
Upload 82 files
Browse filesThis view is limited to 50 files because it contains too many changes.
See raw diff
- .gitattributes +4 -0
- chains/__pycache__/local_doc_qa.cpython-310.pyc +0 -0
- chains/dialogue_answering/__init__.py +7 -0
- chains/dialogue_answering/__main__.py +36 -0
- chains/dialogue_answering/base.py +99 -0
- chains/dialogue_answering/prompts.py +22 -0
- chains/local_doc_qa.py +347 -0
- chains/text_load.py +52 -0
- configs/__pycache__/model_config.cpython-310.pyc +0 -0
- configs/model_config - 副本.py +269 -0
- configs/model_config.py +202 -0
- docs/API.md +1042 -0
- docs/CHANGELOG.md +32 -0
- docs/FAQ.md +179 -0
- docs/INSTALL.md +55 -0
- docs/Issue-with-Installing-Packages-Using-pip-in-Anaconda.md +114 -0
- docs/StartOption.md +76 -0
- docs/cli.md +49 -0
- docs/fastchat.md +24 -0
- docs/启动API服务.md +37 -0
- docs/在Anaconda中使用pip安装包无效问题.md +125 -0
- flagged/component 2/tmp1x130c0q.json +1 -0
- flagged/log.csv +2 -0
- img/docker_logs.png +0 -0
- img/langchain+chatglm.png +3 -0
- img/langchain+chatglm2.png +0 -0
- img/qr_code_43.jpg +0 -0
- img/qr_code_44.jpg +0 -0
- img/qr_code_45.jpg +0 -0
- img/vue_0521_0.png +0 -0
- img/vue_0521_1.png +3 -0
- img/vue_0521_2.png +3 -0
- img/webui_0419.png +0 -0
- img/webui_0510_0.png +0 -0
- img/webui_0510_1.png +0 -0
- img/webui_0510_2.png +0 -0
- img/webui_0521_0.png +0 -0
- knowledge_base/samples/content/README.md +212 -0
- knowledge_base/samples/content/test.jpg +0 -0
- knowledge_base/samples/content/test.pdf +0 -0
- knowledge_base/samples/content/test.txt +835 -0
- knowledge_base/samples/isssues_merge/langchain-ChatGLM_closed.csv +173 -0
- knowledge_base/samples/isssues_merge/langchain-ChatGLM_closed.jsonl +172 -0
- knowledge_base/samples/isssues_merge/langchain-ChatGLM_closed.xlsx +0 -0
- knowledge_base/samples/isssues_merge/langchain-ChatGLM_open.csv +324 -0
- knowledge_base/samples/isssues_merge/langchain-ChatGLM_open.jsonl +323 -0
- knowledge_base/samples/isssues_merge/langchain-ChatGLM_open.xlsx +0 -0
- knowledge_base/samples/vector_store/index.faiss +3 -0
- knowledge_base/samples/vector_store/index.pkl +3 -0
- loader/RSS_loader.py +54 -0
.gitattributes
CHANGED
|
@@ -33,3 +33,7 @@ saved_model/**/* filter=lfs diff=lfs merge=lfs -text
|
|
| 33 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 33 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
| 36 |
+
img/langchain+chatglm.png filter=lfs diff=lfs merge=lfs -text
|
| 37 |
+
img/vue_0521_1.png filter=lfs diff=lfs merge=lfs -text
|
| 38 |
+
img/vue_0521_2.png filter=lfs diff=lfs merge=lfs -text
|
| 39 |
+
knowledge_base/samples/vector_store/index.faiss filter=lfs diff=lfs merge=lfs -text
|
chains/__pycache__/local_doc_qa.cpython-310.pyc
ADDED
|
Binary file (11.3 kB). View file
|
|
|
chains/dialogue_answering/__init__.py
ADDED
|
@@ -0,0 +1,7 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from .base import (
|
| 2 |
+
DialogueWithSharedMemoryChains
|
| 3 |
+
)
|
| 4 |
+
|
| 5 |
+
__all__ = [
|
| 6 |
+
"DialogueWithSharedMemoryChains"
|
| 7 |
+
]
|
chains/dialogue_answering/__main__.py
ADDED
|
@@ -0,0 +1,36 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import sys
|
| 2 |
+
import os
|
| 3 |
+
import argparse
|
| 4 |
+
import asyncio
|
| 5 |
+
from argparse import Namespace
|
| 6 |
+
sys.path.append(os.path.dirname(os.path.abspath(__file__)) + '/../../')
|
| 7 |
+
from chains.dialogue_answering import *
|
| 8 |
+
from langchain.llms import OpenAI
|
| 9 |
+
from models.base import (BaseAnswer,
|
| 10 |
+
AnswerResult)
|
| 11 |
+
import models.shared as shared
|
| 12 |
+
from models.loader.args import parser
|
| 13 |
+
from models.loader import LoaderCheckPoint
|
| 14 |
+
|
| 15 |
+
async def dispatch(args: Namespace):
|
| 16 |
+
|
| 17 |
+
args_dict = vars(args)
|
| 18 |
+
shared.loaderCheckPoint = LoaderCheckPoint(args_dict)
|
| 19 |
+
llm_model_ins = shared.loaderLLM()
|
| 20 |
+
if not os.path.isfile(args.dialogue_path):
|
| 21 |
+
raise FileNotFoundError(f'Invalid dialogue file path for demo mode: "{args.dialogue_path}"')
|
| 22 |
+
llm = OpenAI(temperature=0)
|
| 23 |
+
dialogue_instance = DialogueWithSharedMemoryChains(zero_shot_react_llm=llm, ask_llm=llm_model_ins, params=args_dict)
|
| 24 |
+
|
| 25 |
+
dialogue_instance.agent_chain.run(input="What did David say before, summarize it")
|
| 26 |
+
|
| 27 |
+
|
| 28 |
+
if __name__ == '__main__':
|
| 29 |
+
|
| 30 |
+
parser.add_argument('--dialogue-path', default='', type=str, help='dialogue-path')
|
| 31 |
+
parser.add_argument('--embedding-model', default='', type=str, help='embedding-model')
|
| 32 |
+
args = parser.parse_args(['--dialogue-path', '/home/dmeck/Downloads/log.txt',
|
| 33 |
+
'--embedding-mode', '/media/checkpoint/text2vec-large-chinese/'])
|
| 34 |
+
loop = asyncio.new_event_loop()
|
| 35 |
+
asyncio.set_event_loop(loop)
|
| 36 |
+
loop.run_until_complete(dispatch(args))
|
chains/dialogue_answering/base.py
ADDED
|
@@ -0,0 +1,99 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from langchain.base_language import BaseLanguageModel
|
| 2 |
+
from langchain.agents import ZeroShotAgent, Tool, AgentExecutor
|
| 3 |
+
from langchain.memory import ConversationBufferMemory, ReadOnlySharedMemory
|
| 4 |
+
from langchain.chains import LLMChain, RetrievalQA
|
| 5 |
+
from langchain.embeddings.huggingface import HuggingFaceEmbeddings
|
| 6 |
+
from langchain.prompts import PromptTemplate
|
| 7 |
+
from langchain.text_splitter import CharacterTextSplitter
|
| 8 |
+
from langchain.vectorstores import Chroma
|
| 9 |
+
|
| 10 |
+
from loader import DialogueLoader
|
| 11 |
+
from chains.dialogue_answering.prompts import (
|
| 12 |
+
DIALOGUE_PREFIX,
|
| 13 |
+
DIALOGUE_SUFFIX,
|
| 14 |
+
SUMMARY_PROMPT
|
| 15 |
+
)
|
| 16 |
+
|
| 17 |
+
|
| 18 |
+
class DialogueWithSharedMemoryChains:
|
| 19 |
+
zero_shot_react_llm: BaseLanguageModel = None
|
| 20 |
+
ask_llm: BaseLanguageModel = None
|
| 21 |
+
embeddings: HuggingFaceEmbeddings = None
|
| 22 |
+
embedding_model: str = None
|
| 23 |
+
vector_search_top_k: int = 6
|
| 24 |
+
dialogue_path: str = None
|
| 25 |
+
dialogue_loader: DialogueLoader = None
|
| 26 |
+
device: str = None
|
| 27 |
+
|
| 28 |
+
def __init__(self, zero_shot_react_llm: BaseLanguageModel = None, ask_llm: BaseLanguageModel = None,
|
| 29 |
+
params: dict = None):
|
| 30 |
+
self.zero_shot_react_llm = zero_shot_react_llm
|
| 31 |
+
self.ask_llm = ask_llm
|
| 32 |
+
params = params or {}
|
| 33 |
+
self.embedding_model = params.get('embedding_model', 'GanymedeNil/text2vec-large-chinese')
|
| 34 |
+
self.vector_search_top_k = params.get('vector_search_top_k', 6)
|
| 35 |
+
self.dialogue_path = params.get('dialogue_path', '')
|
| 36 |
+
self.device = 'cuda' if params.get('use_cuda', False) else 'cpu'
|
| 37 |
+
|
| 38 |
+
self.dialogue_loader = DialogueLoader(self.dialogue_path)
|
| 39 |
+
self._init_cfg()
|
| 40 |
+
self._init_state_of_history()
|
| 41 |
+
self.memory_chain, self.memory = self._agents_answer()
|
| 42 |
+
self.agent_chain = self._create_agent_chain()
|
| 43 |
+
|
| 44 |
+
def _init_cfg(self):
|
| 45 |
+
model_kwargs = {
|
| 46 |
+
'device': self.device
|
| 47 |
+
}
|
| 48 |
+
self.embeddings = HuggingFaceEmbeddings(model_name=self.embedding_model, model_kwargs=model_kwargs)
|
| 49 |
+
|
| 50 |
+
def _init_state_of_history(self):
|
| 51 |
+
documents = self.dialogue_loader.load()
|
| 52 |
+
text_splitter = CharacterTextSplitter(chunk_size=3, chunk_overlap=1)
|
| 53 |
+
texts = text_splitter.split_documents(documents)
|
| 54 |
+
docsearch = Chroma.from_documents(texts, self.embeddings, collection_name="state-of-history")
|
| 55 |
+
self.state_of_history = RetrievalQA.from_chain_type(llm=self.ask_llm, chain_type="stuff",
|
| 56 |
+
retriever=docsearch.as_retriever())
|
| 57 |
+
|
| 58 |
+
def _agents_answer(self):
|
| 59 |
+
|
| 60 |
+
memory = ConversationBufferMemory(memory_key="chat_history")
|
| 61 |
+
readonly_memory = ReadOnlySharedMemory(memory=memory)
|
| 62 |
+
memory_chain = LLMChain(
|
| 63 |
+
llm=self.ask_llm,
|
| 64 |
+
prompt=SUMMARY_PROMPT,
|
| 65 |
+
verbose=True,
|
| 66 |
+
memory=readonly_memory, # use the read-only memory to prevent the tool from modifying the memory
|
| 67 |
+
)
|
| 68 |
+
return memory_chain, memory
|
| 69 |
+
|
| 70 |
+
def _create_agent_chain(self):
|
| 71 |
+
dialogue_participants = self.dialogue_loader.dialogue.participants_to_export()
|
| 72 |
+
tools = [
|
| 73 |
+
Tool(
|
| 74 |
+
name="State of Dialogue History System",
|
| 75 |
+
func=self.state_of_history.run,
|
| 76 |
+
description=f"Dialogue with {dialogue_participants} - The answers in this section are very useful "
|
| 77 |
+
f"when searching for chat content between {dialogue_participants}. Input should be a "
|
| 78 |
+
f"complete question. "
|
| 79 |
+
),
|
| 80 |
+
Tool(
|
| 81 |
+
name="Summary",
|
| 82 |
+
func=self.memory_chain.run,
|
| 83 |
+
description="useful for when you summarize a conversation. The input to this tool should be a string, "
|
| 84 |
+
"representing who will read this summary. "
|
| 85 |
+
)
|
| 86 |
+
]
|
| 87 |
+
|
| 88 |
+
prompt = ZeroShotAgent.create_prompt(
|
| 89 |
+
tools,
|
| 90 |
+
prefix=DIALOGUE_PREFIX,
|
| 91 |
+
suffix=DIALOGUE_SUFFIX,
|
| 92 |
+
input_variables=["input", "chat_history", "agent_scratchpad"]
|
| 93 |
+
)
|
| 94 |
+
|
| 95 |
+
llm_chain = LLMChain(llm=self.zero_shot_react_llm, prompt=prompt)
|
| 96 |
+
agent = ZeroShotAgent(llm_chain=llm_chain, tools=tools, verbose=True)
|
| 97 |
+
agent_chain = AgentExecutor.from_agent_and_tools(agent=agent, tools=tools, verbose=True, memory=self.memory)
|
| 98 |
+
|
| 99 |
+
return agent_chain
|
chains/dialogue_answering/prompts.py
ADDED
|
@@ -0,0 +1,22 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from langchain.prompts.prompt import PromptTemplate
|
| 2 |
+
|
| 3 |
+
|
| 4 |
+
SUMMARY_TEMPLATE = """This is a conversation between a human and a bot:
|
| 5 |
+
|
| 6 |
+
{chat_history}
|
| 7 |
+
|
| 8 |
+
Write a summary of the conversation for {input}:
|
| 9 |
+
"""
|
| 10 |
+
|
| 11 |
+
SUMMARY_PROMPT = PromptTemplate(
|
| 12 |
+
input_variables=["input", "chat_history"],
|
| 13 |
+
template=SUMMARY_TEMPLATE
|
| 14 |
+
)
|
| 15 |
+
|
| 16 |
+
DIALOGUE_PREFIX = """Have a conversation with a human,Analyze the content of the conversation.
|
| 17 |
+
You have access to the following tools: """
|
| 18 |
+
DIALOGUE_SUFFIX = """Begin!
|
| 19 |
+
|
| 20 |
+
{chat_history}
|
| 21 |
+
Question: {input}
|
| 22 |
+
{agent_scratchpad}"""
|
chains/local_doc_qa.py
ADDED
|
@@ -0,0 +1,347 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from langchain.embeddings.huggingface import HuggingFaceEmbeddings
|
| 2 |
+
from vectorstores import MyFAISS
|
| 3 |
+
from langchain.document_loaders import UnstructuredFileLoader, TextLoader, CSVLoader
|
| 4 |
+
from configs.model_config import *
|
| 5 |
+
import datetime
|
| 6 |
+
from textsplitter import ChineseTextSplitter
|
| 7 |
+
from typing import List
|
| 8 |
+
from utils import torch_gc
|
| 9 |
+
from tqdm import tqdm
|
| 10 |
+
from pypinyin import lazy_pinyin
|
| 11 |
+
from loader import UnstructuredPaddleImageLoader, UnstructuredPaddlePDFLoader
|
| 12 |
+
from models.base import (BaseAnswer,
|
| 13 |
+
AnswerResult)
|
| 14 |
+
from models.loader.args import parser
|
| 15 |
+
from models.loader import LoaderCheckPoint
|
| 16 |
+
import models.shared as shared
|
| 17 |
+
from agent import bing_search
|
| 18 |
+
from langchain.docstore.document import Document
|
| 19 |
+
from functools import lru_cache
|
| 20 |
+
from textsplitter.zh_title_enhance import zh_title_enhance
|
| 21 |
+
|
| 22 |
+
|
| 23 |
+
# patch HuggingFaceEmbeddings to make it hashable
|
| 24 |
+
def _embeddings_hash(self):
|
| 25 |
+
return hash(self.model_name)
|
| 26 |
+
|
| 27 |
+
|
| 28 |
+
HuggingFaceEmbeddings.__hash__ = _embeddings_hash
|
| 29 |
+
|
| 30 |
+
|
| 31 |
+
# will keep CACHED_VS_NUM of vector store caches
|
| 32 |
+
@lru_cache(CACHED_VS_NUM)
|
| 33 |
+
def load_vector_store(vs_path, embeddings):
|
| 34 |
+
return MyFAISS.load_local(vs_path, embeddings)
|
| 35 |
+
|
| 36 |
+
|
| 37 |
+
def tree(filepath, ignore_dir_names=None, ignore_file_names=None):
|
| 38 |
+
"""返回两个列表,第一个列表为 filepath 下全部文件的完整路径, 第二个为对应的文件名"""
|
| 39 |
+
if ignore_dir_names is None:
|
| 40 |
+
ignore_dir_names = []
|
| 41 |
+
if ignore_file_names is None:
|
| 42 |
+
ignore_file_names = []
|
| 43 |
+
ret_list = []
|
| 44 |
+
if isinstance(filepath, str):
|
| 45 |
+
if not os.path.exists(filepath):
|
| 46 |
+
print("路径不存在")
|
| 47 |
+
return None, None
|
| 48 |
+
elif os.path.isfile(filepath) and os.path.basename(filepath) not in ignore_file_names:
|
| 49 |
+
return [filepath], [os.path.basename(filepath)]
|
| 50 |
+
elif os.path.isdir(filepath) and os.path.basename(filepath) not in ignore_dir_names:
|
| 51 |
+
for file in os.listdir(filepath):
|
| 52 |
+
fullfilepath = os.path.join(filepath, file)
|
| 53 |
+
if os.path.isfile(fullfilepath) and os.path.basename(fullfilepath) not in ignore_file_names:
|
| 54 |
+
ret_list.append(fullfilepath)
|
| 55 |
+
if os.path.isdir(fullfilepath) and os.path.basename(fullfilepath) not in ignore_dir_names:
|
| 56 |
+
ret_list.extend(tree(fullfilepath, ignore_dir_names, ignore_file_names)[0])
|
| 57 |
+
return ret_list, [os.path.basename(p) for p in ret_list]
|
| 58 |
+
|
| 59 |
+
|
| 60 |
+
def load_file(filepath, sentence_size=SENTENCE_SIZE, using_zh_title_enhance=ZH_TITLE_ENHANCE):
|
| 61 |
+
if filepath.lower().endswith(".md"):
|
| 62 |
+
loader = UnstructuredFileLoader(filepath, mode="elements")
|
| 63 |
+
docs = loader.load()
|
| 64 |
+
elif filepath.lower().endswith(".txt"):
|
| 65 |
+
loader = TextLoader(filepath, autodetect_encoding=True)
|
| 66 |
+
textsplitter = ChineseTextSplitter(pdf=False, sentence_size=sentence_size)
|
| 67 |
+
docs = loader.load_and_split(textsplitter)
|
| 68 |
+
elif filepath.lower().endswith(".pdf"):
|
| 69 |
+
loader = UnstructuredPaddlePDFLoader(filepath)
|
| 70 |
+
textsplitter = ChineseTextSplitter(pdf=True, sentence_size=sentence_size)
|
| 71 |
+
docs = loader.load_and_split(textsplitter)
|
| 72 |
+
elif filepath.lower().endswith(".jpg") or filepath.lower().endswith(".png"):
|
| 73 |
+
loader = UnstructuredPaddleImageLoader(filepath, mode="elements")
|
| 74 |
+
textsplitter = ChineseTextSplitter(pdf=False, sentence_size=sentence_size)
|
| 75 |
+
docs = loader.load_and_split(text_splitter=textsplitter)
|
| 76 |
+
elif filepath.lower().endswith(".csv"):
|
| 77 |
+
loader = CSVLoader(filepath)
|
| 78 |
+
docs = loader.load()
|
| 79 |
+
else:
|
| 80 |
+
loader = UnstructuredFileLoader(filepath, mode="elements")
|
| 81 |
+
textsplitter = ChineseTextSplitter(pdf=False, sentence_size=sentence_size)
|
| 82 |
+
docs = loader.load_and_split(text_splitter=textsplitter)
|
| 83 |
+
if using_zh_title_enhance:
|
| 84 |
+
docs = zh_title_enhance(docs)
|
| 85 |
+
write_check_file(filepath, docs)
|
| 86 |
+
return docs
|
| 87 |
+
|
| 88 |
+
|
| 89 |
+
def write_check_file(filepath, docs):
|
| 90 |
+
folder_path = os.path.join(os.path.dirname(filepath), "tmp_files")
|
| 91 |
+
if not os.path.exists(folder_path):
|
| 92 |
+
os.makedirs(folder_path)
|
| 93 |
+
fp = os.path.join(folder_path, 'load_file.txt')
|
| 94 |
+
with open(fp, 'a+', encoding='utf-8') as fout:
|
| 95 |
+
fout.write("filepath=%s,len=%s" % (filepath, len(docs)))
|
| 96 |
+
fout.write('\n')
|
| 97 |
+
for i in docs:
|
| 98 |
+
fout.write(str(i))
|
| 99 |
+
fout.write('\n')
|
| 100 |
+
fout.close()
|
| 101 |
+
|
| 102 |
+
|
| 103 |
+
def generate_prompt(related_docs: List[str],
|
| 104 |
+
query: str,
|
| 105 |
+
prompt_template: str = PROMPT_TEMPLATE, ) -> str:
|
| 106 |
+
context = "\n".join([doc.page_content for doc in related_docs])
|
| 107 |
+
prompt = prompt_template.replace("{question}", query).replace("{context}", context)
|
| 108 |
+
return prompt
|
| 109 |
+
|
| 110 |
+
|
| 111 |
+
def search_result2docs(search_results):
|
| 112 |
+
docs = []
|
| 113 |
+
for result in search_results:
|
| 114 |
+
doc = Document(page_content=result["snippet"] if "snippet" in result.keys() else "",
|
| 115 |
+
metadata={"source": result["link"] if "link" in result.keys() else "",
|
| 116 |
+
"filename": result["title"] if "title" in result.keys() else ""})
|
| 117 |
+
docs.append(doc)
|
| 118 |
+
return docs
|
| 119 |
+
|
| 120 |
+
|
| 121 |
+
class LocalDocQA:
|
| 122 |
+
llm: BaseAnswer = None
|
| 123 |
+
embeddings: object = None
|
| 124 |
+
top_k: int = VECTOR_SEARCH_TOP_K
|
| 125 |
+
chunk_size: int = CHUNK_SIZE
|
| 126 |
+
chunk_conent: bool = True
|
| 127 |
+
score_threshold: int = VECTOR_SEARCH_SCORE_THRESHOLD
|
| 128 |
+
|
| 129 |
+
def init_cfg(self,
|
| 130 |
+
embedding_model: str = EMBEDDING_MODEL,
|
| 131 |
+
embedding_device=EMBEDDING_DEVICE,
|
| 132 |
+
llm_model: BaseAnswer = None,
|
| 133 |
+
top_k=VECTOR_SEARCH_TOP_K,
|
| 134 |
+
):
|
| 135 |
+
self.llm = llm_model
|
| 136 |
+
self.embeddings = HuggingFaceEmbeddings(model_name="C:/Users/Administrator/text2vec-large-chinese",
|
| 137 |
+
model_kwargs={'device': embedding_device})
|
| 138 |
+
# self.embeddings = HuggingFaceEmbeddings(model_name=embedding_model_dict[embedding_model],
|
| 139 |
+
# model_kwargs={'device': embedding_device})
|
| 140 |
+
|
| 141 |
+
self.top_k = top_k
|
| 142 |
+
|
| 143 |
+
def init_knowledge_vector_store(self,
|
| 144 |
+
filepath: str or List[str],
|
| 145 |
+
vs_path: str or os.PathLike = None,
|
| 146 |
+
sentence_size=SENTENCE_SIZE):
|
| 147 |
+
loaded_files = []
|
| 148 |
+
failed_files = []
|
| 149 |
+
if isinstance(filepath, str):
|
| 150 |
+
if not os.path.exists(filepath):
|
| 151 |
+
print("路径不存在")
|
| 152 |
+
return None
|
| 153 |
+
elif os.path.isfile(filepath):
|
| 154 |
+
file = os.path.split(filepath)[-1]
|
| 155 |
+
try:
|
| 156 |
+
docs = load_file(filepath, sentence_size)
|
| 157 |
+
logger.info(f"{file} 已成功加载")
|
| 158 |
+
loaded_files.append(filepath)
|
| 159 |
+
except Exception as e:
|
| 160 |
+
logger.error(e)
|
| 161 |
+
logger.info(f"{file} 未能成功加载")
|
| 162 |
+
return None
|
| 163 |
+
elif os.path.isdir(filepath):
|
| 164 |
+
docs = []
|
| 165 |
+
for fullfilepath, file in tqdm(zip(*tree(filepath, ignore_dir_names=['tmp_files'])), desc="加载文件"):
|
| 166 |
+
try:
|
| 167 |
+
docs += load_file(fullfilepath, sentence_size)
|
| 168 |
+
loaded_files.append(fullfilepath)
|
| 169 |
+
except Exception as e:
|
| 170 |
+
logger.error(e)
|
| 171 |
+
failed_files.append(file)
|
| 172 |
+
|
| 173 |
+
if len(failed_files) > 0:
|
| 174 |
+
logger.info("以下文件未能成功加载:")
|
| 175 |
+
for file in failed_files:
|
| 176 |
+
logger.info(f"{file}\n")
|
| 177 |
+
|
| 178 |
+
else:
|
| 179 |
+
docs = []
|
| 180 |
+
for file in filepath:
|
| 181 |
+
try:
|
| 182 |
+
docs += load_file(file)
|
| 183 |
+
logger.info(f"{file} 已成功加载")
|
| 184 |
+
loaded_files.append(file)
|
| 185 |
+
except Exception as e:
|
| 186 |
+
logger.error(e)
|
| 187 |
+
logger.info(f"{file} 未能成功加载")
|
| 188 |
+
if len(docs) > 0:
|
| 189 |
+
logger.info("文件加载完毕,正在生成向量库")
|
| 190 |
+
if vs_path and os.path.isdir(vs_path) and "index.faiss" in os.listdir(vs_path):
|
| 191 |
+
vector_store = load_vector_store(vs_path, self.embeddings)
|
| 192 |
+
vector_store.add_documents(docs)
|
| 193 |
+
torch_gc()
|
| 194 |
+
else:
|
| 195 |
+
if not vs_path:
|
| 196 |
+
vs_path = os.path.join(KB_ROOT_PATH,
|
| 197 |
+
f"""{"".join(lazy_pinyin(os.path.splitext(file)[0]))}_FAISS_{datetime.datetime.now().strftime("%Y%m%d_%H%M%S")}""",
|
| 198 |
+
"vector_store")
|
| 199 |
+
vector_store = MyFAISS.from_documents(docs, self.embeddings) # docs 为Document列表
|
| 200 |
+
torch_gc()
|
| 201 |
+
|
| 202 |
+
vector_store.save_local(vs_path)
|
| 203 |
+
return vs_path, loaded_files
|
| 204 |
+
else:
|
| 205 |
+
logger.info("文件均未成功加载,请检查依赖包或替换为其他文件再次上传。")
|
| 206 |
+
return None, loaded_files
|
| 207 |
+
|
| 208 |
+
def one_knowledge_add(self, vs_path, one_title, one_conent, one_content_segmentation, sentence_size):
|
| 209 |
+
try:
|
| 210 |
+
if not vs_path or not one_title or not one_conent:
|
| 211 |
+
logger.info("知识库添加错误,请确认知识库名字、标题、内容是否正确!")
|
| 212 |
+
return None, [one_title]
|
| 213 |
+
docs = [Document(page_content=one_conent + "\n", metadata={"source": one_title})]
|
| 214 |
+
if not one_content_segmentation:
|
| 215 |
+
text_splitter = ChineseTextSplitter(pdf=False, sentence_size=sentence_size)
|
| 216 |
+
docs = text_splitter.split_documents(docs)
|
| 217 |
+
if os.path.isdir(vs_path) and os.path.isfile(vs_path + "/index.faiss"):
|
| 218 |
+
vector_store = load_vector_store(vs_path, self.embeddings)
|
| 219 |
+
vector_store.add_documents(docs)
|
| 220 |
+
else:
|
| 221 |
+
vector_store = MyFAISS.from_documents(docs, self.embeddings) ##docs 为Document列表
|
| 222 |
+
torch_gc()
|
| 223 |
+
vector_store.save_local(vs_path)
|
| 224 |
+
return vs_path, [one_title]
|
| 225 |
+
except Exception as e:
|
| 226 |
+
logger.error(e)
|
| 227 |
+
return None, [one_title]
|
| 228 |
+
|
| 229 |
+
def get_knowledge_based_answer(self, query, vs_path, chat_history=[], streaming: bool = STREAMING):
|
| 230 |
+
vector_store = load_vector_store(vs_path, self.embeddings)
|
| 231 |
+
vector_store.chunk_size = self.chunk_size
|
| 232 |
+
vector_store.chunk_conent = self.chunk_conent
|
| 233 |
+
vector_store.score_threshold = self.score_threshold
|
| 234 |
+
related_docs_with_score = vector_store.similarity_search_with_score(query, k=self.top_k)
|
| 235 |
+
torch_gc()
|
| 236 |
+
if len(related_docs_with_score) > 0:
|
| 237 |
+
prompt = generate_prompt(related_docs_with_score, query)
|
| 238 |
+
else:
|
| 239 |
+
prompt = query
|
| 240 |
+
|
| 241 |
+
for answer_result in self.llm.generatorAnswer(prompt=prompt, history=chat_history,
|
| 242 |
+
streaming=streaming):
|
| 243 |
+
resp = answer_result.llm_output["answer"]
|
| 244 |
+
history = answer_result.history
|
| 245 |
+
history[-1][0] = query
|
| 246 |
+
response = {"query": query,
|
| 247 |
+
"result": resp,
|
| 248 |
+
"source_documents": related_docs_with_score}
|
| 249 |
+
yield response, history
|
| 250 |
+
|
| 251 |
+
# query 查询内容
|
| 252 |
+
# vs_path 知识库路径
|
| 253 |
+
# chunk_conent 是否启用上下文关联
|
| 254 |
+
# score_threshold 搜索匹配score阈值
|
| 255 |
+
# vector_search_top_k 搜索知识库内容条数,默认搜索5条结果
|
| 256 |
+
# chunk_sizes 匹配单段内容的连接上下文长度
|
| 257 |
+
def get_knowledge_based_conent_test(self, query, vs_path, chunk_conent,
|
| 258 |
+
score_threshold=VECTOR_SEARCH_SCORE_THRESHOLD,
|
| 259 |
+
vector_search_top_k=VECTOR_SEARCH_TOP_K, chunk_size=CHUNK_SIZE):
|
| 260 |
+
vector_store = load_vector_store(vs_path, self.embeddings)
|
| 261 |
+
# FAISS.similarity_search_with_score_by_vector = similarity_search_with_score_by_vector
|
| 262 |
+
vector_store.chunk_conent = chunk_conent
|
| 263 |
+
vector_store.score_threshold = score_threshold
|
| 264 |
+
vector_store.chunk_size = chunk_size
|
| 265 |
+
related_docs_with_score = vector_store.similarity_search_with_score(query, k=vector_search_top_k)
|
| 266 |
+
if not related_docs_with_score:
|
| 267 |
+
response = {"query": query,
|
| 268 |
+
"source_documents": []}
|
| 269 |
+
return response, ""
|
| 270 |
+
torch_gc()
|
| 271 |
+
prompt = "\n".join([doc.page_content for doc in related_docs_with_score])
|
| 272 |
+
response = {"query": query,
|
| 273 |
+
"source_documents": related_docs_with_score}
|
| 274 |
+
return response, prompt
|
| 275 |
+
|
| 276 |
+
def get_search_result_based_answer(self, query, chat_history=[], streaming: bool = STREAMING):
|
| 277 |
+
results = bing_search(query)
|
| 278 |
+
result_docs = search_result2docs(results)
|
| 279 |
+
prompt = generate_prompt(result_docs, query)
|
| 280 |
+
|
| 281 |
+
for answer_result in self.llm.generatorAnswer(prompt=prompt, history=chat_history,
|
| 282 |
+
streaming=streaming):
|
| 283 |
+
resp = answer_result.llm_output["answer"]
|
| 284 |
+
history = answer_result.history
|
| 285 |
+
history[-1][0] = query
|
| 286 |
+
response = {"query": query,
|
| 287 |
+
"result": resp,
|
| 288 |
+
"source_documents": result_docs}
|
| 289 |
+
yield response, history
|
| 290 |
+
|
| 291 |
+
def delete_file_from_vector_store(self,
|
| 292 |
+
filepath: str or List[str],
|
| 293 |
+
vs_path):
|
| 294 |
+
vector_store = load_vector_store(vs_path, self.embeddings)
|
| 295 |
+
status = vector_store.delete_doc(filepath)
|
| 296 |
+
return status
|
| 297 |
+
|
| 298 |
+
def update_file_from_vector_store(self,
|
| 299 |
+
filepath: str or List[str],
|
| 300 |
+
vs_path,
|
| 301 |
+
docs: List[Document],):
|
| 302 |
+
vector_store = load_vector_store(vs_path, self.embeddings)
|
| 303 |
+
status = vector_store.update_doc(filepath, docs)
|
| 304 |
+
return status
|
| 305 |
+
|
| 306 |
+
def list_file_from_vector_store(self,
|
| 307 |
+
vs_path,
|
| 308 |
+
fullpath=False):
|
| 309 |
+
vector_store = load_vector_store(vs_path, self.embeddings)
|
| 310 |
+
docs = vector_store.list_docs()
|
| 311 |
+
if fullpath:
|
| 312 |
+
return docs
|
| 313 |
+
else:
|
| 314 |
+
return [os.path.split(doc)[-1] for doc in docs]
|
| 315 |
+
|
| 316 |
+
|
| 317 |
+
if __name__ == "__main__":
|
| 318 |
+
# 初始化消息
|
| 319 |
+
args = None
|
| 320 |
+
args = parser.parse_args(args=['--model-dir', '/media/checkpoint/', '--model', 'chatglm-6b', '--no-remote-model'])
|
| 321 |
+
|
| 322 |
+
args_dict = vars(args)
|
| 323 |
+
shared.loaderCheckPoint = LoaderCheckPoint(args_dict)
|
| 324 |
+
llm_model_ins = shared.loaderLLM()
|
| 325 |
+
llm_model_ins.set_history_len(LLM_HISTORY_LEN)
|
| 326 |
+
|
| 327 |
+
local_doc_qa = LocalDocQA()
|
| 328 |
+
local_doc_qa.init_cfg(llm_model=llm_model_ins)
|
| 329 |
+
query = "本项目使用的embedding模型是什么,消耗多少显存"
|
| 330 |
+
vs_path = "/media/gpt4-pdf-chatbot-langchain/dev-langchain-ChatGLM/vector_store/test"
|
| 331 |
+
last_print_len = 0
|
| 332 |
+
# for resp, history in local_doc_qa.get_knowledge_based_answer(query=query,
|
| 333 |
+
# vs_path=vs_path,
|
| 334 |
+
# chat_history=[],
|
| 335 |
+
# streaming=True):
|
| 336 |
+
for resp, history in local_doc_qa.get_search_result_based_answer(query=query,
|
| 337 |
+
chat_history=[],
|
| 338 |
+
streaming=True):
|
| 339 |
+
print(resp["result"][last_print_len:], end="", flush=True)
|
| 340 |
+
last_print_len = len(resp["result"])
|
| 341 |
+
source_text = [f"""出处 [{inum + 1}] {doc.metadata['source'] if doc.metadata['source'].startswith("http")
|
| 342 |
+
else os.path.split(doc.metadata['source'])[-1]}:\n\n{doc.page_content}\n\n"""
|
| 343 |
+
# f"""相关度:{doc.metadata['score']}\n\n"""
|
| 344 |
+
for inum, doc in
|
| 345 |
+
enumerate(resp["source_documents"])]
|
| 346 |
+
logger.info("\n\n" + "\n\n".join(source_text))
|
| 347 |
+
pass
|
chains/text_load.py
ADDED
|
@@ -0,0 +1,52 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import os
|
| 2 |
+
import pinecone
|
| 3 |
+
from tqdm import tqdm
|
| 4 |
+
from langchain.llms import OpenAI
|
| 5 |
+
from langchain.text_splitter import SpacyTextSplitter
|
| 6 |
+
from langchain.document_loaders import TextLoader
|
| 7 |
+
from langchain.document_loaders import DirectoryLoader
|
| 8 |
+
from langchain.indexes import VectorstoreIndexCreator
|
| 9 |
+
from langchain.embeddings.openai import OpenAIEmbeddings
|
| 10 |
+
from langchain.vectorstores import Pinecone
|
| 11 |
+
|
| 12 |
+
#一些配置文件
|
| 13 |
+
openai_key="你的key" # 注册 openai.com 后获得
|
| 14 |
+
pinecone_key="你的key" # 注册 app.pinecone.io 后获得
|
| 15 |
+
pinecone_index="你的库" #app.pinecone.io 获得
|
| 16 |
+
pinecone_environment="你的Environment" # 登录pinecone后,在indexes页面 查看Environment
|
| 17 |
+
pinecone_namespace="你的Namespace" #如果不存在自动创建
|
| 18 |
+
|
| 19 |
+
#科学上网你懂得
|
| 20 |
+
os.environ['HTTP_PROXY'] = 'http://127.0.0.1:7890'
|
| 21 |
+
os.environ['HTTPS_PROXY'] = 'http://127.0.0.1:7890'
|
| 22 |
+
|
| 23 |
+
#初始化pinecone
|
| 24 |
+
pinecone.init(
|
| 25 |
+
api_key=pinecone_key,
|
| 26 |
+
environment=pinecone_environment
|
| 27 |
+
)
|
| 28 |
+
index = pinecone.Index(pinecone_index)
|
| 29 |
+
|
| 30 |
+
#初始化OpenAI的embeddings
|
| 31 |
+
embeddings = OpenAIEmbeddings(openai_api_key=openai_key)
|
| 32 |
+
|
| 33 |
+
#初始化text_splitter
|
| 34 |
+
text_splitter = SpacyTextSplitter(pipeline='zh_core_web_sm',chunk_size=1000,chunk_overlap=200)
|
| 35 |
+
|
| 36 |
+
# 读取目录下所有后缀是txt的文件
|
| 37 |
+
loader = DirectoryLoader('../docs', glob="**/*.txt", loader_cls=TextLoader)
|
| 38 |
+
|
| 39 |
+
#读取文本文件
|
| 40 |
+
documents = loader.load()
|
| 41 |
+
|
| 42 |
+
# 使用text_splitter对文档进行分割
|
| 43 |
+
split_text = text_splitter.split_documents(documents)
|
| 44 |
+
try:
|
| 45 |
+
for document in tqdm(split_text):
|
| 46 |
+
# 获取向量并储存到pinecone
|
| 47 |
+
Pinecone.from_documents([document], embeddings, index_name=pinecone_index)
|
| 48 |
+
except Exception as e:
|
| 49 |
+
print(f"Error: {e}")
|
| 50 |
+
quit()
|
| 51 |
+
|
| 52 |
+
|
configs/__pycache__/model_config.cpython-310.pyc
ADDED
|
Binary file (2.96 kB). View file
|
|
|
configs/model_config - 副本.py
ADDED
|
@@ -0,0 +1,269 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import torch.cuda
|
| 2 |
+
import torch.backends
|
| 3 |
+
import os
|
| 4 |
+
import logging
|
| 5 |
+
import uuid
|
| 6 |
+
|
| 7 |
+
LOG_FORMAT = "%(levelname) -5s %(asctime)s" "-1d: %(message)s"
|
| 8 |
+
logger = logging.getLogger()
|
| 9 |
+
logger.setLevel(logging.INFO)
|
| 10 |
+
logging.basicConfig(format=LOG_FORMAT)
|
| 11 |
+
|
| 12 |
+
# 在以下字典中修改属性值,以指定本地embedding模型存储位置
|
| 13 |
+
# 如将 "text2vec": "GanymedeNil/text2vec-large-chinese" 修改为 "text2vec": "User/Downloads/text2vec-large-chinese"
|
| 14 |
+
# 此处请写绝对路径
|
| 15 |
+
embedding_model_dict = {
|
| 16 |
+
"ernie-tiny": "nghuyong/ernie-3.0-nano-zh",
|
| 17 |
+
"ernie-base": "nghuyong/ernie-3.0-base-zh",
|
| 18 |
+
"text2vec-base": "shibing624/text2vec-base-chinese",
|
| 19 |
+
"text2vec": "GanymedeNil/text2vec-large-chinese",
|
| 20 |
+
"m3e-small": "moka-ai/m3e-small",
|
| 21 |
+
"m3e-base": "moka-ai/m3e-base",
|
| 22 |
+
}
|
| 23 |
+
|
| 24 |
+
# Embedding model name
|
| 25 |
+
EMBEDDING_MODEL = "text2vec"
|
| 26 |
+
|
| 27 |
+
# Embedding running device
|
| 28 |
+
EMBEDDING_DEVICE = "cuda" if torch.cuda.is_available() else "mps" if torch.backends.mps.is_available() else "cpu"
|
| 29 |
+
|
| 30 |
+
# supported LLM models
|
| 31 |
+
# llm_model_dict 处理了loader的一些预设行为,如加载位置,模型名称,模型处理器实例
|
| 32 |
+
# 在以下字典中修改属性值,以指定本地 LLM 模型存储位置
|
| 33 |
+
# 如将 "chatglm-6b" 的 "local_model_path" 由 None 修改为 "User/Downloads/chatglm-6b"
|
| 34 |
+
# 此处请写绝对路径
|
| 35 |
+
llm_model_dict = {
|
| 36 |
+
"chatglm-6b-int4-qe": {
|
| 37 |
+
"name": "chatglm-6b-int4-qe",
|
| 38 |
+
"pretrained_model_name": "THUDM/chatglm-6b-int4-qe",
|
| 39 |
+
"local_model_path": None,
|
| 40 |
+
"provides": "ChatGLMLLMChain"
|
| 41 |
+
},
|
| 42 |
+
"chatglm-6b-int4": {
|
| 43 |
+
"name": "chatglm-6b-int4",
|
| 44 |
+
"pretrained_model_name": "THUDM/chatglm-6b-int4",
|
| 45 |
+
"local_model_path": None,
|
| 46 |
+
"provides": "ChatGLMLLMChain"
|
| 47 |
+
},
|
| 48 |
+
"chatglm-6b-int8": {
|
| 49 |
+
"name": "chatglm-6b-int8",
|
| 50 |
+
"pretrained_model_name": "THUDM/chatglm-6b-int8",
|
| 51 |
+
"local_model_path": None,
|
| 52 |
+
"provides": "ChatGLMLLMChain"
|
| 53 |
+
},
|
| 54 |
+
"chatglm-6b": {
|
| 55 |
+
"name": "chatglm-6b",
|
| 56 |
+
"pretrained_model_name": "THUDM/chatglm-6b",
|
| 57 |
+
"local_model_path": None,
|
| 58 |
+
"provides": "ChatGLMLLMChain"
|
| 59 |
+
},
|
| 60 |
+
"chatglm2-6b": {
|
| 61 |
+
"name": "chatglm2-6b",
|
| 62 |
+
"pretrained_model_name": "THUDM/chatglm2-6b",
|
| 63 |
+
"local_model_path": None,
|
| 64 |
+
"provides": "ChatGLMLLMChain"
|
| 65 |
+
},
|
| 66 |
+
"chatglm2-6b-int4": {
|
| 67 |
+
"name": "chatglm2-6b-int4",
|
| 68 |
+
"pretrained_model_name": "THUDM/chatglm2-6b-int4",
|
| 69 |
+
"local_model_path": None,
|
| 70 |
+
"provides": "ChatGLMLLMChain"
|
| 71 |
+
},
|
| 72 |
+
"chatglm2-6b-int8": {
|
| 73 |
+
"name": "chatglm2-6b-int8",
|
| 74 |
+
"pretrained_model_name": "THUDM/chatglm2-6b-int8",
|
| 75 |
+
"local_model_path": None,
|
| 76 |
+
"provides": "ChatGLMLLMChain"
|
| 77 |
+
},
|
| 78 |
+
"chatyuan": {
|
| 79 |
+
"name": "chatyuan",
|
| 80 |
+
"pretrained_model_name": "ClueAI/ChatYuan-large-v2",
|
| 81 |
+
"local_model_path": None,
|
| 82 |
+
"provides": "MOSSLLMChain"
|
| 83 |
+
},
|
| 84 |
+
"moss": {
|
| 85 |
+
"name": "moss",
|
| 86 |
+
"pretrained_model_name": "fnlp/moss-moon-003-sft",
|
| 87 |
+
"local_model_path": None,
|
| 88 |
+
"provides": "MOSSLLMChain"
|
| 89 |
+
},
|
| 90 |
+
"vicuna-13b-hf": {
|
| 91 |
+
"name": "vicuna-13b-hf",
|
| 92 |
+
"pretrained_model_name": "vicuna-13b-hf",
|
| 93 |
+
"local_model_path": None,
|
| 94 |
+
"provides": "LLamaLLMChain"
|
| 95 |
+
},
|
| 96 |
+
"vicuna-7b-hf": {
|
| 97 |
+
"name": "vicuna-13b-hf",
|
| 98 |
+
"pretrained_model_name": "vicuna-13b-hf",
|
| 99 |
+
"local_model_path": None,
|
| 100 |
+
"provides": "LLamaLLMChain"
|
| 101 |
+
},
|
| 102 |
+
# 直接调用返回requests.exceptions.ConnectionError错误,需要通过huggingface_hub包里的snapshot_download函数
|
| 103 |
+
# 下载模型,如果snapshot_download还是返回网络错误,多试几次,一般是可以的,
|
| 104 |
+
# 如果仍然不行,则应该是网络加了防火墙(在服务器上这种情况比较常见),基本只能从别的设备上下载,
|
| 105 |
+
# 然后转移到目标设备了.
|
| 106 |
+
"bloomz-7b1": {
|
| 107 |
+
"name": "bloomz-7b1",
|
| 108 |
+
"pretrained_model_name": "bigscience/bloomz-7b1",
|
| 109 |
+
"local_model_path": None,
|
| 110 |
+
"provides": "MOSSLLMChain"
|
| 111 |
+
|
| 112 |
+
},
|
| 113 |
+
# 实测加载bigscience/bloom-3b需要170秒左右,暂不清楚为什么这么慢
|
| 114 |
+
# 应与它要加载专有token有关
|
| 115 |
+
"bloom-3b": {
|
| 116 |
+
"name": "bloom-3b",
|
| 117 |
+
"pretrained_model_name": "bigscience/bloom-3b",
|
| 118 |
+
"local_model_path": None,
|
| 119 |
+
"provides": "MOSSLLMChain"
|
| 120 |
+
|
| 121 |
+
},
|
| 122 |
+
"baichuan-7b": {
|
| 123 |
+
"name": "baichuan-7b",
|
| 124 |
+
"pretrained_model_name": "baichuan-inc/baichuan-7B",
|
| 125 |
+
"local_model_path": None,
|
| 126 |
+
"provides": "MOSSLLMChain"
|
| 127 |
+
},
|
| 128 |
+
# llama-cpp模型的兼容性问题参考https://github.com/abetlen/llama-cpp-python/issues/204
|
| 129 |
+
"ggml-vicuna-13b-1.1-q5": {
|
| 130 |
+
"name": "ggml-vicuna-13b-1.1-q5",
|
| 131 |
+
"pretrained_model_name": "lmsys/vicuna-13b-delta-v1.1",
|
| 132 |
+
# 这里需要下载好模型的路径,如果下载模型是默认路径则它会下载到用户工作区的
|
| 133 |
+
# /.cache/huggingface/hub/models--vicuna--ggml-vicuna-13b-1.1/
|
| 134 |
+
# 还有就是由于本项目加载模型的方式设置的比较严格,下载完成后仍需手动修改模型的文件名
|
| 135 |
+
# 将其设置为与Huggface Hub一致的文件名
|
| 136 |
+
# 此外不同时期的ggml格式并不兼容,因此不同时期的ggml需要安装不同的llama-cpp-python库,且实测pip install 不好使
|
| 137 |
+
# 需要手动从https://github.com/abetlen/llama-cpp-python/releases/tag/下载对应的wheel安装
|
| 138 |
+
# 实测v0.1.63与本模型的vicuna/ggml-vicuna-13b-1.1/ggml-vic13b-q5_1.bin可以兼容
|
| 139 |
+
"local_model_path": f'''{"/".join(os.path.abspath(__file__).split("/")[:3])}/.cache/huggingface/hub/models--vicuna--ggml-vicuna-13b-1.1/blobs/''',
|
| 140 |
+
"provides": "LLamaLLMChain"
|
| 141 |
+
},
|
| 142 |
+
|
| 143 |
+
# 通过 fastchat 调用的模型请参考如下格式
|
| 144 |
+
"fastchat-chatglm-6b": {
|
| 145 |
+
"name": "chatglm-6b", # "name"修改为fastchat服务中的"model_name"
|
| 146 |
+
"pretrained_model_name": "chatglm-6b",
|
| 147 |
+
"local_model_path": None,
|
| 148 |
+
"provides": "FastChatOpenAILLMChain", # 使用fastchat api时,需保证"provides"为"FastChatOpenAILLMChain"
|
| 149 |
+
"api_base_url": "http://localhost:8000/v1", # "name"修改为fastchat服务中的"api_base_url"
|
| 150 |
+
"api_key": "EMPTY"
|
| 151 |
+
},
|
| 152 |
+
"fastchat-chatglm2-6b": {
|
| 153 |
+
"name": "chatglm2-6b", # "name"修改为fastchat服务中的"model_name"
|
| 154 |
+
"pretrained_model_name": "chatglm2-6b",
|
| 155 |
+
"local_model_path": None,
|
| 156 |
+
"provides": "FastChatOpenAILLMChain", # 使用fastchat api时,需保证"provides"为"FastChatOpenAILLMChain"
|
| 157 |
+
"api_base_url": "http://localhost:8000/v1" # "name"修改为fastchat服务中的"api_base_url"
|
| 158 |
+
},
|
| 159 |
+
|
| 160 |
+
# 通过 fastchat 调用的模型请参考如下格式
|
| 161 |
+
"fastchat-vicuna-13b-hf": {
|
| 162 |
+
"name": "vicuna-13b-hf", # "name"修改为fastchat服务中的"model_name"
|
| 163 |
+
"pretrained_model_name": "vicuna-13b-hf",
|
| 164 |
+
"local_model_path": None,
|
| 165 |
+
"provides": "FastChatOpenAILLMChain", # 使用fastchat api时,需保证"provides"为"FastChatOpenAILLMChain"
|
| 166 |
+
"api_base_url": "http://localhost:8000/v1", # "name"修改为fastchat服务中的"api_base_url"
|
| 167 |
+
"api_key": "EMPTY"
|
| 168 |
+
},
|
| 169 |
+
# 调用chatgpt时如果报出: urllib3.exceptions.MaxRetryError: HTTPSConnectionPool(host='api.openai.com', port=443):
|
| 170 |
+
# Max retries exceeded with url: /v1/chat/completions
|
| 171 |
+
# 则需要将urllib3版本修改为1.25.11
|
| 172 |
+
|
| 173 |
+
# 如果报出:raise NewConnectionError(
|
| 174 |
+
# urllib3.exceptions.NewConnectionError: <urllib3.connection.HTTPSConnection object at 0x000001FE4BDB85E0>:
|
| 175 |
+
# Failed to establish a new connection: [WinError 10060]
|
| 176 |
+
# 则是因为内地和香港的IP都被OPENAI封了,需要挂切换为日本、新加坡等地
|
| 177 |
+
"openai-chatgpt-3.5": {
|
| 178 |
+
"name": "gpt-3.5-turbo",
|
| 179 |
+
"pretrained_model_name": "gpt-3.5-turbo",
|
| 180 |
+
"provides": "FastChatOpenAILLMChain",
|
| 181 |
+
"local_model_path": None,
|
| 182 |
+
"api_base_url": "https://api.openapi.com/v1",
|
| 183 |
+
"api_key": ""
|
| 184 |
+
},
|
| 185 |
+
|
| 186 |
+
}
|
| 187 |
+
|
| 188 |
+
# LLM 名称
|
| 189 |
+
LLM_MODEL = "chatglm-6b"
|
| 190 |
+
# 量化加载8bit 模型
|
| 191 |
+
LOAD_IN_8BIT = False
|
| 192 |
+
# Load the model with bfloat16 precision. Requires NVIDIA Ampere GPU.
|
| 193 |
+
BF16 = False
|
| 194 |
+
# 本地lora存放的位置
|
| 195 |
+
LORA_DIR = "loras/"
|
| 196 |
+
|
| 197 |
+
# LLM lora path,默认为空,如果有请直接指定文件夹路径
|
| 198 |
+
LLM_LORA_PATH = ""
|
| 199 |
+
USE_LORA = True if LLM_LORA_PATH else False
|
| 200 |
+
|
| 201 |
+
# LLM streaming reponse
|
| 202 |
+
STREAMING = True
|
| 203 |
+
|
| 204 |
+
# Use p-tuning-v2 PrefixEncoder
|
| 205 |
+
USE_PTUNING_V2 = False
|
| 206 |
+
|
| 207 |
+
# LLM running device
|
| 208 |
+
LLM_DEVICE = "cuda" if torch.cuda.is_available() else "mps" if torch.backends.mps.is_available() else "cpu"
|
| 209 |
+
|
| 210 |
+
# 知识库默认存储路径
|
| 211 |
+
KB_ROOT_PATH = os.path.join(os.path.dirname(os.path.dirname(__file__)), "knowledge_base")
|
| 212 |
+
|
| 213 |
+
# 基于上下文的prompt模版,请务必保留"{question}"和"{context}"
|
| 214 |
+
PROMPT_TEMPLATE = """已知信息:
|
| 215 |
+
{context}
|
| 216 |
+
|
| 217 |
+
根据上述已知信息,简洁和专业的来回答用户的问题。如果无法从中得到答案,请说 “根据已知信息无法回答该问题” 或 “没有提供足够的相关信息”,不允许在答案中添加编造成分,答案请使用中文。 问题是:{question}"""
|
| 218 |
+
|
| 219 |
+
# 缓存知识库数量,如果是ChatGLM2,ChatGLM2-int4,ChatGLM2-int8模型若检索效果不好可以调成’10’
|
| 220 |
+
CACHED_VS_NUM = 1
|
| 221 |
+
|
| 222 |
+
# 文本分句长度
|
| 223 |
+
SENTENCE_SIZE = 100
|
| 224 |
+
|
| 225 |
+
# 匹配后单段上下文长度
|
| 226 |
+
CHUNK_SIZE = 250
|
| 227 |
+
|
| 228 |
+
# 传入LLM的历史记录长度
|
| 229 |
+
LLM_HISTORY_LEN = 3
|
| 230 |
+
|
| 231 |
+
# 知识库检索时返回的匹配内容条数
|
| 232 |
+
VECTOR_SEARCH_TOP_K = 5
|
| 233 |
+
|
| 234 |
+
# 知识检索内容相关度 Score, 数值范围约为0-1100,如果为0,则不生效,建议设置为500左右,经测试设置为小于500时,匹配结果更精准
|
| 235 |
+
VECTOR_SEARCH_SCORE_THRESHOLD = 500
|
| 236 |
+
|
| 237 |
+
NLTK_DATA_PATH = os.path.join(os.path.dirname(os.path.dirname(__file__)), "nltk_data")
|
| 238 |
+
|
| 239 |
+
FLAG_USER_NAME = uuid.uuid4().hex
|
| 240 |
+
|
| 241 |
+
logger.info(f"""
|
| 242 |
+
loading model config
|
| 243 |
+
llm device: {LLM_DEVICE}
|
| 244 |
+
embedding device: {EMBEDDING_DEVICE}
|
| 245 |
+
dir: {os.path.dirname(os.path.dirname(__file__))}
|
| 246 |
+
flagging username: {FLAG_USER_NAME}
|
| 247 |
+
""")
|
| 248 |
+
|
| 249 |
+
# 是否开启跨域,默认为False,如果需要开启,请设置为True
|
| 250 |
+
# is open cross domain
|
| 251 |
+
OPEN_CROSS_DOMAIN = False
|
| 252 |
+
|
| 253 |
+
# Bing 搜索必备变量
|
| 254 |
+
# 使用 Bing 搜索需要使用 Bing Subscription Key,需要在azure port中申请试用bing search
|
| 255 |
+
# 具体申请方式请见
|
| 256 |
+
# https://learn.microsoft.com/en-us/bing/search-apis/bing-web-search/create-bing-search-service-resource
|
| 257 |
+
# 使用python创建bing api 搜索实例详见:
|
| 258 |
+
# https://learn.microsoft.com/en-us/bing/search-apis/bing-web-search/quickstarts/rest/python
|
| 259 |
+
BING_SEARCH_URL = "https://api.bing.microsoft.com/v7.0/search"
|
| 260 |
+
# 注意不是bing Webmaster Tools的api key,
|
| 261 |
+
|
| 262 |
+
# 此外,如果是在服务器上,报Failed to establish a new connection: [Errno 110] Connection timed out
|
| 263 |
+
# 是因为服务器加了防火墙,需要联系管理员加白名单,如果公司的服务器的话,就别想了GG
|
| 264 |
+
BING_SUBSCRIPTION_KEY = ""
|
| 265 |
+
|
| 266 |
+
# 是否开启中文标题加强,以及标题增强的相关配置
|
| 267 |
+
# 通过增加标题判断,判断哪些文本为标题,并在metadata中进行标记;
|
| 268 |
+
# 然后将文本与往上一级的标题进行拼合,实现文本信息的增强。
|
| 269 |
+
ZH_TITLE_ENHANCE = False
|
configs/model_config.py
ADDED
|
@@ -0,0 +1,202 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import torch.cuda
|
| 2 |
+
import torch.backends
|
| 3 |
+
import os
|
| 4 |
+
import logging
|
| 5 |
+
import uuid
|
| 6 |
+
|
| 7 |
+
LOG_FORMAT = "%(levelname) -5s %(asctime)s" "-1d: %(message)s"
|
| 8 |
+
logger = logging.getLogger()
|
| 9 |
+
logger.setLevel(logging.INFO)
|
| 10 |
+
logging.basicConfig(format=LOG_FORMAT)
|
| 11 |
+
|
| 12 |
+
# 在以下字典中修改属性值,以指定本地embedding模型存储位置
|
| 13 |
+
# 如将 "text2vec": "GanymedeNil/text2vec-large-chinese" 修改为 "text2vec": "User/Downloads/text2vec-large-chinese"
|
| 14 |
+
# 此处请写绝对路径 C:\Program Files\Git\your_path\text2vec C:/Users/Administrator/text2vec-large-chinese
|
| 15 |
+
embedding_model_dict = {
|
| 16 |
+
"ernie-tiny": "nghuyong/ernie-3.0-nano-zh",
|
| 17 |
+
"ernie-base": "nghuyong/ernie-3.0-base-zh",
|
| 18 |
+
"text2vec-base": "shibing624/text2vec-base-chinese",
|
| 19 |
+
"text2vec": " C:/Users/Administrator/text2vec-large-chinese",
|
| 20 |
+
"m3e-small": "moka-ai/m3e-small",
|
| 21 |
+
"m3e-base": "moka-ai/m3e-base",
|
| 22 |
+
}
|
| 23 |
+
|
| 24 |
+
# Embedding model name
|
| 25 |
+
EMBEDDING_MODEL = "text2vec"
|
| 26 |
+
|
| 27 |
+
# Embedding running device
|
| 28 |
+
EMBEDDING_DEVICE = "cuda" if torch.cuda.is_available() else "mps" if torch.backends.mps.is_available() else "cpu"
|
| 29 |
+
|
| 30 |
+
|
| 31 |
+
# supported LLM models
|
| 32 |
+
# llm_model_dict 处理了loader的一些预设行为,如加载位置,模型名称,模型处理器实例
|
| 33 |
+
# 在以下字典中修改属性值,以指定本地 LLM 模型存储位置
|
| 34 |
+
# 如将 "chatglm-6b" 的 "local_model_path" 由 None 修改为 "User/Downloads/chatglm-6b"
|
| 35 |
+
# 此处请写绝对路径
|
| 36 |
+
llm_model_dict = {
|
| 37 |
+
"chatglm-6b-int4-qe": {
|
| 38 |
+
"name": "chatglm-6b-int4-qe",
|
| 39 |
+
"pretrained_model_name": "THUDM/chatglm-6b-int4-qe",
|
| 40 |
+
"local_model_path": None,
|
| 41 |
+
"provides": "ChatGLM"
|
| 42 |
+
},
|
| 43 |
+
"chatglm-6b-int4": {
|
| 44 |
+
"name": "chatglm-6b-int4",
|
| 45 |
+
"pretrained_model_name": "THUDM/chatglm-6b-int4",
|
| 46 |
+
"local_model_path": None,
|
| 47 |
+
"provides": "ChatGLM"
|
| 48 |
+
},
|
| 49 |
+
"chatglm-6b-int8": {
|
| 50 |
+
"name": "chatglm-6b-int8",
|
| 51 |
+
"pretrained_model_name": "THUDM/chatglm-6b-int8",
|
| 52 |
+
"local_model_path": None,
|
| 53 |
+
"provides": "ChatGLM"
|
| 54 |
+
},
|
| 55 |
+
# "chatglm-6b": {
|
| 56 |
+
# "name": "chatglm-6b",
|
| 57 |
+
# "pretrained_model_name": "THUDM/chatglm-6b",
|
| 58 |
+
# "local_model_path": None,
|
| 59 |
+
# "provides": "ChatGLM"
|
| 60 |
+
# },
|
| 61 |
+
"chatglm-6b": {
|
| 62 |
+
"name": "chatglm-6b",
|
| 63 |
+
"pretrained_model_name": "chatglm-6b",
|
| 64 |
+
"local_model_path": "C:/Users/Administrator/VisualGLM-6B/model",
|
| 65 |
+
"provides": "ChatGLM"
|
| 66 |
+
},
|
| 67 |
+
"chatglm2-6b": {
|
| 68 |
+
"name": "chatglm2-6b",
|
| 69 |
+
"pretrained_model_name": "chatglm2-6b",
|
| 70 |
+
"local_model_path": "C:/Users/Administrator/ChatGLM2-6B/model",
|
| 71 |
+
"provides": "ChatGLM"
|
| 72 |
+
},
|
| 73 |
+
|
| 74 |
+
"chatyuan": {
|
| 75 |
+
"name": "chatyuan",
|
| 76 |
+
"pretrained_model_name": "ClueAI/ChatYuan-large-v2",
|
| 77 |
+
"local_model_path": None,
|
| 78 |
+
"provides": None
|
| 79 |
+
},
|
| 80 |
+
"moss": {
|
| 81 |
+
"name": "moss",
|
| 82 |
+
"pretrained_model_name": "fnlp/moss-moon-003-sft",
|
| 83 |
+
"local_model_path": None,
|
| 84 |
+
"provides": "MOSSLLM"
|
| 85 |
+
},
|
| 86 |
+
"vicuna-13b-hf": {
|
| 87 |
+
"name": "vicuna-13b-hf",
|
| 88 |
+
"pretrained_model_name": "vicuna-13b-hf",
|
| 89 |
+
"local_model_path": None,
|
| 90 |
+
"provides": "LLamaLLM"
|
| 91 |
+
},
|
| 92 |
+
|
| 93 |
+
# 通过 fastchat 调用的模型请参考如下格式
|
| 94 |
+
"fastchat-chatglm-6b": {
|
| 95 |
+
"name": "chatglm-6b", # "name"修改为fastchat服务中的"model_name"
|
| 96 |
+
"pretrained_model_name": "chatglm-6b",
|
| 97 |
+
"local_model_path": None,
|
| 98 |
+
"provides": "FastChatOpenAILLM", # 使用fastchat api时,需保证"provides"为"FastChatOpenAILLM"
|
| 99 |
+
"api_base_url": "http://localhost:8000/v1" # "name"修改为fastchat服务中的"api_base_url"
|
| 100 |
+
},
|
| 101 |
+
"fastchat-chatglm2-6b": {
|
| 102 |
+
"name": "chatglm2-6b", # "name"修改为fastchat服务中的"model_name"
|
| 103 |
+
"pretrained_model_name": "chatglm2-6b",
|
| 104 |
+
"local_model_path":None,
|
| 105 |
+
"provides": "FastChatOpenAILLM", # 使用fastchat api时,需保证"provides"为"FastChatOpenAILLM"
|
| 106 |
+
"api_base_url": "http://localhost:8000/v1" # "name"修改为fastchat服务中的"api_base_url"
|
| 107 |
+
},
|
| 108 |
+
|
| 109 |
+
# 通过 fastchat 调用的模型请参考如下格式
|
| 110 |
+
"fastchat-vicuna-13b-hf": {
|
| 111 |
+
"name": "vicuna-13b-hf", # "name"修改为fastchat服务中的"model_name"
|
| 112 |
+
"pretrained_model_name": "vicuna-13b-hf",
|
| 113 |
+
"local_model_path": None,
|
| 114 |
+
"provides": "FastChatOpenAILLM", # 使用fastchat api时,需保证"provides"为"FastChatOpenAILLM"
|
| 115 |
+
"api_base_url": "http://localhost:8000/v1" # "name"修改为fastchat服务中的"api_base_url"
|
| 116 |
+
},
|
| 117 |
+
}
|
| 118 |
+
|
| 119 |
+
# LLM 名称
|
| 120 |
+
# LLM_MODEL = "chatglm2-6b"
|
| 121 |
+
LLM_MODEL = "chatglm2-6b"
|
| 122 |
+
|
| 123 |
+
# 量化加载8bit 模型
|
| 124 |
+
LOAD_IN_8BIT = False
|
| 125 |
+
# Load the model with bfloat16 precision. Requires NVIDIA Ampere GPU.
|
| 126 |
+
BF16 = False
|
| 127 |
+
# 本地lora存放的位置
|
| 128 |
+
LORA_DIR = "loras/"
|
| 129 |
+
|
| 130 |
+
# LLM lora path,默认为空,如果有请直接指定文件夹路径
|
| 131 |
+
LLM_LORA_PATH = ""
|
| 132 |
+
USE_LORA = True if LLM_LORA_PATH else False
|
| 133 |
+
|
| 134 |
+
# LLM streaming reponse
|
| 135 |
+
STREAMING = True
|
| 136 |
+
|
| 137 |
+
# Use p-tuning-v2 PrefixEncoder
|
| 138 |
+
USE_PTUNING_V2 = False
|
| 139 |
+
|
| 140 |
+
# LLM running device
|
| 141 |
+
LLM_DEVICE = "cuda" if torch.cuda.is_available() else "mps" if torch.backends.mps.is_available() else "cpu"
|
| 142 |
+
|
| 143 |
+
# 知识库默认存储路径
|
| 144 |
+
KB_ROOT_PATH = os.path.join(os.path.dirname(os.path.dirname(__file__)), "knowledge_base")
|
| 145 |
+
|
| 146 |
+
# 基于上下文的prompt模版,请务必保留"{question}"和"{context}"
|
| 147 |
+
PROMPT_TEMPLATE = """已知信息:
|
| 148 |
+
{context}
|
| 149 |
+
|
| 150 |
+
根据上述已知信息,简洁和专业的来回答用户的问题。如果无法从中得到答案,请说 “根据已知信息无法回答该问题” 或 “没有提供足够的相关信息”,不允许在答案中添加编造成分,答案请使用中文。 问题是:{question}"""
|
| 151 |
+
|
| 152 |
+
# 缓存知识库数量
|
| 153 |
+
CACHED_VS_NUM = 1
|
| 154 |
+
|
| 155 |
+
# 文本分句长度
|
| 156 |
+
SENTENCE_SIZE = 100
|
| 157 |
+
|
| 158 |
+
# 匹配后单段上下文长度
|
| 159 |
+
CHUNK_SIZE = 250
|
| 160 |
+
|
| 161 |
+
# 传入LLM的历史记录长度
|
| 162 |
+
LLM_HISTORY_LEN = 3
|
| 163 |
+
|
| 164 |
+
# 知识库检索时返回的匹配内容条数
|
| 165 |
+
VECTOR_SEARCH_TOP_K = 5
|
| 166 |
+
|
| 167 |
+
# 知识检索内容相关度 Score, 数值范围约为0-1100,如果为0,则不生效,经测试设置为小于500时,匹配结果更精准
|
| 168 |
+
VECTOR_SEARCH_SCORE_THRESHOLD = 500
|
| 169 |
+
|
| 170 |
+
NLTK_DATA_PATH = os.path.join(os.path.dirname(os.path.dirname(__file__)), "nltk_data")
|
| 171 |
+
|
| 172 |
+
FLAG_USER_NAME = uuid.uuid4().hex
|
| 173 |
+
|
| 174 |
+
logger.info(f"""
|
| 175 |
+
loading model config
|
| 176 |
+
llm device: {LLM_DEVICE}
|
| 177 |
+
embedding device: {EMBEDDING_DEVICE}
|
| 178 |
+
dir: {os.path.dirname(os.path.dirname(__file__))}
|
| 179 |
+
flagging username: {FLAG_USER_NAME}
|
| 180 |
+
""")
|
| 181 |
+
|
| 182 |
+
# 是否开启跨域,默认为False,如果需要开启,请设置为True
|
| 183 |
+
# is open cross domain
|
| 184 |
+
OPEN_CROSS_DOMAIN = False
|
| 185 |
+
|
| 186 |
+
# Bing 搜索必备变量
|
| 187 |
+
# 使用 Bing 搜索需要使用 Bing Subscription Key,需要在azure port中申请试用bing search
|
| 188 |
+
# 具体申请方式请见
|
| 189 |
+
# https://learn.microsoft.com/en-us/bing/search-apis/bing-web-search/create-bing-search-service-resource
|
| 190 |
+
# 使用python创建bing api 搜索实例详见:
|
| 191 |
+
# https://learn.microsoft.com/en-us/bing/search-apis/bing-web-search/quickstarts/rest/python
|
| 192 |
+
BING_SEARCH_URL = "https://api.bing.microsoft.com/v7.0/search"
|
| 193 |
+
# 注意不是bing Webmaster Tools的api key,
|
| 194 |
+
|
| 195 |
+
# 此外,如果是在服务器上,报Failed to establish a new connection: [Errno 110] Connection timed out
|
| 196 |
+
# 是因为服务器加了防火墙,需要联系管理员加白名单,如果公司的服务器的话,就别想了GG
|
| 197 |
+
BING_SUBSCRIPTION_KEY = ""
|
| 198 |
+
|
| 199 |
+
# 是否开启中文标题加强,以及标题增强的相关配置
|
| 200 |
+
# 通过增加标题判断,判断哪些文本为标题,并在metadata中进行标记;
|
| 201 |
+
# 然后将文本与往上一级的标题进行拼合,实现文本信息的增强。
|
| 202 |
+
ZH_TITLE_ENHANCE = False
|
docs/API.md
ADDED
|
@@ -0,0 +1,1042 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
title: FastAPI v0.1.0
|
| 3 |
+
language_tabs:
|
| 4 |
+
- shell: Shell
|
| 5 |
+
- http: HTTP
|
| 6 |
+
- javascript: JavaScript
|
| 7 |
+
- ruby: Ruby
|
| 8 |
+
- python: Python
|
| 9 |
+
- php: PHP
|
| 10 |
+
- java: Java
|
| 11 |
+
- go: Go
|
| 12 |
+
toc_footers: []
|
| 13 |
+
includes: []
|
| 14 |
+
search: true
|
| 15 |
+
highlight_theme: darkula
|
| 16 |
+
headingLevel: 2
|
| 17 |
+
|
| 18 |
+
---
|
| 19 |
+
|
| 20 |
+
<!-- Generator: Widdershins v4.0.1 -->
|
| 21 |
+
|
| 22 |
+
<h1 id="fastapi">FastAPI v0.1.0</h1>
|
| 23 |
+
|
| 24 |
+
> Scroll down for code samples, example requests and responses. Select a language for code samples from the tabs above or the mobile navigation menu.
|
| 25 |
+
|
| 26 |
+
<h1 id="fastapi-default">Default</h1>
|
| 27 |
+
|
| 28 |
+
## chat_chat_docs_chat_post
|
| 29 |
+
|
| 30 |
+
<a id="opIdchat_chat_docs_chat_post"></a>
|
| 31 |
+
|
| 32 |
+
> Code samples
|
| 33 |
+
|
| 34 |
+
```shell
|
| 35 |
+
# You can also use wget
|
| 36 |
+
curl -X POST /chat-docs/chat \
|
| 37 |
+
-H 'Content-Type: application/json' \
|
| 38 |
+
-H 'Accept: application/json'
|
| 39 |
+
|
| 40 |
+
```
|
| 41 |
+
|
| 42 |
+
```http
|
| 43 |
+
POST /chat-docs/chat HTTP/1.1
|
| 44 |
+
|
| 45 |
+
Content-Type: application/json
|
| 46 |
+
Accept: application/json
|
| 47 |
+
|
| 48 |
+
```
|
| 49 |
+
|
| 50 |
+
```javascript
|
| 51 |
+
const inputBody = '{
|
| 52 |
+
"knowledge_base_id": "string",
|
| 53 |
+
"question": "string",
|
| 54 |
+
"history": []
|
| 55 |
+
}';
|
| 56 |
+
const headers = {
|
| 57 |
+
'Content-Type':'application/json',
|
| 58 |
+
'Accept':'application/json'
|
| 59 |
+
};
|
| 60 |
+
|
| 61 |
+
fetch('/chat-docs/chat',
|
| 62 |
+
{
|
| 63 |
+
method: 'POST',
|
| 64 |
+
body: inputBody,
|
| 65 |
+
headers: headers
|
| 66 |
+
})
|
| 67 |
+
.then(function(res) {
|
| 68 |
+
return res.json();
|
| 69 |
+
}).then(function(body) {
|
| 70 |
+
console.log(body);
|
| 71 |
+
});
|
| 72 |
+
|
| 73 |
+
```
|
| 74 |
+
|
| 75 |
+
```ruby
|
| 76 |
+
require 'rest-client'
|
| 77 |
+
require 'json'
|
| 78 |
+
|
| 79 |
+
headers = {
|
| 80 |
+
'Content-Type' => 'application/json',
|
| 81 |
+
'Accept' => 'application/json'
|
| 82 |
+
}
|
| 83 |
+
|
| 84 |
+
result = RestClient.post '/chat-docs/chat',
|
| 85 |
+
params: {
|
| 86 |
+
}, headers: headers
|
| 87 |
+
|
| 88 |
+
p JSON.parse(result)
|
| 89 |
+
|
| 90 |
+
```
|
| 91 |
+
|
| 92 |
+
```python
|
| 93 |
+
import requests
|
| 94 |
+
headers = {
|
| 95 |
+
'Content-Type': 'application/json',
|
| 96 |
+
'Accept': 'application/json'
|
| 97 |
+
}
|
| 98 |
+
|
| 99 |
+
r = requests.post('/chat-docs/chat', headers = headers)
|
| 100 |
+
|
| 101 |
+
print(r.json())
|
| 102 |
+
|
| 103 |
+
```
|
| 104 |
+
|
| 105 |
+
```php
|
| 106 |
+
<?php
|
| 107 |
+
|
| 108 |
+
require 'vendor/autoload.php';
|
| 109 |
+
|
| 110 |
+
$headers = array(
|
| 111 |
+
'Content-Type' => 'application/json',
|
| 112 |
+
'Accept' => 'application/json',
|
| 113 |
+
);
|
| 114 |
+
|
| 115 |
+
$client = new \GuzzleHttp\Client();
|
| 116 |
+
|
| 117 |
+
// Define array of request body.
|
| 118 |
+
$request_body = array();
|
| 119 |
+
|
| 120 |
+
try {
|
| 121 |
+
$response = $client->request('POST','/chat-docs/chat', array(
|
| 122 |
+
'headers' => $headers,
|
| 123 |
+
'json' => $request_body,
|
| 124 |
+
)
|
| 125 |
+
);
|
| 126 |
+
print_r($response->getBody()->getContents());
|
| 127 |
+
}
|
| 128 |
+
catch (\GuzzleHttp\Exception\BadResponseException $e) {
|
| 129 |
+
// handle exception or api errors.
|
| 130 |
+
print_r($e->getMessage());
|
| 131 |
+
}
|
| 132 |
+
|
| 133 |
+
// ...
|
| 134 |
+
|
| 135 |
+
```
|
| 136 |
+
|
| 137 |
+
```java
|
| 138 |
+
URL obj = new URL("/chat-docs/chat");
|
| 139 |
+
HttpURLConnection con = (HttpURLConnection) obj.openConnection();
|
| 140 |
+
con.setRequestMethod("POST");
|
| 141 |
+
int responseCode = con.getResponseCode();
|
| 142 |
+
BufferedReader in = new BufferedReader(
|
| 143 |
+
new InputStreamReader(con.getInputStream()));
|
| 144 |
+
String inputLine;
|
| 145 |
+
StringBuffer response = new StringBuffer();
|
| 146 |
+
while ((inputLine = in.readLine()) != null) {
|
| 147 |
+
response.append(inputLine);
|
| 148 |
+
}
|
| 149 |
+
in.close();
|
| 150 |
+
System.out.println(response.toString());
|
| 151 |
+
|
| 152 |
+
```
|
| 153 |
+
|
| 154 |
+
```go
|
| 155 |
+
package main
|
| 156 |
+
|
| 157 |
+
import (
|
| 158 |
+
"bytes"
|
| 159 |
+
"net/http"
|
| 160 |
+
)
|
| 161 |
+
|
| 162 |
+
func main() {
|
| 163 |
+
|
| 164 |
+
headers := map[string][]string{
|
| 165 |
+
"Content-Type": []string{"application/json"},
|
| 166 |
+
"Accept": []string{"application/json"},
|
| 167 |
+
}
|
| 168 |
+
|
| 169 |
+
data := bytes.NewBuffer([]byte{jsonReq})
|
| 170 |
+
req, err := http.NewRequest("POST", "/chat-docs/chat", data)
|
| 171 |
+
req.Header = headers
|
| 172 |
+
|
| 173 |
+
client := &http.Client{}
|
| 174 |
+
resp, err := client.Do(req)
|
| 175 |
+
// ...
|
| 176 |
+
}
|
| 177 |
+
|
| 178 |
+
```
|
| 179 |
+
|
| 180 |
+
`POST /chat-docs/chat`
|
| 181 |
+
|
| 182 |
+
*Chat*
|
| 183 |
+
|
| 184 |
+
> Body parameter
|
| 185 |
+
|
| 186 |
+
```json
|
| 187 |
+
{
|
| 188 |
+
"knowledge_base_id": "string",
|
| 189 |
+
"question": "string",
|
| 190 |
+
"history": []
|
| 191 |
+
}
|
| 192 |
+
```
|
| 193 |
+
|
| 194 |
+
<h3 id="chat_chat_docs_chat_post-parameters">Parameters</h3>
|
| 195 |
+
|
| 196 |
+
|Name|In|Type|Required|Description|
|
| 197 |
+
|---|---|---|---|---|
|
| 198 |
+
|body|body|[Body_chat_chat_docs_chat_post](#schemabody_chat_chat_docs_chat_post)|true|none|
|
| 199 |
+
|
| 200 |
+
> Example responses
|
| 201 |
+
|
| 202 |
+
> 200 Response
|
| 203 |
+
|
| 204 |
+
```json
|
| 205 |
+
{
|
| 206 |
+
"question": "工伤保险如何办理?",
|
| 207 |
+
"response": "根据已知信息,可以总结如下:\n\n1. 参保单位为员工缴纳工伤保险费,以保障员工在发生工伤时能够获得相应的待遇。\n2. 不同地区的工伤保险缴费规定可能有所不同,需要向当地社保部门咨询以了解具体的缴费标准和规定。\n3. 工伤从业人员及其近亲属需要申请工伤认定,确认享受的待遇资格,并按时缴纳工伤保险费。\n4. 工伤保险待遇包括工伤医疗、康复、辅助器具配置费用、伤残待遇、工亡待遇、一次性工亡补助金等。\n5. 工伤保险待遇领取资格认证包括长期待遇领取人员认证和一次性待遇领取人员认证。\n6. 工伤保险基金支付的待遇项目包括工伤医疗待遇、康复待遇、辅助器具配置费用、一次性工亡补助金、丧葬补助金等。",
|
| 208 |
+
"history": [
|
| 209 |
+
[
|
| 210 |
+
"工伤保险是什么?",
|
| 211 |
+
"工伤保险是指用人单位按照国家规定,为本单位的职工和用人单位的其他人员,缴纳工伤保险费,由保险机构按照国家规定的标准,给予工伤保险待遇的社会保险制度。"
|
| 212 |
+
]
|
| 213 |
+
],
|
| 214 |
+
"source_documents": [
|
| 215 |
+
"出处 [1] 广州市单位从业的特定人员参加工伤保险��事指引.docx:\n\n\t( 一) 从业单位 (组织) 按“自愿参保”原则, 为未建 立劳动关系的特定从业人员单项参加工伤保险 、缴纳工伤保 险费。",
|
| 216 |
+
"出处 [2] ...",
|
| 217 |
+
"出处 [3] ..."
|
| 218 |
+
]
|
| 219 |
+
}
|
| 220 |
+
```
|
| 221 |
+
|
| 222 |
+
<h3 id="chat_chat_docs_chat_post-responses">Responses</h3>
|
| 223 |
+
|
| 224 |
+
|Status|Meaning|Description|Schema|
|
| 225 |
+
|---|---|---|---|
|
| 226 |
+
|200|[OK](https://tools.ietf.org/html/rfc7231#section-6.3.1)|Successful Response|[ChatMessage](#schemachatmessage)|
|
| 227 |
+
|422|[Unprocessable Entity](https://tools.ietf.org/html/rfc2518#section-10.3)|Validation Error|[HTTPValidationError](#schemahttpvalidationerror)|
|
| 228 |
+
|
| 229 |
+
<aside class="success">
|
| 230 |
+
This operation does not require authentication
|
| 231 |
+
</aside>
|
| 232 |
+
|
| 233 |
+
## upload_file_chat_docs_upload_post
|
| 234 |
+
|
| 235 |
+
<a id="opIdupload_file_chat_docs_upload_post"></a>
|
| 236 |
+
|
| 237 |
+
> Code samples
|
| 238 |
+
|
| 239 |
+
```shell
|
| 240 |
+
# You can also use wget
|
| 241 |
+
curl -X POST /chat-docs/upload \
|
| 242 |
+
-H 'Content-Type: multipart/form-data' \
|
| 243 |
+
-H 'Accept: application/json'
|
| 244 |
+
|
| 245 |
+
```
|
| 246 |
+
|
| 247 |
+
```http
|
| 248 |
+
POST /chat-docs/upload HTTP/1.1
|
| 249 |
+
|
| 250 |
+
Content-Type: multipart/form-data
|
| 251 |
+
Accept: application/json
|
| 252 |
+
|
| 253 |
+
```
|
| 254 |
+
|
| 255 |
+
```javascript
|
| 256 |
+
const inputBody = '{
|
| 257 |
+
"files": [
|
| 258 |
+
"string"
|
| 259 |
+
],
|
| 260 |
+
"knowledge_base_id": "string"
|
| 261 |
+
}';
|
| 262 |
+
const headers = {
|
| 263 |
+
'Content-Type':'multipart/form-data',
|
| 264 |
+
'Accept':'application/json'
|
| 265 |
+
};
|
| 266 |
+
|
| 267 |
+
fetch('/chat-docs/upload',
|
| 268 |
+
