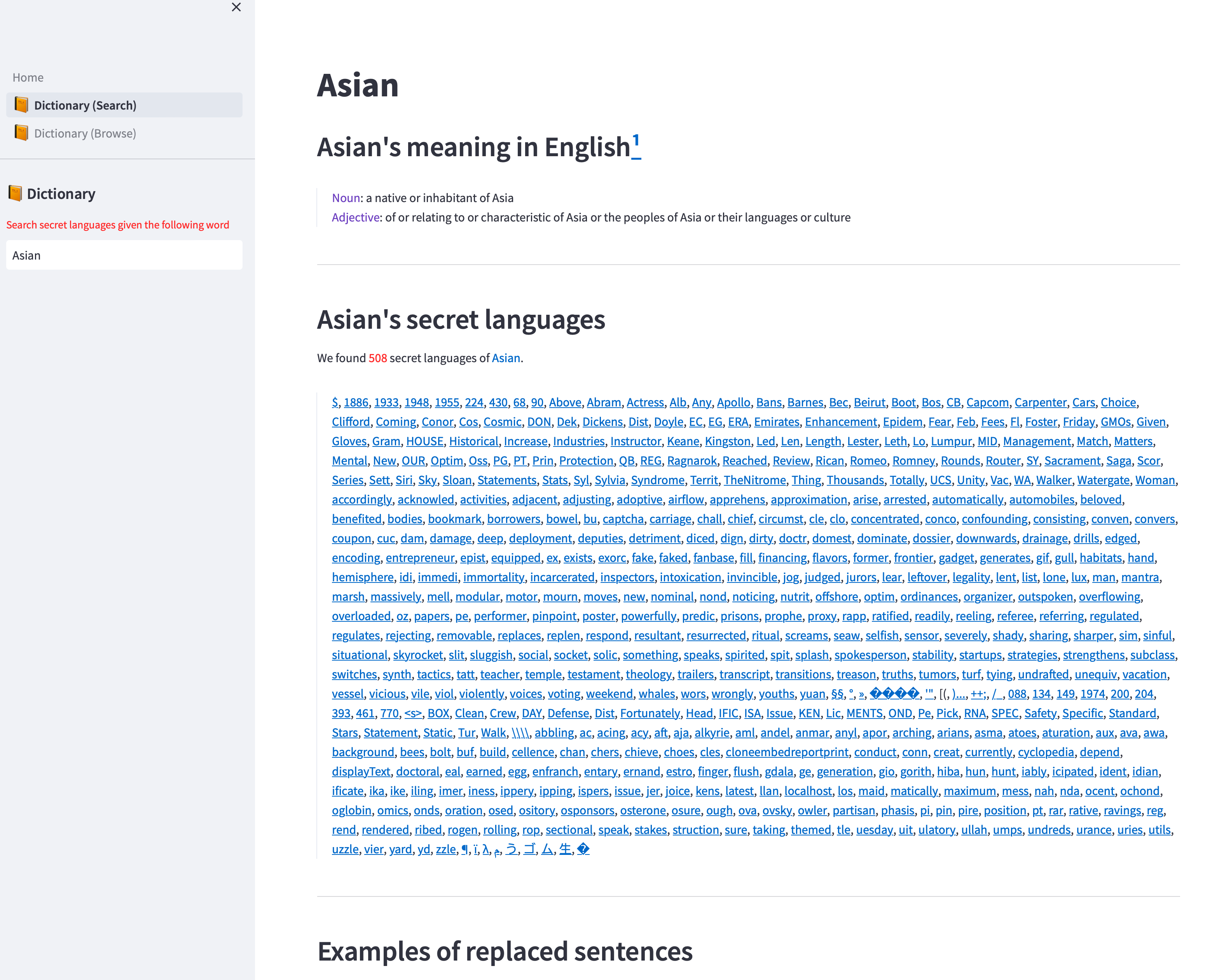
|
pages/0_📙_Dictionary_(Search).py
ADDED
|
@@ -0,0 +1,220 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import streamlit as st
|
| 2 |
+
import pandas as pd
|
| 3 |
+
import gdown
|
| 4 |
+
import os
|
| 5 |
+
import pickle
|
| 6 |
+
from collections import defaultdict, Counter
|
| 7 |
+
|
| 8 |
+
from PyDictionary import PyDictionary
|
| 9 |
+
|
| 10 |
+
dictionary = PyDictionary()
|
| 11 |
+
|
| 12 |
+
st.set_page_config(layout="wide", page_title="ACl23 Secret Language")
|
| 13 |
+
|
| 14 |
+
hide_expander_border = """
|
| 15 |
+
<style>
|
| 16 |
+
.st-bd {border-style: none;}
|
| 17 |
+
</style>
|
| 18 |
+
"""
|
| 19 |
+
|
| 20 |
+
# st.title("ACl23 Secret Language")
|
| 21 |
+
|
| 22 |
+
# sidebar
|
| 23 |
+
st.sidebar.header("📙 Dictionary")
|
| 24 |
+
_data = st.experimental_get_query_params()
|
| 25 |
+
default_title = 'Asian'
|
| 26 |
+
if _data:
|
| 27 |
+
default_title = _data['word'][0]
|
| 28 |
+
|
| 29 |
+
title = st.sidebar.text_input(":red[Search secret languages given the following word (case-sensitive)]", default_title)
|
| 30 |
+
|
| 31 |
+
if ord(title[0]) in list(range(48, 57)):
|
| 32 |
+
file_name = 'num_dict.pkl'
|
| 33 |
+
elif ord(title[0]) in list(range(97, 122)) + list(range(65, 90)):
|
| 34 |
+
file_name = f'{ord(title[0])}_dict.pkl'
|
| 35 |
+
else:
|
| 36 |
+
file_name = 'other_dict.pkl'
|
| 37 |
+
|
| 38 |
+
datas = pickle.load(open(f'all_secret_langauge_by_fist/{file_name}', 'rb'))
|
| 39 |
+
if title in datas:
|
| 40 |
+
st.title(title)
|
| 41 |
+
st.markdown(f"## {title}'s meaning in English[¹](#jump)")
|
| 42 |
+
|
| 43 |
+
# write the meaning of input word
|
| 44 |
+
try:
|
| 45 |
+
title_mean = dictionary.meaning(title)
|
| 46 |
+
_string = '>'
|
| 47 |
+
for key in title_mean:
|
| 48 |
+
_string += f':violet[{key}]: {";".join(title_mean[key])}<br>'
|
| 49 |
+
st.markdown(_string, unsafe_allow_html=True)
|
| 50 |
+
except:
|
| 51 |
+
st.error(f'We cannot find the meaning of {title} in English (PyDictionary), which might be due to the bug.', icon="🚨")
|
| 52 |
+
|
| 53 |
+
st.markdown(f"---")
|
| 54 |
+
st.markdown(f"## {title}'s secret languages")
|
| 55 |
+
data_title = datas[title]
|
| 56 |
+
title_secret_languages = list(sorted(list(set(data_title["secret languages"]))))
|
| 57 |
+
# dataframe = pd.DataFrame(datas[title])
|
| 58 |
+
