
alvanli
commited on
Commit
•
1f43fd8
1
Parent(s):
844bec9
Add cheese model
Browse files- .gitignore +168 -0
- Dockerfile +16 -0
- FROMAGe_example_notebook.ipynb +0 -0
- README.md +1 -1
- app.py +125 -0
- example_1.png +0 -0
- example_2.png +0 -0
- example_3.png +0 -0
- fromage/__init__.py +0 -0
- fromage/data.py +129 -0
- fromage/evaluate.py +307 -0
- fromage/losses.py +44 -0
- fromage/models.py +658 -0
- fromage/utils.py +250 -0
- fromage_model/fromage_vis4/cc3m_embeddings.pkl +3 -0
- fromage_model/fromage_vis4/model_args.json +16 -0
- fromage_model/model_args.json +22 -0
- main.py +642 -0
- requirements.txt +35 -0
.gitignore
ADDED
|
@@ -0,0 +1,168 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
.DS_Store
|
| 2 |
+
*.pyc
|
| 3 |
+
__pycache__
|
| 4 |
+
.pytest_cache
|
| 5 |
+
venv
|
| 6 |
+
runs/
|
| 7 |
+
data/
|
| 8 |
+
|
| 9 |
+
# Byte-compiled / optimized / DLL files
|
| 10 |
+
__pycache__/
|
| 11 |
+
*.py[cod]
|
| 12 |
+
*$py.class
|
| 13 |
+
|
| 14 |
+
# C extensions
|
| 15 |
+
*.so
|
| 16 |
+
|
| 17 |
+
# Distribution / packaging
|
| 18 |
+
.Python
|
| 19 |
+
build/
|
| 20 |
+
develop-eggs/
|
| 21 |
+
dist/
|
| 22 |
+
downloads/
|
| 23 |
+
eggs/
|
| 24 |
+
.eggs/
|
| 25 |
+
lib/
|
| 26 |
+
lib64/
|
| 27 |
+
parts/
|
| 28 |
+
sdist/
|
| 29 |
+
var/
|
| 30 |
+
wheels/
|
| 31 |
+
share/python-wheels/
|
| 32 |
+
*.egg-info/
|
| 33 |
+
.installed.cfg
|
| 34 |
+
*.egg
|
| 35 |
+
MANIFEST
|
| 36 |
+
|
| 37 |
+
# PyInstaller
|
| 38 |
+
# Usually these files are written by a python script from a template
|
| 39 |
+
# before PyInstaller builds the exe, so as to inject date/other infos into it.
|
| 40 |
+
*.manifest
|
| 41 |
+
*.spec
|
| 42 |
+
|
| 43 |
+
# Installer logs
|
| 44 |
+
pip-log.txt
|
| 45 |
+
pip-delete-this-directory.txt
|
| 46 |
+
|
| 47 |
+
# Unit test / coverage reports
|
| 48 |
+
htmlcov/
|
| 49 |
+
.tox/
|
| 50 |
+
.nox/
|
| 51 |
+
.coverage
|
| 52 |
+
.coverage.*
|
| 53 |
+
.cache
|
| 54 |
+
nosetests.xml
|
| 55 |
+
coverage.xml
|
| 56 |
+
*.cover
|
| 57 |
+
*.py,cover
|
| 58 |
+
.hypothesis/
|
| 59 |
+
.pytest_cache/
|
| 60 |
+
cover/
|
| 61 |
+
|
| 62 |
+
# Translations
|
| 63 |
+
*.mo
|
| 64 |
+
*.pot
|
| 65 |
+
|
| 66 |
+
# Django stuff:
|
| 67 |
+
*.log
|
| 68 |
+
local_settings.py
|
| 69 |
+
db.sqlite3
|
| 70 |
+
db.sqlite3-journal
|
| 71 |
+
|
| 72 |
+
# Flask stuff:
|
| 73 |
+
instance/
|
| 74 |
+
.webassets-cache
|
| 75 |
+
|
| 76 |
+
# Scrapy stuff:
|
| 77 |
+
.scrapy
|
| 78 |
+
|
| 79 |
+
# Sphinx documentation
|
| 80 |
+
docs/_build/
|
| 81 |
+
|
| 82 |
+
# PyBuilder
|
| 83 |
+
.pybuilder/
|
| 84 |
+
target/
|
| 85 |
+
|
| 86 |
+
# Jupyter Notebook
|
| 87 |
+
.ipynb_checkpoints
|
| 88 |
+
|
| 89 |
+
# IPython
|
| 90 |
+
profile_default/
|
| 91 |
+
ipython_config.py
|
| 92 |
+
|
| 93 |
+
# pyenv
|
| 94 |
+
# For a library or package, you might want to ignore these files since the code is
|
| 95 |
+
# intended to run in multiple environments; otherwise, check them in:
|
| 96 |
+
# .python-version
|
| 97 |
+
|
| 98 |
+
# pipenv
|
| 99 |
+
# According to pypa/pipenv#598, it is recommended to include Pipfile.lock in version control.
|
| 100 |
+
# However, in case of collaboration, if having platform-specific dependencies or dependencies
|
| 101 |
+
# having no cross-platform support, pipenv may install dependencies that don't work, or not
|
| 102 |
+
# install all needed dependencies.
|
| 103 |
+
#Pipfile.lock
|
| 104 |
+
|
| 105 |
+
# poetry
|
| 106 |
+
# Similar to Pipfile.lock, it is generally recommended to include poetry.lock in version control.
|
| 107 |
+
# This is especially recommended for binary packages to ensure reproducibility, and is more
|
| 108 |
+
# commonly ignored for libraries.
|
| 109 |
+
# https://python-poetry.org/docs/basic-usage/#commit-your-poetrylock-file-to-version-control
|
| 110 |
+
#poetry.lock
|
| 111 |
+
|
| 112 |
+
# pdm
|
| 113 |
+
# Similar to Pipfile.lock, it is generally recommended to include pdm.lock in version control.
|
| 114 |
+
#pdm.lock
|
| 115 |
+
# pdm stores project-wide configurations in .pdm.toml, but it is recommended to not include it
|
| 116 |
+
# in version control.
|
| 117 |
+
# https://pdm.fming.dev/#use-with-ide
|
| 118 |
+
.pdm.toml
|
| 119 |
+
|
| 120 |
+
# PEP 582; used by e.g. github.com/David-OConnor/pyflow and github.com/pdm-project/pdm
|
| 121 |
+
__pypackages__/
|
| 122 |
+
|
| 123 |
+
# Celery stuff
|
| 124 |
+
celerybeat-schedule
|
| 125 |
+
celerybeat.pid
|
| 126 |
+
|
| 127 |
+
# SageMath parsed files
|
| 128 |
+
*.sage.py
|
| 129 |
+
|
| 130 |
+
# Environments
|
| 131 |
+
.env
|
| 132 |
+
.venv
|
| 133 |
+
env/
|
| 134 |
+
venv/
|
| 135 |
+
ENV/
|
| 136 |
+
env.bak/
|
| 137 |
+
venv.bak/
|
| 138 |
+
|
| 139 |
+
# Spyder project settings
|
| 140 |
+
.spyderproject
|
| 141 |
+
.spyproject
|
| 142 |
+
|
| 143 |
+
# Rope project settings
|
| 144 |
+
.ropeproject
|
| 145 |
+
|
| 146 |
+
# mkdocs documentation
|
| 147 |
+
/site
|
| 148 |
+
|
| 149 |
+
# mypy
|
| 150 |
+
.mypy_cache/
|
| 151 |
+
.dmypy.json
|
| 152 |
+
dmypy.json
|
| 153 |
+
|
| 154 |
+
# Pyre type checker
|
| 155 |
+
.pyre/
|
| 156 |
+
|
| 157 |
+
# pytype static type analyzer
|
| 158 |
+
.pytype/
|
| 159 |
+
|
| 160 |
+
# Cython debug symbols
|
| 161 |
+
cython_debug/
|
| 162 |
+
|
| 163 |
+
# PyCharm
|
| 164 |
+
# JetBrains specific template is maintained in a separate JetBrains.gitignore that can
|
| 165 |
+
# be found at https://github.com/github/gitignore/blob/main/Global/JetBrains.gitignore
|
| 166 |
+
# and can be added to the global gitignore or merged into this file. For a more nuclear
|
| 167 |
+
# option (not recommended) you can uncomment the following to ignore the entire idea folder.
|
| 168 |
+
#.idea/
|
Dockerfile
ADDED
|
@@ -0,0 +1,16 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
FROM pytorch/pytorch:1.11.0-cuda11.3-cudnn8-devel as base
|
| 2 |
+
RUN apt-key adv --keyserver keyserver.ubuntu.com --recv-keys A4B469963BF863CC
|
| 3 |
+
|
| 4 |
+
ENV HOME=/exp/fromage
|
| 5 |
+
|
| 6 |
+
RUN apt-get update && apt-get -y install git
|
| 7 |
+
|
| 8 |
+
WORKDIR /exp/fromage
|
| 9 |
+
COPY ./requirements.txt ./requirements.txt
|
| 10 |
+
RUN python -m pip install -r ./requirements.txt
|
| 11 |
+
RUN python -m pip install gradio
|
| 12 |
+
|
| 13 |
+
COPY . .
|
| 14 |
+
RUN chmod -R a+rwX .
|
| 15 |
+
|
| 16 |
+
CMD ["uvicorn", "app:main", "--host", "0.0.0.0", "--port", "7860"]
|
FROMAGe_example_notebook.ipynb
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
README.md
CHANGED
|
@@ -1,6 +1,6 @@
|
|
| 1 |
---
|
| 2 |
title: FROMAGe
|
| 3 |
-
emoji:
|
| 4 |
colorFrom: pink
|
| 5 |
colorTo: red
|
| 6 |
sdk: docker
|
|
|
|
| 1 |
---
|
| 2 |
title: FROMAGe
|
| 3 |
+
emoji: 🧀
|
| 4 |
colorFrom: pink
|
| 5 |
colorTo: red
|
| 6 |
sdk: docker
|
app.py
ADDED
|
@@ -0,0 +1,125 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
eexitimport os, time, copy
|
| 2 |
+
os.environ["HF_HUB_ENABLE_HF_TRANSFER"] = "False"
|
| 3 |
+
|
| 4 |
+
from PIL import Image
|
| 5 |
+
|
| 6 |
+
import gradio as gr
|
| 7 |
+
|
| 8 |
+
import numpy as np
|
| 9 |
+
import torch
|
| 10 |
+
from transformers import logging
|
| 11 |
+
logging.set_verbosity_error()
|
| 12 |
+
|
| 13 |
+
from fromage import models
|
| 14 |
+
from fromage import utils
|
| 15 |
+
|
| 16 |
+
BASE_WIDTH = 512
|
| 17 |
+
MODEL_DIR = './fromage_model/fromage_vis4'
|
| 18 |
+
|
| 19 |
+
def upload_image(file):
|
| 20 |
+
return Image.open(file)
|
| 21 |
+
|
| 22 |
+
def upload_button_config():
|
| 23 |
+
return gr.update(visible=False)
|
| 24 |
+
|
| 25 |
+
def upload_textbox_config(text_in):
|
| 26 |
+
return gr.update(visible=True)
|
| 27 |
+
|
| 28 |
+
|
| 29 |
+
class ChatBotCheese:
|
| 30 |
+
def __init__(self):
|
| 31 |
+
from huggingface_hub import hf_hub_download
|
| 32 |
+
model_ckpt_path = hf_hub_download("alvanlii/fromage", "pretrained_ckpt.pth.tar")
|
| 33 |
+
self.model = models.load_fromage(MODEL_DIR, model_ckpt_path)
|
| 34 |
+
self.curr_image = None
|
| 35 |
+
self.chat_history = ''
|
| 36 |
+
|
| 37 |
+
def add_image(self, state, image_in):
|
| 38 |
+
state = state + [(f"", "Ok, now type your message")]
|
| 39 |
+
self.curr_image = Image.open(image_in.name).convert('RGB')
|
| 40 |
+
return state, state
|
| 41 |
+
|
| 42 |
+
def save_im(self, image_pil):
|
| 43 |
+
file_name = f"{int(time.time())}_{np.random.randint(100)}.png"
|
| 44 |
+
image_pil.save(file_name)
|
| 45 |
+
return file_name
|
| 46 |
+
|
| 47 |
+
def chat(self, input_text, state, ret_scale_factor, num_ims, num_words, temp):
|
| 48 |
+
# model_outputs = ["heyo", []]
|
| 49 |
+
self.chat_history += f'Q: {input_text} \nA:'
|
| 50 |
+
if self.curr_image is not None:
|
| 51 |
+
model_outputs = self.model.generate_for_images_and_texts([self.curr_image, self.chat_history], num_words=num_words, max_num_rets=num_ims, ret_scale_factor=ret_scale_factor, temperature=temp)
|
| 52 |
+
else:
|
| 53 |
+
model_outputs = self.model.generate_for_images_and_texts([self.chat_history], max_num_rets=num_ims, num_words=num_words, ret_scale_factor=ret_scale_factor, temperature=temp)
|
| 54 |
+
self.chat_history += ' '.join([s for s in model_outputs if type(s) == str]) + '\n'
|
| 55 |
+
|
| 56 |
+
im_names = []
|
| 57 |
+
if len(model_outputs) > 1:
|
| 58 |
+
im_names = [self.save_im(im) for im in model_outputs[1]]
|
| 59 |
+
|
| 60 |
+
response = model_outputs[0]
|
| 61 |
+
for im_name in im_names:
|
| 62 |
+
response += f'<img src="/file={im_name}">'
|
| 63 |
+
state.append((input_text, response.replace("[RET]", "")))
|
| 64 |
+
self.curr_image = None
|
| 65 |
+
return state, state
|
| 66 |
+
|
| 67 |
+
def reset(self):
|
| 68 |
+
self.chat_history = ""
|
| 69 |
+
self.curr_image = None
|
| 70 |
+
return [], []
|
| 71 |
+
|
| 72 |
+
def main(self):
|
| 73 |
+
with gr.Blocks(css="#chatbot .overflow-y-auto{height:1500px}") as demo:
|
| 74 |
+
gr.Markdown(
|
| 75 |
+
"""
|
| 76 |
+
## FROMAGe
|
| 77 |
+
### Grounding Language Models to Images for Multimodal Generation
|
| 78 |
+
Jing Yu Koh, Ruslan Salakhutdinov, Daniel Fried <br/>
|
| 79 |
+
[Paper](https://arxiv.org/abs/2301.13823) [Github](https://github.com/kohjingyu/fromage) <br/>
|
| 80 |
+
- Upload an image (optional)
|
| 81 |
+
- Chat with FROMAGe!
|
| 82 |
+
- Check out the examples at the bottom!
|
| 83 |
+
"""
|
| 84 |
+
)
|
| 85 |
+
|
| 86 |
+
chatbot = gr.Chatbot(elem_id="chatbot")
|
| 87 |
+
gr_state = gr.State([])
|
| 88 |
+
|
| 89 |
+
with gr.Row():
|
| 90 |
+
with gr.Column(scale=0.85):
|
| 91 |
+
txt = gr.Textbox(show_label=False, placeholder="Upload an image first [Optional]. Then enter text and press enter,").style(container=False)
|
| 92 |
+
with gr.Column(scale=0.15, min_width=0):
|
| 93 |
+
btn = gr.UploadButton("🖼️", file_types=["image"])
|
| 94 |
+
|
| 95 |
+
with gr.Row():
|
| 96 |
+
with gr.Column(scale=0.20, min_width=0):
|
| 97 |
+
reset_btn = gr.Button("Reset Messages")
|
| 98 |
+
gr_ret_scale_factor = gr.Number(value=1.0, label="Increased prob of returning images", interactive=True)
|
| 99 |
+
gr_num_ims = gr.Number(value=3, precision=1, label="Max # of Images returned", interactive=True)
|
| 100 |
+
gr_num_words = gr.Number(value=32, precision=1, label="Max # of words returned", interactive=True)
|
| 101 |
+
gr_temp = gr.Number(value=0.0, label="Temperature", interactive=True)
|
| 102 |
+
|
| 103 |
+
with gr.Row():
|
| 104 |
+
gr.Image("example_1.png", label="Example 1")
|
| 105 |
+
gr.Image("example_2.png", label="Example 2")
|
| 106 |
+
gr.Image("example_3.png", label="Example 3")
|
| 107 |
+
|
| 108 |
+
|
| 109 |
+
txt.submit(self.chat, [txt, gr_state, gr_ret_scale_factor, gr_num_ims, gr_num_words, gr_temp], [gr_state, chatbot])
|
| 110 |
+
txt.submit(lambda :"", None, txt)
|
| 111 |
+
btn.upload(self.add_image, [gr_state, btn], [gr_state, chatbot])
|
| 112 |
+
reset_btn.click(self.reset, [], [gr_state, chatbot])
|
| 113 |
+
|
| 114 |
+
# chatbot.change(fn = upload_button_config, outputs=btn_upload)
|
| 115 |
+
# text_in.submit(None, [], [], _js = "() => document.getElementById('#chatbot-component').scrollTop = document.getElementById('#chatbot-component').scrollHeight")
|
| 116 |
+
|
| 117 |
+
demo.launch(share=False, server_name="0.0.0.0")
|
| 118 |
+
|
| 119 |
+
def main():
|
| 120 |
+
cheddar = ChatBotCheese()
|
| 121 |
+
cheddar.main()
|
| 122 |
+
|
| 123 |
+
if __name__ == "__main__":
|
| 124 |
+
cheddar = ChatBotCheese()
|
| 125 |
+
cheddar.main()
|
example_1.png
ADDED
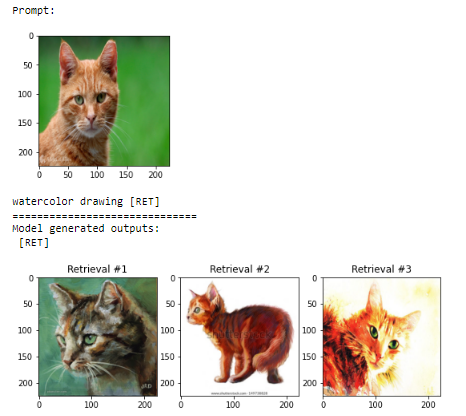
|
example_2.png
ADDED

|
example_3.png
ADDED
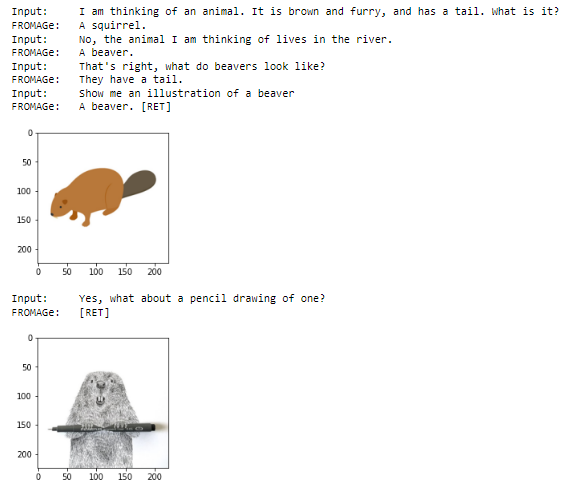
|
fromage/__init__.py
ADDED
|
File without changes
|
fromage/data.py
ADDED
|
@@ -0,0 +1,129 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""Modified from https://github.com/mlfoundations/open_clip"""
|
| 2 |
+
|
| 3 |
+
from typing import Optional, Tuple
|
| 4 |
+
|
| 5 |
+
import collections
|
| 6 |
+
import logging
|
| 7 |
+
import os
|
| 8 |
+
import numpy as np
|
| 9 |
+
import pandas as pd
|
| 10 |
+
import torch
|
| 11 |
+
import torchvision.datasets as datasets
|
| 12 |
+
from torchvision import transforms as T
|
| 13 |
+
from PIL import Image, ImageFont
|
| 14 |
+
from torch.utils.data import Dataset
|
| 15 |
+
|
| 16 |
+
from fromage import utils
|
| 17 |
+
|
| 18 |
+
|
| 19 |
+
def collate_fn(batch):
|
| 20 |
+
batch = list(filter(lambda x: x is not None, batch))
|
| 21 |
+
return torch.utils.data.dataloader.default_collate(batch)
|
| 22 |
+
|
| 23 |
+
|
| 24 |
+
def get_dataset(args, split: str, tokenizer, precision: str = 'fp32') -> Dataset:
|
| 25 |
+
assert split in ['train', 'val'
|
| 26 |
+
], 'Expected split to be one of "train" or "val", got {split} instead.'
