Spaces:
Runtime error

Runtime error
Commit
•
c41cba9
1
Parent(s):
e3540ce
Upload folder using huggingface_hub
Browse filesThis view is limited to 50 files because it contains too many changes.
See raw diff
- .env.example +9 -0
- .gitattributes +4 -0
- .gitignore +162 -0
- CODE_OF_CONDUCT.md +9 -0
- Dockerfile +43 -0
- LICENSE +21 -0
- README.md +165 -7
- SECURITY.md +41 -0
- SUPPORT.md +25 -0
- assets/method2_xyz.png +3 -0
- assets/som_bench_bottom.jpg +0 -0
- assets/som_bench_upper.jpg +0 -0
- assets/som_gpt4v_demo.mp4 +3 -0
- assets/som_logo.png +0 -0
- assets/som_toolbox_interface.jpg +0 -0
- assets/teaser.png +3 -0
- benchmark/README.md +96 -0
- client.py +36 -0
- configs/seem_focall_unicl_lang_v1.yaml +401 -0
- configs/semantic_sam_only_sa-1b_swinL.yaml +524 -0
- demo_gpt4v_som.py +226 -0
- demo_som.py +181 -0
- deploy.py +720 -0
- deploy_requirements.txt +9 -0
- docker-build-ec2.yml.j2 +44 -0
- download_ckpt.sh +3 -0
- entrypoint.sh +10 -0
- examples/gpt-4v-som-example.jpg +0 -0
- examples/ironing_man.jpg +0 -0
- examples/ironing_man_som.png +0 -0
- examples/som_logo.png +0 -0
- gpt4v.py +69 -0
- ops/cuda-repo-ubuntu2004-11-8-local_11.8.0-520.61.05-1_amd64.deb +3 -0
- ops/functions/__init__.py +13 -0
- ops/functions/ms_deform_attn_func.py +72 -0
- ops/make.sh +35 -0
- ops/modules/__init__.py +12 -0
- ops/modules/ms_deform_attn.py +125 -0
- ops/setup.py +78 -0
- ops/src/cpu/ms_deform_attn_cpu.cpp +46 -0
- ops/src/cpu/ms_deform_attn_cpu.h +38 -0
- ops/src/cuda/ms_deform_attn_cuda.cu +158 -0
- ops/src/cuda/ms_deform_attn_cuda.h +35 -0
- ops/src/cuda/ms_deform_im2col_cuda.cuh +1332 -0
- ops/src/ms_deform_attn.h +67 -0
- ops/src/vision.cpp +21 -0
- ops/test.py +92 -0
- sam_vit_h_4b8939.pth +3 -0
- seem_focall_v1.pt +3 -0
- swinl_only_sam_many2many.pth +3 -0
.env.example
ADDED
|
@@ -0,0 +1,9 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
AWS_ACCESS_KEY_ID=
|
| 2 |
+
AWS_SECRET_ACCESS_KEY=
|
| 3 |
+
AWS_REGION=
|
| 4 |
+
GITHUB_OWNER=
|
| 5 |
+
GITHUB_REPO=
|
| 6 |
+
GITHUB_TOKEN=
|
| 7 |
+
PROJECT_NAME=
|
| 8 |
+
# optional
|
| 9 |
+
OPENAI_API_KEY=
|
.gitattributes
CHANGED
|
@@ -33,3 +33,7 @@ saved_model/**/* filter=lfs diff=lfs merge=lfs -text
|
|
| 33 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 33 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
| 36 |
+
assets/method2_xyz.png filter=lfs diff=lfs merge=lfs -text
|
| 37 |
+
assets/som_gpt4v_demo.mp4 filter=lfs diff=lfs merge=lfs -text
|
| 38 |
+
assets/teaser.png filter=lfs diff=lfs merge=lfs -text
|
| 39 |
+
ops/cuda-repo-ubuntu2004-11-8-local_11.8.0-520.61.05-1_amd64.deb filter=lfs diff=lfs merge=lfs -text
|
.gitignore
ADDED
|
@@ -0,0 +1,162 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Byte-compiled / optimized / DLL files
|
| 2 |
+
__pycache__/
|
| 3 |
+
*.py[cod]
|
| 4 |
+
*$py.class
|
| 5 |
+
|
| 6 |
+
# C extensions
|
| 7 |
+
*.so
|
| 8 |
+
|
| 9 |
+
# Distribution / packaging
|
| 10 |
+
.Python
|
| 11 |
+
build/
|
| 12 |
+
develop-eggs/
|
| 13 |
+
dist/
|
| 14 |
+
downloads/
|
| 15 |
+
eggs/
|
| 16 |
+
.eggs/
|
| 17 |
+
lib/
|
| 18 |
+
lib64/
|
| 19 |
+
parts/
|
| 20 |
+
sdist/
|
| 21 |
+
var/
|
| 22 |
+
wheels/
|
| 23 |
+
share/python-wheels/
|
| 24 |
+
*.egg-info/
|
| 25 |
+
.installed.cfg
|
| 26 |
+
*.egg
|
| 27 |
+
MANIFEST
|
| 28 |
+
|
| 29 |
+
# PyInstaller
|
| 30 |
+
# Usually these files are written by a python script from a template
|
| 31 |
+
# before PyInstaller builds the exe, so as to inject date/other infos into it.
|
| 32 |
+
*.manifest
|
| 33 |
+
*.spec
|
| 34 |
+
|
| 35 |
+
# Installer logs
|
| 36 |
+
pip-log.txt
|
| 37 |
+
pip-delete-this-directory.txt
|
| 38 |
+
|
| 39 |
+
# Unit test / coverage reports
|
| 40 |
+
htmlcov/
|
| 41 |
+
.tox/
|
| 42 |
+
.nox/
|
| 43 |
+
.coverage
|
| 44 |
+
.coverage.*
|
| 45 |
+
.cache
|
| 46 |
+
nosetests.xml
|
| 47 |
+
coverage.xml
|
| 48 |
+
*.cover
|
| 49 |
+
*.py,cover
|
| 50 |
+
.hypothesis/
|
| 51 |
+
.pytest_cache/
|
| 52 |
+
cover/
|
| 53 |
+
|
| 54 |
+
# Translations
|
| 55 |
+
*.mo
|
| 56 |
+
*.pot
|
| 57 |
+
|
| 58 |
+
# Django stuff:
|
| 59 |
+
*.log
|
| 60 |
+
local_settings.py
|
| 61 |
+
db.sqlite3
|
| 62 |
+
db.sqlite3-journal
|
| 63 |
+
|
| 64 |
+
# Flask stuff:
|
| 65 |
+
instance/
|
| 66 |
+
.webassets-cache
|
| 67 |
+
|
| 68 |
+
# Scrapy stuff:
|
| 69 |
+
.scrapy
|
| 70 |
+
|
| 71 |
+
# Sphinx documentation
|
| 72 |
+
docs/_build/
|
| 73 |
+
|
| 74 |
+
# PyBuilder
|
| 75 |
+
.pybuilder/
|
| 76 |
+
target/
|
| 77 |
+
|
| 78 |
+
# Jupyter Notebook
|
| 79 |
+
.ipynb_checkpoints
|
| 80 |
+
|
| 81 |
+
# IPython
|
| 82 |
+
profile_default/
|
| 83 |
+
ipython_config.py
|
| 84 |
+
|
| 85 |
+
# pyenv
|
| 86 |
+
# For a library or package, you might want to ignore these files since the code is
|
| 87 |
+
# intended to run in multiple environments; otherwise, check them in:
|
| 88 |
+
# .python-version
|
| 89 |
+
|
| 90 |
+
# pipenv
|
| 91 |
+
# According to pypa/pipenv#598, it is recommended to include Pipfile.lock in version control.
|
| 92 |
+
# However, in case of collaboration, if having platform-specific dependencies or dependencies
|
| 93 |
+
# having no cross-platform support, pipenv may install dependencies that don't work, or not
|
| 94 |
+
# install all needed dependencies.
|
| 95 |
+
#Pipfile.lock
|
| 96 |
+
|
| 97 |
+
# poetry
|
| 98 |
+
# Similar to Pipfile.lock, it is generally recommended to include poetry.lock in version control.
|
| 99 |
+
# This is especially recommended for binary packages to ensure reproducibility, and is more
|
| 100 |
+
# commonly ignored for libraries.
|
| 101 |
+
# https://python-poetry.org/docs/basic-usage/#commit-your-poetrylock-file-to-version-control
|
| 102 |
+
#poetry.lock
|
| 103 |
+
|
| 104 |
+
# pdm
|
| 105 |
+
# Similar to Pipfile.lock, it is generally recommended to include pdm.lock in version control.
|
| 106 |
+
#pdm.lock
|
| 107 |
+
# pdm stores project-wide configurations in .pdm.toml, but it is recommended to not include it
|
| 108 |
+
# in version control.
|
| 109 |
+
# https://pdm.fming.dev/#use-with-ide
|
| 110 |
+
.pdm.toml
|
| 111 |
+
|
| 112 |
+
# PEP 582; used by e.g. github.com/David-OConnor/pyflow and github.com/pdm-project/pdm
|
| 113 |
+
__pypackages__/
|
| 114 |
+
|
| 115 |
+
# Celery stuff
|
| 116 |
+
celerybeat-schedule
|
| 117 |
+
celerybeat.pid
|
| 118 |
+
|
| 119 |
+
# SageMath parsed files
|
| 120 |
+
*.sage.py
|
| 121 |
+
|
| 122 |
+
# Environments
|
| 123 |
+
.env
|
| 124 |
+
.venv
|
| 125 |
+
env/
|
| 126 |
+
venv/
|
| 127 |
+
ENV/
|
| 128 |
+
env.bak/
|
| 129 |
+
venv.bak/
|
| 130 |
+
|
| 131 |
+
# Spyder project settings
|
| 132 |
+
.spyderproject
|
| 133 |
+
.spyproject
|
| 134 |
+
|
| 135 |
+
# Rope project settings
|
| 136 |
+
.ropeproject
|
| 137 |
+
|
| 138 |
+
# mkdocs documentation
|
| 139 |
+
/site
|
| 140 |
+
|
| 141 |
+
# mypy
|
| 142 |
+
.mypy_cache/
|
| 143 |
+
.dmypy.json
|
| 144 |
+
dmypy.json
|
| 145 |
+
|
| 146 |
+
# Pyre type checker
|
| 147 |
+
.pyre/
|
| 148 |
+
|
| 149 |
+
# pytype static type analyzer
|
| 150 |
+
.pytype/
|
| 151 |
+
|
| 152 |
+
# Cython debug symbols
|
| 153 |
+
cython_debug/
|
| 154 |
+
|
| 155 |
+
# PyCharm
|
| 156 |
+
# JetBrains specific template is maintained in a separate JetBrains.gitignore that can
|
| 157 |
+
# be found at https://github.com/github/gitignore/blob/main/Global/JetBrains.gitignore
|
| 158 |
+
# and can be added to the global gitignore or merged into this file. For a more nuclear
|
| 159 |
+
# option (not recommended) you can uncomment the following to ignore the entire idea folder.
|
| 160 |
+
#.idea/
|
| 161 |
+
|
| 162 |
+
*.sw[m-p]
|
CODE_OF_CONDUCT.md
ADDED
|
@@ -0,0 +1,9 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Microsoft Open Source Code of Conduct
|
| 2 |
+
|
| 3 |
+
This project has adopted the [Microsoft Open Source Code of Conduct](https://opensource.microsoft.com/codeofconduct/).
|
| 4 |
+
|
| 5 |
+
Resources:
|
| 6 |
+
|
| 7 |
+
- [Microsoft Open Source Code of Conduct](https://opensource.microsoft.com/codeofconduct/)
|
| 8 |
+
- [Microsoft Code of Conduct FAQ](https://opensource.microsoft.com/codeofconduct/faq/)
|
| 9 |
+
- Contact [opencode@microsoft.com](mailto:opencode@microsoft.com) with questions or concerns
|
Dockerfile
ADDED
|
@@ -0,0 +1,43 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
FROM nvidia/cuda:12.3.1-devel-ubuntu22.04
|
| 2 |
+
|
| 3 |
+
# Install system dependencies
|
| 4 |
+
RUN apt-get update && \
|
| 5 |
+
apt-get install -y \
|
| 6 |
+
python3-pip python3-dev git ninja-build wget \
|
| 7 |
+
ffmpeg libsm6 libxext6 \
|
| 8 |
+
openmpi-bin libopenmpi-dev && \
|
| 9 |
+
ln -sf /usr/bin/python3 /usr/bin/python && \
|
| 10 |
+
ln -sf /usr/bin/pip3 /usr/bin/pip
|
| 11 |
+
|
| 12 |
+
# Set the working directory in the container
|
| 13 |
+
WORKDIR /usr/src/app
|
| 14 |
+
|
| 15 |
+
# Copy the current directory contents into the container at /usr/src/app
|
| 16 |
+
COPY . .
|
| 17 |
+
|
| 18 |
+
ENV FORCE_CUDA=1
|
| 19 |
+
|
| 20 |
+
# Upgrade pip
|
| 21 |
+
RUN python -m pip install --upgrade pip
|
| 22 |
+
|
| 23 |
+
# Install Python dependencies
|
| 24 |
+
RUN pip install torch torchvision torchaudio --extra-index-url https://download.pytorch.org/whl/cu123 \
|
| 25 |
+
&& pip install git+https://github.com/UX-Decoder/Segment-Everything-Everywhere-All-At-Once.git@33f2c898fdc8d7c95dda014a4b9ebe4e413dbb2b \
|
| 26 |
+
&& pip install git+https://github.com/facebookresearch/segment-anything.git \
|
| 27 |
+
&& pip install git+https://github.com/UX-Decoder/Semantic-SAM.git@package \
|
| 28 |
+
&& cd ops && bash make.sh && cd .. \
|
| 29 |
+
&& pip install mpi4py \
|
| 30 |
+
&& pip install openai \
|
| 31 |
+
&& pip install gradio==4.17.0
|
| 32 |
+
|
| 33 |
+
# Download pretrained models
|
| 34 |
+
RUN sh download_ckpt.sh
|
| 35 |
+
|
| 36 |
+
# Make port 6092 available to the world outside this container
|
| 37 |
+
EXPOSE 6092
|
| 38 |
+
|
| 39 |
+
# Make Gradio server accessible outside 127.0.0.1
|
| 40 |
+
ENV GRADIO_SERVER_NAME="0.0.0.0"
|
| 41 |
+
|
| 42 |
+
RUN chmod +x /usr/src/app/entrypoint.sh
|
| 43 |
+
CMD ["/usr/src/app/entrypoint.sh"]
|
LICENSE
ADDED
|
@@ -0,0 +1,21 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
MIT License
|
| 2 |
+
|
| 3 |
+
Copyright (c) Microsoft Corporation.
|
| 4 |
+
|
| 5 |
+
Permission is hereby granted, free of charge, to any person obtaining a copy
|
| 6 |
+
of this software and associated documentation files (the "Software"), to deal
|
| 7 |
+
in the Software without restriction, including without limitation the rights
|
| 8 |
+
to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
|
| 9 |
+
copies of the Software, and to permit persons to whom the Software is
|
| 10 |
+
furnished to do so, subject to the following conditions:
|
| 11 |
+
|
| 12 |
+
The above copyright notice and this permission notice shall be included in all
|
| 13 |
+
copies or substantial portions of the Software.
|
| 14 |
+
|
| 15 |
+
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
|
| 16 |
+
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
|
| 17 |
+
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
|
| 18 |
+
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
|
| 19 |
+
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
|
| 20 |
+
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
|
| 21 |
+
SOFTWARE
|
README.md
CHANGED
|
@@ -1,12 +1,170 @@
|
|
| 1 |
---
|
| 2 |
title: SoM
|
| 3 |
-
|
| 4 |
-
colorFrom: green
|
| 5 |
-
colorTo: pink
|
| 6 |
sdk: gradio
|
| 7 |
-
sdk_version: 4.
|
| 8 |
-
app_file: app.py
|
| 9 |
-
pinned: false
|
| 10 |
---
|
|
|
|
| 11 |
|
| 12 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
---
|
| 2 |
title: SoM
|
| 3 |
+
app_file: demo_som.py
|
|
|
|
|
|
|
| 4 |
sdk: gradio
|
| 5 |
+
sdk_version: 4.17.0
|
|
|
|
|
|
|
| 6 |
---
|
| 7 |
+
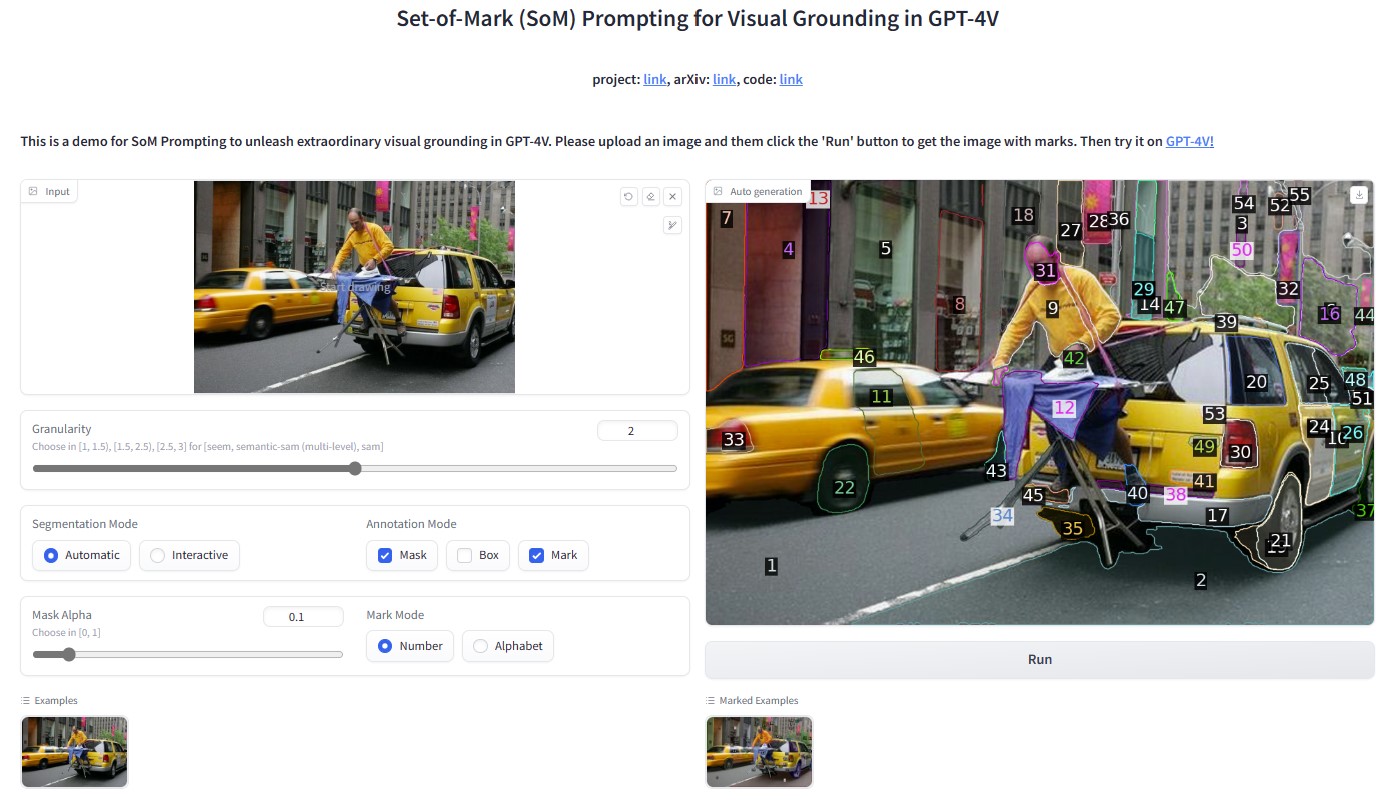
# <img src="assets/som_logo.png" alt="Logo" width="40" height="40" align="left"> Set-of-Mark Visual Prompting for GPT-4V
|
| 8 |
|
| 9 |
+
:grapes: \[[Read our arXiv Paper](https://arxiv.org/pdf/2310.11441.pdf)\] :apple: \[[Project Page](https://som-gpt4v.github.io/)\]
|
| 10 |
+
|
| 11 |
+
[Jianwei Yang](https://jwyang.github.io/)\*⚑, [Hao Zhang](https://haozhang534.github.io/)\*, [Feng Li](https://fengli-ust.github.io/)\*, [Xueyan Zou](https://maureenzou.github.io/)\*, [Chunyuan Li](https://chunyuan.li/), [Jianfeng Gao](https://www.microsoft.com/en-us/research/people/jfgao/)
|
| 12 |
+
|
| 13 |
+
\* Core Contributors ⚑ Project Lead
|
| 14 |
+
|
| 15 |
+
### Introduction
|
| 16 |
+
|
| 17 |
+
We present **S**et-**o**f-**M**ark (SoM) prompting, simply overlaying a number of spatial and speakable marks on the images, to unleash the visual grounding abilities in the strongest LMM -- GPT-4V. **Let's using visual prompting for vision**!
|
| 18 |
+
|
| 19 |
+

|
| 20 |
+
|
| 21 |
+
|
| 22 |
+
### GPT-4V + SoM Demo
|
| 23 |
+
|
| 24 |
+
https://github.com/microsoft/SoM/assets/3894247/8f827871-7ebd-4a5e-bef5-861516c4427b
|
| 25 |
+
|
| 26 |
+
### 🔥 News
|
| 27 |
+
|
| 28 |
+
* [11/21] Thanks to Roboflow and @SkalskiP, a [huggingface demo](https://huggingface.co/spaces/Roboflow/SoM) for SoM + GPT-4V is online! Try it out!
|
| 29 |
+
* [11/07] We released the vision benchmark we used to evaluate GPT-4V with SoM prompting! Check out the [benchmark page](https://github.com/microsoft/SoM/tree/main/benchmark)!
|
| 30 |
+
|
| 31 |
+
* [11/07] Now that GPT-4V API has been released, we are releasing a demo integrating SoM into GPT-4V!
|
| 32 |
+
```bash
|
| 33 |
+
export OPENAI_API_KEY=YOUR_API_KEY
|
| 34 |
+
python demo_gpt4v_som.py
|
| 35 |
+
```
|
| 36 |
+
|
| 37 |
+
* [10/23] We released the SoM toolbox code for generating set-of-mark prompts for GPT-4V. Try it out!
|
| 38 |
+
|
| 39 |
+
### 🔗 Fascinating Applications
|
| 40 |
+
|
| 41 |
+
Fascinating applications of SoM in GPT-4V:
|
| 42 |
+
* [11/13/2023] [Smartphone GUI Navigation boosted by Set-of-Mark Prompting](https://github.com/zzxslp/MM-Navigator)
|
| 43 |
+
* [11/05/2023] [Zero-shot Anomaly Detection with GPT-4V and SoM prompting](https://github.com/zhangzjn/GPT-4V-AD)
|
| 44 |
+
* [10/21/2023] [Web UI Navigation Agent inspired by Set-of-Mark Prompting](https://github.com/ddupont808/GPT-4V-Act)
|
| 45 |
+
* [10/20/2023] [Set-of-Mark Prompting Reimplementation by @SkalskiP from Roboflow](https://github.com/SkalskiP/SoM.git)
|
| 46 |
+
|
| 47 |
+
### 🔗 Related Works
|
| 48 |
+
|
| 49 |
+
Our method compiles the following models to generate the set of marks:
|
| 50 |
+
|
| 51 |
+
- [Mask DINO](https://github.com/IDEA-Research/MaskDINO): State-of-the-art closed-set image segmentation model
|
| 52 |
+
- [OpenSeeD](https://github.com/IDEA-Research/OpenSeeD): State-of-the-art open-vocabulary image segmentation model
|
| 53 |
+
- [GroundingDINO](https://github.com/IDEA-Research/GroundingDINO): State-of-the-art open-vocabulary object detection model
|
| 54 |
+
- [SEEM](https://github.com/UX-Decoder/Segment-Everything-Everywhere-All-At-Once): Versatile, promptable, interactive and semantic-aware segmentation model
|
| 55 |
+
- [Semantic-SAM](https://github.com/UX-Decoder/Semantic-SAM): Segment and recognize anything at any granularity
|
| 56 |
+
- [Segment Anything](https://github.com/facebookresearch/segment-anything): Segment anything
|
| 57 |
+
|
| 58 |
+
We are standing on the shoulder of the giant GPT-4V ([playground](https://chat.openai.com/))!
|
| 59 |
+
|
| 60 |
+
### :rocket: Quick Start
|
| 61 |
+
|
| 62 |
+
* Install segmentation packages
|
| 63 |
+
|
| 64 |
+
```bash
|
| 65 |
+
# install SEEM
|
| 66 |
+
pip install git+https://github.com/UX-Decoder/Segment-Everything-Everywhere-All-At-Once.git@package
|
| 67 |
+
# install SAM
|
| 68 |
+
pip install git+https://github.com/facebookresearch/segment-anything.git
|
| 69 |
+
# install Semantic-SAM
|
| 70 |
+
pip install git+https://github.com/UX-Decoder/Semantic-SAM.git@package
|
| 71 |
+
# install Deformable Convolution for Semantic-SAM
|
| 72 |
+
cd ops && sh make.sh && cd ..
|
| 73 |
+
|
| 74 |
+
# common error fix:
|
| 75 |
+
python -m pip install 'git+https://github.com/MaureenZOU/detectron2-xyz.git'
|
| 76 |
+
```
|
| 77 |
+
|
| 78 |
+
* Download the pretrained models
|
| 79 |
+
|
| 80 |
+
```bash
|
| 81 |
+
sh download_ckpt.sh
|
| 82 |
+
```
|
| 83 |
+
|
| 84 |
+
* Run the demo
|
| 85 |
+
|
| 86 |
+
```bash
|
| 87 |
+
python demo_som.py
|
| 88 |
+
```
|
| 89 |
+
|
| 90 |
+
And you will see this interface:
|
| 91 |
+
|
| 92 |
+

|
| 93 |
+
|
| 94 |
+
## Deploy to AWS
|
| 95 |
+
|
| 96 |
+
To deploy SoM to EC2 on AWS via Github Actions:
|
| 97 |
+
|
| 98 |
+
1. Fork this repository and clone your fork to your local machine.
|
| 99 |
+
2. Follow the instructions at the top of `deploy.py`.
|
| 100 |
+
|
| 101 |
+
### :point_right: Comparing standard GPT-4V and its combination with SoM Prompting
|
| 102 |
+

|
| 103 |
+
|
| 104 |
+
### :round_pushpin: SoM Toolbox for image partition
|
| 105 |
+

|
| 106 |
+
Users can select which granularity of masks to generate, and which mode to use between automatic (top) and interactive (bottom). A higher alpha blending value (0.4) is used for better visualization.
|
| 107 |
+
### :unicorn: Interleaved Prompt
|
| 108 |
+
SoM enables interleaved prompts which include textual and visual content. The visual content can be represented using the region indices.
|
| 109 |
+
<img width="975" alt="Screenshot 2023-10-18 at 10 06 18" src="https://github.com/microsoft/SoM/assets/34880758/859edfda-ab04-450c-bd28-93762460ac1d">
|
| 110 |
+
|
| 111 |
+
### :medal_military: Mark types used in SoM
|
| 112 |
+

|
| 113 |
+
### :volcano: Evaluation tasks examples
|
| 114 |
+
<img width="946" alt="Screenshot 2023-10-18 at 10 12 18" src="https://github.com/microsoft/SoM/assets/34880758/f5e0c0b0-58de-4b60-bf01-4906dbcb229e">
|
| 115 |
+
|
| 116 |
+
## Use case
|
| 117 |
+
### :tulip: Grounded Reasoning and Cross-Image Reference
|
| 118 |
+
|
| 119 |
+
<img width="972" alt="Screenshot 2023-10-18 at 10 10 41" src="https://github.com/microsoft/SoM/assets/34880758/033cd16c-876c-4c03-961e-590a4189bc9e">
|
| 120 |
+
|
| 121 |
+
In comparison to GPT-4V without SoM, adding marks enables GPT-4V to ground the
|
| 122 |
+
reasoning on detailed contents of the image (Left). Clear object cross-image references are observed
|
| 123 |
+
on the right.
|
| 124 |
+
17
|
| 125 |
+
### :camping: Problem Solving
|
| 126 |
+
<img width="972" alt="Screenshot 2023-10-18 at 10 18 03" src="https://github.com/microsoft/SoM/assets/34880758/8b112126-d164-47d7-b18c-b4b51b903d57">
|
| 127 |
+
|
| 128 |
+
Case study on solving CAPTCHA. GPT-4V gives the wrong answer with a wrong number
|
| 129 |
+
of squares while finding the correct squares with corresponding marks after SoM prompting.
|
| 130 |
+
### :mountain_snow: Knowledge Sharing
|
| 131 |
+
<img width="733" alt="Screenshot 2023-10-18 at 10 18 44" src="https://github.com/microsoft/SoM/assets/34880758/dc753c3f-ada8-47a4-83f1-1576bcfb146a">
|
| 132 |
+
|
| 133 |
+
Case study on an image of dish for GPT-4V. GPT-4V does not produce a grounded answer
|
| 134 |
+
with the original image. Based on SoM prompting, GPT-4V not only speaks out the ingredients but
|
| 135 |
+
also corresponds them to the regions.
|
| 136 |
+
### :mosque: Personalized Suggestion
|
| 137 |
+
<img width="733" alt="Screenshot 2023-10-18 at 10 19 12" src="https://github.com/microsoft/SoM/assets/34880758/88188c90-84f2-49c6-812e-44770b0c2ca5">
|
| 138 |
+
|
| 139 |
+
SoM-pormpted GPT-4V gives very precise suggestions while the original one fails, even
|
| 140 |
+
with hallucinated foods, e.g., soft drinks
|
| 141 |
+
### :blossom: Tool Usage Instruction
|
| 142 |
+
<img width="734" alt="Screenshot 2023-10-18 at 10 19 39" src="https://github.com/microsoft/SoM/assets/34880758/9b35b143-96af-41bd-ad83-9c1f1e0f322f">
|
| 143 |
+
Likewise, GPT4-V with SoM can help to provide thorough tool usage instruction
|
| 144 |
+
, teaching
|
| 145 |
+
users the function of each button on a controller. Note that this image is not fully labeled, while
|
| 146 |
+
GPT-4V can also provide information about the non-labeled buttons.
|
| 147 |
+
|
| 148 |
+
### :sunflower: 2D Game Planning
|
| 149 |
+
<img width="730" alt="Screenshot 2023-10-18 at 10 20 03" src="https://github.com/microsoft/SoM/assets/34880758/0bc86109-5512-4dee-aac9-bab0ef96ed4c">
|
| 150 |
+
|
| 151 |
+
GPT-4V with SoM gives a reasonable suggestion on how to achieve a goal in a gaming
|
| 152 |
+
scenario.
|
| 153 |
+
### :mosque: Simulated Navigation
|
| 154 |
+
<img width="729" alt="Screenshot 2023-10-18 at 10 21 24" src="https://github.com/microsoft/SoM/assets/34880758/7f139250-5350-4790-a35c-444ec2ec883b">
|
| 155 |
+
|
| 156 |
+
### :deciduous_tree: Results
|
| 157 |
+
We conduct experiments on various vision tasks to verify the effectiveness of our SoM. Results show that GPT4V+SoM outperforms specialists on most vision tasks and is comparable to MaskDINO on COCO panoptic segmentation.
|
| 158 |
+

|
| 159 |
+
|
| 160 |
+
## :black_nib: Citation
|
| 161 |
+
|
| 162 |
+
If you find our work helpful for your research, please consider citing the following BibTeX entry.
|
| 163 |
+
```bibtex
|
| 164 |
+
@article{yang2023setofmark,
|
| 165 |
+
title={Set-of-Mark Prompting Unleashes Extraordinary Visual Grounding in GPT-4V},
|
| 166 |
+
author={Jianwei Yang and Hao Zhang and Feng Li and Xueyan Zou and Chunyuan Li and Jianfeng Gao},
|
| 167 |
+
journal={arXiv preprint arXiv:2310.11441},
|
| 168 |
+
year={2023},
|
| 169 |
+
}
|
| 170 |
+
```
|
SECURITY.md
ADDED
|
@@ -0,0 +1,41 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
<!-- BEGIN MICROSOFT SECURITY.MD V0.0.9 BLOCK -->
|
| 2 |
+
|
| 3 |
+
## Security
|
| 4 |
+
|
| 5 |
+
Microsoft takes the security of our software products and services seriously, which includes all source code repositories managed through our GitHub organizations, which include [Microsoft](https://github.com/Microsoft), [Azure](https://github.com/Azure), [DotNet](https://github.com/dotnet), [AspNet](https://github.com/aspnet) and [Xamarin](https://github.com/xamarin).
|
| 6 |
+
|
| 7 |
+
If you believe you have found a security vulnerability in any Microsoft-owned repository that meets [Microsoft's definition of a security vulnerability](https://aka.ms/security.md/definition), please report it to us as described below.
|
| 8 |
+
|
| 9 |
+
## Reporting Security Issues
|
| 10 |
+
|
| 11 |
+
**Please do not report security vulnerabilities through public GitHub issues.**
|
| 12 |
+
|
| 13 |
+
Instead, please report them to the Microsoft Security Response Center (MSRC) at [https://msrc.microsoft.com/create-report](https://aka.ms/security.md/msrc/create-report).
|
| 14 |
+
|
| 15 |
+
If you prefer to submit without logging in, send email to [secure@microsoft.com](mailto:secure@microsoft.com). If possible, encrypt your message with our PGP key; please download it from the [Microsoft Security Response Center PGP Key page](https://aka.ms/security.md/msrc/pgp).
|
| 16 |
+
|
| 17 |
+
You should receive a response within 24 hours. If for some reason you do not, please follow up via email to ensure we received your original message. Additional information can be found at [microsoft.com/msrc](https://www.microsoft.com/msrc).
|
| 18 |
+
|
| 19 |
+
Please include the requested information listed below (as much as you can provide) to help us better understand the nature and scope of the possible issue:
|
| 20 |
+
|
| 21 |
+
* Type of issue (e.g. buffer overflow, SQL injection, cross-site scripting, etc.)
|
| 22 |
+
* Full paths of source file(s) related to the manifestation of the issue
|
| 23 |
+
* The location of the affected source code (tag/branch/commit or direct URL)
|
| 24 |
+
* Any special configuration required to reproduce the issue
|
| 25 |
+
* Step-by-step instructions to reproduce the issue
|
| 26 |
+
* Proof-of-concept or exploit code (if possible)
|
| 27 |
+
* Impact of the issue, including how an attacker might exploit the issue
|
| 28 |
+
|
| 29 |
+
This information will help us triage your report more quickly.
|
| 30 |
+
|
| 31 |
+
If you are reporting for a bug bounty, more complete reports can contribute to a higher bounty award. Please visit our [Microsoft Bug Bounty Program](https://aka.ms/security.md/msrc/bounty) page for more details about our active programs.
|
| 32 |
+
|
| 33 |
+
## Preferred Languages
|
| 34 |
+
|
| 35 |
+
We prefer all communications to be in English.
|
| 36 |
+
|
| 37 |
+
## Policy
|
| 38 |
+
|
| 39 |
+
Microsoft follows the principle of [Coordinated Vulnerability Disclosure](https://aka.ms/security.md/cvd).
|
| 40 |
+
|
| 41 |
+
<!-- END MICROSOFT SECURITY.MD BLOCK -->
|
SUPPORT.md
ADDED
|
@@ -0,0 +1,25 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# TODO: The maintainer of this repo has not yet edited this file
|
| 2 |
+
|
| 3 |
+
**REPO OWNER**: Do you want Customer Service & Support (CSS) support for this product/project?
|
| 4 |
+
|
| 5 |
+
- **No CSS support:** Fill out this template with information about how to file issues and get help.
|
| 6 |
+
- **Yes CSS support:** Fill out an intake form at [aka.ms/onboardsupport](https://aka.ms/onboardsupport). CSS will work with/help you to determine next steps.
|
| 7 |
+
- **Not sure?** Fill out an intake as though the answer were "Yes". CSS will help you decide.
|
| 8 |
+
|
| 9 |
+
*Then remove this first heading from this SUPPORT.MD file before publishing your repo.*
|
| 10 |
+
|
| 11 |
+
# Support
|
| 12 |
+
|
| 13 |
+
## How to file issues and get help
|
| 14 |
+
|
| 15 |
+
This project uses GitHub Issues to track bugs and feature requests. Please search the existing
|
| 16 |
+
issues before filing new issues to avoid duplicates. For new issues, file your bug or
|
| 17 |
+
feature request as a new Issue.
|
| 18 |
+
|
| 19 |
+
For help and questions about using this project, please **REPO MAINTAINER: INSERT INSTRUCTIONS HERE
|
| 20 |
+
FOR HOW TO ENGAGE REPO OWNERS OR COMMUNITY FOR HELP. COULD BE A STACK OVERFLOW TAG OR OTHER
|
| 21 |
+
CHANNEL. WHERE WILL YOU HELP PEOPLE?**.
|
| 22 |
+
|
| 23 |
+
## Microsoft Support Policy
|
| 24 |
+
|
| 25 |
+
Support for this **PROJECT or PRODUCT** is limited to the resources listed above.
|
assets/method2_xyz.png
ADDED

|
Git LFS Details
|
assets/som_bench_bottom.jpg
ADDED

|
assets/som_bench_upper.jpg
ADDED

|
assets/som_gpt4v_demo.mp4
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:c6a8f8b077dcbe8f7b693b51045a0ded80a1681565c793c2dba3c90d3836b5c4
|
| 3 |
+
size 50609514
|
assets/som_logo.png
ADDED
|
|
assets/som_toolbox_interface.jpg
ADDED
|
assets/teaser.png
ADDED

|
Git LFS Details
|
benchmark/README.md
ADDED
|
@@ -0,0 +1,96 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# SoM-Bench: Evaluating Visual Grounding with Visual Prompting
|
| 2 |
+
|
| 3 |
+
We build a new benchmark called SoM-Bench to evaluate the visual grounding capability of LLMs with visual prompting.
|
| 4 |
+
|
| 5 |
+
## Dataset
|
| 6 |
+
|
| 7 |
+
| Vision Taks | Source | #Images | #Instances | Marks | Metric | Data
|
| 8 |
+
| -------- | -------- | -------- | -------- | -------- | -------- | -------- |
|
| 9 |
+
| Open-Vocab Segmentation | [COCO](https://cocodataset.org/#home) | 100 | 567 | Numeric IDs and Masks | Precision | [Download](https://github.com/microsoft/SoM/releases/download/v1.0/coco_ovseg.zip)
|
| 10 |
+
| Open-Vocab Segmentation | [ADE20K](https://groups.csail.mit.edu/vision/datasets/ADE20K/) | 100 | 488 | Numeric IDs and Masks | Precision | [Download](https://github.com/microsoft/SoM/releases/download/v1.0/ade20k_ovseg.zip)
|
| 11 |
+
| Phrase Grounding | [Flickr30K](https://shannon.cs.illinois.edu/DenotationGraph/) | 100 | 274 | Numeric IDs and Masks and Boxes | Recall @ 1 | [Download](https://github.com/microsoft/SoM/releases/download/v1.0/flickr30k_grounding.zip)
|
| 12 |
+
| Referring Comprehension | [RefCOCO](https://github.com/lichengunc/refer) | 100 | 177 | Numeric IDs and Masks | ACC @ 0.5 | [Download](https://github.com/microsoft/SoM/releases/download/v1.0/refcocog_refseg.zip)
|
| 13 |
+
| Referring Segmentation | [RefCOCO](https://github.com/lichengunc/refer) | 100 | 177 | Numeric IDs and Masks | mIoU | [Download](https://github.com/microsoft/SoM/releases/download/v1.0/refcocog_refseg.zip)
|
| 14 |
+
|
| 15 |
+
## Dataset Structure
|
| 16 |
+
|
| 17 |
+
### Open-Vocab Segmentation on COCO
|
| 18 |
+
|
| 19 |
+
We provide COCO in the following structure:
|
| 20 |
+
|
| 21 |
+
```
|
| 22 |
+
coco_ovseg
|
| 23 |
+
├── som_images
|
| 24 |
+
├── 000000000285_0.jpg
|
| 25 |
+
├── 000000000872_0.jpg
|
| 26 |
+
|── 000000000872_5.jpg
|
| 27 |
+
├── ...