# st.markdown(f'### We found {len(set(dataframe.loc[:, "secret languages"]))} secret languages of {title}.', unsafe_allow_html=True)
|
| 59 |
+
st.markdown(f'Overall, we found :red[{len(title_secret_languages)}] secret languages of :blue[{title}].', unsafe_allow_html=True)
|
| 60 |
+
special = '"'
|
| 61 |
+
# _title_secret_languages = [f'[{i}](#{i.strip().replace("(", ",,").replace(")", "..").replace("[", ",,,").replace("]", "...").replace(special, "././")})'
|
| 62 |
+
# for i in title_secret_languages]
|
| 63 |
+
# st.markdown('>' + ', '.join(_title_secret_languages).replace('<s>', '\<s\>').replace('$', '\$').replace('~', '\~'),
|
| 64 |
+
# unsafe_allow_html=True)
|
| 65 |
+
|
| 66 |
+
secret_language_by_task = {
|
| 67 |
+
'QA':[],
|
| 68 |
+
'NLI':[],
|
| 69 |
+
'paraphrase':[],
|
| 70 |
+
}
|
| 71 |
+
for i in range(len(data_title['secret languages'])):
|
| 72 |
+
secret_language_by_task[data_title['tasks'][i]].append(data_title['secret languages'][i])
|
| 73 |
+
for k in secret_language_by_task:
|
| 74 |
+
secret_language_by_task[k] = list(set(secret_language_by_task[k]))
|
| 75 |
+
|
| 76 |
+
def present_sl_task(secret_language_by_task, task):
|
| 77 |
+
all_sl = sorted(secret_language_by_task[task])
|
| 78 |
+
st.markdown(f':red[{len(all_sl)}] secret languages of :blue[{title}] on {task.replace("paraphrase", "Paraphrase")}', unsafe_allow_html=True)
|
| 79 |
+
special = '"'
|
| 80 |
+
_title_secret_languages = [f'[{i}](#{i.strip().replace("(", ",,").replace(")", "..").replace("[", ",,,").replace("]", "...").replace(special, "././")}_{task})'
|
| 81 |
+
for i in all_sl]
|
| 82 |
+
st.markdown('>' + ', '.join(_title_secret_languages).replace('<s>', '\<s\>').replace('$', '\$').replace('~', '\~'),
|
| 83 |
+
unsafe_allow_html=True)
|
| 84 |
+
present_sl_task(secret_language_by_task, 'NLI')
|
| 85 |
+
present_sl_task(secret_language_by_task, 'QA')
|
| 86 |
+
present_sl_task(secret_language_by_task, 'paraphrase')
|
| 87 |
+
|
| 88 |
+
st.markdown(f"*Hyperlinks only function when the corresponding tab is open. "
|
| 89 |
+
f"For example, the hyperlinks in the paraphrase section will only work when the paraphrase tab is open.*")
|
| 90 |
+
st.markdown(f"---")
|
| 91 |
+
st.markdown(f"## Examples of replaced sentences")
|
| 92 |
+
|
| 93 |
+
# st.text(','.join(title_secret_languages).replace('<s>', '\<s\>'))
|
| 94 |
+
# st.dataframe(dataframe)
|
| 95 |