|
| 27 |
+
|
| 28 |
+
dataset_paths = []
|
| 29 |
+
image_data_dirs = []
|
| 30 |
+
train = split == 'train'
|
| 31 |
+
|
| 32 |
+
# Default configs for datasets.
|
| 33 |
+
# Folder structure should look like:
|
| 34 |
+
if split == 'train':
|
| 35 |
+
if 'cc3m' in args.dataset:
|
| 36 |
+
dataset_paths.append(os.path.join(args.dataset_dir, 'cc3m_train.tsv'))
|
| 37 |
+
image_data_dirs.append(os.path.join(args.image_dir, 'cc3m/training/'))
|
| 38 |
+
else:
|
| 39 |
+
raise NotImplementedError
|
| 40 |
+
|
| 41 |
+
elif split == 'val':
|
| 42 |
+
if 'cc3m' in args.val_dataset:
|
| 43 |
+
dataset_paths.append(os.path.join(args.dataset_dir, 'cc3m_val.tsv'))
|
| 44 |
+
image_data_dirs.append(os.path.join(args.image_dir, 'cc3m/validation'))
|
| 45 |
+
else:
|
| 46 |
+
raise NotImplementedError
|
| 47 |
+
|
| 48 |
+
assert len(dataset_paths) == len(image_data_dirs) == 1, (dataset_paths, image_data_dirs)
|
| 49 |
+
else:
|
| 50 |
+
raise NotImplementedError
|
| 51 |
+
|
| 52 |
+
if len(dataset_paths) > 1:
|
| 53 |
+
print(f'{len(dataset_paths)} datasets requested: {dataset_paths}')
|
| 54 |
+
dataset = torch.utils.data.ConcatDataset([
|
| 55 |
+
CsvDataset(path, image_dir, tokenizer, 'image',
|
| 56 |
+
'caption', args.visual_model, train=train, max_len=args.max_len, precision=args.precision,
|
| 57 |
+
image_size=args.image_size, retrieval_token_idx=args.retrieval_token_idx)
|
| 58 |
+
for (path, image_dir) in zip(dataset_paths, image_data_dirs)])
|
| 59 |
+
elif len(dataset_paths) == 1:
|
| 60 |
+
dataset = CsvDataset(dataset_paths[0], image_data_dirs[0], tokenizer, 'image',
|
| 61 |
+
'caption', args.visual_model, train=train, max_len=args.max_len, precision=args.precision,
|
| 62 |
+
image_size=args.image_size, retrieval_token_idx=args.retrieval_token_idx)
|
| 63 |
+
else:
|
| 64 |
+
raise ValueError(f'There should be at least one valid dataset, got train={args.dataset}, val={args.val_dataset} instead.')
|
| 65 |
+
return dataset
|
| 66 |
+
|
| 67 |
+
|
| 68 |
+
class CsvDataset(Dataset):
|
| 69 |
+
def __init__(self, input_filename, base_image_dir, tokenizer, img_key,
|
| 70 |
+
caption_key, feature_extractor_model: str,
|
| 71 |
+
train: bool = True, max_len: int = 32, sep="\t", precision: str = 'fp32',
|
| 72 |
+
image_size: int = 224, retrieval_token_idx: int = -1):
|
| 73 |
+
logging.debug(f'Loading tsv data from {input_filename}.')
|
| 74 |
+
df = pd.read_csv(input_filename, sep=sep)
|
| 75 |
+
|
| 76 |
+
self.base_image_dir = base_image_dir
|
| 77 |
+
self.images = df[img_key].tolist()
|
| 78 |
+
self.captions = df[caption_key].tolist()
|
| 79 |
+
assert len(self.images) == len(self.captions)
|
| 80 |
+
|
| 81 |
+
self.feature_extractor_model = feature_extractor_model
|
| 82 |
+
self.feature_extractor = utils.get_feature_extractor_for_model(
|
| 83 |
+
feature_extractor_model, image_size=image_size, train=False)
|
| 84 |
+
self.image_size = image_size
|
| 85 |
+
|
| 86 |
+
self.tokenizer = tokenizer
|
| 87 |
+
self.max_len = max_len
|
| 88 |
+
self.precision = precision
|
| 89 |
+
self.retrieval_token_idx = retrieval_token_idx
|
| 90 |
+
|
| 91 |
+
self.font = None
|
| 92 |
+
|
| 93 |
+
logging.debug('Done loading data.')
|
| 94 |
+
|
| 95 |
+
def __len__(self):
|
| 96 |
+
return len(self.captions)
|
| 97 |
+
|
| 98 |
+
def __getitem__(self, idx):
|
| 99 |
+
while True:
|
| 100 |
+
image_path = os.path.join(self.base_image_dir, str(self.images[idx]))
|
| 101 |
+
caption = str(self.captions[idx])
|
| 102 |
+
|
| 103 |
+
try:
|
| 104 |
+
img = Image.open(image_path)
|
| 105 |
+
images = utils.get_pixel_values_for_model(self.feature_extractor, img)
|
| 106 |
+
|
| 107 |
+
caption += '[RET]'
|
| 108 |
+
tokenized_data = self.tokenizer(
|
| 109 |
+
caption,
|
| 110 |
+
return_tensors="pt",
|
| 111 |
+
padding='max_length',
|
| 112 |
+
truncation=True,
|
| 113 |
+
max_length=self.max_len)
|
| 114 |
+
tokens = tokenized_data.input_ids[0]
|
| 115 |
+
|
| 116 |
+
caption_len = tokenized_data.attention_mask[0].sum()
|
| 117 |
+
|
| 118 |
+
decode_caption = self.tokenizer.decode(tokens, skip_special_tokens=False)
|
| 119 |
+
self.font = self.font or ImageFont.load_default()
|
| 120 |
+
cap_img = utils.create_image_of_text(decode_caption.encode('ascii', 'ignore'), width=self.image_size, nrows=2, font=self.font)
|
| 121 |
+
|
| 122 |
+
if tokens[-1] not in [self.retrieval_token_idx, self.tokenizer.pad_token_id]:
|
| 123 |
+
tokens[-1] = self.retrieval_token_idx
|
| 124 |
+
|
| 125 |
+
return image_path, images, cap_img, tokens, caption_len
|
| 126 |
+
except Exception as e:
|
| 127 |
+
print(f'Error reading {image_path} with caption {caption}: {e}')
|
| 128 |
+
# Pick a new example at random.
|
| 129 |
+
idx = np.random.randint(0, len(self)-1)
|
fromage/evaluate.py
ADDED
|
@@ -0,0 +1,307 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import collections
|
| 2 |
+
import json
|
| 3 |
+
import os
|
| 4 |
+
from PIL import Image
|
| 5 |
+
import numpy as np
|
| 6 |
+
import time
|
| 7 |
+
import tqdm
|
| 8 |
+
import torch
|
| 9 |
+
import torch.distributed as dist
|
| 10 |
+
from torch.utils.tensorboard import SummaryWriter
|
| 11 |
+
from torchmetrics import BLEUScore
|
| 12 |
+
import torchvision
|
| 13 |
+
|
| 14 |
+
from fromage import losses as losses_utils
|
| 15 |
+
from fromage import utils
|
| 16 |
+
|
| 17 |
+
|
| 18 |
+
def validate(val_loader, model, tokenizer, criterion, epoch, args):
|
| 19 |
+
ngpus_per_node = torch.cuda.device_count()
|
| 20 |
+
writer = SummaryWriter(args.log_dir)
|
| 21 |
+
bleu_scorers = [BLEUScore(n_gram=i) for i in [1, 2, 3, 4]]
|
| 22 |
+
actual_step = (epoch + 1) * args.steps_per_epoch
|
| 23 |
+
model_modes = ['captioning', 'retrieval']
|
| 24 |
+
num_words = 32 # Number of tokens to generate.
|
| 25 |
+
|
| 26 |
+
feature_extractor = utils.get_feature_extractor_for_model(args.visual_model, image_size=args.image_size, train=False)
|
| 27 |
+
|
| 28 |
+
def get_pixel_values_from_path(path: str):
|
| 29 |
+
img = Image.open(path)
|
| 30 |
+
img = img.resize((args.image_size, args.image_size))
|
| 31 |
+
pixel_values = utils.get_pixel_values_for_model(feature_extractor, img)[None, ...]
|
| 32 |
+
|
| 33 |
+
if args.precision == 'fp16':
|
| 34 |
+
pixel_values = pixel_values.half()
|
| 35 |
+
elif args.precision == 'bf16':
|
| 36 |
+
pixel_values = pixel_values.bfloat16()
|
| 37 |
+
if torch.cuda.is_available():
|
| 38 |
+
pixel_values = pixel_values.cuda()
|
| 39 |
+
return pixel_values
|
| 40 |
+
|
| 41 |
+
def run_validate(loader, base_progress=0):
|
| 42 |
+
with torch.no_grad():
|
| 43 |
+
end = time.time()
|
| 44 |
+
all_generated_captions = []
|
| 45 |
+
all_gt_captions = []
|
| 46 |
+
all_generated_image_paths = []
|
| 47 |
+
all_image_features = []
|
| 48 |
+
all_text_features = []
|
| 49 |
+
|
| 50 |
+
for i, (image_paths, images, caption_images, tgt_tokens, token_len) in tqdm.tqdm(enumerate(loader), position=0, total=len(loader)):
|
| 51 |
+
i = base_progress + i
|
| 52 |
+
|
| 53 |
+
if torch.cuda.is_available():
|
| 54 |
+
tgt_tokens = tgt_tokens.cuda(args.gpu, non_blocking=True)
|
| 55 |
+
token_len = token_len.cuda(args.gpu, non_blocking=True)
|
| 56 |
+
images = images.cuda()
|
| 57 |
+
|
| 58 |
+
if args.precision == 'fp16':
|
| 59 |
+
images = images.half()
|
| 60 |
+
elif args.precision == 'bf16':
|
| 61 |
+
images = images.bfloat16()
|
| 62 |
+
|
| 63 |
+
for model_mode in model_modes:
|
| 64 |
+
(model_output, full_labels, last_embedding, _, visual_embs) = model(
|
| 65 |
+
images, tgt_tokens, token_len, mode=model_mode, input_prefix=args.input_prompt, inference=True) # (N, T, C)
|
| 66 |
+
|
| 67 |
+
if model_mode == 'captioning':
|
| 68 |
+
loss = args.cap_loss_scale * model_output.loss
|
| 69 |
+
elif model_mode == 'retrieval':
|
| 70 |
+
loss = args.ret_loss_scale * model_output.loss
|
| 71 |
+
else:
|
| 72 |
+
raise NotImplementedError
|
| 73 |
+
|
| 74 |
+
output = model_output.logits
|
| 75 |
+
if model_mode == 'captioning':
|
| 76 |
+
acc1, acc5 = utils.accuracy(output[:, :-1, :], full_labels[:, 1:], -100, topk=(1, 5))
|
| 77 |
+
top1.update(acc1[0], images.size(0))
|
| 78 |
+
top5.update(acc5[0], images.size(0))
|
| 79 |
+
ce_losses.update(loss.item(), images.size(0))
|
| 80 |
+
|
| 81 |
+
if model_mode == 'captioning':
|
| 82 |
+
losses.update(loss.item(), images.size(0))
|
| 83 |
+
elif model_mode == 'retrieval':
|
| 84 |
+
if args.distributed:
|
| 85 |
+
original_last_embedding = torch.clone(last_embedding)
|
| 86 |
+
all_visual_embs = [torch.zeros_like(visual_embs) for _ in range(dist.get_world_size())]
|
| 87 |
+
all_last_embedding = [torch.zeros_like(last_embedding) for _ in range(dist.get_world_size())]
|
| 88 |
+
dist.all_gather(all_visual_embs, visual_embs)
|
| 89 |
+
dist.all_gather(all_last_embedding, last_embedding)
|
| 90 |
+
|
| 91 |
+
# Overwrite with embeddings produced on this replica, which track the gradients.
|
| 92 |
+
all_visual_embs[dist.get_rank()] = visual_embs
|
| 93 |
+
all_last_embedding[dist.get_rank()] = last_embedding
|
| 94 |
+
visual_embs = torch.cat(all_visual_embs)
|
| 95 |
+
last_embedding = torch.cat(all_last_embedding)
|
| 96 |
+
start_idx = args.rank * images.shape[0]
|
| 97 |
+
end_idx = start_idx + images.shape[0]
|
| 98 |
+
assert torch.all(last_embedding[start_idx:end_idx] == original_last_embedding), args.rank
|
| 99 |
+
|
| 100 |
+
all_text_features.append(last_embedding.cpu())
|
| 101 |
+
all_image_features.append(visual_embs.cpu())
|
| 102 |
+
|
| 103 |
+
# Run auto-regressive generation sample
|
| 104 |
+
if model_mode == 'captioning':
|
| 105 |
+
input_embs = model.module.model.get_visual_embs(images, mode='captioning') # (2, n_visual_tokens, D)
|
| 106 |
+
if args.input_prompt is not None:
|
| 107 |
+
print(f'Adding prefix "{args.input_prompt}" to captioning generate=True.')
|
| 108 |
+
prompt_ids = tokenizer(args.input_prompt, add_special_tokens=False, return_tensors="pt").input_ids
|
| 109 |
+
prompt_ids = prompt_ids.to(visual_embs.device)
|
| 110 |
+
prompt_embs = model.module.model.input_embeddings(prompt_ids)
|
| 111 |
+
prompt_embs = prompt_embs.repeat(input_embs.shape[0], 1, 1)
|
| 112 |
+
input_embs = torch.cat([input_embs, prompt_embs], dim=1)
|
| 113 |
+
|
| 114 |
+
generated_ids, _, _ = model(input_embs, tgt_tokens, token_len,
|
| 115 |
+
generate=True, num_words=num_words, temperature=0.0, top_p=1.0,
|
| 116 |
+
min_word_tokens=num_words)
|
| 117 |
+
|
| 118 |
+
if args.distributed and ngpus_per_node > 1:
|
| 119 |
+
all_generated_ids = [torch.zeros_like(generated_ids) for _ in range(dist.get_world_size())]
|
| 120 |
+
dist.all_gather(all_generated_ids, generated_ids)
|
| 121 |
+
all_generated_ids[dist.get_rank()] = generated_ids
|
| 122 |
+
generated_ids = torch.cat(all_generated_ids)
|
| 123 |
+
|
| 124 |
+
all_tgt_tokens = [torch.zeros_like(tgt_tokens) for _ in range(dist.get_world_size())]
|
| 125 |
+
dist.all_gather(all_tgt_tokens, tgt_tokens)
|
| 126 |
+
all_tgt_tokens[dist.get_rank()] = tgt_tokens
|
| 127 |
+
all_tgt_tokens = torch.cat(all_tgt_tokens)
|
| 128 |
+
|
| 129 |
+
all_image_paths = [[None for _ in image_paths] for _ in range(dist.get_world_size())]
|
| 130 |
+
dist.all_gather_object(all_image_paths, image_paths)
|
| 131 |
+
all_image_paths[dist.get_rank()] = image_paths
|
| 132 |
+
image_paths = []
|
| 133 |
+
for p in all_image_paths:
|
| 134 |
+
image_paths.extend(p)
|
| 135 |
+
else:
|
| 136 |
+
all_tgt_tokens = tgt_tokens
|
| 137 |
+
|
| 138 |
+
all_tgt_tokens[all_tgt_tokens == -100] = tokenizer.pad_token_id
|
| 139 |
+
generated_captions = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)
|
| 140 |
+
gt_captions = tokenizer.batch_decode(all_tgt_tokens, skip_special_tokens=True)
|
| 141 |
+
|
| 142 |
+
for cap_i in range(len(generated_captions)):
|
| 143 |
+
image_path = image_paths[cap_i]
|
| 144 |
+
all_generated_image_paths.append(image_path)
|
| 145 |
+
stop_idx = generated_captions[cap_i].find('.')
|
| 146 |
+
if stop_idx > 5:
|
| 147 |
+
all_generated_captions.append(generated_captions[cap_i][:stop_idx])
|
| 148 |
+
else:
|
| 149 |
+
all_generated_captions.append(generated_captions[cap_i])
|
| 150 |
+
all_gt_captions.append([gt_captions[cap_i]])
|
| 151 |
+
elif model_mode == 'retrieval':
|
| 152 |
+
if i == 0:
|
| 153 |
+
# Generate without image input to visualize text-generation ability.
|
| 154 |
+
input_ids = tgt_tokens[:, :3] # Use first 3 tokens as initial prompt for generation.
|
| 155 |
+
input_embs = model.module.model.input_embeddings(input_ids) # (N, T, D)
|
| 156 |
+
generated_ids, _, _ = model(input_embs, tgt_tokens, token_len, generate=True, num_words=num_words, temperature=0.0, top_p=1.0)
|
| 157 |
+
generated_ids = torch.cat([input_ids, generated_ids], dim=1)
|
| 158 |
+
generated_captions = tokenizer.batch_decode(generated_ids, skip_special_tokens=False)
|
| 159 |
+
gt_captions = tokenizer.batch_decode(tgt_tokens, skip_special_tokens=False)
|
| 160 |
+
else:
|
| 161 |
+
raise NotImplementedError
|
| 162 |
+
|
| 163 |
+
if i == 0:
|
| 164 |
+
max_to_display = 5
|
| 165 |
+
print('=' * 30)
|
| 166 |
+
print('Generated samples:')
|
| 167 |
+
for cap_i, cap in enumerate(generated_captions[:max_to_display]):
|
| 168 |
+
print(f'{cap_i}) {cap}')
|
| 169 |
+
print('=' * 30)
|
| 170 |
+
print('Real samples:')
|
| 171 |
+
for cap_i, cap in enumerate(gt_captions[:max_to_display]):
|
| 172 |
+
print(f'{cap_i}) {cap}')
|
| 173 |
+
print('=' * 30)
|
| 174 |
+
|
| 175 |
+
# Write images and captions to Tensorboard.
|
| 176 |
+
if not args.distributed or (args.rank % ngpus_per_node == 0):
|
| 177 |
+
max_images_to_show = 16
|
| 178 |
+
normalized_images = images - images.min()
|
| 179 |
+
normalized_images /= normalized_images.max() # (N, 3, H, W)
|
| 180 |
+
# Create generated caption text.
|
| 181 |
+
generated_cap_images = torch.stack([
|
| 182 |
+
utils.create_image_of_text(
|
| 183 |
+
generated_captions[j].encode('ascii', 'ignore'),
|
| 184 |
+
width=normalized_images.shape[3],
|
| 185 |
+
color=(255, 255, 0))
|
| 186 |
+
for j in range(normalized_images.shape[0])], axis=0)
|
| 187 |
+
# Append gt/generated caption images.
|
| 188 |
+
display_images = torch.cat([normalized_images.float().cpu(), caption_images, generated_cap_images], axis=2)[:max_images_to_show]
|
| 189 |
+
grid = torchvision.utils.make_grid(display_images, nrow=int(max_images_to_show ** 0.5), padding=4)
|
| 190 |
+
writer.add_image(f'val/images_{model_mode}', grid, actual_step)
|
| 191 |
+
|
| 192 |
+
# measure elapsed time
|
| 193 |
+
batch_time.update(time.time() - end)
|
| 194 |
+
end = time.time()
|
| 195 |
+
|
| 196 |
+
if i % args.print_freq == 0:
|
| 197 |
+
progress.display(i + 1)
|
| 198 |
+
|
| 199 |
+
if i == args.val_steps_per_epoch - 1:
|
| 200 |
+
break
|
| 201 |
+
|
| 202 |
+
# Measure captioning metrics.
|
| 203 |
+
path2captions = collections.defaultdict(list)
|
| 204 |
+
for image_path, caption in zip(all_generated_image_paths, all_gt_captions):
|
| 205 |
+
assert len(caption) == 1, caption
|
| 206 |
+
path2captions[image_path].append(caption[0].replace('[RET]', ''))
|
| 207 |
+
full_gt_captions = [path2captions[path] for path in all_generated_image_paths]
|
| 208 |
+
|
| 209 |
+
print(f'Computing BLEU with {len(all_generated_captions)} generated captions:'
|
| 210 |
+
f'{all_generated_captions[:5]} and {len(full_gt_captions)} groundtruth captions:',
|
| 211 |
+
f'{full_gt_captions[:5]}.')