{
|
| 269 |
+
method: 'POST',
|
| 270 |
+
body: inputBody,
|
| 271 |
+
headers: headers
|
| 272 |
+
})
|
| 273 |
+
.then(function(res) {
|
| 274 |
+
return res.json();
|
| 275 |
+
}).then(function(body) {
|
| 276 |
+
console.log(body);
|
| 277 |
+
});
|
| 278 |
+
|
| 279 |
+
```
|
| 280 |
+
|
| 281 |
+
```ruby
|
| 282 |
+
require 'rest-client'
|
| 283 |
+
require 'json'
|
| 284 |
+
|
| 285 |
+
headers = {
|
| 286 |
+
'Content-Type' => 'multipart/form-data',
|
| 287 |
+
'Accept' => 'application/json'
|
| 288 |
+
}
|
| 289 |
+
|
| 290 |
+
result = RestClient.post '/chat-docs/upload',
|
| 291 |
+
params: {
|
| 292 |
+
}, headers: headers
|
| 293 |
+
|
| 294 |
+
p JSON.parse(result)
|
| 295 |
+
|
| 296 |
+
```
|
| 297 |
+
|
| 298 |
+
```python
|
| 299 |
+
import requests
|
| 300 |
+
headers = {
|
| 301 |
+
'Content-Type': 'multipart/form-data',
|
| 302 |
+
'Accept': 'application/json'
|
| 303 |
+
}
|
| 304 |
+
|
| 305 |
+
r = requests.post('/chat-docs/upload', headers = headers)
|
| 306 |
+
|
| 307 |
+
print(r.json())
|
| 308 |
+
|
| 309 |
+
```
|
| 310 |
+
|
| 311 |
+
```php
|
| 312 |
+
<?php
|
| 313 |
+
|
| 314 |
+
require 'vendor/autoload.php';
|
| 315 |
+
|
| 316 |
+
$headers = array(
|
| 317 |
+
'Content-Type' => 'multipart/form-data',
|
| 318 |
+
'Accept' => 'application/json',
|
| 319 |
+
);
|
| 320 |
+
|
| 321 |
+
$client = new \GuzzleHttp\Client();
|
| 322 |
+
|
| 323 |
+
// Define array of request body.
|
| 324 |
+
$request_body = array();
|
| 325 |
+
|
| 326 |
+
try {
|
| 327 |
+
$response = $client->request('POST','/chat-docs/upload', array(
|
| 328 |
+
'headers' => $headers,
|
| 329 |
+
'json' => $request_body,
|
| 330 |
+
)
|
| 331 |
+
);
|
| 332 |
+
print_r($response->getBody()->getContents());
|
| 333 |
+
}
|
| 334 |
+
catch (\GuzzleHttp\Exception\BadResponseException $e) {
|
| 335 |
+
// handle exception or api errors.
|
| 336 |
+
print_r($e->getMessage());
|
| 337 |
+
}
|
| 338 |
+
|
| 339 |
+
// ...
|
| 340 |
+
|
| 341 |
+
```
|
| 342 |
+
|
| 343 |
+
```java
|
| 344 |
+
URL obj = new URL("/chat-docs/upload");
|
| 345 |
+
HttpURLConnection con = (HttpURLConnection) obj.openConnection();
|
| 346 |
+
con.setRequestMethod("POST");
|
| 347 |
+
int responseCode = con.getResponseCode();
|
| 348 |
+
BufferedReader in = new BufferedReader(
|
| 349 |
+
new InputStreamReader(con.getInputStream()));
|
| 350 |
+
String inputLine;
|
| 351 |
+
StringBuffer response = new StringBuffer();
|
| 352 |
+
while ((inputLine = in.readLine()) != null) {
|
| 353 |
+
response.append(inputLine);
|
| 354 |
+
}
|
| 355 |
+
in.close();
|
| 356 |
+
System.out.println(response.toString());
|
| 357 |
+
|
| 358 |
+
```
|
| 359 |
+
|
| 360 |
+
```go
|
| 361 |
+
package main
|
| 362 |
+
|
| 363 |
+
import (
|
| 364 |
+
"bytes"
|
| 365 |
+
"net/http"
|
| 366 |
+
)
|
| 367 |
+
|
| 368 |
+
func main() {
|
| 369 |
+
|
| 370 |
+
headers := map[string][]string{
|
| 371 |
+
"Content-Type": []string{"multipart/form-data"},
|
| 372 |
+
"Accept": []string{"application/json"},
|
| 373 |
+
}
|
| 374 |
+
|
| 375 |
+
data := bytes.NewBuffer([]byte{jsonReq})
|
| 376 |
+
req, err := http.NewRequest("POST", "/chat-docs/upload", data)
|
| 377 |
+
req.Header = headers
|
| 378 |
+
|
| 379 |
+
client := &http.Client{}
|
| 380 |
+
resp, err := client.Do(req)
|
| 381 |
+
// ...
|
| 382 |
+
}
|
| 383 |
+
|
| 384 |
+
```
|
| 385 |
+
|
| 386 |
+
`POST /chat-docs/upload`
|
| 387 |
+
|
| 388 |
+
*Upload File*
|
| 389 |
+
|
| 390 |
+
> Body parameter
|
| 391 |
+
|
| 392 |
+
```yaml
|
| 393 |
+
files:
|
| 394 |
+
- string
|
| 395 |
+
knowledge_base_id: string
|
| 396 |
+
|
| 397 |
+
```
|
| 398 |
+
|
| 399 |
+
<h3 id="upload_file_chat_docs_upload_post-parameters">Parameters</h3>
|
| 400 |
+
|
| 401 |
+
|Name|In|Type|Required|Description|
|
| 402 |
+
|---|---|---|---|---|
|
| 403 |
+
|body|body|[Body_upload_file_chat_docs_upload_post](#schemabody_upload_file_chat_docs_upload_post)|true|none|
|
| 404 |
+
|
| 405 |
+
> Example responses
|
| 406 |
+
|
| 407 |
+
> 200 Response
|
| 408 |
+
|
| 409 |
+
```json
|
| 410 |
+
{
|
| 411 |
+
"code": 200,
|
| 412 |
+
"msg": "success"
|
| 413 |
+
}
|
| 414 |
+
```
|
| 415 |
+
|
| 416 |
+
<h3 id="upload_file_chat_docs_upload_post-responses">Responses</h3>
|
| 417 |
+
|
| 418 |
+
|Status|Meaning|Description|Schema|
|
| 419 |
+
|---|---|---|---|
|
| 420 |
+
|200|[OK](https://tools.ietf.org/html/rfc7231#section-6.3.1)|Successful Response|[BaseResponse](#schemabaseresponse)|
|
| 421 |
+
|422|[Unprocessable Entity](https://tools.ietf.org/html/rfc2518#section-10.3)|Validation Error|[HTTPValidationError](#schemahttpvalidationerror)|
|
| 422 |
+
|
| 423 |
+
<aside class="success">
|
| 424 |
+
This operation does not require authentication
|
| 425 |
+
</aside>
|
| 426 |
+
|
| 427 |
+
## list_docs_chat_docs_list_get
|
| 428 |
+
|
| 429 |
+
<a id="opIdlist_docs_chat_docs_list_get"></a>
|
| 430 |
+
|
| 431 |
+
> Code samples
|
| 432 |
+
|
| 433 |
+
```shell
|
| 434 |
+
# You can also use wget
|
| 435 |
+
curl -X GET /chat-docs/list?knowledge_base_id=doc_id1 \
|
| 436 |
+
-H 'Accept: application/json'
|
| 437 |
+
|
| 438 |
+
```
|
| 439 |
+
|
| 440 |
+
```http
|
| 441 |
+
GET /chat-docs/list?knowledge_base_id=doc_id1 HTTP/1.1
|
| 442 |
+
|
| 443 |
+
Accept: application/json
|
| 444 |
+
|
| 445 |
+
```
|
| 446 |
+
|
| 447 |
+
```javascript
|
| 448 |
+
|
| 449 |
+
const headers = {
|
| 450 |
+
'Accept':'application/json'
|
| 451 |
+
};
|
| 452 |
+
|
| 453 |
+
fetch('/chat-docs/list?knowledge_base_id=doc_id1',
|
| 454 |
+
{
|
| 455 |
+
method: 'GET',
|
| 456 |
+
|
| 457 |
+
headers: headers
|
| 458 |
+
})
|
| 459 |
+
.then(function(res) {
|
| 460 |
+
return res.json();
|
| 461 |
+
}).then(function(body) {
|
| 462 |
+
console.log(body);
|
| 463 |
+
});
|
| 464 |
+
|
| 465 |
+
```
|
| 466 |
+
|
| 467 |
+
```ruby
|
| 468 |
+
require 'rest-client'
|
| 469 |
+
require 'json'
|
| 470 |
+
|
| 471 |
+
headers = {
|
| 472 |
+
'Accept' => 'application/json'
|
| 473 |
+
}
|
| 474 |
+
|
| 475 |
+
result = RestClient.get '/chat-docs/list',
|
| 476 |
+
params: {
|
| 477 |
+
'knowledge_base_id' => 'string'
|
| 478 |
+
}, headers: headers
|
| 479 |
+
|
| 480 |
+
p JSON.parse(result)
|
| 481 |
+
|
| 482 |
+
```
|
| 483 |
+
|
| 484 |
+
```python
|
| 485 |
+
import requests
|
| 486 |
+
headers = {
|
| 487 |
+
'Accept': 'application/json'
|
| 488 |
+
}
|
| 489 |
+
|
| 490 |
+
r = requests.get('/chat-docs/list', params={
|
| 491 |
+
'knowledge_base_id': 'doc_id1'
|
| 492 |
+
}, headers = headers)
|
| 493 |
+
|
| 494 |
+
print(r.json())
|
| 495 |
+
|
| 496 |
+
```
|
| 497 |
+
|
| 498 |
+
```php
|
| 499 |
+
<?php
|
| 500 |
+
|
| 501 |
+
require 'vendor/autoload.php';
|
| 502 |
+
|
| 503 |
+
$headers = array(
|
| 504 |
+
'Accept' => 'application/json',
|
| 505 |
+
);
|
| 506 |
+
|
| 507 |
+
$client = new \GuzzleHttp\Client();
|
| 508 |
+
|
| 509 |
+
// Define array of request body.
|
| 510 |
+
$request_body = array();
|
| 511 |
+
|
| 512 |
+
try {
|
| 513 |
+
$response = $client->request('GET','/chat-docs/list', array(
|
| 514 |
+
'headers' => $headers,
|
| 515 |
+
'json' => $request_body,
|
| 516 |
+
)
|
| 517 |
+
);
|
| 518 |
+
print_r($response->getBody()->getContents());
|
| 519 |
+
}
|
| 520 |
+
catch (\GuzzleHttp\Exception\BadResponseException $e) {
|
| 521 |
+
// handle exception or api errors.
|
| 522 |
+
print_r($e->getMessage());
|
| 523 |
+
}
|
| 524 |
+
|
| 525 |
+
// ...
|
| 526 |
+
|
| 527 |
+
```
|
| 528 |
+
|
| 529 |
+
```java
|
| 530 |
+
URL obj = new URL("/chat-docs/list?knowledge_base_id=doc_id1");
|
| 531 |
+
HttpURLConnection con = (HttpURLConnection) obj.openConnection();
|
| 532 |
+
con.setRequestMethod("GET");
|
| 533 |
+
int responseCode = con.getResponseCode();
|
| 534 |
+
BufferedReader in = new BufferedReader(
|
| 535 |
+
new InputStreamReader(con.getInputStream()));
|
| 536 |
+
String inputLine;
|
| 537 |
+
StringBuffer response = new StringBuffer();
|
| 538 |
+
while ((inputLine = in.readLine()) != null) {
|
| 539 |
+
response.append(inputLine);
|
| 540 |
+
}
|
| 541 |
+
in.close();
|
| 542 |
+
System.out.println(response.toString());
|
| 543 |
+
|
| 544 |
+
```
|
| 545 |
+
|
| 546 |
+
```go
|
| 547 |
+
package main
|
| 548 |
+
|
| 549 |
+
import (
|
| 550 |
+
"bytes"
|
| 551 |
+
"net/http"
|
| 552 |
+
)
|
| 553 |
+
|
| 554 |
+
func main() {
|
| 555 |
+
|
| 556 |
+
headers := map[string][]string{
|
| 557 |
+
"Accept": []string{"application/json"},
|
| 558 |
+
}
|
| 559 |
+
|
| 560 |
+
data := bytes.NewBuffer([]byte{jsonReq})
|
| 561 |
+
req, err := http.NewRequest("GET", "/chat-docs/list", data)
|
| 562 |
+
req.Header = headers
|
| 563 |
+
|
| 564 |
+
client := &http.Client{}
|
| 565 |
+
resp, err := client.Do(req)
|
| 566 |
+
// ...
|
| 567 |
+
}
|
| 568 |
+
|
| 569 |
+
```
|
| 570 |
+
|
| 571 |
+
`GET /chat-docs/list`
|
| 572 |
+
|
| 573 |
+
*List Docs*
|
| 574 |
+
|
| 575 |
+
<h3 id="list_docs_chat_docs_list_get-parameters">Parameters</h3>
|
| 576 |
+
|
| 577 |
+
|Name|In|Type|Required|Description|
|
| 578 |
+
|---|---|---|---|---|
|
| 579 |
+
|knowledge_base_id|query|string|true|Document ID|
|
| 580 |
+
|
| 581 |
+
> Example responses
|
| 582 |
+
|
| 583 |
+
> 200 Response
|
| 584 |
+
|
| 585 |
+
```json
|
| 586 |
+
{
|
| 587 |
+
"code": 200,
|
| 588 |
+
"msg": "success",
|
| 589 |
+
"data": [
|
| 590 |
+
"doc1.docx",
|
| 591 |
+
"doc2.pdf",
|
| 592 |
+
"doc3.txt"
|
| 593 |
+
]
|
| 594 |
+
}
|
| 595 |
+
```
|
| 596 |
+
|
| 597 |
+
<h3 id="list_docs_chat_docs_list_get-responses">Responses</h3>
|
| 598 |
+
|
| 599 |
+
|Status|Meaning|Description|Schema|
|
| 600 |
+
|---|---|---|---|
|
| 601 |
+
|200|[OK](https://tools.ietf.org/html/rfc7231#section-6.3.1)|Successful Response|[ListDocsResponse](#schemalistdocsresponse)|
|
| 602 |
+
|422|[Unprocessable Entity](https://tools.ietf.org/html/rfc2518#section-10.3)|Validation Error|[HTTPValidationError](#schemahttpvalidationerror)|
|
| 603 |
+
|
| 604 |
+
<aside class="success">
|
| 605 |
+
This operation does not require authentication
|
| 606 |
+
</aside>
|
| 607 |
+
|
| 608 |
+
## delete_docs_chat_docs_delete_delete
|
| 609 |
+
|
| 610 |
+
<a id="opIddelete_docs_chat_docs_delete_delete"></a>
|
| 611 |
+
|
| 612 |
+
> Code samples
|
| 613 |
+
|
| 614 |
+
```shell
|
| 615 |
+
# You can also use wget
|
| 616 |
+
curl -X DELETE /chat-docs/delete \
|
| 617 |
+
-H 'Content-Type: application/x-www-form-urlencoded' \
|
| 618 |
+
-H 'Accept: application/json'
|
| 619 |
+
|
| 620 |
+
```
|
| 621 |
+
|
| 622 |
+
```http
|
| 623 |
+
DELETE /chat-docs/delete HTTP/1.1
|
| 624 |
+
|
| 625 |
+
Content-Type: application/x-www-form-urlencoded
|
| 626 |
+
Accept: application/json
|
| 627 |
+
|
| 628 |
+
```
|
| 629 |
+
|
| 630 |
+
```javascript
|
| 631 |
+
const inputBody = '{
|
| 632 |
+
"knowledge_base_id": "string",
|
| 633 |
+
"doc_name": "string"
|
| 634 |
+
}';
|
| 635 |
+
const headers = {
|
| 636 |
+
'Content-Type':'application/x-www-form-urlencoded',
|
| 637 |
+
'Accept':'application/json'
|
| 638 |
+
};
|
| 639 |
+
|
| 640 |
+
fetch('/chat-docs/delete',
|
| 641 |
+
{
|
| 642 |
+
method: 'DELETE',
|
| 643 |
+
body: inputBody,
|
| 644 |
+
headers: headers
|
| 645 |
+
})
|
| 646 |
+
.then(function(res) {
|
| 647 |
+
return res.json();
|
| 648 |
+
}).then(function(body) {
|
| 649 |
+
console.log(body);
|
| 650 |
+
});
|
| 651 |
+
|
| 652 |
+
```
|
| 653 |
+
|
| 654 |
+
```ruby
|
| 655 |
+
require 'rest-client'
|
| 656 |
+
require 'json'
|
| 657 |
+
|
| 658 |
+
headers = {
|
| 659 |
+
'Content-Type' => 'application/x-www-form-urlencoded',
|
| 660 |
+
'Accept' => 'application/json'
|
| 661 |
+
}
|
| 662 |
+
|
| 663 |
+
result = RestClient.delete '/chat-docs/delete',
|
| 664 |
+
params: {
|
| 665 |
+
}, headers: headers
|
| 666 |
+
|
| 667 |
+
p JSON.parse(result)
|
| 668 |
+
|
| 669 |
+
```
|
| 670 |
+
|
| 671 |
+
```python
|
| 672 |
+
import requests
|
| 673 |
+
headers = {
|
| 674 |
+
'Content-Type': 'application/x-www-form-urlencoded',
|
| 675 |
+
'Accept': 'application/json'
|
| 676 |
+
}
|
| 677 |
+
|
| 678 |
+
r = requests.delete('/chat-docs/delete', headers = headers)
|
| 679 |
+
|
| 680 |
+
print(r.json())
|
| 681 |
+
|
| 682 |
+
```
|
| 683 |
+
|
| 684 |
+
```php
|
| 685 |
+
<?php
|
| 686 |
+
|
| 687 |
+
require 'vendor/autoload.php';
|
| 688 |
+
|
| 689 |
+
$headers = array(
|
| 690 |
+
'Content-Type' => 'application/x-www-form-urlencoded',
|
| 691 |
+
'Accept' => 'application/json',
|
| 692 |
+
);
|
| 693 |
+
|
| 694 |
+
$client = new \GuzzleHttp\Client();
|
| 695 |
+
|
| 696 |
+
// Define array of request body.
|
| 697 |
+
$request_body = array();
|
| 698 |
+
|
| 699 |
+
try {
|
| 700 |
+
$response = $client->request('DELETE','/chat-docs/delete', array(
|
| 701 |
+
'headers' => $headers,
|
| 702 |
+
'json' => $request_body,
|
| 703 |
+
)
|
| 704 |
+
);
|
| 705 |
+
print_r($response->getBody()->getContents());
|
| 706 |
+
}
|
| 707 |
+
catch (\GuzzleHttp\Exception\BadResponseException $e) {
|
| 708 |
+
// handle exception or api errors.
|
| 709 |
+
print_r($e->getMessage());
|
| 710 |
+
}
|
| 711 |
+
|
| 712 |
+
// ...
|
| 713 |
+
|
| 714 |
+
```
|
| 715 |
+
|
| 716 |
+
```java
|
| 717 |
+
URL obj = new URL("/chat-docs/delete");
|
| 718 |
+
HttpURLConnection con = (HttpURLConnection) obj.openConnection();
|
| 719 |
+
con.setRequestMethod("DELETE");
|
| 720 |
+
int responseCode = con.getResponseCode();
|
| 721 |
+
BufferedReader in = new BufferedReader(
|
| 722 |
+
new InputStreamReader(con.getInputStream()));
|
| 723 |
+
String inputLine;
|
| 724 |
+
StringBuffer response = new StringBuffer();
|
| 725 |
+
while ((inputLine = in.readLine()) != null) {
|
| 726 |
+
response.append(inputLine);
|
| 727 |
+
}
|
| 728 |
+
in.close();
|
| 729 |
+
System.out.println(response.toString());
|
| 730 |
+
|
| 731 |
+
```
|
| 732 |
+
|
| 733 |
+
```go
|
| 734 |
+
package main
|
| 735 |
+
|
| 736 |
+
import (
|
| 737 |
+
"bytes"
|
| 738 |
+
"net/http"
|
| 739 |
+
)
|
| 740 |
+
|
| 741 |
+
func main() {
|
| 742 |
+
|
| 743 |
+
headers := map[string][]string{
|
| 744 |
+
"Content-Type": []string{"application/x-www-form-urlencoded"},
|
| 745 |
+
"Accept": []string{"application/json"},
|
| 746 |
+
}
|
| 747 |
+
|
| 748 |
+
data := bytes.NewBuffer([]byte{jsonReq})
|
| 749 |
+
req, err := http.NewRequest("DELETE", "/chat-docs/delete", data)
|
| 750 |
+
req.Header = headers
|
| 751 |
+
|
| 752 |
+
client := &http.Client{}
|
| 753 |
+
resp, err := client.Do(req)
|
| 754 |
+
// ...
|
| 755 |
+
}
|
| 756 |
+
|
| 757 |
+
```
|
| 758 |
+
|
| 759 |
+
`DELETE /chat-docs/delete`
|
| 760 |
+
|
| 761 |
+
*Delete Docs*
|
| 762 |
+
|
| 763 |
+
> Body parameter
|
| 764 |
+
|
| 765 |
+
```yaml
|
| 766 |
+
knowledge_base_id: string
|
| 767 |
+
doc_name: string
|
| 768 |
+
|
| 769 |
+
```
|
| 770 |
+
|
| 771 |
+
<h3 id="delete_docs_chat_docs_delete_delete-parameters">Parameters</h3>
|
| 772 |
+
|
| 773 |
+
|Name|In|Type|Required|Description|
|
| 774 |
+
|---|---|---|---|---|
|
| 775 |
+
|body|body|[Body_delete_docs_chat_docs_delete_delete](#schemabody_delete_docs_chat_docs_delete_delete)|true|none|
|
| 776 |
+
|
| 777 |
+
> Example responses
|
| 778 |
+
|
| 779 |
+
> 200 Response
|
| 780 |
+
|
| 781 |
+
```json
|
| 782 |
+
{
|
| 783 |
+
"code": 200,
|
| 784 |
+
"msg": "success"
|
| 785 |
+
}
|
| 786 |
+
```
|
| 787 |
+
|
| 788 |
+
<h3 id="delete_docs_chat_docs_delete_delete-responses">Responses</h3>
|
| 789 |
+
|
| 790 |
+
|Status|Meaning|Description|Schema|
|
| 791 |
+
|---|---|---|---|
|
| 792 |
+
|200|[OK](https://tools.ietf.org/html/rfc7231#section-6.3.1)|Successful Response|[BaseResponse](#schemabaseresponse)|
|
| 793 |
+
|422|[Unprocessable Entity](https://tools.ietf.org/html/rfc2518#section-10.3)|Validation Error|[HTTPValidationError](#schemahttpvalidationerror)|
|
| 794 |
+
|
| 795 |
+
<aside class="success">
|
| 796 |
+
This operation does not require authentication
|
| 797 |
+
</aside>
|
| 798 |
+
|
| 799 |
+
# Schemas
|
| 800 |
+
|
| 801 |
+
<h2 id="tocS_BaseResponse">BaseResponse</h2>
|
| 802 |
+
<!-- backwards compatibility -->
|
| 803 |
+
<a id="schemabaseresponse"></a>
|
| 804 |
+
<a id="schema_BaseResponse"></a>
|
| 805 |
+
<a id="tocSbaseresponse"></a>
|
| 806 |
+
<a id="tocsbaseresponse"></a>
|
| 807 |
+
|
| 808 |
+
```json
|
| 809 |
+
{
|
| 810 |
+
"code": 200,
|
| 811 |
+
"msg": "success"
|
| 812 |
+
}
|
| 813 |
+
|
| 814 |
+
```
|
| 815 |
+
|
| 816 |
+
BaseResponse
|
| 817 |
+
|
| 818 |
+
### Properties
|
| 819 |
+
|
| 820 |
+
|Name|Type|Required|Restrictions|Description|
|
| 821 |
+
|---|---|---|---|---|
|
| 822 |
+
|code|integer|false|none|HTTP status code|
|
| 823 |
+
|msg|string|false|none|HTTP status message|
|
| 824 |
+
|
| 825 |
+
<h2 id="tocS_Body_chat_chat_docs_chat_post">Body_chat_chat_docs_chat_post</h2>
|
| 826 |
+
<!-- backwards compatibility -->
|
| 827 |
+
<a id="schemabody_chat_chat_docs_chat_post"></a>
|
| 828 |
+
<a id="schema_Body_chat_chat_docs_chat_post"></a>
|
| 829 |
+
<a id="tocSbody_chat_chat_docs_chat_post"></a>
|
| 830 |
+
<a id="tocsbody_chat_chat_docs_chat_post"></a>
|
| 831 |
+
|
| 832 |
+
```json
|
| 833 |
+
{
|
| 834 |
+
"knowledge_base_id": "string",
|
| 835 |
+
"question": "string",
|
| 836 |
+
"history": []
|
| 837 |
+
}
|
| 838 |
+
|
| 839 |
+
```
|
| 840 |
+
|
| 841 |
+
Body_chat_chat_docs_chat_post
|
| 842 |
+
|
| 843 |
+
### Properties
|
| 844 |
+
|
| 845 |
+
|Name|Type|Required|Restrictions|Description|
|
| 846 |
+
|---|---|---|---|---|
|
| 847 |
+
|knowledge_base_id|string|true|none|Knowledge Base Name|
|
| 848 |
+
|question|string|true|none|Question|
|
| 849 |
+
|history|[array]|false|none|History of previous questions and answers|
|
| 850 |
+
|
| 851 |
+
<h2 id="tocS_Body_delete_docs_chat_docs_delete_delete">Body_delete_docs_chat_docs_delete_delete</h2>
|
| 852 |
+
<!-- backwards compatibility -->
|
| 853 |
+
<a id="schemabody_delete_docs_chat_docs_delete_delete"></a>
|
| 854 |
+
<a id="schema_Body_delete_docs_chat_docs_delete_delete"></a>
|
| 855 |
+
<a id="tocSbody_delete_docs_chat_docs_delete_delete"></a>
|
| 856 |
+
<a id="tocsbody_delete_docs_chat_docs_delete_delete"></a>
|
| 857 |
+
|
| 858 |
+
```json
|
| 859 |
+
{
|
| 860 |
+
"knowledge_base_id": "string",
|
| 861 |
+
"doc_name": "string"
|
| 862 |
+
}
|
| 863 |
+
|
| 864 |
+
```
|
| 865 |
+
|
| 866 |
+
Body_delete_docs_chat_docs_delete_delete
|
| 867 |
+
|
| 868 |
+
### Properties
|
| 869 |
+
|
| 870 |
+
|Name|Type|Required|Restrictions|Description|
|
| 871 |
+
|---|---|---|---|---|
|
| 872 |
+
|knowledge_base_id|string|true|none|Knowledge Base Name|
|
| 873 |
+
|doc_name|string|false|none|doc name|
|
| 874 |
+
|
| 875 |
+
<h2 id="tocS_Body_upload_file_chat_docs_upload_post">Body_upload_file_chat_docs_upload_post</h2>
|
| 876 |
+
<!-- backwards compatibility -->
|
| 877 |
+
<a id="schemabody_upload_file_chat_docs_upload_post"></a>
|
| 878 |
+
<a id="schema_Body_upload_file_chat_docs_upload_post"></a>
|
| 879 |
+
<a id="tocSbody_upload_file_chat_docs_upload_post"></a>
|
| 880 |
+
<a id="tocsbody_upload_file_chat_docs_upload_post"></a>
|
| 881 |
+
|
| 882 |
+
```json
|
| 883 |
+
{
|
| 884 |
+
"files": [
|
| 885 |
+
"string"
|
| 886 |
+
],
|
| 887 |
+
"knowledge_base_id": "string"
|
| 888 |
+
}
|
| 889 |
+
|
| 890 |
+
```
|
| 891 |
+
|
| 892 |
+
Body_upload_file_chat_docs_upload_post
|
| 893 |
+
|
| 894 |
+
### Properties
|
| 895 |
+
|
| 896 |
+
|Name|Type|Required|Restrictions|Description|
|
| 897 |
+
|---|---|---|---|---|
|
| 898 |
+
|files|[string]|true|none|none|
|
| 899 |
+
|knowledge_base_id|string|true|none|Knowledge Base Name|
|
| 900 |
+
|
| 901 |
+
<h2 id="tocS_ChatMessage">ChatMessage</h2>
|
| 902 |
+
<!-- backwards compatibility -->
|
| 903 |
+
<a id="schemachatmessage"></a>
|
| 904 |
+
<a id="schema_ChatMessage"></a>
|
| 905 |
+
<a id="tocSchatmessage"></a>
|
| 906 |
+
<a id="tocschatmessage"></a>
|
| 907 |
+
|
| 908 |
+
```json
|
| 909 |
+
{
|
| 910 |
+
"question": "工伤保险如何办理?",
|
| 911 |
+
"response": "根据已知信息,可以总结如下:\n\n1. 参保单位为员工缴纳工伤保险费,以保障员工在发生工伤时能够获得相应的待遇。\n2. 不同地区的工伤保险缴费规定可能有所不同,需要向当地社保部门咨询以了解具体的缴费标准和规定。\n3. 工伤从业人员及其近亲属需要申请工伤认定,确认享受的待遇资格,并按时缴纳工伤保险费。\n4. 工伤保险待遇包括工伤医疗、康复、辅助器具配置费用、伤残待遇、工亡待遇、一次性工亡补助金等。\n5. 工伤保险待遇领取资格认证��括长期待遇领取人员认证和一次性待遇领取人员认证。\n6. 工伤保险基金支付的待遇项目包括工伤医疗待遇、康复待遇、辅助器具配置费用、一次性工亡补助金、丧葬补助金等。",
|
| 912 |
+
"history": [
|
| 913 |
+
[
|
| 914 |
+
"工伤保险是什么?",
|
| 915 |
+
"工伤保险是指用人单位按照国家规定,为本单位的职工和用人单位的其他人员,缴纳工伤保险费,由保险机构按照国家规定的标准,给予工伤保险待遇的社会保险制度。"
|
| 916 |
+
]
|
| 917 |
+
],
|
| 918 |
+
"source_documents": [
|
| 919 |
+
"出处 [1] 广州市单位从业的特定人员参加工伤保险办事指引.docx:\n\n\t( 一) 从业单位 (组织) 按“自愿参保”原则, 为未建 立劳动关系的特定从业人员单项参加工伤保险 、缴纳工伤保 险费。",
|
| 920 |
+
"出处 [2] ...",
|
| 921 |
+
"出处 [3] ..."
|
| 922 |
+
]
|
| 923 |
+
}
|
| 924 |
+
|
| 925 |
+
```
|
| 926 |
+
|
| 927 |
+
ChatMessage
|
| 928 |
+
|
| 929 |
+
### Properties
|
| 930 |
+
|
| 931 |
+
|Name|Type|Required|Restrictions|Description|
|
| 932 |
+
|---|---|---|---|---|
|
| 933 |
+
|question|string|true|none|Question text|
|
| 934 |
+
|response|string|true|none|Response text|
|
| 935 |
+
|history|[array]|true|none|History text|
|
| 936 |
+
|source_documents|[string]|true|none|List of source documents and their scores|
|
| 937 |
+
|
| 938 |
+
<h2 id="tocS_HTTPValidationError">HTTPValidationError</h2>
|
| 939 |
+
<!-- backwards compatibility -->
|
| 940 |
+
<a id="schemahttpvalidationerror"></a>
|
| 941 |
+
<a id="schema_HTTPValidationError"></a>
|
| 942 |
+
<a id="tocShttpvalidationerror"></a>
|
| 943 |
+
<a id="tocshttpvalidationerror"></a>
|
| 944 |
+
|
| 945 |
+
```json
|
| 946 |
+
{
|
| 947 |
+
"detail": [
|
| 948 |
+
{
|
| 949 |
+
"loc": [
|
| 950 |
+
"string"
|
| 951 |
+
],
|
| 952 |
+
"msg": "string",
|
| 953 |
+
"type": "string"
|
| 954 |
+
}
|
| 955 |
+
]
|
| 956 |
+
}
|
| 957 |
+
|
| 958 |
+
```
|
| 959 |
+
|
| 960 |
+
HTTPValidationError
|
| 961 |
+
|
| 962 |
+
### Properties
|
| 963 |
+
|
| 964 |
+
|Name|Type|Required|Restrictions|Description|
|
| 965 |
+
|---|---|---|---|---|
|
| 966 |
+
|detail|[[ValidationError](#schemavalidationerror)]|false|none|none|
|
| 967 |
+
|
| 968 |
+
<h2 id="tocS_ListDocsResponse">ListDocsResponse</h2>
|
| 969 |
+
<!-- backwards compatibility -->
|
| 970 |
+
<a id="schemalistdocsresponse"></a>
|
| 971 |
+
<a id="schema_ListDocsResponse"></a>
|
| 972 |
+
<a id="tocSlistdocsresponse"></a>
|
| 973 |
+
<a id="tocslistdocsresponse"></a>
|
| 974 |
+
|
| 975 |
+
```json
|
| 976 |
+
{
|
| 977 |
+
"code": 200,
|
| 978 |
+
"msg": "success",
|
| 979 |
+
"data": [
|
| 980 |
+
"doc1.docx",
|
| 981 |
+
"doc2.pdf",
|
| 982 |
+
"doc3.txt"
|
| 983 |
+
]
|
| 984 |
+
}
|
| 985 |
+
|
| 986 |
+
```
|
| 987 |
+
|
| 988 |
+
ListDocsResponse
|
| 989 |
+
|
| 990 |
+
### Properties
|
| 991 |
+
|
| 992 |
+
|Name|Type|Required|Restrictions|Description|
|
| 993 |
+
|---|---|---|---|---|
|
| 994 |
+
|code|integer|false|none|HTTP status code|
|
| 995 |
+
|msg|string|false|none|HTTP status message|
|
| 996 |
+
|data|[string]|true|none|List of document names|
|
| 997 |
+
|
| 998 |
+
<h2 id="tocS_ValidationError">ValidationError</h2>
|
| 999 |
+
<!-- backwards compatibility -->
|
| 1000 |
+
<a id="schemavalidationerror"></a>
|
| 1001 |
+
<a id="schema_ValidationError"></a>
|
| 1002 |
+
<a id="tocSvalidationerror"></a>
|
| 1003 |
+
<a id="tocsvalidationerror"></a>
|
| 1004 |
+
|
| 1005 |
+
```json
|
| 1006 |
+
{
|
| 1007 |
+
"loc": [
|
| 1008 |
+
"string"
|
| 1009 |
+
],
|
| 1010 |
+
"msg": "string",
|
| 1011 |
+
"type": "string"
|
| 1012 |
+
}
|
| 1013 |
+
|
| 1014 |
+
```
|
| 1015 |
+
|
| 1016 |
+
ValidationError
|
| 1017 |
+
|
| 1018 |
+
### Properties
|
| 1019 |
+
|
| 1020 |
+
|Name|Type|Required|Restrictions|Description|
|
| 1021 |
+
|---|---|---|---|---|
|
| 1022 |
+
|loc|[anyOf]|true|none|none|
|
| 1023 |
+
|
| 1024 |
+
anyOf
|
| 1025 |
+
|
| 1026 |
+
|Name|Type|Required|Restrictions|Description|
|
| 1027 |
+
|---|---|---|---|---|
|
| 1028 |
+
|» *anonymous*|string|false|none|none|
|
| 1029 |
+
|
| 1030 |
+
or
|
| 1031 |
+
|
| 1032 |
+
|Name|Type|Required|Restrictions|Description|
|
| 1033 |
+
|---|---|---|---|---|
|
| 1034 |
+
|» *anonymous*|integer|false|none|none|
|
| 1035 |
+
|
| 1036 |
+
continued
|
| 1037 |
+
|
| 1038 |
+
|Name|Type|Required|Restrictions|Description|
|
| 1039 |
+
|---|---|---|---|---|
|
| 1040 |
+
|msg|string|true|none|none|
|
| 1041 |
+
|type|string|true|none|none|
|
| 1042 |
+
|
docs/CHANGELOG.md
ADDED
|
@@ -0,0 +1,32 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
## 变更日志
|
| 2 |
+
|
| 3 |
+
**[2023/04/15]**
|
| 4 |
+
|
| 5 |
+
1. 重构项目结构,在根目录下保留命令行 Demo [cli_demo.py](../cli_demo.py) 和 Web UI Demo [webui.py](../webui.py);
|
| 6 |
+
2. 对 Web UI 进行改进,修改为运行 Web UI 后首先按照 [configs/model_config.py](../configs/model_config.py) 默认选项加载模型,并增加报错提示信息等;
|
| 7 |
+
3. 对常见问题进行补充说明。
|
| 8 |
+
|
| 9 |
+
**[2023/04/12]**
|
| 10 |
+
|
| 11 |
+
1. 替换 Web UI 中的样例文件,避免出现 Ubuntu 中出现因文件编码无法读取的问题;
|
| 12 |
+
2. 替换`knowledge_based_chatglm.py`中的 prompt 模版,避免出现因 prompt 模版包含中英双语导致 chatglm 返回内容错乱的问题。
|
| 13 |
+
|
| 14 |
+
**[2023/04/11]**
|
| 15 |
+
|
| 16 |
+
1. 加入 Web UI V0.1 版本(感谢 [@liangtongt](https://github.com/liangtongt));
|
| 17 |
+
2. `README.md`中增加常见问题(感谢 [@calcitem](https://github.com/calcitem) 和 [@bolongliu](https://github.com/bolongliu));
|
| 18 |
+
3. 增加 LLM 和 Embedding 模型运行设备是否可用`cuda`、`mps`、`cpu`的自动判断。
|
| 19 |
+
4. 在`knowledge_based_chatglm.py`中增加对`filepath`的判断,在之前支持单个文件导入的基础上,现支持单个文件夹路径作为输入,输入后将会遍历文件夹中各个文件,并在命令行中显示每个文件是否成功加载。
|
| 20 |
+
|
| 21 |
+
**[2023/04/09]**
|
| 22 |
+
|
| 23 |
+
1. 使用`langchain`中的`RetrievalQA`替代之前选用的`ChatVectorDBChain`,替换后可以有效减少提问 2-3 次后因显存不足而停止运行的问题;
|
| 24 |
+
2. 在`knowledge_based_chatglm.py`中增加`EMBEDDING_MODEL`、`VECTOR_SEARCH_TOP_K`、`LLM_MODEL`、`LLM_HISTORY_LEN`、`REPLY_WITH_SOURCE`参数值设置;
|
| 25 |
+
3. 增加 GPU 显存需求更小的`chatglm-6b-int4`、`chatglm-6b-int4-qe`作为 LLM 模型备选项;
|
| 26 |
+
4. 更正`README.md`中的代码错误(感谢 [@calcitem](https://github.com/calcitem))。
|
| 27 |
+
|
| 28 |
+
**[2023/04/07]**
|
| 29 |
+
|
| 30 |
+
1. 解决加载 ChatGLM 模型时发生显存占用为双倍的问题 (感谢 [@suc16](https://github.com/suc16) 和 [@myml](https://github.com/myml)) ;
|
| 31 |
+
2. 新增清理显存机制;
|
| 32 |
+
3. 新增`nghuyong/ernie-3.0-nano-zh`和`nghuyong/ernie-3.0-base-zh`作为 Embedding 模型备选项,相比`GanymedeNil/text2vec-large-chinese`占用显存资源更少 (感谢 [@lastrei](https://github.com/lastrei))。
|
docs/FAQ.md
ADDED
|
@@ -0,0 +1,179 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
### 常见问题
|
| 2 |
+
|
| 3 |
+
Q1: 本项目支持哪些文件格式?
|
| 4 |
+
|
| 5 |
+
A1: 目前已测试支持 txt、docx、md、pdf 格式文件,更多文件格式请参考 [langchain 文档](https://python.langchain.com/en/latest/modules/indexes/document_loaders/examples/unstructured_file.html)。目前已知文档中若含有特殊字符,可能存在文件无法加载的问题。
|
| 6 |
+
|
| 7 |
+
---
|
| 8 |
+
|
| 9 |
+
Q2: 执行 `pip install -r requirements.txt` 过程中,安装 `detectron2` 时发生报错怎么办?
|
| 10 |
+
|
| 11 |
+
A2: 如果不需要对 `pdf` 格式文件读取,可不安装 `detectron2`;如需对 `pdf` 文件进行高精度文本提取,建议按照如下方法安装:
|
| 12 |
+
|
| 13 |
+
```commandline
|
| 14 |
+
$ git clone https://github.com/facebookresearch/detectron2.git
|
| 15 |
+
$ cd detectron2
|
| 16 |
+
$ pip install -e .
|
| 17 |
+
```
|
| 18 |
+
|
| 19 |
+
---
|
| 20 |
+
|
| 21 |
+
Q3: 使用过程中 Python 包 `nltk`发生了 `Resource punkt not found.`报错,该如何解决?
|
| 22 |
+
|
| 23 |
+
A3: 方法一:https://github.com/nltk/nltk_data/raw/gh-pages/packages/tokenizers/punkt.zip 中的 `packages/tokenizers` 解压,放到 `nltk_data/tokenizers` 存储路径下。
|
| 24 |
+
|
| 25 |
+
`nltk_data` 存储路径可以通过 `nltk.data.path` 查询。
|
| 26 |
+
|
| 27 |
+
方法二:执行python代码
|
| 28 |
+
|
| 29 |
+
```
|
| 30 |
+
import nltk
|
| 31 |
+
nltk.download()
|
| 32 |
+
```
|
| 33 |
+
|
| 34 |
+
---
|
| 35 |
+
|
| 36 |
+
Q4: 使用过程中 Python 包 `nltk`发生了 `Resource averaged_perceptron_tagger not found.`报错,该如何解决?
|
| 37 |
+
|
| 38 |
+
A4: 方法一:将 https://github.com/nltk/nltk_data/blob/gh-pages/packages/taggers/averaged_perceptron_tagger.zip 下载,解压放到 `nltk_data/taggers` 存储路径下。
|
| 39 |
+
|
| 40 |
+
`nltk_data` 存储路径可以通过 `nltk.data.path` 查询。
|
| 41 |
+
|
| 42 |
+
方法二:执行python代码
|
| 43 |
+
|
| 44 |
+
```
|
| 45 |
+
import nltk
|
| 46 |
+
nltk.download()
|
| 47 |
+
```
|
| 48 |
+
|
| 49 |
+
---
|
| 50 |
+
|
| 51 |
+
Q5: 本项目可否在 colab 中运行?
|
| 52 |
+
|
| 53 |
+
A5: 可以尝试使用 chatglm-6b-int4 模型在 colab 中运行,需要注意的是,如需在 colab 中运行 Web UI,需将 `webui.py`中 `demo.queue(concurrency_count=3).launch( server_name='0.0.0.0', share=False, inbrowser=False)`中参数 `share`设置为 `True`。
|
| 54 |
+
|
| 55 |
+
---
|
| 56 |
+
|
| 57 |
+
Q6: 在 Anaconda 中使用 pip 安装包无效如何解决?
|
| 58 |
+
|
| 59 |
+
A6: 此问题是系统环境问题,详细见 [在Anaconda中使用pip安装包无效问题](在Anaconda中使用pip安装包无效问题.md)
|
| 60 |
+
|
| 61 |
+
---
|
| 62 |
+
|
| 63 |
+
Q7: 本项目中所需模型如何下载至本地?
|
| 64 |
+
|
| 65 |
+
A7: 本项目中使用的模型均为 `huggingface.com`中可下载的开源模型,以默认选择的 `chatglm-6b`和 `text2vec-large-chinese`模型为例,下载模型可执行如下代码:
|
| 66 |
+
|
| 67 |
+
```shell
|
| 68 |
+
# 安装 git lfs
|
| 69 |
+
$ git lfs install
|
| 70 |
+
|
| 71 |
+
# 下载 LLM 模型
|
| 72 |
+
$ git clone https://huggingface.co/THUDM/chatglm-6b /your_path/chatglm-6b
|
| 73 |
+
|
| 74 |
+
# 下载 Embedding 模型
|
| 75 |
+
$ git clone https://huggingface.co/GanymedeNil/text2vec-large-chinese /your_path/text2vec
|
| 76 |
+
|
| 77 |
+
# 模型需要更新时,可打开模型所在文件夹后拉取最新模型文件/代码
|
| 78 |
+
$ git pull
|
| 79 |
+
```
|
| 80 |
+
|
| 81 |
+
---
|
| 82 |
+
|
| 83 |
+
Q8: `huggingface.com`中模型下载速度较慢怎么办?
|
| 84 |
+
|
| 85 |
+
A8: 可使用本项目用到的模型权重文件百度网盘地址:
|
| 86 |
+
|
| 87 |
+
- ernie-3.0-base-zh.zip 链接: https://pan.baidu.com/s/1CIvKnD3qzE-orFouA8qvNQ?pwd=4wih
|
| 88 |
+
- ernie-3.0-nano-zh.zip 链接: https://pan.baidu.com/s/1Fh8fgzVdavf5P1omAJJ-Zw?pwd=q6s5
|
| 89 |
+
- text2vec-large-chinese.zip 链接: https://pan.baidu.com/s/1sMyPzBIXdEzHygftEoyBuA?pwd=4xs7
|
| 90 |
+
- chatglm-6b-int4-qe.zip 链接: https://pan.baidu.com/s/1DDKMOMHtNZccOOBGWIOYww?pwd=22ji
|
| 91 |
+
- chatglm-6b-int4.zip 链接: https://pan.baidu.com/s/1pvZ6pMzovjhkA6uPcRLuJA?pwd=3gjd
|
| 92 |
+
- chatglm-6b.zip 链接: https://pan.baidu.com/s/1B-MpsVVs1GHhteVBetaquw?pwd=djay
|
| 93 |
+
|
| 94 |
+
---
|
| 95 |
+
|
| 96 |
+
Q9: 下载完模型后,如何修改代码以执行本地模型?
|
| 97 |
+
|
| 98 |
+
A9: 模型下载完成后,请在 [configs/model_config.py](../configs/model_config.py) 文件中,对 `embedding_model_dict`和 `llm_model_dict`参数进行修改,如把 `llm_model_dict`从
|
| 99 |
+
|
| 100 |
+
```python
|
| 101 |
+
embedding_model_dict = {
|
| 102 |
+
"ernie-tiny": "nghuyong/ernie-3.0-nano-zh",
|
| 103 |
+
"ernie-base": "nghuyong/ernie-3.0-base-zh",
|
| 104 |
+
"text2vec": "GanymedeNil/text2vec-large-chinese"
|
| 105 |
+
}
|
| 106 |
+
```
|
| 107 |
+
|
| 108 |
+
修改为
|
| 109 |
+
|
| 110 |
+
```python
|
| 111 |
+
embedding_model_dict = {
|
| 112 |
+
"ernie-tiny": "nghuyong/ernie-3.0-nano-zh",
|
| 113 |
+
"ernie-base": "nghuyong/ernie-3.0-base-zh",
|
| 114 |
+
"text2vec": "/Users/liuqian/Downloads/ChatGLM-6B/text2vec-large-chinese"
|
| 115 |
+
}
|
| 116 |
+
```
|
| 117 |
+
|
| 118 |
+
---
|
| 119 |
+
|
| 120 |
+
Q10: 执行 `python cli_demo.py`过程中,显卡内存爆了,提示"OutOfMemoryError: CUDA out of memory"
|
| 121 |
+
|
| 122 |
+
A10: 将 `VECTOR_SEARCH_TOP_K` 和 `LLM_HISTORY_LEN` 的值调低,比如 `VECTOR_SEARCH_TOP_K = 5` 和 `LLM_HISTORY_LEN = 2`,这样由 `query` 和 `context` 拼接得到的 `prompt` 会变短,会减少内存的占用。
|
| 123 |
+
|
| 124 |
+
---
|
| 125 |
+
|
| 126 |
+
Q11: 执行 `pip install -r requirements.txt` 过程中遇到 python 包,如 langchain 找不到对应版本的问题
|
| 127 |
+
|
| 128 |
+
A11: 更换 pypi 源后重新安装,如阿里源、清华源等,网络条件允许时建议直接使用 pypi.org 源,具体操作命令如下:
|
| 129 |
+
|
| 130 |
+
```shell
|
| 131 |
+
# 使用 pypi 源
|
| 132 |
+
$ pip install -r requirements.txt -i https://pypi.python.org/simple
|
| 133 |
+
```
|
| 134 |
+
|
| 135 |
+
或
|
| 136 |
+
|
| 137 |
+
```shell
|
| 138 |
+
# 使用阿里源
|
| 139 |
+
$ pip install -r requirements.txt -i http://mirrors.aliyun.com/pypi/simple/
|
| 140 |
+
```
|
| 141 |
+
|
| 142 |
+
或
|
| 143 |
+
|
| 144 |
+
```shell
|
| 145 |
+
# 使用清华源
|
| 146 |
+
$ pip install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple/
|
| 147 |
+
```
|
| 148 |
+
|
| 149 |
+
Q12 启动api.py时upload_file接口抛出 `partially initialized module 'charset_normalizer' has no attribute 'md__mypyc' (most likely due to a circular import)`
|
| 150 |
+
|
| 151 |
+
这是由于 charset_normalizer模块版本过高导致的,需要降低低charset_normalizer的版本,测试在charset_normalizer==2.1.0上可用。
|
| 152 |
+
|
| 153 |
+
---
|
| 154 |
+
|
| 155 |
+
Q13 启动api.py时upload_file接口,上传PDF或图片时,抛出OSError: [Errno 101] Network is unreachable
|
| 156 |
+
|
| 157 |
+
某些情况下,linux系统上的ip在请求下载ch_PP-OCRv3_rec_infer.tar等文件时,可能会抛出OSError: [Errno 101] Network is unreachable,此时需要首先修改anaconda3/envs/[虚拟环境名]/lib/[python版本]/site-packages/paddleocr/ppocr/utils/network.py脚本,将57行的:
|
| 158 |
+
|
| 159 |
+
```
|
| 160 |
+
download_with_progressbar(url, tmp_path)
|
| 161 |
+
```
|
| 162 |
+
|
| 163 |
+
修改为:
|
| 164 |
+
|
| 165 |
+
```
|
| 166 |
+
try:
|
| 167 |
+
download_with_progressbar(url, tmp_path)
|
| 168 |
+
except Exception as e:
|
| 169 |
+
print(f"download {url} error,please download it manually:")
|
| 170 |
+
print(e)
|
| 171 |
+
```
|
| 172 |
+
|
| 173 |
+
然后按照给定网址,如"https://paddleocr.bj.bcebos.com/PP-OCRv3/chinese/ch_PP-OCRv3_rec_infer.tar"手动下载文件,上传到对应的文件夹中,如“.paddleocr/whl/rec/ch/ch_PP-OCRv3_rec_infer/ch_PP-OCRv3_rec_infer.tar”.
|
| 174 |
+
|
| 175 |
+
---
|
| 176 |
+
|
| 177 |
+
Q14 调用api中的 `bing_search_chat`接口时,报出 `Failed to establish a new connection: [Errno 110] Connection timed out`
|
| 178 |
+
|
| 179 |
+
这是因为服务器加了防火墙,需要联系管理员加白名单,如果公司的服务器的话,就别想了GG--!
|
docs/INSTALL.md
ADDED
|
@@ -0,0 +1,55 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# 安装
|
| 2 |
+
|
| 3 |
+
## 环境检查
|
| 4 |
+
|
| 5 |
+
```shell
|
| 6 |
+
# 首先,确信你的机器安装了 Python 3.8 及以上版本
|
| 7 |
+
$ python --version
|
| 8 |
+
Python 3.8.13
|
| 9 |
+
|
| 10 |
+
# 如果低于这个版本,可使用conda安装环境
|
| 11 |
+
$ conda create -p /your_path/env_name python=3.8
|
| 12 |
+
|
| 13 |
+
# 激活环境
|
| 14 |
+
$ source activate /your_path/env_name
|
| 15 |
+
$ pip3 install --upgrade pip
|
| 16 |
+
|
| 17 |
+
# 关闭环境
|
| 18 |
+
$ source deactivate /your_path/env_name
|
| 19 |
+
|
| 20 |
+
# 删除环境
|
| 21 |
+
$ conda env remove -p /your_path/env_name
|
| 22 |
+
```
|
| 23 |
+
|
| 24 |
+
## 项目依赖
|
| 25 |
+
|
| 26 |
+
```shell
|
| 27 |
+
# 拉取仓库
|
| 28 |
+
$ git clone https://github.com/imClumsyPanda/langchain-ChatGLM.git
|
| 29 |
+
|
| 30 |
+
# 进入目录
|
| 31 |
+
$ cd langchain-ChatGLM
|
| 32 |
+
|
| 33 |
+
# 项目中 pdf 加载由先前的 detectron2 替换为使用 paddleocr,如果之前有安装过 detectron2 需要先完成卸载避免引发 tools 冲突
|
| 34 |
+
$ pip uninstall detectron2
|
| 35 |
+
|
| 36 |
+
# 检查paddleocr依赖,linux环境下paddleocr依赖libX11,libXext
|
| 37 |
+
$ yum install libX11
|
| 38 |
+
$ yum install libXext
|
| 39 |
+
|
| 40 |
+
# 安装依赖
|
| 41 |
+
$ pip install -r requirements.txt
|
| 42 |
+
|
| 43 |
+
# 验证paddleocr是否成功,首次运行会下载约18M模型到~/.paddleocr
|
| 44 |
+
$ python loader/image_loader.py
|
| 45 |
+
|
| 46 |
+
```
|
| 47 |
+
|
| 48 |
+
注:使用 `langchain.document_loaders.UnstructuredFileLoader` 进行非结构化文件接入时,可能需要依据文档进行其他依赖包的安装,请参考 [langchain 文档](https://python.langchain.com/en/latest/modules/indexes/document_loaders/examples/unstructured_file.html)。
|
| 49 |
+
|
| 50 |
+
## llama-cpp模型调用的说明
|
| 51 |
+
|
| 52 |
+
1. 首先从huggingface hub中下载对应的模型,如 [https://huggingface.co/vicuna/ggml-vicuna-13b-1.1/](https://huggingface.co/vicuna/ggml-vicuna-13b-1.1/) 的 [ggml-vic13b-q5_1.bin](https://huggingface.co/vicuna/ggml-vicuna-13b-1.1/blob/main/ggml-vic13b-q5_1.bin),建议使用huggingface_hub库的snapshot_download下载。
|
| 53 |
+
2. 将下载的模型重命名。通过huggingface_hub下载的模型会被重命名为随机序列,因此需要重命名为原始文件名,如[ggml-vic13b-q5_1.bin](https://huggingface.co/vicuna/ggml-vicuna-13b-1.1/blob/main/ggml-vic13b-q5_1.bin)。
|
| 54 |
+
3. 基于下载模型的ggml的加载时间,推测对应的llama-cpp版本,下载对应的llama-cpp-python库的wheel文件,实测[ggml-vic13b-q5_1.bin](https://huggingface.co/vicuna/ggml-vicuna-13b-1.1/blob/main/ggml-vic13b-q5_1.bin)与llama-cpp-python库兼容,然后手动安装wheel文件。
|
| 55 |
+
4. 将下载的模型信息写入configs/model_config.py文件里 `llm_model_dict`中,注意保证参数的兼容性,一些参数组合可能会报错.
|
docs/Issue-with-Installing-Packages-Using-pip-in-Anaconda.md
ADDED
|
@@ -0,0 +1,114 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
## Issue with Installing Packages Using pip in Anaconda
|
| 2 |
+
|
| 3 |
+
## Problem
|
| 4 |
+
|
| 5 |
+
Recently, when running open-source code, I encountered an issue: after creating a virtual environment with conda and switching to the new environment, using pip to install packages would be "ineffective." Here, "ineffective" means that the packages installed with pip are not in this new environment.
|
| 6 |
+
|
| 7 |
+
------
|
| 8 |
+
|
| 9 |
+
## Analysis
|
| 10 |
+
|
| 11 |
+
1. First, create a test environment called test: `conda create -n test`
|
| 12 |
+
2. Activate the test environment: `conda activate test`
|
| 13 |
+
3. Use pip to install numpy: `pip install numpy`. You'll find that numpy already exists in the default environment.
|
| 14 |
+
|
| 15 |
+
```powershell
|
| 16 |
+
Looking in indexes: https://pypi.tuna.tsinghua.edu.cn/simple
|
| 17 |
+
Requirement already satisfied: numpy in c:\programdata\anaconda3\lib\site-packages (1.20.3)
|
| 18 |
+
```
|
| 19 |
+
|
| 20 |
+
4. Check the information of pip: `pip show pip`
|
| 21 |
+
|
| 22 |
+
```powershell
|
| 23 |
+
Name: pip
|
| 24 |
+
Version: 21.2.4
|
| 25 |
+
Summary: The PyPA recommended tool for installing Python packages.
|
| 26 |
+
Home-page: https://pip.pypa.io/
|
| 27 |
+
Author: The pip developers
|
| 28 |
+
Author-email: distutils-sig@python.org
|
| 29 |
+
License: MIT
|
| 30 |
+
Location: c:\programdata\anaconda3\lib\site-packages
|
| 31 |
+
Requires:
|
| 32 |
+
Required-by:
|
| 33 |
+
```
|
| 34 |
+
|
| 35 |
+
5. We can see that the current pip is in the default conda environment. This explains why the package is not in the new virtual environment when we directly use pip to install packages - because the pip being used belongs to the default environment, the installed package either already exists or is installed directly into the default environment.
|
| 36 |
+
|
| 37 |
+
------
|
| 38 |
+
|
| 39 |
+
## Solution
|
| 40 |
+
|
| 41 |
+
1. We can directly use the conda command to install new packages, but sometimes conda may not have certain packages/libraries, so we still need to use pip to install.
|
| 42 |
+
2. We can first use the conda command to install the pip package for the current virtual environment, and then use pip to install new packages.
|
| 43 |
+
|
| 44 |
+
```powershell
|
| 45 |
+
# Use conda to install the pip package
|
| 46 |
+
(test) PS C:\Users\Administrator> conda install pip
|
| 47 |
+
Collecting package metadata (current_repodata.json): done
|
| 48 |
+
Solving environment: done
|
| 49 |
+
....
|
| 50 |
+
done
|
| 51 |
+
|
| 52 |
+
# Display the information of the current pip, and find that pip is in the test environment
|
| 53 |
+
(test) PS C:\Users\Administrator> pip show pip
|
| 54 |
+
Name: pip
|
| 55 |
+
Version: 21.2.4
|
| 56 |
+
Summary: The PyPA recommended tool for installing Python packages.
|
| 57 |
+
Home-page: https://pip.pypa.io/
|
| 58 |
+
Author: The pip developers
|
| 59 |
+
Author-email: distutils-sig@python.org
|
| 60 |
+
License: MIT
|
| 61 |
+
Location: c:\programdata\anaconda3\envs\test\lib\site-packages
|
| 62 |
+
Requires:
|
| 63 |
+
Required-by:
|
| 64 |
+
|
| 65 |
+
# Now use pip to install the numpy package, and it is installed successfully
|
| 66 |
+
(test) PS C:\Users\Administrator> pip install numpy
|
| 67 |
+
Looking in indexes:
|
| 68 |
+
https://pypi.tuna.tsinghua.edu.cn/simple
|
| 69 |
+
Collecting numpy
|
| 70 |
+
Using cached https://pypi.tuna.tsinghua.edu.cn/packages/4b/23/140ec5a509d992fe39db17200e96c00fd29603c1531ce633ef93dbad5e9e/numpy-1.22.2-cp39-cp39-win_amd64.whl (14.7 MB)
|
| 71 |
+
Installing collected packages: numpy
|
| 72 |
+
Successfully installed numpy-1.22.2
|
| 73 |
+
|
| 74 |
+
# Use pip list to view the currently installed packages, no problem
|
| 75 |
+
(test) PS C:\Users\Administrator> pip list
|
| 76 |
+
Package Version
|
| 77 |
+
------------ ---------
|
| 78 |
+
certifi 2021.10.8
|
| 79 |
+
numpy 1.22.2
|
| 80 |
+
pip 21.2.4
|
| 81 |
+
setuptools 58.0.4
|
| 82 |
+
wheel 0.37.1
|
| 83 |
+
wincertstore 0.2
|
| 84 |
+
```
|
| 85 |
+
|
| 86 |
+
## Supplement
|
| 87 |
+
|
| 88 |
+
1. The reason I didn't notice this problem before might be because the packages installed in the virtual environment were of a specific version, which overwrote the packages in the default environment. The main issue was actually a lack of careful observation:), otherwise, I could have noticed `Successfully uninstalled numpy-xxx` **default version** and `Successfully installed numpy-1.20.3` **specified version**.
|
| 89 |
+
2. During testing, I found that if the Python version is specified when creating a new package, there shouldn't be this issue. I guess this is because pip will be installed in the virtual environment, while in our case, including pip, no packages were installed, so the default environment's pip was used.
|
| 90 |
+
3. There's a question: I should have specified the Python version when creating a new virtual environment before, but I still used the default environment's pip package. However, I just couldn't reproduce the issue successfully on two different machines, which led to the second point mentioned above.
|
| 91 |
+
4. After encountering the problem mentioned in point 3, I solved it by using `python -m pip install package-name`, adding `python -m` before pip. As for why, you can refer to the answer on [StackOverflow](https://stackoverflow.com/questions/41060382/using-pip-to-install-packages-to-anaconda-environment):
|
| 92 |
+
|
| 93 |
+
>1. If you have a non-conda pip as your default pip but conda python as your default python (as below):
|
| 94 |
+
>
|
| 95 |
+
>```shell
|
| 96 |
+
>>which -a pip
|
| 97 |
+
>/home/<user>/.local/bin/pip
|
| 98 |
+
>/home/<user>/.conda/envs/newenv/bin/pip
|
| 99 |
+
>/usr/bin/pip
|
| 100 |
+
>
|
| 101 |
+
>>which -a python
|
| 102 |
+
>/home/<user>/.conda/envs/newenv/bin/python
|
| 103 |
+
>/usr/bin/python
|
| 104 |
+
>```
|
| 105 |
+
>
|
| 106 |
+
>2. Then, instead of calling `pip install <package>` directly, you can use the module flag -m in python so that it installs with the anaconda python
|
| 107 |
+
>
|
| 108 |
+
>```shell
|
| 109 |
+
>python -m pip install <package>
|
| 110 |
+
>```
|
| 111 |
+
>
|
| 112 |
+
>3. This will install the package to the anaconda library directory rather than the library directory associated with the (non-anaconda) pip
|
| 113 |
+
>4. The reason for doing this is as follows: the pip command references a specific pip file/shortcut (which -a pip will tell you which one). Similarly, the python command references a specific python file (which -a python will tell you which one). For one reason or another, these two commands can become out of sync, so your "default" pip is in a different folder than your default python and therefore is associated with different versions of python.
|
| 114 |
+
>5. In contrast, the python -m pip construct does not use the shortcut that the pip command points to. Instead, it asks python to find its pip version and use that version to install a package.
|
docs/StartOption.md
ADDED
|
@@ -0,0 +1,76 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
|
| 2 |
+
#### 项目启动选项
|
| 3 |
+
```test
|
| 4 |
+
usage: langchina-ChatGLM [-h] [--no-remote-model] [--model MODEL] [--lora LORA] [--model-dir MODEL_DIR] [--lora-dir LORA_DIR] [--cpu] [--auto-devices] [--gpu-memory GPU_MEMORY [GPU_MEMORY ...]] [--cpu-memory CPU_MEMORY]
|
| 5 |
+
[--load-in-8bit] [--bf16]
|
| 6 |
+
|
| 7 |
+
基于langchain和chatGML的LLM文档阅读器
|
| 8 |
+
|
| 9 |
+
options:
|
| 10 |
+
-h, --help show this help message and exit
|
| 11 |
+
--no-remote-model remote in the model on loader checkpoint, if your load local model to add the ` --no-remote-model`
|
| 12 |
+
--model MODEL Name of the model to load by default.
|
| 13 |
+
--lora LORA Name of the LoRA to apply to the model by default.
|
| 14 |
+
--model-dir MODEL_DIR
|
| 15 |
+
Path to directory with all the models
|
| 16 |
+
--lora-dir LORA_DIR Path to directory with all the loras
|
| 17 |
+
--cpu Use the CPU to generate text. Warning: Training on CPU is extremely slow.
|
| 18 |
+
--auto-devices Automatically split the model across the available GPU(s) and CPU.
|
| 19 |
+
--gpu-memory GPU_MEMORY [GPU_MEMORY ...]
|
| 20 |
+
Maxmimum GPU memory in GiB to be allocated per GPU. Example: --gpu-memory 10 for a single GPU, --gpu-memory 10 5 for two GPUs. You can also set values in MiB like --gpu-memory 3500MiB.
|
| 21 |
+
--cpu-memory CPU_MEMORY
|
| 22 |
+
Maximum CPU memory in GiB to allocate for offloaded weights. Same as above.
|
| 23 |
+
--load-in-8bit Load the model with 8-bit precision.
|
| 24 |
+
--bf16 Load the model with bfloat16 precision. Requires NVIDIA Ampere GPU.
|
| 25 |
+
|
| 26 |
+
```
|
| 27 |
+
|
| 28 |
+
#### 示例
|
| 29 |
+
|
| 30 |
+
- 1、加载本地模型
|
| 31 |
+
|
| 32 |
+
```text
|
| 33 |
+
--model-dir 本地checkpoint存放文件夹
|
| 34 |
+
--model 模型名称
|
| 35 |
+
--no-remote-model 不从远程加载模型
|
| 36 |
+
```
|
| 37 |
+
```shell
|
| 38 |
+
$ python cli_demo.py --model-dir /media/mnt/ --model chatglm-6b --no-remote-model
|
| 39 |
+
```
|
| 40 |
+
|
| 41 |
+
- 2、低精度加载模型
|
| 42 |
+
```text
|
| 43 |
+
--model-dir 本地checkpoint存放文件夹
|
| 44 |
+
--model 模型名称
|
| 45 |
+
--no-remote-model 不从远程加载模型
|
| 46 |
+
--load-in-8bit 以8位精度加载模型
|
| 47 |
+
```
|
| 48 |
+
```shell
|
| 49 |
+
$ python cli_demo.py --model-dir /media/mnt/ --model chatglm-6b --no-remote-model --load-in-8bit
|
| 50 |
+
```
|
| 51 |
+
|
| 52 |
+
|
| 53 |
+
- 3、使用cpu预测模型
|
| 54 |
+
```text
|
| 55 |
+
--model-dir 本地checkpoint存放文件夹
|
| 56 |
+
--model 模型名称
|
| 57 |
+
--no-remote-model 不从远程加载模型
|
| 58 |
+
--cpu 使用CPU生成文本。警告:CPU上的训练非常缓慢。
|
| 59 |
+
```
|
| 60 |
+
```shell
|
| 61 |
+
$ python cli_demo.py --model-dir /media/mnt/ --model chatglm-6b --no-remote-model --cpu
|
| 62 |
+
```
|
| 63 |
+
|
| 64 |
+
|
| 65 |
+
|
| 66 |
+
- 3、加载lora微调文件
|
| 67 |
+
```text
|
| 68 |
+
--model-dir 本地checkpoint存放文件夹
|
| 69 |
+
--model 模型名称
|
| 70 |
+
--no-remote-model 不从远程加载模型
|
| 71 |
+
--lora-dir 本地lora存放文件夹
|
| 72 |
+
--lora lora名称
|
| 73 |
+
```
|
| 74 |
+
```shell
|
| 75 |
+
$ python cli_demo.py --model-dir /media/mnt/ --model chatglm-6b --no-remote-model --lora-dir /media/mnt/loras --lora chatglm-step100
|
| 76 |
+
```
|
docs/cli.md
ADDED
|
@@ -0,0 +1,49 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
## 命令行工具
|
| 2 |
+
|
| 3 |
+
windows cli.bat
|
| 4 |
+
linux cli.sh
|
| 5 |
+
|
| 6 |
+
## 命令列表
|
| 7 |
+
|
| 8 |
+
### llm 管理
|
| 9 |
+
|
| 10 |
+
llm 支持列表
|
| 11 |
+
|
| 12 |
+
```shell
|
| 13 |
+
cli.bat llm ls
|
| 14 |
+
```
|
| 15 |
+
|
| 16 |
+
### embedding 管理
|
| 17 |
+
|
| 18 |
+
embedding 支持列表
|
| 19 |
+
|
| 20 |
+
```shell
|
| 21 |
+
cli.bat embedding ls
|
| 22 |
+
```
|
| 23 |
+
|
| 24 |
+
### start 启动管理
|
| 25 |
+
|
| 26 |
+
查看启动选择
|
| 27 |
+
|
| 28 |
+
```shell
|
| 29 |
+
cli.bat start
|
| 30 |
+
```
|
| 31 |
+
|
| 32 |
+
启动命令行交互
|
| 33 |
+
|
| 34 |
+
```shell
|
| 35 |
+
cli.bat start cli
|
| 36 |
+
```
|
| 37 |
+
|
| 38 |
+
启动Web 交互
|
| 39 |
+
|
| 40 |
+
```shell
|
| 41 |
+
cli.bat start webui
|
| 42 |
+
```
|
| 43 |
+
|
| 44 |
+
启动api服务
|
| 45 |
+
|
| 46 |
+
```shell
|
| 47 |
+
cli.bat start api
|
| 48 |
+
```
|
| 49 |
+
|
docs/fastchat.md
ADDED
|
@@ -0,0 +1,24 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# fastchat 调用实现教程
|
| 2 |
+
langchain-ChatGLM 现已支持通过调用 FastChat API 进行 LLM 调用,支持的 API 形式为 **OpenAI API 形式**。
|
| 3 |
+
1. 首先请参考 [FastChat 官方文档](https://github.com/lm-sys/FastChat/blob/main/docs/openai_api.md#restful-api-server) 进行 FastChat OpenAI 形式 API 部署
|
| 4 |
+
2. 依据 FastChat API 启用时的 `model_name` 和 `api_base` 链接,在本项目的 `configs/model_config.py` 的 `llm_model_dict` 中增加选项。如:
|
| 5 |
+
```python
|
| 6 |
+
llm_model_dict = {
|
| 7 |
+
|
| 8 |
+
# 通过 fastchat 调用的模型请参考如下格式
|
| 9 |
+
"fastchat-chatglm-6b": {
|
| 10 |
+
"name": "chatglm-6b", # "name"修改为fastchat服务中的"model_name"
|
| 11 |
+
"pretrained_model_name": "chatglm-6b",
|
| 12 |
+
"local_model_path": None,
|
| 13 |
+
"provides": "FastChatOpenAILLM", # 使用fastchat api时,需保证"provides"为"FastChatOpenAILLM"
|
| 14 |
+
"api_base_url": "http://localhost:8000/v1" # "name"修改为fastchat服务中的"api_base_url"
|
| 15 |
+
},
|
| 16 |
+
}
|
| 17 |
+
```
|
| 18 |
+
其中 `api_base_url` 根据 FastChat 部署时的 ip 地址和端口号得到,如 ip 地址设置为 `localhost`,端口号为 `8000`,则应设置的 `api_base_url` 为 `http://localhost:8000/v1`
|
| 19 |
+
|
| 20 |
+
3. 将 `configs/model_config.py` 中的 `LLM_MODEL` 修改为对应模型名。如:
|
| 21 |
+
```python
|
| 22 |
+
LLM_MODEL = "fastchat-chatglm-6b"
|
| 23 |
+
```
|
| 24 |
+
4. 根据需求运行 `api.py`, `cli_demo.py` 或 `webui.py`。
|
docs/启动API服务.md
ADDED
|
@@ -0,0 +1,37 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# 启动API服务
|
| 2 |
+
|
| 3 |
+
## 通过py文件启动
|
| 4 |
+
可以通过直接执行`api.py`文件启动API服务,默认以ip:0.0.0.0和port:7861启动http和ws服务。
|
| 5 |
+
```shell
|
| 6 |
+
python api.py
|
| 7 |
+
```
|
| 8 |
+
同时,启动时支持StartOption所列的模型加载参数,同时还支持IP和端口设置。
|
| 9 |
+
```shell
|
| 10 |
+
python api.py --model-name chatglm-6b-int8 --port 7862
|
| 11 |
+
```
|
| 12 |
+
|
| 13 |
+
## 通过cli.bat/cli.sh启动
|
| 14 |
+
也可以通过命令行控制文件继续启动。
|
| 15 |
+
```shell
|
| 16 |
+
cli.sh api --help
|
| 17 |
+
```
|
| 18 |
+
其他可设置参数和上述py文件启动方式相同。
|
| 19 |
+
|
| 20 |
+
|
| 21 |
+
# 以https、wss启动API服务
|
| 22 |
+
## 本地创建ssl相关证书文件
|
| 23 |
+
如果没有正式签发的CA证书,可以[安装mkcert](https://github.com/FiloSottile/mkcert#installation)工具, 然后用如下指令生成本地CA证书:
|
| 24 |
+
```shell
|
| 25 |
+
mkcert -install
|
| 26 |
+
mkcert api.example.com 47.123.123.123 localhost 127.0.0.1 ::1
|
| 27 |
+
```
|
| 28 |
+
默认回车保存在当前目录下,会有以生成指令第一个域名命名为前缀命名的两个pem文件。
|
| 29 |
+
|
| 30 |
+
附带两个文件参数启动即可。
|
| 31 |
+
````shell
|
| 32 |
+
python api --port 7862 --ssl_keyfile api.example.com+4-key.pem --ssl_certfile api.example.com+4.pem
|
| 33 |
+
|
| 34 |
+
./cli.sh api --port 7862 --ssl_keyfile api.example.com+4-key.pem --ssl_certfile api.example.com+4.pem
|
| 35 |
+
````
|
| 36 |
+
|
| 37 |
+
此外可以通过前置Nginx转发实现类似效果,可另行查阅相关资料。
|
docs/在Anaconda中使用pip安装包无效问题.md
ADDED
|
@@ -0,0 +1,125 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
## 在 Anaconda 中使用 pip 安装包无效问题
|
| 2 |
+
|
| 3 |
+
## 问题
|
| 4 |
+
|
| 5 |
+
最近在跑开源代码的时候遇到的问题:使用 conda 创建虚拟环境并切换到新的虚拟环境后,再使用 pip 来安装包会“无效”。这里的“无效”指的是使用 pip 安装的包不在这个新的环境中。
|
| 6 |
+
|
| 7 |
+
------
|
| 8 |
+
|
| 9 |
+
## 分析
|
| 10 |
+
|
| 11 |
+
1、首先创建一个测试环境 test,`conda create -n test`
|
| 12 |
+
|
| 13 |
+
2、激活该测试环境,`conda activate test`
|
| 14 |
+
|
| 15 |
+
3、使用 pip 安装 numpy,`pip install numpy`,会发现 numpy 已经存在默认的环境中
|
| 16 |
+
|
| 17 |
+
```powershell
|
| 18 |
+
Looking in indexes: https://pypi.tuna.tsinghua.edu.cn/simple
|
| 19 |
+
Requirement already satisfied: numpy in c:\programdata\anaconda3\lib\site-packages (1.20.3)
|
| 20 |
+
```
|
| 21 |
+
|
| 22 |
+
4、这时候看一下 pip 的信息,`pip show pip`
|
| 23 |
+
|
| 24 |
+
```powershell
|
| 25 |
+
Name: pip
|
| 26 |
+
Version: 21.2.4
|
| 27 |
+
Summary: The PyPA recommended tool for installing Python packages.
|
| 28 |
+
Home-page: https://pip.pypa.io/
|
| 29 |
+
Author: The pip developers
|
| 30 |
+
Author-email: distutils-sig@python.org
|
| 31 |
+
License: MIT
|
| 32 |
+
Location: c:\programdata\anaconda3\lib\site-packages
|
| 33 |
+
Requires:
|
| 34 |
+
Required-by:
|
| 35 |
+
```
|
| 36 |
+
|
| 37 |
+
5、可以发现当前 pip 是在默认的 conda 环境中。这也就解释了当我们直接使用 pip 安装包时为什么包不在这个新的虚拟环境中,因为使用的 pip 属于默认环境,安装的包要么已经存在,要么直接装到默认环境中去了。
|
| 38 |
+
|
| 39 |
+
------
|
| 40 |
+
|
| 41 |
+
## 解决
|
| 42 |
+
|
| 43 |
+
1、我们可以直接使用 conda 命令安装新的包,但有些时候 conda 可能没有某些包/库,所以还是得用 pip 安装
|
| 44 |
+
|
| 45 |
+
2、我们可以先使用 conda 命令为当前虚拟环境安装 pip 包,再使用 pip 安装新的包
|
| 46 |
+
|
| 47 |
+
```powershell
|
| 48 |
+
# 使用 conda 安装 pip 包
|
| 49 |
+
(test) PS C:\Users\Administrator> conda install pip
|
| 50 |
+
Collecting package metadata (current_repodata.json): done
|
| 51 |
+
Solving environment: done
|
| 52 |
+
....
|
| 53 |
+
done
|
| 54 |
+
|
| 55 |
+
# 显示当前 pip 的信息,发现 pip 在测试环境 test 中
|
| 56 |
+
(test) PS C:\Users\Administrator> pip show pip
|
| 57 |
+
Name: pip
|
| 58 |
+
Version: 21.2.4
|
| 59 |
+
Summary: The PyPA recommended tool for installing Python packages.
|
| 60 |
+
Home-page: https://pip.pypa.io/
|
| 61 |
+
Author: The pip developers
|
| 62 |
+
Author-email: distutils-sig@python.org
|
| 63 |
+
License: MIT
|
| 64 |
+
Location: c:\programdata\anaconda3\envs\test\lib\site-packages
|
| 65 |
+
Requires:
|
| 66 |
+
Required-by:
|
| 67 |
+
|
| 68 |
+
# 再使用 pip 安装 numpy 包,成功安装
|
| 69 |
+
(test) PS C:\Users\Administrator> pip install numpy
|
| 70 |
+
Looking in indexes: https://pypi.tuna.tsinghua.edu.cn/simple
|
| 71 |
+
Collecting numpy
|
| 72 |
+
Using cached https://pypi.tuna.tsinghua.edu.cn/packages/4b/23/140ec5a509d992fe39db17200e96c00fd29603c1531ce633ef93dbad5e9e/numpy-1.22.2-cp39-cp39-win_amd64.whl (14.7 MB)
|
| 73 |
+
Installing collected packages: numpy
|
| 74 |
+
Successfully installed numpy-1.22.2
|
| 75 |
+
|
| 76 |
+
# 使用 pip list 查看当前安装的包,没有问题
|
| 77 |
+
(test) PS C:\Users\Administrator> pip list
|
| 78 |
+
Package Version
|
| 79 |
+
------------ ---------
|
| 80 |
+
certifi 2021.10.8
|
| 81 |
+
numpy 1.22.2
|
| 82 |
+
pip 21.2.4
|
| 83 |
+
setuptools 58.0.4
|
| 84 |
+
wheel 0.37.1
|
| 85 |
+
wincertstore 0.2
|
| 86 |
+
```
|
| 87 |
+
|
| 88 |
+
------
|
| 89 |
+
|
| 90 |
+
## 补充
|
| 91 |
+
|
| 92 |
+
1、之前没有发现这个问题可能时因为在虚拟环境中安装的包是指定版本的,覆盖了默认环境中的包。其实主要还是观察不仔细:),不然可以发现 `Successfully uninstalled numpy-xxx`【默认版本】 以及 `Successfully installed numpy-1.20.3`【指定版本】
|
| 93 |
+
|
| 94 |
+
2、测试时发现如果在新建包的时候指定了 python 版本的话应该是没有这个问题的,猜测时因为会在虚拟环境中安装好 pip ,而我们这里包括 pip 在内啥包也没有装,所以使用的是默认环境的 pip
|
| 95 |
+
|
| 96 |
+
3、有个问题,之前我在创建新的虚拟环境时应该指定了 python 版本,但还是使用的默认环境的 pip 包,但是刚在在两台机器上都没有复现成功,于是有了上面的第 2 点
|
| 97 |
+
|
| 98 |
+
4、出现了第 3 点的问题后,我当时是使用 `python -m pip install package-name` 解决的,在 pip 前面加上了 python -m。至于为什么,可以参考 [StackOverflow](https://stackoverflow.com/questions/41060382/using-pip-to-install-packages-to-anaconda-environment) 上的回答:
|
| 99 |
+
|
| 100 |
+
> 1、如果你有一个非 conda 的 pip 作为你的默认 pip,但是 conda 的 python 是你的默认 python(如下):
|
| 101 |
+
>
|
| 102 |
+
> ```shell
|
| 103 |
+
> >which -a pip
|
| 104 |
+
> /home/<user>/.local/bin/pip
|
| 105 |
+
> /home/<user>/.conda/envs/newenv/bin/pip
|
| 106 |
+
> /usr/bin/pip
|
| 107 |
+
>
|
| 108 |
+
> >which -a python
|
| 109 |
+
> /home/<user>/.conda/envs/newenv/bin/python
|
| 110 |
+
> /usr/bin/python
|
| 111 |
+
> ```
|
| 112 |
+
>
|
| 113 |
+
> 2、然后,而不是直接调用 `pip install <package>`,你可以在 python 中使用模块标志 -m,以便它使用 anaconda python 进行安装
|
| 114 |
+
>
|
| 115 |
+
> ```shell
|
| 116 |
+
>python -m pip install <package>
|
| 117 |
+
> ```
|
| 118 |
+
>
|
| 119 |
+
> 3、这将把包安装到 anaconda 库目录,而不是与(非anaconda) pip 关联的库目录
|
| 120 |
+
>
|
| 121 |
+
> 4、这样做的原因如下:命令 pip 引用了一个特定的 pip 文件 / 快捷方式(which -a pip 会告诉你是哪一个)。类似地,命令 python 引用一个特定的 python 文件(which -a python 会告诉你是哪个)。由于这样或那样的原因,这两个命令可能���得不同步,因此你的“默认” pip 与你的默认 python 位于不同的文件夹中,因此与不同版本的 python 相关联。
|
| 122 |
+
>
|
| 123 |
+
> 5、与此相反,python -m pip 构造不使用 pip 命令指向的快捷方式。相反,它要求 python 找到它的pip 版本,并使用该版本安装一个包。
|
| 124 |
+
|
| 125 |
+
-
|
flagged/component 2/tmp1x130c0q.json
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
[[null, "<p>\u6b22\u8fce\u4f7f\u7528 \u5f20\u5e73\u7684\u4e13\u5c5e\u77e5\u8bc6\u5e93\uff01</p></p>\n<p>\u8bf7\u5728\u53f3\u4fa7\u5207\u6362\u6a21\u5f0f\uff0c\u76ee\u524d\u652f\u6301\u76f4\u63a5\u4e0e LLM \u6a21\u578b\u5bf9\u8bdd\u6216\u57fa\u4e8e\u672c\u5730\u77e5\u8bc6\u5e93\u95ee\u7b54\u3002\n\u77e5\u8bc6\u5e93\u95ee\u7b54\u6a21\u5f0f\uff0c\u9009\u62e9\u77e5\u8bc6\u5e93\u540d\u79f0\u540e\uff0c\u5373\u53ef\u5f00\u59cb\u95ee\u7b54\uff0c\u5982\u6709\u9700\u8981\u53ef\u4ee5\u4e0a\u4f20\u6587\u4ef6/\u6587\u4ef6\u5939\u81f3\u77e5\u8bc6\u5e93\u3002\n\u77e5\u8bc6\u5e93\u6682\u4e0d\u652f\u6301\u6587\u4ef6\u5220\u9664\u3002"], [null, "\u6a21\u578b\u5df2\u6210\u529f\u52a0\u8f7d\uff0c\u53ef\u4ee5\u5f00\u59cb\u5bf9\u8bdd\uff0c\u6216\u4ece\u53f3\u4fa7\u9009\u62e9\u6a21\u5f0f\u540e\u5f00\u59cb\u5bf9\u8bdd"], ["\u4f60\u597d\uff0c\u662f\u8c01\uff1f", "\u4f60\u597d\uff0c\u6211\u662f ChatGLM2-6B\uff0c\u662f\u6e05\u534e\u5927\u5b66KEG\u5b9e\u9a8c\u5ba4\u548c\u667a\u8c31AI\u516c\u53f8\u5171\u540c\u8bad\u7ec3\u7684\u8bed\u8a00\u6a21\u578b\u3002\u6211\u7684\u4efb\u52a1\u662f\u9488\u5bf9\u7528\u6237\u7684\u95ee\u9898\u548c\u8981\u6c42\u63d0\u4f9b\u9002\u5f53\u7684\u7b54\u590d\u548c\u652f\u6301\u3002\u7531\u4e8e\u6211\u662f\u4e00\u4e2a\u8ba1\u7b97\u673a\u7a0b\u5e8f\uff0c\u6240\u4ee5\u6211\u6ca1\u6709\u81ea\u6211\u610f\u8bc6\uff0c\u4e5f\u4e0d\u80fd\u50cf\u4eba\u7c7b\u4e00\u6837\u611f\u77e5\u4e16\u754c\u3002\u6211\u53ea\u80fd\u901a\u8fc7\u5206\u6790\u6211\u6240\u5b66\u5230\u7684\u4fe1\u606f\u6765\u56de\u7b54\u95ee\u9898\u3002"]]
|
flagged/log.csv
ADDED
|
@@ -0,0 +1,2 @@
|
|
|
|
|
|
|
|
|
|
| 1 |
+
component 0,component 1,component 2,请选择使用模式,flag,username,timestamp
|
| 2 |
+
你好,是谁?,C:\Users\Administrator\langchain-ChatGLM\knowledge_base\新建知识库\vector_store,C:\Users\Administrator\langchain-ChatGLM\flagged\component 2\tmp1x130c0q.json,LLM 对话,,cc50a8c8af9d4c2bb932c7c6155e41b4,2023-07-29 11:09:36.035363
|
img/docker_logs.png
ADDED

