


local gradio
Browse files- .gitignore +1 -2
- OpenVoice/api.py +202 -0
- OpenVoice/attentions.py +466 -0
- OpenVoice/commons.py +160 -0
- OpenVoice/mel_processing.py +183 -0
- OpenVoice/models.py +497 -0
- OpenVoice/modules.py +598 -0
- OpenVoice/resources/framework.jpg +0 -0
- OpenVoice/resources/lepton.jpg +0 -0
- OpenVoice/resources/myshell.jpg +0 -0
- OpenVoice/resources/openvoicelogo.jpg +0 -0
- OpenVoice/se_extractor.py +138 -0
- OpenVoice/text/__init__.py +78 -0
- OpenVoice/text/cleaners.py +16 -0
- OpenVoice/text/english.py +189 -0
- OpenVoice/text/mandarin.py +326 -0
- OpenVoice/text/symbols.py +88 -0
- OpenVoice/transforms.py +209 -0
- OpenVoice/utils.py +194 -0
- app_locally.py +314 -0
- requirement_locally.txt +15 -0
.gitignore
CHANGED
|
@@ -6,5 +6,4 @@ checkpoints
|
|
| 6 |
*.pyc
|
| 7 |
*.bak
|
| 8 |
*.ipynb
|
| 9 |
-
*.zip
|
| 10 |
-
OpenVoice/
|
|
|
|
| 6 |
*.pyc
|
| 7 |
*.bak
|
| 8 |
*.ipynb
|
| 9 |
+
*.zip
|
|
|
OpenVoice/api.py
ADDED
|
@@ -0,0 +1,202 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import torch
|
| 2 |
+
import numpy as np
|
| 3 |
+
import re
|
| 4 |
+
import soundfile
|
| 5 |
+
|
| 6 |
+
import os
|
| 7 |
+
import librosa
|
| 8 |
+
from . import utils
|
| 9 |
+
from . import commons
|
| 10 |
+
from .text import text_to_sequence
|
| 11 |
+
from .models import SynthesizerTrn
|
| 12 |
+
from .mel_processing import spectrogram_torch
|
| 13 |
+
|
| 14 |
+
|
| 15 |
+
class OpenVoiceBaseClass(object):
|
| 16 |
+
def __init__(self,
|
| 17 |
+
config_path,
|
| 18 |
+
device='cuda:0'):
|
| 19 |
+
if 'cuda' in device:
|
| 20 |
+
assert torch.cuda.is_available()
|
| 21 |
+
|
| 22 |
+
hps = utils.get_hparams_from_file(config_path)
|
| 23 |
+
|
| 24 |
+
model = SynthesizerTrn(
|
| 25 |
+
len(getattr(hps, 'symbols', [])),
|
| 26 |
+
hps.data.filter_length // 2 + 1,
|
| 27 |
+
n_speakers=hps.data.n_speakers,
|
| 28 |
+
**hps.model,
|
| 29 |
+
).to(device)
|
| 30 |
+
|
| 31 |
+
model.eval()
|
| 32 |
+
self.model = model
|
| 33 |
+
self.hps = hps
|
| 34 |
+
self.device = device
|
| 35 |
+
|
| 36 |
+
def load_ckpt(self, ckpt_path):
|
| 37 |
+
checkpoint_dict = torch.load(ckpt_path, map_location='cpu')
|
| 38 |
+
a, b = self.model.load_state_dict(checkpoint_dict['model'], strict=False)
|
| 39 |
+
print("Loaded checkpoint '{}'".format(ckpt_path))
|
| 40 |
+
print('missing/unexpected keys:', a, b)
|
| 41 |
+
|
| 42 |
+
|
| 43 |
+
class BaseSpeakerTTS(OpenVoiceBaseClass):
|
| 44 |
+
language_marks = {
|
| 45 |
+
"english": "EN",
|
| 46 |
+
"chinese": "ZH",
|
| 47 |
+
}
|
| 48 |
+
|
| 49 |
+
@staticmethod
|
| 50 |
+
def get_text(text, hps, is_symbol):
|
| 51 |
+
text_norm = text_to_sequence(text, hps.symbols, [] if is_symbol else hps.data.text_cleaners)
|
| 52 |
+
if hps.data.add_blank:
|
| 53 |
+
text_norm = commons.intersperse(text_norm, 0)
|
| 54 |
+
text_norm = torch.LongTensor(text_norm)
|
| 55 |
+
return text_norm
|
| 56 |
+
|
| 57 |
+
@staticmethod
|
| 58 |
+
def audio_numpy_concat(segment_data_list, sr, speed=1.):
|
| 59 |
+
audio_segments = []
|
| 60 |
+
for segment_data in segment_data_list:
|
| 61 |
+
audio_segments += segment_data.reshape(-1).tolist()
|
| 62 |
+
audio_segments += [0] * int((sr * 0.05)/speed)
|
| 63 |
+
audio_segments = np.array(audio_segments).astype(np.float32)
|
| 64 |
+
return audio_segments
|
| 65 |
+
|
| 66 |
+
@staticmethod
|
| 67 |
+
def split_sentences_into_pieces(text, language_str):
|
| 68 |
+
texts = utils.split_sentence(text, language_str=language_str)
|
| 69 |
+
print(" > Text splitted to sentences.")
|
| 70 |
+
print('\n'.join(texts))
|
| 71 |
+
print(" > ===========================")
|
| 72 |
+
return texts
|
| 73 |
+
|
| 74 |
+
def tts(self, text, output_path, speaker, language='English', speed=1.0):
|
| 75 |
+
mark = self.language_marks.get(language.lower(), None)
|
| 76 |
+
assert mark is not None, f"language {language} is not supported"
|
| 77 |
+
|
| 78 |
+
texts = self.split_sentences_into_pieces(text, mark)
|
| 79 |
+
|
| 80 |
+
audio_list = []
|
| 81 |
+
for t in texts:
|
| 82 |
+
t = re.sub(r'([a-z])([A-Z])', r'\1 \2', t)
|
| 83 |
+
t = f'[{mark}]{t}[{mark}]'
|
| 84 |
+
stn_tst = self.get_text(t, self.hps, False)
|
| 85 |
+
device = self.device
|
| 86 |
+
speaker_id = self.hps.speakers[speaker]
|
| 87 |
+
with torch.no_grad():
|
| 88 |
+
x_tst = stn_tst.unsqueeze(0).to(device)
|
| 89 |
+
x_tst_lengths = torch.LongTensor([stn_tst.size(0)]).to(device)
|
| 90 |
+
sid = torch.LongTensor([speaker_id]).to(device)
|
| 91 |
+
audio = self.model.infer(x_tst, x_tst_lengths, sid=sid, noise_scale=0.667, noise_scale_w=0.6,
|
| 92 |
+
length_scale=1.0 / speed)[0][0, 0].data.cpu().float().numpy()
|
| 93 |
+
audio_list.append(audio)
|
| 94 |
+
audio = self.audio_numpy_concat(audio_list, sr=self.hps.data.sampling_rate, speed=speed)
|
| 95 |
+
|
| 96 |
+
if output_path is None:
|
| 97 |
+
return audio
|
| 98 |
+
else:
|
| 99 |
+
soundfile.write(output_path, audio, self.hps.data.sampling_rate)
|
| 100 |
+
|
| 101 |
+
|
| 102 |
+
class ToneColorConverter(OpenVoiceBaseClass):
|
| 103 |
+
def __init__(self, *args, **kwargs):
|
| 104 |
+
super().__init__(*args, **kwargs)
|
| 105 |
+
|
| 106 |
+
if kwargs.get('enable_watermark', True):
|
| 107 |
+
import wavmark
|
| 108 |
+
self.watermark_model = wavmark.load_model().to(self.device)
|
| 109 |
+
else:
|
| 110 |
+
self.watermark_model = None
|
| 111 |
+
|
| 112 |
+
|
| 113 |
+
|
| 114 |
+
def extract_se(self, ref_wav_list, se_save_path=None):
|
| 115 |
+
if isinstance(ref_wav_list, str):
|
| 116 |
+
ref_wav_list = [ref_wav_list]
|
| 117 |
+
|
| 118 |
+
device = self.device
|
| 119 |
+
hps = self.hps
|
| 120 |
+
gs = []
|
| 121 |
+
|
| 122 |
+
for fname in ref_wav_list:
|
| 123 |
+
audio_ref, sr = librosa.load(fname, sr=hps.data.sampling_rate)
|
| 124 |
+
y = torch.FloatTensor(audio_ref)
|
| 125 |
+
y = y.to(device)
|
| 126 |
+
y = y.unsqueeze(0)
|
| 127 |
+
y = spectrogram_torch(y, hps.data.filter_length,
|
| 128 |
+
hps.data.sampling_rate, hps.data.hop_length, hps.data.win_length,
|
| 129 |
+
center=False).to(device)
|
| 130 |
+
with torch.no_grad():
|
| 131 |
+
g = self.model.ref_enc(y.transpose(1, 2)).unsqueeze(-1)
|
| 132 |
+
gs.append(g.detach())
|
| 133 |
+
gs = torch.stack(gs).mean(0)
|
| 134 |
+
|
| 135 |
+
if se_save_path is not None:
|
| 136 |
+
os.makedirs(os.path.dirname(se_save_path), exist_ok=True)
|
| 137 |
+
torch.save(gs.cpu(), se_save_path)
|
| 138 |
+
|
| 139 |
+
return gs
|
| 140 |
+
|
| 141 |
+
def convert(self, audio_src_path, src_se, tgt_se, output_path=None, tau=0.3, message="default"):
|
| 142 |
+
hps = self.hps
|
| 143 |
+
# load audio
|
| 144 |
+
audio, sample_rate = librosa.load(audio_src_path, sr=hps.data.sampling_rate)
|
| 145 |
+
audio = torch.tensor(audio).float()
|
| 146 |
+
|
| 147 |
+
with torch.no_grad():
|
| 148 |
+
y = torch.FloatTensor(audio).to(self.device)
|
| 149 |
+
y = y.unsqueeze(0)
|
| 150 |
+
spec = spectrogram_torch(y, hps.data.filter_length,
|
| 151 |
+
hps.data.sampling_rate, hps.data.hop_length, hps.data.win_length,
|
| 152 |
+
center=False).to(self.device)
|
| 153 |
+
spec_lengths = torch.LongTensor([spec.size(-1)]).to(self.device)
|
| 154 |
+
audio = self.model.voice_conversion(spec, spec_lengths, sid_src=src_se, sid_tgt=tgt_se, tau=tau)[0][
|
| 155 |
+
0, 0].data.cpu().float().numpy()
|
| 156 |
+
audio = self.add_watermark(audio, message)
|
| 157 |
+
if output_path is None:
|
| 158 |
+
return audio
|
| 159 |
+
else:
|
| 160 |
+
soundfile.write(output_path, audio, hps.data.sampling_rate)
|
| 161 |
+
|
| 162 |
+
def add_watermark(self, audio, message):
|
| 163 |
+
if self.watermark_model is None:
|
| 164 |
+
return audio
|
| 165 |
+
device = self.device
|
| 166 |
+
bits = utils.string_to_bits(message).reshape(-1)
|
| 167 |
+
n_repeat = len(bits) // 32
|
| 168 |
+
|
| 169 |
+
K = 16000
|
| 170 |
+
coeff = 2
|
| 171 |
+
for n in range(n_repeat):
|
| 172 |
+
trunck = audio[(coeff * n) * K: (coeff * n + 1) * K]
|
| 173 |
+
if len(trunck) != K:
|
| 174 |
+
print('Audio too short, fail to add watermark')
|
| 175 |
+
break
|
| 176 |
+
message_npy = bits[n * 32: (n + 1) * 32]
|
| 177 |
+
|
| 178 |
+
with torch.no_grad():
|
| 179 |
+
signal = torch.FloatTensor(trunck).to(device)[None]
|
| 180 |
+
message_tensor = torch.FloatTensor(message_npy).to(device)[None]
|
| 181 |
+
signal_wmd_tensor = self.watermark_model.encode(signal, message_tensor)
|
| 182 |
+
signal_wmd_npy = signal_wmd_tensor.detach().cpu().squeeze()
|
| 183 |
+
audio[(coeff * n) * K: (coeff * n + 1) * K] = signal_wmd_npy
|
| 184 |
+
return audio
|
| 185 |
+
|
| 186 |
+
def detect_watermark(self, audio, n_repeat):
|
| 187 |
+
bits = []
|
| 188 |
+
K = 16000
|
| 189 |
+
coeff = 2
|
| 190 |
+
for n in range(n_repeat):
|
| 191 |
+
trunck = audio[(coeff * n) * K: (coeff * n + 1) * K]
|
| 192 |
+
if len(trunck) != K:
|
| 193 |
+
print('Audio too short, fail to detect watermark')
|
| 194 |
+
return 'Fail'
|
| 195 |
+
with torch.no_grad():
|
| 196 |
+
signal = torch.FloatTensor(trunck).to(self.device).unsqueeze(0)
|
| 197 |
+
message_decoded_npy = (self.watermark_model.decode(signal) >= 0.5).int().detach().cpu().numpy().squeeze()
|
| 198 |
+
bits.append(message_decoded_npy)
|
| 199 |
+
bits = np.stack(bits).reshape(-1, 8)
|
| 200 |
+
message = utils.bits_to_string(bits)
|
| 201 |
+
return message
|
| 202 |
+
|
OpenVoice/attentions.py
ADDED
|
@@ -0,0 +1,466 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import math
|
| 2 |
+
import torch
|
| 3 |
+
import logging
|
| 4 |
+
|
| 5 |
+
from torch import nn
|
| 6 |
+
from torch.nn import functional as F
|
| 7 |
+
from . import commons
|
| 8 |
+
|
| 9 |
+
|
| 10 |
+
logger = logging.getLogger(__name__)
|
| 11 |
+
|
| 12 |
+
|
| 13 |
+
class LayerNorm(nn.Module):
|
| 14 |
+
def __init__(self, channels, eps=1e-5):
|
| 15 |
+
super().__init__()
|
| 16 |
+
self.channels = channels
|
| 17 |
+
self.eps = eps
|
| 18 |
+
|
| 19 |
+
self.gamma = nn.Parameter(torch.ones(channels))
|
| 20 |
+
self.beta = nn.Parameter(torch.zeros(channels))
|
| 21 |
+
|
| 22 |
+
def forward(self, x):
|
| 23 |
+
x = x.transpose(1, -1)
|
| 24 |
+
x = F.layer_norm(x, (self.channels,), self.gamma, self.beta, self.eps)
|
| 25 |
+
return x.transpose(1, -1)
|
| 26 |
+
|
| 27 |
+
|
| 28 |
+
@torch.jit.script
|
| 29 |
+
def fused_add_tanh_sigmoid_multiply(input_a, input_b, n_channels):
|
| 30 |
+
n_channels_int = n_channels[0]
|
| 31 |
+
in_act = input_a + input_b
|
| 32 |
+
t_act = torch.tanh(in_act[:, :n_channels_int, :])
|
| 33 |
+
s_act = torch.sigmoid(in_act[:, n_channels_int:, :])
|
| 34 |
+
acts = t_act * s_act
|
| 35 |
+
return acts
|
| 36 |
+
|
| 37 |
+
|
| 38 |
+
class Encoder(nn.Module):
|
| 39 |
+
def __init__(
|
| 40 |
+
self,
|
| 41 |
+
hidden_channels,
|
| 42 |
+
filter_channels,
|
| 43 |
+
n_heads,
|
| 44 |
+
n_layers,
|
| 45 |
+
kernel_size=1,
|
| 46 |
+
p_dropout=0.0,
|
| 47 |
+
window_size=4,
|
| 48 |
+
isflow=True,
|
| 49 |
+
**kwargs
|
| 50 |
+
):
|
| 51 |
+
super().__init__()
|
| 52 |
+
self.hidden_channels = hidden_channels
|
| 53 |
+
self.filter_channels = filter_channels
|
| 54 |
+
self.n_heads = n_heads
|
| 55 |
+
self.n_layers = n_layers
|
| 56 |
+
self.kernel_size = kernel_size
|
| 57 |
+
self.p_dropout = p_dropout
|
| 58 |
+
self.window_size = window_size
|
| 59 |
+
# if isflow:
|
| 60 |
+
# cond_layer = torch.nn.Conv1d(256, 2*hidden_channels*n_layers, 1)
|
| 61 |
+
# self.cond_pre = torch.nn.Conv1d(hidden_channels, 2*hidden_channels, 1)
|
| 62 |
+
# self.cond_layer = weight_norm(cond_layer, name='weight')
|
| 63 |
+
# self.gin_channels = 256
|
| 64 |
+
self.cond_layer_idx = self.n_layers
|
| 65 |
+
if "gin_channels" in kwargs:
|
| 66 |
+
self.gin_channels = kwargs["gin_channels"]
|
| 67 |
+
if self.gin_channels != 0:
|
| 68 |
+
self.spk_emb_linear = nn.Linear(self.gin_channels, self.hidden_channels)
|
| 69 |
+
# vits2 says 3rd block, so idx is 2 by default
|
| 70 |
+
self.cond_layer_idx = (
|
| 71 |
+
kwargs["cond_layer_idx"] if "cond_layer_idx" in kwargs else 2
|
| 72 |
+
)
|
| 73 |
+
# logging.debug(self.gin_channels, self.cond_layer_idx)
|
| 74 |
+
assert (
|
| 75 |
+
self.cond_layer_idx < self.n_layers
|
| 76 |
+
), "cond_layer_idx should be less than n_layers"
|
| 77 |
+
self.drop = nn.Dropout(p_dropout)
|
| 78 |
+
self.attn_layers = nn.ModuleList()
|
| 79 |
+
self.norm_layers_1 = nn.ModuleList()
|
| 80 |
+
self.ffn_layers = nn.ModuleList()
|
| 81 |
+
self.norm_layers_2 = nn.ModuleList()
|
| 82 |
+
|
| 83 |
+
for i in range(self.n_layers):
|
| 84 |
+
self.attn_layers.append(
|
| 85 |
+
MultiHeadAttention(
|
| 86 |
+
hidden_channels,
|
| 87 |
+
hidden_channels,
|
| 88 |
+
n_heads,
|
| 89 |
+
p_dropout=p_dropout,
|
| 90 |
+
window_size=window_size,
|
| 91 |
+
)
|
| 92 |
+
)
|
| 93 |
+
self.norm_layers_1.append(LayerNorm(hidden_channels))
|
| 94 |
+
self.ffn_layers.append(
|
| 95 |
+
FFN(
|
| 96 |
+
hidden_channels,
|
| 97 |
+
hidden_channels,
|
| 98 |
+
filter_channels,
|
| 99 |
+
kernel_size,
|
| 100 |
+
p_dropout=p_dropout,
|
| 101 |
+
)
|
| 102 |
+
)
|
| 103 |
+
self.norm_layers_2.append(LayerNorm(hidden_channels))
|
| 104 |
+
|
| 105 |
+
def forward(self, x, x_mask, g=None):
|
| 106 |
+
attn_mask = x_mask.unsqueeze(2) * x_mask.unsqueeze(-1)
|
| 107 |
+
x = x * x_mask
|
| 108 |
+
for i in range(self.n_layers):
|
| 109 |
+
if i == self.cond_layer_idx and g is not None:
|
| 110 |
+
g = self.spk_emb_linear(g.transpose(1, 2))
|
| 111 |
+
g = g.transpose(1, 2)
|
| 112 |
+
x = x + g
|
| 113 |
+
x = x * x_mask
|
| 114 |
+
y = self.attn_layers[i](x, x, attn_mask)
|
| 115 |
+
y = self.drop(y)
|
| 116 |
+
x = self.norm_layers_1[i](x + y)
|
| 117 |
+
|
| 118 |
+
y = self.ffn_layers[i](x, x_mask)
|
| 119 |
+
y = self.drop(y)
|
| 120 |
+
x = self.norm_layers_2[i](x + y)
|
| 121 |
+
x = x * x_mask
|
| 122 |
+
return x
|
| 123 |
+
|
| 124 |
+
|
| 125 |
+
class Decoder(nn.Module):
|
| 126 |
+
def __init__(
|
| 127 |
+
self,
|
| 128 |
+
hidden_channels,
|
| 129 |
+
filter_channels,
|
| 130 |
+
n_heads,
|
| 131 |
+
n_layers,
|
| 132 |
+
kernel_size=1,
|
| 133 |
+
p_dropout=0.0,
|
| 134 |
+
proximal_bias=False,
|
| 135 |
+
proximal_init=True,
|
| 136 |
+
**kwargs
|
| 137 |
+
):
|
| 138 |
+
super().__init__()
|
| 139 |
+
self.hidden_channels = hidden_channels
|
| 140 |
+
self.filter_channels = filter_channels
|
| 141 |
+
self.n_heads = n_heads
|
| 142 |
+
self.n_layers = n_layers
|
| 143 |
+
self.kernel_size = kernel_size
|
| 144 |
+
self.p_dropout = p_dropout
|
| 145 |
+
self.proximal_bias = proximal_bias
|
| 146 |
+
self.proximal_init = proximal_init
|
| 147 |
+
|
| 148 |
+
self.drop = nn.Dropout(p_dropout)
|
| 149 |
+
self.self_attn_layers = nn.ModuleList()
|
| 150 |
+
self.norm_layers_0 = nn.ModuleList()
|
| 151 |
+
self.encdec_attn_layers = nn.ModuleList()
|
| 152 |
+
self.norm_layers_1 = nn.ModuleList()
|
| 153 |
+
self.ffn_layers = nn.ModuleList()
|
| 154 |
+
self.norm_layers_2 = nn.ModuleList()
|
| 155 |
+
for i in range(self.n_layers):
|
| 156 |
+
self.self_attn_layers.append(
|
| 157 |
+
MultiHeadAttention(
|
| 158 |
+
hidden_channels,
|
| 159 |
+
hidden_channels,
|
| 160 |
+
n_heads,
|
| 161 |
+
p_dropout=p_dropout,
|
| 162 |
+
proximal_bias=proximal_bias,
|
| 163 |
+
proximal_init=proximal_init,
|
| 164 |
+
)
|
| 165 |
+
)
|
| 166 |
+
self.norm_layers_0.append(LayerNorm(hidden_channels))
|
| 167 |
+
self.encdec_attn_layers.append(
|
| 168 |
+
MultiHeadAttention(
|
| 169 |
+
hidden_channels, hidden_channels, n_heads, p_dropout=p_dropout
|
| 170 |
+
)
|
| 171 |
+
)
|
| 172 |
+
self.norm_layers_1.append(LayerNorm(hidden_channels))
|
| 173 |
+
self.ffn_layers.append(
|
| 174 |
+
FFN(
|
| 175 |
+
hidden_channels,
|
| 176 |
+
hidden_channels,
|
| 177 |
+
filter_channels,
|
| 178 |
+
kernel_size,
|
| 179 |
+
p_dropout=p_dropout,
|
| 180 |
+
causal=True,
|
| 181 |
+
)
|
| 182 |
+
)
|
| 183 |
+
self.norm_layers_2.append(LayerNorm(hidden_channels))
|
| 184 |
+
|
| 185 |
+
def forward(self, x, x_mask, h, h_mask):
|
| 186 |
+
"""
|
| 187 |
+
x: decoder input
|
| 188 |
+
h: encoder output
|
| 189 |
+
"""
|
| 190 |
+
self_attn_mask = commons.subsequent_mask(x_mask.size(2)).to(
|
| 191 |
+
device=x.device, dtype=x.dtype
|
| 192 |
+
)
|
| 193 |
+
encdec_attn_mask = h_mask.unsqueeze(2) * x_mask.unsqueeze(-1)
|
| 194 |
+
x = x * x_mask
|
| 195 |
+
for i in range(self.n_layers):
|
| 196 |
+
y = self.self_attn_layers[i](x, x, self_attn_mask)
|
| 197 |
+
y = self.drop(y)
|
| 198 |
+
x = self.norm_layers_0[i](x + y)
|
| 199 |
+
|
| 200 |
+
y = self.encdec_attn_layers[i](x, h, encdec_attn_mask)
|
| 201 |
+
y = self.drop(y)
|
| 202 |
+
x = self.norm_layers_1[i](x + y)
|
| 203 |
+
|
| 204 |
+
y = self.ffn_layers[i](x, x_mask)
|
| 205 |
+
y = self.drop(y)
|
| 206 |
+
x = self.norm_layers_2[i](x + y)
|
| 207 |
+
x = x * x_mask
|
| 208 |
+
return x
|
| 209 |
+
|
| 210 |
+
|
| 211 |
+
class MultiHeadAttention(nn.Module):
|
| 212 |
+
def __init__(
|
| 213 |
+
self,
|
| 214 |
+
channels,
|
| 215 |
+
out_channels,
|
| 216 |
+
n_heads,
|
| 217 |
+
p_dropout=0.0,
|
| 218 |
+
window_size=None,
|
| 219 |
+
heads_share=True,
|
| 220 |
+
block_length=None,
|
| 221 |
+
proximal_bias=False,
|
| 222 |
+
proximal_init=False,
|
| 223 |
+
):
|
| 224 |
+
super().__init__()
|
| 225 |
+
assert channels % n_heads == 0
|
| 226 |
+
|
| 227 |
+
self.channels = channels
|
| 228 |
+
self.out_channels = out_channels
|
| 229 |
+
self.n_heads = n_heads
|
| 230 |
+
self.p_dropout = p_dropout
|
| 231 |
+
self.window_size = window_size
|
| 232 |
+
self.heads_share = heads_share
|
| 233 |
+
self.block_length = block_length
|
| 234 |
+
self.proximal_bias = proximal_bias
|
| 235 |
+
self.proximal_init = proximal_init
|
| 236 |
+
self.attn = None
|
| 237 |
+
|
| 238 |
+
self.k_channels = channels // n_heads
|
| 239 |
+
self.conv_q = nn.Conv1d(channels, channels, 1)
|
| 240 |
+
self.conv_k = nn.Conv1d(channels, channels, 1)
|
| 241 |
+
self.conv_v = nn.Conv1d(channels, channels, 1)
|
| 242 |
+
self.conv_o = nn.Conv1d(channels, out_channels, 1)
|
| 243 |
+
self.drop = nn.Dropout(p_dropout)
|
| 244 |
+
|
| 245 |
+
if window_size is not None:
|
| 246 |
+
n_heads_rel = 1 if heads_share else n_heads
|
| 247 |
+
rel_stddev = self.k_channels**-0.5
|
| 248 |
+
self.emb_rel_k = nn.Parameter(
|
| 249 |
+
torch.randn(n_heads_rel, window_size * 2 + 1, self.k_channels)
|
| 250 |
+
* rel_stddev
|
| 251 |
+
)
|
| 252 |
+
self.emb_rel_v = nn.Parameter(
|
| 253 |
+
torch.randn(n_heads_rel, window_size * 2 + 1, self.k_channels)
|
| 254 |
+
* rel_stddev
|
| 255 |
+
)
|
| 256 |
+
|
| 257 |
+
nn.init.xavier_uniform_(self.conv_q.weight)
|
| 258 |
+
nn.init.xavier_uniform_(self.conv_k.weight)
|
| 259 |
+
nn.init.xavier_uniform_(self.conv_v.weight)
|
| 260 |
+
if proximal_init:
|
| 261 |
+
with torch.no_grad():
|
| 262 |
+
self.conv_k.weight.copy_(self.conv_q.weight)
|
| 263 |
+
self.conv_k.bias.copy_(self.conv_q.bias)
|
| 264 |
+
|
| 265 |
+
def forward(self, x, c, attn_mask=None):
|
| 266 |
+
q = self.conv_q(x)
|
| 267 |
+
k = self.conv_k(c)
|
| 268 |
+
v = self.conv_v(c)
|
| 269 |
+
|
| 270 |
+
x, self.attn = self.attention(q, k, v, mask=attn_mask)
|
| 271 |
+
|
| 272 |
+
x = self.conv_o(x)
|
| 273 |
+
return x
|
| 274 |
+
|
| 275 |
+
def attention(self, query, key, value, mask=None):
|
| 276 |
+
# reshape [b, d, t] -> [b, n_h, t, d_k]
|
| 277 |
+
b, d, t_s, t_t = (*key.size(), query.size(2))
|
| 278 |
+
query = query.view(b, self.n_heads, self.k_channels, t_t).transpose(2, 3)
|
| 279 |
+
key = key.view(b, self.n_heads, self.k_channels, t_s).transpose(2, 3)
|
| 280 |
+
value = value.view(b, self.n_heads, self.k_channels, t_s).transpose(2, 3)
|
| 281 |
+
|
| 282 |
+
scores = torch.matmul(query / math.sqrt(self.k_channels), key.transpose(-2, -1))
|
| 283 |
+
if self.window_size is not None:
|
| 284 |
+
assert (
|
| 285 |
+
t_s == t_t
|
| 286 |
+
), "Relative attention is only available for self-attention."