|
| 28 |
+
├── 000000002153_5.jpg
|
| 29 |
+
└── 000000002261_0.jpg
|
| 30 |
+
```
|
| 31 |
+
|
| 32 |
+
For some of the samples, the regions are very dense, so we split the regions into multiple groups of size 5,. For example, `000000000872_0.jpg` has 5 regions, and `000000000872_5.jpg` has the other 5 regions. Note that you can use the image_id to track the original image.
|
| 33 |
+
|
| 34 |
+
We used the following language prompt for the task:
|
| 35 |
+
```
|
| 36 |
+
I have labeled a bright numeric ID at the center for each visual object in the image. Please enumerate their names. You must answer by selecting from the following names: [COCO Vocabulary]
|
| 37 |
+
```
|
| 38 |
+
|
| 39 |
+
### Open-Vocab Segmentation on ADE20K
|
| 40 |
+
|
| 41 |
+
```
|
| 42 |
+
ade20k_ovseg
|
| 43 |
+
├── som_images
|
| 44 |
+
├── ADE_val_00000001_0.jpg
|
| 45 |
+
├── ADE_val_00000001_5.jpg
|
| 46 |
+
|── ADE_val_00000011_5.jpg
|
| 47 |
+
├── ...
|
| 48 |
+
├── ADE_val_00000039_5.jpg
|
| 49 |
+
└── ADE_val_00000040_0.jpg
|
| 50 |
+
```
|
| 51 |
+
Similar to COCO, the regions in ADE20K are also very dense, so we split the regions into multiple groups of size 5,. For example, `ADE_val_00000001_0.jpg` has 5 regions, and `ADE_val_00000001_5.jpg` has the other 5 regions. Note that you can use the image_id to track the original image.
|
| 52 |
+
|
| 53 |
+
We used the following language prompt for the task:
|
| 54 |
+
```
|
| 55 |
+
I have labeled a bright numeric ID at the center for each visual object in the image. Please enumerate their names. You must answer by selecting from the following names: [ADE20K Vocabulary]
|
| 56 |
+
```
|
| 57 |
+
|
| 58 |
+
### Phrase Grounding on Flickr30K
|
| 59 |
+
|
| 60 |
+
```
|
| 61 |
+
flickr30k_grounding
|
| 62 |
+
├── som_images
|
| 63 |
+
├── 14868339.jpg
|
| 64 |
+
├── 14868339_wbox.jpg
|
| 65 |
+
|── 14868339.json
|
| 66 |
+
├── ...
|
| 67 |
+
├── 302740416.jpg
|
| 68 |
+
|── 319185571_wbox.jpg
|
| 69 |
+
└── 302740416.json
|
| 70 |
+
```
|
| 71 |
+
|
| 72 |
+
For Flickr30K, we provide the image with numeric IDs and masks, and also the image with additional bounding boxes. The json file containing the ground truth bounding boxes and the corresponding phrases. Note that the bounding boxes are in the format of [x1, y1, x2, y2].
|
| 73 |
+
|
| 74 |
+
We used the following language prompt for the task:
|
| 75 |
+
```
|
| 76 |
+
I have labeled a bright numeric ID at the center for each visual object in the image. Given the image showing a man in glasses holding a piece of paper, find the corresponding regions for a man in glasses, a piece of paper.
|
| 77 |
+
```
|
| 78 |
+
|
| 79 |
+
### Referring Expression Comprehension and Segmentation on RefCOCOg
|
| 80 |
+
|
| 81 |
+
```
|
| 82 |
+
refcocog_refseg
|
| 83 |
+
├── som_images
|
| 84 |
+
├── 000000000795.jpg
|
| 85 |
+
|── 000000000795.json
|
| 86 |
+
├── ...
|
| 87 |
+
|── 000000007852.jpg
|
| 88 |
+
└── 000000007852.json
|
| 89 |
+
```
|
| 90 |
+
|
| 91 |
+
For RefCOCOg, we provide the image with numeric IDs and masks, and also the json file containing the referring expressions and the corresponding referring ids.
|
| 92 |
+
|
| 93 |
+
We used the following language prompt for the task:
|
| 94 |
+
```
|
| 95 |
+
I have labeled a bright numeric ID at the center for each visual object in the image. Please tell me the IDs for: The laptop behind the beer bottle; Laptop turned on.
|
| 96 |
+
```
|
client.py
ADDED
|
@@ -0,0 +1,36 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""
|
| 2 |
+
This module provides a command-line interface to interact with the SoM server.
|
| 3 |
+
|
| 4 |
+
The server URL is printed during deployment via `python deploy.py run`.
|
| 5 |
+
|
| 6 |
+
Usage:
|
| 7 |
+
python client.py "http://<server_ip>:6092"
|
| 8 |
+
"""
|
| 9 |
+
|
| 10 |
+
import fire
|
| 11 |
+
from gradio_client import Client
|
| 12 |
+
from loguru import logger
|
| 13 |
+
|
| 14 |
+
def predict(server_url: str):
|
| 15 |
+
"""
|
| 16 |
+
Makes a prediction using the Gradio client with the provided IP address.
|
| 17 |
+
|
| 18 |
+
Args:
|
| 19 |
+
server_url (str): The URL of the SoM Gradio server.
|
| 20 |
+
"""
|
| 21 |
+
client = Client(server_url)
|
| 22 |
+
result = client.predict(
|
| 23 |
+
{
|
| 24 |
+
"background": "https://raw.githubusercontent.com/gradio-app/gradio/main/test/test_files/bus.png",
|
| 25 |
+
}, # filepath in 'parameter_1' Image component
|
| 26 |
+
2.5, # float (numeric value between 1 and 3) in 'Granularity' Slider component
|
| 27 |
+
"Automatic", # Literal['Automatic', 'Interactive'] in 'Segmentation Mode' Radio component
|
| 28 |
+
0.5, # float (numeric value between 0 and 1) in 'Mask Alpha' Slider component
|
| 29 |
+
"Number", # Literal['Number', 'Alphabet'] in 'Mark Mode' Radio component
|
| 30 |
+
["Mark"], # List[Literal['Mask', 'Box', 'Mark']] in 'Annotation Mode' Checkboxgroup component
|
| 31 |
+
api_name="/inference"
|
| 32 |
+
)
|
| 33 |
+
logger.info(result)
|
| 34 |
+
|
| 35 |
+
if __name__ == "__main__":
|
| 36 |
+
fire.Fire(predict)
|
configs/seem_focall_unicl_lang_v1.yaml
ADDED
|
@@ -0,0 +1,401 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# --------------------------------------------------------
|
| 2 |
+
# X-Decoder -- Generalized Decoding for Pixel, Image, and Language
|
| 3 |
+
# Copyright (c) 2022 Microsoft
|
| 4 |
+
# Licensed under The MIT License [see LICENSE for details]
|
| 5 |
+
# Written by Xueyan Zou (xueyan@cs.wisc.edu)
|
| 6 |
+
# --------------------------------------------------------
|
| 7 |
+
|
| 8 |
+
# Define Test/Trainer/Saving
|
| 9 |
+
PIPELINE: XDecoderPipeline
|
| 10 |
+
TRAINER: xdecoder
|
| 11 |
+
SAVE_DIR: '../../data/output/test'
|
| 12 |
+
base_path: "./"
|
| 13 |
+
|
| 14 |
+
# Resume Logistic
|
| 15 |
+
RESUME: false
|
| 16 |
+
WEIGHT: false
|
| 17 |
+
RESUME_FROM: ''
|
| 18 |
+
EVAL_AT_START: False
|
| 19 |
+
|
| 20 |
+
# Logging and Debug
|
| 21 |
+
WANDB: False
|
| 22 |
+
LOG_EVERY: 100
|
| 23 |
+
FIND_UNUSED_PARAMETERS: false
|
| 24 |
+
|
| 25 |
+
# Speed up training
|
| 26 |
+
FP16: false
|
| 27 |
+
PORT: '36873'
|
| 28 |
+
|
| 29 |
+
# misc
|
| 30 |
+
LOADER:
|
| 31 |
+
JOINT: False
|
| 32 |
+
KEY_DATASET: 'coco'
|
| 33 |
+
|
| 34 |
+
##################
|
| 35 |
+
# Task settings
|
| 36 |
+
##################
|
| 37 |
+
VERBOSE: true
|
| 38 |
+
MODEL:
|
| 39 |
+
NAME: seem_model_v1
|
| 40 |
+
HEAD: xdecoder_head
|
| 41 |
+
MASK_ON: false
|
| 42 |
+
KEYPOINT_ON: false
|
| 43 |
+
LOAD_PROPOSALS: false
|
| 44 |
+
DIM_PROJ: 512
|
| 45 |
+
TEXT:
|
| 46 |
+
ARCH: vlpencoder
|
| 47 |
+
NAME: transformer
|
| 48 |
+
TOKENIZER: clip
|
| 49 |
+
CONTEXT_LENGTH: 77 # 77
|
| 50 |
+
WIDTH: 512
|
| 51 |
+
HEADS: 8
|
| 52 |
+
LAYERS: 12 # 6
|
| 53 |
+
AUTOGRESSIVE: True
|
| 54 |
+
BACKBONE:
|
| 55 |
+
NAME: focal
|
| 56 |
+
PRETRAINED: ''
|
| 57 |
+
LOAD_PRETRAINED: false
|
| 58 |
+
FOCAL:
|
| 59 |
+
PRETRAIN_IMG_SIZE: 224
|
| 60 |
+
PATCH_SIZE: 4
|
| 61 |
+
EMBED_DIM: 192
|
| 62 |
+
DEPTHS: [2, 2, 18, 2]
|
| 63 |
+
FOCAL_LEVELS: [4, 4, 4, 4]
|
| 64 |
+
FOCAL_WINDOWS: [3, 3, 3, 3]
|
| 65 |
+
DROP_PATH_RATE: 0.3
|
| 66 |
+
MLP_RATIO: 4.0
|
| 67 |
+
DROP_RATE: 0.0
|
| 68 |
+
PATCH_NORM: True
|
| 69 |
+
USE_CONV_EMBED: True
|
| 70 |
+
SCALING_MODULATOR: True
|
| 71 |
+
USE_CHECKPOINT: False
|
| 72 |
+
USE_POSTLN: true
|
| 73 |
+
USE_POSTLN_IN_MODULATION: false
|
| 74 |
+
USE_LAYERSCALE: True
|
| 75 |
+
OUT_FEATURES: ["res2", "res3", "res4", "res5"]
|
| 76 |
+
OUT_INDICES: [0, 1, 2, 3]
|
| 77 |
+
ENCODER:
|
| 78 |
+
NAME: transformer_encoder_fpn
|
| 79 |
+
IGNORE_VALUE: 255
|
| 80 |
+
NUM_CLASSES: 133
|
| 81 |
+
LOSS_WEIGHT: 1.0
|
| 82 |
+
CONVS_DIM: 512
|
| 83 |
+
MASK_DIM: 512
|
| 84 |
+
NORM: "GN"
|
| 85 |
+
IN_FEATURES: ["res2", "res3", "res4", "res5"]
|
| 86 |
+
DEFORMABLE_TRANSFORMER_ENCODER_IN_FEATURES: ["res3", "res4", "res5"]
|
| 87 |
+
COMMON_STRIDE: 4
|
| 88 |
+
TRANSFORMER_ENC_LAYERS: 6
|
| 89 |
+
DECODER:
|
| 90 |
+
NAME: seem_v1
|
| 91 |
+
TRANSFORMER_IN_FEATURE: "multi_scale_pixel_decoder"
|
| 92 |
+
MASK:
|
| 93 |
+
ENABLED: True
|
| 94 |
+
DETECTION: False
|
| 95 |
+
SPATIAL:
|
| 96 |
+
ENABLED: True
|
| 97 |
+
MAX_ITER: 1
|
| 98 |
+
GROUNDING:
|
| 99 |
+
ENABLED: True
|
| 100 |
+
MAX_LEN: 5
|
| 101 |
+
TEXT_WEIGHT: 2.0
|
| 102 |
+
CLASS_WEIGHT: 0.5
|
| 103 |
+
RETRIEVAL:
|
| 104 |
+
ENABLED: False
|
| 105 |
+
LVIS:
|
| 106 |
+
ENABLED: True
|
| 107 |
+
THRES: 0.7
|
| 108 |
+
OPENIMAGE:
|
| 109 |
+
ENABLED: False
|
| 110 |
+
NEGATIVE_SAMPLES: 5
|
| 111 |
+
GROUNDING:
|
| 112 |
+
ENABLED: False
|
| 113 |
+
MAX_LEN: 5
|
| 114 |
+
CAPTION:
|
| 115 |
+
ENABLED: False
|
| 116 |
+
PHRASE_PROB: 0.5
|
| 117 |
+
SIM_THRES: 0.95
|
| 118 |
+
DEEP_SUPERVISION: True
|
| 119 |
+
NO_OBJECT_WEIGHT: 0.1
|
| 120 |
+
GCLASS_WEIGHT: 0.4
|
| 121 |
+
GMASK_WEIGHT: 1.0
|
| 122 |
+
GDICE_WEIGHT: 1.0
|
| 123 |
+
SCLASS_WEIGHT: 0.4
|
| 124 |
+
SMASK_WEIGHT: 1.0
|
| 125 |
+
SDICE_WEIGHT: 1.0
|
| 126 |
+
OCLASS_WEIGHT: 0.4
|
| 127 |
+
OMASK_WEIGHT: 1.0
|
| 128 |
+
ODICE_WEIGHT: 1.0
|
| 129 |
+
CLASS_WEIGHT: 2.0
|
| 130 |
+
MASK_WEIGHT: 5.0
|
| 131 |
+
DICE_WEIGHT: 5.0
|
| 132 |
+
BBOX_WEIGHT: 5.0
|
| 133 |
+
GIOU_WEIGHT: 2.0
|
| 134 |
+
CAPTION_WEIGHT: 2.0
|
| 135 |
+
COST_SPATIAL:
|
| 136 |
+
CLASS_WEIGHT: 5.0
|
| 137 |
+
MASK_WEIGHT: 2.0
|
| 138 |
+
DICE_WEIGHT: 2.0
|
| 139 |
+
HIDDEN_DIM: 512
|
| 140 |
+
NUM_OBJECT_QUERIES: 101
|
| 141 |
+
NHEADS: 8
|
| 142 |
+
DROPOUT: 0.0
|
| 143 |
+
DIM_FEEDFORWARD: 2048
|
| 144 |
+
MAX_SPATIAL_LEN: [512, 512, 512, 512]
|
| 145 |
+
# ENC_LAYERS: 0
|
| 146 |
+
PRE_NORM: False
|
| 147 |
+
ENFORCE_INPUT_PROJ: False
|
| 148 |
+
SIZE_DIVISIBILITY: 32
|
| 149 |
+
TRAIN_NUM_POINTS: 12544
|
| 150 |
+
OVERSAMPLE_RATIO: 3.0
|
| 151 |
+
IMPORTANCE_SAMPLE_RATIO: 0.75
|
| 152 |
+
DEC_LAYERS: 10 # 9 decoder layers, add one for the loss on learnable query
|
| 153 |
+
TOP_GROUNDING_LAYERS: 10
|
| 154 |
+
TOP_CAPTION_LAYERS: 10
|
| 155 |
+
TOP_SPATIAL_LAYERS: 10
|
| 156 |
+
TOP_OPENIMAGE_LAYERS: 10
|
| 157 |
+
TEST:
|
| 158 |
+
SEMANTIC_ON: True
|
| 159 |
+
INSTANCE_ON: True
|
| 160 |
+
PANOPTIC_ON: True
|
| 161 |
+
OVERLAP_THRESHOLD: 0.8
|
| 162 |
+
OBJECT_MASK_THRESHOLD: 0.8
|
| 163 |
+
SEM_SEG_POSTPROCESSING_BEFORE_INFERENCE: false
|
| 164 |
+
|
| 165 |
+
# Spatial sampler
|
| 166 |
+
STROKE_SAMPLER:
|
| 167 |
+
MAX_CANDIDATE: 1
|
| 168 |
+
CANDIDATE_PROBS: [0.25, 0.25, 0.25, 0.25] # for training only
|
| 169 |
+
CANDIDATE_NAMES: ["Point", "Polygon", "Scribble", "Circle"]
|
| 170 |
+
DILATION: 3
|
| 171 |
+
CIRCLE:
|
| 172 |
+
NUM_STROKES: 5
|
| 173 |
+
STROKE_PRESET: ['object_like', 'object_like_middle', 'object_like_small']
|
| 174 |
+
STROKE_PROB: [0.33, 0.33, 0.33]
|
| 175 |
+
SCRIBBLE:
|
| 176 |
+
NUM_STROKES: 5
|
| 177 |
+
STROKE_PRESET: ['rand_curve', 'rand_curve_small']
|
| 178 |
+
STROKE_PROB: [0.5, 0.5]
|
| 179 |
+
POINT:
|
| 180 |
+
NUM_POINTS: 20
|
| 181 |
+
POLYGON:
|
| 182 |
+
MAX_POINTS: 9
|
| 183 |
+
EVAL:
|
| 184 |
+
MODE: 'best' # best/random/best_random
|
| 185 |
+
NEGATIVE: False
|
| 186 |
+
MAX_ITER: 20
|
| 187 |
+
IOU_ITER: 1
|
| 188 |
+
GROUNDING: False
|
| 189 |
+
|
| 190 |
+
# Multi-modal Architecture, order matters
|
| 191 |
+
ATTENTION_ARCH:
|
| 192 |
+
VARIABLE:
|
| 193 |
+
queries: ['object', 'grounding', 'spatial']
|
| 194 |
+
tokens: ['grounding', 'spatial']
|
| 195 |
+
memories: ['spatial']
|
| 196 |
+
SELF_ATTENTION:
|
| 197 |
+
queries:
|
| 198 |
+
object: ['queries_object']
|
| 199 |
+
grounding: ['queries_grounding', 'tokens_grounding']
|
| 200 |
+
spatial: ['queries_spatial', 'tokens_spatial', 'memories_spatial']
|
| 201 |
+
tokens:
|
| 202 |
+
grounding: ['queries_grounding', 'tokens_grounding']
|
| 203 |
+
spatial: ['tokens_spatial']
|
| 204 |
+
memories:
|
| 205 |
+
spatial: ['memories_spatial']
|
| 206 |
+
CROSS_ATTENTION:
|
| 207 |
+
queries:
|
| 208 |
+
object: True
|
| 209 |
+
grounding: True
|
| 210 |
+
spatial: True
|
| 211 |
+
memories:
|
| 212 |
+
spatial: True
|
| 213 |
+
tokens:
|
| 214 |
+
grounding: False
|
| 215 |
+
spatial: False
|
| 216 |
+
MASKING: ['tokens_spatial', 'tokens_grounding']
|
| 217 |
+
DUPLICATION:
|
| 218 |
+
queries:
|
| 219 |
+
grounding: 'queries_object'
|
| 220 |
+
spatial: 'queries_object'
|
| 221 |
+
SPATIAL_MEMORIES: 32
|
| 222 |
+
QUERY_NUMBER: 3
|
| 223 |
+
|
| 224 |
+
DATASETS:
|
| 225 |
+
TRAIN: ["coco_2017_train_panoptic_filtrefgumdval_with_sem_seg_caption_grounding_lvis",]
|
| 226 |
+
# TRAIN: ["coco_2017_train_panoptic_with_sem_seg_caption_grounding",]
|
| 227 |
+
TEST: ["coco_2017_val_panoptic_with_sem_seg", "pascalvoc_val_Point", "refcocog_val_umd"] # to evaluate instance and semantic performance as well
|
| 228 |
+
# TEST: ["pascalvoc_val_Point"] # [pascalvoc, openimage600, ade600, davis, cocomini], [Point, Scribble, Polygon, Circle, Box]
|
| 229 |
+
# TEST: ["cocomini_val_Point", "cocomini_val_Circle", "cocomini_val_Scribble", "cocomini_val_Polygon", "cocomini_val_Box"] # [pascalvoc, openimage600, ade600, davis, cocomini], [Point, Scribble, Polygon, Circle, Box]
|
| 230 |
+
# TEST: ["ade600_val_Point", "ade600_val_Circle", "ade600_val_Scribble", "ade600_val_Polygon", "ade600_val_Box"] # [pascalvoc, openimage600, ade600, davis, cocomini], [Point, Scribble, Polygon, Circle, Box]
|
| 231 |
+
# TEST: ["openimage600_val_Point", "openimage600_val_Circle", "openimage600_val_Scribble", "openimage600_val_Polygon", "openimage600_val_Box"] # [pascalvoc, openimage600, ade600, davis, cocomini], [Point, Scribble, Polygon, Circle, Box]
|
| 232 |
+
CLASS_CONCAT: false
|
| 233 |
+
SIZE_DIVISIBILITY: 32
|
| 234 |
+
PROPOSAL_FILES_TRAIN: []
|
| 235 |
+
|
| 236 |
+
INPUT:
|
| 237 |
+
PIXEL_MEAN: [123.675, 116.280, 103.530]
|
| 238 |
+
PIXEL_STD: [58.395, 57.120, 57.375]
|
| 239 |
+
|
| 240 |
+
TRAIN:
|
| 241 |
+
ASPECT_RATIO_GROUPING: true
|
| 242 |
+
BATCH_SIZE_TOTAL: 4
|
| 243 |
+
BATCH_SIZE_PER_GPU: 4
|
| 244 |
+
SHUFFLE: true
|
| 245 |
+
|
| 246 |
+
TEST:
|
| 247 |
+
DETECTIONS_PER_IMAGE: 100
|
| 248 |
+
NAME: coco_eval
|
| 249 |
+
IOU_TYPE: ['bbox', 'segm']
|
| 250 |
+
USE_MULTISCALE: false
|
| 251 |
+
BATCH_SIZE_TOTAL: 8
|
| 252 |
+
MODEL_FILE: ''
|
| 253 |
+
AUG:
|
| 254 |
+
ENABLED: False
|
| 255 |
+
|
| 256 |
+
DATALOADER:
|
| 257 |
+
FILTER_EMPTY_ANNOTATIONS: False
|
| 258 |
+
NUM_WORKERS: 8
|
| 259 |
+
LOAD_PROPOSALS: False
|
| 260 |
+
SAMPLER_TRAIN: "TrainingSampler"
|
| 261 |
+
ASPECT_RATIO_GROUPING: True
|
| 262 |
+
|
| 263 |
+
COCO:
|
| 264 |
+
INPUT:
|
| 265 |
+
MIN_SIZE_TRAIN: 800
|
| 266 |
+
MAX_SIZE_TRAIN: 1333
|
| 267 |
+
MIN_SIZE_TRAIN_SAMPLING: 'choice'
|
| 268 |
+
MIN_SIZE_TEST: 800
|
| 269 |
+
MAX_SIZE_TEST: 1333
|
| 270 |
+
IMAGE_SIZE: 1024
|
| 271 |
+
MIN_SCALE: 0.1
|
| 272 |
+
MAX_SCALE: 2.0
|
| 273 |
+
DATASET_MAPPER_NAME: "coco_interactive"
|
| 274 |
+
IGNORE_VALUE: 255
|
| 275 |
+
COLOR_AUG_SSD: False
|
| 276 |
+
SIZE_DIVISIBILITY: 32
|
| 277 |
+
RANDOM_FLIP: "horizontal"
|
| 278 |
+
MASK_FORMAT: "polygon"
|
| 279 |
+
FORMAT: "RGB"
|
| 280 |
+
CROP:
|
| 281 |
+
ENABLED: True
|
| 282 |
+
DATASET:
|
| 283 |
+
DATASET: 'coco'
|
| 284 |
+
|
| 285 |
+
# Validation dataset
|
| 286 |
+
ADE20K:
|
| 287 |
+
INPUT:
|
| 288 |
+
MIN_SIZE_TRAIN: 640
|
| 289 |
+
MIN_SIZE_TRAIN_SAMPLING: "choice"
|
| 290 |
+
MIN_SIZE_TEST: 640
|
| 291 |
+
MAX_SIZE_TRAIN: 2560
|
| 292 |
+
MAX_SIZE_TEST: 2560
|
| 293 |
+
MASK_FORMAT: "polygon"
|
| 294 |
+
CROP:
|
| 295 |
+
ENABLED: True
|
| 296 |
+
TYPE: "absolute"
|
| 297 |
+
SIZE: (640, 640)
|
| 298 |
+
SINGLE_CATEGORY_MAX_AREA: 1.0
|
| 299 |
+
COLOR_AUG_SSD: True
|
| 300 |
+
SIZE_DIVISIBILITY: 640 # used in dataset mapper
|
| 301 |
+
DATASET_MAPPER_NAME: "mask_former_panoptic"
|
| 302 |
+
FORMAT: "RGB"
|
| 303 |
+
DATASET:
|
| 304 |
+
DATASET: 'ade'
|
| 305 |
+
|
| 306 |
+
SBD:
|
| 307 |
+
INPUT:
|
| 308 |
+
MIN_SIZE_TEST: 800
|
| 309 |
+
MAX_SIZE_TEST: 1333
|
| 310 |
+
DATALOADER:
|
| 311 |
+
FILTER_EMPTY_ANNOTATIONS: False
|
| 312 |
+
NUM_WORKERS: 0
|
| 313 |
+
LOAD_PROPOSALS: False
|
| 314 |
+
SAMPLER_TRAIN: "TrainingSampler"
|
| 315 |
+
ASPECT_RATIO_GROUPING: False
|
| 316 |
+
TEST:
|
| 317 |
+
BATCH_SIZE_TOTAL: 1
|
| 318 |
+
|
| 319 |
+
VOC:
|
| 320 |
+
INPUT:
|
| 321 |
+
MIN_SIZE_TEST: 800
|
| 322 |
+
MAX_SIZE_TEST: 1333
|
| 323 |
+
DATALOADER:
|
| 324 |
+
FILTER_EMPTY_ANNOTATIONS: False
|
| 325 |
+
NUM_WORKERS: 0
|
| 326 |
+
LOAD_PROPOSALS: False
|
| 327 |
+
SAMPLER_TRAIN: "TrainingSampler"
|
| 328 |
+
ASPECT_RATIO_GROUPING: False
|
| 329 |
+
TEST:
|
| 330 |
+
BATCH_SIZE_TOTAL: 8
|
| 331 |
+
|
| 332 |
+
DAVIS:
|
| 333 |
+
INPUT:
|
| 334 |
+
MIN_SIZE_TEST: 800
|
| 335 |
+
MAX_SIZE_TEST: 1333
|
| 336 |
+
DATALOADER:
|
| 337 |
+
FILTER_EMPTY_ANNOTATIONS: False
|
| 338 |
+
NUM_WORKERS: 0
|
| 339 |
+
LOAD_PROPOSALS: False
|
| 340 |
+
SAMPLER_TRAIN: "TrainingSampler"
|
| 341 |
+
ASPECT_RATIO_GROUPING: False
|
| 342 |
+
TEST:
|
| 343 |
+
BATCH_SIZE_TOTAL: 8
|
| 344 |
+
|
| 345 |
+
VOS:
|
| 346 |
+
INPUT:
|
| 347 |
+
MIN_SIZE_TEST: 800
|
| 348 |
+
MAX_SIZE_TEST: 1333
|
| 349 |
+
DATALOADER:
|
| 350 |
+
FILTER_EMPTY_ANNOTATIONS: False
|
| 351 |
+
NUM_WORKERS: 0
|
| 352 |
+
LOAD_PROPOSALS: False
|
| 353 |
+
SAMPLER_TRAIN: "TrainingSampler"
|
| 354 |
+
ASPECT_RATIO_GROUPING: False
|
| 355 |
+
TEST:
|
| 356 |
+
BATCH_SIZE_TOTAL: 1
|
| 357 |
+
|
| 358 |
+
REF:
|
| 359 |
+
INPUT:
|
| 360 |
+
PIXEL_MEAN: [123.675, 116.280, 103.530]
|
| 361 |
+
PIXEL_STD: [58.395, 57.120, 57.375]
|
| 362 |
+
MIN_SIZE_TEST: 512
|
| 363 |
+
MAX_SIZE_TEST: 1024
|
| 364 |
+
FORMAT: "RGB"
|
| 365 |
+
SPATIAL: False
|
| 366 |
+
DATALOADER:
|
| 367 |
+
FILTER_EMPTY_ANNOTATIONS: False
|
| 368 |
+
NUM_WORKERS: 4
|
| 369 |
+
LOAD_PROPOSALS: False
|
| 370 |
+
SAMPLER_TRAIN: "TrainingSampler"
|
| 371 |
+
ASPECT_RATIO_GROUPING: False
|
| 372 |
+
TEST:
|
| 373 |
+
BATCH_SIZE_TOTAL: 8
|
| 374 |
+
|
| 375 |
+
# Detectron2 training config for optimizer and lr scheduler
|
| 376 |
+
SOLVER:
|
| 377 |
+
BASE_LR: 0.0001
|
| 378 |
+
STEPS: [0.88889, 0.96296]
|
| 379 |
+
MAX_ITER: 1
|
| 380 |
+
GAMMA: 0.1
|
| 381 |
+
WARMUP_FACTOR: 1.0
|
| 382 |
+
WARMUP_ITERS: 10
|
| 383 |
+
WARMUP_METHOD: "linear"
|
| 384 |
+
WEIGHT_DECAY: 0.05
|
| 385 |
+
OPTIMIZER: "ADAMW"
|
| 386 |
+
LR_SCHEDULER_NAME: "WarmupMultiStepLR"
|
| 387 |
+
LR_MULTIPLIER:
|
| 388 |
+
backbone: 0.1
|
| 389 |
+
lang_encoder: 0.1
|
| 390 |
+
FIX_PARAM:
|
| 391 |
+
backbone: True
|
| 392 |
+
lang_encoder: True
|
| 393 |
+
pixel_decoder: True
|
| 394 |
+
WEIGHT_DECAY_NORM: 0.0
|
| 395 |
+
WEIGHT_DECAY_EMBED: 0.0
|
| 396 |
+
CLIP_GRADIENTS:
|
| 397 |
+
ENABLED: True
|
| 398 |
+
CLIP_TYPE: "full_model"
|
| 399 |
+
CLIP_VALUE: 5.0 # 0.01
|
| 400 |
+
NORM_TYPE: 2.0
|
| 401 |
+
MAX_NUM_EPOCHS: 50
|
configs/semantic_sam_only_sa-1b_swinL.yaml
ADDED
|
@@ -0,0 +1,524 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# ------------------------------------------------------------------------
|
| 2 |
+
# Semantic SAM
|
| 3 |
+
# Copyright (c) MicroSoft, Inc. and its affiliates.
|
| 4 |
+
# Modified from OpenSeed https://github.com/IDEA-Research/OpenSeed by Feng Li.
|
| 5 |
+
# ------------------------------------------------------------------------
|
| 6 |
+
|
| 7 |
+
##################
|
| 8 |
+
# Task settings
|
| 9 |
+
##################
|
| 10 |
+
WEIGHT: ''
|
| 11 |
+
PORT: 53711
|
| 12 |
+
VERBOSE: true
|
| 13 |
+
|
| 14 |
+
OUTPUT_DIR: '../../data/output/test'
|
| 15 |
+
# misc
|
| 16 |
+
LOADER:
|
| 17 |
+
JOINT: True
|
| 18 |
+
KEY_DATASET: 'coco'
|
| 19 |
+
# model
|
| 20 |
+
MODEL:
|
| 21 |
+
NAME: interactive_mask_dino
|
| 22 |
+
HEAD: general_head
|
| 23 |
+
MASK_ON: false
|
| 24 |
+
KEYPOINT_ON: false
|
| 25 |
+
LOAD_PROPOSALS: false
|
| 26 |
+
DIM_PROJ: 512
|
| 27 |
+
BACKBONE_DIM: 768
|
| 28 |
+
BACKGROUND: False
|
| 29 |
+
WEIGHTS: ''
|
| 30 |
+
TEXT:
|
| 31 |
+
ARCH: noencoder # no language encoder for training only sa-1b data
|
| 32 |
+
NAME: transformer
|
| 33 |
+
TOKENIZER: clip
|
| 34 |
+
CONTEXT_LENGTH: 18 # 77
|
| 35 |
+
WIDTH: 512
|
| 36 |
+
HEADS: 8
|
| 37 |
+
LAYERS: 12 # 6
|
| 38 |
+
AUTOGRESSIVE: True
|
| 39 |
+
BACKBONE:
|
| 40 |
+
NAME: swin
|
| 41 |
+
PRETRAINED: 'https://github.com/SwinTransformer/storage/releases/download/v1.0.0/swin_large_patch4_window12_384_22k.pth'
|
| 42 |
+
LOAD_PRETRAINED: true
|
| 43 |
+
SWIN:
|
| 44 |
+
PRETRAIN_IMG_SIZE: 384
|
| 45 |
+
PATCH_SIZE: 4
|
| 46 |
+
EMBED_DIM: 192
|
| 47 |
+
DEPTHS: [ 2, 2, 18, 2 ]
|
| 48 |
+
NUM_HEADS: [ 6, 12, 24, 48 ]
|
| 49 |
+
WINDOW_SIZE: 12
|
| 50 |
+
MLP_RATIO: 4.0
|
| 51 |
+
QKV_BIAS: true
|
| 52 |
+
QK_SCALE: ~
|
| 53 |
+
DROP_RATE: 0.0
|
| 54 |
+
ATTN_DROP_RATE: 0.0
|
| 55 |
+
DROP_PATH_RATE: 0.3
|
| 56 |
+
APE: false
|
| 57 |
+
PATCH_NORM: true
|
| 58 |
+
USE_CHECKPOINT: false
|
| 59 |
+
OUT_FEATURES: [ 'res2', 'res3', 'res4', 'res5' ]
|
| 60 |
+
ENCODER:
|
| 61 |
+
NAME: encoder_deform
|
| 62 |
+
IGNORE_VALUE: 255
|
| 63 |
+
NUM_CLASSES: 1
|
| 64 |
+
LOSS_WEIGHT: 1.0
|
| 65 |
+
CONVS_DIM: 256
|
| 66 |
+
MASK_DIM: 256
|
| 67 |
+
NORM: "GN"
|
| 68 |
+
IN_FEATURES: [ "res2", "res3", "res4", "res5" ]
|
| 69 |
+
DEFORMABLE_TRANSFORMER_ENCODER_IN_FEATURES: [ "res3", "res4", "res5" ]
|
| 70 |
+
COMMON_STRIDE: 4
|
| 71 |
+
TRANSFORMER_ENC_LAYERS: 6
|
| 72 |
+
TOTAL_NUM_FEATURE_LEVELS: 4
|
| 73 |
+
NUM_FEATURE_LEVELS: 3
|
| 74 |
+
FEATURE_ORDER: "low2high"
|
| 75 |
+
DECODER:
|
| 76 |
+
NAME: interactive_mask_dino
|
| 77 |
+
TRANSFORMER_IN_FEATURE: "multi_scale_pixel_decoder"
|
| 78 |
+
MASK: True
|
| 79 |
+
BOX: True
|
| 80 |
+
PART: True
|
| 81 |
+
GROUNDING:
|
| 82 |
+
ENABLED: False
|
| 83 |
+
MAX_LEN: 5
|
| 84 |
+
TEXT_WEIGHT: 2.0
|
| 85 |
+
CLASS_WEIGHT: 0.5
|
| 86 |
+
CAPTION:
|
| 87 |
+
ENABLED: False
|
| 88 |
+
PHRASE_PROB: 0.0
|
| 89 |
+
SIM_THRES: 0.95
|
| 90 |
+
CAPTIONING:
|
| 91 |
+
ENABLED: False
|
| 92 |
+
STEP: 50
|
| 93 |
+
RETRIEVAL:
|
| 94 |
+
ENABLED: False
|
| 95 |
+
DIM_IMG: 768
|
| 96 |
+
ENSEMBLE: True
|
| 97 |
+
OPENIMAGE:
|
| 98 |
+
ENABLED: False
|
| 99 |
+
NEGATIVE_SAMPLES: 5
|
| 100 |
+
GROUNDING:
|
| 101 |
+
ENABLED: False
|
| 102 |
+
MAX_LEN: 5
|
| 103 |
+
DEEP_SUPERVISION: True
|
| 104 |
+
NO_OBJECT_WEIGHT: 0.1
|
| 105 |
+
CLASS_WEIGHT: 4.0
|
| 106 |
+
MASK_WEIGHT: 5.0
|
| 107 |
+
DICE_WEIGHT: 5.0
|
| 108 |
+
BOX_WEIGHT: 5.0
|
| 109 |
+
GIOU_WEIGHT: 2.0
|
| 110 |
+
IOU_WEIGHT: 1.0
|
| 111 |
+
COST_CLASS_WEIGHT: 4.0
|
| 112 |
+
COST_DICE_WEIGHT: 5.0
|
| 113 |
+
COST_MASK_WEIGHT: 5.0
|
| 114 |
+
COST_BOX_WEIGHT: 5.0
|
| 115 |
+
COST_GIOU_WEIGHT: 2.0
|
| 116 |
+
HIDDEN_DIM: 256
|
| 117 |
+
NUM_OBJECT_QUERIES: 0
|
| 118 |
+
NHEADS: 8
|
| 119 |
+
DROPOUT: 0.0
|
| 120 |
+
DIM_FEEDFORWARD: 2048
|
| 121 |
+
ENC_LAYERS: 0
|
| 122 |
+
PRE_NORM: False
|
| 123 |
+
ENFORCE_INPUT_PROJ: False
|
| 124 |
+
SIZE_DIVISIBILITY: 32
|
| 125 |
+
DEC_LAYERS: 9 # 9 decoder layers, add one for the loss on learnable query
|
| 126 |
+
TRAIN_NUM_POINTS: 12544
|
| 127 |
+
OVERSAMPLE_RATIO: 3.0
|
| 128 |
+
IMPORTANCE_SAMPLE_RATIO: 0.75
|
| 129 |
+
TWO_STAGE: False
|
| 130 |
+
INITIALIZE_BOX_TYPE: 'no'
|
| 131 |
+
DN: seg
|
| 132 |
+
DN_NOISE_SCALE: 0.4
|
| 133 |
+
DN_NUM: 100
|
| 134 |
+
INITIAL_PRED: False
|
| 135 |
+
LEARN_TGT: False
|
| 136 |
+
TOTAL_NUM_FEATURE_LEVELS: 4
|
| 137 |
+
SEMANTIC_CE_LOSS: False
|
| 138 |
+
PANO_BOX_LOSS: False
|
| 139 |
+
COCO: False
|
| 140 |
+
O365: False
|
| 141 |
+
SAM: True
|
| 142 |
+
PASCAL: False
|
| 143 |
+
RE_POINT: True
|
| 144 |
+
NUM_INTERACTIVE_TOKENS: 6
|
| 145 |
+
MAX_NUM_INSTANCE: 60
|
| 146 |
+
TEST:
|
| 147 |
+
SEMANTIC_ON: True
|
| 148 |
+
INSTANCE_ON: True
|
| 149 |
+
PANOPTIC_ON: True
|
| 150 |
+
BOX_INTERACTIVE: False
|
| 151 |
+
CLASSIFICATION_ON: False
|
| 152 |
+
OVERLAP_THRESHOLD: 0.8
|
| 153 |
+
OBJECT_MASK_THRESHOLD: 0.25
|
| 154 |
+
SEM_SEG_POSTPROCESSING_BEFORE_INFERENCE: false
|
| 155 |
+
TEST_FOUCUS_ON_BOX: False
|
| 156 |
+
PANO_TRANSFORM_EVAL: True
|
| 157 |
+
PANO_TEMPERATURE: 0.06
|
| 158 |
+
|
| 159 |
+
TEST:
|
| 160 |
+
EVAL_PERIOD: 500000
|
| 161 |
+
PRECISE_BN:
|
| 162 |
+
NUM_ITER: 1
|
| 163 |
+
ENABLED: False
|
| 164 |
+
AUG:
|
| 165 |
+
ENABLED: False
|
| 166 |
+
|
| 167 |
+
SAM:
|
| 168 |
+
INPUT:
|
| 169 |
+
MIN_SIZE_TEST: 800
|
| 170 |
+
MAX_SIZE_TEST: 1333
|
| 171 |
+
IMAGE_SIZE: 1024
|
| 172 |
+
MIN_SCALE: 0.99
|
| 173 |
+
MAX_SCALE: 1.01
|
| 174 |
+
DATASET_MAPPER_NAME: "sam"
|
| 175 |
+
IGNORE_VALUE: 255
|
| 176 |
+
COLOR_AUG_SSD: False
|
| 177 |
+
SIZE_DIVISIBILITY: 32
|
| 178 |
+
RANDOM_FLIP: "horizontal"
|
| 179 |
+
MASK_FORMAT: "polygon"
|
| 180 |
+
FORMAT: "RGB"
|
| 181 |
+
CROP:
|
| 182 |
+
ENABLED: True
|
| 183 |
+
DATASET:
|
| 184 |
+
DATASET: 'sam'
|
| 185 |
+
TEST:
|
| 186 |
+
DETECTIONS_PER_IMAGE: 100
|
| 187 |
+
NAME: coco_eval
|
| 188 |
+
IOU_TYPE: ['bbox', 'segm']
|
| 189 |
+
USE_MULTISCALE: false
|
| 190 |
+
BATCH_SIZE_TOTAL: 8
|
| 191 |
+
MODEL_FILE: ''
|
| 192 |
+
AUG:
|
| 193 |
+
ENABLED: False
|
| 194 |
+
TRAIN:
|
| 195 |
+
BATCH_SIZE_TOTAL: 1
|
| 196 |
+
BATCH_SIZE_PER_GPU: 1
|
| 197 |
+
SHUFFLE: true
|
| 198 |
+
DATALOADER:
|
| 199 |
+
FILTER_EMPTY_ANNOTATIONS: False
|
| 200 |
+
NUM_WORKERS: 4
|
| 201 |
+
LOAD_PROPOSALS: False
|
| 202 |
+
SAMPLER_TRAIN: "TrainingSampler"
|
| 203 |
+
ASPECT_RATIO_GROUPING: True
|
| 204 |
+
|
| 205 |
+
COCO:
|
| 206 |
+
INPUT:
|
| 207 |
+
MIN_SIZE_TEST: 800
|
| 208 |
+
MAX_SIZE_TEST: 1333
|
| 209 |
+
IMAGE_SIZE: 1024
|
| 210 |
+
MIN_SCALE: 0.1
|
| 211 |
+
MAX_SCALE: 2.0
|
| 212 |
+
DATASET_MAPPER_NAME: "coco_interactive_panoptic_lsj"
|
| 213 |
+
IGNORE_VALUE: 255
|
| 214 |
+
COLOR_AUG_SSD: False
|
| 215 |
+
SIZE_DIVISIBILITY: 32
|
| 216 |
+
RANDOM_FLIP: "horizontal"
|
| 217 |
+
MASK_FORMAT: "polygon"
|
| 218 |
+
FORMAT: "RGB"
|
| 219 |
+
CROP:
|
| 220 |
+
ENABLED: True
|
| 221 |
+
DATASET:
|
| 222 |
+
DATASET: 'coco'
|
| 223 |
+
TEST:
|
| 224 |
+
DETECTIONS_PER_IMAGE: 100
|
| 225 |
+
NAME: coco_eval
|
| 226 |
+
IOU_TYPE: ['bbox', 'segm']
|
| 227 |
+
USE_MULTISCALE: false
|
| 228 |
+
BATCH_SIZE_TOTAL: 1
|
| 229 |
+
MODEL_FILE: ''
|
| 230 |
+
AUG:
|
| 231 |
+
ENABLED: False
|
| 232 |
+
TRAIN:
|
| 233 |
+
BATCH_SIZE_TOTAL: 1
|
| 234 |
+
BATCH_SIZE_PER_GPU: 1
|
| 235 |
+
SHUFFLE: true
|
| 236 |
+
DATALOADER:
|
| 237 |
+
FILTER_EMPTY_ANNOTATIONS: False
|
| 238 |
+
NUM_WORKERS: 2
|
| 239 |
+
LOAD_PROPOSALS: False
|
| 240 |
+
SAMPLER_TRAIN: "TrainingSampler"
|
| 241 |
+
ASPECT_RATIO_GROUPING: True
|
| 242 |
+
|
| 243 |
+
VLP:
|
| 244 |
+
INPUT:
|
| 245 |
+
IMAGE_SIZE: 224
|
| 246 |
+
DATASET_MAPPER_NAME: "vlpretrain"
|
| 247 |
+
IGNORE_VALUE: 255
|
| 248 |
+
COLOR_AUG_SSD: False
|
| 249 |
+
SIZE_DIVISIBILITY: 32
|
| 250 |
+
MASK_FORMAT: "polygon"
|
| 251 |
+
FORMAT: "RGB"
|
| 252 |
+
CROP:
|
| 253 |
+
ENABLED: True
|
| 254 |
+
TRAIN:
|
| 255 |
+
BATCH_SIZE_TOTAL: 2
|
| 256 |
+
BATCH_SIZE_PER_GPU: 2
|
| 257 |
+
TEST:
|
| 258 |
+
BATCH_SIZE_TOTAL: 256
|
| 259 |
+
DATALOADER:
|
| 260 |
+
FILTER_EMPTY_ANNOTATIONS: False
|
| 261 |
+
NUM_WORKERS: 16
|
| 262 |
+
LOAD_PROPOSALS: False
|
| 263 |
+
SAMPLER_TRAIN: "TrainingSampler"
|
| 264 |
+
ASPECT_RATIO_GROUPING: True
|
| 265 |
+
|
| 266 |
+
INPUT:
|
| 267 |
+
PIXEL_MEAN: [123.675, 116.280, 103.530]
|
| 268 |
+
PIXEL_STD: [58.395, 57.120, 57.375]
|
| 269 |
+
|
| 270 |
+
DATASETS:
|
| 271 |
+
TRAIN: ["sam_train"]