|
img/langchain+chatglm.png
ADDED

|
Git LFS Details
|
img/langchain+chatglm2.png
ADDED
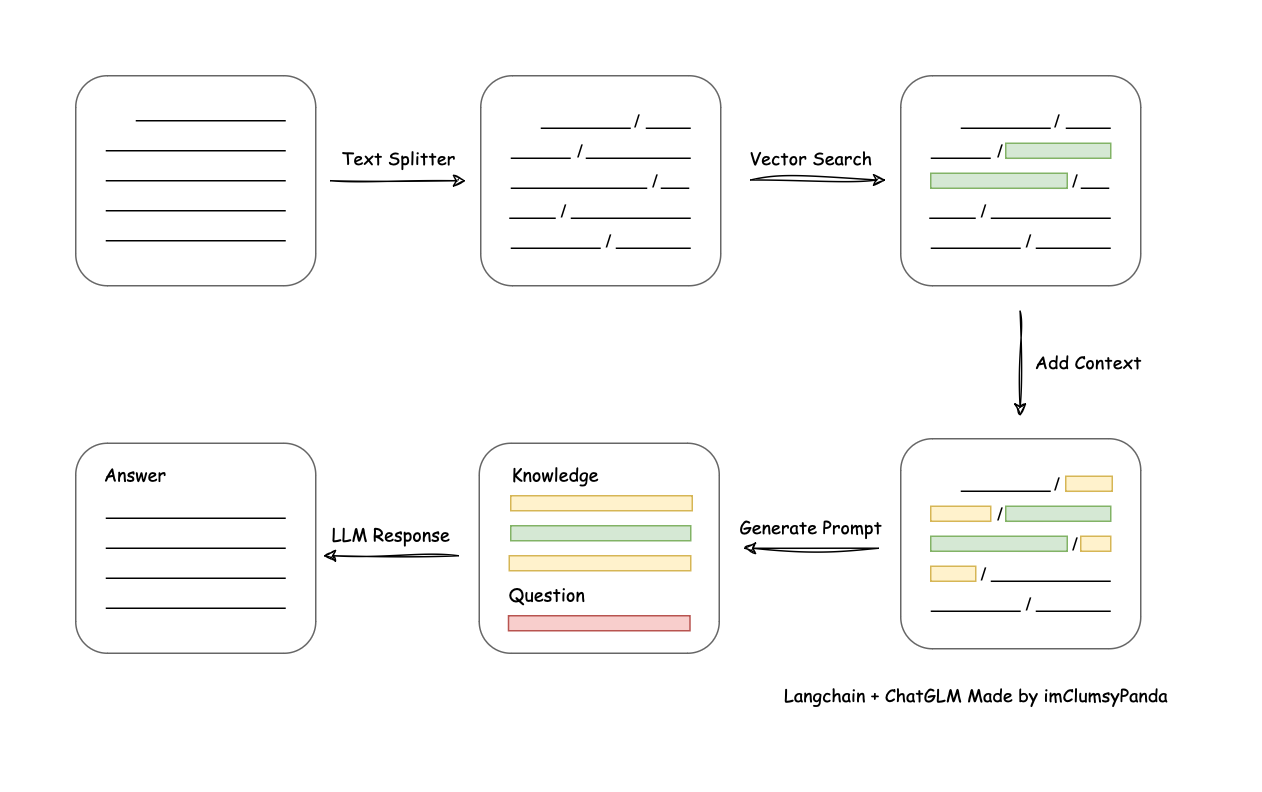
|
img/qr_code_43.jpg
ADDED

|
img/qr_code_44.jpg
ADDED

|
img/qr_code_45.jpg
ADDED

|
img/vue_0521_0.png
ADDED
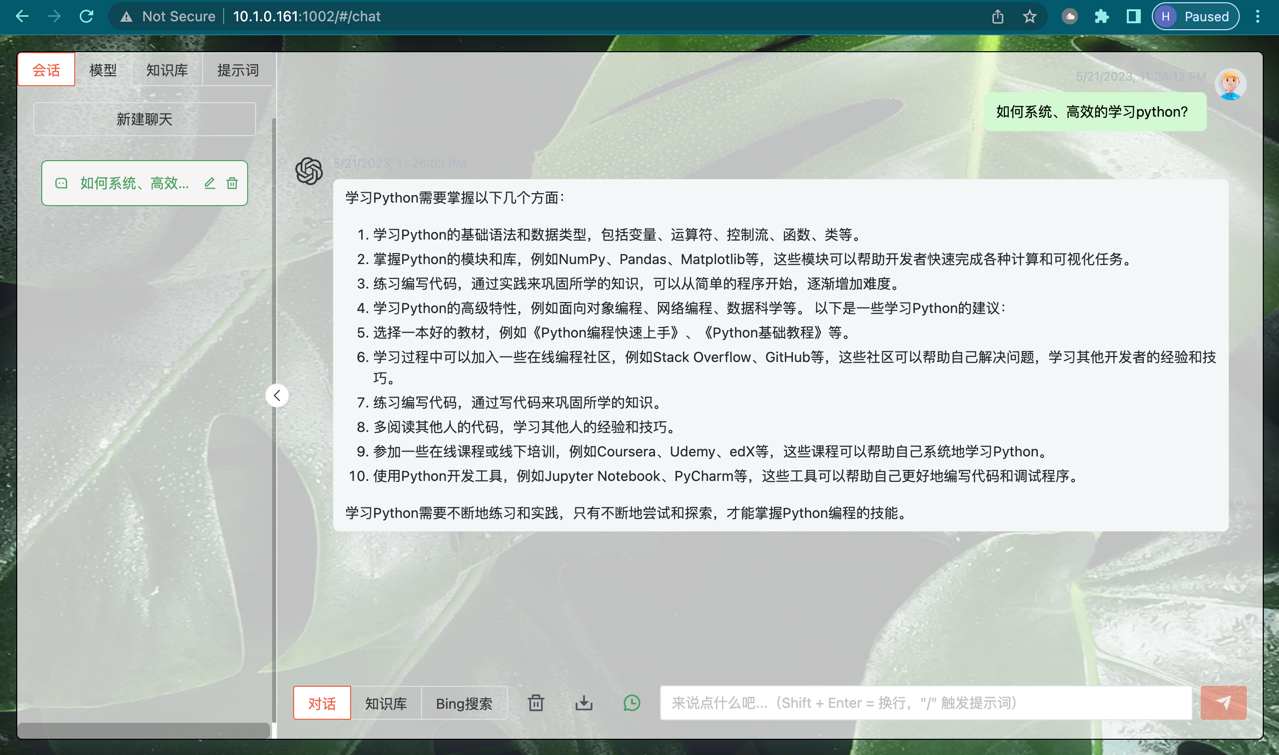
|
img/vue_0521_1.png
ADDED

|
Git LFS Details
|
img/vue_0521_2.png
ADDED

|
Git LFS Details
|
img/webui_0419.png
ADDED
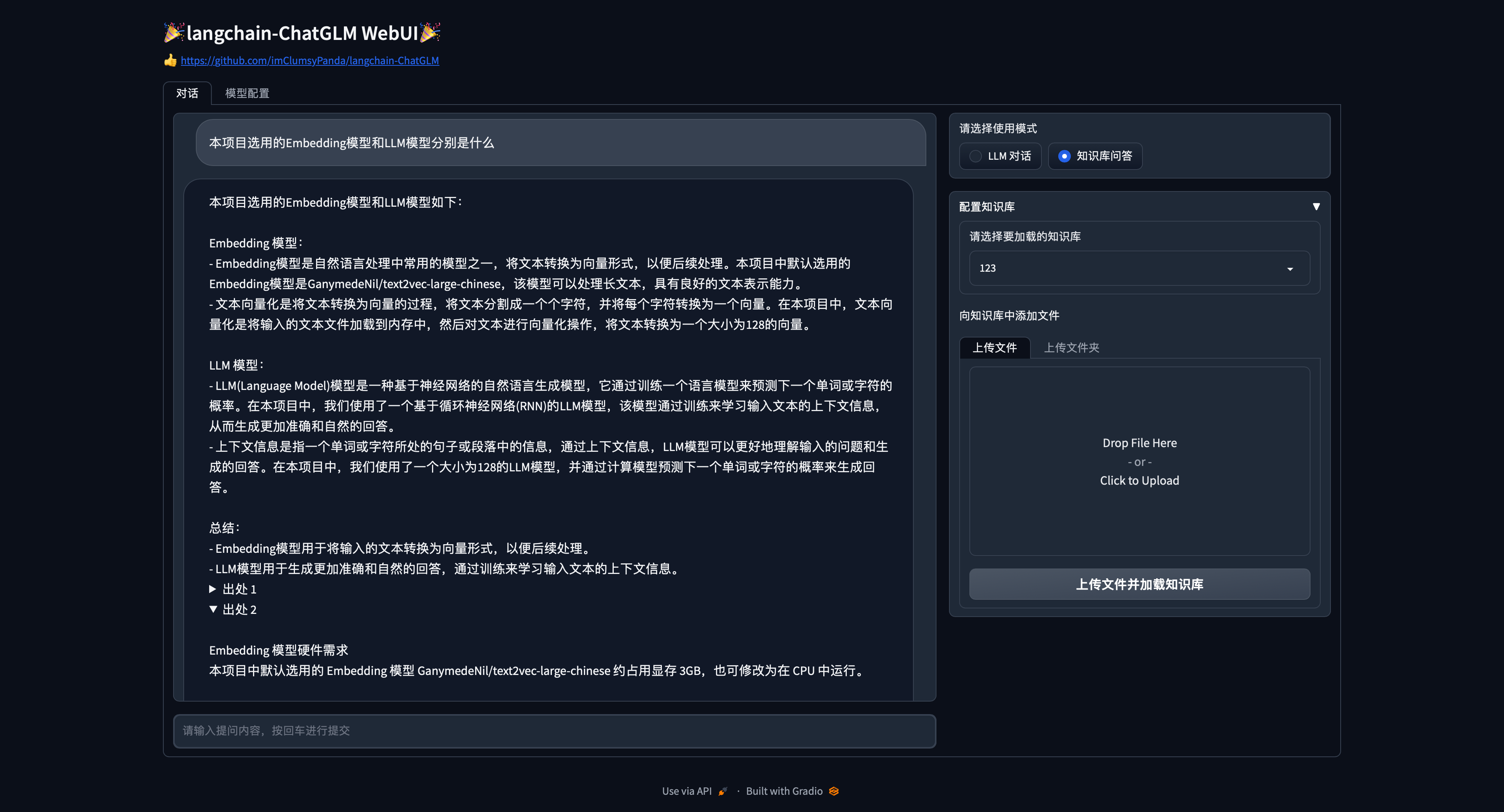
|
img/webui_0510_0.png
ADDED