|
| 287 |
+
key_relative_embeddings = self._get_relative_embeddings(self.emb_rel_k, t_s)
|
| 288 |
+
rel_logits = self._matmul_with_relative_keys(
|
| 289 |
+
query / math.sqrt(self.k_channels), key_relative_embeddings
|
| 290 |
+
)
|
| 291 |
+
scores_local = self._relative_position_to_absolute_position(rel_logits)
|
| 292 |
+
scores = scores + scores_local
|
| 293 |
+
if self.proximal_bias:
|
| 294 |
+
assert t_s == t_t, "Proximal bias is only available for self-attention."
|
| 295 |
+
scores = scores + self._attention_bias_proximal(t_s).to(
|
| 296 |
+
device=scores.device, dtype=scores.dtype
|
| 297 |
+
)
|
| 298 |
+
if mask is not None:
|
| 299 |
+
scores = scores.masked_fill(mask == 0, -1e4)
|
| 300 |
+
if self.block_length is not None:
|
| 301 |
+
assert (
|
| 302 |
+
t_s == t_t
|
| 303 |
+
), "Local attention is only available for self-attention."
|
| 304 |
+
block_mask = (
|
| 305 |
+
torch.ones_like(scores)
|
| 306 |
+
.triu(-self.block_length)
|
| 307 |
+
.tril(self.block_length)
|
| 308 |
+
)
|
| 309 |
+
scores = scores.masked_fill(block_mask == 0, -1e4)
|
| 310 |
+
p_attn = F.softmax(scores, dim=-1) # [b, n_h, t_t, t_s]
|
| 311 |
+
p_attn = self.drop(p_attn)
|
| 312 |
+
output = torch.matmul(p_attn, value)
|
| 313 |
+
if self.window_size is not None:
|
| 314 |
+
relative_weights = self._absolute_position_to_relative_position(p_attn)
|
| 315 |
+
value_relative_embeddings = self._get_relative_embeddings(
|
| 316 |
+
self.emb_rel_v, t_s
|
| 317 |
+
)
|
| 318 |
+
output = output + self._matmul_with_relative_values(
|
| 319 |
+
relative_weights, value_relative_embeddings
|
| 320 |
+
)
|
| 321 |
+
output = (
|
| 322 |
+
output.transpose(2, 3).contiguous().view(b, d, t_t)
|
| 323 |
+
) # [b, n_h, t_t, d_k] -> [b, d, t_t]
|
| 324 |
+
return output, p_attn
|
| 325 |
+
|
| 326 |
+
def _matmul_with_relative_values(self, x, y):
|
| 327 |
+
"""
|
| 328 |
+
x: [b, h, l, m]
|
| 329 |
+
y: [h or 1, m, d]
|
| 330 |
+
ret: [b, h, l, d]
|
| 331 |
+
"""
|
| 332 |
+
ret = torch.matmul(x, y.unsqueeze(0))
|
| 333 |
+
return ret
|
| 334 |
+
|
| 335 |
+
def _matmul_with_relative_keys(self, x, y):
|
| 336 |
+
"""
|
| 337 |
+
x: [b, h, l, d]
|
| 338 |
+
y: [h or 1, m, d]
|
| 339 |
+
ret: [b, h, l, m]
|
| 340 |
+
"""
|
| 341 |
+
ret = torch.matmul(x, y.unsqueeze(0).transpose(-2, -1))
|
| 342 |
+
return ret
|
| 343 |
+
|
| 344 |
+
def _get_relative_embeddings(self, relative_embeddings, length):
|
| 345 |
+
2 * self.window_size + 1
|
| 346 |
+
# Pad first before slice to avoid using cond ops.
|
| 347 |
+
pad_length = max(length - (self.window_size + 1), 0)
|
| 348 |
+
slice_start_position = max((self.window_size + 1) - length, 0)
|
| 349 |
+
slice_end_position = slice_start_position + 2 * length - 1
|
| 350 |
+
if pad_length > 0:
|
| 351 |
+
padded_relative_embeddings = F.pad(
|
| 352 |
+
relative_embeddings,
|
| 353 |
+
commons.convert_pad_shape([[0, 0], [pad_length, pad_length], [0, 0]]),
|
| 354 |
+
)
|
| 355 |
+
else:
|
| 356 |
+
padded_relative_embeddings = relative_embeddings
|
| 357 |
+
used_relative_embeddings = padded_relative_embeddings[
|
| 358 |
+
:, slice_start_position:slice_end_position
|
| 359 |
+
]
|
| 360 |
+
return used_relative_embeddings
|
| 361 |
+
|
| 362 |
+
def _relative_position_to_absolute_position(self, x):
|
| 363 |
+
"""
|
| 364 |
+
x: [b, h, l, 2*l-1]
|
| 365 |
+
ret: [b, h, l, l]
|
| 366 |
+
"""
|
| 367 |
+
batch, heads, length, _ = x.size()
|
| 368 |
+
# Concat columns of pad to shift from relative to absolute indexing.
|
| 369 |
+
x = F.pad(x, commons.convert_pad_shape([[0, 0], [0, 0], [0, 0], [0, 1]]))
|
| 370 |
+
|
| 371 |
+
# Concat extra elements so to add up to shape (len+1, 2*len-1).
|
| 372 |
+
x_flat = x.view([batch, heads, length * 2 * length])
|
| 373 |
+
x_flat = F.pad(
|
| 374 |
+
x_flat, commons.convert_pad_shape([[0, 0], [0, 0], [0, length - 1]])
|
| 375 |
+
)
|
| 376 |
+
|
| 377 |
+
# Reshape and slice out the padded elements.
|
| 378 |
+
x_final = x_flat.view([batch, heads, length + 1, 2 * length - 1])[
|
| 379 |
+
:, :, :length, length - 1 :
|
| 380 |
+
]
|
| 381 |
+
return x_final
|
| 382 |
+
|
| 383 |
+
def _absolute_position_to_relative_position(self, x):
|
| 384 |
+
"""
|
| 385 |
+
x: [b, h, l, l]
|
| 386 |
+
ret: [b, h, l, 2*l-1]
|
| 387 |
+
"""
|
| 388 |
+
batch, heads, length, _ = x.size()
|
| 389 |
+
# pad along column
|
| 390 |
+
x = F.pad(
|
| 391 |
+
x, commons.convert_pad_shape([[0, 0], [0, 0], [0, 0], [0, length - 1]])
|
| 392 |
+
)
|
| 393 |
+
x_flat = x.view([batch, heads, length**2 + length * (length - 1)])
|
| 394 |
+
# add 0's in the beginning that will skew the elements after reshape
|
| 395 |
+
x_flat = F.pad(x_flat, commons.convert_pad_shape([[0, 0], [0, 0], [length, 0]]))
|
| 396 |
+
x_final = x_flat.view([batch, heads, length, 2 * length])[:, :, :, 1:]
|
| 397 |
+
return x_final
|
| 398 |
+
|
| 399 |
+
def _attention_bias_proximal(self, length):
|
| 400 |
+
"""Bias for self-attention to encourage attention to close positions.
|
| 401 |
+
Args:
|
| 402 |
+
length: an integer scalar.
|
| 403 |
+
Returns:
|
| 404 |
+
a Tensor with shape [1, 1, length, length]
|
| 405 |
+
"""
|
| 406 |
+
r = torch.arange(length, dtype=torch.float32)
|
| 407 |
+
diff = torch.unsqueeze(r, 0) - torch.unsqueeze(r, 1)
|
| 408 |
+
return torch.unsqueeze(torch.unsqueeze(-torch.log1p(torch.abs(diff)), 0), 0)
|
| 409 |
+
|
| 410 |
+
|
| 411 |
+
class FFN(nn.Module):
|
| 412 |
+
def __init__(
|
| 413 |
+
self,
|
| 414 |
+
in_channels,
|
| 415 |
+
out_channels,
|
| 416 |
+
filter_channels,
|
| 417 |
+
kernel_size,
|
| 418 |
+
p_dropout=0.0,
|
| 419 |
+
activation=None,
|
| 420 |
+
causal=False,
|
| 421 |
+
):
|
| 422 |
+
super().__init__()
|
| 423 |
+
self.in_channels = in_channels
|
| 424 |
+
self.out_channels = out_channels
|
| 425 |
+
self.filter_channels = filter_channels
|
| 426 |
+
self.kernel_size = kernel_size
|
| 427 |
+
self.p_dropout = p_dropout
|
| 428 |
+
self.activation = activation
|
| 429 |
+
self.causal = causal
|
| 430 |
+
|
| 431 |
+
if causal:
|
| 432 |
+
self.padding = self._causal_padding
|
| 433 |
+
else:
|
| 434 |
+
self.padding = self._same_padding
|
| 435 |
+
|
| 436 |
+
self.conv_1 = nn.Conv1d(in_channels, filter_channels, kernel_size)
|
| 437 |
+
self.conv_2 = nn.Conv1d(filter_channels, out_channels, kernel_size)
|
| 438 |
+
self.drop = nn.Dropout(p_dropout)
|
| 439 |
+
|
| 440 |
+
def forward(self, x, x_mask):
|
| 441 |
+
x = self.conv_1(self.padding(x * x_mask))
|
| 442 |
+
if self.activation == "gelu":
|
| 443 |
+
x = x * torch.sigmoid(1.702 * x)
|
| 444 |
+
else:
|
| 445 |
+
x = torch.relu(x)
|
| 446 |
+
x = self.drop(x)
|
| 447 |
+
x = self.conv_2(self.padding(x * x_mask))
|
| 448 |
+
return x * x_mask
|
| 449 |
+
|
| 450 |
+
def _causal_padding(self, x):
|
| 451 |
+
if self.kernel_size == 1:
|
| 452 |
+
return x
|
| 453 |
+
pad_l = self.kernel_size - 1
|
| 454 |
+
pad_r = 0
|
| 455 |
+
padding = [[0, 0], [0, 0], [pad_l, pad_r]]
|
| 456 |
+
x = F.pad(x, commons.convert_pad_shape(padding))
|
| 457 |
+
return x
|
| 458 |
+
|
| 459 |
+
def _same_padding(self, x):
|
| 460 |
+
if self.kernel_size == 1:
|
| 461 |
+
return x
|
| 462 |
+
pad_l = (self.kernel_size - 1) // 2
|
| 463 |
+
pad_r = self.kernel_size // 2
|
| 464 |
+
padding = [[0, 0], [0, 0], [pad_l, pad_r]]
|
| 465 |
+
x = F.pad(x, commons.convert_pad_shape(padding))
|
| 466 |
+
return x
|
OpenVoice/commons.py
ADDED
|
@@ -0,0 +1,160 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import math
|
| 2 |
+
import torch
|
| 3 |
+
from torch.nn import functional as F
|
| 4 |
+
|
| 5 |
+
|
| 6 |
+
def init_weights(m, mean=0.0, std=0.01):
|
| 7 |
+
classname = m.__class__.__name__
|
| 8 |
+
if classname.find("Conv") != -1:
|
| 9 |
+
m.weight.data.normal_(mean, std)
|
| 10 |
+
|
| 11 |
+
|
| 12 |
+
def get_padding(kernel_size, dilation=1):
|
| 13 |
+
return int((kernel_size * dilation - dilation) / 2)
|
| 14 |
+
|
| 15 |
+
|
| 16 |
+
def convert_pad_shape(pad_shape):
|
| 17 |
+
layer = pad_shape[::-1]
|
| 18 |
+
pad_shape = [item for sublist in layer for item in sublist]
|
| 19 |
+
return pad_shape
|
| 20 |
+
|
| 21 |
+
|
| 22 |
+
def intersperse(lst, item):
|
| 23 |
+
result = [item] * (len(lst) * 2 + 1)
|
| 24 |
+
result[1::2] = lst
|
| 25 |
+
return result
|
| 26 |
+
|
| 27 |
+
|
| 28 |
+
def kl_divergence(m_p, logs_p, m_q, logs_q):
|
| 29 |
+
"""KL(P||Q)"""
|
| 30 |
+
kl = (logs_q - logs_p) - 0.5
|
| 31 |
+
kl += (
|
| 32 |
+
0.5 * (torch.exp(2.0 * logs_p) + ((m_p - m_q) ** 2)) * torch.exp(-2.0 * logs_q)
|
| 33 |
+
)
|
| 34 |
+
return kl
|
| 35 |
+
|
| 36 |
+
|
| 37 |
+
def rand_gumbel(shape):
|
| 38 |
+
"""Sample from the Gumbel distribution, protect from overflows."""
|
| 39 |
+
uniform_samples = torch.rand(shape) * 0.99998 + 0.00001
|
| 40 |
+
return -torch.log(-torch.log(uniform_samples))
|
| 41 |
+
|
| 42 |
+
|
| 43 |
+
def rand_gumbel_like(x):
|
| 44 |
+
g = rand_gumbel(x.size()).to(dtype=x.dtype, device=x.device)
|
| 45 |
+
return g
|
| 46 |
+
|
| 47 |
+
|
| 48 |
+
def slice_segments(x, ids_str, segment_size=4):
|
| 49 |
+
ret = torch.zeros_like(x[:, :, :segment_size])
|
| 50 |
+
for i in range(x.size(0)):
|
| 51 |
+
idx_str = ids_str[i]
|
| 52 |
+
idx_end = idx_str + segment_size
|
| 53 |
+
ret[i] = x[i, :, idx_str:idx_end]
|
| 54 |
+
return ret
|
| 55 |
+
|
| 56 |
+
|
| 57 |
+
def rand_slice_segments(x, x_lengths=None, segment_size=4):
|
| 58 |
+
b, d, t = x.size()
|
| 59 |
+
if x_lengths is None:
|
| 60 |
+
x_lengths = t
|
| 61 |
+
ids_str_max = x_lengths - segment_size + 1
|
| 62 |
+
ids_str = (torch.rand([b]).to(device=x.device) * ids_str_max).to(dtype=torch.long)
|
| 63 |
+
ret = slice_segments(x, ids_str, segment_size)
|
| 64 |
+
return ret, ids_str
|
| 65 |
+
|
| 66 |
+
|
| 67 |
+
def get_timing_signal_1d(length, channels, min_timescale=1.0, max_timescale=1.0e4):
|
| 68 |
+
position = torch.arange(length, dtype=torch.float)
|
| 69 |
+
num_timescales = channels // 2
|
| 70 |
+
log_timescale_increment = math.log(float(max_timescale) / float(min_timescale)) / (
|
| 71 |
+
num_timescales - 1
|
| 72 |
+
)
|
| 73 |
+
inv_timescales = min_timescale * torch.exp(
|
| 74 |
+
torch.arange(num_timescales, dtype=torch.float) * -log_timescale_increment
|
| 75 |
+
)
|
| 76 |
+
scaled_time = position.unsqueeze(0) * inv_timescales.unsqueeze(1)
|
| 77 |
+
signal = torch.cat([torch.sin(scaled_time), torch.cos(scaled_time)], 0)
|
| 78 |
+
signal = F.pad(signal, [0, 0, 0, channels % 2])
|
| 79 |
+
signal = signal.view(1, channels, length)
|
| 80 |
+
return signal
|
| 81 |
+
|
| 82 |
+
|
| 83 |
+
def add_timing_signal_1d(x, min_timescale=1.0, max_timescale=1.0e4):
|
| 84 |
+
b, channels, length = x.size()
|
| 85 |
+
signal = get_timing_signal_1d(length, channels, min_timescale, max_timescale)
|
| 86 |
+
return x + signal.to(dtype=x.dtype, device=x.device)
|
| 87 |
+
|
| 88 |
+
|
| 89 |
+
def cat_timing_signal_1d(x, min_timescale=1.0, max_timescale=1.0e4, axis=1):
|
| 90 |
+
b, channels, length = x.size()
|
| 91 |
+
signal = get_timing_signal_1d(length, channels, min_timescale, max_timescale)
|
| 92 |
+
return torch.cat([x, signal.to(dtype=x.dtype, device=x.device)], axis)
|
| 93 |
+
|
| 94 |
+
|
| 95 |
+
def subsequent_mask(length):
|
| 96 |
+
mask = torch.tril(torch.ones(length, length)).unsqueeze(0).unsqueeze(0)
|
| 97 |
+
return mask
|
| 98 |
+
|
| 99 |
+
|
| 100 |
+
@torch.jit.script
|
| 101 |
+
def fused_add_tanh_sigmoid_multiply(input_a, input_b, n_channels):
|
| 102 |
+
n_channels_int = n_channels[0]
|
| 103 |
+
in_act = input_a + input_b
|
| 104 |
+
t_act = torch.tanh(in_act[:, :n_channels_int, :])
|
| 105 |
+
s_act = torch.sigmoid(in_act[:, n_channels_int:, :])
|
| 106 |
+
acts = t_act * s_act
|
| 107 |
+
return acts
|
| 108 |
+
|
| 109 |
+
|
| 110 |
+
def convert_pad_shape(pad_shape):
|
| 111 |
+
layer = pad_shape[::-1]
|
| 112 |
+
pad_shape = [item for sublist in layer for item in sublist]
|
| 113 |
+
return pad_shape
|
| 114 |
+
|
| 115 |
+
|
| 116 |
+
def shift_1d(x):
|
| 117 |
+
x = F.pad(x, convert_pad_shape([[0, 0], [0, 0], [1, 0]]))[:, :, :-1]
|
| 118 |
+
return x
|
| 119 |
+
|
| 120 |
+
|
| 121 |
+
def sequence_mask(length, max_length=None):
|
| 122 |
+
if max_length is None:
|
| 123 |
+
max_length = length.max()
|
| 124 |
+
x = torch.arange(max_length, dtype=length.dtype, device=length.device)
|
| 125 |
+
return x.unsqueeze(0) < length.unsqueeze(1)
|
| 126 |
+
|
| 127 |
+
|
| 128 |
+
def generate_path(duration, mask):
|
| 129 |
+
"""
|
| 130 |
+
duration: [b, 1, t_x]
|
| 131 |
+
mask: [b, 1, t_y, t_x]
|
| 132 |
+
"""
|
| 133 |
+
|
| 134 |
+
b, _, t_y, t_x = mask.shape
|
| 135 |
+
cum_duration = torch.cumsum(duration, -1)
|
| 136 |
+
|
| 137 |
+
cum_duration_flat = cum_duration.view(b * t_x)
|
| 138 |
+
path = sequence_mask(cum_duration_flat, t_y).to(mask.dtype)
|
| 139 |
+
path = path.view(b, t_x, t_y)
|
| 140 |
+
path = path - F.pad(path, convert_pad_shape([[0, 0], [1, 0], [0, 0]]))[:, :-1]
|
| 141 |
+
path = path.unsqueeze(1).transpose(2, 3) * mask
|
| 142 |
+
return path
|
| 143 |
+
|
| 144 |
+
|
| 145 |
+
def clip_grad_value_(parameters, clip_value, norm_type=2):
|
| 146 |
+
if isinstance(parameters, torch.Tensor):
|
| 147 |
+
parameters = [parameters]
|
| 148 |
+
parameters = list(filter(lambda p: p.grad is not None, parameters))
|
| 149 |
+
norm_type = float(norm_type)
|
| 150 |
+
if clip_value is not None:
|
| 151 |
+
clip_value = float(clip_value)
|
| 152 |
+
|
| 153 |
+
total_norm = 0
|
| 154 |
+
for p in parameters:
|
| 155 |
+
param_norm = p.grad.data.norm(norm_type)
|
| 156 |
+
total_norm += param_norm.item() ** norm_type
|
| 157 |
+
if clip_value is not None:
|
| 158 |
+
p.grad.data.clamp_(min=-clip_value, max=clip_value)
|
| 159 |
+
total_norm = total_norm ** (1.0 / norm_type)
|
| 160 |
+
return total_norm
|
OpenVoice/mel_processing.py
ADDED
|
@@ -0,0 +1,183 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import torch
|
| 2 |
+
import torch.utils.data
|
| 3 |
+
from librosa.filters import mel as librosa_mel_fn
|
| 4 |
+
|
| 5 |
+
MAX_WAV_VALUE = 32768.0
|
| 6 |
+
|
| 7 |
+
|
| 8 |
+
def dynamic_range_compression_torch(x, C=1, clip_val=1e-5):
|
| 9 |
+
"""
|
| 10 |
+
PARAMS
|
| 11 |
+
------
|
| 12 |
+
C: compression factor
|
| 13 |
+
"""
|
| 14 |
+
return torch.log(torch.clamp(x, min=clip_val) * C)
|
| 15 |
+
|
| 16 |
+
|
| 17 |
+
def dynamic_range_decompression_torch(x, C=1):
|
| 18 |
+
"""
|
| 19 |
+
PARAMS
|
| 20 |
+
------
|
| 21 |
+
C: compression factor used to compress
|
| 22 |
+
"""
|
| 23 |
+
return torch.exp(x) / C
|
| 24 |
+
|
| 25 |
+
|
| 26 |
+
def spectral_normalize_torch(magnitudes):
|
| 27 |
+
output = dynamic_range_compression_torch(magnitudes)
|
| 28 |
+
return output
|
| 29 |
+
|
| 30 |
+
|
| 31 |
+
def spectral_de_normalize_torch(magnitudes):
|
| 32 |
+
output = dynamic_range_decompression_torch(magnitudes)
|
| 33 |
+
return output
|
| 34 |
+
|
| 35 |
+
|
| 36 |
+
mel_basis = {}
|
| 37 |
+
hann_window = {}
|
| 38 |
+
|
| 39 |
+
|
| 40 |
+
def spectrogram_torch(y, n_fft, sampling_rate, hop_size, win_size, center=False):
|
| 41 |
+
if torch.min(y) < -1.1:
|
| 42 |
+
print("min value is ", torch.min(y))
|
| 43 |
+
if torch.max(y) > 1.1:
|
| 44 |
+
print("max value is ", torch.max(y))
|
| 45 |
+
|
| 46 |
+
global hann_window
|
| 47 |
+
dtype_device = str(y.dtype) + "_" + str(y.device)
|
| 48 |
+
wnsize_dtype_device = str(win_size) + "_" + dtype_device
|
| 49 |
+
if wnsize_dtype_device not in hann_window:
|
| 50 |
+
hann_window[wnsize_dtype_device] = torch.hann_window(win_size).to(
|
| 51 |
+
dtype=y.dtype, device=y.device
|
| 52 |
+
)
|
| 53 |
+
|
| 54 |
+
y = torch.nn.functional.pad(
|
| 55 |
+
y.unsqueeze(1),
|
| 56 |
+
(int((n_fft - hop_size) / 2), int((n_fft - hop_size) / 2)),
|
| 57 |
+
mode="reflect",
|
| 58 |
+
)
|
| 59 |
+
y = y.squeeze(1)
|
| 60 |
+
|
| 61 |
+
spec = torch.stft(
|
| 62 |
+
y,
|
| 63 |
+
n_fft,
|
| 64 |
+
hop_length=hop_size,
|
| 65 |
+
win_length=win_size,
|
| 66 |
+
window=hann_window[wnsize_dtype_device],
|
| 67 |
+
center=center,
|
| 68 |
+
pad_mode="reflect",
|
| 69 |
+
normalized=False,
|
| 70 |
+
onesided=True,
|
| 71 |
+
return_complex=False,
|
| 72 |
+
)
|
| 73 |
+
|
| 74 |
+
spec = torch.sqrt(spec.pow(2).sum(-1) + 1e-6)
|
| 75 |
+
return spec
|
| 76 |
+
|
| 77 |
+
|
| 78 |
+
def spectrogram_torch_conv(y, n_fft, sampling_rate, hop_size, win_size, center=False):
|
| 79 |
+
# if torch.min(y) < -1.:
|
| 80 |
+
# print('min value is ', torch.min(y))
|
