
Finished milestone2
Browse files- README.md +56 -67
- app.py +21 -13
- milestone2/HF_token.png +0 -0
- milestone2/app_UI.png +0 -0
- milestone2/github_token.png +0 -0
- milestone2/new_HF_space.png +0 -0
README.md
CHANGED
|
@@ -13,93 +13,82 @@ pinned: false
|
|
| 13 |
|
| 14 |
Hello! This is a project for CS-UY 4613: Artificial Intelligence. I'm providing a step-by-step instruction on finetuning language models for detecting toxic tweets.
|
| 15 |
|
| 16 |
-
# Milestone
|
| 17 |
|
| 18 |
-
This milestone includes
|
| 19 |
|
| 20 |
-
|
| 21 |
|
| 22 |
-
|
| 23 |
|
| 24 |
-
|
| 25 |
-
wsl --install
|
| 26 |
-
```
|
| 27 |
-
|
| 28 |
-
Ubuntu is the default distribution installed and WSL2 is the default version.
|
| 29 |
-
After creating linux username and password, Ubuntu can be seen in Windows Terminal now.
|
| 30 |
-
Details can be found [here](https://learn.microsoft.com/en-us/windows/wsl/install).
|
| 31 |
-
|
| 32 |
-

|
| 33 |
|
| 34 |
-
|
| 35 |
|
| 36 |
-
|
| 37 |
-
|
|
|
|
| 38 |
|
| 39 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 40 |
|
| 41 |
-
|
| 42 |
-
Successfully ran update [package](https://docs.microsoft.com/windows/wsl/wsl2-kernel).
|
| 43 |
|
| 44 |
-

|
| 45 |
|
| 46 |
-
##
|
| 47 |
|
| 48 |
-
|
| 49 |
-
If not, follow [this link](https://docs.docker.com/desktop/windows/wsl/) for steps to turn on WSL2 backend.
|
| 50 |
-
Open the app and input `docker version` in Terminal to check server running.
|
| 51 |
|
| 52 |
-

|
| 74 |
|
| 75 |
-
##
|
| 76 |
|
| 77 |
-
|
| 78 |
-
First we update and upgrade packages by: (`apt` is Advanced Packaging Tool)
|
| 79 |
-
```
|
| 80 |
-
apt update && apt upgrade
|
| 81 |
-
```
|
| 82 |
-
Then we download python and pip with:
|
| 83 |
-
```
|
| 84 |
-
apt install python3 pip
|
| 85 |
-
```
|
| 86 |
-
We can confirm successful installation by checking the current version of python and pip.
|
| 87 |
-
Then create a script file of *hello_world.py* under `root` directory, and run the script.
|
| 88 |
-
You will see the following in VSCode and Terminal.
|
| 89 |
|
| 90 |
-

|
| 92 |
|
| 93 |
-
## 6. Commit changes to a new image specifically for the project
|
| 94 |
-
|
| 95 |
-
After setting up the container we can commit changes to a specific project image with a tag of *milestone1* with:
|
| 96 |
-
```
|
| 97 |
-
docker commit [CONTAINER] [NEW_IMAGE]:[TAG]
|
| 98 |
-
```
|
| 99 |
-
Now if we check the available images there should be a new image for the project. If we list all containers we should be able to identify the one we were working on through container ID.
|
| 100 |
|
| 101 |
-
|
|
|
|
| 102 |
|
| 103 |
-
|
| 104 |
|
| 105 |
-
|
|
|
|
| 13 |
|
| 14 |
Hello! This is a project for CS-UY 4613: Artificial Intelligence. I'm providing a step-by-step instruction on finetuning language models for detecting toxic tweets.
|
| 15 |
|
| 16 |
+
# Milestone 2
|
| 17 |
|
| 18 |
+
This milestone includes creating a Streamlit app in HuggingFace for sentiment analysis.
