Spaces:
Running

Running
Upload 254 files
Browse filesThis view is limited to 50 files because it contains too many changes.
See raw diff
- .gitattributes +3 -0
- chains/llmchain_with_history.py +22 -0
- common/__init__.py +0 -0
- configs/__init__.py +8 -0
- configs/basic_config.py.example +32 -0
- configs/kb_config.py.example +145 -0
- configs/model_config.py.example +302 -0
- configs/prompt_config.py.example +127 -0
- configs/server_config.py.example +137 -0
- docs/ES部署指南.md +29 -0
- document_loaders/FilteredCSVloader.py +81 -0
- document_loaders/__init__.py +4 -0
- document_loaders/mydocloader.py +71 -0
- document_loaders/myimgloader.py +25 -0
- document_loaders/mypdfloader.py +51 -0
- document_loaders/mypptloader.py +59 -0
- document_loaders/ocr.py +18 -0
- embeddings/__init__.py +0 -0
- embeddings/add_embedding_keywords.py +79 -0
- embeddings/embedding_keywords.txt +3 -0
- img/LLM_success.png +0 -0
- img/agent_continue.png +0 -0
- img/agent_success.png +0 -0
- img/chatchat-qrcode.jpg +0 -0
- img/chatchat_icon_blue_square_v2.png +0 -0
- img/docker_logs.png +0 -0
- img/fastapi_docs_026.png +0 -0
- img/init_knowledge_base.jpg +0 -0
- img/knowledge_base_success.jpg +0 -0
- img/langchain+chatglm.png +3 -0
- img/langchain+chatglm2.png +0 -0
- img/logo-long-chatchat-trans-v2.png +0 -0
- img/official_account_qr.png +0 -0
- img/official_wechat_mp_account.png +3 -0
- img/partners/autodl.svg +0 -0
- img/partners/aws.svg +9 -0
- img/partners/chatglm.svg +55 -0
- img/partners/zhenfund.svg +9 -0
- img/qr_code_86.jpg +0 -0
- img/qr_code_87.jpg +0 -0
- img/qr_code_88.jpg +0 -0
- knowledge_base/samples/content/llm/img//345/210/206/345/270/203/345/274/217/350/256/255/347/273/203/346/212/200/346/234/257/345/216/237/347/220/206-/345/271/225/345/270/203/345/233/276/347/211/207-124076-270516.jpg +0 -0
- knowledge_base/samples/content/llm/img//345/210/206/345/270/203/345/274/217/350/256/255/347/273/203/346/212/200/346/234/257/345/216/237/347/220/206-/345/271/225/345/270/203/345/233/276/347/211/207-20096-279847.jpg +0 -0
- knowledge_base/samples/content/llm/img//345/210/206/345/270/203/345/274/217/350/256/255/347/273/203/346/212/200/346/234/257/345/216/237/347/220/206-/345/271/225/345/270/203/345/233/276/347/211/207-220157-552735.jpg +0 -0
- knowledge_base/samples/content/llm/img//345/210/206/345/270/203/345/274/217/350/256/255/347/273/203/346/212/200/346/234/257/345/216/237/347/220/206-/345/271/225/345/270/203/345/233/276/347/211/207-36114-765327.jpg +0 -0
- knowledge_base/samples/content/llm/img/分布式训练技术原理-幕布图片-392521-261326.jpg +3 -0
- knowledge_base/samples/content/llm/img//345/210/206/345/270/203/345/274/217/350/256/255/347/273/203/346/212/200/346/234/257/345/216/237/347/220/206-/345/271/225/345/270/203/345/233/276/347/211/207-42284-124759.jpg +0 -0
- knowledge_base/samples/content/llm/img//345/210/206/345/270/203/345/274/217/350/256/255/347/273/203/346/212/200/346/234/257/345/216/237/347/220/206-/345/271/225/345/270/203/345/233/276/347/211/207-57107-679259.jpg +0 -0
- knowledge_base/samples/content/llm/img//345/210/206/345/270/203/345/274/217/350/256/255/347/273/203/346/212/200/346/234/257/345/216/237/347/220/206-/345/271/225/345/270/203/345/233/276/347/211/207-618350-869132.jpg +0 -0
- knowledge_base/samples/content/llm/img//345/210/206/345/270/203/345/274/217/350/256/255/347/273/203/346/212/200/346/234/257/345/216/237/347/220/206-/345/271/225/345/270/203/345/233/276/347/211/207-838373-426344.jpg +0 -0
.gitattributes
CHANGED
|
@@ -33,3 +33,6 @@ saved_model/**/* filter=lfs diff=lfs merge=lfs -text
|
|
| 33 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
|
|
|
|
|
|
|
|
|
|
|
| 33 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
| 36 |
+
img/langchain+chatglm.png filter=lfs diff=lfs merge=lfs -text
|
| 37 |
+
img/official_wechat_mp_account.png filter=lfs diff=lfs merge=lfs -text
|
| 38 |
+
knowledge_base/samples/content/llm/img/分布式训练技术原理-幕布图片-392521-261326.jpg filter=lfs diff=lfs merge=lfs -text
|
chains/llmchain_with_history.py
ADDED
|
@@ -0,0 +1,22 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from server.utils import get_ChatOpenAI
|
| 2 |
+
from configs.model_config import LLM_MODELS, TEMPERATURE
|
| 3 |
+
from langchain.chains import LLMChain
|
| 4 |
+
from langchain.prompts.chat import (
|
| 5 |
+
ChatPromptTemplate,
|
| 6 |
+
HumanMessagePromptTemplate,
|
| 7 |
+
)
|
| 8 |
+
|
| 9 |
+
model = get_ChatOpenAI(model_name=LLM_MODELS[0], temperature=TEMPERATURE)
|
| 10 |
+
|
| 11 |
+
|
| 12 |
+
human_prompt = "{input}"
|
| 13 |
+
human_message_template = HumanMessagePromptTemplate.from_template(human_prompt)
|
| 14 |
+
|
| 15 |
+
chat_prompt = ChatPromptTemplate.from_messages(
|
| 16 |
+
[("human", "我们来玩成语接龙,我先来,生龙活虎"),
|
| 17 |
+
("ai", "虎头虎脑"),
|
| 18 |
+
("human", "{input}")])
|
| 19 |
+
|
| 20 |
+
|
| 21 |
+
chain = LLMChain(prompt=chat_prompt, llm=model, verbose=True)
|
| 22 |
+
print(chain({"input": "恼羞成怒"}))
|
common/__init__.py
ADDED
|
File without changes
|
configs/__init__.py
ADDED
|
@@ -0,0 +1,8 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from .basic_config import *
|
| 2 |
+
from .model_config import *
|
| 3 |
+
from .kb_config import *
|
| 4 |
+
from .server_config import *
|
| 5 |
+
from .prompt_config import *
|
| 6 |
+
|
| 7 |
+
|
| 8 |
+
VERSION = "v0.2.10"
|
configs/basic_config.py.example
ADDED
|
@@ -0,0 +1,32 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import logging
|
| 2 |
+
import os
|
| 3 |
+
import langchain
|
| 4 |
+
import tempfile
|
| 5 |
+
import shutil
|
| 6 |
+
|
| 7 |
+
|
| 8 |
+
# 是否显示详细日志
|
| 9 |
+
log_verbose = False
|
| 10 |
+
langchain.verbose = False
|
| 11 |
+
|
| 12 |
+
# 通常情况下不需要更改以下内容
|
| 13 |
+
|
| 14 |
+
# 日志格式
|
| 15 |
+
LOG_FORMAT = "%(asctime)s - %(filename)s[line:%(lineno)d] - %(levelname)s: %(message)s"
|
| 16 |
+
logger = logging.getLogger()
|
| 17 |
+
logger.setLevel(logging.INFO)
|
| 18 |
+
logging.basicConfig(format=LOG_FORMAT)
|
| 19 |
+
|
| 20 |
+
|
| 21 |
+
# 日志存储路径
|
| 22 |
+
LOG_PATH = os.path.join(os.path.dirname(os.path.dirname(__file__)), "logs")
|
| 23 |
+
if not os.path.exists(LOG_PATH):
|
| 24 |
+
os.mkdir(LOG_PATH)
|
| 25 |
+
|
| 26 |
+
# 临时文件目录,主要用于文件对话
|
| 27 |
+
BASE_TEMP_DIR = os.path.join(tempfile.gettempdir(), "chatchat")
|
| 28 |
+
try:
|
| 29 |
+
shutil.rmtree(BASE_TEMP_DIR)
|
| 30 |
+
except Exception:
|
| 31 |
+
pass
|
| 32 |
+
os.makedirs(BASE_TEMP_DIR, exist_ok=True)
|
configs/kb_config.py.example
ADDED
|
@@ -0,0 +1,145 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import os
|
| 2 |
+
|
| 3 |
+
# 默认使用的知识库
|
| 4 |
+
DEFAULT_KNOWLEDGE_BASE = "samples"
|
| 5 |
+
|
| 6 |
+
# 默认向量库/全文检索引擎类型。可选:faiss, milvus(离线) & zilliz(在线), pgvector,全文检索引擎es
|
| 7 |
+
DEFAULT_VS_TYPE = "faiss"
|
| 8 |
+
|
| 9 |
+
# 缓存向量库数量(针对FAISS)
|
| 10 |
+
CACHED_VS_NUM = 1
|
| 11 |
+
|
| 12 |
+
# 缓存临时向量库数量(针对FAISS),用于文件对话
|
| 13 |
+
CACHED_MEMO_VS_NUM = 10
|
| 14 |
+
|
| 15 |
+
# 知识库中单段文本长度(不适用MarkdownHeaderTextSplitter)
|
| 16 |
+
CHUNK_SIZE = 250
|
| 17 |
+
|
| 18 |
+
# 知识库中相邻文本重合长度(不适用MarkdownHeaderTextSplitter)
|
| 19 |
+
OVERLAP_SIZE = 50
|
| 20 |
+
|
| 21 |
+
# 知识库匹配向量数量
|
| 22 |
+
VECTOR_SEARCH_TOP_K = 3
|
| 23 |
+
|
| 24 |
+
# 知识库匹配的距离阈值,一般取值范围在0-1之间,SCORE越小,距离越小从而相关度越高。
|
| 25 |
+
# 但有用户报告遇到过匹配分值超过1的情况,为了兼容性默认设为1,在WEBUI中调整范围为0-2
|
| 26 |
+
SCORE_THRESHOLD = 1.0
|
| 27 |
+
|
| 28 |
+
# 默认搜索引擎。可选:bing, duckduckgo, metaphor
|
| 29 |
+
DEFAULT_SEARCH_ENGINE = "duckduckgo"
|
| 30 |
+
|
| 31 |
+
# 搜索引擎匹配结题数量
|
| 32 |
+
SEARCH_ENGINE_TOP_K = 3
|
| 33 |
+
|
| 34 |
+
|
| 35 |
+
# Bing 搜索必备变量
|
| 36 |
+
# 使用 Bing 搜索需要使用 Bing Subscription Key,需要在azure port中申请试用bing search
|
| 37 |
+
# 具体申请方式请见
|
| 38 |
+
# https://learn.microsoft.com/en-us/bing/search-apis/bing-web-search/create-bing-search-service-resource
|
| 39 |
+
# 使用python创建bing api 搜索实例详见:
|
| 40 |
+
# https://learn.microsoft.com/en-us/bing/search-apis/bing-web-search/quickstarts/rest/python
|
| 41 |
+
BING_SEARCH_URL = "https://api.bing.microsoft.com/v7.0/search"
|
| 42 |
+
# 注意不是bing Webmaster Tools的api key,
|
| 43 |
+
|
| 44 |
+
# 此外,如果是在服务器上,报Failed to establish a new connection: [Errno 110] Connection timed out
|
| 45 |
+
# 是因为服务器加了防火墙,需要联系管理员加白名单,如果公司的服务器的话,就别想了GG
|
| 46 |
+
BING_SUBSCRIPTION_KEY = ""
|
| 47 |
+
|
| 48 |
+
# metaphor搜索需要KEY
|
| 49 |
+
METAPHOR_API_KEY = ""
|
| 50 |
+
|
| 51 |
+
# 心知天气 API KEY,用于天气Agent。申请:https://www.seniverse.com/
|
| 52 |
+
SENIVERSE_API_KEY = ""
|
| 53 |
+
|
| 54 |
+
# 是否开启中文标题加强,以及标题增强的相关配置
|
| 55 |
+
# 通过增加标题判断,判断哪些文本为标题,并在metadata中进行标记;
|
| 56 |
+
# 然后将文本与往上一级的标题进行拼合,实现文本信息的增强。
|
| 57 |
+
ZH_TITLE_ENHANCE = False
|
| 58 |
+
|
| 59 |
+
# PDF OCR 控制:只对宽高超过页面一定比例(图片宽/页面宽,图片高/页面高)的图片进行 OCR。
|
| 60 |
+
# 这样可以避免 PDF 中一些小图片的干扰,提高非扫描版 PDF 处理速度
|
| 61 |
+
PDF_OCR_THRESHOLD = (0.6, 0.6)
|
| 62 |
+
|
| 63 |
+
# 每个知识库的初始化介绍,用于在初始化知识库时显示和Agent调用,没写则没有介绍,不会被Agent调用。
|
| 64 |
+
KB_INFO = {
|
| 65 |
+
"知识库名称": "知识库介绍",
|
| 66 |
+
"samples": "关于本项目issue的解答",
|
| 67 |
+
}
|
| 68 |
+
|
| 69 |
+
|
| 70 |
+
# 通常情况下不需要更改以下内容
|
| 71 |
+
|
| 72 |
+
# 知识库默认存储路径
|
| 73 |
+
KB_ROOT_PATH = os.path.join(os.path.dirname(os.path.dirname(__file__)), "knowledge_base")
|
| 74 |
+
if not os.path.exists(KB_ROOT_PATH):
|
| 75 |
+
os.mkdir(KB_ROOT_PATH)
|
| 76 |
+
# 数据库默认存储路径。
|
| 77 |
+
# 如果使用sqlite,可以直接修改DB_ROOT_PATH;如果使用其它数据库,请直接修改SQLALCHEMY_DATABASE_URI。
|
| 78 |
+
DB_ROOT_PATH = os.path.join(KB_ROOT_PATH, "info.db")
|
| 79 |
+
SQLALCHEMY_DATABASE_URI = f"sqlite:///{DB_ROOT_PATH}"
|
| 80 |
+
|
| 81 |
+
# 可选向量库类型及对应配置
|
| 82 |
+
kbs_config = {
|
| 83 |
+
"faiss": {
|
| 84 |
+
},
|
| 85 |
+
"milvus": {
|
| 86 |
+
"host": "127.0.0.1",
|
| 87 |
+
"port": "19530",
|
| 88 |
+
"user": "",
|
| 89 |
+
"password": "",
|
| 90 |
+
"secure": False,
|
| 91 |
+
},
|
| 92 |
+
"zilliz": {
|
| 93 |
+
"host": "in01-a7ce524e41e3935.ali-cn-hangzhou.vectordb.zilliz.com.cn",
|
| 94 |
+
"port": "19530",
|
| 95 |
+
"user": "",
|
| 96 |
+
"password": "",
|
| 97 |
+
"secure": True,
|
| 98 |
+
},
|
| 99 |
+
"pg": {
|
| 100 |
+
"connection_uri": "postgresql://postgres:postgres@127.0.0.1:5432/langchain_chatchat",
|
| 101 |
+
},
|
| 102 |
+
|
| 103 |
+
"es": {
|
| 104 |
+
"host": "127.0.0.1",
|
| 105 |
+
"port": "9200",
|
| 106 |
+
"index_name": "test_index",
|
| 107 |
+
"user": "",
|
| 108 |
+
"password": ""
|
| 109 |
+
},
|
| 110 |
+