|
| 212 |
+
bleu1_score = bleu_scorers[0](all_generated_captions, full_gt_captions)
|
| 213 |
+
bleu1.update(bleu1_score, 1)
|
| 214 |
+
bleu2_score = bleu_scorers[1](all_generated_captions, full_gt_captions)
|
| 215 |
+
bleu2.update(bleu2_score, 1)
|
| 216 |
+
bleu3_score = bleu_scorers[2](all_generated_captions, full_gt_captions)
|
| 217 |
+
bleu3.update(bleu3_score, 2)
|
| 218 |
+
bleu4_score = bleu_scorers[3](all_generated_captions, full_gt_captions)
|
| 219 |
+
bleu4.update(bleu4_score, 3)
|
| 220 |
+
|
| 221 |
+
# Measure retrieval metrics over the entire validation set.
|
| 222 |
+
all_image_features = torch.cat(all_image_features, axis=0) # (coco_val_len, 2048)
|
| 223 |
+
all_text_features = torch.cat(all_text_features, axis=0) # (coco_val_len, 2048)
|
| 224 |
+
|
| 225 |
+
print(f"Computing similarity between {all_image_features.shape} and {all_text_features.shape}.")
|
| 226 |
+
logits_per_image = all_image_features @ all_text_features.t()
|
| 227 |
+
logits_per_text = logits_per_image.t()
|
| 228 |
+
all_image_acc1, all_image_acc5 = losses_utils.contrastive_acc(logits_per_image, topk=(1, 5))
|
| 229 |
+
all_caption_acc1, all_caption_acc5 = losses_utils.contrastive_acc(logits_per_text, topk=(1, 5))
|
| 230 |
+
image_loss = losses_utils.contrastive_loss(logits_per_image)
|
| 231 |
+
caption_loss = losses_utils.contrastive_loss(logits_per_text)
|
| 232 |
+
|
| 233 |
+
loss = args.ret_loss_scale * (image_loss + caption_loss) / 2.0
|
| 234 |
+
losses.update(loss.item(), logits_per_image.size(0))
|
| 235 |
+
top1_caption.update(all_caption_acc1.item(), logits_per_image.size(0))
|
| 236 |
+
top5_caption.update(all_caption_acc5.item(), logits_per_image.size(0))
|
| 237 |
+
top1_image.update(all_image_acc1.item(), logits_per_image.size(0))
|
| 238 |
+
top5_image.update(all_image_acc5.item(), logits_per_image.size(0))
|
| 239 |
+
|
| 240 |
+
|
| 241 |
+
batch_time = utils.AverageMeter('Time', ':6.3f', utils.Summary.AVERAGE)
|
| 242 |
+
losses = utils.AverageMeter('Loss', ':.4e', utils.Summary.AVERAGE)
|
| 243 |
+
ce_losses = utils.AverageMeter('CeLoss', ':.4e', utils.Summary.AVERAGE)
|
| 244 |
+
top1 = utils.AverageMeter('Acc@1', ':6.2f', utils.Summary.AVERAGE)
|
| 245 |
+
top5 = utils.AverageMeter('Acc@5', ':6.2f', utils.Summary.AVERAGE)
|
| 246 |
+
bleu1 = utils.AverageMeter('BLEU@1', ':6.2f', utils.Summary.AVERAGE)
|
| 247 |
+
bleu2 = utils.AverageMeter('BLEU@2', ':6.2f', utils.Summary.AVERAGE)
|
| 248 |
+
bleu3 = utils.AverageMeter('BLEU@3', ':6.2f', utils.Summary.AVERAGE)
|
| 249 |
+
bleu4 = utils.AverageMeter('BLEU@4', ':6.2f', utils.Summary.AVERAGE)
|
| 250 |
+
top1_caption = utils.AverageMeter('CaptionAcc@1', ':6.2f', utils.Summary.AVERAGE)
|
| 251 |
+
top5_caption = utils.AverageMeter('CaptionAcc@5', ':6.2f', utils.Summary.AVERAGE)
|
| 252 |
+
top1_image = utils.AverageMeter('ImageAcc@1', ':6.2f', utils.Summary.AVERAGE)
|
| 253 |
+
top5_image = utils.AverageMeter('ImageAcc@5', ':6.2f', utils.Summary.AVERAGE)
|
| 254 |
+
|
| 255 |
+
progress = utils.ProgressMeter(
|
| 256 |
+
len(val_loader) + (args.distributed and (len(val_loader.sampler) * args.world_size < len(val_loader.dataset))),
|
| 257 |
+
[batch_time, losses, top1, top5, bleu4],
|
| 258 |
+
prefix='Test: ')
|
| 259 |
+
|
| 260 |
+
# switch to evaluate mode
|
| 261 |
+
model.eval()
|
| 262 |
+
|
| 263 |
+
run_validate(val_loader)
|
| 264 |
+
if args.distributed:
|
| 265 |
+
batch_time.all_reduce()
|
| 266 |
+
losses.all_reduce()
|
| 267 |
+
bleu1.all_reduce()
|
| 268 |
+
bleu2.all_reduce()
|
| 269 |
+
bleu3.all_reduce()
|
| 270 |
+
bleu4.all_reduce()
|
| 271 |
+
top1.all_reduce()
|
| 272 |
+
top5.all_reduce()
|
| 273 |
+
top1_caption.all_reduce()
|
| 274 |
+
top5_caption.all_reduce()
|
| 275 |
+
top1_image.all_reduce()
|
| 276 |
+
top5_image.all_reduce()
|
| 277 |
+
|
| 278 |
+
if args.distributed and (len(val_loader.sampler) * args.world_size < len(val_loader.dataset)):
|
| 279 |
+
aux_val_dataset = Subset(val_loader.dataset,
|
| 280 |
+
range(len(val_loader.sampler) * args.world_size, len(val_loader.dataset)))
|
| 281 |
+
aux_val_loader = torch.utils.data.DataLoader(
|
| 282 |
+
aux_val_dataset, batch_size=(args.val_batch_size or args.batch_size), shuffle=False,
|
| 283 |
+
num_workers=args.workers, pin_memory=True, collate_fn=data.collate_fn)
|
| 284 |
+
run_validate(aux_val_loader, len(val_loader))
|
| 285 |
+
|
| 286 |
+
progress.display_summary()
|
| 287 |
+
|
| 288 |
+
writer.add_scalar('val/total_secs_per_batch', batch_time.avg, actual_step)
|
| 289 |
+
writer.add_scalar('val/seq_top1_acc', top1.avg, actual_step)
|
| 290 |
+
writer.add_scalar('val/seq_top5_acc', top5.avg, actual_step)
|
| 291 |
+
writer.add_scalar('val/ce_loss', losses.avg, actual_step)
|
| 292 |
+
writer.add_scalar('val/bleu1', bleu1.avg, actual_step)
|
| 293 |
+
writer.add_scalar('val/bleu2', bleu2.avg, actual_step)
|
| 294 |
+
writer.add_scalar('val/bleu3', bleu3.avg, actual_step)
|
| 295 |
+
writer.add_scalar('val/bleu4', bleu4.avg, actual_step)
|
| 296 |
+
writer.add_scalar('val/contrastive_loss', losses.avg, actual_step)
|
| 297 |
+
writer.add_scalar('val/t2i_top1_acc', top1_caption.avg, actual_step)
|
| 298 |
+
writer.add_scalar('val/t2i_top5_acc', top5_caption.avg, actual_step)
|
| 299 |
+
writer.add_scalar('val/i2t_top1_acc', top1_image.avg, actual_step)
|
| 300 |
+
writer.add_scalar('val/i2t_top5_acc', top5_image.avg, actual_step)
|
| 301 |
+
writer.add_scalar('val/top1_acc', (top1_caption.avg + top1_image.avg) / 2.0, actual_step)
|
| 302 |
+
writer.add_scalar('val/top5_acc', (top5_caption.avg + top5_image.avg) / 2.0, actual_step)
|
| 303 |
+
|
| 304 |
+
writer.close()
|
| 305 |
+
|
| 306 |
+
# Use top1 accuracy as the metric for keeping the best checkpoint.
|
| 307 |
+
return top1_caption.avg
|
fromage/losses.py
ADDED
|
@@ -0,0 +1,44 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from typing import Optional
|
| 2 |
+
import torch
|
| 3 |
+
from fromage import utils
|
| 4 |
+
|
| 5 |
+
def contrastive_loss(logits: torch.Tensor) -> torch.Tensor:
|
| 6 |
+
return torch.nn.functional.cross_entropy(logits, torch.arange(len(logits), device=logits.device))
|
| 7 |
+
|
| 8 |
+
|
| 9 |
+
def contrastive_acc(logits: torch.Tensor, target: Optional[torch.Tensor] = None, topk=(1,)) -> torch.Tensor:
|
| 10 |
+
"""
|
| 11 |
+
Args:
|
| 12 |
+
logits: (N, N) predictions.
|
| 13 |
+
target: (N, num_correct_answers) labels.
|
| 14 |
+
"""
|
| 15 |
+
assert len(logits.shape) == 2, logits.shape
|
| 16 |
+
batch_size = logits.shape[0]
|
| 17 |
+
|
| 18 |
+
if target is None:
|
| 19 |
+
target = torch.arange(len(logits), device=logits.device)
|
| 20 |
+
return utils.accuracy(logits, target, -1, topk)
|
| 21 |
+
else:
|
| 22 |
+
assert len(target.shape) == 2, target.shape
|
| 23 |
+
with torch.no_grad():
|
| 24 |
+
maxk = max(topk)
|
| 25 |
+
if logits.shape[-1] < maxk:
|
| 26 |
+
print(f"[WARNING] Less than {maxk} predictions available. Using {logits.shape[-1]} for topk.")
|
| 27 |
+
maxk = min(maxk, logits.shape[-1])
|
| 28 |
+
|
| 29 |
+
# Take topk along the last dimension.
|
| 30 |
+
_, pred = logits.topk(maxk, -1, True, True) # (N, topk)
|
| 31 |
+
assert pred.shape == (batch_size, maxk)
|
| 32 |
+
|
| 33 |
+
target_expand = target[:, :, None].repeat(1, 1, maxk) # (N, num_correct_answers, topk)
|
| 34 |
+
pred_expand = pred[:, None, :].repeat(1, target.shape[1], 1) # (N, num_correct_answers, topk)
|
| 35 |
+
correct = pred_expand.eq(target_expand) # (N, num_correct_answers, topk)
|
| 36 |
+
correct = torch.any(correct, dim=1) # (N, topk)
|
| 37 |
+
|
| 38 |
+
res = []
|
| 39 |
+
for k in topk:
|
| 40 |
+
any_k_correct = torch.clamp(correct[:, :k].sum(1), max=1) # (N,)
|
| 41 |
+
correct_k = any_k_correct.float().sum(0, keepdim=True)
|
| 42 |
+
res.append(correct_k.mul_(100.0 / batch_size))
|
| 43 |
+
return res
|
| 44 |
+
|
fromage/models.py
ADDED
|
@@ -0,0 +1,658 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from typing import Callable, List, Optional, Tuple, Union
|
| 2 |
+
from collections import namedtuple
|
| 3 |
+
import json
|
| 4 |
+
import glob
|
| 5 |
+
import math
|
| 6 |
+
import numpy as np
|
| 7 |
+
import os
|
| 8 |
+
import torch
|
| 9 |
+
from torch import Tensor
|
| 10 |
+
import torch.nn as nn
|
| 11 |
+
import torch.nn.functional as F
|
| 12 |
+
from einops import rearrange
|
| 13 |
+
from functools import partial
|
| 14 |
+
import pickle as pkl
|
| 15 |
+
from PIL import Image, UnidentifiedImageError
|
| 16 |
+
|
| 17 |
+
from transformers import AutoConfig, AutoModel, AutoModelForCausalLM
|
| 18 |
+
from transformers import OPTForCausalLM, GPT2Tokenizer
|
| 19 |
+
from transformers import CLIPVisionModel, CLIPVisionConfig
|
| 20 |
+
|
| 21 |
+
from fromage import utils
|
| 22 |
+
|
| 23 |
+
|
| 24 |
+
class FrozenArgs:
|
| 25 |
+
freeze_lm: bool = True
|
| 26 |
+
freeze_vm: bool = True
|
| 27 |
+
opt_version: str = 'facebook/opt-6.7b'
|
| 28 |
+
visual_encoder: str = 'openai/clip-vit-large-patch14'
|
| 29 |
+
n_visual_tokens: int = 1
|
| 30 |
+
image_embed_dropout_prob: float = 0.0
|
| 31 |
+
task: str = 'captioning'
|
| 32 |
+
shared_emb_dim: Optional[int] = 256
|
| 33 |
+
text_emb_layers: List[int] = [-1]
|
| 34 |
+
retrieval_token_idx: int = 0
|
| 35 |
+
|
| 36 |
+
|
| 37 |
+
class FromageModel(nn.Module):
|
| 38 |
+
def __init__(self, tokenizer, args: FrozenArgs = FrozenArgs()):
|
| 39 |
+
super().__init__()
|
| 40 |
+
self.tokenizer = tokenizer
|
| 41 |
+
self.feature_extractor = utils.get_feature_extractor_for_model(args.visual_encoder, train=False)
|
| 42 |
+
self.image_token = self.tokenizer.cls_token_id
|
| 43 |
+
assert args.text_emb_layers != set(args.text_emb_layers), 'text_emb_layers not unique'
|
| 44 |
+
self.args = args
|
| 45 |
+
|
| 46 |
+
opt_version = args.opt_version
|
| 47 |
+
visual_encoder = args.visual_encoder
|
| 48 |
+
n_visual_tokens = args.n_visual_tokens
|
| 49 |
+
print(f"Using {opt_version} for the language model.")
|
| 50 |
+
print(f"Using {visual_encoder} for the visual model with {n_visual_tokens} visual tokens.")
|
| 51 |
+
|
| 52 |
+
self.logit_scale = nn.Parameter(torch.ones([]) * np.log(1 / 0.07))
|
| 53 |
+
|
| 54 |
+
if 'facebook/opt' in opt_version:
|
| 55 |
+
self.lm = OPTForCausalLM.from_pretrained(opt_version)
|
| 56 |
+
else:
|
| 57 |
+
raise NotImplementedError
|
| 58 |
+
|
| 59 |
+
self.opt_version = opt_version
|
| 60 |
+
|
| 61 |
+
if self.args.freeze_lm:
|
| 62 |
+
self.lm.eval()
|
| 63 |
+
print("Freezing the LM.")
|
| 64 |
+
for param in self.lm.parameters():
|
| 65 |
+
param.requires_grad = False
|
| 66 |
+
else:
|
| 67 |
+
self.lm.train()
|
| 68 |
+
|
| 69 |
+
self.retrieval_token_idx = args.retrieval_token_idx
|
| 70 |
+
print(f'Initializing embedding for the retrieval token [RET] (id = {self.retrieval_token_idx}).')
|
| 71 |
+
self.lm.resize_token_embeddings(len(tokenizer))
|
| 72 |
+
|
| 73 |
+
self.input_embeddings = self.lm.get_input_embeddings()
|
| 74 |
+
|
| 75 |
+
print("Restoring pretrained weights for the visual model.")
|
| 76 |
+
if 'clip' in visual_encoder:
|
| 77 |
+
self.visual_model = CLIPVisionModel.from_pretrained(visual_encoder)
|
| 78 |
+
else:
|
| 79 |
+
self.visual_model = AutoModel.from_pretrained(visual_encoder)
|
| 80 |
+
|
| 81 |
+
if 'clip' in visual_encoder:
|
| 82 |
+
hidden_size = self.visual_model.config.hidden_size
|
| 83 |
+
else:
|
| 84 |
+
raise NotImplementedError
|
| 85 |
+
|
| 86 |
+
if self.args.freeze_vm:
|
| 87 |
+
print("Freezing the VM.")
|
| 88 |
+
self.visual_model.eval()
|
| 89 |
+
for param in self.visual_model.parameters():
|
| 90 |
+
param.requires_grad = False
|
| 91 |
+
else:
|
| 92 |
+
self.visual_model.train()
|
| 93 |
+
|
| 94 |
+
self.visual_model_name = visual_encoder
|
| 95 |
+
|
| 96 |
+
embedding_dim = self.input_embeddings.embedding_dim * self.args.n_visual_tokens
|
| 97 |
+
self.text_hidden_fcs = nn.ModuleList([])
|
| 98 |
+
if self.args.shared_emb_dim is None:
|
| 99 |
+
if len(self.args.text_emb_layers) == 1:
|
| 100 |
+
if (self.args.text_emb_layers[0] in [-1, self.lm.config.num_hidden_layers]) and ('bert' not in opt_version):
|
| 101 |
+
out_dim = self.lm.config.word_embed_proj_dim
|
| 102 |
+
else:
|
| 103 |
+
out_dim = self.lm.config.hidden_size
|
| 104 |
+
else:
|
| 105 |
+
if (-1 in self.args.text_emb_layers) or (self.lm.config.num_hidden_layers in self.args.text_emb_layers) \
|
| 106 |
+
and (self.lm.config.word_embed_proj_dim != self.lm.config.hidden_size):
|
| 107 |
+
raise ValueError('No projection dim specified but model uses last output layer and an intermediate one (which have different dims).')
|
| 108 |
+
else:
|
| 109 |
+
out_dim = self.lm.config.hidden_size
|
| 110 |
+
else:
|
| 111 |
+
out_dim = self.args.shared_emb_dim
|
| 112 |
+
|
| 113 |
+
for layer_idx in self.args.text_emb_layers:
|
| 114 |
+
if (layer_idx == -1 or layer_idx == self.lm.config.num_hidden_layers) and ('bert' not in opt_version):
|
| 115 |
+
in_dim = self.lm.config.word_embed_proj_dim
|
| 116 |
+
|
| 117 |
+
text_fc = [nn.Linear(in_dim, out_dim), nn.Dropout(self.args.text_embed_dropout_prob)]
|
| 118 |
+
self.text_hidden_fcs.append(nn.Sequential(*text_fc))
|
| 119 |
+
|
| 120 |
+
elif layer_idx < self.lm.config.num_hidden_layers:
|
| 121 |
+
text_fc = [nn.Linear(self.lm.config.hidden_size, out_dim), nn.Dropout(self.args.text_embed_dropout_prob)]
|
| 122 |
+
self.text_hidden_fcs.append(nn.Sequential(*text_fc))
|
| 123 |
+
else:
|
| 124 |
+
raise ValueError(f'Embedding of layer {layer_idx} was requested but model only has {self.lm.config.num_hidden_layers} layers.')