|
| 19 |
|
| 20 |
+
Link to app: https://huggingface.co/spaces/andyqin18/sentiment-analysis-app
|
| 21 |
|
| 22 |
+
## 1. Space setup
|
| 23 |
|
| 24 |
+
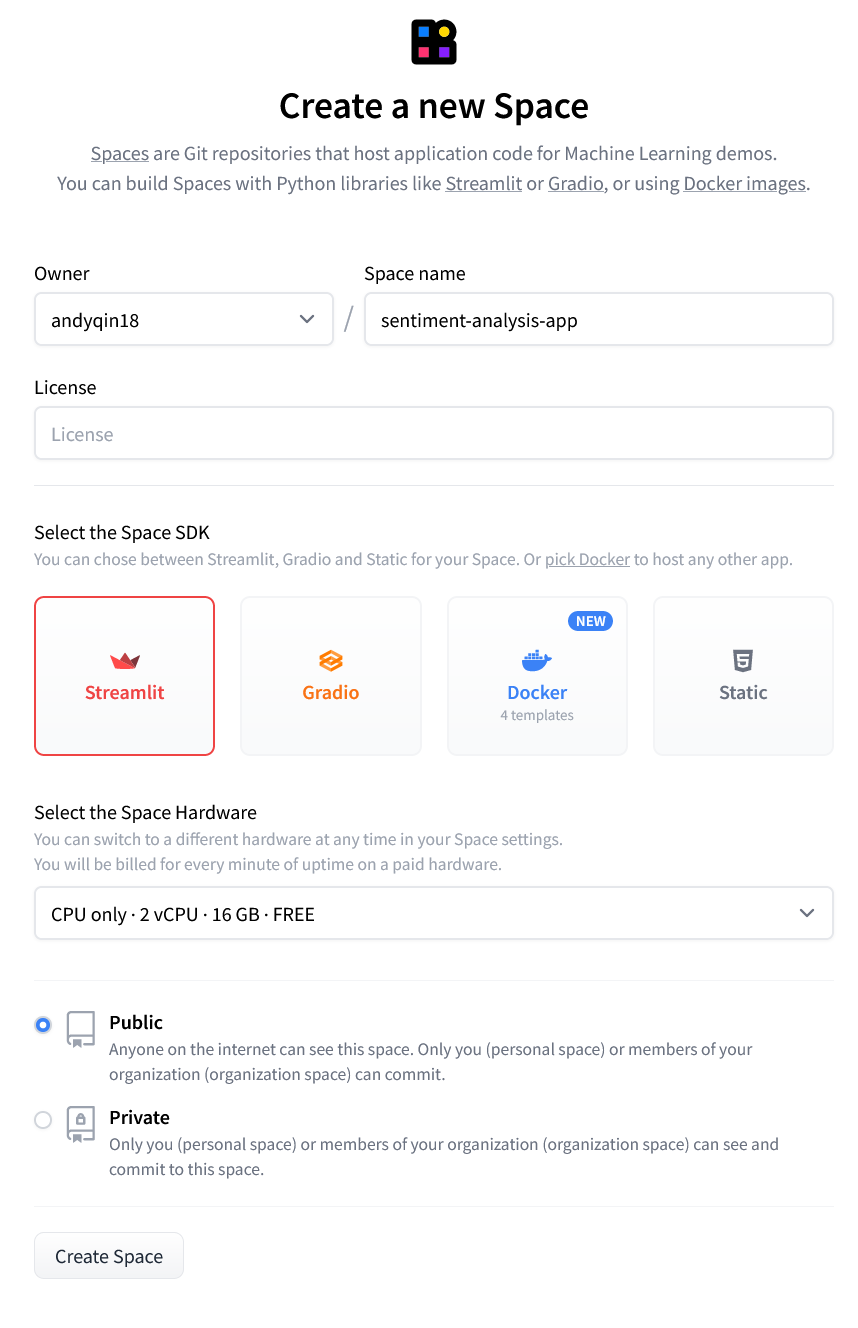
After creating a HuggingFace account, we can create our app as a space and choose Streamlit as the space SDK.