| 81 |
+
# if torch.max(y) > 1.:
|
| 82 |
+
# print('max value is ', torch.max(y))
|
| 83 |
+
|
| 84 |
+
global hann_window
|
| 85 |
+
dtype_device = str(y.dtype) + '_' + str(y.device)
|
| 86 |
+
wnsize_dtype_device = str(win_size) + '_' + dtype_device
|
| 87 |
+
if wnsize_dtype_device not in hann_window:
|
| 88 |
+
hann_window[wnsize_dtype_device] = torch.hann_window(win_size).to(dtype=y.dtype, device=y.device)
|
| 89 |
+
|
| 90 |
+
y = torch.nn.functional.pad(y.unsqueeze(1), (int((n_fft-hop_size)/2), int((n_fft-hop_size)/2)), mode='reflect')
|
| 91 |
+
|
| 92 |
+
# ******************** original ************************#
|
| 93 |
+
# y = y.squeeze(1)
|
| 94 |
+
# spec1 = torch.stft(y, n_fft, hop_length=hop_size, win_length=win_size, window=hann_window[wnsize_dtype_device],
|
| 95 |
+
# center=center, pad_mode='reflect', normalized=False, onesided=True, return_complex=False)
|
| 96 |
+
|
| 97 |
+
# ******************** ConvSTFT ************************#
|
| 98 |
+
freq_cutoff = n_fft // 2 + 1
|
| 99 |
+
fourier_basis = torch.view_as_real(torch.fft.fft(torch.eye(n_fft)))
|
| 100 |
+
forward_basis = fourier_basis[:freq_cutoff].permute(2, 0, 1).reshape(-1, 1, fourier_basis.shape[1])
|
| 101 |
+
forward_basis = forward_basis * torch.as_tensor(librosa.util.pad_center(torch.hann_window(win_size), size=n_fft)).float()
|
| 102 |
+
|
| 103 |
+
import torch.nn.functional as F
|
| 104 |
+
|
| 105 |
+
# if center:
|
| 106 |
+
# signal = F.pad(y[:, None, None, :], (n_fft // 2, n_fft // 2, 0, 0), mode = 'reflect').squeeze(1)
|
| 107 |
+
assert center is False
|
| 108 |
+
|
| 109 |
+
forward_transform_squared = F.conv1d(y, forward_basis.to(y.device), stride = hop_size)
|
| 110 |
+
spec2 = torch.stack([forward_transform_squared[:, :freq_cutoff, :], forward_transform_squared[:, freq_cutoff:, :]], dim = -1)
|
| 111 |
+
|
| 112 |
+
|
| 113 |
+
# ******************** Verification ************************#
|
| 114 |
+
spec1 = torch.stft(y.squeeze(1), n_fft, hop_length=hop_size, win_length=win_size, window=hann_window[wnsize_dtype_device],
|
| 115 |
+
center=center, pad_mode='reflect', normalized=False, onesided=True, return_complex=False)
|
| 116 |
+
assert torch.allclose(spec1, spec2, atol=1e-4)
|
| 117 |
+
|
| 118 |
+
spec = torch.sqrt(spec2.pow(2).sum(-1) + 1e-6)
|
| 119 |
+
return spec
|
| 120 |
+
|
| 121 |
+
|
| 122 |
+
def spec_to_mel_torch(spec, n_fft, num_mels, sampling_rate, fmin, fmax):
|
| 123 |
+
global mel_basis
|
| 124 |
+
dtype_device = str(spec.dtype) + "_" + str(spec.device)
|
| 125 |
+
fmax_dtype_device = str(fmax) + "_" + dtype_device
|
| 126 |
+
if fmax_dtype_device not in mel_basis:
|
| 127 |
+
mel = librosa_mel_fn(sampling_rate, n_fft, num_mels, fmin, fmax)
|
| 128 |
+
mel_basis[fmax_dtype_device] = torch.from_numpy(mel).to(
|
| 129 |
+
dtype=spec.dtype, device=spec.device
|
| 130 |
+
)
|
| 131 |
+
spec = torch.matmul(mel_basis[fmax_dtype_device], spec)
|
| 132 |
+
spec = spectral_normalize_torch(spec)
|
| 133 |
+
return spec
|
| 134 |
+
|
| 135 |
+
|
| 136 |
+
def mel_spectrogram_torch(
|
| 137 |
+
y, n_fft, num_mels, sampling_rate, hop_size, win_size, fmin, fmax, center=False
|
| 138 |
+
):
|
| 139 |
+
if torch.min(y) < -1.0:
|
| 140 |
+
print("min value is ", torch.min(y))
|
| 141 |
+
if torch.max(y) > 1.0:
|
| 142 |
+
print("max value is ", torch.max(y))
|
| 143 |
+
|
| 144 |
+
global mel_basis, hann_window
|
| 145 |
+
dtype_device = str(y.dtype) + "_" + str(y.device)
|
| 146 |
+
fmax_dtype_device = str(fmax) + "_" + dtype_device
|
| 147 |
+
wnsize_dtype_device = str(win_size) + "_" + dtype_device
|
| 148 |
+
if fmax_dtype_device not in mel_basis:
|
| 149 |
+
mel = librosa_mel_fn(sampling_rate, n_fft, num_mels, fmin, fmax)
|
| 150 |
+
mel_basis[fmax_dtype_device] = torch.from_numpy(mel).to(
|
| 151 |
+
dtype=y.dtype, device=y.device
|
| 152 |
+
)
|
| 153 |
+
if wnsize_dtype_device not in hann_window:
|
| 154 |
+
hann_window[wnsize_dtype_device] = torch.hann_window(win_size).to(
|
| 155 |
+
dtype=y.dtype, device=y.device
|
| 156 |
+
)
|
| 157 |
+
|
| 158 |
+
y = torch.nn.functional.pad(
|
| 159 |
+
y.unsqueeze(1),
|
| 160 |
+
(int((n_fft - hop_size) / 2), int((n_fft - hop_size) / 2)),
|
| 161 |
+
mode="reflect",
|
| 162 |
+
)
|
| 163 |
+
y = y.squeeze(1)
|
| 164 |
+
|
| 165 |
+
spec = torch.stft(
|
| 166 |
+
y,
|
| 167 |
+
n_fft,
|
| 168 |
+
hop_length=hop_size,
|
| 169 |
+
win_length=win_size,
|
| 170 |
+
window=hann_window[wnsize_dtype_device],
|
| 171 |
+
center=center,
|
| 172 |
+
pad_mode="reflect",
|
| 173 |
+
normalized=False,
|
| 174 |
+
onesided=True,
|
| 175 |
+
return_complex=False,
|
| 176 |
+
)
|
| 177 |
+
|
| 178 |
+
spec = torch.sqrt(spec.pow(2).sum(-1) + 1e-6)
|
| 179 |
+
|
| 180 |
+
spec = torch.matmul(mel_basis[fmax_dtype_device], spec)
|
| 181 |
+
spec = spectral_normalize_torch(spec)
|
| 182 |
+
|
| 183 |
+
return spec
|
OpenVoice/models.py
ADDED
|
@@ -0,0 +1,497 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import math
|
| 2 |
+
import torch
|
| 3 |
+
from torch import nn
|
| 4 |
+
from torch.nn import functional as F
|
| 5 |
+
|
| 6 |
+
from . import commons
|
| 7 |
+
from . import modules
|
| 8 |
+
from . import attentions
|
| 9 |
+
|
| 10 |
+
from torch.nn import Conv1d, ConvTranspose1d, Conv2d
|
| 11 |
+
from torch.nn.utils import weight_norm, remove_weight_norm, spectral_norm
|
| 12 |
+
|
| 13 |
+
from .commons import init_weights
|
| 14 |
+
|
| 15 |
+
|
| 16 |
+
class TextEncoder(nn.Module):
|
| 17 |
+
def __init__(self,
|
| 18 |
+
n_vocab,
|
| 19 |
+
out_channels,
|
| 20 |
+
hidden_channels,
|
| 21 |
+
filter_channels,
|
| 22 |
+
n_heads,
|
| 23 |
+
n_layers,
|
| 24 |
+
kernel_size,
|
| 25 |
+
p_dropout):
|
| 26 |
+
super().__init__()
|
| 27 |
+
self.n_vocab = n_vocab
|
| 28 |
+
self.out_channels = out_channels
|
| 29 |
+
self.hidden_channels = hidden_channels
|
| 30 |
+
self.filter_channels = filter_channels
|
| 31 |
+
self.n_heads = n_heads
|
| 32 |
+
self.n_layers = n_layers
|
| 33 |
+
self.kernel_size = kernel_size
|
| 34 |
+
self.p_dropout = p_dropout
|
| 35 |
+
|
| 36 |
+
self.emb = nn.Embedding(n_vocab, hidden_channels)
|
| 37 |
+
nn.init.normal_(self.emb.weight, 0.0, hidden_channels**-0.5)
|
| 38 |
+
|
| 39 |
+
self.encoder = attentions.Encoder(
|
| 40 |
+
hidden_channels,
|
| 41 |
+
filter_channels,
|
| 42 |
+
n_heads,
|
| 43 |
+
n_layers,
|
| 44 |
+
kernel_size,
|
| 45 |
+
p_dropout)
|
| 46 |
+
self.proj= nn.Conv1d(hidden_channels, out_channels * 2, 1)
|
| 47 |
+
|
| 48 |
+
def forward(self, x, x_lengths):
|
| 49 |
+
x = self.emb(x) * math.sqrt(self.hidden_channels) # [b, t, h]
|
| 50 |
+
x = torch.transpose(x, 1, -1) # [b, h, t]
|
| 51 |
+
x_mask = torch.unsqueeze(commons.sequence_mask(x_lengths, x.size(2)), 1).to(x.dtype)
|
| 52 |
+
|
| 53 |
+
x = self.encoder(x * x_mask, x_mask)
|
| 54 |
+
stats = self.proj(x) * x_mask
|
| 55 |
+
|
| 56 |
+
m, logs = torch.split(stats, self.out_channels, dim=1)
|
| 57 |
+
return x, m, logs, x_mask
|
| 58 |
+
|
| 59 |
+
|
| 60 |
+
class DurationPredictor(nn.Module):
|
| 61 |
+
def __init__(
|
| 62 |
+
self, in_channels, filter_channels, kernel_size, p_dropout, gin_channels=0
|
| 63 |
+
):
|
| 64 |
+
super().__init__()
|
| 65 |
+
|
| 66 |
+
self.in_channels = in_channels
|
| 67 |
+
self.filter_channels = filter_channels
|
| 68 |
+
self.kernel_size = kernel_size
|
| 69 |
+
self.p_dropout = p_dropout
|
| 70 |
+
self.gin_channels = gin_channels
|
| 71 |
+
|
| 72 |
+
self.drop = nn.Dropout(p_dropout)
|
| 73 |
+
self.conv_1 = nn.Conv1d(
|
| 74 |
+
in_channels, filter_channels, kernel_size, padding=kernel_size // 2
|
| 75 |
+
)
|
| 76 |
+
self.norm_1 = modules.LayerNorm(filter_channels)
|
| 77 |
+
self.conv_2 = nn.Conv1d(
|
| 78 |
+
filter_channels, filter_channels, kernel_size, padding=kernel_size // 2
|
| 79 |
+
)
|
| 80 |
+
self.norm_2 = modules.LayerNorm(filter_channels)
|
| 81 |
+
self.proj = nn.Conv1d(filter_channels, 1, 1)
|
| 82 |
+
|
| 83 |
+
if gin_channels != 0:
|
| 84 |
+
self.cond = nn.Conv1d(gin_channels, in_channels, 1)
|
| 85 |
+
|
| 86 |
+
def forward(self, x, x_mask, g=None):
|
| 87 |
+
x = torch.detach(x)
|
| 88 |
+
if g is not None:
|
| 89 |
+
g = torch.detach(g)
|
| 90 |
+
x = x + self.cond(g)
|
| 91 |
+
x = self.conv_1(x * x_mask)
|
| 92 |
+
x = torch.relu(x)
|
| 93 |
+
x = self.norm_1(x)
|
| 94 |
+
x = self.drop(x)
|
| 95 |
+
x = self.conv_2(x * x_mask)
|
| 96 |
+
x = torch.relu(x)
|
| 97 |
+
x = self.norm_2(x)
|
| 98 |
+
x = self.drop(x)
|
| 99 |
+
x = self.proj(x * x_mask)
|
| 100 |
+
return x * x_mask
|
| 101 |
+
|
| 102 |
+
class StochasticDurationPredictor(nn.Module):
|
| 103 |
+
def __init__(self, in_channels, filter_channels, kernel_size, p_dropout, n_flows=4, gin_channels=0):
|
| 104 |
+
super().__init__()
|
| 105 |
+
filter_channels = in_channels # it needs to be removed from future version.
|
| 106 |
+
self.in_channels = in_channels
|
| 107 |
+
self.filter_channels = filter_channels
|
| 108 |
+
self.kernel_size = kernel_size
|
| 109 |
+
self.p_dropout = p_dropout
|
| 110 |
+
self.n_flows = n_flows
|
| 111 |
+
self.gin_channels = gin_channels
|
| 112 |
+
|
| 113 |
+
self.log_flow = modules.Log()
|
| 114 |
+
self.flows = nn.ModuleList()
|
| 115 |
+
self.flows.append(modules.ElementwiseAffine(2))
|
| 116 |
+
for i in range(n_flows):
|
| 117 |
+
self.flows.append(modules.ConvFlow(2, filter_channels, kernel_size, n_layers=3))
|
| 118 |
+
self.flows.append(modules.Flip())
|
| 119 |
+
|
| 120 |
+
self.post_pre = nn.Conv1d(1, filter_channels, 1)
|
| 121 |
+
self.post_proj = nn.Conv1d(filter_channels, filter_channels, 1)
|
| 122 |
+
self.post_convs = modules.DDSConv(filter_channels, kernel_size, n_layers=3, p_dropout=p_dropout)
|
| 123 |
+
self.post_flows = nn.ModuleList()
|
| 124 |
+
self.post_flows.append(modules.ElementwiseAffine(2))
|
| 125 |
+
for i in range(4):
|
| 126 |
+
self.post_flows.append(modules.ConvFlow(2, filter_channels, kernel_size, n_layers=3))
|
| 127 |
+
self.post_flows.append(modules.Flip())
|
| 128 |
+
|
| 129 |
+
self.pre = nn.Conv1d(in_channels, filter_channels, 1)
|
| 130 |
+
self.proj = nn.Conv1d(filter_channels, filter_channels, 1)
|
| 131 |
+
self.convs = modules.DDSConv(filter_channels, kernel_size, n_layers=3, p_dropout=p_dropout)
|
| 132 |
+
if gin_channels != 0:
|
| 133 |
+
self.cond = nn.Conv1d(gin_channels, filter_channels, 1)
|
| 134 |
+
|
| 135 |
+
def forward(self, x, x_mask, w=None, g=None, reverse=False, noise_scale=1.0):
|
| 136 |
+
x = torch.detach(x)
|
| 137 |
+
x = self.pre(x)
|
| 138 |
+
if g is not None:
|
| 139 |
+
g = torch.detach(g)
|
| 140 |
+
x = x + self.cond(g)
|
| 141 |
+
x = self.convs(x, x_mask)
|
| 142 |
+
x = self.proj(x) * x_mask
|
| 143 |
+
|
| 144 |
+
if not reverse:
|
| 145 |
+
flows = self.flows
|
| 146 |
+
assert w is not None
|
| 147 |
+
|
| 148 |
+
logdet_tot_q = 0
|
| 149 |
+
h_w = self.post_pre(w)
|
| 150 |
+
h_w = self.post_convs(h_w, x_mask)
|
| 151 |
+
h_w = self.post_proj(h_w) * x_mask
|
| 152 |
+
e_q = torch.randn(w.size(0), 2, w.size(2)).to(device=x.device, dtype=x.dtype) * x_mask
|
| 153 |
+
z_q = e_q
|
| 154 |
+
for flow in self.post_flows:
|
| 155 |
+
z_q, logdet_q = flow(z_q, x_mask, g=(x + h_w))
|
| 156 |
+
logdet_tot_q += logdet_q
|
| 157 |
+
z_u, z1 = torch.split(z_q, [1, 1], 1)
|
| 158 |
+
u = torch.sigmoid(z_u) * x_mask
|
| 159 |
+
z0 = (w - u) * x_mask
|
| 160 |
+
logdet_tot_q += torch.sum((F.logsigmoid(z_u) + F.logsigmoid(-z_u)) * x_mask, [1,2])
|
| 161 |
+
logq = torch.sum(-0.5 * (math.log(2*math.pi) + (e_q**2)) * x_mask, [1,2]) - logdet_tot_q
|
| 162 |
+
|
| 163 |
+
logdet_tot = 0
|
| 164 |
+
z0, logdet = self.log_flow(z0, x_mask)
|
| 165 |
+
logdet_tot += logdet
|
| 166 |
+
z = torch.cat([z0, z1], 1)
|
| 167 |
+
for flow in flows:
|
| 168 |
+
z, logdet = flow(z, x_mask, g=x, reverse=reverse)
|
| 169 |
+
logdet_tot = logdet_tot + logdet
|
| 170 |
+
nll = torch.sum(0.5 * (math.log(2*math.pi) + (z**2)) * x_mask, [1,2]) - logdet_tot
|
| 171 |
+
return nll + logq # [b]
|
| 172 |
+
else:
|
| 173 |
+
flows = list(reversed(self.flows))
|
| 174 |
+
flows = flows[:-2] + [flows[-1]] # remove a useless vflow
|
| 175 |
+
z = torch.randn(x.size(0), 2, x.size(2)).to(device=x.device, dtype=x.dtype) * noise_scale
|
| 176 |
+
for flow in flows:
|
| 177 |
+
z = flow(z, x_mask, g=x, reverse=reverse)
|
| 178 |
+
z0, z1 = torch.split(z, [1, 1], 1)
|
| 179 |
+
logw = z0
|
| 180 |
+
return logw
|
| 181 |
+
|
| 182 |
+
class PosteriorEncoder(nn.Module):
|
| 183 |
+
def __init__(
|
| 184 |
+
self,
|
| 185 |
+
in_channels,
|
| 186 |
+
out_channels,
|
| 187 |
+
hidden_channels,
|
| 188 |
+
kernel_size,
|
| 189 |
+
dilation_rate,
|
| 190 |
+
n_layers,
|
| 191 |
+
gin_channels=0,
|
| 192 |
+
):
|
| 193 |
+
super().__init__()
|
| 194 |
+
self.in_channels = in_channels
|
| 195 |
+
self.out_channels = out_channels
|
| 196 |
+
self.hidden_channels = hidden_channels
|
| 197 |
+
self.kernel_size = kernel_size
|
| 198 |
+
self.dilation_rate = dilation_rate
|
| 199 |
+
self.n_layers = n_layers
|
| 200 |
+
self.gin_channels = gin_channels
|
| 201 |
+
|
| 202 |
+
self.pre = nn.Conv1d(in_channels, hidden_channels, 1)
|
| 203 |
+
self.enc = modules.WN(
|
| 204 |
+
hidden_channels,
|
| 205 |
+
kernel_size,
|
| 206 |
+
dilation_rate,
|
| 207 |
+
n_layers,
|
| 208 |
+
gin_channels=gin_channels,
|
| 209 |
+
)
|
| 210 |
+
self.proj = nn.Conv1d(hidden_channels, out_channels * 2, 1)
|
| 211 |
+
|
| 212 |
+
def forward(self, x, x_lengths, g=None, tau=1.0):
|
| 213 |
+
x_mask = torch.unsqueeze(commons.sequence_mask(x_lengths, x.size(2)), 1).to(
|
| 214 |
+
x.dtype
|
| 215 |
+
)
|
| 216 |
+
x = self.pre(x) * x_mask
|
| 217 |
+
x = self.enc(x, x_mask, g=g)
|
| 218 |
+
stats = self.proj(x) * x_mask
|
| 219 |
+
m, logs = torch.split(stats, self.out_channels, dim=1)
|
| 220 |
+
z = (m + torch.randn_like(m) * tau * torch.exp(logs)) * x_mask
|
| 221 |
+
return z, m, logs, x_mask
|
| 222 |
+
|
| 223 |
+
|
| 224 |
+
class Generator(torch.nn.Module):
|
| 225 |
+
def __init__(
|
| 226 |
+
self,
|
| 227 |
+
initial_channel,
|
| 228 |
+
resblock,
|
| 229 |
+
resblock_kernel_sizes,
|
| 230 |
+
resblock_dilation_sizes,
|
| 231 |
+
upsample_rates,
|
| 232 |
+
upsample_initial_channel,
|
| 233 |
+
upsample_kernel_sizes,
|
| 234 |
+
gin_channels=0,
|
| 235 |
+
):
|
| 236 |
+
super(Generator, self).__init__()
|
| 237 |
+
self.num_kernels = len(resblock_kernel_sizes)
|
| 238 |
+
self.num_upsamples = len(upsample_rates)
|
| 239 |
+
self.conv_pre = Conv1d(
|
| 240 |
+
initial_channel, upsample_initial_channel, 7, 1, padding=3
|
| 241 |
+
)
|
| 242 |
+
resblock = modules.ResBlock1 if resblock == "1" else modules.ResBlock2
|
| 243 |
+
|
| 244 |
+
self.ups = nn.ModuleList()
|
| 245 |
+
for i, (u, k) in enumerate(zip(upsample_rates, upsample_kernel_sizes)):
|
| 246 |
+
self.ups.append(
|
| 247 |
+
weight_norm(
|
| 248 |
+
ConvTranspose1d(
|
| 249 |
+
upsample_initial_channel // (2**i),
|
| 250 |
+
upsample_initial_channel // (2 ** (i + 1)),
|
| 251 |
+
k,
|
| 252 |
+
u,
|
| 253 |
+
padding=(k - u) // 2,
|
| 254 |
+
)
|
| 255 |
+
)
|
| 256 |
+
)
|
| 257 |
+
|
| 258 |
+
self.resblocks = nn.ModuleList()
|
| 259 |
+
for i in range(len(self.ups)):
|
| 260 |
+
ch = upsample_initial_channel // (2 ** (i + 1))
|
| 261 |
+
for j, (k, d) in enumerate(
|
| 262 |
+
zip(resblock_kernel_sizes, resblock_dilation_sizes)
|
| 263 |
+
):
|
| 264 |
+
self.resblocks.append(resblock(ch, k, d))
|
| 265 |
+
|
| 266 |
+
self.conv_post = Conv1d(ch, 1, 7, 1, padding=3, bias=False)
|
| 267 |
+
self.ups.apply(init_weights)
|
| 268 |
+
|
| 269 |
+
if gin_channels != 0:
|
| 270 |
+
self.cond = nn.Conv1d(gin_channels, upsample_initial_channel, 1)
|
| 271 |
+
|
| 272 |
+
def forward(self, x, g=None):
|
| 273 |
+
x = self.conv_pre(x)
|
| 274 |
+
if g is not None:
|
| 275 |
+
x = x + self.cond(g)
|
| 276 |
+
|
| 277 |
+
for i in range(self.num_upsamples):
|
| 278 |
+
x = F.leaky_relu(x, modules.LRELU_SLOPE)
|
| 279 |
+
x = self.ups[i](x)
|
| 280 |
+
xs = None
|
| 281 |
+
for j in range(self.num_kernels):
|
| 282 |
+
if xs is None:
|
| 283 |
+
xs = self.resblocks[i * self.num_kernels + j](x)
|
| 284 |
+
else:
|
| 285 |
+
xs += self.resblocks[i * self.num_kernels + j](x)
|
| 286 |
+
x = xs / self.num_kernels
|
| 287 |
+
x = F.leaky_relu(x)
|
| 288 |
+
x = self.conv_post(x)
|
| 289 |
+
x = torch.tanh(x)
|
| 290 |
+
|
| 291 |
+
return x
|
| 292 |
+
|
| 293 |
+
def remove_weight_norm(self):
|
| 294 |
+
print("Removing weight norm...")