|
| 125 |
+
|
| 126 |
+
self.visual_embeddings = nn.Linear(hidden_size, embedding_dim)
|
| 127 |
+
self.visual_fc = nn.Linear(hidden_size, out_dim)
|
| 128 |
+
|
| 129 |
+
self.image_dropout = nn.Dropout(self.args.image_embed_dropout_prob)
|
| 130 |
+
|
| 131 |
+
|
| 132 |
+
def get_visual_embs(self, pixel_values: torch.FloatTensor, mode: str = 'captioning'):
|
| 133 |
+
if mode not in ['captioning', 'retrieval']:
|
| 134 |
+
raise ValueError(f'mode should be one of ["caption", "retrieval"], got {mode} instead.')
|
| 135 |
+
|
| 136 |
+
# Extract visual embeddings from the vision encoder.
|
| 137 |
+
if 'clip' in self.visual_model_name:
|
| 138 |
+
outputs = self.visual_model(pixel_values)
|
| 139 |
+
encoder_outputs = outputs.pooler_output
|
| 140 |
+
else:
|
| 141 |
+
raise NotImplementedError
|
| 142 |
+
|
| 143 |
+
# Use the correct fc based on function argument.
|
| 144 |
+
if mode == 'captioning':
|
| 145 |
+
visual_embs = self.visual_embeddings(encoder_outputs) # (2, D * n_visual_tokens)
|
| 146 |
+
visual_embs = torch.reshape(visual_embs, (visual_embs.shape[0], self.args.n_visual_tokens, -1))
|
| 147 |
+
elif mode == 'retrieval':
|
| 148 |
+
visual_embs = self.visual_fc(encoder_outputs) # (2, D * n_visual_tokens)
|
| 149 |
+
visual_embs = torch.reshape(visual_embs, (visual_embs.shape[0], 1, -1))
|
| 150 |
+
else:
|
| 151 |
+
raise NotImplementedError
|
| 152 |
+
|
| 153 |
+
visual_embs = self.image_dropout(visual_embs)
|
| 154 |
+
return visual_embs
|
| 155 |
+
|
| 156 |
+
|
| 157 |
+
def train(self, mode=True):
|
| 158 |
+
super(FromageModel, self).train(mode=mode)
|
| 159 |
+
# Overwrite train() to ensure Frozen models remain frozen.
|
| 160 |
+
if self.args.freeze_lm:
|
| 161 |
+
self.lm.eval()
|
| 162 |
+
if self.args.freeze_vm:
|
| 163 |
+
self.visual_model.eval()
|
| 164 |
+
|
| 165 |
+
|
| 166 |
+
def forward(
|
| 167 |
+
self,
|
| 168 |
+
pixel_values: torch.FloatTensor,
|
| 169 |
+
labels: torch.LongTensor,
|
| 170 |
+
caption_len: torch.LongTensor,
|
| 171 |
+
mode: str = 'captioning',
|
| 172 |
+
concat_captions: bool = False,
|
| 173 |
+
input_prefix: Optional[str] = None,
|
| 174 |
+
inference: bool = False,
|
| 175 |
+
):
|
| 176 |
+
visual_embs = self.get_visual_embs(pixel_values, mode)
|
| 177 |
+
|
| 178 |
+
batch_size, vis_seq_len, _ = visual_embs.shape # vis_seq_len = n_visual_tokens
|
| 179 |
+
if labels is not None:
|
| 180 |
+
assert labels.shape[0] == batch_size, (visual_embs.shape, labels.shape)
|
| 181 |
+
|
| 182 |
+
input_embs = self.input_embeddings(labels) # (N, T, D)
|
| 183 |
+
|
| 184 |
+
last_embedding_idx = caption_len - 1 # -1 to retrieve the token before the eos token
|
| 185 |
+
|
| 186 |
+
if input_prefix is not None:
|
| 187 |
+
prompt_ids = self.tokenizer(input_prefix, add_special_tokens=False, return_tensors="pt").input_ids
|
| 188 |
+
prompt_ids = prompt_ids.to(visual_embs.device)
|
| 189 |
+
prompt_embs = self.input_embeddings(prompt_ids)
|
| 190 |
+
prompt_embs = prompt_embs.repeat(batch_size, 1, 1)
|
| 191 |
+
assert prompt_embs.shape[0] == batch_size, prompt_embs.shape
|
| 192 |
+
assert prompt_embs.shape[2] == input_embs.shape[2], prompt_embs.shape
|
| 193 |
+
assert len(prompt_embs.shape) == 3, prompt_embs.shape
|
| 194 |
+
|
| 195 |
+
if mode == 'captioning':
|
| 196 |
+
# Concat to text embeddings.
|
| 197 |
+
condition_seq_len = 0
|
| 198 |
+
if input_prefix is None:
|
| 199 |
+
# Just add visual embeddings.
|
| 200 |
+
input_embs = torch.cat([visual_embs, input_embs], axis=1)
|
| 201 |
+
last_embedding_idx += vis_seq_len
|
| 202 |
+
condition_seq_len += vis_seq_len
|
| 203 |
+
full_labels = torch.zeros(visual_embs.shape[:2], dtype=torch.int64).to(visual_embs.device) - 100
|
| 204 |
+
else:
|
| 205 |
+
# Add visual and prompt embeddings.
|
| 206 |
+
prefix_embs = torch.cat([visual_embs, prompt_embs], axis=1)
|
| 207 |
+
input_embs = torch.cat([prefix_embs, input_embs], axis=1)
|
| 208 |
+
|
| 209 |
+
last_embedding_idx += prefix_embs.shape[1]
|
| 210 |
+
condition_seq_len += prefix_embs.shape[1]
|
| 211 |
+
full_labels = torch.zeros(prefix_embs.shape[:2], dtype=torch.int64).to(visual_embs.device) - 100
|
| 212 |
+
|
| 213 |
+
# Mask out embedding tokens in the labels.
|
| 214 |
+
full_labels = torch.cat([full_labels, labels], axis=1)
|
| 215 |
+
|
| 216 |
+
pad_idx = []
|
| 217 |
+
|
| 218 |
+
for label in full_labels:
|
| 219 |
+
for k, token in enumerate(label):
|
| 220 |
+
# Mask out retrieval token if it exists.
|
| 221 |
+
if token in [self.tokenizer.pad_token_id, self.retrieval_token_idx]:
|
| 222 |
+
label[k:] = -100
|
| 223 |
+
pad_idx.append(k)
|
| 224 |
+
break
|
| 225 |
+
if k == len(label) - 1: # No padding found.
|
| 226 |
+
pad_idx.append(k + 1)
|
| 227 |
+
assert len(pad_idx) == batch_size, (len(pad_idx), batch_size)
|
| 228 |
+
|
| 229 |
+
bs, seq_len, embs_dim = input_embs.shape
|
| 230 |
+
if concat_captions:
|
| 231 |
+
assert len(input_embs.shape) == 3, input_embs
|
| 232 |
+
assert len(full_labels.shape) == 2, full_labels
|
| 233 |
+
assert batch_size % 2 == 0
|
| 234 |
+
all_concat_input_embs = []
|
| 235 |
+
all_concat_labels = []
|
| 236 |
+
|
| 237 |
+
# Rearrange embeddings and labels (and their padding) to concatenate captions.
|
| 238 |
+
for i in range(batch_size // 2):
|
| 239 |
+
first_idx = i * 2
|
| 240 |
+
second_idx = first_idx + 1
|
| 241 |
+
first_emb = input_embs[first_idx, :pad_idx[first_idx], :]
|
| 242 |
+
first_labels = full_labels[first_idx, :pad_idx[first_idx]]
|
| 243 |
+
first_padding = input_embs[first_idx, pad_idx[first_idx]:, :]
|
| 244 |
+
first_labels_padding = full_labels[first_idx, pad_idx[first_idx]:]
|
| 245 |
+
|
| 246 |
+
second_emb = input_embs[second_idx, :pad_idx[second_idx], :]
|
| 247 |
+
second_labels = full_labels[second_idx, :pad_idx[second_idx]]
|
| 248 |
+
second_padding = input_embs[second_idx, pad_idx[second_idx]:, :]
|
| 249 |
+
second_labels_padding = full_labels[second_idx, pad_idx[second_idx]:]
|
| 250 |
+
|
| 251 |
+
assert torch.all(first_labels_padding == -100), first_labels_padding
|
| 252 |
+
assert torch.all(second_labels_padding == -100), second_labels_padding
|
| 253 |
+
concat_input_embs = torch.cat([first_emb, second_emb, first_padding, second_padding], axis=0) # (T*2, 768)
|
| 254 |
+
concat_labels = torch.cat([first_labels, second_labels, first_labels_padding, second_labels_padding], axis=0) # (T*2, 768)
|
| 255 |
+
all_concat_input_embs.append(concat_input_embs)
|
| 256 |
+
all_concat_labels.append(concat_labels)
|
| 257 |
+
|
| 258 |
+
# Pad to max length.
|
| 259 |
+
input_embs = torch.stack(all_concat_input_embs, axis=0) # (N/2, T*2, 768)
|
| 260 |
+
full_labels = torch.stack(all_concat_labels, axis=0) # (N/2, T*2, 768)
|
| 261 |
+
assert input_embs.shape == (bs // 2, seq_len * 2, embs_dim), input_embs.shape
|
| 262 |
+
assert full_labels.shape == (bs // 2, seq_len * 2), full_labels.shape
|
| 263 |
+
|
| 264 |
+
output = self.lm(inputs_embeds=input_embs,
|
| 265 |
+
labels=full_labels,
|
| 266 |
+
output_hidden_states=True)
|
| 267 |
+
elif mode == 'retrieval':
|
| 268 |
+
full_labels = torch.clone(labels)
|
| 269 |
+
if input_prefix is not None:
|
| 270 |
+
print(f'Adding prefix "{input_prefix}" to retrieval.')
|
| 271 |
+
# Add prompt embeddings.
|
| 272 |
+
prefix_embs = prompt_embs
|
| 273 |
+
input_embs = torch.cat([prefix_embs, input_embs], axis=1)
|
| 274 |
+
last_embedding_idx += prefix_embs.shape[1]
|
| 275 |
+
full_labels = torch.cat([
|
| 276 |
+
torch.zeros(prefix_embs.shape[:2], dtype=torch.int64).to(labels.device) - 100,
|
| 277 |
+
full_labels
|
| 278 |
+
], axis=1)
|
| 279 |
+
|
| 280 |
+
pad_idx = []
|
| 281 |
+
for label in full_labels:
|
| 282 |
+
for k, token in enumerate(label):
|
| 283 |
+
if token == self.tokenizer.pad_token_id:
|
| 284 |
+
label[k:] = -100
|
| 285 |
+
pad_idx.append(k)
|
| 286 |
+
break
|
| 287 |
+
if k == len(label) - 1: # No padding found.
|
| 288 |
+
pad_idx.append(k + 1)
|
| 289 |
+
assert len(pad_idx) == batch_size, (len(pad_idx), batch_size)
|
| 290 |
+
|
| 291 |
+
output = self.lm(inputs_embeds=input_embs,
|
| 292 |
+
labels=full_labels,
|
| 293 |
+
output_hidden_states=True)
|
| 294 |
+
else:
|
| 295 |
+
raise NotImplementedError
|
| 296 |
+
|
| 297 |
+
last_embedding = None
|
| 298 |
+
last_output_logit = None
|
| 299 |
+
hidden_states = []
|
| 300 |
+
|
| 301 |
+
if mode == 'retrieval':
|
| 302 |
+
if self.args.shared_emb_dim is not None:
|
| 303 |
+
for idx, fc_layer in zip(self.args.text_emb_layers, self.text_hidden_fcs):
|
| 304 |
+
hidden_states.append(fc_layer(output.hidden_states[idx])) # (N, seq_len, 2048)
|
| 305 |
+
else:
|
| 306 |
+
for idx in self.args.text_emb_layers:
|
| 307 |
+
hidden_states.append(output.hidden_states[idx])
|
| 308 |
+
|
| 309 |
+
# Add hidden states together.
|
| 310 |
+
last_hidden_state = torch.stack(hidden_states, dim=-1).sum(dim=-1)
|
| 311 |
+
|
| 312 |
+
if not concat_captions:
|
| 313 |
+
last_embedding = torch.stack([last_hidden_state[i, last_embedding_idx[i], :] for i in range(batch_size)], axis=0) # (N, D)
|
| 314 |
+
last_output_logit = torch.stack([output.logits[i, last_embedding_idx[i] - 1, :] for i in range(batch_size)], axis=0) # (N, D)
|
| 315 |
+
else:
|
| 316 |
+
# Concatenate two captioning examples together.
|
| 317 |
+
all_last_embedding = []
|
| 318 |
+
all_last_output_logit = []
|
| 319 |
+
for i in range(batch_size // 2):
|
| 320 |
+
first_last_embedding_idx, second_last_embedding_idx = all_last_embedding_idx[i]
|
| 321 |
+
first_last_embedding = last_hidden_state[i, first_last_embedding_idx, :] # (N, D)
|
| 322 |
+
first_last_output_logit = output.logits[i, first_last_embedding_idx - 1, :] # (N, D)
|
| 323 |
+
second_last_embedding = last_hidden_state[i, second_last_embedding_idx, :] # (N, D)
|
| 324 |
+
second_last_output_logit = output.logits[i, second_last_embedding_idx - 1, :] # (N, D)
|
| 325 |
+
all_last_embedding.append(first_last_embedding)
|
| 326 |
+
all_last_embedding.append(second_last_embedding)
|
| 327 |
+
all_last_output_logit.append(first_last_output_logit)
|
| 328 |
+
all_last_output_logit.append(second_last_output_logit)
|
| 329 |
+
|
| 330 |
+
last_embedding = torch.stack(all_last_embedding)
|
| 331 |
+
last_output_logit = torch.stack(all_last_output_logit)
|
| 332 |
+
|
| 333 |
+
# Compute retrieval loss.
|
| 334 |
+
assert visual_embs.shape[1] == 1, visual_embs.shape
|
| 335 |
+
visual_embs = visual_embs[:, 0, :]
|
| 336 |
+
visual_embs = visual_embs / visual_embs.norm(dim=1, keepdim=True)
|
| 337 |
+
last_embedding = last_embedding / last_embedding.norm(dim=1, keepdim=True)
|
| 338 |
+
|
| 339 |
+
# cosine similarity as logits
|
| 340 |
+
logit_scale = self.logit_scale.exp()
|
| 341 |
+
visual_embs = logit_scale * visual_embs
|
| 342 |
+
elif mode == 'captioning':
|
| 343 |
+
pass
|
| 344 |
+
else:
|
| 345 |
+
raise NotImplementedError
|
| 346 |
+
|
| 347 |
+
return output, full_labels, last_embedding, last_output_logit, visual_embs
|
| 348 |
+
|
| 349 |
+
def generate(self, embeddings = torch.FloatTensor, max_len: int = 32,
|
| 350 |
+
temperature: float = 0.0, top_p: float = 1.0, min_word_tokens: int = 0,
|
| 351 |
+
ret_scale_factor: float = 1.0, filter_value: float = -float('Inf')):
|
| 352 |
+
"""Runs greedy decoding and returns generated captions.
|
| 353 |
+
|
| 354 |
+
Args:
|
| 355 |
+
embeddings: Input condition that the model uses for autoregressive generation.
|
| 356 |
+
max_len: Maximum number of tokens to generate.
|
| 357 |
+
temperature: Used to modulate logit distribution.
|
| 358 |
+
top_p: If set to < 1, the smallest set of tokens with highest probabilities that add up to top_p or higher are kept for generation.
|
| 359 |
+
min_word_tokens: Minimum number of words to generate before allowing a [RET] output.
|
| 360 |
+
ret_scale_factor: Proportion to scale [RET] token logits by. A higher value may increase the probability of the model generating [RET] outputs.
|
| 361 |
+
filter_value: Value to assign to tokens that should never be generated.
|
| 362 |
+
Outputs:
|
| 363 |
+
out: (N, T) int32 sequence of output tokens.
|
| 364 |
+
output_embeddings: (N, T, 256) sequence of text output embeddings.
|
| 365 |
+
"""
|
| 366 |
+
self.lm.eval()
|
| 367 |
+
|
| 368 |
+
with torch.no_grad(): # no tracking history
|
| 369 |
+
batch_size, s, _ = embeddings.shape
|
| 370 |
+
# init output with image tokens
|
| 371 |
+
out = None
|
| 372 |
+
past_key_values = None
|
| 373 |
+
output_embeddings = []
|
| 374 |
+
output_logits = []
|
| 375 |
+
|
| 376 |
+
for i in range(max_len):
|
| 377 |
+
if 'opt' in self.opt_version:
|
| 378 |
+
output = self.lm(inputs_embeds=embeddings, use_cache=False, output_hidden_states=True)
|
| 379 |
+
else:
|
| 380 |
+
if i == 0:
|
| 381 |
+
output = self.lm(inputs_embeds=embeddings, use_cache=True, past_key_values=None, output_hidden_states=True)
|
| 382 |
+
else:
|
| 383 |
+
output = self.lm(input_ids=out[:, -1:], use_cache=True, past_key_values=past_key_values, output_hidden_states=True)
|
| 384 |
+
|
| 385 |
+
# Collect and sum the hidden states.
|
| 386 |
+
hidden_states = []
|
| 387 |
+
if self.args.shared_emb_dim is not None:
|
| 388 |
+
for idx, fc_layer in zip(self.args.text_emb_layers, self.text_hidden_fcs):
|
| 389 |
+
hidden_states.append(fc_layer(output.hidden_states[idx])) # (N, seq_len, 2048)
|
| 390 |
+
else:
|
| 391 |
+
for idx in self.args.text_emb_layers:
|
| 392 |
+
hidden_states.append(output.hidden_states[idx])
|
| 393 |
+
# Add hidden states together.
|
| 394 |
+
last_hidden_state = torch.stack(hidden_states, dim=-1).sum(dim=-1) # (N, T, 256)
|
| 395 |
+
last_embedding = last_hidden_state / last_hidden_state.norm(dim=-1, keepdim=True)
|
| 396 |
+
output_embeddings.append(last_embedding)
|
| 397 |
+
|
| 398 |
+
logits = output.logits[:, -1, :] # (N, vocab_size)
|
| 399 |
+
if top_p == 1.0:
|
| 400 |
+
logits = logits.cpu()
|
| 401 |
+
output_logits.append(logits)
|
| 402 |
+
|
| 403 |
+
if self.retrieval_token_idx != -1 and self.retrieval_token_idx is not None:
|
| 404 |
+
if i < min_word_tokens:
|
| 405 |
+
# Eliminate probability of generating [RET] if this is earlier than min_word_tokens.
|
| 406 |
+
logits[:, self.retrieval_token_idx] = filter_value
|
| 407 |
+
else:
|
| 408 |
+
# Multiply by scaling factor.
|
| 409 |
+
logits[:, self.retrieval_token_idx] = logits[:, self.retrieval_token_idx] * ret_scale_factor
|
| 410 |
+
|
| 411 |
+
past_key_values = output.past_key_values
|
| 412 |
+
|
| 413 |
+
if temperature == 0.0:
|
| 414 |
+
if top_p != 1.0:
|
| 415 |
+
raise ValueError('top_p cannot be set if temperature is 0 (greedy decoding).')
|
| 416 |
+
next_token = torch.argmax(logits, keepdim=True, dim=-1) # (N, 1)
|
| 417 |
+
else:
|
| 418 |
+
logits = logits / temperature
|
| 419 |
+
|
| 420 |
+
# Apply top-p filtering.
|
| 421 |
+
if top_p < 1.0:
|
| 422 |
+
assert top_p > 0, f'top_p should be above 0, got {top_p} instead.'