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 25 |
|
| 26 |
+

|
| 27 |
|
| 28 |
+
Then we can go back to our Github Repo and create the following files.
|
| 29 |
+
In order for the space to run properly, there must be at least three files in the root directory:
|
| 30 |
+
[README.md](README.md), [app.py](app.py), and [requirements.txt](requirements.txt)
|
| 31 |
|
| 32 |
+
Make sure the following metadata is at the top of **README.md** for HuggingFace to identify.
|
| 33 |
+
```
|
| 34 |
+
---
|
| 35 |
+
title: Sentiment Analysis App
|
| 36 |
+
emoji: 🚀
|
| 37 |
+
colorFrom: green
|
| 38 |
+
colorTo: purple
|
| 39 |
+
sdk: streamlit
|
| 40 |
+
sdk_version: 1.17.0
|
| 41 |
+
app_file: app.py
|
| 42 |
+
pinned: false
|
| 43 |
+
---
|
| 44 |
+
```
|
| 45 |
|
| 46 |
+
The **app.py** file is the main code of the app and **requirements.txt** should include all the libraries the code uses. HuggingFace will install the libraries listed before running the virtual environment
|
|
|
|
| 47 |
|
|
|
|
| 48 |
|
| 49 |
+
## 2. Connect and sync to HuggingFace
|
| 50 |
|
| 51 |
+
Then we go to settings of the Github Repo and create a secret token to access the new HuggingFace space.
|
|
|
|
|
|
|
| 52 |
|
| 53 |
+

|
| 54 |
+

|
| 55 |
|
| 56 |
+
Next, we need to setup a workflow in Github Actions. Click "set up a workflow yourself" and replace all the code in `main.yaml` with the following: (Replace `HF_USERNAME` and `SPACE_NAME` with our own)
|
| 57 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 58 |
```
|
| 59 |
+
name: Sync to Hugging Face hub
|
| 60 |
+
on:
|
| 61 |
+
push:
|
| 62 |
+
branches: [main]
|
| 63 |
+
|
| 64 |
+
# to run this workflow manually from the Actions tab
|
| 65 |
+
workflow_dispatch:
|
| 66 |
+
|
| 67 |
+
jobs:
|
| 68 |
+
sync-to-hub:
|
| 69 |
+
runs-on: ubuntu-latest
|
| 70 |
+
steps:
|
| 71 |
+
- uses: actions/checkout@v3
|
| 72 |
+
with:
|
| 73 |
+
fetch-depth: 0
|
| 74 |
+
lfs: true
|
| 75 |
+
- name: Push to hub
|
| 76 |
+
env:
|
| 77 |
+
HF_TOKEN: ${{ secrets.HF_TOKEN }}
|
| 78 |
+
run: git push --force https://HF_USERNAME:$HF_TOKEN@huggingface.co/spaces/HF_USERNAME/SPACE_NAME main
|
| 79 |
```
|
| 80 |
+
The Repo is now connected and synced with HuggingFace space!