+
_num = Counter(data_title['tasks'])
|
| 96 |
+
tab1, tab2, tab3 = st.tabs([f'NLI ({_num["NLI"]})', f'QA ({_num["QA"]})', f'Paraphrase ({_num["paraphrase"]})'])
|
| 97 |
+
|
| 98 |
+
|
| 99 |
+
def present_dataframe(dataframe, key, title):
|
| 100 |
+
new_dataframe = dataframe.loc[dataframe['tasks'] == key].reset_index()
|
| 101 |
+
new_dataframe['replaced sentences'] = new_dataframe['replaced sentences'].str.replace('<s>', '[POS]')
|
| 102 |
+
if len(new_dataframe):
|
| 103 |
+
new_dataframe = new_dataframe.drop(columns=['tasks', 'index'])
|
| 104 |
+
# st.markdown(new_dataframe.columns)
|
| 105 |
+
for i in range(len(new_dataframe)):
|
| 106 |
+
_title = f'{i + 1}\. **[{new_dataframe.loc[i, "secret languages"]}]**'
|
| 107 |
+
with st.expander(_title):
|
| 108 |
+
# _string = f'{i + 1}. :red[{new_dataframe.loc[i, "secret languages"]}]'
|
| 109 |
+
_string = 'Original '
|
| 110 |
+
if key == 'NLI':
|
| 111 |
+
_string += 'hypothesis: :'
|
| 112 |
+
elif key == 'QA':
|
| 113 |
+
_string += 'question: :'
|
| 114 |
+
elif key == 'Paraphrase':
|
| 115 |
+
_string += 'sentence 1: :'
|
| 116 |
+
_string += f'blue[{new_dataframe.loc[i, "original sentences"]}]'.replace(":", "[colon]")
|
| 117 |
+
_string += '<br>Replaced '
|
| 118 |
+
if key == 'NLI':
|
| 119 |
+
_string += 'hypothesis: :'
|
| 120 |
+
elif key == 'QA':
|
| 121 |
+
_string += 'question: :'
|
| 122 |
+
elif key == 'Paraphrase':
|
| 123 |
+
_string += 'sentence 1: :'
|
| 124 |
+
_string += f'red[{new_dataframe.loc[i, "replaced sentences"]}]'.replace(":", "[colon]")
|
| 125 |
+
if key == 'NLI':
|
| 126 |
+
_string += '<br>premise: :'
|
| 127 |
+
elif key == 'QA':
|
| 128 |
+
_string += '<br>text: :'
|
| 129 |
+
elif key == 'Paraphrase':
|
| 130 |
+
_string += '<br>sentence 2: :'
|
| 131 |
+
_string += f'blue[{new_dataframe.loc[i, "premise / sentence 2 / text"]}]'.replace(":", "[colon]")
|
| 132 |
+
st.markdown(_string, unsafe_allow_html=True)
|
| 133 |
+
# st.text(f'Examples: :blue[{new_dataframe.loc[i, "replaced sentences".replace(":", "[colon]")]}]')
|
| 134 |
+
# st.dataframe(new_dataframe)
|
| 135 |
+
st.markdown(hide_expander_border, unsafe_allow_html=True)
|
| 136 |
+
else:
|
| 137 |
+
st.error(f'We did not find any Secret Language of {title} on {key}.')
|
| 138 |
+
|
| 139 |
+
|
| 140 |
+
def present_dict(_dict, task):
|
| 141 |
+
# st.text(set(_dict['tasks']))
|
| 142 |