|
| 423 |
+
sorted_logits, sorted_indices = torch.sort(logits, descending=True) # (N, D) and (N, D)
|
| 424 |
+
cumulative_probs = torch.cumsum(F.softmax(sorted_logits, dim=-1), dim=-1) # (N, D)
|
| 425 |
+
|
| 426 |
+
# Remove tokens with cumulative probability above the threshold
|
| 427 |
+
sorted_indices_to_remove = cumulative_probs > top_p
|
| 428 |
+
# Shift the indices to the right to keep also the first token above the threshold
|
| 429 |
+
sorted_indices_to_remove[..., 1:] = sorted_indices_to_remove[..., :-1].clone()
|
| 430 |
+
sorted_indices_to_remove[..., 0] = 0
|
| 431 |
+
|
| 432 |
+
for j in range(sorted_indices.shape[0]):
|
| 433 |
+
indices_to_remove = sorted_indices[j, sorted_indices_to_remove[j, :]]
|
| 434 |
+
logits[j, indices_to_remove] = filter_value
|
| 435 |
+
|
| 436 |
+
token_weights = logits.exp() # (N, vocab_size)
|
| 437 |
+
next_token = torch.multinomial(token_weights, 1) # (N, 1)
|
| 438 |
+
|
| 439 |
+
next_token = next_token.long().to(embeddings.device)
|
| 440 |
+
if out is not None:
|
| 441 |
+
out = torch.cat([out, next_token], dim=-1)
|
| 442 |
+
else:
|
| 443 |
+
out = next_token
|
| 444 |
+
|
| 445 |
+
if 'opt' in self.opt_version:
|
| 446 |
+
next_embedding = self.input_embeddings(next_token)
|
| 447 |
+
embeddings = torch.cat([embeddings, next_embedding], dim=1)
|
| 448 |
+
elif (self.tokenizer.eos_token_id and (next_token == self.tokenizer.eos_token_id).all()):
|
| 449 |
+
# End of generation.
|
| 450 |
+
break
|
| 451 |
+
|
| 452 |
+
return out, output_embeddings, output_logits
|
| 453 |
+
|
| 454 |
+
|
| 455 |
+
class Fromage(nn.Module):
|
| 456 |
+
def __init__(self, tokenizer, model_args: Optional[FrozenArgs] = None,
|
| 457 |
+
path_array: Optional[List[str]] = None, emb_matrix: Optional[torch.tensor] = None):
|
| 458 |
+
super().__init__()
|
| 459 |
+
self.model = FromageModel(tokenizer, model_args)
|
| 460 |
+
self.path_array = path_array
|
| 461 |
+
self.emb_matrix = emb_matrix
|
| 462 |
+
|
| 463 |
+
def __call__(self, images: Tensor, tgt_tokens: Optional[Tensor] = None, caption_len: Optional[Tensor] = None,
|
| 464 |
+
generate: bool = False, num_words: int = 32, temperature: float = 1.0, top_p: float = 1.0,
|
| 465 |
+
ret_scale_factor: float = 1.0, min_word_tokens: int = 0,
|
| 466 |
+
mode: str = 'captioning', concat_captions: bool = False,
|
| 467 |
+
input_prefix: Optional[str] = None, inference: bool = False) -> Tensor:
|
| 468 |
+
if generate:
|
| 469 |
+
return self.model.generate(images, num_words, temperature=temperature, top_p=top_p,
|
| 470 |
+
min_word_tokens=min_word_tokens, ret_scale_factor=ret_scale_factor)
|
| 471 |
+
else:
|
| 472 |
+
output = self.model(
|
| 473 |
+
pixel_values = images,
|
| 474 |
+
labels = tgt_tokens,
|
| 475 |
+
caption_len = caption_len,
|
| 476 |
+
mode = mode,
|
| 477 |
+
concat_captions = concat_captions,
|
| 478 |
+
input_prefix = input_prefix,
|
| 479 |
+
inference = inference)
|
| 480 |
+
return output
|
| 481 |
+
|
| 482 |
+
def generate_for_images_and_texts(
|
| 483 |
+
self, prompts: List, num_words: int = 0, ret_scale_factor: float = 1.0, top_p: float = 1.0, temperature: float = 0.0,
|
| 484 |
+
max_num_rets: int = 1):
|
| 485 |
+
"""
|
| 486 |
+
Encode prompts into embeddings.
|
| 487 |
+
|
| 488 |
+
Args:
|
| 489 |
+
prompts: List of interleaved PIL.Image.Image and strings representing input to the model.
|
| 490 |
+
num_words: Maximum number of words to generate for. If num_words = 0, the model will run its forward pass and return the outputs.
|
| 491 |
+
ret_scale_factor: Proportion to scale [RET] token logits by. A higher value may increase the probability of the model generating [RET] outputs.
|
| 492 |
+
top_p: If set to < 1, the smallest set of tokens with highest probabilities that add up to top_p or higher are kept for generation.
|
| 493 |
+
temperature: Used to modulate logit distribution.
|
| 494 |
+
max_num_rets: Maximum number of images to return in one generation pass.
|
| 495 |
+
Returns:
|
| 496 |
+
return_outputs: List consisting of either str or List[PIL.Image.Image] objects, representing image-text interleaved model outputs.
|
| 497 |
+
"""
|
| 498 |
+
input_embs = []
|
| 499 |
+
input_ids = []
|
| 500 |
+
add_bos = True
|
| 501 |
+
|
| 502 |
+
for i, p in enumerate(prompts):
|
| 503 |
+
if type(p) == Image.Image:
|
| 504 |
+
# Encode as image.
|
| 505 |
+
pixel_values = utils.get_pixel_values_for_model(self.model.feature_extractor, p)
|
| 506 |
+
pixel_values = pixel_values.to(device=self.model.logit_scale.device, dtype=self.model.logit_scale.dtype)
|
| 507 |
+
pixel_values = pixel_values[None, ...]
|
| 508 |
+
|
| 509 |
+
visual_embs = self.model.get_visual_embs(pixel_values, mode='captioning') # (1, n_visual_tokens, D)
|
| 510 |
+
input_embs.append(visual_embs)
|
| 511 |
+
elif type(p) == str:
|
| 512 |
+
text_ids = self.model.tokenizer(p, add_special_tokens=True, return_tensors="pt").input_ids.to(self.model.logit_scale.device)
|
| 513 |
+
if not add_bos:
|
| 514 |
+
# Remove <bos> tag.
|
| 515 |
+
text_ids = text_ids[:, 1:]
|
| 516 |
+
else:
|
| 517 |
+
# Only add <bos> once.
|
| 518 |
+
add_bos = False
|
| 519 |
+
|
| 520 |
+
text_embs = self.model.input_embeddings(text_ids) # (1, T, D)
|
| 521 |
+
input_embs.append(text_embs)
|
| 522 |
+
input_ids.append(text_ids)
|
| 523 |
+
else:
|
| 524 |
+
raise ValueError(f'Input prompts should be either PIL.Image.Image or str types, got {type(p)} instead.')
|
| 525 |
+
input_embs = torch.cat(input_embs, dim=1)
|
| 526 |
+
input_ids = torch.cat(input_ids, dim=1)
|
| 527 |
+
|
| 528 |
+
if num_words == 0:
|
| 529 |
+
generated_ids = input_ids
|
| 530 |
+
outputs = self.model.lm(inputs_embeds=input_embs, use_cache=False, output_hidden_states=True)
|
| 531 |
+
# Map outputs to embeddings, so we can retrieve embeddings from the [RET] tokens.
|
| 532 |
+
out = []
|
| 533 |
+
for x, fc in zip(self.model.args.text_emb_layers, self.model.text_hidden_fcs):
|
| 534 |
+
out.append(fc(outputs.hidden_states[x]))
|
| 535 |
+
embeddings = torch.stack(out, dim=-1).sum(dim=-1)
|
| 536 |
+
embeddings = embeddings / embeddings.norm(dim=-1, keepdim=True) # (N, T, 256)
|
| 537 |
+
elif num_words > 0:
|
| 538 |
+
generated_ids, generated_embeddings, _ = self.model.generate(input_embs, num_words,
|
| 539 |
+
temperature=temperature, top_p=top_p, ret_scale_factor=ret_scale_factor)
|
| 540 |
+
embeddings = generated_embeddings[-1][:, input_embs.shape[1]:]
|
| 541 |
+
|
| 542 |
+
# Truncate to newline.
|
| 543 |
+
newline_token_id = self.model.tokenizer('\n', add_special_tokens=False).input_ids[0]
|
| 544 |
+
trunc_idx = 0
|
| 545 |
+
for j in range(generated_ids.shape[1]):
|
| 546 |
+
if generated_ids[0, j] == newline_token_id:
|
| 547 |
+
trunc_idx = j
|
| 548 |
+
break
|
| 549 |
+
if trunc_idx > 0:
|
| 550 |
+
generated_ids = generated_ids[:, :trunc_idx]
|
| 551 |
+
embeddings = embeddings[:, :trunc_idx]
|
| 552 |
+
else:
|
| 553 |
+
raise ValueError
|
| 554 |
+
|
| 555 |
+
# Save outputs as an interleaved list.
|
| 556 |
+
return_outputs = []
|
| 557 |
+
# Find up to max_num_rets [RET] tokens, and their corresponding scores.
|
| 558 |
+
all_ret_idx = [i for i, x in enumerate(generated_ids[0, :] == self.model.retrieval_token_idx) if x][:max_num_rets]
|
| 559 |
+
seen_image_idx = [] # Avoid showing the same image multiple times.
|
| 560 |
+
|
| 561 |
+
last_ret_idx = 0
|
| 562 |
+
if len(all_ret_idx) == 0:
|
| 563 |
+
# No [RET] tokens.
|
| 564 |
+
caption = self.model.tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
|
| 565 |
+
return_outputs.append(utils.truncate_caption(caption))
|
| 566 |
+
else:
|
| 567 |
+
for ret_idx in all_ret_idx:
|
| 568 |
+
ret_emb = embeddings[:, ret_idx, :]
|
| 569 |
+
scores = self.emb_matrix @ ret_emb.T
|
| 570 |
+
|
| 571 |
+
# Downweight seen images.
|
| 572 |
+
for seen_idx in seen_image_idx:
|
| 573 |
+
scores[seen_idx, :] -= 1000
|
| 574 |
+
|
| 575 |
+
# Get the top 3 images for each image.
|
| 576 |
+
_, top_image_idx = scores.squeeze().topk(3)
|
| 577 |
+
image_outputs = []
|
| 578 |
+
for img_idx in top_image_idx:
|
| 579 |
+
# Find the first image that does not error out.
|
| 580 |
+
try:
|
| 581 |
+
seen_image_idx.append(img_idx)
|
| 582 |
+
img = utils.get_image_from_url(self.path_array[img_idx])
|
| 583 |
+
image_outputs.append(img)
|
| 584 |
+
if len(image_outputs) == max_num_rets:
|
| 585 |
+
break
|
| 586 |
+
except UnidentifiedImageError:
|
| 587 |
+
pass
|
| 588 |
+
|
| 589 |
+
caption = self.model.tokenizer.batch_decode(generated_ids[:, last_ret_idx:ret_idx], skip_special_tokens=True)[0]
|
| 590 |
+
last_ret_idx = ret_idx + 1
|
| 591 |
+
return_outputs.append(utils.truncate_caption(caption) + ' [RET]')
|
| 592 |
+
return_outputs.append(image_outputs)
|
| 593 |
+
|
| 594 |
+
return return_outputs
|
| 595 |
+
|
| 596 |
+
|
| 597 |
+
def load_fromage(model_dir: str, ckpt_path: str) -> Fromage:
|
| 598 |
+
model_args_path = os.path.join(model_dir, 'model_args.json')
|
| 599 |
+
model_ckpt_path = os.path.join(ckpt_path)
|
| 600 |
+
embs_paths = [s for s in glob.glob(os.path.join(model_dir, 'cc3m_embeddings*.pkl'))]
|
| 601 |
+
|
| 602 |
+
if not os.path.exists(model_args_path):
|
| 603 |
+
raise ValueError(f'model_args.json does not exist in {model_dir}.')
|
| 604 |
+
if not os.path.exists(model_ckpt_path):
|
| 605 |
+
raise ValueError(f'pretrained_ckpt.pth.tar does not exist in {model_dir}.')
|
| 606 |
+
if len(embs_paths) == 0:
|
| 607 |
+
raise ValueError(f'cc3m_embeddings_*.pkl files do not exist in {model_dir}.')
|
| 608 |
+
|
| 609 |
+
# Load embeddings.
|
| 610 |
+
# Construct embedding matrix for nearest neighbor lookup.
|
| 611 |
+
path_array = []
|
| 612 |
+
emb_matrix = []
|
| 613 |
+
|
| 614 |
+
# These were precomputed for all CC3M images with `model.get_visual_embs(image, mode='retrieval')`.
|
| 615 |
+
for p in embs_paths:
|
| 616 |
+
with open(p, 'rb') as wf:
|
| 617 |
+
train_embs_data = pkl.load(wf)
|
| 618 |
+
path_array.extend(train_embs_data['paths'])
|
| 619 |
+
emb_matrix.append(train_embs_data['embeddings'])
|
| 620 |
+
emb_matrix = np.concatenate(emb_matrix, axis=0)
|
| 621 |
+
|
| 622 |
+
# Number of paths should be equal to number of embeddings.
|
| 623 |
+
assert len(path_array) == emb_matrix.shape[0], (len(path_array), emb_matrix.shape[0])
|
| 624 |
+
|
| 625 |
+
with open(model_args_path, 'r') as f:
|
| 626 |
+
model_kwargs = json.load(f)
|
| 627 |
+
|
| 628 |
+
# Initialize tokenizer.
|
| 629 |
+
tokenizer = GPT2Tokenizer.from_pretrained(model_kwargs['opt_version'])
|
| 630 |
+
tokenizer.pad_token = tokenizer.eos_token
|
| 631 |
+
# Add special tokens to the model to enable [RET].
|
| 632 |
+
tokenizer.add_special_tokens({"cls_token": "<|image|>"})
|
| 633 |
+
tokenizer.add_tokens('[RET]')
|
| 634 |
+
ret_token_idx = tokenizer('[RET]', add_special_tokens=False).input_ids
|
| 635 |
+
assert len(ret_token_idx) == 1, ret_token_idx
|
| 636 |
+
model_kwargs['retrieval_token_idx'] = ret_token_idx[0]
|
| 637 |
+
args = namedtuple('args', model_kwargs)(**model_kwargs)
|
| 638 |
+
|
| 639 |
+
# Initialize model for inference.
|
| 640 |
+
model = Fromage(tokenizer, args, path_array=path_array, emb_matrix=emb_matrix)
|
| 641 |
+
model = model.eval()
|
| 642 |
+
model = model.bfloat16()
|
| 643 |
+
model = model.cuda()
|
| 644 |
+
|
| 645 |
+
# Load pretrained linear mappings and [RET] embeddings.
|
| 646 |
+
checkpoint = torch.load(model_ckpt_path)
|
| 647 |
+
model.load_state_dict(checkpoint['state_dict'], strict=False)
|
| 648 |
+
with torch.no_grad():
|
| 649 |
+
model.model.input_embeddings.weight[model.model.retrieval_token_idx, :].copy_(checkpoint['state_dict']['ret_input_embeddings.weight'].cpu().detach())
|
| 650 |
+
|
| 651 |
+
logit_scale = model.model.logit_scale.exp()
|
| 652 |
+
emb_matrix = torch.tensor(emb_matrix, dtype=logit_scale.dtype).to(logit_scale.device)
|
| 653 |
+
emb_matrix = emb_matrix / emb_matrix.norm(dim=1, keepdim=True)
|
| 654 |
+
emb_matrix = logit_scale * emb_matrix
|
| 655 |
+
model.emb_matrix = emb_matrix
|
| 656 |
+
|
| 657 |
+
return model
|
| 658 |
+
|
fromage/utils.py
ADDED
|
@@ -0,0 +1,250 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from enum import Enum
|
| 2 |
+
import subprocess
|
| 3 |
+
import sys
|
| 4 |
+
import shutil
|
| 5 |
+
import torch
|
| 6 |
+
import torch.distributed as dist
|
| 7 |
+
from torchvision.transforms import functional as F
|
| 8 |
+
from torchvision import transforms as T
|
| 9 |
+
from transformers import AutoFeatureExtractor
|
| 10 |
+
from PIL import Image, ImageDraw, ImageFont, ImageOps
|
| 11 |
+
import requests
|
| 12 |
+
from io import BytesIO
|
| 13 |
+
|
| 14 |
+
import random
|
| 15 |
+
|
| 16 |
+
|
| 17 |
+
def dump_git_status(out_file=sys.stdout, exclude_file_patterns=['*.ipynb', '*.th', '*.sh', '*.txt', '*.json']):
|
| 18 |
+
"""Logs git status to stdout."""
|
| 19 |
+
subprocess.call('git rev-parse HEAD', shell=True, stdout=out_file)
|
| 20 |
+
subprocess.call('echo', shell=True, stdout=out_file)
|
| 21 |
+
exclude_string = ''
|
| 22 |
+
subprocess.call('git --no-pager diff -- . {}'.format(exclude_string), shell=True, stdout=out_file)
|
| 23 |
+
|
| 24 |
+
|
| 25 |
+
def get_image_from_url(url: str):
|
| 26 |
+
response = requests.get(url)
|
| 27 |
+
img = Image.open(BytesIO(response.content))
|
| 28 |
+
img = img.resize((224, 224))
|
| 29 |
+
img = img.convert('RGB')
|
| 30 |
+
return img
|
| 31 |
+
|
| 32 |
+
|
| 33 |
+
def truncate_caption(caption: str) -> str:
|
| 34 |
+
"""Truncate captions at periods and newlines."""
|
| 35 |
+
trunc_index = caption.find('\n') + 1
|
| 36 |
+
if trunc_index <= 0:
|
| 37 |
+
trunc_index = caption.find('.') + 1
|
| 38 |
+
caption = caption[:trunc_index]
|
| 39 |
+
return caption
|
| 40 |
+
|
| 41 |
+
|
| 42 |
+
def pad_to_size(x, size=256):
|
| 43 |
+
delta_w = size - x.size[0]
|
| 44 |
+
delta_h = size - x.size[1]
|
| 45 |
+
padding = (
|
| 46 |
+
delta_w // 2,
|
| 47 |
+
delta_h // 2,
|
| 48 |
+
delta_w - (delta_w // 2),
|
| 49 |
+
delta_h - (delta_h // 2),
|
| 50 |
+
)
|
| 51 |
+
new_im = ImageOps.expand(x, padding)
|
| 52 |
+
return new_im
|
| 53 |
+
|
| 54 |
+
|
| 55 |
+
class RandCropResize(object):
|
| 56 |
+
|
| 57 |
+
"""
|
| 58 |
+
Randomly crops, then randomly resizes, then randomly crops again, an image. Mirroring the augmentations from https://arxiv.org/abs/2102.12092
|
| 59 |
+
"""
|
| 60 |
+
|
| 61 |
+
def __init__(self, target_size):
|
| 62 |
+
self.target_size = target_size
|
| 63 |
+
|
| 64 |
+
def __call__(self, img):
|
| 65 |
+
img = pad_to_size(img, self.target_size)
|
| 66 |
+
d_min = min(img.size)
|
| 67 |
+
img = T.RandomCrop(size=d_min)(img)
|
| 68 |
+
t_min = min(d_min, round(9 / 8 * self.target_size))
|
| 69 |
+
t_max = min(d_min, round(12 / 8 * self.target_size))
|
| 70 |
+
t = random.randint(t_min, t_max + 1)
|
| 71 |
+
img = T.Resize(t)(img)
|
| 72 |
+
if min(img.size) < 256:
|
| 73 |
+
img = T.Resize(256)(img)
|
| 74 |
+
return T.RandomCrop(size=self.target_size)(img)
|
| 75 |
+
|
| 76 |
+
|
| 77 |
+
class SquarePad(object):
|
| 78 |
+
"""Pads image to square.