|
img/webui_0510_1.png
ADDED
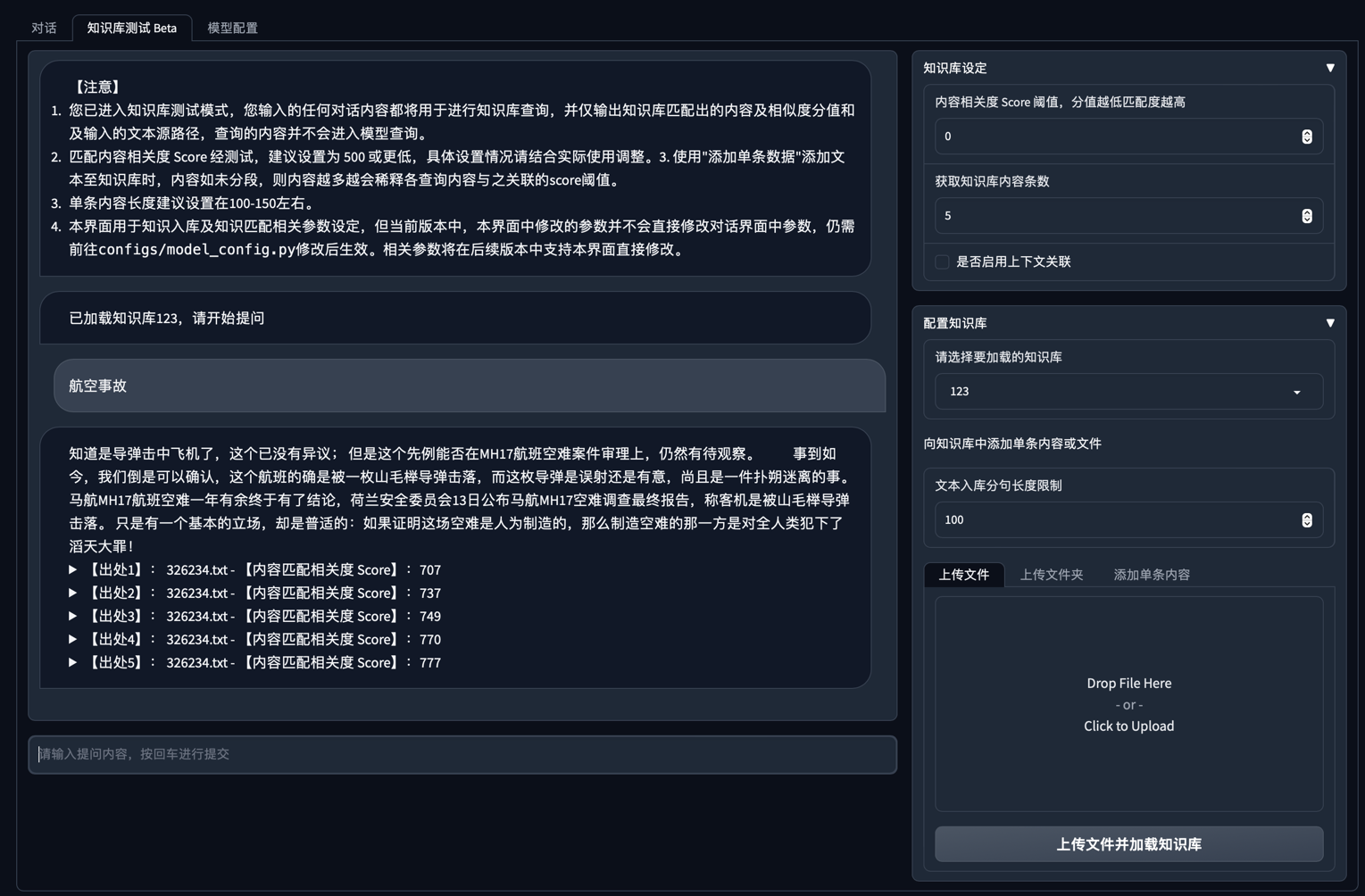
|
img/webui_0510_2.png
ADDED
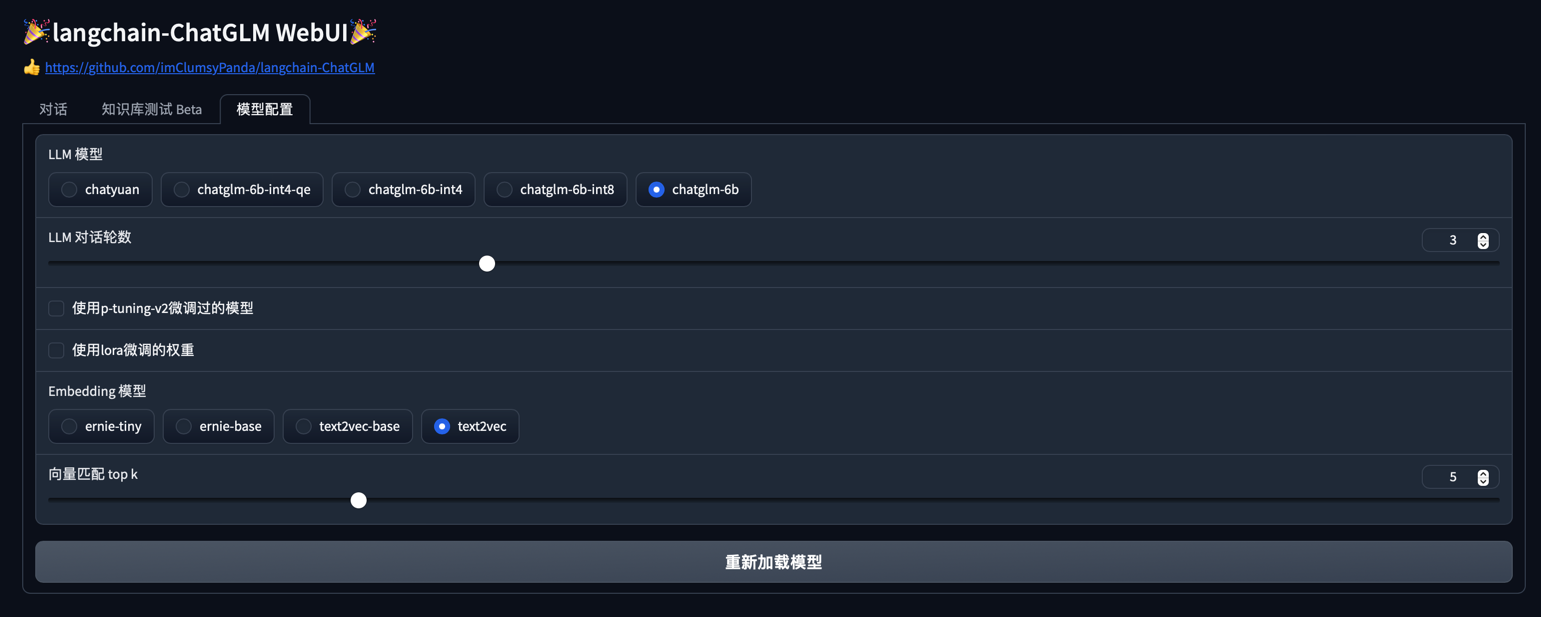
|
img/webui_0521_0.png
ADDED
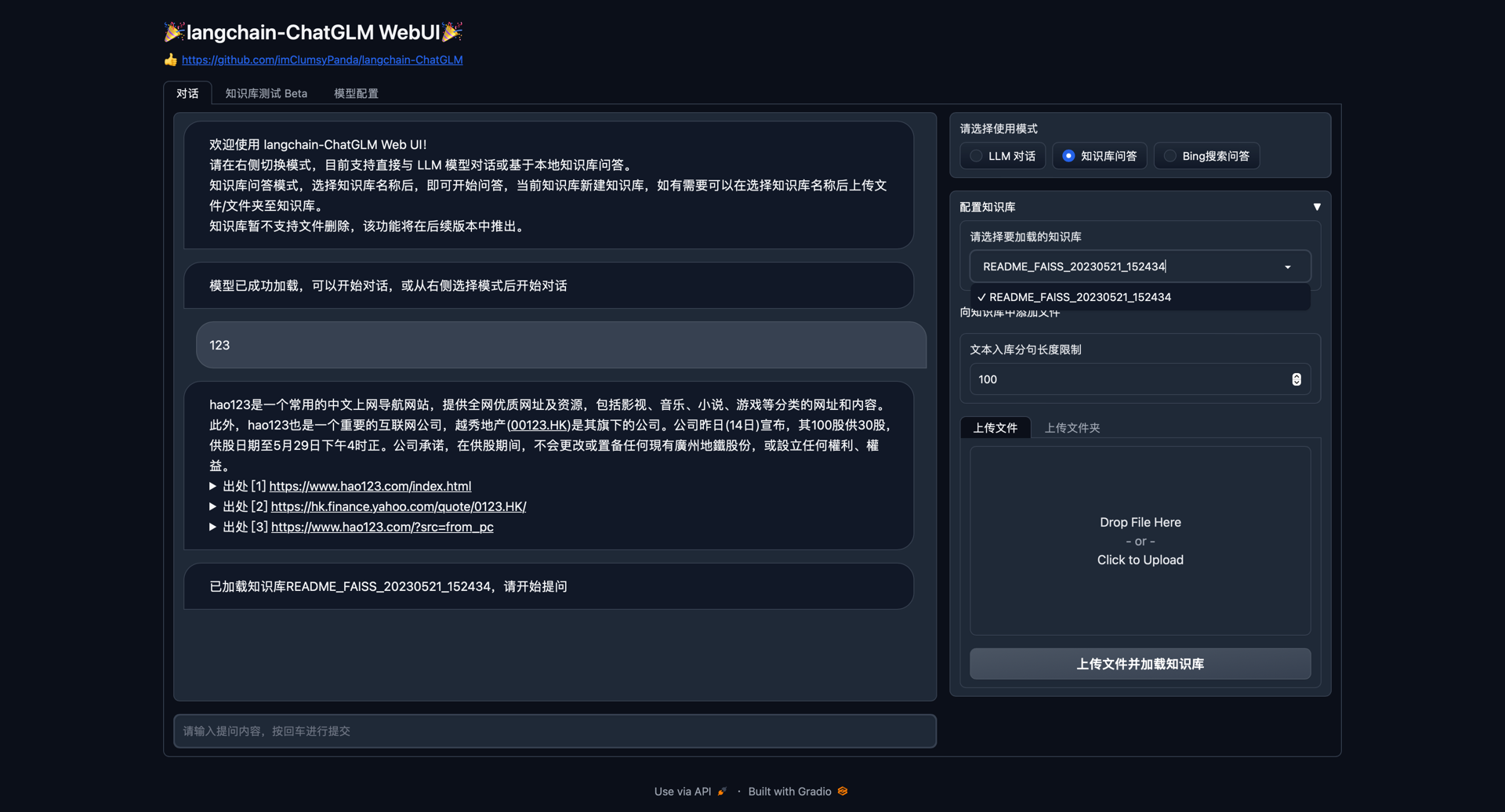
|
knowledge_base/samples/content/README.md
ADDED
|
@@ -0,0 +1,212 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# 基于本地知识的 ChatGLM 应用实现
|
| 2 |
+
|
| 3 |
+
## 介绍
|
| 4 |
+
|
| 5 |
+
🌍 [_READ THIS IN ENGLISH_](README_en.md)
|
| 6 |
+
|
| 7 |
+
🤖️ 一种利用 [ChatGLM-6B](https://github.com/THUDM/ChatGLM-6B) + [langchain](https://github.com/hwchase17/langchain) 实现的基于本地知识的 ChatGLM 应用。增加 [clue-ai/ChatYuan](https://github.com/clue-ai/ChatYuan) 项目的模型 [ClueAI/ChatYuan-large-v2](https://huggingface.co/ClueAI/ChatYuan-large-v2) 的支持。
|
| 8 |
+
|
| 9 |
+
💡 受 [GanymedeNil](https://github.com/GanymedeNil) 的项目 [document.ai](https://github.com/GanymedeNil/document.ai) 和 [AlexZhangji](https://github.com/AlexZhangji) 创建的 [ChatGLM-6B Pull Request](https://github.com/THUDM/ChatGLM-6B/pull/216) 启发,建立了全部基于开源模型实现的本地知识问答应用。
|
| 10 |
+
|
| 11 |
+
✅ 本项目中 Embedding 默认选用的是 [GanymedeNil/text2vec-large-chinese](https://huggingface.co/GanymedeNil/text2vec-large-chinese/tree/main),LLM 默认选用的是 [ChatGLM-6B](https://github.com/THUDM/ChatGLM-6B)。依托上述模型,本项目可实现全部使用**开源**模型**离线私有部署**。
|
| 12 |
+
|
| 13 |
+
⛓️ 本项目实现原理如下图所示,过程包括加载文件 -> 读取文本 -> 文本分割 -> 文本向量化 -> 问句向量化 -> 在文本向量中匹配出与问句向量最相似的`top k`个 -> 匹配出的文本作为上下文和问题一起添加到`prompt`中 -> 提交给`LLM`生成回答。
|
| 14 |
+
|
| 15 |
+

|
| 16 |
+
|
| 17 |
+
从文档处理角度来看,实现流程如下:
|
| 18 |
+
|
| 19 |
+

|
| 20 |
+
|
| 21 |
+
🚩 本项目未涉及微调、训练过程,但可利用微调或训练对本项目效果进行优化。
|
| 22 |
+
|
| 23 |
+
🌐 [AutoDL 镜像](https://www.codewithgpu.com/i/imClumsyPanda/langchain-ChatGLM/langchain-ChatGLM)
|
| 24 |
+
|
| 25 |
+
📓 [ModelWhale 在线运行项目](https://www.heywhale.com/mw/project/643977aa446c45f4592a1e59)
|
| 26 |
+
|
| 27 |
+
## 变更日志
|
| 28 |
+
|
| 29 |
+
参见 [变更日志](docs/CHANGELOG.md)。
|
| 30 |
+
|
| 31 |
+
## 硬件需求
|
| 32 |
+
|
| 33 |
+
- ChatGLM-6B 模型硬件需求
|
| 34 |
+
|
| 35 |
+
注:如未将模型下载至本地,请执行前检查`$HOME/.cache/huggingface/`文件夹剩余空间,模型文件下载至本地需要 15 GB 存储空间。
|
| 36 |
+
|
| 37 |
+
模型下载方法可参考 [常见问题](docs/FAQ.md) 中 Q8。
|
| 38 |
+
|
| 39 |
+
| **量化等级** | **最低 GPU 显存**(推理) | **最低 GPU 显存**(高效参数微调) |
|
| 40 |
+
| -------------- | ------------------------- | --------------------------------- |
|
| 41 |
+
| FP16(无量化) | 13 GB | 14 GB |
|
| 42 |
+
| INT8 | 8 GB | 9 GB |
|
| 43 |
+
| INT4 | 6 GB | 7 GB |
|
| 44 |
+
|
| 45 |
+
- MOSS 模型硬件需求
|
| 46 |
+
|
| 47 |
+
注:如未将模型下载至本地,请执行前检查`$HOME/.cache/huggingface/`文件夹剩余空间,模型文件下载至本地需要 70 GB 存储空间
|
| 48 |
+
|
| 49 |
+
模型下载方法可参考 [常见问题](docs/FAQ.md) 中 Q8。
|
| 50 |
+
|
| 51 |
+
| **量化等级** | **最低 GPU 显存**(推理) | **最低 GPU 显存**(高效参数微调) |
|
| 52 |
+
|-------------------|-----------------------| --------------------------------- |
|
| 53 |
+
| FP16(无量化) | 68 GB | - |
|
| 54 |
+
| INT8 | 20 GB | - |
|
| 55 |
+
|
| 56 |
+
- Embedding 模型硬件需求
|
| 57 |
+
|
| 58 |
+
本项目中默认选用的 Embedding 模型 [GanymedeNil/text2vec-large-chinese](https://huggingface.co/GanymedeNil/text2vec-large-chinese/tree/main) 约占用显存 3GB,也可修改为在 CPU 中运行。
|
| 59 |
+
|
| 60 |
+
## Docker 部署
|
| 61 |
+
为了能让容器使用主机GPU资源,需要在主机上安装 [NVIDIA Container Toolkit](https://github.com/NVIDIA/nvidia-container-toolkit)。具体安装步骤如下:
|
| 62 |
+
```shell
|
| 63 |
+
sudo apt-get update
|
| 64 |
+
sudo apt-get install -y nvidia-container-toolkit-base
|
| 65 |
+
sudo systemctl daemon-reload
|
| 66 |
+
sudo systemctl restart docker
|
| 67 |
+
```
|
| 68 |
+
安装完成后,可以使用以下命令编译镜像和启动容器:
|
| 69 |
+
```
|
| 70 |
+
docker build -f Dockerfile-cuda -t chatglm-cuda:latest .
|
| 71 |
+
docker run --gpus all -d --name chatglm -p 7860:7860 chatglm-cuda:latest
|
| 72 |
+
|
| 73 |
+
#若要使用离线模型,请配置好模型路径,然后此repo挂载到Container
|
| 74 |
+
docker run --gpus all -d --name chatglm -p 7860:7860 -v ~/github/langchain-ChatGLM:/chatGLM chatglm-cuda:latest
|
| 75 |
+
```
|
| 76 |
+
|
| 77 |
+
|
| 78 |
+
## 开发部署
|
| 79 |
+
|
| 80 |
+
### 软件需求
|
| 81 |
+
|
| 82 |
+
本项目已在 Python 3.8 - 3.10,CUDA 11.7 环境下完成测试。已在 Windows、ARM 架构的 macOS、Linux 系统中完成测试。
|
| 83 |
+
|
| 84 |
+
vue前端需要node18环境
|
| 85 |
+
### 从本地加载模型
|
| 86 |
+
|
| 87 |
+
请参考 [THUDM/ChatGLM-6B#从本地加载模型](https://github.com/THUDM/ChatGLM-6B#从本地加载模型)
|
| 88 |
+
|
| 89 |
+
### 1. 安装环境
|
| 90 |
+
|
| 91 |
+
参见 [安装指南](docs/INSTALL.md)。
|
| 92 |
+
|
| 93 |
+
### 2. 设置模型默认参数
|
| 94 |
+
|
| 95 |
+
在开始执行 Web UI 或命令行交互前,请先检查 [configs/model_config.py](configs/model_config.py) 中的各项模型参数设计是否符合需求。
|
| 96 |
+
|
| 97 |
+
### 3. 执行脚本体验 Web UI 或命令行交互
|
| 98 |
+
|
| 99 |
+
> 注:鉴于环境部署过程中可能遇到问题��建议首先测试命令行脚本。建议命令行脚本测试可正常运行后再运行 Web UI。
|
| 100 |
+
|
| 101 |
+
执行 [cli_demo.py](cli_demo.py) 脚本体验**命令行交互**:
|
| 102 |
+
```shell
|
| 103 |
+
$ python cli_demo.py
|
| 104 |
+
```
|
| 105 |
+
|
| 106 |
+
或执行 [webui.py](webui.py) 脚本体验 **Web 交互**
|
| 107 |
+
|
| 108 |
+
```shell
|
| 109 |
+
$ python webui.py
|
| 110 |
+
```
|
| 111 |
+
|
| 112 |
+
或执行 [api.py](api.py) 利用 fastapi 部署 API
|
| 113 |
+
```shell
|
| 114 |
+
$ python api.py
|
| 115 |
+
```
|
| 116 |
+
或成功部署 API 后,执行以下脚本体验基于 VUE 的前端页面
|
| 117 |
+
```shell
|
| 118 |
+
$ cd views
|
| 119 |
+
|
| 120 |
+
$ pnpm i
|
| 121 |
+
|
| 122 |
+
$ npm run dev
|
| 123 |
+
```
|
| 124 |
+
|
| 125 |
+
执行后效果如下图所示:
|
| 126 |
+
1. `对话` Tab 界面
|
| 127 |
+

|
| 128 |
+
2. `知识库测试 Beta` Tab 界面
|
| 129 |
+

|
| 130 |
+
3. `模型配置` Tab 界面
|
| 131 |
+

|
| 132 |
+
|
| 133 |
+
Web UI 可以实现如下功能:
|
| 134 |
+
|
| 135 |
+
1. 运行前自动读取`configs/model_config.py`中`LLM`及`Embedding`模型枚举及默认模型设置运行模型,如需重新加载模型,可在 `模型配置` Tab 重新选择后点击 `重新加载模型` 进行模型加载;
|
| 136 |
+
2. 可手动调节保留对话历史长度、匹配知识库文段数量,可根据显存大小自行调节;
|
| 137 |
+
3. `对话` Tab 具备模式选择功能,可选择 `LLM对话` 与 `知识库问答` 模式进行对话,支持流式对话;
|
| 138 |
+
4. 添加 `配置知识库` 功能,支持选择已有知识库或新建知识库,并可向知识库中**新增**上传文件/文件夹,使用文件上传组件选择好文件后点击 `上传文件并加载知识库`,会将所选上传文档数据加载至知识库中,并基于更新后知识库进行问答;
|
| 139 |
+
5. 新增 `知识库测试 Beta` Tab,可用于测试不同文本切分方法与检索相关度阈值设置,暂不支持将测试参数作为 `对话` Tab 设置参数。
|
| 140 |
+
6. 后续版本中将会增加对知识库的修改或删除,及知识库中已导入文件的查看。
|
| 141 |
+
|
| 142 |
+
### 常见问题
|
| 143 |
+
|
| 144 |
+
参见 [常见问题](docs/FAQ.md)。
|
| 145 |
+
|
| 146 |
+
## Demo
|
| 147 |
+
|
| 148 |
+
以问题`chatglm-6b 的局限性具体体现在哪里,如何实现改进`为例:
|
| 149 |
+
|
| 150 |
+
未使用 langchain 接入本地文档时:
|
| 151 |
+
|
| 152 |
+
>ChatGLM-6B 是一个基于 GPT-3 的聊天机器人,它的局限性主要体现在以下几个方面:
|
| 153 |
+
>1. 语言模型的精度:GPT-3 是一种大型的语言模型,它的精度比较高,但是仍然有一些局限性。例如,它可能无法准确地理解某些方言、口音或者复杂的句子结构。
|
| 154 |
+
>2. 知识图谱的完整性:GPT-3 可以生成一些知识图谱,但是其完整性和准确性可能不够。例如,它可能无法准确地理解某些领域的专业知识和术语。
|
| 155 |
+
>3. 对话生成的连贯性:GPT-3 可以生成一些连贯的对话,但是其生成的对话可能不够自然。例如,它可能会生成一些虚假的、不连贯的对话或者误解用户的意图。
|
| 156 |
+
>
|
| 157 |
+
>为了改进 ChatGLM-6B,可以考虑以下几个方面:
|
| 158 |
+
>1. 提高语言模型的精度:可以通过增加训练数据、使用更好的语言模型架构、优化模型训练过程等方式来提高语言模型的精度。
|
| 159 |
+
>2. 增强知识图谱的完整性:可以通过增加知识图谱的维度、使用更好的知识图谱构建方法、优化知识图谱的匹配算法等方式来增强知识图谱的完整性。
|
| 160 |
+
>3. 提高对话生成的连贯性:可以通过增加对话生成模型的上下文信息、使用更好的上下文信息提取方法、优化对话生成模型的算法等方式来提高对话生成的连贯性。
|
| 161 |
+
>4. 引入更多的人类反馈:人类反馈可以帮助 ChatGLM-6B 更好地理解用户的意图和需求,从而提高对话生成的质量和准确性。可以通过引入更多的人类客服、使用人类反馈收集器等方式来引入更多的人类反馈。
|
| 162 |
+
|
| 163 |
+
使用 langchain 接入 ChatGLM-6B 项目的 README.md 文件后 ChatGLM 的回答:
|
| 164 |
+
>ChatGLM-6B 是一个基于深度学习的自然语言处理模型,它在回答问题方面表现出色。但是,它也有一些局限性,具体如下:
|
| 165 |
+
>1. 语言理解有限:ChatGLM-6B 只学习了中文自然语言,对于其他语言可能会存在理解上的局限性。
|
| 166 |
+
>2. 知识储备不足:ChatGLM-6B 的训练数据集只包含了中文语料,因此它可能无法回答一些非中文的问题或者某些特定领域的问题。
|
| 167 |
+
>3. 数据量有限:ChatGLM-6B 的训练数据集只有几百万条记录,因此它可能无法回答一些非常具体或者复杂的问题。
|
| 168 |
+
>
|
| 169 |
+
>为了改进 ChatGLM-6B,可以考虑以下几个方面:
|
| 170 |
+
>1. 学习更多的语言知识:可以学习其他语言的自然语言处理技术,扩大语言理解的范围。
|
| 171 |
+
>2. 扩大知识储备:可以收集更多的中文语料,或者使用其他语言的数据集来扩充知识储备。
|
| 172 |
+
>3. 增加数据量:可以使用更大的数据集来训练 ChatGLM-6B,提高模型的表现。
|
| 173 |
+
>4. 引入更多的评估指标:可以引入更多的评估指标来评估模型的表现,从而发现 ChatGLM-6B 存在的不足和局限性。
|
| 174 |
+
>5. 改进模型架构:可以改进 ChatGLM-6B 的模型架构,提高模型的性能和表现。例如,可以使用更大的神经网络或者改进的卷积神经网络结构。
|
| 175 |
+
|
| 176 |
+
## 路线图
|
| 177 |
+
|
| 178 |
+
- [ ] Langchain 应用
|
| 179 |
+
- [x] 接入非结构化文档(已支持 md、pdf、docx、txt 文件格式)
|
| 180 |
+
- [ ] 搜索引擎与本地网页接入
|
| 181 |
+
- [ ] 结构化数据接入(如 csv、Excel、SQL 等)
|
| 182 |
+
- [ ] 知识图谱/图数据库接入
|
| 183 |
+
- [ ] Agent 实现
|
| 184 |
+
- [ ] 增加更多 LLM 模型支持
|
| 185 |
+
- [x] [THUDM/chatglm-6b](https://huggingface.co/THUDM/chatglm-6b)
|
| 186 |
+
- [x] [THUDM/chatglm-6b-int8](https://huggingface.co/THUDM/chatglm-6b-int8)
|
| 187 |
+
- [x] [THUDM/chatglm-6b-int4](https://huggingface.co/THUDM/chatglm-6b-int4)
|
| 188 |
+
- [x] [THUDM/chatglm-6b-int4-qe](https://huggingface.co/THUDM/chatglm-6b-int4-qe)
|
| 189 |
+
- [x] [ClueAI/ChatYuan-large-v2](https://huggingface.co/ClueAI/ChatYuan-large-v2)
|
| 190 |
+
- [x] [fnlp/moss-moon-003-sft](https://huggingface.co/fnlp/moss-moon-003-sft)
|
| 191 |
+
- [ ] 增加更多 Embedding 模型支持
|
| 192 |
+
- [x] [nghuyong/ernie-3.0-nano-zh](https://huggingface.co/nghuyong/ernie-3.0-nano-zh)
|
| 193 |
+
- [x] [nghuyong/ernie-3.0-base-zh](https://huggingface.co/nghuyong/ernie-3.0-base-zh)
|
| 194 |
+
- [x] [shibing624/text2vec-base-chinese](https://huggingface.co/shibing624/text2vec-base-chinese)
|
| 195 |
+
- [x] [GanymedeNil/text2vec-large-chinese](https://huggingface.co/GanymedeNil/text2vec-large-chinese)
|
| 196 |
+
- [ ] Web UI
|
| 197 |
+
- [x] 利用 gradio 实现 Web UI DEMO
|
| 198 |
+
- [x] 添加输出内容及错误提示
|
| 199 |
+
- [x] 引用标注
|
| 200 |
+
- [ ] 增加知识库管理
|
| 201 |
+
- [x] 选择知识库开始问答
|
| 202 |
+
- [x] 上传文件/文件夹至知识库
|
| 203 |
+
- [ ] 删除知识库中文件
|
| 204 |
+
- [ ] 利用 streamlit 实现 Web UI Demo
|
| 205 |
+
- [ ] 增加 API 支持
|
| 206 |
+
- [x] 利用 fastapi 实现 API 部署方式
|
| 207 |
+
- [ ] 实现调用 API 的 Web UI Demo
|
| 208 |
+
|
| 209 |
+
## 项目交流群
|
| 210 |
+

|
| 211 |
+
|
| 212 |
+
🎉 langchain-ChatGLM 项目交流群,如果你也对本项目感兴趣,欢迎加入群聊参与讨论交流。
|
knowledge_base/samples/content/test.jpg
ADDED