+
_all = defaultdict(int)
|
| 143 |
+
for i in range(len(_dict['secret languages'])):
|
| 144 |
+
if _dict['tasks'][i] == task:
|
| 145 |
+
_sl = _dict['secret languages'][i]
|
| 146 |
+
if type(_all[_sl]) == int:
|
| 147 |
+
_all[_sl] = {
|
| 148 |
+
'Original hypothesis': [],
|
| 149 |
+
'Replaced hypothesis': [],
|
| 150 |
+
'Premise': []
|
| 151 |
+
}
|
| 152 |
+
_all[_sl]['Original hypothesis'].append(_dict['original sentences'][i])
|
| 153 |
+
if task == 'QA':
|
| 154 |
+
_all[_sl]['Replaced hypothesis'].append(_dict['replaced sentences'][i].replace('<s>', ''))
|
| 155 |
+
else:
|
| 156 |
+
_all[_sl]['Replaced hypothesis'].append(_dict['replaced sentences'][i])
|
| 157 |
+
_all[_sl]['Premise'].append(_dict['premise / sentence 2 / text'][i])
|
| 158 |
+
if len(_all.keys()):
|
| 159 |
+
all_keys = sorted(list(_all.keys()))
|
| 160 |
+
for i in range(len(all_keys)):
|
| 161 |
+
_sl = all_keys[i]
|
| 162 |
+
_sl_in_span = _sl.strip().replace("(", ",,").replace(")", "..").replace("[", ",,,").replace("]", "...").replace(special, "././")
|
| 163 |
+
_title = f'{i + 1}. <span id="{_sl_in_span}_{task}"> **:red[{_sl}]**</span>'
|
| 164 |
+
# with st.expander(_title, expanded=True):
|
| 165 |
+
_string = _title + '<br>Examples:<br>'
|
| 166 |
+
# st.markdown(_title, unsafe_allow_html=True)
|
| 167 |
+
# st.markdown(f'Examples:', unsafe_allow_html=True)
|
| 168 |
+
_string += '<blockquote><ol>'
|
| 169 |
+
for j in range(len(_all[_sl]['Original hypothesis'])):
|
| 170 |
+
# _string += f'{j+1}. Original '
|
| 171 |
+
_string += f'<li> **Original '
|
| 172 |
+
if task == 'NLI':
|
| 173 |
+
_string += 'hypothesis**: :'
|
| 174 |
+
elif task == 'QA':
|
| 175 |
+
_string += 'question**: :'
|
| 176 |
+
elif task == 'paraphrase':
|
| 177 |
+
_string += 'sentence 1**: :'
|
| 178 |
+
_string += f'blue[{_all[_sl]["Original hypothesis"][j]}]'.replace(":", "[colon]")
|
| 179 |
+
_string += '<br> **Replaced '
|
| 180 |
+
if task == 'NLI':
|
| 181 |
+
_string += 'hypothesis**: :'
|
| 182 |
+
elif task == 'QA':
|
| 183 |
+
_string += 'question**: :'
|
| 184 |
+
elif task == 'paraphrase':
|
| 185 |
+
_string += 'sentence 1**: :'
|
| 186 |
+
_string += f'red[{_all[_sl]["Replaced hypothesis"][j]}]'.replace(":", "[colon]")
|
| 187 |
+
if task == 'NLI':
|
| 188 |
+
_string += '<br> **premise**: :'
|
| 189 |
+
elif task == 'QA':
|
| 190 |
+
_string += '<br> **text**: :'