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 81 |
|
| 82 |
+
## 3. Create the app
|
| 83 |
|
| 84 |
+
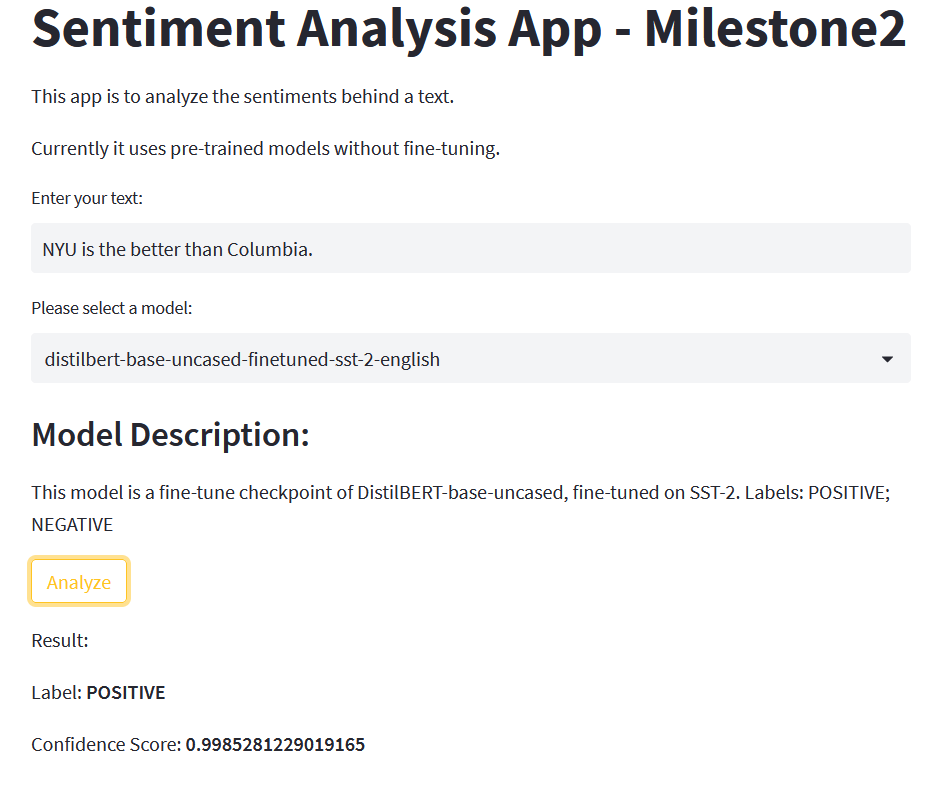
Modify [app.py](app.py) so that it takes in one text and generate an analysis using one of the provided models. Details are explained in comment lines. The app should look like this:
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 85 |
|
| 86 |
+

|
|
|
|
| 87 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 88 |
|
| 89 |
+
## Reference:
|
| 90 |
+
For connecting Github with HuggingFace, check this [video](https://www.youtube.com/watch?v=8hOzsFETm4I).
|
| 91 |
|
| 92 |
+
For creating the app, check this [video](https://www.youtube.com/watch?v=GSt00_-0ncQ)
|
| 93 |
|
| 94 |
+
The HuggingFace documentation is [here](https://huggingface.co/docs), and Streamlit APIs [here](https://docs.streamlit.io/library/api-reference).
|
app.py
CHANGED
|
@@ -1,40 +1,48 @@
|
|
| 1 |
import streamlit as st
|
| 2 |
from transformers import pipeline, AutoTokenizer, AutoModelForSequenceClassification
|
| 3 |
|
| 4 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
| 5 |
model = AutoModelForSequenceClassification.from_pretrained(model_name)
|
| 6 |
tokenizer = AutoTokenizer.from_pretrained(model_name)
|
| 7 |
classifier = pipeline("sentiment-analysis", model=model, tokenizer=tokenizer)
|
| 8 |
return classifier(text)
|
| 9 |
|
| 10 |
-
|
| 11 |
-
st.
|
| 12 |
-
|
|
|
|
| 13 |
|
|
|
|
| 14 |
model_descrip = {
|
| 15 |
-
"distilbert-base-uncased-finetuned-sst-2-english": "This model is a fine-tune checkpoint of DistilBERT-base-uncased, fine-tuned on SST-2
|
| 16 |
Labels: POSITIVE; NEGATIVE ",
|
| 17 |
-
"cardiffnlp/twitter-roberta-base-sentiment": "This is a roBERTa-base model trained on ~58M tweets and finetuned for sentiment analysis with the TweetEval benchmark
|
| 18 |
Labels: 0 -> Negative; 1 -> Neutral; 2 -> Positive",
|
| 19 |
-
"finiteautomata/bertweet-base-sentiment-analysis": "Model trained with SemEval 2017 corpus (around ~40k tweets). Base model is BERTweet, a RoBERTa model trained on English tweets.
|
| 20 |
Labels: POS; NEU; NEG"
|
| 21 |
}
|
| 22 |
|
|
|
|
|
|
|
| 23 |
|
| 24 |
-
|
| 25 |
-
user_model = st.selectbox("Please select a model:",
|
| 26 |
-
model_descrip)
|
| 27 |
-
|
| 28 |
st.write("### Model Description:")
|
| 29 |
st.write(model_descrip[user_model])
|
| 30 |
|
| 31 |
-
|
| 32 |
if st.button("Analyze"):
|
| 33 |
if not user_input:
|
| 34 |
st.write("Please enter a text.")