|
knowledge_base/samples/content/test.pdf
ADDED
|
Binary file (25.8 kB). View file
|
|
|
knowledge_base/samples/content/test.txt
ADDED
|
@@ -0,0 +1,835 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
ChatGPT是OpenAI开发的一个大型语言模型,可以提供各种主题的信息,
|
| 2 |
+
|
| 3 |
+
# 如何向 ChatGPT 提问以获得高质量答案:提示技巧工程完全指南
|
| 4 |
+
|
| 5 |
+
## 介绍
|
| 6 |
+
|
| 7 |
+
我很高兴欢迎您阅读我的最新书籍《The Art of Asking ChatGPT for High-Quality Answers: A complete Guide to Prompt Engineering Techniques》。本书是一本全面指南,介绍了各种提示技术,用于从ChatGPT中生成高质量的答案。
|
| 8 |
+
|
| 9 |
+
我们将探讨如何使用不同的提示工程技术来实现不同的目标。ChatGPT是一款最先进的语言模型,能够生成类似人类的文本。然而,理解如何正确地向ChatGPT提问以获得我们所需的高质量输出非常重要。而这正是本书的目的。
|
| 10 |
+
|
| 11 |
+
无论您是普通人、研究人员、开发人员,还是只是想在自己的领域中将ChatGPT作为个人助手的人,本书都是为您编写的。我使用简单易懂的语言,提供实用的解释,并在每个提示技术中提供了示例和提示公式。通过本书,您将学习如何使用提示工程技术来控制ChatGPT的输出,并生成符合您特定需求的文本。
|
| 12 |
+
|
| 13 |
+
在整本书中,我们还提供了如何结合不同的提示技术以实现更具体结果的示例。我希望您能像我写作时一样,享受阅读本书并从中获得知识。
|
| 14 |
+
|
| 15 |
+
<div style="page-break-after:always;"></div>
|
| 16 |
+
|
| 17 |
+
## 第一章:Prompt 工程技术简介
|
| 18 |
+
|
| 19 |
+
什么是 Prompt 工程?
|
| 20 |
+
|
| 21 |
+
Prompt 工程是创建提示或指导像 ChatGPT 这样的语言模型输出的过程。它允许用户控制模型的输出并生成符合其特定需求的文本。
|
| 22 |
+
|
| 23 |
+
ChatGPT 是一种先进的语言模型,能够生成类似于人类的文本。它建立在 Transformer 架构上,可以处理大量数据并生成高质量的文本。
|
| 24 |
+
|
| 25 |
+
然而,为了从 ChatGPT 中获得最佳结果,重要的是要了解如何正确地提示模型。 提示可以让用户控制模型的输出并生成相关、准确和高质量的文本。 在使用 ChatGPT 时,了解它的能力和限制非常重要。
|
| 26 |
+
|
| 27 |
+
该模型能够生成类似于人类的文本,但如果没有适当的指导,它可能无法始终产生期望的输出。
|
| 28 |
+
|
| 29 |
+
这就是 Prompt 工程的作用,通过提供清晰而具体的指令,您可以引导模型的输出并确保其相关。
|
| 30 |
+
|
| 31 |
+
**Prompt 公式是提示的特定格式,通常由三个主要元素组成:**
|
| 32 |
+
|
| 33 |
+
- 任务:对提示要求模型生成的内容进行清晰而简洁的陈述。
|
| 34 |
+
|
| 35 |
+
- 指令:在生成文本时模型应遵循的指令。
|
| 36 |
+
|
| 37 |
+
- 角色:模型在生成文本时应扮演的角色。
|
| 38 |
+
|
| 39 |
+
在本书中,我们将探讨可用于 ChatGPT 的各种 Prompt 工程技术。我们将讨论不同类型的提示,以及如何使用它们实现您想要的特定目标。
|
| 40 |
+
|
| 41 |
+
<div style="page-break-after:always;"></div>
|
| 42 |
+
|
| 43 |
+
## 第二章:指令提示技术
|
| 44 |
+
|
| 45 |
+
现在,让我们开始探索“指令提示技术”,以及如何使用它从ChatGPT中生成高质量的文本。
|
| 46 |
+
|
| 47 |
+
指令提示技术是通过为模型提供具体指令来引导ChatGPT的输出的一种方法。这种技术对于确保输出相关和高质量非常有用。
|
| 48 |
+
|
| 49 |
+
要使用指令提示技术,您需要为模型提供清晰简洁的任务,以及具体的指令以供模型遵循。
|
| 50 |
+
|
| 51 |
+
例如,如果您正在生成客户服务响应,您将提供任务,例如“生成响应客户查询”的指令,例如“响应应该专业且提供准确的信息”。
|
| 52 |
+
|
| 53 |
+
提示公式:“按照以下指示生成[任务]:[指令]”
|
| 54 |
+
|
| 55 |
+
示例:
|
| 56 |
+
|
| 57 |
+
**生成客户服务响应:**
|
| 58 |
+
|
| 59 |
+
- 任务:生成响应客户查询
|
| 60 |
+
- 指令:响应应该专业且提供准确的信息
|
| 61 |
+
- 提示公式:“按照以下指示生成专业且准确的客户查询响应:响应应该专业且提供准确的信息。”
|
| 62 |
+
|
| 63 |
+
**生成法律文件:**
|
| 64 |
+
|
| 65 |
+
- 任务:生成法律文件
|
| 66 |
+
- 指令:文件应符合相关法律法规
|
| 67 |
+
- 提示公式:“按照以下指示生成符合相关法律法规的法律文件:文件应符合相关法律法规。”
|
| 68 |
+
|
| 69 |
+
使用指令提示技术时,重要的是要记住指令应该清晰具体。这将有助于确保输出相关和高质量。可以将指令提示技术与下一章节中解释的“角色提示”和“种子词提示”相结合,以增强ChatGPT的输出。
|
| 70 |
+
|
| 71 |
+
<div style="page-break-after:always;"></div>
|
| 72 |
+
|
| 73 |
+
## 第三章:角色提示
|
| 74 |
+
|
| 75 |
+
角色提示技术是通过为ChatGPT指定一个特定的角色来引导其输出的一种方式。这种技术对于生成针对特定上下文或受众的文本非常有用。
|
| 76 |
+
|
| 77 |
+
要使用角色提示技术,您需要为模型提供一个清晰具体的角色。
|
| 78 |
+
|
| 79 |
+
例如,如果您正在生成客户服务回复,您可以提供一个角色,如“客户服务代表”。
|
| 80 |
+
|
| 81 |
+
提示公式:“作为[角色]生成[任务]”
|
| 82 |
+
|
| 83 |
+
示例:
|
| 84 |
+
|
| 85 |
+
**生成客户服务回复:**
|
| 86 |
+
|
| 87 |
+
- 任务:生成对客户查询的回复
|
| 88 |
+
- 角色:客户服务代表
|
| 89 |
+
- 提示公式:“作为客户服务代表,生成对客户查询的回复。”
|
| 90 |
+
|
| 91 |
+
**生成法律文件:**
|
| 92 |
+
|
| 93 |
+
- 任务:生成法律文件
|
| 94 |
+
- 角色:律师
|
| 95 |
+
- 提示公式:“作为律师,生成法律文件。”
|
| 96 |
+
|
| 97 |
+
将角色提示技术与指令提示和种子词提示结合使用可以增强ChatGPT的输出。
|
| 98 |
+
|
| 99 |
+
**下面是一个示例,展示了如何将指令提示、角色提示和种子词提示技术结合使用:**
|
| 100 |
+
|
| 101 |
+
- 任务:为新智能手机生成产品描述
|
| 102 |
+
- 指令:描述应该是有信息量的,具有说服力,并突出智能手机的独特功能
|
| 103 |
+
- 角色:市场代表 种子词:“创新的”
|
| 104 |
+
- 提示公式:“作为市场代表,生成一个有信息量的、有说服力的产品描述,突出新智能手机的创新功能。该智能手机具有以下功能[插入您的功能]”
|
| 105 |
+
|
| 106 |
+
在这个示例中,指令提示用于确保产品描述具有信息量和说服力。角色提示用于确保描述是从市场代表的角度书写的。而种子词提示则用于确保描述侧重于智能手机的创新功能。
|
| 107 |
+
|
| 108 |
+
<div style="page-break-after:always;"></div>
|
| 109 |
+
|
| 110 |
+
## 第四章:标准提示
|
| 111 |
+
|
| 112 |
+
标准提示是一种简单的方法,通过为模型提供一个特定的任务来引导ChatGPT的输出。例如,如果您想生成一篇新闻文章的摘要,您可以提供一个任务,如“总结这篇新闻文章”。
|
| 113 |
+
|
| 114 |
+
提示公式:“生成一个[任务]”
|
| 115 |
+
|
| 116 |
+
例如:
|
| 117 |
+
|
| 118 |
+
**生成新闻文章的摘要:**
|
| 119 |
+
|
| 120 |
+
- 任务:总结这篇新闻文章
|
| 121 |
+
- 提示公式:“生成这篇新闻文章的摘要”
|
| 122 |
+
|
| 123 |
+
**生成一篇产品评论:**
|
| 124 |
+
|
| 125 |
+
- 任务:为一款新智能手机撰写评论
|
| 126 |
+
- 提示公式:“生成这款新智能手机的评论”
|
| 127 |
+
|
| 128 |
+
此外,标准提示可以与其他技术(如角色提示和种子词提示)结合使用,以增强ChatGPT的输出。
|
| 129 |
+
|
| 130 |
+
**以下是如何将标准提示、角色提示和种子词提示技术结合使用的示例:**
|
| 131 |
+
|
| 132 |
+
- 任务:为一台新笔记本电脑撰写产品评论
|
| 133 |
+
- 说明:评论应客观、信息丰富,强调笔记本电脑的独特特点
|
| 134 |
+
- 角色:技术专家
|
| 135 |
+
- 种子词:“强大的”
|
| 136 |
+
- 提示公式:“作为一名技术专家,生成一个客观而且信息丰富的产品评论,强调新笔记本电脑的强大特点。”
|
| 137 |
+
|
| 138 |
+
在这个示例中,标准提示技术用于确保模型生成产品评论。角色提示用于确保评论是从技术专家的角度写的。而种子词提示用于确保评论侧重于笔记本电脑的强大特点。
|
| 139 |
+
|
| 140 |
+
<div style="page-break-after:always;"></div>
|
| 141 |
+
|
| 142 |
+
## 第五章:零、一和少样本提示
|
| 143 |
+
|
| 144 |
+
零样本、一样本和少样本提示是用于从ChatGPT生成文本的技术,最少或没有任何示例。当特定任务的数据有限或任务是新的且未定义时,这些技术非常有用。
|
| 145 |
+
|
| 146 |
+
当任务没有可用的示例时,使用零样本提示技术。模型提供一个通用任务,根据对任务的理解生成文本。
|
| 147 |
+
|
| 148 |
+
当任务只有一个示例可用时,使用一样本提示技术。模型提供示例,并根据对示例的理解生成文本。
|
| 149 |
+
|
| 150 |
+
当任务只有有限数量的示例可用时,使用少样本提示技术。模型提供示例,并根据对示例的理解生成文本。
|
| 151 |
+
|
| 152 |
+
提示公式:“基于[数量]个示例生成文本”
|
| 153 |
+
|
| 154 |
+
例如:
|
| 155 |
+
|
| 156 |
+
**为没有可用示例的新产品编写产品描述:**
|
| 157 |
+
|
| 158 |
+
- 任务:为新的智能手表编写产品描述
|
| 159 |
+
|
| 160 |
+
- 提示公式:“基于零个示例为这款新智能手表生成产品描述”
|
| 161 |
+
|
| 162 |
+
**使用一个示例生成产品比较:**
|
| 163 |
+
|
| 164 |
+
- 任务:将新款智能手机与最新的iPhone进行比较
|
| 165 |
+
|
| 166 |
+
- 提示公式:“使用一个示例(最新的iPhone)为这款新智能手机生成产品比较”
|
| 167 |
+
|
| 168 |
+
**使用少量示例生成产品评论:**
|
| 169 |
+
|
| 170 |
+
- 任务:为新的电子阅读器撰写评论
|
| 171 |
+
|
| 172 |
+
- 提示公式:“使用少量示例(3个其他电子阅读器)为这款新电子阅读器生成评论”
|
| 173 |
+
|
| 174 |
+
|
| 175 |
+
这些技术可用于根据模型对任务或提供的示例的理解生成文本。
|
| 176 |
+
|
| 177 |
+
<div style="page-break-after:always;"></div>
|
| 178 |
+
|
| 179 |
+
## 第六章:“让我们思考一下”提示
|
| 180 |
+
|
| 181 |
+
“让我们思考一下”提示是一种技巧,可鼓励ChatGPT生成反思和思考性的文本。这种技术适用于撰写论文、诗歌或创意写作等任务。
|
| 182 |
+
|
| 183 |
+
“让我们思考一下”提示的公式非常简单,即“让我们思考一下”后跟一个主题或问题。
|
| 184 |
+
|
| 185 |
+
例如:
|
| 186 |
+
|
| 187 |
+
**生成一篇反思性论文:**
|
| 188 |
+
|
| 189 |
+
- 任务:就个人成长主题写一篇反思性论文
|
| 190 |
+
|
| 191 |
+
- 提示公式:“让我们思考一下:个人成长”
|
| 192 |
+
|
| 193 |
+
**生成一首诗:**
|
| 194 |
+
|
| 195 |
+
- 任务:写一首关于季节变化的诗
|
| 196 |
+
|
| 197 |
+
- 提示公式:“让我们思考一下:季节变化”
|
| 198 |
+
|
| 199 |
+
|
| 200 |
+
这个提示要求对特定主题或想法展开对话或讨论。发言者邀请ChatGPT参与讨论相关主题。
|
| 201 |
+
|
| 202 |
+
模型提供了一个提示,作为对话或文本生成的起点。
|
| 203 |
+
|
| 204 |
+
然后,模型使用其训练数据和算法生成与提示相关的响应。这种技术允许ChatGPT根据提供的提示生成上下文适当且连贯的文本。
|
| 205 |
+
|
| 206 |
+
**要使用“让我们思考一下提示”技术与ChatGPT,您可以遵循以下步骤:**
|
| 207 |
+
|
| 208 |
+
1. 确定您要讨论的主题或想法。
|
| 209 |
+
|
| 210 |
+
2. 制定一个明确表达主题或想法的提示,并开始对话或文本生成。
|
| 211 |
+
|
| 212 |
+
3. 用“让我们思考”或“让我们讨论”开头的提示,表明您正在启动对话或讨论。
|
| 213 |
+
|
| 214 |
+
**以下是使用此技术的一些提示示例:**
|
| 215 |
+
|
| 216 |
+
- 提示:“让我们思考气候变化对农业的影响”
|
| 217 |
+
|
| 218 |
+
- 提示:“让我们讨论人工智能的当前状态”
|
| 219 |
+
|
| 220 |
+
- 提示:“让我们谈谈远程工作的好处和缺点” 您还可以添加开放式问题、陈述或一段您希望模型继续或扩展的文本。
|
| 221 |
+
|
| 222 |
+
|
| 223 |
+
提供提示后,模型将使用其训练数据和算法生成与提示相关的响应,并以连贯的方式继续对话。
|
| 224 |
+
|
| 225 |
+
这种独特的提示有助于ChatGPT以不同的视角和角度给出答案,从而产生更具动态性和信息性的段落。
|
| 226 |
+
|
| 227 |
+
使用提示的步骤简单易行,可以真正提高您的写作水平。尝试一下,看看效果如何吧。
|
| 228 |
+
|
| 229 |
+
<div style="page-break-after:always;"></div>
|
| 230 |
+
|
| 231 |
+
## 第七章:自洽提示
|
| 232 |
+
|
| 233 |
+
自洽提示是一种技术,用于确保ChatGPT的输出与提供的输入一致。这种技术对于事实核查、数据验证或文本生成中的一致性检查等任务非常有用。
|
| 234 |
+
|
| 235 |
+
自洽提示的提示公式是输入文本后跟着指令“请确保以下文本是自洽的”。
|
| 236 |
+
|
| 237 |
+
或者,可以提示模型生成与提供的输入一致的文本。
|
| 238 |
+
|
| 239 |
+
提示示例及其公式:
|
| 240 |
+
|
| 241 |
+
**示例1:文本生成**
|
| 242 |
+
|
| 243 |
+
- 任务:生成产品评论
|
| 244 |
+
|
| 245 |
+
- 指令:评论应与输入中提供的产品信息一致
|
| 246 |
+
|
| 247 |
+
- 提示公式:“生成与以下产品信息一致的产品评论[插入产品信息]”
|
| 248 |
+
|
| 249 |
+
**示例2:文本摘要**
|
| 250 |
+
|
| 251 |
+
- 任务:概括一篇新闻文章
|
| 252 |
+
|
| 253 |
+
- 指令:摘要应与文章中提供的信息一致
|
| 254 |
+
|
| 255 |
+
- 提示公式:“用与提供的信息一致的方式概括以下新闻文章[插入新闻文章]”
|
| 256 |
+
|
| 257 |
+
**示例3:文本完成**
|
| 258 |
+
|
| 259 |
+
- 任务:完成一个句子
|
| 260 |
+
|
| 261 |
+
- 指令:完成应与输入中提供的上下文一致
|
| 262 |
+
|
| 263 |
+
- 提示公式:“以与提供的上下文一致的方式完成以下句子[插入句子]”
|
| 264 |
+
|
| 265 |
+
**示例4:**
|
| 266 |
+
|
| 267 |
+
1. **事实核查:**
|
| 268 |
+
|
| 269 |
+
任务:检查给定新闻文章的一致性
|
| 270 |
+
|
| 271 |
+
输入文本:“文章中陈述该城市的人口为500万,但后来又说该城市的人口为700万。”
|
| 272 |
+
|
| 273 |
+
提示公式:“请确保以下文本是自洽的:文章中陈述该城市的人口为500万,但后来又说该城市的人口为700万。”
|
| 274 |
+
|
| 275 |
+
2. **数据验证:**
|
| 276 |
+
|
| 277 |
+
任务:检查给定数据集的一致性
|
| 278 |
+
|
| 279 |
+
输入文本:“数据显示7月份的平均温度为30度,但最低温度记录为20度。”
|
| 280 |
+
|
| 281 |
+
提示公式:“请确保以下文本是自洽的:数据显示7月份的平均温度为30度,但最低温度记录为20度。”
|
| 282 |
+
|
| 283 |
+
<div style="page-break-after:always;"></div>
|
| 284 |
+
|
| 285 |
+
## 第八章:种子词提示
|
| 286 |
+
|
| 287 |
+
种子词提示是一种通过提供特定的种子词或短语来控制ChatGPT输出的技术。种子词提示的提示公式是种子词或短语,后跟指令“请根据以下种子词生成文本”。
|
| 288 |
+
|
| 289 |
+
示例:
|
| 290 |
+
|
| 291 |
+
**文本生成:**
|
| 292 |
+
|
| 293 |
+
- 任务:编写一篇有关龙的故事
|
| 294 |
+
- 种子词:“龙”
|
| 295 |
+
- 提示公式:“请根据以下种子词生成文本:龙”
|
| 296 |
+
|
| 297 |
+
**语言翻译:**
|
| 298 |
+
|
| 299 |
+
- 任务:将一句话从英语翻译成西班牙语
|
| 300 |
+
- 种子词:“你好”
|
| 301 |
+
- 提示公式:“请根据以下种子词生成文本:你好”
|
| 302 |
+
|
| 303 |
+
这种技术允许模型生成与种子词相关的文本并对其进行扩展。这是一种控制模型生成文本与某个特定主题或背景相关的方式。
|
| 304 |
+
|
| 305 |
+
种子词提示可以与角色提示和指令提示相结合,以创建更具体和有针对性的生成文本。通过提供种子词或短语,模型可以生成与该种子词或短语相关的文本,并通过提供有关期望输出和角色的信息,模型可以以特定于角色或指令的风格或语气生成文本。这样可以更好地控制生成的文本,并可用于各种应用程序。
|
| 306 |
+
|
| 307 |
+
以下是提示示例及其公式:
|
| 308 |
+
|
| 309 |
+
**示例1:文本生成**
|
| 310 |
+
|
| 311 |
+
- 任务:编写一首诗
|
| 312 |
+
- 指令:诗应与种子词“爱”相关,并以十四行诗的形式书写。
|
| 313 |
+
- 角色:诗人
|
| 314 |
+
- 提示公式:“作为诗人,根据以下种子词生成与“爱”相关的十四行诗:”
|
| 315 |
+
|
| 316 |
+
**示例2:文本完成**
|
| 317 |
+
|
| 318 |
+
- 任务:完成一句话
|
| 319 |
+
- 指令:完成应与种子词“科学”相关,并以研究论文的形式书写。
|
| 320 |
+
- 角色:研究员
|
| 321 |
+
- 提示公式:“作为研究员,请在与种子词“科学”相关且以研究论文的形式书写的情况下完成以下句子:[插入句子]”
|
| 322 |
+
|
| 323 |
+
**示例3:文本摘要**
|
| 324 |
+
|
| 325 |
+
- 任务:摘要一篇新闻文章
|
| 326 |
+
- 指令:摘要应与种子词“政治”相关,并以中立和公正的语气书写。
|
| 327 |
+
- 角色:记者
|
| 328 |
+
- 提示公式:“作为记者,请以中立和公正的语气摘要以下新闻文章,与种子词“政治”相关:[插入新闻文章]”
|
| 329 |
+
|
| 330 |
+
<div style="page-break-after:always;"></div>
|
| 331 |
+
|
| 332 |
+
## 第九章:知识生成提示
|
| 333 |
+
|
| 334 |
+
知识生成提示是一种从ChatGPT中引出新的、原创的信息的技术。
|
| 335 |
+
|
| 336 |
+
知识生成提示的公式是“请生成关于X的新的和原创的信息”,其中X是感兴趣的主题。
|
| 337 |
+
|
| 338 |
+
这是一种利用模型预先存在的知识来生成新的信息或回答问题的技术。
|
| 339 |
+
|
| 340 |
+
要将此提示与ChatGPT一起使用,需要将问题或主题作为输入提供给模型,以及指定所生成文本的任务或目标的提示。
|
| 341 |
+
|
| 342 |
+
提示应包括有关所需输出的信息,例如要生成的文本类型以及任何特定的要求或限制。
|
| 343 |
+
|
| 344 |
+
以下是提示示例及其公式:
|
| 345 |
+
|
| 346 |
+
**示例1:知识生成**
|
| 347 |
+
|
| 348 |
+
- 任务:生成有关特定主题的新信息
|
| 349 |
+
- 说明:生成的信息应准确且与主题相关
|
| 350 |
+
- 提示公式:“生成有关[特定主题]的新的准确信息”
|
| 351 |
+
|
| 352 |
+
**示例2:问答**
|
| 353 |
+
|
| 354 |
+
- 任务:回答问题
|
| 355 |
+
- 说明:答案应准确且与问题相关
|
| 356 |
+
- 提示公式:“回答以下问题:[插入问题]”
|
| 357 |
+
|
| 358 |
+
**示例3:知识整合**
|
| 359 |
+
|
| 360 |
+
- 任务:将新信息与现有知识整合
|
| 361 |
+
- 说明:整合应准确且与主题相关
|
| 362 |
+
- 提示公式:“将以下信息与有关[特定主题]的现有知识整合:[插入新信息]”
|
| 363 |
+
|
| 364 |
+
**示例4:数据分析**
|
| 365 |
+
|
| 366 |
+
- 任务:从给定的数据集中生成有关客户行为的见解
|
| 367 |
+
- 提示公式:“请从这个数据集中生成有关客户行为的新的和原创的信息”
|
| 368 |
+
|
| 369 |
+
<div style="page-break-after:always;"></div>
|
| 370 |
+
|
| 371 |
+
## 第十章:知识整合提示
|
| 372 |
+
|
| 373 |
+
这种技术利用模型的现有知识来整合新信息或连接不同的信息片段。
|
| 374 |
+
|
| 375 |
+
这种技术对于将现有知识与新信息相结合,以生成更全面的特定主题的理解非常有用。
|
| 376 |
+
|
| 377 |
+
**如何与ChatGPT一起使用:**
|
| 378 |
+
|
| 379 |
+
- 模型应该提供新信息和现有知识作为输入,以及指定生成文本的任务或目标的提示。
|
| 380 |
+
- 提示应包括有关所需输出的信息,例如要生成的文本类型以及任何特定的要求或限制。
|
| 381 |
+
|
| 382 |
+
提示示例及其公式:
|
| 383 |
+
|
| 384 |
+
**示例1:知识整合**
|
| 385 |
+
|
| 386 |
+
- 任务:将新信息与现有知识整合
|
| 387 |
+
- 说明:整合应准确且与主题相关
|
| 388 |
+
- 提示公式:“将以下信息与关于[具体主题]的现有知识整合:[插入新信息]”
|
| 389 |
+
|
| 390 |
+
**示例2:连接信息片段**
|
| 391 |
+
|
| 392 |
+
- 任务:连接不同的信息片段
|
| 393 |
+
- 说明:连接应相关且逻辑清晰
|
| 394 |
+
- 提示公式:“以相关且逻辑清晰的方式连接以下信息片段:[插入信息1] [插入信息2]”
|
| 395 |
+
|
| 396 |
+
**示例3:更新现有知识**
|
| 397 |
+
|
| 398 |
+
- 任务:使用新信息更新现有知识
|
| 399 |
+
- 说明:更新的信息应准确且相关
|
| 400 |
+
- 提示公式:“使用以下信息更新[具体主题]的现有知识:[插入新信息]”
|
| 401 |
+
|
| 402 |
+
<div style="page-break-after:always;"></div>
|
| 403 |
+
|
| 404 |
+
## 第十一章:多项选择提示
|
| 405 |
+
|
| 406 |
+
这种技术向模型提供一个问题或任务以及一组预定义的选项作为潜在答案。
|
| 407 |
+
|
| 408 |
+
该技术对于生成仅限于特定选项集的文本非常有用,可用于问答、文本完成和其他任务。模型可以生成仅限于预定义选项的文本。
|
| 409 |
+
|
| 410 |
+
要使用ChatGPT的多项选择提示,需要向模型提供一个问题或任务作为输入,以及一组预定义的选项作为潜在答案。提示还应包括有关所需输出的信息,例如要生成的文本类型以及任何特定要求或限制。
|
| 411 |
+
|
| 412 |
+
提示示例及其公式:
|
| 413 |
+
|
| 414 |
+
**示例1:问答**
|
| 415 |
+
|
| 416 |
+
- 任务:回答一个多项选择题
|
| 417 |
+
- 说明:答案应该是预定义的选项之一
|
| 418 |
+
- 提示公式:“通过选择以下选项之一回答以下问题:[插入问题] [插入选项1] [插入选项2] [插入选项3]”
|
| 419 |
+
|
| 420 |
+
**示例2:文本完成**
|
| 421 |
+
|
| 422 |
+
- 任务:使用预定义选项之一完成句子
|
| 423 |
+
- 说明:完成应该是预定义的选项之一
|
| 424 |
+
- 提示公式:“通过选择以下选项之一完成以下句子:[插入句子] [插入选项1] [插入选项2] [插入选项3]”
|
| 425 |
+
|
| 426 |
+
**示例3:情感分析**
|
| 427 |
+
|
| 428 |
+
- 任务:将文本分类为积极、中立或消极
|
| 429 |
+
- 说明:分类应该是预定义的选项之一
|
| 430 |
+
- 提示公式:“通过选择以下选项之一,将以下文本分类为积极、中立或消极:[插入文本] [积极] [中立] [消极]”
|
| 431 |
+
|
| 432 |
+
<div style="page-break-after:always;"></div>
|
| 433 |
+
|
| 434 |
+
## 第十二章:可解释的软提示
|
| 435 |
+
|
| 436 |
+
可解释的软提示是一种技术,可以在提供一定的灵活性的同时控制模型生成的文本。它通过提供一组受控输入和关于所需输出的附加信息来实现。这种技术可以生成更具解释性和可控性的生成文本。
|
| 437 |
+
|
| 438 |
+
提示示例及其公式:
|
| 439 |
+
|
| 440 |
+
**示例1:文本生成**
|
| 441 |
+
|
| 442 |
+
- 任务:生成一个故事
|
| 443 |
+
- 指令:故事应基于一组给定的角色和特定的主题
|
| 444 |
+
- 提示公式:“基于以下角色生成故事:[插入角色]和主题:[插入主题]”
|
| 445 |
+
|
| 446 |
+
**示例2:文本完成**
|
| 447 |
+
|
| 448 |
+
- 任务:完成一句话
|
| 449 |
+
- 指令:完成应以特定作者的风格为基础
|
| 450 |
+
- 提示公式:“以[特定作者]的风格完成以下句子:[插入句子]”
|
| 451 |
+
|
| 452 |
+
**示例3:语言建模**
|
| 453 |
+
|
| 454 |
+
- 任务:以特定风格生成文本
|
| 455 |
+
- 指令:文本应以特定时期的风格为基础
|
| 456 |
+
- 提示公式:“以[特定时期]的风格生成文本:[插入上下文]”
|
| 457 |
+
|
| 458 |
+
<div style="page-break-after:always;"></div>
|
| 459 |
+
|
| 460 |
+
## 第十三章:控制生成提示
|
| 461 |
+
|
| 462 |
+
控制生成提示是一种技术,可让模型在生成文本时对输出进行高度控制。
|
| 463 |
+
|
| 464 |
+
这可以通过提供一组特定的输入来实现,例如模板、特定词汇或一组约束条件,这些输入可用于指导生成过程。
|
| 465 |
+
|
| 466 |
+
以下是一些示例和它们的公式:
|
| 467 |
+
|
| 468 |
+
**示例1:文本生成**
|
| 469 |
+
|
| 470 |
+
- 任务:生成一个故事
|
| 471 |
+
- 说明:该故事应基于特定的模板
|
| 472 |
+
- 提示公式:“根据以下模板生成故事:[插入模板]”
|
| 473 |
+
|
| 474 |
+
**示例2:文本补全**
|
| 475 |
+
|
| 476 |
+
- 任务:完成一句话
|
| 477 |
+
- 说明:完成应使用特定的词汇
|
| 478 |
+
- 提示公式:“使用以下词汇完成以下句子:[插入词汇]:[插入句子]”
|
| 479 |
+
|
| 480 |
+
**示例3:语言建模**
|
| 481 |
+
|
| 482 |
+
- 任务:以特定风格生成文本
|
| 483 |
+
- 说明:文本应遵循一组特定的语法规则
|
| 484 |
+
- 提示公式:“生成遵循以下语法规则的文本:[插入规则]:[插入上下文]”
|
| 485 |
+
|
| 486 |
+
通过提供一组特定的输入来指导生成过程,控制生成提示使得生成的文本更具可控性和可预测性。
|
| 487 |
+
|
| 488 |
+
<div style="page-break-after:always;"></div>
|
| 489 |
+
|
| 490 |
+
## 第十四章:问答提示
|
| 491 |
+
|
| 492 |
+
问答提示是一种技术,可以让模型生成回答特定问题或任务的文本。通过将问题或任务与可能与问题或任务相关的任何其他信息一起作为输入提供给模型来实现此目的。
|
| 493 |
+
|
| 494 |
+
一些提示示例及其公式如下:
|
| 495 |
+
|
| 496 |
+
**示例1:事实问题回答**
|
| 497 |
+
|
| 498 |
+
- 任务:回答一个事实性问题
|
| 499 |
+
- 说明:答案应准确且相关
|
| 500 |
+
- 提示公式:“回答以下事实问题:[插入问题]”
|
| 501 |
+
|
| 502 |
+
**示例2:定义**
|
| 503 |
+
|
| 504 |
+
- 任务:提供一个词的定义
|
| 505 |
+
- 说明:定义应准确
|
| 506 |
+
- 提示公式:“定义以下词汇:[插入单词]”
|
| 507 |
+
|
| 508 |
+
**示例3:信息检索**
|
| 509 |
+
|
| 510 |
+
- 任务:从特定来源检索信息
|
| 511 |
+
- 说明:检索到的信息应相关
|
| 512 |
+
- 提示公式:“从以下来源检索有关[特定主题]的信息:[插入来源]” 这对于问答和信息检索等任务非常有用。
|
| 513 |
+
|
| 514 |
+
<div style="page-break-after:always;"></div>
|
| 515 |
+
|
| 516 |
+
## 第十五章:概述提示
|
| 517 |
+
|
| 518 |
+
概述提示是一种技术,允许模型在保留其主要思想和信息的同时生成给定文本的较短版本。
|
| 519 |
+
|
| 520 |
+
这可以通过将较长的文本作为输入提供给模型并要求其生成该文本的摘要来实现。
|
| 521 |
+
|
| 522 |
+
这种技术对于文本概述和信息压缩等任务非常有用。
|
| 523 |
+
|
| 524 |
+
**如何在ChatGPT中使用:**
|
| 525 |
+
|
| 526 |
+
- 应该向模型提供较长的文本作为输入,并要求其生成该文本的摘要。
|
| 527 |
+
- 提示还应包括有关所需输出的信息,例如摘要的所需长度和任何特定要求或限制。
|
| 528 |
+
|
| 529 |
+
提示示例及其公式:
|
| 530 |
+
|
| 531 |
+
**示例1:文章概述**
|
| 532 |
+
|
| 533 |
+
- 任务:概述新闻文章
|
| 534 |
+
- 说明:摘要应是文章主要观点的简要概述
|
| 535 |
+
- 提示公式:“用一句简短的话概括以下新闻文章:[插入文章]”
|
| 536 |
+
|
| 537 |
+
**示例2:会议记录**
|
| 538 |
+
|
| 539 |
+
- 任务:概括会议记录
|
| 540 |
+
- 说明:摘要应突出会议的主要决策和行动
|
| 541 |
+
- 提示公式:“通过列出主要决策和行动来总结以下会议记录:[插入记录]”
|
| 542 |
+
|
| 543 |
+
**示例3:书籍摘要**
|
| 544 |
+
|
| 545 |
+
- 任务:总结一本书
|
| 546 |
+
- 说明:摘要应是书的主要观点的简要概述
|
| 547 |
+
- 提示公式:“用一段简短的段落总结以下书籍:[插入书名]”
|
| 548 |
+
|
| 549 |
+
<div style="page-break-after:always;"></div>
|
| 550 |
+
|
| 551 |
+
## 第十六章:对话提示
|
| 552 |
+
|
| 553 |
+
对话提示是一种技术,允许模型生成模拟两个或更多实体之间对话的文本。通过为模型提供一个上下文和一组角色或实体,以及它们的角色和背景,并要求模型在它们之间生成对话。
|
| 554 |
+
|
| 555 |
+
因此,应为模型提供上下文和一组角色或实体,以及它们的角色和背景。还应向模型提供有关所需输出的信息,例如对话或交谈的类型以及任何特定的要求或限制。
|
| 556 |
+
|
| 557 |
+
提示示例及其公式:
|
| 558 |
+
|
| 559 |
+
**示例1:对话生成**
|
| 560 |
+
|
| 561 |
+
- 任务:生成两个角色之间的对话
|
| 562 |
+
- 说明:对话应自然且与给定上下文相关
|
| 563 |
+
- 提示公式:“在以下情境中生成以下角色之间的对话[插入角色]”
|
| 564 |
+
|
| 565 |
+
**示例2:故事写作**
|
| 566 |
+
|
| 567 |
+
- 任务:在故事中生成对话
|
| 568 |
+
- 说明:对话应与故事的角色和事件一致
|
| 569 |
+
- 提示公式:“在以下故事中生成以下角色之间的对话[插入故事]”
|
| 570 |
+
|
| 571 |
+
**示例3:聊天机器人开发**
|
| 572 |
+
|
| 573 |
+
- 任务:为客服聊天机器人生成对话
|
| 574 |
+
- 说明:对话应专业且提供准确的信息
|
| 575 |
+
- 提示公式:“在客户询问[插入主题]时,为客服聊天机器人生成专业和准确的对话”
|
| 576 |
+
|
| 577 |
+
因此,这种技术对于对话生成、故事写作和聊天机器人开发等任务非常有用。
|
| 578 |
+
|
| 579 |
+
<div style="page-break-after:always;"></div>
|
| 580 |
+
|
| 581 |
+
## 第十七章:对抗性提示
|
| 582 |
+
|
| 583 |
+
对抗性提示是一种技术,它允许模型生成抵抗某些类型的攻击或偏见的文本。这种技术可用于训练更为稳健和抵抗某些类型攻击或偏见的模型。
|
| 584 |
+
|
| 585 |
+
要在ChatGPT中使用对抗性提示,需要为模型提供一个提示,该提示旨在使模型难以生成符合期望输出的文本。提示还应包括有关所需输出的信息,例如要生成的文本类型和任何特定要求或约束。
|
| 586 |
+
|
| 587 |
+
提示示例及其公式:
|
| 588 |
+
|
| 589 |
+
**示例1:用于文本分类的对抗性提示**
|
| 590 |
+
|
| 591 |
+
- 任务:生成被分类为特定标签的文本
|
| 592 |
+
- 说明:生成的文本应难以分类为特定标签
|
| 593 |
+
- 提示公式:“生成难以分类为[插入标签]的文本”
|
| 594 |
+
|
| 595 |
+
**示例2:用于情感分析的对抗性提示**
|
| 596 |
+
|
| 597 |
+
- 任务:生成难以分类为特定情感的文本
|
| 598 |
+
- 说明:生成的文本应难以分类为特定情感
|
| 599 |
+
- 提示公式:“生成难以分类为具有[插入情感]情感的文本”
|
| 600 |
+
|
| 601 |
+
**示例3:用于语言翻译的对抗性提示**
|
| 602 |
+
|
| 603 |
+
- 任务:生成难以翻译的文本
|
| 604 |
+
- 说明:生成的文本应难以翻译为目标语言
|
| 605 |
+
- 提示公式:“生成难以翻译为[插入目标语言]的文本”
|
| 606 |
+
|
| 607 |
+
<div style="page-break-after:always;"></div>
|
| 608 |
+
|
| 609 |
+
## 第十八章:聚类提示
|
| 610 |
+
|
| 611 |
+
聚类提示是一种技术,它可以让模型根据某些特征或特点将相似的数据点分组在一起。
|
| 612 |
+
|
| 613 |
+
通过提供一组数据点并要求模型根据某些特征或特点将它们分组成簇,可以实现这一目标。
|
| 614 |
+
|
| 615 |
+
这种技术在数据分析、机器学习和自然语言处理等任务中非常有用。
|
| 616 |
+
|
| 617 |
+
**如何在ChatGPT中使用:**
|
| 618 |
+
|
| 619 |
+
应该向模型提供一组数据点,并要求它根据某些特征或特点将它们分组成簇。提示还应包括有关所需输出的信息,例如要生成的簇数和任何特定的要求或约束。
|
| 620 |
+
|
| 621 |
+
提示示例及其公式:
|
| 622 |
+
|
| 623 |
+
**示例1:客户评论的聚类**
|
| 624 |
+
|
| 625 |
+
- 任务:将相似的客户评论分组在一起
|
| 626 |
+
- 说明:应根据情感将评论分组
|
| 627 |
+
- 提示公式:“将以下客户评论根据情感分组成簇:[插入评论]”
|
| 628 |
+
|
| 629 |
+
**示例2:新闻文章的聚类**
|
| 630 |
+
|
| 631 |
+
- 任务:将相似的新闻文章分组在一起
|
| 632 |
+
- 说明:应根据主题将文章分组
|
| 633 |
+
- 提示公式:“将以下新闻文章根据主题分组成簇:[插入文章]”
|
| 634 |
+
|
| 635 |
+
**示例3:科学论文的聚类**
|
| 636 |
+
|
| 637 |
+
- 任务:将相似的科学论文分组在一起
|
| 638 |
+
- 说明:应根据研究领域将论文分组
|
| 639 |
+
- 提示公式:“将以下科学论文根据研究领域分组成簇:[插入论文]”
|
| 640 |
+
|
| 641 |
+
<div style="page-break-after:always;"></div>
|
| 642 |
+
|
| 643 |
+
## 第十九章:强化学习提示
|
| 644 |
+
|
| 645 |
+
强化学习提示是一种技术,可以使模型从过去的行动中学习,并随着时间的推移提高其性能。要在ChatGPT中使用强化学习提示,需要为模型提供一组输入和奖励,并允许其根据接收到的奖励调整其行为。提示还应包括有关期望输出的信息,例如要完成的任务以及任何特定要求或限制。这种技术对于决策制定、游戏玩法和自然语言生成等任务非常有用。
|
| 646 |
+
|
| 647 |
+
提示示例及其公式:
|
| 648 |
+
|
| 649 |
+
**示例1:用于文本生成的强化学习**
|
| 650 |
+
|
| 651 |
+
- 任务:生成与特定风格一致的文本
|
| 652 |
+
- 说明:模型应根据为生成与特定风格一致的文本而接收到的奖励来调整其行为
|
| 653 |
+
- 提示公式:“使用强化学习来生成与以下风格一致的文本[插入风格]”
|
| 654 |
+
|
| 655 |
+
**示例2:用于语言翻译的强化学习**
|
| 656 |
+
|
| 657 |
+
- 任务:将文本从一种语言翻译成另一种语言
|
| 658 |
+
- 说明:模型应根据为生成准确翻译而接收到的奖励来调整其行为
|
| 659 |
+
- 提示公式:“使用强化学习将以下文本[插入文本]从[插入语言]翻译成[插入语言]”
|
| 660 |
+
|
| 661 |
+
**示例3:用于问答的强化学习**
|
| 662 |
+
|
| 663 |
+
- 任务:回答问题
|
| 664 |
+
- 说明:模型应根据为生成准确答案而接收到的奖励来调整其行为
|
| 665 |
+
- 提示公式:“使用强化学习来回答以下问题[插入问题]”
|
| 666 |
+
|
| 667 |
+
<div style="page-break-after:always;"></div>
|
| 668 |
+
|
| 669 |
+
## 第二十章:课程学习提示
|
| 670 |
+
|
| 671 |
+
课程学习是一种技术,允许模型通过先训练简单任务,逐渐增加难度来学习复杂任务。
|
| 672 |
+
|
| 673 |
+
要在ChatGPT中使用课程学习提示,模型应该提供一系列任务,这些任务逐渐增加难度。
|
| 674 |
+
|
| 675 |
+
提示还应包括有关期望输出的信息,例如要完成的最终任务以及任何特定要求或约束条件。
|
| 676 |
+
|
| 677 |
+
此技术对自然语言处理、图像识别和机器学习等任务非常有用。
|
| 678 |
+
|
| 679 |
+
提示示例及其公式:
|
| 680 |
+
|
| 681 |
+
**示例1:用于文本生成的课程学习**
|
| 682 |
+
|
| 683 |
+
- 任务:生成与特定风格一致的文本
|
| 684 |
+
- 说明:模型应该在移动到更复杂的风格之前先在简单的风格上进行训练。
|
| 685 |
+
- 提示公式:“使用课程学习来生成与以下风格[插入风格]一致的文本,按照以下顺序[插入顺序]。”
|
| 686 |
+
|
| 687 |
+
**示例2:用于语言翻译的课程学习**
|
| 688 |
+
|
| 689 |
+
- 任务:将文本从一种语言翻译成另一种语言
|
| 690 |
+
- 说明:模型应该在移动到更复杂的语言之前先在简单的语言上进行训练。
|
| 691 |
+
- 提示公式:“使用课程学习将以下语言[插入语言]的文本翻译成以下顺序[插入顺序]。”
|
| 692 |
+
|
| 693 |
+
**示例3:用于问题回答的课程学习**
|
| 694 |
+
|
| 695 |
+
- 任务:回答问题
|
| 696 |
+
- 说明:模型应该在移动到更复杂的问题之前先在简单的问题上进行训练。
|
| 697 |
+
- 提示公式:“使用课程学习来回答以下问题[插入问题],按照以下顺序[插入顺序]生成答案。”
|
| 698 |
+
|
| 699 |
+
<div style="page-break-after:always;"></div>
|
| 700 |
+
|
| 701 |
+
## 第二十一章:情感分析提示
|
| 702 |
+
|
| 703 |
+
情感分析是一种技术,允许模型确定文本的情绪色彩或态度,例如它是积极的、消极的还是中立的。
|
| 704 |
+
|
| 705 |
+
要在ChatGPT中使用情感分析提示,模型应该提供一段文本并要求根据其情感分类。
|
| 706 |
+
|
| 707 |
+
提示还应包括关于所需输出的信息,例如要检测的情感类型(例如积极的、消极的、中立的)和任何特定要求或约束条件。
|
| 708 |
+
|
| 709 |
+
提示示例及其公式:
|
| 710 |
+
|
| 711 |
+
**示例1:客户评论的情感分析**
|
| 712 |
+
|
| 713 |
+
- 任务:确定客户评论的情感
|
| 714 |
+
- 说明:模型应该将评论分类为积极的、消极的或中立的
|
| 715 |
+
- 提示公式:“对以下客户评论进行情感分析[插入评论],并将它们分类为积极的、消极的或中立的。”
|
| 716 |
+
|
| 717 |
+
**示例2:推文的情感分析**
|
| 718 |
+
|
| 719 |
+
- 任务:确定推文的情感
|
| 720 |
+
- 说明:模型应该将推文分类为积极的、消极的或中立的
|
| 721 |
+
- 提示公式:“对以下推文进行情感分析[插入推文],并将它们分类为积极的、消极的或中立的。”
|
| 722 |
+
|
| 723 |
+
**示例3:产品评论的情感分析**
|
| 724 |
+
|
| 725 |
+
- 任务:确定产品评论的情感
|
| 726 |
+
- 说明:模型应该将评论分类为积极的、消极的或中立的
|
| 727 |
+
- 提示公式:“对以下产品评论进行情感分析[插入评论],并将它们分类为积极的、消极的或中立的。”
|
| 728 |
+
|
| 729 |
+
这种技术对自然语言处理、客户服务和市场研究等任务非常有用。
|
| 730 |
+
|
| 731 |
+
<div style="page-break-after:always;"></div>
|
| 732 |
+
|
| 733 |
+
## 第二十二章:命名实体识别提示
|
| 734 |
+
|
| 735 |
+
命名实体识别(NER)是一种技术,它可以使模型识别和分类文本中的命名实体,例如人名、组织机构、地点和日期等。
|
| 736 |
+
|
| 737 |
+
要在ChatGPT中使用命名实体识别提示,需要向模型提供一段文本,并要求它识别和分类文本中的命名实体。
|
| 738 |
+
|
| 739 |
+
提示还应包括有关所需输出的信息,例如要识别的命名实体类型(例如人名、组织机构、地点、日期)以及任何特定要求或约束条件。
|
| 740 |
+
|
| 741 |
+
提示示例及其公式:
|
| 742 |
+
|
| 743 |
+
**示例1:新闻文章中的命名实体识别**
|
| 744 |
+
|
| 745 |
+
- 任务:在新闻文章中识别和分类命名实体
|
| 746 |
+
- 说明:模型应识别和分类人名、组织机构、地点和日期
|
| 747 |
+
- 提示公式:“在以下新闻文章[插入文章]上执行命名实体识别,并识别和分类人名、组织机构、地点和日期。”
|
| 748 |
+
|
| 749 |
+
**示例2:法律文件中的命名实体识别**
|
| 750 |
+
|
| 751 |
+
- 任务:在法律文件中识别和分类命名实体
|
| 752 |
+
- 说明:模型应识别和分类人名、组织机构、地点和日期
|
| 753 |
+
- 提示公式:“在以下法律文件[插入文件]上执行命名实体识别,并识别和分类人名、组织机构、地点和日期。”
|
| 754 |
+
|
| 755 |
+
**示例3:研究论文中的命名实体识别**
|
| 756 |
+
|
| 757 |
+
- 任务:在研究论文中识别和分类命名实体
|
| 758 |
+
- 说明:模型应识别和分类人名、组织机构、地点和日期
|
| 759 |
+
- 提示公式:“在以下研究论文[插入论文]上执行命名实体识别,并识别和分类人名、组织机构、地点和日期。”
|
| 760 |
+
|
| 761 |
+
<div style="page-break-after:always;"></div>
|
| 762 |
+
|
| 763 |
+
## 第二十三章:文本分类提示
|
| 764 |
+
|
| 765 |
+
文本分类是一种技术,它可以让模型将文本分成不同的类别。这种技术对于自然语言处理、文本分析和情感分析等任务非常有用。
|
| 766 |
+
|
| 767 |
+
需要注意的是,文本分类和情感分析是不同的。情感分析特别关注于确定文本中表达的情感或情绪。这可能包括确定文本表达了积极、消极还是中性的情感。情感分析通常用于客户评论、社交媒体帖子和其他需要表达情感的文本。
|
| 768 |
+
|
| 769 |
+
要在ChatGPT中使用文本分类提示,模型需要提供一段文本,并要求它根据预定义的类别或标签进行分类。提示还应包括有关所需输出的信息,例如类别或标签的数量以及任何特定的要求或约束。
|
| 770 |
+
|
| 771 |
+
提示示例及其公式:
|
| 772 |
+
|
| 773 |
+
**示例1:对客户评论进行文本分类**
|
| 774 |
+
|
| 775 |
+
- 任务:将客户评论分类为不同的类别,例如电子产品、服装和家具
|
| 776 |
+
- 说明:模型应根据评论的内容对其进行分类
|
| 777 |
+
- 提示公式:“对以下客户评论 [插入评论] 进行文本分类,并根据其内容将其分类为不同的类别,例如电子产品、服装和家具。”
|
| 778 |
+
|
| 779 |
+
**示例2:对新闻文章进行文本分类**
|
| 780 |
+
|
| 781 |
+
- 任务:将新闻文章分类为不同的类别,例如体育、政治和娱乐
|
| 782 |
+
- 说明:模型应根据文章的内容对其进行分类
|
| 783 |
+
- 提示公式:“对以下新闻文章 [插入文章] 进行文本分类,并根据其内容将其分类��不同的类别,例如体育、政治和娱乐。”
|
| 784 |
+
|
| 785 |
+
**示例3:对电子邮件进行文本分类**
|
| 786 |
+
|
| 787 |
+
- 任务:将电子邮件分类为不同的类别,例如垃圾邮件、重要邮件或紧急邮件
|
| 788 |
+
- 说明:模型应根据电子邮件的内容和发件人对其进行分类
|
| 789 |
+
- 提示公式:“对以下电子邮件 [插入电子邮件] 进行文本分类,并根据其内容和发件人将其分类为不同的类别,例如垃圾邮件、重要邮件或紧急邮件。”
|
| 790 |
+
|
| 791 |
+
<div style="page-break-after:always;"></div>
|
| 792 |
+
|
| 793 |
+
## 第二十四章:文本生成提示
|
| 794 |
+
|
| 795 |
+
文本生成提示与本书中提到的其他提示技术相关,例如:零、一、几次提示,受控生成提示,翻译提示,语言建模提示,句子补全提示等。这些提示都与生成文本有关,但它们在生成文本的方式和放置在生成文本上的特定要求或限制方面有所不同。文本生成提示可用于微调预训练模型或训练新模型以执行特定任务。
|
| 796 |
+
|
| 797 |
+
提示示例及其公式:
|
| 798 |
+
|
| 799 |
+
**示例1:故事创作的文本生成**
|
| 800 |
+
|
| 801 |
+
- 任务:根据给定的提示生成故事
|
| 802 |
+
- 说明:故事应至少包含1000个单词,并包括一组特定的角色和情节。
|
| 803 |
+
- 提示公式:“根据以下提示[插入提示]生成一个至少包含1000个单词,包括角色[插入角色]和情节[插入情节]的故事。”
|
| 804 |
+
|
| 805 |
+
**示例2:语言翻译的文本生成**
|
| 806 |
+
|
| 807 |
+
- 任务:将给定的文本翻译成另一种语言
|
| 808 |
+
- 说明:翻译应准确并符合习惯用语。
|
| 809 |
+
- 提示公式:“将以下文本[插入文本]翻译成[插入目标语言],并确保其准确且符合习惯用语。”
|
| 810 |
+
|
| 811 |
+
**示例3:文本完成的文本生成**
|
| 812 |
+
|
| 813 |
+
- 任务:完成给定的文本
|
| 814 |
+
- 说明:生成的文本应与输入文本连贯一致。
|
| 815 |
+
- 提示公式:“完成以下文本[插入文本],并确保其连贯一致且符合输入文本。”
|
| 816 |
+
|
| 817 |
+
<div style="page-break-after:always;"></div>
|
| 818 |
+
|
| 819 |
+
## 结语
|
| 820 |
+
|
| 821 |
+
正如本书中所探讨的那样,快速工程是一种利用像ChatGPT这样的语言模型获得高质量答案的强大工具。通过精心设计各种技巧的提示,我们可以引导模型生成符合我们特定需求和要求的文本。
|
| 822 |
+
|
| 823 |
+
在第二章中,我们讨论了如何使用指令提示向模型提供清晰明确的指导。在第三章中,我们探讨了如何使用角色提示生成特定的语音或风格的文本。在第四章中,我们研究了如何使用标准提示作为微调模型性能的起点。我们还研究了几种高级提示技术,例如Zero、One和Few Shot Prompting、Self-Consistency、Seed-word Prompt、Knowledge Generation Prompt、Knowledge Integration prompts、Multiple Choice prompts、Interpretable Soft Prompts、Controlled generation prompts、Question-answering prompts、Summarization prompts、Dialogue prompts、Adversarial prompts、Clustering prompts、Reinforcement learning prompts、Curriculum learning prompts、Sentiment analysis prompts、Named entity recognition prompts和Text classification prompts(对应章节的名字)。
|
| 824 |
+
|
| 825 |
+
这些技术中的每一种都可以以不同的方式使用,以实现各种不同的结果。随着您继续使用ChatGPT和其他语言模型,值得尝试不同的技巧组合,以找到最适合您特定用例的方法。
|
| 826 |
+
|
| 827 |
+
最后,您可以查看我写的其他主题的书籍。
|
| 828 |
+
|
| 829 |
+
感谢您阅读整本书。期待在我的其他书中与您见面。
|
| 830 |
+
|
| 831 |
+
(本文翻译自《The Art of Asking ChatGPT for High-Quality Answers A Complete Guide to Prompt Engineering Techniques》这本书,本文的翻译全部由ChatGpt完成,我只是把翻译内容给稍微排版了一下。做完了才发现这个工作早就有人做过了...下面是我以此事件让New Bing编写的一个小故事,希望大家喜欢)
|
| 832 |
+
|
| 833 |
+
> 他终于画完了他的画,心满意足地把它挂在了墙上。他觉得这是他一生中最伟大的作品,无人能及。他邀请了所有的朋友来欣赏,期待着他们的赞美和惊叹。 可是当他们看到画时,却没有一个人说话。他们只是互相对视,然后低头咳嗽,或者假装看手机。他感到很奇怪,难道他们都不懂艺术吗?难道他们都没有眼光吗? 他忍不住问其中一个朋友:“你觉得我的画怎么样?” 朋友犹豫了一下,说:“嗯……其实……这个画……我以前在哪里见过。” “见过?你在哪里见过?”他惊讶地问。 “就在……就在那边啊。”朋友指了指墙角的一个小框架,“那不就是你上个月买回来的那幅名画吗?你怎么把它照抄了一遍? ——New Bing
|
| 834 |
+
|
| 835 |
+
[这就是那幅名画]: http://yesaiwen.com/art-of-asking-chatgpt-for-high-quality-answ-engineering-techniques/#i-3 "《如何向ChatGPT提问并获得高质量的答案》"
|
knowledge_base/samples/isssues_merge/langchain-ChatGLM_closed.csv
ADDED
|
@@ -0,0 +1,173 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
,title,file,url,detail,id
|
| 2 |
+
0,加油~以及一些建议,2023-03-31.0002,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/2,加油,我认为你的方向是对的。,0
|
| 3 |
+
1,当前的运行环境是什么,windows还是Linux,2023-04-01.0003,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/3,当前的运行环境是什么,windows还是Linux,python是什么版本?,1
|
| 4 |
+
2,请问这是在CLM基础上运行吗?,2023-04-01.0004,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/4,请问是不是需要本地安装好clm并正常运行的情况下,再按文中的步骤执行才能运行起来?,2
|
| 5 |
+
3,[复现问题] 构造 prompt 时从知识库中提取的文字乱码,2023-04-01.0005,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/5,hi,我在尝试复现 README 中的效果,也使用了 ChatGLM-6B 的 README 作为输入文本,但发现从知识库中提取的文字是乱码,导致构造的 prompt 不可用。想了解如何解决这个问题。,3
|
| 6 |
+
4,后面能否加入上下文对话功能?,2023-04-02.0006,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/6,目前的get_wiki_agent_answer函数中已经实现了历史消息传递的功能,后面我再确认一下是否有langchain中model调用过程中是否传递了chat_history。,4
|
| 7 |
+
5,请问:纯cpu可以吗?,2023-04-03.0007,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/7,很酷的实现,极大地开拓了我的眼界!很顺利的在gpu机器上运行了,5
|
| 8 |
+
6,运行报错:AttributeError: 'NoneType' object has no attribute 'message_types_by_name',2023-04-03.0008,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/8,报错:,6
|
| 9 |
+
7,运行环境:GPU需要多大的?,2023-04-03.0009,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/9,如果按照THUDM/ChatGLM-6B的说法,使用的GPU大小应该在13GB左右,但运行脚本后,占用了24GB还不够。,7
|
| 10 |
+
8,请问本地知识的格式是什么?,2023-04-03.0010,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/10,已测试格式包括docx、md文件中的文本信息,具体格式可以参考 [langchain文档](https://python.langchain.com/en/latest/modules/indexes/document_loaders/examples/unstructured_file.html?highlight=pdf#),8
|
| 11 |
+
9,24G的显存还是爆掉了,是否支持双卡运行,2023-04-03.0011,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/11,RuntimeError: CUDA out of memory. Tried to allocate 96.00 MiB (GPU 0; 23.70 GiB total capacity; 22.18 GiB already allocated; 12.75 MiB free; 22.18 GiB reserved in total by PyTorch) If reserved memory is >> allocated memory try setting max_split_size_mb to avoid fragmentation. See documentation for Memory Management and PYTORCH_CUDA_ALLOC_CONF,9
|
| 12 |
+
10,你怎么知道embeddings方式和模型训练时候的方式是一样的?,2023-04-03.0012,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/12,embedding和LLM的方式不用一致,embedding能够解决语义检索的需求就行。这个项目里用到embedding是在对本地知识建立索引和对问句转换成向量的过程。,10
|
| 13 |
+
11,是否能提供本地知识文件的格式?,2023-04-04.0013,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/13,是否能提供本地知识文件的格式?,11
|
| 14 |
+
12,是否可以像清华原版跑在8G一以下的卡?,2023-04-04.0016,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/16,是否可以像清华原版跑在8G一以下的卡?我的8G卡爆显存了🤣🤣🤣,12
|
| 15 |
+
13,请教一下langchain协调使用向量库和chatGLM工作的,2023-04-05.0018,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/18,代码里面这段是创建问答模型的,会接入ChatGLM和本地语料的向量库,langchain回答的时候是怎么个优先顺序?先搜向量库,没有再找chatglm么? 还是什么机制?,13
|
| 16 |
+
14,在mac m2max上抛出了ValueError: 150001 is not in list这个异常,2023-04-05.0019,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/19,我把chatglm_llm.py加载模型的代码改成如下,14
|
| 17 |
+
15,程序运行后一直卡住,2023-04-05.0020,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/20,感谢作者的付出,不过本人在运行时出现了问题,请大家帮助。,15
|
| 18 |
+
16,问一下chat_history的逻辑,2023-04-06.0022,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/22,感谢开源。,16
|
| 19 |
+
17,为什么每次运行都会loading checkpoint,2023-04-06.0023,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/23,我把这个embeding模型下载到本地后,无法正常启动。,17
|
| 20 |
+
18,本地知识文件能否上传一些示例?,2023-04-06.0025,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/25,如题,怎么构造知识文件,效果更好?能否提供一个样例,18
|
| 21 |
+
19,What version of you are using?,2023-04-06.0026,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/26,"Hi Panda, I saw the `pip install -r requirements` command in README, and want to confirm you are using python2 or python3? because my pip and pip3 version are all is 22.3.",19
|
| 22 |
+
20,有���趣交流本项目应用的朋友可以加一下微信群,2023-04-07.0027,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/27,,20
|
| 23 |
+
21,本地知识越多,回答时检索的时间是否会越长,2023-04-07.0029,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/29,是的 因为需要进行向量匹配检索,21
|
| 24 |
+
22,爲啥最後還是報錯 哭。。,2023-04-07.0030,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/30,Failed to import transformers.models.t5.configuration_t5 because of the following error (look up to see,22
|
| 25 |
+
23,对话到第二次的时候就报错UnicodeDecodeError: 'utf-8' codec can't decode,2023-04-07.0031,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/31,对话第一次是没问题的,模型返回输出后又给到请输入你的问题,我再输入问题就报错,23
|
| 26 |
+
24,用的in4的量化版本,推理的时候显示需要申请10Gb的显存,2023-04-07.0033,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/33,"File ""/root/.cache/huggingface/modules/transformers_modules/chatglm-6b-int4-qe/modeling_chatglm.py"", line 581, in forward",24
|
| 27 |
+
25,使用colab运行,python3.9,提示包导入有问题,2023-04-07.0034,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/34,"from ._util import is_directory, is_path",25
|
| 28 |
+
26,运行失败,Loading checkpoint未达到100%被kill了,请问下是什么原因?,2023-04-07.0035,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/35,日志如下:,26
|
| 29 |
+
27,弄了个交流群,自己弄好多细节不会,大家技术讨论 加connection-image 我来拉你,2023-04-08.0036,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/36,自己搞好多不清楚的,一起来弄吧。。准备搞个部署问题的解决文档出来,27
|
| 30 |
+
28,Error using the new version with langchain,2023-04-09.0043,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/43,Error with the new changes:,28
|
| 31 |
+
29,程序报错torch.cuda.OutOfMemoryError如何解决?,2023-04-10.0044,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/44,报错详细信息如下:,29
|
| 32 |
+
30,qa的训练数据格式是如何设置的,2023-04-10.0045,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/45,本项目不是使用微调的方式,所以并不涉及到训练过程。,30
|
| 33 |
+
31,The FileType.UNK file type is not supported in partition. 解决办法,2023-04-10.0046,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/46,ValueError: Invalid file /home/yawu/Documents/langchain-ChatGLM-master/data. The FileType.UNK file type is not supported in partition.,31
|
| 34 |
+
32,如何读取多个txt文档?,2023-04-10.0047,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/47,如题,请教一下如何读取多个txt文档?示例代码中只给了读一个文档的案例,这个input我换成string之后也只能指定一个文档,无法用通配符指定多个文档,也无法传入多个文件路径的列表。,32
|
| 35 |
+
33,nltk package unable to either download or load local nltk_data folder,2023-04-10.0049,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/49,I'm running this project on an offline Windows Server environment so I download the Punkt and averaged_perceptron_tagger tokenizer in this directory:,33
|
| 36 |
+
34,requirements.txt中需要指定langchain版本,2023-04-11.0055,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/55,langchain版本0.116下无法引入RetrievalQA,需要指定更高版本(0.136版本下无问题),34
|
| 37 |
+
35,Demo演示无法给出输出内容,2023-04-12.0059,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/59,你好,测试了项目自带新闻稿示例和自行上传的一个文本,可以加载进去,但是无法给出答案,请问属于什么情况,如何解决,谢谢。PS: 1、今天早上刚下载全部代码;2、硬件服务器满足要求;3、按操作说明正常操作。,35
|
| 38 |
+
36,群人数过多无法进群,求帮忙拉进群,2023-04-12.0061,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/61,您好,您的群人数超过了200人,目前无法通过二维码加群,请问您方便加我微信拉我进群吗?万分感谢,36
|
| 39 |
+
37,群人数已满,求大佬拉入群,2023-04-12.0062,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/62,已在README中更新拉群二维码,37
|
| 40 |
+
38,requirements中langchain版本错误,2023-04-12.0065,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/65,langchain版本应该是0.0.12而不是0.0.120,38
|
| 41 |
+
39,Linux : Searchd in,2023-04-13.0068,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/68,import nltk,39
|
| 42 |
+
40,No sentence-transformers model found,2023-04-13.0069,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/69,加载不了这个模型,错误原因是找不到这个模型,但是路径是配置好了的,40
|
| 43 |
+
41,Error loading punkt: <urlopen error [Errno 111] Connection,2023-04-13.0070,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/70,运行knowledge_based_chatglm.py,出���nltk报错,具体情况如下:,41
|
| 44 |
+
42,[不懂就问] ptuning数据集格式,2023-04-13.0072,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/72,大家好请教 微调数据集的格式有什么玄机吗?我看 ChatGLM-6B/ptuning/readme.md的demo数据集ADGEN里content为啥都写成 类型#裙*风格#简约 这种格式的?这里面有啥玄机的? 特此请教,42
|
| 45 |
+
43,Embedding model请教,2023-04-13.0074,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/74,您好,我看到项目里的embedding模型用的是:GanymedeNil/text2vec-large-chinese,请问这个项目里的embedding模型可以直接用ChatGLM嘛?,43
|
| 46 |
+
44,Macbook M1 运行 webui.py 时报错,请问是否可支持M系列芯片,2023-04-13.0080,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/80,```,44
|
| 47 |
+
45,new feature: 添加对P-tunningv2微调后的模型支持,2023-04-14.0099,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/99,能否添加新的功能,对使用[P-tunningv2](https://github.com/THUDM/ChatGLM-6B/tree/main/ptuning)微调chatglm后的模型提供加载支持,45
|
| 48 |
+
46,txt文件加载成功,但读取报错,2023-04-15.0106,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/106,最新版的代码。比较诡异的是我的电脑是没有D盘的,报错信息里怎么有个D盘出来了...,46
|
| 49 |
+
47,模型加载成功?文件无法导入。,2023-04-15.0107,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/107,所有模型均在本地。,47
|
| 50 |
+
48,请问用的什么操作系统呢?,2023-04-16.0110,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/110,ubuntu、centos还是windows?,48
|
| 51 |
+
49,报错ModuleNotFoundError: No module named 'configs.model_config',2023-04-17.0112,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/112,更新代码后,运行webui.py,报错ModuleNotFoundError: No module named 'configs.model_config'。未查得解决方法。,49
|
| 52 |
+
50,问特定问题会出现爆显存,2023-04-17.0116,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/116,正常提问没问题。,50
|
| 53 |
+
51,loading进不去?,2023-04-18.0127,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/127,在linux系统上python webui.py之后打开网页,一直在loading,是不是跟我没装detectron2有关呢?,51
|
| 54 |
+
52,本地知识内容数量限制?,2023-04-18.0129,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/129,本地知识文件类型是txt,超过5条以上的数据,提问的时候就爆显存了。,52
|
| 55 |
+
53,我本来也计划做一个类似的产品,看来不用从头开始做了,2023-04-18.0130,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/130,文本切割,还有优化空间吗?微信群已经加不进去了。,53
|
| 56 |
+
54,load model failed. 加载模型失败,2023-04-18.0132,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/132,```,54
|
| 57 |
+
55,如何在webui里回答时同时返回引用的本地数据内容?,2023-04-18.0133,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/133,如题,55
|
| 58 |
+
56,交流群满200人加不了了,能不能给个负责人的联系方式拉我进群?,2023-04-20.0143,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/143,同求,56
|
| 59 |
+
57,No sentence-transformers model found with name ‘/text2vec/‘,但是再路径下面确实有模型文件,2023-04-20.0145,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/145,另外:The dtype of attention mask (torch.int64) is not bool,57
|
| 60 |
+
58,请问加载模型的路径在哪里修改,默认好像前面会带上transformers_modules.,2023-04-20.0148,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/148,"<img width=""1181"" alt=""1681977897052"" src=""https://user-images.githubusercontent.com/30926001/233301106-3846680a-d842-41d2-874e-5b6514d732c4.png"">",58
|
| 61 |
+
59,为啥放到方法调用会出错,这个怎么处理?,2023-04-20.0150,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/150,```python,59
|
| 62 |
+
60,No sentence-transformers model found with name C:\Users\Administrator/.cache\torch\sentence_transformers\GanymedeNil_text2vec-large-chinese. Creating a new one with MEAN pooling.,2023-04-21.0154,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/154,卡在这块很久是正常现象吗,60
|
| 63 |
+
61,微信群需要邀请才能加入,2023-04-21.0155,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/155,RT,给个个人联系方式白,61
|
| 64 |
+
62,No sentence-transformers model found with name GanymedeNil/text2vec-large-chinese. Creating a new one with MEAN pooling,2023-04-21.0156,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/156,ls GanymedeNil/text2vec-large-chinese,62
|
| 65 |
+
63,embedding会加载两次,2023-04-23.0159,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/159,你好,为什么要这样设置呢,这样会加载两次呀。,63
|
| 66 |
+
64,扫二维码加的那个群,群成员满了进不去了,2023-04-23.0160,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/160,如题,64
|
| 67 |
+
65,执行python3 cli_demo.py 报错AttributeError: 'NoneType' object has no attribute 'chat',2023-04-24.0163,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/163,"刚开始怀疑是内存不足问题,换成int4,int4-qe也不行,有人知道是什么原因吗",65
|
| 68 |
+
66,匹配得分,2023-04-24.0167,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/167,在示例cli_demo.py中返回的匹配文本没有对应的score,可以加上这个feature吗,66
|
| 69 |
+
67,大佬有计划往web_ui.py加入打字机功能吗,2023-04-25.0170,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/170,目前在载入了知识库后,单张V100 32G在回答垂直领域的问题时也需要20S以上,没有打字机逐字输出的使用体验还是比较煎熬的....,67
|
| 70 |
+
68,Is it possible to use a verctorDB for the embedings?,2023-04-25.0171,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/171,"when I play, I have to load the local data again and again when to start. I wonder if it is possible to use",68
|
| 71 |
+
69,请问通过lora训练官方模型得到的微调模型文件该如何加载?,2023-04-25.0173,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/173,通过lora训练的方式得到以下文件:,69
|
| 72 |
+
70,from langchain.chains import RetrievalQA的代码在哪里?,2023-04-25.0174,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/174,local_doc_qa.py,70
|
| 73 |
+
71,哪里有knowledge_based_chatglm.py文件?怎么找不到了??是被替换成cli_demo.py文件了吗?,2023-04-26.0175,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/175,哪里有knowledge_based_chatglm.py文件?怎么找不到了??是被替换成cli_demo.py文件了吗?,71
|
| 74 |
+
72,AttributeError: 'Chatbot' object has no attribute 'value',2023-04-26.0177,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/177,Traceback (most recent call last):,72
|
| 75 |
+
73,控制台调api.py报警告,2023-04-26.0178,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/178,"you must pass the application as an import string to enable ""reload"" or ""workers""",73
|
| 76 |
+
74,如何加入群聊,2023-04-27.0183,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/183,微信群超过200人了,需要邀请,如何加入呢?,74
|
| 77 |
+
75,如何将Chatglm和本地知识相结合,2023-04-27.0185,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/185,您好,我想请教一下怎么才能让知识库匹配到的文本和chatglm生成的相结合,而不是说如果没搜索到,就说根据已知信息无法回答该问题,谢谢,75
|
| 78 |
+
76,一点建议,2023-04-27.0189,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/189,1.weiui的get_vector_store方法里面添加一个判断以兼容gradio版本导致的上传异常,76
|
| 79 |
+
77,windows环境下,按照教程,配置好conda环境,git完项目,修改完模型路径相关内容后,运行demo报错缺少,2023-04-28.0194,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/194,报错代码如下:,77
|
| 80 |
+
78,ValueError: too many values to unpack (expected 2),2023-04-28.0198,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/198,"When i tried to use the non-streaming, `ValueError: too many values to unpack (expected 2)` error came out.",78
|
| 81 |
+
79,加载doc后覆盖原本知识,2023-04-28.0201,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/201,加载较大量级的私有知识库后,原本的知识会被覆盖,79
|
| 82 |
+
80,自定义知识库回答效果很差,2023-04-28.0203,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/203,"请问加了自定义知识库知识库,回答效果很差,是因为数据量太小的原因么",80
|
| 83 |
+
81,python310下,安装pycocotools失败,提示低版本cython,实际已安装高版本,2023-04-29.0208,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/208,RT,纯离线环境安装,依赖安装的十分艰难,最后碰到pycocotools,始终无法安装上,求教方法!,81
|
| 84 |
+
82,[FEATURE] 支持 RWKV 模型(目前已有 pip package & rwkv.cpp 等等),2023-05-01.0216,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/216,您好,我是 RWKV 的作者,介绍见:https://zhuanlan.zhihu.com/p/626083366,82
|
| 85 |
+
83,[BUG] 为啥主机/服务器不联网不能正常启动服务?,2023-05-02.0220,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/220,**问题描述 / Problem Description**,83
|
| 86 |
+
84,[BUG] 简洁阐述问题 / Concise description of the issue,2023-05-03.0222,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/222,**local variable 'torch' referenced before assignment**,84
|
| 87 |
+
85,不支持txt文件的中文输入,2023-05-04.0235,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/235,"vs_path, _ = local_doc_qa.init_knowledge_vector_store(filepath)",85
|
| 88 |
+
86,文件均未成功加载,请检查依赖包或替换为其他文件再次上传。 文件未成功加载,请重新上传文件,2023-05-05.0237,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/237,请大佬帮忙解决,谢谢!,86
|
| 89 |
+
87,[BUG] 使用多卡时chatglm模型加载两次,2023-05-05.0241,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/241,chatglm_llm.py文件下第129行先加载了一次chatglm模型,第143行又加载了一次,87
|
| 90 |
+
88,[BUG] similarity_search_with_score_by_vector函数返回多个doc时的score结果错误,2023-05-06.0252,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/252,**问题描述 / Problem Description**,88
|
| 91 |
+
89,可以再建一个交流群吗,这个群满了进不去。,2023-05-06.0255,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/255,上午应该已经在readme里更新过了,如果不能添加可能是网页缓存问题,可以试试看直接扫描img/qr_code_12.jpg,89
|
| 92 |
+
90,请问这是什么错误哇?KeyError: 'serialized_input',2023-05-06.0257,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/257,运行“python webui.py” 后这是什么错误?怎么解决啊?,90
|
| 93 |
+
91,修改哪里的代码,可以再cpu上跑?,2023-05-06.0258,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/258,**问题描述 / Problem Description**,91
|
| 94 |
+
92,ModuleNotFoundError: No module named 'modelscope',2023-05-07.0266,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/266,安装这个,92
|
| 95 |
+
93,加载lora微调模型时,lora参数加载成功,但显示模型未成功加载?,2023-05-08.0270,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/270,什么原因呀?,93
|
| 96 |
+
94,[BUG] 运行webui.py报错:name 'EMBEDDING_DEVICE' is not defined,2023-05-08.0274,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/274,解决了,我修改model_config时候把这个变量改错了,94
|
| 97 |
+
95,基于ptuning训练完成,新老模型都进行了加载,但是只有新的,2023-05-08.0280,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/280,licitly passing a `revision` is encouraged when loading a model with custom code to ensure no malicious code has been contributed in a newer revision.,95
|
| 98 |
+
96,[BUG] 使用chatyuan模型时,对话Error,has no attribute 'stream_chat',2023-05-08.0282,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/282,**问题描述 / Problem Description**,96
|
| 99 |
+
97,chaglm调用过程中 _call提示有一个 stop,2023-05-09.0286,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/286,**功能描述 / Feature Description**,97
|
| 100 |
+
98,Logger._log() got an unexpected keyword argument 'end',2023-05-10.0295,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/295,使用cli_demo的时候,加载一个普通txt文件,输入问题后,报错:“TypeError: Logger._log() got an unexpected keyword argument 'end'”,98
|
| 101 |
+
99,[BUG] 请问可以解释下这个FAISS.similarity_search_with_score_by_vector = similarity_search_with_score_by_vector的目的吗,2023-05-10.0296,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/296,我不太明白这个库自己写的similarity_search_with_score_by_vector方法做的事情,因为langchain原版的similarity_search_with_score_by_vector只是search faiss之后把返回的topk句子组合起来。我觉得原版理解起来没什么问题,但是这个库里自己写的我就没太看明白多做了什么其他的事情,因为没有注释。,99
|
| 102 |
+
100,[BUG] Windows下上传中文文件名文件,faiss无法生成向量数据库文件,2023-05-11.0318,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/318,**问题描述 / Problem Description**,100
|
| 103 |
+
101,cli_demo中的流式输出能否接着前一答案输出?,2023-05-11.0320,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/320,现有流式输出结果样式为:,101
|
| 104 |
+
102,内网部署时网页无法加载,能否增加离线静态资源,2023-05-12.0326,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/326,内网部署时网页无法加载,能否增加离线静态资源,102
|
| 105 |
+
103,我想把文件字符的编码格式改为encoding='utf-8'在哪修改呢,因为会有ascii codec can't decode byte报错,2023-05-14.0360,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/360,上传中文的txt文件时报错,编码格式为utf-8,103
|
| 106 |
+
104,Batches的进度条是在哪里设置的?能否关闭显示?,2023-05-15.0366,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/366,"使用cli_demo.py进行命令行测试时,每句回答前都有个Batches的进度条",104
|
| 107 |
+
105,ImportError: dlopen: cannot load any more object with static TLS or Segmentation fault,2023-05-15.0368,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/368,**问题描述 / Problem Description**,105
|
| 108 |
+
106,读取PDF时报错,2023-05-16.0373,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/373,在Colab上执行cli_demo.py时,在路径文件夹里放了pdf文件,在加载的过程中会显示错误,然后无法加载PDF文件,106
|
| 109 |
+
107,[BUG] webui报错 InvalidURL,2023-05-16.0375,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/375,python 版本:3.8.16,107
|
| 110 |
+
108,[FEATURE] 如果让回答不包含出处,应该怎么处理,2023-05-16.0380,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/380,**功能描述 / Feature Description**,108
|
| 111 |
+
109,加载PDF文件时,出现 unsupported colorspace for 'png',2023-05-16.0381,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/381,**问题描述 / Problem Description**,109
|
| 112 |
+
110,'ascii' codec can't encode characters in position 14-44: ordinal not in range(128) 经典bug,2023-05-16.0382,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/382,添加了知识库之后进行对话,之后再新增知识库就会出现这个问题。,110
|
| 113 |
+
111,微信群人数超过200了,扫码进不去了,群主可以再创建一个新群吗,2023-05-17.0391,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/391,**功能描述 / Feature Description**,111
|
| 114 |
+
112,TypeError: 'ListDocsResponse' object is not subscriptable,2023-05-17.0393,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/393,应该是用remain_docs.code和remain_docs.data吧?吗?,112
|
| 115 |
+
113,[BUG] 加载chatglm模型报错:'NoneType' object has no attribute 'message_types_by_name',2023-05-17.0398,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/398,**问题描述 / Problem Description**,113
|
| 116 |
+
114,[BUG] 执行 python webui.py 没有报错,但是ui界面提示 Something went wrong Expecting value: line 1 column 1 (char 0,2023-05-18.0399,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/399,**环境配置**,114
|
| 117 |
+
115,启动后调用api接口正常,过一会就不断的爆出 Since the angle classifier is not initialized,2023-05-18.0404,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/404,**问题描述 / Problem Description**,115
|
| 118 |
+
116,[BUG] write_check_file方法中,open函数未指定编码,2023-05-18.0408,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/408,"def write_check_file(filepath, docs):",116
|
| 119 |
+
117,导入的PDF中存在图片,有大概率出现 “unsupported colorspace for 'png'”异常,2023-05-18.0409,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/409,"pix = fitz.Pixmap(doc, img[0])",117
|
| 120 |
+
118,请问流程图是用什么软件画的,2023-05-18.0410,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/410,draw.io,118
|
| 121 |
+
119,mac 加载模型失败,2023-05-19.0417,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/417,Explicitly passing a `revision` is encouraged when loading a model with custom code to ensure no malicious code has been contributed in a newer revision.,119
|
| 122 |
+
120,使用GPU本地运行知识库问答,提问第一个问题出现异常。,2023-05-20.0419,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/419,配置文件model_config.py为:,120
|
| 123 |
+
121,想加入讨论群,2023-05-20.0420,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/420,OK,121
|
| 124 |
+
122,有没有直接调用LLM的API,目前只有知识库的API?,2023-05-22.0426,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/426,-------------------------------------------------------------------------------,122
|
| 125 |
+
123,上传文件后出现 ERROR __init__() got an unexpected keyword argument 'autodetect_encoding',2023-05-22.0428,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/428,"上传文件后出现这个问题:ERROR 2023-05-22 11:46:19,568-1d: __init__() got an unexpected keyword argument 'autodetect_encoding'",123
|
| 126 |
+
124,想问下README中用到的流程图用什么软件画的,2023-05-22.0431,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/431,**功能描述 / Feature Description**,124
|
| 127 |
+
125,No matching distribution found for langchain==0.0.174,2023-05-23.0436,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/436,ERROR: Could not find a version that satisfies the requirement langchain==0.0.174 ,125
|
| 128 |
+
126,[FEATURE] bing是必须的么?,2023-05-23.0437,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/437,从这个[脚步](https://github.com/imClumsyPanda/langchain-ChatGLM/blob/master/configs/model_config.py#L129)里面发现需要申请bing api,如果不申请,纯用模型推理不可吗?,126
|
| 129 |
+
127,同一台环境下部署了5.22号更新的langchain-chatglm v0.1.13和之前的版本,回复速度明显变慢,2023-05-23.0442,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/442,新langchain-chatglm v0.1.13版本速度很慢,127
|
| 130 |
+
128,Error reported during startup,2023-05-23.0443,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/443,Traceback (most recent call last):,128
|
| 131 |
+
129,"ValueError: not enough values to unpack (expected 2, got 1)on of the issue",2023-05-24.0449,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/449,"File "".cache\huggingface\modules\transformers_modules\chatglm-6b-int4\modeling_chatglm.py"", line 1280, in chat",129
|
| 132 |
+
130,[BUG] API部署,流式输出的函数,少了个question,2023-05-24.0451,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/451,**问题描述 / Problem Description**,130
|
| 133 |
+
131,项目结构的简洁性保持,2023-05-24.0454,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/454,**功能描述 / Feature Description**,131
|
| 134 |
+
132,项目群扫码进不去了,2023-05-24.0455,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/455,项目群扫码进不去了,是否可以加一下微信拉我进群,谢谢!微信号:daniel-0527,132
|
| 135 |
+
133,请求拉我入群讨论,海硕一枚,专注于LLM等相关技术,2023-05-24.0461,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/461,**功能描述 / Feature Description**,133
|
| 136 |
+
134,[BUG] chatglm-6b模型报错OSError: Error no file named pytorch_model.bin found in directory /chatGLM/model/model-6b,2023-05-26.0474,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/474,**1、简述:**,134
|
| 137 |
+
135,现在本项目交流群二维码扫描不进去了,需要群主通过,2023-05-27.0478,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/478,现在本项目交流群二维码扫描不进去了,需要群主通过,135
|
| 138 |
+
136,RuntimeError: Only Tensors of floating point and complex dtype can require gradients,2023-05-28.0483,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/483,刚更新了最新版本:,136
|
| 139 |
+
137,"RuntimeError: ""LayerNormKernelImpl"" not implemented for 'Half'",2023-05-28.0484,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/484,"已经解决了 params 只用两个参数 {'trust_remote_code': True, 'torch_dtype': torch.float16}",137
|
| 140 |
+
138,[BUG] 文件未成功加载,请重新上传文件,2023-05-31.0504,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/504,webui.py,138
|
| 141 |
+
139,[BUG] bug 17 ,pdf和pdf为啥还不一样呢?为啥有的pdf能识别?有的pdf识别不了呢?,2023-05-31.0506,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/506,bug 17 ,pdf和pdf为啥还不一样呢?为啥有的pdf能识别?有的pdf识别不了呢?,139
|
| 142 |
+
140,[FEATURE] 简洁阐述功能 / Concise description of the feature,2023-05-31.0513,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/513,**功能描述 / Feature Description**,140
|
| 143 |
+
141,[BUG] webui.py 加载chatglm-6b-int4 失败,2023-06-02.0524,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/524,**问题描述 / Problem Description**,141
|
| 144 |
+
142,[BUG] webui.py 加载chatglm-6b模型异常,2023-06-02.0525,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/525,**问题描述 / Problem Description**,142
|
| 145 |
+
143,增加对chatgpt的embedding和api调用的支持,2023-06-02.0531,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/531,能否支持openai的embedding api和对话的api?,143
|
| 146 |
+
144,[FEATURE] 调整模型下载的位置,2023-06-02.0537,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/537,模型默认下载到 $HOME/.cache/huggingface/,当 C 盘空间不足时无法完成模型的下载。configs/model_config.py 中也没有调整模型位置的参数。,144
|
| 147 |
+
145,[BUG] langchain=0.0.174 出错,2023-06-04.0543,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/543,**问题描述 / Problem Description**,145
|
| 148 |
+
146,[BUG] 更新后加载本地模型路径不正确,2023-06-05.0545,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/545,**问题描述 / Problem Description**,146
|
| 149 |
+
147,SystemError: 8bit 模型需要 CUDA 支持,或者改用量化后模型!,2023-06-06.0550,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/550,"docker 部署后,启动docker,过会儿容器会自动退出,logs报错 SystemError: 8bit 模型需要 CUDA 支持,或者改用量化后模型! [NVIDIA Container Toolkit](https://github.com/NVIDIA/nvidia-container-toolkit) 也已经安装了",147
|
| 150 |
+
148,[BUG] 上传知识库超过1M报错,2023-06-06.0556,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/556,**问题描述 / Problem Description**,148
|
| 151 |
+
149,打开跨域访问后仍然报错,不能请求,2023-06-06.0560,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/560,报错信息:,149
|
| 152 |
+
150,dialogue_answering 里面的代码是不是没有用到?,没有看到调用,2023-06-07.0571,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/571,dialogue_answering 是干啥的,150
|
| 153 |
+
151,[BUG] 响应速度极慢,应从哪里入手优化?48C/128G/8卡,2023-06-07.0573,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/573,运行环境:ubuntu20.04,151
|
| 154 |
+
152,纯CPU环境下运行cli_demo时报错,提示找不到nvcuda.dll,2023-06-08.0576,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/576,本地部署环境是纯CPU,之前的版本在纯CPU环境下能正常运行,但上传本地知识库经常出现encode问题。今天重新git项目后,运行时出现如下问题,请问该如何解决。,152
|
| 155 |
+
153,如何加载本地的embedding模型(text2vec-large-chinese模型文件),2023-06-08.0582,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/582,"因为需要离线部署,所以要把模型放到本地,我修改了chains/local_doc_qa.py中的HuggingFaceEmbeddings(),在其中加了一个cache_folder的参数,保证下载的文件在cache_folder中,model_name是text2vec-large-chinese。如cache_folder='/home/xx/model/text2vec-large-chinese', model_name='text2vec-large-chinese',这样仍然需要联网下载报错,请问大佬如何解决该问题?",153
|
| 156 |
+
154,ChatGLM-6B 在另外服务器安装好了,请问如何修改model.cofnig.py 来使用它的接口呢??,2023-06-09.0588,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/588,我本来想在这加一个api base url 但是运行web.py 发现 还是会去连huggingface 下载模型,154
|
| 157 |
+
155,[BUG] raise partially initialized module 'charset_normalizer' has no attribute 'md__mypyc' when call interface `upload_file`,2023-06-10.0591,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/591,**问题描述 / Problem Description**,155
|
| 158 |
+
156,[BUG] raise OSError: [Errno 101] Network is unreachable when call interface upload_file and upload .pdf files,2023-06-10.0592,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/592,**问题描述 / Problem Description**,156
|
| 159 |
+
157,如果直接用vicuna作为基座大模型,需要修改的地方有哪些?,2023-06-12.0596,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/596,vicuna模型有直接转换好的没有?也就是llama转换之后的vicuna。,157
|
| 160 |
+
158,[BUG] 通过cli.py调用api时抛出AttributeError: 'NoneType' object has no attribute 'get'错误,2023-06-12.0598,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/598,通过`python cli.py start api --ip localhost --port 8001` 命令调用api时,抛出:,158
|
| 161 |
+
159,[BUG] 通过cli.py调用api时直接报错`langchain-ChatGLM: error: unrecognized arguments: start cli`,2023-06-12.0601,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/601,通过python cli.py start cli启动cli_demo时,报错:,159
|
| 162 |
+
160,[BUG] error: unrecognized arguments: --model-dir conf/models/,2023-06-12.0602,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/602,关键字参数修改了吗?有没有文档啊?大佬,160
|
| 163 |
+
161,[BUG] 上传文件全部失败,2023-06-12.0603,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/603,ERROR: Exception in ASGI application,161
|
| 164 |
+
162,[BUG] config 使用 chatyuan 无法启动,2023-06-12.0604,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/604,"""chatyuan"": {",162
|
| 165 |
+
163,使用fashchat api之后,后台报错APIError 如图所示,2023-06-12.0606,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/606,我按照https://github.com/imClumsyPanda/langchain-ChatGLM/blob/master/docs/fastchat.md,163
|
| 166 |
+
164,[BUG] 启用上下文关联,每次embedding搜索到的内容都会比前一次多一段,2023-06-13.0613,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/613,**问题描述 / Problem Description**,164
|
| 167 |
+
165,local_doc_qa.py中MyFAISS.from_documents() 这个语句看不太懂。MyFAISS类中没有这个方法,其父类FAISS和VectorStore中也只有from_texts方法[BUG] 简洁阐述问题 / Concise description of the issue,2023-06-14.0619,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/619,local_doc_qa.py中MyFAISS.from_documents() 这个语句看不太懂。MyFAISS类中没有这个方法,其父类FAISS和VectorStore中也只有from_texts方法,165
|
| 168 |
+
166,[BUG] TypeError: similarity_search_with_score_by_vector() got an unexpected keyword argument 'filter',2023-06-14.0624,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/624,**问题描述 / Problem Description**,166
|
| 169 |
+
167,please delete this issue,2023-06-15.0633,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/633,"sorry, incorrect submission. Please remove this issue!",167
