Spaces:
Build error

Build error
seperate inference vs training
Browse filesThis view is limited to 50 files because it contains too many changes.
See raw diff
- .DS_Store +0 -0
- README.md +25 -1
- app.py +17 -39
- db/chroma-collections.parquet +1 -1
- db/chroma-embeddings.parquet +2 -2
- db/index/{id_to_uuid_e74c977c-3ca1-40c8-995b-0b8edf1729d3.pkl → id_to_uuid_ffa1636e-55aa-4d0b-943d-f99dc83f1b2b.pkl} +2 -2
- db/index/{uuid_to_id_e74c977c-3ca1-40c8-995b-0b8edf1729d3.pkl → index_ffa1636e-55aa-4d0b-943d-f99dc83f1b2b.bin} +2 -2
- db/index/{index_metadata_e74c977c-3ca1-40c8-995b-0b8edf1729d3.pkl → index_metadata_ffa1636e-55aa-4d0b-943d-f99dc83f1b2b.pkl} +2 -2
- db/index/{index_e74c977c-3ca1-40c8-995b-0b8edf1729d3.bin → uuid_to_id_ffa1636e-55aa-4d0b-943d-f99dc83f1b2b.pkl} +2 -2
- docs/.DS_Store +0 -0
- docs/CODE_OF_CONDUCT.md +77 -0
- docs/CONTRIBUTING.md +95 -0
- docs/README.md +51 -0
- docs/_config.yml +13 -0
- docs/_feature-guide-template.md +83 -0
- docs/act-on-metadata.md +15 -0
- docs/act-on-metadata/impact-analysis.md +93 -0
- docs/actions/README.md +255 -0
- docs/actions/actions/executor.md +82 -0
- docs/actions/actions/hello_world.md +59 -0
- docs/actions/actions/slack.md +282 -0
- docs/actions/actions/teams.md +184 -0
- docs/actions/concepts.md +101 -0
- docs/actions/events/entity-change-event.md +352 -0
- docs/actions/events/metadata-change-log-event.md +151 -0
- docs/actions/guides/developing-a-transformer.md +133 -0
- docs/actions/guides/developing-an-action.md +132 -0
- docs/actions/imgs/.DS_Store +0 -0
- docs/actions/quickstart.md +169 -0
- docs/actions/sources/kafka-event-source.md +93 -0
- docs/advanced/aspect-versioning.md +47 -0
- docs/advanced/backfilling.md +3 -0
- docs/advanced/browse-paths-upgrade.md +137 -0
- docs/advanced/db-retention.md +79 -0
- docs/advanced/derived-aspects.md +3 -0
- docs/advanced/entity-hierarchy.md +3 -0
- docs/advanced/es-7-upgrade.md +38 -0
- docs/advanced/field-path-spec-v2.md +352 -0
- docs/advanced/high-cardinality.md +46 -0
- docs/advanced/mcp-mcl.md +159 -0
- docs/advanced/monitoring.md +97 -0
- docs/advanced/no-code-modeling.md +403 -0
- docs/advanced/no-code-upgrade.md +205 -0
- docs/advanced/partial-update.md +3 -0
- docs/advanced/pdl-best-practices.md +3 -0
- docs/api/datahub-apis.md +81 -0
- docs/api/graphql/getting-started.md +64 -0
- docs/api/graphql/overview.md +55 -0
- docs/api/graphql/querying-entities.md +551 -0
- docs/api/graphql/token-management.md +125 -0
.DS_Store
CHANGED
|
Binary files a/.DS_Store and b/.DS_Store differ
|
|
|
README.md
CHANGED
|
@@ -10,4 +10,28 @@ pinned: false
|
|
| 10 |
license: mit
|
| 11 |
---
|
| 12 |
|
| 13 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 10 |
license: mit
|
| 11 |
---
|
| 12 |
|
| 13 |
+
# DataHub documentation bot
|
| 14 |
+
Using [OpenAI](https://platform.openai.com/docs/introduction), [Langchain](https://python.langchain.com/en/latest/index.html) and [streamlit](https://docs.streamlit.io/) to train DataHub documentation to provide a DataHub QA BOT on [huggingface space](https://huggingface.co/spaces/abdvl/datahub_qa_bot?logs=build)
|
| 15 |
+
|
| 16 |
+
# How to run locally
|
| 17 |
+
1. Clone the repo
|
| 18 |
+
2. Run:
|
| 19 |
+
```
|
| 20 |
+
source .venv/bin/activate
|
| 21 |
+
pip install -r requirements.txt
|
| 22 |
+
streamlit run app.py
|
| 23 |
+
```
|
| 24 |
+
|
| 25 |
+
## How to train your own model
|
| 26 |
+
1. Delete the db folder
|
| 27 |
+
2. Copy the docs folder from [DataHub docs folder](https://github.com/datahub-project/datahub/tree/master/docs) to `./docs`
|
| 28 |
+
3. Update the `os.environ["OPENAI_API_KEY"] ` in the `train.py`
|
| 29 |
+
4. Run `python3 train.py`
|
| 30 |
+
|
| 31 |
+
The training will take 15 seconds, and cost around $2.00
|
| 32 |
+
```
|
| 33 |
+
chromadb.db.duckdb: loaded in 236 embeddings
|
| 34 |
+
chromadb.db.duckdb: loaded in 1 collections
|
| 35 |
+
```
|
| 36 |
+
|
| 37 |
+
|
app.py
CHANGED
|
@@ -9,64 +9,42 @@ from langchain.embeddings import OpenAIEmbeddings
|
|
| 9 |
from langchain.vectorstores import Chroma
|
| 10 |
from langchain.callbacks import get_openai_callback
|
| 11 |
|
| 12 |
-
# set your OpenAI API key
|
| 13 |
-
OPENAI_API_KEY = st.text_input('OPENAI API KEY')
|
| 14 |
-
if OPENAI_API_KEY:
|
| 15 |
-
os.environ["OPENAI_API_KEY"] = OPENAI_API_KEY
|
| 16 |
|
| 17 |
# variables
|
| 18 |
db_folder = "db"
|
|
|
|
| 19 |
|
|
|
|
|
|
|
|
|
|
|
|
|
| 20 |
|
| 21 |
-
# initialize the language model
|
| 22 |
-
llm = OpenAI(model_name="text-ada-001", n=2, best_of=2)
|
| 23 |
-
with get_openai_callback() as cb:
|
| 24 |
-
# load the documents
|
| 25 |
-
loader = DirectoryLoader('./docs', glob="**/*.md")
|
| 26 |
-
documents = loader.load()
|
| 27 |
-
# print(documents[0])
|
| 28 |
|
| 29 |
-
# split the documents into chunks
|
| 30 |
-
text_splitter = CharacterTextSplitter(chunk_size=1000, chunk_overlap=0)
|
| 31 |
-
texts = text_splitter.split_documents(documents)
|
| 32 |
|
|
|
|
|
|
|
|
|
|
| 33 |
# create the embeddings and index
|
| 34 |
embeddings = OpenAIEmbeddings()
|
| 35 |
-
|
| 36 |
-
# create the vectorstore and retriever
|
| 37 |
-
if os.path.exists(db_folder):
|
| 38 |
-
db = Chroma(persist_directory=db_folder, embedding_function=embeddings)
|
| 39 |
-
else:
|
| 40 |
-
db = Chroma.from_documents(
|
| 41 |
-
texts, embeddings, persist_directory=db_folder)
|
| 42 |
-
|
| 43 |
retriever = db.as_retriever(search_type="mmr")
|
| 44 |
|
| 45 |
# initialize the chain
|
| 46 |
qa = RetrievalQA.from_chain_type(
|
| 47 |
llm=llm, chain_type="stuff", retriever=retriever)
|
| 48 |
|
| 49 |
-
|
| 50 |
-
|
| 51 |
-
#
|
| 52 |
-
# query = "how to config a recipe"
|
| 53 |
-
|
| 54 |
-
# result = llm("Tell me a joke")
|
| 55 |
-
print(f"Total Tokens: {cb.total_tokens}")
|
| 56 |
-
print(f"Prompt Tokens: {cb.prompt_tokens}")
|
| 57 |
-
print(f"Completion Tokens: {cb.completion_tokens}")
|
| 58 |
-
print(f"Successful Requests: {cb.successful_requests}")
|
| 59 |
-
print(f"Total Cost (USD): ${cb.total_cost}")
|
| 60 |
-
|
| 61 |
|
| 62 |
-
def query(query):
|
| 63 |
-
docs = db.similarity_search(query)
|
| 64 |
-
return docs[0]
|
| 65 |
|
| 66 |
|
| 67 |
-
|
|
|
|
| 68 |
|
|
|
|
| 69 |
if st.button('Query'):
|
| 70 |
-
|
|
|
|
| 71 |
st.write(result.page_content)
|
| 72 |
st.write(result.metadata)
|
|
|
|
| 9 |
from langchain.vectorstores import Chroma
|
| 10 |
from langchain.callbacks import get_openai_callback
|
| 11 |
|
|
|
|
|
|
|
|
|
|
|
|
|
| 12 |
|
| 13 |
# variables
|
| 14 |
db_folder = "db"
|
| 15 |
+
mode = "infer" # "train" or "infer"
|
| 16 |
|
| 17 |
+
# set your OpenAI API key
|
| 18 |
+
api_key = st.text_input('OPENAI API KEY')
|
| 19 |
+
if api_key:
|
| 20 |
+
os.environ["OPENAI_API_KEY"] = api_key
|
| 21 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 22 |
|
|
|
|
|
|
|
|
|
|
| 23 |
|
| 24 |
+
# initialize the language model
|
| 25 |
+
llm = OpenAI(model_name="gpt-3.5-turbo", n=2, best_of=2)
|
| 26 |
+
with get_openai_callback() as cb:
|
| 27 |
# create the embeddings and index
|
| 28 |
embeddings = OpenAIEmbeddings()
|
| 29 |
+
db = Chroma(persist_directory=db_folder, embedding_function=embeddings)
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 30 |
retriever = db.as_retriever(search_type="mmr")
|
| 31 |
|
| 32 |
# initialize the chain
|
| 33 |
qa = RetrievalQA.from_chain_type(
|
| 34 |
llm=llm, chain_type="stuff", retriever=retriever)
|
| 35 |
|
| 36 |
+
# query = "What is DataHub"
|
| 37 |
+
# qa.run(query)
|
| 38 |
+
# print(db.similarity_search(query))
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 39 |
|
|
|
|
|
|
|
|
|
|
| 40 |
|
| 41 |
|
| 42 |
+
# query input box
|
| 43 |
+
question = st.text_input('Ask a question', 'What is DataHub')
|
| 44 |
|
| 45 |
+
# query button
|
| 46 |
if st.button('Query'):
|
| 47 |
+
docs = db.similarity_search(question)
|
| 48 |
+
result = docs[0]
|
| 49 |
st.write(result.page_content)
|
| 50 |
st.write(result.metadata)
|
db/chroma-collections.parquet
CHANGED
|
@@ -1,3 +1,3 @@
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
-
oid sha256:
|
| 3 |
size 557
|
|
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:8effbdfbbd10000b5f1bf4c1d65f6a5fc1655a0941ada1ecc07b0d5dd9cc492e
|
| 3 |
size 557
|
db/chroma-embeddings.parquet
CHANGED
|
@@ -1,3 +1,3 @@
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
-
oid sha256:
|
| 3 |
-
size
|
|
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:8bbc3e8eecd2c57f8ae1e473721681fc09190f56a70563d421482fe7c9c0aed1
|
| 3 |
+
size 9935573
|
db/index/{id_to_uuid_e74c977c-3ca1-40c8-995b-0b8edf1729d3.pkl → id_to_uuid_ffa1636e-55aa-4d0b-943d-f99dc83f1b2b.pkl}
RENAMED
|
@@ -1,3 +1,3 @@
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
-
oid sha256:
|
| 3 |
-
size
|
|
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:dd1c172d63e1712feb5fe369b33f027c17e3f278fc14dfebb0e3f209ceaff84f
|
| 3 |
+
size 34114
|
db/index/{uuid_to_id_e74c977c-3ca1-40c8-995b-0b8edf1729d3.pkl → index_ffa1636e-55aa-4d0b-943d-f99dc83f1b2b.bin}
RENAMED
|
@@ -1,3 +1,3 @@
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
-
oid sha256:
|
| 3 |
-
size
|
|
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:488b6f67744186c4fbc5e90c9e01a5c0b9e1d8b401b980dfa2bedfbbe5d20871
|
| 3 |
+
size 6644644
|
db/index/{index_metadata_e74c977c-3ca1-40c8-995b-0b8edf1729d3.pkl → index_metadata_ffa1636e-55aa-4d0b-943d-f99dc83f1b2b.pkl}
RENAMED
|
@@ -1,3 +1,3 @@
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
-
oid sha256:
|
| 3 |
-
size
|
|
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:5a1a27240a6b0c0768fe49b9889b4a50024e0dbd1e8a282cc95028212272a90c
|
| 3 |
+
size 74
|
db/index/{index_e74c977c-3ca1-40c8-995b-0b8edf1729d3.bin → uuid_to_id_ffa1636e-55aa-4d0b-943d-f99dc83f1b2b.pkl}
RENAMED
|
@@ -1,3 +1,3 @@
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
-
oid sha256:
|
| 3 |
-
size
|
|
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:f460d04a207b1cd106d65a31569defcb4a50b43203cfebc75eae24fe888af4f5
|
| 3 |
+
size 39891
|
docs/.DS_Store
ADDED
|
Binary file (10.2 kB). View file
|
|
|
docs/CODE_OF_CONDUCT.md
ADDED
|
@@ -0,0 +1,77 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Contributor Covenant Code of Conduct
|
| 2 |
+
|
| 3 |
+
## Our Pledge
|
| 4 |
+
|
| 5 |
+
In the interest of fostering an open and welcoming environment, we as
|
| 6 |
+
contributors and maintainers pledge to making participation in our project and
|
| 7 |
+
our community a harassment-free experience for everyone, regardless of age, body
|
| 8 |
+
size, disability, ethnicity, sex characteristics, gender identity and expression,
|
| 9 |
+
level of experience, education, socio-economic status, nationality, personal
|
| 10 |
+
appearance, race, religion, or sexual identity and orientation.
|
| 11 |
+
|
| 12 |
+
## Our Standards
|
| 13 |
+
|
| 14 |
+
Examples of behavior that contributes to creating a positive environment
|
| 15 |
+
include:
|
| 16 |
+
|
| 17 |
+
* Using welcoming and inclusive language
|
| 18 |
+
* Being respectful of differing viewpoints and experiences
|
| 19 |
+
* Gracefully accepting constructive criticism
|
| 20 |
+
* Focusing on what is best for the community
|
| 21 |
+
* Showing empathy towards other community members
|
| 22 |
+
|
| 23 |
+
Examples of unacceptable behavior by participants include:
|
| 24 |
+
|
| 25 |
+
* The use of sexualized language or imagery and unwelcome sexual attention or
|
| 26 |
+
advances
|
| 27 |
+
* Trolling, insulting/derogatory comments, and personal or political attacks
|
| 28 |
+
* Public or private harassment
|
| 29 |
+
* Publishing others' private information, such as a physical or electronic
|
| 30 |
+
address, without explicit permission
|
| 31 |
+
* Other conduct which could reasonably be considered inappropriate in a
|
| 32 |
+
professional setting
|
| 33 |
+
|
| 34 |
+
## Our Responsibilities
|
| 35 |
+
|
| 36 |
+
Project maintainers are responsible for clarifying the standards of acceptable
|
| 37 |
+
behavior and are expected to take appropriate and fair corrective action in
|
| 38 |
+
response to any instances of unacceptable behavior.
|
| 39 |
+
|
| 40 |
+
Project maintainers have the right and responsibility to remove, edit, or
|
| 41 |
+
reject comments, commits, code, wiki edits, issues, and other contributions
|
| 42 |
+
that are not aligned to this Code of Conduct, or to ban temporarily or
|
| 43 |
+
permanently any contributor for other behaviors that they deem inappropriate,
|
| 44 |
+
threatening, offensive, or harmful.
|
| 45 |
+
|
| 46 |
+
## Scope
|
| 47 |
+
|
| 48 |
+
This Code of Conduct applies both within project spaces and in public spaces
|
| 49 |
+
when an individual is representing the project or its community. Examples of
|
| 50 |
+
representing a project or community include using an official project e-mail
|
| 51 |
+
address, posting via an official social media account, or acting as an appointed
|
| 52 |
+
representative at an online or offline event. Representation of a project may be
|
| 53 |
+
further defined and clarified by project maintainers.
|
| 54 |
+
|
| 55 |
+
## Enforcement
|
| 56 |
+
|
| 57 |
+
Instances of abusive, harassing, or otherwise unacceptable behavior may be
|
| 58 |
+
reported by direct messaging the project team on [Slack]. All
|
| 59 |
+
complaints will be reviewed and investigated and will result in a response that
|
| 60 |
+
is deemed necessary and appropriate to the circumstances. The project team is
|
| 61 |
+
obligated to maintain confidentiality with regard to the reporter of an incident.
|
| 62 |
+
Further details of specific enforcement policies may be posted separately.
|
| 63 |
+
|
| 64 |
+
Project maintainers who do not follow or enforce the Code of Conduct in good
|
| 65 |
+
faith may face temporary or permanent repercussions as determined by other
|
| 66 |
+
members of the project's leadership.
|
| 67 |
+
|
| 68 |
+
## Attribution
|
| 69 |
+
|
| 70 |
+
This Code of Conduct is adapted from the [Contributor Covenant][homepage], version 1.4,
|
| 71 |
+
available at https://www.contributor-covenant.org/version/1/4/code-of-conduct.html
|
| 72 |
+
|
| 73 |
+
[Slack]: https://slack.datahubproject.io
|
| 74 |
+
[homepage]: https://www.contributor-covenant.org
|
| 75 |
+
|
| 76 |
+
For answers to common questions about this code of conduct, see
|
| 77 |
+
https://www.contributor-covenant.org/faq
|
docs/CONTRIBUTING.md
ADDED
|
@@ -0,0 +1,95 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Contributing
|
| 2 |
+
|
| 3 |
+
We always welcome contributions to help make DataHub better. Take a moment to read this document if you would like to contribute.
|
| 4 |
+
|
| 5 |
+
## Provide Feedback
|
| 6 |
+
|
| 7 |
+
Have ideas about how to make DataHub better? Head over to [DataHub Feature Requests](https://feature-requests.datahubproject.io/) and tell us all about it!
|
| 8 |
+
|
| 9 |
+
Show your support for other requests by upvoting; stay up to date on progess by subscribing for updates via email.
|
| 10 |
+
|
| 11 |
+
## Reporting Issues
|
| 12 |
+
|
| 13 |
+
We use GitHub issues to track bug reports and submitting pull requests.
|
| 14 |
+
|
| 15 |
+
If you find a bug:
|
| 16 |
+
|
| 17 |
+
1. Use the GitHub issue search to check whether the bug has already been reported.
|
| 18 |
+
|
| 19 |
+
1. If the issue has been fixed, try to reproduce the issue using the latest master branch of the repository.
|
| 20 |
+
|
| 21 |
+
1. If the issue still reproduces or has not yet been reported, try to isolate the problem before opening an issue.
|
| 22 |
+
|
| 23 |
+
## Submitting a Request For Comment (RFC)
|
| 24 |
+
|
| 25 |
+
If you have a substantial feature or a design discussion that you'd like to have with the community follow the RFC process outlined [here](./rfc.md)
|
| 26 |
+
|
| 27 |
+
## Submitting a Pull Request (PR)
|
| 28 |
+
|
| 29 |
+
Before you submit your Pull Request (PR), consider the following guidelines:
|
| 30 |
+
|
| 31 |
+
* Search GitHub for an open or closed PR that relates to your submission. You don't want to duplicate effort.
|
| 32 |
+
* Follow the [standard GitHub approach](https://help.github.com/en/github/collaborating-with-issues-and-pull-requests/creating-a-pull-request-from-a-fork) to create the PR. Please also follow our [commit message format](#commit-message-format).
|
| 33 |
+
* If there are any breaking changes, potential downtime, deprecations, or big feature please add an update in [Updating DataHub under Next](how/updating-datahub.md).
|
| 34 |
+
* That's it! Thank you for your contribution!
|
| 35 |
+
|
| 36 |
+
## Commit Message Format
|
| 37 |
+
|
| 38 |
+
Please follow the [Conventional Commits](https://www.conventionalcommits.org/) specification for the commit message format. In summary, each commit message consists of a *header*, a *body* and a *footer*, separated by a single blank line.
|
| 39 |
+
|
| 40 |
+
```
|
| 41 |
+
<type>[optional scope]: <description>
|
| 42 |
+
|
| 43 |
+
[optional body]
|
| 44 |
+
|
| 45 |
+
[optional footer(s)]
|
| 46 |
+
```
|
| 47 |
+
|
| 48 |
+
Any line of the commit message cannot be longer than 88 characters! This allows the message to be easier to read on GitHub as well as in various Git tools.
|
| 49 |
+
|
| 50 |
+
### Type
|
| 51 |
+
|
| 52 |
+
Must be one of the following (based on the [Angular convention](https://github.com/angular/angular/blob/22b96b9/CONTRIBUTING.md#-commit-message-guidelines)):
|
| 53 |
+
|
| 54 |
+
* *feat*: A new feature
|
| 55 |
+
* *fix*: A bug fix
|
| 56 |
+
* *refactor*: A code change that neither fixes a bug nor adds a feature
|
| 57 |
+
* *docs*: Documentation only changes
|
| 58 |
+
* *test*: Adding missing tests or correcting existing tests
|
| 59 |
+
* *perf*: A code change that improves performance
|
| 60 |
+
* *style*: Changes that do not affect the meaning of the code (whitespace, formatting, missing semicolons, etc.)
|
| 61 |
+
* *build*: Changes that affect the build system or external dependencies
|
| 62 |
+
* *ci*: Changes to our CI configuration files and scripts
|
| 63 |
+
|
| 64 |
+
A scope may be provided to a commit’s type, to provide additional contextual information and is contained within parenthesis, e.g.,
|
| 65 |
+
```
|
| 66 |
+
feat(parser): add ability to parse arrays
|
| 67 |
+
```
|
| 68 |
+
|
| 69 |
+
### Description
|
| 70 |
+
|
| 71 |
+
Each commit must contain a succinct description of the change:
|
| 72 |
+
|
| 73 |
+
* use the imperative, present tense: "change" not "changed" nor "changes"
|
| 74 |
+
* don't capitalize the first letter
|
| 75 |
+
* no dot(.) at the end
|
| 76 |
+
|
| 77 |
+
### Body
|
| 78 |
+
|
| 79 |
+
Just as in the description, use the imperative, present tense: "change" not "changed" nor "changes". The body should include the motivation for the change and contrast this with previous behavior.
|
| 80 |
+
|
| 81 |
+
### Footer
|
| 82 |
+
|
| 83 |
+
The footer should contain any information about *Breaking Changes*, and is also the place to reference GitHub issues that this commit *Closes*.
|
| 84 |
+
|
| 85 |
+
*Breaking Changes* should start with the words `BREAKING CHANGE:` with a space or two new lines. The rest of the commit message is then used for this.
|
| 86 |
+
|
| 87 |
+
### Revert
|
| 88 |
+
|
| 89 |
+
If the commit reverts a previous commit, it should begin with `revert:`, followed by the description. In the body it should say: `Refs: <hash1> <hash2> ...`, where the hashs are the SHA of the commits being reverted, e.g.
|
| 90 |
+
|
| 91 |
+
```
|
| 92 |
+
revert: let us never again speak of the noodle incident
|
| 93 |
+
|
| 94 |
+
Refs: 676104e, a215868
|
| 95 |
+
```
|
docs/README.md
ADDED
|
@@ -0,0 +1,51 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# DataHub Docs Overview
|
| 2 |
+
|
| 3 |
+
DataHub's project documentation is hosted at [datahubproject.io](https://datahubproject.io/docs)
|
| 4 |
+
|
| 5 |
+
## Types of Documentation
|
| 6 |
+
|
| 7 |
+
### Feature Guide
|
| 8 |
+
|
| 9 |
+
A Feature Guide should follow the [Feature Guide Template](_feature-guide-template.md), and should provide the following value:
|
| 10 |
+
|
| 11 |
+
* At a high level, what is the concept/feature within DataHub?
|
| 12 |
+
* Why is the feature useful?
|
| 13 |
+
* What are the common use cases of the feature?
|
| 14 |
+
* What are the simple steps one needs to take to use the feature?
|
| 15 |
+
|
| 16 |
+
When creating a Feature Guide, please remember to:
|
| 17 |
+
|
| 18 |
+
* Provide plain-language descriptions for both technical and non-technical readers
|
| 19 |
+
* Avoid using industry jargon, abbreviations, or acryonyms
|
| 20 |
+
* Provide descriptive screenshots, links out to relevant YouTube videos, and any other relevant resources
|
| 21 |
+
* Provide links out to Tutorials for advanced use cases
|
| 22 |
+
|
| 23 |
+
*Not all Feature Guides will require a Tutorial.*
|
| 24 |
+
|
| 25 |
+
### Tutorial
|
| 26 |
+
|
| 27 |
+
A Tutorial is meant to provide very specific steps to accomplish complex workflows and advanced use cases that are out of scope of a Feature Guide.
|
| 28 |
+
|
| 29 |
+
Tutorials should be written to accomodate the targeted persona, i.e. Developer, Admin, End-User, etc.
|
| 30 |
+
|
| 31 |
+
*Not all Tutorials require an associated Feature Guide.*
|
| 32 |
+
|
| 33 |
+
## Docs Best Practices
|
| 34 |
+
|
| 35 |
+
### Embedding GIFs and or Screenshots
|
| 36 |
+
|
| 37 |
+
* Store GIFs and screenshots in [datahub-project/static-assets](https://github.com/datahub-project/static-assets); this minimizes unnecessarily large image/file sizes in the main repo
|
| 38 |
+
* Center-align screenshots and size down to 70% - this improves readability/skimability within the site
|
| 39 |
+
|
| 40 |
+
Example snippet:
|
| 41 |
+
|
| 42 |
+
```
|
| 43 |
+
<p align="center">
|
| 44 |
+
<img width="70%" src="https://raw.githubusercontent.com/datahub-project/static-assets/main/imgs/impact-analysis-export-full-list.png"/>
|
| 45 |
+
</p>
|
| 46 |
+
```
|
| 47 |
+
|
| 48 |
+
* Use the "raw" GitHub image link (right click image from GitHub > Open in New Tab > copy URL):
|
| 49 |
+
|
| 50 |
+
* Good: https://raw.githubusercontent.com/datahub-project/static-assets/main/imgs/dbt-test-logic-view.png
|
| 51 |
+
* Bad: https://github.com/datahub-project/static-assets/blob/main/imgs/dbt-test-logic-view.png
|
docs/_config.yml
ADDED
|
@@ -0,0 +1,13 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
plugins:
|
| 2 |
+
- jekyll-relative-links
|
| 3 |
+
relative_links:
|
| 4 |
+
enabled: true
|
| 5 |
+
collections: true
|
| 6 |
+
include:
|
| 7 |
+
- CODE_OF_CONDUCT.md
|
| 8 |
+
- CONTRIBUTING.md
|
| 9 |
+
- README.md
|
| 10 |
+
|
| 11 |
+
theme: jekyll-theme-cayman
|
| 12 |
+
title: DataHub
|
| 13 |
+
description: A Generalized Metadata Search & Discovery Tool
|
docs/_feature-guide-template.md
ADDED
|
@@ -0,0 +1,83 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import FeatureAvailability from '@site/src/components/FeatureAvailability';
|
| 2 |
+
|
| 3 |
+
# About DataHub [Feature Name]
|
| 4 |
+
|
| 5 |
+
<!-- All Feature Guides should begin with `About DataHub ` to improve SEO -->
|
| 6 |
+
|
| 7 |
+
<!--
|
| 8 |
+
Update feature availability; by default, feature availabilty is Self-Hosted and Managed DataHub
|
| 9 |
+
|
| 10 |
+
Add in `saasOnly` for Managed DataHub-only features
|
| 11 |
+
-->
|
| 12 |
+
|
| 13 |
+
<FeatureAvailability/>
|
| 14 |
+
|
| 15 |
+
<!-- This section should provide a plain-language overview of feature. Consider the following:
|
| 16 |
+
|
| 17 |
+
* What does this feature do? Why is it useful?
|
| 18 |
+
* What are the typical use cases?
|
| 19 |
+
* Who are the typical users?
|
| 20 |
+
* In which DataHub Version did this become available? -->
|
| 21 |
+
|
| 22 |
+
## [Feature Name] Setup, Prerequisites, and Permissions
|
| 23 |
+
|
| 24 |
+
<!-- This section should provide plain-language instructions on how to configure the feature:
|
| 25 |
+
|
| 26 |
+
* What special configuration is required, if any?
|
| 27 |
+
* How can you confirm you configured it correctly? What is the expected behavior?
|
| 28 |
+
* What access levels/permissions are required within DataHub? -->
|
| 29 |
+
|
| 30 |
+
## Using [Feature Name]
|
| 31 |
+
|
| 32 |
+
<!-- Plain-language instructions of how to use the feature
|
| 33 |
+
|
| 34 |
+
Provide a step-by-step guide to use feature, including relevant screenshots and/or GIFs
|
| 35 |
+
|
| 36 |
+
* Where/how do you access it?
|
| 37 |
+
* What best practices exist?
|
| 38 |
+
* What are common code snippets?
|
| 39 |
+
-->
|
| 40 |
+
|
| 41 |
+
## Additional Resources
|
| 42 |
+
|
| 43 |
+
<!-- Comment out any irrelevant or empty sections -->
|
| 44 |
+
|
| 45 |
+
### Videos
|
| 46 |
+
|
| 47 |
+
<!-- Use the following format to embed YouTube videos:
|
| 48 |
+
|
| 49 |
+
**Title of YouTube video in bold text**
|
| 50 |
+
|
| 51 |
+
<p align="center">
|
| 52 |
+
<iframe width="560" height="315" src="www.youtube.com/embed/VIDEO_ID" title="YouTube video player" frameborder="0" allow="accelerometer; autoplay; clipboard-write; encrypted-media; gyroscope; picture-in-picture" allowfullscreen></iframe>
|
| 53 |
+
</p>
|
| 54 |
+
|
| 55 |
+
-->
|
| 56 |
+
|
| 57 |
+
<!--
|
| 58 |
+
NOTE: Find the iframe details in YouTube by going to Share > Embed
|
| 59 |
+
-->
|
| 60 |
+
|
| 61 |
+
### GraphQL
|
| 62 |
+
|
| 63 |
+
<!-- Bulleted list of relevant GraphQL docs; comment out section if none -->
|
| 64 |
+
|
| 65 |
+
### DataHub Blog
|
| 66 |
+
|
| 67 |
+
<!-- Bulleted list of relevant DataHub Blog posts; comment out section if none -->
|
| 68 |
+
|
| 69 |
+
## FAQ and Troubleshooting
|
| 70 |
+
|
| 71 |
+
<!-- Use the following format:
|
| 72 |
+
|
| 73 |
+
**Question in bold text**
|
| 74 |
+
|
| 75 |
+
Response in plain text
|
| 76 |
+
|
| 77 |
+
-->
|
| 78 |
+
|
| 79 |
+
*Need more help? Join the conversation in [Slack](http://slack.datahubproject.io)!*
|
| 80 |
+
|
| 81 |
+
### Related Features
|
| 82 |
+
|
| 83 |
+
<!-- Bulleted list of related features; comment out section if none -->
|
docs/act-on-metadata.md
ADDED
|
@@ -0,0 +1,15 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Act on Metadata Overview
|
| 2 |
+
|
| 3 |
+
DataHub's metadata infrastructure is stream-oriented, meaning that all changes in metadata are communicated and reflected within the platform within seconds.
|
| 4 |
+
|
| 5 |
+
This unlocks endless opportunities to automate data governance and data management workflows, such as:
|
| 6 |
+
|
| 7 |
+
* Automatically enrich or annotate existing data entities within DataHub, i.e., apply Tags, Terms, Owners, etc.
|
| 8 |
+
* Leverage the [Actions Framework](actions/README.md) to trigger external workflows or send alerts to external systems, i.e., send a message to a team channel when there's a schema change
|
| 9 |
+
* Proactively identify what business-critical data resources will be impacted by a breaking schema change
|
| 10 |
+
|
| 11 |
+
This section contains resources to help you take real-time action on your rapidly evolving data stack.
|
| 12 |
+
|
| 13 |
+
<p align="center">
|
| 14 |
+
<iframe width="560" height="315" src="https://www.youtube.com/embed/yeloymkK5ow" title="YouTube video player" frameborder="0" allow="accelerometer; autoplay; clipboard-write; encrypted-media; gyroscope; picture-in-picture" allowfullscreen></iframe>
|
| 15 |
+
</p>
|
docs/act-on-metadata/impact-analysis.md
ADDED
|
@@ -0,0 +1,93 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import FeatureAvailability from '@site/src/components/FeatureAvailability';
|
| 2 |
+
|
| 3 |
+
# About DataHub Lineage Impact Analysis
|
| 4 |
+
|
| 5 |
+
<FeatureAvailability/>
|
| 6 |
+
|
| 7 |
+
Lineage Impact Analysis is a powerful workflow for understanding the complete set of upstream and downstream dependencies of a Dataset, Dashboard, Chart, and many other DataHub Entities.
|
| 8 |
+
|
| 9 |
+
This allows Data Practitioners to proactively identify the impact of breaking schema changes or failed data pipelines on downstream dependencies, rapidly discover which upstream dependencies may have caused unexpected data quality issues, and more.
|
| 10 |
+
|
| 11 |
+
Lineage Impact Analysis is available via the DataHub UI and GraphQL endpoints, supporting manual and automated workflows.
|
| 12 |
+
|
| 13 |
+
## Lineage Impact Analysis Setup, Prerequisites, and Permissions
|
| 14 |
+
|
| 15 |
+
Lineage Impact Analysis is enabled for any Entity that has associated Lineage relationships with other Entities and does not require any additional configuration.
|
| 16 |
+
|
| 17 |
+
Any DataHub user with “View Entity Page” permissions is able to view the full set of upstream or downstream Entities and export results to CSV from the DataHub UI.
|
| 18 |
+
|
| 19 |
+
## Using Lineage Impact Analysis
|
| 20 |
+
|
| 21 |
+
Follow these simple steps to understand the full dependency chain of your data entities.
|
| 22 |
+
|
| 23 |
+
1. On a given Entity Page, select the **Lineage** tab
|
| 24 |
+
|
| 25 |
+
<p align="center">
|
| 26 |
+
<img width="70%" src="https://raw.githubusercontent.com/datahub-project/static-assets/main/imgs/impact-analysis-lineage-tab.png"/>
|
| 27 |
+
</p>
|
| 28 |
+
|
| 29 |
+
2. Easily toggle between **Upstream** and **Downstream** dependencies
|
| 30 |
+
|
| 31 |
+
<p align="center">
|
| 32 |
+
<img width="70%" src="https://raw.githubusercontent.com/datahub-project/static-assets/main/imgs/impact-analysis-choose-upstream-downstream.png"/>
|
| 33 |
+
</p>
|
| 34 |
+
|
| 35 |
+
3. Choose the **Degree of Dependencies** you are interested in. The default filter is “1 Degree of Dependency” to minimize processor-intensive queries.
|
| 36 |
+
|
| 37 |
+
<p align="center">
|
| 38 |
+
<img width="70%" src="https://raw.githubusercontent.com/datahub-project/static-assets/main/imgs/impact-analysis-filter-dependencies.png"/>
|
| 39 |
+
</p>
|
| 40 |
+
|
| 41 |
+
4. Slice and dice the result list by Entity Type, Platfrom, Owner, and more to isolate the relevant dependencies
|
| 42 |
+
|
| 43 |
+
<p align="center">
|
| 44 |
+
<img width="70%" src="https://raw.githubusercontent.com/datahub-project/static-assets/main/imgs/impact-analysis-apply-filters.png"/>
|
| 45 |
+
</p>
|
| 46 |
+
|
| 47 |
+
5. Export the full list of dependencies to CSV
|
| 48 |
+
|
| 49 |
+
<p align="center">
|
| 50 |
+
<img width="70%" src="https://raw.githubusercontent.com/datahub-project/static-assets/main/imgs/impact-analysis-export-full-list.png"/>
|
| 51 |
+
</p>
|
| 52 |
+
|
| 53 |
+
6. View the filtered set of dependencies via CSV, with details about assigned ownership, domain, tags, terms, and quick links back to those entities within DataHub
|
| 54 |
+
|
| 55 |
+
<p align="center">
|
| 56 |
+
<img width="70%" src="https://raw.githubusercontent.com/datahub-project/static-assets/main/imgs/impact-analysis-view-export-results.png"/>
|
| 57 |
+
</p>
|
| 58 |
+
|
| 59 |
+
## Additional Resources
|
| 60 |
+
|
| 61 |
+
### Videos
|
| 62 |
+
|
| 63 |
+
**DataHub 201: Impact Analysis**
|
| 64 |
+
|
| 65 |
+
<p align="center">
|
| 66 |
+
<iframe width="560" height="315" src="https://www.youtube.com/embed/BHG_kzpQ_aQ" title="YouTube video player" frameborder="0" allow="accelerometer; autoplay; clipboard-write; encrypted-media; gyroscope; picture-in-picture" allowfullscreen></iframe>
|
| 67 |
+
</p>
|
| 68 |
+
|
| 69 |
+
### GraphQL
|
| 70 |
+
|
| 71 |
+
* [searchAcrossLineage](../../graphql/queries.md#searchacrosslineage)
|
| 72 |
+
* [searchAcrossLineageInput](../../graphql/inputObjects.md#searchacrosslineageinput)
|
| 73 |
+
|
| 74 |
+
### DataHub Blog
|
| 75 |
+
|
| 76 |
+
* [Dependency Impact Analysis, Data Validation Outcomes, and MORE! - Highlights from DataHub v0.8.27 & v.0.8.28](https://blog.datahubproject.io/dependency-impact-analysis-data-validation-outcomes-and-more-1302604da233)
|
| 77 |
+
|
| 78 |
+
|
| 79 |
+
### FAQ and Troubleshooting
|
| 80 |
+
|
| 81 |
+
**The Lineage Tab is greyed out - why can’t I click on it?**
|
| 82 |
+
|
| 83 |
+
This means you have not yet ingested Lineage metadata for that entity. Please see the Lineage Guide to get started.
|
| 84 |
+
|
| 85 |
+
**Why is my list of exported dependencies incomplete?**
|
| 86 |
+
|
| 87 |
+
We currently limit the list of dependencies to 10,000 records; we suggest applying filters to narrow the result set if you hit that limit.