|
| 191 |
+
elif task == 'paraphrase':
|
| 192 |
+
_string += '<br> **sentence 2**: :'
|
| 193 |
+
_string += f'blue[{_all[_sl]["Premise"][j]}]'.replace(":", "[colon]")
|
| 194 |
+
_string += '<br></li>'
|
| 195 |
+
_string += '</ol></blockquote>'
|
| 196 |
+
st.markdown(_string.replace('<s>', '\<s\>').replace('$', '\$').replace('~', '\~'), unsafe_allow_html=True)
|
| 197 |
+
# st.text(f'Examples: :blue[{new_dataframe.loc[i, "replaced sentences".replace(":", "[colon]")]}]')
|
| 198 |
+
# st.dataframe(new_dataframe)
|
| 199 |
+
st.markdown(hide_expander_border, unsafe_allow_html=True)
|
| 200 |
+
else:
|
| 201 |
+
st.error(f'We did not find any Secret Language of {title} on {task}.', icon="⚠️")
|
| 202 |
+
|
| 203 |
+
|
| 204 |
+
with tab1:
|
| 205 |
+
# st.header("NLI")
|
| 206 |
+
# present(dataframe, 'NLI', title)
|
| 207 |
+
present_dict(data_title, 'NLI')
|
| 208 |
+
with tab2:
|
| 209 |
+
# st.header("QA")
|
| 210 |
+
# present(dataframe, 'QA', title)
|
| 211 |
+
present_dict(data_title, 'QA')
|
| 212 |
+
with tab3:
|
| 213 |
+
# present(dataframe, 'Paraphrase', title)
|
| 214 |
+
present_dict(data_title, 'paraphrase')
|
| 215 |
+
st.markdown(
|
| 216 |
+
f'<span id="jump">¹</span>*Enlish meaning is supported by [PyDictionary](https://pypi.org/project/PyDictionary/).*',
|
| 217 |
+
unsafe_allow_html=True)
|
| 218 |
+
else:
|
| 219 |
+
st.error(f'{title} is not in the dictionary of Secret Language.', icon="⚠️")
|
| 220 |
+
|
pages/1_📙_Dictionary_(Browse).py
ADDED
|
@@ -0,0 +1,79 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import streamlit as st
|
| 2 |
+
import pandas as pd
|
| 3 |
+
import gdown
|
| 4 |
+
import os
|
| 5 |
+
import pickle
|
| 6 |
+
from streamlit import session_state as _state
|
| 7 |
+
|
| 8 |
+
|
| 9 |
+
from PyDictionary import PyDictionary
|
| 10 |
+
dictionary=PyDictionary()
|
| 11 |
+
|
| 12 |
+
st.set_page_config(layout="wide", page_title="ACl23 Secret Language")
|
| 13 |
+
|
| 14 |
+
|
| 15 |
+
# st.title("ACl23 Secret Language")
|
| 16 |
+
|
| 17 |
+
# sidebar
|
| 18 |
+
st.sidebar.header("📙 Dictionary (Browse)")
|
| 19 |
+
# title = st.sidebar.text_input(":red[Search secret languages given the following word]", 'Asian')
|
| 20 |
+
buttons = {}
|
| 21 |
+
|
| 22 |
+
# def call_back():
|
| 23 |
+
# for k in buttons:
|
| 24 |
+
# if buttons[k]:
|
| 25 |
+
# st.text(k)
|
| 26 |
+
|
| 27 |
+