|
| 272 |
+
# interactive segmentation evaluation.
|
| 273 |
+
TEST: ["coco_2017_val_panoptic_with_sem_seg_interactive_jointboxpoint"]
|
| 274 |
+
# TEST: ["sam_minival"]
|
| 275 |
+
|
| 276 |
+
CLASS_CONCAT: false
|
| 277 |
+
SIZE_DIVISIBILITY: 32
|
| 278 |
+
PROPOSAL_FILES_TRAIN: []
|
| 279 |
+
|
| 280 |
+
DATALOADER:
|
| 281 |
+
FILTER_EMPTY_ANNOTATIONS: False
|
| 282 |
+
NUM_WORKERS: 16
|
| 283 |
+
LOAD_PROPOSALS: False
|
| 284 |
+
SAMPLER_TRAIN: "TrainingSampler"
|
| 285 |
+
ASPECT_RATIO_GROUPING: True
|
| 286 |
+
|
| 287 |
+
# Detectron2 training config for optimizer and lr scheduler
|
| 288 |
+
SOLVER:
|
| 289 |
+
BASE_LR_END: 0.0
|
| 290 |
+
MOMENTUM: 0.9
|
| 291 |
+
NESTEROV: False
|
| 292 |
+
CHECKPOINT_PERIOD: 5000
|
| 293 |
+
IMS_PER_BATCH: 1
|
| 294 |
+
REFERENCE_WORLD_SIZE: 0
|
| 295 |
+
BIAS_LR_FACTOR: 1.0
|
| 296 |
+
WEIGHT_DECAY_BIAS: None
|
| 297 |
+
# original
|
| 298 |
+
BASE_LR: 0.0001
|
| 299 |
+
STEPS: [327778, 355092]
|
| 300 |
+
MAX_ITER: 368750
|
| 301 |
+
GAMMA: 0.1
|
| 302 |
+
WARMUP_FACTOR: 1.0
|
| 303 |
+
WARMUP_ITERS: 10
|
| 304 |
+
WARMUP_METHOD: "linear"
|
| 305 |
+
WEIGHT_DECAY: 0.05
|
| 306 |
+
OPTIMIZER: "ADAMW"
|
| 307 |
+
LR_SCHEDULER_NAME: "WarmupMultiStepLR"
|
| 308 |
+
LR_MULTIPLIER:
|
| 309 |
+
backbone: 0.1
|
| 310 |
+
lang_encoder: 0.1
|
| 311 |
+
WEIGHT_DECAY_NORM: 0.0
|
| 312 |
+
WEIGHT_DECAY_EMBED: 0.0
|
| 313 |
+
CLIP_GRADIENTS:
|
| 314 |
+
ENABLED: True
|
| 315 |
+
CLIP_TYPE: "full_model"
|
| 316 |
+
CLIP_VALUE: 0.01
|
| 317 |
+
NORM_TYPE: 2.0
|
| 318 |
+
AMP:
|
| 319 |
+
ENABLED: True
|
| 320 |
+
|
| 321 |
+
# Evaluation Dataset
|
| 322 |
+
ADE20K:
|
| 323 |
+
INPUT:
|
| 324 |
+
MIN_SIZE_TRAIN: [320, 384, 448, 512, 576, 640, 704, 768, 832, 896, 960, 1024, 1088, 1152, 1216, 1280]
|
| 325 |
+
MIN_SIZE_TRAIN_SAMPLING: "choice"
|
| 326 |
+
MIN_SIZE_TEST: 640
|
| 327 |
+
MAX_SIZE_TRAIN: 2560
|
| 328 |
+
MAX_SIZE_TEST: 2560
|
| 329 |
+
MASK_FORMAT: "polygon"
|
| 330 |
+
CROP:
|
| 331 |
+
ENABLED: True
|
| 332 |
+
TYPE: "absolute"
|
| 333 |
+
SIZE: [640, 640]
|
| 334 |
+
SINGLE_CATEGORY_MAX_AREA: 1.0
|
| 335 |
+
IGNORE_VALUE: 255
|
| 336 |
+
COLOR_AUG_SSD: True
|
| 337 |
+
SIZE_DIVISIBILITY: 640 # used in dataset mapper
|
| 338 |
+
DATASET_MAPPER_NAME: "mask_former_panoptic"
|
| 339 |
+
FORMAT: "RGB"
|
| 340 |
+
DATASET:
|
| 341 |
+
DATASET: 'ade'
|
| 342 |
+
TRAIN:
|
| 343 |
+
ASPECT_RATIO_GROUPING: true
|
| 344 |
+
BATCH_SIZE_TOTAL: 16
|
| 345 |
+
BATCH_SIZE_PER_GPU: 2
|
| 346 |
+
SHUFFLE: true
|
| 347 |
+
TEST:
|
| 348 |
+
DETECTIONS_PER_IMAGE: 100
|
| 349 |
+
NAME: coco_eval
|
| 350 |
+
IOU_TYPE: ['bbox', 'segm']
|
| 351 |
+
USE_MULTISCALE: false
|
| 352 |
+
BATCH_SIZE_TOTAL: 8
|
| 353 |
+
MODEL_FILE: ''
|
| 354 |
+
AUG:
|
| 355 |
+
ENABLED: False
|
| 356 |
+
DATALOADER:
|
| 357 |
+
FILTER_EMPTY_ANNOTATIONS: False
|
| 358 |
+
NUM_WORKERS: 8
|
| 359 |
+
LOAD_PROPOSALS: False
|
| 360 |
+
SAMPLER_TRAIN: "TrainingSampler"
|
| 361 |
+
ASPECT_RATIO_GROUPING: True
|
| 362 |
+
#ADE20K:
|
| 363 |
+
# INPUT:
|
| 364 |
+
# MIN_SIZE_TRAIN: 640
|
| 365 |
+
# MIN_SIZE_TRAIN_SAMPLING: "choice"
|
| 366 |
+
# MIN_SIZE_TEST: 640
|
| 367 |
+
# MAX_SIZE_TRAIN: 2560
|
| 368 |
+
# MAX_SIZE_TEST: 2560
|
| 369 |
+
# MASK_FORMAT: "polygon"
|
| 370 |
+
# CROP:
|
| 371 |
+
# ENABLED: True
|
| 372 |
+
# TYPE: "absolute"
|
| 373 |
+
# SIZE: (640, 640)
|
| 374 |
+
# SINGLE_CATEGORY_MAX_AREA: 1.0
|
| 375 |
+
# COLOR_AUG_SSD: True
|
| 376 |
+
# SIZE_DIVISIBILITY: 640 # used in dataset mapper
|
| 377 |
+
# DATASET_MAPPER_NAME: "mask_former_panoptic"
|
| 378 |
+
# FORMAT: "RGB"
|
| 379 |
+
# DATASET:
|
| 380 |
+
# DATASET: 'ade'
|
| 381 |
+
# TEST:
|
| 382 |
+
# BATCH_SIZE_TOTAL: 8
|
| 383 |
+
|
| 384 |
+
|
| 385 |
+
REF:
|
| 386 |
+
INPUT:
|
| 387 |
+
PIXEL_MEAN: [123.675, 116.280, 103.530]
|
| 388 |
+
PIXEL_STD: [58.395, 57.120, 57.375]
|
| 389 |
+
MIN_SIZE_TEST: 512
|
| 390 |
+
MAX_SIZE_TEST: 1024
|
| 391 |
+
FORMAT: "RGB"
|
| 392 |
+
DATALOADER:
|
| 393 |
+
FILTER_EMPTY_ANNOTATIONS: False
|
| 394 |
+
NUM_WORKERS: 0
|
| 395 |
+
LOAD_PROPOSALS: False
|
| 396 |
+
SAMPLER_TRAIN: "TrainingSampler"
|
| 397 |
+
ASPECT_RATIO_GROUPING: False
|
| 398 |
+
TEST:
|
| 399 |
+
BATCH_SIZE_TOTAL: 8
|
| 400 |
+
|
| 401 |
+
SUN:
|
| 402 |
+
INPUT:
|
| 403 |
+
PIXEL_MEAN: [123.675, 116.280, 103.530]
|
| 404 |
+
PIXEL_STD: [58.395, 57.120, 57.375]
|
| 405 |
+
MIN_SIZE_TEST: 512
|
| 406 |
+
MAX_SIZE_TEST: 1024
|
| 407 |
+
DATALOADER:
|
| 408 |
+
FILTER_EMPTY_ANNOTATIONS: False
|
| 409 |
+
NUM_WORKERS: 0
|
| 410 |
+
LOAD_PROPOSALS: False
|
| 411 |
+
SAMPLER_TRAIN: "TrainingSampler"
|
| 412 |
+
ASPECT_RATIO_GROUPING: False
|
| 413 |
+
TEST:
|
| 414 |
+
BATCH_SIZE_TOTAL: 8
|
| 415 |
+
|
| 416 |
+
SCAN:
|
| 417 |
+
INPUT:
|
| 418 |
+
PIXEL_MEAN: [123.675, 116.280, 103.530]
|
| 419 |
+
PIXEL_STD: [58.395, 57.120, 57.375]
|
| 420 |
+
MIN_SIZE_TEST: 512
|
| 421 |
+
MAX_SIZE_TEST: 1024
|
| 422 |
+
DATALOADER:
|
| 423 |
+
FILTER_EMPTY_ANNOTATIONS: False
|
| 424 |
+
NUM_WORKERS: 0
|
| 425 |
+
LOAD_PROPOSALS: False
|
| 426 |
+
SAMPLER_TRAIN: "TrainingSampler"
|
| 427 |
+
ASPECT_RATIO_GROUPING: False
|
| 428 |
+
TEST:
|
| 429 |
+
BATCH_SIZE_TOTAL: 8
|
| 430 |
+
|
| 431 |
+
BDD:
|
| 432 |
+
INPUT:
|
| 433 |
+
PIXEL_MEAN: [123.675, 116.280, 103.530]
|
| 434 |
+
PIXEL_STD: [58.395, 57.120, 57.375]
|
| 435 |
+
MIN_SIZE_TEST: 800
|
| 436 |
+
MAX_SIZE_TEST: 1333
|
| 437 |
+
DATALOADER:
|
| 438 |
+
FILTER_EMPTY_ANNOTATIONS: False
|
| 439 |
+
NUM_WORKERS: 0
|
| 440 |
+
LOAD_PROPOSALS: False
|
| 441 |
+
SAMPLER_TRAIN: "TrainingSampler"
|
| 442 |
+
ASPECT_RATIO_GROUPING: False
|
| 443 |
+
TEST:
|
| 444 |
+
BATCH_SIZE_TOTAL: 8
|
| 445 |
+
|
| 446 |
+
CITY:
|
| 447 |
+
INPUT:
|
| 448 |
+
MIN_SIZE_TRAIN: [ 512, 614, 716, 819, 921, 1024, 1126, 1228, 1331, 1433, 1536, 1638, 1740, 1843, 1945, 2048 ]
|
| 449 |
+
MIN_SIZE_TRAIN_SAMPLING: "choice"
|
| 450 |
+
MIN_SIZE_TEST: 1024
|
| 451 |
+
MAX_SIZE_TRAIN: 4096
|
| 452 |
+
MAX_SIZE_TEST: 2048
|
| 453 |
+
CROP:
|
| 454 |
+
ENABLED: True
|
| 455 |
+
TYPE: "absolute"
|
| 456 |
+
SIZE: [ 512, 1024 ]
|
| 457 |
+
SINGLE_CATEGORY_MAX_AREA: 1.0
|
| 458 |
+
IGNORE_VALUE: 255
|
| 459 |
+
COLOR_AUG_SSD: True
|
| 460 |
+
SIZE_DIVISIBILITY: -1
|
| 461 |
+
FORMAT: "RGB"
|
| 462 |
+
DATASET_MAPPER_NAME: "mask_former_panoptic"
|
| 463 |
+
MASK_FORMAT: "polygon"
|
| 464 |
+
TEST:
|
| 465 |
+
EVAL_PERIOD: 5000
|
| 466 |
+
BATCH_SIZE_TOTAL: 1
|
| 467 |
+
AUG:
|
| 468 |
+
ENABLED: False
|
| 469 |
+
MIN_SIZES: [ 512, 768, 1024, 1280, 1536, 1792 ]
|
| 470 |
+
MAX_SIZE: 4096
|
| 471 |
+
FLIP: True
|
| 472 |
+
DATALOADER:
|
| 473 |
+
FILTER_EMPTY_ANNOTATIONS: True
|
| 474 |
+
NUM_WORKERS: 2
|
| 475 |
+
LOAD_PROPOSALS: False
|
| 476 |
+
SAMPLER_TRAIN: "TrainingSampler"
|
| 477 |
+
ASPECT_RATIO_GROUPING: True
|
| 478 |
+
TRAIN:
|
| 479 |
+
ASPECT_RATIO_GROUPING: true
|
| 480 |
+
BATCH_SIZE_TOTAL: 2
|
| 481 |
+
BATCH_SIZE_PER_GPU: 2
|
| 482 |
+
SHUFFLE: true
|
| 483 |
+
|
| 484 |
+
PSACAL_PART:
|
| 485 |
+
INPUT:
|
| 486 |
+
MIN_SIZE_TEST: 800
|
| 487 |
+
MAX_SIZE_TEST: 1333
|
| 488 |
+
IMAGE_SIZE: 1024
|
| 489 |
+
MIN_SCALE: 0.1
|
| 490 |
+
MAX_SCALE: 2.0
|
| 491 |
+
DATASET_MAPPER_NAME: "pascal_part_lsj"
|
| 492 |
+
IGNORE_VALUE: 255
|
| 493 |
+
COLOR_AUG_SSD: False
|
| 494 |
+
SIZE_DIVISIBILITY: 32
|
| 495 |
+
RANDOM_FLIP: "horizontal"
|
| 496 |
+
MASK_FORMAT: "polygon"
|
| 497 |
+
FORMAT: "RGB"
|
| 498 |
+
CROP:
|
| 499 |
+
ENABLED: True
|
| 500 |
+
MODEL:
|
| 501 |
+
MASK_ON: True
|
| 502 |
+
KEYPOINT_ON: False
|
| 503 |
+
LOAD_PROPOSALS: False
|
| 504 |
+
# DATASET:
|
| 505 |
+
# DATASET: 'coco'
|
| 506 |
+
TEST:
|
| 507 |
+
DETECTIONS_PER_IMAGE: 100
|
| 508 |
+
NAME: coco_eval
|
| 509 |
+
IOU_TYPE: ['bbox', 'segm']
|
| 510 |
+
USE_MULTISCALE: false
|
| 511 |
+
BATCH_SIZE_TOTAL: 8
|
| 512 |
+
MODEL_FILE: ''
|
| 513 |
+
AUG:
|
| 514 |
+
ENABLED: False
|
| 515 |
+
TRAIN:
|
| 516 |
+
BATCH_SIZE_TOTAL: 1
|
| 517 |
+
BATCH_SIZE_PER_GPU: 1
|
| 518 |
+
SHUFFLE: true
|
| 519 |
+
DATALOADER:
|
| 520 |
+
FILTER_EMPTY_ANNOTATIONS: False
|
| 521 |
+
NUM_WORKERS: 2
|
| 522 |
+
LOAD_PROPOSALS: False
|
| 523 |
+
SAMPLER_TRAIN: "TrainingSampler"
|
| 524 |
+
ASPECT_RATIO_GROUPING: True
|
demo_gpt4v_som.py
ADDED
|
@@ -0,0 +1,226 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# --------------------------------------------------------
|
| 2 |
+
# Set-of-Mark (SoM) Prompting for Visual Grounding in GPT-4V
|
| 3 |
+
# Copyright (c) 2023 Microsoft
|
| 4 |
+
# Licensed under The MIT License [see LICENSE for details]
|
| 5 |
+
# Written by:
|
| 6 |
+
# Jianwei Yang (jianwyan@microsoft.com)
|
| 7 |
+
# Xueyan Zou (xueyan@cs.wisc.edu)
|
| 8 |
+
# Hao Zhang (hzhangcx@connect.ust.hk)
|
| 9 |
+
# --------------------------------------------------------
|
| 10 |
+
import io
|
| 11 |
+
import gradio as gr
|
| 12 |
+
import torch
|
| 13 |
+
import argparse
|
| 14 |
+
from PIL import Image
|
| 15 |
+
# seem
|
| 16 |
+
from seem.modeling.BaseModel import BaseModel as BaseModel_Seem
|
| 17 |
+
from seem.utils.distributed import init_distributed as init_distributed_seem
|
| 18 |
+
from seem.modeling import build_model as build_model_seem
|
| 19 |
+
from task_adapter.seem.tasks import interactive_seem_m2m_auto, inference_seem_pano, inference_seem_interactive
|
| 20 |
+
|
| 21 |
+
# semantic sam
|
| 22 |
+
from semantic_sam.BaseModel import BaseModel
|
| 23 |
+
from semantic_sam import build_model
|
| 24 |
+
from semantic_sam.utils.dist import init_distributed_mode
|
| 25 |
+
from semantic_sam.utils.arguments import load_opt_from_config_file
|
| 26 |
+
from semantic_sam.utils.constants import COCO_PANOPTIC_CLASSES
|
| 27 |
+
from task_adapter.semantic_sam.tasks import inference_semsam_m2m_auto, prompt_switch
|
| 28 |
+
|
| 29 |
+
# sam
|
| 30 |
+
from segment_anything import sam_model_registry
|
| 31 |
+
from task_adapter.sam.tasks.inference_sam_m2m_auto import inference_sam_m2m_auto
|
| 32 |
+
from task_adapter.sam.tasks.inference_sam_m2m_interactive import inference_sam_m2m_interactive
|
| 33 |
+
|
| 34 |
+
|
| 35 |
+
from task_adapter.utils.visualizer import Visualizer
|
| 36 |
+
from detectron2.data import MetadataCatalog
|
| 37 |
+
metadata = MetadataCatalog.get('coco_2017_train_panoptic')
|
| 38 |
+
|
| 39 |
+
from scipy.ndimage import label
|
| 40 |
+
import numpy as np
|
| 41 |
+
|
| 42 |
+
from gpt4v import request_gpt4v
|
| 43 |
+
from openai import OpenAI
|
| 44 |
+
from pydub import AudioSegment
|
| 45 |
+
from pydub.playback import play
|
| 46 |
+
|
| 47 |
+
import matplotlib.colors as mcolors
|
| 48 |
+
css4_colors = mcolors.CSS4_COLORS
|
| 49 |
+
color_proposals = [list(mcolors.hex2color(color)) for color in css4_colors.values()]
|
| 50 |
+
|
| 51 |
+
client = OpenAI()
|
| 52 |
+
|
| 53 |
+
'''
|
| 54 |
+
build args
|
| 55 |
+
'''
|
| 56 |
+
semsam_cfg = "configs/semantic_sam_only_sa-1b_swinL.yaml"
|
| 57 |
+
seem_cfg = "configs/seem_focall_unicl_lang_v1.yaml"
|
| 58 |
+
|
| 59 |
+
semsam_ckpt = "./swinl_only_sam_many2many.pth"
|
| 60 |
+
sam_ckpt = "./sam_vit_h_4b8939.pth"
|
| 61 |
+
seem_ckpt = "./seem_focall_v1.pt"
|
| 62 |
+
|
| 63 |
+
opt_semsam = load_opt_from_config_file(semsam_cfg)
|
| 64 |
+
opt_seem = load_opt_from_config_file(seem_cfg)
|
| 65 |
+
opt_seem = init_distributed_seem(opt_seem)
|
| 66 |
+
|
| 67 |
+
|
| 68 |
+
'''
|
| 69 |
+
build model
|
| 70 |
+
'''
|
| 71 |
+
model_semsam = BaseModel(opt_semsam, build_model(opt_semsam)).from_pretrained(semsam_ckpt).eval().cuda()
|
| 72 |
+
model_sam = sam_model_registry["vit_h"](checkpoint=sam_ckpt).eval().cuda()
|
| 73 |
+
model_seem = BaseModel_Seem(opt_seem, build_model_seem(opt_seem)).from_pretrained(seem_ckpt).eval().cuda()
|
| 74 |
+
|
| 75 |
+
with torch.no_grad():
|
| 76 |
+
with torch.autocast(device_type='cuda', dtype=torch.float16):
|
| 77 |
+
model_seem.model.sem_seg_head.predictor.lang_encoder.get_text_embeddings(COCO_PANOPTIC_CLASSES + ["background"], is_eval=True)
|
| 78 |
+
|
| 79 |
+
history_images = []
|
| 80 |
+
history_masks = []
|
| 81 |
+
history_texts = []
|
| 82 |
+
@torch.no_grad()
|
| 83 |
+
def inference(image, slider, mode, alpha, label_mode, anno_mode, *args, **kwargs):
|
| 84 |
+
global history_images; history_images = []
|
| 85 |
+
global history_masks; history_masks = []
|
| 86 |
+
|
| 87 |
+
_image = image['background'].convert('RGB')
|
| 88 |
+
_mask = image['layers'][0].convert('L') if image['layers'] else None
|
| 89 |
+
|
| 90 |
+
if slider < 1.5:
|
| 91 |
+
model_name = 'seem'
|
| 92 |
+
elif slider > 2.5:
|
| 93 |
+
model_name = 'sam'
|
| 94 |
+
else:
|
| 95 |
+
if mode == 'Automatic':
|
| 96 |
+
model_name = 'semantic-sam'
|
| 97 |
+
if slider < 1.5 + 0.14:
|
| 98 |
+
level = [1]
|
| 99 |
+
elif slider < 1.5 + 0.28:
|
| 100 |
+
level = [2]
|
| 101 |
+
elif slider < 1.5 + 0.42:
|
| 102 |
+
level = [3]
|
| 103 |
+
elif slider < 1.5 + 0.56:
|
| 104 |
+
level = [4]
|
| 105 |
+
elif slider < 1.5 + 0.70:
|
| 106 |
+
level = [5]
|
| 107 |
+
elif slider < 1.5 + 0.84:
|
| 108 |
+
level = [6]
|
| 109 |
+
else:
|
| 110 |
+
level = [6, 1, 2, 3, 4, 5]
|
| 111 |
+
else:
|
| 112 |
+
model_name = 'sam'
|
| 113 |
+
|
| 114 |
+
|
| 115 |
+
if label_mode == 'Alphabet':
|
| 116 |
+
label_mode = 'a'
|
| 117 |
+
else:
|
| 118 |
+
label_mode = '1'
|
| 119 |
+
|
| 120 |
+
text_size, hole_scale, island_scale=640,100,100
|
| 121 |
+
text, text_part, text_thresh = '','','0.0'
|
| 122 |
+
with torch.autocast(device_type='cuda', dtype=torch.float16):
|
| 123 |
+
semantic=False
|
| 124 |
+
|
| 125 |
+
if mode == "Interactive":
|
| 126 |
+
labeled_array, num_features = label(np.asarray(_mask))
|
| 127 |
+
spatial_masks = torch.stack([torch.from_numpy(labeled_array == i+1) for i in range(num_features)])
|
| 128 |
+
|
| 129 |
+
if model_name == 'semantic-sam':
|
| 130 |
+
model = model_semsam
|
| 131 |
+
output, mask = inference_semsam_m2m_auto(model, _image, level, text, text_part, text_thresh, text_size, hole_scale, island_scale, semantic, label_mode=label_mode, alpha=alpha, anno_mode=anno_mode, *args, **kwargs)
|
| 132 |
+
|
| 133 |
+
elif model_name == 'sam':
|
| 134 |
+
model = model_sam
|
| 135 |
+
if mode == "Automatic":
|
| 136 |
+
output, mask = inference_sam_m2m_auto(model, _image, text_size, label_mode, alpha, anno_mode)
|
| 137 |
+
elif mode == "Interactive":
|
| 138 |
+
output, mask = inference_sam_m2m_interactive(model, _image, spatial_masks, text_size, label_mode, alpha, anno_mode)
|
| 139 |
+
|
| 140 |
+
elif model_name == 'seem':
|
| 141 |
+
model = model_seem
|
| 142 |
+
if mode == "Automatic":
|
| 143 |
+
output, mask = inference_seem_pano(model, _image, text_size, label_mode, alpha, anno_mode)
|
| 144 |
+
elif mode == "Interactive":
|
| 145 |
+
output, mask = inference_seem_interactive(model, _image, spatial_masks, text_size, label_mode, alpha, anno_mode)
|
| 146 |
+
|
| 147 |
+
# convert output to PIL image
|
| 148 |
+
history_masks.append(mask)
|
| 149 |
+
history_images.append(Image.fromarray(output))
|
| 150 |
+
return (output, [])
|
| 151 |
+
|
| 152 |
+
|
| 153 |
+
def gpt4v_response(message, history):
|
| 154 |
+
global history_images
|
| 155 |
+
global history_texts; history_texts = []
|
| 156 |
+
try:
|
| 157 |
+
res = request_gpt4v(message, history_images[0])
|
| 158 |
+
history_texts.append(res)
|
| 159 |
+
return res
|
| 160 |
+
except Exception as e:
|
| 161 |
+
return None
|
| 162 |
+
|
| 163 |
+
def highlight(mode, alpha, label_mode, anno_mode, *args, **kwargs):
|
| 164 |
+
res = history_texts[0]
|
| 165 |
+
# find the seperate numbers in sentence res
|
| 166 |
+
res = res.split(' ')
|
| 167 |
+
res = [r.replace('.','').replace(',','').replace(')','').replace('"','') for r in res]
|
| 168 |
+
# find all numbers in '[]'
|
| 169 |
+
res = [r for r in res if '[' in r]
|
| 170 |
+
res = [r.split('[')[1] for r in res]
|
| 171 |
+
res = [r.split(']')[0] for r in res]
|
| 172 |
+
res = [r for r in res if r.isdigit()]
|
| 173 |
+
res = list(set(res))
|
| 174 |
+
sections = []
|
| 175 |
+
for i, r in enumerate(res):
|
| 176 |
+
mask_i = history_masks[0][int(r)-1]['segmentation']
|
| 177 |
+
sections.append((mask_i, r))
|
| 178 |
+
return (history_images[0], sections)
|
| 179 |
+
|
| 180 |
+
'''
|
| 181 |
+
launch app
|
| 182 |
+
'''
|
| 183 |
+
|
| 184 |
+
demo = gr.Blocks()
|
| 185 |
+
image = gr.ImageMask(label="Input", type="pil", sources=["upload"], interactive=True, brush=gr.Brush(colors=["#FFFFFF"]))
|
| 186 |
+
slider = gr.Slider(1, 3, value=1.8, label="Granularity") # info="Choose in [1, 1.5), [1.5, 2.5), [2.5, 3] for [seem, semantic-sam (multi-level), sam]"
|
| 187 |
+
mode = gr.Radio(['Automatic', 'Interactive', ], value='Automatic', label="Segmentation Mode")
|
| 188 |
+
anno_mode = gr.CheckboxGroup(choices=["Mark", "Mask", "Box"], value=['Mark'], label="Annotation Mode")
|
| 189 |
+
image_out = gr.AnnotatedImage(label="SoM Visual Prompt", height=512)
|
| 190 |
+
runBtn = gr.Button("Run")
|
| 191 |
+
highlightBtn = gr.Button("Highlight")
|
| 192 |
+
bot = gr.Chatbot(label="GPT-4V + SoM", height=256)
|
| 193 |
+
slider_alpha = gr.Slider(0, 1, value=0.05, label="Mask Alpha") #info="Choose in [0, 1]"
|
| 194 |
+
label_mode = gr.Radio(['Number', 'Alphabet'], value='Number', label="Mark Mode")
|
| 195 |
+
|
| 196 |
+
title = "Set-of-Mark (SoM) Visual Prompting for Extraordinary Visual Grounding in GPT-4V"
|
| 197 |
+
description = "This is a demo for SoM Prompting to unleash extraordinary visual grounding in GPT-4V. Please upload an image and them click the 'Run' button to get the image with marks. Then chat with GPT-4V below!"