"milvus_kwargs":{
|
| 111 |
+
"search_params":{"metric_type": "L2"}, #在此处增加search_params
|
| 112 |
+
"index_params":{"metric_type": "L2","index_type": "HNSW"} # 在此处增加index_params
|
| 113 |
+
}
|
| 114 |
+
}
|
| 115 |
+
|
| 116 |
+
# TextSplitter配置项,如果你不明白其中的含义,就不要修改。
|
| 117 |
+
text_splitter_dict = {
|
| 118 |
+
"ChineseRecursiveTextSplitter": {
|
| 119 |
+
"source": "huggingface", # 选择tiktoken则使用openai的方法
|
| 120 |
+
"tokenizer_name_or_path": "",
|
| 121 |
+
},
|
| 122 |
+
"SpacyTextSplitter": {
|
| 123 |
+
"source": "huggingface",
|
| 124 |
+
"tokenizer_name_or_path": "gpt2",
|
| 125 |
+
},
|
| 126 |
+
"RecursiveCharacterTextSplitter": {
|
| 127 |
+
"source": "tiktoken",
|
| 128 |
+
"tokenizer_name_or_path": "cl100k_base",
|
| 129 |
+
},
|
| 130 |
+
"MarkdownHeaderTextSplitter": {
|
| 131 |
+
"headers_to_split_on":
|
| 132 |
+
[
|
| 133 |
+
("#", "head1"),
|
| 134 |
+
("##", "head2"),
|
| 135 |
+
("###", "head3"),
|
| 136 |
+
("####", "head4"),
|
| 137 |
+
]
|
| 138 |
+
},
|
| 139 |
+
}
|
| 140 |
+
|
| 141 |
+
# TEXT_SPLITTER 名称
|
| 142 |
+
TEXT_SPLITTER_NAME = "ChineseRecursiveTextSplitter"
|
| 143 |
+
|
| 144 |
+
# Embedding模型定制��语的词表文件
|
| 145 |
+
EMBEDDING_KEYWORD_FILE = "embedding_keywords.txt"
|
configs/model_config.py.example
ADDED
|
@@ -0,0 +1,302 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import os
|
| 2 |
+
|
| 3 |
+
# 可以指定一个绝对路径,统一存放所有的Embedding和LLM模型。
|
| 4 |
+
# 每个模型可以是一个单独的目录,也可以是某个目录下的二级子目录。
|
| 5 |
+
# 如果模型目录名称和 MODEL_PATH 中的 key 或 value 相同,程序会自动检测加载,无需修改 MODEL_PATH 中的路径。
|
| 6 |
+
MODEL_ROOT_PATH = ""
|
| 7 |
+
|
| 8 |
+
# 选用的 Embedding 名称
|
| 9 |
+
EMBEDDING_MODEL = "bge-large-zh-v1.5"
|
| 10 |
+
|
| 11 |
+
# Embedding 模型运行设备。设为 "auto" 会自动检测(会有警告),也可手动设定为 "cuda","mps","cpu","xpu" 其中之一。
|
| 12 |
+
EMBEDDING_DEVICE = "auto"
|
| 13 |
+
|
| 14 |
+
# 选用的reranker模型
|
| 15 |
+
RERANKER_MODEL = "bge-reranker-large"
|
| 16 |
+
# 是否启用reranker模型
|
| 17 |
+
USE_RERANKER = False
|
| 18 |
+
RERANKER_MAX_LENGTH = 1024
|
| 19 |
+
|
| 20 |
+
# 如果需要在 EMBEDDING_MODEL 中增加自定义的关键字时配置
|
| 21 |
+
EMBEDDING_KEYWORD_FILE = "keywords.txt"
|
| 22 |
+
EMBEDDING_MODEL_OUTPUT_PATH = "output"
|
| 23 |
+
|
| 24 |
+
# 要运行的 LLM 名称,可以包括本地模型和在线模型。列表中本地模型将在启动项目时全部加载。
|
| 25 |
+
# 列表中第一个模型将作为 API 和 WEBUI 的默认模型。
|
| 26 |
+
# 在这里,我们使用目前主流的两个离线模型,其中,chatglm3-6b 为默认加载模型。
|
| 27 |
+
# 如果你的显存不足,可使用 Qwen-1_8B-Chat, 该模型 FP16 仅需 3.8G显存。
|
| 28 |
+
|
| 29 |
+
LLM_MODELS = ["chatglm3-6b", "zhipu-api", "openai-api"]
|
| 30 |
+
Agent_MODEL = None
|
| 31 |
+
|
| 32 |
+
# LLM 模型运行设备。设为"auto"会自动检测(会有警告),也可手动设定为 "cuda","mps","cpu","xpu" 其中之一。
|
| 33 |
+
LLM_DEVICE = "auto"
|
| 34 |
+
|
| 35 |
+
HISTORY_LEN = 3
|
| 36 |
+
|
| 37 |
+
MAX_TOKENS = 2048
|
| 38 |
+
|
| 39 |
+
TEMPERATURE = 0.7
|
| 40 |
+
|
| 41 |
+
ONLINE_LLM_MODEL = {
|
| 42 |
+
"openai-api": {
|
| 43 |
+
"model_name": "gpt-4",
|
| 44 |
+
"api_base_url": "https://api.openai.com/v1",
|
| 45 |
+
"api_key": "",
|
| 46 |
+
"openai_proxy": "",
|
| 47 |
+
},
|
| 48 |
+
|
| 49 |
+
# 智谱AI API,具体注册及api key获取请前往 http://open.bigmodel.cn
|
| 50 |
+
"zhipu-api": {
|
| 51 |
+
"api_key": "",
|
| 52 |
+
"version": "glm-4",
|
| 53 |
+
"provider": "ChatGLMWorker",
|
| 54 |
+
},
|
| 55 |
+
|
| 56 |
+
# 具体注册及api key获取请前往 https://api.minimax.chat/
|
| 57 |
+
"minimax-api": {
|
| 58 |
+
"group_id": "",
|
| 59 |
+
"api_key": "",
|
| 60 |
+
"is_pro": False,
|
| 61 |
+
"provider": "MiniMaxWorker",
|
| 62 |
+
},
|
| 63 |
+
|
| 64 |
+
# 具体注册及api key获取请前往 https://xinghuo.xfyun.cn/
|
| 65 |
+
"xinghuo-api": {
|
| 66 |
+
"APPID": "",
|
| 67 |
+
"APISecret": "",
|
| 68 |
+
"api_key": "",
|
| 69 |
+
"version": "v3.0", # 你使用的讯飞星火大模型版本,可选包括 "v3.0", "v2.0", "v1.5"
|
| 70 |
+
"provider": "XingHuoWorker",
|
| 71 |
+
},
|
| 72 |
+
|
| 73 |
+
# 百度千帆 API,申请方式请参考 https://cloud.baidu.com/doc/WENXINWORKSHOP/s/4lilb2lpf
|
| 74 |
+
"qianfan-api": {
|
| 75 |
+
"version": "ERNIE-Bot", # 注意大小写。当前支持 "ERNIE-Bot" 或 "ERNIE-Bot-turbo", 更多的见官方文档。
|
| 76 |
+
"version_url": "", # 也可以不填写version,直接填写在千帆申请模型发布的API地址
|
| 77 |
+
"api_key": "",
|
| 78 |
+
"secret_key": "",
|
| 79 |
+
"provider": "QianFanWorker",
|
| 80 |
+
},
|
| 81 |
+
|
| 82 |
+
# 火山方舟 API,文档参考 https://www.volcengine.com/docs/82379
|
| 83 |
+
"fangzhou-api": {
|
| 84 |
+
"version": "chatglm-6b-model",
|
| 85 |
+
"version_url": "",
|
| 86 |
+
"api_key": "",
|
| 87 |
+
"secret_key": "",
|
| 88 |
+
"provider": "FangZhouWorker",
|
| 89 |
+
},
|
| 90 |
+
|
| 91 |
+
# 阿里云通义千问 API,文档参考 https://help.aliyun.com/zh/dashscope/developer-reference/api-details
|
| 92 |
+
"qwen-api": {
|
| 93 |
+
"version": "qwen-max",
|
| 94 |
+
"api_key": "",
|
| 95 |
+
"provider": "QwenWorker",
|
| 96 |
+
"embed_model": "text-embedding-v1" # embedding 模型名称
|
| 97 |
+
},
|
| 98 |
+
|
| 99 |
+
# 百川 API,申请方式请参考 https://www.baichuan-ai.com/home#api-enter
|
| 100 |
+
"baichuan-api": {
|
| 101 |
+
"version": "Baichuan2-53B",
|
| 102 |
+
"api_key": "",
|
| 103 |
+
"secret_key": "",
|
| 104 |
+
"provider": "BaiChuanWorker",
|
| 105 |
+
},
|
| 106 |
+
|
| 107 |
+
# Azure API
|
| 108 |
+
"azure-api": {
|
| 109 |
+
"deployment_name": "", # 部署容器的名字
|
| 110 |
+
"resource_name": "", # https://{resource_name}.openai.azure.com/openai/ 填写resource_name的部分,其他部分不要填写
|
| 111 |
+
"api_version": "", # API的版本,不是模型版本
|
| 112 |
+
"api_key": "",
|
| 113 |
+
"provider": "AzureWorker",
|
| 114 |
+
},
|
| 115 |
+
|
| 116 |
+
# 昆仑万维天工 API https://model-platform.tiangong.cn/
|
| 117 |
+
"tiangong-api": {
|
| 118 |
+
"version": "SkyChat-MegaVerse",
|
| 119 |
+
"api_key": "",
|
| 120 |
+
"secret_key": "",
|
| 121 |
+
"provider": "TianGongWorker",
|
| 122 |
+
},
|
| 123 |
+
# Gemini API https://makersuite.google.com/app/apikey
|
| 124 |
+
"gemini-api": {
|
| 125 |
+
"api_key": "",
|
| 126 |
+
"provider": "GeminiWorker",
|
| 127 |
+
}
|
| 128 |
+
|
| 129 |
+
}
|
| 130 |
+
|
| 131 |
+
# 在以下字典中修改属性值,以指定本地embedding模型存储位置。支持3种设置方法:
|
| 132 |
+
# 1、将对应的值修改为模型绝对路径
|
| 133 |
+
# 2、不修改此处的值(以 text2vec 为例):
|
| 134 |
+
# 2.1 如果{MODEL_ROOT_PATH}下存在如下任一子目录:
|
| 135 |
+
# - text2vec
|
| 136 |
+
# - GanymedeNil/text2vec-large-chinese
|
| 137 |
+
# - text2vec-large-chinese
|
| 138 |
+
# 2.2 如果以上本地路径不存在,则使用huggingface模型
|
| 139 |
+
|
| 140 |
+
MODEL_PATH = {
|
| 141 |
+
"embed_model": {
|
| 142 |
+
"ernie-tiny": "nghuyong/ernie-3.0-nano-zh",
|
| 143 |
+
"ernie-base": "nghuyong/ernie-3.0-base-zh",
|
| 144 |
+
"text2vec-base": "shibing624/text2vec-base-chinese",
|
| 145 |
+
"text2vec": "GanymedeNil/text2vec-large-chinese",
|
| 146 |
+
"text2vec-paraphrase": "shibing624/text2vec-base-chinese-paraphrase",
|
| 147 |
+
"text2vec-sentence": "shibing624/text2vec-base-chinese-sentence",
|
| 148 |
+
"text2vec-multilingual": "shibing624/text2vec-base-multilingual",
|
| 149 |
+
"text2vec-bge-large-chinese": "shibing624/text2vec-bge-large-chinese",
|
| 150 |
+
"m3e-small": "moka-ai/m3e-small",
|
| 151 |
+
"m3e-base": "moka-ai/m3e-base",
|
| 152 |
+
"m3e-large": "moka-ai/m3e-large",
|
| 153 |
+
"bge-small-zh": "BAAI/bge-small-zh",
|
| 154 |
+
"bge-base-zh": "BAAI/bge-base-zh",
|
| 155 |
+
"bge-large-zh": "BAAI/bge-large-zh",
|
| 156 |
+
"bge-large-zh-noinstruct": "BAAI/bge-large-zh-noinstruct",
|
| 157 |
+
"bge-base-zh-v1.5": "BAAI/bge-base-zh-v1.5",
|
| 158 |
+
"bge-large-zh-v1.5": "BAAI/bge-large-zh-v1.5",
|
| 159 |
+
"piccolo-base-zh": "sensenova/piccolo-base-zh",
|
| 160 |
+
"piccolo-large-zh": "sensenova/piccolo-large-zh",
|
| 161 |
+
"nlp_gte_sentence-embedding_chinese-large": "damo/nlp_gte_sentence-embedding_chinese-large",
|
| 162 |
+
"text-embedding-ada-002": "your OPENAI_API_KEY",
|
| 163 |
+
},
|
| 164 |
+
|
| 165 |
+
"llm_model": {
|
| 166 |
+
"chatglm2-6b": "THUDM/chatglm2-6b",
|
| 167 |
+
"chatglm2-6b-32k": "THUDM/chatglm2-6b-32k",
|
| 168 |
+
"chatglm3-6b": "THUDM/chatglm3-6b",
|
| 169 |
+
"chatglm3-6b-32k": "THUDM/chatglm3-6b-32k",
|
| 170 |
+
|
| 171 |
+
"Orion-14B-Chat": "OrionStarAI/Orion-14B-Chat",
|
| 172 |
+
"Orion-14B-Chat-Plugin": "OrionStarAI/Orion-14B-Chat-Plugin",
|
| 173 |
+
"Orion-14B-LongChat": "OrionStarAI/Orion-14B-LongChat",
|
| 174 |
+
|
| 175 |
+
"Llama-2-7b-chat-hf": "meta-llama/Llama-2-7b-chat-hf",
|
| 176 |
+
"Llama-2-13b-chat-hf": "meta-llama/Llama-2-13b-chat-hf",
|
| 177 |
+
"Llama-2-70b-chat-hf": "meta-llama/Llama-2-70b-chat-hf",
|
| 178 |
+
|
| 179 |
+
"Qwen-1_8B-Chat": "Qwen/Qwen-1_8B-Chat",
|
| 180 |
+
"Qwen-7B-Chat": "Qwen/Qwen-7B-Chat",
|
| 181 |
+
"Qwen-14B-Chat": "Qwen/Qwen-14B-Chat",
|
| 182 |
+
"Qwen-72B-Chat": "Qwen/Qwen-72B-Chat",
|
| 183 |
+
|
| 184 |
+
"baichuan-7b-chat": "baichuan-inc/Baichuan-7B-Chat",
|
| 185 |
+
"baichuan-13b-chat": "baichuan-inc/Baichuan-13B-Chat",
|
| 186 |
+
"baichuan2-7b-chat": "baichuan-inc/Baichuan2-7B-Chat",
|
| 187 |
+
"baichuan2-13b-chat": "baichuan-inc/Baichuan2-13B-Chat",
|
| 188 |
+
|
| 189 |
+
"internlm-7b": "internlm/internlm-7b",
|
| 190 |
+
"internlm-chat-7b": "internlm/internlm-chat-7b",
|
| 191 |
+
"internlm2-chat-7b": "internlm/internlm2-chat-7b",
|
| 192 |
+
"internlm2-chat-20b": "internlm/internlm2-chat-20b",
|
| 193 |
+
|
| 194 |
+
"BlueLM-7B-Chat": "vivo-ai/BlueLM-7B-Chat",
|
| 195 |
+
"BlueLM-7B-Chat-32k": "vivo-ai/BlueLM-7B-Chat-32k",
|
| 196 |
+
|
| 197 |
+
"Yi-34B-Chat": "https://huggingface.co/01-ai/Yi-34B-Chat",
|
| 198 |
+
|
| 199 |
+
"agentlm-7b": "THUDM/agentlm-7b",
|
| 200 |
+
"agentlm-13b": "THUDM/agentlm-13b",
|
| 201 |
+
"agentlm-70b": "THUDM/agentlm-70b",
|
| 202 |
+
|
| 203 |
+
"falcon-7b": "tiiuae/falcon-7b",
|
| 204 |
+
"falcon-40b": "tiiuae/falcon-40b",
|
| 205 |
+
"falcon-rw-7b": "tiiuae/falcon-rw-7b",
|
| 206 |
+
|
| 207 |
+
"aquila-7b": "BAAI/Aquila-7B",
|
| 208 |
+
"aquilachat-7b": "BAAI/AquilaChat-7B",
|
| 209 |
+
"open_llama_13b": "openlm-research/open_llama_13b",
|
| 210 |
+
"vicuna-13b-v1.5": "lmsys/vicuna-13b-v1.5",
|
| 211 |
+
"koala": "young-geng/koala",
|
| 212 |
+
"mpt-7b": "mosaicml/mpt-7b",
|
| 213 |
+
"mpt-7b-storywriter": "mosaicml/mpt-7b-storywriter",
|
| 214 |
+
"mpt-30b": "mosaicml/mpt-30b",
|
| 215 |
+
"opt-66b": "facebook/opt-66b",
|
| 216 |
+
"opt-iml-max-30b": "facebook/opt-iml-max-30b",
|
| 217 |
+
"gpt2": "gpt2",
|
| 218 |
+
"gpt2-xl": "gpt2-xl",
|
| 219 |
+
"gpt-j-6b": "EleutherAI/gpt-j-6b",
|
| 220 |
+
"gpt4all-j": "nomic-ai/gpt4all-j",
|
| 221 |
+
"gpt-neox-20b": "EleutherAI/gpt-neox-20b",
|
| 222 |
+
"pythia-12b": "EleutherAI/pythia-12b",
|
| 223 |
+