|
| 88 |
+
|
| 89 |
+
*Need more help? Join the conversation in [Slack](http://slack.datahubproject.io)!*
|
| 90 |
+
|
| 91 |
+
### Related Features
|
| 92 |
+
|
| 93 |
+
* [DataHub Lineage](../lineage/lineage-feature-guide.md)
|
docs/actions/README.md
ADDED
|
@@ -0,0 +1,255 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# ⚡ DataHub Actions Framework
|
| 2 |
+
|
| 3 |
+
Welcome to DataHub Actions! The Actions framework makes responding to realtime changes in your Metadata Graph easy, enabling you to seamlessly integrate [DataHub](https://github.com/datahub-project/datahub) into a broader events-based architecture.
|
| 4 |
+
|
| 5 |
+
For a detailed introduction, check out the [original announcement](https://www.youtube.com/watch?v=7iwNxHgqxtg&t=2189s) of the DataHub Actions Framework at the DataHub April 2022 Town Hall. For a more in-depth look at use cases and concepts, check out [DataHub Actions Concepts](concepts.md).
|
| 6 |
+
|
| 7 |
+
## Quickstart
|
| 8 |
+
|
| 9 |
+
To get started right away, check out the [DataHub Actions Quickstart](quickstart.md) Guide.
|
| 10 |
+
|
| 11 |
+
|
| 12 |
+
## Prerequisites
|
| 13 |
+
|
| 14 |
+
The DataHub Actions CLI commands are an extension of the base `datahub` CLI commands. We recommend
|
| 15 |
+
first installing the `datahub` CLI:
|
| 16 |
+
|
| 17 |
+
```shell
|
| 18 |
+
python3 -m pip install --upgrade pip wheel setuptools
|
| 19 |
+
python3 -m pip install --upgrade acryl-datahub
|
| 20 |
+
datahub --version
|
| 21 |
+
```
|
| 22 |
+
|
| 23 |
+
> Note that the Actions Framework requires a version of `acryl-datahub` >= v0.8.34
|
| 24 |
+
|
| 25 |
+
|
| 26 |
+
## Installation
|
| 27 |
+
|
| 28 |
+
Next, simply install the `acryl-datahub-actions` package from PyPi:
|
| 29 |
+
|
| 30 |
+
```shell
|
| 31 |
+
python3 -m pip install --upgrade pip wheel setuptools
|
| 32 |
+
python3 -m pip install --upgrade acryl-datahub-actions
|
| 33 |
+
datahub actions version
|
| 34 |
+
```
|
| 35 |
+
|
| 36 |
+
|
| 37 |
+
## Configuring an Action
|
| 38 |
+
|
| 39 |
+
Actions are configured using a YAML file, much in the same way DataHub ingestion sources are. An action configuration file consists of the following
|
| 40 |
+
|
| 41 |
+
1. Action Pipeline Name (Should be unique and static)
|
| 42 |
+
2. Source Configurations
|
| 43 |
+
3. Transform + Filter Configurations
|
| 44 |
+
4. Action Configuration
|
| 45 |
+
5. Pipeline Options (Optional)
|
| 46 |
+
6. DataHub API configs (Optional - required for select actions)
|
| 47 |
+
|
| 48 |
+
With each component being independently pluggable and configurable.
|
| 49 |
+
|
| 50 |
+
```yml
|
| 51 |
+
# 1. Required: Action Pipeline Name
|
| 52 |
+
name: <action-pipeline-name>
|
| 53 |
+
|
| 54 |
+
# 2. Required: Event Source - Where to source event from.
|
| 55 |
+
source:
|
| 56 |
+
type: <source-type>
|
| 57 |
+
config:
|
| 58 |
+
# Event Source specific configs (map)
|
| 59 |
+
|
| 60 |
+
# 3a. Optional: Filter to run on events (map)
|
| 61 |
+
filter:
|
| 62 |
+
event_type: <filtered-event-type>
|
| 63 |
+
event:
|
| 64 |
+
# Filter event fields by exact-match
|
| 65 |
+
<filtered-event-fields>
|
| 66 |
+
|
| 67 |
+
# 3b. Optional: Custom Transformers to run on events (array)
|
| 68 |
+
transform:
|
| 69 |
+
- type: <transformer-type>
|
| 70 |
+
config:
|
| 71 |
+
# Transformer-specific configs (map)
|
| 72 |
+
|
| 73 |
+
# 4. Required: Action - What action to take on events.
|
| 74 |
+
action:
|
| 75 |
+
type: <action-type>
|
| 76 |
+
config:
|
| 77 |
+
# Action-specific configs (map)
|
| 78 |
+
|
| 79 |
+
# 5. Optional: Additional pipeline options (error handling, etc)
|
| 80 |
+
options:
|
| 81 |
+
retry_count: 0 # The number of times to retry an Action with the same event. (If an exception is thrown). 0 by default.
|
| 82 |
+
failure_mode: "CONTINUE" # What to do when an event fails to be processed. Either 'CONTINUE' to make progress or 'THROW' to stop the pipeline. Either way, the failed event will be logged to a failed_events.log file.
|
| 83 |
+
failed_events_dir: "/tmp/datahub/actions" # The directory in which to write a failed_events.log file that tracks events which fail to be processed. Defaults to "/tmp/logs/datahub/actions".
|
| 84 |
+
|
| 85 |
+
# 6. Optional: DataHub API configuration
|
| 86 |
+
datahub:
|
| 87 |
+
server: "http://localhost:8080" # Location of DataHub API
|
| 88 |
+
# token: <your-access-token> # Required if Metadata Service Auth enabled
|
| 89 |
+
```
|
| 90 |
+
|
| 91 |
+
### Example: Hello World
|
| 92 |
+
|
| 93 |
+
An simple configuration file for a "Hello World" action, which simply prints all events it receives, is
|
| 94 |
+
|
| 95 |
+
```yml
|
| 96 |
+
# 1. Action Pipeline Name
|
| 97 |
+
name: "hello_world"
|
| 98 |
+
# 2. Event Source: Where to source event from.
|
| 99 |
+
source:
|
| 100 |
+
type: "kafka"
|
| 101 |
+
config:
|
| 102 |
+
connection:
|
| 103 |
+
bootstrap: ${KAFKA_BOOTSTRAP_SERVER:-localhost:9092}
|
| 104 |
+
schema_registry_url: ${SCHEMA_REGISTRY_URL:-http://localhost:8081}
|
| 105 |
+
# 3. Action: What action to take on events.
|
| 106 |
+
action:
|
| 107 |
+
type: "hello_world"
|
| 108 |
+
```
|
| 109 |
+
|
| 110 |
+
We can modify this configuration further to filter for specific events, by adding a "filter" block.
|
| 111 |
+
|
| 112 |
+
```yml
|
| 113 |
+
# 1. Action Pipeline Name
|
| 114 |
+
name: "hello_world"
|
| 115 |
+
|
| 116 |
+
# 2. Event Source - Where to source event from.
|
| 117 |
+
source:
|
| 118 |
+
type: "kafka"
|
| 119 |
+
config:
|
| 120 |
+
connection:
|
| 121 |
+
bootstrap: ${KAFKA_BOOTSTRAP_SERVER:-localhost:9092}
|
| 122 |
+
schema_registry_url: ${SCHEMA_REGISTRY_URL:-http://localhost:8081}
|
| 123 |
+
|
| 124 |
+
# 3. Filter - Filter events that reach the Action
|
| 125 |
+
filter:
|
| 126 |
+
event_type: "EntityChangeEvent_v1"
|
| 127 |
+
event:
|
| 128 |
+
category: "TAG"
|
| 129 |
+
operation: "ADD"
|
| 130 |
+
modifier: "urn:li:tag:pii"
|
| 131 |
+
|
| 132 |
+
# 4. Action - What action to take on events.
|
| 133 |
+
action:
|
| 134 |
+
type: "hello_world"
|
| 135 |
+
```
|
| 136 |
+
|
| 137 |
+
|
| 138 |
+
## Running an Action
|
| 139 |
+
|
| 140 |
+
To run a new Action, just use the `actions` CLI command
|
| 141 |
+
|
| 142 |
+
```
|
| 143 |
+
datahub actions -c <config.yml>
|
| 144 |
+
```
|
| 145 |
+
|
| 146 |
+
Once the Action is running, you will see
|
| 147 |
+
|
| 148 |
+
```
|
| 149 |
+
Action Pipeline with name '<action-pipeline-name>' is now running.
|
| 150 |
+
```
|
| 151 |
+
|
| 152 |
+
### Running multiple Actions
|
| 153 |
+
|
| 154 |
+
You can run multiple actions pipeline within the same command. Simply provide multiple
|
| 155 |
+
config files by restating the "-c" command line argument.
|
| 156 |
+
|
| 157 |
+
For example,
|
| 158 |
+
|
| 159 |
+
```
|
| 160 |
+
datahub actions -c <config-1.yaml> -c <config-2.yaml>
|
| 161 |
+
```
|
| 162 |
+
|
| 163 |
+
### Running in debug mode
|
| 164 |
+
|
| 165 |
+
Simply append the `--debug` flag to the CLI to run your action in debug mode.
|
| 166 |
+
|
| 167 |
+
```
|
| 168 |
+
datahub actions -c <config.yaml> --debug
|
| 169 |
+
```
|
| 170 |
+
|
| 171 |
+
### Stopping an Action
|
| 172 |
+
|
| 173 |
+
Just issue a Control-C as usual. You should see the Actions Pipeline shut down gracefully, with a small
|
| 174 |
+
summary of processing results.
|
| 175 |
+
|
| 176 |
+
```
|
| 177 |
+
Actions Pipeline with name '<action-pipeline-name' has been stopped.
|
| 178 |
+
```
|
| 179 |
+
|
| 180 |
+
|
| 181 |
+
## Supported Events
|
| 182 |
+
|
| 183 |
+
Two event types are currently supported. Read more about them below.
|
| 184 |
+
|
| 185 |
+
- [Entity Change Event V1](events/entity-change-event.md)
|
| 186 |
+
- [Metadata Change Log V1](events/metadata-change-log-event.md)
|
| 187 |
+
|
| 188 |
+
|
| 189 |
+
## Supported Event Sources
|
| 190 |
+
|
| 191 |
+
Currently, the only event source that is officially supported is `kafka`, which polls for events
|
| 192 |
+
via a Kafka Consumer.
|
| 193 |
+
|
| 194 |
+
- [Kafka Event Source](sources/kafka-event-source.md)
|
| 195 |
+
|
| 196 |
+
|
| 197 |
+
## Supported Actions
|
| 198 |
+
|
| 199 |
+
By default, DataHub supports a set of standard actions plugins. These can be found inside the folder
|
| 200 |
+
`src/datahub-actions/plugins`.
|
| 201 |
+
|
| 202 |
+
Some pre-included Actions include
|
| 203 |
+
|
| 204 |
+
- [Hello World](actions/hello_world.md)
|
| 205 |
+
- [Executor](actions/executor.md)
|
| 206 |
+
- [Slack](actions/slack.md)
|
| 207 |
+
- [Microsoft Teams](actions/teams.md)
|
| 208 |
+
|
| 209 |
+
|
| 210 |
+
## Development
|
| 211 |
+
|
| 212 |
+
### Build and Test
|
| 213 |
+
|
| 214 |
+
Notice that we support all actions command using a separate `datahub-actions` CLI entry point. Feel free
|
| 215 |
+
to use this during development.
|
| 216 |
+
|
| 217 |
+
```
|
| 218 |
+
# Build datahub-actions module
|
| 219 |
+
./gradlew datahub-actions:build
|
| 220 |
+
|
| 221 |
+
# Drop into virtual env
|
| 222 |
+
cd datahub-actions && source venv/bin/activate
|
| 223 |
+
|
| 224 |
+
# Start hello world action
|
| 225 |
+
datahub-actions actions -c ../examples/hello_world.yaml
|
| 226 |
+
|
| 227 |
+
# Start ingestion executor action
|
| 228 |
+
datahub-actions actions -c ../examples/executor.yaml
|
| 229 |
+
|
| 230 |
+
# Start multiple actions
|
| 231 |
+
datahub-actions actions -c ../examples/executor.yaml -c ../examples/hello_world.yaml
|
| 232 |
+
```
|
| 233 |
+
|
| 234 |
+
### Developing a Transformer
|
| 235 |
+
|
| 236 |
+
To develop a new Transformer, check out the [Developing a Transformer](guides/developing-a-transformer.md) guide.
|
| 237 |
+
|
| 238 |
+
### Developing an Action
|
| 239 |
+
|
| 240 |
+
To develop a new Action, check out the [Developing an Action](guides/developing-an-action.md) guide.
|
| 241 |
+
|
| 242 |
+
|
| 243 |
+
## Contributing
|
| 244 |
+
|
| 245 |
+
Contributing guidelines follow those of the [main DataHub project](docs/CONTRIBUTING.md). We are accepting contributions for Actions, Transformers, and general framework improvements (tests, error handling, etc).
|
| 246 |
+
|
| 247 |
+
|
| 248 |
+
## Resources
|
| 249 |
+
|
| 250 |
+
Check out the [original announcement](https://www.youtube.com/watch?v=7iwNxHgqxtg&t=2189s) of the DataHub Actions Framework at the DataHub April 2022 Town Hall.
|
| 251 |
+
|
| 252 |
+
|
| 253 |
+
## License
|
| 254 |
+
|
| 255 |
+
Apache 2.0
|
docs/actions/actions/executor.md
ADDED
|
@@ -0,0 +1,82 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Ingestion Executor
|
| 2 |
+
<!-- Set Support Status -->
|
| 3 |
+

|
| 4 |
+
|
| 5 |
+
|
| 6 |
+
## Overview
|
| 7 |
+
|
| 8 |
+
This Action executes ingestion recipes that are configured via the UI.
|
| 9 |
+
|
| 10 |
+
### Capabilities
|
| 11 |
+
|
| 12 |
+
- Executing `datahub ingest` command in a sub-process when an Execution Request command is received from DataHub. (Scheduled or manual ingestion run)
|
| 13 |
+
- Resolving secrets within an ingestion recipe from DataHub
|
| 14 |
+
- Reporting ingestion execution status to DataHub
|
| 15 |
+
|
| 16 |
+
### Supported Events
|
| 17 |
+
|
| 18 |
+
- `MetadataChangeLog_v1`
|
| 19 |
+
|
| 20 |
+
Specifically, changes to the `dataHubExecutionRequestInput` and `dataHubExecutionRequestSignal` aspects of the `dataHubExecutionRequest` entity are required.
|
| 21 |
+
|
| 22 |
+
|
| 23 |
+
## Action Quickstart
|
| 24 |
+
|
| 25 |
+
### Prerequisites
|
| 26 |
+
|
| 27 |
+
#### DataHub Privileges
|
| 28 |
+
|
| 29 |
+
This action must be executed as a privileged DataHub user (e.g. using Personal Access Tokens). Specifically, the user must have the `Manage Secrets` Platform Privilege, which allows for retrieval
|
| 30 |
+
of decrypted secrets for injection into an ingestion recipe.
|
| 31 |
+
|
| 32 |
+
An access token generated from a privileged account must be configured in the `datahub` configuration
|
| 33 |
+
block of the YAML configuration, as shown in the example below.
|
| 34 |
+
|
| 35 |
+
#### Connecting to Ingestion Sources
|
| 36 |
+
|
| 37 |
+
In order for ingestion to run successfully, the process running the Actions must have
|
| 38 |
+
network connectivity to any source systems that are required for ingestion.
|
| 39 |
+
|
| 40 |
+
For example, if the ingestion recipe is pulling from an internal DBMS, the actions container
|
| 41 |
+
must be able to resolve & connect to that DBMS system for the ingestion command to run successfully.
|
| 42 |
+
|
| 43 |
+
### Install the Plugin(s)
|
| 44 |
+
|
| 45 |
+
Run the following commands to install the relevant action plugin(s):
|
| 46 |
+
|
| 47 |
+
`pip install 'acryl-datahub-actions[executor]'`
|
| 48 |
+
|
| 49 |
+
|
| 50 |
+
### Configure the Action Config
|
| 51 |
+
|
| 52 |
+
Use the following config(s) to get started with this Action.
|
| 53 |
+
|
| 54 |
+
```yml
|
| 55 |
+
name: "pipeline-name"
|
| 56 |
+
source:
|
| 57 |
+
# source configs
|
| 58 |
+
action:
|
| 59 |
+
type: "executor"
|
| 60 |
+
# Requires DataHub API configurations to report to DataHub
|
| 61 |
+
datahub:
|
| 62 |
+
server: "http://${DATAHUB_GMS_HOST:-localhost}:${DATAHUB_GMS_PORT:-8080}"
|
| 63 |
+
# token: <token> # Must have "Manage Secrets" privilege
|
| 64 |
+
```
|
| 65 |
+
|
| 66 |
+
<details>
|
| 67 |
+
<summary>View All Configuration Options</summary>
|
| 68 |
+
|
| 69 |
+
| Field | Required | Default | Description |
|
| 70 |
+
| --- | :-: | :-: | --- |
|
| 71 |
+
| `executor_id` | ❌ | `default` | An executor ID assigned to the executor. This can be used to manage multiple distinct executors. |
|
| 72 |
+
</details>
|
| 73 |
+
|
| 74 |
+
|
| 75 |
+
## Troubleshooting
|
| 76 |
+
|
| 77 |
+
### Quitting the Actions Framework
|
| 78 |
+
|
| 79 |
+
Currently, when you quit the Actions framework, any in-flight ingestion processing will continue to execute as a subprocess on your system. This means that there may be "orphaned" processes which
|
| 80 |
+
are never marked as "Succeeded" or "Failed" in the UI, even though they may have completed.
|
| 81 |
+
|
| 82 |
+
To address this, simply "Cancel" the ingestion source on the UI once you've restarted the Ingestion Executor action.
|
docs/actions/actions/hello_world.md
ADDED
|
@@ -0,0 +1,59 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Hello World
|
| 2 |
+
|
| 3 |
+
<!-- Set Support Status -->
|
| 4 |
+

|
| 5 |
+
|
| 6 |
+
|
| 7 |
+
## Overview
|
| 8 |
+
|
| 9 |
+
This Action is an example action which simply prints all Events it receives as JSON.
|
| 10 |
+
|
| 11 |
+
### Capabilities
|
| 12 |
+
|
| 13 |
+
- Printing events that are received by the Action to the console.
|
| 14 |
+
|
| 15 |
+
### Supported Events
|
| 16 |
+
|
| 17 |
+
All event types, including
|
| 18 |
+
|
| 19 |
+
- `EntityChangeEvent_v1`
|
| 20 |
+
- `MetadataChangeLog_v1`
|
| 21 |
+
|
| 22 |
+
|
| 23 |
+
## Action Quickstart
|
| 24 |
+
|
| 25 |
+
### Prerequisites
|
| 26 |
+
|
| 27 |
+
No prerequisites. This action comes pre-loaded with `acryl-datahub-actions`.
|
| 28 |
+
|
| 29 |
+
### Install the Plugin(s)
|
| 30 |
+
|
| 31 |
+
This action comes with the Actions Framework by default:
|
| 32 |
+
|
| 33 |
+
`pip install 'acryl-datahub-actions'`
|
| 34 |
+
|
| 35 |
+
|
| 36 |
+
### Configure the Action Config
|
| 37 |
+
|
| 38 |
+
Use the following config(s) to get started with this Action.
|
| 39 |
+
|
| 40 |
+
```yml
|
| 41 |
+
name: "pipeline-name"
|
| 42 |
+
source:
|
| 43 |
+
# source configs
|
| 44 |
+
action:
|
| 45 |
+
type: "hello_world"
|
| 46 |
+
```
|
| 47 |
+
|
| 48 |
+
<details>
|
| 49 |
+
<summary>View All Configuration Options</summary>
|
| 50 |
+
|
| 51 |
+
| Field | Required | Default | Description |
|
| 52 |
+
| --- | :-: | :-: | --- |
|
| 53 |
+
| `to_upper` | ❌| `False` | Whether to print events in upper case. |
|
| 54 |
+
</details>
|
| 55 |
+
|
| 56 |
+
|
| 57 |
+
## Troubleshooting
|
| 58 |
+
|
| 59 |
+
N/A
|
docs/actions/actions/slack.md
ADDED
|
@@ -0,0 +1,282 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import FeatureAvailability from '@site/src/components/FeatureAvailability';
|
| 2 |
+
|
| 3 |
+
# Slack
|
| 4 |
+
|
| 5 |
+
<FeatureAvailability />
|
| 6 |
+
|
| 7 |
+
|
| 8 |
+
# Slack
|
| 9 |
+
|
| 10 |
+
| <!-- --> | <!-- --> |
|
| 11 |
+
| --- | --- |
|
| 12 |
+
| **Status** |  |
|
| 13 |
+
| **Version Requirements** |  |
|
| 14 |
+
|
| 15 |
+
|
| 16 |
+
## Overview
|
| 17 |
+
|
| 18 |
+
This Action integrates DataHub with Slack to send notifications to a configured Slack channel in your workspace.
|
| 19 |
+
|
| 20 |
+
### Capabilities
|
| 21 |
+
|
| 22 |
+
- Sending notifications of important events to a Slack channel
|
| 23 |
+
- Adding or Removing a tag from an entity (dataset, dashboard etc.)
|
| 24 |
+
- Updating documentation at the entity or field (column) level.
|
| 25 |
+
- Adding or Removing ownership from an entity (dataset, dashboard, etc.)
|
| 26 |
+
- Creating a Domain
|
| 27 |
+
- and many more.
|
| 28 |
+
|
| 29 |
+
### User Experience
|
| 30 |
+
|
| 31 |
+
On startup, the action will produce a welcome message that looks like the one below.
|
| 32 |
+
|
| 33 |
+
|
| 34 |
+
|
| 35 |
+
On each event, the action will produce a notification message that looks like the one below.
|
| 36 |
+
|
| 37 |
+
|
| 38 |
+
Watch the townhall demo to see this in action:
|
| 39 |
+
[](https://www.youtube.com/watch?v=BlCLhG8lGoY&t=2998s)
|
| 40 |
+
|
| 41 |
+
### Supported Events
|
| 42 |
+
|
| 43 |
+
- `EntityChangeEvent_v1`
|
| 44 |
+
- Currently, the `MetadataChangeLog_v1` event is **not** processed by the Action.
|
| 45 |
+
|
| 46 |
+
## Action Quickstart
|
| 47 |
+
|
| 48 |
+
### Prerequisites
|
| 49 |
+
|
| 50 |
+
Ensure that you have configured the Slack App in your Slack workspace.
|
| 51 |
+
|
| 52 |
+
#### Install the DataHub Slack App into your Slack workspace
|
| 53 |
+
|
| 54 |
+
The following steps should be performed by a Slack Workspace Admin.
|
| 55 |
+
- Navigate to https://api.slack.com/apps/
|
| 56 |
+
- Click Create New App
|
| 57 |
+
- Use “From an app manifest” option
|
| 58 |
+
- Select your workspace
|
| 59 |
+
- Paste this Manifest in YAML. We suggest changing the name and `display_name` to be `DataHub App YOUR_TEAM_NAME` but this is not required. This name will show up in your Slack workspace.
|
| 60 |
+
```yml
|
| 61 |
+
display_information:
|
| 62 |
+
name: DataHub App
|
| 63 |
+
description: An app to integrate DataHub with Slack
|
| 64 |
+
background_color: "#000000"
|
| 65 |
+
features:
|
| 66 |
+
bot_user:
|
| 67 |
+
display_name: DataHub App
|
| 68 |
+
always_online: false
|
| 69 |
+
oauth_config:
|
| 70 |
+
scopes:
|
| 71 |
+
bot:
|
| 72 |
+
- channels:history
|
| 73 |
+
- channels:read
|
| 74 |
+
- chat:write
|
| 75 |
+
- commands
|
| 76 |
+
- groups:read
|
| 77 |
+
- im:read
|
| 78 |
+
- mpim:read
|
| 79 |
+
- team:read
|
| 80 |
+
- users:read
|
| 81 |
+
- users:read.email
|
| 82 |
+
settings:
|
| 83 |
+
org_deploy_enabled: false
|
| 84 |
+
socket_mode_enabled: false
|
| 85 |
+
token_rotation_enabled: false
|
| 86 |
+
```
|
| 87 |
+
|
| 88 |
+
- Confirm you see the Basic Information Tab
|
| 89 |
+
|
| 90 |
+
|
| 91 |
+
|
| 92 |
+
- Click **Install to Workspace**
|
| 93 |
+
- It will show you permissions the Slack App is asking for, what they mean and a default channel in which you want to add the slack app
|
| 94 |
+
- Note that the Slack App will only be able to post in channels that the app has been added to. This is made clear by slack’s Authentication screen also.
|
| 95 |
+
- Select the channel you'd like notifications to go to and click **Allow**
|
| 96 |
+
- Go to the DataHub App page
|
| 97 |
+
- You can find your workspace's list of apps at https://api.slack.com/apps/
|
| 98 |
+
|
| 99 |
+
#### Getting Credentials and Configuration
|
| 100 |
+
|
| 101 |
+
Now that you've created your app and installed it in your workspace, you need a few pieces of information before you can activate your Slack action.
|
| 102 |
+
|
| 103 |
+
#### 1. The Signing Secret
|
| 104 |
+
|
| 105 |
+
On your app's Basic Information page, you will see a App Credentials area. Take note of the Signing Secret information, you will need it later.
|
| 106 |
+
|
| 107 |
+
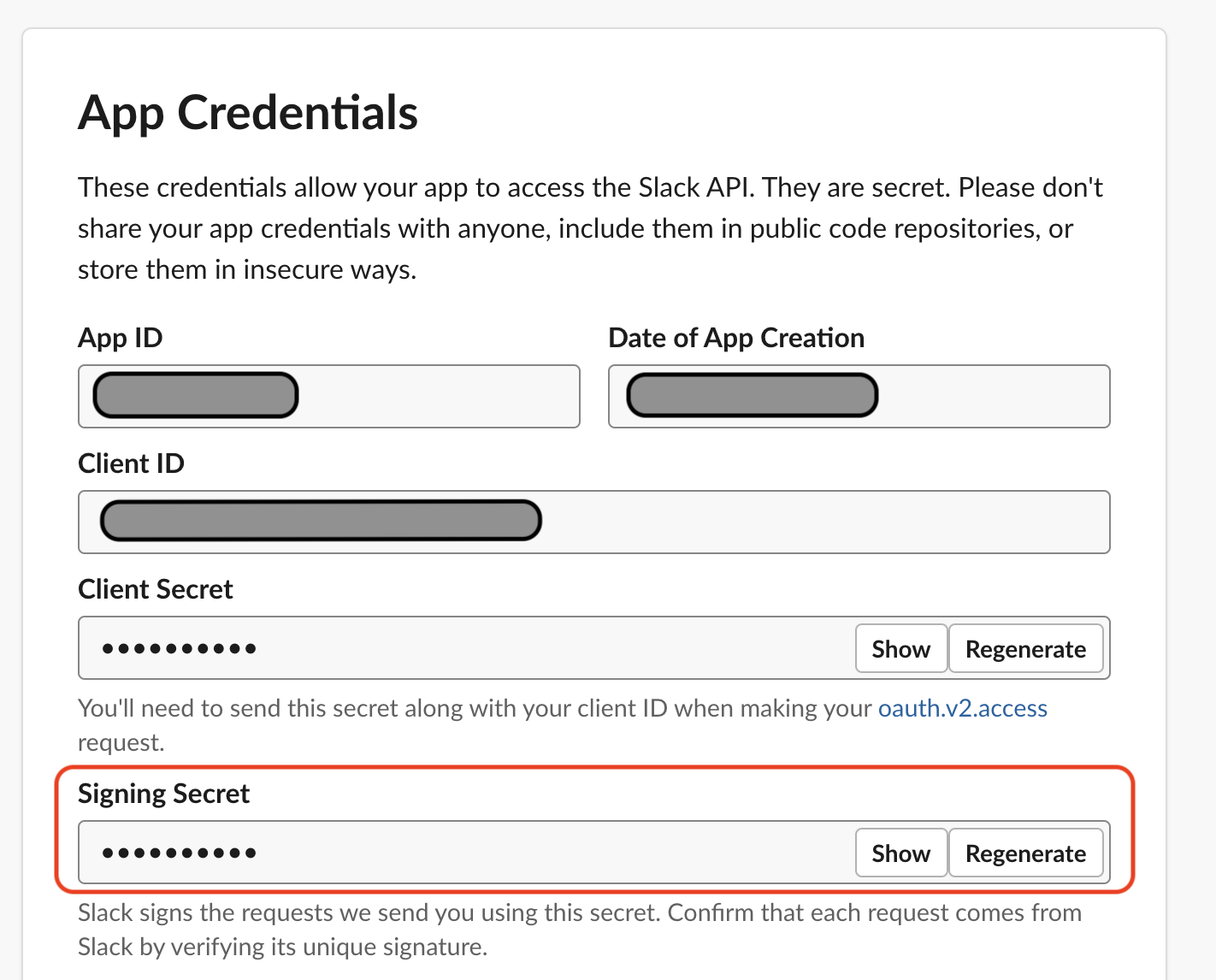
|
| 108 |
+
|
| 109 |
+
|
| 110 |
+
#### 2. The Bot Token
|
| 111 |
+
|
| 112 |
+
Navigate to the **OAuth & Permissions** Tab
|
| 113 |
+
|
| 114 |
+
|
| 115 |
+
|
| 116 |
+
Here you'll find a “Bot User OAuth Token” which DataHub will need to communicate with your Slack workspace through the bot.
|
| 117 |
+
|
| 118 |
+
#### 3. The Slack Channel
|
| 119 |
+
|
| 120 |
+
Finally, you need to figure out which Slack channel you will send notifications to. Perhaps it should be called #datahub-notifications or maybe, #data-notifications or maybe you already have a channel where important notifications about datasets and pipelines are already being routed to. Once you have decided what channel to send notifications to, make sure to add the app to the channel.
|
| 121 |
+
|
| 122 |
+
|
| 123 |
+
|
| 124 |
+
Next, figure out the channel id for this Slack channel. You can find it in the About section for the channel if you scroll to the very bottom of the app.
|
| 125 |
+
|
| 126 |
+
|
| 127 |
+
Alternately, if you are on the browser, you can figure it out from the URL. e.g. for the troubleshoot channel in OSS DataHub slack
|
| 128 |
+
|
| 129 |
+
|
| 130 |
+
|
| 131 |
+
- Notice `TUMKD5EGJ/C029A3M079U` in the URL
|
| 132 |
+
- Channel ID = `C029A3M079U` from above
|
| 133 |
+
|
| 134 |
+
|
| 135 |
+
In the next steps, we'll show you how to configure the Slack Action based on the credentials and configuration values that you have collected.
|
| 136 |
+
|
| 137 |
+
### Installation Instructions (Deployment specific)
|
| 138 |
+
|
| 139 |
+
#### Managed DataHub
|
| 140 |
+
|
| 141 |
+
Head over to the [Configuring Notifications](../../managed-datahub/saas-slack-setup.md#configuring-notifications) section in the Managed DataHub guide to configure Slack notifications for your Managed DataHub instance.
|
| 142 |
+
|
| 143 |
+
|
| 144 |
+
#### Quickstart
|
| 145 |
+
|
| 146 |
+
If you are running DataHub using the docker quickstart option, there are no additional software installation steps. The `datahub-actions` container comes pre-installed with the Slack action.
|
| 147 |
+
|
| 148 |
+
All you need to do is export a few environment variables to activate and configure the integration. See below for the list of environment variables to export.
|
| 149 |
+
|
| 150 |
+
| Env Variable | Required for Integration | Purpose |
|
| 151 |
+
| --- | --- | --- |
|
| 152 |
+
| DATAHUB_ACTIONS_SLACK_ENABLED | ✅ | Set to "true" to enable the Slack action |
|
| 153 |
+
| DATAHUB_ACTIONS_SLACK_SIGNING_SECRET | ✅ | Set to the [Slack Signing Secret](#1-the-signing-secret) that you configured in the pre-requisites step above |
|
| 154 |
+
| DATAHUB_ACTIONS_SLACK_BOT_TOKEN | ✅ | Set to the [Bot User OAuth Token](#2-the-bot-token) that you configured in the pre-requisites step above |
|
| 155 |
+
| DATAHUB_ACTIONS_SLACK_CHANNEL | ✅ | Set to the [Slack Channel ID](#3-the-slack-channel) that you want the action to send messages to |
|
| 156 |
+
| DATAHUB_ACTIONS_SLACK_DATAHUB_BASE_URL | ❌ | Defaults to "http://localhost:9002". Set to the location where your DataHub UI is running. On a local quickstart this is usually "http://localhost:9002", so you shouldn't need to modify this |
|
| 157 |
+
|
| 158 |
+
:::note
|
| 159 |
+
|
| 160 |
+
You will have to restart the `datahub-actions` docker container after you have exported these environment variables if this is the first time. The simplest way to do it is via the Docker Desktop UI, or by just issuing a `datahub docker quickstart --stop && datahub docker quickstart` command to restart the whole instance.
|
| 161 |
+
|
| 162 |
+
:::
|
| 163 |
+
|
| 164 |
+
|
| 165 |
+
For example:
|
| 166 |
+
```shell
|
| 167 |
+
export DATAHUB_ACTIONS_SLACK_ENABLED=true
|
| 168 |
+
export DATAHUB_ACTIONS_SLACK_SIGNING_SECRET=<slack-signing-secret>
|
| 169 |
+
....
|
| 170 |
+
export DATAHUB_ACTIONS_SLACK_CHANNEL=<slack_channel_id>
|
| 171 |
+
|
| 172 |
+
datahub docker quickstart --stop && datahub docker quickstart
|
| 173 |
+
```
|
| 174 |
+
|
| 175 |
+
#### k8s / helm
|
| 176 |
+
|
| 177 |
+
Similar to the quickstart scenario, there are no specific software installation steps. The `datahub-actions` container comes pre-installed with the Slack action. You just need to export a few environment variables and make them available to the `datahub-actions` container to activate and configure the integration. See below for the list of environment variables to export.
|
| 178 |
+
|
| 179 |
+
| Env Variable | Required for Integration | Purpose |
|
| 180 |
+
| --- | --- | --- |
|
| 181 |
+
| DATAHUB_ACTIONS_SLACK_ENABLED | ✅ | Set to "true" to enable the Slack action |
|
| 182 |
+
| DATAHUB_ACTIONS_SLACK_SIGNING_SECRET | ✅ | Set to the [Slack Signing Secret](#1-the-signing-secret) that you configured in the pre-requisites step above |
|
| 183 |
+
| DATAHUB_ACTIONS_SLACK_BOT_TOKEN | ✅ | Set to the [Bot User OAuth Token](#2-the-bot-token) that you configured in the pre-requisites step above |
|
| 184 |
+
| DATAHUB_ACTIONS_SLACK_CHANNEL | ✅ | Set to the [Slack Channel ID](#3-the-slack-channel) that you want the action to send messages to |
|
| 185 |
+
| DATAHUB_ACTIONS_DATAHUB_BASE_URL | ✅| Set to the location where your DataHub UI is running. For example, if your DataHub UI is hosted at "https://datahub.my-company.biz", set this to "https://datahub.my-company.biz"|
|
| 186 |
+
|
| 187 |
+
|
| 188 |
+
#### Bare Metal - CLI or Python-based
|
| 189 |
+
|
| 190 |
+
If you are using the `datahub-actions` library directly from Python, or the `datahub-actions` cli directly, then you need to first install the `slack` action plugin in your Python virtualenv.
|
| 191 |
+
|
| 192 |
+
```
|
| 193 |
+
pip install "datahub-actions[slack]"
|
| 194 |
+
```
|
| 195 |
+
|
| 196 |
+
Then run the action with a configuration file that you have modified to capture your credentials and configuration.
|
| 197 |
+
|
| 198 |
+
##### Sample Slack Action Configuration File
|
| 199 |
+
|
| 200 |
+
```yml
|
| 201 |
+
name: datahub_slack_action
|
| 202 |
+
enabled: true
|
| 203 |
+
source:
|
| 204 |
+
type: "kafka"
|
| 205 |
+
config:
|
| 206 |
+
connection:
|
| 207 |
+
bootstrap: ${KAFKA_BOOTSTRAP_SERVER:-localhost:9092}
|
| 208 |
+
schema_registry_url: ${SCHEMA_REGISTRY_URL:-http://localhost:8081}
|
| 209 |
+
topic_routes:
|
| 210 |
+
mcl: ${METADATA_CHANGE_LOG_VERSIONED_TOPIC_NAME:-MetadataChangeLog_Versioned_v1}
|
| 211 |
+
pe: ${PLATFORM_EVENT_TOPIC_NAME:-PlatformEvent_v1}
|
| 212 |
+
|
| 213 |
+
## 3a. Optional: Filter to run on events (map)
|
| 214 |
+
# filter:
|
| 215 |
+
# event_type: <filtered-event-type>
|
| 216 |
+
# event:
|
| 217 |
+
# # Filter event fields by exact-match
|
| 218 |
+
# <filtered-event-fields>
|
| 219 |
+
|
| 220 |
+
# 3b. Optional: Custom Transformers to run on events (array)
|
| 221 |
+
# transform:
|
| 222 |
+
# - type: <transformer-type>
|
| 223 |
+
# config:
|
| 224 |
+
# # Transformer-specific configs (map)
|
| 225 |
+
|
| 226 |
+
action:
|
| 227 |
+
type: slack
|
| 228 |
+
config:
|
| 229 |
+
# Action-specific configs (map)
|
| 230 |
+
base_url: ${DATAHUB_ACTIONS_SLACK_DATAHUB_BASE_URL:-http://localhost:9002}
|
| 231 |
+
bot_token: ${DATAHUB_ACTIONS_SLACK_BOT_TOKEN}
|
| 232 |
+
signing_secret: ${DATAHUB_ACTIONS_SLACK_SIGNING_SECRET}
|
| 233 |
+
default_channel: ${DATAHUB_ACTIONS_SLACK_CHANNEL}
|
| 234 |
+
suppress_system_activity: ${DATAHUB_ACTIONS_SLACK_SUPPRESS_SYSTEM_ACTIVITY:-true}
|
| 235 |
+
|
| 236 |
+
datahub:
|
| 237 |
+
server: "http://${DATAHUB_GMS_HOST:-localhost}:${DATAHUB_GMS_PORT:-8080}"
|
| 238 |
+
|
| 239 |
+
```
|
| 240 |
+
|
| 241 |
+
##### Slack Action Configuration Parameters
|
| 242 |
+
|
| 243 |
+
| Field | Required | Default | Description |
|
| 244 |
+
| --- | --- | --- | --- |
|
| 245 |
+
| `base_url` | ❌| `False` | Whether to print events in upper case. |
|
| 246 |
+
| `signing_secret` | ✅ | | Set to the [Slack Signing Secret](#1-the-signing-secret) that you configured in the pre-requisites step above |
|
| 247 |
+
| `bot_token` | ✅ | | Set to the [Bot User OAuth Token](#2-the-bot-token) that you configured in the pre-requisites step above |
|
| 248 |
+
| `default_channel` | ✅ | | Set to the [Slack Channel ID](#3-the-slack-channel) that you want the action to send messages to |
|
| 249 |
+
| `suppress_system_activity` | ❌ | `True` | Set to `False` if you want to get low level system activity events, e.g. when datasets are ingested, etc. Note: this will currently result in a very spammy Slack notifications experience, so this is not recommended to be changed. |
|
| 250 |
+
|
| 251 |
+
|
| 252 |
+
## Troubleshooting
|
| 253 |
+
|
| 254 |
+
If things are configured correctly, you should see logs on the `datahub-actions` container that indicate success in enabling and running the Slack action.