|
| 198 |
+
|
| 199 |
+
with demo:
|
| 200 |
+
gr.Markdown("<h1 style='text-align: center'><img src='https://som-gpt4v.github.io/website/img/som_logo.png' style='height:50px;display:inline-block'/> Set-of-Mark (SoM) Prompting Unleashes Extraordinary Visual Grounding in GPT-4V</h1>")
|
| 201 |
+
# gr.Markdown("<h2 style='text-align: center; margin-bottom: 1rem'>Project: <a href='https://som-gpt4v.github.io/'>link</a> arXiv: <a href='https://arxiv.org/abs/2310.11441'>link</a> Code: <a href='https://github.com/microsoft/SoM'>link</a></h2>")
|
| 202 |
+
with gr.Row():
|
| 203 |
+
with gr.Column():
|
| 204 |
+
image.render()
|
| 205 |
+
slider.render()
|
| 206 |
+
with gr.Accordion("Detailed prompt settings (e.g., mark type)", open=False):
|
| 207 |
+
with gr.Row():
|
| 208 |
+
mode.render()
|
| 209 |
+
anno_mode.render()
|
| 210 |
+
with gr.Row():
|
| 211 |
+
slider_alpha.render()
|
| 212 |
+
label_mode.render()
|
| 213 |
+
with gr.Column():
|
| 214 |
+
image_out.render()
|
| 215 |
+
runBtn.render()
|
| 216 |
+
highlightBtn.render()
|
| 217 |
+
with gr.Row():
|
| 218 |
+
gr.ChatInterface(chatbot=bot, fn=gpt4v_response)
|
| 219 |
+
|
| 220 |
+
runBtn.click(inference, inputs=[image, slider, mode, slider_alpha, label_mode, anno_mode],
|
| 221 |
+
outputs = image_out)
|
| 222 |
+
highlightBtn.click(highlight, inputs=[image, mode, slider_alpha, label_mode, anno_mode],
|
| 223 |
+
outputs = image_out)
|
| 224 |
+
|
| 225 |
+
demo.queue().launch(share=True,server_port=6092)
|
| 226 |
+
|
demo_som.py
ADDED
|
@@ -0,0 +1,181 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# --------------------------------------------------------
|
| 2 |
+
# Set-of-Mark (SoM) Prompting for Visual Grounding in GPT-4V
|
| 3 |
+
# Copyright (c) 2023 Microsoft
|
| 4 |
+
# Licensed under The MIT License [see LICENSE for details]
|
| 5 |
+
# Written by:
|
| 6 |
+
# Jianwei Yang (jianwyan@microsoft.com)
|
| 7 |
+
# Xueyan Zou (xueyan@cs.wisc.edu)
|
| 8 |
+
# Hao Zhang (hzhangcx@connect.ust.hk)
|
| 9 |
+
# --------------------------------------------------------
|
| 10 |
+
|
| 11 |
+
import gradio as gr
|
| 12 |
+
import torch
|
| 13 |
+
import argparse
|
| 14 |
+
|
| 15 |
+
# seem
|
| 16 |
+
from seem.modeling.BaseModel import BaseModel as BaseModel_Seem
|
| 17 |
+
from seem.utils.distributed import init_distributed as init_distributed_seem
|
| 18 |
+
from seem.modeling import build_model as build_model_seem
|
| 19 |
+
from task_adapter.seem.tasks import interactive_seem_m2m_auto, inference_seem_pano, inference_seem_interactive
|
| 20 |
+
|
| 21 |
+
# semantic sam
|
| 22 |
+
from semantic_sam.BaseModel import BaseModel
|
| 23 |
+
from semantic_sam import build_model
|
| 24 |
+
from semantic_sam.utils.dist import init_distributed_mode
|
| 25 |
+
from semantic_sam.utils.arguments import load_opt_from_config_file
|
| 26 |
+
from semantic_sam.utils.constants import COCO_PANOPTIC_CLASSES
|
| 27 |
+
from task_adapter.semantic_sam.tasks import inference_semsam_m2m_auto, prompt_switch
|
| 28 |
+
|
| 29 |
+
# sam
|
| 30 |
+
from segment_anything import sam_model_registry
|
| 31 |
+
from task_adapter.sam.tasks.inference_sam_m2m_auto import inference_sam_m2m_auto
|
| 32 |
+
from task_adapter.sam.tasks.inference_sam_m2m_interactive import inference_sam_m2m_interactive
|
| 33 |
+
|
| 34 |
+
from scipy.ndimage import label
|
| 35 |
+
import numpy as np
|
| 36 |
+
|
| 37 |
+
'''
|
| 38 |
+
build args
|
| 39 |
+
'''
|
| 40 |
+
semsam_cfg = "configs/semantic_sam_only_sa-1b_swinL.yaml"
|
| 41 |
+
seem_cfg = "configs/seem_focall_unicl_lang_v1.yaml"
|
| 42 |
+
|
| 43 |
+
semsam_ckpt = "./swinl_only_sam_many2many.pth"
|
| 44 |
+
sam_ckpt = "./sam_vit_h_4b8939.pth"
|
| 45 |
+
seem_ckpt = "./seem_focall_v1.pt"
|
| 46 |
+
|
| 47 |
+
opt_semsam = load_opt_from_config_file(semsam_cfg)
|
| 48 |
+
opt_seem = load_opt_from_config_file(seem_cfg)
|
| 49 |
+
opt_seem = init_distributed_seem(opt_seem)
|
| 50 |
+
|
| 51 |
+
|
| 52 |
+
'''
|
| 53 |
+
build model
|
| 54 |
+
'''
|
| 55 |
+
model_semsam = BaseModel(opt_semsam, build_model(opt_semsam)).from_pretrained(semsam_ckpt).eval().cuda()
|
| 56 |
+
model_sam = sam_model_registry["vit_h"](checkpoint=sam_ckpt).eval().cuda()
|
| 57 |
+
model_seem = BaseModel_Seem(opt_seem, build_model_seem(opt_seem)).from_pretrained(seem_ckpt).eval().cuda()
|
| 58 |
+
|
| 59 |
+
with torch.no_grad():
|
| 60 |
+
with torch.autocast(device_type='cuda', dtype=torch.float16):
|
| 61 |
+
model_seem.model.sem_seg_head.predictor.lang_encoder.get_text_embeddings(COCO_PANOPTIC_CLASSES + ["background"], is_eval=True)
|
| 62 |
+
|
| 63 |
+
@torch.no_grad()
|
| 64 |
+
def inference(image, slider, mode, alpha, label_mode, anno_mode, *args, **kwargs):
|
| 65 |
+
_image = image['background'].convert('RGB')
|
| 66 |
+
_mask = image['layers'][0].convert('L') if image['layers'] else None
|
| 67 |
+
|
| 68 |
+
if slider < 1.5:
|
| 69 |
+
model_name = 'seem'
|
| 70 |
+
elif slider > 2.5:
|
| 71 |
+
model_name = 'sam'
|
| 72 |
+
else:
|
| 73 |
+
if mode == 'Automatic':
|
| 74 |
+
model_name = 'semantic-sam'
|
| 75 |
+
if slider < 1.5 + 0.14:
|
| 76 |
+
level = [1]
|
| 77 |
+
elif slider < 1.5 + 0.28:
|
| 78 |
+
level = [2]
|
| 79 |
+
elif slider < 1.5 + 0.42:
|
| 80 |
+
level = [3]
|
| 81 |
+
elif slider < 1.5 + 0.56:
|
| 82 |
+
level = [4]
|
| 83 |
+
elif slider < 1.5 + 0.70:
|
| 84 |
+
level = [5]
|
| 85 |
+
elif slider < 1.5 + 0.84:
|
| 86 |
+
level = [6]
|
| 87 |
+
else:
|
| 88 |
+
level = [6, 1, 2, 3, 4, 5]
|
| 89 |
+
else:
|
| 90 |
+
model_name = 'sam'
|
| 91 |
+
|
| 92 |
+
|
| 93 |
+
if label_mode == 'Alphabet':
|
| 94 |
+
label_mode = 'a'
|
| 95 |
+
else:
|
| 96 |
+
label_mode = '1'
|
| 97 |
+
|
| 98 |
+
text_size, hole_scale, island_scale=640,100,100
|
| 99 |
+
text, text_part, text_thresh = '','','0.0'
|
| 100 |
+
with torch.autocast(device_type='cuda', dtype=torch.float16):
|
| 101 |
+
semantic=False
|
| 102 |
+
|
| 103 |
+
if mode == "Interactive":
|
| 104 |
+
labeled_array, num_features = label(np.asarray(_mask))
|
| 105 |
+
spatial_masks = torch.stack([torch.from_numpy(labeled_array == i+1) for i in range(num_features)])
|
| 106 |
+
|
| 107 |
+
if model_name == 'semantic-sam':
|
| 108 |
+
model = model_semsam
|
| 109 |
+
output, mask = inference_semsam_m2m_auto(model, _image, level, text, text_part, text_thresh, text_size, hole_scale, island_scale, semantic, label_mode=label_mode, alpha=alpha, anno_mode=anno_mode, *args, **kwargs)
|
| 110 |
+
|
| 111 |
+
elif model_name == 'sam':
|
| 112 |
+
model = model_sam
|
| 113 |
+
if mode == "Automatic":
|
| 114 |
+
output, mask = inference_sam_m2m_auto(model, _image, text_size, label_mode, alpha, anno_mode)
|
| 115 |
+
elif mode == "Interactive":
|
| 116 |
+
output, mask = inference_sam_m2m_interactive(model, _image, spatial_masks, text_size, label_mode, alpha, anno_mode)
|
| 117 |
+
|
| 118 |
+
elif model_name == 'seem':
|
| 119 |
+
model = model_seem
|
| 120 |
+
if mode == "Automatic":
|
| 121 |
+
output, mask = inference_seem_pano(model, _image, text_size, label_mode, alpha, anno_mode)
|
| 122 |
+
elif mode == "Interactive":
|
| 123 |
+
output, mask = inference_seem_interactive(model, _image, spatial_masks, text_size, label_mode, alpha, anno_mode)
|
| 124 |
+
|
| 125 |
+
return output
|
| 126 |
+
|
| 127 |
+
'''
|
| 128 |
+
launch app
|
| 129 |
+
'''
|
| 130 |
+
|
| 131 |
+
demo = gr.Blocks()
|
| 132 |
+
image = gr.ImageMask(label="Input", type="pil", sources=["upload"], interactive=True, brush=gr.Brush(colors=["#FFFFFF"]))
|
| 133 |
+
slider = gr.Slider(1, 3, value=2, label="Granularity", info="Choose in [1, 1.5), [1.5, 2.5), [2.5, 3] for [seem, semantic-sam (multi-level), sam]")
|
| 134 |
+
mode = gr.Radio(['Automatic', 'Interactive', ], value='Automatic', label="Segmentation Mode")
|
| 135 |
+
image_out = gr.Image(label="Auto generation",type="pil")
|
| 136 |
+
runBtn = gr.Button("Run")
|
| 137 |
+
slider_alpha = gr.Slider(0, 1, value=0.1, label="Mask Alpha", info="Choose in [0, 1]")
|
| 138 |
+
label_mode = gr.Radio(['Number', 'Alphabet'], value='Number', label="Mark Mode")
|
| 139 |
+
anno_mode = gr.CheckboxGroup(choices=["Mask", "Box", "Mark"], value=['Mask', 'Mark'], label="Annotation Mode")
|
| 140 |
+
|
| 141 |
+
title = "Set-of-Mark (SoM) Prompting for Visual Grounding in GPT-4V"
|
| 142 |
+
description = "This is a demo for SoM Prompting to unleash extraordinary visual grounding in GPT-4V. Please upload an image and them click the 'Run' button to get the image with marks. Then try it on <a href='https://chat.openai.com/'>GPT-4V<a>!"
|
| 143 |
+
|
| 144 |
+
with demo:
|
| 145 |
+
gr.Markdown(f"<h1 style='text-align: center;'>{title}</h1>")
|
| 146 |
+
gr.Markdown("<h3 style='text-align: center; margin-bottom: 1rem'>project: <a href='https://som-gpt4v.github.io/'>link</a>, arXiv: <a href='https://arxiv.org/abs/2310.11441'>link</a>, code: <a href='https://github.com/microsoft/SoM'>link</a></h3>")
|
| 147 |
+
gr.Markdown(f"<h3 style='margin-bottom: 1rem'>{description}</h3>")
|
| 148 |
+
with gr.Row():
|
| 149 |
+
with gr.Column():
|
| 150 |
+
image.render()
|
| 151 |
+
slider.render()
|
| 152 |
+
with gr.Row():
|
| 153 |
+
mode.render()
|
| 154 |
+
anno_mode.render()
|
| 155 |
+
with gr.Row():
|
| 156 |
+
slider_alpha.render()
|
| 157 |
+
label_mode.render()
|
| 158 |
+
with gr.Column():
|
| 159 |
+
image_out.render()
|
| 160 |
+
runBtn.render()
|
| 161 |
+
with gr.Row():
|
| 162 |
+
example = gr.Examples(
|
| 163 |
+
examples=[
|
| 164 |
+
["examples/ironing_man.jpg"],
|
| 165 |
+
],
|
| 166 |
+
inputs=image,
|
| 167 |
+
cache_examples=False,
|
| 168 |
+
)
|
| 169 |
+
example = gr.Examples(
|
| 170 |
+
examples=[
|
| 171 |
+
["examples/ironing_man_som.png"],
|
| 172 |
+
],
|
| 173 |
+
inputs=image,
|
| 174 |
+
cache_examples=False,
|
| 175 |
+
label='Marked Examples',
|
| 176 |
+
)
|
| 177 |
+
|
| 178 |
+
runBtn.click(inference, inputs=[image, slider, mode, slider_alpha, label_mode, anno_mode],
|
| 179 |
+
outputs = image_out)
|
| 180 |
+
|
| 181 |
+
demo.queue().launch(share=True,server_port=6092)
|
deploy.py
ADDED
|
@@ -0,0 +1,720 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""Deploy SoM to AWS EC2 via Github action.
|
| 2 |
+
|
| 3 |
+
Usage:
|
| 4 |
+
|
| 5 |
+
1. Create and populate the .env file:
|
| 6 |
+
|
| 7 |
+
cat > .env <<EOF
|
| 8 |
+
AWS_ACCESS_KEY_ID=<your aws access key id>
|
| 9 |
+
AWS_SECRET_ACCESS_KEY=<your aws secret access key (required)>
|
| 10 |
+
AWS_REGION=<your aws region (required)>
|
| 11 |
+
GITHUB_OWNER=<your github owner (required)> # e.g. microsoft
|
| 12 |
+
GITHUB_REPO=<your github repo (required)> # e.g. SoM
|
| 13 |
+
GITHUB_TOKEN=<your github token (required)>
|
| 14 |
+
PROJECT_NAME=<your project name (required)> # for tagging AWS resources
|
| 15 |
+
OPENAI_API_KEY=<your openai api key (optional)>
|
| 16 |
+
EOF
|
| 17 |
+
|
| 18 |
+
2. Create a virtual environment for deployment:
|
| 19 |
+
|
| 20 |
+
python3.10 -m venv venv
|
| 21 |
+
source venv/bin/activate
|
| 22 |
+
pip install -r deploy_requirements.txt
|
| 23 |
+
|
| 24 |
+
3. Run the deployment script:
|
| 25 |
+
|
| 26 |
+
python deploy.py start
|
| 27 |
+
|
| 28 |
+
4. Wait for the build to succeed in Github actions (see console output for URL)
|
| 29 |
+
|
| 30 |
+
5. Open the gradio interface (see console output for URL) and test it out.
|
| 31 |
+
Note that it may take a minute for the interface to become available.
|
| 32 |
+
You can also interact with the server programmatically:
|
| 33 |
+
|
| 34 |
+
python client.py "http://<server_ip>:6092"
|
| 35 |
+
|
| 36 |
+
6. Terminate the EC2 instance and stop incurring charges:
|
| 37 |
+
|
| 38 |
+
python deploy.py stop
|
| 39 |
+
|
| 40 |
+
Or, to shut it down without removing it:
|
| 41 |
+
|
| 42 |
+
python deploy.py pause
|
| 43 |
+
|
| 44 |
+
(This can later be re-started with the `start` command.)
|
| 45 |
+
|
| 46 |
+
7. (optional) List all tagged instances with their respective statuses:
|
| 47 |
+
|
| 48 |
+
python deploy.py status
|
| 49 |
+
|
| 50 |
+
Troubleshooting Token Scope Error:
|
| 51 |
+
|
| 52 |
+
If you encounter an error similar to the following when pushing changes to
|
| 53 |
+
GitHub Actions workflow files:
|
| 54 |
+
|
| 55 |
+
! [remote rejected] feat/docker -> feat/docker (refusing to allow a
|
| 56 |
+
Personal Access Token to create or update workflow
|
| 57 |
+
`.github/workflows/docker-build-ec2.yml` without `workflow` scope)
|
| 58 |
+
|
| 59 |
+
This indicates that the Personal Access Token (PAT) being used does not
|
| 60 |
+
have the necessary permissions ('workflow' scope) to create or update GitHub
|
| 61 |
+
Actions workflows. To resolve this issue, you will need to create or update
|
| 62 |
+
your PAT with the appropriate scope.
|
| 63 |
+
|
| 64 |
+
Creating or Updating a Classic PAT with 'workflow' Scope:
|
| 65 |
+
|
| 66 |
+
1. Go to GitHub and sign in to your account.
|
| 67 |
+
2. Click on your profile picture in the top right corner, and then click 'Settings'.
|
| 68 |
+
3. In the sidebar, click 'Developer settings'.
|
| 69 |
+
4. Click 'Personal access tokens', then 'Classic tokens'.
|
| 70 |
+
5. To update an existing token:
|
| 71 |
+
a. Find the token you wish to update in the list and click on it.
|
| 72 |
+
b. Scroll down to the 'Select scopes' section.
|
| 73 |
+
c. Make sure the 'workflow' scope is checked. This scope allows for
|
| 74 |
+
managing GitHub Actions workflows.
|
| 75 |
+
d. Click 'Update token' at the bottom of the page.
|
| 76 |
+
6. To create a new token:
|
| 77 |
+
a. Click 'Generate new token'.
|
| 78 |
+
b. Give your token a descriptive name under 'Note'.
|
| 79 |
+
c. Scroll down to the 'Select scopes' section.
|
| 80 |
+
d. Check the 'workflow' scope to allow managing GitHub Actions workflows.
|
| 81 |
+
e. Optionally, select any other scopes needed for your project.
|
| 82 |
+
f. Click 'Generate token' at the bottom of the page.
|
| 83 |
+
7. Copy the generated token. Make sure to save it securely, as you will not
|
| 84 |
+
be able to see it again.
|
| 85 |
+
|
| 86 |
+
After creating or updating your PAT with the 'workflow' scope, update the
|
| 87 |
+
Git remote configuration to use the new token, and try pushing your changes
|
| 88 |
+
again.
|
| 89 |
+
|
| 90 |
+
Note: Always keep your tokens secure and never share them publicly.
|
| 91 |
+
|
| 92 |
+
"""
|
| 93 |
+
|
| 94 |
+
import base64
|
| 95 |
+
import json
|
| 96 |
+
import os
|
| 97 |
+
import subprocess
|
| 98 |
+
import time
|
| 99 |
+
|
| 100 |
+
from botocore.exceptions import ClientError
|
| 101 |
+
from jinja2 import Environment, FileSystemLoader
|
| 102 |
+
from loguru import logger
|
| 103 |
+
from nacl import encoding, public
|
| 104 |
+
from pydantic_settings import BaseSettings
|
| 105 |
+
import boto3
|
| 106 |
+
import fire
|
| 107 |
+
import git
|
| 108 |
+
import paramiko
|
| 109 |
+
import requests
|
| 110 |
+
|
| 111 |
+
class Config(BaseSettings):
|
| 112 |
+
AWS_ACCESS_KEY_ID: str
|
| 113 |
+
AWS_SECRET_ACCESS_KEY: str
|
| 114 |
+
AWS_REGION: str
|
| 115 |
+
GITHUB_OWNER: str
|
| 116 |
+
GITHUB_REPO: str
|
| 117 |
+
GITHUB_TOKEN: str
|
| 118 |
+
OPENAI_API_KEY: str | None = None
|
| 119 |
+
PROJECT_NAME: str
|
| 120 |
+
|
| 121 |
+
AWS_EC2_AMI: str = "ami-0f9c346cdcac09fb5" # Deep Learning AMI GPU PyTorch 2.0.1 (Ubuntu 20.04) 20230827
|
| 122 |
+
AWS_EC2_DISK_SIZE: int = 100 # GB
|
| 123 |
+
#AWS_EC2_INSTANCE_TYPE: str = "p3.2xlarge" # (V100 16GB $3.06/hr x86_64)
|
| 124 |
+
AWS_EC2_INSTANCE_TYPE: str = "g4dn.xlarge" # (T4 16GB $0.526/hr x86_64)
|
| 125 |
+
AWS_EC2_USER: str = "ubuntu"
|
| 126 |
+
|
| 127 |
+
class Config:
|
| 128 |
+
env_file = ".env"
|
| 129 |
+
env_file_encoding = 'utf-8'
|
| 130 |
+
|
| 131 |
+
@property
|
| 132 |
+
def AWS_EC2_KEY_NAME(self) -> str:
|
| 133 |
+
return f"{self.PROJECT_NAME}-key"
|
| 134 |
+
|
| 135 |
+
@property
|
| 136 |
+
def AWS_EC2_KEY_PATH(self) -> str:
|
| 137 |
+
return f"./{self.AWS_EC2_KEY_NAME}.pem"
|
| 138 |
+
|
| 139 |
+
@property
|
| 140 |
+
def AWS_EC2_SECURITY_GROUP(self) -> str:
|
| 141 |
+
return f"{self.PROJECT_NAME}-SecurityGroup"
|
| 142 |
+
|
| 143 |
+
@property
|
| 144 |
+
def AWS_SSM_ROLE_NAME(self) -> str:
|
| 145 |
+
return f"{self.PROJECT_NAME}-SSMRole"
|
| 146 |
+
|
| 147 |
+
@property
|
| 148 |
+
def AWS_SSM_PROFILE_NAME(self) -> str:
|
| 149 |
+
return f"{self.PROJECT_NAME}-SSMInstanceProfile"
|
| 150 |
+
|
| 151 |
+
@property
|
| 152 |
+
def GITHUB_PATH(self) -> str:
|
| 153 |
+
return f"{self.GITHUB_OWNER}/{self.GITHUB_REPO}"
|
| 154 |
+
|
| 155 |
+
config = Config()
|
| 156 |
+
|
| 157 |
+
def encrypt(public_key: str, secret_value: str) -> str:
|
| 158 |
+
"""
|
| 159 |
+
Encrypts a Unicode string using the provided public key.
|
| 160 |
+
|
| 161 |
+
Args:
|
| 162 |
+
public_key (str): The public key for encryption, encoded in Base64.
|
| 163 |
+
secret_value (str): The Unicode string to be encrypted.
|
| 164 |
+
|
| 165 |
+
Returns:
|
| 166 |
+
str: The encrypted value, encoded in Base64.
|
| 167 |
+
"""
|
| 168 |
+
public_key = public.PublicKey(public_key.encode("utf-8"), encoding.Base64Encoder())
|
| 169 |
+
sealed_box = public.SealedBox(public_key)
|
| 170 |
+
encrypted = sealed_box.encrypt(secret_value.encode("utf-8"))
|
| 171 |
+
return base64.b64encode(encrypted).decode("utf-8")
|
| 172 |
+
|
| 173 |
+
def set_github_secret(token: str, repo: str, secret_name: str, secret_value: str) -> None:
|
| 174 |
+
"""
|
| 175 |
+
Sets a secret in the specified GitHub repository.
|
| 176 |
+
|
| 177 |
+
Args:
|
| 178 |
+
token (str): GitHub token with permissions to set secrets.
|
| 179 |
+
repo (str): Repository path in the format "owner/repo".
|
| 180 |
+
secret_name (str): The name of the secret to set.
|
| 181 |
+
secret_value (str): The value of the secret.
|
| 182 |
+
|
| 183 |
+
Returns:
|
| 184 |
+
None
|
| 185 |
+
"""
|
| 186 |
+
secret_value = secret_value or ""
|
| 187 |
+
headers = {
|
| 188 |
+
"Authorization": f"token {token}",
|
| 189 |
+
"Accept": "application/vnd.github.v3+json"
|
| 190 |
+
}
|
| 191 |
+
response = requests.get(f"https://api.github.com/repos/{repo}/actions/secrets/public-key", headers=headers)
|
| 192 |
+
response.raise_for_status()
|
| 193 |
+
key = response.json()['key']
|
| 194 |
+
key_id = response.json()['key_id']
|
| 195 |
+
encrypted_value = encrypt(key, secret_value)
|
| 196 |
+
secret_url = f"https://api.github.com/repos/{repo}/actions/secrets/{secret_name}"
|
| 197 |
+
data = {"encrypted_value": encrypted_value, "key_id": key_id}
|
| 198 |
+
response = requests.put(secret_url, headers=headers, json=data)
|
| 199 |
+
response.raise_for_status()
|
| 200 |
+
logger.info(f"set {secret_name=}")
|
| 201 |
+
|
| 202 |
+
def set_github_secrets() -> None:
|
| 203 |
+
"""
|
| 204 |
+
Sets required AWS credentials and SSH private key as GitHub Secrets.
|
| 205 |
+
|
| 206 |
+
Returns:
|
| 207 |
+
None
|
| 208 |
+
"""
|
| 209 |
+
# Set AWS secrets
|
| 210 |
+
set_github_secret(config.GITHUB_TOKEN, config.GITHUB_PATH, 'AWS_ACCESS_KEY_ID', config.AWS_ACCESS_KEY_ID)
|
| 211 |
+
set_github_secret(config.GITHUB_TOKEN, config.GITHUB_PATH, 'AWS_SECRET_ACCESS_KEY', config.AWS_SECRET_ACCESS_KEY)
|
| 212 |
+
set_github_secret(config.GITHUB_TOKEN, config.GITHUB_PATH, 'OPENAI_API_KEY', config.OPENAI_API_KEY)
|
| 213 |
+
|
| 214 |
+
# Read the SSH private key from the file
|
| 215 |
+
try:
|
| 216 |
+
with open(config.AWS_EC2_KEY_PATH, 'r') as key_file:
|
| 217 |
+
ssh_private_key = key_file.read()
|
| 218 |
+
set_github_secret(config.GITHUB_TOKEN, config.GITHUB_PATH, 'SSH_PRIVATE_KEY', ssh_private_key)
|
| 219 |
+
except IOError as e:
|
| 220 |
+
logger.error(f"Error reading SSH private key file: {e}")
|
| 221 |
+
|
| 222 |
+
def create_key_pair(key_name: str = config.AWS_EC2_KEY_NAME, key_path: str = config.AWS_EC2_KEY_PATH) -> str | None:
|
| 223 |
+
"""
|
| 224 |
+
Creates a new EC2 key pair and saves it to a file.
|
| 225 |
+
|
| 226 |
+
Args:
|
| 227 |
+
key_name (str): The name of the key pair to create. Defaults to config.AWS_EC2_KEY_NAME.
|
| 228 |
+
key_path (str): The path where the key file should be saved. Defaults to config.AWS_EC2_KEY_PATH.
|
| 229 |
+
|
| 230 |
+
Returns:
|
| 231 |
+
str | None: The name of the created key pair or None if an error occurred.
|
| 232 |
+
"""
|
| 233 |
+
ec2_client = boto3.client('ec2', region_name=config.AWS_REGION)
|
| 234 |
+
try:
|
| 235 |
+
key_pair = ec2_client.create_key_pair(KeyName=key_name)
|
| 236 |
+
private_key = key_pair['KeyMaterial']
|
| 237 |
+
|
| 238 |
+
# Save the private key to a file
|
| 239 |
+
with open(key_path, "w") as key_file:
|
| 240 |
+
key_file.write(private_key)
|
| 241 |
+
os.chmod(key_path, 0o400) # Set read-only permissions
|
| 242 |
+
|
| 243 |
+
logger.info(f"Key pair {key_name} created and saved to {key_path}")
|
| 244 |
+
return key_name
|
| 245 |
+
except ClientError as e:
|
| 246 |
+
logger.error(f"Error creating key pair: {e}")
|
| 247 |
+
return None
|
| 248 |
+
|
| 249 |
+
def get_or_create_security_group_id(ports: list[int] = [22, 6092]) -> str | None:
|
| 250 |
+
"""
|
| 251 |
+
Retrieves or creates a security group with the specified ports opened.
|
| 252 |
+
|
| 253 |
+
Args:
|
| 254 |
+
ports (list[int]): A list of ports to open in the security group. Defaults to [22, 6092].
|
| 255 |
+
|
| 256 |
+
Returns:
|
| 257 |
+
str | None: The ID of the security group, or None if an error occurred.
|
| 258 |
+
"""
|
| 259 |
+
ec2 = boto3.client('ec2', region_name=config.AWS_REGION)
|
| 260 |
+
|
| 261 |
+
# Construct ip_permissions list
|
| 262 |
+
ip_permissions = [{
|
| 263 |
+
'IpProtocol': 'tcp',
|
| 264 |
+
'FromPort': port,
|
| 265 |
+
'ToPort': port,
|
| 266 |
+
'IpRanges': [{'CidrIp': '0.0.0.0/0'}]
|
| 267 |
+
} for port in ports]
|
| 268 |
+
|
| 269 |
+
try:
|
| 270 |
+
response = ec2.describe_security_groups(GroupNames=[config.AWS_EC2_SECURITY_GROUP])
|
| 271 |
+
security_group_id = response['SecurityGroups'][0]['GroupId']
|
| 272 |
+
logger.info(f"Security group '{config.AWS_EC2_SECURITY_GROUP}' already exists: {security_group_id}")
|
| 273 |
+
|
| 274 |
+
for ip_permission in ip_permissions:
|
| 275 |
+
try:
|
| 276 |
+
ec2.authorize_security_group_ingress(
|
| 277 |
+
GroupId=security_group_id,
|
| 278 |
+
IpPermissions=[ip_permission]
|
| 279 |
+
)
|
| 280 |
+
logger.info(f"Added inbound rule to allow TCP traffic on port {ip_permission['FromPort']} from any IP")
|
| 281 |
+
except ClientError as e:
|
| 282 |
+
if e.response['Error']['Code'] == 'InvalidPermission.Duplicate':
|
| 283 |
+
logger.info(f"Rule for port {ip_permission['FromPort']} already exists")
|
| 284 |
+
else:
|
| 285 |
+
logger.error(f"Error adding rule for port {ip_permission['FromPort']}: {e}")
|
| 286 |
+
|
| 287 |
+
return security_group_id
|
| 288 |
+
except ClientError as e:
|
| 289 |
+
if e.response['Error']['Code'] == 'InvalidGroup.NotFound':
|
| 290 |
+
try:
|
| 291 |
+
# Create the security group
|
| 292 |
+
response = ec2.create_security_group(
|
| 293 |
+
GroupName=config.AWS_EC2_SECURITY_GROUP,
|
| 294 |
+
Description='Security group for specified port access',
|
| 295 |
+
TagSpecifications=[
|
| 296 |
+
{
|
| 297 |
+
'ResourceType': 'security-group',
|
| 298 |
+
'Tags': [{'Key': 'Name', 'Value': config.PROJECT_NAME}]
|
| 299 |
+
}
|
| 300 |
+
]
|
| 301 |
+
)
|
| 302 |
+
security_group_id = response['GroupId']
|
| 303 |
+
logger.info(f"Created security group '{config.AWS_EC2_SECURITY_GROUP}' with ID: {security_group_id}")
|
| 304 |
+
|
| 305 |
+
# Add rules for the given ports
|
| 306 |
+
ec2.authorize_security_group_ingress(GroupId=security_group_id, IpPermissions=ip_permissions)
|
| 307 |
+
logger.info(f"Added inbound rules to allow access on {ports=}")
|
| 308 |
+
|
| 309 |
+
return security_group_id
|
| 310 |
+
except ClientError as e:
|
| 311 |
+
logger.error(f"Error creating security group: {e}")
|
| 312 |
+
return None
|
| 313 |
+
else:
|
| 314 |
+
logger.error(f"Error describing security groups: {e}")
|
| 315 |
+
return None
|
| 316 |
+
|
| 317 |
+
def deploy_ec2_instance(
|
| 318 |
+
ami: str = config.AWS_EC2_AMI,
|
| 319 |
+
instance_type: str = config.AWS_EC2_INSTANCE_TYPE,
|
| 320 |
+
project_name: str = config.PROJECT_NAME,
|
| 321 |
+
key_name: str = config.AWS_EC2_KEY_NAME,
|
| 322 |
+
disk_size: int = config.AWS_EC2_DISK_SIZE,
|
| 323 |
+
) -> tuple[str | None, str | None]:
|
| 324 |
+
"""
|
| 325 |
+
Deploys an EC2 instance with the specified parameters.
|
| 326 |
+
|
| 327 |
+
Args:
|
| 328 |
+
ami (str): The Amazon Machine Image ID to use for the instance. Defaults to config.AWS_EC2_AMI.
|
| 329 |
+
instance_type (str): The type of instance to deploy. Defaults to config.AWS_EC2_INSTANCE_TYPE.
|
| 330 |
+
project_name (str): The project name, used for tagging the instance. Defaults to config.PROJECT_NAME.
|
| 331 |
+
key_name (str): The name of the key pair to use for the instance. Defaults to config.AWS_EC2_KEY_NAME.
|
| 332 |
+
disk_size (int): The size of the disk in GB. Defaults to config.AWS_EC2_DISK_SIZE.
|
| 333 |
+
|
| 334 |
+
Returns:
|
| 335 |
+
tuple[str | None, str | None]: A tuple containing the instance ID and IP address, or None, None if deployment fails.
|
| 336 |
+
"""
|
| 337 |
+
ec2 = boto3.resource('ec2')
|
| 338 |
+
ec2_client = boto3.client('ec2')
|
| 339 |
+
|
| 340 |
+
# Check if key pair exists, if not create one
|
| 341 |
+
try:
|
| 342 |
+
ec2_client.describe_key_pairs(KeyNames=[key_name])
|
| 343 |
+
except ClientError as e:
|
| 344 |
+
create_key_pair(key_name)
|
| 345 |
+
|
| 346 |
+
# Fetch the security group ID
|
| 347 |
+
security_group_id = get_or_create_security_group_id()
|
| 348 |
+
if not security_group_id:
|
| 349 |
+
logger.error("Unable to retrieve security group ID. Instance deployment aborted.")
|
| 350 |
+
return None, None
|
| 351 |
+
|
| 352 |
+
# Check for existing instances
|
| 353 |
+
instances = ec2.instances.filter(
|
| 354 |
+
Filters=[
|
| 355 |
+
{'Name': 'tag:Name', 'Values': [config.PROJECT_NAME]},
|
| 356 |
+
{'Name': 'instance-state-name', 'Values': ['running', 'pending', 'stopped']}
|
| 357 |
+
]
|
| 358 |
+
)
|
| 359 |
+
|
| 360 |
+
for instance in instances:
|
| 361 |
+
if instance.state['Name'] == 'running':
|
| 362 |
+
logger.info(f"Instance already running: ID - {instance.id}, IP - {instance.public_ip_address}")
|
| 363 |
+
return instance.id, instance.public_ip_address
|
| 364 |
+
elif instance.state['Name'] == 'stopped':
|
| 365 |
+
logger.info(f"Starting existing stopped instance: ID - {instance.id}")
|
| 366 |
+
ec2_client.start_instances(InstanceIds=[instance.id])
|
| 367 |
+
instance.wait_until_running()
|
| 368 |
+
instance.reload()
|
| 369 |
+
logger.info(f"Instance started: ID - {instance.id}, IP - {instance.public_ip_address}")
|
| 370 |
+
return instance.id, instance.public_ip_address
|
| 371 |
+
elif state == 'pending':
|
| 372 |
+
logger.info(f"Instance is pending: ID - {instance.id}. Waiting for 'running' state.")
|
| 373 |
+
try:
|
| 374 |
+
instance.wait_until_running() # Wait for the instance to be in 'running' state
|
| 375 |
+
instance.reload() # Reload the instance attributes
|
| 376 |
+
logger.info(f"Instance is now running: ID - {instance.id}, IP - {instance.public_ip_address}")
|
| 377 |
+
return instance.id, instance.public_ip_address
|
| 378 |
+
except botocore.exceptions.WaiterError as e:
|
| 379 |
+
logger.error(f"Error waiting for instance to run: {e}")
|
| 380 |
+
return None, None
|
| 381 |
+
# Define EBS volume configuration
|
| 382 |
+
ebs_config = {
|
| 383 |
+
'DeviceName': '/dev/sda1', # You may need to change this depending on the instance type and AMI
|
| 384 |
+
'Ebs': {
|
| 385 |
+
'VolumeSize': disk_size,
|
| 386 |
+
'VolumeType': 'gp3', # Or other volume types like gp2, io1, etc.
|
| 387 |
+
'DeleteOnTermination': True # Set to False if you want to keep the volume after instance termination
|
| 388 |
+
},
|
| 389 |
+
}
|
| 390 |
+
|
| 391 |
+
# Create a new instance if none exist
|
| 392 |
+
new_instance = ec2.create_instances(
|
| 393 |
+
ImageId=ami,
|
| 394 |
+
MinCount=1,
|
| 395 |
+
MaxCount=1,
|
| 396 |
+
InstanceType=instance_type,
|
| 397 |
+
KeyName=key_name,
|
| 398 |
+
SecurityGroupIds=[security_group_id],
|
| 399 |
+
BlockDeviceMappings=[ebs_config],
|
| 400 |
+
TagSpecifications=[
|
| 401 |
+
{
|
| 402 |
+
'ResourceType': 'instance',
|
| 403 |
+
'Tags': [{'Key': 'Name', 'Value': project_name}]
|
| 404 |
+
},
|
| 405 |
+
]
|
| 406 |
+
)[0]
|
| 407 |
+
|
| 408 |
+
new_instance.wait_until_running()
|
| 409 |
+
new_instance.reload()
|
| 410 |
+
logger.info(f"New instance created: ID - {new_instance.id}, IP - {new_instance.public_ip_address}")
|
| 411 |
+
return new_instance.id, new_instance.public_ip_address
|
| 412 |
+
|
| 413 |
+
def configure_ec2_instance(
|
| 414 |
+
instance_id: str | None = None,
|
| 415 |
+
instance_ip: str | None = None,
|
| 416 |
+
max_ssh_retries: int = 10,
|
| 417 |
+
ssh_retry_delay: int = 10,
|
| 418 |
+
max_cmd_retries: int = 10,
|
| 419 |
+
cmd_retry_delay: int = 30,
|
| 420 |
+
) -> tuple[str | None, str | None]:
|
| 421 |
+
"""
|
| 422 |
+
Configures the specified EC2 instance for Docker builds.
|
| 423 |
+
|
| 424 |
+
Args:
|
| 425 |
+
instance_id (str | None): The ID of the instance to configure. If None, a new instance will be deployed. Defaults to None.
|
| 426 |
+
instance_ip (str | None): The IP address of the instance. Must be provided if instance_id is manually passed. Defaults to None.
|
| 427 |
+
max_ssh_retries (int): Maximum number of SSH connection retries. Defaults to 10.
|
| 428 |
+
ssh_retry_delay (int): Delay between SSH connection retries in seconds. Defaults to 10.
|
| 429 |
+
max_cmd_retries (int): Maximum number of command execution retries. Defaults to 10.
|
| 430 |
+
cmd_retry_delay (int): Delay between command execution retries in seconds. Defaults to 30.
|
| 431 |
+
|
| 432 |
+
Returns:
|
| 433 |
+
tuple[str | None, str | None]: A tuple containing the instance ID and IP address, or None, None if configuration fails.
|
| 434 |
+
"""
|
| 435 |
+
if not instance_id:
|
| 436 |
+
ec2_instance_id, ec2_instance_ip = deploy_ec2_instance()
|
| 437 |
+
else:
|
| 438 |
+
ec2_instance_id = instance_id
|
| 439 |
+
ec2_instance_ip = instance_ip # Ensure instance IP is provided if instance_id is manually passed
|
| 440 |
+
|
| 441 |
+
key = paramiko.RSAKey.from_private_key_file(config.AWS_EC2_KEY_PATH)
|
| 442 |
+
ssh_client = paramiko.SSHClient()
|
| 443 |
+
ssh_client.set_missing_host_key_policy(paramiko.AutoAddPolicy())
|
| 444 |
+
|
| 445 |
+
ssh_retries = 0
|
| 446 |
+
while ssh_retries < max_ssh_retries:
|
| 447 |
+
try:
|
| 448 |
+
ssh_client.connect(hostname=ec2_instance_ip, username='ubuntu', pkey=key)
|
| 449 |
+
break # Successful SSH connection, break out of the loop
|
| 450 |
+
except Exception as e:
|
| 451 |
+
ssh_retries += 1
|
| 452 |
+
logger.error(f"SSH connection attempt {ssh_retries} failed: {e}")
|
| 453 |
+
if ssh_retries < max_ssh_retries:
|
| 454 |
+
logger.info(f"Retrying SSH connection in {ssh_retry_delay} seconds...")
|
| 455 |
+
time.sleep(ssh_retry_delay)
|
| 456 |
+
else:
|
| 457 |
+
logger.error("Maximum SSH connection attempts reached. Aborting.")
|
| 458 |
+
return
|
| 459 |
+
|
| 460 |
+
# Commands to set up the EC2 instance for Docker builds
|
| 461 |
+
commands = [
|
| 462 |
+
"sudo apt-get update",
|
| 463 |
+
"sudo apt-get install -y docker.io",
|
| 464 |
+
"sudo systemctl start docker",
|
| 465 |
+
"sudo systemctl enable docker",
|
| 466 |
+
"sudo usermod -a -G docker ${USER}",
|
| 467 |
+
"sudo curl -L \"https://github.com/docker/compose/releases/download/1.29.2/docker-compose-$(uname -s)-$(uname -m)\" -o /usr/local/bin/docker-compose",
|
| 468 |
+
"sudo chmod +x /usr/local/bin/docker-compose",
|
| 469 |
+
"sudo ln -s /usr/local/bin/docker-compose /usr/bin/docker-compose",
|
| 470 |
+
]
|
| 471 |
+
|
| 472 |
+
for command in commands:
|
| 473 |
+
logger.info(f"Executing command: {command}")
|
| 474 |
+
cmd_retries = 0
|
| 475 |
+
while cmd_retries < max_cmd_retries:
|
| 476 |
+
stdin, stdout, stderr = ssh_client.exec_command(command)
|
| 477 |
+
exit_status = stdout.channel.recv_exit_status() # Blocking call
|
| 478 |
+
|
| 479 |
+
if exit_status == 0:
|
| 480 |
+
logger.info(f"Command executed successfully")
|
| 481 |
+
break
|
| 482 |
+
else:
|
| 483 |
+
error_message = stderr.read()
|
| 484 |
+
if "Could not get lock" in str(error_message):
|
| 485 |
+
cmd_retries += 1
|
| 486 |
+
logger.warning(f"dpkg is locked, retrying command in {cmd_retry_delay} seconds... Attempt {cmd_retries}/{max_cmd_retries}")
|
| 487 |
+
time.sleep(cmd_retry_delay)
|
| 488 |
+
else:
|
| 489 |
+
logger.error(f"Error in command: {command}, Exit Status: {exit_status}, Error: {error_message}")
|
| 490 |
+
break # Non-dpkg lock error, break out of the loop
|
| 491 |
+
|
| 492 |
+
ssh_client.close()
|
| 493 |
+
return ec2_instance_id, ec2_instance_ip
|
| 494 |
+
|
| 495 |
+
def generate_github_actions_workflow() -> None:
|
| 496 |
+
"""
|
| 497 |
+
Generates and writes the GitHub Actions workflow file for Docker build on EC2.