|
| 295 |
+
for layer in self.ups:
|
| 296 |
+
remove_weight_norm(layer)
|
| 297 |
+
for layer in self.resblocks:
|
| 298 |
+
layer.remove_weight_norm()
|
| 299 |
+
|
| 300 |
+
|
| 301 |
+
class ReferenceEncoder(nn.Module):
|
| 302 |
+
"""
|
| 303 |
+
inputs --- [N, Ty/r, n_mels*r] mels
|
| 304 |
+
outputs --- [N, ref_enc_gru_size]
|
| 305 |
+
"""
|
| 306 |
+
|
| 307 |
+
def __init__(self, spec_channels, gin_channels=0, layernorm=True):
|
| 308 |
+
super().__init__()
|
| 309 |
+
self.spec_channels = spec_channels
|
| 310 |
+
ref_enc_filters = [32, 32, 64, 64, 128, 128]
|
| 311 |
+
K = len(ref_enc_filters)
|
| 312 |
+
filters = [1] + ref_enc_filters
|
| 313 |
+
convs = [
|
| 314 |
+
weight_norm(
|
| 315 |
+
nn.Conv2d(
|
| 316 |
+
in_channels=filters[i],
|
| 317 |
+
out_channels=filters[i + 1],
|
| 318 |
+
kernel_size=(3, 3),
|
| 319 |
+
stride=(2, 2),
|
| 320 |
+
padding=(1, 1),
|
| 321 |
+
)
|
| 322 |
+
)
|
| 323 |
+
for i in range(K)
|
| 324 |
+
]
|
| 325 |
+
self.convs = nn.ModuleList(convs)
|
| 326 |
+
|
| 327 |
+
out_channels = self.calculate_channels(spec_channels, 3, 2, 1, K)
|
| 328 |
+
self.gru = nn.GRU(
|
| 329 |
+
input_size=ref_enc_filters[-1] * out_channels,
|
| 330 |
+
hidden_size=256 // 2,
|
| 331 |
+
batch_first=True,
|
| 332 |
+
)
|
| 333 |
+
self.proj = nn.Linear(128, gin_channels)
|
| 334 |
+
if layernorm:
|
| 335 |
+
self.layernorm = nn.LayerNorm(self.spec_channels)
|
| 336 |
+
else:
|
| 337 |
+
self.layernorm = None
|
| 338 |
+
|
| 339 |
+
def forward(self, inputs, mask=None):
|
| 340 |
+
N = inputs.size(0)
|
| 341 |
+
|
| 342 |
+
out = inputs.view(N, 1, -1, self.spec_channels) # [N, 1, Ty, n_freqs]
|
| 343 |
+
if self.layernorm is not None:
|
| 344 |
+
out = self.layernorm(out)
|
| 345 |
+
|
| 346 |
+
for conv in self.convs:
|
| 347 |
+
out = conv(out)
|
| 348 |
+
# out = wn(out)
|
| 349 |
+
out = F.relu(out) # [N, 128, Ty//2^K, n_mels//2^K]
|
| 350 |
+
|
| 351 |
+
out = out.transpose(1, 2) # [N, Ty//2^K, 128, n_mels//2^K]
|
| 352 |
+
T = out.size(1)
|
| 353 |
+
N = out.size(0)
|
| 354 |
+
out = out.contiguous().view(N, T, -1) # [N, Ty//2^K, 128*n_mels//2^K]
|
| 355 |
+
|
| 356 |
+
self.gru.flatten_parameters()
|
| 357 |
+
memory, out = self.gru(out) # out --- [1, N, 128]
|
| 358 |
+
|
| 359 |
+
return self.proj(out.squeeze(0))
|
| 360 |
+
|
| 361 |
+
def calculate_channels(self, L, kernel_size, stride, pad, n_convs):
|
| 362 |
+
for i in range(n_convs):
|
| 363 |
+
L = (L - kernel_size + 2 * pad) // stride + 1
|
| 364 |
+
return L
|
| 365 |
+
|
| 366 |
+
|
| 367 |
+
class ResidualCouplingBlock(nn.Module):
|
| 368 |
+
def __init__(self,
|
| 369 |
+
channels,
|
| 370 |
+
hidden_channels,
|
| 371 |
+
kernel_size,
|
| 372 |
+
dilation_rate,
|
| 373 |
+
n_layers,
|
| 374 |
+
n_flows=4,
|
| 375 |
+
gin_channels=0):
|
| 376 |
+
super().__init__()
|
| 377 |
+
self.channels = channels
|
| 378 |
+
self.hidden_channels = hidden_channels
|
| 379 |
+
self.kernel_size = kernel_size
|
| 380 |
+
self.dilation_rate = dilation_rate
|
| 381 |
+
self.n_layers = n_layers
|
| 382 |
+
self.n_flows = n_flows
|
| 383 |
+
self.gin_channels = gin_channels
|
| 384 |
+
|
| 385 |
+
self.flows = nn.ModuleList()
|
| 386 |
+
for i in range(n_flows):
|
| 387 |
+
self.flows.append(modules.ResidualCouplingLayer(channels, hidden_channels, kernel_size, dilation_rate, n_layers, gin_channels=gin_channels, mean_only=True))
|
| 388 |
+
self.flows.append(modules.Flip())
|
| 389 |
+
|
| 390 |
+
def forward(self, x, x_mask, g=None, reverse=False):
|
| 391 |
+
if not reverse:
|
| 392 |
+
for flow in self.flows:
|
| 393 |
+
x, _ = flow(x, x_mask, g=g, reverse=reverse)
|
| 394 |
+
else:
|
| 395 |
+
for flow in reversed(self.flows):
|
| 396 |
+
x = flow(x, x_mask, g=g, reverse=reverse)
|
| 397 |
+
return x
|
| 398 |
+
|
| 399 |
+
class SynthesizerTrn(nn.Module):
|
| 400 |
+
"""
|
| 401 |
+
Synthesizer for Training
|
| 402 |
+
"""
|
| 403 |
+
|
| 404 |
+
def __init__(
|
| 405 |
+
self,
|
| 406 |
+
n_vocab,
|
| 407 |
+
spec_channels,
|
| 408 |
+
inter_channels,
|
| 409 |
+
hidden_channels,
|
| 410 |
+
filter_channels,
|
| 411 |
+
n_heads,
|
| 412 |
+
n_layers,
|
| 413 |
+
kernel_size,
|
| 414 |
+
p_dropout,
|
| 415 |
+
resblock,
|
| 416 |
+
resblock_kernel_sizes,
|
| 417 |
+
resblock_dilation_sizes,
|
| 418 |
+
upsample_rates,
|
| 419 |
+
upsample_initial_channel,
|
| 420 |
+
upsample_kernel_sizes,
|
| 421 |
+
n_speakers=256,
|
| 422 |
+
gin_channels=256,
|
| 423 |
+
**kwargs
|
| 424 |
+
):
|
| 425 |
+
super().__init__()
|
| 426 |
+
|
| 427 |
+
self.dec = Generator(
|
| 428 |
+
inter_channels,
|
| 429 |
+
resblock,
|
| 430 |
+
resblock_kernel_sizes,
|
| 431 |
+
resblock_dilation_sizes,
|
| 432 |
+
upsample_rates,
|
| 433 |
+
upsample_initial_channel,
|
| 434 |
+
upsample_kernel_sizes,
|
| 435 |
+
gin_channels=gin_channels,
|
| 436 |
+
)
|
| 437 |
+
self.enc_q = PosteriorEncoder(
|
| 438 |
+
spec_channels,
|
| 439 |
+
inter_channels,
|
| 440 |
+
hidden_channels,
|
| 441 |
+
5,
|
| 442 |
+
1,
|
| 443 |
+
16,
|
| 444 |
+
gin_channels=gin_channels,
|
| 445 |
+
)
|
| 446 |
+
|
| 447 |
+
self.flow = ResidualCouplingBlock(inter_channels, hidden_channels, 5, 1, 4, gin_channels=gin_channels)
|
| 448 |
+
|
| 449 |
+
self.n_speakers = n_speakers
|
| 450 |
+
if n_speakers == 0:
|
| 451 |
+
self.ref_enc = ReferenceEncoder(spec_channels, gin_channels)
|
| 452 |
+
else:
|
| 453 |
+
self.enc_p = TextEncoder(n_vocab,
|
| 454 |
+
inter_channels,
|
| 455 |
+
hidden_channels,
|
| 456 |
+
filter_channels,
|
| 457 |
+
n_heads,
|
| 458 |
+
n_layers,
|
| 459 |
+
kernel_size,
|
| 460 |
+
p_dropout)
|
| 461 |
+
self.sdp = StochasticDurationPredictor(hidden_channels, 192, 3, 0.5, 4, gin_channels=gin_channels)
|
| 462 |
+
self.dp = DurationPredictor(hidden_channels, 256, 3, 0.5, gin_channels=gin_channels)
|
| 463 |
+
self.emb_g = nn.Embedding(n_speakers, gin_channels)
|
| 464 |
+
|
| 465 |
+
def infer(self, x, x_lengths, sid=None, noise_scale=1, length_scale=1, noise_scale_w=1., sdp_ratio=0.2, max_len=None):
|
| 466 |
+
x, m_p, logs_p, x_mask = self.enc_p(x, x_lengths)
|
| 467 |
+
if self.n_speakers > 0:
|
| 468 |
+
g = self.emb_g(sid).unsqueeze(-1) # [b, h, 1]
|
| 469 |
+
else:
|
| 470 |
+
g = None
|
| 471 |
+
|
| 472 |
+
logw = self.sdp(x, x_mask, g=g, reverse=True, noise_scale=noise_scale_w) * sdp_ratio \
|
| 473 |
+
+ self.dp(x, x_mask, g=g) * (1 - sdp_ratio)
|
| 474 |
+
|
| 475 |
+
w = torch.exp(logw) * x_mask * length_scale
|
| 476 |
+
w_ceil = torch.ceil(w)
|
| 477 |
+
y_lengths = torch.clamp_min(torch.sum(w_ceil, [1, 2]), 1).long()
|
| 478 |
+
y_mask = torch.unsqueeze(commons.sequence_mask(y_lengths, None), 1).to(x_mask.dtype)
|
| 479 |
+
attn_mask = torch.unsqueeze(x_mask, 2) * torch.unsqueeze(y_mask, -1)
|
| 480 |
+
attn = commons.generate_path(w_ceil, attn_mask)
|
| 481 |
+
|
| 482 |
+
m_p = torch.matmul(attn.squeeze(1), m_p.transpose(1, 2)).transpose(1, 2) # [b, t', t], [b, t, d] -> [b, d, t']
|
| 483 |
+
logs_p = torch.matmul(attn.squeeze(1), logs_p.transpose(1, 2)).transpose(1, 2) # [b, t', t], [b, t, d] -> [b, d, t']
|
| 484 |
+
|
| 485 |
+
z_p = m_p + torch.randn_like(m_p) * torch.exp(logs_p) * noise_scale
|
| 486 |
+
z = self.flow(z_p, y_mask, g=g, reverse=True)
|
| 487 |
+
o = self.dec((z * y_mask)[:,:,:max_len], g=g)
|
| 488 |
+
return o, attn, y_mask, (z, z_p, m_p, logs_p)
|
| 489 |
+
|
| 490 |
+
def voice_conversion(self, y, y_lengths, sid_src, sid_tgt, tau=1.0):
|
| 491 |
+
g_src = sid_src
|
| 492 |
+
g_tgt = sid_tgt
|
| 493 |
+
z, m_q, logs_q, y_mask = self.enc_q(y, y_lengths, g=g_src, tau=tau)
|
| 494 |
+
z_p = self.flow(z, y_mask, g=g_src)
|
| 495 |
+
z_hat = self.flow(z_p, y_mask, g=g_tgt, reverse=True)
|
| 496 |
+
o_hat = self.dec(z_hat * y_mask, g=g_tgt)
|
| 497 |
+
return o_hat, y_mask, (z, z_p, z_hat)
|
OpenVoice/modules.py
ADDED
|
@@ -0,0 +1,598 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import math
|
| 2 |
+
import torch
|
| 3 |
+
from torch import nn
|
| 4 |
+
from torch.nn import functional as F
|
| 5 |
+
|
| 6 |
+
from torch.nn import Conv1d
|
| 7 |
+
from torch.nn.utils import weight_norm, remove_weight_norm
|
| 8 |
+
|
| 9 |
+
from . import commons
|
| 10 |
+
from .commons import init_weights, get_padding
|
| 11 |
+
from .transforms import piecewise_rational_quadratic_transform
|
| 12 |
+
from .attentions import Encoder
|
| 13 |
+
|
| 14 |
+
LRELU_SLOPE = 0.1
|
| 15 |
+
|
| 16 |
+
|
| 17 |
+
class LayerNorm(nn.Module):
|
| 18 |
+
def __init__(self, channels, eps=1e-5):
|
| 19 |
+
super().__init__()
|
| 20 |
+
self.channels = channels
|
| 21 |
+
self.eps = eps
|
| 22 |
+
|
| 23 |
+
self.gamma = nn.Parameter(torch.ones(channels))
|
| 24 |
+
self.beta = nn.Parameter(torch.zeros(channels))
|
| 25 |
+
|
| 26 |
+
def forward(self, x):
|
| 27 |
+
x = x.transpose(1, -1)
|
| 28 |
+
x = F.layer_norm(x, (self.channels,), self.gamma, self.beta, self.eps)
|
| 29 |
+
return x.transpose(1, -1)
|
| 30 |
+
|
| 31 |
+
|
| 32 |
+
class ConvReluNorm(nn.Module):
|
| 33 |
+
def __init__(
|
| 34 |
+
self,
|
| 35 |
+
in_channels,
|
| 36 |
+
hidden_channels,
|
| 37 |
+
out_channels,
|
| 38 |
+
kernel_size,
|
| 39 |
+
n_layers,
|
| 40 |
+
p_dropout,
|
| 41 |
+
):
|
| 42 |
+
super().__init__()
|
| 43 |
+
self.in_channels = in_channels
|
| 44 |
+
self.hidden_channels = hidden_channels
|
| 45 |
+
self.out_channels = out_channels
|
| 46 |
+
self.kernel_size = kernel_size
|
| 47 |
+
self.n_layers = n_layers
|
| 48 |
+
self.p_dropout = p_dropout
|
| 49 |
+
assert n_layers > 1, "Number of layers should be larger than 0."
|
| 50 |
+
|
| 51 |
+
self.conv_layers = nn.ModuleList()
|
| 52 |
+
self.norm_layers = nn.ModuleList()
|
| 53 |
+
self.conv_layers.append(
|
| 54 |
+
nn.Conv1d(
|
| 55 |
+
in_channels, hidden_channels, kernel_size, padding=kernel_size // 2
|
| 56 |
+
)
|
| 57 |
+
)
|
| 58 |
+
self.norm_layers.append(LayerNorm(hidden_channels))
|
| 59 |
+
self.relu_drop = nn.Sequential(nn.ReLU(), nn.Dropout(p_dropout))
|
| 60 |
+
for _ in range(n_layers - 1):
|
| 61 |
+
self.conv_layers.append(
|
| 62 |
+
nn.Conv1d(
|
| 63 |
+
hidden_channels,
|
| 64 |
+
hidden_channels,
|
| 65 |
+
kernel_size,
|
| 66 |
+
padding=kernel_size // 2,
|
| 67 |
+
)
|
| 68 |
+
)
|
| 69 |
+
self.norm_layers.append(LayerNorm(hidden_channels))
|
| 70 |
+
self.proj = nn.Conv1d(hidden_channels, out_channels, 1)
|
| 71 |
+
self.proj.weight.data.zero_()
|
| 72 |
+
self.proj.bias.data.zero_()
|
| 73 |
+
|
| 74 |
+
def forward(self, x, x_mask):
|
| 75 |
+
x_org = x
|
| 76 |
+
for i in range(self.n_layers):
|
| 77 |
+
x = self.conv_layers[i](x * x_mask)
|
| 78 |
+
x = self.norm_layers[i](x)
|
| 79 |
+
x = self.relu_drop(x)
|
| 80 |
+
x = x_org + self.proj(x)
|
| 81 |
+
return x * x_mask
|
| 82 |
+
|
| 83 |
+
|
| 84 |
+
class DDSConv(nn.Module):
|
| 85 |
+
"""
|
| 86 |
+
Dilated and Depth-Separable Convolution
|
| 87 |
+
"""
|
| 88 |
+
|
| 89 |
+
def __init__(self, channels, kernel_size, n_layers, p_dropout=0.0):
|
| 90 |
+
super().__init__()
|
| 91 |
+
self.channels = channels
|
| 92 |
+
self.kernel_size = kernel_size
|
| 93 |
+
self.n_layers = n_layers
|
| 94 |
+
self.p_dropout = p_dropout
|
| 95 |
+
|
| 96 |
+
self.drop = nn.Dropout(p_dropout)
|
| 97 |
+
self.convs_sep = nn.ModuleList()
|
| 98 |
+
self.convs_1x1 = nn.ModuleList()
|
| 99 |
+
self.norms_1 = nn.ModuleList()
|
| 100 |
+
self.norms_2 = nn.ModuleList()
|
| 101 |
+
for i in range(n_layers):
|
| 102 |
+
dilation = kernel_size**i
|
| 103 |
+
padding = (kernel_size * dilation - dilation) // 2
|
| 104 |
+
self.convs_sep.append(
|
| 105 |
+
nn.Conv1d(
|
| 106 |
+
channels,
|
| 107 |
+
channels,
|
| 108 |
+
kernel_size,
|
| 109 |
+
groups=channels,
|
| 110 |
+
dilation=dilation,
|
| 111 |
+
padding=padding,
|
| 112 |
+
)
|
| 113 |
+
)
|
| 114 |
+
self.convs_1x1.append(nn.Conv1d(channels, channels, 1))
|
| 115 |
+
self.norms_1.append(LayerNorm(channels))
|
| 116 |
+
self.norms_2.append(LayerNorm(channels))
|
| 117 |
+
|
| 118 |
+
def forward(self, x, x_mask, g=None):
|
| 119 |
+
if g is not None:
|
| 120 |
+
x = x + g
|
| 121 |
+
for i in range(self.n_layers):
|
| 122 |
+
y = self.convs_sep[i](x * x_mask)
|
| 123 |
+
y = self.norms_1[i](y)
|
| 124 |
+
y = F.gelu(y)
|
| 125 |
+
y = self.convs_1x1[i](y)
|
| 126 |
+
y = self.norms_2[i](y)
|
| 127 |
+
y = F.gelu(y)
|
| 128 |
+
y = self.drop(y)
|
| 129 |
+
x = x + y
|
| 130 |
+
return x * x_mask
|
| 131 |
+
|
| 132 |
+
|
| 133 |
+
class WN(torch.nn.Module):
|
| 134 |
+
def __init__(
|
| 135 |
+
self,
|
| 136 |
+
hidden_channels,
|
| 137 |
+
kernel_size,
|
| 138 |
+
dilation_rate,
|
| 139 |
+
n_layers,
|
| 140 |
+
gin_channels=0,
|
| 141 |
+
p_dropout=0,
|
| 142 |
+
):
|
| 143 |
+
super(WN, self).__init__()
|
| 144 |
+
assert kernel_size % 2 == 1
|
| 145 |
+
self.hidden_channels = hidden_channels
|
| 146 |
+
self.kernel_size = (kernel_size,)
|
| 147 |
+
self.dilation_rate = dilation_rate
|
| 148 |
+
self.n_layers = n_layers
|
| 149 |
+
self.gin_channels = gin_channels
|
| 150 |
+
self.p_dropout = p_dropout
|
| 151 |
+
|
| 152 |
+
self.in_layers = torch.nn.ModuleList()
|
| 153 |
+
self.res_skip_layers = torch.nn.ModuleList()
|
| 154 |
+
self.drop = nn.Dropout(p_dropout)
|
| 155 |
+
|
| 156 |
+
if gin_channels != 0:
|
| 157 |
+
cond_layer = torch.nn.Conv1d(
|
| 158 |
+
gin_channels, 2 * hidden_channels * n_layers, 1
|
| 159 |
+
)
|
| 160 |
+
self.cond_layer = torch.nn.utils.weight_norm(cond_layer, name="weight")
|
| 161 |
+
|
| 162 |
+
for i in range(n_layers):
|
| 163 |
+
dilation = dilation_rate**i
|
| 164 |
+
padding = int((kernel_size * dilation - dilation) / 2)
|
| 165 |
+
in_layer = torch.nn.Conv1d(
|
| 166 |
+
hidden_channels,
|
| 167 |
+
2 * hidden_channels,
|
| 168 |
+
kernel_size,
|
| 169 |
+
dilation=dilation,
|
| 170 |
+
padding=padding,
|
| 171 |
+
)
|
| 172 |
+
in_layer = torch.nn.utils.weight_norm(in_layer, name="weight")
|
| 173 |
+
self.in_layers.append(in_layer)
|
| 174 |
+
|
| 175 |
+
# last one is not necessary
|
| 176 |
+
if i < n_layers - 1:
|
| 177 |
+
res_skip_channels = 2 * hidden_channels
|
| 178 |
+
else:
|
| 179 |
+
res_skip_channels = hidden_channels
|
| 180 |
+
|
| 181 |
+
res_skip_layer = torch.nn.Conv1d(hidden_channels, res_skip_channels, 1)
|
| 182 |
+
res_skip_layer = torch.nn.utils.weight_norm(res_skip_layer, name="weight")
|
| 183 |
+
self.res_skip_layers.append(res_skip_layer)
|
| 184 |
+
|
| 185 |
+
def forward(self, x, x_mask, g=None, **kwargs):
|
| 186 |
+
output = torch.zeros_like(x)
|
| 187 |
+
n_channels_tensor = torch.IntTensor([self.hidden_channels])
|
| 188 |
+
|
| 189 |
+
if g is not None:
|
| 190 |
+
g = self.cond_layer(g)
|
| 191 |
+
|
| 192 |
+
for i in range(self.n_layers):
|
| 193 |
+
x_in = self.in_layers[i](x)
|
| 194 |
+
if g is not None:
|
| 195 |
+
cond_offset = i * 2 * self.hidden_channels
|
| 196 |
+
g_l = g[:, cond_offset : cond_offset + 2 * self.hidden_channels, :]
|
| 197 |
+
else:
|
| 198 |
+
g_l = torch.zeros_like(x_in)
|
| 199 |
+
|
| 200 |
+
acts = commons.fused_add_tanh_sigmoid_multiply(x_in, g_l, n_channels_tensor)
|
| 201 |
+
acts = self.drop(acts)
|
| 202 |
+
|
| 203 |
+
res_skip_acts = self.res_skip_layers[i](acts)
|
| 204 |
+
if i < self.n_layers - 1:
|
| 205 |
+
res_acts = res_skip_acts[:, : self.hidden_channels, :]
|
| 206 |
+
x = (x + res_acts) * x_mask
|
| 207 |
+
output = output + res_skip_acts[:, self.hidden_channels :, :]
|
| 208 |
+
else:
|
| 209 |
+
output = output + res_skip_acts
|
| 210 |
+
return output * x_mask
|
| 211 |
+
|
| 212 |
+
def remove_weight_norm(self):
|
| 213 |
+
if self.gin_channels != 0:
|
| 214 |
+
torch.nn.utils.remove_weight_norm(self.cond_layer)
|
| 215 |
+
for l in self.in_layers:
|
| 216 |
+
torch.nn.utils.remove_weight_norm(l)
|
| 217 |
+
for l in self.res_skip_layers:
|
| 218 |
+
torch.nn.utils.remove_weight_norm(l)
|
| 219 |
+
|
| 220 |
+
|
| 221 |
+
class ResBlock1(torch.nn.Module):
|
| 222 |
+
def __init__(self, channels, kernel_size=3, dilation=(1, 3, 5)):
|
| 223 |
+
super(ResBlock1, self).__init__()
|
| 224 |
+
self.convs1 = nn.ModuleList(
|
| 225 |
+
[
|
| 226 |
+
weight_norm(
|
| 227 |
+
Conv1d(
|
| 228 |
+
channels,
|
| 229 |
+
channels,
|
| 230 |
+
kernel_size,
|
| 231 |
+
1,
|
| 232 |
+
dilation=dilation[0],
|
| 233 |
+
padding=get_padding(kernel_size, dilation[0]),
|
| 234 |
+
)
|
| 235 |
+
),
|
| 236 |
+
weight_norm(
|
| 237 |
+
Conv1d(
|
| 238 |
+
channels,
|
| 239 |
+
channels,
|
| 240 |
+
kernel_size,
|
| 241 |
+
1,
|
| 242 |
+
dilation=dilation[1],
|
| 243 |
+
padding=get_padding(kernel_size, dilation[1]),
|
| 244 |
+
)
|
| 245 |
+
),
|
| 246 |
+
weight_norm(
|
| 247 |
+
Conv1d(
|
| 248 |
+
channels,
|
| 249 |
+
channels,
|
| 250 |
+
kernel_size,
|
| 251 |
+
1,
|
| 252 |
+
dilation=dilation[2],
|
| 253 |
+
padding=get_padding(kernel_size, dilation[2]),
|
| 254 |
+
)
|
| 255 |
+
),
|
| 256 |
+
]
|
| 257 |
+
)
|
| 258 |
+
self.convs1.apply(init_weights)
|
| 259 |
+
|
| 260 |
+
self.convs2 = nn.ModuleList(
|
| 261 |
+
[
|
| 262 |
+
weight_norm(
|
| 263 |
+
Conv1d(
|
| 264 |
+
channels,
|
| 265 |
+
channels,
|
| 266 |
+
kernel_size,
|
| 267 |
+
1,
|
| 268 |
+
dilation=1,
|
| 269 |
+
padding=get_padding(kernel_size, 1),
|
| 270 |
+
)
|
| 271 |
+
),
|
| 272 |
+
weight_norm(
|
| 273 |
+
Conv1d(
|
| 274 |
+
channels,
|
| 275 |
+
channels,
|
| 276 |
+
kernel_size,
|
| 277 |
+
1,
|
| 278 |
+
dilation=1,
|
| 279 |
+
padding=get_padding(kernel_size, 1),
|
| 280 |
+
)
|
| 281 |
+
),
|
| 282 |
+
weight_norm(
|
| 283 |
+
Conv1d(
|
| 284 |
+
channels,
|
| 285 |
+
channels,
|
| 286 |
+
kernel_size,
|
| 287 |
+
1,
|
| 288 |
+
dilation=1,
|
| 289 |
+
padding=get_padding(kernel_size, 1),
|
| 290 |
+
)
|
| 291 |
+
),
|
| 292 |
+
]
|
| 293 |
+
)
|
| 294 |
+
self.convs2.apply(init_weights)
|
| 295 |
+
|
| 296 |
+
def forward(self, x, x_mask=None):
|
| 297 |
+
for c1, c2 in zip(self.convs1, self.convs2):
|
| 298 |
+
xt = F.leaky_relu(x, LRELU_SLOPE)
|
| 299 |
+
if x_mask is not None:
|
| 300 |
+
xt = xt * x_mask
|
| 301 |
+
xt = c1(xt)
|
| 302 |
+
xt = F.leaky_relu(xt, LRELU_SLOPE)
|
| 303 |
+
if x_mask is not None:
|
| 304 |
+
xt = xt * x_mask
|
| 305 |
+
xt = c2(xt)
|
| 306 |
+
x = xt + x
|
| 307 |
+
if x_mask is not None:
|
| 308 |
+
x = x * x_mask
|
| 309 |
+
return x
|
| 310 |
+
|
| 311 |
+
def remove_weight_norm(self):
|
| 312 |
+
for l in self.convs1:
|
| 313 |
+
remove_weight_norm(l)
|
| 314 |
+
for l in self.convs2:
|
| 315 |
+
remove_weight_norm(l)
|
| 316 |
+
|
| 317 |
+
|
| 318 |
+
class ResBlock2(torch.nn.Module):
|
| 319 |
+
def __init__(self, channels, kernel_size=3, dilation=(1, 3)):
|
| 320 |
+
super(ResBlock2, self).__init__()
|
| 321 |
+
self.convs = nn.ModuleList(
|
| 322 |
+
[
|
| 323 |
+
weight_norm(
|
| 324 |
+
Conv1d(
|
| 325 |
+
channels,
|
| 326 |
+
channels,
|
| 327 |
+
kernel_size,
|
| 328 |
+
1,
|
| 329 |
+
dilation=dilation[0],
|
| 330 |
+
padding=get_padding(kernel_size, dilation[0]),
|
| 331 |
+
)
|
| 332 |
+
),
|
| 333 |
+
weight_norm(
|
| 334 |
+
Conv1d(
|
| 335 |
+
channels,
|
| 336 |
+
channels,
|
| 337 |
+
kernel_size,
|
| 338 |
+
1,
|
| 339 |
+
dilation=dilation[1],
|
| 340 |
+
padding=get_padding(kernel_size, dilation[1]),
|
| 341 |
+
)
|
| 342 |
+
),
|
| 343 |
+
]
|
| 344 |
+
)
|
| 345 |
+
self.convs.apply(init_weights)
|
| 346 |
+
|
| 347 |
+
def forward(self, x, x_mask=None):
|
| 348 |
+
for c in self.convs:
|
| 349 |
+
xt = F.leaky_relu(x, LRELU_SLOPE)
|
| 350 |
+
if x_mask is not None:
|
| 351 |
+
xt = xt * x_mask
|
| 352 |
+
xt = c(xt)
|
| 353 |
+
x = xt + x
|
| 354 |
+
if x_mask is not None:
|
| 355 |
+
x = x * x_mask
|
| 356 |
+
return x
|
| 357 |
+
|
| 358 |
+
def remove_weight_norm(self):
|
| 359 |
+
for l in self.convs:
|
| 360 |
+
remove_weight_norm(l)
|
| 361 |
+
|
| 362 |
+
|
| 363 |
+
class Log(nn.Module):
|
| 364 |
+
def forward(self, x, x_mask, reverse=False, **kwargs):
|
| 365 |
+
if not reverse:
|
| 366 |
+
y = torch.log(torch.clamp_min(x, 1e-5)) * x_mask
|
| 367 |
+
logdet = torch.sum(-y, [1, 2])
|
| 368 |
+
return y, logdet
|
| 369 |
+
else:
|
| 370 |
+
x = torch.exp(x) * x_mask
|
| 371 |
+
return x
|
| 372 |
+
|
| 373 |
+
|
| 374 |
+
class Flip(nn.Module):
|
| 375 |
+
def forward(self, x, *args, reverse=False, **kwargs):
|
| 376 |
+
x = torch.flip(x, [1])
|
| 377 |
+
if not reverse:
|
| 378 |
+
logdet = torch.zeros(x.size(0)).to(dtype=x.dtype, device=x.device)
|
| 379 |
+
return x, logdet
|
| 380 |
+
else:
|
| 381 |
+
return x
|
| 382 |
+
|
| 383 |
+
|
| 384 |
+
class ElementwiseAffine(nn.Module):
|
| 385 |
+
def __init__(self, channels):
|
| 386 |
+
super().__init__()
|
| 387 |
+
self.channels = channels
|
| 388 |
+
self.m = nn.Parameter(torch.zeros(channels, 1))
|
| 389 |
+
self.logs = nn.Parameter(torch.zeros(channels, 1))
|
| 390 |
+
|
| 391 |
+
def forward(self, x, x_mask, reverse=False, **kwargs):
|
| 392 |
+
if not reverse:
|
| 393 |
+
y = self.m + torch.exp(self.logs) * x
|
| 394 |
+
y = y * x_mask
|
| 395 |
+
logdet = torch.sum(self.logs * x_mask, [1, 2])
|
| 396 |
+
return y, logdet
|
| 397 |
+
else:
|
| 398 |
+
x = (x - self.m) * torch.exp(-self.logs) * x_mask
|
| 399 |
+
return x
|
| 400 |
+
|
| 401 |
+
|
| 402 |
+
class ResidualCouplingLayer(nn.Module):
|
| 403 |
+
def __init__(
|
| 404 |
+
self,
|
| 405 |
+
channels,
|
| 406 |
+
hidden_channels,
|
| 407 |
+
kernel_size,
|
| 408 |
+
dilation_rate,
|
| 409 |
+
n_layers,
|
| 410 |
+
p_dropout=0,
|
| 411 |
+
gin_channels=0,
|
| 412 |
+
mean_only=False,
|
| 413 |
+
):
|
| 414 |
+
assert channels % 2 == 0, "channels should be divisible by 2"
|
| 415 |
+
super().__init__()
|
| 416 |
+
self.channels = channels
|
| 417 |
+
self.hidden_channels = hidden_channels
|
| 418 |
+
self.kernel_size = kernel_size
|
| 419 |
+
self.dilation_rate = dilation_rate
|
| 420 |
+
self.n_layers = n_layers
|
| 421 |
+
self.half_channels = channels // 2
|
| 422 |
+
self.mean_only = mean_only
|
| 423 |
+
|
| 424 |
+
self.pre = nn.Conv1d(self.half_channels, hidden_channels, 1)
|
| 425 |
+
self.enc = WN(
|
| 426 |
+
hidden_channels,
|
| 427 |
+
kernel_size,
|
| 428 |
+
dilation_rate,
|
| 429 |
+
n_layers,
|
| 430 |
+
p_dropout=p_dropout,
|
| 431 |
+
gin_channels=gin_channels,
|
| 432 |
+
)
|
| 433 |
+
self.post = nn.Conv1d(hidden_channels, self.half_channels * (2 - mean_only), 1)
|
| 434 |
+
self.post.weight.data.zero_()
|
| 435 |
+
self.post.bias.data.zero_()
|
| 436 |
+
|
| 437 |
+
def forward(self, x, x_mask, g=None, reverse=False):
|
| 438 |
+
x0, x1 = torch.split(x, [self.half_channels] * 2, 1)
|
| 439 |
+
h = self.pre(x0) * x_mask
|
| 440 |
+
h = self.enc(h, x_mask, g=g)
|
| 441 |
+
stats = self.post(h) * x_mask
|
| 442 |
+
if not self.mean_only:
|
| 443 |
+
m, logs = torch.split(stats, [self.half_channels] * 2, 1)
|
| 444 |
+
else:
|
| 445 |
+
m = stats
|
| 446 |
+
logs = torch.zeros_like(m)
|
| 447 |
+
|
| 448 |
+
if not reverse:
|
| 449 |
+
x1 = m + x1 * torch.exp(logs) * x_mask
|
| 450 |
+
x = torch.cat([x0, x1], 1)
|
| 451 |
+
logdet = torch.sum(logs, [1, 2])
|
| 452 |
+
return x, logdet
|
| 453 |
+
else:
|
| 454 |
+
x1 = (x1 - m) * torch.exp(-logs) * x_mask
|
| 455 |
+
x = torch.cat([x0, x1], 1)
|
| 456 |
+
return x
|
| 457 |
+
|
| 458 |
+
|
| 459 |
+
class ConvFlow(nn.Module):
|
| 460 |
+
def __init__(
|
| 461 |
+
self,
|
| 462 |
+
in_channels,
|
| 463 |
+
filter_channels,
|
| 464 |
+
kernel_size,
|
| 465 |
+
n_layers,
|
| 466 |
+
num_bins=10,
|
| 467 |
+
tail_bound=5.0,
|
| 468 |
+
):
|
| 469 |
+
super().__init__()
|
| 470 |
+
self.in_channels = in_channels
|
| 471 |
+
self.filter_channels = filter_channels
|
| 472 |
+
self.kernel_size = kernel_size
|
| 473 |
+
self.n_layers = n_layers
|
| 474 |
+
self.num_bins = num_bins
|
| 475 |
+
self.tail_bound = tail_bound
|
| 476 |
+
self.half_channels = in_channels // 2
|
| 477 |
+
|
| 478 |
+
self.pre = nn.Conv1d(self.half_channels, filter_channels, 1)
|
| 479 |
+
self.convs = DDSConv(filter_channels, kernel_size, n_layers, p_dropout=0.0)
|
| 480 |
+
self.proj = nn.Conv1d(
|
| 481 |
+
filter_channels, self.half_channels * (num_bins * 3 - 1), 1
|
| 482 |
+
)
|
| 483 |
+
self.proj.weight.data.zero_()
|
| 484 |
+
self.proj.bias.data.zero_()
|
| 485 |
+
|
| 486 |
+
def forward(self, x, x_mask, g=None, reverse=False):
|
| 487 |
+
x0, x1 = torch.split(x, [self.half_channels] * 2, 1)
|
| 488 |
+
h = self.pre(x0)
|
| 489 |
+
h = self.convs(h, x_mask, g=g)
|
| 490 |
+
h = self.proj(h) * x_mask
|
| 491 |
+
|
| 492 |
+
b, c, t = x0.shape
|
| 493 |
+
h = h.reshape(b, c, -1, t).permute(0, 1, 3, 2) # [b, cx?, t] -> [b, c, t, ?]