|
| 255 |
+
|
| 256 |
+
```shell
|
| 257 |
+
docker logs datahub-datahub-actions-1
|
| 258 |
+
|
| 259 |
+
...
|
| 260 |
+
[2022-12-04 07:07:53,804] INFO {datahub_actions.plugin.action.slack.slack:96} - Slack notification action configured with bot_token=SecretStr('**********') signing_secret=SecretStr('**********') default_channel='C04CZUSSR5X' base_url='http://localhost:9002' suppress_system_activity=True
|
| 261 |
+
[2022-12-04 07:07:54,506] WARNING {datahub_actions.cli.actions:103} - Skipping pipeline datahub_teams_action as it is not enabled
|
| 262 |
+
[2022-12-04 07:07:54,506] INFO {datahub_actions.cli.actions:119} - Action Pipeline with name 'ingestion_executor' is now running.
|
| 263 |
+
[2022-12-04 07:07:54,507] INFO {datahub_actions.cli.actions:119} - Action Pipeline with name 'datahub_slack_action' is now running.
|
| 264 |
+
...
|
| 265 |
+
```
|
| 266 |
+
|
| 267 |
+
|
| 268 |
+
If the Slack action was not enabled, you would see messages indicating that.
|
| 269 |
+
e.g. the following logs below show that neither the Slack or Teams action were enabled.
|
| 270 |
+
|
| 271 |
+
```shell
|
| 272 |
+
docker logs datahub-datahub-actions-1
|
| 273 |
+
|
| 274 |
+
....
|
| 275 |
+
No user action configurations found. Not starting user actions.
|
| 276 |
+
[2022-12-04 06:45:27,509] INFO {datahub_actions.cli.actions:76} - DataHub Actions version: unavailable (installed editable via git)
|
| 277 |
+
[2022-12-04 06:45:27,647] WARNING {datahub_actions.cli.actions:103} - Skipping pipeline datahub_slack_action as it is not enabled
|
| 278 |
+
[2022-12-04 06:45:27,649] WARNING {datahub_actions.cli.actions:103} - Skipping pipeline datahub_teams_action as it is not enabled
|
| 279 |
+
[2022-12-04 06:45:27,649] INFO {datahub_actions.cli.actions:119} - Action Pipeline with name 'ingestion_executor' is now running.
|
| 280 |
+
...
|
| 281 |
+
|
| 282 |
+
```
|
docs/actions/actions/teams.md
ADDED
|
@@ -0,0 +1,184 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import FeatureAvailability from '@site/src/components/FeatureAvailability';
|
| 2 |
+
|
| 3 |
+
# Microsoft Teams
|
| 4 |
+
|
| 5 |
+
<FeatureAvailability ossOnly />
|
| 6 |
+
|
| 7 |
+
| <!-- --> | <!-- --> |
|
| 8 |
+
| --- | --- |
|
| 9 |
+
| **Status** |  |
|
| 10 |
+
| **Version Requirements** |  |
|
| 11 |
+
|
| 12 |
+
## Overview
|
| 13 |
+
|
| 14 |
+
This Action integrates DataHub with Microsoft Teams to send notifications to a configured Teams channel in your workspace.
|
| 15 |
+
|
| 16 |
+
### Capabilities
|
| 17 |
+
|
| 18 |
+
- Sending notifications of important events to a Teams channel
|
| 19 |
+
- Adding or Removing a tag from an entity (dataset, dashboard etc.)
|
| 20 |
+
- Updating documentation at the entity or field (column) level.
|
| 21 |
+
- Adding or Removing ownership from an entity (dataset, dashboard, etc.)
|
| 22 |
+
- Creating a Domain
|
| 23 |
+
- and many more.
|
| 24 |
+
|
| 25 |
+
### User Experience
|
| 26 |
+
|
| 27 |
+
On startup, the action will produce a welcome message that looks like the one below.
|
| 28 |
+
|
| 29 |
+
|
| 30 |
+
|
| 31 |
+
On each event, the action will produce a notification message that looks like the one below.
|
| 32 |
+

|
| 33 |
+
|
| 34 |
+
Watch the townhall demo to see this in action:
|
| 35 |
+
[](https://www.youtube.com/watch?v=BlCLhG8lGoY&t=2998s)
|
| 36 |
+
|
| 37 |
+
|
| 38 |
+
### Supported Events
|
| 39 |
+
|
| 40 |
+
- `EntityChangeEvent_v1`
|
| 41 |
+
- Currently, the `MetadataChangeLog_v1` event is **not** processed by the Action.
|
| 42 |
+
|
| 43 |
+
## Action Quickstart
|
| 44 |
+
|
| 45 |
+
### Prerequisites
|
| 46 |
+
|
| 47 |
+
Ensure that you have configured an incoming webhook in your Teams channel.
|
| 48 |
+
|
| 49 |
+
Follow the guide [here](https://learn.microsoft.com/en-us/microsoftteams/platform/webhooks-and-connectors/how-to/add-incoming-webhook) to set it up.
|
| 50 |
+
|
| 51 |
+
Take note of the incoming webhook url as you will need to use that to configure the Team action.
|
| 52 |
+
|
| 53 |
+
### Installation Instructions (Deployment specific)
|
| 54 |
+
|
| 55 |
+
#### Quickstart
|
| 56 |
+
|
| 57 |
+
If you are running DataHub using the docker quickstart option, there are no additional software installation steps. The `datahub-actions` container comes pre-installed with the Teams action.
|
| 58 |
+
|
| 59 |
+
All you need to do is export a few environment variables to activate and configure the integration. See below for the list of environment variables to export.
|
| 60 |
+
|
| 61 |
+
| Env Variable | Required for Integration | Purpose |
|
| 62 |
+
| --- | --- | --- |
|
| 63 |
+
| DATAHUB_ACTIONS_TEAMS_ENABLED | ✅ | Set to "true" to enable the Teams action |
|
| 64 |
+
| DATAHUB_ACTIONS_TEAMS_WEBHOOK_URL | ✅ | Set to the incoming webhook url that you configured in the [pre-requisites step](#prerequisites) above |
|
| 65 |
+
| DATAHUB_ACTIONS_DATAHUB_BASE_URL | ❌ | Defaults to "http://localhost:9002". Set to the location where your DataHub UI is running. On a local quickstart this is usually "http://localhost:9002", so you shouldn't need to modify this |
|
| 66 |
+
|
| 67 |
+
:::note
|
| 68 |
+
|
| 69 |
+
You will have to restart the `datahub-actions` docker container after you have exported these environment variables if this is the first time. The simplest way to do it is via the Docker Desktop UI, or by just issuing a `datahub docker quickstart --stop && datahub docker quickstart` command to restart the whole instance.
|
| 70 |
+
|
| 71 |
+
:::
|
| 72 |
+
|
| 73 |
+
|
| 74 |
+
For example:
|
| 75 |
+
```shell
|
| 76 |
+
export DATAHUB_ACTIONS_TEAMS_ENABLED=true
|
| 77 |
+
export DATAHUB_ACTIONS_TEAMS_WEBHOOK_URL=<teams_webhook_url>
|
| 78 |
+
|
| 79 |
+
datahub docker quickstart --stop && datahub docker quickstart
|
| 80 |
+
```
|
| 81 |
+
|
| 82 |
+
#### k8s / helm
|
| 83 |
+
|
| 84 |
+
Similar to the quickstart scenario, there are no specific software installation steps. The `datahub-actions` container comes pre-installed with the Teams action. You just need to export a few environment variables and make them available to the `datahub-actions` container to activate and configure the integration. See below for the list of environment variables to export.
|
| 85 |
+
|
| 86 |
+
| Env Variable | Required for Integration | Purpose |
|
| 87 |
+
| --- | --- | --- |
|
| 88 |
+
| DATAHUB_ACTIONS_TEAMS_ENABLED | ✅ | Set to "true" to enable the Teams action |
|
| 89 |
+
| DATAHUB_ACTIONS_TEAMS_WEBHOOK_URL | ✅ | Set to the incoming webhook url that you configured in the [pre-requisites step](#prerequisites) above |
|
| 90 |
+
| DATAHUB_ACTIONS_TEAMS_DATAHUB_BASE_URL | ✅| Set to the location where your DataHub UI is running. For example, if your DataHub UI is hosted at "https://datahub.my-company.biz", set this to "https://datahub.my-company.biz"|
|
| 91 |
+
|
| 92 |
+
|
| 93 |
+
#### Bare Metal - CLI or Python-based
|
| 94 |
+
|
| 95 |
+
If you are using the `datahub-actions` library directly from Python, or the `datahub-actions` cli directly, then you need to first install the `teams` action plugin in your Python virtualenv.
|
| 96 |
+
|
| 97 |
+
```
|
| 98 |
+
pip install "datahub-actions[teams]"
|
| 99 |
+
```
|
| 100 |
+
|
| 101 |
+
Then run the action with a configuration file that you have modified to capture your credentials and configuration.
|
| 102 |
+
|
| 103 |
+
##### Sample Teams Action Configuration File
|
| 104 |
+
|
| 105 |
+
```yml
|
| 106 |
+
name: datahub_teams_action
|
| 107 |
+
enabled: true
|
| 108 |
+
source:
|
| 109 |
+
type: "kafka"
|
| 110 |
+
config:
|
| 111 |
+
connection:
|
| 112 |
+
bootstrap: ${KAFKA_BOOTSTRAP_SERVER:-localhost:9092}
|
| 113 |
+
schema_registry_url: ${SCHEMA_REGISTRY_URL:-http://localhost:8081}
|
| 114 |
+
topic_routes:
|
| 115 |
+
mcl: ${METADATA_CHANGE_LOG_VERSIONED_TOPIC_NAME:-MetadataChangeLog_Versioned_v1}
|
| 116 |
+
pe: ${PLATFORM_EVENT_TOPIC_NAME:-PlatformEvent_v1}
|
| 117 |
+
|
| 118 |
+
## 3a. Optional: Filter to run on events (map)
|
| 119 |
+
# filter:
|
| 120 |
+
# event_type: <filtered-event-type>
|
| 121 |
+
# event:
|
| 122 |
+
# # Filter event fields by exact-match
|
| 123 |
+
# <filtered-event-fields>
|
| 124 |
+
|
| 125 |
+
# 3b. Optional: Custom Transformers to run on events (array)
|
| 126 |
+
# transform:
|
| 127 |
+
# - type: <transformer-type>
|
| 128 |
+
# config:
|
| 129 |
+
# # Transformer-specific configs (map)
|
| 130 |
+
|
| 131 |
+
action:
|
| 132 |
+
type: teams
|
| 133 |
+
config:
|
| 134 |
+
# Action-specific configs (map)
|
| 135 |
+
base_url: ${DATAHUB_ACTIONS_TEAMS_DATAHUB_BASE_URL:-http://localhost:9002}
|
| 136 |
+
webhook_url: ${DATAHUB_ACTIONS_TEAMS_WEBHOOK_URL}
|
| 137 |
+
suppress_system_activity: ${DATAHUB_ACTIONS_TEAMS_SUPPRESS_SYSTEM_ACTIVITY:-true}
|
| 138 |
+
|
| 139 |
+
datahub:
|
| 140 |
+
server: "http://${DATAHUB_GMS_HOST:-localhost}:${DATAHUB_GMS_PORT:-8080}"
|
| 141 |
+
```
|
| 142 |
+
|
| 143 |
+
##### Teams Action Configuration Parameters
|
| 144 |
+
|
| 145 |
+
| Field | Required | Default | Description |
|
| 146 |
+
| --- | --- | --- | --- |
|
| 147 |
+
| `base_url` | ❌| `False` | Whether to print events in upper case. |
|
| 148 |
+
| `webhook_url` | ✅ | Set to the incoming webhook url that you configured in the [pre-requisites step](#prerequisites) above |
|
| 149 |
+
| `suppress_system_activity` | ❌ | `True` | Set to `False` if you want to get low level system activity events, e.g. when datasets are ingested, etc. Note: this will currently result in a very spammy Teams notifications experience, so this is not recommended to be changed. |
|
| 150 |
+
|
| 151 |
+
|
| 152 |
+
## Troubleshooting
|
| 153 |
+
|
| 154 |
+
If things are configured correctly, you should see logs on the `datahub-actions` container that indicate success in enabling and running the Teams action.
|
| 155 |
+
|
| 156 |
+
```shell
|
| 157 |
+
docker logs datahub-datahub-actions-1
|
| 158 |
+
|
| 159 |
+
...
|
| 160 |
+
[2022-12-04 16:47:44,536] INFO {datahub_actions.cli.actions:76} - DataHub Actions version: unavailable (installed editable via git)
|
| 161 |
+
[2022-12-04 16:47:44,565] WARNING {datahub_actions.cli.actions:103} - Skipping pipeline datahub_slack_action as it is not enabled
|
| 162 |
+
[2022-12-04 16:47:44,581] INFO {datahub_actions.plugin.action.teams.teams:60} - Teams notification action configured with webhook_url=SecretStr('**********') base_url='http://localhost:9002' suppress_system_activity=True
|
| 163 |
+
[2022-12-04 16:47:46,393] INFO {datahub_actions.cli.actions:119} - Action Pipeline with name 'ingestion_executor' is now running.
|
| 164 |
+
[2022-12-04 16:47:46,393] INFO {datahub_actions.cli.actions:119} - Action Pipeline with name 'datahub_teams_action' is now running.
|
| 165 |
+
...
|
| 166 |
+
```
|
| 167 |
+
|
| 168 |
+
|
| 169 |
+
If the Teams action was not enabled, you would see messages indicating that.
|
| 170 |
+
e.g. the following logs below show that neither the Teams or Slack action were enabled.
|
| 171 |
+
|
| 172 |
+
```shell
|
| 173 |
+
docker logs datahub-datahub-actions-1
|
| 174 |
+
|
| 175 |
+
....
|
| 176 |
+
No user action configurations found. Not starting user actions.
|
| 177 |
+
[2022-12-04 06:45:27,509] INFO {datahub_actions.cli.actions:76} - DataHub Actions version: unavailable (installed editable via git)
|
| 178 |
+
[2022-12-04 06:45:27,647] WARNING {datahub_actions.cli.actions:103} - Skipping pipeline datahub_slack_action as it is not enabled
|
| 179 |
+
[2022-12-04 06:45:27,649] WARNING {datahub_actions.cli.actions:103} - Skipping pipeline datahub_teams_action as it is not enabled
|
| 180 |
+
[2022-12-04 06:45:27,649] INFO {datahub_actions.cli.actions:119} - Action Pipeline with name 'ingestion_executor' is now running.
|
| 181 |
+
...
|
| 182 |
+
|
| 183 |
+
```
|
| 184 |
+
|
docs/actions/concepts.md
ADDED
|
@@ -0,0 +1,101 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# DataHub Actions Concepts
|
| 2 |
+
|
| 3 |
+
The Actions framework includes pluggable components for filtering, transforming, and reacting to important DataHub, such as
|
| 4 |
+
|
| 5 |
+
- Tag Additions / Removals
|
| 6 |
+
- Glossary Term Additions / Removals
|
| 7 |
+
- Schema Field Additions / Removals
|
| 8 |
+
- Owner Additions / Removals
|
| 9 |
+
|
| 10 |
+
& more, in real time.
|
| 11 |
+
|
| 12 |
+
DataHub Actions comes with open library of freely available Transformers, Actions, Events, and more.
|
| 13 |
+
|
| 14 |
+
Finally, the framework is highly configurable & scalable. Notable highlights include:
|
| 15 |
+
|
| 16 |
+
- **Distributed Actions**: Ability to scale-out processing for a single action. Support for running the same Action configuration across multiple nodes to load balance the traffic from the event stream.
|
| 17 |
+
- **At-least Once Delivery**: Native support for independent processing state for each Action via post-processing acking to achieve at-least once semantics.
|
| 18 |
+
- **Robust Error Handling**: Configurable failure policies featuring event-retry, dead letter queue, and failed-event continuation policy to achieve the guarantees required by your organization.
|
| 19 |
+
|
| 20 |
+
|
| 21 |
+
### Use Cases
|
| 22 |
+
|
| 23 |
+
Real-time use cases broadly fall into the following categories:
|
| 24 |
+
|
| 25 |
+
- **Notifications**: Generate organization-specific notifications when a change is made on DataHub. For example, send an email to the governance team when a "PII" tag is added to any data asset.
|
| 26 |
+
- **Workflow Integration**: Integrate DataHub into your organization's internal workflows. For example, create a Jira ticket when specific Tags or Terms are proposed on a Dataset.
|
| 27 |
+
- **Synchronization**: Syncing changes made in DataHub into a 3rd party system. For example, reflecting Tag additions in DataHub into Snowflake.
|
| 28 |
+
- **Auditing**: Audit who is making what changes on DataHub through time.
|
| 29 |
+
|
| 30 |
+
and more!
|
| 31 |
+
|
| 32 |
+
## Concepts
|
| 33 |
+
|
| 34 |
+
The Actions Framework consists of a few core concepts--
|
| 35 |
+
|
| 36 |
+
- **Pipelines**
|
| 37 |
+
- **Events** and **Event Sources**
|
| 38 |
+
- **Transformers**
|
| 39 |
+
- **Actions**
|
| 40 |
+
|
| 41 |
+
Each of these will be described in detail below.
|
| 42 |
+
|
| 43 |
+

|
| 44 |
+
**In the Actions Framework, Events flow continuously from left-to-right.**
|
| 45 |
+
|
| 46 |
+
### Pipelines
|
| 47 |
+
|
| 48 |
+
A **Pipeline** is a continuously running process which performs the following functions:
|
| 49 |
+
|
| 50 |
+
1. Polls events from a configured Event Source (described below)
|
| 51 |
+
2. Applies configured Transformation + Filtering to the Event
|
| 52 |
+
3. Executes the configured Action on the resulting Event
|
| 53 |
+
|
| 54 |
+
in addition to handling initialization, errors, retries, logging, and more.
|
| 55 |
+
|
| 56 |
+
Each Action Configuration file corresponds to a unique Pipeline. In practice,
|
| 57 |
+
each Pipeline has its very own Event Source, Transforms, and Actions. This makes it easy to maintain state for mission-critical Actions independently.
|
| 58 |
+
|
| 59 |
+
Importantly, each Action must have a unique name. This serves as a stable identifier across Pipeline run which can be useful in saving the Pipeline's consumer state (ie. resiliency + reliability). For example, the Kafka Event Source (default) uses the pipeline name as the Kafka Consumer Group id. This enables you to easily scale-out your Actions by running multiple processes with the same exact configuration file. Each will simply become different consumers in the same consumer group, sharing traffic of the DataHub Events stream.
|
| 60 |
+
|
| 61 |
+
### Events
|
| 62 |
+
|
| 63 |
+
**Events** are data objects representing changes that have occurred on DataHub. Strictly speaking, the only requirement that the Actions framework imposes is that these objects must be
|
| 64 |
+
|
| 65 |
+
a. Convertible to JSON
|
| 66 |
+
b. Convertible from JSON
|
| 67 |
+
|
| 68 |
+
So that in the event of processing failures, events can be written and read from a failed events file.
|
| 69 |
+
|
| 70 |
+
|
| 71 |
+
#### Event Types
|
| 72 |
+
|
| 73 |
+
Each Event instance inside the framework corresponds to a single **Event Type**, which is common name (e.g. "EntityChangeEvent_v1") which can be used to understand the shape of the Event. This can be thought of as a "topic" or "stream" name. That being said, Events associated with a single type are not expected to change in backwards-breaking ways across versons.
|
| 74 |
+
|
| 75 |
+
### Event Sources
|
| 76 |
+
|
| 77 |
+
Events are produced to the framework by **Event Sources**. Event Sources may include their own guarantees, configurations, behaviors, and semantics. They usually produce a fixed set of Event Types.
|
| 78 |
+
|
| 79 |
+
In addition to sourcing events, Event Sources are also responsible for acking the succesful processing of an event by implementing the `ack` method. This is invoked by the framework once the Event is guaranteed to have reached the configured Action successfully.
|
| 80 |
+
|
| 81 |
+
### Transformers
|
| 82 |
+
|
| 83 |
+
**Transformers** are pluggable components which take an Event as input, and produce an Event (or nothing) as output. This can be used to enrich the information of an Event prior to sending it to an Action.
|
| 84 |
+
|
| 85 |
+
Multiple Transformers can be configured to run in sequence, filtering and transforming an event in multiple steps.
|
| 86 |
+
|
| 87 |
+
Transformers can also be used to generate a completely new type of Event (i.e. registered at runtime via the Event Registry) which can subsequently serve as input to an Action.
|
| 88 |
+
|
| 89 |
+
Transformers can be easily customized and plugged in to meet an organization's unqique requirements. For more information on developing a Transformer, check out [Developing a Transformer](guides/developing-a-transformer.md)
|
| 90 |
+
|
| 91 |
+
|
| 92 |
+
### Action
|
| 93 |
+
|
| 94 |
+
**Actions** are pluggable components which take an Event as input and perform some business logic. Examples may be sending a Slack notification, logging to a file,
|
| 95 |
+
or creating a Jira ticket, etc.
|
| 96 |
+
|
| 97 |
+
Each Pipeline can be configured to have a single Action which runs after the filtering and transformations have occurred.
|
| 98 |
+
|
| 99 |
+
Actions can be easily customized and plugged in to meet an organization's unqique requirements. For more information on developing a Action, check out [Developing a Action](guides/developing-an-action.md)
|
| 100 |
+
|
| 101 |
+
|
docs/actions/events/entity-change-event.md
ADDED
|
@@ -0,0 +1,352 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Entity Change Event V1
|
| 2 |
+
|
| 3 |
+
## Event Type
|
| 4 |
+
|
| 5 |
+
`EntityChangeEvent_v1`
|
| 6 |
+
|
| 7 |
+
## Overview
|
| 8 |
+
|
| 9 |
+
This Event is emitted when certain changes are made to an entity (dataset, dashboard, chart, etc) on DataHub.
|
| 10 |
+
|
| 11 |
+
## Event Structure
|
| 12 |
+
|
| 13 |
+
Entity Change Events are generated in a variety of circumstances, but share a common set of fields.
|
| 14 |
+
|
| 15 |
+
### Common Fields
|
| 16 |
+
|
| 17 |
+
| Name | Type | Description | Optional |
|
| 18 |
+
|------------------|--------|--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|----------|
|
| 19 |
+
| entityUrn | String | The unique identifier for the Entity being changed. For example, a Dataset's urn. | False |
|
| 20 |
+
| entityType | String | The type of the entity being changed. Supported values include dataset, chart, dashboard, dataFlow (Pipeline), dataJob (Task), domain, tag, glossaryTerm, corpGroup, & corpUser. | False |
|
| 21 |
+
| category | String | The category of the change, related to the kind of operation that was performed. Examples include TAG, GLOSSARY_TERM, DOMAIN, LIFECYCLE, and more. | False |
|
| 22 |
+
| operation | String | The operation being performed on the entity given the category. For example, ADD ,REMOVE, MODIFY. For the set of valid operations, see the full catalog below. | False |
|
| 23 |
+
| modifier | String | The modifier that has been applied to the entity. The value depends on the category. An example includes the URN of a tag being applied to a Dataset or Schema Field. | True |
|
| 24 |
+
| parameters | Dict | Additional key-value parameters used to provide specific context. The precise contents depends on the category + operation of the event. See the catalog below for a full summary of the combinations. | True |
|
| 25 |
+
| auditStamp.actor | String | The urn of the actor who triggered the change. | False |
|
| 26 |
+
| auditStamp.time | Number | The timestamp in milliseconds corresponding to the event. | False |
|
| 27 |
+
|
| 28 |
+
|
| 29 |
+
|
| 30 |
+
In following sections, we will provide sample events for each scenario in which Entity Change Events are fired.
|
| 31 |
+
|
| 32 |
+
|
| 33 |
+
### Add Tag Event
|
| 34 |
+
|
| 35 |
+
This event is emitted when a Tag has been added to an entity on DataHub.
|
| 36 |
+
|
| 37 |
+
#### Sample Event
|
| 38 |
+
|
| 39 |
+
```json
|
| 40 |
+
{
|
| 41 |
+
"entityUrn": "urn:li:dataset:abc",
|
| 42 |
+
"entityType": "dataset",
|
| 43 |
+
"category": "TAG",
|
| 44 |
+
"operation": "ADD",
|
| 45 |
+
"modifier": "urn:li:tag:PII",
|
| 46 |
+
"parameters": {
|
| 47 |
+
"tagUrn": "urn:li:tag:PII"
|
| 48 |
+
},
|
| 49 |
+
"auditStamp": {
|
| 50 |
+
"actor": "urn:li:corpuser:jdoe",
|
| 51 |
+
"time": 1649953100653
|
| 52 |
+
}
|
| 53 |
+
}
|
| 54 |
+
```
|
| 55 |
+
|
| 56 |
+
|
| 57 |
+
### Remove Tag Event
|
| 58 |
+
|
| 59 |
+
This event is emitted when a Tag has been removed from an entity on DataHub.
|
| 60 |
+
Header
|
| 61 |
+
|
| 62 |
+
#### Sample Event
|
| 63 |
+
```json
|
| 64 |
+
{
|
| 65 |
+
"entityUrn": "urn:li:dataset:abc",
|
| 66 |
+
"entityType": "dataset",
|
| 67 |
+
"category": "TAG",
|
| 68 |
+
"operation": "REMOVE",
|
| 69 |
+
"modifier": "urn:li:tag:PII",
|
| 70 |
+
"parameters": {
|
| 71 |
+
"tagUrn": "urn:li:tag:PII"
|
| 72 |
+
},
|
| 73 |
+
"auditStamp": {
|
| 74 |
+
"actor": "urn:li:corpuser:jdoe",
|
| 75 |
+
"time": 1649953100653
|
| 76 |
+
}
|
| 77 |
+
}
|
| 78 |
+
```
|
| 79 |
+
|
| 80 |
+
|
| 81 |
+
### Add Glossary Term Event
|
| 82 |
+
|
| 83 |
+
This event is emitted when a Glossary Term has been added to an entity on DataHub.
|
| 84 |
+
Header
|
| 85 |
+
|
| 86 |
+
#### Sample Event
|
| 87 |
+
```json
|
| 88 |
+
{
|
| 89 |
+
"entityUrn": "urn:li:dataset:abc",
|
| 90 |
+
"entityType": "dataset",
|
| 91 |
+
"category": "GLOSSARY_TERM",
|
| 92 |
+
"operation": "ADD",
|
| 93 |
+
"modifier": "urn:li:glossaryTerm:ExampleNode.ExampleTerm",
|
| 94 |
+
"parameters": {
|
| 95 |
+
"termUrn": "urn:li:glossaryTerm:ExampleNode.ExampleTerm"
|
| 96 |
+
},
|
| 97 |
+
"auditStamp": {
|
| 98 |
+
"actor": "urn:li:corpuser:jdoe",
|
| 99 |
+
"time": 1649953100653
|
| 100 |
+
}
|
| 101 |
+
}
|
| 102 |
+
```
|
| 103 |
+
|
| 104 |
+
|
| 105 |
+
### Remove Glossary Term Event
|
| 106 |
+
|
| 107 |
+
This event is emitted when a Glossary Term has been removed from an entity on DataHub.
|
| 108 |
+
|
| 109 |
+
#### Sample Event
|
| 110 |
+
```json
|
| 111 |
+
{
|
| 112 |
+
"entityUrn": "urn:li:dataset:abc",
|
| 113 |
+
"entityType": "dataset",
|
| 114 |
+
"category": "GLOSSARY_TERM",
|
| 115 |
+
"operation": "REMOVE",
|
| 116 |
+
"modifier": "urn:li:glossaryTerm:ExampleNode.ExampleTerm",
|
| 117 |
+
"parameters": {
|
| 118 |
+
"termUrn": "urn:li:glossaryTerm:ExampleNode.ExampleTerm"
|
| 119 |
+
},
|
| 120 |
+
"auditStamp": {
|
| 121 |
+
"actor": "urn:li:corpuser:jdoe",
|
| 122 |
+
"time": 1649953100653
|
| 123 |
+
}
|
| 124 |
+
}
|
| 125 |
+
```
|
| 126 |
+
|
| 127 |
+
|
| 128 |
+
### Add Domain Event
|
| 129 |
+
|
| 130 |
+
This event is emitted when Domain has been added to an entity on DataHub.
|
| 131 |
+
|
| 132 |
+
#### Sample Event
|
| 133 |
+
```json
|
| 134 |
+
{
|
| 135 |
+
"entityUrn": "urn:li:dataset:abc",
|
| 136 |
+
"entityType": "dataset",
|
| 137 |
+
"category": "DOMAIN",
|
| 138 |
+
"operation": "ADD",
|
| 139 |
+
"modifier": "urn:li:domain:ExampleDomain",
|
| 140 |
+
"parameters": {
|
| 141 |
+
"domainUrn": "urn:li:domain:ExampleDomain"
|
| 142 |
+
},
|
| 143 |
+
"auditStamp": {
|
| 144 |
+
"actor": "urn:li:corpuser:jdoe",
|
| 145 |
+
"time": 1649953100653
|
| 146 |
+
}
|
| 147 |
+
}
|
| 148 |
+
```
|
| 149 |
+
|
| 150 |
+
|
| 151 |
+
### Remove Domain Event
|
| 152 |
+
|
| 153 |
+
This event is emitted when Domain has been removed from an entity on DataHub.
|
| 154 |
+
Header
|
| 155 |
+
|
| 156 |
+
#### Sample Event
|
| 157 |
+
```json
|
| 158 |
+
{
|
| 159 |
+
"entityUrn": "urn:li:dataset:abc",
|
| 160 |
+
"entityType": "dataset",
|
| 161 |
+
"category": "DOMAIN",
|
| 162 |
+
"operation": "REMOVE",
|
| 163 |
+
"modifier": "urn:li:domain:ExampleDomain",
|
| 164 |
+
"parameters": {
|
| 165 |
+
"domainUrn": "urn:li:domain:ExampleDomain"
|
| 166 |
+
},
|
| 167 |
+
"auditStamp": {
|
| 168 |
+
"actor": "urn:li:corpuser:jdoe",
|
| 169 |
+
"time": 1649953100653
|
| 170 |
+
}
|
| 171 |
+
}
|
| 172 |
+
```
|
| 173 |
+
|
| 174 |
+
|
| 175 |
+
### Add Owner Event
|
| 176 |
+
|
| 177 |
+
This event is emitted when a new owner has been assigned to an entity on DataHub.
|
| 178 |
+
|
| 179 |
+
#### Sample Event
|
| 180 |
+
```json
|
| 181 |
+
{
|
| 182 |
+
"entityUrn": "urn:li:dataset:abc",
|
| 183 |
+
"entityType": "dataset",
|
| 184 |
+
"category": "OWNER",
|
| 185 |
+
"operation": "ADD",
|
| 186 |
+
"modifier": "urn:li:corpuser:jdoe",
|
| 187 |
+
"parameters": {
|
| 188 |
+
"ownerUrn": "urn:li:corpuser:jdoe",
|
| 189 |
+
"ownerType": "BUSINESS_OWNER"
|
| 190 |
+
},
|
| 191 |
+
"auditStamp": {
|
| 192 |
+
"actor": "urn:li:corpuser:jdoe",
|
| 193 |
+
"time": 1649953100653
|
| 194 |
+
}
|
| 195 |
+
}
|
| 196 |
+
```
|
| 197 |
+
|
| 198 |
+
|
| 199 |
+
### Remove Owner Event
|
| 200 |
+
|
| 201 |
+
This event is emitted when an existing owner has been removed from an entity on DataHub.
|
| 202 |
+
|
| 203 |
+
#### Sample Event
|
| 204 |
+
```json
|
| 205 |
+
{
|
| 206 |
+
"entityUrn": "urn:li:dataset:abc",
|
| 207 |
+
"entityType": "dataset",
|
| 208 |
+
"category": "OWNER",
|
| 209 |
+
"operation": "REMOVE",
|
| 210 |
+
"modifier": "urn:li:corpuser:jdoe",
|
| 211 |
+
"parameters": {
|
| 212 |
+
"ownerUrn": "urn:li:corpuser:jdoe",
|
| 213 |
+
"ownerType": "BUSINESS_OWNER"
|
| 214 |
+
},
|
| 215 |
+
"auditStamp": {
|
| 216 |
+
"actor": "urn:li:corpuser:jdoe",
|
| 217 |
+
"time": 1649953100653
|
| 218 |
+
}
|
| 219 |
+
}
|
| 220 |
+
```
|
| 221 |
+
|
| 222 |
+
|
| 223 |
+
### Modify Deprecation Event
|
| 224 |
+
|
| 225 |
+
This event is emitted when the deprecation status of an entity has been modified on DataHub.
|
| 226 |
+
|
| 227 |
+
#### Sample Event
|
| 228 |
+
```json
|
| 229 |
+
{
|
| 230 |
+
"entityUrn": "urn:li:dataset:abc",
|
| 231 |
+
"entityType": "dataset",
|
| 232 |
+
"category": "DEPRECATION",
|
| 233 |
+
"operation": "MODIFY",
|
| 234 |
+
"modifier": "DEPRECATED",
|
| 235 |
+
"parameters": {
|
| 236 |
+
"status": "DEPRECATED"
|
| 237 |
+
},
|
| 238 |
+
"auditStamp": {
|
| 239 |
+
"actor": "urn:li:corpuser:jdoe",
|
| 240 |
+
"time": 1649953100653
|
| 241 |
+
}
|
| 242 |
+
}
|
| 243 |
+
```
|
| 244 |
+
|
| 245 |
+
|
| 246 |
+
### Add Dataset Schema Field Event
|
| 247 |
+
|
| 248 |
+
This event is emitted when a new field has been added to a Dataset Schema.
|
| 249 |
+
|
| 250 |
+
#### Sample Event
|
| 251 |
+
|
| 252 |
+
```json
|
| 253 |
+
{
|
| 254 |
+
"entityUrn": "urn:li:dataset:abc",
|
| 255 |
+
"entityType": "dataset",
|
| 256 |
+
"category": "TECHNICAL_SCHEMA",
|
| 257 |
+
"operation": "ADD",
|
| 258 |
+
"modifier": "urn:li:schemaField:(urn:li:dataset:abc,newFieldName)",
|
| 259 |
+
"parameters": {
|
| 260 |
+
"fieldUrn": "urn:li:schemaField:(urn:li:dataset:abc,newFieldName)",
|
| 261 |
+
"fieldPath": "newFieldName",
|
| 262 |
+
"nullable": false
|
| 263 |
+
},
|
| 264 |
+
"auditStamp": {
|
| 265 |
+
"actor": "urn:li:corpuser:jdoe",
|
| 266 |
+
"time": 1649953100653
|
| 267 |
+
}
|
| 268 |
+
}
|
| 269 |
+
```
|
| 270 |
+
|
| 271 |
+
|
| 272 |
+
### Remove Dataset Schema Field Event
|
| 273 |
+
|
| 274 |
+
This event is emitted when a new field has been remove from a Dataset Schema.
|
| 275 |
+
|
| 276 |
+
#### Sample Event
|
| 277 |
+
```json
|
| 278 |
+
{
|
| 279 |
+
"entityUrn": "urn:li:dataset:abc",
|
| 280 |
+
"entityType": "dataset",
|
| 281 |
+
"category": "TECHNICAL_SCHEMA",
|
| 282 |
+
"operation": "REMOVE",
|
| 283 |
+
"modifier": "urn:li:schemaField:(urn:li:dataset:abc,newFieldName)",
|
| 284 |
+
"parameters": {
|
| 285 |
+
"fieldUrn": "urn:li:schemaField:(urn:li:dataset:abc,newFieldName)",
|
| 286 |
+
"fieldPath": "newFieldName",
|
| 287 |
+
"nullable": false
|
| 288 |
+
},
|
| 289 |
+
"auditStamp": {
|
| 290 |
+
"actor": "urn:li:corpuser:jdoe",
|
| 291 |
+
"time": 1649953100653
|
| 292 |
+
}
|
| 293 |
+
}
|
| 294 |
+
```
|
| 295 |
+
|
| 296 |
+
|
| 297 |
+
### Entity Create Event
|
| 298 |
+
|
| 299 |
+
This event is emitted when a new entity has been created on DataHub.
|
| 300 |
+
Header
|
| 301 |
+
|
| 302 |
+
#### Sample Event
|
| 303 |
+
```json
|
| 304 |
+
{
|
| 305 |
+
"entityUrn": "urn:li:dataset:abc",
|
| 306 |
+
"entityType": "dataset",
|
| 307 |
+
"category": "LIFECYCLE",
|
| 308 |
+
"operation": "CREATE",
|
| 309 |
+
"auditStamp": {
|
| 310 |
+
"actor": "urn:li:corpuser:jdoe",
|
| 311 |
+
"time": 1649953100653
|
| 312 |
+
}
|
| 313 |
+
}
|
| 314 |
+
```
|
| 315 |
+
|
| 316 |
+
|
| 317 |
+
### Entity Soft-Delete Event
|
| 318 |
+
|
| 319 |
+
This event is emitted when a new entity has been soft-deleted on DataHub.
|
| 320 |
+
|
| 321 |
+
#### Sample Event
|
| 322 |
+
```json
|
| 323 |
+
{
|
| 324 |
+
"entityUrn": "urn:li:dataset:abc",
|
| 325 |
+
"entityType": "dataset",
|
| 326 |
+
"category": "LIFECYCLE",
|
| 327 |
+
"operation": "SOFT_DELETE",
|
| 328 |
+
"auditStamp": {
|
| 329 |
+
"actor": "urn:li:corpuser:jdoe",
|
| 330 |
+
"time": 1649953100653
|
| 331 |
+
}
|
| 332 |
+
}
|
| 333 |
+
```
|
| 334 |
+
|
| 335 |
+
|
| 336 |
+
### Entity Hard-Delete Event
|
| 337 |
+
|
| 338 |
+
This event is emitted when a new entity has been hard-deleted on DataHub.