|
| 498 |
+
|
| 499 |
+
Returns:
|
| 500 |
+
None
|
| 501 |
+
"""
|
| 502 |
+
current_branch = get_current_git_branch()
|
| 503 |
+
|
| 504 |
+
_, host = deploy_ec2_instance()
|
| 505 |
+
|
| 506 |
+
# Set up Jinja2 environment
|
| 507 |
+
env = Environment(loader=FileSystemLoader('.'))
|
| 508 |
+
template = env.get_template('docker-build-ec2.yml.j2')
|
| 509 |
+
|
| 510 |
+
# Render the template with the current branch
|
| 511 |
+
rendered_workflow = template.render(
|
| 512 |
+
branch_name=current_branch,
|
| 513 |
+
host=host,
|
| 514 |
+
username=config.AWS_EC2_USER,
|
| 515 |
+
project_name=config.PROJECT_NAME,
|
| 516 |
+
github_path=config.GITHUB_PATH,
|
| 517 |
+
github_repo=config.GITHUB_REPO,
|
| 518 |
+
)
|
| 519 |
+
|
| 520 |
+
# Write the rendered workflow to a file
|
| 521 |
+
workflows_dir = '.github/workflows'
|
| 522 |
+
os.makedirs(workflows_dir, exist_ok=True)
|
| 523 |
+
with open(os.path.join(workflows_dir, 'docker-build-ec2.yml'), 'w') as file:
|
| 524 |
+
file.write("# Autogenerated via deploy.py, do not edit!\n\n")
|
| 525 |
+
file.write(rendered_workflow)
|
| 526 |
+
logger.info("GitHub Actions EC2 workflow file generated successfully.")
|
| 527 |
+
|
| 528 |
+
def get_current_git_branch() -> str:
|
| 529 |
+
"""
|
| 530 |
+
Retrieves the current active git branch name.
|
| 531 |
+
|
| 532 |
+
Returns:
|
| 533 |
+
str: The name of the current git branch.
|
| 534 |
+
"""
|
| 535 |
+
repo = git.Repo(search_parent_directories=True)
|
| 536 |
+
branch = repo.active_branch.name
|
| 537 |
+
return branch
|
| 538 |
+
|
| 539 |
+
def get_github_actions_url() -> str:
|
| 540 |
+
"""
|
| 541 |
+
Get the GitHub Actions URL for the user's repository.
|
| 542 |
+
|
| 543 |
+
Returns:
|
| 544 |
+
str: The Github Actions URL
|
| 545 |
+
"""
|
| 546 |
+
url = f"https://github.com/{config.GITHUB_OWNER}/{config.GITHUB_REPO}/actions"
|
| 547 |
+
return url
|
| 548 |
+
|
| 549 |
+
def get_gradio_server_url(ip_address: str) -> str:
|
| 550 |
+
"""
|
| 551 |
+
Get the Gradio server URL using the provided IP address.
|
| 552 |
+
|
| 553 |
+
Args:
|
| 554 |
+
ip_address (str): The IP address of the EC2 instance running the Gradio server.
|
| 555 |
+
|
| 556 |
+
Returns:
|
| 557 |
+
str: The Gradio server URL
|
| 558 |
+
"""
|
| 559 |
+
url = f"http://{ip_address}:6092" # TODO: make port configurable
|
| 560 |
+
return url
|
| 561 |
+
|
| 562 |
+
def git_push_set_upstream(branch_name: str):
|
| 563 |
+
"""
|
| 564 |
+
Pushes the current branch to the remote 'origin' and sets it to track the upstream branch.
|
| 565 |
+
|
| 566 |
+
Args:
|
| 567 |
+
branch_name (str): The name of the current branch to push.
|
| 568 |
+
"""
|
| 569 |
+
try:
|
| 570 |
+
# Push the current branch and set the remote 'origin' as upstream
|
| 571 |
+
subprocess.run(["git", "push", "--set-upstream", "origin", branch_name], check=True)
|
| 572 |
+
logger.info(f"Branch '{branch_name}' pushed and set up to track 'origin/{branch_name}'.")
|
| 573 |
+
except subprocess.CalledProcessError as e:
|
| 574 |
+
logger.error(f"Failed to push branch '{branch_name}' to 'origin': {e}")
|
| 575 |
+
|
| 576 |
+
def update_git_remote_with_pat(github_owner: str, repo_name: str, pat: str):
|
| 577 |
+
"""
|
| 578 |
+
Updates the git remote 'origin' to include the Personal Access Token in the URL.
|
| 579 |
+
|
| 580 |
+
Args:
|
| 581 |
+
github_owner (str): GitHub repository owner.
|
| 582 |
+
repo_name (str): GitHub repository name.
|
| 583 |
+
pat (str): Personal Access Token with the necessary scopes.
|
| 584 |
+
|
| 585 |
+
"""
|
| 586 |
+
new_origin_url = f"https://{github_owner}:{pat}@github.com/{github_owner}/{repo_name}.git"
|
| 587 |
+
try:
|
| 588 |
+
# Remove the existing 'origin' remote
|
| 589 |
+
subprocess.run(["git", "remote", "remove", "origin"], check=True)
|
| 590 |
+
# Add the new 'origin' with the PAT in the URL
|
| 591 |
+
subprocess.run(["git", "remote", "add", "origin", new_origin_url], check=True)
|
| 592 |
+
logger.info("Git remote 'origin' updated successfully.")
|
| 593 |
+
except subprocess.CalledProcessError as e:
|
| 594 |
+
logger.error(f"Failed to update git remote 'origin': {e}")
|
| 595 |
+
|
| 596 |
+
class Deploy:
|
| 597 |
+
|
| 598 |
+
@staticmethod
|
| 599 |
+
def start() -> None:
|
| 600 |
+
"""
|
| 601 |
+
Main method to execute the deployment process.
|
| 602 |
+
|
| 603 |
+
Returns:
|
| 604 |
+
None
|
| 605 |
+
"""
|
| 606 |
+
set_github_secrets()
|
| 607 |
+
instance_id, instance_ip = configure_ec2_instance()
|
| 608 |
+
assert instance_ip, f"invalid {instance_ip=}"
|
| 609 |
+
generate_github_actions_workflow()
|
| 610 |
+
|
| 611 |
+
# Update the Git remote configuration to include the PAT
|
| 612 |
+
update_git_remote_with_pat(
|
| 613 |
+
config.GITHUB_OWNER, config.GITHUB_REPO, config.GITHUB_TOKEN,
|
| 614 |
+
)
|
| 615 |
+
|
| 616 |
+
# Add, commit, and push the workflow file changes, setting the upstream branch
|
| 617 |
+
try:
|
| 618 |
+
subprocess.run(
|
| 619 |
+
["git", "add", ".github/workflows/docker-build-ec2.yml"], check=True,
|
| 620 |
+
)
|
| 621 |
+
subprocess.run(
|
| 622 |
+
["git", "commit", "-m", "'add workflow file'"], check=True,
|
| 623 |
+
)
|
| 624 |
+
current_branch = get_current_git_branch()
|
| 625 |
+
git_push_set_upstream(current_branch)
|
| 626 |
+
except subprocess.CalledProcessError as e:
|
| 627 |
+
logger.error(f"Failed to commit or push changes: {e}")
|
| 628 |
+
|
| 629 |
+
github_actions_url = get_github_actions_url()
|
| 630 |
+
gradio_server_url = get_gradio_server_url(instance_ip)
|
| 631 |
+
logger.info("Deployment process completed.")
|
| 632 |
+
logger.info(f"Check the GitHub Actions at {github_actions_url}.")
|
| 633 |
+
logger.info("Once the action is complete, run:")
|
| 634 |
+
logger.info(f" python client.py {gradio_server_url}")
|
| 635 |
+
|
| 636 |
+
@staticmethod
|
| 637 |
+
def pause(project_name: str = config.PROJECT_NAME) -> None:
|
| 638 |
+
"""
|
| 639 |
+
Shuts down the EC2 instance associated with the specified project name.
|
| 640 |
+
|
| 641 |
+
Args:
|
| 642 |
+
project_name (str): The project name used to tag the instance. Defaults to config.PROJECT_NAME.
|
| 643 |
+
|
| 644 |
+
Returns:
|
| 645 |
+
None
|
| 646 |
+
"""
|
| 647 |
+
ec2 = boto3.resource('ec2')
|
| 648 |
+
|
| 649 |
+
instances = ec2.instances.filter(
|
| 650 |
+
Filters=[
|
| 651 |
+
{'Name': 'tag:Name', 'Values': [project_name]},
|
| 652 |
+
{'Name': 'instance-state-name', 'Values': ['running']}
|
| 653 |
+
]
|
| 654 |
+
)
|
| 655 |
+
|
| 656 |
+
for instance in instances:
|
| 657 |
+
logger.info(f"Shutting down instance: ID - {instance.id}")
|
| 658 |
+
instance.stop()
|
| 659 |
+
|
| 660 |
+
@staticmethod
|
| 661 |
+
def stop(
|
| 662 |
+
project_name: str = config.PROJECT_NAME,
|
| 663 |
+
security_group_name: str = config.AWS_EC2_SECURITY_GROUP,
|
| 664 |
+
) -> None:
|
| 665 |
+
"""
|
| 666 |
+
Terminates the EC2 instance and deletes the associated security group.
|
| 667 |
+
|
| 668 |
+
Args:
|
| 669 |
+
project_name (str): The project name used to tag the instance. Defaults to config.PROJECT_NAME.
|
| 670 |
+
security_group_name (str): The name of the security group to delete. Defaults to config.AWS_EC2_SECURITY_GROUP.
|
| 671 |
+
|
| 672 |
+
Returns:
|
| 673 |
+
None
|
| 674 |
+
"""
|
| 675 |
+
ec2_resource = boto3.resource('ec2')
|
| 676 |
+
ec2_client = boto3.client('ec2')
|
| 677 |
+
|
| 678 |
+
# Terminate EC2 instances
|
| 679 |
+
instances = ec2_resource.instances.filter(
|
| 680 |
+
Filters=[
|
| 681 |
+
{'Name': 'tag:Name', 'Values': [project_name]},
|
| 682 |
+
{'Name': 'instance-state-name', 'Values': ['pending', 'running', 'shutting-down', 'stopped', 'stopping']}
|
| 683 |
+
]
|
| 684 |
+
)
|
| 685 |
+
|
| 686 |
+
for instance in instances:
|
| 687 |
+
logger.info(f"Terminating instance: ID - {instance.id}")
|
| 688 |
+
instance.terminate()
|
| 689 |
+
instance.wait_until_terminated()
|
| 690 |
+
logger.info(f"Instance {instance.id} terminated successfully.")
|
| 691 |
+
|
| 692 |
+
# Delete security group
|
| 693 |
+
try:
|
| 694 |
+
ec2_client.delete_security_group(GroupName=security_group_name)
|
| 695 |
+
logger.info(f"Deleted security group: {security_group_name}")
|
| 696 |
+
except ClientError as e:
|
| 697 |
+
if e.response['Error']['Code'] == 'InvalidGroup.NotFound':
|
| 698 |
+
logger.info(f"Security group {security_group_name} does not exist or already deleted.")
|
| 699 |
+
else:
|
| 700 |
+
logger.error(f"Error deleting security group: {e}")
|
| 701 |
+
|
| 702 |
+
@staticmethod
|
| 703 |
+
def status() -> None:
|
| 704 |
+
"""
|
| 705 |
+
Lists all EC2 instances tagged with the project name.
|
| 706 |
+
|
| 707 |
+
Returns:
|
| 708 |
+
None
|
| 709 |
+
"""
|
| 710 |
+
ec2 = boto3.resource('ec2')
|
| 711 |
+
|
| 712 |
+
instances = ec2.instances.filter(
|
| 713 |
+
Filters=[{'Name': 'tag:Name', 'Values': [config.PROJECT_NAME]}]
|
| 714 |
+
)
|
| 715 |
+
|
| 716 |
+
for instance in instances:
|
| 717 |
+
logger.info(f"Instance ID: {instance.id}, State: {instance.state['Name']}")
|
| 718 |
+
|
| 719 |
+
if __name__ == "__main__":
|
| 720 |
+
fire.Fire(Deploy)
|
deploy_requirements.txt
ADDED
|
@@ -0,0 +1,9 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
boto3==1.34.18
|
| 2 |
+
fire==0.5.0
|
| 3 |
+
gitpython==3.1.41
|
| 4 |
+
jinja2==3.1.3
|
| 5 |
+
loguru==0.7.2
|
| 6 |
+
paramiko==3.4.0
|
| 7 |
+
pydantic_settings==2.1.0
|
| 8 |
+
pynacl==1.5.0
|
| 9 |
+
requests==2.31.0
|
docker-build-ec2.yml.j2
ADDED
|
@@ -0,0 +1,44 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
name: Docker Build on EC2 Instance
|
| 2 |
+
|
| 3 |
+
on:
|
| 4 |
+
push:
|
| 5 |
+
branches:
|
| 6 |
+
- {{ branch_name }}
|
| 7 |
+
|
| 8 |
+
jobs:
|
| 9 |
+
build:
|
| 10 |
+
runs-on: ubuntu-latest
|
| 11 |
+
steps:
|
| 12 |
+
- name: Checkout code
|
| 13 |
+
uses: actions/checkout@v2
|
| 14 |
+
|
| 15 |
+
- name: SSH and Execute Build on EC2
|
| 16 |
+
uses: appleboy/ssh-action@master
|
| 17 |
+
with:
|
| 18 |
+
command_timeout: "60m"
|
| 19 |
+
host: {{ host }}
|
| 20 |
+
username: {{ username }} # Usually 'ubuntu' or 'ec2-user'
|
| 21 |
+
{% raw %}
|
| 22 |
+
key: ${{ secrets.SSH_PRIVATE_KEY }}
|
| 23 |
+
{% endraw %}
|
| 24 |
+
script: |
|
| 25 |
+
source activate pytorch
|
| 26 |
+
nvidia-smi
|
| 27 |
+
|
| 28 |
+
rm -rf {{ github_repo }} || true
|
| 29 |
+
git clone https://github.com/{{ github_path }}
|
| 30 |
+
cd {{ github_repo }}
|
| 31 |
+
git checkout {{ branch_name }}
|
| 32 |
+
git pull
|
| 33 |
+
|
| 34 |
+
# Stop and remove existing container if it's running
|
| 35 |
+
sudo docker stop {{ project_name }}-container || true
|
| 36 |
+
sudo docker rm {{ project_name }}-container || true
|
| 37 |
+
|
| 38 |
+
# Build the image
|
| 39 |
+
sudo nvidia-docker build -t {{ project_name }} . || exit 1
|
| 40 |
+
|
| 41 |
+
# Run the image
|
| 42 |
+
sudo docker run -d -p 6092:6092 --gpus all --name {{ project_name }}-container \
|
| 43 |
+
-e OPENAI_API_KEY={% raw %}${{ secrets.OPENAI_API_KEY }}{% endraw %} \
|
| 44 |
+
{{ project_name }}
|
download_ckpt.sh
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
wget https://github.com/UX-Decoder/Semantic-SAM/releases/download/checkpoint/swinl_only_sam_many2many.pth
|
| 2 |
+
wget https://huggingface.co/xdecoder/SEEM/resolve/main/seem_focall_v1.pt
|
| 3 |
+
wget https://dl.fbaipublicfiles.com/segment_anything/sam_vit_h_4b8939.pth
|
entrypoint.sh
ADDED
|
@@ -0,0 +1,10 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
#!/bin/bash
|
| 2 |
+
|
| 3 |
+
# Check if OPENAI_API_KEY is set and not empty
|
| 4 |
+
if [ -n "$OPENAI_API_KEY" ]; then
|
| 5 |
+
# If OPENAI_API_KEY is set, run demo_gpt4v_som.py
|
| 6 |
+
python ./demo_gpt4v_som.py
|
| 7 |
+
else
|
| 8 |
+
# If OPENAI_API_KEY is not set, run demo_som.py
|
| 9 |
+
python ./demo_som.py
|
| 10 |
+
fi
|
examples/gpt-4v-som-example.jpg
ADDED
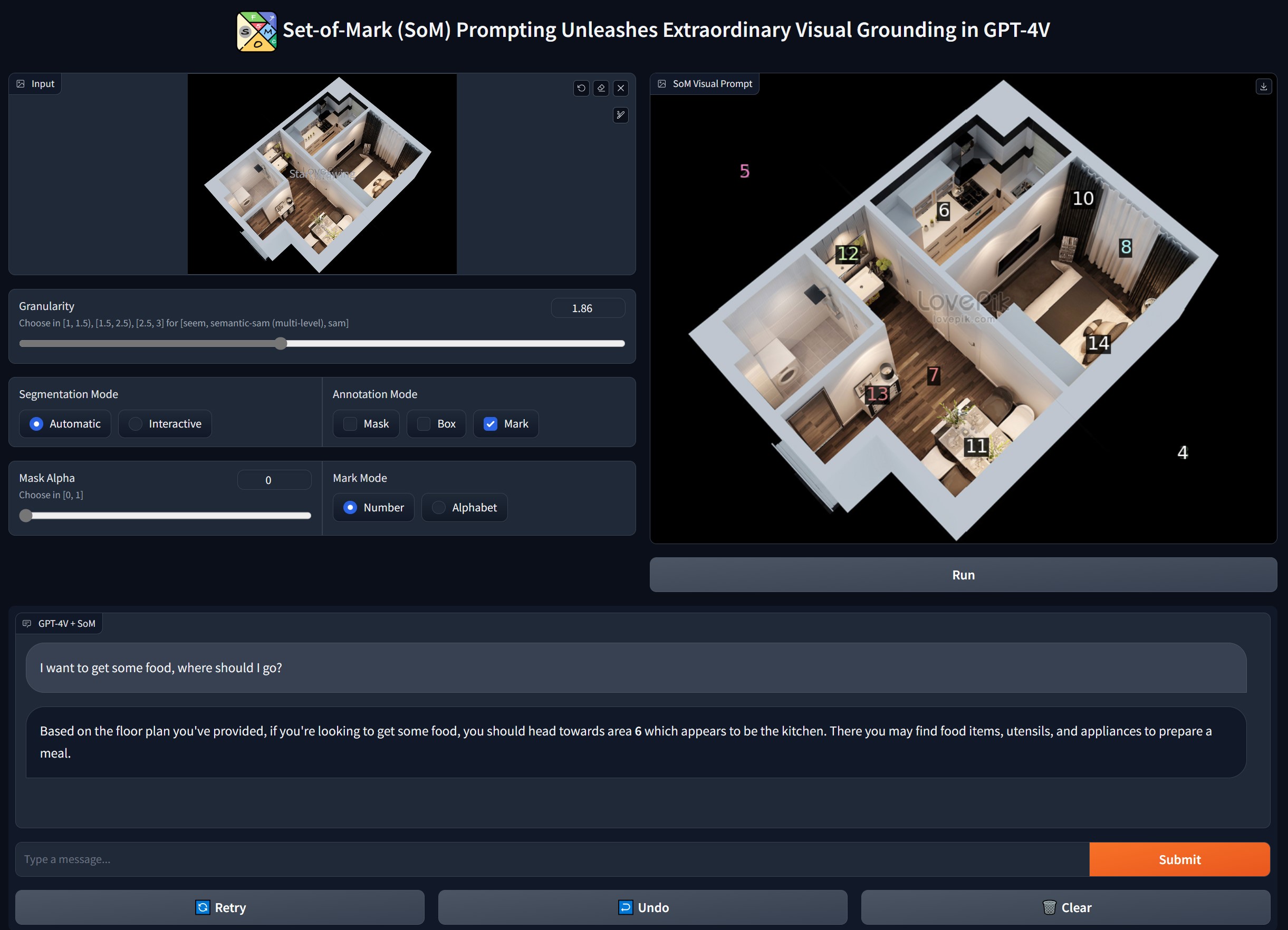
|
examples/ironing_man.jpg
ADDED

|
examples/ironing_man_som.png
ADDED

|
examples/som_logo.png
ADDED
|
|
gpt4v.py
ADDED
|
@@ -0,0 +1,69 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import os
|
| 2 |
+
import base64
|
| 3 |
+
import requests
|
| 4 |
+
from io import BytesIO
|
| 5 |
+
|
| 6 |
+
# Get OpenAI API Key from environment variable
|
| 7 |
+
api_key = os.environ["OPENAI_API_KEY"]
|
| 8 |
+
headers = {
|
| 9 |
+
"Content-Type": "application/json",
|
| 10 |
+
"Authorization": f"Bearer {api_key}"
|
| 11 |
+
}
|
| 12 |
+
|
| 13 |
+
metaprompt = '''
|
| 14 |
+
- For any marks mentioned in your answer, please highlight them with [].
|
| 15 |
+
'''
|
| 16 |
+
|
| 17 |
+
# Function to encode the image
|
| 18 |
+
def encode_image_from_file(image_path):
|
| 19 |
+
with open(image_path, "rb") as image_file:
|
| 20 |
+
return base64.b64encode(image_file.read()).decode('utf-8')
|
| 21 |
+
|
| 22 |
+
def encode_image_from_pil(image):
|
| 23 |
+
buffered = BytesIO()
|
| 24 |
+
image.save(buffered, format="JPEG")
|
| 25 |
+
return base64.b64encode(buffered.getvalue()).decode('utf-8')
|
| 26 |
+
|
| 27 |
+
def prepare_inputs(message, image):
|
| 28 |
+
|
| 29 |
+
# # Path to your image
|
| 30 |
+
# image_path = "temp.jpg"
|
| 31 |
+
# # Getting the base64 string
|
| 32 |
+
# base64_image = encode_image(image_path)
|
| 33 |
+
base64_image = encode_image_from_pil(image)
|
| 34 |
+
|
| 35 |
+
payload = {
|
| 36 |
+
"model": "gpt-4-vision-preview",
|
| 37 |
+
"messages": [
|
| 38 |
+
{
|
| 39 |
+
"role": "system",
|
| 40 |
+
"content": [
|
| 41 |
+
metaprompt
|
| 42 |
+
]
|
| 43 |
+
},
|
| 44 |
+
{
|
| 45 |
+
"role": "user",
|
| 46 |
+
"content": [
|
| 47 |
+
{
|
| 48 |
+
"type": "text",
|
| 49 |
+
"text": message,
|
| 50 |
+
},
|
| 51 |
+
{
|
| 52 |
+
"type": "image_url",
|
| 53 |
+
"image_url": {
|
| 54 |
+
"url": f"data:image/jpeg;base64,{base64_image}"
|
| 55 |
+
}
|
| 56 |
+
}
|
| 57 |
+
]
|
| 58 |
+
}
|
| 59 |
+
],
|
| 60 |
+
"max_tokens": 800
|
| 61 |
+
}
|
| 62 |
+
|
| 63 |
+
return payload
|
| 64 |
+
|
| 65 |
+
def request_gpt4v(message, image):
|
| 66 |
+
payload = prepare_inputs(message, image)
|
| 67 |
+
response = requests.post("https://api.openai.com/v1/chat/completions", headers=headers, json=payload)
|
| 68 |
+
res = response.json()['choices'][0]['message']['content']
|
| 69 |
+
return res
|
ops/cuda-repo-ubuntu2004-11-8-local_11.8.0-520.61.05-1_amd64.deb
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:94c5ab8de3d38ecca4608fdcdf07ef05d1459cf1a8871d65d4ae92621afef9e4
|
| 3 |
+
size 3181876424
|
ops/functions/__init__.py
ADDED
|
@@ -0,0 +1,13 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# ------------------------------------------------------------------------------------------------
|
| 2 |
+
# Deformable DETR
|
| 3 |
+
# Copyright (c) 2020 SenseTime. All Rights Reserved.
|
| 4 |
+
# Licensed under the Apache License, Version 2.0 [see LICENSE for details]
|
| 5 |
+
# ------------------------------------------------------------------------------------------------
|
| 6 |
+
# Modified from https://github.com/chengdazhi/Deformable-Convolution-V2-PyTorch/tree/pytorch_1.0.0
|
| 7 |
+
# ------------------------------------------------------------------------------------------------
|
| 8 |
+
|
| 9 |
+
# Copyright (c) Facebook, Inc. and its affiliates.
|
| 10 |
+
# Modified by Bowen Cheng from https://github.com/fundamentalvision/Deformable-DETR
|
| 11 |
+
|
| 12 |
+
from .ms_deform_attn_func import MSDeformAttnFunction
|
| 13 |
+
|
ops/functions/ms_deform_attn_func.py
ADDED
|
@@ -0,0 +1,72 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# ------------------------------------------------------------------------------------------------
|
| 2 |
+
# Deformable DETR
|
| 3 |
+
# Copyright (c) 2020 SenseTime. All Rights Reserved.
|
| 4 |
+
# Licensed under the Apache License, Version 2.0 [see LICENSE for details]
|
| 5 |
+
# ------------------------------------------------------------------------------------------------
|
| 6 |
+
# Modified from https://github.com/chengdazhi/Deformable-Convolution-V2-PyTorch/tree/pytorch_1.0.0
|
| 7 |
+
# ------------------------------------------------------------------------------------------------
|
| 8 |
+
|
| 9 |
+
# Copyright (c) Facebook, Inc. and its affiliates.
|
| 10 |
+
# Modified by Bowen Cheng from https://github.com/fundamentalvision/Deformable-DETR
|
| 11 |
+
|
| 12 |
+
from __future__ import absolute_import
|
| 13 |
+
from __future__ import print_function
|
| 14 |
+
from __future__ import division
|
| 15 |
+
|
| 16 |
+
import torch
|
| 17 |
+
import torch.nn.functional as F
|
| 18 |
+
from torch.autograd import Function
|
| 19 |
+
from torch.autograd.function import once_differentiable
|
| 20 |
+
|
| 21 |
+
try:
|
| 22 |
+
import MultiScaleDeformableAttention as MSDA
|
| 23 |
+
except ModuleNotFoundError as e:
|
| 24 |
+
info_string = (
|
| 25 |
+
"\n\nPlease compile MultiScaleDeformableAttention CUDA op with the following commands:\n"
|
| 26 |
+
"\t`cd mask2former/modeling/pixel_decoder/ops`\n"
|
| 27 |
+
"\t`sh make.sh`\n"
|
| 28 |
+
)
|
| 29 |
+
raise ModuleNotFoundError(info_string)
|
| 30 |
+
|
| 31 |
+
|
| 32 |
+
class MSDeformAttnFunction(Function):
|
| 33 |
+
@staticmethod
|
| 34 |
+
def forward(ctx, value, value_spatial_shapes, value_level_start_index, sampling_locations, attention_weights, im2col_step):
|
| 35 |
+
ctx.im2col_step = im2col_step
|
| 36 |
+
output = MSDA.ms_deform_attn_forward(
|
| 37 |
+
value, value_spatial_shapes, value_level_start_index, sampling_locations, attention_weights, ctx.im2col_step)
|
| 38 |
+
ctx.save_for_backward(value, value_spatial_shapes, value_level_start_index, sampling_locations, attention_weights)
|
| 39 |
+
return output
|
| 40 |
+
|
| 41 |
+
@staticmethod
|
| 42 |
+
@once_differentiable
|
| 43 |
+
def backward(ctx, grad_output):
|
| 44 |
+
value, value_spatial_shapes, value_level_start_index, sampling_locations, attention_weights = ctx.saved_tensors
|
| 45 |
+
grad_value, grad_sampling_loc, grad_attn_weight = \
|
| 46 |
+
MSDA.ms_deform_attn_backward(
|
| 47 |
+
value, value_spatial_shapes, value_level_start_index, sampling_locations, attention_weights, grad_output, ctx.im2col_step)
|
| 48 |
+
|
| 49 |
+
return grad_value, None, None, grad_sampling_loc, grad_attn_weight, None
|
| 50 |
+
|
| 51 |
+
|
| 52 |
+
def ms_deform_attn_core_pytorch(value, value_spatial_shapes, sampling_locations, attention_weights):
|
| 53 |
+
# for debug and test only,
|
| 54 |
+
# need to use cuda version instead
|
| 55 |
+
N_, S_, M_, D_ = value.shape
|
| 56 |
+
_, Lq_, M_, L_, P_, _ = sampling_locations.shape
|
| 57 |
+
value_list = value.split([H_ * W_ for H_, W_ in value_spatial_shapes], dim=1)
|
| 58 |
+
sampling_grids = 2 * sampling_locations - 1
|
| 59 |
+
sampling_value_list = []
|
| 60 |
+
for lid_, (H_, W_) in enumerate(value_spatial_shapes):
|
| 61 |
+
# N_, H_*W_, M_, D_ -> N_, H_*W_, M_*D_ -> N_, M_*D_, H_*W_ -> N_*M_, D_, H_, W_
|
| 62 |
+
value_l_ = value_list[lid_].flatten(2).transpose(1, 2).reshape(N_*M_, D_, H_, W_)
|
| 63 |
+
# N_, Lq_, M_, P_, 2 -> N_, M_, Lq_, P_, 2 -> N_*M_, Lq_, P_, 2
|
| 64 |
+
sampling_grid_l_ = sampling_grids[:, :, :, lid_].transpose(1, 2).flatten(0, 1)
|
| 65 |
+
# N_*M_, D_, Lq_, P_
|
| 66 |
+
sampling_value_l_ = F.grid_sample(value_l_, sampling_grid_l_,
|
| 67 |
+
mode='bilinear', padding_mode='zeros', align_corners=False)
|
| 68 |
+
sampling_value_list.append(sampling_value_l_)
|
| 69 |
+
# (N_, Lq_, M_, L_, P_) -> (N_, M_, Lq_, L_, P_) -> (N_, M_, 1, Lq_, L_*P_)
|
| 70 |
+
attention_weights = attention_weights.transpose(1, 2).reshape(N_*M_, 1, Lq_, L_*P_)
|
| 71 |
+
output = (torch.stack(sampling_value_list, dim=-2).flatten(-2) * attention_weights).sum(-1).view(N_, M_*D_, Lq_)
|
| 72 |
+
return output.transpose(1, 2).contiguous()
|
ops/make.sh
ADDED
|
@@ -0,0 +1,35 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
#!/usr/bin/env bash
|
| 2 |
+
# ------------------------------------------------------------------------------------------------
|
| 3 |
+
# Deformable DETR
|
| 4 |
+
# Copyright (c) 2020 SenseTime. All Rights Reserved.
|
| 5 |
+
# Licensed under the Apache License, Version 2.0 [see LICENSE for details]
|
| 6 |
+
# ------------------------------------------------------------------------------------------------
|
| 7 |
+
# Modified from https://github.com/chengdazhi/Deformable-Convolution-V2-PyTorch/tree/pytorch_1.0.0
|
| 8 |
+
# ------------------------------------------------------------------------------------------------
|
| 9 |
+
|
| 10 |
+
# Copyright (c) Facebook, Inc. and its affiliates.
|
| 11 |
+
# Modified by Bowen Cheng from https://github.com/fundamentalvision/Deformable-DETR
|
| 12 |
+
# Modified by Richard Abrich from https://github.com/OpenAdaptAI/OpenAdapt
|
| 13 |
+
|
| 14 |
+
# from https://github.com/pytorch/extension-cpp/issues/71#issuecomment-1778326052
|
| 15 |
+
CUDA_VERSION=$(/usr/local/cuda/bin/nvcc --version | sed -n 's/^.*release \([0-9]\+\.[0-9]\+\).*$/\1/p')
|
| 16 |
+
if [[ ${CUDA_VERSION} == 9.0* ]]; then
|
| 17 |
+
export TORCH_CUDA_ARCH_LIST="3.5;5.0;6.0;7.0+PTX"
|
| 18 |
+
elif [[ ${CUDA_VERSION} == 9.2* ]]; then
|
| 19 |
+
export TORCH_CUDA_ARCH_LIST="3.5;5.0;6.0;6.1;7.0+PTX"
|
| 20 |
+
elif [[ ${CUDA_VERSION} == 10.* ]]; then
|
| 21 |
+
export TORCH_CUDA_ARCH_LIST="3.5;5.0;6.0;6.1;7.0;7.5+PTX"
|
| 22 |
+
elif [[ ${CUDA_VERSION} == 11.0* ]]; then
|
| 23 |
+
export TORCH_CUDA_ARCH_LIST="3.5;5.0;6.0;6.1;7.0;7.5;8.0+PTX"
|
| 24 |
+
elif [[ ${CUDA_VERSION} == 11.* ]]; then
|
| 25 |
+
export TORCH_CUDA_ARCH_LIST="3.5;5.0;6.0;6.1;7.0;7.5;8.0;8.6+PTX"
|
| 26 |
+
elif [[ ${CUDA_VERSION} == 12.* ]]; then
|
| 27 |
+
export TORCH_CUDA_ARCH_LIST="5.0;5.2;5.3;6.0;6.1;6.2;7.0;7.2;7.5;8.0;8.6;8.7;8.9;9.0+PTX"
|
| 28 |
+
else
|
| 29 |
+
echo "unsupported cuda version."
|
| 30 |
+
exit 1
|
| 31 |
+
fi
|
| 32 |
+
|
| 33 |
+
python -m pip install git+https://github.com/facebookresearch/detectron2.git
|
| 34 |
+
|
| 35 |
+
python setup.py build install
|
ops/modules/__init__.py
ADDED
|
@@ -0,0 +1,12 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# ------------------------------------------------------------------------------------------------
|
| 2 |
+
# Deformable DETR
|
| 3 |
+
# Copyright (c) 2020 SenseTime. All Rights Reserved.
|
| 4 |
+
# Licensed under the Apache License, Version 2.0 [see LICENSE for details]
|
| 5 |
+
# ------------------------------------------------------------------------------------------------
|
| 6 |
+
# Modified from https://github.com/chengdazhi/Deformable-Convolution-V2-PyTorch/tree/pytorch_1.0.0
|
| 7 |
+
# ------------------------------------------------------------------------------------------------
|
| 8 |
+
|
| 9 |
+
# Copyright (c) Facebook, Inc. and its affiliates.
|
| 10 |
+
# Modified by Bowen Cheng from https://github.com/fundamentalvision/Deformable-DETR
|
| 11 |
+
|
| 12 |
+
from .ms_deform_attn import MSDeformAttn
|
ops/modules/ms_deform_attn.py
ADDED
|
@@ -0,0 +1,125 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# ------------------------------------------------------------------------------------------------
|
| 2 |
+
# Deformable DETR
|
| 3 |
+
# Copyright (c) 2020 SenseTime. All Rights Reserved.
|
| 4 |
+
# Licensed under the Apache License, Version 2.0 [see LICENSE for details]
|
| 5 |
+
# ------------------------------------------------------------------------------------------------
|
| 6 |
+
# Modified from https://github.com/chengdazhi/Deformable-Convolution-V2-PyTorch/tree/pytorch_1.0.0
|
| 7 |
+
# ------------------------------------------------------------------------------------------------
|
| 8 |
+
|
| 9 |
+
# Copyright (c) Facebook, Inc. and its affiliates.
|
| 10 |
+
# Modified by Bowen Cheng from https://github.com/fundamentalvision/Deformable-DETR
|
| 11 |
+
|
| 12 |
+
from __future__ import absolute_import
|
| 13 |
+
from __future__ import print_function
|
| 14 |
+
from __future__ import division
|
| 15 |
+
|
| 16 |
+
import warnings
|
| 17 |
+
import math
|
| 18 |
+
|
| 19 |
+
import torch
|
| 20 |
+
from torch import nn
|
| 21 |
+
import torch.nn.functional as F
|
| 22 |
+
from torch.nn.init import xavier_uniform_, constant_
|
| 23 |
+
|
| 24 |
+
from ..functions import MSDeformAttnFunction
|
| 25 |
+
from ..functions.ms_deform_attn_func import ms_deform_attn_core_pytorch
|
| 26 |
+
|
| 27 |
+
|
| 28 |
+
def _is_power_of_2(n):
|
| 29 |
+
if (not isinstance(n, int)) or (n < 0):
|
| 30 |
+
raise ValueError("invalid input for _is_power_of_2: {} (type: {})".format(n, type(n)))
|
| 31 |
+
return (n & (n-1) == 0) and n != 0
|
| 32 |
+
|
| 33 |
+
|
| 34 |
+
class MSDeformAttn(nn.Module):
|
| 35 |
+
def __init__(self, d_model=256, n_levels=4, n_heads=8, n_points=4):
|
| 36 |
+
"""
|
| 37 |
+
Multi-Scale Deformable Attention Module
|
| 38 |
+
:param d_model hidden dimension
|
| 39 |
+
:param n_levels number of feature levels
|
| 40 |
+
:param n_heads number of attention heads
|
| 41 |
+
:param n_points number of sampling points per attention head per feature level
|
| 42 |
+
"""
|
| 43 |
+
super().__init__()
|
| 44 |
+
if d_model % n_heads != 0:
|
| 45 |
+
raise ValueError('d_model must be divisible by n_heads, but got {} and {}'.format(d_model, n_heads))
|
| 46 |
+
_d_per_head = d_model // n_heads
|
| 47 |
+
# you'd better set _d_per_head to a power of 2 which is more efficient in our CUDA implementation
|
| 48 |
+
if not _is_power_of_2(_d_per_head):
|
| 49 |
+
warnings.warn("You'd better set d_model in MSDeformAttn to make the dimension of each attention head a power of 2 "
|
| 50 |
+
"which is more efficient in our CUDA implementation.")
|
| 51 |
+
|
| 52 |
+
self.im2col_step = 128
|
| 53 |
+
|
| 54 |
+
self.d_model = d_model
|
| 55 |
+
self.n_levels = n_levels
|
| 56 |
+
self.n_heads = n_heads
|
| 57 |
+
self.n_points = n_points
|
| 58 |
+
|
| 59 |
+
self.sampling_offsets = nn.Linear(d_model, n_heads * n_levels * n_points * 2)
|
| 60 |
+
self.attention_weights = nn.Linear(d_model, n_heads * n_levels * n_points)
|
| 61 |
+
self.value_proj = nn.Linear(d_model, d_model)
|
| 62 |
+
self.output_proj = nn.Linear(d_model, d_model)
|
| 63 |
+
|
| 64 |
+
self._reset_parameters()
|
| 65 |
+
|
| 66 |
+
def _reset_parameters(self):
|
| 67 |
+
constant_(self.sampling_offsets.weight.data, 0.)
|
| 68 |
+
thetas = torch.arange(self.n_heads, dtype=torch.float32) * (2.0 * math.pi / self.n_heads)
|
| 69 |
+
grid_init = torch.stack([thetas.cos(), thetas.sin()], -1)
|
| 70 |
+
grid_init = (grid_init / grid_init.abs().max(-1, keepdim=True)[0]).view(self.n_heads, 1, 1, 2).repeat(1, self.n_levels, self.n_points, 1)
|
| 71 |
+
for i in range(self.n_points):
|
| 72 |
+
grid_init[:, :, i, :] *= i + 1
|
| 73 |
+
with torch.no_grad():
|
| 74 |
+
self.sampling_offsets.bias = nn.Parameter(grid_init.view(-1))
|
| 75 |
+
constant_(self.attention_weights.weight.data, 0.)
|
| 76 |
+
constant_(self.attention_weights.bias.data, 0.)
|
| 77 |
+
xavier_uniform_(self.value_proj.weight.data)
|
| 78 |
+
constant_(self.value_proj.bias.data, 0.)
|
| 79 |
+
xavier_uniform_(self.output_proj.weight.data)
|
| 80 |
+
constant_(self.output_proj.bias.data, 0.)