|
| 494 |
+
|
| 495 |
+
unnormalized_widths = h[..., : self.num_bins] / math.sqrt(self.filter_channels)
|
| 496 |
+
unnormalized_heights = h[..., self.num_bins : 2 * self.num_bins] / math.sqrt(
|
| 497 |
+
self.filter_channels
|
| 498 |
+
)
|
| 499 |
+
unnormalized_derivatives = h[..., 2 * self.num_bins :]
|
| 500 |
+
|
| 501 |
+
x1, logabsdet = piecewise_rational_quadratic_transform(
|
| 502 |
+
x1,
|
| 503 |
+
unnormalized_widths,
|
| 504 |
+
unnormalized_heights,
|
| 505 |
+
unnormalized_derivatives,
|
| 506 |
+
inverse=reverse,
|
| 507 |
+
tails="linear",
|
| 508 |
+
tail_bound=self.tail_bound,
|
| 509 |
+
)
|
| 510 |
+
|
| 511 |
+
x = torch.cat([x0, x1], 1) * x_mask
|
| 512 |
+
logdet = torch.sum(logabsdet * x_mask, [1, 2])
|
| 513 |
+
if not reverse:
|
| 514 |
+
return x, logdet
|
| 515 |
+
else:
|
| 516 |
+
return x
|
| 517 |
+
|
| 518 |
+
|
| 519 |
+
class TransformerCouplingLayer(nn.Module):
|
| 520 |
+
def __init__(
|
| 521 |
+
self,
|
| 522 |
+
channels,
|
| 523 |
+
hidden_channels,
|
| 524 |
+
kernel_size,
|
| 525 |
+
n_layers,
|
| 526 |
+
n_heads,
|
| 527 |
+
p_dropout=0,
|
| 528 |
+
filter_channels=0,
|
| 529 |
+
mean_only=False,
|
| 530 |
+
wn_sharing_parameter=None,
|
| 531 |
+
gin_channels=0,
|
| 532 |
+
):
|
| 533 |
+
assert n_layers == 3, n_layers
|
| 534 |
+
assert channels % 2 == 0, "channels should be divisible by 2"
|
| 535 |
+
super().__init__()
|
| 536 |
+
self.channels = channels
|
| 537 |
+
self.hidden_channels = hidden_channels
|
| 538 |
+
self.kernel_size = kernel_size
|
| 539 |
+
self.n_layers = n_layers
|
| 540 |
+
self.half_channels = channels // 2
|
| 541 |
+
self.mean_only = mean_only
|
| 542 |
+
|
| 543 |
+
self.pre = nn.Conv1d(self.half_channels, hidden_channels, 1)
|
| 544 |
+
self.enc = (
|
| 545 |
+
Encoder(
|
| 546 |
+
hidden_channels,
|
| 547 |
+
filter_channels,
|
| 548 |
+
n_heads,
|
| 549 |
+
n_layers,
|
| 550 |
+
kernel_size,
|
| 551 |
+
p_dropout,
|
| 552 |
+
isflow=True,
|
| 553 |
+
gin_channels=gin_channels,
|
| 554 |
+
)
|
| 555 |
+
if wn_sharing_parameter is None
|
| 556 |
+
else wn_sharing_parameter
|
| 557 |
+
)
|
| 558 |
+
self.post = nn.Conv1d(hidden_channels, self.half_channels * (2 - mean_only), 1)
|
| 559 |
+
self.post.weight.data.zero_()
|
| 560 |
+
self.post.bias.data.zero_()
|
| 561 |
+
|
| 562 |
+
def forward(self, x, x_mask, g=None, reverse=False):
|
| 563 |
+
x0, x1 = torch.split(x, [self.half_channels] * 2, 1)
|
| 564 |
+
h = self.pre(x0) * x_mask
|
| 565 |
+
h = self.enc(h, x_mask, g=g)
|
| 566 |
+
stats = self.post(h) * x_mask
|
| 567 |
+
if not self.mean_only:
|
| 568 |
+
m, logs = torch.split(stats, [self.half_channels] * 2, 1)
|
| 569 |
+
else:
|
| 570 |
+
m = stats
|
| 571 |
+
logs = torch.zeros_like(m)
|
| 572 |
+
|
| 573 |
+
if not reverse:
|
| 574 |
+
x1 = m + x1 * torch.exp(logs) * x_mask
|
| 575 |
+
x = torch.cat([x0, x1], 1)
|
| 576 |
+
logdet = torch.sum(logs, [1, 2])
|
| 577 |
+
return x, logdet
|
| 578 |
+
else:
|
| 579 |
+
x1 = (x1 - m) * torch.exp(-logs) * x_mask
|
| 580 |
+
x = torch.cat([x0, x1], 1)
|
| 581 |
+
return x
|
| 582 |
+
|
| 583 |
+
x1, logabsdet = piecewise_rational_quadratic_transform(
|
| 584 |
+
x1,
|
| 585 |
+
unnormalized_widths,
|
| 586 |
+
unnormalized_heights,
|
| 587 |
+
unnormalized_derivatives,
|
| 588 |
+
inverse=reverse,
|
| 589 |
+
tails="linear",
|
| 590 |
+
tail_bound=self.tail_bound,
|
| 591 |
+
)
|
| 592 |
+
|
| 593 |
+
x = torch.cat([x0, x1], 1) * x_mask
|
| 594 |
+
logdet = torch.sum(logabsdet * x_mask, [1, 2])
|
| 595 |
+
if not reverse:
|
| 596 |
+
return x, logdet
|
| 597 |
+
else:
|
| 598 |
+
return x
|
OpenVoice/resources/framework.jpg
ADDED
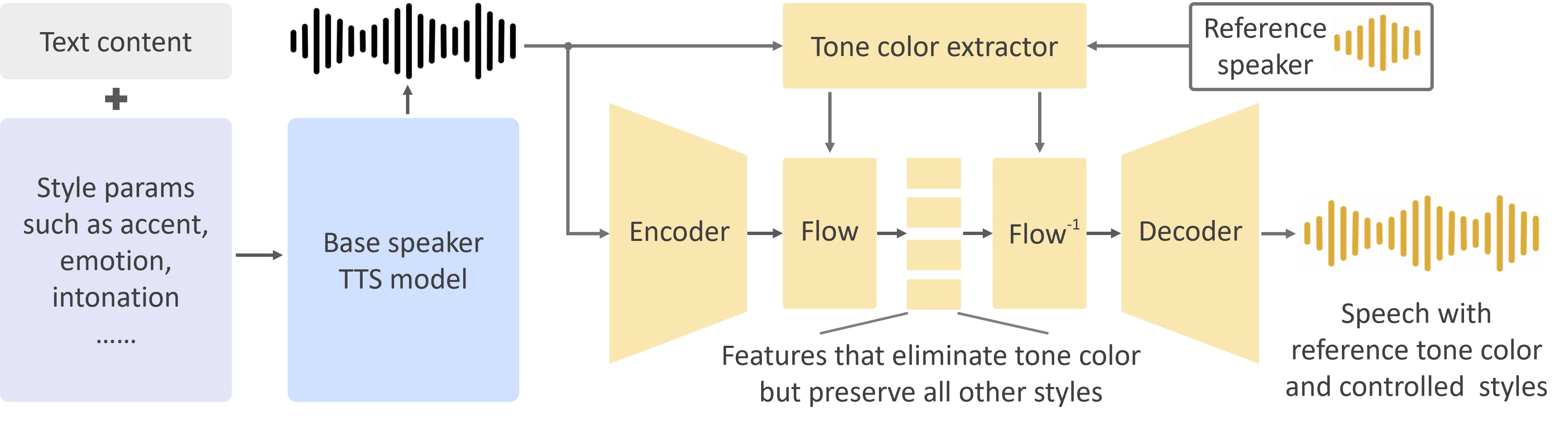
|
OpenVoice/resources/lepton.jpg
ADDED

|
OpenVoice/resources/myshell.jpg
ADDED

|
OpenVoice/resources/openvoicelogo.jpg
ADDED

|
OpenVoice/se_extractor.py
ADDED
|
@@ -0,0 +1,138 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import os
|
| 2 |
+
import glob
|
| 3 |
+
import torch
|
| 4 |
+
from glob import glob
|
| 5 |
+
import numpy as np
|
| 6 |
+
from pydub import AudioSegment
|
| 7 |
+
from faster_whisper import WhisperModel
|
| 8 |
+
from whisper_timestamped.transcribe import get_audio_tensor, get_vad_segments
|
| 9 |
+
|
| 10 |
+
model_size = "medium"
|
| 11 |
+
# Run on GPU with FP16
|
| 12 |
+
model = None
|
| 13 |
+
def split_audio_whisper(audio_path, device='cuda', target_dir='processed'):
|
| 14 |
+
global model
|
| 15 |
+
if model is None:
|
| 16 |
+
if device == 'cpu':
|
| 17 |
+
model = WhisperModel(model_size, device=device)
|
| 18 |
+
else:
|
| 19 |
+
model = WhisperModel(model_size, device=device, compute_type="float16")
|
| 20 |
+
audio = AudioSegment.from_file(audio_path)
|
| 21 |
+
max_len = len(audio)
|
| 22 |
+
|
| 23 |
+
audio_name = os.path.basename(audio_path).rsplit('.', 1)[0]
|
| 24 |
+
target_folder = os.path.join(target_dir, audio_name)
|
| 25 |
+
|
| 26 |
+
segments, info = model.transcribe(audio_path, beam_size=5, word_timestamps=True)
|
| 27 |
+
segments = list(segments)
|
| 28 |
+
|
| 29 |
+
# create directory
|
| 30 |
+
os.makedirs(target_folder, exist_ok=True)
|
| 31 |
+
wavs_folder = os.path.join(target_folder, 'wavs')
|
| 32 |
+
os.makedirs(wavs_folder, exist_ok=True)
|
| 33 |
+
|
| 34 |
+
# segments
|
| 35 |
+
s_ind = 0
|
| 36 |
+
start_time = None
|
| 37 |
+
|
| 38 |
+
for k, w in enumerate(segments):
|
| 39 |
+
# process with the time
|
| 40 |
+
if k == 0:
|
| 41 |
+
start_time = max(0, w.start)
|
| 42 |
+
|
| 43 |
+
end_time = w.end
|
| 44 |
+
|
| 45 |
+
# calculate confidence
|
| 46 |
+
if len(w.words) > 0:
|
| 47 |
+
confidence = sum([s.probability for s in w.words]) / len(w.words)
|
| 48 |
+
else:
|
| 49 |
+
confidence = 0.
|
| 50 |
+
# clean text
|
| 51 |
+
text = w.text.replace('...', '')
|
| 52 |
+
|
| 53 |
+
# left 0.08s for each audios
|
| 54 |
+
audio_seg = audio[int( start_time * 1000) : min(max_len, int(end_time * 1000) + 80)]
|
| 55 |
+
|
| 56 |
+
# segment file name
|
| 57 |
+
fname = f"{audio_name}_seg{s_ind}.wav"
|
| 58 |
+
|
| 59 |
+
# filter out the segment shorter than 1.5s and longer than 20s
|
| 60 |
+
save = audio_seg.duration_seconds > 1.5 and \
|
| 61 |
+
audio_seg.duration_seconds < 20. and \
|
| 62 |
+
len(text) >= 2 and len(text) < 200
|
| 63 |
+
|
| 64 |
+
if save:
|
| 65 |
+
output_file = os.path.join(wavs_folder, fname)
|
| 66 |
+
audio_seg.export(output_file, format='wav')
|
| 67 |
+
|
| 68 |
+
if k < len(segments) - 1:
|
| 69 |
+
start_time = max(0, segments[k+1].start - 0.08)
|
| 70 |
+
|
| 71 |
+
s_ind = s_ind + 1
|
| 72 |
+
return wavs_folder
|
| 73 |
+
|
| 74 |
+
|
| 75 |
+
def split_audio_vad(audio_path, target_dir, split_seconds=10.0, max_length=60.):
|
| 76 |
+
SAMPLE_RATE = 16000
|
| 77 |
+
audio_vad = get_audio_tensor(audio_path)[:int(max_length * SAMPLE_RATE)]
|
| 78 |
+
segments = get_vad_segments(
|
| 79 |
+
audio_vad,
|
| 80 |
+
output_sample=True,
|
| 81 |
+
min_speech_duration=0.1,
|
| 82 |
+
min_silence_duration=1,
|
| 83 |
+
method="silero",
|
| 84 |
+
)
|
| 85 |
+
segments = [(seg["start"], seg["end"]) for seg in segments]
|
| 86 |
+
segments = [(float(s) / SAMPLE_RATE, float(e) / SAMPLE_RATE) for s,e in segments]
|
| 87 |
+
print(segments)
|
| 88 |
+
audio_active = AudioSegment.silent(duration=0)
|
| 89 |
+
audio = AudioSegment.from_file(audio_path)
|
| 90 |
+
|
| 91 |
+
for start_time, end_time in segments:
|
| 92 |
+
audio_active += audio[int( start_time * 1000) : int(end_time * 1000)]
|
| 93 |
+
|
| 94 |
+
audio_dur = audio_active.duration_seconds
|
| 95 |
+
print(f'after vad: dur = {audio_dur}')
|
| 96 |
+
audio_name = os.path.basename(audio_path).rsplit('.', 1)[0]
|
| 97 |
+
target_folder = os.path.join(target_dir, audio_name)
|
| 98 |
+
wavs_folder = os.path.join(target_folder, 'wavs')
|
| 99 |
+
os.makedirs(wavs_folder, exist_ok=True)
|
| 100 |
+
start_time = 0.
|
| 101 |
+
count = 0
|
| 102 |
+
num_splits = int(np.round(audio_dur / split_seconds))
|
| 103 |
+
assert num_splits > 0, 'input audio is too short'
|
| 104 |
+
interval = audio_dur / num_splits
|
| 105 |
+
|
| 106 |
+
for i in range(num_splits):
|
| 107 |
+
end_time = min(start_time + interval, audio_dur)
|
| 108 |
+
if i == num_splits - 1:
|
| 109 |
+
end_time = audio_dur
|
| 110 |
+
output_file = f"{wavs_folder}/{audio_name}_seg{count}.wav"
|
| 111 |
+
audio_seg = audio_active[int(start_time * 1000): int(end_time * 1000)]
|
| 112 |
+
audio_seg.export(output_file, format='wav')
|
| 113 |
+
start_time = end_time
|
| 114 |
+
count += 1
|
| 115 |
+
return wavs_folder
|
| 116 |
+
|
| 117 |
+
def get_se(audio_path, vc_model, target_dir='processed', max_length=60., vad=True):
|
| 118 |
+
device = vc_model.device
|
| 119 |
+
|
| 120 |
+
audio_name = os.path.basename(audio_path).rsplit('.', 1)[0]
|
| 121 |
+
se_path = os.path.join(target_dir, audio_name, 'se.pth')
|
| 122 |
+
|
| 123 |
+
if os.path.isfile(se_path):
|
| 124 |
+
se = torch.load(se_path).to(device)
|
| 125 |
+
return se, audio_name
|
| 126 |
+
if os.path.isdir(audio_path):
|
| 127 |
+
wavs_folder = audio_path
|
| 128 |
+
elif vad:
|
| 129 |
+
wavs_folder = split_audio_vad(audio_path, target_dir, max_length=max_length)
|
| 130 |
+
else:
|
| 131 |
+
wavs_folder = split_audio_whisper(audio_path, device=device, target_dir=target_dir)
|
| 132 |
+
|
| 133 |
+
audio_segs = glob(f'{wavs_folder}/*.wav')
|
| 134 |
+
|
| 135 |
+
if len(audio_segs) == 0:
|
| 136 |
+
raise NotImplementedError('No audio segments found!')
|
| 137 |
+
|
| 138 |
+
return vc_model.extract_se(audio_segs, se_save_path=se_path), wavs_folder
|
OpenVoice/text/__init__.py
ADDED
|
@@ -0,0 +1,78 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
""" from https://github.com/keithito/tacotron """
|
| 2 |
+
from . import cleaners
|
| 3 |
+
from .symbols import *
|
| 4 |
+
|
| 5 |
+
# Mappings from symbol to numeric ID and vice versa:
|
| 6 |
+
_symbol_to_id = {s: i for i, s in enumerate(symbols)}
|
| 7 |
+
_id_to_symbol = {i: s for i, s in enumerate(symbols)}
|
| 8 |
+
|
| 9 |
+
|
| 10 |
+
def text_to_sequence(text, symbols, cleaner_names):
|
| 11 |
+
'''Converts a string of text to a sequence of IDs corresponding to the symbols in the text.
|
| 12 |
+
Args:
|
| 13 |
+
text: string to convert to a sequence
|
| 14 |
+
cleaner_names: names of the cleaner functions to run the text through
|
| 15 |
+
Returns:
|
| 16 |
+
List of integers corresponding to the symbols in the text
|
| 17 |
+
'''
|
| 18 |
+
sequence = []
|
| 19 |
+
symbol_to_id = {s: i for i, s in enumerate(symbols)}
|
| 20 |
+
clean_text = _clean_text(text, cleaner_names)
|
| 21 |
+
print(clean_text)
|
| 22 |
+
print(f" length:{len(clean_text)}")
|
| 23 |
+
for symbol in clean_text:
|
| 24 |
+
if symbol not in symbol_to_id.keys():
|
| 25 |
+
continue
|
| 26 |
+
symbol_id = symbol_to_id[symbol]
|
| 27 |
+
sequence += [symbol_id]
|
| 28 |
+
print(f" length:{len(sequence)}")
|
| 29 |
+
return sequence
|
| 30 |
+
|
| 31 |
+
|
| 32 |
+
def cleaned_text_to_sequence(cleaned_text, symbols):
|
| 33 |
+
'''Converts a string of text to a sequence of IDs corresponding to the symbols in the text.
|
| 34 |
+
Args:
|
| 35 |
+
text: string to convert to a sequence
|
| 36 |
+
Returns:
|
| 37 |
+
List of integers corresponding to the symbols in the text
|
| 38 |
+
'''
|
| 39 |
+
symbol_to_id = {s: i for i, s in enumerate(symbols)}
|
| 40 |
+
sequence = [symbol_to_id[symbol] for symbol in cleaned_text if symbol in symbol_to_id.keys()]
|
| 41 |
+
return sequence
|
| 42 |
+
|
| 43 |
+
|
| 44 |
+
|
| 45 |
+
from .symbols import language_tone_start_map
|
| 46 |
+
def cleaned_text_to_sequence_vits2(cleaned_text, tones, language, symbols, languages):
|
| 47 |
+
"""Converts a string of text to a sequence of IDs corresponding to the symbols in the text.