"oasst-sft-4-pythia-12b-epoch-3.5": "OpenAssistant/oasst-sft-4-pythia-12b-epoch-3.5",
|
| 224 |
+
"dolly-v2-12b": "databricks/dolly-v2-12b",
|
| 225 |
+
"stablelm-tuned-alpha-7b": "stabilityai/stablelm-tuned-alpha-7b",
|
| 226 |
+
},
|
| 227 |
+
|
| 228 |
+
"reranker": {
|
| 229 |
+
"bge-reranker-large": "BAAI/bge-reranker-large",
|
| 230 |
+
"bge-reranker-base": "BAAI/bge-reranker-base",
|
| 231 |
+
}
|
| 232 |
+
}
|
| 233 |
+
|
| 234 |
+
# 通常情况下不需要更改以下内容
|
| 235 |
+
|
| 236 |
+
# nltk 模型存储路径
|
| 237 |
+
NLTK_DATA_PATH = os.path.join(os.path.dirname(os.path.dirname(__file__)), "nltk_data")
|
| 238 |
+
|
| 239 |
+
# 使用VLLM可能导致模型推理能力下降,无法完成Agent任务
|
| 240 |
+
VLLM_MODEL_DICT = {
|
| 241 |
+
"chatglm2-6b": "THUDM/chatglm2-6b",
|
| 242 |
+
"chatglm2-6b-32k": "THUDM/chatglm2-6b-32k",
|
| 243 |
+
"chatglm3-6b": "THUDM/chatglm3-6b",
|
| 244 |
+
"chatglm3-6b-32k": "THUDM/chatglm3-6b-32k",
|
| 245 |
+
|
| 246 |
+
"Llama-2-7b-chat-hf": "meta-llama/Llama-2-7b-chat-hf",
|
| 247 |
+
"Llama-2-13b-chat-hf": "meta-llama/Llama-2-13b-chat-hf",
|
| 248 |
+
"Llama-2-70b-chat-hf": "meta-llama/Llama-2-70b-chat-hf",
|
| 249 |
+
|
| 250 |
+
"Qwen-1_8B-Chat": "Qwen/Qwen-1_8B-Chat",
|
| 251 |
+
"Qwen-7B-Chat": "Qwen/Qwen-7B-Chat",
|
| 252 |
+
"Qwen-14B-Chat": "Qwen/Qwen-14B-Chat",
|
| 253 |
+
"Qwen-72B-Chat": "Qwen/Qwen-72B-Chat",
|
| 254 |
+
|
| 255 |
+
"baichuan-7b-chat": "baichuan-inc/Baichuan-7B-Chat",
|
| 256 |
+
"baichuan-13b-chat": "baichuan-inc/Baichuan-13B-Chat",
|
| 257 |
+
"baichuan2-7b-chat": "baichuan-inc/Baichuan-7B-Chat",
|
| 258 |
+
"baichuan2-13b-chat": "baichuan-inc/Baichuan-13B-Chat",
|
| 259 |
+
|
| 260 |
+
"BlueLM-7B-Chat": "vivo-ai/BlueLM-7B-Chat",
|
| 261 |
+
"BlueLM-7B-Chat-32k": "vivo-ai/BlueLM-7B-Chat-32k",
|
| 262 |
+
|
| 263 |
+
"internlm-7b": "internlm/internlm-7b",
|
| 264 |
+
"internlm-chat-7b": "internlm/internlm-chat-7b",
|
| 265 |
+
"internlm2-chat-7b": "internlm/Models/internlm2-chat-7b",
|
| 266 |
+
"internlm2-chat-20b": "internlm/Models/internlm2-chat-20b",
|
| 267 |
+
|
| 268 |
+
"aquila-7b": "BAAI/Aquila-7B",
|
| 269 |
+
"aquilachat-7b": "BAAI/AquilaChat-7B",
|
| 270 |
+
|
| 271 |
+
"falcon-7b": "tiiuae/falcon-7b",
|
| 272 |
+
"falcon-40b": "tiiuae/falcon-40b",
|
| 273 |
+
"falcon-rw-7b": "tiiuae/falcon-rw-7b",
|
| 274 |
+
"gpt2": "gpt2",
|
| 275 |
+
"gpt2-xl": "gpt2-xl",
|
| 276 |
+
"gpt-j-6b": "EleutherAI/gpt-j-6b",
|
| 277 |
+
"gpt4all-j": "nomic-ai/gpt4all-j",
|
| 278 |
+
"gpt-neox-20b": "EleutherAI/gpt-neox-20b",
|
| 279 |
+
"pythia-12b": "EleutherAI/pythia-12b",
|
| 280 |
+
"oasst-sft-4-pythia-12b-epoch-3.5": "OpenAssistant/oasst-sft-4-pythia-12b-epoch-3.5",
|
| 281 |
+
"dolly-v2-12b": "databricks/dolly-v2-12b",
|
| 282 |
+
"stablelm-tuned-alpha-7b": "stabilityai/stablelm-tuned-alpha-7b",
|
| 283 |
+
"open_llama_13b": "openlm-research/open_llama_13b",
|
| 284 |
+
"vicuna-13b-v1.3": "lmsys/vicuna-13b-v1.3",
|
| 285 |
+
"koala": "young-geng/koala",
|
| 286 |
+
"mpt-7b": "mosaicml/mpt-7b",
|
| 287 |
+
"mpt-7b-storywriter": "mosaicml/mpt-7b-storywriter",
|
| 288 |
+
"mpt-30b": "mosaicml/mpt-30b",
|
| 289 |
+
"opt-66b": "facebook/opt-66b",
|
| 290 |
+
"opt-iml-max-30b": "facebook/opt-iml-max-30b",
|
| 291 |
+
|
| 292 |
+
}
|
| 293 |
+
|
| 294 |
+
SUPPORT_AGENT_MODEL = [
|
| 295 |
+
"openai-api", # GPT4 模型
|
| 296 |
+
"qwen-api", # Qwen Max模型
|
| 297 |
+
"zhipu-api", # 智谱AI GLM4模型
|
| 298 |
+
"Qwen", # 所有Qwen系列本地模型
|
| 299 |
+
"chatglm3-6b",
|
| 300 |
+
"internlm2-chat-20b",
|
| 301 |
+
"Orion-14B-Chat-Plugin",
|
| 302 |
+
]
|
configs/prompt_config.py.example
ADDED
|
@@ -0,0 +1,127 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# prompt模板使用Jinja2语法,简单点就是用双大括号代替f-string的单大括号
|
| 2 |
+
# 本配置文件支持热加载,修改prompt模板后无需重启服务。
|
| 3 |
+
|
| 4 |
+
# LLM对话支持的变量:
|
| 5 |
+
# - input: 用户输入内容
|
| 6 |
+
|
| 7 |
+
# 知识库和搜索引擎对话支持的变量:
|
| 8 |
+
# - context: 从检索结果拼接的知识文本
|
| 9 |
+
# - question: 用户提出的问题
|
| 10 |
+
|
| 11 |
+
# Agent对话支持的变量:
|
| 12 |
+
|
| 13 |
+
# - tools: 可用的工具列表
|
| 14 |
+
# - tool_names: 可用的工具名称列表
|
| 15 |
+
# - history: 用户和Agent的对话历史
|
| 16 |
+
# - input: 用户输入内容
|
| 17 |
+
# - agent_scratchpad: Agent的思维记录
|
| 18 |
+
|
| 19 |
+
PROMPT_TEMPLATES = {
|
| 20 |
+
"llm_chat": {
|
| 21 |
+
"default":
|
| 22 |
+
'{{ input }}',
|
| 23 |
+
|
| 24 |
+
"with_history":
|
| 25 |
+
'The following is a friendly conversation between a human and an AI. '
|
| 26 |
+
'The AI is talkative and provides lots of specific details from its context. '
|
| 27 |
+
'If the AI does not know the answer to a question, it truthfully says it does not know.\n\n'
|
| 28 |
+
'Current conversation:\n'
|
| 29 |
+
'{history}\n'
|
| 30 |
+
'Human: {input}\n'
|
| 31 |
+
'AI:',
|
| 32 |
+
|
| 33 |
+
"py":
|
| 34 |
+
'你是一个聪明的代码助手,请你给我写出简单的py代码。 \n'
|
| 35 |
+
'{{ input }}',
|
| 36 |
+
},
|
| 37 |
+
|
| 38 |
+
|
| 39 |
+
"knowledge_base_chat": {
|
| 40 |
+
"default":
|
| 41 |
+
'<指令>根据已知信息,简洁和专业的来回答问题。如果无法从中得到答案,请说 “根据已知信息无法回答该问题”,'
|
| 42 |
+
'不允许在答案中添加编造成分,答案请使用中文。 </指令>\n'
|
| 43 |
+
'<已知信息>{{ context }}</已知信息>\n'
|
| 44 |
+
'<问题>{{ question }}</问题>\n',
|
| 45 |
+
|
| 46 |
+
"text":
|
| 47 |
+
'<指令>根据已知信息,简洁和专业的来回答问题。如果无法从中得到答案,请说 “根据已知信息无法回答该问题”,答案请使用中文。 </指令>\n'
|
| 48 |
+
'<已知信息>{{ context }}</已知信息>\n'
|
| 49 |
+
'<问题>{{ question }}</问题>\n',
|
| 50 |
+
|
| 51 |
+
"empty": # 搜不到知识库的时候使用
|
| 52 |
+
'请你回答我的问题:\n'
|
| 53 |
+
'{{ question }}\n\n',
|
| 54 |
+
},
|
| 55 |
+
|
| 56 |
+
|
| 57 |
+
"search_engine_chat": {
|
| 58 |
+
"default":
|
| 59 |
+
'<指令>这是我搜索到的互联网信息,请你根据这些信息进行提取并有调理,简洁的回答问题。'
|
| 60 |
+
'如果无法从中得到答案,请说 “无法搜索到能回答问题的内容”。 </指令>\n'
|
| 61 |
+
'<已知信息>{{ context }}</已知信息>\n'
|
| 62 |
+
'<问题>{{ question }}</问题>\n',
|
| 63 |
+
|
| 64 |
+
"search":
|
| 65 |
+
'<指令>根据已知信息,简洁和专业的来回答问题。如果无法从中得到答案,请说 “根据已知信息无法回答该问题”,答案请使用中文。 </指令>\n'
|
| 66 |
+
'<已知信息>{{ context }}</已知信息>\n'
|
| 67 |
+
'<问题>{{ question }}</问题>\n',
|
| 68 |
+
},
|
| 69 |
+
|
| 70 |
+
|
| 71 |
+
"agent_chat": {
|
| 72 |
+
"default":
|
| 73 |
+
'Answer the following questions as best you can. If it is in order, you can use some tools appropriately. '
|
| 74 |
+
'You have access to the following tools:\n\n'
|
| 75 |
+
'{tools}\n\n'
|
| 76 |
+
'Use the following format:\n'
|
| 77 |
+
'Question: the input question you must answer1\n'
|
| 78 |
+
'Thought: you should always think about what to do and what tools to use.\n'
|
| 79 |
+
'Action: the action to take, should be one of [{tool_names}]\n'
|
| 80 |
+
'Action Input: the input to the action\n'
|
| 81 |
+
'Observation: the result of the action\n'
|
| 82 |
+
'... (this Thought/Action/Action Input/Observation can be repeated zero or more times)\n'
|
| 83 |
+
'Thought: I now know the final answer\n'
|
| 84 |
+
'Final Answer: the final answer to the original input question\n'
|
| 85 |
+
'Begin!\n\n'
|
| 86 |
+
'history: {history}\n\n'
|
| 87 |
+
'Question: {input}\n\n'
|
| 88 |
+
'Thought: {agent_scratchpad}\n',
|
| 89 |
+
|
| 90 |
+
"ChatGLM3":
|
| 91 |
+
'You can answer using the tools, or answer directly using your knowledge without using the tools. '
|
| 92 |
+
'Respond to the human as helpfully and accurately as possible.\n'
|
| 93 |
+
'You have access to the following tools:\n'
|
| 94 |
+
'{tools}\n'
|
| 95 |
+
'Use a json blob to specify a tool by providing an action key (tool name) '
|
| 96 |
+
'and an action_input key (tool input).\n'
|
| 97 |
+
'Valid "action" values: "Final Answer" or [{tool_names}]'
|
| 98 |
+
'Provide only ONE action per $JSON_BLOB, as shown:\n\n'
|
| 99 |
+
'```\n'
|
| 100 |
+
'{{{{\n'
|
| 101 |
+
' "action": $TOOL_NAME,\n'
|
| 102 |
+
' "action_input": $INPUT\n'
|
| 103 |
+
'}}}}\n'
|
| 104 |
+
'```\n\n'
|
| 105 |
+
'Follow this format:\n\n'
|
| 106 |
+
'Question: input question to answer\n'
|
| 107 |
+
'Thought: consider previous and subsequent steps\n'
|
| 108 |
+
'Action:\n'
|
| 109 |
+
'```\n'
|
| 110 |
+
'$JSON_BLOB\n'
|
| 111 |
+
'```\n'
|
| 112 |
+
'Observation: action result\n'
|
| 113 |
+
'... (repeat Thought/Action/Observation N times)\n'
|
| 114 |
+
'Thought: I know what to respond\n'
|
| 115 |
+
'Action:\n'
|
| 116 |
+
'```\n'
|
| 117 |
+
'{{{{\n'
|
| 118 |
+
' "action": "Final Answer",\n'
|
| 119 |
+
' "action_input": "Final response to human"\n'
|
| 120 |
+
'}}}}\n'
|
| 121 |
+
'Begin! Reminder to ALWAYS respond with a valid json blob of a single action. Use tools if necessary. '
|
| 122 |
+
'Respond directly if appropriate. Format is Action:```$JSON_BLOB```then Observation:.\n'
|
| 123 |
+
'history: {history}\n\n'
|
| 124 |
+
'Question: {input}\n\n'
|
| 125 |
+
'Thought: {agent_scratchpad}',
|
| 126 |
+
}
|
| 127 |
+
}
|
configs/server_config.py.example
ADDED
|
@@ -0,0 +1,137 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import sys
|
| 2 |
+
from configs.model_config import LLM_DEVICE
|
| 3 |
+
|
| 4 |
+
# httpx 请求默认超时时间(秒)。如果加载模型或对话较慢,出现超时错误,可以适当加大该值。
|
| 5 |
+
HTTPX_DEFAULT_TIMEOUT = 300.0
|
| 6 |
+
|
| 7 |
+
# API 是否开启跨域,默认为False,如果需要开启,请设置为True
|
| 8 |
+
# is open cross domain
|
| 9 |
+
OPEN_CROSS_DOMAIN = False
|
| 10 |
+
|
| 11 |
+
# 各服务器默认绑定host。如改为"0.0.0.0"需要修改下方所有XX_SERVER的host
|
| 12 |
+
DEFAULT_BIND_HOST = "0.0.0.0" if sys.platform != "win32" else "127.0.0.1"
|
| 13 |
+
|
| 14 |
+
# webui.py server
|
| 15 |
+
WEBUI_SERVER = {
|
| 16 |
+
"host": DEFAULT_BIND_HOST,
|
| 17 |
+
"port": 8501,
|
| 18 |
+
}
|
| 19 |
+
|
| 20 |
+
# api.py server
|
| 21 |
+
API_SERVER = {
|
| 22 |
+
"host": DEFAULT_BIND_HOST,
|
| 23 |
+
"port": 7861,
|
| 24 |
+
}
|
| 25 |
+
|
| 26 |
+
# fastchat openai_api server
|
| 27 |
+
FSCHAT_OPENAI_API = {
|
| 28 |
+
"host": DEFAULT_BIND_HOST,
|
| 29 |
+
"port": 20000,
|
| 30 |
+
}
|
| 31 |
+
|
| 32 |
+
# fastchat model_worker server
|
| 33 |
+
# 这些模型必须是在model_config.MODEL_PATH或ONLINE_MODEL中正确配置的。
|
| 34 |
+
# 在启动startup.py时,可用通过`--model-name xxxx yyyy`指定模型,不指定则为LLM_MODELS
|
| 35 |
+
FSCHAT_MODEL_WORKERS = {
|
| 36 |
+
# 所有模型共用的默认配置,可在模型专项配置中进行覆盖。
|
| 37 |
+
"default": {
|
| 38 |
+
"host": DEFAULT_BIND_HOST,
|
| 39 |
+
"port": 20002,
|
| 40 |
+
"device": LLM_DEVICE,
|
| 41 |
+
# False,'vllm',使用的推理加速框架,使用vllm如果出现HuggingFace通信问题,参见doc/FAQ
|
| 42 |
+
# vllm对一些模型支持还不成熟,暂时默认关闭
|
| 43 |
+
"infer_turbo": False,
|
| 44 |
+
|
| 45 |
+
# model_worker多卡加载需要配置的参数
|
| 46 |
+
# "gpus": None, # 使用的GPU,以str的格式指定,如"0,1",如失效请使用CUDA_VISIBLE_DEVICES="0,1"等形式指定
|
| 47 |
+
# "num_gpus": 1, # 使用GPU的数量
|
| 48 |