|
| 79 |
+
From https://discuss.pytorch.org/t/how-to-resize-and-pad-in-a-torchvision-transforms-compose/71850/9
|
| 80 |
+
"""
|
| 81 |
+
def __call__(self, image):
|
| 82 |
+
max_wh = max(image.size)
|
| 83 |
+
p_left, p_top = [(max_wh - s) // 2 for s in image.size]
|
| 84 |
+
p_right, p_bottom = [max_wh - (s+pad) for s, pad in zip(image.size, [p_left, p_top])]
|
| 85 |
+
padding = (p_left, p_top, p_right, p_bottom)
|
| 86 |
+
return F.pad(image, padding, 0, 'constant')
|
| 87 |
+
|
| 88 |
+
|
| 89 |
+
def create_image_of_text(text: str, width: int = 224, nrows: int = 2, color=(255, 255, 255), font=None) -> torch.Tensor:
|
| 90 |
+
"""Creates a (3, nrows * 14, width) image of text.
|
| 91 |
+
|
| 92 |
+
Returns:
|
| 93 |
+
cap_img: (3, 14 * nrows, width) image of wrapped text.
|
| 94 |
+
"""
|
| 95 |
+
height = 12
|
| 96 |
+
padding = 5
|
| 97 |
+
effective_width = width - 2 * padding
|
| 98 |
+
# Create a black image to draw text on.
|
| 99 |
+
cap_img = Image.new('RGB', (effective_width * nrows, height), color = (0, 0, 0))
|
| 100 |
+
draw = ImageDraw.Draw(cap_img)
|
| 101 |
+
draw.text((0, 0), text, color, font=font or ImageFont.load_default())
|
| 102 |
+
cap_img = F.convert_image_dtype(F.pil_to_tensor(cap_img), torch.float32) # (3, height, W * nrows)
|
| 103 |
+
cap_img = torch.split(cap_img, effective_width, dim=-1) # List of nrow elements of shape (3, height, W)
|
| 104 |
+
cap_img = torch.cat(cap_img, dim=1) # (3, height * nrows, W)
|
| 105 |
+
# Add zero padding.
|
| 106 |
+
cap_img = torch.nn.functional.pad(cap_img, [padding, padding, 0, padding])
|
| 107 |
+
return cap_img
|
| 108 |
+
|
| 109 |
+
|
| 110 |
+
def get_feature_extractor_for_model(model_name: str, image_size: int = 224, train: bool = True):
|
| 111 |
+
print(f'Using HuggingFace AutoFeatureExtractor for {model_name}.')
|
| 112 |
+
feature_extractor = AutoFeatureExtractor.from_pretrained(model_name)
|
| 113 |
+
return feature_extractor
|
| 114 |
+
|
| 115 |
+
|
| 116 |
+
def get_pixel_values_for_model(feature_extractor, img):
|
| 117 |
+
pixel_values = feature_extractor(
|
| 118 |
+
img.convert('RGB'),
|
| 119 |
+
return_tensors="pt").pixel_values[0, ...] # (3, H, W)
|
| 120 |
+
return pixel_values
|
| 121 |
+
|
| 122 |
+
|
| 123 |
+
def save_checkpoint(state, is_best, filename='checkpoint'):
|
| 124 |
+
torch.save(state, filename + '.pth.tar')
|
| 125 |
+
if is_best:
|
| 126 |
+
shutil.copyfile(filename + '.pth.tar', filename + '_best.pth.tar')
|
| 127 |
+
|
| 128 |
+
|
| 129 |
+
def accuracy(output, target, padding, topk=(1,)):
|
| 130 |
+
"""Computes the accuracy over the k top predictions for the specified values of k"""
|
| 131 |
+
with torch.no_grad():
|
| 132 |
+
maxk = max(topk)
|
| 133 |
+
if output.shape[-1] < maxk:
|
| 134 |
+
print(f"[WARNING] Less than {maxk} predictions available. Using {output.shape[-1]} for topk.")
|
| 135 |
+
|
| 136 |
+
maxk = min(maxk, output.shape[-1])
|
| 137 |
+
batch_size = target.size(0)
|
| 138 |
+
|
| 139 |
+
# Take topk along the last dimension.
|
| 140 |
+
_, pred = output.topk(maxk, -1, True, True) # (N, T, topk)
|
| 141 |
+
|
| 142 |
+
mask = (target != padding).type(target.dtype)
|
| 143 |
+
target_expand = target[..., None].expand_as(pred)
|
| 144 |
+
correct = pred.eq(target_expand)
|
| 145 |
+
correct = correct * mask[..., None].expand_as(correct)
|
| 146 |
+
|
| 147 |
+
res = []
|
| 148 |
+
for k in topk:
|
| 149 |
+
correct_k = correct[..., :k].reshape(-1).float().sum(0, keepdim=True)
|
| 150 |
+
res.append(correct_k.mul_(100.0 / mask.sum()))
|
| 151 |
+
return res
|
| 152 |
+
|
| 153 |
+
|
| 154 |
+
def get_params_count(model, max_name_len: int = 60):
|
| 155 |
+
params = [(name[:max_name_len], p.numel(), str(tuple(p.shape)), p.requires_grad) for name, p in model.named_parameters()]
|
| 156 |
+
total_trainable_params = sum([x[1] for x in params if x[-1]])
|
| 157 |
+
total_nontrainable_params = sum([x[1] for x in params if not x[-1]])
|
| 158 |
+
return params, total_trainable_params, total_nontrainable_params
|
| 159 |
+
|
| 160 |
+
|
| 161 |
+
def get_params_count_str(model, max_name_len: int = 60):
|
| 162 |
+
padding = 70 # Hardcoded depending on desired amount of padding and separators.
|
| 163 |
+
params, total_trainable_params, total_nontrainable_params = get_params_count(model, max_name_len)
|
| 164 |
+
param_counts_text = ''
|
| 165 |
+
param_counts_text += '=' * (max_name_len + padding) + '\n'
|
| 166 |
+
param_counts_text += f'| {"Module":<{max_name_len}} | {"Trainable":<10} | {"Shape":>15} | {"Param Count":>12} |\n'
|
| 167 |
+
param_counts_text += '-' * (max_name_len + padding) + '\n'
|
| 168 |
+
for name, param_count, shape, trainable in params:
|
| 169 |
+
param_counts_text += f'| {name:<{max_name_len}} | {"True" if trainable else "False":<10} | {shape:>15} | {param_count:>12,} |\n'
|
| 170 |
+
param_counts_text += '-' * (max_name_len + padding) + '\n'
|
| 171 |
+
param_counts_text += f'| {"Total trainable params":<{max_name_len}} | {"":<10} | {"":<15} | {total_trainable_params:>12,} |\n'
|
| 172 |
+
param_counts_text += f'| {"Total non-trainable params":<{max_name_len}} | {"":<10} | {"":<15} | {total_nontrainable_params:>12,} |\n'
|
| 173 |
+
param_counts_text += '=' * (max_name_len + padding) + '\n'
|
| 174 |
+
return param_counts_text
|
| 175 |
+
|
| 176 |
+
|
| 177 |
+
class Summary(Enum):
|
| 178 |
+
NONE = 0
|
| 179 |
+
AVERAGE = 1
|
| 180 |
+
SUM = 2
|
| 181 |
+
COUNT = 3
|
| 182 |
+
|
| 183 |
+
|
| 184 |
+
class ProgressMeter(object):
|
| 185 |
+
def __init__(self, num_batches, meters, prefix=""):
|
| 186 |
+
self.batch_fmtstr = self._get_batch_fmtstr(num_batches)
|
| 187 |
+
self.meters = meters
|
| 188 |
+
self.prefix = prefix
|
| 189 |
+
|
| 190 |
+
def display(self, batch):
|
| 191 |
+
entries = [self.prefix + self.batch_fmtstr.format(batch)]
|
| 192 |
+
entries += [str(meter) for meter in self.meters]
|
| 193 |
+
print('\t'.join(entries))
|
| 194 |
+
|
| 195 |
+
def display_summary(self):
|
| 196 |
+
entries = [" *"]
|
| 197 |
+
entries += [meter.summary() for meter in self.meters]
|
| 198 |
+
print(' '.join(entries))
|
| 199 |
+
|
| 200 |
+
def _get_batch_fmtstr(self, num_batches):
|
| 201 |
+
num_digits = len(str(num_batches // 1))
|
| 202 |
+
fmt = '{:' + str(num_digits) + 'd}'
|
| 203 |
+
return '[' + fmt + '/' + fmt.format(num_batches) + ']'
|
| 204 |
+
|
| 205 |
+
|
| 206 |
+
class AverageMeter(object):
|
| 207 |
+
"""Computes and stores the average and current value"""
|
| 208 |
+
def __init__(self, name, fmt=':f', summary_type=Summary.AVERAGE):
|
| 209 |
+
self.name = name
|
| 210 |
+
self.fmt = fmt
|
| 211 |
+
self.summary_type = summary_type
|
| 212 |
+
self.reset()
|
| 213 |
+
|
| 214 |
+
def reset(self):
|
| 215 |
+
self.val = 0
|
| 216 |
+
self.avg = 0
|
| 217 |
+
self.sum = 0
|
| 218 |
+
self.count = 0
|
| 219 |
+
|
| 220 |
+
def update(self, val, n=1):
|
| 221 |
+
self.val = val
|
| 222 |
+
self.sum += val * n
|
| 223 |
+
self.count += n
|
| 224 |
+
self.avg = self.sum / self.count
|
| 225 |
+
|
| 226 |
+
def all_reduce(self):
|
| 227 |
+
device = "cuda" if torch.cuda.is_available() else "cpu"
|
| 228 |
+
total = torch.tensor([self.sum, self.count], dtype=torch.float32, device=device)
|
| 229 |
+
dist.all_reduce(total, dist.ReduceOp.SUM, async_op=False)
|
| 230 |
+
self.sum, self.count = total.tolist()
|
| 231 |
+
self.avg = self.sum / self.count
|
| 232 |
+
|
| 233 |
+
def __str__(self):
|
| 234 |
+
fmtstr = '{name} {val' + self.fmt + '} ({avg' + self.fmt + '})'
|
| 235 |
+
return fmtstr.format(**self.__dict__)
|
| 236 |
+
|
| 237 |
+
def summary(self):
|
| 238 |
+
fmtstr = ''
|
| 239 |
+
if self.summary_type is Summary.NONE:
|
| 240 |
+
fmtstr = ''
|
| 241 |
+
elif self.summary_type is Summary.AVERAGE:
|
| 242 |
+
fmtstr = '{name} {avg:.3f}'
|
| 243 |
+
elif self.summary_type is Summary.SUM:
|
| 244 |
+
fmtstr = '{name} {sum:.3f}'
|
| 245 |
+
elif self.summary_type is Summary.COUNT:
|
| 246 |
+
fmtstr = '{name} {count:.3f}'
|
| 247 |
+
else:
|
| 248 |
+
raise ValueError('invalid summary type %r' % self.summary_type)
|
| 249 |
+
|
| 250 |
+
return fmtstr.format(**self.__dict__)
|
fromage_model/fromage_vis4/cc3m_embeddings.pkl
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:a20fa8168bd72e848ff088820b767383dded455a57ac5dd2d97d43e600402195
|
| 3 |
+
size 2979901225
|
fromage_model/fromage_vis4/model_args.json
ADDED
|
@@ -0,0 +1,16 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"opt_version": "facebook/opt-6.7b",
|
| 3 |
+
"freeze_lm": true,
|
| 4 |
+
"visual_encoder": "openai/clip-vit-large-patch14",
|
| 5 |
+
"freeze_vm": true,
|
| 6 |
+
"n_visual_tokens": 4,
|
| 7 |
+
"use_image_embed_norm": false,
|
| 8 |
+
"image_embed_dropout_prob": 0.0,
|
| 9 |
+
"use_text_embed_layernorm": false,
|
| 10 |
+
"text_embed_dropout_prob": 0.0,
|
| 11 |
+
"shared_emb_dim": 256,
|
| 12 |
+
"text_emb_layers": [
|
| 13 |
+
-1
|
| 14 |
+
],
|
| 15 |
+
"retrieval_token_idx": 50266
|
| 16 |
+
}
|
fromage_model/model_args.json
ADDED
|
@@ -0,0 +1,22 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"opt_version": "facebook/opt-6.7b",
|
| 3 |
+
"task": "multitask",
|
| 4 |
+
"freeze_lm": true,
|
| 5 |
+
"visual_encoder": "openai/clip-vit-large-patch14",
|
| 6 |
+
"freeze_vm": true,
|
| 7 |
+
"pretrained_visual": true,
|
| 8 |
+
"use_pooler": true,
|
| 9 |
+
"n_visual_tokens": 1,
|
| 10 |
+
"image_embed_dropout_prob": 0.0,
|
| 11 |
+
"text_embed_dropout_prob": 0.0,
|
| 12 |
+
"shared_emb_dim": 256,
|
| 13 |
+
"text_emb_layers": [
|
| 14 |
+
-1
|
| 15 |
+
],
|
| 16 |
+
"append_retrieval_token": true,
|
| 17 |
+
"num_appended_retrieval_tokens": 1,
|
| 18 |
+
"input_prompt": "A picture of",
|
| 19 |
+
"add_input_to_ret": true,
|
| 20 |
+
"tunable_prompt_length": 0,
|
| 21 |
+
"retrieval_token_idx": 50266
|
| 22 |
+
}
|
main.py
ADDED
|
@@ -0,0 +1,642 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""Training example.
|
| 2 |
+
|
| 3 |
+
Modified from https://github.com/pytorch/examples/blob/main/imagenet/main.py.
|
| 4 |
+
"""
|
| 5 |
+
import argparse
|
| 6 |
+
import json
|
| 7 |
+
import os
|
| 8 |
+
import sys
|
| 9 |
+
import time
|
| 10 |
+
import warnings
|
| 11 |
+
|
| 12 |
+
import numpy as np
|
| 13 |
+
from PIL import Image
|
| 14 |
+
import torch
|
| 15 |
+
import torch.nn as nn
|
| 16 |
+
import torch.nn.parallel
|
| 17 |
+
import torch.backends.cudnn as cudnn
|
| 18 |
+
import torch.distributed as dist
|
| 19 |
+
import torch.optim
|
| 20 |
+
from torch.optim.lr_scheduler import StepLR
|
| 21 |
+
from warmup_scheduler import GradualWarmupScheduler
|
| 22 |
+
import torch.multiprocessing as mp
|
| 23 |
+
import torch.utils.data
|
| 24 |
+
import torch.utils.data.distributed
|
| 25 |
+
import torchvision.transforms as transforms
|
| 26 |
+
import torchvision.datasets as datasets
|
| 27 |
+
from torch.utils.tensorboard import SummaryWriter
|
| 28 |
+
import torchvision
|
| 29 |
+
|
| 30 |
+
from fromage import data
|
| 31 |
+
from fromage import losses as losses_utils
|
| 32 |
+
from fromage import models
|
| 33 |
+
from fromage import utils
|
| 34 |
+
from fromage import evaluate
|
| 35 |
+
from transformers import AutoTokenizer
|
| 36 |
+
|
| 37 |
+
# Disable HuggingFace tokenizer parallelism.
|
| 38 |
+
os.environ["TOKENIZERS_PARALLELISM"] = "false"
|
| 39 |
+
|
| 40 |
+
# Available LLM models.
|
| 41 |
+
llm_models = ['facebook/opt-125m', 'facebook/opt-350m', 'facebook/opt-1.3b',
|
| 42 |
+
'facebook/opt-2.7b', 'facebook/opt-6.7b', 'facebook/opt-13b', 'facebook/opt-30b',
|
| 43 |
+
'facebook/opt-66b']
|
| 44 |
+
datasets = ['cc3m']
|
| 45 |
+
best_score = 0 # Variable to keep track of best model so far.
|
| 46 |
+
|
| 47 |
+
|
| 48 |
+
def parse_args(args):
|
| 49 |
+
parser = argparse.ArgumentParser(description='FROMAGe training')
|
| 50 |
+
parser.add_argument('--opt-version', default='facebook/opt-6.7b',
|
| 51 |
+
choices=llm_models,
|
| 52 |
+
help='OPT versions: ' +
|
| 53 |
+
' | '.join(llm_models) +
|
| 54 |
+
' (default: "facebook/opt-6.7b")')
|
| 55 |
+
parser.add_argument('--visual-model', default='openai/clip-vit-large-patch14', type=str,
|
| 56 |
+
help="Visual encoder to use.")
|
| 57 |
+
parser.add_argument('-d', '--dataset', metavar='DATASET', help='Delimited list of datasets:' +
|
| 58 |
+
' | '.join(datasets), default='cc3m',
|
| 59 |
+
type=lambda s: [x for x in s.split(',')])
|
| 60 |
+
|
| 61 |
+
parser.add_argument('--val-dataset', metavar='DATASET', default='cc3m',
|
| 62 |
+
type=lambda s: [x for x in s.split(',')],
|
| 63 |
+
help='Validation dataset: ' +
|
| 64 |
+
' | '.join(datasets) +
|
| 65 |
+
' (default: cc3m)')
|
| 66 |
+
parser.add_argument('--dataset_dir', default='datasets', type=str,
|
| 67 |
+
help='Dataset directory containing .tsv files.')
|
| 68 |
+
parser.add_argument('--image-dir', default='./data/', type=str,
|
| 69 |
+
help='Dataset directory containing image folders.')
|
| 70 |
+
parser.add_argument('--log-base-dir', default='./runs/', type=str,
|
| 71 |
+
help='Base directory to write logs and ckpts to.')
|
| 72 |
+
parser.add_argument('--exp_name', default='frozen', type=str,
|
| 73 |
+
help='Name of experiment, used for saving checkpoints.')
|
| 74 |
+
|
| 75 |
+
parser.add_argument('-j', '--workers', default=4, type=int, metavar='N',
|
| 76 |
+
help='number of data loading workers (default: 4)')
|
| 77 |
+
parser.add_argument('--epochs', default=10, type=int, metavar='N',
|
| 78 |
+
help='number of total epochs to run')
|
| 79 |
+
parser.add_argument('--steps-per-epoch', default=2000, type=int, metavar='N',
|
| 80 |
+
help='number of training steps per epoch')
|
| 81 |
+
parser.add_argument('--start-epoch', default=0, type=int, metavar='N',
|
| 82 |
+
help='manual epoch number (useful on restarts)')
|
| 83 |
+
parser.add_argument('--val-steps-per-epoch', default=-1, type=int, metavar='N',
|
| 84 |
+
help='number of validation steps per epoch.')
|
| 85 |
+
parser.add_argument('-b', '--batch-size', default=180, type=int,
|
| 86 |
+
metavar='N',
|
| 87 |
+
help='mini-batch size (default: 180), this is the total '
|
| 88 |
+
'batch size of all GPUs on the current node when '
|
| 89 |
+
'using Data Parallel or Distributed Data Parallel')
|
| 90 |
+
parser.add_argument('--val-batch-size', default=None, type=int)
|
| 91 |
+
parser.add_argument('--lr', '--learning-rate', default=0.0003, type=float,
|
| 92 |
+
metavar='LR', help='initial learning rate', dest='lr')
|
| 93 |
+
parser.add_argument('--lr-warmup-steps', default=100, type=int,
|
| 94 |
+
metavar='N', help='Number of steps to warm up lr.')
|
| 95 |
+
parser.add_argument('--lr-schedule-step-size', default=10, type=int,
|
| 96 |
+
metavar='N', help='Number of steps before decaying lr.')