|
| 48 |
+
Args:
|
| 49 |
+
text: string to convert to a sequence
|
| 50 |
+
Returns:
|
| 51 |
+
List of integers corresponding to the symbols in the text
|
| 52 |
+
"""
|
| 53 |
+
symbol_to_id = {s: i for i, s in enumerate(symbols)}
|
| 54 |
+
language_id_map = {s: i for i, s in enumerate(languages)}
|
| 55 |
+
phones = [symbol_to_id[symbol] for symbol in cleaned_text]
|
| 56 |
+
tone_start = language_tone_start_map[language]
|
| 57 |
+
tones = [i + tone_start for i in tones]
|
| 58 |
+
lang_id = language_id_map[language]
|
| 59 |
+
lang_ids = [lang_id for i in phones]
|
| 60 |
+
return phones, tones, lang_ids
|
| 61 |
+
|
| 62 |
+
|
| 63 |
+
def sequence_to_text(sequence):
|
| 64 |
+
'''Converts a sequence of IDs back to a string'''
|
| 65 |
+
result = ''
|
| 66 |
+
for symbol_id in sequence:
|
| 67 |
+
s = _id_to_symbol[symbol_id]
|
| 68 |
+
result += s
|
| 69 |
+
return result
|
| 70 |
+
|
| 71 |
+
|
| 72 |
+
def _clean_text(text, cleaner_names):
|
| 73 |
+
for name in cleaner_names:
|
| 74 |
+
cleaner = getattr(cleaners, name)
|
| 75 |
+
if not cleaner:
|
| 76 |
+
raise Exception('Unknown cleaner: %s' % name)
|
| 77 |
+
text = cleaner(text)
|
| 78 |
+
return text
|
OpenVoice/text/cleaners.py
ADDED
|
@@ -0,0 +1,16 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import re
|
| 2 |
+
from .english import english_to_lazy_ipa, english_to_ipa2, english_to_lazy_ipa2
|
| 3 |
+
from .mandarin import number_to_chinese, chinese_to_bopomofo, latin_to_bopomofo, chinese_to_romaji, chinese_to_lazy_ipa, chinese_to_ipa, chinese_to_ipa2
|
| 4 |
+
|
| 5 |
+
def cjke_cleaners2(text):
|
| 6 |
+
text = re.sub(r'\[ZH\](.*?)\[ZH\]',
|
| 7 |
+
lambda x: chinese_to_ipa(x.group(1))+' ', text)
|
| 8 |
+
text = re.sub(r'\[JA\](.*?)\[JA\]',
|
| 9 |
+
lambda x: japanese_to_ipa2(x.group(1))+' ', text)
|
| 10 |
+
text = re.sub(r'\[KO\](.*?)\[KO\]',
|
| 11 |
+
lambda x: korean_to_ipa(x.group(1))+' ', text)
|
| 12 |
+
text = re.sub(r'\[EN\](.*?)\[EN\]',
|
| 13 |
+
lambda x: english_to_ipa2(x.group(1))+' ', text)
|
| 14 |
+
text = re.sub(r'\s+$', '', text)
|
| 15 |
+
text = re.sub(r'([^\.,!\?\-…~])$', r'\1.', text)
|
| 16 |
+
return text
|
OpenVoice/text/english.py
ADDED
|
@@ -0,0 +1,189 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
""" from https://github.com/keithito/tacotron """
|
| 2 |
+
|
| 3 |
+
'''
|
| 4 |
+
Cleaners are transformations that run over the input text at both training and eval time.
|
| 5 |
+
|
| 6 |
+
Cleaners can be selected by passing a comma-delimited list of cleaner names as the "cleaners"
|
| 7 |
+
hyperparameter. Some cleaners are English-specific. You'll typically want to use:
|
| 8 |
+
1. "english_cleaners" for English text
|
| 9 |
+
2. "transliteration_cleaners" for non-English text that can be transliterated to ASCII using
|
| 10 |
+
the Unidecode library (https://pypi.python.org/pypi/Unidecode)
|
| 11 |
+
3. "basic_cleaners" if you do not want to transliterate (in this case, you should also update
|
| 12 |
+
the symbols in symbols.py to match your data).
|
| 13 |
+
'''
|
| 14 |
+
|
| 15 |
+
|
| 16 |
+
# Regular expression matching whitespace:
|
| 17 |
+
|
| 18 |
+
|
| 19 |
+
import re
|
| 20 |
+
import inflect
|
| 21 |
+
from unidecode import unidecode
|
| 22 |
+
import eng_to_ipa as ipa
|
| 23 |
+
|
| 24 |
+
_inflect = inflect.engine()
|
| 25 |
+
_comma_number_re = re.compile(r'([0-9][0-9\,]+[0-9])')
|
| 26 |
+
_decimal_number_re = re.compile(r'([0-9]+\.[0-9]+)')
|
| 27 |
+
_pounds_re = re.compile(r'£([0-9\,]*[0-9]+)')
|
| 28 |
+
_dollars_re = re.compile(r'\$([0-9\.\,]*[0-9]+)')
|
| 29 |
+
_ordinal_re = re.compile(r'[0-9]+(st|nd|rd|th)')
|
| 30 |
+
_number_re = re.compile(r'[0-9]+')
|
| 31 |
+
|
| 32 |
+
# List of (regular expression, replacement) pairs for abbreviations:
|
| 33 |
+
_abbreviations = [(re.compile('\\b%s\\.' % x[0], re.IGNORECASE), x[1]) for x in [
|
| 34 |
+
('mrs', 'misess'),
|
| 35 |
+
('mr', 'mister'),
|
| 36 |
+
('dr', 'doctor'),
|
| 37 |
+
('st', 'saint'),
|
| 38 |
+
('co', 'company'),
|
| 39 |
+
('jr', 'junior'),
|
| 40 |
+
('maj', 'major'),
|
| 41 |
+
('gen', 'general'),
|
| 42 |
+
('drs', 'doctors'),
|
| 43 |
+
('rev', 'reverend'),
|
| 44 |
+
('lt', 'lieutenant'),
|
| 45 |
+
('hon', 'honorable'),
|
| 46 |
+
('sgt', 'sergeant'),
|
| 47 |
+
('capt', 'captain'),
|
| 48 |
+
('esq', 'esquire'),
|
| 49 |
+
('ltd', 'limited'),
|
| 50 |
+
('col', 'colonel'),
|
| 51 |
+
('ft', 'fort'),
|
| 52 |
+
]]
|
| 53 |
+
|
| 54 |
+
|
| 55 |
+
# List of (ipa, lazy ipa) pairs:
|
| 56 |
+
_lazy_ipa = [(re.compile('%s' % x[0]), x[1]) for x in [
|
| 57 |
+
('r', 'ɹ'),
|
| 58 |
+
('æ', 'e'),
|
| 59 |
+
('ɑ', 'a'),
|
| 60 |
+
('ɔ', 'o'),
|
| 61 |
+
('ð', 'z'),
|
| 62 |
+
('θ', 's'),
|
| 63 |
+
('ɛ', 'e'),
|
| 64 |
+
('ɪ', 'i'),
|
| 65 |
+
('ʊ', 'u'),
|
| 66 |
+
('ʒ', 'ʥ'),
|
| 67 |
+
('ʤ', 'ʥ'),
|
| 68 |
+
('ˈ', '↓'),
|
| 69 |
+
]]
|
| 70 |
+
|
| 71 |
+
# List of (ipa, lazy ipa2) pairs:
|
| 72 |
+
_lazy_ipa2 = [(re.compile('%s' % x[0]), x[1]) for x in [
|
| 73 |
+
('r', 'ɹ'),
|
| 74 |
+
('ð', 'z'),
|
| 75 |
+
('θ', 's'),
|
| 76 |
+
('ʒ', 'ʑ'),
|
| 77 |
+
('ʤ', 'dʑ'),
|
| 78 |
+
('ˈ', '↓'),
|
| 79 |
+
]]
|
| 80 |
+
|
| 81 |
+
# List of (ipa, ipa2) pairs
|
| 82 |
+
_ipa_to_ipa2 = [(re.compile('%s' % x[0]), x[1]) for x in [
|
| 83 |
+
('r', 'ɹ'),
|
| 84 |
+
('ʤ', 'dʒ'),
|
| 85 |
+
('ʧ', 'tʃ')
|
| 86 |
+
]]
|
| 87 |
+
|
| 88 |
+
|
| 89 |
+
def expand_abbreviations(text):
|
| 90 |
+
for regex, replacement in _abbreviations:
|
| 91 |
+
text = re.sub(regex, replacement, text)
|
| 92 |
+
return text
|
| 93 |
+
|
| 94 |
+
|
| 95 |
+
def collapse_whitespace(text):
|
| 96 |
+
return re.sub(r'\s+', ' ', text)
|
| 97 |
+
|
| 98 |
+
|
| 99 |
+
def _remove_commas(m):
|
| 100 |
+
return m.group(1).replace(',', '')
|
| 101 |
+
|
| 102 |
+
|
| 103 |
+
def _expand_decimal_point(m):
|
| 104 |
+
return m.group(1).replace('.', ' point ')
|
| 105 |
+
|
| 106 |
+
|
| 107 |
+
def _expand_dollars(m):
|
| 108 |
+
match = m.group(1)
|
| 109 |
+
parts = match.split('.')
|
| 110 |
+
if len(parts) > 2:
|
| 111 |
+
return match + ' dollars' # Unexpected format
|
| 112 |
+
dollars = int(parts[0]) if parts[0] else 0
|
| 113 |
+
cents = int(parts[1]) if len(parts) > 1 and parts[1] else 0
|
| 114 |
+
if dollars and cents:
|
| 115 |
+
dollar_unit = 'dollar' if dollars == 1 else 'dollars'
|
| 116 |
+
cent_unit = 'cent' if cents == 1 else 'cents'
|
| 117 |
+
return '%s %s, %s %s' % (dollars, dollar_unit, cents, cent_unit)
|
| 118 |
+
elif dollars:
|
| 119 |
+
dollar_unit = 'dollar' if dollars == 1 else 'dollars'
|
| 120 |
+
return '%s %s' % (dollars, dollar_unit)
|
| 121 |
+
elif cents:
|
| 122 |
+
cent_unit = 'cent' if cents == 1 else 'cents'
|
| 123 |
+
return '%s %s' % (cents, cent_unit)
|
| 124 |
+
else:
|
| 125 |
+
return 'zero dollars'
|
| 126 |
+
|
| 127 |
+
|
| 128 |
+
def _expand_ordinal(m):
|
| 129 |
+
return _inflect.number_to_words(m.group(0))
|
| 130 |
+
|
| 131 |
+
|
| 132 |
+
def _expand_number(m):
|
| 133 |
+
num = int(m.group(0))
|
| 134 |
+
if num > 1000 and num < 3000:
|
| 135 |
+
if num == 2000:
|
| 136 |
+
return 'two thousand'
|
| 137 |
+
elif num > 2000 and num < 2010:
|
| 138 |
+
return 'two thousand ' + _inflect.number_to_words(num % 100)
|
| 139 |
+
elif num % 100 == 0:
|
| 140 |
+
return _inflect.number_to_words(num // 100) + ' hundred'
|
| 141 |
+
else:
|
| 142 |
+
return _inflect.number_to_words(num, andword='', zero='oh', group=2).replace(', ', ' ')
|
| 143 |
+
else:
|
| 144 |
+
return _inflect.number_to_words(num, andword='')
|
| 145 |
+
|
| 146 |
+
|
| 147 |
+
def normalize_numbers(text):
|
| 148 |
+
text = re.sub(_comma_number_re, _remove_commas, text)
|
| 149 |
+
text = re.sub(_pounds_re, r'\1 pounds', text)
|
| 150 |
+
text = re.sub(_dollars_re, _expand_dollars, text)
|
| 151 |
+
text = re.sub(_decimal_number_re, _expand_decimal_point, text)
|
| 152 |
+
text = re.sub(_ordinal_re, _expand_ordinal, text)
|
| 153 |
+
text = re.sub(_number_re, _expand_number, text)
|
| 154 |
+
return text
|
| 155 |
+
|
| 156 |
+
|
| 157 |
+
def mark_dark_l(text):
|
| 158 |
+
return re.sub(r'l([^aeiouæɑɔəɛɪʊ ]*(?: |$))', lambda x: 'ɫ'+x.group(1), text)
|
| 159 |
+
|
| 160 |
+
|
| 161 |
+
def english_to_ipa(text):
|
| 162 |
+
text = unidecode(text).lower()
|
| 163 |
+
text = expand_abbreviations(text)
|
| 164 |
+
text = normalize_numbers(text)
|
| 165 |
+
phonemes = ipa.convert(text)
|
| 166 |
+
phonemes = collapse_whitespace(phonemes)
|
| 167 |
+
return phonemes
|
| 168 |
+
|
| 169 |
+
|
| 170 |
+
def english_to_lazy_ipa(text):
|
| 171 |
+
text = english_to_ipa(text)
|
| 172 |
+
for regex, replacement in _lazy_ipa:
|
| 173 |
+
text = re.sub(regex, replacement, text)
|
| 174 |
+
return text
|
| 175 |
+
|
| 176 |
+
|
| 177 |
+
def english_to_ipa2(text):
|
| 178 |
+
text = english_to_ipa(text)
|
| 179 |
+
text = mark_dark_l(text)
|
| 180 |
+
for regex, replacement in _ipa_to_ipa2:
|
| 181 |
+
text = re.sub(regex, replacement, text)
|
| 182 |
+
return text.replace('...', '…')
|
| 183 |
+
|
| 184 |
+
|
| 185 |
+
def english_to_lazy_ipa2(text):
|
| 186 |
+
text = english_to_ipa(text)
|
| 187 |
+
for regex, replacement in _lazy_ipa2:
|
| 188 |
+
text = re.sub(regex, replacement, text)
|
| 189 |
+
return text
|
OpenVoice/text/mandarin.py
ADDED
|
@@ -0,0 +1,326 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import os
|
| 2 |
+
import sys
|
| 3 |
+
import re
|
| 4 |
+
from pypinyin import lazy_pinyin, BOPOMOFO
|
| 5 |
+
import jieba
|
| 6 |
+
import cn2an
|
| 7 |
+
import logging
|
| 8 |
+
|
| 9 |
+
|
| 10 |
+
# List of (Latin alphabet, bopomofo) pairs:
|
| 11 |
+
_latin_to_bopomofo = [(re.compile('%s' % x[0], re.IGNORECASE), x[1]) for x in [
|
| 12 |
+
('a', 'ㄟˉ'),
|
| 13 |
+
('b', 'ㄅㄧˋ'),
|
| 14 |
+
('c', 'ㄙㄧˉ'),
|
| 15 |
+
('d', 'ㄉㄧˋ'),
|
| 16 |
+
('e', 'ㄧˋ'),
|
| 17 |
+
('f', 'ㄝˊㄈㄨˋ'),
|
| 18 |
+
('g', 'ㄐㄧˋ'),
|
| 19 |
+
('h', 'ㄝˇㄑㄩˋ'),
|
| 20 |
+
('i', 'ㄞˋ'),
|
| 21 |
+
('j', 'ㄐㄟˋ'),
|
| 22 |
+
('k', 'ㄎㄟˋ'),
|
| 23 |
+
('l', 'ㄝˊㄛˋ'),
|
| 24 |
+
('m', 'ㄝˊㄇㄨˋ'),
|
| 25 |
+
('n', 'ㄣˉ'),
|
| 26 |
+
('o', 'ㄡˉ'),
|
| 27 |
+
('p', 'ㄆㄧˉ'),
|
| 28 |
+
('q', 'ㄎㄧㄡˉ'),
|
| 29 |
+
('r', 'ㄚˋ'),
|
| 30 |
+
('s', 'ㄝˊㄙˋ'),
|
| 31 |
+
('t', 'ㄊㄧˋ'),
|
| 32 |
+
('u', 'ㄧㄡˉ'),
|
| 33 |
+
('v', 'ㄨㄧˉ'),
|
| 34 |
+
('w', 'ㄉㄚˋㄅㄨˋㄌㄧㄡˋ'),
|
| 35 |
+
('x', 'ㄝˉㄎㄨˋㄙˋ'),
|
| 36 |
+
('y', 'ㄨㄞˋ'),
|
| 37 |
+
('z', 'ㄗㄟˋ')
|
| 38 |
+
]]
|
| 39 |
+
|
| 40 |
+
# List of (bopomofo, romaji) pairs:
|
| 41 |
+
_bopomofo_to_romaji = [(re.compile('%s' % x[0]), x[1]) for x in [
|
| 42 |
+
('ㄅㄛ', 'p⁼wo'),
|
| 43 |
+
('ㄆㄛ', 'pʰwo'),
|
| 44 |
+
('ㄇㄛ', 'mwo'),
|
| 45 |
+
('ㄈㄛ', 'fwo'),
|
| 46 |
+
('ㄅ', 'p⁼'),
|
| 47 |
+
('ㄆ', 'pʰ'),
|
| 48 |
+
('ㄇ', 'm'),
|
| 49 |
+
('ㄈ', 'f'),
|
| 50 |
+
('ㄉ', 't⁼'),
|
| 51 |
+
('ㄊ', 'tʰ'),
|
| 52 |
+
('ㄋ', 'n'),
|
| 53 |
+
('ㄌ', 'l'),
|
| 54 |
+
('ㄍ', 'k⁼'),
|
| 55 |
+
('ㄎ', 'kʰ'),
|
| 56 |
+
('ㄏ', 'h'),
|
| 57 |
+
('ㄐ', 'ʧ⁼'),
|
| 58 |
+
('ㄑ', 'ʧʰ'),
|
| 59 |
+
('ㄒ', 'ʃ'),
|
| 60 |
+
('ㄓ', 'ʦ`⁼'),
|
| 61 |
+
('ㄔ', 'ʦ`ʰ'),
|
| 62 |
+
('ㄕ', 's`'),
|
| 63 |
+
('ㄖ', 'ɹ`'),
|
| 64 |
+
('ㄗ', 'ʦ⁼'),
|
| 65 |
+
('ㄘ', 'ʦʰ'),
|
| 66 |
+
('ㄙ', 's'),
|
| 67 |
+
('ㄚ', 'a'),
|
| 68 |
+
('ㄛ', 'o'),
|
| 69 |
+
('ㄜ', 'ə'),
|
| 70 |
+
('ㄝ', 'e'),
|
| 71 |
+
('ㄞ', 'ai'),
|
| 72 |
+
('ㄟ', 'ei'),
|
| 73 |
+
('ㄠ', 'au'),
|
| 74 |
+
('ㄡ', 'ou'),
|
| 75 |
+
('ㄧㄢ', 'yeNN'),
|
| 76 |
+
('ㄢ', 'aNN'),
|
| 77 |
+
('ㄧㄣ', 'iNN'),
|
| 78 |
+
('ㄣ', 'əNN'),
|
| 79 |
+
('ㄤ', 'aNg'),
|
| 80 |
+
('ㄧㄥ', 'iNg'),
|
| 81 |
+
('ㄨㄥ', 'uNg'),
|
| 82 |
+
('ㄩㄥ', 'yuNg'),
|
| 83 |
+
('ㄥ', 'əNg'),
|
| 84 |
+
('ㄦ', 'əɻ'),
|
| 85 |
+
('ㄧ', 'i'),
|
| 86 |
+
('ㄨ', 'u'),
|
| 87 |
+
('ㄩ', 'ɥ'),
|
| 88 |
+
('ˉ', '→'),
|
| 89 |
+
('ˊ', '↑'),
|
| 90 |
+
('ˇ', '↓↑'),
|
| 91 |
+
('ˋ', '↓'),
|
| 92 |
+
('˙', ''),
|
| 93 |
+
(',', ','),
|
| 94 |
+
('。', '.'),
|
| 95 |
+
('!', '!'),
|
| 96 |
+
('?', '?'),
|
| 97 |
+
('—', '-')
|
| 98 |
+
]]
|
| 99 |
+
|
| 100 |
+
# List of (romaji, ipa) pairs:
|
| 101 |
+
_romaji_to_ipa = [(re.compile('%s' % x[0], re.IGNORECASE), x[1]) for x in [
|
| 102 |
+
('ʃy', 'ʃ'),
|
| 103 |
+
('ʧʰy', 'ʧʰ'),
|
| 104 |
+
('ʧ⁼y', 'ʧ⁼'),
|
| 105 |
+
('NN', 'n'),
|
| 106 |
+
('Ng', 'ŋ'),
|
| 107 |
+
('y', 'j'),
|
| 108 |
+
('h', 'x')
|
| 109 |
+
]]
|
| 110 |
+
|
| 111 |
+
# List of (bopomofo, ipa) pairs:
|
| 112 |
+
_bopomofo_to_ipa = [(re.compile('%s' % x[0]), x[1]) for x in [
|
| 113 |
+
('ㄅㄛ', 'p⁼wo'),
|
| 114 |
+
('ㄆㄛ', 'pʰwo'),
|
| 115 |
+
('ㄇㄛ', 'mwo'),
|
| 116 |
+
('ㄈㄛ', 'fwo'),
|
| 117 |
+
('ㄅ', 'p⁼'),
|
| 118 |
+
('ㄆ', 'pʰ'),
|
| 119 |
+
('ㄇ', 'm'),
|
| 120 |
+
('ㄈ', 'f'),
|
| 121 |
+
('ㄉ', 't⁼'),
|
| 122 |
+
('ㄊ', 'tʰ'),
|
| 123 |
+
('ㄋ', 'n'),
|
| 124 |
+
('ㄌ', 'l'),
|
| 125 |
+
('ㄍ', 'k⁼'),
|
| 126 |
+
('ㄎ', 'kʰ'),
|
| 127 |
+
('ㄏ', 'x'),
|
| 128 |
+
('ㄐ', 'tʃ⁼'),
|
| 129 |
+
('ㄑ', 'tʃʰ'),
|
| 130 |
+
('ㄒ', 'ʃ'),
|
| 131 |
+
('ㄓ', 'ts`⁼'),
|
| 132 |
+
('ㄔ', 'ts`ʰ'),
|
| 133 |
+
('ㄕ', 's`'),
|
| 134 |
+
('ㄖ', 'ɹ`'),
|
| 135 |
+
('ㄗ', 'ts⁼'),
|
| 136 |
+
('ㄘ', 'tsʰ'),
|
| 137 |
+
('ㄙ', 's'),
|
| 138 |
+
('ㄚ', 'a'),
|
| 139 |
+
('ㄛ', 'o'),
|
| 140 |
+
('ㄜ', 'ə'),
|
| 141 |
+
('ㄝ', 'ɛ'),
|
| 142 |
+
('ㄞ', 'aɪ'),
|
| 143 |
+
('ㄟ', 'eɪ'),
|
| 144 |
+
('ㄠ', 'ɑʊ'),
|
| 145 |
+
('ㄡ', 'oʊ'),
|
| 146 |
+
('ㄧㄢ', 'jɛn'),
|
| 147 |
+
('ㄩㄢ', 'ɥæn'),
|
| 148 |
+
('ㄢ', 'an'),
|
| 149 |
+
('ㄧㄣ', 'in'),
|
| 150 |
+
('ㄩㄣ', 'ɥn'),
|
| 151 |
+
('ㄣ', 'ən'),
|
| 152 |
+
('ㄤ', 'ɑŋ'),
|
| 153 |
+
('ㄧㄥ', 'iŋ'),
|
| 154 |
+
('ㄨㄥ', 'ʊŋ'),
|
| 155 |
+
('ㄩㄥ', 'jʊŋ'),
|
| 156 |
+
('ㄥ', 'əŋ'),
|
| 157 |
+
('ㄦ', 'əɻ'),
|
| 158 |
+
('ㄧ', 'i'),
|
| 159 |
+
('ㄨ', 'u'),
|
| 160 |
+
('ㄩ', 'ɥ'),
|
| 161 |
+
('ˉ', '→'),
|
| 162 |
+
('ˊ', '↑'),
|
| 163 |
+
('ˇ', '↓↑'),
|
| 164 |
+
('ˋ', '↓'),
|
| 165 |
+
('˙', ''),
|
| 166 |
+
(',', ','),
|
| 167 |
+
('。', '.'),
|
| 168 |
+
('!', '!'),
|
| 169 |
+
('?', '?'),
|
| 170 |
+
('—', '-')
|
| 171 |
+
]]
|
| 172 |
+
|
| 173 |
+
# List of (bopomofo, ipa2) pairs:
|
| 174 |
+
_bopomofo_to_ipa2 = [(re.compile('%s' % x[0]), x[1]) for x in [
|
| 175 |
+
('ㄅㄛ', 'pwo'),
|
| 176 |
+
('ㄆㄛ', 'pʰwo'),
|
| 177 |
+
('ㄇㄛ', 'mwo'),
|
| 178 |
+
('ㄈㄛ', 'fwo'),
|
| 179 |
+
('ㄅ', 'p'),
|
| 180 |
+
('ㄆ', 'pʰ'),
|
| 181 |
+
('ㄇ', 'm'),
|
| 182 |
+
('ㄈ', 'f'),
|
| 183 |
+
('ㄉ', 't'),
|
| 184 |
+
('ㄊ', 'tʰ'),
|
| 185 |
+
('ㄋ', 'n'),
|
| 186 |
+
('ㄌ', 'l'),
|
| 187 |
+
('ㄍ', 'k'),
|
| 188 |
+
('ㄎ', 'kʰ'),
|
| 189 |
+
('ㄏ', 'h'),
|
| 190 |
+
('ㄐ', 'tɕ'),
|
| 191 |
+
('ㄑ', 'tɕʰ'),
|
| 192 |
+
('ㄒ', 'ɕ'),
|
| 193 |
+
('ㄓ', 'tʂ'),
|
| 194 |
+
('ㄔ', 'tʂʰ'),
|
| 195 |
+
('ㄕ', 'ʂ'),
|
| 196 |
+
('ㄖ', 'ɻ'),
|
| 197 |
+
('ㄗ', 'ts'),
|
| 198 |
+
('ㄘ', 'tsʰ'),
|
| 199 |
+
('ㄙ', 's'),
|
| 200 |
+
('ㄚ', 'a'),
|
| 201 |
+
('ㄛ', 'o'),
|
| 202 |
+
('ㄜ', 'ɤ'),
|
| 203 |
+
('ㄝ', 'ɛ'),
|
| 204 |
+
('ㄞ', 'aɪ'),
|
| 205 |
+
('ㄟ', 'eɪ'),
|
| 206 |
+
('ㄠ', 'ɑʊ'),
|
| 207 |
+
('ㄡ', 'oʊ'),
|
| 208 |
+
('ㄧㄢ', 'jɛn'),
|
| 209 |
+
('ㄩㄢ', 'yæn'),
|
| 210 |
+
('ㄢ', 'an'),
|
| 211 |
+
('ㄧㄣ', 'in'),
|
| 212 |
+
('ㄩㄣ', 'yn'),
|
| 213 |
+
('ㄣ', 'ən'),
|
| 214 |
+
('ㄤ', 'ɑŋ'),
|
| 215 |
+
('ㄧㄥ', 'iŋ'),
|
| 216 |
+
('ㄨㄥ', 'ʊŋ'),
|
| 217 |
+
('ㄩㄥ', 'jʊŋ'),
|
| 218 |
+
('ㄥ', 'ɤŋ'),
|
| 219 |
+
('ㄦ', 'əɻ'),
|
| 220 |
+
('ㄧ', 'i'),
|
| 221 |
+
('ㄨ', 'u'),
|
| 222 |
+
('ㄩ', 'y'),
|
| 223 |
+
('ˉ', '˥'),
|
| 224 |
+
('ˊ', '˧˥'),
|
| 225 |
+
('ˇ', '˨˩˦'),
|
| 226 |
+
('ˋ', '˥˩'),
|
| 227 |
+
('˙', ''),
|
| 228 |
+
(',', ','),
|
| 229 |
+
('。', '.'),
|
| 230 |
+
('!', '!'),
|
| 231 |
+
('?', '?'),
|
| 232 |
+
('—', '-')
|
| 233 |
+
]]
|
| 234 |
+
|
| 235 |
+
|
| 236 |
+
def number_to_chinese(text):
|
| 237 |
+
numbers = re.findall(r'\d+(?:\.?\d+)?', text)
|
| 238 |
+
for number in numbers:
|
| 239 |
+
text = text.replace(number, cn2an.an2cn(number), 1)
|
| 240 |
+
return text
|
| 241 |
+
|
| 242 |
+
|
| 243 |
+
def chinese_to_bopomofo(text):
|
| 244 |
+
text = text.replace('、', ',').replace(';', ',').replace(':', ',')
|
| 245 |
+
words = jieba.lcut(text, cut_all=False)
|
| 246 |
+
text = ''
|
| 247 |
+
for word in words:
|
| 248 |
+
bopomofos = lazy_pinyin(word, BOPOMOFO)
|
| 249 |
+
if not re.search('[\u4e00-\u9fff]', word):
|
| 250 |
+
text += word
|
| 251 |
+
continue
|
| 252 |
+
for i in range(len(bopomofos)):
|
| 253 |
+
bopomofos[i] = re.sub(r'([\u3105-\u3129])$', r'\1ˉ', bopomofos[i])
|
| 254 |
+
if text != '':
|
| 255 |
+
text += ' '
|
| 256 |
+
text += ''.join(bopomofos)
|
| 257 |
+
return text
|
| 258 |
+
|
| 259 |
+
|
| 260 |
+
def latin_to_bopomofo(text):
|
| 261 |
+
for regex, replacement in _latin_to_bopomofo:
|
| 262 |
+
text = re.sub(regex, replacement, text)
|
| 263 |
+
return text
|
| 264 |
+
|
| 265 |
+
|
| 266 |
+
def bopomofo_to_romaji(text):
|
| 267 |
+
for regex, replacement in _bopomofo_to_romaji:
|
| 268 |
+
text = re.sub(regex, replacement, text)
|
| 269 |
+
return text
|
| 270 |
+
|
| 271 |
+
|
| 272 |
+
def bopomofo_to_ipa(text):
|
| 273 |
+
for regex, replacement in _bopomofo_to_ipa:
|
| 274 |
+
text = re.sub(regex, replacement, text)
|
| 275 |
+
return text
|
| 276 |
+
|
| 277 |
+
|
| 278 |
+
def bopomofo_to_ipa2(text):
|
| 279 |
+
for regex, replacement in _bopomofo_to_ipa2:
|
| 280 |
+
text = re.sub(regex, replacement, text)
|
| 281 |
+
return text
|
| 282 |
+
|
| 283 |
+
|
| 284 |
+
def chinese_to_romaji(text):
|
| 285 |
+
text = number_to_chinese(text)
|
| 286 |
+
text = chinese_to_bopomofo(text)
|
| 287 |
+
text = latin_to_bopomofo(text)
|
| 288 |
+
text = bopomofo_to_romaji(text)
|
| 289 |
+
text = re.sub('i([aoe])', r'y\1', text)
|
| 290 |
+
text = re.sub('u([aoəe])', r'w\1', text)
|
| 291 |
+
text = re.sub('([ʦsɹ]`[⁼ʰ]?)([→↓↑ ]+|$)',
|
| 292 |
+
r'\1ɹ`\2', text).replace('ɻ', 'ɹ`')
|
| 293 |
+
text = re.sub('([ʦs][⁼ʰ]?)([→↓↑ ]+|$)', r'\1ɹ\2', text)
|
| 294 |
+
return text
|
| 295 |
+
|
| 296 |
+
|
| 297 |
+
def chinese_to_lazy_ipa(text):
|
| 298 |
+
text = chinese_to_romaji(text)
|
| 299 |
+
for regex, replacement in _romaji_to_ipa:
|
| 300 |
+
text = re.sub(regex, replacement, text)
|
| 301 |
+
return text
|
| 302 |
+
|
| 303 |
+
|
| 304 |
+
def chinese_to_ipa(text):
|
| 305 |
+
text = number_to_chinese(text)
|
| 306 |
+
text = chinese_to_bopomofo(text)
|
| 307 |
+
text = latin_to_bopomofo(text)
|
| 308 |
+
text = bopomofo_to_ipa(text)
|
| 309 |
+
text = re.sub('i([aoe])', r'j\1', text)
|
| 310 |
+
text = re.sub('u([aoəe])', r'w\1', text)
|
| 311 |
+
text = re.sub('([sɹ]`[⁼ʰ]?)([→↓↑ ]+|$)',
|
| 312 |
+
r'\1ɹ`\2', text).replace('ɻ', 'ɹ`')
|
| 313 |
+
text = re.sub('([s][⁼ʰ]?)([→↓↑ ]+|$)', r'\1ɹ\2', text)
|
| 314 |
+
return text
|
| 315 |
+
|
| 316 |
+
|
| 317 |
+
def chinese_to_ipa2(text):
|
| 318 |
+
text = number_to_chinese(text)
|
| 319 |
+
text = chinese_to_bopomofo(text)
|
| 320 |
+
text = latin_to_bopomofo(text)
|
| 321 |
+
text = bopomofo_to_ipa2(text)
|
| 322 |
+
text = re.sub(r'i([aoe])', r'j\1', text)
|
| 323 |
+
text = re.sub(r'u([aoəe])', r'w\1', text)
|
| 324 |
+
text = re.sub(r'([ʂɹ]ʰ?)([˩˨˧˦˥ ]+|$)', r'\1ʅ\2', text)
|
| 325 |
+
text = re.sub(r'(sʰ?)([˩˨˧˦˥ ]+|$)', r'\1ɿ\2', text)
|
| 326 |
+
return text
|
OpenVoice/text/symbols.py
ADDED
|
@@ -0,0 +1,88 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
'''
|
| 2 |
+
Defines the set of symbols used in text input to the model.