|
| 81 |
+
|
| 82 |
+
def forward(self, query, reference_points, input_flatten, input_spatial_shapes, input_level_start_index, input_padding_mask=None):
|
| 83 |
+
"""
|
| 84 |
+
:param query (N, Length_{query}, C)
|
| 85 |
+
:param reference_points (N, Length_{query}, n_levels, 2), range in [0, 1], top-left (0,0), bottom-right (1, 1), including padding area
|
| 86 |
+
or (N, Length_{query}, n_levels, 4), add additional (w, h) to form reference boxes
|
| 87 |
+
:param input_flatten (N, \sum_{l=0}^{L-1} H_l \cdot W_l, C)
|
| 88 |
+
:param input_spatial_shapes (n_levels, 2), [(H_0, W_0), (H_1, W_1), ..., (H_{L-1}, W_{L-1})]
|
| 89 |
+
:param input_level_start_index (n_levels, ), [0, H_0*W_0, H_0*W_0+H_1*W_1, H_0*W_0+H_1*W_1+H_2*W_2, ..., H_0*W_0+H_1*W_1+...+H_{L-1}*W_{L-1}]
|
| 90 |
+
:param input_padding_mask (N, \sum_{l=0}^{L-1} H_l \cdot W_l), True for padding elements, False for non-padding elements
|
| 91 |
+
|
| 92 |
+
:return output (N, Length_{query}, C)
|
| 93 |
+
"""
|
| 94 |
+
N, Len_q, _ = query.shape
|
| 95 |
+
N, Len_in, _ = input_flatten.shape
|
| 96 |
+
assert (input_spatial_shapes[:, 0] * input_spatial_shapes[:, 1]).sum() == Len_in
|
| 97 |
+
|
| 98 |
+
value = self.value_proj(input_flatten)
|
| 99 |
+
if input_padding_mask is not None:
|
| 100 |
+
value = value.masked_fill(input_padding_mask[..., None], float(0))
|
| 101 |
+
value = value.view(N, Len_in, self.n_heads, self.d_model // self.n_heads)
|
| 102 |
+
sampling_offsets = self.sampling_offsets(query).view(N, Len_q, self.n_heads, self.n_levels, self.n_points, 2)
|
| 103 |
+
attention_weights = self.attention_weights(query).view(N, Len_q, self.n_heads, self.n_levels * self.n_points)
|
| 104 |
+
attention_weights = F.softmax(attention_weights, -1).view(N, Len_q, self.n_heads, self.n_levels, self.n_points)
|
| 105 |
+
# N, Len_q, n_heads, n_levels, n_points, 2
|
| 106 |
+
if reference_points.shape[-1] == 2:
|
| 107 |
+
offset_normalizer = torch.stack([input_spatial_shapes[..., 1], input_spatial_shapes[..., 0]], -1)
|
| 108 |
+
sampling_locations = reference_points[:, :, None, :, None, :] \
|
| 109 |
+
+ sampling_offsets / offset_normalizer[None, None, None, :, None, :]
|
| 110 |
+
elif reference_points.shape[-1] == 4:
|
| 111 |
+
sampling_locations = reference_points[:, :, None, :, None, :2] \
|
| 112 |
+
+ sampling_offsets / self.n_points * reference_points[:, :, None, :, None, 2:] * 0.5
|
| 113 |
+
else:
|
| 114 |
+
raise ValueError(
|
| 115 |
+
'Last dim of reference_points must be 2 or 4, but get {} instead.'.format(reference_points.shape[-1]))
|
| 116 |
+
try:
|
| 117 |
+
output = MSDeformAttnFunction.apply(
|
| 118 |
+
value, input_spatial_shapes, input_level_start_index, sampling_locations, attention_weights, self.im2col_step)
|
| 119 |
+
except:
|
| 120 |
+
# CPU
|
| 121 |
+
output = ms_deform_attn_core_pytorch(value, input_spatial_shapes, sampling_locations, attention_weights)
|
| 122 |
+
# # For FLOPs calculation only
|
| 123 |
+
# output = ms_deform_attn_core_pytorch(value, input_spatial_shapes, sampling_locations, attention_weights)
|
| 124 |
+
output = self.output_proj(output)
|
| 125 |
+
return output
|
ops/setup.py
ADDED
|
@@ -0,0 +1,78 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# ------------------------------------------------------------------------------------------------
|
| 2 |
+
# Deformable DETR
|
| 3 |
+
# Copyright (c) 2020 SenseTime. All Rights Reserved.
|
| 4 |
+
# Licensed under the Apache License, Version 2.0 [see LICENSE for details]
|
| 5 |
+
# ------------------------------------------------------------------------------------------------
|
| 6 |
+
# Modified from https://github.com/chengdazhi/Deformable-Convolution-V2-PyTorch/tree/pytorch_1.0.0
|
| 7 |
+
# ------------------------------------------------------------------------------------------------
|
| 8 |
+
|
| 9 |
+
# Copyright (c) Facebook, Inc. and its affiliates.
|
| 10 |
+
# Modified by Bowen Cheng from https://github.com/fundamentalvision/Deformable-DETR
|
| 11 |
+
|
| 12 |
+
import os
|
| 13 |
+
import glob
|
| 14 |
+
|
| 15 |
+
import torch
|
| 16 |
+
|
| 17 |
+
from torch.utils.cpp_extension import CUDA_HOME
|
| 18 |
+
from torch.utils.cpp_extension import CppExtension
|
| 19 |
+
from torch.utils.cpp_extension import CUDAExtension
|
| 20 |
+
|
| 21 |
+
from setuptools import find_packages
|
| 22 |
+
from setuptools import setup
|
| 23 |
+
|
| 24 |
+
requirements = ["torch", "torchvision"]
|
| 25 |
+
|
| 26 |
+
def get_extensions():
|
| 27 |
+
this_dir = os.path.dirname(os.path.abspath(__file__))
|
| 28 |
+
extensions_dir = os.path.join(this_dir, "src")
|
| 29 |
+
|
| 30 |
+
main_file = glob.glob(os.path.join(extensions_dir, "*.cpp"))
|
| 31 |
+
source_cpu = glob.glob(os.path.join(extensions_dir, "cpu", "*.cpp"))
|
| 32 |
+
source_cuda = glob.glob(os.path.join(extensions_dir, "cuda", "*.cu"))
|
| 33 |
+
|
| 34 |
+
sources = main_file + source_cpu
|
| 35 |
+
extension = CppExtension
|
| 36 |
+
extra_compile_args = {"cxx": []}
|
| 37 |
+
define_macros = []
|
| 38 |
+
|
| 39 |
+
# Force cuda since torch ask for a device, not if cuda is in fact available.
|
| 40 |
+
if (os.environ.get('FORCE_CUDA') or torch.cuda.is_available()) and CUDA_HOME is not None:
|
| 41 |
+
extension = CUDAExtension
|
| 42 |
+
sources += source_cuda
|
| 43 |
+
define_macros += [("WITH_CUDA", None)]
|
| 44 |
+
extra_compile_args["nvcc"] = [
|
| 45 |
+
"-DCUDA_HAS_FP16=1",
|
| 46 |
+
"-D__CUDA_NO_HALF_OPERATORS__",
|
| 47 |
+
"-D__CUDA_NO_HALF_CONVERSIONS__",
|
| 48 |
+
"-D__CUDA_NO_HALF2_OPERATORS__",
|
| 49 |
+
]
|
| 50 |
+
else:
|
| 51 |
+
if CUDA_HOME is None:
|
| 52 |
+
raise NotImplementedError('CUDA_HOME is None. Please set environment variable CUDA_HOME.')
|
| 53 |
+
else:
|
| 54 |
+
raise NotImplementedError('No CUDA runtime is found. Please set FORCE_CUDA=1 or test it by running torch.cuda.is_available().')
|
| 55 |
+
|
| 56 |
+
sources = [os.path.join(extensions_dir, s) for s in sources]
|
| 57 |
+
include_dirs = [extensions_dir]
|
| 58 |
+
ext_modules = [
|
| 59 |
+
extension(
|
| 60 |
+
"MultiScaleDeformableAttention",
|
| 61 |
+
sources,
|
| 62 |
+
include_dirs=include_dirs,
|
| 63 |
+
define_macros=define_macros,
|
| 64 |
+
extra_compile_args=extra_compile_args,
|
| 65 |
+
)
|
| 66 |
+
]
|
| 67 |
+
return ext_modules
|
| 68 |
+
|
| 69 |
+
setup(
|
| 70 |
+
name="MultiScaleDeformableAttention",
|
| 71 |
+
version="1.0",
|
| 72 |
+
author="Weijie Su",
|
| 73 |
+
url="https://github.com/fundamentalvision/Deformable-DETR",
|
| 74 |
+
description="PyTorch Wrapper for CUDA Functions of Multi-Scale Deformable Attention",
|
| 75 |
+
packages=find_packages(exclude=("configs", "tests",)),
|
| 76 |
+
ext_modules=get_extensions(),
|
| 77 |
+
cmdclass={"build_ext": torch.utils.cpp_extension.BuildExtension},
|
| 78 |
+
)
|
ops/src/cpu/ms_deform_attn_cpu.cpp
ADDED
|
@@ -0,0 +1,46 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
/*!
|
| 2 |
+
**************************************************************************************************
|
| 3 |
+
* Deformable DETR
|
| 4 |
+
* Copyright (c) 2020 SenseTime. All Rights Reserved.
|
| 5 |
+
* Licensed under the Apache License, Version 2.0 [see LICENSE for details]
|
| 6 |
+
**************************************************************************************************
|
| 7 |
+
* Modified from https://github.com/chengdazhi/Deformable-Convolution-V2-PyTorch/tree/pytorch_1.0.0
|
| 8 |
+
**************************************************************************************************
|
| 9 |
+
*/
|
| 10 |
+
|
| 11 |
+
/*!
|
| 12 |
+
* Copyright (c) Facebook, Inc. and its affiliates.
|
| 13 |
+
* Modified by Bowen Cheng from https://github.com/fundamentalvision/Deformable-DETR
|
| 14 |
+
*/
|
| 15 |
+
|
| 16 |
+
#include <vector>
|
| 17 |
+
|
| 18 |
+
#include <ATen/ATen.h>
|
| 19 |
+
#include <ATen/cuda/CUDAContext.h>
|
| 20 |
+
|
| 21 |
+
|
| 22 |
+
at::Tensor
|
| 23 |
+
ms_deform_attn_cpu_forward(
|
| 24 |
+
const at::Tensor &value,
|
| 25 |
+
const at::Tensor &spatial_shapes,
|
| 26 |
+
const at::Tensor &level_start_index,
|
| 27 |
+
const at::Tensor &sampling_loc,
|
| 28 |
+
const at::Tensor &attn_weight,
|
| 29 |
+
const int im2col_step)
|
| 30 |
+
{
|
| 31 |
+
AT_ERROR("Not implement on cpu");
|
| 32 |
+
}
|
| 33 |
+
|
| 34 |
+
std::vector<at::Tensor>
|
| 35 |
+
ms_deform_attn_cpu_backward(
|
| 36 |
+
const at::Tensor &value,
|
| 37 |
+
const at::Tensor &spatial_shapes,
|
| 38 |
+
const at::Tensor &level_start_index,
|
| 39 |
+
const at::Tensor &sampling_loc,
|
| 40 |
+
const at::Tensor &attn_weight,
|
| 41 |
+
const at::Tensor &grad_output,
|
| 42 |
+
const int im2col_step)
|
| 43 |
+
{
|
| 44 |
+
AT_ERROR("Not implement on cpu");
|
| 45 |
+
}
|
| 46 |
+
|
ops/src/cpu/ms_deform_attn_cpu.h
ADDED
|
@@ -0,0 +1,38 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
/*!
|
| 2 |
+
**************************************************************************************************
|
| 3 |
+
* Deformable DETR
|
| 4 |
+
* Copyright (c) 2020 SenseTime. All Rights Reserved.
|
| 5 |
+
* Licensed under the Apache License, Version 2.0 [see LICENSE for details]
|
| 6 |
+
**************************************************************************************************
|
| 7 |
+
* Modified from https://github.com/chengdazhi/Deformable-Convolution-V2-PyTorch/tree/pytorch_1.0.0
|
| 8 |
+
**************************************************************************************************
|
| 9 |
+
*/
|
| 10 |
+
|
| 11 |
+
/*!
|
| 12 |
+
* Copyright (c) Facebook, Inc. and its affiliates.
|
| 13 |
+
* Modified by Bowen Cheng from https://github.com/fundamentalvision/Deformable-DETR
|
| 14 |
+
*/
|
| 15 |
+
|
| 16 |
+
#pragma once
|
| 17 |
+
#include <torch/extension.h>
|
| 18 |
+
|
| 19 |
+
at::Tensor
|
| 20 |
+
ms_deform_attn_cpu_forward(
|
| 21 |
+
const at::Tensor &value,
|
| 22 |
+
const at::Tensor &spatial_shapes,
|
| 23 |
+
const at::Tensor &level_start_index,
|
| 24 |
+
const at::Tensor &sampling_loc,
|
| 25 |
+
const at::Tensor &attn_weight,
|
| 26 |
+
const int im2col_step);
|
| 27 |
+
|
| 28 |
+
std::vector<at::Tensor>
|
| 29 |
+
ms_deform_attn_cpu_backward(
|
| 30 |
+
const at::Tensor &value,
|
| 31 |
+
const at::Tensor &spatial_shapes,
|
| 32 |
+
const at::Tensor &level_start_index,
|
| 33 |
+
const at::Tensor &sampling_loc,
|
| 34 |
+
const at::Tensor &attn_weight,
|
| 35 |
+
const at::Tensor &grad_output,
|
| 36 |
+
const int im2col_step);
|
| 37 |
+
|
| 38 |
+
|
ops/src/cuda/ms_deform_attn_cuda.cu
ADDED
|
@@ -0,0 +1,158 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
/*!
|
| 2 |
+
**************************************************************************************************
|
| 3 |
+
* Deformable DETR
|
| 4 |
+
* Copyright (c) 2020 SenseTime. All Rights Reserved.
|
| 5 |
+
* Licensed under the Apache License, Version 2.0 [see LICENSE for details]
|
| 6 |
+
**************************************************************************************************
|
| 7 |
+
* Modified from https://github.com/chengdazhi/Deformable-Convolution-V2-PyTorch/tree/pytorch_1.0.0
|
| 8 |
+
**************************************************************************************************
|
| 9 |
+
*/
|
| 10 |
+
|
| 11 |
+
/*!
|
| 12 |
+
* Copyright (c) Facebook, Inc. and its affiliates.
|
| 13 |
+
* Modified by Bowen Cheng from https://github.com/fundamentalvision/Deformable-DETR
|
| 14 |
+
*/
|
| 15 |
+
|
| 16 |
+
#include <vector>
|
| 17 |
+
#include "cuda/ms_deform_im2col_cuda.cuh"
|
| 18 |
+
|
| 19 |
+
#include <ATen/ATen.h>
|
| 20 |
+
#include <ATen/cuda/CUDAContext.h>
|
| 21 |
+
#include <cuda.h>
|
| 22 |
+
#include <cuda_runtime.h>
|
| 23 |
+
|
| 24 |
+
|
| 25 |
+
at::Tensor ms_deform_attn_cuda_forward(
|
| 26 |
+
const at::Tensor &value,
|
| 27 |
+
const at::Tensor &spatial_shapes,
|
| 28 |
+
const at::Tensor &level_start_index,
|
| 29 |
+
const at::Tensor &sampling_loc,
|
| 30 |
+
const at::Tensor &attn_weight,
|
| 31 |
+
const int im2col_step)
|
| 32 |
+
{
|
| 33 |
+
AT_ASSERTM(value.is_contiguous(), "value tensor has to be contiguous");
|
| 34 |
+
AT_ASSERTM(spatial_shapes.is_contiguous(), "spatial_shapes tensor has to be contiguous");
|
| 35 |
+
AT_ASSERTM(level_start_index.is_contiguous(), "level_start_index tensor has to be contiguous");
|
| 36 |
+
AT_ASSERTM(sampling_loc.is_contiguous(), "sampling_loc tensor has to be contiguous");
|
| 37 |
+
AT_ASSERTM(attn_weight.is_contiguous(), "attn_weight tensor has to be contiguous");
|
| 38 |
+
|
| 39 |
+
AT_ASSERTM(value.type().is_cuda(), "value must be a CUDA tensor");
|
| 40 |
+
AT_ASSERTM(spatial_shapes.type().is_cuda(), "spatial_shapes must be a CUDA tensor");
|
| 41 |
+
AT_ASSERTM(level_start_index.type().is_cuda(), "level_start_index must be a CUDA tensor");
|
| 42 |
+
AT_ASSERTM(sampling_loc.type().is_cuda(), "sampling_loc must be a CUDA tensor");
|
| 43 |
+
AT_ASSERTM(attn_weight.type().is_cuda(), "attn_weight must be a CUDA tensor");
|
| 44 |
+
|
| 45 |
+
const int batch = value.size(0);
|
| 46 |
+
const int spatial_size = value.size(1);
|
| 47 |
+
const int num_heads = value.size(2);
|
| 48 |
+
const int channels = value.size(3);
|
| 49 |
+
|
| 50 |
+
const int num_levels = spatial_shapes.size(0);
|
| 51 |
+
|
| 52 |
+
const int num_query = sampling_loc.size(1);
|
| 53 |
+
const int num_point = sampling_loc.size(4);
|
| 54 |
+
|
| 55 |
+
const int im2col_step_ = std::min(batch, im2col_step);
|
| 56 |
+
|
| 57 |
+
AT_ASSERTM(batch % im2col_step_ == 0, "batch(%d) must divide im2col_step(%d)", batch, im2col_step_);
|
| 58 |
+
|
| 59 |
+
auto output = at::zeros({batch, num_query, num_heads, channels}, value.options());
|
| 60 |
+
|
| 61 |
+
const int batch_n = im2col_step_;
|
| 62 |
+
auto output_n = output.view({batch/im2col_step_, batch_n, num_query, num_heads, channels});
|
| 63 |
+
auto per_value_size = spatial_size * num_heads * channels;
|
| 64 |
+
auto per_sample_loc_size = num_query * num_heads * num_levels * num_point * 2;
|
| 65 |
+
auto per_attn_weight_size = num_query * num_heads * num_levels * num_point;
|
| 66 |
+
for (int n = 0; n < batch/im2col_step_; ++n)
|
| 67 |
+
{
|
| 68 |
+
auto columns = output_n.select(0, n);
|
| 69 |
+
AT_DISPATCH_FLOATING_TYPES(value.type(), "ms_deform_attn_forward_cuda", ([&] {
|
| 70 |
+
ms_deformable_im2col_cuda(at::cuda::getCurrentCUDAStream(),
|
| 71 |
+
value.data<scalar_t>() + n * im2col_step_ * per_value_size,
|
| 72 |
+
spatial_shapes.data<int64_t>(),
|
| 73 |
+
level_start_index.data<int64_t>(),
|
| 74 |
+
sampling_loc.data<scalar_t>() + n * im2col_step_ * per_sample_loc_size,
|
| 75 |
+
attn_weight.data<scalar_t>() + n * im2col_step_ * per_attn_weight_size,
|
| 76 |
+
batch_n, spatial_size, num_heads, channels, num_levels, num_query, num_point,
|
| 77 |
+
columns.data<scalar_t>());
|
| 78 |
+
|
| 79 |
+
}));
|
| 80 |
+
}
|
| 81 |
+
|
| 82 |
+
output = output.view({batch, num_query, num_heads*channels});
|
| 83 |
+
|
| 84 |
+
return output;
|
| 85 |
+
}
|
| 86 |
+
|
| 87 |
+
|
| 88 |
+
std::vector<at::Tensor> ms_deform_attn_cuda_backward(
|
| 89 |
+
const at::Tensor &value,
|
| 90 |
+
const at::Tensor &spatial_shapes,
|
| 91 |
+
const at::Tensor &level_start_index,
|
| 92 |
+
const at::Tensor &sampling_loc,
|
| 93 |
+
const at::Tensor &attn_weight,
|
| 94 |
+
const at::Tensor &grad_output,
|
| 95 |
+
const int im2col_step)
|
| 96 |
+
{
|
| 97 |
+
|
| 98 |
+
AT_ASSERTM(value.is_contiguous(), "value tensor has to be contiguous");
|
| 99 |
+
AT_ASSERTM(spatial_shapes.is_contiguous(), "spatial_shapes tensor has to be contiguous");
|
| 100 |
+
AT_ASSERTM(level_start_index.is_contiguous(), "level_start_index tensor has to be contiguous");
|
| 101 |
+
AT_ASSERTM(sampling_loc.is_contiguous(), "sampling_loc tensor has to be contiguous");
|
| 102 |
+
AT_ASSERTM(attn_weight.is_contiguous(), "attn_weight tensor has to be contiguous");
|
| 103 |
+
AT_ASSERTM(grad_output.is_contiguous(), "grad_output tensor has to be contiguous");
|
| 104 |
+
|
| 105 |
+
AT_ASSERTM(value.type().is_cuda(), "value must be a CUDA tensor");
|
| 106 |
+
AT_ASSERTM(spatial_shapes.type().is_cuda(), "spatial_shapes must be a CUDA tensor");
|
| 107 |
+
AT_ASSERTM(level_start_index.type().is_cuda(), "level_start_index must be a CUDA tensor");
|
| 108 |
+
AT_ASSERTM(sampling_loc.type().is_cuda(), "sampling_loc must be a CUDA tensor");
|
| 109 |
+
AT_ASSERTM(attn_weight.type().is_cuda(), "attn_weight must be a CUDA tensor");
|
| 110 |
+
AT_ASSERTM(grad_output.type().is_cuda(), "grad_output must be a CUDA tensor");
|
| 111 |
+
|
| 112 |
+
const int batch = value.size(0);
|
| 113 |
+
const int spatial_size = value.size(1);
|
| 114 |
+
const int num_heads = value.size(2);
|
| 115 |
+
const int channels = value.size(3);
|
| 116 |
+
|
| 117 |
+
const int num_levels = spatial_shapes.size(0);
|
| 118 |
+
|
| 119 |
+
const int num_query = sampling_loc.size(1);
|
| 120 |
+
const int num_point = sampling_loc.size(4);
|
| 121 |
+
|
| 122 |
+
const int im2col_step_ = std::min(batch, im2col_step);
|
| 123 |
+
|
| 124 |
+
AT_ASSERTM(batch % im2col_step_ == 0, "batch(%d) must divide im2col_step(%d)", batch, im2col_step_);
|
| 125 |
+
|
| 126 |
+
auto grad_value = at::zeros_like(value);
|
| 127 |
+
auto grad_sampling_loc = at::zeros_like(sampling_loc);
|
| 128 |
+
auto grad_attn_weight = at::zeros_like(attn_weight);
|
| 129 |
+
|
| 130 |
+
const int batch_n = im2col_step_;
|
| 131 |
+
auto per_value_size = spatial_size * num_heads * channels;
|
| 132 |
+
auto per_sample_loc_size = num_query * num_heads * num_levels * num_point * 2;
|
| 133 |
+
auto per_attn_weight_size = num_query * num_heads * num_levels * num_point;
|
| 134 |
+
auto grad_output_n = grad_output.view({batch/im2col_step_, batch_n, num_query, num_heads, channels});
|
| 135 |
+
|
| 136 |
+
for (int n = 0; n < batch/im2col_step_; ++n)
|
| 137 |
+
{
|
| 138 |
+
auto grad_output_g = grad_output_n.select(0, n);
|
| 139 |
+
AT_DISPATCH_FLOATING_TYPES(value.type(), "ms_deform_attn_backward_cuda", ([&] {
|
| 140 |
+
ms_deformable_col2im_cuda(at::cuda::getCurrentCUDAStream(),
|
| 141 |
+
grad_output_g.data<scalar_t>(),
|
| 142 |
+
value.data<scalar_t>() + n * im2col_step_ * per_value_size,
|
| 143 |
+
spatial_shapes.data<int64_t>(),
|
| 144 |
+
level_start_index.data<int64_t>(),
|
| 145 |
+
sampling_loc.data<scalar_t>() + n * im2col_step_ * per_sample_loc_size,
|
| 146 |
+
attn_weight.data<scalar_t>() + n * im2col_step_ * per_attn_weight_size,
|
| 147 |
+
batch_n, spatial_size, num_heads, channels, num_levels, num_query, num_point,
|
| 148 |
+
grad_value.data<scalar_t>() + n * im2col_step_ * per_value_size,
|
| 149 |
+
grad_sampling_loc.data<scalar_t>() + n * im2col_step_ * per_sample_loc_size,
|
| 150 |
+
grad_attn_weight.data<scalar_t>() + n * im2col_step_ * per_attn_weight_size);
|
| 151 |
+
|
| 152 |
+
}));
|
| 153 |
+
}
|
| 154 |
+
|
| 155 |
+
return {
|
| 156 |
+
grad_value, grad_sampling_loc, grad_attn_weight
|
| 157 |
+
};
|
| 158 |
+
}
|
ops/src/cuda/ms_deform_attn_cuda.h
ADDED
|
@@ -0,0 +1,35 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
/*!
|
| 2 |
+
**************************************************************************************************
|
| 3 |
+
* Deformable DETR
|
| 4 |
+
* Copyright (c) 2020 SenseTime. All Rights Reserved.
|
| 5 |
+
* Licensed under the Apache License, Version 2.0 [see LICENSE for details]
|
| 6 |
+
**************************************************************************************************
|
| 7 |
+
* Modified from https://github.com/chengdazhi/Deformable-Convolution-V2-PyTorch/tree/pytorch_1.0.0
|
| 8 |
+
**************************************************************************************************
|
| 9 |
+
*/
|
| 10 |
+
|
| 11 |
+
/*!
|
| 12 |
+
* Copyright (c) Facebook, Inc. and its affiliates.
|
| 13 |
+
* Modified by Bowen Cheng from https://github.com/fundamentalvision/Deformable-DETR
|
| 14 |
+
*/
|
| 15 |
+
|
| 16 |
+
#pragma once
|
| 17 |
+
#include <torch/extension.h>
|
| 18 |
+
|
| 19 |
+
at::Tensor ms_deform_attn_cuda_forward(
|
| 20 |
+
const at::Tensor &value,
|
| 21 |
+
const at::Tensor &spatial_shapes,
|
| 22 |
+
const at::Tensor &level_start_index,
|
| 23 |
+
const at::Tensor &sampling_loc,
|
| 24 |
+
const at::Tensor &attn_weight,
|
| 25 |
+
const int im2col_step);
|
| 26 |
+
|
| 27 |
+
std::vector<at::Tensor> ms_deform_attn_cuda_backward(
|
| 28 |
+
const at::Tensor &value,
|
| 29 |
+
const at::Tensor &spatial_shapes,
|
| 30 |
+
const at::Tensor &level_start_index,
|
| 31 |
+
const at::Tensor &sampling_loc,
|
| 32 |
+
const at::Tensor &attn_weight,
|
| 33 |
+
const at::Tensor &grad_output,
|
| 34 |
+
const int im2col_step);
|
| 35 |
+
|
ops/src/cuda/ms_deform_im2col_cuda.cuh
ADDED
|
@@ -0,0 +1,1332 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
/*!
|
| 2 |
+
**************************************************************************
|
| 3 |
+
* Deformable DETR
|
| 4 |
+
* Copyright (c) 2020 SenseTime. All Rights Reserved.
|
| 5 |
+
* Licensed under the Apache License, Version 2.0 [see LICENSE for details]
|
| 6 |
+
**************************************************************************
|
| 7 |
+
* Modified from DCN (https://github.com/msracver/Deformable-ConvNets)
|
| 8 |
+
* Copyright (c) 2018 Microsoft
|
| 9 |
+
**************************************************************************
|
| 10 |
+
*/
|
| 11 |
+
|
| 12 |
+
/*!
|
| 13 |
+
* Copyright (c) Facebook, Inc. and its affiliates.
|
| 14 |
+
* Modified by Bowen Cheng from https://github.com/fundamentalvision/Deformable-DETR
|
| 15 |
+
*/
|
| 16 |
+
|
| 17 |
+
#include <cstdio>
|
| 18 |
+
#include <algorithm>
|
| 19 |
+
#include <cstring>
|
| 20 |
+
|
| 21 |
+
#include <ATen/ATen.h>
|
| 22 |
+
#include <ATen/cuda/CUDAContext.h>
|
| 23 |
+
|
| 24 |
+
#include <THC/THCAtomics.cuh>
|
| 25 |
+
|
| 26 |
+
#define CUDA_KERNEL_LOOP(i, n) \
|
| 27 |
+
for (int i = blockIdx.x * blockDim.x + threadIdx.x; \
|
| 28 |
+
i < (n); \
|
| 29 |
+
i += blockDim.x * gridDim.x)
|
| 30 |
+
|
| 31 |
+
const int CUDA_NUM_THREADS = 1024;
|
| 32 |
+
inline int GET_BLOCKS(const int N, const int num_threads)
|
| 33 |
+
{
|
| 34 |
+
return (N + num_threads - 1) / num_threads;
|
| 35 |
+
}
|
| 36 |
+
|
| 37 |
+
|
| 38 |
+
template <typename scalar_t>
|
| 39 |
+
__device__ scalar_t ms_deform_attn_im2col_bilinear(const scalar_t* &bottom_data,
|
| 40 |
+
const int &height, const int &width, const int &nheads, const int &channels,
|
| 41 |
+
const scalar_t &h, const scalar_t &w, const int &m, const int &c)
|
| 42 |
+
{
|
| 43 |
+
const int h_low = floor(h);
|
| 44 |
+
const int w_low = floor(w);
|
| 45 |
+
const int h_high = h_low + 1;
|
| 46 |
+
const int w_high = w_low + 1;
|
| 47 |
+
|
| 48 |
+
const scalar_t lh = h - h_low;
|
| 49 |
+
const scalar_t lw = w - w_low;
|
| 50 |
+
const scalar_t hh = 1 - lh, hw = 1 - lw;
|
| 51 |
+
|
| 52 |
+
const int w_stride = nheads * channels;
|
| 53 |
+
const int h_stride = width * w_stride;
|
| 54 |
+
const int h_low_ptr_offset = h_low * h_stride;
|
| 55 |
+
const int h_high_ptr_offset = h_low_ptr_offset + h_stride;
|
| 56 |
+
const int w_low_ptr_offset = w_low * w_stride;
|
| 57 |
+
const int w_high_ptr_offset = w_low_ptr_offset + w_stride;
|
| 58 |
+
const int base_ptr = m * channels + c;
|
| 59 |
+
|
| 60 |
+
scalar_t v1 = 0;
|
| 61 |
+
if (h_low >= 0 && w_low >= 0)
|
| 62 |
+
{
|
| 63 |
+
const int ptr1 = h_low_ptr_offset + w_low_ptr_offset + base_ptr;
|
| 64 |
+
v1 = bottom_data[ptr1];
|
| 65 |
+
}
|
| 66 |
+
scalar_t v2 = 0;
|
| 67 |
+
if (h_low >= 0 && w_high <= width - 1)
|
| 68 |
+
{
|
| 69 |
+
const int ptr2 = h_low_ptr_offset + w_high_ptr_offset + base_ptr;
|
| 70 |
+
v2 = bottom_data[ptr2];
|
| 71 |
+
}
|
| 72 |
+
scalar_t v3 = 0;
|
| 73 |
+
if (h_high <= height - 1 && w_low >= 0)
|
| 74 |
+
{
|
| 75 |
+
const int ptr3 = h_high_ptr_offset + w_low_ptr_offset + base_ptr;
|
| 76 |
+
v3 = bottom_data[ptr3];
|
| 77 |
+
}
|
| 78 |
+
scalar_t v4 = 0;
|
| 79 |
+
if (h_high <= height - 1 && w_high <= width - 1)
|
| 80 |
+
{
|
| 81 |
+
const int ptr4 = h_high_ptr_offset + w_high_ptr_offset + base_ptr;
|
| 82 |
+
v4 = bottom_data[ptr4];
|
| 83 |
+
}
|
| 84 |
+
|
| 85 |
+
const scalar_t w1 = hh * hw, w2 = hh * lw, w3 = lh * hw, w4 = lh * lw;
|
| 86 |
+
|
| 87 |
+
const scalar_t val = (w1 * v1 + w2 * v2 + w3 * v3 + w4 * v4);
|
| 88 |
+
return val;
|
| 89 |
+
}
|
| 90 |
+
|
| 91 |
+
|
| 92 |
+
template <typename scalar_t>
|
| 93 |
+
__device__ void ms_deform_attn_col2im_bilinear(const scalar_t* &bottom_data,
|
| 94 |
+
const int &height, const int &width, const int &nheads, const int &channels,
|
| 95 |
+
const scalar_t &h, const scalar_t &w, const int &m, const int &c,
|
| 96 |
+
const scalar_t &top_grad,
|
| 97 |
+
const scalar_t &attn_weight,
|
| 98 |
+
scalar_t* &grad_value,
|
| 99 |
+
scalar_t* grad_sampling_loc,
|
| 100 |
+
scalar_t* grad_attn_weight)
|
| 101 |
+
{
|
| 102 |
+
const int h_low = floor(h);
|
| 103 |
+
const int w_low = floor(w);
|
| 104 |
+
const int h_high = h_low + 1;
|
| 105 |
+
const int w_high = w_low + 1;
|
| 106 |
+
|
| 107 |
+
const scalar_t lh = h - h_low;
|
| 108 |
+
const scalar_t lw = w - w_low;
|
| 109 |
+
const scalar_t hh = 1 - lh, hw = 1 - lw;
|
| 110 |
+
|
| 111 |
+
const int w_stride = nheads * channels;
|
| 112 |
+
const int h_stride = width * w_stride;
|
| 113 |
+
const int h_low_ptr_offset = h_low * h_stride;
|
| 114 |
+
const int h_high_ptr_offset = h_low_ptr_offset + h_stride;
|
| 115 |
+
const int w_low_ptr_offset = w_low * w_stride;
|
| 116 |
+
const int w_high_ptr_offset = w_low_ptr_offset + w_stride;
|
| 117 |
+
const int base_ptr = m * channels + c;
|
| 118 |
+
|
| 119 |
+
const scalar_t w1 = hh * hw, w2 = hh * lw, w3 = lh * hw, w4 = lh * lw;
|
| 120 |
+
const scalar_t top_grad_value = top_grad * attn_weight;
|
| 121 |
+
scalar_t grad_h_weight = 0, grad_w_weight = 0;
|
| 122 |
+
|
| 123 |
+
scalar_t v1 = 0;
|
| 124 |
+
if (h_low >= 0 && w_low >= 0)
|
| 125 |
+
{
|
| 126 |
+
const int ptr1 = h_low_ptr_offset + w_low_ptr_offset + base_ptr;
|
| 127 |
+
v1 = bottom_data[ptr1];
|
| 128 |
+
grad_h_weight -= hw * v1;
|
| 129 |
+
grad_w_weight -= hh * v1;
|
| 130 |
+
atomicAdd(grad_value+ptr1, w1*top_grad_value);
|
| 131 |
+
}
|
| 132 |
+
scalar_t v2 = 0;
|
| 133 |
+
if (h_low >= 0 && w_high <= width - 1)
|
| 134 |
+
{
|
| 135 |
+
const int ptr2 = h_low_ptr_offset + w_high_ptr_offset + base_ptr;
|
| 136 |
+
v2 = bottom_data[ptr2];
|
| 137 |
+
grad_h_weight -= lw * v2;
|
| 138 |
+
grad_w_weight += hh * v2;
|
| 139 |
+
atomicAdd(grad_value+ptr2, w2*top_grad_value);
|
| 140 |
+
}
|
| 141 |
+
scalar_t v3 = 0;
|
| 142 |
+
if (h_high <= height - 1 && w_low >= 0)
|
| 143 |
+
{
|
| 144 |
+
const int ptr3 = h_high_ptr_offset + w_low_ptr_offset + base_ptr;
|
| 145 |
+
v3 = bottom_data[ptr3];
|
| 146 |
+
grad_h_weight += hw * v3;
|
| 147 |
+
grad_w_weight -= lh * v3;
|
| 148 |
+
atomicAdd(grad_value+ptr3, w3*top_grad_value);
|
| 149 |
+
}
|
| 150 |
+
scalar_t v4 = 0;
|
| 151 |
+
if (h_high <= height - 1 && w_high <= width - 1)
|
| 152 |
+
{
|
| 153 |
+
const int ptr4 = h_high_ptr_offset + w_high_ptr_offset + base_ptr;
|
| 154 |
+
v4 = bottom_data[ptr4];
|
| 155 |
+
grad_h_weight += lw * v4;
|
| 156 |
+
grad_w_weight += lh * v4;
|
| 157 |
+
atomicAdd(grad_value+ptr4, w4*top_grad_value);
|
| 158 |
+
}
|
| 159 |
+
|
| 160 |
+
const scalar_t val = (w1 * v1 + w2 * v2 + w3 * v3 + w4 * v4);
|
| 161 |
+
*grad_attn_weight = top_grad * val;
|
| 162 |
+
*grad_sampling_loc = width * grad_w_weight * top_grad_value;
|
| 163 |
+
*(grad_sampling_loc + 1) = height * grad_h_weight * top_grad_value;
|
| 164 |
+
}
|
| 165 |
+
|
| 166 |
+
|
| 167 |
+
template <typename scalar_t>
|
| 168 |
+
__device__ void ms_deform_attn_col2im_bilinear_gm(const scalar_t* &bottom_data,
|
| 169 |
+
const int &height, const int &width, const int &nheads, const int &channels,
|
| 170 |
+
const scalar_t &h, const scalar_t &w, const int &m, const int &c,
|
| 171 |
+
const scalar_t &top_grad,
|
| 172 |
+
const scalar_t &attn_weight,
|
| 173 |
+
scalar_t* &grad_value,
|
| 174 |
+