|
| 35 |
else:
|
| 36 |
with st.spinner("Hang on.... Analyzing..."):
|
| 37 |
result = analyze(user_model, user_input)
|
| 38 |
-
st.write(
|
|
|
|
|
|
|
|
|
|
| 39 |
else:
|
| 40 |
st.write("Go on! Try the app!")
|
|
|
|
| 1 |
import streamlit as st
|
| 2 |
from transformers import pipeline, AutoTokenizer, AutoModelForSequenceClassification
|
| 3 |
|
| 4 |
+
# Define analyze function
|
| 5 |
+
def analyze(model_name: str, text: str) -> dict:
|
| 6 |
+
'''
|
| 7 |
+
Output result of sentiment analysis of a text through a defined model
|
| 8 |
+
'''
|
| 9 |
model = AutoModelForSequenceClassification.from_pretrained(model_name)
|
| 10 |
tokenizer = AutoTokenizer.from_pretrained(model_name)
|
| 11 |
classifier = pipeline("sentiment-analysis", model=model, tokenizer=tokenizer)
|
| 12 |
return classifier(text)
|
| 13 |
|
| 14 |
+
# App title
|
| 15 |
+
st.title("Sentiment Analysis App - Milestone2")
|
| 16 |
+
st.write("This app is to analyze the sentiments behind a text.")
|
| 17 |
+
st.write("Currently it uses pre-trained models without fine-tuning.")
|
| 18 |
|
| 19 |
+
# Model hub
|
| 20 |
model_descrip = {
|
| 21 |
+
"distilbert-base-uncased-finetuned-sst-2-english": "This model is a fine-tune checkpoint of DistilBERT-base-uncased, fine-tuned on SST-2. \
|
| 22 |
Labels: POSITIVE; NEGATIVE ",
|
| 23 |
+
"cardiffnlp/twitter-roberta-base-sentiment": "This is a roBERTa-base model trained on ~58M tweets and finetuned for sentiment analysis with the TweetEval benchmark. \
|
| 24 |
Labels: 0 -> Negative; 1 -> Neutral; 2 -> Positive",
|
| 25 |
+
"finiteautomata/bertweet-base-sentiment-analysis": "Model trained with SemEval 2017 corpus (around ~40k tweets). Base model is BERTweet, a RoBERTa model trained on English tweets. \
|
| 26 |
Labels: POS; NEU; NEG"
|
| 27 |
}
|
| 28 |
|
| 29 |
+
user_input = st.text_input("Enter your text:", value="NYU is the better than Columbia.")
|
| 30 |
+
user_model = st.selectbox("Please select a model:", model_descrip)
|
| 31 |
|
| 32 |
+
# Display model information
|
|
|
|
|
|
|
|
|
|
| 33 |
st.write("### Model Description:")
|
| 34 |
st.write(model_descrip[user_model])
|
| 35 |
|
| 36 |
+
# Perform analysis and print result
|
| 37 |
if st.button("Analyze"):
|
| 38 |
if not user_input:
|
| 39 |
st.write("Please enter a text.")
|
| 40 |
else:
|
| 41 |
with st.spinner("Hang on.... Analyzing..."):
|
| 42 |
result = analyze(user_model, user_input)
|
| 43 |
+
st.write("Result:")
|
| 44 |
+
st.write(f"Label: **{result[0]['label']}**")
|
| 45 |
+
st.write(f"Confidence Score: **{result[0]['score']}**")
|
| 46 |
+
|
| 47 |
else:
|
| 48 |
st.write("Go on! Try the app!")
|
milestone2/HF_token.png
ADDED

|
milestone2/app_UI.png
ADDED
|
milestone2/github_token.png
ADDED

|
milestone2/new_HF_space.png
ADDED
|