|
| 339 |
+
|
| 340 |
+
#### Sample Event
|
| 341 |
+
```json
|
| 342 |
+
{
|
| 343 |
+
"entityUrn": "urn:li:dataset:abc",
|
| 344 |
+
"entityType": "dataset",
|
| 345 |
+
"category": "LIFECYCLE",
|
| 346 |
+
"operation": "HARD_DELETE",
|
| 347 |
+
"auditStamp": {
|
| 348 |
+
"actor": "urn:li:corpuser:jdoe",
|
| 349 |
+
"time": 1649953100653
|
| 350 |
+
}
|
| 351 |
+
}
|
| 352 |
+
```
|
docs/actions/events/metadata-change-log-event.md
ADDED
|
@@ -0,0 +1,151 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Metadata Change Log Event V1
|
| 2 |
+
|
| 3 |
+
## Event Type
|
| 4 |
+
|
| 5 |
+
`MetadataChangeLog_v1`
|
| 6 |
+
|
| 7 |
+
## Overview
|
| 8 |
+
|
| 9 |
+
This event is emitted when any aspect on DataHub Metadata Graph is changed. This includes creates, updates, and removals of both "versioned" aspects and "time-series" aspects.
|
| 10 |
+
|
| 11 |
+
> Disclaimer: This event is quite powerful, but also quite low-level. Because it exposes the underlying metadata model directly, it is subject to more frequent structural and semantic changes than the higher level [Entity Change Event](entity-change-event.md). We recommend using that event instead to achieve your use case when possible.
|
| 12 |
+
|
| 13 |
+
## Event Structure
|
| 14 |
+
|
| 15 |
+
The fields include
|
| 16 |
+
|
| 17 |
+
| Name | Type | Description | Optional |
|
| 18 |
+
|---------------------------------|--------|--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|----------|
|
| 19 |
+
| entityUrn | String | The unique identifier for the Entity being changed. For example, a Dataset's urn. | False |
|
| 20 |
+
| entityType | String | The type of the entity being changed. Supported values include dataset, chart, dashboard, dataFlow (Pipeline), dataJob (Task), domain, tag, glossaryTerm, corpGroup, & corpUser. | False |
|
| 21 |
+
| entityKeyAspect | Object | The key struct of the entity that was changed. Only present if the Metadata Change Proposal contained the raw key struct. | True |
|
| 22 |
+
| changeType | String | The change type. UPSERT or DELETE are currently supported. | False |
|
| 23 |
+
| aspectName | String | The entity aspect which was changed. | False |
|
| 24 |
+
| aspect | Object | The new aspect value. Null if the aspect was deleted. | True |
|
| 25 |
+
| aspect.contentType | String | The serialization type of the aspect itself. The only supported value is `application/json`. | False |
|
| 26 |
+
| aspect.value | String | The serialized aspect. This is a JSON-serialized representing the aspect document originally defined in PDL. See https://github.com/datahub-project/datahub/tree/master/metadata-models/src/main/pegasus/com/linkedin for more. | False |
|
| 27 |
+
| previousAspectValue | Object | The previous aspect value. Null if the aspect did not exist previously. | True |
|
| 28 |
+
| previousAspectValue.contentType | String | The serialization type of the aspect itself. The only supported value is `application/json` | False |
|
| 29 |
+
| previousAspectValue.value | String | The serialized aspect. This is a JSON-serialized representing the aspect document originally defined in PDL. See https://github.com/datahub-project/datahub/tree/master/metadata-models/src/main/pegasus/com/linkedin for more. | False |
|
| 30 |
+
| systemMetadata | Object | The new system metadata. This includes the the ingestion run-id, model registry and more. For the full structure, see https://github.com/datahub-project/datahub/blob/master/metadata-models/src/main/pegasus/com/linkedin/mxe/SystemMetadata.pdl | True |
|
| 31 |
+
| previousSystemMetadata | Object | The previous system metadata. This includes the the ingestion run-id, model registry and more. For the full structure, see https://github.com/datahub-project/datahub/blob/master/metadata-models/src/main/pegasus/com/linkedin/mxe/SystemMetadata.pdl | True |
|
| 32 |
+
| created | Object | Audit stamp about who triggered the Metadata Change and when. | False |
|
| 33 |
+
| created.time | Number | The timestamp in milliseconds when the aspect change occurred. | False |
|
| 34 |
+
| created.actor | String | The URN of the actor (e.g. corpuser) that triggered the change.
|
| 35 |
+
|
| 36 |
+
|
| 37 |
+
### Sample Events
|
| 38 |
+
|
| 39 |
+
#### Tag Change Event
|
| 40 |
+
|
| 41 |
+
```json
|
| 42 |
+
{
|
| 43 |
+
"entityType": "container",
|
| 44 |
+
"entityUrn": "urn:li:container:DATABASE",
|
| 45 |
+
"entityKeyAspect": null,
|
| 46 |
+
"changeType": "UPSERT",
|
| 47 |
+
"aspectName": "globalTags",
|
| 48 |
+
"aspect": {
|
| 49 |
+
"value": "{\"tags\":[{\"tag\":\"urn:li:tag:pii\"}]}",
|
| 50 |
+
"contentType": "application/json"
|
| 51 |
+
},
|
| 52 |
+
"systemMetadata": {
|
| 53 |
+
"lastObserved": 1651516475595,
|
| 54 |
+
"runId": "no-run-id-provided",
|
| 55 |
+
"registryName": "unknownRegistry",
|
| 56 |
+
"registryVersion": "0.0.0.0-dev",
|
| 57 |
+
"properties": null
|
| 58 |
+
},
|
| 59 |
+
"previousAspectValue": null,
|
| 60 |
+
"previousSystemMetadata": null,
|
| 61 |
+
"created": {
|
| 62 |
+
"time": 1651516475594,
|
| 63 |
+
"actor": "urn:li:corpuser:datahub",
|
| 64 |
+
"impersonator": null
|
| 65 |
+
}
|
| 66 |
+
}
|
| 67 |
+
```
|
| 68 |
+
|
| 69 |
+
#### Glossary Term Change Event
|
| 70 |
+
|
| 71 |
+
```json
|
| 72 |
+
{
|
| 73 |
+
"entityType": "dataset",
|
| 74 |
+
"entityUrn": "urn:li:dataset:(urn:li:dataPlatform:hdfs,SampleHdfsDataset,PROD)",
|
| 75 |
+
"entityKeyAspect": null,
|
| 76 |
+
"changeType": "UPSERT",
|
| 77 |
+
"aspectName": "glossaryTerms",
|
| 78 |
+
"aspect": {
|
| 79 |
+
"value": "{\"auditStamp\":{\"actor\":\"urn:li:corpuser:datahub\",\"time\":1651516599479},\"terms\":[{\"urn\":\"urn:li:glossaryTerm:CustomerAccount\"}]}",
|
| 80 |
+
"contentType": "application/json"
|
| 81 |
+
},
|
| 82 |
+
"systemMetadata": {
|
| 83 |
+
"lastObserved": 1651516599486,
|
| 84 |
+
"runId": "no-run-id-provided",
|
| 85 |
+
"registryName": "unknownRegistry",
|
| 86 |
+
"registryVersion": "0.0.0.0-dev",
|
| 87 |
+
"properties": null
|
| 88 |
+
},
|
| 89 |
+
"previousAspectValue": null,
|
| 90 |
+
"previousSystemMetadata": null,
|
| 91 |
+
"created": {
|
| 92 |
+
"time": 1651516599480,
|
| 93 |
+
"actor": "urn:li:corpuser:datahub",
|
| 94 |
+
"impersonator": null
|
| 95 |
+
}
|
| 96 |
+
}
|
| 97 |
+
```
|
| 98 |
+
|
| 99 |
+
#### Owner Change Event
|
| 100 |
+
|
| 101 |
+
```json
|
| 102 |
+
{
|
| 103 |
+
"auditHeader": null,
|
| 104 |
+
"entityType": "dataset",
|
| 105 |
+
"entityUrn": "urn:li:dataset:(urn:li:dataPlatform:hdfs,SampleHdfsDataset,PROD)",
|
| 106 |
+
"entityKeyAspect": null,
|
| 107 |
+
"changeType": "UPSERT",
|
| 108 |
+
"aspectName": "ownership",
|
| 109 |
+
"aspect": {
|
| 110 |
+
"value": "{\"owners\":[{\"type\":\"DATAOWNER\",\"owner\":\"urn:li:corpuser:datahub\"}],\"lastModified\":{\"actor\":\"urn:li:corpuser:datahub\",\"time\":1651516640488}}",
|
| 111 |
+
"contentType": "application/json"
|
| 112 |
+
},
|
| 113 |
+
"systemMetadata": {
|
| 114 |
+
"lastObserved": 1651516640493,
|
| 115 |
+
"runId": "no-run-id-provided",
|
| 116 |
+
"registryName": "unknownRegistry",
|
| 117 |
+
"registryVersion": "0.0.0.0-dev",
|
| 118 |
+
"properties": null
|
| 119 |
+
},
|
| 120 |
+
"previousAspectValue": {
|
| 121 |
+
"value": "{\"owners\":[{\"owner\":\"urn:li:corpuser:jdoe\",\"type\":\"DATAOWNER\"},{\"owner\":\"urn:li:corpuser:datahub\",\"type\":\"DATAOWNER\"}],\"lastModified\":{\"actor\":\"urn:li:corpuser:jdoe\",\"time\":1581407189000}}",
|
| 122 |
+
"contentType": "application/json"
|
| 123 |
+
},
|
| 124 |
+
"previousSystemMetadata": {
|
| 125 |
+
"lastObserved": 1651516415088,
|
| 126 |
+
"runId": "file-2022_05_02-11_33_35",
|
| 127 |
+
"registryName": null,
|
| 128 |
+
"registryVersion": null,
|
| 129 |
+
"properties": null
|
| 130 |
+
},
|
| 131 |
+
"created": {
|
| 132 |
+
"time": 1651516640490,
|
| 133 |
+
"actor": "urn:li:corpuser:datahub",
|
| 134 |
+
"impersonator": null
|
| 135 |
+
}
|
| 136 |
+
}
|
| 137 |
+
```
|
| 138 |
+
## FAQ
|
| 139 |
+
|
| 140 |
+
### Where can I find all the aspects and their schemas?
|
| 141 |
+
|
| 142 |
+
Great Question! All MetadataChangeLog events are based on the Metadata Model which is comprised of Entities,
|
| 143 |
+
Aspects, and Relationships which make up an enterprise Metadata Graph. We recommend checking out the following
|
| 144 |
+
resources to learn more about this:
|
| 145 |
+
|
| 146 |
+
- [Intro to Metadata Model](https://datahubproject.io/docs/metadata-modeling/metadata-model)
|
| 147 |
+
|
| 148 |
+
You can also find a comprehensive list of Entities + Aspects of the Metadata Model under the **Metadata Modeling > Entities** section of the [official DataHub docs](https://datahubproject.io/docs/).
|
| 149 |
+
|
| 150 |
+
|
| 151 |
+
|
docs/actions/guides/developing-a-transformer.md
ADDED
|
@@ -0,0 +1,133 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Developing a Transformer
|
| 2 |
+
|
| 3 |
+
In this guide, we will outline each step to developing a custom Transformer for the DataHub Actions Framework.
|
| 4 |
+
|
| 5 |
+
## Overview
|
| 6 |
+
|
| 7 |
+
Developing a DataHub Actions Transformer is a matter of extending the `Transformer` base class in Python, installing your
|
| 8 |
+
Transformer to make it visible to the framework, and then configuring the framework to use the new Transformer.
|
| 9 |
+
|
| 10 |
+
|
| 11 |
+
## Step 1: Defining a Transformer
|
| 12 |
+
|
| 13 |
+
To implement an Transformer, we'll need to extend the `Transformer` base class and override the following functions:
|
| 14 |
+
|
| 15 |
+
- `create()` - This function is invoked to instantiate the action, with a free-form configuration dictionary
|
| 16 |
+
extracted from the Actions configuration file as input.
|
| 17 |
+
- `transform()` - This function is invoked when an Event is received. It should contain the core logic of the Transformer.
|
| 18 |
+
and will return the transformed Event, or `None` if the Event should be filtered.
|
| 19 |
+
|
| 20 |
+
Let's start by defining a new implementation of Transformer called `CustomTransformer`. We'll keep it simple-- this Transformer will
|
| 21 |
+
print the configuration that is provided when it is created, and print any Events that it receives.
|
| 22 |
+
|
| 23 |
+
```python
|
| 24 |
+
# custom_transformer.py
|
| 25 |
+
from datahub_actions.transform.transformer import Transformer
|
| 26 |
+
from datahub_actions.event.event import EventEnvelope
|
| 27 |
+
from datahub_actions.pipeline.pipeline_context import PipelineContext
|
| 28 |
+
from typing import Optional
|
| 29 |
+
|
| 30 |
+
class CustomTransformer(Transformer):
|
| 31 |
+
@classmethod
|
| 32 |
+
def create(cls, config_dict: dict, ctx: PipelineContext) -> "Transformer":
|
| 33 |
+
# Simply print the config_dict.
|
| 34 |
+
print(config_dict)
|
| 35 |
+
return cls(config_dict, ctx)
|
| 36 |
+
|
| 37 |
+
def __init__(self, ctx: PipelineContext):
|
| 38 |
+
self.ctx = ctx
|
| 39 |
+
|
| 40 |
+
def transform(self, event: EventEnvelope) -> Optional[EventEnvelope]:
|
| 41 |
+
# Simply print the received event.
|
| 42 |
+
print(event)
|
| 43 |
+
# And return the original event (no-op)
|
| 44 |
+
return event
|
| 45 |
+
```
|
| 46 |
+
|
| 47 |
+
|
| 48 |
+
## Step 2: Installing the Transformer
|
| 49 |
+
|
| 50 |
+
Now that we've defined the Transformer, we need to make it visible to the framework by making
|
| 51 |
+
it available in the Python runtime environment.
|
| 52 |
+
|
| 53 |
+
The easiest way to do this is to just place it in the same directory as your configuration file, in which case the module name is the same as the file
|
| 54 |
+
name - in this case it will be `custom_transformer`.
|
| 55 |
+
|
| 56 |
+
### Advanced: Installing as a Package
|
| 57 |
+
|
| 58 |
+
Alternatively, create a `setup.py` file in the same directory as the new Transformer to convert it into a package that pip can understand.
|
| 59 |
+
|
| 60 |
+
```
|
| 61 |
+
from setuptools import find_packages, setup
|
| 62 |
+
|
| 63 |
+
setup(
|
| 64 |
+
name="custom_transformer_example",
|
| 65 |
+
version="1.0",
|
| 66 |
+
packages=find_packages(),
|
| 67 |
+
# if you don't already have DataHub Actions installed, add it under install_requires
|
| 68 |
+
# install_requires=["acryl-datahub-actions"]
|
| 69 |
+
)
|
| 70 |
+
```
|
| 71 |
+
|
| 72 |
+
Next, install the package
|
| 73 |
+
|
| 74 |
+
```shell
|
| 75 |
+
pip install -e .
|
| 76 |
+
```
|
| 77 |
+
|
| 78 |
+
inside the module. (alt.`python setup.py`).
|
| 79 |
+
|
| 80 |
+
Once we have done this, our class will be referencable via `custom_transformer_example.custom_transformer:CustomTransformer`.
|
| 81 |
+
|
| 82 |
+
|
| 83 |
+
## Step 3: Running the Action
|
| 84 |
+
|
| 85 |
+
Now that we've defined our Transformer, we can create an Action configuration file that refers to the new Transformer.
|
| 86 |
+
We will need to provide the fully-qualified Python module & class name when doing so.
|
| 87 |
+
|
| 88 |
+
*Example Configuration*
|
| 89 |
+
|
| 90 |
+
```yaml
|
| 91 |
+
# custom_transformer_action.yaml
|
| 92 |
+
name: "custom_transformer_test"
|
| 93 |
+
source:
|
| 94 |
+
type: "kafka"
|
| 95 |
+
config:
|
| 96 |
+
connection:
|
| 97 |
+
bootstrap: ${KAFKA_BOOTSTRAP_SERVER:-localhost:9092}
|
| 98 |
+
schema_registry_url: ${SCHEMA_REGISTRY_URL:-http://localhost:8081}
|
| 99 |
+
transform:
|
| 100 |
+
- type: "custom_transformer_example.custom_transformer:CustomTransformer"
|
| 101 |
+
config:
|
| 102 |
+
# Some sample configuration which should be printed on create.
|
| 103 |
+
config1: value1
|
| 104 |
+
action:
|
| 105 |
+
# Simply reuse the default hello_world action
|
| 106 |
+
type: "hello_world"
|
| 107 |
+
```
|
| 108 |
+
|
| 109 |
+
Next, run the `datahub actions` command as usual:
|
| 110 |
+
|
| 111 |
+
```shell
|
| 112 |
+
datahub actions -c custom_transformer_action.yaml
|
| 113 |
+
```
|
| 114 |
+
|
| 115 |
+
If all is well, your Transformer should now be receiving & printing Events.
|
| 116 |
+
|
| 117 |
+
|
| 118 |
+
### (Optional) Step 4: Contributing the Transformer
|
| 119 |
+
|
| 120 |
+
If your Transformer is generally applicable, you can raise a PR to include it in the core Transformer library
|
| 121 |
+
provided by DataHub. All Transformers will live under the `datahub_actions/plugin/transform` directory inside the
|
| 122 |
+
[datahub-actions](https://github.com/acryldata/datahub-actions) repository.
|
| 123 |
+
|
| 124 |
+
Once you've added your new Transformer there, make sure that you make it discoverable by updating the `entry_points` section
|
| 125 |
+
of the `setup.py` file. This allows you to assign a globally unique name for you Transformer, so that people can use
|
| 126 |
+
it without defining the full module path.
|
| 127 |
+
|
| 128 |
+
#### Prerequisites:
|
| 129 |
+
|
| 130 |
+
Prerequisites to consideration for inclusion in the core Transformer library include
|
| 131 |
+
|
| 132 |
+
- **Testing** Define unit tests for your Transformer
|
| 133 |
+
- **Deduplication** Confirm that no existing Transformer serves the same purpose, or can be easily extended to serve the same purpose
|
docs/actions/guides/developing-an-action.md
ADDED
|
@@ -0,0 +1,132 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Developing an Action
|
| 2 |
+
|
| 3 |
+
In this guide, we will outline each step to developing a Action for the DataHub Actions Framework.
|
| 4 |
+
|
| 5 |
+
## Overview
|
| 6 |
+
|
| 7 |
+
Developing a DataHub Action is a matter of extending the `Action` base class in Python, installing your
|
| 8 |
+
Action to make it visible to the framework, and then configuring the framework to use the new Action.
|
| 9 |
+
|
| 10 |
+
|
| 11 |
+
## Step 1: Defining an Action
|
| 12 |
+
|
| 13 |
+
To implement an Action, we'll need to extend the `Action` base class and override the following functions:
|
| 14 |
+
|
| 15 |
+
- `create()` - This function is invoked to instantiate the action, with a free-form configuration dictionary
|
| 16 |
+
extracted from the Actions configuration file as input.
|
| 17 |
+
- `act()` - This function is invoked when an Action is received. It should contain the core logic of the Action.
|
| 18 |
+
- `close()` - This function is invoked when the framework has issued a shutdown of the pipeline. It should be used
|
| 19 |
+
to cleanup any processes happening inside the Action.
|
| 20 |
+
|
| 21 |
+
Let's start by defining a new implementation of Action called `CustomAction`. We'll keep it simple-- this Action will
|
| 22 |
+
print the configuration that is provided when it is created, and print any Events that it receives.
|
| 23 |
+
|
| 24 |
+
```python
|
| 25 |
+
# custom_action.py
|
| 26 |
+
from datahub_actions.action.action import Action
|
| 27 |
+
from datahub_actions.event.event_envelope import EventEnvelope
|
| 28 |
+
from datahub_actions.pipeline.pipeline_context import PipelineContext
|
| 29 |
+
|
| 30 |
+
class CustomAction(Action):
|
| 31 |
+
@classmethod
|
| 32 |
+
def create(cls, config_dict: dict, ctx: PipelineContext) -> "Action":
|
| 33 |
+
# Simply print the config_dict.
|
| 34 |
+
print(config_dict)
|
| 35 |
+
return cls(ctx)
|
| 36 |
+
|
| 37 |
+
def __init__(self, ctx: PipelineContext):
|
| 38 |
+
self.ctx = ctx
|
| 39 |
+
|
| 40 |
+
def act(self, event: EventEnvelope) -> None:
|
| 41 |
+
# Do something super important.
|
| 42 |
+
# For now, just print. :)
|
| 43 |
+
print(event)
|
| 44 |
+
|
| 45 |
+
def close(self) -> None:
|
| 46 |
+
pass
|
| 47 |
+
```
|
| 48 |
+
|
| 49 |
+
|
| 50 |
+
## Step 2: Installing the Action
|
| 51 |
+
|
| 52 |
+
Now that we've defined the Action, we need to make it visible to the framework by making it
|
| 53 |
+
available in the Python runtime environment.
|
| 54 |
+
|
| 55 |
+
The easiest way to do this is to just place it in the same directory as your configuration file, in which case the module name is the same as the file
|
| 56 |
+
name - in this case it will be `custom_action`.
|
| 57 |
+
|
| 58 |
+
### Advanced: Installing as a Package
|
| 59 |
+
|
| 60 |
+
Alternatively, create a `setup.py` file in the same directory as the new Action to convert it into a package that pip can understand.
|
| 61 |
+
|
| 62 |
+
```
|
| 63 |
+
from setuptools import find_packages, setup
|
| 64 |
+
|
| 65 |
+
setup(
|
| 66 |
+
name="custom_action_example",
|
| 67 |
+
version="1.0",
|
| 68 |
+
packages=find_packages(),
|
| 69 |
+
# if you don't already have DataHub Actions installed, add it under install_requires
|
| 70 |
+
# install_requires=["acryl-datahub-actions"]
|
| 71 |
+
)
|
| 72 |
+
```
|
| 73 |
+
|
| 74 |
+
Next, install the package
|
| 75 |
+
|
| 76 |
+
```shell
|
| 77 |
+
pip install -e .
|
| 78 |
+
```
|
| 79 |
+
|
| 80 |
+
inside the module. (alt.`python setup.py`).
|
| 81 |
+
|
| 82 |
+
Once we have done this, our class will be referencable via `custom_action_example.custom_action:CustomAction`.
|
| 83 |
+
|
| 84 |
+
|
| 85 |
+
## Step 3: Running the Action
|
| 86 |
+
|
| 87 |
+
Now that we've defined our Action, we can create an Action configuration file that refers to the new Action.
|
| 88 |
+
We will need to provide the fully-qualified Python module & class name when doing so.
|
| 89 |
+
|
| 90 |
+
*Example Configuration*
|
| 91 |
+
|
| 92 |
+
```yaml
|
| 93 |
+
# custom_action.yaml
|
| 94 |
+
name: "custom_action_test"
|
| 95 |
+
source:
|
| 96 |
+
type: "kafka"
|
| 97 |
+
config:
|
| 98 |
+
connection:
|
| 99 |
+
bootstrap: ${KAFKA_BOOTSTRAP_SERVER:-localhost:9092}
|
| 100 |
+
schema_registry_url: ${SCHEMA_REGISTRY_URL:-http://localhost:8081}
|
| 101 |
+
action:
|
| 102 |
+
type: "custom_action_example.custom_action:CustomAction"
|
| 103 |
+
config:
|
| 104 |
+
# Some sample configuration which should be printed on create.
|
| 105 |
+
config1: value1
|
| 106 |
+
```
|
| 107 |
+
|
| 108 |
+
Next, run the `datahub actions` command as usual:
|
| 109 |
+
|
| 110 |
+
```shell
|
| 111 |
+
datahub actions -c custom_action.yaml
|
| 112 |
+
```
|
| 113 |
+
|
| 114 |
+
If all is well, your Action should now be receiving & printing Events.
|
| 115 |
+
|
| 116 |
+
|
| 117 |
+
## (Optional) Step 4: Contributing the Action
|
| 118 |
+
|
| 119 |
+
If your Action is generally applicable, you can raise a PR to include it in the core Action library
|
| 120 |
+
provided by DataHub. All Actions will live under the `datahub_actions/plugin/action` directory inside the
|
| 121 |
+
[datahub-actions](https://github.com/acryldata/datahub-actions) repository.
|
| 122 |
+
|
| 123 |
+
Once you've added your new Action there, make sure that you make it discoverable by updating the `entry_points` section
|
| 124 |
+
of the `setup.py` file. This allows you to assign a globally unique name for you Action, so that people can use
|
| 125 |
+
it without defining the full module path.
|
| 126 |
+
|
| 127 |
+
### Prerequisites:
|
| 128 |
+
|
| 129 |
+
Prerequisites to consideration for inclusion in the core Actions library include
|
| 130 |
+
|
| 131 |
+
- **Testing** Define unit tests for your Action
|
| 132 |
+
- **Deduplication** Confirm that no existing Action serves the same purpose, or can be easily extended to serve the same purpose
|
docs/actions/imgs/.DS_Store
ADDED
|
Binary file (6.15 kB). View file
|
|
|
docs/actions/quickstart.md
ADDED
|
@@ -0,0 +1,169 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# DataHub Actions Quickstart
|
| 2 |
+
|
| 3 |
+
|
| 4 |
+
## Prerequisites
|
| 5 |
+
|
| 6 |
+
The DataHub Actions CLI commands are an extension of the base `datahub` CLI commands. We recommend
|
| 7 |
+
first installing the `datahub` CLI:
|
| 8 |
+
|
| 9 |
+
```shell
|
| 10 |
+
python3 -m pip install --upgrade pip wheel setuptools
|
| 11 |
+
python3 -m pip install --upgrade acryl-datahub
|
| 12 |
+
datahub --version
|
| 13 |
+
```
|
| 14 |
+
|
| 15 |
+
> Note that the Actions Framework requires a version of `acryl-datahub` >= v0.8.34
|
| 16 |
+
|
| 17 |
+
|
| 18 |
+
## Installation
|
| 19 |
+
|
| 20 |
+
To install DataHub Actions, you need to install the `acryl-datahub-actions` package from PyPi
|
| 21 |
+
|
| 22 |
+
```shell
|
| 23 |
+
python3 -m pip install --upgrade pip wheel setuptools
|
| 24 |
+
python3 -m pip install --upgrade acryl-datahub-actions
|
| 25 |
+
|
| 26 |
+
# Verify the installation by checking the version.
|
| 27 |
+
datahub actions version
|
| 28 |
+
```
|
| 29 |
+
|
| 30 |
+
### Hello World
|
| 31 |
+
|
| 32 |
+
DataHub ships with a "Hello World" Action which logs all events it receives to the console.
|
| 33 |
+
To run this action, simply create a new Action configuration file:
|
| 34 |
+
|
| 35 |
+
```yaml
|
| 36 |
+
# hello_world.yaml
|
| 37 |
+
name: "hello_world"
|
| 38 |
+
source:
|
| 39 |
+
type: "kafka"
|
| 40 |
+
config:
|
| 41 |
+
connection:
|
| 42 |
+
bootstrap: ${KAFKA_BOOTSTRAP_SERVER:-localhost:9092}
|
| 43 |
+
schema_registry_url: ${SCHEMA_REGISTRY_URL:-http://localhost:8081}
|
| 44 |
+
action:
|
| 45 |
+
type: "hello_world"
|
| 46 |
+
```
|
| 47 |
+
|
| 48 |
+
and then run it using the `datahub actions` command:
|
| 49 |
+
|
| 50 |
+
```shell
|
| 51 |
+
datahub actions -c hello_world.yaml
|
| 52 |
+
```
|
| 53 |
+
|
| 54 |
+
You should the see the following output if the Action has been started successfully:
|
| 55 |
+
|
| 56 |
+
```shell
|
| 57 |
+
Action Pipeline with name 'hello_world' is now running.
|
| 58 |
+
```
|
| 59 |
+
|
| 60 |
+
Now, navigate to the instance of DataHub that you've connected to and perform an Action such as
|
| 61 |
+
|
| 62 |
+
- Adding / removing a Tag
|
| 63 |
+
- Adding / removing a Glossary Term
|
| 64 |
+
- Adding / removing a Domain
|
| 65 |
+
|
| 66 |
+
If all is well, you should see some events being logged to the console
|
| 67 |
+
|
| 68 |
+
```shell
|
| 69 |
+
Hello world! Received event:
|
| 70 |
+
{
|
| 71 |
+
"event_type": "EntityChangeEvent_v1",
|
| 72 |
+
"event": {
|
| 73 |
+
"entityType": "dataset",
|
| 74 |
+
"entityUrn": "urn:li:dataset:(urn:li:dataPlatform:hdfs,SampleHdfsDataset,PROD)",
|
| 75 |
+
"category": "TAG",
|
| 76 |
+
"operation": "ADD",
|
| 77 |
+
"modifier": "urn:li:tag:pii",
|
| 78 |
+
"parameters": {},
|
| 79 |
+
"auditStamp": {
|
| 80 |
+
"time": 1651082697703,
|
| 81 |
+
"actor": "urn:li:corpuser:datahub",
|
| 82 |
+
"impersonator": null
|
| 83 |
+
},
|
| 84 |
+
"version": 0,
|
| 85 |
+
"source": null
|
| 86 |
+
},
|
| 87 |
+
"meta": {
|
| 88 |
+
"kafka": {
|
| 89 |
+
"topic": "PlatformEvent_v1",
|
| 90 |
+
"offset": 1262,
|
| 91 |
+
"partition": 0
|
| 92 |
+
}
|
| 93 |
+
}
|
| 94 |
+
}
|
| 95 |
+
```
|
| 96 |
+
*An example of an event emitted when a 'pii' tag has been added to a Dataset.*
|
| 97 |
+
|
| 98 |
+
Woohoo! You've successfully started using the Actions framework. Now, let's see how we can get fancy.
|
| 99 |
+
|
| 100 |
+
|
| 101 |
+
#### Filtering events
|
| 102 |
+
|
| 103 |
+
If we know which Event types we'd like to consume, we can optionally add a `filter` configuration, which
|
| 104 |
+
will prevent events that do not match the filter from being forwarded to the action.
|
| 105 |
+
|
| 106 |
+
```yaml
|
| 107 |
+
# hello_world.yaml
|
| 108 |
+
name: "hello_world"
|
| 109 |
+
source:
|
| 110 |
+
type: "kafka"
|
| 111 |
+
config:
|
| 112 |
+
connection:
|
| 113 |
+
bootstrap: ${KAFKA_BOOTSTRAP_SERVER:-localhost:9092}
|
| 114 |
+
schema_registry_url: ${SCHEMA_REGISTRY_URL:-http://localhost:8081}
|
| 115 |
+
filter:
|
| 116 |
+
event_type: "EntityChangeEvent_v1"
|
| 117 |
+
action:
|
| 118 |
+
type: "hello_world"
|
| 119 |
+
```
|
| 120 |
+
*Filtering for events of type EntityChangeEvent_v1 only*
|
| 121 |
+
|
| 122 |
+
|
| 123 |
+
#### Advanced Filtering
|
| 124 |
+
|
| 125 |
+
Beyond simply filtering by event type, we can also filter events by matching against the values of their fields. To do so,
|
| 126 |
+
use the `event` block. Each field provided will be compared against the real event's value. An event that matches
|
| 127 |
+
**all** of the fields will be forwarded to the action.
|
| 128 |
+
|
| 129 |
+
```yaml
|
| 130 |
+
# hello_world.yaml
|
| 131 |
+
name: "hello_world"
|
| 132 |
+
source:
|
| 133 |
+
type: "kafka"
|
| 134 |
+
config:
|
| 135 |
+
connection:
|
| 136 |
+
bootstrap: ${KAFKA_BOOTSTRAP_SERVER:-localhost:9092}
|
| 137 |
+
schema_registry_url: ${SCHEMA_REGISTRY_URL:-http://localhost:8081}
|
| 138 |
+
filter:
|
| 139 |
+
event_type: "EntityChangeEvent_v1"
|
| 140 |
+
event:
|
| 141 |
+
category: "TAG"
|
| 142 |
+
operation: "ADD"
|
| 143 |
+
modifier: "urn:li:tag:pii"
|
| 144 |
+
action:
|
| 145 |
+
type: "hello_world"
|
| 146 |
+
```
|
| 147 |
+
*This filter only matches events representing "PII" tag additions to an entity.*
|
| 148 |
+
|
| 149 |
+
And more, we can achieve "OR" semantics on a particular field by providing an array of values.
|
| 150 |
+
|
| 151 |
+
```yaml
|
| 152 |
+
# hello_world.yaml
|
| 153 |
+
name: "hello_world"
|
| 154 |
+
source:
|
| 155 |
+
type: "kafka"
|
| 156 |
+
config:
|
| 157 |
+
connection:
|
| 158 |
+
bootstrap: ${KAFKA_BOOTSTRAP_SERVER:-localhost:9092}
|
| 159 |
+
schema_registry_url: ${SCHEMA_REGISTRY_URL:-http://localhost:8081}
|
| 160 |
+
filter:
|
| 161 |
+
event_type: "EntityChangeEvent_v1"
|
| 162 |
+
event:
|
| 163 |
+
category: "TAG"
|
| 164 |
+
operation: [ "ADD", "REMOVE" ]
|
| 165 |
+
modifier: "urn:li:tag:pii"
|
| 166 |
+
action:
|
| 167 |
+
type: "hello_world"
|
| 168 |
+
```
|
| 169 |
+
*This filter only matches events representing "PII" tag additions to OR removals from an entity. How fancy!*
|
docs/actions/sources/kafka-event-source.md
ADDED
|
@@ -0,0 +1,93 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Kafka Event Source
|
| 2 |
+
|
| 3 |
+
## Overview
|
| 4 |
+
|
| 5 |
+
The Kafka Event Source is the default Event Source used within the DataHub Actions Framework.
|
| 6 |
+
|
| 7 |
+
Under the hood, the Kafka Event Source uses a Kafka Consumer to subscribe to the topics streaming
|
| 8 |
+
out of DataHub (MetadataChangeLog_v1, PlatformEvent_v1). Each Action is automatically placed into a unique
|
| 9 |
+
[consumer group](https://docs.confluent.io/platform/current/clients/consumer.html#consumer-groups) based on
|
| 10 |
+
the unique `name` provided inside the Action configuration file.
|
| 11 |
+
|
| 12 |
+
This means that you can easily scale-out Actions processing by sharing the same Action configuration file across
|
| 13 |
+
multiple nodes or processes. As long as the `name` of the Action is the same, each instance of the Actions framework will subscribe as a member in the same Kafka Consumer Group, which allows for load balancing the
|
| 14 |
+
topic traffic across consumers which each consume independent [partitions](https://developer.confluent.io/learn-kafka/apache-kafka/partitions/#kafka-partitioning).
|
| 15 |
+
|
| 16 |
+
Because the Kafka Event Source uses consumer groups by default, actions using this source will be **stateful**.
|
| 17 |
+
This means that Actions will keep track of their processing offsets of the upstream Kafka topics. If you
|
| 18 |
+
stop an Action and restart it sometime later, it will first "catch up" by processing the messages that the topic
|
| 19 |
+
has received since the Action last ran. Be mindful of this - if your Action is computationally expensive, it may be preferable to start consuming from the end of the log, instead of playing catch up. The easiest way to achieve this is to simply rename the Action inside the Action configuration file - this will create a new Kafka Consumer Group which will begin processing new messages at the end of the log (latest policy).
|
| 20 |
+
|
| 21 |
+
### Processing Guarantees
|
| 22 |
+
|
| 23 |
+
This event source implements an "ack" function which is invoked if and only if an event is successfully processed
|
| 24 |
+
by the Actions framework, meaning that the event made it through the Transformers and into the Action without
|
| 25 |
+
any errors. Under the hood, the "ack" method synchronously commits Kafka Consumer Offsets on behalf of the Action. This means that by default, the framework provides *at-least once* processing semantics. That is, in the unusual case that a failure occurs when attempting to commit offsets back to Kafka, that event may be replayed on restart of the Action.
|
| 26 |
+
|
| 27 |
+
If you've configured your Action pipeline `failure_mode` to be `CONTINUE` (the default), then events which
|
| 28 |
+
fail to be processed will simply be logged to a `failed_events.log` file for further investigation (dead letter queue). The Kafka Event Source will continue to make progress against the underlying topics and continue to commit offsets even in the case of failed messages.
|
| 29 |
+
|
| 30 |
+
If you've configured your Action pipeline `failure_mode` to be `THROW`, then events which fail to be processed result in an Action Pipeline error. This in turn terminates the pipeline before committing offsets back to Kafka. Thus the message will not be marked as "processed" by the Action consumer.
|
| 31 |
+
|
| 32 |
+
|
| 33 |
+
## Supported Events
|
| 34 |
+
|
| 35 |
+
The Kafka Event Source produces
|
| 36 |
+
|
| 37 |
+
- [Entity Change Event V1](../events/entity-change-event.md)
|
| 38 |
+
- [Metadata Change Log V1](../events/metadata-change-log-event.md)
|
| 39 |
+
|
| 40 |
+
|
| 41 |
+
## Configure the Event Source
|
| 42 |
+
|
| 43 |
+
Use the following config(s) to get started with the Kafka Event Source.
|
| 44 |
+
|
| 45 |
+
```yml
|
| 46 |
+
name: "pipeline-name"
|
| 47 |
+
source:
|
| 48 |
+
type: "kafka"
|
| 49 |
+
config:
|
| 50 |
+
# Connection-related configuration
|
| 51 |
+
connection:
|
| 52 |
+
bootstrap: ${KAFKA_BOOTSTRAP_SERVER:-localhost:9092}
|
| 53 |
+
schema_registry_url: ${SCHEMA_REGISTRY_URL:-http://localhost:8081}
|
| 54 |
+
# Dictionary of freeform consumer configs propagated to underlying Kafka Consumer
|
| 55 |
+
consumer_config:
|
| 56 |
+
#security.protocol: ${KAFKA_PROPERTIES_SECURITY_PROTOCOL:-PLAINTEXT}
|
| 57 |
+
#ssl.keystore.location: ${KAFKA_PROPERTIES_SSL_KEYSTORE_LOCATION:-/mnt/certs/keystore}
|
| 58 |
+
#ssl.truststore.location: ${KAFKA_PROPERTIES_SSL_TRUSTSTORE_LOCATION:-/mnt/certs/truststore}
|
| 59 |
+
#ssl.keystore.password: ${KAFKA_PROPERTIES_SSL_KEYSTORE_PASSWORD:-keystore_password}
|
| 60 |
+
#ssl.key.password: ${KAFKA_PROPERTIES_SSL_KEY_PASSWORD:-keystore_password}
|
| 61 |
+
#ssl.truststore.password: ${KAFKA_PROPERTIES_SSL_TRUSTSTORE_PASSWORD:-truststore_password}
|
| 62 |
+
# Topic Routing - which topics to read from.
|
| 63 |
+
topic_routes:
|
| 64 |
+
mcl: ${METADATA_CHANGE_LOG_VERSIONED_TOPIC_NAME:-MetadataChangeLog_Versioned_v1} # Topic name for MetadataChangeLog_v1 events.