|
| 3 |
+
'''
|
| 4 |
+
|
| 5 |
+
# japanese_cleaners
|
| 6 |
+
# _pad = '_'
|
| 7 |
+
# _punctuation = ',.!?-'
|
| 8 |
+
# _letters = 'AEINOQUabdefghijkmnoprstuvwyzʃʧ↓↑ '
|
| 9 |
+
|
| 10 |
+
|
| 11 |
+
'''# japanese_cleaners2
|
| 12 |
+
_pad = '_'
|
| 13 |
+
_punctuation = ',.!?-~…'
|
| 14 |
+
_letters = 'AEINOQUabdefghijkmnoprstuvwyzʃʧʦ↓↑ '
|
| 15 |
+
'''
|
| 16 |
+
|
| 17 |
+
|
| 18 |
+
'''# korean_cleaners
|
| 19 |
+
_pad = '_'
|
| 20 |
+
_punctuation = ',.!?…~'
|
| 21 |
+
_letters = 'ㄱㄴㄷㄹㅁㅂㅅㅇㅈㅊㅋㅌㅍㅎㄲㄸㅃㅆㅉㅏㅓㅗㅜㅡㅣㅐㅔ '
|
| 22 |
+
'''
|
| 23 |
+
|
| 24 |
+
'''# chinese_cleaners
|
| 25 |
+
_pad = '_'
|
| 26 |
+
_punctuation = ',。!?—…'
|
| 27 |
+
_letters = 'ㄅㄆㄇㄈㄉㄊㄋㄌㄍㄎㄏㄐㄑㄒㄓㄔㄕㄖㄗㄘㄙㄚㄛㄜㄝㄞㄟㄠㄡㄢㄣㄤㄥㄦㄧㄨㄩˉˊˇˋ˙ '
|
| 28 |
+
'''
|
| 29 |
+
|
| 30 |
+
# # zh_ja_mixture_cleaners
|
| 31 |
+
# _pad = '_'
|
| 32 |
+
# _punctuation = ',.!?-~…'
|
| 33 |
+
# _letters = 'AEINOQUabdefghijklmnoprstuvwyzʃʧʦɯɹəɥ⁼ʰ`→↓↑ '
|
| 34 |
+
|
| 35 |
+
|
| 36 |
+
'''# sanskrit_cleaners
|
| 37 |
+
_pad = '_'
|
| 38 |
+
_punctuation = '।'
|
| 39 |
+
_letters = 'ँंःअआइईउऊऋएऐओऔकखगघङचछजझञटठडढणतथदधनपफबभमयरलळवशषसहऽािीुूृॄेैोौ्ॠॢ '
|
| 40 |
+
'''
|
| 41 |
+
|
| 42 |
+
'''# cjks_cleaners
|
| 43 |
+
_pad = '_'
|
| 44 |
+
_punctuation = ',.!?-~…'
|
| 45 |
+
_letters = 'NQabdefghijklmnopstuvwxyzʃʧʥʦɯɹəɥçɸɾβŋɦː⁼ʰ`^#*=→↓↑ '
|
| 46 |
+
'''
|
| 47 |
+
|
| 48 |
+
'''# thai_cleaners
|
| 49 |
+
_pad = '_'
|
| 50 |
+
_punctuation = '.!? '
|
| 51 |
+
_letters = 'กขฃคฆงจฉชซฌญฎฏฐฑฒณดตถทธนบปผฝพฟภมยรฤลวศษสหฬอฮฯะัาำิีึืุูเแโใไๅๆ็่้๊๋์'
|
| 52 |
+
'''
|
| 53 |
+
|
| 54 |
+
# # cjke_cleaners2
|
| 55 |
+
_pad = '_'
|
| 56 |
+
_punctuation = ',.!?-~…'
|
| 57 |
+
_letters = 'NQabdefghijklmnopstuvwxyzɑæʃʑçɯɪɔɛɹðəɫɥɸʊɾʒθβŋɦ⁼ʰ`^#*=ˈˌ→↓↑ '
|
| 58 |
+
|
| 59 |
+
|
| 60 |
+
'''# shanghainese_cleaners
|
| 61 |
+
_pad = '_'
|
| 62 |
+
_punctuation = ',.!?…'
|
| 63 |
+
_letters = 'abdfghiklmnopstuvyzøŋȵɑɔɕəɤɦɪɿʑʔʰ̩̃ᴀᴇ15678 '
|
| 64 |
+
'''
|
| 65 |
+
|
| 66 |
+
'''# chinese_dialect_cleaners
|
| 67 |
+
_pad = '_'
|
| 68 |
+
_punctuation = ',.!?~…─'
|
| 69 |
+
_letters = '#Nabdefghijklmnoprstuvwxyzæçøŋœȵɐɑɒɓɔɕɗɘəɚɛɜɣɤɦɪɭɯɵɷɸɻɾɿʂʅʊʋʌʏʑʔʦʮʰʷˀː˥˦˧˨˩̥̩̃̚ᴀᴇ↑↓∅ⱼ '
|
| 70 |
+
'''
|
| 71 |
+
|
| 72 |
+
# Export all symbols:
|
| 73 |
+
symbols = [_pad] + list(_punctuation) + list(_letters)
|
| 74 |
+
|
| 75 |
+
# Special symbol ids
|
| 76 |
+
SPACE_ID = symbols.index(" ")
|
| 77 |
+
|
| 78 |
+
num_ja_tones = 1
|
| 79 |
+
num_kr_tones = 1
|
| 80 |
+
num_zh_tones = 6
|
| 81 |
+
num_en_tones = 4
|
| 82 |
+
|
| 83 |
+
language_tone_start_map = {
|
| 84 |
+
"ZH": 0,
|
| 85 |
+
"JP": num_zh_tones,
|
| 86 |
+
"EN": num_zh_tones + num_ja_tones,
|
| 87 |
+
'KR': num_zh_tones + num_ja_tones + num_en_tones,
|
| 88 |
+
}
|
OpenVoice/transforms.py
ADDED
|
@@ -0,0 +1,209 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import torch
|
| 2 |
+
from torch.nn import functional as F
|
| 3 |
+
|
| 4 |
+
import numpy as np
|
| 5 |
+
|
| 6 |
+
|
| 7 |
+
DEFAULT_MIN_BIN_WIDTH = 1e-3
|
| 8 |
+
DEFAULT_MIN_BIN_HEIGHT = 1e-3
|
| 9 |
+
DEFAULT_MIN_DERIVATIVE = 1e-3
|
| 10 |
+
|
| 11 |
+
|
| 12 |
+
def piecewise_rational_quadratic_transform(
|
| 13 |
+
inputs,
|
| 14 |
+
unnormalized_widths,
|
| 15 |
+
unnormalized_heights,
|
| 16 |
+
unnormalized_derivatives,
|
| 17 |
+
inverse=False,
|
| 18 |
+
tails=None,
|
| 19 |
+
tail_bound=1.0,
|
| 20 |
+
min_bin_width=DEFAULT_MIN_BIN_WIDTH,
|
| 21 |
+
min_bin_height=DEFAULT_MIN_BIN_HEIGHT,
|
| 22 |
+
min_derivative=DEFAULT_MIN_DERIVATIVE,
|
| 23 |
+
):
|
| 24 |
+
if tails is None:
|
| 25 |
+
spline_fn = rational_quadratic_spline
|
| 26 |
+
spline_kwargs = {}
|
| 27 |
+
else:
|
| 28 |
+
spline_fn = unconstrained_rational_quadratic_spline
|
| 29 |
+
spline_kwargs = {"tails": tails, "tail_bound": tail_bound}
|
| 30 |
+
|
| 31 |
+
outputs, logabsdet = spline_fn(
|
| 32 |
+
inputs=inputs,
|
| 33 |
+
unnormalized_widths=unnormalized_widths,
|
| 34 |
+
unnormalized_heights=unnormalized_heights,
|
| 35 |
+
unnormalized_derivatives=unnormalized_derivatives,
|
| 36 |
+
inverse=inverse,
|
| 37 |
+
min_bin_width=min_bin_width,
|
| 38 |
+
min_bin_height=min_bin_height,
|
| 39 |
+
min_derivative=min_derivative,
|
| 40 |
+
**spline_kwargs
|
| 41 |
+
)
|
| 42 |
+
return outputs, logabsdet
|
| 43 |
+
|
| 44 |
+
|
| 45 |
+
def searchsorted(bin_locations, inputs, eps=1e-6):
|
| 46 |
+
bin_locations[..., -1] += eps
|
| 47 |
+
return torch.sum(inputs[..., None] >= bin_locations, dim=-1) - 1
|
| 48 |
+
|
| 49 |
+
|
| 50 |
+
def unconstrained_rational_quadratic_spline(
|
| 51 |
+
inputs,
|
| 52 |
+
unnormalized_widths,
|
| 53 |
+
unnormalized_heights,
|
| 54 |
+
unnormalized_derivatives,
|
| 55 |
+
inverse=False,
|
| 56 |
+
tails="linear",
|
| 57 |
+
tail_bound=1.0,
|
| 58 |
+
min_bin_width=DEFAULT_MIN_BIN_WIDTH,
|
| 59 |
+
min_bin_height=DEFAULT_MIN_BIN_HEIGHT,
|
| 60 |
+
min_derivative=DEFAULT_MIN_DERIVATIVE,
|
| 61 |
+
):
|
| 62 |
+
inside_interval_mask = (inputs >= -tail_bound) & (inputs <= tail_bound)
|
| 63 |
+
outside_interval_mask = ~inside_interval_mask
|
| 64 |
+
|
| 65 |
+
outputs = torch.zeros_like(inputs)
|
| 66 |
+
logabsdet = torch.zeros_like(inputs)
|
| 67 |
+
|
| 68 |
+
if tails == "linear":
|
| 69 |
+
unnormalized_derivatives = F.pad(unnormalized_derivatives, pad=(1, 1))
|
| 70 |
+
constant = np.log(np.exp(1 - min_derivative) - 1)
|
| 71 |
+
unnormalized_derivatives[..., 0] = constant
|
| 72 |
+
unnormalized_derivatives[..., -1] = constant
|
| 73 |
+
|
| 74 |
+
outputs[outside_interval_mask] = inputs[outside_interval_mask]
|
| 75 |
+
logabsdet[outside_interval_mask] = 0
|
| 76 |
+
else:
|
| 77 |
+
raise RuntimeError("{} tails are not implemented.".format(tails))
|
| 78 |
+
|
| 79 |
+
(
|
| 80 |
+
outputs[inside_interval_mask],
|
| 81 |
+
logabsdet[inside_interval_mask],
|
| 82 |
+
) = rational_quadratic_spline(
|
| 83 |
+
inputs=inputs[inside_interval_mask],
|
| 84 |
+
unnormalized_widths=unnormalized_widths[inside_interval_mask, :],
|
| 85 |
+
unnormalized_heights=unnormalized_heights[inside_interval_mask, :],
|
| 86 |
+
unnormalized_derivatives=unnormalized_derivatives[inside_interval_mask, :],
|
| 87 |
+
inverse=inverse,
|
| 88 |
+
left=-tail_bound,
|
| 89 |
+
right=tail_bound,
|
| 90 |
+
bottom=-tail_bound,
|
| 91 |
+
top=tail_bound,
|
| 92 |
+
min_bin_width=min_bin_width,
|
| 93 |
+
min_bin_height=min_bin_height,
|
| 94 |
+
min_derivative=min_derivative,
|
| 95 |
+
)
|
| 96 |
+
|
| 97 |
+
return outputs, logabsdet
|
| 98 |
+
|
| 99 |
+
|
| 100 |
+
def rational_quadratic_spline(
|
| 101 |
+
inputs,
|
| 102 |
+
unnormalized_widths,
|
| 103 |
+
unnormalized_heights,
|
| 104 |
+
unnormalized_derivatives,
|
| 105 |
+
inverse=False,
|
| 106 |
+
left=0.0,
|
| 107 |
+
right=1.0,
|
| 108 |
+
bottom=0.0,
|
| 109 |
+
top=1.0,
|
| 110 |
+
min_bin_width=DEFAULT_MIN_BIN_WIDTH,
|
| 111 |
+
min_bin_height=DEFAULT_MIN_BIN_HEIGHT,
|
| 112 |
+
min_derivative=DEFAULT_MIN_DERIVATIVE,
|
| 113 |
+
):
|
| 114 |
+
if torch.min(inputs) < left or torch.max(inputs) > right:
|
| 115 |
+
raise ValueError("Input to a transform is not within its domain")
|
| 116 |
+
|
| 117 |
+
num_bins = unnormalized_widths.shape[-1]
|
| 118 |
+
|
| 119 |
+
if min_bin_width * num_bins > 1.0:
|
| 120 |
+
raise ValueError("Minimal bin width too large for the number of bins")
|
| 121 |
+
if min_bin_height * num_bins > 1.0:
|
| 122 |
+
raise ValueError("Minimal bin height too large for the number of bins")
|
| 123 |
+
|
| 124 |
+
widths = F.softmax(unnormalized_widths, dim=-1)
|
| 125 |
+
widths = min_bin_width + (1 - min_bin_width * num_bins) * widths
|
| 126 |
+
cumwidths = torch.cumsum(widths, dim=-1)
|
| 127 |
+
cumwidths = F.pad(cumwidths, pad=(1, 0), mode="constant", value=0.0)
|
| 128 |
+
cumwidths = (right - left) * cumwidths + left
|
| 129 |
+
cumwidths[..., 0] = left
|
| 130 |
+
cumwidths[..., -1] = right
|
| 131 |
+
widths = cumwidths[..., 1:] - cumwidths[..., :-1]
|
| 132 |
+
|
| 133 |
+
derivatives = min_derivative + F.softplus(unnormalized_derivatives)
|
| 134 |
+
|
| 135 |
+
heights = F.softmax(unnormalized_heights, dim=-1)
|
| 136 |
+
heights = min_bin_height + (1 - min_bin_height * num_bins) * heights
|
| 137 |
+
cumheights = torch.cumsum(heights, dim=-1)
|
| 138 |
+
cumheights = F.pad(cumheights, pad=(1, 0), mode="constant", value=0.0)
|
| 139 |
+
cumheights = (top - bottom) * cumheights + bottom
|
| 140 |
+
cumheights[..., 0] = bottom
|
| 141 |
+
cumheights[..., -1] = top
|
| 142 |
+
heights = cumheights[..., 1:] - cumheights[..., :-1]
|
| 143 |
+
|
| 144 |
+
if inverse:
|
| 145 |
+
bin_idx = searchsorted(cumheights, inputs)[..., None]
|
| 146 |
+
else:
|
| 147 |
+
bin_idx = searchsorted(cumwidths, inputs)[..., None]
|
| 148 |
+
|
| 149 |
+
input_cumwidths = cumwidths.gather(-1, bin_idx)[..., 0]
|
| 150 |
+
input_bin_widths = widths.gather(-1, bin_idx)[..., 0]
|
| 151 |
+
|
| 152 |
+
input_cumheights = cumheights.gather(-1, bin_idx)[..., 0]
|
| 153 |
+
delta = heights / widths
|
| 154 |
+
input_delta = delta.gather(-1, bin_idx)[..., 0]
|
| 155 |
+
|
| 156 |
+
input_derivatives = derivatives.gather(-1, bin_idx)[..., 0]
|
| 157 |
+
input_derivatives_plus_one = derivatives[..., 1:].gather(-1, bin_idx)[..., 0]
|
| 158 |
+
|
| 159 |
+
input_heights = heights.gather(-1, bin_idx)[..., 0]
|
| 160 |
+
|
| 161 |
+
if inverse:
|
| 162 |
+
a = (inputs - input_cumheights) * (
|
| 163 |
+
input_derivatives + input_derivatives_plus_one - 2 * input_delta
|
| 164 |
+
) + input_heights * (input_delta - input_derivatives)
|
| 165 |
+
b = input_heights * input_derivatives - (inputs - input_cumheights) * (
|
| 166 |
+
input_derivatives + input_derivatives_plus_one - 2 * input_delta
|
| 167 |
+
)
|
| 168 |
+
c = -input_delta * (inputs - input_cumheights)
|
| 169 |
+
|
| 170 |
+
discriminant = b.pow(2) - 4 * a * c
|
| 171 |
+
assert (discriminant >= 0).all()
|
| 172 |
+
|
| 173 |
+
root = (2 * c) / (-b - torch.sqrt(discriminant))
|
| 174 |
+
outputs = root * input_bin_widths + input_cumwidths
|
| 175 |
+
|
| 176 |
+
theta_one_minus_theta = root * (1 - root)
|
| 177 |
+
denominator = input_delta + (
|
| 178 |
+
(input_derivatives + input_derivatives_plus_one - 2 * input_delta)
|
| 179 |
+
* theta_one_minus_theta
|
| 180 |
+
)
|
| 181 |
+
derivative_numerator = input_delta.pow(2) * (
|
| 182 |
+
input_derivatives_plus_one * root.pow(2)
|
| 183 |
+
+ 2 * input_delta * theta_one_minus_theta
|
| 184 |
+
+ input_derivatives * (1 - root).pow(2)
|
| 185 |
+
)
|
| 186 |
+
logabsdet = torch.log(derivative_numerator) - 2 * torch.log(denominator)
|
| 187 |
+
|
| 188 |
+
return outputs, -logabsdet
|
| 189 |
+
else:
|
| 190 |
+
theta = (inputs - input_cumwidths) / input_bin_widths
|
| 191 |
+
theta_one_minus_theta = theta * (1 - theta)
|
| 192 |
+
|
| 193 |
+
numerator = input_heights * (
|
| 194 |
+
input_delta * theta.pow(2) + input_derivatives * theta_one_minus_theta
|
| 195 |
+
)
|
| 196 |
+
denominator = input_delta + (
|
| 197 |
+
(input_derivatives + input_derivatives_plus_one - 2 * input_delta)
|
| 198 |
+
* theta_one_minus_theta
|
| 199 |
+
)
|
| 200 |
+
outputs = input_cumheights + numerator / denominator
|
| 201 |
+
|
| 202 |
+
derivative_numerator = input_delta.pow(2) * (
|
| 203 |
+
input_derivatives_plus_one * theta.pow(2)
|
| 204 |
+
+ 2 * input_delta * theta_one_minus_theta
|
| 205 |
+
+ input_derivatives * (1 - theta).pow(2)
|
| 206 |
+
)
|
| 207 |
+
logabsdet = torch.log(derivative_numerator) - 2 * torch.log(denominator)
|
| 208 |
+
|
| 209 |
+
return outputs, logabsdet
|
OpenVoice/utils.py
ADDED
|
@@ -0,0 +1,194 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import re
|
| 2 |
+
import json
|
| 3 |
+
import numpy as np
|
| 4 |
+
|
| 5 |
+
|
| 6 |
+
def get_hparams_from_file(config_path):
|
| 7 |
+
with open(config_path, "r", encoding="utf-8") as f:
|
| 8 |
+
data = f.read()
|
| 9 |
+
config = json.loads(data)
|
| 10 |
+
|
| 11 |
+
hparams = HParams(**config)
|
| 12 |
+
return hparams
|
| 13 |
+
|
| 14 |
+
class HParams:
|
| 15 |
+
def __init__(self, **kwargs):
|
| 16 |
+
for k, v in kwargs.items():
|
| 17 |
+
if type(v) == dict:
|
| 18 |
+
v = HParams(**v)
|
| 19 |
+
self[k] = v
|
| 20 |
+
|
| 21 |
+
def keys(self):
|
| 22 |
+
return self.__dict__.keys()
|
| 23 |
+
|
| 24 |
+
def items(self):
|
| 25 |
+
return self.__dict__.items()
|
| 26 |
+
|
| 27 |
+
def values(self):
|
| 28 |
+
return self.__dict__.values()
|
| 29 |
+
|
| 30 |
+
def __len__(self):
|
| 31 |
+
return len(self.__dict__)
|
| 32 |
+
|
| 33 |
+
def __getitem__(self, key):
|
| 34 |
+
return getattr(self, key)
|
| 35 |
+
|
| 36 |
+
def __setitem__(self, key, value):
|
| 37 |
+
return setattr(self, key, value)
|
| 38 |
+
|
| 39 |
+
def __contains__(self, key):
|
| 40 |
+
return key in self.__dict__
|
| 41 |
+
|
| 42 |
+
def __repr__(self):
|
| 43 |
+
return self.__dict__.__repr__()
|
| 44 |
+
|
| 45 |
+
|
| 46 |
+
def string_to_bits(string, pad_len=8):
|
| 47 |
+
# Convert each character to its ASCII value
|
| 48 |
+
ascii_values = [ord(char) for char in string]
|
| 49 |
+
|
| 50 |
+
# Convert ASCII values to binary representation
|
| 51 |
+
binary_values = [bin(value)[2:].zfill(8) for value in ascii_values]
|
| 52 |
+
|
| 53 |
+
# Convert binary strings to integer arrays
|
| 54 |
+
bit_arrays = [[int(bit) for bit in binary] for binary in binary_values]
|
| 55 |
+
|
| 56 |
+
# Convert list of arrays to NumPy array
|
| 57 |
+
numpy_array = np.array(bit_arrays)
|
| 58 |
+
numpy_array_full = np.zeros((pad_len, 8), dtype=numpy_array.dtype)
|
| 59 |
+
numpy_array_full[:, 2] = 1
|
| 60 |
+
max_len = min(pad_len, len(numpy_array))
|
| 61 |
+
numpy_array_full[:max_len] = numpy_array[:max_len]
|
| 62 |
+
return numpy_array_full
|
| 63 |
+
|
| 64 |
+
|
| 65 |
+
def bits_to_string(bits_array):
|
| 66 |
+
# Convert each row of the array to a binary string
|
| 67 |
+
binary_values = [''.join(str(bit) for bit in row) for row in bits_array]
|
| 68 |
+
|
| 69 |
+
# Convert binary strings to ASCII values
|
| 70 |
+
ascii_values = [int(binary, 2) for binary in binary_values]
|
| 71 |
+
|
| 72 |
+
# Convert ASCII values to characters
|
| 73 |
+
output_string = ''.join(chr(value) for value in ascii_values)
|
| 74 |
+
|
| 75 |
+
return output_string
|
| 76 |
+
|
| 77 |
+
|
| 78 |
+
def split_sentence(text, min_len=10, language_str='[EN]'):
|
| 79 |
+
if language_str in ['EN']:
|
| 80 |
+
sentences = split_sentences_latin(text, min_len=min_len)
|
| 81 |
+
else:
|
| 82 |
+
sentences = split_sentences_zh(text, min_len=min_len)
|
| 83 |
+
return sentences
|
| 84 |
+
|
| 85 |
+
def split_sentences_latin(text, min_len=10):
|
| 86 |
+
"""Split Long sentences into list of short ones
|
| 87 |
+
|
| 88 |
+
Args:
|
| 89 |
+
str: Input sentences.