scalar_t* grad_sampling_loc,
|
| 175 |
+
scalar_t* grad_attn_weight)
|
| 176 |
+
{
|
| 177 |
+
const int h_low = floor(h);
|
| 178 |
+
const int w_low = floor(w);
|
| 179 |
+
const int h_high = h_low + 1;
|
| 180 |
+
const int w_high = w_low + 1;
|
| 181 |
+
|
| 182 |
+
const scalar_t lh = h - h_low;
|
| 183 |
+
const scalar_t lw = w - w_low;
|
| 184 |
+
const scalar_t hh = 1 - lh, hw = 1 - lw;
|
| 185 |
+
|
| 186 |
+
const int w_stride = nheads * channels;
|
| 187 |
+
const int h_stride = width * w_stride;
|
| 188 |
+
const int h_low_ptr_offset = h_low * h_stride;
|
| 189 |
+
const int h_high_ptr_offset = h_low_ptr_offset + h_stride;
|
| 190 |
+
const int w_low_ptr_offset = w_low * w_stride;
|
| 191 |
+
const int w_high_ptr_offset = w_low_ptr_offset + w_stride;
|
| 192 |
+
const int base_ptr = m * channels + c;
|
| 193 |
+
|
| 194 |
+
const scalar_t w1 = hh * hw, w2 = hh * lw, w3 = lh * hw, w4 = lh * lw;
|
| 195 |
+
const scalar_t top_grad_value = top_grad * attn_weight;
|
| 196 |
+
scalar_t grad_h_weight = 0, grad_w_weight = 0;
|
| 197 |
+
|
| 198 |
+
scalar_t v1 = 0;
|
| 199 |
+
if (h_low >= 0 && w_low >= 0)
|
| 200 |
+
{
|
| 201 |
+
const int ptr1 = h_low_ptr_offset + w_low_ptr_offset + base_ptr;
|
| 202 |
+
v1 = bottom_data[ptr1];
|
| 203 |
+
grad_h_weight -= hw * v1;
|
| 204 |
+
grad_w_weight -= hh * v1;
|
| 205 |
+
atomicAdd(grad_value+ptr1, w1*top_grad_value);
|
| 206 |
+
}
|
| 207 |
+
scalar_t v2 = 0;
|
| 208 |
+
if (h_low >= 0 && w_high <= width - 1)
|
| 209 |
+
{
|
| 210 |
+
const int ptr2 = h_low_ptr_offset + w_high_ptr_offset + base_ptr;
|
| 211 |
+
v2 = bottom_data[ptr2];
|
| 212 |
+
grad_h_weight -= lw * v2;
|
| 213 |
+
grad_w_weight += hh * v2;
|
| 214 |
+
atomicAdd(grad_value+ptr2, w2*top_grad_value);
|
| 215 |
+
}
|
| 216 |
+
scalar_t v3 = 0;
|
| 217 |
+
if (h_high <= height - 1 && w_low >= 0)
|
| 218 |
+
{
|
| 219 |
+
const int ptr3 = h_high_ptr_offset + w_low_ptr_offset + base_ptr;
|
| 220 |
+
v3 = bottom_data[ptr3];
|
| 221 |
+
grad_h_weight += hw * v3;
|
| 222 |
+
grad_w_weight -= lh * v3;
|
| 223 |
+
atomicAdd(grad_value+ptr3, w3*top_grad_value);
|
| 224 |
+
}
|
| 225 |
+
scalar_t v4 = 0;
|
| 226 |
+
if (h_high <= height - 1 && w_high <= width - 1)
|
| 227 |
+
{
|
| 228 |
+
const int ptr4 = h_high_ptr_offset + w_high_ptr_offset + base_ptr;
|
| 229 |
+
v4 = bottom_data[ptr4];
|
| 230 |
+
grad_h_weight += lw * v4;
|
| 231 |
+
grad_w_weight += lh * v4;
|
| 232 |
+
atomicAdd(grad_value+ptr4, w4*top_grad_value);
|
| 233 |
+
}
|
| 234 |
+
|
| 235 |
+
const scalar_t val = (w1 * v1 + w2 * v2 + w3 * v3 + w4 * v4);
|
| 236 |
+
atomicAdd(grad_attn_weight, top_grad * val);
|
| 237 |
+
atomicAdd(grad_sampling_loc, width * grad_w_weight * top_grad_value);
|
| 238 |
+
atomicAdd(grad_sampling_loc + 1, height * grad_h_weight * top_grad_value);
|
| 239 |
+
}
|
| 240 |
+
|
| 241 |
+
|
| 242 |
+
template <typename scalar_t>
|
| 243 |
+
__global__ void ms_deformable_im2col_gpu_kernel(const int n,
|
| 244 |
+
const scalar_t *data_value,
|
| 245 |
+
const int64_t *data_spatial_shapes,
|
| 246 |
+
const int64_t *data_level_start_index,
|
| 247 |
+
const scalar_t *data_sampling_loc,
|
| 248 |
+
const scalar_t *data_attn_weight,
|
| 249 |
+
const int batch_size,
|
| 250 |
+
const int spatial_size,
|
| 251 |
+
const int num_heads,
|
| 252 |
+
const int channels,
|
| 253 |
+
const int num_levels,
|
| 254 |
+
const int num_query,
|
| 255 |
+
const int num_point,
|
| 256 |
+
scalar_t *data_col)
|
| 257 |
+
{
|
| 258 |
+
CUDA_KERNEL_LOOP(index, n)
|
| 259 |
+
{
|
| 260 |
+
int _temp = index;
|
| 261 |
+
const int c_col = _temp % channels;
|
| 262 |
+
_temp /= channels;
|
| 263 |
+
const int sampling_index = _temp;
|
| 264 |
+
const int m_col = _temp % num_heads;
|
| 265 |
+
_temp /= num_heads;
|
| 266 |
+
const int q_col = _temp % num_query;
|
| 267 |
+
_temp /= num_query;
|
| 268 |
+
const int b_col = _temp;
|
| 269 |
+
|
| 270 |
+
scalar_t *data_col_ptr = data_col + index;
|
| 271 |
+
int data_weight_ptr = sampling_index * num_levels * num_point;
|
| 272 |
+
int data_loc_w_ptr = data_weight_ptr << 1;
|
| 273 |
+
const int qid_stride = num_heads * channels;
|
| 274 |
+
const int data_value_ptr_init_offset = b_col * spatial_size * qid_stride;
|
| 275 |
+
scalar_t col = 0;
|
| 276 |
+
|
| 277 |
+
for (int l_col=0; l_col < num_levels; ++l_col)
|
| 278 |
+
{
|
| 279 |
+
const int level_start_id = data_level_start_index[l_col];
|
| 280 |
+
const int spatial_h_ptr = l_col << 1;
|
| 281 |
+
const int spatial_h = data_spatial_shapes[spatial_h_ptr];
|
| 282 |
+
const int spatial_w = data_spatial_shapes[spatial_h_ptr + 1];
|
| 283 |
+
const scalar_t *data_value_ptr = data_value + (data_value_ptr_init_offset + level_start_id * qid_stride);
|
| 284 |
+
for (int p_col=0; p_col < num_point; ++p_col)
|
| 285 |
+
{
|
| 286 |
+
const scalar_t loc_w = data_sampling_loc[data_loc_w_ptr];
|
| 287 |
+
const scalar_t loc_h = data_sampling_loc[data_loc_w_ptr + 1];
|
| 288 |
+
const scalar_t weight = data_attn_weight[data_weight_ptr];
|
| 289 |
+
|
| 290 |
+
const scalar_t h_im = loc_h * spatial_h - 0.5;
|
| 291 |
+
const scalar_t w_im = loc_w * spatial_w - 0.5;
|
| 292 |
+
|
| 293 |
+
if (h_im > -1 && w_im > -1 && h_im < spatial_h && w_im < spatial_w)
|
| 294 |
+
{
|
| 295 |
+
col += ms_deform_attn_im2col_bilinear(data_value_ptr, spatial_h, spatial_w, num_heads, channels, h_im, w_im, m_col, c_col) * weight;
|
| 296 |
+
}
|
| 297 |
+
|
| 298 |
+
data_weight_ptr += 1;
|
| 299 |
+
data_loc_w_ptr += 2;
|
| 300 |
+
}
|
| 301 |
+
}
|
| 302 |
+
*data_col_ptr = col;
|
| 303 |
+
}
|
| 304 |
+
}
|
| 305 |
+
|
| 306 |
+
template <typename scalar_t, unsigned int blockSize>
|
| 307 |
+
__global__ void ms_deformable_col2im_gpu_kernel_shm_blocksize_aware_reduce_v1(const int n,
|
| 308 |
+
const scalar_t *grad_col,
|
| 309 |
+
const scalar_t *data_value,
|
| 310 |
+
const int64_t *data_spatial_shapes,
|
| 311 |
+
const int64_t *data_level_start_index,
|
| 312 |
+
const scalar_t *data_sampling_loc,
|
| 313 |
+
const scalar_t *data_attn_weight,
|
| 314 |
+
const int batch_size,
|
| 315 |
+
const int spatial_size,
|
| 316 |
+
const int num_heads,
|
| 317 |
+
const int channels,
|
| 318 |
+
const int num_levels,
|
| 319 |
+
const int num_query,
|
| 320 |
+
const int num_point,
|
| 321 |
+
scalar_t *grad_value,
|
| 322 |
+
scalar_t *grad_sampling_loc,
|
| 323 |
+
scalar_t *grad_attn_weight)
|
| 324 |
+
{
|
| 325 |
+
CUDA_KERNEL_LOOP(index, n)
|
| 326 |
+
{
|
| 327 |
+
__shared__ scalar_t cache_grad_sampling_loc[blockSize * 2];
|
| 328 |
+
__shared__ scalar_t cache_grad_attn_weight[blockSize];
|
| 329 |
+
unsigned int tid = threadIdx.x;
|
| 330 |
+
int _temp = index;
|
| 331 |
+
const int c_col = _temp % channels;
|
| 332 |
+
_temp /= channels;
|
| 333 |
+
const int sampling_index = _temp;
|
| 334 |
+
const int m_col = _temp % num_heads;
|
| 335 |
+
_temp /= num_heads;
|
| 336 |
+
const int q_col = _temp % num_query;
|
| 337 |
+
_temp /= num_query;
|
| 338 |
+
const int b_col = _temp;
|
| 339 |
+
|
| 340 |
+
const scalar_t top_grad = grad_col[index];
|
| 341 |
+
|
| 342 |
+
int data_weight_ptr = sampling_index * num_levels * num_point;
|
| 343 |
+
int data_loc_w_ptr = data_weight_ptr << 1;
|
| 344 |
+
const int grad_sampling_ptr = data_weight_ptr;
|
| 345 |
+
grad_sampling_loc += grad_sampling_ptr << 1;
|
| 346 |
+
grad_attn_weight += grad_sampling_ptr;
|
| 347 |
+
const int grad_weight_stride = 1;
|
| 348 |
+
const int grad_loc_stride = 2;
|
| 349 |
+
const int qid_stride = num_heads * channels;
|
| 350 |
+
const int data_value_ptr_init_offset = b_col * spatial_size * qid_stride;
|
| 351 |
+
|
| 352 |
+
for (int l_col=0; l_col < num_levels; ++l_col)
|
| 353 |
+
{
|
| 354 |
+
const int level_start_id = data_level_start_index[l_col];
|
| 355 |
+
const int spatial_h_ptr = l_col << 1;
|
| 356 |
+
const int spatial_h = data_spatial_shapes[spatial_h_ptr];
|
| 357 |
+
const int spatial_w = data_spatial_shapes[spatial_h_ptr + 1];
|
| 358 |
+
const int value_ptr_offset = data_value_ptr_init_offset + level_start_id * qid_stride;
|
| 359 |
+
const scalar_t *data_value_ptr = data_value + value_ptr_offset;
|
| 360 |
+
scalar_t *grad_value_ptr = grad_value + value_ptr_offset;
|
| 361 |
+
|
| 362 |
+
for (int p_col=0; p_col < num_point; ++p_col)
|
| 363 |
+
{
|
| 364 |
+
const scalar_t loc_w = data_sampling_loc[data_loc_w_ptr];
|
| 365 |
+
const scalar_t loc_h = data_sampling_loc[data_loc_w_ptr + 1];
|
| 366 |
+
const scalar_t weight = data_attn_weight[data_weight_ptr];
|
| 367 |
+
|
| 368 |
+
const scalar_t h_im = loc_h * spatial_h - 0.5;
|
| 369 |
+
const scalar_t w_im = loc_w * spatial_w - 0.5;
|
| 370 |
+
*(cache_grad_sampling_loc+(threadIdx.x << 1)) = 0;
|
| 371 |
+
*(cache_grad_sampling_loc+((threadIdx.x << 1) + 1)) = 0;
|
| 372 |
+
*(cache_grad_attn_weight+threadIdx.x)=0;
|
| 373 |
+
if (h_im > -1 && w_im > -1 && h_im < spatial_h && w_im < spatial_w)
|
| 374 |
+
{
|
| 375 |
+
ms_deform_attn_col2im_bilinear(
|
| 376 |
+
data_value_ptr, spatial_h, spatial_w, num_heads, channels, h_im, w_im, m_col, c_col,
|
| 377 |
+
top_grad, weight, grad_value_ptr,
|
| 378 |
+
cache_grad_sampling_loc+(threadIdx.x << 1), cache_grad_attn_weight+threadIdx.x);
|
| 379 |
+
}
|
| 380 |
+
|
| 381 |
+
__syncthreads();
|
| 382 |
+
if (tid == 0)
|
| 383 |
+
{
|
| 384 |
+
scalar_t _grad_w=cache_grad_sampling_loc[0], _grad_h=cache_grad_sampling_loc[1], _grad_a=cache_grad_attn_weight[0];
|
| 385 |
+
int sid=2;
|
| 386 |
+
for (unsigned int tid = 1; tid < blockSize; ++tid)
|
| 387 |
+
{
|
| 388 |
+
_grad_w += cache_grad_sampling_loc[sid];
|
| 389 |
+
_grad_h += cache_grad_sampling_loc[sid + 1];
|
| 390 |
+
_grad_a += cache_grad_attn_weight[tid];
|
| 391 |
+
sid += 2;
|
| 392 |
+
}
|
| 393 |
+
|
| 394 |
+
|
| 395 |
+
*grad_sampling_loc = _grad_w;
|
| 396 |
+
*(grad_sampling_loc + 1) = _grad_h;
|
| 397 |
+
*grad_attn_weight = _grad_a;
|
| 398 |
+
}
|
| 399 |
+
__syncthreads();
|
| 400 |
+
|
| 401 |
+
data_weight_ptr += 1;
|
| 402 |
+
data_loc_w_ptr += 2;
|
| 403 |
+
grad_attn_weight += grad_weight_stride;
|
| 404 |
+
grad_sampling_loc += grad_loc_stride;
|
| 405 |
+
}
|
| 406 |
+
}
|
| 407 |
+
}
|
| 408 |
+
}
|
| 409 |
+
|
| 410 |
+
|
| 411 |
+
template <typename scalar_t, unsigned int blockSize>
|
| 412 |
+
__global__ void ms_deformable_col2im_gpu_kernel_shm_blocksize_aware_reduce_v2(const int n,
|
| 413 |
+
const scalar_t *grad_col,
|
| 414 |
+
const scalar_t *data_value,
|
| 415 |
+
const int64_t *data_spatial_shapes,
|
| 416 |
+
const int64_t *data_level_start_index,
|
| 417 |
+
const scalar_t *data_sampling_loc,
|
| 418 |
+
const scalar_t *data_attn_weight,
|
| 419 |
+
const int batch_size,
|
| 420 |
+
const int spatial_size,
|
| 421 |
+
const int num_heads,
|
| 422 |
+
const int channels,
|
| 423 |
+
const int num_levels,
|
| 424 |
+
const int num_query,
|
| 425 |
+
const int num_point,
|
| 426 |
+
scalar_t *grad_value,
|
| 427 |
+
scalar_t *grad_sampling_loc,
|
| 428 |
+
scalar_t *grad_attn_weight)
|
| 429 |
+
{
|
| 430 |
+
CUDA_KERNEL_LOOP(index, n)
|
| 431 |
+
{
|
| 432 |
+
__shared__ scalar_t cache_grad_sampling_loc[blockSize * 2];
|
| 433 |
+
__shared__ scalar_t cache_grad_attn_weight[blockSize];
|
| 434 |
+
unsigned int tid = threadIdx.x;
|
| 435 |
+
int _temp = index;
|
| 436 |
+
const int c_col = _temp % channels;
|
| 437 |
+
_temp /= channels;
|
| 438 |
+
const int sampling_index = _temp;
|
| 439 |
+
const int m_col = _temp % num_heads;
|
| 440 |
+
_temp /= num_heads;
|
| 441 |
+
const int q_col = _temp % num_query;
|
| 442 |
+
_temp /= num_query;
|
| 443 |
+
const int b_col = _temp;
|
| 444 |
+
|
| 445 |
+
const scalar_t top_grad = grad_col[index];
|
| 446 |
+
|
| 447 |
+
int data_weight_ptr = sampling_index * num_levels * num_point;
|
| 448 |
+
int data_loc_w_ptr = data_weight_ptr << 1;
|
| 449 |
+
const int grad_sampling_ptr = data_weight_ptr;
|
| 450 |
+
grad_sampling_loc += grad_sampling_ptr << 1;
|
| 451 |
+
grad_attn_weight += grad_sampling_ptr;
|
| 452 |
+
const int grad_weight_stride = 1;
|
| 453 |
+
const int grad_loc_stride = 2;
|
| 454 |
+
const int qid_stride = num_heads * channels;
|
| 455 |
+
const int data_value_ptr_init_offset = b_col * spatial_size * qid_stride;
|
| 456 |
+
|
| 457 |
+
for (int l_col=0; l_col < num_levels; ++l_col)
|
| 458 |
+
{
|
| 459 |
+
const int level_start_id = data_level_start_index[l_col];
|
| 460 |
+
const int spatial_h_ptr = l_col << 1;
|
| 461 |
+
const int spatial_h = data_spatial_shapes[spatial_h_ptr];
|
| 462 |
+
const int spatial_w = data_spatial_shapes[spatial_h_ptr + 1];
|
| 463 |
+
const int value_ptr_offset = data_value_ptr_init_offset + level_start_id * qid_stride;
|
| 464 |
+
const scalar_t *data_value_ptr = data_value + value_ptr_offset;
|
| 465 |
+
scalar_t *grad_value_ptr = grad_value + value_ptr_offset;
|
| 466 |
+
|
| 467 |
+
for (int p_col=0; p_col < num_point; ++p_col)
|
| 468 |
+
{
|
| 469 |
+
const scalar_t loc_w = data_sampling_loc[data_loc_w_ptr];
|
| 470 |
+
const scalar_t loc_h = data_sampling_loc[data_loc_w_ptr + 1];
|
| 471 |
+
const scalar_t weight = data_attn_weight[data_weight_ptr];
|
| 472 |
+
|
| 473 |
+
const scalar_t h_im = loc_h * spatial_h - 0.5;
|
| 474 |
+
const scalar_t w_im = loc_w * spatial_w - 0.5;
|
| 475 |
+
*(cache_grad_sampling_loc+(threadIdx.x << 1)) = 0;
|
| 476 |
+
*(cache_grad_sampling_loc+((threadIdx.x << 1) + 1)) = 0;
|
| 477 |
+
*(cache_grad_attn_weight+threadIdx.x)=0;
|
| 478 |
+
if (h_im > -1 && w_im > -1 && h_im < spatial_h && w_im < spatial_w)
|
| 479 |
+
{
|
| 480 |
+
ms_deform_attn_col2im_bilinear(
|
| 481 |
+
data_value_ptr, spatial_h, spatial_w, num_heads, channels, h_im, w_im, m_col, c_col,
|
| 482 |
+
top_grad, weight, grad_value_ptr,
|
| 483 |
+
cache_grad_sampling_loc+(threadIdx.x << 1), cache_grad_attn_weight+threadIdx.x);
|
| 484 |
+
}
|
| 485 |
+
|
| 486 |
+
__syncthreads();
|
| 487 |
+
|
| 488 |
+
for (unsigned int s=blockSize/2; s>0; s>>=1)
|
| 489 |
+
{
|
| 490 |
+
if (tid < s) {
|
| 491 |
+
const unsigned int xid1 = tid << 1;
|
| 492 |
+
const unsigned int xid2 = (tid + s) << 1;
|
| 493 |
+
cache_grad_attn_weight[tid] += cache_grad_attn_weight[tid + s];
|
| 494 |
+
cache_grad_sampling_loc[xid1] += cache_grad_sampling_loc[xid2];
|
| 495 |
+
cache_grad_sampling_loc[xid1 + 1] += cache_grad_sampling_loc[xid2 + 1];
|
| 496 |
+
}
|
| 497 |
+
__syncthreads();
|
| 498 |
+
}
|
| 499 |
+
|
| 500 |
+
if (tid == 0)
|
| 501 |
+
{
|
| 502 |
+
*grad_sampling_loc = cache_grad_sampling_loc[0];
|
| 503 |
+
*(grad_sampling_loc + 1) = cache_grad_sampling_loc[1];
|
| 504 |
+
*grad_attn_weight = cache_grad_attn_weight[0];
|
| 505 |
+
}
|
| 506 |
+
__syncthreads();
|
| 507 |
+
|
| 508 |
+
data_weight_ptr += 1;
|
| 509 |
+
data_loc_w_ptr += 2;
|
| 510 |
+
grad_attn_weight += grad_weight_stride;
|
| 511 |
+
grad_sampling_loc += grad_loc_stride;
|
| 512 |
+
}
|
| 513 |
+
}
|
| 514 |
+
}
|
| 515 |
+
}
|
| 516 |
+
|
| 517 |
+
|
| 518 |
+
template <typename scalar_t>
|
| 519 |
+
__global__ void ms_deformable_col2im_gpu_kernel_shm_reduce_v1(const int n,
|
| 520 |
+
const scalar_t *grad_col,
|
| 521 |
+
const scalar_t *data_value,
|
| 522 |
+
const int64_t *data_spatial_shapes,
|
| 523 |
+
const int64_t *data_level_start_index,
|
| 524 |
+
const scalar_t *data_sampling_loc,
|
| 525 |
+
const scalar_t *data_attn_weight,
|
| 526 |
+
const int batch_size,
|
| 527 |
+
const int spatial_size,
|
| 528 |
+
const int num_heads,
|
| 529 |
+
const int channels,
|
| 530 |
+
const int num_levels,
|
| 531 |
+
const int num_query,
|
| 532 |
+
const int num_point,
|
| 533 |
+
scalar_t *grad_value,
|
| 534 |
+
scalar_t *grad_sampling_loc,
|
| 535 |
+
scalar_t *grad_attn_weight)
|
| 536 |
+
{
|
| 537 |
+
CUDA_KERNEL_LOOP(index, n)
|
| 538 |
+
{
|
| 539 |
+
extern __shared__ int _s[];
|
| 540 |
+
scalar_t* cache_grad_sampling_loc = (scalar_t*)_s;
|
| 541 |
+
scalar_t* cache_grad_attn_weight = cache_grad_sampling_loc + 2 * blockDim.x;
|
| 542 |
+
unsigned int tid = threadIdx.x;
|
| 543 |
+
int _temp = index;
|
| 544 |
+
const int c_col = _temp % channels;
|
| 545 |
+
_temp /= channels;
|
| 546 |
+
const int sampling_index = _temp;
|
| 547 |
+
const int m_col = _temp % num_heads;
|
| 548 |
+
_temp /= num_heads;
|
| 549 |
+
const int q_col = _temp % num_query;
|
| 550 |
+
_temp /= num_query;
|
| 551 |
+
const int b_col = _temp;
|
| 552 |
+
|
| 553 |
+
const scalar_t top_grad = grad_col[index];
|
| 554 |
+
|
| 555 |
+
int data_weight_ptr = sampling_index * num_levels * num_point;
|
| 556 |
+
int data_loc_w_ptr = data_weight_ptr << 1;
|
| 557 |
+
const int grad_sampling_ptr = data_weight_ptr;
|
| 558 |
+
grad_sampling_loc += grad_sampling_ptr << 1;
|
| 559 |
+
grad_attn_weight += grad_sampling_ptr;
|
| 560 |
+
const int grad_weight_stride = 1;
|
| 561 |
+
const int grad_loc_stride = 2;
|
| 562 |
+
const int qid_stride = num_heads * channels;
|
| 563 |
+
const int data_value_ptr_init_offset = b_col * spatial_size * qid_stride;
|
| 564 |
+
|
| 565 |
+
for (int l_col=0; l_col < num_levels; ++l_col)
|
| 566 |
+
{
|
| 567 |
+
const int level_start_id = data_level_start_index[l_col];
|
| 568 |
+
const int spatial_h_ptr = l_col << 1;
|
| 569 |
+
const int spatial_h = data_spatial_shapes[spatial_h_ptr];
|
| 570 |
+
const int spatial_w = data_spatial_shapes[spatial_h_ptr + 1];
|
| 571 |
+
const int value_ptr_offset = data_value_ptr_init_offset + level_start_id * qid_stride;
|
| 572 |
+
const scalar_t *data_value_ptr = data_value + value_ptr_offset;
|
| 573 |
+
scalar_t *grad_value_ptr = grad_value + value_ptr_offset;
|
| 574 |
+
|
| 575 |
+
for (int p_col=0; p_col < num_point; ++p_col)
|
| 576 |
+
{
|
| 577 |
+
const scalar_t loc_w = data_sampling_loc[data_loc_w_ptr];
|
| 578 |
+
const scalar_t loc_h = data_sampling_loc[data_loc_w_ptr + 1];
|
| 579 |
+
const scalar_t weight = data_attn_weight[data_weight_ptr];
|
| 580 |
+
|
| 581 |
+
const scalar_t h_im = loc_h * spatial_h - 0.5;
|
| 582 |
+
const scalar_t w_im = loc_w * spatial_w - 0.5;
|
| 583 |
+
*(cache_grad_sampling_loc+(threadIdx.x << 1)) = 0;
|
| 584 |
+
*(cache_grad_sampling_loc+((threadIdx.x << 1) + 1)) = 0;
|
| 585 |
+
*(cache_grad_attn_weight+threadIdx.x)=0;
|
| 586 |
+
if (h_im > -1 && w_im > -1 && h_im < spatial_h && w_im < spatial_w)
|
| 587 |
+
{
|
| 588 |
+
ms_deform_attn_col2im_bilinear(
|
| 589 |
+
data_value_ptr, spatial_h, spatial_w, num_heads, channels, h_im, w_im, m_col, c_col,
|
| 590 |
+
top_grad, weight, grad_value_ptr,
|
| 591 |
+
cache_grad_sampling_loc+(threadIdx.x << 1), cache_grad_attn_weight+threadIdx.x);
|
| 592 |
+
}
|
| 593 |
+
|
| 594 |
+
__syncthreads();
|
| 595 |
+
if (tid == 0)
|
| 596 |
+
{
|
| 597 |
+
scalar_t _grad_w=cache_grad_sampling_loc[0], _grad_h=cache_grad_sampling_loc[1], _grad_a=cache_grad_attn_weight[0];
|
| 598 |
+
int sid=2;
|
| 599 |
+
for (unsigned int tid = 1; tid < blockDim.x; ++tid)
|
| 600 |
+
{
|
| 601 |
+
_grad_w += cache_grad_sampling_loc[sid];
|
| 602 |
+
_grad_h += cache_grad_sampling_loc[sid + 1];
|
| 603 |
+
_grad_a += cache_grad_attn_weight[tid];
|
| 604 |
+
sid += 2;
|
| 605 |
+
}
|
| 606 |
+
|
| 607 |
+
|
| 608 |
+
*grad_sampling_loc = _grad_w;
|
| 609 |
+
*(grad_sampling_loc + 1) = _grad_h;
|
| 610 |
+
*grad_attn_weight = _grad_a;
|
| 611 |
+
}
|
| 612 |
+
__syncthreads();
|
| 613 |
+
|
| 614 |
+
data_weight_ptr += 1;
|
| 615 |
+
data_loc_w_ptr += 2;
|
| 616 |
+
grad_attn_weight += grad_weight_stride;
|
| 617 |
+
grad_sampling_loc += grad_loc_stride;
|
| 618 |
+
}
|
| 619 |
+
}
|
| 620 |
+
}
|
| 621 |
+
}
|
| 622 |
+
|
| 623 |
+
template <typename scalar_t>
|
| 624 |
+
__global__ void ms_deformable_col2im_gpu_kernel_shm_reduce_v2(const int n,
|
| 625 |
+
const scalar_t *grad_col,
|
| 626 |
+
const scalar_t *data_value,
|
| 627 |
+
const int64_t *data_spatial_shapes,
|
| 628 |
+
const int64_t *data_level_start_index,
|
| 629 |
+
const scalar_t *data_sampling_loc,
|
| 630 |
+
const scalar_t *data_attn_weight,
|
| 631 |
+
const int batch_size,
|
| 632 |
+
const int spatial_size,
|
| 633 |
+
const int num_heads,
|
| 634 |
+
const int channels,
|
| 635 |
+
const int num_levels,
|
| 636 |
+
const int num_query,
|
| 637 |
+
const int num_point,
|
| 638 |
+
scalar_t *grad_value,
|
| 639 |
+
scalar_t *grad_sampling_loc,
|
| 640 |
+
scalar_t *grad_attn_weight)
|
| 641 |
+
{
|
| 642 |
+
CUDA_KERNEL_LOOP(index, n)
|
| 643 |
+
{
|
| 644 |
+
extern __shared__ int _s[];
|
| 645 |
+
scalar_t* cache_grad_sampling_loc = (scalar_t*)_s;
|
| 646 |
+
scalar_t* cache_grad_attn_weight = cache_grad_sampling_loc + 2 * blockDim.x;
|
| 647 |
+
unsigned int tid = threadIdx.x;
|
| 648 |
+
int _temp = index;
|
| 649 |
+
const int c_col = _temp % channels;
|
| 650 |
+
_temp /= channels;
|
| 651 |
+
const int sampling_index = _temp;
|
| 652 |
+
const int m_col = _temp % num_heads;
|
| 653 |
+
_temp /= num_heads;
|
| 654 |
+
const int q_col = _temp % num_query;
|
| 655 |
+
_temp /= num_query;
|
| 656 |
+
const int b_col = _temp;
|
| 657 |
+
|
| 658 |
+
const scalar_t top_grad = grad_col[index];
|
| 659 |
+
|
| 660 |
+
int data_weight_ptr = sampling_index * num_levels * num_point;
|
| 661 |
+
int data_loc_w_ptr = data_weight_ptr << 1;
|
| 662 |
+
const int grad_sampling_ptr = data_weight_ptr;
|
| 663 |
+
grad_sampling_loc += grad_sampling_ptr << 1;
|
| 664 |
+
grad_attn_weight += grad_sampling_ptr;
|
| 665 |
+
const int grad_weight_stride = 1;
|
| 666 |
+
const int grad_loc_stride = 2;
|
| 667 |
+
const int qid_stride = num_heads * channels;
|
| 668 |
+
const int data_value_ptr_init_offset = b_col * spatial_size * qid_stride;
|
| 669 |
+
|
| 670 |
+
for (int l_col=0; l_col < num_levels; ++l_col)
|
| 671 |
+
{
|
| 672 |
+
const int level_start_id = data_level_start_index[l_col];
|
| 673 |
+
const int spatial_h_ptr = l_col << 1;
|
| 674 |
+
const int spatial_h = data_spatial_shapes[spatial_h_ptr];
|
| 675 |
+
const int spatial_w = data_spatial_shapes[spatial_h_ptr + 1];
|
| 676 |
+
const int value_ptr_offset = data_value_ptr_init_offset + level_start_id * qid_stride;
|
| 677 |
+
const scalar_t *data_value_ptr = data_value + value_ptr_offset;
|
| 678 |
+
scalar_t *grad_value_ptr = grad_value + value_ptr_offset;
|
| 679 |
+
|
| 680 |
+
for (int p_col=0; p_col < num_point; ++p_col)
|
| 681 |
+
{
|
| 682 |
+
const scalar_t loc_w = data_sampling_loc[data_loc_w_ptr];
|
| 683 |
+
const scalar_t loc_h = data_sampling_loc[data_loc_w_ptr + 1];
|
| 684 |
+
const scalar_t weight = data_attn_weight[data_weight_ptr];
|
| 685 |
+
|
| 686 |
+
const scalar_t h_im = loc_h * spatial_h - 0.5;
|
| 687 |
+
const scalar_t w_im = loc_w * spatial_w - 0.5;
|
| 688 |
+
*(cache_grad_sampling_loc+(threadIdx.x << 1)) = 0;
|
| 689 |
+
*(cache_grad_sampling_loc+((threadIdx.x << 1) + 1)) = 0;
|
| 690 |
+
*(cache_grad_attn_weight+threadIdx.x)=0;
|
| 691 |
+
if (h_im > -1 && w_im > -1 && h_im < spatial_h && w_im < spatial_w)
|
| 692 |
+
{
|
| 693 |
+
ms_deform_attn_col2im_bilinear(
|
| 694 |
+
data_value_ptr, spatial_h, spatial_w, num_heads, channels, h_im, w_im, m_col, c_col,
|
| 695 |
+
top_grad, weight, grad_value_ptr,
|
| 696 |
+
cache_grad_sampling_loc+(threadIdx.x << 1), cache_grad_attn_weight+threadIdx.x);
|
| 697 |
+
}
|
| 698 |
+
|
| 699 |
+
__syncthreads();
|
| 700 |
+
|
| 701 |
+
for (unsigned int s=blockDim.x/2, spre=blockDim.x; s>0; s>>=1, spre>>=1)
|
| 702 |
+
{
|
| 703 |
+
if (tid < s) {
|
| 704 |
+
const unsigned int xid1 = tid << 1;
|
| 705 |
+
const unsigned int xid2 = (tid + s) << 1;
|
| 706 |
+
cache_grad_attn_weight[tid] += cache_grad_attn_weight[tid + s];
|
| 707 |
+
cache_grad_sampling_loc[xid1] += cache_grad_sampling_loc[xid2];
|
| 708 |
+
cache_grad_sampling_loc[xid1 + 1] += cache_grad_sampling_loc[xid2 + 1];
|
| 709 |
+
if (tid + (s << 1) < spre)
|
| 710 |
+
{
|
| 711 |
+
cache_grad_attn_weight[tid] += cache_grad_attn_weight[tid + (s << 1)];
|
| 712 |
+
cache_grad_sampling_loc[xid1] += cache_grad_sampling_loc[xid2 + (s << 1)];
|
| 713 |
+
cache_grad_sampling_loc[xid1 + 1] += cache_grad_sampling_loc[xid2 + 1 + (s << 1)];
|
| 714 |
+
}
|
| 715 |
+
}
|
| 716 |
+
__syncthreads();
|
| 717 |
+
}
|
| 718 |
+
|
| 719 |
+
if (tid == 0)
|
| 720 |
+
{
|
| 721 |
+
*grad_sampling_loc = cache_grad_sampling_loc[0];
|
| 722 |
+
*(grad_sampling_loc + 1) = cache_grad_sampling_loc[1];
|
| 723 |
+
*grad_attn_weight = cache_grad_attn_weight[0];
|
| 724 |
+
}
|
| 725 |
+
__syncthreads();
|
| 726 |
+
|
| 727 |
+
data_weight_ptr += 1;
|
| 728 |
+
data_loc_w_ptr += 2;
|
| 729 |
+
grad_attn_weight += grad_weight_stride;
|
| 730 |
+
grad_sampling_loc += grad_loc_stride;
|
| 731 |
+
}
|
| 732 |
+
}
|
| 733 |
+
}
|
| 734 |
+
}
|
| 735 |
+
|
| 736 |
+
template <typename scalar_t>
|
| 737 |
+
__global__ void ms_deformable_col2im_gpu_kernel_shm_reduce_v2_multi_blocks(const int n,
|
| 738 |
+
const scalar_t *grad_col,
|
| 739 |
+
const scalar_t *data_value,
|
| 740 |
+
const int64_t *data_spatial_shapes,
|
| 741 |
+
const int64_t *data_level_start_index,
|
| 742 |
+
const scalar_t *data_sampling_loc,
|
| 743 |
+
const scalar_t *data_attn_weight,
|
| 744 |
+
const int batch_size,
|
| 745 |
+
const int spatial_size,
|
| 746 |
+
const int num_heads,
|
| 747 |
+
const int channels,
|
| 748 |
+
const int num_levels,
|
| 749 |
+
const int num_query,
|
| 750 |
+
const int num_point,
|
| 751 |
+
scalar_t *grad_value,
|
| 752 |
+
scalar_t *grad_sampling_loc,
|
| 753 |
+
scalar_t *grad_attn_weight)
|
| 754 |
+
{
|
| 755 |
+
CUDA_KERNEL_LOOP(index, n)
|
| 756 |
+
{
|
| 757 |
+
extern __shared__ int _s[];
|
| 758 |
+
scalar_t* cache_grad_sampling_loc = (scalar_t*)_s;
|
| 759 |
+
scalar_t* cache_grad_attn_weight = cache_grad_sampling_loc + 2 * blockDim.x;
|
| 760 |
+
unsigned int tid = threadIdx.x;
|
| 761 |
+
int _temp = index;
|
| 762 |
+
const int c_col = _temp % channels;
|
| 763 |
+
_temp /= channels;
|
| 764 |
+
const int sampling_index = _temp;
|
| 765 |
+
const int m_col = _temp % num_heads;
|
| 766 |
+
_temp /= num_heads;
|
| 767 |
+
const int q_col = _temp % num_query;
|
| 768 |
+
_temp /= num_query;
|
| 769 |
+
const int b_col = _temp;
|
| 770 |
+
|
| 771 |
+
const scalar_t top_grad = grad_col[index];
|
| 772 |
+
|
| 773 |
+
int data_weight_ptr = sampling_index * num_levels * num_point;
|
| 774 |
+
int data_loc_w_ptr = data_weight_ptr << 1;
|
| 775 |
+
const int grad_sampling_ptr = data_weight_ptr;
|
| 776 |
+
grad_sampling_loc += grad_sampling_ptr << 1;
|
| 777 |
+
grad_attn_weight += grad_sampling_ptr;
|
| 778 |
+
const int grad_weight_stride = 1;
|
| 779 |
+
const int grad_loc_stride = 2;
|
| 780 |
+
const int qid_stride = num_heads * channels;
|
| 781 |
+
const int data_value_ptr_init_offset = b_col * spatial_size * qid_stride;
|
| 782 |
+
|
| 783 |
+
for (int l_col=0; l_col < num_levels; ++l_col)
|
| 784 |
+
{
|
| 785 |
+
const int level_start_id = data_level_start_index[l_col];
|
| 786 |
+
const int spatial_h_ptr = l_col << 1;
|
| 787 |
+
const int spatial_h = data_spatial_shapes[spatial_h_ptr];
|
| 788 |
+
const int spatial_w = data_spatial_shapes[spatial_h_ptr + 1];
|
| 789 |
+
const int value_ptr_offset = data_value_ptr_init_offset + level_start_id * qid_stride;
|
| 790 |
+
const scalar_t *data_value_ptr = data_value + value_ptr_offset;
|
| 791 |
+
scalar_t *grad_value_ptr = grad_value + value_ptr_offset;
|
| 792 |
+
|
| 793 |
+
for (int p_col=0; p_col < num_point; ++p_col)
|
| 794 |
+
{
|
| 795 |
+
const scalar_t loc_w = data_sampling_loc[data_loc_w_ptr];
|
| 796 |
+
const scalar_t loc_h = data_sampling_loc[data_loc_w_ptr + 1];
|
| 797 |
+
const scalar_t weight = data_attn_weight[data_weight_ptr];
|
| 798 |
+
|
| 799 |
+
const scalar_t h_im = loc_h * spatial_h - 0.5;
|
| 800 |
+
const scalar_t w_im = loc_w * spatial_w - 0.5;
|
| 801 |
+
*(cache_grad_sampling_loc+(threadIdx.x << 1)) = 0;
|
| 802 |
+
*(cache_grad_sampling_loc+((threadIdx.x << 1) + 1)) = 0;
|
| 803 |
+
*(cache_grad_attn_weight+threadIdx.x)=0;
|
| 804 |
+
if (h_im > -1 && w_im > -1 && h_im < spatial_h && w_im < spatial_w)
|
| 805 |
+
{
|
| 806 |
+
ms_deform_attn_col2im_bilinear(
|
| 807 |
+
data_value_ptr, spatial_h, spatial_w, num_heads, channels, h_im, w_im, m_col, c_col,
|
| 808 |
+
top_grad, weight, grad_value_ptr,
|
| 809 |
+