|
| 65 |
+
pe: ${PLATFORM_EVENT_TOPIC_NAME:-PlatformEvent_v1} # Topic name for PlatformEvent_v1 events.
|
| 66 |
+
action:
|
| 67 |
+
# action configs
|
| 68 |
+
```
|
| 69 |
+
|
| 70 |
+
<details>
|
| 71 |
+
<summary>View All Configuration Options</summary>
|
| 72 |
+
|
| 73 |
+
| Field | Required | Default | Description |
|
| 74 |
+
| --- | :-: | :-: | --- |
|
| 75 |
+
| `connection.bootstrap` | ✅ | N/A | The Kafka bootstrap URI, e.g. `localhost:9092`. |
|
| 76 |
+
| `connection.schema_registry_url` | ✅ | N/A | The URL for the Kafka schema registry, e.g. `http://localhost:8081` |
|
| 77 |
+
| `connection.consumer_config` | ❌ | {} | A set of key-value pairs that represents arbitrary Kafka Consumer configs |
|
| 78 |
+
| `topic_routes.mcl` | ❌ | `MetadataChangeLog_v1` | The name of the topic containing MetadataChangeLog events |
|
| 79 |
+
| `topic_routes.pe` | ❌ | `PlatformEvent_v1` | The name of the topic containing PlatformEvent events |
|
| 80 |
+
</details>
|
| 81 |
+
|
| 82 |
+
|
| 83 |
+
## FAQ
|
| 84 |
+
|
| 85 |
+
1. Is there a way to always start processing from the end of the topics on Actions start?
|
| 86 |
+
|
| 87 |
+
Currently, the only way is to change the `name` of the Action in its configuration file. In the future,
|
| 88 |
+
we are hoping to add first-class support for configuring the action to be "stateless", ie only process
|
| 89 |
+
messages that are received while the Action is running.
|
| 90 |
+
|
| 91 |
+
2. Is there a way to asynchronously commit offsets back to Kafka?
|
| 92 |
+
|
| 93 |
+
Currently, all consumer offset commits are made synchronously for each message received. For now we've optimized for correctness over performance. If this commit policy does not accommodate your organization's needs, certainly reach out on [Slack](https://slack.datahubproject.io/).
|
docs/advanced/aspect-versioning.md
ADDED
|
@@ -0,0 +1,47 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Aspect Versioning
|
| 2 |
+
As each version of [metadata aspect](../what/aspect.md) is immutable, any update to an existing aspect results in the creation of a new version. Typically one would expect the version number increases sequentially with the largest version number being the latest version, i.e. `v1` (oldest), `v2` (second oldest), ..., `vN` (latest). However, this approach results in major challenges in both rest.li modeling & transaction isolation and therefore requires a rethinking.
|
| 3 |
+
|
| 4 |
+
## Rest.li Modeling
|
| 5 |
+
As it's common to create dedicated rest.li sub-resources for a specific aspect, e.g. `/datasets/{datasetKey}/ownership`, the concept of versions become an interesting modeling question. Should the sub-resource be a [Simple](https://linkedin.github.io/rest.li/modeling/modeling#simple) or a [Collection](https://linkedin.github.io/rest.li/modeling/modeling#collection) type?
|
| 6 |
+
|
| 7 |
+
If Simple, the [GET](https://linkedin.github.io/rest.li/user_guide/restli_server#get) method is expected to return the latest version, and the only way to retrieve non-latest versions is through a custom [ACTION](https://linkedin.github.io/rest.li/user_guide/restli_server#action) method, which is going against the [REST](https://en.wikipedia.org/wiki/Representational_state_transfer) principle. As a result, a Simple sub-resource doesn't seem to a be a good fit.
|
| 8 |
+
|
| 9 |
+
If Collection, the version number naturally becomes the key so it's easy to retrieve specific version number using the typical GET method. It's also easy to list all versions using the standard [GET_ALL](https://linkedin.github.io/rest.li/user_guide/restli_server#get_all) method or get a set of versions via [BATCH_GET](https://linkedin.github.io/rest.li/user_guide/restli_server#batch_get). However, Collection resources don't support a simple way to get the latest/largest key directly. To achieve that, one must do one of the following
|
| 10 |
+
|
| 11 |
+
- a GET_ALL (assuming descending key order) with a page size of 1
|
| 12 |
+
- a [FINDER](https://linkedin.github.io/rest.li/user_guide/restli_server#finder) with special parameters and a page size of 1
|
| 13 |
+
- a custom ACTION method again
|
| 14 |
+
|
| 15 |
+
None of these options seems like a natural way to ask for the latest version of an aspect, which is one of the most common use cases.
|
| 16 |
+
|
| 17 |
+
## Transaction Isolation
|
| 18 |
+
[Transaction isolation](https://en.wikipedia.org/wiki/Isolation_(database_systems)) is a complex topic so make sure to familiarize yourself with the basics first.
|
| 19 |
+
|
| 20 |
+
To support concurrent update of a metadata aspect, the following pseudo DB operations must be run in a single transaction,
|
| 21 |
+
```
|
| 22 |
+
1. Retrieve the current max version (Vmax)
|
| 23 |
+
2. Write the new value as (Vmax + 1)
|
| 24 |
+
```
|
| 25 |
+
Operation 1 above can easily suffer from [Phantom Reads](https://en.wikipedia.org/wiki/Isolation_(database_systems)#Phantom_reads). This subsequently leads to Operation 2 computing the incorrect version and thus overwrites an existing version instead of creating a new one.
|
| 26 |
+
|
| 27 |
+
One way to solve this is by enforcing [Serializable](https://en.wikipedia.org/wiki/Isolation_(database_systems)#Serializable) isolation level in DB at the [cost of performance](https://logicalread.com/optimize-mysql-perf-part-2-mc13/#.XjxSRSlKh1N). In reality, very few DB even supports this level of isolation, especially for distributed document stores. It's more common to support [Repeatable Reads](https://en.wikipedia.org/wiki/Isolation_(database_systems)#Repeatable_reads) or [Read Committed](https://en.wikipedia.org/wiki/Isolation_(database_systems)#Read_committed) isolation levels—sadly neither would help in this case.
|
| 28 |
+
|
| 29 |
+
Another possible solution is to transactionally keep track of `Vmax` directly in a separate table to avoid the need to compute that through a `select` (thus prevent Phantom Reads). However, cross-table/document/entity transaction is not a feature supported by all distributed document stores, which precludes this as a generalized solution.
|
| 30 |
+
|
| 31 |
+
## Solution: Version 0
|
| 32 |
+
The solution to both challenges turns out to be surprisingly simple. Instead of using a "floating" version number to represent the latest version, one can use a "fixed/sentinel" version number instead. In this case we choose Version 0 as we want all non-latest versions to still keep increasing sequentially. In other words, it'd be `v0` (latest), `v1` (oldest), `v2` (second oldest), etc. Alternatively, you can also simply view all the non-zero versions as an audit trail.
|
| 33 |
+
|
| 34 |
+
Let's examine how Version 0 can solve the aforementioned challenges.
|
| 35 |
+
|
| 36 |
+
### Rest.li Modeling
|
| 37 |
+
With Version 0, getting the latest version becomes calling the GET method of a Collection aspect-specific sub-resource with a deterministic key, e.g. `/datasets/{datasetkey}/ownership/0`, which is a lot more natural than using GET_ALL or FINDER.
|
| 38 |
+
|
| 39 |
+
### Transaction Isolation
|
| 40 |
+
The pseudo DB operations change to the following transaction block with version 0,
|
| 41 |
+
```
|
| 42 |
+
1. Retrieve v0 of the aspect
|
| 43 |
+
2. Retrieve the current max version (Vmax)
|
| 44 |
+
3. Write the old value back as (Vmax + 1)
|
| 45 |
+
4. Write the new value back as v0
|
| 46 |
+
```
|
| 47 |
+
While Operation 2 still suffers from potential Phantom Reads and thus corrupting existing version in Operation 3, Repeatable Reads isolation level will ensure that the transaction fails due to [Lost Update](https://codingsight.com/the-lost-update-problem-in-concurrent-transactions/) detected in Operation 4. Note that this happens to also be the [default isolation level](https://dev.mysql.com/doc/refman/8.0/en/innodb-transaction-isolation-levels.html) for InnoDB in MySQL.
|
docs/advanced/backfilling.md
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Backfilling Search Index & Graph DB
|
| 2 |
+
|
| 3 |
+
WIP
|
docs/advanced/browse-paths-upgrade.md
ADDED
|
@@ -0,0 +1,137 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Browse Paths Upgrade (August 2022)
|
| 2 |
+
|
| 3 |
+
## Background
|
| 4 |
+
|
| 5 |
+
Up to this point, there's been a historical constraint on all entity browse paths. Namely, each browse path has been
|
| 6 |
+
required to end with a path component that represents "simple name" for an entity. For example, a Browse Path for a
|
| 7 |
+
Snowflake Table called "test_table" may look something like this:
|
| 8 |
+
|
| 9 |
+
```
|
| 10 |
+
/prod/snowflake/warehouse1/db1/test_table
|
| 11 |
+
```
|
| 12 |
+
|
| 13 |
+
In the UI, we artificially truncate the final path component when you are browsing the Entity hierarchy, so your browse experience
|
| 14 |
+
would be:
|
| 15 |
+
|
| 16 |
+
`prod` > `snowflake` > `warehouse1`> `db1` > `Click Entity`
|
| 17 |
+
|
| 18 |
+
As you can see, the final path component `test_table` is effectively ignored. It could have any value, and we would still ignore
|
| 19 |
+
it in the UI. This behavior serves as a workaround to the historical requirement that all browse paths end with a simple name.
|
| 20 |
+
|
| 21 |
+
This data constraint stands in opposition the original intention of Browse Paths: to provide a simple mechanism for organizing
|
| 22 |
+
assets into a hierarchical folder structure. For this reason, we've changed the semantics of Browse Paths to better align with the original intention.
|
| 23 |
+
Going forward, you will not be required to provide a final component detailing the "name". Instead, you will be able to provide a simpler path that
|
| 24 |
+
omits this final component:
|
| 25 |
+
|
| 26 |
+
```
|
| 27 |
+
/prod/snowflake/warehouse1/db1
|
| 28 |
+
```
|
| 29 |
+
|
| 30 |
+
and the browse experience from the UI will continue to work as you would expect:
|
| 31 |
+
|
| 32 |
+
`prod` > `snowflake` > `warehouse1`> `db1` > `Click Entity`.
|
| 33 |
+
|
| 34 |
+
With this change comes a fix to a longstanding bug where multiple browse paths could not be attached to a single URN. Going forward,
|
| 35 |
+
we will support producing multiple browse paths for the same entity, and allow you to traverse via multiple paths. For example
|
| 36 |
+
|
| 37 |
+
```python
|
| 38 |
+
browse_path = BrowsePathsClass(
|
| 39 |
+
paths=["/powerbi/my/custom/path", "/my/other/custom/path"]
|
| 40 |
+
)
|
| 41 |
+
return MetadataChangeProposalWrapper(
|
| 42 |
+
entityType="dataset",
|
| 43 |
+
changeType="UPSERT",
|
| 44 |
+
entityUrn="urn:li:dataset:(urn:li:dataPlatform:custom,MyFileName,PROD),
|
| 45 |
+
aspectName="browsePaths",
|
| 46 |
+
aspect=browse_path,
|
| 47 |
+
)
|
| 48 |
+
```
|
| 49 |
+
*Using the Python Emitter SDK to produce multiple Browse Paths for the same entity*
|
| 50 |
+
|
| 51 |
+
We've received multiple bug reports, such as [this issue](https://github.com/datahub-project/datahub/issues/5525), and requests to address these issues with Browse, and thus are deciding
|
| 52 |
+
to do it now before more workarounds are created.
|
| 53 |
+
|
| 54 |
+
## What this means for you
|
| 55 |
+
|
| 56 |
+
Once you upgrade to DataHub `v0.8.45` you will immediately notice that traversing your Browse Path hierarchy will require
|
| 57 |
+
one extra click to find the entity. This is because we are correctly displaying the FULL browse path, including the simple name mentioned above.
|
| 58 |
+
|
| 59 |
+
There will be 2 ways to upgrade to the new browse path format. Depending on your ingestion sources, you may want to use one or both:
|
| 60 |
+
|
| 61 |
+
1. Migrate default browse paths to the new format by restarting DataHub
|
| 62 |
+
2. Upgrade your version of the `datahub` CLI to push new browse path format (version `v0.8.45`)
|
| 63 |
+
|
| 64 |
+
Each step will be discussed in detail below.
|
| 65 |
+
|
| 66 |
+
### 1. Migrating default browse paths to the new format
|
| 67 |
+
|
| 68 |
+
To migrate those Browse Paths that are generated by DataHub by default (when no path is provided), simply restart the `datahub-gms` container / pod with a single
|
| 69 |
+
additional environment variable:
|
| 70 |
+
|
| 71 |
+
```
|
| 72 |
+
UPGRADE_DEFAULT_BROWSE_PATHS_ENABLED=true
|
| 73 |
+
```
|
| 74 |
+
|
| 75 |
+
And restart the `datahub-gms` instance. This will cause GMS to perform a boot-time migration of all your existing Browse Paths
|
| 76 |
+
to the new format, removing the unnecessarily name component at the very end.
|
| 77 |
+
|
| 78 |
+
If the migration is successful, you'll see the following in your GMS logs:
|
| 79 |
+
|
| 80 |
+
```
|
| 81 |
+
18:58:17.414 [main] INFO c.l.m.b.s.UpgradeDefaultBrowsePathsStep:60 - Successfully upgraded all browse paths!
|
| 82 |
+
```
|
| 83 |
+
|
| 84 |
+
After this one-time migration is complete, you should be able to navigate the Browse hierarchy exactly as you did previously.
|
| 85 |
+
|
| 86 |
+
> Note that certain ingestion sources actively produce their own Browse Paths, which overrides the default path
|
| 87 |
+
> computed by DataHub.
|
| 88 |
+
>
|
| 89 |
+
> In these cases, getting the updated Browse Path will require re-running your ingestion process with the updated
|
| 90 |
+
> version of the connector. This is discussed in more detail in the next section.
|
| 91 |
+
|
| 92 |
+
### 2. Upgrading the `datahub` CLI to push new browse paths
|
| 93 |
+
|
| 94 |
+
If you are actively ingesting metadata from one or more of following sources
|
| 95 |
+
|
| 96 |
+
1. Sagemaker
|
| 97 |
+
2. Looker / LookML
|
| 98 |
+
3. Feast
|
| 99 |
+
4. Kafka
|
| 100 |
+
5. Mode
|
| 101 |
+
6. PowerBi
|
| 102 |
+
7. Pulsar
|
| 103 |
+
8. Tableau
|
| 104 |
+
9. Business Glossary
|
| 105 |
+
|
| 106 |
+
You will need to upgrade the DataHub CLI to >= `v0.8.45` and re-run metadata ingestion. This will generate the new browse path format
|
| 107 |
+
and overwrite the existing paths for entities that were extracted from these sources.
|
| 108 |
+
|
| 109 |
+
### If you are producing custom Browse Paths
|
| 110 |
+
|
| 111 |
+
If you've decided to produce your own custom Browse Paths to organize your assets (e.g. via the Python Emitter SDK), you'll want to change the code to produce those paths
|
| 112 |
+
to truncate the final path component. For example, if you were previously emitting a browse path like this:
|
| 113 |
+
|
| 114 |
+
```
|
| 115 |
+
"my/custom/browse/path/suffix"
|
| 116 |
+
```
|
| 117 |
+
|
| 118 |
+
You can simply remove the final "suffix" piece:
|
| 119 |
+
|
| 120 |
+
```
|
| 121 |
+
"my/custom/browse/path"
|
| 122 |
+
```
|
| 123 |
+
|
| 124 |
+
Your users will be able to find the entity by traversing through these folders in the UI:
|
| 125 |
+
|
| 126 |
+
`my` > `custom` > `browse`> `path` > `Click Entity`.
|
| 127 |
+
|
| 128 |
+
|
| 129 |
+
> Note that if you are using the Browse Path Transformer you *will* be impacted in the same way. It is recommended that you revisit the
|
| 130 |
+
> paths that you are producing, and update them to the new format.
|
| 131 |
+
|
| 132 |
+
## Support
|
| 133 |
+
|
| 134 |
+
The Acryl team will be on standby to assist you in your migration. Please
|
| 135 |
+
join [#release-0_8_0](https://datahubspace.slack.com/archives/C0244FHMHJQ) channel and reach out to us if you find
|
| 136 |
+
trouble with the upgrade or have feedback on the process. We will work closely to make sure you can continue to operate
|
| 137 |
+
DataHub smoothly.
|
docs/advanced/db-retention.md
ADDED
|
@@ -0,0 +1,79 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Configuring Database Retention
|
| 2 |
+
|
| 3 |
+
## Goal
|
| 4 |
+
|
| 5 |
+
DataHub stores different versions of [metadata aspects](https://datahubproject.io/docs/what/aspect) as they are ingested
|
| 6 |
+
using a database (or key-value store). These multiple versions allow us to look at an aspect's historical changes and
|
| 7 |
+
rollback to a previous version if incorrect metadata is ingested. However, every stored version takes additional storage
|
| 8 |
+
space, while possibly bringing less value to the system. We need to be able to impose a **retention** policy on these
|
| 9 |
+
records to keep the size of the DB in check.
|
| 10 |
+
|
| 11 |
+
Goal of the retention system is to be able to **configure and enforce retention policies** on documents at each of these
|
| 12 |
+
various levels:
|
| 13 |
+
- global
|
| 14 |
+
- entity-level
|
| 15 |
+
- aspect-level
|
| 16 |
+
|
| 17 |
+
## What type of retention policies are supported?
|
| 18 |
+
|
| 19 |
+
We support 3 types of retention policies for aspects:
|
| 20 |
+
|
| 21 |
+
| Policy | Versions Kept |
|
| 22 |
+
|:-------------:|:-----------------------------------:|
|
| 23 |
+
| Indefinite | All versions |
|
| 24 |
+
| Version-based | Latest *N* versions |
|
| 25 |
+
| Time-based | Versions ingested in last *N* seconds |
|
| 26 |
+
|
| 27 |
+
**Note:** The latest version (version 0) is never deleted. This ensures core functionality of DataHub is not impacted while applying retention.
|
| 28 |
+
|
| 29 |
+
## When is the retention policy applied?
|
| 30 |
+
|
| 31 |
+
As of now, retention policies are applied in two places:
|
| 32 |
+
|
| 33 |
+
1. **GMS boot-up**: A bootstrap step ingests the predefined set of retention policies. If no policy existed before or the existing policy
|
| 34 |
+
was updated, an asynchronous call will be triggered. It will apply the retention policy (or policies) to **all** records in the database.
|
| 35 |
+
2. **Ingest**: On every ingest, if an existing aspect got updated, it applies the retention policy to the urn-aspect pair being ingested.
|
| 36 |
+
|
| 37 |
+
We are planning to support a cron-based application of retention in the near future to ensure that the time-based retention is applied correctly.
|
| 38 |
+
|
| 39 |
+
## How to configure?
|
| 40 |
+
|
| 41 |
+
For the initial iteration, we have made this feature opt-in. Please set **ENTITY_SERVICE_ENABLE_RETENTION=true** when
|
| 42 |
+
creating the datahub-gms container/k8s pod.
|
| 43 |
+
|
| 44 |
+
On GMS start up, retention policies are initialized with:
|
| 45 |
+
1. First, the default provided **version-based** retention to keep **20 latest aspects** for all entity-aspect pairs.
|
| 46 |
+
2. Second, we read YAML files from the `/etc/datahub/plugins/retention` directory and overlay them on the default set of policies we provide.
|
| 47 |
+
|
| 48 |
+
For docker, we set docker-compose to mount `${HOME}/.datahub` directory to `/etc/datahub` directory
|
| 49 |
+
within the containers, so you can customize the initial set of retention policies by creating
|
| 50 |
+
a `${HOME}/.datahub/plugins/retention/retention.yaml` file.
|
| 51 |
+
|
| 52 |
+
We will support a standardized way to do this in Kubernetes setup in the near future.
|
| 53 |
+
|
| 54 |
+
The format for the YAML file is as follows:
|
| 55 |
+
|
| 56 |
+
```yaml
|
| 57 |
+
- entity: "*" # denotes that policy will be applied to all entities
|
| 58 |
+
aspect: "*" # denotes that policy will be applied to all aspects
|
| 59 |
+
config:
|
| 60 |
+
retention:
|
| 61 |
+
version:
|
| 62 |
+
maxVersions: 20
|
| 63 |
+
- entity: "dataset"
|
| 64 |
+
aspect: "datasetProperties"
|
| 65 |
+
config:
|
| 66 |
+
retention:
|
| 67 |
+
version:
|
| 68 |
+
maxVersions: 20
|
| 69 |
+
time:
|
| 70 |
+
maxAgeInSeconds: 2592000 # 30 days
|
| 71 |
+
```
|
| 72 |
+
|
| 73 |
+
Note, it searches for the policies corresponding to the entity, aspect pair in the following order:
|
| 74 |
+
1. entity, aspect
|
| 75 |
+
2. *, aspect
|
| 76 |
+
3. entity, *
|
| 77 |
+
4. *, *
|
| 78 |
+
|
| 79 |
+
By restarting datahub-gms after creating the plugin yaml file, the new set of retention policies will be applied.
|
docs/advanced/derived-aspects.md
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Derived Aspects
|
| 2 |
+
|
| 3 |
+
WIP
|
docs/advanced/entity-hierarchy.md
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Entity Hierarchy
|
| 2 |
+
|
| 3 |
+
WIP
|
docs/advanced/es-7-upgrade.md
ADDED
|
@@ -0,0 +1,38 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Elasticsearch upgrade from 5.6.8 to 7.9.3
|
| 2 |
+
|
| 3 |
+
## Summary of changes
|
| 4 |
+
Checkout the list of breaking changes for [Elasticsearch 6](https://www.elastic.co/guide/en/elasticsearch/reference/6.8/breaking-changes-6.0.html) and [Elasticsearch 7](https://www.elastic.co/guide/en/elasticsearch/reference/7.x/breaking-changes-7.0.html). Following is the summary of changes that impact Datahub.
|
| 5 |
+
|
| 6 |
+
### Search index mapping & settings
|
| 7 |
+
- Removal of mapping types (as mentioned [here](https://www.elastic.co/guide/en/elasticsearch/reference/current/removal-of-types.html))
|
| 8 |
+
- Specify the maximum allowed difference between `min_gram` and `max_gram` for NGramTokenizer and NGramTokenFilter by adding property `max_ngram_diff` in index settings, particularly if the difference is greater than 1 (as mentioned [here](https://www.elastic.co/guide/en/elasticsearch/reference/current/index-modules.html))
|
| 9 |
+
|
| 10 |
+
### Search query
|
| 11 |
+
The following parameters are/were `optional` and hence automatically populated in the search query. Some tests that expect a certain search query to be sent to ES will change with the ES upgrade.
|
| 12 |
+
- `disable_coord` parameter of the `bool` and `common_terms` queries has been removed (as mentioned [here](https://www.elastic.co/guide/en/elasticsearch/reference/6.8/breaking-changes-6.0.html))
|
| 13 |
+
- `auto_generate_synonyms_phrase_query` parameter in `match` query is added with a default value of `true` (as mentioned [here](https://www.elastic.co/guide/en/elasticsearch/reference/7.x/query-dsl-match-query.html))
|
| 14 |
+
|
| 15 |
+
### Java High Level Rest Client
|
| 16 |
+
- In 7.9.3, Java High Level Rest Client instance needs a REST low-level client builder to be built. In 5.6.8, the same instance needs REST low-level client
|
| 17 |
+
- Document APIs such as the Index API, Delete API, etc no longer takes the doc `type` as an input
|
| 18 |
+
|
| 19 |
+
## Migration strategy
|
| 20 |
+
|
| 21 |
+
As mentioned in the docs, indices created in Elasticsearch 5.x are not readable by Elasticsearch 7.x. Running the upgraded elasticsearch container on the existing esdata volume will fail.
|
| 22 |
+
|
| 23 |
+
For local development, our recommendation is to run the `docker/nuke.sh` script to remove the existing esdata volume before starting up the containers. Note, all data will be lost.
|
| 24 |
+
|
| 25 |
+
To migrate without losing data, please refer to the python script and Dockerfile in `contrib/elasticsearch/es7-upgrade`. The script takes source and destination elasticsearch cluster URL and SSL configuration (if applicable) as input. It ports the mappings and settings for all indices in the source cluster to the destination cluster making the necessary changes stated above. Then it transfers all documents in the source cluster to the destination cluster.
|
| 26 |
+
|
| 27 |
+
You can run the script in a docker container as follows
|
| 28 |
+
```
|
| 29 |
+
docker build -t migrate-es-7 .
|
| 30 |
+
docker run migrate-es-7 -s SOURCE -d DEST [--disable-source-ssl]
|
| 31 |
+
[--disable-dest-ssl] [--cert-file CERT_FILE]
|
| 32 |
+
[--key-file KEY_FILE] [--ca-file CA_FILE] [--create-only]
|
| 33 |
+
[-i INDICES] [--name-override NAME_OVERRIDE]
|
| 34 |
+
```
|
| 35 |
+
|
| 36 |
+
## Plan
|
| 37 |
+
|
| 38 |
+
We will create an "elasticsearch-5-legacy" branch with the version of master prior to the elasticsearch 7 upgrade. However, we will not be supporting this branch moving forward and all future development will be done using elasticsearch 7.9.3
|
docs/advanced/field-path-spec-v2.md
ADDED
|
@@ -0,0 +1,352 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# SchemaFieldPath Specification (Version 2)
|
| 2 |
+
|
| 3 |
+
This document outlines the formal specification for the fieldPath member of
|
| 4 |
+
the [SchemaField](https://github.com/datahub-project/datahub/blob/master/metadata-models/src/main/pegasus/com/linkedin/schema/SchemaField.pdl)
|
| 5 |
+
model. This specification (version 2) takes into account the unique requirements of supporting a wide variety of nested
|
| 6 |
+
types, unions and optional fields and is a substantial improvement over the current implementation (version 1).
|
| 7 |
+
|
| 8 |
+
## Requirements
|
| 9 |
+
|
| 10 |
+
The `fieldPath` field is currently used by datahub for not just rendering the schema fields in the UI, but also as a
|
| 11 |
+
primary identifier of a field in other places such
|
| 12 |
+
as [EditableSchemaFieldInfo](https://github.com/datahub-project/datahub/blob/master/metadata-models/src/main/pegasus/com/linkedin/schema/EditableSchemaFieldInfo.pdl#L12),
|
| 13 |
+
usage stats and data profiles. Therefore, it must satisfy the following requirements.
|
| 14 |
+
|
| 15 |
+
* must be unique across all fields within a schema.
|
| 16 |
+
* make schema navigation in the UI more intuitive.
|
| 17 |
+
* allow for identifying the type of schema the field is part of, such as a `key-schema` or a `value-schema`.
|
| 18 |
+
* allow for future-evolution
|
| 19 |
+
|
| 20 |
+
## Existing Convention(v1)
|
| 21 |
+
|
| 22 |
+
The existing convention is to simply use the field's name as the `fieldPath` for simple fields, and use the `dot`
|
| 23 |
+
delimited names for nested fields. This scheme does not satisfy the [requirements](#requirements) stated above. The
|
| 24 |
+
following example illustrates where the `uniqueness` requirement is not satisfied.
|
| 25 |
+
|
| 26 |
+
### Example: Ambiguous field path
|
| 27 |
+
|
| 28 |
+
Consider the following `Avro` schema which is a `union` of two record types `A` and `B`, each having a simple field with
|
| 29 |
+
the same name `f` that is of type `string`. The v1 naming scheme cannot differentiate if a `fieldPath=f` is referring to
|
| 30 |
+
the record type `A` or `B`.
|
| 31 |
+
|
| 32 |
+
```
|
| 33 |
+
[
|
| 34 |
+
{
|
| 35 |
+
"type": "record",
|
| 36 |
+
"name": "A",
|
| 37 |
+
"fields": [{ "name": "f", "type": "string" } ]
|
| 38 |
+
}, {
|
| 39 |
+
"type": "record",
|
| 40 |
+
"name": "B",
|
| 41 |
+
"fields": [{ "name": "f", "type": "string" } ]
|
| 42 |
+
}
|
| 43 |
+
]
|
| 44 |
+
```
|
| 45 |
+
|
| 46 |
+
## The FieldPath encoding scheme(v2)
|
| 47 |
+
|
| 48 |
+
The syntax for V2 encoding of the `fieldPath` is captured in the following grammar. The `FieldPathSpec` is essentially
|
| 49 |
+
the type annotated path of the member, with each token along the path representing one level of nested member,
|
| 50 |
+
starting from the most-enclosing type, leading up to the member. In the case of `unions` that have `one-of` semantics,
|
| 51 |
+
the corresponding field will be emitted once for each `member` of the union as its `type`, along with one path
|
| 52 |
+
corresponding to the `union` itself.
|
| 53 |
+
|
| 54 |
+
### Formal Spec:
|
| 55 |
+
|
| 56 |
+
```
|
| 57 |
+
<SchemaFieldPath> := <VersionToken>.<PartOfKeySchemaToken>.<FieldPathSpec> // when part of a key-schema
|
| 58 |
+
| <VersionToken>.<FieldPathSpec> // when part of a value schema
|
| 59 |
+
<VersionToken> := [version=<VersionId>] // [version=2.0] for v2
|
| 60 |
+
<PartOfKeySchemaToken> := [key=True] // when part of a key schema
|
| 61 |
+
<FieldPathSpec> := <FieldToken>+ // this is the type prefixed path field (nested if repeats).
|
| 62 |
+
<FieldToken> := <TypePrefixToken>.<name_of_the_field> // type prefixed path of a field.
|
| 63 |
+
<TypePrefixToken> := <NestedTypePrefixToken>.<SimpleTypeToken> | <SimpleTypeToken>
|
| 64 |
+
<NestedTypePrefixToken> := [type=<NestedType>]
|
| 65 |
+
<SimpleTypeToken> := [type=<SimpleType>]
|
| 66 |
+
<NestedType> := <name of a struct/record> | union | array | map
|
| 67 |
+
<SimpleType> := int | float | double | string | fixed | enum
|
| 68 |
+
```
|
| 69 |
+
|
| 70 |
+
For the [example above](#example-ambiguous-field-path), this encoding would produce the following 2 unique paths
|
| 71 |
+
corresponding to the `A.f` and `B.f` fields.
|
| 72 |
+
|
| 73 |
+
```python
|
| 74 |
+
unique_v2_field_paths = [
|
| 75 |
+
"[version=2.0].[type=union].[type=A].[type=string].f",
|
| 76 |
+
"[version=2.0].[type=union].[type=B].[type=string].f"
|
| 77 |
+
]
|
| 78 |
+
```
|
| 79 |
+
|
| 80 |
+
NOTE:
|
| 81 |
+
|
| 82 |
+
- this encoding always ensures uniqueness within a schema since the full type annotation leading to a field is encoded
|
| 83 |
+
in the fieldPath itself.
|
| 84 |
+
- processing a fieldPath, such as from UI, gets simplified simply by walking each token along the path from
|
| 85 |
+
left-to-right.
|
| 86 |
+
- adding PartOfKeySchemaToken allows for identifying if the field is part of key-schema.
|
| 87 |
+
- adding VersionToken allows for future evolvability.
|
| 88 |
+
- to represent `optional` fields, which sometimes are modeled as `unions` in formats like `Avro`, instead of treating it
|
| 89 |
+
as a `union` member, set the `nullable` member of `SchemaField` to `True`.
|
| 90 |
+
|
| 91 |
+
## Examples
|
| 92 |
+
|
| 93 |
+
### Primitive types
|
| 94 |
+
|
| 95 |
+
```python
|
| 96 |
+
avro_schema = """
|
| 97 |
+
{
|
| 98 |
+
"type": "string"
|
| 99 |
+
}
|
| 100 |
+
"""
|
| 101 |
+
unique_v2_field_paths = [
|
| 102 |
+
"[version=2.0].[type=string]"
|
| 103 |
+
]
|
| 104 |
+
```
|
| 105 |
+
### Records
|
| 106 |
+
**Simple Record**
|
| 107 |
+
```python
|
| 108 |
+
avro_schema = """
|
| 109 |
+
{
|
| 110 |
+
"type": "record",
|
| 111 |
+
"name": "some.event.E",
|
| 112 |
+
"namespace": "some.event.N",
|
| 113 |
+
"doc": "this is the event record E"
|
| 114 |
+
"fields": [
|
| 115 |
+
{
|
| 116 |
+
"name": "a",
|
| 117 |
+
"type": "string",
|
| 118 |
+
"doc": "this is string field a of E"
|
| 119 |
+
},
|
| 120 |
+
{
|
| 121 |
+
"name": "b",
|
| 122 |
+
"type": "string",
|
| 123 |
+
"doc": "this is string field b of E"
|
| 124 |
+
}
|
| 125 |
+
]
|
| 126 |
+
}
|
| 127 |
+
"""
|
| 128 |
+
|
| 129 |
+
unique_v2_field_paths = [
|
| 130 |
+
"[version=2.0].[type=E].[type=string].a",
|
| 131 |
+
"[version=2.0].[type=E].[type=string].b",
|
| 132 |
+
]
|
| 133 |
+
```
|
| 134 |
+
**Nested Record**
|
| 135 |
+
```python
|
| 136 |
+
avro_schema = """
|
| 137 |
+
{
|
| 138 |
+
"type": "record",
|
| 139 |
+
"name": "SimpleNested",
|
| 140 |
+
"namespace": "com.linkedin",
|
| 141 |
+
"fields": [{
|
| 142 |
+
"name": "nestedRcd",
|
| 143 |
+
"type": {
|
| 144 |
+
"type": "record",
|
| 145 |
+
"name": "InnerRcd",
|
| 146 |
+
"fields": [{
|
| 147 |
+
"name": "aStringField",
|
| 148 |
+
"type": "string"
|
| 149 |
+
} ]
|
| 150 |
+
}
|
| 151 |
+
}]
|
| 152 |
+
}
|
| 153 |
+
"""
|
| 154 |
+
|
| 155 |
+
unique_v2_field_paths = [
|
| 156 |
+
"[version=2.0].[key=True].[type=SimpleNested].[type=InnerRcd].nestedRcd",
|
| 157 |
+
"[version=2.0].[key=True].[type=SimpleNested].[type=InnerRcd].nestedRcd.[type=string].aStringField",
|
| 158 |
+
]
|
| 159 |
+
```
|
| 160 |
+
|
| 161 |
+
**Recursive Record**
|
| 162 |
+
```python
|
| 163 |
+
avro_schema = """
|
| 164 |
+
{
|
| 165 |
+
"type": "record",
|
| 166 |
+
"name": "Recursive",
|
| 167 |
+
"namespace": "com.linkedin",
|
| 168 |
+
"fields": [{
|
| 169 |
+
"name": "r",
|
| 170 |
+
"type": {
|
| 171 |
+
"type": "record",
|
| 172 |
+
"name": "R",
|
| 173 |
+
"fields": [
|
| 174 |
+
{ "name" : "anIntegerField", "type" : "int" },
|
| 175 |
+
{ "name": "aRecursiveField", "type": "com.linkedin.R"}
|
| 176 |
+
]
|
| 177 |
+
}
|
| 178 |
+
}]
|
| 179 |
+
}
|
| 180 |
+
"""
|
| 181 |
+
|
| 182 |
+
unique_v2_field_paths = [
|
| 183 |
+
"[version=2.0].[type=Recursive].[type=R].r",
|
| 184 |
+
"[version=2.0].[type=Recursive].[type=R].r.[type=int].anIntegerField",
|
| 185 |
+
"[version=2.0].[type=Recursive].[type=R].r.[type=R].aRecursiveField"
|
| 186 |
+
]
|
| 187 |
+
```
|
| 188 |
+
|
| 189 |
+
```python
|
| 190 |
+
avro_schema ="""
|
| 191 |
+
{
|
| 192 |
+
"type": "record",
|
| 193 |
+
"name": "TreeNode",
|
| 194 |
+
"fields": [
|
| 195 |
+
{
|
| 196 |
+
"name": "value",
|
| 197 |
+
"type": "long"
|
| 198 |
+
},
|
| 199 |
+
{
|
| 200 |
+
"name": "children",
|
| 201 |
+
"type": { "type": "array", "items": "TreeNode" }
|
| 202 |
+
}
|
| 203 |
+
]
|
| 204 |
+
}
|
| 205 |
+
"""
|
| 206 |
+
unique_v2_field_paths = [
|
| 207 |
+
"[version=2.0].[type=TreeNode].[type=long].value",
|
| 208 |
+
"[version=2.0].[type=TreeNode].[type=array].[type=TreeNode].children",
|
| 209 |
+
]
|
| 210 |
+
```
|
| 211 |
+
### Unions
|
| 212 |
+
```python
|
| 213 |
+
avro_schema = """
|
| 214 |
+
{
|
| 215 |
+
"type": "record",
|
| 216 |
+
"name": "ABUnion",
|
| 217 |
+
"namespace": "com.linkedin",
|
| 218 |
+
"fields": [{
|
| 219 |
+
"name": "a",
|
| 220 |
+
"type": [{
|
| 221 |
+
"type": "record",
|
| 222 |
+
"name": "A",
|
| 223 |
+
"fields": [{ "name": "f", "type": "string" } ]
|
| 224 |
+
}, {
|
| 225 |
+
"type": "record",
|
| 226 |
+
"name": "B",
|
| 227 |
+
"fields": [{ "name": "f", "type": "string" } ]
|
| 228 |
+
}
|
| 229 |
+
]
|
| 230 |
+
}]
|
| 231 |
+
}
|
| 232 |
+
"""
|
| 233 |
+
unique_v2_field_paths: List[str] = [
|
| 234 |
+
"[version=2.0].[key=True].[type=ABUnion].[type=union].a",
|
| 235 |
+
"[version=2.0].[key=True].[type=ABUnion].[type=union].[type=A].a",
|
| 236 |
+
"[version=2.0].[key=True].[type=ABUnion].[type=union].[type=A].a.[type=string].f",
|
| 237 |
+
"[version=2.0].[key=True].[type=ABUnion].[type=union].[type=B].a",
|
| 238 |
+
"[version=2.0].[key=True].[type=ABUnion].[type=union].[type=B].a.[type=string].f",
|
| 239 |
+
]
|
| 240 |
+
```
|
| 241 |
+
### Arrays
|
| 242 |
+
```python
|
| 243 |
+
avro_schema = """
|
| 244 |
+
{
|
| 245 |
+
"type": "record",
|
| 246 |
+
"name": "NestedArray",
|
| 247 |
+
"namespace": "com.linkedin",
|
| 248 |
+
"fields": [{
|
| 249 |
+
"name": "ar",
|
| 250 |
+
"type": {
|
| 251 |
+
"type": "array",
|
| 252 |
+
"items": {
|
| 253 |
+
"type": "array",
|
| 254 |
+
"items": [
|
| 255 |
+
"null",
|
| 256 |
+
{
|
| 257 |
+
"type": "record",
|
| 258 |
+
"name": "Foo",
|
| 259 |
+
"fields": [ {
|
| 260 |
+
"name": "a",
|
| 261 |
+
"type": "long"
|
| 262 |
+
} ]
|
| 263 |
+
}
|
| 264 |
+
]
|
| 265 |
+
}
|
| 266 |
+
}
|
| 267 |
+
}]
|
| 268 |
+
}
|
| 269 |
+
"""
|
| 270 |
+
unique_v2_field_paths: List[str] = [
|
| 271 |
+
"[version=2.0].[type=NestedArray].[type=array].[type=array].[type=Foo].ar",
|
| 272 |
+
"[version=2.0].[type=NestedArray].[type=array].[type=array].[type=Foo].ar.[type=long].a",
|
| 273 |
+
]
|
| 274 |
+
```
|
| 275 |
+
### Maps
|
| 276 |
+
```python
|
| 277 |
+
avro_schema = """
|
| 278 |
+
{
|
| 279 |
+
"type": "record",
|
| 280 |
+
"name": "R",
|
| 281 |
+
"namespace": "some.namespace",
|
| 282 |
+
"fields": [
|
| 283 |
+
{
|
| 284 |
+
"name": "a_map_of_longs_field",
|
| 285 |
+
"type": {
|
| 286 |
+
"type": "map",
|
| 287 |
+
"values": "long"
|
| 288 |
+
}
|
| 289 |
+
}
|
| 290 |
+
]
|
| 291 |
+
}
|
| 292 |
+
"""
|
| 293 |
+
unique_v2_field_paths = [
|
| 294 |
+
"[version=2.0].[type=R].[type=map].[type=long].a_map_of_longs_field",
|
| 295 |
+
]
|
| 296 |
+
|
| 297 |
+
|
| 298 |
+
```
|
| 299 |
+
### Mixed Complex Type Examples
|
| 300 |
+
```python
|
| 301 |
+
# Combines arrays, unions and records.
|
| 302 |
+
avro_schema = """
|
| 303 |
+
{
|
| 304 |
+
"type": "record",
|
| 305 |
+
"name": "ABFooUnion",
|
| 306 |
+
"namespace": "com.linkedin",
|
| 307 |
+
"fields": [{
|
| 308 |
+
"name": "a",
|
| 309 |
+
"type": [ {
|
| 310 |
+
"type": "record",
|
| 311 |
+
"name": "A",
|
| 312 |
+
"fields": [{ "name": "f", "type": "string" } ]
|
| 313 |
+
}, {
|
| 314 |
+
"type": "record",
|
| 315 |
+
"name": "B",
|
| 316 |
+
"fields": [{ "name": "f", "type": "string" } ]
|
| 317 |
+
}, {
|
| 318 |
+
"type": "array",
|
| 319 |
+
"items": {
|
| 320 |
+
"type": "array",
|
| 321 |
+
"items": [
|
| 322 |
+
"null",
|
| 323 |
+
{
|
| 324 |
+
"type": "record",
|
| 325 |
+
"name": "Foo",
|
| 326 |
+
"fields": [{ "name": "f", "type": "long" }]
|
| 327 |
+
}
|
| 328 |
+
]
|
| 329 |
+
}
|
| 330 |
+
}]
|
| 331 |
+
}]
|
| 332 |
+
}
|
| 333 |
+
"""
|
| 334 |
+
|
| 335 |
+
unique_v2_field_paths: List[str] = [
|
| 336 |
+
"[version=2.0].[type=ABFooUnion].[type=union].a",
|
| 337 |
+
"[version=2.0].[type=ABFooUnion].[type=union].[type=A].a",
|
| 338 |
+
"[version=2.0].[type=ABFooUnion].[type=union].[type=A].a.[type=string].f",
|
| 339 |
+
"[version=2.0].[type=ABFooUnion].[type=union].[type=B].a",
|
| 340 |
+
"[version=2.0].[type=ABFooUnion].[type=union].[type=B].a.[type=string].f",
|
| 341 |
+
"[version=2.0].[type=ABFooUnion].[type=union].[type=array].[type=array].[type=Foo].a",
|
| 342 |
+
"[version=2.0].[type=ABFooUnion].[type=union].[type=array].[type=array].[type=Foo].a.[type=long].f",
|
| 343 |
+
]
|
| 344 |
+
```
|
| 345 |
+
|
| 346 |
+
For more examples, see
|
| 347 |
+
the [unit-tests for AvroToMceSchemaConverter](https://github.com/datahub-project/datahub/blob/master/metadata-ingestion/tests/unit/test_schema_util.py).