with st.sidebar:
|
| 28 |
+
cols0 = st.columns(8)
|
| 29 |
+
for i in range(len(cols0)):
|
| 30 |
+
with cols0[i]:
|
| 31 |
+
buttons[chr(65 + i)] = st.button(chr(65 + i))
|
| 32 |
+
cols1 = st.columns(8)
|
| 33 |
+
for i in range(len(cols1)):
|
| 34 |
+
with cols1[i]:
|
| 35 |
+
buttons[chr(65 + 8 + i)] = st.button(chr(65 + 8 + i))
|
| 36 |
+
cols2 = st.columns(8)
|
| 37 |
+
for i in range(len(cols2)):
|
| 38 |
+
with cols2[i]:
|
| 39 |
+
buttons[chr(65 + 16 + i)] = st.button(chr(65 + 16 + i))
|
| 40 |
+
cols3 = st.columns(8)
|
| 41 |
+
for i in range(2):
|
| 42 |
+
with cols3[i]:
|
| 43 |
+
buttons[chr(65 + 24 + i)] = st.button(chr(65 + 24 + i))
|
| 44 |
+
cols4 = st.columns(2)
|
| 45 |
+
buttons['0-9'] = cols4[0].button('0-9')
|
| 46 |
+
buttons['Others'] = cols4[1].button('Others')
|
| 47 |
+
|
| 48 |
+
|
| 49 |
+
# all_condition = False
|
| 50 |
+
for k in buttons:
|
| 51 |
+
if buttons[k]:
|
| 52 |
+
if k == '0-9':
|
| 53 |
+
st.title(k)
|
| 54 |
+
file_names = ['num_dict.pkl']
|
| 55 |
+
elif k == 'Others':
|
| 56 |
+
st.title(k)
|
| 57 |
+
file_names = ['other_dict.pkl']
|
| 58 |
+
elif ord(k[0]) in list(range(97, 123)) + list(range(65, 91)):
|
| 59 |
+
st.title(chr(ord(k)))
|
| 60 |
+
file_names = [f'{ord(k[0]) + 32}_dict.pkl', f'{ord(k[0])}_dict.pkl']
|
| 61 |
+
all_data = {}
|
| 62 |
+
all_key = []
|
| 63 |
+
for file_name in file_names:
|
| 64 |
+
_data = pickle.load(open(f'all_secret_langauge_by_fist/{file_name}', 'rb'))
|
| 65 |
+
all_data.update(_data)
|
| 66 |
+
all_key.extend(sorted(list(_data.keys())))
|
| 67 |
+
# st.markdown(file_name, unsafe_allow_html=True)
|
| 68 |
+
# st.markdown(_data.keys(), unsafe_allow_html=True)
|
| 69 |
+
|
| 70 |
+
all_key = list(set(all_key))
|
| 71 |
+
|
| 72 |
+
for key in all_key:
|
| 73 |
+
# if len(key) and key[0] != '"':
|
| 74 |
+
# st.markdown(key, unsafe_allow_html=True)
|
| 75 |
+
# st.change_page("home")
|
| 76 |
+
st.markdown(f'<a href="Dictionary_(Search)?word={key}" target="_self">{key}</a>', unsafe_allow_html=True)
|
| 77 |
+
# with st.expander(key):
|
| 78 |
+
# st.markdown(':red[Secret Languages:' + ','.join(all_data[key]['secret languages']), unsafe_allow_html=True)
|
| 79 |
+
|
style.css
ADDED
|
@@ -0,0 +1,4 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
h1 {
|
| 2 |
+
font-family: "Lucida Handwriting", Times, serif;
|
| 3 |
+
letter-spacing: 0.3em;
|
| 4 |
+
}
|