Spaces:
Runtime error

Runtime error
Upload 4 files
Browse files- .gitignore +14 -0
- README.md +20 -13
- gradio_app.py +48 -0
- requirements.txt +8 -0
.gitignore
ADDED
|
@@ -0,0 +1,14 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
|
| 2 |
+
data/
|
| 3 |
+
|
| 4 |
+
.vscode/
|
| 5 |
+
|
| 6 |
+
.ipynb_checkpoints/
|
| 7 |
+
|
| 8 |
+
src/__pycache__/
|
| 9 |
+
|
| 10 |
+
flagged/
|
| 11 |
+
|
| 12 |
+
__pycache__/
|
| 13 |
+
|
| 14 |
+
.idea/
|
README.md
CHANGED
|
@@ -1,13 +1,20 @@
|
|
| 1 |
-
|
| 2 |
-
|
| 3 |
-
|
| 4 |
-
|
| 5 |
-
|
| 6 |
-
|
| 7 |
-
|
| 8 |
-
|
| 9 |
-
|
| 10 |
-
|
| 11 |
-
|
| 12 |
-
|
| 13 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Hindi-Character-Recognition
|
| 2 |
+
|
| 3 |
+
Install the requirements: `pip install -r requirements.txt`
|
| 4 |
+
|
| 5 |
+
1. Hindi Character Recognition
|
| 6 |
+
|
| 7 |
+
|
| 8 |
+
|
| 9 |
+
Getting the data:
|
| 10 |
+
- Download the data from [here](https://www.kaggle.com/datasets/suvooo/hindi-character-recognition)
|
| 11 |
+
- Unzip it. You need to split the data into 4 different directories, since we are training for Hindi digits & letters separately.
|
| 12 |
+
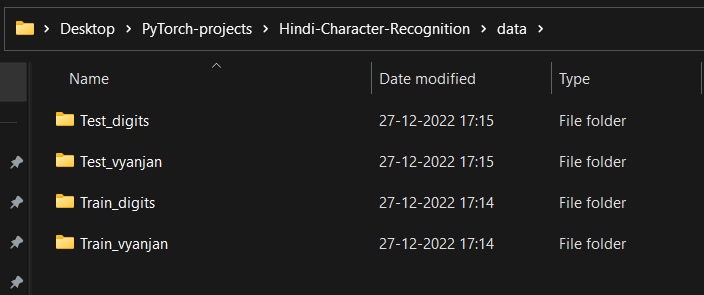
|
| 13 |
+
|
| 14 |
+
How to run ?
|
| 15 |
+
- You can create your custom model in the `model.py` file or can go with the `HNet` already present. For custom models created, you need to import them to `train.py`, for them to to use. Remember we are training different models for Hindi Digit & Characters.
|
| 16 |
+
- Now to train the model with default params do, `python train.py`. You can also specify epochs and lr. Most important, is the `model_type`
|
| 17 |
+
- To train do, `python train.py --epochs <num-epochs> --lr <learning-rate> --model_type <type-of-model>`
|
| 18 |
+
|
| 19 |
+
Running the app:
|
| 20 |
+
- Just so, `streamlit run app.py`
|
gradio_app.py
ADDED
|
@@ -0,0 +1,48 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import gradio as gr
|
| 2 |
+
import torch
|
| 3 |
+
import json
|
| 4 |
+
import src.config as CFG
|
| 5 |
+
from src.model import HNet
|
| 6 |
+
|
| 7 |
+
|
| 8 |
+
def classify(model, image, mapping):
|
| 9 |
+
image = torch.from_numpy(image).float()
|
| 10 |
+
image = image.permute(2, 0, 1).unsqueeze(0)
|
| 11 |
+
|
| 12 |
+
outputs = model(image)
|
| 13 |
+
|
| 14 |
+
_, preds = torch.max(outputs, 1)
|
| 15 |
+
|
| 16 |
+
return f"The predicted character is: {mapping[str(preds[0].item())]}"
|
| 17 |
+
|
| 18 |
+
|
| 19 |
+
def upload_and_clasify(image, option):
|
| 20 |
+
|
| 21 |
+
mapping, model = None, None
|
| 22 |
+
|
| 23 |
+
if option == "Digit":
|
| 24 |
+
if CFG.BEST_MODEL_DIGIT.exists():
|
| 25 |
+
model = HNet(num_classes=10)
|
| 26 |
+
model.load_state_dict(
|
| 27 |
+
torch.load(CFG.BEST_MODEL_DIGIT, map_location=CFG.DEVICE)
|
| 28 |
+
)
|
| 29 |
+
with open(CFG.INDEX_DIGIT, "r") as f:
|
| 30 |
+
mapping = json.load(f)
|
| 31 |
+
return classify(model, image, mapping)
|
| 32 |
+
else:
|
| 33 |
+
if CFG.BEST_MODEL_VYANJAN.exists():
|
| 34 |
+
model = HNet(num_classes=36)
|
| 35 |
+
model.load_state_dict(
|
| 36 |
+
torch.load(CFG.BEST_MODEL_VYANJAN, map_location=CFG.DEVICE)
|
| 37 |
+
)
|
| 38 |
+
with open(CFG.INDEX_VYNAJAN, "r") as f:
|
| 39 |
+
mapping = json.load(f)
|
| 40 |
+
return classify(model, image, mapping)
|
| 41 |
+
|
| 42 |
+
|
| 43 |
+
demo = gr.Interface(
|
| 44 |
+
fn=upload_and_clasify,
|
| 45 |
+
inputs=["image", gr.Dropdown(["Digit", "Vyanjan"])],
|
| 46 |
+
outputs="text",
|
| 47 |
+
)
|
| 48 |
+
demo.launch(share=True, server_port=8080)
|
requirements.txt
ADDED
|
@@ -0,0 +1,8 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
gradio==3.19.1
|
| 2 |
+
numpy==1.21.2
|
| 3 |
+
Pillow==9.4.0
|
| 4 |
+
prettytable==3.6.0
|
| 5 |
+
streamlit==1.4.0
|
| 6 |
+
torch==1.11.0
|
| 7 |
+
torchvision==0.12.0
|
| 8 |
+
tqdm==4.62.3
|