cache_grad_sampling_loc+(threadIdx.x << 1), cache_grad_attn_weight+threadIdx.x);
|
| 810 |
+
}
|
| 811 |
+
|
| 812 |
+
__syncthreads();
|
| 813 |
+
|
| 814 |
+
for (unsigned int s=blockDim.x/2, spre=blockDim.x; s>0; s>>=1, spre>>=1)
|
| 815 |
+
{
|
| 816 |
+
if (tid < s) {
|
| 817 |
+
const unsigned int xid1 = tid << 1;
|
| 818 |
+
const unsigned int xid2 = (tid + s) << 1;
|
| 819 |
+
cache_grad_attn_weight[tid] += cache_grad_attn_weight[tid + s];
|
| 820 |
+
cache_grad_sampling_loc[xid1] += cache_grad_sampling_loc[xid2];
|
| 821 |
+
cache_grad_sampling_loc[xid1 + 1] += cache_grad_sampling_loc[xid2 + 1];
|
| 822 |
+
if (tid + (s << 1) < spre)
|
| 823 |
+
{
|
| 824 |
+
cache_grad_attn_weight[tid] += cache_grad_attn_weight[tid + (s << 1)];
|
| 825 |
+
cache_grad_sampling_loc[xid1] += cache_grad_sampling_loc[xid2 + (s << 1)];
|
| 826 |
+
cache_grad_sampling_loc[xid1 + 1] += cache_grad_sampling_loc[xid2 + 1 + (s << 1)];
|
| 827 |
+
}
|
| 828 |
+
}
|
| 829 |
+
__syncthreads();
|
| 830 |
+
}
|
| 831 |
+
|
| 832 |
+
if (tid == 0)
|
| 833 |
+
{
|
| 834 |
+
atomicAdd(grad_sampling_loc, cache_grad_sampling_loc[0]);
|
| 835 |
+
atomicAdd(grad_sampling_loc + 1, cache_grad_sampling_loc[1]);
|
| 836 |
+
atomicAdd(grad_attn_weight, cache_grad_attn_weight[0]);
|
| 837 |
+
}
|
| 838 |
+
__syncthreads();
|
| 839 |
+
|
| 840 |
+
data_weight_ptr += 1;
|
| 841 |
+
data_loc_w_ptr += 2;
|
| 842 |
+
grad_attn_weight += grad_weight_stride;
|
| 843 |
+
grad_sampling_loc += grad_loc_stride;
|
| 844 |
+
}
|
| 845 |
+
}
|
| 846 |
+
}
|
| 847 |
+
}
|
| 848 |
+
|
| 849 |
+
|
| 850 |
+
template <typename scalar_t>
|
| 851 |
+
__global__ void ms_deformable_col2im_gpu_kernel_gm(const int n,
|
| 852 |
+
const scalar_t *grad_col,
|
| 853 |
+
const scalar_t *data_value,
|
| 854 |
+
const int64_t *data_spatial_shapes,
|
| 855 |
+
const int64_t *data_level_start_index,
|
| 856 |
+
const scalar_t *data_sampling_loc,
|
| 857 |
+
const scalar_t *data_attn_weight,
|
| 858 |
+
const int batch_size,
|
| 859 |
+
const int spatial_size,
|
| 860 |
+
const int num_heads,
|
| 861 |
+
const int channels,
|
| 862 |
+
const int num_levels,
|
| 863 |
+
const int num_query,
|
| 864 |
+
const int num_point,
|
| 865 |
+
scalar_t *grad_value,
|
| 866 |
+
scalar_t *grad_sampling_loc,
|
| 867 |
+
scalar_t *grad_attn_weight)
|
| 868 |
+
{
|
| 869 |
+
CUDA_KERNEL_LOOP(index, n)
|
| 870 |
+
{
|
| 871 |
+
int _temp = index;
|
| 872 |
+
const int c_col = _temp % channels;
|
| 873 |
+
_temp /= channels;
|
| 874 |
+
const int sampling_index = _temp;
|
| 875 |
+
const int m_col = _temp % num_heads;
|
| 876 |
+
_temp /= num_heads;
|
| 877 |
+
const int q_col = _temp % num_query;
|
| 878 |
+
_temp /= num_query;
|
| 879 |
+
const int b_col = _temp;
|
| 880 |
+
|
| 881 |
+
const scalar_t top_grad = grad_col[index];
|
| 882 |
+
|
| 883 |
+
int data_weight_ptr = sampling_index * num_levels * num_point;
|
| 884 |
+
int data_loc_w_ptr = data_weight_ptr << 1;
|
| 885 |
+
const int grad_sampling_ptr = data_weight_ptr;
|
| 886 |
+
grad_sampling_loc += grad_sampling_ptr << 1;
|
| 887 |
+
grad_attn_weight += grad_sampling_ptr;
|
| 888 |
+
const int grad_weight_stride = 1;
|
| 889 |
+
const int grad_loc_stride = 2;
|
| 890 |
+
const int qid_stride = num_heads * channels;
|
| 891 |
+
const int data_value_ptr_init_offset = b_col * spatial_size * qid_stride;
|
| 892 |
+
|
| 893 |
+
for (int l_col=0; l_col < num_levels; ++l_col)
|
| 894 |
+
{
|
| 895 |
+
const int level_start_id = data_level_start_index[l_col];
|
| 896 |
+
const int spatial_h_ptr = l_col << 1;
|
| 897 |
+
const int spatial_h = data_spatial_shapes[spatial_h_ptr];
|
| 898 |
+
const int spatial_w = data_spatial_shapes[spatial_h_ptr + 1];
|
| 899 |
+
const int value_ptr_offset = data_value_ptr_init_offset + level_start_id * qid_stride;
|
| 900 |
+
const scalar_t *data_value_ptr = data_value + value_ptr_offset;
|
| 901 |
+
scalar_t *grad_value_ptr = grad_value + value_ptr_offset;
|
| 902 |
+
|
| 903 |
+
for (int p_col=0; p_col < num_point; ++p_col)
|
| 904 |
+
{
|
| 905 |
+
const scalar_t loc_w = data_sampling_loc[data_loc_w_ptr];
|
| 906 |
+
const scalar_t loc_h = data_sampling_loc[data_loc_w_ptr + 1];
|
| 907 |
+
const scalar_t weight = data_attn_weight[data_weight_ptr];
|
| 908 |
+
|
| 909 |
+
const scalar_t h_im = loc_h * spatial_h - 0.5;
|
| 910 |
+
const scalar_t w_im = loc_w * spatial_w - 0.5;
|
| 911 |
+
if (h_im > -1 && w_im > -1 && h_im < spatial_h && w_im < spatial_w)
|
| 912 |
+
{
|
| 913 |
+
ms_deform_attn_col2im_bilinear_gm(
|
| 914 |
+
data_value_ptr, spatial_h, spatial_w, num_heads, channels, h_im, w_im, m_col, c_col,
|
| 915 |
+
top_grad, weight, grad_value_ptr,
|
| 916 |
+
grad_sampling_loc, grad_attn_weight);
|
| 917 |
+
}
|
| 918 |
+
data_weight_ptr += 1;
|
| 919 |
+
data_loc_w_ptr += 2;
|
| 920 |
+
grad_attn_weight += grad_weight_stride;
|
| 921 |
+
grad_sampling_loc += grad_loc_stride;
|
| 922 |
+
}
|
| 923 |
+
}
|
| 924 |
+
}
|
| 925 |
+
}
|
| 926 |
+
|
| 927 |
+
|
| 928 |
+
template <typename scalar_t>
|
| 929 |
+
void ms_deformable_im2col_cuda(cudaStream_t stream,
|
| 930 |
+
const scalar_t* data_value,
|
| 931 |
+
const int64_t* data_spatial_shapes,
|
| 932 |
+
const int64_t* data_level_start_index,
|
| 933 |
+
const scalar_t* data_sampling_loc,
|
| 934 |
+
const scalar_t* data_attn_weight,
|
| 935 |
+
const int batch_size,
|
| 936 |
+
const int spatial_size,
|
| 937 |
+
const int num_heads,
|
| 938 |
+
const int channels,
|
| 939 |
+
const int num_levels,
|
| 940 |
+
const int num_query,
|
| 941 |
+
const int num_point,
|
| 942 |
+
scalar_t* data_col)
|
| 943 |
+
{
|
| 944 |
+
const int num_kernels = batch_size * num_query * num_heads * channels;
|
| 945 |
+
const int num_actual_kernels = batch_size * num_query * num_heads * channels;
|
| 946 |
+
const int num_threads = CUDA_NUM_THREADS;
|
| 947 |
+
ms_deformable_im2col_gpu_kernel<scalar_t>
|
| 948 |
+
<<<GET_BLOCKS(num_actual_kernels, num_threads), num_threads,
|
| 949 |
+
0, stream>>>(
|
| 950 |
+
num_kernels, data_value, data_spatial_shapes, data_level_start_index, data_sampling_loc, data_attn_weight,
|
| 951 |
+
batch_size, spatial_size, num_heads, channels, num_levels, num_query, num_point, data_col);
|
| 952 |
+
|
| 953 |
+
cudaError_t err = cudaGetLastError();
|
| 954 |
+
if (err != cudaSuccess)
|
| 955 |
+
{
|
| 956 |
+
printf("error in ms_deformable_im2col_cuda: %s\n", cudaGetErrorString(err));
|
| 957 |
+
}
|
| 958 |
+
|
| 959 |
+
}
|
| 960 |
+
|
| 961 |
+
template <typename scalar_t>
|
| 962 |
+
void ms_deformable_col2im_cuda(cudaStream_t stream,
|
| 963 |
+
const scalar_t* grad_col,
|
| 964 |
+
const scalar_t* data_value,
|
| 965 |
+
const int64_t * data_spatial_shapes,
|
| 966 |
+
const int64_t * data_level_start_index,
|
| 967 |
+
const scalar_t * data_sampling_loc,
|
| 968 |
+
const scalar_t * data_attn_weight,
|
| 969 |
+
const int batch_size,
|
| 970 |
+
const int spatial_size,
|
| 971 |
+
const int num_heads,
|
| 972 |
+
const int channels,
|
| 973 |
+
const int num_levels,
|
| 974 |
+
const int num_query,
|
| 975 |
+
const int num_point,
|
| 976 |
+
scalar_t* grad_value,
|
| 977 |
+
scalar_t* grad_sampling_loc,
|
| 978 |
+
scalar_t* grad_attn_weight)
|
| 979 |
+
{
|
| 980 |
+
const int num_threads = (channels > CUDA_NUM_THREADS)?CUDA_NUM_THREADS:channels;
|
| 981 |
+
const int num_kernels = batch_size * num_query * num_heads * channels;
|
| 982 |
+
const int num_actual_kernels = batch_size * num_query * num_heads * channels;
|
| 983 |
+
if (channels > 1024)
|
| 984 |
+
{
|
| 985 |
+
if ((channels & 1023) == 0)
|
| 986 |
+
{
|
| 987 |
+
ms_deformable_col2im_gpu_kernel_shm_reduce_v2_multi_blocks<scalar_t>
|
| 988 |
+
<<<GET_BLOCKS(num_actual_kernels, num_threads), num_threads,
|
| 989 |
+
num_threads*3*sizeof(scalar_t), stream>>>(
|
| 990 |
+
num_kernels,
|
| 991 |
+
grad_col,
|
| 992 |
+
data_value,
|
| 993 |
+
data_spatial_shapes,
|
| 994 |
+
data_level_start_index,
|
| 995 |
+
data_sampling_loc,
|
| 996 |
+
data_attn_weight,
|
| 997 |
+
batch_size,
|
| 998 |
+
spatial_size,
|
| 999 |
+
num_heads,
|
| 1000 |
+
channels,
|
| 1001 |
+
num_levels,
|
| 1002 |
+
num_query,
|
| 1003 |
+
num_point,
|
| 1004 |
+
grad_value,
|
| 1005 |
+
grad_sampling_loc,
|
| 1006 |
+
grad_attn_weight);
|
| 1007 |
+
}
|
| 1008 |
+
else
|
| 1009 |
+
{
|
| 1010 |
+
ms_deformable_col2im_gpu_kernel_gm<scalar_t>
|
| 1011 |
+
<<<GET_BLOCKS(num_actual_kernels, num_threads), num_threads,
|
| 1012 |
+
0, stream>>>(
|
| 1013 |
+
num_kernels,
|
| 1014 |
+
grad_col,
|
| 1015 |
+
data_value,
|
| 1016 |
+
data_spatial_shapes,
|
| 1017 |
+
data_level_start_index,
|
| 1018 |
+
data_sampling_loc,
|
| 1019 |
+
data_attn_weight,
|
| 1020 |
+
batch_size,
|
| 1021 |
+
spatial_size,
|
| 1022 |
+
num_heads,
|
| 1023 |
+
channels,
|
| 1024 |
+
num_levels,
|
| 1025 |
+
num_query,
|
| 1026 |
+
num_point,
|
| 1027 |
+
grad_value,
|
| 1028 |
+
grad_sampling_loc,
|
| 1029 |
+
grad_attn_weight);
|
| 1030 |
+
}
|
| 1031 |
+
}
|
| 1032 |
+
else{
|
| 1033 |
+
switch(channels)
|
| 1034 |
+
{
|
| 1035 |
+
case 1:
|
| 1036 |
+
ms_deformable_col2im_gpu_kernel_shm_blocksize_aware_reduce_v1<scalar_t, 1>
|
| 1037 |
+
<<<GET_BLOCKS(num_actual_kernels, num_threads), num_threads,
|
| 1038 |
+
0, stream>>>(
|
| 1039 |
+
num_kernels,
|
| 1040 |
+
grad_col,
|
| 1041 |
+
data_value,
|
| 1042 |
+
data_spatial_shapes,
|
| 1043 |
+
data_level_start_index,
|
| 1044 |
+
data_sampling_loc,
|
| 1045 |
+
data_attn_weight,
|
| 1046 |
+
batch_size,
|
| 1047 |
+
spatial_size,
|
| 1048 |
+
num_heads,
|
| 1049 |
+
channels,
|
| 1050 |
+
num_levels,
|
| 1051 |
+
num_query,
|
| 1052 |
+
num_point,
|
| 1053 |
+
grad_value,
|
| 1054 |
+
grad_sampling_loc,
|
| 1055 |
+
grad_attn_weight);
|
| 1056 |
+
break;
|
| 1057 |
+
case 2:
|
| 1058 |
+
ms_deformable_col2im_gpu_kernel_shm_blocksize_aware_reduce_v1<scalar_t, 2>
|
| 1059 |
+
<<<GET_BLOCKS(num_actual_kernels, num_threads), num_threads,
|
| 1060 |
+
0, stream>>>(
|
| 1061 |
+
num_kernels,
|
| 1062 |
+
grad_col,
|
| 1063 |
+
data_value,
|
| 1064 |
+
data_spatial_shapes,
|
| 1065 |
+
data_level_start_index,
|
| 1066 |
+
data_sampling_loc,
|
| 1067 |
+
data_attn_weight,
|
| 1068 |
+
batch_size,
|
| 1069 |
+
spatial_size,
|
| 1070 |
+
num_heads,
|
| 1071 |
+
channels,
|
| 1072 |
+
num_levels,
|
| 1073 |
+
num_query,
|
| 1074 |
+
num_point,
|
| 1075 |
+
grad_value,
|
| 1076 |
+
grad_sampling_loc,
|
| 1077 |
+
grad_attn_weight);
|
| 1078 |
+
break;
|
| 1079 |
+
case 4:
|
| 1080 |
+
ms_deformable_col2im_gpu_kernel_shm_blocksize_aware_reduce_v1<scalar_t, 4>
|
| 1081 |
+
<<<GET_BLOCKS(num_actual_kernels, num_threads), num_threads,
|
| 1082 |
+
0, stream>>>(
|
| 1083 |
+
num_kernels,
|
| 1084 |
+
grad_col,
|
| 1085 |
+
data_value,
|
| 1086 |
+
data_spatial_shapes,
|
| 1087 |
+
data_level_start_index,
|
| 1088 |
+
data_sampling_loc,
|
| 1089 |
+
data_attn_weight,
|
| 1090 |
+
batch_size,
|
| 1091 |
+
spatial_size,
|
| 1092 |
+
num_heads,
|
| 1093 |
+
channels,
|
| 1094 |
+
num_levels,
|
| 1095 |
+
num_query,
|
| 1096 |
+
num_point,
|
| 1097 |
+
grad_value,
|
| 1098 |
+
grad_sampling_loc,
|
| 1099 |
+
grad_attn_weight);
|
| 1100 |
+
break;
|
| 1101 |
+
case 8:
|
| 1102 |
+
ms_deformable_col2im_gpu_kernel_shm_blocksize_aware_reduce_v1<scalar_t, 8>
|
| 1103 |
+
<<<GET_BLOCKS(num_actual_kernels, num_threads), num_threads,
|
| 1104 |
+
0, stream>>>(
|
| 1105 |
+
num_kernels,
|
| 1106 |
+
grad_col,
|
| 1107 |
+
data_value,
|
| 1108 |
+
data_spatial_shapes,
|
| 1109 |
+
data_level_start_index,
|
| 1110 |
+
data_sampling_loc,
|
| 1111 |
+
data_attn_weight,
|
| 1112 |
+
batch_size,
|
| 1113 |
+
spatial_size,
|
| 1114 |
+
num_heads,
|
| 1115 |
+
channels,
|
| 1116 |
+
num_levels,
|
| 1117 |
+
num_query,
|
| 1118 |
+
num_point,
|
| 1119 |
+
grad_value,
|
| 1120 |
+
grad_sampling_loc,
|
| 1121 |
+
grad_attn_weight);
|
| 1122 |
+
break;
|
| 1123 |
+
case 16:
|
| 1124 |
+
ms_deformable_col2im_gpu_kernel_shm_blocksize_aware_reduce_v1<scalar_t, 16>
|
| 1125 |
+
<<<GET_BLOCKS(num_actual_kernels, num_threads), num_threads,
|
| 1126 |
+
0, stream>>>(
|
| 1127 |
+
num_kernels,
|
| 1128 |
+
grad_col,
|
| 1129 |
+
data_value,
|
| 1130 |
+
data_spatial_shapes,
|
| 1131 |
+
data_level_start_index,
|
| 1132 |
+
data_sampling_loc,
|
| 1133 |
+
data_attn_weight,
|
| 1134 |
+
batch_size,
|
| 1135 |
+
spatial_size,
|
| 1136 |
+
num_heads,
|
| 1137 |
+
channels,
|
| 1138 |
+
num_levels,
|
| 1139 |
+
num_query,
|
| 1140 |
+
num_point,
|
| 1141 |
+
grad_value,
|
| 1142 |
+
grad_sampling_loc,
|
| 1143 |
+
grad_attn_weight);
|
| 1144 |
+
break;
|
| 1145 |
+
case 32:
|
| 1146 |
+
ms_deformable_col2im_gpu_kernel_shm_blocksize_aware_reduce_v1<scalar_t, 32>
|
| 1147 |
+
<<<GET_BLOCKS(num_actual_kernels, num_threads), num_threads,
|
| 1148 |
+
0, stream>>>(
|
| 1149 |
+
num_kernels,
|
| 1150 |
+
grad_col,
|
| 1151 |
+
data_value,
|
| 1152 |
+
data_spatial_shapes,
|
| 1153 |
+
data_level_start_index,
|
| 1154 |
+
data_sampling_loc,
|
| 1155 |
+
data_attn_weight,
|
| 1156 |
+
batch_size,
|
| 1157 |
+
spatial_size,
|
| 1158 |
+
num_heads,
|
| 1159 |
+
channels,
|
| 1160 |
+
num_levels,
|
| 1161 |
+
num_query,
|
| 1162 |
+
num_point,
|
| 1163 |
+
grad_value,
|
| 1164 |
+
grad_sampling_loc,
|
| 1165 |
+
grad_attn_weight);
|
| 1166 |
+
break;
|
| 1167 |
+
case 64:
|
| 1168 |
+
ms_deformable_col2im_gpu_kernel_shm_blocksize_aware_reduce_v2<scalar_t, 64>
|
| 1169 |
+
<<<GET_BLOCKS(num_actual_kernels, num_threads), num_threads,
|
| 1170 |
+
0, stream>>>(
|
| 1171 |
+
num_kernels,
|
| 1172 |
+
grad_col,
|
| 1173 |
+
data_value,
|
| 1174 |
+
data_spatial_shapes,
|
| 1175 |
+
data_level_start_index,
|
| 1176 |
+
data_sampling_loc,
|
| 1177 |
+
data_attn_weight,
|
| 1178 |
+
batch_size,
|
| 1179 |
+
spatial_size,
|
| 1180 |
+
num_heads,
|
| 1181 |
+
channels,
|
| 1182 |
+
num_levels,
|
| 1183 |
+
num_query,
|
| 1184 |
+
num_point,
|
| 1185 |
+
grad_value,
|
| 1186 |
+
grad_sampling_loc,
|
| 1187 |
+
grad_attn_weight);
|
| 1188 |
+
break;
|
| 1189 |
+
case 128:
|
| 1190 |
+
ms_deformable_col2im_gpu_kernel_shm_blocksize_aware_reduce_v2<scalar_t, 128>
|
| 1191 |
+
<<<GET_BLOCKS(num_actual_kernels, num_threads), num_threads,
|
| 1192 |
+
0, stream>>>(
|
| 1193 |
+
num_kernels,
|
| 1194 |
+
grad_col,
|
| 1195 |
+
data_value,
|
| 1196 |
+
data_spatial_shapes,
|
| 1197 |
+
data_level_start_index,
|
| 1198 |
+
data_sampling_loc,
|
| 1199 |
+
data_attn_weight,
|
| 1200 |
+
batch_size,
|
| 1201 |
+
spatial_size,
|
| 1202 |
+
num_heads,
|
| 1203 |
+
channels,
|
| 1204 |
+
num_levels,
|
| 1205 |
+
num_query,
|
| 1206 |
+
num_point,
|
| 1207 |
+
grad_value,
|
| 1208 |
+
grad_sampling_loc,
|
| 1209 |
+
grad_attn_weight);
|
| 1210 |
+
break;
|
| 1211 |
+
case 256:
|
| 1212 |
+
ms_deformable_col2im_gpu_kernel_shm_blocksize_aware_reduce_v2<scalar_t, 256>
|
| 1213 |
+
<<<GET_BLOCKS(num_actual_kernels, num_threads), num_threads,
|
| 1214 |
+
0, stream>>>(
|
| 1215 |
+
num_kernels,
|
| 1216 |
+
grad_col,
|
| 1217 |
+
data_value,
|
| 1218 |
+
data_spatial_shapes,
|
| 1219 |
+
data_level_start_index,
|
| 1220 |
+
data_sampling_loc,
|
| 1221 |
+
data_attn_weight,
|
| 1222 |
+
batch_size,
|
| 1223 |
+
spatial_size,
|
| 1224 |
+
num_heads,
|
| 1225 |
+
channels,
|
| 1226 |
+
num_levels,
|
| 1227 |
+
num_query,
|
| 1228 |
+
num_point,
|
| 1229 |
+
grad_value,
|
| 1230 |
+
grad_sampling_loc,
|
| 1231 |
+
grad_attn_weight);
|
| 1232 |
+
break;
|
| 1233 |
+
case 512:
|
| 1234 |
+
ms_deformable_col2im_gpu_kernel_shm_blocksize_aware_reduce_v2<scalar_t, 512>
|
| 1235 |
+
<<<GET_BLOCKS(num_actual_kernels, num_threads), num_threads,
|
| 1236 |
+
0, stream>>>(
|
| 1237 |
+
num_kernels,
|
| 1238 |
+
grad_col,
|
| 1239 |
+
data_value,
|
| 1240 |
+
data_spatial_shapes,
|
| 1241 |
+
data_level_start_index,
|
| 1242 |
+
data_sampling_loc,
|
| 1243 |
+
data_attn_weight,
|
| 1244 |
+
batch_size,
|
| 1245 |
+
spatial_size,
|
| 1246 |
+
num_heads,
|
| 1247 |
+
channels,
|
| 1248 |
+
num_levels,
|
| 1249 |
+
num_query,
|
| 1250 |
+
num_point,
|
| 1251 |
+
grad_value,
|
| 1252 |
+
grad_sampling_loc,
|
| 1253 |
+
grad_attn_weight);
|
| 1254 |
+
break;
|
| 1255 |
+
case 1024:
|
| 1256 |
+
ms_deformable_col2im_gpu_kernel_shm_blocksize_aware_reduce_v2<scalar_t, 1024>
|
| 1257 |
+
<<<GET_BLOCKS(num_actual_kernels, num_threads), num_threads,
|
| 1258 |
+
0, stream>>>(
|
| 1259 |
+
num_kernels,
|
| 1260 |
+
grad_col,
|
| 1261 |
+
data_value,
|
| 1262 |
+
data_spatial_shapes,
|
| 1263 |
+
data_level_start_index,
|
| 1264 |
+
data_sampling_loc,
|
| 1265 |
+
data_attn_weight,
|
| 1266 |
+
batch_size,
|
| 1267 |
+
spatial_size,
|
| 1268 |
+
num_heads,
|
| 1269 |
+
channels,
|
| 1270 |
+
num_levels,
|
| 1271 |
+
num_query,
|
| 1272 |
+
num_point,
|
| 1273 |
+
grad_value,
|
| 1274 |
+
grad_sampling_loc,
|
| 1275 |
+
grad_attn_weight);
|
| 1276 |
+
break;
|
| 1277 |
+
default:
|
| 1278 |
+
if (channels < 64)
|
| 1279 |
+
{
|
| 1280 |
+
ms_deformable_col2im_gpu_kernel_shm_reduce_v1<scalar_t>
|
| 1281 |
+
<<<GET_BLOCKS(num_actual_kernels, num_threads), num_threads,
|
| 1282 |
+
num_threads*3*sizeof(scalar_t), stream>>>(
|
| 1283 |
+
num_kernels,
|
| 1284 |
+
grad_col,
|
| 1285 |
+
data_value,
|
| 1286 |
+
data_spatial_shapes,
|
| 1287 |
+
data_level_start_index,
|
| 1288 |
+
data_sampling_loc,
|
| 1289 |
+
data_attn_weight,
|
| 1290 |
+
batch_size,
|
| 1291 |
+
spatial_size,
|
| 1292 |
+
num_heads,
|
| 1293 |
+
channels,
|
| 1294 |
+
num_levels,
|
| 1295 |
+
num_query,
|
| 1296 |
+
num_point,
|
| 1297 |
+
grad_value,
|
| 1298 |
+
grad_sampling_loc,
|
| 1299 |
+
grad_attn_weight);
|
| 1300 |
+
}
|
| 1301 |
+
else
|
| 1302 |
+
{
|
| 1303 |
+
ms_deformable_col2im_gpu_kernel_shm_reduce_v2<scalar_t>
|
| 1304 |
+
<<<GET_BLOCKS(num_actual_kernels, num_threads), num_threads,
|
| 1305 |
+
num_threads*3*sizeof(scalar_t), stream>>>(
|
| 1306 |
+
num_kernels,
|
| 1307 |
+
grad_col,
|
| 1308 |
+
data_value,
|
| 1309 |
+
data_spatial_shapes,
|
| 1310 |
+
data_level_start_index,
|
| 1311 |
+
data_sampling_loc,
|
| 1312 |
+
data_attn_weight,
|
| 1313 |
+
batch_size,
|
| 1314 |
+
spatial_size,
|
| 1315 |
+
num_heads,
|
| 1316 |
+
channels,
|
| 1317 |
+
num_levels,
|
| 1318 |
+
num_query,
|
| 1319 |
+
num_point,
|
| 1320 |
+
grad_value,
|
| 1321 |
+
grad_sampling_loc,
|
| 1322 |
+
grad_attn_weight);
|
| 1323 |
+
}
|
| 1324 |
+
}
|
| 1325 |
+
}
|
| 1326 |
+
cudaError_t err = cudaGetLastError();
|
| 1327 |
+
if (err != cudaSuccess)
|
| 1328 |
+
{
|
| 1329 |
+
printf("error in ms_deformable_col2im_cuda: %s\n", cudaGetErrorString(err));
|
| 1330 |
+
}
|
| 1331 |
+
|
| 1332 |
+
}
|
ops/src/ms_deform_attn.h
ADDED
|
@@ -0,0 +1,67 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
/*!
|
| 2 |
+
**************************************************************************************************
|
| 3 |
+
* Deformable DETR
|
| 4 |
+
* Copyright (c) 2020 SenseTime. All Rights Reserved.
|
| 5 |
+
* Licensed under the Apache License, Version 2.0 [see LICENSE for details]
|
| 6 |
+
**************************************************************************************************
|
| 7 |
+
* Modified from https://github.com/chengdazhi/Deformable-Convolution-V2-PyTorch/tree/pytorch_1.0.0
|
| 8 |
+
**************************************************************************************************
|
| 9 |
+
*/
|
| 10 |
+
|
| 11 |
+
/*!
|
| 12 |
+
* Copyright (c) Facebook, Inc. and its affiliates.
|
| 13 |
+
* Modified by Bowen Cheng from https://github.com/fundamentalvision/Deformable-DETR
|
| 14 |
+
*/
|
| 15 |
+
|
| 16 |
+
#pragma once
|
| 17 |
+
|
| 18 |
+
#include "cpu/ms_deform_attn_cpu.h"
|
| 19 |
+
|
| 20 |
+
#ifdef WITH_CUDA
|
| 21 |
+
#include "cuda/ms_deform_attn_cuda.h"
|
| 22 |
+
#endif
|
| 23 |
+
|
| 24 |
+
|
| 25 |
+
at::Tensor
|
| 26 |
+
ms_deform_attn_forward(
|
| 27 |
+
const at::Tensor &value,
|
| 28 |
+
const at::Tensor &spatial_shapes,
|
| 29 |
+
const at::Tensor &level_start_index,
|
| 30 |
+
const at::Tensor &sampling_loc,
|
| 31 |
+
const at::Tensor &attn_weight,
|
| 32 |
+
const int im2col_step)
|
| 33 |
+
{
|
| 34 |
+
if (value.type().is_cuda())
|
| 35 |
+
{
|
| 36 |
+
#ifdef WITH_CUDA
|
| 37 |
+
return ms_deform_attn_cuda_forward(
|
| 38 |
+
value, spatial_shapes, level_start_index, sampling_loc, attn_weight, im2col_step);
|
| 39 |
+
#else
|
| 40 |
+
AT_ERROR("Not compiled with GPU support");
|
| 41 |
+
#endif
|
| 42 |
+
}
|
| 43 |
+
AT_ERROR("Not implemented on the CPU");
|
| 44 |
+
}
|
| 45 |
+
|
| 46 |
+
std::vector<at::Tensor>
|
| 47 |
+
ms_deform_attn_backward(
|
| 48 |
+
const at::Tensor &value,
|
| 49 |
+
const at::Tensor &spatial_shapes,
|
| 50 |
+
const at::Tensor &level_start_index,
|
| 51 |
+
const at::Tensor &sampling_loc,
|
| 52 |
+
const at::Tensor &attn_weight,
|
| 53 |
+
const at::Tensor &grad_output,
|
| 54 |
+
const int im2col_step)
|
| 55 |
+
{
|
| 56 |
+
if (value.type().is_cuda())
|
| 57 |
+
{
|
| 58 |
+
#ifdef WITH_CUDA
|
| 59 |
+
return ms_deform_attn_cuda_backward(
|
| 60 |
+
value, spatial_shapes, level_start_index, sampling_loc, attn_weight, grad_output, im2col_step);
|
| 61 |
+
#else
|
| 62 |
+
AT_ERROR("Not compiled with GPU support");
|
| 63 |
+
#endif
|
| 64 |
+
}
|
| 65 |
+
AT_ERROR("Not implemented on the CPU");
|
| 66 |
+
}
|
| 67 |
+
|
ops/src/vision.cpp
ADDED
|
@@ -0,0 +1,21 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
/*!
|
| 2 |
+
**************************************************************************************************
|
| 3 |
+
* Deformable DETR
|
| 4 |
+
* Copyright (c) 2020 SenseTime. All Rights Reserved.
|
| 5 |
+
* Licensed under the Apache License, Version 2.0 [see LICENSE for details]
|
| 6 |
+
**************************************************************************************************
|
| 7 |
+
* Modified from https://github.com/chengdazhi/Deformable-Convolution-V2-PyTorch/tree/pytorch_1.0.0
|
| 8 |
+
**************************************************************************************************
|
| 9 |
+
*/
|
| 10 |
+
|
| 11 |
+
/*!
|
| 12 |
+
* Copyright (c) Facebook, Inc. and its affiliates.
|
| 13 |
+
* Modified by Bowen Cheng from https://github.com/fundamentalvision/Deformable-DETR
|
| 14 |
+
*/
|
| 15 |
+
|
| 16 |
+
#include "ms_deform_attn.h"
|
| 17 |
+
|
| 18 |
+
PYBIND11_MODULE(TORCH_EXTENSION_NAME, m) {
|
| 19 |
+
m.def("ms_deform_attn_forward", &ms_deform_attn_forward, "ms_deform_attn_forward");
|
| 20 |
+
m.def("ms_deform_attn_backward", &ms_deform_attn_backward, "ms_deform_attn_backward");
|
| 21 |
+
}
|
ops/test.py
ADDED
|
@@ -0,0 +1,92 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# ------------------------------------------------------------------------------------------------
|
| 2 |
+
# Deformable DETR
|
| 3 |
+
# Copyright (c) 2020 SenseTime. All Rights Reserved.
|
| 4 |
+
# Licensed under the Apache License, Version 2.0 [see LICENSE for details]
|
| 5 |
+
# ------------------------------------------------------------------------------------------------
|
| 6 |
+
# Modified from https://github.com/chengdazhi/Deformable-Convolution-V2-PyTorch/tree/pytorch_1.0.0
|
| 7 |
+
# ------------------------------------------------------------------------------------------------
|
| 8 |
+
|
| 9 |
+
# Copyright (c) Facebook, Inc. and its affiliates.
|
| 10 |
+
# Modified by Bowen Cheng from https://github.com/fundamentalvision/Deformable-DETR
|
| 11 |
+
|
| 12 |
+
from __future__ import absolute_import
|
| 13 |
+
from __future__ import print_function
|
| 14 |
+
from __future__ import division
|
| 15 |
+
|
| 16 |
+
import time
|
| 17 |
+
import torch
|
| 18 |
+
import torch.nn as nn
|
| 19 |
+
from torch.autograd import gradcheck
|
| 20 |
+
|
| 21 |
+
from functions.ms_deform_attn_func import MSDeformAttnFunction, ms_deform_attn_core_pytorch
|
| 22 |
+
|
| 23 |
+
|
| 24 |
+
N, M, D = 1, 2, 2
|
| 25 |
+
Lq, L, P = 2, 2, 2
|
| 26 |
+
shapes = torch.as_tensor([(6, 4), (3, 2)], dtype=torch.long).cuda()
|
| 27 |
+
level_start_index = torch.cat((shapes.new_zeros((1, )), shapes.prod(1).cumsum(0)[:-1]))
|
| 28 |
+
S = sum([(H*W).item() for H, W in shapes])
|
| 29 |
+
|
| 30 |
+
|
| 31 |
+
torch.manual_seed(3)
|
| 32 |
+
|
| 33 |
+
|
| 34 |
+
@torch.no_grad()
|
| 35 |
+
def check_forward_equal_with_pytorch_double():
|
| 36 |
+
value = torch.rand(N, S, M, D).cuda() * 0.01
|
| 37 |
+
sampling_locations = torch.rand(N, Lq, M, L, P, 2).cuda()
|
| 38 |
+
attention_weights = torch.rand(N, Lq, M, L, P).cuda() + 1e-5
|
| 39 |
+
attention_weights /= attention_weights.sum(-1, keepdim=True).sum(-2, keepdim=True)
|
| 40 |
+
im2col_step = 2
|
| 41 |
+
output_pytorch = ms_deform_attn_core_pytorch(value.double(), shapes, sampling_locations.double(), attention_weights.double()).detach().cpu()
|
| 42 |
+
output_cuda = MSDeformAttnFunction.apply(value.double(), shapes, level_start_index, sampling_locations.double(), attention_weights.double(), im2col_step).detach().cpu()
|
| 43 |
+
fwdok = torch.allclose(output_cuda, output_pytorch)
|
| 44 |
+
max_abs_err = (output_cuda - output_pytorch).abs().max()
|
| 45 |
+
max_rel_err = ((output_cuda - output_pytorch).abs() / output_pytorch.abs()).max()
|
| 46 |
+
|
| 47 |
+
print(f'* {fwdok} check_forward_equal_with_pytorch_double: max_abs_err {max_abs_err:.2e} max_rel_err {max_rel_err:.2e}')
|
| 48 |
+
|
| 49 |
+
|
| 50 |
+
@torch.no_grad()
|
| 51 |
+
def check_forward_equal_with_pytorch_float():
|
| 52 |
+
value = torch.rand(N, S, M, D).cuda() * 0.01
|
| 53 |
+
sampling_locations = torch.rand(N, Lq, M, L, P, 2).cuda()
|
| 54 |
+
attention_weights = torch.rand(N, Lq, M, L, P).cuda() + 1e-5
|
| 55 |
+
attention_weights /= attention_weights.sum(-1, keepdim=True).sum(-2, keepdim=True)
|
| 56 |
+
im2col_step = 2
|
| 57 |
+
output_pytorch = ms_deform_attn_core_pytorch(value, shapes, sampling_locations, attention_weights).detach().cpu()
|
| 58 |
+
output_cuda = MSDeformAttnFunction.apply(value, shapes, level_start_index, sampling_locations, attention_weights, im2col_step).detach().cpu()
|
| 59 |
+
fwdok = torch.allclose(output_cuda, output_pytorch, rtol=1e-2, atol=1e-3)
|
| 60 |
+
max_abs_err = (output_cuda - output_pytorch).abs().max()
|
| 61 |
+
max_rel_err = ((output_cuda - output_pytorch).abs() / output_pytorch.abs()).max()
|
| 62 |
+
|
| 63 |
+
print(f'* {fwdok} check_forward_equal_with_pytorch_float: max_abs_err {max_abs_err:.2e} max_rel_err {max_rel_err:.2e}')
|
| 64 |
+
|
| 65 |
+
|
| 66 |
+
def check_gradient_numerical(channels=4, grad_value=True, grad_sampling_loc=True, grad_attn_weight=True):
|
| 67 |
+
|
| 68 |
+
value = torch.rand(N, S, M, channels).cuda() * 0.01
|
| 69 |
+
sampling_locations = torch.rand(N, Lq, M, L, P, 2).cuda()
|
| 70 |
+
attention_weights = torch.rand(N, Lq, M, L, P).cuda() + 1e-5
|
| 71 |
+
attention_weights /= attention_weights.sum(-1, keepdim=True).sum(-2, keepdim=True)
|
| 72 |
+
im2col_step = 2
|
| 73 |
+
func = MSDeformAttnFunction.apply
|
| 74 |
+
|
| 75 |
+
value.requires_grad = grad_value
|
| 76 |
+
sampling_locations.requires_grad = grad_sampling_loc
|
| 77 |
+
attention_weights.requires_grad = grad_attn_weight
|
| 78 |
+
|
| 79 |
+
gradok = gradcheck(func, (value.double(), shapes, level_start_index, sampling_locations.double(), attention_weights.double(), im2col_step))
|
| 80 |
+
|
| 81 |
+
print(f'* {gradok} check_gradient_numerical(D={channels})')
|
| 82 |
+
|
| 83 |
+
|
| 84 |
+
if __name__ == '__main__':
|
| 85 |
+
check_forward_equal_with_pytorch_double()
|
| 86 |
+
check_forward_equal_with_pytorch_float()
|
| 87 |
+
|
| 88 |
+
for channels in [30, 32, 64, 71, 1025, 2048, 3096]:
|
| 89 |
+
check_gradient_numerical(channels, True, True, True)
|
| 90 |
+
|
| 91 |
+
|
| 92 |
+
|
sam_vit_h_4b8939.pth
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:a7bf3b02f3ebf1267aba913ff637d9a2d5c33d3173bb679e46d9f338c26f262e
|
| 3 |
+
size 2564550879
|
seem_focall_v1.pt
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:06cad58bde442ce4f2b3ce00e3a218791dfb060a2d7f2d709ff509669c28a705
|
| 3 |
+
size 1365136278
|
swinl_only_sam_many2many.pth
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:f85bee1faa64154831a75598048d133e345874dbd7ef87d00b6446c1ae772956
|
| 3 |
+
size 895495739
|