|
| 170 |
+
168,[BUG] vue前端镜像构建失败,2023-06-15.0635,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/635,**问题描述 / Problem Description**,168
|
| 171 |
+
169,ChatGLM-6B模型能否回答英文问题?,2023-06-15.0640,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/640,大佬,请问一下,如果本地知识文档是英文,ChatGLM-6B模型能否回答英文问题?不能的话,有没有替代的模型推荐,期待你的回复,谢谢,169
|
| 172 |
+
170,[BUG] 简洁阐述问题 / Concise description of the issue,2023-06-16.0644,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/644,**问题描述 / Problem Description**,170
|
| 173 |
+
171,KeyError: 3224,2023-06-16.0645,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/645,```,171
|
knowledge_base/samples/isssues_merge/langchain-ChatGLM_closed.jsonl
ADDED
|
@@ -0,0 +1,172 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{"title": "加油~以及一些建议", "file": "2023-03-31.0002", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/2", "detail": "加油,我认为你的方向是对的。", "id": 0}
|
| 2 |
+
{"title": "当前的运行环境是什么,windows还是Linux", "file": "2023-04-01.0003", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/3", "detail": "当前的运行环境是什么,windows还是Linux,python是什么版本?", "id": 1}
|
| 3 |
+
{"title": "请问这是在CLM基础上运行吗?", "file": "2023-04-01.0004", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/4", "detail": "请问是不是需要本地安装好clm并正常运行的情况下,再按文中的步骤执行才能运行起来?", "id": 2}
|
| 4 |
+
{"title": "[复现问题] 构造 prompt 时从知识库中提取的文字乱码", "file": "2023-04-01.0005", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/5", "detail": "hi,我在尝试复现 README 中的效果,也使用了 ChatGLM-6B 的 README 作为输入文本,但发现从知识库中提取的文字是乱码,导致构造的 prompt 不可用。想了解如何解决这个问题。", "id": 3}
|
| 5 |
+
{"title": "后面能否加入上下文对话功能?", "file": "2023-04-02.0006", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/6", "detail": "目前的get_wiki_agent_answer函数中已经实现了历史消息传递的功能,后面我再确认一下是否有langchain中model调用过程中是否传递了chat_history。", "id": 4}
|
| 6 |
+
{"title": "请问:纯cpu可以吗?", "file": "2023-04-03.0007", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/7", "detail": "很酷的实现,极大地开拓了我的眼界!很顺利的在gpu机器上运行了", "id": 5}
|
| 7 |
+
{"title": "运行报错:AttributeError: 'NoneType' object has no attribute 'message_types_by_name'", "file": "2023-04-03.0008", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/8", "detail": "报错:", "id": 6}
|
| 8 |
+
{"title": "运行环境:GPU需要多大的?", "file": "2023-04-03.0009", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/9", "detail": "如果按照THUDM/ChatGLM-6B的说法,使用的GPU大小应该在13GB左右,但运行脚本后,占用了24GB还不够。", "id": 7}
|
| 9 |
+
{"title": "请问本地知识的格式是什么?", "file": "2023-04-03.0010", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/10", "detail": "已测试格式包括docx、md文件中的文本信息,具体格式可以参考 [langchain文档](https://python.langchain.com/en/latest/modules/indexes/document_loaders/examples/unstructured_file.html?highlight=pdf#)", "id": 8}
|
| 10 |
+
{"title": "24G的显存还是爆掉了,是否支持双卡运行", "file": "2023-04-03.0011", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/11", "detail": "RuntimeError: CUDA out of memory. Tried to allocate 96.00 MiB (GPU 0; 23.70 GiB total capacity; 22.18 GiB already allocated; 12.75 MiB free; 22.18 GiB reserved in total by PyTorch) If reserved memory is >> allocated memory try setting max_split_size_mb to avoid fragmentation. See documentation for Memory Management and PYTORCH_CUDA_ALLOC_CONF", "id": 9}
|
| 11 |
+
{"title": "你怎么知道embeddings方式和模型训练时候的方式是一样的?", "file": "2023-04-03.0012", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/12", "detail": "embedding和LLM的方式不用一致,embedding能够解决语义检索的需求就行。这个项目里用到embedding是在对本地知识建立索引和对问句转换成向量的过程。", "id": 10}
|
| 12 |
+
{"title": "是否能提供本地知识文件的格式?", "file": "2023-04-04.0013", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/13", "detail": "是否能提供本地知识文件的格式?", "id": 11}
|
| 13 |
+
{"title": "是否可以像清华原版跑在8G一以下的卡?", "file": "2023-04-04.0016", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/16", "detail": "是否可以像清华原版跑在8G一以下的卡?我的8G卡爆显存了🤣🤣🤣", "id": 12}
|
| 14 |
+
{"title": "请教一下langchain协调使用向量库和chatGLM工作的", "file": "2023-04-05.0018", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/18", "detail": "代码里面这段是创建问答模型的,会接入ChatGLM和本地语料的向量库,langchain回答的时候是怎么个优先顺序?先搜向量库,没有再找chatglm么? 还是什么机制?", "id": 13}
|
| 15 |
+
{"title": "在mac m2max上抛出了ValueError: 150001 is not in list这个异常", "file": "2023-04-05.0019", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/19", "detail": "我把chatglm_llm.py加载模型的代码改成如下", "id": 14}
|
| 16 |
+
{"title": "程序运行后一直卡住", "file": "2023-04-05.0020", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/20", "detail": "感谢作者的付出,不过本人在运行时出现了问题,请大家帮助。", "id": 15}
|
| 17 |
+
{"title": "问一下chat_history���逻辑", "file": "2023-04-06.0022", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/22", "detail": "感谢开源。", "id": 16}
|
| 18 |
+
{"title": "为什么每次运行都会loading checkpoint", "file": "2023-04-06.0023", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/23", "detail": "我把这个embeding模型下载到本地后,无法正常启动。", "id": 17}
|
| 19 |
+
{"title": "本地知识文件能否上传一些示例?", "file": "2023-04-06.0025", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/25", "detail": "如题,怎么构造知识文件,效果更好?能否提供一个样例", "id": 18}
|
| 20 |
+
{"title": "What version of you are using?", "file": "2023-04-06.0026", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/26", "detail": "Hi Panda, I saw the `pip install -r requirements` command in README, and want to confirm you are using python2 or python3? because my pip and pip3 version are all is 22.3.", "id": 19}
|
| 21 |
+
{"title": "有兴趣交流本项目应用的朋友可以加一下微信群", "file": "2023-04-07.0027", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/27", "detail": "", "id": 20}
|
| 22 |
+
{"title": "本地知识越多,回答时检索的时间是否会越长", "file": "2023-04-07.0029", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/29", "detail": "是的 因为需要进行向量匹配检索", "id": 21}
|
| 23 |
+
{"title": "爲啥最後還是報錯 哭。。", "file": "2023-04-07.0030", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/30", "detail": "Failed to import transformers.models.t5.configuration_t5 because of the following error (look up to see", "id": 22}
|
| 24 |
+
{"title": "对话到第二次的时候就报错UnicodeDecodeError: 'utf-8' codec can't decode", "file": "2023-04-07.0031", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/31", "detail": "对话第一次是没问题的,模型返回输出后又给到请输入你的问题,我再输入问题就报错", "id": 23}
|
| 25 |
+
{"title": "用的in4的量化版本,推理的时候显示需要申请10Gb的显存", "file": "2023-04-07.0033", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/33", "detail": "File \"/root/.cache/huggingface/modules/transformers_modules/chatglm-6b-int4-qe/modeling_chatglm.py\", line 581, in forward", "id": 24}
|
| 26 |
+
{"title": "使用colab运行,python3.9,提示包导入有问题", "file": "2023-04-07.0034", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/34", "detail": "from ._util import is_directory, is_path", "id": 25}
|
| 27 |
+
{"title": "运行失败,Loading checkpoint未达到100%被kill了,请问下是什么原因?", "file": "2023-04-07.0035", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/35", "detail": "日志如下:", "id": 26}
|
| 28 |
+
{"title": "弄了个交流群,自己弄好多细节不会,大家技术讨论 加connection-image 我来拉你", "file": "2023-04-08.0036", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/36", "detail": "自己搞好多不清楚的,一起来弄吧。。准备搞个部署问题的解决文档出来", "id": 27}
|
| 29 |
+
{"title": "Error using the new version with langchain", "file": "2023-04-09.0043", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/43", "detail": "Error with the new changes:", "id": 28}
|
| 30 |
+
{"title": "程序报错torch.cuda.OutOfMemoryError如何解决?", "file": "2023-04-10.0044", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/44", "detail": "报错详细信息如下:", "id": 29}
|
| 31 |
+
{"title": "qa的训练数据格式是如何设置的", "file": "2023-04-10.0045", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/45", "detail": "本项目不是使用微调的方式,所以并不涉及到训练过程。", "id": 30}
|
| 32 |
+
{"title": "The FileType.UNK file type is not supported in partition. 解决办法", "file": "2023-04-10.0046", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/46", "detail": "ValueError: Invalid file /home/yawu/Documents/langchain-ChatGLM-master/data. The FileType.UNK file type is not supported in partition.", "id": 31}
|
| 33 |
+
{"title": "如何读取多个txt文档?", "file": "2023-04-10.0047", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/47", "detail": "如题,请教一下如何读取多个txt文档?示例代码中只给了读一个文档的案例,这个input我换成string之后也只能指定一个文档,无法用通配符指定多个文档,也无法传入多个文件路径的列表。", "id": 32}
|
| 34 |
+
{"title": "nltk package unable to either download or load local nltk_data folder", "file": "2023-04-10.0049", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/49", "detail": "I'm running this project on an offline Windows Server environment so I download the Punkt and averaged_perceptron_tagger tokenizer in this directory:", "id": 33}
|
| 35 |
+
{"title": "requirements.txt中需要��定langchain版本", "file": "2023-04-11.0055", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/55", "detail": "langchain版本0.116下无法引入RetrievalQA,需要指定更高版本(0.136版本下无问题)", "id": 34}
|
| 36 |
+
{"title": "Demo演示无法给出输出内容", "file": "2023-04-12.0059", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/59", "detail": "你好,测试了项目自带新闻稿示例和自行上传的一个文本,可以加载进去,但是无法给出答案,请问属于什么情况,如何解决,谢谢。PS: 1、今天早上刚下载全部代码;2、硬件服务器满足要求;3、按操作说明正常操作。", "id": 35}
|
| 37 |
+
{"title": "群人数过多无法进群,求帮忙拉进群", "file": "2023-04-12.0061", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/61", "detail": "您好,您的群人数超过了200人,目前无法通过二维码加群,请问您方便加我微信拉我进群吗?万分感谢", "id": 36}
|
| 38 |
+
{"title": "群人数已满,求大佬拉入群", "file": "2023-04-12.0062", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/62", "detail": "已在README中更新拉群二维码", "id": 37}
|
| 39 |
+
{"title": "requirements中langchain版本错误", "file": "2023-04-12.0065", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/65", "detail": "langchain版本应该是0.0.12而不是0.0.120", "id": 38}
|
| 40 |
+
{"title": "Linux : Searchd in", "file": "2023-04-13.0068", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/68", "detail": "import nltk", "id": 39}
|
| 41 |
+
{"title": "No sentence-transformers model found", "file": "2023-04-13.0069", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/69", "detail": "加载不了这个模型,错误原因是找不到这个模型,但是路径是配置好了的", "id": 40}
|
| 42 |
+
{"title": "Error loading punkt: <urlopen error [Errno 111] Connection", "file": "2023-04-13.0070", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/70", "detail": "运行knowledge_based_chatglm.py,出现nltk报错,具体情况如下:", "id": 41}
|
| 43 |
+
{"title": "[不懂就问] ptuning数据集格式", "file": "2023-04-13.0072", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/72", "detail": "大家好请教 微调数据集的格式有什么玄机吗?我看 ChatGLM-6B/ptuning/readme.md的demo数据集ADGEN里content为啥都写成 类型#裙*风格#简约 这种格式的?这里面有啥玄机的? 特此请教", "id": 42}
|
| 44 |
+
{"title": "Embedding model请教", "file": "2023-04-13.0074", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/74", "detail": "您好,我看到项目里的embedding模型用的是:GanymedeNil/text2vec-large-chinese,请问这个项目里的embedding模型可以直接用ChatGLM嘛?", "id": 43}
|
| 45 |
+
{"title": "Macbook M1 运行 webui.py 时报错,请问是否可支持M系列芯片", "file": "2023-04-13.0080", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/80", "detail": "```", "id": 44}
|
| 46 |
+
{"title": "new feature: 添加对P-tunningv2微调后的模型支持", "file": "2023-04-14.0099", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/99", "detail": "能否添加新的功能,对使用[P-tunningv2](https://github.com/THUDM/ChatGLM-6B/tree/main/ptuning)微调chatglm后的模型提供加载支持", "id": 45}
|
| 47 |
+
{"title": "txt文件加载成功,但读取报错", "file": "2023-04-15.0106", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/106", "detail": "最新版的代码。比较诡异的是我的电脑是没有D盘的,报错信息里怎么有个D盘出来了...", "id": 46}
|
| 48 |
+
{"title": "模型加载成功?文件无法导入。", "file": "2023-04-15.0107", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/107", "detail": "所有模型均在本地。", "id": 47}
|
| 49 |
+
{"title": "请问用的什么操作系统呢?", "file": "2023-04-16.0110", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/110", "detail": "ubuntu、centos还是windows?", "id": 48}
|
| 50 |
+
{"title": "报错ModuleNotFoundError: No module named 'configs.model_config'", "file": "2023-04-17.0112", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/112", "detail": "更新代码后,运行webui.py,报错ModuleNotFoundError: No module named 'configs.model_config'。未查得解决方法。", "id": 49}
|
| 51 |
+
{"title": "问特定问题会出现爆显存", "file": "2023-04-17.0116", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/116", "detail": "正常提问没问题。", "id": 50}
|
| 52 |
+
{"title": "loading进不去?", "file": "2023-04-18.0127", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/127", "detail": "在linux系统上python webui.py之后打开网页,一直在loading,是不是跟我没装detectron2有关呢?", "id": 51}
|
| 53 |
+
{"title": "本地知识内容数量限制?", "file": "2023-04-18.0129", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/129", "detail": "本地知识文件类型是txt,超过5条以上的数据,提问的时候就爆显存了。", "id": 52}
|
| 54 |
+
{"title": "我本来也计划做一个类似的产品,看来不用从头开始做了", "file": "2023-04-18.0130", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/130", "detail": "文本切割,还有优化空间吗?微信群已经加不进去了。", "id": 53}
|
| 55 |
+
{"title": "load model failed. 加载模型失败", "file": "2023-04-18.0132", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/132", "detail": "```", "id": 54}
|
| 56 |
+
{"title": "如何在webui里回答时同时返回引用的本地数据内容?", "file": "2023-04-18.0133", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/133", "detail": "如题", "id": 55}
|
| 57 |
+
{"title": "交流群满200人加不了了,能不能给个负责人的联系方式拉我进群?", "file": "2023-04-20.0143", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/143", "detail": "同求", "id": 56}
|
| 58 |
+
{"title": "No sentence-transformers model found with name ‘/text2vec/‘,但是再路径下面确实有模型文件", "file": "2023-04-20.0145", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/145", "detail": "另外:The dtype of attention mask (torch.int64) is not bool", "id": 57}
|
| 59 |
+
{"title": "请问加载模型的路径在哪里修改,默认好像前面会带上transformers_modules.", "file": "2023-04-20.0148", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/148", "detail": "<img width=\"1181\" alt=\"1681977897052\" src=\"https://user-images.githubusercontent.com/30926001/233301106-3846680a-d842-41d2-874e-5b6514d732c4.png\">", "id": 58}
|
| 60 |
+
{"title": "为啥放到方法调用会出错,这个怎么处理?", "file": "2023-04-20.0150", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/150", "detail": "```python", "id": 59}
|
| 61 |
+
{"title": "No sentence-transformers model found with name C:\\Users\\Administrator/.cache\\torch\\sentence_transformers\\GanymedeNil_text2vec-large-chinese. Creating a new one with MEAN pooling.", "file": "2023-04-21.0154", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/154", "detail": "卡在这块很久是正常现象吗", "id": 60}
|
| 62 |
+
{"title": "微信群需要邀请才能加入", "file": "2023-04-21.0155", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/155", "detail": "RT,给个个人联系方式白", "id": 61}
|
| 63 |
+
{"title": "No sentence-transformers model found with name GanymedeNil/text2vec-large-chinese. Creating a new one with MEAN pooling", "file": "2023-04-21.0156", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/156", "detail": "ls GanymedeNil/text2vec-large-chinese", "id": 62}
|
| 64 |
+
{"title": "embedding会加载两次", "file": "2023-04-23.0159", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/159", "detail": "你好,为什么要这样设置呢,这样会加载两次呀。", "id": 63}
|
| 65 |
+
{"title": "扫二维码加的那个群,群成员满了进不去了", "file": "2023-04-23.0160", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/160", "detail": "如题", "id": 64}
|
| 66 |
+
{"title": "执行python3 cli_demo.py 报错AttributeError: 'NoneType' object has no attribute 'chat'", "file": "2023-04-24.0163", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/163", "detail": "刚开始怀疑是内存不足问题,换成int4,int4-qe也不行,有人知道是什么原因吗", "id": 65}
|
| 67 |
+
{"title": "匹配得分", "file": "2023-04-24.0167", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/167", "detail": "在示例cli_demo.py中返回的匹配文本没有对应的score,可以加上这个feature吗", "id": 66}
|
| 68 |
+
{"title": "大佬有计划往web_ui.py加入打字机功能吗", "file": "2023-04-25.0170", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/170", "detail": "目前在载入了知识库后,单张V100 32G在回答垂直领域的问题时也需要20S以上,没有打字机逐字输出的使用体验还是比较煎熬的....", "id": 67}
|
| 69 |
+
{"title": "Is it possible to use a verctorDB for the embedings?", "file": "2023-04-25.0171", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/171", "detail": "when I play, I have to load the local data again and again when to start. I wonder if it is possible to use", "id": 68}
|
| 70 |
+
{"title": "请问通过lora训练官方模型得到的微调模型文件该如何加载?", "file": "2023-04-25.0173", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/173", "detail": "通过lora训练的方式得到以下文件:", "id": 69}
|
| 71 |
+
{"title": "from langchain.chains import RetrievalQA的代码在哪里?", "file": "2023-04-25.0174", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/174", "detail": "local_doc_qa.py", "id": 70}
|
| 72 |
+
{"title": "哪里有knowledge_based_chatglm.py文件?怎么找不到了??是被替换成cli_demo.py文件了吗?", "file": "2023-04-26.0175", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/175", "detail": "哪里有knowledge_based_chatglm.py文件?怎么找不到了??是被替换成cli_demo.py文件了吗?", "id": 71}
|
| 73 |
+
{"title": "AttributeError: 'Chatbot' object has no attribute 'value'", "file": "2023-04-26.0177", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/177", "detail": "Traceback (most recent call last):", "id": 72}
|
| 74 |
+
{"title": "控制台调api.py报警告", "file": "2023-04-26.0178", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/178", "detail": "you must pass the application as an import string to enable \"reload\" or \"workers\"", "id": 73}
|
| 75 |
+
{"title": "如何加入群聊", "file": "2023-04-27.0183", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/183", "detail": "微信群超过200人了,需要邀请,如何加入呢?", "id": 74}
|
| 76 |
+
{"title": "如何将Chatglm和本地知识相结合", "file": "2023-04-27.0185", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/185", "detail": "您好,我想请教一下怎么才能让知识库匹配到的文本和chatglm生成的相结合,而不是说如果没搜索到,就说根据已知信息无法回答该问题,谢谢", "id": 75}
|
| 77 |
+
{"title": "一点建议", "file": "2023-04-27.0189", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/189", "detail": "1.weiui的get_vector_store方法里面添加一个判断以兼容gradio版本导致的上传异常", "id": 76}
|
| 78 |
+
{"title": "windows环境下,按照教程,配置好conda环境,git完项目,修改完模型路径相关内容后,运行demo报错缺少", "file": "2023-04-28.0194", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/194", "detail": "报错代码如下:", "id": 77}
|
| 79 |
+
{"title": "ValueError: too many values to unpack (expected 2)", "file": "2023-04-28.0198", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/198", "detail": "When i tried to use the non-streaming, `ValueError: too many values to unpack (expected 2)` error came out.", "id": 78}
|
| 80 |
+
{"title": "加载doc后覆盖原本知识", "file": "2023-04-28.0201", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/201", "detail": "加载较大量级的私有知识库后,原本的知识会被覆盖", "id": 79}
|
| 81 |
+
{"title": "自定义知识库回答效果很差", "file": "2023-04-28.0203", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/203", "detail": "请问加了自定义知识库知识库,回答效果很差,是因为数据量太小的原因么", "id": 80}
|
| 82 |
+
{"title": "python310下,安装pycocotools失败,提示低版本cython,实际已安装高版本", "file": "2023-04-29.0208", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/208", "detail": "RT,纯离线环境安装,依赖安装的十分艰难,最后碰到pycocotools,始终无法安装上,求教方法!", "id": 81}
|
| 83 |
+
{"title": "[FEATURE] 支持 RWKV 模型(目前已有 pip package & rwkv.cpp 等等)", "file": "2023-05-01.0216", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/216", "detail": "您好,我是 RWKV 的作者,介绍见:https://zhuanlan.zhihu.com/p/626083366", "id": 82}
|
| 84 |
+
{"title": "[BUG] 为啥主机/服务器不联网不能正常启动服务?", "file": "2023-05-02.0220", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/220", "detail": "**问题描述 / Problem Description**", "id": 83}
|
| 85 |
+
{"title": "[BUG] 简洁阐述问题 / Concise description of the issue", "file": "2023-05-03.0222", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/222", "detail": "**local variable 'torch' referenced before assignment**", "id": 84}
|
| 86 |
+
{"title": "不支持txt文件的中文输入", "file": "2023-05-04.0235", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/235", "detail": "vs_path, _ = local_doc_qa.init_knowledge_vector_store(filepath)", "id": 85}
|
| 87 |
+
{"title": "文件均未成功加载,请检查依赖包或替换为其他文件再次上传。 文件未成功加载,请重新上传文件", "file": "2023-05-05.0237", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/237", "detail": "请大佬帮忙解决,谢谢!", "id": 86}
|
| 88 |
+
{"title": "[BUG] 使用多卡时chatglm模型加载两次", "file": "2023-05-05.0241", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/241", "detail": "chatglm_llm.py文件下第129行先加载了一次chatglm模型,第143行又加载了一次", "id": 87}
|
| 89 |
+
{"title": "[BUG] similarity_search_with_score_by_vector函数返回多个doc时的score结果错误", "file": "2023-05-06.0252", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/252", "detail": "**问题描述 / Problem Description**", "id": 88}
|
| 90 |
+
{"title": "可以再建一个交流群吗,这个群满了进不去。", "file": "2023-05-06.0255", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/255", "detail": "上午应该已经在readme里更新过了,如果不能添加可能是网页缓存问题,可以试试看直接扫描img/qr_code_12.jpg", "id": 89}
|
| 91 |
+
{"title": "请问这是什么错误哇?KeyError: 'serialized_input'", "file": "2023-05-06.0257", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/257", "detail": "运行“python webui.py” 后这是什么错误?怎么解决啊?", "id": 90}
|
| 92 |
+
{"title": "修改哪里的代码,可以再cpu上跑?", "file": "2023-05-06.0258", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/258", "detail": "**问题描述 / Problem Description**", "id": 91}
|
| 93 |
+
{"title": "ModuleNotFoundError: No module named 'modelscope'", "file": "2023-05-07.0266", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/266", "detail": "安装这个", "id": 92}
|
| 94 |
+
{"title": "加载lora微调模型时,lora参数加载成功,但显示模型未成功加载?", "file": "2023-05-08.0270", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/270", "detail": "什么原因呀?", "id": 93}
|
| 95 |
+
{"title": "[BUG] 运行webui.py报错:name 'EMBEDDING_DEVICE' is not defined", "file": "2023-05-08.0274", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/274", "detail": "解决了,我修改model_config时候把这个变量改错了", "id": 94}
|
| 96 |
+
{"title": "基于ptuning训练完成,新老模型都进行了加载,但是只有新的", "file": "2023-05-08.0280", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/280", "detail": "licitly passing a `revision` is encouraged when loading a model with custom code to ensure no malicious code has been contributed in a newer revision.", "id": 95}
|
| 97 |
+
{"title": "[BUG] 使用chatyuan模型时,对话Error,has no attribute 'stream_chat'", "file": "2023-05-08.0282", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/282", "detail": "**问题描述 / Problem Description**", "id": 96}
|
| 98 |
+
{"title": "chaglm调用过程中 _call提示有一个 stop", "file": "2023-05-09.0286", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/286", "detail": "**功能描述 / Feature Description**", "id": 97}
|
| 99 |
+
{"title": "Logger._log() got an unexpected keyword argument 'end'", "file": "2023-05-10.0295", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/295", "detail": "使用cli_demo的时候,加载一个普通txt文件,输入问题后,报错:“TypeError: Logger._log() got an unexpected keyword argument 'end'”", "id": 98}
|
| 100 |
+
{"title": "[BUG] 请问可以解释下这个FAISS.similarity_search_with_score_by_vector = similarity_search_with_score_by_vector的目的吗", "file": "2023-05-10.0296", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/296", "detail": "我不太明白这个库自己写的similarity_search_with_score_by_vector方法做的事情,因为langchain原版的similarity_search_with_score_by_vector只是search faiss之后把返回的topk句子组合起来。我觉得原版理解起来没什么问题,但是这个库里自己写的我就没太看明白多做了什么其他的事情,因为没有注释。", "id": 99}
|
| 101 |
+
{"title": "[BUG] Windows下上传中文文件名文件,faiss无法生成向量数据库文件", "file": "2023-05-11.0318", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/318", "detail": "**问题描述 / Problem Description**", "id": 100}
|
| 102 |
+
{"title": "cli_demo中的流式输出能否接着前一答案输出?", "file": "2023-05-11.0320", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/320", "detail": "现有流式输出结果样式为:", "id": 101}
|
| 103 |
+
{"title": "内网部署时网页无法加载,能否增加离线静态资源", "file": "2023-05-12.0326", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/326", "detail": "内网部署时网页无法加载,能否增加离线静态资源", "id": 102}
|
| 104 |
+
{"title": "我想把文件字符的编码格式改为encoding='utf-8'在哪修改呢,因为会有ascii codec can't decode byte报错", "file": "2023-05-14.0360", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/360", "detail": "上传中文的txt文件时报错,编码格式为utf-8", "id": 103}
|
| 105 |
+
{"title": "Batches的进度条是在哪里设置的?能否关闭显示?", "file": "2023-05-15.0366", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/366", "detail": "使用cli_demo.py进行命令行测试时,每句回答前都有个Batches的进度条", "id": 104}
|
| 106 |
+
{"title": "ImportError: dlopen: cannot load any more object with static TLS or Segmentation fault", "file": "2023-05-15.0368", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/368", "detail": "**问题描述 / Problem Description**", "id": 105}
|
| 107 |
+
{"title": "读取PDF时报错", "file": "2023-05-16.0373", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/373", "detail": "在Colab上执行cli_demo.py时,在路径文件夹里放了pdf文件,在加载的过程中会显示错误,然后无法加载PDF文件", "id": 106}
|
| 108 |
+
{"title": "[BUG] webui报错 InvalidURL", "file": "2023-05-16.0375", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/375", "detail": "python 版本:3.8.16", "id": 107}
|
| 109 |
+
{"title": "[FEATURE] 如果让回答不包含出处,���该怎么处理", "file": "2023-05-16.0380", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/380", "detail": "**功能描述 / Feature Description**", "id": 108}
|
| 110 |
+
{"title": "加载PDF文件时,出现 unsupported colorspace for 'png'", "file": "2023-05-16.0381", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/381", "detail": "**问题描述 / Problem Description**", "id": 109}
|
| 111 |
+
{"title": "'ascii' codec can't encode characters in position 14-44: ordinal not in range(128) 经典bug", "file": "2023-05-16.0382", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/382", "detail": "添加了知识库之后进行对话,之后再新增知识库就会出现这个问题。", "id": 110}
|
| 112 |
+
{"title": "微信群人数超过200了,扫码进不去了,群主可以再创建一个新群吗", "file": "2023-05-17.0391", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/391", "detail": "**功能描述 / Feature Description**", "id": 111}
|
| 113 |
+
{"title": "TypeError: 'ListDocsResponse' object is not subscriptable", "file": "2023-05-17.0393", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/393", "detail": "应该是用remain_docs.code和remain_docs.data吧?吗?", "id": 112}
|
| 114 |
+
{"title": "[BUG] 加载chatglm模型报错:'NoneType' object has no attribute 'message_types_by_name'", "file": "2023-05-17.0398", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/398", "detail": "**问题描述 / Problem Description**", "id": 113}
|
| 115 |
+
{"title": "[BUG] 执行 python webui.py 没有报错,但是ui界面提示 Something went wrong Expecting value: line 1 column 1 (char 0", "file": "2023-05-18.0399", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/399", "detail": "**环境配置**", "id": 114}
|
| 116 |
+
{"title": "启动后调用api接口正常,过一会就不断的爆出 Since the angle classifier is not initialized", "file": "2023-05-18.0404", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/404", "detail": "**问题描述 / Problem Description**", "id": 115}
|
| 117 |
+
{"title": "[BUG] write_check_file方法中,open函数未指定编码", "file": "2023-05-18.0408", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/408", "detail": "def write_check_file(filepath, docs):", "id": 116}
|
| 118 |
+
{"title": "导入的PDF中存在图片,有大概率出现 “unsupported colorspace for 'png'”异常", "file": "2023-05-18.0409", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/409", "detail": "pix = fitz.Pixmap(doc, img[0])", "id": 117}
|
| 119 |
+
{"title": "请问流程图是用什么软件画的", "file": "2023-05-18.0410", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/410", "detail": "draw.io", "id": 118}
|
| 120 |
+
{"title": "mac 加载模型失败", "file": "2023-05-19.0417", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/417", "detail": "Explicitly passing a `revision` is encouraged when loading a model with custom code to ensure no malicious code has been contributed in a newer revision.", "id": 119}
|
| 121 |
+
{"title": "使用GPU本地运行知识库问答,提问第一个问题出现异常。", "file": "2023-05-20.0419", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/419", "detail": "配置文件model_config.py为:", "id": 120}
|
| 122 |
+
{"title": "想加入讨论群", "file": "2023-05-20.0420", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/420", "detail": "OK", "id": 121}
|
| 123 |
+
{"title": "有没有直接调用LLM的API,目前只有知识库的API?", "file": "2023-05-22.0426", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/426", "detail": "-------------------------------------------------------------------------------", "id": 122}
|
| 124 |
+
{"title": "上传文件后出现 ERROR __init__() got an unexpected keyword argument 'autodetect_encoding'", "file": "2023-05-22.0428", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/428", "detail": "上传文件后出现这个问题:ERROR 2023-05-22 11:46:19,568-1d: __init__() got an unexpected keyword argument 'autodetect_encoding'", "id": 123}
|
| 125 |
+
{"title": "想问下README中用到的流程图用什么软件画的", "file": "2023-05-22.0431", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/431", "detail": "**功能描述 / Feature Description**", "id": 124}
|
| 126 |
+
{"title": "No matching distribution found for langchain==0.0.174", "file": "2023-05-23.0436", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/436", "detail": "ERROR: Could not find a version that satisfies the requirement langchain==0.0.174 ", "id": 125}
|
| 127 |
+
{"title": "[FEATURE] bing是必须的么?", "file": "2023-05-23.0437", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/437", "detail": "从这个[脚步](https://github.com/imClumsyPanda/langchain-ChatGLM/blob/master/configs/model_config.py#L129)里面发现需要申请bing api,如果不申请,纯用模型推理不可吗?", "id": 126}
|
| 128 |
+
{"title": "同一台环境下部署了5.22号更新的langchain-chatglm v0.1.13和之前的版本,回复速度明显变慢", "file": "2023-05-23.0442", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/442", "detail": "新langchain-chatglm v0.1.13版本速度很慢", "id": 127}
|
| 129 |
+
{"title": "Error reported during startup", "file": "2023-05-23.0443", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/443", "detail": "Traceback (most recent call last):", "id": 128}
|
| 130 |
+
{"title": "ValueError: not enough values to unpack (expected 2, got 1)on of the issue", "file": "2023-05-24.0449", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/449", "detail": "File \".cache\\huggingface\\modules\\transformers_modules\\chatglm-6b-int4\\modeling_chatglm.py\", line 1280, in chat", "id": 129}
|
| 131 |
+
{"title": "[BUG] API部署,流式输出的函数,少了个question", "file": "2023-05-24.0451", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/451", "detail": "**问题描述 / Problem Description**", "id": 130}
|
| 132 |
+
{"title": "项目结构的简洁性保持", "file": "2023-05-24.0454", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/454", "detail": "**功能描述 / Feature Description**", "id": 131}
|
| 133 |
+
{"title": "项目群扫码进不去了", "file": "2023-05-24.0455", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/455", "detail": "项目群扫码进不去了,是否可以加一下微信拉我进群,谢谢!微信号:daniel-0527", "id": 132}
|
| 134 |
+
{"title": "请求拉我入群讨论,海硕一枚,专注于LLM等相关技术", "file": "2023-05-24.0461", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/461", "detail": "**功能描述 / Feature Description**", "id": 133}
|
| 135 |
+
{"title": "[BUG] chatglm-6b模型报错OSError: Error no file named pytorch_model.bin found in directory /chatGLM/model/model-6b", "file": "2023-05-26.0474", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/474", "detail": "**1、简述:**", "id": 134}
|
| 136 |
+
{"title": "现在本项目交流群二维码扫描不进去了,需要群主通过", "file": "2023-05-27.0478", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/478", "detail": "现在本项目交流群二维码扫描不进去了,需要群主通过", "id": 135}
|
| 137 |
+
{"title": "RuntimeError: Only Tensors of floating point and complex dtype can require gradients", "file": "2023-05-28.0483", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/483", "detail": "刚更新了最新版本:", "id": 136}
|
| 138 |
+
{"title": "RuntimeError: \"LayerNormKernelImpl\" not implemented for 'Half'", "file": "2023-05-28.0484", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/484", "detail": "已经解决了 params 只用两个参数 {'trust_remote_code': True, 'torch_dtype': torch.float16}", "id": 137}
|
| 139 |
+
{"title": "[BUG] 文件未成功加载,请重新上传文件", "file": "2023-05-31.0504", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/504", "detail": "webui.py", "id": 138}
|
| 140 |
+
{"title": "[BUG] bug 17 ,pdf和pdf为啥还不一样呢?为啥有的pdf能识别?有的pdf识别不了呢?", "file": "2023-05-31.0506", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/506", "detail": "bug 17 ,pdf和pdf为啥还不一样呢?为啥有的pdf能识别?有的pdf识别不了呢?", "id": 139}
|
| 141 |
+
{"title": "[FEATURE] 简洁阐述功能 / Concise description of the feature", "file": "2023-05-31.0513", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/513", "detail": "**功能描述 / Feature Description**", "id": 140}
|
| 142 |
+
{"title": "[BUG] webui.py 加载chatglm-6b-int4 失败", "file": "2023-06-02.0524", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/524", "detail": "**问题描述 / Problem Description**", "id": 141}
|
| 143 |
+
{"title": "[BUG] webui.py 加载chatglm-6b模型异常", "file": "2023-06-02.0525", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/525", "detail": "**问题描述 / Problem Description**", "id": 142}
|
| 144 |
+
{"title": "增加对chatgpt的embedding和api调用的支持", "file": "2023-06-02.0531", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/531", "detail": "能否支持openai的embedding api和对话的api?", "id": 143}
|
| 145 |
+
{"title": "[FEATURE] 调整模型下载的位置", "file": "2023-06-02.0537", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/537", "detail": "模型默认下载到 $HOME/.cache/huggingface/,当 C 盘空间不足时无法完成模型的下载。configs/model_config.py 中也没有调整模型位置的参数。", "id": 144}
|
| 146 |
+
{"title": "[BUG] langchain=0.0.174 出错", "file": "2023-06-04.0543", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/543", "detail": "**问题描述 / Problem Description**", "id": 145}
|
| 147 |
+
{"title": "[BUG] 更新后加载本地模型路径不正确", "file": "2023-06-05.0545", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/545", "detail": "**问题描述 / Problem Description**", "id": 146}
|
| 148 |
+
{"title": "SystemError: 8bit 模型需要 CUDA 支持,或者改用量化后模型��", "file": "2023-06-06.0550", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/550", "detail": "docker 部署后,启动docker,过会儿容器会自动退出,logs报错 SystemError: 8bit 模型需要 CUDA 支持,或者改用量化后模型! [NVIDIA Container Toolkit](https://github.com/NVIDIA/nvidia-container-toolkit) 也已经安装了", "id": 147}
|
| 149 |
+
{"title": "[BUG] 上传知识库超过1M报错", "file": "2023-06-06.0556", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/556", "detail": "**问题描述 / Problem Description**", "id": 148}
|
| 150 |
+
{"title": "打开跨域访问后仍然报错,不能请求", "file": "2023-06-06.0560", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/560", "detail": "报错信息:", "id": 149}
|
| 151 |
+
{"title": "dialogue_answering 里面的代码是不是没有用到?,没有看到调用", "file": "2023-06-07.0571", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/571", "detail": "dialogue_answering 是干啥的", "id": 150}
|
| 152 |
+
{"title": "[BUG] 响应速度极慢,应从哪里入手优化?48C/128G/8卡", "file": "2023-06-07.0573", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/573", "detail": "运行环境:ubuntu20.04", "id": 151}
|
| 153 |
+
{"title": "纯CPU环境下运行cli_demo时报错,提示找不到nvcuda.dll", "file": "2023-06-08.0576", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/576", "detail": "本地部署环境是纯CPU,之前的版本在纯CPU环境下能正常运行,但上传本地知识库经常出现encode问题。今天重新git项目后,运行时出现如下问题,请问该如何解决。", "id": 152}
|
| 154 |
+
{"title": "如何加载本地的embedding模型(text2vec-large-chinese模型文件)", "file": "2023-06-08.0582", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/582", "detail": "因为需要离线部署,所以要把模型放到本地,我修改了chains/local_doc_qa.py中的HuggingFaceEmbeddings(),在其中加了一个cache_folder的参数,保证下载的文件在cache_folder中,model_name是text2vec-large-chinese。如cache_folder='/home/xx/model/text2vec-large-chinese', model_name='text2vec-large-chinese',这样仍然需要联网下载报错,请问大佬如何解决该问题?", "id": 153}
|
| 155 |
+
{"title": "ChatGLM-6B 在另外服务器安装好了,请问如何修改model.cofnig.py 来使用它的接口呢??", "file": "2023-06-09.0588", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/588", "detail": "我本来想在这加一个api base url 但是运行web.py 发现 还是会去连huggingface 下载模型", "id": 154}
|
| 156 |
+
{"title": "[BUG] raise partially initialized module 'charset_normalizer' has no attribute 'md__mypyc' when call interface `upload_file`", "file": "2023-06-10.0591", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/591", "detail": "**问题描述 / Problem Description**", "id": 155}
|
| 157 |
+
{"title": "[BUG] raise OSError: [Errno 101] Network is unreachable when call interface upload_file and upload .pdf files", "file": "2023-06-10.0592", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/592", "detail": "**问题描述 / Problem Description**", "id": 156}
|
| 158 |
+
{"title": "如果直接用vicuna作为基座大模型,需要修改的地方有哪些?", "file": "2023-06-12.0596", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/596", "detail": "vicuna模型有直接转换好的没有?也就是llama转换之后的vicuna。", "id": 157}
|
| 159 |
+
{"title": "[BUG] 通过cli.py调用api时抛出AttributeError: 'NoneType' object has no attribute 'get'错误", "file": "2023-06-12.0598", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/598", "detail": "通过`python cli.py start api --ip localhost --port 8001` 命令调用api时,抛出:", "id": 158}
|
| 160 |
+
{"title": "[BUG] 通过cli.py调用api时直接报错`langchain-ChatGLM: error: unrecognized arguments: start cli`", "file": "2023-06-12.0601", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/601", "detail": "通过python cli.py start cli启动cli_demo时,报错:", "id": 159}
|
| 161 |
+
{"title": "[BUG] error: unrecognized arguments: --model-dir conf/models/", "file": "2023-06-12.0602", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/602", "detail": "关键字参数修改了吗?有没有文档啊?大佬", "id": 160}
|
| 162 |
+
{"title": "[BUG] 上传文件全部失败", "file": "2023-06-12.0603", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/603", "detail": "ERROR: Exception in ASGI application", "id": 161}
|
| 163 |
+
{"title": "[BUG] config 使用 chatyuan 无法启动", "file": "2023-06-12.0604", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/604", "detail": "\"chatyuan\": {", "id": 162}
|
| 164 |
+
{"title": "使用fashchat api之后,后台报错APIError 如图所示", "file": "2023-06-12.0606", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/606", "detail": "我按照https://github.com/imClumsyPanda/langchain-ChatGLM/blob/master/docs/fastchat.md", "id": 163}
|
| 165 |
+
{"title": "[BUG] 启用上下文关联,每次embedding搜索到的内容都会比前一次多一段", "file": "2023-06-13.0613", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/613", "detail": "**问题描述 / Problem Description**", "id": 164}
|
| 166 |
+
{"title": "local_doc_qa.py中MyFAISS.from_documents() 这个语句看不太懂。MyFAISS类中没有这个方法,其父类FAISS和VectorStore中也只有from_texts方法[BUG] 简洁阐述问题 / Concise description of the issue", "file": "2023-06-14.0619", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/619", "detail": "local_doc_qa.py中MyFAISS.from_documents() 这个语句看不太懂。MyFAISS类中没有这个方法,其父类FAISS和VectorStore中也只有from_texts方法", "id": 165}
|
| 167 |
+
{"title": "[BUG] TypeError: similarity_search_with_score_by_vector() got an unexpected keyword argument 'filter'", "file": "2023-06-14.0624", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/624", "detail": "**问题描述 / Problem Description**", "id": 166}
|
| 168 |
+
{"title": "please delete this issue", "file": "2023-06-15.0633", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/633", "detail": "sorry, incorrect submission. Please remove this issue!", "id": 167}
|
| 169 |
+
{"title": "[BUG] vue前端镜像构建失败", "file": "2023-06-15.0635", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/635", "detail": "**问题描述 / Problem Description**", "id": 168}
|
| 170 |
+
{"title": "ChatGLM-6B模型能否回答英文问题?", "file": "2023-06-15.0640", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/640", "detail": "大佬,请问一下,如果本地知识文档是英文,ChatGLM-6B模型能否回答英文问题?不能的话,有没有替代的模型推荐,期待你的回复,谢谢", "id": 169}
|
| 171 |
+
{"title": "[BUG] 简洁阐述问题 / Concise description of the issue", "file": "2023-06-16.0644", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/644", "detail": "**问题描述 / Problem Description**", "id": 170}
|
| 172 |
+
{"title": "KeyError: 3224", "file": "2023-06-16.0645", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/645", "detail": "```", "id": 171}
|
knowledge_base/samples/isssues_merge/langchain-ChatGLM_closed.xlsx
ADDED
|
Binary file (27.8 kB). View file
|
|
|
knowledge_base/samples/isssues_merge/langchain-ChatGLM_open.csv
ADDED
|
@@ -0,0 +1,324 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
,title,file,url,detail,id
|
| 2 |
+
0,效果如何优化,2023-04-04.00,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/14,如图所示,将该项目的README.md和该项目结合后,回答效果并不理想,请问可以从哪些方面进行优化,0
|
| 3 |
+
1,怎么让模型严格根据检索的数据进行回答,减少胡说八道的回答呢,2023-04-04.00,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/15,举个例子:,1
|
| 4 |
+
2,"When I try to run the `python knowledge_based_chatglm.py`, I got this error in macOS(M1 Max, OS 13.2)",2023-04-07.00,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/32,```python,2
|
| 5 |
+
3,萌新求教大佬怎么改成AMD显卡或者CPU?,2023-04-10.00,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/48,把.cuda()去掉就行,3
|
| 6 |
+
4,输出answer的时间很长,是否可以把文本向量化的部分提前做好存储起来?,2023-04-10.00,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/50,GPU:4090 24G显存,4
|
| 7 |
+
5,报错Use `repo_type` argument if needed.,2023-04-11.00,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/57,Traceback (most recent call last):,5
|
| 8 |
+
6,无法打开gradio的页面,2023-04-11.00,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/58,$ python webui.py,6
|
| 9 |
+
7,支持word,那word里面的图片正常显示吗?,2023-04-12.00,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/60,如题,刚刚从隔壁转过来的,想先了解下,7
|
| 10 |
+
8,detectron2 is not installed. Cannot use the hi_res partitioning strategy. Falling back to partitioning with the fast strategy.,2023-04-12.00,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/63,能够正常的跑起来,在加载content文件夹中的文件时,每加载一个文件都会提示:,8
|
| 11 |
+
9,cpu上运行webui,step3 asking时报错,2023-04-12.00,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/66,web运行,文件加载都正常,asking时报错,9
|
| 12 |
+
10,建议弄一个插件系统,2023-04-13.00,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/67,如题弄成stable-diffusion-webui那种能装插件,再开一个存储库给使用者或插件开发,存储或下载插件。,10
|
| 13 |
+
11,请教加载模型出错!?,2023-04-13.00,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/75,AttributeError: module 'transformers_modules.chatglm-6b.configuration_chatglm' has no attribute 'ChatGLMConfig 怎么解决呀,11
|
| 14 |
+
12,从本地知识检索内容的时候,是否可以设置相似度阈值,小于这个阈值的内容不返回,即使会小于设置的VECTOR_SEARCH_TOP_K参数呢?谢谢大佬,2023-04-13.00,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/76,比如 问一些 你好/你是谁 等一些跟本地知识库无关的问题,12
|
| 15 |
+
13,如何改成多卡推理?,2023-04-13.00,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/77,+1,13
|
| 16 |
+
14,能否弄个懒人包,可以一键体验?,2023-04-13.00,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/78,能否弄个懒人包,可以一键体验?,14
|
| 17 |
+
15,连续问问题会导致崩溃,2023-04-13.00,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/79,看上去不是爆内存的问题,连续问问题后,会出现如下报错,15
|
| 18 |
+
16,AttributeError: 'NoneType' object has no attribute 'as_retriever',2023-04-14.00,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/86,"环境:windows 11, anaconda/python 3.8",16
|
| 19 |
+
17,FileNotFoundError: Could not find module 'nvcuda.dll' (or one of its dependencies). Try using the full path with constructor syntax.,2023-04-14.00,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/87,请检查一下cuda或cudnn是否存在安装问题,17
|
| 20 |
+
18,加载txt文件失败?,2023-04-14.00,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/89,,18
|
| 21 |
+
19,NameError: name 'chatglm' is not defined,2023-04-14.00,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/90,"This share link expires in 72 hours. For free permanent hosting and GPU upgrades (NEW!), check out Spaces: https://huggingface.co/spaces",19
|
| 22 |
+
20,打不开地址?,2023-04-14.00,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/91,报错数据如下:,20
|
| 23 |
+
21,加载md文件出错,2023-04-14.00,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/98,运行 webui.py后能访问页面,上传一个md文件后,日志中有错误。等待后能加载完成,提示可以提问了,但提问没反应,日志中有错误。 具体日志如下。,21
|
| 24 |
+
22,建议增加获取在线知识的能力,2023-04-15.01,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/101,建议增加获取在线知识的能力,22
|
| 25 |
+
23,txt 未能成功加载,2023-04-15.01,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/103,hinese. Creating a new one with MEAN pooling.,23
|
| 26 |
+
24,pdf加载失败,2023-04-15.01,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/105,e:\a.txt加载成功了,e:\a.pdf加载就失败,pdf文件里面前面几页是图片,后面都是文字,加载失败没有报更多错误,请问该怎么排查?,24
|
| 27 |
+
25,一直停在文本加载处,2023-04-15.01,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/108,一直停在文本加载处,25
|
| 28 |
+
26," File ""/root/.cache/huggingface/modules/transformers_modules/chatglm-6b/modeling_chatglm.py"", line 440, in forward new_tensor_shape = mixed_raw_layer.size()[:-1] + ( TypeError: torch.Size() takes an iterable of 'int' (item 2 is 'float')",2023-04-17.01,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/113,按照最新的代码,发现,26
|
| 29 |
+
27,后续会提供前后端分离的功能吗?,2023-04-17.01,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/114,类似这种https://github.com/lm-sys/FastChat/tree/main/fastchat/serve,27
|
| 30 |
+
28,安装依赖报错,2023-04-17.01,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/115,(test) C:\Users\linh\Desktop\langchain-ChatGLM-master>pip install -r requirements.txt,28
|
| 31 |
+
29,问特定问题会出现爆显存,2023-04-17.01,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/117,正常提问没问题。,29
|
| 32 |
+
30,Expecting value: line 1 column 1 (char 0),2023-04-17.01,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/118,运行后 第一步加载配置一直报错:,30
|
| 33 |
+
31,embedding https://huggingface.co/GanymedeNil/text2vec-large-chinese/tree/main是免费的,效果比对openai的如何?,2023-04-17.01,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/119,-------------------------------------------------------------------------------,31
|
| 34 |
+
32,这是什么错误,在Colab上运行的。,2023-04-17.01,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/120,libcuda.so.1: cannot open shared object file: No such file or directory,32
|
| 35 |
+
33,只想用自己的lora微调后的模型进行对话,不想加载任何本地文档,该如何调整?,2023-04-18.01,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/121,能出一个单独的教程吗,33
|
| 36 |
+
34,"租的gpu,Running on local URL: http://0.0.0.0:7860 To create a public link, set `share=True` in `launch()`. 浏览器上访问不了???",2023-04-18.01,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/122,(chatglm20230401) root@autodl-container-e82d11963c-10ece0d7:~/autodl-tmp/chatglm/langchain-ChatGLM-20230418# python3.9 webui.py,34
|
| 37 |
+
35,本地部署中的报错请教,2023-04-18.01,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/124,"您好,在本地运行langchain-ChatGLM过程中,环境及依赖的包都已经满足条件,但是运行webui.py,报错如下(运行cli_demo.py报错类似),请问是哪里出了错呢?盼望您的回复,谢谢!",35
|
| 38 |
+
36,报错。The dtype of attention mask (torch.int64) is not bool,2023-04-18.01,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/131,The dtype of attention mask (torch.int64) is not bool,36
|
| 39 |
+
37,[求助] pip install -r requirements.txt 的时候出现以下报错。。。有大佬帮忙看看怎么搞么,下的release里面的包,2023-04-18.01,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/134,$ pip install -r requirements.txt,37
|
| 40 |
+
38,如何提升根据问题搜索到对应知识的准确率,2023-04-19.01,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/136,外链知识库最大的问题在于问题是短文本,知识是中长文本。如何根据问题精准的搜索到对应的知识是个最大的问题。这类本地化项目不像百度,由无数的网页,基本上每个问题都可以找到对应的页面。,38
|
| 41 |
+
39,是否可以增加向量召回的阈值设定,有些召回内容相关性太低,导致模型胡言乱语,2023-04-20.01,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/140,如题,39
|
| 42 |
+
40,输入长度问题,2023-04-20.01,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/141,感谢作者支持ptuning微调模型。,40
|
| 43 |
+
41,已有部署好的chatGLM-6b,如何通过接口接入?,2023-04-20.01,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/144,已有部署好的chatGLM-6b,如何通过接口接入,而不是重新加载一个模型;,41
|
| 44 |
+
42,执行web_demo.py后,显示Killed,就退出了,是不是配置不足呢?,2023-04-20.01,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/146,,42
|
| 45 |
+
43,执行python cli_demo1.py,2023-04-20.01,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/147,Traceback (most recent call last):,43
|
| 46 |
+
44,报错:ImportError: cannot import name 'GENERATION_CONFIG_NAME' from 'transformers.utils',2023-04-20.01,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/149,(mychatGLM) PS D:\Users\admin3\zrh\langchain-ChatGLM> python cli_demo.py,44
|
| 47 |
+
45,上传文件并加载知识库时,会不停地出现临时文件,2023-04-21.01,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/153,环境:ubuntu 18.04,45
|
| 48 |
+
46,向知识库中添加文件后点击”上传文件并加载知识库“后Segmentation fault报错。,2023-04-23.01,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/161,运行服务后的提示如下:,46
|
| 49 |
+
47,langchain-serve 集成,2023-04-24.01,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/162,Hey 我是来自 [langchain-serve](https://github.com/jina-ai/langchain-serve) 的dev!,47
|
| 50 |
+
48,大佬们,wsl的ubuntu怎么配置用cuda加速,装了运行后发现是cpu在跑,2023-04-24.01,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/164,大佬们,wsl的ubuntu怎么配置用cuda加速,装了运行后发现是cpu在跑,48
|
| 51 |
+
49,在github codespaces docker运行出错,2023-04-24.01,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/165,docker run -d --restart=always --name chatglm -p 7860:7860 -v /www/wwwroot/code/langchain-ChatGLM:/chatGLM chatglm,49
|
| 52 |
+
50,有计划接入Moss模型嘛,2023-04-24.01,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/166,后续会开展测试,目前主要在优化langchain部分效果,如果有兴趣也欢迎提PR,50
|
| 53 |
+
51,怎么实现 API 部署?,2023-04-24.01,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/168,利用 fastapi 实现 API 部署方式,具体怎么实现,有方法说明吗?,51
|
| 54 |
+
52, 'NoneType' object has no attribute 'message_types_by_name'报错,2023-04-24.01,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/169,_HISTOGRAMPROTO = DESCRIPTOR.message_types_by_name['HistogramProto'],52
|
| 55 |
+
53,能否指定自己训练的text2vector模型?,2023-04-25.01,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/172,请问大佬:,53
|
| 56 |
+
54,关于项目支持的模型以及quantization_bit潜在的影响的问题,2023-04-26.01,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/176,作者您好~,54
|
| 57 |
+
55,运行python3.9 api.py WARNING: You must pass the application as an import string to enable 'reload' or 'workers'.,2023-04-26.01,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/179,api.py文件最下面改成这样试试:,55
|
| 58 |
+
56,ValidationError: 1 validation error for HuggingFaceEmbeddings model_kwargs extra fields not permitted (type=value_error.extra),2023-04-26.01,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/180,ValidationError: 1 validation error for HuggingFaceEmbeddings,56
|
| 59 |
+
57,如果没有检索到相关性比较高的,回答“我不知道”,2023-04-26.01,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/181,如果通过设计system_template,让模型在搜索到的文档都不太相关的情况下回答“我不知道”,57
|
| 60 |
+
58,请问如果不能联网,6B之类的文件从本地上传需要放到哪里,2023-04-26.01,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/182,感谢大佬的项目,很有启发~,58
|
| 61 |
+
59,知识库问答--输入新的知识库名称是中文的话,会报error,2023-04-27.01,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/184,知识库问答--输入新的知识库名称是中文的话,会报error,选择要加载的知识库那里也不显示之前添加的知识库,59
|
| 62 |
+
60,现在能通过问题匹配的相似度值,来直接返回文档中的文段,而不经过模型吗?因为有些答案在文档中,模型自己回答,不能回答文档中的答案,2023-04-27.01,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/186,现在能通过问题匹配的相似度值,来直接返回文档中的文段,而不经过模型吗?因为有些答案在文档中,模型自己回答,不能回答文档中的答案。也就是说,提供向量检索回答+模型回答相结合的策略。如果相似度值高于一定数值,直接返回文档中的文本,没有高于就返回模型的回答或者不知道,60
|
| 63 |
+
61,"TypeError: The type of ChatGLM.callback_manager differs from the new default value; if you wish to change the type of this field, please use a type annotation",2023-04-27.01,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/188,"Mac 运行 python3 ./webui.py 报 TypeError: The type of ChatGLM.callback_manager differs from the new default value; if you wish to change the type of this field, please use a type annotation",61
|
| 64 |
+
62,Not Enough Memory,2023-04-27.01,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/190,"运行命令行程序python cli_demo.py, 已经成功加载pdf文件, 报“DefaultCPUAllocator: not enough memory: you tried to allocate 458288380900 bytes”错误,请问哪里可以配置default memory",62
|
| 65 |
+
63,参与开发问题,2023-04-27.01,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/191,1.是否需要进专门的开发群,63
|
| 66 |
+
64,对话框中代码片段格式需改进,2023-04-27.01,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/192,最好能改进下输出代码片段的格式,目前输出的格式还不友好。,64
|
| 67 |
+
65,请问未来有可能支持belle吗,2023-04-28.01,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/195,如题,谢谢大佬,65
|
| 68 |
+
66,TypeError: cannot unpack non-iterable NoneType object,2023-04-28.02,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/200,"When i tried to change the knowledge vector store through `init_knowledge_vector_store`, the error `TypeError: cannot unpack non-iterable NoneType object` came out.",66
|
| 69 |
+
67,生成结果,2023-04-28.02,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/202,你好,想问一下langchain+chatglm-6B,找到相似匹配的prompt,是直接返回prompt对应的答案信息,还是chatglm-6B在此基础上自己优化答案?,67
|
| 70 |
+
68,在win、ubuntu下都出现这个错误:attributeerror: 't5forconditionalgeneration' object has no attribute 'stream_chat',2023-04-29.02,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/207,在win、ubuntu。下载完模型后,没办法修改代码以执行本地模型,每次都要重新输入路径; LLM 模型、Embedding 模型支持也都在官网下的,在其他项目(wenda)下可以使用,68
|
| 71 |
+
69,[FEATURE] knowledge_based_chatglm.py: renamed or missing?,2023-04-30.02,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/210,"Not found. Was it renamed? Or, is it missing? How can I get it?",69
|
| 72 |
+
70,sudo apt-get install -y nvidia-container-toolkit-base执行报错,2023-05-01.02,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/211,**问题描述 / Problem Description**,70
|
| 73 |
+
71,效果不佳几乎答不上来,2023-05-01.02,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/212,提供了50条问答的docx文件,71
|
| 74 |
+
72,有没有可能新增一个基于chatglm api调用的方式构建langchain,2023-05-02.02,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/218,我有两台8G GPU/40G内存的服务器,一个台做成了chatglm的api ;想基于另外一台服务器部署langchain;网上好像没有类似的代码。,72
|
| 75 |
+
73,电脑是intel的集成显卡; 运行时告知我找不到nvcuda.dll,模型无法运行,2023-05-02.02,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/219,您好,我的电脑是intel的集成显卡,不过CPU是i5-11400 @ 2.60GHz ,内存64G;,73
|
| 76 |
+
74,根据langchain官方的文档和使用模式,是否可以改Faiss为Elasticsearch?会需要做哪些额外调整?求解,2023-05-03.02,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/221,本人新手小白,由于业务模式的原因(有一些自己的场景和优化),希望利用Elasticsearch做这个体系内部的检索机制,不知道是否可以替换,同时,还会涉及到哪些地方的改动?或者说可能会有哪些其他影响,希望作者和大佬们不吝赐教!,74
|
| 77 |
+
75,请问未来有可能支持t5吗,2023-05-04.02,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/224,请问可能支持基於t5的模型吗?,75
|
| 78 |
+
76,[BUG] 内存溢出 / torch.cuda.OutOfMemoryError:,2023-05-04.02,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/229,**问题描述 / Problem Description**,76
|
| 79 |
+
77,报错 No module named 'chatglm_llm',2023-05-04.02,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/230,明明已经安装了包,却在python里吊不出来,77
|
| 80 |
+
78,能出一个api部署的描述文档吗,2023-05-04.02,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/233,**功能描述 / Feature Description**,78
|
| 81 |
+
79,使用docs/API.md 出错,2023-05-04.02,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/234,使用API.md文档2种方法,出错,79
|
| 82 |
+
80,加载pdf文档报错?,2023-05-05.02,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/238,ew one with MEAN pooling.,80
|
| 83 |
+
81,上传的本地知识文件后再次上传不能显示,只显示成功了一个,别的上传成功后再次刷新就没了,2023-05-05.02,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/239,您好,项目有很大启发,感谢~,81
|
| 84 |
+
82,创建了新的虚拟环境,安装了相关包,并且自动下载了相关的模型,但是仍旧出现:OSError: Unable to load weights from pytorch checkpoint file for,2023-05-05.02,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/240,,82
|
| 85 |
+
83,[BUG] 数据加载不进来,2023-05-05.02,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/243,使用的.txt格式,utf-8编码,报以下错误,83
|
| 86 |
+
84,不能读取pdf,2023-05-05.02,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/244,请问是webui还是cli_demo,84
|
| 87 |
+
85,本地txt文件有500M,加载的时候很慢,如何提高速度?,2023-05-06.02,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/251,,85
|
| 88 |
+
86,[BUG] gradio上传知识库后刷新之后 知识库就不见了 只有重启才能看到之前的上传的知识库,2023-05-06.02,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/253,gradio上传知识库后刷新之后 知识库就不见了 只有重启才能看到之前的上传的知识库,86
|
| 89 |
+
87,[FEATURE] 可以支持 OpenAI 的模型嘛?比如 GPT-3、GPT-3.5、GPT-4;embedding 增加 text-embedding-ada-002,2023-05-06.02,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/254,**功能描述 / Feature Description**,87
|
| 90 |
+
88,[FEATURE] 能否增加对于milvus向量数据库的支持 / Concise description of the feature,2023-05-06.02,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/256,**功能描述 / Feature Description**,88
|
| 91 |
+
89,CPU和GPU上跑,除了速度有区别,准确率效果回答上有区别吗?,2023-05-06.02,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/259,理论上没有区别,89
|
| 92 |
+
90,m1,请问在生成回答时怎么看是否使用了mps or cpu?,2023-05-06.02,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/260,m1,请问在生成回答时怎么看是否使用了mps or cpu?,90
|
| 93 |
+
91,知识库一刷新就没了,2023-05-07.02,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/263,知识库上传后刷新就没了,91
|
| 94 |
+
92,本地部署报没有模型,2023-05-07.02,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/267,建议在下载llm和embedding模型至本地后在configs/model_config中写入模型本地存储路径后再运行,92
|
| 95 |
+
93,[BUG] python3: can't open file 'webui.py': [Errno 2] No such file or directory,2023-05-08.02,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/269,**问题描述 / Problem Description**,93
|
| 96 |
+
94,模块缺失提示,2023-05-08.02,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/271,因为已有自己使用的docker环境,直接启动webui.py,提示,94
|
| 97 |
+
95,"运行api.py后,执行curl -X POST ""http://127.0.0.1:7861"" 报错?",2023-05-08.02,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/272,"执行curl -X POST ""http://127.0.0.1:7861"" \ -H 'Content-Type: application/json' \ -d '{""prompt"": ""你好"", ""history"": []}',报错怎么解决",95
|
| 98 |
+
96,[BUG] colab安装requirements提示protobuf版本问题?,2023-05-08.02,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/273,pip's dependency resolver does not currently take into account all the packages that are installed. This behaviour is the source of the following dependency conflicts.,96
|
| 99 |