|
| 97 |
+
parser.add_argument('--lr-schedule-gamma', default=0.1, type=float,
|
| 98 |
+
metavar='N', help='Decay parameter for learning rate scheduler.')
|
| 99 |
+
parser.add_argument('--grad-accumulation-steps', default=1, type=int, metavar='N',
|
| 100 |
+
help='number of gradient accumulation steps')
|
| 101 |
+
parser.add_argument('--grad-clip', default=1.0, type=float, help='gradient clipping amount')
|
| 102 |
+
|
| 103 |
+
parser.add_argument('--precision', default='fp32', type=str, choices=['fp32', 'fp16', 'bf16'], help="Precision to train in.")
|
| 104 |
+
parser.add_argument('--cap-loss-scale', type=float, default=1.0, help="Scale on captioning loss.")
|
| 105 |
+
parser.add_argument('--ret-loss-scale', type=float, default=1.0, help="Scale on retrieval loss.")
|
| 106 |
+
|
| 107 |
+
parser.add_argument('--concat-captions-prob', type=float, default=0.5, help="Probability of concatenating two examples sequentially for captioning.")
|
| 108 |
+
parser.add_argument('--concat-for-ret', action='store_true', default=False, help="Whether to concatenate examples for retrieval mode.")
|
| 109 |
+
parser.add_argument('--input-prompt', default=None, type=str, help="Input prompt for the language model, if any.")
|
| 110 |
+
|
| 111 |
+
parser.add_argument('--image-size', default=224, type=int, metavar='N', help='Size of images.')
|
| 112 |
+
parser.add_argument('--use_image_embed_norm', action='store_true', default=False, help="Whether to use norm on the image embeddings to make them equal to language.")
|
| 113 |
+
parser.add_argument('--image_embed_dropout_prob', type=float, default=0.0, help="Dropout probability on the image embeddings.")
|
| 114 |
+
parser.add_argument('--use_text_embed_layernorm', action='store_true', default=False, help="Whether to use layer norm on the text embeddings for retrieval.")
|
| 115 |
+
parser.add_argument('--text_embed_dropout_prob', type=float, default=0.0, help="Dropout probability on the text embeddings.")
|
| 116 |
+
parser.add_argument('--shared-emb-dim', default=256, type=int, metavar='N', help='Embedding dimension for retrieval.')
|
| 117 |
+
parser.add_argument('--text-emb-layers', help='Layer to use for text embeddings. OPT-2.7b has 33 layers.', default='-1',
|
| 118 |
+
type=lambda s: [int(x) for x in s.split(',')])
|
| 119 |
+
|
| 120 |
+
parser.add_argument('--max-len', default=24, type=int,
|
| 121 |
+
metavar='N', help='Maximum length to truncate captions / generations to.')
|
| 122 |
+
parser.add_argument('--n-visual-tokens', default=1, type=int,
|
| 123 |
+
metavar='N', help='Number of visual tokens to use for the Frozen model.')
|
| 124 |
+
|
| 125 |
+
parser.add_argument('--beta1', default=0.9, type=float, metavar='M', help='beta1 for Adam')
|
| 126 |
+
parser.add_argument('--beta2', default=0.95, type=float, metavar='M', help='beta2 for Adam')
|
| 127 |
+
parser.add_argument('--wd', '--weight-decay', default=0.0, type=float,
|
| 128 |
+
metavar='W', help='weight decay (default: 0.0)', dest='weight_decay')
|
| 129 |
+
parser.add_argument('-p', '--print-freq', default=10, type=int,
|
| 130 |
+
metavar='N', help='print frequency (default: 10)')
|
| 131 |
+
parser.add_argument('--resume', default='', type=str, metavar='PATH',
|
| 132 |
+
help='path to latest checkpoint (default: none)')
|
| 133 |
+
parser.add_argument('-e', '--evaluate', dest='evaluate', action='store_true',
|
| 134 |
+
help='evaluate model on validation set')
|
| 135 |
+
parser.add_argument('--world-size', default=-1, type=int,
|
| 136 |
+
help='number of nodes for distributed training')
|
| 137 |
+
parser.add_argument('--rank', default=-1, type=int,
|
| 138 |
+
help='node rank for distributed training')
|
| 139 |
+
parser.add_argument('--dist-url', default='tcp://127.0.0.1:1337', type=str,
|
| 140 |
+
help='url used to set up distributed training')
|
| 141 |
+
parser.add_argument('--dist-backend', default='nccl', type=str,
|
| 142 |
+
help='distributed backend')
|
| 143 |
+
parser.add_argument('--seed', default=None, type=int,
|
| 144 |
+
help='seed for initializing training. ')
|
| 145 |
+
parser.add_argument('--gpu', default=None, type=int,
|
| 146 |
+
help='GPU id to use.')
|
| 147 |
+
parser.add_argument('--multiprocessing-distributed', action='store_true',
|
| 148 |
+
help='Use multi-processing distributed training to launch '
|
| 149 |
+
'N processes per node, which has N GPUs. This is the '
|
| 150 |
+
'fastest way to use PyTorch for either single node or '
|
| 151 |
+
'multi node data parallel training')
|
| 152 |
+
return parser.parse_args(args)
|
| 153 |
+
|
| 154 |
+
|
| 155 |
+
def main(args):
|
| 156 |
+
args = parse_args(args)
|
| 157 |
+
i = 1
|
| 158 |
+
args.log_dir = os.path.join(args.log_base_dir, args.exp_name)
|
| 159 |
+
while os.path.exists(args.log_dir):
|
| 160 |
+
args.log_dir = os.path.join(args.log_base_dir, f'{args.exp_name}_{i}')
|
| 161 |
+
i += 1
|
| 162 |
+
os.makedirs(args.log_dir)
|
| 163 |
+
|
| 164 |
+
with open(os.path.join(args.log_dir, f'args.json'), 'w') as wf:
|
| 165 |
+
json.dump(vars(args), wf, indent=4)
|
| 166 |
+
|
| 167 |
+
with open(os.path.join(args.log_dir, f'git_info.txt'), 'w') as wf:
|
| 168 |
+
utils.dump_git_status(out_file=wf)
|
| 169 |
+
|
| 170 |
+
print(f'Logging to {args.log_dir}.')
|
| 171 |
+
|
| 172 |
+
if args.seed is not None:
|
| 173 |
+
torch.manual_seed(args.seed)
|
| 174 |
+
cudnn.deterministic = True
|
| 175 |
+
warnings.warn('You have chosen to seed training. '
|
| 176 |
+
'This will turn on the CUDNN deterministic setting, '
|
| 177 |
+
'which can slow down your training considerably! '
|
| 178 |
+
'You may see unexpected behavior when restarting '
|
| 179 |
+
'from checkpoints.')
|
| 180 |
+
|
| 181 |
+
if args.gpu is not None:
|
| 182 |
+
warnings.warn('You have chosen a specific GPU. This will completely '
|
| 183 |
+
'disable data parallelism.')
|
| 184 |
+
|
| 185 |
+
if args.dist_url == "env://" and args.world_size == -1:
|
| 186 |
+
args.world_size = int(os.environ["WORLD_SIZE"])
|
| 187 |
+
|
| 188 |
+
args.distributed = args.world_size > 1 or args.multiprocessing_distributed
|
| 189 |
+
|
| 190 |
+
ngpus_per_node = torch.cuda.device_count()
|
| 191 |
+
if args.multiprocessing_distributed:
|
| 192 |
+
# Since we have ngpus_per_node processes per node, the total world_size
|
| 193 |
+
# needs to be adjusted accordingly
|
| 194 |
+
args.world_size = ngpus_per_node * args.world_size
|
| 195 |
+
# Use torch.multiprocessing.spawn to launch distributed processes: the
|
| 196 |
+
# main_worker process function
|
| 197 |
+
mp.spawn(main_worker, nprocs=ngpus_per_node, args=(ngpus_per_node, args))
|
| 198 |
+
else:
|
| 199 |
+
# Simply call main_worker function
|
| 200 |
+
main_worker(args.gpu, ngpus_per_node, args)
|
| 201 |
+
|
| 202 |
+
|
| 203 |
+
def main_worker(gpu, ngpus_per_node, args):
|
| 204 |
+
"""Setup code."""
|
| 205 |
+
global best_score
|
| 206 |
+
args.gpu = gpu
|
| 207 |
+
|
| 208 |
+
if args.gpu is not None:
|
| 209 |
+
print("Use GPU: {} for training".format(args.gpu))
|
| 210 |
+
|
| 211 |
+
if args.distributed:
|
| 212 |
+
if args.dist_url == "env://" and args.rank == -1:
|
| 213 |
+
args.rank = int(os.environ["RANK"])
|
| 214 |
+
if args.multiprocessing_distributed:
|
| 215 |
+
# For multiprocessing distributed training, rank needs to be the
|
| 216 |
+
# global rank among all the processes
|
| 217 |
+
args.rank = args.rank * ngpus_per_node + gpu
|
| 218 |
+
dist.init_process_group(backend=args.dist_backend, init_method=args.dist_url,
|
| 219 |
+
world_size=args.world_size, rank=args.rank)
|
| 220 |
+
|
| 221 |
+
# Create model
|
| 222 |
+
model_args = models.FrozenArgs()
|
| 223 |
+
model_args.opt_version = args.opt_version
|
| 224 |
+
model_args.freeze_lm = True
|
| 225 |
+
model_args.visual_encoder = args.visual_model
|
| 226 |
+
model_args.freeze_vm = True
|
| 227 |
+
model_args.n_visual_tokens = args.n_visual_tokens
|
| 228 |
+
model_args.use_image_embed_norm = args.use_image_embed_norm
|
| 229 |
+
model_args.image_embed_dropout_prob = args.image_embed_dropout_prob
|
| 230 |
+
model_args.use_text_embed_layernorm = args.use_text_embed_layernorm
|
| 231 |
+
model_args.text_embed_dropout_prob = args.text_embed_dropout_prob
|
| 232 |
+
model_args.shared_emb_dim = args.shared_emb_dim
|
| 233 |
+
model_args.text_emb_layers = args.text_emb_layers
|
| 234 |
+
|
| 235 |
+
tokenizer = AutoTokenizer.from_pretrained(args.opt_version, use_fast=False)
|
| 236 |
+
# Add an image token for loss masking (and visualization) purposes.
|
| 237 |
+
tokenizer.add_special_tokens({"cls_token": "<|image|>"}) # add special image token to tokenizer
|
| 238 |
+
print('Adding [RET] token to vocabulary.')
|
| 239 |
+
print('Before adding new token, tokenizer("[RET]") =', tokenizer('[RET]', add_special_tokens=False))
|
| 240 |
+
num_added_tokens = tokenizer.add_tokens('[RET]')
|
| 241 |
+
print(f'After adding {num_added_tokens} new tokens, tokenizer("[RET]") =', tokenizer('[RET]', add_special_tokens=False))
|
| 242 |
+
ret_token_idx = tokenizer('[RET]', add_special_tokens=False).input_ids
|
| 243 |
+
assert len(ret_token_idx) == 1, ret_token_idx
|
| 244 |
+
model_args.retrieval_token_idx = ret_token_idx[0]
|
| 245 |
+
args.retrieval_token_idx = ret_token_idx[0]
|
| 246 |
+
|
| 247 |
+
# Save model args to disk.
|
| 248 |
+
with open(os.path.join(args.log_dir, 'model_args.json'), 'w') as f:
|
| 249 |
+
json.dump(vars(model_args), f, indent=4)
|
| 250 |
+
|
| 251 |
+
model = models.Fromage(tokenizer, model_args)
|
| 252 |
+
if args.precision == 'fp16':
|
| 253 |
+
model = model.float()
|
| 254 |
+
elif args.precision == 'bf16':
|
| 255 |
+
model = model.bfloat16()
|
| 256 |
+
|
| 257 |
+
# Print parameters and count of model.
|
| 258 |
+
param_counts_text = utils.get_params_count_str(model)
|
| 259 |
+
with open(os.path.join(args.log_dir, 'param_count.txt'), 'w') as f:
|
| 260 |
+
f.write(param_counts_text)
|
| 261 |
+
|
| 262 |
+
# Log trainable parameters to Tensorboard.
|
| 263 |
+
_, total_trainable_params, total_nontrainable_params = utils.get_params_count(model)
|
| 264 |
+
writer = SummaryWriter(args.log_dir)
|
| 265 |
+
writer.add_scalar('params/total', total_trainable_params + total_nontrainable_params, 0)
|
| 266 |
+
writer.add_scalar('params/total_trainable', total_trainable_params, 0)
|
| 267 |
+
writer.add_scalar('params/total_non_trainable', total_nontrainable_params, 0)
|
| 268 |
+
writer.close()
|
| 269 |
+
|
| 270 |
+
if not torch.cuda.is_available():
|
| 271 |
+
print('WARNING: using CPU, this will be slow!')
|
| 272 |
+
model = torch.nn.DataParallel(model)
|
| 273 |
+
elif args.distributed:
|
| 274 |
+
# For multiprocessing distributed, DistributedDataParallel constructor
|
| 275 |
+
# should always set the single device scope, otherwise,
|
| 276 |
+
# DistributedDataParallel will use all available devices.
|
| 277 |
+
if args.gpu is not None:
|
| 278 |
+
torch.cuda.set_device(args.gpu)
|
| 279 |
+
model.cuda(args.gpu)
|
| 280 |
+
# When using a single GPU per process and per
|
| 281 |
+
# DistributedDataParallel, we need to divide the batch size
|
| 282 |
+
# ourselves based on the total number of GPUs of the current node.
|
| 283 |
+
args.batch_size = int(args.batch_size / ngpus_per_node)
|
| 284 |
+
args.val_batch_size = int((args.val_batch_size or args.batch_size) / ngpus_per_node)
|
| 285 |
+
args.workers = int((args.workers + ngpus_per_node - 1) / ngpus_per_node)
|
| 286 |
+
model = torch.nn.parallel.DistributedDataParallel(model, device_ids=[args.gpu], find_unused_parameters=False)
|
| 287 |
+
else:
|
| 288 |
+
model.cuda()
|
| 289 |
+
# DistributedDataParallel will divide and allocate batch_size to all
|
| 290 |
+
# available GPUs if device_ids are not set
|
| 291 |
+
model = torch.nn.parallel.DistributedDataParallel(model, find_unused_parameters=False)
|
| 292 |
+
elif args.gpu is not None:
|
| 293 |
+
torch.cuda.set_device(args.gpu)
|
| 294 |
+
model = model.cuda(args.gpu)
|
| 295 |
+
else:
|
| 296 |
+
model = torch.nn.DataParallel(model).cuda()
|
| 297 |
+
|
| 298 |
+
# define loss function (criterion), optimizer, and learning rate scheduler
|
| 299 |
+
criterion = nn.CrossEntropyLoss().cuda(args.gpu)
|
| 300 |
+
optimizer_cls = torch.optim.AdamW
|
| 301 |
+
print('Using torch.optim.AdamW as the optimizer.')
|
| 302 |
+
optimizer = optimizer_cls(model.parameters(), args.lr,
|
| 303 |
+
betas=(args.beta1, args.beta2),
|
| 304 |
+
weight_decay=args.weight_decay,
|
| 305 |
+
eps=1e-8)
|
| 306 |
+
|
| 307 |
+
"""Sets the learning rate to the initial LR decayed by 10 every 5 epochs"""
|
| 308 |
+
scheduler_steplr = StepLR(optimizer, step_size=args.lr_schedule_step_size * args.steps_per_epoch, gamma=args.lr_schedule_gamma)
|
| 309 |
+
scheduler = GradualWarmupScheduler(optimizer, multiplier=1.0, total_epoch=args.lr_warmup_steps, after_scheduler=scheduler_steplr)
|
| 310 |
+
|
| 311 |
+
# optionally resume from a checkpoint
|
| 312 |
+
if args.resume:
|
| 313 |
+
if os.path.isfile(args.resume):
|
| 314 |
+
print("=> loading checkpoint '{}'".format(args.resume))
|
| 315 |
+
if args.gpu is None:
|
| 316 |
+
checkpoint = torch.load(args.resume)
|
| 317 |
+
else:
|
| 318 |
+
# Map model to be loaded to specified single gpu.
|
| 319 |
+
loc = 'cuda:{}'.format(args.gpu)
|
| 320 |
+
checkpoint = torch.load(args.resume, map_location=loc)
|
| 321 |
+
args.start_epoch = checkpoint['epoch']
|
| 322 |
+
best_score = checkpoint['best_score']
|
| 323 |
+
if args.gpu is not None:
|
| 324 |
+
# best_score may be from a checkpoint from a different GPU
|
| 325 |
+
best_score = best_score.to(args.gpu)
|
| 326 |
+
model.load_state_dict(checkpoint['state_dict'])
|
| 327 |
+
optimizer.load_state_dict(checkpoint['optimizer'])
|
| 328 |
+
scheduler.load_state_dict(checkpoint['scheduler'])
|
| 329 |
+
print("=> loaded checkpoint '{}' (epoch {})"
|
| 330 |
+
.format(args.resume, checkpoint['epoch']))
|
| 331 |
+
else:
|
| 332 |
+
print("=> no checkpoint found at '{}'".format(args.resume))
|
| 333 |
+
|
| 334 |
+
cudnn.benchmark = True
|
| 335 |
+
|
| 336 |
+
# Data loading code
|
| 337 |
+
train_dataset = data.get_dataset(args, 'train', tokenizer)
|
| 338 |
+
val_dataset = data.get_dataset(args, 'val', tokenizer)
|
| 339 |
+
print(f'Training with {len(train_dataset)} examples and validating with {len(val_dataset)} examples.')
|
| 340 |
+
|
| 341 |
+
if args.distributed:
|
| 342 |
+
train_sampler = torch.utils.data.distributed.DistributedSampler(train_dataset, drop_last=True)
|
| 343 |
+
val_sampler = torch.utils.data.distributed.DistributedSampler(val_dataset, shuffle=False, drop_last=True)
|
| 344 |
+
else:
|
| 345 |
+
train_sampler = None
|
| 346 |
+
val_sampler = None
|
| 347 |
+
|
| 348 |
+
train_loader = torch.utils.data.DataLoader(
|
| 349 |
+
train_dataset, batch_size=args.batch_size, shuffle=(train_sampler is None),
|
| 350 |
+
num_workers=args.workers, pin_memory=True, sampler=train_sampler)
|
| 351 |
+
val_loader = torch.utils.data.DataLoader(
|
| 352 |
+
val_dataset, batch_size=(args.val_batch_size or args.batch_size), shuffle=False,
|
| 353 |
+
num_workers=args.workers, pin_memory=True, sampler=val_sampler)
|
| 354 |
+
|
| 355 |
+
if args.evaluate:
|
| 356 |
+
evaluate.validate(val_loader, model, tokenizer, criterion, epoch, args)
|
| 357 |
+
return
|
| 358 |
+
|
| 359 |
+
for epoch in range(args.start_epoch, args.epochs):
|
| 360 |
+
if epoch == 0:
|
| 361 |
+
evaluate.validate(val_loader, model, tokenizer, criterion, epoch-1, args)
|
| 362 |
+
if args.distributed:
|
| 363 |
+
train_sampler.set_epoch(epoch)
|
| 364 |
+
|
| 365 |
+
# train for one epoch
|
| 366 |
+
train(train_loader, model, tokenizer, criterion, optimizer, epoch, scheduler, args)
|
| 367 |
+
|
| 368 |
+
# evaluate on validation set
|
| 369 |
+
eval_score = evaluate.validate(val_loader, model, tokenizer, criterion, epoch, args)
|
| 370 |
+
|
| 371 |
+
# remember best score and save checkpoint
|
| 372 |
+
is_best = eval_score > best_score
|
| 373 |
+
best_score = max(eval_score, best_score)
|
| 374 |
+
|
| 375 |
+
if not args.multiprocessing_distributed or (args.multiprocessing_distributed
|
| 376 |
+
and args.rank % ngpus_per_node == 0):
|
| 377 |
+
utils.save_checkpoint({
|
| 378 |
+
'epoch': epoch + 1,
|
| 379 |
+
'state_dict': model.state_dict(),
|
| 380 |
+
'best_score': best_score,
|
| 381 |
+
'optimizer' : optimizer.state_dict(),
|
| 382 |
+
'scheduler' : scheduler.state_dict()
|
| 383 |
+
}, is_best, os.path.join(args.log_dir, 'ckpt'))
|
| 384 |
+
|
| 385 |
+
|
| 386 |
+
def train(train_loader, model, tokenizer, criterion, optimizer, epoch, scheduler, args):
|
| 387 |
+
"""Main training loop."""