+
# "max_gpu_memory": "20GiB", # 每个GPU占用的最大显存
|
| 49 |
+
|
| 50 |
+
# 以下为model_worker非常用参数,可根据需要配置
|
| 51 |
+
# "load_8bit": False, # 开启8bit量化
|
| 52 |
+
# "cpu_offloading": None,
|
| 53 |
+
# "gptq_ckpt": None,
|
| 54 |
+
# "gptq_wbits": 16,
|
| 55 |
+
# "gptq_groupsize": -1,
|
| 56 |
+
# "gptq_act_order": False,
|
| 57 |
+
# "awq_ckpt": None,
|
| 58 |
+
# "awq_wbits": 16,
|
| 59 |
+
# "awq_groupsize": -1,
|
| 60 |
+
# "model_names": LLM_MODELS,
|
| 61 |
+
# "conv_template": None,
|
| 62 |
+
# "limit_worker_concurrency": 5,
|
| 63 |
+
# "stream_interval": 2,
|
| 64 |
+
# "no_register": False,
|
| 65 |
+
# "embed_in_truncate": False,
|
| 66 |
+
|
| 67 |
+
# 以下为vllm_worker配置参数,注意使用vllm必须有gpu,仅在Linux测试通过
|
| 68 |
+
|
| 69 |
+
# tokenizer = model_path # 如果tokenizer与model_path不一致在此处添加
|
| 70 |
+
# 'tokenizer_mode':'auto',
|
| 71 |
+
# 'trust_remote_code':True,
|
| 72 |
+
# 'download_dir':None,
|
| 73 |
+
# 'load_format':'auto',
|
| 74 |
+
# 'dtype':'auto',
|
| 75 |
+
# 'seed':0,
|
| 76 |
+
# 'worker_use_ray':False,
|
| 77 |
+
# 'pipeline_parallel_size':1,
|
| 78 |
+
# 'tensor_parallel_size':1,
|
| 79 |
+
# 'block_size':16,
|
| 80 |
+
# 'swap_space':4 , # GiB
|
| 81 |
+
# 'gpu_memory_utilization':0.90,
|
| 82 |
+
# 'max_num_batched_tokens':2560,
|
| 83 |
+
# 'max_num_seqs':256,
|
| 84 |
+
# 'disable_log_stats':False,
|
| 85 |
+
# 'conv_template':None,
|
| 86 |
+
# 'limit_worker_concurrency':5,
|
| 87 |
+
# 'no_register':False,
|
| 88 |
+
# 'num_gpus': 1
|
| 89 |
+
# 'engine_use_ray': False,
|
| 90 |
+
# 'disable_log_requests': False
|
| 91 |
+
|
| 92 |
+
},
|
| 93 |
+
"Qwen-1_8B-Chat": {
|
| 94 |
+
"device": "cpu",
|
| 95 |
+
},
|
| 96 |
+
"chatglm3-6b": {
|
| 97 |
+
"device": "cuda",
|
| 98 |
+
},
|
| 99 |
+
|
| 100 |
+
# 以下配置可以不用修改,在model_config中设置启动的模型
|
| 101 |
+
"zhipu-api": {
|
| 102 |
+
"port": 21001,
|
| 103 |
+
},
|
| 104 |
+
"minimax-api": {
|
| 105 |
+
"port": 21002,
|
| 106 |
+
},
|
| 107 |
+
"xinghuo-api": {
|
| 108 |
+
"port": 21003,
|
| 109 |
+
},
|
| 110 |
+
"qianfan-api": {
|
| 111 |
+
"port": 21004,
|
| 112 |
+
},
|
| 113 |
+
"fangzhou-api": {
|
| 114 |
+
"port": 21005,
|
| 115 |
+
},
|
| 116 |
+
"qwen-api": {
|
| 117 |
+
"port": 21006,
|
| 118 |
+
},
|
| 119 |
+
"baichuan-api": {
|
| 120 |
+
"port": 21007,
|
| 121 |
+
},
|
| 122 |
+
"azure-api": {
|
| 123 |
+
"port": 21008,
|
| 124 |
+
},
|
| 125 |
+
"tiangong-api": {
|
| 126 |
+
"port": 21009,
|
| 127 |
+
},
|
| 128 |
+
"gemini-api": {
|
| 129 |
+
"port": 21010,
|
| 130 |
+
},
|
| 131 |
+
}
|
| 132 |
+
|
| 133 |
+
FSCHAT_CONTROLLER = {
|
| 134 |
+
"host": DEFAULT_BIND_HOST,
|
| 135 |
+
"port": 20001,
|
| 136 |
+
"dispatch_method": "shortest_queue",
|
| 137 |
+
}
|
docs/ES部署指南.md
ADDED
|
@@ -0,0 +1,29 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
|
| 2 |
+
# 实现基于ES的数据插入、检索、删除、更新
|
| 3 |
+
```shell
|
| 4 |
+
author: 唐国梁Tommy
|
| 5 |
+
e-mail: flytang186@qq.com
|
| 6 |
+
|
| 7 |
+
如果遇到任何问题,可以与我联系,我这边部署后服务是没有问题的。
|
| 8 |
+
```
|
| 9 |
+
|
| 10 |
+
## 第1步:ES docker部署
|
| 11 |
+
```shell
|
| 12 |
+
docker network create elastic
|
| 13 |
+
docker run -id --name elasticsearch --net elastic -p 9200:9200 -p 9300:9300 -e "discovery.type=single-node" -e "xpack.security.enabled=false" -e "xpack.security.http.ssl.enabled=false" -t docker.elastic.co/elasticsearch/elasticsearch:8.8.2
|
| 14 |
+
```
|
| 15 |
+
|
| 16 |
+
### 第2步:Kibana docker部署
|
| 17 |
+
**注意:Kibana版本与ES保持一致**
|
| 18 |
+
```shell
|
| 19 |
+
docker pull docker.elastic.co/kibana/kibana:{version}
|
| 20 |
+
docker run --name kibana --net elastic -p 5601:5601 docker.elastic.co/kibana/kibana:{version}
|
| 21 |
+
```
|
| 22 |
+
|
| 23 |
+
### 第3步:核心代码
|
| 24 |
+
```shell
|
| 25 |
+
1. 核心代码路径
|
| 26 |
+
server/knowledge_base/kb_service/es_kb_service.py
|
| 27 |
+
|
| 28 |
+
2. 需要在 configs/model_config.py 中 配置 ES参数(IP, PORT)等;
|
| 29 |
+
```
|
document_loaders/FilteredCSVloader.py
ADDED
|
@@ -0,0 +1,81 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
## 指定制定列的csv文件加载器
|
| 2 |
+
|
| 3 |
+
from langchain.document_loaders import CSVLoader
|
| 4 |
+
import csv
|
| 5 |
+
from io import TextIOWrapper
|
| 6 |
+
from typing import Dict, List, Optional
|
| 7 |
+
from langchain.docstore.document import Document
|
| 8 |
+
from langchain.document_loaders.helpers import detect_file_encodings
|
| 9 |
+
|
| 10 |
+
|
| 11 |
+
class FilteredCSVLoader(CSVLoader):
|
| 12 |
+
def __init__(
|
| 13 |
+
self,
|
| 14 |
+
file_path: str,
|
| 15 |
+
columns_to_read: List[str],
|
| 16 |
+
source_column: Optional[str] = None,
|
| 17 |
+
metadata_columns: List[str] = [],
|
| 18 |
+
csv_args: Optional[Dict] = None,
|
| 19 |
+
encoding: Optional[str] = None,
|
| 20 |
+
autodetect_encoding: bool = False,
|
| 21 |
+
):
|
| 22 |
+
super().__init__(
|
| 23 |
+
file_path=file_path,
|
| 24 |
+
source_column=source_column,
|
| 25 |
+
metadata_columns=metadata_columns,
|
| 26 |
+
csv_args=csv_args,
|
| 27 |
+
encoding=encoding,
|
| 28 |
+
autodetect_encoding=autodetect_encoding,
|
| 29 |
+
)
|
| 30 |
+
self.columns_to_read = columns_to_read
|
| 31 |
+
|
| 32 |
+
def load(self) -> List[Document]:
|
| 33 |
+
"""Load data into document objects."""
|
| 34 |
+
|
| 35 |
+
docs = []
|
| 36 |
+
try:
|
| 37 |
+
with open(self.file_path, newline="", encoding=self.encoding) as csvfile:
|
| 38 |
+
docs = self.__read_file(csvfile)
|
| 39 |
+
except UnicodeDecodeError as e:
|
| 40 |
+
if self.autodetect_encoding:
|
| 41 |
+
detected_encodings = detect_file_encodings(self.file_path)
|
| 42 |
+
for encoding in detected_encodings:
|
| 43 |
+
try:
|
| 44 |
+
with open(
|
| 45 |
+
self.file_path, newline="", encoding=encoding.encoding
|
| 46 |
+
) as csvfile:
|
| 47 |
+
docs = self.__read_file(csvfile)
|
| 48 |
+
break
|
| 49 |
+
except UnicodeDecodeError:
|
| 50 |
+
continue
|
| 51 |
+
else:
|
| 52 |
+
raise RuntimeError(f"Error loading {self.file_path}") from e
|
| 53 |
+
except Exception as e:
|
| 54 |
+
raise RuntimeError(f"Error loading {self.file_path}") from e
|
| 55 |
+
|
| 56 |
+
return docs
|
| 57 |
+
|
| 58 |
+
def __read_file(self, csvfile: TextIOWrapper) -> List[Document]:
|
| 59 |
+
docs = []
|
| 60 |
+
csv_reader = csv.DictReader(csvfile, **self.csv_args) # type: ignore
|
| 61 |
+
for i, row in enumerate(csv_reader):
|
| 62 |
+
if self.columns_to_read[0] in row:
|
| 63 |
+
content = row[self.columns_to_read[0]]
|
| 64 |
+
# Extract the source if available
|
| 65 |
+
source = (
|
| 66 |
+
row.get(self.source_column, None)
|
| 67 |
+
if self.source_column is not None
|
| 68 |
+
else self.file_path
|
| 69 |
+
)
|
| 70 |
+
metadata = {"source": source, "row": i}
|
| 71 |
+
|
| 72 |
+
for col in self.metadata_columns:
|
| 73 |
+
if col in row:
|
| 74 |
+
metadata[col] = row[col]
|
| 75 |
+
|
| 76 |
+
doc = Document(page_content=content, metadata=metadata)
|
| 77 |
+
docs.append(doc)
|
| 78 |
+
else:
|
| 79 |
+
raise ValueError(f"Column '{self.columns_to_read[0]}' not found in CSV file.")
|
| 80 |
+
|
| 81 |
+
return docs
|
document_loaders/__init__.py
ADDED
|
@@ -0,0 +1,4 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from .mypdfloader import RapidOCRPDFLoader
|
| 2 |
+
from .myimgloader import RapidOCRLoader
|
| 3 |
+
from .mydocloader import RapidOCRDocLoader
|
| 4 |
+
from .mypptloader import RapidOCRPPTLoader
|
document_loaders/mydocloader.py
ADDED
|
@@ -0,0 +1,71 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from langchain.document_loaders.unstructured import UnstructuredFileLoader
|
| 2 |
+
from typing import List
|
| 3 |
+
import tqdm
|
| 4 |
+
|
| 5 |
+
|
| 6 |
+
class RapidOCRDocLoader(UnstructuredFileLoader):
|
| 7 |
+
def _get_elements(self) -> List:
|
| 8 |
+
def doc2text(filepath):
|
| 9 |
+
from docx.table import _Cell, Table
|
| 10 |
+
from docx.oxml.table import CT_Tbl
|
| 11 |
+
from docx.oxml.text.paragraph import CT_P
|
| 12 |
+
from docx.text.paragraph import Paragraph
|
| 13 |
+
from docx import Document, ImagePart
|
| 14 |
+
from PIL import Image
|
| 15 |
+
from io import BytesIO
|
| 16 |
+
import numpy as np
|
| 17 |
+
from rapidocr_onnxruntime import RapidOCR
|
| 18 |
+
ocr = RapidOCR()
|
| 19 |
+
doc = Document(filepath)
|
| 20 |
+
resp = ""
|
| 21 |
+
|
| 22 |
+
def iter_block_items(parent):
|
| 23 |
+
from docx.document import Document
|
| 24 |
+
if isinstance(parent, Document):
|
| 25 |
+
parent_elm = parent.element.body
|
| 26 |
+
elif isinstance(parent, _Cell):
|
| 27 |
+
parent_elm = parent._tc
|
| 28 |
+
else:
|
| 29 |
+
raise ValueError("RapidOCRDocLoader parse fail")
|
| 30 |
+
|
| 31 |
+
for child in parent_elm.iterchildren():
|
| 32 |
+
if isinstance(child, CT_P):
|
| 33 |
+
yield Paragraph(child, parent)
|
| 34 |
+
elif isinstance(child, CT_Tbl):
|
| 35 |
+
yield Table(child, parent)
|
| 36 |
+
|
| 37 |
+
b_unit = tqdm.tqdm(total=len(doc.paragraphs)+len(doc.tables),
|
| 38 |
+
desc="RapidOCRDocLoader block index: 0")
|
| 39 |
+
for i, block in enumerate(iter_block_items(doc)):
|
| 40 |
+
b_unit.set_description(
|
| 41 |
+
"RapidOCRDocLoader block index: {}".format(i))
|
| 42 |
+
b_unit.refresh()
|
| 43 |
+
if isinstance(block, Paragraph):
|
| 44 |
+
resp += block.text.strip() + "\n"
|
| 45 |
+
images = block._element.xpath('.//pic:pic') # 获取所有图片
|
| 46 |
+
for image in images:
|
| 47 |
+
for img_id in image.xpath('.//a:blip/@r:embed'): # 获取图片id
|
| 48 |
+
part = doc.part.related_parts[img_id] # 根据图片id获取对应的图片
|
| 49 |
+
if isinstance(part, ImagePart):
|
| 50 |
+
image = Image.open(BytesIO(part._blob))
|
| 51 |
+
result, _ = ocr(np.array(image))
|
| 52 |
+
if result:
|
| 53 |
+
ocr_result = [line[1] for line in result]
|
| 54 |
+
resp += "\n".join(ocr_result)
|
| 55 |
+
elif isinstance(block, Table):
|
| 56 |
+
for row in block.rows:
|
| 57 |
+
for cell in row.cells:
|
| 58 |
+
for paragraph in cell.paragraphs:
|
| 59 |
+
resp += paragraph.text.strip() + "\n"
|
| 60 |
+
b_unit.update(1)
|
| 61 |
+
return resp
|
| 62 |
+
|
| 63 |
+
text = doc2text(self.file_path)
|
| 64 |
+
from unstructured.partition.text import partition_text
|
| 65 |
+
return partition_text(text=text, **self.unstructured_kwargs)
|
| 66 |
+
|
| 67 |
+
|
| 68 |
+
if __name__ == '__main__':
|
| 69 |
+
loader = RapidOCRDocLoader(file_path="../tests/samples/ocr_test.docx")
|
| 70 |
+
docs = loader.load()
|
| 71 |
+
print(docs)
|
document_loaders/myimgloader.py
ADDED