|
| 90 |
+
|
| 91 |
+
Returns:
|
| 92 |
+
List[str]: list of output sentences.
|
| 93 |
+
"""
|
| 94 |
+
# deal with dirty sentences
|
| 95 |
+
text = re.sub('[。!?;]', '.', text)
|
| 96 |
+
text = re.sub('[,]', ',', text)
|
| 97 |
+
text = re.sub('[“”]', '"', text)
|
| 98 |
+
text = re.sub('[‘’]', "'", text)
|
| 99 |
+
text = re.sub(r"[\<\>\(\)\[\]\"\«\»]+", "", text)
|
| 100 |
+
text = re.sub('[\n\t ]+', ' ', text)
|
| 101 |
+
text = re.sub('([,.!?;])', r'\1 $#!', text)
|
| 102 |
+
# split
|
| 103 |
+
sentences = [s.strip() for s in text.split('$#!')]
|
| 104 |
+
if len(sentences[-1]) == 0: del sentences[-1]
|
| 105 |
+
|
| 106 |
+
new_sentences = []
|
| 107 |
+
new_sent = []
|
| 108 |
+
count_len = 0
|
| 109 |
+
for ind, sent in enumerate(sentences):
|
| 110 |
+
# print(sent)
|
| 111 |
+
new_sent.append(sent)
|
| 112 |
+
count_len += len(sent.split(" "))
|
| 113 |
+
if count_len > min_len or ind == len(sentences) - 1:
|
| 114 |
+
count_len = 0
|
| 115 |
+
new_sentences.append(' '.join(new_sent))
|
| 116 |
+
new_sent = []
|
| 117 |
+
return merge_short_sentences_latin(new_sentences)
|
| 118 |
+
|
| 119 |
+
|
| 120 |
+
def merge_short_sentences_latin(sens):
|
| 121 |
+
"""Avoid short sentences by merging them with the following sentence.
|
| 122 |
+
|
| 123 |
+
Args:
|
| 124 |
+
List[str]: list of input sentences.
|
| 125 |
+
|
| 126 |
+
Returns:
|
| 127 |
+
List[str]: list of output sentences.
|
| 128 |
+
"""
|
| 129 |
+
sens_out = []
|
| 130 |
+
for s in sens:
|
| 131 |
+
# If the previous sentense is too short, merge them with
|
| 132 |
+
# the current sentence.
|
| 133 |
+
if len(sens_out) > 0 and len(sens_out[-1].split(" ")) <= 2:
|
| 134 |
+
sens_out[-1] = sens_out[-1] + " " + s
|
| 135 |
+
else:
|
| 136 |
+
sens_out.append(s)
|
| 137 |
+
try:
|
| 138 |
+
if len(sens_out[-1].split(" ")) <= 2:
|
| 139 |
+
sens_out[-2] = sens_out[-2] + " " + sens_out[-1]
|
| 140 |
+
sens_out.pop(-1)
|
| 141 |
+
except:
|
| 142 |
+
pass
|
| 143 |
+
return sens_out
|
| 144 |
+
|
| 145 |
+
def split_sentences_zh(text, min_len=10):
|
| 146 |
+
text = re.sub('[。!?;]', '.', text)
|
| 147 |
+
text = re.sub('[,]', ',', text)
|
| 148 |
+
# 将文本中的换行符、空格和制表符替换为空格
|
| 149 |
+
text = re.sub('[\n\t ]+', ' ', text)
|
| 150 |
+
# 在标点符号后添加一个空格
|
| 151 |
+
text = re.sub('([,.!?;])', r'\1 $#!', text)
|
| 152 |
+
# 分隔句子并去除前后空格
|
| 153 |
+
# sentences = [s.strip() for s in re.split('(。|!|?|;)', text)]
|
| 154 |
+
sentences = [s.strip() for s in text.split('$#!')]
|
| 155 |
+
if len(sentences[-1]) == 0: del sentences[-1]
|
| 156 |
+
|
| 157 |
+
new_sentences = []
|
| 158 |
+
new_sent = []
|
| 159 |
+
count_len = 0
|
| 160 |
+
for ind, sent in enumerate(sentences):
|
| 161 |
+
new_sent.append(sent)
|
| 162 |
+
count_len += len(sent)
|
| 163 |
+
if count_len > min_len or ind == len(sentences) - 1:
|
| 164 |
+
count_len = 0
|
| 165 |
+
new_sentences.append(' '.join(new_sent))
|
| 166 |
+
new_sent = []
|
| 167 |
+
return merge_short_sentences_zh(new_sentences)
|
| 168 |
+
|
| 169 |
+
|
| 170 |
+
def merge_short_sentences_zh(sens):
|
| 171 |
+
# return sens
|
| 172 |
+
"""Avoid short sentences by merging them with the following sentence.
|
| 173 |
+
|
| 174 |
+
Args:
|
| 175 |
+
List[str]: list of input sentences.
|
| 176 |
+
|
| 177 |
+
Returns:
|
| 178 |
+
List[str]: list of output sentences.
|
| 179 |
+
"""
|
| 180 |
+
sens_out = []
|
| 181 |
+
for s in sens:
|
| 182 |
+
# If the previous sentense is too short, merge them with
|
| 183 |
+
# the current sentence.
|
| 184 |
+
if len(sens_out) > 0 and len(sens_out[-1]) <= 2:
|
| 185 |
+
sens_out[-1] = sens_out[-1] + " " + s
|
| 186 |
+
else:
|
| 187 |
+
sens_out.append(s)
|
| 188 |
+
try:
|
| 189 |
+
if len(sens_out[-1]) <= 2:
|
| 190 |
+
sens_out[-2] = sens_out[-2] + " " + sens_out[-1]
|
| 191 |
+
sens_out.pop(-1)
|
| 192 |
+
except:
|
| 193 |
+
pass
|
| 194 |
+
return sens_out
|
app_locally.py
ADDED
|
@@ -0,0 +1,314 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import os
|
| 2 |
+
import torch
|
| 3 |
+
import argparse
|
| 4 |
+
import gradio as gr
|
| 5 |
+
from zipfile import ZipFile
|
| 6 |
+
import langid
|
| 7 |
+
|
| 8 |
+
|
| 9 |
+
parser = argparse.ArgumentParser()
|
| 10 |
+
parser.add_argument("--online_checkpoint_url", default="https://myshell-public-repo-hosting.s3.amazonaws.com/checkpoints_1226.zip")
|
| 11 |
+
parser.add_argument("--share", action='store_true', default=False, help="make link public")
|
| 12 |
+
args = parser.parse_args()
|
| 13 |
+
|
| 14 |
+
# first download the checkpoints from server
|
| 15 |
+
if not os.path.exists('checkpoints/'):
|
| 16 |
+
print('Downloading OpenVoice checkpoint ...')
|
| 17 |
+
os.system(f'wget {args.online_checkpoint_url} -O ckpt.zip')
|
| 18 |
+
print('Extracting OpenVoice checkpoint ...')
|
| 19 |
+
ZipFile("ckpt.zip").extractall()
|
| 20 |
+
|
| 21 |
+
# Init EN/ZH baseTTS and ToneConvertor
|
| 22 |
+
from OpenVoice import se_extractor
|
| 23 |
+
from OpenVoice.api import BaseSpeakerTTS, ToneColorConverter
|
| 24 |
+
|
| 25 |
+
en_ckpt_base = 'checkpoints/base_speakers/EN'
|
| 26 |
+
zh_ckpt_base = 'checkpoints/base_speakers/ZH'
|
| 27 |
+
ckpt_converter = 'checkpoints/converter'
|
| 28 |
+
device = 'cuda' if torch.cuda.is_available() else 'cpu'
|
| 29 |
+
output_dir = 'outputs'
|
| 30 |
+
os.makedirs(output_dir, exist_ok=True)
|
| 31 |
+
en_base_speaker_tts = BaseSpeakerTTS(f'{en_ckpt_base}/config.json', device=device)
|
| 32 |
+
en_base_speaker_tts.load_ckpt(f'{en_ckpt_base}/checkpoint.pth')
|
| 33 |
+
zh_base_speaker_tts = BaseSpeakerTTS(f'{zh_ckpt_base}/config.json', device=device)
|
| 34 |
+
zh_base_speaker_tts.load_ckpt(f'{zh_ckpt_base}/checkpoint.pth')
|
| 35 |
+
tone_color_converter = ToneColorConverter(f'{ckpt_converter}/config.json', device=device)
|
| 36 |
+
tone_color_converter.load_ckpt(f'{ckpt_converter}/checkpoint.pth')
|
| 37 |
+
en_source_default_se = torch.load(f'{en_ckpt_base}/en_default_se.pth').to(device)
|
| 38 |
+
en_source_style_se = torch.load(f'{en_ckpt_base}/en_style_se.pth').to(device)
|
| 39 |
+
zh_source_se = torch.load(f'{zh_ckpt_base}/zh_default_se.pth').to(device)
|
| 40 |
+
|
| 41 |
+
supported_languages = ['zh', 'en']
|
| 42 |
+
|
| 43 |
+
def predict(prompt, style, audio_file_pth, mic_file_path, use_mic, agree):
|
| 44 |
+
# initialize a empty info
|
| 45 |
+
text_hint = ''
|
| 46 |
+
# agree with the terms
|
| 47 |
+
if agree == False:
|
| 48 |
+
text_hint += '[ERROR] Please accept the Terms & Condition!\n'
|
| 49 |
+
gr.Warning("Please accept the Terms & Condition!")
|
| 50 |
+
return (
|
| 51 |
+
text_hint,
|
| 52 |
+
None,
|
| 53 |
+
None,
|
| 54 |
+
)
|
| 55 |
+
|
| 56 |
+
# first detect the input language
|
| 57 |
+
language_predicted = langid.classify(prompt)[0].strip()
|
| 58 |
+
print(f"Detected language:{language_predicted}")
|
| 59 |
+
|
| 60 |
+
if language_predicted not in supported_languages:
|
| 61 |
+
text_hint += f"[ERROR] The detected language {language_predicted} for your input text is not in our Supported Languages: {supported_languages}\n"
|
| 62 |
+
gr.Warning(
|
| 63 |
+
f"The detected language {language_predicted} for your input text is not in our Supported Languages: {supported_languages}"
|
| 64 |
+
)
|
| 65 |
+
|
| 66 |
+
return (
|
| 67 |
+
text_hint,
|
| 68 |
+
None,
|
| 69 |
+
None,
|
| 70 |
+
)
|
| 71 |
+
|
| 72 |
+
if language_predicted == "zh":
|
| 73 |
+
tts_model = zh_base_speaker_tts
|
| 74 |
+
source_se = zh_source_se
|
| 75 |
+
language = 'Chinese'
|
| 76 |
+
if style not in ['default']:
|
| 77 |
+
text_hint += f"[ERROR] The style {style} is not supported for Chinese, which should be in ['default']\n"
|
| 78 |
+
gr.Warning(f"The style {style} is not supported for Chinese, which should be in ['default']")
|
| 79 |
+
return (
|
| 80 |
+
text_hint,
|
| 81 |
+
None,
|
| 82 |
+
None,
|
| 83 |
+
)
|
| 84 |
+
|
| 85 |
+
else:
|
| 86 |
+
tts_model = en_base_speaker_tts
|
| 87 |
+
if style == 'default':
|
| 88 |
+
source_se = en_source_default_se
|
| 89 |
+
else:
|
| 90 |
+
source_se = en_source_style_se
|
| 91 |
+
language = 'English'
|
| 92 |
+
if style not in ['default', 'whispering', 'shouting', 'excited', 'cheerful', 'terrified', 'angry', 'sad', 'friendly']:
|
| 93 |
+
text_hint += f"[ERROR] The style {style} is not supported for English, which should be in ['default', 'whispering', 'shouting', 'excited', 'cheerful', 'terrified', 'angry', 'sad', 'friendly']\n"
|
| 94 |
+
gr.Warning(f"The style {style} is not supported for English, which should be in ['default', 'whispering', 'shouting', 'excited', 'cheerful', 'terrified', 'angry', 'sad', 'friendly']")
|
| 95 |
+
return (
|
| 96 |
+
text_hint,
|
| 97 |
+
None,
|
| 98 |
+
None,
|
| 99 |
+
)
|
| 100 |
+
|
| 101 |
+
if use_mic == True:
|
| 102 |
+
if mic_file_path is not None:
|
| 103 |
+
speaker_wav = mic_file_path
|
| 104 |
+
else:
|
| 105 |
+
text_hint += f"[ERROR] Please record your voice with Microphone, or uncheck Use Microphone to use reference audios\n"
|
| 106 |
+
gr.Warning(
|
| 107 |
+
"Please record your voice with Microphone, or uncheck Use Microphone to use reference audios"
|
| 108 |
+
)
|
| 109 |
+
return (
|
| 110 |
+
text_hint,
|
| 111 |
+
None,
|
| 112 |
+
None,
|
| 113 |
+
)
|
| 114 |
+
|
| 115 |
+
else:
|
| 116 |
+
speaker_wav = audio_file_pth
|
| 117 |
+
|
| 118 |
+
if len(prompt) < 2:
|
| 119 |
+
text_hint += f"[ERROR] Please give a longer prompt text \n"
|
| 120 |
+
gr.Warning("Please give a longer prompt text")
|
| 121 |
+
return (
|
| 122 |
+
text_hint,
|
| 123 |
+
None,
|
| 124 |
+
None,
|
| 125 |
+
)
|
| 126 |
+
if len(prompt) > 200:
|
| 127 |
+
text_hint += f"[ERROR] Text length limited to 200 characters for this demo, please try shorter text. You can clone our open-source repo and try for your usage \n"
|
| 128 |
+
gr.Warning(
|
| 129 |
+
"Text length limited to 200 characters for this demo, please try shorter text. You can clone our open-source repo for your usage"
|
| 130 |
+
)
|
| 131 |
+
return (
|
| 132 |
+
text_hint,
|
| 133 |
+
None,
|
| 134 |
+
None,
|
| 135 |
+
)
|
| 136 |
+
|
| 137 |
+
# note diffusion_conditioning not used on hifigan (default mode), it will be empty but need to pass it to model.inference
|
| 138 |
+
try:
|
| 139 |
+
target_se, wavs_folder = se_extractor.get_se(speaker_wav, tone_color_converter, target_dir='processed', max_length=60., vad=True)
|
| 140 |
+
# os.system(f'rm -rf {wavs_folder}')
|
| 141 |
+
except Exception as e:
|
| 142 |
+
text_hint += f"[ERROR] Get target tone color error {str(e)} \n"
|
| 143 |
+
gr.Warning(
|
| 144 |
+
"[ERROR] Get target tone color error {str(e)} \n"
|
| 145 |
+
)
|
| 146 |
+
return (
|
| 147 |
+
text_hint,
|
| 148 |
+
None,
|
| 149 |
+
None,
|
| 150 |
+
)
|
| 151 |
+
|
| 152 |
+
src_path = f'{output_dir}/tmp.wav'
|
| 153 |
+
tts_model.tts(prompt, src_path, speaker=style, language=language)
|
| 154 |
+
|
| 155 |
+
save_path = f'{output_dir}/output.wav'
|
| 156 |
+
# Run the tone color converter
|
| 157 |
+
encode_message = "@MyShell"
|
| 158 |
+
tone_color_converter.convert(
|
| 159 |
+
audio_src_path=src_path,
|
| 160 |
+
src_se=source_se,
|
| 161 |
+
tgt_se=target_se,
|
| 162 |
+
output_path=save_path,
|
| 163 |
+
message=encode_message)
|
| 164 |
+
|
| 165 |
+
text_hint += f'''Get response successfully \n'''
|
| 166 |
+
|
| 167 |
+
return (
|
| 168 |
+
text_hint,
|
| 169 |
+
save_path,
|
| 170 |
+
speaker_wav,
|
| 171 |
+
)
|
| 172 |
+
|
| 173 |
+
|
| 174 |
+
|
| 175 |
+
title = "MyShell OpenVoice"
|
| 176 |
+
|
| 177 |
+
description = """
|
| 178 |
+
We introduce OpenVoice, a versatile instant voice cloning approach that requires only a short audio clip from the reference speaker to replicate their voice and generate speech in multiple languages. OpenVoice enables granular control over voice styles, including emotion, accent, rhythm, pauses, and intonation, in addition to replicating the tone color of the reference speaker. OpenVoice also achieves zero-shot cross-lingual voice cloning for languages not included in the massive-speaker training set.
|
| 179 |
+
"""
|
| 180 |
+
|
| 181 |
+
markdown_table = """
|
| 182 |
+
<div align="center" style="margin-bottom: 10px;">
|
| 183 |
+
|
| 184 |
+
| | | |
|
| 185 |
+
| :-----------: | :-----------: | :-----------: |
|
| 186 |
+
| **OpenSource Repo** | **Project Page** | **Join the Community** |
|
| 187 |
+
| <div style='text-align: center;'><a style="display:inline-block,align:center" href='https://github.com/myshell-ai/OpenVoice'><img src='https://img.shields.io/github/stars/myshell-ai/OpenVoice?style=social' /></a></div> | [OpenVoice](https://research.myshell.ai/open-voice) | [](https://discord.gg/myshell) |
|
| 188 |
+
|
| 189 |
+
</div>
|
| 190 |
+
"""
|
| 191 |
+
|
| 192 |
+
markdown_table_v2 = """
|
| 193 |
+
<div align="center" style="margin-bottom: 2px;">
|
| 194 |
+
|
| 195 |
+
| | | | |
|
| 196 |
+
| :-----------: | :-----------: | :-----------: | :-----------: |
|
| 197 |
+
| **OpenSource Repo** | <div style='text-align: center;'><a style="display:inline-block,align:center" href='https://github.com/myshell-ai/OpenVoice'><img src='https://img.shields.io/github/stars/myshell-ai/OpenVoice?style=social' /></a></div> | **Project Page** | [OpenVoice](https://research.myshell.ai/open-voice) |
|
| 198 |
+
|
| 199 |
+
| | |
|
| 200 |
+
| :-----------: | :-----------: |
|
| 201 |
+
**Join the Community** | [](https://discord.gg/myshell) |
|
| 202 |
+
|
| 203 |
+
</div>
|
| 204 |
+
"""
|
| 205 |
+
content = """
|
| 206 |
+
<div>
|
| 207 |
+
<strong>For multi-lingual & cross-lingual examples, please refer to <a href='https://github.com/myshell-ai/OpenVoice/blob/main/demo_part2.ipynb'>this jupyter notebook</a>.</strong>
|
| 208 |
+
This online demo mainly supports <strong>English</strong>. The <em>default</em> style also supports <strong>Chinese</strong>. But OpenVoice can adapt to any other language as long as a base speaker is provided.
|
| 209 |
+
</div>
|
| 210 |
+
"""
|
| 211 |
+
wrapped_markdown_content = f"<div style='border: 1px solid #000; padding: 10px;'>{content}</div>"
|
| 212 |
+
|
| 213 |
+
|
| 214 |
+
examples = [
|
| 215 |
+
[
|
| 216 |
+
"今天天气真好,我们一起出去吃饭吧。",
|
| 217 |
+
'default',
|
| 218 |
+
"examples/speaker0.mp3",
|
| 219 |
+
None,
|
| 220 |
+
False,
|
| 221 |
+
True,
|
| 222 |
+
],[
|
| 223 |
+
"This audio is generated by open voice with a half-performance model.",
|
| 224 |
+
'whispering',
|
| 225 |
+
"examples/speaker1.mp3",
|
| 226 |
+
None,
|
| 227 |
+
False,
|
| 228 |
+
True,
|
| 229 |
+
],
|
| 230 |
+
[
|
| 231 |
+
"He hoped there would be stew for dinner, turnips and carrots and bruised potatoes and fat mutton pieces to be ladled out in thick, peppered, flour-fattened sauce.",
|
| 232 |
+
'sad',
|
| 233 |
+
"examples/speaker2.mp3",
|
| 234 |
+
None,
|
| 235 |
+
False,
|
| 236 |
+
True,
|
| 237 |
+
],
|
| 238 |
+
]
|
| 239 |
+
|
| 240 |
+
with gr.Blocks(analytics_enabled=False) as demo:
|
| 241 |
+
|
| 242 |
+
with gr.Row():
|
| 243 |
+
with gr.Column():
|
| 244 |
+
with gr.Row():
|
| 245 |
+
gr.Markdown(
|
| 246 |
+
"""
|
| 247 |
+
## <img src="https://huggingface.co/spaces/myshell-ai/OpenVoice/raw/main/logo.jpg" height="40"/>
|
| 248 |
+
"""
|
| 249 |
+
)
|
| 250 |
+
with gr.Row():
|
| 251 |
+
gr.Markdown(markdown_table_v2)
|
| 252 |
+
with gr.Row():
|
| 253 |
+
gr.Markdown(description)
|
| 254 |
+
with gr.Column():
|
| 255 |
+
gr.Video('./open_voice.mp4', autoplay=True)
|
| 256 |
+
|
| 257 |
+
with gr.Row():
|
| 258 |
+
gr.HTML(wrapped_markdown_content)
|
| 259 |
+
|
| 260 |
+
with gr.Row():
|
| 261 |
+
with gr.Column():
|
| 262 |
+
input_text_gr = gr.Textbox(
|
| 263 |
+
label="Text Prompt",
|
| 264 |
+
info="One or two sentences at a time is better. Up to 200 text characters.",
|
| 265 |
+
value="He hoped there would be stew for dinner, turnips and carrots and bruised potatoes and fat mutton pieces to be ladled out in thick, peppered, flour-fattened sauce.",
|
| 266 |
+
)
|
| 267 |
+
style_gr = gr.Dropdown(
|
| 268 |
+
label="Style",
|
| 269 |
+
info="Select a style of output audio for the synthesised speech. (Chinese only support 'default' now)",
|
| 270 |
+
choices=['default', 'whispering', 'cheerful', 'terrified', 'angry', 'sad', 'friendly'],
|
| 271 |
+
max_choices=1,
|
| 272 |
+
value="default",
|
| 273 |
+
)
|
| 274 |
+
ref_gr = gr.Audio(
|
| 275 |
+
label="Reference Audio",
|
| 276 |
+
info="Click on the ✎ button to upload your own target speaker audio",
|
| 277 |
+
type="filepath",
|
| 278 |
+
value="examples/speaker0.mp3",
|
| 279 |
+
)
|
| 280 |
+
mic_gr = gr.Audio(
|
| 281 |
+
source="microphone",
|
| 282 |
+
type="filepath",
|
| 283 |
+
info="Use your microphone to record audio",
|
| 284 |
+
label="Use Microphone for Reference",
|
| 285 |
+
)
|
| 286 |
+
use_mic_gr = gr.Checkbox(
|
| 287 |
+
label="Use Microphone",
|
| 288 |
+
value=False,
|
| 289 |
+
info="Notice: Microphone input may not work properly under traffic",
|
| 290 |
+
)
|
| 291 |
+
tos_gr = gr.Checkbox(
|
| 292 |
+
label="Agree",
|
| 293 |
+
value=False,
|
| 294 |
+
info="I agree to the terms of the cc-by-nc-4.0 license-: https://github.com/myshell-ai/OpenVoice/blob/main/LICENSE",
|
| 295 |
+
)
|
| 296 |
+
|
| 297 |
+
tts_button = gr.Button("Send", elem_id="send-btn", visible=True)
|
| 298 |
+
|
| 299 |
+
|
| 300 |
+
with gr.Column():
|
| 301 |
+
out_text_gr = gr.Text(label="Info")
|
| 302 |
+
audio_gr = gr.Audio(label="Synthesised Audio", autoplay=True)
|
| 303 |
+
ref_audio_gr = gr.Audio(label="Reference Audio Used")
|
| 304 |
+
|
| 305 |
+
gr.Examples(examples,
|
| 306 |
+
label="Examples",
|
| 307 |
+
inputs=[input_text_gr, style_gr, ref_gr, mic_gr, use_mic_gr, tos_gr],
|
| 308 |
+
outputs=[out_text_gr, audio_gr, ref_audio_gr],
|
| 309 |
+
fn=predict,
|
| 310 |
+
cache_examples=False,)
|
| 311 |
+
tts_button.click(predict, [input_text_gr, style_gr, ref_gr, mic_gr, use_mic_gr, tos_gr], outputs=[out_text_gr, audio_gr, ref_audio_gr])
|
| 312 |
+
|
| 313 |
+
demo.queue()
|
| 314 |
+
demo.launch(debug=True, show_api=True, share=args.share)
|
requirement_locally.txt
ADDED
|
@@ -0,0 +1,15 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
langid
|
| 2 |
+
librosa==0.9.1
|
| 3 |
+
faster-whisper==0.9.0
|
| 4 |
+
pydub==0.25.1
|
| 5 |
+
wavmark==0.0.2
|
| 6 |
+
numpy==1.22.0
|
| 7 |
+
eng_to_ipa==0.0.2
|
| 8 |
+
inflect==7.0.0
|
| 9 |
+
unidecode==1.3.7
|
| 10 |
+
whisper-timestamped==1.14.2
|
| 11 |
+
openai
|
| 12 |
+
python-dotenv
|
| 13 |
+
pypinyin==0.50.0
|
| 14 |
+
cn2an==0.5.22
|
| 15 |
+
jieba==0.42.1
|