+
97,请问项目里面向量相似度使用了什么方法计算呀?,2023-05-08.02,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/275,基本按照langchain里的FAISS.similarity_search_with_score_by_vector实现,97
|
| 100 |
+
98,[BUG] 安装detectron2后,pdf无法加载,2023-05-08.02,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/276,**问题描述 / Problem Description**,98
|
| 101 |
+
99,[BUG] 使用ChatYuan-V2模型无法流式输出,会报错,2023-05-08.02,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/277,一方面好像是ChatYuan本身不支持stream_chat,有人在clueai那边提了issue他们说还没开发,所以估计这个attribute调不起来;但是另一方面看报错好像是T5模型本身就不是decoder-only模型,所以不能流式输出吧(个人理解),99
|
| 102 |
+
100,[BUG] 无法加载text2vec模型,2023-05-08.02,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/278,**问题描述 / Problem Description**,100
|
| 103 |
+
101,请问能否增加网络搜索功能,2023-05-08.02,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/281,请问能否增加网络搜索功能,101
|
| 104 |
+
102,[FEATURE] 结构化数据sql、excel、csv啥时会支持呐。,2023-05-08.02,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/283,**功能描述 / Feature Description**,102
|
| 105 |
+
103,TypeError: ChatGLM._call() got an unexpected keyword argument 'stop',2023-05-08.02,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/284,No sentence-transformers model found with name D:\DevProject\langchain-ChatGLM\GanymedeNil\text2vec-large-chinese. Creating a new one with MEAN pooling.,103
|
| 106 |
+
104,关于api.py的一些bug和设计逻辑问题?,2023-05-09.02,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/285,首先冒昧的问一下,这个api.py,开发者大佬们是在自己电脑上测试后确实没问题吗?,104
|
| 107 |
+
105,有没有租用的算力平台上,运行api.py后,浏览器http://localhost:7861/报错,2023-05-09.02,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/287,是不是租用的gpu平台上都会出现这个问题???,105
|
| 108 |
+
106,请问一下项目中有用到文档段落切割方法吗?,2023-05-09.02,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/288,text_load中的文档切割方法用上了吗?在代码中看好像没有用到?,106
|
| 109 |
+
107,"报错 raise ValueError(f""Knowledge base {knowledge_base_id} not found"") ValueError: Knowledge base ./vector_store not found",2023-05-09.02,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/289,"File ""/root/autodl-tmp/chatglm/langchain-ChatGLM-master/api.py"", line 183, in chat",107
|
| 110 |
+
108,能接入vicuna模型吗,2023-05-09.02,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/290,目前本地已经有了vicuna模型能直接接入吗?,108
|
| 111 |
+
109,[BUG] 提问公式相关问题大概率爆显存,2023-05-09.02,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/291,**问题描述 / Problem Description**,109
|
| 112 |
+
110,安装pycocotools失败,找了好多方法都不能解决。,2023-05-10.02,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/292,**问题描述 / Problem Description**,110
|
| 113 |
+
111,使用requirements安装,PyTorch安装的是CPU版本,2023-05-10.02,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/294,如题目,使用requirements安装,PyTorch安装的是CPU版本,运行程序的时候,也是使用CPU在工作。,111
|
| 114 |
+
112,能不能给一个毛坯服务器的部署教程,2023-05-10.02,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/298,“开发部署”你当成服务器的部署教程用就行了。,112
|
| 115 |
+
113, Error(s) in loading state_dict for ChatGLMForConditionalGeneration:,2023-05-10.02,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/299,运行中出现的问题,7860的端口页面显示不出来,求助。,113
|
| 116 |
+
114,ChatYuan-large-v2模型加载失败,2023-05-10.03,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/300,**实际结果 / Actual Result**,114
|
| 117 |
+
115,新增摘要功能,2023-05-10.03,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/303,你好,后续会考虑新增对长文本信息进行推理和语音理解功能吗?比如生成摘要,115
|
| 118 |
+
116,[BUG] pip install -r requirements.txt 出错,2023-05-10.03,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/304,pip install langchain -i https://pypi.org/simple,116
|
| 119 |
+
117,[BUG] 上传知识库文件报错,2023-05-10.03,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/305,,117
|
| 120 |
+
118,[BUG] AssertionError: <class 'gradio.layouts.Accordion'> Component with id 41 not a valid input component.,2023-05-10.03,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/306,**问题描述 / Problem Description**,118
|
| 121 |
+
119,[BUG] CUDA out of memory with container deployment,2023-05-10.03,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/310,**问题描述 / Problem Description**,119
|
| 122 |
+
120,[FEATURE] 增加微调训练功能,2023-05-11.03,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/311,**功能描述 / Feature Description**,120
|
| 123 |
+
121,如何使用多卡部署,多个gpu,2023-05-11.03,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/315,"机器上有多个gpu,如何全使用了",121
|
| 124 |
+
122,请问这个知识库问答,和chatglm的关系是什么,2023-05-11.03,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/319,这个知识库问答,哪部分关联到了chatglm,是不是没有这个chatglm,知识库问答也可单单拎出来,122
|
| 125 |
+
123,[BUG] 运行的时候报错ImportError: libcudnn.so.8: cannot open shared object file: No such file or directory,2023-05-12.03,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/324,**问题描述 / Problem Description**raceback (most recent call last):,123
|
| 126 |
+
124,webui启动成功,但有报错,2023-05-12.03,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/325,**问题描述 / Problem Description**,124
|
| 127 |
+
125,切换MOSS的时候报错,2023-05-12.03,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/327,danshi但是发布的源码中,,125
|
| 128 |
+
126,vicuna模型是否能接入?,2023-05-12.03,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/328,您好!关于MOSS模型和vicuna模型,都是AutoModelForCausalLM来加载模型的,但是稍作更改(模型路径这些)会报这个错误。这个错误的造成是什么,126
|
| 129 |
+
127,你好,请问一下在阿里云CPU服务器上跑可以吗?可以的话比较理想的cpu配置是什么?,2023-05-12.03,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/330,你好,请问一下在阿里云CPU服务器上跑可以吗?可以的话比较理想的cpu配置是什么?,127
|
| 130 |
+
128,你好,请问8核32g的CPU可以跑多轮对话吗?,2023-05-12.03,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/331,什么样的cpu配置比较好呢?我目前想部署CPU下的多轮对话?,128
|
| 131 |
+
129,[BUG] 聊天内容输入超过10000个字符系统出现错误,2023-05-12.03,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/332,聊天内容输入超过10000个字符系统出现错误,如下图所示:,129
|
| 132 |
+
130,能增加API的多用户访问接口部署吗?,2023-05-12.03,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/333,默认部署程序仅支持单用户访问,多用户则需要排队访问。测试过相关的几个Github多用户工程,但是其中一些仍然不满足要求。本节将系统介绍如何实现多用户同时访问ChatGLM的部署接口,包括http、websocket(流式输出,stream)和web页面等方式,主要目录如下所示。,130
|
| 133 |
+
131,多卡部署,2023-05-12.03,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/334,用单机多卡或多机多卡,fastapi部署模型,怎样提高并发,131
|
| 134 |
+
132,WEBUI能否指定知识库目录?,2023-05-12.03,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/335,**功能描述 / Feature Description**,132
|
| 135 |
+
133,[BUG] Cannot read properties of undefined (reading 'error'),2023-05-12.03,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/336,**问题描述 / Problem Description**,133
|
| 136 |
+
134,[BUG] 1 validation error for HuggingFaceEmbeddings model_kwargs extra fields not permitted.,2023-05-12.03,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/337,模型加载到 100% 后出现问题:,134
|
| 137 |
+
135,上传知识库需要重启能不能修复一下,2023-05-12.03,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/338,挺严重的这个问题,135
|
| 138 |
+
136,[BUG] 4块v100卡爆显存,在LLM会话模式也一样,2023-05-12.03,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/339,**问题描述 / Problem Description**,136
|
| 139 |
+
137,针对上传的文件配置不同的TextSpliter,2023-05-12.03,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/341,1. 目前的ChineseTextSpliter切分对英文尤其是代码文件不友好,而且限制固定长度;导致对话结果不如人意,137
|
| 140 |
+
138,[FEATURE] 未来可增加Bloom系列模型吗?根据甲骨易的测试,这系列中文评测效果不错,2023-05-13.03,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/346,**功能描述 / Feature Description**,138
|
| 141 |
+
139,[BUG] v0.1.12打包镜像后启动webui.py失败 / Concise description of the issue,2023-05-13.03,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/347,**问题描述 / Problem Description**,139
|
| 142 |
+
140,切换MOSS模型时报错,2023-05-13.03,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/349,昨天问了下,说是transformers版本不对,需要4.30.0,发现没有这个版本,今天更新到4.29.1,依旧报错,错误如下,140
|
| 143 |
+
141,[BUG] pdf文档加载失败,2023-05-13.03,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/350,**问题描述 / Problem Description**,141
|
| 144 |
+
142,建议可以在后期增强一波注释,这样也有助于更多人跟进提PR,2023-05-13.03,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/351,知道作者和团队在疯狂更新审查代码,只是建议后续稳定后可以把核心代码进行一些注释的补充,从而能帮助更多人了解各个模块作者的思路从而提出更好的优化。,142
|
| 145 |
+
143,[FEATURE] MOSS 量化版支援,2023-05-13.03,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/353,**功能描述 / Feature Description**,143
|
| 146 |
+
144,[BUG] moss模型无法加载,2023-05-13.03,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/356,**问题描述 / Problem Description**,144
|
| 147 |
+
145,[BUG] load_doc_qa.py 中的 load_file 函数有bug,2023-05-14.03,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/358,原函数为:,145
|
| 148 |
+
146,[FEATURE] API模式,知识库加载优化,2023-05-14.03,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/359,如题,当前版本,每次调用本地知识库接口,都将加载一次知识库,是否有更好的方式?,146
|
| 149 |
+
147,运行Python api.py脚本后端部署后,怎么使用curl命令调用?,2023-05-15.03,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/361,也就是说,我现在想做个对话机器人,想和公司的前后端联调?怎么与前后端相互调用呢?可私信,有偿解答!!!,147
|
| 150 |
+
148,上传知识库需要重启能不能修复一下,2023-05-15.03,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/363,上传知识库需要重启能不能修复一下,148
|
| 151 |
+
149,[BUG] pip install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple,2023-05-15.03,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/364,我的python是3.8.5的,149
|
| 152 |
+
150,pip install gradio 报错,2023-05-15.03,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/367,大佬帮我一下,150
|
| 153 |
+
151,[BUG] pip install gradio 一直卡不动,2023-05-15.03,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/369,,151
|
| 154 |
+
152,[BUG] 简洁阐述问题 / Concise description of the issue,2023-05-16.03,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/370,初次加载本地知识库成功,但提问后,就无法重写加载本地知识库,152
|
| 155 |
+
153,[FEATURE] 简洁阐述功能 / Concise description of the feature,2023-05-16.03,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/371,**功能描述 / Feature Description**,153
|
| 156 |
+
154,在windows上,模型文件默认会安装到哪,2023-05-16.03,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/372,-------------------------------------------------------------------------------,154
|
| 157 |
+
155,[FEATURE] 兼顾对话管理,2023-05-16.03,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/374,如何在知识库检索的情况下,兼顾对话管理?,155
|
| 158 |
+
156,llm device: cpu embedding device: cpu,2023-05-16.03,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/376,**问题描述 / Problem Description**,156
|
| 159 |
+
157,[FEATURE] 简洁阐述功能 /文本文件的知识点之间使用什么分隔符可以分割?,2023-05-16.03,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/377,**功���描述 / Feature Description**,157
|
| 160 |
+
158,[BUG] 上传文件失败:PermissionError: [WinError 32] 另一个程序正在使用此文件,进程无法访问。,2023-05-16.03,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/379,**问题描述 / Problem Description**,158
|
| 161 |
+
159,[BUG] 执行python api.py 报错,2023-05-16.03,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/383,错误信息,159
|
| 162 |
+
160,model_kwargs extra fields not permitted (type=value_error.extra),2023-05-16.03,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/384,"大家好,请问这个有遇到的么,?",160
|
| 163 |
+
161,[BUG] 简洁阐述问题 / Concise description of the issue,2023-05-17.03,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/385,执行的时候出现了ls1 = [ls[0]],161
|
| 164 |
+
162,[FEATURE] 性能优化,2023-05-17.03,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/388,**功能描述 / Feature Description**,162
|
| 165 |
+
163,"[BUG] Moss模型问答,RuntimeError: probability tensor contains either inf, nan or element < 0",2023-05-17.03,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/390,**问题描述 / Problem Description**,163
|
| 166 |
+
164,有没有人知道v100GPU的32G显存,会报错吗?支持V100GPU吗?,2023-05-17.03,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/392,**问题描述 / Problem Description**,164
|
| 167 |
+
165,针对于编码问题比如'gbk' codec can't encode character '\xab' in position 14: illegal multibyte sequence粗浅的解决方法,2023-05-17.03,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/397,**功能描述 / Feature Description**,165
|
| 168 |
+
166,Could not import sentence_transformers python package. Please install it with `pip install sentence_transformers`.,2023-05-18.04,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/400,**问题描述 / Problem Description**,166
|
| 169 |
+
167,支持模型问答与检索问答,2023-05-18.04,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/401,不同的query,根据意图不一致,回答也应该不一样。,167
|
| 170 |
+
168,文本分割的时候,能不能按照txt文件的每行进行分割,也就是按照换行符号\n进行分割???,2023-05-18.04,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/403,下面的代码应该怎么修改?,168
|
| 171 |
+
169,local_doc_qa/local_doc_chat 接口响应是串行,2023-05-18.04,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/405,**问题描述 / Problem Description**,169
|
| 172 |
+
170,"为什么找到出处了,但是还是无法回答该问题?",2023-05-18.04,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/406,,170
|
| 173 |
+
171,"请问下:知识库测试中的:添加单条内容,如果换成文本导入是是怎样的格式?我发现添加单条内容测试效果很好.",2023-05-18.04,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/412,"我发现在知识库测试中`添加单条内容`,并且勾选`禁止内容分句入库`,即使 `不开启上下文关联`的测试效果都非常好.",171
|
| 174 |
+
172,[BUG] 无法配置知识库,2023-05-18.04,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/413,**问题描述 / Problem Description**,172
|
| 175 |
+
173,[BUG] 部署在阿里PAI平台的EAS上访问页面是白屏,2023-05-19.04,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/414,**问题描述 / Problem Description**,173
|
| 176 |
+
174,API部署后调用/local_doc_qa/local_doc_chat 返回Knowledge base samples not found,2023-05-19.04,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/416,入参,174
|
| 177 |
+
175,[FEATURE] 上传word另存为的txt文件报 'ascii' codec can't decode byte 0xb9 in position 6: ordinal not in range(128),2023-05-20.04,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/421,上传word另存为的txt文件报,175
|
| 178 |
+
176,创建保存的知识库刷新后没有出来,这个知识库是永久保存的吗?可以连外部的 向量知识库吗?,2023-05-21.04,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/422,创建保存的知识库刷新后没有出来,这个知识库是永久保存的吗?可以连外部的 向量知识库吗?,176
|
| 179 |
+
177,[BUG] 用colab运行,无法加载模型,报错:'NoneType' object has no attribute 'message_types_by_name',2023-05-21.04,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/423,**问题描述 / Problem Description**,177
|
| 180 |
+
178,请问是否需要用到向量数据库?以及什么时候需要用到向量数据库?,2023-05-21.04,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/424,目前用的是 text2vec , 请问是否需要用到向量数据库?以及什么时候需要用到向量数据库?,178
|
| 181 |
+
179,huggingface模型引用问题,2023-05-22.04,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/427,它最近似乎变成了一个Error?,179
|
| 182 |
+
180,你好,加载本地txt文件出现这个killed错误,TXT文件有100M左右大小。原因是?谢谢。,2023-05-22.04,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/429,"<img width=""677"" alt=""929aca3b22b8cd74e997a87b61d241b"" src=""https://github.com/imClumsyPanda/langchain-ChatGLM/assets/109277248/24024522-c884-4170-b5cf-a498491bd8bc"">",180
|
| 183 |
+
181,想请问一下,关于对本地知识的管理是如何管理?例如:通过http API接口添加数据 或者 删除某条数据,2023-05-22.04,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/430,例如:通过http API接口添加、删除、修改 某条数据。,181
|
| 184 |
+
182,[FEATURE] 双栏pdf识别问题,2023-05-22.04,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/432,试了一下模型,感觉对单栏pdf识别的准确性较高,但是由于使用的基本是ocr的技术,对一些双栏pdf论文识别出来有很多问题,请问有什么办法改善吗?,182
|
| 185 |
+
183,部署启动小问题,小弟初学求大佬解答,2023-05-22.04,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/433,1.python loader/image_loader.py时,提示ModuleNotFoundError: No module named 'configs',但是跑python webui.py还是还能跑,183
|
| 186 |
+
184,能否支持检测到目录下文档有增加而去增量加载文档,不影响前台对话,其实就是支持读写分离。如果能支持查询哪些文档向量化了,删除过时文档等就更好了,谢谢。,2023-05-22.04,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/434,**功能描述 / Feature Description**,184
|
| 187 |
+
185,[BUG] 简洁阐述问题 / windows 下cuda错误,请用https://github.com/Keith-Hon/bitsandbytes-windows.git,2023-05-22.04,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/435,pip install git+https://github.com/Keith-Hon/bitsandbytes-windows.git,185
|
| 188 |
+
186,"[BUG] from commit 33bbb47, Required library version not found: libbitsandbytes_cuda121_nocublaslt.so. Maybe you need to compile it from source?",2023-05-23.04,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/438,**问题描述 / Problem Description**,186
|
| 189 |
+
187,[BUG] 简洁阐述问题 / Concise description of the issue上传60m的txt文件报错,显示超时,请问这个能上传的文件大小有限制吗,2023-05-23.04,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/439,"ERROR 2023-05-23 11:13:09,627-1d: Timeout reached while detecting encoding for ./docs/GLM模型格式数据.txt",187
|
| 190 |
+
188,[BUG] TypeError: issubclass() arg 1 must be a class,2023-05-23.04,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/440,**问题描述**,188
|
| 191 |
+
189,"执行python3 webui.py后,一直提示”模型未成功加载,请到页面左上角""模型配置""选项卡中重新选择后点击""加载模型""按钮“",2023-05-23.04,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/441,**问题描述 / Problem Description**,189
|
| 192 |
+
190,是否能提供网页文档得导入支持,2023-05-23.04,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/444,现在很多都是在线文档作为协作得工具,所以通过URL导入在线文档需求更大,190
|
| 193 |
+
191,[BUG] history 索引问题,2023-05-23.04,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/445,在比较对话框的history和模型chat function 中的history时, 发现并不匹配,在传入 llm._call 时,history用的索引是不是有点问题,导致上一轮对话的内容并不输入给模型。,191
|
| 194 |
+
192,[BUG] moss_llm没有实现,2023-05-23.04,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/447,有些方法没支持,如history_len,192
|
| 195 |
+
193,请问langchain-ChatGLM如何删除一条本地知识库的数据?,2023-05-23.04,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/448,例如:用户刚刚提交了一条错误的数据到本地知识库中了,现在如何在本地知识库从找到,并且对此删除。,193
|
| 196 |
+
194,[BUG] 简洁阐述问题 / UnboundLocalError: local variable 'resp' referenced before assignment,2023-05-24.04,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/450,"在最新一版的代码中, 运行api.py 出现了以上错误(UnboundLocalError: local variable 'resp' referenced before assignment), 通过debug的方式观察到local_doc_qa.llm.generatorAnswer(prompt=question, history=history,streaming=True)可能不返回任何值。",194
|
| 197 |
+
195,请问有没有 PROMPT_TEMPLATE 能让模型不回答敏感问题,2023-05-24.04,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/452,## PROMPT_TEMPLATE问题,195
|
| 198 |
+
196,[BUG] 测试环境 Python 版本有误,2023-05-24.04,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/456,**问题描述 / Problem Description**,196
|
| 199 |
+
197,[BUG] webui 部署后样式不正确,2023-05-24.04,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/458,**问题描述 / Problem Description**,197
|
| 200 |
+
198,配置默认LLM模型的问题,2023-05-24.04,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/459,**问题描述 / Problem Description**,198
|
| 201 |
+
199,[FEATURE]是时候更新一下autoDL的镜像了,2023-05-24.04,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/460,如题,跑了下autoDL的镜像,发现是4.27号的,git pull新版本的代码功能+老的依赖环境,各种奇奇怪怪的问题。,199
|
| 202 |
+
200,[BUG] tag:0.1.13 以cpu模式下,想使用本地模型无法跑起来,各种路径参数问题,2023-05-24.04,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/462,-------------------------------------------------------------------------------,200
|
| 203 |
+
201,[BUG] 有没有同学遇到过这个错!!!加载本地txt文件出现这个killed错误,TXT文件有100M左右大小。,2023-05-25.04,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/463,运行cli_demo.py。是本地的txt文件太大了吗?100M左右。,201
|
| 204 |
+
202,API版本能否提供WEBSOCKET的流式接口,2023-05-25.04,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/464,webui 版本中,采用了WS的流式输出,整体感知反应很快,202
|
| 205 |
+
203,[BUG] 安装bug记录,2023-05-25.04,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/465,按照[install文档](https://github.com/imClumsyPanda/langchain-ChatGLM/blob/master/docs/INSTALL.md)安装的,,203
|
| 206 |
+
204,VUE的pnmp i执行失败的修复-用npm i命令即可,2023-05-25.04,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/466,感谢作者!非常棒的应用,用的很开心。,204
|
| 207 |
+
205,请教个问题,有没有人知道cuda11.4是否支持???,2023-05-25.04,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/467,请教个问题,有没有人知道cuda11.4是否支持???,205
|
| 208 |
+
206,请问有实现多轮问答中基于问题的搜索上下文关联么,2023-05-25.04,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/468,在基于知识库的多轮问答中,第一个问题讲述了一个主题,后续的问题描述没有包含这个主题的关键词,但又存在上下文的关联。如果用后续问题去搜索知识库有可能会搜索出无关的信息,从而导致大模型无法正确回答问题。请问这个项目要考虑这种情况吗?,206
|
| 209 |
+
207,[BUG] 内存不足的问题,2023-05-26.04,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/470,我用了本地的chatglm-6b-int4模型,然后显示了内存不足(win10+32G内存+1080ti11G),一般需要多少内存才足够?这个bug应该如何解决?,207
|
| 210 |
+
208,[BUG] 纯内网环境安装pycocotools失败,2023-05-26.04,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/472,**问题描述 / Problem Description**,208
|
| 211 |
+
209,[BUG] webui.py 重新加载模型会导致 KeyError,2023-05-26.04,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/473,**问题描述 / Problem Description**,209
|
| 212 |
+
210,chatyuan无法使用,2023-05-26.04,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/475,**问题描述 / Problem Description**,210
|
| 213 |
+
211,[BUG] 文本分割模型AliTextSplitter存在bug,会把“.”作为分割符,2023-05-26.04,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/476,"阿里达摩院的语义分割模型存在bug,默认会把"".”作为分割符进行分割而不管上下文语义。是否还有其他分割符则未知。建议的修改方案:把“.”统一替换为其他字符,分割后再替换回来。或者添加其他分割模型。",211
|
| 214 |
+
212,[BUG] RuntimeError: Error in faiss::FileIOReader::FileIOReader(const char*) a,2023-05-27.04,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/479,**问题描述 / Problem Description**,212
|
| 215 |
+
213,[FEATURE] 安装,为什么conda create要额外指定路径 用-p ,而不是默认的/envs下面,2023-05-28.04,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/481,##**功能描述 / Feature Description**,213
|
| 216 |
+
214,[小白求助] 通过Anaconda执行webui.py后,无法打开web链接,2023-05-28.04,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/485,在执行webui.py命令后,http://0.0.0.0:7860复制到浏览器后无法打开,显示“无法访问此网站”。,214
|
| 217 |
+
215,[BUG] 使用 p-tuningv2后的模型,重新加载报错,2023-05-29.04,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/486,把p-tunningv2训练完后的相关文件放到了p-tunningv2文件夹下,勾选使用p-tuningv2点重新加载模型,控制台输错错误信息:,215
|
| 218 |
+
216,[小白求助] 服务器上执行webui.py后,在本地无法打开web链接,2023-05-29.04,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/487,此项目执行在xxx.xx.xxx.xxx服务器上,我在webui.py上的代码为 (demo,216
|
| 219 |
+
217,[FEATURE] 能不能支持VisualGLM-6B,2023-05-29.04,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/488,**功能描述 / Feature Description**,217
|
| 220 |
+
218,你好,问一下各位,后端api部署的时候,支持多用户同时问答吗???,2023-05-29.04,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/489,支持多用户的话,最多支持多少用户问答?根据硬件而定吧?,218
|
| 221 |
+
219,V100GPU显存占满,而利用率却为0,这是为什么?,2023-05-29.04,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/491,"<img width=""731"" alt=""de45fe2b6cb76fa091b6e8f76a3de60"" src=""https://github.com/imClumsyPanda/langchain-ChatGLM/assets/109277248/c32efd52-7dbf-4e9b-bd4d-0944d73d0b8b"">",219
|
| 222 |
+
220,[求助] 如果在公司内部搭建产品知识库,使用INT-4模型,200人规模需要配置多少显存的服务器?,2023-05-29.04,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/492,如题,计划给公司搭一个在线知识库。,220
|
| 223 |
+
221,你好,请教个问题,目前问答回复需要20秒左右,如何提高速度?V10032G服务器。,2023-05-29.04,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/493,**问题描述 / Problem Description**,221
|
| 224 |
+
222,[FEATURE] 如何实现只匹配下文,而不要上文的结果,2023-05-29.04,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/494,在构建自己的知识库时,主要采用问答对的形式,那么也就是我需要的回答是在我的问题下面的内容,但是目前设置了chunk_size的值以后匹配的是上下文的内容,但我实际并不需要上文的。为了实现更完整的展示下面的答案,我只能调大chunk_size的值,但实际上上文的一半内容都是我不需要的。也就是扔了一半没用的东西给prompt,在faiss.py中我也没找到这块的一些描述,请问该如何进行修改呢?,222
|
| 225 |
+
223,你好,问一下,我调用api.py部署,为什么用ip加端口可以使用postman调用,而改为域名使用postman无法调用?,2023-05-30.04,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/497,,223
|
| 226 |
+
224,调用api.py中的stream_chat,返回source_documents中出现中文乱码。,2023-05-30.04,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/498,-------------------------------------------------------------------------------,224
|
| 227 |
+
225,[BUG] 捉个虫,api.py中的stream_chat解析json问题,2023-05-30.05,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/501,**问题描述 / Problem Description**,225
|
| 228 |
+
226,windows本地部署遇到了omp错误,2023-05-31.05,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/502,**问题描述 / Problem Description**,226
|
| 229 |
+
227,"[BUG] bug14 ,""POST /local_doc_qa/upload_file HTTP/1.1"" 422 Unprocessable Entity",2023-05-31.05,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/503,上传的文件报错,返回错误,api.py,227
|
| 230 |
+
228,你好,请教个问题,api.py部署的时候,如何改为多线程调用?谢谢,2023-05-31.05,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/505,目前的api.py脚本不支持多线程,228
|
| 231 |
+
229,你好,请教一下。api.py部署的时候,能不能提供给后端流失返回结果。,2023-05-31.05,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/507,curl -X 'POST' \,229
|
| 232 |
+
230,流式输出,流式接口,使用server-sent events技术。,2023-05-31.05,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/508,想这样一样,https://blog.csdn.net/weixin_43228814/article/details/130063010,230
|
| 233 |
+
231,计划增加流式输出功能吗?ChatGLM模型通过api方式调用响应时间慢怎么破,Fastapi流式接口来解惑,能快速提升响应速度,2023-05-31.05,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/509,**问题描述 / Problem Description**,231
|
| 234 |
+
232,[BUG] 知识库上传时发生ERROR (could not open xxx for reading: No such file or directory),2023-05-31.05,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/510,**问题描述 / Problem Description**,232
|
| 235 |
+
233,api.py脚本打算增加SSE流式输出吗?,2023-05-31.05,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/511,curl调用的时候可以检测第一个字,从而提升回复的体验,233
|
| 236 |
+
234,[BUG] 使用tornado实现webSocket,可以多个客户端同时连接,并且实现流式回复,但是多个客户端同时使用,答案就很乱,是模型不支持多线程吗,2023-05-31.05,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/512,import asyncio,234
|
| 237 |
+
235,支持 chinese_alpaca_plus_lora 吗 基于llama的,2023-06-01.05,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/514,支持 chinese_alpaca_plus_lora 吗 基于llama的,https://github.com/ymcui/Chinese-LLaMA-Alpaca这个项目的,235
|
| 238 |
+
236,[BUG] 现在能读图片的pdf了,但是文字的pdf反而读不了了,什么情况???,2023-06-01.05,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/515,**问题描述 / Problem Description**,236
|
| 239 |
+
237,在推理的过程中卡住不动,进程无法正常结束,2023-06-01.05,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/516,**问题描述 / Problem Description**,237
|
| 240 |
+
238,curl调用的时候,从第二轮开始,curl如何传参可以实现多轮对话?,2023-06-01.05,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/517,第一轮调用:,238
|
| 241 |
+
239,建议添加api.py部署后的日志管理功能?,2023-06-01.05,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/518,-------------------------------------------------------------------------------,239
|
| 242 |
+
240,有大佬知道,怎么多线程部署api.py脚本吗?,2023-06-01.05,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/519,api.py部署��,使用下面的请求,时间较慢,好像是单线程,如何改为多线程部署api.py:,240
|
| 243 |
+
241,[BUG] 上传文件到知识库 任何格式与内容都永远失败,2023-06-01.05,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/520,上传知识库的时候,传txt无法解析,就算是穿content/sample里的样例txt也无法解析,上传md、pdf等都无法加载,会持续性等待,等到了超过30分钟也不行。,241
|
| 244 |
+
242,关于prompt_template的问题,2023-06-01.05,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/521,请问这段prompt_template是什么意思,要怎么使用?可以给一个具体模板参考下吗?,242
|
| 245 |
+
243,[BUG] 简洁阐述问题 / Concise description of the issue,2023-06-01.05,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/522,**问题描述 / Problem Description**,243
|
| 246 |
+
244,"中文分词句号处理(关于表达金额之间的""."")",2023-06-02.05,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/523,建议处理12.6亿元的这样的分词,最好别分成12 和6亿这样的,需要放到一起,244
|
| 247 |
+
245,ImportError: cannot import name 'inference' from 'paddle',2023-06-02.05,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/526,在网上找了一圈,有说升级paddle的,我做了还是没有用,有说安装paddlepaddle的,我找了豆瓣的镜像源,但安装报错cannot detect archive format,245
|
| 248 |
+
246,[BUG] webscoket 接口串行问题(/local_doc_qa/stream-chat/{knowledge_base_id}),2023-06-02.05,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/527,**问题描述 / Problem Description**,246
|
| 249 |
+
247,[FEATURE] 刷新页面更新知识库列表,2023-06-02.05,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/528,**功能描述以及改进方案**,247
|
| 250 |
+
248,[BUG] 使用ptuning微调模型后,问答效果并不好,2023-06-02.05,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/530,### 未调用ptuning,248
|
| 251 |
+
249,[BUG] 多轮对话效果不佳,2023-06-02.05,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/532,在进行多轮对话的时候,无论设置的history_len是多少,效果都不好。事实上我将其设置成了最大值10,但在对话中,仍然无法实现多轮对话:,249
|
| 252 |
+
250,"RuntimeError: MPS backend out of memory (MPS allocated: 18.00 GB, other allocations: 4.87 MB, max allowed: 18.13 GB)",2023-06-02.05,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/533,**问题描述**,250
|
| 253 |
+
251, 请大家重视这个issue!真正使用肯定是多用户并发问答,希望增加此功能!!!,2023-06-02.05,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/534,这得看你有多少显卡,251
|
| 254 |
+
252,在启动项目的时候如何使用到多张gpu啊?,2023-06-02.05,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/535,**在启动项目的时候如何使用到多张gpu啊?**,252
|
| 255 |
+
253, 使用流式输出的时候,curl调用的格式是什么?,2023-06-02.05,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/536,"app.websocket(""/local_doc_qa/stream-chat/{knowledge_base_id}"")(stream_chat)中的knowledge_base_id应该填什么???",253
|
| 256 |
+
254,使用本地 vicuna-7b模型启动错误,2023-06-02.05,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/538,环境: ubuntu 22.04 cuda 12.1 没有安装nccl,使用rtx2080与m60显卡并行计算,254
|
| 257 |
+
255,为什么会不调用GPU直接调用CPU呢,2023-06-02.05,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/539,我的阿里云配置是16G显存,用默认代码跑webui.py时提示,255
|
| 258 |
+
256,上传多个文件时会互相覆盖,2023-06-03.05,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/541,1、在同一个知识库中上传多个文件时会互相覆盖,无法结合多个文档的知识,有大佬知道怎么解决吗?,256
|
| 259 |
+
257,[BUG] ‘gcc’不是内部或外部命令/LLM对话只能持续一轮,2023-06-03.05,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/542,No compiled kernel found.,257
|
| 260 |
+
258,以API模式启动项目却没有知识库的接口列表?,2023-06-04.05,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/544,请问如何获取知识库的接口列表?如果没有需要自行编写的话,可不可以提供相关的获取方式,感谢,258
|
| 261 |
+
259,程序以API模式启动的时候,如何才能让接口以stream模式被调用呢?,2023-06-05.05,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/546,作者您好,我在以API模式进行程序启动后,我发现接口响应时间很长,怎么样才能让接口以stream模式被调用呢?我想实现像webui模式的回答那样,259
|
| 262 |
+
260,关于原文中表格转为文本后数据相关度问题。,2023-06-06.05,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/547,原文中表格数据转换为文本,以 (X-Y:值;...) 的格式每一行组织成一句话,但这样做后发现相关度较低,效果很差,有何好的方案吗?,260
|
| 263 |
+
261,启动后LLM和知识库问答模式均只有最后一轮记录,2023-06-06.05,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/548,拉取最新代码,问答时,每次页面只显示最后一次问答记录,需要修改什么参数才可以保留历史记录?,261
|
| 264 |
+
262,提供system message配置,以便于让回答不要超出知识库范围,2023-06-06.05,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/549,**功能描述 / Feature Description**,262
|
| 265 |
+
263,[BUG] 使用p-tunningv2报错,2023-06-06.05,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/551,按照readme的指示把p-tunningv2训练完后的文件放到了p-tunningv2文件夹下,勾选使用p-tuningv2点重新加载模型,控制台提示错误信息:,263
|
| 266 |
+
264,[BUG] 智障,这么多问题,也好意思放出来,浪费时间,2023-06-06.05,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/553,。。。,264
|
| 267 |
+
265,[FEATURE] 我看代码文件中有一个ali_text_splitter.py,为什么不用他这个文本分割器了?,2023-06-06.05,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/554,我看代码文件中有一个ali_text_splitter.py,为什么不用他这个文本分割器了?,265
|
| 268 |
+
266,加载文档函数报错,2023-06-06.05,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/557,"def load_file(filepath, sentence_size=SENTENCE_SIZE):",266
|
| 269 |
+
267,参考指引安装docker后,运行cli_demo.py,提示killed,2023-06-06.05,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/558,root@b3d1bd08095c:/chatGLM# python3 cli_demo.py,267
|
| 270 |
+
268,注意:如果安装错误,注意这两个包的版本 wandb==0.11.0 protobuf==3.18.3,2023-06-06.05,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/559,Error1: 如果启动异常报错 `protobuf` 需要更新到 `protobuf==3.18.3 `,268
|
| 271 |
+
269,知识库对长文的知识相关度匹配不太理想有何优化方向,2023-06-07.05,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/563,我们可能录入一个文章有 1W 字,里面涉及这个文章主题的很多角度问题,我们针对他提问,他相关度匹配的内容和实际我们需要的答案相差很大怎么办。,269
|
| 272 |
+
270,使用stream-chat函数进行流式输出的时候,能使用curl调用吗?,2023-06-07.05,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/565,为什么下面这样调用会报错???,270
|
| 273 |
+
271,有大佬实践过 并行 或者 多线程 的部署方案吗?,2023-06-07.05,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/566,+1,271
|
| 274 |
+
272,多线程部署遇到问题?,2023-06-07.05,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/567,"<img width=""615"" alt=""3d87bf74f0cf1a4820cc9e46b245859"" src=""https://github.com/imClumsyPanda/langchain-ChatGLM/assets/109277248/8787570d-88bd-434e-aaa4-cb9276d1aa50"">",272
|
| 275 |
+
273,[BUG] 用fastchat加载vicuna-13b模型进行知识库的问答有token的限制错误,2023-06-07.05,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/569,当我开启fastchat的vicuna-13b的api服务,然后config那里配置好(api本地测试过可以返回结果),然后知识库加载好之后(知识库大概有1000多个文档,用chatGLM可以正常推理),进行问答时出现token超过限制,就问了一句hello;,273
|
| 276 |
+
274,现在的添加知识库,文件多了总是报错,也不知道自己加载了哪些文件,报错后也不知道是全部失败还是一部分成功;希望能有个加载指定文件夹作为知识库的功能,2023-06-07.05,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/574,**功能描述 / Feature Description**,274
|
| 277 |
+
275,[BUG] moss模型本地加载报错,2023-06-08.05,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/577,moss模型本地加载报错:,275
|
| 278 |
+
276,加载本地moss模型报错Can't instantiate abstract class MOSSLLM with abstract methods _history_len,2023-06-08.05,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/578,(vicuna) ps@ps[13:56:20]:/data/chat/langchain-ChatGLM2/langchain-ChatGLM-0.1.13$ python webui.py --model-dir local_models --model moss --no-remote-model,276
|
| 279 |
+
277,[FEATURE] 能增加在前端页面控制prompt_template吗?或是能支持前端页面选择使用哪个prompt?,2023-06-08.05,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/579,目前只能在config里修改一个prompt,想在多个不同场景切换比较麻烦,277
|
| 280 |
+
278,[BUG] streamlit ui的bug,在增加知识库时会报错,2023-06-08.05,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/580,**问题描述 / Problem Description**,278
|
| 281 |
+
279,[FEATURE] webui/webui_st可以支持history吗?目前仅能一次对话,2023-06-08.05,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/581,试了下webui和webui_st都不支持历史对话啊,只能对话一次,不能默认开启所有history吗?,279
|
| 282 |
+
280,启动python cli_demo.py --model chatglm-6b-int4-qe报错,2023-06-09.05,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/585,下载好模型,和相关依赖环境,之间运行`python cli_demo.py --model chatglm-6b-int4-qe`报错了:,280
|
| 283 |
+
281,重新构建知识库报错,2023-06-09.05,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/586,**问题描述 / Problem Description**,281
|
| 284 |
+
282,[FEATURE] 能否屏蔽paddle,我不需要OCR,效果差依赖环境还很复杂,2023-06-09.05,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/587,希望能不依赖paddle,282
|
| 285 |
+
283,question :文档向量化这个可以自己手动实现么?,2023-06-09.05,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/589,现有公司级数据500G+,需要使用这个功能,请问如何手动实现这个向量化,然后并加载,283
|
| 286 |
+
284,view前端能进行流式的返回吗??,2023-06-09.05,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/590,view前端能进行流式的返回吗??,284
|
| 287 |
+
285,"[BUG] Load parallel cpu kernel failed, using default cpu kernel code",2023-06-11.05,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/594,**问题描述 / Problem Description**,285
|
| 288 |
+
286,[BUG] 简洁阐述问题 / Concise description of the issue,2023-06-11.05,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/595,**问题描述 / Problem Description**,286
|
| 289 |
+
287,我在上传本地知识库时提示KeyError: 'name'错误,本地知识库都是.txt文件,文件数量大约是2000+。,2023-06-12.05,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/597,"<img width=""649"" alt=""KError"" src=""https://github.com/imClumsyPanda/langchain-ChatGLM/assets/59411575/1ecc8182-aeee-4a0a-bbc3-74c2f1373f2d"">",287
|
| 290 |
+
288,model_config.py中有vicuna-13b-hf模型的配置信息,但是好像还是不可用?,2023-06-12.06,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/600,@dongyihua543,288
|
| 291 |
+
289,"ImportError: Using SOCKS proxy, but the 'socksio' package is not installed. Make sure to install httpx using `pip install httpx[socks]`.",2023-06-12.06,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/605,应该代理问题,但是尝试了好多方法都解决不了,,289
|
| 292 |
+
290,[BUG] similarity_search_with_score_by_vector在找不到匹配的情况下出错,2023-06-12.06,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/607,在设置匹配阈值 VECTOR_SEARCH_SCORE_THRESHOLD 的情况下,vectorstore会返回空,此时上述处理函数会出错,290
|
| 293 |
+
291,[FEATURE] 请问如何搭建英文知识库呢,2023-06-12.06,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/609,**功能描述 / Feature Description**,291
|
| 294 |
+
292,谁有vicuna权重?llama转换之后的,2023-06-13.06,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/611,**问题描述 / Problem Description**,292
|
| 295 |
+
293,[FEATURE] API能实现上传文件夹的功能么?,2023-06-13.06,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/612,用户懒得全选所有的文件,就想上传个文件夹,请问下API能实现这个功能么?,293
|
| 296 |
+
294,请问在多卡部署后,上传单个文件作为知识库,用的是单卡在生成向量还是多卡?,2023-06-13.06,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/614,目前我检测我本地多卡部署的,好像生成知识库向量的时候用的还是单卡,294
|
| 297 |
+
295,[BUG] python webui.py提示非法指令,2023-06-13.06,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/615,(/data/conda-langchain [root@chatglm langchain-ChatGLM]# python webui.py,295
|
| 298 |
+
296,知识库文件跨行切分问题,2023-06-13.06,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/616,我的知识库文件txt文件,是一行一条知识,用\n分行。,296
|
| 299 |
+
297,[FEATURE] bing搜索问答有流式的API么?,2023-06-13.06,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/617,web端是有这个bing搜索回答,但api接口没有发现,大佬能给个提示么?,297
|
| 300 |
+
298,希望出一个macos m2的安装教程,2023-06-14.06,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/620,mac m2安装,模型加载成功了,知识库文件也上传成功了,但是一问答就会报错,报错内容如下,298
|
| 301 |
+
299,为【出处】提供高亮显示,2023-06-14.06,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/621,具体出处里面,对相关的内容高亮显示,不包含前后文。,299
|
| 302 |
+
300,[BUG] CPU运行cli_demo.py,不回答,hang住,2023-06-14.06,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/622,没有GPU;32G内存的ubuntu机器。,300
|
| 303 |
+
301,关于删除知识库里面的文档后,LLM知识库对话的时候还是会返回该被删除文档的内容,2023-06-14.06,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/623,如题,在vue前端成功执行删除知识库里面文档A.txt后,未能也在faiss索引中也删除该文档,LLM还是会返回这个A.txt的内容,并且以A.txt为出处,未能达到删除的效果,301
|
| 304 |
+
302,"[BUG] 调用知识库进行问答,显存会一直叠加",2023-06-14.06,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/625,"14G的显存,调用的chatglm-6b-int8模型,进行知识库问答时,最多问答四次就会爆显存了,观察了一下显存使用情况,每一次使用就会增加一次显存,请问这样是正常的吗?是否有什么配置需要开启可以解决���个问题?例如进行一次知识库问答清空上次问题的显存?",302
|
| 305 |
+
303,[BUG] web页面 重新构建数据库 失败,导致 原来的上传的数据库都没了,2023-06-14.06,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/626,web页面 重新构建数据库 失败,导致 原来的上传的数据库都没了,303
|
| 306 |
+
304,在CPU上运行webui.py报错Tensor on device cpu is not on the expected device meta!,2023-06-14.06,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/627,在CPU上运行python webui.py能启动,但最后有:RuntimeError: Tensor on device cpu is not on the expected device meta!,304
|
| 307 |
+
305,"OSError: [WinError 1114] 动态链接库(DLL)初始化例程失败。 Error loading ""E:\xxx\envs\langchain\lib\site-packages\torch\lib\caffe2_nvrtc.dll"" or one of its dependencies.哪位大佬知道如何解决吗?",2023-06-14.06,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/629,**问题描述 / Problem Description**,305
|
| 308 |
+
306,[BUG] WEBUI删除知识库文档,会导致知识库问答失败,2023-06-15.06,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/632,如题,从知识库已有文件中选择要删除的文件,点击删除后,在问答框输入内容回车报错,306
|
| 309 |
+
307,更新后的版本中,删除知识库中的文件,再提问出现error错误,2023-06-15.06,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/634,针对更新版本,识别到一个问题,过程如下:,307
|
| 310 |
+
308,我配置好了环境,想要实现本地知识库的问答?可是它返回给我的,2023-06-15.06,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/637,没有总结,只有相关度的回复,但是我看演示里面表现的,回复是可以实现总结的,我去查询代码,308
|
| 311 |
+
309,[BUG] NPM run dev can not successfully start the VUE frontend,2023-06-15.06,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/638,**问题描述 / Problem Description**,309
|
| 312 |
+
310,[BUG] 简洁阐述问题 / Concise description of the issue,2023-06-15.06,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/639,**问题描述 / Problem Description**,310
|
| 313 |
+
311,提一个模型加载的bug,我在截图中修复了,你们有空可以看一下。,2023-06-15.06,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/642,,311
|
| 314 |
+
312,[求助]关于设置embedding model路径的问题,2023-06-16.06,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/643,如题,我之前成功跑起来过一次,但因环境丢失重新配置 再运行webui就总是报错,312
|
| 315 |
+
313,Lora微调后的模型可以直接使用吗,2023-06-16.06,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/646,看model_config.py里是有USE_LORA这个参数的,但是在cli_demo.py和webui.py这两个里面都没有用到,实际测试下来模型没有微调的效果,想问问现在这个功能实现了吗,313
|
| 316 |
+
314,write_check_file在tmp_files目录下生成的load_file.txt是否需要一直保留,占用空间很大,在建完索引后能否删除,2023-06-16.06,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/647,**功能描述 / Feature Description**,314
|
| 317 |
+
315,[BUG] /local_doc_qa/list_files?knowledge_base_id=test删除知识库bug,2023-06-16.06,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/649,1.新建test知识库并上传文件(在vue前端完成并检查后端发现确实生成了test文件夹以及下面的content和vec_store,315
|
| 318 |
+
316,[BUG] vue webui无法加载知识库,2023-06-16.06,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/650,拉取了最新的代码,分别运行了后端api和前端web,点击知识库,始终只能显示simple,无法加载知识库,316
|
| 319 |
+
317,不能本地加载moss模型吗?,2023-06-16.06,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/652,手动下载模型设置local_model_path路径依旧提示缺少文件,该如何正确配置?,317
|
| 320 |
+
318,macos m2 pro docker 安装失败,2023-06-17.06,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/654,macos m2 pro docker 安装失败,318
|
| 321 |
+
319, [BUG] mac m1 pro 运行提示 zsh: segmentation fault,2023-06-17.06,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/655,运行: python webui.py,319
|
| 322 |
+
320,安装 requirements 报错,2023-06-17.06,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/656,(langchainchatglm) D:\github\langchain-ChatGLM>pip install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple/,320
|
| 323 |
+
321,[BUG] AssertionError,2023-06-17.06,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/658,**问题描述 / Problem Description**,321
|
| 324 |
+
322,[FEATURE] 支持AMD win10 本地部署吗?,2023-06-18.06,https://github.com/imClumsyPanda/langchain-ChatGLM/issues/660,**功能描述 / Feature Description**,322
|
knowledge_base/samples/isssues_merge/langchain-ChatGLM_open.jsonl
ADDED
|
@@ -0,0 +1,323 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{"title": "效果如何优化", "file": "2023-04-04.00", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/14", "detail": "如图所示,将该项目的README.md和该项目结合后,回答效果并不理想,请问可以从哪些方面进行优化", "id": 0}
|
| 2 |
+
{"title": "怎么让模型严格根据检索的数据进行回答,减少胡说八道的回答呢", "file": "2023-04-04.00", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/15", "detail": "举个例子:", "id": 1}
|
| 3 |
+
{"title": "When I try to run the `python knowledge_based_chatglm.py`, I got this error in macOS(M1 Max, OS 13.2)", "file": "2023-04-07.00", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/32", "detail": "```python", "id": 2}
|
| 4 |
+
{"title": "萌新求教大佬怎么改成AMD显卡或者CPU?", "file": "2023-04-10.00", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/48", "detail": "把.cuda()去掉就行", "id": 3}
|
| 5 |
+
{"title": "输出answer的时间很长,是否可以把文本向量化的部分提前做好存储起来?", "file": "2023-04-10.00", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/50", "detail": "GPU:4090 24G显存", "id": 4}
|
| 6 |
+
{"title": "报错Use `repo_type` argument if needed.", "file": "2023-04-11.00", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/57", "detail": "Traceback (most recent call last):", "id": 5}
|
| 7 |
+
{"title": "无法打开gradio的页面", "file": "2023-04-11.00", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/58", "detail": "$ python webui.py", "id": 6}
|
| 8 |
+
{"title": "支持word,那word里面的图片正常显示吗?", "file": "2023-04-12.00", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/60", "detail": "如题,刚刚从隔壁转过来的,想先了解下", "id": 7}
|
| 9 |
+
{"title": "detectron2 is not installed. Cannot use the hi_res partitioning strategy. Falling back to partitioning with the fast strategy.", "file": "2023-04-12.00", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/63", "detail": "能够正常的跑起来,在加载content文件夹中的文件时,每加载一个文件都会提示:", "id": 8}
|
| 10 |
+
{"title": "cpu上运行webui,step3 asking时报错", "file": "2023-04-12.00", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/66", "detail": "web运行,文件加载都正常,asking时报错", "id": 9}
|
| 11 |
+
{"title": "建议弄一个插件系统", "file": "2023-04-13.00", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/67", "detail": "如题弄成stable-diffusion-webui那种能装插件,再开一个存储库给使用者或插件开发,存储或下载插件。", "id": 10}
|
| 12 |
+
{"title": "请教加载模型出错!?", "file": "2023-04-13.00", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/75", "detail": "AttributeError: module 'transformers_modules.chatglm-6b.configuration_chatglm' has no attribute 'ChatGLMConfig 怎么解决呀", "id": 11}
|
| 13 |
+
{"title": "从本地知识检索内容的时候,是否可以设置相似度阈值,小于这个阈值的内容不返回,即使会小于设置的VECTOR_SEARCH_TOP_K参数呢?谢谢大佬", "file": "2023-04-13.00", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/76", "detail": "比如 问一些 你好/你是谁 等一些跟本地知识库无关的问题", "id": 12}
|
| 14 |
+
{"title": "如何改成多卡推理?", "file": "2023-04-13.00", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/77", "detail": "+1", "id": 13}
|
| 15 |
+
{"title": "能否弄个懒人包,可以一键体验?", "file": "2023-04-13.00", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/78", "detail": "能否弄个懒人包,可以一键体验?", "id": 14}
|
| 16 |
+
{"title": "连续问问题会导致崩溃", "file": "2023-04-13.00", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/79", "detail": "看上去不是爆内存的问题,连续问问题后,会出现如下报错", "id": 15}
|
| 17 |
+
{"title": "AttributeError: 'NoneType' object has no attribute 'as_retriever'", "file": "2023-04-14.00", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/86", "detail": "环境:windows 11, anaconda/python 3.8", "id": 16}
|
| 18 |
+
{"title": "FileNotFoundError: Could not find module 'nvcuda.dll' (or one of its dependencies). Try using the full path with constructor syntax.", "file": "2023-04-14.00", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/87", "detail": "请检查一下cuda或cudnn是否存在安装问题", "id": 17}
|
| 19 |
+
{"title": "加载txt文件失败?", "file": "2023-04-14.00", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/89", "detail": "", "id": 18}
|
| 20 |
+
{"title": "NameError: name 'chatglm' is not defined", "file": "2023-04-14.00", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/90", "detail": "This share link expires in 72 hours. For free permanent hosting and GPU upgrades (NEW!), check out Spaces: https://huggingface.co/spaces", "id": 19}
|
| 21 |
+
{"title": "打不开地址?", "file": "2023-04-14.00", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/91", "detail": "报错数据如下:", "id": 20}
|
| 22 |
+
{"title": "加载md文件出错", "file": "2023-04-14.00", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/98", "detail": "运行 webui.py后能访问页面,上传一个md文件后,日志中有错误。等待后能加载完成,提示可以提问了,但提问没反应,日志中有错误。 具体日志如下。", "id": 21}
|
| 23 |
+
{"title": "建议增加获取在线知识的能力", "file": "2023-04-15.01", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/101", "detail": "建议增加获取在线知识的能力", "id": 22}
|
| 24 |
+
{"title": "txt 未能成功加载", "file": "2023-04-15.01", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/103", "detail": "hinese. Creating a new one with MEAN pooling.", "id": 23}
|
| 25 |
+
{"title": "pdf加载失败", "file": "2023-04-15.01", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/105", "detail": "e:\\a.txt加载成功了,e:\\a.pdf加载就失败,pdf文件里面前面几页是图片,后面都是文字,加载失败没有报更多错误,请问该怎么排查?", "id": 24}
|
| 26 |
+
{"title": "一直停在文本加载处", "file": "2023-04-15.01", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/108", "detail": "一直停在文本加载处", "id": 25}
|
| 27 |
+
{"title": " File \"/root/.cache/huggingface/modules/transformers_modules/chatglm-6b/modeling_chatglm.py\", line 440, in forward new_tensor_shape = mixed_raw_layer.size()[:-1] + ( TypeError: torch.Size() takes an iterable of 'int' (item 2 is 'float')", "file": "2023-04-17.01", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/113", "detail": "按照最新的代码,发现", "id": 26}
|
| 28 |
+
{"title": "后续会提供前后端分离的功能吗?", "file": "2023-04-17.01", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/114", "detail": "类似这种https://github.com/lm-sys/FastChat/tree/main/fastchat/serve", "id": 27}
|
| 29 |
+
{"title": "安装依赖报错", "file": "2023-04-17.01", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/115", "detail": "(test) C:\\Users\\linh\\Desktop\\langchain-ChatGLM-master>pip install -r requirements.txt", "id": 28}
|
| 30 |
+
{"title": "问特定问题会出现爆显存", "file": "2023-04-17.01", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/117", "detail": "正常提问没问题。", "id": 29}
|
| 31 |
+
{"title": "Expecting value: line 1 column 1 (char 0)", "file": "2023-04-17.01", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/118", "detail": "运行后 第一步加载配置一直报错:", "id": 30}
|
| 32 |
+
{"title": "embedding https://huggingface.co/GanymedeNil/text2vec-large-chinese/tree/main是免费的,效果比对openai的如何?", "file": "2023-04-17.01", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/119", "detail": "-------------------------------------------------------------------------------", "id": 31}
|
| 33 |
+
{"title": "这是什么错误,在Colab上运行的。", "file": "2023-04-17.01", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/120", "detail": "libcuda.so.1: cannot open shared object file: No such file or directory", "id": 32}
|
| 34 |
+
{"title": "只想用自己的lora微调后的模型进行对话,不想加载任何本地文档,该如何调整?", "file": "2023-04-18.01", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/121", "detail": "能出一个单独的教程吗", "id": 33}
|
| 35 |
+
{"title": "租的gpu,Running on local URL: http://0.0.0.0:7860 To create a public link, set `share=True` in `launch()`. 浏览器上访问不了???", "file": "2023-04-18.01", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/122", "detail": "(chatglm20230401) root@autodl-container-e82d11963c-10ece0d7:~/autodl-tmp/chatglm/langchain-ChatGLM-20230418# python3.9 webui.py", "id": 34}
|
| 36 |
+
{"title": "本地部署中的报错请教", "file": "2023-04-18.01", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/124", "detail": "您好,在本地运行langchain-ChatGLM过程中,环境及依赖的包都已经满足条件,但是运行webui.py,报错如下(运行cli_demo.py报错类似),请问是哪里出了错呢?盼望您的回复,谢谢!", "id": 35}
|
| 37 |
+
{"title": "报错。The dtype of attention mask (torch.int64) is not bool", "file": "2023-04-18.01", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/131", "detail": "The dtype of attention mask (torch.int64) is not bool", "id": 36}
|
| 38 |
+
{"title": "[求助] pip install -r requirements.txt 的时候出现以下报错。。。有大佬帮忙看看怎么搞么,下的release里面的包", "file": "2023-04-18.01", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/134", "detail": "$ pip install -r requirements.txt", "id": 37}
|
| 39 |
+
{"title": "如何提升根据��题搜索到对应知识的准确率", "file": "2023-04-19.01", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/136", "detail": "外链知识库最大的问题在于问题是短文本,知识是中长文本。如何根据问题精准的搜索到对应的知识是个最大的问题。这类本地化项目不像百度,由无数的网页,基本上每个问题都可以找到对应的页面。", "id": 38}
|
| 40 |
+
{"title": "是否可以增加向量召回的阈值设定,有些召回内容相关性太低,导致模型胡言乱语", "file": "2023-04-20.01", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/140", "detail": "如题", "id": 39}
|
| 41 |
+
{"title": "输入长度问题", "file": "2023-04-20.01", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/141", "detail": "感谢作者支持ptuning微调模型。", "id": 40}
|
| 42 |
+
{"title": "已有部署好的chatGLM-6b,如何通过接口接入?", "file": "2023-04-20.01", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/144", "detail": "已有部署好的chatGLM-6b,如何通过接口接入,而不是重新加载一个模型;", "id": 41}
|
| 43 |
+
{"title": "执行web_demo.py后,显示Killed,就退出了,是不是配置不足呢?", "file": "2023-04-20.01", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/146", "detail": "", "id": 42}
|
| 44 |
+
{"title": "执行python cli_demo1.py", "file": "2023-04-20.01", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/147", "detail": "Traceback (most recent call last):", "id": 43}
|
| 45 |
+
{"title": "报错:ImportError: cannot import name 'GENERATION_CONFIG_NAME' from 'transformers.utils'", "file": "2023-04-20.01", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/149", "detail": "(mychatGLM) PS D:\\Users\\admin3\\zrh\\langchain-ChatGLM> python cli_demo.py", "id": 44}
|
| 46 |
+
{"title": "上传文件并加载知识库时,会不停地出现临时文件", "file": "2023-04-21.01", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/153", "detail": "环境:ubuntu 18.04", "id": 45}
|
| 47 |
+
{"title": "向知识库中添加文件后点击”上传文件并加载知识库“后Segmentation fault报错。", "file": "2023-04-23.01", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/161", "detail": "运行服务后的提示如下:", "id": 46}
|
| 48 |
+
{"title": "langchain-serve 集成", "file": "2023-04-24.01", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/162", "detail": "Hey 我是来自 [langchain-serve](https://github.com/jina-ai/langchain-serve) 的dev!", "id": 47}
|
| 49 |
+
{"title": "大佬们,wsl的ubuntu怎么配置用cuda加速,装了运行后发现是cpu在跑", "file": "2023-04-24.01", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/164", "detail": "大佬们,wsl的ubuntu怎么配置用cuda加速,装了运行后发现是cpu在跑", "id": 48}
|
| 50 |
+
{"title": "在github codespaces docker运行出错", "file": "2023-04-24.01", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/165", "detail": "docker run -d --restart=always --name chatglm -p 7860:7860 -v /www/wwwroot/code/langchain-ChatGLM:/chatGLM chatglm", "id": 49}
|
| 51 |
+
{"title": "有计划接入Moss模型嘛", "file": "2023-04-24.01", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/166", "detail": "后续会开展测试,目前主要在优化langchain部分效果,如果有兴趣也欢迎提PR", "id": 50}
|
| 52 |
+
{"title": "怎么实现 API 部署?", "file": "2023-04-24.01", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/168", "detail": "利用 fastapi 实现 API 部署方式,具体怎么实现,有方法说明吗?", "id": 51}
|
| 53 |
+
{"title": " 'NoneType' object has no attribute 'message_types_by_name'报错", "file": "2023-04-24.01", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/169", "detail": "_HISTOGRAMPROTO = DESCRIPTOR.message_types_by_name['HistogramProto']", "id": 52}
|
| 54 |
+
{"title": "能否指定自己训练的text2vector模型?", "file": "2023-04-25.01", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/172", "detail": "请问大佬:", "id": 53}
|
| 55 |
+
{"title": "关于项目支持的模型以及quantization_bit潜在的影响的问题", "file": "2023-04-26.01", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/176", "detail": "作者您好~", "id": 54}
|
| 56 |
+
{"title": "运行python3.9 api.py WARNING: You must pass the application as an import string to enable 'reload' or 'workers'.", "file": "2023-04-26.01", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/179", "detail": "api.py文件最下面改成这样试试:", "id": 55}
|
| 57 |
+
{"title": "ValidationError: 1 validation error for HuggingFaceEmbeddings model_kwargs extra fields not permitted (type=value_error.extra)", "file": "2023-04-26.01", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/180", "detail": "ValidationError: 1 validation error for HuggingFaceEmbeddings", "id": 56}
|
| 58 |
+
{"title": "如果没有检索到相关性比较高的,回答“我不知道”", "file": "2023-04-26.01", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/181", "detail": "如果通过设计system_template,让模型在搜索到的文档都不太相关的情况下回答“我不知道”", "id": 57}
|
| 59 |
+
{"title": "请问如果不能联网,6B之类的文件从本地上传需要放到哪里", "file": "2023-04-26.01", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/182", "detail": "感谢大佬的项目,很有启发~", "id": 58}
|
| 60 |
+
{"title": "知识库问答--输入新的知识库名称是中文的话,会报error", "file": "2023-04-27.01", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/184", "detail": "知识库问答--输入新的知识库名称是中文的话,会报error,选择要加载的知识库那里也不显示之前添加的知识库", "id": 59}
|
| 61 |
+
{"title": "现在能通过问题匹配的相似度值,来直接返回文档中的文段,而不经过模型吗?因为有些答案在文档中,模型自己回答,不能回答文档中的答案", "file": "2023-04-27.01", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/186", "detail": "现在能通过问题匹配的相似度值,来直接返回文档中的文段,而不经过模型吗?因为有些答案在文档中,模型自己回答,不能回答文档中的答案。也就是说,提供向量检索回答+模型回答相结合的策略。如果相似度值高于一定数值,直接返回文档中的文本,没有高于就返回模型的回答或者不知道", "id": 60}
|
| 62 |
+
{"title": "TypeError: The type of ChatGLM.callback_manager differs from the new default value; if you wish to change the type of this field, please use a type annotation", "file": "2023-04-27.01", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/188", "detail": "Mac 运行 python3 ./webui.py 报 TypeError: The type of ChatGLM.callback_manager differs from the new default value; if you wish to change the type of this field, please use a type annotation", "id": 61}
|
| 63 |
+
{"title": "Not Enough Memory", "file": "2023-04-27.01", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/190", "detail": "运行命令行程序python cli_demo.py, 已经成功加载pdf文件, 报“DefaultCPUAllocator: not enough memory: you tried to allocate 458288380900 bytes”错误,请问哪里可以配置default memory", "id": 62}
|
| 64 |
+
{"title": "参与开发问题", "file": "2023-04-27.01", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/191", "detail": "1.是否需要进专门的开发群", "id": 63}
|
| 65 |
+
{"title": "对话框中代码片段格式需改进", "file": "2023-04-27.01", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/192", "detail": "最好能改进下输出代码片段的格式,目前输出的格式还不友好。", "id": 64}
|
| 66 |
+
{"title": "请问未来有可能支持belle吗", "file": "2023-04-28.01", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/195", "detail": "如题,谢谢大佬", "id": 65}
|
| 67 |
+
{"title": "TypeError: cannot unpack non-iterable NoneType object", "file": "2023-04-28.02", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/200", "detail": "When i tried to change the knowledge vector store through `init_knowledge_vector_store`, the error `TypeError: cannot unpack non-iterable NoneType object` came out.", "id": 66}
|
| 68 |
+
{"title": "生成结果", "file": "2023-04-28.02", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/202", "detail": "你好,想问一下langchain+chatglm-6B,找到相似匹配的prompt,是直接返回prompt对应的答案信息,还是chatglm-6B在此基础上自己优化答案?", "id": 67}
|
| 69 |
+
{"title": "在win、ubuntu下都出现这个错误:attributeerror: 't5forconditionalgeneration' object has no attribute 'stream_chat'", "file": "2023-04-29.02", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/207", "detail": "在win、ubuntu。下载完模型后,没办法修改代码以执行本地模型,每次都要重新输入路径; LLM 模型、Embedding 模型支持也都在官网下的,在其他项目(wenda)下可以使用", "id": 68}
|
| 70 |
+
{"title": "[FEATURE] knowledge_based_chatglm.py: renamed or missing?", "file": "2023-04-30.02", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/210", "detail": "Not found. Was it renamed? Or, is it missing? How can I get it?", "id": 69}
|
| 71 |
+
{"title": "sudo apt-get install -y nvidia-container-toolkit-base执行报错", "file": "2023-05-01.02", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/211", "detail": "**问题描述 / Problem Description**", "id": 70}
|
| 72 |
+
{"title": "效果不佳几乎答不上来", "file": "2023-05-01.02", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/212", "detail": "提供了50条问答的docx文件", "id": 71}
|
| 73 |
+
{"title": "有没有可能新增一个基于chatglm api调用的方式构建langchain", "file": "2023-05-02.02", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/218", "detail": "我有两台8G GPU/40G内存的服务器,一个台做成了chatglm的api ;想基于另外一台服务器部署langchain;网上好像没有类似的代码。", "id": 72}
|
| 74 |
+
{"title": "电脑是intel的集成显卡; 运行时告知我找不到nvcuda.dll,模型无法运行", "file": "2023-05-02.02", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/219", "detail": "您好,我的电脑是intel的集成显卡,不过CPU是i5-11400 @ 2.60GHz ,内存64G;", "id": 73}
|