|
@@ -0,0 +1,25 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from typing import List
|
| 2 |
+
from langchain.document_loaders.unstructured import UnstructuredFileLoader
|
| 3 |
+
from document_loaders.ocr import get_ocr
|
| 4 |
+
|
| 5 |
+
|
| 6 |
+
class RapidOCRLoader(UnstructuredFileLoader):
|
| 7 |
+
def _get_elements(self) -> List:
|
| 8 |
+
def img2text(filepath):
|
| 9 |
+
resp = ""
|
| 10 |
+
ocr = get_ocr()
|
| 11 |
+
result, _ = ocr(filepath)
|
| 12 |
+
if result:
|
| 13 |
+
ocr_result = [line[1] for line in result]
|
| 14 |
+
resp += "\n".join(ocr_result)
|
| 15 |
+
return resp
|
| 16 |
+
|
| 17 |
+
text = img2text(self.file_path)
|
| 18 |
+
from unstructured.partition.text import partition_text
|
| 19 |
+
return partition_text(text=text, **self.unstructured_kwargs)
|
| 20 |
+
|
| 21 |
+
|
| 22 |
+
if __name__ == "__main__":
|
| 23 |
+
loader = RapidOCRLoader(file_path="../tests/samples/ocr_test.jpg")
|
| 24 |
+
docs = loader.load()
|
| 25 |
+
print(docs)
|
document_loaders/mypdfloader.py
ADDED
|
@@ -0,0 +1,51 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from typing import List
|
| 2 |
+
from langchain.document_loaders.unstructured import UnstructuredFileLoader
|
| 3 |
+
from configs import PDF_OCR_THRESHOLD
|
| 4 |
+
from document_loaders.ocr import get_ocr
|
| 5 |
+
import tqdm
|
| 6 |
+
|
| 7 |
+
|
| 8 |
+
class RapidOCRPDFLoader(UnstructuredFileLoader):
|
| 9 |
+
def _get_elements(self) -> List:
|
| 10 |
+
def pdf2text(filepath):
|
| 11 |
+
import fitz # pyMuPDF里面的fitz包,不要与pip install fitz混淆
|
| 12 |
+
import numpy as np
|
| 13 |
+
ocr = get_ocr()
|
| 14 |
+
doc = fitz.open(filepath)
|
| 15 |
+
resp = ""
|
| 16 |
+
|
| 17 |
+
b_unit = tqdm.tqdm(total=doc.page_count, desc="RapidOCRPDFLoader context page index: 0")
|
| 18 |
+
for i, page in enumerate(doc):
|
| 19 |
+
b_unit.set_description("RapidOCRPDFLoader context page index: {}".format(i))
|
| 20 |
+
b_unit.refresh()
|
| 21 |
+
text = page.get_text("")
|
| 22 |
+
resp += text + "\n"
|
| 23 |
+
|
| 24 |
+
img_list = page.get_image_info(xrefs=True)
|
| 25 |
+
for img in img_list:
|
| 26 |
+
if xref := img.get("xref"):
|
| 27 |
+
bbox = img["bbox"]
|
| 28 |
+
# 检查图片尺寸是否超过设定的阈值
|
| 29 |
+
if ((bbox[2] - bbox[0]) / (page.rect.width) < PDF_OCR_THRESHOLD[0]
|
| 30 |
+
or (bbox[3] - bbox[1]) / (page.rect.height) < PDF_OCR_THRESHOLD[1]):
|
| 31 |
+
continue
|
| 32 |
+
pix = fitz.Pixmap(doc, xref)
|
| 33 |
+
img_array = np.frombuffer(pix.samples, dtype=np.uint8).reshape(pix.height, pix.width, -1)
|
| 34 |
+
result, _ = ocr(img_array)
|
| 35 |
+
if result:
|
| 36 |
+
ocr_result = [line[1] for line in result]
|
| 37 |
+
resp += "\n".join(ocr_result)
|
| 38 |
+
|
| 39 |
+
# 更新进度
|
| 40 |
+
b_unit.update(1)
|
| 41 |
+
return resp
|
| 42 |
+
|
| 43 |
+
text = pdf2text(self.file_path)
|
| 44 |
+
from unstructured.partition.text import partition_text
|
| 45 |
+
return partition_text(text=text, **self.unstructured_kwargs)
|
| 46 |
+
|
| 47 |
+
|
| 48 |
+
if __name__ == "__main__":
|
| 49 |
+
loader = RapidOCRPDFLoader(file_path="../tests/samples/ocr_test.pdf")
|
| 50 |
+
docs = loader.load()
|
| 51 |
+
print(docs)
|
document_loaders/mypptloader.py
ADDED
|
@@ -0,0 +1,59 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from langchain.document_loaders.unstructured import UnstructuredFileLoader
|
| 2 |
+
from typing import List
|
| 3 |
+
import tqdm
|
| 4 |
+
|
| 5 |
+
|
| 6 |
+
class RapidOCRPPTLoader(UnstructuredFileLoader):
|
| 7 |
+
def _get_elements(self) -> List:
|
| 8 |
+
def ppt2text(filepath):
|
| 9 |
+
from pptx import Presentation
|
| 10 |
+
from PIL import Image
|
| 11 |
+
import numpy as np
|
| 12 |
+
from io import BytesIO
|
| 13 |
+
from rapidocr_onnxruntime import RapidOCR
|
| 14 |
+
ocr = RapidOCR()
|
| 15 |
+
prs = Presentation(filepath)
|
| 16 |
+
resp = ""
|
| 17 |
+
|
| 18 |
+
def extract_text(shape):
|
| 19 |
+
nonlocal resp
|
| 20 |
+
if shape.has_text_frame:
|
| 21 |
+
resp += shape.text.strip() + "\n"
|
| 22 |
+
if shape.has_table:
|
| 23 |
+
for row in shape.table.rows:
|
| 24 |
+
for cell in row.cells:
|
| 25 |
+
for paragraph in cell.text_frame.paragraphs:
|
| 26 |
+
resp += paragraph.text.strip() + "\n"
|
| 27 |
+
if shape.shape_type == 13: # 13 表示图片
|
| 28 |
+
image = Image.open(BytesIO(shape.image.blob))
|
| 29 |
+
result, _ = ocr(np.array(image))
|
| 30 |
+
if result:
|
| 31 |
+
ocr_result = [line[1] for line in result]
|
| 32 |
+
resp += "\n".join(ocr_result)
|
| 33 |
+
elif shape.shape_type == 6: # 6 表示组合
|
| 34 |
+
for child_shape in shape.shapes:
|
| 35 |
+
extract_text(child_shape)
|
| 36 |
+
|
| 37 |
+
b_unit = tqdm.tqdm(total=len(prs.slides),
|
| 38 |
+
desc="RapidOCRPPTLoader slide index: 1")
|
| 39 |
+
# 遍历所有幻灯片
|
| 40 |
+
for slide_number, slide in enumerate(prs.slides, start=1):
|
| 41 |
+
b_unit.set_description(
|
| 42 |
+
"RapidOCRPPTLoader slide index: {}".format(slide_number))
|
| 43 |
+
b_unit.refresh()
|
| 44 |
+
sorted_shapes = sorted(slide.shapes,
|
| 45 |
+
key=lambda x: (x.top, x.left)) # 从上到下、从左到右遍历
|
| 46 |
+
for shape in sorted_shapes:
|
| 47 |
+
extract_text(shape)
|
| 48 |
+
b_unit.update(1)
|
| 49 |
+
return resp
|
| 50 |
+
|
| 51 |
+
text = ppt2text(self.file_path)
|
| 52 |
+
from unstructured.partition.text import partition_text
|
| 53 |
+
return partition_text(text=text, **self.unstructured_kwargs)
|
| 54 |
+
|
| 55 |
+
|
| 56 |
+
if __name__ == '__main__':
|
| 57 |
+
loader = RapidOCRPPTLoader(file_path="../tests/samples/ocr_test.pptx")
|
| 58 |
+
docs = loader.load()
|
| 59 |
+
print(docs)
|
document_loaders/ocr.py
ADDED
|
@@ -0,0 +1,18 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from typing import TYPE_CHECKING
|
| 2 |
+
|
| 3 |
+
|
| 4 |
+
if TYPE_CHECKING:
|
| 5 |
+
try:
|
| 6 |
+
from rapidocr_paddle import RapidOCR
|
| 7 |
+
except ImportError:
|
| 8 |
+
from rapidocr_onnxruntime import RapidOCR
|
| 9 |
+
|
| 10 |
+
|
| 11 |
+
def get_ocr(use_cuda: bool = True) -> "RapidOCR":
|
| 12 |
+
try:
|
| 13 |
+
from rapidocr_paddle import RapidOCR
|
| 14 |
+
ocr = RapidOCR(det_use_cuda=use_cuda, cls_use_cuda=use_cuda, rec_use_cuda=use_cuda)
|
| 15 |
+
except ImportError:
|
| 16 |
+
from rapidocr_onnxruntime import RapidOCR
|
| 17 |
+
ocr = RapidOCR()
|
| 18 |
+
return ocr
|
embeddings/__init__.py
ADDED
|
File without changes
|
embeddings/add_embedding_keywords.py
ADDED
|
@@ -0,0 +1,79 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
'''
|
| 2 |
+
该功能是为了将关键词加入到embedding模型中,以便于在embedding模型中进行关键词的embedding
|
| 3 |
+
该功能的实现是通过修改embedding模型的tokenizer来实现的
|
| 4 |
+
该功能仅仅对EMBEDDING_MODEL参数对应的的模型有效,输出后的模型保存在原本模型
|
| 5 |
+
感谢@CharlesJu1和@charlesyju的贡献提出了想法和最基础的PR
|
| 6 |
+
|
| 7 |
+
保存的模型的位置位于原本嵌入模型的目录下,模型的名称为原模型名称+Merge_Keywords_时间戳
|
| 8 |
+
'''
|
| 9 |
+
import sys
|
| 10 |
+
|
| 11 |
+
sys.path.append("..")
|
| 12 |
+
import os
|
| 13 |
+
import torch
|
| 14 |
+
|
| 15 |
+
from datetime import datetime
|
| 16 |
+
from configs import (
|
| 17 |
+
MODEL_PATH,
|
| 18 |
+
EMBEDDING_MODEL,
|
| 19 |
+
EMBEDDING_KEYWORD_FILE,
|
| 20 |
+
)
|
| 21 |
+
|
| 22 |
+
from safetensors.torch import save_model
|
| 23 |
+
from sentence_transformers import SentenceTransformer
|
| 24 |
+
from langchain_core._api import deprecated
|
| 25 |
+
|
| 26 |
+
|
| 27 |
+
@deprecated(
|
| 28 |
+
since="0.3.0",
|
| 29 |
+
message="自定义关键词 Langchain-Chatchat 0.3.x 重写, 0.2.x中相关功能将废弃",
|
| 30 |
+
removal="0.3.0"
|
| 31 |
+
)
|
| 32 |
+
def get_keyword_embedding(bert_model, tokenizer, key_words):
|
| 33 |
+
tokenizer_output = tokenizer(key_words, return_tensors="pt", padding=True, truncation=True)
|
| 34 |
+
input_ids = tokenizer_output['input_ids']
|
| 35 |
+
input_ids = input_ids[:, 1:-1]
|
| 36 |
+
|
| 37 |
+
keyword_embedding = bert_model.embeddings.word_embeddings(input_ids)
|
| 38 |
+
keyword_embedding = torch.mean(keyword_embedding, 1)
|
| 39 |
+
return keyword_embedding
|
| 40 |
+
|
| 41 |
+
|
| 42 |
+
def add_keyword_to_model(model_name=EMBEDDING_MODEL, keyword_file: str = "", output_model_path: str = None):
|
| 43 |
+
key_words = []
|
| 44 |
+
with open(keyword_file, "r") as f:
|
| 45 |
+
for line in f:
|
| 46 |
+
key_words.append(line.strip())
|
| 47 |
+
|
| 48 |
+
st_model = SentenceTransformer(model_name)
|
| 49 |
+
key_words_len = len(key_words)
|
| 50 |
+
word_embedding_model = st_model._first_module()
|
| 51 |
+
bert_model = word_embedding_model.auto_model
|
| 52 |
+
tokenizer = word_embedding_model.tokenizer
|
| 53 |
+
key_words_embedding = get_keyword_embedding(bert_model, tokenizer, key_words)
|
| 54 |
+
|
| 55 |
+
embedding_weight = bert_model.embeddings.word_embeddings.weight
|
| 56 |
+
embedding_weight_len = len(embedding_weight)
|
| 57 |
+
tokenizer.add_tokens(key_words)
|
| 58 |
+
bert_model.resize_token_embeddings(len(tokenizer), pad_to_multiple_of=32)
|
| 59 |
+
embedding_weight = bert_model.embeddings.word_embeddings.weight
|
| 60 |
+
with torch.no_grad():
|
| 61 |
+
embedding_weight[embedding_weight_len:embedding_weight_len + key_words_len, :] = key_words_embedding
|
| 62 |
+
|
| 63 |
+
if output_model_path:
|
| 64 |
+
os.makedirs(output_model_path, exist_ok=True)
|
| 65 |
+
word_embedding_model.save(output_model_path)
|
| 66 |
+
safetensors_file = os.path.join(output_model_path, "model.safetensors")
|
| 67 |
+
metadata = {'format': 'pt'}
|
| 68 |
+
save_model(bert_model, safetensors_file, metadata)
|
| 69 |
+
print("save model to {}".format(output_model_path))
|
| 70 |
+
|
| 71 |
+
|
| 72 |
+
def add_keyword_to_embedding_model(path: str = EMBEDDING_KEYWORD_FILE):
|
| 73 |
+
keyword_file = os.path.join(path)
|
| 74 |
+
model_name = MODEL_PATH["embed_model"][EMBEDDING_MODEL]
|
| 75 |
+
model_parent_directory = os.path.dirname(model_name)
|
| 76 |
+
current_time = datetime.now().strftime('%Y%m%d_%H%M%S')
|
| 77 |
+
output_model_name = "{}_Merge_Keywords_{}".format(EMBEDDING_MODEL, current_time)
|
| 78 |
+
output_model_path = os.path.join(model_parent_directory, output_model_name)
|
| 79 |
+
add_keyword_to_model(model_name, keyword_file, output_model_path)
|
embeddings/embedding_keywords.txt
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
Langchain-Chatchat
|
| 2 |
+
数据科学与大数据技术
|
| 3 |
+
人工智能与先进计算
|
img/LLM_success.png
ADDED
|
img/agent_continue.png
ADDED
|
img/agent_success.png
ADDED
|
img/chatchat-qrcode.jpg
ADDED