|
| 348 |
+
|
| 349 |
+
### Backward-compatibility
|
| 350 |
+
|
| 351 |
+
While this format is not directly compatible with the v1 format, the v1 equivalent can easily be constructed from the v2
|
| 352 |
+
encoding by stripping away all the v2 tokens enclosed in the square-brackets `[<new_in_v2>]`.
|
docs/advanced/high-cardinality.md
ADDED
|
@@ -0,0 +1,46 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# High Cardinality Relationships
|
| 2 |
+
|
| 3 |
+
As explained in [What is a Relationship](../what/relationship.md), the raw metadata for forming relationships is captured directly inside of a [Metadata Aspect](../what/aspect.md). The most natural way to model this is using an array, e.g. a group membership aspect contains an array of user [URNs](../what/urn.md). However, this poses some challenges when the cardinality of the relationship is expected to be large (say, greater than 10,000). The aspect becomes large in size, which leads to slow update and retrieval. It may even exceed the underlying limit of the document store, which is often in the range of a few MBs. Furthermore, sending large messages (> 1MB) over Kafka requires special tuning and is generally discouraged.
|
| 4 |
+
|
| 5 |
+
Depending on the type of relationships, there are different strategies for dealing with high cardinality.
|
| 6 |
+
|
| 7 |
+
### 1:N Relationships
|
| 8 |
+
|
| 9 |
+
When `N` is large, simply store the relationship as a reverse pointer on the `N` side, instead of an `N`-element array on the `1` side. In other words, instead of doing this
|
| 10 |
+
|
| 11 |
+
```
|
| 12 |
+
record MemberList {
|
| 13 |
+
members: array[UserUrn]
|
| 14 |
+
}
|
| 15 |
+
```
|
| 16 |
+
|
| 17 |
+
do this
|
| 18 |
+
|
| 19 |
+
```
|
| 20 |
+
record Membership {
|
| 21 |
+
group: GroupUrn
|
| 22 |
+
}
|
| 23 |
+
```
|
| 24 |
+
|
| 25 |
+
One drawback with this approach is that batch updating the member list becomes multiple DB operations and non-atomic. If the list is provided by an external metadata provider via [MCEs](../what/mxe.md), this also means that multiple MCEs will be required to update the list, instead of having one giant array in a single MCE.
|
| 26 |
+
|
| 27 |
+
### M:N Relationships
|
| 28 |
+
|
| 29 |
+
When one side of the relation (`M` or `N`) has low cardinality, you can apply the same trick in [1:N Relationship] by creating the array on the side with low-cardinality. For example, assuming a user can only be part of a small number of groups but each group can have a large number of users, the following model will be more efficient than the reverse.
|
| 30 |
+
|
| 31 |
+
```
|
| 32 |
+
record Membership {
|
| 33 |
+
groups: array[GroupUrn]
|
| 34 |
+
}
|
| 35 |
+
```
|
| 36 |
+
|
| 37 |
+
When both `M` and `N` are of high cardinality (e.g. millions of users, each belongs to million of groups), the only way to store such relationships efficiently is by creating a new "Mapping Entity" with a single aspect like this
|
| 38 |
+
|
| 39 |
+
```
|
| 40 |
+
record UserGroupMap {
|
| 41 |
+
user: UserUrn
|
| 42 |
+
group: GroupUrn
|
| 43 |
+
}
|
| 44 |
+
```
|
| 45 |
+
|
| 46 |
+
This means that the relationship now can only be created & updated at a single source-destination pair granularity.
|
docs/advanced/mcp-mcl.md
ADDED
|
@@ -0,0 +1,159 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# MetadataChangeProposal & MetadataChangeLog Events
|
| 2 |
+
|
| 3 |
+
## Overview & Vision
|
| 4 |
+
|
| 5 |
+
As of release v0.8.7, two new important event streams have been introduced: MetadataChangeProposal & MetadataChangeLog. These topics serve as a more generic (and more appropriately named) versions of the classic MetadataChangeEvent and MetadataAuditEvent events, used for a) proposing and b) logging changes to the DataHub Metadata Graph.
|
| 6 |
+
|
| 7 |
+
With these events, we move towards a more generic world, in which Metadata models are not strongly-typed parts of the event schemas themselves. This provides flexibility, allowing for the core models comprising the Metadata Graph to be added and changed dynamically, without requiring structural updates to Kafka or REST API schemas used for ingesting and serving Metadata.
|
| 8 |
+
|
| 9 |
+
Moreover, we've focused in on the "aspect" as the atomic unit of write in DataHub. MetadataChangeProposal & MetadataChangeLog with carry only a single aspect in their payload, as opposed to the list of aspects carried by today's MCE & MAE. This more accurately reflects the atomicity contract of the metadata model, hopefully lessening confusion about transactional guarantees for multi-aspect writes in addition to making it simpler to tune into the metadata changes a consumer cares about.
|
| 10 |
+
|
| 11 |
+
Making these events more generic does not come for free; we give up some in the form of Restli and Kafka-native schema validation and defer this responsibility to DataHub itself, who is the sole enforcer of the graph model contracts. Additionally, we add an extra step to unbundling the actual metadata by requiring a double-deserialization: that of the event / response body itself and another of the nested Metadata aspect.
|
| 12 |
+
|
| 13 |
+
To mitigate these downsides, we are committed to providing cross-language client libraries capable of doing the hard work for you. We intend to publish these as strongly-typed artifacts generated from the "default" model set DataHub ships with. This stands in addition to an initiative to introduce an OpenAPI layer in DataHub's backend (gms) which would provide a strongly typed model.
|
| 14 |
+
|
| 15 |
+
Ultimately, we intend to realize a state in which the Entities and Aspect schemas can be altered without requiring generated code and without maintaining a single mega-model schema (looking at you, Snapshot.pdl). The intention is that changes to the metadata model become even easier than they are today.
|
| 16 |
+
|
| 17 |
+
## Modeling
|
| 18 |
+
|
| 19 |
+
A Metadata Change Proposal is defined (in PDL) as follows
|
| 20 |
+
|
| 21 |
+
```protobuf
|
| 22 |
+
record MetadataChangeProposal {
|
| 23 |
+
|
| 24 |
+
/**
|
| 25 |
+
* Kafka audit header. See go/kafkaauditheader for more info.
|
| 26 |
+
*/
|
| 27 |
+
auditHeader: optional KafkaAuditHeader
|
| 28 |
+
|
| 29 |
+
/**
|
| 30 |
+
* Type of the entity being written to
|
| 31 |
+
*/
|
| 32 |
+
entityType: string
|
| 33 |
+
|
| 34 |
+
/**
|
| 35 |
+
* Urn of the entity being written
|
| 36 |
+
**/
|
| 37 |
+
entityUrn: optional Urn,
|
| 38 |
+
|
| 39 |
+
/**
|
| 40 |
+
* Key aspect of the entity being written
|
| 41 |
+
*/
|
| 42 |
+
entityKeyAspect: optional GenericAspect
|
| 43 |
+
|
| 44 |
+
/**
|
| 45 |
+
* Type of change being proposed
|
| 46 |
+
*/
|
| 47 |
+
changeType: ChangeType
|
| 48 |
+
|
| 49 |
+
/**
|
| 50 |
+
* Aspect of the entity being written to
|
| 51 |
+
* Not filling this out implies that the writer wants to affect the entire entity
|
| 52 |
+
* Note: This is only valid for CREATE and DELETE operations.
|
| 53 |
+
**/
|
| 54 |
+
aspectName: optional string
|
| 55 |
+
|
| 56 |
+
aspect: optional GenericAspect
|
| 57 |
+
|
| 58 |
+
/**
|
| 59 |
+
* A string->string map of custom properties that one might want to attach to an event
|
| 60 |
+
**/
|
| 61 |
+
systemMetadata: optional SystemMetadata
|
| 62 |
+
|
| 63 |
+
}
|
| 64 |
+
```
|
| 65 |
+
|
| 66 |
+
Each proposal comprises of the following:
|
| 67 |
+
|
| 68 |
+
1. entityType
|
| 69 |
+
|
| 70 |
+
Refers to the type of the entity e.g. dataset, chart
|
| 71 |
+
|
| 72 |
+
2. entityUrn
|
| 73 |
+
|
| 74 |
+
Urn of the entity being updated. Note, **exactly one** of entityUrn or entityKeyAspect must be filled out to correctly identify an entity.
|
| 75 |
+
|
| 76 |
+
3. entityKeyAspect
|
| 77 |
+
|
| 78 |
+
Key aspect of the entity. Instead of having a string URN, we will support identifying entities by their key aspect structs. Note, this is not supported as of now.
|
| 79 |
+
|
| 80 |
+
4. changeType
|
| 81 |
+
|
| 82 |
+
Type of change you are proposing: one of
|
| 83 |
+
|
| 84 |
+
- UPSERT: Insert if not exists, update otherwise
|
| 85 |
+
- CREATE: Insert if not exists, fail otherwise
|
| 86 |
+
- UPDATE: Update if exists, fail otherwise
|
| 87 |
+
- DELETE: Delete
|
| 88 |
+
- PATCH: Patch the aspect instead of doing a full replace
|
| 89 |
+
|
| 90 |
+
Only UPSERT is supported as of now.
|
| 91 |
+
|
| 92 |
+
5. aspectName
|
| 93 |
+
|
| 94 |
+
Name of the aspect. Must match the name in the "@Aspect" annotation.
|
| 95 |
+
|
| 96 |
+
6. aspect
|
| 97 |
+
|
| 98 |
+
To support strongly typed aspects, without having to keep track of a union of all existing aspects, we introduced a new object called GenericAspect.
|
| 99 |
+
|
| 100 |
+
```xml
|
| 101 |
+
record GenericAspect {
|
| 102 |
+
value: bytes
|
| 103 |
+
contentType: string
|
| 104 |
+
}
|
| 105 |
+
```
|
| 106 |
+
|
| 107 |
+
It contains the type of serialization and the serialized value. Note, currently we only support "application/json" as contentType but will be adding more forms of serialization in the future. Validation of the serialized object happens in GMS against the schema matching the aspectName.
|
| 108 |
+
|
| 109 |
+
7. systemMetadata
|
| 110 |
+
|
| 111 |
+
Extra metadata about the proposal like run_id or updated timestamp.
|
| 112 |
+
|
| 113 |
+
GMS processes the proposal and produces the Metadata Change Log, which looks like this.
|
| 114 |
+
|
| 115 |
+
```protobuf
|
| 116 |
+
record MetadataChangeLog includes MetadataChangeProposal {
|
| 117 |
+
|
| 118 |
+
previousAspectValue: optional GenericAspect
|
| 119 |
+
|
| 120 |
+
previousSystemMetadata: optional SystemMetadata
|
| 121 |
+
|
| 122 |
+
}
|
| 123 |
+
```
|
| 124 |
+
|
| 125 |
+
It includes all fields in the proposal, but also has the previous version of the aspect value and system metadata. This allows the MCL processor to know the previous value before deciding to update all indices.
|
| 126 |
+
|
| 127 |
+
## Topics
|
| 128 |
+
|
| 129 |
+
Following the change in our event models, we introduced 4 new topics. The old topics will get deprecated as we fully migrate to this model.
|
| 130 |
+
|
| 131 |
+
1. **MetadataChangeProposal_v1, FailedMetadataChangeProposal_v1**
|
| 132 |
+
|
| 133 |
+
Analogous to the MCE topic, proposals that get produced into the MetadataChangeProposal_v1 topic, will get ingested to GMS asynchronously, and any failed ingestion will produce a failed MCP in the FailedMetadataChangeProposal_v1 topic.
|
| 134 |
+
|
| 135 |
+
|
| 136 |
+
2. **MetadataChangeLog_Versioned_v1**
|
| 137 |
+
|
| 138 |
+
Analogous to the MAE topic, MCLs for versioned aspects will get produced into this topic. Since versioned aspects have a source of truth that can be separately backed up, the retention of this topic is short (by default 7 days). Note both this and the next topic are consumed by the same MCL processor.
|
| 139 |
+
|
| 140 |
+
|
| 141 |
+
3. **MetadataChangeLog_Timeseries_v1**
|
| 142 |
+
|
| 143 |
+
Analogous to the MAE topics, MCLs for timeseries aspects will get produced into this topic. Since timeseries aspects do not have a source of truth, but rather gets ingested straight to elasticsearch, we set the retention of this topic to be longer (90 days). You can backup timeseries aspect by replaying this topic.
|
| 144 |
+
|
| 145 |
+
## Configuration
|
| 146 |
+
|
| 147 |
+
With MetadataChangeProposal and MetadataChangeLog, we will introduce a new mechanism for configuring the association between Metadata Entities & Aspects. Specifically, the Snapshot.pdl model will no longer encode this information by way of [Rest.li](http://rest.li) union. Instead, a more explicit yaml file will provide these links. This file will be leveraged at runtime to construct the in-memory Entity Registry which contains the global Metadata schema along with some additional metadata.
|
| 148 |
+
|
| 149 |
+
An example of the configuration file that will be used for MCP & MCL, which defines a "dataset" entity that is associated with to two aspects: "datasetKey" and "datasetProfile".
|
| 150 |
+
|
| 151 |
+
```
|
| 152 |
+
# entity-registry.yml
|
| 153 |
+
|
| 154 |
+
entities:
|
| 155 |
+
- name: dataset
|
| 156 |
+
keyAspect: datasetKey
|
| 157 |
+
aspects:
|
| 158 |
+
- datasetProfile
|
| 159 |
+
```
|
docs/advanced/monitoring.md
ADDED
|
@@ -0,0 +1,97 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Monitoring DataHub
|
| 2 |
+
|
| 3 |
+
Monitoring DataHub's system components is critical for operating and improving DataHub. This doc explains how to add
|
| 4 |
+
tracing and metrics measurements in the DataHub containers.
|
| 5 |
+
|
| 6 |
+
## Tracing
|
| 7 |
+
|
| 8 |
+
Traces let us track the life of a request across multiple components. Each trace is consisted of multiple spans, which
|
| 9 |
+
are units of work, containing various context about the work being done as well as time taken to finish the work. By
|
| 10 |
+
looking at the trace, we can more easily identify performance bottlenecks.
|
| 11 |
+
|
| 12 |
+
We enable tracing by using
|
| 13 |
+
the [OpenTelemetry java instrumentation library](https://github.com/open-telemetry/opentelemetry-java-instrumentation).
|
| 14 |
+
This project provides a Java agent JAR that is attached to java applications. The agent injects bytecode to capture
|
| 15 |
+
telemetry from popular libraries.
|
| 16 |
+
|
| 17 |
+
Using the agent we are able to
|
| 18 |
+
|
| 19 |
+
1) Plug and play different tracing tools based on the user's setup: Jaeger, Zipkin, or other tools
|
| 20 |
+
2) Get traces for Kafka, JDBC, and Elasticsearch without any additional code
|
| 21 |
+
3) Track traces of any function with a simple `@WithSpan` annotation
|
| 22 |
+
|
| 23 |
+
You can enable the agent by setting env variable `ENABLE_OTEL` to `true` for GMS and MAE/MCE consumers. In our
|
| 24 |
+
example [docker-compose](../../docker/monitoring/docker-compose.monitoring.yml), we export metrics to a local Jaeger
|
| 25 |
+
instance by setting env variable `OTEL_TRACES_EXPORTER` to `jaeger`
|
| 26 |
+
and `OTEL_EXPORTER_JAEGER_ENDPOINT` to `http://jaeger-all-in-one:14250`, but you can easily change this behavior by
|
| 27 |
+
setting the correct env variables. Refer to
|
| 28 |
+
this [doc](https://github.com/open-telemetry/opentelemetry-java/blob/main/sdk-extensions/autoconfigure/README.md) for
|
| 29 |
+
all configs.
|
| 30 |
+
|
| 31 |
+
Once the above is set up, you should be able to see a detailed trace as a request is sent to GMS. We added
|
| 32 |
+
the `@WithSpan` annotation in various places to make the trace more readable. You should start to see traces in the
|
| 33 |
+
tracing collector of choice. Our example [docker-compose](../../docker/monitoring/docker-compose.monitoring.yml) deploys
|
| 34 |
+
an instance of Jaeger with port 16686. The traces should be available at http://localhost:16686.
|
| 35 |
+
|
| 36 |
+
## Metrics
|
| 37 |
+
|
| 38 |
+
With tracing, we can observe how a request flows through our system into the persistence layer. However, for a more
|
| 39 |
+
holistic picture, we need to be able to export metrics and measure them across time. Unfortunately, OpenTelemetry's java
|
| 40 |
+
metrics library is still in active development.
|
| 41 |
+
|
| 42 |
+
As such, we decided to use [Dropwizard Metrics](https://metrics.dropwizard.io/4.2.0/) to export custom metrics to JMX,
|
| 43 |
+
and then use [Prometheus-JMX exporter](https://github.com/prometheus/jmx_exporter) to export all JMX metrics to
|
| 44 |
+
Prometheus. This allows our code base to be independent of the metrics collection tool, making it easy for people to use
|
| 45 |
+
their tool of choice. You can enable the agent by setting env variable `ENABLE_PROMETHEUS` to `true` for GMS and MAE/MCE
|
| 46 |
+
consumers. Refer to this example [docker-compose](../../docker/monitoring/docker-compose.monitoring.yml) for setting the
|
| 47 |
+
variables.
|
| 48 |
+
|
| 49 |
+
In our example [docker-compose](../../docker/monitoring/docker-compose.monitoring.yml), we have configured prometheus to
|
| 50 |
+
scrape from 4318 ports of each container used by the JMX exporter to export metrics. We also configured grafana to
|
| 51 |
+
listen to prometheus and create useful dashboards. By default, we provide two
|
| 52 |
+
dashboards: [JVM dashboard](https://grafana.com/grafana/dashboards/14845) and DataHub dashboard.
|
| 53 |
+
|
| 54 |
+
In the JVM dashboard, you can find detailed charts based on JVM metrics like CPU/memory/disk usage. In the DataHub
|
| 55 |
+
dashboard, you can find charts to monitor each endpoint and the kafka topics. Using the example implementation, go
|
| 56 |
+
to http://localhost:3001 to find the grafana dashboards! (Username: admin, PW: admin)
|
| 57 |
+
|
| 58 |
+
To make it easy to track various metrics within the code base, we created MetricUtils class. This util class creates a
|
| 59 |
+
central metric registry, sets up the JMX reporter, and provides convenient functions for setting up counters and timers.
|
| 60 |
+
You can run the following to create a counter and increment.
|
| 61 |
+
|
| 62 |
+
```java
|
| 63 |
+
MetricUtils.counter(this.getClass(),"metricName").increment();
|
| 64 |
+
```
|
| 65 |
+
|
| 66 |
+
You can run the following to time a block of code.
|
| 67 |
+
|
| 68 |
+
```java
|
| 69 |
+
try(Timer.Context ignored=MetricUtils.timer(this.getClass(),"timerName").timer()){
|
| 70 |
+
...block of code
|
| 71 |
+
}
|
| 72 |
+
```
|
| 73 |
+
|
| 74 |
+
## Enable monitoring through docker-compose
|
| 75 |
+
|
| 76 |
+
We provide some example configuration for enabling monitoring in
|
| 77 |
+
this [directory](https://github.com/datahub-project/datahub/tree/master/docker/monitoring). Take a look at the docker-compose
|
| 78 |
+
files, which adds necessary env variables to existing containers, and spawns new containers (Jaeger, Prometheus,
|
| 79 |
+
Grafana).
|
| 80 |
+
|
| 81 |
+
You can add in the above docker-compose using the `-f <<path-to-compose-file>>` when running docker-compose commands.
|
| 82 |
+
For instance,
|
| 83 |
+
|
| 84 |
+
```shell
|
| 85 |
+
docker-compose \
|
| 86 |
+
-f quickstart/docker-compose.quickstart.yml \
|
| 87 |
+
-f monitoring/docker-compose.monitoring.yml \
|
| 88 |
+
pull && \
|
| 89 |
+
docker-compose -p datahub \
|
| 90 |
+
-f quickstart/docker-compose.quickstart.yml \
|
| 91 |
+
-f monitoring/docker-compose.monitoring.yml \
|
| 92 |
+
up
|
| 93 |
+
```
|
| 94 |
+
|
| 95 |
+
We set up quickstart.sh, dev.sh, and dev-without-neo4j.sh to add the above docker-compose when MONITORING=true. For
|
| 96 |
+
instance `MONITORING=true ./docker/quickstart.sh` will add the correct env variables to start collecting traces and
|
| 97 |
+
metrics, and also deploy Jaeger, Prometheus, and Grafana. We will soon support this as a flag during quickstart.
|
docs/advanced/no-code-modeling.md
ADDED
|
@@ -0,0 +1,403 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# No Code Metadata
|
| 2 |
+
|
| 3 |
+
## Summary of changes
|
| 4 |
+
|
| 5 |
+
As part of the No Code Metadata Modeling initiative, we've made radical changes to the DataHub stack.
|
| 6 |
+
|
| 7 |
+
Specifically, we've
|
| 8 |
+
|
| 9 |
+
- Decoupled the persistence layer from Java + Rest.li specific concepts
|
| 10 |
+
- Consolidated the per-entity Rest.li resources into a single general-purpose Entity Resource
|
| 11 |
+
- Consolidated the per-entity Graph Index Writers + Readers into a single general-purpose Neo4J DAO
|
| 12 |
+
- Consolidated the per-entity Search Index Writers + Readers into a single general-purpose ES DAO.
|
| 13 |
+
- Developed mechanisms for declaring search indexing configurations + foreign key relationships as annotations
|
| 14 |
+
on PDL models themselves.
|
| 15 |
+
- Introduced a special "Browse Paths" aspect that allows the browse configuration to be
|
| 16 |
+
pushed into DataHub, as opposed to computed in a blackbox lambda sitting within DataHub
|
| 17 |
+
- Introduced special "Key" aspects for conveniently representing the information that identifies a DataHub entities via
|
| 18 |
+
a normal struct.
|
| 19 |
+
- Removed the need for hand-written Elastic `settings.json` and `mappings.json`. (Now generated at runtime)
|
| 20 |
+
- Removed the need for the Elastic Set Up container (indexes are not registered at runtime)
|
| 21 |
+
- Simplified the number of models that need to be maintained for each DataHub entity. We removed the need for
|
| 22 |
+
1. Relationship Models
|
| 23 |
+
2. Entity Models
|
| 24 |
+
3. Urn models + the associated Java container classes
|
| 25 |
+
4. 'Value' models, those which are returned by the Rest.li resource
|
| 26 |
+
|
| 27 |
+
In doing so, dramatically reducing the level of effort required to add or extend an existing entity.
|
| 28 |
+
|
| 29 |
+
For more on the design considerations, see the **Design** section below.
|
| 30 |
+
|
| 31 |
+
|
| 32 |
+
## Engineering Spec
|
| 33 |
+
|
| 34 |
+
This section will provide a more in-depth overview of the design considerations that were at play when working on the No
|
| 35 |
+
Code initiative.
|
| 36 |
+
|
| 37 |
+
# Use Cases
|
| 38 |
+
|
| 39 |
+
Who needs what & why?
|
| 40 |
+
|
| 41 |
+
| As a | I want to | because
|
| 42 |
+
| ---------------- | ------------------------ | ------------------------------
|
| 43 |
+
| DataHub Operator | Add new entities | The default domain model does not match my business needs
|
| 44 |
+
| DataHub Operator | Extend existing entities | The default domain model does not match my business needs
|
| 45 |
+
|
| 46 |
+
What we heard from folks in the community is that adding new entities + aspects is just **too difficult**.
|
| 47 |
+
|
| 48 |
+
They'd be happy if this process was streamlined and simple. **Extra** happy if there was no chance of merge conflicts in the future. (no fork necessary)
|
| 49 |
+
|
| 50 |
+
# Goals
|
| 51 |
+
|
| 52 |
+
### Primary Goal
|
| 53 |
+
|
| 54 |
+
**Reduce the friction** of adding new entities, aspects, and relationships.
|
| 55 |
+
|
| 56 |
+
### Secondary Goal
|
| 57 |
+
|
| 58 |
+
Achieve the primary goal in a way that does not require a fork.
|
| 59 |
+
|
| 60 |
+
# Requirements
|
| 61 |
+
|
| 62 |
+
### Must-Haves
|
| 63 |
+
|
| 64 |
+
1. Mechanisms for **adding** a browsable, searchable, linkable GMS entity by defining one or more PDL models
|
| 65 |
+
- GMS Endpoint for fetching entity
|
| 66 |
+
- GMS Endpoint for fetching entity relationships
|
| 67 |
+
- GMS Endpoint for searching entity
|
| 68 |
+
- GMS Endpoint for browsing entity
|
| 69 |
+
2. Mechanisms for **extending** a ****browsable, searchable, linkable GMS ****entity by defining one or more PDL models
|
| 70 |
+
- GMS Endpoint for fetching entity
|
| 71 |
+
- GMS Endpoint for fetching entity relationships
|
| 72 |
+
- GMS Endpoint for searching entity
|
| 73 |
+
- GMS Endpoint for browsing entity
|
| 74 |
+
3. Mechanisms + conventions for introducing a new **relationship** between 2 GMS entities without writing code
|
| 75 |
+
4. Clear documentation describing how to perform actions in #1, #2, and #3 above published on [datahubproject.io](http://datahubproject.io)
|
| 76 |
+
|
| 77 |
+
## Nice-to-haves
|
| 78 |
+
|
| 79 |
+
1. Mechanisms for automatically generating a working GraphQL API using the entity PDL models
|
| 80 |
+
2. Ability to add / extend GMS entities without a fork.
|
| 81 |
+
- e.g. **Register** new entity / extensions *at runtime*. (Unlikely due to code generation)
|
| 82 |
+
- or, **configure** new entities at *deploy time*
|
| 83 |
+
|
| 84 |
+
## What Success Looks Like
|
| 85 |
+
|
| 86 |
+
1. Adding a new browsable, searchable entity to GMS (not DataHub UI / frontend) takes 1 dev < 15 minutes.
|
| 87 |
+
2. Extending an existing browsable, searchable entity in GMS takes 1 dev < 15 minutes
|
| 88 |
+
3. Adding a new relationship among 2 GMS entities takes 1 dev < 15 minutes
|
| 89 |
+
4. [Bonus] Implementing the `datahub-frontend` GraphQL API for a new / extended entity takes < 10 minutes
|
| 90 |
+
|
| 91 |
+
|
| 92 |
+
## Design
|
| 93 |
+
|
| 94 |
+
## State of the World
|
| 95 |
+
|
| 96 |
+
### Modeling
|
| 97 |
+
|
| 98 |
+
Currently, there are various models in GMS:
|
| 99 |
+
|
| 100 |
+
1. [Urn](https://github.com/datahub-project/datahub/blob/master/li-utils/src/main/pegasus/com/linkedin/common/DatasetUrn.pdl) - Structs composing primary keys
|
| 101 |
+
2. [Root] [Snapshots](https://github.com/datahub-project/datahub/blob/master/metadata-models/src/main/pegasus/com/linkedin/metadata/snapshot/Snapshot.pdl) - Container of aspects
|
| 102 |
+
3. [Aspects](https://github.com/datahub-project/datahub/blob/master/metadata-models/src/main/pegasus/com/linkedin/metadata/aspect/DashboardAspect.pdl) - Optional container of fields
|
| 103 |
+
4. [Values](https://github.com/datahub-project/datahub/blob/master/gms/api/src/main/pegasus/com/linkedin/dataset/Dataset.pdl), [Keys](https://github.com/datahub-project/datahub/blob/master/gms/api/src/main/pegasus/com/linkedin/dataset/DatasetKey.pdl) - Model returned by GMS [Rest.li](http://rest.li) API (public facing)
|
| 104 |
+
5. [Entities](https://github.com/datahub-project/datahub/blob/master/metadata-models/src/main/pegasus/com/linkedin/metadata/entity/DatasetEntity.pdl) - Records with fields derived from the URN. Used only in graph / relationships
|
| 105 |
+
6. [Relationships](https://github.com/datahub-project/datahub/blob/master/metadata-models/src/main/pegasus/com/linkedin/metadata/relationship/Relationship.pdl) - Edges between 2 entities with optional edge properties
|
| 106 |
+
7. [Search Documents](https://github.com/datahub-project/datahub/blob/master/metadata-models/src/main/pegasus/com/linkedin/metadata/search/ChartDocument.pdl) - Flat documents for indexing within Elastic index
|
| 107 |
+
- And corresponding index [mappings.json](https://github.com/datahub-project/datahub/blob/master/gms/impl/src/main/resources/index/chart/mappings.json), [settings.json](https://github.com/datahub-project/datahub/blob/master/gms/impl/src/main/resources/index/chart/settings.json)
|
| 108 |
+
|
| 109 |
+
Various components of GMS depend on / make assumptions about these model types:
|
| 110 |
+
|
| 111 |
+
1. IndexBuilders depend on **Documents**
|
| 112 |
+
2. GraphBuilders depend on **Snapshots**
|
| 113 |
+
3. RelationshipBuilders depend on **Aspects**
|
| 114 |
+
4. Mae Processor depend on **Snapshots, Documents, Relationships**
|
| 115 |
+
5. Mce Processor depend on **Snapshots, Urns**
|
| 116 |
+
6. [Rest.li](http://rest.li) Resources on **Documents, Snapshots, Aspects, Values, Urns**
|
| 117 |
+
7. Graph Reader Dao (BaseQueryDao) depends on **Relationships, Entity**
|
| 118 |
+
8. Graph Writer Dao (BaseGraphWriterDAO) depends on **Relationships, Entity**
|
| 119 |
+
9. Local Dao Depends on **aspects, urns**
|
| 120 |
+
10. Search Dao depends on **Documents**
|
| 121 |
+
|
| 122 |
+
Additionally, there are some implicit concepts that require additional caveats / logic:
|
| 123 |
+
|
| 124 |
+
1. Browse Paths - Requires defining logic in an entity-specific index builder to generate.
|
| 125 |
+
2. Urns - Requires defining a) an Urn PDL model and b) a hand-written Urn class
|
| 126 |
+
|
| 127 |
+
As you can see, there are many tied up concepts. Fundamentally changing the model would require a serious amount of refactoring, as it would require new versions of numerous components.
|
| 128 |
+
|
| 129 |
+
The challenge is, how can we meet the requirements without fundamentally altering the model?
|
| 130 |
+
|
| 131 |
+
## Proposed Solution
|
| 132 |
+
|
| 133 |
+
In a nutshell, the idea is to consolidate the number of models + code we need to write on a per-entity basis.
|
| 134 |
+
We intend to achieve this by making search index + relationship configuration declarative, specified as part of the model
|
| 135 |
+
definition itself.
|
| 136 |
+
|
| 137 |
+
We will use this configuration to drive more generic versions of the index builders + rest resources,
|
| 138 |
+
with the intention of reducing the overall surface area of GMS.
|
| 139 |
+
|
| 140 |
+
During this initiative, we will also seek to make the concepts of Browse Paths and Urns declarative. Browse Paths
|
| 141 |
+
will be provided using a special BrowsePaths aspect. Urns will no longer be strongly typed.
|
| 142 |
+
|
| 143 |
+
To achieve this, we will attempt to generify many components throughout the stack. Currently, many of them are defined on
|
| 144 |
+
a *per-entity* basis, including
|
| 145 |
+
|
| 146 |
+
- Rest.li Resources
|
| 147 |
+
- Index Builders
|
| 148 |
+
- Graph Builders
|
| 149 |
+
- Local, Search, Browse, Graph DAOs
|
| 150 |
+
- Clients
|
| 151 |
+
- Browse Path Logic
|
| 152 |
+
|
| 153 |
+
along with simplifying the number of raw data models that need defined, including
|
| 154 |
+
|
| 155 |
+
- Rest.li Resource Models
|
| 156 |
+
- Search Document Models
|
| 157 |
+
- Relationship Models
|
| 158 |
+
- Urns + their java classes
|
| 159 |
+
|
| 160 |
+
From an architectural PoV, we will move from a before that looks something like this:
|
| 161 |
+
|
| 162 |
+

|
| 163 |
+
|
| 164 |
+
to an after that looks like this
|
| 165 |
+
|
| 166 |
+

|
| 167 |
+
|
| 168 |
+
That is, a move away from patterns of strong-typing-everywhere to a more generic + flexible world.
|
| 169 |
+
|
| 170 |
+
### How will we do it?
|
| 171 |
+
|
| 172 |
+
We will accomplish this by building the following:
|
| 173 |
+
|
| 174 |
+
1. Set of custom annotations to permit declarative entity, search, graph configurations
|
| 175 |
+
- @Entity & @Aspect
|
| 176 |
+
- @Searchable
|
| 177 |
+
- @Relationship
|
| 178 |
+
2. Entity Registry: In-memory structures for representing, storing & serving metadata associated with a particular Entity, including search and relationship configurations.
|
| 179 |
+
3. Generic Entity, Search, Graph Service classes: Replaces traditional strongly-typed DAOs with flexible, pluggable APIs that can be used for CRUD, search, and graph across all entities.