| 75 |
+
{"title": "根据langchain官方的文档和使用模式,是否可以改Faiss为Elasticsearch?会需要做哪些额外调整?求解", "file": "2023-05-03.02", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/221", "detail": "本人新手小白,由于业务模式的原因(有一些自己的场景和优化),希望利用Elasticsearch做这个体系内部的检索机制,不知道是否可以替换,同时,还会涉及到哪些地方的改动?或者说可能会有哪些其他影响,希望作者和大佬们不吝赐教!", "id": 74}
|
| 76 |
+
{"title": "请问未来有可能支持t5吗", "file": "2023-05-04.02", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/224", "detail": "请问可能支持基於t5的模型吗?", "id": 75}
|
| 77 |
+
{"title": "[BUG] 内存溢出 / torch.cuda.OutOfMemoryError:", "file": "2023-05-04.02", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/229", "detail": "**问题描述 / Problem Description**", "id": 76}
|
| 78 |
+
{"title": "报错 No module named 'chatglm_llm'", "file": "2023-05-04.02", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/230", "detail": "明明已经安装了包,却在python里吊不出来", "id": 77}
|
| 79 |
+
{"title": "能出一个api部署的描述文档吗", "file": "2023-05-04.02", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/233", "detail": "**功能描述 / Feature Description**", "id": 78}
|
| 80 |
+
{"title": "使用docs/API.md 出错", "file": "2023-05-04.02", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/234", "detail": "使用API.md文档2种方法,出错", "id": 79}
|
| 81 |
+
{"title": "加载pdf文档报错?", "file": "2023-05-05.02", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/238", "detail": "ew one with MEAN pooling.", "id": 80}
|
| 82 |
+
{"title": "上传的本地知识文件后再次上传不能显示,只显示成功了一个,别的上传成功后再次刷新就没了", "file": "2023-05-05.02", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/239", "detail": "您好,项目有很大启发,感谢~", "id": 81}
|
| 83 |
+
{"title": "创建了新的虚拟环境,安装了相关包,并且自动下载了相关的模型,但是仍旧出现:OSError: Unable to load weights from pytorch checkpoint file for", "file": "2023-05-05.02", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/240", "detail": "", "id": 82}
|
| 84 |
+
{"title": "[BUG] 数据加载不进来", "file": "2023-05-05.02", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/243", "detail": "使用的.txt格式,utf-8编码,报以下错误", "id": 83}
|
| 85 |
+
{"title": "不能读取pdf", "file": "2023-05-05.02", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/244", "detail": "请问是webui还是cli_demo", "id": 84}
|
| 86 |
+
{"title": "本地txt文件有500M,加载的时候很慢,如何提高速度?", "file": "2023-05-06.02", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/251", "detail": "", "id": 85}
|
| 87 |
+
{"title": "[BUG] gradio上传知识库后刷新之后 知识库就不见了 只有重启才能看到之前的上传的知识库", "file": "2023-05-06.02", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/253", "detail": "gradio上传知识库后刷新之后 知识库就不见了 只有重启才能看到之前的上传的知识库", "id": 86}
|
| 88 |
+
{"title": "[FEATURE] 可以支持 OpenAI 的模型嘛?比如 GPT-3、GPT-3.5、GPT-4;embedding 增加 text-embedding-ada-002", "file": "2023-05-06.02", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/254", "detail": "**功能描述 / Feature Description**", "id": 87}
|
| 89 |
+
{"title": "[FEATURE] 能否增加对于milvus向量数据库的支持 / Concise description of the feature", "file": "2023-05-06.02", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/256", "detail": "**功能描述 / Feature Description**", "id": 88}
|
| 90 |
+
{"title": "CPU和GPU上跑,除了速度有区别,准确率效果回答上有区别吗?", "file": "2023-05-06.02", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/259", "detail": "理论上没有区别", "id": 89}
|
| 91 |
+
{"title": "m1,请问在生成回答时怎么看是否使用了mps or cpu?", "file": "2023-05-06.02", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/260", "detail": "m1,请问在生成回答时怎么看是否使用了mps or cpu?", "id": 90}
|
| 92 |
+
{"title": "知识库一刷新就没了", "file": "2023-05-07.02", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/263", "detail": "知识库上传后刷新就没了", "id": 91}
|
| 93 |
+
{"title": "本地部署报没有模型", "file": "2023-05-07.02", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/267", "detail": "建议在下载llm和embedding模型至本地后在configs/model_config中写入模型本地存储路径后再运行", "id": 92}
|
| 94 |
+
{"title": "[BUG] python3: can't open file 'webui.py': [Errno 2] No such file or directory", "file": "2023-05-08.02", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/269", "detail": "**问题描述 / Problem Description**", "id": 93}
|
| 95 |
+
{"title": "模块缺失提示", "file": "2023-05-08.02", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/271", "detail": "因为已有自己使用的docker环境,直接启动webui.py,提示", "id": 94}
|
| 96 |
+
{"title": "运行api.py后,执行curl -X POST \"http://127.0.0.1:7861\" 报错?", "file": "2023-05-08.02", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/272", "detail": "执行curl -X POST \"http://127.0.0.1:7861\" \\ -H 'Content-Type: application/json' \\ -d '{\"prompt\": \"你好\", \"history\": []}',报错怎么解决", "id": 95}
|
| 97 |
+
{"title": "[BUG] colab安装requirements提示protobuf版本问题?", "file": "2023-05-08.02", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/273", "detail": "pip's dependency resolver does not currently take into account all the packages that are installed. This behaviour is the source of the following dependency conflicts.", "id": 96}
|
| 98 |
+
{"title": "请问项目里面向量相似度使用了什么方法计算呀?", "file": "2023-05-08.02", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/275", "detail": "基本按照langchain里的FAISS.similarity_search_with_score_by_vector实现", "id": 97}
|
| 99 |
+
{"title": "[BUG] 安装detectron2后,pdf无法加载", "file": "2023-05-08.02", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/276", "detail": "**问题描述 / Problem Description**", "id": 98}
|
| 100 |
+
{"title": "[BUG] 使用ChatYuan-V2模型无法流式输出,会报错", "file": "2023-05-08.02", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/277", "detail": "一方面好像是ChatYuan本身不支持stream_chat,有人在clueai那边提了issue他们说还没开发,所以估计这个attribute调不起来;但是另一方面看报错好像是T5模型本身就不是decoder-only模型,所以不能流式输出吧(个人理解)", "id": 99}
|
| 101 |
+
{"title": "[BUG] 无法加载text2vec模型", "file": "2023-05-08.02", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/278", "detail": "**问题描述 / Problem Description**", "id": 100}
|
| 102 |
+
{"title": "请问能否增加网络搜索功能", "file": "2023-05-08.02", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/281", "detail": "请问能否增加网络搜索功能", "id": 101}
|
| 103 |
+
{"title": "[FEATURE] 结构化数据sql、excel、csv啥时会支持呐。", "file": "2023-05-08.02", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/283", "detail": "**功能描述 / Feature Description**", "id": 102}
|
| 104 |
+
{"title": "TypeError: ChatGLM._call() got an unexpected keyword argument 'stop'", "file": "2023-05-08.02", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/284", "detail": "No sentence-transformers model found with name D:\\DevProject\\langchain-ChatGLM\\GanymedeNil\\text2vec-large-chinese. Creating a new one with MEAN pooling.", "id": 103}
|
| 105 |
+
{"title": "关于api.py的一些bug和设计逻辑问题?", "file": "2023-05-09.02", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/285", "detail": "首先冒昧的问一下,这个api.py,开发者大佬们是在自己电脑上测试后确实没问题吗?", "id": 104}
|
| 106 |
+
{"title": "有没有租用的算力平台上,运行api.py后,浏览器http://localhost:7861/报错", "file": "2023-05-09.02", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/287", "detail": "是不是租用的gpu平台上都会出现这个问题???", "id": 105}
|
| 107 |
+
{"title": "请问一下项目中有用到文档段落切割方法吗?", "file": "2023-05-09.02", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/288", "detail": "text_load中的文档切割方法用上了吗?在代码中看好像没有用到?", "id": 106}
|
| 108 |
+
{"title": "报错 raise ValueError(f\"Knowledge base {knowledge_base_id} not found\") ValueError: Knowledge base ./vector_store not found", "file": "2023-05-09.02", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/289", "detail": "File \"/root/autodl-tmp/chatglm/langchain-ChatGLM-master/api.py\", line 183, in chat", "id": 107}
|
| 109 |
+
{"title": "能接入vicuna模型吗", "file": "2023-05-09.02", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/290", "detail": "目前本地已经有了vicuna模型能直接接入吗?", "id": 108}
|
| 110 |
+
{"title": "[BUG] 提问公式相关问题大概率爆显存", "file": "2023-05-09.02", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/291", "detail": "**问题描述 / Problem Description**", "id": 109}
|
| 111 |
+
{"title": "安装pycocotools失败,找了好多方法都不能解决。", "file": "2023-05-10.02", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/292", "detail": "**问题描述 / Problem Description**", "id": 110}
|
| 112 |
+
{"title": "使用requirements安装,PyTorch安装的是CPU版本", "file": "2023-05-10.02", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/294", "detail": "如题目,使用requirements安装,PyTorch安装的是CPU版本,运行程序的时候,也是使用CPU在工作。", "id": 111}
|
| 113 |
+
{"title": "能不能给一个毛坯服务器的部署教程", "file": "2023-05-10.02", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/298", "detail": "“开发部署”你当成服务器的部署教程用就行了。", "id": 112}
|
| 114 |
+
{"title": " Error(s) in loading state_dict for ChatGLMForConditionalGeneration:", "file": "2023-05-10.02", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/299", "detail": "运行中出现的问题,7860的端口页面显示不出来,求助。", "id": 113}
|
| 115 |
+
{"title": "ChatYuan-large-v2模型加载失败", "file": "2023-05-10.03", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/300", "detail": "**实际结果 / Actual Result**", "id": 114}
|
| 116 |
+
{"title": "新增摘要功能", "file": "2023-05-10.03", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/303", "detail": "你好,后续会考虑新增对长文本信息进行推理和语音理解功能吗?比如生成摘要", "id": 115}
|
| 117 |
+
{"title": "[BUG] pip install -r requirements.txt 出错", "file": "2023-05-10.03", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/304", "detail": "pip install langchain -i https://pypi.org/simple", "id": 116}
|
| 118 |
+
{"title": "[BUG] 上传知识库文件报错", "file": "2023-05-10.03", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/305", "detail": "", "id": 117}
|
| 119 |
+
{"title": "[BUG] AssertionError: <class 'gradio.layouts.Accordion'> Component with id 41 not a valid input component.", "file": "2023-05-10.03", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/306", "detail": "**问题描述 / Problem Description**", "id": 118}
|
| 120 |
+
{"title": "[BUG] CUDA out of memory with container deployment", "file": "2023-05-10.03", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/310", "detail": "**问题描述 / Problem Description**", "id": 119}
|
| 121 |
+
{"title": "[FEATURE] 增加微调训练功能", "file": "2023-05-11.03", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/311", "detail": "**功能描述 / Feature Description**", "id": 120}
|
| 122 |
+
{"title": "如何使用多卡部署,多个gpu", "file": "2023-05-11.03", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/315", "detail": "机器上有多个gpu,如何全使用了", "id": 121}
|
| 123 |
+
{"title": "请问这个知识库问答,和chatglm的关系是什么", "file": "2023-05-11.03", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/319", "detail": "这个知识库问答,哪部分关联到了chatglm,是不是没有这个chatglm,知识库问答也可单单拎出来", "id": 122}
|
| 124 |
+
{"title": "[BUG] 运行的时候报错ImportError: libcudnn.so.8: cannot open shared object file: No such file or directory", "file": "2023-05-12.03", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/324", "detail": "**问题描述 / Problem Description**raceback (most recent call last):", "id": 123}
|
| 125 |
+
{"title": "webui启动成功,但有报错", "file": "2023-05-12.03", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/325", "detail": "**问题描述 / Problem Description**", "id": 124}
|
| 126 |
+
{"title": "切换MOSS的时候报错", "file": "2023-05-12.03", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/327", "detail": "danshi但是发布的源码中,", "id": 125}
|
| 127 |
+
{"title": "vicuna模型是否能接入?", "file": "2023-05-12.03", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/328", "detail": "您好!关于MOSS模型和vicuna模型,都是AutoModelForCausalLM来加载模型的,但是稍作更改(模型路径这些)会报这个错误。这个错误的造成是什么", "id": 126}
|
| 128 |
+
{"title": "你好,请问一下在阿里云CPU服务器上跑可以吗?可以的话比较理想的cpu配置是什么?", "file": "2023-05-12.03", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/330", "detail": "你好,请问一下在阿里云CPU服务器上跑可以吗?可以的话比较理想的cpu配置是什么?", "id": 127}
|
| 129 |
+
{"title": "你好,请问8核32g的CPU可以跑多轮对话吗?", "file": "2023-05-12.03", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/331", "detail": "什么样的cpu配置比较好呢?我目前想部署CPU下的多轮对话?", "id": 128}
|
| 130 |
+
{"title": "[BUG] 聊天内容输入超过10000个字符系统出现错误", "file": "2023-05-12.03", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/332", "detail": "聊天内容输入超过10000个字符系统出现错误,如下图所示:", "id": 129}
|
| 131 |
+
{"title": "能增加API的多用户访问接口部署吗?", "file": "2023-05-12.03", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/333", "detail": "默认部署程序仅支持单用户访问,多用户则需要排队访问。测试过相关的几个Github多用户工程,但是其中一些仍然不满足要求。本节将系统介绍如何实现多用户同时访问ChatGLM的部署接口,包括http、websocket(流式输出,stream)和web页面等方式,主要目录如下所示。", "id": 130}
|
| 132 |
+
{"title": "多卡部署", "file": "2023-05-12.03", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/334", "detail": "用单机多卡或多机多卡,fastapi部署模型,怎样提高并发", "id": 131}
|
| 133 |
+
{"title": "WEBUI能否指定知识库目录?", "file": "2023-05-12.03", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/335", "detail": "**功能描述 / Feature Description**", "id": 132}
|
| 134 |
+
{"title": "[BUG] Cannot read properties of undefined (reading 'error')", "file": "2023-05-12.03", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/336", "detail": "**问题描述 / Problem Description**", "id": 133}
|
| 135 |
+
{"title": "[BUG] 1 validation error for HuggingFaceEmbeddings model_kwargs extra fields not permitted.", "file": "2023-05-12.03", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/337", "detail": "模型加载到 100% 后出现问题:", "id": 134}
|
| 136 |
+
{"title": "上传知识库需要重启能不能修复一下", "file": "2023-05-12.03", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/338", "detail": "挺严重的这个问题", "id": 135}
|
| 137 |
+
{"title": "[BUG] 4块v100卡爆显存,在LLM会话模式也一样", "file": "2023-05-12.03", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/339", "detail": "**问题描述 / Problem Description**", "id": 136}
|
| 138 |
+
{"title": "针对上传的文件配置不同的TextSpliter", "file": "2023-05-12.03", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/341", "detail": "1. 目前的ChineseTextSpliter切分对英文尤其是代码文件不友好,而且限制固定长度;导致对话结果不如人意", "id": 137}
|
| 139 |
+
{"title": "[FEATURE] 未来可增加Bloom系列模型吗?根据甲骨易的测试,这系列中文评测效果不错", "file": "2023-05-13.03", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/346", "detail": "**功能描述 / Feature Description**", "id": 138}
|
| 140 |
+
{"title": "[BUG] v0.1.12打包镜像后启动webui.py失败 / Concise description of the issue", "file": "2023-05-13.03", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/347", "detail": "**问题描述 / Problem Description**", "id": 139}
|
| 141 |
+
{"title": "切换MOSS模型时报错", "file": "2023-05-13.03", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/349", "detail": "昨天问了下,说是transformers版本不对,需要4.30.0,发现没有这个版本,今天更新到4.29.1,依旧报错,错误如下", "id": 140}
|
| 142 |
+
{"title": "[BUG] pdf文档加载失败", "file": "2023-05-13.03", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/350", "detail": "**问题描述 / Problem Description**", "id": 141}
|
| 143 |
+
{"title": "建议可以在后期增强一波注释,这样也有助于更多人跟进提PR", "file": "2023-05-13.03", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/351", "detail": "知道作者和团队在疯狂更新审查代码,只是建议后续稳定后可以把核心代码进行一些注释的补充,从而能帮助更多人了解各个模块作者的思路从而提出更好的优化。", "id": 142}
|
| 144 |
+
{"title": "[FEATURE] MOSS 量化版支援", "file": "2023-05-13.03", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/353", "detail": "**功能描述 / Feature Description**", "id": 143}
|
| 145 |
+
{"title": "[BUG] moss模型无法加载", "file": "2023-05-13.03", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/356", "detail": "**问题描述 / Problem Description**", "id": 144}
|
| 146 |
+
{"title": "[BUG] load_doc_qa.py 中的 load_file 函数有bug", "file": "2023-05-14.03", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/358", "detail": "原函数为:", "id": 145}
|
| 147 |
+
{"title": "[FEATURE] API模式,知识库加载优化", "file": "2023-05-14.03", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/359", "detail": "如题,当前版本,每次调用本地知识库接口,都将加载一次知识库,是否有更好的方式?", "id": 146}
|
| 148 |
+
{"title": "运行Python api.py脚本后端部署后,怎么使用curl命令调用?", "file": "2023-05-15.03", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/361", "detail": "也就是说,我现在想做个对话机器人,想和公司的前后端联调?怎么与前后端相互调用呢?可私信,有偿解答!!!", "id": 147}
|
| 149 |
+
{"title": "上传知识库需要重启能不能修复一下", "file": "2023-05-15.03", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/363", "detail": "上传知识库需要重启能不能修复一下", "id": 148}
|
| 150 |
+
{"title": "[BUG] pip install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple", "file": "2023-05-15.03", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/364", "detail": "我的python是3.8.5的", "id": 149}
|
| 151 |
+
{"title": "pip install gradio 报错", "file": "2023-05-15.03", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/367", "detail": "大佬帮我一下", "id": 150}
|
| 152 |
+
{"title": "[BUG] pip install gradio 一直卡不动", "file": "2023-05-15.03", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/369", "detail": "", "id": 151}
|
| 153 |
+
{"title": "[BUG] 简洁阐述问题 / Concise description of the issue", "file": "2023-05-16.03", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/370", "detail": "初次加载本地知识库成功,但提问后,就无法重写加载本地知识库", "id": 152}
|
| 154 |
+
{"title": "[FEATURE] 简洁阐述功能 / Concise description of the feature", "file": "2023-05-16.03", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/371", "detail": "**功能描述 / Feature Description**", "id": 153}
|
| 155 |
+
{"title": "在windows上,模型文件默认会安装到哪", "file": "2023-05-16.03", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/372", "detail": "-------------------------------------------------------------------------------", "id": 154}
|
| 156 |
+
{"title": "[FEATURE] 兼顾对话管理", "file": "2023-05-16.03", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/374", "detail": "如何在知识库检索的情况下,兼顾对话管理?", "id": 155}
|
| 157 |
+
{"title": "llm device: cpu embedding device: cpu", "file": "2023-05-16.03", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/376", "detail": "**问题描述 / Problem Description**", "id": 156}
|
| 158 |
+
{"title": "[FEATURE] 简洁阐述功能 /文本文件的知识点之间使用什么分隔符可以分割?", "file": "2023-05-16.03", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/377", "detail": "**功能描述 / Feature Description**", "id": 157}
|
| 159 |
+
{"title": "[BUG] 上传文件失败:PermissionError: [WinError 32] 另一个程序正在使用此文件,进程无法访问。", "file": "2023-05-16.03", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/379", "detail": "**问题描述 / Problem Description**", "id": 158}
|
| 160 |
+
{"title": "[BUG] 执行python api.py 报错", "file": "2023-05-16.03", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/383", "detail": "错误信息", "id": 159}
|
| 161 |
+
{"title": "model_kwargs extra fields not permitted (type=value_error.extra)", "file": "2023-05-16.03", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/384", "detail": "大家好,请问这个有遇到的么,?", "id": 160}
|
| 162 |
+
{"title": "[BUG] 简洁阐述问题 / Concise description of the issue", "file": "2023-05-17.03", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/385", "detail": "执行的时候出现了ls1 = [ls[0]]", "id": 161}
|
| 163 |
+
{"title": "[FEATURE] 性能优化", "file": "2023-05-17.03", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/388", "detail": "**功能描述 / Feature Description**", "id": 162}
|
| 164 |
+
{"title": "[BUG] Moss模型问答,RuntimeError: probability tensor contains either inf, nan or element < 0", "file": "2023-05-17.03", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/390", "detail": "**问题描述 / Problem Description**", "id": 163}
|
| 165 |
+
{"title": "有没有人知道v100GPU的32G显存,会报错吗?支持V100GPU吗?", "file": "2023-05-17.03", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/392", "detail": "**问题描述 / Problem Description**", "id": 164}
|
| 166 |
+
{"title": "针对于编码问题比如'gbk' codec can't encode character '\\xab' in position 14: illegal multibyte sequence粗浅的解决方法", "file": "2023-05-17.03", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/397", "detail": "**功能描述 / Feature Description**", "id": 165}
|
| 167 |
+
{"title": "Could not import sentence_transformers python package. Please install it with `pip install sentence_transformers`.", "file": "2023-05-18.04", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/400", "detail": "**问题描述 / Problem Description**", "id": 166}
|
| 168 |
+
{"title": "支持模型问答与检索问答", "file": "2023-05-18.04", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/401", "detail": "不同的query,根据意图不一致,回答也应该不一样。", "id": 167}
|
| 169 |
+
{"title": "文本分割的时候,能不能按照txt文件的每行进行分割,也就是按照换行符号\\n进行分割???", "file": "2023-05-18.04", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/403", "detail": "下面的代码应该怎么修改?", "id": 168}
|
| 170 |
+
{"title": "local_doc_qa/local_doc_chat 接口响应是串行", "file": "2023-05-18.04", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/405", "detail": "**问题描述 / Problem Description**", "id": 169}
|
| 171 |
+
{"title": "为什么找到出处了,但是还是无法回答该问题?", "file": "2023-05-18.04", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/406", "detail": "", "id": 170}
|
| 172 |
+
{"title": "请问下:知识库测试中的:添加单条内容,如果换成文本导入是是怎样的格式?我发现添加单条内容测试效果很好.", "file": "2023-05-18.04", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/412", "detail": "我发现在知识库测试中`添加单条内容`,并且勾选`禁止内容分句入库`,即使 `不开启上下文关联`的测试效果都非常好.", "id": 171}
|
| 173 |
+
{"title": "[BUG] 无法配置知识库", "file": "2023-05-18.04", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/413", "detail": "**问题描述 / Problem Description**", "id": 172}
|
| 174 |
+
{"title": "[BUG] 部署在阿里PAI平台的EAS上访问页面是白屏", "file": "2023-05-19.04", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/414", "detail": "**问题描述 / Problem Description**", "id": 173}
|
| 175 |
+
{"title": "API部署后调用/local_doc_qa/local_doc_chat 返回Knowledge base samples not found", "file": "2023-05-19.04", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/416", "detail": "入参", "id": 174}
|
| 176 |
+
{"title": "[FEATURE] 上传word另存为的txt文件报 'ascii' codec can't decode byte 0xb9 in position 6: ordinal not in range(128)", "file": "2023-05-20.04", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/421", "detail": "上传word另存为的txt文件报", "id": 175}
|
| 177 |
+
{"title": "创建保存的知识库刷新后没有出来,这个知识库是永久保存的吗?可以连外部的 向量知识库吗?", "file": "2023-05-21.04", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/422", "detail": "创建保存的知识库刷新后没有出来,这个知识库是永久保存的吗?可以连外部的 向量知识库吗?", "id": 176}
|
| 178 |
+
{"title": "[BUG] 用colab运行,无法加载模型,报错:'NoneType' object has no attribute 'message_types_by_name'", "file": "2023-05-21.04", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/423", "detail": "**问题描述 / Problem Description**", "id": 177}
|
| 179 |
+
{"title": "请问是否需要用到向量数据库?以及什么时候需要用到向量数据库?", "file": "2023-05-21.04", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/424", "detail": "目前用的是 text2vec , 请问是否需要用到向量数据库?以及什么时候需要用到向量数据库?", "id": 178}
|
| 180 |
+
{"title": "huggingface模型引用问题", "file": "2023-05-22.04", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/427", "detail": "它最近似乎变成了一个Error?", "id": 179}
|
| 181 |
+
{"title": "你好,加载本地txt文件出现这个killed错误,TXT文件有100M左右大小。原因是?谢谢。", "file": "2023-05-22.04", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/429", "detail": "<img width=\"677\" alt=\"929aca3b22b8cd74e997a87b61d241b\" src=\"https://github.com/imClumsyPanda/langchain-ChatGLM/assets/109277248/24024522-c884-4170-b5cf-a498491bd8bc\">", "id": 180}
|
| 182 |
+
{"title": "想请问一下,关于对本地知识的管理是如何管理?例如:通过http API接口添加数据 或者 删除某条数据", "file": "2023-05-22.04", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/430", "detail": "例如:通过http API接口添加、删除、修改 某条数据。", "id": 181}
|
| 183 |
+
{"title": "[FEATURE] 双栏pdf识别问题", "file": "2023-05-22.04", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/432", "detail": "试了一下模型,感觉对单栏pdf识别的准确性较高,但是由于使用的基本是ocr的技术,对一些双栏pdf论文识别出来有很多问题,请问有什么办法改善吗?", "id": 182}
|
| 184 |
+
{"title": "部署启动小问题,小弟初学求大佬解答", "file": "2023-05-22.04", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/433", "detail": "1.python loader/image_loader.py时,提示ModuleNotFoundError: No module named 'configs',但是跑python webui.py还是还能跑", "id": 183}
|
| 185 |
+
{"title": "能否支持检测到目录下文档有增加而去增量加载文档,不影响前台对话,其实就是支持读写分离。如果能支持查询哪些文档向量化了,删除过时文档等就更好了,谢谢。", "file": "2023-05-22.04", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/434", "detail": "**功能描述 / Feature Description**", "id": 184}
|
| 186 |
+
{"title": "[BUG] 简洁阐述问题 / windows 下cuda错误,请用https://github.com/Keith-Hon/bitsandbytes-windows.git", "file": "2023-05-22.04", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/435", "detail": "pip install git+https://github.com/Keith-Hon/bitsandbytes-windows.git", "id": 185}
|
| 187 |
+
{"title": "[BUG] from commit 33bbb47, Required library version not found: libbitsandbytes_cuda121_nocublaslt.so. Maybe you need to compile it from source?", "file": "2023-05-23.04", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/438", "detail": "**问题描述 / Problem Description**", "id": 186}
|
| 188 |
+
{"title": "[BUG] 简洁阐述问题 / Concise description of the issue上传60m的txt文件报错,显示超时,请问这个能上传的文件大小有限制吗", "file": "2023-05-23.04", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/439", "detail": "ERROR 2023-05-23 11:13:09,627-1d: Timeout reached while detecting encoding for ./docs/GLM模型格式数据.txt", "id": 187}
|
| 189 |
+
{"title": "[BUG] TypeError: issubclass() arg 1 must be a class", "file": "2023-05-23.04", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/440", "detail": "**问题描述**", "id": 188}
|
| 190 |
+
{"title": "执行python3 webui.py后,一直提示”模型未成功加载,请到页面左上角\"模型配置\"选项卡中重新选择后点击\"加载模型\"按钮“", "file": "2023-05-23.04", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/441", "detail": "**问题描述 / Problem Description**", "id": 189}
|
| 191 |
+
{"title": "是否能提供网页文档得导入支持", "file": "2023-05-23.04", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/444", "detail": "现在很多都是在线文档作为协作得工具,所以通过URL导入在线文档需求更大", "id": 190}
|
| 192 |
+
{"title": "[BUG] history 索引问题", "file": "2023-05-23.04", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/445", "detail": "在比较对话框的history和模型chat function 中的history时, 发现并不匹配,在传入 llm._call 时,history用的索引是不是有点问题,导致上一轮对话的内容并不输入给模型。", "id": 191}
|
| 193 |
+
{"title": "[BUG] moss_llm没有实现", "file": "2023-05-23.04", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/447", "detail": "有些方法没支持,如history_len", "id": 192}
|
| 194 |
+
{"title": "请问langchain-ChatGLM如何删除一条本地知识库的数据?", "file": "2023-05-23.04", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/448", "detail": "例如:用户刚刚提交了一条错误的数据到本地知识库中了,现在如何在本地知识库从找到,并且对此删除。", "id": 193}
|
| 195 |
+
{"title": "[BUG] 简洁阐述问题 / UnboundLocalError: local variable 'resp' referenced before assignment", "file": "2023-05-24.04", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/450", "detail": "在最新一版的代码中, 运行api.py 出现了以上错误(UnboundLocalError: local variable 'resp' referenced before assignment), 通过debug的方式观察到local_doc_qa.llm.generatorAnswer(prompt=question, history=history,streaming=True)可能不返回任何值。", "id": 194}
|
| 196 |
+
{"title": "请问有没有 PROMPT_TEMPLATE 能让模型不回答敏感问题", "file": "2023-05-24.04", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/452", "detail": "## PROMPT_TEMPLATE问题", "id": 195}
|
| 197 |
+
{"title": "[BUG] 测试环境 Python 版本有误", "file": "2023-05-24.04", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/456", "detail": "**问题描述 / Problem Description**", "id": 196}
|
| 198 |
+
{"title": "[BUG] webui 部署后样式不正确", "file": "2023-05-24.04", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/458", "detail": "**问题描述 / Problem Description**", "id": 197}
|
| 199 |
+
{"title": "配置默认LLM模型的问题", "file": "2023-05-24.04", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/459", "detail": "**问题描述 / Problem Description**", "id": 198}
|
| 200 |
+
{"title": "[FEATURE]是时候更新一下autoDL的镜像了", "file": "2023-05-24.04", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/460", "detail": "如题,跑了下autoDL的镜像,发现是4.27号的,git pull新版本的代码功能+老的依赖环境,各种奇奇怪怪的问题。", "id": 199}
|
| 201 |
+
{"title": "[BUG] tag:0.1.13 以cpu模式下,想使用本地模型无法跑起来,各种路径参数问题", "file": "2023-05-24.04", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/462", "detail": "-------------------------------------------------------------------------------", "id": 200}
|
| 202 |
+
{"title": "[BUG] 有没有同学遇到过这个错!!!加载本地txt文件出现这个killed错误,TXT文件有100M左右大小。", "file": "2023-05-25.04", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/463", "detail": "运行cli_demo.py。是本地的txt文件太大了吗?100M左右。", "id": 201}
|
| 203 |
+
{"title": "API版本能否提供WEBSOCKET的流式接口", "file": "2023-05-25.04", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/464", "detail": "webui 版本中,采用了WS的流式输出,整体感知反应很快", "id": 202}
|
| 204 |
+
{"title": "[BUG] 安装bug记录", "file": "2023-05-25.04", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/465", "detail": "按照[install文档](https://github.com/imClumsyPanda/langchain-ChatGLM/blob/master/docs/INSTALL.md)安装的,", "id": 203}
|
| 205 |
+
{"title": "VUE的pnmp i执行失败的修复-用npm i命令即可", "file": "2023-05-25.04", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/466", "detail": "感谢作者!非常棒的应用,用的很开心。", "id": 204}
|
| 206 |
+
{"title": "请教个问题,有没有人知道cuda11.4是否支持???", "file": "2023-05-25.04", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/467", "detail": "请教个问题,有没有人知道cuda11.4是否支持???", "id": 205}
|
| 207 |
+
{"title": "请问有实现多轮问答中基于问题的搜索上下文关联么", "file": "2023-05-25.04", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/468", "detail": "在基于知识库的多轮问答中,第一个问题讲述了一个主题,后续的问题描述没有包含这个主题的关键词,但又存在上下文的关联。如果用后续问题去搜索知识库有可能会搜索出无关的信息,从而导致大模型无法正确回答问题。请问这个项目要考虑这种情况吗?", "id": 206}
|
| 208 |
+
{"title": "[BUG] 内存不足的问题", "file": "2023-05-26.04", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/470", "detail": "我用了本地的chatglm-6b-int4模型,然后显示了内存不足(win10+32G内存+1080ti11G),一般需要多少内存才足够?这个bug应该如何解决?", "id": 207}
|
| 209 |
+
{"title": "[BUG] 纯内网环境安装pycocotools失败", "file": "2023-05-26.04", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/472", "detail": "**问题描述 / Problem Description**", "id": 208}
|
| 210 |
+
{"title": "[BUG] webui.py 重新加载模型会导致 KeyError", "file": "2023-05-26.04", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/473", "detail": "**问题描述 / Problem Description**", "id": 209}
|
| 211 |
+
{"title": "chatyuan无法使用", "file": "2023-05-26.04", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/475", "detail": "**问题描述 / Problem Description**", "id": 210}
|
| 212 |
+
{"title": "[BUG] 文本分割模型AliTextSplitter存在bug,会把“.”作为分割符", "file": "2023-05-26.04", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/476", "detail": "阿里达摩院的语义分割模型存在bug,默认会把\".”作为分割符进行分割而不管上下文语义。是否还有其他分割符则未知。建议的修改方案:把“.”统一替换为其他字符,分割后再替换回来。或者添加其他分割模型。", "id": 211}
|
| 213 |
+
{"title": "[BUG] RuntimeError: Error in faiss::FileIOReader::FileIOReader(const char*) a", "file": "2023-05-27.04", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/479", "detail": "**问题描述 / Problem Description**", "id": 212}
|
| 214 |
+
{"title": "[FEATURE] 安装,为什么conda create要额外指定路径 用-p ,而不是默认的/envs下面", "file": "2023-05-28.04", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/481", "detail": "##**功能描述 / Feature Description**", "id": 213}
|
| 215 |
+
{"title": "[小白求助] 通过Anaconda执行webui.py后,无法打开web链接", "file": "2023-05-28.04", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/485", "detail": "在执行webui.py命令后,http://0.0.0.0:7860复制到浏览器后无法打开,显示“无法访问此网站”。", "id": 214}
|
| 216 |
+
{"title": "[BUG] 使用 p-tuningv2后的模型,重新加载报错", "file": "2023-05-29.04", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/486", "detail": "把p-tunningv2训练完后的相关文件放到了p-tunningv2文件夹下,勾选使用p-tuningv2点重新加载模型,控制台输错错误信息:", "id": 215}
|
| 217 |
+
{"title": "[小白求助] 服务器上执行webui.py后,在本地无法打开web链接", "file": "2023-05-29.04", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/487", "detail": "此项目执行在xxx.xx.xxx.xxx服务器上,我在webui.py上的代码为 (demo", "id": 216}
|
| 218 |
+
{"title": "[FEATURE] 能不能支持VisualGLM-6B", "file": "2023-05-29.04", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/488", "detail": "**功能描述 / Feature Description**", "id": 217}
|
| 219 |
+
{"title": "你好,问一下各位,后端api部署的时候,支持多用户同时问答吗???", "file": "2023-05-29.04", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/489", "detail": "支持多用户的话,最多支持多少用户问答?根据硬件而定吧?", "id": 218}
|
| 220 |
+
{"title": "V100GPU显存占满,而利用率却为0,这是为什么?", "file": "2023-05-29.04", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/491", "detail": "<img width=\"731\" alt=\"de45fe2b6cb76fa091b6e8f76a3de60\" src=\"https://github.com/imClumsyPanda/langchain-ChatGLM/assets/109277248/c32efd52-7dbf-4e9b-bd4d-0944d73d0b8b\">", "id": 219}
|
| 221 |
+
{"title": "[求助] 如果在公司内部搭建产品知识库,使用INT-4模型,200人规模需要配置多少显存的服务器?", "file": "2023-05-29.04", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/492", "detail": "如题,计划给公司搭一个在线知识库。", "id": 220}
|
| 222 |
+
{"title": "你好,请教个问题,目前问答回复需要20秒左右,如何提高速度?V10032G服务器。", "file": "2023-05-29.04", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/493", "detail": "**问题描述 / Problem Description**", "id": 221}
|
| 223 |
+
{"title": "[FEATURE] 如何实现只匹配下文,而不要上文的结果", "file": "2023-05-29.04", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/494", "detail": "在构建自己的知识库时,主要采用问答对的形式,那么也就是我需要的回答是在我的问题下面的内容,但是目前设置了chunk_size的值以后匹配的是上下文的内容,但我实际并不需要上文的。为了实现更完整的展示下面的答案,我只能调大chunk_size的值,但实际上上文的一半内容都是我不需要的。也就是扔了一半没用的东西给prompt,在faiss.py中我也没找到这块的一些描述,请问该如何进行修改呢?", "id": 222}
|
| 224 |
+
{"title": "你好,问一下,我调用api.py部署,为什么用ip加端口可以使用postman调用,而改为域名使用postman无法调用?", "file": "2023-05-30.04", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/497", "detail": "", "id": 223}
|
| 225 |
+
{"title": "调用api.py中的stream_chat,返回source_documents中出现中文乱码。", "file": "2023-05-30.04", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/498", "detail": "-------------------------------------------------------------------------------", "id": 224}
|
| 226 |
+
{"title": "[BUG] 捉个虫,api.py中的stream_chat解析json问题", "file": "2023-05-30.05", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/501", "detail": "**问题描述 / Problem Description**", "id": 225}
|
| 227 |
+
{"title": "windows本地部署遇到了omp错误", "file": "2023-05-31.05", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/502", "detail": "**问题描述 / Problem Description**", "id": 226}
|
| 228 |
+
{"title": "[BUG] bug14 ,\"POST /local_doc_qa/upload_file HTTP/1.1\" 422 Unprocessable Entity", "file": "2023-05-31.05", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/503", "detail": "上传的文件报错,返回错误,api.py", "id": 227}
|
| 229 |
+
{"title": "你好,请教个问题,api.py部署的时候,如何改为多线程调用?谢谢", "file": "2023-05-31.05", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/505", "detail": "目前的api.py脚本不支持多线程", "id": 228}
|
| 230 |
+
{"title": "你好,请教一下。api.py部署的时候,能不能提供给后端流失返回结果。", "file": "2023-05-31.05", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/507", "detail": "curl -X 'POST' \\", "id": 229}
|
| 231 |
+
{"title": "流式输出,流式接口,使用server-sent events技术。", "file": "2023-05-31.05", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/508", "detail": "想这样一样,https://blog.csdn.net/weixin_43228814/article/details/130063010", "id": 230}
|
| 232 |
+
{"title": "计划增加流式输出功能吗?ChatGLM模型通过api方式调用响应时间慢怎么破,Fastapi流式接口来解惑,能快速提升响应速度", "file": "2023-05-31.05", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/509", "detail": "**问题描述 / Problem Description**", "id": 231}
|
| 233 |
+
{"title": "[BUG] 知识库上传时发生ERROR (could not open xxx for reading: No such file or directory)", "file": "2023-05-31.05", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/510", "detail": "**问题描述 / Problem Description**", "id": 232}
|
| 234 |
+
{"title": "api.py脚本打算增加SSE流式输出吗?", "file": "2023-05-31.05", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/511", "detail": "curl调用的时候可以检测第一个字,从而提升回复的体验", "id": 233}
|
| 235 |
+
{"title": "[BUG] 使用tornado实现webSocket,可以多个客户端同时连接,并且实现流式回复,但是多个客户端同时使用,答案就很乱,是模型不支持多线程吗", "file": "2023-05-31.05", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/512", "detail": "import asyncio", "id": 234}
|
| 236 |
+
{"title": "支持 chinese_alpaca_plus_lora 吗 基于llama的", "file": "2023-06-01.05", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/514", "detail": "支持 chinese_alpaca_plus_lora 吗 基于llama的,https://github.com/ymcui/Chinese-LLaMA-Alpaca这个项目的", "id": 235}
|
| 237 |
+
{"title": "[BUG] 现在能读图片的pdf了,但是文字的pdf反而读不了了,什么情况???", "file": "2023-06-01.05", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/515", "detail": "**问题描述 / Problem Description**", "id": 236}
|
| 238 |
+
{"title": "在推理的过程中卡住不动,进程无法正常结束", "file": "2023-06-01.05", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/516", "detail": "**问题描述 / Problem Description**", "id": 237}
|
| 239 |
+
{"title": "curl调用的时候,从第二轮开始,curl如何传参可以实现多轮对话?", "file": "2023-06-01.05", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/517", "detail": "第一轮调用:", "id": 238}
|
| 240 |
+
{"title": "建议添加api.py部署后的日志管理功能?", "file": "2023-06-01.05", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/518", "detail": "-------------------------------------------------------------------------------", "id": 239}
|
| 241 |
+
{"title": "有大佬知道,怎么多线程部署api.py脚本吗?", "file": "2023-06-01.05", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/519", "detail": "api.py部署后,使用下面的请求,时间较慢,好像是单线程,如何改为多线程部署api.py:", "id": 240}
|
| 242 |
+
{"title": "[BUG] 上传文件到知识库 任何格式与内容都永远失败", "file": "2023-06-01.05", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/520", "detail": "上传知识库的时候,传txt无法解析,就算是穿content/sample里的样例txt也无法解析,上传md、pdf等都无法加载,会持续性等待,等到了超过30分钟也不行。", "id": 241}
|
| 243 |
+
{"title": "关于prompt_template的问题", "file": "2023-06-01.05", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/521", "detail": "请问这段prompt_template是什么意思,要怎么使用?可以给一个具体模板参考下吗?", "id": 242}
|
| 244 |
+
{"title": "[BUG] 简洁阐述问题 / Concise description of the issue", "file": "2023-06-01.05", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/522", "detail": "**问题描述 / Problem Description**", "id": 243}
|
| 245 |
+
{"title": "中文分词句号处理(关于表达金额之间的\".\")", "file": "2023-06-02.05", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/523", "detail": "建议处理12.6亿元的这样的分词,最好别分成12 和6亿这样的,需要放到一起", "id": 244}
|
| 246 |
+
{"title": "ImportError: cannot import name 'inference' from 'paddle'", "file": "2023-06-02.05", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/526", "detail": "在网上找了一圈,有说升级paddle的,我做了还是没有用,有说安装paddlepaddle的,我找了豆瓣的镜像源,但安装报错cannot detect archive format", "id": 245}
|
| 247 |
+
{"title": "[BUG] webscoket 接口串行问题(/local_doc_qa/stream-chat/{knowledge_base_id})", "file": "2023-06-02.05", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/527", "detail": "**问题描述 / Problem Description**", "id": 246}
|
| 248 |
+
{"title": "[FEATURE] 刷新页面更新知识库列表", "file": "2023-06-02.05", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/528", "detail": "**功能描述以及改进方案**", "id": 247}
|
| 249 |
+
{"title": "[BUG] 使用ptuning微调模型后,问答效果并不好", "file": "2023-06-02.05", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/530", "detail": "### 未调用ptuning", "id": 248}
|
| 250 |
+
{"title": "[BUG] 多轮对话效果不佳", "file": "2023-06-02.05", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/532", "detail": "在进行多轮对话的时候,无论设置的history_len是多少,效果都不好。事实上我将其设置成了最大值10,但在对话中,仍然无法实现多轮对话:", "id": 249}
|
| 251 |
+
{"title": "RuntimeError: MPS backend out of memory (MPS allocated: 18.00 GB, other allocations: 4.87 MB, max allowed: 18.13 GB)", "file": "2023-06-02.05", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/533", "detail": "**问题描述**", "id": 250}
|
| 252 |
+
{"title": " 请大家重视这个issue!真正使用肯定是多用户并发问答,希望增加此功能!!!", "file": "2023-06-02.05", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/534", "detail": "这得看你有多少显卡", "id": 251}
|
| 253 |
+
{"title": "在启动项目的时候如何使用到多张gpu啊?", "file": "2023-06-02.05", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/535", "detail": "**在启动项目的时候如何使用到多张gpu啊?**", "id": 252}
|
| 254 |
+
{"title": " 使用流式输出的时候,curl调用的格式是什么?", "file": "2023-06-02.05", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/536", "detail": "app.websocket(\"/local_doc_qa/stream-chat/{knowledge_base_id}\")(stream_chat)中的knowledge_base_id应该填什么???", "id": 253}
|
| 255 |
+
{"title": "使用本地 vicuna-7b模型启动错误", "file": "2023-06-02.05", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/538", "detail": "环境: ubuntu 22.04 cuda 12.1 没有安装nccl,使用rtx2080与m60显卡并行计算", "id": 254}
|
| 256 |
+
{"title": "为什么会不调用GPU直接调用CPU呢", "file": "2023-06-02.05", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/539", "detail": "我的阿里云配置是16G显存,用默认代码跑webui.py时提示", "id": 255}
|
| 257 |
+
{"title": "上传多个文件时会互相覆盖", "file": "2023-06-03.05", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/541", "detail": "1、在同一个知识库中上传多个文件时会互相覆盖,无法结合多个文档的知识,有大佬知道怎么解决吗?", "id": 256}
|
| 258 |
+
{"title": "[BUG] ‘gcc’不是内部或外部命令/LLM对话只能持续一轮", "file": "2023-06-03.05", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/542", "detail": "No compiled kernel found.", "id": 257}
|
| 259 |
+
{"title": "以API模式启动项目却没有知识库的接口列表?", "file": "2023-06-04.05", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/544", "detail": "请问如何获取知识库的接口列表?如果没有需要自行编写的话,可不可以提供相关的获取方式,感谢", "id": 258}
|
| 260 |
+
{"title": "程序以API模式启动的时候,如何才能让接口以stream模式被调用呢?", "file": "2023-06-05.05", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/546", "detail": "作者您好,我在以API模式进行程序启动后,我发现接口响应时间很长,怎么样才能让接口以stream模式被调用呢?我想实现像webui模式的回答那样", "id": 259}
|
| 261 |
+
{"title": "关于原文中表格转为文本后数据相关度问题。", "file": "2023-06-06.05", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/547", "detail": "原文中表格数据转换为文本,以 (X-Y:值;...) 的格式每一行组织成一句话,但这样做后发现相关度较低,效果很差,有何好的方案吗?", "id": 260}
|
| 262 |
+
{"title": "启动后LLM和知识库问答模式均只有最后一轮记录", "file": "2023-06-06.05", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/548", "detail": "拉取最新代码,问答时,每次页面只显示最后一次问答记录,需要修改什么参数才可以保留历史记录?", "id": 261}
|
| 263 |
+
{"title": "提供system message配置,以便于让回答不要超出知识库范围", "file": "2023-06-06.05", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/549", "detail": "**功能描述 / Feature Description**", "id": 262}
|
| 264 |
+
{"title": "[BUG] 使用p-tunningv2报错", "file": "2023-06-06.05", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/551", "detail": "按照readme的指示把p-tunningv2训练完后的文件放到了p-tunningv2文件夹下,勾选使用p-tuningv2点重新加载模型,控制台提示错误信息:", "id": 263}
|
| 265 |
+
{"title": "[BUG] 智障,这么多问题,也好意思放出来,浪费时间", "file": "2023-06-06.05", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/553", "detail": "。。。", "id": 264}
|
| 266 |
+
{"title": "[FEATURE] 我看代码文件中有一个ali_text_splitter.py,为什么不用他这个文本分割器了?", "file": "2023-06-06.05", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/554", "detail": "我看代码文件中有一个ali_text_splitter.py,为什么不用他这个文本分割器了?", "id": 265}
|
| 267 |
+
{"title": "加载文档函数报错", "file": "2023-06-06.05", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/557", "detail": "def load_file(filepath, sentence_size=SENTENCE_SIZE):", "id": 266}
|
| 268 |
+
{"title": "参考指引安装docker后,运行cli_demo.py,提示killed", "file": "2023-06-06.05", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/558", "detail": "root@b3d1bd08095c:/chatGLM# python3 cli_demo.py", "id": 267}
|
| 269 |
+
{"title": "注意:如果安装错误,注意这两个包的版本 wandb==0.11.0 protobuf==3.18.3", "file": "2023-06-06.05", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/559", "detail": "Error1: 如果启动异常报错 `protobuf` 需要更新到 `protobuf==3.18.3 `", "id": 268}
|
| 270 |
+
{"title": "知识库对长文的知识相关度匹配不太理想有何优化方向", "file": "2023-06-07.05", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/563", "detail": "我们可能录入一个文章有 1W 字,里面涉及这个文章主题的很多角度问题,我们针对他提问,他相关度匹配的内容和实际我们需要的答案相差很大怎么办。", "id": 269}
|
| 271 |
+
{"title": "使用stream-chat函数进行流式输出的时候,能使用curl调用吗?", "file": "2023-06-07.05", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/565", "detail": "为什么下面这样调用会报错???", "id": 270}
|
| 272 |
+
{"title": "有大佬实践过 并行 或者 多线程 的部署方案吗?", "file": "2023-06-07.05", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/566", "detail": "+1", "id": 271}
|
| 273 |
+
{"title": "多线程部署遇到问题?", "file": "2023-06-07.05", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/567", "detail": "<img width=\"615\" alt=\"3d87bf74f0cf1a4820cc9e46b245859\" src=\"https://github.com/imClumsyPanda/langchain-ChatGLM/assets/109277248/8787570d-88bd-434e-aaa4-cb9276d1aa50\">", "id": 272}
|
| 274 |
+
{"title": "[BUG] 用fastchat加载vicuna-13b模型进行知识库的问答有token的限制错误", "file": "2023-06-07.05", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/569", "detail": "当我开启fastchat的vicuna-13b的api服务,然后config那里配置好(api本地测试过可以返回结果),然后知识库加载好之后(知识库大概有1000多个文档,用chatGLM可以正常推理),进行问答时出现token超过限制,就问了一句hello;", "id": 273}
|
| 275 |
+
{"title": "现在的添加知识库,文件多了总是报错,也不知道自己加载了哪些文件,报错后也不知道是全部失败还是一部分成功;希望能有个加载指定文件夹作为知识库的功能", "file": "2023-06-07.05", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/574", "detail": "**功能描述 / Feature Description**", "id": 274}
|
| 276 |
+
{"title": "[BUG] moss模型本地加载报错", "file": "2023-06-08.05", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/577", "detail": "moss模型本地加载报错:", "id": 275}
|
| 277 |
+
{"title": "加载本地moss模型报错Can't instantiate abstract class MOSSLLM with abstract methods _history_len", "file": "2023-06-08.05", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/578", "detail": "(vicuna) ps@ps[13:56:20]:/data/chat/langchain-ChatGLM2/langchain-ChatGLM-0.1.13$ python webui.py --model-dir local_models --model moss --no-remote-model", "id": 276}
|
| 278 |
+
{"title": "[FEATURE] 能增加在前端页面控制prompt_template吗?或是能支持前端页面选择使用哪个prompt?", "file": "2023-06-08.05", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/579", "detail": "目前只能在config里修改一个prompt,想在多个不同场景切换比较麻烦", "id": 277}
|
| 279 |
+
{"title": "[BUG] streamlit ui的bug,在增加知识库时会报错", "file": "2023-06-08.05", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/580", "detail": "**问题描述 / Problem Description**", "id": 278}
|
| 280 |
+
{"title": "[FEATURE] webui/webui_st可以支持history吗?目前仅能一次对话", "file": "2023-06-08.05", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/581", "detail": "试了下webui和webui_st都不支持历史对话啊,只能对话一次,不能默认开启所有history吗?", "id": 279}
|
| 281 |
+
{"title": "启动python cli_demo.py --model chatglm-6b-int4-qe报错", "file": "2023-06-09.05", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/585", "detail": "下载好模型,和相关依赖环境,之间运行`python cli_demo.py --model chatglm-6b-int4-qe`报错了:", "id": 280}
|
| 282 |
+
{"title": "重新构建知识库报错", "file": "2023-06-09.05", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/586", "detail": "**问题描述 / Problem Description**", "id": 281}
|
| 283 |
+
{"title": "[FEATURE] 能否屏蔽paddle,我不需要OCR,效果差依赖环境还很复杂", "file": "2023-06-09.05", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/587", "detail": "希望能不依赖paddle", "id": 282}
|
| 284 |
+
{"title": "question :文档向量化这个可以自己手动实现么?", "file": "2023-06-09.05", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/589", "detail": "现有公司级数据500G+,需要使用这个功能,请问如何手动实现这个向量化,然后并加载", "id": 283}
|
| 285 |
+
{"title": "view前端能进行流式的返回吗??", "file": "2023-06-09.05", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/590", "detail": "view前端能进行流式的返回吗??", "id": 284}
|
| 286 |
+
{"title": "[BUG] Load parallel cpu kernel failed, using default cpu kernel code", "file": "2023-06-11.05", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/594", "detail": "**问题描述 / Problem Description**", "id": 285}
|
| 287 |
+
{"title": "[BUG] 简洁阐述问题 / Concise description of the issue", "file": "2023-06-11.05", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/595", "detail": "**问题描述 / Problem Description**", "id": 286}
|
| 288 |
+
{"title": "我在上传本地知识库时提示KeyError: 'name'错误,本地知识库都是.txt文件,文件数量大约是2000+。", "file": "2023-06-12.05", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/597", "detail": "<img width=\"649\" alt=\"KError\" src=\"https://github.com/imClumsyPanda/langchain-ChatGLM/assets/59411575/1ecc8182-aeee-4a0a-bbc3-74c2f1373f2d\">", "id": 287}
|
| 289 |
+
{"title": "model_config.py中有vicuna-13b-hf模型的配置信息,但是好像还是不可用?", "file": "2023-06-12.06", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/600", "detail": "@dongyihua543", "id": 288}
|
| 290 |
+
{"title": "ImportError: Using SOCKS proxy, but the 'socksio' package is not installed. Make sure to install httpx using `pip install httpx[socks]`.", "file": "2023-06-12.06", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/605", "detail": "应该代理问题,但是尝试了好多方法都解决不了,", "id": 289}
|
| 291 |
+
{"title": "[BUG] similarity_search_with_score_by_vector在找不到匹配的情况下出错", "file": "2023-06-12.06", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/607", "detail": "在设置匹配阈值 VECTOR_SEARCH_SCORE_THRESHOLD 的情况下,vectorstore会返回空,此时上述处理函数会出错", "id": 290}
|
| 292 |
+
{"title": "[FEATURE] 请问如何搭建英文知识库呢", "file": "2023-06-12.06", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/609", "detail": "**功能描述 / Feature Description**", "id": 291}
|
| 293 |
+
{"title": "谁有vicuna权重?llama转换之后的", "file": "2023-06-13.06", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/611", "detail": "**问题描述 / Problem Description**", "id": 292}
|
| 294 |
+
{"title": "[FEATURE] API能实现上传文件夹的功能么?", "file": "2023-06-13.06", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/612", "detail": "用户懒得全选所有的文件,就想上传个文件夹,请问下API能实现这个功能么?", "id": 293}
|
| 295 |
+
{"title": "请问在多卡部署后,上传单个文件作为知识库,用的是单卡在生成向量还是多卡?", "file": "2023-06-13.06", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/614", "detail": "目前我检测我本地多卡部署的,好像生成知识库向量的时候用的还是单卡", "id": 294}
|
| 296 |
+
{"title": "[BUG] python webui.py提示非法指令", "file": "2023-06-13.06", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/615", "detail": "(/data/conda-langchain [root@chatglm langchain-ChatGLM]# python webui.py", "id": 295}
|
| 297 |
+
{"title": "知识库文件跨行切分问题", "file": "2023-06-13.06", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/616", "detail": "我的知识库文件txt文件,是一行一条知识,用\\n分行。", "id": 296}
|
| 298 |
+
{"title": "[FEATURE] bing搜索问答有流式的API么?", "file": "2023-06-13.06", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/617", "detail": "web端是有这个bing搜索回答,但api接口没有发现,大佬能给个提示么?", "id": 297}
|
| 299 |
+
{"title": "希望出一个macos m2的安装教程", "file": "2023-06-14.06", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/620", "detail": "mac m2安装,模型加载成功了,知识库文件也上传成功了,但是一问答就会报错,报错内容如下", "id": 298}
|
| 300 |
+
{"title": "为【出处】提供高亮显示", "file": "2023-06-14.06", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/621", "detail": "具体出处里面,对相关的内容高亮显示,不包含前后文。", "id": 299}
|
| 301 |
+
{"title": "[BUG] CPU运行cli_demo.py,不回答,hang住", "file": "2023-06-14.06", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/622", "detail": "没有GPU;32G内存的ubuntu机器。", "id": 300}
|
| 302 |
+
{"title": "关于删除知识库里面的文档后,LLM知识库对话的时候还是会返回该被删除文档的内容", "file": "2023-06-14.06", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/623", "detail": "如题,在vue前端成功执行删除知识库里面文档A.txt后,未能也在faiss索引中也删除该文档,LLM还是会返回这个A.txt的内容,并且以A.txt为出处,未能达到删除的效果", "id": 301}
|
| 303 |
+
{"title": "[BUG] 调用知识库进行问答,显存会一直叠加", "file": "2023-06-14.06", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/625", "detail": "14G的显存,调用的chatglm-6b-int8模型,进行知识库问答时,最多问答四次就会爆显存了,观察了一下显存使用情况,每一次使用就会增加一次显存,请问这样是正常的吗?是否有什么配置需要开启可以解决这个问题?例如进行一次知识库问答清空上次问题的显存?", "id": 302}
|
| 304 |
+
{"title": "[BUG] web页面 重新构建数据库 失败,导致 原来的上传的数据库都没了", "file": "2023-06-14.06", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/626", "detail": "web页面 重新构建数据库 失败,导致 原来的上传的数据库都没了", "id": 303}
|
| 305 |
+
{"title": "在CPU上运行webui.py报错Tensor on device cpu is not on the expected device meta!", "file": "2023-06-14.06", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/627", "detail": "在CPU上运行python webui.py能启动,但最后有:RuntimeError: Tensor on device cpu is not on the expected device meta!", "id": 304}
|
| 306 |
+
{"title": "OSError: [WinError 1114] 动态链接库(DLL)初始化例程失败。 Error loading \"E:\\xxx\\envs\\langchain\\lib\\site-packages\\torch\\lib\\caffe2_nvrtc.dll\" or one of its dependencies.哪位大佬知道如何解决吗?", "file": "2023-06-14.06", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/629", "detail": "**问题描述 / Problem Description**", "id": 305}
|
| 307 |
+
{"title": "[BUG] WEBUI删除知识库文档,会导致知识库问答失败", "file": "2023-06-15.06", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/632", "detail": "如题,从知识库已有文件中选择要删除的文件,点击删除后,在问答框输入内容回车报错", "id": 306}
|
| 308 |
+
{"title": "更新后的版本中,删除知识库中的文件,再提问出现error错误", "file": "2023-06-15.06", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/634", "detail": "针对更新版本,识别到一个问题,过程如下:", "id": 307}
|
| 309 |
+
{"title": "我配置好了环境,想要实现本地知识库的问答?可是它返回给我的", "file": "2023-06-15.06", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/637", "detail": "没有总结,只有相关度的回复,但是我看演示里面表现的,回复是可以实现总结的,我去查询代码", "id": 308}
|
| 310 |
+
{"title": "[BUG] NPM run dev can not successfully start the VUE frontend", "file": "2023-06-15.06", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/638", "detail": "**问题描述 / Problem Description**", "id": 309}
|
| 311 |
+
{"title": "[BUG] 简洁阐述问题 / Concise description of the issue", "file": "2023-06-15.06", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/639", "detail": "**问题描述 / Problem Description**", "id": 310}
|
| 312 |
+
{"title": "提一个模型加载的bug,我在截图中修复了,你们有空可以看一下。", "file": "2023-06-15.06", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/642", "detail": "", "id": 311}
|
| 313 |
+
{"title": "[求助]关于设置embedding model路径的问题", "file": "2023-06-16.06", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/643", "detail": "如题,我之前成功跑起来过一次,但因环境丢失重新配置 再运行webui就总是报错", "id": 312}
|
| 314 |
+
{"title": "Lora微调后的模型可以直接使用吗", "file": "2023-06-16.06", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/646", "detail": "看model_config.py里是有USE_LORA这个参数的,但是在cli_demo.py和webui.py这两个里面都没有用到,实际测试下来模型没有微调的效果,想问问现在这个功能实现了吗", "id": 313}
|
| 315 |
+
{"title": "write_check_file在tmp_files目录下生成的load_file.txt是否需要一直保留,占用空间很大,在建完索引后能否删除", "file": "2023-06-16.06", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/647", "detail": "**功能描述 / Feature Description**", "id": 314}
|
| 316 |
+
{"title": "[BUG] /local_doc_qa/list_files?knowledge_base_id=test删除知识库bug", "file": "2023-06-16.06", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/649", "detail": "1.新建test知识库并上传文件(在vue前端完成并检查后端发现确实生成了test文件夹以及下面的content和vec_store", "id": 315}
|
| 317 |
+
{"title": "[BUG] vue webui无法加载知识库", "file": "2023-06-16.06", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/650", "detail": "拉取了最新的代码,分别运行了后端api和前端web,点击知识库,始终只能显示simple,无法加载知识库", "id": 316}
|
| 318 |
+
{"title": "不能本地加载moss模型吗?", "file": "2023-06-16.06", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/652", "detail": "手动下载模型设置local_model_path路径依旧提示缺少文件,该如何正确配置?", "id": 317}
|
| 319 |
+
{"title": "macos m2 pro docker 安装失败", "file": "2023-06-17.06", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/654", "detail": "macos m2 pro docker 安装失败", "id": 318}
|
| 320 |
+
{"title": " [BUG] mac m1 pro 运行提示 zsh: segmentation fault", "file": "2023-06-17.06", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/655", "detail": "运行: python webui.py", "id": 319}
|
| 321 |
+
{"title": "安装 requirements 报错", "file": "2023-06-17.06", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/656", "detail": "(langchainchatglm) D:\\github\\langchain-ChatGLM>pip install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple/", "id": 320}
|
| 322 |
+
{"title": "[BUG] AssertionError", "file": "2023-06-17.06", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/658", "detail": "**问题描述 / Problem Description**", "id": 321}
|
| 323 |
+
{"title": "[FEATURE] 支持AMD win10 本地部署吗?", "file": "2023-06-18.06", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/660", "detail": "**功能描述 / Feature Description**", "id": 322}
|
knowledge_base/samples/isssues_merge/langchain-ChatGLM_open.xlsx
ADDED
|
Binary file (45.1 kB). View file
|
|
|
knowledge_base/samples/vector_store/index.faiss
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:d681a28e7db0136575491f56a2df0c85e2a2107b8521a54a747a62f9946c1cda
|
| 3 |
+
size 3235885
|
knowledge_base/samples/vector_store/index.pkl
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:689eb8f76853a387deb148f83c3eb638abf1d8a459c37b05d5ae79700147ee09
|
| 3 |
+
size 123880
|
loader/RSS_loader.py
ADDED
|
@@ -0,0 +1,54 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from langchain.docstore.document import Document
|
| 2 |
+
import feedparser
|
| 3 |
+
import html2text
|
| 4 |
+
import ssl
|
| 5 |
+
import time
|
| 6 |
+
|
| 7 |
+
|
| 8 |
+
class RSS_Url_loader:
|
| 9 |
+
def __init__(self, urls=None,interval=60):
|
| 10 |
+
'''可用参数urls数组或者是字符串形式的url列表'''
|
| 11 |
+
self.urls = []
|
| 12 |
+
self.interval = interval
|
| 13 |
+
if urls is not None:
|
| 14 |
+
try:
|
| 15 |
+
if isinstance(urls, str):
|
| 16 |
+
urls = [urls]
|
| 17 |
+
elif isinstance(urls, list):
|
| 18 |
+
pass
|
| 19 |
+
else:
|
| 20 |
+
raise TypeError('urls must be a list or a string.')
|
| 21 |
+
self.urls = urls
|
| 22 |
+
except:
|
| 23 |
+
Warning('urls must be a list or a string.')
|
| 24 |
+
|
| 25 |
+
#定时代码还要考虑是不是引入其他类,暂时先不对外开放
|
| 26 |
+
def scheduled_execution(self):
|
| 27 |
+
while True:
|
| 28 |
+
docs = self.load()
|
| 29 |
+
return docs
|
| 30 |
+
time.sleep(self.interval)
|
| 31 |
+
|
| 32 |
+
def load(self):
|
| 33 |
+
if hasattr(ssl, '_create_unverified_context'):
|
| 34 |
+
ssl._create_default_https_context = ssl._create_unverified_context
|
| 35 |
+
documents = []
|
| 36 |
+
for url in self.urls:
|
| 37 |
+
parsed = feedparser.parse(url)
|
| 38 |
+
for entry in parsed.entries:
|
| 39 |
+
if "content" in entry:
|
| 40 |
+
data = entry.content[0].value
|
| 41 |
+
else:
|
| 42 |
+
data = entry.description or entry.summary
|
| 43 |
+
data = html2text.html2text(data)
|
| 44 |
+
metadata = {"title": entry.title, "link": entry.link}
|
| 45 |
+
documents.append(Document(page_content=data, metadata=metadata))
|
| 46 |
+
return documents
|
| 47 |
+
|
| 48 |
+
if __name__=="__main__":
|
| 49 |
+
#需要在配置文件中加入urls的配置,或者是在用户界面上加入urls的配置
|
| 50 |
+
urls = ["https://www.zhihu.com/rss", "https://www.36kr.com/feed"]
|
| 51 |
+
loader = RSS_Url_loader(urls)
|
| 52 |
+
docs = loader.load()
|
| 53 |
+
for doc in docs:
|
| 54 |
+
print(doc)
|