|
img/chatchat_icon_blue_square_v2.png
ADDED
|
|
img/docker_logs.png
ADDED
|
img/fastapi_docs_026.png
ADDED
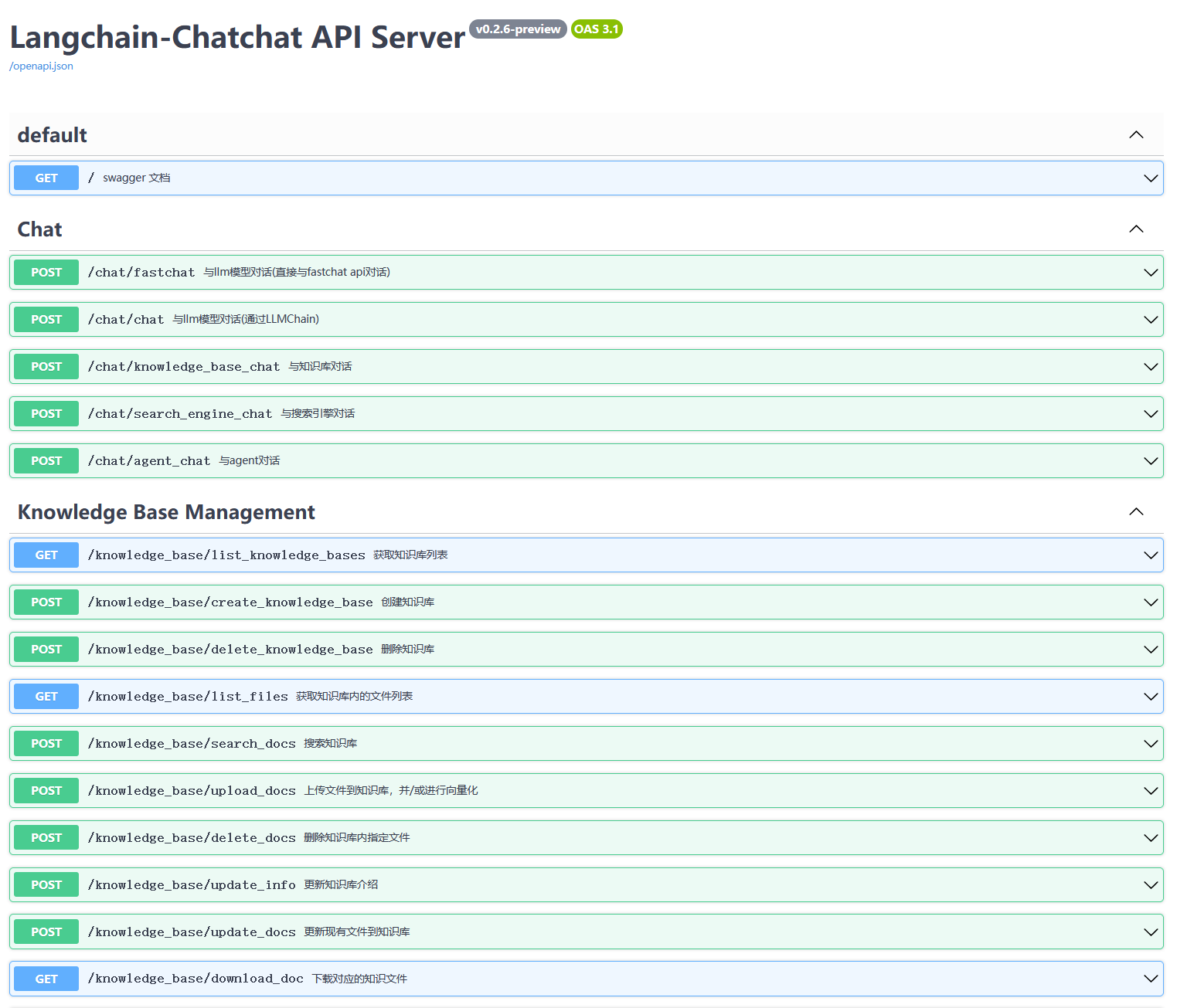
|
img/init_knowledge_base.jpg
ADDED
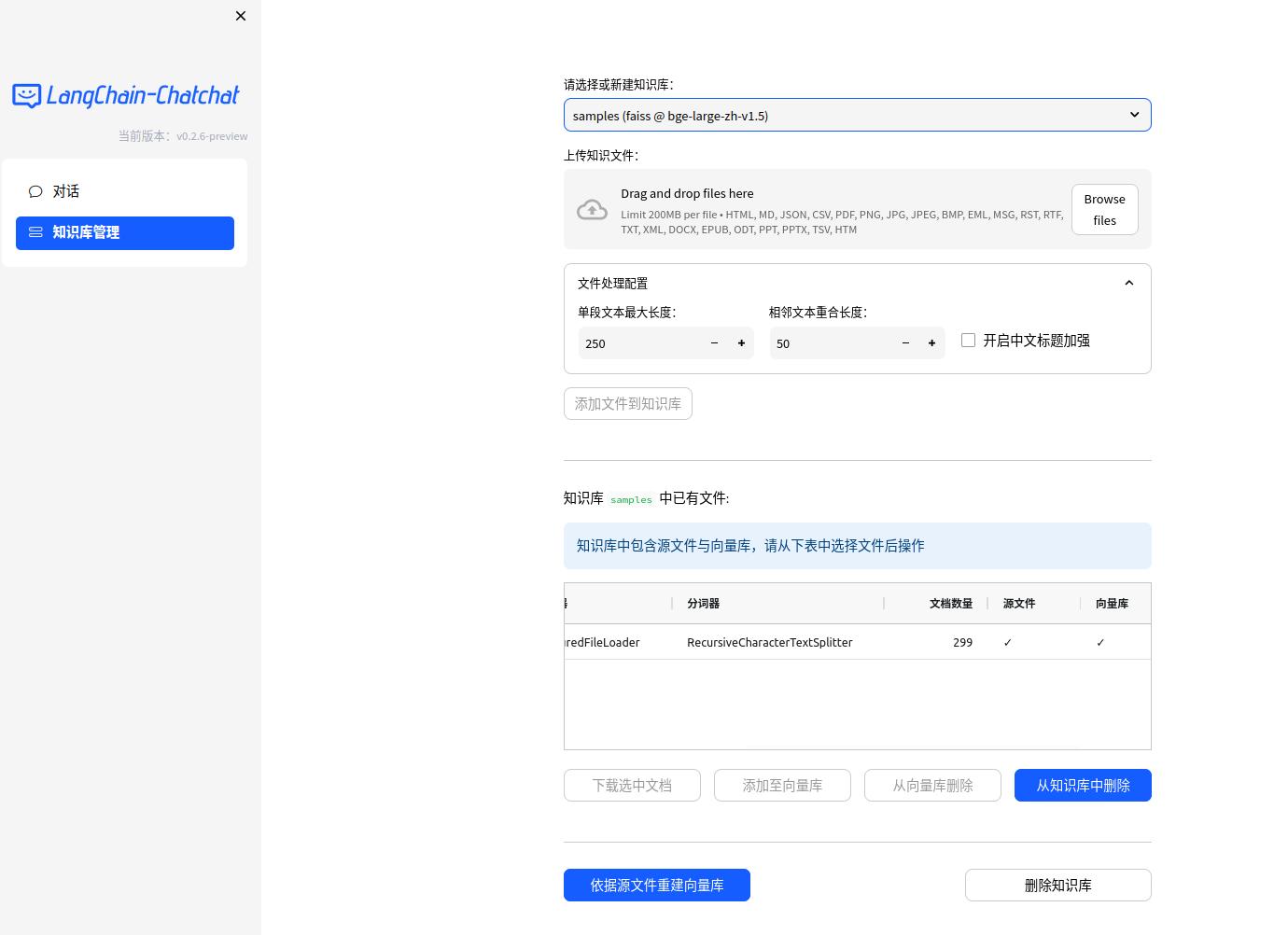
|
img/knowledge_base_success.jpg
ADDED
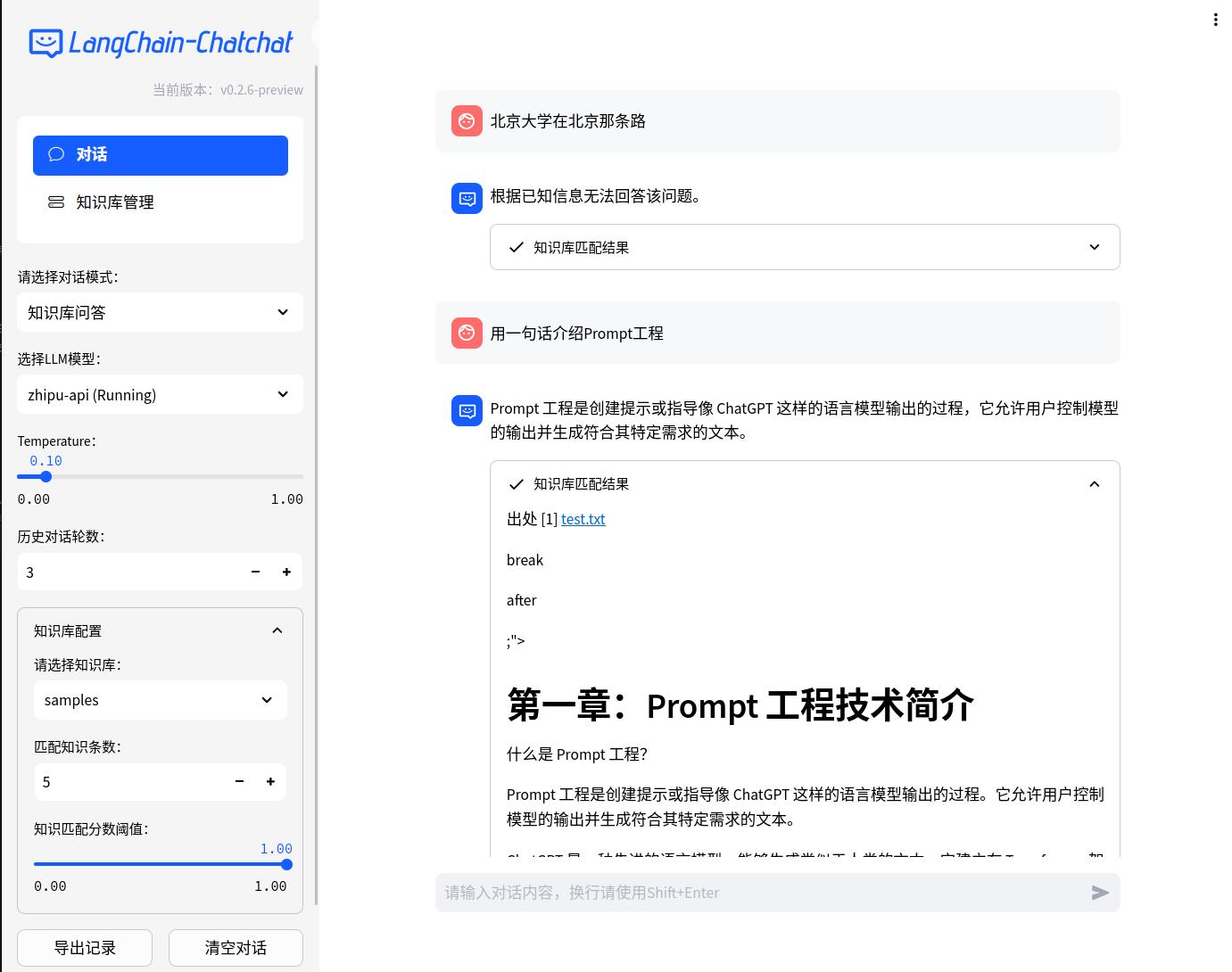
|
img/langchain+chatglm.png
ADDED