|
| 388 |
+
ngpus_per_node = torch.cuda.device_count()
|
| 389 |
+
batch_time = utils.AverageMeter('Time', ':6.3f')
|
| 390 |
+
cap_time = utils.AverageMeter('CaptioningTime', ':6.3f')
|
| 391 |
+
ret_time = utils.AverageMeter('RetrievalTime', ':6.3f')
|
| 392 |
+
data_time = utils.AverageMeter('Data', ':6.3f')
|
| 393 |
+
losses = utils.AverageMeter('Loss', ':.4e')
|
| 394 |
+
ce_losses = utils.AverageMeter('CeLoss', ':.4e')
|
| 395 |
+
top1 = utils.AverageMeter('Acc@1', ':6.2f')
|
| 396 |
+
top5 = utils.AverageMeter('Acc@5', ':6.2f')
|
| 397 |
+
cont_losses = utils.AverageMeter('ContLoss', ':.4e')
|
| 398 |
+
top1_caption = utils.AverageMeter('AccCaption@1', ':6.2f')
|
| 399 |
+
top5_caption = utils.AverageMeter('AccCaption@5', ':6.2f')
|
| 400 |
+
top1_image = utils.AverageMeter('AccImage@1', ':6.2f')
|
| 401 |
+
top5_image = utils.AverageMeter('AccImage@5', ':6.2f')
|
| 402 |
+
|
| 403 |
+
writer = SummaryWriter(args.log_dir)
|
| 404 |
+
|
| 405 |
+
progress = utils.ProgressMeter(
|
| 406 |
+
args.steps_per_epoch,
|
| 407 |
+
[batch_time, losses, ce_losses, cont_losses, top1, top5],
|
| 408 |
+
prefix="Epoch: [{}]".format(epoch))
|
| 409 |
+
|
| 410 |
+
# switch to train mode
|
| 411 |
+
model.train()
|
| 412 |
+
|
| 413 |
+
end = time.time()
|
| 414 |
+
|
| 415 |
+
for i, (image_paths, images, caption_images, tgt_tokens, token_len) in enumerate(train_loader):
|
| 416 |
+
actual_step = epoch * args.steps_per_epoch + i + 1
|
| 417 |
+
# measure data loading time
|
| 418 |
+
data_time.update(time.time() - end)
|
| 419 |
+
|
| 420 |
+
if torch.cuda.is_available():
|
| 421 |
+
images = images.cuda(args.gpu, non_blocking=True)
|
| 422 |
+
tgt_tokens = tgt_tokens.cuda(args.gpu, non_blocking=True)
|
| 423 |
+
token_len = token_len.cuda(args.gpu, non_blocking=True)
|
| 424 |
+
|
| 425 |
+
if args.precision == 'fp16':
|
| 426 |
+
images = images.half()
|
| 427 |
+
elif args.precision == 'bf16':
|
| 428 |
+
images = images.bfloat16()
|
| 429 |
+
|
| 430 |
+
model_modes = ['captioning', 'retrieval']
|
| 431 |
+
loss = 0
|
| 432 |
+
|
| 433 |
+
for model_mode in model_modes:
|
| 434 |
+
mode_start = time.time()
|
| 435 |
+
# compute output
|
| 436 |
+
concat_captions = np.random.uniform(0, 1) < args.concat_captions_prob
|
| 437 |
+
if not args.concat_for_ret:
|
| 438 |
+
concat_captions = concat_captions and model_mode == 'captioning'
|
| 439 |
+
|
| 440 |
+
(model_output, full_labels, last_embedding, _, visual_embs) = model(
|
| 441 |
+
images, tgt_tokens, token_len, mode=model_mode, concat_captions=concat_captions, inference=False)
|
| 442 |
+
output = model_output.logits
|
| 443 |
+
|
| 444 |
+
# Measure captioning accuracy for multi-task models and next-token prediction for retrieval models.
|
| 445 |
+
if model_mode == 'captioning':
|
| 446 |
+
acc1, acc5 = utils.accuracy(output[:, :-1, :], full_labels[:, 1:], -100, topk=(1, 5))
|
| 447 |
+
top1.update(acc1[0], images.size(0))
|
| 448 |
+
top5.update(acc5[0], images.size(0))
|
| 449 |
+
|
| 450 |
+
ce_loss = model_output.loss
|
| 451 |
+
if model_mode == 'captioning':
|
| 452 |
+
ce_loss = ce_loss * args.cap_loss_scale
|
| 453 |
+
elif model_mode == 'retrieval':
|
| 454 |
+
ce_loss = ce_loss * args.ret_loss_scale
|
| 455 |
+
else:
|
| 456 |
+
raise NotImplementedError
|
| 457 |
+
|
| 458 |
+
loss += ce_loss
|
| 459 |
+
ce_losses.update(ce_loss.item(), images.size(0))
|
| 460 |
+
|
| 461 |
+
if model_mode == 'retrieval':
|
| 462 |
+
# Cross replica concat for embeddings.
|
| 463 |
+
if args.distributed:
|
| 464 |
+
all_visual_embs = [torch.zeros_like(visual_embs) for _ in range(dist.get_world_size())]
|
| 465 |
+
all_last_embedding = [torch.zeros_like(last_embedding) for _ in range(dist.get_world_size())]
|
| 466 |
+
dist.all_gather(all_visual_embs, visual_embs)
|
| 467 |
+
dist.all_gather(all_last_embedding, last_embedding)
|
| 468 |
+
# Overwrite with embeddings produced on this replace, which have the gradient.
|
| 469 |
+
all_visual_embs[dist.get_rank()] = visual_embs
|
| 470 |
+
all_last_embedding[dist.get_rank()] = last_embedding
|
| 471 |
+
visual_embs = torch.cat(all_visual_embs)
|
| 472 |
+
last_embedding = torch.cat(all_last_embedding)
|
| 473 |
+
|
| 474 |
+
start_idx = args.rank * images.shape[0]
|
| 475 |
+
end_idx = start_idx + images.shape[0]
|
| 476 |
+
|
| 477 |
+
logits_per_image = visual_embs @ last_embedding.t()
|
| 478 |
+
logits_per_text = logits_per_image.t()
|
| 479 |
+
if i == 0:
|
| 480 |
+
print(f'Running contrastive loss over logits_per_text.shape = {logits_per_text.shape} and logits_per_image.shape = {logits_per_image.shape}')
|
| 481 |
+
|
| 482 |
+
# Compute contrastive losses for retrieval.
|
| 483 |
+
caption_loss = losses_utils.contrastive_loss(logits_per_text)
|
| 484 |
+
image_loss = losses_utils.contrastive_loss(logits_per_image)
|
| 485 |
+
caption_acc1, caption_acc5 = losses_utils.contrastive_acc(logits_per_text, topk=(1, 5))
|
| 486 |
+
image_acc1, image_acc5 = losses_utils.contrastive_acc(logits_per_image, topk=(1, 5))
|
| 487 |
+
loss += args.ret_loss_scale * (caption_loss + image_loss) / 2.0
|
| 488 |
+
cont_losses.update(loss.item(), images.size(0))
|
| 489 |
+
|
| 490 |
+
# measure accuracy and record loss
|
| 491 |
+
top1_caption.update(caption_acc1[0], images.size(0))
|
| 492 |
+
top5_caption.update(caption_acc5[0], images.size(0))
|
| 493 |
+
top1_image.update(image_acc1[0], images.size(0))
|
| 494 |
+
top5_image.update(image_acc5[0], images.size(0))
|
| 495 |
+
|
| 496 |
+
if model_mode == 'retrieval':
|
| 497 |
+
ret_time.update(time.time() - mode_start)
|
| 498 |
+
elif model_mode == 'captioning':
|
| 499 |
+
cap_time.update(time.time() - mode_start)
|
| 500 |
+
|
| 501 |
+
loss = loss / args.grad_accumulation_steps
|
| 502 |
+
losses.update(loss.item(), images.size(0))
|
| 503 |
+
loss.backward()
|
| 504 |
+
|
| 505 |
+
# Update weights
|
| 506 |
+
if ((i + 1) % args.grad_accumulation_steps == 0) or (i == args.steps_per_epoch - 1):
|
| 507 |
+
# Zero out gradients of the embedding matrix outside of [RET].
|
| 508 |
+
for param in model.module.model.input_embeddings.parameters():
|
| 509 |
+
assert param.grad.shape[0] == len(tokenizer)
|
| 510 |
+
# Keep other embeddings frozen.
|
| 511 |
+
mask = torch.arange(param.grad.shape[0]) != args.retrieval_token_idx
|
| 512 |
+
param.grad[mask, :] = 0
|
| 513 |
+
|
| 514 |
+
# compute gradient and do SGD step
|
| 515 |
+
if args.grad_clip > 0:
|
| 516 |
+
nn.utils.clip_grad_norm_(model.parameters(), args.grad_clip)
|
| 517 |
+
optimizer.step()
|
| 518 |
+
optimizer.zero_grad()
|
| 519 |
+
|
| 520 |
+
with torch.no_grad():
|
| 521 |
+
# Normalize trainable embeddings.
|
| 522 |
+
frozen_norm = torch.norm(model.module.model.input_embeddings.weight[:-1, :], dim=1).mean(0)
|
| 523 |
+
trainable_weight = model.module.model.input_embeddings.weight[-1, :]
|
| 524 |
+
model.module.model.input_embeddings.weight[-1, :].div_(torch.norm(trainable_weight) / frozen_norm)
|
| 525 |
+
|
| 526 |
+
# measure elapsed time
|
| 527 |
+
batch_time.update(time.time() - end)
|
| 528 |
+
end = time.time()
|
| 529 |
+
|
| 530 |
+
if actual_step == 1 or (i + 1) % args.print_freq == 0:
|
| 531 |
+
ex_per_sec = args.batch_size / batch_time.avg
|
| 532 |
+
if args.distributed:
|
| 533 |
+
batch_time.all_reduce()
|
| 534 |
+
data_time.all_reduce()
|
| 535 |
+
ex_per_sec = (args.batch_size / batch_time.avg) * ngpus_per_node
|
| 536 |
+
|
| 537 |
+
losses.all_reduce()
|
| 538 |
+
ce_losses.all_reduce()
|
| 539 |
+
top1.all_reduce()
|
| 540 |
+
top5.all_reduce()
|
| 541 |
+
ret_time.all_reduce()
|
| 542 |
+
cont_losses.all_reduce()
|
| 543 |
+
top1_caption.all_reduce()
|
| 544 |
+
top5_caption.all_reduce()
|
| 545 |
+
top1_image.all_reduce()
|
| 546 |
+
top5_image.all_reduce()
|
| 547 |
+
cap_time.all_reduce()
|
| 548 |
+
|
| 549 |
+
progress.display(i + 1)
|
| 550 |
+
|
| 551 |
+
writer.add_scalar('train/loss', losses.avg, actual_step)
|
| 552 |
+
writer.add_scalar('train/ce_loss', ce_losses.avg, actual_step)
|
| 553 |
+
writer.add_scalar('train/seq_top1_acc', top1.avg, actual_step)
|
| 554 |
+
writer.add_scalar('train/seq_top5_acc', top5.avg, actual_step)
|
| 555 |
+
writer.add_scalar('train/contrastive_loss', cont_losses.avg, actual_step)
|
| 556 |
+
writer.add_scalar('train/t2i_top1_acc', top1_caption.avg, actual_step)
|
| 557 |
+
writer.add_scalar('train/t2i_top5_acc', top5_caption.avg, actual_step)
|
| 558 |
+
writer.add_scalar('train/i2t_top1_acc', top1_image.avg, actual_step)
|
| 559 |
+
writer.add_scalar('train/i2t_top5_acc', top5_image.avg, actual_step)
|
| 560 |
+
writer.add_scalar('metrics/total_secs_per_batch', batch_time.avg, actual_step)
|
| 561 |
+
writer.add_scalar('metrics/total_secs_captioning', cap_time.avg, actual_step)
|
| 562 |
+
writer.add_scalar('metrics/total_secs_retrieval', ret_time.avg, actual_step)
|
| 563 |
+
writer.add_scalar('metrics/data_secs_per_batch', data_time.avg, actual_step)
|
| 564 |
+
writer.add_scalar('metrics/examples_per_sec', ex_per_sec, actual_step)
|
| 565 |
+
|
| 566 |
+
if not args.multiprocessing_distributed or (args.multiprocessing_distributed
|
| 567 |
+
and args.rank % ngpus_per_node == 0):
|
| 568 |
+
image_bs = images.shape[0]
|
| 569 |
+
normalized_images = images - images.min()
|
| 570 |
+
normalized_images /= normalized_images.max() # (N, 3, H, W)
|
| 571 |
+
max_images_to_show = 16
|
| 572 |
+
|
| 573 |
+
# Append caption text.
|
| 574 |
+
pred_tokens = output[:, args.n_visual_tokens-1:-1, :].argmax(dim=-1)
|
| 575 |
+
generated_captions = tokenizer.batch_decode(pred_tokens, skip_special_tokens=False)
|
| 576 |
+
|
| 577 |
+
# Log image (and generated caption) outputs to Tensorboard.
|
| 578 |
+
if model_mode == 'captioning':
|
| 579 |
+
# Create generated caption text.
|
| 580 |
+
generated_cap_images = torch.stack([
|
| 581 |
+
utils.create_image_of_text(
|
| 582 |
+
generated_captions[i].encode('ascii', 'ignore'),
|
| 583 |
+
width=normalized_images.shape[3],
|
| 584 |
+
color=(255, 255, 0))
|
| 585 |
+
for i in range(len(generated_captions))], axis=0)
|
| 586 |
+
|
| 587 |
+
# Duplicate captions if we concatenated them.
|
| 588 |
+
if (args.concat_captions_prob > 0 and model_mode == 'captioning' and generated_cap_images.shape[0] != caption_images.shape[0]):
|
| 589 |
+
generated_cap_images = torch.cat([generated_cap_images, generated_cap_images], axis=0)
|
| 590 |
+
|
| 591 |
+
display_images = torch.cat([normalized_images.float().cpu(), caption_images, generated_cap_images], axis=2)[:max_images_to_show]
|
| 592 |
+
grid = torchvision.utils.make_grid(display_images, nrow=int(max_images_to_show ** 0.5), padding=4)
|
| 593 |
+
writer.add_image('train/images_gen_cap', grid, actual_step)
|
| 594 |
+
|
| 595 |
+
# Retrieved images (from text).
|
| 596 |
+
retrieved_image_idx = logits_per_text[:image_bs, :image_bs].argmax(-1)
|
| 597 |
+
t2i_images = torch.stack(
|
| 598 |
+
[normalized_images[retrieved_image_idx[i], ...] for i in range(len(retrieved_image_idx))],
|
| 599 |
+
axis=0)
|
| 600 |
+
t2i_images = torch.cat([t2i_images.float().cpu(), caption_images], axis=2)[:max_images_to_show]
|
| 601 |
+
t2i_grid = torchvision.utils.make_grid(t2i_images, nrow=int(max_images_to_show ** 0.5), padding=4)
|
| 602 |
+
writer.add_image('train/t2i_ret', t2i_grid, actual_step)
|
| 603 |
+
|
| 604 |
+
# Retrieved text (from image).
|
| 605 |
+
retrieved_text_idx = logits_per_image[:image_bs, :image_bs].argmax(-1)
|
| 606 |
+
retrieved_text = torch.stack(
|
| 607 |
+
[caption_images[retrieved_text_idx[i], ...] for i in range(len(retrieved_text_idx))],
|
| 608 |
+
axis=0)
|
| 609 |
+
i2t_images = torch.cat([normalized_images.float().cpu(), retrieved_text], axis=2)[:max_images_to_show]
|
| 610 |
+
i2t_grid = torchvision.utils.make_grid(i2t_images, nrow=int(max_images_to_show ** 0.5), padding=4)
|
| 611 |
+
writer.add_image('train/i2t_ret', i2t_grid, actual_step)
|
| 612 |
+
|
| 613 |
+
batch_time.reset()
|
| 614 |
+
cap_time.reset()
|
| 615 |
+
ret_time.reset()
|
| 616 |
+
data_time.reset()
|
| 617 |
+
losses.reset()
|
| 618 |
+
ce_losses.reset()
|
| 619 |
+
top1.reset()
|
| 620 |
+
top5.reset()
|
| 621 |
+
cont_losses.reset()
|
| 622 |
+
top1_caption.reset()
|
| 623 |
+
top5_caption.reset()
|
| 624 |
+
top1_image.reset()
|
| 625 |
+
top5_image.reset()
|
| 626 |
+
|
| 627 |
+
if i == args.steps_per_epoch - 1:
|
| 628 |
+
break
|
| 629 |
+
|
| 630 |
+
scheduler.step()
|
| 631 |
+
curr_lr = scheduler.get_last_lr()
|
| 632 |
+
if (actual_step == 1) or (i + 1) % args.print_freq == 0:
|
| 633 |
+
# Write current learning rate to Tensorboard.
|
| 634 |
+
writer = SummaryWriter(args.log_dir)
|
| 635 |
+
writer.add_scalar('train/lr', curr_lr[0], actual_step)
|
| 636 |
+
writer.close()
|
| 637 |
+
|
| 638 |
+
writer.close()
|
| 639 |
+
|
| 640 |
+
|
| 641 |
+
if __name__ == '__main__':
|
| 642 |
+
main(sys.argv[1:])
|
requirements.txt
ADDED
|
@@ -0,0 +1,35 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
attrs==22.2.0
|
| 2 |
+
certifi==2022.12.7
|
| 3 |
+
charset-normalizer
|
| 4 |
+
contourpy==1.0.7
|
| 5 |
+
cycler==0.11.0
|
| 6 |
+
einops==0.4.1
|
| 7 |
+
exceptiongroup==1.1.0
|
| 8 |
+
filelock==3.9.0
|
| 9 |
+
fonttools==4.38.0
|
| 10 |
+
huggingface-hub==0.12.0
|
| 11 |
+
idna==3.4
|
| 12 |
+
iniconfig==2.0.0
|
| 13 |
+
kiwisolver==1.4.4
|
| 14 |
+
matplotlib
|
| 15 |
+
numpy
|
| 16 |
+
packaging==23.0
|
| 17 |
+
Pillow==9.4.0
|
| 18 |
+
pluggy==1.0.0
|
| 19 |
+
pyparsing==3.0.9
|
| 20 |
+
pytest==7.2.1
|
| 21 |
+
python-dateutil==2.8.2
|
| 22 |
+
PyYAML
|
| 23 |
+
regex
|
| 24 |
+
requests
|
| 25 |
+
six==1.16.0
|
| 26 |
+
tokenizers==0.12.1
|
| 27 |
+
tomli==2.0.1
|
| 28 |
+
torchaudio==0.11.0
|
| 29 |
+
torchmetrics==0.9.3
|
| 30 |
+
torchvision==0.12.0
|
| 31 |
+
tqdm
|
| 32 |
+
transformers==4.21.3
|
| 33 |
+
typing_extensions==4.4.0
|
| 34 |
+
urllib3==1.26.14
|
| 35 |
+
warmup-scheduler
|