|
| 180 |
+
2. Generic Rest.li Resources:
|
| 181 |
+
- 1 permitting reading, writing, searching, autocompleting, and browsing arbitrary entities
|
| 182 |
+
- 1 permitting reading of arbitrary entity-entity relationship edges
|
| 183 |
+
2. Generic Search Index Builder: Given a MAE and a specification of the Search Configuration for an entity, updates the search index.
|
| 184 |
+
3. Generic Graph Index Builder: Given a MAE and a specification of the Relationship Configuration for an entity, updates the graph index.
|
| 185 |
+
4. Generic Index + Mappings Builder: Dynamically generates index mappings and creates indices on the fly.
|
| 186 |
+
5. Introduce of special aspects to address other imperative code requirements
|
| 187 |
+
- BrowsePaths Aspect: Include an aspect to permit customization of the indexed browse paths.
|
| 188 |
+
- Key aspects: Include "virtual" aspects for representing the fields that uniquely identify an Entity for easy
|
| 189 |
+
reading by clients of DataHub.
|
| 190 |
+
|
| 191 |
+
### Final Developer Experience: Defining an Entity
|
| 192 |
+
|
| 193 |
+
We will outline what the experience of adding a new Entity should look like. We will imagine we want to define a "Service" entity representing
|
| 194 |
+
online microservices.
|
| 195 |
+
|
| 196 |
+
#### Step 1. Add aspects
|
| 197 |
+
|
| 198 |
+
ServiceKey.pdl
|
| 199 |
+
|
| 200 |
+
```
|
| 201 |
+
namespace com.linkedin.metadata.key
|
| 202 |
+
|
| 203 |
+
/**
|
| 204 |
+
* Key for a Service
|
| 205 |
+
*/
|
| 206 |
+
@Aspect = {
|
| 207 |
+
"name": "serviceKey"
|
| 208 |
+
}
|
| 209 |
+
record ServiceKey {
|
| 210 |
+
/**
|
| 211 |
+
* Name of the service
|
| 212 |
+
*/
|
| 213 |
+
@Searchable = {
|
| 214 |
+
"fieldType": "TEXT_PARTIAL",
|
| 215 |
+
"enableAutocomplete": true
|
| 216 |
+
}
|
| 217 |
+
name: string
|
| 218 |
+
}
|
| 219 |
+
```
|
| 220 |
+
|
| 221 |
+
ServiceInfo.pdl
|
| 222 |
+
|
| 223 |
+
```
|
| 224 |
+
namespace com.linkedin.service
|
| 225 |
+
|
| 226 |
+
import com.linkedin.common.Urn
|
| 227 |
+
|
| 228 |
+
/**
|
| 229 |
+
* Properties associated with a Tag
|
| 230 |
+
*/
|
| 231 |
+
@Aspect = {
|
| 232 |
+
"name": "serviceInfo"
|
| 233 |
+
}
|
| 234 |
+
record ServiceInfo {
|
| 235 |
+
|
| 236 |
+
/**
|
| 237 |
+
* Description of the service
|
| 238 |
+
*/
|
| 239 |
+
@Searchable = {}
|
| 240 |
+
description: string
|
| 241 |
+
|
| 242 |
+
/**
|
| 243 |
+
* The owners of the
|
| 244 |
+
*/
|
| 245 |
+
@Relationship = {
|
| 246 |
+
"name": "OwnedBy",
|
| 247 |
+
"entityTypes": ["corpUser"]
|
| 248 |
+
}
|
| 249 |
+
owner: Urn
|
| 250 |
+
}
|
| 251 |
+
```
|
| 252 |
+
|
| 253 |
+
#### Step 2. Add aspect union.
|
| 254 |
+
|
| 255 |
+
ServiceAspect.pdl
|
| 256 |
+
|
| 257 |
+
```
|
| 258 |
+
namespace com.linkedin.metadata.aspect
|
| 259 |
+
|
| 260 |
+
import com.linkedin.metadata.key.ServiceKey
|
| 261 |
+
import com.linkedin.service.ServiceInfo
|
| 262 |
+
import com.linkedin.common.BrowsePaths
|
| 263 |
+
|
| 264 |
+
/**
|
| 265 |
+
* Service Info
|
| 266 |
+
*/
|
| 267 |
+
typeref ServiceAspect = union[
|
| 268 |
+
ServiceKey,
|
| 269 |
+
ServiceInfo,
|
| 270 |
+
BrowsePaths
|
| 271 |
+
]
|
| 272 |
+
```
|
| 273 |
+
|
| 274 |
+
#### Step 3. Add Snapshot model.
|
| 275 |
+
|
| 276 |
+
ServiceSnapshot.pdl
|
| 277 |
+
|
| 278 |
+
```
|
| 279 |
+
namespace com.linkedin.metadata.snapshot
|
| 280 |
+
|
| 281 |
+
import com.linkedin.common.Urn
|
| 282 |
+
import com.linkedin.metadata.aspect.ServiceAspect
|
| 283 |
+
|
| 284 |
+
@Entity = {
|
| 285 |
+
"name": "service",
|
| 286 |
+
"keyAspect": "serviceKey"
|
| 287 |
+
}
|
| 288 |
+
record ServiceSnapshot {
|
| 289 |
+
|
| 290 |
+
/**
|
| 291 |
+
* Urn for the service
|
| 292 |
+
*/
|
| 293 |
+
urn: Urn
|
| 294 |
+
|
| 295 |
+
/**
|
| 296 |
+
* The list of service aspects
|
| 297 |
+
*/
|
| 298 |
+
aspects: array[ServiceAspect]
|
| 299 |
+
}
|
| 300 |
+
```
|
| 301 |
+
|
| 302 |
+
#### Step 4. Update Snapshot union.
|
| 303 |
+
|
| 304 |
+
Snapshot.pdl
|
| 305 |
+
|
| 306 |
+
```
|
| 307 |
+
namespace com.linkedin.metadata.snapshot
|
| 308 |
+
|
| 309 |
+
/**
|
| 310 |
+
* A union of all supported metadata snapshot types.
|
| 311 |
+
*/
|
| 312 |
+
typeref Snapshot = union[
|
| 313 |
+
...
|
| 314 |
+
ServiceSnapshot
|
| 315 |
+
]
|
| 316 |
+
```
|
| 317 |
+
|
| 318 |
+
### Interacting with New Entity
|
| 319 |
+
|
| 320 |
+
1. Write Entity
|
| 321 |
+
|
| 322 |
+
```
|
| 323 |
+
curl 'http://localhost:8080/entities?action=ingest' -X POST -H 'X-RestLi-Protocol-Version:2.0.0' --data '{
|
| 324 |
+
"entity":{
|
| 325 |
+
"value":{
|
| 326 |
+
"com.linkedin.metadata.snapshot.ServiceSnapshot":{
|
| 327 |
+
"urn": "urn:li:service:mydemoservice",
|
| 328 |
+
"aspects":[
|
| 329 |
+
{
|
| 330 |
+
"com.linkedin.service.ServiceInfo":{
|
| 331 |
+
"description":"My demo service",
|
| 332 |
+
"owner": "urn:li:corpuser:user1"
|
| 333 |
+
}
|
| 334 |
+
},
|
| 335 |
+
{
|
| 336 |
+
"com.linkedin.common.BrowsePaths":{
|
| 337 |
+
"paths":[
|
| 338 |
+
"/my/custom/browse/path1",
|
| 339 |
+
"/my/custom/browse/path2"
|
| 340 |
+
]
|
| 341 |
+
}
|
| 342 |
+
}
|
| 343 |
+
]
|
| 344 |
+
}
|
| 345 |
+
}
|
| 346 |
+
}
|
| 347 |
+
}'
|
| 348 |
+
```
|
| 349 |
+
|
| 350 |
+
2. Read Entity
|
| 351 |
+
|
| 352 |
+
```
|
| 353 |
+
curl 'http://localhost:8080/entities/urn%3Ali%3Aservice%3Amydemoservice' -H 'X-RestLi-Protocol-Version:2.0.0'
|
| 354 |
+
```
|
| 355 |
+
|
| 356 |
+
3. Search Entity
|
| 357 |
+
|
| 358 |
+
```
|
| 359 |
+
curl --location --request POST 'http://localhost:8080/entities?action=search' \
|
| 360 |
+
--header 'X-RestLi-Protocol-Version: 2.0.0' \
|
| 361 |
+
--header 'Content-Type: application/json' \
|
| 362 |
+
--data-raw '{
|
| 363 |
+
"input": "My demo",
|
| 364 |
+
"entity": "service",
|
| 365 |
+
"start": 0,
|
| 366 |
+
"count": 10
|
| 367 |
+
}'
|
| 368 |
+
```
|
| 369 |
+
|
| 370 |
+
4. Autocomplete
|
| 371 |
+
|
| 372 |
+
```
|
| 373 |
+
curl --location --request POST 'http://localhost:8080/entities?action=autocomplete' \
|
| 374 |
+
--header 'X-RestLi-Protocol-Version: 2.0.0' \
|
| 375 |
+
--header 'Content-Type: application/json' \
|
| 376 |
+
--data-raw '{
|
| 377 |
+
"query": "mydem",
|
| 378 |
+
"entity": "service",
|
| 379 |
+
"limit": 10
|
| 380 |
+
}'
|
| 381 |
+
```
|
| 382 |
+
|
| 383 |
+
5. Browse
|
| 384 |
+
|
| 385 |
+
```
|
| 386 |
+
curl --location --request POST 'http://localhost:8080/entities?action=browse' \
|
| 387 |
+
--header 'X-RestLi-Protocol-Version: 2.0.0' \
|
| 388 |
+
--header 'Content-Type: application/json' \
|
| 389 |
+
--data-raw '{
|
| 390 |
+
"path": "/my/custom/browse",
|
| 391 |
+
"entity": "service",
|
| 392 |
+
"start": 0,
|
| 393 |
+
"limit": 10
|
| 394 |
+
}'
|
| 395 |
+
```
|
| 396 |
+
|
| 397 |
+
6. Relationships
|
| 398 |
+
|
| 399 |
+
```
|
| 400 |
+
curl --location --request GET 'http://localhost:8080/relationships?direction=INCOMING&urn=urn%3Ali%3Acorpuser%3Auser1&types=OwnedBy' \
|
| 401 |
+
--header 'X-RestLi-Protocol-Version: 2.0.0'
|
| 402 |
+
```
|
| 403 |
+
|
docs/advanced/no-code-upgrade.md
ADDED
|
@@ -0,0 +1,205 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# No Code Upgrade (In-Place Migration Guide)
|
| 2 |
+
|
| 3 |
+
## Summary of changes
|
| 4 |
+
|
| 5 |
+
With the No Code metadata initiative, we've introduced various major changes:
|
| 6 |
+
|
| 7 |
+
1. New Ebean Aspect table (metadata_aspect_v2)
|
| 8 |
+
2. New Elastic Indices (*entityName*index_v2)
|
| 9 |
+
3. New edge triples. (Remove fully qualified classpaths from nodes & edges)
|
| 10 |
+
4. Dynamic DataPlatform entities (no more hardcoded DataPlatformInfo.json)
|
| 11 |
+
5. Dynamic Browse Paths (no more hardcoded browse path creation logic)
|
| 12 |
+
6. Addition of Entity Key aspects, dropped requirement for strongly-typed Urns.
|
| 13 |
+
7. Addition of @Entity, @Aspect, @Searchable, @Relationship annotations to existing models.
|
| 14 |
+
|
| 15 |
+
Because of these changes, it is required that your persistence layer be migrated after the NoCode containers have been
|
| 16 |
+
deployed.
|
| 17 |
+
|
| 18 |
+
For more information about the No Code Update, please see [no-code-modeling](./no-code-modeling.md).
|
| 19 |
+
|
| 20 |
+
## Migration strategy
|
| 21 |
+
|
| 22 |
+
We are merging these breaking changes into the main branch upfront because we feel they are fundamental to subsequent
|
| 23 |
+
changes, providing a more solid foundation upon which exciting new features will be built upon. We will continue to
|
| 24 |
+
offer limited support for previous verions of DataHub.
|
| 25 |
+
|
| 26 |
+
This approach means that companies who actively deploy the latest version of DataHub will need to perform an upgrade to
|
| 27 |
+
continue operating DataHub smoothly.
|
| 28 |
+
|
| 29 |
+
## Upgrade Steps
|
| 30 |
+
|
| 31 |
+
### Step 1: Pull & deploy latest container images
|
| 32 |
+
|
| 33 |
+
It is important that the following containers are pulled and deployed simultaneously:
|
| 34 |
+
|
| 35 |
+
- datahub-frontend-react
|
| 36 |
+
- datahub-gms
|
| 37 |
+
- datahub-mae-consumer
|
| 38 |
+
- datahub-mce-consumer
|
| 39 |
+
|
| 40 |
+
#### Docker Compose Deployments
|
| 41 |
+
|
| 42 |
+
From the `docker` directory:
|
| 43 |
+
|
| 44 |
+
```aidl
|
| 45 |
+
docker-compose down --remove-orphans && docker-compose pull && docker-compose -p datahub up --force-recreate
|
| 46 |
+
```
|
| 47 |
+
|
| 48 |
+
#### Helm
|
| 49 |
+
|
| 50 |
+
Deploying latest helm charts will upgrade all components to version 0.8.0. Once all the pods are up and running, it will
|
| 51 |
+
run the datahub-upgrade job, which will run the above docker container to migrate to the new sources.
|
| 52 |
+
|
| 53 |
+
### Step 2: Execute Migration Job
|
| 54 |
+
|
| 55 |
+
#### Docker Compose Deployments - Preserve Data
|
| 56 |
+
|
| 57 |
+
If you do not care about migrating your data, you can refer to the Docker Compose Deployments - Lose All Existing Data
|
| 58 |
+
section below.
|
| 59 |
+
|
| 60 |
+
To migrate existing data, the easiest option is to execute the `run_upgrade.sh` script located under `docker/datahub-upgrade/nocode`.
|
| 61 |
+
|
| 62 |
+
```
|
| 63 |
+
cd docker/datahub-upgrade/nocode
|
| 64 |
+
./run_upgrade.sh
|
| 65 |
+
```
|
| 66 |
+
|
| 67 |
+
Using this command, the default environment variables will be used (`docker/datahub-upgrade/env/docker.env`). These assume
|
| 68 |
+
that your deployment is local & that you are running MySQL. If this is not the case, you'll need to define your own environment variables to tell the
|
| 69 |
+
upgrade system where your DataHub containers reside and run
|
| 70 |
+
|
| 71 |
+
To update the default environment variables, you can either
|
| 72 |
+
|
| 73 |
+
1. Change `docker/datahub-upgrade/env/docker.env` in place and then run one of the above commands OR
|
| 74 |
+
2. Define a new ".env" file containing your variables and execute `docker pull acryldata/datahub-upgrade && docker run acryldata/datahub-upgrade:latest -u NoCodeDataMigration`
|
| 75 |
+
|
| 76 |
+
To see the required environment variables, see the [datahub-upgrade](../../docker/datahub-upgrade/README.md)
|
| 77 |
+
documentation.
|
| 78 |
+
|
| 79 |
+
To run the upgrade against a database other than MySQL, you can use the `-a dbType=<db-type>` argument.
|
| 80 |
+
|
| 81 |
+
Execute
|
| 82 |
+
```
|
| 83 |
+
./docker/datahub-upgrade.sh -u NoCodeDataMigration -a dbType=POSTGRES
|
| 84 |
+
```
|
| 85 |
+
|
| 86 |
+
where dbType can be either `MYSQL`, `MARIA`, `POSTGRES`.
|
| 87 |
+
|
| 88 |
+
#### Docker Compose Deployments - Lose All Existing Data
|
| 89 |
+
|
| 90 |
+
This path is quickest but will wipe your DataHub's database.
|
| 91 |
+
|
| 92 |
+
If you want to make sure your current data is migrated, refer to the Docker Compose Deployments - Preserve Data section above.
|
| 93 |
+
If you are ok losing your data and re-ingesting, this approach is simplest.
|
| 94 |
+
|
| 95 |
+
```
|
| 96 |
+
# make sure you are on the latest
|
| 97 |
+
git checkout master
|
| 98 |
+
git pull origin master
|
| 99 |
+
|
| 100 |
+
# wipe all your existing data and turn off all processes
|
| 101 |
+
./docker/nuke.sh
|
| 102 |
+
|
| 103 |
+
# spin up latest datahub
|
| 104 |
+
./docker/quickstart.sh
|
| 105 |
+
|
| 106 |
+
# re-ingest data, for example, to ingest sample data:
|
| 107 |
+
./docker/ingestion/ingestion.sh
|
| 108 |
+
```
|
| 109 |
+
|
| 110 |
+
After that, you will be ready to go.
|
| 111 |
+
|
| 112 |
+
|
| 113 |
+
##### How to fix the "listening to port 5005" issue
|
| 114 |
+
|
| 115 |
+
Fix for this issue have been published to the acryldata/datahub-upgrade:head tag. Please pull latest master and rerun
|
| 116 |
+
the upgrade script.
|
| 117 |
+
|
| 118 |
+
However, we have seen cases where the problematic docker image is cached and docker does not pull the latest version. If
|
| 119 |
+
the script fails with the same error after pulling latest master, please run the following command to clear the docker
|
| 120 |
+
image cache.
|
| 121 |
+
|
| 122 |
+
```
|
| 123 |
+
docker images -a | grep acryldata/datahub-upgrade | awk '{print $3}' | xargs docker rmi -f
|
| 124 |
+
```
|
| 125 |
+
|
| 126 |
+
#### Helm Deployments
|
| 127 |
+
|
| 128 |
+
Upgrade to latest helm charts by running the following after pulling latest master.
|
| 129 |
+
|
| 130 |
+
```(shell)
|
| 131 |
+
helm upgrade datahub datahub/
|
| 132 |
+
```
|
| 133 |
+
|
| 134 |
+
In the latest helm charts, we added a datahub-upgrade-job, which runs the above mentioned docker container to migrate to
|
| 135 |
+
the new storage layer. Note, the job will fail in the beginning as it waits for GMS and MAE consumer to be deployed with
|
| 136 |
+
the NoCode code. It will rerun until it runs successfully.
|
| 137 |
+
|
| 138 |
+
Once the storage layer has been migrated, subsequent runs of this job will be a noop.
|
| 139 |
+
|
| 140 |
+
### Step 3 (Optional): Cleaning Up
|
| 141 |
+
|
| 142 |
+
Warning: This step clears all legacy metadata. If something is wrong with the upgraded metadata, there will no easy way to
|
| 143 |
+
re-run the migration.
|
| 144 |
+
|
| 145 |
+
This step involves removing data from previous versions of DataHub. This step should only be performed once you've
|
| 146 |
+
validated that your DataHub deployment is healthy after performing the upgrade. If you're able to search, browse, and
|
| 147 |
+
view your Metadata after the upgrade steps have been completed, you should be in good shape.
|
| 148 |
+
|
| 149 |
+
In advanced DataHub deployments, or cases in which you cannot easily rebuild the state stored in DataHub, it is strongly
|
| 150 |
+
advised that you do due diligence prior to running cleanup. This may involve manually inspecting the relational
|
| 151 |
+
tables (metadata_aspect_v2), search indices, and graph topology.
|
| 152 |
+
|
| 153 |
+
#### Docker Compose Deployments
|
| 154 |
+
|
| 155 |
+
The easiest option is to execute the `run_clean.sh` script located under `docker/datahub-upgrade/nocode`.
|
| 156 |
+
|
| 157 |
+
```
|
| 158 |
+
cd docker/datahub-upgrade/nocode
|
| 159 |
+
./run_clean.sh
|
| 160 |
+
```
|
| 161 |
+
|
| 162 |
+
Using this command, the default environment variables will be used (`docker/datahub-upgrade/env/docker.env`). These assume
|
| 163 |
+
that your deployment is local. If this is not the case, you'll need to define your own environment variables to tell the
|
| 164 |
+
upgrade system where your DataHub containers reside.
|
| 165 |
+
|
| 166 |
+
To update the default environment variables, you can either
|
| 167 |
+
|
| 168 |
+
1. Change `docker/datahub-upgrade/env/docker.env` in place and then run one of the above commands OR
|
| 169 |
+
2. Define a new ".env" file containing your variables and execute
|
| 170 |
+
`docker pull acryldata/datahub-upgrade && docker run acryldata/datahub-upgrade:latest -u NoCodeDataMigrationCleanup`
|
| 171 |
+
|
| 172 |
+
To see the required environment variables, see the [datahub-upgrade](../../docker/datahub-upgrade/README.md)
|
| 173 |
+
documentation
|
| 174 |
+
|
| 175 |
+
#### Helm Deployments
|
| 176 |
+
|
| 177 |
+
Assuming the latest helm chart has been deployed in the previous step, datahub-cleanup-job-template cronJob should have
|
| 178 |
+
been created. You can check by running the following:
|
| 179 |
+
|
| 180 |
+
```
|
| 181 |
+
kubectl get cronjobs
|
| 182 |
+
```
|
| 183 |
+
|
| 184 |
+
You should see an output like below:
|
| 185 |
+
|
| 186 |
+
```
|
| 187 |
+
NAME SCHEDULE SUSPEND ACTIVE LAST SCHEDULE AGE
|
| 188 |
+
datahub-datahub-cleanup-job-template * * * * * True 0 <none> 12m
|
| 189 |
+
```
|
| 190 |
+
|
| 191 |
+
Note that the cronJob has been suspended. It is intended to be run in an adhoc fashion when ready to clean up. Make sure
|
| 192 |
+
the migration was successful and DataHub is working as expected. Then run the following command to run the clean up job:
|
| 193 |
+
|
| 194 |
+
```
|
| 195 |
+
kubectl create job --from=cronjob/<<release-name>>-datahub-cleanup-job-template datahub-cleanup-job
|
| 196 |
+
```
|
| 197 |
+
|
| 198 |
+
Replace release-name with the name of the helm release. If you followed the kubernetes guide, it should be "datahub".
|
| 199 |
+
|
| 200 |
+
## Support
|
| 201 |
+
|
| 202 |
+
The Acryl team will be on standby to assist you in your migration. Please
|
| 203 |
+
join [#release-0_8_0](https://datahubspace.slack.com/archives/C0244FHMHJQ) channel and reach out to us if you find
|
| 204 |
+
trouble with the upgrade or have feedback on the process. We will work closely to make sure you can continue to operate
|
| 205 |
+
DataHub smoothly.
|
docs/advanced/partial-update.md
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Supporting Partial Aspect Update
|
| 2 |
+
|
| 3 |
+
WIP
|
docs/advanced/pdl-best-practices.md
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# PDL Best Practices
|
| 2 |
+
|
| 3 |
+
WIP
|
docs/api/datahub-apis.md
ADDED
|
@@ -0,0 +1,81 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Which DataHub API is for me?
|
| 2 |
+
|
| 3 |
+
DataHub supplys several APIs to manipulate metadata on the platform. These are our most-to-least recommended approaches:
|
| 4 |
+
|
| 5 |
+
- Our most recommended tools for extending and customizing the behavior of your DataHub instance are our SDKs in [Python](metadata-ingestion/as-a-library.md) and [Java](metadata-integration/java/as-a-library.md).
|
| 6 |
+
- If you'd like to customize the DataHub client or roll your own; the [GraphQL API](docs/api/graphql/getting-started.md) is our what powers our frontend. We figure if it's good enough for us, it's good enough for everyone! If GraphQL doesn't cover everything in your usecase, drop into [our slack](docs/slack.md) and let us know how we can improve it!
|
| 7 |
+
- If you are less familiar with GraphQL and would rather use OpenAPI, we offer [OpenAPI](docs/api/openapi/openapi-usage-guide.md) endpoints that allow you to produce metadata events and query metadata.
|
| 8 |
+
- Finally, if you're a brave soul and know exactly what you are doing... are you sure you don't just want to use the SDK directly? If you insist, the [Rest.li API](docs/api/restli/restli-overview.md) is a much more powerful, low level API intended only for advanced users.
|
| 9 |
+
|
| 10 |
+
## Python and Java SDK
|
| 11 |
+
|
| 12 |
+
We offer an SDK for both Python and Java that provide full functionality when it comes to CRUD operations and any complex functionality you may want to build into DataHub.
|
| 13 |
+
<a
|
| 14 |
+
className='button button--primary button--lg'
|
| 15 |
+
href="/docs/metadata-ingestion/as-a-library">
|
| 16 |
+
Get started with the Python SDK
|
| 17 |
+
</a>
|
| 18 |
+
|
| 19 |
+
<a
|
| 20 |
+
className='button button--primary button--lg'
|
| 21 |
+
href="/docs/metadata-integration/java/as-a-library">
|
| 22 |
+
Get started with the Java SDK
|
| 23 |
+
</a>
|
| 24 |
+
|
| 25 |
+
## GraphQL API
|
| 26 |
+
|
| 27 |
+
The GraphQL API serves as the primary public API for the platform. It can be used to fetch and update metadata programatically in the language of your choice. Intended as a higher-level API that simplifies the most common operations.
|
| 28 |
+
|
| 29 |
+
<a
|
| 30 |
+
className='button button--primary button--lg'
|
| 31 |
+
href="/docs/api/graphql/getting-started">
|
| 32 |
+
Get started with the GraphQL API
|
| 33 |
+
</a>
|
| 34 |
+
|
| 35 |
+
## OpenAPI
|
| 36 |
+
|
| 37 |
+
For developers who prefer OpenAPI to GraphQL for programmatic operations. Provides lower-level API access to the entire DataHub metadata model for writes, reads and queries.
|
| 38 |
+
<a
|
| 39 |
+
className='button button--primary button--lg'
|
| 40 |
+
href="/docs/api/openapi/openapi-usage-guide">
|
| 41 |
+
Get started with OpenAPI
|
| 42 |
+
</a>
|
| 43 |
+
|
| 44 |
+
## Rest.li API
|
| 45 |
+
|
| 46 |
+
:::caution
|
| 47 |
+
The Rest.li API is intended only for advanced users. If you're just getting started with DataHub, we recommend the GraphQL API
|
| 48 |
+
:::
|
| 49 |
+
|
| 50 |
+
The Rest.li API represents the underlying persistence layer, and exposes the raw PDL models used in storage. Under the hood, it powers the GraphQL API. Aside from that, it is also used for system-specific ingestion of metadata, being used by the Metadata Ingestion Framework for pushing metadata into DataHub directly. For all intents and purposes, the Rest.li API is considered system-internal, meaning DataHub components are the only ones to consume this API directly.
|
| 51 |
+
<a
|
| 52 |
+
className='button button--primary button--lg'
|
| 53 |
+
href="/docs/api/restli/restli-overview">
|
| 54 |
+
Get started with our Rest.li API
|
| 55 |
+
</a>
|
| 56 |
+
|
| 57 |
+
## DataHub API Comparison
|
| 58 |
+
DataHub supports several APIs, each with its own unique usage and format.
|
| 59 |
+
Here's an overview of what each API can do.
|
| 60 |
+
|
| 61 |
+
|
| 62 |
+
> Last Updated : Mar 21 2023
|
| 63 |
+
|
| 64 |
+
| Feature | GraphQL | Python SDK | OpenAPI |
|
| 65 |
+
|---------------------------------------------------------|-----------------------------------------------------------------|----------------------------------------------------------------|---------|
|
| 66 |
+
| Create a dataset | 🚫 | ✅ [[Guide]](/docs/api/tutorials/creating-datasets.md) | ✅ |
|
| 67 |
+
| Create a tag | ✅ [[Guide]](/docs/api/tutorials/creating-tags.md) | ✅ [[Guide]](/docs/api/tutorials/creating-tags.md) | ✅ |
|
| 68 |
+
| Create a glossary term | ✅ [[Guide]](/docs/api/tutorials/creating-terms.md) | ✅ [[Guide]](/docs/api/tutorials/creating-terms.md) | ✅ |
|
| 69 |
+
| Add tags to a column of a dataset | ✅ [[Guide]](/docs/api/tutorials/adding-tags.md) | ✅ [[Guide]](/docs/api/tutorials/adding-tags.md) | ✅ |
|
| 70 |
+
| Add terms to a column of a dataset | ✅ [[Guide]](/docs/api/tutorials/adding-terms.md) | ✅ [[Guide]](/docs/api/tutorials/adding-terms.md) | ✅ |
|
| 71 |
+
| Add terms to a column of a dataset | ✅ [[Guide]](/docs/api/tutorials/adding-ownerships.md) | ✅ [[Guide]](/docs/api/tutorials/adding-ownerships.md) | ✅ |
|
| 72 |
+
| Add tags to a dataset | ✅ [[Guide]](/docs/api/tutorials/adding-tags.md) | ✅ | ✅ |
|
| 73 |
+
| Add terms to a dataset | ✅ [[Guide]](/docs/api/tutorials/adding-terms.md) | ✅ | ✅ |
|
| 74 |
+
| Add owner to a dataset | ✅ [[Guide]](/docs/api/tutorials/adding-ownerships.md) | ✅ | ✅ |
|
| 75 |
+
| Add lineage | ✅ [[Guide]](/docs/api/tutorials/adding-lineage.md) | ✅ [[Guide]](/docs/api/tutorials/adding-lineage.md) | ✅ |
|
| 76 |
+
| Add column level(Fine Grained) lineage | 🚫 | ✅ | ✅ |
|
| 77 |
+
| Add documentation(description) to a column of a dataset | ✅ [[Guide]](/docs/api/tutorials/adding-column-description.md) | ✅ [[Guide]](/docs/api/tutorials/adding-column-description.md) | ✅ |
|
| 78 |
+
| Add documentation(description) to a dataset | 🚫 | ✅ [[Guide]](/docs/api/tutorials/adding-dataset-description.md) | ✅ |
|
| 79 |
+
| Delete a dataset (Soft delete) | ✅ [[Guide]](/docs/api/tutorials/deleting-entities-by-urn.md) | ✅ [[Guide]](/docs/api/tutorials/deleting-entities-by-urn.md) | ✅ |
|
| 80 |
+
| Delete a dataset (Hard delele) | 🚫 | ✅ [[Guide]](/docs/api/tutorials/deleting-entities-by-urn.md) | ✅ |
|
| 81 |
+
| Search a dataset | ✅ | ✅ | ✅ |
|
docs/api/graphql/getting-started.md
ADDED
|
@@ -0,0 +1,64 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Getting Started
|
| 2 |
+
|
| 3 |
+
Get started using the DataHub GraphQL API.
|
| 4 |
+
|
| 5 |
+
## Introduction to GraphQL
|
| 6 |
+
|
| 7 |
+
The GraphQL community provides many freely available resources for learning about GraphQL. We recommend starting with [Introduction to GraphQL](https://graphql.org/learn/),
|
| 8 |
+
which will introduce you to key concepts like [Queries, Mutations, Variables, Schemas & more](https://graphql.org/learn/queries/).
|
| 9 |
+
|
| 10 |
+
We'll reiterate a few important points before proceeding:
|
| 11 |
+
|
| 12 |
+
- GraphQL Operations are exposed via a single service endpoint, in the case of DataHub located at `/api/graphql`. This will be described in more detail below.
|
| 13 |
+
- GraphQL supports reads using a top-level **Query** object, and writes using a top-level **Mutation** object.
|
| 14 |
+
- GraphQL supports [schema introspection](https://graphql.org/learn/introspection/), wherein clients can query for details about the GraphQL schema itself.
|
| 15 |
+
|
| 16 |
+
## Setup
|
| 17 |
+
|
| 18 |
+
The first thing you'll need to use the GraphQL API is a deployed instance of DataHub with some metadata ingested. Unsure how to do that? Check out the [Deployment Quickstart](../../../docs/quickstart.md).
|
| 19 |
+
|
| 20 |
+
## Querying the GraphQL API
|
| 21 |
+
|
| 22 |
+
DataHub's GraphQL endpoint is served at the path `/api/graphql`, e.g. `https://my-company.datahub.com/api/graphql`.
|
| 23 |
+
There are a few options when it comes to querying the GraphQL endpoint.
|
| 24 |
+
|
| 25 |
+
For **Testing**, we recommend [Postman](https://learning.postman.com/docs/sending-requests/supported-api-frameworks/graphql/), GraphQL Explorer (described below), or CURL.
|
| 26 |
+
For **Production**, we recommend a GraphQL [Client SDK](https://graphql.org/code/) for the language of your choice, or a basic HTTP client.
|
| 27 |
+
|
| 28 |
+
#### Authentication + Authorization
|
| 29 |
+
|
| 30 |
+
In general, you'll need to provide an [Access Token](../../authentication/personal-access-tokens.md) when querying the GraphQL by
|
| 31 |
+
providing an `Authorization` header containing a `Bearer` token. The header should take the following format:
|
| 32 |
+
|
| 33 |
+
```bash
|
| 34 |
+
Authorization: Bearer <access-token>
|
| 35 |
+
```
|
| 36 |
+
|
| 37 |
+
Authorization for actions exposed by the GraphQL endpoint will be performed based on the actor making the request.
|
| 38 |
+
For Personal Access Tokens, the token will carry the user's privileges.
|
| 39 |
+
|
| 40 |
+
> Notice: The DataHub GraphQL endpoint only supports POST requests at this time.
|
| 41 |
+
|
| 42 |
+
### On the Horizon
|
| 43 |
+
|
| 44 |
+
- **Service Tokens**: In the near future, the DataHub team intends to introduce service users, which will provide a way to generate and use API access
|
| 45 |
+
tokens when querying both the Frontend Proxy Server and the Metadata Service. If you're interested in contributing, please [reach out on our Slack](https://datahubspace.slack.com/join/shared_invite/zt-nx7i0dj7-I3IJYC551vpnvvjIaNRRGw#/shared-invite/email).
|
| 46 |
+
- **DataHub Client SDKs**: Libraries wrapping the DataHub GraphQL API on a per-language basis (based on community demand).
|
| 47 |
+
|
| 48 |
+
## GraphQL Explorer
|
| 49 |
+
|
| 50 |
+
DataHub provides a browser-based GraphQL Explorer Tool ([GraphiQL](https://github.com/graphql/graphiql)) for live interaction with the GraphQL API. This tool is available at the path `/api/graphiql` (e.g. `https://my-company.datahub.com/api/graphiql`)
|
| 51 |
+
This interface allows you to easily craft queries and mutations against real metadata stored in your live DataHub deployment. For a detailed usage guide,
|
| 52 |
+
check out [How to use GraphiQL](https://www.gatsbyjs.com/docs/how-to/querying-data/running-queries-with-graphiql/).
|
| 53 |
+
|
| 54 |
+
|
| 55 |
+
## Where to go from here
|
| 56 |
+
|
| 57 |
+
Once you've gotten the API deployed and responding, proceed to [Working with Metadata Entities](./querying-entities.md) to learn how to read and write the Entities
|
| 58 |
+
on your Metadata Graph.
|
| 59 |
+
If you're interested in administrative actions considering have a look at [Token Management](./token-management.md) to learn how to generate, list & revoke access tokens for programmatic use in DataHub.
|
| 60 |
+
|
| 61 |
+
## Feedback, Feature Requests, & Support
|
| 62 |
+
|
| 63 |
+
Visit our [Slack channel](https://slack.datahubproject.io) to ask questions, tell us what we can do better, & make requests for what you'd like to see in the future. Or just
|
| 64 |
+
stop by to say 'Hi'.
|
docs/api/graphql/overview.md
ADDED
|
@@ -0,0 +1,55 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# DataHub GraphQL API
|
| 2 |
+
|
| 3 |
+
DataHub provides a rich [GraphQL](https://graphql.org/) API for programmatically interacting with the Entities & Relationships comprising your organization's Metadata Graph.
|
| 4 |
+
|
| 5 |
+
## Getting Started
|
| 6 |
+
|
| 7 |
+
Check out [Getting Started](./getting-started.md) to start using the DataHub GraphQL API right away.
|
| 8 |
+
|
| 9 |
+
## About GraphQL
|
| 10 |
+
|
| 11 |
+
[GraphQL](https://graphql.org/) provides a data query language and API with the following characteristics:
|
| 12 |
+
|
| 13 |
+
- A **validated specification**: The GraphQL spec verifies a *schema* on the API server. The server in turn is responsible
|
| 14 |
+
for validating incoming queries from the clients against that schema.
|
| 15 |
+
- **Strongly typed**: A GraphQL schema declares the universe of types and relationships composing the interface.
|
| 16 |
+
- **Document-oriented & hierarchical**: GraphQL makes it eay to ask for related entities using a familiar JSON document
|
| 17 |
+
structure. This minimizes the number of round-trip API requests a client must make to answer a particular question.
|
| 18 |
+
- **Flexible & efficient**: GraphQL provides a way to ask for only the data you want, and that's it. Ignore all
|
| 19 |
+
the rest. It allows you to replace multiple REST calls with one GraphQL call.
|
| 20 |
+
- **Large Open Source Ecosystem**: Open source GraphQL projects have been developed for [virtually every programming language](https://graphql.org/code/). With a thriving
|
| 21 |
+
community, it offers a sturdy foundation to build upon.
|
| 22 |
+
|
| 23 |
+
For these reasons among others DataHub provides a GraphQL API on top of the Metadata Graph,
|
| 24 |
+
permitting easy exploration of the Entities & Relationships composing it.
|
| 25 |
+
|
| 26 |
+
For more information about the GraphQL specification, check out [Introduction to GraphQL](https://graphql.org/learn/).
|
| 27 |
+
|
| 28 |
+
## GraphQL Schema Reference
|
| 29 |
+
|
| 30 |
+
The Reference docs in the sidebar are generated from the DataHub GraphQL schema. Each call to the `/api/graphql` endpoint is
|
| 31 |
+
validated against this schema. You can use these docs to understand data that is available for retrieval and operations
|
| 32 |
+
that may be performed using the API.
|
| 33 |
+
|
| 34 |
+
- Available Operations: [Queries](/graphql/queries.md) (Reads) & [Mutations](/graphql/mutations.md) (Writes)
|
| 35 |
+
- Schema Types: [Objects](/graphql/objects.md), [Input Objects](/graphql/inputObjects.md), [Interfaces](/graphql/interfaces.md), [Unions](/graphql/unions.md), [Enums](/graphql/enums.md), [Scalars](/graphql/scalars.md)
|
| 36 |
+
|
| 37 |
+
## On the Horizon
|
| 38 |
+
|
| 39 |
+
The GraphQL API undergoing continuous development. A few of the things we're most excited about can be found below.
|
| 40 |
+
|
| 41 |
+
### Supporting Additional Use Cases
|
| 42 |
+
|
| 43 |
+
DataHub plans to support the following use cases via the GraphQL API:
|
| 44 |
+
|
| 45 |
+
- **Creating entities**: Programmatically creating Datasets, Dashboards, Charts, Data Flows (Pipelines), Data Jobs (Tasks) and more.