|
Git LFS Details
|
img/langchain+chatglm2.png
ADDED
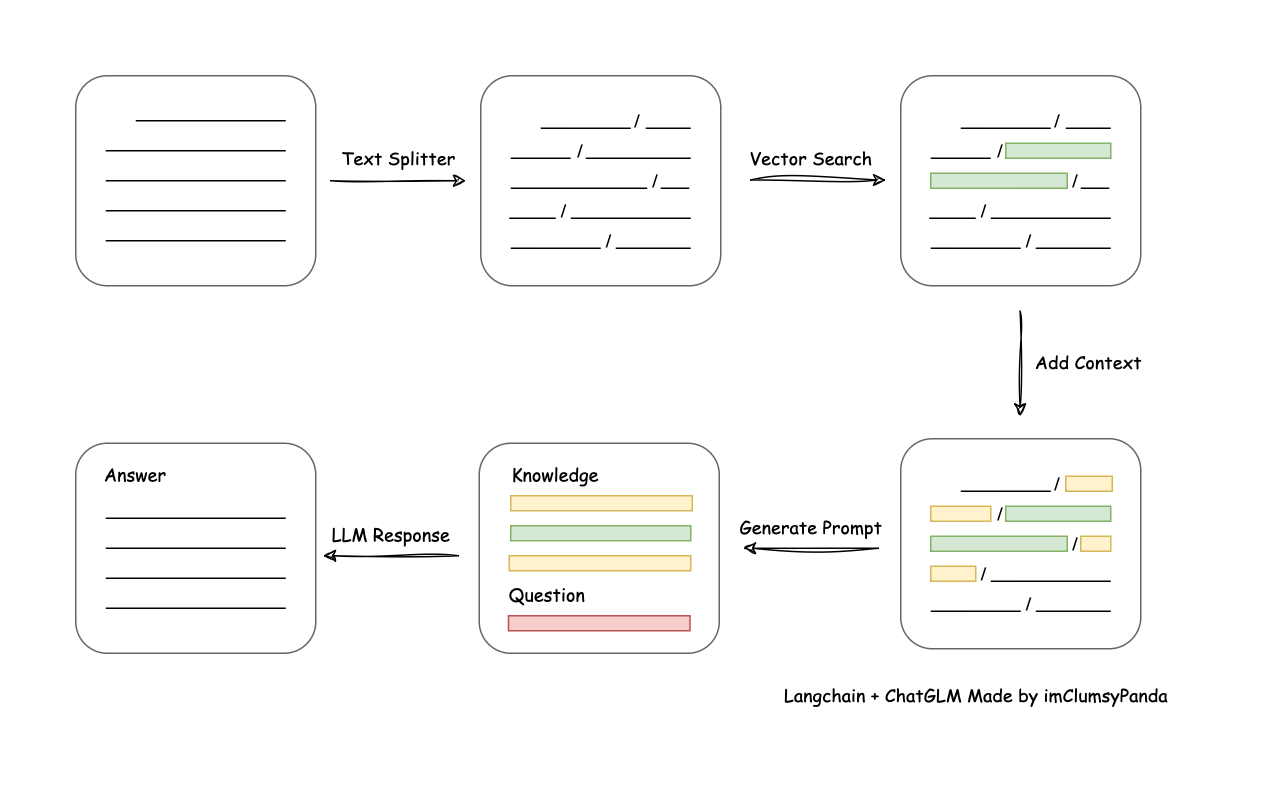
|
img/logo-long-chatchat-trans-v2.png
ADDED
|
|
img/official_account_qr.png
ADDED

|
img/official_wechat_mp_account.png
ADDED

|
Git LFS Details
|
img/partners/autodl.svg
ADDED

|
img/partners/aws.svg
ADDED

|
img/partners/chatglm.svg
ADDED

|
img/partners/zhenfund.svg
ADDED

|
img/qr_code_86.jpg
ADDED

|
img/qr_code_87.jpg
ADDED

|
img/qr_code_88.jpg
ADDED

|
knowledge_base/samples/content/llm/img//345/210/206/345/270/203/345/274/217/350/256/255/347/273/203/346/212/200/346/234/257/345/216/237/347/220/206-/345/271/225/345/270/203/345/233/276/347/211/207-124076-270516.jpg
ADDED

|
knowledge_base/samples/content/llm/img//345/210/206/345/270/203/345/274/217/350/256/255/347/273/203/346/212/200/346/234/257/345/216/237/347/220/206-/345/271/225/345/270/203/345/233/276/347/211/207-20096-279847.jpg
ADDED

|
knowledge_base/samples/content/llm/img//345/210/206/345/270/203/345/274/217/350/256/255/347/273/203/346/212/200/346/234/257/345/216/237/347/220/206-/345/271/225/345/270/203/345/233/276/347/211/207-220157-552735.jpg
ADDED

|
knowledge_base/samples/content/llm/img//345/210/206/345/270/203/345/274/217/350/256/255/347/273/203/346/212/200/346/234/257/345/216/237/347/220/206-/345/271/225/345/270/203/345/233/276/347/211/207-36114-765327.jpg
ADDED

|
knowledge_base/samples/content/llm/img/分布式训练技术原理-幕布图片-392521-261326.jpg
ADDED

|
Git LFS Details
|
knowledge_base/samples/content/llm/img//345/210/206/345/270/203/345/274/217/350/256/255/347/273/203/346/212/200/346/234/257/345/216/237/347/220/206-/345/271/225/345/270/203/345/233/276/347/211/207-42284-124759.jpg
ADDED

|
knowledge_base/samples/content/llm/img//345/210/206/345/270/203/345/274/217/350/256/255/347/273/203/346/212/200/346/234/257/345/216/237/347/220/206-/345/271/225/345/270/203/345/233/276/347/211/207-57107-679259.jpg
ADDED

|
knowledge_base/samples/content/llm/img//345/210/206/345/270/203/345/274/217/350/256/255/347/273/203/346/212/200/346/234/257/345/216/237/347/220/206-/345/271/225/345/270/203/345/233/276/347/211/207-618350-869132.jpg
ADDED

|
knowledge_base/samples/content/llm/img//345/210/206/345/270/203/345/274/217/350/256/255/347/273/203/346/212/200/346/234/257/345/216/237/347/220/206-/345/271/225/345/270/203/345/233/276/347/211/207-838373-426344.jpg
ADDED

|