|
| 46 |
+
|
| 47 |
+
### Client SDKs
|
| 48 |
+
|
| 49 |
+
DataHub plans to develop Open Source Client SDKs for Python, Java, Javascript among others on top of this API. If you're interested
|
| 50 |
+
in contributing, [join us on Slack](https://datahubspace.slack.com/join/shared_invite/zt-nx7i0dj7-I3IJYC551vpnvvjIaNRRGw#/shared-invite/email)!
|
| 51 |
+
|
| 52 |
+
## Feedback, Feature Requests, & Support
|
| 53 |
+
|
| 54 |
+
Visit our [Slack channel](https://slack.datahubproject.io) to ask questions, tell us what we can do better, & make requests for what you'd like to see in the future. Or just
|
| 55 |
+
stop by to say 'Hi'.
|
docs/api/graphql/querying-entities.md
ADDED
|
@@ -0,0 +1,551 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Working with Metadata Entities
|
| 2 |
+
|
| 3 |
+
Learn how to find, retrieve & update entities comprising your Metadata Graph programmatically.
|
| 4 |
+
|
| 5 |
+
## Reading an Entity: Queries
|
| 6 |
+
|
| 7 |
+
DataHub provides the following GraphQL queries for retrieving entities in your Metadata Graph.
|
| 8 |
+
|
| 9 |
+
### Getting a Metadata Entity
|
| 10 |
+
|
| 11 |
+
To retrieve a Metadata Entity by primary key (urn), simply use the `<entityName>(urn: String!)` GraphQL Query.
|
| 12 |
+
|
| 13 |
+
For example, to retrieve a `dataset` entity, you can issue the following GraphQL Query:
|
| 14 |
+
|
| 15 |
+
*As GraphQL*
|
| 16 |
+
|
| 17 |
+
```graphql
|
| 18 |
+
{
|
| 19 |
+
dataset(urn: "urn:li:dataset:(urn:li:dataPlatform:kafka,SampleKafkaDataset,PROD)") {
|
| 20 |
+
urn
|
| 21 |
+
properties {
|
| 22 |
+
name
|
| 23 |
+
}
|
| 24 |
+
}
|
| 25 |
+
}
|
| 26 |
+
```
|
| 27 |
+
|
| 28 |
+
*As CURL*
|
| 29 |
+
|
| 30 |
+
```curl
|
| 31 |
+
curl --location --request POST 'http://localhost:8080/api/graphql' \
|
| 32 |
+
--header 'Authorization: Bearer <my-access-token>' \
|
| 33 |
+
--header 'Content-Type: application/json' \
|
| 34 |
+
--data-raw '{ "query":"{ dataset(urn: \"urn:li:dataset:(urn:li:dataPlatform:kafka,SampleKafkaDataset,PROD)\") { urn properties { name } } }", "variables":{}}'
|
| 35 |
+
```
|
| 36 |
+
|
| 37 |
+
In the following examples, we'll look at how to fetch specific types of metadata for an asset.
|
| 38 |
+
|
| 39 |
+
#### Querying for Owners of an entity
|
| 40 |
+
|
| 41 |
+
As GraphQL:
|
| 42 |
+
|
| 43 |
+
```graphql
|
| 44 |
+
query {
|
| 45 |
+
dataset(urn: "urn:li:dataset:(urn:li:dataPlatform:hdfs,SampleHdfsDataset,PROD)") {
|
| 46 |
+
ownership {
|
| 47 |
+
owners {
|
| 48 |
+
owner {
|
| 49 |
+
... on CorpUser {
|
| 50 |
+
urn
|
| 51 |
+
type
|
| 52 |
+
}
|
| 53 |
+
... on CorpGroup {
|
| 54 |
+
urn
|
| 55 |
+
type
|
| 56 |
+
}
|
| 57 |
+
}
|
| 58 |
+
}
|
| 59 |
+
}
|
| 60 |
+
}
|
| 61 |
+
}
|
| 62 |
+
```
|
| 63 |
+
|
| 64 |
+
#### Querying for Tags of an asset
|
| 65 |
+
|
| 66 |
+
As GraphQL:
|
| 67 |
+
|
| 68 |
+
```graphql
|
| 69 |
+
query {
|
| 70 |
+
dataset(urn: "urn:li:dataset:(urn:li:dataPlatform:hdfs,SampleHdfsDataset,PROD)") {
|
| 71 |
+
tags {
|
| 72 |
+
tags {
|
| 73 |
+
tag {
|
| 74 |
+
name
|
| 75 |
+
}
|
| 76 |
+
}
|
| 77 |
+
}
|
| 78 |
+
}
|
| 79 |
+
}
|
| 80 |
+
```
|
| 81 |
+
|
| 82 |
+
#### Querying for Domain of an asset
|
| 83 |
+
|
| 84 |
+
As GraphQL:
|
| 85 |
+
|
| 86 |
+
```graphql
|
| 87 |
+
query {
|
| 88 |
+
dataset(urn: "urn:li:dataset:(urn:li:dataPlatform:hdfs,SampleHdfsDataset,PROD)") {
|
| 89 |
+
domain {
|
| 90 |
+
domain {
|
| 91 |
+
urn
|
| 92 |
+
}
|
| 93 |
+
}
|
| 94 |
+
}
|
| 95 |
+
}
|
| 96 |
+
```
|
| 97 |
+
|
| 98 |
+
#### Querying for Glossary Terms of an asset
|
| 99 |
+
|
| 100 |
+
As GraphQL:
|
| 101 |
+
|
| 102 |
+
```graphql
|
| 103 |
+
query {
|
| 104 |
+
dataset(urn: "urn:li:dataset:(urn:li:dataPlatform:hdfs,SampleHdfsDataset,PROD)") {
|
| 105 |
+
glossaryTerms {
|
| 106 |
+
terms {
|
| 107 |
+
term {
|
| 108 |
+
urn
|
| 109 |
+
}
|
| 110 |
+
}
|
| 111 |
+
}
|
| 112 |
+
}
|
| 113 |
+
}
|
| 114 |
+
```
|
| 115 |
+
|
| 116 |
+
#### Querying for Deprecation of an asset
|
| 117 |
+
|
| 118 |
+
As GraphQL:
|
| 119 |
+
|
| 120 |
+
```graphql
|
| 121 |
+
query {
|
| 122 |
+
dataset(urn: "urn:li:dataset:(urn:li:dataPlatform:hdfs,SampleHdfsDataset,PROD)") {
|
| 123 |
+
deprecation {
|
| 124 |
+
deprecated
|
| 125 |
+
decommissionTime
|
| 126 |
+
}
|
| 127 |
+
}
|
| 128 |
+
}
|
| 129 |
+
```
|
| 130 |
+
|
| 131 |
+
#### Relevant Queries
|
| 132 |
+
|
| 133 |
+
- [dataset](../../../graphql/queries.md#dataset)
|
| 134 |
+
- [container](../../../graphql/queries.md#container)
|
| 135 |
+
- [dashboard](../../../graphql/queries.md#dashboard)
|
| 136 |
+
- [chart](../../../graphql/queries.md#chart)
|
| 137 |
+
- [dataFlow](../../../graphql/queries.md#dataflow)
|
| 138 |
+
- [dataJob](../../../graphql/queries.md#datajob)
|
| 139 |
+
- [domain](../../../graphql/queries.md#domain)
|
| 140 |
+
- [glossaryTerm](../../../graphql/queries.md#glossaryterm)
|
| 141 |
+
- [glossaryNode](../../../graphql/queries.md#glossarynode)
|
| 142 |
+
- [tag](../../../graphql/queries.md#tag)
|
| 143 |
+
- [notebook](../../../graphql/queries.md#notebook)
|
| 144 |
+
- [corpUser](../../../graphql/queries.md#corpuser)
|
| 145 |
+
- [corpGroup](../../../graphql/queries.md#corpgroup)
|
| 146 |
+
|
| 147 |
+
|
| 148 |
+
### Searching for a Metadata Entity
|
| 149 |
+
|
| 150 |
+
To perform full-text search against an Entity of a particular type, use the `search(input: SearchInput!)` GraphQL Query.
|
| 151 |
+
|
| 152 |
+
As GraphQL:
|
| 153 |
+
|
| 154 |
+
```graphql
|
| 155 |
+
{
|
| 156 |
+
search(input: { type: DATASET, query: "my sql dataset", start: 0, count: 10 }) {
|
| 157 |
+
start
|
| 158 |
+
count
|
| 159 |
+
total
|
| 160 |
+
searchResults {
|
| 161 |
+
entity {
|
| 162 |
+
urn
|
| 163 |
+
type
|
| 164 |
+
...on Dataset {
|
| 165 |
+
name
|
| 166 |
+
}
|
| 167 |
+
}
|
| 168 |
+
}
|
| 169 |
+
}
|
| 170 |
+
}
|
| 171 |
+
```
|
| 172 |
+
|
| 173 |
+
As CURL:
|
| 174 |
+
|
| 175 |
+
```curl
|
| 176 |
+
curl --location --request POST 'http://localhost:8080/api/graphql' \
|
| 177 |
+
--header 'Authorization: Bearer <my-access-token>' \
|
| 178 |
+
--header 'Content-Type: application/json' \
|
| 179 |
+
--data-raw '{ "query":"{ search(input: { type: DATASET, query: \"my sql dataset\", start: 0, count: 10 }) { start count total searchResults { entity { urn type ...on Dataset { name } } } } }", "variables":{}}'
|
| 180 |
+
```
|
| 181 |
+
|
| 182 |
+
> **Note** that by default Elasticsearch only allows pagination through 10,000 entities via the search API.
|
| 183 |
+
> If you need to paginate through more, you can change the default value for the `index.max_result_window` setting in Elasticsearch,
|
| 184 |
+
> or using the [scroll API](https://www.elastic.co/guide/en/elasticsearch/reference/current/scroll-api.html) to read from the index directly.
|
| 185 |
+
|
| 186 |
+
#### Relevant Queries
|
| 187 |
+
|
| 188 |
+
- [search](../../../graphql/queries.md#search)
|
| 189 |
+
- [searchAcrossEntities](../../../graphql/queries.md#searchacrossentities)
|
| 190 |
+
- [searchAcrossLineage](../../../graphql/queries.md#searchacrosslineage)
|
| 191 |
+
- [browse](../../../graphql/queries.md#browse)
|
| 192 |
+
- [browsePaths](../../../graphql/queries.md#browsepaths)
|
| 193 |
+
|
| 194 |
+
|
| 195 |
+
## Modifying an Entity: Mutations
|
| 196 |
+
|
| 197 |
+
### Authorization
|
| 198 |
+
|
| 199 |
+
Mutations which change Entity metadata are subject to [DataHub Access Policies](../../authorization/policies.md). This means that DataHub's server
|
| 200 |
+
will check whether the requesting actor is authorized to perform the action.
|
| 201 |
+
|
| 202 |
+
### Updating a Metadata Entity
|
| 203 |
+
|
| 204 |
+
To update an existing Metadata Entity, simply use the `update<entityName>(urn: String!, input: EntityUpdateInput!)` GraphQL Query.
|
| 205 |
+
|
| 206 |
+
For example, to update a Dashboard entity, you can issue the following GraphQL mutation:
|
| 207 |
+
|
| 208 |
+
*As GraphQL*
|
| 209 |
+
|
| 210 |
+
```graphql
|
| 211 |
+
mutation updateDashboard {
|
| 212 |
+
updateDashboard(
|
| 213 |
+
urn: "urn:li:dashboard:(looker,baz)",
|
| 214 |
+
input: {
|
| 215 |
+
editableProperties: {
|
| 216 |
+
description: "My new desription"
|
| 217 |
+
}
|
| 218 |
+
}
|
| 219 |
+
) {
|
| 220 |
+
urn
|
| 221 |
+
}
|
| 222 |
+
}
|
| 223 |
+
```
|
| 224 |
+
|
| 225 |
+
*As CURL*
|
| 226 |
+
|
| 227 |
+
```curl
|
| 228 |
+
curl --location --request POST 'http://localhost:8080/api/graphql' \
|
| 229 |
+
--header 'Authorization: Bearer <my-access-token>' \
|
| 230 |
+
--header 'Content-Type: application/json' \
|
| 231 |
+
--data-raw '{ "query": "mutation updateDashboard { updateDashboard(urn:\"urn:li:dashboard:(looker,baz)\", input: { editableProperties: { description: \"My new desription\" } } ) { urn } }", "variables":{}}'
|
| 232 |
+
```
|
| 233 |
+
|
| 234 |
+
**Be careful**: these APIs allow you to make significant changes to a Metadata Entity, often including
|
| 235 |
+
updating the entire set of Owners & Tags.
|
| 236 |
+
|
| 237 |
+
#### Relevant Mutations
|
| 238 |
+
|
| 239 |
+
- [updateDataset](../../../graphql/mutations.md#updatedataset)
|
| 240 |
+
- [updateChart](../../../graphql/mutations.md#updatechart)
|
| 241 |
+
- [updateDashboard](../../../graphql/mutations.md#updatedashboard)
|
| 242 |
+
- [updateDataFlow](../../../graphql/mutations.md#updatedataFlow)
|
| 243 |
+
- [updateDataJob](../../../graphql/mutations.md#updatedataJob)
|
| 244 |
+
- [updateNotebook](../../../graphql/mutations.md#updatenotebook)
|
| 245 |
+
|
| 246 |
+
|
| 247 |
+
### Adding & Removing Tags
|
| 248 |
+
|
| 249 |
+
To attach Tags to a Metadata Entity, you can use the `addTags` or `batchAddTags` mutations.
|
| 250 |
+
To remove them, you can use the `removeTag` or `batchRemoveTags` mutations.
|
| 251 |
+
|
| 252 |
+
For example, to add a Tag a Pipeline entity, you can issue the following GraphQL mutation:
|
| 253 |
+
|
| 254 |
+
*As GraphQL*
|
| 255 |
+
|
| 256 |
+
```graphql
|
| 257 |
+
mutation addTags {
|
| 258 |
+
addTags(input: { tagUrns: ["urn:li:tag:NewTag"], resourceUrn: "urn:li:dataFlow:(airflow,dag_abc,PROD)" })
|
| 259 |
+
}
|
| 260 |
+
```
|
| 261 |
+
|
| 262 |
+
*As CURL*
|
| 263 |
+
|
| 264 |
+
```curl
|
| 265 |
+
curl --location --request POST 'http://localhost:8080/api/graphql' \
|
| 266 |
+
--header 'Authorization: Bearer <my-access-token>' \
|
| 267 |
+
--header 'Content-Type: application/json' \
|
| 268 |
+
--data-raw '{ "query": "mutation addTags { addTags(input: { tagUrns: [\"urn:li:tag:NewTag\"], resourceUrn: \"urn:li:dataFlow:(airflow,dag_abc,PROD)\" }) }", "variables":{}}'
|
| 269 |
+
```
|
| 270 |
+
|
| 271 |
+
> **Pro-Tip**! You can also add or remove Tags from Dataset Schema Fields (or *Columns*) by
|
| 272 |
+
> providing 2 additional fields in your Query input:
|
| 273 |
+
>
|
| 274 |
+
> - subResourceType
|
| 275 |
+
> - subResource
|
| 276 |
+
>
|
| 277 |
+
> Where `subResourceType` is set to `DATASET_FIELD` and `subResource` is the field path of the column
|
| 278 |
+
> to change.
|
| 279 |
+
|
| 280 |
+
#### Relevant Mutations
|
| 281 |
+
|
| 282 |
+
- [addTags](../../../graphql/mutations.md#addtags)
|
| 283 |
+
- [batchAddTags](../../../graphql/mutations.md#batchaddtags)
|
| 284 |
+
- [removeTag](../../../graphql/mutations.md#removetag)
|
| 285 |
+
- [batchRemoveTags](../../../graphql/mutations.md#batchremovetags)
|
| 286 |
+
|
| 287 |
+
|
| 288 |
+
### Adding & Removing Glossary Terms
|
| 289 |
+
|
| 290 |
+
To attach Glossary Terms to a Metadata Entity, you can use the `addTerms` or `batchAddTerms` mutations.
|
| 291 |
+
To remove them, you can use the `removeTerm` or `batchRemoveTerms` mutations.
|
| 292 |
+
|
| 293 |
+
For example, to add a Glossary Term a Pipeline entity, you could issue the following GraphQL mutation:
|
| 294 |
+
|
| 295 |
+
*As GraphQL*
|
| 296 |
+
|
| 297 |
+
```graphql
|
| 298 |
+
mutation addTerms {
|
| 299 |
+
addTerms(input: { termUrns: ["urn:li:glossaryTerm:NewTerm"], resourceUrn: "urn:li:dataFlow:(airflow,dag_abc,PROD)" })
|
| 300 |
+
}
|
| 301 |
+
```
|
| 302 |
+
|
| 303 |
+
*As CURL*
|
| 304 |
+
|
| 305 |
+
```curl
|
| 306 |
+
curl --location --request POST 'http://localhost:8080/api/graphql' \
|
| 307 |
+
--header 'Authorization: Bearer <my-access-token>' \
|
| 308 |
+
--header 'Content-Type: application/json' \
|
| 309 |
+
--data-raw '{ "query": "mutation addTerms { addTerms(input: { termUrns: [\"urn:li:glossaryTerm:NewTerm\"], resourceUrn: \"urn:li:dataFlow:(airflow,dag_abc,PROD)\" }) }", "variables":{}}'
|
| 310 |
+
```
|
| 311 |
+
|
| 312 |
+
> **Pro-Tip**! You can also add or remove Glossary Terms from Dataset Schema Fields (or *Columns*) by
|
| 313 |
+
> providing 2 additional fields in your Query input:
|
| 314 |
+
>
|
| 315 |
+
> - subResourceType
|
| 316 |
+
> - subResource
|
| 317 |
+
>
|
| 318 |
+
> Where `subResourceType` is set to `DATASET_FIELD` and `subResource` is the field path of the column
|
| 319 |
+
> to change.
|
| 320 |
+
|
| 321 |
+
#### Relevant Mutations
|
| 322 |
+
|
| 323 |
+
- [addTerms](../../../graphql/mutations.md#addterms)
|
| 324 |
+
- [batchAddTerms](../../../graphql/mutations.md#batchaddterms)
|
| 325 |
+
- [removeTerm](../../../graphql/mutations.md#removeterm)
|
| 326 |
+
- [batchRemoveTerms](../../../graphql/mutations.md#batchremoveterms)
|
| 327 |
+
|
| 328 |
+
|
| 329 |
+
### Adding & Removing Domain
|
| 330 |
+
|
| 331 |
+
To add an entity to a Domain, you can use the `setDomain` and `batchSetDomain` mutations.
|
| 332 |
+
To remove entities from a Domain, you can use the `unsetDomain` mutation or the `batchSetDomain` mutation.
|
| 333 |
+
|
| 334 |
+
For example, to add a Pipeline entity to the "Marketing" Domain, you can issue the following GraphQL mutation:
|
| 335 |
+
|
| 336 |
+
*As GraphQL*
|
| 337 |
+
|
| 338 |
+
```graphql
|
| 339 |
+
mutation setDomain {
|
| 340 |
+
setDomain(domainUrn: "urn:li:domain:Marketing", entityUrn: "urn:li:dataFlow:(airflow,dag_abc,PROD)")
|
| 341 |
+
}
|
| 342 |
+
```
|
| 343 |
+
|
| 344 |
+
*As CURL*
|
| 345 |
+
|
| 346 |
+
```curl
|
| 347 |
+
curl --location --request POST 'http://localhost:8080/api/graphql' \
|
| 348 |
+
--header 'Authorization: Bearer <my-access-token>' \
|
| 349 |
+
--header 'Content-Type: application/json' \
|
| 350 |
+
--data-raw '{ "query": "mutation setDomain { setDomain(domainUrn: \"urn:li:domain:Marketing\", entityUrn: \"urn:li:dataFlow:(airflow,dag_abc,PROD)\") }", "variables":{}}'
|
| 351 |
+
```
|
| 352 |
+
|
| 353 |
+
#### Relevant Mutations
|
| 354 |
+
|
| 355 |
+
- [setDomain](../../../graphql/mutations.md#setdomain)
|
| 356 |
+
- [batchSetDomain](../../../graphql/mutations.md#batchsetdomain)
|
| 357 |
+
- [unsetDomain](../../../graphql/mutations.md#unsetdomain)
|
| 358 |
+
|
| 359 |
+
|
| 360 |
+
### Adding & Removing Owners
|
| 361 |
+
|
| 362 |
+
To attach Owners to a Metadata Entity, you can use the `addOwners` or `batchAddOwners` mutations.
|
| 363 |
+
To remove them, you can use the `removeOwner` or `batchRemoveOwners` mutations.
|
| 364 |
+
|
| 365 |
+
For example, to add an Owner a Pipeline entity, you can issue the following GraphQL mutation:
|
| 366 |
+
|
| 367 |
+
*As GraphQL*
|
| 368 |
+
|
| 369 |
+
```graphql
|
| 370 |
+
mutation addOwners {
|
| 371 |
+
addOwners(input: { owners: [ { ownerUrn: "urn:li:corpuser:datahub", ownerEntityType: CORP_USER, type: TECHNICAL_OWNER } ], resourceUrn: "urn:li:dataFlow:(airflow,dag_abc,PROD)" })
|
| 372 |
+
}
|
| 373 |
+
```
|
| 374 |
+
|
| 375 |
+
*As CURL*
|
| 376 |
+
|
| 377 |
+
```curl
|
| 378 |
+
curl --location --request POST 'http://localhost:8080/api/graphql' \
|
| 379 |
+
--header 'Authorization: Bearer <my-access-token>' \
|
| 380 |
+
--header 'Content-Type: application/json' \
|
| 381 |
+
--data-raw '{ "query": "mutation addOwners { addOwners(input: { owners: [ { ownerUrn: \"urn:li:corpuser:datahub\", ownerEntityType: CORP_USER, type: TECHNICAL_OWNER } ], resourceUrn: \"urn:li:dataFlow:(airflow,dag_abc,PROD)\" }) }", "variables":{}}'
|
| 382 |
+
```
|
| 383 |
+
|
| 384 |
+
#### Relevant Mutations
|
| 385 |
+
|
| 386 |
+
- [addOwners](../../../graphql/mutations.md#addowners)
|
| 387 |
+
- [batchAddOwners](../../../graphql/mutations.md#batchaddowners)
|
| 388 |
+
- [removeOwner](../../../graphql/mutations.md#removeowner)
|
| 389 |
+
- [batchRemoveOwners](../../../graphql/mutations.md#batchremoveowners)
|
| 390 |
+
|
| 391 |
+
|
| 392 |
+
### Updating Deprecation
|
| 393 |
+
|
| 394 |
+
To update deprecation for a Metadata Entity, you can use the `updateDeprecation` or `batchUpdateDeprecation` mutations.
|
| 395 |
+
|
| 396 |
+
For example, to mark a Pipeline entity as deprecated, you can issue the following GraphQL mutation:
|
| 397 |
+
|
| 398 |
+
*As GraphQL*
|
| 399 |
+
|
| 400 |
+
```graphql
|
| 401 |
+
mutation updateDeprecation {
|
| 402 |
+
updateDeprecation(input: { urn: "urn:li:dataFlow:(airflow,dag_abc,PROD)", deprecated: true })
|
| 403 |
+
}
|
| 404 |
+
```
|
| 405 |
+
|
| 406 |
+
*As CURL*
|
| 407 |
+
|
| 408 |
+
```curl
|
| 409 |
+
curl --location --request POST 'http://localhost:8080/api/graphql' \
|
| 410 |
+
--header 'Authorization: Bearer <my-access-token>' \
|
| 411 |
+
--header 'Content-Type: application/json' \
|
| 412 |
+
--data-raw '{ "query": "mutation updateDeprecation { updateDeprecation(input: { urn: \"urn:li:dataFlow:(airflow,dag_abc,PROD)\", deprecated: true }) }", "variables":{}}'
|
| 413 |
+
```
|
| 414 |
+
|
| 415 |
+
> **Note** that deprecation is NOT currently supported for assets of type `container`.
|
| 416 |
+
|
| 417 |
+
#### Relevant Mutations
|
| 418 |
+
|
| 419 |
+
- [updateDeprecation](../../../graphql/mutations.md#updatedeprecation)
|
| 420 |
+
- [batchUpdateDeprecation](../../../graphql/mutations.md#batchupdatedeprecation)
|
| 421 |
+
|
| 422 |
+
|
| 423 |
+
### Editing Description (i.e. Documentation)
|
| 424 |
+
|
| 425 |
+
> Notice that this API is currently evolving and in an experimental state. It supports the following entities today:
|
| 426 |
+
> - dataset
|
| 427 |
+
> - container
|
| 428 |
+
> - domain
|
| 429 |
+
> - glossary term
|
| 430 |
+
> - glossary node
|
| 431 |
+
> - tag
|
| 432 |
+
> - group
|
| 433 |
+
> - notebook
|
| 434 |
+
> - all ML entities
|
| 435 |
+
|
| 436 |
+
To edit the documentation for an entity, you can use the `updateDescription` mutation. `updateDescription` currently supports Dataset Schema Fields, Containers.
|
| 437 |
+
|
| 438 |
+
For example, to edit the documentation for a Pipeline, you can issue the following GraphQL mutation:
|
| 439 |
+
|
| 440 |
+
*As GraphQL*
|
| 441 |
+
|
| 442 |
+
```graphql
|
| 443 |
+
mutation updateDescription {
|
| 444 |
+
updateDescription(
|
| 445 |
+
input: {
|
| 446 |
+
description: "Name of the user who was deleted. This description is updated via GrpahQL.",
|
| 447 |
+
resourceUrn:"urn:li:dataset:(urn:li:dataPlatform:hive,fct_users_deleted,PROD)",
|
| 448 |
+
subResource: "user_name",
|
| 449 |
+
subResourceType:DATASET_FIELD
|
| 450 |
+
}
|
| 451 |
+
)
|
| 452 |
+
}
|
| 453 |
+
```
|
| 454 |
+
|
| 455 |
+
*As CURL*
|
| 456 |
+
|
| 457 |
+
```curl
|
| 458 |
+
curl --location --request POST 'http://localhost:8080/api/graphql' \
|
| 459 |
+
--header 'Authorization: Bearer <my-access-token>' \
|
| 460 |
+
--header 'Content-Type: application/json' \
|
| 461 |
+
--data-raw '{ "query": "mutation updateDescription { updateDescription ( input: { description: \"Name of the user who was deleted. This description is updated via GrpahQL.\", resourceUrn: \"urn:li:dataset:(urn:li:dataPlatform:hive,fct_users_deleted,PROD)\", subResource: \"user_name\", subResourceType:DATASET_FIELD }) }", "variables":{}}'
|
| 462 |
+
```
|
| 463 |
+
|
| 464 |
+
|
| 465 |
+
#### Relevant Mutations
|
| 466 |
+
|
| 467 |
+
- [updateDescription](../../../graphql/mutations.md#updatedescription)
|
| 468 |
+
|
| 469 |
+
|
| 470 |
+
### Soft Deleting
|
| 471 |
+
|
| 472 |
+
DataHub allows you to soft-delete entities. This will effectively hide them from the search,
|
| 473 |
+
browse, and lineage experiences.
|
| 474 |
+
|
| 475 |
+
To mark an entity as soft-deleted, you can use the `batchUpdateSoftDeleted` mutation.
|
| 476 |
+
|
| 477 |
+
For example, to mark a Pipeline as soft deleted, you can issue the following GraphQL mutation:
|
| 478 |
+
|
| 479 |
+
*As GraphQL*
|
| 480 |
+
|
| 481 |
+
```graphql
|
| 482 |
+
mutation batchUpdateSoftDeleted {
|
| 483 |
+
batchUpdateSoftDeleted(input: { : urns: ["urn:li:dataFlow:(airflow,dag_abc,PROD)"], deleted: true })
|
| 484 |
+
}
|
| 485 |
+
```
|
| 486 |
+
|
| 487 |
+
Similarly, you can "un delete" an entity by setting deleted to 'false'.
|
| 488 |
+
|
| 489 |
+
*As CURL*
|
| 490 |
+
|
| 491 |
+
```curl
|
| 492 |
+
curl --location --request POST 'http://localhost:8080/api/graphql' \
|
| 493 |
+
--header 'Authorization: Bearer <my-access-token>' \
|
| 494 |
+
--header 'Content-Type: application/json' \
|
| 495 |
+
--data-raw '{ "query": "mutation batchUpdateSoftDeleted { batchUpdateSoftDeleted(input: { deleted: true, urns: [\"urn:li:dataFlow:(airflow,dag_abc,PROD)\"] }) }", "variables":{}}'
|
| 496 |
+
```
|
| 497 |
+
|
| 498 |
+
#### Relevant Mutations
|
| 499 |
+
|
| 500 |
+
- [batchUpdateSoftDeleted](../../../graphql/mutations.md#batchupdatesoftdeleted)
|
| 501 |
+
|
| 502 |
+
|
| 503 |
+
## Handling Errors
|
| 504 |
+
|
| 505 |
+
In GraphQL, requests that have errors do not always result in a non-200 HTTP response body. Instead, errors will be
|
| 506 |
+
present in the response body inside a top-level `errors` field.
|
| 507 |
+
|
| 508 |
+
This enables situations in which the client is able to deal gracefully will partial data returned by the application server.
|
| 509 |
+
To verify that no error has returned after making a GraphQL request, make sure you check *both* the `data` and `errors` fields that are returned.
|
| 510 |
+
|
| 511 |
+
To catch a GraphQL error, simply check the `errors` field side the GraphQL response. It will contain a message, a path, and a set of extensions
|
| 512 |
+
which contain a standard error code.
|
| 513 |
+
|
| 514 |
+
```json
|
| 515 |
+
{
|
| 516 |
+
"errors":[
|
| 517 |
+
{
|
| 518 |
+
"message":"Failed to change ownership for resource urn:li:dataFlow:(airflow,dag_abc,PROD). Expected a corp user urn.",
|
| 519 |
+
"locations":[
|
| 520 |
+
{
|
| 521 |
+
"line":1,
|
| 522 |
+
"column":22
|
| 523 |
+
}
|
| 524 |
+
],
|
| 525 |
+
"path":[
|
| 526 |
+
"addOwners"
|
| 527 |
+
],
|
| 528 |
+
"extensions":{
|
| 529 |
+
"code":400,
|
| 530 |
+
"type":"BAD_REQUEST",
|
| 531 |
+
"classification":"DataFetchingException"
|
| 532 |
+
}
|
| 533 |
+
}
|
| 534 |
+
]
|
| 535 |
+
}
|
| 536 |
+
```
|
| 537 |
+
|
| 538 |
+
With the following error codes officially supported:
|
| 539 |
+
|
| 540 |
+
| Code | Type | Description |
|
| 541 |
+
|------|--------------|------------------------------------------------------------------------------------------------|
|
| 542 |
+
| 400 | BAD_REQUEST | The query or mutation was malformed. |
|
| 543 |
+
| 403 | UNAUTHORIZED | The current actor is not authorized to perform the requested action. |
|
| 544 |
+
| 404 | NOT_FOUND | The resource is not found. |
|
| 545 |
+
| 500 | SERVER_ERROR | An internal error has occurred. Check your server logs or contact your DataHub administrator. |
|
| 546 |
+
|
| 547 |
+
## Feedback, Feature Requests, & Support
|
| 548 |
+
|
| 549 |
+
Visit our [Slack channel](https://slack.datahubproject.io) to ask questions, tell us what we can do better, & make requests for what you'd like to see in the future. Or just
|
| 550 |
+
stop by to say 'Hi'.
|
| 551 |
+
|
docs/api/graphql/token-management.md
ADDED
|
@@ -0,0 +1,125 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Access Token Management
|
| 2 |
+
|
| 3 |
+
DataHub provides the following GraphQL endpoints for managing Access Tokens. In this page you will see examples as well
|
| 4 |
+
as explanations as to how to administrate access tokens within the project whether for yourself or others, depending on the caller's privileges.
|
| 5 |
+
|
| 6 |
+
*Note*: This API makes use of DataHub Policies to safeguard against improper use. By default, a user will not be able to interact with it at all unless they have at least `Generate Personal Access Tokens` privileges.
|
| 7 |
+
|
| 8 |
+
### Generating Access Tokens
|
| 9 |
+
|
| 10 |
+
To generate an access token, simply use the `createAccessToken(input: GetAccessTokenInput!)` GraphQL Query.
|
| 11 |
+
This endpoint will return an `AccessToken` object, containing the access token string itself alongside with metadata
|
| 12 |
+
which will allow you to identify said access token later on.
|
| 13 |
+
|
| 14 |
+
For example, to generate an access token for the `datahub` corp user, you can issue the following GraphQL Query:
|
| 15 |
+
|
| 16 |
+
*As GraphQL*
|
| 17 |
+
|
| 18 |
+
```graphql
|
| 19 |
+
mutation {
|
| 20 |
+
createAccessToken(input: {type: PERSONAL, actorUrn: "urn:li:corpuser:datahub", duration: ONE_HOUR, name: "my personal token"}) {
|
| 21 |
+
accessToken
|
| 22 |
+
metadata {
|
| 23 |
+
id
|
| 24 |
+
name
|
| 25 |
+
description
|
| 26 |
+
}
|
| 27 |
+
}
|
| 28 |
+
}
|
| 29 |
+
```
|
| 30 |
+
|
| 31 |
+
*As CURL*
|
| 32 |
+
|
| 33 |
+
```curl
|
| 34 |
+
curl --location --request POST 'http://localhost:8080/api/graphql' \
|
| 35 |
+
--header 'X-DataHub-Actor: urn:li:corpuser:datahub' \
|
| 36 |
+
--header 'Content-Type: application/json' \
|
| 37 |
+
--data-raw '{ "query":"mutation { createAccessToken(input: { type: PERSONAL, actorUrn: \"urn:li:corpuser:datahub\", duration: ONE_HOUR, name: \"my personal token\" } ) { accessToken metadata { id name description} } }", "variables":{}}'
|
| 38 |
+
```
|
| 39 |
+
|
| 40 |
+
### Listing Access Tokens
|
| 41 |
+
|
| 42 |
+
Listing tokens is a powerful endpoint that allows you to list the tokens owned by a particular user (ie. YOU).
|
| 43 |
+
To list all tokens that you own, you must specify a filter with: `{field: "actorUrn", value: "<your user urn>"}` configuration.
|
| 44 |
+
|
| 45 |
+
*As GraphQL*
|
| 46 |
+
|
| 47 |
+
```graphql
|
| 48 |
+
{
|
| 49 |
+
listAccessTokens(input: {start: 0, count: 100, filters: [{field: "ownerUrn", value: "urn:li:corpuser:datahub"}]}) {
|
| 50 |
+
start
|
| 51 |
+
count
|
| 52 |
+
total
|
| 53 |
+
tokens {
|
| 54 |
+
urn
|
| 55 |
+
id
|
| 56 |
+
actorUrn
|
| 57 |
+
}
|
| 58 |
+
}
|
| 59 |
+
}
|
| 60 |
+
```
|
| 61 |
+
|
| 62 |
+
*As CURL*
|
| 63 |
+
|
| 64 |
+
```curl
|
| 65 |
+
curl --location --request POST 'http://localhost:8080/api/graphql' \
|
| 66 |
+
--header 'X-DataHub-Actor: urn:li:corpuser:datahub' \
|
| 67 |
+
--header 'Content-Type: application/json' \
|
| 68 |
+
--data-raw '{ "query":"{ listAccessTokens(input: {start: 0, count: 100, filters: [{field: \"ownerUrn\", value: \"urn:li:corpuser:datahub\"}]}) { start count total tokens {urn id actorUrn} } }", "variables":{}}'
|
| 69 |
+
```
|
| 70 |
+
|
| 71 |
+
Admin users can also list tokens owned by other users of the platform. To list tokens belonging to other users, you must have the `Manage All Access Tokens` Platform privilege.
|
| 72 |
+
|
| 73 |
+
*As GraphQL*
|
| 74 |
+
|
| 75 |
+
```graphql
|
| 76 |
+
{
|
| 77 |
+
listAccessTokens(input: {start: 0, count: 100, filters: []}) {
|
| 78 |
+
start
|
| 79 |
+
count
|
| 80 |
+
total
|
| 81 |
+
tokens {
|
| 82 |
+
urn
|
| 83 |
+
id
|
| 84 |
+
actorUrn
|
| 85 |
+
}
|
| 86 |
+
}
|
| 87 |
+
}
|
| 88 |
+
```
|
| 89 |
+
|
| 90 |
+
*As CURL*
|
| 91 |
+
|
| 92 |
+
```curl
|
| 93 |
+
curl --location --request POST 'http://localhost:8080/api/graphql' \
|
| 94 |
+
--header 'X-DataHub-Actor: urn:li:corpuser:datahub' \
|
| 95 |
+
--header 'Content-Type: application/json' \
|
| 96 |
+
--data-raw '{ "query":"{ listAccessTokens(input: {start: 0, count: 100, filters: []}) { start count total tokens {urn id actorUrn} } }", "variables":{}}'
|
| 97 |
+
```
|
| 98 |
+
|
| 99 |
+
Other filters besides `actorUrn=<some value>` are possible. You can filter by property in the `DataHubAccessTokenInfo` aspect which you can find in the Entities documentation.
|
| 100 |
+
|
| 101 |
+
### Revoking Access Tokens
|
| 102 |
+
|
| 103 |
+
To revoke an existing access token, you can use the `revokeAccessToken` mutation.
|
| 104 |
+
|
| 105 |
+
*As GraphQL*
|
| 106 |
+
|
| 107 |
+
```graphql
|
| 108 |
+
mutation {
|
| 109 |
+
revokeAccessToken(tokenId: "HnMJylxuowJ1FKN74BbGogLvXCS4w+fsd3MZdI35+8A=")
|
| 110 |
+
}
|
| 111 |
+
```
|
| 112 |
+
|
| 113 |
+
```curl
|
| 114 |
+
curl --location --request POST 'http://localhost:8080/api/graphql' \
|
| 115 |
+
--header 'X-DataHub-Actor: urn:li:corpuser:datahub' \
|
| 116 |
+
--header 'Content-Type: application/json' \
|
| 117 |
+
--data-raw '{"query":"mutation {revokeAccessToken(tokenId: \"HnMJylxuowJ1FKN74BbGogLvXCS4w+fsd3MZdI35+8A=\")}","variables":{}}}'
|
| 118 |
+
```
|
| 119 |
+
|
| 120 |
+
This endpoint will return a boolean detailing whether the operation was successful. In case of failure, an error message will appear explaining what went wrong.
|
| 121 |
+
|
| 122 |
+
## Feedback, Feature Requests, & Support
|
| 123 |
+
|
| 124 |
+
Visit our [Slack channel](https://slack.datahubproject.io) to ask questions, tell us what we can do better, & make requests for what you'd like to see in the future. Or just
|
| 125 |
+
stop by to say 'Hi'.
|